- 投稿日:2020-04-02T23:53:03+09:00
pythonで相対パスの指定の方法で悩んだ話。
自分の備忘録を兼ねて、問題の直接原因とは関係のないソースコードも記載
事象
pythonでiniファイルを読み込む処理を行おうとしたら、
何故か、KeyErrorが出てしまい上手く行かない。ソースは以下の通り
config.ini[USER_INFO] address=testUser password=testpasstest.pyimport configparser config = configparser.ConfigParser() config.read('./config.ini', encoding='utf-8') address = config['USER_INFO']['address']keyの値が間違っている様子もない。
config.iniが読み込めていないのではないかと思い、ファイルの存在確認。
結果、Falseが返却された。import os print(os.path.exists('./config.ini'))フォルダの取得がうまくいっていなかった。
【原因&解決方法】
プログラムを実行する際に、VSCodeから実行をしていたのだが、
実行する際のカレントディレクトリがtest.pyの存在しているファイルではなかったことが原因。
test.pyが存在するディレクトリに移動してから実行したら、無事にiniファイルからの値の取得もうまくいった。
- 投稿日:2020-04-02T23:12:45+09:00
【Python】複数クラスタの散布図を描くなら
この記事の目的
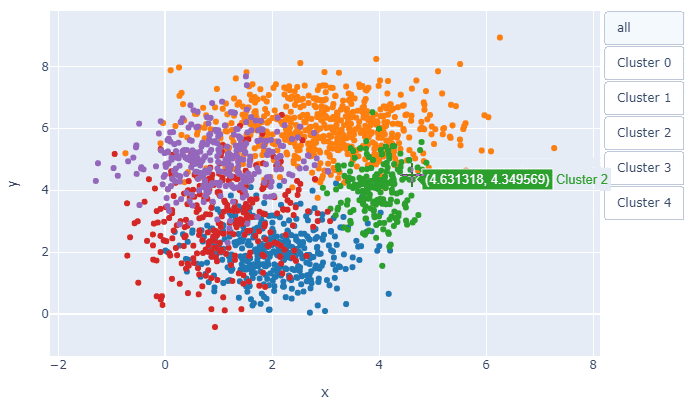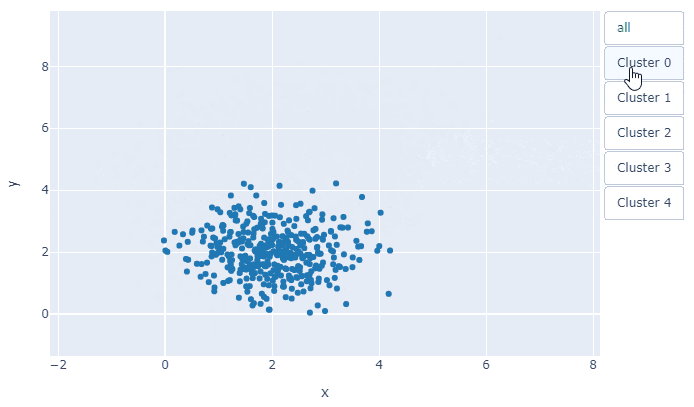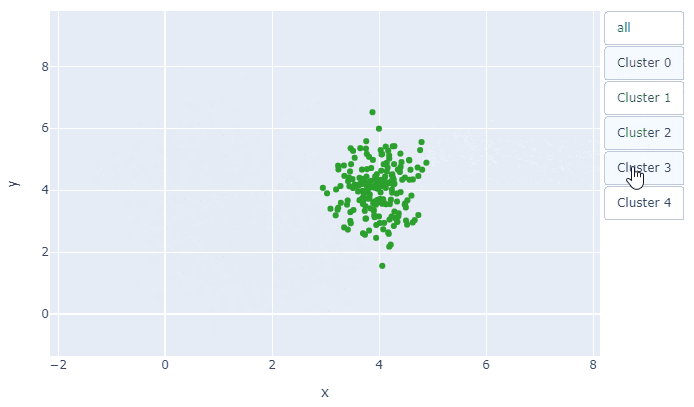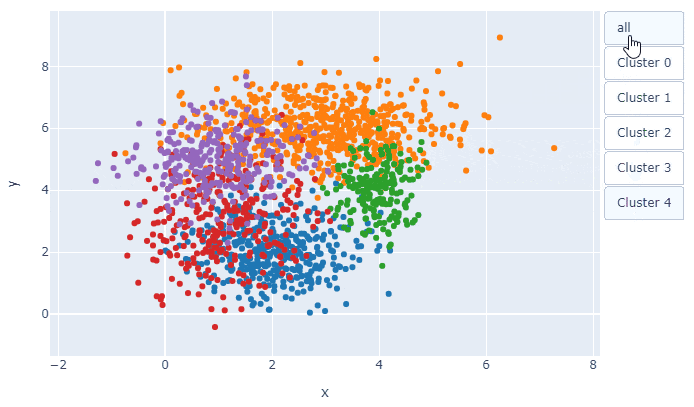
複数のクラスターの散布図を描いたときに, 点が重なって見づらいことありますよね.
そこで,Plotlyを使って1クラスターずつ確認できるようなプロットを作成しました.
背景
例えば, 5つのクラスターに分かれたxy座標を持つこんなデータがあったとき,
例えば,
seabornなら1行で以下のプロットが描けます.sns.scatterplot(x="x", y="y", hue="class", data=df)
ただ, 上のままだとちょっと見づらいので, 透明度
alphaを指定しますが,sns.scatterplot(x="x", y="y", hue="class", data=df, alpha=0.5)
少し改善したものの, 今回のデータでは相変わらず見づらいです.
そこでクラスターを1つ1つ分けてプロットすることができれば...と考え
Plotlyを使ってみました.解説
まず, ライブラリの準備をして,
import numpy as np import pandas as pd import seaborn as sns import matplotlib.pyplot as plt import plotly.graph_objects as go import plotlyダミーデータを準備します.
x0 = np.random.normal(2, 0.8, 400) y0 = np.random.normal(2, 0.8, 400) x1 = np.random.normal(3, 1.2, 600) y1 = np.random.normal(6, 0.8, 600) x2 = np.random.normal(4, 0.4, 200) y2 = np.random.normal(4, 0.8, 200) x3 = np.random.normal(1, 0.8, 300) y3 = np.random.normal(3, 1.2, 300) x4 = np.random.normal(1, 0.8, 300) y4 = np.random.normal(5, 0.8, 300) df = pd.DataFrame() df["x"] = np.concatenate([x0, x1, x2, x3, x4]) df["y"] = np.concatenate([y0, y1, y2, y3, y4]) df["class"] = ["Cluster 0"]*400 + ["Cluster 1"]*600 + ["Cluster 2"]*200+ ["Cluster 3"]*300+ ["Cluster 4"]*300続いて, 本題のプロット部分ですが,
先にすべてのコードを一旦お見せします.def plotly_scatterplot(x, y, hue, data, title=""): cluster = df[hue].unique() n_cluster = len(cluster) colors = plt.rcParams['axes.prop_cycle'].by_key()['color'] fig = go.Figure() button = [] tf = [True]*n_cluster tmp = dict(label="all", method="update", args=[{"visible": tf}] ) button.append(tmp) for i,clu in enumerate(cluster): fig.add_trace( go.Scatter( x = df[df[hue]==clu][x], y = df[df[hue]==clu][y], mode="markers", name=clu, marker=dict(color=colors[i]) ) ) tf = [False]*n_cluster tf[i] = True tmp = dict(label=clu, method="update", args=[{"visible": tf}] ) button.append(tmp) fig.update_layout( updatemenus=[ dict(type="buttons", x=1.15, y=1, buttons=button ) ]) x_min = df[x].min() x_max = df[x].max() x_range = x_max - x_min y_min = df[y].min() y_max = df[y].max() y_range = y_max - y_min fig.update_xaxes(range=[x_min-x_range/10, x_max+x_range/10]) fig.update_yaxes(range=[y_min-y_range/10, y_max+x_range/10]) fig.update_layout( title_text=title, xaxis_title=x, yaxis_title=y, showlegend=False, ) fig.show() #plotly.offline.plot(fig, filename='graph.html')めちゃくちゃ長くてすみません...
ポイントは2か所あります.ポイント1
fig.add_trace( go.Scatter( x = df[df[hue]==clu][x], y = df[df[hue]==clu][y], mode="markers", name=clu, marker=dict(color=colors[i]) ) )この部分では, データフレーム
dfの中のクラスター1つ1つの散布図を作成しています.colorsにはpltで自動で選択される色列が入っているので,color=colors[i]で, それを順番に指定しています.ポイント2
tf = [False]*n_cluster tf[i] = True tmp = dict(label=clu, method="update", args=[{"visible": tf}] ) button.append(tmp)
tfには[False, True, False, False, False]のように真偽値が入っていて, どのtraceを表示・非表示にするかを選択しています.
今回は,fig.add_traceで5枚の散布図が重なっていて, その何枚目を表示するかということです.tf=[True, True, True, True, True]とすべてTrueにすれば, 全データの散布図が表示されます.あとは, 次の1行で,
plotly_scatterplot(x="x", y="y", hue="class", data=df, title="Scatter Plot")冒頭のプロットが描けます.
以上!
参考
Plotly:Update Button
stack overflow:Get default line colour cycle
- 投稿日:2020-04-02T22:44:12+09:00
PythonからRustを呼んで高速化! PyO3 チュートリアル:クラスをラップする その➁
概要
1. Pyhtonでアルゴリズムまで書いてあるのは速度面では好ましくないな〜
2. よし、C, C++あたりで書いてあるものを探して、それをPythonから呼んで高速化しよう。
3. なかなかいいライブラリ見つからんな、
4. おっ、Rustていう言語で書かれてるのならあったぞ
5. RustてPythonから呼べんのか??これは、PythonからRustを呼んで高速化! PyO3 チュートリアル:クラスをラップする その➀
の続きになります。
目標
目標は、
Rustのクラス(struct + method)を定義し、それをPythonから呼ぶ
でしたが、
前回でRustで書かれたクラスをPythonから呼ぶ方法を解説しました。
クラスのコンストラクタおよび、プロパティのgetter,setterもPythonからPyO3経由で呼ぶことができました。今回は、クラスメソッドをいくつか追加して、
RustからPythonへの型にPyO3経由で変換するところを解説していきます。PyO3のgitレポジトリ(ここ)を参照し、
RustのオブジェクトをPython側にどうPyO3で引き渡すかを解説します。
Vec->ListHashmap->DictVec->Tupleなどです。
手順
前回までに
cargo new --lib exampleで作ったプロジェクトを使用します。
新しく作ってももちろん問題ありません。おさらいとして、前回はクラスのコンストラクタ、プロパティの
numのgetter,setterをPyO3経由でPythonから呼べるようにしました。
以下が、前回完成させたコードです。//lib.rs use pyo3::prelude::*; use pyo3::{wrap_pyfunction}; // ======================RUST CLASS TO PYTHON ====================================== /// Class for demonstration // this class, MyClass can be called from python #[pyclass(module = "my_class")] struct MyClass { num: i32, debug: bool, } #[pymethods] impl MyClass{ #[new] fn new(num:i32, debug:bool) -> Self{ MyClass{ num: num, debug: debug } } #[getter] fn get_num(&self) -> PyResult<i32>{ Ok(self.num) } #[setter] fn set_num(&mut self, num: i32) -> PyResult<()>{ self.num = num; Ok(()) } } // =================CREATING MODULE FOR PYTHON========================= /// This module is a python module implemented in Rust. #[pymodule] fn test_library(py: Python, m: &PyModule) -> PyResult<()> { m.add_wrapped(wrap_pyfunction!(get_prime_numbers))?; m.add_class::<MyClass>()?; Ok(()) }この
MyClassに、今回は関数を6つ追加します。
早速ですが、以下がコードです。//lib.rs use pyo3::types::PyType; use pyo3::types::PyInt; use pyo3::types::PyList; use pyo3::types::PyTuple; use pyo3::types::PyDateTime; use std::collections::HashMap; #[pymethods] impl MyClass{ fn test1(&self) -> PyResult<bool>{ if self.num > 3{ Ok(true) }else{ Ok(false) } } fn test2(&self) -> PyResult<String>{ if self.debug == true{ let result: &str = "your debug is True"; Ok(result.to_string()) }else{ let result: &str = "your debug is False"; Ok(result.to_string()) } } fn test3<'py>(&self, py: Python<'py>) -> PyResult<&'py PyList>{ let mut vec = vec![1,2,3]; let result = PyList::new(py, &vec); Ok(result) } fn test4(&self, py: Python) -> PyResult<PyObject>{ let mut map = HashMap::new(); map.insert("key1", 1); map.insert("key2", 2); map.insert("key3", 3); assert_eq!(map["key1"], 1); assert_eq!(map["key2"], 2); assert_eq!(map["key3"], 3); Ok(map.to_object(py)) } fn test5(&self) -> PyResult<f64>{ let result:f64 = 1.23; Ok(result) } fn test6<'py>(&self, py: Python<'py>, dt: &PyDateTime) -> PyResult<&'py PyTuple>{ let mut vec = vec![3,4,5]; let result = PyTuple::new(py, &vec); Ok(result) } }fn test1
Rustのboolを、PythonのboolへとPyO3経由で受け渡ししています。fn test2
RustのStringを、PythonのstrへとPyO3経由で受け渡ししています。fn test3
RustのVecを、PythonのListへとPyO3経由で受け渡ししています。
この書き方がきちんと理解できてません。。fn test4
RustのHashmapを、PythonのDictへとPyO3経由で受け渡ししています。fn test5
Rustのf64を、PythonのfloatへとPyO3経由で受け渡ししています。fn test6
RustのVecを、PythonのtupleへとPyO3経由で受け渡ししています。この際、関数の引数として、PythonのDatetimeを受け取っています。
この書き方がきちんと理解できてません。。testを実行する
test3, test6に関しては、正直書き方がうまく理解できていませんが、テストを実行します。
前回と同じようにCargo.toml、setup.pyを用意することで、python setup.py installでビルドすることができます。
その後、
test.pyを以下のように準備し、テストを実行します。test.pyimport test_library if __name__ == "__main__": # Testing class print("\ntest for class") num = 2 debug = True test = test_library.MyClass(num=num, debug=debug) print(test.num) # getter test test.num = 4 # setter test print(test.num) result = test.test1() print(result) print(type(result)) result = test.test2() print(result) print(type(result)) result = test.test3() print(result) print(type(result)) result = test.test4() print(result) print(type(result)) result = test.test5() print(result) print(type(result)) import datetime now = datetime.datetime.now() result = test.test6(now) print(result) print(type(result))まとめ
今回は、クラスメソッドをいくつか追加して、RustからPythonへの型にPyO3経由で変換するところを解説しました。
Cythonよりは比較的わかりやすい感覚があるものの、PyO3自体バージョンがどんどん更新されているため、一番いいのはバージョンをきちんと意識して(Fixして)開発するか、
もしくはGitをきちんと追い、APIの呼び方の変更にきちんと気を配るべきでしょう。ただ、Rust面白いので、これからも勉強していこうと思います。
今回はこの辺で。
おわり。
- 投稿日:2020-04-02T22:36:03+09:00
TWELITE のチェックサムを計算する
「超簡単!標準アプリ」で使われているチェックサムの計算方法は、バイトごとの和の補数。
バイト文字列を入れると補数を計算してくれるツールを作りました。
言語は Python です。#!/usr/bin/env python3 import sys chain = sys.argv[1] chainbytes = bytes.fromhex(chain) sum = 0 for item in chainbytes: sum=sum+item twilitechecksum = 256 - ( sum % 256 ) print('{:02X}'.format(twilitechecksum))実行すると、
./checksum.py 00A01301FF123456 B1となるので、TWELITEには
00A01301FF123456B1
を送ると良い。
- 投稿日:2020-04-02T21:25:01+09:00
docker環境下でのtensorflowの使い方
メモ。
docker pull tensorflow/tensorflow:latest-gpu-py3
docker run -it -p 8888:8888 -v $HOME:$HOME tensorflow/tensorflow:latest-gpu-py3 bash
特に重要なのはgpuが入っていること。
これがなかったらエラーが出た。
jupyterのoptionでやってもできたが、python2になった。
- 投稿日:2020-04-02T20:29:06+09:00
Googleのロゴをダウンロード → OCR → HTMLにする
概要
以下の様に、Google 検索のトップページにあるロゴをテキストに変換し、それをHTML上で表示します。
↓
実行ステップ
- Google 検索のトップページをスクレイピングして Google のロゴ画像のURLを取得します。さらに、画像をダウンロードします。
- ロゴ画像にOCRをかけてテキスト化します。
- このテキストをHTML上で表示します。
事前にライブラリをインストール
bash# ステップ 1 用 pip install beautifulsoup4 # ステップ 2 用 brew install tesseract pip install pyocr # ステップ 3 用 pip install jinja2実行
ステップ1:ロゴ画像のダウンロード
pythonimport requests from bs4 import BeautifulSoup # html 取得 url = 'https://www.google.com' res = requests.get(url) soup = BeautifulSoup(res.text, 'html.parser') # 画像を抽出 img = soup.find('img', {'id': 'hplogo'}) # 画像のURLを作成 img_url = 'https://www.google.com' + img['src'] # 画像をダウンロード r = requests.get(img_url) # 画像を保存 with open('hplogo.jpg' ,'wb') as file: file.write(r.content)ステップ2:OCRでロゴ画像をテキスト化
pythonfrom PIL import Image import pyocr import pyocr.builders # 事前設定 1 tools = pyocr.get_available_tools() tool = tools[0] # 事前設定 2 builder = pyocr.builders.TextBuilder() # 画像をロード img = Image.open('hplogo.jpg') # OCRを実行 result = tool.image_to_string(img, builder=builder)ステップ3:テキストをHTML上で表示
pythonfrom jinja2 import Template # view を生成 html = ''' <!DOCTYPE html> <html lang="en"> <head> <title>The Farther Reaches Of Human Nature</title> </head> <body> <h1>{{ result }}</h1> </body> </html> ''' template = Template(html) data = { 'result': result } view = template.render(data) # 保存 with open('hplogo.html', 'w', encoding='utf-8') as f: f.write(view)生成される
hplogo.htmlをブラウザで開くと次のように「Google」というテキストが表示されるはずです。(画像を再掲)
参考
10分で理解する Beautiful Soup - Qiita
Pythonで画像スクレイピングをしよう - Qiita
PythonでOCRを実行する方法 | ガンマソフト株式会社
Pythonで久しぶりにHTMLを出力したくなったのでテンプレートについて調べる - Qiita


- 投稿日:2020-04-02T20:29:06+09:00
Googleのロゴをダウンロード → OCRでテキスト化 → HTML上で表示
概要
以下の様に、Google 検索のトップページにあるロゴをテキストに変換し、それをHTML上で表示します。
↓
応用例
画像形式でネット上に公開されている英文の書物などをこの方法でHTMLにまとめ、 Chrome のページ翻訳機能で日本語化して読む、という応用ができます。
実行ステップ
- Google 検索のトップページをスクレイピングして Google のロゴ画像のURLを取得します。さらに、画像をダウンロードします。
- ロゴ画像にOCRをかけてテキスト化します。
- このテキストをHTML上で表示します。
事前にライブラリをインストール
bash# ステップ 1 用 pip install beautifulsoup4 # ステップ 2 用 brew install tesseract pip install pyocr # ステップ 3 用 pip install jinja2実行
ステップ1:ロゴ画像のダウンロード
pythonimport requests from bs4 import BeautifulSoup # html 取得 url = 'https://www.google.com' res = requests.get(url) soup = BeautifulSoup(res.text, 'html.parser') # 画像を抽出 img = soup.find('img', {'id': 'hplogo'}) # 画像のURLを作成 img_url = 'https://www.google.com' + img['src'] # 画像をダウンロード r = requests.get(img_url) # 画像を保存 with open('hplogo.jpg' ,'wb') as file: file.write(r.content)ステップ2:OCRでロゴ画像をテキスト化
pythonfrom PIL import Image import pyocr import pyocr.builders # 事前設定 1 tools = pyocr.get_available_tools() tool = tools[0] # 事前設定 2 builder = pyocr.builders.TextBuilder() # 画像をロード img = Image.open('hplogo.jpg') # OCRを実行 result = tool.image_to_string(img, builder=builder)ステップ3:テキストをHTML上で表示
pythonfrom jinja2 import Template # view を生成 html = ''' <!DOCTYPE html> <html lang="en"> <head> <title>The Farther Reaches Of Human Nature</title> </head> <body> <h1>{{ result }}</h1> </body> </html> ''' template = Template(html) data = { 'result': result } view = template.render(data) # 保存 with open('hplogo.html', 'w', encoding='utf-8') as f: f.write(view)生成される
hplogo.htmlをブラウザで開くと次のように「Google」というテキストが表示されるはずです。(画像を再掲)
参考
10分で理解する Beautiful Soup - Qiita
Pythonで画像スクレイピングをしよう - Qiita
PythonでOCRを実行する方法 | ガンマソフト株式会社
Pythonで久しぶりにHTMLを出力したくなったのでテンプレートについて調べる - Qiita
- 投稿日:2020-04-02T20:11:32+09:00
Mac OSXで「Tello_Video」の環境構築
はじめに
このページは,
Tello-Pythonのサンプル「Tello_Video」を動かす
の補足ページです.
※注意
筆者のMacは古い(High Sierra)ので,試したのはXcode 10です.
新しいMacでは別の問題が生じるかもしれません...概要
DJI公式のTello用Pythonサンプルプログラム「Tello-Python」のうち,
Tello_Video
を試すためには、あらかじめ
- 様々な依存ライブラリのインストール
- H.264ビデオのデコードライブラリのビルド
を行う必要があります。
gitの Tello-Pythonのページ には,インストール方法として
・Mac i. Make sure you have the latest Xcode command line tools installed. If not, you might need to update your OS X and XCode to the latest version in order to compile the h264 decoder module ii. Go to the "install\Mac" folder folder in command line, run chmod a+x ./mac_install.sh ./mac_install.sh If you see no errors during installation, you are good to go!と書いてあります.
すなわち,Macの開発環境であるXcodeのコマンドラインツールをインストールした後で,フォルダ移動・ファイルの属性変更・シェルファイル実行$ cd install/Mac/ $ chmod a+x ./mac_install.sh $ ./mac_install.shとコマンドを打てよ,ということです.
mac_install.shが,Mac用の環境構築を自動的に行ってくれるシェルスクリプトです.Macに精通した方は「なんだ,shファイルがあるなら実行すればスグじゃん」と思うでしょう.
しかし,そのまま実行すると
- matplotlibのインストール時にnoseとtornadoが無いと言われる.
- OpenCVのバージョンが3.x系がインストールされない.(4.x系になる)
- h264デコードライブラリのビルド前に,cmakeが通らない
という不具合が生じます.
というわけで,mac_install.shを書き換えます.
参考にしたページ
・Command Line Toolsのインストール方法 筆者はこちらでXcode10用を探してインストールした
・MavericksでCommand Line Tools for Xcodeをインストールする 既にGUI版のXcodeがインストールされている人向け
・Python:[pip install requests]実行時の[matplotlib 1.3.1 requires nose, which is not installed.]の対処方法
・Tello_Video & Tello_Video_With_Pose_Recognition #41 #42前提条件
ホームフォルダ(~)にTello-Pythonがインストールされているという前提で話を進めます.
ディレクトリの移動
まずはコンソール(端末)を開き,以下のコマンドを打って,Tello-Videoのフォルダへ移動します.
cd(change_directory)$ cd ~/Tello-Python/Tello-VideolsコマンドでTello_Videoディレクトリの中を見てみると,
Tello_Videoの中身$ ls LICENSE.md README.md h264decoder img install main.py tello.py tello_control_ui.py
installというディレクトリがあることが分かります.
このディレクトリの中身は,installディレクトリの中$ ls install/ Linux Mac Windowsこの様になっていて,Linux,Mac,Windowsそれぞれのディレクトリにインストール用のファイルが置いてあるのですが,どれも古くて使い物になりません.
ですが,Macは多少の変更で対応できます.
Mac_install.shの書き換え
Macの場合,mac_install.shの中身を少し書き換えれば,自動インストールできます.
※加えた変更
easy_installでnoseとtornadoをインストールするように追記しました.
OpenCVのバージョンははSHIFTの使える3.4.2.17にしました.
cmakeでboost_pythonが無いというトラブルは,issueの通りに書き換えました.
テキストエディタ(テキストエディット,miなど)を使って以下の様に mac_install.sh を書き換えてください.
mac_install.sh#!/bin/sh echo 'Compiling and Installing the Tello Video Stream module' echo 'You might need to enter your password' # go to /sample_code folder cd .. cd .. # install Homebrew /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)" brew update # install pip #sudo easy_install pip curl https://bootstrap.pypa.io/get-pip.py -o get-pip.py sudo python get-pip.py # install cmake brew install cmake # install dependencies brew install boost brew install boost-python brew install ffmpeg brew install tcl-tk # added by hsgucci sudo easy_install nose # added by hsgucci sudo easy_install tornado sudo pip install numpy --ignore-installed sudo pip install matplotlib --ignore-installed sudo pip install pillow --ignore-installed sudo pip install opencv-python==3.4.2.17 --ignore-installed # pull and build h264 decoder library cd h264decoder mkdir build cd build # comment out by hsgucci #cmake .. # added by hsgucci cmake -D Boost_NO_BOOST_CMAKE:BOOL=ON .. make # copy source .so file to tello.py directory cp libh264decoder.so ../../ echo 'Compilation and Installation Done!'mac_install.shの実行
書き換えたら,シェルファイルのあるフォルダへ移動して,
chmodで実行権限を与え,実行します.フォルダ移動・ファイルの属性変更・シェルファイル実行$ cd ~/Tello-Python/Tello_Video/install/Mac/ $ chmod a+x mac_install.sh $ ./mac_install.sh以上で自動インストールされます.
インストールが完了したら,Tello-Videoのディレクトリに戻っておきましょう.
2つ上の階層へもどる$ cd ../../これで作業は完了です.
注意点
mac_install.shでのインストールで注意すべき点は,
必ず~/Tello-Python/Tello_Video/install/Mac/へカレントディレクトリを移動させ,
そこでmac_install.shを実行すること です.というのは,
mac_install.shの一部を抜粋cd .. # 1つ上のディレクトリへ移動 cd .. # 1つ上のディレクトリへ移動 # Homebrew のインストール /usr/bin/ruby -e "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install)" brew update (略) # pull and build h264 decoder library cd h264decoder # h264decoderというフォルダへ入る mkdir build cd build # buildというフォルダへ入る cmake .. make # copy source .so file to tello.py directory cp libh264decoder.so ../../ # 2階層上のフォルダへファイルをコピーこの様に,フォルダを2階層上がってaptやpipのインストールを行い,
h264decoderフォルダへ移動してライブラリのビルド&コピーを行っているからです.もしも,Tello_Videoフォルダから以下の様に
このように直接ファイルを呼んではいけない$ ./install/Mac/mac_install.sh相対パス指定してシェルを実行するとどうなるでしょうか.
~/Tello-Python/Tello_Video/の2階層上,すなわちホームディレクトリ~/まで上がってh264decoderへ入ろうとしてしまいます.当然そんなフォルダはありませんから,ビルドできるわけがありません.おわりに
やっとLinux, Raspberry Pi,Windows,Macが全部終わった〜(喜
でも時代はPython3...
- 投稿日:2020-04-02T19:41:00+09:00
PythonからRustを呼んで高速化? PyO3 チュートリアル:クラスをラップする
概要
1. Pyhtonでアルゴリズムまで書いてあるのは速度面では好ましくないな〜
2. よし、C, C++あたりで書いてあるものを探して、それをPythonから呼んで高速化しよう。
3. なかなかいいライブラリ見つからんな、
4. おっ、Rustていう言語で書かれてるのならあったぞ
5. RustてPythonから呼べんのか??これは、PythonからRustを呼んで高速化! PyO3 チュートリアル:簡単な関数をラップする その➁
の続きになります。
目標
Rustのクラス(struct + method)を定義し、それをPythonから呼ぶ
ことを目標にします。今回は、クラスのパースの仕方と、getter, setterのPyO3経由での呼び方まで解説します。
手順
前回
cargo new --lib exampleで作ったプロジェクトを使用します。
新しく作ってももちろん問題ありません。クラスの宣言
lib.rsに以下のように書きます。//lib.rs use pyo3::prelude::*; // ======================RUST CLASS TO PYTHON ====================================== /// Class for demonstration // this class, MyClass can be called from python #[pyclass(module = "my_class")] struct MyClass { num: i32, debug: bool, }ここで、
#[pyclass(module = "my_class")]により、PyO3を経由してPythonから呼べるようにしています。
(module = "my_class")はおまじないのように書きましたが、あまり意味がわかっていません。すみません。ここで、
MyClassはStructとして定義され、プロパティとして
num: i32とdebug: boolを持っています。まず、このクラスをPythonのオブジェクトとして呼べるようにするため、コンストラクタを書きます。
#[pymethods] impl MyClass{ #[new] fn new(num:i32, debug:bool) -> Self{ MyClass{ num: num, debug: debug } }ここで、
implの上に#[pymethods]と宣言(デコレート?)されていること、
コンストラクタを示すfn new(num:i32, debug:bool)の上にも#[new]と宣言されていること、に注意します。
クラスのモジュールへの追加
これを、以前の関数のように以下のようにモジュールに追加します。
//lib.rs use pyo3::{wrap_pyfunction}; // =================CREATING MODULE FOR PYTHON========================= /// This module is a python module implemented in Rust. #[pymodule] fn test_library(py: Python, m: &PyModule) -> PyResult<()> { m.add_wrapped(wrap_pyfunction!(get_prime_numbers))?; m.add_class::<MyClass>()?; Ok(()) }ここで、
m.add_class::<MyClass>()?;の行でMyClassをモジュールに追加しています。
getter, setter の追加
今回は、クラスの宣言に加えて、プロパティのgetter, setterに関してもPythonから呼べるように書きます。
//lib.rs #[pymethods] impl MyClass{ #[new] fn new(num:i32, debug:bool) -> Self{ MyClass{ num: num, debug: debug } } #[getter] fn get_num(&self) -> PyResult<i32>{ Ok(self.num) } #[setter] fn set_num(&mut self, num: i32) -> PyResult<()>{ self.num = num; Ok(()) } }このように、
#[getter],#[setter]のデコレータを使うことで、PyO3経由でPythonからgetter, setterも呼べます。今回はプロパティである
numについてだけ書きました。
getterの返り値に関しては、numの型がi32であることから、Python側はPyResult<i32>として受け取ります。
setterの返り値はないので、PyResult<()>と書けます。どちらもPythonオブジェクトを引き渡す時は、
Ok(self.num) Ok(())を使って引き渡すことは前回と同じです。
setup.py を使ってコンパイル
setup.py,Cargo.tomlに関しては前回と同じものですが、念のため書いておくと、Cargo.toml[package] name = "test" version = "0.1.0" edition = "2018" [lib] name = "test_library" crate-type = ["cdylib"] [dependencies.pyo3] version = "0.9.1" features = ["extension-module"]setup.pyfrom setuptools import setup from setuptools_rust import Binding, RustExtension setup(name='ope_rust', version='0.1', rust_extensions=[ RustExtension('ope_rust', 'Cargo.toml', binding=Binding.PyO3)], zip_safe=False)となります。
python setup.py installを行うことで、コンパイルができます。
テスト実行
以下のようなテストプログラムを実行すると、
test.pyimport test_library if __name__ == "__main__": # Testing class print("\ntest for class") num = 2 debug = True test = test_library.MyClass(num=num, debug=debug) print(test.num) # getter test test.num = 4 # setter test print(test.num)$ python test.py test for class 2 4となり、確かにクラスをコンストラクトでき、プロパティのget,setが実行できたことがわかりました。
まとめ
目標は、
Rustのクラス(struct + method)を定義し、それをPythonから呼ぶ
でしたが、
今回でRustで書かれたクラスをPythonから呼ぶ方法を解説しました。クラスのコンストラクタおよび、プロパティのgetter,setterもPythonからPyO3経由で呼ぶことができました。
次回は、クラスのメソッドをいくつか追加して、色々な型変換を解説できたらと思います。
今回はこの辺で。
おわり。
- 投稿日:2020-04-02T19:41:00+09:00
PythonからRustを呼んで高速化! PyO3 チュートリアル:クラスをラップする その➀
概要
1. Pyhtonでアルゴリズムまで書いてあるのは速度面では好ましくないな〜
2. よし、C, C++あたりで書いてあるものを探して、それをPythonから呼んで高速化しよう。
3. なかなかいいライブラリ見つからんな、
4. おっ、Rustていう言語で書かれてるのならあったぞ
5. RustてPythonから呼べんのか??これは、PythonからRustを呼んで高速化! PyO3 チュートリアル:簡単な関数をラップする その➁
の続きになります。
目標
Rustのクラス(struct + method)を定義し、それをPythonから呼ぶ
ことを目標にします。今回は、クラスのパースの仕方と、getter, setterのPyO3経由での呼び方まで解説します。
手順
前回
cargo new --lib exampleで作ったプロジェクトを使用します。
新しく作ってももちろん問題ありません。クラスの宣言
lib.rsに以下のように書きます。//lib.rs use pyo3::prelude::*; // ======================RUST CLASS TO PYTHON ====================================== /// Class for demonstration // this class, MyClass can be called from python #[pyclass(module = "my_class")] struct MyClass { num: i32, debug: bool, }ここで、
#[pyclass(module = "my_class")]により、PyO3を経由してPythonから呼べるようにしています。
(module = "my_class")はおまじないのように書きましたが、あまり意味がわかっていません。すみません。ここで、
MyClassはStructとして定義され、プロパティとして
num: i32とdebug: boolを持っています。まず、このクラスをPythonのオブジェクトとして呼べるようにするため、コンストラクタを書きます。
#[pymethods] impl MyClass{ #[new] fn new(num:i32, debug:bool) -> Self{ MyClass{ num: num, debug: debug } }ここで、
implの上に#[pymethods]と宣言(デコレート?)されていること、
コンストラクタを示すfn new(num:i32, debug:bool)の上にも#[new]と宣言されていること、に注意します。
クラスのモジュールへの追加
これを、以前の関数のように以下のようにモジュールに追加します。
//lib.rs use pyo3::{wrap_pyfunction}; // =================CREATING MODULE FOR PYTHON========================= /// This module is a python module implemented in Rust. #[pymodule] fn test_library(py: Python, m: &PyModule) -> PyResult<()> { m.add_wrapped(wrap_pyfunction!(get_prime_numbers))?; m.add_class::<MyClass>()?; Ok(()) }ここで、
m.add_class::<MyClass>()?;の行でMyClassをモジュールに追加しています。
getter, setter の追加
今回は、クラスの宣言に加えて、プロパティのgetter, setterに関してもPythonから呼べるように書きます。
//lib.rs #[pymethods] impl MyClass{ #[new] fn new(num:i32, debug:bool) -> Self{ MyClass{ num: num, debug: debug } } #[getter] fn get_num(&self) -> PyResult<i32>{ Ok(self.num) } #[setter] fn set_num(&mut self, num: i32) -> PyResult<()>{ self.num = num; Ok(()) } }このように、
#[getter],#[setter]のデコレータを使うことで、PyO3経由でPythonからgetter, setterも呼べます。今回はプロパティである
numについてだけ書きました。
getterの返り値に関しては、numの型がi32であることから、Python側はPyResult<i32>として受け取ります。
setterの返り値はないので、PyResult<()>と書けます。どちらもPythonオブジェクトを引き渡す時は、
Ok(self.num) Ok(())を使って引き渡すことは前回と同じです。
setup.py を使ってコンパイル
setup.py,Cargo.tomlに関しては前回と同じものですが、念のため書いておくと、Cargo.toml[package] name = "test" version = "0.1.0" edition = "2018" [lib] name = "test_library" crate-type = ["cdylib"] [dependencies.pyo3] version = "0.9.1" features = ["extension-module"]setup.pyfrom setuptools import setup from setuptools_rust import Binding, RustExtension setup(name='ope_rust', version='0.1', rust_extensions=[ RustExtension('ope_rust', 'Cargo.toml', binding=Binding.PyO3)], zip_safe=False)となります。
python setup.py installを行うことで、コンパイルができます。
テスト実行
以下のようなテストプログラムを実行すると、
test.pyimport test_library if __name__ == "__main__": # Testing class print("\ntest for class") num = 2 debug = True test = test_library.MyClass(num=num, debug=debug) print(test.num) # getter test test.num = 4 # setter test print(test.num)$ python test.py test for class 2 4となり、確かにクラスをコンストラクトでき、プロパティのget,setが実行できたことがわかりました。
まとめ
目標は、
Rustのクラス(struct + method)を定義し、それをPythonから呼ぶ
でしたが、
今回でRustで書かれたクラスをPythonから呼ぶ方法を解説しました。クラスのコンストラクタおよび、プロパティのgetter,setterもPythonからPyO3経由で呼ぶことができました。
次回は、クラスのメソッドをいくつか追加して、色々な型変換を解説できたらと思います。
今回はこの辺で。
おわり。
- 投稿日:2020-04-02T19:28:21+09:00
主成分分析 (主成分解析、Principal component analysis : PCA)
主成分分析 (主成分解析、Principal component analysis : PCA)
概要
- 主成分分析は、教師なし線形変換法の1つ
- データセットの座標軸を、データの分散が最大になる方向に変換し、元の次元と同じもしくは、元の次元数より低い新しい特徴部分空間を作成する手法
- 主なタスク
- 次元削減
- 次元削減を行うことで以下の目的を達成できる
- 特徴抽出
- データの可視化
- 次元削減を行うメリット
- 計算コスト(計算時間、メモリ使用量)を削減できる
- 特徴量を削減したことによる情報の喪失をできるだけ小さくする
- モデルを簡素化できる(パラメータが減る)ため、オーバーフィッティングを防げる
- 人間が理解可能な空間にデータを投影することができる(非常に高次元な空間を、身近な3次元、2次元に落とし込むことができる)
応用例
- タンパク質分子の立体構造モデルの構造空間の次元削減と可視化
- タンパク質の全原子モデルの立体構造は、分子内に含まれる原子の座標情報で表すことができる (原子数 × 3 (x, y, z) 次元のベクトル)
以下は、タンパク質の分子シミュレーションで使われるモデルの1例。
(紫色とオレンジ色で表されたリボンモデルがタンパク質で、周りに水とイオンが表示されている)
(この場合、3547 個の原子 --> 10641 次元)
主成分分析により、この立体構造空間を、2次元空間に投影することができる。
以下は、その投影に対して自由エネルギーを計算した図。
2次元空間上の1点が、1つの立体構造を表している。
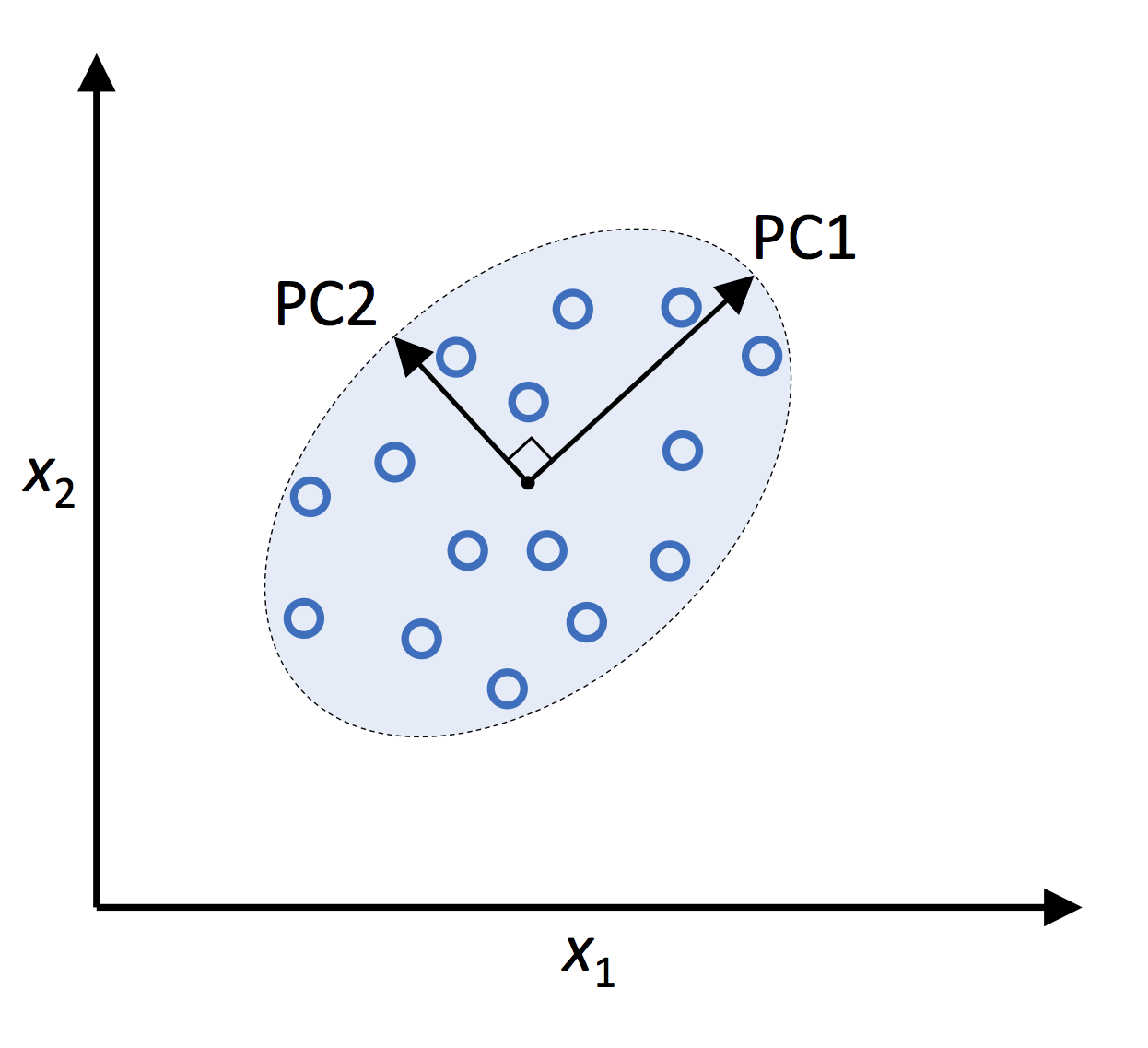
つまり、この例では、もともと10641次元あった空間を2次元にまで削減している。主成分分析 (PCA) が行う座標変換のイメージ
以下は、PCAが行う座標変換の例
$x_1$ , $x_2$ は、データセットの元々の座標軸であり、
PC1, PC2 は座標変換後に得られる新しい座標軸、主成分1、主成分2 である (Principal Components)。
- PCA は、高次元データにおいて分散が最大となる方向を見つけ出し、座標を変換する (これはつまり、すべての主成分が、他の主成分と相関がない(直交する) ように座標変換している)
- 最初の主成分 (PC1) の分散が最大となる
主成分分析の主要な手順
d 次元のデータを k 次元に削減する場合
- d 次元のデータの標準化(特徴量間のスケールが異なる場合のみ)
- 分散共分散行列の作成
- 分散共分散行列の固有値と固有ベクトルを求める
- 固有値を降順にソートして、固有ベクトルをランク付けする
- 最も大きい k 個の固有値に対応する k 個の固有ベクトルを選択 (k ≦ d)
- k 個の固有ベクトルから射影(変換)行列 W を作成
- 射影(変換)行列を使って d 次元の入力データセットを新しい k 次元の特徴部分空間を取得する
固有値問題を解くことで、線形独立な基底ベクトルを得ることができる。
詳細は、線形代数の書籍等を参考にする(ここでは詳細な解説をしない)。参考)
python による PCA の実行
以下、Python を使った PCA の実行を順番に見ていく。
その後、scikit-learn ライブラリを使った PCA の簡単で効率のよい実装を見る。データセット
- データセットは、 Wine というオープンソースのデータセットを使う。
- 178 行のワインサンプルと、それらの化学的性質を表す 13 列の特徴量で構成されている。
- それぞれのサンプルに、クラス 1, 2, 3 のいずれかがラベルされており、 イタリアの同じ地域で栽培されている異なる品種のブドウを表している (PCA は教師なし学習なので、学習時にラベルは使わない)。
from IPython.display import Image %matplotlib inlineimport pandas as pd # df_wine = pd.read_csv('https://archive.ics.uci.edu/ml/' # 'machine-learning-databases/wine/wine.data', # header=None) # if the Wine dataset is temporarily unavailable from the # UCI machine learning repository, un-comment the following line # of code to load the dataset from a local path: df_wine = pd.read_csv('https://github.com/rasbt/python-machine-learning-book-2nd-edition' '/raw/master/code/ch05/wine.data', header=None) df_wine.columns = ['Class label', 'Alcohol', 'Malic acid', 'Ash', 'Alcalinity of ash', 'Magnesium', 'Total phenols', 'Flavanoids', 'Nonflavanoid phenols', 'Proanthocyanins', 'Color intensity', 'Hue', 'OD280/OD315 of diluted wines', 'Proline'] df_wine.head()
Class label Alcohol Malic acid Ash Alcalinity of ash Magnesium Total phenols Flavanoids Nonflavanoid phenols Proanthocyanins Color intensity Hue OD280/OD315 of diluted wines Proline 0 1 14.23 1.71 2.43 15.6 127 2.80 3.06 0.28 2.29 5.64 1.04 3.92 1065 1 1 13.20 1.78 2.14 11.2 100 2.65 2.76 0.26 1.28 4.38 1.05 3.40 1050 2 1 13.16 2.36 2.67 18.6 101 2.80 3.24 0.30 2.81 5.68 1.03 3.17 1185 3 1 14.37 1.95 2.50 16.8 113 3.85 3.49 0.24 2.18 7.80 0.86 3.45 1480 4 1 13.24 2.59 2.87 21.0 118 2.80 2.69 0.39 1.82 4.32 1.04 2.93 735 Wine データセットの先頭 5 行のデータは上記。
for i_label in df_wine['Class label'].unique(): print('label:', i_label) print('shape:', df_wine[df_wine['Class label'] == i_label].shape)label: 1 shape: (59, 14) label: 2 shape: (71, 14) label: 3 shape: (48, 14)ラベルの数はおおよそ揃っている。
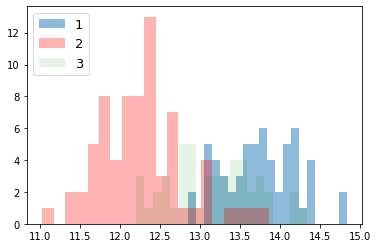
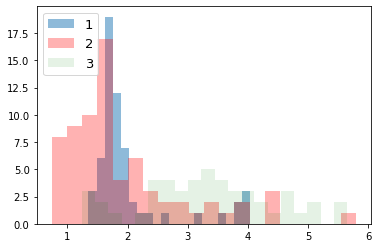
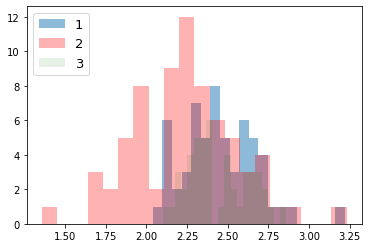
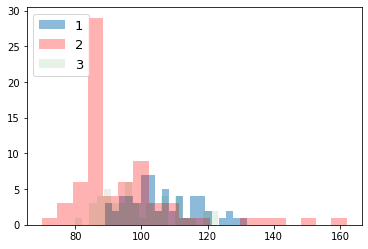
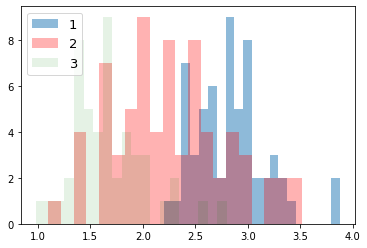
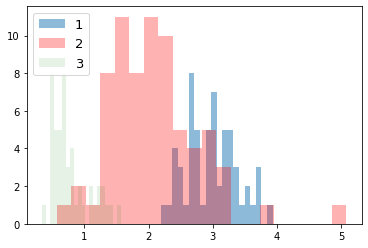
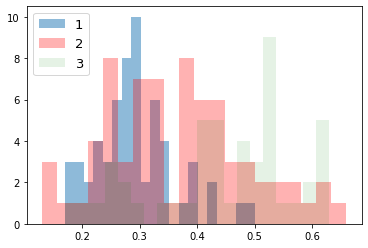
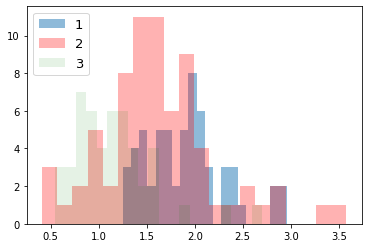
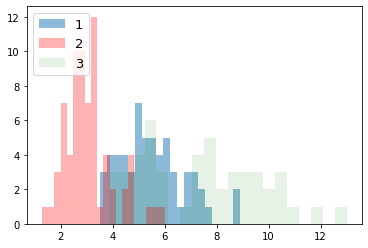
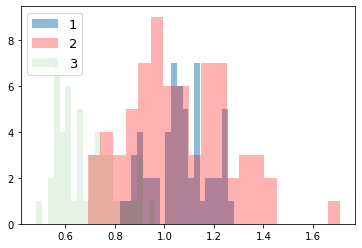
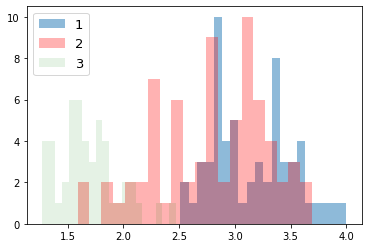
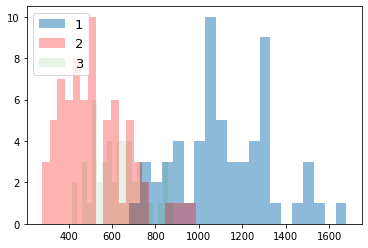
次に、ラベルごとにデータの分布を見てみる。import numpy as np import matplotlib.pyplot as plt for i_feature in df_wine.columns: if i_feature == 'Class label': continue print('feature: ' + str(i_feature)) # ヒストグラムの描画 plt.hist(df_wine[df_wine['Class label'] == 1][i_feature], alpha=0.5, bins=20, label="1") plt.hist(df_wine[df_wine['Class label'] == 2][i_feature], alpha=0.3, bins=20, label="2", color='r') plt.hist(df_wine[df_wine['Class label'] == 3][i_feature], alpha=0.1, bins=20, label="3", color='g') plt.legend(loc="upper left", fontsize=13) # 凡例表示 plt.show()feature: Alcohol
feature: Malic acid
feature: Ash
feature: Alcalinity of ash
feature: Magnesium
feature: Total phenols
feature: Flavanoids
feature: Nonflavanoid phenols
feature: Proanthocyanins
feature: Color intensity
feature: Hue
feature: OD280/OD315 of diluted wines
feature: Proline
データを70%のトレーニングと30%のテストサブセットに分割する。
from sklearn.model_selection import train_test_split X, y = df_wine.iloc[:, 1:].values, df_wine.iloc[:, 0].values X_train, X_test, y_train, y_test = \ train_test_split(X, y, test_size=0.3, stratify=y, random_state=0)データの標準化を行う。
from sklearn.preprocessing import StandardScaler sc = StandardScaler() X_train_std = sc.fit_transform(X_train) # トレーニングセットの標準偏差と平均値を使って、標準化を行う X_test_std = sc.transform(X_test) # "トレーニングセット"の標準偏差と平均値を使って、標準化を行う # いずれの特徴量も、値がおおよそ、-1 から +1 の範囲にあることを確認する。 print('standardize train', X_train_std[0:2]) print('standardize test', X_test_std[0:2])standardize train [[ 0.71225893 2.22048673 -0.13025864 0.05962872 -0.50432733 -0.52831584 -1.24000033 0.84118003 -1.05215112 -0.29218864 -0.20017028 -0.82164144 -0.62946362] [ 0.88229214 -0.70457155 1.17533605 -0.09065504 2.34147876 1.01675879 0.66299475 1.0887425 -0.49293533 0.13152077 1.33982592 0.54931269 1.47568796]] standardize test [[ 0.89443737 -0.38811788 1.10073064 -0.81201711 1.13201117 1.09807851 0.71204102 0.18101342 0.06628046 0.51285923 0.79629785 0.44829502 1.90593792] [-1.04879931 -0.77299397 0.54119006 -0.24093881 0.3494145 -0.70721922 -0.30812129 0.67613838 -1.03520519 -0.90656727 2.24570604 -0.56188171 -1.22874035]]
注意
テストデータの標準化の際に、テストデータの標準偏差と平均値を用いてはいけない(トレーニングデータの標準偏差と平均値を用いること)。
また、ここで求めた標準偏差と平均値は、未知のデータを標準化する際にも再使用するので、記録しておくこと。
(今回は、ノートブックだけで完結するので、外部ファイル等に記録しなくても問題ない)
- 分散共分散行列を作成
- 固有値問題を解いて、固有値と固有ベクトルを求める
固有値問題とは、以下の条件を満たす、固有ベクトル $v$ と、スカラー値である固有値 $\lambda$ を求める問題のことである
(詳細は線形代数の書籍等を参考)。$$\Sigma v=\lambda v$$
$\Sigma$ は分散共分散行列である(総和記号ではないことに注意)。
分散共分散行列に関しては、 前回の資料 を参照。
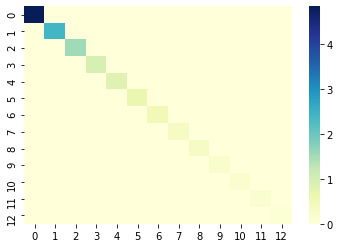
import numpy as np import seaborn as sns cov_mat = np.cov(X_train_std.T) # 共分散行列のヒートマップ df = pd.DataFrame(cov_mat, index=df_wine.columns[1:], columns=df_wine.columns[1:]) ax = sns.heatmap(df, cmap="YlGnBu")
# 固有値問題を解く(固有値分解) eigen_vals, eigen_vecs = np.linalg.eigh(cov_mat) print('\nEigenvalues \n%s' % eigen_vals) print('\nShape of eigen vectors\n', eigen_vecs.shape)Eigenvalues [0.10754642 0.15362835 0.1808613 0.21357215 0.3131368 0.34650377 0.51828472 0.6620634 0.84166161 0.96120438 1.54845825 2.41602459 4.84274532] Shape of eigen vectors (13, 13)注意:
固有値分解(固有分解とも呼ばれる)する numpy の関数は、
がある。
numpy.linalg.eigは対称正方行列と非対称正方行列を固有値分解する関数。複素数の固有値を返すことがある。
numpy.linalg.eighはエルミート行列(各成分が複素数で、転置させた各成分の虚部の値の正負を反転させたものがもとの行列と等しくなる行列)を固有値分解する関数。常に実数の固有値を返す。分散共分散行列は、対称正方行列であり、虚数部が 0 のエルミート行列でもある。
対称正方行列の操作では、numpy.linalg.eighの方が数値的に安定しているらしい。Ref) Python Machine Learning 2nd Edition by Sebastian Raschka, Packt Publishing Ltd. 2017.
全分散と説明分散(Total and explained variance)
- 固有値の大きさは、データに含まれる情報(分散)の大きさに対応している
- 主成分j (PCj: j-th principal component) に対応する固有値 $\lambda_j$ の分散説明率(寄与率、contribution ratio/propotion とも呼ばれる)は以下のように定義される。
\dfrac {\lambda _{j}}{\sum ^{d}_{j=1}\lambda j}$\lambda_j$ は、j 番目の固有値、d は全固有値の数(元々の特徴量の数/次元数)。
分散説明率を見ることで、その主成分が特徴量全体がもつ情報のうち、どれぐらいの情報を表すことができているかを確認できる。
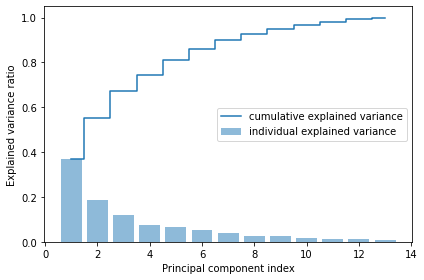
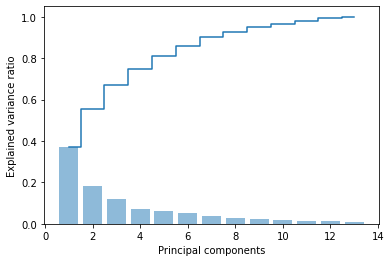
以下に、分散説明率と、その累積和をプロットする。# 固有値の合計 tot = sum(eigen_vals) # 分散説明率の配列を作成 var_exp = [(i / tot) for i in sorted(eigen_vals, reverse=True)] # 分散説明率の累積和を作成 cum_var_exp = np.cumsum(var_exp)import matplotlib.pyplot as plt plt.bar(range(1, 14), var_exp, alpha=0.5, align='center', label='individual explained variance') plt.step(range(1, 14), cum_var_exp, where='mid', label='cumulative explained variance') plt.ylabel('Explained variance ratio') plt.xlabel('Principal component index') plt.legend(loc='best') plt.tight_layout() # plt.savefig('images/05_02.png', dpi=300) plt.show()
グラフから以下のことがわかる。
- 最初の主成分だけで、全体の約 4 割の分散を占めている
- 2 つの主成分も用いるだけで、もともとあった特徴量全体の約 6 割を説明できている
特徴変換 (Feature transformation)
射影(変換)行列を取得し、適用して特徴変換を行う。
$X' = XW$
$X'$ : 射影(変換)後の座標(行列)
$X$ : もともとの座標(行列)
$W$ : 射影(変換)行列$W$ は、次元削減後の次元数の固有ベクトルから構成される。
$W = [v_1 v_2 ... v_k] \in \mathbb{R} ^{n\times k}$
# Make a list of (eigenvalue, eigenvector) tuples eigen_pairs = [(np.abs(eigen_vals[i]), eigen_vecs[:, i]) for i in range(len(eigen_vals))] # Sort the (eigenvalue, eigenvector) tuples from high to low eigen_pairs.sort(key=lambda k: k[0], reverse=True)まずは、次元削減を行わずに、13 次元 --> 13 次元の座標変換を見てみる
$X' = XW$
$W = [v_1 v_2 ... v_13] \in \mathbb{R} ^{13\times 13}$
$x \in \mathbb{R} ^{13}$
$x' \in \mathbb{R} ^{13}$# 変換行列 w の作成 w = eigen_pairs[0][1][:, np.newaxis] for i in range(1, len(eigen_pairs)): # print(i) w = np.hstack((w, eigen_pairs[i][1][:, np.newaxis])) w.shape(13, 13)# 座標変換 X_train_pca = X_train_std.dot(w) # print(X_train_pca.shape) cov_mat = np.cov(X_train_pca.T) # 共分散行列のヒートマップ df = pd.DataFrame(cov_mat) ax = sns.heatmap(df, cmap="YlGnBu")
主成分空間に変換後の各特徴量は、互いに相関が全くないことがわかる(互いに線形独立)。
対角成分は分散値であり、第1主成分から大きい順に並んでいることがわかる。座標変換された空間から元の空間への復元
座標変換された空間から元の空間への復元
$X = X'W^T$
$X'$ : 座標変換後の座標(行列)
$X$ : もともとの空間に復元された座標(行列)
$W^T \in \mathbb{R} ^{n\times n}$ : 転置された変)行列$x' \in \mathbb{R} ^{n}$
$x_{approx} \in \mathbb{R} ^{n}$# 1つ目のサンプルに射影行列を適用(内積を作用させる) x0 = X_train_std[0] print('もともとの特徴量:', x0) z0 = x0.dot(w) print('変換後の特徴量:', z0) x0_reconstructed = z0.dot(w.T) print('復元された特徴量:', x0_reconstructed)もともとの特徴量: [ 0.71225893 2.22048673 -0.13025864 0.05962872 -0.50432733 -0.52831584 -1.24000033 0.84118003 -1.05215112 -0.29218864 -0.20017028 -0.82164144 -0.62946362] 変換後の特徴量: [ 2.38299011 0.45458499 0.22703207 0.57988399 -0.57994169 -1.73317476 -0.70180475 -0.21617248 0.23666876 0.16548767 -0.29726982 -0.23489704 0.40161994] 復元された特徴量: [ 0.71225893 2.22048673 -0.13025864 0.05962872 -0.50432733 -0.52831584 -1.24000033 0.84118003 -1.05215112 -0.29218864 -0.20017028 -0.82164144 -0.62946362]完全に復元できていることがわかる。
13 次元 --> 2 次元に次元削減する
$X' = XW$
$W = [v_1 v_2] \in \mathbb{R} ^{13\times 2}$
$x \in \mathbb{R} ^{13}$
$x' \in \mathbb{R} ^{2}$w = np.hstack((eigen_pairs[0][1][:, np.newaxis], eigen_pairs[1][1][:, np.newaxis])) print('Matrix W:\n', w)Matrix W: [[-0.13724218 0.50303478] [ 0.24724326 0.16487119] [-0.02545159 0.24456476] [ 0.20694508 -0.11352904] [-0.15436582 0.28974518] [-0.39376952 0.05080104] [-0.41735106 -0.02287338] [ 0.30572896 0.09048885] [-0.30668347 0.00835233] [ 0.07554066 0.54977581] [-0.32613263 -0.20716433] [-0.36861022 -0.24902536] [-0.29669651 0.38022942]]注意
NumPy と LAPACK のバージョンによっては、上記の例とは符号が反転した射影行列 w が作成されることがあるが、問題はない。
以下の式が成り立つからである。行列 $\Sigma$ に対して、 $v$ が固有ベクトル、$\lambda$ が固有値のとき、
$$\Sigma v = \lambda v,$$ここで $-v$ もまた同じ固有値をもつ固有ベクトルとなる。
$$\Sigma \cdot (-v) = -\Sigma v = -\lambda v = \lambda \cdot (-v).$$(主成分軸のベクトルの向きの違い)
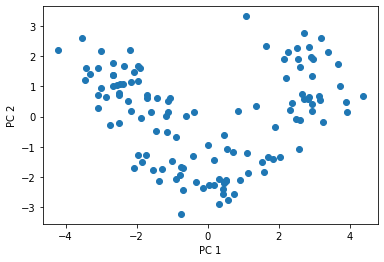
# 各サンプルに射影行列を適用(内積を作用)させることで、変換後の座標(特徴量)を得ることができる。 X_train_std[0].dot(w)array([2.38299011, 0.45458499])2次元に射影後の全データを、ラベルごとに色付けしてプロットする
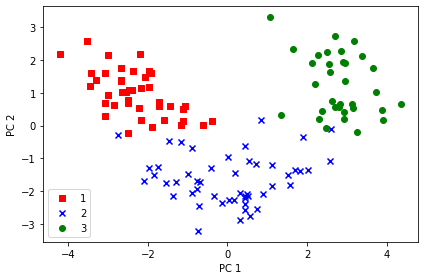
X_train_pca = X_train_std.dot(w) colors = ['r', 'b', 'g'] markers = ['s', 'x', 'o'] for l, c, m in zip(np.unique(y_train), colors, markers): plt.scatter(X_train_pca[y_train == l, 0], X_train_pca[y_train == l, 1], c=c, label=l, marker=m) plt.xlabel('PC 1') plt.ylabel('PC 2') plt.legend(loc='lower left') plt.tight_layout() # plt.savefig('images/05_03.png', dpi=300) plt.show()
PC1 軸方向をみると、PC2 軸方向よりもよりもデータが広く分布しており、データをよりよく区別できていることがわかる。
次元削減された空間から元の空間への復元
$X_{approx} = X'W^T$
$X'$ : 射影後の座標(行列)
$X_{approx}$ : もともとの空間に、近似的に、復元された座標(行列)
$W^T \in \mathbb{R} ^{n\times k}$ : 転置された射影(変換)行列$x' \in \mathbb{R} ^{k}$
$x_{approx} \in \mathbb{R} ^{n}$$k = n$ のとき、$X = X_{approx}$ が成り立つ(上述)。
# 1つ目のサンプルに射影行列を適用(内積を作用させる) x0 = X_train_std[0] print('もともとの特徴量:', x0) z0 = x0.dot(w) print('変換後の特徴量:', z0) x0_reconstructed = z0.dot(w.T) print('復元された特徴量:', x0_reconstructed)もともとの特徴量: [ 0.71225893 2.22048673 -0.13025864 0.05962872 -0.50432733 -0.52831584 -1.24000033 0.84118003 -1.05215112 -0.29218864 -0.20017028 -0.82164144 -0.62946362] 変換後の特徴量: [2.38299011 0.45458499] 復元された特徴量: [-0.09837469 0.66412622 0.05052458 0.44153949 -0.23613841 -0.91525549 -1.00494135 0.76968396 -0.72702683 0.42993247 -0.87134462 -0.9915977 -0.53417827]完全には復元できていないことがわかる(近似値に復元される)。
Principal component analysis in scikit-learn
上記で行った PCA の実装は、scikit-learn を使うことで簡単に実装できる。
以下にその実装を示す。from sklearn.decomposition import PCA pca = PCA() # 主成分分析の実行 X_train_pca = pca.fit_transform(X_train_std) # 分散説明率の表示 pca.explained_variance_ratio_array([0.36951469, 0.18434927, 0.11815159, 0.07334252, 0.06422108, 0.05051724, 0.03954654, 0.02643918, 0.02389319, 0.01629614, 0.01380021, 0.01172226, 0.00820609])# 分散説明率とその累積和のプロット plt.bar(range(1, 14), pca.explained_variance_ratio_, alpha=0.5, align='center') plt.step(range(1, 14), np.cumsum(pca.explained_variance_ratio_), where='mid') plt.ylabel('Explained variance ratio') plt.xlabel('Principal components') plt.show()
# 2次元に削減 pca = PCA(n_components=2) X_train_pca = pca.fit_transform(X_train_std) X_test_pca = pca.transform(X_test_std)# 2次元空間にプロット plt.scatter(X_train_pca[:, 0], X_train_pca[:, 1]) plt.xlabel('PC 1') plt.ylabel('PC 2') plt.show()
2次元に次元削減された特徴量を用いてロジスティック回帰を行ってみる
from matplotlib.colors import ListedColormap def plot_decision_regions(X, y, classifier, resolution=0.02): # setup marker generator and color map markers = ('s', 'x', 'o', '^', 'v') colors = ('red', 'blue', 'lightgreen', 'gray', 'cyan') cmap = ListedColormap(colors[:len(np.unique(y))]) # plot the decision surface x1_min, x1_max = X[:, 0].min() - 1, X[:, 0].max() + 1 x2_min, x2_max = X[:, 1].min() - 1, X[:, 1].max() + 1 xx1, xx2 = np.meshgrid(np.arange(x1_min, x1_max, resolution), np.arange(x2_min, x2_max, resolution)) Z = classifier.predict(np.array([xx1.ravel(), xx2.ravel()]).T) Z = Z.reshape(xx1.shape) plt.contourf(xx1, xx2, Z, alpha=0.4, cmap=cmap) plt.xlim(xx1.min(), xx1.max()) plt.ylim(xx2.min(), xx2.max()) # plot class samples for idx, cl in enumerate(np.unique(y)): plt.scatter(x=X[y == cl, 0], y=X[y == cl, 1], alpha=0.6, c=cmap(idx), edgecolor='black', marker=markers[idx], label=cl)Training logistic regression classifier using the first 2 principal components.
from sklearn.linear_model import LogisticRegression pca = PCA(n_components=2) X_train_pca = pca.fit_transform(X_train_std) X_test_pca = pca.transform(X_test_std) lr = LogisticRegression(penalty='l2', C=1.0) # lr = LogisticRegression(penalty='none') lr = lr.fit(X_train_pca, y_train)print(X_train_pca.shape)(124, 2)print('Cumulative explained variance ratio:', sum(pca.explained_variance_ratio_))Cumulative explained variance ratio: 0.5538639565949177学習時間の計測
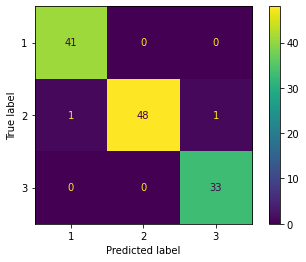
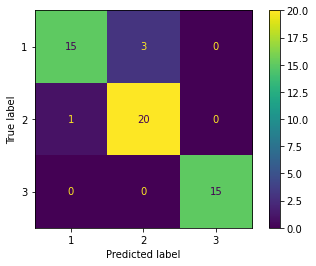
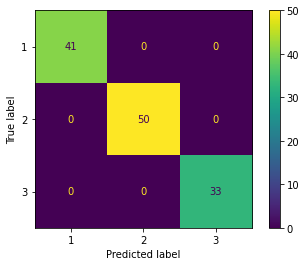
%timeit lr.fit(X_train_pca, y_train)100 loops, best of 3: 5.11 ms per loopfrom sklearn.metrics import plot_confusion_matrix # 精度 print('accuracy', lr.score(X_train_pca, y_train)) # confusion matrix plot_confusion_matrix(lr, X_train_pca, y_train)accuracy 0.9838709677419355 <sklearn.metrics._plot.confusion_matrix.ConfusionMatrixDisplay at 0x7f54fca16da0>
トレーニングデータセットの予測結果
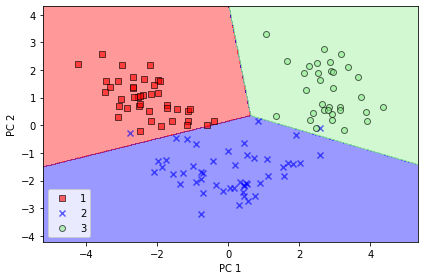
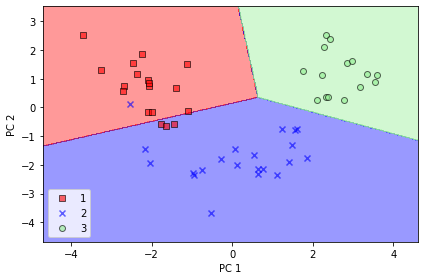
plot_decision_regions(X_train_pca, y_train, classifier=lr) plt.xlabel('PC 1') plt.ylabel('PC 2') plt.legend(loc='lower left') plt.tight_layout() # plt.savefig('images/05_04.png', dpi=300) plt.show()'c' argument looks like a single numeric RGB or RGBA sequence, which should be avoided as value-mapping will have precedence in case its length matches with 'x' & 'y'. Please use a 2-D array with a single row if you really want to specify the same RGB or RGBA value for all points. 'c' argument looks like a single numeric RGB or RGBA sequence, which should be avoided as value-mapping will have precedence in case its length matches with 'x' & 'y'. Please use a 2-D array with a single row if you really want to specify the same RGB or RGBA value for all points. 'c' argument looks like a single numeric RGB or RGBA sequence, which should be avoided as value-mapping will have precedence in case its length matches with 'x' & 'y'. Please use a 2-D array with a single row if you really want to specify the same RGB or RGBA value for all points.
テストデータに対する予測結果
from sklearn.metrics import plot_confusion_matrix # 精度 print('accuracy', lr.score(X_test_pca, y_test)) # confusion matrix plot_confusion_matrix(lr, X_test_pca, y_test)accuracy 0.9259259259259259 <sklearn.metrics._plot.confusion_matrix.ConfusionMatrixDisplay at 0x7f54f53ec160>
plot_decision_regions(X_test_pca, y_test, classifier=lr) plt.xlabel('PC 1') plt.ylabel('PC 2') plt.legend(loc='lower left') plt.tight_layout() # plt.savefig('images/05_05.png', dpi=300) plt.show()'c' argument looks like a single numeric RGB or RGBA sequence, which should be avoided as value-mapping will have precedence in case its length matches with 'x' & 'y'. Please use a 2-D array with a single row if you really want to specify the same RGB or RGBA value for all points. 'c' argument looks like a single numeric RGB or RGBA sequence, which should be avoided as value-mapping will have precedence in case its length matches with 'x' & 'y'. Please use a 2-D array with a single row if you really want to specify the same RGB or RGBA value for all points. 'c' argument looks like a single numeric RGB or RGBA sequence, which should be avoided as value-mapping will have precedence in case its length matches with 'x' & 'y'. Please use a 2-D array with a single row if you really want to specify the same RGB or RGBA value for all points.
次元削減せずに全てのの主成分を取得したい場合は、
n_components=Noneにする。pca = PCA(n_components=None) X_train_pca = pca.fit_transform(X_train_std) pca.explained_variance_ratio_array([0.36951469, 0.18434927, 0.11815159, 0.07334252, 0.06422108, 0.05051724, 0.03954654, 0.02643918, 0.02389319, 0.01629614, 0.01380021, 0.01172226, 0.00820609])3 次元に次元削減された特徴量を用いてロジスティック回帰を行ってみる
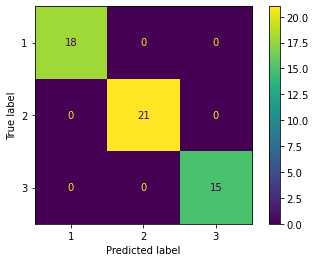
from sklearn.linear_model import LogisticRegression k = 3 pca = PCA(n_components=3) X_train_pca = pca.fit_transform(X_train_std) X_test_pca = pca.transform(X_test_std) lr = LogisticRegression(penalty='l2', C=1.0) # lr = LogisticRegression(penalty='none') lr = lr.fit(X_train_pca, y_train)print(X_train_pca.shape)(124, 3)print('Cumulative explained variance ratio:', sum(pca.explained_variance_ratio_))Cumulative explained variance ratio: 0.6720155475408875%timeit lr.fit(X_train_pca, y_train)100 loops, best of 3: 5.76 ms per loopfrom sklearn.metrics import plot_confusion_matrix # 精度 print('accuracy', lr.score(X_train_pca, y_train)) # confusion matrix plot_confusion_matrix(lr, X_train_pca, y_train)accuracy 0.9838709677419355 <sklearn.metrics._plot.confusion_matrix.ConfusionMatrixDisplay at 0x7f54f606fcf8>
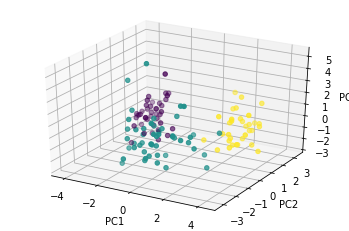
from mpl_toolkits.mplot3d import Axes3D import matplotlib.pyplot as plt fig = plt.figure() ax = fig.add_subplot(111, projection='3d') # ax.scatter(X_train_pca[:,0], X_train_pca[:,1], X_train_pca[:,2], c='r', marker='o') ax.scatter(X_train_pca[:,0], X_train_pca[:,1], X_train_pca[:,2], c=y_train, marker='o') ax.set_xlabel('PC1') ax.set_ylabel('PC2') ax.set_zlabel('PC3') plt.show()
# plotly を使った interactive な 3D 散布図 import plotly.express as px df = pd.DataFrame(X_train_pca, columns=['PC1', 'PC2', 'PC3']) df['label'] = y_train fig = px.scatter_3d(df, x='PC1', y='PC2', z='PC3', color='label', opacity=0.7, ) fig.show()(出力結果は、Google Colab 上で確認できます)
人間の目で確認できるのは 3 次元が限界。
次元削減せずにロジスティック回帰を行ってみる
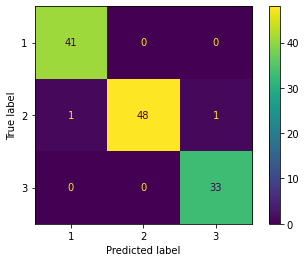
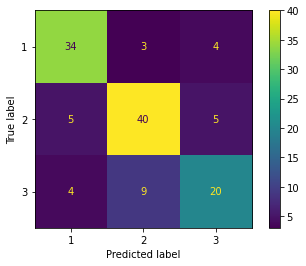
from sklearn.linear_model import LogisticRegression lr = LogisticRegression(penalty='l2', C=1.0) # lr = LogisticRegression(penalty='none') lr = lr.fit(X_train_std, y_train)# 学習時間 %timeit lr.fit(X_train_std, y_train)100 loops, best of 3: 7.23 ms per loopfrom sklearn.metrics import plot_confusion_matrix print('Evaluation of training dataset') # 精度 print('accuracy', lr.score(X_train_std, y_train)) # confusion matrix plot_confusion_matrix(lr, X_train_std, y_train) print('Evaluation of test dataset') # 精度 print('accuracy', lr.score(X_test_std, y_test)) # confusion matrix plot_confusion_matrix(lr, X_test_std, y_test)Evaluation of training dataset accuracy 1.0 Evaluation of test dataset accuracy 1.0 <sklearn.metrics._plot.confusion_matrix.ConfusionMatrixDisplay at 0x7f54f56a2c50>
元々の全ての特徴量を使って学習させた方が精度が高くなった。
学習時間は、次元削減したほうがわずかに早くなっている。
(主成分 2 つで学習した場合 4.9 ms に対し、元々の特徴量全て使った場合 5.64 ms)
結論として、今回のタスクでは、PCA を適用するべきではなく、すべての特徴量を使用したほうが良い。もっとデータ数が大きい場合や、モデルのパラメータ数が多い場合には、次元削減が効果的となる。
2つの特徴量だけでロジスティック回帰を行ってみる
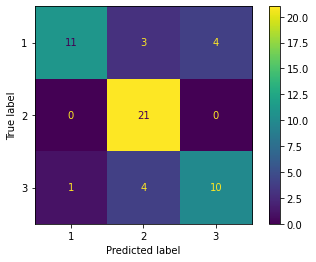
from sklearn.linear_model import LogisticRegression lr = LogisticRegression(penalty='l2', C=1.0) # lr = LogisticRegression(penalty='none') lr = lr.fit(X_train_std[:,:2], y_train)%timeit lr.fit(X_train_std[:,:2], y_train)100 loops, best of 3: 3.53 ms per loopfrom sklearn.metrics import plot_confusion_matrix print('Evaluation of training dataset') # 精度 print('accuracy', lr.score(X_train_std[:,:2], y_train)) # confusion matrix plot_confusion_matrix(lr, X_train_std[:,:2], y_train) print('Evaluation of test dataset') # 精度 print('accuracy', lr.score(X_test_std[:,:2], y_test)) # confusion matrix plot_confusion_matrix(lr, X_test_std[:,:2], y_test)Evaluation of training dataset accuracy 0.7580645161290323 Evaluation of test dataset accuracy 0.7777777777777778 <sklearn.metrics._plot.confusion_matrix.ConfusionMatrixDisplay at 0x7f54f560de10>
もともとの特徴量を 2 つだけ使った場合、精度はかなり下がる。
これと比べると、PCA によって特徴抽出した 2 つの主成分を使った場合には、精度がかなり高いことがわかる。まとめ
主成分分析により以下のタスクを行うことができる。
- 次元削減
- データを格納するためのメモリやディスク使用量を削減できる
- 学習アルゴリズムを高速化できる
- 可視化
- 多数の特徴量(次元)をもつデータを2次元などの理解しやすい空間に落とし込んで議論、解釈することができる。
しかし、機械学習の前処理として利用する場合には、以下のことに注意する必要がある。
- 次元削減を行うことによって、多少なりとも情報が失われている
- まずは、すべての特徴量を使ってトレーニングを試すことが大事
- 次元削減によってオーバーフィッティングを防ぐことができるが、次元削減を使う前に正則化を使うべし
- 上記を試してから、それでも望む結果を得られない場合、次元削減を使う
- 機械学習のトレーニングでは、通常は、99% の累積寄与率が得られるように削減後の次元数を選ぶことが多い
参考) Andrew Ng先生の講義
References
- Python Machine Learning 2nd Edition by Sebastian Raschka, Packt Publishing Ltd. 2017. Code Repository: https://github.com/rasbt/python-machine-learning-book-2nd-edition
- Andrew Ng先生の講義




- 投稿日:2020-04-02T18:54:42+09:00
??日本を対象とした?コロナウイルス情報 Web APIが無かったので2日間で公開した話
今や社会課題と言っても過言では無いほど?コロナウイルス騒動は人々の注目を集めています。また、世界中のエンジニアがコロナウイルスに関するWebサイトやオープンソースプロダクトを開発しています。(GitHubでCOVID-19などで調べるとたくさん出てきます)その中で世界のコロナウイルス情報をWebAPIとして公開している人もいましたが、日本に特化したコロナウイルス情報WebAPIは無いみたいでした。(多分)
という背景もあり、今回は日本を対象としたコロナウイルス情報 Web APIを作ったら使う人もいるだろうなぐらいのノリで作成し、公開しました。
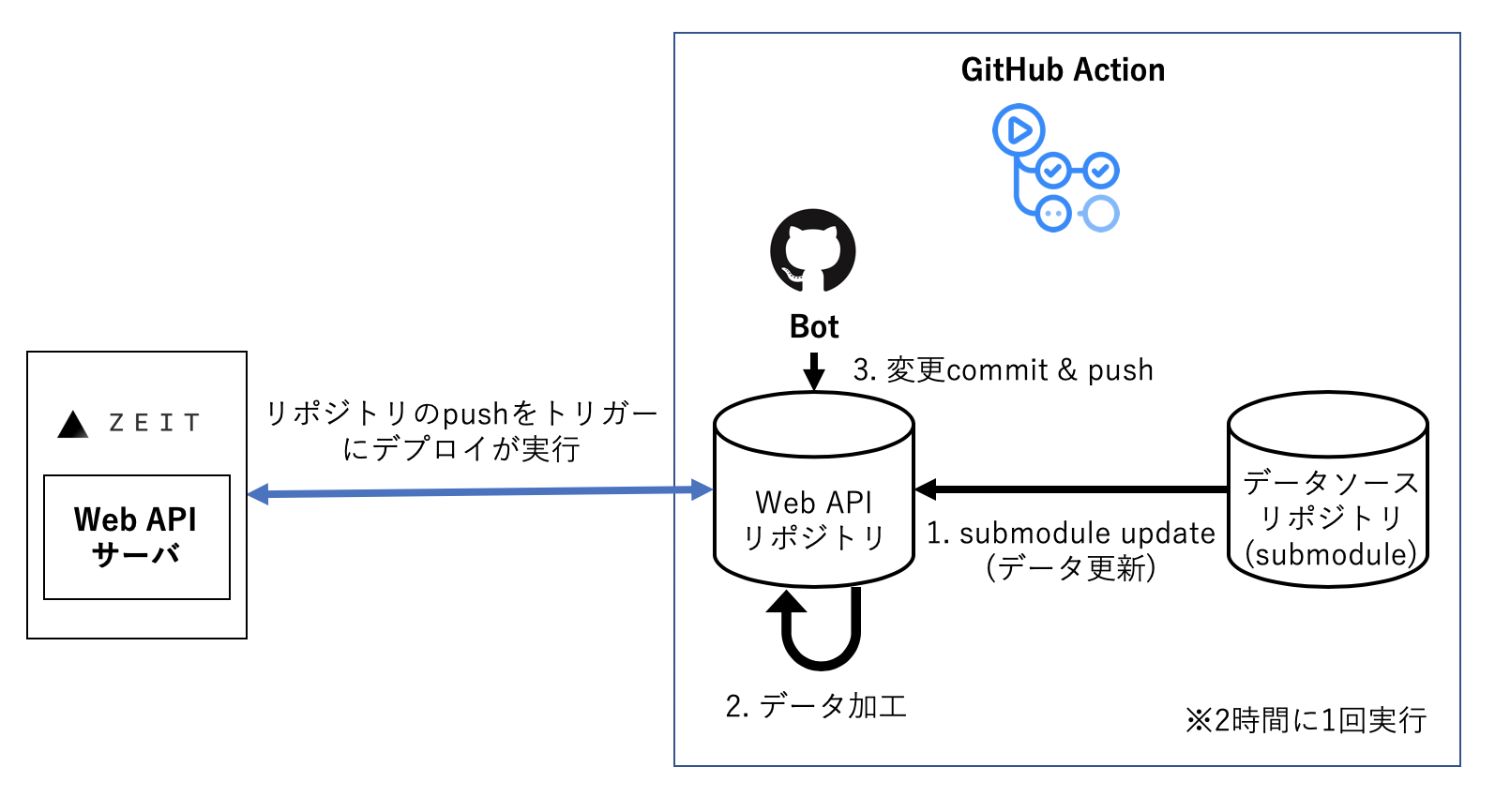
? 作成したリポジトリ (https://github.com/ryo-ma/covid19-japan-web-api)使用技術
- Python 3系
- sanic (Python用 非同期Webアプリケーションフレームワーク, ASGI対応,
ソニックのパチモノキャラをモチーフにしてる)- zeit now (Paas, GitHubと連携が可能でデプロイが簡単なPaaS) 現在は無料枠を利用
- GitHub Action (自動でデータ収集、更新するためのCI)
データソース
APIで提供するデータはGitHub上でcsvデータをオープンに公開してくれているリポジトリから収集してくることにしました。GitHub Actionを利用して2時間に1回データを更新してリポジトリにpushしています。
今後は分析結果などを公開してくれている他のリポジトリからの情報も利用したいと考えています。
データ更新 & デプロイ アーキテクチャ
zeit nowとGitHub Actionを利用することで2時間に1回データを更新してデプロイを自動で行います。
開発期間
完璧さは求めずに、なるべく早く公開して少しずつ改善していこうというスタンスで行いました。
実装自体は大したことが無いのと、zeit nowとGitHub Actionの利用方法がとても簡単だったので、2日間という短い期間で基本機能を作成することができました。
1日目:
・静的に取得してきたデータを提供する県ごとのAPIを作成
・リポジトリ作成
・zeit nowとGitHub 自動デプロイ連携2日目:
・GitHub Actionを利用してデータ自動収集、更新以降:
・ API追加
・ README整備
など作成したAPI
県ごとの感染数、死者数
Endpont: https://covid19-japan-web-api.now.sh/api/v1/prefectures
$ curl https://covid19-japan-web-api.now.sh/api/v1/prefecturesResponse:
[ { "id": 1, "name_ja": "北海道", "name_en": "Hokkaido", "lat": 43.46722222, "lng": 142.8277778, "cases": 176, "deaths": 7 }, { "id": 2, "name_ja": "青森", "name_en": "Aomori", "lat": 40.78027778, "lng": 140.83194440000003, "cases": 8, "deaths": 0 }, ...国内の様々な集計データ
Endpont: https://covid19-japan-web-api.now.sh/api/v1/total
$ curl https://covid19-japan-web-api.now.sh/api/v1/totalResponse:
{ "date": 20200329, "pcr": 26401, "positive": 1647, "symptom": 1352, "symptomless": 162, "symtomConfirming": 133, "hospitalize": 1187, "mild": 659, "severe": 59, "confirming": 323, "waiting": 13, "discharge": 408, "death": 52 }陽性者一覧
Endpont: https://covid19-japan-web-api.now.sh/api/v1/positives
$ curl https://covid19-japan-web-api.now.sh/api/v1/positivesResponse:
[ { "prefecture": "北海道", "residence_prefecture": "国外(武漢市)", "age": "40代", "gender": "女性", "attribute": "来日観光客", "prefecture_number": "北海道1", "travel_or_contact": "渡航歴", "detail": "中国(武漢)", "src": "https://www.mhlw.go.jp/stf/newpage_09158.html", "onset": "1月26日", "symptom": "1", "death_or_discharge_date": "", "comment1": "", "outcome": "", "outcome_src": "", "comment2": "" }, { "prefecture": "北海道", "residence_prefecture": "札幌市", "age": "50代", "gender": "男性", "attribute": "来日観光客", "prefecture_number": "北海道2", "travel_or_contact": "", "detail": "", "src": "http://www.pref.hokkaido.lg.jp/hf/kth/kak/hasseijoukyou.htm", "onset": "1月31日", "symptom": "1", "death_or_discharge_date": "", "comment1": "", "outcome": "", "outcome_src": "", "comment2": "" }, ...まとめ
今回は短期間で日本のコロナウイルスWebAPIを公開しました。
誰かがこのAPIを利用して、コロナウイルス情報の拡散の手助けに少しでもなればいいなと考えております。?APIの仕様に対しての要望や質問などお待ちしております。
リポジトリ:https://github.com/ryo-ma/covid19-japan-web-api

- 投稿日:2020-04-02T18:51:25+09:00
Python実行時のカスタム
siteは初期化時に自動的にimportされるモジュールであり、サイト固有の組み込み関数の追加などを行います。
さらに、このモジュールは指定された追加モジュールを読み込むことでカスタマイズ機能を実現しており、サイト固有、ユーザ固有のカスタマイズが可能となっています。動機
usercustomizeを書いたので、書いたということを忘れないようにするため。
環境
macOS Catalina
Python 3.7方法
siteによって読み込まれるモジュールは、sitecustomizeとusercustomizeの2つです。適用範囲が異なります。
設置場所は、それぞれのsite-packagesディレクトリです。以下のように調べることができます。>>> import site >>> site.getsitepackages() ['/usr/local/var/pyenv/versions/3.7.4/lib/python3.7/site-packages'] >>> site.getusersitepackages() '/Users/[user_name]/.local/lib/python3.7/site-packages'/User/[user_name]/.local/lib/python3.7/site-packages.pyprint('Hi')インタプリタの起動
[user_name]@MacBook ~ % python Hi Python 3.7.4 (default, Oct 5 2019, 02:45:54) [Clang 10.0.1 (clang-1001.0.46.4)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>>Hiと表示されています。
おまけ
パーフェクトPythonでは、
pdbを利用して、例外捕捉時に自動でデバッガを起動するフックが紹介されていました。
pdbに慣れるにはもってこいな気がします。
- 投稿日:2020-04-02T18:51:25+09:00
Python実行時の
siteは初期化時に自動的にimportされるモジュールであり、サイト固有の組み込み関数の追加などを行います。
さらに、このモジュールは指定された追加モジュールを読み込むことでカスタマイズ機能を実現しており、サイト固有、ユーザ固有のカスタマイズが可能となっています。動機
usercustomizeを書いたので、書いたということを忘れないようにするため。
環境
macOS Catalina
Python 3.7方法
siteによって読み込まれるモジュールは、sitecustomizeとusercustomizeの2つです。適用範囲が異なります。
設置場所は、それぞれのsite-packagesディレクトリです。以下のように調べることができます。>>> import site >>> site.getsitepackages() ['/usr/local/var/pyenv/versions/3.7.4/lib/python3.7/site-packages'] >>> site.getusersitepackages() '/Users/[user_name]/.local/lib/python3.7/site-packages'/User/[user_name]/.local/lib/python3.7/site-packages.pyprint('Hi')インタプリタの起動
[user_name]@MacBook ~ % python Hi Python 3.7.4 (default, Oct 5 2019, 02:45:54) [Clang 10.0.1 (clang-1001.0.46.4)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>>Hiと表示されています。
おまけ
パーフェクトPythonでは、
pdbを利用して、例外捕捉時に自動でデバッガを起動するフックが紹介されていました。
Exceptionの度にデバッガが起動するのでpdbに慣れるにはもってこいな気がします。
- 投稿日:2020-04-02T18:51:25+09:00
Python実行時のカスタマイズ[sitecustomize,usercustomize]
siteは初期化時に自動的にimportされるモジュールであり、サイト固有の組み込み関数の追加などを行います。
さらに、このモジュールは指定された追加モジュールを読み込むことでカスタマイズ機能を実現しており、サイト固有、ユーザ固有のカスタマイズが可能となっています。動機
usercustomizeを書いたので、書いたということを忘れないようにするため。
環境
macOS Catalina
Python 3.7方法
siteによって読み込まれるモジュールは、sitecustomizeとusercustomizeの2つです。適用範囲が異なります。
設置場所は、それぞれのsite-packagesディレクトリです。以下のように調べることができます。>>> import site >>> site.getsitepackages() ['/usr/local/var/pyenv/versions/3.7.4/lib/python3.7/site-packages'] >>> site.getusersitepackages() '/Users/[user_name]/.local/lib/python3.7/site-packages'/User/[user_name]/.local/lib/python3.7/site-packages.pyprint('Hi')インタプリタの起動
[user_name]@MacBook ~ % python Hi Python 3.7.4 (default, Oct 5 2019, 02:45:54) [Clang 10.0.1 (clang-1001.0.46.4)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>>Hiと表示されています。
おまけ
パーフェクトPythonでは、
pdbを利用して、例外捕捉時に自動でデバッガを起動するフックが紹介されていました。
Exceptionの度にデバッガが起動するのでpdbに慣れるにはもってこいな気がします。
- 投稿日:2020-04-02T18:30:30+09:00
Pythonで簡単な作業を自動化する Part0
こんにちは。
最近Javaを、13から14へアップデートしたFaguriです。どんな作業が自動化できるのか
・単純作業
.....(やばい思いつかん)そもそもPythonとは
完全に順番が逆だけど許してください。
文法を極力単純化してコードの可読性を高め、読みやすく、また書きやすくしてプログラマの作業性とコードの信頼性を高めることを重視してデザインされた、汎用の高水準言語である。
核となる本体部分は必要最小限に抑えられている。一方で標準ライブラリやサードパーティ製のライブラリ、関数など、さまざまな領域に特化した豊富で大規模なツール群が用意され、インターネット上から無料で入手でき、自らの使用目的に応じて機能を拡張していくことができる。またPythonは多くのハードウェアとOS (プラットフォーム) に対応しており、複数のプログラミングパラダイムに対応している。Pythonはオブジェクト指向、命令型、手続き型、関数型などの形式でプログラムを書くことができる。動的型付け言語であり、参照カウントベースの自動メモリ管理(ガベージコレクタ)を持つ。
これらの特性によりPythonは広い支持を獲得し、Webアプリケーションやデスクトップアプリケーションなどの開発はもとより、システム用の記述 (script) や、各種の自動処理、理工学や統計・解析など、幅広い領域における有力なプログラム言語となった。プログラミング作業が容易で能率的であることは、ソフトウェア企業にとっては投入人員の節約、開発時間の短縮、ひいてはコスト削減に有益であることから、産業分野でも広く利用されている。Googleなど主要言語に採用している企業も多い。
Pythonのリファレンス実装であるCPythonは、フリーかつオープンソースのソフトウェアであり、コミュニティベースの開発モデルを採用している。CPythonは、非営利団体であるPythonソフトウェア財団が管理している。その他の実装としては、PyPyやIronPythonなどが有名である。
Pythonは、オランダ人のグイド・ヴァンロッサムが開発した。名前の由来は、イギリスのテレビ局 BBC が製作したコメディ番組『空飛ぶモンティ・パイソン』である。Pythonという英単語が意味する爬虫類のニシキヘビがPython言語のマスコットやアイコンとして使われている。NARUHODOWAKARAN
自動化の例
Excelに今日の日付と株価を書く日課 → PythonでOpenpyxlとBeautifulSoupなどを使い自動化!
......
....
...
(やばい思いつかん)などができます。
終わりに
ある本を買いその本を読んでから上級者になって気がしています。(実際は下の上)
こんな感じで次からはどんどんコードを書いていきます。
いつかGitHubで公開しようかな。
- 投稿日:2020-04-02T18:09:37+09:00
Python入門
よーしPythonやるぞー
環境
OS:Windows10
本文
Pythonとは人工知能に向いてる言語です。
まあ人工知能を作る方法は知りませんがー
顔認証?ならカメラ搭載してID変数でコードやったらできるのでは?
とりまコンソロール(画面に文字が出るやつ、説明ムズイ)に"Hello Python!"と出させましょうか?
コード下です(見ればわかると思うけど)script.pyprint("Hello Python!");したらそのファイルをダブルクリック(設定によってはワンクリック)
すると?
.....
一瞬だったじゃないですか?
これじゃあ分からないですよねー
だからコマンドでやりますrun.batファイル名.py pauseこれを実行します。
すると?(本日2回目)
Hello Python! と出ました!
次は、入力された文字を出しましょう(出力)
コードscript.pyinput_data = input("enter:") print(input_data);またやると?
ちゃんと出力されています!今回はここまでで。
また会いましょう!


- 投稿日:2020-04-02T18:03:06+09:00
PythonからRustを呼んで高速化! PyO3 チュートリアル:簡単な関数をラップする その➁
概要
1. Pyhtonでアルゴリズムまで書いてあるのは速度面では好ましくないな〜
2. よし、C, C++あたりで書いてあるものを探して、それをPythonから呼んで高速化しよう。
3. なかなかいいライブラリ見つからんな、
4. おっ、Rustていう言語で書かれてるのならあったぞ
5. RustてPythonから呼べんのか??これは、PythonからRustを呼んで高速化! PyO3 チュートリアル:簡単な関数をラップする その➀
の続きになります。
今回の目標
今回は、
-lib.rsを追記
-setup.pyを加え実際にコンパイルしていきます。
最終的な目標は、
Rustで書いた関数やクラス(的なもの?)をPythonから気軽に呼べるようになること
です。Rustの関数をPythonへ引き渡す
//lib.rsの続き use pyo3::{wrap_pyfunction}; // ======================CREATING MODULE FOR PYTHON================================================== /// This module is a python module implemented in Rust. #[pymodule] fn test_library(py: Python, m: &PyModule) -> PyResult<()> { m.add_wrapped(wrap_pyfunction!(get_prime_numbers))?; Ok(()) }ここでは、
#[pymodule]のデコレータがtest_libraryがPythonのモジュールになることを宣言しています。そして、先ほどの
get_prime_numbers関数が、m.add_wrapped(wrap_pyfunction!(get_prime_numbers))?;でそのモジュールに関数としてラップされています。
最後に
Ok(())となっていて、このモジュールが関数として定義され、
rust
PyResult<()>
空のPyResultを返すようになっている(Void関数はこれでラップできる)のが少し気になりますが、
この辺はおまじないとしてチュートリアルをそのまま書きました。setup.py を作る
Cythonでも使用したおなじみの
setup.pyを作っていきます。
今回はシンプルで簡単です。setup.pyfrom setuptools import setup from setuptools_rust import Binding, RustExtension setup(name='test_library', version='0.1', rust_extensions=[ RustExtension('test_library', 'Cargo.toml', binding=Binding.PyO3)], zip_safe=False)name='test_library',によりPython側から
import test_libraryのように呼べます。RustExtension('test_library', 'Cargo.toml', binding=Binding.PyO3)],で
lib.rsの中のtest_libraryモジュールをpyo3によってライブラリ化します。
この時、使う依存関係がCargo.tomlと書くだけなのがとても簡単ですね。。ビルドしてみる
以上で準備ができたので、実際にビルドしPythonから関数を呼んでみます。
python setup.py installを実行し、テストコード
test.pyimport test_library import time import sys def get_prime_numbers(n: int): flags = [True for _ in range(n+2)] upper = int(n ** 0.5) for i in range(2, upper+1): if not flags[i]: continue prime = i j = prime * 2 while j <= n: flags[j] = False j += prime primes = [] for i in range(2, n+1): if flags[i]: primes.append(i) return primes if __name__ == "__main__": # just calling rust function from created library a = 123 b = 456 c = test_library.sum_as_string(a, b) print(c) # just calling rust function from created library, to find primes # rust is (of course) a lot faster than python # if you wanna call python function, python test.py, # if you wanna call rust function, python test.py --rust use_rust = len(sys.argv) == 2 and sys.argv[1] == "--rust" n = 10000 t1 = time.time() for _ in range(10): if use_rust: primes = test_library.get_prime_numbers(n) else: primes = get_prime_numbers(n) t2 = time.time() print(f"time took is: {t2-t1} sec")を実行します。
python test.pyでpythonベースの関数が走り、
python test.py --rustでRustベースの関数を呼んでいます。
結果、
$ python test.py time took is: 0.013466835021972656 sec$ python test.py --rust time took is: 0.0005574226379394531 secとなり、実行速度差が顕著に現れてくれました。
まとめ
最終的な目標は、
Rustで書いた関数やクラス(的なもの?)をPythonから気軽に呼べるようになること
でしたが、
今回でRustで書かれた関数をPythonから呼ぶ方法を解説しました。
まだカバーした型変換がVec -> Listだけなので、次の記事でまた他の型に関しても書ければと思います。ただ、あまり記述は変わらないので、簡単です。また、Rustのクラス的なもの(Struct + method)をPython側のクラスオブジェクトとしてパースするやり方に関しても書いていきたいと思います。
今回はこの辺で。
おわり。
- 投稿日:2020-04-02T18:02:34+09:00
PythonからRustを呼んで高速化! PyO3 チュートリアル:簡単な関数をラップする その➀
概要
1. Pyhtonでアルゴリズムまで書いてあるのは速度面では好ましくないな〜
2. よし、C, C++あたりで書いてあるものを探して、それをPythonから呼んで高速化しよう。
3. なかなかいいライブラリ見つからんな、
4. おっ、Rustていう言語で書かれてるのならあったぞ
5. RustてPythonから呼べんのか??最終的な目標
というわけで、今までC++のライブラリをPythonから呼んで高速化を図るための「Cython」チュートリアルを書いてきましたが、
今回からはRustをPythonから呼んで高速化するための「PyO3」というライブラリのチュートリアルを書いていきます。
最終的な目標は、
Rustで書いた関数やクラス(的なもの?)をPythonから気軽に呼べるようになること
です。このPyO3(gitはここ)は、開発の真っ只中であり、バージョン更新が(おそらく)凄まじい速度で行われております。
今回の目標
そもそもRust初見の状態からスタートして、
PythonからRustで書いた関数を呼べるようになる、という目標のもとPyO3を触ってみました。キータにも、他ブログでもいくつかの解説記事が出ております。
- [Rust] PyO3 で Python パッケージを作成
- Pyo3でPythonとRustを連携させる
- RustモジュールをPythonから実行する (PyO3)
- PythonとRustを使ってPythonの拡張モジュールを書く今回は、
RustモジュールをPythonから実行する (PyO3)
さんのコードをお借りして、それにsetup.pyを付け加えて、Rustで書かれた関数をPythonから呼んでみたいと思います。手順
rustのインストール
1行目を実行するとインストールについて3択で聞かれますがdefaultインストールの1を選んで問題ないかと思います。
curl https://sh.rustup.rs -sSf | sh source $HOME/.cargo/envrust nightlyのインストール
PyO3を使用するために必要になります。
開発中のクレートをたくさん含んだβバージョンと言うようなものでしょうか。バージョンを確認してみる
このバージョンを今回は使います。$rustc --version rustc 1.44.0-nightly (f509b26a7 2020-03-18) $ rustup --version rustup 1.21.1 (7832b2ebe 2019-12-20)rustup install nightly rustup default nightlyrust のプロジェクトを作る
--libをつけることで、ライブラリ用のプロジェクトを作ります。
今回は、プロジェクト名をexampleとしました。cargo new --lib example $ tree example/ ├── Cargo.toml ├── setup.py ├── src │ └── lib.rsフォルダ構造はこのようになっています。
Cargo.tomlを設定する
RustがC++などより優れていると言われていることのひとつ、ライブラリの管理の手軽さがここにあります。
Cargo.tomlに必要なライブラリを書くのですが、CMakeLists.txtとかよりはるかに簡単で見やすいです。Cargo.toml[package] name = "test" version = "0.1.0" edition = "2018" [lib] name = "test_library" crate-type = ["cdylib"] [dependencies.pyo3] version = "0.9.1" features = ["extension-module"]今回はpyo3をライブラリとして使用し、
作る目的のライブラリは、test_libraryです。すなわち、Pythonで
test.pyimport test_libraryみたいに書きたいわけです。
Rustで関数を作る
とりあえず写経してみる
コードはRustモジュールをPythonから実行する (PyO3)
さんのものを丸々持ってきました。
エラトステネスのふるいの実装だそうです。//lib.rs use pyo3::prelude::*; // This is the test function in Rust, getting prime number, which is called by python as get_prime_numbers #[pyfunction] fn get_prime_numbers(n: i32) -> PyResult<Vec<i32>> { let mut flags = Vec::new(); for _ in 0..n+1 { flags.push(true); } let upper = (n as f32).sqrt().floor() as i32; for i in 2..upper+1 { if !flags[i as usize] { continue; } let prime = i; let mut j = prime * 2; while j <= n { flags[j as usize] = false; j += prime; } } let mut primes = Vec::new(); for i in 2..n+1 { if flags[i as usize] { primes.push(i); } } Ok(primes) }Rustの構文を細かく解説できるだけの能力がありませんので、
この関数はあっているものとし、どうこれがPythonから呼べる形にラップされているかというところを解説します。#[pyfunction] fn get_prime_numbers(n: i32) -> PyResult<Vec<i32>>をみてみると、
まず#[pyfunction]のデコレータ的なものがこの関数の引数もしくは返り値にPyO3によりパースされたPythonオブジェクトが入ることを宣言しています。この
get_prime_numbers関数はint32を引数に取り、それ以下の素数をリストとして返す関数です。
このとき、返り値のところが、PyResult<Vec<i32>>となっていますが、
このPyResultはuse pyo3::prelude::*;から来ています。また、
Vec<i32>は、下の型の対応表のようになっており、PyResut によってPythonのList型に変換されます。
Rust Python i32,usize等intf32,f64floatboolboolVec<T>listStringstrHashMapdict[[Rust] PyO3 で Python パッケージを作成]からの引用 (https://qiita.com/osanshouo/items/671888bdd6afeec1e939)
また、最後の
Ok(primes)が
Vecをlistへと変換しています。まとめ
ここで終わると参考文献をほとんどコピペしたものになって申し訳ないのですが、
一度ここで区切ります。まとめとして、
- Rustのインストールを行った。
- Rustのライブラリ用のプロジェクトを作成した。
- Cargo.tomlを書いた。
- 関数を写経し、Rust->Pythonの型変換を確認した。
以上になります。
次は
lib.rsを追記し、setup.pyも加え実際にライブラリのオブジェクトファイルとしてコンパイルしていきます。今回はこの辺で。
おわり。
- 投稿日:2020-04-02T17:17:20+09:00
楽譜をランダム生成するコード
楽譜をランダムで生成するコードを作りました。機械学習の楽譜のデータセット作成用として使ってください。
こんな感じの画像ができます



環境
- chromebookのdebian9 (stretch)
- numpy (1.16.6)
- music21 (5.7.2)
- lilypond (2.18.2)
- python3 (3.5.3)
必要なライブラリーやソフト
pythonのライブラリー:
- numpy
- music21
ソフト:
- lilypond
コード
randomScore.pyimport music21 as m21 from numpy.random import choice def makeScore(symbleNum=200, scoreNum=20, noteRange=[3, 4, 5, 6, 7], noteRangeProbs=[0.05, 0.4, 0.4, 0.1, 0.05], sharpProb=0.1, restProb=0.2, exportDir='/home'): ''' symbleNum:楽譜一枚あたり何個の音符と休符があるか scoreNum:楽譜を何枚生成するか noteRange:何オクターブ目から何オクターブ目の音符があるか(デフォルトはC3からB#7まで) noteRangeProbs:それぞれの音符がオクターブ別にどのくらい出てくるかの確率のリスト sharpProb:音符にシャープがつく確率 restProb:休符が出る確率 exportDir:出力ファイルの保存先 =========================== デフォルトではファイル名は1, 2, 3, ... となっております。 .pngファイルの他に色々なファイルが出ますが、消していいです。 ''' quarterLengths = [4, 2.5, 2, 1.5, 1, 0.75, 0.5, 0.25] notes = ['C', 'D', 'E', 'F', 'G', 'A', 'B'] noteRange = list(map(lambda x: str(x), noteRange)) typeProbs = [1 - restProb, restProb] sharpProbs = [sharpProb, 1 - sharpProb] chooseThese = [True, False] for i in range(scoreNum): noteList = [] measure = m21.stream.Measure() for j in range(symbleNum): if choice(a=chooseThese, p=typeProbs): if choice(a=chooseThese, p=sharpProbs): pitchName = choice(notes) + '#' + choice(a=noteRange, p=noteRangeProbs) else: pitchName = choice(notes) + choice(a=noteRange, p=noteRangeProbs) n = m21.note.Note(pitchName, quarterLength=choice(quarterLengths)) noteList.append(n) else: n = m21.note.Rest(quarterLength = choice(quarterLengths)) noteList.append(n) measure.append(noteList) fileName = exportDir + str(i) measure.write('lily.png', fileName) if __name__ == "__main__": makeScore()悪いところ
- 四拍子だけ
- 一小節内の音符の数がおかしい
- 音楽的に(旋律)おかしい
- フラットがない
- 題名がない
- ダイナミクス、アーティキュレーションがない
などなど
追記
音がほしい方は言ってください :)

- 投稿日:2020-04-02T16:53:44+09:00
OCTAでUDFManagerを使って、設定条件をCSVファイルで保存する
- 投稿日:2020-04-02T16:38:09+09:00
ヒアリング調査結果をテキストマイニングで分析してみた
背景
某大学の某研究の某街興しの研究で、某地域の住民の方に対してヒアリングを行ったそうなのですが、そのヒアリングの内容からその地域の人達が無意識に意識している何かがないか…という分析をしたいとのことで、やってみることになりました。
使ったもの
MeCab
こちらも、おなじみの形態素解析エンジンです。
形態素解析とは
文書を単語の品詞情報をもとに,形態素(単語が意味を持つ最小の単位)に分解することですね。
よくすももも…の例があるので、他の例で実行したものをお見せすると、以下のような形で単語に分解し、その品詞を示してくれます。echo '町長ちょっとチョウチョとった調書とってちょうだい' | Mecab 町長 名詞,一般,*,*,*,*,町長,チョウチョウ,チョーチョー ちょっと 副詞,助詞類接続,*,*,*,*,ちょっと,チョット,チョット チョウチョ 名詞,一般,*,*,*,*,チョウチョ,チョウチョ,チョーチョ とっ 動詞,自立,*,*,五段・ラ行,連用タ接続,とる,トッ,トッ た 助動詞,*,*,*,特殊・タ,基本形,た,タ,タ 調書 名詞,一般,*,*,*,*,調書,チョウショ,チョーショ とっ 動詞,自立,*,*,五段・ラ行,連用タ接続,とる,トッ,トッ て 助詞,接続助詞,*,*,*,*,て,テ,テ ちょうだい 名詞,動詞非自立的,*,*,*,*,ちょうだい,チョウダイ,チョーダイwacati
先ほどの値は
-Ochasenというオプションを付けてもでてくるののですが、、Mecabのコマンドのオブションに-Owakatiというものがあります。
これを使うと、単語毎に区切った文字列を得ることができます。
文書の前処理をするのによく使います。echo '町長ちょっとチョウチョとった調書とってちょうだい' | Mecab -Owakati 町長 ちょっと チョウチョ とっ た 調書 とっ て ちょうだいインストール
MacならHomebrewを使ってしまえば早いです。
brew install mecab brew install mecab-ipadic # 標準のシステム辞書 # Web上の文書に強い、mecab-ipadic-NEologd という辞書もあります。 (https://github.com/neologd/mecab-ipadic-neologd) ### 辞書のインストール cd git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git cd mecab-ipadic-neologd ./bin/install-mecab-ipadic-neologd -n -aWindowsであればReleaseされているインストーラを実行してしまうのがいいです。
https://github.com/ikegami-yukino/mecab/releasesWord2Vec
テキストマイニングでおなじみword2vecを使いました。
テキストデータを解析し、単語をベクトル化するライブラリですね。
パッケージはgensimを使いました。ベクトル化って何してるの
簡単に言ってしまうと単語と単語の関係姓を数値化すると言ってしまうのが良いでしょうか。
分散表現(Word Embeddings)※1という高次元ベクトルでの表現方法が使われているのですが、各単語に対して、以下の図のような形で、単語間の類似度を測っているわけです。
※1. one-hot表現の問題を解決した表現方法
学習アルゴリズム
gensimのword2vecには2種類の学習アルゴリズム(モデル)が含まれてます。
どちらもone-hotベクトルを入力層とし、n次元の隠れ層を介して出力層に変換される構造のニューラルネットです。ちなみに、one-hotベクトルとは単語数分の次元ベクトルの各要素に単語を割り当てたもので、要するに単語帳のようなものをイメージしてもらったらいいですかね。
卵を現したいなら卵のフラグが立つ感じです。
Skip-gramモデル
対象の単語から周辺単語を学習するモデルです。
Countinuous Bag-of-Wordsモデル(CBOW)
周辺単語から対象の単語を学習するモデルです。
基本的にSkip-gramの方が少ないデータで精度が出るため、こちらで実行するのがお薦めです。
インストール
gensimに含まれているword2vecを今回は使ったので、インストールは以下のコマンドだけで行いました。
pip install gensim類似パッケージ
- GloVe
- WordNet
- Doc2Vec ← 今回使うべきはこっちだったかもしれない
- fastText ← Facebookの人工知能研究所が公開した自然言語処理を高速化するライブラリ。開発者はWord2Vecを作ったMikolov氏なので、上位互換?
scikit-learn
機械学習のオープンソースライブラリといえば…という感じですが、今回は出てきた単語のクラスタリングをするために使いました。
scikit-learnって何ができるの
書くのが疲れてきたので、ざっくりですが…以下のことができます。
分類(classification)
教師あり学習の分類問題を解けます。以下の手法が利用できます。
1. SGD(stochastic gradient descent)
2. カーネル近似
3. Linear SVC
4. k近傍法回帰(regression)
回帰分析を行えます。機械学習のチュートリアルなんかで、やったりするやつですね。
使える手法は以下の通りです。
1. SGD(stochastic gradient descent)
2. LASSO、ElasticNet
3. Ridge、Liner SVR
4. SVR(ガウスカーネル)、Ensembleクラスタリング(clustering)
教師なし学習のクラスタリング問題を解くことができます。
今回は教師なしで実施したかったので、これを用いました。
使える手法は以下の通りです。
1. KMeans
今回はこの手法でやっています。
2. スペクトラルクラスタリング、GMM
KMeansではうまく分析できない場合に利用する、非線形なクラスタリング分析手法…だそうです。
ちゃんと勉強できてません。
3. MeanShift、VBGMMやったこと
まず、ヒアリングデータをMecabで形態素分析しました。
# 初期化 chasen = MeCab.Tagger('-Ochasen -d ./resource/dictionary/') # ./resource/dictionary/ ← これは辞書をいれたディレクトリです。 # テキストの形態素分析 raw = self.get_chasen(s) # sは # 分析結果の文書を列ごとに分割 chunks = raw.splitlines()[:-1] # 各項目毎の変数に保存し、その後の計算に利用してます。 surface, yomi, origin, feature = chunk.split('\t')[:4]それから、Word2Vecに入れるためのテキストを
-Owacatiオプションを使って作成し、word2Vecに取込ます。# 初期化 file_path = 'hoge.txt' f = open(file_path, 'w', encoding="utf-8_sig") wakati = MeCab.Tagger('-Owakati -d ./resource/dictionary/') raw = wakati.parse(s) f.write(raw) # 文毎に読み込みを行います。 sentences = word2vec.LineSentence(file_path)今書いているのは最終的に用いた方法の内容を書いてますが、最初別の方法で実装し、しかも、少ない文字起こしデータでやっていた時には、全然欲しいデータにならず、クラスタリングもバラバラ。
そんな理由から、既存の学習済みのモデルを利用し、そこに、ヒアリングデータを追加して学習させ、分析するという方法をとるようにしました。
なので、ネットからとってきた学習済みのモデルを読み込みさせます。
学習済みモデルについてmodel = word2vec.Word2Vec.load(学習済みモデルのパス) # トレーニングデータの追加 model.build_vocab(sentences, update=True) # トレーニングデータに対して、biasをかける処理 (既存の学習モデルに飲まれてしまうため少し過学習をさせてます) for epoch in range(BIAS): model.train(sentences, epochs=model.epochs, total_examples=model.corpus_count) model.alpha -= 0.002 # 学習率の設定 model.min_alpha = model.alpha # 学習率の修正トレーニングさせた後は、単語をモデルにいれてやることで、ベクトルを得ることができます。
model.wv[単語]次にclusteringです。
from sklearn.cluster import KMeans # KMeansをsklernからimportし、モデルを呼び出しておきます。 kmeans_model = KMeans(n_clusters=CLUSTER_NUM, verbose=1, random_state=42, n_jobs=-1) # ここに先ほどの手に居たベクトルの配列をツッコめばクラスタリングされます。 kmeans_model.fit(vectors)ざっくり流れとしてはそんな感じです。
詳細はソースコードにて: https://github.com/AMDlab/questionnaire_mining結果こんな感じの値を得られるのですが、
cluster name, words cluster_0,研究,建築,仕事,雑誌,職人,物件 cluster_1,営業,地域,独立,下,企画,フリー,交換,用意,上の,情報,メディア,友人,紹介,販売,メンバー,中心,経営,趣旨,自身,協会,出身,写真,ギャラリー,フォーク,ロケ,美術,そうだ,展示,デザイナー,ライター,フリーランス,ホテル,事務所,ありません,地図,百貨店,従業員,作業,協力,業務用,スタッフ,業務,ビル,社長,鈴木,ストリート,倉庫,にも,青山,インタビュー,出荷,勉強,実演,町おこし,アルバイト,買い物,クライアント,お礼,弁当,書店,インターネット,お願い,工房,デパート,カメラマン,昭和26年,クラフト,打ち合わせ,商店,オフィス,知り合い,友達,カフェ,ドコモ,フード,ケーキ,思い出,伺い,あいさつ,目黒,催事,取引先,カルチャー,肩書,おじさん,六本木,台東,フィーチャー,お父さん,お伝え,名刺,飲み会,パティシエ,タウンページ,フードコーディネーター cluster_2,時代,理由,関係,世界,スタイル,内容,バランス,過程,声,一つ,文化,芸術,方法,部分,名前,流れ,プロセス,意味,背景,逆,しよう,いない,ある意味,お互い,商品,店舗,男性,女性,父親,つながり,建物,興味,方向,想像力,観察,エリア,世代,実験,きっかけ,家族,反対,表,横,関心,技術,個人,意識,価値,状況,記憶,環境,タイミング,両方,イメージ,良さ,日常,アプローチ,チャンス,親,気持ち,地下,動き,メニュー,印象,事情,業種,スーパー,口,やろう,お金,雰囲気,若者,コミュニケーション,裏,天,モチベーション,本当,感覚,世の中,エネルギー,悩み,商売,周り,キーワード,若手,仕方,からだ,モノ,夫婦,グラフィック,食べ物,やる気,どこか,せがれ,自分たち,アドバイス,目線,癖,発想,お客さん,ブログ,素地,こだわり,散歩,手触り,悪いこと,コミュニティー,皆さん,使い勝手,横丁,持論,平気,子どもたち,思い入れ,上下関係,心地,かっこ,お母さん,のれん分け,いいもの,ラーメン屋,私自身,ジュエリー,町工場,深み,お話,におい,美大,若い人,五感,居心地,さい子 cluster_3,1,一,学校,母親,地元,隣,不動産,角,子ども,一緒,松屋,私たち,近所,おでん,浅草,谷中,蔵前,向こう,屋台,鳥越,芸大,コロッケ,おやじ,この辺,銭湯,肉屋,お子さん,餓鬼,焼き豚 cluster_4,放送,移動,撤退,提供,2代,3人,剣,敵,ストーリー,ベース,開発,マップ,バトル,説明,演出,条件,固定,最終,組織,身,再生,表示,再現,理屈,製作,ポスター,一般,アクセス,別,位置,設計,対応,基本的,構成,指定,幅,しない,考え方,手法,実現,周辺,テーマ,自体,理解,表現,可能性,日本,した,象徴,外国,関連,ブランド,ロゴ,和,専門店,公開,連絡,相談,究極,二つ,シフト,基本,タイトル,交流,都市,面積,本人,成功,話題,確信,プロジェクト,2008年,一人,ページ,車,そのもの,技,全国,字,活動,収集,撮影,1999年,試み,歌舞伎,準備,節約,調査,親近感,道具,下火,約束,同期,募集,体験,段階,プロデュース,オリジナル,魅力,電動,東,創業,2本,しながら,連携,具体,ボタン,印刷,賛成,資料,外,素材,種類,年齢,構造,扉,追加,地方,スペース,戦略,交渉,還元,具体的,パフォーマンス,はさん,駅,設計事務所,記録,母体,継承,平屋,誘導,解析,活性,実験室,開放,ラーメン,勝負,分解,下請け,工程,チーム,大手,感情,引き合い,意味合い,秘伝,質問,プレー,本格的,加工,デベロッパー,キー,西側,プレ,コスト,オンエア,装飾,再開発,貢献,大きめ,復活,集積,改装,一大,床,感動,才能,オブジェ,おかげさま,電話,待た,ベスト,傍ら,カメラ,派生,指示,格好,何人,血縁,作業員,プラットフォーム,ハードル,根本,引き出し,水槽,氷,血,ネットワーク,要望,現状,労力,競合,シェア,後ろ,意匠,誰か,パッケージ,共有,表紙,応援,完結,邪魔,認知,空気,民衆,GPS,団結,カー,後悔,納得,びっくり,決めて,喜び,追及,リング,常設,大量生産,戦略的,それなり,実感,仕掛け,アイデア,町並み,手元,出版社,インテリア,矢印,プロダクト,在庫,出店,自信,モダン,一点,酸素,スケッチ,剣道,回遊,罵声,試行錯誤,宝飾,通行人,差別化,可視,年寄り,子育て,ポテンシャル,好意,率先,イヤリング,主語,しゃべる,目的地,フィルター,冷蔵庫,小売り,バックボーン,経費,経済成長,承諾,温かみ,余談,共存,プラス,参加者,C4,継,前書き,同業,失礼,リピート,ブックマーク,門戸,共感,口コミ,ないと,斜陽,社会実験,ロット,包丁,普通に,肥やし,手数,スケルトン,気合,コンタクト,タブレット,車いす,カーナビ,トライ,おやつ,懐かしさ,コンサルティング,物量,ギャラリスト,激変,茶漬け,幾何学模様,やり口,オーバーラップ,仕方がない,はやり,ディスプレー,一読,食い物,直射,クリエーション,ブランディング,クオリティー,彫金,協力会社,ルーティン,店構え,お断り,お話し,作りました,1410,2521 cluster_5,卵,色,中国,産地,貴金属,値段,油,牛,魚屋,1本,グラム,火,塩,水,天井,袋,コーヒー,3本,銀,松,パック,宇治,ブタ,香り,肉,食材,メロン,ジュース,着物,竹,豆腐,焼き物,肩,お菓子,飯,味付け,イチゴ,お茶,手作り,コップ,高温,衣,服,居酒屋,貝,幾ら,チョコレート,アサリ,しば,餅,豚肉,鶏,コンロ,フライ,ナス,ウリ,調味料,ハム,まめ,郡司,畜産,ネギ,鶏肉,葉っぱ,みそ,おにぎり,煮物,串,カレー,サツマイモ,具材,味噌,芋,漬物,梱包,ウズラ,かまぼこ,しょうゆ,量り売り,ラード,片栗粉,ショウガ,ウズラの卵,パン粉,焼き魚,カラメル,ブローチ,マヨネーズ,総菜,揚げ物,ロース,蕪,きょうは,かけら,素揚げ,フライドポテト,豚カツ,チャーシュー,シジミ,ミョウガ,練り物,あずき,メンチ,もも肉,そぼろ,ベーグル,ラー油,七味 cluster_6,ネット,沖縄,旅,家,男,3年,妹,子,長男,父,妻,14歳,娘,仲間,作品,場所,代,3,同士,ザ,2,タイ,言葉,ご飯,大学,学生,合い,看板,株式会社,交差点,俳優,アメリカ,知人,マンション,道,中学,縁,向かい,アート,ボン,息子,出会い,緑,文句,昭和,実家,先輩,民芸,民芸運動,ドイツ,ブーム,スタート,そば屋,老舗,一緒に,昔ながらの,西,並び,専門,修行,世,自宅,田中,家で,養子,万,面識,琉球,壁,土,木,会長,誰も知らない,幼稚園,保育園,奥,駐車場,時計,2丁目,花,区,工場,ライフ,1期,3代目,95,東側,出て,住まい,商,長老,一番町,所帯,東北,6人,現役,同級生,商店街,おいで,立ち話,正月,行事,1階,手紙,ストレート,塊,たま,真ん中,400円,観光地,NTT,入り口,財布,ファッション,銀座,2代目,缶,パッケージデザイン,下町,サクラ,コンテナ,そば,大人,行き来,仲,神社,研究室,神田,料理,スター,コンビニ,出口,会い,籠,暇,とんでも,小道具,申し訳,問屋,繁盛,剛,建築家,親族,ホームページ,前回,個人的,フライヤー,屋号,威勢,呼び方,望月,0001,換気扇,小島町,はん,バラ,開店,NPO法人,革,神奈川,佐竹,ジャン,0041,441,スズキ,和菓子,斜め,一杯,大学院生,弟子入り,150円,田舎,飲食店,食料品,何回,10人,好きだから,いつの,三角形,フォークソング,左側に,グループ会社,1929,飲み屋,じいさん,アキ,お客,うわさ,久しぶり,文京区,ブリキ,八百屋,あるとき,御徒町,被災地,まつり,江東区,食料品店,日常的,米屋,不動産会社,モガミ,雑貨,モト,墨田区,ヨシ,森岡,徳島,お花,クラシコ,木村拓哉,お土産,MEN'S NON-NO,1500円,おばさん,ノブ,丸亀,酒屋,長屋,ヒツジ,美容師,1905,ディナー,晴れ男,おじいさん,コーヒーショップ,2227,1202,台東区,グール,一歩,切り出し,つばめ,ランチ,2127,お祭り,あの日,インド料理,9回目,ミズ,ひいき,9年前,なじみ,おばあちゃん,忘年会,さんま,ミヤ,もも,蕪木,交流会,2550,らいい,死活問題,雷門,1224,すき焼き,帽子屋,フラワーアーティスト,ぶっちゃけ,1307,兄ちゃん,キタ,2225,茅場町,誰々,乾物,マロニエ,かに,ヨコ,ヤマ,入船,15年前,仏生山,田中さん,軽食,工務店,話して,ベビーカー,駄菓子屋,入谷,キャッチー,おんぶ,1200円,買い方,3901,花屋,チク,1329,カミさん,ダラ,桜木,お薦め,愚痴,珈琲,定食屋,引っ掛かり,いいね,トリイ,0052,いやいや,お茶屋,5150,2204,なのはな,馬喰町,マチ,盛会,神山町,うれしいこと,1527,ますが,ミライ,にす,先ほど,1411,お嬢さま,ばあちゃん,ギョーザ,かたがた,ヨシノ,デパ地下,2117,真裏,古道具,和菓子屋,よろしくお願いします,みぞれ,みその,アガタ,大黒屋,ここだけの話,チャリ,セガール,竹澤,1547,0125,でんと,NTT都市開発,3744,女子美,1518,米久,イシイ,0814,タカオ,3039 cluster_7,9年,番組,開始,範囲,海外,4月15日,10年,10月7日,4月,限定,10,2年,1人,20年,最後,間,1995年,後継者,4年,状態,4,次,数,週,顔,5月,5,きた,ラジオ,生産,テレビ,11月,9月,7月,2回,小学校,十,20,2時間,1回,民放,20代,11月4日,百,冬,1年,変化,1年間,具合,需要,これだけ,延長,2月,頭,予定,注文,1時間,オープン,1日,2位,夏,FM,雨,家賃,春,NHK,30歳,ジャズ,東大,売り上げ,1週間,出して,祭り,ストップ,1週,5時間,DVD,食事,40,30代,大雨,10時,25年,限界,6年間,80,1期生,30年,40年,曜日,4日,7時間,3時,このまま,早め,6時,年末年始,土日,受注,40代,卸,取材,おかず,5日,パレード,1歳,昼食,Facebook,3カ月,休業,AM,80人,6時間,5秒,50代,晩,完売,1時,昼休み,5年前,2時,45年,15時,明かり,かき氷,80代,50本 cluster_8,イベント,最初,会社,デザイン,編集,発信,食,自転車,ヒアリング,ものづくり,SyuRo cluster_9,自分,人たち,町,おかず横丁この後も値の調整などもろもろ行ってて、最終的にどんな特色があるか出していった感じです。


- 投稿日:2020-04-02T16:30:10+09:00
GCP CloudFunctionsからCloudAPIを呼び出す方法
PythonのSDKでライブラリ化されてない関数をCloudFunctionsから呼び出したかったが、gcloudコマンドはCloudFunctionsに入ってないので(CloudFunctionsが動くコンピュートノードにgcloudはインストールされていない)CloudAPIを直接呼ぶ必要があった
CloudFunctionsからCloudAPIをRESTで呼びたい場合以下の様に認証をして呼び出すことが出来る
def hello_world(request): import google.auth from google.auth.transport import requests # Get the credentials and project ID from the environment. credentials, project = google.auth.default( scopes=['https://www.googleapis.com/auth/cloud-platform']) # Create a requests Session object with the credentials. session = requests.AuthorizedSession(credentials) # Make an authenticated API request response = session.get( 'https://www.googleapis.com/storage/v1/b'.format(project), params={'project': project}) response.raise_for_status() retrun response.textAPI単体のテストだと、テストフォームが用意されているので、こちらが便利
https://cloud.google.com/storage/docs/json_api/v1/buckets/list
- 投稿日:2020-04-02T16:19:55+09:00
Blender Scriptを外部エディタ(VS Code)で編集する時の参考サイトまとめ
きっかけ
検索してもなかなかヒットしなかったので忘れないように書いておきます。Blenderにもエディタはありますが、ログが出なかったりして不便なので、外部エディタを使う方が便利です。
方法
まず、こちらのサイトを参考にしてVS Codeに拡張機能を追加します。(コマンドパレットはCtrl+Shift+Pで開きます)
https://reincarnation-plus.gitbook.io/project/blender/scripts/01_vscode_addon
そして、こちらのサイトを参考にして実行します。
https://reincarnation-plus.gitbook.io/project/blender/scripts/05_vscode_send_script
- 投稿日:2020-04-02T14:59:48+09:00
Anaconda におけるExecuting transaction: failedの対処法
エラー内容
Preparing transaction: done Verifying transaction: done Executing transaction: failed ERROR conda.core.link:_execute(543): An error occurred while uninstalling package 'defaults::python.app-2-py38_10'. PermissionError(1, 'Operation not permitted') Attempting to roll back. Rolling back transaction: done解決方法
$ conda update -n base -c defaults conda以上です。
- 投稿日:2020-04-02T14:53:51+09:00
Python lambda Djangoでドヤ りたいけどやめます
Pythonのlambdaでドヤりたいけどやめる
sum(list(map(lambda item3: len(item3), list(filter(lambda item2: item2[0].hoge == 3, list( map(lambda item: list(item.huga.all()), list(piyo.all()))))) )))Djangoのクエリと組み合わせたどやどやラムダ式。
1ヶ月後見ると死ぬのでやめる
# データの取得 piyo_list = list(piyo.all()) # 詳細データを取得 huga_list = list(map(lambda item:list(item.huga.all()), piyo_list)) # レベル1,2を取得 hoge_list = list(filter(lambda item: item[0].level == 1 or item[0].level == 2,huga_list)) # レベル1,2の件数を取得 level_list = list(map(lambda item: len(item), hoge_list)) # レベルの合計件数を取得 sum_level = sum(level_list)ドヤりたいのはわかるけどやめときます。
- 投稿日:2020-04-02T14:42:56+09:00
Pythonで毎日AtCoder #24
はじめに
#24
ABC045-C
1110diff考えたこと
初めてbit全探索という手法を知ったので使っていきます。文字の間に記号を入れるかを全探索します。s = input() ans = 0 n = len(s) - 1 #間は文字数よりも1少ない for i in range(2 ** n): op = [''] * n for j in range(n): if ((i >> j) & 1): op[n - j - 1] = '+' formula = '' for p_n, p_o in zip(s,op+['']): formula += (p_n+p_o) ans += eval(formula) print(ans)ABC079-C
302diff考えたこと
前の問題と違うのは記号が二つになったことですが、ほとんど同じです。
evalは文字の式を計算してintを返してくれます。abcd = input() n = len(abcd) - 1 for i in range(2 ** n): op = ['-'] * n for j in range(n): if ((i >> j) & 1): op[n - j - 1] = '+' formula = '' for p_n, p_o in zip(abcd, op + ['']): formula += (p_n + p_o) if eval(formula) == 7: print(formula + '=7') breakARC029
465diff考えたこと
どっちの肉焼き機を使うかでbit全探索。あとは、最小値を更新していくだけ。n = int(input()) t = [int(input()) for _ in range(n)] ans = 10**9 for i in range(2 ** n): niku = ['Left'] * n for j in range(n): if ((i >> j) & 1): niku[n - j - 1] = 'Right' wait_time_left = 0 wait_time_rignt = 0 for k in range(n): if niku[k] == 'Left': wait_time_left += t[k] if niku[k] == 'Right': wait_time_rignt += t[k] wait_time = max(wait_time_left,wait_time_rignt) ans = min(ans,wait_time) print(ans)できなかった問題
ABC104-C
中途半端に解く問題の処理を書けなかった。d, g = map(int,input().split()) pc = [list(map(int,input().split())) for _ in range(d)] n = len(pc) ans = 10**9 for i in range(2 ** n): cost = 0 score = 0 check = [False] * n for j in range(n): if ((i >> j) & 1): check[n - j - 1] = True for k in range(n): if check[k]: for l in range(pc[k][0]): cost += 1 score += 100 * (k+1) if l == pc[k][0]-1: score += pc[k][1] if score >= g: ans = min(ans,cost) print(ans)ABC002-C
議員12人を派閥に含むか否かを考えたときに、知り合い同士を確認するコード書くすることができなかった。まとめ
難しい。新しいことを学習するのは楽しいけど、解けないと意味がないので定着するように過去問を解く。では、また
- 投稿日:2020-04-02T14:40:38+09:00
QiitaのストックとLGTMを「はてなブックマーク」に移行する
はじめに
Qiitaで、ブックマーク代わりにLGTMやストックを使用している人もいるでしょう。
昨今、なにが起こるかわからない世情を考えてみるに、一つのサービスだけでブックマークを保持しておくと、リスクになります。今回は、せっかく貯めた、LGTMやストックの情報を、はてなブックマークに移行するスクリプトを書いてみます。
なお、私のケースでは以下のように移行されました。
https://b.hatena.ne.jp/mima3/Qiita/Qiitaのストック
登録したはてなブックマーク
環境
Windows10
Python 3.7.4事前準備
QiitaのAPIを実行する準備
下記を参考にアクセス用のトークンを取得してください。
https://qiita.com/mima_ita/items/ec33706c20f11a95516aはてなブックマークのRESTAPIを実行する準備
下記を参考に、はてなブックマークのRESTAPIを実行するためのConsumer KeyとConsumer Secretを作成してください
使用方法
(1)以下からスクリプトを取得します
https://github.com/mima3/qiita_exporter(2)LGTMをJSON形式でエクスポートします
python export_qiita_lgtm.py QiitaのID lgtm.json(3)ストックをJSON形式でエクスポートします
python export_qiita_stock.py QiitaのID "Qiitaのアクセストークン" stock.json(4)作成したJSONを、はてなブックマークに登録します。
python import_hatena_bookmark.py はてなユーザID はてなパスワード はてなのConsumerKey はてなのConsumerSecret lgtm.json stock.jsonブックマークに登録の際、Qiitaの記事にあったタグのほかに[Qiita]というタグを付与して登録しています。
解説
LGTMについては残念ながらQiitaのAPI経由で取得することはできません。
下記のページで、スクレイピングでQiitaの「いいね」一覧を取得するで先駆者様がいましたが、これは全部の記事に対して自分が「LGTM」または「ストック」しているか調べる挙動になっているようです。
2020年4月段階では画面としてLGTMした記事が見れるので、今回は画面を解析して取得しています。
当然、画面の解析のためQiitaの画面の仕様変更であっさり動作しなくなる可能性があります。
いろいろなまとめ
今回はストックやLGTMを、はてなブックマークに移行してみました。
また、いままでに記事をGitHubやWordPressに移行する方法も紹介しています。編集リクエストや、自動保存、ページ内の目次とか色々、便利な機能があるQiitaでありましたが、なにがあるかわからない世の中なので、皆様もそれぞれの方法で移行先を探してみるといいと思います。

- 投稿日:2020-04-02T13:07:54+09:00
受験経験ゼロの底辺文系大卒が大手ホワイト企業のデータアナリストとして内定もらうまで
はじめに
プログラミングを始めて7ヶ月、ありがたいことにデータアナリストとして3社から内定をいただきました。受験経験ゼロのガチ文系大卒が内定もらうまでの軌跡を紹介したいと思います。後ほど自己紹介しますが、その辺の文系卒とは一線を画します。私こそが文系界のサラブレットです。批判的なコメントやフィードバック大歓迎ですので、お気軽にコメントでご指摘頂けると幸いです。
簡単な経歴と自己紹介
2013年: 野球特待生として東海大学付属福岡高校に入学(甲子園予選福岡県大会準優勝)
2016年: 指定校推薦で福岡の文系大学に何の苦労もせず入学(男女比率で女性の方が多いのでこの大学を選びました)
2020年: 大学を無事に卒業
2021年: データアナリストとして新卒入社予定大学生活では可愛い博多女子に囲まれながらヤフオクドームでビールの売り子をしたり、ほぼタダでアメリカ留学したり、アメリカ領事館で半年間インターンしたり、世界17ヵ国一人旅したり、中国政府が50万円相当のプログラムを3万円で提供してくれたり、興味のあることは一通り試した学生生活でした。
なぜデータアナリストを目指すようになったのか?
以前は総合職で就職活動をしていました。2019年の3月に第一志望の会社から内定をいただき、内定者インターンとして働いてみるも飲み会多発のブラック企業でした。私のリサーチ不足ではあるが、理想と現実のギャップが大きく酷く落ち込みました。
しかし、理不尽な野球環境で育った私はそんなことでは負けない。直ちに何か新しいことを始めなければと思いつつも、一旦クッションを挟むためNetflixで映画鑑賞。12年間野球していたにも関わらず、ここで初めて運命の作品と出会う。データアナリストを目指すきっかけになったのは、ブラット・ピット主演の映画「マネーボール」。
「マネーボール」を簡単に紹介すると、弱小チームだったMLB球団が今までとは180度異なった手法で選手を評価して、他球団では評価されていない選手を集めて全米一位を目指す映画です。この映画を観て、データ分析は人間には発見困難なことでもデータ間の因果関係や相関関係を分析することで新たな発見が可能だということを知り興味を持ちました。
行動力だけがウリなので、早速どうしたらいいのか調べました。どうやら「Python」っていうやつでデータ分析できるらしい。しかも、なに?AI??機械学習??データサイエンティスト??なんかカッコイイ。そんなノリでプログラミングを始めました。
1ヶ月目
まずは初学者てっぱんのProgateでPythonの基本構文の習得と環境構築。とりあえず、プログラミングに慣れることを意識。
また、次のようなことを習慣づけた。
- 今日理解したこと
- 理解できなかったこと
- 上記二つから、明日取り組む予定立て
2ヶ月目
Progateを試みるも、決められたカリキュラムで全く面白くないからモチベ上がらない。また、Progateを行った結果どうなるのかイメージが湧かない。早くも挫折しそう。私の行動原理として何かワクワクすることや明確な目標、○○をした結果どういった変化が起こるのか想像できれば爆走できる。早速、おもしろそうな記事をQiitaで探してみる。
・【Python】?機械学習で「隠れた名店」を探してみた。(そして実際に行ってみた)?
・「赤の他人」の対義語は「白い恋人」 これを自動生成したい物語
・AIが三国志を読んだら、孔明が知力100、関羽が武力99、を求められるのか?をガチで考える物語(自然言語処理編)
・米津玄師の歌詞をWordCloudで可視化してみた。なんだこれは??Pythonでこんなこともできんの?? 早くこういった作品を作れるようになりたいなぁ。一通り見て、「米津玄師の歌詞をWordCloudで可視化してみた。」だったらコードも少ないし、すぐできそうだな。
なになに、まず歌詞を収集して、次に単語を分解して、最後に歌詞を可視化したらできるのか!どうせならオリジナル作品っぽくしたい。
Qiitaでバズったら面接ウケよさそうだし。来年で嵐活動休止だし、日本国民全員知ってる「嵐」なら共通言語になりそうだな。よし、嵐の歌詞の可視化してみよっ。そして、想像以上にバズった。また、面接でめっちゃウケた。
@Senple さん、参考にさせていただきました。ありがとうございます。
3ヶ月目
こればりおもろいやん。
【Python】?機械学習で「隠れた名店」を探してみた。(そして実際に行ってみた)?月一で鰻食べてて、行けつけの鰻屋さんに類似したお店あればいいなぁ。そんな想いでリコメンドシステム作ってみたけど、精度めちゃ悪。まぁいい。今はそれでいいんだ。とにかく手を動かしてプログラミングの面白さを実感するんだ。
@toshiyuki_tsutsui さん、参考にさせていただきました。ありがとうございます。
4ヶ月目
この時期から就活について考え始め、どうやら野球アナリストという職種があるらしい。データ分析で選手の強化育成や怪我対策に携われる!!7年後、絶対野球アナリストになるんだと決意。
また、プログラミングの面白さも分かったことだし、そろそろ実務で使いそうなことを学ばなくては。pandasでデータの前処理と集計、matplotlibでの可視化くらいはできるようになりたい。
丁度いい、試しに野球分析してみるか。
*まだセイバーメトリクスの知識は持っていない。
5ヶ月目
ここで初めて、とある企業のプログラミングテストを受けるが、アルゴリズムの理解ができておらず戦闘不能。1ヶ月間、Checkioでひたすらアルゴリズムの理解に励む。
6ヶ月目
ここまで一人でプログラミングを頑張ってきて、ここで初めて勉強仲間ができる。それぞれ機械学習を学ぶためkaggleで実装。そして、週に一度オンラインで発表。機械学習と同時にプレゼンテーションを学ぶ。
7ヶ月目以降
kaggleをする中で、標準偏差??微積??線形代数??なにそれ?? これまで勉強してこなかった私にとって、サイコロの確立すらわからない。これはやばい。
データサイエンティストになったとき、あっキミ文系出身で受験経験ゼロ。出たでた。たまにいるんだよね。アルゴリズムとか理解せず、小手先の技術でライブラリ回す再現性の低い奴。
そんなこと何が何でも言われたくないし、プロフェッショナルとしてあってはならない。5月までに統計検定2級を取得して、大学基礎レベルの統計・数学知識を身に付けてやる。
そんな思いで現在は、Web統計と過去問、そして予備校のノリで学ぶ「大学の数学・物理」で統計検定2級と基礎数学を勉強中。
機械学習の基本となる数学大事やん。スポーツと一緒で基礎練せな応用できんけんね。
継続のコツ
プログラミング初心者の約9割が挫折すると言われている。新たなことを継続するコツとして、どうすればモチベーションを保てるのか理解することが重要だと思う。私の場合、「ワクワクすること・明確な目標がある・○○を行った結果、どう変化するのかなんとなくイメージできる」。これさえあれば、大抵モチベーションを維持することが容易である。
そのうえで、プログラミングの面白さを実体験してみると尚いいだろう。技術はそのあと。スポーツと同じでルールはやりながら覚える。っていうのが私の鉄則。
例)野球楽しい→ルール分からんけど、とりあえず楽しいから試合に参加してみよ→なんとなくルールわかってきた→おれ、バッティングへぼいな→素振してフォーム固めるか→実践練習で応用できるか確認や→わーい、ホームラン打てた!!
おわりに
7ヶ月間の学習を通して、自分の理性と本能のバランスを上手く保ちながら学習できたと思う。とはいえ、まだまだ戦闘力1.5のミジンコキャラなのでこれからも課題を明確化し勉強に励みたいと思う。
2021年4月までの学習計画を立てたので、フィードバックをいただけると大変嬉しいです。また、現在2021年3月までデータ分析or機械学習の開発ができるインターン先を探しています(場所は問いません)。スキル的にはまだまだですが、主体的に学習に取り組めます。受け入れ可能な企業様がございました、プロフィール欄にEmailを記載していますのご連絡いただけますと幸いです。
長くなりましたが、ここまで読んでくださりありがとうございます。参考になるかは分かりませんが、たくさんの方に記事が届くと嬉しいです。
- 投稿日:2020-04-02T11:49:43+09:00
TeamsやZoomでカメラ画像を加工する方法 アニメ風に加工するの巻
本記事はこちらでも紹介しております。
https://cloud.flect.co.jp/entry/2020/04/02/114756#f-459f23dc前回と前々回の投稿では、TeamsやZoomでカメラ画像を加工する方法をご紹介しました。これらの投稿では、笑顔や感情(表情)を検出してニコニコマークを表示するデモをご紹介しています。
https://qiita.com/wok/items/0a7c82c6f97f756bde65
https://qiita.com/wok/items/06bdc6b0a0a3f93eab91今回、もう少し拡張して、画像をアニメ風に変換して表示する実験をしてみたので、ご紹介します。最初にネタバレしておくと、リアルタイムでアニメ風画像に変換するにはCPUだとちょっとラグが大きすぎて使いづらいかなと思います。(GPUだとマシになるのかは試してない。)
それでは早速ご紹介いたします。
アニメ風画像変換
半年ほど前にニュースメディアにも取り上げられていたようなので、ご存知の方も多いかと思いますが、写真をアニメ風に変換する手法が下記のページで公開されています。
https://github.com/taki0112/UGATIT
このUGATITでは、単純なimage2imageのスタイル変換とは違い、GeneratorとDiscriminatorを用いるいわゆるGANの技術をベースに、独自のAdaLINという機能を追加することで形状の変化にも対応ができるようになったようです。
In our work, we propose an Adaptive Layer-Instance Normalization (AdaLIN) function to adaptively select a proper ratio between IN and LN. Through the AdaLIN, our attention-guided model can flexibly control the amount of change in shape and texture.
詳細は、本論文1や解説記事2を見ていただくとして、上記ページに公開されているトレーニング済みのモデルを使って、実際に変換してみるとこんな感じになります。
被写体が遠いとあまりうまく変換してくれないようです。また、おじさんはあまりうまく対応できていないみたいです。トレーニングで用いられたデータセットも上記ページで公開されていますが、若い女性に偏っているようなので、これが原因かと思われます。(私はまだおじさんではない、、、というのは無理があるか。)
実装の概要
上記のとおり、被写体(人物の顔)に近い画像(≒顔が画面の大部分を占める)にする必要がありそうです。今回は、前々回までにご紹介した顔検出機能により顔の場所を特定し、その場所を切り出してUGATITで変換をかけるという手順でやってみました。
実装の詳細は、下記で言及するリポジトリをご参照ください。3
環境構築
前回までの記事を参考に、v4l2loopbackや、顔認識のモデルなどを準備しておいてください。
また、前回までと同様に、下記のリポジトリからスクリプトをcloneして、必要なモジュールをインストールしてください。
$ git clone https://github.com/dannadori/WebCamHooker.git $ cd WebCamHooker/ $ pip3 install -r requirements.txtUGATITのトレーニング済みモデルの配置
UGATITの公式ではTensorflow版とPyTorch版のソースコードが提供されていますが、トレーニング済みのモデルはTensorflow版しかないようです。これを取得して展開してください。
なお、WindowsやLinuxの通常のzip展開ツールだと展開に失敗するようです。Windowsを用いる場合は7zipだとうまく行くという報告がissueに上がっています。また、Macだと問題は発生しないようです。なお、Linuxは解決策は不明です・・・。4
一応、正常に動くモデルのハッシュ値(md5sum)を記載しておきます。(多分ここが一番のつまずきポイントなので。)$ find . -type f |xargs -I{} md5sum {} 43a47eb34ad056427457b1f8452e3f79 ./UGATIT.model-1000000.data-00000-of-00001 388e18fe2d6cedab8b1dbaefdddab4da ./UGATIT.model-1000000.meta a08353525ecf78c4b6b33b0b2ab2b75c ./UGATIT.model-1000000.index f8c38782b22e3c4c61d4937316cd3493 ./checkpointこれらのファイルを上記git からcloneしたフォルダの、
UGATIT/checkpointに格納します。このような感じになっていればOKです。$ ls UGATIT/checkpoint/ -1 UGATIT.model-1000000.data-00000-of-00001 UGATIT.model-1000000.index UGATIT.model-1000000.meta checkpointビデオ会議をしてみよう!
実行は次のように行います。オプションが一つ追加されてます。
- input_video_num には実際のウェブカメラのデバイス番号を入れてください。/dev/video0なら末尾の0を入力します。
- output_video_dev には仮想ウェブカメラデバイスのデバイスファイルを指定してください。
- anime_mode はTrueにしてください。
なお、終了のさせ方はctrl+cでお願いします。
$ python3 webcamhooker.py --input_video_num 0 --output_video_dev /dev/video2 --anime_mode True上のコマンドを実行するとffmpegが動き、仮想カメラデバイスに映像が配信されはじめます。
前回と同様に、ビデオ会議をするときにビデオデバイスの一覧にdummy〜〜というものが現れると思うのでそれを選択してください。
これはTeamsの例です。画面上右上にワイプで変換元の画像も表示しています。思ったよりちゃんとアニメ風に変換されて配信されますね。ただし、とても重く、ちょっと古めのPCだと1秒1コマとかそういうレベルです(Intel(R) Core(TM) i7-4770 CPU @ 3.40GHz, 32G RAM)。普通に運用するには厳しいかもしれません。いまのところは出落ち要員かな。いずれGPUでも試してみたいと思います。
最後に
在宅勤務が長引き、気軽なコミュニケーションがなかなか難しいかもしれませんが、こういった遊び心をビデオ会議に持ち込んで、会話を活性化させるのもいいのではないかと思っています。
もっといろいろできると思いますので、みなさんもいろいろ試してみてください。
https://www.slideshare.net/meownoisy/ugatit-195710494 ざくっと理解するにはこのスライドが良さそう。 ↩
2020/4/2現在、注ぎ足しつぎ足しで作っているので、ソースコードが汚い。どこかでリファクタリングします)) ↩
いずれも2020/4/2現在 ↩