- 投稿日:2020-04-09T19:42:38+09:00
Datadog APMをGoで使う
はじめに
Datadog APMの簡単な特徴とGoで使用するための方法をまとめました。
公式サイトのドキュメントを見ていただくことを勧めますが、
補足資料として見ていただければと思います。また、ここではDatadogのAPM以外の機能については割愛します。
APMとは
Application Performance Managementの頭文字をとった略語で、一般的にはアプリケーションやシステムの性能を管理・監視するものです。
DatadogのAPMではマネージドクライド、オンプレミスに関わらず分散トレーシングに対応しています。
Flame GraphやSpan Listなど整理された形でトレース結果を取得できるようになっています。
- Flame Graph

- Span List

使用するには
- Agentのインストールと起動
- APM用パッケージを取得
Agentのインストール
下記のページから各環境に合わせてインストールとAgentの起動を実施します。
https://app.datadoghq.com/account/settings#agent基本的には上記のページに従ってインストールを実施すればAgentプロセス起動も実施してくれるが、再起動等を行う場合や設定を変更する場合は下記を参照してくだしあ
APM用パッケージを取得
go get gopkg.in/DataDog/dd-trace-go.v1/ddtraceトレースの仕方
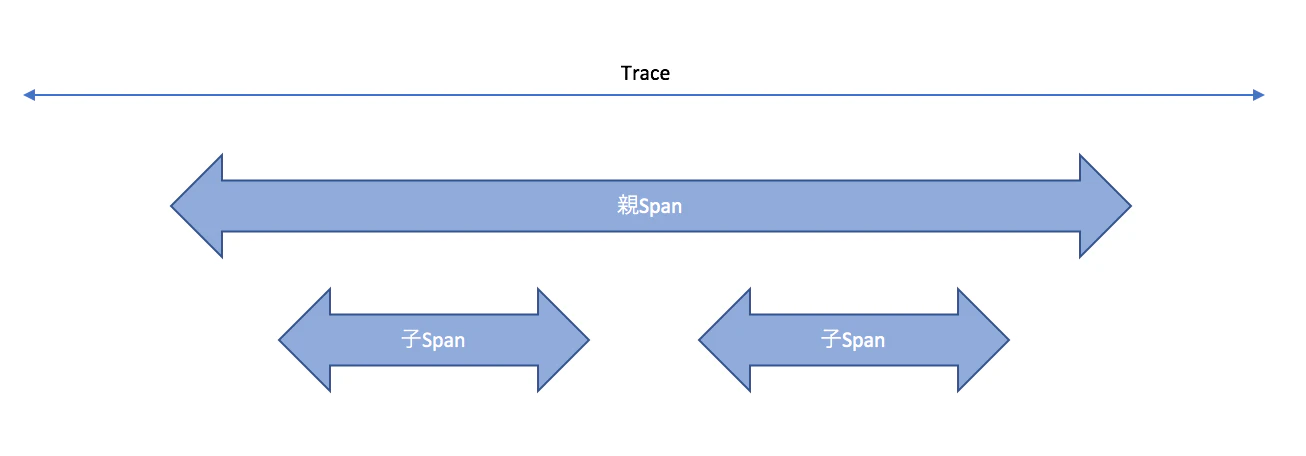
TraceとSpan
トレースを行うにあたり下記の要素が存在します。
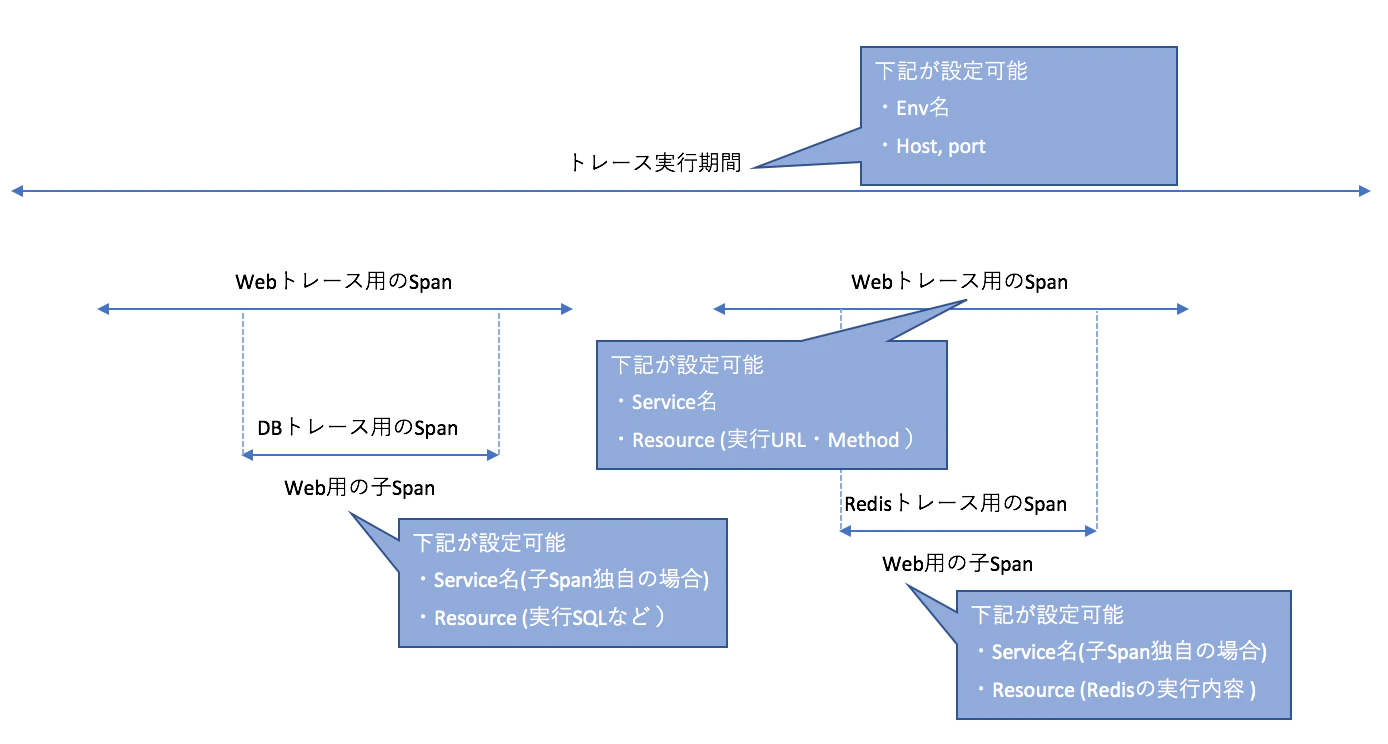
用語 内容 Trace アプリケーションにおけるトレースの開始・実行の単位 Span 1ロジックの開始・終了の実行時間を計測する単位。Traceは1つ以上のSpanを持つ。Span同士は親子関係をもたせられる Service 処理の名前。複数Spanを一つのService名にすることも、各々独自のService名にすることも可能 Resource 処理の中身を示す。DBにおけるSQLクエリやHTTPにおけるクエリなどを格納する Span
トレースしたい処理の開始から終了までの計測単位を指します。
Spanはさらに細かいSpanを配下に持つことが可能です。トレースの中における親子Spanの関係
例えばWebの1リクエストにおけるトランザクションを親Spanとし
その配下にDBのSpan、キャッシュのSpan、外部通信のSpanやさらには特定のロジックなどを子Spanとすること可能です。
ソース
Datadog APM用のパッケージは下記の通りです。
こちらをトレース開始・終了、必要Spanの開始終了に伴い実行していく
1. トレース開始
tracer.Start() defer trace.Stop() // Closehttps://godoc.org/gopkg.in/DataDog/dd-trace-go.v1/ddtrace
2. 汎用的なSpan
Spanの開始と終了
span, ctx := tracer.StartSpanFromContext(ctx, "parent-op", // operation Name tracer.ServiceName("parent-service"), // Service Name(必要であれば入れる) tracer.ResourceName("parent-resource"), // Resource Name(必要であれば入れる) ) defer span.Finish()子Spanの使用
先程作成したSpanの配下に子Spanを設ける場合
親が投入されたcontext.Contextを使用して子Spanの開始すれば親Span情報が継承されます。子Spanの開始と終了
span, ctx := tracer.StartSpanFromContext(ctx, "child-op", // operation Name tracer.ServiceName("child-service"), // Service Name(必要であれば入れる) tracer.ResourceName("child-resource"), // Resource Name(必要であれば入れる) ) defer span.Finish()専用Spanパッケージを使用する
Web(HTTP Routing)用Span
アプリケーションのHTTPのRoutingで下記のいずれかのパッケージを使用していた場合は専用のパッケージが存在します。
gorilla/mux使用の場合
router = muxtrace.NewRouter( muxtrace.WithServiceName("web-service"), // ServiceName設定 ) router.HandleFunc("/", handler) http.ListenAndServe(":8080", router)DB用Span
database/sql使用の場合
// 登録(DBはMySQLの場合、ServiceNameは省略可) sqltrace.Register("mysql", &mysql.MySQLDriver{}, sqltrace.WithServiceName("db")) // traceに登録済のdriverを使用してDBをオープン db, err := sqltrace.Open("mysql", "user:password@/dbname") if err != nil { log.Fatal(err) } // Span作成・開始 span, ctx := tracer.StartSpanFromContext(ctx, "db", // operation Name(必要であれば入れる) tracer.SpanType(ext.SpanTypeSQL), tracer.ServiceName("db"), // DB用Service Name(必要であれば入れる) tracer.ResourceName("db-access"), // Resource Name(必要であれば入れる) ) // contextを通じて親Spanを継承している rows, err := db.QueryContext(ctx, "SELECT * FROM memo") if err != nil { log.Fatal(err) } rows.Close() span.Finish(tracer.WithError(err)) // Span終了その他
Agent関連
Agentのインストールの詳細
Agentのインストールを実施するとdatadog.yamlが指定の場所にダウンロードされます。Agentはそのyamlファイルを設定ファイルとして使用します。
datadog.yamlの設定サンプルはこちら
ダウンロードしたデフォルト設定のままでAPMは使用可能ですが、
API Keyを変えたりAPM関連の設定を変えたりした場合はdatadog.yamlの中身をチェックする必要があります。
- API Keyが正しく指定されているか
- 値を確認する際はこちら
- APM関連の各種設定
設定変更後はAgentの再起動を行う
再起動コマンドはこちらAgentコマンド
Agentの起動・終了・再起動コマンド
https://docs.datadoghq.com/ja/agent/guide/agent-commands/?tab=agentv6v7Grpcの場合
こちらを参考にgRPC Client側/Server側それぞれにTraceとSpanを設けた場合
下記のようにトレースされます。
OpenTracing, OpenCensus, OpenTelemetry
分散トレーシング標準仕様でOpenTracing, OpenCensusに対応済み
OpenTelemetryはまだ正式なRegistoryには入っていない模様(2020/04/10現在)
https://opentelemetry.io/registry/この辺は今後も見ていきたいです。
最後に
以上のようにセットアップも非常に簡単です。
また、有料サービスだけあって専用サーバー管理がいらないのは楽で良いです。ただ、もし実導入するようであればトレーシングによるアプリの負荷については注意深く見ておく必要があると思います。(Datadogに限った話ではないのですが)


- 投稿日:2020-04-09T12:30:13+09:00
アーキテクチャのアの字も知らない駆け出しエンジニアがドメイン駆動開発における依存性の逆転をgolangで実装しながら理解してみた
アーキテクチャのアの字も知らない駆け出しエンジニアがドメイン駆動開発における依存性の逆転をgolangで実装しながら理解してみた
こんにちは!例のウイルスで大学の休みが延期されて、引きこもりながらますます楽しいプログラミングライフを送っているとさです。
今回は、ドメイン駆動開発における「アプリケーションサービス」と「リポジトリ」の部分の実装をしながら、
学習していきたいと思います。機能を分割して、コードをわかりやすくすることを目標にやっていきます。アプリケーションサービス
A君
アプリケーションサービスは、ユーザーのユースケースの機能を実装する部分になります。B君
ユースケースってなんぞや??A君
ユースケースっていうのは、ユーザーがシステムに対してできること
例えば、よくあるSNSで言えば、「ユーザーデータを登録」したり「ユーザー情報を更新」したり「ツイート」したり
なんてものがユースケースに当たるよ。B君
へ〜、つまりはユーザーがシステムに対してできることって感じだな。A君
そうそう、その機能を実装する部分を今回はアプリケーションサービスって読んでいるんだ!
じゃあ早速ディレクトリを作成していこう!ddd_sample - applicationこのapplicationディレクトリ内にあとでコードを書いていくよ!
B君
ここで、ユースケースを実装していくんだね。リポジトリ
A君
リポジトリでは、データを永続化する処理を担当する部分になります
データを永続化するためには、データベースに保存したり、ファイルに書き出して保存したり
しなくちゃいけないよね。そのような機能をリポジトリが担当するよ。B君
なるほど、リポジトリはデータベースとのやり取り担当なんだねA君
そうだね!具体的にはデータベースからデータを取ってきたり、受け取ったデータを元に保存したり
更新したりする役割を担うよ。
さっきのサンプルにリポジトリも作成していこうか!B君
了解!mkdir ...っとddd_sample - application - repositoryできた!ここに、データベースに関連する処理を書くんだね!
A君
そう。applicationでユーザーがユーザーを登録したり、変更したりって処理をrepositoryさんに
お願いしてデータベースに反映してもらうんだ。じゃあ、どんどん実装していきましょう!B君
ラジャー!依存性逆転の原則
B君
めんどいな〜A君
どうした??いや、言われた通りにアプリケーションサービスとリポジトリに機能を分けて作成してみたんですよ
A君
うんうんB君
それで、別々にテストできたら便利やろうなって思ってテストコード書こうとしたんだけど、、、
データベースとの接続を担当するリポジトリの部分はわかるんやけど、アプリケーションサービスの部分まで
データベースを用意しないとテストできないんですよ。。。A君
なるほどB君
機能を分けたのに、、別々にテストできないなんて、この構造にした意味あるの??って思いまして...A君
いい質問だね!今の君の書いたコードを一緒に様子を見てみようかB君
はい!A君
ユーザーの登録処理を作ってみたんだね!B君
そうです。ユーザーが名前を入力してそのデータを登録する処理を作りました!A君
うんうん、言われた通りにapplicationでユーザーの名前を受け取って、データベースに接続する部分はきちんと、リポジトリに分割できてるね!ddd_sample - application - user_service.go <- ユースケース機能の実装 - repository - user_repository.go <-データベースとのやり取りを書く - domain - model - user.gotype User struct { ID uint64 `gorm:"primary_key"` Name string Updatetime time.Time Createtime time.Time }// リポジトリの実装(データベースの処理を書くよ) // 構造体を定義(多言語で言うクラスのようなもの) type UserRepository struct { // DBインスタンスのポインタを保存 // このデータベースですよって指してる DB *gorm.DB } // この構造体の実態を返す関数 // このデータベースを使用してね!ってきたらそれをセットしてUserRepositoryを返す func NewUserRepository(DB *gorm.DB) repository.UserRepository { return &UserRepositoryt{ DB: DB, } } // 構造体のメソッド // userのデータを受け取って、データベースに新規保存している // 返り値は(*model.User, error)でUserとエラーを返している func (r *UserRepository) Save(user *model.User) (*model.User, error) { r.DB.Create(&user) return user, nil }// ユーザーサービスの実装 // 構造体を定義 type UserService struct { // リポジトリーを受け取っている UserRepository repository.UserRepository } // リポジトリーをセット func NewUserService(repository repository.UserRepository) UserService { return UserService{UserRepository: repository} } // ユーザー登録の処理を書くよ! func (UserService *UserService) CreateUser(name string) (*model.User, error) { // 名前を受け取って、user構造体を作成したら user := model.User{ Name: name, Createtime: time.Now(), Updatetime: time.Now(), } // データベースの処理はリポジトリに任せるので // リポジトリを使用して保存します return UserService.UserRepository.Save(&user) }※ golangのormマッパーであるgormを使用しています。
A君
一度、このアプリの依存関係を図にしてみようか
依存関係っていうのは、あるオブジェクトから別のオブジェクトを参照するときに
発生するんだけど...
今回の場合だとUserServiceがUserRepositoryに依存しているということができるよね!
[図1]application -> repository
B君
そうですね!でも、リポジトリにデータベースを保存する処理を書いている
のなら依存しなくちゃ、データを保存できないですよね?A君
そうだね、ただこの実装だとリポジトリだけではなくアプリケーションサービスも
データベースのような特定の技術基盤に結びついてしまうよね、例えばデータベースがMySQLなのか
NoSQLなのか、はたまたローカルに保存するのかでリポジトリだけではなくアプリケーション
サービスまで書き換えて変更しなくてはいけなくなってしまうよね。そこで「依存関係逆転の法則」が出てくるんだ。
その法則の一つに
「抽象は実装の詳細に依存してはならない。実装の詳細に抽象が依存すべきである」ドメイン駆動設計入門 p165 より引用
ってのがあるのだけど
B君
うう、「抽象は実装の詳細に依存してはならない。実装の詳細に抽象が依存すべきである」って言葉が抽象的すぎてよくわからないです。A君
まあまあ、じゃあ一緒に実装しながら学習していこうか
さっきの図をもう一度出すよ!図1
この図これにinterfaceを噛ませてあげると図2
のようにすることができるよね。IUserRepository(抽象)がInterfaceでUserRepository(実装の詳細)に具体的な実装をするよ。UserService(実装の詳細)の依存先(オブジェクトの参照先)をIUserRepotory(抽象)に図のように変更してみると依存関係が全部IUserRepository(抽象)に向けることができるよね!
これで「依存関係逆転の法則」を満たすことができるんだ!じゃあ実際にgolangで実装してみよう!
ディレクトリ構造
ddd_sample - application - user_service.go - repository - user_repository_interface.go <- わかりやすくするために名称変更 - infrastructure - datastore - user_repository.go <- 具体的な実装はこちらに移動 - domain - model - user.gouser_repository_interface.go
// Interface // ここでは具体的な実装はしないが // ここに含まれている四つの関数を実装してくださいね〜って指定しています type IUserRepository interface { GetByID(id uint64) (model.User, error) Save(user *model.User) (*model.User, error) Update(user *model.User) error Delete(id uint64) error }user_repository.go
// Impliment ... 実装する // UserRepositoryを実装しています // IUserRepositoryのinterfaceで指定された四つの関数を具体的に実装しています。 type UserRepositoryImpliment struct { DB *gorm.DB } func NewUserRepositoryImpliment(DB *gorm.DB) repository.IUserRepository { return &UserRepositoryImpliment{ DB: DB, } } func (r *UserRepositoryImpliment) GetByID(id uint64) (model.User, error) { var user model.User r.DB.Where("id = ?", id).Find(&user) return user, nil } func (r *UserRepositoryImpliment) Save(user *model.User) (*model.User, error) { r.DB.Create(&user) return user, nil } func (r *UserRepositoryImpliment) Update(user *model.User) error { r.DB.Save(&user) return nil } func (r *UserRepositoryImpliment) Delete(id uint64) error { r.DB.Where("id = ?", id).Delete(&model.User{}) return nil }user_service.go
// UserServiceの方もIUserRepository(インターフェイス) // に依存するように変更 type UserService struct { UserRepository repository.IUserRepository } func NewUserService(repository repository.IUserRepository) UserService { return UserService{UserRepository: repository} } func (userService *UserService) GetUser(userID uint64) (model.User, error) { return userService.UserRepository.GetByID(userID) } func (UserService *UserService) CreateUser(name string) (*model.User, error) { user := model.User{ Name: name, Createtime: time.Now(), Updatetime: time.Now(), } return UserService.UserRepository.Save(&user) } func (UserService *UserService) UpdateUser(user *model.User) error { return UserService.UserRepository.Update(user) } func (UserService *UserService) DeleteUser(userID uint64) error { return UserService.UserRepository.Delete(userID) }B君
おお、難しそう。
これをすると何がどういいんですか??A君
アプリケーションサービスが抽象に依存しているから、もしアプリケーションサービスのテストをしたいってなったら
IUserRepositoryを実装したテスト用リポジトリ(インメモリに保存 etc)に差し替えれば、データベースを用意しなくても
アプリケーションサービスのテストをすることができるよ!B君
なるほど!A君
他にも、データベースをRDBからNoSQLに差し替える時とかも簡単に移行できそうだねB君
へ〜、なんとなくですがわかった気がします?A君
それはよかった!
これからも、DDDを頑張って勉強していこうね!!具体的な実装や依存性の注入を含めたコードはこちら->https://github.com/harukitosa/ddd_sample
(この記事は学習のために書き込んでいます。不備や理解不足の部分等ありましたら、ご指導とご伝達のほどよろしくお願いします?♂️)
参考文献
ドメイン駆動設計入門 成瀬允宣
めちゃくちゃわかりやすいのでおすすめです!

