- 投稿日:2020-04-09T23:59:37+09:00
Docker入門(1)/忘備録
Dockerとは
・アプリの実行環境をラップしてくれる
=> ホストがライブラリやミドルウェアで汚れない(node.jsやrubyなどをホストに入れなくて済む)
=> 環境構築が楽になる。・実行環境を共有できる
=> チーム開発でもチーム間で同じ環境を一瞬で揃えられる
=> ネット上の猛者たちが作ってくれたコンテナ(開発環境)がネットに沢山転がっている。・VMと比べて軽い
イメージ[ Image ]とは
・オブジェクト志向で言うところのクラス(設計書)
・Dockerfileを基にビルドされる。
・Dockehubを用いてイメージそのものの共有も可能
=> Dockerfileも共有可能だけどDockerfileをbuildして作成されたイメージの共有も可能
・もう大体のケースを想定して作られたイメージが既にDockerhubに配布されている
・Dockerfileをビルドするコマンド
=> $ docker build [Dockerfileのpath]コンテナ[ container ]とは
・オブジェクト志向で言うところのインスタンス(具現化)
・イメージで作成された実際の動作環境
・起動時のコマンドが終了すると自動で終了する(?)
・原則一つのコンテナに一つのアプリケーション
=> データベースのコンテナ、アプリのコンテナに分けるといいらしい
・起動のコマンド
=> docker run : imageからコンテナを作成して起動
=> docker start : 既にあるコンテナを起動
例えば、Nginxのコンテナを起動
=> docker run nginx
=> Docker をインストールしてこのコマンドを叩くだけでnginxのwebサーバが立つ!!
=> docker -volume で操作したい対象(例:app/ とか)をマウントが可能
=> volume : コンテナを削除しても情報をコンテナの外に残す(例:DBとか)Dockerfileとは
・このファイル内でライブラリやミドルウェアのインストールを記述できる
・これを他人に配布すると同じ環境が作れる
・既に便利なイメージがあるので(初心者は)そこまで書くことはないかも
・docker build でビルドが可能
- 投稿日:2020-04-09T20:15:13+09:00
初心者のKubernetes入門(書籍 Kubernetes 実践入門の写経から学ぶ)ReplicaSet 編
背景
個人的にインフラの知識以上にこれからのアプリケーションが動く環境を作ってデプロイしたりしてこれからの知識を身に着けたい。そしてより一層、自分の知識のアップデートをしたいと思いました。
その中でこの本に出会い、これから少しずつやったことを残し、未来の自分への手紙としてもあり、見つめ直せればと思いました。
引用や参考と今回の自分の勉強用の書籍の紹介
技術評論社『Kubernetes実践入門』のサンプルコード
Kubernetes実践入門 プロダクションレディなコンテナ&アプリケーションの作り方
実際の学びについて
書籍を読みながら、章ごとに少しずつ進めていきたいと思います。
GitHub のソースコードも使いながら学んで行きたいと思います。勉強開始
ここから ReplicaSet を学んでいきます。
my-rs.yamlapiVersion: apps/v1 kind: ReplicaSet metadata: name: my-rs spec: replicas: 3 #Podレプリカ数 (1) selector: matchLabels: app: my-rs template: #Podレプリカの元となるPodテンプレート (2) metadata: labels: app: my-rs spec: containers: - name: nginx image: k8spracticalguide/nginx:1.15.5コマンド郡
ReplicaSet のマニュフェストファイルを適用する
$ kubectl apply -f my-rs.yamlPod を削除してみる
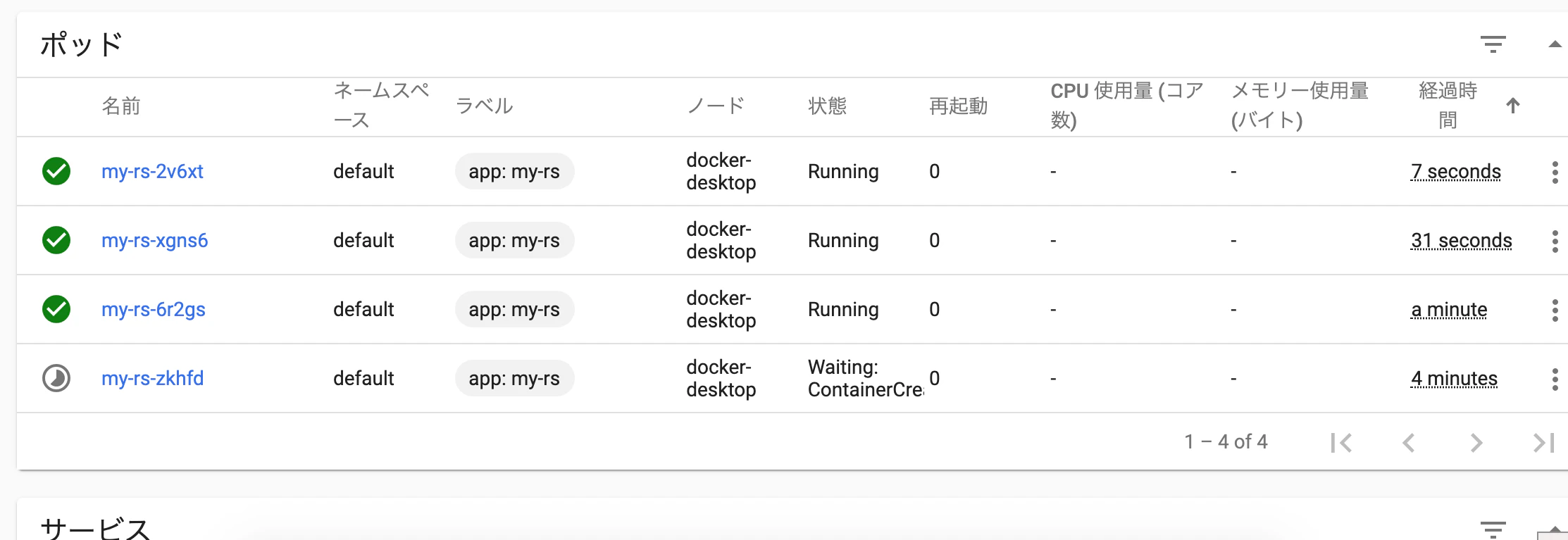
$ kubectl delete pods my-rs-zkhfdDashboad からの確認
一つの Pod を削除してすぐにスクリーンショットとったので見ずらいかもしれませんが、上から4番目が削除されている状態だっと思います。
次は Deployment をやっていきます。
今は多分コツコツと基礎部分だとおもいます。
ブルーグリーンデプロイメント、カナリア、イミュータブルとか色々あると思うけど、一旦はデプロイを学び
コンテナでのリリース方法として親和性が高いものがなにかを自分なりに学んで行きたいと思います。最後に
世間は色々と今の時期(2020/04/09)時点で大変な時期ではありますが、エンジニアリングで未来の自身に少しでも明るくなれるように!

- 投稿日:2020-04-09T16:51:37+09:00
クロスアカウントで s3 バケットを非同期コピーするコンテナを定時実行する
1. はじめに
こんな感じで S3 バケットのバックアップを定期的に取りたい。
- バックアップ元の S3 バケットとバックアップ先の S3 バケットを異なるAWSアカウントにしたい。
- バックアップ元の S3 でオブジェクトファイルが削除されても、バックアップ先のオブジェクトファイルでは削除したくない。
- バックアップバッチ用のEC2(常時起動)ではなく、コンテナ(バックアップ処理時間だけ起動)で実行したい。
S3 の レプリケーション機能で実現できるかどうか少し調べてみたけど、次の理由で今回は見送りした。
- バックアップ元の S3 バケットにはすでにオブジェクトが入っている。
- 既存のオブジェクトをレプリケーションする場合は、AWS サポートへ対応を依頼しないといけない。
- レプリケーションがいつ開始されるのか不明(参考:いつの間に!?既存オブジェクトを S3 レプリケーション出来るようになっていた!)。
2. 構成図
3. 概要
3.1. バックアップ元側の AWS アカウント
AWSアカウント
- example-1
アカウントID
- 111111111111
バックアップ元S3バケット
- バケット名: original-111111111111
- 「パブリックアクセスを全てブロックする」設定をチェックする。
- バージョニング設定は任意(停止でもよい)。
Role
- Containerに割り当てる。
- バックアップ元S3バケット original-111111111111 に対して、 「s3:ListBucket」 と 「s3:GetObject」 を許可する。
- バックアック先S3バケット backup-222222222222 に対して、 「s3:ListBucket」 と 「s3:PutObject」 を許可する。
ECR
- リポジトリ名: infra-batch-repository
- 作業PCで作成したバックアップバッチ用のコンテナイメージを登録する。
ECS
- ECSクラスター名: infra-batch
- 起動タイプ: Fargate
Fargate, Container
- CloudWatchイベントのトリガで ECR からイメージを取得して、パブリックサブネット内にコンテナを作成して、s3 sync を実行する。
- s3 sync を実行する Container は外部ネットワークへ出ていける環境で起動する。
- パブリックサブネット
- Security group の アウトバウンド はすべてを許可する
- パブリック IP の自動割り当ては 「ENABLED」 にする
3.2. バックアップ先側の AWS アカウント
AWSアカウント名
- example-2
アカウントID
- 222222222222
バックアップ先S3バケット
- バケット名: backup-222222222222
- 「パブリックアクセスを全てブロックする」設定をチェックする
- バージョニング設定は任意(停止でもよい)
- バケットポリシーで、AWSアカウント example-1(111111111111) の Role にアクセス権限を付与する。
- バックアップオブジェクトは S3 スタンダード-IA クラスに保存する(s3 sycn 実行時に 「--storage-class STANDARD_IA」 を指定)。
4. 設定
4.1. Container に割り当てる Role を作成 (バックアップ元側の AWS アカウントでの作業)
- IAMポリシー作成
- 名前: s3-sync-backup
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:ListBucket", "s3:GetObject" ], "Resource": [ "arn:aws:s3:::original-111111111111", "arn:aws:s3:::original-111111111111/*" ] }, { "Effect": "Allow", "Action": [ "s3:ListBucket", "s3:PutObject" ], "Resource": [ "arn:aws:s3:::backup-222222222222", "arn:aws:s3:::backup-222222222222/*" ] } ] }
- IAMロール作成
- 名前: s3-sync-backup
- 信頼されたエンティティ: ecs-tasks.amazonaws.com
- アタッチするポリシー: s3-sync-backup
4.2. バックアップ先 S3 バケットの バケットポリシー (バックアップ先側の AWS アカウントでの作業)
- AWSアカウント example-2 (222222222222) の S3 バケット backup-222222222222 への 「s3:ListBucket」 と 「s3:PutObject」 の許可権限を、AWSアカウント example-1 (111111111111) の Role s3-sync-backup に付与する。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::111111111111:role/s3-sync-backup" }, "Action": [ "s3:ListBucket", "s3:PutObject" ], "Resource": [ "arn:aws:s3:::backup-222222222222", "arn:aws:s3:::backup-222222222222/*" ] } ] }4.3. ECR リポジトリ作成 (バックアップ元側の AWS アカウントでの作業)
- 詳しい設定方法は割愛。
- ここでは、「infra-batch-repository」というリポジトリを作成して利用する。
4.4. コンテナイメージを作成して、ECRへプッシュする (作業PCでの実施)
- Dockerfile
- 最近リリースされた 「AWS CLI v2 Docker image」 を使う。
FROM amazon/aws-cli:latest ENTRYPOINT ["aws"] CMD ["s3","sync","--dryrun","--storage-class STANDARD_IA","s3://original-111111111111","s3://backup-222222222222"]
- タグを付けてビルドする
$ docker build -t infra-batch-repository:s3-sync-backup .
- ECRにプッシュするためのタグを付ける
$ docker tag infra-batch-repository:s3-sync-backup 111111111111.dkr.ecr.ap-northeast-1.amazonaws.com/infra-batch-repository:s3-sync-backup
- AWS ECR レジストリ用の docker login 認証コマンド文字列(12時間有効な認証トークン)を取得する
$ aws ecr get-login --no-include-email $ docker login -u AWS -p 認証トークン
- イメージを ECR へ プッシュする
$ docker push 111111111111.dkr.ecr.ap-northeast-1.amazonaws.com/infra-batch-repository:s3-sync-backup4.5. ECSクラスター作成 (バックアップ元側の AWS アカウントでの作業)
- 「AWS Fargate を使用」 を利用する。
- クラスター名
- infra-batch
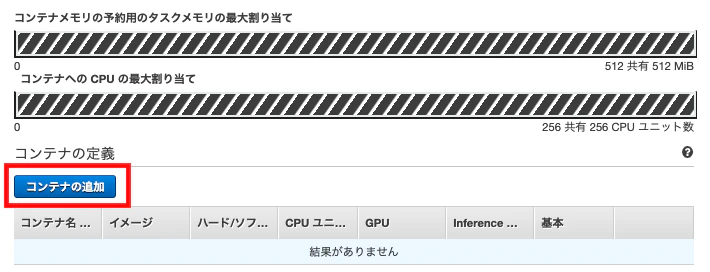
4.6. タスク定義を作成
↓
↓
↓
↓
↓
↓
確認
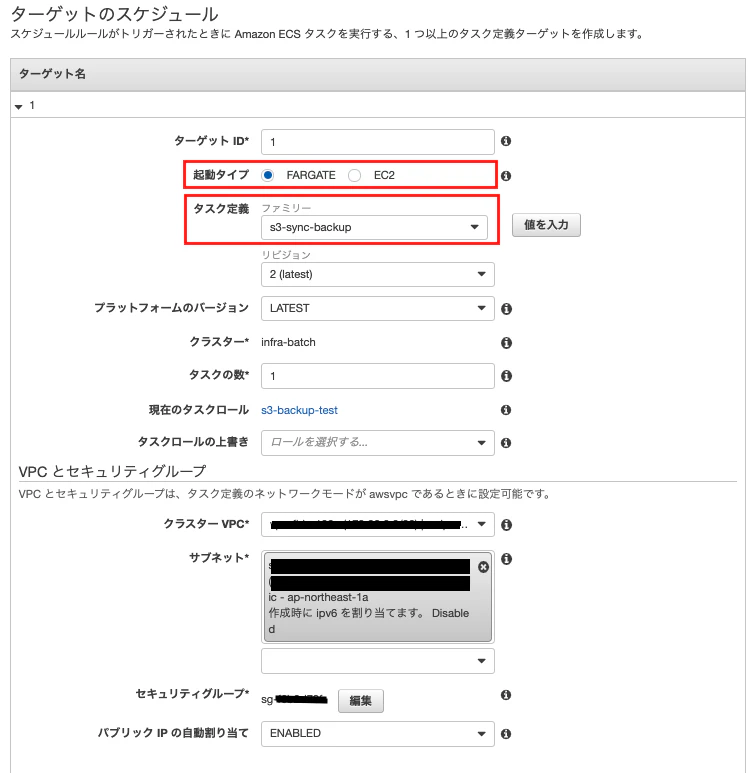
4.7. タスクスケジュールを作成
↓
Cron式の設定は UTC なので、 cron(0 19 * * ? *) は日本時間で 毎日04:00
サブネットは、任意のパブリックサブネットを指定する
セキュリティグループは、アウトバウンドをすべて許可の設定になっている任意のものを指定する。
パブリック IP の自動割り当ては「ENABLED」にする。
↓
確認
※CloudWatch のイベントルールや、Amazon EventBridge のイベントルールにも設定が反映される。5. タスク実行のログ
- 実行ログは CloudWatch のロググループの /ecs/s3-sync-backup に出力される
- ログの例

6. 注意点
s3 sync の動作確認は、--dryrun オプションを付けて実行し、実行ログから挙動が正しいか確認する。
- --dryrun: Displays the operations that would be performed using the specified command without actually running them.
バックアップ元のS3バケットのオブジェクト数やサイズが多い場合は、最初の s3 sync (フルサイズバックアップ)は作業PC上から s3 sync を実行した方がよい。
$ s3 sync --dryrun --storage-class STANDARD_IA s3://original-111111111111 s3://backup-222222222222 <ログ確認> $ s3 sync --storage-class STANDARD_IA s3://original-111111111111 s3://backup-222222222222











- 投稿日:2020-04-09T16:37:50+09:00
nvidia-docker環境更新
nvidia-dockerの環境が立ち上がらなくなってしまったので、更新した際のメモです。
行ったこと
こちらの記事を参考に、「Docker 19.03 以降の環境で前だけを見て生きる場合」にしたがって以下の手順ですすめます。
1. 最新の NVIDIA ドライバーをインストール
2. Docker の最新バージョン (19.03) をインストール
3. nvidia-container-toolkit パッケージをインストール環境
OS$ cat /etc/lsb-release DISTRIB_ID=Ubuntu DISTRIB_RELEASE=16.04 DISTRIB_CODENAME=xenial DISTRIB_DESCRIPTION="Ubuntu 16.04.6 LTS"GPU(更新前)$ lspci -vv|grep -i nvidia 01:00.0 VGA compatible controller: NVIDIA Corporation GP102 [GeForce GTX 1080 Ti] (rev a1) (prog-if 00 [VGA controller]) Kernel driver in use: nvidia Kernel modules: nvidiafb, nouveau, nvidia_396, nvidia_396_drm 01:00.1 Audio device: NVIDIA Corporation GP102 HDMI Audio Controller (rev a1)1. 最新の NVIDIA ドライバーをインストール
おすすめの「cuda-driversパッケージを使う」方法に従う。
手順$wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/cuda-ubuntu1604.pin $sudo mv cuda-ubuntu1604.pin /etc/apt/preferences.d/cuda-repository-pin-600 $sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/7fa2af80.pub $sudo add-apt-repository "deb http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/ /" $sudo apt-get update $sudo apt-get -y install cuda-drivers但し、3行目のkeyの取得のところで以下のエラーがでたため、以下のサイトを参考に処理を追加。
ERROR1$sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/7fa2af80.pub Executing: /tmp/tmp.AxRPl9JGE0/gpg.1.sh --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/7fa2af80.pub gpgkeys: protocol `https' not supported gpg: 鍵サーバ・スキーム「https」用のハンドラがありません gpg: *警告*: URI https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/7fa2af80.pub からデータを取れません: 鍵サーバのエラーOK$sudo apt-get install gnupg-curl $sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos Executing: /tmp/tmp.kbe6EjNXFn/gpg.1.sh --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/7fa2af80.pub gpg: 鍵7FA2AF80:"cudatools <cudatools@nvidia.com>"変更なし gpg: 処理数の合計: 1 gpg: 変更なし: 1さらに、5行目のupdateのところでも、公開鍵が利用できないというエラーが出たため、こちらの記事などを参考に処理を追加。
ERROR2$sudo apt-get update エラー:13 https://nvidia.github.io/libnvidia-container/ubuntu16.04/amd64 InRelease 公開鍵を利用できないため、以下の署名は検証できませんでした: NO_PUBKEY 6ED91CA3AC1160CDOK$sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys [エラーとして表示された鍵(NO_PUBKEYの後)] 例)$sudo apt-key adv --keyserver keyserver.ubuntu.com --recv-keys 6ED91CA3AC1160CD2. Docker の最新バージョン (19.03) をインストール
こちらの公式サイトにしたがってインストールします。前提条件を確認した上で、古いdockerをアンインストールします。以下のようなメッセージがでたので、autoremoveによりアンインストールを行いました。
uninstall$sudo apt-get remove docker docker-engine docker.io containerd runc パッケージリストを読み込んでいます... 完了 依存関係ツリーを作成しています 状態情報を読み取っています... 完了 パッケージ 'docker-engine' はインストールされていないため削除もされません パッケージ 'docker' はインストールされていないため削除もされません パッケージ 'containerd' はインストールされていないため削除もされません パッケージ 'docker.io' はインストールされていないため削除もされません パッケージ 'runc' はインストールされていないため削除もされません 以下のパッケージが自動でインストールされましたが、もう必要とされていません: containerd.io docker-ce docker-ce-cli libnvidia-container-tools libnvidia-container1 libvdpau-dev linux-headers-4.15.0-38 linux-headers-4.15.0-38-generic linux-image-4.15.0-38-generic linux-modules-4.15.0-38-generic linux-modules-extra-4.15.0-38-generic これを削除するには 'sudo apt autoremove' を利用してください。 アップグレード: 0 個、新規インストール: 0 個、削除: 0 個、保留: 367 個。 $sudo apt autoremove次に、dockerのインストールには以下の3種類の方法があるそうですが、その中で1のリポジトリによる方法を選択しました。それ以外の方法については、上記の公式サイトに記載があります。
・リポジトリを用いる方法
・手動による方法
・スクリプトを用いる方法。リポジトリを用いたインストール
2.1 aptがHTTPSを通じてリポジトリを使えるようにする。
$ sudo apt-get update $ sudo apt-get install apt-transport-https ca-certificates curl gnupg-agent software-properties-common2.2 dockerの公式鍵を追加して、確認する。
$ curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add - $ sudo apt-key fingerprint 0EBFCD88 pub 4096R/0EBFCD88 2017-02-22 フィンガー・プリント = 9DC8 5822 9FC7 DD38 854A E2D8 8D81 803C 0EBF CD88 uid Docker Release (CE deb) <docker@docker.com> sub 4096R/F273FCD8 2017-02-222.3 stableなリポジトリを設定し、公式リポジトリとして etc/apt/sources.list に登録されていることを確認する。
$sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" (確認)$grep download.docker.com /etc/apt/sources.list2.4 dockerのインストール
$sudo apt-get update $sudo apt-get install docker-ce docker-ce-cli containerd.io2.5 インストールの確認
$sudo docker run hello-world Unable to find image 'hello-world:latest' locally latest: Pulling from library/hello-world 1b930d010525: Pull complete Digest: sha256:*** Status: Downloaded newer image for hello-world:latest Hello from Docker! ...(省略)...........3. nvidia-container-toolkit パッケージをインストール
こちらのquickstartに基づき、toolkitをインストールする.
3.1 公式鍵の追加。
$distribution=$(. /etc/os-release;echo $ID$VERSION_ID) $curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -3.2 リポジトリの追加。
$curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list deb https://nvidia.github.io/libnvidia-container/ubuntu16.04/$(ARCH) / deb https://nvidia.github.io/nvidia-container-runtime/ubuntu16.04/$(ARCH) / deb https://nvidia.github.io/nvidia-docker/ubuntu16.04/$(ARCH) /3.3 インストール
$sudo apt-get update $sudo apt-get install -y nvidia-container-toolkit $sudo systemctl restart docker $sudo reboot3.4 インストールの確認
$docker run --gpus all nvidia/cuda nvidia-smi Thu Apr 9 07:15:13 2020 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 440.64.00 Driver Version: 440.64.00 CUDA Version: 10.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 GeForce GTX 108... Off | 00000000:01:00.0 On | N/A | | 33% 44C P8 11W / 250W | 402MiB / 11175MiB | 0% Default | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| +-----------------------------------------------------------------------------+4. これまで使っていたイメージの起動
$docker images REPOSITORY TAG IMAGE ID CREATED SIZE nvcr.io/nvidia/tensorflow 19.12-tf1-py3 af027926c1a0 3 months ago 8.32GB nvcr.io/nvidia/tensorflow 18.06-py3 0d13c9061269 22 months ago 3.4GBこれまで使っていたimageは、--runtime=nvidia の部分を --gpus all に変更するだけで、問題なく立ち上がりました。
$ docker run --gpus all -it --rm nvcr.io/nvidia/tensorflow:18.06-py3 ================ == TensorFlow == ================ NVIDIA Release 18.06 (build 512350) Container image Copyright (c) 2018, NVIDIA CORPORATION. All rights reserved. Copyright 2017 The TensorFlow Authors. All rights reserved. Various files include modifications (c) NVIDIA CORPORATION. All rights reserved. NVIDIA modifications are covered by the license terms that apply to the underlying project or file. NOTE: The SHMEM allocation limit is set to the default of 64MB. This may be insufficient for TensorFlow. NVIDIA recommends the use of the following flags: nvidia-docker run --shm-size=1g --ulimit memlock=-1 --ulimit stack=67108864 ...
- 投稿日:2020-04-09T15:24:25+09:00
[Docker] コンテナ内で日本語を入力可能にするためのDockerfile記述方法
はじめに
Dockerコンテナ内で
rails cからデータベースにレコードを追加しようとした時に、日本語を入力できなかったので、Dockerコンテナを立ち上げた時に、日本語対応がなされるようにDockerifleを書き換えた。以下の記事を参考にした。
【Docker】MySQLの日本語化内容
DockerfileFROM ruby:2.5.3 RUN apt-get update -qq && apt-get install -y vim nodejs default-mysql-client \ locales locales-all && \ #追加 echo "ja_JP.UTF-8 UTF-8" > /etc/locale.gen && \ #追加 locale-gen && \ # 追加 update-locale LANG=ja_JP.UTF-8 #追加 COPY . /fishingshares ENV LANG="ja_JP.UTF-8" \ #追加 TZ="Asia/Tokyo" \ #追加 APP_HOME="/fishingshares" WORKDIR $APP_HOME RUN bundle install ADD . $APP_HOMEコメントを書いているところが追記した箇所である。
以上のDockerfileを基に、コンテナを立ち上げて起動すると、コンテナ内で日本語が入力できるようになる。
以上
- 投稿日:2020-04-09T11:02:42+09:00
Private Docker RegistryからPullできないとき
会社とかで立ててるプライベートなDocoker RegistryからPullできずこんなメッセージが、、、
unauthorized: authentication requiredpullする前にPrivate Docker Registryへログインする必要があるようだ。
ログインするには?
docker login -p [ユーザーパスワード] -u [ユーザー名] [サーバ名]このようにPrivate Docker Registryの認証情報を引数につけてloginする
そのあとにdocker pullするとPrivateなDocker Registryイメージをpullできる。Private Docker Registryからログアウトするときは
docker logout [サーバ名]たまに忘れるので備忘録として
- 投稿日:2020-04-09T02:22:30+09:00
Dockerを導入したい
はじめに
Macでpython3を使おうとしたら、見事に環境が破壊されたため、Dockerを導入してコンテナ上でPythonを実行することにする。
筆者の能力
- python3を入れようとして、元環境を破壊してしまうくらいの雑魚さ
- Dockerはかなり前に一度触ったことがあるため、インストールはされているPC : MacbookPro Early2015
OS : macOS Catelina自分の頭の中整理くらいに書いていきます。
参考ページ
https://qiita.com/k5n/items/2212b87feac5ebc33ecb
https://note.com/motchalini/n/nc0486b630b67
https://qiita.com/chroju/items/ce9cae248cc016745c66作業
イメージの取得
今回はpython3を利用するための環境が欲しいため、python3のイメージをローカルに落としてくる。python3のためのイメージはpython:3らしい
$ docker pull python:3これでpython3のイメージをダウンロードできた。
Dockerfileの作成&ビルド
最初なので、vimとpipが使えたらいいかなと思い、それだけデフォルトでインストールしておく。
適当なフォルダにDockerfileという名前のファイルを作っておくDockerfileFROM python:3 MAINTAINER koji-satoyama # パッケージのインストールとアップデート RUN apt-get update && apt-get -y upgrade && apt-get clean RUN apt-get -y install vim RUN pip install --upgrade pip$ docker built -t <イメージの名前> .すげー長いシステムログと共に、ビルドが成功した。
おそらくvimやらapt-getやらを取っていた模様。イメージのリストを確認すると、自分の名付けたイメージが作成されていた。
python:3というイメージから派生させて、新しくイメージを作成したというニュアンスだろうか。$ docker images REPOSITORY TAG IMAGE ID CREATED SIZE <イメージの名前> latest xxxxxxxxxxxx 6 minutes ago 1GBコンテナの起動
あとは作成したイメージを元にコンテナを起動するのだが、いろいろオプションがある模様。
実行したコマンドは以下。
$ docker run -it --name <コンテナの名前> -v [ホストPCの絶対パス]:[コンテナ上のパス] -w [コンテナ上のパス] <イメージの名前> /bin/bashコマンドを説明していく。
詳しくは公式ドキュメントを参考にされたい。
http://docs.docker.jp/engine/reference/commandline/run.html
オプション 意味 -it インタラクティブかつ擬似ターミナル割当 --name 作成するコンテナ名の指定。 -v コンテナでホストPCのフォルダをマウントする。次で指定したホストPCのフォルダをコンテナ上に作る -w 初期ディレクトリの指定。コンテナに入ったときの現在ディレクトリ python_test 利用するイメージの名前 /bin/bash コンテナを起動してはじめに実行するコマンド。bashを起動している このコマンドで、コンテナの中に入って作業ができる
作業が終わったら
コンテナ内の作業が終わったら、
exitでコンテナから抜け出す。(他にも方法はあるが、省略)
次からコンテナに入る時は次を実行
# コンテナの再起動 $ docker restart <コンテナの名前> # コンテナに入る $ docker attach <コンテナの名前>終わりに
いろいろ調べながらだと、2時間くらいかかってしまった。
慣れないと覚えられないことも多いので、Dockerは毎日触りたい。
- 投稿日:2020-04-09T01:36:27+09:00
Deep Learning Workstation構築計画 遂に完結 (Jupyter Notebookサーバー構築編)
eGPUでハイスペックLinuxデスクトップをDeep Learning Workstation化計画(eGPUセットアップ編)でeGPUのセットアップを実施しました。これでNVIDIAドライバーやCUDA 10.2のインストールが完了し、GPUが利用出来る様になりました。今回はDocker及びNVIDIA DockerをインストールしてGPUが利用出来るDocker環境を構築し、最終的にJupyter Notebookサーバーを構築する所までをやってみようと思います。構築マシンはeGPUをThundebolt 3接続という特殊構成のため、セットアップ中に怒濤のエラーが出て断念
という恐れも十分に有り得ますが、折角作り上げたマシーンなので何事も無く完成1となることを願いつつセットアップを行います。
本記事で紹介するセットアップ方法は2020/4/6現在最新の情報に基づいていますが、今後のアップグレードでより簡便な方法が可能となる可能性は十分有ります。その時は内容を随時更新していこうと思います。
Dockerのインストール
まずはDockerをインストールします。今回は新規に環境構築する為、最新版をインストールします。
Docker本体のインストール前に必要なアプリケーションをインストールします。
sudo apt install -y apt-transport-https ca-certificates curl gnupg-agent software-properties-commonリポジトリキーを追加します。
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add -
実行結果
$ curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add - OKsudo apt-key fingerprint 0EBFCD88
実行結果
$ sudo apt-key fingerprint 0EBFCD88 pub rsa4096 2017-02-22 [SCEA] 9DC8 5822 9FC7 DD38 854A E2D8 8D81 803C 0EBF CD88 uid [ 不明 ] Docker Release (CE deb) <docker@docker.com> sub rsa4096 2017-02-22 [S]リポジトリ情報を追加します。
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"本体のインストールを実行します。
sudo apt update && sudo apt install -y docker-ce docker-ce-cli containerd.io正常にインストール出来たか確認します。
$ docker -v Docker version 19.03.8, build afacb8b7f0sudo無しでDockerを実行出来る様に設定します。
dockerグループを追加します。sudo groupadd docker
既に存在する場合の表示
$ sudo groupadd docker groupadd: グループ 'docker' は既に存在します現在ログイン中のユーザーを
dockerグループに追加します。sudo gpasswd -a $USER docker
実行結果
$ sudo gpasswd -a $USER docker ユーザ USER をグループ docker に追加一旦ログアウトし、再ログインすることで有効になります。
exitHello Worldコンテナの起動と実行
Hello Worldコンテナを起動し実行します。正常にコンテナが起動されるかの確認の為に用意されています。
docker container run hello-world
正常に起動出来ている場合
$ docker container run hello-world Unable to find image 'hello-world:latest' locally latest: Pulling from library/hello-world 1b930d010525: Pull complete Digest: sha256:f9dfddf63636d84ef479d645ab5885156ae030f611a56f3a7ac7f2fdd86d7e4e Status: Downloaded newer image for hello-world:latest Hello from Docker! This message shows that your installation appears to be working correctly. To generate this message, Docker took the following steps: 1. The Docker client contacted the Docker daemon. 2. The Docker daemon pulled the "hello-world" image from the Docker Hub. (amd64) 3. The Docker daemon created a new container from that image which runs the executable that produces the output you are currently reading. 4. The Docker daemon streamed that output to the Docker client, which sent it to your terminal. To try something more ambitious, you can run an Ubuntu container with: $ docker run -it ubuntu bash Share images, automate workflows, and more with a free Docker ID: https://hub.docker.com/ For more examples and ideas, visit: https://docs.docker.com/get-started/Docker Composeのインストール
Docker Composeをインストールします。最新版のバージョンは公式のGitHubで確認出来ます。現在の最新安定版は
v1.25.4です。まずは実行ファイルをダウンロードします。sudo curl -L "https://github.com/docker/compose/releases/download/1.25.4/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-composeダウンロード後、実行権限を付与します。
sudo chmod +x /usr/local/bin/docker-compose正常に動作するか確認します。
$ docker-compose -v docker-compose version 1.25.4, build 8d51620anvidia-container-runtimeのインストール
ここからいよいよDockerからGPUを動作させるために必要なセットアップを行います。使用するGPUがNVIDIAのGPUの場合はnvidia-container-runtimeというランタイムが用意されています。AMDのGPU2では以降の行程は実行出来ません。
curl -s -L https://nvidia.github.io/nvidia-container-runtime/gpgkey | sudo apt-key add -
実行結果
$ curl -s -L https://nvidia.github.io/nvidia-container-runtime/gpgkey | sudo apt-key add - OKexport distribution=$(. /etc/os-release;echo $ID$VERSION_ID)curl -s -L https://nvidia.github.io/nvidia-container-runtime/$distribution/nvidia-container-runtime.list | sudo tee /etc/apt/sources.list.d/nvidia-container-runtime.list
実行結果
$ curl -s -L https://nvidia.github.io/nvidia-container-runtime/$distribution/nvidia-container-runtime.list | sudo tee /etc/apt/sources.list.d/nvidia-container-runtime.list deb https://nvidia.github.io/libnvidia-container/ubuntu18.04/$(ARCH) / deb https://nvidia.github.io/nvidia-container-runtime/ubuntu18.04/$(ARCH) /sudo apt update && sudo apt install -y nvidia-container-runtimesudo rebootDocker上でnvidia-smiの動作確認
セットアップが完了したらDocker上でnvidia-smiが動作するか確認します。今回はGPUが1台なのでオプションに
--gpus allを渡しています。docker container run --gpus all --rm nvidia/cuda nvidia-sminvidia-container-runtimeをインストール後は必ず再起動します。再起動していない場合はエラーが出ます。
Digest: sha256:31e2a1ca7b0e1f678fb1dd0c985b4223273f7c0f3dbde60053b371e2a1aee2cd Status: Downloaded newer image for nvidia/cuda:latest docker: Error response from daemon: could not select device driver "" with capabilities: [[gpu]].以下の様な表示が出ればインストールに成功しています。
$ docker container run --gpus all --rm nvidia/cuda nvidia-smi Mon Apr 6 00:51:45 2020 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 440.64 Driver Version: 440.64 CUDA Version: 10.2 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 GeForce RTX 208... Off | 00000000:07:00.0 Off | N/A | | 0% 31C P8 16W / 250W | 0MiB / 7982MiB | 0% Default | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+Docker ComposeでGPU対応コンテナを起動するための設定
Issue情報より、2020/4現在Dockerの最新版で導入された
--gpusオプションにDocker Composeは対応出来ていない様です。その為、旧来の--runtime=nvidiaオプションを有効にする設定が必要です。最初はnvidia-dockerというコマンドで起動していたGPU対応コンテナが--runtime=nvidiaオプションとなり、--gpusオプションへ進化し簡単になりました。Docker Composeも早く対応して欲しいところです。まず
nvidia-container-runtimeの所在地を調べます。$ which nvidia-container-runtime /usr/bin/nvidia-container-runtime
/etc/docker/daemon.jsonファイルを作成します。$ sudo vim /etc/docker/daemon.json/etc/docker/daemon.json{ "runtimes": { "nvidia": { "path": "/usr/bin/nvidia-container-runtime", "runtimeArgs": [] } } }sudo rebootこの操作によって以下の2種類のコマンドが有効になります。
新方式のコマンドdocker container run --gpus all --rm nvidia/cuda nvidia-smi旧形式のコマンドdocker container run --runtime=nvidia --rm nvidia/cuda nvidia-smiJupyte Notebookサーバー化に向けた設定
TensorFlowやPyTorchを実行する環境としてマシーンを活用したいと予てから思っていました。しかし、ローカルに環境構築すると管理が煩雑になります。そこで、Docker及びJupyter Notebookの出番です。Dockerfileの作成
Jupyter公式の
tensorflo-notebookというイメージをベースに環境を構築します。基本的な機械学習、Deep LearningのPythonライブラリ及びLinuxのアプリケーションをインストールします。自然言語処理の勉強もしたいと考えているのでJanomeもインストールしています。MeCabは頻繁に更新される為、敢えて初期設定ではインストールしないこととします。DockerfileFROM jupyter/tensorflow-notebook # Install basic ML libralies RUN pip install torch torchvision keras scikit-learn janome USER root RUN apt update && apt upgrade -y RUN apt install -y build-essential curl wget vim git bash-completiondocker-compose.ymlの作成
コンテナの管理を容易にする為に、docker-compose.ymlを作成しました。注意として、Version3.Xは現在
runtimeオプションに非対応です。故にVersion2.Xを指定する必要が有ります。docker-compose.ymlversion: "2.4" services: tensorflow_notebook: build: context: . dockerfile: Dockerfile runtime: nvidia environment: - NVIDIA_VISIBLE_DEVICES=all - NVIDIA_DRIVER_CAPABILITIES=all ports: - 8888:8888 volumes: - ../work:/home/jovyan/work restart: alwaysコンテナの起動
Docker Composeでコンテナを起動します。最初の起動では
-d(バックグラウンド実行オプション)は付けません。これはJupyter Notebookへのログイン用トークンを確認する為です。ターミナル上にhttp://127.0.0.1:8888/?token=(48桁の英数字の羅列:アクセストークン)という表示が出ます。英数字の羅列を控えておきます。また、ターミナルを閉じるとコンテナが落ちてしまうため、そのままにしておきます。docker-compose upWebブラウザを開き
コンテナを稼働させているマシーンのIP:8888でアクセスします。以下の画面が表示されれば一先ず成功です。
ここで
Password or token:欄に先程控えておいた英数字を入力すればログインが完了し、利用可能になります。しかし、今回は所望のパスワードでログイン出来る様にしたいので下のSetup a Password欄を利用します。Token欄に先程控えた英数字を入力し、New Password欄に所望のパスワードを入力します。Log in and set new passwordをクリックすれば設定完了です。下図の様な画面に遷移すれば成功です。
設定したパスワードで再ログイン
画面右上の
Logoutをクリックし、一旦終了します。これからコンテナの起動を永続化します。コンテナを起動したターミナル上でcontrol + Cを打鍵しコンテナを終了します。Stopping コンテナ名 ... doneと表示されます。以下のコマンドを実行し、今度はバックグラウンドでコンテナを起動します。Starting コンテナ名 ... doneと出たら、再度Webブラウザでコンテナを稼働させていマシーンのIP:8888にアクセスします。docker-compose up -d以下の画面が出たら、設定したパスワードを入力しログインします。
下図の画面に遷移し、無事再ログインが出来ました。
実際にTensorFlowやPyTorchがGPUモードで動作するかの確認
そもそも巨費を投じてPC自作を行ったのはTensorFlowやPyTorchでDeep Learningの学習や推論の実験をやってみたいと思っていた為です。故に両者がGPUモードで動作しなければ今回の構築は水泡に帰します。最後に動作確認を行って終了です。GPUで動作するかの確認方法は以下のコードを実行します。適当なNotebook上で実行するだけで確認出来ます。
TensorFlowfrom tensorflow.python.client import device_lib device_lib.list_local_devices()
実行結果
GPUに関する情報が出力されれば成功です。[name: "/device:CPU:0" device_type: "CPU" memory_limit: 268435456 locality { } incarnation: 845859908487858210, name: "/device:XLA_CPU:0" device_type: "XLA_CPU" memory_limit: 17179869184 locality { } incarnation: 2134477200705340707 physical_device_desc: "device: XLA_CPU device", name: "/device:XLA_GPU:0" device_type: "XLA_GPU" memory_limit: 17179869184 locality { } incarnation: 6110340117972168618 physical_device_desc: "device: XLA_GPU device"]PyTorchimport torch print(torch.cuda.is_available())
実行結果
Trueと表示されれば成功です。TrueKerasでMNIST
この世界のHello World的な位置付けのプログラムは矢張りKerasでMNISTを学習、推論させるプログラムでは無いでしょうか?動作テストも兼ねて以下のコードをNotebook上で実行してみます。
モデル本体from keras.datasets import mnist from keras.utils import to_categorical from keras.layers import Conv2D, MaxPooling2D, Flatten, Dense from keras import models model = models.Sequential() model.add(Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1))) model.add(MaxPooling2D((2, 2))) model.add(Conv2D(64, (3, 3), activation='relu')) model.add(MaxPooling2D((2, 2))) model.add(Conv2D(64, (3, 3), activation='relu')) model.add(Flatten()) model.add(Dense(64, activation='relu')) model.add(Dense(10, activation='softmax')) (train_images, train_labels), (test_images, test_labels) = mnist.load_data() train_images = train_images.reshape((60000, 28, 28, 1)) train_images = train_images.astype('float32') / 255 test_images = test_images.reshape((10000, 28, 28, 1)) test_images = test_images.astype('float32') / 255 train_labels = to_categorical(train_labels) test_labels = to_categorical(test_labels) test_loss, test_acc = model.evaluate(test_images, test_labels)モデルの構造を表示model.summary()
モデルの構造
Model: "sequential_2" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= conv2d_2 (Conv2D) (None, 26, 26, 32) 320 _________________________________________________________________ max_pooling2d_1 (MaxPooling2 (None, 13, 13, 32) 0 _________________________________________________________________ conv2d_3 (Conv2D) (None, 11, 11, 64) 18496 _________________________________________________________________ max_pooling2d_2 (MaxPooling2 (None, 5, 5, 64) 0 _________________________________________________________________ conv2d_4 (Conv2D) (None, 3, 3, 64) 36928 _________________________________________________________________ flatten_1 (Flatten) (None, 576) 0 _________________________________________________________________ dense_1 (Dense) (None, 64) 36928 _________________________________________________________________ dense_2 (Dense) (None, 10) 650 ================================================================= Total params: 93,322 Trainable params: 93,322 Non-trainable params: 0 _________________________________________________________________実行結果
下図の様に約99.1%の正答率を達成しました。
<おまけ> JupyterLabを使いたい場合
デフォルト状態はJupter Notebook Serverで動作しますが、
JupyterLabも使用することが出来ます。方法は簡単でURL(コンテナが稼働しているマシーンのIP:8888)の末尾に/labを追加するだけです。下図がJupyterLabが起動したスタートページです。小洒落たUIになりました。(昨今流行のダークモードも利用可)タブに表示されているタイトルもHome Page - Select or create a notebookからJupyterLabに変わります。
まとめ
過去記事でeGPUのセットアップを実施し、GPUマシーンとして動作するマシーンとなりました。今回、DockerやNvidia Dockerをインストールしたことで、Deep Learning Workstationとして使えるマシーンが完成しました。今後投じた予算の元を取って更にお釣りが来るぐらいに活用したいと思います。
Reference
- NVIDIA Docker って今どうなってるの? (19.11版)
- Dockerで、GPU対応なコンテナ環境を整備する
- docker-composeでgpuを使う方法
- nVIDIA-docker2 を dockerから導入してみよう。
結論から言ってしまうと何事も無く無事完了しました。eGPU自体のセットアップを終えてOSから認識させることに成功すれば後はPCIExpress接続のGPUと操作は全く変わりません。寧ろDockerの進化にDocker Composeの開発が追い付いていないと痛感したセットアップになりました。 ↩
割り切りが必要かもしれませんが、AMDのGPUが機械学習の分野でNVIDIAと互角に渡り合う為の課題として、CUDAやcuDNNに匹敵するライブラリの開発、周辺環境の充実が挙げられると思います。TensorFlowは近々AMD GPUに完全対応との噂が出てますが、現状NVIDIAの独占市場であることは否めません。 ↩