- 投稿日:2020-04-07T23:40:24+09:00
テレワークで役立つAmazon Workspacesをちゃんと監視できるのか?
概要
- 2020/04/07、緊急事態宣言が発令したこともあり、どこの企業もテレワークや在宅勤務
- AWSの「Workspaces」で環境をサクッとバリッと作成
- ちゃんとCloudTrailで監査ログ見れることを確認
対象読者
- テレワーク・在宅勤務を推奨している会社の情報システム部などの人
- テレワークするための論理武装したい人
- Workspaces好きで推進したい人
- CloudTrail好きな人
事の発端
ずっと前々から騒がれていたことですが、2020/04/07にとうとう緊急事態宣言が発令しました。これに伴い、どこの企業もテレワークや在宅勤務が発動しています。
筆者の周りでも強烈な動きが巻き起こっており、一斉に環境構築がなされています。Workspacesでやっちゃえば?
筆者はクラウドサービスのなかでAWSに最も慣れており、AWSが最も好きです。そう、AWSにはリモート環境が用意されています。それが「Amazon Workspaces」です。Amazon Workspacesを使うと、Windows または Linux のデスクトップが数分でセットアップできちゃいます。加えて、追加コストを払えばOfficeソフトをつけたWindowsもセットアップできます。
他のソリューションでもいいのですが、かんたんにスケールして多くの企業で使われているOfficeを使わなきゃいけないという要件は意外と辛いのですが、これなら解決できそうです。
ちゃんとログとれるよね?
ここからが本題です。使うはいいけど、誰が使ったか情報システムとかに関わる人は気になりますよね。上から、本当に大丈夫とか言われて、ログもとってるんで大丈夫って言えたら楽ですよね。
となったのでちゃんと確認しとこうとなりました。AWSでサービスを利用したログを確認となったら「AWS CloudTrail」です。
こちらを見ていただいたら分かる通り、CloudTrailの情報を確認する経路はたくさんあります。サポートされるサービス種類は下記のとおりです。
よし。Workspaces入ってるから問題ない。
CloudTrail dashboardから確認
ログ取れていることみたいだけなのでダッシュボードから確認します。なお、CloudTrailで気をつけるべきはログ転送までに15分程度かかることです。よくある質問にも記載があります。WorkSpacesにアクセスして、ダッシュボードから確認してみましょう。
問題なく取れてますね。よかったよかった(なんか時間が少し古いような・・・)。
ダッシュボードにログが出てこないときは・・・
当方最初ダッシュボードから検索しても何もHITしませんでした。もちろん15分以上時間を撮ってアクセスしています。あれーー?ってなっててS3にストアされているログをあさりにいきました。S3から復元するのはめんどくさいので、Amazon Athena(S3に対してSQL文を発行してインタラクティブにログ検索できるサービス)を使いました。CloudTrailログをAthenaで検索することは割と簡単です。CloudTrailの画面上にある「探していたものが見つからない場合は、 Amazon Athena で高度なクエリを実行します」の手順に沿ってS3のバケットの設定などをしていくと利用できます。
Athenaを使うとごそっとログが抽出でき、最近の時間のものまで取得ができました。極力リアルタイムにすべてのログを抜き取るときはCloudTrailダッシュボードではなく、Athenaを利用して、Workspacesのログを取得したほうがよいことがわかりました。
まとめ
- こんな状況なので、できる限りテレワークや在宅勤務をしましょう。
- Workspacesを使えば比較的カンタンにサクッとリモート環境構築できます。
- CloudTrailでWorkspacesのログを見るときはダッシュボード、見つからなくて急ぎのときはAthenaを使いましょう。
- 投稿日:2020-04-07T21:24:37+09:00
サーバーレスライブラリbrefを使い、素のPHPでHello world
ちょっと素のPHPが欲しいときがあったら、以下のようにさくっとデプロイできます。
$ serverless # プロジェクト作成 https://github.com/umihico/bref-demo/commit/0269a62 Serverless: No project detected. Do you want to create a new one? Yes Serverless: What do you want to make? AWS Node.js Serverless: What do you want to call this project? bref-demo Project successfully created in 'bref-demo' folder. You can monitor, troubleshoot, and test your new service with a free Serverless account. Serverless: Would you like to enable this? No You can run the “serverless” command again if you change your mind later. $ cd bref-demo $ composer require bref/bref # brefインストール https://github.com/umihico/bref-demo/commit/2143b4e本命のPHPファイルを追加し、serverless.ymlを設定します。0e8c61d
index.php+ <?php + + require __DIR__ . '/vendor/autoload.php'; + + lambda(function ($event) { + return [ + 'headers' => [ + 'Content-Type' => 'text/html' + ], + 'statusCode' => 200, + 'body' => '<html><!doctype html><head></head><body><h1>Go Serverless v1.0! Your function executed successfully!</h1></html>', + ]; + });serverless.ymlprovider: name: aws - runtime: nodejs12.x + runtime: provided + +plugins: + - ./vendor/bref/bref functions: hello: - handler: handler.hello -# The following are a few example events you can configure -# NOTE: Please make sure to change your handler code to work with those events -# Check the event documentation for details -# events: -# - http: -# path: users/create -# method: get + handler: index.php + timeout: 28 + layers: + - ${bref:layer.php-73-fpm} + events: + - http: 'ANY /' + - http: 'ANY /{proxy+}' # - websocket: $connect
serverless deployで発行されたURLにアクセスしてみると、
ちゃんとHTMLが描写されていますね。jsonを返したい場合はこうです。66df3alambda(function ($event) { - return [ - 'headers' => [ - 'Content-Type' => 'text/html' - ], - 'statusCode' => 200, - 'body' => '<html><!doctype html><head></head><body><h1>Go Serverless v1.0! Your function executed successfully!</h1></html>', - ]; + return [ + 'headers' => [ + 'Content-Type' => "application/json", + ], + 'statusCode' => 200, + 'body' => json_encode(['json_key' => 'json_value']), + ]; });参考

- 投稿日:2020-04-07T20:55:34+09:00
Rails5.2以降でAWSへデプロイ完全版+DBはmysql+無料でSSL化+独自ドメイン取得(お名前.com)
はじめに
表題の通りですがAWSにて環境構築から独自ドメイン取得までを記載しております。
rails5.2以降でのデプロイが難航し環境構築から独自ドメイン取得まで一貫した記事が無く、人柱となりて共有できればと思い記事として残すことにしました。
rails5.2以降ではsecrets.ymlがcredentials.yml.encに変更になり、呼び出し方が異なるのでその部分が躓くかと存じます。また、ドメイン・SSL化はなかなか教材には無かったのでご参考になれば幸いです。不手際がございましたら、コメントにいただけると有り難いです。
できるだけコピペでいきたいですね。では参りましょう!前提条件
- githubにリポジトリが登録できている
- そのリポジトリに rails new したもの(rails5.2以降)が登録できている
- databaseはmysqlである
- AWSでアカウントが登録できている
- 寛大な心を持っている
流れ
- AWS内の環境構築
- unicornの導入
- nginxの導入
- capistranoの導入
- お名前.comでドメインを購入し、AWSと紐付け
- 無料SSL化(Let's Encrypt)
AWS内の環境構築
AWSのEC2というサービスを使って、全世界に作成したサイトを公開するサーバを作成します。いくつかの設定をし、作成したサーバにログインして操作できるようにします。EC2で作成したサーバは、結局はターミナルを介して遠隔操作できるパソコンです。慣れましょう!(投げやり感)
- AWSアカウントのリージョン設定
リージョンとは、AWSの物理的なサーバの場所を指定するものです。リージョンは世界各地に10箇所以上存在し、そのうちの一つは東京にあります。
まずは【こちら】からAWSアカウントにログインします。次に日本にお住まいの方は「東京」を選択してください。
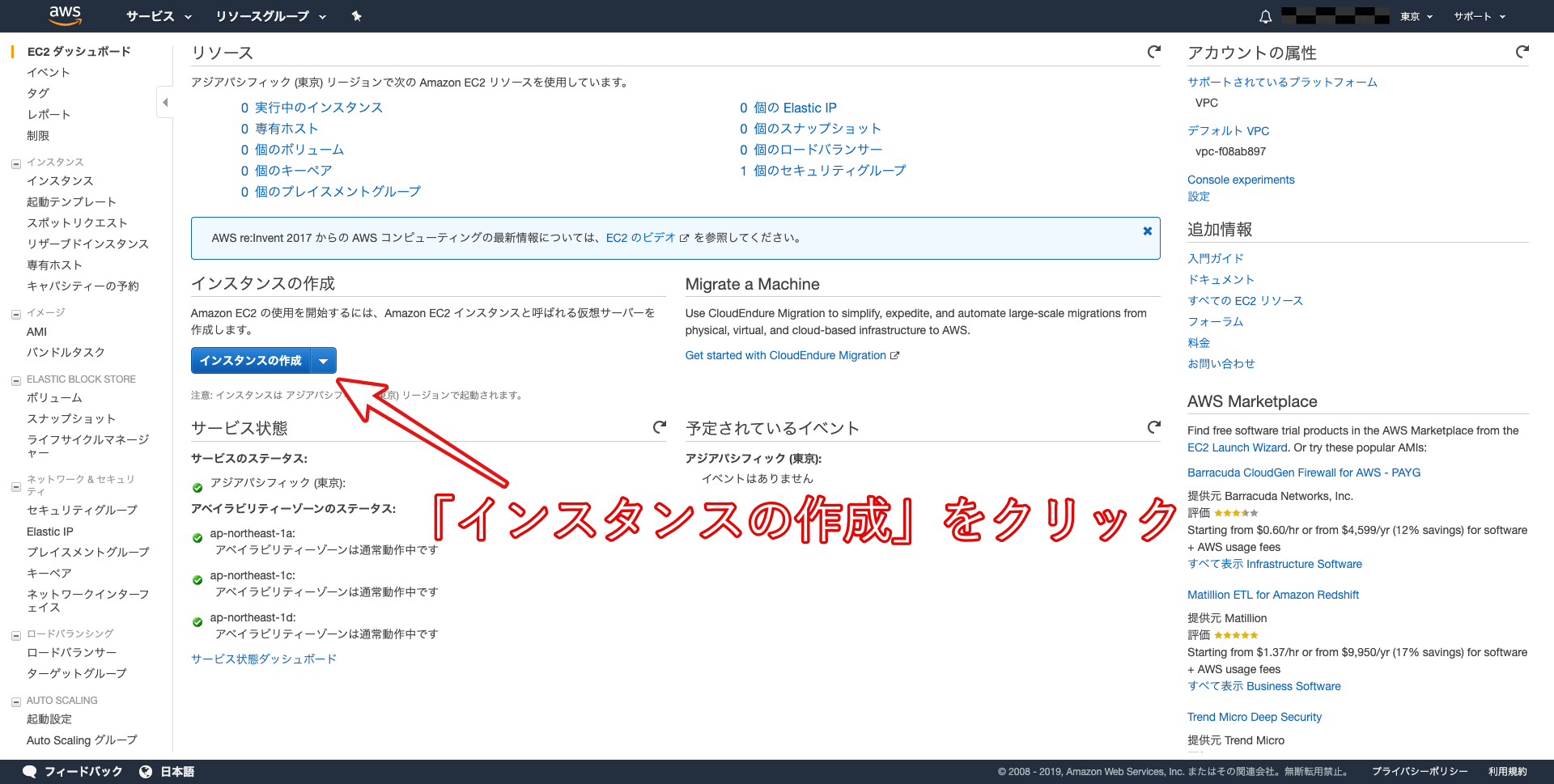
- EC2インスタンスの作成
「仮想マシン」のことをAWSでは「EC2インスタンス」と呼んでいます。
「EC2」を選択しましょう。
以下の画像のように「インスタンスの作成」をクリックしましょう。
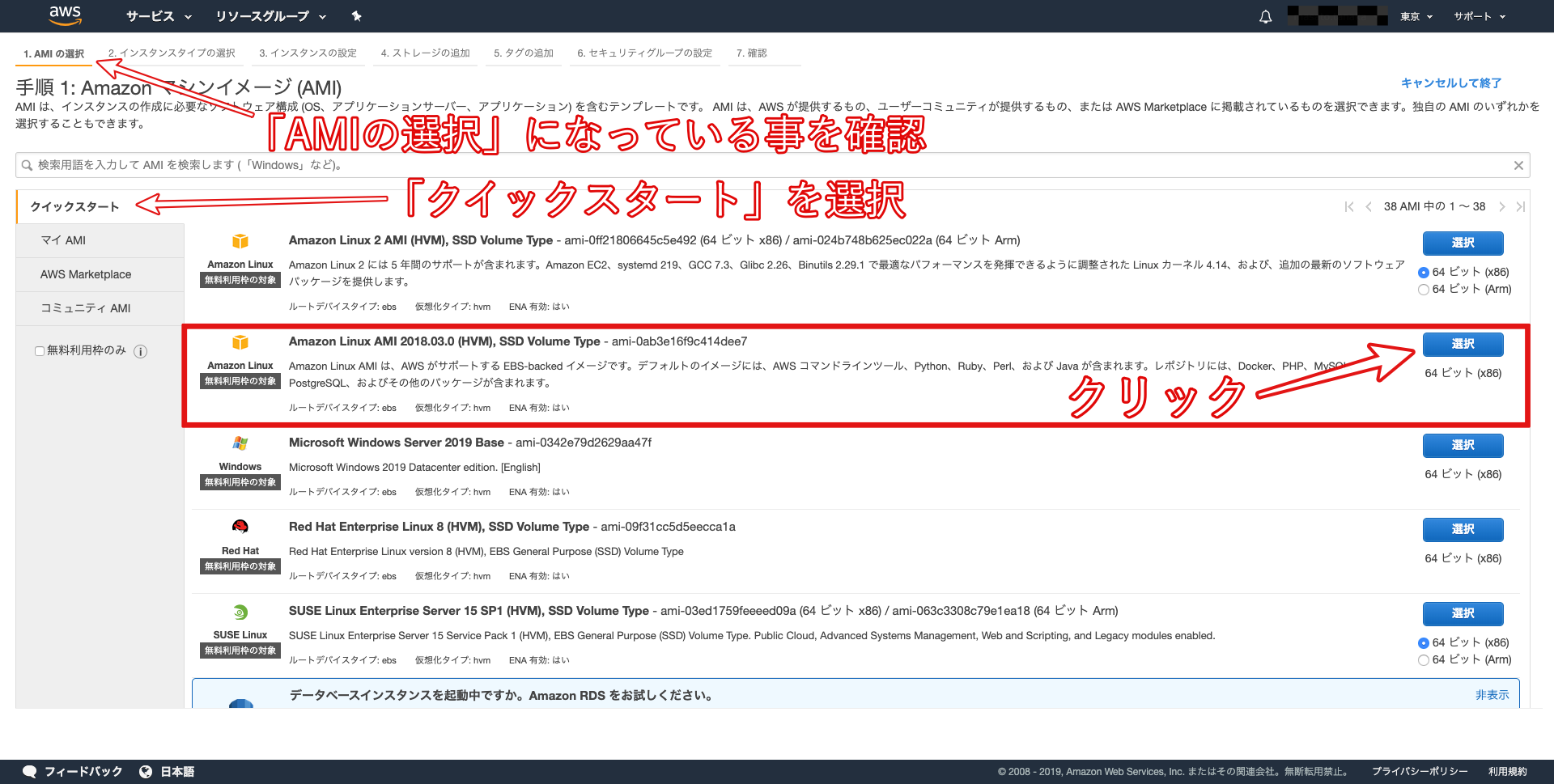
以下の画像のように「 Amazon Linux AMI 」を選択してください。
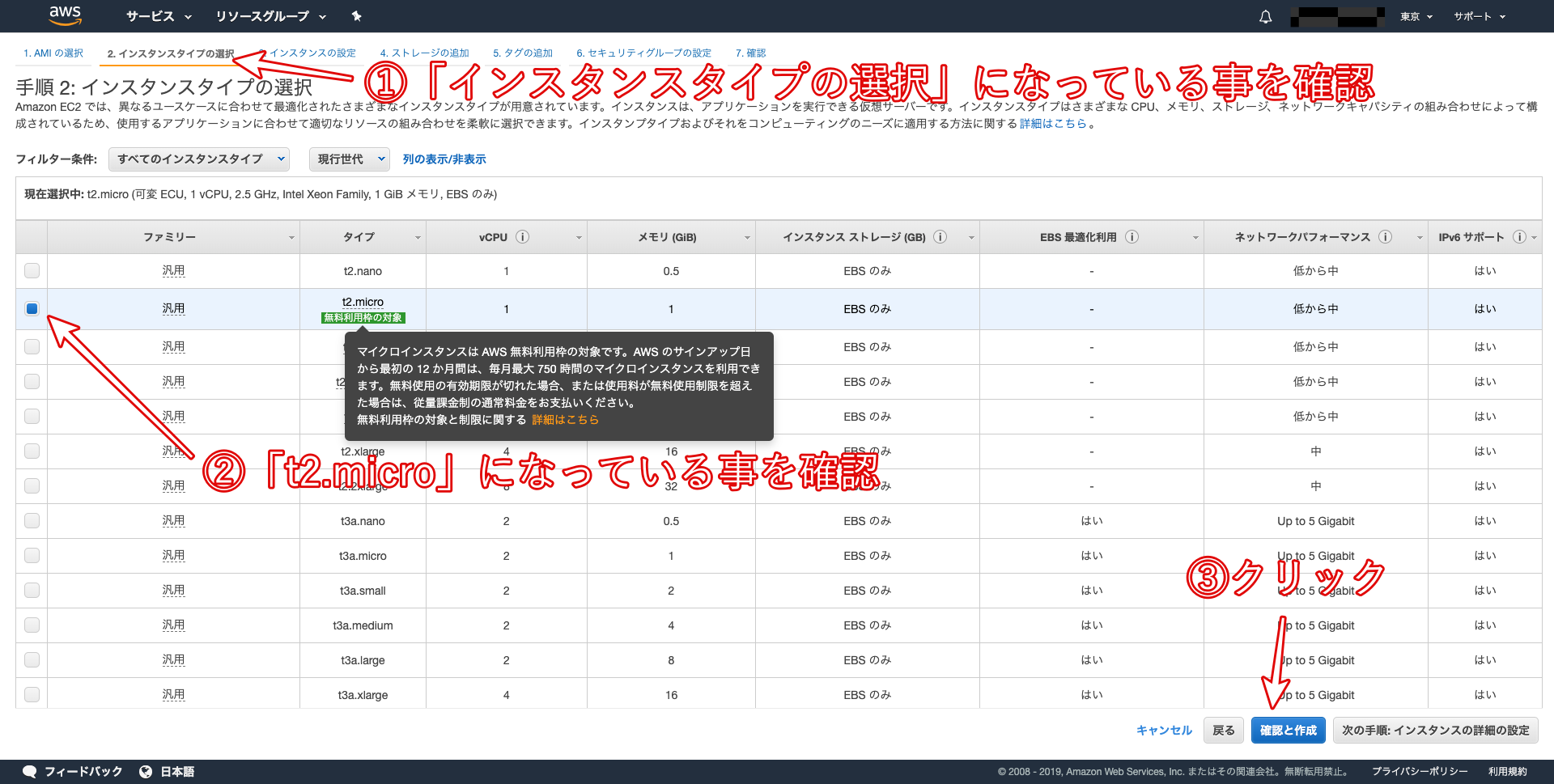
EC2インスタンスのタイプを選択します。EC2ではさまざまなインスタンスタイプが用意されており、CPUやメモリなどのスペックを柔軟に指定することができます。
今回は、無料枠で利用できる「t2.micro」を選択しましょう。
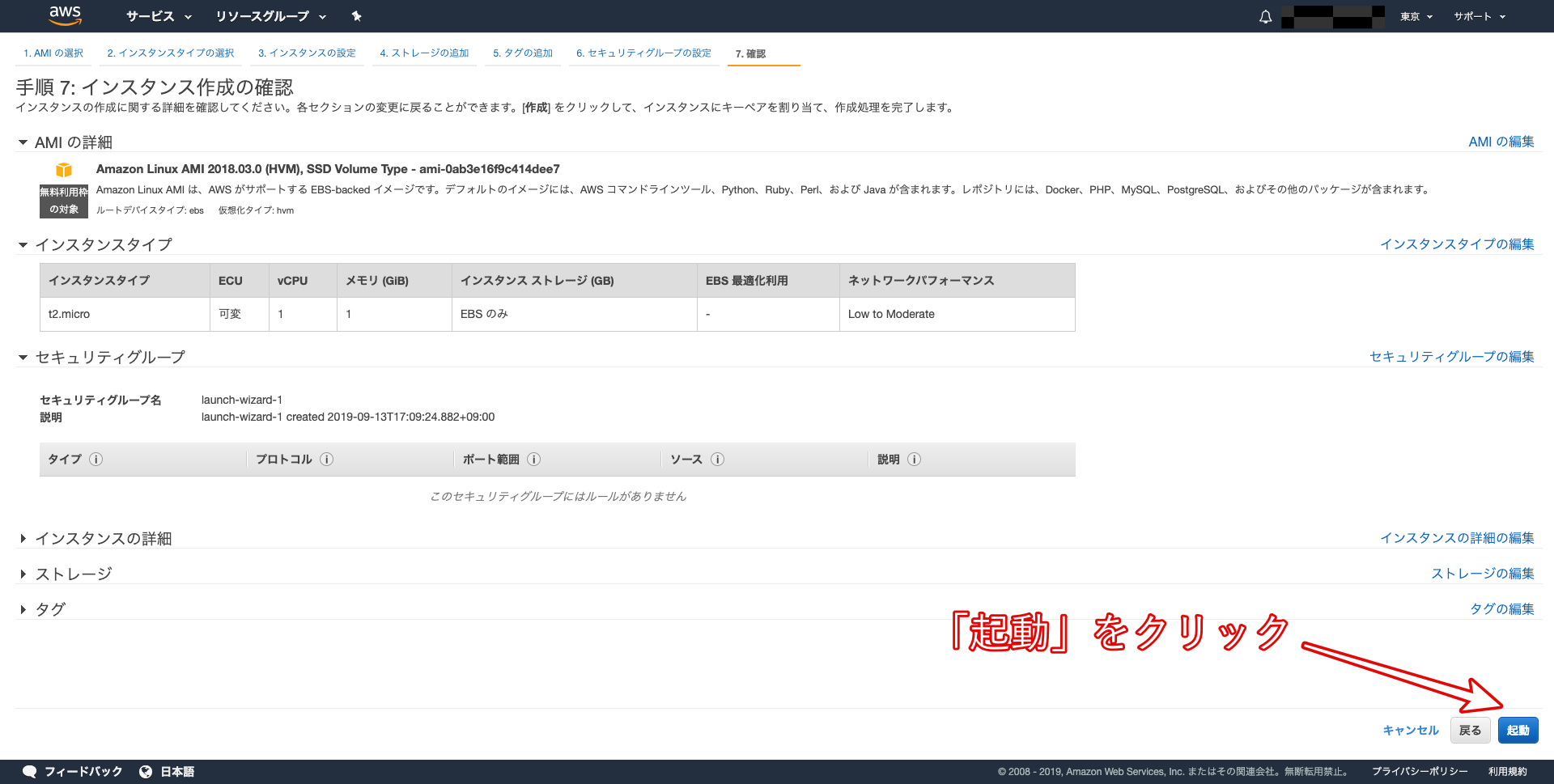
起動をクリックします。
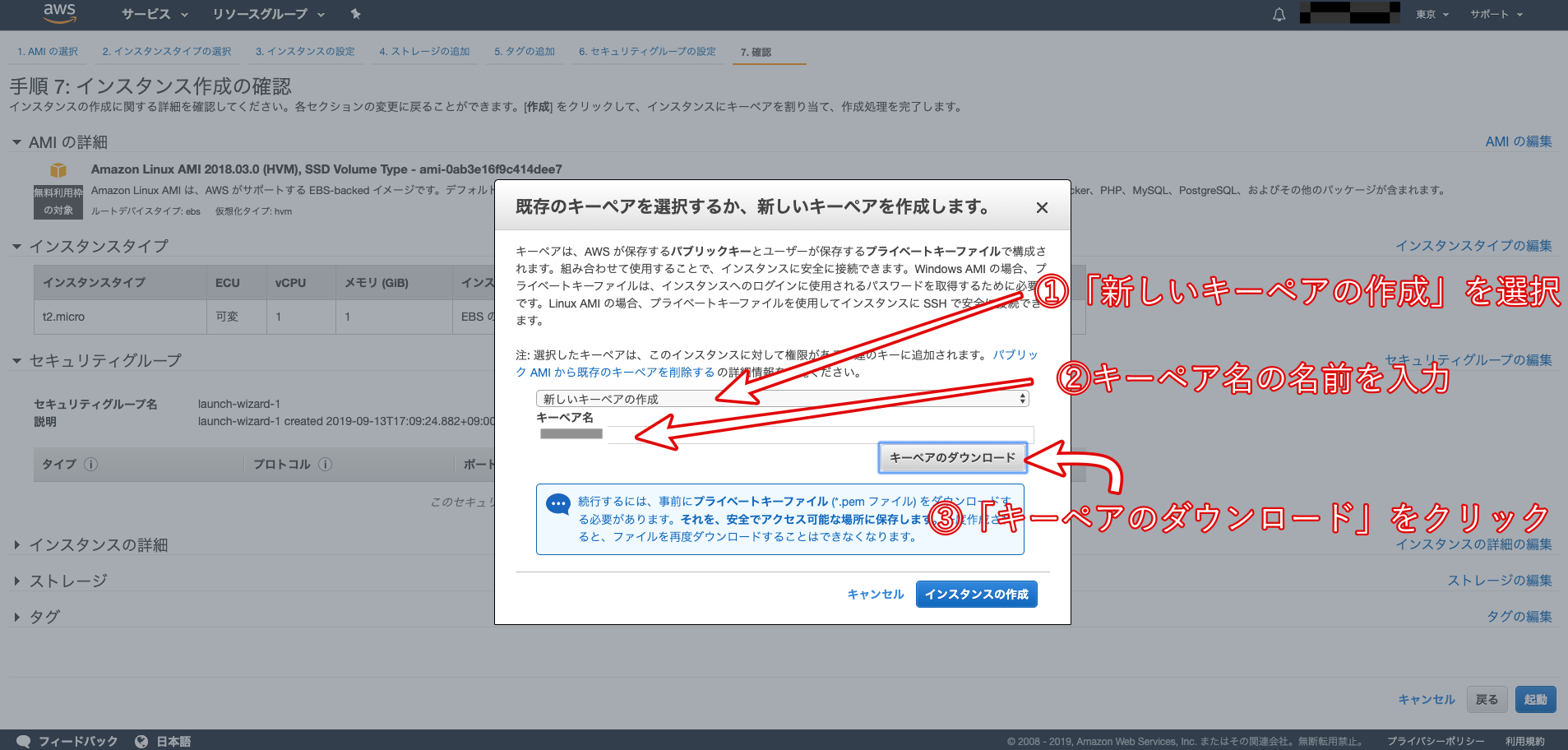
「キーペア」をダウンロードすることが出来ます。こちらはインスタンスにSSHでログインする際に必要となる「秘密鍵」です。これがないとEC2インスタンスにログインできないので、必ずダウンロードしてパソコンに保存しておきましょう。
※スペースを含まない名前の秘密鍵を作成するようにしましょう!キーペアのダウンロードが完了すると、クリック出来ない状態になっていた「インスタンスの作成」が、クリックできるように変更されます。そちらをクリックして、EC2インスタンスを作成しましょう。
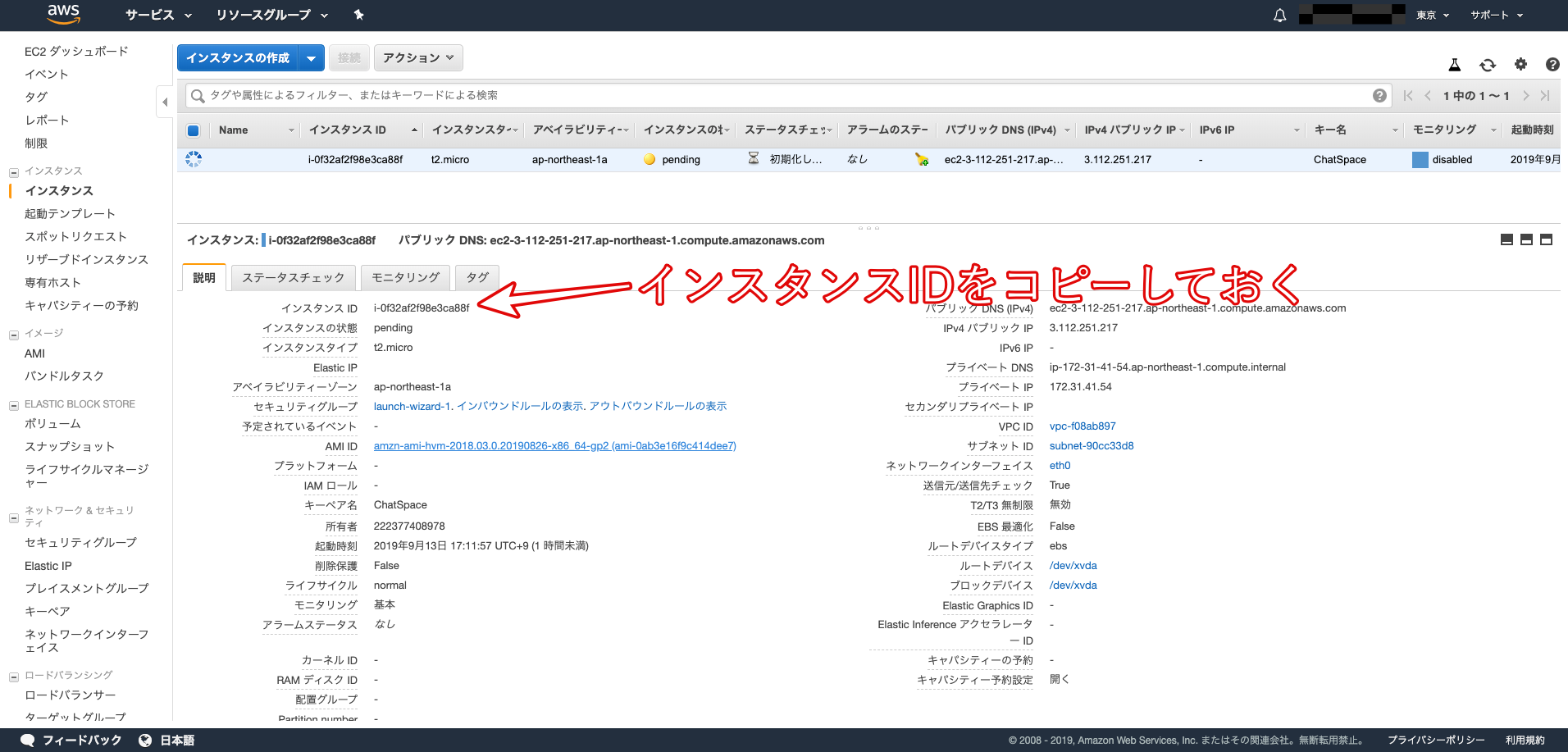
その後、インスタンス一覧画面に戻り、作成した「インスタンスID」をコピーしてメモしておきましょう。
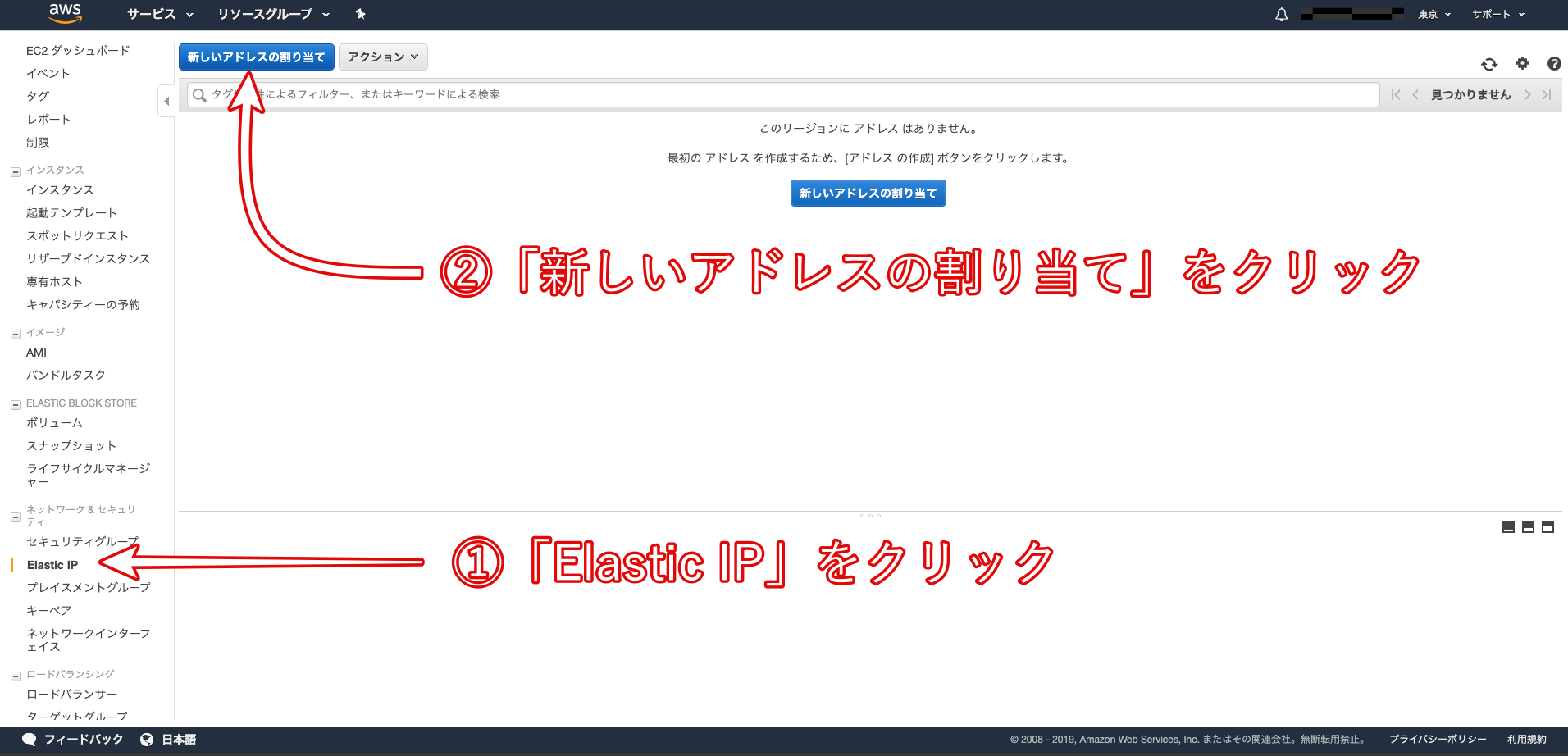
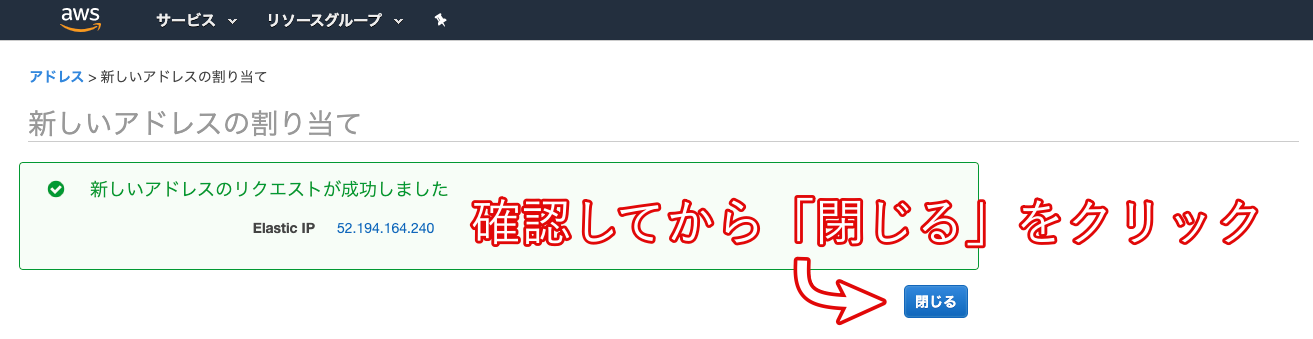
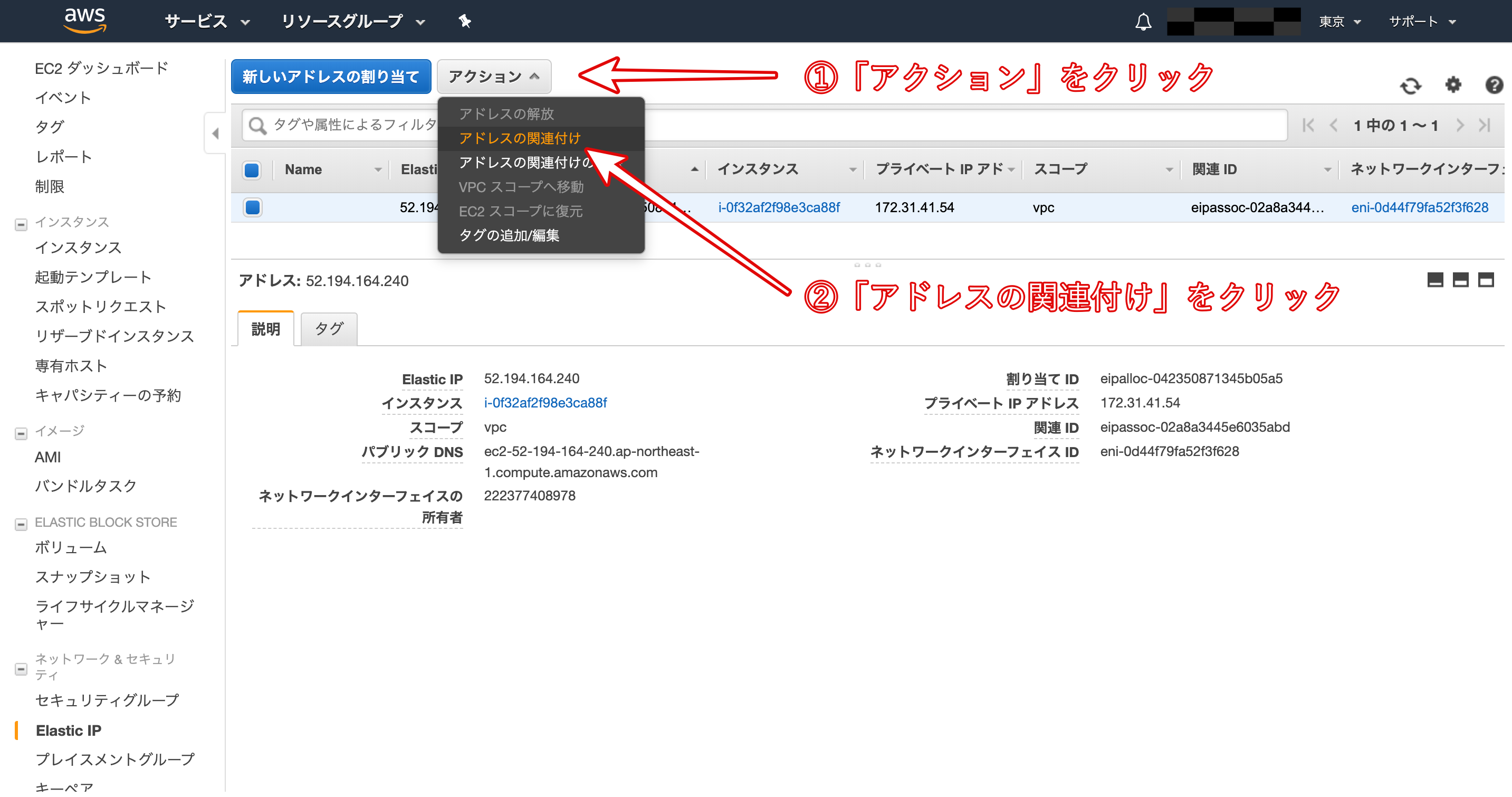
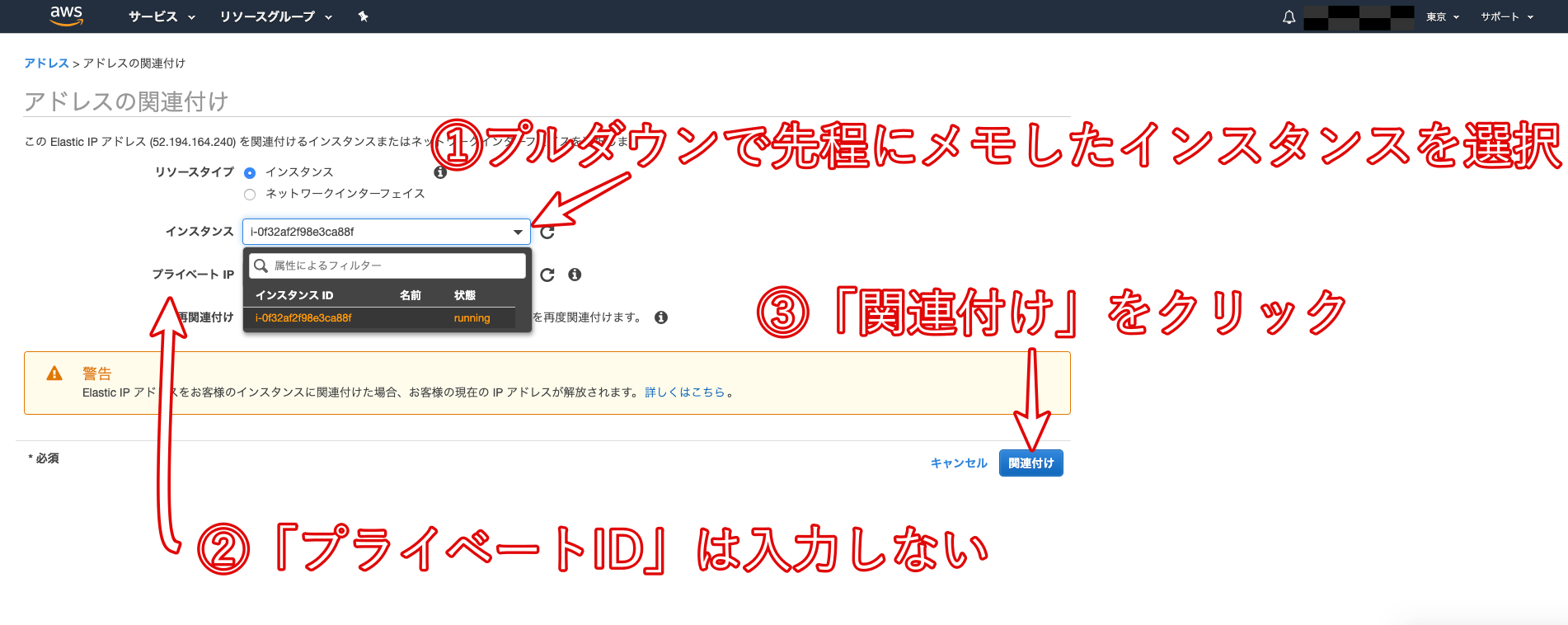
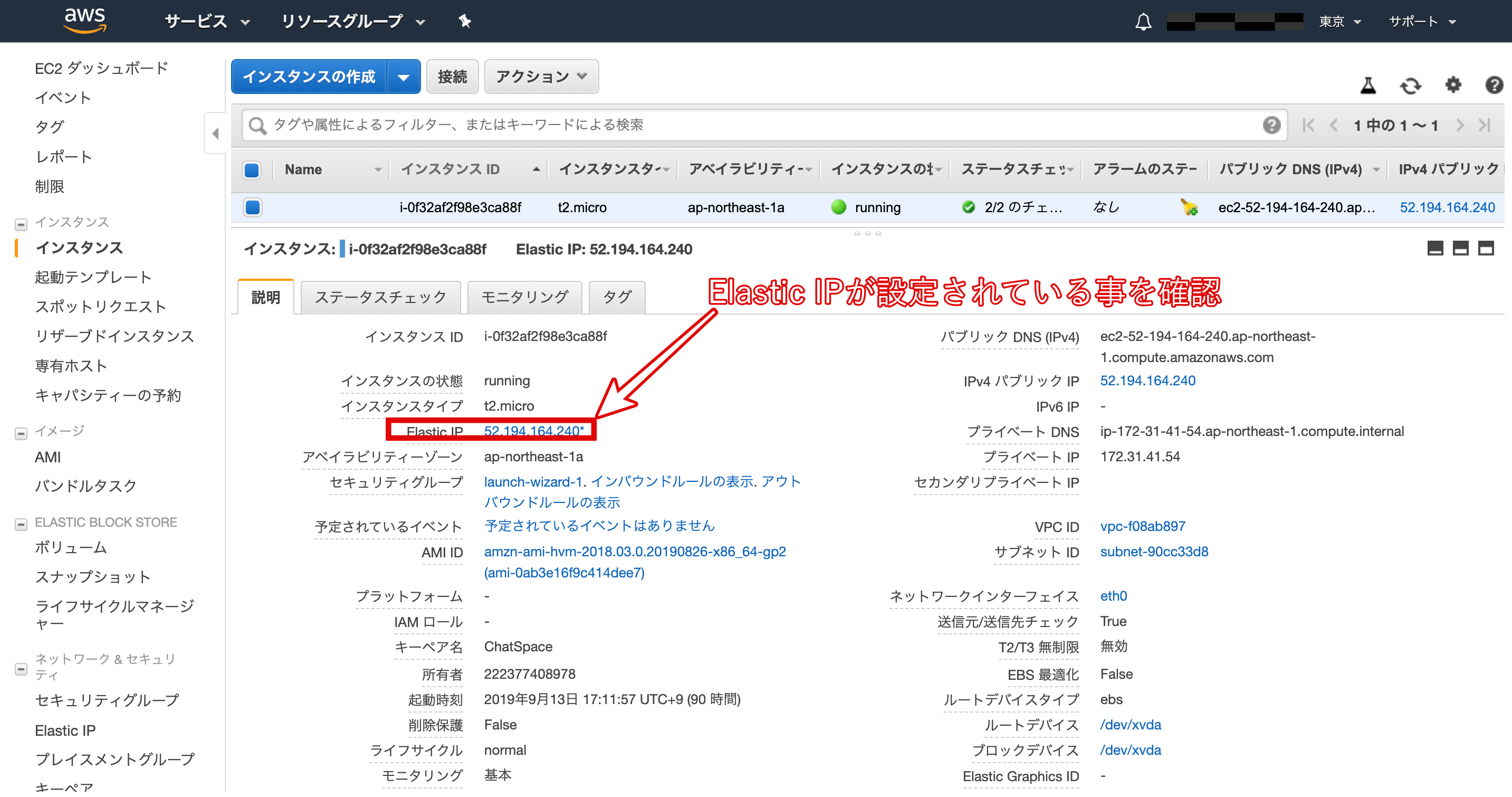
- Elastic IPの作成と紐付け
Elastic IPとは、AWSから割り振られた固定のパブリックIPアドレスのことです。
Elastic IPを取得するために、以下の画像の手順に従って作業をしていきましょう。
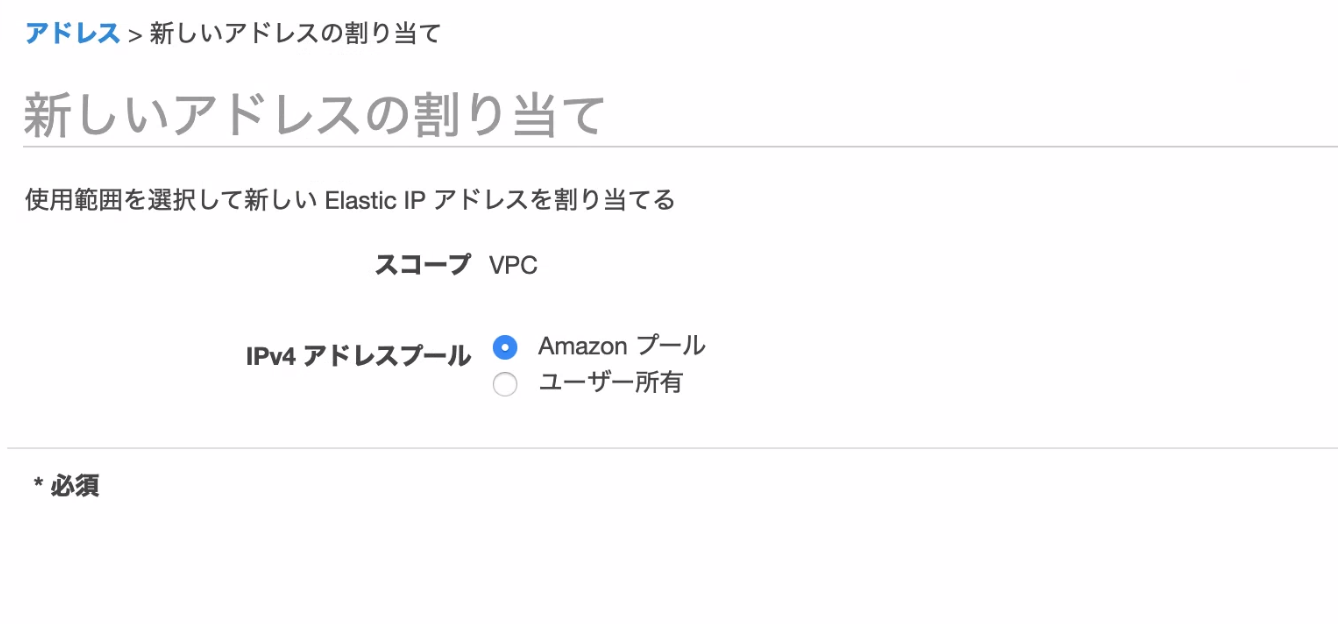
Amazonプールを選択して次へ。
上の画像のようにインスタンスを選択すると、その下にあるプライベートIPアドレスが自動で選択されます。
再びインスタンス一覧画面に戻り、作成したインスタンスの「パブリック IP」と「Elastic IP」が同じものに設定されていることを確認しましょう。
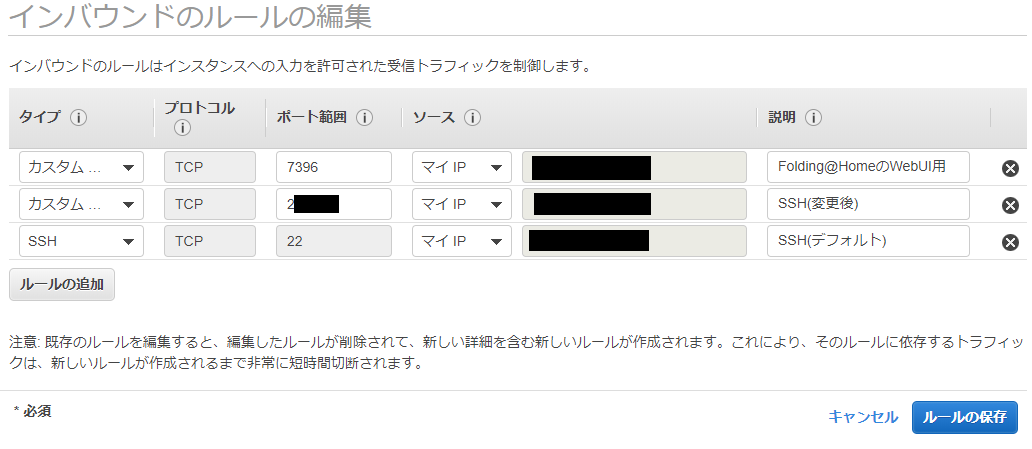
- ポート解放1
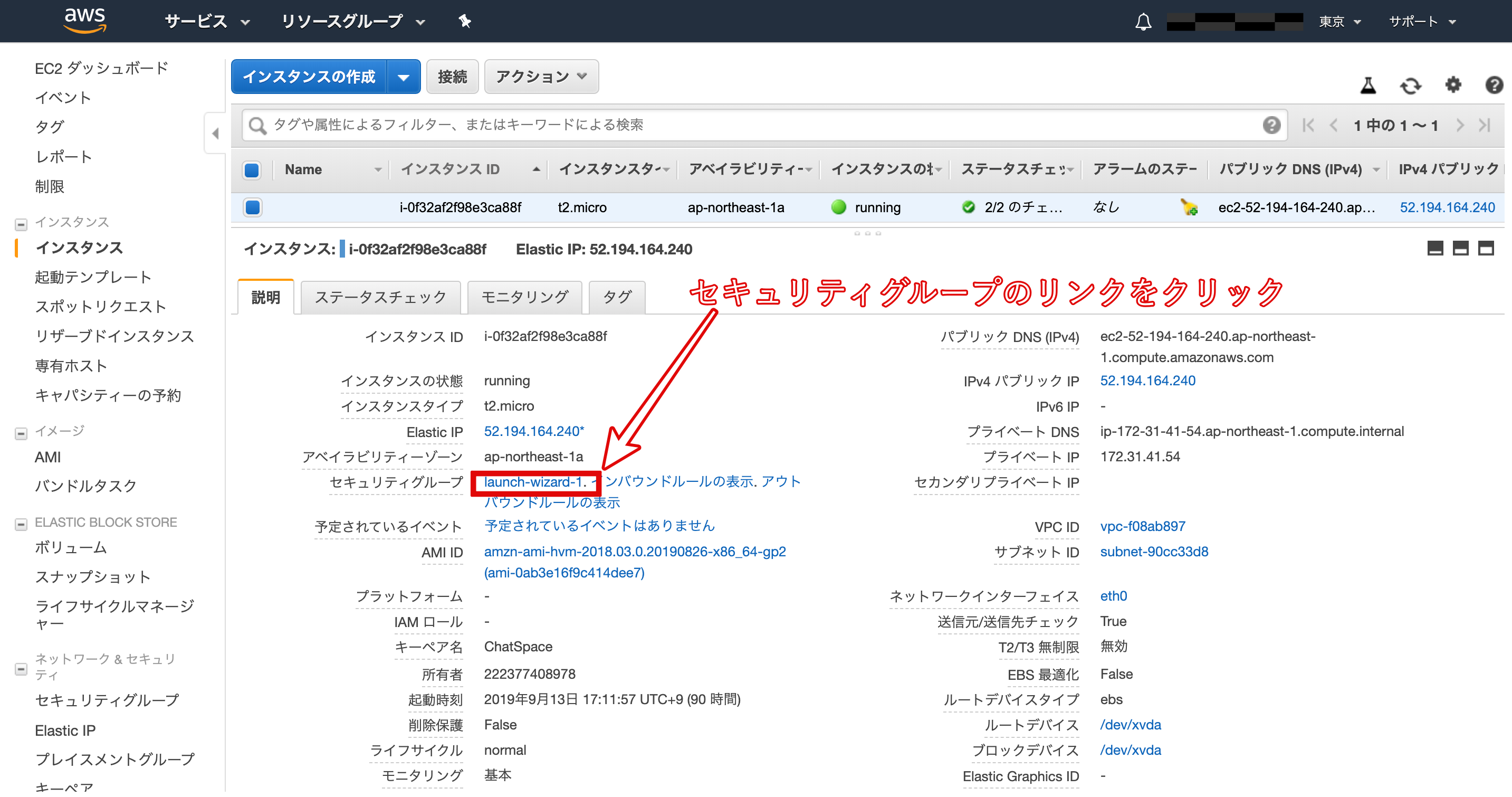
立ち上げたばかりのEC2インスタンスはSSHでアクセスすることはできますが、HTTPなどの他の接続は一切つながらないようになっています。そのため、WEBサーバとして利用するEC2インスタンスは事前にHTTPがつながるように「ポート」を開放する必要があります。
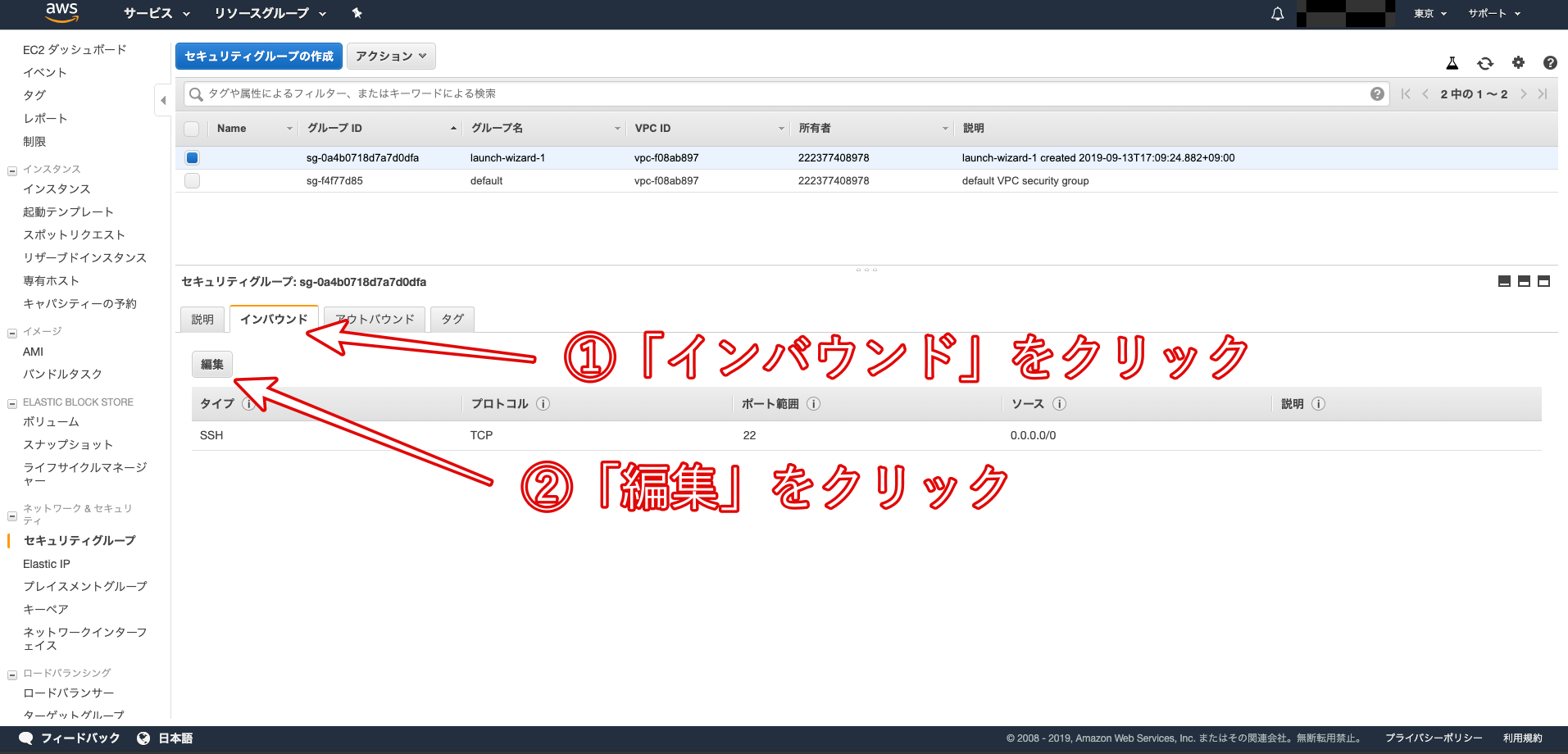
「セキュリティグループ」のリンクlaunch-wizard-1をクリックします。
「インバウンド」タブの中の「編集」をクリックします。
「ルールの追加」をクリックします。
タイプを「HTTP」、プロトコルを「TCP」、ポート範囲を「80」、送信元を「カスタム / 0.0.0.0/0, ::/0」に設定します。「0.0.0.0」や「::/0」は「全てのアクセスを許可する」という意味です。
- EC2インスタンスへのログイン
EC2インスタンスを作成すると、ec2-userというユーザーと対応するSSH秘密鍵が生成されました。
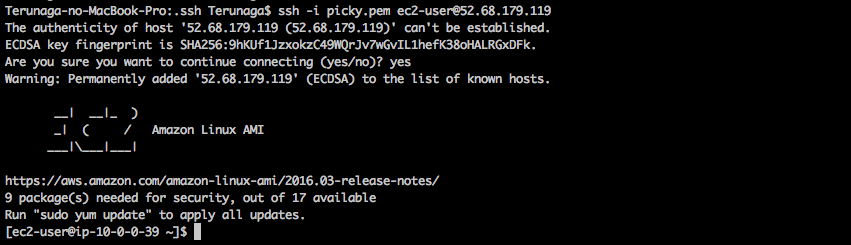
ターミナルで以下のコマンドを実行しましょう。ターミナル(ローカル)$ cd ~ $ mkdir ~/.ssh # .sshというディレクトリを作成 # File existsとエラーが表示されたとしても、.sshディレクトリは存在しているということなので、そのまま進みましょう。 $ mv Downloads/ダウンロードした鍵の名前.pem .ssh/ # mvコマンドで、ダウンロードしたpemファイルを、ダウンロードディレクトリから、.sshディレクトリに移動します。 $ cd .ssh/ $ ls # pemファイルが存在するか確認しましょう $ chmod 600 ダウンロードした鍵の名前.pem $ ssh -i ダウンロードした鍵の名前.pem ec2-user@作成したEC2インスタンスと紐付けたElastic IP #(例えばElastic IPが123.456.789であれば、shh -i ダウンロードした鍵の名前.pem ec2-user@123.456.789 というコマンドになります) #(ダウンロードした鍵を用いて、ec2-userとしてログイン)Elastic IP は各自のAWSアカウントから確認してください。
以下の様なメッセージが表示されることがありますが、「yes」と入力して下さい。ターミナル(ローカル)$ ssh -i aws_key.pem ec2-user@52.68.~~~~~~ The authenticity of host '52.68.~~~~~~ (52.68.~~~~~~)' can't be established. RSA key fingerprint is eb:7a:bd:e6:aa:da:~~~~~~~~~~~~~~~~~~~~~~~~. Are you sure you want to continue connecting (yes/no)?ターミナルのコマンド待ちの際の左側の表示が、以下の画像のように
[ec2-user| ...となればログイン成功です!
以上で、AWSの設定とEC2インスタンスの生成が完了でございます。
- 必要なツールのインストール
ターミナルで以下のコマンドを実行しパッケージをアップデートしましょう。
ターミナル(EC2サーバー)[ec2-user@ip-172-31-25-189 ~]$ sudo yum -y update次に、その他環境構築に必要なパッケージを諸々インストールします。
ターミナル(EC2サーバー)[ec2-user@ip-172-31-25-189 ~]$ sudo yum -y install git make gcc-c++ patch libyaml-devel libffi-devel libicu-devel zlib-devel readline-devel libxml2-devel libxslt-devel ImageMagick ImageMagick-devel openssl-devel libcurl libcurl-devel curlちなみに-y はyumコマンドのオプションで全ての問いにYesで自動的に答えるという意味だぞ❤️
- Node.jsをインストール
サーバーサイドで動くJavaScriptのパッケージです。今後のデプロイに向けた作業の中で、CSSや画像を圧縮する際に活用されます。ターミナルでNode.jsをインストールしましょう。
ターミナル(EC2サーバー)[ec2-user@ip-172-31-25-189 ~]$ sudo curl -sL https://rpm.nodesource.com/setup_6.x | sudo bash - [ec2-user@ip-172-31-25-189 ~]$ sudo yum -y install nodejs
- rbenvとruby-buildをインストール
ターミナルでrbenvとruby-buildをインストールしましょう。
ターミナル(EC2サーバー)#rbenvのインストール [ec2-user@ip-172-31-25-189 ~]$ git clone https://github.com/sstephenson/rbenv.git ~/.rbenv #パスを通す [ec2-user@ip-172-31-25-189 ~]$ echo 'export PATH="$HOME/.rbenv/bin:$PATH"' >> ~/.bash_profile #rbenvを呼び出すための記述 [ec2-user@ip-172-31-25-189 ~]$ echo 'eval "$(rbenv init -)"' >> ~/.bash_profile #.bash_profileの読み込み [ec2-user@ip-172-31-25-189 ~]$ source .bash_profile #ruby-buildのインストール [ec2-user@ip-172-31-25-189 ~]$ git clone https://github.com/sstephenson/ruby-build.git ~/.rbenv/plugins/ruby-build #rehashを行う [ec2-user@ip-172-31-25-189 ~]$ rbenv rehash
- Rubyをインストール
自身のアプリケーションで使っているRubyのバージョンによって適宜変更してください。
ここでは、2.5.1をインストールしていきます。ターミナル(EC2サーバー)[ec2-user@ip-172-31-25-189 ~]$ rbenv install 2.5.1 [ec2-user@ip-172-31-25-189 ~]$ rbenv global 2.5.1 [ec2-user@ip-172-31-25-189 ~]$ rbenv rehash #rehashを行う [ec2-user@ip-172-31-25-189 ~]$ ruby -v # バージョンを確認
- MySQLをインストール
Amazon Linuxを利用している場合、MySQLは yum コマンドからインストールすることができます。
以下のコマンドを実行してください。ターミナル(EC2サーバー)[ec2-user@ip-172-31-25-189 ~]$ sudo yum -y install mysql56-server mysql56-devel mysql56これは、MySQLのバージョン5.6をインストールすることを意味します。
- MySQLを起動しよう
ターミナル(EC2サーバー)[ec2-user@ip-172-31-25-189 ~]$ sudo service mysqld startmysql ではなく mysqld であることに注意しましょう。「d」はLinuxの用語で「サーバ」を意味する「デーモン(daemon)」の頭文字です。
起動できたか確認するために、以下のコマンドを打ってみましょう。ターミナル(EC2サーバー)[ec2-user@ip-172-31-25-189 ~]$ sudo service mysqld status mysqld (pid 15692) is running...「running」と表示されれば、MySQLの起動は成功です。
- MySQLのrootパスワードの設定
以下のコマンドでパスワードを設定しましょう。'設定したいパスワード'の部分については、例えばpassword0000という文字列を設定するとしたら、 'password0000'と記載しましょう。
※0から始まるpasswordは読み込んでくれないケースが多いので、避けましょう!ターミナル(EC2サーバー)[ec2-user@ip-172-31-25-189 ~]$ sudo /usr/libexec/mysql56/mysqladmin -u root password 'ここを設定したいパスワードに変更してからコマンドを実行してください'このパスワードは、後ほどRailsからアクセスする時にも利用するので記憶しておいてください。
この時、Warning: Using a password on the command line interface can be insecure.
と警告がでることがありますが、ここでは無視していただいて問題ありません。設定したパスワードが使えるか確認してみましょう。以下のコマンドを入力してください。
ターミナル(EC2サーバー)[ec2-user@ip-172-31-25-189 ~]$ mysql -u root -pEnter password: とパスワードを入力するように表示されるので、先程設定したパスワードを入力して、Enterしてください。以下のように表示されれば、MySQLの設定は終了です。
ターミナル(EC2サーバー)Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 4 Server version: 5.6.33 MySQL Community Server (GPL) Copyright (c) 2000, 2016, Oracle and/or its affiliates. All rights reserved. Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners. Type 'help;' or '\h' for help. Type '\c' to clear the current input statement. mysql>以上で、各ツールのインストールが完了でございます。
- EC2のサーバにGithubのコードをクローン
現状、EC2サーバにアプリケーションのコードをクローンしようとしてもpermission deniedとエラーが出てしまいます。
これは、Githubから見てこのEC2インスタンスが何者かわからないためです。
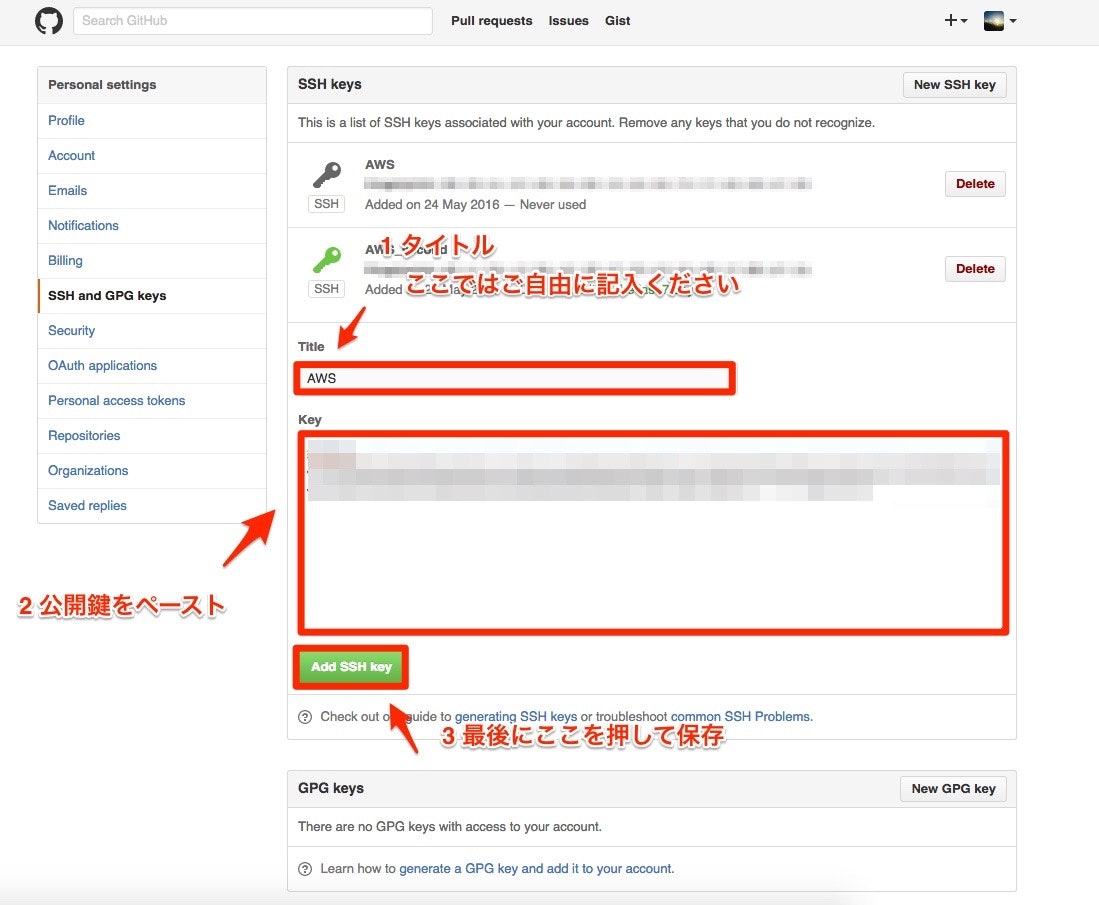
以下のコマンド入力して、EC2サーバのSSH鍵ペアを作成しましょう。ターミナル(EC2サーバー)[ec2-user@ip-172-31-23-189 ~]$ ssh-keygen -t rsa -b 4096 Generating public/private rsa key pair. Enter file in which to save the key (/home/ec2-user/.ssh/id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/ec2-user/.ssh/id_rsa. Your public key has been saved in /home/ec2-user/.ssh/id_rsa.pub. The key fingerprint is: 3a:8c:1d:d1:a9:22:c7:6e:6b:43:22:31:0f:ca:63:fa ec2-user@ip-172-31-23-189 The key's randomart image is: +--[ RSA 4096]----+ | + | | . . = | | = . o . | | * o . o | |= * S | |.* + . | | * + | | .E+ . | | .o | +-----------------+次に、以下のコマンドで生成されたSSH公開鍵を表示し、値をコピーします。
ターミナル(EC2サーバー)[ec2-user@ip-172-31-23-189 ~]$ cat ~/.ssh/id_rsa.pub ssh-rsa AAAAB3NzaC1yc2E......そして、catで表示させた公開鍵を、Githubにアクセスして登録していきます。
まず、以下のURLにアクセスしてください。
https://github.com/settings/keys
Githubに鍵を登録できたら、SSH接続できるか以下のコマンドで確認してみましょう。
ターミナル(EC2サーバー)[ec2-user@ip-172-31-23-189 ~]$ ssh -T git@github.com Hi <Githubユーザー名>! You've successfully authenticated, but GitHub does not provide shell access.途中でこのまま続けるかどうかYes/Noで聞かれることがありますが、Yesで進んでください。
Permission denied (publickey).
と表示された場合は、SSH鍵の設定が間違っているので、作業を確認してください。unicornの導入
unicornは rails s の代わりを担ってくれるアプリケーションサーバです。(アバウトすぎw)
- Unicornをインストール
次のように ローカルでGemfile を編集しましょう。
Gemfilegroup :production do gem 'unicorn', '5.4.1' endローカルのrails newしたディレクトリでbundle installコマンドを実行してください。
ターミナル(ローカル)$ bundle installconfig/unicorn.rbを作成し、内容を以下のように編集して保存しましょう。
config/unicorn.rb#サーバ上でのアプリケーションコードが設置されているディレクトリを変数に入れておく app_path = File.expand_path('../../', __FILE__) #アプリケーションサーバの性能を決定する worker_processes 1 #アプリケーションの設置されているディレクトリを指定 working_directory app_path #Unicornの起動に必要なファイルの設置場所を指定 pid "#{app_path}/tmp/pids/unicorn.pid" #ポート番号を指定 listen 3000 #エラーのログを記録するファイルを指定 stderr_path "#{app_path}/log/unicorn.stderr.log" #通常のログを記録するファイルを指定 stdout_path "#{app_path}/log/unicorn.stdout.log" #Railsアプリケーションの応答を待つ上限時間を設定 timeout 60 #以下は応用的な設定なので説明は割愛 preload_app true GC.respond_to?(:copy_on_write_friendly=) && GC.copy_on_write_friendly = true check_client_connection false run_once = true before_fork do |server, worker| defined?(ActiveRecord::Base) && ActiveRecord::Base.connection.disconnect! if run_once run_once = false # prevent from firing again end old_pid = "#{server.config[:pid]}.oldbin" if File.exist?(old_pid) && server.pid != old_pid begin sig = (worker.nr + 1) >= server.worker_processes ? :QUIT : :TTOU Process.kill(sig, File.read(old_pid).to_i) rescue Errno::ENOENT, Errno::ESRCH => e logger.error e end end end after_fork do |_server, _worker| defined?(ActiveRecord::Base) && ActiveRecord::Base.establish_connection end
- デプロイ時のエラー対策
Uglifierというgemがあり、これはJavaScriptを軽量化するためのものです。しかし、ChatSpaceのJavaScriptで使用しているテンプレートリテラル記法(`)に対応していません。そのため、デプロイ時にエラーの原因となります。
デプロイ時にエラーの原因となる記述の対策として、下記のフォルダを編集しましょう。config/environments/production.rb(修正前)config.assets.js_compressor = :uglifierconfig/environments/production.rb(修正後)# config.assets.js_compressor = :uglifier
- 変更修正をリモートリポジトリに反映
ここまで、ローカルのフォルダ内で変更修正を行ったので、GitHub Desktopからコミットしてプッシュしましょう。この時必ず、masterブランチで行うようにしてください。もし、別ブランチでコミット&プッシュした場合は、リモートリポジトリでプルリクエストを作成し、ブランチをmasterへマージしてください。
- Githubからコードをクローン
続いて、Unicornの設定を済ませたコードをEC2インスタンスにクローンしましょう。
まず、以下のコマンドを入力して、ディレクトリを作成します。今回は、ここで作成したディレクトリにアプリケーションを設置することにします。ターミナル(EC2サーバー)#mkdirコマンドで新たにディレクトリを作成 [ec2-user@ip-172-31-23-189 ~]$ sudo mkdir /var/www/ #作成したwwwディレクトリの権限をec2-userに変更 [ec2-user@ip-172-31-23-189 ~]$ sudo chown ec2-user /var/www/Githubから「リポジトリURL」を取得します。
取得した「リポジトリURL」を使って、コードをクローンします。
ターミナル(EC2サーバー)[ec2-user@ip-172-31-23-189 ~]$ cd /var/www/ [ec2-user@ip-172-31-23-189 www]$ git clone https://github.com/<ユーザー名>/<リポジトリ名>.git
- Swap領域を用意
コンピュータが処理を行う際、メモリと呼ばれる場所に処理内容が一時的に記録されます。メモリは容量が決まっており、容量を超えてしまうとエラーで処理が止まってしまいます。Swap領域は、メモリが使い切られそうになった時にメモリの容量を一時的に増やすために準備されるファイルです。
まずは、ホームディレクトリに移動します。
ターミナル(EC2サーバー)#ホームディレクトリに移動 [ec2-user@ip-172-31-25-189 ~]$ cd続いて、以下の順番でコマンドを実行します。
ターミナル(EC2サーバー)#処理に時間がかかる可能性があるコマンドです [ec2-user@ip-172-31-25-189 ~]$ sudo dd if=/dev/zero of=/swapfile1 bs=1M count=512 # しばらく待って、以下のように表示されれば成功 512+0 レコード入力 512+0 レコード出力 536870912 バイト (537 MB) コピーされました、 7.35077 秒、 73.0 MB/秒ターミナル(EC2サーバー)[ec2-user@ip-172-31-25-189 ~]$ sudo chmod 600 /swapfile1ターミナル(EC2サーバー)[ec2-user@ip-172-31-25-189 ~]$ sudo mkswap /swapfile1 # 以下のように表示されれば成功 スワップ空間バージョン1を設定します、サイズ = 524284 KiB ラベルはありません, UUID=74a961ba-7a33-4c18-b1cd-9779bcda8ab1ターミナル(EC2サーバー)[ec2-user@ip-172-31-25-189 ~]$ sudo swapon /swapfile1ターミナル(EC2サーバー)[ec2-user@ip-172-31-25-189 ~]$ sudo sh -c 'echo "/swapfile1 none swap sw 0 0" >> /etc/fstab'※最後のコードは見づらくなっていますが、「/swapfile1 none」より右に続きがありますのでご注意ください。
これで、Swap領域を確保することができました。
- クローンしたディレクトリに移動し、 rbenvでインストールされたRubyが使われているかチェック
ターミナル(EC2サーバー)[ec2-user@ip-172-31-23-189 www]$ cd /var/www/<リポジトリ名> [ec2-user@ip-172-31-23-189 <リポジトリ名>]$ ruby -v ruby 2.5.1p112 (2016-04-26 revision 54768) [x86_64-linux]ruby 2.5.1 ...となっていれば成功です。そうでない場合は、もともと用意されているRubyが利用されているので、Rubyのインストールが成功しているか確認してください。
- bundlerをインストール
まず今まで開発環境(ローカル)で開発してきたアプリにおいて、どのバージョンのbundlerが使われていたのか確認します。
ターミナル(ローカル)#アプリのディレクトリで以下を実行 $ bundler -v Bundler version 2.0.1 # 開発環境によってバージョンは異なります。開発環境で仕様しているbundlerのバージョンがわかったので、同じバージョンのものをEC2サーバ側にも導入します。上記の場合では、bundler 2.0.1のバージョンを導入して bundle install を実行します。
ターミナル(EC2サーバー)[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ gem install bundler -v 2.0.1 # ローカルで確認したbundlerのバージョンを導入する [ec2-user@ip-172-31-23-189 <リポジトリ名>]$ bundle install # 上記コマンドは、数分以上かかる場合もあります。
- 環境変数の設定
データベースのパスワードなどセキュリティのためにGithubにアップロードすることができない情報は、環境変数というものを利用して設定します。
- secret_key_base
secret_key_baseとは、Cookieの暗号化に用いられる文字列です。Railsアプリケーションを動作させる際は必ず用意する必要があります。また、外部に漏らしてはいけない値であるため、こちらも環境変数から参照します。
以下のコマンドを打つことで生成できます。ターミナル(EC2サーバー)[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ rake secret 69619d9a75b78f2e1c87ec5e07541b42f23efeb6a54e97da3723de06fe74af29d5718adff77d2b04b2805d3a1e143fa61baacfbf4ca2c6fcc608cff8d5a28e8dこの長い英数の羅列は、この後利用するのでコピーしておきましょう。
- 実際にEC2インスタンスに環境変数を設定
環境変数は /etc/environment というファイルに保存することで、サーバ全体に適用されます。環境変数の書き込みはvimコマンドを使用して行います。
ターミナル(EC2サーバー)[ec2-user@ip-172-31-23-189 ~]$ sudo vim /etc/environmentiと打ち込んで入力モードに切り替えた後、下記の記述を打ち込みます。=の前後にスペースは入れません。
/etc/environment#先程設定したMySQLのrootユーザーのパスワードを入力 DATABASE_PASSWORD='MySQLのrootユーザーのパスワード' SECRET_KEY_BASE='先程コピーしたsecret_key_base'入力ができたら、escキーを押した後、:wqで保存しましょう。
- 設定した環境変数を反映させるために、一度本番環境をログアウト
ターミナル(EC2サーバー)[ec2-user@ip-172-31-23-189 ~]$ exit logout Connection to 52.xx.xx.xx closed.
- もう一度本番環境へログイン
ターミナル(ローカル)$ ssh -i [ダウンロードした鍵の名前].pem ec2-user@[作成したEC2インスタンスと紐付けたElastic IP] (ダウンロードした鍵を用いて、ec2-userとしてログイン)
- 設定した環境変数が本当に適用されているか確認
ターミナル(EC2サーバー)[ec2-user@ip-172-31-23-189 ~]$ env | grep SECRET_KEY_BASE SECRET_KEY_BASE='secret_key_base' [ec2-user@ip-172-31-23-189 ~]$ env | grep DATABASE_PASSWORD DATABASE_PASSWORD='MySQLのrootユーザーのパスワード'
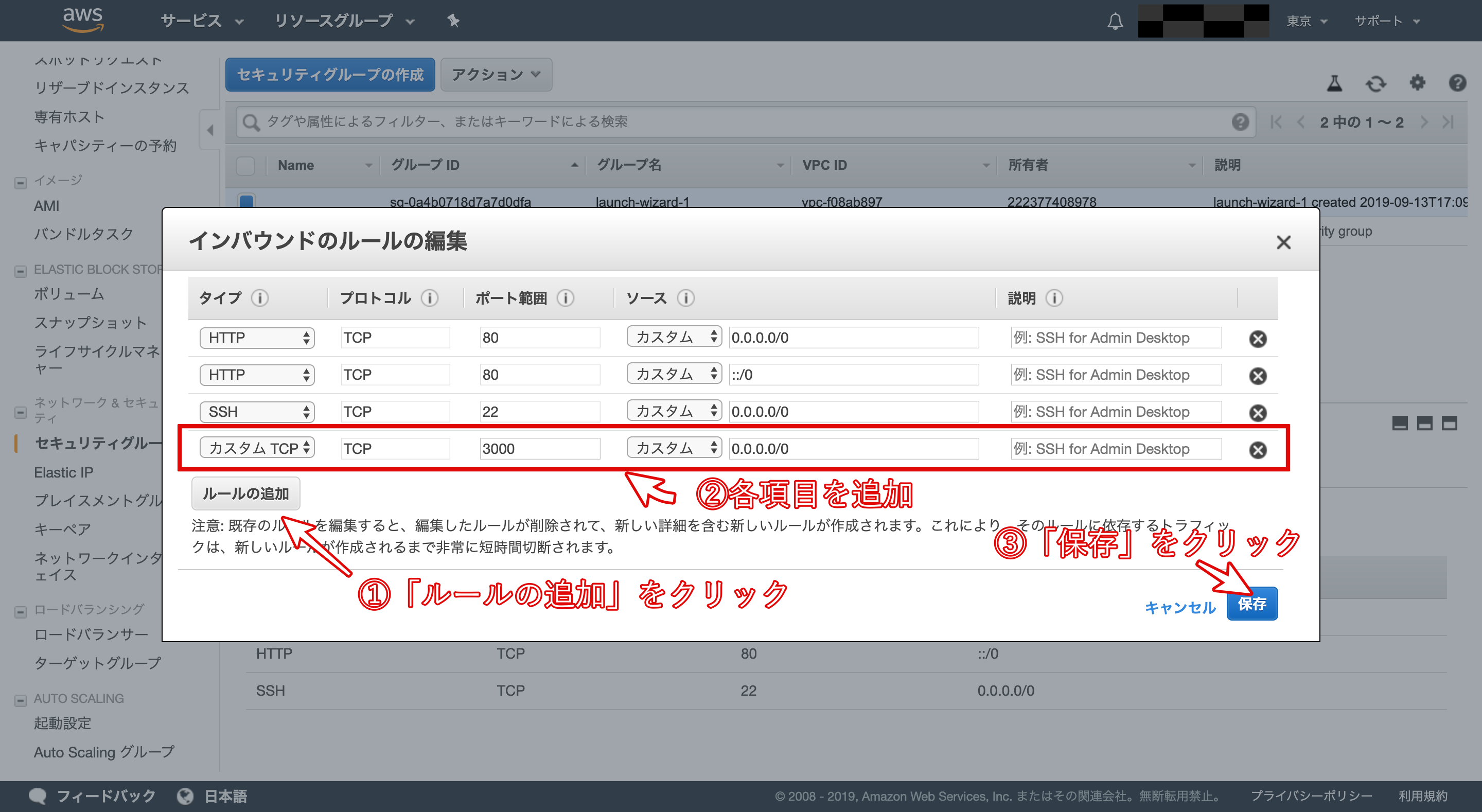
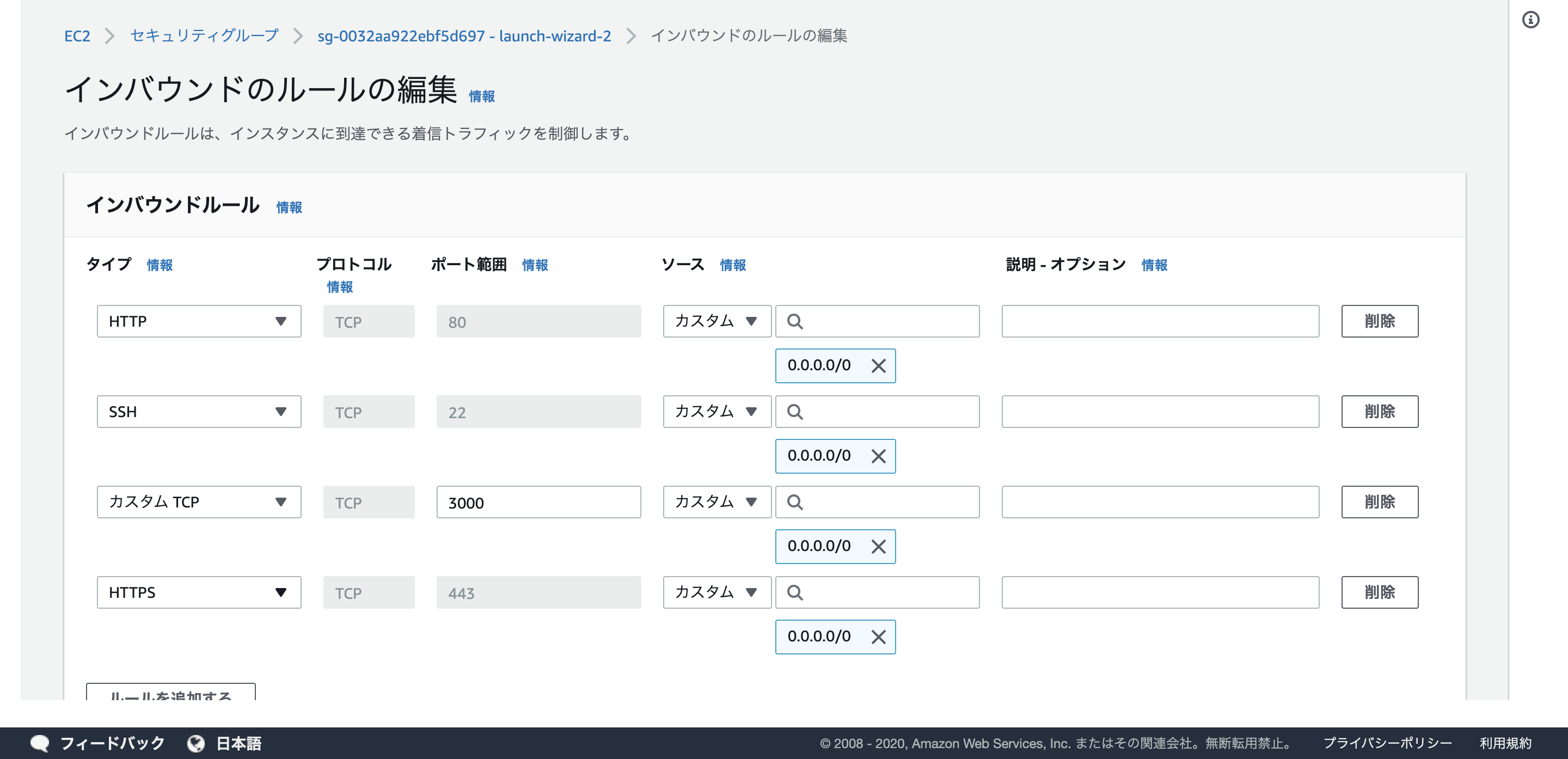
- ポート解放2
先程、 config/unicorn.rb に listen 3000を設定しました。そのため、WEBサーバとして利用するEC2インスタンスは事前にHTTPがつながるように「ポート」を開放する必要があります。
「セキュリティグループ」のリンクlaunch-wizard-1をクリックします。
「インバウンド」タブの中の「編集」をクリックします。
「ルールの追加」をクリックします。
タイプを「カスタムTCPルール」、プロトコルを「TCP」、ポート範囲を「3000」、送信元を「カスタム」「0.0.0.0/0」に設定します。
以上で、ポートの開放が完了です。
この作業が終わっていないと、起動したRailsにアクセスできないので注意してください。
- Railsを起動する
いよいよRailsの起動です。
以下のコマンドを実行し、ユニコーンを起動ターミナル(EC2サーバー)[ec2-user@ip-172-31-23-189 ~]$ cd /var/www/[リポジトリ名] [ec2-user@ip-172-31-23-189 <リポジトリ名>]$ bundle exec unicorn_rails -c config/unicorn.rb -E production -Dこのコマンドを実行すると、以下のようにすぐにコマンドが終了してしまいます。
ターミナル(EC2サーバー)[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ bundle exec unicorn_rails -c config/unicorn.rb -E production -D master failed to start, check stderr log for detailsなので、Unicornのエラーログを確認しましょう。
ターミナル(EC2サーバー)[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ less log/unicorn.stderr.log I, [2016-12-21T04:01:19.135154 #18813] INFO -- : Refreshing Gem list I, [2016-12-21T04:01:20.732521 #18813] INFO -- : listening on addr=0.0.0.0:3000 fd=10 E, [2016-12-21T04:01:20.734067 #18813] ERROR -- : Can't connect to local MySQL server through socket '/tmp/mysql.sock' (2) /home/ec2-user/.rbenv/versions/2.5.1/lib/ruby/gems/2.5.0/gems/activerecord-5.0.0.1/lib/active_record/connection_adapters/mysql2_adapter.rb:29:in `rescue in mysql2_connection' /home/ec2-user/.rbenv/versions/2.5.1/lib/ruby/gems/2.5.0/gems/activerecord-5.0.0.1/lib/active_record/connection_adapters/mysql2_adapter.rb:12:in `mysql2_connection' /home/ec2-user/.rbenv/versions/2.5.1/lib/ruby/gems/2.3.0/gems/activerecord-5.0.0.1/lib/active_record/connection_adapters/abstract/connection_pool.rb:721:in `new_connection' /home/ec2-user/.rbenv/versions/2.5.1/lib/ruby/gems/2.5.0/gems/activerecord-5.0.0.1/lib/active_record/connection_adapters/abstract/connection_pool.rb:765:in `checkout_new_connection' /home/ec2-user/.rbenv/versions/2.5.1/lib/ruby/gems/2.5.0/gems/activerecord-5.0.0.1/lib/active_record/connection_adapters/abstract/connection_pool.rb:744:in `try_to_checkout_new_connection' /home/ec2-user/.rbenv/versions/2.5.1/lib/ruby/gems/2.5.0/gems/activerecord-5.0.0.1/lib/active_record/connection_adapters/abstract/connection_pool.rb:705:in `acquire_connection' /home/ec2-user/.rbenv/versions/2.5.1/lib/ruby/gems/2.5.0/gems/activerecord-5.0.0.1/lib/active_record/connection_adapters/abstract/connection_pool.rb:501:in `checkout' /home/ec2-user/.rbenv/versions/2.5.1/lib/ruby/gems/2.5.0/gems/activerecord-5.0.0.1/lib/active_record/connection_adapters/abstract/connection_pool.rb:364:in `connection' /home/ec2-user/.rbenv/versions/2.5.1/lib/ruby/gems/2.5.0/gems/activerecord-5.0.0.1/lib/active_record/connection_adapters/abstract/connection_pool.rb:875:in `retrieve_connection' /home/ec2-user/.rbenv/versions/2.5.1/lib/ruby/gems/2.5.0/gems/activerecord-5.0.0.1/lib/active_record/connection_handling.rb:128:in `retrieve_connection' /home/ec2-user/.rbenv/versions/2.5.1/lib/ruby/gems/2.5.0/gems/activerecord-5.0.0.1/lib/active_record/connection_handling.rb:91:in `connection' config/unicorn.rb:36:in `block in reload' /home/ec2-user/.rbenv/versions/2.5.1/lib/ruby/gems/2.5.0/gems/unicorn-5.1.0/lib/unicorn/http_server.rb:502:in `spawn_missing_workers' /home/ec2-user/.rbenv/versions/2.5.1/lib/ruby/gems/2.5.0/gems/unicorn-5.1.0/lib/unicorn/http_server.rb:132:in `start' /home/ec2-user/.rbenv/versions/2.5.1/lib/ruby/gems/2.5.0/gems/unicorn-5.1.0/bin/unicorn_rails:209:in `<top (required)>' /home/ec2-user/.rbenv/versions/2.5.1/bin/unicorn_rails:23:in `load' /home/ec2-user/.rbenv/versions/2.5.1/bin/unicorn_rails:23:in `<main>'このERRORという行を見てみると、これは本番環境でインストールするmysqlの設定がローカルとは異なるため、mysqlへ接続できなくなっている状態です。
database.ymlの本番環境の設定を編集
config/database.yml(ローカル)production: <<: *default database: <リポジトリ名>_production(それぞれのアプリケーション名によって異なっています。) username: root password: <%= ENV['DATABASE_PASSWORD'] %> socket: /var/lib/mysql/mysql.sockローカルでの編集をコミットして、GitHubにプッシュ。
サーバ上のアプリケーションにも反映させたいので、以下のようにコマンドを実行してください。
ターミナル(EC2サーバー)[ec2-user@ip-172-31-23-189 <リポジトリ名>] git pull origin masterデータベースを作成しマイグレーションを実行し直し。
ターミナル(EC2サーバー)[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ rails db:create RAILS_ENV=production Created database '<データベース名>' [ec2-user@ip-172-31-23-189 <リポジトリ名>]$ rails db:migrate RAILS_ENV=productionもしここでMysql2::Error: Can't connect to local MySQL server through socket '/var/lib/mysql/mysql.sock'というエラーが起こった場合、mysqlが起動していない可能性があります。sudo service mysqld startというコマンドをターミナルから打ち込み、mysqlの起動を試してみましょう。
再度Railsを起動。
ターミナル(EC2サーバー)[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ bundle exec unicorn_rails -c config/unicorn.rb -E production -Dブラウザで http://<サーバに紐付けたElastic IP>:3000/ にアクセスしてみましょう。
ブラウザにCSSの反映されていない(ビューが崩れている)画面が表示されていれば成功です。アセットファイルをコンパイル
ターミナル(EC2サーバー)[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ rails assets:precompile RAILS_ENV=productionコンパイルが成功したら反映を確認するため、Railsを再起動したいので今動いているUnicornをストップ&スタートします。
ターミナル(EC2サーバー)[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ ps aux | grep unicorn ...すると、以下のようにプロセスが表示されるはずです。
ターミナル(EC2サーバー)ec2-user 17877 0.4 18.1 588472 182840 ? Sl 01:55 0:02 unicorn_rails master -c config/unicorn.rb -E production -D ec2-user 17881 0.0 17.3 589088 175164 ? Sl 01:55 0:00 unicorn_rails worker[0] -c config/unicorn.rb -E production -D ec2-user 17911 0.0 0.2 110532 2180 pts/0 S+ 02:05 0:00 grep --color=auto unicornkillコマンドを入力してUnicornのプロセスを停止
ターミナル(EC2サーバー)[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ kill <確認したunicorn rails masterのPID> ...再度、プロセスを表示させ終了できていることを確認しましょう。
ターミナル(EC2サーバー)[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ ps aux | grep unicorn ... ec2-user 17911 0.0 0.2 110532 2180 pts/0 S+ 02:05 0:00 grep --color=auto unicorn下記の2行が表示が消えていない場合はプロセスが終了できていないことになります。
ターミナル(EC2サーバー)ec2-user 17877 0.4 18.1 588472 182840 ? Sl 01:55 0:02 unicorn_rails master -c config/unicorn.rb -E production -D ec2-user 17881 0.0 17.3 589088 175164 ? Sl 01:55 0:00 unicorn_rails worker[0] -c config/unicorn.rb -E production -Dそのような場合は、プロセスを強制終了しましょう。オプション-9をkillコマンドにつけると強制終了を実行できます。通常のkillコマンドで削除できない場合はこちらを使用しましょう。
ターミナル(EC2サーバー)[ec2-user@ip-172-31-25-189 ~]$ kill -9 [プロセスID] #プロセスIDはpsコマンドで検索した結果の数字に置き換えてください。上記であれば17877です。unicornを起動
ターミナル(EC2サーバー)[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ RAILS_SERVE_STATIC_FILES=1 unicorn_rails -c config/unicorn.rb -E production -D ...もう一度、ブラウザで http://<Elastic IP>:3000/ にアクセスしてみましょう。今度はレイアウト崩れも無くサイトが正常に表示されていることでしょう。
nginxの導入
Nginx(エンジン・エックス)とは、Webサーバの一種です。
- Nginxをインストール
ターミナル(EC2サーバー)[ec2-user@ip-172-31-25-189 ~]$ sudo yum -y install nginx
- Nginxの設定ファイルを編集
vimコマンドを使ってターミナル上で編集していきます。
ターミナル(EC2サーバー)[ec2-user@ip-172-31-25-189 ~]$ sudo vim /etc/nginx/conf.d/rails.confrails.confupstream app_server { # Unicornと連携させるための設定。アプリケーション名を自身のアプリ名に書き換えることに注意。今回であればおそらくchat-space server unix:/var/www/<アプリケーション名>/tmp/sockets/unicorn.sock; } # {}で囲った部分をブロックと呼ぶ。サーバの設定ができる server { # このプログラムが接続を受け付けるポート番号 listen 80; # 接続を受け付けるリクエストURL ここに書いていないURLではアクセスできない server_name <Elastic IP>; # クライアントからアップロードされてくるファイルの容量の上限を2ギガに設定。デフォルトは1メガなので大きめにしておく client_max_body_size 2g; # 接続が来た際のrootディレクトリ root /var/www/<アプリケーション名>/public; # assetsファイル(CSSやJavaScriptのファイルなど)にアクセスが来た際に適用される設定 location ^~ /assets/ { gzip_static on; expires max; add_header Cache-Control public; } try_files $uri/index.html $uri @unicorn; location @unicorn { proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; proxy_pass http://app_server; } error_page 500 502 503 504 /500.html; }以下の3点は書き換えが必須です。
3行目の<アプリケーション名> となっている箇所は、ご自身のものに変更してください。
11行目の<Elastic IP>となっている箇所も同様に、ご自身のものに変更してください。
14行目の<アプリケーション名> となっている箇所は、ご自身のものに変更してください。※この場合<>は記入不要なもの/表示されないものとして捉えてください。説明のための日本語文字列を明示するために<>で囲んでいます。
- nginxの権限を変更
設定が完了したら、POSTメソッドでもエラーが出ないようにするために、下記のコマンドも実行してください。
ターミナル(EC2サーバー)[ec2-user@ip-172-31-25-189 ~]$ cd /var/lib [ec2-user@ip-172-31-25-189 lib]$ sudo chmod -R 775 nginxこれで、Nginxの設定が完了しました。
- Nginxを再起動して設定ファイルを再読み込み
ターミナル(EC2サーバー)[ec2-user@ip-172-31-25-189 lib]$ cd ~ [ec2-user@ip-172-31-25-189 ~]$ sudo service nginx restart
- ローカルでunicorn.rbを修正
次にNginxを介した処理を行うためにunicornの設定を修正します。
unicorn.rb(ローカル)listen 3000 ↓以下のように修正 listen "#{app_path}/tmp/sockets/unicorn.sock"ローカルで編集したファイルをリモートへpush
- ローカルの変更点を本番環境へ反映
ターミナル(EC2サーバー)# まず、chat-spaceのディレクトリに移動 [ec2-user@ip-172-31-25-189 ~]$ cd /var/www/chat-space [ec2-user@ip-172-31-23-189 <レポジトリ名>]$ git pull origin master
- Unicornを再起動
まず、プロセスの番号を確認します。
ターミナル(EC2サーバー)[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ ps aux | grep unicorn ec2-user 17877 0.4 18.1 588472 182840 ? Sl 01:55 0:02 unicorn_rails master -c config/unicorn.rb -E production -D ec2-user 17881 0.0 17.3 589088 175164 ? Sl 01:55 0:00 unicorn_rails worker[0] -c config/unicorn.rb -E production -D ec2-user 17911 0.0 0.2 110532 2180 pts/0 S+ 02:05 0:00 grep --color=auto unicorn続いて、プロセスをkillします。
ターミナル(EC2サーバー)[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ kill <確認したunicorn rails masterのPID(上のコードでは17877)> ...Unicornを起動します。
ターミナル(EC2サーバー)[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ RAILS_SERVE_STATIC_FILES=1 unicorn_rails -c config/unicorn.rb -E production -D ...
- ブラウザからElastic IPでアクセス
ブラウザからElastic IPでアクセスすると、アプリケーションにアクセスできます(:3000をつける必要はありません)。なお、この時もunicornが起動している必要があります。
capistranoの導入
capistranoは、自動デプロイツールと呼ばれるものの一種です。自動デプロイツールを利用することによって、デプロイ時に必要なコマンド操作が1回で済むようになります。
- capistranoを利用するためのGemをインストール
gemfile(ローカル)group :development, :test do gem 'capistrano' gem 'capistrano-rbenv' gem 'capistrano-bundler' gem 'capistrano-rails' gem 'capistrano3-unicorn' end続いて、Gemfileを読み込みましょう。
ターミナル(ローカル)bundle installgemを読み込めたら、下記のコマンドを打ちます。
ターミナル(ローカル)bundle exec cap installすると、下記のようにファイルが生成されます。
アプリケーション名
?capfile
?config
?deploy
?production.rb
?staging.rb
?deploy.rb
?lib
?capistrano
?tasks
- Capfileを編集
capfilerequire "capistrano/setup" require "capistrano/deploy" require 'capistrano/rbenv' require 'capistrano/bundler' require 'capistrano/rails/assets' require 'capistrano/rails/migrations' require 'capistrano3/unicorn' Dir.glob("lib/capistrano/tasks/*.rake").each { |r| import r }
- production.rbを下記のように編集
config/deploy/production.rbserver '<用意したElastic IP>', user: 'ec2-user', roles: %w{app db web}
- 下記の指示に従い、deploy.rbを編集
deploy.rbの記述をすべて削除し、以下のコードを貼り付けます。
config/deploy.rb# config valid only for current version of Capistrano # capistranoのバージョンを記載。固定のバージョンを利用し続け、バージョン変更によるトラブルを防止する lock '<Capistranoのバージョン>' # Capistranoのログの表示に利用する set :application, '<自身のアプリケーション名>' # どのリポジトリからアプリをpullするかを指定する set :repo_url, 'git@github.com:<Githubのユーザー名>/<レポジトリ名>.git' # バージョンが変わっても共通で参照するディレクトリを指定 set :linked_dirs, fetch(:linked_dirs, []).push('log', 'tmp/pids', 'tmp/cache', 'tmp/sockets', 'vendor/bundle', 'public/system', 'public/uploads') set :rbenv_type, :user set :rbenv_ruby, 2.5.1 #<このアプリで使用しているrubyのバージョン> # credentials.yml.encではmasterkeyにする set :linked_files, %w{config/master.key} # どの公開鍵を利用してデプロイするか set :ssh_options, auth_methods: ['publickey'], keys: ['<ローカルPCのEC2インスタンスのSSH鍵(pem)へのパス(例:~/.ssh/key_pem.pem)>'] # プロセス番号を記載したファイルの場所 set :unicorn_pid, -> { "#{shared_path}/tmp/pids/unicorn.pid" } # Unicornの設定ファイルの場所 set :unicorn_config_path, -> { "#{current_path}/config/unicorn.rb" } set :keep_releases, 5 # デプロイ処理が終わった後、Unicornを再起動するための記述 after 'deploy:publishing', 'deploy:restart' namespace :deploy do task :restart do invoke 'unicorn:stop' invoke 'unicorn:start' end desc 'upload master.key' task :upload do on roles(:app) do |host| if test "[ ! -d #{shared_path}/config ]" execute "mkdir -p #{shared_path}/config" end upload!('config/master.key', "#{shared_path}/config/master.key") end end before :starting, 'deploy:upload' after :finishing, 'deploy:cleanup' end以下の5点は書き換えが必須です。
- 3行目のはご自身のバージョンを記述しましょう。
- 6行目の<自身のアプリケーション名>はご自身のものを記述しましょう。
- 9行目の/<レポジトリ名>も同様に、ご自身のもの記述してください。
- 14行目の<このアプリで使用しているrubyのバージョン>はご自身のものを確認して記述してください。
- 21行目の<ローカルPCのEC2インスタンスのSSH鍵(pem)へのパス>も同様に、ご自身のもの記述してください。
- 以下の指示にしたがって、unicorn.rbの記述を編集
config/unicorn.rb#サーバ上でのアプリケーションコードが設置されているディレクトリを変数に入れておく app_path = File.expand_path('../../../', __FILE__) #アプリケーションサーバの性能を決定する worker_processes 1 #アプリケーションの設置されているディレクトリを指定 working_directory "#{app_path}/current" # それぞれ、sharedの中を参照するよう変更 listen "#{app_path}/shared/tmp/sockets/unicorn.sock" pid "#{app_path}/shared/tmp/pids/unicorn.pid" stderr_path "#{app_path}/shared/log/unicorn.stderr.log" stdout_path "#{app_path}/shared/log/unicorn.stdout.log" #Railsアプリケーションの応答を待つ上限時間を設定 timeout 60 #以下は応用的な設定なので説明は割愛 preload_app true GC.respond_to?(:copy_on_write_friendly=) && GC.copy_on_write_friendly = true check_client_connection false run_once = true before_fork do |server, worker| defined?(ActiveRecord::Base) && ActiveRecord::Base.connection.disconnect! if run_once run_once = false # prevent from firing again end old_pid = "#{server.config[:pid]}.oldbin" if File.exist?(old_pid) && server.pid != old_pid begin sig = (worker.nr + 1) >= server.worker_processes ? :QUIT : :TTOU Process.kill(sig, File.read(old_pid).to_i) rescue Errno::ENOENT, Errno::ESRCH => e logger.error e end end end after_fork do |_server, _worker| defined?(ActiveRecord::Base) && ActiveRecord::Base.establish_connection end
- 本番環境でのnginxの設定ファイルも変更
ターミナル(EC2サーバー)[ec2-user@ip-172-31-25-189 ~]$ sudo vim /etc/nginx/conf.d/rails.conf以下のように変更しましょう
rails.confupstream app_server { # sharedの中を参照するよう変更 server unix:/var/www/<アプリケーション名>/shared/tmp/sockets/unicorn.sock; } server { listen 80; server_name <Elastic IPを記入>; # クライアントからアップロードされてくるファイルの容量の上限を2ギガに設定。デフォルトは1メガなので大きめにしておく client_max_body_size 2g; # currentの中を参照するよう変更 root /var/www/<アプリケーション名>/current/public; location ^~ /assets/ { gzip_static on; expires max; add_header Cache-Control public; # currentの中を参照するよう変更 root /var/www/<アプリケーション名>/current/public; } try_files $uri/index.html $uri @unicorn; location @unicorn { proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; proxy_pass http://app_server; } error_page 500 502 503 504 /500.html; }もう一度記述すべき箇所が記述できているか確認しましょう。
- 3行目の<アプリケーション名> となっている箇所は、ご自身のものに変更してください。
- 11行目の<アプリケーション名>となっている箇所も同様に、ご自身のものに変更してください。
- 18行目の<アプリケーション名>となっている箇所も同様に、ご自身のものに変更してください。
Nginxの設定を変更したら、忘れずに再読込・再起動をしましょう。
ターミナル(EC2サーバー)[ec2-user@ip-172-31-25-189 ~]$ sudo service nginx reload [ec2-user@ip-172-31-25-189 ~]$ sudo service nginx restart
- MySQLの起動を確認
ターミナル(EC2サーバー)[ec2-user@ip-172-31-25-189 ~]$ sudo service mysqld restart
- unicornのプロセスをkill
自動デプロイを実行する前にunicornのコマンドをkillしておきましょう。
まず、プロセスを確認します。ターミナル(EC2サーバー)[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ ps aux | grep unicorn ec2-user 17877 0.4 18.1 588472 182840 ? Sl 01:55 0:02 unicorn_rails master -c config/unicorn.rb -E production -D ec2-user 17881 0.0 17.3 589088 175164 ? Sl 01:55 0:00 unicorn_rails worker[0] -c config/unicorn.rb -E production -D ec2-user 17911 0.0 0.2 110532 2180 pts/0 S+ 02:05 0:00 grep --color=auto unicorn続いて、プロセスをkillします。
ターミナル(EC2サーバー)[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ kill <確認したunicorn rails masterのPID(上記では17877)> ...
- ローカルのcredentials.yml.encを編集
ここで注意したいのが、本番環境のcredentials.yml.encを編集すると、master.keyが自動生成されてしまい、ローカル環境のmester.keyが一致しなくなり、起動できなくなるので注意が必要です。
もし、本番環境のcredentials.yml.encを編集してしまった場合は、一度master.keyとcredentials.yml.encをコマンドで消去し、ローカルのcredentials.yml.encをpullしましょう。下記コマンドで暗号化されていない、credentials.yml.encを開くことができ、編集することができます。
ターミナル(ローカル)$ EDITOR=vim bin/rails credentials:editcredentials.yml.enc# S3使用時 # aws: # access_key_id: 123 # secret_access_key: 123 # Used as the base secret for all MessageVerifiers in Rails, including the one protecting cookies. secret_key_base: 先程コピーしたsecret_key_basesecret_key_baseは上記で作成したものを貼り付けましょう。
もし、忘れてしまった場合、本番環境での確認方法は下記の通りです。ターミナル(EC2サーバー)[ec2-user@ip-172-31-23-189 ~]$ env | grep SECRET_KEY_BASE SECRET_KEY_BASE='secret_key_base'
- 本番環境のshared/configにmaster.keyを作成
このままデプロイしても以下のようなエラーが出てしまいます。
ターミナル(ローカル)ERROR linked file /var/www/techlog/shared/config/master.key does not exist on <Elastic IP>エラー通り、本番環境のshared/configにmaster.keyを作ります。
ターミナル(EC2サーバー)[ec2-user@ip-172-31-23-189 ~]$ touch /var/www/アプリケーション名/shared/config/master.key作成したmaster.keyを編集します。
ターミナル(EC2サーバー)[ec2-user@ip-172-31-23-189 ~]$ vim /var/www/アプリケーション名/shared/config/master.keyローカルのmaster.keyの内容をコピーし、本番環境のmaster.keyにコピーします。
以上で編集作業完了です。
- 最後に魔法の一文
ローカルで下記のコマンドを入力すると、自動デプロイを実行できます。
ターミナル(ローカル)# アプリケーションのディレクトリで実行する $ bundle exec cap production deploy上記コマンドを実行し、以下の画像のようにエラーが表示されずに完了したら自動デプロイは完了です。
もし、途中でエラーが出て止まってしまった場合は、以下を試します。
- そのままもう一度同じコマンドを実行してみる 特に、bundle installのタスクの際に、初めて自動デプロイを実行する場合は、メモリ不足で落ちることがあります
- 記述ミスが無いか 特に、本カリキュラムにおいて、修正したファイルに注目して確認しましょう
- 手順を飛ばしていないか bundle installなどのコマンド実行を忘れていないか確認しましょう
- ブラウザからElastic IPでアクセス
ブラウザからElastic IPでアクセスすると、アプリケーションにアクセスできます(:3000をつける必要はありません)。正しく動いていることを確認しましょう。
確認できればデプロイは一旦完了です。長時間お疲れ様でした!
お名前.comでドメインを購入し、AWSと紐付け
大まかな流れです。
- お名前.comでドメインを購入
- route53にDNSの設定と、ElasticIPの登録
- お名前ドットコムにroute53の情報を登録
では参りましょう!
- お名前.comでドメインを購入
お名前.comでアカウント登録と取得したいドメインを購入しましょう。
年単位での契約になります。
- route53とは
AWSのDNSサービスで、AWS上の各サービスを独自ドメインで利用する上で便利な機能が用意されていて親和性が高いサービスになっています。
- route53の設定!
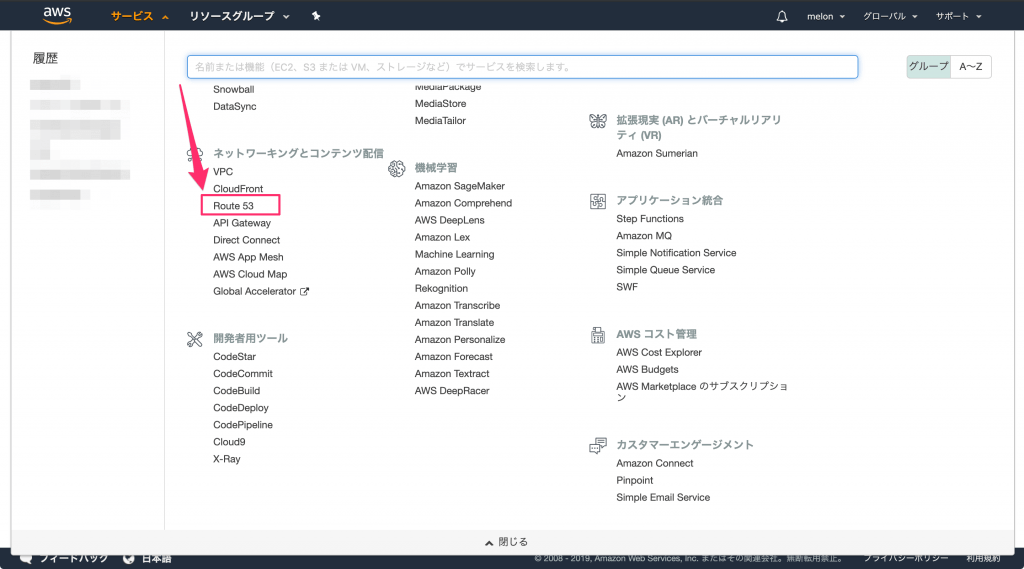
route53にログイン
awsマネジメントコンソールのサービスから、Route 53を開きます。
DNS管理のところにある「今すぐ始める」ボタンを押していきます。
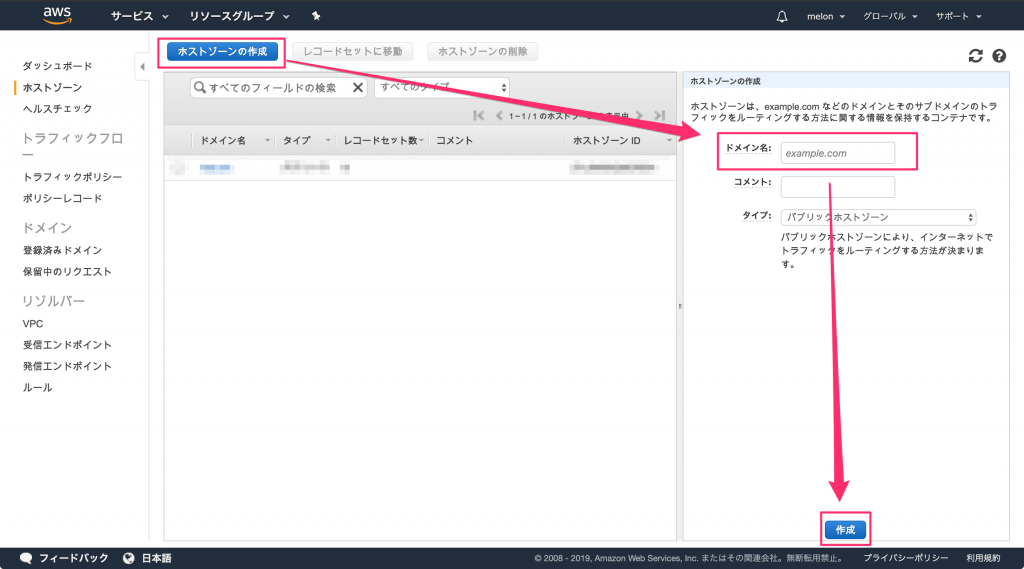
「ホストゾーンを作成」ボタンを押して、どのドメインに関するホストゾーンを作成するかを設定していきます。
「ドメイン名」のところには、お名前.comで取得したドメインを入力します。
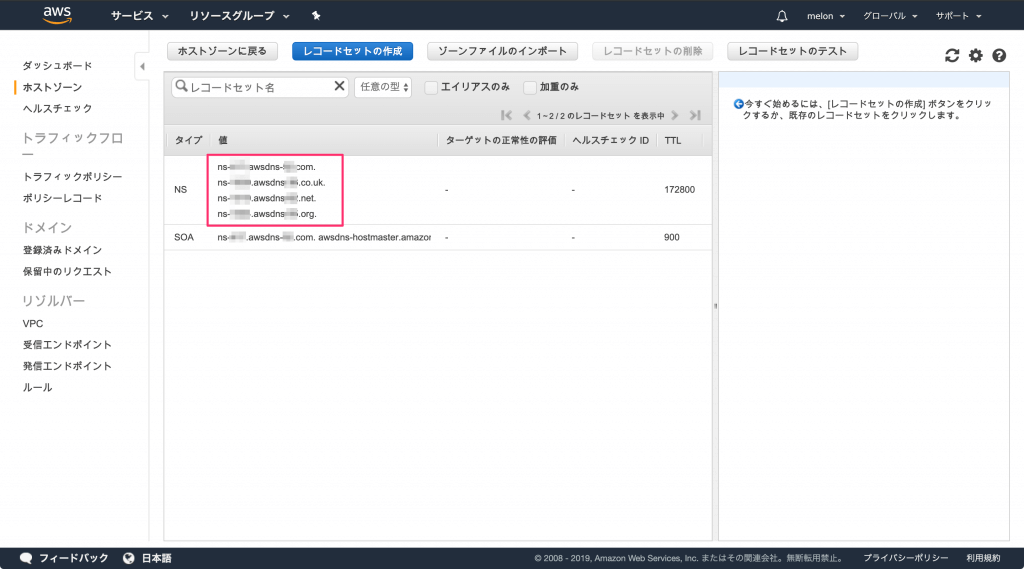
ホストゾーンを作成すると、NSレコードにネームサーバーが4つ割り当てられています。
このネームサーバーの情報はお名前.com側の設定で入力するので内容をメモしておきます。
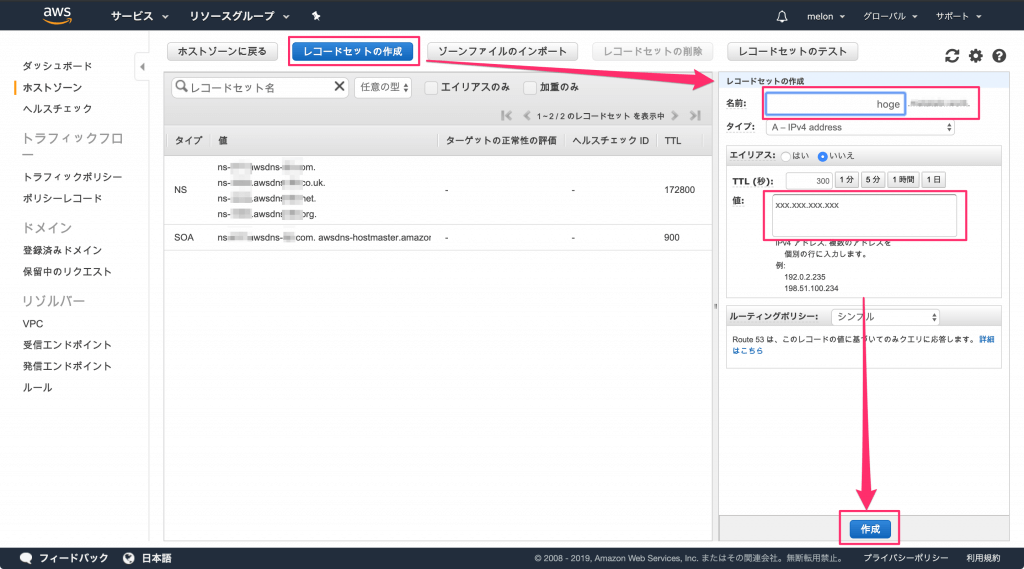
- 作成したホストゾーンにEC2の固定IPアドレスを割り当てる
「レコードセットの作成」ボタンを押して、「名前」に対象のドメイン、値にEC2で割り当てられた固定IPアドレスを入力し「作成」ボタンを押せば完了です。
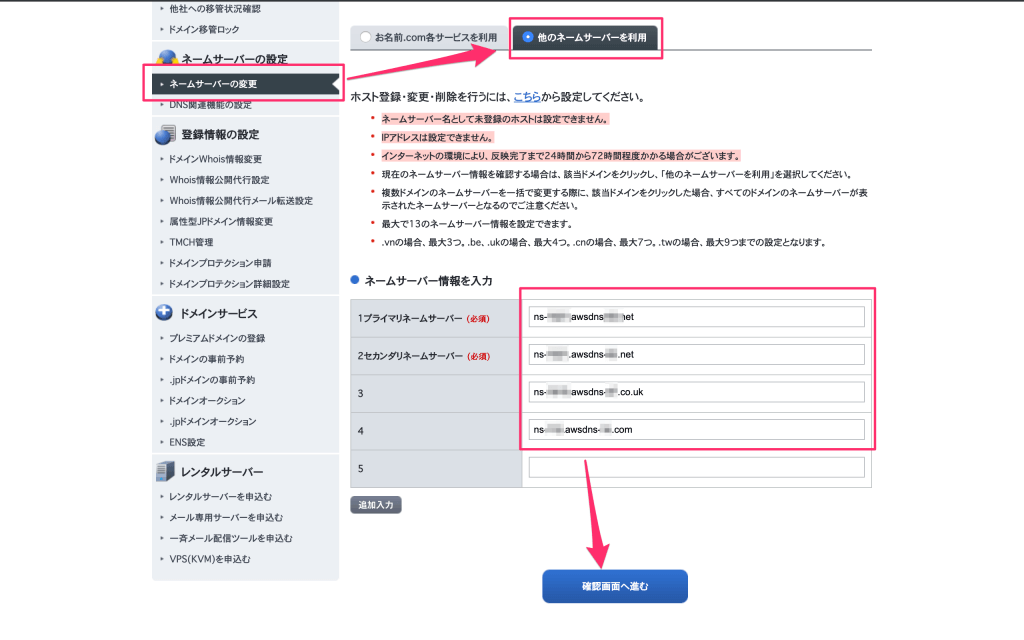
- お名前.comの設定でRoute 53に向けるネームサーバーの設定を行う
ドメインNaviでAWSで利用するドメインの設定を開き、ネームサーバーの変更から「他のネームサーバーを利用」を選択します。
ネームサーバー情報の入力欄に、Route 53のホストゾーンのNSレコードに表示されていたネームサーバーを4つとも入力し登録できれば設定は完了です。
これでお名前.comで取得したドメインにアクセスした際に、AWSのRoute 53で受けることができるようになりました。
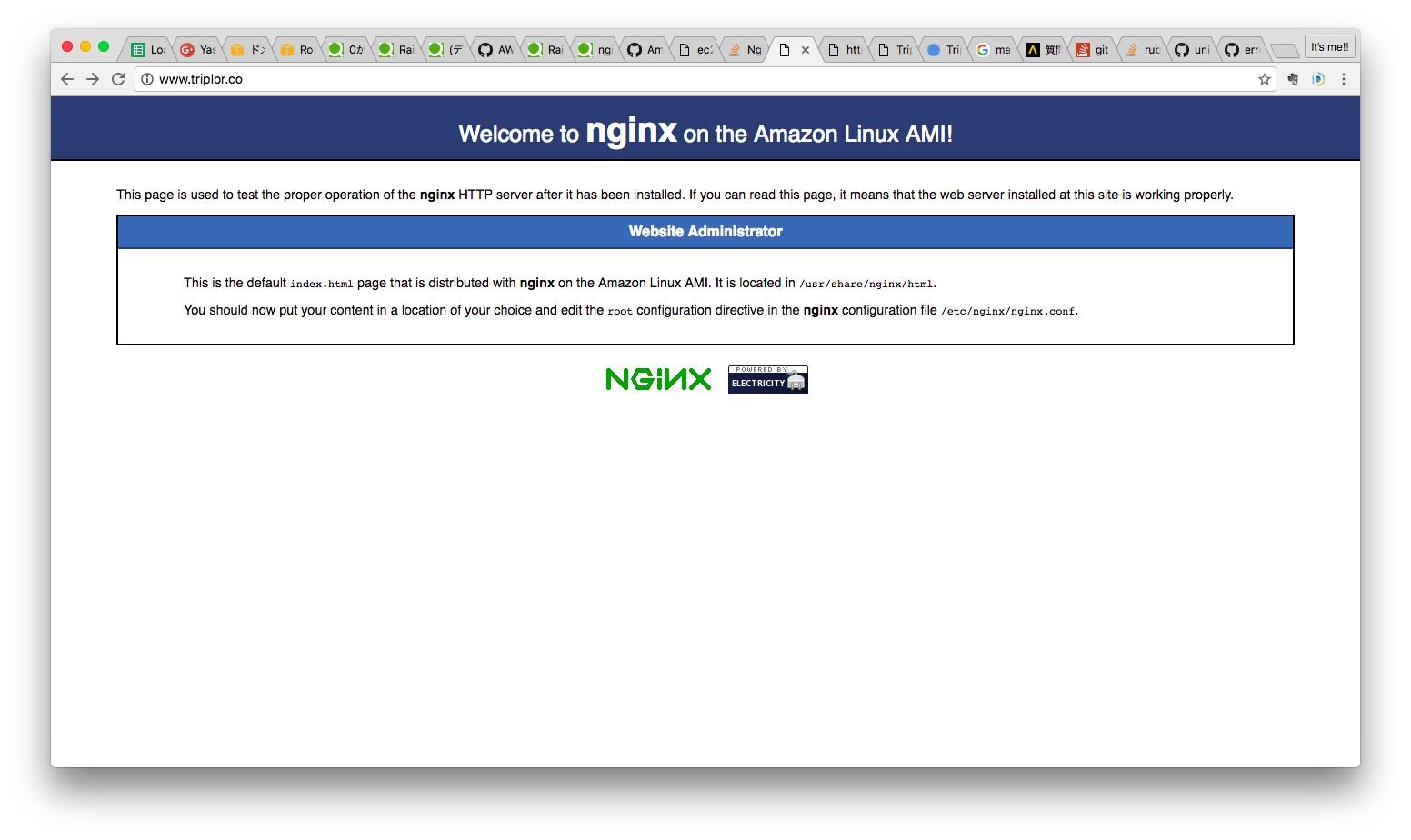
- ドメインの動作確認
最後に動作確認をします。
本番環境で下記のコードを入力しましょう。
グローバル IP アドレスが返ってくれば名前解決が出来ています。ターミナル(EC2サーバー)[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ nslookup xxxxxxxxxx.com Server: 10.0.0.2 Address: 10.0.0.2#53 Non-authoritative answer: Name: xxxxxxxx.com Address: 54.178.156.248 Name: xxxxxxxx.com Address: 52.197.167.212 [ec2-user@ip-172-31-23-189 <リポジトリ名>]$ブラウザを開き、ドメイン名を入力し、インターネット経由でアクセスできるか確認します。
Welcome to nginx on the Amazon Linux AMI!と表示されていれば成功です。
- nginxの設定ファイルを編集
これではまだ、表示することができないので、nginxの設定ファイルを編集しましょう。
vimコマンドを使ってターミナル上で編集していきます。ターミナル(EC2サーバー)[ec2-user@ip-172-31-25-189 ~]$ sudo vim /etc/nginx/conf.d/rails.confrails.confupstream app_server { # sharedの中を参照するよう変更 server unix:/var/www/<アプリケーション名>/shared/tmp/sockets/unicorn.sock; } server { listen 80; server_name <Elastic IPを記入> <ドメイン名>; # クライアントからアップロードされてくるファイルの容量の上限を2ギガに設定。デフォルトは1メガなので大きめにしておく client_max_body_size 2g; # currentの中を参照するよう変更 root /var/www/<アプリケーション名>/current/public; location ^~ /assets/ { gzip_static on; expires max; add_header Cache-Control public; # currentの中を参照するよう変更 root /var/www/<アプリケーション名>/current/public; } try_files $uri/index.html $uri @unicorn; location @unicorn { proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; proxy_pass http://app_server; } error_page 500 502 503 504 /500.html; }注目すべきは8行目です。
rails.confserver_name <Elastic IPを記入> <ドメイン名>;ドメイン名が追加されていますね!
xxx.comの場合はserver_name <Elastic IPを記入> xxx.com
としましょう。escキーを入力後に:wqで上書き保存を忘れずに!
Elastic IPとドメイン名の間は必ず半角スペースを入力しましょう。
Nginxの設定を変更したら、忘れずに再読込・再起動をしましょう。
ターミナル(EC2サーバー)[ec2-user@ip-172-31-25-189 ~]$ sudo service nginx restartブラウザをリロードし、ドメインで表示できていれば成功です。
できない場合、ブラウザのキャッシュを消去した後、ブラウザをリロードすれば表示できるかと存じます。無料SSL化(Let's Encrypt)
無料のSSLサーバー証明書(以下、SSL証明書)であるLet’s Encryptは、米国の非営利団体であるISRG(Internet Security Research Group)により運営されています。全てのWebサイトを暗号化することを目指したプロジェクトであり、2019年6月現在では世界で1億枚以上の有効な証明書を発行しています。
非営利団体ということで財務基盤に不安を覚える方もいるかもしれませんが、現在ではFacebookやシスコシステムズ、Akamai Technologies、Verizonといった数多くの大手企業に支えられています。
Let’s Encryptでは、90日間有効なDV(Domain Validation)SSL証明書を2つの認証方式(ドメイン認証、DNS認証)で提供しています。SSL証明書は無料で提供されていますが、暗号強度などは一般的に販売されているSSL証明書と違いはありません。
ではレッツゴー!
- certbotをクローン
ターミナル(EC2サーバー)[ec2-user@ip-172-31-25-189 ~]$ cd /usr/local [ec2-user@ip-172-31-25-189 local]$ sudo git clone https://github.com/certbot/certbot [ec2-user@ip-172-31-25-189 local]$ cd certbot
- 証明書の作成を申請
申請するにあたって、Let's Encryptが認証するためのディレクトリを作成します。
(他の記事では/var/www/htmlなどとしている場合が多いですが、Amazon Linuxではデフォルトでそのようなディレクトリはないので、新たに作成します。)ターミナル(EC2サーバー)# ディレクトリ名は自由ですが、今回は letsencrypt-webroot とします。 [ec2-user@ip-172-31-25-189 ~]$ sudo mkdir /var/www/letsencrypt-webrootさらに、nginxを書き換えます。
rails.conf[ec2-user@ip-172-31-25-189 ~]$ sudo vim /etc/nginx/conf.d/rails.confrails.confupstream app_server { # sharedの中を参照するよう変更 server unix:/var/www/<アプリケーション名>/shared/tmp/sockets/unicorn.sock; } server { listen 80; server_name <Elastic IPを記入> <ドメイン名>; # クライアントからアップロードされてくるファイルの容量の上限を2ギガに設定。デフォルトは1メガなので大きめにしておく client_max_body_size 2g; # currentの中を参照するよう変更 root /var/www/<アプリケーション名>/current/public; location ^~ /assets/ { gzip_static on; expires max; add_header Cache-Control public; # currentの中を参照するよう変更 root /var/www/<アプリケーション名>/current/public; } try_files $uri/index.html $uri @unicorn; location @unicorn { proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; proxy_pass http://app_server; } # 以下を追加(^~は前方一致です) location ^~ /.well-known/acme-challenge/ { root /var/www/letsencrypt-webroot; } error_page 500 502 503 504 /500.html; }その後、nginxを再起動します。
ターミナル(EC2サーバー)[ec2-user@ip-172-31-25-189 ~]$ sudo service nginx restart次に、以下のコマンドで認証可能かどうかを確認します。
(認証申請が1時間に5回Failすると、一定時間申請できなくなります(Rate Limits - Let's Encrypt - Free SSL/TLS Certificates)。そのため、先に認証可能かどうかを確認します。)ターミナル(EC2サーバー)# 【】の所は置き換えてください [ec2-user@ip-172-31-25-189 ~]$ /usr/local/certbot/certbot-auto certonly --webroot --agree-tos --debug -m 【メールアドレス(例:○○@○○.com)】 -d 【ドメイン名(例:○○.com)】 -w /var/www/letsencrypt-webroot --dry-run以下が出たら認証可能です。
ターミナル(EC2サーバー)IMPORTANT NOTES: - The dry run was successful.上のコマンドの--dry-runを外して認証申請をします。
(登録されたメールアドレスには、Let's Encryptからの通知(認証の有効期限が近づいてきた時の通知など)が届きます。)ターミナル(EC2サーバー)# 【】の所は置き換えてください [ec2-user@ip-172-31-25-189 ~]$ /usr/local/certbot/certbot-auto certonly --webroot --agree-tos --debug -m 【メールアドレス(例:○○@○○.com)】 -d 【ドメイン名(例:○○.com)】 -w /var/www/letsencrypt-webroot以下が出たら認証成功です。
ターミナル(EC2サーバー)IMPORTANT NOTES: - Congratulations! Your certificate and chain have been saved at: /etc/letsencrypt/live/○○.com/fullchain.pem Your key file has been saved at: /etc/letsencrypt/live/○○.com/privkey.pem Your cert will expire on 2019-07-30. To obtain a new or tweaked version of this certificate in the future, simply run certbot-auto again. To non-interactively renew *all* of your certificates, run "certbot-auto renew" - If you like Certbot, please consider supporting our work by: Donating to ISRG / Let's Encrypt: https://letsencrypt.org/donate Donating to EFF: https://eff.org/donate-le証明書が発行されたかを確認します。
ターミナル(EC2サーバー)# 【】の所は置き換えてください [ec2-user@ip-172-31-25-189 ~]$ sudo ls -lrth /etc/letsencrypt/live/【ドメイン名(例:○○.com)】/以下が表示されればOKです。
ターミナル(EC2サーバー)total 4.0K -rw-r--r-- 1 root root 692 May 1 11:41 README lrwxrwxrwx 1 root root 51 May 1 11:41 privkey.pem -> ../../archive/【ドメイン名(例:○○.com)】/privkey1.pem lrwxrwxrwx 1 root root 53 May 1 11:41 fullchain.pem -> ../../archive/【ドメイン名(例:○○.com)】/fullchain1.pem lrwxrwxrwx 1 root root 49 May 1 11:41 chain.pem -> ../../archive/【ドメイン名(例:○○.com)】/chain1.pem lrwxrwxrwx 1 root root 48 May 1 11:41 cert.pem -> ../../archive/【ドメイン名(例:○○.com)】/cert1.pem次に、nginxの設定ファイルをSSL用に更新します。
ターミナル(EC2サーバー)[ec2-user@ip-172-31-25-189 ~]$ sudo vim /etc/nginx/conf.d/rails.confrails.confupstream app_server { # sharedの中を参照するよう変更 server unix:/var/www/<アプリケーション名>/shared/tmp/sockets/unicorn.sock; } server { listen 443 ssl; ssl_certificate /etc/letsencrypt/live/roro-or.com/fullchain.pem; ssl_certificate_key /etc/letsencrypt/live/roro-or.com/privkey.pem; ssl_protocols TLSv1 TLSv1.1 TLSv1.2; # クライアントからアップロードされてくるファイルの容量の上限を2ギガに設定。デフォルトは1メガなので大きめにしておく client_max_body_size 2g; # currentの中を参照するよう変更 root /var/www/<アプリケーション名>/current/public; location ^~ /assets/ { gzip_static on; expires max; add_header Cache-Control public; # currentの中を参照するよう変更 root /var/www/<アプリケーション名>/current/public; } try_files $uri/index.html $uri @unicorn; location @unicorn { proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-Proto $scheme; proxy_pass http://app_server; } error_page 500 502 503 504 /500.html; } server { listen 80; server_name <ドメイン名>; return 301 https://$host$request_uri; }nginxを再起動します。
ターミナル(EC2サーバー)[ec2-user@ip-172-31-25-189 ~]$ sudo service nginx restart設定ファイルの更新はこれで最後になります。あと一息です!
- ポート解放3
私はここで躓きました。
設定ファイルを更新して、「長い戦いが終わった(ニンマリ)」と意気揚々とリロードしたら、タイムアウトで表示されないじゃないか。ふと、
ssl化のポート解放はあるのだろうかと、できているのだろうかと
閃いた。
やはり、ssl化に伴ってポートを開ける必要があるようです。
「セキュリティグループ」のリンクlaunch-wizard-1をクリックします。
「インバウンド」タブの中の「編集」をクリックします。
「ルールの追加」をクリックします。
タイプを「HTTPS」、プロトコルを「TCP」、ポート範囲を「443」、送信元を「カスタム / 0.0.0.0/0, ::/0」に設定します。「0.0.0.0」や「::/0」は「全てのアクセスを許可する」という意味です。
- rails側の設定
ローカルで下記フォルダの記述を変更しましょう。
config/environments/production.rb(修正前)# config.force_ssl = trueconfig/environments/production.rb(修正後)config.force_ssl = true変更後にmasterへpushしましょう。
ターミナル(ローカル)# アプリケーションのディレクトリで実行する $ bundle exec cap production deploy以上でSSLの設定は完了です。
ブラウザからこのサイトにアクセスしてみましょう。https接続になるはずです。
また、http://として接続した場合でも、自動でhttps接続になるはずです。
- Let's Encryptの自動更新
Let's Encryptの有効期間は3カ月と短いです。
自動で更新されるように、crontabで設定しておきましょう。ターミナル(EC2サーバー)[ec2-user@ip-172-31-25-189 ~]$ sudo crontab -u root -e # rootユーザーでcrontabを編集することにより、cronでsudoを使わなくて済むようになります。crontab0 4 1 * * /usr/local/certbot/certbot-auto renew --no-self-upgrade && service nginx restartこの例では、毎月1日午前4時に自動で更新されるようになります。
設定後、cronデーモンを再起動します。
ターミナル(EC2サーバー)[ec2-user@ip-172-31-25-189 ~]$ sudo service crond restart上記の方法では Amazon Linux 2 でエラーが出るようです。
こちらの記事は Amazon Linux の程なのでご了承ください?♂️最後に
最後までお付き合いいただき、ありがとうございました。
twitterやっておりますので是非フォローよろしくお願いいたします!
https://twitter.com/syomabusiness
youtubeも始める予定です!




- 投稿日:2020-04-07T20:12:14+09:00
AWS認定クラウドプラクティショナーになろう(超インフラ初心者向け)
おことわり
本記事はクラウドプラクティショナー、つまりAWSの概要を把握しているレベルの知識をキャッチアップできるものになっています。
なので、めちゃくちゃ長いです。
ご注意ください。
また、内容や画像はAWSの公式サイトの物を多く使用しておりますが、中にはキャッチアップのために別のサイトから学んだ内容も入っていると思います。
そちらについては、勉強を実際に行っていたのが1年前のため、判明次第引用として追加させてください。はじめに
皆さん、業務でAWS使ってますか。
AWSを日常的に触る方も、そうでない方もいらっしゃると思いますが、最近以下の記事がトレンドに入っているのを見かけました。
https://qiita.com/aki_number16/items/8ab86ff69200e45cd1bfこれを見て、意外とクラウドプラクティショナーに興味のある方がいらっしゃるんだなと思いまして、クラウドプラクティショナーをとるために学ぶべきことをまとめたものを公開しようと思います。
私も文系エンジニアでインフラ1年目に取得したので、割と0から学ぶにしても網羅できているはずです。対象者
主に、AWS入門者向け、かつインフラ初心者向けの内容となっています。
AWSの概要知識について知りたい方は読むと良いです。
本記事の内容を把握しておけば、クラウドプラクティショナーには合格できます。受験結果
ちなみに、ここまでの知識状態でクラウドプラクティショナー模擬試験を受講したところ、23/25で92%の正答率となりました。
以下内訳です。総合スコア92% Cloud Concepts 80% Security 100% Technology 100% Billing and Pricing 66%この結果不足していると思われた部分については資料内に補足しておきました。
実際の試験ではスコアは891点で、全領域十分な理解をしているとのことだったので、大体本記事くらいの知識を身に付ければ合格できる資格だと思います。良く出た内容としては以下になります。
・サポートプランの差
・EC2 DB ストレージのケース問題(1か月間24時間稼働したい場合EC2のどの運用プランを選ぶかなど)
・ある状況でトラステッドアドバイザーを使うか、クラウドトレイルをつかうか、クラウドウォッチを使うか
・各種設計原則
・TCOについて試験情報
もしクラウドプラクティショナーを受けるようでしたら、以下の動画を参考にするとよいと思います。
https://aws.amazon.com/jp/blogs/news/webinar-bb-practitioner-2018/試験申し込みと模擬試験は下記から行えます。
https://aws.amazon.com/jp/certification/certified-cloud-practitioner/ホワイトペーパーは以下にあり、日本語の物もあります。
著者は本記事の内容を覚えた後、サービス概要だけ読みました。
https://aws.amazon.com/jp/whitepapers/概要
下記のAWSが用意している動画を要約しています。(無料)
資料内で使われる画像も、この動画からキャプチャしたものになります。
https://www.aws.training/transcript/curriculumplayer?transcriptId=yYaEAfD2gEq1JuCJNn7yEw2動画を見て理解できる方なら、この記事より動画を見たほうが、章末問題などがあってよいと思います。
ただ、機械音声とちょっと怪しい日本語が絶妙にストレスになることは覚悟しましょう。
また、動画内に出てきた単語の説明なども行っているので、初学者も理解しやすい内容になっています。
ただし、AWS全般を触っているのでめちゃくちゃ長いです。(私の記事ではいつものことです)読むべき内容は背景を灰色、見出しを赤にしています。
見出しが青の内容は単語の補足です。クラウドの概念
クラウドコンピューティングの定義
量課金制による、インターネット経由の、ITリソースとアプリケーションの、オンデマンド配信サービス「従量課金制」
従量制とは、サービスを利用した時間に応じて料金を課す方式「ITリソース」
システムを構成するハード・ソフトウェアの総称「オンデマンド」
On-Demandとは、英語で「要求(Demand)に応じて」という意味である。
つまり、注文に応じた対応を表す。クラウドコンピューティングができる前
クラウドができる前は、ピーク時にかかる負荷を予想して、キャパシティをプロビジョニングする必要があった。
この場合、予測に満たない負荷の間は使用しないリソースにコストをかけることになり、予測を超えた場合はシステムが耐え切れないという事態になっていた。
また、物理的にマシンを用意する必要があったので、電力や場所など、間接的な費用も掛かっていた。「キャパシティ」
保持、受け入れ、または取り込む能力を言う。
システムの負荷耐性と思えばよい。「プロビジョニング」
準備、用意AWSによって解決された現状
たいして、現在はAWSというITリソースを仮想(物理的に存在しない)の状態で用意できるサービスができた。
AWSのクラウドコンピューティングを使用すると、物理的なITリソースのキャパシティ限界や間接費の問題を解決し、必要な時に必要なだけの高度な機能を使い捨てで使用できるようになった。
これによって今までになかった柔軟性と俊敏性を得ることができた。
例えば、開発者が新しいテスト環境が必要となれば、従来であれば物理的にサーバーを購入するところから始まって、数週間もの時間をかけてプロビジョニングをおこなっていたはずが、AWSを使うことで、数分で環境を立ち上げることも可能となった。
そのため、1つの環境をみんなで初期化したりしながら使いまわして事故が起きたりすることもなく、必要な時に必要な数の環境を用意したりすることができ、より迅速かつ柔軟な開発が行える。クラウドコンピューティングの特徴
システムに伸縮性があることが特徴といえる。
伸縮性はITリソースをスケールアップ(より高い性能にする)やスケールアウト(台数を増やす)を実現できる能力のことである。
必要なマシンの数が1台でも1000台でも、1時間でも24時間でも対応できる。・新しいアプリケーションをすばやくデプロイ(実行可能な状態に)する
・ワークロード(負荷)に応じて瞬時のスケールアップ・アウトが行える
・不要なリソースを即座にシャットダウンできる。
・スケールダウンした分のインフラ料金はかからない
さらに、システムの伸縮性やら柔軟性というだけでなく、高い安全性を実現するのにも非常に有効である。
AWSクラウドインフラストラクチャはリージョンとアベイラビリティゾーンを中心として構成される。
アベイラビリティゾーンを分けてアプリケーションやデータベースを管理することで、今までありがちだった単一のデータセンターでは実現できない、高い可用性・耐障害性・拡張性を実現できる。
「リージョン」
世界中にある、AWSのリソースが保管された物理的な場所、2つ以上のアベイラビリティゾーンで構築される「アベイラビリティゾーン」
リージョン内にある1つ以上のデータセンターで構築される拠点
同一リージョンでも、アベイラビリティゾーンが違えばそれらのITリソースは物理的かつ地理的に独立して存在していることを表す。「可用性」
トラブルがあっても、どれだけシステムを動かし続けられるか
加えて、AWSでは多要素認証・アクセスコントロールが導入されており、アカウントの管理を単純なID/PWだけではなく、外部のハードやアプリケーションと連携して安全性を高めている。
つまるところ、便利で安全で簡単ということ。AWSの基本的なインフラについての説明
グローバルインフラストラクチャ
AWSのグローバルインフラは以下の3つの要素で説明できる
- リージョン
- アベイラビリティゾーン
- エッジロケーション
- AWS Local Zones
- AWS Wavelength Zone
- AWS Outposts
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/using-regions-availability-zones.html「リージョン」
リージョンは世界中にある物理的な場所、2つ以上のアベイラビリティゾーンで構築されるある区域を指す。
リージョンはAWSのあらゆるサービスを配信するデータセンターの所在を区分けしているもので、ユーザーはリージョンとそこに所属するアベイラビリティゾーンを選択し、そこでAWSのサービスを使用する。
AWSサービスやストレージ(データの保存場所)等は、リージョン別に存在しているものもあるため、どのリージョンを選ぶかという話がまず存在する。
このときに重要なのは、対象リージョンに自分の使用したいサービスが存在するかと、レイテンシー(遅延)がどの程度発生するかである。
レイテンシーについては単純に自分の端末から地理的に近いリージョンを選択すれば問題ない。
サービスについては公式サイトを確認するのが良い。
https://aws.amazon.com/jp/about-aws/global-infrastructure/regional-product-services/リージョンは地理的に離れて存在するため、システムの可用性を高めるためにマルチリージョン(複数のリージョン)に同じ構成のシステムを構築するということも検討できる。
例えば日本に地震が起きてデータセンターがすべて機能しなくなっても、アメリカに構築したシステムには影響がないからだ。「アベイラビリティゾーン」
アベイラビリティゾーンはリージョン内にある1つ以上のデータセンターである。
(複数のデータセンターをまたいで構築されることもあるので、単一のデータセンターというわけではない。)
例えば、日本リージョンに存在する東京AZと京都AZといったように想像すればわかりやすい。
此方も地理的に離れており、AZ同士は電力元も含めてあらゆるリソースを独立して持っているため、システムの可用性を高めるために同じ構成のシステムを構築することも検討できる。
マルチリージョンまでしなくとも、マルチアベイラビリティゾーンにはしておくということが多い。
AWSはマルチAZでデータをプロビジョニングすることをベストプラクティスとしている。
AZ間は高速かつ低レイテンシー(遅延)で接続されている。「エッジロケーション」
アベイラビリティゾーンとは別で立っている小さなデータセンター。
エッジロケーションではAmazon CloudFrontというコンテンツ配信ネットワーク(CDN)が提供される。
CloudFronとはコンテンツへのリクエストがあった際、最もユーザーに近いエッジロケーションからコンテンツを配信するサービスで、エンドユーザーに対して素早くコンテンツを配信できる。
また、ElastiCacheというキャッシングを行うサービスにも使われる。「AWS Local Zones」
コンピューティング、ストレージ、データベース、およびその他の選択された AWS のサービスを、エンドユーザーから近い場所に配置できる、アベイラビリティゾーンのさらに細かいものです。
地理的にエンドユーザーと近い場所で、レイテンシーの影響を受けやすいアプリケーションを実行できます。「AWS Wavelength Zone」
モバイルデバイスおよびエンドユーザーに対して 10 ミリ秒未満のレイテンシーを実現するアプリケーションを、開発者が構築できるようになります。
AWS 開発者は、Wavelength Zone にアプリケーションを配置することができます。
AWS Wavelength により、AWS のサービスを 5G ネットワークのエッジで提供できるため、モバイルデバイスからアプリケーションに接続する際のレイテンシーを最小限に抑えることができます。アプリケーショントラフィックは、モバイルプロバイダーネットワークから出ることなく、Wavelength Zone で実行されるアプリケーションサーバーに到達できます。これにより、インターネットまでの間にある、100 ミリ秒以上のレイテンシーを引き起こし得る余分なネットワークホップ数が削減されるため、お客様は、5G の広い帯域幅と低いレイテンシーを使い切らずにすみます。
対モバイルで高速な動作が要求されるときに使用します。「AWS Outposts」
AWS Outposts は、オンプレミス(物理的にPCを用意してそこで動作する)のシステム、ローカルのデータ処理、またはローカルのデータストレージへの低レイテンシーのアクセスを必要とするワークロードに最適です。
要約すると、AWS上ではなくオンプレミス上で動作するシステムがAWSと高速に連携できるようになるものです。ネットワーク(Amazon Virtual Private Cloud VPC)
AWSはクラウドコンピューティングサービスであり、それらが提供するITリソースは仮想のものである。
そのため、ネットワークも自社のものではなく、外部に作ることになるわけだが、その時によりセキュアなネットワークでITリソースを管理したいなどの欲求がある。
そこで使用するのがこのVPCというサービスである。
VPCは、AWSクラウド内にプライベートなネットワークを構築することができる。
このネットワークは、構築するうえで様々な項目を設定可能としており、
使用するIPアドレスの範囲やサブネット、ルートテーブルといった標準的なネットワークの構成項目を定義できる。
こうすることで、インターネット上に公開するものや、アクセス制限をかけるものを分けて管理することができるようになる。「サブネット」
文字通り、VPCの大きなネットワークの中をさらに区切るサブのネットワーク「ルートテーブル」
ルートテーブルとは通信をどこに流すかを定義するための情報で、サブネット毎に存在する
例えばVPCネットワークAに所属するサブネットAに紐づいているルートテーブルに送信先は10.0.0.0/16のIPアドレスの範囲にのみ通信を許可すると書かれていたとすると、サブネットAに所属するサーバーからは10.0.0.0/16の範囲にしか通信を行えなくなったりする。VPCを使う上での注意点
VPC内にサーバーを立てたりすると、同時にそのサーバーに住所が割り振られる。
この住所がIPアドレスである。
ネットワーク内での通信はこの住所を指定して行う。
このIPアドレスのどこからどこまでを使用するかという定義は、複数のVPCを使用する場合には意味を持つ。
VPCピアリングというサービスをつかって複数のネットワーク(VPC)をまたいで通信を行う場合、IPアドレスの範囲がかぶっていると、ネットワークAのIPアドレスかネットワークBのIPアドレスかを特定することができない。
そのため、複数のVPCネットワークを使用する場合、そのIPアドレスの使用範囲がかぶらないようにネットワークを構築する必要がある。また、VPCはAWSの基幹部分ともいえるサービスで、VPC内で使用できるAWSは非常に多い。
例えば、サーバーを立てるEC2などが代表される。VPCはリージョン単位で使用するもので、アベイラビリティゾーンごとにVPCを用意することができない。
そのため、リージョンにVPCを建て、その中にアベイラビリティゾーンを分割してサブネットをいくつか作り、そこにサーバーを立てたりするような使い方になる。サブネットは、複雑化を避けるためなるべく少数にとどめることが推奨される。
デフォルトではVPC内のすべての場所に通信を許可するため、プライベートかパブリックか等も含めてサブネットを差別化したい場合は、ルートテーブルの編集を忘れないこと。「パブリックネットワーク」
インターネットにアクセスできるネットワーク
VPCにインターネットゲートウェイをアタッチし、VPC内以外の通信トラフィック(ネットワークを流れる情報)をインターネットゲートウェイに送信するようにルートテーブルを設定した場合、実現することができる。
また、VPC内のインスタンスがパブリックな通信を行おうとした場合、パブリックIP(インターネットに公開されるIP)が必要になる。「インターネットゲートウェイ IGW」
インターネットにアクセスするための通信の出入り口「プライベートネットワーク」
インターネットにアクセスできず、特定の範囲でのみ通信を許可されたネットワークコンピューティングサービス(EC2・Lightsail・ECS...)
どのようなサービスを立ち上げるにしろ、サーバーレスで実装することを除けば、まずはコンピューターを用意してサーバーを立てるところから始まる。
サーバーを物理的に用意するオンプレミス環境では、物理的にPCを購入し、保守人員を確保し、物理的な環境を整え、定期的にメンテナンスを行うと多額のコストがかかる。
また、PCは利用状況ではなくプロジェクトの計画によってスペックが決定されるため、運用や計画が後に変わった場合に対応することも難しい。「オンプレミス」
自社内の設備によって運用することを指します。
会社でコンピュータを買ってきて、設置して、そこで動くシステムをオンプレミスで稼働するシステムと呼びます。
しかし、AWSにおいては使うときだけ仮想上に指定したスペックでサーバーを起動できるため、スケールアップもスケールアウトも思いのままだ。
物理的なサーバーを管理する必要がないので、物理的な環境も必要がなく、早い話がクライアントPC1台を用意してAWSが提供するサービスを使うだけでよいのだ。「スケールアップ・スケールアウト」
スケールアップはサーバーを増強すること、スペックを上げることを言います。
スケールアウトはサーバーの台数を増やすことを言います。
どちらもサーバーにかかる負荷が大きくなったときに行う対応です。代表的なのは
Amazon Elastic Compute Cloud(EC2)で、安全でサイズ変更可能なコンピューティング性能をクラウド内で提供してくれる。
EC2を使うことによって、プロジェクトの計画による事前のプロビジョニングではなく、現状・必要にあわせたサーバーを使用することができる。
他にも、AWSはAmazon Lightsailというサービスを提供している。
これは、数分で仮想プライベートサーバーを起動して、ウェブサーバーとアプリケーションサーバーを管理できるようにしてくれる。他にも、AWSは
Amazon Lightsailというサービスを提供している。
これは、数分で仮想プライベートサーバーを起動して、ウェブサーバーとアプリケーションサーバーを管理できるようにしてくれる。また、Dockerコンテナ(仮想環境の一種)を使用している場合にも、
Amazon Elastic Container Service(ECS)が対応している。
このサービスは、インフラストラクチャの部分もまるごと管理してくれるため、ユーザー独自で運用システムを用意する必要がなくなる。さらに、
AWS Lambdaというコード実行サービスを使えば、そもそもサーバーを建てる必要もなく、ただコード実行のみ行うこともできる。
もはやサーバーを起動したりすることを考える必要すらない、サーバーレスを実現できる。
これもまた、物理的なリソースを必要としないクラウドだからこそ実現できるメリットであるといえる。セキュリティグループ
セキュリティグループは仮想サーバーにおけるファイアーウォール(通信制限をかける機構)といえる。
セキュリティグループを詳細に設定することで、自分が構築したサーバーへのアクセスをコントロールすることができる。例えば、以下ではDBServerにアクセスできるのはAdminNetworkを除けばAPPServerだけである。
WWWServerからアクセスすることはできない。
そういったコントロールを行うのがセキュリティグループ(SG)である(多層ウェブアーキテクチャを前提とした多層セキュリティグループの例)
「多層ウェブアーキテクチャ」
アプリケーションを複数のソフトウェアエージェントで実行するクライアントサーバーモデル。
代表的なモデルとして三層アーキテクチャがある。
三層アーキテクチャはユーザインタフェース・ビジネスロジック・データベースでアプリケーションを分割して稼働させるもであるである。「クライアント・サーバーモデル」
昔はメインフレームと呼ばれる一台の巨大なPCを操作していたが、現在はPCの価格低下により複数台のPCをそれぞれ役割に特化させて組み合わせて使うようになった。
こうして、操作するPC(クライアント)と提供するPC(サーバ)に分けた運用が一般的となり、これをクライアントサーバーモデルと呼ぶ
基本的にサービス提供を行う側がサーバーを用意し、ユーザーは自分の持つ端末をクライアントにすることが多い。(例:google検索)上の図を読み解いていくと、まずウェブアプリケーション層(ユーザーインターフェース)がインターネットからの接続を受け付けているため、SGによって送信元0.0.0.0/0(デフォルト設定)ですべての接続を受け付ける状態であることがわかる。
ちなみに、ルートテーブルとの違いは、ネットワーク全体の設定であるか、SGに所属するサーバーの設定であるかである。
その後、アプリケーション層(ビジネスロジック)ではウェブアプリケーション層からのアクセスだけを受け付け、データベース層はアプリケーション層からのアクセスのみを受け付けることがわかる。このような細かいアクセスの設定を行えるのが、SGである。
主要なサービスの紹介
全てを紹介することはさすがに難しいのですが、よく使われる主要なサービスを紹介します。
クラウドプラクティショナー試験の選択肢に出てきたものは全て載せるようにしています。Amazon Elastic Compute Cloud EC2
よくEC2と呼ばれるが、Amazon Elastic Compute Cloudの略で、サーバーを立てるときに使う。
AWSではサーバーのことをインスタンスと呼ぶので、今後インスタンスを記載されたらEC2によって建てられたサーバーのことだと覚えておく
仮想のサーバーなので、AMIという形でバックアップを取っておけるし、AMIを共有することで誰でも決まった構成のインスタンスを立てることもできる。ec2インスタンスは、用途に合わせて様々な種類を要している。
例えば、データベースサーバーにするなら物理メモリ容量を最適化したいが、そういった場合はr4シリーズのインスタンスを使うなどである。
これによって、ユーザーは様々な役割に合わせて最適なサーバーをプロビジョニングできるようになる。さらに、インスタンスの運用方式にもいくつかの種類がある。
これには3種類の実行方式がある。「オンデマンド」
リクエストに応じてインスタンスを起動する。
通常はこの形態で、必要な時にインスタンスを起動し、不要な時に止める。「リザーブド」
事前に1年もしくは3年の単位で料金を払っておくことで、通常より安い金額でインスタンスを起動できる。
長期的かつあるていど安定した運用を行えるものはこの方式にすることでコストを抑えられる「スポット」
インスタンスの料金が常に変動し、一定金額以下の場合に起動、高くなったら停止という運用方式。
作業を中断したり、1日のうちどこかで作業を行えればよいものなどはこれを使うことでコストを安く抑えられる。AWS Lambda
以前説明したように、AWS Lambdaはサーバーレスでコードを実行することができるイベントドリブン型のサーバーレスコンピューティングサービスである。
AWSでは、様々なサービスが動作をしており、これらがどのように実行されたかをイベントとしてキャッチしてコードを実行することができる。「イベントドリブン」」
event driven 何かイベントが発生して、それに対応してプログラムが動くこと
イベント駆動ともいわれる。
AWS Lambdaでは、サービスのプロビジョニングを行わずにコードを実行できるので、サーバーを管理する必要がない。
これをサーバーレスという。
AWS Lambdaでは可用性の高いコンピューティングインフラストラクチャでコードが実行されており、ログをとったりコードをモニタリングしたりと、あらゆる管理を行える。
また。サポートされている言語もNode.js Java C# pythonなど幅広い。
また、AWSのイベントだけでなく、Amazon API Gatewayを使用したhttpリクエストへの応答などでも起動することが可能である。
また、実行されるコード自体についても、Amazon CodePipelineやAWS CodeDeployを使用して自動的にデプロイすることもできる。スペックとしては以下のようになる。
・ディスクスペース 512MBまで
・メモリ 128~1536MBまで
・実行時間 最大5分まで
・リクエストとレスポンスのペイロード 6MBまで
・イベントリクエストの本文 128kbitまでElastic Load Balancing(ELB) Application Load Balancer(ALB)
ALBはELB(Elastic Load Balancing)のサービスの一部として導入された2種類目のロードバランサー
CLB(Classic Load Balancer)の後継機で、これにいくつかの機能を追加した強化版
「ロードバランシング」
複数のサーバ、コンピュータ機器に対してリクエストや処理などを振り分けること
例えば同じ内容のアプリケーションをデプロイしたサーバーインスタンスを複数用意し、これらにアクセスを分散させて負荷分散を実現したいときなどに、ALBはそれらを適切に行ってくれます。
ALBでは様々なリクエストを受け付ける中で、どのような通信ポート番号でアクセスしてくるかによって、アクセス先のpathを差別化することもできます。「path」
ファイルまでの階層 C:\Users\works\Desktop....みたいな
ALBを知る上で、以下の3つの要素について知っておきましょう。
「Listener」
リスナーは接続要求をチェックするプロセスです。
設定したプロトコルとポートを使用します。
リスナーに対して定義したルールによって、ロードバランサーが1つ以上のターゲットグループ内のターゲットに要求をルーティングする方法が決まります。「Target」
ターゲットは、確立されたリスナールールに基づくトラフィックの宛先です。
「Target Group」
各ターゲットグループは、指定された通信プロトコルとポート番号を使用して、要求を1つ以上の登録済みターゲットにルーティングします。
ターゲットは複数のターゲットグループに登録できます。 ヘルスチェックは、ターゲットグループごとに設定できます。「ポート」
通信機器や個々のコンピュータの持つIPアドレスの下に設けられた補助アドレスとして、0から65535までの「ポート番号」が使われる。
これにより、1台のコンピュータで複数のサービスを提供したり、複数のコンピュータと同時に通信できるようになっている。
例えば、同じサーバーにアクセスするのでも、ポート1001番はテスト環境、ポート1000番は本番環境というように分けることができる。
例 http://172.255.255.255:10001/ ここでいう:の左側がIPアドレスで、どのサーバーにつなぐかを表しており、:より右側がポート番号「通信プロトコル」
プログラムの通信方式
SSHやTCP等といった種類があるが、主に相互に通信を送受信するために、お互いが同じ方式でデータを解釈できるようにきめたフォーマット、ルール。
「日本語で話す」プロトコルを自分と相手で共有が取れてないと、例えばアメリカ人に日本語で話しかけてもいい返事は帰ってこない。
多分エラーメッセージ「ぱーどぅん?」が返ってくる。ネットワーク接続は、前述したIPアドレス・ポート・通信プロトコルを組み合わせて行われるということがわかればよい。
AutoScaling
オートスケーリングは非常に便利な機能です。
ロードバランサーの話がありましたが、オートスケーリングは負荷に合わせて自動でインスタンスの数を増やし、ロードバランサーが自動でそのインスタンスにアクセスを割り振ってくれます。
もちろん、その逆も可能です。オートスケーリングでは、起動設定・Auto Scaling グループ・Auto Scaling ポリシーを登録する必要があります。
グループでは、いくつ以上いくつ以下のインスタンス数を保つか、どのロードバランサーで管理するかなどの情報を設定します。
ポリシーはスケールを行うスケジュール登録です。
負荷分散だけでなく、サービスを自動的に停止・開始するという使い方もできます。Amazon Elastic Block Store EBS
EBSはEC2でつかえるストレージです。
これはドライブをHDDにするかSSDするかなども選べ、容量が不足したら簡単に追加することができます。
これらは使用した分だけ料金がかかります。「ストレージ」
ファイル置き場、倉庫、保管ボックスみたいなイメージ「HDD」
HDDはHard Disk Drive(ハードディスクドライブ)の略で、データやプログラムなどを電磁的に書き込んだり読み出したりする記憶装置です。
SSDと較べて1ドライブで保存できるデータ量が大きい
「容量単価」としては安価になる
消費電力が比較的大きい「SSD」
SSDはSolid State Drive(ソリッドステートドライブ)の略で、HDDと同様の記憶装置です。
半導体素子メモリを使ったドライブ(記憶媒体)のことを指します。
読み書きの速度が非常に速い
容量が少ない
まだまだ容量単価としての価格は高い物理的に存在しているストレージ(皆さんのPCの中にあるHDDなど)と比較し、EBSは物理的な故障もなくレプリケーションもできるため耐久性が高く、カスタマイズも自由です。
ログ置き場は速度がいらない安価なHDD、アクセスを繰り返す部分には高速なSSDなど運用も効率的に行えます。
データはスナップショット(ある時点のバックアップ)を作成でき、リージョンをまたいで移動することもできます。
容量が足りなくなれば、あとから簡単に拡張することもできます。「レプリケーション」
データを別のところで同じように複製する。EBSの種類は、大きく5つ。SSD2種類、HDD2種類、旧世代のマグネティック1種類、となっています。
SSDとHDDの比較としては、IOPS(インプット・アウトプット Per Second、1秒あたりの処理できるデータの出し入れの数)とスループット、コストがよく用いられます。あとそれらを考慮した上での具体的な使い分け、とか。
ざっくりまとめると、SSDは「高IOPS」「ランダムアクセス向き」、HDDは「高スループット(処理能力)」「シーケンシャルアクセス(記憶媒体の先頭から順に検索しアクセスしていく)」「低コスト」、という感じ。
マグネティックはコストを下げたければというところです。
あと、HDDは起動ボリュームに指定できません。
SSD、HDDともに、それぞれ汎用・高性能が選択できます。EBSの特徴
•AZごとに独立、他のAZのEC2からは使用不可
•スナップショットをS3に保存可能、S3経由で他AZに移動可能
•EC2とEBSは1:Nの関係で構築できるAmazon simple Store service S3
こちらもストレージサービスです。
EBSがインスタンスのストレージとなるもので、インスタンスごとに別にで用意されるストレージなら、こちらはインスタンスに関係なくどんと用意されているストレージです。
グローバルサービスといって、同一リージョン内のリソースが共通で使用することができます。
様々な場所から共通でアクセスできる保存ボックスです。EBSは容量の制限があり、その使用料から料金が決められていました。
S3は数テラバイトあろうがすべて保存できます。
それゆえ、料金はリクエスト単位となっています。
PUT COPY POST LIST GETはすべてお金がかかります。
また、データはHTTPアクセスできるためすべてURLが自動で付与されますし、低レイテンシーです。
プライベートなネットワークからでもアクセスできます。
S3はバケットという単位で内部を区切ることができ、バケット別にアクセスをコントロールしたりもできます。Amazon Glacier
ぐれいしあって読みます。これもストレージです。
S3より遅いけど安いやつで、法律上必要だけど普段まったくアクセスしないみたいなファイルを長期間保存することにむいています。
グレイシアは遅いので、データの取り出しには数分から数時間かかります。ここに保存されるデータは「アーカイブ」という単位で保管されます。
また、S3でいうバケットにあたる、保管場所のことを「ボールド」と呼んでいます。
グレイシアでは、S3などのアクセス可能なあらゆる場所のデータをアーカイブできます。
例えば、S3に保存された30日以上アクセスのないデータはグレイシアに自動的に移動するといったことも可能です。
S3は最大5TBのファイルを保存できますが、グレイシアは40TBものファイルを保存できます。
これはどちらも1ファイル当たりの最大容量で、ストレージ自体の容量限界はありません。
料金はアップロードと取り出し時にかかります。Amazon Storage Gateway
オンプレ環境とAWS環境の間でシームレスに使えるストレージ
Amazon Command Line Interface CLI
AWSのアカウントを作成すると、ブラウザ上でマネジメントコンソールを開いてそのうえでリソースを操作します。
CLIはブラウザではなくコマンドプロンプトやターミナルからコマンドでawsを操作できる機能です。
スクリプト化すればawsへの操作を自動化することもできます。
例えば、pythonのboto3モジュールなどを使ってAWSのAPIを実行することで、AWSを画面から操作しなくてもインスタンスの情報を取ったりできます。Amazon Relational Database Service RDS
これはアマゾンが提供するリレーショナルデータベースです。
リレーショナルデータベースというのは、表でデータを管理していて、SQLを使って高度なデータの検索が行えたり、トランザクションの管理ができたりするデータベースです。
例としてはOracleやDB2などがあります。
対して、KVSという、キーと値だけでデータを持っているデータベースもあります。
RDBは複雑な条件を指定した検索に向いており、KVSは速度を重視する場合に使用します。
業務用のアプリケーションでは、ほとんどがRDBを使用しています。通常、データベースとはデータが追加でどんどん入ってきて容量が大きくなったり、頻繁にアクセスされたりするものなので、スケールやらセキュリティやらパッチ適用やら、そもそもインストールやらとたくさんの管理タスクが存在します。
内容も単純でなく、専門的な知識を必要とするものが多いです。
RDSではそれらを大幅に自動化しています。
パッチ適用やバックアップ、スケーリングやらの管理タスクも自動になるのです。
また、データの内容をコピーし、スタンバイ状態で別のアベイラビリティゾーンにデータベースインスタンスを立てておくこともできます。
これによってデータベースインスタンスのあるアベイラビリティゾーン単位で障害が起きた場合でも、迅速な復旧を行えます。RDSでは6種類のリレーショナルデータベースに対応しており、ユーザーのニーズに応じて選ぶことができます。
Amazon Aurora
RDSは様々なリレーショナルデータベースを提供するサービスでした。
Auroraは、RDSで提供されるリレーショナルデータベースのうちの一つです。
Amazon Aurora は、標準的な MySQL データベースと比べて最大で 5 倍、標準的な PostgreSQL データベースと比べて最大で 3 倍高速です。
また、商用データベースと同等のセキュリティ、可用性、信頼性を、10 分の 1 のコストで実現します。
Amazon Aurora のストレージシステムは分散型で耐障害性と自己修復機能を備えており、データベースインスタンスごとに最大 64 TB まで自動スケールされます。
Amazon Aurora は、最大 15 個の低レイテンシーリードレプリカ、ポイントインタイムリカバリ、Amazon S3 への継続的なバックアップ、3 つのアベイラビリティーゾーン (AZ) 間でのレプリケーションにより、優れたパフォーマンスと可用性を発揮します。つまり、一般的なリレーショナルデータベースよりも早くて安い上で安全安定性は一般的な水準を出せ、単一障害点(ここが壊れたらシステムが止まる)となりやすいデータベースの弱点を分散型にすることで補っており、自己修復もスケールもできてリカバリーもできるすごいデータベースですよということです。
Auroraは高性能なDBですが、今まで使っていたアプリケーションをクラウドに移行するという場合、データベースは既存のものを使用しているはずです。
この置き換えを行うか否かという判断は、Auroraの可用性にあるといえます。当然ですが、たいていの場合はデータベースは一つで、その中にデータを入れています。
その場合、対象のデータベースは単一障害点となります。
これは、データベースがトラブルにあった場合、システムは止まってしまうということです。
Amazon Auroraでは、高可用性を実現できます。
Auroraでは継続的にS3にバックアップを作成しながら、3つのアベイラビリティゾーンにデータのコピーを6つ保存します。
また、データベースはマスター(更新対象)とリードレプリカ(参照対象)にわけて管理され、リードレプリカは15個まで用意できるため、データの損失が発生することはありません。
さらに、Auroraはプライマリーデータベース(データベースが作成され、メンテナンスされる本番データベース)がクラッシュした場合、60秒以内に復帰できるように設計されています。
これは、通常であればREDOログというデータベースに対して行われた更新ログからすべてのSQLを実行しなおして復旧するところを、データベースへの読み込み動作があるたびに細かく行って状態を保存しているためです。これらの耐障害性能がどうしても欲しいなら、データベースのリプレイスは十分検討されるべきでしょう。
Amazon DynamoDB
DynamoDBは、NoSQLのデータベースです。
リレーショナルデータベースのようなSQLを使って複雑にデータの検索を行えるデータベースに対して、高い速度が評価できます。
また、リレーショナルデータベースではテーブル(データを入れておく場所)の構造を更新する場合はすべてのデータを更新する必要がありますが、NoSQLでは古い構造と新しい構造を同時に持つことができるというのも特徴です。
これは、アプリケーションの進化に応じて柔軟なデータベースを苦労なく保てるという利点があります。
DynamoDBはオートスケーリングにも対応しており、負荷に対して柔軟です。
ストレージの拡張なども自動で行えます。
多数のユーザーが高い頻度でアクセスを繰り返すようなDBには非常に有効で、低レイテンシーで柔軟な運用を行うことができます。
また、DynamoDBでは、インフラストラクチャは完全にアマゾンが管理しており、これについて気にする必要もありません。
データの検索方法は基本的にはKVSですが、データに紐づけられた属性から検索を行うことも可能です。
しかし、その方法はパフォーマンスに良くない影響を与えるでしょう。
そのため、複雑なデータ管理には向いていないといえます。
そういった場合はRDSを使うと良いでしょうAmazon ElastiCache
キャッシュを行う機能です。
「キャッシュ」
よく使うデータを高速低用量のメモリ内に保存しておくことで、次回使用時に素早くデータを取り出し使用できる機能つまり、アプリケーションの速度を高速化するための機能です。
RedisとMemcachedという既存のキャッシュシステムに対応しています。
RDBの紹介の時に、KVSが早くてSQLをつかうRDBは遅いという話をしましたが、RedisはNoSQL、つまり高速なデータ検索を可能にするシステムです。Amazon Redshift
これは高速なデータウェアハウスです。
「データウェアハウス」
データを時系列順で保管する倉庫で、書き換えや部分的な消去などができません。
データベースは今の状態を記録し更新することに強みがありますが、データウェアハウスは連続したデータの履歴保管が主な用途です。
SQLや既存のBIツール(データ分析ツール)を使って高度なデータ分析を行えます。
しかも、高速に大量のデータを処理できます。
料金は使用した分だけかかりますが、1時間当たり25セントからです。
年間でテラバイトあたり1000ドル程度の料金で処理でき、これは従来のデータウェアハウス製品の1/10のコストしかかかっていないことを表します。
しかもデータの扱いは保管中でも通信中でもすべて暗号化されているため、安心安全です。
ビックデータの解析などにも向いているといえるでしょう。Redshift Spectrum を使うと、Amazon S3 に保存されたオープンデータフォーマットに直接クエリを実行することもできます。
また、これらを使用した分析サイクルを自動化することは非常に簡単で、ユーザーはそのデータを使ったビジネスの改善に集中することができるようになります。Amazon CloudWatch
AWSのクラウドリソースと実行されるアプリケーションをモニタリングするサービス
ログの収集やモニタリング、アラーム設定などが行える。Amazon CloudTrail
AWS内で、だれがいつどこで何をしたかを監視しているサービス。
何らかの想定外な作業が確認された場合は、ここから誰が作業したのかを確認することができる。AWS Config
AWSのセキュリティと統治を行うための機能で、構成変更を通知したり履歴を確認したりするだけでなく、あらかじめルールを記載しておくことで、AWSリソースがルールに従って構築されているかを確認したりもできます。
Amazon Trusted Advisor
AWSを使用していると、リソースのあれやこれやと確認したいものが出てくるわけですが、AWSでは所有するリソースは膨大です。
たとえば、全く使われていないストレージや、動作していないインスタンスにアタッチされたEIPなど、お金はかかるが最適化されていないもの、有ったらどうにかしたいものなどは無数にありますね。Trusted Advisorは、アカウントのすべてのリソースをチェックし、ベストプラクティスを提供してくれます。
これは、サービスの制限・セキュリティ・耐障害性・パフォーマンス・コストのそれぞれ項目で実行されます。
これはコンソール画面の一部ですが、一目でどの分野に問題があり、どれくらいコストが無駄になっているかを見ることができます。
さらに、この機能にはapiも用意されており、自動でこれらを適用することも可能です。Amazon CloudFormation
AWSのリソースを使った構成まるごとをテンプレートという形に落とし込むことで、依存関係などを一切考慮せずに環境構築を行うことができます。
つまるところ、インフラを設定ファイルのようにまとめてしまえます。テンプレートをyamlやjsonで書いて、cloudFormationでスタックにする。
スタックはリソースの集合体を表していて、要は環境丸ごとまとめたものだと思えばよい。
スタック内部のリソースをどういった順番で構築するかなどはCloudFormationが自動的におこなってくれる。AWSで環境構築などを行う際に、Cloudformationのテンプレートをコードで管理して複数のリソースの集合体を管理したりします。
同じような環境を顧客ごとに立てたりする場合は、必須に近いサービスです。AWS OpsWorks
AWSインスタンスに対してChefを使える機能
「Chef」
ファイルに記述した設定内容に応じて自動的にユーザーの作成やパッケージのインストール、設定ファイルの編集などを行うツール
自動化につかうAmazon Batch
バッチ処理を行うためのサービス
バッチ処理は大量のデータを決められたルールで処理していくというようなものが多く、非常に時間もかかる。
AWS Batchは、処理データの要領などによって動的にコンピューティングリソースを決定し、高いパフォーマンスで処理を行える。「バッチ処理」
あらかじめ定めた処理を順次実行すること。
営業時間中に行われた処理に対して、大量のデータを夜中のうちに加工したりするのにつかわれることがおおい。Amazon simple Queue Service SQS
メッセージキューイングを行う機能です。
メッセージを保管しておくことができます。「メッセージキューイング」
あるプログラムが送信したメッセージを格納しておく
そのメッセージは取り出されるまではそこにおり、そのメッセージを必要とするプログラムが何らかのタイミングでメッセージを受け取りに行くことができる。
そして、そのプログラムは受け取ったメッセージに応じて動くという機構。
先に入れたものを先に取り出すFIFO(ファストインファストアウト)とかその逆のFILOとか取り出しの順番がきまってたりする。
それによってスタックとキューで名前が分かれてたりする。
非同期で動くプログラムどうして連携を取りたいケースなどに使用する。「非同期」
Aが実行されるまでBは待機するという状態を同期しているという。
非同期は逆で、Aを実行したらその結果を待たずにBも動けること、を表す。Amazon simple Notification Service SNS
これはメッセージをためておくSQSと違って、メッセージを送るための機能です。
Amazon SNS を利用すれば、アプリケーションは「プッシュ」メカニズムを使用して、複数のサブスクライバーにタイミングが重要なメッセージを送信することができます。
そのため、更新を定期的に確認したり、ポーリング(一定間隔で順繰りに要求がないか尋ねる)したりする必要性がなくなりますAmazon EC2 Container Service ECS
Dockerコンテナを使うための機能です。
「Docker」
EC2のような仮想環境をつくるためのツール。
windowsのなかにlinux環境を用意したりできるため、AWS以外でも広く使われているもともと仮想環境を使用していたユーザーとしてはDockerはEC2よりもなじみ深いものですし、既にdockerが提供する優れた環境もたくさんあるので、EC2ではdockerをより利用しやすくしつつそのまま使えるようになっています
Amazon EC2 Container Registry ECR
dockerにもEC2でいうAMIのようなイメージ存在し、それを利用することで簡単に環境を立てることができる。
ECRはそういったDockerコンテナのレジストリである「レジストリ」
情報を保存しておくデータベース
Windows OSが設定情報を保存しておくデータベースをレジストリと呼んでいる。Amazon Lightsail
こちらも仮想サーバーを立てるためのサービスで、数分でプライベートなクラウド環境を構築できる。
サーバー料金にインターネット転送料金やディスク料金が含まれているのが特徴的で、VPCも専用の物が用意されるのでEC2と連携したりするのは苦手(無理ではない)、後停止していても金がかかる
インターネットへの転送料金に追加のお金がかからないので、サーバー1台で運用する、画像や動画など配信データ量が比較的多いWebサイト向け。
ロードバランサーとかはないので、簡単にサーバー立ち上げてちょっと使って本運用はEC2とか、おためしにもいい。AWS Elastic Beanstalk
Elastic Beanstalk を使用すると、アプリケーションを実行しているインフラストラクチャについて考えることなく、AWS クラウドでアプリケーションのデプロイと管理を簡単に行うことができます。
我々は単にそのアプリケーションをアップロードするだけで、Elastic Beanstalk がキャパシティーのプロビジョニング、ロードバランシング、スケーリング、およびアプリケーション状態モニタリングといった詳細を自動的に処理します。
しかも、Elastic Beanstalk に関して別途料金が発生することはありません。Elastic Beanstarkはplatform as a service (PaaS)です。
Paasとは、ネットワークを通じたサービスとして、アプリケーションを利用するためのプラットフォーム(土台)を顧客に提供する形態をいいます。
なんやかんや言いますが、Elastic Beanstalkがサポートしている言語で書かれたコードを、自分の環境に簡単に配置・管理できますよという話です。
Elastic Beanstalk は、Go、Java、PHP、.NET、Node.js、PHP、Python、および Ruby で作成されたアプリケーションと、各言語に対応するさまざまな種類のプラットフォーム設定をサポートしています。以下のように、ホストコンピュータやOS、アプリケーション実行サービスやHTTPサービスも用意してくれているので、我々は、アプリケーションをAPサービスに、画面情報をHTTPサービスに渡すだけでアプリケーションを動かせるのです。
また、この環境への負荷があがれば、自動でスケーリングしたり、それによって増設されたAPサーバーに適切なロードバランシングを自動で行ってくれますよというサービスですね。
我々がやるべきことはコードを書いて、アップロードするだけです。
コードがアップロードされると、AWS Elastic Beanstalkはコードの実行に必要な環境を自動で起動して管理もやってくれます。
アプリケーションを運用するためのインフラをAWS上に構築するためには、AWSの知識はもちろんのこと、OSやネットワーク等について多様な知識が必要です。
AWSは、各システム固有の細かい要件に柔軟に対応するために、詳細で複雑な設定項目が無数にあり、正直なところ一朝一夕でどうにかなる知識の量ではありません。
(この記事が鬼長いことでもわかると思います)ただ、逆に考えれば「細かい要求はしない、とにかくオススメのインフラをくれ、アプリケーションはそれに合わせて作る」と割り切れるのであれば、複雑な部分を隠蔽した状態で、シンプルにAWSを利用できるはずです。
Elastic Beanstalkはそのような要求に応えるサービスです。オンプレからAWSへの移行用サービス
AWS Application Discovery Service ADS
サーバーやストレージ、ネットワーク機器から設定や使用状況のデータを自動収集し、アプリケーションのリストや動作方法、依存関係を把握できるサービス。
AWS Database Migration Service DMS
データベース移行用のサービス
処理中も移行元のデータベースは動かしたままで問題ありませんし、oracleからAuroraというような別のDBへの移行もサポートしています。AWS Server Migration Service SMS
オンプレミスの VMware vSphere または Microsoft Hyper-V/SCVMM 仮想マシンの AWS クラウド AWS SMS への移行を自動化
AWS Organizations
アカウント一元管理を行えます。
たとえば、複数アカウント使用している場合に請求を一回にまとめたりできます。AWS inspector
セキュリティを評価できます。
Amazon Inspector では、自動的にアプリケーションを評価し、露出、脆弱性、ベストプラクティスからの逸脱がないかどうかを確認できます。
評価の実行後、重大性の順に結果を表示した詳細なリストが Amazon Inspector によって作成されます。
この調査結果は直接確認することもできますが、Amazon Inspector コンソールまたは API を介して入手可能な詳細な評価レポートで確認することもきます。AWS Server Migration Service SMS
オンプレミスの VMware vSphere または Microsoft Hyper-V/SCVMM 仮想マシンの AWS クラウド AWS SMS への移行を自動化
AWS snowbal
AWSとオンプレ環境の間で大量のデータ転送を行えるサービス
AWSのセキュリティ
責任共有モデル
AWSは様々な機能を提供していますが、あくまでこれは何かを成し遂げるためのツールを提供しているにすぎません。
そのため、AWSとユーザー、それぞれが責任を持つべき領域が存在します。
そのため、AWSのユーザーはこの責任共有モデルについて理解する必要があります。AWSの責任範囲
AWSはクラウドのセキュリティに責任を負います。
これは、AWSを運営するのに必要な物理的なサーバーなどのすべてのグローバルインフラストラクチャを保護する責任があるという意味です。
そのため、自信によって物理的なサーバーが故障し、AWSが動かなくなったとしてもユーザーに責任は在りません。
リージョン・アベイラビリティゾーン・エッジロケーションに含まれるもの等、すべてAWSの責任です。
また、それだけでなくデータベースやストレージ、ネットワーキングなどの基本的とみなされた製品のセキュリティ設定にも責任を持っています。
これらのサービスが使用するオペレーティングシステム(OS)やパッチ適用などもAWSの責任となりますユーザーの責任範囲
ユーザーはクラウド上に保存するあらゆるものを保護する責任を負います。
例えば、データベース自体のパッチ適用などの管理はAWSの仕事ですが、そのデータベースをプライベートなネットワークに設置してデータに対しての外部からの攻撃に備えるのはユーザーの仕事です。
以下のようなものが対象となります。
- AWSに保存するコンテンツ
- コンテンツで使用されるサービス
- コンテンツが保存される国(リージョンの選択)
- コンテンツの形式・構造、暗号化など
- コンテンツにアクセスできるユーザーの制御EC2やVPCなど、Iaasのカテゴリに分類される製品はユーザーがすべて管理します。
「Iaas」
Infrastructure as a Service
IaaSはサーバーやストレージ、ネットワークなどのハードウェアやインフラまでを提供するクラウドサービスの総称「Paas」
Platform as a Service
システム開発に必要なアプリケーションとOSをつなぐミドルウェアやデータベース管理システム、プログラミング言語、WebサーバーOSなどといったソフトウェア一式を提供してくれます。「Saas」
Software as a Service
従来はパッケージとして提供されていたアプリケーションを、インターネット上で利用する提供形態です。
エンドユーザーにとっては、このSaaSが一番なじみのあるクラウドサービスかもしれません。
端末にアプリケーションをインストールすることなく、必要なサービスをインターネット経由で手軽に利用することができます。セキュリティサービスの紹介
AWSのセキュリティ用件は、最も厳しい顧客のニーズを満たすように設計されています。
Identity and AccessManagement 、 ログ作成とモニタリング、 暗号化とキー管理、 ネットワークのセグメンテーション、 DDos保護など様々なセキュリティサービスは、ほぼ追加料金なしで使用することができます。(使用した分だけお金がかかるものもあります)
これらのサービスを、オンプレミス環境にインフラを構築するよりもはるかに低い運用オーバーヘッドで、ニーズに合わせて使用できます。「オーバーヘッド」
システムを利用するための付加的処理や、余分な時間などAWSでは、ネットワークや構成管理、アクセスやデータについて、セキュリティに特化したツールを提供しています。
加えて、モニタリングやログ作成機能を使うことで、環境内の出来事を完全に可視化できます。ネットワークについては、プライベート(社内)からのアクセスのみを許可したり、パブリックなネットワークを構築したりできます。
全サーバーにおいて、データのやり取りはTransport Layer Securityによって暗号化され、AutoScalingやコンテンツ配信戦略の一部としてDDosを緩和する技術もあります。「DDos」
コンピュータに対して複数のマシンから大量の処理負荷を与えることでサービスを機能停止状態へ追い込む手法
AWSにはクラウドリソースを組織の基準とベストプラクティスに準拠させつつ、スピードを向上させるための幅広いツールが用意されています。
AWSリソースを組織の基準に従って行うためのデプロイツールや、AWSリソースへの変更を追跡管理するインベントリおよび構成管理ツール、EC2インスタンス向けに標準的な設定済みの強固な仮想マシンを作成するテンプレート定義および管理ツールがあります。
AWSはクラウド内に保管しているデータにセキュリティレイヤーを追加し、スケーラブルで効率的な暗号化機能を提供します。
EBS S3 Glacier RDS Redshift などのストレージやデータベースサービスで利用できるデータ暗号化機能もあります。
また、AWS内で開発されたりデプロイされたサービスにも暗号化とデータ保護を行えます。
AWSではサービス全体に対してユーザーアクセスポリシーを定義し、管理します。
例えば、個々のアカウントにAWSリソース全体での権限を定義できるIdentity and Access Managementや
ハードウェアによる認証をおこなえるMulti-Factor Authenticationなどがあります。
AWSには、環境で何が起きているかを把握することができるツールがあります。
例えば、APIをコールした実行者や内容・時間・発生地点などに関する高い可視性や調査とコンプライアンスレポートを容易にするログ収集オプション。
特定の閾値を条件としたアラート機能などがあります。「コンプライアンスレポート」
監督当局や官公庁によって定められる規則、標準、法律、規制などに準拠することを目的として企業によって作成されるレポートを指します。ユーザーはAWS Service Catalogを使用することができます。
これは、IT管理部門向けには、CloudFormationのテンプレートとして管理されるAWSリソース定義や、これらの利用権限をカタログとして一元管理する機能を提供します。
ユーザ部門ではIT管理部門が作成したカタログより、求める機能に応じたAWS環境を必要に応じて起動する事が可能となります。
CloudFormationはテンプレートに記載された内容でインスタンスを立てたりできる機能ですが、これは通常そこで使用されるすべてのAWSサービスに対してIAMによる許可が必要になります。
しかし、権限を広範囲に付与するのは危険といえます。
そのため、この機能はIT管理者が問題ないと提示したテンプレートを作成でき、ユーザーはそれを使用してインスタンスを立てることができるようになる機能です。
そのテンプレートの集合体をポートフォリオといいます。AWS Marketplaceでは、皆さんのオンプレミス環境にある既存の制御と同等かそれ以上の制御を行える、業界のトップ製品が多数提供されています。
ここにはマルウェア対策やウェブアプリケーションファイアーウォール、侵入に対しての保護なども含まれます。
これらの製品がAWSの様々な機能を補完し、顧客のニーズに合わせたセキュリティを実現できます。アクセスコントロール IAM
AWSのあらゆるサービスへのアクセスは、アカウントに対して付与する権限の有無によってコントロールすることができます。
これを行うのがIAM(Identity and Access Management)です。
IAMでは以下のことが行えます。
- IAMユーザーとそのアクセス権限の管理(アカウントのID/PW等の管理)
- IAMロールとその権限の管理(サービスに対しての権限管理)
- フェデレーションユーザーとその権限の管理「フェデレーション」
複数のインターネット サービス間のユーザ認証連携を意味します。
複数のサービスで認証情報を共有することで、1度のユーザ認証で複数のサービスを利用可能にします。アクセスコントロールのベストプラクティス
1.AWSリソースに無制限にアクセスできるルートアカウントのアクセスキーを削除します。 代わりにIAMユーザーアクセスキーか、一時的なセキュリティ認証を使用します。 2.アカウントのセキュリティを確保するために、AWSルートアカウントでMFAを有効にして保護を強化します。 3.IAMユーザーを作成し、必要な権限のみ付与します。 ルートアカウントは権限が強く危険なため、日常的には使用しません。 4.ユーザー単位で権限を管理するのは複雑なので、IAMユーザーグループの単位で権限を管理します。 5.IAMパスワードポリシーを使用し、定期的なパスワード変更をおこないます。 6.EC2インスタンスで実行されるアプリケーションに対してIAMロールを使用してアクセスできるサービスを制限します。 7.強い権限で作業をする場合はユーザーの認証情報を共有するのではなく、ロールを使用して権限を委任します。 8.退職者など不要なユーザーは常に削除します。 9.ポリシー条件を使用してセキュリティを強化します。 10.AWSアカウントのアクティビティをCloudTrailでモニタリングし、誰がどこで何をしたかをCloudWatchで記録します。コンプライアンスプログラム
AWSでは以下のようにコンプライアンスをサポートしている。
「コンプライアンス」
法令遵守、企業などが、法令や規則をよく守ること。保証プログラムを含むAWSのコンプライアンスアプローチ
- 業界の認証と独立したサードパティ認証機関による証明書の取得
- AWSのセキュリティと統制の方法に関する情報をホワイトペーパー及びウェブサイトコンテンツで公表
- NDAに基づいて証明書やレポートなどのドキュメントを提供
「NDA」
秘密保持契約(NDA)とは、取引を行う上で知った相手方の営業秘密や顧客の個人情報などを、取引の目的以外に利用したり、他人に開示・漏洩することを、禁止する契約のことです。リスク管理、統制環境、情報セキュリティといった、AWSのリスク管理とコンプライアンスプログラム
下記ページにて、コンプライアンスプログラムごとにどのような対応がされているかなどを確認できる。
https://aws.amazon.com/jp/compliance/programs/AWSのユーザーが担うべきコンプライアンスの責任
AWSはあらゆるコンプライアンスプログラムに対応しており、AWSが提供するサービスは適切な設定を行うことでコンプライアンスを守ることができる。
なので、ユーザーは自分が守るべきコンプライアンスを理解し、適切な運用を行うことが求められる。
そのための機能はAWSが提供するし、ドキュメントも用意する。
つまり、コンプライアンスの達成にはAWSとユーザーの連携が必要であるということです。コンプライアンスを守るためには、以下のようなステップを踏むと良い。
確認 AWSから提供される情報や他の情報を確認して、IT環境全体について可能な限り多くのことを把握してから、全てのコンプライアンス要件をドキュメント化します。 設計 エンタープライズのコンプライアンス要件を満たすために統制目標を設計及び実装 特定 サードパーティが所有する統制を特定及びドキュメント化します。 検証 統制目標がすべて達成され、主要な統制がすべて効果的に設計及び運用されていることを確認します。様々なサポート
AWSクラウド上に保管されるユーザーのデータを保護する様々な取り組みを紹介します。
AWS Trusted Advisor AWSリソースの問題を自動で見つけ、可視化してくれるオンラインツール。 AWSアカウントチーム ユーザーからの最初の問い合わせ窓口 セキュリティ問題を解消するための適切なリソースを紹介してくれる。 AWSエンタープライズサポート 15分以内対応、24時間サポート年中無休で電話・チャット・メール対応してくれる。 専任のテクニカルアカウントマネージャによるコンシェルジュサービス AWSプロフェッショナルサービス/AWSパートナーネットワーク プロフェッショナルサービスはAWS クラウドを使用して期待するビジネス上の成果を実現するようお客様をサポートできる、専門家からなるグローバルチームです。 パートナーネットワークはAWSを使う側の企業が所属するネットワークで、AWSのサービスや技術に長けたベンダーとして公式サイトで紹介され、いち早く新たなサービス・技術の試用ができたり、技術者向けに特別な教育を受けることができる制度です。 どちらも、実証済みの設計に基づいてお客様のセキュリティポリシー及びセキュリティ手順の構築をサポートします。 AWS勧告・速報 現在判明している脆弱性や脅威を提供 AWS監査人のラーニングパス 監査人・コンプライアンス・法的なロールの担当者はAWSを使って内部オペレーションのコンプライアンスを実現する方法を学ぶことができます。 AWSコンプライアンスソリューションガイド コンプライアンスに関して、何から手を付けてよいかわからないというときは、こちらから学習をすることができます。AWSにおける設計原則
自社のインフラストラクチャをベストプラクティスにのっとってAWSで構築するためのサポートとして設計のフレームワークは用意されています。
AWSでは5つの柱に基づいてアーキテクチャを設計します。「フレームワーク」
枠組み、決まりきった手順
ITにおいては、みんなが使いそうな決まりきったプログラムがあらかじめ用意されており、穴埋めするだけで目標とするものが完成するようなひな形を指すこともある。
ここでは決まりきった手順の意味。アーキテクチャ設計における5つの柱
セキュリティ
IAM リソースへのアクセス制限 検出制御 ログの取得と分析など インフラストラクチャの保護 ネットワークの分割やパッチ適用、ファイヤーウォールやゲートウェイなど外部からの侵入への対処 データの保護 データの分類や暗号化、バックアップ、複製復旧 インシデントへの対応 インシデントへの対応プロセスの手順化セキュリティ設計原則
「全てのレイヤーにセキュリティを適用する。」 どの場所にあるインフラもすべてのレイヤーが保護されてなければなりません。 「追跡可能性の実現」 あらゆるアクションを記録し監査し、だれがいつどこで何をしたのかを把握できる必要があります。 「自社システムの保護」 基本的に、AWSはインフラとサービスにおいてセキュリティを担保しているので、ユーザーは自社システムの保護に全力をつぎ込むべきです。 「セキュリティのベストプラクティスを自動化」 例えば、日常的もしくは異常なセキュリティイベントへの対応などは自動化されるべきです。信頼性
これは、障害児の復旧能力と、アクセス量に対してのシステムの速度など需要を満たす機能を指します。
クラウド上の信頼性は以下の要素で担保されます。基盤 アーキテクチャやシステムの基礎的な要素が綿密に計画され、確固としたものであり、需要や要件の変化に対応で木、障害を自動で復旧できる仕組みを用意しましょう。 変更管理 システムを構築する前に、信頼性に影響を与える基盤の要件を整えておく必要があります。 変更管理は、変更によってシステムが受ける影響を完全に理解し、意識することです。 障害管理 障害管理は、システムを変更する前に前もって計画を立ててシステムをモニタリングし、予測し、検知し、対応することに加え障害発生を未然に防ぐことです。信頼性設計原則
「復旧手順のテスト」 実際に障害が発生しなくても、シミュレーションが簡単に行えるのがクラウドなので、実際の障害が発生する前に確認しましょう。 「障害からの自動復旧」 AWSでは閾値を超えた瞬間にアラートするようなっていも、それを受けとってプログラムを実施するようなこともできますので、自動かは容易です。 「集計システムの可用性向上」 単一の大規模リソースは、単一障害点になりやすいです。 なので、これらは複数の小規模なリソースに分割することで、システムへの影響を軽減できます。 これを水平スケーリングといいます。 つまり、負荷が高くなったからインスタンスを大きくするというスケーリングではなく、もう一台同じアプリを立てて負荷を分散するほうがよいということです。 「キャパシティを予測しないこと」 自動でスケーリングできるのだから、予測する必要はない。 これぐらい必要だろうで固定のリソースを管理するのではなく、どうであっても対応できるように自動化しよう 「変更管理とオートメーション」 アーキテクチャやインフラストラクチャにて変更を加える際には、自動化する仕組みをつくっておいて、それが対応する範囲のみにとどめるべきです。 そうすることで、個別に単独なのシステムやリソースを調整する必要がなくなります。 ### パフォーマンス効率選別
アーキテクチャを最適化するための最適なソリューションを選定しましょう。レビュー
AWSは仮想化されているがゆえに、リソースのカスタマイズやソリューションの検証が容易です。
そのため、レビューを繰り返して継続的なソリューションのイノベーションを行いましょう。モニタリング
運用が始まったら、パフォーマンスをモニタリングし、問題は影響が出る前に修正する必要があります。
CloudWatchやkinesis、SQSやLambdaなどモニタリングに適した機能も多く取り揃えています。トレードオフ
全てにおいて最高のパフォーマンスを発揮するソリューションは在りません。
一貫性、耐久性、容量を時間やレイテンシーとトレードすることが必要になります。
```パフォーマンス効率設計原則
「最新テクノロジーの標準化」 知識が必要で複雑な実装が難しいテクノロジーは、AWSがサービス化して提供する。 なので、ユーザーはそれをちゃんとキャッチして使っていこう。 「分単位で世界中にデプロイ」 アーキテクチャの変更をしたら、すぐにすべてのシステムにデプロイしましょう。 AWSは世界中の複数リージョンにあるシステムに簡単にデプロイでき、レイテンシーの短縮と顧客サービスの向上を最低限のコストで実現できます。 「サーバーレスアーキテクチャの使用」 インフラ管理がなければ運用コストはなくなり、トランザクションコスト(仲介料)もなくなります。 「頻繁な実験」 仮想化によって既存環境を破壊せずにテストをおこなうことができるようになります。 そのため、従来よりも気軽かつ高速にテストが行えるので、テストを繰り返してシステムの効率を向上させましょう。 「変更管理とオートメーション」 アーキテクチャやインフラストラクチャにて変更を加える際には、自動化する仕組みをつくっておいて、それが対応する範囲のみにとどめるべきです。 そうすることで、個別に単独なのシステムやリソースを調整する必要がなくなります。 「メカニカルシンパシー」 実現しようとすることに最も適した技術を使うコストの最適化
コスト効率の高いリソース コストが十分に最適化されたシステムは、所有するリソースをすべて利用することで最低限のコストで最高のパフォーマンスと機能要件を満たします。 需要と供給の一致 柔軟なスケーリングを実施し、必要な時に必要なだけのリソースを使うべきです。 支出の認識 自分たちの使用するリソースにどれだけのコストがかかっているかを一点の曇りなく把握しましょう。 時間の経過に伴う最適化 設計時ではなく、運用が始まってからも徐々に改善を続けましょうコストの最適化設計原則
「消費モデルの導入」 固定のコストを払い続けるのではなく、使用したコンピューティングリソースの消費量に応じて料金を支払いましょう 「全体的な効率の評価」 システムの生産量とコストのバランスを常に把握しましょう そしてそこから生産量を上げコストを削減したときどれだけの利益が出るかを認識しましょう 「データセンター運用の費用をなくす」 データセンターにかかる費用を自社でもつのではなくすべてAWSでまかなうことで完全になくしましょう 「支出を分析し、帰結させる」 何によっていくらかかっているかを完全に把握しましょう。 これによりどの部分を改善する必要があるかを明確にし、それによってどれだけのコストが軽減できるかを検討できます。 「マネージド型サービスの仕様」 AWSが提供するサービスにはインフラを一切気にしなくてよいS3などのマネージド型サービスもあれば、EC2のようなインフラ構成の把握が必要なサービスもあります。 なるべくサービスをマネージド型サービスに集約することで、運用コストを下げることができます運用上の優秀性
ここではビジネスの価値を提供するためのシステムの実行とモニタリング、および継続的にプロセスと手順を改善することに焦点を当てています。
ここでは以下のことが重要になります。
- 変更の管理
- 自動化
- イベントへの対応
- 日常業務をうまく管理するための標準の定義AWSの料金
料金の基礎
AWSの料金は以下のような特性があります。
従量課金制(使用した分だけお金がかかる)
予測ではなく、ニーズによってお金がかかることで、ビジネスの拡大縮小を自在におこなえるようにしている。
予約による値引き
EC2やRDSのような特定のサービスについてはリザーブドキャパシティー料金が適用されます。
EC2を例にしてみると、リザーブドインスタンスには全額前払い、一部前払い、前払いなしのプランがあり、最大で75%にまで価格が変動します。
基本的には予測ではなくニーズによって料金がかかりますが、完全に予想が立つような分野ではこのような方法でコスト削減を行える可能性があります。使用量が増加するほど、1単位当たりに値引きがかかる
AmazonS3やEC2は、ボリュームディスカウントの精度があります。
つまり、たくさん使えば使うほど安くなります。AWSの拡大にあわせて値引きがかかる
AWS自体の事業拡大や技術革新によっても値下げが行われます。
AWSでは2006年以降すでに44回もの値下げが行われています。
ちなみに、これをスケールメリットといいます。AWSでは、これらの料金要件があわないユーザーのために、大規模プロジェクト向けカスタム料金を設定することもできます。
また、AWSは新規のユーザーが参入しやすいように1年間の無料枠も用意しています。
さらに、AWS上のサービスには常に無料のサービスもいくつかあります。
VPC, Elastic Beanstalk, CloudFormation, IAM, Autoscaling, OpsWorksなどのサービスがそれにあたります。メジャーサービスにかかるコスト
AWSの支払い要素には以下のようなものがあります。
- データ転送
- コンピューティング
- ストレージここですこし、データ転送について詳しく説明します。
データ転送にかかるコスト
データ転送に料金は発生しますが、着信データ転送及び同一リージョン内での他サービスとの間のデータ転送については料金が発生しません。
EC2,S3,RDS,SimpleDB,SQS,SNS,VPCにおける発信データは集約され、発信データ転送レートで課金されます。
明細書ではAWS Data Transfer Outという項目になります。次に、サービスごとの特徴を見ていきます。
EC2
EC2ではサーバーの起動時間を元に料金が発生します。
インスタンスを作成したから終了するまでですね。
また、インスタンスのマシン構成を良くしようとしたら、1単位当たりの料金は高くなります。
前述しましたが、EC2にはリザーブドインスタンスの制度があるため、購入プランによって割引はあります。
また、インスタンスの数を増やして負荷分散をするというのは一般的な運用ですが、AutoScalingでインスタンスの数を増やすという行為には料金は発生しませんが、当然増やしたインスタンスの分だけ使用料はかかるようになります。
また、増やしたインスタンスに対して着信を割り振るELBの実行時間や通信料も料金が発生します。
EC2インスタンスはcloudwatchを使って使用状況を監視できますが、これも基本モニタリングだけなら料金はかかりませんが、詳細モニタリングの機能を使用すると料金が発生します。
EC2ではIPを静的に管理したいことがあるため、ElasticIPを使用する場合があります。
これも基本的に料金はかかりませんが、アタッチしたインスタンスが動いていない場合無駄に静的アドレスを確保していることになるので、料金が発生するようになっています。S3
S3はまずストレージのクラスによって料金が変わります。
標準では99.999999999%の耐久性(イレブンナイン)と99.99%の可用性(フォーナイン)を保証しますが、助長性を少し下げるSIA(標準ー低頻度アクセス)オプションをつけることでやすくなります。
ちなみにこちらはイレブンナインとスリーナインになります。
0.01%の可用性の差にこだわらないなら安いほうでいいですね。
また、S3に対してはPUT COPY POST LIST GETなどのリクエストでお金がかかります。
IOPSは考慮されません。(ファイルの大きさではなくリクエストでお金ががかる)EBS
こちらはボリュームタイプで料金が変わります。
汎用(SSD)、プロビジョンドIOPS(SSD)、マグネティックの3種類があります。
まず、料金はストレージをプロビジョンした量(何GBのストレージを用意するか)で毎月お金がかかります。
また、通信にもお金がかかります。
汎用なら入出力、マグネティックはリクエストの数、プロビジョンドIOPSはIOPSをプロビジョンした量もお金がかかります。
プロビジョンドIOPSはデータの出し入れ速度をAWSに保証してもらう機能です。また、EBSではスナップショット(バックアップ)をS3に保存する機能があるので、それもGBあたりでお金がかかります。
また、こちらも着信は無料ですが発信データ転送はお金がかかります。RDS
EC2と同じようにDBインスタンスを立ててから終了するまでの稼働時間でお金がかかります。
RDSは複数の種類のデータベースを管理しているので、どれを使うかによっても価格が上下します。
RDSにもオンデマンドだけでなくリザーブドを行うサービスがあり、こちらは1年もしくは3年の期間でDBインスタンス料金を前払いすると全体的に見て安い金額でRDSを使えるようになります。
また、RDSは負荷があがったときに備えて複数のデータベースをプロビジョンできますが、こちらはアクティブである限り、メインで使用しているデータベースストレージが100%を超えるまでは料金は発生しません。
DBインスタンスが終了していると、バックアップストレージに対して料金がかかります。
また、アベイラビリティゾーンをまたいで複数のDBを管理しようとすると料金がかかります。Cloud front
データをエッジロケーションを通じて低レイテンシーかつ高速に送信するサービスで、料金はリクエストの数によって決まりますが、リージョンによって料金は変わります。
TCO計算ツール
オンプレ環境で運用をしているが、AWSに乗り換えたらどうなるかなということをサーバーの数などを入力することで計算できます。
AWS Total Cost of Ownership 総所有コスト計算ツールは以下から起動できます。
https://awstcocalculator.comこれは以下のことに使用します。
- AWSを使用してコスト削減を見積もる。
- 役員へのプレゼンテーションで使用できるレポートの詳細に使う
- ニーズに最も適合するように前提条件を変更する。これを使用することによって、AWSを使うことでどれだけコストダウンできるかなどの試算をすることができます。
AWS サポートプランの概要
AWSサポートは、すでにAWSを使用しているしていないにかかわらず、すべてのお客様をサポートします。
積極的なアドバイスが必要な場合
テクニカルアカウントマネージャを用意します。
TAMはアドバイス、アーキテクチャレビュー、および継続的な意思疎通によって
ユーザーに常に情報を提供します。
TAMはユーザー専任の担当者です。既にAWSを使用しており、ベストプラクティスを実践しようと考えている場合
AWS Trusted Advisorを使用します。
アカウントの支援が必要な場合
課金・アカウント管理のエキスパートであるサポートコンシェルジュを用意します。
コンシェルジュは技術的なこと以外のすべての課金・アカウントレベルの質問に対応できます。サポートプランのオプション
ベーシックは無料で、下に行くほどレベルの高いサービスが提供されます。
ビジネスサポートまでは、ソリューションアーキテクトによる優れた設計レビューを受けることができません。ベーシックサポートプラン
AWS Trusted Advisor4項目
技術サポートケースを作成できるユーザー0
フォーラム
料金Q&A開発者サポートプラン
AWS Trusted Advisor4項目
技術サポートケースを作成できるユーザー1
フォーラム
料金Q&A
技術Q&A(回答まで最短12時間で電話は不可 メールでの対応で、平日9-18時までの対応)ビジネスサポートプラン
AWS Trusted Advisor全項目
技術サポートケースを作成できるユーザー無制限
フォーラム
料金Q&A
技術Q&A(最短60分で対応し、24時間365日対応 電話もメールもOK)エンタープライズサポートプラン
AWS Trusted Advisor全項目
技術サポートケースを作成できるユーザー無制限
フォーラム
料金Q&A(コンシェルジュ)
技術Q&A(最短15分で対応し、24時間365日対応 電話もメールもOK)
最優先対応
TAMがつくおわりに
はい、疲れました。
大体これくらいの内容を把握していればクラウドプラクティショナーに合格できます。
多くのサービスはやはりインフラとして必要な要素を実現しているものにすぎないので、そういった知識があればすんなりとサービスを理解できると思います。
ただ、運用経験が無かったりインフラ初心者であれば、単語の意味を理解するだけでも手間取り、なかなかAWSについて理解することも難しいと思います。
そんな方に、この記事が少しでも誰かの役に立てば幸いです。
そのうちソリューションアーキテクト(アソシエイト)を取得したら、これらを前提としたうえでさらに必要な知識が何なのかをお伝えする記事を作らせてもらおうかと思っています。(たぶん6月以降...)
正直これをおさらいするだけでも吐きそうなのですが、頑張ります。以上、お疲れ様でした。
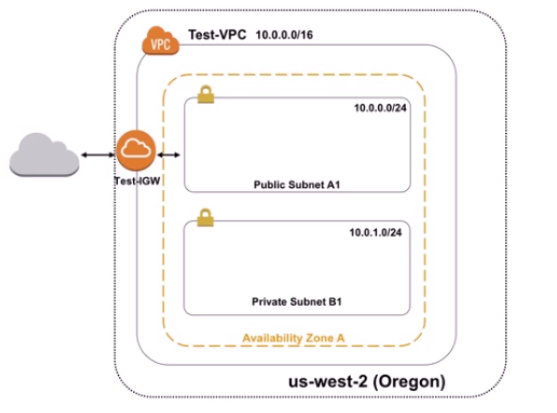
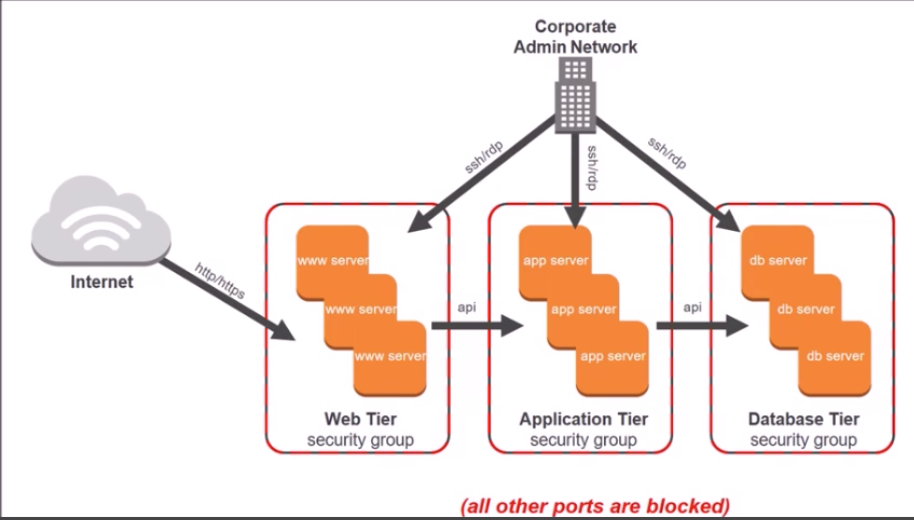
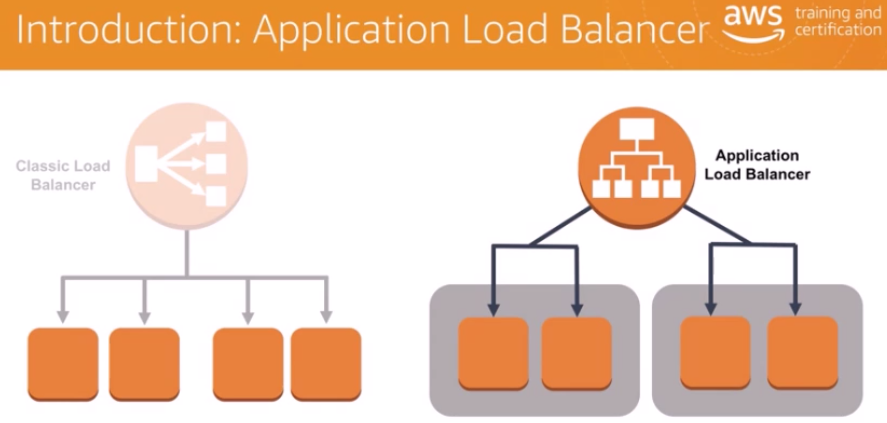
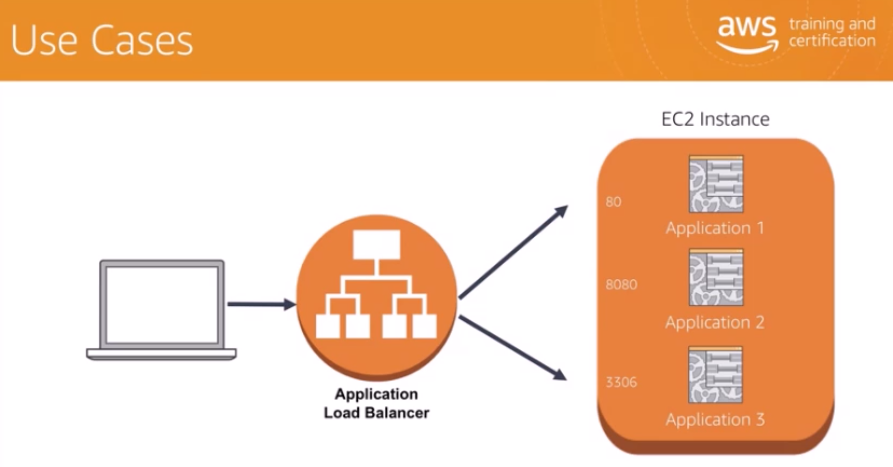
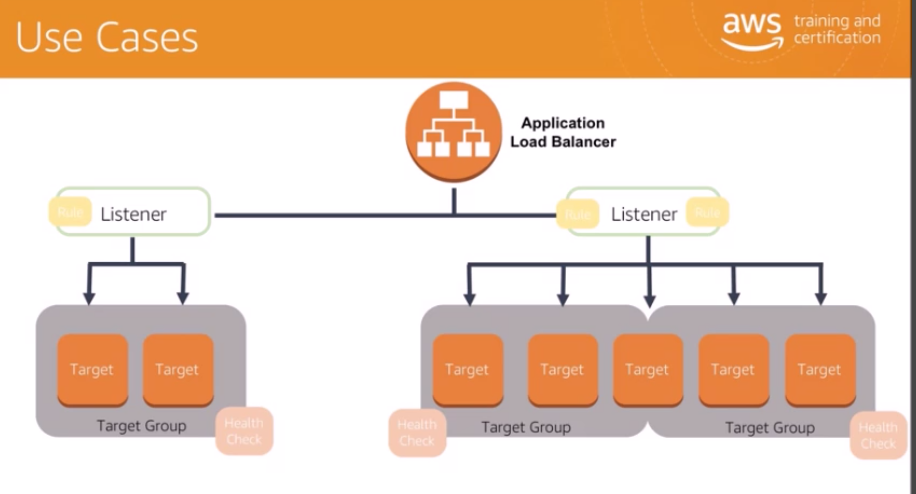

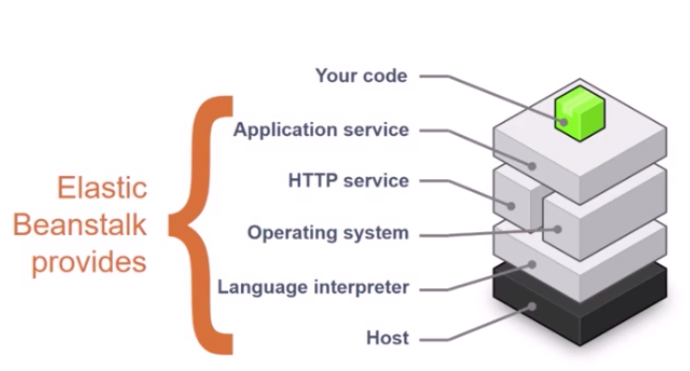
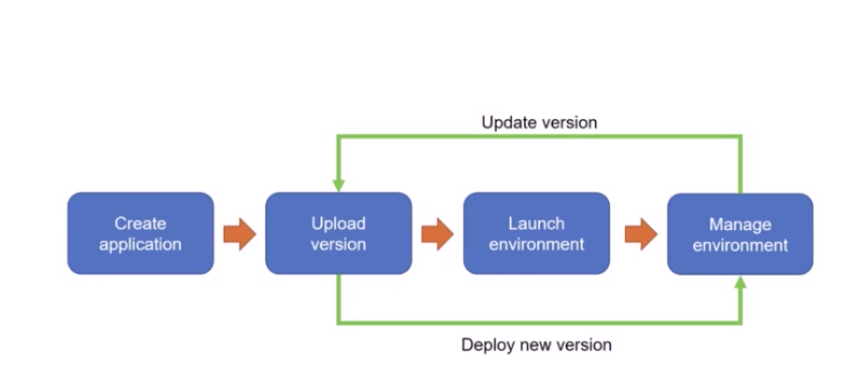
- 投稿日:2020-04-07T19:10:55+09:00
【AWS】DeepComposerを使ってみる
DeepComposerについて
Generative Adversarial Networks(GAN)を利用し、音楽を生成するサービスです。
GANのスキル向上のために、作られたサービスなので、すごい音楽が出力される訳ではありません。利用開始
AWSのアカウントは先に作成しておいてください。
料金について(2020年4月7日時点の情報)
AWS DeepComposerには、下記2つのサービスがあります。
- 推論
音楽を生成する- トレーニング
生成するモデルを学習させるそれぞれに、無料利用枠があるので、気兼ねなく試してみる事ができます?♂️
推論の料金
◆ 無料利用枠
Generative AI を使って 12 か月間、最大500個の音楽作品を無料で生成する事ができます。
◆ 無料利用枠終了後の利用料
2.14 USD / 時トレーニングの料金
◆ 無料利用枠
30日間無料でトレーニングする事が可能です。
◆ 無料利用枠終了後の利用料
1.26 USD / 時サービスの選択
AWSマネジメントコンソールを起動して、サービスの選択画面で
DeepComposerを検索し、選択します。
AWS DeepComposerの初期画面
初期画面に表示された
Get startedをクリックします。
生成AIとGANの基本を学ぶ
Deep Composerを開くと、「Getting started」の内容が表示されるので、
Start learning generative AIを選択します。「Press play on machine learning」という画面が表示されますので、
Get startedを選択すると学習するページが表示されます。
全部英語で長いので翻訳しました→DeepComposerの学習コンテンツ実際に生成してみる
DeepComposerを開いた際に表示される左のメニューから
Music studioを選択します。
メロディーをキーボードで入力する
パソコンのキーボードでも鍵盤を操作する事が可能です。
鍵盤に書かれているキーを押して操作します。
伴奏の自動生成
「Select Model」と記載されている部分から利用したいモデルを選択する
初期状態で選べるモデルは以下の通りです。
- Jazz
- Pop
- Rock
- Symphony
- Jonathan-Coulton
モデルを選択したら、
Generate compositionを選択します。
すると、すぐに伴奏が生成されます。
まとめ
やはり、学習用のサービスであるため、現状は、変な伴奏を生成する部分が多いです。
時間があれば、トレーニングに挑戦して自分だけの伴奏生成モデルを作ってみたいです!DeepComposerのメニューに「Learning capsules」という物があるので、この内容を参考に学習しながらGANについて勉強してみます!


- 投稿日:2020-04-07T18:23:01+09:00
AWS Config / CloudTrail ログをSplunkに取り込んでみた (SQS base S3方式)
はじめに
前回の記事ではSQSベースでS3上の一般的なデータをSplunkに取り込んだのですが、今回はAWSログである AWS Configと CloudTrail ログを取得してみたいと思います。
この2つのログは、ガバナンスを効かせる上で重要になるログで、誰がいつどのような操作をしたのか。リソースに対してどのような設定がされており、どのような変更が加えられたのか。などを記録しておくことで、問題が発生した際の追跡が可能となったり、日頃から問題のある行動や設定をチェックしたりすることができます。
ちなみに、こちらの設定はSplunkが推奨している SNSを使った方法ではなく、S3からイベント通知をあげて取り込む方法で試しております。通知する主体が各サービスなのか、S3なのかの違いになりますが、取り込むデータは同じです。
あとAWS側の設定に関しては、もっといい方法やそもそも間違っている可能性もありますので、ゆるーく見て頂けるとうれしいです。
AWS Config / CloudTrail とは
設定に入るまえに、AWS Configと CloudTrailについて理解しておきたいと思います。
ちなみに今回はこちらの資料を参考にさせていただきました。
https://d1.awsstatic.com/events/jp/2017/summit/slide/D4T3-6.pdfAWS Configログとは?
特定のAWSリソースの設定情報や変更履歴をロギングしたものです。設定情報については定期的にスナップショットとしてS3に保存することができます。対応しているAWSリソースはこちらです。またConfig Ruleのサービスを利用すると設定ルールが守られているかをチェックすることができます。
設定はリージョン毎に行う必要があります。
AWS Configは記録される設定項目につき 0.003 USDかかりますAWS CloudTrailとは?
Configがリソースに対してのログに対して、CloudTrailはユーザーに対しての操作(API)ログになります。誰が、いつ・何に対して・何をしたのか。を確認することができます。
設定は一括に全リージョンを対象に行うことができます。
CloudTrailは無料で利用可能です。取り込み方法
AWSログ別Splunkの推奨取得方法について (Best Practice Input Type参照)
https://docs.splunk.com/Documentation/AddOns/released/AWS/ConfigureInputsConfig と CloudTrailともに SQS Based S3からの取得が推奨されております。
なので前回の取り込み方法で基本的にはいけるかと思います。AWS Configの設定
設定はリージョン毎に行う必要があります
[Config] - [設定] - [編集]
今回は全てのリソースを対象にして、保持期間はSplunkに取り込むため最短の30日とします。ロールはデフォルトのものを利用します。
保存先にS3 Bucketを新規作成します。フォルダー名をeu-west-2とします。SNSトピックなどは設定しません。
設定は以上です。監視対象のリージョンで同じように設定してください。ただし同一のS3 Bucketに保存する際はS3へのアクセス許可を変更する必要があります。
AWS Config Ruleの設定
こちらはオプションですが、 Config Ruleを設定すると、コンプライアンスに準拠しているかチェックすることができます。AWS側で100個以上のルールが用意されているので、そちらを簡単に有効化できます。Compliance状況についてはSplunk側でも確認できます。
[Config] - [ルール] - [ルールの追加]
適当にルールを追加しました。こちらのデータはS3に保管される訳ではなく、直接Splunkとやりとりします。
CloudTrailの設定
[CloudTrail] - [認証情報] - [認証情報の作成]
とりあえず、全てのリージョンを対象にして、読み書き両方のログを設定します。(ログ量が増えるため運用時には要検討).その他の設定はデフォルトのまま。データイベントは記録しません。
CloudTrailの保存用に S3 Bucketを作成します。(既存のS3上でも構いません)
SQSを利用したSplunkへの取り込み
それではログがS3上に保存されているのを確認後、SQSを使ってSplunkに取り込みたいと思います。設定方法に関しては、以前の記事と重複するので割愛します。
こちらの記事をご覧ください。
https://qiita.com/maroon/items/76bc6cae205335924f1a注意点としては
SQS をConfig用とCloudTrail用の2つずつ作成する必要があります(実際は Dead letter queueもあるので、2x2必要ですが)。理由としてはSplunk側で取り込む際にソースタイプが異なるためInputも分ける必要があるからです。そうしないと同一のソースタイプが割り当てられてしまいます。取り込んだ後に苦労します。Splunk側のInput作成では、[Add-On for AWS]Appを開いて Input画面に移動します。
[Create New Input]-[Cloudtrail]-[SQS-Based S3] を選択します。
インデックスはどこでも大丈夫です。(今回はdefault (main)にしました)
続いてconfig についても作成します。
[Create New Input]-[Config]-[SQS-Based S3]
(*)インデックスを default以外にした場合でも、App for AWSを利用できます。(後ほどのSaved searchを実行すると base search macro の indexに追加してくれます)
Add-on for AWSのサーチ画面で確認すると、データが早速取り込まれているのがわかります。
また、Add-On for AWS の「健全性チェック」では、SQSベースの取り込みエラーを確認できます。
少しハマった所としては、同じ環境に Splunk App for Infrastructure (SAI)がインストールされていると、aws:cloudtrail のパースが、他のAppからうまく行きませんでした。これはSAIの中にも aws:cloudtrail のソースタイプがあり、これが KV_MODE=none となっていたため、そちらが優先されてしまいました。修正方法としては SAIのprops.conf に KV_MODE=json と追記して Splunkを再起動してください。
/opt/splunk/etc/apps/splunk_app_infrastructure/local/props.confprops.conf[aws:cloudtrail] KV_MODE = jsonあと、Config Ruleを設定した場合、追加のInput設定が必要です。
[Create New Input] - [Config Rule] をクリックして、必要項目を入力します。(リージョン毎必要)
App for AWS のインストール&確認
AWSログを取り込んだら、App for AWSをインストールして、用意されているダッシュボードを使って中身を確認してみましょう。
App for AWSはこちらから利用できます。あらかじめインストールしておいてください。
https://splunkbase.splunk.com/app/1274/またセットアップについては以下のドキュメントに従って実施します。
https://docs.splunk.com/Documentation/AWS/6.0.1/Installation/CreateIndexesRunSavedSearchesApp用Index作成
最初にAppが利用するIndexを作成します。ドキュメントによると以下のIndexがSummary Index用に必要なようです。「設定」ー「インデックス」ー「新規インデックス」で作成
aws_topology_history
aws_topology_daily_snapshot
aws_topology_monthly_snapshot
aws_topology_playback
aws_vpc_flow_logs
aws_anomaly_detection保存済みサーチ (saved search) のスケジュール実行設定
Indexを作成後、保存済みサーチを実行します。保存済みサーチの中身の解説についてはこちら
https://docs.splunk.com/Documentation/AWS/6.0.1/Installation/Savedsearches「設定」ー「サーチ、レポート、アラート」にて、以下の2つのサーチを実行
・ Addon Synchronization
・ App Upgrader(*)マニュアルにはないのですが、レポートにて「Addon Metadata - Summarize AWS Inputs」も実行するように画面にメッセージが出ていたので、実行した上で上記の設定を行いました。
Addon Synchronization の例 - 実行をクリック
このサーチ実行で、ベースサーチのマクロに AddOn for AWSで保存したAWS logのIndexをマクロに追加されます。これによって main以外に保存されたIndexに対しても Appで確認することができます。
次に「編集」ー「スケジュール設定」ー「スケジュールを有効」 ーそのまま保存(設定値はそのまま)
App を確認してみよう
ほんの一部ですが、App for AWS に含まれているダッシュボードをご紹介します。
(注意)今回 config / cloudtrail 以外に descriptionログも入っておりますので、キャプチャした画面はみなさんのと少し異なるかもしれません。 descriptionは SQSなどの設定も不要なので試してみてください。
概要画面
まだ、CloudWatch などの主要なログが入っていないため一部はまだ表示されてませんが、ほとんどの箇所がうまりました。
「トポロジー」
config ログが入ったため、このようなトポロジーも確認できます。視覚的に各オブジェクトの関係性がわかります。
「Security Group」
セキュリティグループの設定一覧等も可能です。
「IAM Activity」
ユーザーの活動状況なども可視化
「ユーザーアクティビティ」
「EC2 Instance 使用量」
EC2の使用量がチェックできます。CloudWatchログを入れるともっと詳細なデータが確認できます。
[Config Rules]
他にも色々なダッシュボードが用意されておりますので是非試してみてください。
さいごに
今回はガバナンスを効かせるという観点で、AWS Config / Cloudtrailのログを取り込んでみました。これによってリソースがどのように使われているとか、どのような設定になっているか、また誰がどのようなリソースにアクセスしているかなどが確認できるようになります。しかもリアルタイムに。
今度はCloudWatchや VPC Flow logにもチャレンジしてみたいと思います。
(追記)
現時点(4/8)では、Add-on for AWSと ITSI4.4.x を同じインスタンスに同居させてはダメなようです。思いっきりハマってました。https://splunkbase.splunk.com/app/1841/
NOTE: If you're using the Splunk Add-on for Amazon Web Services and Splunk App for Infrastructure (SAI) to monitor AWS data, don't install ITSI version 4.4.x. These versions of ITSI contain SAI versions 2.0.x, which aren't compatible with the Splunk Add-on for Amazon Web Services. If you're using SAI to monitor AWS data with the add-on, these versions of ITSI provide no way to continue doing so
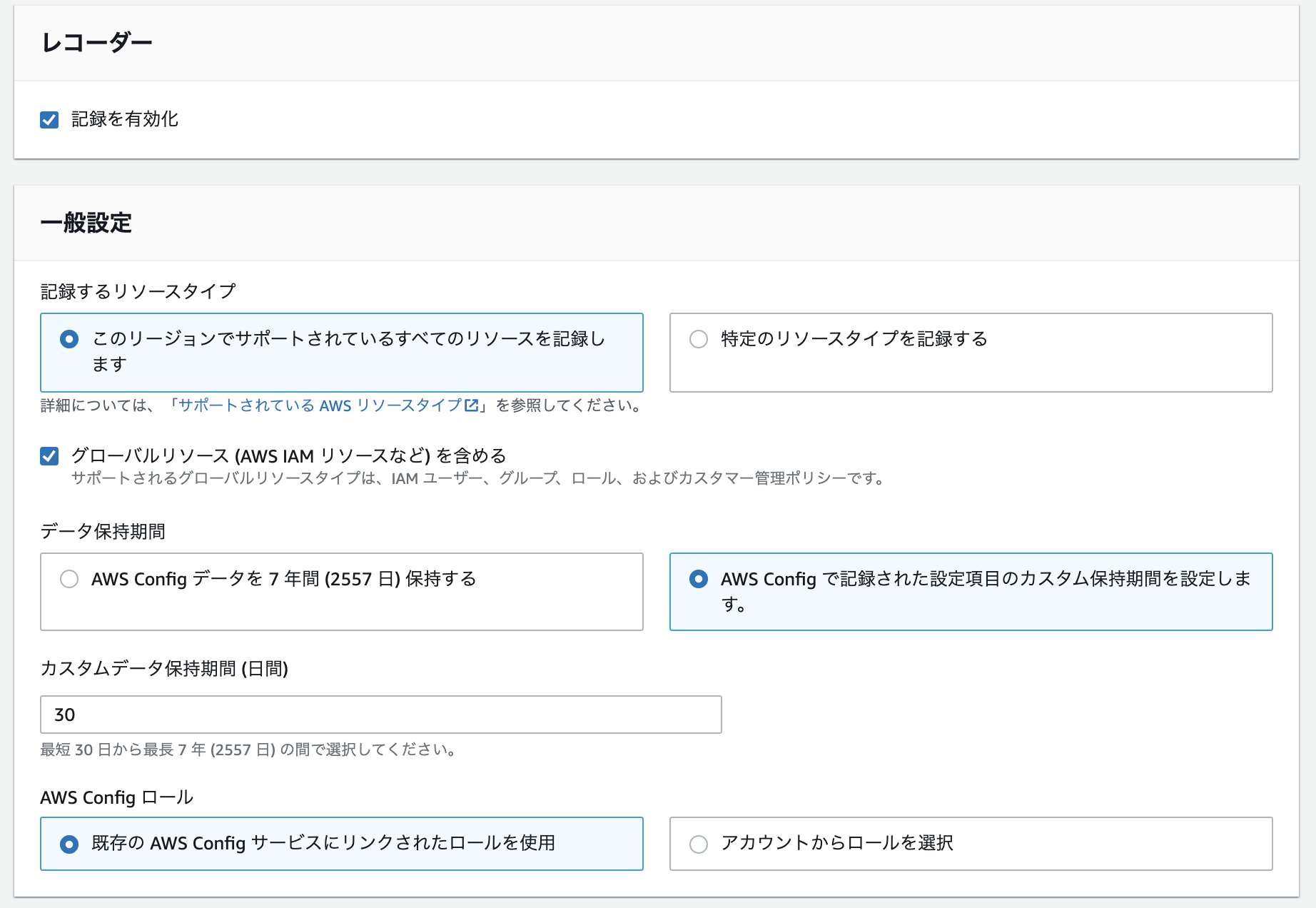
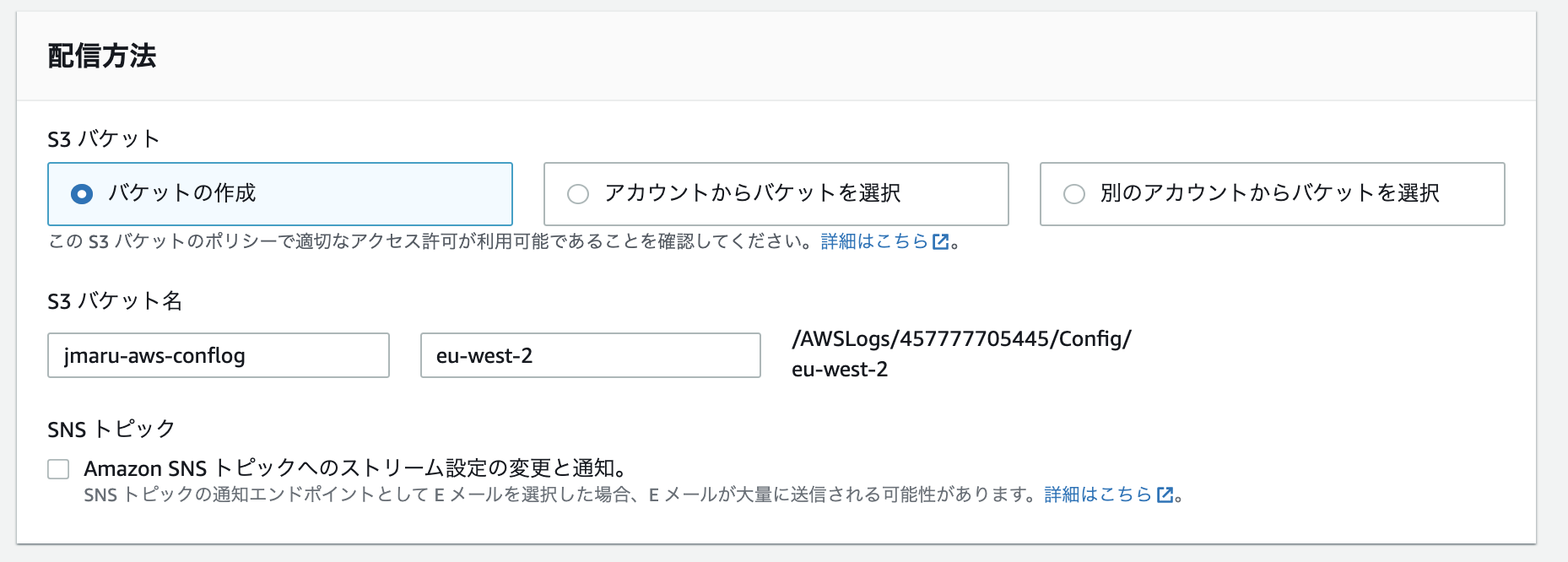
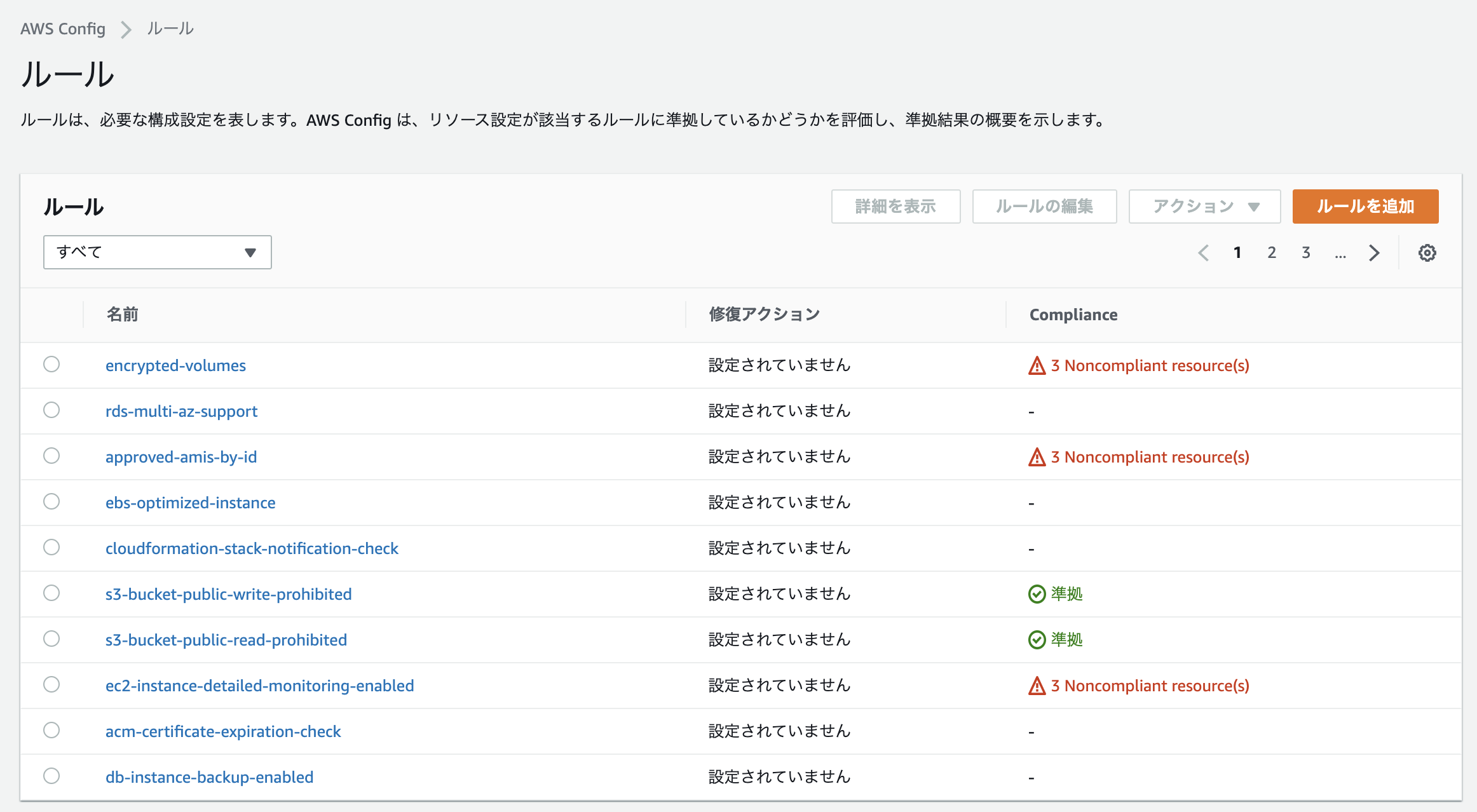
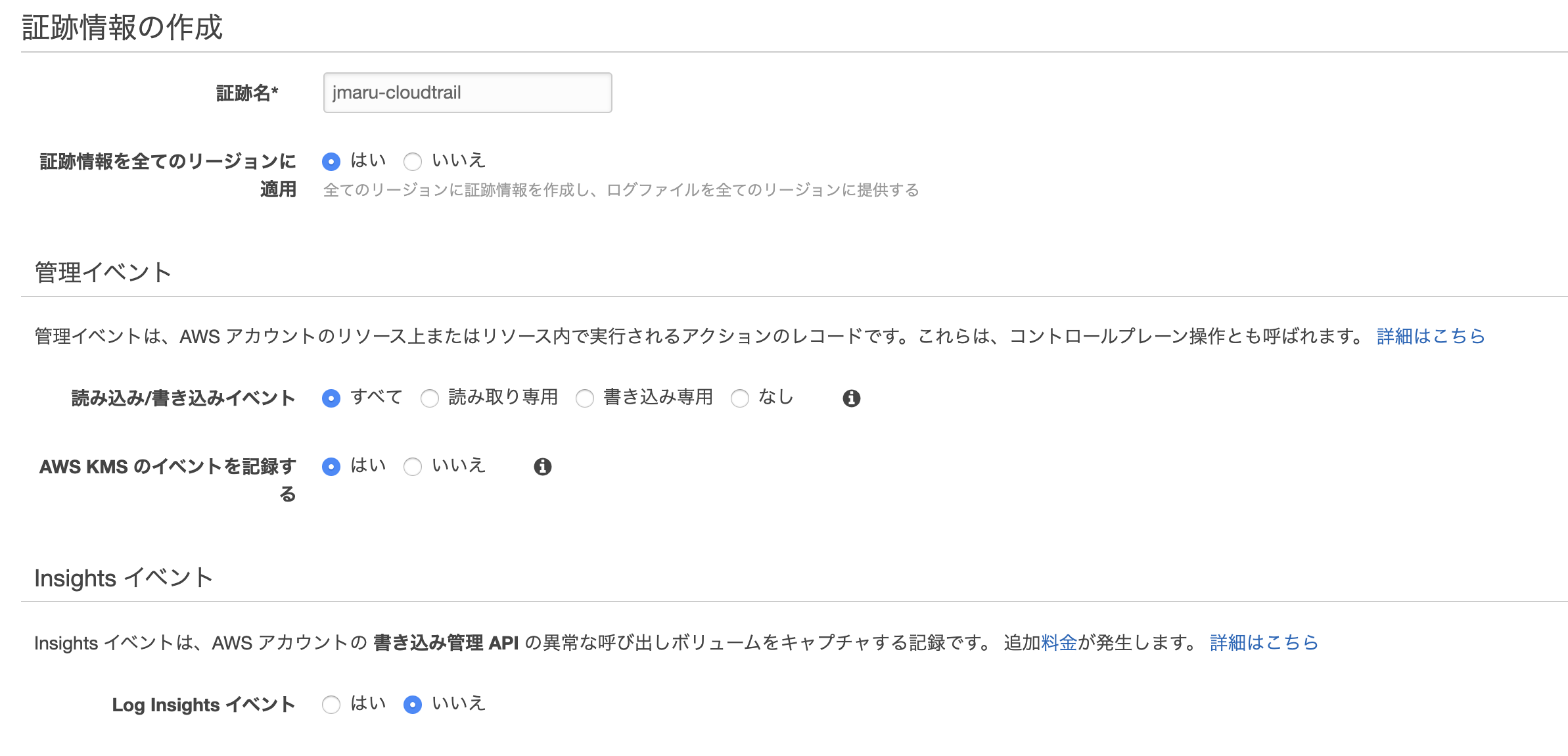
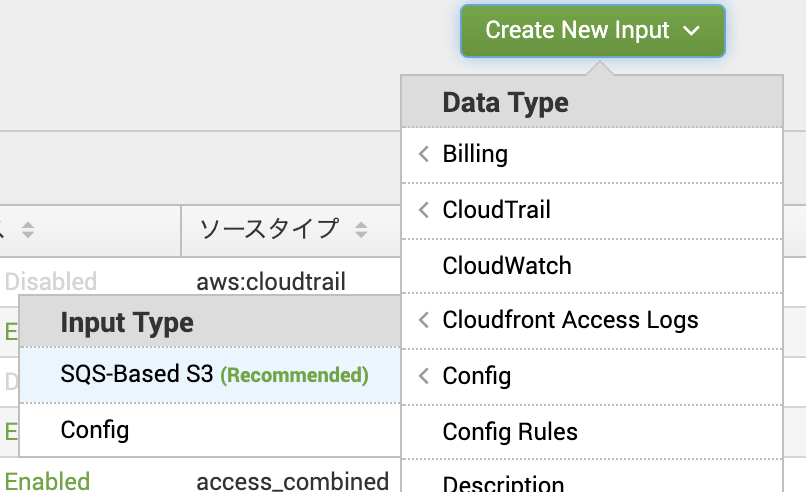
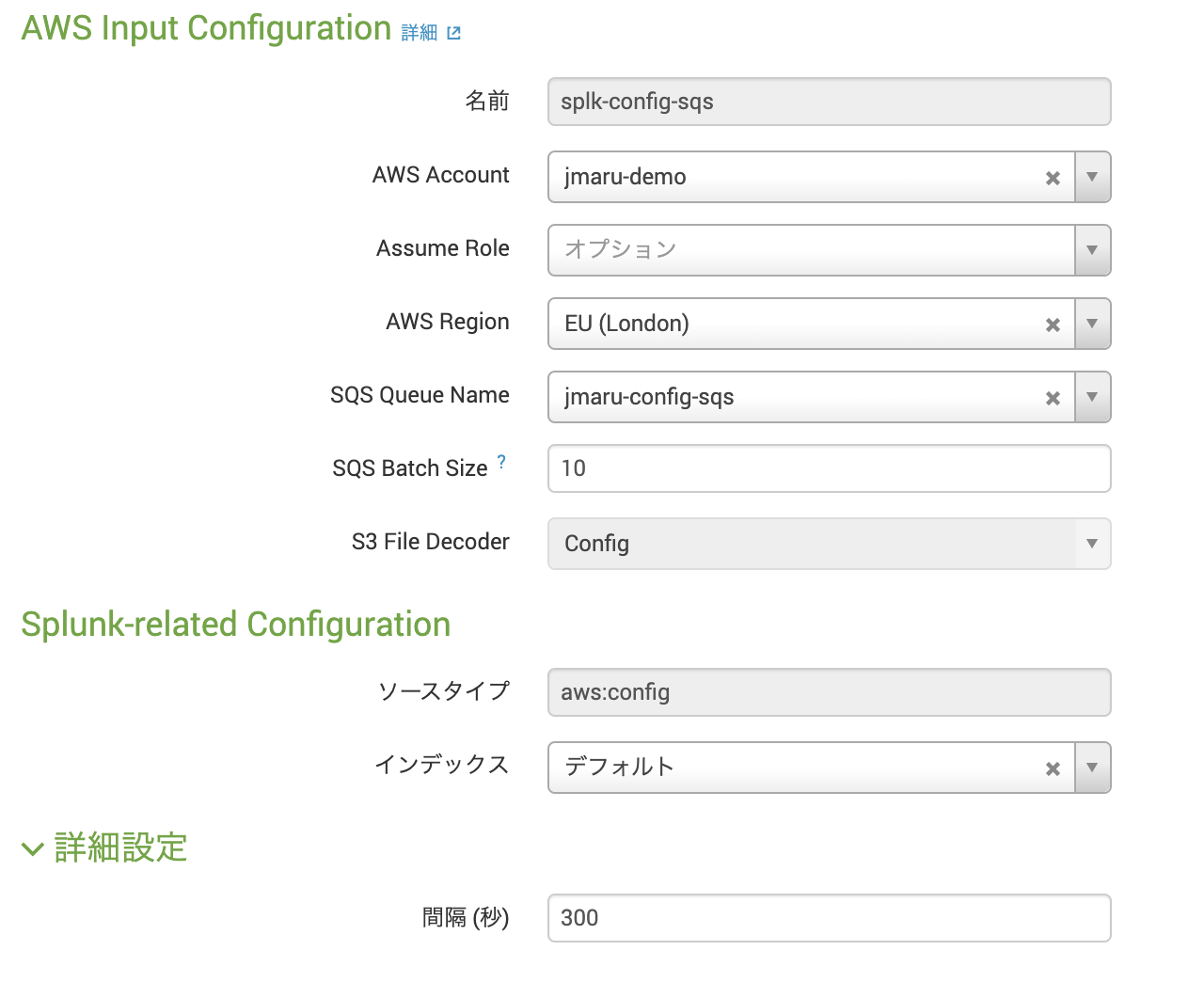
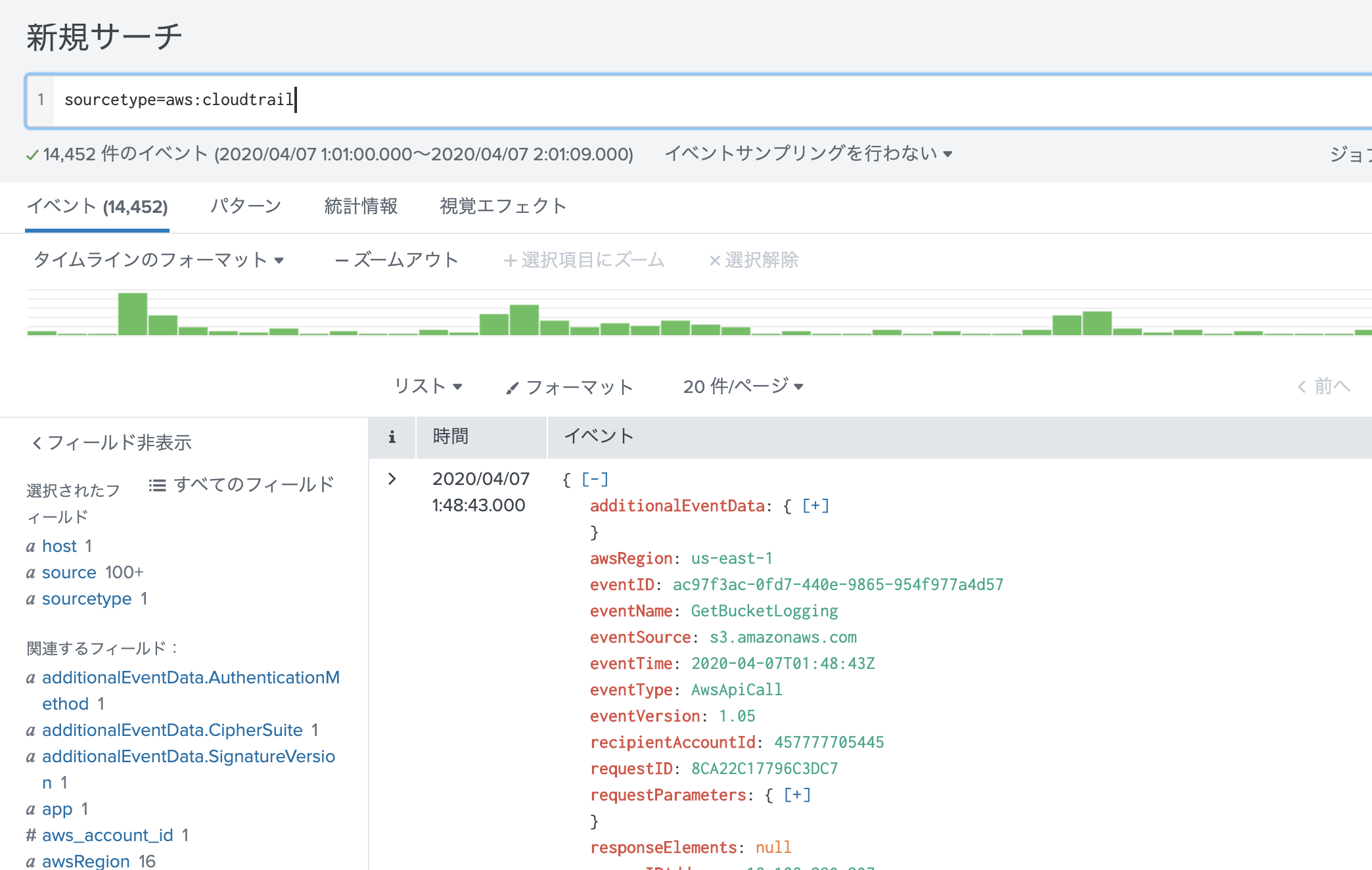
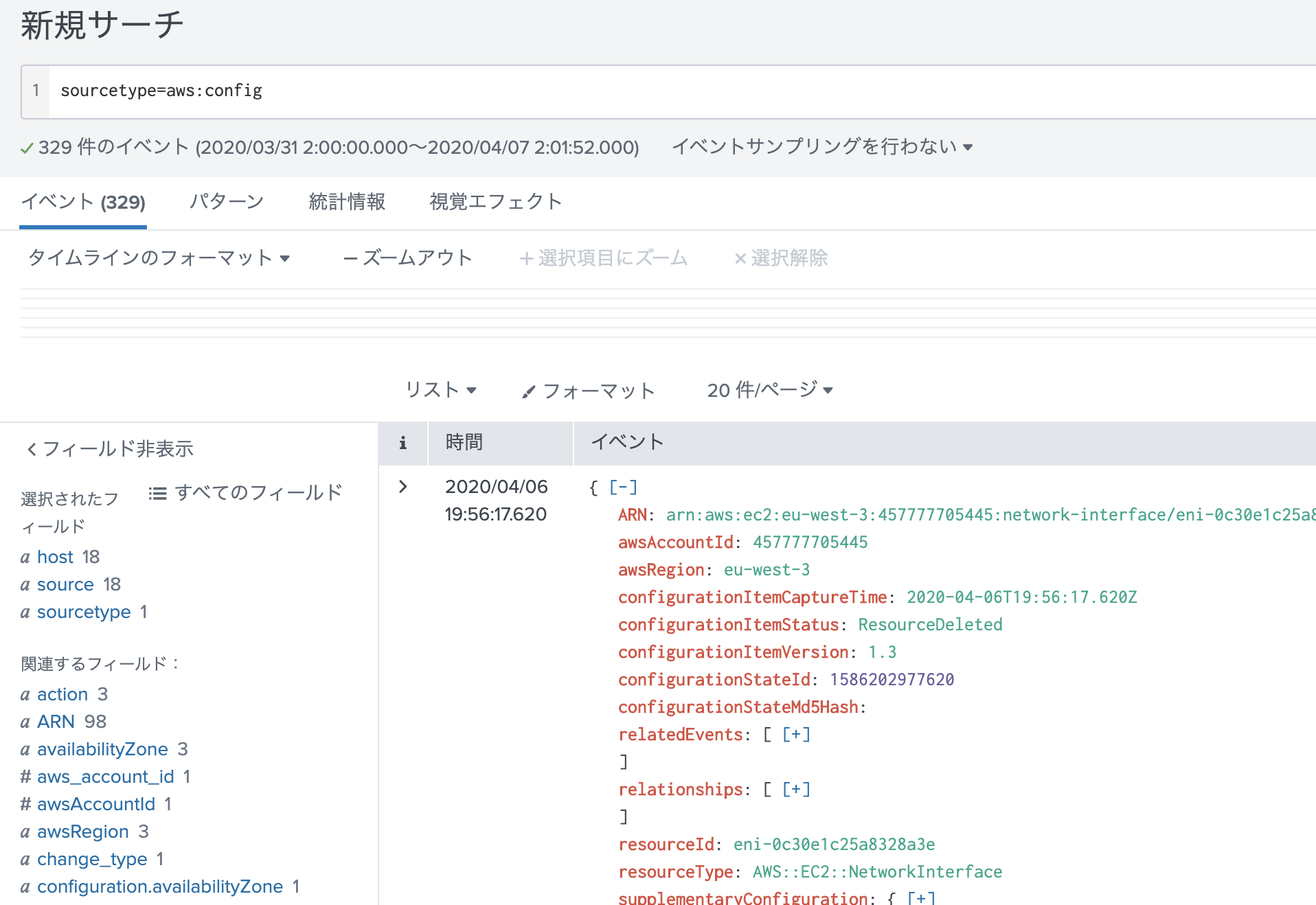
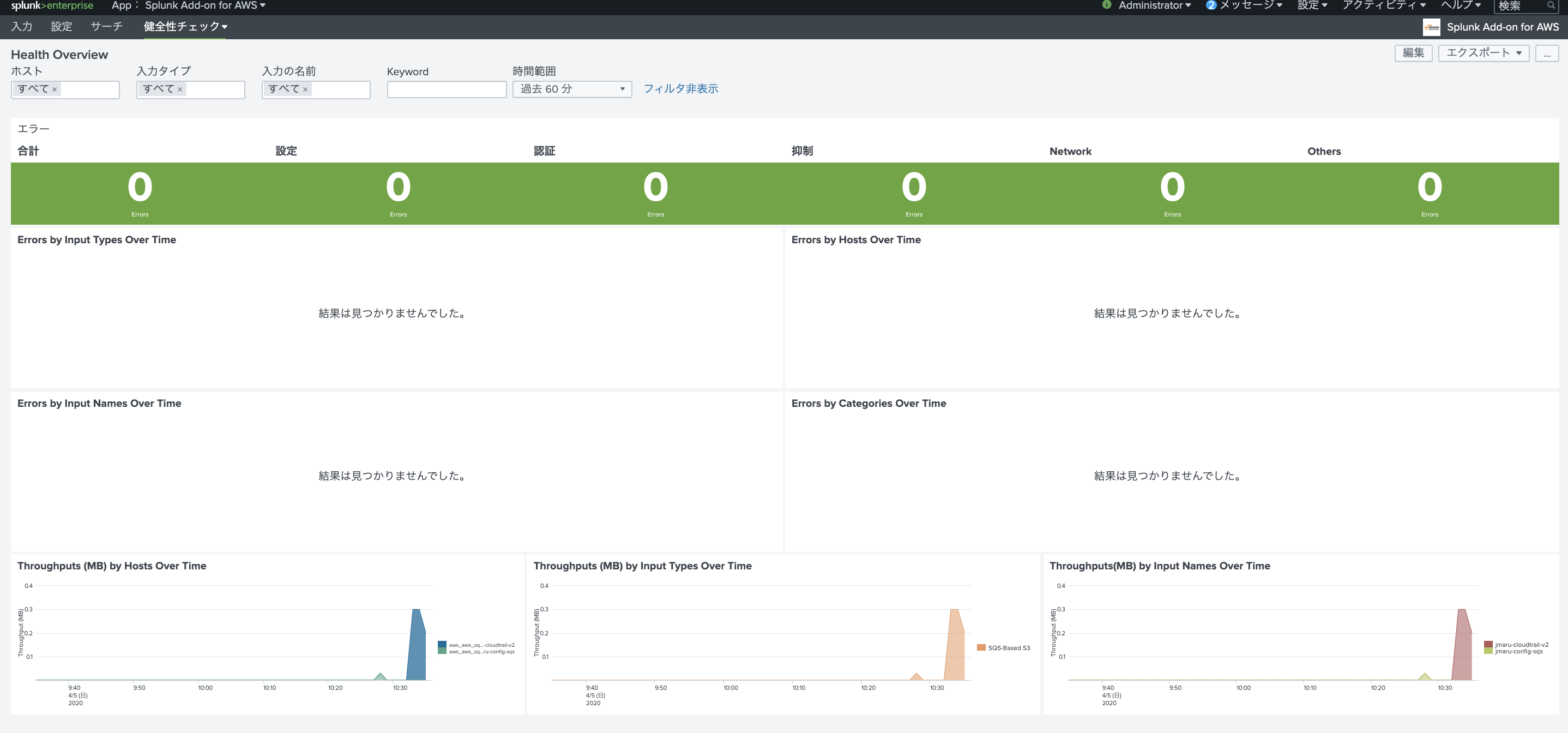

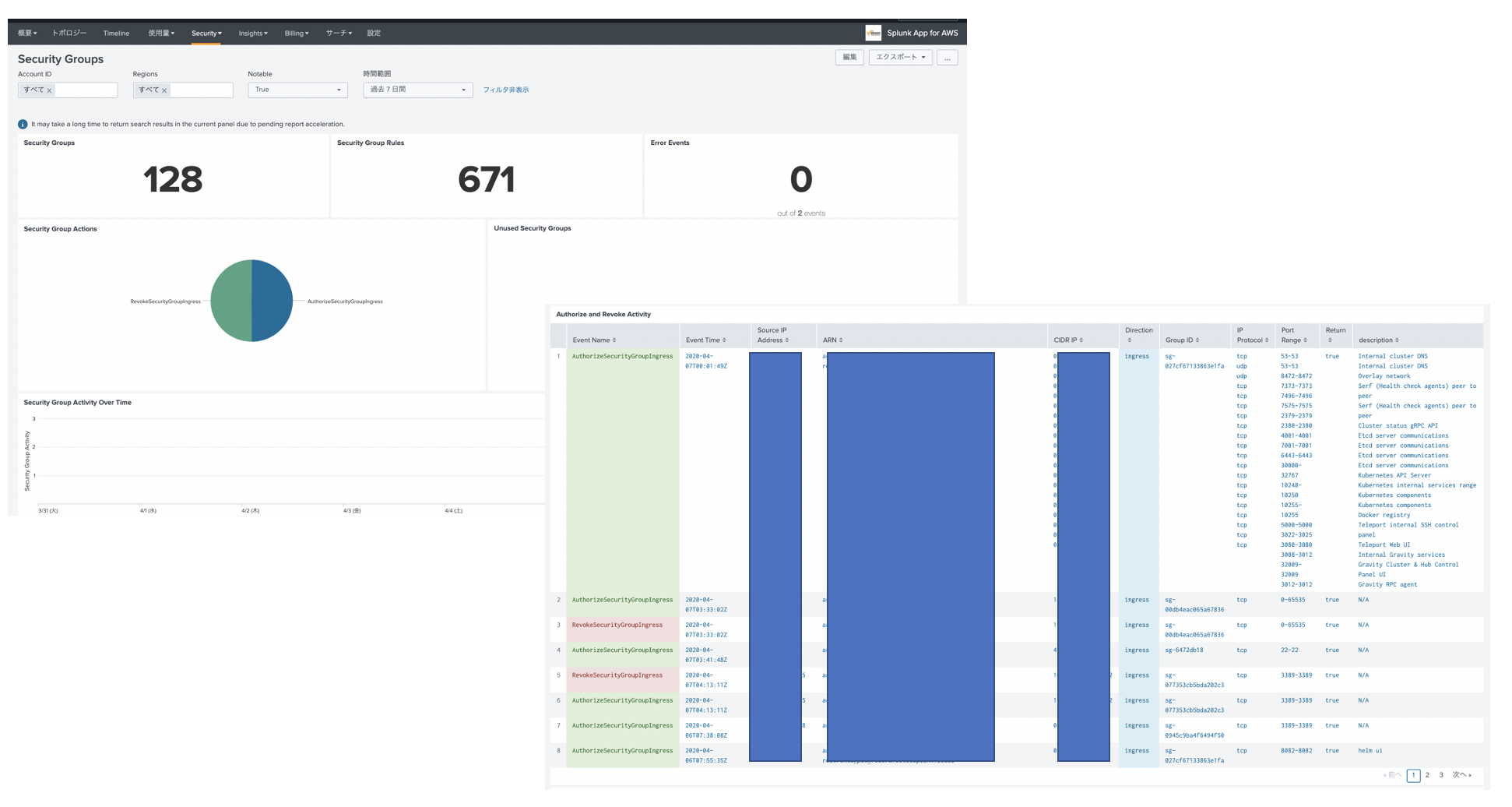
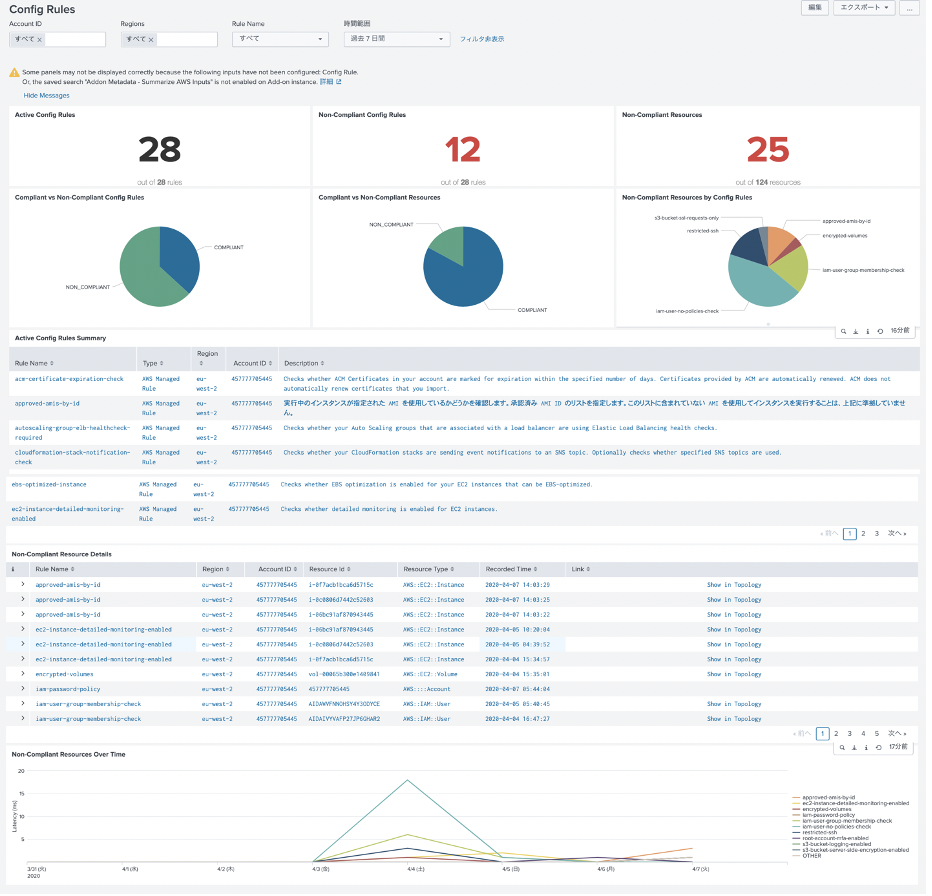
- 投稿日:2020-04-07T18:02:15+09:00
Lambda@Edgeを使用してカスタムゲームコンテンツをプレーヤーに配信する方法
はじめに
AWS の「 Amazon Game Tech 」公式ブログで、ゲームコンテンツをいかにすればネット遅延なく、配信できるのか?という記事をご紹介します!
AWS を利用して構築されている某モバイルゲームなどをよくプレイしていると、画質は綺麗だし動きもまるでコンシューマーゲームと変わらないようなクオリティでプレイできます。
誰かがゲームをプレイするたびに、データがチェックされてダウンロードされています。
プレーヤーの場所に関係なく、どのようにして超高速配信を確実にしているのか、という疑問を説明していきます。超高速配信の為に何をすべきか?
この問題には、 AWS のさまざまな解決策があります!
ほとんどは着信要求を調べ、プレイヤーのリクエストをみて、提供するどのファイルをレスポンスで返すかを決めるコードを実行する web 機能を実装します。ただし、「電光石火の速さ」を必要とすることは少し問題があります。
プレイヤーが世界中にいる場合、ファイルが海中を走っているネット回線を介してダウンロードされているため、ゲームが読み込まれるのを待つ必要がないようにするにはどうすればよいか?
そのデータは CDN(コンテンツ配信ネットワーク)上にある必要があります。コンテンツ配信システム
CDN
- 世界中の複数のサーバーがコンテンツを配信するシステム
- 「マスター」サーバーにチェックインすることで、常に最新のファイルを保持
- 世界中にサーバーがあるので、サーバーがプレイヤーの近くにある可能性が高く、ダウンロードがはるかに高速になる
しかし、CDN だけでは問題は解決しません。
1つのURLがヒットしているため、実際に送信するファイルを決定するコードが必要です。
CDN でコードを実行することはできません。Amazon CloudFront について
AWSは、Amazon CloudFront と呼ばれる、高速で安全性の高いコンテンツ配信ネットワーク(CDN)を提供しています。
CloudFront には、この問題の解決に役立つ 「Lambda@Edge」 と呼ばれる機能があります。
AWS Lambda
サーバーをプロビジョニングまたは管理せずにコードを実行できるサービスです。
Lambda@Edge は、このサーバーレスなテクノロジーを CloudFront にもたらします。Lambda@Edge 関数
- プレーヤーにコンテンツを提供している近くの同じサーバーで実行される
- データを取得するときに CloudFront がプレーヤーに送信するものを決定でき、コンテンツを送信する前に、追加の待機時間が起きるのを防ぐ
- Lambda@Edge にはトリガーのタイプに関する制限があり(すべてCloudFrontを中心)、許可される実行時間が短いが、静的な CDN にはないレベルの実用性が CloudFront に追加される
オリジンとエッジの関係
まず「オリジンサーバー」と「エッジサーバー」とは何なんだと。
「オリジンサーバー」
- ファイルの作成元であり、ファイルの最新バージョンが存在する場所
- CloudFront にデータを取得するために、すべてのサーバーにデータをプッシュする必要がなく、代わりにオリジンサーバーにデータを配置する
「エッジサーバー」
- プレーヤーにデータを提供する、複数のリージョン(地域)のすべてのサーバー
- プレーヤーに送信する前に、常に元のサーバー(オリジン)に新しいデータがあるかどうかを確認し、そのデータもキャッシュする
- データはプレーヤーのために常に準備されており、再びオリジンからそれを取得する必要がない
これが高速な理由です。
遠くから投げられたボールをキャッチするよりも、近くのボールをキャッチするほうが断然早いですよね。
デフォルトでは、キャッシュは24時間残りますが、必要に応じてキャッシュを長くしたり短くしたりできます。所感
よく海外のWEBページの観覧や、ゲームをやっているとなかなか通信が重かったりします。
それは直接遠くにあるオリジンサーバーにアクセスして、大量の負荷がかかり、キャッシュより重いデータメモリにアクセスしているからなんだなと知ることができました。
CloudFront があるだけで、アクセス遅延によるユーザー離れも免れます。公式サイトリンク
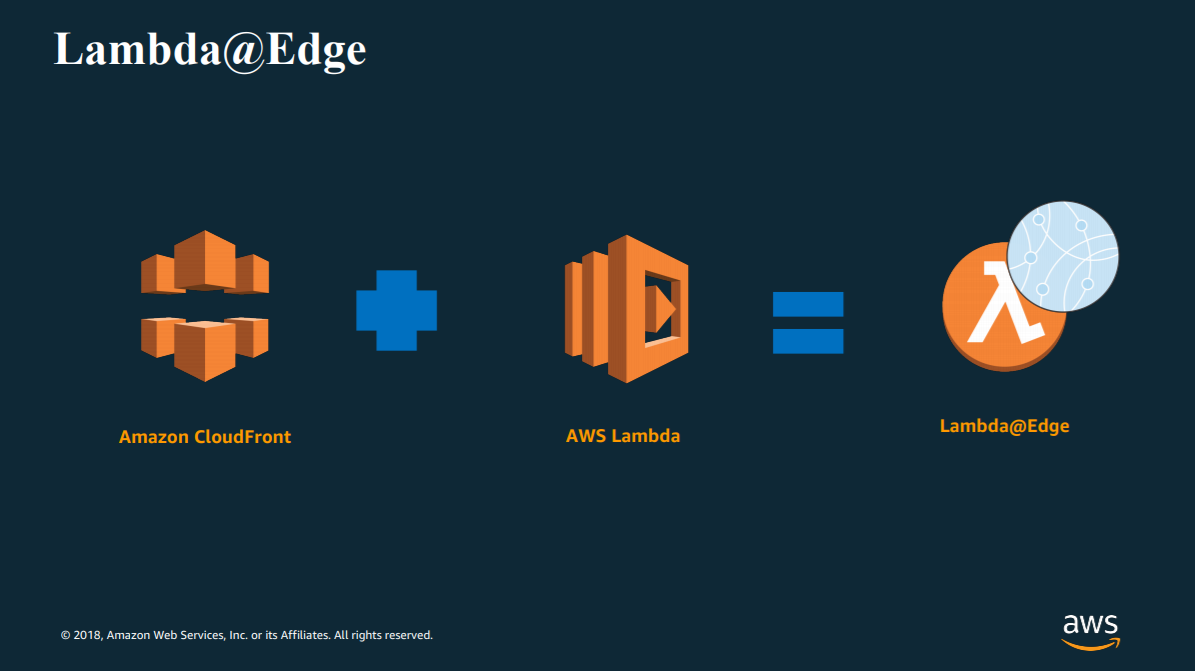
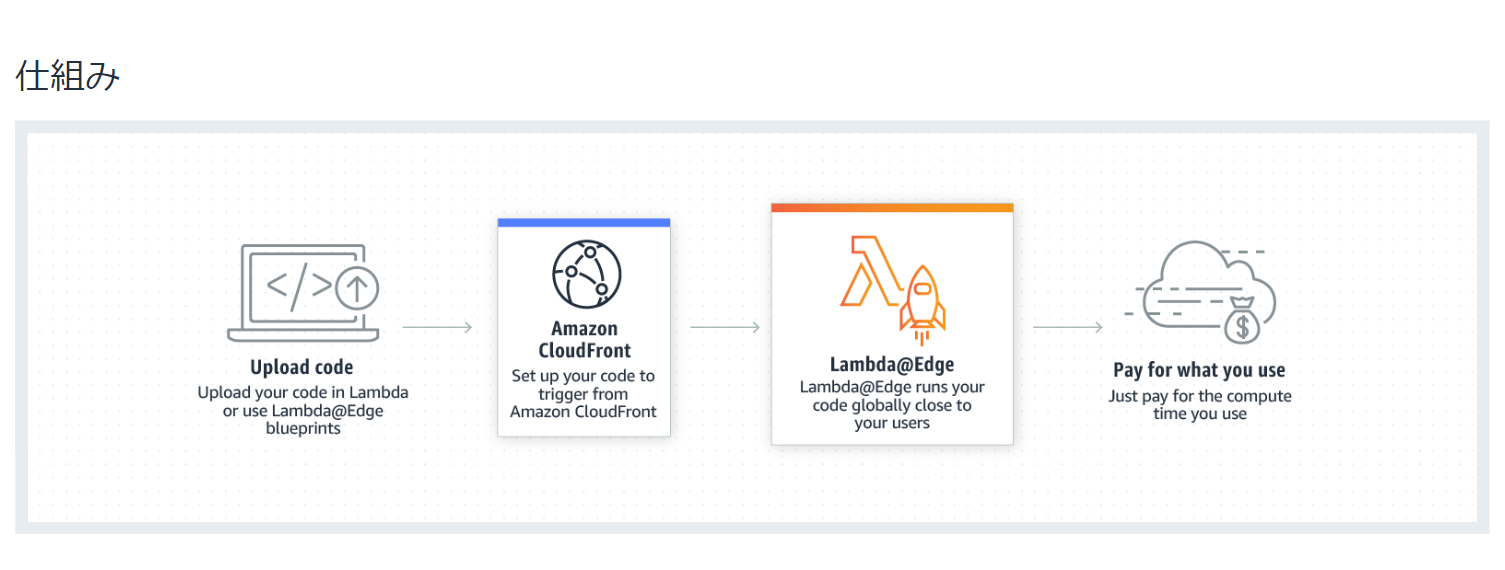
- 投稿日:2020-04-07T17:48:44+09:00
試験に出るAWS:SAAでしょう 第1夜
水曜どうでしょうのパロディにして
勉強のモチベーションを上げようと思ったんですが
水曜どうでしょうそのものにモチベーションを
がっつり持っていかれそう(観てしまいそう)なので
タイトルと語呂合わせくらいにとどめて、
あとは普通に進行していきますちなみにHBCに見学に行ったときに買った
水曜どうでしょうタオルを何年も飾っていたのですが
使ってなんぼちゃう? と思い、とうとう使うことにしました!受験生諸君(自分)!!
これ↓をもとに勉強しています
第1夜はこれを覚えよう!
リージョンとは
- AWSが使う、国や地域のこと
AZ(アベイラビリティゾーン)は
- リージョンの中にいくつもあるし
- 電源とかも独自で供給してるし
- 周りに何もないところに建ててるし
- 一つの部屋の電源落ちてもほかがあるんだよ
AZ(アベイラビリティゾーン)の可用性とは
- AZ(アベイラビリティゾーン)は複数で同期しつつ使うんだ
- 一個だけだと心もとないからね
- これが可用性(-英:Availability; アベイラビリティ- は、システムが継続して稼働できる能力)
- マルチAZ
語呂合わせはこれだ!①(まるいち=マルチ)AZ(あず=明日)はたくさん(あるから)通う(可用)生徒がいるよVPCとは
- 柵に囲まれた村
- 村にインターネットゲートウェイという関所があってここから外に出れる
- 地下通路(仮想プライベートゲートウェイ)からは顧客オンプレミス(別の村の村長の家)に行ける
これぞAWSの中心である
VPCにおいてのIPアドレスとは
- 好きなIPアドレスにできる
- AZの住所
サブネット
- VPC内のアドレスレンジ(住所範囲)、村みたいなものかな
- 仮想ルータがあってデフォルトゲートウェイになっている、村に入る関所みたいなものかな
- 村の中の公民館とか公共施設(パブリックサブネット)
- 村の中のそれぞれの家(プライベートサブネット)
ルートテーブル
- 村に設置された案内板
- 村に一つの案内板でも、村々に対して一つの案内板としてもいい
- ただし村にいくつも案内板を作ってはだめ
語呂合わせはこれだ!いやー、寒いね(サブネット)ー! お客さん、今日はカレールートテーブルは1つしかないよセキュリティグループとネットワークALC
- セキュリティグループは護衛兵っていうことかな(各インスタンスに一つは必要)
- インバウンドは管理人、アウトバウンドは見回りの警備員
- セキュリティグループはステートフル、新人の警備員、インスタンス単位で広く取り締まります
- ネットワークACLはベテランの警備員、サブネットごとに厳しく取り締まります
インターネットゲートウェイ
- 村の関所
- 外部の人とやり取りができる
- 一つだけ設置することができる
- ルートテーブル(案内板)に「関所(IGW)はこちら(0.0.0.0/0)」と書かれる
語呂合わせはこれだ!パプリカ(パブリックサブネット)がこっちを向いていたね、イェイ(インターネットゲートウェイ)仮想プライベートゲートウェイ
- 関所だけど地下通路になっている、ろうそくが壁に刺さって、灯りがゆらゆら…ゆらめいている
- この通路の関所も一つしか作れない、が複数の通路とつなげることができる、迷わないようにしないと…
- こころなしかAWSさんが作ってくれたDirect Connect(通路)のほうが作りがしっかりしてるようだ
語呂合わせはこれだ!へーっVPCっ! くしゃみがでたなら貸そう(仮想)か? ウェア(ウェイ)を1つだけVPCエンドポイント
- 村のー、村の、なんだ、村の勝手口(裏口?)
- 村の外には一見大菜藻(Dynamo)っていう高原しか見えないんだけど、ある入り方をするとその大菜藻高原だった所には、なんと妖精だけが暮らしている村がぼんやり見え出して、そこで管理している金庫があって、そこに村で起きたこと、村人の人数、個人情報が格納されているんだ!きっとそうだ!人々は妖精や妖怪と伝えてはいるが、もしかしたらその時代に地球を調査していた宇宙人かもしれない、大菜藻高原に宇宙船が降り立ってて、村人の何人かだけ、その宇宙船DBに入ることが許されていたんだ!そうに違いない!何を言っているんだ!
語呂合わせはこれだ!遠藤(エンド)ポイッと(ポイント)投げると、しかたなないなーもー(ダイナモ)と江角さん(S3)が受け取るピアリング接続
- 村と村との地下通路で、その通路がつながっているところなら、どの村にでも行き来できる
VPCフローログ
- 門番の持っている帳面ですね
ほんとにこれで試験に受かるのか甚だ疑問ですが
はじめてしまったものは仕方ないですよね最初に村という例えを思いついて書いてしまったもんだから
その後も村の設定してしまいましたが
個人的にはイメージつきやすくなった気もします語呂合わせ、これはどうなの?
語呂合わせ考えるのにめっちゃ時間かかるんだけど、
もはやなんなのかわからなくなってきた続きます

- 投稿日:2020-04-07T17:00:52+09:00
【AWS】Deep Composer 機械学習についての記事
この記事は、こちらのページを日本語化したものです。
機械学習と生成型AIの概要
機械学習の全体像
人工知能(AI)のサブセットである機械学習(ML)は、ビジネス上のより良い意思決定に役立ちます。
機械学習は、機械がデータを分解し、そこから学習して、結果を生成するプロセスです。これらの結果を使用して、主要なビジネス上の意思決定(教師あり学習)、顧客のセグメント化(教師なし学習)、または広告の配置(強化学習)を行うことができます。
強化学習
強化学習モデルは経験から学習し、時間の経過とともにどのアクションが最高の報酬につながるかを識別できます。強化学習では、エージェントは環境を調査して、指定されたタスクを実行する方法を学びます。結果が良好なアクションを実行し、結果が不良なアクションを回避します。
強化学習は、AWS DeepRacerで使用される機械学習のタイプです。
機械学習技術
人工知能(AI)のサブセットである機械学習(ML)は、ビジネス上のより良い意思決定に役立ちます。
機械学習は、機械がデータを分解し、そこから学習して、結果を生成するプロセスです。これらの結果を使用して、主要なビジネス上の意思決定(教師あり学習)、顧客のセグメント化(教師なし学習)、または広告の配置(強化学習)を行うことができます。
教師あり学習
教師あり学習は、予測または分類を生成するために使用される手法です。目標は、入力データと出力データを取得し、2つの変数間のドットを接続する方法についてアルゴリズムをトレーニングすることです。その結果、アルゴリズムは新しい入力から値を分類または出力する方法を学習します。
教師なし学習
教師なし学習を使用して、入力データの分布をよりよく理解します。ドットを出力変数に接続する代わりに、入力変数の間にドットを接続しようとしています。後でこの情報を使用して、教師あり学習ベースのアルゴリズムを開発できます。
AWS DeepComposerで使用される生成AIテクニックは、音楽の基本的なパターン分布を理解して、新しい音楽を生成します。
ジェネレーティブAI
MIT_Technologies_ReviewOne of the most promising advances in AI in the past decade. 過去10年間で最も有望なAIの進歩の1つ。ジェネレーティブAIは、人間とコンピュータの創造性の可能性の世界への扉を開きます。スケッチを画像にして製品開発を加速し、複雑なオブジェクトのコンピュータ支援設計を改善することまで、さまざまな業界で実用的なアプリケーションが出現しています。
生成AIを使用すると、コンピューターは特定の問題の根本的なパターンを学習し、この知識を使用して入力(画像、音楽、テキストなど)から新しいコンテンツを生成できます。活用事例
エアバス
継続的な取り組みの一環として、エアバスは、オートデスクのジェネレーティブデザインを適用して、パフォーマンスと安全性の基準を超える軽量部品を開発することにより、複数の航空機の構造部品を再考しています。
NASA JPL
何百万マイルも離れた惑星(Jupiterは地球から3億6500万マイル)にある着陸船の設計とエンジニアリングの課題に対処するために、JPLとオートデスクは複数年にわたる共同研究プロジェクトに取り組んでいます。JPLは、オートデスクの生成設計技術のカスタムアプリケーションを使用して、宇宙探査のための設計および製造プロセスへの新しいアプローチを模索しています。
グライドウェル研究所
Glidewell Dentalは、画像から詳細な3Dモデルを再構築することに長けているGPUを利用した生成敵対ネットワークをトレーニングしています。彼らは王冠デザインの深度マップをGANと組み合わせています。このネットワークでは、1つのネットワークが画像を生成し、2番目のネットワークがそれらの画像を検査します。これにより、元の歯よりも解剖学的に細かい歯冠ができます。
ジェネレーティブAIプレイグラウンド
人間かAIか?
作曲とは、私たちが独自に人間と考える創造性の行為です。機械は、音楽の連続した構造を再現することを学び、後続の音符の可能性の離散的なセットから選択できる必要があります。
音楽はポリフォニックです—さまざまな楽器で同時に演奏される複数のノートストリーム。ピアニストがコードを保持している間、ギタリストはより速いノートを演奏し、機械学習タスクに複雑さを加えます。ジェネレーティブミュージックの例
AWS DeepComposerで利用できる生成AIネットワークには、U-NetとMuseGANの2つのタイプがあります。
U-Netアーキテクチャは、もともと画像を生成するために作成されました。ネットワークは、音楽を解釈する前に画像のような表現に変換します。このように音楽をエンコードおよびデコードすることにより、ネットワークは音楽の一般的な表現を学習できます。
MuseGANアーキテクチャは、音楽を生成するために特別に構築されており、各楽器と曲全体のコンポーネントがあります。各楽器の固有の特性をキャプチャし、それらが互いに調和して全体的な歌を生成する方法を把握できます。ジェネレーティブAI — GAN
ジェネレーティブAIアルゴリズム
ジェネレーティブAIは幅広いカテゴリのアルゴリズムであり、最も一般的なものはジェネレーティブアドバサリアルネットワーク(GAN)、変分オートエンコーダー(VAE)、自己回帰(AR)モデルなどです。
ジェネレーティブAIアルゴリズム
ジェネレーティブAIは幅広いカテゴリのアルゴリズムであり、最も一般的なものはジェネレーティブアドバサリアルネットワーク(GAN)、変分オートエンコーダー(VAE)、自己回帰(AR)モデルなどです。
生成的敵対的ネットワーク
生成的敵対的ネットワーク(GAN)は、2つのニューラルネットワークが競合する機械学習ネットワークの一種です。一方のネットワークは、現実的なコンテンツ(教師なし学習)の生成を担当し、もう一方のネットワークは、生成したコンテンツを実際のデータ(教師あり学習)と区別する役割を果たします。
Generator(ジェネレーター)
GAN内のGeneratorは、現実的な外観の出力を生成するようにトレーニングされた機械学習モデルです。
ジェネレーターはオーケストラのようなものです—洗練された音楽をトレーニング、練習、生成しようとします。Discriminator(ディスクリミネーター)
Discriminatorは入力を取り、入力が実数または生成するか否かを分類するように訓練された別のマシン学習モデルです。
Discriminatorはオーケストラの指揮者のようなものです—出力の品質を判断し、訓練された音楽のスタイルを達成しようとします。GANの動作の流れ
コンテンツ生成
最初に、Generatorはランダム入力に基づいてコンテンツサンプルを生成します。
コンテンツの分類
Discriminatorは、Generatorが作成したコンテンツサンプルで、訓練されたデータセット(例:ポップ、ロック、クラシック)から特徴(例:テンポ)を探します。コンテンツサンプルがトレーニングセットに属するかどうかを決定します。
GANのトレーニング
Discriminatorの判断の結果は、両方のモデルのトレーニングに使用されます。Generatorは、Discriminatorが実際のサンプルと区別できない現実的なコンテンツを生成するために最適化するようにトレーニングされています。一方、Discriminatorは、生成されたコンテンツを検出する能力を高めるように訓練されています。
2つのモデルが互いに直接競合するこの前後の動作は、GANの敵対的な部分です。コンピュータが音楽を理解する方法
コンピュータ音楽入門
機械学習モデルが音楽を解釈および生成できるようにするには、音楽の再生方法の正確な詳細を保持する形式で音楽を表すことが重要です。
サウンドファイルを処理する代わりに、AWS DeepComposerで使用されているような機械学習モデルがこれらの詳細を調べて、楽器や音楽スタイルを忠実に再現します。これらの属性のいくつかを見てみましょう…
ピッチ
ピッチは、音階上の相対位置が割り当てられているトーンです。各音符には数値が割り当てられており、0から最低音まで、最高音は127まであります。
AWS DeepComposerキーボードのキーの範囲は41〜72です。オクターブ調整ボタンは、ピッチの値を12の倍数単位で上下にシフトして、ピッチを高くしたり低くしたりします。速度
Velocityは、単一のノートが押される強さをエンコードします。キーをより速く押すと、ベロシティの値が高くなり、より大きなサウンドが作成されます。速度の値の範囲は、1(最小、ほとんど聞こえない)から127(最大)です。
テンポ
テンポは、音楽の再生速度を表します。音楽は通常、特定のビートまたはメーターに追従し、演奏されるノートのリズムを動かします。このビートの速度は、ビート/分で測定されます。1分あたりのビート数が多いほど、再生速度が速くなります(テンポ)。
MIDI
MIDIのファイル形式は、レコードや店舗の音楽をコンピュータで使用される業界標準です。ファイル形式は、使用される楽器の再生テンポや、ノートのピッチやベロシティなど、押したり離したりするノートをエンコードする一連のイベントなどの詳細をエンコードします。
ピアノロールの視覚化
MIDI形式は、ピアノロールビジュアライゼーションを使用して部分的に表すことができます。これは、データの視覚化に役立ちます。時間は水平次元で表され、ピッチは垂直次元で表されます。バーは押されているノートを表します。小節の始まりは演奏されているノートの始まりであり、小節の終わりはリリースされているノートです。
ジェネレーティブAIとDeepComposer
モデルをトレーニングする
独自のモデルをトレーニングして、実践的な体験をしてください。モデルの仕組みを理解し始めます。GANには2つの競合するニューラルネットワークがあります。1つのモデルは生成的で、もう1つのモデルは識別的です。Generatorは、目的のデータ分布にマップするデータを生成しようとします。
1.アルゴリズムを選択する
モデルをトレーニングする生成アルゴリズムを選択します。
2.データセットを選択
データセットとして音楽のジャンルを選択します。
3.ハイパーパラメーターを微調整する
モデルのトレーニング方法を選択します。
モデルを理解する
トレーニング中にジェネレーターとディスクリミネーターの損失がどのように変化したかを調べます。トレーニング中に特定の音楽指標がどのように変化したかを理解します。すべての反復で固定入力に対して生成された音楽出力を視覚化します。
ミュージックスタジオ
Music Studioを使用すると、音楽を再生してGANを使用できます。まず、メロディーを録音するか、デフォルトのメロディーを選択します。次に、事前トレーニング済みモデルまたはカスタムモデルを使用して、オリジナルのAI音楽作品を生成します。
1.メロディーを録音する
AWS DeepComposerキーボードまたはコンピューターのキーボードを使用して、入力用の短いメロディーを録音します。
2.構成を生成する
入力メロディーに満足したら、モデルを選択してから、[ コンポジションを生成]を選択します。
3. AWS DeepComposerは付随するトラックを生成します
AWS DeepComposerは入力メロディーを取り、最大4つの伴奏トラックを生成します。
AWS DeepComposerに飛び込む
ミュージックスタジオ
AWS DeepComposerキーボードまたはウェブブラウザを使用してメロディーを入力します。事前トレーニング済みのジャンルモデルをすぐに試すことができます。
生成モデルのトレーニング
アルゴリズムアーキテクチャを実際に試すために、トレーニングモデルを実験して評価します。
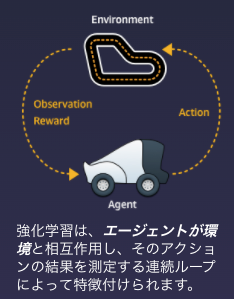


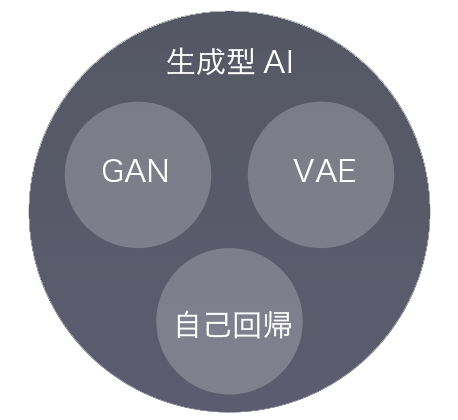
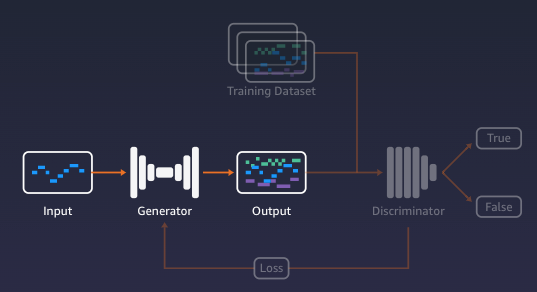
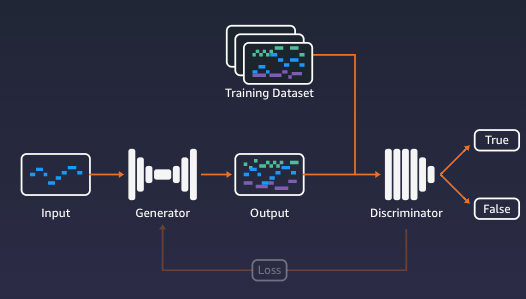
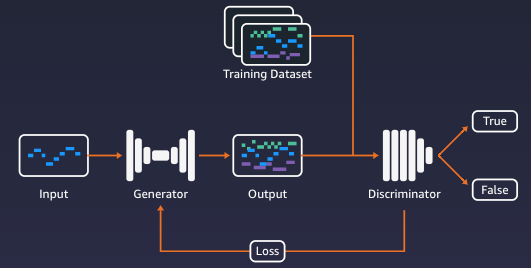

- 投稿日:2020-04-07T15:41:03+09:00
AWS CodeCommitでMFA認証してHTTPSで通信する方法
Assume Role実施(以下はサンプルです)
RESPONSE = `aws sts assume-role \ --duration-seconds 3600 \ --role-arn $arn \ --role-session-name session-$timestamp \ --token-code $token \ --serial-number $number \ --profile xxx` export AWS_ACCESS_KEY_ID=`echo ${RESPONSE} | jq .Credentials.AccessKeyId -r` export AWS_SECRET_ACCESS_KEY=`echo ${RESPONSE} | jq .Credentials.SecretAccessKey -r` export AWS_SESSION_TOKEN=`echo ${RESPONSE} | jq .Credentials.SessionToken -r`以下の設定をCodeCommitのリポジトリに設定しましょう
$ git config --local credential.helper '!aws codecommit credential-helper $@' $ git config --local credential.UseHttpPath trueちょっとこれだけだと不親切な記事だと思うので、後日補足予定です。
- 投稿日:2020-04-07T15:18:32+09:00
ECSのタスクのスケジューリングを使用時に設定すべきこと
やること
ECSのタスクのスケジューリングを使用する場合、タスク起動の失敗を検知して通知されるようにしておく。
理由
タスクのスケジューリング機能を使用すると、設定した時間にタスクが新規に立ち上がり、プログラムを実行した後、タスクは終了する。
しかし、何らかの理由でタスクの起動に失敗し、プログラムを実行しないままタスクが終了することがある。このとき、タスクの起動に失敗したからといって自動でもう一度タスクの起動を試みるということはない。
プログラムの実行中にエラーが発生したら通知する仕組みを入れていても、そもそもプログラムが実行される前にタスクが終了するので検知することができない。
つまり、タスクのスケジューリングでバッチを実行していた場合、バッチがコケたことに気づくことができない状況が発生する。
実際、本番運用中のシステムにおいてタスクのスケジューリングでバッチを実行していたが、検証時にバッチで更新されるはずのデータが更新されていないことに気付き、調査してはじめてタスクの起動に失敗している(バッチがコケている)ことが分かった。
具体的な方法
CloudWatch Eventでタスク起動の失敗を検知して通知する。
WebコンソールでCloudWatch Eventsのルールの作成からルールを新規に作成していく。
イベントパターンを選択し、サービス名は「Elastic Container Service (ECS)」、イベントタイプは「すべてのイベント」にし、あとはイベントパターンのJSONを編集して下記の内容にする。{ "source": [ "aws.ecs" ], "detail-type": [ "ECS Service Action" ], "detail": { "eventType": [ "WARN", "ERROR" ] } }ターゲットに、システム運用のエンジニアメンバーに通知するSNSトピック等を設定してルールを作成する。
設定は以上。これで検知できるイベントやイベント発生時に配信される内容の形式は公式ページを参照。
Amazon ECS イベント サービスアクションイベント以下は
detail-typeがECS Service Actionで、detail-typeのeventTypeがWARNまたはERRORのイベントについての引用。WARN イベントタイプのサービスアクションイベント
SERVICE_TASK_START_IMPAIRED
サービスは一貫してタスクを正常に起動することができません。SERVICE_DISCOVERY_INSTANCE_UNHEALTHY
サービス検出を使用するサービスに、異常なタスクが含まれています。サービススケジューラは、サービスレジストリ内のタスクが正常でないことを検出します。ERROR イベントタイプのサービスアクションイベント
SERVICE_DAEMON_PLACEMENT_CONSTRAINT_VIOLATED
DAEMON サービススケジューラ戦略を使用するサービス内のタスクは、サービスの配置制約戦略を満たさなくなりました。ECS_OPERATION_THROTTLED
Amazon ECS API スロットルの制限により、サービススケジューラが調整されました。SERVICE_DISCOVERY_OPERATION_THROTTLED
AWS Cloud Map API スロットルの制限により、サービススケジューラが調整されました。これは、サービス検出を使用するように設定されたサービスで発生する可能性があります。SERVICE_TASK_PLACEMENT_FAILURE
サービススケジューラがタスクを配置できません。原因は、reason フィールドに説明されます。このサービスイベントがトリガーされる一般的な原因は、タスクを配置するためのクラスターでリソースが不足しているためです。たとえば、使用可能なコンテナインスタンスに CPU またはメモリ容量が不足しているか、使用可能なコンテナインスタンスがない場合などです。もう 1 つの一般的な原因は、Amazon ECS コンテナエージェントがコンテナインスタンスで切断され、スケジューラがタスクを配置できない場合です。
SERVICE_TASK_CONFIGURATION_FAILURE
設定エラーのため、サービススケジューラがタスクを配置できません。原因は、reason フィールドに説明されます。このサービスイベントがトリガーされる一般的な原因は、タグがサービスに適用されてはいるが、ユーザーまたはロールがリージョンで新しい Amazon リソースネーム (ARN) 形式にオプトインしていないためです。詳細については、「Amazon リソースネーム (ARN) と ID」を参照してください。もう 1 つの一般的な原因は、Amazon ECS が IAM ロールが提供するタスクを継承できなかったことです。
記事投稿日:2020/4/7
- 投稿日:2020-04-07T15:04:39+09:00
awscurlを使う
署名を作成しなくてもインスタンスプロファイルから取得したクレデンシャルでAWSリソースの認可を取得できるので便利。
awscurl
https://github.com/okigan/awscurl
留意点
アクセスキー等のクレデンシャルはexportして環境変数とするか、awscurlのオプションとして渡す必要がある。
参考:一時的な認証情報を使用した IAM 認証
https://docs.aws.amazon.com/ja_jp/neptune/latest/userguide/iam-auth-temporary-credentials.html
- 投稿日:2020-04-07T13:58:33+09:00
AWS CDKで使用するSystems Managerのパラメータの作成方法
はじめに
AWS CDKを使用する時、ARNなどをコードにベタ書きすると、セキュリティ面がいまいちなので、Systems Managerのパラメータストアにセキュアにしたい値を入れて使いたいなと思いました。
もともとはパラメータストアのスタックもCDKのデプロイ時にcontextとかから、渡して作成したいなと思っていたのですが、現状それはできなさそうです。
じゃあどうすればいいのか?
それはAWSのドキュメントに書いてありました。
https://docs.aws.amazon.com/cdk/latest/guide/get_ssm_value.html#ssm_write
どうやらSystems Managerへのパラメータの登録はAWS CLIからのようです。つまりCDKからは厳しそうですね。パラメータ登録用のスクリプト
CDKでは「必要なパラメータのリストを一覧して、多くのパラメータを一気に登録する」ということができなさそうだったので、登録用のスクリプトを作成しました。
create_parameters.sh#!/bin/bash # # パラメータキーの一覧表示 # key=("PARA1" "PARA2") declare -a value echo "登録が必要なパラメータキー一覧です" echo for ((i=0;i<${#key[@]};i++)) do echo "${key[i]}" done # # パラメータキーの正誤確認 # while : do echo read -p "パラメータキー一覧は正しいですか?(y/n): " PARAM_CHECK case "$PARAM_CHECK" in [yY]) echo echo "パラメータの値を入力してください" break ;; [nN]) echo "パラメータキー一覧の編集をしてください" exit ;; *) echo "yかnのみ入力してください" esac done # # パラメータ値の入力 # for ((i=0;i<${#key[@]};i++)) do read -p "${key[i]}: " VALUE value[i]=$VALUE done echo echo "入力した値の一覧です" echo for ((i=0;i<${#key[@]};i++)) do echo "${key[i]}: ${value[i]}" done # # パラメータ値の入力内容確認 # while : do echo read -p "入力した値は正しいですか?(y/n): " VALUE_CHECK case "$VALUE_CHECK" in [yY]) echo read -p "パラメータを登録するAWSプロファイル名を入力してください: " PROFILE break ;; [nN]) echo "パラメータの値を入力し直してください" exit ;; *) echo "yかnのみ入力してください" esac done # # パラメータの登録 # echo echo " パラメータを登録しています" for ((i=0;i<${#key[@]};i++)) do aws ssm put-parameter --overwrite --name "${key[i]}" --type "SecureString" --value "${value[i]}" --profile $PROFILE done echo " 登録が完了しました。"このshファイル内の
keyリストのところに登録したいパラメータキーを予め入力しておいて$ sh create_parameters.shを実行し、表示された案内に沿って値を入力していけば、パラメータストアに値を登録することができます。(すでに登録されている場合は上書きされます。)
- 投稿日:2020-04-07T12:34:37+09:00
AWSのEC2へのアクセス分散と自動拡張について
ELB(イー・エル・ビー)
外部からの通信リクエストを分散をさせたい場合、AWSでは"ELB"を利用します。
ELBには、
CLB(Classic Load Balancer)
ALB(Application Load Balancer)
NLB(Network Load Banancer)
の3種類があります。
参考サイトロードバランサ
インターネット等の外部ネットワークからのリクエストを複数のサーバに割り振る装置です。これによって、ネットワークの負荷を分散(ロードバランシング)することができます。
パソコン=>インターネット=>ロードバランサ=>サーバ、、、がいくつもある感じです。ロードバランサを利用する理由とは
スマートフォンのブラウザで動くゲームAを例に説明します。
このゲームAでは、常時100人以上の人がアクセスしています。このゲーム用のサーバは同時に100アクセスであれば1台のサーバで対応できるものの、ブラウザのゲームなので画面が変わるたびにアクセスが発生します。そうなると常時100人以上の人がアクセスしている場合、サーバへのアクセス数はその数倍となる300〜500アクセスとなります。そのため、1台のサーバでは処理できません。
このような時にロードバランサを利用します。例えば、ロードバランサに6台のサーバを配下に持たせます。こうすることで1台では100アクセスしか対応できなかったものが、6台あるので600アクセス(6台×100アクセス)まで対応できるようになります。
さらにこのゲームでは6台配下に持たせているので、1台サーバが停止しても500アクセス受け付けられるのでユーザには影響ありません。つまり、サーバ障害に強い構成にすることができます。SSL
SSLという暗号を利用したWeb用の通信(HTTPS通信)が推奨されていますが、ロードバランサを利用することでロードバランサにそのSSLの設定を行うことで、ロードバランサ配下のサーバにはSSLの設定が不要にすることができます。
これによって、サーバ自体の設定を簡略することができます。ELB設定例
AWSのALBやCLBには無料枠がありますが、2台以上のELBを稼働させたりELBを通過した一ヶ月の通信量が15GBを超える場合は課金が発生します。
ELBの配下に接続するEC2インスタンスは事前準備をしてください。またnginxも動いている状態にしておいてください。
ELBの作成を開始します
1、AWSのコンソールにサインインします。
2、サービス→EC2をクリックします。
3、ロードバランサをクリック(左側カラムの真ん中あたりにあります)し、「ロードバランサの作成」をクリックします。
4、必要な設定値を入力して、セキュリティ設定の構成をクリックします。
(ALBの名前の入力やHTTP/HTTPSの別、対象VPCとアベイラビリティゾーンのチェックなどを実施)
5、右下にある「セキュリティグループの設定」をクリックしてから、HTTP/HTTPSの別に合わせてセキュリティグループを設定し、設定後ルーティングの設定をクリックします。
6、ターゲットグループの設定値を入力してから「ターゲットの登録」をクリックします。(ターゲットグループの名前を入力したり、配下のサーバの生存確認=ヘルスチェックで利用するパス等を入力)
7、配下に組み入れるEC2インスタンス選択(チェック)してから「登録済みに追加」をクリックし、追加できたら「次の手順:確認」をクリックします。
8、設定内容を確認して問題なければ「作成」をクリックします。
9、作成が完了したら「閉じる」をクリックするします。
10、サービス→EC2→ターゲットグループ(左のロードバランシングにあります)→ターゲットをクリックし、ステータスがhealthyになってことを確認します。
11、ロードバランサー(左のロードバランシングにあります)をクリックし、説明→DNS名でアクセスできるかを確認します。
これでELB(ALB)の設定が完了です。
もし使わない場合はすぐに削除して、不要な課金が発生しないようにしてください。ELBを使う時の注意点
ELBはリクエストを分散できるので便利なのですが、以下のような場合は注意が必要です。
アプリケーションが1台のサーバで完結することを前提にしている場合
例えばショッピングサイトでは「商品をカゴに入れる→注文に必要な情報を入れる→最終確認後に注文ボタンを押す→注文が確定する」という一連の流れが発生します。しかしロードバランサによって最初に振り分けられたサーバと別のサーバに振り分けられると、そこで一連の流れが途切れてしまいまた最初からやり直しが必要だったりします。
そこでこのような場合は、ELBでセッション維持の設定を行います。
設定したい場合は、以下のように設定することで設定情報を持つ秒数の間は一定のサーバに振り分けられるようになります。
1、ELBを作成した後に"維持設定の編集"をクリックします。
2、"ロードバランサーによって生成された Cookie の維持を有効化"を選択します。
3、設定情報を持つ秒数を入力します。
なおこれはELBに限らず、ロードバランサを利用する時も同様です。
(設定方法はロードバランサによって異なるので、利用しているロードバランサに合わせて設定方法を確認ください)
なおセッション維持はELBの設定による方法だけでなく、redisなどのKVSを利用する方法等もあります。それぞれメリットとデメリットがあるのでサービスの要件に応じて使い分けるようにしてください。AutoScale(オートスケール)
AWSならではのサービスとして"AutoScale"と呼ばれるサービスがあります。
Webサービスには、昼間はほとんどアクセス数はないが夜になるとアクセス数が増えるとか、突発的にアクセス数が増えるといったものがあります。
時間帯によるアクセス数の増減が大きかったり予測ができない場合に役立つのが、AutoScaleです。これによって、必要な時に必要な数のインスタンスを用意することが可能となります。
CPU使用率やトラフィック量を事前に設定しておいた値を超えたらインスタンス台数が増え、その値より下がったら起動するインスタンス台数を減らすといった挙動ができます。AutoScaleでは外部からのアクセスはまずはELBで受けるため、ユーザはその配下のインスタンス台数を意識しなくても大丈夫です。AutoScale設定例
※なお課金はEC2インスタンスやELBの利用として発生します。(無料枠もEC2インスタンスやELBに従う)
起動設定の作成
1、AWSのコンソールにサインインします。
2、EC2→Auto Scaling グループ(左にあります)クリック→Auto Scaling グループの作成をクリックします。
3、「今すぐ始める」をクリックします。
4、AutoScaleで利用するAMI(今回はAmazon Linux AMI)の「選択」をクリックします。
5、インスタンスサイズを選択(今回は上から2番目をクリックしてます)し、「次の手順:詳細設定」をクリックします。
6、設定名(名前を入力)を入力して「確認画面にスキップ」をクリックします。
7、設定内容を確認し、問題なければ「起動設定の作成」をクリックします。
8、EC2インスタンスで利用するキーペアを選択して「起動設定の作成」をクリックします。(EC2インスタンス作成時と同様に行います)AutoScalingグループの作成
1、設定値を入力してから「スケーリングポリシーの設定」をクリックします。
2、「このグループを初期のサイズに維持する」→「次の手順:通知の設定」をクリックします。
これはEC2インスタンスに障害が発生してシャットダウンしても、自動的に1台起動する設定です。
これによって、いつでも必ず1台のEC2インスタンスが動いている状態を作り出すことでサービス全体が停止する状態を防ぐことができます。
なおAutoScaleの発動条件や起動するEC2インスタンスの最大数を設定したい場合は、もう一つの「スケーリングポリシーを使用して(以下略)」の方を選びます。
3、通知に必要な設定値を入力して「次の手順:タグを設定」をクリックします。
AutoScaleが動いた時の通知設定をします。
「通知の送信先」は設定名を、「受信者」の欄には実際に存在するメールアドレスを、通知するイベント種類をチェックしてください。
4、必要に応じてタグの設定をしてから「確認」をクリックします。(問題なければ何も入力せずに確認をクリックで大丈夫です)
タグの設定は任意なので、未設定でも問題ありません。
5、設定値を確認して問題なければ「Auto Scalingグループの作成」をクリックします。
6、「閉じる」をクリックして終了です。
- 投稿日:2020-04-07T11:12:42+09:00
Rails on Lambdaの環境構築
はじめに
Rails+Lambdaの記事が少なかったので投稿します。
この記事はRails+Lambda(+APIGateway)でGET /meが実行できるところを目指します。
Railsはある程度分かるけど、Docker使ったことない、サーバレスやりたい人向けです。
今回SAMは使わずある泥臭いやり方で行います。
mysqlは今回コード上では使いませんが、デプロイの関係で構築は行っています。もしRDSやDyanamo使いたい場合は適時調べて行ってください。環境
Docker for Windows
Ruby 2.7
Rails 6
MySQL 5.xディレクトリ構成
rails_api ├── Dockerfile ├── docker-compose.yml ├── Gemfile ├── Gemfile.lock各種ファイル
Dockerfile
native extension を含む gem を lambci/lambdaの docker イメージでビルドしなおしをするため、イメージはLambdaのものを使用します。
FROM lambci/lambda:build-ruby2.7 # install required libraries RUN yum -y install mysql-devel # install bundler RUN gem install bundler WORKDIR /tmp ADD Gemfile Gemfile ADD Gemfile.lock Gemfile.lock RUN bundle install WORKDIR /app COPY . /appdocker-compose.yml
version: '3' services: mysql: image: mysql:5.7 command: mysqld --character-set-server=utf8 --collation-server=utf8_general_ci ports: - "3306:3306" volumes: - mysql-data:/var/lib/mysql environment: MYSQL_DATABASE: app_development MYSQL_USER: root MYSQL_PASSWORD: password MYSQL_ROOT_PASSWORD: password app: tty: true stdin_open: true build: . command: bash -c "rm -f tmp/pids/server.pid && bundle exec rails s -p 3000 -b '0.0.0.0'" volumes: - .:/app ports: - "3000:3000" depends_on: - mysql volumes: mysql-data: driver: localGemfile
railsは最新版をとりあえず。
すでにローカル環境でRailsを動かせている人は不要です。source 'https://rubygems.org' gem 'rails', '~> 6.0.2', '>= 6.0.2.1'Gemfile.lock
空ファイルで作成
すでにローカル環境でRailsを動かせている人は不要です。Rails作成(Rails new + Rails Server)
ネット環境の良い場所で行いましょう。そこそこ時間がかかります。
すでにローカル環境でRailsを動かせている人は不要です。$ docker-compose run app bundle exec rails new . --force --database=mysql Starting rails_api_mysql_1 ... done exist force README.md identical Rakefile create .ruby-version create config.ru create .gitignore force Gemfile 以下省略ここでGemfileが新しく生成されるので不要なgemを削除します。(必要な場合は入れてください。)
## 以下削除 gem 'sass-rails', '>= 6' # Transpile app-like JavaScript. Read more: https://github.com/rails/webpacker gem 'webpacker', '~> 4.0' # Turbolinks makes navigating your web application faster. Read more: https://github.com/turbolinks/turbolinks gem 'turbolinks', '~> 5' # Build JSON APIs with ease. Read more: https://github.com/rails/jbuilder gem 'jbuilder', '~> 2.7'docker build & railsサーバ起動
Railsサーバ起動
$ docker-compose build $ docker-compose up ※問題があればここでエラーします。 app_1 | => Booting Puma app_1 | => Rails 6.0.2.1 application starting in development app_1 | => Run `rails server --help` for more startup options app_1 | /var/runtime/gems/actionpack-6.0.2.1/lib/action_dispatch/middleware/stack.rb:37: warning: Using the last argument as keyword parameters is deprecated; maybe ** should be added to the call app_1 | /var/runtime/gems/actionpack-6.0.2.1/lib/action_dispatch/middleware/static.rb:110: warning: The called method `initialize' is defined here app_1 | Puma starting in single mode... app_1 | * Version 4.3.3 (ruby 2.7.0-p0), codename: Mysterious Traveller app_1 | * Min threads: 5, max threads: 5 app_1 | * Environment: development app_1 | * Listening on tcp://0.0.0.0:3000 app_1 | Use Ctrl-C to stopとりあえず、localhost:3000 で確認
Mysql2::Error::ConnectionErrorが発生しているので、すこし修正します。
database.ymlの修正
将来のことも考え、productionも記載します。
productionには環境変数で設定しているため、Lambdaの環境変数を使ってユーザ名、パスワードなどを設定します。default: &default adapter: mysql2 encoding: utf8 pool: <%= ENV.fetch("RAILS_MAX_THREADS") { 5 } %> timeout: 5000 username: root password: password host: mysql development: <<: *default database: app_development # Warning: The database defined as "test" will be erased and # re-generated from your development database when you run "rake". # Do not set this db to the same as development or production. test: <<: *default database: app_test production: <<: *default username: <%= ENV['MYSQL_USER'] %> password: <%= ENV['MYSQL_ROOT_PASSWORD'] %> database: <%= ENV['MYSQL_DATABASE'] %> host: <%= ENV['MYSQL_HOST'] %> socket: <%= ENV['MYSQL_SOCKET'] %>再度Railsサーバ起動+localhost:3000 確認
$ docker-compose upここでエラーがでなければ、一応初期セットアップ完了、APIサーバとして動かすため、事前に/meを作成しておきます。
APIの作成
コントローラーとRouteのみ記載しlocalhostで確認します。
- app/controller/me_controller.rb
class MeController < ApplicationController def index render json: { 'me' => 'me' } end end
- config/routes.rb
Rails.application.routes.draw do # For details on the DSL available within this file, see https://guides.rubyonrails.org/routing.html resources :me, only: [:index] end
GET /meの確認
念のためdockerコンテナを再起動して、APIの確認を行います。$ docker-compose up $ curl localhost:3000/me {"me":"me"}Lambda(+ API Gateway)化
Lambda 用の Rack ブリッジサンプルをダウンロード
下記のサンプルソースからLambda用のブリッジサンプルを入手し、
https://github.com/aws-samples/serverless-sinatra-sample/blob/master/lambda.rb
中身のパスを1箇所だけ修正します。- $app ||= Rack::Builder.parse_file("#{__dir__}/app/config.ru").first + $app ||= Rack::Builder.parse_file("#{__dir__}/config.ru").firstNative Extensions のローカルへのリビルド
dockerの中に入って作業します。この作業を行わないとNative Extensions系のライブラリが動作しないです。Postgresqlを使用する場合は別途コピー元のディレクトリを変更します。
dockerの中に入るコマンド
$ docker-compose ps ※ここでdockerの名前を確認 $ docker exec -it docker名 bash bash-4.2#リビルド
bash-4.2# bundle install --path /bundle bash-4.2# mv /bundle /app/vendor/ bash-4.2# sed -e 's|/bundle|vendor/bundle|' -i .bundle/config bash-4.2# cat .bundle/config --- BUNDLE_PATH: "vendor/bundle" # 下記作業はmysqlを使う場合 bash-4.2# /sbin/ldconfig -p | grep mysql | cut -d\> -f2 bash-4.2# cp /usr/lib64/mysql/libmysqlclient.so.18 lib/動くか確認します。
$ docker-compose stop $ docker-compose up $ curl http://localhost:3000/meファイルをzipで固めてlambdaへデプロイします。今回はdockerの中でやっています。
$ zip -r lambda_function.zip .bundle app config Gemfile* config.ru lambda_function.rb vendor lib publicLambdaの作成
※細かい部分は省略。
デプロイするときzip容量が大きいのでS3からアップロード。
Lambda作成時の環境変数は以下のとおり。
Name Value BOOTSNAP_CACHE_DIR /tmp/cache BUNDLE_APP_CONFIG /var/task/.bundle PASSWORD password RAILS_ENV production RAILS_LOG_TO_STDOUT true RAILS_SERVE_STATIC_FILES true USER root ポイントは
bootsnap_cache_dirで、bootsnap は ${WORKING_DIR}/tmp/cache にキャッシュを生成することになっており、このままLambdaを使うと、/var/task/tmp自体は読み込み専用ディレクトリなっているためエラーが発生します。テストイベントの作成
新しいテストイベントの作成 > イベントテンプレート > Amazon API Gateway AWS Proxy を選択
pathhttpMethodpathParametersを下記のように/me用に変更する"path": "/me" "httpMethod": "GET" "pathParameters": { "proxy": "/me" }テストを実行して下記レスポンスが返ってくるか確認する
{ "statusCode": 200, "headers": { "X-Frame-Options": "SAMEORIGIN", "X-XSS-Protection": "1; mode=block", "X-Content-Type-Options": "nosniff", "X-Download-Options": "noopen", "X-Permitted-Cross-Domain-Policies": "none", "Referrer-Policy": "strict-origin-when-cross-origin", "Content-Type": "application/json; charset=utf-8", "ETag": "W/\"hogehoge\"", "Cache-Control": "max-age=0, private, must-revalidate", "X-Request-Id": "hoge-hoge-hoge-hoge-hoge", "X-Runtime": "0.004623" }, "body": "{\"me\":\"me\"}" }API Gatewayの作成+Lambda連携
※細かい部分は省略。
proxyとして動作。
ステージからAPIGatewayのデプロイを行い、APIの実行を行う
$ curl https://hogehoge.execute-api.ap-northeast-1.amazonaws.com/hoge/me {"me":"me"}おわり
あとはRoute53やAPI Gatewayのカスタムドメインの設定を行えば本番運用可能です。またAPIGatewayの代わりにALBを使用することも可能です。その場合Lambdaのコードは修正不要です。

- 投稿日:2020-04-07T10:39:49+09:00
Node.jsを使用したAWS S3への画像アップロード
まずは、ここからs3へのアクセスキーと、シークレットきーを取得してください。
S3 Bucketを作る
$ npm i --save aws-sdkcreate-bucket.jsconst AWS = require('aws-sdk'); // Enter copied or downloaded access ID and secret key here const ID = ''; const SECRET = ''; // The name of the bucket that you have created const BUCKET_NAME = 'test-bucket'; //同じバケット名は作れない ユニーク必須 const s3 = new AWS.S3({ accessKeyId: ID, secretAccessKey: SECRET }); const params = { Bucket: BUCKET_NAME, CreateBucketConfiguration: { // アジアパシフィック (東京) LocationConstraint: "ap-northeast-1" } }; s3.createBucket(params, function(err, data) { if (err) console.log(err, err.stack); else console.log('Bucket Created Successfully', data.Location); });こんな感じ。で、実行
$ node create-bucket.jsS3で画像をアップする
uplode-bucket.jsconst fs = require('fs'); const AWS = require('aws-sdk'); // Enter copied or downloaded access ID and secret key here const ID = ''; const SECRET = ''; const s3 = new AWS.S3({ accessKeyId: ID, secretAccessKey: SECRET }); const uploadFile = (fileName) => { // Read content from the file const fileContent = fs.readFileSync(fileName); // Setting up S3 upload parameters const params = { Bucket: "test-bucket", Key: 'uniquename.jpg', // s3へ保存される名前 ユニーク必須 Body: fileContent }; // Uploading files to the bucket s3.upload(params, function(err, data) { if (err) { throw err; } console.log(`File uploaded successfully. ${data.Location}`); }); }; uploadFile('/Users/user-name/Desktop/test.png'); //ここにファイルの実体を入れるこんな感じ。で、実行
$ node uplode-bucket.js参考
https://stackabuse.com/uploading-files-to-aws-s3-with-node-js/
- 投稿日:2020-04-07T10:39:49+09:00
『コピペOK』NodeでS3へ画像アップロード【2020】
まずは、ここからs3へのアクセスキーと、シークレットきーを取得してください。
S3 Bucketを作る
$ npm i --save aws-sdkcreate-bucket.jsconst AWS = require('aws-sdk'); // Enter copied or downloaded access ID and secret key here const ID = ''; const SECRET = ''; // The name of the bucket that you have created const BUCKET_NAME = 'test-bucket'; //同じバケット名は作れない ユニーク必須 const s3 = new AWS.S3({ accessKeyId: ID, secretAccessKey: SECRET }); const params = { Bucket: BUCKET_NAME, CreateBucketConfiguration: { // アジアパシフィック (東京) LocationConstraint: "ap-northeast-1" } }; s3.createBucket(params, function(err, data) { if (err) console.log(err, err.stack); else console.log('Bucket Created Successfully', data.Location); });こんな感じ。で、実行
$ node create-bucket.jsS3で画像をアップする
uplode-bucket.jsconst fs = require('fs'); const AWS = require('aws-sdk'); // Enter copied or downloaded access ID and secret key here const ID = ''; const SECRET = ''; const s3 = new AWS.S3({ accessKeyId: ID, secretAccessKey: SECRET }); const uploadFile = (fileName) => { // Read content from the file const fileContent = fs.readFileSync(fileName); // Setting up S3 upload parameters const params = { Bucket: "test-bucket", Key: 'uniquename.jpg', // s3へ保存される名前 ユニーク必須 Body: fileContent }; // Uploading files to the bucket s3.upload(params, function(err, data) { if (err) { throw err; } console.log(`File uploaded successfully. ${data.Location}`); }); }; uploadFile('/Users/user-name/Desktop/test.png'); //ここにファイルの実体を入れるこんな感じ。で、実行
$ node uplode-bucket.js参考
https://stackabuse.com/uploading-files-to-aws-s3-with-node-js/
- 投稿日:2020-04-07T10:02:15+09:00
AWSのS3のアクセスキーとシークレットキーを作る方法『2020』
1) IAMユーザーを作る
S3のアクセスキーとシークレットキーを作るには、IAMユーザーを作る必要があります。
2) グループを作る
これは、IAMユーザーへ割り当てる権限のグループです。ec2とs3へのアクセス権限をこのIAMユーザーへ付与する〜みたいな。
3) グループの名前と使用用途を決める
今回は、nodejsからs3へ画像をアップしたり、取得したいので、プログラマティックにアクセスする設定にします。
4) とうとうユーザーを作る
5) S3へのフルアクセスをIAMユーザーへ許可する
6) この権限をどのグループへ付与するか
7) キーは空白で良い
8) 確認項目、良い感じですね。
9) アクセスキーとシークレットきーができた
この値は、nodejsで使う。nodejsから、s3へアクセスできるはず
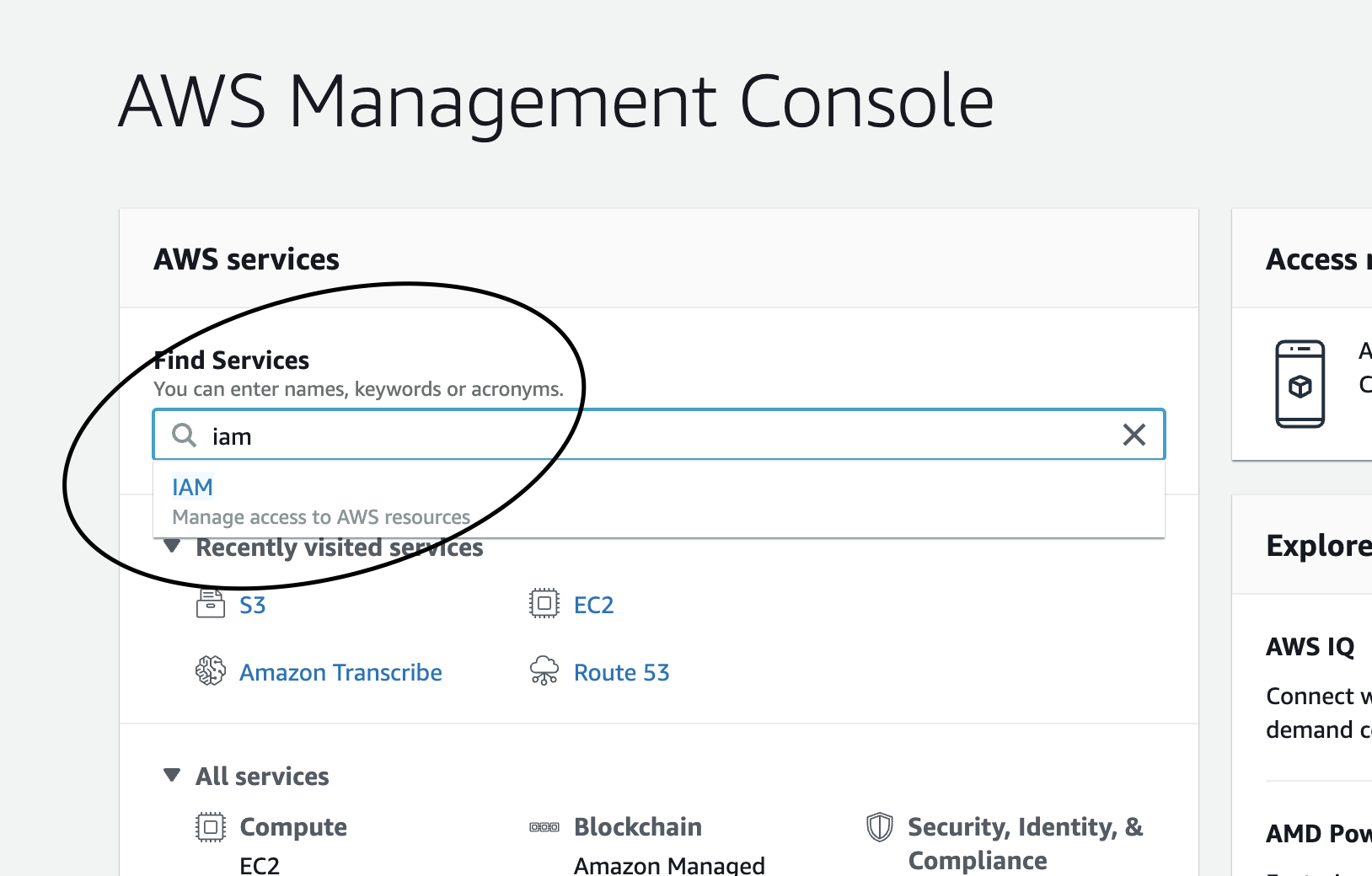
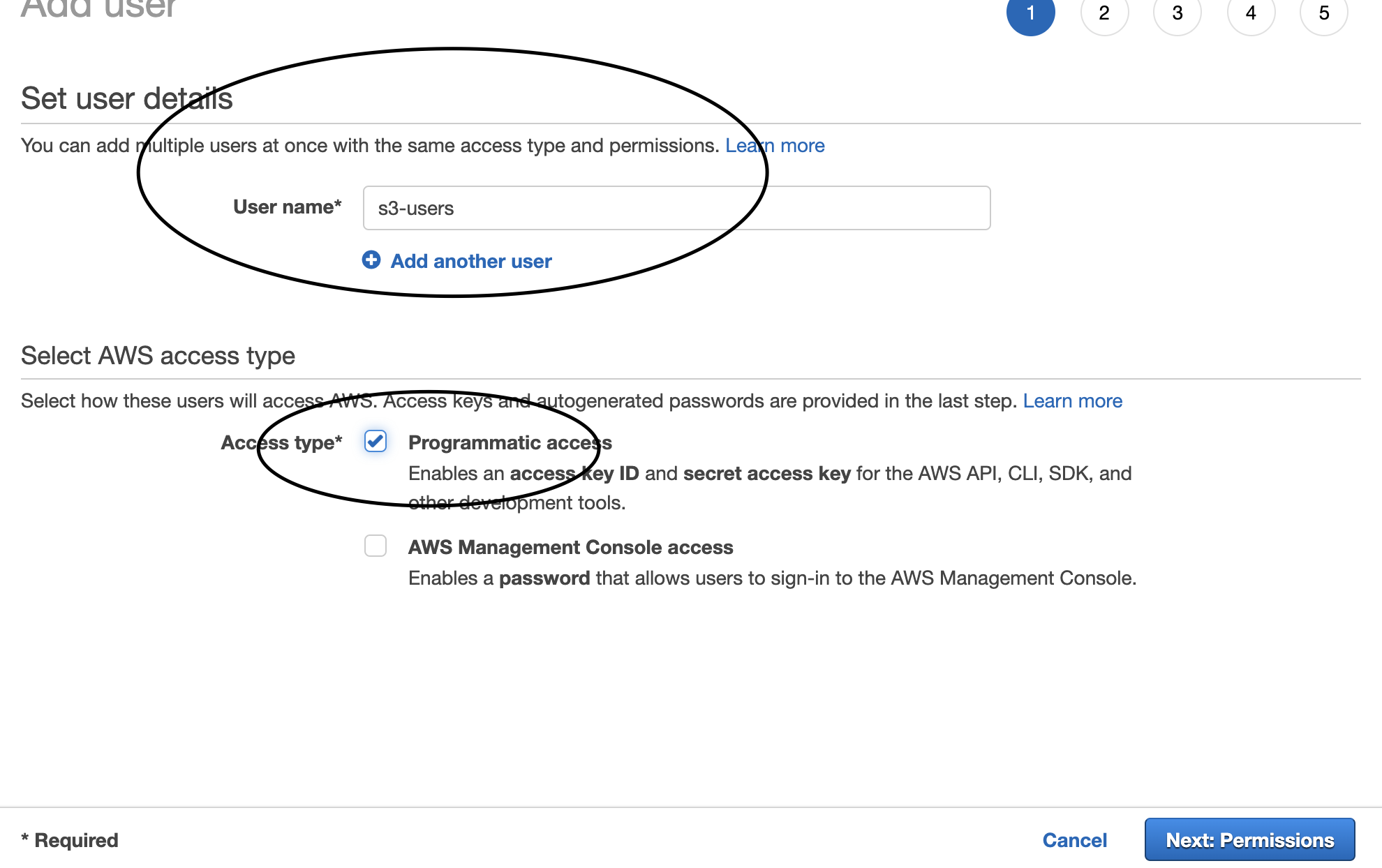
- 投稿日:2020-04-07T02:36:47+09:00
Oracle Cloud Infrastructure Data Scienceを使って、AWS Redshiftのデータにアクセスしてみる
本記事の狙い
2020/2に、Oracle Cloud Infrastructure Data Science(OCI-Data Science)がリリースされました。
前回、OCI-Data ScienceからAWS S3上のファイルのデータにクエリしてみたので(Qiita記事:Oracle Cloud Infrastructure Data Scienceを使って、OCI Object StorageとAWS S3のファイルデータにアクセスしてみる)、本記事では、OCI-Data Scienceから、Pythonを使ってAWS Redshift上のデータにアクセスしてデータ取得する手順を、実施してみたいと思います。参考文献
実施に参考になるリンク
- Oracle Cloud Infrastructure Data Science(OCI-Data Science)を使ってみよう
- OCI-Data Science 公式ドキュメント
- Oracle Accelerated Data Science SDK (ADS) 公式ドキュメント
- Qiita記事:Redshiftをはじめて触ってみた!
- Amazon Redshiftって何ができるの?AWSのデータウェアハウスサービスを解説
- Redshiftからデータ読み込んでpandasのデータフレームに入れる
- Qiita記事:リモートのpython3(psycopg2)からubuntu16.04@AWSのpostgresqlに接続
手順
以下のような手順で実施します。
1.OCI-Data Scienceの設定
2.Redshiftを起動し、テーブル作成、データを登録
2-1.Redshiftのクラスタ作成、起動
2-2.Redshiftにテーブル作成、S3にファイルから、テーブルにデータを登録
3.OCI-Data ScienceからRedshiftのテーブルにアクセスする1.OCI-Data Scienceの設定
OCI-Data Scienceのノートブック環境を構築、初期設定をします。
上記参考文献の「Oracle Cloud Infrastructure Data Science(OCI-Data Science)を使ってみよう」を参考に下記を実施します。・Oracle Cloudの基本的な設定の後に、ノートブック環境を構築します。
・getting-started.ipynbを使って、ノートブック環境(JupyerLab)の初期作業を行います。2.Redshiftを起動し、テーブル作成、データを登録
2-1.Redshiftのクラスタ作成、起動
上記参考文献の「Qiita記事:Redshiftをはじめて触ってみた!」を参考にRedshiftクラスタを作成しました。
2-2.Redshiftにテーブル作成、S3にファイルから、テーブルにデータを登録
今回は、上記参考文献の「Amazon Redshiftって何ができるの?AWSのデータウェアハウスサービスを解説」の” Amazon Redshiftを使ってみる”を参考に、IAMロールの作成、Redshift上にテーブルを作成、S3上のcsvファイルからRedshift上のテーブルにデータを登録、の手順でデータを登録しました。
今回は下記のテーブルを作成し、サンプルデータを登録しています。
CREATE TABLE PURCHASE_ITEM ( CUST_ID integer, AGE integer, MARRIED VARCHAR(4000), ADDRESS VARCHAR(4000), CHILD VARCHAR(4000), OCCUPATION VARCHAR(4000), LASTCONTACT VARCHAR(4000), LASTCALL integer, CONTACT integer, CONTACT_BEFORE_CAMPAIGN integer, Purchased VARCHAR(4000) );3.OCI-Data ScienceからRedshiftのテーブルにアクセスする
では、実際に、OCI-Data ScienceからRedshiftのテーブルにアクセスしてみます。
今回は、上記参考文献の「Redshiftからデータ読み込んでpandasのデータフレームに入れる」のとおりに、sqlalchemy-redshiftを利用します。まず、モジュールsqlalchemy-redshiftをインストールします。
pip install sqlalchemy-redshift次に必要なライブラリをインストールします。
import redshift_sqlalchemy from sqlalchemy import create_engineRedshiftに接続します。
engine = create_engine('{dialect}+{driver}://{user}:{pwd}@{url}:{port}/{db}'.format( dialect = 'redshift', driver = 'psycopg2', user='awsuser', #Redshiftのユーザー名 pwd ='XXXXXX', #パスワード url='redshift-cluster-1.XXX.XXX.redshift.amazonaws.com', #Redshiftのクラスター画面のエンドポイント port=5439, #Redshiftのポート番号 db='dev' #Redshiftのデータベース名 ))ここで下記のようなConnection timed outエラーが発生しました。
調べたところ、上記参考資料「リモートのpython3(psycopg2)からubuntu16.04@AWSのpostgresqlに接続」と同じようにみえるので、RedshiftのVNCセキュリティグループのインバウンドルールを下記のように設定します。
*今回は「0.0.0.0/0」を設定しましたが、実際の設定に関しては適切な値を設定してください。
*ここらへん、あまり自信ないので間違っていたらご指摘ください。。セキュリティグループを設定後は、正常に接続できました。
Redshift上のデータを読み込み、データフレームに入れます。
import pandas as pd redshift_data = pd.read_sql_query('SELECT * FROM PURCHASE_ITEM limit 100;', engine)結果を確認してみます。
redshift_data.head()
確かに、無事取得できました。
終わりに
今回は、OCI-Data Scienceから、sqlalchemy-redshift を使って、AWS Redshift上のデータにアクセスしてみました。
これ以外にもう少しいい接続方法があるかもしれませんので、ぜひ試してみてください。(そして教えてください。。)
OCI-Data Scienceは、最大30日間300$分の無償クレジットが使えるOracle Free Trialの、対象サービスですので、ぜひ実際に使ってみることをおすすめします。
Let's Enjoy Data Science!
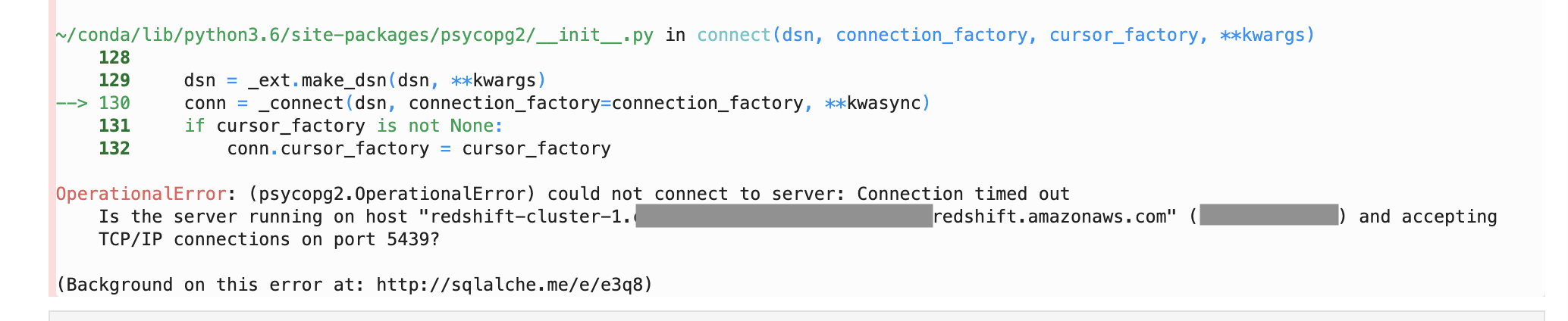
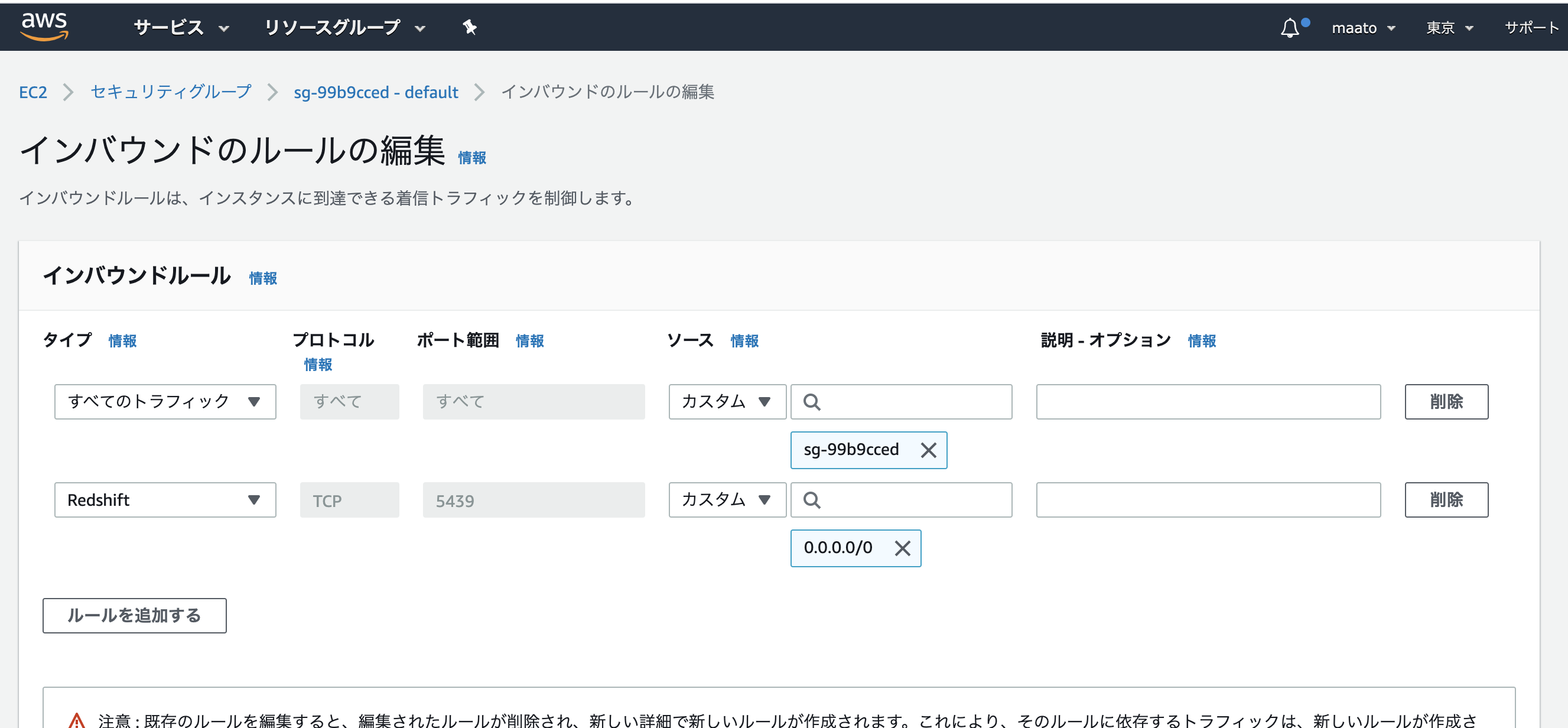

- 投稿日:2020-04-07T02:36:16+09:00
AWS で マインクラフトサーバ (途中)
環境
- Ubuntu 18.04.2 LTS
- シンガポールリージョン の T2.micro
AWSの既存のインスタンスを使ってみましたが、メモリが少なすぎてうまくいきませんでした。
改めてチャレンジ予定。ポートを開ける。
minecraft_server.1.15.2.jarjdk1.8をインストール
$ sudo apt install openjdk-8-jdkサーバプログラムの用意
ここからURLをコピーして
https://www.minecraft.net/ja-jp/download/server/サーバをダウンロードして
$ wget https://launcher.mojang.com/v1/objects/bb2b6b1aefcd70dfd1892149ac3a215f6c636b07/server.jarserver.jar という名前で落ちてくるので、名前を変更
$ mv server.jar minecraft_server.1.15.2.jar起動→失敗!
サーバのロードアベレージを見てみる
$ top top - 04:52:25 up 38 days, 10:53, 1 user, load average: 0.04, 0.12, 0.06 Tasks: 93 total, 1 running, 52 sleeping, 0 stopped, 0 zombie %Cpu(s): 0.0 us, 0.3 sy, 0.0 ni, 99.7 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st KiB Mem : 1007612 total, 93060 free, 196672 used, 717880 buff/cache KiB Swap: 0 total, 0 free, 0 used. 644768 avail Mem PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND 31248 ubuntu 20 0 44516 3924 3332 R 0.3 0.4 0:00.01 top 1 root 20 0 225416 8580 6136 S 0.0 0.9 0:25.72 systemd 2 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kthreadd 4 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 kworker/0:0H 6 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 mm_percpu_wq 7 root 20 0 0 0 0 S 0.0 0.0 0:03.68 ksoftirqd/0 8 root 20 0 0 0 0 I 0.0 0.0 0:05.66 rcu_sched 9 root 20 0 0 0 0 I 0.0 0.0 0:00.00 rcu_bh 10 root rt 0 0 0 0 S 0.0 0.0 0:00.00 migration/0 11 root rt 0 0 0 0 S 0.0 0.0 0:09.07 watchdog/0 12 root 20 0 0 0 0 S 0.0 0.0 0:00.00 cpuhp/0 13 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kdevtmpfs 14 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 netns 15 root 20 0 0 0 0 S 0.0 0.0 0:00.00 rcu_tasks_kthre 16 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kauditd 17 root 20 0 0 0 0 S 0.0 0.0 0:00.00 xenbus 18 root 20 0 0 0 0 S 0.0 0.0 0:00.01 xenwatch 20 root 20 0 0 0 0 S 0.0 0.0 0:01.01 khungtaskd 21 root 20 0 0 0 0 S 0.0 0.0 0:00.00 oom_reaper 22 root 0 -20 0 0 0 I 0.0 0.0 0:00.00 writeback 23 root 20 0 0 0 0 S 0.0 0.0 0:00.00 kcompactd0メモリ1G だけど、試しに起動してみる
$ java -Xms1024M -Xmx1024M -jar minecraft_server.1.15.2.jar nogui [04:54:09] [main/ERROR]: Failed to load properties from file: server.properties [04:54:09] [main/WARN]: Failed to load eula.txt [04:54:09] [main/INFO]: You need to agree to the EULA in order to run the server. Go to eula.txt for more info.EULAを書き換える
$ vi eula.txtもう一度起動
$ java -Xms1024M -Xmx1024M -jar minecraft_server.1.15.2.jar nogui [04:54:57] [main/WARN]: Ambiguity between arguments [teleport, destination] and [teleport, targets] with inputs: [Player, 0123, @e, dd12be42-52a9-4a91-a8a1-11c01849e498] [04:54:57] [main/WARN]: Ambiguity between arguments [teleport, location] and [teleport, destination] with inputs: [0.1 -0.5 .9, 0 0 0] [04:54:57] [main/WARN]: Ambiguity between arguments [teleport, location] and [teleport, targets] with inputs: [0.1 -0.5 .9, 0 0 0] [04:54:57] [main/WARN]: Ambiguity between arguments [teleport, targets] and [teleport, destination] with inputs: [Player, 0123, dd12be42-52a9-4a91-a8a1-11c01849e498] [04:54:57] [main/WARN]: Ambiguity between arguments [teleport, targets, location] and [teleport, targets, destination] with inputs: [0.1 -0.5 .9, 0 0 0] [04:54:57] [Server thread/INFO]: Starting minecraft server version 1.15.2 [04:54:57] [Server thread/INFO]: Loading properties [04:54:57] [Server thread/INFO]: Default game type: SURVIVAL [04:54:57] [Server thread/INFO]: Generating keypair [04:54:58] [Server thread/INFO]: Starting Minecraft server on *:25565 [04:54:58] [Server thread/INFO]: Using epoll channel type [04:54:58] [Server thread/INFO]: Preparing level "world" [04:54:59] [Server thread/INFO]: Found new data pack vanilla, loading it automatically [04:54:59] [Server thread/INFO]: Reloading ResourceManager: Default [04:55:03] [Server thread/INFO]: Loaded 6 recipes [04:55:04] [Server thread/INFO]: Loaded 825 advancements [04:55:46] [Server thread/INFO]: Preparing start region for dimension minecraft:overworld [04:55:47] [Server-Worker-1/INFO]: Preparing spawn area: 0% [04:55:47] [Server-Worker-1/INFO]: Preparing spawn area: 0% [04:55:47] [Server-Worker-1/INFO]: Preparing spawn area: 0% [04:55:48] [Server-Worker-1/INFO]: Preparing spawn area: 0% [04:55:48] [Server-Worker-1/INFO]: Preparing spawn area: 0% [04:55:49] [Server-Worker-1/INFO]: Preparing spawn area: 0% [04:55:50] [Server-Worker-1/INFO]: Preparing spawn area: 0% [04:55:50] [Server-Worker-1/INFO]: Preparing spawn area: 0% [04:55:51] [Server-Worker-1/INFO]: Preparing spawn area: 0% [04:55:51] [Server-Worker-1/INFO]: Preparing spawn area: 0% [04:55:51] [Server-Worker-1/INFO]: Preparing spawn area: 0% [04:55:52] [Server-Worker-1/INFO]: Preparing spawn area: 1% [04:55:52] [Server-Worker-1/INFO]: Preparing spawn area: 2% [04:55:53] [Server-Worker-1/INFO]: Preparing spawn area: 2% [04:55:54] [Server-Worker-1/INFO]: Preparing spawn area: 2% [04:55:54] [Server-Worker-1/INFO]: Preparing spawn area: 3% [04:55:55] [Server-Worker-1/INFO]: Preparing spawn area: 3% [04:55:55] [Server-Worker-1/INFO]: Preparing spawn area: 4% [04:55:55] [Server-Worker-1/INFO]: Preparing spawn area: 5% [04:55:56] [Server-Worker-1/INFO]: Preparing spawn area: 5% [04:55:56] [Server-Worker-1/INFO]: Preparing spawn area: 6% [04:55:57] [Server-Worker-1/INFO]: Preparing spawn area: 7% [04:55:57] [Server-Worker-1/INFO]: Preparing spawn area: 8% [04:55:58] [Server-Worker-1/INFO]: Preparing spawn area: 9% [04:55:58] [Server-Worker-1/INFO]: Preparing spawn area: 10% [04:55:59] [Server-Worker-1/INFO]: Preparing spawn area: 11% [04:55:59] [Server-Worker-1/INFO]: Preparing spawn area: 12% [04:56:00] [Server-Worker-1/INFO]: Preparing spawn area: 14% [04:56:00] [Server-Worker-1/INFO]: Preparing spawn area: 15% [04:56:01] [Server-Worker-1/INFO]: Preparing spawn area: 16% [04:56:01] [Server-Worker-1/INFO]: Preparing spawn area: 17% [04:56:02] [Server-Worker-1/INFO]: Preparing spawn area: 18% [04:56:02] [Server-Worker-1/INFO]: Preparing spawn area: 19% [04:56:03] [Server-Worker-1/INFO]: Preparing spawn area: 21% [04:56:03] [Server-Worker-1/INFO]: Preparing spawn area: 22% [04:56:04] [Server-Worker-1/INFO]: Preparing spawn area: 24% [04:56:04] [Server-Worker-1/INFO]: Preparing spawn area: 24% [04:56:05] [Server-Worker-1/INFO]: Preparing spawn area: 26% [04:56:05] [Server-Worker-1/INFO]: Preparing spawn area: 27% [04:56:06] [Server-Worker-1/INFO]: Preparing spawn area: 29% [04:56:06] [Server-Worker-1/INFO]: Preparing spawn area: 31% [04:56:07] [Server-Worker-1/INFO]: Preparing spawn area: 32% [04:56:07] [Server-Worker-1/INFO]: Preparing spawn area: 33% [04:56:08] [Server-Worker-1/INFO]: Preparing spawn area: 34% [04:56:08] [Server-Worker-1/INFO]: Preparing spawn area: 36% [04:56:09] [Server-Worker-1/INFO]: Preparing spawn area: 37% [04:56:09] [Server-Worker-1/INFO]: Preparing spawn area: 38% [04:56:10] [Server-Worker-1/INFO]: Preparing spawn area: 41% [04:56:10] [Server-Worker-1/INFO]: Preparing spawn area: 43% [04:56:11] [Server-Worker-1/INFO]: Preparing spawn area: 44% [04:56:11] [Server-Worker-1/INFO]: Preparing spawn area: 45% [04:56:12] [Server-Worker-1/INFO]: Preparing spawn area: 48% [04:56:12] [Server-Worker-1/INFO]: Preparing spawn area: 50% [04:56:13] [Server-Worker-1/INFO]: Preparing spawn area: 51% [04:56:13] [Server-Worker-1/INFO]: Preparing spawn area: 53% [04:56:14] [Server-Worker-1/INFO]: Preparing spawn area: 55% [04:56:14] [Server-Worker-1/INFO]: Preparing spawn area: 58% [04:56:15] [Server-Worker-1/INFO]: Preparing spawn area: 61% [04:56:15] [Server-Worker-1/INFO]: Preparing spawn area: 64% [04:56:16] [Server-Worker-1/INFO]: Preparing spawn area: 67% [04:56:16] [Server-Worker-1/INFO]: Preparing spawn area: 69% [04:56:17] [Server-Worker-1/INFO]: Preparing spawn area: 72% [04:56:17] [Server-Worker-1/INFO]: Preparing spawn area: 74% [04:56:18] [Server-Worker-1/INFO]: Preparing spawn area: 77% [04:56:18] [Server-Worker-1/INFO]: Preparing spawn area: 80% [04:56:19] [Server-Worker-1/INFO]: Preparing spawn area: 83% [04:56:19] [Server-Worker-1/INFO]: Preparing spawn area: 85% [04:56:20] [Server-Worker-1/INFO]: Preparing spawn area: 87% [04:56:20] [Server-Worker-1/INFO]: Preparing spawn area: 88% [04:56:21] [Server-Worker-1/INFO]: Preparing spawn area: 90% [04:56:21] [Server-Worker-1/INFO]: Preparing spawn area: 93% [04:56:22] [Server-Worker-1/INFO]: Preparing spawn area: 96% [04:56:22] [Server-Worker-1/INFO]: Preparing spawn area: 99% [04:56:22] [Server thread/INFO]: Time elapsed: 36086 ms [04:56:23] [Server thread/INFO]: Done (84.106s)! For help, type "help" [04:57:25] [Server Watchdog/FATAL]: A single server tick took 60.06 seconds (should be max 0.05) [04:57:26] [Server Watchdog/FATAL]: Considering it to be crashed, server will forcibly shutdown. [05:09:32] [Server Watchdog/ERROR]: This crash report has been saved to: /home/ubuntu/minecraft_server/./crash-reports/crash-2020-04-06_05.08.53-server.txtうーん、落ちた。元々メモリ1Gしかないのに1G指定で起動したから当然かな。
別のインスタンスを用意して、再チャレンジしてみます。
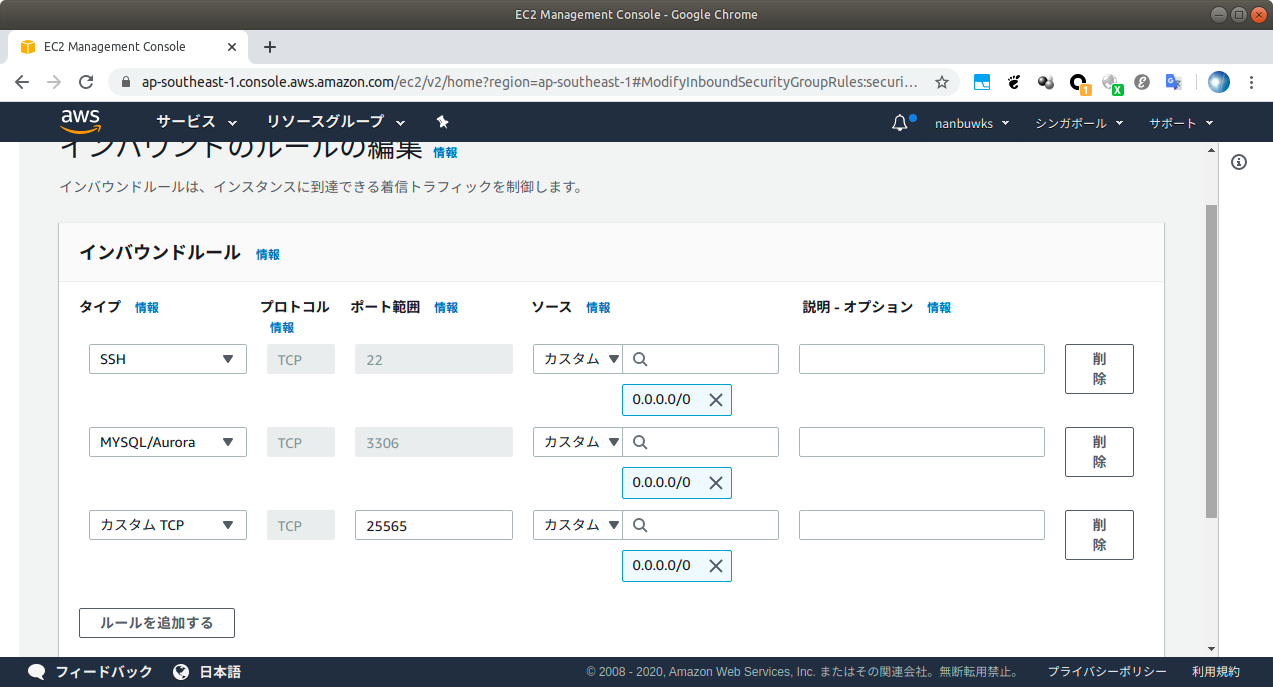
- 投稿日:2020-04-07T00:00:58+09:00
AWS ALBの認証機能でGoogleアカウント認証を設定する (OpenIDConnect)
About
- 社内用のシステムやリリース前の機能を限定公開したい場合新規にログイン機能を実装するのは非効率です。
- AWSにはALBの認証機能としてOpenIDConnectをサポートしています。
- Facebook,Yahoo,Googleなどを利用している場合、ALBをアプリケーションとして登録するだけで簡単に認証機能が実装できます。
- リモートワークが推奨されている昨今、突然社内用の管理画面にログイン機能が必要になってお困りになっている方もいらっしゃるのではないでしょうか?
- 今回はGoogleのOauthクライアントIDを利用してOIDCする方法を説明します。
利点
- アプリケーション毎に管理機能を実装する必要がなくなる。
認証のフロー
- ALBにアクセス
- ログイン状態をGoogleAPIに問い合わせる
- 非ログイン状態であればGoogleの認証画面を表示、ログイン状態ならALBにリダイレクト
- ALBからはターゲットグループ(EC2など)にリクエストを振り分ける。
X-Amzn-Oidc-DataヘッダーにALBによって署名されたJWTのトークンが入るので、
アプリケーション側でペイロード(ユーザークレーム)を取得してユーザを判定する事も可能。- EC2からアプリケーションのレスポンス
- ユーザからはどこのレイヤーで認証されているかを意識する事はないし、いつも使っているアカウントで入れて幸せ
認証設定
GoogleOauth2.0クライアントID を取得する
1. GoogleCloudPlatformにアクセス
- Google Cloud Platformにアクセス
- 左ナビから [APIとサービス] > [認証情報] を選択
2. Oauth同意画面設定
- 左ナビから OAuth同意画面を選択(プロジェクトを作成していない場合は新規に作成)
- UserType > 内部 > 作成
- Oauth同意画面で下記項目を入力して保存
項目 内容 名前 任意 承認済みドメイン ALBのDNS名 3. 認証情報を作成
- 左ナビから [認証情報] を選択
- 画面上部の [認証情報を作成] > [OauthクライアントIDの作成]
- 下記項目を入力して保存
項目 内容 アプリケーションの種類 ウェブアプリケーション 名前 任意 承認済みのリダイレクトURI https://ALBのDNS名/oauth2/idpresponse
* 上記ダイアログが出るのでクライアントIDとクライアントシークレットをコピーしておくAWSのロードバランサー上で認証の設定を行う
1. ロードバランサーの設定画面
ALBは既に作成済みの前提
- EC2 > ロードバランサー
- 認証設定したいALBを選択
- リスナータブを開いて [ルールの表示/編集] を選択
- ルールの編集タブを選択

- デフォルトアクションの左のペン(編集ボタン)を選択
- [アクションの追加] > [認証]
- 下記項目を入力して更新
項目 内容 認証 OIDC 発行者 https://accounts.google.com 認証エンドポイント https://accounts.google.com/o/oauth2/v2/auth トークンエンドポイント https://www.googleapis.com/oauth2/v4/token ユーザー情報エンドポイント https://www.googleapis.com/oauth2/v3/userinfo クライアントID 発行したクライアントID クライアントシークレット 発行したクライアントシークレット
ロードバランサーにアクセスする
- Googleに非ログインの状態でロードバランサーにアクセスするとGoogleの認証画面にリダイレクト
- 認証を行うとアクセスしたURLにリダイレクトされる
参考記事はこちら。
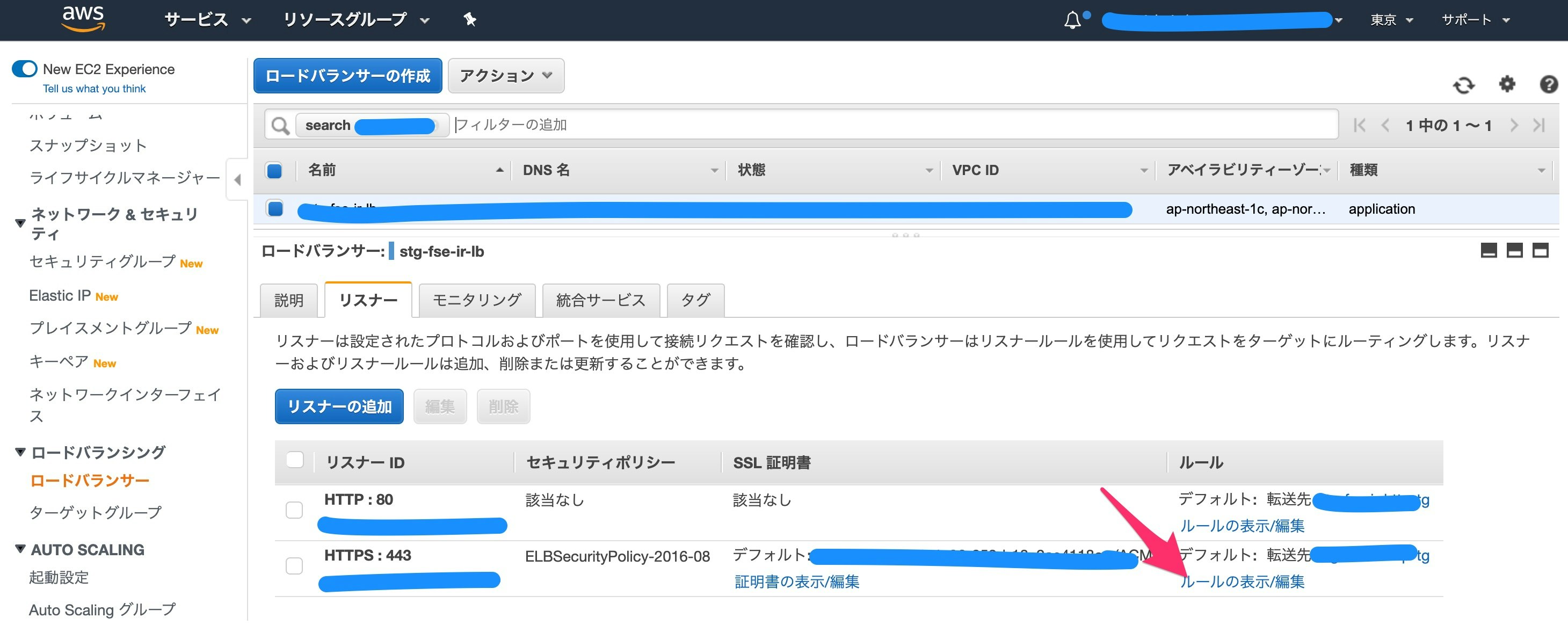
- 投稿日:2020-04-07T00:00:53+09:00
AWSの無料枠でCOVID-19解析に貢献しようとしてうまくいってない話
(自ブログに書いた記事の転載です)
はじめに
「新型コロナウイルスの解析に貢献しつつ、AmazonWebServiceの環境構築を実践してみよう」とした話です。
結果、「正常に動作はしたが、無料枠ではスペック不足ゆえにあまり貢献できていない」という結論になってしまいましたが、
作業の記録として、残しておきます。背景
コロナ流行辛い。なんとか解決早めらんないか。
↓
「今からでも3分ではじめられるコロナ解析貢献「Folding@home」の使い方」というPC Watchの記事を見つける
↓
即自宅ノートPC(旧世代のGPU搭載)にインストール。1週間程度走らせ続けて25タスクほどこなすが、まだ物足りない感。
↓
スペックは上げられないから、稼働台数増やしたい。でも物理マシンは1台しかもっていない...
↓
そうだAWSアカウント持ってた。これ使ってみよう。無料枠でできるなら記事化すれば真似してくれる人いるかも?
↓
行動。
やったこと①: VPC環境の作成
VPC環境をまず構築し、その中にEC2環境を立てることにした。
基本、こちらのブログ記事の通りに作業。唯一セキュリティグループだけは、今回の利用目的に合わせて以下のように変更。
- Webサービスを立てるわけではないので80番ポートはクローズ。
- 代わりに、Folding@HomeのWebコントローラ用に7396番を開放
- セキュリティ対策として22番以外のSSH用ポートを開放、初期ログイン用に22番はいったん残す。
- 今回の環境は「自分だけアクセスできればいい」ので、ソースはすべてマイIPに限定
やったこと②: VPC上にEC2環境構築
①で作ったVPC環境上に、EC2環境を作成。この作業もこちらのブログ記事を参考にした。
今回は無料利用枠で作れる環境にしたかったので、構成は以下の通り
- OS: Amazon Linux 2 AMI(x86)
- インスタンスタイプ:t2.micro
- ストレージ: 汎用SSD 8GB
やったこと③: Linuxの設定
- SSHのポート番号変更
$ sudo vi /etc/ssh/sshd_config ### 22行あたりに以下を追加(①で指定したポート番号) Port 2**** ### 保存後 $ sudo service sshd reload
- EC2作成時とは別のRSA鍵でアカウントを作り、デフォルトの"ec2-user"削除
### ユーザ新規作成(root権限) # useradd newuser # passwd newuser ### SSH設定(root権限) # cd /home/newuser/ # mkdir .ssh # chmod 700 .ssh # chown newuser:newuser .ssh ### ここで公開鍵をSCPで送信 # mv /home/ec2-user/id_rsa.pub .ssh/authorized_keys # chmod 600 .ssh/authorized_keys # chown newuser:newuser .ssh/authorized_keys ### sudoできる権限を与える # usermod -aG wheel newuser ### 別窓で"newuser"としてログイン。以降newuser側の画面で操作 $ sudo su - ### rootになれることを確認したら、ec2-user削除 # userdel ec2-userやったこと④: Folding@Homeの導入
今回は、最低限必要な
FAHClientのみ導入。
- インストール
設定
/etc/fahclient/config.xmlを編集。更新にはroot権限必須。<config> <!-- GPUを使うか --> <!-- Folding Slot Configuration --> <gpu v='false'/> <!-- どの程度CPU資源を利用するか。light,middle,fullの3択 --> <!-- Slot Control --> <power v='full'/> <!-- ユーザ情報。ユーザ名を入れておけば個人でどれだけ貢献したか集計される --> <!-- User Information --> <user v='deflat'/> <!-- スロット番号とタイプ。今回はCPU1個しかないのでいじらない --> <!-- Folding Slots --> <slot id='0' type='CPU'/> <!-- Webコントローラへのアクセス権限設定。xxx.xxx.xxx.xxxのところに自分のIPアドレスを記入 --> <allow>127.0.0.1 xxx.xxx.xxx.xxx</allow> <web-allow>127.0.0.1 xxx.xxx.xxx.xxx</web-allow> </config>
- 設定反映&サービス再起動
- タスク処理中にstopしても、次startしたときはちゃんと続きから計算してくれる。
$ sudo /etc/init.d/FAHClient stop $ sudo /etc/init.d/FAHClient start結果
- Webブラウザで
http://<EC2環境のIPアドレス>:7396にアクセスすると、下記のようにちゃんと動いているのが見える。 ...が、めちゃくちゃ処理が遅い
- 画像は処理開始から24時間ほどたったときのもの。個人持ちのノートPCでも、このくらいなら3~4時間で終わるはず。
後から調べて分かったこと
- EC2のt2インスタンスには、「CPUクレジット残高」という概念があり、これが枯れている状態だと使えるCPU資源が限定される。
- 今回使用したt2-microだと、CPU使用率10%にしかならないのだとか。
- インスタンス自体の停止→起動をすれば初期クレジットまで回復するそうなので、今後検討してみる。
- 参考
まとめと感想
- 「新型コロナウイルスの解析に貢献しつつ、AmazonWebServiceの環境構築を実践してみよう」とした話。
- 初めてやる自分でも、全行程完了まで2~3時間で行けた。先人の皆様ありがとうございます。
- 今後、上記にもあった「インスタンスの停止→起動によるクレジット回復」を定期実行する方法も試してみたい
- 加えて、ほかのIaaSサービスでも同様のことを試してみたい。