- 投稿日:2020-04-09T22:50:18+09:00
Django 汎用クラスビューでアクセス元を一意に識別する方法
2020-04-08 作成: windows10/Python-3.8.2-amd64/Django-3.0.4
Django でユーザーの行動解析を行うためには、アクセス元の IP アドレスをログに残すだけでは不足しています。ユーザーを一意に識別するには、誰がアクセスしたかを HTTP サーバーのログに残すのが簡単です。
HTTP サーバーのログに Django のユーザー ID を残すには、レスポンスヘッダをカスタマイズします。汎用クラスビューで Django のユーザー ID をリクエストヘッダに追加する方法を書いておきます。
参考
https://blog.howtelevision.co.jp/entry/2014/09/05/170917Django を初めて使う人は、こちら。
10 分で終わる Django の実用チュートリアルレスポンスヘッダを追加したビュークラスを定義
追加したいレスポンスヘッダ userid を汎用ビュークラスに追加。
custom_views.pyclass CustomListView(generic.ListView): def dispatch(self, *args, **kwargs): response = super().dispatch(*args, **kwargs) response['userid'] = self.request.user return response実際に呼び出すビュークラスを定義
ListView を継承するのではなく、CustomListView を継承して、実際に使用するビュークラスを宣言。
views.pyfrom .custom_views import * from .models import MyClass from django.contrib.auth.mixins import LoginRequiredMixin class MemoListView(LoginRequiredMixin, CustomListView): model = MyClassListView だけでなく他のビュークラスでも同様のことは可能。
Nginx などの HTTP サーバーの設定を変更して、新たに作成したレスポンスヘッダをログに残せば、ログにアクセス元が記録される。
おしまい
- 投稿日:2020-04-09T22:43:36+09:00
NetworkXでConnecting Nearest Neighborを作る
少し前にConnecting Nearest Neighborのアルゴリズムでネットワークを作りたい!と相談された時に、調べまわってもPythonで、かつNetworkX等のパッケージを使ってやってみている例が見当たらなかった記憶があるので投稿します。自分だけの力で作り上げたわけではないですが、投稿にあたっていろいろ手を加え分かりやすくしました(したつもりです)。改善点等あれば、いろいろ教えていただければと思います。
環境
- python 3.6.9
- networkx 2.4
- matplotlib 3.2.1 Google Colabを使いました
NetworkXとは
諸先輩方がためになることを沢山書いてくださっているので、多くは語りません。
を参考にしながら勉強させていただきました。
Connecting Nearest Neighborとは
Vazquezによって提案されたネットワーク生成のモデル。原著は
Growing network with local rules: Preferential attachment, clustering hierarchy, and degree correlations自分がネットワーク関連の研究をしていたわけではないので、詳しくないですごめんなさい。
今回書き直すにあたってはを参考にさせて頂きました。
アルゴリズム
- パラメータuを定める
- 必要なノード数になるまで、以下を繰り返す
- 1-uの確率で新しくノードを作成する。ランダムに既存のノードを一つ選び、新たなノードと実リンクを結ぶ。選ばれたノードと実リンクで繋がっている全ノードと、新しいノードの間に、ポテンシャルリンクを結ぶ。
- uの確率で、ポテンシャルリンクをランダムに選び実リンクに変える
プログラム
CNNクラス
import networkx as nx import random import matplotlib.pyplot as plt class CNN: def __init__(self, node_num, u, seed = 0): self.graph = nx.Graph() self.node_num = node_num self.u = u random.seed(seed) self.make_cnn() def make_cnn(self): self.graph.add_node(0) while len(list(self.graph.nodes)) < self.node_num: # 確率uでノードを新しく追加 if random.random() < 1 - self.u: new_node = len(list(self.graph.nodes)) self.graph.add_node(new_node) # すでにネットワーク中に存在するノードをランダムに選ぶ node_list = list(self.graph.nodes) node_list.remove(new_node) selected_node = random.choice(node_list) # selected_nodeの隣接ノード全てにnew_nodeとのポテンシャルエッジを結ぶ neighbor_nodes = self.get_neighbors(selected_node) for nn in neighbor_nodes: self.graph.add_edge(nn, new_node, attribute="potential") # リアルエッジを結ぶ self.graph.add_edge(selected_node, new_node, attribute="real") # 確率1-uでランダムにポテンシャルリンクを選びリアルエッジに変換 else: potential_edge_list = self.get_attribute_edgelist("potential") if len(potential_edge_list) > 0: node_a, node_b = random.choice(potential_edge_list) self.graph.edges[node_a, node_b]["attribute"] = "real" def get_attribute_edgelist(self, attr): ''' エッジの持つ値がattr(potenntialもしくはreal)のエッジのリストを返す ''' # {(node, node): 属性}となるdictを取得 edge_dict = nx.get_edge_attributes(self.graph, "attribute") attr_edgelist = [] for edge, attribute in edge_dict.items(): if attribute == attr: attr_edgelist.append(edge) return attr_edgelist def get_neighbors(self, node): ''' nodeとreal_edgeでつながるノードのリストを返す ''' edgelist = self.get_attribute_edgelist("real") nodelist = [] for node_a, node_b in edgelist: if node_a == node: nodelist.append(node_b) elif node_b == node: nodelist.append(node_a) return nodelist def plot_graph(self): plt.figure(figsize=(15, 10), facecolor="w") pos = nx.spring_layout(self.graph, k=1.0) real_edge_list = self.get_attribute_edgelist("real") nx.draw_networkx_nodes(self.graph, pos, node_color="r") nx.draw_networkx_edges(self.graph, pos, edgelist=real_edge_list) nx.draw_networkx_labels(self.graph, pos, font_size=10) plt.axis("off") plt.show()実行
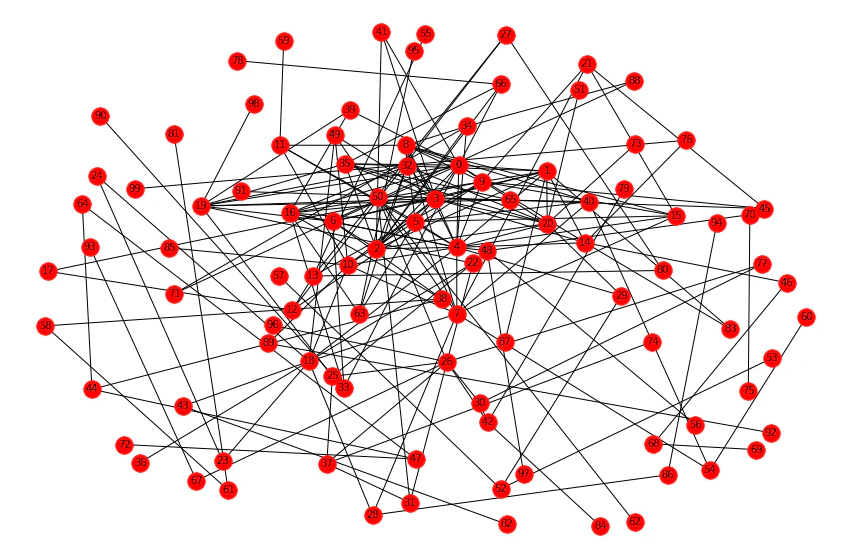
cnn = CNN(node_num=100, u=0.9) cnn.make_cnn() cnn.plot_graph()するとこんな図が得られます。
u=0.1
u=0.5
u=0.9


- 投稿日:2020-04-09T21:00:53+09:00
Numpy100本ノックで出会った「こりゃあ、便利だなぁ~」と思った関数一覧
概要
会社の研修中にNumpy100本ノックに取り組みさせられましたが、そもそも関数を知らないと倒せない問題が数多くあり、知識不足を痛感しました。
その、僕が初めましての関数の中でも「便利だなぁ~」と思ったものを忘備録を兼ねてご紹介するのがこの記事になります。筆者プロフィール
プログラミング歴:約1年(Pythonのみ)
Numpyはこの本で勉強しました。初めに
初めての関数に出会ったら、ググるよりも先にhelpを見た方が圧倒的に理解が早いです。
helpはnp.info([関数名]) ex) np.info(np.add)jupyter notebookであれば
[関数名]? ex) np.add?で表示されます。
関数の説明のみならず、引数の種類や使用例まで載っており、情報量がとても多いです。
英語なので慣れていないと苦痛に感じるかも知れませんが、是非参考にしていただきたいです。「便利だなぁ~」な関数
np.flip
配列を反転します。
a = np.arange(10) np.flip(a) -> array([9, 8, 7, 6, 5, 4, 3, 2, 1, 0])ベクトルであればスライス([::-1])で事足りますが、行列の場合などに重宝しそうです。
行列の場合、axisを指定すると任意の方向にひっくり返すことができます。a = np.arange(9).reshape(3,3) np.flip(a) -> array([[8, 7, 6], [5, 4, 3], [2, 1, 0]]) np.flip(a, axis=0) ->array([[6, 7, 8], [3, 4, 5], [0, 1, 2]]) np.flip(a, axis=1) -> array([[2, 1, 0], [5, 4, 3], [8, 7, 6]])np.eye
単位行列を生成します。
np.eye(3) -> array([[1., 0., 0., 0.], [0., 1., 0., 0.], [0., 0., 1., 0.], [0., 0., 0., 1.]])np.diag
対角成分を抽出します。
a = np.random.randint(0,10, (3,3)) print(a) -> [[5 2 8] [2 7 5] [5 1 0]] p.diag(a) -> array([5, 7, 0])np.tile
配列を敷き詰めます。
a = np.array([[0, 1], [1, 0]]) np.tile(a, (2,2)) -> array([[0, 1, 0, 1], [1, 0, 1, 0], [0, 1, 0, 1], [1, 0, 1, 0]])np.bincount
配列中の数値(非負、int型)をカウントし、その値のindexに格納します。
a = np.random.randint(0, 10, 10) print(a) -> array([8 6 0 8 4 6 2 5 2 1]) np.bincount(a) -> array([1, 1, 2, 0, 1, 1, 2, 0, 2], dtype=int64)np.repeat
要素を指定した数だけ繰り返します。
np.repeat(3, 4) -> array([3, 3, 3, 3])np.roll
配列を指定した数だけ右にシフトします。
a = np.arange(10) np.roll(a, 2) -> array([8, 9, 0, 1, 2, 3, 4, 5, 6, 7])np.flatten
元の配列を1次元配列に直します。
a = np.arange(9).reshape(3,3) print(a) -> [[0 1 2] [3 4 5] [6 7 8]] b = a.flatten() print(b) -> [0 1 2 3 4 5 6 7 8]np.nonzero
0以外の値が含まれているindexを教えてくれます。
a = np.array([1,0,0,1]) b = np.array([1,1,1,1]) print(np.nonzero(a)) -> (array([0, 3], dtype=int64),) print(np.nonzero(b)) -> (array([0, 1, 2, 3], dtype=int64),)np.copysign
第1引数の符号を第2引数と同じに変換します。
a = np.arange(10) b = np.repeat([1, -1], 5) np.copysign(a, b) -> array([ 0., 1., 2., 3., 4., -5., -6., -7., -8., -9.])np.intersect1d
2配列の共通する要素を取り出します。
a = np.arange(10) b = np.arange(5, 15) np.intersect1d(a, b) -> array([5, 6, 7, 8, 9])最後に
こういった関数は暗記するのではありませんが、そもそも知らないと使うことができません。
ご紹介した関数達が皆様の頭の片隅にでも残っていただけるととても嬉しいです!
- 投稿日:2020-04-09T18:57:32+09:00
HDAのUIにPySideを使用する
概要
Houdini18.0からHDAのUIにPySideを使えるようになりました。
例えばこういったリストビューを使ったマテリアルを一覧し、アサインするツールを作ったりする事が可能です。
方法
HDAのUIをPySideにするにはPython Panel Editorを使います。
Python Panel Editorについては下記ページが参考になると思います。上記に書かれてるのはPySideのUIをHoudiniのパネルに組み込む物ですが、HDAに適用するにはShow in Parameters Paneにチェックを入れ、For Operatorsの欄にオペレータ名を指定します。
オペレータ名は<ネットワークタイプ名>/<オペレータ名>もしくは画像のようにHDAにプレフィックスを付けてる場合は<プレフィックス>::<ネットワークタイプ名>/<オペレータ名>にします。
あとはタブメニューからノードを作成するとPySideのUIが適用された状態で表示されます。
注意点
注意点としてはこのPython Panelファイル自体も読み込める場所に配置されてる必要があります。
基本的には下記どちらかに入れ、HDAは親階層のotlsフォルダに入れると自動で読み込まれます。
- $HOUDINI_PATH/python_panels
- $HOUDINI_USER_PREF_DIR/python_panels
ちなみにPython Panel Editorに使用してるコードはMayaなどのPySideが対応してるツールでも使う事が出来ます。
このツールの場合はマテリアルを適用する箇所は書き換える必要がありますが、それ以外の箇所は共通で使える為、使い回すことが出来ます。
通常のUIと切り替え
UIの表示をPySideにするか通常の物にするかは図のボタンを押すことで切り替えることが出来ます。
ちなみにMaterial Browserの通常UIはこのようになっています。
グループとマテリアルまでのパスが書かれただけのシンプルな物です。
HDAではUIをPySideにしても、パラメータの情報は通常UIからしか取得する事が出来ないので、PySideから実行するコマンドではHDA内にマテリアルを作り、選択してた面とマテリアルのパスをパラメータに設定するという処理を行っています。問題点
本来HDAノード自体をPythonで取得しようと思うと
hou.pwd()やkwargs['node']を使いますが、PySide側では取得する事が出来ません。
これが出来ないとマテリアルを適用する時にどのノードを対象にするか指定する事が出来ないのです。この問題に対して調べても解決策が出なかったので、これはあくまで私が考えた方法ですが、HDAのOnCreatedとOnLoadedに下記スクリプトを登録しています。
def set_current_node(node, event_type, **kwargs): hou.setPwd(node) node = kwargs['node'] node.addEventCallback((hou.nodeEventType.AppearanceChanged, ), set_current_node)OnCreatedはHDA作成時、OnLoadedはシーンファイルを開いた時に実行されるスクリプトです。
ここにaddEventCallbackでノードの状態(選択やフラグなど)が変わった時にこのHDAを現行ノードに設定するというものです。
かなり強引ですが、こうする事でPySideからhou.pwd()でHDAノードを取得する事が出来ます。もっと良い方法をご存じの方は教えていただけると助かります…
まとめ
以上HDAのUIにPySideを使用する方法でした。
まだ対応して間もないので、情報や実装例がほとんどありませんが、HDAで出来ることの幅が増えるので、是非チャレンジしてみて下さい。
ちなみに私は今後、Houdiniからゲーム用にモデルをパブリッシュするHDAのUIをPySideに変更しようと思っています。






- 投稿日:2020-04-09T18:30:39+09:00
【競プロ初心者向け】AOJ 「ITP I」40問をpythonで解いてみた
はじめに
本記事では「レッドコーダーが教える、競プロ・AtCoder上達のガイドライン【初級編:競プロを始めよう】」で紹介されているAOJの「Introduction To Programming I」の40問をPythonで解説します。
僕自身、プログラム未経験で競技プログラミングをはじめました。入門書である「独学プログラマー Python言語の基本から仕事のやり方まで」を読んでから「Introduction To Programming I」に取り組みました。あくまで個人の話ですが、40問を解いたあとにはAtcoderで開催されいているAtCoder Beginner Contest(ABC)で茶パフォが出せるようになっていたので競技プログラミングをするうえでの基本的な知識は身につくのだと思います。
ITP1_1_A Hello World
ITP1_1_Aprint("Hello World")【解説】
Hello Worldを出力します。ITP1_1_B X:Cubic
ITP1_1_Bx=int(input()) print(x**3)【解説】
input()は文字列として受け取るのでint()で数値にしてから処理します。ITP1_1_C Rectangle
ITP1_1_Ca,b=map(int,input().split()) print(a*b,2*(a+b))【解説】 1行/複数列の入力は
input().split()が利用できます。ただし文字列として受け取るのでmapとintで数値にしてから処理します。入力については「AtCoderで始めるPython入門」が参考になります。ITP1_1_D Watch
ITP1_1_DS=int(input()) print(S//3600,":",(S%3600)//60,":",S%60, sep="")【解説】秒数を
3600で割った商がhに、秒数を3600で割った余りを60で割った商がmに、秒数を60で割った余りがsになります。h,m,sと:を+で繋ぐにはh,m,sを文字列にする必要があります。文字列と数値が混じっていてもITP1_2_A Small, Large, or Equal
ITP1_2_Aa,b=map(int,input().split()) if a>b: print("a > b") elif a<b: print("a < b") else: print("a == b")【解説】言われている通りに書きます。
ITP1_2_B Range
ITP1_2_Ba,b,c=map(int,input().split()) if a<b and b<c: print("Yes") else: print("No")【解説】
a<b<cと記述しても問題ありません。ITP1_2_C Sorting Three Numbers
ITP1_2_Cthree_numbers=list(map(int,input().split())) three_numbers.sort() print(*three_numbers)【解説】はじめて
listが登場します。listは複数の要素を含むオブジェクトです。「【Python入門】listの使い方とメソッドまとめ」が参考になります。もし余裕があればtuple、dictについても勉強しておくといいです。リストをソートするには、"list名".sort()もしくはsorted("list名")があります。これらの違いについては、「Pythonでリストをソートするsortとsortedの違い」が参考になります。ITP1_2_D Circle in a Rectangle
ITP1_2_DW,H,x,y,r = map(int,input().split()) Flag=True if x+r>W or x-r<0: Flag=False if y+r>H or y-r<0: Flag=False if Flag: print("Yes") else: print("No")【解説】横と縦でそれぞれ円が長方形からはみ出さないかを確認します。
Flagを作成しておき、条件を満たさなくなった時点でFalseにします。最後までTrueであれば、円が長方形に収まり、そうでなければ縦か横のどちらかがはみ出すことになります。TrueFalseはbool型と呼ばれます。「【Python入門】ブール型(Boolean)の用途と使い方を学ぼう!」が参考になります。ITP1_3_A Print Many Hello World
ITP1_3_Afor i in range(1000): print("Hello World")【解説】はじめて繰り返しの
forの登場です。こちら「【Python入門】for文を使った繰り返し文の書き方」が参考になります。ITP1_3_B Print Test Cases
ITP1_3_Bcase_number=0 while True: x=int(input()) case_number+=1 if x==0: break print("Case {}: {}".format(case_number,x))【解説】
whileで入力が0になるまで実行します。whileについては「Pythonのwhile文によるループ処理(無限ループなど)」が参考になります。競技プログラミングではしばしばCase i:結果で出力することがあります。pythonではいくつかの出力方法がありますが、そのうちの1つとしてformatがあります。formatは文字列のメソッドで文字列内に変数を埋め込むことができます(Python2.6以降でのみ使用可能)。こちら「【Python入門】formatメソッドで変数の内容を出力する方法」が参考になります。ITP1_3_C Swapping Two Numbers
ITP1_3_Cwhile True: x,y=map(int,input().split()) if x==0 and y==0: break if x>y: print(y,x) else: print(x,y)【解説】
whileで入力が0 0になるまで実行します。あとはx,yの大小関係を確認して出力します。ITP1_3_D How Many Divisors?
ITP1_3_Da,b,c=map(int,input().split()) cnt=0 for k in range(a,b+1): if c%k==0: cnt+=1 print(cnt)【解説】
aからbまでの整数がcの約数かどうか1つずつ調べます。約数であればcnt(カウント)を1つ大きくします。ITP1_4_A A/B Problem
ITP1_4_Aa,b=map(int,input().split()) print(a//b,a%b,"{:.6f}".format(a/b))ITP1_4_A(別解)a,b=map(int,input().split()) print(a//b,a%b,round((a/b),6))【解説】
a/bの小数の誤差をどう処理するかが問題です。formatを用いることで、数値の小数点の桁を指定できます。「Pythonのformat()メソッドを使いこなす」が参考になります。もしくは四捨五入を行い、小数の誤差を問題の制約内に抑えることも可能です。roundは厳密には四捨五入ではないので注意が必要です。四捨五入は「Pythonで小数・整数を四捨五入するroundとDecimal.quantize」が参考になります。ITP1_4_C Simple Calculator
ITP1_4_Cwhile True: a,op,b=input().split() a=int(a) b=int(b) if op=="?": break if op=="+": print(a+b) if op=="-": print(a-b) if op=="*": print(a*b) if op=="/": print(a//b)【解説】
whileで?がでるまで実行します。あとは足し算、引き算、掛け算、割り算をそれぞれ出力します。ITP1_4_D Min, Max and Sum
ITP1_4_DN=int(input()) a=list(map(int,input().split())) print(min(a),max(a),sum(a))【解説】
Pythonではlistの最大や最小、合計をそれぞれmax(list名)min(list名)sum(list名)で求めることができます。ITP1_5_A Print a Rectangle
ITP1_5_Awhile True: H,W= map(int,input().split()) if H==0 and W==0: break for i in range(H): print("#"*W) print()【解説】文字列では
*は繰り返しになります。例えば"Hello World"*3とすれば"Hello WorldHello WorldHello World"となります。最後のprint()は長方形と長方形の間の1行を意味します。ITP1_5_B Print a Frame
ITP1_5_Bwhile True: H,W= map(int,input().split()) if H==0 and W==0: break print("#"*W) for i in range(H-2): print("#"+"."*(W-2)+"#") print("#"*W) print()【解説】先ほどの問題に似ています。ただし、1行目とH行目は
"###・・・###"ですが、2行目からH-1行目は"#…・・・…#"となります。そのため「1行目を出力」「2行目からH-1行目(つまりH-2行)までを出力」「H行目を出力」とします。ITP1_5_C Print a Chessboard
ITP1_5_Cwhile True: H,W=map(int,input().split()) if H==0 and W==0: break for h in range(H): for w in range(W): if (h+w)%2==0: print("#",end="") else: print(".",end="") print() print()【解説】
forのなかにforを書くことができます。二重ループと言われます。(参考:「Pythonで多重ループ(ネストしたforループ)からbreak」)出力したいチェック柄をじっと見ると、行数と列数を足した値が偶数の時は#、奇数の時は.であることに気づきます(Pythonでは0行目、1行目…と数えることに注意)。各行で順に出力していき、最後の列で改行します。ただprint("#")のようにすると#のあとに改行されてしまいます。それを避けるためにend=""で出力時に改行しないようにします。ITP1_5_D Structured Programming
ITP1_5_DN=int(input()) for i in range(1,N+1): if i%3==0 or "3" in str(i): print(" {}".format(i),end="") print()【解説】問題の意味をまずは理解します。C++のコードを読めないと辛い問題ですが、競技プログラミングの解説ではC++がよく使われるため、読めるようにしておくといいかもしれません。例えば通称「蟻本」と呼ばれる本もコードはC++で書かれています。今回の問題では「n以下の自然数のうち、3の倍数もしくは3がつく数を小さいものから順に出力しなさい」という問題です。3の倍数であることは3で割った余りを見ればすぐにわかります。3がつくことの確認は今回は文字列として
inを用いて行いました。任意の文字列を含むかの判定は「Pythonで文字列を検索(〜を含むか判定、位置取得、カウント)」が参考になります。ITP1_6_A Reversing Numbers
ITP1_6_AN=int(input()) a=list(map(int,input().split())) a=a[::-1] print(*a)【解説】リストの順を逆順にするには、リスト型のメソッド
reverse、組み込み関数のreversed、スライスによって並び替えることができます。今回はスライスを利用しました。リストの逆順は「Pythonでリストや文字列を逆順に並べ替え」が、スライスは「Pythonのスライスによるリストや文字列の部分選択・代入」が参考になります。ITP1_6_B Finding Missing Cards
ITP1_6_BN=int(input()) suits=["S","H","C","D"] cards=[] for _ in range(N): s,n=input().split() if s=="S": cards.append(int(n)) elif s=="H": cards.append(13+int(n)) elif s=="C": cards.append(26+int(n)) else: cards.append(39+int(n)) for i in range(1,53): if i not in cards: print(suits[(i-1)//13],(i-1)%13+1)【解説】トランプのマークと数字を一緒に表現する方法を考えます。スペードを1から13で、ハートを14から26で、クローバーを27から39で、ダイヤを40から52で表すことでマークと数字を同時に表せます。例えばハートの3は16となります。次に最初に持っていたカードのリストを作成します。あとは1から52までの番号(つまり52枚のトランプ全て)を一つ一つ持っているか確認して、持っていなければ出力します。
【メモ】実は計算量を意識する必要がある問題では
inを用いるのは注意が必要です。計算量については「計算量オーダーの求め方を総整理! 〜 どこから log が出て来るか 〜」が参考になります。iがlistにあるか調べるi in listでの計算量は $O(n)$になります。これはlistにおける要素ひとつひとつとiが等しいかを確認していることになります。トランプ程度の枚数であれば問題ありませんが、大きな数になると膨大な計算量になることがあり注意が必要です。ITP1_6_C Official House
ITP1_6_CN=int(input()) room=[[[0]*10 for _ in range(3)] for _ in range(4)] for _ in range(N): b,f,r,v=map(int,input().split()) room[b-1][f-1][r-1]+=v for i in range(4): for j in range(3): for k in range(10): print(" {}".format(room[i][j][k]), end="") print() if i!=3: print("####################")【解説】この問題は多次元配列で解くことができます。「Pythonで多次元配列を扱う方法【初心者向け】」が参考になります。出力の形式を合わせるのが少し大変な問題です。
ITP1_6_D Matrix Vector Multiplication
ITP1_6_Dn,m=map(int,input().split()) A=[list(map(int,input().split())) for i in range(n)] b=[int(input()) for i in range(m)] for i in range(n): ans=0 for j in range(m): ans+=A[i][j]*b[j] print(ans)【解説】この問題も多次元配列で処理することで解くことができます。行列の計算になります。
ITP1_7_A Grading
ITP1_7_Awhile True: m,f,r=map(int,input().split()) if m==-1 and f==-1 and r==-1: break sum=m+f if m==-1 or f==-1 : print("F") elif sum>=80: print("A") elif sum>=65: print("B") elif sum>=50: print("C") elif sum>=30: if r>=50: print("C") else: print("D") else: print("F")【解説】問題をよく読み、条件分岐を行います。
ITP1_7_B How many ways?
ITP1_7_Cwhile True: n,x=map(int,input().split()) if n==0 and x==0 : break cnt=0 for i in range(1,n-1): for j in range(i+1,n): if j<x-i-j<=n: cnt+=1 print(cnt)【解説】少し数学的な考え方が含まれる問題です。
nまでの数のなかから重複無しで3つの数を足してxにすることを考えます。例えば1から5までの数から9をつくるとします。このとき、1+3+5と3+5+1は同じ数字の組み合わせなので同一の組み合わせとみなします。このような組み合わせを複数回数えることがないように、「次に選ぶ数は必ず前に選んだ数よりも大きい」というルールのもとで選んでいくことにします。はじめにiを選び、それより大きいjを選びます。あとはx-i-jがjよりも大きくn以下であれば組み合わせとして成立します。ITP1_7_C Spreadsheet
ITP1_7_Cr,c=map(int,input().split()) sheet=[list(map(int,input().split())) for i in range(r)] for i in range(r): sheet[i].append(sum(sheet[i])) Column_sum=[0]*(c+1) for j in range(c+1): for i in range(r): Column_sum[j]+=sheet[i][j] for i in range(r): print(*sheet[i]) print(*Column_sum)【解説】はじめに
r*cの2次元配列を作成します。各行の合計と、各列の合計をそれぞれ求めて加えていきます。今までの考え方を合わせることで解ける問題です。今回は行の合計はsumで、列の合計は各行のj列目の数を一つずつ足すことで求めています。ITP1_7_D Matrix Multiplication
ITP1_7_Dn,m,l=map(int,input().split()) A=[list(map(int,input().split())) for i in range(n)] B=[list(map(int,input().split())) for i in range(m)] C=[] for i in range(n): line=[] for j in range(l): c=0 for k in range(m): c+=A[i][k]*B[k][j] line.append(c) C.append(line) for line in C: print(*line)【解説】2次元配列を用います。インデックスを理解して書く必要があります。
ITP1_8_A Toggling Cases
ITP1_8_Awords=input() print(str.swapcase(words))【解説】英字の大文字と小文字の変換に利用できるメソッドはいくつかあります。そのうちの一つである
swapcaseを用いると今回の問題は簡単に解くことができます。upperやlowerなど他にも知っておくべきメソッドはあります。「Python 英字の大文字と小文字を変換(upper/lower/capitalize/swapcase/title)」を一読するといいと思います。ITP1_8_B Sum of Numbers
ITP1_8_Bwhile True: str_n=input() if str_n=="0": break list_n=list(str_n) ans=0 for n in list_n: ans+=int(n) print(ans)ITP1_8_B別解while True: str_n=input() if str_n=="0": break print(sum(list(map(int,str_n))))【解説】今回はあえて数値を文字列として受け取ります。文字列をリストにします。例えば文字列
"123"に対して、list("123")とすると["1","2","3"]となります。あとはforで各位の数を1つずつ取り出します。ただし取り出せるのは文字列としてなので、int()で数値に直してから足します。今まで標準入力で利用してきたmapを用いてより簡潔に書くこともできます。ITP1_8_C Counting Characters
ITP1_8_Cimport sys texts=sys.stdin.read() texts=texts.lower() cnt=[0]*26 letters=list('abcdefghijklmnopqrstuvwxyz') for x in texts: i=0 for y in letters: if x==y: cnt[i]+=1 i+=1 for i in range(26): print(letters[i]+" : "+str(cnt[i]))【解説】今までは
inputを用いて標準入力を受け取りました。今回は複数行かつ行数がわからない英文を読み取らなければいけません。whileとinputを組み合わせることも可能ですが、sysモジュールのsys.stdin.readを利用します。複数行の文字列を複数行のまま受け取ることができます。詳しくは「Python】標準入力でキーボードからデータを受け取り(sys.stdin.readlines、input関数)」を参考にして下さい。入力後は、すべて小文字にしたうえで英文の1文字ずつアルファベットを確認して、カウントしていきます。ITP1_8_D Ring
ITP1_8_Ds=input() p=input() s*=2 if s.find(p)!=-1: print("Yes") else : print("No")【解説】リング状の文字列からある文字列を作成できるかを考えます。リング状の文字列では始まりと終わりがなくどれだけでも長い文字列を作ることができます。ただし今回の問題では
pはsよりも短いという条件がついています。そのためリング2周分で考えれば十分です。リング2周に該当する文字列を作成し、そこでpを作ることができるか調べます。pがあるかを確かめるために文字列のメソッドfindを利用します。findは特定の文字列の位置を取得しますが、文字列がなければ-1を返します。「Pythonで文字列を検索(〜を含むか判定、位置取得、カウント)」が参考になります。ITP1_9_A Finding a Word
ITP1_9_Aimport sys word=input() text=sys.stdin.read() print(text.lower().split().count(word))【解説】入力は
sys.stdin.readで行います。text.lower().split().count(word)について解説します。lower()で小文字にします。split()でスペースごとに区切りリストにします。普段の標準入力でinput().split()のsplitと同様です。「Pythonで文字列を分割(区切り文字、改行、正規表現、文字数)」が参考になります。リストのなかに含まれる個数を調べるにはcountメソッドを利用します。「【Python】 特定の文字や文字列の出現回数を数える(count)」が参考になります。ITP1_9_B Shuffle
ITP1_9_Bwhile True: cards=input() if cards=="-": break m=int(input()) for i in range(m): sh=int(input()) former=cards[:sh] later=cards[sh:] cards=later+former print(cards)【解説】リストのスライスを利用して解くことができます。
ITP1_9_C Card Game
ITP1_9_Cn=int(input()) T=0 H=0 for i in range(n): card_t,card_h=input().split() if card_t==card_h: T+=1 H+=1 else: if card_h>card_t: H+=3 else: T+=3 print(T,H)【解説】文字列に
>や<を用いると、辞書順で比較した結果が返されます。これを利用して解くことができます。ITP1_9_D Transformation
ITP1_9_Dtext=input() n=int(input()) for i in range(n): order=input().split() a,b=map(int,order[1:3]) if order[0]=="print": print(text[a:b+1]) elif order[0]=="reverse": re_text=text[a:b+1] text=text[:a]+re_text[::-1]+text[b+1:] else : text=text[:a]+order[3]+text[b+1:]【解説】先ほどと同じく、リストのスライスを利用して解くことができます。ただし
reverseのときに少し注意が必要です。スライスでstepを-1にするときstartとendは文字通りの解釈がされません。こちらの質問が参考になります。今回はreverseしたい範囲のリストを作成してから逆順にしました。ITP1_10_A Distance
ITP1_10_Ax1,y1,x2,y2=map(float,input().split()) print(((x1-x2)**2+(y1-y2)**2)**0.5)【解説】ルートの計算は
mathモジュールをインポートして、math.sqrt()で行うか、もしくは**0.5することで求めることができます。ITP1_10_B Triangle
ITP1_10_Bimport math a,b,C=map(float,input().split()) θ=math.radians(C) h=b*math.sin(θ) S=(a*h)/2 c=math.sqrt(a**2+b**2-2*a*b*math.cos(θ)) L=a+b+c print(S,L,h,sep="\n")【解説】三角比は
mathモジュールを利用します。ラジアンと度数法の変換は「ラジアンと度数法単位の相互変換」を、三角比は「Pythonで三角関数を計算(sin, cos, tan, arcsin, arccos, arctan)」が参考になります。cの長さは余弦定理で求めています。ITP1_10_C Standard Deviation
ITP1_10_Cwhile True: n=int(input()) if n==0: break score=list(map(int,input().split())) mean=sum(score)/n var_sum=0 for i in range(n): var_sum+=(score[i]-mean)**2 print((var_sum/n)**0.5)【解説】統計量は
statisticsなどのモジュールを用いて求めることもできますが、今回は問題文にあるとおりに計算して求めます。まずは平均値を算出します。平均値との差の二乗の平均を求めます。これは分散に当たります。それのルートをとれば今回求める標準偏差になります。ITP1_10_D Distance II
ITP1_10_Ddef Distance(X,Y,p): s=0 for x,y in zip(X,Y): s+=abs(x-y)**p print(s**(1/p)) n=int(input()) X=list(map(int,input().split())) Y=list(map(int,input().split())) for p in range(1,4): Distance(X,Y,p) print(max(abs(x-y) for x,y in zip(X,Y)))【解説】今までは既存のライブラリを利用してきましたが、自分で関数を定義することもできます。今回は
Distanceという距離を出力する関数を定義します。関数の定義は「Pythonで関数を定義・呼び出し(def, return)」が参考になります。チェビシェフの距離だけは別に計算をします。またzip関数は複数のリストなどから要素を取得する時に役立ちます。「Python, zip関数の使い方: 複数のリストの要素をまとめて取得」が参考になります。最後に
解説を書くにあたり、できるだけ簡潔にかつできるだけ触れられる情報が多くなるように意識しました。複数のリストを用いれば解けるような問題でも敢えて多次元配列で解くようにしました。とはいえ、いきなり難しくならないように1問あたり新しいことは1つもしくは2つに収まるようにしました。ぼくもまだまだ初心者ですが、Pythonをはじめたばかりの自分が喜ぶような記事になっているとは思います。
「Introduction To Programming I」のあとは、「レッドコーダーが教える、競プロ・AtCoder上達のガイドライン【初級編:競プロを始めよう】」で紹介されている通りに全探索の問題に取り組めばいいと思います。ぼくは全探索の問題に取り組みつつ、ABCコンテストのA問題とB問題とC問題の3問を合計30分以内に解けるように早解きの練習も行いました。皆さんの参考になれば幸いです。最後まで読んでくださりありがとうございました。
- 投稿日:2020-04-09T18:21:21+09:00
新型コロナウイルス感染者情報の特徴をwordcloudで可視化してみた
概要
- 新型コロナウイルス(COVID-19)の日本の感染者情報を取得
- mecabで形態素解析
- wordcloudで特徴語を可視化
参考
新型コロナウイルス(COVID-19)の感染者情報
config
- config.py
import re import os ### MeCab POS_LIST = [10, 11, 31, 32, 34] POS_LIST.extend(list(range(36,50))) POS_LIST.extend([59, 60, 62, 67]) STOP_WORDS = ["する", "ない", "なる", "もう", "しよ", "でき", "なっ", "くっ", "やっ", "ある", "しれ", "思う", "今日", "それ", "これ", "あれ", "どれ", "どの", "NULL", "れる", "なり", "あっ", "できる", "私"] RE_ALPHABET = re.compile("^[0-9a-zA-Z0-9 .,*<>]+$") # alphabet, number, space, comma or dot current_dir = os.getcwd() OUTPUT_PNG_FILE = os.path.join(current_dir, "wordcloud.png")
- 前処理
(略)
形態素解析
import MeCab from os import path from wordcloud import WordCloud import matplotlib matplotlib.use('Agg') import matplotlib.pyplot as plt import re def create_mecab_list(text_list): mecab_list = [] mecab = MeCab.Tagger("-Ochasen -d /usr/local/lib/mecab/dic/mecab-ipadic-neologd") # MacOS mecab.parse("") # encoding = text.encode('utf-8') for text in text_list: node = mecab.parseToNode(text) while node: # [品詞,品詞細分類1,品詞細分類2,品詞細分類3,活用形,活用型,原形,読み,発音] # 忙しく 形容詞,自立,*,*,形容詞・イ段,連用テ接続,忙しい,イソガシク,イソガシク morpheme = node.feature.split(",")[6] if RE_ALPHABET.match(morpheme): node = node.next continue if morpheme in STOP_WORDS: node = node.next continue if len(morpheme) > 1: if node.posid in POS_LIST: mecab_list.append(morpheme) node = node.next return mecab_listwordcloud
import MeCab from os import path from wordcloud import WordCloud import matplotlib matplotlib.use('Agg') import matplotlib.pyplot as plt import re def create_wordcloud(morphemes): # fpath = "/usr/share/fonts/truetype/takao-gothic/TakaoPGothic.ttf" # Ubuntu fpath = "/System/Library/Fonts/ヒラギノ丸ゴ ProN W4.ttc" # Mac OS X wordcloud = WordCloud( background_color="whitesmoke", collocations=False, stopwords=set(STOP_WORDS), max_font_size=80, relative_scaling=.5, width=800, height=500, font_path=fpath ).generate(morphemes) plt.figure() plt.imshow(wordcloud) plt.axis("off") wordcloud.to_file(OUTPUT_PNG_FILE)結果
- 「女性」より「男性」のほうが感染者が多い
- → 「女性」より「男性」のほうが文字サイズが大きい
- 「20代」が以外に多い
- 「マスク」大事…
その他新型コロナ関連情報
- 厚生労働省
- 新型コロナウイルスに関するQ&A:
- 新型コロナウイルス感染症についての相談・受診の目安
- 東京都
- 新型コロナウイルス感染症対策サイト
- 世界の感染者可視化

- 投稿日:2020-04-09T18:10:55+09:00
サイバーセキュリティプログラミングをすすめる
目的
linux,ネットワーク、python初心者がサイバーセキュリティプログラミングを読み進めるうえで引っかかったことを残しておく。未解決も残しておく。 (進捗に応じて追記する。)
2.6 TCPプロキシの構築
引っかかったこと
Non-ASCII character '\xe3'
- 参考
- Python2系ではUTF-8で書いていることを明示する必要がある
- コメントになっているのに意味があったなんて…
実行にあたって
- sudo ./proxy.py 127.0.0.1 21 ftp.example.com 21 True
- これ実行できない気がするんだけど…
- sudo しなくても21番待ち受けはできてるっぽい(root権限だからかな…)
- FTPクライアントソフトを21番ポートで"別に"起動しなければならない
- kali linux標準?でftpサーバは起動できそう
- server.accept()で応答が返ってこない。。。
- 同様のことを、外部ftpサーバ利用して試している人がいるので、真似してみようかな…参考
- ↑kaliからfilezillaで接続できないftpサーバをvsftpdでローカルに立ててみた。server.acceptでとまることはなくなったが、データのやり取りじたいはできてないみたい。。。
Wing IDEでタブやスペースを明示的に表示したい
- 初っ端のインデントずれを直すのに苦労
- 投稿日:2020-04-09T17:37:28+09:00
TwitchIOでTwitchのBotを作る
はじめに
TwitchのBotってPythonで作れるのかな~と調べていたところ日本語の記事が見つからず、英語アレルギーの自分には苦しい翻訳作業の連続だったので、僕と同じような英語アレルギーの人のお役に立てたらなと記事にして残しておきたいと思います。
TwitchIOというラッパーで簡単に作れるようなので、今回はこれを使用してBotを実際に作るところまで1から説明していきたいと思います。(エディタは省略)
原理まで書くととても長くなってしまうので機能を深く掘り下げるのはまた今度として、挨拶を返してくれるBotが完成するところまでです。面倒くさいわけでは決してありません(クソデカボイス)この記事をきっかけに日本人ユーザーが増えてQiitaの記事も沢山出始めてくれたらな~と願っています。
また、間違った説明をしてしまっている箇所がありましたらコメントの方にお願いします
TwitchIOとは
https://github.com/TwitchIO/TwitchIO
An Asynchronous IRC/API Wrapper currently in Development for TwitchBots made in Python!
(https://pypi.org/project/twitchio/ より引用)PythonでTwitchのBotを作ることが出来るラッパーだよ!と思ってもらえれば大体あってます。
Let's make a Twitch bot with Python!という記事を参考にしながら作成していきます。OSはWindows 10を使用しています。
といってもMacでもやり方はほぼ変わりません。手順
- Twitchアカウントの作成
- Pythonをインストール
- TwitchIOをインストール
- OAuthパスワードを作成
- Twitch Developersでアプリケーション登録
- コーディング
- 実践テスト
1. Twitchアカウントの作成
まずはBotとして扱うTwitchのアカウントを作成していきます。
そのアカウントそのものがBotとして動作するので、普段配信や視聴しているアカウントとは別で作成したほうがいいと思います。
これは自分のアカウントでbot登録してしまった為、自らがbot化してしまったmaguro869 pic.twitter.com/EhBItUtmeH
— ? (@maguro869) April 8, 2020今後Botを運用していく上で、Botが発言したことは無視するように設計しますので放送主のアカウントではBotを作らないようにして下さい。
そういう設計をしなかったとしてもちょっと寂しいBotになってしまいます。
https://www.twitch.tv/ を開いて右上の「登録」をクリックして下さい。
(既に普段使いのアカウントでログインしている場合はログアウトしてから)
アカウント情報を入力して「登録」をクリックしてください。
今回私はsalmon869という名前のBotを作成します。サーモンよりマグロの方が絶対おいしい登録したメールアドレスの方にTwitchから6桁のアカウント認証コードが届いていると思うので、遷移した画面にそれを入力してください。
(Gmailだとプロモーションの所に届いていたので見つけづらいかもしれません...)
これにてアカウント登録は完了です。
この後、Twitch Developersにアプリケーション登録する際に2段階認証を済ませておく必要があるので、それを先にしておきましょう。
https://www.twitch.tv/settings/security こちらのページを開いて「セキュリティ」のところにある「2段階認証」の「2段階認証を設定する」というボタンをクリックして下さい。
左側は+81を選択し右側にお使いの携帯番号を入力して下さい。続行を押すと携帯の方に認証コードが記載されているSMSが届きます。
それを入力して認証完了です。これでBotに使用するアカウントの準備は完了です。
2. Pythonをインストール
Githubには
TwitchIO requires Python 3.6 or higher.
と書いてありますので、最新版でも対応してるみたいです。
2020/04/09現在で最新のPython3.8.2をインストールします。
既に3.6より上のバージョンをインストールしている場合は次の「3. TwitchIOをインストール」に進んでも大丈夫です。
https://www.python.org/downloads/ を開いて「Download Python 3.8.2」をクリックして下さい。
ダウンロードされた「python-3.8.2.exe」を起動してください。
「Add Python 3.8 to PATH」にチェックを入れた後、「Install Now」をクリックして下さい。
この画面になったら完了です。「Close」をクリックして閉じて大丈夫です。
これでPythonのインストールは完了です。3. TwitchIOをインストール
TwitchIOをインストールするにはpipコマンドを使用します。
デスクトップ左下のWindowsマークをクリックし、「cmd」と入力すると「コマンドプロンプト」と検索結果に出ますのでクリックして下さい。
起動したら「py -m pip install twitchio」と入力してEnterキーを押して下さい。
色々バーっと出た後に「Successfully installed twitchio-1.0.0」と出たらインストール完了です。4. OAuthパスワードを作成
TwitchのAPIを利用するためにはOAuthパスワードを取得する必要があります。
https://twitchapps.com/tmi/ このサイトでとても簡単に取得可能です。
「Connect」をクリックして下さい。
「許可」をクリックして下さい。
「oauth:~」とパスワードが表示されるのでどこかにメモをしておいて下さい。
これでOAuthパスワードの作成は完了です。5. Twitch Developersでアプリケーション登録
続いて、Twitch Developersでアプリケーション登録をしてクライアントIDを取得します。
https://dev.twitch.tv/console/apps/create を開いてください。
「Authorize」をクリックして承認してください。
このような画面に遷移するのでそれぞれの項目を入力/選択してください。
- 名前:Botのアカウント名(分かりやすければOK)
- OAuthのリダイレクトURL:先ほどメモしたoauth:~
- カテゴリー:Chat Botを選択
終わったら「作成」をクリックして下さい。
このような画面に遷移したら「管理」をクリックして下さい。
クライアントIDが記載されているのでそれをメモしておいてください。今回はシークレットトークンは使用しないので作成しなくて結構です。これでTwitch Developersでアプリケーション登録は完了です。
6. コーディング
それでは実際にコーディングしていきましょう。
Twitch_botというフォルダを作成し、その中で作業していきます。
まずはデータを格納しておくconfig.pyを作成します。
以下は例ですので各々の情報を入力してください。Twitch_bot/config.pyTMI_TOKEN = 'oauth:~' # メモしたoauth:~のアレ CLIENT_ID = 'xxxxxxxxxxxxxxxxxxxx' # メモしたクライアントID BOT_NICK = 'salmon869' # Botのアカウント名 BOT_PREFIX = '!' # この文字を作成したコマンドの頭に付けることでコマンドと認識してくれます CHANNEL = ['maguro869'] # 実際に配信をするアカウント名これでmaguro869というアカウントで動くBotのconfig.pyは作成できました。
続いてBotの本体となるbot.pyを作成します。Twitch_bot/bot.pyfrom twitchio.ext import commands from config import * bot = commands.Bot( irc_token=TMI_TOKEN, client_id=CLIENT_ID, nick=BOT_NICK, prefix=BOT_PREFIX, initial_channels=CHANNEL ) @bot.event async def event_ready(): print(f"{BOT_NICK}がオンラインになりました!") if __name__ == "__main__": bot.run()これでコーディングは終了です。
7. 実践テスト
入力が終わったら一度実行してみましょう。
Twitch_botフォルダを開いてShiftを押したまま右クリックして「PowerShellウィンドウをここで開く」でPowerShellを開いてください。機能としては大体コマンドプロンプトと同じです(大きいお友達のみんな、怒らないで)
起動したら「py bot.py」と入力しEnterキーを押してBotを起動してみましょう。
「{Botのアカウント名}がオンラインになりました!」と表示されたら正常に起動出来ています。しかし、これだけではコマンドの実装は何も出来ていないのでbot.pyを以下のように編集して挨拶を返してくれるようにしましょう。
Twitch_bot/bot.pyfrom twitchio.ext import commands from config import * bot = commands.Bot( irc_token=TMI_TOKEN, client_id=CLIENT_ID, nick=BOT_NICK, prefix=BOT_PREFIX, initial_channels=CHANNEL ) @bot.event async def event_ready(): print(f"{BOT_NICK}がオンラインになりました!") # ここから追加 @bot.command(name='hello') async def hello(ctx): await ctx.channel.send(f'{ctx.author.name}さん こんにちは~ VoHiYo') # ここまで追加 if __name__ == "__main__": bot.run()これでBotを起動した後に「!hello」と配信チャットを打つと「○○さん こんにちわ~ VoHiYo」とBotが発言してくれるようになります。
※ VoHiYoとはTwitchが絵文字として認識してくれる単語の一つです。実行結果で確認してみましょう。
これで挨拶機能の実装、Botの運用に成功しました。
お疲れ様でした!おわりに
現段階では挨拶の機能しかありませんが、勿論オリジナリティー溢れるコマンドを用意することもできます。
あなたのアイデア次第でBotは無限の可能性を秘めています。
是非公式ドキュメントとにらめっこしながらあなただけのBotを作ってみてください!
TwitchIOコミュニティーの繁栄を願っています参考資料
Let's make a Twitch bot with Python!
TwitchIO(Github)
TwitchIO Document


















- 投稿日:2020-04-09T16:04:31+09:00
ABC備忘録[ABC161 C - Replacing Integer] (Python)
ABC161 C - Replacing Integer
問題文
青木君は任意の整数$x$に対し、以下の操作を行うことができます。
操作
$x$を$x$と$K$の差の絶対値で置き換える。
整数 Nの初期値が与えられます。この整数に上記の操作を0回以上好きな回数行った時、とりうるNの最小値を求めてください。
制約
$$
0≤N≤10^{18}
$$
$$
1≤K≤10^{18}
$$
入力は全て整数解法
行う操作は、例えば$N=7$、$K=4$のとき$x$から$K$を差分の絶対値が最小になるまで引くことなので、$x=7,x=3,x=1,x=3$と$x$が変化していく。
よって求める$x$は$1$となる。
なお、$x=1$以降は$x$は$1$と$3$を繰り返す。ただこの操作を$N$と$K$が大きいときに愚直に繰り返すと大変なので、求める最小値は$N/K$の余りか$K - (N/K)$の余りであることを利用する。
N, K = map(int,input().split()) print(min(N % K, K - (N % K)))間違いがある場合は指摘してください。
- 投稿日:2020-04-09T14:44:45+09:00
PythonGUIによる簡易営業ツール作成:社員番号検索
Pythonで簡易営業ツール作成方法:社員番号検索
営業でちょっとしたときに作成したツールを共有します。
Googleで調べながらSpyder(Python3.7)で作成してみました。import tkinter as tk root=tk.Tk() root.geometry('300x200') root.title('社員') def btn_click(): x=txt_1.get() if x=="田中": txt_2.insert(0,1) elif x=="鈴木": txt_2.insert(0,2) elif x=="山田": txt_2.insert(0,3) else: txt_2.insert(0,"該当なし") lbl_1 = tk.Label(text='苗字') lbl_1.place(x=30, y=70) lbl_2 = tk.Label(text='社員番号') lbl_2.place(x=30, y=100) txt_1 = tk.Entry(width=20) txt_1.place(x=90, y=70) txt_2 = tk.Entry(width=20) txt_2.place(x=90, y=100) btn = tk.Button(root, text='実行', command=btn_click) btn.place(x=140, y=170) root.mainloop()
- 投稿日:2020-04-09T13:41:18+09:00
Python の基本③
基本はこれで最後です。
関数、組込関数
プログラムのまとまりを関数として定義して使うことができます。
また、pythonそのものに予め設定されてる関数を
組込関数といいます。変数のプログラム番と考えればいいかと
メソッド
特定の値に大して処理を行う物をメソッドといいます。
メソッド値.メソッド名()という形で書きます。
また、値の要素などを取り出すインスタンス変数というものもあります。
インスタンス変数は関数ではなく変数なので引数を持ちません。インスタンス変数値.インスタンス変数名という形式で書きます。
appendを例に出すと以下のようになります。
append# append()は、リストに新しい要素を1つだけ追加したい場合に使用するメソッドです。 alphabet = ["a","b","c","d","e"] alphabet.append("f") print(alphabet) # ["a", "b", "c", "d", "e", "f"]が出力される文字列型のメソッド(upper/count)
文字の拡大と、数えを行うメソッドです。
city = "Tokyo" print(city.upper()) # 「TOKYO」が出力される print(city.count("o")) # 「2」が出力される。文字列型のメソッド(format)
format()メソッド は文字列型に使えるメソッドで、文字列に変数を埋め込むことができます。
主にテンプレートに変数の値を挿入するときに使用します。
値を埋め込みたい箇所を{}で指定します。引数は文字列型でなくても構いません。print("私は{}生まれ、{}育ち".format("東京", "埼玉")) # 「私は東京生まれ、埼玉育ち」と出力される # {}に挿入する値は、挿入する順番を指定することも可能です。また、同じ値を繰り返し挿入することもできます。 print("私は{1}生まれ、{0}育ち、{1}在住".format("東京", "埼玉")) # 「私は埼玉生まれ、東京育ち、埼玉在住」と出力されるリスト型のメソッド(index)
リスト型にはインデックス番号が存在します。
インデックス番号とは、リストの中身を0から順番に数えた時の番号です。
目的のオブジェクトが どのインデックス番号にあるのか探すためのメソッド として
index()があります。
また、リスト型でも先ほど扱ったcount()を使うことができます。
alphabet = ["a", "b", "c", "d", "d"] print(alphabet.index("a")) # インデックス番号0番目にあるので、「0」と出力されます print(alphabet.count("d")) # "d"がインデックス番号3番目と4番目にあるので、「2」と出力されますリスト型のメソッド(sort,reverse,sorted)
sort()これはリストの中を小さい順に並べ替えてくれます。
reverse()これを用いるとリストの要素の順番を反対 にすることができます。
注意点として
- sort()メソッドやreverse()メソッドを使うと、リストの中身が直接変更されます。
- 戻り値をとらないので、print(list.sort())としてもNoneが返ってきます。
並べ替えたリストを参照したいだけであれば、ソート後の配列を戻り値としている組み込み関数のsorted()を使います。
soted()使用例はこちらです。
# sort()の利用例 list = [1, 10, 2, 20] list.sort() print(list) # [1, 2, 10, 20]と表示されます。 # reverse()の利用例 list = ["あ", "い", "う", "え", "お"] list.reverse() print(list) # ["お", "え", "う", "い", "あ"]と表示されます。関数
下記のように作成します。
「 def 関数名(): 」関数には必要な処理をまとめられるのでプログラムが簡潔になり
全体の動きが把握しやすくなるというメリットがあります。同じ処理を複数箇所で使い回すことができ 記述量の削減 、 可読性の向上 に繋がります。
def sing(): print ("歌います!") # インデントで処理の範囲を明示します。 # また、定義した関数の呼び出しは「関数名()」と書きます。 sing() # 出力結果 歌います!引数
関数を定義する際に 引数(argument)を設定しておけば、
関数内でその値を使用できるようになります。def 関数名(引数):def introduce(n): print(n + "です") introduce("Yamada") # 「Yamadaです」と出力される # この時、引数を変数で指定すると、引数を直接変えなくても出力結果を変えること ができます。 def introduce(n): print(n + "です") name = "Yamada" introduce(name) # 「Yamadaです」と出力される name = "Tanaka" introduce(name) # 「Tanakaです」と出力される # なお、関数内で定義した変数や引数は、関数内でのみ使用可能となります。複数の引数
引数はカンマで区切って複数指定することが可能 です。
def introduce(first, family): print("名字は" + family + "で、名前は" + first + "です。") introduce("taro", "Yamada") # 「名字はYamadaで、名前はtaroです。」と出力される引数の初期値
引数に 初期(デフォルト)値を設定すると
引数が空欄の場合、自動的に初期値が設定されます。 引数 = 初期値 という形で設定します。def introduce(family="Yamada", first="Taro"): print("名字は" + family + "で、名前は" + first + "です。") introduce("Suzuki") # 「名字はSuzukiで、名前はTaroです。」と出力される # この場合は、firstのみが初期値として設定され、familyは"Suzuki"で上書きされています。 # もしfirstの引数のみ渡したい場合はintroduce(first="Jiro")と指定してあげればよいです。 # なお、初期値を設定した引数の後ろの引数にも、必ず初期値を設定する必要があります。 # したがって、次のように後ろの引数にだけ初期値を設定することは可能です。 def introduce(family, first="Taro"): print("名字は" + family + "で、名前は"+ first + "です。") # しかし、次のように前の引数にだけ初期値を設定し、後ろの引数に設定しないとエラーになります。 def introduce(family="Suzuki", first): print("名字は" + family + "で、名前は" + first + "です。") # この場合に出力されるエラーは、non-default argument follows default argumentです。return
関数で定義した変数や引数は関数外では使用できません。
しかし、returnを使用することで、関数の呼び出し元に戻り値を渡すことができるようになります。erroref introduce(family = "Yamada", first = "Taro"): comment = "名字は" + family + "で、名前は" + first + "です。" print(introduce("Suzuki")) # Noneが出力される # こちらは戻り値がないので、出力結果がNone(なし)になります。def introduce(family = "Yamada", first = "Taro"): comment = "名字は" + family + "で、名前は" + first + "です。" return comment #関数に戻り値を渡す print(introduce("Suzuki")) # 「名字はSuzukiで、名前はTaroです。」と出力されるこのように、returnを使用することで、関数の呼び出し元に戻り値を渡すことができるのです。
関数のインポート(パッケージ、サブパッケージ 、モジュール)
関数のインポートとして直近でモジュールから
そのまとまりをパッケージから取り出す形式です。scipyパッケージとtimeモジュールなどがあります。
パッケージ: 関連する複数のモジュールを一つのディレクトリにまとめた物
サブパッケージ: パッケージの中にさらにパッケージが入れ子になっていることもあります。 この場合入れ子になっている方のパッケージを と呼びます。
モジュール: 頻繁に行われるいくつかの処理を一つのファイルにまとめ、他のソースコードから利用できるようにした物
プログラム内でパッケージやモジュールを使用する際には、下記のような インポートという処理が必要になります。
import scipy # scipyパッケージをインポートする import time # timeモジュールをインポートする # インポートしたパッケージ内のメソッドを使用する場合 # 一般的には、 パッケージ名.サブパッケージ名.メソッド名 と書きます。メソッドと同様の仕組みだと覚えていてください。 import scipy.linalg scipy.linalg.norm([1,1]) > 出力結果 1.4142135623730951下記の例ではtimeモジュールのtimeというメソッドを使用して、現在の時刻を出力しています。
import time now_time = time.time() #現在時刻をnow_timeに代入する print(now_time) #現在時刻が出力されるまた、from パッケージ名.サブパッケージ名 import メソッド名 という書き方で
メソッドを直接読み込む方法もあります。この場合はメソッド呼び出しの際に
パッケージ名・サブパッケージ名が省略できます。from scipy.linalg import norm norm([1, 1]) # パッケージ名・モジュール名を省略できる # 出力結果 1.4142135623730951from モジュール名 import メソッド名 という書き方でモジュール名を省略することができます。
from time import time # timeモジュールのtimeメソッドをインポートする now_time = time() #モジュール名を省略できる print(now_time) #現在時刻が出力されるimport パッケージ名 as 呼称とすることで
任意の名前でパッケージを呼び出すことができます。from time import time as t # timeモジュールのtimeメソッドをインポートしてtという名前で扱う now_time = t() print(now_time) #現在時刻が出力されるクラス
オブジェクト
Pythonは オブジェクト指向言語です。
オブジェクトとは、データやそのデータに対する手続き(メソッド)を一つにまとめたものを言います。手続きとは、オブジェクトが持つ処理を記述したものです。
オブジェクトのイメージとしては設計図です。オブジェクトをインスタンス化(実体化)して
メッセージ(命令)を送ると処理が行われます。処理対象をオブジェクトとして捉え、それをモジュール化することでプログラムを再利用するやり方のことを
オブジェクト指向と言います。クラス
オブジェクトの構造の設計図のようなものです。
大判焼きで言うなら。クラス: 型
インスタンス: 大判焼き
オブジェクト: 大判焼きセット(クラス+インスタンス)
クラスの内容
クラスにはイニシャライザ、メソッド、メンバ変数などが含まれています。
- イニシャライザ: クラスからインスタンスが生成された直後に実行される処理のことです。基本的に一度だけ呼び出されます。 下記の名前で作ると構文で決まっています。
__init__()
メソッド: 以前説明した通り
メンバ変数はクラス内で使用する変数のことです。
class MyProduct: #クラスを定義 def __init__(self, name, price): # イニシャライザを定義 self.name = name # 引数をメンバに格納 self.price = price self.stock = 0 self.sales = 0 # 定義したクラスからインスタンスを生成 # MyProductを呼び出し、product1を作成 product1 = MyProduct("cake", 500) print(product1.name) # product1のnameを出力 cake print(product1.price) # product1のpriceを出力 500クラスのルール(self,イニシャライザ)
クラス名の先頭文字を大文字にする
慣習であり複数の単語を含む場合は
それぞれの先頭をMyProductというように大文字にします。初期化( init ,selfz)
クラスは設計図ですので、インスタンスを生成する際に初期化が必要です
イニシャライザは init という名前で定義し
第一引数を selfにするという慣例があります。class MyProduct: #クラスを定義 def __init__(self, 引数): # イニシャライザを定義
- selfの使用
selfはインスタンス本体(この場合MyProduct)を参照しており
selfを使用することでインスタンスが持つ他のメンバ変数を取得したり
メソッドを呼び出すことができます。例class MyProduct: #クラスを定義 def __init__(self, name, price): # イニシャライザを定義 self.name = name # 引数をメンバに格納 self.price = price self.stock = 0 # stock, salesは0で初期化 self.sales = 0 # 次に、定義したクラスからインスタンスを生成。 # インスタンス生成では、クラス(MyProduct)を呼び出して変数に代入します。 # MyProductを呼び出し、product1を作成 product1 = MyProduct("cake", 500) print(product1.name) # product1のnameを出力 > 出力結果 cake print(product1.price) # product1のpriceを出力 > 出力結果 500 print(product1.stock) > 出力結果 0クラス(メソッド)
クラスで定義できるメソッドには以下の3種類あります。
- 通常のメソッド ... 第一引数がselfになります。
- クラスメソッド ... クラス全体の操作を行う。
- スタティックメソッド(静的メソッド) ... 引数がなくても実行できる。
class MyClass: # クラス名 def __init__(self, 引数2, 引数3, …): # イニシャライザ self.変数名 = 初期値 # 変数を初期化する def normal_method(self, 引数2, 引数3, …): # 通常メソッド self.name = name return name @classmethod # クラスメソッド #クラスメソッドは第一引数をclsにするという決まりがあります。 def class_method(cls, 引数2, 引数3, …): cls.name = cname return cname @staticmethod # スタティックメソッド #スタティックメソッドは決まりがなく、引数自体が必須ではありません。 def static_method(引数1, 引数2, 引数3, …): 引数1.name = sname return snameクラスメソッドは第一引数をclsにするという決まりがありますが
スタティックメソッドは決まりがなく、引数自体が必須ではありません。また、メソッドの呼び出しは、オブジェクト.メソッド名と書きます。
オビジェクト.メソッド名クラス(継承、オーバーライド、スーパー)
- 継承(インヘリタンス): クラスの内容を継承させる。
オーバーライド: 継承したクラスで継承元のクラスのメソッドを上書きすること
親クラス、スーパークラス、基底クラス: 継承元のクラス
子クラス、サブクラス、派生クラス: 継承先のクラス
# 親クラス class MyProduct: def __init__(self, name, price, stock): self.name = name self.price = price self.stock = stock self.sales = 0 def buy_up(self, n): # 仕入れメソッド self.stock += n def get_name(self): # 商品名メソッド return self.name def sell(self, n): # 販売メソッド self.stock -= n self.sales += n * self.price def summary(self): # 概要メソッド message = "called summary().\n name: " + self.name + \ "\n price: " + str(self.price) + \ "\n price: " + str(self.get_price_with_tax()) + \ "\n sales: " + str(self.sales) print(message)# 継承の手順は下記の通りです。 # MyProductクラスを継承してMyProductSalesTaxを定義 class MyProductSalesTax(MyProduct): # イニシャライザの第四引数に消費税率を設定 def __init__(self, name, price, stock, tax_rate): #親クラスのイニシャライザを呼び出す super().__init__(name, price, stock) self.tax_rate = tax_rate # MyProductのget_nameを上書き def get_name(self): return self.name + "(税込)" #get_price_with_taxを追加 def get_price_with_tax(self): return int(self.price * (1 + self.tax_rate)) # super()で親クラスのメソッドを呼び出すことができます。このプログラムを実行すると下記のようになります。 product_3 = MyProductSalesTax("phone", 30000, 100, 0.1) print(product_3.get_name()) print(product_3.get_price_with_tax()) # MyProductのsummaryメソッドを呼び出す product_3.summary() phone(税込) # 期待通りの出力 33000 # 期待通りの出力 called summary() name: phone price: 30000 stock: 100 sales: 0文字列のフォーマット指定
コンソールに出力する文字列の書式は「formatメソッド」を使って形式を整えられます。
文字列に含まれる数値部分を整える場合に、使用する書式を一部紹介します。:d int型のデータを10進法で表示
:.0f float型データの整数部分のみ表示
:.2f float型データの小数第2位まで表示
これらの書式は以下に例示するコードのように使います。# 円周率の近似値を定義 pi = 3.141592 #円周率を3として定義 pi2 = 3 print("円周率は{:d}".format(pi2)) # 「円周率は3」と出力される print("円周率は{:.0f}".format(pi)) # 「円周率は3」と出力される print("円周率は{:.2f}".format(pi)) # 「円周率は3.14」と出力される。


- 投稿日:2020-04-09T13:22:50+09:00
Qiskit: Qiskit Aquaを使わないQAOAの実装
はじめに
私の最初の記事で,TSPをQAOAで解いてみたというものを投稿しました.しかし,これはqiskit aquaという自分で回路を設計しなくても可能ないわゆるモジュール化されたものを使用していました.
そこで今回はqiskit aquaを使わずにQAOAを使ってみたいと思います.まず,最初の段階としてmax cutを用います.正直,他の問題もハミルトニアンを変更するだけでなんとかなると思いますので,qiskitで量子プログラミングをしていく人たちの参考になればなと思います.
日本語で量子プログラミングを解説いているサイトは複数ありますが,どれも別の量子プログラミング言語を用いていることから,qiskitで記述している私の記事にも意味はあると考えています.なお,今回の記事でもQAOA自体の解説は他の方にお任せするとしてqiskitのコードの解説をしていきたいと思います.
code
まずは全体のcodeを
# coding: utf-8 from qiskit import QuantumCircuit, QuantumRegister, ClassicalRegister, execute from qiskit.aqua.utils import tensorproduct from qiskit import BasicAer from qiskit.quantum_info.analysis import average_data from scipy.optimize import minimize import numpy as np import time def classical_minimize(cost_func, initial_params, options, method='powell'): print('classical minimize is starting now... ') start_time = time.time() result = minimize(cost_func, initial_params, options=options, method=method) print('running time: {}'.format(time.time() - start_time)) print('opt_cost: {}'.format(result.fun)) print('opt_params: {}'.format(result.x)) return result.x class MAXCUT: # 初期値設定 def __init__(self, n_qubits, weight_matrix, p=1, num_steps=1): self.n_qubits = n_qubits self.weight_matrix = weight_matrix self.P = p self.num_steps = num_steps self.edge_list = [] self._make_edge_list() # edge list の作成 from weight matrix def _make_edge_list(self): for i in range(self.weight_matrix.shape[0]): for j in range(i+1, self.weight_matrix.shape[1]): if self.weight_matrix[i][j] != 0: self.edge_list.append([i, j]) '------------------------------------------------------------------------------------------------------------------' def Zi_Zj(self, q1, q2): I_mat = np.array([[1, 0], [0, 1]]) Z_mat = np.array([[1, 0], [0, -1]]) if q1 == 0 or q2 == 0: tensor = Z_mat else: tensor = I_mat for i in range(1, self.n_qubits): if i == q1 or i == q2: tensor = tensorproduct(tensor, Z_mat) else: tensor = tensorproduct(tensor, I_mat) return tensor def observable(self): obs = np.zeros((2**self.n_qubits, 2**self.n_qubits)) for a_edge in self.edge_list: q1, q2 = a_edge obs = obs + 0.5 * self.Zi_Zj(q1, q2) return obs '------------------------------------------------------------------------------------------------------------------' # U_C(gamma) def add_U_C(self, qc, gamma): for a_edge in self.edge_list: q1, q2 = a_edge qc.cx(q1, q2) qc.rz(-2**gamma, q2) qc.cx(q1, q2) return qc # U_X(beta) def add_U_X(self, qc, beta): for i in range(self.n_qubits): qc.rx(-2*beta, i) return qc def QAOA_output_onelayer(self, params, run=False): beta, gamma = params qr = QuantumRegister(self.n_qubits) cr = ClassicalRegister(self.n_qubits) qc = QuantumCircuit(qr, cr) qc.h(range(self.n_qubits)) qc = self.add_U_C(qc, gamma) qc = self.add_U_X(qc, beta) qc.measure(range(self.n_qubits), range(self.n_qubits)) NUM_SHOTS = 10000 seed = 1234 backend = BasicAer.get_backend('qasm_simulator') results = execute(qc, backend, shots=NUM_SHOTS, seed_simulator=seed).result() counts = results.get_counts(qc) expectation = average_data(counts, self.observable()) return expectation '------------------------------------------------------------------------------------------------------------------' def minimize(self): initial_params = np.array([0.1, 0.1]) opt_params = classical_minimize(self.QAOA_output_onelayer, initial_params, options={'maxiter':500}, method='powell') return opt_params def run(self): opt_params = self.minimize() beta_opt, gamma_opt = opt_params qr = QuantumRegister(self.n_qubits) cr = ClassicalRegister(self.n_qubits) qc = QuantumCircuit(qr, cr) qc.h(range(self.n_qubits)) qc = self.add_U_C(qc, gamma_opt) qc = self.add_U_X(qc, beta_opt) qc.measure(range(self.n_qubits), range(self.n_qubits)) NUM_SHOTS = 10000 seed = 1234 backend = BasicAer.get_backend('qasm_simulator') results = execute(qc, backend, shots=NUM_SHOTS, seed_simulator=seed).result() print(results.get_counts()) if __name__ == '__main__': weight_matrix = np.array([[0, 1, 0, 1], [1, 0, 1, 0], [0, 1, 0, 1], [1, 0, 1, 0]]) cut = MAXCUT(4, weight_matrix, p=1) cut.run()気になる関数だけをピックアップして解説していきます.
C(Z)の作成
def Zi_Zj(self, q1, q2): I_mat = np.array([[1, 0], [0, 1]]) Z_mat = np.array([[1, 0], [0, -1]]) if q1 == 0 or q2 == 0: tensor = Z_mat else: tensor = I_mat for i in range(1, self.n_qubits): if i == q1 or i == q2: tensor = tensorproduct(tensor, Z_mat) else: tensor = tensorproduct(tensor, I_mat) return tensor def observable(self): obs = np.zeros((2**self.n_qubits, 2**self.n_qubits)) for a_edge in self.edge_list: q1, q2 = a_edge obs = obs + 0.5 * self.Zi_Zj(q1, q2) return obs<\beta,\gamma|C(Z)|\beta,\gamma>を計算する際に必要なC(Z)をここで作成しています.
この際にテンソル積を計算する必要がありますが,qiskit.aqua.utilsのtensorproductで計算可能です.期待値の計算
qiskitで期待値を計算するには
results = execute(qc, backend, shots=NUM_SHOTS, seed_simulator=seed).result() counts = results.get_counts(qc) expectation = average_data(counts, self.observable())の方法でできます.
結果
実行結果は以下の通りになりました.
{'0101': 2578, '1110': 171, '1101': 146, '1001': 793, '1111': 141, '0011': 815, '0111': 122, '0010': 159, '0000': 161, '0100': 170, '0001': 151, '0110': 802, '1000': 160, '1100': 811, '1010': 2682, '1011': 138}値が大きい,0101と1010が解として取り出すことができます.
- 投稿日:2020-04-09T12:56:27+09:00
文系のプログラミング素人がPython3エンジニア認定基礎試験を取得した話
はじめに
概要
文系のプログラミング初心者である私がPython3エンジニア認定基礎試験を取得するまでの話です。
プログラミング初心者の方がPythonの勉強を始める際の参考になればと思います。私の経歴
国立大文系学部卒でネットワークメインのセールスエンジニアを2年ほどしています。
普段は中小企業向けにネットワーク機器の提案・設計を行っています。
いちおうエンジニアの端くれではありますが、業務で求められるスキルはネットワーク、セキュリティが中心です。業務でプログラミングを使用することは全くなく、学生時代に勉強したこともないド素人です。
ちなみにネットワークの知識も入社後に勉強したものなのでITに関するバックグラウンドは全くないです。受験の動機
・事務作業を自動化するスキルを身につけたかった
・データ分析に興味がある勉強法
pythonそのものの勉強
なにせプログラミングに関する知識が皆無なので色々手を出しました。
色々ネットで調べたうえで書籍中心に学習しました。順序としては、
①プログラミングとは?②Python入門③Python基礎固め④公式テキスト⑤模擬試験
となりあmす。①プログラミングとは?
まずはプログラミングとは?ということを学ぶために新書を一冊読みました
教養としてのプログラミング講座(清水 亮)あくまで新書ですし、非常に読みやすい本なので最初に読んでおいてよかったです。
プログラミングとは?という全体像を漠然とでも知っておけば、勉強しているときに「今自分が何を勉強しているのか」を見失わずに済むと思います。②Python入門
次に初心者向けのPythonの本としてこの本を選びました。
Pythonスタートブック(辻 真吾)初心者向けのPython本はたくさん出版されているのでここについては自分が読みやすい、わかりやすいと思った本を選べばよいと思います。
Pythonスタートブックは全くの初心者向けに書かれており、開発環境の構築からPythonの初歩的な概要をざっくり学べるので私のような初心者にちょうど良かったです。
ただし、あくまで入門の本なので具体的にPythonでどんなことができるのかはあまり見えてきませんでした。
なので、モチベ面では我慢する必要がありました。③Python基礎固め
Pythonの初歩的な概要をざっくり理解したとところでみんなのPythonに取り掛かりました。
みんなのPython(柴田 淳)みんなのPythonも初心者向けの本ですが、内容が充実しているため2冊目として基礎固めを行うのにちょうどよいと思います。(プログラミング初心者の方が1冊目に選ぶと難しく感じると思います。)
第4版ではデータ分析なども追加され、Pythonで何ができるのか、少しづつ理解することができました。
Pythonスタートブックをやっていたため、知っている部分は流しつつ勉強できたので重要なことの理解がしやすかったです。以上のことをPythonの勉強としてやりました。
オンラインの講座ってどうなの?
オンラインの講座も考えたのですが、これまでの勉強は基本的に本でやってきたので、慣れた方法がいいなぁと思って本での独学を選びました。
幸いPythonの本は数も多く、評判のいい本が多数出版されていたので、環境としても学びやすいと思います。ということなので、申し訳ありませんが本ととオンライン講座どっちがいいののかについてはわかりません。
試験対策
試験対策としてはPythonチュートリアルでの学習と模擬試験を行いました。
④Pythonチュートリアル
PythonチュートリアルはPythonエンジニア認定基礎試験の公式テキストですので、試験を受ける上では重要です。
Pythonチュートリアルただし、Pythonチュートリアルは正直初心者にはわかりにくかったです。
他の言語との比較を用いて説明されるのでPythonしか知らない私にとっては苦痛でした。
私は一度読んでからコードを一通り写経しましたが、写経ではなく自分で考えながらコードを試して理解を深めていくべきと思います。⑤模擬試験
DIVE INTO EXAMで模擬試験を受験することができます。
会員登録は必要ですが、なんと無料です。
DIVE INTO EXAM私はこの模試を安定して満点がとれるようになるまでやりこみました。
ある程度やると問題を覚えてしまいますが、なぜその答えになるのかをコードを動かしながら理解していくことが重要だと感じました。感想
試験結果
825/1000で合格でした。
もう少しいい点がとれるかと思っていましたが、そんなに甘くはありませんでした。感想
試験は思ったより難しく感じました。
その理由は私にPythonの実務経験がなく、コードを書いた量・経験が圧倒的に少なかったからだと思います。きちんと理解していないと問題をすこし変えられるだけでわからなくなってしまいます。
なので自分で考えながらコードを試していくことが重要だと思います。
そういった点では自分の仕事・プライベートでPythonを使ってみるとよい勉強になると感じました。今後
Pythonの基礎は理解できたので、今後は事務作業の自動化とデータ分析の2つを目指して勉強していく予定です。
Python以外だとAWSも勉強したいと思っているので同時並行になるかもしれませんが。基本情報を取得していないので基本情報受けるときに午後でPython選んでみようかなぁと思っています。
- 投稿日:2020-04-09T12:56:27+09:00
文系のプログラミング素人がPythonエンジニア認定基礎試験を取得した話
はじめに
概要
文系のプログラミング初心者である私がPythonエンジニア認定基礎試験を取得するまでの話です。
プログラミング初心者の方がPythonの勉強を始める際の参考になればと思います。私の経歴
国立大文系学部卒でネットワークメインのセールスエンジニアを2年ほどしています。
普段は中小企業向けにネットワーク機器の提案・設計を行っています。
いちおうエンジニアの端くれではありますが、業務で求められるスキルはネットワーク、セキュリティが中心です。業務でプログラミングを使用することは全くなく、学生時代に勉強したこともないド素人です。
ちなみにネットワークの知識も入社後に勉強したものなのでITに関するバックグラウンドは全くないです。受験の動機
・事務作業を自動化するスキルを身につけたかった
・データ分析に興味がある勉強法
pythonそのものの勉強
なにせプログラミングに関する知識が皆無なので色々手を出しました。
色々ネットで調べたうえで書籍中心に学習しました。順序としては、
①プログラミングとは?②Python入門③Python基礎固め④公式テキスト⑤模擬試験
となりあmす。①プログラミングとは?
まずはプログラミングとは?ということを学ぶために新書を一冊読みました
教養としてのプログラミング講座(清水 亮)あくまで新書ですし、非常に読みやすい本なので最初に読んでおいてよかったです。
プログラミングとは?という全体像を漠然とでも知っておけば、勉強しているときに「今自分が何を勉強しているのか」を見失わずに済むと思います。②Python入門
次に初心者向けのPythonの本としてこの本を選びました。
Pythonスタートブック(辻 真吾)初心者向けのPython本はたくさん出版されているのでここについては自分が読みやすい、わかりやすいと思った本を選べばよいと思います。
Pythonスタートブックは全くの初心者向けに書かれており、開発環境の構築からPythonの初歩的な概要をざっくり学べるので私のような初心者にちょうど良かったです。
ただし、あくまで入門の本なので具体的にPythonでどんなことができるのかはあまり見えてきませんでした。
なので、モチベ面では我慢する必要がありました。③Python基礎固め
Pythonの初歩的な概要をざっくり理解したとところでみんなのPythonに取り掛かりました。
みんなのPython(柴田 淳)みんなのPythonも初心者向けの本ですが、内容が充実しているため2冊目として基礎固めを行うのにちょうどよいと思います。(プログラミング初心者の方が1冊目に選ぶと難しく感じると思います。)
第4版ではデータ分析なども追加され、Pythonで何ができるのか、少しづつ理解することができました。
Pythonスタートブックをやっていたため、知っている部分は流しつつ勉強できたので重要なことの理解がしやすかったです。以上のことをPythonの勉強としてやりました。
オンラインの講座ってどうなの?
オンラインの講座も考えたのですが、これまでの勉強は基本的に本でやってきたので、慣れた方法がいいなぁと思って本での独学を選びました。
幸いPythonの本は数も多く、評判のいい本が多数出版されていたので、環境としても学びやすいと思います。ということなので、申し訳ありませんが本ととオンライン講座どっちがいいののかについてはわかりません。
試験対策
試験対策としてはPythonチュートリアルでの学習と模擬試験を行いました。
④Pythonチュートリアル
PythonチュートリアルはPythonエンジニア認定基礎試験の公式テキストですので、試験を受ける上では重要です。
Pythonチュートリアルただし、Pythonチュートリアルは正直初心者にはわかりにくかったです。
他の言語との比較を用いて説明されるのでPythonしか知らない私にとっては苦痛でした。
私は一度読んでからコードを一通り写経しましたが、写経ではなく自分で考えながらコードを試して理解を深めていくべきと思います。⑤模擬試験
DIVE INTO EXAMで模擬試験を受験することができます。
会員登録は必要ですが、なんと無料です。
DIVE INTO EXAM私はこの模試を安定して満点がとれるようになるまでやりこみました。
ある程度やると問題を覚えてしまいますが、なぜその答えになるのかをコードを動かしながら理解していくことが重要だと感じました。感想
試験結果
825/1000で合格でした。
もう少しいい点がとれるかと思っていましたが、そんなに甘くはありませんでした。感想
試験は思ったより難しく感じました。
その理由は私にPythonの実務経験がなく、コードを書いた量・経験が圧倒的に少なかったからだと思います。きちんと理解していないと問題をすこし変えられるだけでわからなくなってしまいます。
なので自分で考えながらコードを試していくことが重要だと思います。
そういった点では自分の仕事・プライベートでPythonを使ってみるとよい勉強になると感じました。今後
Pythonの基礎は理解できたので、今後は事務作業の自動化とデータ分析の2つを目指して勉強していく予定です。
Python以外だとAWSも勉強したいと思っているので同時並行になるかもしれませんが。基本情報を取得していないので基本情報受けるときに午後でPython選んでみようかなぁと思っています。
- 投稿日:2020-04-09T12:21:38+09:00
[Python] 前月を取得する
やりたいこと
- ファイル名に前月をつけたい → 前月を取得したい
ポイント
datetimeで現在日付を取得して1か月引けばいいdateutilを使うと簡単らしいサンプルコード
まずは
dateutilをインストールpip install python-dateutil今日の日付を取得して、1か月ひいてみる
tesy.py#今日 today = datetime.date.today() #先月 sengetsu = today - relativedelta(months=1)結果2020-03-09ファイル名に使いたいのは
yyyyMMなのでフォーマットtest.pyを修正sengetsu = (today - relativedelta(months=1)).strftime('%Y%m') print(sengetsu)結果202003感想
意外と面倒くさいことがわかった
powershellだと(get-date).AddMonths(-1).ToString('yyyyMM')で1行で終わり
- 投稿日:2020-04-09T12:11:42+09:00
宇宙の研究を始める人向けのソフトウェア講習
はじめに
宇宙を志す人向けのソフトウェアの基礎について、在宅でも出来るように簡単に紹介したい。ソフトウェアは授業で少しやりました、くらいの学生を想定してます。(2020.4.9. とりあえずの初版)
基礎知識編
ソフトウェアとは何か?なぜ大事なのか。
ソフトウェアとは端的にはコンピュターの世界の言語で、言語とは、「自分の考えを相手に伝える」「相手の考えを理解する」ために必要なツールともいえます。つまりは、「コミュニケーションツール」なのです。誰と誰を繋ぐものか?というと、その対象がハードウェアとCPUであったり、ハードウェアと人間、であったり、その対象は今では「モノ」と「人」を繋ぐ上でも重要な存在です。それが宇宙の研究?とどう関わるかというと、宇宙の綺麗な画像や、世界で初めて目にするようなデータと「会話」するためのツールとして、ソフトウェアが不可欠になっています。
今では、宇宙の研究において、ソフトウェアは一つの"実験装置"や"実験技術"と認識されています。例えば、実際、NASAにはソフトウェアの専門家の部隊が存在しますし、実験装置を開発している研究所にはソフトウェアの専門家がいます。最先端の観測装置と上手に"意思疎通"し、膨大なデータと"対話"するためのツールがソフトウェア言語で、英語と同じくらい重要な"外国語"という認識で、ソフトウェアの「単語」「文法」「作文」の力を若いうちに修行しておくとよいです。
ソフトウェア言語
批判を恐れずに最低限は何か?いえば、今は python でしょう。ただし、言語には英語やフランス語以外にもたくさんあるように、コンピュータの言語にも色々あって良し悪しありますので、何かある言語だけ知っていれば万事OKということはないです。そこで、まずはコンピューター言語の種類を概観してみましょう。
CUIコマンド
CUIは、Character User Interface (CUI) の略です。windows であれば、コマンドプロンプトでの操作、Mac や linux であればターミナルでの操作に対応します。それぞれ初見という人は下記の記事をまずは一読ください。
若い人だと、なぜ低レベルなコマンドを打たないとダメなのか?と思ったかもしれません。ソフトウェアの世界では、低レベルな操作(CUI)は、高レベルな操作(GUI)よりも古くてダメということはないのです。特に、宇宙の観測装置やデータを解析する上では、低レベルから高レベルまで層状になったソフトウェアを巧みに操れることが大切です。操作の自動化や保守運用も簡単で安全にできないといけません。その根底をなすのはコマンドラインでのツールで、これを早めに知っておかないと時間を無駄に費やしてしまいます。
そのうち、パターン処理言語の3つをまず知っておきましょう。「awk」「sed」「grep」です。「awk」は、文字列の分割や選択、演算ができます。「sed」は文字の置換です。「grep」は文字の検索ができます。unix のコマンドなので、linuxとmacはデフォルトで所定の動作をしますが、windowsは素直にはいきませんので、無理にコマンドプロンプトでやる必要はないです(windowsにlinuxベースの入れる方が楽かも)。最近はwindowsに、Windows Subsystem for Linux (WSL)があるので、これでlinux環境も簡単に構築できます。WSL (Windows Subsystem for Linux)の基本メモを参照ください。3つのコマンドについては、
- 一般的な話
- Mac, linux 向け
- windows 向け
- gawk awk入門 コマンドの使い方とスクリプトの書き方
- findstr Windows標準コマンドでgrepする
- sed sedでこういう時はどう書く?
を一読ください。でも、これだけだとまだ有り難みが分かりませんね。
具体例を出すと、1万天体の銀河カタログの書かれたテキストファイルが(gal.txt)があったとします。そこに、NGCカタログがどのくらいあるかは、「grep NGC gal.txt」で検索できます。"NGC"という文字を"N"と短くしたい場合は、「sed "s/NGC/N/g" gal.txt」で可能です。10行目が以降だけ取得したい場合は、「awk 'NR>10{print $0} gal.txt'」で可能です。このようにデータの前処理を手軽にやるのに便利です。もうひとつ挙げると、rsync というコマンドです。これは、ファイルの同期やコピーをするために使います。時々刻々と増えていくデータをコピーする場合、すでにコピーしたデータをもう一度コピーするのは避けて、変更分だけコピーしたいでしょう。rsyncはそのような差分を計算し、差分だけを圧縮してコピーする優れたコマンドツールで、宇宙の研究で扱う巨大なデータの転送や実験では今でもよく使われています。初めての人は、
あたりを一読ください。
低級なスクリプト言語
CUIのコマンドは便利であるが、それを組み合わせるともっといろんなことができる。例えば、「1時間に一回ファイルをコピーして、ファイルの中のデータを加工して、別のファイルに書き出す」、という一連の処理をしたい場合があるとしよう。そのような一連の処理の流れのことをバッチ処理といいます。これを簡単にやってくれるのが、「シェルスクリプト」というものです。web上に山のように説明があるので、初見の人は、
に目を通してください。これを操れるだけで研究人生が大きく変わるといっても過言ではないと思います。
「1時間に一回〇〇の処理をする」を実現するには、cron が簡単です。
を参考にしてください。また、最近では、python の schedule を使うことも多いです。
あたりをご参考に。
高級なスクリプト言語
さて、スクリプト言語とはインタプリータ言語(プログラムを 1 行ずつ機械語に翻訳して実行)するものです。"高級"とはここではオブジェクト指向を意味することにします。
宇宙天文では、python か ruby が主流だと思いますが、ここでは python を王様扱いします。python の使い方は後述しますので、ここでは一般論だけ紹介します。インタプリータ言語は逐次解釈するので、実行速度は次に紹介するコンパイラ言語に比べると桁で遅いです。ただし、宇宙天文のように、ベクトルや行列演算などの単純な処理をする場合は、その部分だけC言語やfortranで書かれたプログラムを読み出すことができます。numpy という python の数値計算ライブラリの多くは過去のレガシーな高速モジュールを使うことで、python だけど早い処理の実現に成功しています。少し専門的になりますが、これは、binding という技術のおかげで、python は C/C++言語とお話することができるのです。
python の思想として、誰が書いても同じようになる、というのがあります。これは過去のperlやC言語などは、同じ処理を全く違う書き方ができるような自由な世界でしたが、その一方で、読みにくさやチーム開発の難しさがありました。python はルールが厳しいこともありますが、その分、読みやすい言語になっています。
宇宙天文では、ベクトルや行列の演算が多いのですが、python では C/C++言語よりもその演算を圧倒的にシンプルに記述することができます。C/C++言語では for ループを多用しますが、python では 「for ループ を使わない」方が python っぽいと言われるくらい、ループしなくても配列の演算やアクセスがしやすいです。最近では、機械学習のためのツールもpythonをベースとしたものが多いです。今から初める若い人はpythonからスタートするので大間違いはないでしょう。
コンパイラ言語
コンパイラ言語は、一度、全体をコンパイルといって、プログラムが最適に動くように機械語に翻訳して、実行ファイルが生成されて、それを動かすタイプものです。C/C++はコンパイラ言語です。とにかくスピードが必要な場所では、今でもC/C++言語を使います。例えば、FPGAとCPUのクライエントとサーバーのプログラムは普通はC++で書かれます。高エネルギー分野の人は rootを使いますので、C++も勉強しておきましょう。モンテカルロシミュレーションの代表格であるgeant4を使う人もC++は必携になります。
ソフトウェアを扱う前の基礎知識
環境変数
環境変数とは、OSが設定値を保存し、ユーザーや実行されるプログラムから設定・参照できるようにしたものです。例えば、
- パス(path)を設定する「PATH」
- 現在の利用者のホームディレクトリのパスを表す「HOME」
- 利用者の使う言語(日本語、英語など)を設定する「LANG」
- カレントディレクトリを表す「PWD」
- デフォルトのシェルのパスを指定する「SHELL」
などがあります。研究室に入ると、「PATH を通した?」という言葉をよく耳にします。その意味は、
を参照ください。あるプログラムがどこにあるのか、PATHに書かれた順番に探していきます。
CPU、GPU、FPGA、組み込みOSとは?
宇宙天文を研究する上で、ソフトウェアとハードウェアは切り離せない。基礎として、ソフトウェアが動く土台を知っておこう。
- CPU : CPUは命令を逐次実行する装置です。命令列さえあればOSがなくても動きます。組み込みのCPUでは、OSを搭載せずに動作確認することが多いです。普段使うパソコンにはOS(windows、mac, linuxなど)が搭載されていますね。OSはソフトウェアの塊であり、ハードウェアとのインターフェースを担うものです。例えば、キーボードを叩く、音楽を聴く、USBでファイルをやりとりする、などの基礎的な機能をOSというソフトウェアが担当しています。
- GPU : GPUは最近流行りの機械学習を支えているものです。これはCPUと違って、定型的な計算を並列処理するのが得意なものです。CPUが数個のコアなのにたいして、GPUの CUDA core というの1万コアなど数が桁違いで、その並列性の高さから機械学習が飛躍的に進みました。ただし、並列化できない計算には向かないです。
- FPGA : FPGA は Field Programmable Gate Array の略で、「書き換え可能な論理回路が多数配列されたもの」 になります。従来はASICと呼ばれる書き換え不可能なモノを使ってましたが、高価な上に書き換え不能なのが難点でした。FPGAは書き換えが可能な上に廉価で手に入るため、最近の宇宙天文の実験装置では不可欠なパートになっています。VHDL、Verilog というソフトウェアで記述しますが、最近ではC言語でも設計可能な方法が広まっています。FPGAでCPUを作ることもできます。microblazeというCPUは有名な一つです。
- 組み込みOS : 組込みOS/システムとは(エンベデッドシステムともいいます)、デジタル機器や家電製品などに組み込まれ、特定の機能を実行するコンピュータシステムのことです。宇宙天文の場合は、高度なリアルタイム性や特化した機能が求められる場合に使います。例えば、人工衛星にmacやwindowsを搭載することもできますが、汎用性が高すぎて無駄が多く使われません。最近では、Xilinx Zynq UltraScale+ MPSoC の宇宙での実用化 が進められています。
このように、宇宙天文で扱うソフトウェアといっても、それが走る舞台がCPUなのか、GPUなのか、あるいはFPGAを記述する言語や、組み込みOSを搭載したCPU向けのソフトウェアなのか、など多岐にわたります。ハードウェアとソフトウェアは別々に設計することもありますが、最近ではハードウェアとソフトウェアの機能をお互いに考慮しながら設計する協調設計(コデザイン、co-design)と言う設計手法が大切になりますので、若い人はぜひ知っておいてください。
エディタについて
ソフトウェアを書くためのエディタは、紙とペンのようなもので、結構大事です。
- emacs これは linux や実験などでは多様される昔の王道エディタです。教養として知っておいた方がよいです。
- sublimetext pythonを開発するには書きやすいエディタです。
- emacsユーザーは、EmacsユーザーがSublimeTextでpythonのコードを書く時に知っておいた方が良いこと というのも参考に。
他にもたくさんありますが、自分で使いやすいエディタを見つけましょう。
python の設定と使い方
pythonのインストール方法
宇宙天文系であれば、anaconda で python をインストールするのをお勧めします。astropy や matplotlib, ipython などが一式入ります。2020年3月でpythonの2系が正式に止まったので、python3系を使いましょう。ただし、古いpython2系を使う可能性がある人は、pyenv で anaconda python を入れる事をお勧めします。pyenv はディレクトリごとにpythonのバージョンを切り替えられるため、バージョンの異なるモジュールが混在する人にはお勧めします。
matplotlib を使ったプロット
ここ数年で、MATLABの python 版が爆発的に使われていて、matplotlib をお勧めします。インストールは、anaconda を入れれば自動で入ります。
例えば、fft も python で簡単にできます。例えば、
を参照ください。スピードは、fortran のバイナリでFFT部を実行しているのでC++等と比較してもほどんと変わりません。
今や、実験、観測、宇宙論など、多くの人が matplotlib で図を書いてますので、習得しておくと良いでしょう。
など、日本語の解説記事が山ほどあるのも初めてのひとには優しいです。
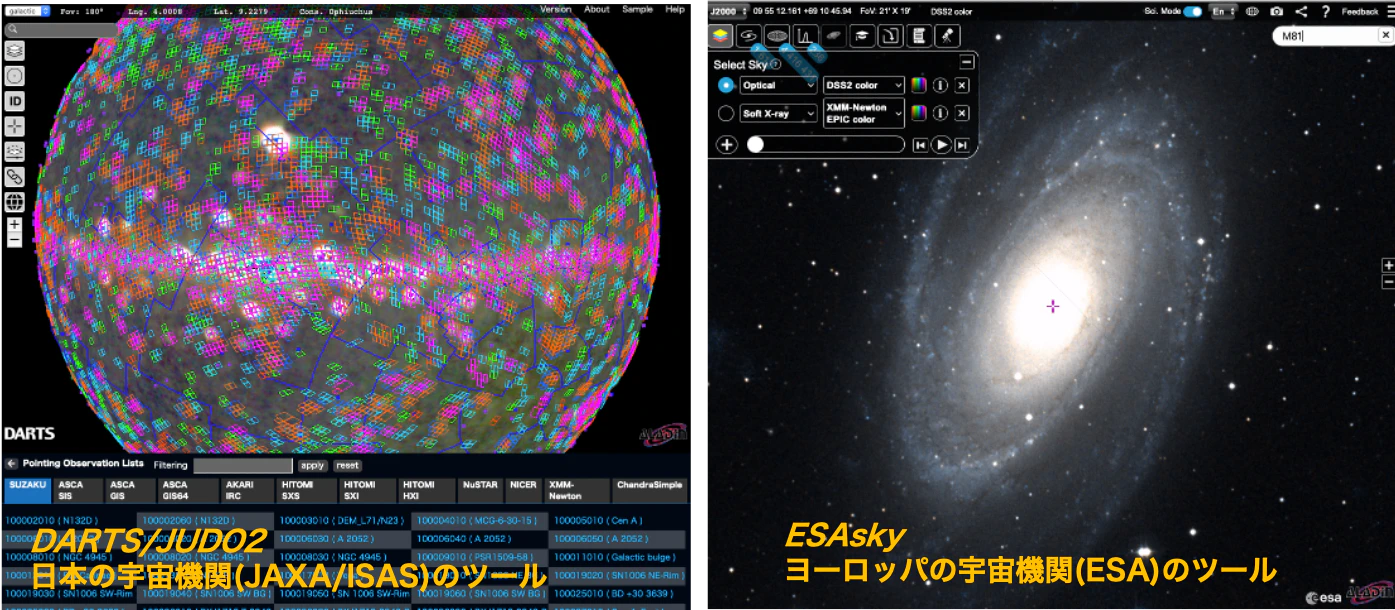
宇宙の綺麗な絵を見ながら検索する方法
宇宙は綺麗な絵が一つの魅力でしょう。それを見ながら過去にどういう観測データがあるのかなど、調べられると面白いですよね。現時点では、
- ESAsky ヨーロッパの宇宙機関(ESA)のツール。
- DARTS/JUDO2 日本の宇宙機関(JAXA/ISAS)のツール。
がよくできてると思います。この辺りは急激に技術が進歩しているので、新しく良いものがどんどん出てくると思います。リンクを押すのが面倒な人向けに2つの絵を紹介します。
さて、これをどう研究に使うのか?という例として、XMM-Newton衛星を使って説明してます。
天体を探す、データを探す、というのは簡単なようで、観測ごとに個性があって丁寧に見る必要があります。他にもありますが、便利ツールを上手に使いこなしましょう。
python を使った宇宙のカタログ研究
今では、astroquery を使って、様々な宇宙のカタログについて python から統一的にアクセスすることができます。そのやり方や例をいくつか紹介しています。
- python の astroquery を用いた宇宙天文カタログの検索と銀河を用いた簡単なプロット方法
- pythonのastroqueryを用いて検索し、skyviewでfits画像を取得する方法
- pythonでOpenNGCデータベースを用いて銀河の可視光データをプロットする方法
- pythonを用いて銀経銀緯で複数のfits画像を並べてプロットする方法
天体解析関係
NASA関係のソフトウェア
ds9 イメージ解析専用のソフトウェア。波長によらず、イメージ解析では王道のツール。最近はダウンロードするだけで使える。
NASA の heasoft のページから、必要なソフトをダウンロードする。(宇宙天文向け)
hesoftを動作するにはソースコードをダウンロードしてコンパイルする方法と、バイナリで済ませる方法がある。バイナリでまずは試して、パスを通すだけで動くはずで、もし動かなければ、ソースコードからコンパイルしてみてください。
"パスを通す"というのは、下記の記述を .bashrc などの設定ファイルに
書き込むことです。例えば、私は2つのマシン環境が手元にあるので、
その2例を示しておきます。export HEADAS=/usr/local/astroh/software/HEASOFT/Hitomi_Release_03_rc1/x86_64-debian-linux-gnu-libc2.19-18+ source $HEADAS/headas-init.sh ## For suzaku analysis export CALDB=/usr/local/xray/caldb export CALDBCONFIG=$CALDB/software/tools/caldb.config export CALDBALIAS=$CALDB/software/tools/alias_config.fits要するに、$HEADAS を設定し、headas-init.sh がどこにあるかを設定する。
衛星関係のツールは、CALDB という衛星の設定データが必要なので、
CALDBをダウンロードして、パスを設定します。データ形式
宇宙の研究を始めると、FITS (フィッツと読む) が何度も出てくると思うが、これは、天文業界の標準的なファイル形式のこと。
ヘッダー部分の基礎情報は非圧縮のテキストファイルで、データは圧縮されたバイナリファイルで構成される。バイナリファイルについては、テキストファイルとバイナリファイルとはを参照ください。
天文以外では、HDF5がpythonと相性のよいファイルで、使われることも多い。fitsファイルは宇宙天文向けにガチガチに仕様が固められたファイルであり、天文以外で使うことはまずない。fits ファイルを見るには、fvという heasoft のコマンドラインツールや、astropy を使う。
統計学
榎戸氏(理研)の 榎戸輝揚の公開資料リポジトリ に色々とあります。その中の一つ、
を一読しましょう。
電子的にメモをとる必要性
宇宙天体解析をやる場合、大量にログを取る必要あります。ファイル名の数もそうだし、プログラムを走らせたときの引数やメッセージなどの情報です。これは大切な実験データで、記録を取る必要あります。また自分のためにもなります。あとで自分が何をしたのか、プログラムが動いてたけど実はエラーを吐いてたなど、未来の自分の為になる時が必ずきます。手で記録をとれる情報量ではないので、電子的にログをとりましょう。最近は、evernoteやbearなど、いろんなツールがありますのでお好みに合わせて。(注: 紙の実験ノートが不要、という意味ではないです。)
論文執筆、文献検索、英語学習方法
検索方法
研究の世界に入ったら、「英語で検索」する習慣をつけましょう。日本でも十分に情報が手に入る場合はそれでもよいですが、少し専門的になると英語圏の方が情報量が圧倒的に多いので、英語で調べる癖をつけましょう。
論文執筆関係
早いうちに、texを習得しましょう。tex も一つの言語です。最近は、brew で一発で tex がインストールされるので、これが使える人はこれが一番楽です。
- tex の install (Macユーザー向け)
- windows 向け
最近は、overleafを使うことも増えている。オンラインで共同で編集する場合はこれが一番よい。
最近では、beamer というので、tex でスライドもノートも作れるようになってます。beamer って何?という人は、
を参照ください。
文献検索方法
ads が王道。ここで検索に引っかからない宇宙の論文はほぼないはず。一つの論文を検索したら、その論文を refer している論文や、citation している論文など、孫引きすることで、芋ずる式に文献が増える。今の時代、一生かかっても読めないほど論文があるので、取捨選択と強弱をつけて論文を読む訓練を若いうちからしておこう。
もう一つ有名なのは、 arxiv です。ここには、世界中の論文が最速で集まります。ただし、論文が受理される前に公開されるものもありますので、後々に棄却された論文も含まれる点には注意してください。あとは、受理された論文でも、100%正しいわけではないです。科学は試行と検証の積み重ねが必要で、よいジャーナルの論文でも後で間違とわかることも頻繁にあります。
今は情報の洪水の時代で、適当な情報は簡単に手に入るけども、本当に欲しい情報や真偽を見極めるのが難しくなってます。逆に言うと、真に必要な情報を素早く収集し、真偽を見極める力がある人が、研究に限らず社会から必要とされる人材でもあります。宇宙物理や天文学の研究をすることは、そのような力を楽しく身につけられる最高の舞台でもあります。
科学英語の勉強
オススメは、 grammarly です。これは何故ダメなのか、を教えてくれるので、反復する事でエラーが減っていきます。先生から文法間違いを指摘される数はほぼゼロになるはずです。
科学論文の書き方
いろんな流派はありますが、初めての人は、牧島先生の資料を参考にしてください。
一般的には分野によって、書き方や流派は違うので、論文を投稿するジャーナルに応じて、スタイルは合わせて書きましょう。論文で一番大切なのは、新しい事を1つでよいので、それを核にして伝えることだと思います。"新しい"といっても、世界中の人があっと驚くことでなくても大丈夫です。どんな小さな一歩でも、まだ誰も到達できてない一歩であれば、貴重な科学的な営みです。論文化を意識することで目標がハッキリと見えてきますので、常に論文化を意識して研究する習慣をつけましょう。
パソコン操作、設定
ディスプレイの写し方
手元のPCとプロジェクターの画面を同じにしたい場合は、
ミラーリングをONにする。変えたい場合は、ミラーリングをオフする。
http://tokyo.secret.jp/macs/macbook-mirroring-option.htmlパソコンの画面をディスプレイに移すには、アナログとデジタルの2種類がある。最近は、HDMIケーブル(デジタル)が主流です。HDMIケーブルは映像と音声の2種類を伝送できるので、パソコンの音声出力がHDMIになっていると、マイクから「音が出ない」という事がありえるので注意してください。
ノートパソコンを壊さないコツ
- トラックパットの深押しでクリックを解除
トラックパッドの深押しでクリックにすると機械的な磨耗が発生する。macユーザーの場合は、システム環境設定==>トラックパッド==>タップでクリック 一本指でクリックにチェックをつける。これでソフトタッチでクリックできるようになる。(もっと気にするなら、外付けキーボード、マウス、トラックパッドを使えば良いが、それならノートPCでなくてもよいか。。)
- 電源を長期間ONしたままにしない。
電源の寿命の観点からは、こまめに電源をON/OFFするか、少なくするか、どちらがよいかは諸説あります。ただし、明らかに遅いという場合は、死んだアプリがメモリを解放してないだけで、無駄にエネルギーを消費している場合も多いので、個人的には1週間に一回くらいは電源をオフしておいてください。
インストールツールについて (macユーザー向け)
macには、fink, macport, homebrew の 3 種類がありますが、今からPCのセットアップという人は、間違いなく、homebrew を使うことをオススメします。 他の2つは今ではサポートが不十分というのが理由です。
homebrew でなきゃダメなことはないですが、気をつけて欲しいのは、一つだけ使うことです。混在すると、片方を動かしたときに、設定ファイルを書き換えてしまったりすることがあり、ハマることが多いです。
パスワードの検索方法 (macユーザー向け)
macユーザーの人はパスワードを覚えなくても、あるいはパスワードを書いたテキストファイルを自分で管理しなくても、OSの機能としてパスワードを管理する keychain というツールがあります。
スポットライト(右上の虫眼鏡マーク)で、keychain と打つ。
http://www.danshihack.com/2014/01/05/junp/mactips_keychain.html
(アプリケーション --> ユーティリティ --> keychain でもよいですが、スポットライトの方が早い。)スクリーンショット (macユーザー向け)
「コマンド + shift + 4」を全部同時に押す。https://support.apple.com/ja-jp/HT201361
「コマンド + shift + 5」で選択画面に従う
macOSのバージョンに依存しますので、オフィシャルな説明で自分のOSの解説を参照してください。
上級者向けのツール
zsh の 使い方(おまけ)
zshの何がよい点であるか、簡単に紹介する。bash, tcsh に比べて新しいので、良いことは多い。そもそも「シェルって何?」と言う人は、shell を一読ください。
- ファイルの検索が一瞬
例えば、どこに保存したか思い出せないけど、拡張子は cc というファイルを探す場合は、
> ls **/*cc とすると、カレントディレクトリ以下の *cc ファイルを探してくれます。
- コマンドごとの履歴検索が可能、オプションがすぐに思い出せる。
たとえば、rsync の後にどんなオプションをつけたか思い出せないとき、
> rsyncまで打って、ctl + p とすると、rsync + ○○ と打ったヒストリを教えてくれます。
その他、http://blog.blueblack.net/item_204 などを参照してください。
簡単に初期設定をしたい人は、.zshrc の中に、
HISTFILE=$HOME/.zsh-history # used for storing commands HISTSIZE=100000 SAVEHIST=100000 setopt extended_history # add time stump for the history function history-all { history -E 1 } # output all history when putting history-all autoload -U compinit compinit autoload colors colors PROMPT="%{${fg[cyan]}%}[%n] %(!.#.$) %{${reset_color}%}" #PROMPT="%{${fg[cyan]}%}[%n@%m] %(!.#.$) %{${reset_color}%}" PROMPT2="%{${fg[cyan]}%}%_> %{${reset_color}%}" SPROMPT="%{${fg[red]}%}correct: %R -> %r [nyae]? %{${reset_color}%}" RPROMPT="%{${fg[cyan]}%}[%~]%{${reset_color}%}" #setopt list_types setopt auto_list setopt autopushd setopt pushd_ignore_dups setopt auto_menu # get history with ctl+p copied from Yuasa autoload history-search-end zle -N history-beginning-search-backward-end history-search-end zle -N history-beginning-search-forward-end history-search-end bindkey "^P" history-beginning-search-backward-end bindkey "^N" history-beginning-search-forward-end setopt list_packed zstyle ':completion:*:default' menu select=1と入れると、いろんな機能が使えます。
- 投稿日:2020-04-09T11:22:40+09:00
ベイズ更新、二項分布・尤度関数について理解しようとした
はじめに
前回、機械学習を学ぶ上で避けて通れない(と思っている)ベイズ推定について学びました。今回は、それに引き続きベイズ更新、二項分布及び尤度関数についてまとめました。機械学習で避けて通れない(と思っている)ベイズの定理を頑張って理解しようとした
https://qiita.com/Fumio-eisan/items/f33533c1e5bc8d6c93db
- ベイズ更新を理解する
- ベルヌーイ分布及び二項定理を理解する
- 尤度関数を理解する
機械学習とその理論 (情報オリンピック2015春合宿講義資料)
https://www.slideshare.net/irrrrr/2015-46395273ベイズ更新を理解する
ベイズの定理を応用した考え方にベイズ更新というものがあります。これは、事前確率を更新された事後確率とする考え方を指します。
迷惑メールのフィルタの考え方を例にして、具体的に計算をします。迷惑メールフィルタ
あるメール$A$が、迷惑メール$A_1$か非迷惑メール$A_2$かを判定することを考えます。メールには迷惑メールで入りやすい単語「絶対必勝」、「完全無料」などという言葉が含まれていました。迷惑メールと非迷惑メールにこれらの言葉が含まれている確率はデータベースより下記表になります。
迷惑メール 非迷惑メール 絶対必勝 0.11 0.01 完全無料 0.12 0.02 さて、「絶対必勝」という言葉が含まれている事象を$B_1$、含まれていない事象を$B_2$とします。すると、
P(B_1|A_1) = P(絶対必勝|迷惑メール) = 0.11\\ P(B_1|A_2) = P(絶対必勝|非迷惑メール) = 0.01となります。非迷惑メールの中にも100通に1通くらいは、絶対必勝と書かれていることがあることを示します。さて、データベースより全メールに対する迷惑メールの割合は$P(A_1)=0.6$であることが示されています。
この時、「「絶対必勝」という言葉が含まれるメールが迷惑メールである確率」をベイズの定理から求めます。\begin{align} P(A_1|B_1)& = P(迷惑メール|絶対必勝)= \frac{P(B_1|A_1)P(A_1)}{P(B_1)}\\ &=\frac{P(絶対必勝|迷惑メール)P(迷惑メール)}{P(絶対必勝)}\\ &=\frac{0.11×0.6}{0.11×0.6+0.01×(1-0.6))}\\ &=0.9429 \end{align}となります。
従って、「絶対必勝」が含まれいるメールのうち約94%は迷惑メール、約6%が非迷惑メールであることが分かりました。この計算から、先ほどの前提では60%が迷惑メールだった前提から94%が迷惑メールという前提に代わりました。これが、事後確率を事前確率とする考え方になります。この考え方を元に、「完全無料」についてもベイズ更新の原理を適用します。
\begin{align} P(A_1|B_2)& = P(迷惑メール|完全無料)= \frac{P(B_2|A_1)P(A_1)}{P(B_2)}\\ &=\frac{P(完全無料|迷惑メール)P(迷惑メール)}{P(完全無料)}\\ &=\frac{0.12×0.9429}{0.12×0.9429+0.01×(1-0.9429))}\\ &=0.9900 \end{align}となりました。つまり、「完全無料」が含まれているメールのうち約99%が迷惑メールであることが分かりました。このような考え方がベイズ更新と呼びます。
ベルヌーイ分布及び二項定理を理解する
確率分布を示す分布としてベルヌーイ分布があります。
f(x|θ) = θ^x(1-θ)^{1-x}, x=0,1$x$が確率変数であり、1か0を取ります。通常、コインの表裏や、病気の罹患、非罹患などをこの1,0で表します。また、$θ$はその事象が起こる確率を指します。この$θ$は母数とも呼ばれ、確率分布を特徴づける数的指標です。
二項分布を理解する
さて、先ほどのベルヌーイ分布では1回の試行を表したものです。次に、この試行をN回行った場合を考えます。
バスケットボールを例に考えます。フリースローを$\frac{1}{3}$で成功することができる選手がいます。3回投げて2回成功する確率を考えます。
例えば、成功⇒成功⇒失敗が観察される確率は、
θ^2×(1-θ)^1 = {\frac{1}{3}}^2×(1-\frac{1}{3})=\frac{2}{27}となります。しかし、2回成功するケースは成功⇒失敗⇒成功、失敗⇒成功⇒成功と全てで3パターンあります。従って、\frac{2}{9}と試算することができます。
これを一般化するとf(x;N,θ) = nCx×θ^x(1-θ)^{n-x}, x=0,1$n=30$,$θ=0.3,0.5,0.8$のときにこの確率分布がどのように描かれるかみてみます。
bayes.ipynbimport matplotlib.pyplot as plt import numpy as np from scipy.stats import binom k = np.arange(0,30,1) p_1 = binom.pmf(k, 30, 0.3, loc=0) p_2 = binom.pmf(k, 30, 0.5, loc=0) p_3 = binom.pmf(k, 30, 0.8, loc=0) plt.plot(k,p_1,label='p_1=0.3') plt.plot(k,p_2, color="orange",label='p_2=0.5') plt.plot(k,p_3, color="green",label='p_3=0.8') plt.legend() plt.show()
30回試行する前提の場合、確率0.3では9回程度、確率0.5では15回程度、確率0.8では25回程度が最も観察される回数が高いことが分かりました。
確率0.5でピークが一番低い理由は、分散が最も大きいためです。尤度関数を理解する
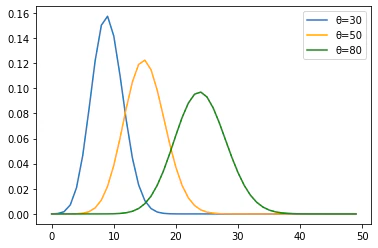
先ほど表れて二項分布について考えます。先ほどの例では、30回試行する母数を定数として、確率を変数として考えました。この考えを逆にして、試行回数である母数を変数、確率を定数とした関数を尤度関数(ゆうどかんすう)と呼びます。この尤度関数により求まる値を尤度、と呼びます。
f(x;N,θ) = nCx×θ^x(1-θ)^{n-x}, x=0,1
先ほどと同じような考え方で図式化してみます。$θ=30,50,80$、確率は0.3として計算します。bayes.ipynbimport matplotlib.pyplot as plt import numpy as np from scipy.stats import binom k = np.arange(0,50,1) p_1 = binom.pmf(k, 30, 0.3, loc=0) p_2 = binom.pmf(k, 50, 0.3, loc=0) p_3 = binom.pmf(k, 80, 0.3, loc=0) plt.plot(k,p_1,label='θ=30') plt.plot(k,p_2, color="orange",label='θ=50') plt.plot(k,p_3, color="green",label='θ=80') plt.legend() plt.show()
試行回数が高くなるにつれて、分散が大きくなり期待値(ピーク)も低くなることが分かりました。
おわりに
今回、二項定理に関しては高校数学でも習う範囲であるため理解しやすかったです。ただ、尤度関数と確率としての考え方は何を変数と置くかで意味するところが若干変わることは新鮮でした。
また、ベイズ更新については機械学習で応用できる考え方だと理解できた一方、自ら事前確率を決めることは非常に注意が必要であることが分かりました。その前提は本当に妥当か、という視点で取り組まなければ落とし穴があるかもしれません。参考URL
https://lib-arts.hatenablog.com/entry/implement_bayes1

- 投稿日:2020-04-09T11:14:28+09:00
foliumを使ってみた
はじめに
最近foliumという、データを地図上で表示するライブラリを使ってみたので、勉強しながら記事にまとめてみました。
foliumとは
FoliumはデータをLeaflet.jsのマップで可視化をするpythonのライブラリです。
pythonのデータ操作とleafletのマッピングの両方の強みが利用できます。
Github:https://github.com/python-visualization/folium
Documentation:https://python-visualization.github.io/folium/インストール
pip installでインストールできます。
foliumのインストール$ pip install folium地図を表示してみよう!
まずはjupyterで東京駅([35.681167, 139.767052])を中心とした日本地図を表示。
locationに緯度経度を入力すると、その位置を中心としたmapが表示できます。東京駅を中心とした日本地図をplotimport folium map_ = folium.Map(location=[35.681167, 139.767052], zoom_start=7) map_
3行だけで地図が表示できました。
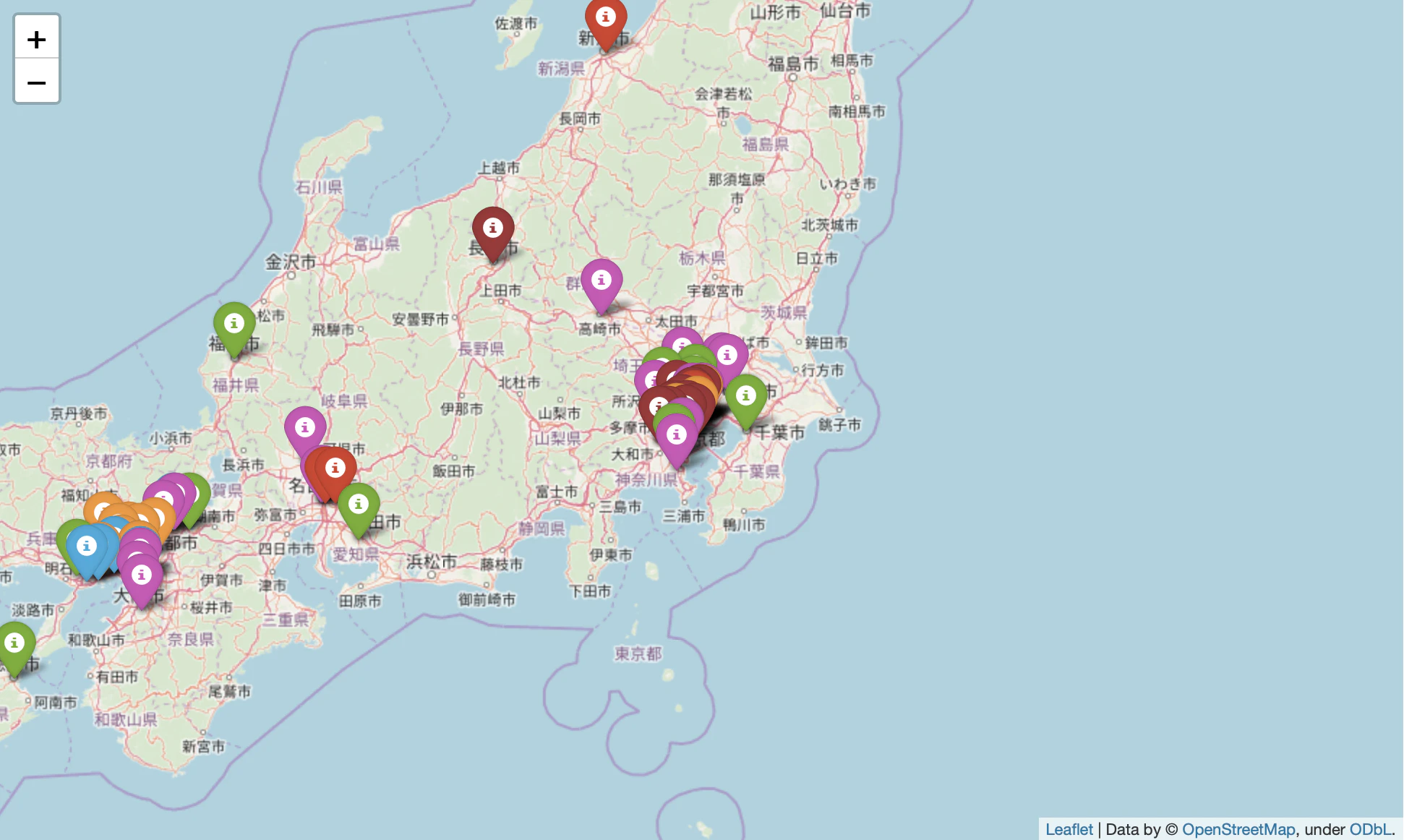
次は作成した日本地図に、百貨店の位置情報をマッピングしてみます。
百貨店の位置情報はHPで検索し、csvファイルとして保存しました。csvファイルはこんな形式で保存しています。(
department_info.csv)
store_name contry area prefecture city address latitude longitude depart 0 日本橋三越本店 日本 関東 東京都 中央区 東京都中央区日本橋室町1-4-1 35.685633 139.773430 三越 1 銀座三越 日本 関東 東京都 中央区 東京都中央区銀座4-6-16 35.671370 139.765738 三越 ・・・ 88 ShinQs ビューティー パレット 町田店 日本 関東 東京都 町田市 東京都町田市原町田6-4-1 町田東急ツインズ WEST 3F 35.542690 139.446409 東急百貨店 89 ながの東急百貨店 日本 中部 長野県 長野市 長野県長野市南千歳1-1-1 36.645052 138.188676 東急百貨店 先ほど表示したmapに百貨店のマーカーを追加するimport pandas as pd data = pd.read_csv('department_info.csv') color_list = {'三越':'red', '大丸':'blue', '西武・そごう':'green', '高島屋':'purple', '阪急阪神':'orange', '東急百貨店':'darkred'} for k, v in data.iterrows(): folium.Marker([v.latitude, v.longitude], popup=v.store_name, icon=folium.Icon(color=color_list[v.depart])).add_to(map_) map_
popup=xxx
xxxにコメントを追加すると、ポップアップとして表示できます。
icon=folium.Icon(color=xxx1, icon=xxx2)
マーカーiconの種類はxxx1とxxx2を指定すると変更できます。xxx1に使用できるカラー
[‘red’, ‘blue’, ‘green’, ‘purple’, ‘orange’, ‘darkred’, ’lightred’, ‘beige’, ‘darkblue’, ‘darkgreen’, ‘cadetblue’, ‘darkpurple’, ‘white’, ‘pink’, ‘lightblue’, ‘lightgreen’, ‘gray’, ‘black’, ‘lightgray’]xxx2に使用できるマーカー
https://glyphsearch.com/?library=font-awesome次は表示した百貨店ごとに、半径20kmの円を表示してみます。
百貨店から20km圏を円で表示for k, v in data.iterrows(): folium.Circle([v.latitude, v.longitude], radius=20 * 1000, tooltip='20km', popup=v.store_name , color=color_list[v.depart], fill_color=None).add_to(map_) map_
最後に作成したmapをhtml形式で保存しました。
作成したmapを保存map_.save('department_location.html')おわりに
思った以上に簡単に、綺麗な地図可視化することができました。
(アカウント移行に伴い再掲)


- 投稿日:2020-04-09T09:06:39+09:00
pythonwebスクレイピング-要素を一括取得
PythonによるWebスクレイピング〜入門編〜【業務効率化への第一歩】の9-10勉強メモ
https://www.udemy.com/course/python-scraping-beginner/
スクレイピング対象ページ(PW制限あり)
https://scraping-for-beginner.herokuapp.com/mypage要件: 下記テーブルの右側部分のテキスト情報を一括取得すること
F12を押し、開発ツールで確認すると右側のテキストは、すべてtdでマークアップされていることがわかる。
1. ブラウザからtdの要素を取得する。
elems_td = browser.find_elements_by_tag_name('td')2. tdの中から要素を一つづつ取り出しvalueに入れる
tdの要素をすべて取得したelems_tdの情報を、elem_tdに入れる。
values = [] #elems_tdの中から要素を一つづつ取り出しelem_tdに入れる for elem_td in elems_td:3.elem_tdの要素(text形式)を、valueに入れる。
#elem_tdの要素(text形式)を、valueに入れる value = elem_td.text4. valueの要素をすべて、valuesのリストに追加
#valueの要素をすべて、valuesのリストに追加 values.append(value)すべてのコード
#ブラウザからtdの要素を取得 elems_td = browser.find_elements_by_tag_name('td') values = [] #elems_tdの中から要素を一つづつ取り出しelem_tdに入れる for elem_td in elems_td: #elem_tdの要素(text形式)を、valueに入れる value = elem_td.text #valueの要素をすべて、valuesのリストに追加 values.append(value)#valuesを打つ values結果
['今西 航平', '株式会社キカガク', '1994年7月15日', '千葉県', 'バスケットボール\n読書\nガジェット集め']


- 投稿日:2020-04-09T08:16:09+09:00
Python:pyenvを何も考えずに更新し「Pythonどこいった?」を解決する
Mac で Home brew を使っております。OS は Catalina ですが、Python のバージョンは自分で決めたいので、システムの Python3 ではなく、pyenv と pip で Python 環境を管理しています。
2回ほどあったのですが、Home brew で
brew updateをかけ、何も考えずにbrew upgradeすると、pyenv が更新されているときがあります。
pyenv が更新されたあと、python3しても「そんなファイルがありません」といわれ焦ることになります。この場合は、
pyenv rehash pyenv global 3.8.1というように、rehash のあと global で使いたいバージョンを再指定すれば、もとにもどります。
普段から pyenv に馴染んでいる方々には常識でしょうが、自分の備忘録もかねて、念の為アップしておきます。以 上
- 投稿日:2020-04-09T08:16:09+09:00
Python:pyenvを何も考えずに更新し「Pythonどこいった?」現象を解決する
Mac で Home brew を使っております。OS は Catalina ですが、Python のバージョンは自分で決めたいので、システムの Python3 ではなく、pyenv と pip で Python 環境を管理しています。
2回ほどあったのですが、Home brew で
brew updateをかけ、何も考えずにbrew upgradeすると、pyenv が更新されているときがあります。
pyenv が更新されたあと、python3しても「そんなファイルがありません」といわれ焦ることになります。この場合は、
pyenv rehash pyenv global 3.8.1というように、rehash のあと global で使いたいバージョンを再指定すれば、もとにもどります。
普段から pyenv に馴染んでいる方々には常識でしょうが、自分の備忘録もかねて、念の為アップしておきます。以 上
- 投稿日:2020-04-09T05:16:55+09:00
Python3 平衡二分探索木は知らないがソートされた集合があったらいいなあって話
はじめに結論
Pythonのsetは集合の管理ができますが、要素にindexを持っていないので「小さい方からx番目の要素を出力する」という操作を要素数 N に対して $O(N)$ でしか行えません。
あ〜遅すぎる。
結論を言うと、Binary Indexed Treeと二分探索で$O((logN)^2)$になります。もっと高速化できるかはよく知りません。
どんな理屈?
Binary Indexed Tree(以下BIT)を用意しましょう。なに?BITを知らない?
https://ja.wikipedia.org/wiki/フェニック木xを集合に追加する場合、BITのx番目の要素に+1するということにしましょう。
例えば、{3, 1, 4}の集合を作りたい!と思ったら、BIT配列の3番目の要素に+1
BIT配列の1番目の要素に+1
BIT配列の4番目の要素に+1これでOKです。
ではlower_boundを考えていきましょう。二分探索します。小さい方からx番目の要素が欲しい時、
「y以下の要素がx個以上あるか?」という判定を使って二分探索すると、BITでy以下の要素の個数は$O(logN)$でわかり、
さらに二分探索自体に$O(logN)$かかるので
合計$O((logN)^2)$です。なるほどね。
制約
floatやstrを扱いたい場合は工夫が必要です。floatだったら元々の数を定数倍しておけばよし、strは文字コードを使えばいいですが実用的には見えません。
また動的な変更に思ったより強くないのでオンラインクエリに弱いかもしれません。
でかい数を格納する際も座標圧縮などをしないとうまくいきません。結論
まあsetで順序集合を考えるよりは速いかなあ...
平衡二分探索木の方が便利そう(終了)どんな記事にも終わりはある
そういえばコード書いてないですね。
- 投稿日:2020-04-09T04:34:52+09:00
データエンジニアがMLOpsを視野にDevOpsを学ぶ。 ①とっかかり
tl; dr
今後のために、DevOps/MLOps実務を体系的にマスターしておこうシリーズ
私の場合、とっかかりとして、フロントエンド言語のTypescript(ts)と、バックエンド言語のScala/Python(with Sparkエコシステム)をつなげるところから取り組むの良いと思った。判断理由:
1) フロントエンド開発者(js/tsユーザー)にpythonは親和的 ※js/tsユーザーが併用するプログラム言語の定番の一つがpythonとなっているらしい ★1 2) tsのモデル定義とsparkのモデル定義の親和性が高い ※Typescriptのインターフェース定義とSpark向けのcase classが特に類似。 3) tsとsparkとの相互呼び出しが容易となりつつある(「jsii」の魔法)。 ※例、jsiiによって、typescriptで書かれたnodejsアプリのテストをScala/Pythonで行うことが可能に。 4) terraform/ansible/docker/hashi stackあたりはなんとかなる私の課題は、今風のフロントエンド。★1の出典 : JavaScriptユーザーが使う"第2のプログラミング言語"、第1位はPython
[1] nodejs上のTypescriptエコシステムの成熟。
型有りなjs互換言語であるTypescript。jsと比べ敷居が高いところもあるのだろうが、バックエンドを型有り言語(C#/Scala etc.)で書いているエンジニアにとってはTypescriptは安心できる選択肢だ。web開発に外せない選択肢となっているnodejs上でTypescriptを動かす際のノウハウも蓄積されている模様。
以下では、
Typescript on nodejsの近年の解の一つらしい、Nest.jsフレームワークを例に取る(フレームワークの流行り廃りはあるにしても、Typescript on nodejsは、今後も標準的な選択肢であり続けるたろう。)
参考 Nest.jsは素晴らしい[2] バックエンドとフロントエンドの狭間。
インターフェースを持つTypescriptのモデル定義は、C#やScalaと親和的だ。
一例を上げよう。
↑のNest.js素晴らしい記事、Nest.jsによるUserインターフェースの作成のところで作っておられるUserモデルのインターフェースuser.interface.tsは以下:user.interface.tsexport interface IUser { id: string; name: string; kana: string; email: string; postcode: string; address: string; phone: string; password: string; admin: boolean; createdAt: Date; updatedAt: Date; }対して、対応するSpark向けのscalaのクラスは例えば、以下のようになる:
IUser.scalacase class IUser ( id: String, name: String, kana: String, email: String, postcode: String, address: String, phone: String, password: String, admin: Boolean, createdAt:TimeStamp, updatedAt:TimeStamp )機械的な置換で行けてしまうレベルだ(ここではscalaとしたが、Typscript同様に型アノテーションのあるPython(PySpark)でも同様)。Sparkに永続化するプロパティはString/Int/Boolean/TimeStampといった基本的な型のみを使うのが実務的に簡易である。フロントエンド側も同様の書き方で安全に書いていけるならば、話が早い(nest.jsは概観するに、安全かつ生産的に書いていけそうな気がする...実際に自身で書くかどうかは別にして)。
Typescriptで書かれたnode.js上からjsonを生成し、(間にKafka等を挟んだり、準ストリーム処理にしたりして)sparkに流し込むことができれば、後はどうとでもなる。バックエンド側では、Sparkはデータストア間のデータハブを記述する標準解の一つだ(csv,cassandra,hive,neo4j,機械学習基盤 etc.をつなぐ)。[3] jsiiを介し、Python/ScalaでTypescripe on nodejsのテストが可能に。
以下の記事で知った、AWS謹製のjsii。
TypeScriptで書いたプログラムをPython等で動かす魔法の「jsii」を紹介jsiiによって、TypeScriptのコードをPython/JVM言語(Scala)/C#から直接に呼出すことができるようになるということだ。つまり、PythonやScalaでTypescriptのテストコードを書けるということだ。実運用に入ったシステムでは、フロントエンド側の事情(サービス拡張等)によりTypescriptのモデルは変化していくもの。モデルの変化に併せ、継続的にデータの授受をテストできることはありがたい(cf. 型がないデータ(例、CSV)をsparkの世界に持ち込む際のテストはなかなか面倒)。
次回から手を動かす。
最近、パフォーマンスを追求したwebフロントエンドを持つシステムの裏方(データ基盤)をサクッと作ることを個人的にお勉強してきた。フロントエンドの技術には疎くなっているが、Svelte/typescript/nodejs/firebase...と順に触りながら、感覚を掴みんできた。今後も、nestjs/SSR/ts2elm...と手を動かしながら、バックエンドspark側とのつなぎをお試ししたい。nodejsとDockerをターゲットにCI/CDできるgithub actionが役に立ってくれるかな、と期待。
- 投稿日:2020-04-09T01:51:41+09:00
あつ森の株価の変化を見れるプログラム(未完成)
あつ森で1週間の株価推移を調べるときに、グラフ化出来たら見やすいなぁと思って作ってみました。
(2020/04/09追記 グラフ上に数字が出せないので未完成です。折れ線グラフが良かったかなぁ。。。どなたか手直ししてください。。。)
以下コード
import matplotlib.pyplot as plt import japanize_matplotlib week = ["月", "火", "水", "木", "金", "土"] ap = ["前", "後"] stock = [] labels = [] for i in range(len(week)): for j in range(len(ap)): print("--------------------------------------------------") q = int(input(week[i] + "曜日,午" + ap[j] + "の株価を入力してください 000で終了:")) if q == 000: break else: stock.append(q) labels.append(week[i] + "/" + ap[j]) else: continue break if len(stock) != 0: print(stock) x = range(0, 12) y = stock plt.bar(x, y, tick_label = labels) plt.show() else: print("終了しました")
- 投稿日:2020-04-09T01:00:45+09:00
SAML 認証による一時的な認証情報で boto3 を利用する
弊社では全社員が G Suite のアカウントを持っており、AWS マネジメントコンソールにアクセスする際は Google を Identity Provider として SAML 認証してシングルサインオン 1 をしている。この場合、STS の Assume Role という仕組み 2 を使って一時的な認証情報を入手し、フェデレーションユーザとしてマネジメントコンソールにアクセスすることになる。マネジメントコンソールにアクセスするために社員ごとに IAM ユーザを作成する必要がなくなるため、アカウント管理の手間が削減できる。
ただ、シングルサインオンを導入した場合にひとつだけ困るのがアクセスキーである。そもそも IAM ユーザが存在しないため、(永続的な) アクセスキーを発行することができない。ローカル端末にあるファイルを AWS CLI を用いて S3 に転送したいときや、Jupyter Notebook から boto3 を用いて AWS リソースにアクセスしたいときなど、アクセスキーが必要になるケースは少なくない。3
そこで今回は、SAML 認証による一時的な認証情報で boto3 を利用する方法についてまとめる。
内容としては、SAML 認証で AWS CLI を使う方法が公式ドキュメントに書かれている 4 ので、それを Python (boto3) に置き換えただけである。
Role ARN と IdP ARN を用意する
Role ARN は Assume Role で利用している Role の ARN で、IdP ARN は SAML 認証の Identity Provider の ARN。
role_arn = 'arn:aws:iam::123456789012:role/GSuiteMember' idp_arn = 'arn:aws:iam::123456789012:saml-provider/Google'SAML Response を取得する
トラブルシューティングのためにブラウザで SAML レスポンスを表示する方法 - AWS Identity and Access Management
これに従ってブラウザ上で SAML 認証を行うことで、SAML Resnponse という文字列を得ることができる。
saml_response = '...とても長い文字列...'SAML Response は Base64 エンコードされており、とても長い文字列なのでコピペする際は注意が必要。
アクセスキーを取得する
ここまでの情報があれば、AssumeRoleWithSAML という API 5 を用いて一時的なアクセスキーを得ることができる。この操作は SAML 認証をしてから5分以内に行う必要がある。
sts = boto3.client('sts') response = sts.assume_role_with_saml(RoleArn=role_arn, PrincipalArn=idp_arn, SAMLAssertion=saml_response) credentials = response['Credentials']アクセスキーを利用する
あとは通常通りアクセスキーを用いて AWS リソースにアクセスすることができる。
session = boto3.session.Session( aws_access_key_id=credentials['AccessKeyId'], aws_secret_access_key=credentials['SecretAccessKey'], aws_session_token=credentials['SessionToken'], region_name='ap-northeast-1', ) # EC2 インスタンスの一覧を取得する ec2 = session.client('ec2') ec2.describe_instances()
そもそも強い権限を持った アクセスキーをローカル端末に保存するのはセキュリティリスクでしかないという話はある ↩
- 投稿日:2020-04-09T00:53:38+09:00
AttributeError: 'Series' object has no attribute 'isna' 解決法
Python pandas を利用中・・・
Python 実践データ分析100本ノックという本を写経している時、こんなエラーができました!
AttributeError: 'Series' object has no attribute 'isna'
正しく写経しているはずなのに、エラー?
解決方法
原因は、バージョンの問題だった。
Python3.6を使っていましたが、3.7にアップデートしたら動きました。
pandasもアップデートしたけど、Pythonの問題だったらしい。
良かった!
Anacondaの人は以下のコマンドで一発
conda install python=3.7ちなみに・・・
Python3.8でも動きました。
解決はしたけど、なぜかはよくわかってないので、分かる人教えてくださいm(_ _)m
- 投稿日:2020-04-09T00:43:22+09:00
VS Code で Jupyter を動かしてみる
VS Code でJupyter が使えるらしいのでやってみました。
1. 環境
OS:Windows 10
VS Code:1.43.2
拡張機能:Anaconda Extension Pack 1.0.1
Pythonインタープリター:3.7.3 64-bit2. 拡張機能 Jupyterのインストール
3. コードを入力
# %% from matplotlib import pyplot as plt import numpy as np # %% x = np.linspace(-10, 10, 100) # %% y = (x**3) + (5*x**2) + (2*x) # %% print(x) #%% print(y) #%% plt.plot(x, y) plt.show() # %% z = np.sin(x) # %% print(z) # %% plt.plot(x, z) plt.show()4. コードを実行(Run Cell)
5. 参考サイト
https://qiita.com/surei/items/9f25d7efa7c67d55d98f
https://www.atmarkit.co.jp/ait/articles/1806/12/news041.html


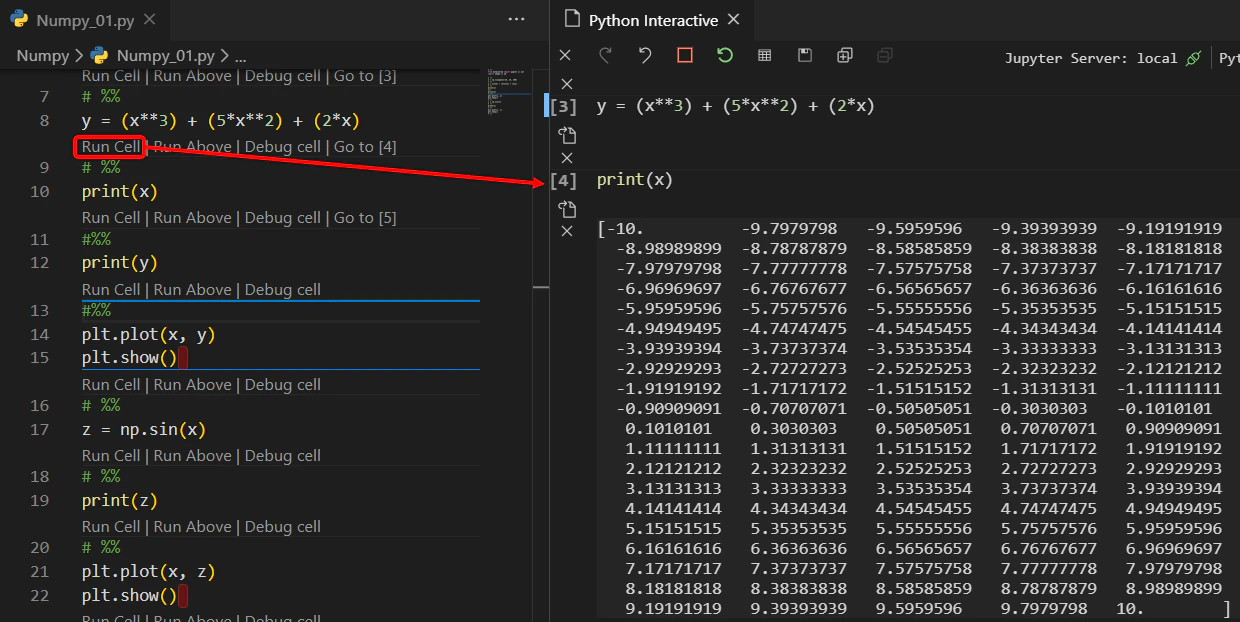




- 投稿日:2020-04-09T00:40:54+09:00
TypeError: Cannot change data-type for object array.
ある日、matplotlibを使用した場合に、こんなエラーが出た。
File "/System/Library/Frameworks/Python.framework/Versions/2.7/Extras/lib/python/numpy/lib/stride_tricks.py", line 119, in broadcast_arrays
zip(args, shapes, strides)]
File "/System/Library/Frameworks/Python.framework/Versions/2.7/Extras/lib/python/numpy/lib/stride_tricks.py", line 32, in as_strided
array.dtype = x.dtype
TypeError: Cannot change data-type for object array.matplotlibを再インストールしたら解決した.
$ pip uninstall matplotlib
$ pip install matplotlib
- 投稿日:2020-04-09T00:03:54+09:00
【Python】三井住友信託銀行プログラミングコンテスト2019C(DPの使いどころさん)【AtCoder】
※この記事は、DP(動的計画法)の基本中の基本である
かえるくん問題2問がとけることを前提としています。DPでとけるんだ!!!
と感動した問題がありましたので記事にします。
DPの考え方は知っているけれども、実際の問題と結びつかない!
という人は参考になるかも(ならないかもw)三井住友信託銀行プログラミングコンテスト2019C
Difficulty:205
問題を読んで、bit全探索や6重for文が一瞬頭をよぎりましたがダメそう。ちなみにDPが思いつかなくても解けます。(記事の最後に別解として載せておきます。)
しかしDPが思いつかなかった場合、
たぶん法則性をみつけるのに15分くらいかかる気がします。レートをあげるには早解きが必須!
DPのメリット
DPのいいところは、(DPに限らずの話ですが)
「この問題、DPで解ける!」と気づいた瞬間、ほぼ脳死でコーディングできる
こと!
するとそこに思考を挟まないので、
このレベルの問題は5分くらいでACを目指せるようになると思います!DPを使えることに気付けるかどうかがポイント!
具体例を考えよう
とにもかくにもノートとペンを用意して、
OKパターン・NGパターンを考えましょう。1~99:NG
100,101,102,103,104,105:OK
106~199:NG
200,201,202,203,204,205,206,207,208,209,210:OK
211~299:NG
300,301,302,303,304,305,306,307,308,309,310,311,312,313,314,315:OK
...なぜ
200~205がOKなのか?
それは、もともとOKの100に100~105を足しているから。
なぜ201~206がOKなのか?
それは、もともとOKの101に100~105を足しているから。
なるほど!
ではもともとOKの200~210それぞれに対して100~105を足せば、それもOKになりそう。あ、DPでいけそう!
0円をOKとしてやれば、もともとOKの0に100~105を足してOKとなる!
うまくいきそう!
あとはコーディングするだけ!!!答え
DPMapのIndex番号だけちょっと考えれば、あとは脳死でいけるはず!
また、問題を読んだ瞬間にDPだとわかればノートとペンも必要なさそう!test.pydef I(): return int(input()) ################################################## X = I() dp = [0]*(X+1) #dpのIndex番号の範囲:0~X dp[0] = 1 #0円をOKとしてやる! for i in range(X+1): if dp[i]: for j in range(100,106): if i+j<=X: #「out of lange」対策。 dp[i+j] = 1 print(dp[-1])DPを使えるかどうかの目安
具体例を順番にあげていくときに、前の値から次の具体例を導き出せる場合
→DPが使えるかどうか考えてみる価値がありそう!!!別解
俺は初見でDPと気づかなかったのでこっちでやりました。
コード量は少ないけど、このコードを導くのに時間がかかると思います。
(こういう法則を見つけるのに慣れてる人はこっちの方が早いのかなぁ)test.pydef I(): return int(input()) ################################################## X = I() a,b = divmod(X,100) print(1 if a*5>=b else 0)おわり!