- 投稿日:2020-04-09T23:40:10+09:00
【Terraform】for_each で AWS SSM パラメータストア に パラメータを一括登録する
はじめに
TerraformでAWSの環境構築を行う際に
for_eachを利用してAWS SSM (System Manager) パラメータストアにパラメータを一括登録する方法を備忘録として投稿させていただきます。terraform
variables.tfvariable "list" { description = "AWS SSM パラメータストアに登録する名前と値のセット" type = map(string) default = { "DB/HOST " = "xxxxx" "DB/USER" = "xxxxx" "DB/PASSWORD" = "xxxxx" "DB/DATABASE" = "xxxxx" } }main.tfresource "aws_ssm_parameter" "list" { for_each = var.list name = "/${each.key}" value = each.value type = "String" }実行結果

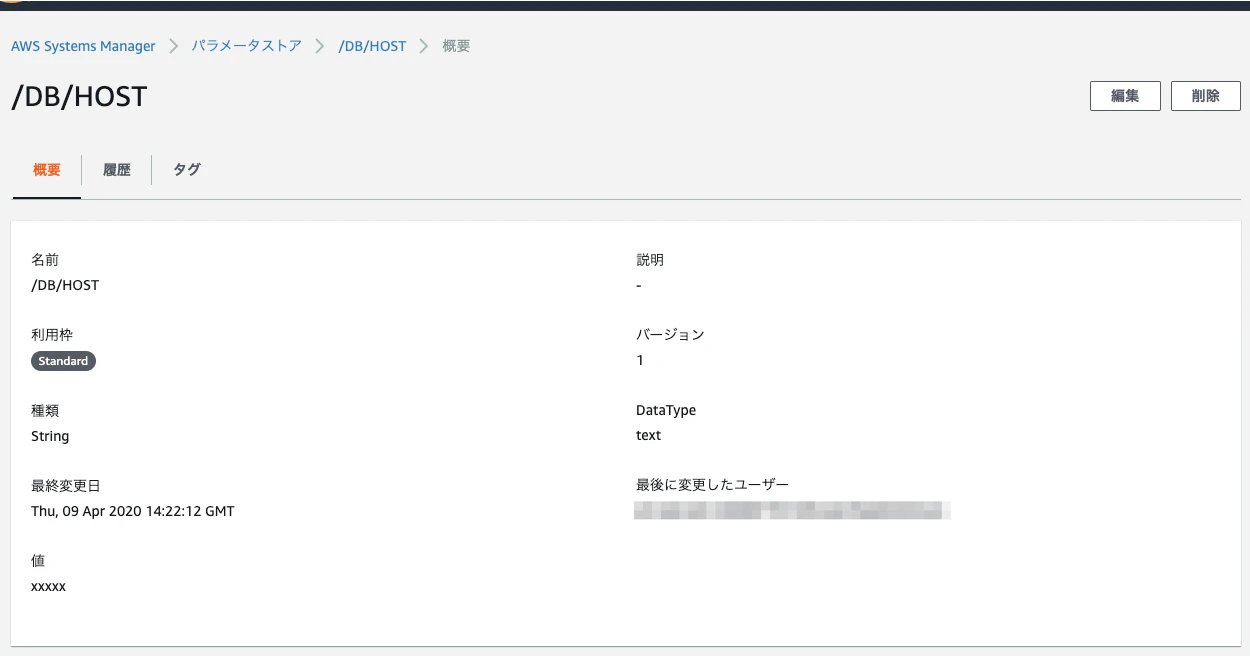
- 投稿日:2020-04-09T21:13:59+09:00
AWSソリューションアーキテクト学習方法
はじめに
本記事は社内でAWSやろうぜ!という空気が生まれたので、
それに伴い作成した学習ガイダンスとして作成しました。
内容は書きすぎず極力シンプルに書いておきます。
※先人様の情報ソースや公式に一杯書いてありますしね。AWS経験
- 提案、製品比較、自己学習で触った程度。ガッツリは触ってないです。むしろ触りまくりたいお年頃。
試験難易度
- 初学者が初受験合格は難しいかもしれない。
- 開き直って一度落ちて感覚掴む程度がちょうど良いかと。 ※一回落ちました。
取得したAWS資格
- AWS 認定ソリューションアーキテクト – アソシエイト
- AWS 認定 SysOps アドミニストレーター – アソシエイト
※次はAWS 認定ソリューションアーキテクト – プロフェッショナルを取得予定。学習方法
◆ポイント
実環境を可能な限り触ること。※必須ではないですが、イメージはつきやすくなると思います。基本編
- 概要→詳細→理解の流れで把握すること。
- 次の流れが一番内容を理解しやすいと思う。
- 概要:Blackbelt資料
- 概要把握だけならこれでもOK。
- 詳細:Udemyの模擬テスト問題
- 過去問題などのユースケース詳細を知る。
- 理解:Udemyの模擬テスト問題
- テスト結果に書かれている解説理解。説明内に公式リンクの説明が書かれているので、それらも合わせて読む。それ以外の情報リソースや実機操作も交えて理解の浅い箇所について補習しておきます。
AWS クラウドサービス活用資料集(Blackbeltシリーズ)
サービス別資料 | AWS クラウドサービス活用資料集
この資料を一通り読めばAWSの概要把握は何とかなると思う。ただ資料が多いため、試験対策や主要サービスだけを抑えたいという目的なら対象は絞ること。Udemyテスト問題
AWS Certified Solutions Architect Associate模擬試験| Udemy
Udemyでは日本/海外などで色々な学習リソースが乱立していますが、個人的には英語ですがJonBonsoさんの模擬問題が一押しです。知ってる限り、2018年のリリース後もメンテナンスが今なお(2020/4時点も)高頻度で続けられており、ただのテスト問題ではなく鍛え上げられた解説に基づいたテスト問題集となっております。
英語なので困ったときはChrome翻訳に任せながら進めば、特に困ることはないと思います。
もし数問やってさっぱりわからないとかであれば、試験を終了させて解説を読んで参考書代わりにしてから再戦した方が良いです。なお、Redditでも結構評判は良かったです。
https://www.reddit.com/r/AWSCertifications/comments/b9gyhp/jon_bonso_practice_exams/TutorialDojo(JohnBonsoさんのラーニングポータル)
TutorialDojo
Udemyで紹介された方のラーニングポータルです。スタディガイドで学習フローを見て、チートシートで各機能単位の詳細を把握できます。これもChrome翻訳に任せましょう。Jayendra's Blog
Jayendra's Blog
過去問を検索すると高確率でヒットします。AWS試験を高得点で試験をクリアした方のブログですが、情報量が多く検索リソースとして秀逸です。Linux Academy
Linux Academy
日本の同名の団体とは別物。比較したことはないですが体系だった内容で学習ができるのがポイントです。ただし有料であり英語のため、翻訳なども駆使しながら英語が何となく読み解ければコスパは良いと思います。新し目の動画であれば字幕表示機能があり(古いものにはついてないのが残念)、少し見にくいですがChrome翻訳によりスクリプト表示枠で翻訳しながら見ることはできるため、英語学習もできます。
※ブラックフライデーのタイミングなどで割引サービスを利用しても年間数万はかかるので要覚悟。ですがAWSだけでなく様々なラーニングコースが充実しているのでスキルの底上げに良いと思います。受験に向けて
申込方法は公式を見れば分かるので、注意をするポイントだけ。
試験会場予約時に「キオスク」と会場の末尾に書いてある会場は要注意。
困ったときは英語チャットで助けを求める必要があるので自信のない人は避けたほうが無難。東京圏内では「銀座CBTS歌舞伎座テストセンター」をおすすめしておきます。
最近受験された方がわかりやすい紹介を書かれていたのでご紹介します。AWS認定試験(ソリューションアーキテクト・アソシエイト)受験しました | たろさん7890のブログ - 楽天ブログ
当然私もお奨めする通常のPC(非キオスク端末)で受験可能です。こちらの試験会場は更に日本語で受付対応してくれるので試験環境周りで困ったときはヘルプしてくれます。
※実は一度ネットワークトラブルでフリーズしたのですが無事再開できました。
これキオスク端末だったら時間内に解決できなかった恐れすらあります。その他
本資格を取得したからと言って、業務に直結するスキルが直ちに身につくわけではありませんが、AWSを使用した業務に携わる際の瞬発力が身につく内容だとは思いますので、取得後は社内外へのアピールや履歴書に書く際、付加価値は多少なりとも上がるのではないでしょうか。また新しく取得したら追記します。
- 投稿日:2020-04-09T20:30:40+09:00
素人がWebサービスを作る備忘録(実装編)①
はじめに
今回は前準備編、設計編の続きです。そちらに筆者のスキルレベルやこの記事の目的などが書いてありますので、先にお読みください。
実装にあたって
ここから実装に入っていくわけですが、稚拙な設計となっている為、かなりの回数の手戻り作業が発生することが見込まれます。その辺りもうまくいかなかった理由と改善策をまとめつつまとめていきたいと思います。
そして、実装にあたり個人的にまとめておきたいと思った昨日の追加などは別途記事にしてまとめていきたいと思います。(その方があとで見返すのとかも楽だし、、、)そして差し当たり、
・ユーザー管理機能
・投稿機能
・投稿一覧、投稿詳細機能
・画像ファイルアップロード機能
・ページネーション機能or無限スクロール機能
・DBテーブルのリレーション管理
・単体、統合テストこの辺のrailstutorialで行った内容を実装し、Webサービスの全体像を作りたいと思います。
基本的に開発環境やデプロイはrailstutorialをなぞる感じで行っていきます。
Railsをインストール
まずはじめに
gem install rails -v 5.1.6というコマンドで使用する。railsのバージョンを指定してインストールします。アプリケーションを立ち上げよう
さて、railsのインストールが終わったらやることはアプリの骨組みを作ることです。
ここではrails newコマンドを使用して骨組みを作成します。
しかし、ここで
No value provided for required arguments 'app_path'
というエラーメッセージが出てきました。これは要は「rails newしかしていません」という意味です。
rails newコマンドは出力先を指定してやらないと実行することはできません。なのでここでは
rails new appなどとしてやるのが正しいやり方です。
(このミスをしたということで筆者のレベル感を分かって頂きたい。。。)Bundler
そしたらここでbundlerを実行して必要なgemをインストールしていきましょう。
「???」
初めて見たときは私はこうなりました。分解して見ていきましょう。
gemというのは誰かが作ってくれた、コンピューターの機能(例えばEnter押すだけで勝手にテストしてくれたり)です。
そして、これをインストールしたりアップデートしたりするgemがbundlerという機能(以下ライブラリと言います。)です。
面白いのはこのbundlerはgemfileとかgemfile.lockなどのgemを使用し他のgemを管理してくれる。ライブラリなのですが自身もgemというところです。はい!ではgemfileをインストールしていきましょう。gemfileにインストールしたいgemとバージョンを書いて(今回はrails tutorialと同じgemで基本行っていきます。)
bundle installを実行します。
ここで「bundle updateをしてください」というエラーメッセージが出た場合はbundle updateした後にもう一度bundle installしましょう。Gitで管理
rails tutorialに倣いGitを使用してバージョン管理を行なっていきたいと思います。
Gitって何や?ってことは記事は書こうと思っています。
とりあえず
ルートディレクトリに戻ってgit initをします。これでローカルリポジトリが作成されました。
そしてリポジトリに追加したいファイルをgit add -Aでインデックスに追加します。(追加されたか確かめたいときはgit statusで確認できます。)
そして、git commitでインデックスに追加しておいたファイルをリモートリポジトリに追加します。この時にgit commit -m "コメント"とすることでlogにコメントを残しておくことができます。Github
rails tutorialではソースコードの完全なバックアップと他の開発者との共同作業のためにはbitbucketを使用していましたが、新しい取り組みとしてGithubを使用して行なっていきたいと思います。
まず、Githubで登録します。そしたら公開鍵と秘密鍵を作成します。
ターミナル$ cd #ホームディレクトリに移動 $ cd .ssh #sshを作るディレクトリに移動 $ ssh-keygen #鍵を作成 Generating public/private rsa key pair. Enter file in which to save the key (/home/ec2-user/.ssh/id_rsa): ここにid_rsaと入力 Enter passphrase (empty for no passphrase): パスフレーズを入力 Enter same passphrase again: 確認の為もう一度入力 Your identification has been saved in id_rsa. Your public key has been saved in id_rsa.pub. . . . #変な絵が出る . . . /.ssh $ ls #ここで秘密鍵と公開鍵が生成されていればおっけい作った後はGithubに公開鍵をコピーしましょう。
ターミナル$ cd ~/.ssh ec2-user:~/.ssh $ ls authorized_keys id_rsa id_rsa.pub $ cat id_rsa.pub #ここに出てくる奴をコピーしてGithubに登録これで公開鍵と秘密鍵の作成とGithubへの登録ができました。
次に新規リポジトリをを作成しました。
そしたらターミナル$ git add -A $ git commit -m "new my_app" $ git remote add origin リモートリポジトリのアドレス $ git push origin masterこれでおっけい
コマンド確認
・git remote add origin ~
リモートリポジトリに反映させる前にリモートリポジトリの情報を追加しておいて、どのリモートリポジトリに反映させるのか明らかにさせておく。
・git remote rm origin ~
上記のコマンドの逆でリモートリポジトリの情報を削除する場合に使う。
・git push origin master
このコマンドでローカルリポジトリに貯めておいた変更履歴をリモートリポジトリにpushする。Heroku
デプロイはHerokuで行います。頻繁に本番環境にデプロイすることによって早い段階でサービスの問題点が発見できます。
Gemfilegroup :development, :test do gem 'sqlite3', '1.3.13' . . end . . . group :production do gem 'pg', '0.20.0' endHerokuはSQLiteをサポートしていないためgemを上記のようにいじっておいてローカルではSQLite、本番環境ではpostgreSQLを使用できるようにしておく。
ターミナル$bundle install --without productionこのようにすることにより開発環境でのpg gem が作動しないようにしておく。
さてHerokuをインストールするにあたり以下のコマンドを実行しておく
ターミナル$ source <(curl -sL https://cdn.learnenough.com/heroku_install)意味は理解できませんがこれでインストールできます。
ターミナル$ heroku login # Herokuにログイン $ heroku create # Herokuに実行環境を構築 $ git push heroku master # Herokuにデプロイこれで作成したURLでブラウザを立ち上げて公開できていたら成功です。
参考
今さら聞けない!GitHubの使い方【超初心者向け】
git remoteを使ってリモートリポジトリの追加と削除を行う方法【初心者向け】
Ruby on Rails チュートリアル 第1章 MVCモデルからGitやHeroku 鍵生成までの流れを解説
- 投稿日:2020-04-09T20:02:36+09:00
FargateからのEFSマウントを試す
EFSがFargateで使えるようになったようです。
https://aws.amazon.com/jp/about-aws/whats-new/2020/04/amazon-ecs-aws-fargate-support-amazon-efs-filesystems-generally-available/これはストレージ依存を脱しきれないもろもろのコンテナ化が捗りますね!
というわけで軽く動作確認してみました。
試す構成
最小限の手間で、FargateのコンテナからEFSの中身が読めていることを確認します。
- Fargateでhttpdコンテナを起動し、web閲覧できるようにしておく
- コンテナはドキュメントルートにEFSをマウントしておく
- 編集確認用にEC2を用意&EFSをマウントしておく
この状態を作った上でEC2からEFS内のファイルを読み書きし、httpdをweb経由で閲覧することでFargateコンテナからEFSが読めることを確認します。
なお、通常Fargateをweb公開する際はALBを経由しますが、ここでは一時的なテスト目的のためコンテナのパブリックIPにブラウザで直接アクセスするかたちをとります。httpdなFargateを作る
EFSを試す下準備として、まずはただのhttpdをweb経由で閲覧できるようにします。
Fargateタスク定義
※ECSクラスタは適当に作っておきます
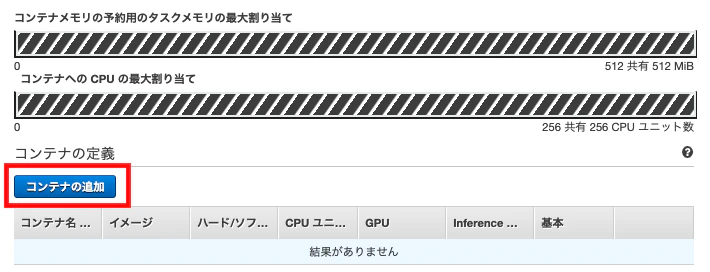
Fargate起動タイプでタスク定義を作成します。現時点ではEFS読み取りもせず、かつDockerHubのパブリックイメージを使用するためタスクロール・タスク実行ロールともに無しで問題ありません。
「コンテナの追加」では、適当なコンテナ名・イメージ(httpd)・ポートマッピング(80)を設定します。
また、デフォルトではCloudwatchLogsへのログ出力が設定されているため、「ストレージとログ」欄にある「Auto-configure CloudWatch Logs」のチェックを外しておきます。1タスクの実行
タスク定義が作成できたら、タスクを実行します。タスクの実行画面にて、
- 作成したタスク定義
- 適当なVPCとサブネット
- ご自身のグローバルIPから80ポートへアクセス可能なセキュリティグループ
- パブリックIPの自動割当: ENABLED
でタスク実行します。ここでは、VPCはAWSアカウントデフォルトのものを使います。2
閲覧確認
タスクの実行ダイアログを完了するとクラスタのタスクリストにコンテナが出現するのでRUNNINGになるまで待ちます。3
RUNNINGになったらタスク詳細ページに行き、パブリックIPの欄にあるIPをコピー&ブラウザのアドレスバーに貼り付けます。
見慣れた「It works!」が見えたらokです。コンテナにEFSをマウントする
コンテナの閲覧確認ができたら、本命のEFSをマウントします。
EFSファイルシステムを作成する
マウント対象のファイルシステムを作成します。
EFSのページに行き、ファイルシステムの作成より進みます。
VPCなどはデフォルトのまま2、ほかも特別な設定はせず作成を完了させます。マウント用のIAMロールを作成する
Fargateの設定に進む前に、タスクロールとして指定するIAMロールを作成します。
IAMロール作成画面にて
- ユースケース: Elastic Container Service -> Elastic Container Service Task
- 権限ポリシー: AmazonElasticFileSystemClientReadOnlyAccess
でロールを作成します。
EFSマウント用にタスク定義を設定する
最初に作成したタスク定義から新しいリビジョンを作成します。変更点は
- タスクロールに先程作成したロールを指定
- ボリューム欄にてボリュームの追加を行い、作成したEFSを指定する
- 名前・ボリュームタイプ・ファイルシステムIDが指定されてればok
- コンテナ定義のストレージとログ欄にて、マウントポイントを指定しコンテナパスを
/usr/local/apache2/htdocsにするとなります。
新しいタスク定義を起動&閲覧する
タスク定義を更新したら、前回起動したコンテナを破棄し新しい定義のコンテナを起動します。
起動時の設定のポイントは以下です:
- 「プラットフォームのバージョン」を明示的に(LATESTではなく)1.4にする
- セキュリティグループには先程の80ポートのものに加え、VPCデフォルトのものを追加しておく2
ポイントは一つ目のプラットフォームバージョンです。
4/9現在、LATESTは1.3を指しているため、EFSを使う場合は1.4を明示的に指定しないと起動時にエラーとなります。自分は最初このあたりでハマっていたのですが、twitterで丁寧に教えていただきました。関連ツイートも参考になります。
https://twitter.com/toricls/status/1248122352174424064
https://twitter.com/toricls/status/1247975937074843648タスクが起動し、コンテナIPをブラウザから閲覧して
Index of /が見えていれば成功です。
ドキュメントルートを空ディレクトリ(EFS)でマウントしたため、デフォルト設定にてDirectoryIndexが見える想定です。EFSのファイルを編集してみる
適当なEC2インスタンスからEFSをマウントし、ファイルの書き込みを行います。
AmazonLinux (1 or 2) のIAMかつssh用+VPCデフォルトのセキュリティグループ2を付与してEC2インスタンスを起動します。
EFSのマウント手順の詳細は省略しますが、ここでは手軽に以下を実行します:
sudo yum install amazon-efs-utils sudo mount -t efs fs-xxxxxxxx:/ /opt
/optにマウントしているため、ここに適当にテストファイルを配置します:echo 'efs works!' | sudo tee /opt/index.htmlこの状態でFargateコンテナのIPにアクセスし、上記の通り「efs works!」が表示されていれば成功です。
補足: ネットワーク周りについて
ここでは設定の手間を省略するためにFargate・EFS・EC2すべてでデフォルトVPC&defaultセキュリティグループを使いましたが、
本来必要な要件は「Fargateコンテナ(やEC2)からEFSにTCP/2049の通信が通ること」です。特に難しくはないのでセキュリティグループを設定してもよいのですが、今回はテストなので略しました。
まとめ
プラットフォームバージョンの注意点はありますが、他には特にトリッキーな設定やCLIでしかできない設定などはなく、AWSコンソールからポチポチするだけで簡単に使える状態になっていました。
今後もFargateが捗りますね!
- 投稿日:2020-04-09T19:50:15+09:00
AWS FargateだとNLB経由のClient IPアドレスは記録されない?
お久しぶりです。ついに在宅勤務になったstreampackのfadoです。個人的には会社の方が色々と作業等捗るのですが在宅なら人との接触7~8割減という目標が達成できそうでいいのかもしれません。出社もそうですがここ最近、当たり前のことがそうではなくなり、まだまだ厳しい状況が続いていくのだろうと思うと不安は拭えないですね。
今回は当たり前だと思っていた
Network Load Balancerの挙動がAWS Fargateを挟むとうまくいかなかった、それにまつわるお話を共有したいと思います。背景
Client側がfirewallのルールなどにより特定のIPアドレスにしかアクセスできないシチュエーションに対応するため、静的IPアドレスをサポートする
Network Load Balancerを採用しました。それに加え、アプリケーション側でログや統計の解析のためClient IPアドレスをそのまま保持したかったのですが、アプリケーションのログに
Network Load BalancerのプライベートIPアドレスが記録されていた問題に直面しました。調べても有力な情報があまり見つからなかったので色々と検証して解決にたどり着きました。同じく壁にぶち当たった方々のために参考になれば何よりです!
リソースと構成
検証環境は
AWS上で構築しました。
- Clientの送信元IPアドレス(以下 Client IPアドレス)
Elastic Load Balancer(以下ELB)の種類の一つであるNetwork Load Balancer(以下NLB)Amazon ECSAWS Fargate- Dockerコンテナアプリケーション:
nginx(以下AWS Fargate(nginx))- Webアプリケーション:
nginx
NLBの詳細設定とAmazon ECSのセットアップ等は割愛させて頂きます。原因
色々と調べた結果、原因は
NLBの仕様によるもので、NLBのターゲットグループの種類が IP であることが分かりました。
NLBで設定するターゲットグループのターゲットの種類によって保持するClient IPアドレスが変わってきます。
ターゲットの種類が、1.インスタンス ID の場合はClient IPアドレス
2.IP の場合はNLBのプライベートIPアドレスが保持され、アプリケーションに提供されます。
Amazon ECSにて起動タイプとしてAWS Fargate、かつNLBを利用する際、ターゲットグループが自動的に作成され、ターゲットの種類がIPとなります。対処法
NLBのProxy Protocol機能を使い、Proxy ProcotolのヘッダーからClient IPアドレスを抽出し、Webアプリケーションに渡せるようにしました。手順
まずはアプリケーション側で
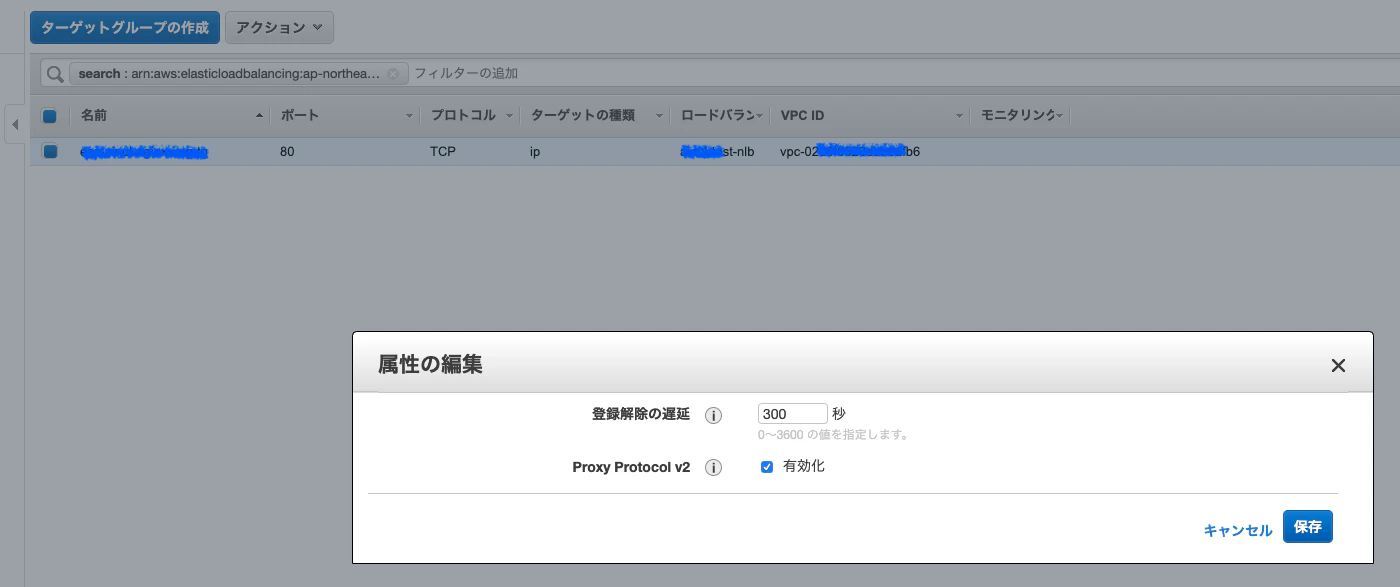
Proxy Protocolに対応していることを確認します。サポートしていないとエラーが出ますのでご注意ください。1.ターゲットグループでProxy Protocol v2を有効にします。
対象NLBのターゲットグループから[属性の編集] -> [Proxy Protocol v2]の有効化にチェック
*反映まで数分かかる場合があります。2.
AWS Fargate側のコンテナアプリケーションをProxy Protocolに対応させます。
今回のアプリケーションはnginxです。nginx.confのserverディレクティブ内を下記を追加
nginx.confserver { listen 80 proxy_protocol; server_name _; set_real_ip_from XXX.XXX.XXX.XXX; ←適宜変更 real_ip_header proxy_protocol; real_ip_recursive on; location / { proxy_pass http://YYY.YYY.YYY.YYY; ←適宜変更 proxy_set_header Host $host; proxy_set_header X-Real-IP $proxy_protocol_addr; proxy_set_header X-Forwarded-For $proxy_protocol_addr; }
- proxy_protocol
- 必須
nginxがProxy Protocolヘッダーを受け付けられるように listenディレクティブに追加- set_real_ip_from
- 必須
- IPアドレス、CIDR、ホスト名を設定可能
- 指定されたIPアドレス以外からはCLient IPアドレスの上書きは許可しません
NLBのプライベートIPアドレスか、NLBのあるVPCを指定。セキュリティー上0.0.0.0/0は避けましょう- real_ip_header
AWS FargateのログにもClient IPを記載したい場合なら必須- Client IPアドレスを上書きする際に使うリクエスヘッダー
- real_ip_recursive
- 任意だがセキュリティー上、あった方が望ましいです
- set_real_ip_fromと一緒に設定
- リクエストヘッダーにIPアドレスが複数ある場合どれを利用するかを設定
- $proxy_protocol_addr
- proxy_protocolを有効にするとClient IPアドレスがこの関数に格納されます
3.proxyされるアプリケーションでの設定
今回のアプリケーションはnginxです。自分の環境に合わせてserverディレクティブに下記行を追加します。
nginx.confset_real_ip_from ZZZ.ZZZ.ZZZ.ZZZ; ← 適宜変更 real_ip_header X-Forwarded-For; real_ip_recursive on;
- set_real_ip_fromは
AWS Fargate(nginx)のプライベートIPアドレスを指定- real_ip_headerは
AWS Fargate(nginx)で設定したproxy_set_headerを指定- real_ip_recursiveはonの場合、Client IPアドレスはreal_ip_headerで送られてきた最後のIPになります。offの場合、Client IPアドレスはset_real_ip_fromに指定されていない最後のIPになります。
結果
Webアプリケーションの
nginxのログにClient IPアドレスが記録されていることを確認できました。
*グローバルIPアドレスは加工してあります。■
AWS Fargate(nginx)のログ
■Webアプリケーションのログ
access.log210.227.xxx.xxx - - [31/Mar/2020:13:55:28 +0900] "GET /player.html HTTP/1.0" 200 395 "-" "curl/7.54.0" "210.227.xxx.xxx" "210.227.xxx.xxx" 210.227.xxx.xxx - - [31/Mar/2020:13:57:17 +0900] "GET /player.html HTTP/1.0" 200 395 "-" "curl/7.54.0" "210.227.xxx.xxx" "210.227.xxx.xxx" 3.84.xxx.xxx - - [31/Mar/2020:13:57:34 +0900] "GET /player.html HTTP/1.0" 206 395 "-" "Slackbot-LinkExpanding 1.0 (+https://api.slack.com/robots)" "3.84.xxx.xxx" "3.84.xxx.xxx" 113.43.xxx.xxx - - [31/Mar/2020:13:58:06 +0900] "GET /player.html HTTP/1.0" 200 395 "-" "Mozilla/5.0 (iPhone; CPU iPhone OS 13_4 like Mac OS X) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/13.1 Mobile/15E148 Safari/604.1" "113.43.xxx.xx" "113.43.xxx.xx"追加検証
NLBはインスタンス ID を使用してターゲットを指定すると、Clientの送信元 IP アドレスが保持され、Targetに渡されます。せっかくなのでこの挙動も検証したいと思います。構成
Client(http) -> NLB(8081/tcp) -> Target(80/tcp)
*こちらの都合で検証時80ポートは既に使用済みなので8081ポートにしました。
- Client側
- グローバルIPアドレス: 210.227.xxx.xxx
- プライベートIPアドレス: 192.168.2.253
NLB側
- Listener: 8081
- URL: xxxx-test-nlb-f3xxxxxx.elb.ap-northeast-1.amazonaws.com
- グルーバルIPアドレス: 13.113.xxx.xxx
- プライベートIPアドレス: 10.16.1.11
Target側
- グローバルIPアドレス:13.231.xxx.xxx
- プライベートIPアドレス: 10.16.1.13
テストとしてClient側でcurlコマンドを実行し、Client側とTarget側でtcpdumpを実施します。
$ curl -I http://xxxx-test-nlb-f3xxxxxx.elb.ap-northeast-1.amazonaws.com:8081/■Target側のtcpdump
送信元IPアドレスはClient側のグローバルIPアドレスであることを確認できました。$ sudo tcpdump -XX -p -n -i eth0 src 210.227.xxx.xxx |grep -v ssh tcpdump: verbose output suppressed, use -v or -vv for full protocol decode 12:14:15.614152 IP 210.227.xxx.xxx.32507 > 10.16.1.13.http: Flags [S], seq 3069243899, win 65535, options [mss 1360,nop,wscale 6,nop,nop,TS val 133874316 ecr 0,sackOK,eol], length 0 0x0000: 06db acd0 82e8 06d4 4729 9c6c 0800 4500 ........G).l..E. 0x0010: 0040 0000 4000 2606 8c45 d2e3 ea72 0a10 .@..@.&..E...r.. 0x0020: 010d 7efb 0050 b6f0 f1fb 0000 0000 b002 ..~..P.......... 0x0030: ffff 7c2e 0000 0204 0550 0103 0306 0101 ..|......P...... 0x0040: 080a 07fa c28c 0000 0000 0402 0000 ..............■Client側のtcpdump
Target側のIPアドレスではなく、NLBのグローバルIPアドレスでリクエストを返されたことを確認できました。$ sudo tcpdump -XX -p -n -i utun1 src 13.113.xxx.xxx tcpdump: verbose output suppressed, use -v or -vv for full protocol decode listening on utun1, link-type NULL (BSD loopback), capture size 262144 bytes 12:31:24.430760 IP 13.113.xxx.xxx.8081 > 192.168.2.253.61858: Flags [S.], seq 3834156092, ack 3564724080, win 26847, options [mss 1460,sackOK,TS val 1006342388 ecr 134891930,nop,wscale 7], length 0 0x0000: 0200 0000 4508 003c 0000 4000 e906 02cf ....E..<..@..... 0x0010: 0d71 bdce c0a8 02fd 1f91 f1a2 e488 943c .q.............< 0x0020: d479 5f70 a012 68df 73b4 0000 0204 05b4 .y_p..h.s....... 0x0030: 0402 080a 3bfb 90f4 080a 499a 0103 0307 ....;.....I.....結論
ELBの一種であるNLBはターゲットグループの種類によって保持する送信元IPアドレスが変わります。種類がインスタンス IDの場合は送信元IPアドレスがClient IPアドレスになりますが種類がIPの場合は
NLBのプライベートIPアドレスになります。自分が想定したIPアドレスがログなどに記録されていない時は上記をご確認下さい。それでは皆さま、くれぐれも手洗いうがい等お忘れなく、ご自愛ください。
参考文献
https://docs.aws.amazon.com/ja_jp/elasticloadbalancing/latest/network/load-balancer-target-groups.html#target-type
https://docs.aws.amazon.com/ja_jp/elasticloadbalancing/latest/network/load-balancer-target-groups.html#proxy-protocol
https://docs.nginx.com/nginx/admin-guide/load-balancer/using-proxy-protocol/
http://nginx.org/en/docs/http/ngx_http_realip_module.html


- 投稿日:2020-04-09T17:25:52+09:00
mithrilとbulmaを使ったSingle Page Application(SPA)開発環境のテンプレ
画面イメージ
ご紹介したいこと
- mithrilを使うとページを高速に切り替える事ができます。
- mithrilは、WEBブラウザ上で稼働するクライアントサイドのjavascriptライブラリです。
- mithrilで作ったサービスは、コストの低いS3で24時間/365日提供が可能です。
開発環境について
- 開発サーバーは、Amazon EC2上に作成します。
- vscodeのremote-sshまたはssh上でtmuxとvimを使って開発します。
- 開発サーバーは、お金がかからないよう利用しない時間には停止させます。
仕上がり予定
tree├── LICENSE ├── README.md ├── package-lock.json ├── package.json ├── src │ ├── home │ │ └── HomeView.js │ ├── index.js │ ├── menu.js │ ├── page1 │ │ └── Page1View.js │ └── style.scss └── webpack.config.js
手順1: 開発サーバーの作成
- この本を参考にEC2上のサーバーにssh。
- windows10のsshは権限設定が難解です。ssh-keygenで作ったid_rsaをコピーしてec2.devとconfigを作るのが簡単です。
.ssh/configHost dev HostName ec2-XXX-XXX-XXX-XXX.ap-northeast-1.compute.amazonaws.com User ec2-user IdentityFile ~/.ssh/ec2.dev
手順2: nvmの導入
- nvmは、バージョンを指定してnode.jsを導入するツールです。
- github掲載の手順に従って、ec2上の開発サーバーにnvmを導入します。
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.35.3/install.sh | bash
手順3: node.jsの導入
新しく起動したbashで以下を導入します。
- node.jsおよびnpm
- git
- tmuxまたはvscode
nvm install --lts sudo yum -y install git tmux
手順4: npmでのプロジェクト初期化
- githubなどにプロジェクトを作成します。
- 開発サーバーの適切な場所にレポジトリをcloneします。
- 次のコマンドでnode.jsプロジェクトを初期化します。
npm init -y
手順5: パッケージの導入
- バンドラとしてwebpackを導入します。
- cssライブラリのbulmaを導入します。
- JSX処理のためにbabelを導入します。
npm install webpack webpack-cli node-sass --save-dev npm install mithril bulma bulma-tooltip --save npm install @babel/core @babel/preset-env @babel/plugin-transform-react-jsx --save-dev
手順6: bulmaの導入
- scssファイルを作成します。
./src/style.scss@charset "utf-8"; // Import a Google Font @import url('https://fonts.googleapis.com/css?family=Noto+Sans+JP|Nunito&display=swap'); @import "bulma"; @import "bulma-tooltip";
手順7: mithrilの導入(1/4)
- 詳細はルーターの説明を参照
./src/index.jsimport './style.scss' import m from 'mithril' import HomeView from './home/HomeView' import Page1View from './page1/Page1View' m.route(document.body, "/", { "/": HomeView, "/page1": Page1View, })
手順7: mithrilの導入(2/4)
./src/home/HomeView.jsimport m from 'mithril' import Menu from '../menu' class HomeView { view() { return m(".section",[ m(Menu), // MenuをPageと共有している。 m("h1", { class: "title" }, "Home") ])} } export default HomeView;
手順7: mithrilの導入(3/4)
./src/page1/Page1View.jsimport m from 'mithril' import Menu from '../menu' class Page1View { view() { return m(".section",[ m(Menu), // MenuをHomeと共有している。 m("h1", { class: "title" }, "Page 1") ])} } export default Page1View;
手順7: mithrilの導入(4/4)
./src/menu.jsimport m from 'mithril' class Menu { view() { return m("nav", { class: "section" }, [ m(m.route.Link, { href: "/", class: "button" }, "Home"), m(m.route.Link, { href: "/page1", class: "button" }, "Page 1"), ]) } } export default Menu;
手順8: webpackの導入
npm install html-webpack-plugin --save-dev npm install clean-webpack-plugin --save-dev npm install sass-loader css-loader style-loader --save-dev npm install babel-loader --save-dev
./webpack.config.js(ver.1)var { CleanWebpackPlugin } = require('clean-webpack-plugin') var HtmlWebpackPlugin = require('html-webpack-plugin') module.exports = { plugins: [ new CleanWebpackPlugin(), new HtmlWebpackPlugin({ title: "femtogram", filename: "index.html" }) ], module: { rules: [ { test: /.\.scss$/, exclude: /\/node_modules\//, use: ['style-loader', 'css-loader', 'sass-loader'] }, { test: /.\.js$/, exclude: /\/node_modules\//, use: ['babel-loader'] } ]}, optimization: { splitChunks: { name: "vendor", chunks: "initial"} } }
手順9: ここまでの確認
- ここまでで、npx webpackするとdistディレクトリにトランスパイル結果が出力されます。
- うまくいったら以下スクリプトを設定します。
./package.json"scripts": { "start": "webpack --mode development --watch", "build": "webpack --mode production" }
手順10: WEBサーバーの導入
- webpack-s3-pluginを導入します。
npm install webpack-s3-plugin dotenv --save-devwebpack.config.js(ver.2)require('dotenv').config(); // 追加。パスワード秘匿のため。 var S3Plugin = require('webpack-s3-plugin'); // 追加 var { CleanWebpackPlugin } = require('clean-webpack-plugin'); var HtmlWebpackPlugin = require('html-webpack-plugin'); ...
webpack.config.js(ver.2)module.exports = { ... plugins: [... new S3Plugin({ include: /.*\.(html|js)/, s3Options: { accessKeyId: process.env.AWS_ACCESS_KEY_ID, secretAccessKey: process.env.AWS_SECRET_ACCESS_KEY, region: 'ap-northeast-1' }, s3UploadOptions: { Bucket: 'femtogram'} }), ... ] ... };
手順11: AWSアクセスコードの登録
- .gitignoreに.envを登録し、パスワード等をレポジトリに登録しないよう設定します。
.envAWS_ACCESS_KEY_ID=XXXXXXXXXXXX AWS_SECRET_ACCESS_KEY=XXXXXXXXXXXXXXXXXXXXXXXX
手順12: S3での設定(1/3)
手順12: S3での設定(2/3)
手順12: S3での設定(3/3)
手順12: S3での設定(3/3)
- ここはマニュアル作業です。
- versionは、AWS側の形式につけられたものです。今日の日付などにするとエラーになります。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "PublicReadForGetBucketObjects", "Effect": "Allow", "Principal": "*", "Action": "s3:GetObject", "Resource": "arn:aws:s3:::femtogram/*" } ] }
開発開始
- s3のStatic Web Site設定画面に記載されたURLで仕上がりを確認します。
- npm startの稼働中にsrc下のソースを変更すると上記サイトに反映されます。



- 投稿日:2020-04-09T16:51:37+09:00
クロスアカウントで s3 バケットを非同期コピーするコンテナを定時実行する
1. はじめに
こんな感じで S3 バケットのバックアップを定期的に取りたい。
- バックアップ元の S3 バケットとバックアップ先の S3 バケットを異なるAWSアカウントにしたい。
- バックアップ元の S3 でオブジェクトファイルが削除されても、バックアップ先のオブジェクトファイルでは削除したくない。
- バックアップバッチ用のEC2(常時起動)ではなく、コンテナ(バックアップ処理時間だけ起動)で実行したい。
S3 の レプリケーション機能で実現できるかどうか少し調べてみたけど、次の理由で今回は見送りした。
- バックアップ元の S3 バケットにはすでにオブジェクトが入っている。
- 既存のオブジェクトをレプリケーションする場合は、AWS サポートへ対応を依頼しないといけない。
- レプリケーションがいつ開始されるのか不明(参考:いつの間に!?既存オブジェクトを S3 レプリケーション出来るようになっていた!)。
2. 構成図
3. 概要
3.1. バックアップ元側の AWS アカウント
AWSアカウント
- example-1
アカウントID
- 111111111111
バックアップ元S3バケット
- バケット名: original-111111111111
- 「パブリックアクセスを全てブロックする」設定をチェックする。
- バージョニング設定は任意(停止でもよい)。
Role
- Containerに割り当てる。
- バックアップ元S3バケット original-111111111111 に対して、 「s3:ListBucket」 と 「s3:GetObject」 を許可する。
- バックアック先S3バケット backup-222222222222 に対して、 「s3:ListBucket」 と 「s3:PutObject」 を許可する。
ECR
- リポジトリ名: infra-batch-repository
- 作業PCで作成したバックアップバッチ用のコンテナイメージを登録する。
ECS
- ECSクラスター名: infra-batch
- 起動タイプ: Fargate
Fargate, Container
- CloudWatchイベントのトリガで ECR からイメージを取得して、パブリックサブネット内にコンテナを作成して、s3 sync を実行する。
- s3 sync を実行する Container は外部ネットワークへ出ていける環境で起動する。
- パブリックサブネット
- Security group の アウトバウンド はすべてを許可する
- パブリック IP の自動割り当ては 「ENABLED」 にする
3.2. バックアップ先側の AWS アカウント
AWSアカウント名
- example-2
アカウントID
- 222222222222
バックアップ先S3バケット
- バケット名: backup-222222222222
- 「パブリックアクセスを全てブロックする」設定をチェックする
- バージョニング設定は任意(停止でもよい)
- バケットポリシーで、AWSアカウント example-1(111111111111) の Role にアクセス権限を付与する。
- バックアップオブジェクトは S3 スタンダード-IA クラスに保存する(s3 sycn 実行時に 「--storage-class STANDARD_IA」 を指定)。
4. 設定
4.1. Container に割り当てる Role を作成 (バックアップ元側の AWS アカウントでの作業)
- IAMポリシー作成
- 名前: s3-sync-backup
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:ListBucket", "s3:GetObject" ], "Resource": [ "arn:aws:s3:::original-111111111111", "arn:aws:s3:::original-111111111111/*" ] }, { "Effect": "Allow", "Action": [ "s3:ListBucket", "s3:PutObject" ], "Resource": [ "arn:aws:s3:::backup-222222222222", "arn:aws:s3:::backup-222222222222/*" ] } ] }
- IAMロール作成
- 名前: s3-sync-backup
- 信頼されたエンティティ: ecs-tasks.amazonaws.com
- アタッチするポリシー: s3-sync-backup
4.2. バックアップ先 S3 バケットの バケットポリシー (バックアップ先側の AWS アカウントでの作業)
- AWSアカウント example-2 (222222222222) の S3 バケット backup-222222222222 への 「s3:ListBucket」 と 「s3:PutObject」 の許可権限を、AWSアカウント example-1 (111111111111) の Role s3-sync-backup に付与する。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::111111111111:role/s3-sync-backup" }, "Action": [ "s3:ListBucket", "s3:PutObject" ], "Resource": [ "arn:aws:s3:::backup-222222222222", "arn:aws:s3:::backup-222222222222/*" ] } ] }4.3. ECR リポジトリ作成 (バックアップ元側の AWS アカウントでの作業)
- 詳しい設定方法は割愛。
- ここでは、「infra-batch-repository」というリポジトリを作成して利用する。
4.4. コンテナイメージを作成して、ECRへプッシュする (作業PCでの実施)
- Dockerfile
- 最近リリースされた 「AWS CLI v2 Docker image」 を使う。
FROM amazon/aws-cli:latest ENTRYPOINT ["aws"] CMD ["s3","sync","--dryrun","--storage-class STANDARD_IA","s3://original-111111111111","s3://backup-222222222222"]
- タグを付けてビルドする
$ docker build -t infra-batch-repository:s3-sync-backup .
- ECRにプッシュするためのタグを付ける
$ docker tag infra-batch-repository:s3-sync-backup 111111111111.dkr.ecr.ap-northeast-1.amazonaws.com/infra-batch-repository:s3-sync-backup
- AWS ECR レジストリ用の docker login 認証コマンド文字列(12時間有効な認証トークン)を取得する
$ aws ecr get-login --no-include-email $ docker login -u AWS -p 認証トークン
- イメージを ECR へ プッシュする
$ docker push 111111111111.dkr.ecr.ap-northeast-1.amazonaws.com/infra-batch-repository:s3-sync-backup4.5. ECSクラスター作成 (バックアップ元側の AWS アカウントでの作業)
- 「AWS Fargate を使用」 を利用する。
- クラスター名
- infra-batch
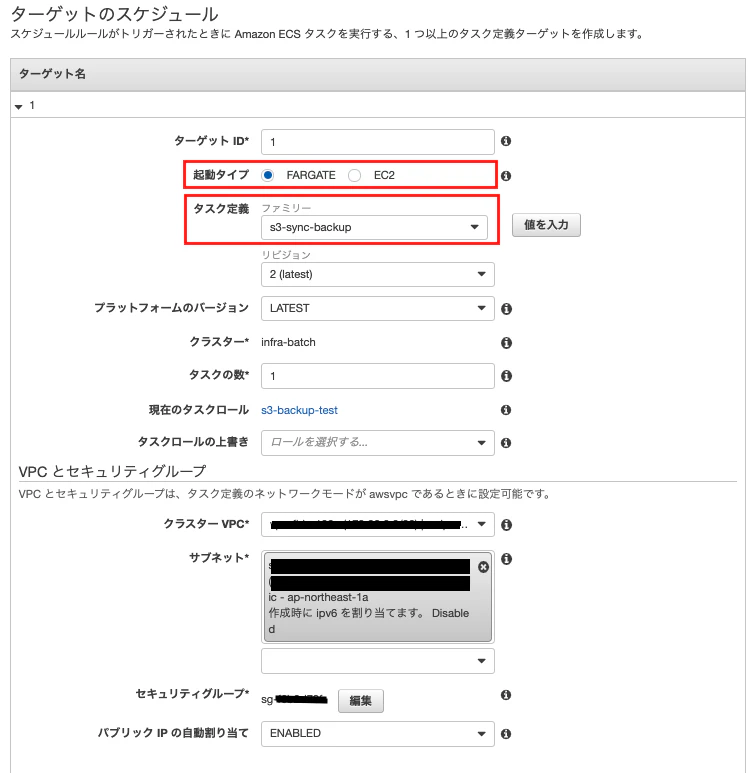
4.6. タスク定義を作成
↓
↓
↓
↓
↓
↓
確認
4.7. タスクスケジュールを作成
↓
Cron式の設定は UTC なので、 cron(0 19 * * ? *) は日本時間で 毎日04:00
サブネットは、任意のパブリックサブネットを指定する
セキュリティグループは、アウトバウンドをすべて許可の設定になっている任意のものを指定する。
パブリック IP の自動割り当ては「ENABLED」にする。
↓
確認
※CloudWatch のイベントルールや、Amazon EventBridge のイベントルールにも設定が反映される。5. タスク実行のログ
- 実行ログは CloudWatch のロググループの /ecs/s3-sync-backup に出力される
- ログの例

6. 注意点
s3 sync の動作確認は、--dryrun オプションを付けて実行し、実行ログから挙動が正しいか確認する。
- --dryrun: Displays the operations that would be performed using the specified command without actually running them.
バックアップ元のS3バケットのオブジェクト数やサイズが多い場合は、最初の s3 sync (フルサイズバックアップ)は作業PC上から s3 sync を実行した方がよい。
$ s3 sync --dryrun --storage-class STANDARD_IA s3://original-111111111111 s3://backup-222222222222 <ログ確認> $ s3 sync --storage-class STANDARD_IA s3://original-111111111111 s3://backup-222222222222











- 投稿日:2020-04-09T14:34:56+09:00
AWS Lambda + API Gatewayで世界へこんにちはする
はじめに
サーバーレスってなんだろう?
という疑問を解決すべく、ある程度勉強したのちにAWS Lambda + API Gatewayで遊んでました。
その中で、とりあえず LambdaとAPIGatewayの使い方はなんとなくわかってきたので、基本であるHello Worldをやってみます!手順
(1)AWS Lambdaで関数を作成
「関数を作成」をクリックします
「1から作成」を選択します。今回は、関数名を「helloWorld」とします。
「関数コード」で「コードをインラインで編集」を選択し、下記コードを入力
exports.handler = async (event) => { // TODO implement const greeting = "Hello World!!" return greeting; };入力後関数を保存します。
テストイベントに関しては、今回は使用しません。
こちらを使用すれば、eventオブジェクトに入るプロパティを作成することができます。
POSTを使用する際に使うのかもしれませんが、まだわかっていません(笑)(2)API GatewayでAPIを作成、デプロイ
「APIを作成」をクリックします。
API名はなんでもいいです。
今回はわかりやすく「HelloWorldAPI」とします。
「リソースを作成」を選択します。
ここでURL規則を設定することができます。今回は「/hello」を追加します。
「〜〜/hello」をいうURLに対しての処理をLambdaに作成した関数にやらせることとなります。
「メソッドを作成」をクリックし、GETを選択します。
Lambda関数名を入力するフォームに。先ほど作成した「helloWorld」関数を入力します。
「APIのデプロイ」を選択します。
ステージ名はなんでも良いです。
(3)curlでテスト
デプロイした際に使用できるURLが表示されるかと思います。
それを使ってcurlでGETメソッドを送ってみましょう。$ curl -X GET https://○○○.amazonaws.com/dev/hello "Hello World!!"終わり
おしまい。
DynamoDBの接続とか、POSTメソッドとかやってみるともっと面白いですね。
DynamoDBの接続はなぜかうまくいかないため苦戦中。






- 投稿日:2020-04-09T14:20:14+09:00
NATゲートウェイを使おうとしたら何か勘違いしていた
プライベートサブネットからインターネットへアクセスする方法としてNATゲートウェイが利用できます。
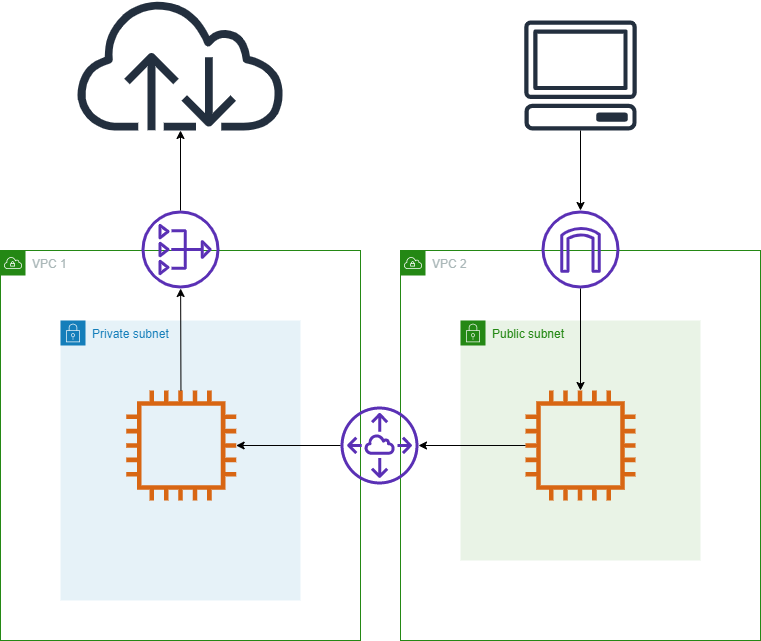
特殊なAMIを使うことでNATインスタンス(実はEC2インスタンス)をつくる方法もありますが、AmazonではNATゲートウェイの方を推奨しているみたいなのでこちらを紹介します。構築した検証環境
NATゲートウェイの使い方をあまり調べずに安直に下の図のような構成を作ろうと考えました。
NATインスタンスではパブリックサブネットに新しくインスタンスを作って設定を変えなきゃいけないのに、NATゲートウェイではプライベートサブネットの0.0.0.0/0のターゲットをNATゲートウェイのIDにするだけでいいんだ。
そんな誤った考えで検証環境を構築し、ping amazon.comを実行しましたが当然帰ってきません。
traceroute amazon.comを実行するとNATゲートウェイの内向きのIPアドレスまでは帰ってきますが、それより先は帰ってきませんでした。改良した検証環境
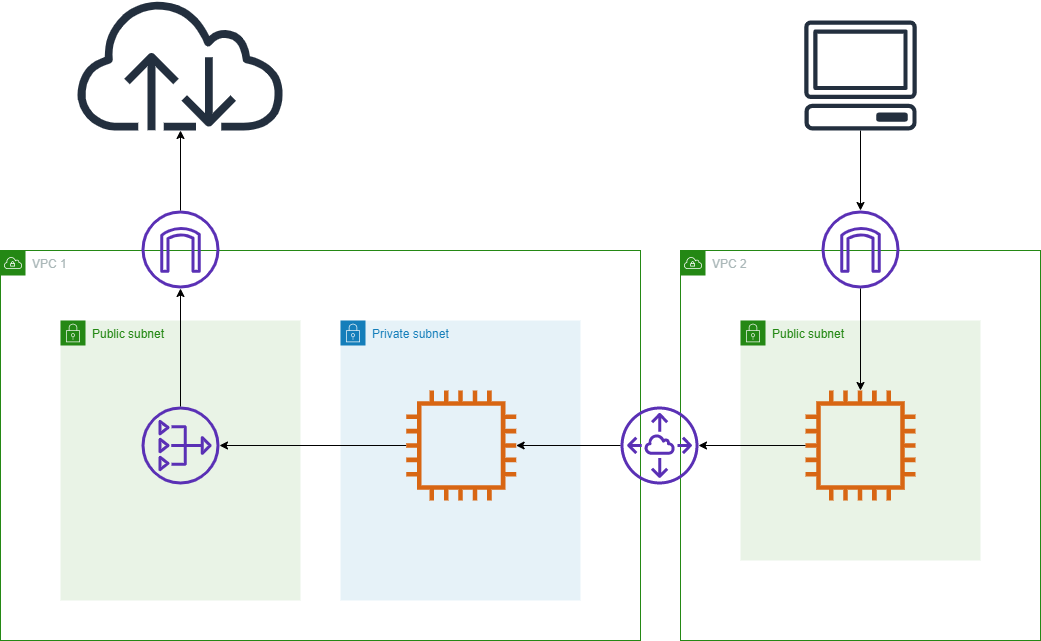
できなさ過ぎて発狂し、日を改めて調べなおして作った構成図が以下の通り。
誤認していた点は以下の通り。
・NATゲートウェイはVPCでなくサブネットに割り当てる
・0.0.0.0/0のターゲットをIGWにしたパブリックサブネットからでないとインターネットへ出れないのはNATゲートウェイを使用しても同じこんなところで躓くの僕くらいかもしれませんが共有いたします。
- 投稿日:2020-04-09T13:26:38+09:00
初心者が爆速で理解するAWS Cognitoで認可認証する開発の流れ
はじめに
初めまして、テクロスでAWSを勉強中の学生アルバイトです。
今回はCognitoとその他AWSサービスを用いたアプリ開発の流れみたいなものをようやく理解したので整理して置いておきます。Cognitoとは
認可、認証を司るAWSサービスです。
認証を担当するのがUser Pool、認可を担当するのがIdentity Poolです。
AWS Cognitoの公式ドキュメント
(最初公式ドキュメント見たときは「なんだこの分かりにくいドキュメントは!」とか思ってたけどある程度理解してから読むと「詳しくて助かる」ってなる。公式ドキュメントってそんなもんか)認証とは
多分一番わかりやすいのがE-mailアドレスとpasswordでユーザー確認をするものですね。
UserPoolを使いこなすことで、さらにFacebook等のアカウントを使ってユーザー確認することができます。認可とは
AWSの他のサービス(例えばDynamoDB等)にアクセスすることを許可すること。
ユーザー認証が完了したユーザーに許可証のようなものを配布するというイメージで理解しました。すなわち
バックエンドを全てAWSで構築するアプリケーションの場合、UserPoolでユーザー認証をし、認証が完了したユーザーにIdentityPoolで認可して、DB等にアクセスするみたいなことができます。
「認証は自前で作ってIdentityPoolだけを使う」とか、「認証だけしたいからUserPoolだけ使う」とかもできます。
しかしAPI gatewayはUserPoolのトークンを用いて呼び出すことができるのでIdentityPoolは不要だったりもします。
この辺がややこしくて少し詰まりました、、さて、それぞれのpoolについて具体的に見ていきます。
UserPool
サインアップ(ユーザー登録)やサインインの具体的なコードはググればたくさん出てくるので自分の環境に合わせて調べてもらえばいいのですが、
結局何をしてるかというと、
- 自分の作成したUserPoolのIDやRegionを指定
- 入力されたメールアドレス等の情報を元にユーザー登録、認証
- 認証が成功すれば3つのトークンを返す
この流れですね。
返ってくるトークンはIDトークン、アクセストークン、更新トークンです。
「IDトークン」は認可の際に使用します。
「アクセストークン」はユーザー属性を変更等するときに使用します。
上記2トークンは一時間で切れてしまうので、「更新トークン」を用いてそれらが切れる前にトークンを作り直すことができます。IdentityPool(Federated Identity)
認可を担当します。
ユーザープール(あるいは自作機構)を用いてユーザー認証を行なった場合、ユーザーは認証されたユーザーと認証されていないユーザーの二つに分けられます(例えばユーザー登録したプレイヤーとゲストプレイヤー)。IdentityPoolを用いることで、この二つのユーザー群それぞれに対してAWSサービスへのアクセス権を与えることができます。
具体的には、あらかじめ認証ユーザー用と非認証ユーザー用のIAMロールを作っておき、認証情報に応じてそれらを割り当てるようなイメージです。そのアクセス権に応じて柔軟にサービスの利用を制限することができるようになります。
アプリケーションの流れ
公式ドキュメントにはこんな感じの図があるんですが、最初時系列がよく分からなくて意味不明でした。
この図は、
- アプリを起動したらまずUserPoolで認証し、結果としてトークンを得る
- そのトークンをIdentityPoolに渡して、credentialsという許可証のようなものを得る
- credentialsを持つユーザーにだけ他のAWSサービスにアクセスを許可する
という流れを表しています。
1と2はログイン画面で、3からアプリのメイン画面というイメージで理解しました。認可した先でAPI gatewayを使う場合
API gatewayのAPIを叩く場合、API gatewayのオーソライザーという仕組みを使えば、UserPoolで認証済みのユーザーはAPIを叩けるようになります。なのでIdentityPoolでの認可は省くことができます。
(APIの先のサービスに対して認可しなくてもいいのかはよく分かりません)おしまい
認可認証あたりについてはすぐ理解できたのですが、プール同士の関係やサービス利用の部分がよく分からなかったので手こずってしまいました、、
認証の部分はいろんな人が分かりやすい記事を作ってくれているのでそれを見ればいいとして、認証後はAWS SDKの開発者ガイドのサンプルコードとにらめっこすればなんとかなりそうです!

- 投稿日:2020-04-09T10:34:26+09:00
AWS WorkSpaces が使っている IP リスト
AWS WorkSpace が利用している IP レンジが 2020/4/20 から増える(た)。
Starting on April 20, 2020, Amazon WorkSpaces will use an expanded list of Amazon EC2 public IP address ranges for its PCoIP gateway servers.
Asia Pacific (Tokyo)
18.180.178.0 - 18.180.178.255
18.180.180.0 - 18.180.181.255
54.250.251.0 - 54.250.251.255US East (N. Virginia)
3.217.228.0 - 3.217.231.255
52.23.61.0 - 52.23.62.255US West (Oregon)
44.234.54.0 - 44.234.55.255
54.244.46.0 - 54.244.47.255Asia Pacific (Seoul)
3.34.37.0 - 3.34.37.255
3.34.38.0 - 3.34.39.255
13.124.247.0 - 13.124.247.255Asia Pacific (Singapore)
18.141.152.0 - 18.141.152.255
18.141.154.0 - 18.141.155.255
52.76.127.0 - 52.76.127.255Asia Pacific (Sydney)
3.25.43.0 - 3.25.43.255
3.25.44.0 - 3.25.45.255
54.153.254.0 - 54.153.254.255Canada (Central)
15.223.100.0 - 15.223.100.255
15.223.102.0 - 15.223.103.255
35.183.255.0 - 35.183.255.255Europe (Frankfurt)
18.156.52.0 - 18.156.52.255
18.156.54.0 - 18.156.55.255
52.59.127.0 - 52.59.127.255Europe (Ireland)
3.249.28.0 - 3.249.29.255
52.19.124.0 - 52.19.125.255Europe (London)
18.132.21.0 - 18.132.21.255
18.132.22.0 - 18.132.23.255
35.176.32.0 - 35.176.32.255South America (Sao Paulo)
18.230.103.0 - 18.230.103.255
18.230.104.0 - 18.230.105.255
54.233.204.0 - 54.233.204.255
- 投稿日:2020-04-09T09:59:55+09:00
AWS CodeBuild でビルドの成功率が下がったとき

- 投稿日:2020-04-09T09:36:51+09:00
Github ActionsでAWS Lambda用のコマンドをBuildする
AWS Lambda で Python や Node のスクリプトを書いていると、「あー、この Linux コマンド使えたら便利なのに」と思うときが時々あります。
そういうときに、便利なBuild用Dockerコンテナを先日作成しました。
→ AWS Lambda で実行できるコマンドを作成する環境を作ってみた
今回は、これをgithub actionsにして公開してみたので、その使い方をご紹介します。
https://github.com/marketplace/actions/aws-lambda-build-and-pack
Buildスクリプトの作成
今回もAWS Lambda上でdigコマンドを動かしてみたいと思います。
デフォルトのディレクトリ構造
. |-- src | `-- build.sh |-- output `-- .github `-- workflows `-- build.yamlsrcディレクトリに下に、ビルドスクリプト、build.shを配置し、Github Actionsを呼び出すと、outputの下にコマンドと必要なライブラリが出力されます。
必要なコマンドの取り出すスクリプト作成
build.shは${OUTPUT_PATH}ディレクトリに必要なコマンドを出力するように書きます。
今回は以下のような Shell Script を src/build.sh として作成します。
- AWS Lambda で実行したいコマンドを yum で取得するか、または、コンパイルします
- コマンドを\${OUTPUT_PATH}にコピーします
src/build.sh#!/bin/sh OUTPUT_PATH=${OUTPUT_PATH:-output} yum install -y bind-utils cp -a /usr/bin/dig ${OUTPUT_PATH}yumでdigコマンドをインストールして、${OUTPUT_PATH}にコピーするだけのシンプルなスクリプトです。
ここで、ソースをダウンロードしてコンパイルしても構いません。コマンドを呼び出すAWS Lambda Function
今回もPythonで書いてみます。
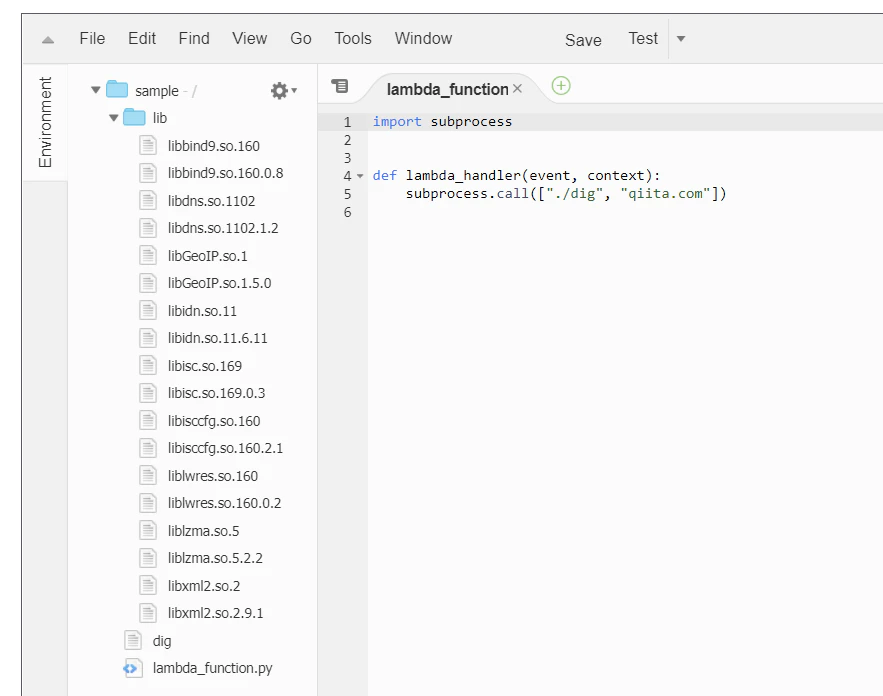
py/lambda_function.pyとして作成し、Github Actionsでoutputにできあがったものと合わせてzipすることにします。Python実行時のディレクトリにdigコマンドが存在するようになります。
py/lambda_function.pyimport subprocess def lambda_handler(event, context): subprocess.call(["./dig", "qiita.com"])Github ActionsのWorkflowを作成
Github ActionsのWorkflowを作成します。
.github/workflows/build.yamlname: Sample on: push: paths: - ".github/workflows/build.yaml" - "src/**" - "py/**" jobs: build: runs-on: ubuntu-latest steps: - name: Checkout uses: actions/checkout@v2 - uses: qualitiaco/action-lambda-build-pack@v1 with: src-path: src build-sh: build.sh output-path: output - run: | cp -a output/* py/ cd py zip -9yr ../deploy.zip * - このあと、できあがったdeploy.zipをlambdaにdeployしたり、 - S3に保存したりするactionを記述します。withの中身はすべてデフォルト値なので、省略可能です。
これで、githubにpushしたら、build.shがAWS Lambdaのbuild環境で実行され、Pythonスクリプトと合わせてdeploy.zipにパッケージされます。
この後は、いつものように、appleboy/lambda-actionを使って直接AWS Lambdaにdeployしたり、S3にアップロードしてdeployしたりしてください。
AWS LambdaにDeployする
appleboy/lambda-actionを使ってAWS Lambdaにdeployしてみます。
.github/workflows/build.yaml続き- name: AWS Lambda Deploy uses: appleboy/lambda-action@v0.0.2 with: aws_access_key_id: ${{ secrets.AWS_ACCESS_KEY_ID }} aws_secret_access_key: ${{ secrets.AWS_SECRET_ACCESS_KEY }} aws_region: ${{ secrets.AWS_REGION }} function_name: sample zip_file: deploy.zip # dry_run: trueこのようなworkflowを先ほどのbuild.yamlの続きに記述し、AWS_ACCESS_KEY_ID、AWS_SECRET_ACCESS_KEY、AWS_REGIONをgithubのSecretsに追加します。
次に、AWSでsampleという名前でPython用のLambda Functionを作成し、githubに変更をpushすることで、lambdaにdeployされます。
確認
いい感じです。
実行してみます。
ちゃんと、動作しているようです。
おわりに
AWS Lambdaで動作するコマンドを簡単に作成するGithub Actionsを作ってみたので、その使い方を紹介しました。
今回作成したものとは少しだけ内容が異なりますが、digコマンドの代わりにgitコマンドを実行するサンプルをgitに置いてありますので、参考にしてみてください。
https://github.com/qualitiaco/action-lambda-build-pack-sample
*本記事は @qualitia_cdevの中の一人、@hirachanさんに作成して頂きました。

- 投稿日:2020-04-09T04:12:01+09:00
個人でAWSのアカウントを作成してみた
直近の業務で使ったことがあったので、試しにアカウントを作成してみました!
現場ではすでにIAMユーザまでが用意されている状態でしたので、
今回最初からの設定は初めて触るものでしたのでとても厄介でした。なお、IAMの設定(のちに出る安全のためにやること全部やるとこ)まで実施しています。
被害出ているようなので念のため。説明については省略します。
※公式での説明の通り実施したので…感じたことや、注意する点について述べていこうと思います。
ここでは最初のユーザを作るまでですので、
AWSでお金はかかっておりません。事前に用意すべきもの
・スマートフォン(電話番号が割り振られているもの)
・クレジットカード
・複雑なパスワード3つ(できれば紙媒体で)アカウントについて
まず初めにここを読みながら登録していきます。
https://aws.amazon.com/jp/register-flow/
※基本全部入力必須と考えてよいです。AWS アカウントの作成
「AWS アカウント名」はのちにルートユーザ名で使いますので任意の文字列でよいです。
ここで任意の値を求められるとは思わなかったよ…、わざわざ調べましたよ…。連絡先情報
連絡先情報を入力ではパーソナルを選びます。
(確か会社名の欄がないくらいだったと思います)住所の書き方が日本式(上から下へ書く様式)ではないです。
お支払い情報を入力
請求が来た時の支払い用ですね、クレジットカードを登録しましょう。
うまくAWSを使えれば請求はされません。SMS または日本語自動音声電話によるアカウント認証
①~③を記入し④を押下するとスマホにコードが届きます。
※私はSMS受け取りにしました。そのコードを入力し次へ進むと本人確認は終了です。
AWS サポートプランの選択
とりあえずベーシックプランで。
今のところ大掛かりなことはやる予定はないのでこれで。ここまででアカウントの登録が完了です。
IAMによるセキュリティ強化
以下のページを参考にせていさせていただきました。
https://note.com/akaikaze/n/n5b1ab59cbef3
https://note.com/akaikaze/n/ne644427856e1最初にパスワードの変更をしておりますが、
特に説明することはないです(普通のパスワード変更と同様です)。本題は以下のIAMダッシュボードの項目です。
ルートアクセスキーの削除
指示に従って削除。
削除しない場合はどう危険なのかは調査中です。ルートアカウントのMFAを有効化
これも手順通りに実施。
2つ入力欄があるが、これは1.<今表示されている数字6桁>
2.<1の直後に切り替わって表示された数字6桁>です(書いてあるが念のため違う言い回しで記載)。
MFAの必要性は以前の私の記事にて簡単に解説済み。
個々のIAMユーザの作成
ルートアカウント以外でログインできるユーザを作成します。
ここでもMFAを設定しておくとよいでしょう。グループを使用してアクセス許可を割り当て
IAMユーザの作成から続けてできます。
直接ユーザにポリシーつけてもいいですが、
グループにポリシーをアタッチしたうえで、グループにユーザを追加したほうが
ユーザを増やした際管理しやすいです。ここでは一番強力な"AdministratorAccess"をつけておいたほうがよいでしょう。
(なのでMFA設定を忘れないように)IAMパスワードポリシーの適用
よくある""大文字を含む"や"何文字以上か"等の設定をすることができ、
IAMユーザ全員に適用させることができます。
これで初期設定は完了です。
これ以降は作成したIAMユーザで入っていろいろAWSを触ってみましょう!

- 投稿日:2020-04-09T01:00:45+09:00
SAML 認証による一時的な認証情報で boto3 を利用する
弊社では全社員が G Suite のアカウントを持っており、AWS マネジメントコンソールにアクセスする際は Google を Identity Provider として SAML 認証してシングルサインオン 1 をしている。この場合、STS の Assume Role という仕組み 2 を使って一時的な認証情報を入手し、フェデレーションユーザとしてマネジメントコンソールにアクセスすることになる。マネジメントコンソールにアクセスするために社員ごとに IAM ユーザを作成する必要がなくなるため、アカウント管理の手間が削減できる。
ただ、シングルサインオンを導入した場合にひとつだけ困るのがアクセスキーである。そもそも IAM ユーザが存在しないため、(永続的な) アクセスキーを発行することができない。ローカル端末にあるファイルを AWS CLI を用いて S3 に転送したいときや、Jupyter Notebook から boto3 を用いて AWS リソースにアクセスしたいときなど、アクセスキーが必要になるケースは少なくない。3
そこで今回は、SAML 認証による一時的な認証情報で boto3 を利用する方法についてまとめる。
内容としては、SAML 認証で AWS CLI を使う方法が公式ドキュメントに書かれている 4 ので、それを Python (boto3) に置き換えただけである。
Role ARN と IdP ARN を用意する
Role ARN は Assume Role で利用している Role の ARN で、IdP ARN は SAML 認証の Identity Provider の ARN。
role_arn = 'arn:aws:iam::123456789012:role/GSuiteMember' idp_arn = 'arn:aws:iam::123456789012:saml-provider/Google'SAML Response を取得する
トラブルシューティングのためにブラウザで SAML レスポンスを表示する方法 - AWS Identity and Access Management
これに従ってブラウザ上で SAML 認証を行うことで、SAML Resnponse という文字列を得ることができる。
saml_response = '...とても長い文字列...'SAML Response は Base64 エンコードされており、とても長い文字列なのでコピペする際は注意が必要。
アクセスキーを取得する
ここまでの情報があれば、AssumeRoleWithSAML という API 5 を用いて一時的なアクセスキーを得ることができる。この操作は SAML 認証をしてから5分以内に行う必要がある。
sts = boto3.client('sts') response = sts.assume_role_with_saml(RoleArn=role_arn, PrincipalArn=idp_arn, SAMLAssertion=saml_response) credentials = response['Credentials']アクセスキーを利用する
あとは通常通りアクセスキーを用いて AWS リソースにアクセスすることができる。
session = boto3.session.Session( aws_access_key_id=credentials['AccessKeyId'], aws_secret_access_key=credentials['SecretAccessKey'], aws_session_token=credentials['SessionToken'], region_name='ap-northeast-1', ) # EC2 インスタンスの一覧を取得する ec2 = session.client('ec2') ec2.describe_instances()
そもそも強い権限を持った アクセスキーをローカル端末に保存するのはセキュリティリスクでしかないという話はある ↩
- 投稿日:2020-04-09T00:36:38+09:00
AWS初心者の自分でも、RailsアプリをAWS EC2にデプロイ成功できた方法
はじめに
備忘録も兼ねて、RailsアプリをAWSにデプロイする手順をまとめました。筆者自身、ずっとデプロイをHerokuに頼り切っていたのもあり、そろそろHeroku以外の方法でデプロイをしてみたいなと思い、試みた次第です。
この記事では、非常に解説が丁寧な世界一丁寧なAWS解説シリーズベースにデプロイ作業を進めていき、途中で詰まった箇所をところどころ訂正していきます。概念などの詳しい説明は上記記事を見ていただくのが早いです。なお、この記事では、コマンドは全てMacでの使用を想定しています。ご了承ください。
また、作業の過程で開発環境(local)でのコマンド操作と、EC2インスタンス内でのコマンド操作(remote)に分かれるので、ターミナルを2ウィンドウ用意しておくと捗るかと思います。1.ざっくりとした流れ
この記事では、AWSのRDSを利用せず、EC2インスタンスにDBのシステムそのものをインストールする方式を採用しています。なので、AWSへのデプロイのざっくりとした順番は、
AWS上に自分のテリトリー(VPC)を作り、ネットワークやセキュリティの設定をする。
↓
VPCの中に、仮想のパソコン(EC2インスタンス)を作成する
↓
EC2インスタンスにSSHログインをし、rubyの環境構築をする。
↓
EC2インスタンス内に、デプロイしたいRailsアプリをclone、更に必要な、Webサーバー(Nginx)や、Unicorn、DB(MySQL)などの環境構築をする。
↓
RailsとWebサーバー、Unicorn、DBを接続する。こんな感じです。頭のどこかにイメージしておくとよいと思います。
2.デプロイしたいRailsアプリへの事前準備
ローカルでの作業です。
ルーティングにトップページを設定します。これがないとエラーが起きます。
(下の例では、topsコントローラーのtopアクションを、トップページとしています。)routes.rbroot 'tops#top'続いて、Gemfileに以下の追記をします。
Gemfilegroup :production do gem 'mysql2', '>= 0.4.4' end group :production, :staging do gem 'unicorn' end gem 'dotenv-rails'config/database.ymlのproduction環境の設定を以下のようにします。
config/database.ymlproduction: adapter: mysql2 encoding: utf8 reconnect: false database: sample_production (#アプリ名_productionにする) username: root password: <%= ENV['DATABASE_PRO_PASSWORD'] %>既にキー流出防止策を取っている方はスキップして問題ありませんが、していない方はdatabaseのパスワードや、クラウドサービスのパスワードなどといった、重要な値は、流出を防ぐために環境変数として.envファイルへと移しておき、.envファイルは.gitignoreファイルに登録しておきましょう。gem 'dotenv-rails'を入れておけば、.envファイルから環境変数の値を読み込んでくれます。
gem 'dotenv-rails'の使い方について、詳しくはこちら最後に、Githubへプッシュして完了です。(リモートリポジトリは既に作られていて、ローカルリポジトリとの紐付けも既にできているものとします。)
local$ git add -A $ git commit -m'preparing-for-deploy' $ git push origin master3.EC2インスタンスの置き場の作成
VPC、サブネット、インターネットゲートウェイ、ルートテーブル、セキュリティグループの設定をしていきます。
(下準備編)世界一丁寧なAWS解説。EC2を利用して、RailsアプリをAWSにあげるまでの手順通りに進めれば問題ありません。しかし、最後の段階でパブリックDNSが割り当てられていないことがあるので、こちらの記事を参考に、割当をしましょう。4.EC2インスタンスの作成
AWS上に作った置き場に、EC2インスタンスを作ります。EC2インスタンス=仮想のパソコンというイメージを持つと、この後の作業が考えやすいと思います。
(DB・サーバー構築編)世界一丁寧なAWS解説。EC2を利用して、RailsアプリをAWSにあげるまでの、8. EC2インスタンスの作成 以降の手順通りに進めれば問題ありません。作成したEC2インスタンスにSSHログインできる段階まで進めてください。
(この記事では、RDSは利用しないので、上記記事のRDSの設定箇所は飛ばしても大丈夫です。)5.EC2インスタンス内の環境構築
AWSに作ったEC2インスタンスの中に、rubyやその他railsアプリケーションを動かすために必要なものを構築していきます。(以降の例では、ログインユーザーをryotaとして進めています。世界一丁寧なAWS解説シリーズでのユーザー名naokiと読み替えてください。)
Gitなどのインストール
まずはgitなどのインストールをします。
remote[ryota ~]$ sudo yum install git make gcc-c++ patch openssl-devel libyaml-devel libffi-devel libicu-devel libxml2 libxslt libxml2-devel libxslt-devel zlib-devel readline-devel mysql mysql-server mysql-devel ImageMagick ImageMagick-devel epel-releaseインストール中に何回か以下のような確認を求められますが、気にせずyを押して進めてください。
総ダウンロード容量: 110 M Is this ok [y/d/N]:もし以下のようなメッセージが出てきたら、言われたとおりコマンドをrunしてください。
remoteepel-release is available in Amazon Linux Extra topic "epel" To use, run # sudo amazon-linux-extras install epelNode.jsのインストール
次にnode.jsをインストールします。コマンドラインで次のように入力して、ノードバージョンマネージャー (nvm) をインストールします。Node.jsのインストールはこちらの記事を参考にしました。
remote[ryota ~]$ curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.34.0/install.sh | bash (#nvmのインストール) [ryota ~]$ . ~/.nvm/nvm.sh (#nvmの有効化) [ryota ~]$ source .bashrc [ryota ~]$ nvm install node (#nvm を使用して Node.js の最新バージョンをインストール。) [ryota ~]$ node -v (#node.jsのバージョン確認)node.jsのバージョンが表示されればnode.jsのインストールは完了です。
Yarnのインストール
次にyarnをインストールします。yarnのインストールはこちらの記事を参考にしました。
remote[ryota ~]$ curl -o- -L https://yarnpkg.com/install.sh | bash [ryota ~]$ source .bashrc [ryota ~]$ yarn -v (#yarnのバージョン確認)yarnのバージョンが表示されればyarnのインストールは完了です。
Rubyのインストール
まずはrbenvをインストールしましょう。rbenvについて詳しくはこちら
remote[ryota|~]$ git clone https://github.com/sstephenson/rbenv.git ~/.rbenv (#rbenvのインストール) [ryota|~]$ echo 'export PATH="$HOME/.rbenv/bin:$PATH"' >> ~/.bash_profile (#パスを通す) [ryota|~]$ echo 'eval "$(rbenv init -)"' >> ~/.bash_profile [ryota|~]$ source .bash_profile (#.bash_profileの読み込み) [ryota|~]$ git clone https://github.com/sstephenson/ruby-build.git ~/.rbenv/plugins/ruby-build (#ruby-buildのインストール) [ryota|~]$ rbenv rehash (#rehashを行う)rbenvがインストールできたら、いよいよrubyのインストールです。
remote[ryota ~]$ rbenv install -v 2.6.5 (#デプロイするrailsで使用するrubyのバージョンに合わせる) [ryota|~]$ rbenv global 2.6.5 [ryota|~]$ rbenv rehash [ryota|~]$ ruby -vruby -vコマンドで、rubyのバージョンが表示されれば成功です。
6.Git、Githubとの連携、railsアプリのクローン
デプロイしたいプロダクトをEC2インスタンス内にクローンします。まずはEC2インスタンス内のgitの設定をします。
remote[ryota|~]$ vim .gitconfig開かれた.gitconfigに以下を転記します。
remote[user] name = your_name (#gitに登録した自分の名前) email = hoge@hoge.com (#git登録時の自分のメールアドレス) [alias] (#普段のローカルでの開発で頻繁に使うgitのエイリアスがあったら登録するのもありです) a = add b = branch co = checkout s = status [url "github:"] (#pull、pushのための設定) InsteadOf = https://github.com/ InsteadOf = git@github.com:もしgitで登録している名前とメールアドレスがわからなくなったら、以下のコマンドをローカルで打ち込めばわかります。
local$ git config user.name (#ユーザー名の確認) $ git config user.email (#登録しているメールアドレスの確認).gitconfigファイルの編集が完了したらファイルを保存し、アプリを配置するディレクトリを作成していきます。
remote[ryota|~]$ cd / [ryota|/]$ sudo chown ryota var (#varフォルダの所有者をEC2ログイン中のユーザーにする) [ryota|/]$ cd var [ryota|var]$ sudo mkdir www [ryota|var]$ sudo chown ryota www [ryota|var]$ cd www (#wwwと同じ処理) [ryota|www]$ sudo mkdir rails [ryota|www]$ sudo chown ryota railschownやchmodについて曖昧な人はこちらの記事を、mkdirについて曖昧な人はこちらを参照してみてください。
GitとGithubの接続
いよいよgithubとの接続です。下記コマンドを打ち込んでください。
remote[ryota|www]$ cd ~ [ryota|~]$ mkdir .ssh (#既に生成されている場合もあります。) [ryota|~]$ chmod 700 .ssh [ryota|.ssh]$ cd .ssh [ryota|.ssh]$ ssh-keygen -t rsa ----------------------------- Enter file in which to save the key ():aws_git_rsa (#ここでファイルの名前を記述して、エンター) Enter passphrase (empty for no passphrase): (#何もせずそのままエンター) Enter same passphrase again: (#何もせずそのままエンター) ----------------------------- [ryota|.ssh]$ ls (#「aws_git_rsa」と「aws_git_rsa.pub」が生成されたことを確認) [ryota|.ssh]$ vim configconfigファイルが開いたら、以下を追記。
configHost github Hostname github.com User git IdentityFile ~/.ssh/aws_git_rsa (#秘密鍵の設定)configファイルを保存したら、公開鍵の中身をコピーしてください。
remote[ryota|.ssh]$ cat aws_git_rsa.pub (#catコマンドの結果、公開鍵の内容が表示されるのでメモ帳などにコピーしておく) ssh-rsa sdfjerijgviodsjcIKJKJSDFJWIRJGIUVSDJFKCNZKXVNJSKDNVMJKNSFUIEJSDFNCJSKDNVJKDSNVJNVJKDSNVJKNXCMXCNMXNVMDSXCKLMKDLSMVKSDLMVKDSLMVKLCA ryota@ip-10-0-1-10Githubに公開鍵を登録します。
鍵の登録ページの右上にある、New SSH Key を開いて、Titleに鍵の名前、Keyに先程コピーした公開鍵の中身をペーストします。
ペーストが終わったら、以下のコマンドでgithubへの接続の確認をしてください。
remote[ryota|.ssh]$ chmod 600 config [ryota|.ssh]$ ssh -T github (途中で、Are you sure you want to continue connecting (yes/no)? と聞かれるので、yesと入力) (#上手く接続できれば、以下のメッセージが表示される。 Hi Ryota! You've succwwwessfully authenticated, but GitHub does not provide shell access.詳しく追求したい人はGitHubでssh接続する手順~公開鍵・秘密鍵の生成から~を参照してください。
Railsアプリのclone
いよいよGithubからデプロイしたいRailsアプリをcloneします。clone後にlsコマンドでcloneを試みたアプリ名が表示されれば完了です。(以下、例ではアプリ名はsampleとして進めていきます。)
remote[ryota|.ssh]$ cd /var/www/rails [ryota|rails]$ git clone git@github.com:~~~~~~~~~~~~ [ryota|rails]$ ls samplecloneが成功したら、railsファイルのconfig/secrets.ymlに記述されている、secrets_key_baseを変更します。本番環境用の設定を変更するので、productの欄のみ編集すれば大丈夫です。
デプロイしたいアプリのローカル環境でのディレクトリで、以下コマンドを実行し、出力されたキーをコピーしておきます。
local$: bundle exec rake secret (#シークレットキーを生成) jr934ugr89vwredvu9iqfj394vj9edfjcvnxii90wefjc9weiodjsc9o i09fiodjvcijdsjcwejdsciojdsxcjdkkdsv (#表示されるキーは人によって違います。表示されるkeyをコピーしておきましょう)続いてEC2インスタンス内のrailsアプリのsecrets.ymlを編集します
remote[ryota|rails]$ cd sample [remote|sample] $ vim config/secrets.yml (#config/database.ymlを開く)config/secrets.ymlproduction: secret_key_base: <%= ENV["SECRET_KEY_BASE"] %>コマンドでSECRET_KEY_BASEにキーをセットしましょう。
remote[ryota|sample] $ export SECRET_KEY_BASE='jr934ugr89vwredvu9iqfj394vj9edfjcvnxii90wefjc9weiodjsc9o i09fiodjvcijdsjcwejdsciojdsxcjdkkdsv'7.Nginx、Unicorn、MySQLの設定
Railsアプリを本番環境で動かすために必要な、Webサーバー、WebサーバーとRackをつなぐ部分、DBの設定をします。
なぜRailsの本番環境にNginxとUnicornを採用するのか、解りやすい 記事があったので興味ある方はぜひ御覧ください。Unicornの設定
remote[ryota|sample] $ gem install bundler [ryota|sample] $ bundle install --without development test [ryota|sample] $ vi config/unicorn.conf.rb (#config/unicorn .conf.rbの作成)Unicornの設定ファイルの編集です。下記を転記してください。
unicorn.conf.rb# set lets $worker = 2 $timeout = 30 $app_dir = "/var/www/rails/sample" #自分のアプリケーション名にする $listen = File.expand_path 'tmp/sockets/.unicorn.sock', $app_dir $pid = File.expand_path 'tmp/pids/unicorn.pid', $app_dir $std_log = File.expand_path 'log/unicorn.log', $app_dir # set config worker_processes $worker working_directory $app_dir stderr_path $std_log stdout_path $std_log timeout $timeout listen $listen pid $pid # loading booster preload_app true # before starting processes before_fork do |server, worker| defined?(ActiveRecord::Base) and ActiveRecord::Base.connection.disconnect! old_pid = "#{server.config[:pid]}.oldbin" if old_pid != server.pid begin Process.kill "QUIT", File.read(old_pid).to_i rescue Errno::ENOENT, Errno::ESRCH end end end # after finishing processes after_fork do |server, worker| defined?(ActiveRecord::Base) and ActiveRecord::Base.establish_connection endNginxの設定
remote[ryota|~]$ cd ~ [ryota|~]$ sudo yum install nginx (#nginxのインストール) [ryota|~]$ cd /etc/nginx/conf.d/ [ryota|conf.d]$ sudo vi sample.conf (#自分のアプリケーション名でファイル名変更)作成したnginxの設定ファイルに以下を転記
remote# log directory error_log /var/www/rails/sample/log/nginx.error.log; #自分のアプリケーション名に変更する箇所あり access_log /var/www/rails/sample/log/nginx.access.log; #自分のアプリケーション名に変更する箇所あり # max body size client_max_body_size 2G; upstream app_server { # for UNIX domain socket setups server unix:/var/www/rails/sample/tmp/sockets/.unicorn.sock fail_timeout=0; #自分のアプリケーション名に変更する箇所あり } server { listen 80; server_name ~~~.~~~.~~~.~~~;(#アプリのElastic IPに変更してください) # nginx so increasing this is generally safe... keepalive_timeout 5; # path for static files root /var/www/rails/sample/public; #自分のアプリケーション名に変更する箇所あり # page cache loading try_files $uri/index.html $uri.html $uri @app; location @app { # HTTP headers proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; proxy_pass http://app_server; } # Rails error pages error_page 500 502 503 504 /500.html; location = /500.html { root /var/www/rails/sample/public; #自分のアプリケーション名に変更する箇所あり } }MySQLの設定と起動
本番環境用にmysqlをインストールします。
remote[ryota|conf.d]$ cd ~ [ryota|~]$ yum list installed | grep mariadb mariadb-libs.x86_64 1:5.5.56-2.amzn2 installed #mysqlがインストールされているか確認 [ryota|~]$ yum list installed | grep mysql #mysqlがインストールできるか確認 [ryota|~]$ yum info mysql 読み込んだプラグイン:extras_suggestions, langpacks, priorities, update-motd エラー: 表示するパッケージはありません #mysql8.0リポジトリの追加(このリポジトリに5.7も含まれています) [ryota|~]$ sudo yum localinstall https://dev.mysql.com/get/mysql80-community-release-el7-1.noarch.rpm -y #mysql8.0リポジトリの無効化 [ryota|~]$ sudo yum-config-manager --disable mysql80-community #mysql5.7リポジトリの有効化 [ryota|~]$ sudo yum-config-manager --enable mysql57-community #mysql5.7がインストールできるか確認 [ryota|~]$ yum info mysql-community-server #mysqlインストール [ryota|~]$ sudo yum install mysql-community-server -y [ryota|~]$ mysqld --version mysqld Ver 5.7.29 for Linux on x86_64 (MySQL Community Server (GPL))つづいて、mysqlの初期設定を行います。
remote[ryota|~]$ sudo service mysqld start #mysqlの起動 [ryota|~]$ sudo cat /var/log/mysqld.log | grep password (#rootパスワードを確認) A temporary password is generated for root@localhost: rootの初期パスワード #初期設定 [ryota|~]$ mysql_secure_installation Enter password for user root: 初期パスワード New password: 新しいパスワード Re-enter new password: 新しいパスワード Change the password for root ? ((Press y|Y for Yes, any other key for No) : No Remove anonymous users? (Press y|Y for Yes, any other key for No) : y Disallow root login remotely? (Press y|Y for Yes, any other key for No) : y Remove test database and access to it? (Press y|Y for Yes, any other key for No) : y Reload privilege tables now? (Press y|Y for Yes, any other key for No) : yremote[ryota|~]$ cd / [ryota|/]$ cd var/www/rails/sample (#アプリのディレクトリまで移動) [ryota|sample]$ export DATABASE_PRO_PASSWORD='mysqlの新しいパスワード' (#MySQLのパスワードのセット) [ryota|sample]$ ln -s /var/lib/mysql/mysql.sock /tmp/mysql.sock [ryota|sample]$ rake db:create RAILS_ENV=production [ryota|sample]$ rake db:migrate RAILS_ENV=productionこれでMYSQLの設定は完了です。
その他環境変数のセットが必要な場合はこのタイミングでしておきましょう。Unicornの起動
Unicornの起動の前に、念の為プリコンパイルもしておきましょう。
remote[ryota|sample]$ bundle exec rake assets:precompile RAILS_ENV=production [ryota|sample]$ bundle exec unicorn_rails -c /var/www/rails/sample(アプリの名前)/config/unicorn.conf.rb -D -E production (#unicornを起動させる)Nginxの起動
remote[ryota|sample]$ sudo service nginx start8.表示の確認
さて、URL欄に、登録したElastic IPを打ち込んでみましょう。アプリのトップページに設定した画面が表示されるはずです。もしエラーが起きている場合はGoogleで検索して耐えてください。
エラーの内容はconfig/unicorn.logの中に書いてあることが多いので、エラーが起きたときはここを確認すると良いかもしれません。
また、何かエラー対応策をした際は、念の為UnicornとNginxを再起動をすると良いでしょう。その際は以下のコマンドを使ってみてください。remote[ryota|sample]$ ps -ef | grep unicorn | grep -v grep (#起動中のUnicornを確認) ryota 27940 1 0 15:07 ? 00:00:00 unicorn_rails master -c /var/www/rails/article/config/unicorn.conf.rb -D -E production ryota 27943 27940 0 15:07 ? 00:00:00 unicorn_rails worker[0] -c /var/www/rails/article/config/unicorn.conf.rb -D -E production ryota 27944 27940 0 15:07 ? 00:00:00 unicorn_rails worker[1] -c /var/www/rails/article/config/unicorn.conf.rb -D -E production [ryota|sample]$ kill -9 27940 (#プロセスの停止) [ryota|sample]$ bundle exec unicorn_rails -c /var/www/rails/sample(アプリの名前)/config/unicorn.conf.rb -D -E production (# Unicornの起動) [ryota|sample]$ sudo nginx -s reload (# Nginxの再起動)おわりに
以上で解説は終了です。
長い記事にお付き合い頂きありがとうございました。
筆者自身勉強が浅く、説明不足な点や間違った説明があるかもしれません。効率の良い方法や説明を発見次第、この記事を更新していきたいと思います。参考記事
・世界一丁寧なAWS解説シリーズ
・AWSのEC2で行うAmazon Linux2(MySQL5.7)環境構築
・チュートリアル: Amazon EC2 インスタンスでの Node.js のセットアップ
・EC2にyarnをインストールする
・なぜrailsの本番環境ではUnicorn,Nginxを使うのか? ~ Rack,Unicorn,Nginxの連携について ~【Ruby On Railsでwebサービス運営】
・Rails5をproduction(本番環境)で起動する時に嵌ったこと
