classApplicationController<ActionController::Base#herokuapp.comから独自ドメインへリダイレクトbefore_action:ensure_domainFQDN='www.hogehoge.net'# redirect correct server from herokuapp domain for SEOdefensure_domainreturnunless/\.herokuapp.com/=~request.host# 主にlocalテスト用の対策80と443以外でアクセスされた場合ポート番号をURLに含める port=":#{request.port}"unless[80,443].include?(request.port)redirect_to"#{request.protocol}#{FQDN}#{port}#{request.path}",status: :moved_permanentlyendend
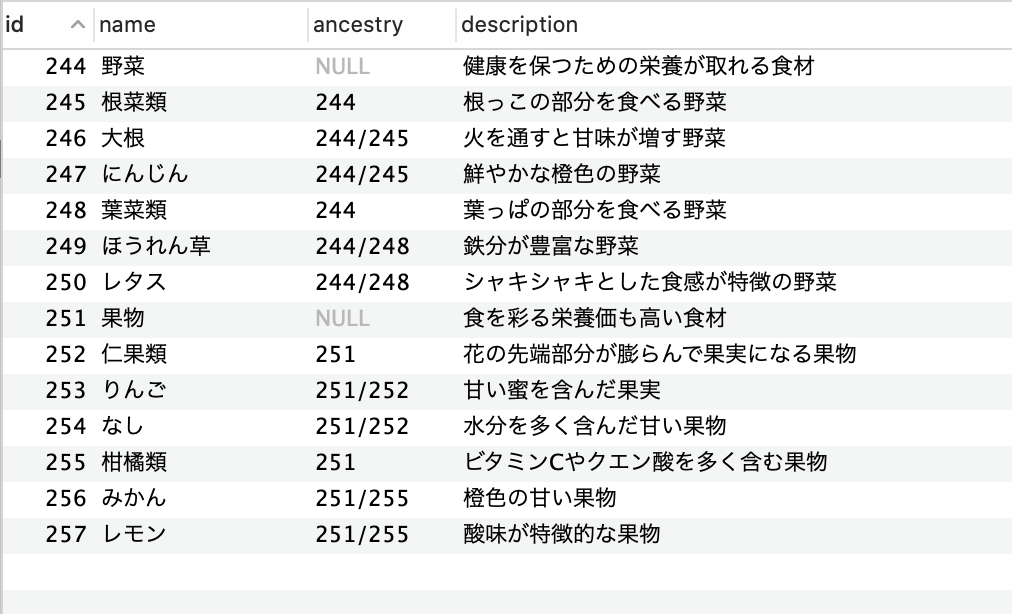
Ruby on Railsのseedファイルを使って、ancestryのデータを挿入するとき、カラムを複数同時に挿入したいと思い、その実装ができたので解説させていただきます。
(とあるプログラミングスクールのカリキュラムによって、某フリマアプリのカテゴリーに関する記事がたくさんありますが、そちらはカラムが1つしかなかったため投稿しようと考えました。)
#起動中のコンテナ名確認
docker-compose ps
#DBコンテナに入る
docker exec -it DBコンテナNAME bash
#mysqlへ接続(パスワードはdocker-compose.ymlに記載したもの)
mysql -u root -p
Enter password:
EC2
#DBコンテナのPORT確認
docker ps
#確認結果(例)
0.0.0.0:3306->3306/tcp
#mysqlへ接続(パスワードはdocker-compose.ymlに記載したもの)
mysql -h 0.0.0.0 -P 3306 -u root -p
Enter password:
データベースの中身閲覧
ターミナル
#データベース接続
mysql -u root -p
#どんなデータベースがあるか
show databases;
#使用したいデータベースに切り替え
use データベ-ス名;
#テーブル一覧
show tables;
#テーブルの構造確認
describe テーブル名複数系;
#テーブルの中身確認
select * from テーブル名複数系;
class Person < ActiveRecord::Base
belongs_to :company
# DBにname, emailカラムを持つ
end
class Company < ActiveRecord::Base
has_many :people
# DBにnameカラムを持つ
end
class Person < ActiveRecord::Base
belongs_to :company
def display_info
if company
"#{name} (#{company.name} 所属)"
else
"#{name} (フリーランス)"
end
end
end
# view
<%= @person.display_info %>
$ docker-compose ps
Name Command State Ports
------------------------------------------------------------------------------------------
sample_app_db_1 docker-entrypoint.sh mysqld Up 0.0.0.0:3306->3306/tcp, 33060/tcp
sample_app_web_1 rails s -p 3000 -b 0.0.0.0 Up 0.0.0.0:3000->3000/tcp
$rails s
=>Booting Puma
=>Rails 5.2.4.2 application starting in development
=>Run `rails server -h`for more startup options
Puma starting in single mode...
* Version 3.12.4 (ruby 2.5.3-p105), codename: Llamas in Pajamas
* Min threads: 5, max threads: 5
* Environment: development
* Listening on tcp://localhost:3000
Use Ctrl-C to stop
Started GET "/" for 127.0.0.1 at 2020-04-02 11:39:55 +0900
Mysql2::Error::ConnectionError - Can't connect to local MySQL server through socket '/tmp/mysql.sock' (2):
$rails new test_migrate -d postgresql
$cd test_migrate
$rails db:create
FATAL: role "vagrant" does not exist
Couldn't create 'test_migrate_test' database. Please check your configuration.
rails aborted!
ActiveRecord::NoDatabaseError: FATAL: role "vagrant" does not exist
bin/rails:4:in `<main>'
Caused by:
PG::ConnectionBad: FATAL: role "vagrant" does not exist
bin/rails:4:in `<main>'
Tasks: TOP => db:create
(See full trace by running task with --trace)
We're requiring both Refile's Rails integration and image processing via the MiniMagick gem, which requires ImageMagick (or GraphicsMagick) to be installed. To install it simply run: