- 投稿日:2020-04-07T23:22:07+09:00
Python で Uplift modeling
はじめに
Uplift modeling は、マーケティング施策によって利益を最大化するための手法です。利益がより大きい顧客にターゲットを絞って、メール送付や広告配信などの施策を打つことで、マーケティングの効率化が実現できます。
この記事では、Uplift modeling の概要と、それを実現するための実装例を備忘録としてまとめます。
Uplift modeling
概要
Uplift modelingは、ある属性を持つ顧客の、施策実施による利益の増加分(施策を実施した場合の利益と実施しない場合の利益の差分)を予測する方法です。通常の機械学習による予測タスクでは、施策に対して単純にどう反応するか(予約するか/しないか、予約金額はいくらか、など)を予測しますが、Uplift modelingでは、施策に対して反応がどう変化するか(予約確率や予約金額がどう変化するか)を予測します。顧客の施策に対する反応がどう変化するかを明らかにすることで、効果が高い顧客にのみ施策を実施するターゲッティングや、各顧客に適したマーケティング施策を実施するパーソナライゼーションが可能になります。Uplift modeling で予測されるものは、顧客の属性を条件づけたとき(つまり、同質な属性を持つ顧客)の、施策実施による利益の増加分とも言い換えられるので、CATE (Conditional Average Treatment Effect)、ITE(Indivisual Treatment Effect)とも呼ばれます。
Uplift modeling における顧客の分類
Uplift modeling の枠組みでは、介入(施策の実施)に対してどう反応する(クリックや予約などのコンバージョン(CV)をする)かによって、顧客を4つのセグメントに分類して考えます。
介入あり 介入なし セグメント名 説明 CVする CVする 鉄板 介入してもしなくてもCVする CVする CVしない 説得可能 介入することではじめてCVする CVしない CVする 天邪鬼 介入するとむしろCVしなくなる CVしない CVしない 無関心 介入してもしなくてもCVしない 鉄板は、介入してもしなくてもCVする顧客層です。介入にコストがかかる場合はコストが無駄になるので介入すべきではありません。例えば、直近の購買履歴があるアクティブユーザーがこの層に該当し、メール配信などによって購買を喚起しなくても購買してくれる場合は、メール配信のコストが無駄になってしまいます。
説得可能は、介入しない場合はCVしませんが、介入することではじめてCVする顧客層です。例えば、購買意欲はあるものの購買に踏み切れないユーザーがこの層に該当し、割引クーポンなどを配信することで、この層に属するユーザーが購買してくれる可能性が高くなります。
天邪鬼は、介入しない場合はCVしますが、介入するとむしろCVしなくなる顧客層です。介入することで利益が減少するため、絶対に介入してはいけない顧客層です。
無関心は、介入してもしなくてもCVしない顧客層です。例えば、直近の購買から長期間が経過している離反・休眠ユーザーがこの層に該当し、メール配信をしても購買が見込めない場合は、メール配信をやめることでコストを削減することができます。Uplift modeling は、説得可能に属する顧客層を見極め、これらの顧客を対象に施策を実施することで、効率的なマーケティングを実現します。
Uplift modeling の主なアルゴリズム
Uplift modelingには、主に2つのアルゴリズムがあります。1つは、Meta-Learner アルゴリズムと呼ばれ、介入する場合の利益と介入しない場合の利益を予測するモデル(base-learner と呼びます)を構築し、利益の増加分を推定するアルゴリズムです。もう1つは、Uplift Tree と呼ばれ、「利益の増加分が大きくなるか?」という基準で、顧客の集団を分割する木を構築するアルゴリズムです。
Meta-Learner アルゴリズム
Meta-Learner アルゴリズムには、介入する場合の利益と介入しない場合の利益をどう予測するかによって、さらに T-Learner, S-Learner, X-Learner, R-Learner などのアルゴリズムに分類されます。
T-Learner
介入する場合の利益の予測するモデルと、介入しない場合の利益を予測するモデルを別個に構築し、それぞれの予測値の差分をとることで、利益の増加分を予測するアルゴリズムです。介入する場合と介入しない場合を分けてモデルを構築するため、介入有無は特徴量として採用しません。
式で書くと、
\mu_1(x) = E(Y_1 | X=x)\mu_0(x) = E(Y_0 | X=x)\hat{\tau}(x) = \hat{\mu}_1(x) - \hat{\mu}_0(x)です。
顧客の背景情報 $x$(デモグラフィック属性や購買履歴など)を特徴量として、介入する場合の利益(予約確率、予約金額など) $Y_1$ を予測するモデルと、介入しない場合の利益 $Y_0$ を予測するモデルを構築し、それらの予測値 $\hat{\mu}_1(x), \hat{\mu}_0(x)$ の差分が、利益の増加分 $\hat{\tau}(x)$ となります。S-Learner
利益を予測するモデルを1つ構築し、介入する場合と介入しない場合の利益を予測し、それらの差分をとることで、利益の増加分を予測するアルゴリズムです。T-Learner と異なり、介入有無を特徴量として採用します。
式で書くと、
\mu(x, z) = E(Y | X=x, Z=z)\hat{\tau}(x) = \hat{\mu}(x, Z=1) - \hat{\mu}(x, Z=0)です。
顧客の背景情報 $x$ と、介入有無を表す群別変数 $z$($z=1$ は介入あり、$z=0$ を表す)を特徴量として、利益 $Y$ を予測するモデルを構築し、介入する場合の予測値 $\hat{\mu}(x, Z=1)$ と介入しない場合の予測値 $\hat{\mu}(x, Z=0)$ の差分が、利益の増加分 $\hat{\tau}(x)$ となります。X-Learner
介入する場合と介入しない場合の pseudo-effects(疑似的な利益の増加分)をそれぞれ推定し、それらを重み付けをして足し合わせることで、利益の増加分を予測するアルゴリズムです。
X-Learner は、まず顧客の背景情報 $x$ を特徴量として、介入する場合の利益 $Y_1$ を予測するモデルと、介入しない場合の利益 $Y_0$ を予測するモデルを構築します。
\mu_1(x) = E(Y_1 | X=x)\mu_0(x) = E(Y_0 | X=x)そして、介入する場合と介入しない場合の pseudo-effects を以下の式で推定します。
D_i^1 = Y_i^1 - \hat{\mu}_0(x_i^1)D_i^0 = \hat{\mu}_1(x_i^0) - Y_i^0上付き数字は、1は介入した顧客に紐づくデータ、0は介入していない顧客に紐づくデータを利用することを示します。$D_i^1$ は、介入した顧客から得られた利益 $Y_i^1$ と、介入した顧客に仮に介入しなかった場合の利益 $\hat{\mu}_0(x_i^1)$ の差分であり、介入する顧客グループにおける疑似的な利益の増加分を表します。$D_i^0$ は、介入しなかった顧客に仮に介入した場合の利益 $\hat{\mu}_1(x_i^0)$ と、介入しなかった顧客から得られた利益 $Y_i^0$ の差分であり、介入しない顧客における疑似的な利益の増加分を表します。
さらに、顧客の背景情報 $x$ から、pseudo-effects $D_1, D_2$ を予測するモデルを構築します。
\tau_1(x) = E(D_1 | X=x)\tau_0(x) = E(D_0 | X=x)最後に、介入する場合の予測値 $\hat{\tau}_0(x)$ と介入しない場合の予測値 $\hat{\tau}_1(x)$ を $g(x)$ で重みを付けて平均をとり、利益の増加分 $\hat{\tau}(x)$ を予測しています。$g(x)$ の値域は $g(x) \in [0,1]$ で、$g(x)$ としては傾向スコア $e(x)=P(Z=1 | X=x)$ を利用することもできます。
\hat{\tau}(x) = g(x)\hat{\tau}_0(x)+(1-g(x))\hat{\tau}_1(x)R-Learner
R-Learner は、それぞれの顧客から得られる平均的な利益 $m(x)$ と傾向スコア(=顧客が介入される確率)$e(x)$ を予測し、利益の増加分の予測誤差を最小化するアルゴリズムです。
R-Learner は、まず顧客の背景情報 $x$ を特徴量とし、平均的な利益 $m(x)$、傾向スコア $e(x)$ を予測するモデルを構築します。
m(x) = E(Y | X=x)e(x) = P(Z=1 | X=x)そして、利益の増加分の予測誤差(損失関数)$\hat{L}_n(\tau(・))$ が最小になるような、利益の増加分 $\tau(・)$ を求めます。
\hat{\tau}(・) = argmin_{\tau}\{\hat{L}_n(\tau(・)) + \Lambda_n(\tau(・))\}\hat{L_n(\tau(・))} = \frac{1}{n}\sum_{i=1}^n((Y_i-\hat{m}^{(-i)}(x_i))-(z_i-\hat{e}^{(-i)}(x_i))\tau(x_i))^2$\Lambda_n(\tau(・))$ は正則化項です。$\hat{m}^{(-i)}(x_i), \hat{e}^{(-i)}(x_i)$ は、顧客 $i$ のデータ以外のデータで構築したモデルで予測した、顧客 $i$ の平均的な利益と傾向スコアを表します。
Uplift Tree
Uplift Tree は、「利益の増加分が大きくなるか?」という基準で、顧客の集団を分割する木を構築するアルゴリズムです。二値分類タスクで用いられる決定木では、分割後の集団におけるクラスの不純度が、分割前に比べて減少するように、ある属性に関する条件で集団を分割します。一方、Uplift Tree では、分割後の集団における、介入ありグループの利益の分布と介入なしグループの利益の分布の距離が、分割前に比べて増加するように、ある属性に関する条件で集団を分割します。つまり、利益の増加に関連が強い属性で顧客集団を分割していきます。
式で書くと、
D_{gain} = D_{after-split}(P^T, P^C) - D_{before-split}(P^T, P^C)で定義される $D_{gain}$ が大きくなるように木を構築していきます。$P^T, P^C$ は、それぞれ介入ありグループと介入なしグループにおける利益の分布を表し、$D$ は分布の距離を表します。$D$ としては、カルバック・ライブラー情報量や、ユークリッド距離が用いられます。
Uplift modeling の評価指標
Uplift modeling の性能は、AUUC(Area Under the Uplift Curve)という指標を用いて評価します。AUUC は、ランダムに選択した顧客に介入する場合と比較して、Uplift moeling で予測した利益の増加分が大きい顧客にのみ介入する場合、どの程度利益が増加するかを正規化した指標です。AUUCの値が大きいほど、Uplift modeling の性能が高いといえます。AUUC を算出する手順は以下の通りです。
- Uplift modeling により予測した利益の増加分が大きいほど大きな値をとるように、それぞれの顧客をスコアリングします。ここでは、このスコアを uplift score と呼びます。(利益としてCVRなどの割合を用いている場合、CVR の増加分をそのまま uplift score として利用できます。)
- uplift score が閾値以上をとる顧客にのみ介入した場合、介入しなかった場合と比較してどれだけ利益が増加したか(ここでは、この値を lift と呼びます)を算出します。
- 2.で介入する顧客と同数の顧客をランダムに選択し介入した場合の利益の増加分と比較して、2.で求めた lift はどの程度増加するかを算出します。
- 2., 3. を閾値を変化させて繰り返し算出した lift を足し合わせ、最後に正規化します。(閾値を変化させて得られる lift をプロットした曲線を uplift curve と呼びます。)
式で書くと、
AUUC = \sum_{k=1}^n AUUC_{\pi}(k)AUUC_{\pi}(k) = AUL_{\pi}^T(k) - AUL_{\pi}^C(k) = \sum_{i=1}^k (R_{\pi}^T(i) - R_{\pi}^C(i)) - \frac{k}{2}(\bar{R}^T(k) - \bar{R}^C(k))です。$n$ は全顧客数、$k$ は uplift score が閾値以上となる顧客数、$\pi$ は顧客の順序(uplift socre が大きい順)を表します。$AUL_{\pi}^T(k)$ は、順序 $\pi$ にしたがって $k$ 番目までの顧客に介入した場合の lift、$AUL_{\pi}^C(k)$ は、ランダムに $k$ 人の顧客を選択して介入した場合の利益の増加分です。$R_{\pi}^T(i)$ は、順序 $\pi$ における $i$ 番目の顧客に介入した場合の利益、$R_{\pi}^C(i))$ は、順序 $\pi$ における $i$ 番目の顧客に介入しなかった場合の利益です。$\bar{R}^T(k)$ は、ランダムに選択した $k$ 人に介入した場合の利益、$\bar{R}^C(k)$ は、ランダムに選択した $k$ 人に介入しなかった場合の利益です。$AUL_{\pi}^C(k)$は、底辺 $k$、高さ $\bar{R}^T(k) - \bar{R}^C(k)$ の三角形の面積と見做すこともできます。
実装例
Python で Uplift modeling により利益の増加分を予測するコードを実装します。ここでは、T-Learner, S-Learner を実装しています。なお、ここでの実装は仕事ではじめる機械学習の9章を参考にしています。また、実行環境は、Python 3.7.6, numpy 1.18.1, pandas 1.0.2, scikit-learn 0.22.2 です。以下、コードです。
- 必要なライブラリの読み込み
import numpy as np import pandas as pd import matplotlib.pyplot as plt %matplotlib inline import seaborn as sns sns.set_style('whitegrid') import random from sklearn.linear_model import LogisticRegression
- 利用するデータの生成
ここでの利益は CVR としています。
def generate_sample_data(num, seed=0): cv_flg_list = [] # コンバージョンしたかを表すフラグのリスト treat_flg_list = [] # 介入したかを表すフラグのリスト feature_vector_list = [] # 特徴量のリスト feature_num = 8 # 特徴量の数 base_weight = [0.02, 0.03, 0.05, -0.04, 0.00, 0.00, 0.00, 0.00] # 特徴量のベース lift_weight = [0.00, 0.00, 0.00, 0.05, -0.05, 0.00, 0.0, 0.00] # 介入時の特徴量の変化量 random_instance = random.Random(seed) for i in range(num): feature_vector = [random_instance.random() for n in range(feature_num)] # 特徴量をランダムに生成 treat_flg = random_instance.choice((1, 0)) # 介入フラグをランダムに生成 cv_rate = sum([feature_vector[n]*base_weight[n] for n in range(feature_num)]) # CVRのベースとなる値を生成 if treat_flg == 1: cv_rate += sum([feature_vector[n]*lift_weight[n] for n in range(feature_num)]) # 介入するならlift_weightを加味してCVRを加算 cv_flg = 1 if cv_rate > random_instance.random() else 0 cv_flg_list.append(cv_flg) treat_flg_list.append(treat_flg) feature_vector_list.append(feature_vector) df = pd.DataFrame(np.c_[cv_flg_list, treat_flg_list, feature_vector_list], columns=['cv_flg', 'treat_flg','feature0', 'feature1', 'feature2', 'feature3', 'feature4', 'feature5', 'feature6', 'feature7']) return df train_data = generate_sample_data(num=10000, seed=0) # モデル構築用データ(学習データ) test_data = generate_sample_data(num=10000, seed=1) # モデル性能評価用データ(検証データ)
- T-Learner の実装
# 介入する場合の利益(CVR)を予測するモデル用のデータを用意 X_train_treat = train_data[train_data['treat_flg']==1].drop(['cv_flg', 'treat_flg'], axis=1) Y_train_treat = train_data.loc[train_data['treat_flg']==1, 'cv_flg'] # 介入しない場合の利益(CVR)を予測するモデル用のデータを用意 X_train_control = train_data[train_data['treat_flg']==0].drop(['cv_flg', 'treat_flg'], axis=1) Y_train_control = train_data.loc[train_data['treat_flg']==0, 'cv_flg'] # 2つのモデルを構築 treat_model = LogisticRegression(C=0.01, random_state=0) control_model = LogisticRegression(C=0.01, random_state=0) treat_model.fit(X_train_treat, Y_train_treat) control_model.fit(X_train_control, Y_train_control) # 検証データに対して CVR を予測 X_test = test_data.drop(['cv_flg', 'treat_flg'], axis=1) treat_score = treat_model.predict_proba(X_test)[:, 1] control_score = control_model.predict_proba(X_test)[:, 1] # uplift score を算出 uplift_score = treat_score - control_score
- AUUC の算出
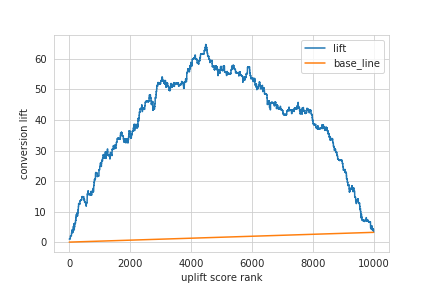
# uplift score が大きい順に検証データを並び替え result = pd.DataFrame(np.c_[test_data['cv_flg'], test_data['treat_flg'], uplift_score], columns=['cv_flg', 'treat_flg', 'uplift_score']) result = result.sort_values(by='uplift_score', ascending=False).reset_index(drop=True) # lift の算出 result['treat_num_cumsum'] = result['treat_flg'].cumsum() result['control_num_cumsum'] = (1 - result['treat_flg']).cumsum() result['treat_cv_cumsum'] = (result['treat_flg'] * result['cv_flg']).cumsum() result['control_cv_cumsum'] = ((1 - result['treat_flg']) * result['cv_flg']).cumsum() result['treat_cvr'] = (result['treat_cv_cumsum'] / result['treat_num_cumsum']).fillna(0) result['control_cvr'] = (result['control_cv_cumsum'] / result['control_num_cumsum']).fillna(0) result['lift'] = (result['treat_cvr'] - result['control_cvr']) * result['treat_num_cumsum'] result['base_line'] = result.index * result['lift'][len(result.index) - 1] / len(result.index) # AUUC の算出 auuc = (result['lift'] - result['base_line']).sum() / len(result['lift']) print('AUUC = {:.2f}'.format(auuc)) # 出力:=> AUUC = 37.70
- uplift curve の描画
result.plot(y=['lift', 'base_line']) plt.xlabel('uplift score rank') plt.ylabel('conversion lift') plt.show()
- S-Learner の実装
# 学習データの用意(介入有無と特徴量の交互作用項を作成) X_train = train_data.drop('cv_flg', axis=1) for feature in ['feature'+str(i) for i in range(8)]: X_train['treat_flg_x_' + feature] = X_train['treat_flg'] * X_train[feature] Y_train = train_data['cv_flg'] # モデルを構築 model = LogisticRegression(C=0.01, random_state=0) model.fit(X_train, Y_train) # 介入する場合の検証データの用意 X_test_treat = test_data.drop('cv_flg', axis=1).copy() X_test_treat['treat_flg'] = 1 for feature in ['feature'+str(i) for i in range(8)]: X_test_treat['treat_flg_x_' + feature] = X_test_treat['treat_flg'] * X_test_treat[feature] # 介入しない場合の検証データの用意 X_test_control = test_data.drop('cv_flg', axis=1).copy() X_test_control['treat_flg'] = 0 for feature in ['feature'+str(i) for i in range(8)]: X_test_control['treat_flg_x_' + feature] = X_test_control['treat_flg'] * X_test_control[feature] # 検証データに対して利益 CVR を予測 treat_score = model.predict_proba(X_test_treat)[:, 1] control_score = model.predict_proba(X_test_control)[:, 1] # uplift score の算出 uplift_score = treat_score - control_scoreT-Learner と同様に AUUC を評価したところ、AUUC = 19.60となり、今回のデータでは T-Learner のほうが性能が高いという結果になりました。
おわりに
Uplift modeling の概要と、それを実現するための実装例をまとめました。
誤りなどありましたら編集リクエストをして頂けると幸いです。参考
- 投稿日:2020-04-07T23:15:50+09:00
Structural Patterns in Python
Decorator
Decorators are great tools to add additional features to an existing object without using subclassing.
from functools import wraps def make_blink(function): """Defines the decorator""" #This makes the decorator transparent in terms of its name and docstring @wraps(function) #Define the inner function def decorator(): #Grab the return value of the function being decorated ret = function() #Add new functionality to the function being decorated return "<blink>" + ret + "</blink>" return decorator #Apply the decorator here! @make_blink def hello_world(): """Original function! """ return "Hello, World!" #Check the result of decorating print(hello_world()) #Check if the function name is still the same name of the function being decorated print(hello_world.__name__) #Check if the docstring is still the same as that of the function being decorated print(hello_world.__doc__)Proxy
Proxy comes in handy when creating an object that is very resource-intensive. It can postpone object creation unless it's absolutely necessary by creating a placeholder.
import time class Producer: """Define the 'resource-intensive' object to instantiate!""" def produce(self): print("Producer is working hard!") def meet(self): print("Producer has time to meet you now!") class Proxy: """"Define the 'relatively less resource-intensive' proxy to instantiate as a middleman""" def __init__(self): self.occupied = 'No' self.producer = None def produce(self): """Check if Producer is available""" print("Artist checking if Producer is available ...") if self.occupied == 'No': #If the producer is available, create a producer object! self.producer = Producer() time.sleep(2) #Make the prodcuer meet the guest! self.producer.meet() else: #Otherwise, don't instantiate a producer time.sleep(2) print("Producer is busy!") #Instantiate a Proxy p = Proxy() #Make the proxy: Artist produce until Producer is available p.produce() #Change the state to 'occupied' p.occupied = 'Yes' #Make the Producer produce p.produce()Adapter
This is used when the interfaces are incompatible between a client and a server.
class Korean: """Korean speaker""" def __init__(self): self.name = "Korean" def speak_korean(self): return "An-neyong?" class British: """English speaker""" def __init__(self): self.name = "British" #Note the different method name here! def speak_english(self): return "Hello!" class Adapter: """This changes the generic method name to individualized method names""" def __init__(self, object, **adapted_method): """Change the name of the method""" self._object = object #Add a new dictionary item that establishes the mapping between the generic method name: speak() and the concrete method #For example, speak() will be translated to speak_korean() if the mapping says so self.__dict__.update(adapted_method) def __getattr__(self, attr): """Simply return the rest of attributes!""" return getattr(self._object, attr) #List to store speaker objects objects = [] #Create a Korean object korean = Korean() #Create a British object british =British() #Append the objects to the objects list objects.append(Adapter(korean, speak=korean.speak_korean)) objects.append(Adapter(british, speak=british.speak_english)) for obj in objects: print("{} says '{}'\n".format(obj.name, obj.speak()))Composite
The composite design pattern maintains a tree data structure to represent part-whole relationships. Here we like to build a recursive tree data structure so that an element of the tree can have its own sub-elements.
class Component(object): """Abstract class""" def __init__(self, *args, **kwargs): pass def component_function(self): pass class Child(Component): #Inherits from the abstract class, Component """Concrete class""" def __init__(self, *args, **kwargs): Component.__init__(self, *args, **kwargs) #This is where we store the name of your child item! self.name = args[0] def component_function(self): #Print the name of your child item here! print("{}".format(self.name)) class Composite(Component): #Inherits from the abstract class, Component """Concrete class and maintains the tree recursive structure""" def __init__(self, *args, **kwargs): Component.__init__(self, *args, **kwargs) #This is where we store the name of the composite object self.name = args[0] #This is where we keep our child items self.children = [] def append_child(self, child): """Method to add a new child item""" self.children.append(child) def remove_child(self, child): """Method to remove a child item""" self.children.remove(child) def component_function(self): #Print the name of the composite object print("{}".format(self.name)) #Iterate through the child objects and invoke their component function printing their names for i in self.children: i.component_function() #Build a composite submenu 1 sub1 = Composite("submenu1") #Create a new child sub_submenu 11 sub11 = Child("sub_submenu 11") #Create a new Child sub_submenu 12 sub12 = Child("sub_submenu 12") #Add the sub_submenu 11 to submenu 1 sub1.append_child(sub11) #Add the sub_submenu 12 to submenu 1 sub1.append_child(sub12) #Build a top-level composite menu top = Composite("top_menu") #Build a submenu 2 that is not a composite sub2 = Child("submenu2") #Add the composite submenu 1 to the top-level composite menu top.append_child(sub1) #Add the plain submenu 2 to the top-level composite menu top.append_child(sub2) #Let's test if our Composite pattern works! top.component_function()Bridge
The bridge pattern helps untangle an unnecessary complicated class hierarchy, especially when implementation specific classes are mixed together with implementation-indendent classes. So our problem here is that there are two parallel or orthogonal abstractions. One is implementation-specific, and the other one is implementation-independent.
class DrawingAPIOne(object): """Implementation-specific abstraction: concrete class one""" def draw_circle(self, x, y, radius): print("API 1 drawing a circle at ({}, {} with radius {}!)".format(x, y, radius)) class DrawingAPITwo(object): """Implementation-specific abstraction: concrete class two""" def draw_circle(self, x, y, radius): print("API 2 drawing a circle at ({}, {} with radius {}!)".format(x, y, radius)) class Circle(object): """Implementation-independent abstraction: for example, there could be a rectangle class!""" def __init__(self, x, y, radius, drawing_api): """Initialize the necessary attributes""" self._x = x self._y = y self._radius = radius self._drawing_api = drawing_api def draw(self): """Implementation-specific abstraction taken care of by another class: DrawingAPI""" self._drawing_api.draw_circle(self._x, self._y, self._radius) def scale(self, percent): """Implementation-independent""" self._radius *= percent #Build the first Circle object using API One circle1 = Circle(1, 2, 3, DrawingAPIOne()) #Draw a circle circle1.draw() #Build the second Circle object using API Two circle2 = Circle(2, 3, 4, DrawingAPITwo()) #Draw a circle circle2.draw()
- 投稿日:2020-04-07T22:29:26+09:00
poetryでrequirements.txtからパッケージをインストールしたい
- 投稿日:2020-04-07T22:23:27+09:00
Python&機械学習 勉強メモ⑥
はじめに
① https://qiita.com/yohiro/items/04984927d0b455700cd1
② https://qiita.com/yohiro/items/5aab5d28aef57ccbb19c
③ https://qiita.com/yohiro/items/cc9bc2631c0306f813b5
④ https://qiita.com/yohiro/items/d376f44fe66831599d0b
⑤ https://qiita.com/yohiro/items/3abaf7b610fbcaa01b9c
の続き
- 参考教材:Udemy みんなのAI講座 ゼロからPythonで学ぶ人工知能と機械学習
- 使用ライブラリ:scikit-learn
課題設定
手書きの数字画像(8×8 px)から、書いてある数字を認識する。
ソースコード
インポート
from sklearn import datasets from sklearn import svm from sklearn import metrics import matplotlib.pyplot as pltサンプルデータの読み込み
# 数字データの読み込み digits = datasets.load_digits()digitsには、以下のようなデータが入っている。
digits.data[[ 0. 0. 5. ... 0. 0. 0.] [ 0. 0. 0. ... 10. 0. 0.] [ 0. 0. 0. ... 16. 9. 0.] ... [ 0. 0. 1. ... 6. 0. 0.] [ 0. 0. 2. ... 12. 0. 0.] [ 0. 0. 10. ... 12. 1. 0.]]digits.target[0 1 2 ... 8 9 8]
digits.dataは64×1797のリストで、要素の値はグレースケールにおける色を表しており、一つの64要素リストが一つの画像を表している。画像表示用にdigits.imageにもリスト形式は異なるが同様の情報が入っている。
digits.targetはそれぞれの画像の正解(=どの数字を表しているか)を示している。サポートベクターマシンによる訓練
# サポートベクターマシン clf = svm.SVC(gamma=0.001, C=100.0) # gamma:一つの訓練データが与える影響の大きさ, C:誤認識許容度 # サポートベクターマシンによる訓練(6割のデータを使用、残りの4割は検証用) clf.fit(digits.data[:int(n*6/10)], digits.target[:int(n*6/10)])前回使ったのは
LinearSVC()だったが、今回はSVC()を使用している。
線形の境界線では分類ができないから?分類
上記で作成したclfにdigits.dataの残りの4割のデータを読ませ、どの数字になるか、それぞれ分類させる。
# 正解 expected = digits.target[int(-n*4/10):] # 予測 predicted = clf.predict(digits.data[int(-n*4/10):]) # 正解率 print(metrics.classification_report(expected, predicted)) # 誤認識のマトリックス print(metrics.confusion_matrix(expected, predicted))結果
正解率
precision recall f1-score support 0 0.99 0.99 0.99 70 1 0.99 0.96 0.97 73 2 0.99 0.97 0.98 71 3 0.97 0.86 0.91 74 4 0.99 0.96 0.97 74 5 0.95 0.99 0.97 71 6 0.99 0.99 0.99 74 7 0.96 1.00 0.98 72 8 0.92 1.00 0.96 68 9 0.96 0.97 0.97 71 accuracy 0.97 718 macro avg 0.97 0.97 0.97 718 weighted avg 0.97 0.97 0.97 7180と予測したものは99%が正解、正解が0だった内正しく0と予想されたものは99%、のように読む。
表の読み方の参考:
- classification_reportの読み方
- KerasでF1スコアをmetircsに入れる際は要注意誤認識マトリックス
[[69 0 0 0 1 0 0 0 0 0] [ 0 70 1 0 0 0 0 0 2 0] [ 1 0 69 1 0 0 0 0 0 0] [ 0 0 0 64 0 3 0 3 4 0] [ 0 0 0 0 71 0 0 0 0 3] [ 0 0 0 0 0 70 1 0 0 0] [ 0 1 0 0 0 0 73 0 0 0] [ 0 0 0 0 0 0 0 72 0 0] [ 0 0 0 0 0 0 0 0 68 0] [ 0 0 0 1 0 1 0 0 0 69]]0の画像の内、0と認識されたものが69件、4と認識されたものが1件、のように読む。
実際の画像と予測値
# 予測と画像の対応(一部) images = digits.images[int(-n*4/10):] for i in range(12): plt.subplot(3, 4, i + 1) plt.axis("off") plt.imshow(images[i], cmap=plt.cm.gray_r, interpolation="nearest") plt.title("Guess: " + str(predicted[i])) plt.show()
数字を認識できていることがわかる。
おまけ
digits.dataを可視化してみた(白黒の2値画像)
for i in range(10): my_s = "" for k, j in enumerate(digits.data[i]): if (j > 0): my_s += " ■ " else: my_s += " " if k % 8 == 7: print(my_s) my_s = "" print("\n")結果
■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ... ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■ ■なんとなく手書き文字になっていることがわかる

- 投稿日:2020-04-07T21:54:01+09:00
Pythonで毎日AtCoder #29
はじめに
前回
おすすめの問題があったらコメントやtwitterでリプ飛して欲しいです。#29
考えたこと
最初は普通に実装(reverseマシマシ)していましたが、reverseはコストが高いのでうまく処理してあげる必要がある。文字を追加するのは先端か末尾の二つなのでdequeを使うことができる。また、逐一reverseしなくても前後のラベルを作ってreverseのたびに反転させればよい。from collections import deque s = deque(input()) q = int(input()) query = [input().split() for _ in range(q)] reverse = False #前後を判定する for i in query: if len(i) == 1: if reverse: reverse = False else: reverse = True else: if reverse: if i[1] == '1': s.append(i[2]) else: s.appendleft(i[2]) #先端にappend else: if i[1] == '1': s.appendleft(i[2]) #先端にappend else: s.append(i[2]) if reverse: #reverseが有効ならsを逆にしなければならない s = reversed(s) s = ''.join(s) print(s) else: s = ''.join(s) print(s)reverseの真偽はもっとうまく処理できると思います。
まとめ
文字列の操作は遅いことを学びました。今回の様に操作する場所が決っている問題は、strよりもlistとかdequeを使った方が良いらしい。ではまた。おやすみなさい。
- 投稿日:2020-04-07T21:50:11+09:00
【Pyro】確率的プログラミング言語Pyroによる統計モデリング① ~Pyroとは~
はじめに
本シリーズでは,確率的プログラミング言語Pyroを用いて統計モデリングを行う方法について,いくつかの例題を交えながら紹介していきます.
例題には,書籍「実践Data Scienceシリーズ RとStanではじめるベイズ統計モデリングによるデータ分析入門」(KS情報科学専門書)に登場する例題を採用します.この本では題名の通りRとStanを用いてベイズモデリングを行っていますが,本シリーズでは同じ例題をPyroを用いて解いていきたいと思います.コーディングを通じて統計モデリングへの理解を深めるとともに,実データにもPyroを用いた柔軟なモデリングを適用できるようになることを目的として執筆します.統計モデリングそのものについての詳しい解説は書籍や他の記事に譲り,本記事では実装をメインに書きます.
読者としては.以下に当てはまるような人を想定しています.
- Pythonの基本的な使い方がわかる人
- ベイズ統計モデリングの基本を理解している人
- 柔軟かつスケーラブルな統計モデリングを行いたい人
- Pytorchユーザ
本記事はそのシリーズの第1回として,Pyroの概要および次回以降のモデリングを実装していく上での基本的なメソッドを説明していきます.
Pyroとは
Pyro はUber AI Labsが開発したPythonで書かれた確率的プログラミング言語の一つです. バックエンドにはPytorchを採用しており,もちろんGPUを利用できます.公式サイトに書いてあることを意訳すると,Pyroを使う利点は以下の通りです.
- 汎用性: あらゆる計算可能な確率分布を表現できる.
- スケーラビリイティ: (並列計算を用いることで)大きなデータセットにも対応可能.
- 最小限: コードの複雑性を可能な限り落としているので挙動を把握しやすい(?)
- 柔軟性: 処理の自動化もできるし,カスタムもできる.
特に,GPUを利用可能なフレームワークの特長として,大きなデータセットに対しても実用的な時間で計算できるという利点(=スケーラビリティー)は注目すべきポイントです.他にGPUを利用できる確率的プログラミング言語にはEdward2などがありますが,PytorchユーザにはPyroの方が使いやすいでしょう.
Pyroのインストール
公式リファレンスにある通り,pipを用いて以下のコマンドでインストールできます.
pip install pyro-pplPyroの基本メソッド
Pyroには統計モデリングを実装するための根幹となるメソッドが用意されていますが,その中で最も基本的な
pyro.sampleおよびpyro.plateについて本稿で紹介します.これらは,確率分布からのサンプリングを容易に記述できるメソッドです.1. 確率分布に従うサンプリング
pyro.sample統計モデリングのフレームワークとして欠かせないのが,確率分布に従うサンプリングです. Pyroでは多くの確率分布(正規分布,二項分布,ポアソン分布,...)が用意されており,
pyro.sample(<識別名>, <確率分布>)
という記述により指定した確率分布から標本を抽出することができます.
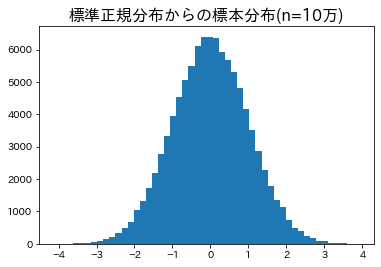
以下のコードは,標準正規分布から10万個のi.i.dなサンプルを抽出し,確認のために抽出した標本の分布を可視化するものです.import matplotlib.pyplot as plt import pyro import pyro.distributions as dist # distにはPyroで利用できる確率分布が実装されている # for文でサンプリングを実行 samples = [] for _ in range(100000): # 標準正規分布から1つのサンプルを抽出 a_sample = pyro.sample("a_sample", dist.Normal(0, 1)) # 標準正規分布より samples.append(a_sample) # 可視化 plt.hist(samples, bins=50) plt.title("標準正規分布からの標本分布(n=10万)", fontsize=16)
適切に標準正規分布からサンプリングされていることが確認できます.
これでも良いのですが,Pyroではよりシンプルな書き方により同様の標本を得ることができます.2. ベクトルとして取得することを宣言
pyro.plate統計モデリングを行うにあたっては特定の確率分布から多数の独立なサンプルを抽出することは非常に頻繁に行われます.
1のようにfor文で記述すると記述・処理の両面において非効率です.
そこで便利なのが,pyro.plateです.
pyro.plate(<コンテクスト名>, <サンプルサイズ>)
によって宣言されたコンテクスト内でpyro.sampleによるサンプリングを行うと,ベクトルとしてサンプルを得られます.以下はその実装です.# pyro.plateを用いてベクトルとして取得する場合 with pyro.plate("plate", size=100000): samples = pyro.sample("samples", dist.Normal(0, 1)) plt.hist(samples, bins=50) plt.title("標準正規分布からサンプリングした標本分布(n=10万)", fontsize=16)結果は上図と同様になるはずです.
pyro.sample,pyro.plateを用いることにより,確率分布からサンプリングを行うことができるようになりました.統計モデリングを行うためには他にも不可欠な機能がありますが,それらは次回以降に実例を交えながら随時説明してまいります.まとめ
本稿では,主に以下の2つの点についての紹介を行いました.
- Pyroの概要や利点
- 確率分布からサンプリングを行うpyro.sample,pyro.plate
冒頭でも述べた通り,次回からは書籍「実践Data Scienceシリーズ RとStanではじめるベイズ統計モデリングによるデータ分析入門」(KS情報科学専門書)に準拠し,書籍で紹介されている例題をPyroで再現する形で進めていきます.
次回は第3部第2章「単回帰モデル」を扱います.
- 投稿日:2020-04-07T20:20:10+09:00
【Python】茶色コーダーになりました〜【AtCoder】
【祝】茶色コーダーになりました〜
12回目でようやく茶色コーダー!!!
一番初めは2重for文も書けなかったのですごい成長!!!
パチパチパチ(拍手)〜
茶色コーダーになるまでにやったこと
競プロ初心者に参考になるかも!
ということでこれまでやってきた事を記事として残しておきます!①けんちょんさんの記事をいろいろ読んでわくわくする!
一番最初に読んだ記事はこれ!
AtCoder に登録したら次にやること ~ これだけ解けば十分闘える!過去問精選 10 問 ~
まずはこれを一通り見てから、実際にPythonで解いてみました!
ほかにもわくわくする記事は、理解できなくても通勤時間とかに読んでいました!
計算量の記事とか、C問題(300点)レベルがとけるようになるための必須知識!
C++のソースコードは雰囲気で読めばいいと思うよ
とりあえず暇な時に他の人の記事も含めていろいろ読みました!②とりあえず(ほぼ)毎週夜9時にあるABCに毎回参加する!
<唐突なラップ>
一番初めはA問題だけでもACで喜ぶ素人!
でも、他の人の回答を見ると簡潔すぎるソースコード!
そしてそんな書き方があったのか!と、湧き出してくる感動と!
人生にわくわくを与えてくれるAtCoder!ありがと!・・・
とにかく感動を覚えたソースコードはメモ帳に残して少しずつ自分のものにしていきました!
またレートも毎週のABCでちょっとずつ上がっていくしモチベも維持できました!③AtCoder Problemsで簡単な問題を解く!
AtCoder Problems
Difficultyが小さいものから解いていって自信をつけていきました!④AOJのプログラミング入門を解く!
AOJのプログラミング入門
この10トピック(40問)を2周する!
(※トピック11(クラスと構造体)は競プロで使用しないので除外)
入門と言いながらそこそこ歯ごたえがあったw
全てが良問!!!
この40問は非常に勉強になったし、実際、基礎力がしっかり身についた実感がありました!
俺にとってこれはめちゃくちゃ大きかったし自信にもつながった!
2次元配列、3次元配列の恐怖心もなくなりました!
この40問をやれば、まずA,B問題(100、200点)が99%解けるようになります!⑤武器を1つ1つ身につける。
DP(動的計画法)、キュー/スタック、DFS/BFS、bit全探索・・・
けんちょんさんの記事などを参考に日々勉強。
めちゃくちゃ典型的な基本問題は解けるようにする(現在進行形)。④と⑤の間くらいで、茶色になることができました!
おまけ タイピングの練習
アルゴリズムの勉強の息抜きににタイピング(寿司打)の練習で遊んでました。
2週間くらい毎日タイピングの練習やってたら、ブラインドタッチができるようになりました〜
ソースコードを書く速度も上がってる気がする→レート上昇に多少はつながってる???次は緑コーダーになれるようにがんばろ!
- 投稿日:2020-04-07T19:58:29+09:00
jupyterlab & matplotlibで作成したグラフのデータ点にリンクを貼る
この記事について
記事タイトルの通りのことがやりたかった。
また使うことがあるかも知れないので、その方法を記録しておく。手順
- matplotlib で リンク付きのグラフを作成
svg形式で保存- Chrome などのブラウザでファイルを開く
環境
自分は jupyter-lab での作業でした。
バージョンはこんな感じ(pip freeze の結果より)jupyterlab-server==1.0.7 matplotlib==3.2.1ファイル作成
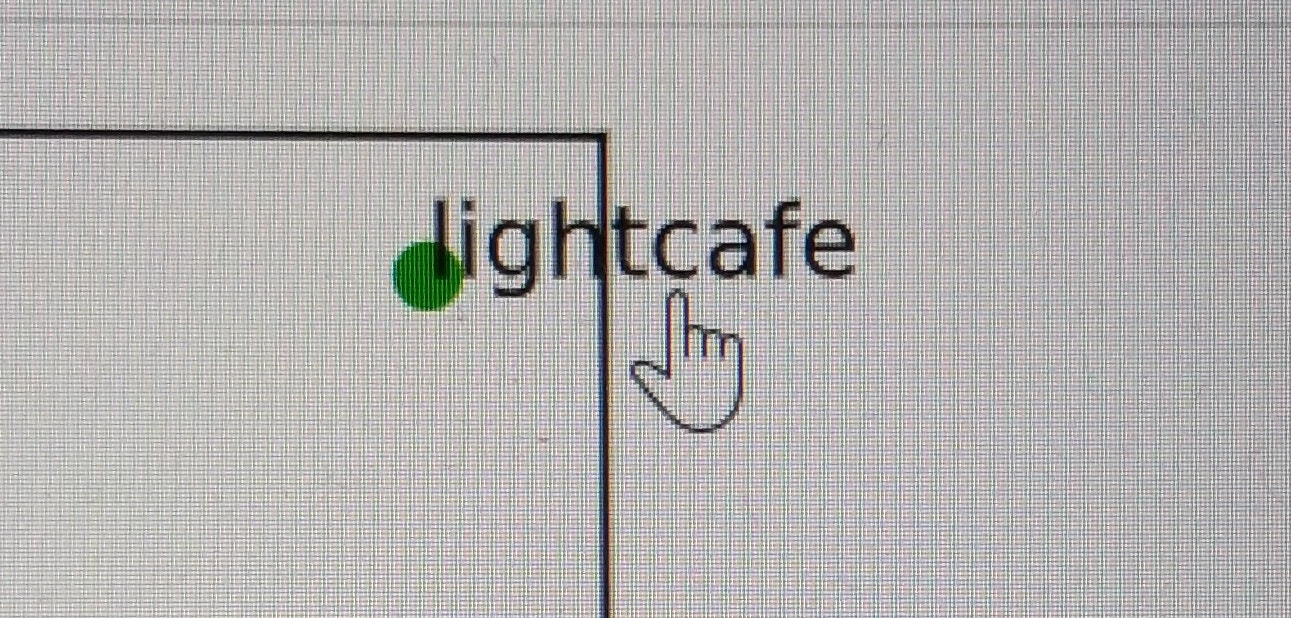
# 各種設定 import matplotlib.pyplot as plt from IPython.display import set_matplotlib_formats set_matplotlib_formats("svg") # テストデータ準備 data_list = [[0, 1], [1,0], [1,1]] label_list = ['google', 'yahoo', 'lightcafe'] url_list = ['https://www.google.com/', 'https://www.yahoo.co.jp/', 'https://www.lightcafe.co.jp/'] # グラフ作成 fig, ax = plt.subplots(1, 1, tight_layout=True) for d, l, u in zip(data_list, label_list, url_list): x, y = d ax.scatter(x, y) #点プロット ax.annotate(l, xy=(x, y), size=10, #文字プロット url=u, bbox=dict(color='w', alpha=1e-6, url=u), ) # 保存 fig.savefig('test.svg')確認
test.svgを ブラウザで開き、グラフ内のデータ点 or ラベルをクリックすれば
設定したリンクに飛ぶ。ちなみに、Google Colaboratory で同じものを実行すると svg 保存しなくても、
セルの Output から飛ぶことが出来ました。
以上
参考
- 投稿日:2020-04-07T19:46:59+09:00
Django 汎用クラスビューでファイルをアップロードする方法
2020-04-07 作成: windows10/Python-3.8.2-amd64/Django-3.0.4
Django でファイルを汎用クラスビューでアップロードする方法について、
日本語情報は意外と多くありません。
そのため、結構時間がかかってしまいました。
忘れないように記事にしておきます。
この記事は、ファイルのアップロードの原理を手軽に知りたい、という人向きです。Django を初めて使う人は、こちら。
10 分で終わる Django の実用チュートリアル前準備
プロジェクト名は mysite、アプリケーション名は fileupload とする。
フォルダ media を mysite/ に作成し、ファイルの保存場所とする。ここまでのファイルの配置はこうなる。
mysite/ mysite/ __pycashe__/ <- 気にしなくていい setting.py, urls.py など *.py が 5 個 fileupload/ migrations/ <- 気にしなくていい models.py, views.py など *.py が 6 個 media/ <- アップロードしたファイルの保存場所 manage.py <- プロジェクトの管理用Django プロジェクトに、アプリケーション fileupload を登録する。
そのために、settings.py の INSTALLED_APPS に追記。mysite/mysite/settings.pyINSTALLED_APPS = [ 'fileupload.apps.FileuploadConfig', 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', ]ファイルのアップロード用のディレクトリも登録する。
そのために、settings.py に 2 行を追記。mysite/mysite/settings.pyMEDIA_ROOT = os.path.join(BASE_DIR, 'media') MEDIA_URL = '/media/'url を登録するため urls.py に追記。
mysite/mysite/urls.pyfrom django.contrib import admin from django.urls import include, path from django.conf import settings from django.conf.urls.static import static urlpatterns = [ path('fileupload/', include('fileupload.urls')), path('admin/', admin.site.urls), ] + static(settings.MEDIA_URL, document_root=settings.MEDIA_ROOT)アプリケーションの実装
モデル Fileupload を作成。
フィールドは、ファイルのタイトルと、ファイルそのものの 2 つ。
ファイルの保存場所は、media/uploads/年/月/日 という名前のフォルダ。
写真をアップロードすることを想定し、拡張子は jpg しか相手にしない。mysite/fileupload/models.pyfrom django.db import models from django.core.validators import FileExtensionValidator class Fileupload(models.Model): titlefield = models.CharField(max_length = 200, null = True) filefield = models.FileField( upload_to = 'uploads/%Y/%m/%d/', verbose_name = 'attached file', validators=[FileExtensionValidator(['jpg', ])], null = True )ビューを作成する。
Django の汎用クラスビューを使うのは、やっぱり楽だから。
汎用クラスビューは、デフォルトの変数名やファイル名など
(たとえばfileupload_object_nameやtemplate_name)を知っていないと使えない。
だから、デフォルト名ではなく、分かりやすい名前を明示的につけておいた。mysite/fileupload/views.pyfrom django.views import generic from .models import Fileupload class FileuploadListView(generic.ListView): model = Fileupload context_object_name = 'fileupload_context_list' class FileuploadCreateView(generic.CreateView): model = Fileupload fields = ['titlefield', 'filefield'] success_url = '/fileupload' template_name = 'fileupload/fileupload_create.html' class FileuploadDetailView(generic.DetailView): model = Fileupload template_name = 'fileupload/fileupload_detail.html' context_object_name = 'fileupload_context' class FileuploadUpdateView(generic.UpdateView): model = Fileupload fields = ['titlefield', 'filefield'] success_url = '/fileupload' template_name = 'fileupload/fileupload_update.html' class FileuploadDeleteView(generic.DeleteView): model = Fileupload success_url = '/fileupload' template_name = 'fileupload/fileupload_delete.html'ビューを url に登録する。
ファイル fileupload/urls.py を新しく作成。
作成したビューを登録する。mysite/fileupload/urls.pyfrom django.urls import path from . import views urlpatterns = [ path('', views.FileuploadListView.as_view()), path('index', views.FileuploadListView.as_view(), name = 'site_index'), path('create', views.FileuploadCreateView.as_view(), name = 'site_create'), path('detail/<int:pk>', views.FileuploadDetailView.as_view(), name = 'site_detail'), path('update/<int:pk>', views.FileuploadUpdateView.as_view(), name = 'site_update'), path('delete/<int:pk>', views.FileuploadDeleteView.as_view(), name = 'site_delete'), ]
fileupload/templates/fileupload/にテンプレート用の html ファイルを作成する。
それぞれのビューに対応する。mysite/fileupload/templates/fileupload/fileupload_list.html<h1>ファイルの一覧表示</h1> {% if fileupload_context_list %} <table> {% for temp in fileupload_context_list %} <tr> <td><a href = "{% url 'site_detail' temp.pk %}"> {{ temp.titlefield }}</a></td> <td>{{ temp.filefield }}</td> <td><a href = "{% url 'site_update' temp.pk %}">Edit</a></td> <td><a href = "{% url 'site_delete' temp.pk %}">Delete</a></td> </tr> {% endfor %} </table> {% else %} <p>No file available.</p> {% endif %} <p><a href = "{% url 'site_create' %}">新しいファイルのアップロード</a></p>mysite/fileupload/templates/fileupload/fileupload_create.html<h1>ファイルのアップロード</h1> <form method = "post" enctype="multipart/form-data"> {% csrf_token %} {{ form.titlefield }} {{ form.filefield }} <input type = "submit" value = "Create" /> </form>mysite/fileupload/templates/fileupload/fileupload_detail.html<h1>ファイルの詳細</h1> {% if fileupload_context %} <ul> <li>Primary Key Number : {{ fileupload_context.pk }}</li> <li>Memo Text : {{ fileupload_context.titlefield }}</li> <li>Memo Text : /media/{{ fileupload_context.filefield }}</li> <li>File : <img src = /media/{{ fileupload_context.filefield }} /></li> </ul> {% else %} <p>No file available.</p> {% endif %} <p><a href = "{% url 'site_index' %}">ファイルの一覧表示</a></p>mysite/fileupload/templates/fileupload/fileupload_update.html<h1>ファイルの更新</h1> <form method = "post" enctype="multipart/form-data"> {% csrf_token %} {{ form.titlefield }} {{ form.filefield }} <input type = "submit" value = "Save" /> </form>mysite/fileupload/templates/fileupload/fileupload_delete.html<h1>ファイルの削除</h1> <form method = "post"> {% csrf_token %} <input type= "submit" value = "Delete" /> </form>仕上げ
マイグレーションを実行し、開発用 www サーバーを起動すれば、
http://localhost:8000/fileupload/ でアクセスできる。課題
ファイルのアップロードに失敗したときの処理は、ちゃんと書いていないので今後の課題。
おしまい
- 投稿日:2020-04-07T19:40:27+09:00
Pythonの環境構築 For Mac
pythonはまるっきり初心者で、触れたことがほぼないので環境構築からやります!
PythonのVersion確認
Macにはpythonがpreinstallされているのでまずは確認。
$ python --version Python 2.7.10 $ python3 --version Python 3.7.7あるので準備はこれでOK!
なんですが、ない場合や最新のpythonを利用したい場合は別途インストールする必要があります
pyenvをhomebrewでインストールしてpythonを落としていきましょうPythonのインストール
$ brew install pyenvbash_profileなどに環境変数設定などをしたら完了
$ echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bash_profile $ echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bash_profile $ echo 'eval "$(pyenv init -)"' >> ~/.bash_profile $ source ~/.bash_profileインストールできるversionを確認して必要なやつをインストール
$ pyenv install --list利用できるversionを確認して、インストールしたversionを利用するように
pyenv globalを実行
(ここでは3.8.2をインストールします)$ pyenv install 3.8.2 $ pyenv versions $ pyenv global 3.8.2 $ python3 --versionこれで準備終わり!
もうsample.pyみたいなの作って、python sample.pyで実行できちゃいます!なんて簡単な環境構築。。
- 投稿日:2020-04-07T19:11:20+09:00
Python の基本②
前回より続いて書きます。
リスト型
これまた基本的な
一つの変数に複数のデータを入れる方法です。リストの基本
直接データを入れることや
下記のように変数として、入れることも可能
また文字列や数値混在でもOKapple = 4 grape = 'グレープ' mikan = 6 fruits = [apple, grape, mikan] print(fruits) # 出力 [4,グレープ,6]多重リスト
リストの中にリストを入れる方法です。
rei = [[1.2],[3,4],[5.6]] # 上記が使い型の例です。 fruits_name_1 = "りんご" fruits_num_1 = 2 fruits_name_2 = "みかん" fruits_num_2 = 10 fruits = [[fruits_name_1, fruits_num_1], [fruits_name_2, fruits_num_2]] print(fruits) # 出力: [["りんご", 2], ["みかん", 10]]リストから値を取り出す。
リストにはインデックス(番号)が割り振られています。0から始まり、数値を指定することで取り出せます
最注意事項として一番最後を-1として
-2,-3と順番に取り出せることもできます。ListSample = [1, 2, 3, 4] print(ListSample [1]) # インデックスが1の「2」が出力される ListSample = [1, 2, 3, 4] print(ListSample [-2]) # リストの後ろから2番目の「3」が出力されるリストからリストから値を取り出す。
多重リストの取り出しのルールですが。
1,番号: で指定番号より取り出し
2,:番号 で番号一つ手前まで取り出し(-の場合左から数えて手前)
3,番号以上の場合、現状の最後までalphabet = ["a", "b", "c", "d", "e", "f", "g", "h", "i", "j"] print(alphabet[1:5]) # インデックス1~4までの["b", "c", "d", "e"]が出力される print(alphabet[:5]) # 先頭からインデックス4までの ["a", "b", "c", "d", "e"]が出力される print(alphabet[6:]) # インデックス6から末尾までの ["g", "h", "i", "j"]が出力される print(alphabet[0:20]) # インデックスは9までなので19までという指定では、 # ["a","b", "c", "d", "e", "f", "g", "h", "i", "j"]と全てが出力される alphabet = ["a", "b", "c", "d", "e", "f", "g", "h", "i", "j"] print(alphabet[1:-5]) # インデックス1~後ろから6番目までの ["b", "c", "d", "e"]が出力されるリストの上書きと追加
ルールとして
- 番号の指定で追加
- appendを使用して最後に追加
- += で最後に追加
alphabet = ["a", "b", "c", "d", "e"] alphabet[0] = "A" #先頭の要素の値を上書き print(alphabet) # ["A", "b", "c", "d", "e"]が出力される alphabet = ["a", "b", "c", "d", "e"] alphabet[1:3] = ["B", "C"] #インデックス1と2にそれぞれ値を代入 print(alphabet) # ["a", "B", "C", "d", "e"]が出力される alphabet = ["a", "b", "c", "d", "e"] alphabet.append("f") #ひとつだけ追加する場合はappendを使う print(alphabet) # ["a", "b", "c", "d", "e", "f"]が出力される # なお、 append は、 複数の要素を追加することはできません。 複数の値を追加したい場合には、「+」を使ってリスト同士を連結させます。 alphabet = ["a", "b", "c", "d", "e"] alphabet += ["f","g"] #複数追加する場合は+を使う print(alphabet) # ["a", "b", "c", "d", "e", "f", "g"]が出力されるリストから要素の削除
del リスト[インデックス] を使用します。
alphabet = ["a", "b", "c", "d", "e"] del alphabet[3:] # インデックス3以降の要素を削除 print(alphabet) # ["a", "b", "c"]が出力される # また、削除の範囲をスライスで指定することも可能です。 alphabet = ["a", "b", "c", "d", "e"] del alphabet[1:3] # インデックス1~2までの要素を削除 print(alphabet) # ["a", "d", "e"]が出力されるリストのコピー
注意点として
リスト変数にリスト変数を代入するだけだと
同じ内容として認識され、
代入先を変えた場合、代入元も変わってしまいます。リストの中身だけ変えたい場合
list()を使用します。```python: 変数そのまま
alphabet = ['a', 'b', 'c']
alphabet_copy = alphabet # alphabet_copyにalphabetの値を代入する
alphabet_copy[0] = 'A' # alphabet_copyの先頭の値を上書きする
print(alphabet_copy)
print(alphabet)['A', 'b', 'c']
['A', 'b', 'c']
``````python: list()を使って中身だけ
alphabet = ['a', 'b', 'c']
alphabet_copy = list(alphabet)
alphabet_copy[0] = 'A'
print(alphabet_copy)
print(alphabet)以下のように出力されます。
['A', 'b', 'c']
['a', 'b', 'c']
```辞書型
ハッシュとも呼ばれる方法です。
キーとバリューのワンセットで扱われます。{}を使用するのが注意点です。
city = {"キー1": "バリュー1", "キー2": "バリュー2"}辞書の取り出し
キーの指定で呼び出します。
dic ={"Japan": "Tokyo", "Korea": "Seoul"} print(dic["Japan"]) # Tokyoと出力される辞書の上書きと追加
どちらも操作は一緒で
キーを指定して操作します。
指定キーがあれば上書き、なければ追加という形式です。上書きdic ={"Japan":"Tokyo","Korea":"Seoul"} dic["Japan"] = "Osaka" print(dic) # {"Japan": "Osaka", "Korea": "Seoul"}と出力される追加dic ={"Japan":"Osaka","Korea":"Seoul"} dic["China"] = "Beijing" print(dic) # {"Japan": "Osaka", "Korea": "Seoul", "China": "Beijing"}と出力される辞書の要素の削除
del 辞書名["削除したいキー"]という記述で、指定したキーの要素を削除できます。
削除dic = {"Japan": "Tokyo", "Korea": "Seoul", "China": "Beijing"} del dic["China"] # 指定した要素を削除 print(dic) # {"Japan": "Tokyo", "Korea": "Seoul"}と出力されます。while文
条件が不成立になるまで行う構文
while 条件式:
条件式がTrueの場合に行われる処理whilen = 2 while n >0: # nが0より大きい場合、下記の処理を行う print(n) n -= 1 # nを-1する # 出力結果 1 2whileとif文
合わせ技で、一定の条件まで続けます。
while x != 0: # whileの中で実行される処理は、変数xから1を引く処理と引いた後に出力させる処理です。 x -= 1 if x != 0: print(x) else: print("Bang")for文
リストや辞書型など複数データを
変数より取り出す構文「 for 変数 in リスト: 」で書きます。
nimals = ["tiger", "dog", "elephant"] for animal in animals: # animalsに含まれる要素の数=3回処理を繰り返す print(animal) # 出力結果 tiger dog elephantbreak
繰り返しの終了処理
breakstorages = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10] for n in storages: # storagesに含まれる要素の数=10回処理を繰り返す print(n) if n >= 5: # nが5以上になった場合、下記の処理を行う print("nが5以上になったので処理を終了します") break # for文の処理を終了するcontinue
処理をスキップしたい場合に使用
continuestorages = [1, 2, 3, 4, 5, 6] # storagesに含まれる要素の数=6回処理を繰り返す for n in storages: if n < 3: #nが3より小さい場合、処理を行わない(スキップする) continue print(n) # 出力結果 3 4 5 6Appendix
enumerate()
for文でindex表示も出したい時使います。
index表示ist_ = ["a", "b"] for index, value in enumerate(list_): # listのインデックスと値を取得する print(index, value) # 出力結果 0 a 1 b多重リストのループ
代入先の変数を用意することで出力できます。
多重リストのループlist_ = [[1, 2, 3], [4, 5, 6]] for a, b, c in list_: print(a, b, c) # 出力結果 1 2 3 4 5 6しかし、元のデータに個数文のデータが無い場合エラーになります。
多重リストのループエラーlist_ = [[1, 2, 3], [4, 5]] for a, b, c in list_: print(a, b, c) # エラーになる # 出力結果 not enough values to unpack (expected 3, got 2)辞書型のループ
items()という関数を使うことで
キーとバリューの両方を変数に格納することができます。辞書形のループfruits = {"strawberry": "red", "peach": "pink", "banana": "yellow"} for fruit, color in fruits.items(): # キーはfruitという変数に、バリューはcolorという変数に格納されています print(fruit+" is "+color) # 出力結果 strawberry is red peach is pink banana is yellow
- 投稿日:2020-04-07T19:09:04+09:00
西暦と和暦変換するメソッド
背景
- ただ書いてみた
コード
def convert_year_to_wareki(year): wareki_start_year = { '明治': 1868, '大正': 1912, '昭和': 1926, '平成': 1989, '令和': 2019 } if year < wareki_start_year['大正']: return f"(明治{year - wareki_start_year['明治'] + 1}年)" elif year == wareki_start_year['大正']: return f"(明治{year - wareki_start_year['明治'] + 1}年/大正{year - wareki_start_year['大正'] + 1}年)" elif year < wareki_start_year['昭和']: return f"(大正{year - wareki_start_year['大正'] + 1}年)" elif year == wareki_start_year['昭和']: return f"(大正{year - wareki_start_year['大正'] + 1}年/昭和{year - wareki_start_year['昭和'] + 1}年)" elif year < wareki_start_year['平成']: return f"(昭和{year - wareki_start_year['昭和'] + 1}年)" elif year == wareki_start_year['平成']: return f"(昭和{year - wareki_start_year['昭和'] + 1}年/平成{year - wareki_start_year['平成'] + 1}年)" elif year < wareki_start_year['令和']: return f"(平成{year - wareki_start_year['平成'] + 1}年)" elif year == wareki_start_year['令和']: return f"(平成{year - wareki_start_year['平成'] + 1}年/令和{year - wareki_start_year['令和'] + 1}年)" else: return f"(令和{year - wareki_start_year['令和'] + 1}年)"
- 投稿日:2020-04-07T18:02:39+09:00
Python の基本
最近Ai教室にお世話になってるので
まとめを書こうと思います。基礎
出力
言わずしれた出力を。
使われてるクォーテーションはシングルでもダブルでもprint('Hello World')コメントの入力
# コメント計算
下記のように計算できます。
使えるのはこのように・足し算:「+」
・引き算:「-」
・掛け算:「*」
・割り算:「/」
・余りの計算:「%」
・べき乗:「**」print(3+6) # 出力結果 9文字列
クォーテーションで囲むと
文字列となります。print('3+6') # 出力結果 3+6変数
続いて基本となる変数を
変数の基本
n = 3 # nが変数名、3が入れる値 print(n) # 3と出力 print(n+5) # 同じように演算でき、8と出力されます。使えるのは下記の3点
- 半角アルファベット(大文字、小文字)
- 半角数字
- _(アンダースコア)
使えないのは下記のように
- 先頭の文字に数字は使用不可
- 定義されている関数名(printやlistなど)
- 予約語やキーワードと同じ文字列 予約語とは、Pythonのプログラムで使用する文法のようなもので、「if」、「for」、「True」、「False」など33種類あります。
注意点
使えなくもないですが、日本語もOK
しかし定義としてあまり好まれない動作したあとで判明の場合
下記の形で削除します。
del(変数名)連結
下記のように連結できます。
n = "田中" print("名前は" + n + "です") ## 出力: 名前は田中です。型
文字や数値など型があります。
種類は下記の通りstr型:文字列
int型:整数
float型:浮動小数点型を知りたい時
print(type(変数名))age = 17 print(type(age)) # ageの型を知りたい時 # 出力結果 <class 'int'>型の変換
違う型で連結しとうとすると
エラーが出るので、下記のように変換します。str() : 文字列に変換
int() : 整数値に変換
float() : 小数点を含む数値型に変換height = 150 print("身長は" + str(height) + "cmです。")if文
比較演算子
下記のように書いて、trueかfalsaを返します。
a == b # aとbは等しい
a != b # aはbと等しくない(反転)
a > b # aはbより大きい
a >= b # aはbより大きいまたは等しい
a < b # aはbより小さい
a <= b # aはbより小さいまたは等しいifの使用例
if: 左記の条件成立で4インデントされた下記の処理を実行
else: ifとelifが成立しなかったら実行
elif: if,elseの間で別途条件と処理をしたっかたら書く。基本ifだけでも実行可能
場合によってelseとelifを追加n = 2 if n == 1: # nが1と等しい場合は下記の処理を行う print("これは1番目の処理です。") elif n == 2: # nが2と等しい場合は下記の処理を行う print("これは2番目の処理です。") elif n == 3: # nが3と等しい場合は下記の処理を行う print("これは3番目の処理です。") else: # 上記の3つの条件式が全て成立しない場合、下記の処理を行う print("これは4番目以降の処理です。")ブール演算子(and・or・not)
条件式A and 条件式B # A、B両方の条件式がTrueの場合、処理を行う
条件式A or 条件式B # A、Bどちらかの条件式がTrueの場合、処理を行う
not 条件式 # 条件式がTrueの時Falseを、Falseの時Trueを返す使用例n_1 = 15 n_2 = 29 print(n_1 > 8 and n_1 < 14) # true print(not n_1 ** 2 < n_2 * 5) # true
- 投稿日:2020-04-07T18:02:39+09:00
Python の基本①
最近Ai教室にお世話になってるので
まとめを書こうと思います。基礎
出力
言わずしれた出力を。
使われてるクォーテーションはシングルでもダブルでもprint('Hello World')コメントの入力
# コメント計算
下記のように計算できます。
使えるのはこのように・足し算:「+」
・引き算:「-」
・掛け算:「*」
・割り算:「/」
・余りの計算:「%」
・べき乗:「**」print(3+6) # 出力結果 9文字列
クォーテーションで囲むと
文字列となります。print('3+6') # 出力結果 3+6変数
続いて基本となる変数を
変数の基本
n = 3 # nが変数名、3が入れる値 print(n) # 3と出力 print(n+5) # 同じように演算でき、8と出力されます。使えるのは下記の3点
- 半角アルファベット(大文字、小文字)
- 半角数字
- _(アンダースコア)
使えないのは下記のように
- 先頭の文字に数字は使用不可
- 定義されている関数名(printやlistなど)
- 予約語やキーワードと同じ文字列 予約語とは、Pythonのプログラムで使用する文法のようなもので、「if」、「for」、「True」、「False」など33種類あります。
注意点
使えなくもないですが、日本語もOK
しかし定義としてあまり好まれない動作したあとで判明の場合
下記の形で削除します。
del 変数名連結
下記のように連結できます。
n = "田中" print("名前は" + n + "です") ## 出力: 名前は田中です。型
文字や数値など型があります。
種類は下記の通りstr型:文字列
int型:整数
float型:浮動小数点型を知りたい時
print(type(変数名))age = 17 print(type(age)) # ageの型を知りたい時 # 出力結果 <class 'int'>型の変換
違う型で連結しとうとすると
エラーが出るので、下記のように変換します。str() : 文字列に変換
int() : 整数値に変換
float() : 小数点を含む数値型に変換height = 150 print("身長は" + str(height) + "cmです。")if文
比較演算子
下記のように書いて、trueかfalsaを返します。
a == b # aとbは等しい
a != b # aはbと等しくない(反転)
a > b # aはbより大きい
a >= b # aはbより大きいまたは等しい
a < b # aはbより小さい
a <= b # aはbより小さいまたは等しいifの使用例
if: 左記の条件成立で4インデントされた下記の処理を実行
else: ifとelifが成立しなかったら実行
elif: if,elseの間で別途条件と処理をしたっかたら書く。基本ifだけでも実行可能
場合によってelseとelifを追加n = 2 if n == 1: # nが1と等しい場合は下記の処理を行う print("これは1番目の処理です。") elif n == 2: # nが2と等しい場合は下記の処理を行う print("これは2番目の処理です。") elif n == 3: # nが3と等しい場合は下記の処理を行う print("これは3番目の処理です。") else: # 上記の3つの条件式が全て成立しない場合、下記の処理を行う print("これは4番目以降の処理です。")ブール演算子(and・or・not)
条件式A and 条件式B # A、B両方の条件式がTrueの場合、処理を行う
条件式A or 条件式B # A、Bどちらかの条件式がTrueの場合、処理を行う
not 条件式 # 条件式がTrueの時Falseを、Falseの時Trueを返す使用例n_1 = 15 n_2 = 29 print(n_1 > 8 and n_1 < 14) # true print(not n_1 ** 2 < n_2 * 5) # true
- 投稿日:2020-04-07T17:30:44+09:00
Creational Patterns in Python
Factory
Factory is great for:
- Uncertainties in types of objects
- Decisions to be made at runtime regarding what classes to useclass Dog: """A simple dog class""" def __init__(self, name): self._name = name def speak(self): return "Woof!" class Cat: """A simple dog class""" def __init__(self, name): self._name = name def speak(self): return "Meow!" def get_pet(pet="dog"): """The factory method""" pets = dict(dog=Dog("Hope"), cat=Cat("Peace")) return pets[pet] d = get_pet("dog") print(d.speak()) c = get_pet("cat") print(c.speak())The attribute name with a single underscore is called a weak private.In the factory function, the mission is really to create these objects and to return these objects to the user of the function.
Abstract Factory
Abstract Factory is great for situations when the user expectation yields multiple related object until runtime.
class Dog: """One of the objects to be returned""" def speak(self): return "Woof!" def __str__(self): return "Dog" class DogFactory: """Concrete Factory""" def get_pet(self): """Returns a Dog object""" return Dog() def get_food(self): """Returns a Dog Food object""" return "Dog Food!" class PetStore: """ PetStore houses our Abstract Factory """ def __init__(self, pet_factory=None): """ pet_factory is our Abstract Factory """ self._pet_factory = pet_factory def show_pet(self): """ Utility method to display the details of the objects retured by the DogFactory """ pet = self._pet_factory.get_pet() pet_food = self._pet_factory.get_food() print("Our pet is '{}'!".format(pet)) print("Our pet says hello by '{}'".format(pet.speak())) print("Its food is '{}'!".format(pet_food)) #Create a Concrete Factory factory = DogFactory() #Create a pet store housing our Abstract Factory shop = PetStore(factory) #Invoke the utility method to show the details of our pet shop.show_pet()Here we have one concrete factory(DogFactory), we can definitely create more concrete factories like CatFactory.
Singleton
Singletons are used for:
- only one instance
- Global Variable in an object-oriented wayA Singleton acts as an information cache share by multiple objects. Modules in Python act as Singletons.
class Borg: """Borg pattern making the class attributes global""" _shared_data = {} # Attribute dictionary def __init__(self): self.__dict__ = self._shared_data # Make it an attribute dictionary class Singleton(Borg): #Inherits from the Borg class """This class now shares all its attributes among its various instances""" #This essenstially makes the singleton objects an object-oriented global variable def __init__(self, **kwargs): Borg.__init__(self) self._shared_data.update(kwargs) # Update the attribute dictionary by inserting a new key-value pair def __str__(self): return str(self._shared_data) # Returns the attribute dictionary for printing #Let's create a singleton object and add our first acronym x = Singleton(HTTP="Hyper Text Transfer Protocol") # Print the object print(x) #Let's create another singleton object and if it refers to the same attribute dictionary by adding another acronym. y = Singleton(SNMP="Simple Network Management Protocol") # Print the object print(y)Builder
Builders are good at solving problems with building a complex object using an excessive number of constructors.
Solution:
Director
Abstract Builder: interfaces
Concrete Builder: implements the interfaces
Product: object being builtclass Director(): """Director""" def __init__(self, builder): self._builder = builder def construct_car(self): self._builder.create_new_car() self._builder.add_model() self._builder.add_tires() self._builder.add_engine() def get_car(self): return self._builder.car class Builder(): """Abstract Builder""" def __init__(self): self.car = None def create_new_car(self): self.car = Car() class SkyLarkBuilder(Builder): """Concrete Builder --> provides parts and tools to work on the parts """ def add_model(self): self.car.model = "Skylark" def add_tires(self): self.car.tires = "Regular tires" def add_engine(self): self.car.engine = "Turbo engine" class Car(): """Product""" def __init__(self): self.model = None self.tires = None self.engine = None def __str__(self): return '{} | {} | {}'.format(self.model, self.tires, self.engine) builder = SkyLarkBuilder() director = Director(builder) director.construct_car() car = director.get_car() print(car)Prototype
Prototypes work well in creating multiple identical items.
import copy class Prototype: def __init__(self): self._objects = {} def register_object(self, name, obj): """Register an object""" self._objects[name] = obj def unregister_object(self, name): """Unregister an object""" del self._objects[name] def clone(self, name, **attr): """Clone a registered object and update its attributes""" obj = copy.deepcopy(self._objects.get(name)) obj.__dict__.update(attr) return obj class Car: def __init__(self): self.name = "Skylark" self.color = "Red" self.options = "Ex" def __str__(self): return '{} | {} | {}'.format(self.name, self.color, self.options) c = Car() prototype = Prototype() prototype.register_object('skylark',c) c1 = prototype.clone('skylark') print(c1)
- 投稿日:2020-04-07T17:23:56+09:00
OCTAのシミュレーション条件をファイルから取得してpandasで保存する
シミュレーションの条件をCSVファイルで保存する方法
OCTAを使用していると、どうしても設定をリスト化して保存したくなります。
毎回gourmetを起動して見るのが手間になるので、一部の設定をCSVファイルで保存できるようにしました。
単純なやり方です。条件を変数にいれて、それをPandasでシリーズにして、データフレームにした後、保存しています。
とりあえずこれを第一弾として、少しずつ改良して良いものにしていこうと思います。from UDFManager import UDFManager import pandas as pd import numpy as np import os path = "c:\path" files = os.listdir(path) filename = "filename_out.bdf" openfile = path + '/' + filename udf = UDFManager(openfile) print(udf) #トータルレコードを取得 totRec = udf.totalRecord() print(totRec) #読み込んだときの最初のレコード位置はマイナス1 #curRec = udf.currentRecord() #print(curRec) #レコード0に飛ぶ #現在のレコード位置は0になる #udf.jump(0) #curRec = udf.currentRecord() #print(curRec) #recNum = udf.get('record_data.record_number') #dynamics_conditions #time max_force = udf.get('Simulation_Conditions.Dynamics_Conditions.Max_Force') delta_t = udf.get('Simulation_Conditions.Dynamics_Conditions.Time.delta_T') total_steps = udf.get('Simulation_Conditions.Dynamics_Conditions.Time.Total_Steps') output_interval_steps = udf.get('Simulation_Conditions.Dynamics_Conditions.Time.Output_Interval_Steps') time_list = (max_force,delta_t,total_steps,output_interval_steps) time_list_s = pd.Series(time_list, index=['Max_Force', 'Time.delta_T', 'Time.Total_Steps','Time.Output_Interval_Steps']) #temp temperature = udf.get('Simulation_Conditions.Dynamics_Conditions.Temperature.Temperature') interval_of_scale_temp = udf.get('Simulation_Conditions.Dynamics_Conditions.Temperature.Interval_of_Scale_Temp') temp_list = (temperature,interval_of_scale_temp) temp_list_s = pd.Series(temp_list,index=['Temperature','Temperature.Interval_of_Scale_Temp']) #pressure pressure = udf.get('Simulation_Conditions.Dynamics_Conditions.Pressure_Stress.Pressure') stress_xx = udf.get('Simulation_Conditions.Dynamics_Conditions.Pressure_Stress.Stress.xx') stress_yy = udf.get('Simulation_Conditions.Dynamics_Conditions.Pressure_Stress.Stress.yy') stress_zz = udf.get('Simulation_Conditions.Dynamics_Conditions.Pressure_Stress.Stress.zz') stress_yz = udf.get('Simulation_Conditions.Dynamics_Conditions.Pressure_Stress.Stress.yz') stress_zx = udf.get('Simulation_Conditions.Dynamics_Conditions.Pressure_Stress.Stress.zx') stress_xy = udf.get('Simulation_Conditions.Dynamics_Conditions.Pressure_Stress.Stress.xy') stress_list = (pressure,stress_xx,stress_yy,stress_zz,stress_yz,stress_zx,stress_xy) stress_list_s = pd.Series(stress_list,index=['Pressure','Stress.xx','Stress.yy','Stress.zz','Stress.yz','Stress.zx','Stress.xy']) #solver solver_type = udf.get('Simulation_Conditions.Solver.Solver_Type') dynamics_algorithm = udf.get('Simulation_Conditions.Solver.Dynamics.Dynamics_Algorithm') solver_list = (solver_type,dynamics_algorithm) solver_list_s = pd.Series(solver_list,index=['Solver_Type','Dynamics_Algorithm']) #Boundary_Conditions boundary_conditions_a_axis = udf.get('Simulation_Conditions.Boundary_Conditions.a_axis') boundary_conditions_b_axis = udf.get('Simulation_Conditions.Boundary_Conditions.b_axis') boundary_conditions_c_axis = udf.get('Simulation_Conditions.Boundary_Conditions.c_axis') boundary_conditions_periodic_bond = udf.get('Simulation_Conditions.Boundary_Conditions.Periodic_Bond') boundary_conditions_list = (boundary_conditions_a_axis,boundary_conditions_b_axis,boundary_conditions_c_axis,boundary_conditions_periodic_bond) boundary_conditions_list_s = pd.Series(boundary_conditions_list,index=['a_axis','b_axis','c_axis','Periodic_Bond']) #Calc_Potential_Flags.Bond calc_potential_flags_bond = udf.get('Simulation_Conditions.Calc_Potential_Flags.Bond') calc_potential_flags_angle = udf.get('Simulation_Conditions.Calc_Potential_Flags.Angle') calc_potential_flags_torsion = udf.get('Simulation_Conditions.Calc_Potential_Flags.Torsion') calc_potential_flags_non_bonding_interchain = udf.get('Simulation_Conditions.Calc_Potential_Flags.Non_Bonding_Interchain') calc_potential_flags_non_bonding_intrachain = udf.get('Simulation_Conditions.Calc_Potential_Flags.Non_Bonding_Intrachain') calc_potential_flags_non_bonding_1_3 = udf.get('Simulation_Conditions.Calc_Potential_Flags.Non_Bonding_1_3') calc_potential_flags_non_bonding_1_4 = udf.get('Simulation_Conditions.Calc_Potential_Flags.Non_Bonding_1_4') calc_potential_flags_external = udf.get('Simulation_Conditions.Calc_Potential_Flags.External') calc_potential_flags_electrostatic = udf.get('Simulation_Conditions.Calc_Potential_Flags.Electrostatic') calc_potential_flags_tail_correction = udf.get('Simulation_Conditions.Calc_Potential_Flags.Tail_Correction') calc_potential_list = (calc_potential_flags_bond, calc_potential_flags_angle,calc_potential_flags_torsion, calc_potential_flags_non_bonding_interchain,calc_potential_flags_non_bonding_intrachain,calc_potential_flags_non_bonding_1_3, calc_potential_flags_non_bonding_1_4,calc_potential_flags_external,calc_potential_flags_electrostatic,calc_potential_flags_tail_correction) calc_potential_list_s = pd.Series(calc_potential_list,index=['Bond','Angle','Torsion','Non_Bonding_Interchain','Non_Bonding_Intrachain','Non_Bonding_1_3', 'Non_Bonding_1_4','External','Electrostatic','Tail_Correction']) #Output_Flags_is_no_count #Initial_Structure initial_unit_cell_density = udf.get('Initial_Structure.Initial_Unit_Cell.Density') initial_unit_cell_cell_size_a = udf.get('Initial_Structure.Initial_Unit_Cell.Cell_Size.a') initial_unit_cell_cell_size_b = udf.get('Initial_Structure.Initial_Unit_Cell.Cell_Size.b') initial_unit_cell_cell_size_c = udf.get('Initial_Structure.Initial_Unit_Cell.Cell_Size.c') initial_unit_cell_cell_size_alpha = udf.get('Initial_Structure.Initial_Unit_Cell.Cell_Size.alpha') initial_unit_cell_cell_size_beta = udf.get('Initial_Structure.Initial_Unit_Cell.Cell_Size.beta') initial_unit_cell_shear_strain = udf.get('Initial_Structure.Initial_Unit_Cell.Shear_Strain') initial_unit_cell_density = udf.get('Initial_Structure.Initial_Unit_Cell.Density') initial_unit_cell_list = (initial_unit_cell_density, initial_unit_cell_cell_size_a,initial_unit_cell_cell_size_b, initial_unit_cell_cell_size_c ,initial_unit_cell_cell_size_alpha,initial_unit_cell_cell_size_beta, initial_unit_cell_shear_strain,initial_unit_cell_density) initial_unit_cell_list_s = pd.Series(initial_unit_cell_list,index=['Density','Cell_Size.a','Cell_Size.b','Cell_Size.c','Cell_Size.alpha','Cell_Size.beta', 'Shear_Strain','Density']) #generated_method generate_method_method= udf.get('Initial_Structure.Generate_Method.Method') relaxation= udf.get('Initial_Structure.Relaxation.Relaxation') relaxation_method= udf.get('Initial_Structure.Relaxation.Method') generated_method_list = (generate_method_method, relaxation,relaxation_method) generated_method_list_s = pd.Series(generated_method_list,index=['Method','Relaxation','Relaxation.Method']) octa_pd = pd.concat([time_list_s, temp_list_s,stress_list_s,solver_list_s, boundary_conditions_list_s, calc_potential_list_s,initial_unit_cell_list_s,generated_method_list_s],axis=0) savefile = path + '/' + filename + 'setteing_info.csv' octa_pd.to_csv(savefile)
- 投稿日:2020-04-07T17:17:11+09:00
IQ Bot のカスタムロジック:他の言語をやっていた人が初めてPythonを初めて触るとびっくりするかもしれないポイント
こんにちは。
IQ Botのカスタムロジックは結局はPythonなので、Pythonが書ける人は難なく扱えるはずです。
そしてPythonはJavaやCなどのプログラミング言語に比べれば、初心者が入りやすい言語だと言われています。
JavaやCなど他のプログラミング言語をやっていた人は、
ゼロから始める人よりは早くPythonをマスターできると思いますが、他の言語をやっていたがゆえに「えっ? そんなのあり?」とびっくりするポイントもあるかもしれません。
この記事では、他言語を扱っていた人ならではのPythonびっくりポイントをまとめてみます。
コンパイルがいらない
Pythonは動的言語なので、動かすにあたってコンパイルが要りません。
なのでIQ Botのカスタムロジックも、コンパイルとか気にすることなく、
書いたら即座に「Test Run」を押せばその場で動きます。動的言語についての説明はWikipediaにまとまっていたのでそちらをご参照ください。
型を宣言しないで変数を使える
Pythonは型付けを動的に行っているので、変数の型を宣言する必要がありません。
Javaの場合、以下のようなコードを書くと、
2行目で怒られてコンパイルエラーになります。javaの場合int num = 3; // ここで変数numの型を宣言! num = "やっほー"; // こういうことすると怒られますint型、つまり「整数しか入らないよ」って言ってる箱(=numという変数)に、
"やっほー"などというふざけた文字列(String型)を突っ込もうとしたからですね。あ、すみません、問題は「型が違う」という点なので、文字列の中身がまじめでも怒られます。
一方、Pythonの場合は以下のようなコードでも全然問題なく動きます。
Pythonの場合num = 3 #こうすれば変数numは勝手にint型になる num = "やっほー" #ここで変数numは勝手にString型に変身する……!!この特徴は、筆者のような雑な性格の人間にとっては非常にありがたいんですが、
他のプログラミング言語のお行儀のいいコーディングに慣れている人からすると、「変数の型が途中で変わる」というのはけっこうびっくりする話かもしれません。
Pythonでも型という概念自体がなくなっているわけではなく、
あくまで型付けをプログラミング言語側で動的にやってくれる機能があるというだけです。Pythonの型の一覧や、型の確認方法、キャスト(型変換)のしかたなどは
こちらのページに非常にわかりやすくまとまっていました。IQ Botにカスタムロジックをかける際も、型のキャストは時々使います。
インデントに実行上の意味がある
他の言語の場合、if文や関数の中でインデントを揃えるのはあくまでも
「人間にとっての可読性向上のためのベストプラクティス」であって、インデントにはプログラムを実行する上での意味は持たせていないという仕様が一般的です。
つまり以下のように、インデントが汚くてもプログラムは問題なく動く、という言語がほとんどです。
javaの場合①:こう書いた方がきれいだけど……class xxx { public static void main (String[] args) throws java.lang.Exception { int num = 3; if (num % 2 == 0) { System.out.println(num + "は、偶数です"); } else { System.out.println(num + "は、奇数です"); } } }javaの場合②:これでも動くことは動く。class xxx { public static void main (String[] args) throws java.lang.Exception { int num = 3; if (num % 2 == 0) { System.out.println(num + "は、偶数です"); } else { System.out.println(num + "は、奇数です"); } } }一方、Pythonは「すべてのプログラマーがすべからく可読性の高いコードを書くことを保証するように」という思想に基づき、
インデントを揃えないとそもそもコードが動かないようになっています。Pythonの場合①:こう書けば動くけど……num = 3 if num % 2 == 0: print(str(num) + "は、偶数です") else: print(str(num) + "は、奇数です")Pythonの場合②:これだと動かないnum = 3 if num % 2 == 0: print(str(num) + "は、偶数です") else: print(str(num) + "は、奇数です")インデントが正しくそろってないと、基本的には「IndentationError」というエラーが出ます。
こちらの記事のように、インデントのレベルが正しくいないがゆえに、
想定と違う結果が出てしまうケースもあるので注意しましょう!ループが楽
PythonとJavaのループ処理をわかりやすくまとめた記事があったので、
そちらを紹介しておきます。ループ処理以外の文法も色々まとまっているので参考にしてみてください。
文字列を配列みたいに扱える
Javaなどの言語をもともとやっていた人からすると、
上記のリンクにあった以下のコードを見ると、けっこうびっくりするかもしれません。Pythonではわりと一般的なループfor char in 'Hello': print(char)上記の処理をやると、以下の結果が返ってくるんですが……
上記ループの処理結果>>>H >>>e >>>l >>>l >>>oなぜこんなことができるのかというと、Pythonでは文字列を、
ひとつひとつの文字を要素として持つシーケンスとして扱うという発想があるからです。なので、Javaみたいにまず配列に分けて、それからループを回して、みたいなことをする必要がなくて、
文字列をそのままループやスライス(文字列の何番目から何番目を取得するような処理)にかけることができます。スライスはIQ Botのカスタムロジックでも意外と(?)使うので、
わかりやすかった記事をリンクしておきます。まとめ
いかがでしたか?
他言語をやっていた人ならびっくりするかもしれないPythonのポイントは、まとめると以下のとおりです。
- Pythonは動的言語なのでコンパイルが要らないよ
- Pythonは動的型付けができるので変数の型を宣言する必要がないよ(型という概念はあるのでキャストはできるよ)
- インデントを揃えないと怒られて実行できないよ
- ループの書き方がJavaとはけっこう違うかも
- 文字列を配列みたいに扱って直接ループにかけたりスライスしたりできるよ
他にも発見したら追記します。
それでは!
- 投稿日:2020-04-07T17:17:11+09:00
IQ Bot のカスタムロジック:他の言語をやっていた人が初めてPythonを触ったとき、びっくりするかもしれない5つのポイント
こんにちは。
IQ Botのカスタムロジックは結局はPythonなので、Pythonが書ける人は難なく扱えるはずです。
そしてPythonはJavaやCなどのプログラミング言語に比べれば、初心者が入りやすい言語だと言われています。
JavaやCなど他のプログラミング言語をやっていた人は、
ゼロから始める人よりは早くPythonをマスターできると思いますが、他の言語をやっていたがゆえに「えっ? そんなのあり?」とびっくりするポイントもあるかもしれません。
この記事では、他言語を扱っていた人ならではのPythonびっくりポイントをまとめてみます。
コンパイルがいらない
Pythonは動的言語なので、動かすにあたってコンパイルが要りません。
なのでIQ Botのカスタムロジックも、コンパイルとか気にすることなく、
書いたら即座に「Test Run」を押せばその場で動きます。動的言語についての説明はWikipediaにまとまっていたのでそちらをご参照ください。
型を宣言しないで変数を使える
Pythonは型付けを動的に行っているので、変数の型を宣言する必要がありません。
Javaの場合、以下のようなコードを書くと、
2行目で怒られてコンパイルエラーになります。javaの場合int num = 3; // ここで変数numの型を宣言! num = "やっほー"; // こういうことすると怒られますint型、つまり「整数しか入らないよ」って言ってる箱(=numという変数)に、
"やっほー"などというふざけた文字列(String型)を突っ込もうとしたからですね。あ、すみません、問題は「型が違う」という点なので、文字列の中身がまじめでも怒られます。
一方、Pythonの場合は以下のようなコードでも全然問題なく動きます。
Pythonの場合num = 3 #こうすれば変数numは勝手にint型になる num = "やっほー" #ここで変数numは勝手にString型に変身する……!!この特徴は、筆者のような雑な性格の人間にとっては非常にありがたいんですが、
他のプログラミング言語のお行儀のいいコーディングに慣れている人からすると、「変数の型が途中で変わる」というのはけっこうびっくりする話かもしれません。
Pythonでも型という概念自体がなくなっているわけではなく、
あくまで型付けをプログラミング言語側で動的にやってくれる機能があるというだけです。Pythonの型の一覧や、型の確認方法、キャスト(型変換)のしかたなどは
こちらのページに非常にわかりやすくまとまっていました。IQ Botにカスタムロジックをかける際も、型のキャストは時々使います。
インデントに実行上の意味がある
他の言語の場合、if文や関数の中でインデントを揃えるのはあくまでも
「人間にとっての可読性向上のためのベストプラクティス」であって、インデントにはプログラムを実行する上での意味は持たせていないという仕様が一般的です。
つまり以下のように、インデントが汚くてもプログラムは問題なく動く、という言語がほとんどです。
javaの場合①:こう書いた方がきれいだけど……class xxx { public static void main (String[] args) throws java.lang.Exception { int num = 3; if (num % 2 == 0) { System.out.println(num + "は、偶数です"); } else { System.out.println(num + "は、奇数です"); } } }javaの場合②:これでも動くことは動く。class xxx { public static void main (String[] args) throws java.lang.Exception { int num = 3; if (num % 2 == 0) { System.out.println(num + "は、偶数です"); } else { System.out.println(num + "は、奇数です"); } } }一方、Pythonは「すべてのプログラマーがすべからく可読性の高いコードを書くことを保証するように」という思想に基づき、
インデントを揃えないとそもそもコードが動かないようになっています。Pythonの場合①:こう書けば動くけど……num = 3 if num % 2 == 0: print(str(num) + "は、偶数です") else: print(str(num) + "は、奇数です")Pythonの場合②:これだと動かないnum = 3 if num % 2 == 0: print(str(num) + "は、偶数です") else: print(str(num) + "は、奇数です")インデントが正しくそろってないと、基本的には「IndentationError」というエラーが出ます。
こちらの記事のように、インデントのレベルが正しくいないがゆえに、
想定と違う結果が出てしまうケースもあるので注意しましょう!ループが楽
PythonとJavaのループ処理をわかりやすくまとめた記事があったので、
そちらを紹介しておきます。ループ処理以外の文法も色々まとまっているので参考にしてみてください。
文字列を配列みたいに扱える
Javaなどの言語をもともとやっていた人からすると、
上記のリンクにあった以下のコードを見ると、けっこうびっくりするかもしれません。Pythonではわりと一般的なループfor char in 'Hello': print(char)上記の処理をやると、以下の結果が返ってくるんですが……
上記ループの処理結果>>>H >>>e >>>l >>>l >>>oなぜこんなことができるのかというと、Pythonでは文字列を、
ひとつひとつの文字を要素として持つシーケンスとして扱うという発想があるからです。なので、Javaみたいにまず配列に分けて、それからループを回して、みたいなことをする必要がなくて、
文字列をそのままループやスライス(文字列の何番目から何番目を取得するような処理)にかけることができます。スライスはIQ Botのカスタムロジックでも意外と(?)使うので、
わかりやすかった記事をリンクしておきます。まとめ
いかがでしたか?
他言語をやっていた人ならびっくりするかもしれないPythonのポイントは、まとめると以下のとおりです。
- Pythonは動的言語なのでコンパイルが要らないよ
- Pythonは動的型付けができるので変数の型を宣言する必要がないよ(型という概念はあるのでキャストはできるよ)
- インデントを揃えないと怒られて実行できないよ
- ループの書き方がJavaとはけっこう違うかも
- 文字列を配列みたいに扱って直接ループにかけたりスライスしたりできるよ
他にも発見したら追記します。
それでは!
- 投稿日:2020-04-07T16:50:48+09:00
NHK番組表APIを使ってオリジナル番組表を作って見ました。
動機
- ネタ探しをしていて、Qiita.com:個人でも使える!おすすめAPI一覧の投稿に出会う。
- コメント欄に「NHK 番組表 APIもいいよ」とあったので覗いて見たら簡単そうだった。
- REST APIから取得(JSON形式)して、加工・整形してHTML作成まではいい練習と思い。
- NHK番組APIを使ってオリジナルの番組表を作って見ました。(見てくれは残念ですが、、、)
API keyの取得の流れ
- NHK番組APIで、アカウント登録を行います。
- メール認証を経て、アプリケーション名:(好きな名称)、URL:(未登録)を登録します。
- 登録が完了すると
API キーが発行されます。これが取得に必要です。APIの概要
- 公開中のAPIは以下の4種類になります。
No. 名称 説明 1 Program List API 地域、サービス、日付を指定 2 Program Genre API 地域、ジャンル、日付を指定 3 Program Info API 番組IDを指定 4 Now On Air API 地域、サービスを指定
- 今回利用する
Program List APIは以下の構成になっています。https://api.nhk.or.jp/v2/pg/list/{area}/{service}/{date}.json?key={apikey}
パラメータ 説明 値 area 地域ID(3byte) 130:東京,他46地域 service サービスID(2byte) g1:NHK総合,e1:Eテレ,s1:BS,s3:BSP date 日付(YYYY-MM-DD形式) 例:2020-04-07 apikey APIキー(32byte) アプリ登録で取得した APIキー
- レスポンスフォーマットは、
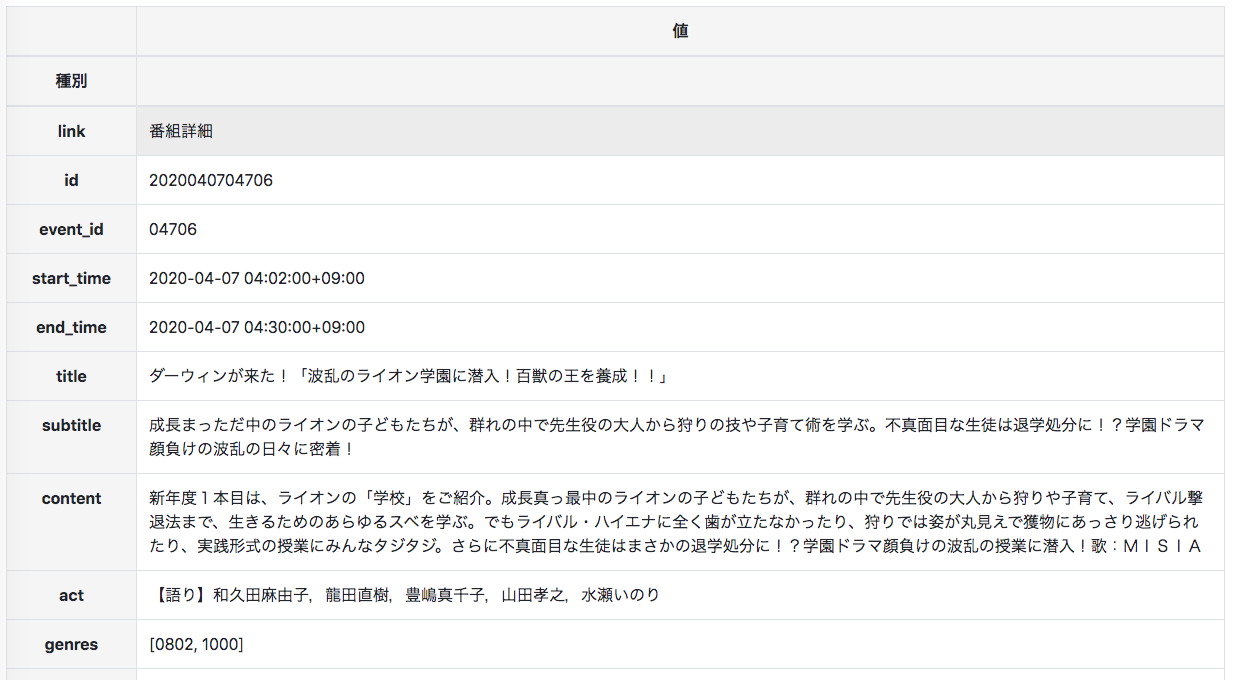
jsonで、利用回数制限は300回/日となっています。- 以下の例は、area:130(東京)、service:g1(NHK総合)、date:2020-04-07で取得した一部です。
{ "list": { "g1": [ { "id": "2020040704706", "event_id": "04706", "start_time": "2020-04-07T04:02:00+09:00", "end_time": "2020-04-07T04:30:00+09:00", "area": { "id": "130", "name": "東京" }, "service": { "id": "g1", "name": "NHK総合1", "logo_s": { "url": "//www.nhk.or.jp/common/img/media/gtv-100x50.png", "width": "100", "height": "50" }, "logo_m": { "url": "//www.nhk.or.jp/common/img/media/gtv-200x100.png", "width": "200", "height": "100" }, "logo_l": { "url": "//www.nhk.or.jp/common/img/media/gtv-200x200.png", "width": "200", "height": "200" } }, "title": "ダーウィンが来た!「波乱のライオン学園に潜入!百獣の王を養成!!」", "subtitle": "成長まっただ中のライオンの子どもたちが、群れの中で先生役の大人から狩りの技や子育て術を学ぶ。不真面目な生徒は退学処分に!?学園ドラマ顔負けの波乱の日々に密着!", "content": "新年度1本目は、ライオンの「学校」をご紹介。成長真っ最中のライオンの子どもたちが、群れの中で先生役の大人から狩りや子育て、ライバル撃退法まで、生きるためのあらゆるスベを学ぶ。でもライバル・ハイエナに全く歯が立たなかったり、狩りでは姿が丸見えで獲物にあっさり逃げられたり、実践形式の授業にみんなタジタジ。さらに不真面目な生徒はまさかの退学処分に!?学園ドラマ顔負けの波乱の授業に潜入!歌:MISIA", "act": "【語り】和久田麻由子,龍田直樹,豊嶋真千子,山田孝之,水瀬いのり", "genres": [ "0802", "1000" ] }, {以下、省略}データ取得
- 取得したAPIキーで、
Program List APIを叩く。- 取得サービスは、g1:総合1、e1:Eテレ、s1:BS1、s3:BSプレミアムの4局です。
- pandasの
json_normalize()を使って、json形式をデータフレームに変換します。import pandas as pd import json import requests import datetime # 取得したAPIキーをセット apikey = 'xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx' # 130:東京 area = '130' # g1:NHK総合1,e1:Eテレ,s1:BS,s3:BSP service = ['g1','e1','s1','s3'] # 日時 date = datetime.date.today() all_results = pd.DataFrame(index=None, columns=[]) for i in range(len(service)): url = 'https://api.nhk.or.jp/v2/pg/list/{0}/{1}/{2}.json?key={3}'.format(area,service[i],date,apikey) request_get = requests.get(url) if request_get.status_code != 200: print('NHK番組表APIのデータが取得出来ません。') break result = pd.json_normalize(request_get.json(), ['list',[service[i]]]) all_results = pd.concat([all_results, result]) all_results = all_results[~all_results['title'].str.contains('放送休止')]取得したデータ概要:
<class 'pandas.core.frame.DataFrame'> Int64Index: 235 entries, 0 to 37 Data columns (total 22 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 id 235 non-null object 1 event_id 235 non-null object 2 start_time 235 non-null object 3 end_time 235 non-null object 4 title 235 non-null object 5 subtitle 235 non-null object 6 content 235 non-null object 7 act 235 non-null object 8 genres 235 non-null object 9 area.id 235 non-null object 10 area.name 235 non-null object 11 service.id 235 non-null object 12 service.name 235 non-null object 13 service.logo_s.url 235 non-null object 14 service.logo_s.width 235 non-null object 15 service.logo_s.height 235 non-null object 16 service.logo_m.url 235 non-null object 17 service.logo_m.width 235 non-null object 18 service.logo_m.height 235 non-null object 19 service.logo_l.url 235 non-null object 20 service.logo_l.width 235 non-null object 21 service.logo_l.height 235 non-null object dtypes: object(22) memory usage: 42.2+ KBデータ加工
- 日付形式に置き換え、放送時間の算出、ページ内リンクのためのHTMLコード列の追加
# 日付形式に変換、放送時間の計算 all_results['start_time'] = pd.to_datetime(all_results['start_time'], format='%Y/%m/%d %H:%M') all_results['end_time'] = pd.to_datetime(all_results['end_time'], format='%Y/%m/%d %H:%M') all_results['airtime'] = all_results['end_time'] - all_results['start_time'] all_results['link'] = all_results['id'] # ページ内リンク情報の作成 func = lambda x: x.replace(x, f'<div id="{x}">番組詳細</div>') all_results['link'] = all_results['link'].apply(func) # 月・日。時間・分を取得する。さらに番組表の時間行名を追加する tmp = pd.concat([all_results['start_time'].dt.month ,all_results['start_time'].dt.day, all_results['start_time'].dt.hour, all_results['start_time'].dt.minute, (all_results['start_time'].dt.day.astype(str)+all_results['start_time'].dt.strftime('%H'))], axis=1) tmp.columns = ['month', 'day', 'hour', 'minute','time_bins'] # 取得データと新規の列を結合する all_results = pd.concat([all_results, tmp], axis=1) # 番組表ための集約 data = all_results.iloc[:,[23,0,1,2,3,4,5,6,7,8,9,10,11,12,22,24,25,26,27,28]]データ整形(その1)
- 番組表の必要データが揃えられたので、最終形のテーブルを作成してHTML形式保存します。
# 最終の番組表のデータフレーム作成 tv_index = data.time_bins.sort_values().unique() tv_table = pd.DataFrame(index=tv_index, columns=['H', 'g1', 'e1', 's1', 's3']).fillna('') # コンテンツを結合して時間帯に挿入する。 cell = '' for s in range(len(service)): for i in range(len(tv_table.index)): tmp = data[(data['time_bins'] == tv_table.index[i]) & (data['service.id'] == service[s])] for c in range(len(tmp)): cell += '[' + str(tmp['minute'].iloc[c]) + '~]' cell += tmp['title'].iloc[c] cell += f'<a href="#{tmp["id"].iloc[c]}">▼</a><br>' tv_table[service[s]].iloc[i] = cell cell = '' # 時間帯追加 for h in range(len(tv_index)): tv_table['H'].iloc[h] = int(tv_index[h][-2:]) tv_table.columns = ['H', 'NHK総合', 'Eテレ', 'BS', 'BSP']データ整形(その2)
- 番組タイトルから、ページ内リンクとして番組詳細情報を提供するためテーブル作成します。
detail_table = data.stack().reset_index() detail_table.drop(columns='level_0', inplace=True) detail_table.columns = ['種別', '値'] detail_table.set_index('種別', drop=True, inplace=True)データ整形(その3)
pandasの
to_htmlを使って、htmlファイルを作成します。htmlファイルの定義情報
html_template = ''' <!doctype html> <html lang="ja"> <head> <!-- Required meta tags --> <meta charset="utf-8"> <meta name="viewport" content="width=device-width, initial-scale=1, shrink-to-fit=no"> <!-- Bootstrap CSS --> <link rel="stylesheet" href="https://stackpath.bootstrapcdn.com/bootstrap/4.4.1/css/bootstrap.min.css" integrity="sha384-Vkoo8x4CGsO3+Hhxv8T/Q5PaXtkKtu6ug5TOeNV6gBiFeWPGFN9MuhOf23Q9Ifjh" crossorigin="anonymous"> <title>私製番組表</title> <!-- #1 --> </head> <body> <h2> NHK番組表APIを使ってオリジナル番組表を作って見ました。{date}版</h2> <!-- #2 --> <!-- Optional JavaScript --> <!-- jQuery first, then Popper.js, then Bootstrap JS --> <script src="https://code.jquery.com/jquery-3.4.1.slim.min.js" integrity="sha384-J6qa4849blE2+poT4WnyKhv5vZF5SrPo0iEjwBvKU7imGFAV0wwj1yYfoRSJoZ+n" crossorigin="anonymous"></script> <script src="https://cdn.jsdelivr.net/npm/popper.js@1.16.0/dist/umd/popper.min.js" integrity="sha384-Q6E9RHvbIyZFJoft+2mJbHaEWldlvI9IOYy5n3zV9zzTtmI3UksdQRVvoxMfooAo" crossorigin="anonymous"></script> <script src="https://stackpath.bootstrapcdn.com/bootstrap/4.4.1/js/bootstrap.min.js" integrity="sha384-wfSDF2E50Y2D1uUdj0O3uMBJnjuUD4Ih7YwaYd1iqfktj0Uod8GCExl3Og8ifwB6" crossorigin="anonymous"></script> <style type="text/css"> th {{ text-align: center; background-color: #f5f5f5}}</style> <div class="container-fluid"> <!-- #3 --> {table} </div> <div class="container-fluid"> <!-- #4 --> {table1} </div> <div>情報提供:NHK</div> <!-- #5 --> </body> </html>定義情報に追加したの以下の内容になります。
1. title:ページタイトル
2. h2:見出し + {date}
3. 4局の番組表table {table} -> table
4. 番組詳細table {table1} -> table1
5. クレジット表示
- htmlファイル形式の保存
table = tv_table.to_html(classes=['table', 'table-bordered', 'table-hover'],escape=False) table1 = detail_table.to_html(classes=['table', 'table-bordered', 'table-hover'],escape=False) html = html_template.format(table=table, table1=table1, date=date) with open('g1_table_' + str(date) + '.html', 'w') as f: f.write(html)▼をクリックすると、ページ内リンクで番組詳細データにスクロールします。
参考サイト
- pandasのDataFrameを元に、画像入りの表をつくる
- 上記のサイト情報から bootstrapのバージョンを最新化しました。
まとめ
pandas.read_jsonとpandas.to_htmlがどこまで使えるか確認したかったので、練習としては最適だった。pandas.read_jsonは軽い入り口的な状態で終わったので、また材料を探そうと思う。pandas.to_htmlは、そもそもの使い方が理解できたのが収穫でした。- ただ
Bootstrapを導入しても自分のWeb力が低いので見てくれは残念な結果となった。- ニュースが気になる状況なので、朝一に実行しておけば、本家サイトの番組表に飛ばずに確認ができます。
- NHK番組表API 利用上の注意を確認の上、用法・用量を守ってご利用ください。

- 投稿日:2020-04-07T16:39:09+09:00
久々にMinicondaを操作するときの道案内
久々にMinicondaを操作するときの道案内
事の発端
久々にMinicondaを操作したが、色んなことを忘れていたので、メモを残します。
動作環境
Windows 10
Anaconda3インストール済
Minicondaインストール済
PyCharmインストール済まず、プロンプトを立ち上げる
Anaconda Prompt(Anaconda3)というのがあるがこれではない。Miniconda Promptというのは無いのようなので、普通のコマンドプロンプトを立ちあげる。
Windowsボタンを押して、cmdと入力してEnterを入力する。Minicondaの環境を立ち上げる
プロンプトに、以下のように入力する。
C:\Users\[ユーザー名]\Miniconda3\Scripts\activate.bat以下の用に表示が変わる
(base) C:\Users\[ユーザー名]>デフォルトでbaseという仮想環境がアクティベートな状態になっている。
過去に作った環境一覧を表示するコマンド
conda info -e一覧の中にMinicondaで作った環境があることを確認する。
仮想環境をアクティベートする
conda activate [仮想環境名]ここから、こっちのルートを参照してもよい
自分のMinicondaの環境構築の備忘メモ - Qiita
新しく仮想環境を作成する
conda create -n [新しい仮想環境名] python=3.6確認してから、新しい環境に入る
conda info -e conda activate [新しい仮想環境名]パッケージをインストールする
conda install numpyとかPyCharmで新しいプロジェクトを作る
プロジェクトのインタープリタに今作った仮想環境を設定する
PyCharmでコーディングする
- 投稿日:2020-04-07T15:45:58+09:00
Python 初心者がチャット BOT を作ったから作り方をまとめてみたよ
最近、AI・IOT セミナーなるものに行ってきました。
内容的にはエンジニア向けというよりは事務担当者のスキルアップにプログラミングなんてどうですか?的な話だったのですが、Python 触ってみようかなーと私が思い至るには充分でした!ありがとう!(*‘∀‘)ってなわけで今回は、Python 初心者の私がいつも作ってる LINEWORKS BOT を Python で実装してみる話です!
制作環境
言語:python
WEB フレームワーク:Flask
エディタ:Visual Studio Code
サーバ:ローカル環境(ngrok)検証サーバを持ってないので相変わらずローカルです(笑
ngrok 大好きー!( ゚Д゚)環境構築
細かい構築手順は先輩方の記事を参考にしました!
ありがとうございます!(*'▽')
ここでは解説しませんので、リンクを貼っておきます('ω')ノ ペタペタ
- PC に Python と Visual Studio Code をインストール
- Flask のインストール
- ngrok で自分のローカルを外部に公開
- LINEWORKS で API を使うための設定と Bot 登録
BOT 登録時の Callback URL は ngrok で取得した URL を使用してください。
もちろん、自前でサーバをお持ちの方はそちらをお使いくださいませ~。
これで設定は完了!いよいよ Python で BOT 本体を作っていきますよ~(*´Д`)
BOT へのメッセージを受け取る
Flask を使って BOT に送られたメッセージを受け取ります。
Flask は Python の WEB フレームワークです。
Python では Django の方が有名で高機能らしいのですが個人開発なので軽量の Flask にしてみました。知見がいっぱいあって本当に助かります!(^▽^)
では、まず受信したメッセージをコンソールに表示するようにします。こんな感じ。
b'{"type":"message","source":{"accountId":"xxx@yyy-zzz"},"createdTime":1585813140779,"content":{"type":"text","text":"hoge"}}'コードを書いていきまする。
bot.pyfrom flask import Flask, request app = Flask(__name__) @app.route('/callback', methods=['POST']) def callback(): data = request.get_data() print(data) return "200 ok" ## port 設定 if __name__ == "__main__": app.run(debug=True, host='0.0.0.0', port=8000)つまづいたところ
- メッセージを受け取る request.get_data() を使うには
最初の1行なんですが、flask の import だけだとメッセージを受け取れないようです。
後ろに,requestと続けて request も import します。
- return 入れないと怒られる
最初、return を空っぽにしてたら怒られました。
TypeError: The view function did not return a valid response. The function either returned None or ended without a return statement.取り合えず受信したよ!ってことで
200 ok返しときました。
…たぶん、javascript のres.sendみたいなちゃんと返すやり方がある気がします。(。-`ω-)
- port のデフォルトは 5000
port 設定で何もしないとデフォルトは 5000 になるそうです。
if __name__ == "__main__": app.run(debug=True) # port は 5000 に設定されるいや、5000 でもいいんですけど、ngrok さんで 8000 に設定してたもので「繋がらない!( ゚Д゚)」ってなりましたw
っていう感じでつまづいてましたが、先輩方の知見のおかげで自己解決しました!
ありがとうございます!(*'▽')では、次の STEP へと進みましょう!
メッセージを受け取ったら返信する
返信するには LINEWORKS API を使用するのですが、PyPI にライブラリを公開してくれている方がいらっしゃいます!感謝!(^▽^)
PyPI - lineworks 0.1.0さっそくインストールして使っていきましょう。
pip install lineworksインストールしたらサンプルを参考にコードを書き足していきます。
lineworks_bot.pyfrom flask import Flask, request app = Flask(__name__) from lineworks import TalkBotApi api_id = "your api id." server_api_consumer_key = "your server api consumer key" server_id = "your server id." private_key = "your private key." domain_id = "your domain id." bot_no = "your bot number." import json @app.route('/callback', methods=['POST']) def callback(): data = json.loads(request.get_data()) talk_bot = TalkBotApi(api_id, server_api_consumer_key, server_id, private_key, domain_id, bot_no) # メッセージ送信(オウム返し) talk_bot.send_text_message(send_text=data['content']['text'], account_id=data['source']['accountId']) return "200 ok" ## port 設定 if __name__ == "__main__": app.run(debug=True, host='0.0.0.0', port=8000)Visual Studio Code で実行して準備完了!
さぁ、話しかけてみましょう!(´▽`)
YES!NINJA!
ちゃんとオウム返ししてくれましたね!成功です♪つまづいたところ
- privateKey の書き方
これはつまづいたというか案の定なのですが、認証キーは実際に見てもらうとわかる通り、もの凄く長い上に変な改行が入っています。なので、少々面倒なのですが、
"-----BEGIN PRIVATE KEY-----\nMIIEvAIBADANBgkqhkiG9...\n-----END PRIVATE KEY-----"となるように\nと\nの間に認証キーを入れて一行で表記します。
- JSON データの取り扱い
JSON ライブラリの loads で parse してから使います。
ですが、data.source.accountIdと、Javascript のようにパラメータで扱おうとするとエラーになります。(私のやり方が悪い可能性は大ですが。。。)
なので中身を取り出すときは前述の通りdata['source']['accountId']と記載します。
例では JSON データ内のtextとaccountIdを取り出して使用しています。何はともあれ、これで無事に完成です!(^O^)
おわりに
ここまでお付き合いいただきありがとうございました。
いやー、やってることはいつもと同じなんですが、言語違うと勝手が違いますね~。
でも、少し仲良くなれた気がします!この勢いで、機械学習 API とかと連携する BOT とか開発していきたいですね~。
ではまた!(^^)/参考にさせていただきましたm(_ _)m
LINEWORKS Developers
windows10にpythonとVisualStudioCodeをインストールする(2020年4月版)
Flaskの簡単な使い方
LINEbot開発、ローカル環境で動作確認したい
LINE WORKSで初めてのBot開発!(前編)
Flaskでpostされたデータをそのまま受け取る時はrequest.get_data()をつかう
LINE WORKSのAPIを呼び出すためのPythonライブラリを作成しました

- 投稿日:2020-04-07T14:49:58+09:00
Djangoのモデルでchoicesを使用した値をtemplateで表示したい場合
問題点
choicesを使用した際に、template側でchoicesのvalueを表示したいことがあった。
そこで、get_xxx_displayを使用することで表示出来たので、メモしておきたいと思います。モデル
AREA_NAME_ASIA = 'asia' AREA_NAME_EUROPE = 'europe' AREA_NAME_CHOICES = ( (AREA_NAME_ASIA, 'アジア'), (AREA_NAME_CHOICES, 'ヨーロッパ'), ) area = models.CharField(max_length=50, choices=AREA_NAME_CHOICES, verbose_name='エリア名')template側
{{ obj.get_area_display }}これで、
アジアと表示することが出来る。
ドキュメントはちゃんと読まないといけないですね、、
- 投稿日:2020-04-07T14:32:40+09:00
プログラマ脳を鍛える数学パズルQ04棒の切り分け
問題概要
長さnの棒をm人で切って1cm単位にする。ただし一回に切れるのは1人。何ステップで切れるか。
Code
とりあえず何も考えずにやってみたバージョン。方針は「長いものから切っていく」
def cutbar(length, member): bar = [length] step = 0 while bar != [1]*len(bar): #すべて長さが1なら終了 for i in range(min(member, len(bar))): piece = bar.pop(0) #先頭(=最大値)を取り出す if piece == 1: break else: cut1 = round(piece/2) cut2 = piece - cut1 bar += [cut1, cut2] bar.sort(reverse=True) #降順でソート step += 1 return step print(cutbar(20, 3)) print(cutbar(100, 5))ToDo
再帰でやったほうがスマートなんだな
- 投稿日:2020-04-07T14:28:32+09:00
ndarrayで行ベクトルを列ベクトルに変換するときに気を付けるべきこと
pythonのndarrayで、行ベクトルを列ベクトルに変換するときのお話です。
思わず、次のようにしてしまいがちですよね。
print(np.array([1,2,3,4,5]).T)
でもこれだと、結果は[1 2 3 4 5]となってしまい、行ベクトルに変換できません。
これは、行ベクトルが1次元配列で表現されているのに対し、
列ベクトルは2次元以上の配列でないと表現できないからです。
実際、
print(np.array([[1,2,3,4,5]]).T)
のように2次元配列で行ベクトルを渡せば、ちゃんと[[1] [2] [3] [4] [5]]という結果を得ます。
ちなみに
print(np.transpose(np.array([1,2,3,4,5])))
においても同様で、列ベクトルは得られません。一次元配列としての行ベクトル
vから(2次元配列としての)列ベクトルmを得たいときは、
m = np.array([v]).Tとしましょう
- 投稿日:2020-04-07T14:17:52+09:00
Design Patterns in Python: Introduction
What is a design pattern?
Design patterns are widely accepted solutions to recurring problems.
Why do we need them?
Reusing these patterns saves our time to reinvent the wheel and encourage us to adopt the best practices.
Facts about design patterns
- language-neutral
- dynamic
- intentionally incomplete for possible customization
Three major design patterns
- Creational : Polymorphism
- Structural : Inheritance
- Behavioral : Methods and their signatures
Polymorphism:
1. relies on inheritance
2. Allows child classes to be instantiated and treated as the same type as its parent
3. Enables a parent class to be manifested into any of its child classesA Pattern Context
- Participants: classes
- Quality attributes: Usability, modifiability, reliability, etc
- Forces: various factors or trade-offs to consider
- Consequences: side effects
Pattern Language
- Name: should be meaningful and memorable
- Context
- Problem
- Solution: Structure: relationships among elements; Behavior: interactions
- Related patterns
Links
To be continued...
- 投稿日:2020-04-07T13:51:42+09:00
プログラマ脳を鍛える数学パズルQ03カードを裏返せ
問題概要
100枚のカードを1回目は1枚おき、2回目は2枚おき・・・に裏返していって最後に裏返っているカードを求める。
Code
#Q03カードを裏返せ cards0 = [-1]*100 #最初。1=表, -1=裏 cards = [-1, 1]*50 #2つ目 step = 3 #何枚おきに裏返すか #step枚ごとにカードを裏返す。裏返すカードがなくなったら終了 while cards0 != cards: cards0 = cards[:] for i in range(step-1, len(cards), step): cards[i] *= -1 step += 1 #裏返っているカードが何枚目かを表示する backs = [i+1 for i in range(len(cards)) if cards[i] == -1] print(backs)参考
配列の生成
list1 = [0] * 3 print(list1) # [0, 0, 0] list2 = [0, 1] * 3 print(list2) # [0, 1, 0, 1, 0, 1]参考:https://note.nkmk.me/python-list-initialize/
配列のコピー
Pythonでは配列のコピーは参照渡しなので、片方を変更するともう片方も変更される。
a = [1, 2, 3] b = a b[2] = 4 print(b) #[1, 2, 4] print(a) #[1, 2, 4]値渡しをしたいときはスライスを使う。
a = [1, 2, 3] b = a[:] b[2] = 4 print(b) #[1, 2, 4] print(a) #[1, 2, 3]参考:https://qiita.com/hrs1985/items/4e7bba39a35056de4e73
リスト内包表記
backs = [i+1 for i in range(len(cards)) if cards[i] == -1] print(backs)は以下と同じ
backs=[] for i in range(len(cards)): if cards[i] == -1: backs.append(i+1) print(backs)
- 投稿日:2020-04-07T11:15:49+09:00
openpyxlのごく一部備忘録
概要
機能が多くて一覧化したほうが後々色々やりやすいってことで、列挙。
あくまでも自分で使ったもののみなのでこれで全部ではないです。
細かいところは公式を参照ください。新しいブックを作る
ブックを作って1つシートも作る。
以降はこれをやってある前提。import openpyxl book = openpyxl.Workbook() sheet = book.activeシート名設定
sheet.name = "しーと"ブック保存
try: book.save("book.xlsx") except exception as e: # excelを開いているとPermission Error。他もあるかも。 finally: book.close()csvからエクセルを作る
import csv with open("file.csv", "r") as f: for l in csv.reader(f): sheet.append(l)セルに罫線を描く
この例はセルの外周に引く場合。
セル指定(num_row, num_column)はR1C1の数値(以下同様)from openpyxl.styles.borders import Side border = openpyxl.styles.borders.Border() border.top = Side(style='hair', color='000000') border.bottom = Side(style='thin', color='ff0000') border.left = Side(style='thick', color='00ff00') border.right = Side(style='medium', color='0000ff') sheet.cell(row=num_row, column=num_column).border = bordercolorは16進数のよくあるRGB値。
既存の罫線を保持して一部のみ変更したい場合は
border = copy(sheet.cell(row=num_row, column=num_col).border)これで現罫線の状態を取得してから、上のやつで変更。
フォント設定
font = openpyxl.styles.fonts.Font() font.name = 'フォント名' font.size = 10 font.color = 'deadbeef' # 特定セル sheet.cell(row=num_row, column=num_col).font = font # 値入力済範囲全体 for r in sheet: for c in r: sheet[c.coordinate].font = fontcolorは16進数の以下略。
セル幅設定
自動で調整するのはエクセル内部機能なので使えないようです。
それっぽくするにはカラムの内容から算出するしか無いみたい。column = openpyxl.utils.get_column_letter(num_column) length = len(sheet.cell(row=num_row, column=num_column) sheet.column_dimensions[column].width = length * 1.5印刷設定
1行目を印刷タイトル、用紙向きを横、横ページ数を1、縦ページ数を無指定で印刷する場合。
sheet.print_title_rows = '1:1' # 印刷タイトル行 sheet.page_setup.orientation = 'landscape' # 縦は'portrait' sheet.page_setup.fitToWidth = 1 sheet.page_setup.fitToHeight = 0 sheet.sheet_properties.pageSetUpPr.fitToPage = Trueセル着色
塗りつぶしの場合はこれ、他のパターンも当然あります。
paint_cell.pyfrom openpyxl.styles.fills import (PatternFill, FILL_SOLID) fill = PatternFill(fgColor='aabbcc', patternType=FILL_SOLID) sheet.cell(row=num_row, column=num_column).fill = fillfgColorは16進数(ry
セル内文字寄せ
下、中央寄せの場合。
align = openpyxl.styles.Alignment() align.horizontal = 'center' align.vertical = 'bottom' sheet.cell(row=num_row, column=num_column).alignment = alignフィルタ設定
セル指定がフィルタを適用するデータの範囲であることに注意。
この場合のセル指定はA1形式。sheet.auto_filter.ref = "B2:D10"カラム名の数値化
R1C1用にカラム番号を取りたいときはこれ。
column_number.pynum_column = openpyxl.utils.column_index_from_string('D')
- 投稿日:2020-04-07T10:21:33+09:00
GoogleのOR-Toolsで組合せ最適化問題を解く(5)デートコースを決めよう
はじめに
本記事は、数理最適化についての参考テキスト「Pythonによる問題解決シリーズ データ分析ライブラリーを用いた最適化モデルの作り方」の練習問題を解く第五回目の記事です。
第一回目の記事は以下です。まずはこちらをご覧下さい。
GoogleのOR-Toolsで数理最適化モデルの練習問題を解く(1)一番易しいマス埋め問題
https://qiita.com/ttlabo/private/7e8c93f387814f99931fデートコースを決めよう
参考テキストに出てくる応用問題です。
以下の問題をさっそく行ってみましょう。
問題
8.4.問題8つのアトラクションがある遊園地でデートをする(8-4図)。 200分の制限時間の中で総満足度を最大化する。 なお、デートコースは全て回る必要はない。 条件を満たすデートコースを最適化せよ。
考え方
■モデル化の方針
200分の制限時間を考慮し、全てを回らずとも可能な範囲で満足度を最大化することを考えます。そのために、次のような変数を用意します。
変数定義
\begin{eqnarray*} S_i\;&\small{:=}&\;\small{i番目のアトラクションを選ぶかどうか}\\ M_{ij}\;&\small{:=}&\;\small{i番目のアトラクションからj番目のアトラクションへ移動するかどうか}\\ satisfy\;&\small{:=}&\;\small{最終的な満足度(の合計)}\\ stayTime\;&\small{:=}&\;\small{最終的な滞在時間(の合計)}\\ moveTime\;&\small{:=}&\;\small{最終的な移動時間(の合計)}\\ totalTime\;&\small{:=}&\;\small{全体時間(最終的な満足度と滞在時間の和)} \end{eqnarray*}最適化を解くとこれらの変数の値のうち最適な値が得られ、デートコースが決まります。
また、予めわかっている値や情報を次のように定数として定義とします。
\begin{eqnarray*} 満足度定数 satisfyDef\\ 滞在時間定数 stayTimeDef\\ 移動時間定数 moveTimeDef \end{eqnarray*}順序が逆になりますが、まず定数について次のように値を設定します。
①満足度定数について、以下のように値を設定します。8.4.renshu.pysatisfyDef = [0,50,36,45,79,55,63,71,42]satisfyDefは配列で、i番目のアトラクションの満足度をsatisfyDef[i]とします。
例えば、2番目のアトラクションの満足度は36です。アトラクションのインデックス番号は0から数えることとします。
②滞在時間定数について、以下のように値を設定します。8.4.renshu.pystayTimeDef = [0,20,28,15,35,17,18,14,22]stayTimeDefは配列で、i番目のアトラクションの滞在時間をstayTimeDef[i]とします。
③移動時間定数について、以下のように値を設定します。8.4.renshu.pymoveTimeDef = {} moveTimeDef[0,3] = 7 ~moveTimeDefはDictinary型で、iからjへ移動するときの時間をmoveTimeDef[i,j]とします。
例えば、アトラクション0番目(入口)からアトラクション3番目(コーヒーカップ)へ移動するときの移動時間はmoveTimeDef[0,3]で、7分という意味です。①満足度定数、②滞在時間定数、③移動時間定数の設定値については、参考テキストで定義されている値です。
次に、変数Si,Mijについて次のように定義します。
①Siについて、以下のように定義します。8.4.renshu.py# アトラクションを選ぶかどうかの変数 # 1:選ぶ / 0:選ばない S = {} for i in range(9): S[i] = solver.BoolVar("S%i" % i)ここでは、アトラクション0番目から8番目について、「1:選ぶ」か「0:選ばない」のどちらかの変数(BoolVar型)で定義しています。例えば、S[4]=1だった場合、4番目のアトラクションを選ぶ、という意味になります。
②Mijについて、以下のように定義します。
8.4.renshu.py# 移動に関して、i→jに移動するかどうかの変数 # 1:移動する / 0:移動しない M = {} for i in range(9): for j in range(9): M[i,j] = solver.BoolVar("M%i%i" % (i,j))ここでは、アトラクション0番目から8番目のそれぞれの組み合わせについて、「1:移動する」か「0:移動しない」のどちらかの変数(BoolVar型)で定義しています。9通り×9通り、全部で81通りの組み合わせを持ちます。例えばM[1,3]=1だった場合、1番目のアトラクションから3番目のアトラクションへ移動する、という意味になります。
以上の変数及び定数を用いて、変数や定数間に様々な条件(制約条件)を設定しながら最適化問題を解きます。
解答
プログラムを検討します。
プログラムの記載内容については、基本的にGoogleのOR-Toolsのガイドに沿っています。(https://developers.google.com/optimization)プログラムの冒頭におまじないを書きます。
8.4.renshu.pyfrom __future__ import print_function from ortools.linear_solver import pywraplp混合整数計画ソルバーで解きますので、以下に宣言します。
8.4.renshu.py# Create the mip solver with the CBC backend. solver = pywraplp.Solver('simple_mip_program', pywraplp.Solver.CBC_MIXED_INTEGER_PROGRAMMING)次に、定数について定義します。
8.4.renshu.py# 定数定義 ================================================================= # アトラクション名 attrDef = ['','入口','喫茶','ボート','カップ','レストラン','観覧車', 'お化け屋敷','コースター','迷路'] # 満足度定数 satisfyDef = [0,50,36,45,79,55,63,71,42] # 滞在時間定数 stayTimeDef = [0,20,28,15,35,17,18,14,22]上記、最初の定義attrDefは本プログラムでは使用しません。今回はとりあえず定義しました。
定数定義の説明で書きましたが、satisfayDefとstayTimeDefは配列で、インデックス番号とアトラクション番号をひもづけています。インデックス番号0はアトラクション番号0番目(入口)に対応し、満足度は0、滞在時間も0です。
移動時間については以下のように定義します。8.4.renshu.py# 移動時間定数 # moveTimeDef[i,j] ← iからjへ移動するときの時間 moveTimeDef = {} moveTimeDef[0,0] = 0 moveTimeDef[0,1] = 9 moveTimeDef[0,2] = 0 moveTimeDef[0,3] = 7 〜ここでは、移動できない経路の移動時間は0にしています。
上記では4経路のみ記載しましたが、後方に掲載するソース全体では全経路分を定義しています。
次に変数を定義します。8.4.renshu.py# 変数定義 ================================================================= # アトラクションを選ぶかどうかの変数 # 1:選ぶ / 0:選ばない S = {} for i in range(9): S[i] = solver.BoolVar("S%i" % i) # 移動に関して、i→jに移動するかどうかの変数 # 1:移動する / 0:移動しない M = {} for i in range(9): for j in range(9): M[i,j] = solver.BoolVar("M%i%i" % (i,j))上記、S,Mについては前に説明した通り、0/1を取る変数として宣言します。
どちらの値を取るかはOR-Toolsソルバーが計算して決めます。8.4.renshu.py# 満足度を宣言する satisfy = solver.IntVar(0.0, 1000, 'satisfy') # 滞在時間を宣言する stayTime = solver.IntVar(0.0, 1000, 'stayTime') # 移動時間変数 moveTime = solver.IntVar(0.0, 1000, 'moveTime') # 全体時間の変数 totalTime = solver.IntVar(0.0, 1000, 'totalTime')上記、満足度、滞在時間、移動時間、全体時間(滞在時間+移動時間)を、それぞれ0〜1000の整数を取る変数として宣言します。
定数及び変数を用意しましたので、次は条件を設定します(制約式を設定します)。制約式の設定について、参考テキストに以下の補足がありますので、この条件も含めて組み立てを行います。
8.4.問題・アトラクションを選んだら、訪れること。 ・アトラクションに入ったら出ること。 ・入口から接続していること。(途中で終了しないこと)以下、制約条件のソースです。
8.4.renshu.py# 制約式 =================================================================== # 入口は必ず通過 solver.Add(S[0] == 1)上記、入口に関する制約式を設定します。
入口は必ず選択するので、S[0]の値を1に設定します。8.4.renshu.py# 移動について制限を設定 # 移動しないルートについてMを0にする solver.Add(M[0,0] == 0) solver.Add(M[0,2] == 0) solver.Add(M[0,5] == 0) ~上記、定数定義と同様に、経路について設定を行います。Mは変数なのでソルバーが決定する場合もありますが、ここでは明示的に設定します。
移動しない経路についてM[i,j]を0にします。例えば、アトラクション0番目から0番目には移動できませんし、アトラクション0番目からアトラクション5番目についても同様です。全部で41通りの経路を0に設定します。8.4.renshu.py# 重複を避ける設定(アトラクションは1回だけ訪れる。両方訪れないケース可) solver.Add(M[0,1] + M[1,0] <= 1) solver.Add(M[0,3] + M[3,0] <= 1) solver.Add(M[0,4] + M[4,0] <= 1) ~上記、あるアトラクションiからjへ移動した後、移動経路を逆戻りして再びiへ戻ることは無いための条件を設定します。例えば、アトラクション0番目からアトラクション1番目に移動した場合はM[0,1]=1となるため、その逆経路のM[1,0]は値が0になる(移動しない)ように設定します。逆の移動経路の場合も同様です。
また、M[0,1] + M[1,0] == 1とすると必ず移動することになるので、移動しない場合も含めM[0,1] + M[1,0] <= 1とします。全部で20通りの経路について設定します。8.4.renshu.py# Mについての条件 # 一つのアトラクションから複数のアトラクションへ同時に移動しない for i in range(9): solver.Add(solver.Sum([M[i,j] for j in range(9)]) <= 1)上記、一つのアトラクションから複数のアトラクションへ同時に移動しない条件を設定します。これは、それぞれのアトラクションiにおいて、各jへ移動する経路は一つしか取れないこととして定義します(下図参照)。
次に、経路の連続性条件について次のように定義します。経路の連続性とは、下図のように経路がつながっていないアトラクションを選択しないという意味です。
経路がつながっている(連続している)条件の制約式は以下です。
8.4.renshu.py# ルートの連続性条件 # 0起点 step = [1,3,4] solver.Add(solver.Sum([M[0,s] for s in step]) == solver.Sum([M[s,0] for s in step])) # 1起点 step = [0,2,3,4,5] solver.Add(solver.Sum([M[1,s] for s in step]) == solver.Sum([M[s,1] for s in step])) ~上記について、アトラクション1番目を起点に見てみます。
アトラクション1へ入る経路はM[0,1],M[3,1],M[4,1]の3通りあります。
下図(パターン1)の通り、例えばアトラクション1へ何らかの経路で入ったとします。
ここでは、M[0,1],M[3,1],M[4,1]のうち、M[4,1]で入ったと仮定しました(赤矢印)。
アトラクション1へ入る経路は3通りのうち1つしか取れませんので、M[0,1],M[3,1],M[4,1]のうちいずれか一つの値が1で、その他の値は0になります。
制約式として以下を設定します。solver.Sum([M[s,1] for s in step]) = 1 … 式①
制約式の設定条件に「アトラクションに入ったら出ること。」とありますので、アトラクション1から別のアトラクションへ移動する経路を考えます。
上図(パターン2)の通り、アトラクション1から移動できるアトラクションは3つありますが、この中から一つを選択することになります。3つの中から一つを選択する制約式はsolver.Sum([M[1,s] for s in step]) = 1 … 式②
になります。但し、先ほどM[4,1]の経路を取ることを仮定したため、実際に取れる経路はM[1,2]かM[1,5]のいずれかです(上図(パターン3))。どの経路を取るかはソルバーが算出します。
また、アトラクション1へ入らない場合もあり得ますし、この場合は次へ移動しないことになります。
この場合は、入る経路と出る経路のいずれのMの和は0です。
よって、アトラクション1へ出入りするための経路の条件は、式①と式②を用いて以下とすれば良いことになります。solver.Sum([M[1,s] for s in step]) == solver.Sum([M[s,1] for s in step])
以上、経路の連続性の制約式をアトラクション1について説明しました。
実際のソース上では、アトラクション0からアトラクション8までそれぞれについて同様の考え方で定義します。残りのアトラクションに関しての制約式は、後方に掲載するソース全体で定義しています。さらに、訪れるアトラクションと前後の出入りの経路の関係性について考えます。
経路の連続性条件と似ていますが、SとMの関係性を制約式として定義します。8.4.renshu.py# SとMの関係性の定義 # 0起点 step = [1,3,4] solver.Add(S[0] - (solver.Sum([M[0,s] for s in step]) + solver.Sum([M[s,0] for s in step])) / 2 == 0) # 1起点 step = [0,2,3,4,5] solver.Add(S[1] - (solver.Sum([M[1,s] for s in step]) + solver.Sum([M[s,1] for s in step])) / 2 == 0) ~上記について、制約式の内容は「あるアトラクションに訪れる場合は、経路に出入りがある。訪れない場合は、経路も取らない。」という意味です。
これについて、アトラクション1を起点に見てみます。まず以下の経路図を確認します。
アトラクション1を選択する場合は、それに入る経路と出る経路が考えられます。
入る経路についてパターン1を見ると、青経路M[0,1]、緑経路M[3,1]、赤経路M[4,1]のいずれかの経路をたどることになるため、以下が成立します。solver.Sum([M[s,1] for s in step]) = 1 … 式①
出る経路についても同様に各色の経路の和の条件は
solver.Sum([M[1,s] for s in step]) = 1 … 式②
アトラクション1を訪れた場合はS[1]の値は1なので、この値と式①式②は以下のようにつなげることができます。
S[1]の値 - (式① + 式②) ÷ 2 = 0 … 式③
また、アトラクション1を訪れない場合についてもこの式③は成立します。S[1]の値は0となり、式①及び式②の値もそれぞれ0となるため、
0 - (0 + 0) ÷ 2 = 0
よってSとMの関係性は式③を用いて定義することができ、以下とします。
S[1] - (solver.Sum([M[1,s] for s in step]) + solver.Sum([M[s,1] for s in step])) / 2 == 0
実際のソース上では、アトラクション0からアトラクション8までそれぞれについて同様の考え方で定義します。残りのアトラクションに関しての制約式は、後方に掲載するソース全体で定義しています。
複雑な制約式の説明は以上となります。以下、残りの制約条件を定義します。
8.4.renshu.py# 満足度の算出 satisfy = solver.Sum([S[i] * satisfyDef[i] for i in range(9)]) # 滞在時間の算出 stayTime = solver.Sum([S[i] * stayTimeDef[i] for i in range(9)]) # 移動時間の算出 moveTime = solver.Sum([M[i,j] * moveTimeDef[i,j] for i in range(9) for j in range(9)]) # 全体時間の算出 totalTime = stayTime + moveTime上記、満足度及び滞在時間は、選択するアトラクションS[i]値とそれぞれの定数値をかけ、それらの和を取ります。アトラクションを選択するする場合はS[i]値が1、しない場合はS[i]が0なので、和を取ると選択するアトラクションの値だけ算出されます。
移動時間については、各i,jの組み合わせについてM[i,j]値と移動経路の定数値をかけ、それらの和を取ります。
また、全体時間は"滞在時間 + 移動時間"です。最後に、「200分の制限時間の中で総満足度を最大化する。」を条件にします。
8.4.renshu.py# 全体時間の制約 solver.Add(totalTime <= 200) # 満足度を最大化する solver.Maximize(satisfy)上記、全体時間が200分以内の条件と、満足度を最大化する条件をそれぞれ分けて定義します。
制約式の設定は以上です。
以下、求解を実行します。8.4.renshu.pystatus = solver.Solve()以下のソースで、解が見つかった場合、各iにおけるS[i]値と移動する場合のi,jにおけるM[i,j]値を表示するようにします。
8.4.renshu.pyif status == pywraplp.Solver.OPTIMAL or status == pywraplp.Solver.FEASIBLE: print('Solution:') print('ok') print('Objective value =', solver.Objective().Value()) print("culculate Time = ", solver.WallTime(), " milliseconds") print('satisfy', satisfy.solution_value()) print('stayTime', stayTime.solution_value()) print('moveTime', moveTime.solution_value()) print('totalTime', totalTime.solution_value()) for i in range(9): print(i,S[i].solution_value()) for i in range(9): for j in range(9): if M[i,j].solution_value() >= 0.5: print('M',i,j,'=',M[i,j].solution_value()) else: print('The problem does not have an optimal solution.')以上でプログラミングは終了です。
実際の実行結果は以下となりました。Solution:
ok
Objective value = 405.0
culculate Time = 427 milliseconds
satisfy 405.0
stayTime 141.0
moveTime 59.0
totalTime 200.0
0 1.0
1 1.0
2 0.0
3 1.0
4 1.0
5 1.0
6 1.0
7 1.0
8 1.0
M 0 3 = 1.0
M 1 0 = 1.0
M 3 6 = 1.0
M 4 1 = 1.0
M 5 4 = 1.0
M 6 7 = 1.0
M 7 8 = 1.0
M 8 5 = 1.0最適化計算の結果、デートコースが決定しました。
ちょうど200分で回る経路で、満足度は405です。また、滞在時間と移動時間の内訳は、滞在時間が141分、移動時間が51分とわかりました。
選択するアトラクションを見てみると、S[2]以外の値が1なので、
ボート以外のアトラクションを訪れる経路となっています。また、周回する経路はM[i,j]の値から、
0 → 3 → 6 → 7 → 8 → 5 → 4 →1→0
という答えが出ました。以下、プログラム全体を示します。
8.4.renshu.pyfrom __future__ import print_function from ortools.linear_solver import pywraplp # Create the mip solver with the CBC backend. solver = pywraplp.Solver('simple_mip_program', pywraplp.Solver.CBC_MIXED_INTEGER_PROGRAMMING) # 定数定義 ================================================================= # アトラクション名 attrDef = ['','入口','喫茶','ボート','カップ','レストラン','観覧車', 'お化け屋敷','コースター','迷路'] # 満足度定数 satisfyDef = [0,50,36,45,79,55,63,71,42] # 滞在時間定数 stayTimeDef = [0,20,28,15,35,17,18,14,22] # 移動時間定数 # moveTimeDef[i,j] ← iからjへ移動するときの時間 moveTimeDef = {} moveTimeDef[0,0] = 0 moveTimeDef[0,1] = 9 moveTimeDef[0,2] = 0 moveTimeDef[0,3] = 7 moveTimeDef[0,4] = 12 moveTimeDef[0,5] = 0 moveTimeDef[0,6] = 0 moveTimeDef[0,7] = 0 moveTimeDef[0,8] = 0 moveTimeDef[1,0] = 9 moveTimeDef[1,1] = 0 moveTimeDef[1,2] = 11 moveTimeDef[1,3] = 12 moveTimeDef[1,4] = 7 moveTimeDef[1,5] = 13 moveTimeDef[1,6] = 0 moveTimeDef[1,7] = 0 moveTimeDef[1,8] = 0 moveTimeDef[2,0] = 0 moveTimeDef[2,1] = 11 moveTimeDef[2,2] = 0 moveTimeDef[2,3] = 0 moveTimeDef[2,4] = 14 moveTimeDef[2,5] = 8 moveTimeDef[2,6] = 0 moveTimeDef[2,7] = 0 moveTimeDef[2,8] = 0 moveTimeDef[3,0] = 7 moveTimeDef[3,1] = 12 moveTimeDef[3,2] = 0 moveTimeDef[3,3] = 0 moveTimeDef[3,4] = 11 moveTimeDef[3,5] = 0 moveTimeDef[3,6] = 7 moveTimeDef[3,7] = 12 moveTimeDef[3,8] = 0 moveTimeDef[4,0] = 12 moveTimeDef[4,1] = 7 moveTimeDef[4,2] = 14 moveTimeDef[4,3] = 11 moveTimeDef[4,4] = 0 moveTimeDef[4,5] = 9 moveTimeDef[4,6] = 13 moveTimeDef[4,7] = 9 moveTimeDef[4,8] = 13 moveTimeDef[5,0] = 0 moveTimeDef[5,1] = 13 moveTimeDef[5,2] = 8 moveTimeDef[5,3] = 0 moveTimeDef[5,4] = 9 moveTimeDef[5,5] = 0 moveTimeDef[5,6] = 0 moveTimeDef[5,7] = 13 moveTimeDef[5,8] = 7 moveTimeDef[6,0] = 0 moveTimeDef[6,1] = 0 moveTimeDef[6,2] = 0 moveTimeDef[6,3] = 7 moveTimeDef[6,4] = 13 moveTimeDef[6,5] = 0 moveTimeDef[6,6] = 0 moveTimeDef[6,7] = 7 moveTimeDef[6,8] = 0 moveTimeDef[7,0] = 0 moveTimeDef[7,1] = 0 moveTimeDef[7,2] = 0 moveTimeDef[7,3] = 12 moveTimeDef[7,4] = 9 moveTimeDef[7,5] = 13 moveTimeDef[7,6] = 7 moveTimeDef[7,7] = 0 moveTimeDef[7,8] = 6 moveTimeDef[8,0] = 0 moveTimeDef[8,1] = 0 moveTimeDef[8,2] = 0 moveTimeDef[8,3] = 0 moveTimeDef[8,4] = 13 moveTimeDef[8,5] = 7 moveTimeDef[8,6] = 0 moveTimeDef[8,7] = 6 moveTimeDef[8,8] = 0 # 変数定義 ================================================================= # アトラクションを選ぶかどうかの変数 # 1:選ぶ / 0:選ばない S = {} for i in range(9): S[i] = solver.BoolVar("S%i" % i) # 移動に関して、i→jに移動するかどうかの変数 # 1:移動する / 0:移動しない M = {} for i in range(9): for j in range(9): M[i,j] = solver.BoolVar("M%i%i" % (i,j)) # 満足度を宣言する satisfy = solver.IntVar(0.0, 1000, 'satisfy') # 滞在時間を宣言する stayTime = solver.IntVar(0.0, 1000, 'stayTime') # 移動時間変数 moveTime = solver.IntVar(0.0, 1000, 'moveTime') # 全体時間の変数 totalTime = solver.IntVar(0.0, 1000, 'totalTime') # 制約式 =================================================================== # 入口は必ず通過 solver.Add(S[0] == 1) # 移動について制限を設定 # 移動しないルートについてMを0にする solver.Add(M[0,0] == 0) solver.Add(M[0,2] == 0) solver.Add(M[0,5] == 0) solver.Add(M[0,6] == 0) solver.Add(M[0,7] == 0) solver.Add(M[0,8] == 0) solver.Add(M[1,1] == 0) solver.Add(M[1,6] == 0) solver.Add(M[1,7] == 0) solver.Add(M[1,8] == 0) solver.Add(M[2,0] == 0) solver.Add(M[2,2] == 0) solver.Add(M[2,3] == 0) solver.Add(M[2,6] == 0) solver.Add(M[2,7] == 0) solver.Add(M[2,8] == 0) solver.Add(M[3,2] == 0) solver.Add(M[3,3] == 0) solver.Add(M[3,5] == 0) solver.Add(M[3,8] == 0) solver.Add(M[4,4] == 0) solver.Add(M[5,0] == 0) solver.Add(M[5,3] == 0) solver.Add(M[5,5] == 0) solver.Add(M[5,6] == 0) solver.Add(M[6,0] == 0) solver.Add(M[6,1] == 0) solver.Add(M[6,2] == 0) solver.Add(M[6,5] == 0) solver.Add(M[6,6] == 0) solver.Add(M[6,8] == 0) solver.Add(M[7,0] == 0) solver.Add(M[7,1] == 0) solver.Add(M[7,2] == 0) solver.Add(M[7,7] == 0) solver.Add(M[8,0] == 0) solver.Add(M[8,1] == 0) solver.Add(M[8,2] == 0) solver.Add(M[8,3] == 0) solver.Add(M[8,6] == 0) solver.Add(M[8,8] == 0) # 重複を避ける設定(アトラクションは1回だけ訪れる。両方訪れないケース可) solver.Add(M[0,1] + M[1,0] <= 1) solver.Add(M[0,3] + M[3,0] <= 1) solver.Add(M[0,4] + M[4,0] <= 1) solver.Add(M[1,2] + M[2,1] <= 1) solver.Add(M[1,3] + M[3,1] <= 1) solver.Add(M[1,4] + M[4,1] <= 1) solver.Add(M[1,5] + M[5,1] <= 1) solver.Add(M[2,4] + M[4,2] <= 1) solver.Add(M[2,5] + M[5,2] <= 1) solver.Add(M[3,4] + M[4,3] <= 1) solver.Add(M[3,6] + M[6,3] <= 1) solver.Add(M[3,7] + M[7,3] <= 1) solver.Add(M[4,5] + M[5,4] <= 1) solver.Add(M[4,6] + M[6,4] <= 1) solver.Add(M[4,7] + M[7,4] <= 1) solver.Add(M[4,8] + M[8,4] <= 1) solver.Add(M[5,7] + M[7,5] <= 1) solver.Add(M[5,8] + M[8,5] <= 1) solver.Add(M[6,7] + M[7,6] <= 1) solver.Add(M[7,8] + M[8,7] <= 1) # Mについての条件 # 一つのアトラクションから複数のアトラクションへ同時に移動しない for i in range(9): solver.Add(solver.Sum([M[i,j] for j in range(9)]) <= 1) # ルートの連続性条件 # 0起点 step = [1,3,4] solver.Add(solver.Sum([M[0,s] for s in step]) == solver.Sum([M[s,0] for s in step])) # 1起点 step = [0,2,3,4,5] solver.Add(solver.Sum([M[1,s] for s in step]) == solver.Sum([M[s,1] for s in step])) # 2起点 step = [1,4,5] solver.Add(solver.Sum([M[2,s] for s in step]) == solver.Sum([M[s,2] for s in step])) # 3起点 step = [0,1,4,6,7] solver.Add(solver.Sum([M[3,s] for s in step]) == solver.Sum([M[s,3] for s in step])) # 4起点 step = [0,1,2,3,5,6,7,8] solver.Add(solver.Sum([M[4,s] for s in step]) == solver.Sum([M[s,4] for s in step])) # 5起点 step = [1,2,4,7,8] solver.Add(solver.Sum([M[5,s] for s in step]) == solver.Sum([M[s,5] for s in step])) # 6起点 step = [3,4,7] solver.Add(solver.Sum([M[6,s] for s in step]) == solver.Sum([M[s,6] for s in step])) # 7起点 step = [3,4,5,6,8] solver.Add(solver.Sum([M[7,s] for s in step]) == solver.Sum([M[s,7] for s in step])) # 8起点 step = [4,5,7] solver.Add(solver.Sum([M[8,s] for s in step]) == solver.Sum([M[s,8] for s in step])) # SとMの関係性の定義 # 0起点 step = [1,3,4] solver.Add(S[0] - (solver.Sum([M[0,s] for s in step]) + solver.Sum([M[s,0] for s in step])) / 2 == 0) # 1起点 step = [0,2,3,4,5] solver.Add(S[1] - (solver.Sum([M[1,s] for s in step]) + solver.Sum([M[s,1] for s in step])) / 2 == 0) # 2起点 step = [1,4,5] solver.Add(S[2] - (solver.Sum([M[2,s] for s in step]) + solver.Sum([M[s,2] for s in step])) / 2 == 0) # 3起点 step = [0,1,4,6,7] solver.Add(S[3] - (solver.Sum([M[3,s] for s in step]) + solver.Sum([M[s,3] for s in step])) / 2 == 0) # 4起点 step = [0,1,2,3,5,6,7,8] solver.Add(S[4] - (solver.Sum([M[4,s] for s in step]) + solver.Sum([M[s,4] for s in step])) / 2 == 0) # 5起点 step = [1,2,4,7,8] solver.Add(S[5] - (solver.Sum([M[5,s] for s in step]) + solver.Sum([M[s,5] for s in step])) / 2 == 0) # 6起点 step = [3,4,7] solver.Add(S[6] - (solver.Sum([M[6,s] for s in step]) + solver.Sum([M[s,6] for s in step])) / 2 == 0) # 7起点 step = [3,4,5,6,8] solver.Add(S[7] - (solver.Sum([M[7,s] for s in step]) + solver.Sum([M[s,7] for s in step])) / 2 == 0) # 8起点 step = [4,5,7] solver.Add(S[8] - (solver.Sum([M[8,s] for s in step]) + solver.Sum([M[s,8] for s in step])) / 2 == 0) # 満足度の算出 satisfy = solver.Sum([S[i] * satisfyDef[i] for i in range(9)]) # 滞在時間の算出 stayTime = solver.Sum([S[i] * stayTimeDef[i] for i in range(9)]) # 移動時間の算出 moveTime = solver.Sum([M[i,j] * moveTimeDef[i,j] for i in range(9) for j in range(9)]) # 全体時間の算出 totalTime = stayTime + moveTime # 全体時間の制約 solver.Add(totalTime <= 200) # 満足度を最大化する solver.Maximize(satisfy) # 求解実行 status = solver.Solve() if status == pywraplp.Solver.OPTIMAL or status == pywraplp.Solver.FEASIBLE: print('Solution:') print('ok') print('Objective value =', solver.Objective().Value()) print("culculate Time = ", solver.WallTime(), " milliseconds") print('satisfy', satisfy.solution_value()) print('stayTime', stayTime.solution_value()) print('moveTime', moveTime.solution_value()) print('totalTime', totalTime.solution_value()) for i in range(9): print(i,S[i].solution_value()) for i in range(9): for j in range(9): if M[i,j].solution_value() >= 0.5: print('M',i,j,'=',M[i,j].solution_value()) else: print('The problem does not have an optimal solution.')出展
本記事は、数理最適化についての参考テキスト「Pythonによる問題解決シリーズ データ分析ライブラリーを用いた最適化モデルの作り方」に記載の練習問題を参考にさせて頂いております。
■参考テキスト
「Pythonによる問題解決シリーズ データ分析ライブラリーを用いた最適化モデルの作り方」
斉藤努[著]
近代科学社[出版]
ご意見など
ご意見、間違い訂正などございましたらお寄せ下さい。
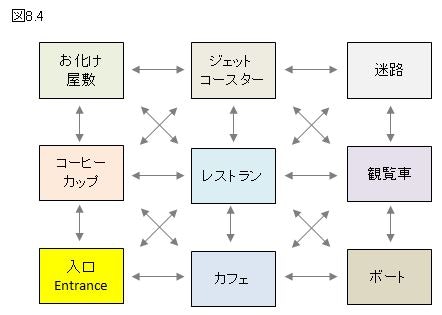
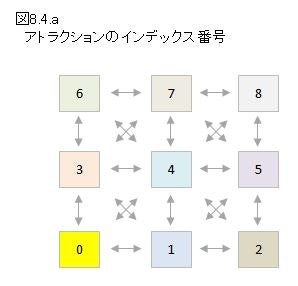
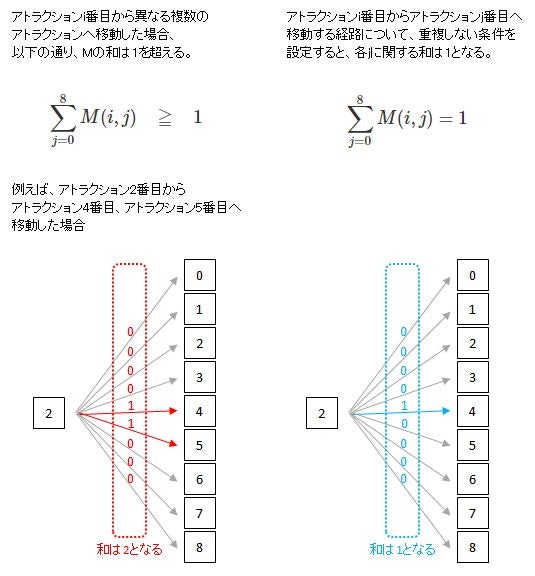


- 投稿日:2020-04-07T09:41:53+09:00
PythonでCSVファイルを読み込んでそのままDataFrameに変換する
はじめに
- CSVで取得したデータをPythonで分析するために読み込んでPandasのDatafarame型で保持する方法をまとめる。
事前準備
- 分析したいCSVファイルをカレントディレクトリに用意しておく
- CSVファイルは成形済前提
コード
import csv, os import pandas as pd import numpy as np #対象のファイルのパス文字列を指定 file_path = os.path.join(".","maerge_Machine11_trd.csv") print("file name:" + file_path) #CSVファイルからdfへ変換 df = pd.read_csv(file_path) #読み込んだデータの表示 df.head() #TODO:dfからの目的のデータの取得 #TODO:統計解析・可視化解説
- os.path.jpin()で環境依存せずにファイルの場所を指定する
- pd.read_csv()でファイルを開きdataframe型へ変換
- この後は、dfから必要な行・列を取得して統計解析や可視化を行えばよい。
- 投稿日:2020-04-07T09:34:02+09:00
TouchDesignerで機械学習(ObjectDetection)動かしてみた
はじめに
勉強ついでに適当に作ってみたモデルをTouchDesigner内で動かしてみたくなったのでやってみました。
実際やってみたらこんな感じ!(この記事で使ったモデルとは違うけれど、だいたいこんな感じです)
https://www.youtube.com/watch?v=ycBvOQUzisU
サンプルのリポジトリはこちら!
ちなみに、今回はWindows前提で記事を書いていますがMacでも動作可能です!
TouchDesignerのPythonについて
TouchDesignerでは、拡張機能としてPythonを使用することができます(私の環境だと内部でPython3.7.2が動作するようです)。
Dialogs > Textport and DATs からPythonのインタプリタを使うことができます。
プリインストールとして、標準ライブラリとOpenCV、numpyなんかが使えます。
今回はこれに加えて機械学習でよく使われるライブラリを使って、TouchDesginer内でObjectDetectionさせたいと思います。
どうやるかというと、Edit > Preferenceの「Add External Python to Search Path」に外部ライブラリへのパスを指定してTouchDesignerで使えるようにします。
ObjectDetectionについて
ObjectDetectionの詳しい説明は省きますが、下の画像みたいな人やモノなどのオブジェクトを検出(四角で囲んで、これが何かを示す)する感じです。
今回はできるだけ処理の軽いアルゴリズムを採用してなんとかFPSを稼ごうという魂胆のもと、モバイル端末でも動いてくれるMobileNetv2-SSDを使ってみます!
Pythonで機械学習(主にDNN)を扱うライブラリ(フレームワーク)としては、
なんかが存在します。
私が普段扱うのはTensorflow/Kerasですが(たまにPytorchも使う)、今回はONNXを使います。(正確にはONNXRuntimeという推論環境を使います)
理由は、なぜか私の環境だとTouchDesigner内のPythonからTensorflowやPytorchを使うとエラーメッセージも吐かずにTouchDesignerが落ちてしまうからです。
そんなことがあった後でダメ元でONNX試したら動いてくれたのでこれを使います!(MXNetはわからない...)
肝心のモデルは、Tensorflowで作ったモデルをONNX形式に書き出したものを用意しました。(リポジトリ内に含めています)
作業環境
- Windows10 home
- Anaconda
- TouchDesigner 64-Bit Build 2020.20625
1. 環境構築
作業環境が揃ったら、さっそくONNXをインストールしてみます!
1-1. Anacondaで仮想環境を作る
$conda create -n touchdesigner python=3.7.21-2. 仮想環境内にONNXをインストールする
$source activate touchdesigner $pip install onnxruntime==1.1.01-3. TouchDesignerに仮想環境のパスを通す
Edit > Preferences をクリックし環境設定を開きます。
以下の画像のように「Add External Python to Search Path」にチェックを入れ、「Python 64-bit Module Path」にAnacondaの仮想環境へのパスを通します。
私の環境だと以下のようなパスを通すことになります。
C:/Users/T-Sumida/Anaconda3/envs/touchdesigner/Lib/site-packagesこれを参考にしてパスを通してみてください!
2. ONNXの準備
それではONNXがTouchDesiger上で動作することを確認します!
Dialogs > Textport and DATs からPythonのインタプリタを起動し、そこに以下のコードを貼り付けて実行してみてください。
※モデルへのパスと、試したい画像のパスは適宜適切に設定してください。
import cv2 import numpy as np import onnxruntime # cocoデータセットのクラス番号:クラス名 coco_classes = { 1: 'person', 2: 'bicycle', 3: 'car', 4: 'motorcycle', 5: 'airplane', 6: 'bus', 7: 'train', 8: 'truck', 9: 'boat', 10: 'traffic light', 11: 'fire hydrant', 12: 'stop sign', 13: 'parking meter', 14: 'bench', 15: 'bird', 16: 'cat', 17: 'dog', 18: 'horse', 19: 'sheep', 20: 'cow', 21: 'elephant', 22: 'bear', 23: 'zebra', 24: 'giraffe', 25: 'backpack', 26: 'umbrella', 27: 'handbag', 28: 'tie', 29: 'suitcase', 30: 'frisbee', 31: 'skis', 32: 'snowboard', 33: 'sports ball', 34: 'kite', 35: 'baseball bat', 36: 'baseball glove', 37: 'skateboard', 38: 'surfboard', 39: 'tennis racket', 40: 'bottle', 41:'wine glass', 42: 'cup', 43: 'fork', 44: 'knife', 45: 'spoon', 46: 'bowl', 47: 'banana', 48: 'apple', 49: 'sandwich', 50: 'orange', 51: 'broccoli', 52: 'carrot', 53: 'hot dog', 54: 'pizza', 55: 'donut', 56: 'cake', 57: 'chair', 58: 'couch', 59: 'potted plant', 60: 'bed', 61: 'dining table', 62: 'toilet', 63: 'tv', 64: 'laptop', 65: 'mouse', 66: 'remote', 67: 'keyboard', 68: 'cell phone', 69: 'microwave', 70: 'oven', 71: 'toaster', 72: 'sink', 73: 'refrigerator', 74: 'book', 75: 'clock', 76: 'vase', 77: 'scissors', 78: 'teddy bear', 79: 'hair drier', 80: 'toothbrush' } # モデルを読み込む session = onnxruntime.InferenceSession("ONNXモデルへのパスを指定") # 画像を読み込む img = cv2.imread("試したい画像のパスを指定") # OpenCVは画像データをBGRで読み込むので、BGRに変換する img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) width, height = img.shape[0], img.shape[1] img_data = np.expand_dims(img, axis=0) # モデルの推論の準備 input_name = session.get_inputs()[0].name # 'image' output_name_boxes = session.get_outputs()[0].name # 'boxes' output_name_classes = session.get_outputs()[1].name # 'classes' output_name_scores = session.get_outputs()[2].name # 'scores' output_name_num = session.get_outputs()[3].name # 'number of detections' # 推論 outputs_index = session.run( [output_name_num, output_name_boxes, output_name_scores, output_name_classes], {input_name: img_data} ) # 結果を受け取る output_num = outputs_index[0] # 検出した物体数 output_boxes = outputs_index[1] # 検出した物体の場所を示すボックス output_scores = outputs_index[2] # 検出した物体の予測確率 output_classes = outputs_index[3] # 検出した物体のクラス番号 # 予測確率の閾値 threshold = 0.6 # 推論結果を画像に変換 img = cv2.cvtColor(img, cv2.COLOR_RGB2BGR) for detection in range(0, int(output_num[0])): if output_scores[0][detection] > threshold: classes = output_classes[0][detection] boxes = output_boxes[0][detection] scores = output_scores[0][detection] top = boxes[0] * width left = boxes[1] * height bottom = boxes[2] * width right = boxes[3] * height top = max(0, top) left = max(0, left) bottom = min(width, bottom) right = min(height, right) img = cv2.rectangle(img, (int(left), int(top)), (int(right), int(bottom)), (0,0,255), 3) img = cv2.putText( img, "{}: {:.2f}".format(coco_classes[classes], scores), (int(left), int(top)), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2, cv2.LINE_AA ) cv2.imshow('img', img) k = cv2.waitKey(0)実行すると以下のような画像が描画されるかと思います。
これが問題なく動けば一旦は大丈夫です!
3. TouchDesignerでPythonを書く
続いてTouchDesigerのパッチで動くようにしていきます。
こちらの記事を参考にさせて頂き(ありがとうございます!)、カメラ画像からの入力に対してObjectDetectionさせようと思います。
プロジェクト自体は非常にシンプルなもので、「Video Device In」からの入力を「OP Execute」で受け取りOpencvの機能で描画するようなモノにしました。
「OP Execute」の中身は以下のようにしました。
# me - this DAT. # changeOp - the operator that has changed # # Make sure the corresponding toggle is enabled in the OP Execute DAT. import cv2 import numpy as np import onnxruntime # 上のテストと一緒なので省略します(使うときは上からコピーして使ってください) coco_classes = { 1: 'person', 2: 'bicycle', ... } session = onnxruntime.InferenceSession("C:/Users/TomoyukiSumida/Documents/Hatena/ObjetDetection4TD/ssdlite_mobilenetv2.onnx") def onPreCook(changeOp): return def onPostCook(changeOp): # 画像の読み込み frame = changeOp.numpyArray(delayed=True) arr = frame[:, :, 0:3] arr = arr * 255 arr = arr.astype(np.uint8) arr = np.flipud(arr) width, height = arr.shape[0:2] image_data = np.expand_dims(arr, axis=0) # モデルの推論の準備 input_name = session.get_inputs()[0].name # 'image' output_name_boxes = session.get_outputs()[0].name # 'boxes' output_name_classes = session.get_outputs()[1].name # 'classes' output_name_scores = session.get_outputs()[2].name # 'scores' output_name_num = session.get_outputs()[3].name # 'number of detections' # 推論 outputs_index = session.run([output_name_num, output_name_boxes, output_name_scores, output_name_classes], {input_name: image_data}) # 結果を受け取る output_num = outputs_index[0] # 検出した物体数 output_boxes = outputs_index[1] # 検出した物体の場所を示すボックス output_scores = outputs_index[2] # 検出した物体の予測確率 output_classes = outputs_index[3] # 検出した物体のクラス番号 # 予測確率の閾値 threshold = 0.6 # 推論結果を画像に変換 for detection in range(0, int(output_num[0])): if output_scores[0][detection] > threshold: classes = output_classes[0][detection] boxes = output_boxes[0][detection] scores = output_scores[0][detection] top = boxes[0] * width left = boxes[1] * height bottom = boxes[2] * width right = boxes[3] * height top = max(0, top) left = max(0, left) bottom = min(width, bottom) right = min(height, right) arr = cv2.rectangle(arr, (int(left), int(top)), (int(right), int(bottom)), (0,0,255), 3) arr = cv2.putText( arr, "{}: {:.2f}".format(coco_classes[classes], scores), (int(left), int(top)), cv2.FONT_HERSHEY_SIMPLEX, 1, (0, 0, 255), 2, cv2.LINE_AA) arr = cv2.cvtColor(arr, cv2.COLOR_RGB2BGR) cv2.imshow('img', arr) return def onDestroy(): return def onFlagChange(changeOp, flag): return def onWireChange(changeOp): return def onNameChange(changeOp): return def onPathChange(changeOp): return def onUIChange(changeOp): return def onNumChildrenChange(changeOp): return def onChildRename(changeOp): return def onCurrentChildChange(changeOp): return def onExtensionChange(changeOp, extension): returnこれが書けたら、「OP Execute」のMonitor OPsに「Video Device In」を指定し、Post CookをONにしてください。
動いた!
おわりに
今回はTouchDesigner内でONNXを使ってObjectDetectionを動かしてみました。何故かTensorflowが動かなくて困りましたが、なんとか動くものができてよかったです。
ただ、TouchDesigner内でObjectDetection(ひいては機械学習)を動かすことには以下のようなデメリットがあります。
- TouchDesignerがシングルスレッドのため、プロジェクト全体のFPSが制限される
- 私が確認した中だと、ONNXに変換されたモデルしか使えない(他のよいアルゴリズムが使えない場合がある)なので、「TouchDesignerの後ろでPythonプロセスを起動しそこからOSCで情報を送る」などのほうが良さげではあります(今後TouchDesignerでマルチスレッドが使えるようになれば有用性はあるかもしれません)。
ONNXのモデルについても今回は私の自作モデルで試しましたが、onnx/modelからモデルファイルをダウンロードして使っても大丈夫です。(私もそこからmask-rcnnをダウンロードして動くことを確認しました)
また、GPUを使っての高速な推論も可能です。(今回のモデルはCPUでも高速に動くものを使いました)
$pip install onnxruntime==1.1.0
これの代わりに
$pip install onnxruntime-gpu==1.1.0
これをインストールしてやればGPU上で推論が行われるようになります。色々試してみても面白いのでしょうか!表現側は難して手を出せていないですが、今後はその辺りも触れればいいなぁと思います!