- 投稿日:2020-05-14T23:16:59+09:00
JMeterで独自サンプラーを作る
背景
JmeterでGMailに来ているURLを手当たり次第踏んでいく。というツールを作成中の事。
MailReaderSamplerの挙動がよくわからない・・・・
imapはリファレンス通りやってもつながらない。
pop3は繋がる。でも本文どうやって抽出するんだ?みたいなことに。
具体的には、
こんな感じでネストしていて、この本文を後処理の正規表現抽出とかで取る方法がわからない
(最下層の1個目のリザルトにフォーカスを合わす方法がわからない)結局、昔サンプラーを自作したことがあるので、サンプラー自作しよ。
ということに。サンプラー自作方法もかなり忘れてたのでどうせなら記事に。
バージョン
apache-jmeter : 5.2.1
JRE : 1.8サンプラーのコード
DemoSampler.javapackage jmeter.extend.sampler; import org.apache.jmeter.config.Arguments; import org.apache.jmeter.protocol.java.sampler.AbstractJavaSamplerClient; import org.apache.jmeter.protocol.java.sampler.JavaSamplerContext; import org.apache.jmeter.samplers.SampleResult; public class DemoSampler extends AbstractJavaSamplerClient { // パラメータのキーを定義 private static final String MAIL_ADDRESS = "mailAddress"; private static final String PASSWORD = "password"; /* (non-Javadoc) * デフォルトのパラメータを設定する */ @Override public Arguments getDefaultParameters() { // デフォルトパラメータの設定 Arguments defaultParameters = new Arguments(); defaultParameters.addArgument(MAIL_ADDRESS, "example@gmail.com"); defaultParameters.addArgument(PASSWORD, "input your password"); return defaultParameters; } @Override public SampleResult runTest(JavaSamplerContext context) { SampleResult result = new SampleResult(); try { // JMeterで入力されたパラメーターをもらう String mail = context.getParameter(MAIL_ADDRESS); String password = context.getParameter(PASSWORD); // 時間計測開始(1) result.sampleStart(); // 計測したい任意の処理 Thread.sleep(500); StringBuilder bulder = new StringBuilder(); bulder.append("this is ResponseData\n"); bulder.append("mail : ").append(mail).append("\n"); bulder.append("password : ").append(password).append("\n"); bulder.append("日本語文字列文字列\n"); bulder.append("URL : https://github.com/"); // 時間計測終了(2) // (2) - (1) の時間がJMeterのレスポンスタイムとして取得できる result.sampleEnd(); // JMeterの取得結果を成功にする result.setSuccessful(true); // JMeterのレスポンスコードをOK(200)に設定する result.setResponseCodeOK(); result.setRequestHeaders("this is RequestHeaders"); result.setResponseData(bulder.toString(), "utf-8"); //こいつはどこにも出ないっぽい result.setResponseMessage("this is ResponseMessage"); } catch (Exception e) { // 時間計測終了(2) // (2) - (1) の時間がJMeterのレスポンスタイムとして取得できる result.sampleEnd(); // JMeterの取得結果を失敗にする result.setSuccessful(false); // JMeterのレスポンスコードをOK(200)以外の数字に設定する result.setResponseCode("500"); // JMeterで表示されるレスポンスデータの中身を詰める result.setResponseMessage("Error!! " + e.getMessage()); } return result; } }必要なライブラリはjmeterのbin以下に全部あります。
JMeterへのimport
上記のパッケージをEclipseのexport機能などでjarにして
jmeterのlibs/ext配下に配置してjmeterを再起動するだけ。
コード内でjmeterlibに最初からあるjar以外のjarに依存している場合は、
そのjarも同一フォルダに配置します。実行イメージ
Javaリクエストを使います。
クラス名のリストにAbstractJavaSamplerClientを継承したクラスが羅列されます
result.setResponseDataに指定した文字がResponseBodyに表示されます
参考
https://qiita.com/kiida/items/6af3e46e5bae14c38242
参考というかほぼ丸パクリです。すみません。追伸
MailReaderSamplerから普通に取れるよ!という方いらっしゃいましたらぜひ教えて下さい。



- 投稿日:2020-05-14T23:15:35+09:00
JSONを使用してJava ServletからiPhoneアプリへ値を受け渡してみる【初心者】
会社の同期に誘われてiPhoneアプリを作成している最中、WebサーバーとiPhoneアプリ間の値の受渡しをどうするか悩んでいました。その時、どうやらJSONを使用して、値を受け渡すらしい!ということを知りました。
そこで、色々調べた結果、無事にJSONを使用した値の受渡しができたので、まとめます。新人研修&自己学習で得た知識で書いてるので、間違っている箇所やより良い方法があれば、コメントください、、、、
作成するアプリ
画面としては、こんなかんじです。
流れとしてはこんな感じです。
① 「JSONを取得する」ボタンを押し、JavaServletへランダムな数値を渡す。
② JavaServletは、受け取った数値に応じたJSONをレスポンスする。
③ Swiftは、受け取ったJSONオブジェクトを変換し、値を画面へ出力する。赤枠で囲まれている箇所に、JavaServletから得たJSONを出力しています。
また、すべてローカル環境で実装します。環境
XcodeとEclipseを使用し、開発しました。
JSONを使用するにあたって、GSONかJacksonで迷いましたが、今回はJacksonを使用しました。実際のコード
Xcode
JSONを取得する画面
ViewController.swiftimport UIKit class ViewController: UIViewController { //表示用の文言 var textId = "" var textName = "" //タプル配列の宣言 var studentList:[(id:String , name:String)] = [] override func viewDidLoad() { super.viewDidLoad() // Do any additional setup after loading the view. } @IBAction func getJson(_ sender: Any) { self.performSegue(withIdentifier: "goResultVC", sender: nil) } override func prepare(for segue: UIStoryboardSegue, sender: Any?) { //リクエストURL JSONを返すサーブレットを指定 guard let req_url = URL(string: "http://localhost:8080/servlet_test/JsonServlet") else{return} //リクエストに必要な情報を生成 var req = URLRequest(url: req_url //0~2のランダムな数値を取得 let id = Int.random(in: 0...2) //データ転送を管理するためのセッションを作成 let session = URLSession(configuration: .default, delegate: nil, delegateQueue: OperationQueue.main) //JavaServletへ渡す情報(ID)をBodyへ設定する req.httpMethod = "POST" req.httpBody = "id=\(id)".data(using: .utf8) //リクエストをタスクとして登録 let task = session.dataTask(with: req, completionHandler: { (data, response ,error) in //セッションの終了 session.finishTasksAndInvalidate() do{ //取得したJSONを変換する let decoder = JSONDecoder() let json = try decoder.decode(StudentJson.self, from: data!) self.textId = json.id! self.textName = json.name! //「JSONを取得する」ボタンに紐づくセグエ if segue.identifier == "goResultVC" { let nextVC = segue.destination as! ResultViewVontroller nextVC.jsonId = self.textId nextVC.jsonName = self.textName } }catch{ print(error) print("エラーがでました") } }) //ダウンロード開始 task.resume() } //JSONのデータ構造 struct StudentJson: Codable { let id: String? let name: String? } }JSONを出力する画面
ResultViewVontroller.swiftimport UIKit class ResultViewVontroller: UIViewController { override func viewDidLoad() { super.viewDidLoad() // Do any additional setup after loading the view. } //出力メッセージのフィールド var jsonId = "" var jsonName = "" //出力ラベル @IBOutlet weak var resultJsonId: UILabel! @IBOutlet weak var resultJsonName: UILabel! override func viewWillAppear(_ animated: Bool) { super.viewWillAppear(true) resultJsonId.text = jsonId resultJsonName.text = jsonName } }Eclipse
Java Servlet
JsonServlet.javapackage servlet; import java.io.IOException; import javax.servlet.ServletException; import javax.servlet.annotation.WebServlet; import javax.servlet.http.HttpServlet; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse; import com.fasterxml.jackson.core.JsonProcessingException; import com.fasterxml.jackson.databind.ObjectMapper; import bean.JsonBean; /** * Servlet implementation class JsonServlet */ @WebServlet("/JsonServlet") public class JsonServlet extends HttpServlet { private static final long serialVersionUID = 1L; /** * @see HttpServlet#HttpServlet() */ public JsonServlet() { super(); // TODO Auto-generated constructor stub } /** * @see HttpServlet#doGet(HttpServletRequest request, HttpServletResponse response) */ protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { } /** * @see HttpServlet#doPost(HttpServletRequest request, HttpServletResponse response) */ protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { JsonBean jsonBeanList[] = new JsonBean[3]; //Javaオブジェクトに値をセット JsonBean jsonBean = new JsonBean(); jsonBean.setId("101"); jsonBean.setName("tanaka"); JsonBean jsonBean2 = new JsonBean(); jsonBean2.setId("102"); jsonBean2.setName("yamada"); JsonBean jsonBean3 = new JsonBean(); jsonBean3.setId("103"); jsonBean3.setName("satou"); jsonBeanList[0] = jsonBean; jsonBeanList[1] = jsonBean2; jsonBeanList[2] = jsonBean3; // String str = request.getParameter("id"); int requestId = Integer.parseInt(str); System.out.println(requestId); ObjectMapper mapper = new ObjectMapper(); try { //JavaオブジェクトからJSONに変換 String testJson = mapper.writeValueAsString(jsonBeanList[requestId]); //JSONの出力 response.getWriter().write(testJson); //出力されるJSONの確認 System.out.println(testJson); } catch (JsonProcessingException e) { e.printStackTrace(); } } }Bean
JsonBean.javapackage bean; import java.util.List; import com.fasterxml.jackson.annotation.JsonProperty; public class JsonBean { @JsonProperty("id") private String id; @JsonProperty("name") private String name; public void setId(String id) { this.id = id; } public void setName(String name) { this.name = name; } }JsonServletの動きを確認するには、Chromeの拡張機能であるTalend API Testerがおすすめです!
Talend API Testerまとめ
これで、フロントエンドとバックエンド間の通信ができるようになりました。
次は、AWS上に乗っけてみます。また、今回の実装をするにあたり、多くのQiita記事と書籍を参考にしました。
拙い内容でしたが、閲覧いただきありがとうございました!
マークダウン記法、めちゃめちゃ書きやすいですね。

- 投稿日:2020-05-14T23:15:35+09:00
JSONを使用してJava ServletからiPhoneアプリへ値を受け渡してみる
会社の同期に誘われてiPhoneアプリを作成している最中、WebサーバーとiPhoneアプリ間の値の受渡しをどうするか悩んでいました。その時、どうやらJSONを使用して、値を受け渡すらしい!ということを知りました。
そこで、色々調べた結果、無事にJSONを使用した値の受渡しができたので、まとめます。新人研修&自己学習で得た知識で書いてるので、間違っている箇所やより良い方法があれば、コメントください、、、、
作成するアプリ
画面としては、こんなかんじです。
流れとしてはこんな感じです。
① 「JSONを取得する」ボタンを押し、JavaServletへランダムな数値を渡す。
② JavaServletは、受け取った数値に応じたJSONをレスポンスする。
③ Swiftは、受け取ったJSONオブジェクトを変換し、値を画面へ出力する。赤枠で囲まれている箇所に、JavaServletから得たJSONを出力しています。
また、すべてローカル環境で実装します。環境
XcodeとEclipseを使用し、開発しました。
JSONを使用するにあたって、GSONかJacksonで迷いましたが、今回はJacksonを使用しました。
EclipceでのJackson のセットアップ方法は以下を参考にしました。
https://tech.pjin.jp/blog/2020/03/09/jackson_setup/実際のコード
Xcode
JSONを取得する画面
ViewController.swiftimport UIKit class ViewController: UIViewController { //表示用の文言 var textId = "" var textName = "" //タプル配列の宣言 var studentList:[(id:String , name:String)] = [] override func viewDidLoad() { super.viewDidLoad() // Do any additional setup after loading the view. } @IBAction func getJson(_ sender: Any) { self.performSegue(withIdentifier: "goResultVC", sender: nil) } override func prepare(for segue: UIStoryboardSegue, sender: Any?) { //リクエストURL JSONを返すサーブレットを指定 guard let req_url = URL(string: "http://localhost:8080/servlet_test/JsonServlet") else{return} //リクエストに必要な情報を生成 var req = URLRequest(url: req_url //0~2のランダムな数値を取得 let id = Int.random(in: 0...2) //データ転送を管理するためのセッションを作成 let session = URLSession(configuration: .default, delegate: nil, delegateQueue: OperationQueue.main) //JavaServletへ渡す情報(ID)をBodyへ設定する req.httpMethod = "POST" req.httpBody = "id=\(id)".data(using: .utf8) //リクエストをタスクとして登録 let task = session.dataTask(with: req, completionHandler: { (data, response ,error) in //セッションの終了 session.finishTasksAndInvalidate() do{ //取得したJSONを変換する let decoder = JSONDecoder() let json = try decoder.decode(StudentJson.self, from: data!) self.textId = json.id! self.textName = json.name! //「JSONを取得する」ボタンに紐づくセグエ if segue.identifier == "goResultVC" { let nextVC = segue.destination as! ResultViewVontroller nextVC.jsonId = self.textId nextVC.jsonName = self.textName } }catch{ print(error) print("エラーがでました") } }) //ダウンロード開始 task.resume() } //JSONのデータ構造 struct StudentJson: Codable { let id: String? let name: String? } }JSONを出力する画面
ResultViewVontroller.swiftimport UIKit class ResultViewVontroller: UIViewController { override func viewDidLoad() { super.viewDidLoad() // Do any additional setup after loading the view. } //出力メッセージのフィールド var jsonId = "" var jsonName = "" //出力ラベル @IBOutlet weak var resultJsonId: UILabel! @IBOutlet weak var resultJsonName: UILabel! override func viewWillAppear(_ animated: Bool) { super.viewWillAppear(true) resultJsonId.text = jsonId resultJsonName.text = jsonName } }Eclipse
Java Servlet
JsonServlet.javapackage servlet; import java.io.IOException; import javax.servlet.ServletException; import javax.servlet.annotation.WebServlet; import javax.servlet.http.HttpServlet; import javax.servlet.http.HttpServletRequest; import javax.servlet.http.HttpServletResponse; import com.fasterxml.jackson.core.JsonProcessingException; import com.fasterxml.jackson.databind.ObjectMapper; import bean.JsonBean; /** * Servlet implementation class JsonServlet */ @WebServlet("/JsonServlet") public class JsonServlet extends HttpServlet { private static final long serialVersionUID = 1L; /** * @see HttpServlet#HttpServlet() */ public JsonServlet() { super(); // TODO Auto-generated constructor stub } /** * @see HttpServlet#doGet(HttpServletRequest request, HttpServletResponse response) */ protected void doGet(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { } /** * @see HttpServlet#doPost(HttpServletRequest request, HttpServletResponse response) */ protected void doPost(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException { JsonBean jsonBeanList[] = new JsonBean[3]; //Javaオブジェクトに値をセット JsonBean jsonBean = new JsonBean(); jsonBean.setId("101"); jsonBean.setName("tanaka"); JsonBean jsonBean2 = new JsonBean(); jsonBean2.setId("102"); jsonBean2.setName("yamada"); JsonBean jsonBean3 = new JsonBean(); jsonBean3.setId("103"); jsonBean3.setName("satou"); jsonBeanList[0] = jsonBean; jsonBeanList[1] = jsonBean2; jsonBeanList[2] = jsonBean3; // String str = request.getParameter("id"); int requestId = Integer.parseInt(str); System.out.println(requestId); ObjectMapper mapper = new ObjectMapper(); try { //JavaオブジェクトからJSONに変換 String testJson = mapper.writeValueAsString(jsonBeanList[requestId]); //JSONの出力 response.getWriter().write(testJson); //出力されるJSONの確認 System.out.println(testJson); } catch (JsonProcessingException e) { e.printStackTrace(); } } }Bean
JsonBean.javapackage bean; import java.util.List; import com.fasterxml.jackson.annotation.JsonProperty; public class JsonBean { @JsonProperty("id") private String id; @JsonProperty("name") private String name; public void setId(String id) { this.id = id; } public void setName(String name) { this.name = name; } }JsonServletの動きを確認するには、Chromeの拡張機能であるTalend API Testerがおすすめです!
Talend API Testerまとめ
これで、フロントエンドとバックエンド間の通信ができるようになりました。
次は、AWS上に乗っけてみます。また、今回の実装をするにあたり、多くのQiita記事と書籍を参考にしました。
拙い内容でしたが、閲覧いただきありがとうございました!
マークダウン記法、めちゃめちゃ書きやすいですね。
- 投稿日:2020-05-14T22:38:31+09:00
javaでアルゴリズム入門 - 探索編(深さ優先探索)
記事の概要
自分の勉強兼メモでまとめている記事シリーズです。
こちらの記事の続きです。
javaでアルゴリズム入門 - 探索編(全探索、二分探索)
今回の記事では
- 深さ優先探索
について勉強します。前回の記事の続きのノリで書いています。
深さ優先探索
ここからもうなんですかこれって感じですが進めましょう。学びつつまとめつつ。
深さ優先探索です。
DFS(depth-first-search)とも呼ばれるらしいですね。そういえば良くこの単語見ますね。
深さ優先探索、幅優先探索は木やグラフの探索に有用らしいですね。木やグラフの説明は割愛でいきます。
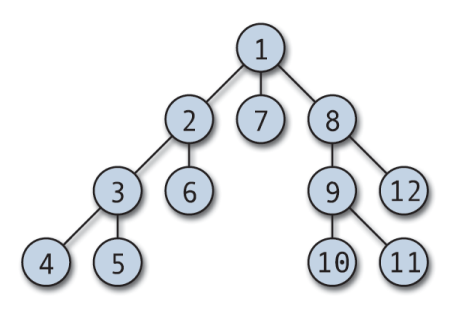
以下に図を載せます。(wikipediaより)
こんな順番で木を深さ優先で探索していくのがDFSみたいですね。
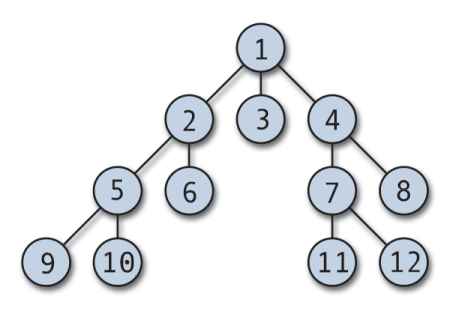
「なにが深さ優先なのかわからないよ!」と言う方は幅優先探索の探索順を見ていただければ一発だと思います。
番号の違いが分かりましたか?
深さ優先探索は、根から子を持たないノードまで一直線で探しにいっていて、幅優先探索は一旦根から深さ1のノードを順番に探索に行ってます。ちなみに実装方法としては2種類あるそうです。
- スタック(後入れ先出しのデータ構造)を使う方法
- 再帰関数を使う方法
・・・ぶっちゃけだからなんやねんって感じです。例を見なければよく分かりませんね。
と思って簡単な例を探してみたらなかなか直感的にわかる例ってないのですね。。
上図の通り、ただ単にそういう順番に探索していくやり方だよ!って感じなのですかね。
問題例を見て解きながら理解していくことにします。理解できたら簡単な例が作れるかも?
問題文・入力例などはここをクリックして表示
※できるだけ問題リンクを参照してください
(セクション開始)
【問題文】
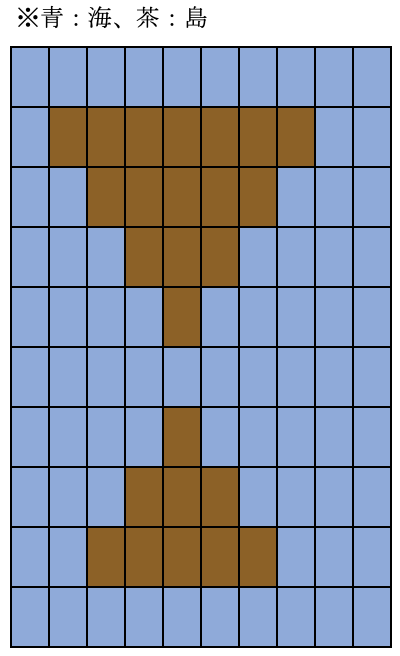
とある所に島国がありました。島国にはいくつかの島があります。このたび、この島国で埋め立て計画が立案されたのですが、どこを埋め立てるか決まっていません。できることなら埋め立てによって島を繋いで、1つの島にしてしまいたいのですが、たくさん埋め立てるわけにもいきません。
10マス × 10マスのこの島国の地図が与えられるので、1マスを埋め立てた時に 1つの島にできるか判定してください。ただし、地図で陸地を表すマスが上下左右につながっている領域のことを島と呼びます。【入力】
入力は以下の形式で標準入力から与えられる。\(A1,1\)\(A1,2\)...\(A1,10\) \(A2,1\)\(A2,2\)...\(A2,10\) : \(A10,1\)\(A10,2\)...\(A10,10\)島国の地図が 10行にわたって与えられる。
各行は 10文字からなり、o は陸地を、x は海を表す。
少なくとも 1マスは陸地があることが保証される。
少なくとも 1マスは海があることが保証される。【出力】
海を 1マスだけ陸地にすることで全体を 1つの島にできるなら YES 、できないなら NO を出力せよ。出力の末尾には改行をつけること。ただし、元から 1つの島だった場合も YES を出力せよ。【入力例】
xxxxxxxxxx
xoooooooxx
xxoooooxxx
xxxoooxxxx
xxxxoxxxxx
xxxxxxxxxx
xxxxoxxxxx
xxxoooxxxx
xxoooooxxx
xxxxxxxxxx(セクション終了)
他の方のソースやいろいろなブログを見て勉強してきました。
方針は以下のとおりです。多分多くの人のやり方がこうでした。
- 10 * 10の土地で、「この一マスを埋め立てれば全体を一つの島にできる」一マスを探索する。
- 最初に選んだマスから深さ優先探索で、島のマス目数を数える。このとき探索したマス目数が、最初の入力で受け取った島のマス目 + (海を埋め立てていれば)1マスであれば、条件に合致。
【回答例】
main.javaimport java.util.Scanner; public class Main { // 島の地図的なもの static char[][] islandMap; public static void main(String[] args) { Scanner sc = new Scanner(System.in); // 島の地図的なもの islandMap = new char[10][10]; // 島のマスの数 int countIsland = 0; // 最終的な出力 String ans = "NO"; // 入力を受け取って島の地図完成、島マスの個数カウント for (int i = 0; i < 10; i++) { islandMap[i] = sc.next().toCharArray(); for (int j = 0; j < 10; j++) { if (islandMap[i][j] == 'o') { countIsland++; } } } // 二重ループでマス目を左上のマスから探索 for (int i = 0; i < 10; i++) { for (int j = 0; j < 10; j++) { // 島数カウント一時変数 int countIslandInLoop = countIsland; // 海の場合、陸地にする。また島の数を一つ増やす if (islandMap[i][j] == 'x') { islandMap[i][j] = 'o'; countIslandInLoop = countIsland + 1; } /* * 深さ優先探索を行う。 * dfsCountIsland・・・dfsでカウントしている、陸続きの島の数 * checked・・・dfsによりマス目が探索済みかどうかの判定 */ dfsIslandCount = 0; boolean[][] checked = new boolean[10][10]; dfs(i, j, checked); if (dfsIslandCount == countIslandInLoop) { ans = "YES"; break; } // 埋め立てたマスを元に戻して次のループへ if (countIslandInLoop == countIsland + 1) { islandMap[i][j] = 'x'; } } if ("YES".equals(ans)) { break; } } System.out.println(ans); } // 現在dfsでカウントしている陸続きの島のマス目数 static int dfsIslandCount; // 深さ優先探索 static void dfs(int i, int j, boolean[][] checked) { // マス目を超えている・探索済み・海であるならば方向転換。 if (i < 0 || i > 9 || j < 0 || j > 9 || checked[i][j] || islandMap[i][j] == 'x') { return; } // 今探索しているマスが陸地であれば陸地カウントをインクリメントする if (islandMap[i][j] == 'o') { dfsIslandCount++; } // 現在のマス目を探索済みにする checked[i][j] = true; // 上下左右のマスを探索する dfs(i + 1, j, checked); dfs(i - 1, j, checked); dfs(i, j + 1, checked); dfs(i, j - 1, checked); return; } }いやね、めっちゃ難しかった。グローバル変数に入れるところとか、探索の再帰のやり方とかめちゃ難しい。
あと関係ないんですけど、こういうアルゴリズムの例題ってAtCoderで用意してくれてるんですね。
AtCoder - atc001-a「深さ優先探索」とりあえずこの問題のコードとしてはかけたので、dfsの部分を上から見ていきましょう。
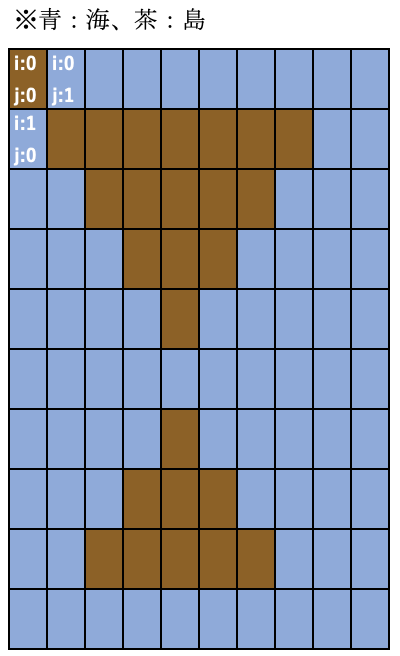
2マス分くらい見れればいいかな。まず例の入力が次のとおりです。
xxxxxxxxxx xoooooooxx xxoooooxxx xxxoooxxxx xxxxoxxxxx xxxxxxxxxx xxxxoxxxxx xxxoooxxxx xxoooooxxx xxxxxxxxxx※×が海で、○が島。
このときのmapは次のような感じです。
(まぁ、文字列からでもわかるけど。)
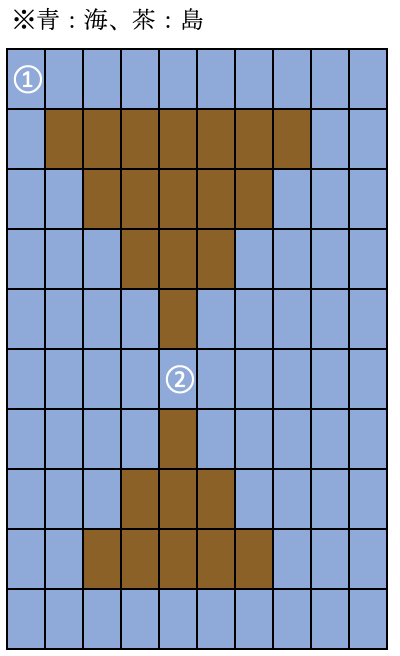
これの、①のマスについてのDFS、②のマスについてのDFSについて考えてみましょうか。
分かりやすさのために上記コードのdfsメソッド内、
1番の処理を「// マス目を超えている・探索済み・海であるならば方向転換。」のif文、
2番の処理を「// 今探索しているマスが陸地であれば陸地カウントをインクリメントする」の処理、
3番の処理を「// 現在のマス目を探索済みにする」の処理、
4番の処理を「// 上下左右のマスを探索する」の処理とします。(どれが呼び出されるかは都度説明します。)①の場合のDFS
ソースを追っていきましょう。
主にdfsでマスを移動するところについて重点的に解説します。2番の処理で、①のマスを埋め立てた図がこちらです。
いちおうi,jの値も加えておきました。ではDFSです。現在いるマスを3番の処理で探索済みにしたあと、4番の処理に進みます。まず呼び出されるのは
dfs(i + 1, j, checked);
です。i=0,j=0なので
dfs(1, 0, checked);
ですね。
これでi=1,j=0のマスに移動しましたが、移動先は海なので1番の処理でif文に引っかかってしまいます。returnされます。次は4番の処理の2行目に進みます。
dfs(i - 1, j, checked);
具体的に言うと
dfs(-1, 0, checked);
ですね。
i=-1,j=0のマス(地図外)に移動し、1番の処理でreturnされます。3,4行目についても同様ですね。これで①のマスについては探索を終えるわけです。
まだ再帰っぽくなってないので分かりづらいですかね。ただまぁこういう分かりやすい例から考えるのもいいのではないかなぁと思います。②の場合のDFS
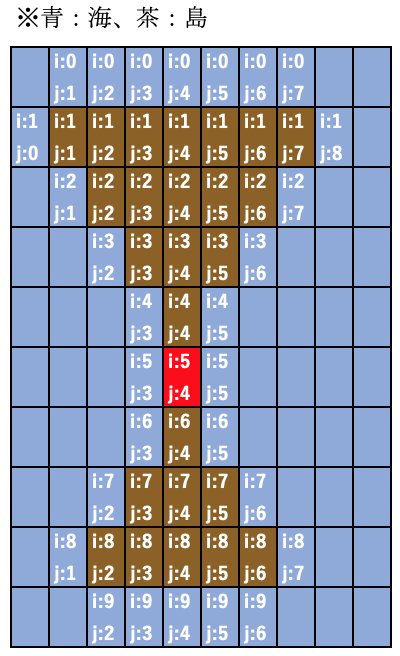
では答えの例です。張り切ってDFSしましょう。
埋め立てをしてi,jの番号を書いた図がこちらです。
1回目の呼び出し、赤い部分について呼び出したあと、の動きをプログラムチックにインデントをつけて順番に書いていきます。インデントつくと再帰みたいな感じですね。
最初のdfs呼び出しの4番目の処理からいきます。はりきっていきましょう!!
現在(i,j) = (5,4)です。
再帰を含めて呼ばれる順番は以下のとおりです。
01.dfs(6, 4, checked);
02.dfs(7, 4, checked);
03.dfs(8, 4, checked);
04.dfs(9, 4, checked);←海なので終わり
05.dfs(7, 4, checked);←02行目で探索済みなので終わり
06.dfs(8, 5, checked);
07.dfs(9, 5, checked);←海なので終わり
08.dfs(7, 5, checked);
09.dfs(8, 5, checked);←06行目で探索済みのため終わり
10.dfs(9, 5, checked);←海なので終わり
11.dfs(7, 4, checked);←02行目で探索済みなので終わり
12.dfs(7, 6, checked);←海なので終わり
13.dfs(8, 6, checked);
14.dfs(9, 6, checked);←海なので終わり
15.dfs(7, 6, checked);←海なので終わり
16.dfs(8, 7, checked);←海なので終わり
17.dfs(8, 5, checked);←06行目で探索済みのため終わり
18.dfs(8, 4, checked);←03行目で探索済みのため終わり
19.dfs(8, 3, checked);
20.dfs(9, 3, checked);←海なので終わり
21.dfs(7, 3, checked);
22.dfs(8, 3, checked);←19行目で探索済みのため終わり
23.dfs(6, 3, checked);←海なので終わり
24.dfs(7, 4, checked);←02行目で探索済みのため終わり
25.dfs(7, 2, checked);←海なので終わり
26.dfs(8, 2, checked);
27.dfs(9, 2, checked);←海なので終わり
28.dfs(7, 2, checked);←海なので終わり
29.dfs(8, 3, checked);←19行目で探索済みのため終わり
30.dfs(8, 1, checked);←海なので終わり
31.dfs(8, 4, checked);←03行目で探索済みのため終わり
32.dfs(6, 4, checked);←01行目で探索済みのため終わり
33.dfs(7, 5, checked);←08行目で探索済みのため終わり
34.dfs(7, 3, checked);←21行目で探索済みのため終わり
35.dfs(5, 4, checked);←一番最初に探索済みのため終わり
36.dfs(6, 5, checked);←海なので終わり
37.dfs(6, 3, checked);←海なので終わり
38.dfs(4, 4, checked);
39.dfs(5, 4, checked);←一番最初に探索済みのため終わり
40.dfs(3, 4, checked);
41.dfs(4, 4, checked);←38行目で探索済みのため終わり
42.dfs(2, 4, checked);
43.dfs(3, 4, checked);←40行目で探索済みのため終わり
44.dfs(1, 4, checked);
45.dfs(2, 4, checked);←42行目で探索済みのため終わり
46.dfs(0, 4, checked);←海なので終わり
48.dfs(1, 5, checked);
49.dfs(2, 5, checked);
50.dfs(3, 5, checked);
51.dfs(4, 5, checked);←海なので終わり
52.dfs(2, 5, checked);←42行目で探索済みのため終わり
53.dfs(3, 6, checked);←海なので終わり
54.dfs(3, 4, checked);←40行目で探索済みのため終わり
55.dfs(1, 5, checked);←42行目で探索済みのため終わり
56.dfs(2, 6, checked);
57.dfs(3, 6, checked);←海なので終わり
58.dfs(1, 6, checked);
59.dfs(2, 6, checked);←56行目で探索済みのため終わり
60.dfs(0, 6, checked);←海なので終わり
61.dfs(1, 7, checked);
62.dfs(2, 7, checked);←海なので終わり
63.dfs(0, 7, checked);←海なので終わり
64.dfs(1, 8, checked);←海なので終わり
65.dfs(1, 6, checked);←58行目で探索済みのため終わり
66.dfs(1, 5, checked);←42行目で探索済みのため終わり
67.dfs(2, 7, checked);←海なので終わり
68.dfs(2, 5, checked);←42行目で探索済みのため終わり
69.dfs(2, 4, checked);←38行目で探索済みのため終わり
70.dfs(0, 5, checked);←海なので終わり
71.dfs(1, 6, checked);←58行目で探索済みのため終わり
72.dfs(1, 4, checked);←44行目で探索済みのため終わり
73.dfs(1, 3, checked);
74.dfs(2, 3, checked);
75.dfs(3, 3, checked);
76.dfs(4, 3, checked);←海なので終わり
77.dfs(2, 3, checked);←74行目で探索済みのため終わり
78.dfs(3, 4, checked);←38行目で探索済みのため終わり
79.dfs(3, 2, checked);←海なので終わり
80.dfs(1, 3, checked);←73行目で探索済みのため終わり
81.dfs(2, 4, checked);←38行目で探索済みのため終わり
82.dfs(2, 2, checked);
83.dfs(3, 2, checked);←海なので終わり
84.dfs(1, 2, checked);
85.dfs(2, 2, checked);←82行目で探索済みのため終わり
86.dfs(0, 2, checked);←海なので終わり
87.dfs(1, 3, checked);←44行目で探索済みのため終わり
88.dfs(1, 1, checked);
89.dfs(2, 1, checked);←海なので終わり
90.dfs(0, 1, checked);←海なので終わり
91.dfs(1, 2, checked);←84行目で探索済みのため終わり
92.dfs(1, 0, checked);←海なので終わり
93.dfs(2, 3, checked);←74行目で探索済みのため終わり
94.dfs(2, 1, checked);←海なので終わり
95.dfs(0, 3, checked);←海なので終わり
96.dfs(1, 4, checked);←44行目で探索済みのため終わり
97.dfs(1, 2, checked);←84行目で探索済みのため終わり
98.dfs(2, 5, checked);←42行目で探索済みのため終わり
99.dfs(2, 3, checked);←74行目で探索済みのため終わり
00.dfs(3, 5, checked);←50行目で探索済みのため終わり
01.dfs(3, 3, checked);←75行目で探索済みのため終わり
02.dfs(4, 5, checked);←海なので終わり
03.dfs(4, 3, checked);←海なので終わり
04.dfs(5, 5, checked);←海なので終わり
05.dfs(5, 3, checked);←海なので終わりお・・・終わったぁ・・・
超疲れました。人の手でやるもんじゃありませんでした。
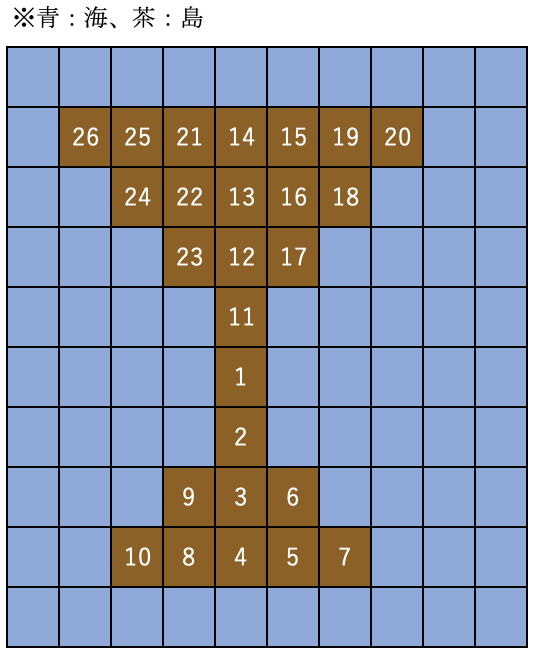
まぁせっかくやったのでどんな動きで探索されていったのか確かめてみましょうね。
白文字で探索の順番を表してみました。
図を見てもらってもわかると思いますしloopの感じ見てもらってもわかると思いますが、DFSは「いけるとこまでいっていけなくなったら方向転換する」みたいな感じなのですね。
あと「スタック」って言葉が出てきたと思うんですけど、この再帰の方法、まさに先入後出しのスタックの順番になっているような感じがしますよね。スタックというデータ構造を使わずとも、再帰で実装書いたらスタックのような処理になることがよく分かりましたね。
深さ優先探索については理解できましたでしょうか?私はほんのり理解できました。(あぁ、疲れた・・・)
だいぶ長くなったので、幅優先探索についてはまた次回解説しようと思います。
次回もお楽しみに!!
- 投稿日:2020-05-14T22:27:45+09:00
java.security.InvalidKeyException: Illegal key size or default parametersとなった時の対応方法
- 環境
- Red Hat Enterprise Linux Server release 6.3 (Santiago)
- java version "1.7.0_79"
事象 : 複合化する処理が動いたらInvalidKeyExceptionが発生した
ほかのサーバから送られてきたパラメータを複合化する処理が動いたらInvalidKeyExceptionが発生した
java.security.InvalidKeyException: Illegal key size or default parameters at javax.crypto.Cipher.checkCryptoPerm(Cipher.java:1011) at javax.crypto.Cipher.implInit(Cipher.java:786) at javax.crypto.Cipher.chooseProvider(Cipher.java:849) at javax.crypto.Cipher.init(Cipher.java:1213) at javax.crypto.Cipher.init(Cipher.java:1153) ...省略...原因 : (Java8以下の場合)AES256bitの鍵長が使えないから
Java では標準ライブラリの Cipher クラスを使えば、サードパーティのライブラリを使うことなく AES 暗号を扱うことができます。しかし、AES 暗号はアメリカの輸出規制の対象になっているらしく、標準では 128bit までの鍵しか扱えません。
Java 9時代のAES 256暗号 - Qiita対応 : ポリシーファイルを入れ替える
- Java Cryptography Extension (JCE) Unlimited Strength Jurisdiction Policy Files for JDK/JRE DownloadからJavaのバージョンに合ったzipファイルをダウンロードする
- 今回はJava1.7なので
UnlimitedJCEPolicyJDK7.zipをダウンロード- 解凍したディレクトリ内のjar(
local_policy.jarUS_export_policy.jar)を配置するサーバへ転送する- Javaのインストールディレクトリを確認する
- 当たり前のことだけど・・・同じバージョンが2箇所にあって最初間違えたディレクトリに配置したのでちゃんと書いた
- Javaのインストールディレクトリがわからなくなった時の探し方 - Qiita
{javaのインストールディレクトリ}/jre/lib/security/にあるlocal_policy.jarUS_export_policy.jarのバックアップを取る{javaのインストールディレクトリ}/jre/lib/security/に解凍したディレクトリ内のjarを配置する# jarを配置するサーバへ転送する $ scp -i /path/to/{秘密鍵}.pem /path/to/zip/UnlimitedJCEPolicy/*.jar ponsuke@{サーバ}:/home/ponsuke/ local_policy.jar 100% 2500 12.2KB/s 00:00 US_export_policy.jar 100% 2487 12.1KB/s 00:00 # サーバにログイン $ ssh -i /path/to/{秘密鍵}.pem ponsuke@{サーバ} Last login: Thu May 14 20:56:50 2020 from 10.0.1.10 # Javaのインストールディレクトリを確認する $ printenv JAVA_HOME /usr/java/default # jarのバックアップを取る $ cd $JAVA_HOME/jre/lib/security/ $ sudo mv local_policy.jar local_policy.jar.bak [sudo] password for ponsuke: $ sudo mv US_export_policy.jar US_export_policy.jar.bak # 解凍したディレクトリ内のjarを配置する $ sudo mv /home/ponsuke/*.jar . $ ls -la | grep jar -rw-r--r-- 1 ponsuke appl 2487 5月 14 21:36 2020 US_export_policy.jar -rw-r--r--. 1 root root 2397 4月 11 03:55 2015 US_export_policy.jar.bak -rw-r--r-- 1 ponsuke appl 2500 5月 14 21:36 2020 local_policy.jar -rw-r--r--. 1 root root 2865 4月 11 03:55 2015 local_policy.jar.bak
- 投稿日:2020-05-14T21:28:38+09:00
Javaのインストールディレクトリがわからなくなった時の探し方
サーバでいろいろな事情によりインストールディレクトリを見失ってしまった。
方法1 : 環境変数の
JAVA_HOMEを見る今使っているバージョン(javaコマンドで動くバージョン)ならこれでOK。
$ printenv JAVA_HOME /usr/java/default方法2 : 環境変数の
PATHを見る今使っているバージョン(javaコマンドで動くバージョン)で
JAVA_HOMEがない時はこれでOK。$ printenv PATH | sed -e 's/:/:\n/g' | grep java /usr/java/default/bin:方法3 :
yumでインストールしたパッケージ名で探すいくつもバージョンをインストールしていることはよくあること。
JAVA_HOMEに設定していないバージョンのJavaを探したいとき。参考 : yumでインストールしたパッケージのインストール場所を調べる - 学生時代に頑張ったことが何もない
# バージョンからインストールしたパッケージを調べる $ yum list installed | grep java-1.7 java-1.7.0-openjdk.x86_64 1:1.7.0.151-2.6.11.0.el6_9 java-1.7.0-openjdk-devel.x86_64 # インストールディレクトリを確認する $ rpm -ql java-1.7.0-openjdk-devel.x86_64 | grep bin /usr/lib/jvm/java-1.7.0-openjdk-1.7.0.151.x86_64/bin /usr/lib/jvm/java-1.7.0-openjdk-1.7.0.151.x86_64/bin/appletviewer ...省略...
- 投稿日:2020-05-14T21:25:07+09:00
【Windows】Javaのコードが文字化け
JavaのコードをWindowsのコマンドプロンプトで実行すると文字化けしてしまう問題。
やり方が2通りあるので紹介します!!
なぜ起こるのか
テキストエディタとコマンドプロンプトの文字設定が食い違ってるからみたいです。
コマンドプロンプトのプロパティの「オプション」タグの下部に、
現在のコードページが932 Shift-JISとなっていますね。
けど、VScodeの設定からEncodingを見るとurf8となってるので合わないから化けちゃったのかもです。
なので今回はVScodeに合わせて設定していきます。前提
- Windowsでプログラミングしている人
- Java初学者
- VScode使ってます。
解決法1 CHCPコマンドを使う
CHCPコマンドとは、文字コードの設定に使えるコマンドのことで、
chcp <コードページ番号>と指定すると変更ができ、コマンドプロンプトの設定も変わります。VScodeと同じUTF-8にしたい場合はコマンドプロンプトで
chcp 65001と打つと画面が切り替わります。
あとはいつも通りコンパイルして実行後に文字化けしていなかったら成功です!javac Sample1.java java Sample1 Hello, Java!解決法2 オプションをつける
コマンドラインのオプションを付けて実行する方法。
これでも良いんですけど付けるのがめんどい人は上のやり方がいいです!javac Sample1.java -J-Dfile.encoding=UTF-8 java Sample1 -J-Dfile.encoding=UTF-8 Hello, Java!参考サイト
![471c1995a62dc4b007e3ab8e72e6e08c[1].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F610089%2Fa8a496a8-3420-a975-ba27-5a006d163917.png?ixlib=rb-1.2.2&auto=format&gif-q=60&q=75&s=13868c79f08871d68fac27084dc44ca3)
- 投稿日:2020-05-14T21:20:16+09:00
初心に帰ってJava入門②制御文、ループ文
はじめに
本記事は、Javaの基礎を復習するアウトプットが目的の記事です。
お暇なときに読んでいただければ嬉しいです。色々な書き方ができる制御文
Javaでの制御文は大きく分けて、
・if文
・三項演算子
・Stream(ちょっと違うけど・・・)
・switch文
・booleanを返すメソッド
で行います。
今回は、上3つを解説していきます。if文
著名な言語では大体存在する文法です。
もちろんJavaにも存在します。Control.javapublic long secondCheck(List<String> checkTarget) { long count = 0L; for(String target : checkTarget) { if(target.length() > 3) { count++; } else if(target.length() > 5) { count++; } else { return count; } } return count; }処理順は以下のとおりです。
①ifの条件式が最初に判定される。
②ifの条件式がfalseを返した場合、else ifの条件式が判定される
③1,2に合致しない場合、elseが実行される。上から順に判定して言って、条件に合致した処理を行う、合致しなければelseブロックの処理が実行されるイメージです。
三項演算子
if文と同様の制御を行います。が、使いどころを間違うと大変読みづらいコードとなってしまいます。
メリットはなんといってもワンライナーで書けることです。Control.javapublic long thridCheck(List<String> checkTarget) { long count = 0L; int i = 0 ; while(i < checkTarget.size()) { count = checkTarget.get(i).length() > 5 ? count++ : count; i++; } return count; }処理は以下のとおりです。
?より前の条件式がtrueを返せば、左の処理を、falseを返せば右の処理を実行します。
私見ですが、Stream登場以前は禁忌とされてきた記述だと思いますが、
Stream導入以降少し市民権を得た気がします。falseのときにさらに条件式をネストすることも可能です。
Control.javapublic long thridCheck(List<String> checkTarget) { long count = 0L; int i = 0 ; while(i < checkTarget.size()) { count = checkTarget.get(i).length() > 5 ? count++ : checkTarget.get(i).length() > 3 ? count++ : count; i++; } return count; }ここまでくると読みづらいので、if elseで完結でき、横にコードが伸びすぎない
場合に使うことをお勧めします。
※実務の1行に書けるコード量の規約にのっとるときれいに書きやすいです。Stream
JavaSE8より追加されたコレクション操作を行う際に活用できるインタフェースです。
詳しい解説は別記事にしますが、上記のコードを以下のように記述できます。Control.javapublic long firstCheck(List<String> checkTarget) { long count = checkTarget.stream().filter(str -> str.length() > 5).count(); return count; }今回の例であれば、JavaScriptの思想をお借りして直接結果を返してやるのも良いですね。
Control.javapublic long firstCheck(List<String> checkTarget) { return checkTarget.stream().filter(str -> str.length() > 5).count(); }こっちも色々ループ文
ループ文は以下のようなものがあります。
・for文
・拡張for文
・Stream
・while文
・do while文
こちらも、上から3つめまでを解説します。for文
多くの言語に存在するループです。
Javaでは
(変数宣言,条件式,カウント処理)
で記述し、条件式がfalseを返すまで処理をループします。Control.javapublic long secondCheck(List<String> checkTarget) { long count = 0L; for(int i = 0 ; i < checkTarget.size() ; i++) { if(checkTarget.get(i).length() > 3) { count++; } } return count; }上記のコードだと、宣言した変数iがcheckTargetリストの件数以上になるまでループします。
拡張for文
他の言語ではforeach文と呼ばれていたりするものです。
コレクションの要素を順番に処理し、すべての要素に対して処理が完了するまでループします。Control.javapublic long secondCheck(List<String> checkTarget) { long count = 0L; for(String target : checkTarget) { if(target.length() > 3) { count++; } } return count; }上記のコードだと、checkTargetListの要素すべてが処理されます。
Stream
forEach()メソッドが用意されています。
こちらも、拡張for文と同様の処理を行います。Control.javapublic void firstCheck(List<String> checkTarget) { checkTarget.stream().filter(str -> str.length() > 5).forEach(System.out::print); }終わりに
私がエンジニアになったときはまだJava7が全盛期で、Streamを使う人のほうが少なかったのですが、記述が短く分かりやすいStreamが主流になり、時代の流れを感じます。
それでもまだ8が主流で古いんですけどね・・・
- 投稿日:2020-05-14T20:45:12+09:00
Stringクラスのメソッド
Stringクラスにはたくさんのメソッドが用意されており、自分自身漏れていたり、知らなかったものもあったので、この際にまとまることにしました。
charAt(int index)
指定されたインデックスのchar値を返す。
String test = "あいうえおかきくけこ"; //指定されたインデックスのchar値を返します。 System.out.println(test.charAt(0)); System.out.println(test.charAt(2)); System.out.println(test.charAt(5));あ う かcodePointAt(int index)
指定されたインデックス位置の文字(Unicodeコード・ポイント)を返す。
String test = "あいうえおかきくけこ"; //指定されたインデックス位置の文字(Unicodeコード・ポイント)を返します。 System.out.println(test.codePointAt(0)); System.out.println(test.codePointAt(1)); System.out.println(test.codePointAt(6));12354 12356 12365codePointBefore(int index)
指定されたインデックスの前の文字(Unicodeコード・ポイント)を返す。
String test = "あいうえおかきくけこ"; //指定されたインデックス位置の文字(Unicodeコード・ポイント)を返します。 System.out.println(test.codePointBefore(1)); System.out.println(test.codePointBefore(2)); System.out.println(test.codePointBefore(7));12354 12356 12365codePointCount(int beginIndex, int endIndex)
このStringの指定されたテキスト範囲のUnicodeコード・ポイントの数を返す。
String test = "あいうえおかきくけこ"; //このStringの指定されたテキスト範囲のUnicodeコード・ポイントの数を返します。 System.out.println(test.codePointCount(0, 1)); System.out.println(test.codePointCount(2, 4)); System.out.println(test.codePointCount(3, 9));1 2 6compareTo(String anotherString)
2つの文字列を辞書的に比較する。
String test = "あいうえおかきくけこ"; //2つの文字列を辞書的に比較します。 //引数文字列がこの文字列に等しい場合は、値0 //文字列が文字列引数より辞書式に小さい場合は、0より小さい値 //文字列引数より辞書式に大きい場合は、0より大きい値 System.out.println(test.compareTo("あいうえおかきくけこ")); System.out.println(test.compareTo("あいうえお")); System.out.println(test.compareTo(""));0 5 10compareToIgnoreCase(String str)
大文字と小文字の区別なしで、2つの文字列を辞書的に比較する。
String test = "ABCD"; //大文字と小文字の区別なしで、2つの文字列を辞書的に比較します。 //大文字と小文字の区別なしで、指定されたStringがこのStringより大きい場合は負の整数、 //同じ場合は0、小さい場合は正の整数。 System.out.println(test.compareToIgnoreCase("abcd")); System.out.println(test.compareToIgnoreCase("ABCD")); System.out.println(test.compareToIgnoreCase("E"));0 0 -4concat(String str)
指定された文字列をこの文字列の最後に連結する。
String test = "ABCD"; //指定された文字列をこの文字列の最後に連結します。 System.out.println(test.concat("E")); System.out.println(test.concat("EWWWW"));ABCDE ABCDEWWWWcontains(CharSequence s)
この文字列が指定されたchar値のシーケンスを含む場合に限りtrueを返す。
String test = "ABCD"; //この文字列が指定されたchar値のシーケンスを含む場合に限りtrueを返す。 System.out.println(test.contains("A")); System.out.println(test.contains("a")); System.out.println(test.contains("w"));true false falsecontentEquals(CharSequence cs)
この文字列と指定されたCharSequenceを比較する。
String test = "ABCD"; //この文字列と指定されたCharSequenceを比較します。 System.out.println(test.contentEquals("ABCD")); System.out.println(test.contentEquals("AC")); System.out.println(test.contentEquals("a"));true false falsecontentEquals(StringBuffer sb)
この文字列と指定されたStringBufferを比較します。
String test = "ABCD"; //この文字列と指定されたStringBufferを比較します。 System.out.println(test.contentEquals("A")); System.out.println(test.contentEquals("ABCD")); System.out.println(test.contentEquals("AD")); System.out.println(test.contentEquals("s"));false true false falseendsWith(String suffix)
この文字列が、指定された接尾辞で終るかどうかを判定する。
String test = "ABCD"; //この文字列が、指定された接尾辞で終るかどうかを判定する。 System.out.println(test.endsWith("D")); System.out.println(test.endsWith("d")); System.out.println(test.endsWith("A"));true false falseequals(Object anObject)
この文字列と指定されたオブジェクトを比較します。
String test1 = "ABCD"; String test2 = "abcd"; //この文字列と指定されたオブジェクトを比較します。 System.out.println(test1.equals(test2));falseequalsIgnoreCase(String anotherString)
大文字と小文字を区別せずに、このStringを別のStringと比較する。
String test1 = "ABCD"; String test2 = "abcd"; //この文字列と指定されたオブジェクトを比較します。 System.out.println(test1.equals(test2));truegetChars(int srcBegin, int srcEnd, char[] dst, int dstBegin)
この文字列から、コピー先の文字配列に文字をコピーする。
srcBegin - コピー対象文字列内の最初の文字のインデックス。
srcEnd - コピー対象文字列内の最後の文字のあとのインデックス。
dst - 転送先配列。
dstBegin - コピー先の配列内での開始座標。コピーされる文字数はsrcEnd - srcBeginである。
String Str1 = new String("ABCD"); char[] Str2 = new char[6]; //この文字列から、コピー先の文字配列に文字をコピーします。 //開始インデックスは0 //コピー対象の文字数は3 //Str2にコピーする //コピー先の配列内の開始座標は0 Str1.getChars(0, 3, Str2, 0); System.out.println(Str2); Str1.getChars(2, 4, Str2, 0); System.out.println(Str2);ABC CDCindexOf(String str), indexOf(int ch)
この文字列内で、指定された文字が最初に出現する位置のインデックスを返す。
※文字がない場合は-1。
String test1 = "ABCD"; //この文字列内で、指定された文字が最初に出現する位置のインデックスを返します。 System.out.println(test1.indexOf("C")); System.out.println(test1.indexOf("A")); System.out.println(test1.indexOf("W"));2 0 -1indexOf(String str, int fromIndex)
指定されたインデックス以降で、指定された部分文字列がこの文字列内で最初に出現する位置のインデックスを返す。
※出現箇所がない場合は-1。
String test1 = "ABCD"; //指定されたインデックス以降で、指定された部分文字列がこの文字列内で最初に出現する位置のインデックスを返します。 //開始位置0から"C"が出現する位置は何か System.out.println(test1.indexOf("C",0)); //開始位置2から"A"が出現する位置は何か System.out.println(test1.indexOf("A",2)); //開始位置3から"D"が出現する位置は何か System.out.println(test1.indexOf("D",3));2 -1 3isEmpty()
length()が0の場合にのみ、trueを返す。
String test1 = "ABCD"; String str1 = ""; String str2 = null; System.out.println(test1.isEmpty()); System.out.println(str1.isEmpty()); //NullPointerException System.out.println(str2.isEmpty());false true NullPointerExceptionlastIndexOf(int ch), lastIndexOf(String str)
この文字列内で、指定された文字が最後に出現する位置のインデックスを返す。
※出現箇所がない場合は-1
String str = "AABBBCD"; //この文字列内で、指定された文字が最後に出現する位置のインデックスを返します。 //'A'は最後に1番目に出現しているので、1 System.out.println(str.lastIndexOf('A')); //"B"は最後に4番目に出現しているので、4 System.out.println(str.lastIndexOf("B")); //"U"は存在しないので、-1 System.out.println(str.lastIndexOf("U"));1 4 -1lastIndexOf(String str, int fromIndex)
この文字列内で、指定された部分文字列が最後に出現する位置のインデックスを返す(検索は指定されたインデックスから開始され、先頭方向に行われる)。
String str = "AABBBCD"; //この文字列内で、指定された部分文字列が最後に出現する位置のインデックスを返します System.out.println(str.lastIndexOf("B",3)); System.out.println(str.lastIndexOf("B",2)); System.out.println(str.lastIndexOf("A",4));3 2 1length()
この文字列の長さを返す。
String str = "AABBBCD"; //文字列の長さを返す。 System.out.println(str.length());7substring(int beginIndex), substring(int beginIndex, int endIndex)
この文字列の部分文字列である文字列を返す。
※部分文字列の長さはendIndex-beginIndexになる。
String str = "AABBBCD"; //文字列の部分文字列である文字列を返します。 System.out.println(str.substring(2)); System.out.println(str.substring(5)); System.out.println(str.substring(2,5)); System.out.println(str.substring(3,6));BBBCD CD BBB BBCtoCharArray()
この文字列を新しい文字配列に変換する。
String str = "AABBBCD"; char[] charAry = str.toCharArray(); //文字列を新しい文字配列に変換します。 for(char i : charAry) { System.out.println(i); }A A B B B C DtoLowerCase()
デフォルト・ロケールのルールを使って、このString内のすべての文字を小文字に変換する。
//String内のすべての文字を小文字に変換します。 System.out.println(str.toLowerCase());aabbbcdtoUpperCase()
デフォルト・ロケールのルールを使って、このString内のすべての文字を大文字に変換する。
String str = "asdfgh"; //String内のすべての文字を大文字に変換します。 System.out.println(str.toUpperCase());ASDFGHtrim()
値がこの文字列である文字列を返します(先頭と末尾の空白は削除される)。
String str = " asdfgh "; //この文字列の先頭と末尾の空白を削除した値を持つ文字列、またはこの文字列(先頭と末尾に空白が存在しない場合)。 System.out.println(str); System.out.println(str.trim());asdfgh asdfghvalueOf(boolean b)
boolean引数の文字列表現を返す。
String str = " asdfgh "; String str2 = "true"; //引数がtrueの場合は"true"に等しい文字列が返され、そうでない場合は"false"に等しい文字列が返される。 System.out.println(Boolean.valueOf(str)); System.out.println(Boolean.valueOf(str2));false truevalueOf(int i)
int引数の文字列表現を返します。
String str = "asdfgh"; String str2 = "123456"; //NumberFormatException System.out.println(Integer.valueOf(str)); System.out.println(Integer.valueOf(str2));NumberFormatException 123456valueOf(double d), valueOf(float f), valueOf(long l)
double,float,long引数の文字列表現を返す。
String str = "1234565"; System.out.println(Long.valueOf(str)); System.out.println(Float.valueOf(str)); System.out.println(Double.valueOf(str));1234565 1234565.0 1234565.0
- 投稿日:2020-05-14T19:52:58+09:00
【言語別】ジェネリクスの型パラメータを書く場所
言語によって型パラメータを書く場所が異なり混乱するためまとめてみた。
(編集リクエストをいただければ他の言語も追加します。)Java
型定義
class MyType<T> { }変数の型指定
MyType<T> myVariable関数定義
public static <T> void myFunction() { }関数呼び出し
this.<String>myFunction()Kotlin
型定義
class MyType<T> { }変数の型指定
val myVariable: MyType<String>関数定義
fun <T> myFunction() { }関数呼び出し
myFunction<String>()TypeScript
型定義
class MyType<T> { }変数の型指定
const myVariable: MyType<string>関数定義
function myFunction<T>(): void { }関数呼び出し
myFunction<string>()
- 投稿日:2020-05-14T19:20:06+09:00
Camunda DMN Engineを使ってDMNを実行する
DMN(Decision Modeling and Notation)とは
OMG(Object Managemnt Group)で規定されている意思決定のモデリング記法です。近年RPAのナレッジ部分における意思決定自動化手法として注目されています。
https://www.omg.org/spec/DMN/About-DMN/
DMNの最大の特長は人間が理解しやすいように記述した意思決定モデルをそのままコードで実行できることです。Camunda社のDMNシミュレータでDMNの動作をテストできます。このサンプルでは季節(Season)とゲスト数(Number of Guests)をもとに最適な料理(Dish)を決定し、さらにその料理と子連れの有無(Guests with children)から最適な飲み物(Beverages)を決定します。ここでいう「最適」とは、あらかじめ定められたロジック(企業や個人のナレッジ)にもとづくという意味です。DMNではこのロジックをディシジョンテーブルという表で与えます。詳しくはこちらをご覧ください。
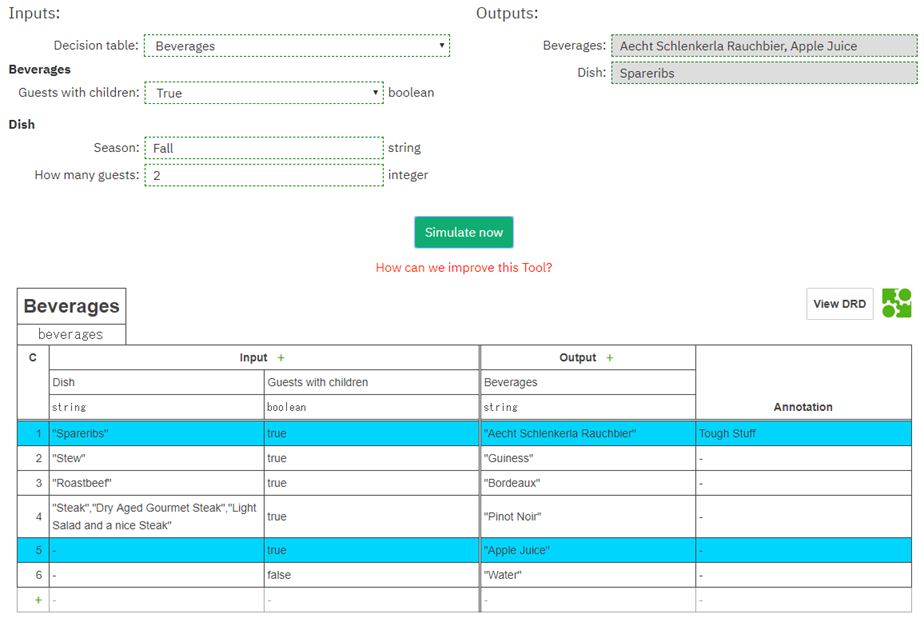
試しにDecision TableをBeveragesにし、Guests with Childrenをtrue、SeasonをFall、How Many Guestsを2にして実行してみます。以下のように二つの飲み物Aecht Schlenkerla RauchbierとApple Juiceが出力されました。画面から、入力した条件に合う料理としてSpareribsが選ばれたことが分かります。Spareribsに合う飲み物として選ばれたのはドイツのビールAecht Schlenkerla Rauchbierです。Apple Juiceは子ども用ですね。これは入力された季節やゲスト数などをもとに、ディシジョンテーブルという「ナレッジ」から最適な飲み物を選択した結果です。
このシミュレータの裏ではCamunda DMN EngineによってDMNが実行されています。今回はこのCamunda DMN Engineをローカルで動かしてDMNを実行します。
DMNファイルの準備
今回は検証用のDMNとしてCamundaのサンプルDMNファイルを使います。DMNシミュレータのページの「Download DMN Table」からサンプルのDMNファイルをダウンロードしてください。DMNファイルを閲覧・編集するにはDMNデザインツールが必要です。個人的にはスタンドアロンで気軽に動かせるCamunda Modelerをお勧めします。ちなみにDMNの実行だけであればデザインツールは必要ありません。
Camunda DMN Engineの取得
Camunda DMN EngineはMaven Centralで公開されています。POMに以下の依存関係を追加してください。
<dependency> <groupId>org.camunda.bpm.dmn</groupId> <artifactId>camunda-engine-dmn</artifactId> </dependency>Camunda DMN Engineを使ったDMNの実行
以下にDMNを実行するJavaコードのサンプルを記述します。
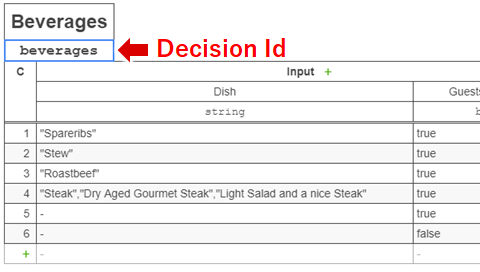
// DMNファイルパスとDecision Idの設定 String dmnFilePath = "./simulation.dmn"; String decisionId = "beverages"; // 入力データの設定 Map<String, Object> input = new HashMap<String, Object>(); input.put("season", "Fall"); // 秋 input.put("guestCount", 2); // ゲスト2名 input.put("guestsWithChildren",true); // 子連れ // DMNエンジンの生成 DmnEngine dmnEngine = DmnEngineConfiguration.createDefaultDmnEngineConfiguration().buildEngine(); // Decisionの生成 DmnDecision decision = dmnEngine.parseDecision(decisionId,new FileInputStream(dmnFilePath)); // DMNの実行 DmnDecisionResult result = dmnEngine.evaluateDecision(decision,input); // 実行結果の取得 for(Map<String,Object> entry : result.getResultList()) { System.out.println(entry.get("beverages")); }ここでdecisionIdに指定するのはディシジョンテーブルのIdで、Camunda Modelerで表示するディシジョンテーブル上では以下の場所に設定している値です。
入力には先ほどDMNシミュレータを実行した例と同じ値を与えています。上記のコードを実行すると、以下のようにDMNシミュレータと同じ結果が得られます。
Aecht Schlenkerla Rauchbier Apple JuiceOutputの追加
ディシジョンテーブル「beverages」のアウトプットはbeverageだけなので、このディシジョンテーブルでは飲み物しか取得できません。しかしどうせなら選択された料理と飲み物の両方を取得したいですね。そこでディシジョンテーブルを編集してアウトプットを増やします。以下の例ではディシジョンテーブルの編集にCamunda Modelerを使っています。
以下のように、beveragesのoutputに一列追加します。そして、このディシジョンテーブルのinputの一つであるDishの値をそのままoutputにします。このoutput列の「desiredDish」はDishのExpression(変数名)への参照を意味しています。
ディシジョンテーブルのInput項目は、表示ラベルであるLabelと、値の変数名または式を設定するExpression、値のデータタイプを示すTypeを持ちます。Camunda ModelerではInputのヘッダをクリックしないとExpressionが表示されません。サンプルのDMNではDish列のExpressionはdesiredDishとなっており、他の列から参照する際はこちらの値を使います。
続いて料理と飲み物の両方を表示できるように、上記Javaコードの「実行結果の取得」を以下のように書き換えます。
// 実行結果の取得 for(Map<String,Object> entry : result.getResultList()) { System.out.println(entry.get("desiredDish") + " with " + entry.get("beverages")); }実行結果を以下に示します。料理と飲み物の両方を取得できるようになりました。
Spareribs with Aecht Schlenkerla Rauchbier Spareribs with Apple Juice


- 投稿日:2020-05-14T13:43:58+09:00
【Javaの基礎知識】型や変数について
はじめに
こちらの記事は、
- Javaをこれから学習し始める
- 基本的なことをおさらいしたいという方向けです。
基本型(プリミティブ型)
Javaで予め用意されている型で、
メモリ領域に決められた分のサイズを使って、情報を保持します。整数のデータ型
データ型名 サイズ 値の範囲 byte 8ビット -128~127 short 16ビット -32768~32767 int 32ビット -2147483648~2147483647 long 64ビット -9223372036854775808~9223372036854775807
浮動小数点数のデータ型
データ型名 サイズ 値の範囲 float 32ビット -3.4028235E+38 ~ -1.401298E-45 1.401298E-45 ~ 3.4028235E+38 double 64ビット -1.79769313486231570E+308 ~ -4.94065645841246544E-324 4.94065645841246544E-324 ~ 1.79769313486231570E+308 int型、double型、float型で計算の結果が違うのが下図でわかると思います。
int a = 7; int b = 3; System.out.println(a / b);//出力結果=2 double c = 7; double d = 3; System.out.println(c / d);//出力結果=2.3333333333333335 float e = 7; float f = 3; System.out.println(e / f);//出力結果=2.3333333
文字のデータ型
1文字を格納できるデータ型です。
データ型名 サイズ 値の範囲 char 16ビット ¥u0000~¥uFFFF Unicodeの文字コードで「A」と表示したいとき下図のようにできます。
参考サイト:Unicode版 文字コード表char a1 = 'A'; char a2 = 65; char a3 = 0x0041; System.out.println(a1);//出力結果=A System.out.println(a2);//出力結果=A System.out.println(a3);//出力結果=Achar型とStirng型の注意点
char型のときは「'」で囲って、String型のときは「"」で囲みましょう。String s = "A"; char c = 'A'; エラーが出る String st = 'A';//Type mismatch: cannot convert from char to String char ch = "A";//Type mismatch: cannot convert from String to char
boolean型
格納できる値はtrueまたはfalseのいずれかだけです。
データ型名 サイズ 値 boolean 1ビット true or false 下図では、aとbは等しくないため、falseと表示されます。
boolean a = true; boolean b = false; System.out.println(a == b);//出力結果=falseデータ型の使い分け
上の表にもあるようにデータ型によって、扱えるデータの範囲が異なります。
メモリの大きさを気にする必要がないぐらいメモリがある場合は、データ型を気にしなくてもなんとかなりますが、
メモリに限りがあったり、莫大なデータを扱うときは、
適切なデータ型を選んでメモリに負担をかけないよう心がけたいところですね。ラッパークラス
Javaには、基本型の値を持つことができるクラスが用意されています。
ラッパークラスは、値型なので、代入時は値がそのまま代入されます。
基本データ型 ラッパークラス boolean Boolean char Character byte Byte short Short int Integer long Long float Float double Double int型とIntegerクラスを使った例をご覧ください。
他のラッパークラスに関しての説明は、基本型(プリミティブ型)と振る舞いが一緒なため割愛させていただきます。int a = 3; Integer b = 7; System.out.println(a + b);//出力結果=10 System.out.println(b instanceof int);//Incompatible conditional operand types Integer and int System.out.println(b instanceof Integer);//出力結果=true int c = b; b = 8; System.out.println(c);//出力結果=7 System.out.println(b);//出力結果=8型を判定するのに「オブジェクトinstanceof 型」という方法がありますが、基本型(プリミティブ型)には使えないので注意が必要です。
Stringクラス
Stringクラスは文字列を扱うためのクラスで、参照型です。
内部に文字列を保持し、それを操作するためのメソッドを提供します。
クラスからオブジェクトを作るときは、通常new演算子を使います。
しかし、String型はnew演算子を使わず、文字列を代入するだけでいいです。String s = "hoge"; String ns = new String("hoge");//わざわざnew演算子使わなくて良いString a = "イニエスタ"; String b = a; System.out.println(a);//出力結果=イニエスタ System.out.println(b);//出力結果=イニエスタ b = "本田"; System.out.println(a);//出力結果=イニエスタ System.out.println(b);//出力結果=本田参照型だけど、値の振る舞いは値渡しのようになっています?うーん
つまり、Stringクラスの特徴として、オブジェクト自身を変更する関数がないということがわかりました。参照型
クラス型、インターフェイス型、配列型があります。
配列型で説明していきます。
int[] a = {1,2,3}; int[] b = a; b[0] = 6; System.out.println(a[0]);//出力結果=6 System.out.println(b[0]);//出力結果=6上図にあるように、配列aの0番目が6になってしまいました。
基本型では、それぞれの「箱」の中に値が入っているのに対し、
参照型は、「同じ場所を見ている(参照している)」ということになります。
よって、同じ場所を指しているため、配列aの0番目が6になってしまうわけです。昇格(プロモーション)
shortやbyteで計算したくても、型が違うとエラーが出てしまう時があります。
下図をご覧ください。short a = 4; short b = 6; short ab = a * b;//Type mismatch: cannot convert from int to short // ↑ shortじゃなくてintに直しなさいと怒られています System.out.println(ab); byte c = 4; byte d = 6; byte cd = c * d;//Type mismatch: cannot convert from int to short // ↑ byteじゃなくてintに直しなさいと怒られています System.out.println(cd);解決方法は、2パターンあります(他にもあったらすみません)
short a = 4; short b = 6; int ab = a * b;//intに変えてあげる System.out.println(ab);//出力結果=24 byte c = 4; byte d = 6; byte cd = (byte) (c * d);//キャストしてあげる System.out.println(cd);//出力結果=24型キャスト(型変換)
ある型から別の型に変換することをキャストといいます。
自動型変換
int i = 7; double d = 3; System.out.println(i / d);//出力結果=2.3333333333333335 //勝手に型が変換され、double型になっています。強制型変換
下図では、int型同士の計算ですが、double型の計算結果を見たい場合、
どちらか一方をキャストすることで型を変えられます。int i = 7; int d = 3; System.out.println((double)i / d);//出力結果=2.3333333333333335変数の宣言/定義
変数名は、データ型や入る値にふさわしい名前をつけましょう。
int number; String name; //データ型[半角スペース]変数名変数の初期化
変数の宣言/定義をすると同時に値を代入することができます。
このことを「変数の初期化」といいます。int number = 3; String name = "イニエスタ";変数名を決める時の注意点
良い例◎text // 英単語であること userId // 2語以上の場合は大文字で区切る(キャメルケース)悪い例 or 好ましくない1text // 数字始まり user_id // アンダーバーで区切る(スネークケース) atai // ローマ字 値 // 日本語
この記事では変換に関しては軽くしか触れてないので、
下記の記事で変換についてより詳しく触れていきます。
【Javaの基礎知識】型変換について
- 投稿日:2020-05-14T13:17:17+09:00
Java 変数のスコープ(有効範囲)
この記事は、他の言語でプログラミングしていた人が、Javaでプログラムを組んでみると言う人に向けて書いた記事です。
スコープとは
スコープとは使える範囲のことです。変数に限らず有効範囲をスコープと言います。今回は変数のスコープについての実例を記載します。
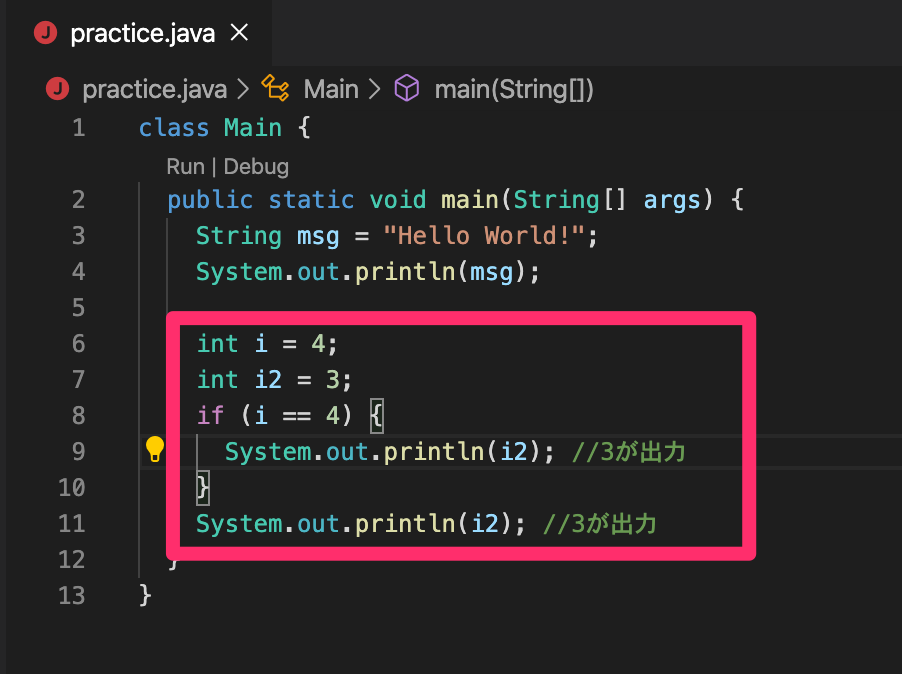
例1)
このように、mainからchainの変数を直接持ってくることはできません。
つまり、chainのiのスコープはchain内、mainのiのスコープはmain内ということです。
例2)
if文の中で宣言した値はif文内のみで使用できます。もし他でも使用したい場合は、if文のそとで宣言した値をif文内で操作するように変更すれば問題ありません。
グローバル変数とローカル変数
変数にはグローバル変数とローカル変数の2つがあります。
ローカル変数はこれまで出てきたように範囲内でしか使えない値(=スコープが有限)です。それに対してグローバル変数はスコープに制限のない変数です。Javaにはグローバル変数そのものは存在しませんが、グローバル変数と同じ状態にすることができます。
記載方法は public static 変数の記載 です。
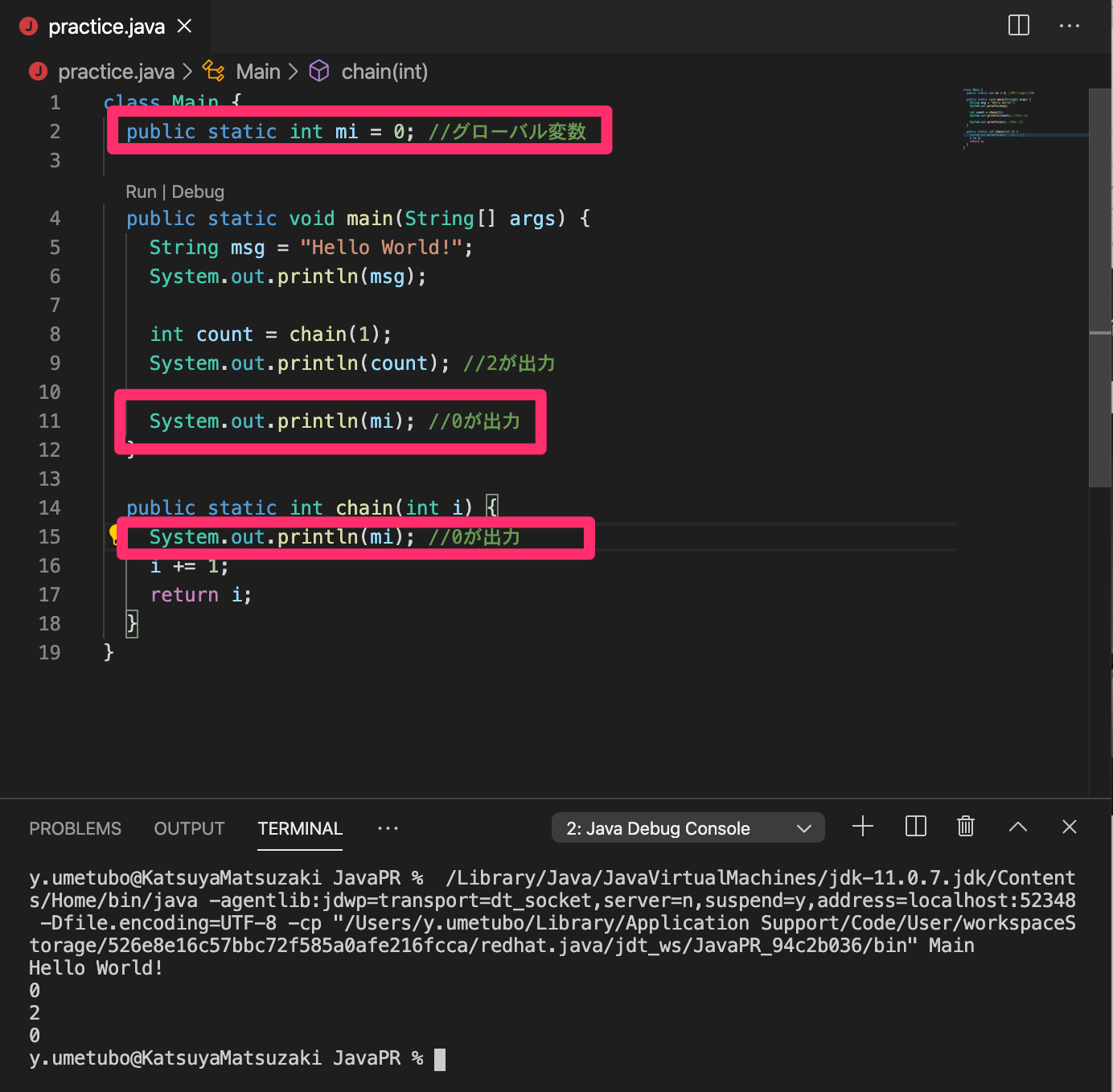
例)
グローバル変数はどこからでも参照できるので、他のクラスなどから値の変更などができます。影響度が非常に大きいので、必要な時のみ使うようにして、できるかぎりローカル変数を使いましょう。public と static
グローバル変数は public static 変数の記載 と書くと記載しましたが、
それはこのpublic と static の2つがそれぞれ使える箇所(スコープ)を拡張するからです。この2点についても説明します。アクセス修飾子
publicはアクセス修飾子というものの1つです。
一つずつあげていきます。
・public(公的な)は制限をつけません。
・protected(保護された) はクラスか、クラスを継承したサブクラス内部からのみアクセスを許可します。
・何もつけない場合は、同じパッケージ内のすべてのクラスからアクセスできます。
・private(私的) はクラス内部からのみ、アクセスが可能です。このうちprotected変数以外では動きが確認できましたが、protectedの動きが想定外だったため、一旦protected以外の条件です。
確認用プログラムpractice.javaclass Main { public static String pubstr = "公的"; protected static String prostr = "保護された"; static String str = "なし"; private static String pristr = "私的"; public static void main(String[] args) { System.out.println(pubstr); // 公的 System.out.println(str); // なし System.out.println(pristr); // 私的 check(); Sub subclass = new Sub(); subclass.sub(); } public static void check() { System.out.println(pubstr); // 公的 System.out.println(str); // なし System.out.println(pristr); // 私的 } } class Sub { public void sub() { Main m = new Main(); System.out.println(m.pubstr); // 公的 System.out.println(m.str); // なし System.out.println(m.pristr); // privateは取得できないのでエラー } }static
static(静的な)とは、staticメソッド(staticがついているメソッド)にでも使用可能にするものです。具体例を表示します。
practice.javaclass Main { public int ni = 10; public static int si = 7; int di = 999; public static void main(String[] args) { System.out.println(ni); // niはstatic変数でないのでエラー System.out.println(si); // siはstatic変数なので7が出力 } public void check(String[] args) { System.out.println(ni); // checkはstaticメソッドでないので10が出力 System.out.println(si); //checkはstaticメソッドでないので7が出力 } }このように、staticとついたメソッドではstaticのついた変数のみ使用可能です。


- 投稿日:2020-05-14T07:15:04+09:00
Apache Camel Spring Boot starters を使った単純なcamelアプリの作成手順
Apache Camel で作られたアプリの動作検証のため、新たに単純なアプリを作りたかったが、Java系は1から作ったことがほとんど無くて勝手がわからない。
ひとまず公式ページの説明に従って、1秒毎にログを出すrouteが存在するcamelアプリを作ってみた。camelの起動などに関しては検証しないので、簡単に作れそうな Camel Spring Boot starters を使った。
環境
- Java: 1.8.0_191
- Maven: 3.6.3
- Camel: 3.2.0
- Spring: 5.2.5.RELEASE
- Spring Boot: 2.2.6.RELEASE
- OS: Ubuntu 18.04
- IDE: IntelliJ IDEA
プロジェクトの用意
mavenの場合
pom.xmlが必要なことは何となく知っているが、この時点で書き方がわからない。camelのページに出ているのは依存関係の書き方だけなので、外枠を用意しなければいけない。仕方ないので、IDE(IntelliJ IDEA)で新しいプロジェクトを作る形で対応した。
- File → New → Project...
- 最初の画面
- 左の一覧から
Mavenを選択- Project SDK はひとまず
1.8のまま- Create from archetype のチェックは外したまま
- 「Next」
- 次の画面
- Name:
mycamelapp- Location: 適当な新規ディレクトリ
- Artifact Coordinates 内はひとまずそのまま
- 「Finish」
念のため、Gitの設定をして作業を保存しておく。
.gitignoreはGitHubにテンプレート集があったのでそれを使うことにした。terminalcd path/to/app git init for kind in Java Maven Global/JetBrains; do echo "###--- github/gitignore : ${kind}.gitignore ---###" curl https://raw.githubusercontent.com/github/gitignore/master/${kind}.gitignore echo done >> .gitignore git add . git commit -m 'Create a Maven project'pom.xml
https://camel.apache.org/camel-spring-boot/latest/index.html に従って依存関係を書き足す。
dependenciesはdependencyManagementの中と外で別々に書く必要があることに気付かず時間を取られた。全体は以下のようになった。
pom.xml (mycamelapp)<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>org.example</groupId> <artifactId>mycamelapp</artifactId> <version>1.0-SNAPSHOT</version> <!-- https://camel.apache.org/camel-spring-boot/latest/index.html --> <dependencyManagement> <dependencies> <!-- Camel BOM --> <dependency> <groupId>org.apache.camel.springboot</groupId> <artifactId>camel-spring-boot-dependencies</artifactId> <version>3.2.0</version> <type>pom</type> <scope>import</scope> </dependency> <!-- ... other BOMs or dependencies ... --> </dependencies> </dependencyManagement> <dependencies> <!-- Camel Starter --> <dependency> <groupId>org.apache.camel.springboot</groupId> <artifactId>camel-spring-boot-starter</artifactId> </dependency> <!-- ... other dependencies ... --> </dependencies> </project>other dependenciesに追加するコンポーネントの例として ActiveMQ が紹介されているが、こちらは使う予定が無いのでスキップ。
route定義
ここは保守中のアプリでたくさん例を見てきたので、個人的に迷うところは無い。 https://camel.apache.org/camel-spring-boot/latest/spring-boot.html#SpringBoot-CamelSpringBootStarter にある短いrouteを定義する。
terminalcd path/to/app mkdir -p src/main/java/org/example/mycamelapp/routes touch src/main/java/org/example/mycamelapp/routes/SampleTimerRoute.javasrc/main/java/org/example/mycamelapp/routes/SampleTimerRoute.javapackage org.example.mycamelapp.routes; import org.apache.camel.builder.RouteBuilder; import org.springframework.stereotype.Component; @Component public class SampleTimerRoute extends RouteBuilder { @Override public void configure() throws Exception { from("timer:foo").to("log:bar"); } }routeとは?
大雑把に言えばパイプライン。Java8の Stream API などを想像すればいいが、続々と流れてくるデータをどのように処理するかをDSLで書いている。
from(uri)はデータの入口。
- データは「exchange」と呼ばれる入れ物に入っている。
- URIの形で様々なコンポーネント(数百種類)とその詳細設定を指定できる。
timerで逐次生成したりfileでファイルをポーリングしたり。to(uri)はデータの渡し先。
- 終端というわけではなく、1回である必要も無い。
- こちらもURIで色々できる。
sqlでDBにクエリを投げたりhttpでHTTPリクエストを投げたり。- データの処理方法も色々。
- 条件分岐・ループ・例外処理などもDSLで構築できる。
- 単純なexchange操作は方法が用意されているし、もっと複雑な処理なら「processor」を定義すればいい。
SpringBootの設定
camelのドキュメントからは見つけられなかったが、さすがにアプリの開始地点は書かなければいけないみたい。書くとIDEで該当行に「Run」マークが表示される。
src/main/java/org/example/mycamelapp/MyCamelApplication.javapackage org.example.mycamelapp; import org.springframework.boot.SpringApplication; import org.springframework.boot.autoconfigure.SpringBootApplication; @SpringBootApplication public class MyCamelApplication { public static void main(String[] args) { SpringApplication.run(MyCamelApplication.class, args); } }アプリが起動後すぐ終了しないようにする。こちらはパラメーターを与えれば済むようなので、yamlで書いておく(propertiesでもいい)。
src/main/resources/application.yml# to keep the JVM running camel: springboot: main-run-controller: true起動
IDE上なら前述の「Run」ボタンを押せばすぐ起動できる。
mavenのコマンドで起動するなら、pom.xmlに設定を加える。
pom.xml (mycamelapp)... <build> <plugins> <plugin> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-maven-plugin</artifactId> <version>2.2.6.RELEASE</version> </plugin> </plugins> </build> ...terminalcd path/to/app mvn spring-boot:run参考
- Apache Camel 公式ドキュメント
- Spring Boot starters
- Spring Boot # Camel Spring Boot Starter
- Apache Camel サンプル
- その他
- 投稿日:2020-05-14T04:02:06+09:00
Eclipseで保存時に未使用のimportが勝手に削除されるのを防止する
なぜ不便なのか
Eclipseで、ソースコードを一時的にコメントアウトして保存をした時に、そこで使用されているクラスのimport文が消えてしまう。
コメントアウトから戻したときにimport文を書くのが面倒ということも勿論あるが、それよりimportミスが怖い。
importするときには、Eclipseの優秀な提案機能によって一覧から選ぶだけでimport文が自動入力されるが、
importするクラス名の中には、同名のクラス名が異なるパッケージに入っているものもあり、コメントアウトから戻したときに選び間違えることもなくはない。環境
Eclipse Java EE IDE for Web Developers.
Version: Neon Release (4.6.0)
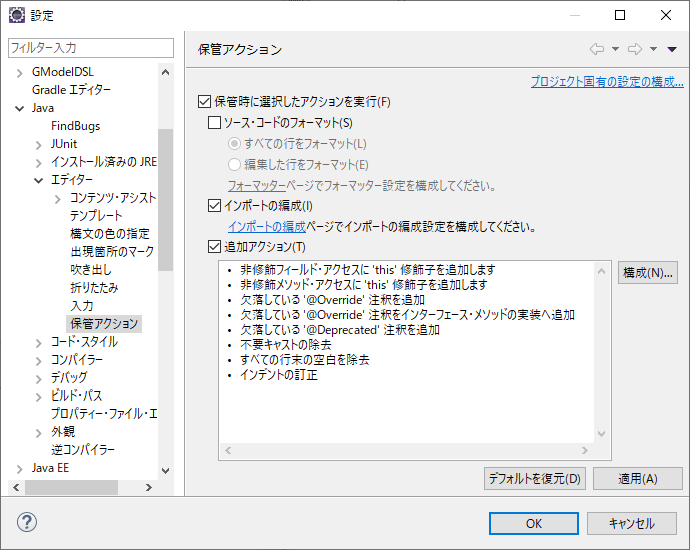
Build id: 20160613-1800改善前
↑ 改善前の設定設定項目を探してみる
上の画像「改善前の設定」にある、「追加アクション」にチェックを入れて「構成」ボタンを押せるようにして、「構成」ボタンを押すと下の画像のような画面が開く。
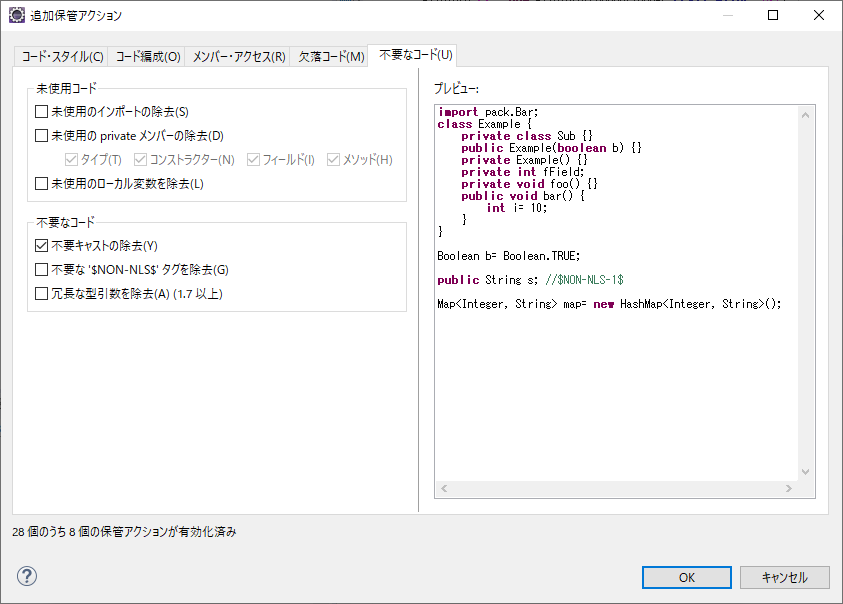
「不要なコード」タブに「未使用のインポートの除去」という設定項目がある。
チェックが外れていることを確認して、OKクリックで画面を閉じる。
これで改善すると思いきや、 消えてしまう 。
なぜか、うまくいかなかった
(改善前は「追加アクション」にチェックが入っていなくて設定を明示していなかったから、チェックを入れれば行けるのでは?と思ったのだが)
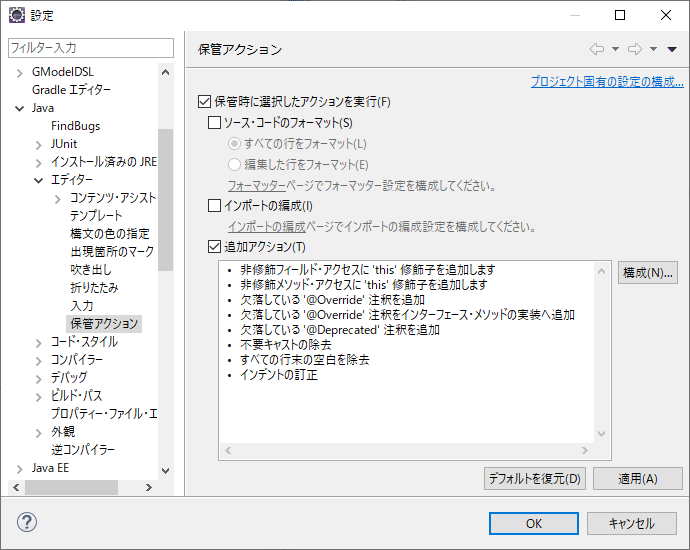
解決策
このページで説明されているように、「インポートの編成」のチェックを外すとimport文が消えなくなった。
「追加アクション」の 「未使用のインポートの除去」設定項目は無視されて、「インポートの編成」の設定が優先されているっぽい。
「インポートの編成」で何をしているのかは不明。ということで、このような設定にした。
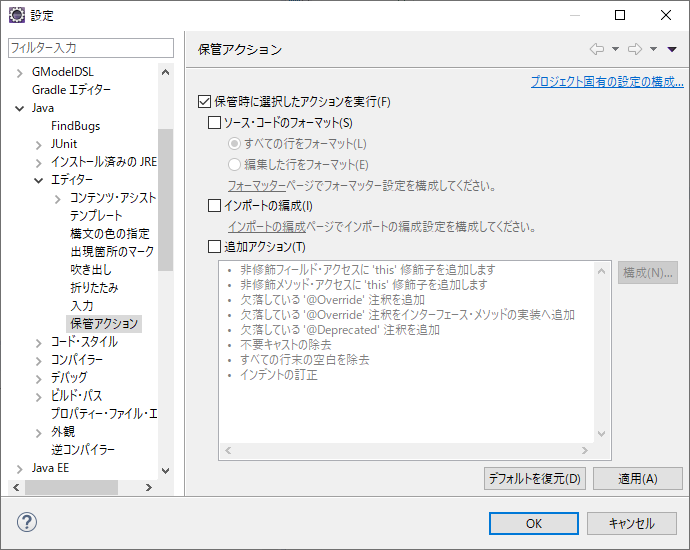
もちろん、下の画像のように「追加アクション」にチェックをいれなくてもOK
以上。

- 投稿日:2020-05-14T00:32:23+09:00
java(ソースファイル分割)
元のソースファイル
public class Calc { public static void main(String[] args) { int a = 10; int b = 2; int total = tasu(a, b); int delta = hiku(a, b); System.out.println("足すと" + total + "、引くと" + delta); } public static int tasu(int a, int b) { return (a + b); } public static int hiku(int a, int b) { return (a - b); } }複数のクラスに分割
main() と tase(),haiku()でファイルを分割
public class Calc { public static void main(String[] args) { int a = 10; int b = 2; int total = CalcLogic.tasu(a, b); int delta = CalcLogic.hiku(a, b); System.out.println("足すと" + total + "、引くと" + delta); } }
CalcLogic.を追加しないと読み込まれないpublic class CalcLogic { public static int tasu(int a, int b) { return (a + b); } public static int hiku(int a, int b) { return (a - b); } }
tase()、haiku()を移動する