- 投稿日:2020-05-14T23:27:47+09:00
PyStan / PyMC3 でベイズ統計モデリング
はじめに
ベイズ統計モデリングは、データを確率モデル(確率分布とパラメータの関係式)に当てはめ、ある現象がどのように起こったか(=データがどのように生成されたか)を解釈し、将来のふるまいを予測するために用いられる手法です。
勾配ブースティング木やニューラルネットワークなどの機械学習の手法では、ある現象がどのように起こったか、つまり、説明変数と目的変数の関係についての背景知識がなくても、ある程度の予測性能を達成するモデルを構築することができます。しかし、構築したモデルはブラックボックスとなっており、結果の解釈が難しく、どの機械学習の手法が適切なのか(=汎化性能が十分なのか)の判断が難しい場合があります。
一方、ベイズ統計モデリングは、データを使って学習を行う前に、現象に関する背景知識(=データ生成に関する仮定)を確率モデルの形で組み込むことができます。つまり、ドメイン知識・基礎集計などによってデータの性質をあらかじめ把握することで、「データは○○分布に従って生成されている」などの仮説を事前に構築した上で、パラメータなどをデータから学習することができます。これにより、解釈しやすく、かつ予測精度も高いモデルを柔軟に構築することができる利点があります。
この記事では、PyStan / PyMC3 による、ベイズ線形回帰の実装例を備忘録としてまとめます。
ベイズ統計モデリング
ベイズ統計モデリングは、パラメータをすべて確率変数と見做し、データが生成される確率分布を考えます。機械学習の手法では、与えられたデータをもとに学習を行い、各パラメータについて一つの値を求めるのに対し、ベイズ統計モデリングでは、データ $Y$ が与えられたときの各パラメータ $\theta$ の確率分布 $p(\theta | Y)$ を求めることができます。
パラメータの事後確率
データが与えられる前のパラメータの分布 $p(\theta)$ を事前分布(prior distribution)と呼び、データが与えられた後のパラメータの分布 $p(\theta | Y)$ を事後分布(posterior distribution)と呼びます。事前分布と事後分布は、それぞれ事前確率(prior probability)、事後確率(posterior probability)と呼ぶこともあります。事後分布は、ベイズの定理により、以下の式にしたがって求めることができます。
p(\theta | Y) = \frac{p(Y | \theta)p(\theta)}{p(Y)} \propto p(Y | \theta)p(\theta)これは、事後分布 $p(\theta | Y)$ は、尤度 $p(Y | \theta)$ と事前分布 $p(\theta)$ の積に比例することを表し、$p(Y)$ は正規化定数(事後確率の総和を1にするための定数)と見做せます。尤度 $p(Y | \theta)$ は、パラメータ $\theta$ の値で形状が決まる関数であり、データ $Y$ の当てはまりの良さを表す指標です。一般に、尤度と事前分布の計算は簡単ですが、$p(Y)$ の計算は簡単ではありません。そこで、計算しやすい $p(Y | \theta)p(\theta)$ から乱数サンプルを大量に得ることで事後分布の代わりとする MCMC(Markov Chain Monte Carlo)と呼ばれるサンプリング手法や、計算しやすい式を使って近似的に事後分布を求める変分推論(variational inference)などの手法を用います。
パラメータは確率分布として得られるため、「そのパラメータが取りうる値の範囲(区間)」を求めることができます。特に、事後分布の両端から $\alpha / 2$%を切り取った $(1-\alpha)$%に対応するパラメータの区間を、$(1-\alpha)$%ベイズ信頼区間と呼びます。
予測分布
新しいデータ $y$ に対する予測値についても、一つの値ではなく、確率分布として求めます。この確率分布は、予測分布(predictive distribution)と呼ばれ、以下の式にしたがって求めることができます。
p(y | Y) = \int p(y | \theta)p(\theta | Y)d\thetaこれは、データ $Y$ をもとに得られたパラメータの事後分布 $p(\theta | Y)$ で重み付けし、確率分布 $p(y | \theta)$ を足し合わせていることを表します。$p(\theta | Y)$ のサンプル $\theta^+$が MCMC などの手法により得られているとすると、これらのサンプルを用いて、確率分布 $p(y | \theta^+)$ にしたがう乱数 $y^+$ を得ることができます。$y^+$は、予測分布 $p(y | Y)$ からのサンプルと見做すことができ、パラメータの事後分布を求めたときと同様に予測分布を求めることができます。このように求められる予測分布の両端から $\alpha / 2$%を切り取った $(1-\alpha)$%に対応する予測値の区間を、$(1-\alpha)$%ベイズ予測区間と呼びます。
利点
ベイズ統計モデリングには
- ドメイン知識・基礎集計などによってあらかじめ把握できるデータに関する前提知識を、事前分布 $p(\theta)$ として取り込むことができる(ただし、前提知識を確率モデルに落とし込むための数理的な知識が必須)
- パラメータや予測値の確率分布を求めることができるため、予測の不確実性を考慮しつつ、データ分析結果を意思決定に活用できる
という利点があります。
実装例
ここでは、ベイズ統計モデリングの簡単な例として、ベイズ線形回帰を実装します。ベイズ線形回帰の確率モデル式は下記の通りです。
Y_n \sim Normal \biggl (w_0 + \sum_{d=1}^D w_iX_{nd}, ~~ \sigma \biggr) ~~~~~~~~~~ n=1, \dots, Nここで、$Y_n$ は目的変数、$X_{nd}$ は説明変数、$w_0$ は直線の切片、$w_d ~ (d=1, \dots, D)$ は直線の傾きを表し、$N$ はデータ数、$D$ は説明変数の数を表します。$\sigma$ は、所与の説明変数以外の影響を表現するノイズの大きさです。目的変数と説明変数の関係は、基本的には直線関係 $Y_n = w_0 + \sum_{d=1}^M w_dX_{nd}$ を想定していますが、所与の説明変数以外の影響として、平均0, 標準偏差 $\sigma$ の正規分布から生成されるノイズを加味したモデルとなっています。
ベイズ統計モデリングを行う際は、確率的プログラミング言語を利用する場合が多いです。確率的プログラミング言語は、確率分布の関数や尤度計算に特化した関数を利用できる、統計モデリングに適したプログラミング言語です。本記事では、PyStan / PyMC3 の2つの Python ライブラリを使った実装例を記載します。実行環境は、Python 3.7.6, pystan 2.19.1.1, arviz 0.7.0, pymc3 3.8 です。上記2つのライブラリを使った実装において共通して利用するライブラリ、および利用するデータを生成するコードは以下の通りです。
- 必要なライブラリの読み込み
import numpy as np import pandas as pd import matplotlib.pyplot as plt %matplotlib inline import seaborn as sns sns.set_style('whitegrid') from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error, r2_score
- データの生成
ここでは、ベイズ線形回帰の確率モデル通りに生成したデータを利用します。説明変数 X_train, 目的変数 y_train を学習データとし、パラメータの事後分布と検証用データ X_test に対する目的変数の予測分布を算出することを目標とします。
def generate_sample_data(num, seed=0): target_list = [] # 目的変数のリスト feature_vector_list = [] # 説明変数(特徴量)のリスト feature_num = 8 # 特徴量の数 intercept = 0.2 # 切片 weight = [0.2, 0.3, 0.5, -0.4, 0.1, 0.2, 0.5, -0.3] # 各特徴量の重み np.random.seed(seed=seed) for i in range(num): feature_vector = [np.random.rand() for n in range(feature_num)] # 特徴量をランダムに生成 noise = [np.random.normal(0, 0.1) for n in range(feature_num)] # ノイズをランダムに生成 target = sum([intercept+feature_vector[n]*weight[n]+noise[n] for n in range(feature_num)]) # 目的変数を生成 target_list.append(target) feature_vector_list.append(feature_vector) df = pd.DataFrame(np.c_[target_list, feature_vector_list], columns=['target', 'feature0', 'feature1', 'feature2', 'feature3', 'feature4', 'feature5', 'feature6', 'feature7']) return df data = generate_sample_data(num=1000, seed=0) X = data.drop('target', axis=1) y = data['target'] X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=0)PyStan による実装
PyStan
PyStan は、確率的プログラミング言語の代表格である Stan を Python で利用可能とするインターフェースを提供するライブラリです。確率分布を計算するアルゴリズムとして、MCMC の一種であるハミルトニアンモンテカルロ(HMC: Hamiltonian Monte Carlo)の一実装である NUTS(No-U-Turn Sampler)を利用しています。また、変分推論の一実装である ADVI(Automatic Differentiation Variational Inference)を利用することもできます。
コード例
- 必要なライブラリの読み込み
pystan に加えて、パラメータの事後分布の推定結果を可視化するためのライブラリとして、arviz を利用します。
import pystan import arviz
- モデル構築・予測分布の算出
sample_code という名前の文字列は、確率分布を表現するための Stan コードです。Stan コードは、主に data, parameters, model の3つのブロックから構成されます。data ブロックは観測されているデータの宣言、parameters ブロックは求めたいパラメータや値が決まっていない確率変数の宣言、model ブロックは尤度や事前分布を記述するために利用されます。また、generated quantities ブロックは、予測分布を求めたい場合など、事後分布とは別に Stan 側で新たにサンプリングしたい変数を定義するために利用されます。
具体的には、下表のように各ブロックを記述しています。
ブロック 内容 data 学習用データ数 N, 説明変数の数 D,
学習用データの説明変数 X, 学習用データの目的変数 y,
検証用データ数 N_new, 検証用データの説明変数 X_newparameters 切片 w0, 傾き(各説明変数の回帰係数) w,
ノイズの大きさ sigmamodel ベイズ線形回帰の確率モデル式 generated quantities 検証用データ X_new に対する目的変数 y_new の計算式 data ブロック、parameters ブロック内の <lower=0> は、値の下限を0とするための記述です。model ブロックにおいて、parameters ブロックで宣言したパラメータの事前分布を記述していませんが、デフォルトで無情報事前分布として一様分布が設定されます。また、generated quantities ブロック内の normal_rng() は、正規分布に従う乱数を生成するための関数です。
sample_data は、stan コード(sample_code)における data ブロックと、python 上のデータの対応付けをする辞書です。
sample_code = """ data { int<lower=0> N; int<lower=0> D; matrix[N, D] X; vector[N] y; int<lower=0> N_new; matrix[N_new, D] X_new; } parameters { real w0; vector[D] w; real<lower=0> sigma; } model { for (i in 1:N) y[i] ~ normal(w0 + dot_product(X[i], w), sigma); } generated quantities { vector[N_new] y_new; for (i in 1:N_new) y_new[i] = normal_rng(w0 + dot_product(X_new[i], w), sigma); } """ sample_data = { 'N': X_train.shape[0], 'D': X_train.shape[1], 'X': X_train, 'y': y_train, 'N_new': X_test.shape[0], 'X_new': X_test }Stan コード(sample_code)をコンパイルします。
sm = pystan.StanModel(model_code=sample_code)sample_code に記述した確率モデルと、所与のデータ(sample_data)をもとに、パラメータ $w_0, w_1, \dots, w_D, \sigma$ の事後分布を計算し、さらに X_test に対する目的変数の予測分布を計算します。ここでは、sampling()関数を使い、サンプリング結果を fit に格納します。
fit の中身は以下の通りです。
まず、2,3行目はサンプリングの設定を表示しています。2行目に 4 chains, each with iter=1000; warmup=500; thin=1 とありますが、これは chain 数が 4、iteration ステップ数が 1000、warm up ステップ数が 500、thinning ステップ数が 1 であることを表します。サンプリングは、ある初期値を適当に定めて開始し、得られたサンプルをもとに次のステップのサンプルを生成します。これを iteration ステップ数だけ繰り返して得られるサンプルの系列を chain と呼びます。また、サンプリングのはじめのうちは初期値への依存が大きいため、サンプルの系列から除外します。除外するステップ数を warm up(または burn in)と呼びます。さらに、得られるサンプルの自己相関が高く有用なサンプリングが行えていない場合、何ステップかのうち1回だけサンプリングを行うことで状況が改善する場合があります。このようにサンプルを間引くことを thinning と呼びます。実装例では、chain を得る操作を4回行っており、各 chain は 1000ステップだけサンプリングを繰り返し、はじめの500ステップ分のサンプルは除外することで得ています。thinning は行っていません。その結果、3行目にあるように、(1000-500)×4=2000 個のサンプルが得られています。5行目以降の表は、サンプリングした各パラメータを要約した統計情報です。1列目はパラメータ名、2列目 mean はサンプルの平均値(事後平均(posterior mean)と呼ばれる)、3列目 se_mean は事後平均の標準誤差、4列目 sd はサンプルの標準偏差、5~9列目はサンプルの分位数を表します。10列目 n_eff は、実効的なサンプル数、11列目 Rhat はサンプリングアルゴリズムが収束したかを表す指標です。収束とは、これ以上サンプリングを繰り返しても事後分布の形状が変化しないことを指します。n_eff は自己相関などから判断され、少なくとも100程度あることが望ましいようです。Rhat は Gelman-Rubin 統計量と呼ばれ、「chain 数が3個以上ですべてのパラメータで Rhat<1.1」であれば収束したと見做すようです。実装例では、サンプリングアルゴリズムが収束していることがわかります。
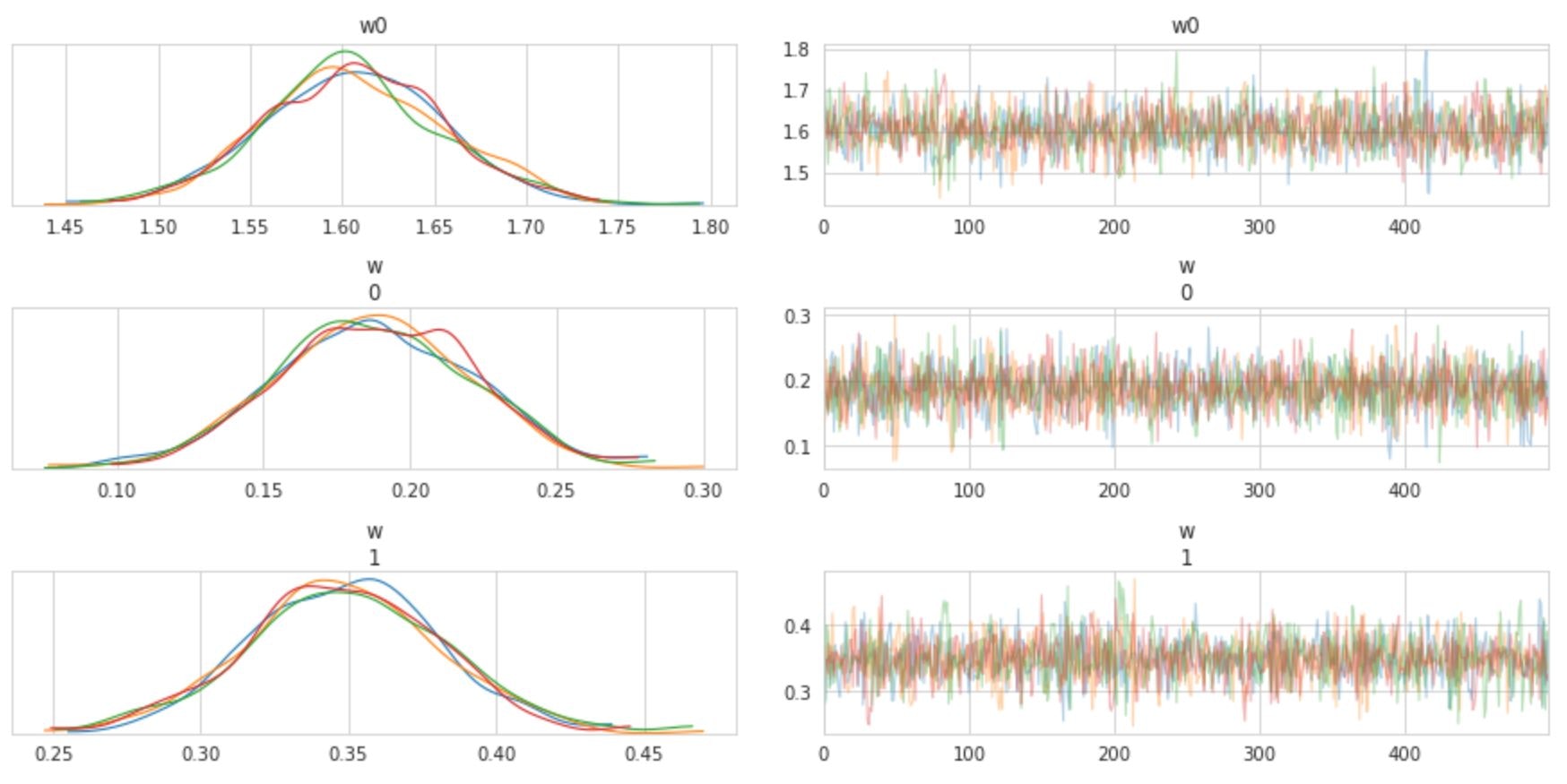
fit = sm.sampling(data=sample_data, iter=1000, chains=4) print(fit) # 出力:=> # Inference for Stan model: anon_model_92cd13fa4b6e158fdf4f4ede934e6196. # 4 chains, each with iter=1000; warmup=500; thin=1; # post-warmup draws per chain=500, total post-warmup draws=2000. # # mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat # w0 1.6 1.4e-3 0.05 1.51 1.57 1.61 1.64 1.7 1270 1.0 # w[1] 0.19 6.3e-4 0.03 0.12 0.17 0.19 0.21 0.25 2726 1.0 # w[2] 0.35 6.6e-4 0.03 0.28 0.33 0.35 0.37 0.41 2531 1.0 # w[3] 0.5 7.0e-4 0.03 0.43 0.47 0.5 0.52 0.57 2479 1.0 # w[4] -0.41 6.7e-4 0.03 -0.48 -0.44 -0.41 -0.39 -0.35 2633 1.0 # w[5] 0.08 6.3e-4 0.03 0.02 0.06 0.08 0.11 0.15 2795 1.0 # w[6] 0.21 6.9e-4 0.04 0.15 0.19 0.21 0.24 0.28 2605 1.0 # w[7] 0.47 6.5e-4 0.03 0.41 0.45 0.47 0.49 0.53 2449 1.0 # w[8] -0.33 6.8e-4 0.03 -0.39 -0.35 -0.33 -0.3 -0.26 2591 1.0 # sigma 0.28 1.3e-4 7.2e-3 0.26 0.27 0.27 0.28 0.29 2881 1.0 # y_new[1] 2.61 5.8e-3 0.27 2.1 2.42 2.61 2.79 3.13 2136 1.0 # y_new[2] 2.09 6.3e-3 0.28 1.54 1.9 2.1 2.29 2.65 2028 1.0 # y_new[3] 1.72 6.2e-3 0.28 1.2 1.53 1.72 1.91 2.27 2019 1.0 # y_new[4] 2.18 6.5e-3 0.28 1.66 1.99 2.19 2.36 2.77 1894 1.0 # y_new[5] 2.47 6.1e-3 0.28 1.94 2.27 2.47 2.67 3.01 2150 1.0 #(以下省略)arviz ライブラリの plot_trace()関数を使うと、各パラメータの分布、および trace plot(横軸にステップ数、縦軸にサンプリングした値をプロットした図)を描画することができます。下図は一部のパラメータについて描画したものです。
arviz.plot_trace(fit) plt.show()
検証用データ X_test に対する目的変数の予測分布も得られているので、サンプリング結果から求めた事後平均を予測値とすれば、機械学習による予測タスクと同様に精度検証することも可能です。
y_pred = fit['y_new'].mean(axis=0) print('MSE(test) = {:.2f}'.format(mean_squared_error(y_test, y_pred))) print('R^2(test) = {:.2f}'.format(r2_score(y_test, y_pred))) # 出力:=> # MSE(test) = 0.07 # R^2(test) = 0.50PyMC3 による実装
PyMC3
PyMC3 は、Python の文法の枠内で統計モデリングができるライブラリです。行列操作や微分などの数式処理ができる Theano を内部で利用することで、確率分布の計算の高速化を図っています。Stan と同様に、 NUTS アルゴリズムによるサンプリングや ADVI による変分推論が可能です。
コード例
- 必要なライブラリの読み込み
import pymc3 as pm import theano
- モデル構築
with pm.Model() ブロック内で、確率モデル式と利用データを記述し、サンプリングを実行します。まず、各パラメータの事前分布を設定し、目的変数の確率モデル式を記述します。実装例では、$w_0, w_1, \dots, w_D$ は $(-\infty, \infty)$ の一様分布 Flat() に、$\sigma$ は $(0, \infty)$ の一様分布 HalfFlat() に設定しています。そして、学習用データの説明変数 X_shared とパラメータを用いて目的変数の確率モデル式を記述し、引数 observed に学習用データの目的変数 y_sahred を指定しています。最後に、sample() 関数でサンプリングを実行しています。実装例では、iteration ステップ数を 1000、warm up ステップ数を 500、chain 数を 4 としています。
学習データを Theano の共有変数としている理由は、検証用データに対する予測分布を計算する際に、モデル(=パラメータの事後分布)を再利用するためです。
X_shared = theano.shared(X_train.values) y_shared = theano.shared(y_train.values) with pm.Model() as linear_model: w0 = pm.Flat('w0') w = pm.Flat('w', shape=X_shared.get_value().shape[1]) sigma = pm.HalfFlat('sigma') y_obs = pm.Normal('y_obs', mu=w0+pm.math.dot(X_shared,w), sigma=sigma, observed=y_shared, shape=y_shared.get_value().shape[0]) trace = pm.sample(500, tune=500, cores=4)各パラメータについて得られたサンプル列は、下記のように取得することができます。chains 引数を指定しない場合、すべての chain におけるサンプル列を取得できます。
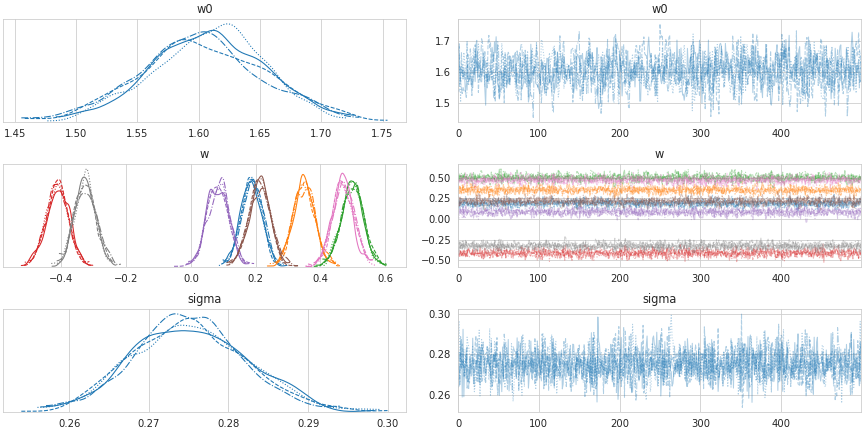
trace.get_values('w0', chains=0) # 出力:=> # array([1.66414789, 1.69065057, 1.5616519 , 1.61380153, 1.59616214, # 1.61042565, 1.57903886, 1.61347858, 1.58324086, 1.53493892, # (以下省略)traceplot() 関数により、各パラメータの事後分布と trace plot を描画することができます。
pm.traceplot(trace) plt.show()
また、gelman_rubin() 関数により、サンプリングアルゴリズムの収束の度合いを表す指標を確認することができます。実装例では、chain 数が 3 以上であり、いずれのパラメータも 1.1 未満となっているため、収束したと見做せます。
pm.gelman_rubin(trace)
さらに、forestplot()関数では、各パラメータについて、各 chain のベイズ信頼区間を表示できます。
pm.forestplot(trace) plt.show()
- 予測分布の算出
検証用データの説明変数を Theano の共有変数に設定し、確率モデルのブロック内で sample_posterior_predictive() 関数を使用することで、予測分布(=検証用データに対する目的変数のサンプル)が得られます。
X_shared.set_value(X_test) y_shared.set_value(np.zeros(X_test.shape[0],)) # 目的変数を初期化 with linear_model: post_pred = pm.sample_posterior_predictive(trace, samples=1000)サンプリング結果から求めた事後平均を予測値とすれば、機械学習による予測タスクと同様に精度検証することも可能です。(Rstan による実装と同程度の予測精度であることが確認できます。)
y_pred = post_pred['y_obs'].mean(axis=0) print('MSE(test) = {:.2f}'.format(mean_squared_error(y_test, y_pred))) print('R^2(test) = {:.2f}'.format(r2_score(y_test, y_pred))) # 出力:=> # MSE(test) = 0.07 # R^2(test) = 0.50おわりに
PyStan / PyMC3 を利用したベイズ統計モデリングの簡単な実装例についてまとめました。
誤りなどありましたら編集リクエストをして頂けると幸いです。参考

- 投稿日:2020-05-14T23:16:55+09:00
Raspberry PiでQRコードを使ってみる
Raspberry PiでQRコードを使ってみる
電子決済を中心に一般生活にも当たり前となったQRコード。
自ら作って、認識させてみたいと思い
RaspberryPiで試した結果を投稿します。やったこと
・任意のQRコード生成
・USBカメラを使ってコード読み取り+内容の表示
実行した見ためはこんな感じ。(https://www.youtube.com/watch?v=xLL4vZN3S7g)
コードの内容(自ら生成可能)を表示。
認識している様子をわかりやすくするため、認識毎に数値が増える表示をしています。
環境
・RasPi4 (RasPi3でも動くはずです)
・USBカメラ(Logicool) → Raspi camでも可能。RasPiのセットアップ
・RasPiやOpenCVのセットアップが完了していれば不要。
Raspberry PiでArUcoを使ってみる・必要なパッケージのインストール
ターミナル で下記を実行pip install --upgrade pip pip install pillow pip install pyzbar pip install qrcodeQRコードを生成する
QRcreate.pyimport qrcode from PIL import Image #サイズを決める qr = qrcode.QRCode(box_size=5) #種類と大きさ一覧。 #1 57x57 #2 114x114 #5 285x285 #10 570x570 #埋め込む内容を指定 qr.add_data('QRコードを身近に試してみる') qr.make() img_qr = qr.make_image() img_qr.save('/home/pi/qr_lena_1.png') #保存したい場所と名前。QRコードを認識する
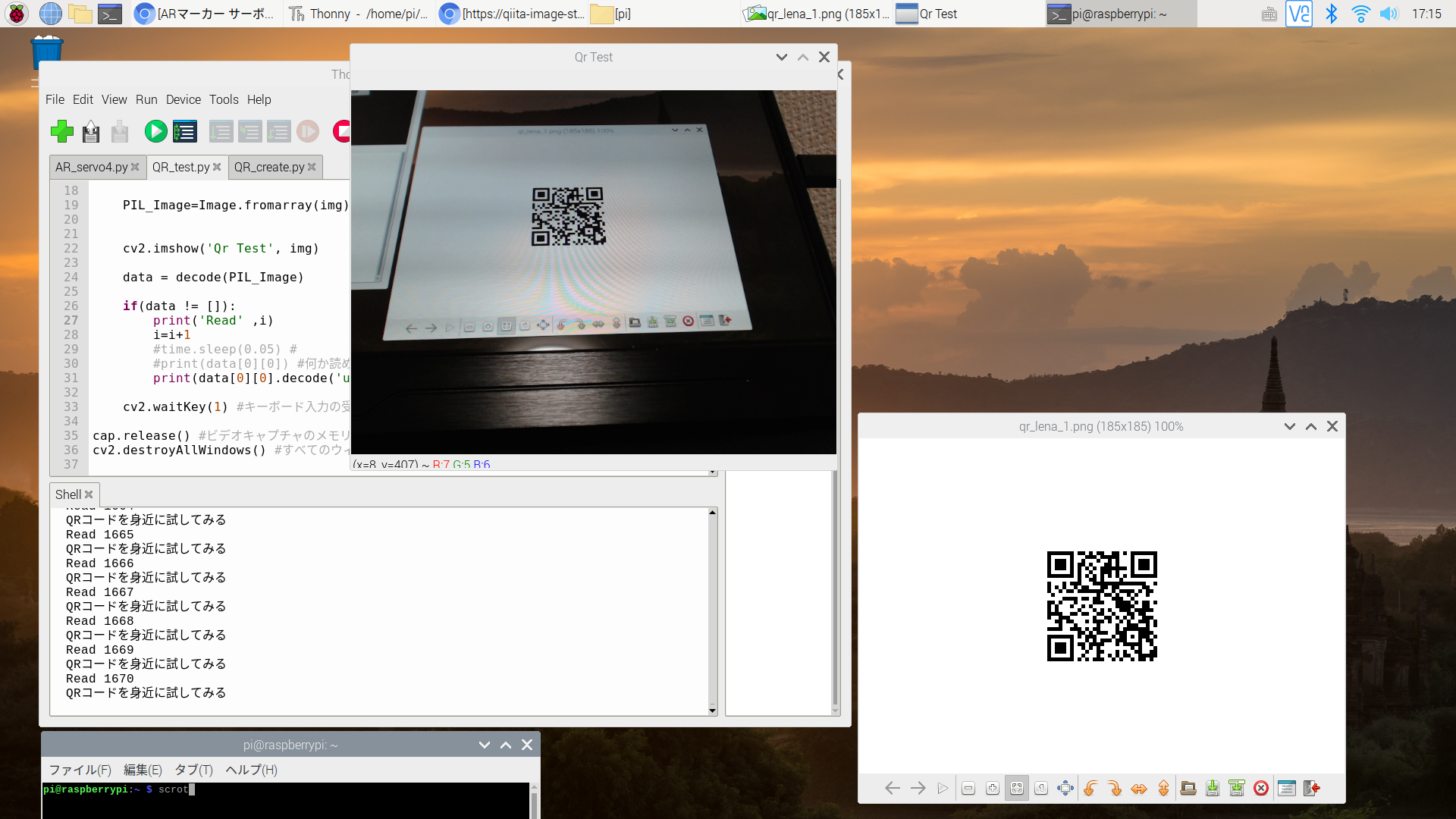
QRdetect.py#!/usr/bin/env python3 # -*- coding: utf-8 -*- from pyzbar.pyzbar import decode from PIL import Image import cv2 import time #test用、無くても可 #ビデオキャプチャの開始 cap = cv2.VideoCapture(1) i=0 #test用 while True: #ビデオキャプチャから画像を取得 ret, frame = cap.read() #sizeを取得 Height, Width = frame.shape[:2] img = cv2.resize(frame,(int(Width),int(Height))) PIL_Image=Image.fromarray(img) #画像の表示 cv2.imshow('Qr Test', img) data = decode(PIL_Image) #何か読めていたら表示する if(data != []): print('Read' ,i) i=i+1 #print(data[0][0]) print(data[0][0].decode('utf-8', 'ignore')) #キーボード入力の受付 cv2.waitKey(1) #ビデオキャプチャのメモリ解放 cap.release() #すべてのウィンドウを閉じる cv2.destroyAllWindows()実行結果
少し見えにくいですが、認識毎に数値が増えているのがわかると思います。
Printをしなければもっと高速で動きます。
(https://www.youtube.com/watch?v=xLL4vZN3S7g)参考
大変参考になるページです。
詳しく解説(https://note.com/yurufuwa_dev/n/n3442772e67ad)
色々な生成方法(https://qiita.com/MuAuan/items/7265da5281aa69623a03)以上。
- 投稿日:2020-05-14T23:15:17+09:00
[Python]02章-03 Pythonプログラムの基礎(入出力)
[Python]02章-03 入出力
この節では、画面への出力についての基礎的な説明と、キーボードからの入力について述べていきます。
ファイルへの出力や、ファイルからの入力については本章では扱わず、後述する予定です。なお、今回はPython Consoleは用いず、PyCharmのエディタ上にプログラムを書いて実行していきたいと思います。
今回は最後に演習問題を用意していますので、取り組んでみてください。
画面への出力
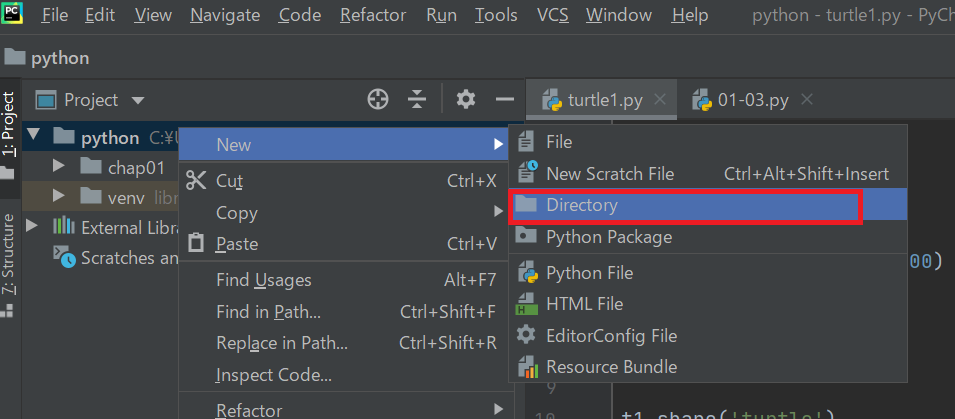
今回はプログラムをエディタに入力するために、フォルダと.pyファイルを作成します。
今回のファイルはchap02フォルダを作成し、その中に02-03-01.pyというファイルを作成します。
作成方法は「01章-03」で説明しましたが、もう一度確認してみます。まず、プロジェクトにある[Python]フォルダを右クリック→[New]→[Directory]を押下します。
そこで、chap02という名前でフォルダを作成します。
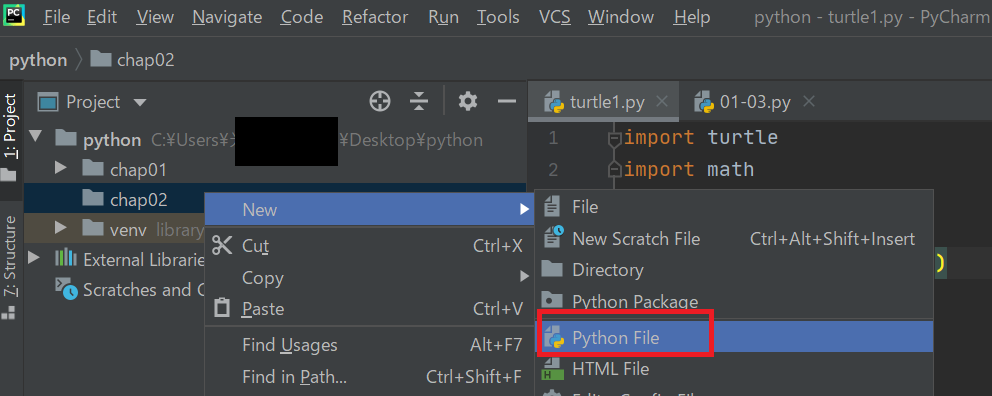
次に、作成されたchap02フォルダで右クリックをして、
[chap02]→[Python File]を押下します。
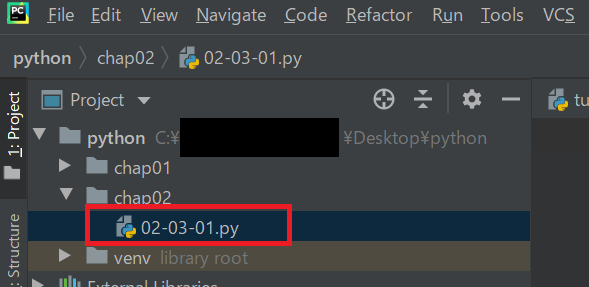
そこで、02-03-01.pyというファイルを作成します。
これで、PyCharmでプログラムを記載することができます。
まず、以下のコードを入力してください。
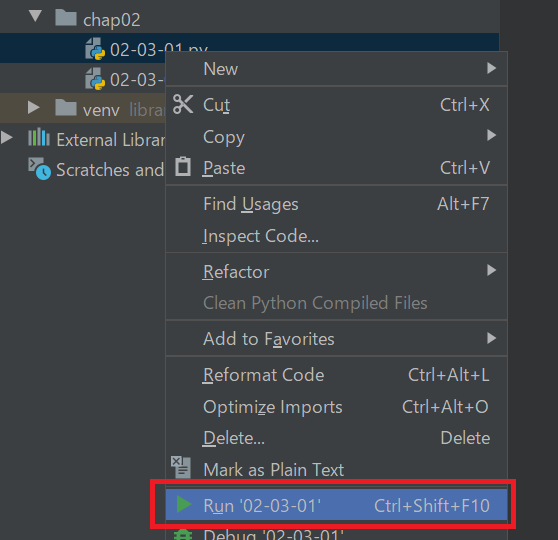
02-03-01.pyprint(123) print('Hello!') print('こんにちは!') print("ようこそ、楽しいプログラミングの世界へ!")そして実行してください。実行は以下の方法でできます。
【実行結果】
123
Hello!
こんにちは!
ようこそ、楽しいプログラミングの世界へ!ここまであまり触れなかったですが、print関数により、()内のものを出力させることができます。
なお、数値であればそのまま入力で問題ないですが、文字列であれば「’」(シングルクオーテーション)または「"」(ダブルクオーテーション)で囲むようにします。エスケープシーケンス
文字列中にエスケープ文字を入れることで、改行できたり、タブを入れることもできます。
chap02フォルダ内に02-03-02.pyというファイルを作成し、以下のプログラムを作成してください。
※「\」はキーボードの「¥」のところです。
※「\n」は「¥n」ととなっている書籍もありますのでご注意ください。02-03-02.pyprint("ようこそ、\n楽しいプログラミングの世界へ!")【実行結果】
ようこそ、
楽しいプログラミングの世界へ!他にも以下のものがあります。(一例です)
文字 意味 \n 改行 \¥ ¥記号の表示 \' シングルクオーテーションの表示 \" ダブルクオーテーションの表示 今作った、02-03-02.pyというファイルに以下のプログラムを追記してください。
※「¥」は「えん」と入力して変換してください。02-03-02.pyprint('ようこそ、\n楽しいプログラミングの世界へ!') print('\¥500になります') print('This is Taro\'s pen.')3行目の「Taro's」の個所はprint関数の()内の両端にあるシングルクオーテーションと区別をつけるために「\」をつけています。
キーボードからの入力
前の節ではプログラムに変数を指定して、それに数値や文字列をプログラム上で指定して実行させてました。
ところがそのままだと、自由な数値や文字列を指定して実行ができず、またいちいちプログラムを書き直さなければなりません。そこで、キーボードからの値の入力について説明します。
キーボードの入力を行うには以下のように指定します。
x = input('ここに何か文字列')実際にプログラムを書いてみましょう。02-03-03.pyというファイルを作成してそこに記載してください。
02-03-03.pyx = input('数値を入力してください:') print(x)実行すると、入力を求められるので、自分の好きな数値を入力してください。
【実行結果】
数値を入力してください:15 (←ここはキーボード入力)
15次に、2つの変数x, yにそれぞれ数値を入力して加算することを考えます。
以下のプログラムを書いてください。02-03-04.pyというファイルを作成してそこに記載してください。02-03-04.pyx = input('変数xに数値を入力してください:') y = input('変数yに数値を入力してください:') print(x + y)そして2つの数値を入力すると以下の結果になったと思います。
【実行結果】
変数xに数値を入力してください:10
変数yに数値を入力してください:20
1020本来、入力した数値が足されるはずなのですが、入力したものが連結されています。
実は、キーボードからの入力はすべて文字列となるのです。したがって、以下のようにint関数で文字列を数値に変更します。(02章-02で説明)02-03-04.pyx = input('変数xに数値を入力してください:') y = input('変数yに数値を入力してください:') print(int(x) + int(y))【実行結果】
変数xに数値を入力してください:10
変数yに数値を入力してください:20
30また以下のように、入力した時点でint関数で文字列を数値にも変換できます。
02-03-04.pyx = int(input('変数xに数値を入力してください:')) y = int(input('変数yに数値を入力してください:')) print(x + y)【実行結果】
変数xに数値を入力してください:10
変数yに数値を入力してください:20
30入力と出力の組み合わせ
以下の問題を考えてみて、プログラムを書いてみましょう。
3つの整数変数x, y, zに数値を入力し、その3つの数の加算(和)の結果を出力するプログラムを作ってください。ただし、出力時に何が計算されたのか分かるように出力してください。例えばxに2, yに4, zに6と入力したとき、「2と4と6の和は12です。」と出力するようにしてください。
なお、和と積のそれぞれの変数はwaにしてください。
実行結果は以下の通りにしてください。【実行結果】
変数x:2
変数y:4
変数z:6
2と4と6の和は12です。まずはプログラムを考えてみてください。02-03-05.pyというファイルを作成してそこに記載してください。
02-03-05.pyx = input('変数x:') y = input('変数y:') z = input('変数z:') wa = int(x) + int(y) + int(z) print(x+'と'+y+'と'+z+'の和は' +str(wa)+ 'です。')ポイントを説明します。
まず、入力したx, y, zは文字列のため、それぞれint関数で数値へ変換します。
それらの結果をwaに代入します。このままprint関数内で連結すると、文字列と数値の連結になりエラーとなるので、str関数で変換してから結合します。
演習問題
演習問題を用意しました。ぜひ解いてみてください。なお、ファイル名は[ ]内に指定したものを使用して、chap02内に作成ください。使用する変数名は好きな変数名を指定してかまいません。
[02-03-p1.py]
【1】3つの整数変数x, y, zに数値を入力し、その3つの数の掛け算(積)の結果を出力するプログラムを作ってください。ただし、出力時に何が計算されたのか分かるように出力してください。例えばxに2, yに4, zに6と入力したとき、「2と4と6の積は48です。」と出力するようにしてください。
[02-03-p2.py]
【2】長方形の縦と横の長さを読み込んで、その長方形の面積を計算して出力するプログラムを作成してください。
[02-03-p3.py]
【3】円の半径を入力して、その円の面積を計算した結果を出力するプログラムを作成してください。(円周率は3.14を使用してください)
[02-03-p4.py]
【4】キーボードから時間を秒で入力して、以下例のように時分秒に分けるプログラムを作成してください。(ヒント:演算子//を使えば商が、%を使えば余りが計算できます。)時間を秒で入力してください:5000
5000秒は1時間23分23秒です。
最後に
今日はエスケープシーケンスをはじめ、キーボードから入力する方法を学びました。
キーボードから入力すると、入力結果は文字列になるので、それをint関数で数値へ変換するのを忘れずに、また出力の際にはstr関数で文字列へ変換するのを忘れないようにしましょう。
- 投稿日:2020-05-14T23:02:19+09:00
Windows Terminal に Anaconda Powershell Prompt を追加するには?
あらすじ
Windows 10で、Windows TerminalにAnaconda PowerShell Promptを追加する話です。イントロ
Anacondaを使っている人も、Minicondaを使っている人も、等しくAnaconda Promptを利用しているはずです。
長いことCondaに触れている人なら、誰しも最新の環境で利用したいと願っていることでしょう。
Anaconda PromptがPowershellに対応しましたが、それでも完璧な対応ではありませんでした。Powershellの起動毎に、condaコマンドのための環境変数%PATH%を設定し、(base)仮想環境をactivateするという、待ち時間の苦痛を強いるものだったからです。ところが、現在は
AnacondaもしくはMinicondaのインストール直後からAnaconda PowerShell PromptとAnaconda PowerShell Promptに分かれてあらかじめショートカットが用意されており、非常に便利になっています。
このような状況のなか、
Windows Terminalというものが、登場しました。
様々な種類のターミナルを、単一ウィンドウ内でタブとして使うことができるという優れものです。
しかも、PowerShellの起動時間が短縮されており、ストレスフリーです。これはもう、
Anaconda Promptを追加するしかないですよね。
さて、どうやったらよいのでしょうか?設定方法
まず、設定ファイルは、
PowerShell風に言うと、$env:LocalAppData\Packages\Microsoft.WindowsTerminal_8wekyb3d8bbwe\LocalState\settings.jsonに置いてあります。
Cmd風に言うと、%LocalAppData%\Packages\Microsoft.WindowsTerminal_8wekyb3d8bbwe\LocalState\settings.jsonに置いてあります。
そして、この
jsonファイルに、以下を追記します。{ "guid": "{61c54bbd-c2c6-5271-96e7-009a87ff44b9}", "name": "Anaconda Prompt", "startingDirectory" : "%HOMEPATH%", "commandline": "%userprofile%\\Documents\\PowerShell\\conda.cmd", "icon": "%SystemDrive%\\tools\\miniconda3\\Menu\\Iconleak-Atrous-PSConsole.ico", "hidden": false }設定項目の詳細
guidには、New-GUIDを使用して作成した値を入れるらしいです。しかし面倒なので、Powershellのものをコピーペーストして、1文字変えただけとしました。
nameは自分が分かれば何でもいいと思います。
iconは好きなものを使っていいですが、私は、公式のアイコンにリンクしました。
commandlineには以下のバッチファイルを実行するように指定しています。%userprofile%\\Documents\\PowerShell\\conda.cmd%windir%\System32\WindowsPowerShell\v1.0\powershell.exe -ExecutionPolicy ByPass -NoExit -Command "& 'C:\tools\miniconda3\shell\condabin\conda-hook.ps1' ; conda activate 'C:\tools\miniconda3' "このバッチファイルの中身は、
C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Anaconda3 (64-bit)にあるショートカットファイルのうち、PowerShellの方のリンク先文字列をコピーペーストしただけです。なぜかといいますと、面倒だったからです。stackoverflowなどを見てみると、「スタートメニューのショートカットファイルから
リンク先文字列をコピーして貼り付ける」と書いてあるものが多いです。しかし、これは動作しません。
C:\ProgramData\Microsoft\Windows\Start Menu\Programs\Anaconda3 (64-bit)にあるショートカットファイルのプロパティは以下ですが、これをコピーペーストしてcommandlineに指定しても正常なコマンドとして受け取ってもらえないからです。
-Command以降の部分がどうしてもエラーになって上手くいきませんでした。といっても、Powershellの引数の受け取りかたが謎すぎるから私には理解できないだけかもしれません。なにか方法があるのでしょう。時間がもったいないので、この文字列をバッチファイルに書き込み、それを実行させることにしました。
設定ファイル例
そして最終的に、私の場合は以下のような設定になりました。
%LocalAppData%\Packages\Microsoft.WindowsTerminal_8wekyb3d8bbwe\LocalState\settings.json// To view the default settings, hold "alt" while clicking on the "Settings" button. // For documentation on these settings, see: https://aka.ms/terminal-documentation { "$schema": "https://aka.ms/terminal-profiles-schema", "defaultProfile": "{574e775e-4f2a-5b96-ac1e-a2962a402336}", "profiles": { "defaults": { // Put settings here that you want to apply to all profiles "fontFace": "Cascadia Code PL", "useAcrylic": true, "acrylicOpacity": 0.7 }, "list": [ { // Make changes here to the powershell.exe profile "guid": "{61c54bbd-c2c6-5271-96e7-009a87ff44bf}", "name": "Windows PowerShell", "commandline": "powershell.exe", "hidden": false }, { // Make changes here to the cmd.exe profile "guid": "{0caa0dad-35be-5f56-a8ff-afceeeaa6101}", "name": "cmd", "commandline": "cmd.exe", "hidden": false }, { //"guid": "{574e775e-4f2a-5b96-ac1e-a2962a402336}", //"hidden": false, //"name": "PowerShell", //"source": "Windows.Terminal.PowershellCore" "guid": "{574e775e-4f2a-5b96-ac1e-a2962a402336}", "name": "PowerShell Core", "source": "Windows.Terminal.PowershellCore", "hidden": false }, { "guid": "{b453ae62-4e3d-5e58-b989-0a998ec441b8}", "hidden": false, "name": "Azure Cloud Shell", "source": "Windows.Terminal.Azure" }, { "guid": "{46ca431a-3a87-5fb3-83cd-11ececc031d2}", "hidden": false, "name": "kali-linux", "source": "Windows.Terminal.Wsl" }, { "guid": "{2c4de342-38b7-51cf-b940-2309a097f518}", "hidden": false, "name": "Ubuntu", "source": "Windows.Terminal.Wsl" }, { "guid": "{61c54bbd-c2c6-5271-96e7-009a87ff44b9}", "name": "Anaconda Prompt", "startingDirectory" : "%HOMEPATH%", "commandline": "%userprofile%\\Documents\\PowerShell\\conda.cmd", "icon": "%SystemDrive%\\tools\\miniconda3\\Menu\\Iconleak-Atrous-PSConsole.ico", "hidden": false } ] }, // Add custom color schemes to this array "schemes": [], // Add any keybinding overrides to this array. // To unbind a default keybinding, set the command to "unbound" "keybindings": [] }結果
以下が設定反映後の状態です。いかがでしょうか。
参考
設定項目について、より詳しく知りたい人は、Editing Windows Terminal JSON Settingsを見てください。
環境
この記事での環境は以下です。
- Windows 10 Pro 1909
- Chocolatey v0.10.15
- Miniconda3 4.7.12.1
- Windows Terminal 0.11.1333.0
Excelsior!
- 投稿日:2020-05-14T22:57:29+09:00
Pythonで浮動小数点数を2進数に変換する方法
最近,表題の件で相談を受けることがしばしばありましたので,Pythonのテキストからの抜粋を上げておきます.
原理自体はどこの学校でも教わるのですが,実際にプログラムを書くとなると面倒に感じる方もおられると思います.
Pythonのmpmathライブラリを使用すると,とても簡単に,しかも高精度で浮動小数点数を2進数表現にすることができます.
→抜粋部分(PDF)
- 投稿日:2020-05-14T22:30:03+09:00
BeautifulSoupを使って、dアニメストアで配信されているアニメをスクレイピングしてみた
はじめに
趣味で、アニメのレコメンドシステムを作ってみました。
http://www.cappu-latte.com/anigime/
このレコメンドシステムでは、
レコメンドされたアニメがAmazon Primeやdアニメストアで配信されていた場合、
各サービスのアイコンが表示されるようになっています。
このWebアプリを作るにあたって、
dアニメストアで配信されているアニメをスクレイピングする必要があったので
そのときに作成したコードを公開します。コード
from bs4 import BeautifulSoup import pickle def get_danime_animes(): animes = [] # #listContainer > div:nth-child(1) > section > div.itemModuleIn > a > div > h3 > span headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36"} text = "" number = 0 for i in range(10): for j in range(5): for k in range(50): response = requests.get(r"https://anime.dmkt-sp.jp/animestore/rest/WS000108?workTypeList=anime&length=" + str(k*10+10) + r"&mainKeyVisualSize=1&initialCollectionKey=" + str(i+1) + "&consonantKey=" + str(j+1) + "&_=1586073865764", headers=headers) soup = str(BeautifulSoup(response.text, "html.parser")) if "error" in soup: break text = soup number = k*10 + 10 for k in range(number): begin = text.find('"workTitle":"') + len('"workTitle":"') if begin == -1: break end = text.find('","link":"') if end == -1: break anime = text[begin:end] text = text[end + len('","link":"'):] animes.append(anime) f = open('danime_animes.txt', 'wb') pickle.dump(animes, f)このコードの以下の部分
for i in range(10): for j in range(5):ここがこんな風になっているのは、
dアニメストアの配信アニメの取得元のページが五十音でわかれていたので、
「あかさたなはまやらわ」の10文字、「あいうえお」の5文字でそれぞれforループすることで
五十音のページをすべてスクレイピングしているためです。
- 投稿日:2020-05-14T22:19:18+09:00
【備忘録】電力使用量予測をやってみよう!(その1)
初めに
半年ほど前からDeep Learningを勉強しており、最近は時系列データの分析に興味が湧いて目下勉強中。
以下のサイトで、元Tableau社員の岩橋氏がやっていることを、python/chainerの勉強も兼ねてやってみたいと思います。URL: Tableauによるデータ理解から始めるディープラーニング
目的:気象データから電力消費量を予測するモデルを作る
- 説明変数:気象データ + α
- 被説明変数:電力消費量まだまだ初心者のやっていることですので全然スマートなやり方になっていないと思いますので、「こうした方が良いよ」、「このほうが楽できるで!」的なコメント、お待ちしてます(笑)
少し長いですが、読んでいただけると幸いです。1. データの取得
データは以下の東京電力及び気象庁のサイトからcsvファイルをダウンロードできます。
東京電力: 過去の電力使用実績データのダウンロード
気象庁: 過去の気象データ・ダウンロードここから、2018年のデータ(1年分)を取得する。気象データについては
- 気温
- 降水量
- 日照時間
- 全天日射量
- 現地気圧
- 相対温度
を使ってみることにする(岩橋氏の使っているものと同じ)。
データをダウンロードしたら、pandasで読み込んでみましょう。なお、分析にはGoogle Colaboratoryを使用しました。(最初はJupyter labを使用していたのですがグラフの描画に異常に時間がかかったので、途中からGoogle Colaboratoryに変更)
Google Driveの接続
ファイルの読み込みにはGoogle Driveにダウンロードしたcsvファイルをアップロードしておいて、Google Colaboratoryと接続して使用。
まずはライブラリのインポートから。これ以降も必要に応じてライブラリをインポートします(一度に全部インポートしても良いですが、私は手探りでやったのでこの時は必要な時にインポートしました)。
# ライブラリのインポート import numpy as np import pandas as pd import matplotlib.pyplot as plt以下のコードを使うとGoogle ColaboratoryとGoogle Driveを連携できます。ググると詳しいやり方が出てくると思いますので、そちらをご参照ください。
参考: ColaboratoryでのGoogle Driveへのマウントが簡単になっていたお話
# Google Driveと接続 from google.colab import drive drive.mount('/content/drive')さて、ここまで来たらファイルの読み込みです。下の「xxx」はGoogle Drive上の任意のフォルダ/ファイル名になります。
# ファイルの読み込み/DataFrameの表示 df = pd.read_csv('drive/My Drive/xxx/xxx.csv') df2. 前処理1:読み込み >> データの確認 >> データの結合
(a)気象データ
Pythonによる前処理
上述の岩橋氏はTableau(DeskTop/Prep)による前処理や可視化をしているが、今回はPythonの勉強なので、同じ(ような)作業をPythonのみでやってみたいと思う。まずは、気象庁のHPからダウンロードした気象データ(data.csvとします)について見ていきます。
ちなみに、Excelだと以下のようになっています。必要ない行や列がありますね。
データの整形
このデータセットから使いたい行列を抜き出します。
(ただ、この程度の量のデータセットであったらExcelでいじったほうが楽ちんです。でもここは敢えてpythonで使いたいデータを抽出します(あくまでpythonの勉強です))。df_weather = pd.read_csv('Original\weather_data_1_2.csv', header=[0], skiprows=3, engine='python') #,index_col=0 df_weather = df_weather.iloc[1:,[0, 1,4,8,12,18,21]] df_weather.head()
年月日時 気温(℃) 降水量(mm) 日照時間(時間) 日射量(MJ/㎡) 相対湿度(%) 現地気圧(hPa) 2018/1/1 1:00:00 1.5 0.0 0.0 0.0 82.0 1009.6 2018/1/1 2:00:00 1.0 0.0 0.0 0.0 83.0 1009.5 2018/1/1 3:00:00 1.2 0.0 0.0 0.0 80.0 1009.0 2018/1/1 4:00:00 0.6 0.0 0.0 0.0 85.0 1008.6 2018/1/1 5:00:00 1.9 0.0 0.0 0.0 80.0 1008.8 と、このような出力になります。
1行目のデータ読み込みの際に、indexの指定(index_col=)・ヘッダーの指定(header=)・不要な行のスキップ(skiprows)を使って大まかに使いたい形にしてます。2行目で.iloc([])を使って必要な行・列をとってきています。
次に、列名が日本語だと使いづらいので列名を変更したいと思います。これは、columnsという変数を作ってディクショナリー型で{'変更前','変更後'}というcodeで以下のようにすると一度に変換できます。
#列名を英語に変換 columns = {'年月日時':'Date_Time', '気温(℃)':'Temperature', '降水量(mm)':'Precipitation', '日照時間(時間)':'Daylighthours', '日射量(MJ/㎡)':'SolarRadiation', '相対湿度(%)':'Humidity', '現地気圧(hPa)':'Airpressure'} df_weather.rename(columns=columns, inplace=True) df_weather.head(3)次にデータ型を確認しましょう。私はいつも以下の3つくらいを確認してます(むしろ他に確認したほうが良いものがあれば教えてください)。
# データ型の確認 print(df_weather.shape) print(df_weather.dtypes) print(df_weather.info)複数ファイルの列方向での結合(pd.concat)
気象庁からデータをダウンロードする際、ダウンロードできるデータのサイズが決まっており、1年分のデータをダウンロード数場合には複数回に分けてダウンロードする必要があります(私の場合は、1ファイルに2カ月分のデータしかダウンロードできませんでした)。ですので、複数のファイルをジョインする必要があります。
ここではファイル名をそれぞれ,df_weather1~6とします。
df_weather_integrate = pd.concat([df_weather, df_weather1, df_weather2, df_weather3, df_weather4, df_weather5],ignore_index=True)結合後のファイル名をdf_weather_integrated(ちょっと長いですね。。。)として、pd.concat()を使って縦方向に6つのファイルを結合しました。
欠損値の確認(.isnull().any / .isnull().sum())
次に欠損値の確認です。欠損値の有無はおなじみのdataframe.isnull().any()で確認します。Boolean型(True or False)で返ってきます。
df_weather_integrated.isnull().any()
1 2 Date_Time False Temperature False Precipitation False Daylighthours True SolarRadiation True Humidity True Airpressure False ここでDaylighthours, SOlarRadiation, Humidityの3つに欠損値があることがわかりましたので、それぞれいくつ欠損値があるのか確認しましょう。.isnull().sum()で確認します。
df_weather_integrated.isnull().sum()
1 2 Date_Time 0 Temperature 0 Precipitation 0 Daylighthours 1 SolarRadiation 1 Humidity 27 Airpressure 0 これで気象データの欠損値の数がわかりましたね。後ほど、電力消費量データと一緒に欠損値の処理をしていきます。
(b)電力消費量データ
次に東京電力のHPからダウンロードしてきた電力データを見てみましょう。Excelだと以下のような感じでダウンロードされます。
df_Elec = pd.read_csv('xxx\elec_2018.csv',header=[0],skiprows=1, engine='python')ここでは先ほどと同様にheader, skiprowsで不要な行を取り除いてます。
電力消費量データについても気象データと同様に列名の変更(日本語 >> 英語)・データ型の確認・欠損値の確認をします(詳細は割愛)。【変換後】
DATE TIME kW 0 2018/1/1 0:00 2962 1 2018/1/1 1:00 2797 2 2018/1/1 2:00 2669 ・・・ ・・・ ・・・ ・・・ ここでお気づきかと思いますが、0行目が2018/1/1 0:00になっています。気象データは2018/1/1 1:00からスタートするので、ここで0行目を削除してインデックスを振り直しておきます。
df_Elec = df_Elec.drop(df_Elec.index[0]) df_Elec =df_Elec.reset_index(drop=True) df_Elec.head(3)【再変換後】
DATE TIME kW 0 2018/1/1 1:00 2962 1 2018/1/1 2:00 2797 2 2018/1/1 3:00 2669 ・・・ ・・・ ・・・ ・・・ 次に気象データは日付と時間が一つの列に合わさってましたので、電力消費量データの1,2列目を結合して気象データと同じ形になるようにします。ここではpd.to_datetimeで新しい列(DATE_TIME)をdatetime型で作ります。
# DATEとTIMEを結合して、新しくDATE_TIMEを作る df_Elec['DATE_TIME'] = pd.to_datetime(df_Elec['DATE'] +' '+ df_Elec['TIME']) df_Elec = df_Elec[['DATE_TIME', 'kW']]これで、気象データと電力消費量データの結合の準備ができました。それではこの2つのデータを結合させてみましょう。ここではpd.merge()を使っています。
2つのファイルの縦方向の結合(pd.merge)
# 2つのファイルを結合 df = pd.merge(df_weather_integrate, df_Elec ,left_on='Date_Time', right_on='DATE_TIME', how='left')これで2つのファイルを(横方向)に結合させることができました!ここでこのデータフレームを見てみると、不要な列(DATE_TIME)が残っていたり最終行でkWにNaNがあったりしますので、最後これらを処理していきます。
# 使う行だけ残す df = df[['Date_Time','Temperature', 'Precipitation', 'Daylighthours', 'SolarRadiation', 'Humidity', 'Airpressure', 'kW']] df.drop(8759,inplace=True) #8759は最終行これでやっとデータ分析できる形になりました!(長かった。。。)
次回は今回前処理したデータをchainerで分析していきたいと思います!
まとめ(備忘)
今回は以下4点をやってみました。
- データ取得
- データの読み込み&確認
- データの整形
- データの結合
次回は、欠損値の処理をやってみたいと思います。
- 投稿日:2020-05-14T22:13:18+09:00
Pyenvでアクティブなバージョンをanacondaから普通のPythonに変更する
これまでの成り行き
最初にPythonに触れるときAnacondaを使う人も多いと思います。しかしAnacondaは環境を破壊するなど諸説あり、(参照: Pythonインストール方法とAnacondaを使わない3つの理由)やっぱり使うのはやめてGoogle colabなどに乗り換える人も多いと思います。
その時にアクティブなPythonのバージョンを切り替える必要があって、その手順がちょっと複雑だったので書いておきます。結論
glocalコマンドを用います。
切り替え先のPythonのバージョンがわかっていない場合は$ pyenv versionsで現在のバージョンと切り替えたいバージョンを確認してから
$ pyenv global (切り替え先のバージョン名)です。
「現在のバージョンとはなんぞや?」という人は順番に読み進めてもらえればと思います。インストール済み一覧の表示
$ pyenv versions * system (set by /Users/yuri/.pyenv/version) 3.7.2 anaconda3-4.2.0 anaconda3-5.0.1*印の付いているsystemが今アクティブなバージョンです。
/Users/yuri/.pyenv/versionで指定されているとのことです。そこで、そのファイルを見てみます。
/Users/yuri/.pyenv/versionanaconda3-5.0.1これですね。というわけで、このファイルを消すと、
$ rm -r /Users/yuri/.pyenv/version $ pyenv versions * system (set by /Users/yuri/.pyenv/version) 3.7.2 anaconda3-4.2.0 anaconda3-5.0.1systemになりました。
3.7.2を使いたい場合はさっきのファイルに3.7.2と書けばよいです。glocalコマンドでバージョンを切り替える
切り替え先のバージョンがわかっている場合、glocalコマンドを使えば一瞬で切り替えられます。
3.7.2に切り替えたいとしましょう。$ pyenv global 3.7.2 $ pyenv versions system (set by /Users/yuri/.pyenv/version) * 3.7.2 anaconda3-4.2.0 anaconda3-5.0.1こうですね。3.7.2になりました。
終わりに
私も最初はAnacondaユーザーでPythonと言えばAnacondaだ!と思っていましたが、Anacondaにも色々と欠点があるみたいです。時間があったら今度詳しく調べて記事書きたいと思っています。今はGoogle Colabなどブラウザ上で実行できる便利なものがあるのでローカルで環境構築する必要に迫られない限りはそちらを使うのがいいかと思います。
参考
こちらを参考にさせていただきました。
Pyenvの使い方
- 投稿日:2020-05-14T21:59:15+09:00
windowsでyolov4を「とりあえず」動かす
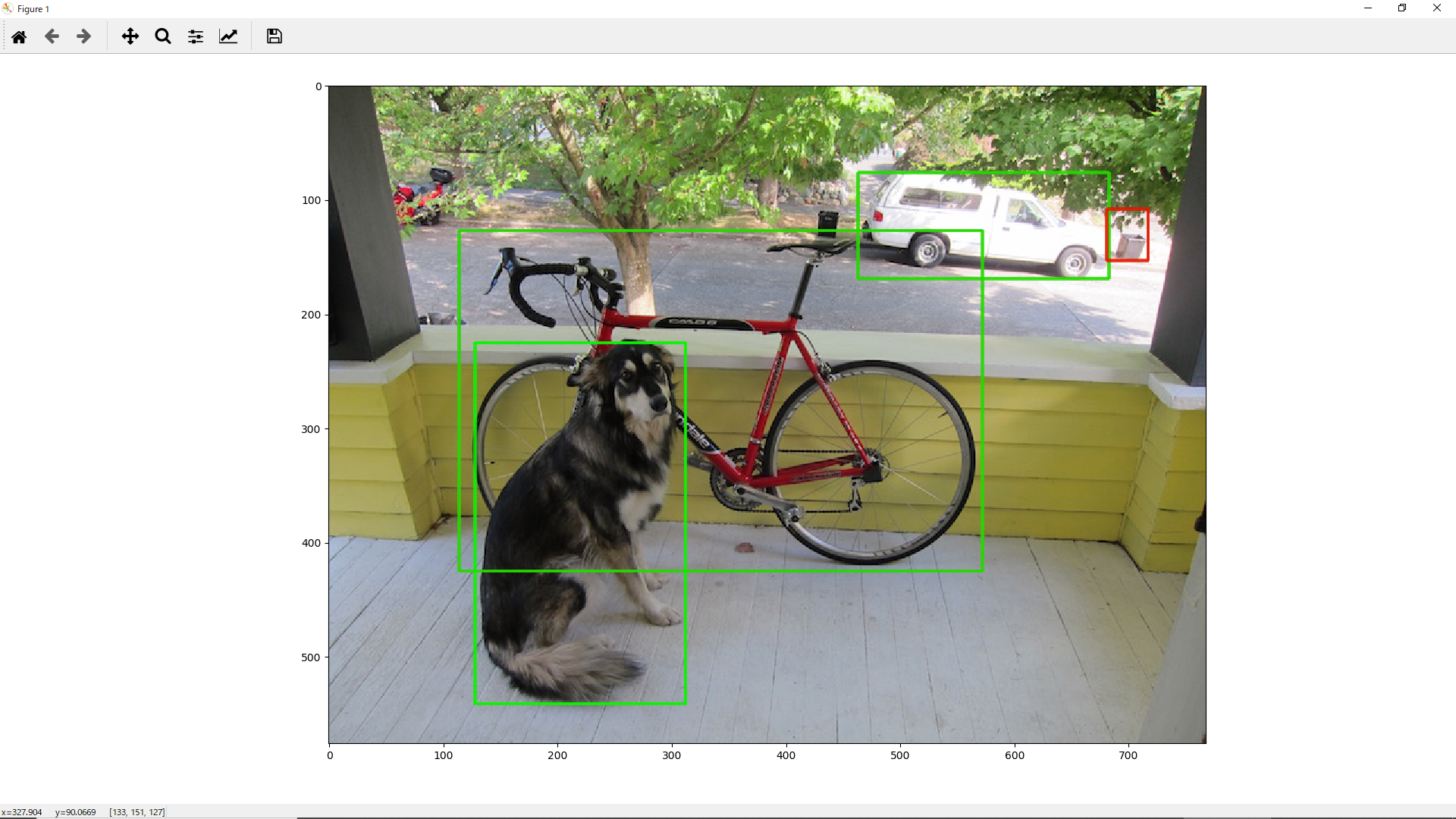
本ページではyolo-v4のチュートリアルである、有名なdog.ipgの推論を行うまでを記述しています。osはwindowsを使います。また、英語が苦手なので無駄な手順を踏んでいることもあるかもしれません。気になる人はhttps://github.com/AlexeyAB/darknet より自分で行ってみてください。
dog.jpg ↓↓↓
初めに
opencvやvisual studioなどの基本的なものはできているものとします。できていない人はそちらを調べてください、やり方はv3までと一緒です。
gitからcloneする
darknetを構築したい場所で以下のコマンドを打ってcloneしてください。
git clone https://github.com/AlexeyAB/darknetcmakeを行う
先ほどcloneしたdarknetフォルダの中にあるbuildの中に移動し、cmakeを行ってください。以下コード。
cd build cmake ..cmakeがコマンドとして認識していない方はcmakeを行うところから始めてください。cmakeは簡単なので頑張って構築してください。
ビルドしていく
buildフォルダの下に2個目のdarknetがあるので、その中にある
- darknet.sln
- yolo_console_dll.sln
- yolo_cpp_dll.sln
この3つをvisual studioを使いビルドしていきます。no_gpuが付いたファイルがあると思いますが、さわったことがないのでどうなるかはわかりません。名前から察するにcpuに切り替わるのかと(-_-;)私はgpuで行うのでgpuのままやります。
各.slnのビルド方法
darknet.slnを例に挙げて行います。他2つも同じ方法で行えます。
darknet.slnをvsで開くとこのような画面になると思います。
手順
- 右上のソリューションエクスプローラー内にあるdarknetを右クリック
- ソース管理から自身のcudaを選択
- 再度右クリック、一番下のプロパティを選択
- 右上の構成マネージャーを開き、アクティブソリューションとプラットフォームをreleaseとx64に変更
- プロパティページに戻り、c/c++からインクルードディレクトリにopencvとcudaのincludeファイルがあるpathを追加(cudaのincludeファイルはwindows→programfiles→nvidia gpu→各バージョンの中にincludeファイルがあります。opencvは自力で頑張ってください)
- include pathを追加したらリンカーを開きます(左にあります)。その中に追加のライブラリディレクトリがあるのでこちらにはopencv、cudaのlibファイルのpathを追加してください
- 適用を押します
- darknetを右クリック後ビルドを押します(ここで何も動かなかったりする人はリビルドを何回か押すと動くかもしれません)。
以上を行い、x64以下にdarknet.exeができていたら成功です。
- darknet.sln→darknet.exe
- yolo_console_dll.sln→yolo_console_dll.exe
- yolo_cpp_dll.sln→yolo_cpp_dll.dll
以上のものが作られます。
ここまでくればほぼ終わりです。推論してみる
x64のフォルダ内で以下のコマンドを実行します。
python darknet.pyこのコマンドでデフォルトのdog.jpgを推論します。
結果
このような結果が出てきます。対応表を作ってないのでbboxのみですね。別の画像を行いたい場合、darknet.pyを編集することで行えます。この後は
学習をさせる、これに関しても行いたいと思っているので学習が完了した時点で記事が増えていないようであれば書きます。
感想
日本語の記事が少ないというだけで難易度が高く、大変でした(;^^A
学習もちゃんと行えるようにしたいですね。英語が苦手な私がかろうじてできたものなので信用性はボロボロですが(笑)気になる人はgithubから自分で行ってみてください。たぶんいらないことを多くやってる気がします。読みづらくてすみませんm( _"m)

- 投稿日:2020-05-14T21:57:17+09:00
pandas DataFrameを適切なグラフを自動で選んで可視化するメソッドを作った
はじめに
データを可視化する際、どのグラフを使ったらよいのかよく迷います。そこで、前回は説明変数と目的変数の種類ごとに適したグラフをまとめました(説明変数、目的変数別データの可視化方法)。でも、「こんなのすぐ忘れるよ!」と自分でも書いていて思ってしまいました。そこで、変数の種類を自動で判別して適したグラフを描いてくれるメソッドを作ってみました。
前回のまとめ
説明変数、目的変数の種類(離散量か否か)ごとの適当なseabornのメソッドは以下の通りです。詳しくは上記リンクから前回の記事を参照してください。
メソッドの内容
以下が自作したメソッドのコードです。
import matplotlib.pyplot as plt import seaborn as sns def visualize_data(data, target_col): for key in data.keys(): if key==target_col: continue length=10 subplot_size=(length, length/2) if is_categorical(data, key) and is_categorical(data, target_col): fig, axes=plt.subplots(1, 2, figsize=subplot_size) sns.countplot(x=key, data=data, ax=axes[0]) sns.countplot(x=key, data=data, hue=target_col, ax=axes[1]) plt.tight_layout() plt.show() elif is_categorical(data, key) and not is_categorical(data, target_col): fig, axes=plt.subplots(1, 2, figsize=subplot_size) sns.countplot(x=key, data=data, ax=axes[0]) sns.violinplot(x=key, y=target_col, data=data, ax=axes[1]) plt.tight_layout() plt.show() elif not is_categorical(data, key) and is_categorical(data, target_col): fig, axes=plt.subplots(1, 2, figsize=subplot_size) sns.distplot(data[key], ax=axes[0], kde=False) g=sns.FacetGrid(data, hue=target_col) g.map(sns.distplot, key, ax=axes[1], kde=False) axes[1].legend() plt.tight_layout() plt.close() plt.show() else: sg=sns.jointplot(x=key, y=target_col, data=data, height=length*2/3) plt.show()なお、is_categoricalについては以下の通り。
def is_categorical(data, key): col_type=data[key].dtype if col_type=='int': nunique=data[key].nunique() return nunique<6 elif col_type=="float": return False else: return True概要は
・可視化したいデータ(pandas.DataFrame)をdataに、目的変数のキーをtarget_colに渡す。
・is_categoricalメソッドで説明変数、目的変数が離散量か連続量かを判定し、適当なseabornメソッドで可視化する。となっています。データ型がintの場合、6種類以上の値が存在すれば連続量、5種類以下の値しかなければ離散量としています。正直ここの判定は改善の余地ありですね。
適用
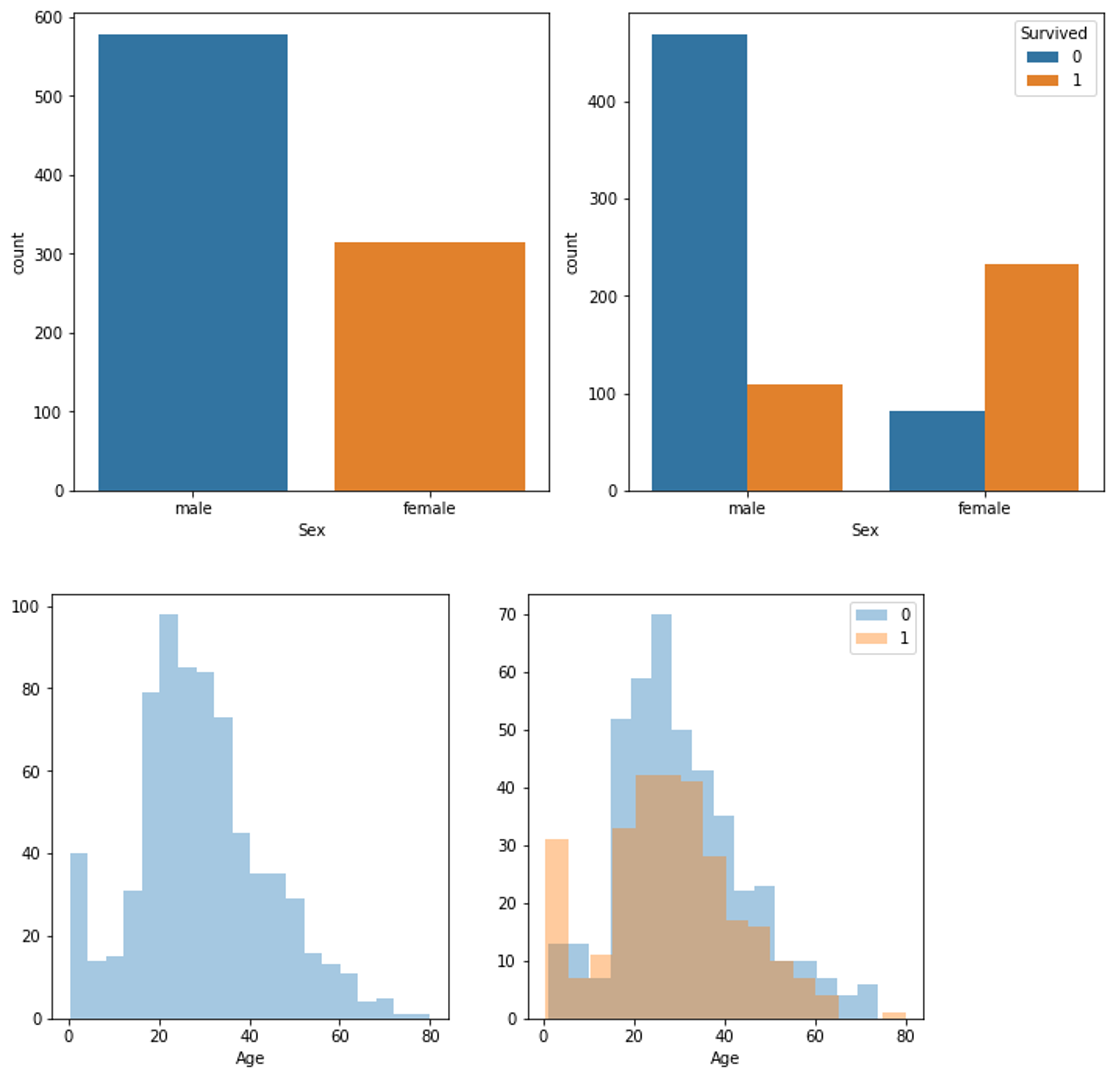
titanicデータに適用してみる(結果は長いので1部だけ)。
import pandas as pd data=pd.read_csv("train.csv") data=data.drop(["PassengerId", "Name", "Ticket", "Cabin"], axis=1) #固有値は除く visualize_data(data, "Survived")
種類ごとに適切なグラフが自動で描けました!終わりに
以前投稿した、Pandasでデータの概要を把握するメソッド とまとめてGitHubに上げました。是非使ってみてください!今後前処理なんかを色々自動化していきたい。

- 投稿日:2020-05-14T21:03:41+09:00
kerasでGAN(mnist)動かしてみた
はじめに
今回はGAN(Generative Adversarial Network)をこちらの本で勉強したのでまとめていきたいと思います。
何回かに分けて書いた後に、最後にしっかりまとめるつもりです。
なので、この記事はとてもざっくりとしたものになっています。
今回の記事は本書で紹介されていた、GANの簡単な実装コードの解説とまとめについて書かせていただきます。
GANの詳しい説明については他サイトに譲らせていただいて本稿では簡単に概要のみに止まらせていただきます。(需要がありそうなら後々まとめたものを投稿したいと思います。)
GAN初心者の方の参考になりそうなGANのサイトを載せておきます。
GAN:敵対的生成ネットワークとは何か ~「教師なし学習」による画像生成GANとは
軽く説明させていただきます。
GANとは日本語で敵対敵生成ネットワークといいます。DNNの亜種的存在で今人工知能の分野でめちゃめちゃ流行っています。
入力されたデータの特徴を学んで、入力データに似た何かを生成します。
データは音声、テキスト、画像等なんでもありです。
例えば、猫の画像を大量に入力とすれば出力されるのは猫の画像になります(うまく学習できていれば)アルゴリズムとしてはふたつのDNNを用意してあげて、それぞれ画像を生成する係と画像が本物か生成された画像かどうかを見分けてあげる係に分けてあげます。この二つのモデルを競わせることで入力された画像に近い画像がアウトプットされる仕組みです。
結果
最初に結果を載せさせて頂きます。
これが生成された画像です。
それに対してこちらが入力されたデータです。
このコードはとてもシンプルなDNNで行われたのでまだまだ改善の余地がありますが、それにしても、少ない層のmodeldでもここまで表現できているのは驚きました。
次回の記事で改善版を載せるつもりでいます。コード
コードになります。
もっと詳しく説明してくれと言われそうです。
しっかりと本を読み終えてから改てまとめようと思っているのでそれまで待ってください!
(いいねくれると。とっっっても励みになります)simple_gan.py%matplotlib inline import numpy as np import matplotlib.pyplot as plt from keras.datasets import mnist from keras.layers import Dense, Flatten, Reshape from keras.layers.advanced_activations import LeakyReLU from keras.models import Sequential from keras.optimizers import Adam #mnistの形状[28, 28, 1]を定義 img_rows = 28 img_cols = 28 channels = 1 img_shape = (img_rows, img_cols, channels) #generatorが画像を生成するために入力させてあげるノイズの次元 z_dim = 100 #generator(生成器)の定義するための関数 def build_generator(img_shape, z_dim): model = Sequential() model.add(Dense(128, input_dim=z_dim)) model.add(LeakyReLU(alpha=0.01)) model.add(Dense(28*28*1, activation='tanh')) model.add(Reshape(img_shape)) return model #discriminator(識別器)の定義するための関数 def build_discriminatior(img_shape): model = Sequential() model.add(Flatten(input_shape=img_shape)) model.add(Dense(128)) model.add(LeakyReLU(alpha=0.01)) model.add(Dense(1, activation='sigmoid')) return model #Ganのモデル定義する(生成器と識別器をつなげてあげる)ための関数 def build_gan(generator, discriminator): model = Sequential() model.add(generator) model.add(discriminator) return model #実際関数を呼び出してにGANのモデルをコンパイルしてあげる discriminator = build_discriminatior(img_shape) discriminator.compile(loss='binary_crossentropy', optimizer=Adam(), metrics=['accuracy']) generator = build_generator(img_shape, z_dim) #識別器の学習機能をオフにしてあげる。こうすることで、識別器と生成者を別々に学習させてあげられる discriminator.trainable = False gan = build_gan(generator, discriminator) gan.compile(loss='binary_crossentropy', optimizer=Adam()) losses = [] accuracies = [] iteration_checkpoint = [] #学習させてあげるための関数。イテレーション数、バッチサイズ、 何イテレーションで画像を生成して可視化するかを引数にとる def train(iterations, batch_size, sample_interval): (x_train, _), (_, _) = mnist.load_data() x_train = x_train / 127.5 - 1 x_train = np.expand_dims(x_train, axis=3) real = np.ones((batch_size, 1)) fake = np.zeros((batch_size, 1)) for iteration in range(iterations): idx = np.random.randint(0, x_train.shape[0], batch_size) imgs = x_train[idx] z = np.random.normal(0, 1, (batch_size, 100)) gen_imgs = generator.predict(z) d_loss_real = discriminator.train_on_batch(imgs, real) d_loss_fake = discriminator.train_on_batch(gen_imgs, fake) d_loss, acc = 0.5 * np.add(d_loss_real, d_loss_fake) z = np.random.normal(0, 1, (batch_size, 100)) gen_imgs = generator.predict(z) g_loss = gan.train_on_batch(z, real) #sample_intervalごとに損失値と精度、チェックポイントを保存 if (iteration+1) % sample_interval == 0: losses.append((d_loss, g_loss)) accuracies.append(acc) iteration_checkpoint.append(iteration+1) #画像を生成 sample_images(generator) #サンプルとして画像を生成するための関数 def sample_images(generator, image_grid_rows =4, image_grid_colmuns=4): z = np.random.normal(0, 1, (image_grid_rows*image_grid_colmuns, z_dim)) gen_images = generator.predict(z) gen_images = 0.5 * gen_images + 0.5 fig, axs = plt.subplots(image_grid_rows, image_grid_colmuns, figsize=(4,4), sharex=True, sharey=True) cnt = 0 for i in range(image_grid_rows): for j in range(image_grid_colmuns): axs[i, j].imshow(gen_images[cnt, :, :, 0], cmap='gray') axs[i, j].axis('off') cnt += 1


- 投稿日:2020-05-14T20:55:29+09:00
ゼロから始めるLeetCode Day25「70. Climbing Stairs」
概要
海外ではエンジニアの面接においてコーディングテストというものが行われるらしく、多くの場合、特定の関数やクラスをお題に沿って実装するという物がメインである。
その対策としてLeetCodeなるサイトで対策を行うようだ。
早い話が本場でも行われているようなコーディングテストに耐えうるようなアルゴリズム力を鍛えるサイト。
せっかくだし人並みのアルゴリズム力くらいは持っておいた方がいいだろうということで不定期に問題を解いてその時に考えたやり方をメモ的に書いていこうかと思います。
前回
ゼロから始めるLeetCode Day24 「21. Merge Two Sorted Lists」基本的にeasyのacceptanceが高い順から解いていこうかと思います。
Twitterやってます。
問題
70. Climbing Stairs
難易度はeasy。
Top 100 Liked Questionsからの抜粋です。中学受験をしたことある人には見覚えがある問題だと思います。
実はすごく簡単な解き方があるのですが、それは解法で説明します。階段を登る時、1段か2段登れます。
自然数nが与えられるので頂上に辿り着くまでの方法が何通りあるかを答えなさい。Example 1:
Input: 2
output: 22の場合、一気に2段あがる方法と1段を2回登る方法があるので2を返します。
Example 2:
Input: 3
Output: 33の場合は1段づつ上がるのを3回繰り返す、1段上がって2段あがる方法、2段上がって1段あがる方法の3通りあるため3を返します。
解法
実はこれフィボナッチ数列の問題なんですよね。
場合の数の勉強をしていた時に見たことがある人もいるかもしれません。ちなみにフィボナッチ数列というのは、
1,1,2,3,5,8,13,21,34,55,
といったように、前の2つの数の和が次の数になる数列です。例のように3段だった場合を考えてみましょう。
この場合、最初の段階での場合分けによって大きく変わります。
1段登るか2段登るかパターンがありますよね。
仮に2段登った場合、その後の選択肢は残りの階段数が1のため、必然的に1通りとなります。
対して1を選んだ場合は残りが2段、つまり例にあるように2通りです。
これらを足し算したときの和が場合分けの答えとなり、これこそが上記のようなフィボナッチ数列の典型的な例なのです。他の数字でも試してみましょう。
仮に4段だとしましょう。すると最初に1段と最初に2段選びます。
最初に1段の場合ですが、残りは3段です。つまり先ほどの3段の時の3通りをそのまま使えます。
そして2段の場合だと残りは2段です。つまりは2通りです。
3通り+2通りなので5通りです。また一つ階段が増えると8,そしてもう一段増えると13...といったように増えていきます。
この足し算の構造が理解できれば後はその法則をコードにするだけです。
簡単な例としては、
class Solution: def climbStairs(self, n: int) -> int: if n <= 1: return n num1, num2 = 0, 1 for i in range(n): num1, num2 = num2, num1+num2 return num2 # Runtime: 32 ms, faster than 39.40% of Python3 online submissions for Climbing Stairs. # Memory Usage: 13.7 MB, less than 5.97% of Python3 online submissions for Climbing Stairs.これが一般的な解き方でしょう。
しかしdiscussを見ているとこれよりも高速な書き方がありました。from functools import lru_cache class Solution: @lru_cache(None) def climbStairs(self, n): if n == 1: return 1 elif n == 2: return 2 else: return self.climbStairs(n-1) + self.climbStairs(n-2) # Runtime: 24 ms, faster than 91.08% of Python3 online submissions for Climbing Stairs. # Memory Usage: 13.9 MB, less than 5.97% of Python3 online submissions for Climbing Stairs.めちゃ速ですね・・・
ところで
lru_cacheってなんやねん。
となったので大人しく公式ドキュメントで調べました。@functools.lru_cache(user_function)
@functools.lru_cache(maxsize=128, typed=False)
関数をメモ化用の呼び出し可能オブジェクトでラップし、最近の呼び出し最大 maxsize 回まで保存するするデコレータです。高価な関数や I/O に束縛されている関数を定期的に同じ引数で呼び出すときに、時間を節約できます。結果のキャッシュには辞書が使われるので、関数の位置引数およびキーワード引数はハッシュ可能でなくてはなりません。
引数のパターンが異なる場合は、異なる呼び出しと見なされ別々のキャッシュエントリーとなります。 例えば、 f(a=1, b=2) と f(b=2, a=1) はキーワード引数の順序が異なっているので、2つの別個のキャッシュエントリーになります。
.....LRU (least recently used) キャッシュ は、最新の呼び出しが次も呼び出される可能性が最も高い場合 (例えば、ニュースサーバーの最も人気のある記事は、毎日変わる傾向にあります) に最も効率が良くなります。キャッシュのサイズ制限は、キャッシュがウェブサーバーなどの長期間に渡るプロセスにおける限界を超えては大きくならないことを保証します。
一般的には、 LRU キャッシュは前回計算した値を再利用したいときにのみ使うべきです。 そのため、副作用のある関数、呼び出すごとに個別の可変なオブジェクトを作成する必要がある関数、 time() や random() のような純粋でない関数をキャッシュする意味はありません。
つまり呼び出した関数の結果を辞書を使ってキャッシュするからそのキャッシュされた結果が最新の呼び出しでも呼び出される場合は実行するときの効率があがる、ということっぽいです。
知らなかったのでとても勉強になりました、やはりdiscussを見るのは大事。
- 投稿日:2020-05-14T19:29:32+09:00
深層学習/ゼロから作るディープラーニング2 第4章メモ
1.はじめに
名著、「ゼロから作るディープラーニング2」を読んでいます。今回は4章のメモ。
コードの実行はGithubからコード全体をダウンロードし、ch04の中で jupyter notebook にて行っています。2.高速版CBOWモデル
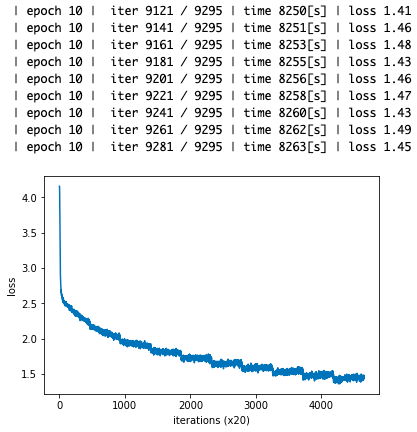
第4章のテーマは、第3章で実装した Word2vec のCBOWモデルを高速化し実用的なモデルにすることです。ch04/train.py を実行し、順番に内容を見て行きます。
なお、データセットは Penn Tree Bankを使っていて、語彙数は10,000個, train のコーパスサイズは約90万語です。
import sys sys.path.append('..') from common import config # GPUで実行する場合は、下記のコメントアウトを消去(要cupy) # =============================================== # config.GPU = True # =============================================== from common.np import * import pickle from common.trainer import Trainer from common.optimizer import Adam from cbow import CBOW from skip_gram import SkipGram from common.util import create_contexts_target, to_cpu, to_gpu from dataset import ptb # ハイパーパラメータの設定 window_size = 5 hidden_size = 100 batch_size = 100 max_epoch = 10 # データの読み込み corpus, word_to_id, id_to_word = ptb.load_data('train') vocab_size = len(word_to_id) # コンテクストとターゲットの取得 contexts, target = create_contexts_target(corpus, window_size) if config.GPU: contexts, target = to_gpu(contexts), to_gpu(target) # ネットワーク構築 model = CBOW(vocab_size, hidden_size, window_size, corpus) # 学習、ロス推移グラフ表示 optimizer = Adam() trainer = Trainer(model, optimizer) trainer.fit(contexts, target, max_epoch, batch_size) trainer.plot() # 後ほど利用できるように、必要なデータを保存 word_vecs = model.word_vecs if config.GPU: word_vecs = to_cpu(word_vecs) params = {} params['word_vecs'] = word_vecs.astype(np.float16) params['word_to_id'] = word_to_id params['id_to_word'] = id_to_word pkl_file = 'cbow_params.pkl' # or 'skipgram_params.pkl' with open(pkl_file, 'wb') as f: pickle.dump(params, f, -1)
ロスは順調に下がったようです。それでは、ポイントとなる。ネットワーク構築の部分の
cbow.pyのclass CBOWを見てみましょう。# --------------- from cbow.py --------------- class CBOW: def __init__(self, vocab_size, hidden_size, window_size, corpus): V, H = vocab_size, hidden_size # 重みの初期化 W_in = 0.01 * np.random.randn(V, H).astype('f') W_out = 0.01 * np.random.randn(V, H).astype('f') # レイヤの生成 self.in_layers = [] for i in range(2 * window_size): layer = Embedding(W_in) # Embeddingレイヤを使用 self.in_layers.append(layer) self.ns_loss = NegativeSamplingLoss(W_out, corpus, power=0.75, sample_size=5) # すべての重みと勾配をリストにまとめる layers = self.in_layers + [self.ns_loss] self.params, self.grads = [], [] for layer in layers: self.params += layer.params self.grads += layer.grads # メンバ変数に単語の分散表現を設定 self.word_vecs = W_in高速化のポイントの1つは、Embedding レイヤの採用です。common/layers.pyを見てみましょう。
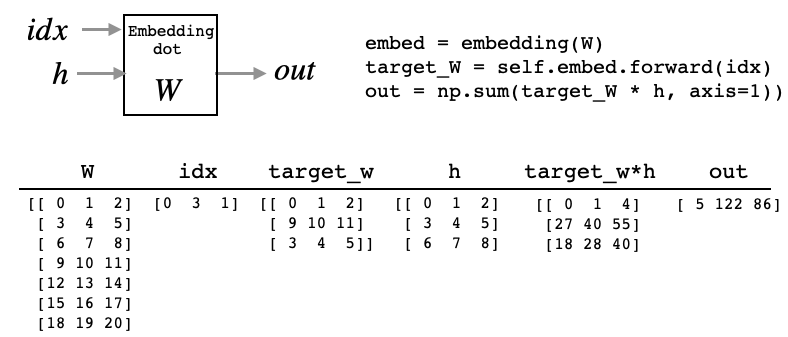
3.Embedding レイヤ
# --------------- from common/layers.py -------------- class Embedding: def __init__(self, W): self.params = [W] self.grads = [np.zeros_like(W)] self.idx = None def forward(self, idx): W, = self.params self.idx = idx out = W[idx] # idx で指定された行を出力 return out def backward(self, dout): dW, = self.grads dW[...] = 0 if GPU: np.scatter_add(dW, self.idx, dout) else: np.add.at(dW, self.idx, dout) # idx で指定された行へデータを加算 return None
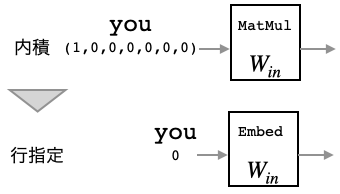
第3章では MatMul レイヤを使って、ベクトルと重み行列の内積を求めていたわけですが、考えてみればワンホットベクトルと重み行列の内積なので、重み行列$W_{in}$の行指定をするだけで良いわけです。これが、Embed レイヤです。
そうすると、逆伝播も前から伝えられるデータで該当する行を更新するだけで済みます。但し、ミニバッチ学習では、たまたま同じ行に複数のデータが戻って来て重なる場合も考えられるので、置き換えではなく、データを加算する形にしています。
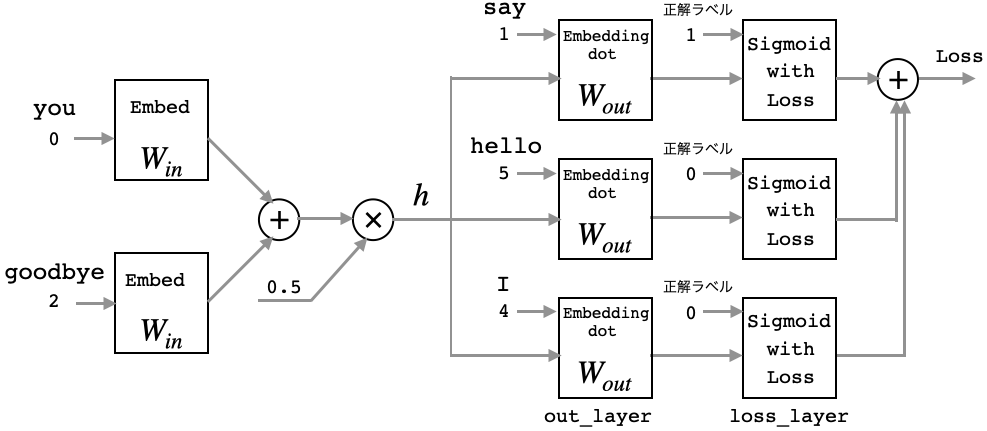
4.Negative Sampling
高速化の2つ目のポイントは、Negative Sampling です。第3章の様に、語彙数分の出力からSoftmaxで分類するというのは、非現実的です。ではどうするか。多値分類問題を二値分類問題に近似して解くというのが、その答えです。
negative_sampling_layer.pyにあるclass NegativeSamplingLossを見てみましょう。# ------------- form negative_sampling_layer.py -------------- class NegativeSamplingLoss: def __init__(self, W, corpus, power=0.75, sample_size=5): self.sample_size = sample_size self.sampler = UnigramSampler(corpus, power, sample_size) self.loss_layers = [SigmoidWithLoss() for _ in range(sample_size + 1)] self.embed_dot_layers = [EmbeddingDot(W) for _ in range(sample_size + 1)] self.params, self.grads = [], [] for layer in self.embed_dot_layers: self.params += layer.params self.grads += layer.grads def forward(self, h, target): batch_size = target.shape[0] negative_sample = self.sampler.get_negative_sample(target) # 正例のフォワード score = self.embed_dot_layers[0].forward(h, target) correct_label = np.ones(batch_size, dtype=np.int32) loss = self.loss_layers[0].forward(score, correct_label) # 負例のフォワード negative_label = np.zeros(batch_size, dtype=np.int32) for i in range(self.sample_size): negative_target = negative_sample[:, i] score = self.embed_dot_layers[1 + i].forward(h, negative_target) loss += self.loss_layers[1 + i].forward(score, negative_label) return loss def backward(self, dout=1): dh = 0 for l0, l1 in zip(self.loss_layers, self.embed_dot_layers): dscore = l0.backward(dout) dh += l1.backward(dscore) return dh
多値分類を二値分類に近似するには、まず、you(0)とgoodbye(2)に挟まれた単語の答えについて、 say(1)が正解となる確率を出来るだけ大きくします(正例)。しかし、これだけでは不十分です。そこで、適当に選んだ hello(5)やI(4)が不正解となる確率を出来るだけ大きくすることを付け加えます(負例)。
この手法を、Negative Sampling と言います。適当に選ぶ負例の数は、コードでは、sample_size = 5 になっています。
ここで、
Embedding_dot_layersが出て来ますので、これも見ておきます。同じく、negative_sampling_layer.pyにあります。# ------------- form negative_sampling_layer.py -------------- class EmbeddingDot: def __init__(self, W): self.embed = Embedding(W) self.params = self.embed.params self.grads = self.embed.grads self.cache = None def forward(self, h, idx): target_W = self.embed.forward(idx) out = np.sum(target_W * h, axis=1) self.cache = (h, target_W) return out def backward(self, dout): h, target_W = self.cache dout = dout.reshape(dout.shape[0], 1) dtarget_W = dout * h self.embed.backward(dtarget_W) dh = dout * target_W return dh
ミニバッチに対応するために、idx, h が複数の場合にも計算出来るように、最後に target_w*h の合計を取るようにしています。5.モデル評価
最初に、ch04/train.py を動かしましたので、学習したパラメータが
cbow_params.pklに保存されています。これを使って、単語の分散表現が上手くできているかeval.pyで確認します。import sys sys.path.append('..') from common.util import most_similar, analogy import pickle pkl_file = 'cbow_params.pkl' # ファイル名指定 # 各パラメータの読み込み with open(pkl_file, 'rb') as f: params = pickle.load(f) word_vecs = params['word_vecs'] word_to_id = params['word_to_id'] id_to_word = params['id_to_word'] # most similar task querys = ['you'] for query in querys: most_similar(query, word_to_id, id_to_word, word_vecs, top=5)
まずは、
most_similarメソッド(common/util.py)を使った、単語の類似性の確認です。you に最も近いものは we, そして i, they, your と人称代名詞が続きます。これは、各単語の類似性を下記のコサイン類似度で計算した結果です。
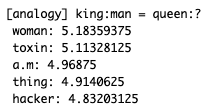
# analogy task analogy('king', 'man', 'queen', word_to_id, id_to_word, word_vecs)
今度は、
alalogyメソッド(common/util.py)を使った、有名な king - man + woman = queen 問題の確認です。確かに、その通りになっていますね。これは、「man → woman」ベクトルに対して「king → x」ベクトルが出来るだけ近くなるような単語 x を探すというタスクを解くことになります。

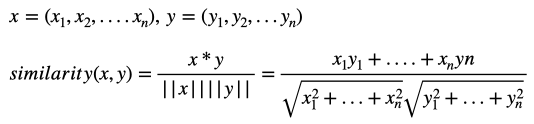
- 投稿日:2020-05-14T19:11:23+09:00
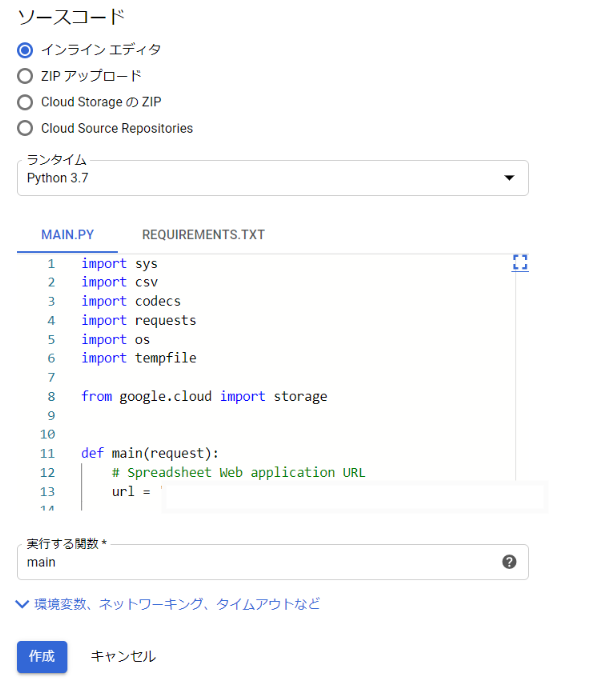
スプレッドシートをCSV化してCloud FunctionsでCloud Storageにアップロードする
目標
APIのエンドポイントを叩いたら特定のスプレッドシートのデータをCSVに書き出してストレージに保存する。
※公開しても問題のないデータの前提使うもの
- Google Apps Script
- Python
- Cloud Storage
- Cloud Functions
手順
1. スプレッドシートをWebアプリケーションとして公開する
スプレッドシートのツールバーから「ツール」→「<>スクリプトエディタ」を選択してGoogle Apps Scriptのエディタを開きます。
既存のコードを削除して以下のコードを貼り付けます。
コード.gsfunction doGet(e) { var output = ContentService.createTextOutput(createCSV()); output.setMimeType(ContentService.MimeType.TEXT); return output; } function createCSV() { var sheetName = 'シート名'; var ss = SpreadsheetApp.getActiveSpreadsheet(); var sheet = ss.getSheetByName(sheetName); var values = sheet.getDataRange().getValues(); var csv = values.join('\n'); return csv; }ツールバーの「公開」→「ウェブアプリケーションとして導入...」をクリックします。
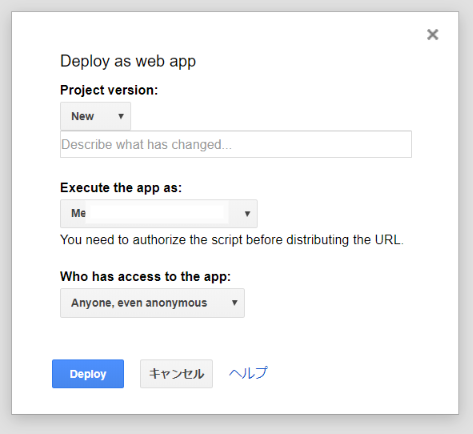
プロジェクト名を聞かれるので適当な名前を付けて「OK」をクリックします。
設定を聞かれるので「Execute the app as:」を「Me(メールアドレス)」、「Who has access to the app:」を「Anyone,even anonymous」に設定して「Deploy」をクリックします。
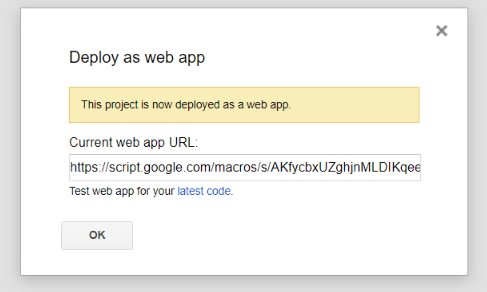
以下の画面が表示されるので、「Current web app URL」に記載のURLにアクセスしてスプレッドシートのデータがCSVの形で表示されれば成功です。
このURLは後で使うので控えておいてください。
2. Cloud Storageにオブジェクト作成の権限を付与する
※細かい設定の説明は省きます。
「IAMと管理」の「サービスアカウント」を開き、「サービスアカウントのを作成」をクリックしてサービスアカウントを作成します。
「Storage」を開き、「バケットを作成」をクリックしてバケットを作成します。
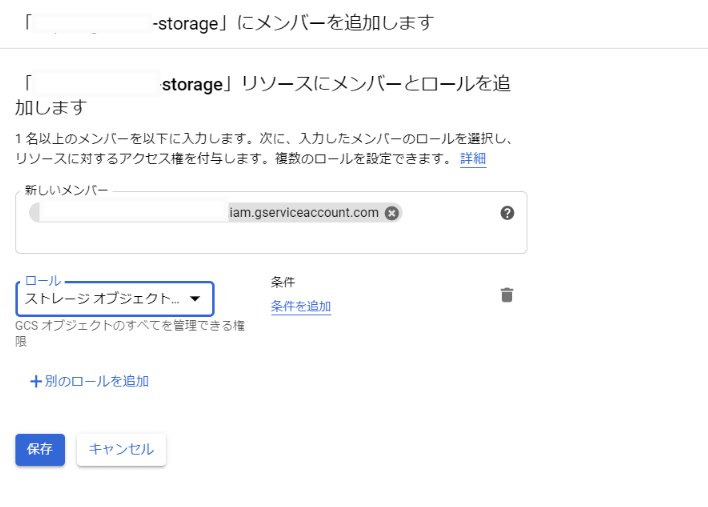
バケット一覧の画面でバケットの右のメニューから「バケットの権限を編集」→「メンバーの追加」をクリックします。
新しいメンバーにさきほど作成したサービスアカウントを追加し、ロールを選択から「Cloud Storage」→「ストレージオブジェクト管理者」を選択して「保存」をクリックします。
3. Cloud FunctionsにCSVをアップロードするスクリプトを配置する
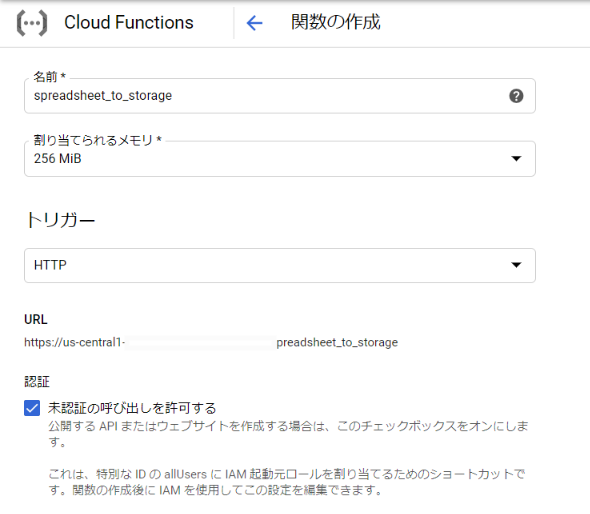
「Cloud Functions」を開き、「関数を作成」をクリックします。
「未承認の呼び出しを許可する」にチェックを入れます。
ランタイムに「Python 3.7」を選択します。
「MAIN.PY」と「REQUIREMENT.TXT」に以下のコードを貼り付けます。main.pyimport sys import csv import codecs import requests import os import tempfile from google.cloud import storage def main(request): # Spreadsheet Web application URL url = '1.で表示されたURL' # Cloud Storage bucket = 'バケット名' dir = 'ディレクり名' fileName = 'csv名' # get data r = requests.get(url) assert r.status_code == requests.codes.ok, "can't read spreadsheet" # pylint: disable=no-member # make file _, temp_local_filename = tempfile.mkstemp() with codecs.open(temp_local_filename, 'w', 'utf_8') as f: f.write(r.text) # upload file client = storage.Client() bucket = client.get_bucket(bucket) blob = bucket.blob(f'{dir}/{fileName}') blob.upload_from_filename(filename=temp_local_filename) return "success"REQUIREMENT>TXTastroid==2.4.0 autopep8==1.5.2 cachetools==4.1.0 certifi==2020.4.5.1 chardet==3.0.4 colorama==0.4.3 google-api-core==1.17.0 google-auth==1.14.1 google-cloud==0.34.0 google-cloud-core==1.3.0 google-cloud-storage==1.28.0 google-resumable-media==0.5.0 googleapis-common-protos==1.51.0 idna==2.9 isort==4.3.21 lazy-object-proxy==1.4.3 mccabe==0.6.1 protobuf==3.11.3 pyasn1==0.4.8 pyasn1-modules==0.2.8 pycodestyle==2.5.0 pylint==2.5.0 pytz==2020.1 requests==2.23.0 rsa==4.0 six==1.14.0 toml==0.10.0 urllib3==1.25.9 wrapt==1.12.1「実行する関数」を「main」にして「作成」をクリックします。
後は関数名をクリック→「トリガー」タブに書いているURLを叩いてCSVが書き出されれば成功です。
参考
- 投稿日:2020-05-14T18:50:13+09:00
AI製品開発チームの読書会:【INSPIRED 熱狂させる製品を生み出すプロダクトマネジメント】編
本投稿では、私がリードする「AI製品開発チーム」で実施した読書会について、その運営方法と内容を紹介します。
今回の読書会で対象にした書籍は、
【INSPIRED 熱狂させる製品を生み出すプロダクトマネジメント】
https://www.amazon.co.jp/dp/B0814STTHV/です。
日本語では「熱狂させる製品を生み出すプロダクトマネジメント」と訳されていますが、英語では
How to Create Tech Products Customers Love
です。愛される製品の作り方ですね。
プロダクトマネジメントがテーマです。
原著はAmazon.comで370レビューの評価4.6という、プロダクトマネジメントの定番書籍です。日本語版も、とても良くできていて、翻訳も丁寧です。
日本でも、もっとプロダクトマネジメントやプロダクトマネージャー(PdM)が定番化されてくれば、さらに注目を浴びる書籍だと思います。
私がリードする「AI製品開発チーム」のメンバは、技術(とくにAI・ディープラーニング)は強いですが、
メンバには今後さらに、
お客様がお金を払ってでも、愛し利用してくださるプロダクトを創る!
そして、私たちはSIerのAI製品開発チームなので、弊社の営業社員の方々にとって
こんな製品があれば、きっとあのお客様の役に立てる、ぜひあのお客様に紹介したい!
と、自社の営業社員が愛し、お客様に紹介したくなる製品。。。
そんな製品を創るべく、プロダクトマネジメントの意識を高め、
そのための知識を身につけてもらいたく、本書を選定しました。本記事では、
●読書会の運営方法
●実施した感想
●メンバが気に入った箇所を紹介します。
読書会の運営方法
開催時期
2020年4月後半から5月中旬。
COVID-19の影響により、全員自宅からのテレワーク状態の時期に開催しました。開催周期
開催は週に1回、毎週木曜日の13:00から14:00の1時間としました。
全部で5回の開催にしました。全5回の分け方
第1回:chap1~chap8
第2回:chap9~chap21
第3回:chap22~chap37
第4回:chap38~chap57
第5回:chap58~chap67だいたい、毎週50~100ページを範囲としました。
参加メンバ数
今回は時間の都合のついた6名(私含む)で実施
当日までの準備
読書会参加のメンバは、次回の開催範囲を読み、自分が気に入った箇所を2つ選択します。
そして、皆で共有しているファイルに、
・気に入った箇所2つとその文言
そして、
・なぜその箇所を選んだのか?自分の業務とどう関わりがあるのか?自分が気に入った理由を書いてもらいました。といっても簡単に2-3行程度です。
当日の運営
読書会は、Teamsでオンライン開催しました。
当日の運営は、初回は私が実施し、
2回目以降は今後リーダーになっていってもらいたい2名に、毎週交互に実施してもらいました。運営者は、皆が記入した「気に入った箇所2つとその理由」を画面共有します。
画面に表示されている内容を書いた人は、
自分が気に入った箇所を読み上げ、そしてなぜこの箇所を挙げたのか、
自分のこれまでの仕事や今後の想い、普段から思っていることなどを語ってもらいました。メモ書きでは2-3行の記載ですが、それをもう少し詳しく話してもらう感じです。
そして、他の参加者はその箇所や挙げた理由に対して、自由に思ったことや自分の体験などを追加し、
話しを膨らませるという流れです。
これを、5人分やって、私は最後にちょろっとだけ話して1時間という感じです。
実施した感想
参加メンバの各自、思い想いの感想はあると思いますが、私は
みなが気にいった箇所がバラけて、バラけたのは各自の異なる案件・開発経験などから来ており、多様な意見が聞けて楽しかった
逆に多くのメンバが気に入った重要箇所などは、「皆が自分たちは何を大切にしたいと思っているのか?」という、非言語化情報が明確に表出した箇所であり、学びになった
実際にリーダーやPdMに近いことをやる人だけでなく、そのフォロワーとなるメンバも参加した読書会であった。プロダクトマネジメントを共有しながら学んだことで、メンバが円滑にリーダーをフォローし、リーダーも円滑に開発をリードしやすい土台ができたように思う
読書会がちょうど、大きめの開発案件をやり切った後だったので、その振り返りを深めることもできた
書籍1冊の読書会やっただけで、プロダクトマネジメントなんて全然無理ですが、
私も含め、皆で1歩前に進めたことが良かったなと思います。何と言いますか・・・
私たちはまだまだプロダクトマネジメントのゴールと言えるレベルにはいないけれども、
ゴールのある方向へ、皆で同じ1歩踏み出せた感覚です。メンバが気に入った箇所の紹介
最後にメンバの皆がピックアップした箇所を紹介します。
といっても、
6人×5回×2か所の合計60か所が挙がったので、そこから抜粋です。
chap.1_優れた製品の背後にあるもの
“私の信念であり、本書の中心となっている考えがある。
優れた製品の背後には必ず、製品開発チームを率いて技術と設計を組み合わせ、
顧客が抱える本当の課題を、ビジネスのニーズに合った形で解決する人間がいる、ということだ。
その人は普段表には出ないが、絶え間なく仕事をしている。
こうした人々は通常、プロダクトマネジャーという肩書を持っている。”chap.4_成長期企業
“最初の製品ニーズに合うように作られた技術インフラは、しばしば能力の限界に達する。
あなたはエンジニアと顔を合わせるたびに、「技術的負債」という言葉を聞くようになる。”chap.5_成長期企業
“リーダーも往々にして製品開発チームから革新的なアイデアが出せれないことにいらだちを募らせる。
そして、しばしば企業買収に走ったり、独立した「イノベーションセンター」を設立して、
保護された環境で新たなビジネスを生み出そうとしたりする。
だが、こうしたことがリーダーの切望するイノベーションにつながることはほとんどない”chap.6_製品開発が失敗する根本的原因の5
“デザインの役割にも同じことが言える。プロセスの中でデザインの真の価値を取り入れるのが遅すぎる。
そして、おこなわれていることのほとんどが、私たちが「豚に口紅」モデルと呼んでいるものだ。
すでにダメージを受けているのに、ガラクタにペンキを塗ろうとしているだけなのだ。
UXデザイナーはこれが間違っていることを知っているが、できる限り見栄え良く、首尾一貫しているように見せようとする。”chap.7_リーンとアジャイルを超えて
“優れた開発チームは期待する結果を得るために、毎週いくつもの製品のアイデアをテストするのが普通だ。
週に10から20、あるいはそれ以上である。"chap.7_包括的な原則3
“大切なのは機能を実装することではなく、問題を解決することである。”chap.8_継続的な製品発見と市場投入
“製品開発チームは常に並行して2つのことに取り組んでいる。
1つは、作る必要のある製品を発見すること。これは基本的にプロダクトマネジャーとデザイナーが日々取り組んでいる。
もう1つは、エンジニアが高品質な製品を市場に投入することである。”chap.9_開発チームがある場所
”もしあなたが1か所にまとまった製品開発チームのメンバーだったことがあるなら、私の言っていることが分かるはずだ。
そうでなくても、製品開発チームでの仕事のやり方を知れば、チームが一緒に座り、一緒にランチを食べ、互いの個人的関係を築いたときに生まれる独特なエネルギーがあることがわかるだろう。”chap.10_プロダクトマネジャーとプロダクトオーナー
"製品企業においてプロダクトマネジャーが同時にプロダクトオーナーであることが欠かせない。
もしこれから役割を2人の人間に分ければ、よくあるありきたりな問題がいくつか生じる。
最も典型的なのは、ビジネスと顧客に対する新しい価値を革新し、絶えず創造する能力が開発チームから失われることである。
特に製品企業では、プロダクトマネージャーが追加的に責任を持てば、優れたプロダクトオーナーの判断できるようになる。"chap.10_冒頭の後半
”本当のことを言うと、プロダクトマネジャーは会社のなかで、最も才能のある人材の1人であるべきだ。
もしプロダクトマネジャーに、技術に関する高度な知識やビジネスの手腕、主要な幹部との信頼関係、顧客に関する深い知識、製品に対する情熱、製品開発チームへの敬意がなかったりすれば、間違いなく失敗する。”chap.23_ロードマップに代わるもの(P. 137, P.138)
”製品開発チームは、ビジネスにおける脈絡をつかんでいなければならない。
つまり、企業がどこへ向かっているを確実に把握し、大きな目標に対して自分のチームがどのように貢献するのが望ましいのかを理解しなければならないのだ。
すべての製品開発チームが、自分たちの仕事が大きな組織全体にどんなふうに貢献しているか、また、企業が今、チームに集中してほしいことは何なのかを理解することが重要である。”chapter24_製品ビジョンと製品戦略
”うまくいけば、製品ビジョンは最も効果的な人材募集ツールの1つになるし、チームのメンバーが毎日働きに来る動機づけにもなる。
有能なエンジニアは刺激的なビジョンに引き寄せられる。
何か意味のあることに取り組みたいからだ。”chap.25_製品ビジョンの原則_その2
”解決策ではなく問題に恋をする”chap.25_製品ビジョンの原則_その5
”製品ビジョンは人の心を揺さぶらなければならない”chap.33_製品発見の原則_その6
”アイデアの妥当性は実際のユーザーや顧客で立証しなければならない。
製品開発において最も陥りやすいワナの1つは、製品に対する顧客の反応を予測できると思い込んでしまうことである。
それは顧客調査や経験に基づいて出した判断かもしれないが、今日ではよくわかっているように、どんな場合でも、実際のユーザーや顧客でアイデアの妥当性を検証しなければならない。
これは、本物の製品を開発するために時間や費用を費やす前におこなう必要がある。あとではいけない。”chap.34_発見のテクニックの概要_発見のフレーミングテクニック
”自分たちが集中すべきビジネスの目標と、顧客のために解決しようとしている具体的な問題、その問題をどのユーザーや顧客のために解決しようとしているのか、そして何を持って成功というのかについて合意を形成する必要がある。
これらは、製品開発チームの目標(Objective)と主要な結果(Key results)に直接結びつかなければならない。”chap46_実現可能性プロトタイプのテクニック
”私の経験では、1つの実現可能実現可能性プロトタイプをビルドするのに必要な時間は1日から2日が普通である。ただし、機械学習技術を使ったアプローチというような、新しい主要技術を検討している場合は、実現可能性プロトタイプのビルドにはビルドにはもっと時間がかかる可能性が高い”COLUMN_分析の役割
“私の経験では、過去の製品開発で最も悪い結果をもたらしたのは部外者の意見への依存である。
発言した人の地位が組織の中で高ければ高いほど、その意見は重視されがちだ。
現在は、データは意見に勝るという精神のもと、私たちが意見を持つのは、テストの実行、データの収集、そのデータを使って私たちの判断を裏付けるときぐらいである。
データがすべてではないし、私たちはデータの奴隷ではないのだが、現在、最も優秀な製品開発チームには、テスト結果の情報に基づいて判断をしている例が無数に見られる。”chap.61_ステークホルダーを管理する_「成功のための戦略」
“通常、企業はプロジェクトにそのミーティングで、プロダクトマネージャーが、作ろうとしているものについてのプレゼンテーションをパワーポイントを使っておこなうという。
これに2つの深刻な(キャリアの障害になりうる)問題がある。
第1に、事業実現性のテストにプレゼンテーションを使うのは、悪名高いひどい方法だ。理由は、あまりにも曖昧なことである。
・・・
それに対して、高忠実度のユーザープロトタイプは理想的だ。”chap.64_良い製品開発チーム/悪い製品開発チーム
“良い開発チームがひらめきや製品のアイデアを得るのは、自分たちのビジョンや目標からであり、顧客が苦労している様子を見ることや、自分たちの製品を使うことで顧客が生み出すデータを分析すること、実際の問題を解決するために常に新しいテクノロジーを適用しようとすることからである。
悪い開発チームは販売部門や顧客から要望を集める。“chap.64_良い製品開発チーム/悪い製品開発チーム
”良い開発チームは自分たちの製品がどんなふうに使われているかを知るために製品を計装し、データに基づいて調整する。
悪い開発チームは、分析と報告は、あればいいが、なくてもかまわないと考えている。”chap.65_イノベーションが失われる最大の理由
“私たちにとってこのうえなくありがたいことに、顧客はいつも満たされていない。
顧客自身が満足していると言い、売れ行きが順調なときですら不満を持っている。
自覚がなかったとしても、顧客は何かがもっと良くならないかと願っている。
だからこそ、私たちは顧客を喜ばせたいという欲求に駆られて、顧客のために新しいものを生み出すのだ”chap.66_スピードが失われる最大の理由
“同じ場所にいて、長続きする開発チームの不在。
開発チームがいくちかの場所に分散指定て、さらに悪いことにエンジニアリングを外注している場合は、イノベーションの機会が激減する上に、仕事のスピードが大きく損なわれるだろう”chap.67_強い製品開発文化を作る
”いずれにせよ、私があなたやあなたの開発チームにしてほしいのは、イノベーションと実行力の両面から自分自身を見直し、あなたが、チームや企業として、どの位置に行きたいのか、どの位置に行く必要があると考えているのかを自分に問いかけることである。”まとめ
以上、読書会の運営方法と内容の紹介でした。
参考になるものがあれば幸いです。
また読書会以外に、私たちのチームの働き方を以下の記事で紹介しています。
以上、ご一読いただき、誠にありがとうございました。
【免責】本記事は著者の意見/発信であり、著者が属する企業等の公式見解ではございません

- 投稿日:2020-05-14T18:49:16+09:00
【実装解説】日本語版BERTをGoogle Colaboratoryで使う方法(PyTorch)
本記事では、Google Colaboratoryで日本語版のBERTを使用する方法について解説します。
BERTそのものについては、昨年執筆した書籍
「つくりながら学ぶ!PyTorchによる発展ディープラーニング」
で詳細に解説しています。
BERTの仕組みを知りたい方は上記の書籍をご覧ください。
書籍では英語版しか扱っていなかったので、本投稿では日本語版でのBERTの使用方法の解説を行います。
(この記事のあと、2つほど書きたいと思っています。)なお本投稿内容の実装コードは以下のGitHubリポジトリに置いています。
GitHub:日本語版BERTのGoogle Colaboratoryでの使用方法:実装コード
の、1_Japanese_BERT_on_Google_Colaboratory.ipynbです。準備1:MeCabをGoogle Colaboratoryにインストール
分かち書き(形態素解析)のツールであるMeCabをインストールします。
pipではインストールできないので、aptでインストールです。!apt install aptitude swig !aptitude install mecab libmecab-dev mecab-ipadic-utf8 git make curl xz-utils file -yPythonからMeCabを使用できるように、mecab-python3をpipでインストールします。
!pip install mecab-python3MeCabで新語(最近の新しい言葉)を使えるように、辞書であるNEologdをインストールします。
(ただし、学習済みBERTでは使用しません)!git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git !echo yes | mecab-ipadic-neologd/bin/install-mecab-ipadic-neologd -n -a新語辞書NEologdへのpathを取得しておきます。
import subprocess cmd='echo `mecab-config --dicdir`"/mecab-ipadic-neologd"' path_neologd = (subprocess.Popen(cmd, stdout=subprocess.PIPE, shell=True).communicate()[0]).decode('utf-8')以上で、MeCabの仕様準備は完了です。
備考(IPAdicとUniDic)
新語辞書のmecab-ipadic-neologdの、ipadicとは「IPA辞書」のことです。
IPA辞書は「IPA品詞体系」で整理されてます。IPAdic以外にUniDicという表現を見たことがあるかもしれません。
UniDicは「国語研短単位自動解析用辞書」で整理されている体系です。例えば、形態素解析のSudachiの場合、デフォルトの辞書はUniDicです。
UniDicとIPAdicでは品詞体系が異なります。
例えばUniDicでは形容動詞というものはなく、形状詞となります(UniDicの品詞体系)。私自身、新卒入社してITを学び始めて3年、機械学習・ディープラーニングを学びはじめて2年半になります。
新入社員の頃から私のメンターをしてくださっている先輩のFさんはインドネシアの方ですが、私より日本語が上手です。
sudachiのデフォルトは、形容動詞でなく形状詞である点も、インドネシア人のメンターのFさんから教えていただき、「そんな文法、日本人は学校で習っていないです、形状詞って初めて聞ききました」と驚きでした。
準備2:MeCabの動作確認
それでは実際に文章を分かち書き(形態素解析)して、MeCabの動作を確認します。
文章は
「私は機械学習が好きです。」
にしましょう。まずは新語辞書NEologdを使用しない場合です。
import MeCab m=MeCab.Tagger("-Ochasen") text = "私は機械学習が好きです。" text_segmented = m.parse(text) print(text_segmented)(出力)
私 ワタシ 私 名詞-代名詞-一般 は ハ は 助詞-係助詞 機械 キカイ 機械 名詞-一般 学習 ガクシュウ 学習 名詞-サ変接続 が ガ が 助詞-格助詞-一般 好き スキ 好き 名詞-形容動詞語幹 です デス です 助動詞 特殊・デス 基本形 。 。 。 記号-句点 EOSMeCab.Tagger("-Ochasen")の、-Ochasenは出力オプションです。
これを、
-Owakatiにすると、分かち書きのみを出力します。
-Oyomiにすると、読みのみを出力します。m=MeCab.Tagger("-Owakati") text_segmented = m.parse(text) print(text_segmented)出力は
私 は 機械 学習 が 好き です 。
です。m=MeCab.Tagger("-Oyomi") text_segmented = m.parse(text) print(text_segmented)の場合、出力は
ワタシハキカイガクシュウガスキデス。
です。続いて、新語辞書NEologdを使用する場合です。
m=MeCab.Tagger("-Ochasen -d "+str(path_neologd)) # NEologdへのパスを追加 text = "私は機械学習が好きです。" text_segmented = m.parse(text) print(text_segmented)(出力)
私 ワタシ 私 名詞-代名詞-一般 は ハ は 助詞-係助詞 機械学習 キカイガクシュウ 機械学習 名詞-固有名詞-一般 が ガ が 助詞-格助詞-一般 好き スキ 好き 名詞-形容動詞語幹 です デス です 助動詞 特殊・デス 基本形 。 。 。 記号-句点 EOSNEologdを使用するために、MeCab.Taggerに対して、-dでオプションを加え、NEologdへのパスを指定しています。
新語辞書を使用していないときには、”機械学習”という単語が、”機械”と”学習”に分離されていましたが、
新語辞書を使用すると、”機械学習”(固有名詞)と1単語になっています。これは”機械学習”という専門用語が新語辞書に登録されているからです。
新語辞書バージョンでも、-Owakatiにすると、分かち書きのみを出力します。
m=MeCab.Tagger("-Owakati -d "+str(path_neologd)) # NEologdへのパスを追加 text_segmented = m.parse(text) print(text_segmented)出力は
私 は 機械学習 が 好き です 。
となります。準備3:日本語版BERTの学習済みモデルと形態素解析を用意
それでは日本語版BERTの学習済みモデルと形態素解析を用意します。
拙著、「つくりながら学ぶ!PyTorchによる発展ディープラーニング」のBERTモデルも使用できるのですが、ここでは最近スタンダードに使用されている、HuggingFaceさんのモデルを使用します。
Huggingとは日本語でハグする(抱きしめる)の意味です。
BERTモデルはHuggingFaceさんのものを使用し、日本語での学習済みパラメータ、および
学習時の形態素解析(Tokenizer)は
東北大学(乾・鈴木先生研究室)で鈴木正敏さんが公開してくださったもの
を使用させていただきます。この東北大学の日本語版学習済みモデルはHuggingFaceさんのOSSであるtransformersに取り込まれているので、transformersから直接、利用できます。
まずはpipでtransformersのバージョン2.9をインストールします。
!pip install transformers==2.9.0注意
transformersは2020年5月8日にバージョンが2.8から2.9にアップされました。
バージョン2.8だと、日本語データへのファイルパスがエラーになるので、2.9をインストールするように注意してください。それでは、PyTorch、BERTモデル、そして日本語のBERT用tokenizer(分かち書きするクラス)をimportします。
import torch from transformers.modeling_bert import BertModel from transformers.tokenization_bert_japanese import BertJapaneseTokenizer日本語用のtokenizerを用意します。引数に'bert-base-japanese-whole-word-masking'を指定します。
# 分かち書きをするtokenizerです tokenizer = BertJapaneseTokenizer.from_pretrained('bert-base-japanese-whole-word-masking')日本語での学習済みモデルを用意します。
# BERTの日本語学習済みパラメータのモデルです model = BertModel.from_pretrained('bert-base-japanese-whole-word-masking') print(model)出力されたモデルの結果を簡単に確認すると以下の通りです。
BertModel( (embeddings): BertEmbeddings( (word_embeddings): Embedding(32000, 768, padding_idx=0) (position_embeddings): Embedding(512, 768) (token_type_embeddings): Embedding(2, 768) (LayerNorm): LayerNorm((768,), eps=1e-12, elementwise_affine=True) (dropout): Dropout(p=0.1, inplace=False) ) (encoder): BertEncoder( ・・・ここで、日本語版モデルの設定(config)を確認しておきます。
from transformers import BertConfig # 東北大学_日本語版の設定を確認 config_japanese = BertConfig.from_pretrained('bert-base-japanese-whole-word-masking') print(config_japanese)出力は以下です。
BertConfig { "architectures": [ "BertForMaskedLM" ], "attention_probs_dropout_prob": 0.1, "hidden_act": "gelu", "hidden_dropout_prob": 0.1, "hidden_size": 768, "initializer_range": 0.02, "intermediate_size": 3072, "layer_norm_eps": 1e-12, "max_position_embeddings": 512, "model_type": "bert", "num_attention_heads": 12, "num_hidden_layers": 12, "pad_token_id": 0, "type_vocab_size": 2, "vocab_size": 32000 }設定を見ると、単語ベクトルは768次元、最大の単語数(サブワード数)は512、BERTのレイヤー数は12層、ボキャブラリのサイズは32,000であることが分かります。
以上で、日本語学習済みモデル、モデルに投入する前に使用する日本語用tokenizerが用意できました。
日本語版BERTで文章を扱う
それでは最後に、文章を日本語版BERTで扱いましょう。
「会社をクビになった。」
「テレワークばかりでクビが痛い。」
「会社を解雇された。」という3つの文章を用意します。
そしてそれぞれの文章の、”クビ”、”クビ”、"解雇"の3単語のベクトルを比較します。
BERTは文脈に応じて単語ベクトルが変化するのが特徴なので、1つ目と2つ目の文章では
”クビ”という同じ単語でも768次元のベクトル表現は異なるものになります。そして、1つ目の文章の”クビ”が、2つ目の文章の”クビ”よりも、3つ目の文章の"解雇"に近いと嬉しいです。
単語ベクトルの類似度はコサイン類似度で計測しましょう。
それでは実装します。
まず文章を用意します。text1 = "会社をクビになった。" text2 = "テレワークばかりでクビが痛い。" text3 = "会社を解雇された。"text1を日本語版BERTの分かち書きtokenizerで処理します。
# 分かち書きをして、idに変換 input_ids1 = tokenizer.encode(text1, return_tensors='pt') # ptはPyTorchの略 print(tokenizer.convert_ids_to_tokens(input_ids1[0].tolist())) # 文章 print(input_ids1) # id出力は
['[CLS]', '会社', 'を', 'クビ', 'に', 'なっ', 'た', '。', '[SEP]'] tensor([[ 2, 811, 11, 13700, 7, 58, 10, 8, 3]])となります。
”クビ”という単語は3番目で、idは13700と分かりました。
2つ目、3つ目の文章も同様に処理します。それぞれの出力は、以下のようになります。
['[CLS]', 'テレ', '##ワーク', 'ばかり', 'で', 'クビ', 'が', '痛', '##い', '。', '[SEP]'] tensor([[ 2, 5521, 3118, 4027, 12, 13700, 14, 4897, 28457, 8, 3]]) ['[CLS]', '会社', 'を', '解雇', 'さ', 'れ', 'た', '。', '[SEP]'] tensor([[ 2, 811, 11, 7279, 26, 20, 10, 8, 3]])2つ目の文章の”クビ”は5番目、3つ目の文章の”解雇”は3番目と分かりました。
それではこのid化された内容を日本語BERTモデルに入力し、出力ベクトルを計算します。
# 日本語BERTモデルに入力 result1 = model(input_ids1) print(result1[0].shape) print(result1[1].shape) # reult は、sequence_output, pooled_output, (hidden_states), (attentions)です。 # ただし、hidden_statesとattentionsはoptionalであり、標準では出力されません。出力は
torch.Size([1, 9, 768])
torch.Size([1, 768])
となります。9は、1つ目の文章の単語数(サブワード数)を表します。
768は単語の埋め込み次元です。
よって、1つ目の文章の"クビ"は3番目にあったので、その単語ベクトルは
result1[0][0][3][:]
となります。なお、BERTモデルの計算で出力されるのは
outputs # sequence_output, pooled_output, (hidden_states), (attentions)
です(ただし、hidden_statesとattentionsはoptionalであり、標準では出力されません)。同様に2つ目の文章の”クビ”(5番目)、3つ目の文章の”解雇”(3番目)の単語ベクトルも求めます。
# 日本語BERTモデルに入力 result2 = model(input_ids2) result3 = model(input_ids3) word_vec1 = result1[0][0][3][:] # 1つ目の文章の”クビ”(3番目) word_vec2 = result2[0][0][5][:] # 2つ目の文章の”クビ”(5番目) word_vec3 = result3[0][0][3][:] # 3つ目の文章の”解雇”(3番目)最後に類似度を求めてみます。
# コサイン類似度を求める cos = torch.nn.CosineSimilarity(dim=0) cos_sim_12 = cos(word_vec1, word_vec2) cos_sim_13 = cos(word_vec1, word_vec3) print(cos_sim_12) print(cos_sim_13)出力は
tensor(0.6647, grad_fn=<DivBackward0>)
tensor(0.7841, grad_fn=<DivBackward0>)
となりました。
よって、BERTで処理された単語表現は、
1つ目の文章の”クビ”と2つ目の文章の”クビ”の類似度は0.66
1つ目の文章の”クビ”と3つ目の文章の"解雇"の類似度は0.78と、1つ目の文章の”クビ”は3つ目の文章の"解雇"に近い(類似度が高い)と分かります。
同じ"クビ"という単語でも、BERTを使うことで、文脈に応じた意味に変化した単語ベクトルになっていることが確認できました。
以上、【実装解説】日本語版BERTをGoogle Colaboratoryで使う方法(PyTorch)でした。
来週は、
【実装解説】日本語版BERTでLivedoorニュースをクラス分類する方法(GoogleColaboratory & PyTorch)
を書きたいな、と思っています。【免責】本記事は著者の意見/発信であり、著者が属する企業等の公式見解ではございません
- 投稿日:2020-05-14T18:41:29+09:00
AtCoderBeginnerContest166復習&まとめ(後半)
AtCoder ABC166
2020-05-03(日)に行われたAtCoderBeginnerContest166の問題をA問題から順に考察も踏まえてまとめたものとなります.
後半ではDEFの問題を扱います.前半はこちら.
問題は引用して記載していますが,詳しくはコンテストページの方で確認してください.
コンテストページはこちら
公式解説PDFD問題 I hate Factorization
問題文
$A^5−B^5=X$を満たす整数の組$(A,B)$をひとつ示してください。 ただし、与えられる$X$に対して、条件を満たす整数の組$(A,B)$が存在することが保証されています。
制約
・$1 \leq X \leq 10^9$
・$X$は整数である。
・条件を満たす整数の組$(A,B)$が存在する。問題を読んで,どんな$X$にも条件を満たす整数の組$(A,B)$が存在すると思ってしまいました(数弱過ぎた…).
いろいろなパターンの$X$を実装したプログラムに入力しても出力がなかったので,探索範囲が足りてないのかと思い,詰みました.
コンテスト終わった後に,解説読んで,もしかしてと思い,実装したプログラム提出したら"AC"だったので,提出しておけばよかったです…abc166d.pyx = int(input()) flag = 0 for a in range(-200, 201): if flag == 1: break for b in range(-200, 201): if a**5 - b**5 == x: print(a, b) flag = 1 breakE問題 This Message Will Self-Destruct in 5s
問題文
AtCoder 王国の優秀なエージェントであるあなたは、盗まれた極秘情報が AlDebaran 王国の手に渡ることを阻止するため、取引現場であるパーティに潜入しました。
パーティには$N$人の参加者がおり、それぞれ$1$から$N$までの番号がついています。参加者$i$の身長は$A_i$です。
あなたは事前の尋問によって、極秘情報を取引するのは以下の条件を満たす$2$人組であることを知っています。
・$2$人の持つ番号の差の絶対値が、$2$人の身長の和に等しい。
$N$人の参加者のうちから$2$人を選んでペアにする方法は$\frac{N(N−1)}{2}$通りありますが、このうち上の条件を満たすペアは何通りあるでしょう?
なお、極秘情報の内容が何であるかはあなたの知るところではありません。コンテスト参加時は,D問題に固執して,E問題の時間があまりとれず解けませんでしたが,このレベルの問題であれば解けるようになりたいです.
「E問題F問題=難しい問題」と意識してしまっていて,コンテスト中に解けるようになかなかならないです.
解説記事に書いてあることを実装し,以下のコードで無事"AC"出ました.abc166e.pyn = int(input()) a_list = list(map(int, input().split())) l_dict = {} ans = 0 for i in range(0, n): a = a_list[i] ri = i - a if ri in l_dict: ans += l_dict[ri] li = i + a if li in l_dict: l_dict[li] += 1 else: l_dict[li] = 1 print(ans)$2$人の持つ番号の差の絶対値っていう表現に惑わされました.
よくよく考えれば,二人を選んだ時点で,$i < j$の条件を付けることができたんですね.
負のとき,絶対値の処理しないとダメなのか,難しそう.と思った時点で負けが確定してたので,難しいと思わないようにしたいです.F問題 Three Variables Game
問題文
あるゲームでは$3$つの変数があり、それぞれ$A,B,C$で表されます。
ゲームの進行と共に、あなたは$N$回の選択に迫られます。それぞれの選択は文字列$s_i$によって示され、$s_i$が"AB"のとき、$A$と$B$のどちらかに$1$を足しもう一方から$1$を引くこと、"AC"のとき、$A$と$C$のどちらかに$1$を足しもう一方から$1$を引くこと、"BC"のとき、$B$と$C$のどちらかに$1$を足しもう一方から$1$を引くことを意味します。
いずれの選択の後にも、$A,B,C$のいずれも負の値になってはいけません。
この条件を満たしつつ$N$回すべての選択を終えることが可能であるか判定し、可能であるならそのような選択方法をひとつ示してください。解説読んで,書いてあることをただただ実装しました.
$A+B+C=2$のときだけ,処理に気を付けないといけないのは,入力例にもないので気づくの難しい気がする.
こういう問題をコンテスト中に解けるようになりたい.abc166f.pydef check(s): if dict_x[s[0]] == 0 and dict_x[s[1]] == 0: return "NOT" elif dict_x[s[0]] > 0 and dict_x[s[1]] == 0: return s[1] elif dict_x[s[0]] == 0 and dict_x[s[1]] > 0: return s[0] elif dict_x[s[0]] == 1 and dict_x[s[1]] == 1: return "EVEN" else: if dict_x[s[0]] > dict_x[s[1]]: return s[1] else: return s[0] def update(s, mozi): if s[1] == mozi: dict_x[s[0]] -= 1 dict_x[s[1]] += 1 else: dict_x[s[0]] += 1 dict_x[s[1]] -= 1 n, a, b, c = map(int, input().split()) dict_x = {"A": a, "B": b, "C": c} s_list = [] ans_list = [] flag = 1 for i in range(0, n): s = input() s_list.append(s) if a + b + c == 0: flag = 0 elif a + b + c == 1: for s in s_list: x = check(s) if x == "NOT": flag = 0 break else: ans_list.append(x) update(s, x) elif a + b + c == 2: i = 0 for s in s_list: x = check(s) if x == "NOT": flag = 0 break elif x == "EVEN": if i == len(s_list) - 1: ans_list.append(s[0]) update(s, x) elif s == s_list[i + 1]: ans_list.append(s[0]) update(s, x) else: if s[0] in s_list[i + 1]: ans_list.append(s[0]) update(s, s[0]) else: ans_list.append(s[1]) update(s, s[1]) else: ans_list.append(x) update(s, x) i += 1 else: for s in s_list: x = check(s) if x == "NOT": flag = 0 break elif x == "EVEN": ans_list.append(s[0]) update(s, s[0]) else: ans_list.append(x) update(s, x) if flag == 1: print("Yes") for ans in ans_list: print(ans) else: print("No")F問題とか自分で書いたコード見直すと,まだまだ無駄が多いなーと実感する.
後半も最後まで読んでいただきありがとうございました.
- 投稿日:2020-05-14T18:35:34+09:00
AtCoderBeginnerContest166復習&まとめ(前半)
AtCoder ABC166
2020-05-03(日)に行われたAtCoderBeginnerContest166の問題をA問題から順に考察も踏まえてまとめたものとなります.
前半ではABCまでの問題を扱います.
問題は引用して記載していますが,詳しくはコンテストページの方で確認してください.
コンテストページはこちら
公式解説PDFA問題 Registration
問題文
AtCoder 社は、毎週土曜日にコンテストを開催しています。
コンテストには ABC と ARC の$2$つの種類があり、毎週どちらか一方が開催されます。
ABC が開催された次の週には ARC が開催され、ARC が行われた次の週には ABC が開催されます。
先週開催されたコンテストを表す文字列$S$が与えられるので、今週開催されるコンテストを表す文字列を出力してください。このあたりは,特に悩むことなく解けるかなと思います.
受けとった文字列が ABC と ARC のどちらであるかをif文で判定すれば終わりです.abc166a.pys = input() if s == "ABC": print("ARC") else: print("ABC")B問題 Trick or Treat
問題文
ある街に、$N$人のすぬけ君(すぬけ君$1$、すぬけ君$2$、...、すぬけ君$N$)が住んでいます。
この街には、$K$種類のお菓子(お菓子$1$、お菓子$2$ 、....、お菓子$K$)が売られています。お菓子$i$を持っているのは、すぬけ君$A_{i,1},A_{i,2},⋯,A_{i,d_i}$の計$d_i$人です。
高橋君は今からこの街を回り、お菓子を$1$つも持っていないすぬけ君にいたずらをします。このとき、何人のすぬけ君がいたずらを受けるでしょうか。いたずらを受けるすぬけ君を記録しておくリスト
kun_listを作ります.
最初にお菓子の情報を与えない場合,全員がお菓子を持ってないことになるので,全すぬけ君はいたずらを受けることになります.
なので,そこに与えられたお菓子の情報を使って,お菓子を持っているすぬけ君をいたずらリストから外していけば,最終的にお菓子を持ってない,いたずらされるすぬけ君がリストに残るので,人数を数えることで解けます.abc166b.pyn, k = map(int, input().split()) kun_list = [1] * n for i in range(0, k): d = int(input()) a_list = list(map(int, input().split())) for a in a_list: kun_list[a-1] = 0 print(sum(kun_list))C問題 Peaks
問題文
AtCoder丘陵には$N$個の展望台があり、展望台$i$の標高は$H_i$です。 また、異なる展望台どうしを結ぶ$M$本の道があり、道$j$は展望台$A_j$と展望台$B_j$を結んでいます。
展望台$i$が良い展望台であるとは、展望台$i$から一本の道を使って辿り着けるどの展望台よりも展望台$i$の方が標高が高いことをいいます。 展望台$i$から一本の道を使って辿り着ける展望台が存在しない場合も、展望台$i$は良い展望台であるといいます。
良い展望台がいくつあるか求めてください。解説では,展望台$i$から一本の道でいける(隣接する)展望台の最大の高さ$maxH_i$を各展望台で求めて,$H_i > maxH_i$であれば,良い展望台であるためその数を数える方法をとっていました.
自分は,全ての展望台をとりあえず良い展望台として,ten_listという展望台のリストを作りました.
道の情報が一つ与えられることにより,どちらか or 両方の展望台が良い展望台ではなくなっていくため,高さを比較して,ten_listを更新していきました(両方の展望台が良い展望台でなくなるのは高さが等しいとき).
最後に,残った良い展望台の数を数えればOKです.abc166c.pyn, m = map(int, input().split()) h_list = list(map(int, input().split())) ten_list = [1] * n for i in range(0, m): a, b = map(int, input().split()) if h_list[a - 1] <= h_list[b - 1]: ten_list[a - 1] = 0 if h_list[a - 1] >= h_list[b - 1]: ten_list[b - 1] = 0 print(sum(ten_list))前半はここまでとなります.
後半はDEF問題の解説となります.
C問題がB問題とほとんど同じような感じで解ける問題だったので,コンテスト時,少し不安でしたが詰まることなくここまでは解けました.
しかし,今回のコンテストもABCまで解いた後,行き詰まり,試行錯誤しましたが結局"AC"は出せずに終わってしまい,C問題までの短距離走の速さ比べになってしまい反省しています.
確かC問題通したのが開始14分ごろだった.
やっぱり,難しい問題を一問くらいは通して,徒競走から抜け出したいと思っています.
とりあえず前半の最後まで読んでいただきありがとうございました.
後半に続く.
- 投稿日:2020-05-14T18:30:52+09:00
Python系のpdfチートシートたち
チートシートを手元におきたい
使いながら随時更新しますが、pdfのチートシートたちを集めておきます。さくっと印刷できるので、手元にない時はこいつらを印刷しておくと便利かもしれません。
基本はもちろんAnaconda
これがないと始まりません。
https://docs.conda.io/projects/conda/en/4.6.0/_downloads/52a95608c49671267e40c689e0bc00ca/conda-cheatsheet.pdfそれからPython3
PythonのリストはNumpyとかと挙動が違って、忘れがちです。手元にあると楽そう。
https://perso.limsi.fr/pointal/_media/python:cours:mementopython3-english.pdfNumpy
Numpyは大規模な三次元以上のデータの処理に便利ですが、忘れて調べることもしばしば。
https://s3.amazonaws.com/assets.datacamp.com/blog_assets/Numpy_Python_Cheat_Sheet.pdfPandas
こちらは絵つきでわかりやすいですが、個々のメソッドの使い方についての情報量は少なめかも。いいのがあればアップデートします。
https://pandas.pydata.org/Pandas_Cheat_Sheet.pdfおまけで、VimとLatexのチートシートも置いておきます。
https://www.math.brown.edu/~jhs/ReferenceCards/TeXRefCard.v1.5.pdf
https://www.cs.cmu.edu/~15131/f17/topics/vim/vim-cheatsheet.pdfそれでは良いチートライフを!
- 投稿日:2020-05-14T18:27:47+09:00
リモートでPythonデータ分析研修をやりました
概要
社内の新卒研修でpythonの研修を2020年4月に実施しましたので、それにあたって検討したあれこれをまとめました。
同じようなことをやろうとしている人の参考になれば。以前やったPythonを使ったデータ分析の研修についても興味があればどうぞ。
勉強会の概要
参加者
弊社の新入社員が対象。
文理、プログラミング経験はばらばら。目標について
研修を行う目的は、Pythonを使ったデータ分析業務を遂行できるようになることです。ただこれは努力目標みたいなところがあるので、もう少しやるべきことを具体化するために行動目標と達成目標を設定しました。
行動目標として「講義内で扱う基本的な機能を理解し、それらを組み合わせた発展的な実装を自分自身で試行錯誤しながら実装する」を、達成目標として「指定した課題をクリアする」としました。
環境
今回は、Anacondaを利用することとしました。
アカウントがあれば初心者でもすぐに利用できるgoogle colabも検討しましたが、ただ触ってみることが目的ではなく実業務で使うことを考えると、自分でインストールし環境を見える化した方が理解が深まると考えたためです。
研修カリキュラム
以下のようなコンテンツで進めました。
あまりちゃんと確認はしてないですが、自分が受験した時の主観では、Python3エンジニア認定基礎試験の4~5割位は取れるコンテンツは網羅していると思います。
なお、データ分析や機械学習の実践については別の研修で扱っているため、ここでは取り扱っていません。(こちらも僕の担当なので、そのうち記事にします)
- オリエンテーション
- 研修の概要
- 進め方や受講者側が意識すべきこと
- データ分析におけるPythonの利用イメージ
- Pythonの特徴について
- Python環境について
- プログラミング時に意識すべきこと
- pythonの基礎
- 型(int, float, str, bool)
- データ構造(list, dict, tuple)
- 構文(if, for, try, def)
- ファイル入出力
- クラス
- モジュール
- 課題
- 演習
- 実データ収集と可視化
- 結果の発表
準備時に考慮したこと
- 「なぜPythonを使うのか」「なぜPythonなのか」について、業務での使い方を交え、最初に理解してもらうようしました
- 具体的なイメージがあった方がモチベーションも上がるという考え
- 後述するレビュー観点にあるような内容ですが、プログラミング時に意識してほしいことを明記しました
- 業務でプログラミングする以上、一過性のものではなく、長期的な運用を見据え、最低限可読性高い必要があるため
講義内で全てを説明するのは困難であるため、サンプルコードを多めに添えて、動かしながら理解してもらうことを意識しました
- また、関連書籍を経費で購入・配布し、利用してもらいました
データ分析をするために必要な知識を身に付けることが目的なので、不要な知識は極力削りました
- 例えば、tryやassertは有用ですが、特に初心者は混乱の元になると思いましたので、紹介程度に留めました
- また、クラスも扱っていますが、最低限の情報に留めています
多くの知識を詰め込むというより、重要な基礎をちゃんと理解してもらうことと色々試行策度する力を身に付けてもらうことを重視しています
- 課題内容の半分程度は、調べることを前提にした内容となっています
- 簡単なサンプルコートは提示しますが、直接的な回答は示さず、リファレンス等を参考にしないと解いてもらいます
- 課題の中でデータ分析でほぼ必須となるpandasやmatplotlibを学習してもらいます
最終的な目的は業務で使える水準に達することなので、実業務を想定した演習を行いました
- 実際の使い方のイメージをつかんでもらいます
- データ分析に関する色々な話は本研修では取り扱っていません
進め方で工夫したこと
- コロナで現地開催するのは現実的でないご時世なので、研修自体はオンラインビデオ会議ツールを使って、リモートにて行いました
- オンサイトと異なり、反応から理解度がどの程度か分かりにくいので、適宜質問を促す等する
- 資料自体を見やすいよう大きめのフォントで簡素に作成する
- 資料に添えたサンプルコードを実際に実行しながら、各機能について説明しました
- Slackで質問用チャンネルを用意し、講義中・講義外共に質問しやすい仕組みを用意しました
- また、各人の理解度の把握した上での個別指導をするため、個別に面談を行い、解いてもらったプログラム課題を見ながら、口頭試問やコードレビューを行いました
- この指導による効果は大きいですが、非常に時間がかかるので、改善ポイントでもあります
課題のレビュー方針について
研修時には課題を設けましたが、そのレビュー時に具体的に何を確認するかは明確に定めました。これは、以下のGoogleのコードレビューガイドラインを参考にしております。
- 設計: 適切に設計されているか
- 機能: 想定通りの挙動をするか
- 複雑さ: シンプルになっているか
- テスト: 適切な自動化テストがあるか
- 命名: 変数・クラス・メソッドなどに明確な名前がつけられているか
- コメント: 適切なコメントがつけられているか
- スタイル: コーディングスタイルに従っているか
- ドキュメント: 関連するドキュメントが更新されているか
資料の抜粋
一部、コンテンツを公開しようと思います。
(全編公開でもいいのですが、口頭説明が前提の資料となっており、あまり十分なものになってないと思うのでやめておきます。)
研修を受ける際の心構え
まず手を動かそう
- 案ずるよりも産むが易し
- 失敗を恐れるな
- 試行錯誤の経験が後々に活きてくる
考えて分からなければ調べる・質問する
- 初心者が困るポイントは、大体誰かが解決している
- コピペで終わるのはNG 原因と解決法をしっかり理解しよう
- どうしても解決できなければ質問する 周りの力を借りるのも時には必要
- トラブル解決時の勘所を身に付けていく
自立的かつ自律的に取り組む
- 本講義内容で扱うのは、あくまで最低限のスキルレベル
- 教わるだけでなく学び取る姿勢が大事
- 終わったら、更に気になる分野を学習してみよう
プログラミング時に意識すべきこと
質の高いプログラムを意識する
- 「動けばいい」精神は悪
- プログラムは、一から書き上げるよりも、読んだり変更を加えることの方が多い
- 品質が低いプログラムは、後々の自分や周りへの生産性に影響を及ぼす
プログラムの品質に関する観点
反省点
オンライン会議特有のコミュニケーションが不得手でした
- オンサイトでは生で感じられる反応ですが、オンラインでは積極的に反応を確かめないといけないです
- また、こちらから届けられる情報も、(やり方にもよりますが)画面共有の情報と音声だけなので、気を使う必要があります
- これは講師側の都合ですが、1人でずっと喋り続けなければならない状況は精神的に疲弊します
質問しやすい仕組みづくりはしましたが、そもそも質問しやすくなるよう心理的安全性を構築することは課題です
- 特に入社からリモートでしか接してない人との関係性の構築ってどうやるの?と感じてます
- 個別の面談はその対策の1つになるかなとは思います
初心者がつまずきやすいトラブルシューティングが足りませんでした
- 経験を積むと何となくわかってくる勘所をどう教えるかは未だに悩ましいです
- 苦労して学んでもらうというのも一つの手段ですが、それではとても解決できない部分もあるので、どこまで自分でやるのかの基準を作る必要があるかと思いました
複雑な課題を解くための考え方が不十分でした
- 簡単な処理を組み合わせ、複雑な処理を実現する課題を設けましたが、初心者にとってハードルが高かったようです
- プログラミングのロジックの考え方を身に付ける意図ですが、他の課題が調べながら進めることを前提にしていたこともあり、解き方が大分変わるためです
- おそらく複雑なプログラムを読んでもらって簡略的な図に落としてもらうなどの作業をしてもらい、どのようにプログラミングを進めていくかを身に付けてもらう必要があったかと思います
最後に
何度目かの自分が講師として研修をする機会でしたが、初めてのオンラインでの実施だったので苦労することが多かったです。
別の講義も担当していますので、そのことについても、いずれ記事しようと思います。
- 投稿日:2020-05-14T17:40:36+09:00
「サイトウの代表は、斎藤なのか?」を科学する
サイトウ問題
- みなさんの近くには、「サイトウ(斎藤さん)」はいらっしゃるでしょうか?
- そのサイトウさん、「斎藤」「齋藤」「斉藤」「齊藤」。どの字でしょうか?
- そう!どの漢字だったか忘れてしまう。通称、「サイトウ問題」です。
なにをやるか
- いっそのこと、代表のサイトウを1字決めて、その字に統一できれば、、とか考えました。
- 漢字のカタチから代表のサイトウ を検討する過程を、ネタ的にお送り致します。
- 次元圧縮(UMAP)とクラスタリング(主にKMeans)を用いていきます。
- ネタです。ネタです。もう一度言います。ネタです。
漢字として認められている「斎藤」
- 4種(新字体2つ、旧字体2つ)です。東洋経済オンラインによると、
- ①斎藤が、源流、
- ②齋藤は、源流(①)の旧字体。
- ③斉藤は、新字体(①)の書き間違い。 (驚愕の事実 その1)
- ④齊藤は、旧字体(②)の書き間違い。 (驚愕の事実 その2
- 下記、カッコ内の日本における人口は、①が一番多く、斎藤が源流 である点が感じられる。
新字体 旧字体 源流 ①U+658E (542,000人)

源流②U+9F4B(86,800人)
源流(①)の旧字体実は、
書き間違い③U+6589(323,000人)
源流(①)の書き間違い④U+9F4A(37,300人)
旧字体(②)の書き間違いで、気持ち的には
やはり、「斎」(①源流)が、全サイの字(4種)の 代表(ど真ん中) にあってほしい。
なので、確認してみる
- サイトウの、代表(ど真ん中) を確認するために、サイトウ地図を作りたい。
- 一方、利用画像は、58x58=3,364ピクセル(3,364次元)で、X-Y座標(2次元)にはマッピングできない。
- そこで、次元圧縮という手法を使って、3,364次元 ⇒ 2次元 に圧縮をしてみたいと思います。
- 文字の次元圧縮については、こちらの記事で取り上げられているので、リンクさせていただきます。
- 今回は、次元圧縮のアルゴリズムとして、UMAPを利用します
- では、UMAPで次元圧縮しておきます。
from umap import UMAP # Umap decomposition decomp = UMAP(n_components=2,random_state=42) # fit_transform umap(サイトウ4文字データ) embedding4 = decomp.fit_transform(all.T[[1,12,31,32]])検証1) 4つのサイトウの代表を決める
- UMapを利用して、2次元(平面)に、漢字画像をマッピングし、「代表」を確認していきます。
- 「中心」(0.5, 0.5)ではなく、全データに対する 「重心」を「代表」 として、見ていきます。
- 「重心」は、xマークで表していますが、いかがでしょう。。(重心 x の下方ですね。)
from sklearn.cluster import KMeans # clustering(クラスタ数1) clustering = KMeans(n_clusters=1,random_state=42,) # fit_predict cluster cl_y = clustering.fit_predict(embedding4) # visualize (実装は後述) showScatter( embeddings = embedding4, clusterlabels = cl_y, centers = clustering.cluster_centers_, imgs = all.T[[1,12,31,32]].reshape(-1,h,w) )
- 微妙ですね、、
- 「重心」から「各文字」へのユークリッド距離を計算するとこんな感じ。
- この結果では、②源流(旧字体)の齋 が代表となってしまった。。
重心からの近さ順 文字 重心からの距離 メモ 1位 0.6281 ②源流(旧字体) 2位 0.6889 ③間違い(新字体) 3位 0.7339 ①源流(新字体) 4位 0.8743 ④間違い(旧字体) 検証2) 33個のサイトウの「代表」を決める
ところで、サイトウは、何種類あるのか?
- 漢字としては4種類だけだが、実を言うとwikipedia によれば、
- 「斉、斎」以外の異体文字は31パターンもある。
- 一方で、法務省が認めているサイの字は、「斎、齋、斉、齊」の4つだけ。
- つまり、全33パターンのうち、漢字として認められているのは4つだけ
- 漢字として認められているサイトウ以外に、全33サイトウの「代表」 を見てみたい
- では、今度は33文字分UMAPで次元圧縮しておきます。
from umap import UMAP # Umap decomposition decomp = UMAP(n_components=2,random_state=42) # fit_transform umap(全33文字データ) embeddings = decomp.fit_transform(all.T)33個の「サイトウ」の「代表」は?
- 同じくUMAPで次元圧縮し、「重心」に近い漢字を確認していきます。
from sklearn.cluster import KMeans # clustering(クラスタ数 : 1) clustering = KMeans(n_clusters=1, random_state=42) # fit_predict cluster cl_y = clustering.fit_predict(embeddings) # visualize showScatter(embeddings, cl_y, clustering.cluster_centers_)
が、代表(ど真ん中)に近い結果となってしまいました。。
重心からの距離順(上位)は以下の通り。なかなか期待通りには行かないww
重心からの近さ順 文字 重心からの距離 メモ 1位 0.494 2位 0.787 3位 1.013 4位 1.014 検証3) 代表の「サイトウ」を4文字選ぶ
- 「ど真ん中」はうまく行かなかったのですが、漢字として認められているのは、4種類。
- では、この地図上の漢字を4クラスタに分離して、それぞれのクラスタの重心はどの漢字となるか?
- つまり、全33字から、代表の4字 を選んで見たいと思います。
- クラスタリングアルゴリズムのKMeansを利用し、4クラスタに分離すると下記のとおり。
from sklearn.cluster import KMeans # clustering(クラスタ数 : 4) clustering = KMeans(n_clusters=4, random_state=42) # fit_predict cluster cl_y = clustering.fit_predict(embeddings) # visualize showScatter(embeddings, cl_y, clustering.cluster_centers_)
- 各クラスタの文字と重心に近い文字は下記の通り。
- なんとなく漢字の特徴(月や示)を捉えたクラスタにはなっていそう。
- クラスタ重心の近傍点がクラスタの特徴を捉えられているか?は微妙。
- 4クラスタだと分類しきれず、赤クラスタは複数のパターンを含む。
- もう少し、細かく分類する必要がありそう
- ざっくり見てみると、倍の8クラスタあれば、キレイに分けられそうな予感。
No クラスタ 重心 他に含まれる字 1 赤 


2 橙 
3 青 

4 緑 

検証4) 8クラスタ化してみる
- 先程は、代表の漢字を4文字選ぶために4クラスタでした。
- ただ、結果を見ると、キレイに分離できていないクラスタも存在したので、クラスタ数を8にしてみます。
- 結果は下記の通り。
from sklearn.cluster import KMeans # clustering(クラスタ数 : 8) clustering = KMeans(n_clusters=8, random_state=42) # fit_predict cluster cl_y = clustering.fit_predict(embeddings) # visualize showScatter(embeddings, cl_y, clustering.cluster_centers_)
- キレイに分離ができているわけではないですが、なんとなく仕分けできた感じです。
No クラスタ クラスタに含まれる字 1 桃 
2 赤 
3 茶 
4 灰 

5 橙 

6 青 
7 紫 
8 緑 
- 惜しいのは、橙の
と、灰の
で、クラスタが割れてしまっています。
- ただ、両者ともクラスタの境界線上のデータであるため、思いは伝わってきます(笑)

検証5) 何クラスタが妥当かを確認する
- 漢字として登録のある4字に合わせて、4クラスタ。
- そして、4クラスタの結果をみて、8クラスタに分離してみたわけですが、、
- 果たして、何クラスタにするのが適切なのでしょうか?
- ここでは、クラスタ数を選定する方法として、下記3手法でクラスタの状態を可視化、検討してみたいと思います。
- Elbow Chart
- Silhouette Chart
- dendrogram
Elbow Chart
- elbow chartは縦軸に 各クラスタでのデータのばらつき 、横軸に クラスタ数 をとった図です。
- クラスタの数を多くすれば、ばらつきを抑えることが出来ますが、クラスタ数が多すぎるのも問題です。
- そこで、そこそこのクラスタ数 でかつ データのばらつきも抑えられる クラスタ数をこの図で検討します。
- 作図には、Yellowbrickを利用していきます。
from yellowbrick.cluster import KElbowVisualizer vis = KElbowVisualizer( KMeans(random_state=42), k=(1,34) # クラスタ数(横軸の範囲) ) vis.fit(embeddings) vis.show()
- 見ている感触では、
- クラスタ数5までは、順調に データのばらつき(の平均)は下がり が、以降はフラットに。
- よって、5クラスタに分類 が良さそう = 代表の漢字は 5種 が良さそうです。
- が、一応拡大版も見ておきましょう(4~18で拡大)
- 5に変曲点がありそうなのですが、概ね10付近 からフラットになっています。
- つまり、 感覚で8クラスタに分類し、代表漢字を8個決めた のも間違いではなさそうです。
from yellowbrick.cluster import KElbowVisualizer vis = KElbowVisualizer( KMeans(random_state=42), k=(4,19) # クラスタ数(横軸の範囲) ) vis.fit(embeddings) vis.show()
Silhouette Chart
- Silhouette Chartは、クラスタ毎に下記を表現した図です。
- 縦軸(グラフの厚み) : そのクラスタのサンプル数
- 横軸(グラフの長さ) : そのクラスタのシルエット係数
- 破線 : シルエット係数の平均
- 見方としては、下記を満たすようなグラスタ数を見つけるのがポイントです。
- どのクラスタも同じサンプル数 = 厚みが一緒
- どのグラスタもシルエット係数が平均に近い = 長さが破線に近い
- 作図には、同じくYellowbrickを利用していきます。
from yellowbrick.cluster import silhouette_visualizer fig = plt.figure(figsize=(15,25)) # クラスタ数4~9までまとめて作図 for i in range(4,10): ax = fig.add_subplot(4,2,i-1) silhouette_visualizer(KMeans(i),embeddings)
- 見る感じでは、右上(クラスタ数5)のパターンがいい感じです。
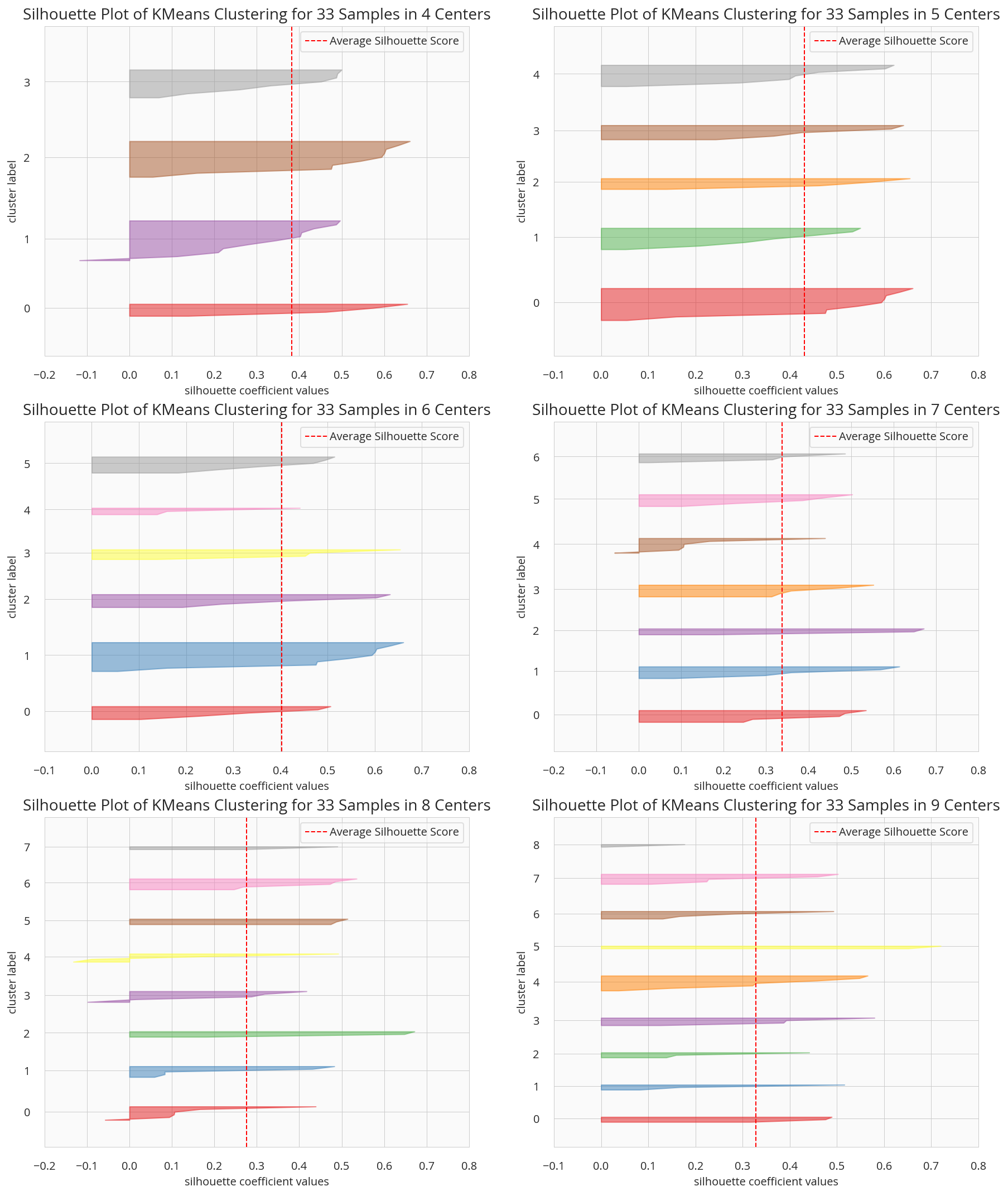
dendrogram
- クラスタ同士の 近さ をトーナメント表の様に表現したグラフです。
- 階層型クラスタリングで利用できる図ですので、KMeansでなく、Scipyの階層型クラスタリングを使っています。
- 見方としては、下記です。
- 葉がデータで、同じ色の枝の範囲が同じクラスタ
- 高さが、クラスタ間の距離
from scipy.cluster.hierarchy import linkage, dendrogram Z = linkage( y = embeddings, method = 'weighted', metric = "euclidean", ) R = dendrogram( Z=Z, color_threshold=1.2, #この閾値でクラスタ数を調整 show_contracted=False, )
- 各色の枝の数がバランスよく、高さも揃っていると いい感じです。やはり、クラスタ数は5程度でしょうか。
クラスタ数 デンドログラム コメント 4 赤だけ、少し高い 5 高さは揃っている
紫の少数が気になるが
なかなかいい感じ8 高さ、数も揃っているが、
細かく分割しすぎか検証6) 5クラスタにしてみる
- クラスタ数を検討してみたので、再び、5クラスタでどんな感じになるかプロットしてみたいと思います。
- なかなか良さそうですね。やはり、5クラスタでしょうか。
from sklearn.cluster import KMeans # clustering(クラスタ数 : 5) clustering = KMeans(n_clusters=5, random_state=42) # fit_predict cluster cl_y = clustering.fit_predict(embeddings) # visualize showScatter(embeddings, cl_y, clustering.cluster_centers_)
No クラスタ 重心 他に含まれる字 1 青 
2 紫 3 緑 
4 赤 
5 橙 まとめ
所感
- 流れとしては、
- 漢字として登録されている4文字の代表選びからスタートし
- 漢字として登録のない全33字については、1,4,8文字を選び
- 適切なクラスタ数を検討し、5クラスタが良さそうということで、最後に5文字選びました
- 代表漢字は下記となるわけですが、代表を決める以上に
- 3000次元を次元圧縮したXY平面上で、カタチの似た漢字は近傍に配置される点も興味深いですし
- 距離ベースのクラスタリングで、部首毎のグループが作れることは興味深かった
- クラスタ数の検討も、エルボー法、シルエット法、デンドグラムでの検討結果で5クラスタと判断し
- 5クラスタのクラスタリング可視化の結果もそこそこしっくりくる点も面白かったです。
検証一覧
No 選び方 代表のサイトウ たち 1 認められた4漢字から
1字選ぶなら代表は2 全33漢字から
1字 選ぶなら3 全33漢字から
4字選ぶなら


4 全33漢字から
8字選ぶなら






5 全33漢字を
何クラスタに分けるべきかは5クラスタ程度 が良さそう 6 全33漢字から
5字選ぶなら




最後に
- こんなくだらないネタにお付き合い頂きありがとうございました。
- よろしくければ、いいね、シェアしていただければ嬉しいです。
参考情報
- UMAPについて
- UMAPでのClusteringについての議論(があるようです)
- KMeansについて
- クラスタ数の検討について(YellowBrick)
- デンドログラムでの作図
可視化関数
- こちらの記事を参考にさせていただきました。ありがとうございます。リンクさせていただきます。
%matplotlib inline %config InlineBackend.figure_format = 'retina' import numpy as np import seaborn as sns import matplotlib.pyplot as plt import matplotlib.lines as mlines from matplotlib import offsetbox from sklearn.preprocessing import MinMaxScaler from PIL import Image import matplotlib.patches as patches rc = { 'font.family': ['sans-serif'], 'font.sans-serif': ['Open Sans', 'Arial Unicode MS'], 'font.size': 12, 'figure.figsize': (8, 6), 'grid.linewidth': 0.5, 'legend.fontsize': 10, 'legend.frameon': True, 'legend.framealpha': 0.6, 'legend.handletextpad': 0.2, 'lines.linewidth': 1, 'axes.facecolor': '#fafafa', 'axes.labelsize': 10, 'axes.titlesize': 14, 'axes.linewidth': 0.5, 'xtick.labelsize': 10, 'xtick.minor.visible': True, 'ytick.labelsize': 10, 'figure.titlesize': 14 } sns.set('notebook', 'whitegrid', rc=rc) def colorize(d, color, alpha=1.0): rgb = np.dstack((d,d,d)) * color return np.dstack((rgb, d * alpha)).astype(np.uint8) colors = sns.color_palette('tab10') def showScatter( embeddings, clusterlabels, centers = [], imgs = all.T.reshape(-1,h,w), ): fig, ax = plt.subplots(figsize=(15,15)) #散布図描画前にスケーリング scaler = MinMaxScaler() embeddings = scaler.fit_transform(embeddings) source = zip(embeddings, imgs ,clusterlabels) #漢字を散布図に描画 cnt = 0 for pos, d , i in source: cnt = cnt + 1 img = colorize(d, colors[i], 0.5) ab = offsetbox.AnnotationBbox(offsetbox.OffsetImage(img),0.03 + pos * 0.94,frameon=False) ax.add_artist(ab) #重心からの同心円を描画 if len(centers) != 0: for c in scaler.transform(centers): for r in np.arange(3,0,-1)*0.05: circle = patches.Circle( xy=(c[0], c[1]), radius=r, fc='#FFFFFF', ec='black' ) circle.set_alpha(0.3) ax.add_patch(circle) ax.scatter(c[0],c[1],s=300,marker="X") # 軸の描画範囲 limit = [-0.1,1.1] plt.xlim(limit) plt.ylim(limit) plt.show()















































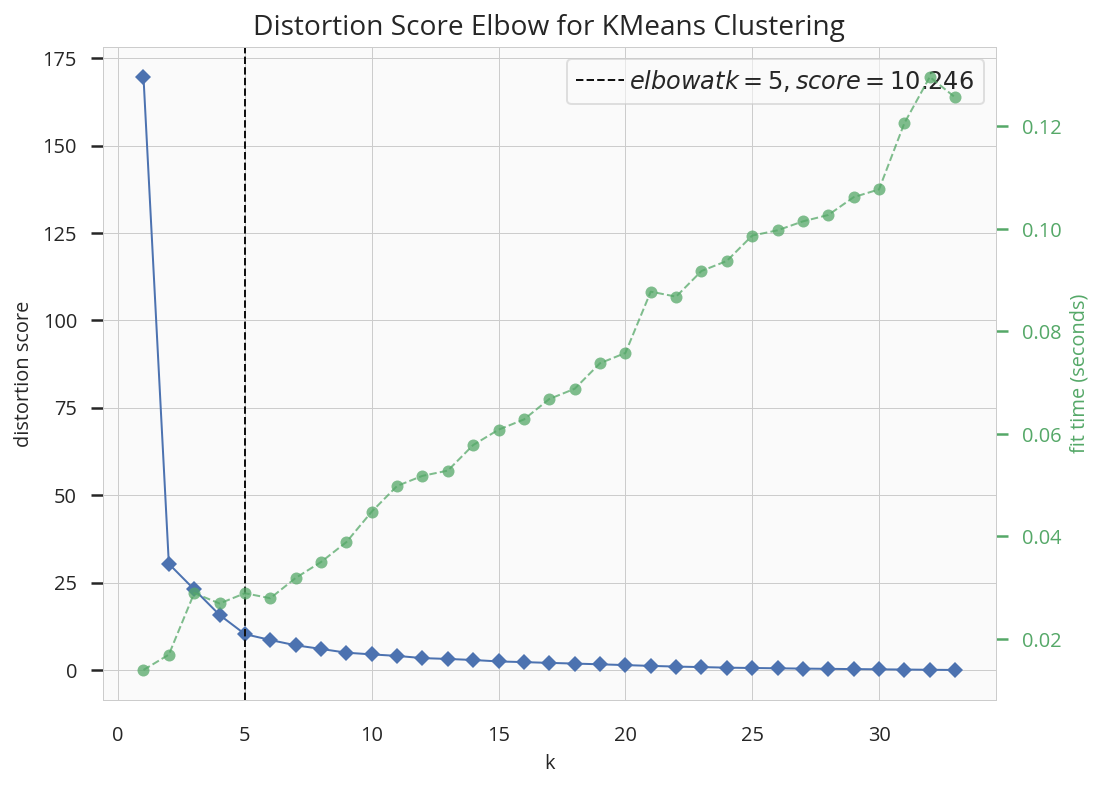
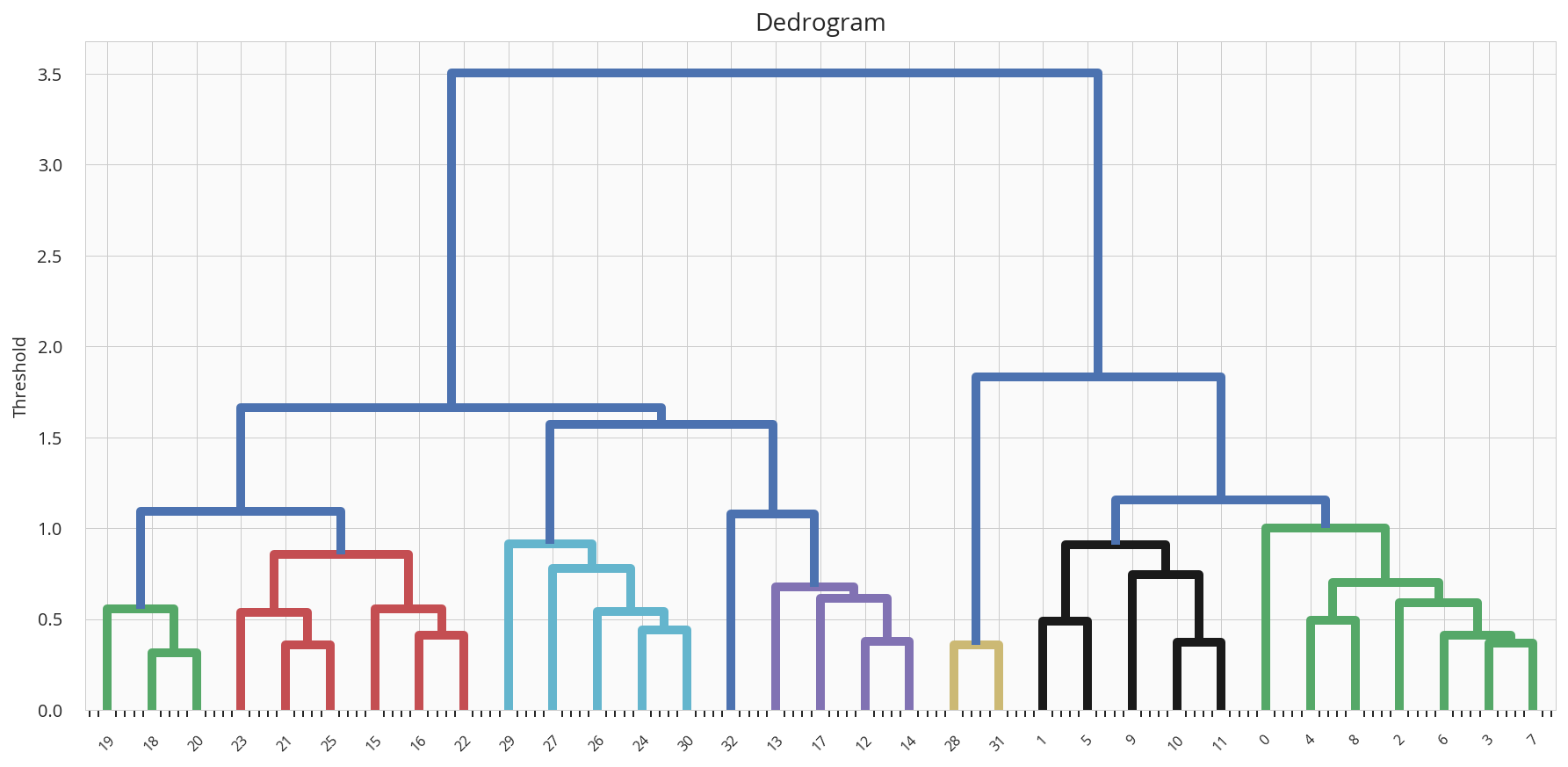


- 投稿日:2020-05-14T17:21:35+09:00
PyCaretで主成分分析ハンズオン【正規化+可視化(plotly)】メモ
概要
- PyCaretでPCAを行いました。(ハイパーパラメータ等の最適化はしていません)
- とある電力量データでPCAを行いました。
ソースコード
- 自前のデータ整形ソースコード(汚い):13行
自前のデータ整形コードimport pandas as pd def load_sampledata(): data = pd.read_csv(r'pycaret_sample.csv', encoding='shift-jis', engine='python', index_col=[0], parse_dates=[0]) data = data.resample('h').sum() data['hour'] = data.index.hour data['date'] = data.index.strftime('%Y-%m-%d (%a)') dataset = data.pivot(index='hour',columns='date',values='電力量') dataset = dataset.T.reset_index() return dataset
- PyCaretのセットアップ:2行
setupfrom pycaret.clustering import * clu = setup(data = load_sampledata(),normalize=True)
setupした内容を確認できる
PyCaretのモデル作成+プロット作成:2行
create_model&plot# creating a model hclust = create_model('hclust') # plotting a model plot_model(hclust,plot='cluster',feature='date')
- 2行でPCAと可視化までできる。
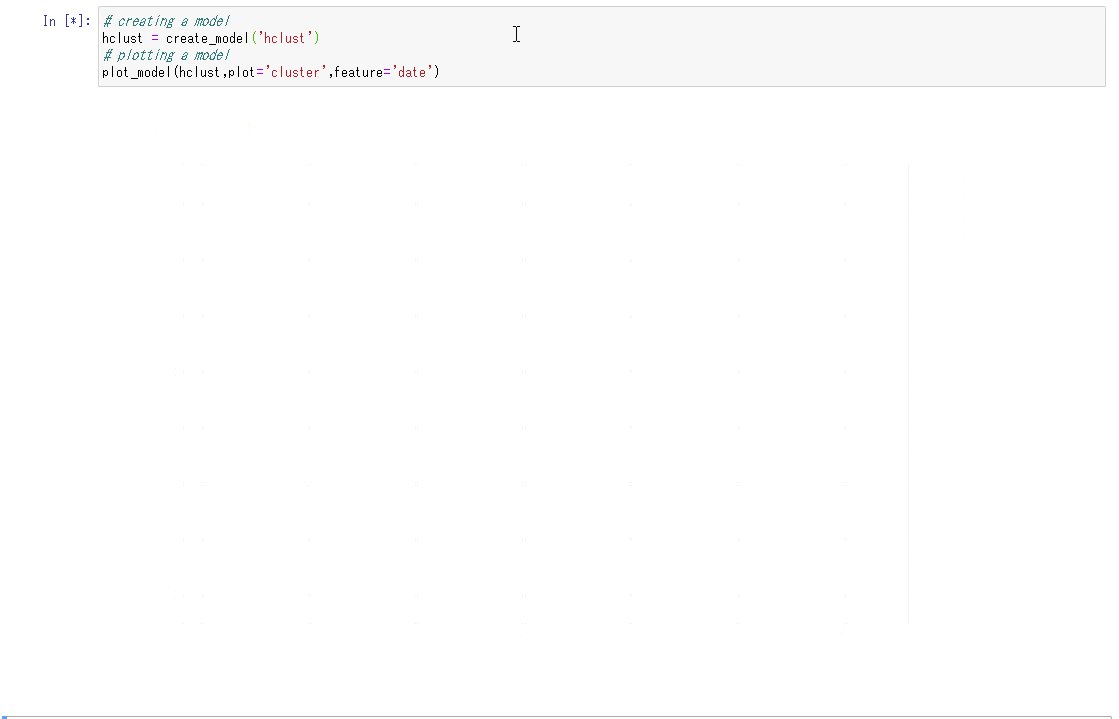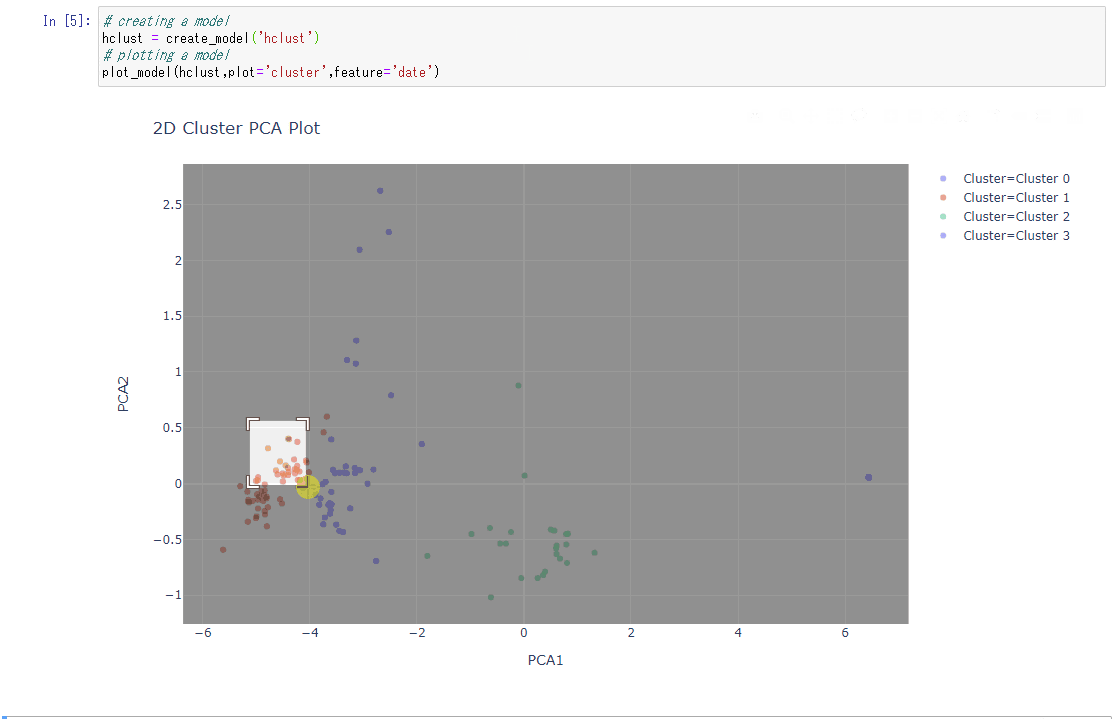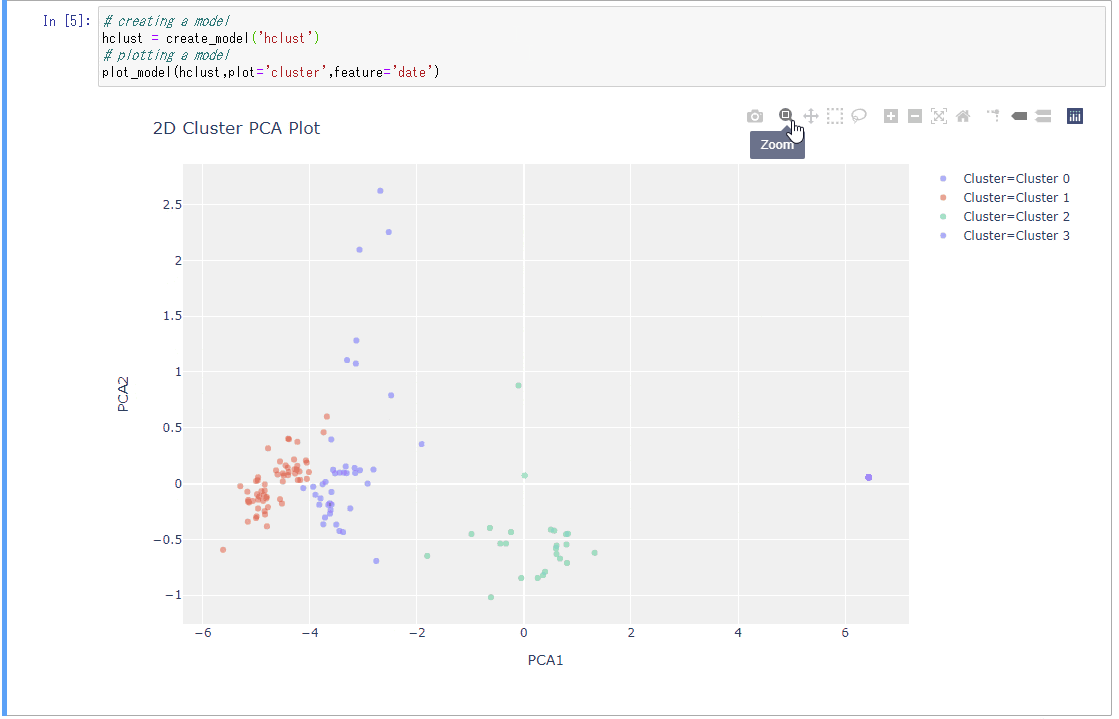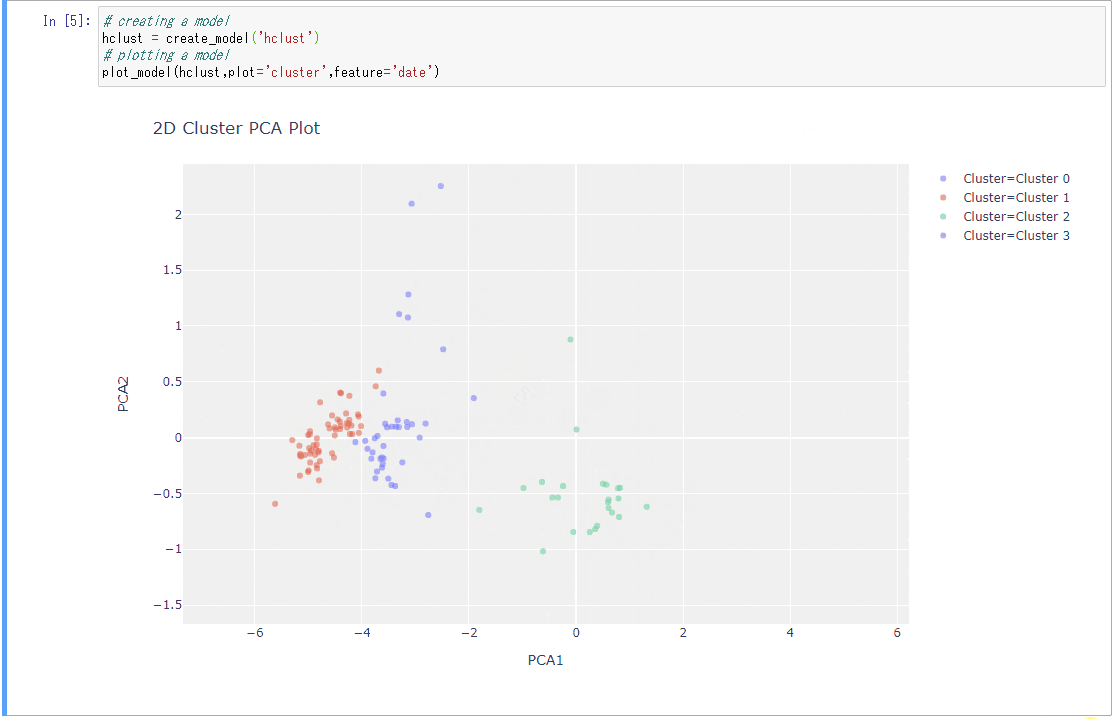
まとめ
- PyCaretすごい。
- これで書き始めるとラッパーなしで書けなくなりそう。
- チューニングもできるし、すごい早さで書ける。すごい。
- 投稿日:2020-05-14T16:56:49+09:00
HTTP APIで動くPDFパース処理をServerless Frameworkで実装する
やりたいこと
Googleドライブ上にあるPDFをテキストに変換して、Webアプリケーションが利用しているAWS Elasticsearch Serviceのインデックスにそのテキストを登録したい。
方針
- PDFパース処理がそこそこ負荷が高い処理であることから、サーバーではなくAWS Lambdaで処理を行う
- WebアプリケーションからHTTP APIを呼び出してLambdaを実行する
- API Gatewayの内、REST APIではなく、機能が制限されているが低コストでシンプルなHTTP APIを利用
- デプロイを簡易にするためにserverless frameworkを利用する
- PDFのパース処理のドキュメントが豊富なことからPythonを利用する
参考
- Serverless Framework
- PyDrive
- Securing AWS HTTP APIs with JWT Authorizers
- How to deploy multiple micro-services under one API domain with Serverless
- G Suite ドメイン全体の権限の委任を行う
環境
- AWS(Lambda, API Gateway)
- Serverless Framework 1.69.0
- Python 3.7
- Auth0(JWT認証のため)
主要な利用パッケージ
- pdfminer.six(PDFをテキストに変換)
- pydrive(Googleドライブアクセス)
- elasticsearch-py(Elasticsearchアクセス)
- rollbar(エラー通知)
対応概要
AWS
Lambda用のセキュリティグループを作成
VPC内のElasticsearch ServiceにアクセスするためにVPC内にLambdaを置く必要があり、その際にセキュリティグループを指定する必要があるため。NATゲートウェイとVPCエンドポイントを持つパブリックサブネットを作成
Lambdaにインターネットアクセス(Rollbar用)およびS3アクセスをさせるため。0.0.0.0/0がNATゲートウェイに向いているプライベートサブネットを作成
最終的にこのサブネットにLambdaが配置される。上記のパブリックサブネットとプライベートサブネットを配置したVPCを作成し、インターネットゲートウェイを設置
上記全て必要であるが、今回の対応では既存のネットワーク構成を流用したため、「Lambda用のセキュリティグループを作成」のみ行った。
Auth0
HTTP APIのアクセスコントロール手段がJWT認証しかないため、Auth0でJWTアクセストークンを発行できるようにする。
以下手順の通りだが、Serverless FrameworkにてHTTP APIとJWTオーソライザの紐付け等全て実施してくれるので、
Configure the JWT Authorizerのセクションに記載のAuth0側の設定だけでよい。
Securing AWS HTTP APIs with JWT AuthorizersServerless Framework
Lambda Layer構築
pdfminer.six、pydrive、elasticsearch-py、rollbarをlayerにする。Lambda関数作成
- pdfParse: APIアクセスをトリガに、GoogleドライブからPDFを取得し、テキストに変換してs3に置く。
- updateDocument: s3PUTをトリガにelasticsearchを更新する。
HTTP APIのカスタムドメインの設定
カスタムドメインを作成しないとデプロイの度にHTTP APIのエンドポイントが変わってしまう。
serverless-domain-managerプラグインを利用してカスタムドメインの作成、HTTP APIとの紐付けを行う。
How to deploy multiple micro-services under one API domain with Serverless構成図
Lambda Layer構築
目的
関数のデプロイ時間を短縮するため、重いパッケージはLambda Layerとして切り出す。
対応
パッケージインストール
pip install -t pdfminer.six/python/lib/python3.7/site-packages pdfminer.six pip install -t pydrive/python/lib/python3.7/site-packages pydrive pip install -t elasticsearch/python/lib/python3.7/site-packages elasticsearch # バージョン指定が厳格なので注意 pip install -t rollbar/python/lib/python3.7/site-packages rollbarフォルダ構成
以下のように配置
layer ├── pdfminer.six │ └── python │ └── lib │ └── python3.7 │ └── site-packages │ └── ... ├── pydrive │ └── python │ └── lib │ └── python3.7 │ └── site-packages │ └── ... ├── elasticsearch │ └── python │ └── lib │ └── python3.7 │ └── site-packages │ └── ... ├── rollbar │ └── python │ └── lib │ └── python3.7 │ └── site-packages │ └── ... └── serverless.ymlserverless.ymlservice: test-layer provider: name: aws runtime: python3.7 stage: production region: ap-northeast-1 layers: pdfminer: path: pdfminer.six description: pdfminer layer CompatibleRuntimes: - python3.7 pydrive: path: pydrive description: pydrive layer CompatibleRuntimes: - python3.7 elasticsearch: path: elasticsearch description: elasticsearch layer CompatibleRuntimes: - python3.7 rollbar: path: rollbar description: rollbar layer CompatibleRuntimes: - python3.7 resources: Outputs: PdfminerLayerExport: Value: Ref: PdfminerLambdaLayer Export: Name: PdfminerLambdaLayer PydriveLayerExport: Value: Ref: PydriveLambdaLayer Export: Name: PydriveLambdaLayer ElasticsearchLayerExport: Value: Ref: ElasticsearchLambdaLayer Export: Name: ElasticsearchLambdaLayer RollbarLayerExport: Value: Ref: RollbarLambdaLayer Export: Name: RollbarLambdaLayerデプロイ
事前に以下を実施しておく
- Serverless Frameworkのインストール
- credencialの設定sls deploy -vLambda関数作成
対応
serverlessプラグインインストール
- serverless-python-requirements
関数を動かすために必要なpythonライブラリをインストールせずとも、sls deploy時にrequirements.txtやPipfileを参照してデプロイパッケージを作ってくれる。
sls plugin install -n serverless-python-requirements
- serverless-prune-plugin
Lambdaのコードストレージにコードを溜めすぎないように指定した数までしか直近のバージョンを保持しないようにしてくれる。
sls plugin install -n serverless-prune-plugin
- serverless-domain-manager
カスタムドメインの設定を行ってくれる。カスタムドメイン作成だけでなく、Route53の設定もしてくれる。
npm install serverless-domain-manager --save-devフォルダ構成
以下のように配置
function ├── package-lock.json ├── package.json ├── service-account.json # Googleドライブアクセス用の認証情報 (詳細 https://developers.google.com/cloud-search/docs/guides/delegation?hl=ja) ├── requirements.txt ├── serverless.yml ├── parse.py └── update.pyserverless.ymlservice: test provider: name: aws runtime: python3.7 stage: production region: ap-northeast-1 timeout: 25 environment: LAYER_SERVICE: test-layer TMP_BUCKET: ${self:provider.s3.tmpBucket.name} OUTPUT_PATH: example/ ROLLBAR_KEY: rollbarのアクセストークン logRetentionInDays: 30 iamRoleStatements: # 適切に - Effect: Allow Action: '*' Resource: '*' httpApi: authorizers: auth0: identitySource: $request.header.Authorization issuerUrl: Auth0のテナントURL audience: - https://auth0-jwt-authorizer s3: tmpBucket: name: testBucket package: exclude: - .git/** - layer/** - package.* functions: parse: handler: parse.post name: parsePdf package: {} events: - httpApi: method: POST path: /example authorizer: name: auth0 layers: - ${cf:${self:provider.environment.LAYER_SERVICE}-${opt:stage, self:provider.stage}.PdfminerLayerExport} - ${cf:${self:provider.environment.LAYER_SERVICE}-${opt:stage, self:provider.stage}.PydriveLayerExport} - ${cf:${self:provider.environment.LAYER_SERVICE}-${opt:stage, self:provider.stage}.RollbarLayerExport} update: handler: update.put name: updateDocument package: {} events: - s3: bucket: tmpBucket event: s3:ObjectCreated:Put rules: - prefix: ${self:provider.environment.OUTPUT_PATH} vpc: securityGroupIds: - 作成したセキュリティグループ subnetIds: - 作成したプライベートサブネット layers: - ${cf:${self:provider.environment.LAYER_SERVICE}-${opt:stage, self:provider.stage}.ElasticsearchLayerExport} - ${cf:${self:provider.environment.LAYER_SERVICE}-${opt:stage, self:provider.stage}.RollbarLayerExport} plugins: - serverless-python-requirements - serverless-prune-plugin - serverless-domain-manager custom: prune: automatic: true includeLayers: true number: 5 customDomain: domainName: 設定したいカスタムドメイン名 certificateName: 証明書名 endpointType: regional securityPolicy: tls_1_2 apiType: httprequirements.txtchardet requests-aws4authparse.pyimport boto3 import json import os import re from http import HTTPStatus from io import StringIO, BytesIO from oauth2client.service_account import ServiceAccountCredentials from pdfminer.converter import TextConverter from pdfminer.layout import LAParams from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter from pdfminer.pdfpage import PDFPage from pydrive.auth import GoogleAuth from pydrive.drive import GoogleDrive from pydrive.files import ApiRequestError import rollbar OUTPUT_BUCKET = os.environ['TMP_BUCKET'] OUTPUT_PATH = os.environ['OUTPUT_PATH'] SCOPE = ['https://www.googleapis.com/auth/drive.readonly'] KEY_FILE = 'service-account.json' SUBJECT = Googleドライブのアカウント SPACE = re.compile(r'[ \t]+') ROLLBAR_TOKEN = os.environ['ROLLBAR_KEY'] rollbar.init(ROLLBAR_TOKEN) @rollbar.lambda_function def post(event, context): body = json.loads(event['body']) file_id = get_params(body) drive = get_drive() file = download_file(file_id, drive) output_filename = f'{OUTPUT_PATH}/{file_id}' output_text = pdfload(file.content) put_file(output_filename, output_text) response = { 'statusCode': HTTPStatus.OK, 'body': 'ok' } return response def get_params(body): # バリデーション return file_id def get_drive(): gauth = GoogleAuth() gauth.credentials = ServiceAccountCredentials.from_json_keyfile_name(KEY_FILE, SCOPE).create_delegated(sub=SUBJECT) return GoogleDrive(gauth) def download_file(file_id, drive): file = drive.CreateFile({'id': file_id}) file.GetContentFile('/tmp/temp_pdf') return file def pdfload(pdf_obj): rsrcmgr = PDFResourceManager() codec = 'utf-8' laparams = LAParams(line_margin=10) with StringIO() as output: device = TextConverter(rsrcmgr, output, codec=codec, laparams=laparams) interpreter = PDFPageInterpreter(rsrcmgr, device) with BytesIO(pdf_obj.read()) as input: for page in PDFPage.get_pages(input): interpreter.process_page(page) text = re.sub(SPACE, '', output.getvalue()) device.close() return text def put_file(output_filename, output_text): s3 = boto3.resource('s3') s3.Object(OUTPUT_BUCKET, output_filename).put(Body=output_text)update.pyimport boto3 import os from elasticsearch import Elasticsearch, RequestsHttpConnection from requests_aws4auth import AWS4Auth import rollbar INPUT_BUCKET = os.environ['TMP_BUCKET'] ES_HOST = Elasticsearch Serviceのホスト名(「vpc-」から始まるやつ) ES_REGION = Elasticsearch Serviceのリージョン ES_INDEX = Elasticsearch Serviceのインデックス名 ROLLBAR_TOKEN = os.environ['ROLLBAR_KEY'] s3 = boto3.client('s3') rollbar.init(ROLLBAR_TOKEN) @rollbar.lambda_function def put(event, context): file_name = event['Records'][0]['s3']['object']['key'] file_id = file_name.split('/')[1] content = get_file_content(file_name) update_document(file_id, content) delete_file(file_name) def get_file_content(file_name): response = s3.get_object(Bucket=INPUT_BUCKET, Key=file_name) content = response['Body'].read().decode('utf-8') return content def update_document(file_id, content): credentials = boto3.Session().get_credentials() awsauth = AWS4Auth(credentials.access_key, credentials.secret_key, ES_REGION, 'es', session_token=credentials.token) es = Elasticsearch( hosts = [{'host': ES_HOST, 'port': 443}], http_auth = awsauth, use_ssl = True, verify_certs = True, connection_class = RequestsHttpConnection ) body = {'doc': {'content': content}, 'detect_noop': False} es.update(id=file_id, body=body, index=ES_INDEX, doc_type='_doc') def delete_file(file_name): s3.delete_object(Bucket=INPUT_BUCKET, Key=file_name)デプロイ
- カスタムドメインを作成
初期化に40分かかると出るが、感覚的に10分くらいで初期化されている。
sls create_domain
- lambda関数のデプロイ
sls deploy -v
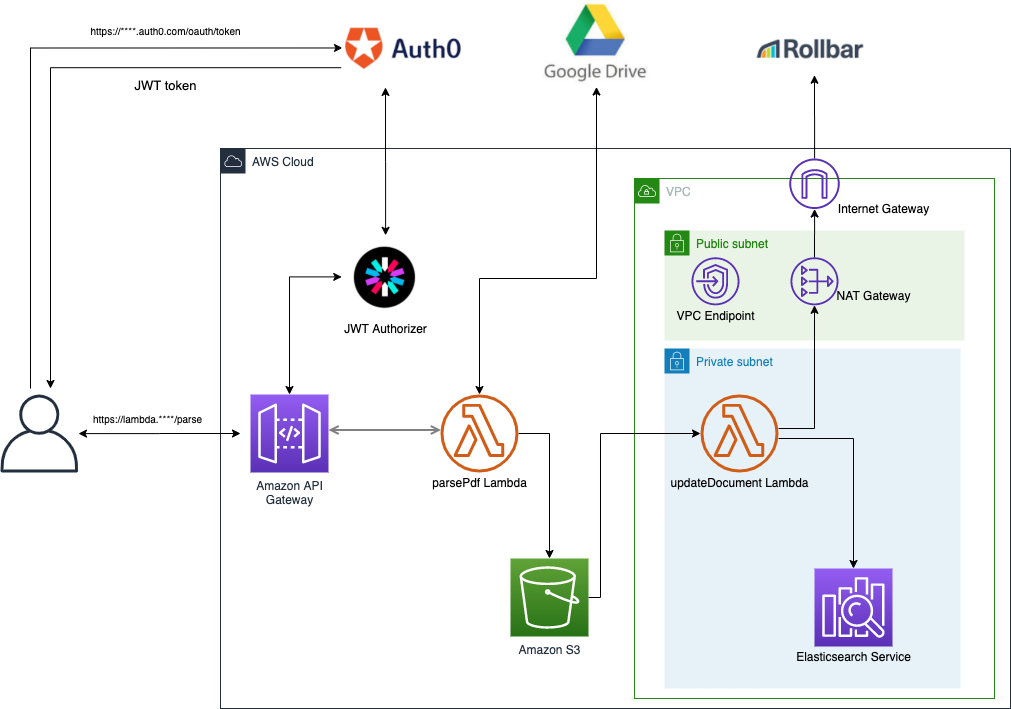
- 投稿日:2020-05-14T16:56:05+09:00
PythonのSeleniumでnanacoギフトコードを自動登録
概要
PythonでSeleniumを使用し、nanacoギフトコードの取得から登録までを自動化します。
入力支援ではなく、自動化です。
※福利厚生倶楽部のギフトコードでテストしました。その他の場所で購入したギフトコードはテストしていませんのでご注意ください。環境
- Chrome
- Selenium
- Selenium Chrome Webdriver
追加ライブラリのインストール方法
pip install selenium pip install chromedriver-binary==<Chromeバージョン>スクリプト
nanaco_transiter.py#!/usr/bin/env python3 import time import re from sys import argv import selenium from selenium import webdriver userName = "" # <- 購入した福利厚生のIDを6桁と4桁で入力してください(例: 012345-6789) nanacoNo = "" # <- nanaco番号16桁を入力してください(例: 0123456789012345) securityCode = "" # <- カード記載の番号を7桁で入力してください(例: 0123456) def getGiftCodes(driver, url): driver.get(url) driver.find_element_by_name("kainno").send_keys(userName) driver.find_element_by_class_name("next").click() elements = driver.find_elements_by_css_selector(".table_gift tbody tr") giftCodes = [] for element in elements: texts = element.text.split(" ") if re.match("^[a-zA-Z\d]{16}$", texts[-3]): giftCodes.append(texts[-3]) return giftCodes # nanacoサイトのセッションを張る def loginNanaco(driver): driver.get('https://www.nanaco-net.jp/pc/emServlet') driver.find_element_by_name("XCID").send_keys(nanacoNo) driver.find_element_by_name("SECURITY_CD").send_keys(securityCode) driver.find_element_by_name("ACT_ACBS_do_LOGIN2").click() # ここでログイン time.sleep(1) driver.find_element_by_link_text("nanacoギフト登録").click() time.sleep(1) # セッション内でギフトコードを登録する def registGiftCode(driver, code): driver.find_element_by_xpath("//input[@alt=\"ご利用約款に同意の上、登録\"]").click() # ここで新規ウィンドウが開く time.sleep(0.3) driver.switch_to.window(driver.window_handles[1]) # 直前に開いた新規ウィンドウをカレントにする driver.find_element_by_id("gift01").send_keys(code[:4]) driver.find_element_by_id("gift02").send_keys(code[4:8]) driver.find_element_by_id("gift03").send_keys(code[8:12]) driver.find_element_by_id("gift04").send_keys(code[12:]) driver.find_element_by_id("submit-button").click() time.sleep(0.1) result = True try: driver.find_element_by_xpath("//input[@alt=\"登録する\"]").click() except selenium.common.exceptions.NoSuchElementException: # 10秒以上経っても「登録する」ボタンが出てこない場合、タイムアウトとする result = False time.sleep(0.1) driver.close() # カレントウィンドウ(さっき開いた新規ウィンドウ)を閉じる driver.switch_to.window(driver.window_handles[0]) # nanacoページのウィンドウをカレントにする return result if __name__ == "__main__": print("Preparing...") driver = selenium.webdriver.Chrome() driver.set_page_load_timeout(10) print("Getting gift codes ...") giftCodes = [] for url in argv[1:]: giftCodes += getGiftCodes(driver, url) print("Logging in nanaco website ...") loginNanaco(driver) sucseeded = 0 missed = 0 print("Registing codes ...") for giftCode in giftCodes: print(giftCode, "...", end = "\r") if registGiftCode(driver, giftCode): sucseeded += 1 print(giftCode, "(%d/%d)" % (sucseeded + missed, len(giftCodes)), "Done") else: missed += 1 print(giftCode, "(%d/%d)" % (sucseeded + missed, len(giftCodes)), "MISSED\a") print("Sucseeded:", sucseeded, " Missed:", missed, " Total:", sucseeded + missed) driver.find_element_by_id("memberInfoInner").click()Githubにも掲載しています。
実行方法
python3 nanaco_transiter.py "ギフトコードのURL" ["ギフトコードのURL" ...] # URLは""で括ることスクリプトの簡単な動作説明
- 実行すると、引数のURLを1つずつ開き、nanacoギフトコードを取得します。
- nanacoサイトにログインします。
- ギフトコード登録ウィンドウを表示します。
- ギフトコードを自動的に入力し、登録実行します。
- 3.4.の手順をギフトコード分繰り返します。
その他
- 引数のURLは""で括る必要があります。括らない場合、文字列中の&をシェル命令の&と解釈されてしまい正しく動作しません。
- 細かなエラー処理は実装していません。本来の使い方でご使用ください。
- ギフトコードの登録中に落ちてしまっても、再実行すれば問題なく登録できます。ただし、重複して登録したものは"MISSED"としてカウントされます。
- 不具合などありましたらご連絡いただけると助かります。
- 投稿日:2020-05-14T16:50:20+09:00
画像処理100ノック Q.6. 減色処理 解説
画像処理100ノックQ.6. 減色処理についての解説記事です。
減色処理は、R(赤),G(緑),B(青)それぞれのとりうる値の種類を限定します。それにより、表現できる色が減ります。
本題ではR,G,Bが各256種類の値(0~255)を取れていたものを、各4種類の値(32,96,160,224)に減らすように指示されています。
元記事ではこちらの処理によって、減色処理を行っています。(下記)
def dicrease_color(img): out = img.copy() out = out // 64 * 64 + 32 return out思っていたより処理が少なくてびっくりしました。この関数の下記の部分のコードで減色処理を行っています。
out = out // 64 * 64 + 32この64と言う数字は256(0~255)を4で割った値です。
つまり、
out // 64とは256を4分割した際のどのクラス(0, 1, 2, 3と言う風に4クラスあるものとする)に属するかを調べていることになります。そして
* 64 + 32とすることでそのクラスの定められた値にしています。(クラス0なら32、クラス1なら96、クラス2なら160、クラス3なら224と定められています。)今回はそのクラス内の中央付近の値にしているようです。(クラス0に属する値は0~63で、その中央は32と33)
例えばout // 64が2だった場合(クラス2)、つまりoutが128~191だった場合は、out // 64で2となり、* 64 + 32とすることでクラス2の定められた値(160)としています。以上のことが理解できれば各2値や各6値、8値など思うように減色
処理を行うことができます。以下参考までにコードを提示しておきます。(※Google Colaboratoryを使用しています。画像の読み込みなどに少し処理が必要です。私はGoogle Colabでcv2.imshow() を利用する方法を参考にしました。)# サポートパッチのインポート from google.colab.patches import cv2_imshow # 画像のインポート !curl -o logo.png https://colab.research.google.com/img/colab_favicon_256px.png import cv2 # 画像を読み込み、imgに格納 img = cv2.imread("imori.jpg", cv2.IMREAD_UNCHANGED) # imと言う変数にimgをコピー im = img.copy() # 画像を表示 cv2_imshow(im)
各2値に分類
sample = im // 128 * 128 + 64 cv2_imshow(sample)
各3値に分類
sample = im // 85 * 85 + 42 cv2_imshow(sample)
各4値に分類(元記事通り)
sample = im // 64 * 64 + 32 cv2_imshow(sample)
各6値に分類
sample = im // 43 * 43 + 22 cv2_imshow(sample)
各8値に分類
sample = im // 32 * 32 + 16 cv2_imshow(sample)
各8値まで表現できるだけで、かなり画質が良いと言うのは驚きですね。以上です。引き続き画像処理100ノックに取り組みましょう。






- 投稿日:2020-05-14T15:56:02+09:00
Amazon SES+Pythonでメールを送信する
Amazon SESとは
- Amazonが提供するEメールプラットフォーム
- 従量課金制
手順
- リージョンの選択
- 送信用のメールアドレスを登録する
- 送信制限を解除する
- メール送信処理の実装
リージョンの選択
Amazon SESでは現在以下のリージョンがサポートされています
送信用のメールアドレスを登録する
Amazon SESでは送信用のメールアドレスを検証し、登録する必要があります。
(検証されていないメールアドレスについては使用する事ができません。)
SESの[Email Addresses]タブの[Verify a New Adress]ボタンから送信用に登録したいメールアドレスを入力
認証メールが届くので、メールのURLから認証を完了させる
送信制限を解除する
何もしない状態の場合、認証したメールアドレス宛てにしかメールを送信できないかつ送信数が限られているため、制限の解除を行う必要があります。
- SESの[Sending Statistics]タブで[Request a Sending Limit Increase]ボタンをクリック
- Support Centerページに遷移するので、必要情報を入力
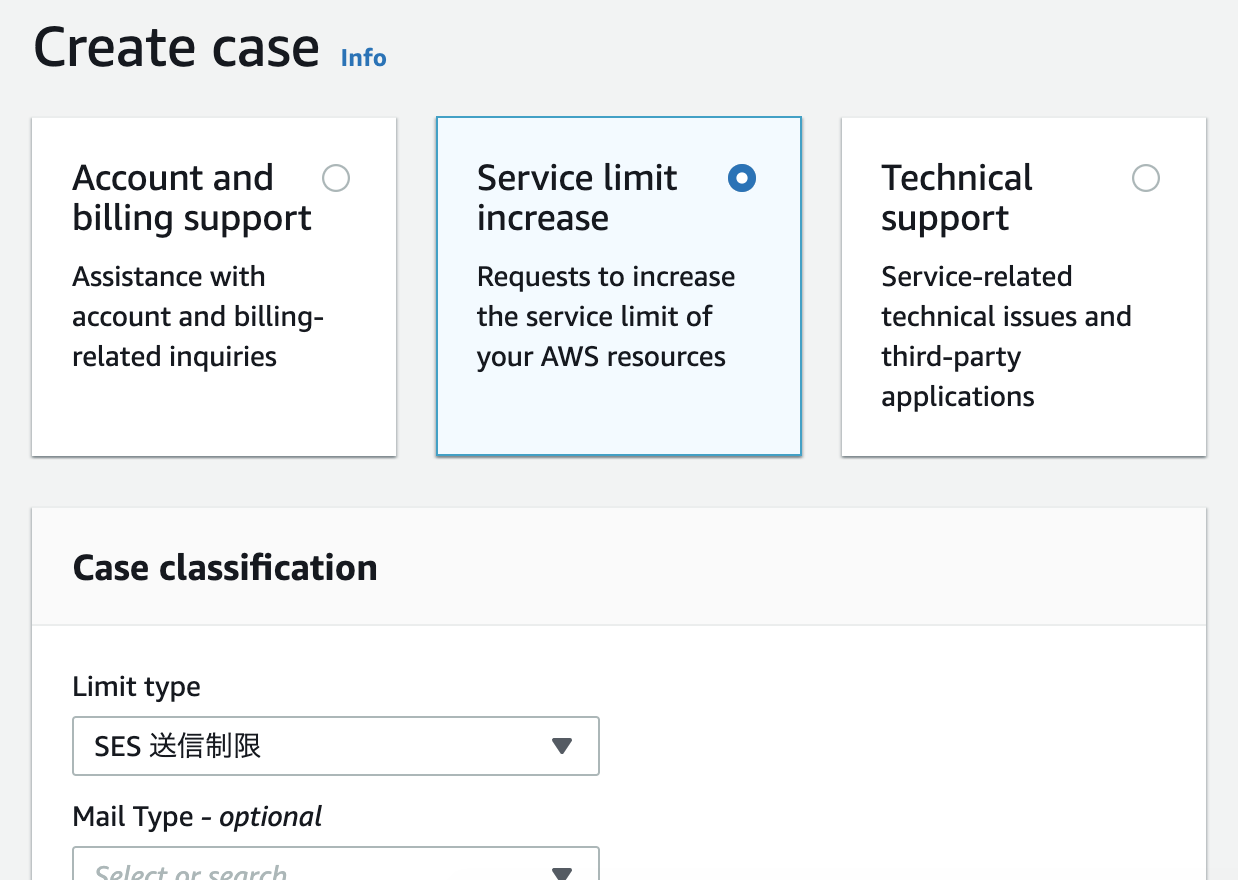
- 申請
メール送信の実装
import boto3 def main(): try: client = boto3.client( 'ses', aws_access_key_id={AWS_ACCESS_KEY_ID}, aws_secret_access_key={AWS_SECRET_ACCESS_KEY}, region_name='us-east-1' # 送信用メールアドレスを登録したリージョン ) client.send_email( Destination={ 'ToAddresses': ['hoge@hoge.com', 'hoge2@hoge.com'], 'BccAddresses': ['hoge_bcc@hoge.com'] }, Message={ 'Body': { 'Text': { 'Data': 'メール本文', 'Charset': 'utf-8' } }, 'Subject': { 'Data': '件名', 'Charset': 'utf-8' } }, Source='hoge_from@hoge.com', # 登録済みのメールアドレス ConfigurationSetName='メール送信者として表示したい名前' ) except ClientError as e: print(e.response['Error']['Message']) else: print(response['MessageId'])参考

- 投稿日:2020-05-14T15:41:31+09:00
Djangoの各種データベース用の設定をまとめてみた(MySQL、PostgreSQL)
Djangoで使用するデータベースをコロコロ変える羽目になったときにやりやすいようにまとめました
SQLite3
デフォルトの設定のままで使えるので割愛
MySQL
settings.pyDATABASES = { 'default': { 'ENGINE': 'django.db.backends.mysql', 'NAME': 'DATABASE', # Database名 'USER': 'USER', # ユーザID 'PASSWORD': 'password', # ユーザIDのパスワード 'HOST': 'localhost', # ホスト名 'PORT': '3306', } }必要なライブラリ:mysqlclient
PyMySQLも使えますが推奨されているのはmysqlclientです。POSTGRESQL
settings.pyDATABASES = { 'default': { 'ENGINE': 'django.db.backends.postgresql', 'NAME': 'DATABASE', # Database名 'USER': 'USER', # ユーザID 'PASSWORD': 'password', # ユーザIDのパスワード 'HOST': 'localhost', # ホスト名 'PORT': 5432, } }必要なライブラリ:psycopg2
- 投稿日:2020-05-14T15:22:04+09:00
Python 総まとめ
色々学んできたので総まとめに入ろうと思います。
Pythonのコード
Pythonの基本
Python の基本①
Python の基本②
Python の基本③Numpy
Pythonの応用: Numpyその1: 基本
Pythonの応用: Numpyその2: 1次元配列
Pythonの応用: Numpyその3: 2重配列Pandas
Pythonの応用: Pandasその1: 基本
Pythonの応用: Pandasその2: Series
Pythonの応用: Pandasその3: Dataframe
Pythonの応用: Pandasその4: DataFrameの連結・結合Pythonのデータの取り扱い
データの可視化
Pythonの応用: データ可視化その1: 基本
Pythonの応用: データ可視化その2: matplotlib
Pythonの応用: データ可視化その3: 様々なグラフデータクレンジング
Pythonの応用: データクレンジングその1: Python記法
Pythonの応用: データクレンジングその2: DataFrameを用いたデータクレンジング
Pythonの応用: データクレンジングその3: OpenCVの利用と画像データの前処理データハンドリング
Pythonの応用: データクハンドリングその1: データの整形とファイルの入出力
Pythonの応用: データクハンドリングその2: 様々なデータフォーマットの解析
Pythonの応用: データクハンドリングその3: データ形式機械学習
機械学習の概要
教師あり学習
Python: 教師あり学習(回帰)
Python: 教師あり学習(回帰)の応用
Python: 教師あり学習(分類)
Python: 教師あり学習:ハイパーパラメーターその1
Python: 教師あり学習:ハイパーパラメーターその2教師なし学習
Python: 教師なし学習: 基礎
Python: 教師なし学習: 非階層的クラスタリング
Python: 教師なし学習: 主成分分析時系列分析
Python: 時系列分析
Python: 時系列分析:定常性、ARMA・ARIMAモデル
Python: 時系列分析:時系列データの前処理
Python: 時系列分析:SARIMAモデルの構築機械学習の前処理
Python:機械学習における前処理:概要
Python:機械学習における前処理:データの取得
Python:機械学習における前処理:欠損値・外れ値・不均衡データの取り扱い
Python:機械学習における前処理:データの変換深層学習
Python:深層学習の実践
Python: 深層学習のチューニング船の生存予測
- 投稿日:2020-05-14T15:13:02+09:00
AWSのIPレンジが取得方法で異なるんだってさ
背景
対象のサービスを運用していて、見れる人を制限したかったので、SecurityGroupを利用していました
そこで、シンセティック監視をRoute 53 health checksを利用しようとしてました
ただ、監視をしつつ見れる人を制限する場合、Route 53 health checksのIPレンジが必要になるので
確認すると、取得方法が2種類あって、それぞれ微妙にIPが違ったのでその共有になります取得方法
Amazon Route 53 health checksのIPレンジを調べてたところ、取り方が下記の2パターンあります
- json
- SDK
1つ目のjsonとは、AWSがメンテしてるこちらのjsonから確認する方法です
2つ目のSDKとは、Route 53のSDKからレンジを確認する方法です。今回はPythonを使います環境
$ python --version Python 3.6.8 $ pip list | grep boto3 boto3 1.13.9確認
jsonの確認
>>> import requests >>> ip_ranges = requests.get('https://ip-ranges.amazonaws.com/ip-ranges.json').json()['prefixes'] >>> route53_ips_json = [item['ip_prefix'] for item in ip_ranges if item["service"] == "ROUTE53_HEALTHCHECKS"] >>> route53_ips_json ['54.252.254.192/26', '177.71.207.128/26', '54.255.254.192/26', '54.244.52.192/26', '54.251.31.128/26', '54.241.32.64/26', '54.245.168.0/26', '54.232.40.64/26', '54.248.220.0/26', '176.34.159.192/26', '54.252.79.128/26', '54.183.255.128/26', '54.250.253.192/26', '15.177.0.0/18', '54.228.16.0/26', '107.23.255.0/26', '54.243.31.192/26'] >>> len(route53_ips_json) 17SDKの確認
>>> import boto3 >>> client = boto3.client('route53') >>> route53_ips_sdk = client.get_checker_ip_ranges() >>> route53_ips_sdk['CheckerIpRanges'] ['15.177.2.0/23', '15.177.6.0/23', '15.177.10.0/23', '15.177.14.0/23', '15.177.18.0/23', '15.177.22.0/23', '15.177.26.0/23', '15.177.30.0/23', '15.177.34.0/23', '15.177.38.0/23', '15.177.42.0/23', '15.177.46.0/23', '15.177.50.0/23', '15.177.54.0/23', '15.177.58.0/23', '15.177.62.0/23', '54.183.255.128/26', '54.228.16.0/26', '54.232.40.64/26', '54.241.32.64/26', '54.243.31.192/26', '54.244.52.192/26', '54.245.168.0/26', '54.248.220.0/26', '54.250.253.192/26', '54.251.31.128/26', '54.252.79.128/26', '54.252.254.192/26', '54.255.254.192/26', '107.23.255.0/26', '176.34.159.192/26', '177.71.207.128/26'] >>> len(route53_ips_sdk['CheckerIpRanges']) 32違い
ということで、上記のように配列の長さが違うので、一致はしませんでした
で、どこが違うというと、下記のようになりました>>> set(route53_ips_json) - set(route53_ips_sdk['CheckerIpRanges']) {'15.177.0.0/18'} >>> set(route53_ips_sdk['CheckerIpRanges']) - set(route53_ips_json) {'15.177.18.0/23', '15.177.2.0/23', '15.177.42.0/23', '15.177.50.0/23', '15.177.34.0/23', '15.177.54.0/23', '15.177.10.0/23', '15.177.6.0/23', '15.177.26.0/23', '15.177.14.0/23', '15.177.46.0/23', '15.177.58.0/23', '15.177.38.0/23', '15.177.62.0/23', '15.177.22.0/23', '15.177.30.0/23'}つまり、15.177.0.0/18で大きく括ってるのがどうかが違ってました
まとめ
Route 53 health checksのIPレンジが取得方法によってIPレンジが異なりました
jsonで取得する方法だと一部大きくIPレンジを取っていて、SDKだと細かく切っている状態でした
どちらが正しいかと言われると正直怪しいですが、個人的にはSecurityGroupのメンテを少なくしたいので、
大きくとるjsonが良いのかなと思いました
- 投稿日:2020-05-14T15:10:39+09:00
エクセルのシートを読込 1行ずつループ処理する Python VBA
これは エクセルからデータを読み込んで スクレイピングするときの自分用メモです
処理イメージ ※ソースは初心者レベルの簡単に
■300店舗ほどある
■各店舗ごとになにかしらのデータを取得したり、更新したりする
↓ そのために
エクセルにある店番号や、店舗コード,URL,ログインIDなど様々な情報を読み込み
読み込んだ内容でループする(1行ずつ処理)
Pythonでエクセルのシートを読み込む
※処理イメージ 設定内容をリストにし、1行ずつループする
openpyxlを使いエクセルの設定シートを読みこむimport openpyxl #openpyxl を使えるようにする wb=openpyxl.load_workbook("test.xlsx") sheet=wb["設定"] #シート名は設定 C=[] for row in sheet: C.append([col.value for col in row]) #エクセルシートの内容をループで処理していく #Cは0から始まる 設定シートの1行目は見出しにしているのでループは1から始めている for i in range(1,len(C)): print(C[i][0]) print(C[i][1])Cに設定シートの内容がリストのリストで取れている。
エクセルの1行1行をループで取得し、処理をしていく。
※
*設定シートはA1から始まるきれいな表にすること。そうすればきれいにループできる。**VBAでエクセルのシートを読み込む
多少複雑だけど、融通が利きます。
Variant型配列に設定シートの内容を読みこみ1行ずつ
ループ処理をするエクセル設定シートの内容を読みこみ1行ずつループ処理するDim CRastRow As Long '設定シートの最終行 A列で判断 Dim i as Long Dim C As Variant '設定シートのA列の最終行を読み込む CRastRow = ThisWorkbook.Sheets("設定").Cells(Rows.Count, 1).End(xlUp).Row '1行目は見出しのことが多いので、A2からG列最終行までを読み込むとする C = ThisWorkbook.Sheets("設定").Range("A2:G" & CRastRow) 'ループは1から始まる 1行ずつ処理 For i = 1 To UBound(C) Debug.Print(C(i,1)) ’A列 Debug.Print(C(i,2) ’B列 next i