- 投稿日:2020-04-07T22:58:29+09:00
#1 世知辛い初心者エンジニアの壁 ~エンジニアになりたい君へ~
初投稿になります。あつぎです?
未経験新卒で入社したものの、初っ端から自宅学習を強いられております。
「あっ、これ前にやったやつだ!」みたいなこともなく、事前に自分で勉強していたjavaやマークアップ言語、Web系言語も意味をなしておりません。
まず初心者の方に伝えたいのは、入社する会社が
【SIer】なのか【Web系】なのか知っておきましょう。
なんとなく開発したいは、悪くもないですが、良くもないです。はい。■C言語めちゃくちゃムズイ
題名の通りです。
研修でC言語を学ぶのは「普通」なのでしょうか?
挫折率の高い言語を研修にするのは、なんとも言えない気持ちです。開発環境はEclipse IDE(統合開発環境)で作業してたのですが、
Javaのようにサクサク実行ができず詰んでおります
■詰んでるところ
プログラミングというのは、
❶コードを書いて
❷コンパイルして(PCが読める言葉に翻訳して)
❸実行結果(画面に表示される)
のですが、Eclipseの環境だと、なぜかコンパイルできずに死亡しております…。
配布資料を読んでも、バイナリー作成されず撃沈。
Windowsなのでコマンドプロンプトで実行するも、Eclipseで動かなきゃ意味がなし。
今妥協してvisualStudio(別の開発環境)でしてみるつもりです。
同じく、EclipseでC言語、ビルドしてもバイナリーできないよ!って躓く初心者いませんかね。
私はいったん放置して、別の手段で試してみます。
では、またの
- 投稿日:2020-04-07T21:33:57+09:00
WindowsからGCPにSSH接続する
GCPのCompute EngineにSSH接続する方法です。AWSのEC2インスタンスにSSH接続するよりも、複雑でした。
前提条件
・WSLやcygwinにより、Linux環境を使うことができる
・gcloudがインストールされている。SSH認証鍵の作成
Linuxであれば以下のコマンドを用いることでSSHの公開鍵・秘密鍵のペアを作成することができる。作成する場所はローカルのPCでも、GCEインスタンス上でもどちらでもよい。
$ ssh-keygen -t rsa -f ~/.ssh/your-key-name -C your-name Enter passphrase (empty for no passphrase): #Input passphrase Enter same passphrase again: #Input passphrase again~/.sshフォルダ内にyour-key-name(秘密鍵)とyour-key-name.pub(公開鍵)が作成される
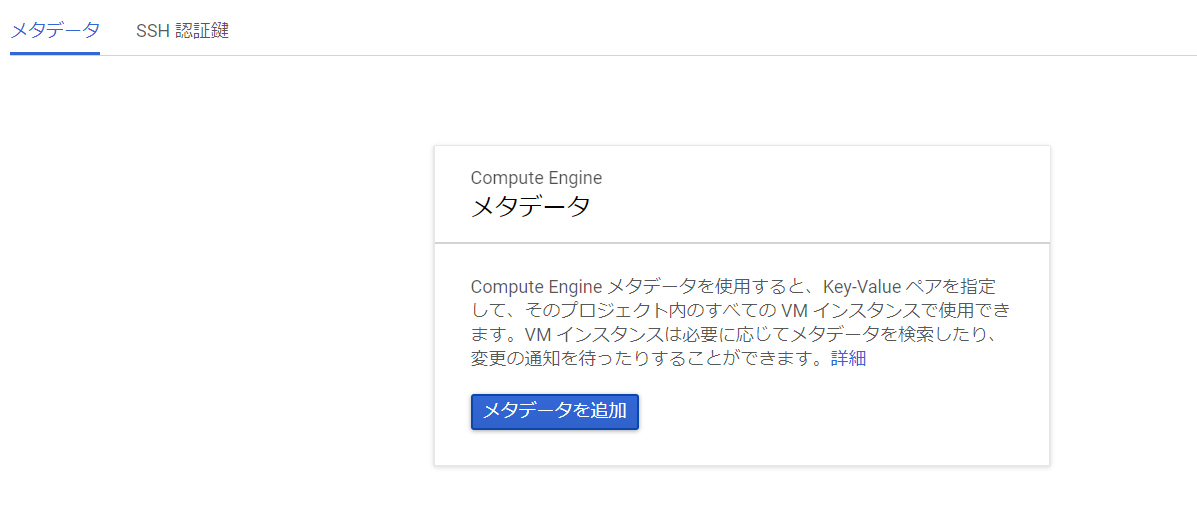
OS ログイン機能の有効化
GCPのメタデータページ(こちらを参照)に移動する
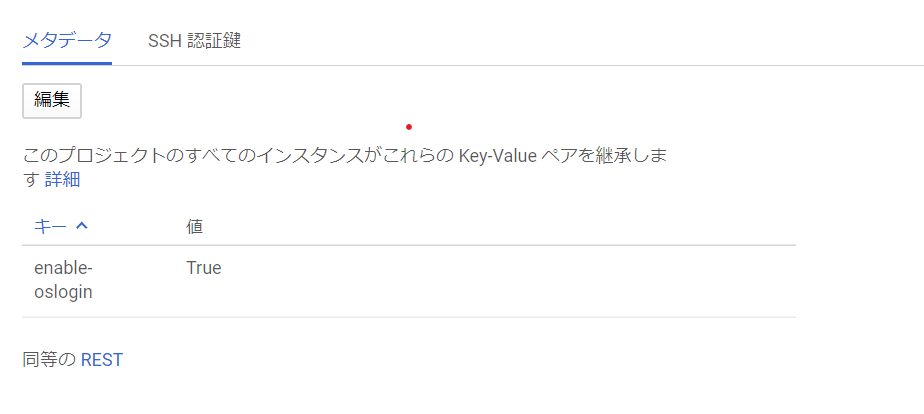
画像のようにメタデータが存在していない場合は「メタデータを追加」をクリックし、
キー「enable-oslogin」の値を「True」として入力、保存する。保存後は以下のように表示される。
OSログインが有効化された。作成した公開鍵を自分のアカウントに追加する
os-loginを有効化したことにより、作成した公開鍵を自分のアカウントに追加することができる。ローカルPCで以下のコマンドを入力すると追加される。
$ gcloud compute os-login ssh-keys add --key-file ~\.ssh\your-key-name.pub以上でローカルPCから、GCEにSSH接続する準備が整った。
認証情報の確認
接続を行う前に認証情報を確認するために、以下のコマンドを入力する
$ gcloud compute os-login describe-profile「username」がSSH接続の再使用するユーザー名
SSH接続を行う
以下のコマンドを入力する
$ ssh -i ~\.ssh\your-key-name username@your-ip-host Enter passphrase for key 'C:\Users\user\.ssh\your-key-name':$ ssh -i ~\.ssh\your-key-name username@your-ip-host Enter passphrase for key 'C:\Users\user\.ssh\your-key-name': Linux api-server 4.9.0-12-amd64 #1 SMP Debian 4.9.210-1 (2020-01-20) x86_64 The programs included with the Debian GNU/Linux system are free software; the exact distribution terms for each program are described in the individual files in /usr/share/doc/*/copyright.接続完了!!
終わりに
~/.sshフォルダ内に「config」という名前のファイルを作成し、接続する際の必要情報を記入しておくことで、ipアドレスや秘密鍵のパスといった情報をいちいち入力しないでよくなるため楽になる。
例:Host hogehoge HostName your-ip-address User your-username IdentityFile ~/.ssh/your-key-nameと、configファイルに追記した場合、
$ ssh hogehogeで接続が可能になる。
- 投稿日:2020-04-07T20:02:30+09:00
diff --ignore-matching-lines=REの正確な挙動
はじめに
diffコマンドには--ignore-matching-lines=REというオプションがあります。manを見ると"ignore changes where all lines match RE"と書かれていて、差分が正規表現にマッチしたときは無視するように見えます。
また日本語訳は「REGEXP にマッチするような行を挿入・削除するだけの変更を無視する。」となっています。これらはかなり誤解を生む表現だと思います。(分かってから読み直すと言いたいことは分からないでもないですが…)
ここではこのオプションの正確な挙動について解説します。具体例
以下の2つのファイルの差分を考えます。
file1.txtDate: 2020/4/7 Time: 20:00:00file2.txtDate: 2020/4/6 Time: 21:00:00普通に
diffを取ると$ diff file1.txt file2.txt 1,2c1,2 < Date: 2020/4/7 < Time: 20:00:00 --- > Date: 2020/4/6 > Time: 21:00:00となります。ここでDateの違いは無視してTimeだけ差分を取りたいとします。
$ diff -I Date file1.txt file2.txt 1,2c1,2 < Date: 2020/4/7 < Time: 20:00:00 --- > Date: 2020/4/6 > Time: 21:00:00しかし結果は全く変わりません。ここでfile1.txtとfile2.txtのDateとTimeの間に空行を入れてみます。
file1.txtDate: 2020/4/7 Time: 20:00:00file2.txtDate: 2020/4/6 Time: 21:00:00同じく
diffを取ると$ diff -I Date file1.txt file2.txt 3c3 < Time: 20:00:00 --- > Time: 21:00:00正しくTimeだけ取り出せました。
これはなぜかというと
--ignore-matching-linesがマッチする対象は行ではなくhunkだからです。
hunkとは一塊の差分のことで、最初の例でいうと1,2c1,2 < Date: 2020/4/7 < Time: 20:00:00 --- > Date: 2020/4/6 > Time: 21:00:00が1個のhunkです。試しに空行を入れた状態で普通に
diffを取ると$ diff file1.txt file2.txt 1c1 < Date: 2020/4/7 --- > Date: 2020/4/6 3c3 < Time: 20:00:00 --- > Time: 21:00:00と2個のhunkに分かれています。このそれぞれのhunkに対して正規表現マッチをかけて、1個目のhunkを無視するというのが
--ignore-matching-linesの正しい挙動です。ドキュメントには
GNUのドキュメントにはこのあたりも含めて正確な挙動が書いてあります。
However, -I only ignores the insertion or deletion of lines that contain the regular expression if every changed line in the hunk—every insertion and every deletion—matches the regular expression. In other words, for each nonignorable change, diff prints the complete set of changes in its vicinity, including the ignorable ones.
ここに"every changed line in the hunk"とかかれている通り、hunkの全行が正規表現にマッチしないと無視されません。
ここまで理解するとmanに書かれている"all"の意味や、日本語訳の「だけの」という文言がhunk全てを指すというのが分かってくるのですが、初見でそれに気づくのはかなり厳しいですね…。
- 投稿日:2020-04-07T18:58:19+09:00
sshでの公開鍵認証の設定方法
はじめに
公開鍵認証のやり方について、怪しい情報が多いので自分なりに整理した。
もし、間違ってたらコメントをいただけるとありがたいです。作業手順
以下の作業はすべて一般ユーザ(ログインするユーザ)で実行する。管理者権限は不要。
鍵生成
<sshクライアントで作業>
公開鍵と秘密鍵がなければ、
ssh-keygenで作る。
過去に作ったことがあれば使いまわすことになる。
(秘密鍵はユーザ自身の証明なので、あるユーザが複数のサーバにログインする場合でも
同じ鍵で複数のサーバにログインすることになる)コマンドを実行するとファイル名を聞かれるが、基本的にはデフォルトでいい。
パスワード(みたいなもの)を入力するとホームディレクトリの'.ssh/'に2つのファイルが生成される。
id_rsa.pubが公開鍵で他人に教えてもいいもの。
id_rsaが秘密鍵で誰にも教えてはいけない。
ls -lで読み取り権限を確認すると、id_rsaは自分以外も読めないようになっている。公開鍵の登録
<sshサーバで作業>
ログインするユーザのホームディレクトリ直下の
.ssh/(なければ作る)にauthorized_keysというファイルを作る。
もしあれば追記する。
ファイルの中身(もしくは追記する内容)は公開鍵情報=id_rsa.pubの一行をそのままコピーする。ディレクトリ
.sshとファイルauthorized_keysを新たに作った場合はパーミッションをchmodで変更する。chmod 700 .ssh cd .ssh chmod 600 authorized_keys補足
ここまでの手順でサーバにログインできるようになるはず。
サーバ側に公開鍵、秘密鍵のどちらもコピーする必要はなく、クライアントに鍵のペア、サーバにauthorized_keysがあればログインできる。
ただし、多段sshでそこからさらに別の場所にsshログインする場合は、その踏み台サーバがsshクライアントになると考えて、そこにも公開鍵と秘密鍵を置くことになる。
この辺を理解して不必要に鍵のコピーをばらまくのはやめましょう。
- 投稿日:2020-04-07T18:37:30+09:00
rsync スラッシュの有無
基本的な構文
rsync [オプション] [コピー元] [コピー先]
留意点
- コピー元の末尾スラッシュの有無で挙動が違う
- コピー先の末尾スラッシュの有無はどちらでも可
ディレクトリ本体を同期したい場合
$ rsync -av /src/a /bkup $ rsync -av /src/a /bkup/ # 上記は同じ意味
- ディレクトリa本体が/bkupの直下にコピーされる
- もしコピー元末尾に/を入れると、/bkup直下にディレクトリaの中身が入るため、コピー先にaフォルダが無い状態となってしまう。
ディレクトリの中身を同期したい場合
$ rsync -av /src/a/ /bkup/a $ rsync -av /src/a/ /bkup/a/ # 上記は同じ意味
- ディレクトリaの中身が/bkup/aの直下にコピーされる。
- もしコピー元末尾の/を消すと、/bkup/aの直下にディレクトリa本体が入るため、/bkup/a/aとなってしまう
参考記事
https://qiita.com/QUANON/items/2953c52df7f65f2ecee5
http://code.lioon.net/shell/how-to-set-paths-for-rsync.html
https://www.itmedia.co.jp/enterprise/articles/0804/21/news013.html一応指摘
https://www.kabegiwablog.com/entry/2018/06/21/100000
こちらの記事は完全に逆のことを言ってしまっています。。
- 投稿日:2020-04-07T17:19:43+09:00
Node.js: child_process.fork()で起動したプロセスを子子孫孫殺す方法
本稿では、Node.jsにて、子プロセス、そこから派生した孫プロセス、さらにそこから派生したひ孫プロセス……を、一括して終了する方法を説明します。
※説明にあたって、実行環境はUNIX/Linuxを前提にしています。
子プロセスを殺しても、孫プロセスは死なない
Node.jsのchild_process.fork()は、子プロセスを起動できて便利です。子プロセスの中で、
fork()を使って、孫プロセスを起動することもでき、さらに、孫プロセスでfork()して、ひ孫プロセスを、といった具合に子プロセスはネストして起動することができます。起動した子プロセスはsubprocess.kill()で終了することができます。しかし、これは直接の子プロセスしか殺すことができません。どういうことかというと、
- oya.js が ko.js のプロセスを起動する。
- ko.js が mago.js のプロセスを起動する。
- このとき、 oya.js が ko.js のプロセスを
kill()したとする。- ko.js は終了する。
- mago.js は生存する。 (※このとき、 mago.js はinitプロセスの養子に出され、親pidは1になる)
といった事態が発生します。
孫プロセスが残存するサンプルコード
上のようなシナリオを再現できるコードを書いてみたいと思います。
まず、oya.jsの実装:
oya.jsconsole.log('oya.js: running') // SIGINTを受け付けたとき process.on('SIGINT', () => { console.log('oya.js: SIGINT') process.exit() }) // プロセスが終了するとき process.on('exit', () => { console.log('oya.js: exit') }) // 子プロセスを起動 const ko = require('child_process') .fork(__dirname + '/ko.js') // 3秒後にproc2.jsを終了する setTimeout(() => { console.log('oya.js: ko.jsを終了させてます...') ko.kill('SIGINT') }, 3000) // ko.jsが終了したとき ko.on('exit', () => { console.log('> Ctrl-Cを押してください...') }) // このプロセスがずっと起動し続けるためのおまじない setInterval(() => null, 10000)oya.jsはko.jsを起動し、3秒後にko.jsを終了するコードになっています。ko.jsを
kill()する際には、SIGINTシグナルを送るようにしています。Linuxのシグナルについては、ここでは詳しく説明しません。ここでは単にSIGINTシグナルはプロセス終了を指示するものと考えてください。次に、ko.js:
ko.jsconsole.log('ko.js: running') // SIGINTを受け付けたとき process.on('SIGINT', () => { console.log('ko.js: SIGINT') process.exit() }) // プロセスが終了するとき process.on('exit', () => { console.log('ko.js: exit') }) // 孫プロセスを起動する require('child_process') .fork(__dirname + '/mago.js') // このプロセスがずっと起動し続けるためのおまじない setInterval(() => null, 10000)最後に、mago.js:
mago.jsconsole.log('mago.js: running') // SIGINTを受け付けたとき process.on('SIGINT', () => { console.log('mago.js: SIGINT') process.exit() }) // プロセスが終了するとき process.on('exit', () => { console.log('mago.js: exit') }) // このプロセスがずっと起動し続けるためのおまじない setInterval(() => null, 10000)このコードを実行してみます:
$ node oya.js oya.js: running ko.js: running mago.js: running oya.js: ko.jsを終了させてます... ko.js: SIGINT ko.js: exit > Ctrl-Cを押してください...3秒後にこのような出力がされ、oya.jsがko.jsを
kill()し、ko.jsが終了したことが確認できます。一方、mago.jsはまだ
SIGINTを受け取っていませんし、終了もしておらず、残存しています。ここで、Ctrl-Cを押すと、oya.jsとmago.jsに
SIGINTが送信されます:... > Ctrl-Cを押してください... ^Coya.js: SIGINT mago.js: SIGINT mago.js: exit oya.js: exitこのタイミングではじめて、mago.jsが終了することが分かります。
感想を言うと、ko.jsに
SIGINTを送信したら、mago.jsにもSIGINTが伝搬されていくものと誤解していたので、この結果は意外でした。起動したプロセスを子子孫孫殺す方法
では、起動した子プロセスを
kill()したタイミングで、孫プロセスも終了になるようにするにはどうしたらいいのでしょうか? それについて、ここで説明したいと思います。プロセスグループ = 「世帯」
まず、Linuxのプロセスの基本として、プロセスグループというものがあります。これはプロセスの「世帯」のような概念で、親プロセス、子プロセス、孫プロセスをグループ化するものです。たとえば、Bashでnodeプロセスであるoya.jsを起動すると、そこから
fork()したko.jsやmago.jsは、同じプロセスグループに属し、同一のグループIDが与えられます。
psコマンドでグループID(GPID)を確認すると、現に同じグループIDが3つのnodeプロセスに割り当てられていることが分かります:$ ps -xo pid,ppid,pgid,command | grep node | grep .js PID PPID GPID COMMAND 17553 3528 17553 node oya.js 17554 17553 17553 node ko.js 17555 17554 17553 node mago.jsこの結果をよく見ると分かりますが、GPIDはoya.jsのプロセスID(PID)と同じです。つまり、親のPIDが子孫のGPIDになるわけです。
プロセスを「世帯」ごと殺す方法
Node.jsでは、グループIDを指定して、プロセスを終了させることができます。やりかたは、process.kill()にGPIDを渡すだけです。このとき、与える値は負の数にしてあげます。正の数を渡してしまうと、プロセスグループではなく個別のプロセスを
kill()するだけになるので注意です。const groupId = 123456 process.kill(-groupId, 'SIGINT')ちなみに、シェルでCtrl-Cを押したときに、親・子・孫がもろとも終了されるのは、Ctrl-Cが送る
SIGINTが親プロセスに対してではなく、プロセスグループに対して送られているからです。(要出典)detached = 別世帯を作る
今回やりたいことは、oya.jsのプロセスは生かしつつ、ko.jsとmago.jsを
kill()したいことです。しかし、GPIDを指定したkill()では、oya.jsまで終了してしまいます。三者とも同じGPIDだからです:PID PPID GPID COMMAND 17553 3528 17553 node oya.js 17554 17553 17553 node ko.js 17555 17554 17553 node mago.jsko.jsとmago.jsを別のGPIDを割り振る必要があります。それをするには、
fork()のオプションにdetachedを指定します。oya.js// 子プロセスを起動 const ko = require('child_process') .fork(__dirname + '/ko.js', [], {detached: true})これを指定すると、ko.jsとmago.jsがいわば「別世帯」になり、別のプロセスグループに属するようになります。GPIDもoya.jsとは別のものが割り当てられているのが確認できます:
$ ps -xo pid,ppid,pgid,command | grep node | grep .js PID PPID GPID COMMAND 21404 3528 21404 node oya.js 21405 21404 21405 node ko.js 21406 21405 21405 node mago.jsプロセスを子子孫孫殺すoya.jsの完成形
以上を踏まえて、oya.jsを子プロセス、孫プロセスを一括して終了できるように変更すると次のようになります:
oya.jsconsole.log('oya.js: running') // SIGINTを受け付けたとき process.on('SIGINT', () => { console.log('oya.js: SIGINT') process.exit() }) // プロセスが終了するとき process.on('exit', () => { console.log('oya.js: exit') }) // 子プロセスを起動 const ko = require('child_process') .fork(__dirname + '/ko.js', [], {detached: true}) // 重要な変更箇所! // 3秒後にko.jsを終了する setTimeout(() => { console.log('oya.js: ko.jsを終了させてます...') process.kill(-ko.pid, 'SIGINT') // 重要な変更箇所! }, 30000) // ko.jsが終了したとき ko.on('exit', () => { console.log('> Ctrl-Cを押してください...') }) // このプロセスがずっと起動し続けるためのおまじない setInterval(() => null, 10000)最後に、このoya.jsを実行して、ko.jsとmago.jsが一緒に終了しているか確認してみましょう:
$ node oya.js oya.js: running ko.js: running mago.js: running oya.js: ko.jsを終了させてます... mago.js: SIGINT ko.js: SIGINT mago.js: exit ko.js: exit > Ctrl-Cを押してください... ^Coya.js: SIGINT oya.js: exit期待通り、ko.jsとmago.jsは同じタイミングで
SIGINTを受け取り終了しています。oya.jsはCtrl-Cを押すまで生存していることも分かります。以上、Node.jsの
child_process.fork()で起動したプロセスを子子孫孫殺す方法についての説明でした。
- 投稿日:2020-04-07T17:15:41+09:00
Rustのコンパイルと実行をコマンドひとつで
以下の記事の一部抜粋と + αとなっております。
Rustを0から学んでみた 〜Part.0 準備/概要 編〜 - Yuto Hongo Portfolio
Macでの利用で、Rustのコンパイラのインストールとpath設定ができている前提となっております。
1. シェルスクリプトの関数として準備
処理内容
- .rsファイルと同じ場所にコンパイル後の実行ファイルを保存
- コンパイル後のファイルを実行
スクリプト
.bashrcや.bash_profileなど#!/bin/sh rust(){ rustc $1 --out-dir `dirname $1` | `echo $1 | sed 's/\.[^\.]*$//'` }実行
% rust path/sample.rsなんかダサイ気もしますが、いったんこんなもんで。。。
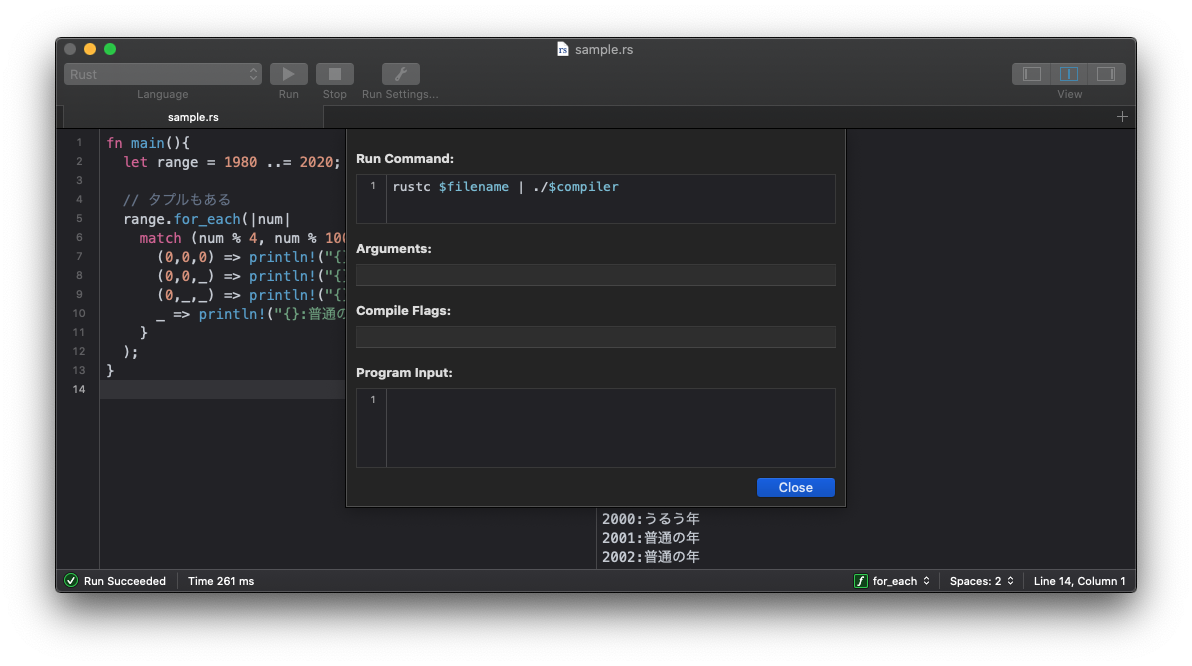
2. CodeRunnerでの設定
CodeRunner – Programming Editor for macOS
こちらのツールでの設定をご紹介します。
設定方法
- CodeRunner起動
- メニューバーの 「CodeRunner」 > 「Preferences」 > 「Languages」 > 「Rust」 を選択
- 「Run Command:」 に、以下記述をする
RunCommandrustc $filename | ./$compiler
実行
実行ボタンをポチる
- 投稿日:2020-04-07T09:27:55+09:00
大切なことはすべてUbuntuが教えてくれた 無人アップグレードを知りましょう
はじめに
本記事はUbuntuの無人アップグレードについて記載しています。
Ubuntuは無人アップグレードという機能がデフォルトで有効になっていて、自動的にOSのパッケージのアップデート及びアップグレードを行ないます。
システム管理者として注意しないといけないのは、無人アップグレードの機能を理解することです。
例えば、本番環境でシングル構成で運用しているサーバがあるとします。
無人アップグレードがデフォルトの状態でサービスの自動起動を設定していない場合は、サービスに支障が出るリスクがあります。過去の事例ですが、サービスがダウンしていていたので原因を調査しました。
uptimeコマンドを実行すると起動時間が短いことから、サーバ再起動が行われたと判断し、シスログより以下のログを確認しました。Feb 20 09:14:48 <ホスト名> systemd[1]: Stopped Unattended Upgrades Shutdown.上記ログの約3〜4分後にOS再起動が行われましたが、その後サービスの自動起動が設定されていなかったため、サービスのダウンタイムを引き起こしました。
本記事では無人アップグレードを考慮し、サービスの自動起動の設定方法についても解説します。
無人アップグレード
無人アップグレードを停止することは根本的な問題解決になりません。
無人アップグレードの仕組みは以下になります。(本記事のUbuntuのバージョンは18.04)/etc/apt/apt.conf.d/20auto-upgrades
/etc/apt/apt.conf.d/20auto-upgradesのファイルを参照するとデフォルトでは以下の設定値になっています。
- /etc/apt/apt.conf.d/20auto-upgrades
APT::Periodic::Update-Package-Lists "1"; APT::Periodic::Unattended-Upgrade "1";Update-Package-Listsが1の場合は、自動でパッケージのリストを更新します。Unattended-Upgradeが1の場合は、自動でパッケージのアップグレードが行われます。
値を0にすることで無効にできます。
また、パッケージのアップデートに関するログは、
/var/log/apt/history.logファイルから履歴を確認できます。/etc/apt/apt.conf.d/50unattended-upgrades
自動アップグレードが有効な状態でスケジュールに従って、OSの再起動を行いたい場合は、
/etc/apt/apt.conf.d/50unattended-upgradesのファイルでスケジュールを設定できます。以下はアップグレードがあった場合に、23:00に再起動を行う例です。
/etc/apt/apt.conf.d/50unattended-upgrades// Automatically reboot *WITHOUT CONFIRMATION* // if the file /var/run/reboot-required is found after the upgrade Unattended-Upgrade::Automatic-Reboot "true"; // If automatic reboot is enabled and needed, reboot at the specific // time instead of immediately // Default: "now" Unattended-Upgrade::Automatic-Reboot-Time "23:00";Automatic-Rebootのデフォルトはfalseで、Automatic-Reboot-Timeはコメントアウトされています。設定を有効にする場合は、Automatic-Rebootをtrueにし、Automatic-Reboot-Timeに任意の時刻を設定します。
自動起動設定
サービスの自動起動の方法はいくつか方法があります。
大きく分けるとOS機能のsystemctlで設定するか、MWのパッケージなどを利用することができます。例としてnodeアプリケーションの場合、PM2というデーモンプロセスマネージャなどがあります。本記事ではsystemctlで一度だけ実行するサービスの設定方法について解説します。
systemctで設定する場合は起動スクリプトを作成し、
/etc/systemd/system配下に以下のファイルを配備します。
- node.service
[Unit] Description = Node.js After=local-fs.target ConditionPathExists=/root [Service] ExecStart=/root/node_start.sh Restart=no Type=oneshot RemainAfterExit=yes [Install] WantedBy=multi-user.target次に以下のコマンドを実行し、systemctlに登録します。
# systemctl daemon-reloadおわりに
CoreOSにも同じ様な機能があります。
以下のサービスを停止することで、OSの自動起動を防ぐことができます。
# systemctl status update-engine参考
- 投稿日:2020-04-07T07:42:26+09:00
シェル(shell)を使ってプログラミングしてみる!
みなさんこんにちわ!
みなさんはシェル(shell)って聞いたことありますか?
こちらのサイトを参考にさせてただくと、
シェルとは、UNIX / Linux でターミナルソフト (kterm など)を利用する場合、ユーザはプロンプトで操作目的のコマンドを入力し、そこで表示される結果を見てまた次のコマンド入力を行う、というサイクルで対話的な作業を行います。本当は UNIX / Linux の中核(kernel: カーネル)が管理している機能を用いて、ユーザは様々な処理を行っているのですが、カーネル自身はユーザと直接対話する能力を持っていません。そこで、ユーザと対話する能力を持ち、カーネルに対して操作のお伺いを立てる仲介役のプログラムが、ユーザとカーネルの間に存在してユーザは操作を行います。この仲介役プログラムは、ユーザから見てカーネルの周りをすっぽり覆っている「殻」(shell) のように見えることからシェルと呼ばれます(図1参照)。簡単に言えば、シェルは、ユーザが入力したコマンドを解釈してカーネルに処理を依頼し、その結果やメッセージなどを画面に表示する機能を持っているのです。
だそうです!
つまり、我々がターミナルからカーネルに指示を出す際、カーネルとの間に割って入り、カーネルがわかるように翻訳してくれる通訳のような存在のようです!
シェルについてさらっと理解したところで、早速ターミナルを使ってシェルプログラミングを行っていきましょう!
シェルにも色々種類があるようですが、最近のLinuxやMac OSなどではbashがシェルの標準環境となっていることから、bashを使います!
シェルを使ったプログラミング
シェルで実行するコマンドをまとめて一つのファイルにしたものをシェルスクリプトと言います。
利用するコマンドについては
など自分の使いたい機能を考えて調べてみてください!
シェルスクリプトの拡張子は「.sh」
サンプルシェルスクリプト(lsコマンドを実行したあとに、dateコマンドを実行、echoコマンドで文字列を出力して、readコマンドで入力結果を受け取って変数に入れて出力するスクリプト)
#!/bin/bash ls date echo メッセージを入力して下さい。 read message echo 入力されたメッセージ: $message※最初の
#!/bin/bashは「シバン」といい、このシェルスクリプトを /bin/bash にある bash シェルで実行する、という意味
- ファイル権限 Linux の全てのファイルには、
・ファイルの所有ユーザー
・所属グループ
・その他のユーザー
の 3 つのアカウントの集団に対して、・読み込み可能
・書き込み可能
・実行可能という3つの権限を管理している
chmod a+x my-first.shでmy-first.shは全てのユーザーが実行可能なようにファイル権限を変更
- シェルスクリプトの実行 必ず
./をつけた相対パスで実行する必要がある→つけないとエラーmy-first.sh: command not foundが発生 ↓ 相対パスを指定しないとコマンドだと認識されるから、「そんなコマンドは存在しないよ!」と怒られる実行結果
$ ./my-first.sh my-first.sh 2018年 3月 29日 木曜日 08:13:52 UTC メッセージを入力して下さい。 入力されたメッセージ: hogereadコマンドで第一引数の変数に対して、入力された文字列を代入し、echoコマンドで
$をつけて変数を指定することで、入力内容を表示
- シェルスクリプトでのif文
#!/bin/bash read -p "日本で二番目に高い山は槍ヶ岳でしょうか? [y/n]" yn if [ $yn = "n" ]; then echo 正解です。日本で二番目に高い山は北岳です。 else echo 不正解です。日本で二番目に高い山は北岳です。 fireadコマンドは、-p"表示したい文字列"というオプションをつけることで、 文字を表示しながら入力を変数に受け取ることができる
if文は
if [ $yn = "n" ]; thenのように、条件は[]内に記入してスペースをつけて、最後はコロンとthenをつける。またif文の終わりにはfiの記載が必要
- シェルスクリプトでのwhile句
while :; doからdoneまでを、終了メッセージを受け取るまでループ例:
while :; do (echo "Thank you for your access!") | nc -l 8000 ; done→8000というポートを使ってサーバーとして起動し、アクセスがあったら、標準出力の内容を返して終了する
echoコマンドでの標準出力を
|(パイプ)を使ってncコマンドに渡しているncコマンド:NetCatの略。 TCPやUDPの読み書きを行うコマンドで、Webサーバーからの情報の取得や、簡易Webサーバーの設置、メールの送信などさまざまな機能がある
ポート:TCPやUDP の通信の取り決めのひとつ。0番から65535番のいずれかの数値を設定して通信を行う。通信をするためには、必ず何かしらのポートを利用しなくてはならず、プロトコルやソフトウェアによって、このポートが決まっているものもたくさんある
- 投稿日:2020-04-07T02:56:12+09:00
Arch Linuxで音楽CDのリッピング(取り込み)
- 投稿日:2020-04-07T02:24:47+09:00
ext4フォーマットするときはmke2fs.confに注意しようという話
3行でまとめると
- mke2fsのフォーマット時のデフォルトパラメータを理解するのはめんどい
- ので、引数に明示的にパラメータ書いたほうがよい
- 作った後dumpe2fsで確認するのを忘れずに
はじめに
突然ですが、mke2fsでext4をフォーマットするときのデフォルトパラメータは下記のどれで決まるでしょうか。
- ボリュームのサイズ
- /etc/mke2fs.conf
- 環境変数
- 上記のすべて
- 上記のすべて以外にもたくさんある
正解は5でした。日頃からext4のsuperblockをhexdumpしているような皆さんには簡単だったかと思います。
というわけで、このへんのぐだぐだした話を書くわけですが、はっきり言って理解するのは無駄だと思います。明示的にmke2fsに引数を指定してフォーマットし、できあがったイメージをdumpe2fsして確認するのが手っ取り早くて確実だと思います。
下記では、Ubuntu-18.04での例を示しつつ、ソースコードはe2fsprogs-v1.45.6を見ています。
e2fsprogs
mke2fsは、e2fsprogsで提供されるコマンドになっている。おおむねここがext2, ext3, ext4の総本家と思って良い。make_ext4fsとかExt2Fsdとかもあるが、細かいオプションで必ずしも本家を追随できているわけではないので、あらぬバグを踏んだりすることがある。
そのe2fsprogsも、必ずしも挙動がすべてmanに記載されているわけではないため、細かいとこを追おうとしたら、ソースコードを直接確認せざるを得ない。
mke2fsの実行コマンド名
mke2fsは、実行するときのコマンド名(つまりargv[0])で挙動が変わる。
e2fsprogs/misc/mke2fs.cのparse_fs_type()とPRS()より、e2fsprogs/misc/mke2fs.cif (fs_type) ext_type = fs_type; else if (is_hurd) ext_type = "ext2"; else if (!strcmp(program_name, "mke3fs")) ext_type = "ext3"; else if (!strcmp(program_name, "mke4fs")) ext_type = "ext4"; else if (progname) { ext_type = strrchr(progname, '/'); if (ext_type) ext_type++; else ext_type = progname; if (!strncmp(ext_type, "mkfs.", 5)) { ext_type += 5; if (ext_type[0] == 0) ext_type = 0; } else ext_type = 0; }e2fsprogs/misc/mke2fs.cif (argc && *argv) { program_name = get_progname(*argv); /* If called as mkfs.ext3, create a journal inode */ if (!strcmp(program_name, "mkfs.ext3") || !strcmp(program_name, "mke3fs")) journal_size = -1; }となっていて、ext_type(-tオプション)の指定がない場合に、プログラム名から、ext2, ext3, ext4のext_typeを決めている。通常はmkfs.ext4でお世話になっている人が多いと思う。
[rarul@tina e2fsprogs]$ ls -l /sbin/mkfs.ext* lrwxrwxrwx 1 root root 6 Jan 25 2019 /sbin/mkfs.ext2 -> mke2fs lrwxrwxrwx 1 root root 6 Jan 25 2019 /sbin/mkfs.ext3 -> mke2fs lrwxrwxrwx 1 root root 6 Jan 25 2019 /sbin/mkfs.ext4 -> mke2fsなおこのへんはmke2fs(8)にも記載がある。
If mke2fs is run as mkfs.XXX (i.e., mkfs.ext2, mkfs.ext3, or mkfs.ext4) the option -t XXX is implied; so mkfs.ext3 will create a file system for use with ext3, mkfs.ext4 will create a file system for use with ext4, and so on.ボリュームサイズ
mke2fsは、フォーマットしようとしているボリュームサイズによっても挙動を変える。e2fsprogs/misc/mke2fs.cのparse_fs_type()より、
e2fsprogs/misc/mke2fs.cif (fs_blocks_count < 3 * meg) size_type = "floppy"; else if (fs_blocks_count < 512 * meg) size_type = "small"; else if (fs_blocks_count < 4 * 1024 * 1024 * meg) size_type = "default"; else if (fs_blocks_count < 16 * 1024 * 1024 * meg) size_type = "big"; else size_type = "huge"; if (!usage_types) usage_types = size_type;となっていて、usage_types(-Tオプション)の指定がない場合に、3MiB, 512MiB, 4TiB, 16TiBで、size_typeの選択を変更している。ここもmanに言及があるとはいえ、サイズとか"floppy"とかの具体的な指定の仕方までは言及されておらず、ソースコードを見ざるを得ない。
mke2fs.conf
先のようにext_typeやusage_typesが決まるが、これらは、mke2fs.confに記載されたセクションを選ぶための値として使われる。
[rarul@tina e2fsprogs]$ cat /etc/mke2fs.conf [defaults] base_features = sparse_super,large_file,filetype,resize_inode,dir_index,ext_attr default_mntopts = acl,user_xattr enable_periodic_fsck = 0 blocksize = 4096 inode_size = 256 inode_ratio = 16384 [fs_types] ext3 = { features = has_journal } ext4 = { features = has_journal,extent,huge_file,flex_bg,metadata_csum,64bit,dir_nlink,extra_isize inode_size = 256 } small = { blocksize = 1024 inode_size = 128 inode_ratio = 4096 } floppy = { blocksize = 1024 inode_size = 128 inode_ratio = 8192 } big = { inode_ratio = 32768 } huge = { inode_ratio = 65536 } news = { inode_ratio = 4096 } largefile = { inode_ratio = 1048576 blocksize = -1 } largefile4 = { inode_ratio = 4194304 blocksize = -1 } hurd = { blocksize = 4096 inode_size = 128 }こんな感じに、mke2fs.confは種類に応じたオプションを持っている。ext_typeとusage_typesに応じて、ここからパラメータが選ばれることになる。このファイルのテンプレートはe2fsprogsが提供するが、実際の中身はLinuxディストリビューションごとに変更が加わっているかもしれない。記事の最後で触れるが、metadata_csumあたりがくせ者。
このmke2fs.confについては、わざわざman mke2fs.conf(5)が提供されていて、オプションも細かく指定することができるようになっている。
このmke2fs.confファイルについても、ファイルをどこから探すかをカスタマイズ可能で、↓の章へ続く。
mke2fs.confの探し方
環境変数MKE2FS_CONFIGでmke2fs.confファイルの場所を指定できる。e2fsprogs/misc/mke2fs.cのPRS()より、
e2fsprogs/misc/mke2fs.cif ((tmp = getenv("MKE2FS_CONFIG")) != NULL) config_fn[0] = tmp;環境変数MKE2FS_CONFIGが定義されていない場合は、コンパイル時に決まるデフォルトの場所(ROOT_SYSCONFDIR)が使われ、これは通常/etcになっている。
mke2fs.confがない場合
mke2fs.confが見つからなかった場合、const char *mke2fs_default_profileの値が使われる。が、ソースコードだけ見てるとこの変数の中身が見つからない。この変数は実は、ビルド時に自動生成される。
e2fsprogs/misc/profile-to-c.awk#!/bin/awk BEGIN { printf("const char *mke2fs_default_profile = \n"); } { printf(" \"%s\\n\"\n", $0); } END { printf(";\n", str) }となっていて、profile-to-c.awkを実行するときの引数が展開される。引数は、
e2fsprogs/misc/Makefile.indefault_profile.c: mke2fs.conf $(srcdir)/profile-to-c.awk $(E) " PROFILE_TO_C mke2fs.conf" $(Q) $(AWK) -f $(srcdir)/profile-to-c.awk < mke2fs.conf \ > default_profile.cとなっていて、./configure時にmke2fs.conf.inから展開されるファイルが使われる。
2fsprogs/misc/mke2fs.conf.in[defaults] base_features = sparse_super,large_file,filetype,resize_inode,dir_index,ext_attr default_mntopts = acl,user_xattr enable_periodic_fsck = 0 blocksize = 4096 inode_size = 256 inode_ratio = 16384 [fs_types] ext3 = { features = has_journal } ext4 = { features = has_journal,extent,huge_file,flex_bg,metadata_csum,64bit,dir_nlink,extra_isize inode_size = 256 } small = { blocksize = 1024 inode_size = 128 inode_ratio = 4096 } floppy = { blocksize = 1024 inode_size = 128 inode_ratio = 8192 } big = { inode_ratio = 32768 } huge = { inode_ratio = 65536 } news = { inode_ratio = 4096 } largefile = { inode_ratio = 1048576 blocksize = -1 } largefile4 = { inode_ratio = 4194304 blocksize = -1 } hurd = { blocksize = 4096 inode_size = 128 } [options] fname_encoding = utf8つまり、e2fsprogsのデフォルトのmke2fs.confをそのままmke2fsプログラムの中に抱えている。
metadata_csumのワナ
metadata_csumにはプチ事件があって、metadata_csumを有効にしたext4を古いUbuntu(16.04)のe2fsprogsが扱えないという問題があった。
- 2018年3月23日号 ext4のmetadata_csumオプションへの対処・initramfsの圧縮方式の変更:Ubuntu Weekly Topics|gihyo.jp … 技術評論社これは、Linuxカーネルはmetadata_csumを理解できるけど、e2fsprogsは古いままだったのでmetadata_csumを理解できなかった、という話。このUbuntu-16.04の場合はLinux-4.15だけど、環境によってはkernelのバージョンが予想できずに、思いもよらぬ環境でmetadata_csumが有効になってしまうという事件が起こる可能性がある。あまりにkernelが古いと、metadata_csumが扱えるとはいえまだext4バグ持ちだったりするわけで、えっと、その、非常に怖いですね、はい。
おわりに
というわけで、mke2fsがどうやってデフォルトパラメータを決めるのかを細かく確認してみた。なにげなく疑問に思ったinodeサイズの違いが起点だったけど、いざ調べてみるときちんと理解するのがめんどい泥沼だった。というか、理解するのはやめたほうが良いと思った。
理解するのはやめて、できるだけmke2fsを実行するときの引数で指定するようにしよう。そして、できあがったイメージに対しdumpe2fsで目的のパラメータになっているかを確認するようにしよう。
参考
- 投稿日:2020-04-07T01:26:50+09:00
Sipeed Lichee ZeroでLチカとか(GPIO操作)
概要
Sipeed Lichee ZeroでLチカとスイッチの読み取りをやってみました。
恐らくLichee Nanoでも同じような感じで出来るんじゃないかな?方法
GPIOにアクセスする方法としては大まかにデバイスファイルを使う方法とメモリアクセスして操作する方法がある。デバイスファイルを使う方法は手軽だが速度が遅い。メモリアクセスして操作する方法は早いが結構面倒。一長一短やなぁ。
方法1 デバイスファイルを使う
基板上のフルカラーLEDはPG0~PG2に繋がっている。この番号に対応する192~194の番号でデバイスファイルにアクセスすればフルカラーLEDが点灯する。
ただこのLEDアノードコモンなので0で点灯1で消灯になる。そもそも初期化でポートは0になるので初期化したら点灯する。# echo 192 > /sys/class/gpio/export # echo out > /sys/class/gpio/gpio192/direction # echo 1 > /sys/class/gpio/gpio192/value # echo 0 > /sys/class/gpio/gpio192/valuePG3に接続したスイッチの値を読みたい場合は下記の様にすれば0か1が返ってくる。
(スイッチにはプルアップ抵抗が必要です。)# echo 195 > /sys/class/gpio/export # echo in > /sys/class/gpio/gpio195/direction # cat /sys/class/gpio/gpio195/valueポート番号とデバイスファイルの番号の対応は公式ドキュメントに書かれているのでそれで確認できる。
http://zero.lichee.pro/%E9%A9%B1%E5%8A%A8/GPIO_file.html方法2 メモリアクセスを使う
公式のドキュメントを読む限りこの方法でGPIOを操作出来るライブラリがあるような事が書かれているが何処にも見つけられなかった。コミュニティの方でも同じような質問が数年前にあったが無いという結論に達していたので恐らく無いのだろう。
なので欲しくなって作ったが初めての事だったので結構大変だった。あまり情報無いし…
機能としてはポートの初期化・設定と入出力のみ。割り込みとかは未実装。
量も少ないので全部ヘッダファイルの中に書いてしまった。test_io.h#include <stdio.h> #include <stdlib.h> #include <fcntl.h> #include <unistd.h> #include <sys/mman.h> #include <errno.h> /* ペリフェラルレジスタの物理アドレス(BCM2835の仕様書より) */ #define REG_ADDR_BASE (0x01C20800) /* bcm_host_get_peripheral_address()の方がbetter */ #define REG_ADDR_GPIO_BASE 0x1C20000 #define REG_ADDR_GPIO_LENGTH 0x1000 #define PORT_OFFSET 0x800 #define REG_ADDR_GPIO_GPFSEL_0 0x0000 + PORT_OFFSET #define REG_ADDR_GPIO_OUTPUT_DATA_0 0x10 + PORT_OFFSET #define REG(addr) (*((volatile unsigned int*)(addr))) #define DUMP_REG(addr) printf("DUMP = %08X\n", REG(addr)); #define IN 0 #define OUT 1 #define DISABLE 2 #ifndef LICHEEIO_H #define LICHEEIO_H int io_init(void); int io_release(void); int port_no_check(int port, int pin); int setup_gpio(char *pin_no, int io_set); int output_gpio(char *pin_no, int hl_set); int input_gpio(char *pin_no); #endif /* LICHEEIO_H */ int address; /* GPIOレジスタへの仮想アドレス(ユーザ空間) */ int fd; int io_init(void){ /* メモリアクセス用のデバイスファイルを開く */ if ((fd = open("/dev/mem", O_RDWR | O_SYNC)) < 0) { perror("open"); return -1; } // long sz = sysconf(_SC_PAGESIZE); // printf("%08X", sz); /* ARM(CPU)から見た物理アドレス → 仮想アドレスへのマッピング */ address = (int)mmap(0, REG_ADDR_GPIO_LENGTH, PROT_READ | PROT_WRITE, MAP_SHARED, fd, REG_ADDR_GPIO_BASE); if (address == (int)MAP_FAILED) { perror("mmap"); close(fd); return -1; } return 0; } int io_release(void){ /* 使い終わったリソースを解放する */ munmap((void*)address, REG_ADDR_GPIO_LENGTH); close(fd); return(0); } int port_no_check(int port, int pin){ int err_F = 0; switch (port){ case 1: if(pin < 0 || pin > 9) err_F = 1; break; case 2: if(pin < 0 || pin > 3) err_F = 1; break; case 4: if(pin < 0 || pin > 24) err_F = 1; break; case 5: if(pin < 0 || pin > 6) err_F = 1; break; case 6: if(pin < 0 || pin > 5) err_F = 1; break; default: err_F = 1; break; } return(err_F); } int setup_gpio(char *pin_no, int io_set){ int err_F = 0; int port ,pin, reg_no; port = pin_no[0] - 'A'; pin = atoi(pin_no + 1); if(port_no_check(port, pin) == 1){ printf("errno"); return(-1); } reg_no = pin / 8; if(io_set == IN){ REG(address + REG_ADDR_GPIO_GPFSEL_0 + port * 0x24 + reg_no) &= ~(0x07 << pin * 4); } else if (io_set == OUT){ REG(address + REG_ADDR_GPIO_GPFSEL_0 + port * 0x24 + reg_no) |= (0x1 << pin * 4); REG(address + REG_ADDR_GPIO_GPFSEL_0 + port * 0x24 + reg_no) &= ~(0x6 << pin * 4); //REG(address + REG_ADDR_GPIO_GPFSEL_0 + port * 0x24) = 0x77777777; } else if (io_set == DISABLE){ REG(address + REG_ADDR_GPIO_GPFSEL_0 + port * 0x24 + reg_no) |= (0x07 << pin * 4); } //DUMP_REG(address + REG_ADDR_GPIO_GPFSEL_0 + port * 0x24); return(0); } int output_gpio(char *pin_no, int hl_set){ int port, pin; port = pin_no[0] - 'A'; pin = atoi(pin_no + 1); if(port_no_check(port, pin) == 1){ printf("errno"); return(-1); } if(hl_set == 0){ //in REG(address + REG_ADDR_GPIO_OUTPUT_DATA_0 + port * 0x24) &= ~(0x1 << pin); } else if (hl_set == 1){ //out REG(address + REG_ADDR_GPIO_OUTPUT_DATA_0 + port * 0x24) |= (0x1 << pin); } //DUMP_REG(address + REG_ADDR_GPIO_OUTPUT_DATA_0 + port * 0x24); return(0); } int input_gpio(char *pin_no){ int port, pin, data; port = pin_no[0] - 'A'; pin = atoi(pin_no + 1); if(port_no_check(port, pin) == 1){ printf("errno"); return(-1); } data = REG(address + REG_ADDR_GPIO_OUTPUT_DATA_0 + port * 0x24) & (0x1 << pin); //DUMP_REG(address + REG_ADDR_GPIO_OUTPUT_DATA_0 + port * 0x24); if(data != 0){ data = 1; } //printf("data = %08X\n", data); return(data); }青と緑が交互に点滅するサンプルプログラム。
Ltika.c#include "test_io.h" #include <unistd.h> int main(){ int sta, data; printf("%d\n", io_init()); sta += setup_gpio("G0", OUT); sta += setup_gpio("G1", OUT); printf("sta=%d\n", sta); while (1){ output_gpio("G0", 0); output_gpio("G1", 1); usleep(1e5); output_gpio("G1", 0); output_gpio("G0", 1); usleep(1e5); } io_release(); }コンパイル・実行
gcc Ltika.c -o Ltika -lm -std=gnu99 sudo ./LtikaPG3に接続したスイッチを押すと点灯するサンプルプログラム
(スイッチにはプルアップ抵抗が必要です。)sw.c#include "test_io.h" #include <unistd.h> int main(){ int sta, data; printf("%d\n", io_init()); sta = setup_gpio("G0", OUT); sta = setup_gpio("G1", DISABLE); //sta = setup_gpio("G2", OUT); sta = setup_gpio("G3", IN); printf("%d\n", sta); //output_gpio("G1", 1); //output_gpio("G2", 1); while(1){ data = input_gpio("G3"); output_gpio("G0", data); usleep(1e3); } io_release(); }コンパイル・実行
gcc sw.c -o sw -lm -std=gnu99 sudo ./sw※std=gnu99オプションはusleep(1e3)を使う為に付けています。
あとこのプログラムPG以外では実際に部品を繋いでのテストはまだしていないのでもしかしたら上手く動かない事があるかもしれません。
一応レジスタの状態が変化しているかはある程度確認してはいますが…おまけ
このプログラムはポート関係のレジスタの状態一覧表示プログラムです。
pin_status.c#include <stdio.h> #include <stdlib.h> #include <fcntl.h> #include <unistd.h> #include <sys/mman.h> #include <errno.h> /* ペリフェラルレジスタの物理アドレス(BCM2835の仕様書より) */ #define REG_ADDR_BASE (0x01C20800) /* bcm_host_get_peripheral_address()の方がbetter */ #define REG_ADDR_GPIO_BASE 0x1C20000 #define REG_ADDR_GPIO_LENGTH 0x1000 #define PORT_OFFSET 0x800 #define REG_ADDR_GPIO_GPFSEL_0 0x0000 + PORT_OFFSET #define REG(addr) (*((volatile unsigned int*)(addr))) #define DUMP_REG(addr) printf("DUMP = %08X\n", REG(addr)); int address; /* GPIOレジスタへの仮想アドレス(ユーザ空間) */ int fd; int io_init(void){ /* メモリアクセス用のデバイスファイルを開く */ if ((fd = open("/dev/mem", O_RDWR | O_SYNC)) < 0) { perror("open"); return -1; } // long sz = sysconf(_SC_PAGESIZE); // printf("%08X", sz); /* ARM(CPU)から見た物理アドレス → 仮想アドレスへのマッピング */ address = (int)mmap(0, REG_ADDR_GPIO_LENGTH, PROT_READ | PROT_WRITE, MAP_SHARED, fd, REG_ADDR_GPIO_BASE); if (address == (int)MAP_FAILED) { perror("mmap"); close(fd); return -1; } return 0; } int io_release(void){ /* 使い終わったリソースを解放する */ munmap((void*)address, REG_ADDR_GPIO_LENGTH); close(fd); return(0); } // int setup_gpio(char *pin_no, int io_set){ // int err_F = 0; // int port ,pin; // port = pin_no[0] - 'A'; // pin = atoi(pin_no + 1); // if(port_no_check(port, pin) == 1){ // printf("errno"); // return(-1); // } // if(io_set == IN){ // REG(address + REG_ADDR_GPIO_GPFSEL_0 + port * 0x24) &= ~(0x07 << pin * 4); // } // else if (io_set == OUT){ // REG(address + REG_ADDR_GPIO_GPFSEL_0 + port * 0x24) |= (0x1 << pin * 4); // REG(address + REG_ADDR_GPIO_GPFSEL_0 + port * 0x24) &= ~(0x6 << pin * 4); // //REG(address + REG_ADDR_GPIO_GPFSEL_0 + port * 0x24) = 0x77777777; // } // else if (io_set == DISABLE){ // REG(address + REG_ADDR_GPIO_GPFSEL_0 + port * 0x24) |= (0x07 << pin * 4); // } // //DUMP_REG(address + REG_ADDR_GPIO_GPFSEL_0 + port * 0x24); // return(0); // } int bit2int(int *bit_data, int *int_data){ for(int i = 0; i < 4; i++){ int mask = 0x0007, x; for(int j = 0; j < 8; j++){ x = bit_data[i] & mask; //printf("%08x ", x); //printf("%08x ", x >> j * 4); int_data[i * 8 + j] = x >> j * 4; //printf("mask = %08X\n", mask); mask = mask << 4; } } //printf("\n"); } int main(){ io_init(); int read_data[4]; int port_status[5][32]; for(int i = 0; i < 5; i++){ if(i == 0){ read_data[0] = REG(address + REG_ADDR_GPIO_GPFSEL_0 + 1 * 0x24); read_data[1] = REG(address + REG_ADDR_GPIO_GPFSEL_0 + 1 * 0x24 + 1); bit2int(read_data, port_status[0]); } if(i == 1){ read_data[0] = REG(address + REG_ADDR_GPIO_GPFSEL_0 + 2 * 0x24); bit2int(read_data, port_status[1]); } if(i == 2){ read_data[0] = REG(address + REG_ADDR_GPIO_GPFSEL_0 + 4 * 0x24); read_data[1] = REG(address + REG_ADDR_GPIO_GPFSEL_0 + 4 * 0x24 + 1); read_data[2] = REG(address + REG_ADDR_GPIO_GPFSEL_0 + 4 * 0x24 + 2); read_data[3] = REG(address + REG_ADDR_GPIO_GPFSEL_0 + 4 * 0x24 + 3); bit2int(read_data, port_status[2]); } if(i == 3){ read_data[0] = REG(address + REG_ADDR_GPIO_GPFSEL_0 + 5 * 0x24); bit2int(read_data, port_status[3]); } if(i == 4){ read_data[0] = REG(address + REG_ADDR_GPIO_GPFSEL_0 + 6 * 0x24); bit2int(read_data, port_status[4]); } } for(int i = 0; i < 5; i++){ int indention = 7; if(i == 0){ printf("PB\n"); } else if(i == 1){ printf("PC\n"); } else if(i == 2){ printf("PE\n"); } else if(i == 3){ printf("PF\n"); } else if(i == 4){ printf("PG\n"); } for(int j = 0; j < 32; j++){ if(port_status[i][j] == 7){ printf("%02d:無効 ", j); } else if(port_status[i][j] == 0){ printf("%02d:入力 ", j); } else if(port_status[i][j] == 1){ printf("%02d:出力 ", j); } else{ printf("%02d:他%02d ", j, port_status[i][j]); } if((i == 0 && j == 9) || (i == 1 && j == 3) || (i == 2 && j == 24) || (i == 3 && j == 6) || (i == 4 && j == 5)){ break; } if(j == indention){ printf("\n"); indention += 8; } } printf("\n\n"); } io_release(); }参考資料
公式ドキュメント:GPIO
メインチップデータシート
Sipeed Lichee Zero回路図
組み込みLinuxデバイスドライバの作り方 (5)
- 投稿日:2020-04-07T00:00:53+09:00
AWSの無料枠でCOVID-19解析に貢献しようとしてうまくいってない話
(自ブログに書いた記事の転載です)
はじめに
「新型コロナウイルスの解析に貢献しつつ、AmazonWebServiceの環境構築を実践してみよう」とした話です。
結果、「正常に動作はしたが、無料枠ではスペック不足ゆえにあまり貢献できていない」という結論になってしまいましたが、
作業の記録として、残しておきます。背景
コロナ流行辛い。なんとか解決早めらんないか。
↓
「今からでも3分ではじめられるコロナ解析貢献「Folding@home」の使い方」というPC Watchの記事を見つける
↓
即自宅ノートPC(旧世代のGPU搭載)にインストール。1週間程度走らせ続けて25タスクほどこなすが、まだ物足りない感。
↓
スペックは上げられないから、稼働台数増やしたい。でも物理マシンは1台しかもっていない...
↓
そうだAWSアカウント持ってた。これ使ってみよう。無料枠でできるなら記事化すれば真似してくれる人いるかも?
↓
行動。
やったこと①: VPC環境の作成
VPC環境をまず構築し、その中にEC2環境を立てることにした。
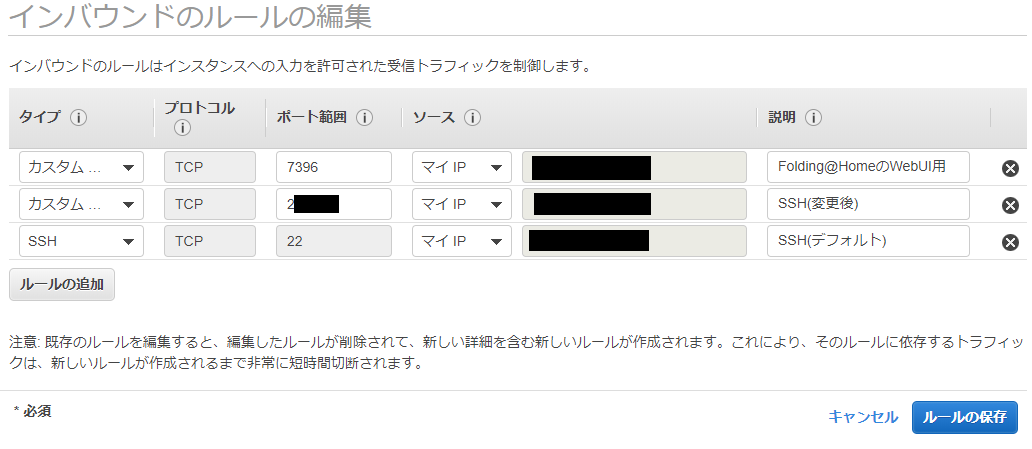
基本、こちらのブログ記事の通りに作業。唯一セキュリティグループだけは、今回の利用目的に合わせて以下のように変更。
- Webサービスを立てるわけではないので80番ポートはクローズ。
- 代わりに、Folding@HomeのWebコントローラ用に7396番を開放
- セキュリティ対策として22番以外のSSH用ポートを開放、初期ログイン用に22番はいったん残す。
- 今回の環境は「自分だけアクセスできればいい」ので、ソースはすべてマイIPに限定
やったこと②: VPC上にEC2環境構築
①で作ったVPC環境上に、EC2環境を作成。この作業もこちらのブログ記事を参考にした。
今回は無料利用枠で作れる環境にしたかったので、構成は以下の通り
- OS: Amazon Linux 2 AMI(x86)
- インスタンスタイプ:t2.micro
- ストレージ: 汎用SSD 8GB
やったこと③: Linuxの設定
- SSHのポート番号変更
$ sudo vi /etc/ssh/sshd_config ### 22行あたりに以下を追加(①で指定したポート番号) Port 2**** ### 保存後 $ sudo service sshd reload
- EC2作成時とは別のRSA鍵でアカウントを作り、デフォルトの"ec2-user"削除
### ユーザ新規作成(root権限) # useradd newuser # passwd newuser ### SSH設定(root権限) # cd /home/newuser/ # mkdir .ssh # chmod 700 .ssh # chown newuser:newuser .ssh ### ここで公開鍵をSCPで送信 # mv /home/ec2-user/id_rsa.pub .ssh/authorized_keys # chmod 600 .ssh/authorized_keys # chown newuser:newuser .ssh/authorized_keys ### sudoできる権限を与える # usermod -aG wheel newuser ### 別窓で"newuser"としてログイン。以降newuser側の画面で操作 $ sudo su - ### rootになれることを確認したら、ec2-user削除 # userdel ec2-userやったこと④: Folding@Homeの導入
今回は、最低限必要な
FAHClientのみ導入。
- インストール
設定
/etc/fahclient/config.xmlを編集。更新にはroot権限必須。<config> <!-- GPUを使うか --> <!-- Folding Slot Configuration --> <gpu v='false'/> <!-- どの程度CPU資源を利用するか。light,middle,fullの3択 --> <!-- Slot Control --> <power v='full'/> <!-- ユーザ情報。ユーザ名を入れておけば個人でどれだけ貢献したか集計される --> <!-- User Information --> <user v='deflat'/> <!-- スロット番号とタイプ。今回はCPU1個しかないのでいじらない --> <!-- Folding Slots --> <slot id='0' type='CPU'/> <!-- Webコントローラへのアクセス権限設定。xxx.xxx.xxx.xxxのところに自分のIPアドレスを記入 --> <allow>127.0.0.1 xxx.xxx.xxx.xxx</allow> <web-allow>127.0.0.1 xxx.xxx.xxx.xxx</web-allow> </config>
- 設定反映&サービス再起動
- タスク処理中にstopしても、次startしたときはちゃんと続きから計算してくれる。
$ sudo /etc/init.d/FAHClient stop $ sudo /etc/init.d/FAHClient start結果
- Webブラウザで
http://<EC2環境のIPアドレス>:7396にアクセスすると、下記のようにちゃんと動いているのが見える。 ...が、めちゃくちゃ処理が遅い
- 画像は処理開始から24時間ほどたったときのもの。個人持ちのノートPCでも、このくらいなら3~4時間で終わるはず。
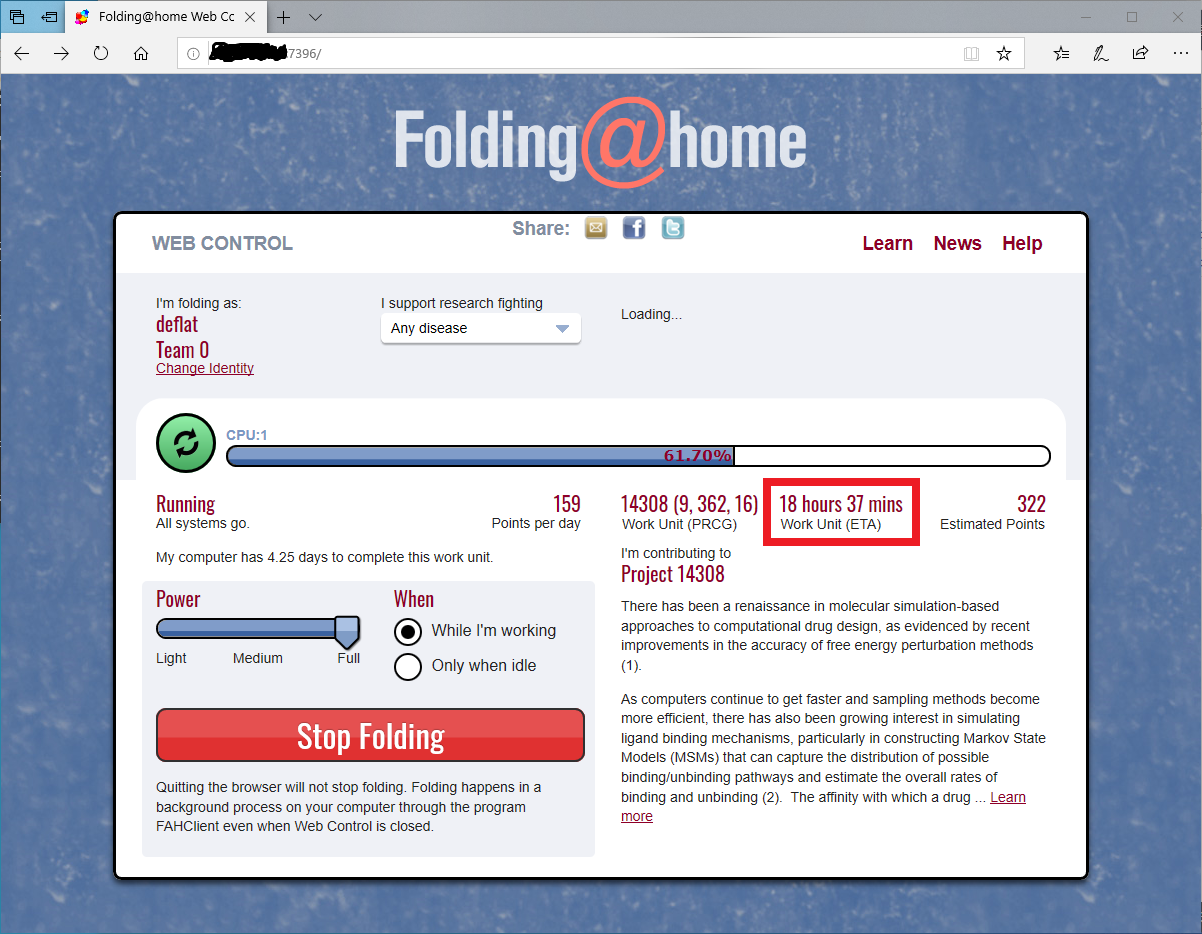
後から調べて分かったこと
- EC2のt2インスタンスには、「CPUクレジット残高」という概念があり、これが枯れている状態だと使えるCPU資源が限定される。
- 今回使用したt2-microだと、CPU使用率10%にしかならないのだとか。
- インスタンス自体の停止→起動をすれば初期クレジットまで回復するそうなので、今後検討してみる。
- 参考
まとめと感想
- 「新型コロナウイルスの解析に貢献しつつ、AmazonWebServiceの環境構築を実践してみよう」とした話。
- 初めてやる自分でも、全行程完了まで2~3時間で行けた。先人の皆様ありがとうございます。
- 今後、上記にもあった「インスタンスの停止→起動によるクレジット回復」を定期実行する方法も試してみたい
- 加えて、ほかのIaaSサービスでも同様のことを試してみたい。