- 投稿日:2020-04-01T23:34:50+09:00
BlenderをPythonで操作する
1.初めに
blender上のPythonで簡単なモデリングを行う手順を紹介します。
なお、環境はblenderのバージョンは2.8.5、OSはWindows10です。
なお2.7から2.8で仕様に大幅な変更があったのでご注意ください。2.7と2.8の互換性はほぼないと思っていただいてよいと思います。2.日本語設定
日本語を使う必要がある方は以下の設定をします。特に難しいことはありません。
User Preferences → Interfaceタブ
Translationにチェックを入れて、LangageをJapaneseに設定
Tooltips、Interface、New Data3つすべてをONにし、ユーザー設定の保存をクリックします。
なお、現時点でのバージョンではエディタ上で日本語は直接入力ができません。必要な時は他のテキストエディタで入力した文字をコピペします。3.blender上でのPythonの使い方
blender上でPythonコードを実行しエラーが発生した場合は、コンソール画面を表示する必要があります。
コンソール画面を表示するにはWindowsの場合
上部のWindowメニューからToggle System Consoleをクリックし、コンソール画面を表示します。
Macの場合
blenderの起動をアイコンをダブルクリックするのではなく、ターミナルから以下のコマンドを入力してblenderを起動してください。
/Applications/blender.app/Contents/MacOS/blender
(アプリフォルダの位置(/Applications/blender.app)は環境によって変わります)3.要素の基本的な構成
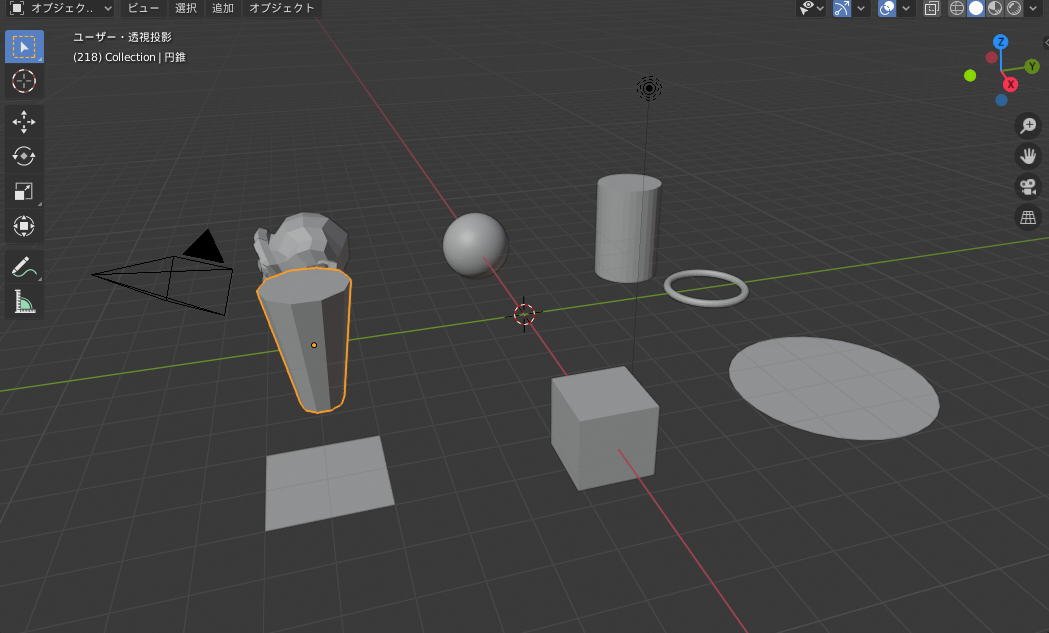
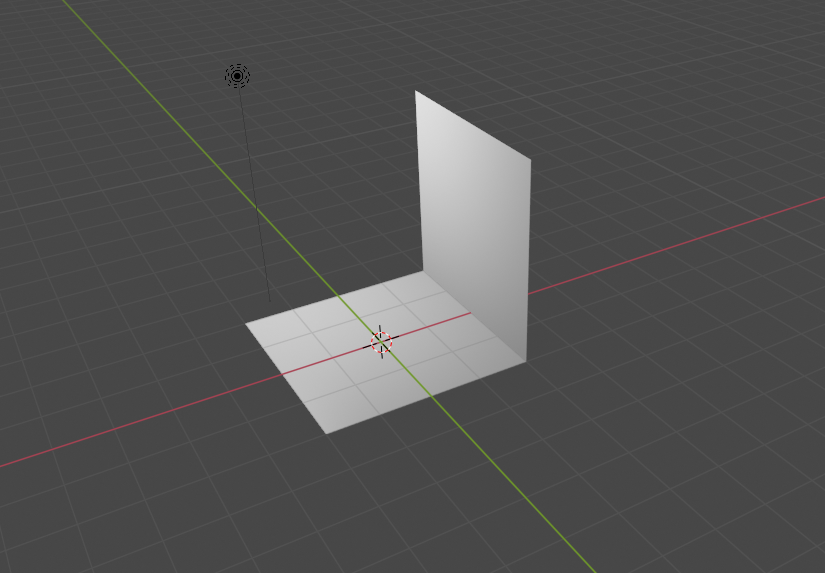
blenderはプリミティブと呼ばれる要素を配置します。
models.pyimport bpy # blenderインポート #1.円柱location:図形の中心座標 radius:円の半径 depth:高さ rotation:立体の回転角(rad) bpy.ops.mesh.primitive_cylinder_add(location=(-5, 5, 0), radius=1, depth=3, rotation=(0, 0, 0)) #2.立方体 location:図形の中心座標 size:立方体の一辺の長さ rotation:立体の回転角(rad) bpy.ops.mesh.primitive_cube_add(location=(5, 0, 0), size=1.5, rotation=(0, 0, 0)) #3.球体 location:図形の中心座標 radius :球の半径 subdivisions:分割数 bpy.ops.mesh.primitive_ico_sphere_add(location=(-5, 0, 0), radius=1, subdivisions=5) #4.monkey location:図形の中心座標 size:サイズ bpy.ops.mesh.primitive_monkey_add(location = (-5, -5, 0), size = 3.0) #5.ドーナツ形 location:図形の中心座標 major_radius:輪の半径 minor_radius:筒の半径 rotation:立体の回転角(rad) bpy.ops.mesh.primitive_torus_add(location=(0, 5, 0), major_radius=1.0, minor_radius=0.1, rotation=(0, 0, 0)) #6.平板(円) location:図形の中心座標 fill_type:塗りつぶし radius:半径 rotation:立体の回転角(rad) bpy.ops.mesh.primitive_circle_add(location=(5, 5, 0), fill_type="NGON", radius=2, rotation=(0, 0, 0)) #7.平板(正方形) location:図形の中心座標 size :辺の長さ rotation:立体の回転角(rad) bpy.ops.mesh.primitive_plane_add(location=(5, -5, 0), rotation=(0, 0, 0), size=2) #8.多角錐 location:図形の中心座標 vertices:頂点の数 radius1,radius2:円の半径 depth:高さ rotation:立体の回転角(rad) bpy.ops.mesh.primitive_cone_add(location=(0,-5,0),vertices=10,radius1=0.5,radius2=1,depth=3, rotation=(0, 0, 0))
4.様々なモデリング
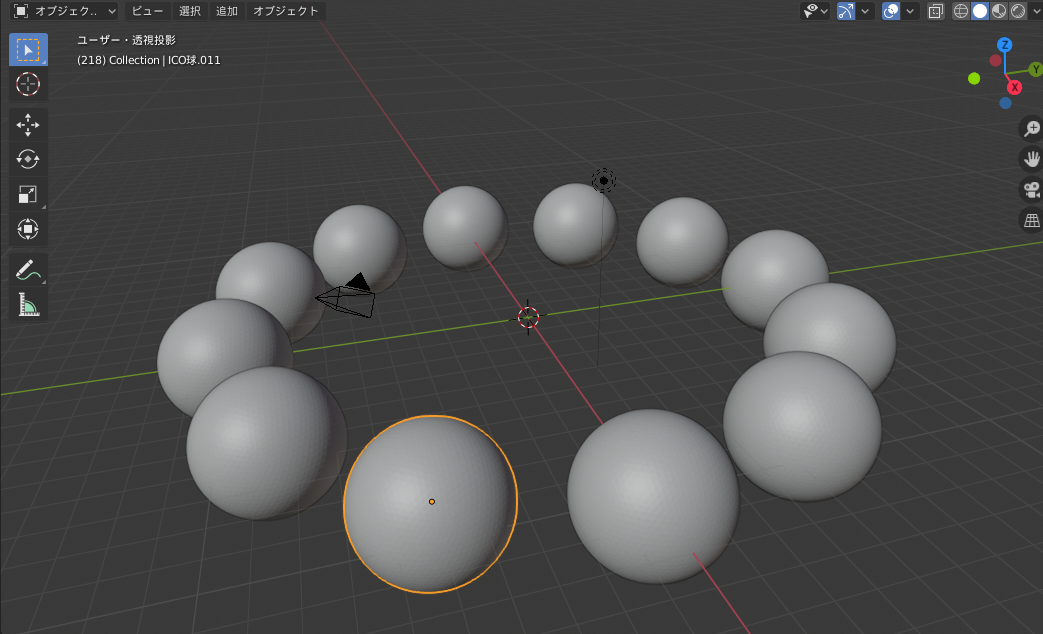
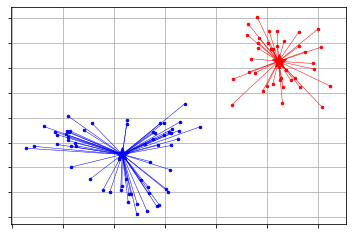
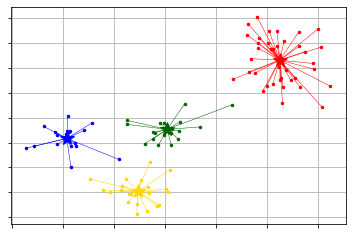
4.1 ループによる球体描画
loop.pyimport bpy import math # 既存要素削除 for item in bpy.data.meshes: bpy.data.meshes.remove(item) N = 12 RR1 = 10.0 RR2 = 2.0 for i in range(0, N): rad = 2 * math.pi * i /N # 角度計算2π i /n xx = RR1 * math.cos(rad) # x座標計算 半径*cosθ yy = RR1 * math.sin(rad) # y座標計算 半径*sinθ # 球体作成 bpy.ops.mesh.primitive_ico_sphere_add(location=(xx, yy, 0),radius= RR2, subdivisions = 5 )
4.2 プリミティブの変形・回転・移動
rectangle.pyimport bpy # 既存要素削除 for item in bpy.data.meshes: bpy.data.meshes.remove(item) #立方体の描画 bpy.ops.mesh.primitive_cube_add(location=(0, 0, 0), size=1.5, rotation=(0, 0, 0)) #図形を変形(X方向2倍、Y方向1倍、厚さ方向0.5倍) bpy.ops.transform.resize(value=(2.0,1.0,0.1)) #図形を回転(Y軸周りに 30°) bpy.ops.transform.rotate(value=3.1415/6 ,orient_axis='Y') #図形を移動(Z軸方向に 5移動) bpy.ops.transform.translate(value=(0,0,5))
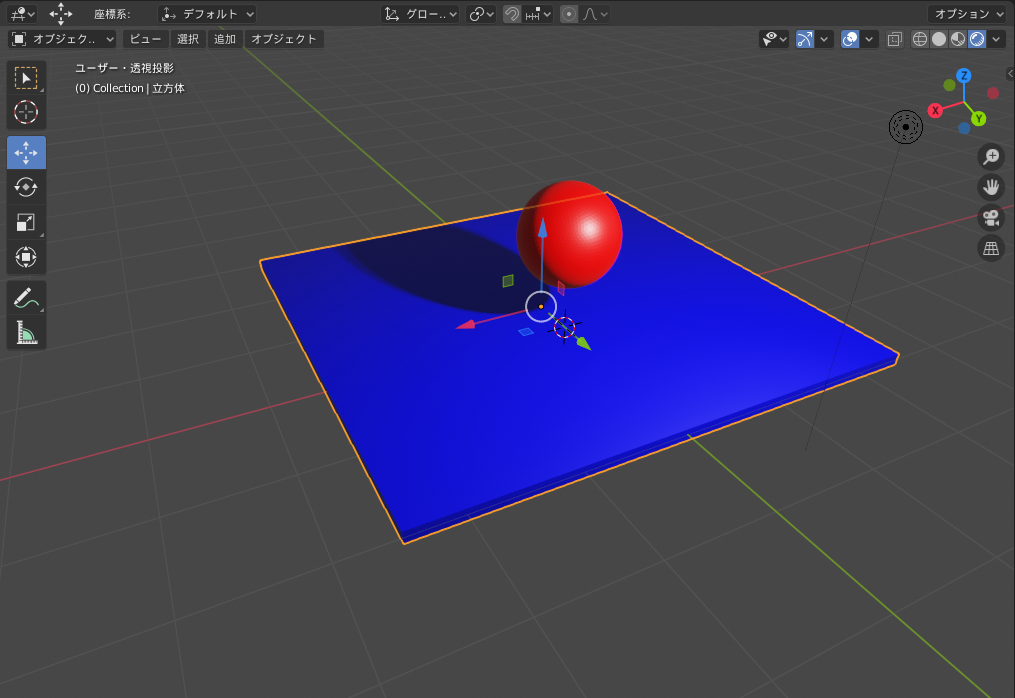
4.3 材質の設定
material.pyimport bpy # 1.既存要素削除 for item in bpy.data.meshes: bpy.data.meshes.remove(item) # 2.材質の定義(赤色) mat1 = bpy.data.materials.new('Red') mat1.diffuse_color = (1.0, 0.0, 0.0, 1.0) # 3.材質の定義(青色) mat2 = bpy.data.materials.new('blue') mat2.diffuse_color = (0.0, 0.0, 1.0, 1.0) # 4.球体作成 bpy.ops.mesh.primitive_ico_sphere_add(location=(0, 0, 1), radius = 0.5, subdivisions=5 ) bpy.context.object.data.materials.append(mat1) # 材質(赤)指定 # 5.平板作成 bpy.ops.mesh.primitive_cube_add(location=(0, -0.5, 0), size=2.5) bpy.ops.transform.resize(value=(2.0,2.0,0.05)) # 図形を変形(X方向2倍、Y方向2倍、厚さ方向0.05倍) bpy.context.object.data.materials.append(mat2) # 材質(青)指定
4.4 メッシュの作成1
mesh1.pyimport bpy # 既存要素削除 for item in bpy.data.meshes: bpy.data.meshes.remove(item) # 頂点データの作成 verts = [[-2.0, -2.0, 0.0], [-2.0, 2.0, 0.0], [2.0, 2.0, 0.0] , [2.0, -2.0, 0.0], [2.0, -2.0, 4.0] , [2.0, 2.0, 4.0] ] # 面データの作成 faces = [[0,1,2,3], [2,3,4,5]] msh = bpy.data.meshes.new("cubemesh") #Meshデータの宣言 msh.from_pydata(verts, [], faces) # 頂点座標と各面の頂点の情報でメッシュを作成 obj = bpy.data.objects.new("cube", msh) # メッシュデータでオブジェクトを作成 bpy.context.scene.collection.objects.link(obj) # シーンにオブジェクトを配置
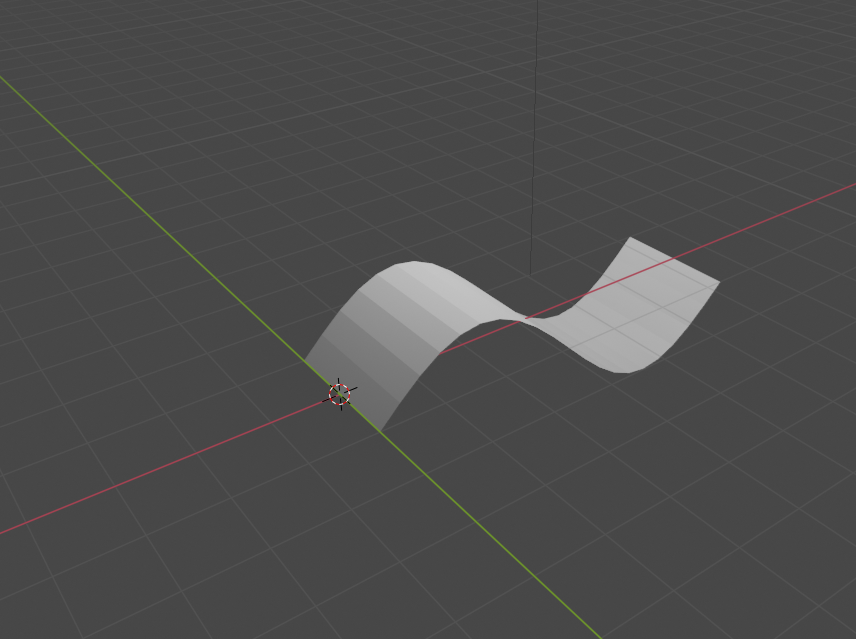
4.5 メッシュの作成2
mesh2.pyimport bpy import math # 既存要素削除 for item in bpy.data.meshes: bpy.data.meshes.remove(item) # 頂点の作成 verts = [] for i in range(0,21): x = 2 *math.pi / 20 * i verts.append([x, -1, math.sin(x)]) for i in range(0,21): x = 2 * math.pi / 20 * i verts.append([x, 1, math.sin(x)]) # 面データの作成 faces = [] for i in range(0,20): faces.append([i, i+1, i+22, i+21]) msh = bpy.data.meshes.new("sinmesh") msh.from_pydata(verts, [], faces) obj = bpy.data.objects.new("sin", msh) bpy.context.scene.collection.objects.link(obj)
5.最後に
Blenderもオープンソースのフリーウェアなのでモデリングをするには悪くありません。
2.7から2.8の仕様変更が衝撃的だったので、これ以上blenderに深入りしないことにしました。
- 投稿日:2020-04-01T23:27:32+09:00
Chalice を使ってみるなかで調べた小ネタ3点
1. 静的ファイルを Lambda 関数に含める方法
- シナリオ: 簡単な設定ファイル (YAML, JSONなど) を Lambda 関数内で読み込むファイルとして扱いたい。
- 問題:
app.pyと同じディレクトリにenv.ymlを置いたが、chalice deployしてもファイルがアップロードされなかった- 解決策: chalice プロジェクトの下に chalicelib というディレクトリを作って、そこにファイルを置く。 以下のtreeの結果を参照。
- 使うときは
filepath = os.path.join(os.path.dirname(__file__), 'chalicelib', 'env.yml')などのように読み込ませて解決。- 公式マニュアルでも同様のことが示されている
$ tree -a . . ├── .chalice │ └── config.json ├── .gitignore ├── app.py ├── chalicelib │ └── env.yml └── requirements.txtなお、chaliceでデプロイをする場合、Linux/Mac などの場合はファイルのパーミッションをそのまま受け継ぐ。 そのため、例えば
750などのファイルをデプロイした場合、そのファイルを読もうとすると実行時に Permission Denied となってしまうため注意。
- 同様の事例 。アップロード時に作った zip file を展開するときにおそらく保存時のパーミッションをそのまま展開していることが原因。
2. IAM Policy が自動生成されない / 自分でPolicyを設定する方法
- シナリオ: Chalice の便利な機能の1つにIAM Policyの自動生成がある。 これは、Lambda 内で boto3 ライブラリを使ってAWSリソースにアクセスしている場合、それを自動的に判断してIAM Policyを動的に自動生成してくれる機能である。
- 問題: なぜか自分のプログラムではこの自動生成・付与を行ってくれなかった。
調べてみると、boto3.client を利用したプログラムのみ自動生成の対象 であるのが原因だった。 boto3 には resource を使う方法もあるのだが、こちらを使った場合ですらIAMの自動生成の対象にならない。 自分のプログラムは全て boto3.resource を利用していた。
そのため、IAM Policy を自動生成するため、 Chaliceでboto3を使うときは常に
boto3.clientを利用する というのは1つの指針になり得る。
逆に、既存のIAM Roleを利用したい、自分でPolicyの記述内容を管理したい、というケースの場合は.chalice/config.json内でautogen_policyを無効にする。 例えば以下の通り。.chalice/config.jsonから抜粋"stages": { "dev": { "api_gateway_stage": "api", "autogen_policy": false } }これを無効にした場合、デフォルトでは
.chalice内のpolicy-<stage name>.json(この場合は policy-dev.json) を読み込む。 別名を指定したい場合はiam_policy_fileでファイル名を指定する。 より詳細な説明はこちら.chalice/policy-dev.jsonにはRole内でのアクセス権限を書いていけばよい{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "dynamodb:*" ], "Resource": [ "*" ], "Sid": "xxxx-xxxx-xxxx-xxxx-1234" }, { "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "arn:aws:logs:*:*:*", "Sid": "xxxx-xxxx-xxxx-xxxx-1235" } ] }外部のライブラリなどを使いたい場合、boto3.resource を利用する場合はこちらを採用することになるだろう。 IAM権限の関係から、そもそもIAMの操作権限がない場合などはIAM Role ARNを指定して付与することもできる (
iam_role_arn) 。client しか IAM Policy の自動生成にならないという記述は、例えば AWS BlackBelt シリーズでの説明 とか この記事よりもはるかに詳しい説明とかで見つけることはできたが、公式ドキュメント内でこの記述を見つけられなかった。 あっても良いはずなのだが……
3. CORS対応
- シナリオ: ブラウザから ajax で API Gateway - Lambda をコールし、レスポンスを取得したい
- 問題: ブラウザから ajax でアクセスしたら CORS が原因ではじかれる。
chalice localで稼働させている場合も同様。ユースケースに合わせた CORS の設定をすることになるのだが、もうこれはそのまま 公式を読んでもらう方が早い ぐらい説明が充実している。
概略としては
chalice.CORSConfigのインスタンスに適当な設定をした後、@app.route(path, cors=config)のようにデコレータ内のcorsに対して設定を渡してやればあとはよしなにしてくれる。
- 投稿日:2020-04-01T23:16:01+09:00
10 分で終わる Django の外部キーのチュートリアル
2020-04-01 作成: windows10/Python-3.8.2-amd64/Django-3.0.4
Django の外部キーについての日本語の情報は、ネットでも豊富ではありません。
しかし普通は、「好きな食べ物」と「住所録」は、別のアプリにするはずで、
外部キーの使い方は基本必修項目なのだろうと思います。同じデータベース内と、外部のデータベースへの外部キーについて、
簡単なチュートリアルを作成しました。
複数のデータベースを相互に関連付ける方法を手軽に知りたい、という人向きです。
- ねこカフェ用のねこ管理アプリ cafe
- ねこの名前のテーブルと、好きな食べ物のテーブルをつくり、外部キーで関連付ける。
- ねこの住所録のアプリ negura
- ねこのすみかのデータベースを作る。cafe アプリから外部キーで呼ばれる。
なお、Django を初めて使う人は、まず基本編のチュートリアルを読んでください。
10 分で終わる Django の実用チュートリアル前準備
プロジェクトの作成
ソースを置きたい場所で以下を実行しプロジェクトを新規作成。
django-admin startproject mysite作成したディレクトリ mysite に入ってアプリケーションを 2 つ、新規作成。
cd mysite python manage.py startapp cafe python manage.py startapp sumikaここまでのファイルの配置はこうなる
mysite/ mysite/ __pycashe__/ <- 気にしなくていい setting.py, urls.py など *.py が 5 個 neko/ migrations/ <- 気にしなくていい models.py, views.py など *.py が 6 個 sumika/ migrations/ <- 気にしなくていい models.py, views.py など *.py が 6 個 manage.pyプロジェクトを構成するアプリの登録
cafe と negura のふたつのアプリを登録。
mysite/mysite/settings.pyINSTALLED_APPS = [ 'cafe.apps.CafeConfig', 'negura.apps.NeguraConfig', 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', ]mysite/mysite/urls.pyfrom django.contrib import admin from django.urls import path, include urlpatterns = [ path('cafe/', include('cafe.urls')), path('negura/', include('negura.urls')), path('admin/', admin.site.urls), ]アプリの実装
cafe アプリの作成
モデル、ビュー、url の作成
neko_food は、cafe アプリ内の同一データベース内での外部キー
neko_negura は、negura アプリ、つまり隣のアプリの別データベースへの外部キー
def __str__(self):メソッドは、ForeignKey を使ったとき、django の汎用ビューでは普通は必要になる。
このメソッドをオーバーライドしておかないと、ブラウザに表示したときに、
さんまではなくfood_name.object(1)のようにインスタンスの名前が表示されてしまう。
このメソッドのおかげで、CreateView や FormView を使うときに、プルダウンリストに文字列が表示される。neko_negura は、外のアプリからモデルを引っ張ってきているので、
negura.NeguraModelと、アプリ名を先頭につけてからモデルを呼び出す。mysite/cafe/models.pyfrom django.db import models from negura.models import NeguraModel class NekoModel(models.Model): neko_name = models.CharField(max_length = 20) neko_food = models.ForeignKey('FoodModel', null = True,on_delete = models.SET_NULL) neko_negura = models.ForeignKey('negura.NeguraModel', null = True,on_delete = models.SET_NULL) class FoodModel(models.Model): food_name = models.CharField(max_length = 20) def __str__(self): return self.food_nameどのビューがどのテンプレートを使うのか、ややこしくならないように、
くどいファイル名を付けている。mysite/cafe/views.pyfrom django.views import generic from .models import NekoModel, FoodModel class NekoListView(generic.ListView): model = NekoModel context_object_name = 'nekolistview_context' template_name = 'cafe/nekolistview_template.html' class NekoCreateView(generic.CreateView): model = NekoModel context_object_name = 'nekocreateview_context' template_name = 'cafe/nekocreateview_template.html' fields = ['neko_name', 'neko_food', 'neko_negura'] success_url = '/cafe/nekolist_url' class FoodListView(generic.ListView): model = FoodModel context_object_name = 'foodlistview_context' template_name = 'cafe/foodlistview_template.html'urls.py はファイルを新設する
どのパス名がどのビューを指すのか混乱しないように、くどい名前を付けている。mysite/cafe/urls.pyfrom django.urls import path from . import views urlpatterns = [ path('nekolist_url', views.NekoListView.as_view(), name = 'nekolistview_path'), path('nekocreate_url', views.NekoCreateView.as_view(), name = 'nekocreateview_path'), path('foodlist_url', views.FoodListView.as_view(), name = 'foodlistview_path'), ]食べ物や住所の入力用ビューは、チュートリアルの手数が多くなるので作成しない。
代わりに admin 画面から入力するため、admin.py を編集し、有効化する。mysite/cafe/admin.pyfrom cafe.models import NekoModel, FoodModel from django.contrib import admin admin.site.register(NekoModel) admin.site.register(FoodModel)テンプレートの作成
テンプレートを 3 つ作成。
置き場所はデフォルトのディレクトリにしたが、階層が深すぎて本当は好きじゃない。mysite/cafe/template/cafe/nekolistview_template.html<h1>ねこのいちらん</h1> <table> {% for neko_param in nekolistview_context %} <tr> <td>{{ neko_param.neko_name }}</td> <td>{{ neko_param.neko_food.food_name }}</td> <td>{{ neko_param.neko_negura.negura_name }}</td> </tr> {% endfor %} </table> <p><a href = "{% url 'foodlistview_path' %}">ねこのたべもの</a></p> <p><a href = "{% url 'neguralistview_path' %}">ねこのねぐら</a></p> <p><a href = "{% url 'nekocreateview_path' %}">ねこのとうろく</a></p>mysite/cafe/template/cafe/foodlistview_template.html<h1>ねこのたべもの</h1> <table> {% for food_param in foodlistview_context %} <tr> <td>{{ food_param.food_name }}</td> </tr> {% endfor %} </table> <p><a href = "{% url 'nekolistview_path' %}">ねこのいちらん</a></p>mysite/cafe/template/cafe/nekocreateview.html<h1>ねこのとうろく</h1> <form method = "post"> {% csrf_token %} {{ form.as_p }} <input type = "submit" value = "とうろく" /> </form> <p><a href = "{% url 'nekolistview_path' %}">ねこのいちらん</a></p>negura アプリの作成
モデル、ビュー、url の作成
基本的にはさきほどの cafe でやったことの繰り返し。
mysite/negura/models.pyfrom django.db import models class NeguraModel(models.Model): negura_name = models.CharField(max_length = 20) def __str__(self): return self.negura_namemysite/negura/views.pyfrom django.views import generic from .models import NeguraModel class NeguraListView(generic.ListView): model = NeguraModel context_object_name = 'neguralistview_context' template_name = 'negura/neguralistview_template.html'mysite/negura/urls.pyfrom django.urls import path from . import views urlpatterns = [ path('neguralist_url', views.NeguraListView.as_view(), name = 'neguralistview_path'), ]mysite/negura/admin.pyfrom cafe.models import NeguraModel from django.contrib import admin admin.site.register(NeguraModel)テンプレートの作成
テンプレートを 1 つ作成
置き場所はデフォルトの場所で。mysite/negura/template/negura/neguralistview_template.html<h1>ねこのねぐら</h1> <table> {% for negura_param in neguralistview_context %} <tr> <td>{{ negura_param.negura_name }}</td> </tr> {% endfor %} </table> <p><a href = "{% url 'nekolistview_path' %}">ねこのいちらん</a></p>仕上げ
マイグレーションと admin の設定
マイグレーションしたあとは、admin サイト用の管理者を作成し、
admin 画面にアクセスできるようにしておく。python manage.py makemigrations python manage.py migrate python manage.py createsuperuserHTTP サーバーの起動と初期データの入力
開発用のサーバーを起動する。デフォルトで起動しているので、ポート番号は 8000。
python manage.py runserverブラウザで以下にアクセスして admin 画面を出す。
「たべもの」、「すみか」のふたつは、このアプリでは直接入力できないので、admin 画面から入力する。http://localhost:8000/admin/たとえば、たべものは、「さんま」「かりかり」、すみかは、「だんぼーる」「もうふ」など。
動作確認
以下を入力すると、ねこのリストが出る。
最初は登録されたねこがいないので、表にはないっていない。http://localhost:8000/neko/「ねこのとうろく」リンクから登録用画面に入ると、
フォームにねこの名前を入力し、
「たべもの」と「ねぐら」はドロップダウンリストから選べるようになっている。おしまい
- 投稿日:2020-04-01T22:57:43+09:00
活性化関数のいらないニューラルネットワークΠ-Netを試した
はじめに
CVPR2020に採択された以下の論文で提案された,新しいニューラルネットワークである$\Pi$-NetをPyTorchで実装しました。
Chrysos, Grigorios G., et al. "$\Pi-$ nets: Deep Polynomial Neural Networks." arXiv preprint arXiv:2003.03828 (2020).
学習に使った全体のコードはGitHubにあります。
Π-Netとは?
$\Pi$-Netではネットワークを途中で分岐させ,再び合流する部分で掛け算を行います。
これにより,出力が入力の多項式で表現されます。普通のニューラルネットワークでは,各層の出力にReLUやSigmoidなどの活性化関数を適用することで非線形性を持たせています。
活性化関数を使わないと,ネットワークの層数をいくら増やしても入力に対して線形な出力しかできないため,意味がありません。しかし,$\Pi$-Netでは中間層の出力同士で掛け算を行うことでネットワークに非線形性を持たせているので,活性化関数を用いなくても多層にすることで高い表現能力を得ることができます。
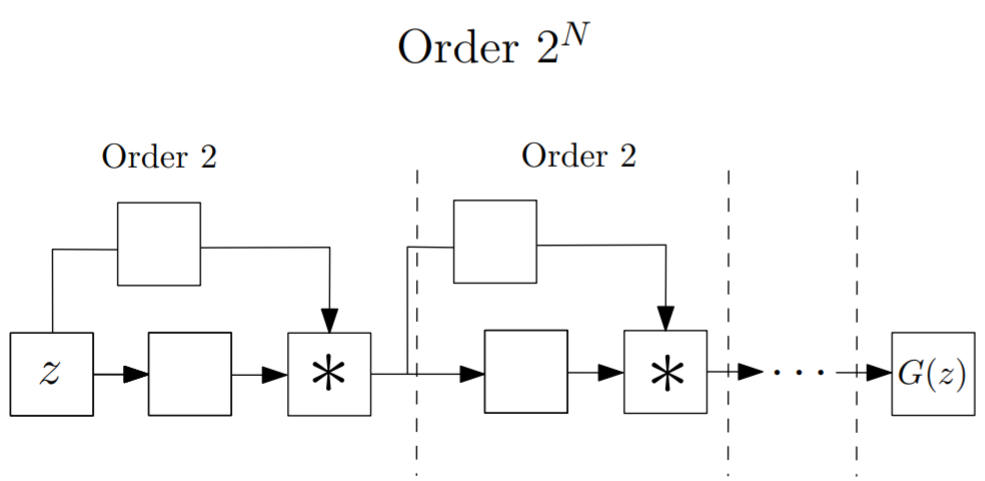
論文中ではいくつかネットワーク構造が提案されていますが,今回はその中の1つである以下の構造をベースに実装しました。
(論文から引用)Skip-connectionがありResNetのような構造をしていますが,合流する部分が足し算ではなく掛け算(アダマール積)になっています。
各ブロックで前のブロックの出力が2乗されるので,ブロックを$N$個重ねることで$2^N$次の多項式になり,指数的にネットワークの表現能力が増加していきます。実装
上図のブロックを5つ重ね,以下のようなモデルを書きました。
従って,ネットワークの出力は$2^5=32$次の多項式で表現されます。
活性化関数を全く使っていない点に注目してください。modelclass PolyNet(nn.Module): def __init__(self, in_channels=1, n_classes=10): super().__init__() N = 16 kwds1 = {"kernel_size": 4, "stride": 2, "padding": 1} kwds2 = {"kernel_size": 2, "stride": 1, "padding": 0} kwds3 = {"kernel_size": 3, "stride": 1, "padding": 1} self.conv11 = nn.Conv2d(in_channels, N, **kwds3) self.conv12 = nn.Conv2d(in_channels, N, **kwds3) self.conv21 = nn.Conv2d(N, N * 2, **kwds1) self.conv22 = nn.Conv2d(N, N * 2, **kwds1) self.conv31 = nn.Conv2d(N * 2, N * 4, **kwds1) self.conv32 = nn.Conv2d(N * 2, N * 4, **kwds1) self.conv41 = nn.Conv2d(N * 4, N * 8, **kwds2) self.conv42 = nn.Conv2d(N * 4, N * 8, **kwds2) self.conv51 = nn.Conv2d(N * 8, N * 16, **kwds1) self.conv52 = nn.Conv2d(N * 8, N * 16, **kwds1) self.fc = nn.Linear(N * 16 * 3 * 3, n_classes) def forward(self, x): h = self.conv11(x) * self.conv12(x) h = self.conv21(h) * self.conv22(h) h = self.conv31(h) * self.conv32(h) h = self.conv41(h) * self.conv42(h) h = self.conv51(h) * self.conv52(h) h = self.fc(h.flatten(start_dim=1)) return h結果
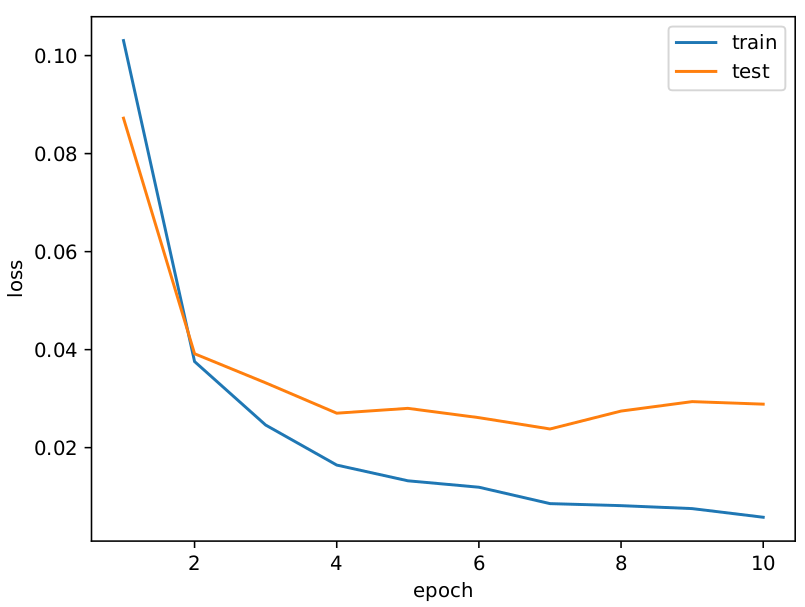
MNISTとCIFAR-10の分類を学習しました。
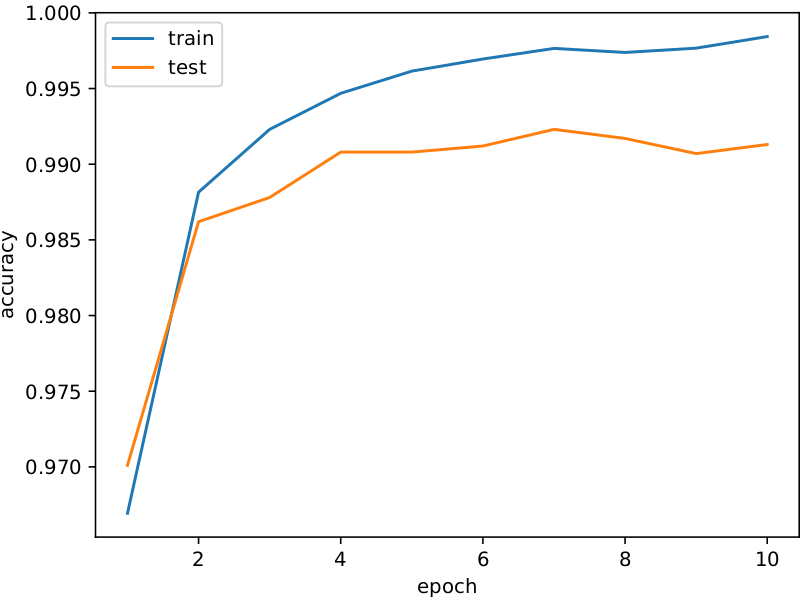
MNIST
Accuracy
Loss
約99%のテスト精度です!
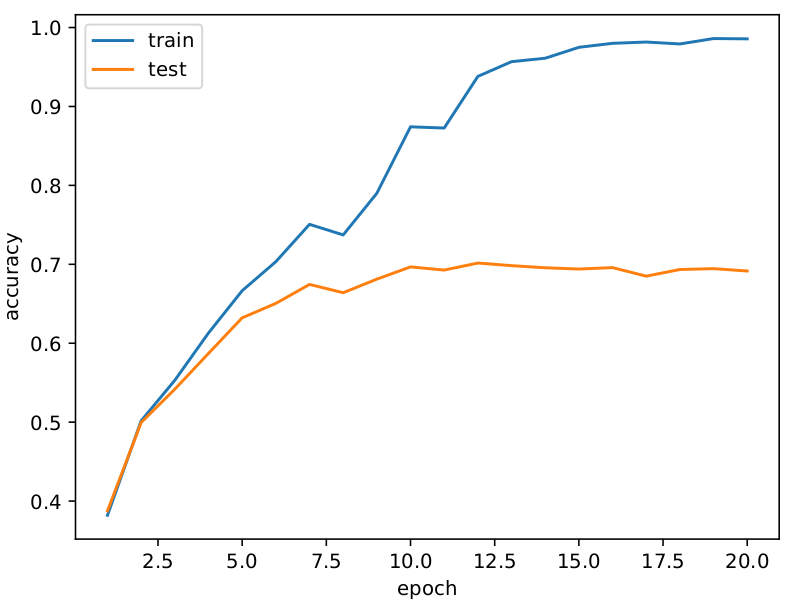
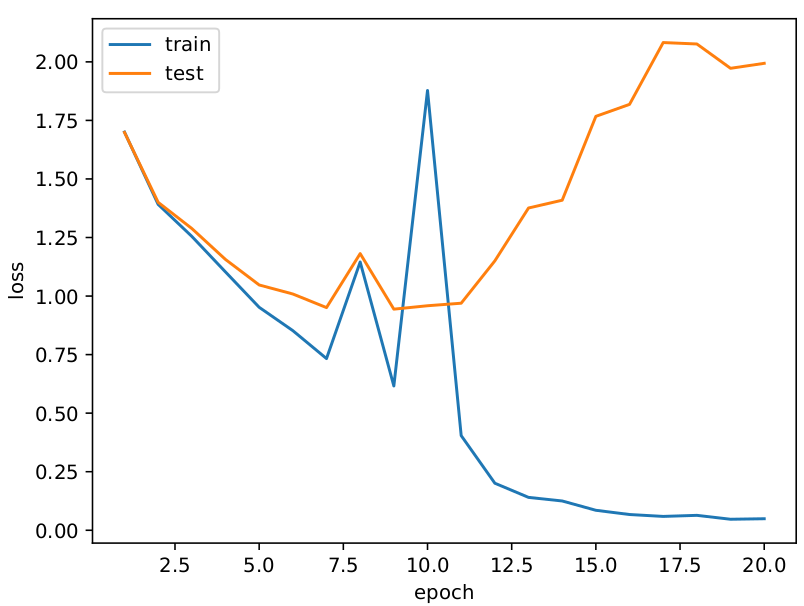
CIFAR-10
Accuracy
Loss
テストが70%くらいの精度ですが過学習していますね・・・
おわりに
出力が入力の多項式になるので活性化関数を使わずに学習ができました。
ブロックを重ねることで表現力が指数的に向上すると上述しましたが、
普通のニューラルネットワークでも層数に対して指数的に表現力が向上することが知られている1ので、正直$\Pi$-Netの利点はよく分からなかったです・・・
Montufar, Guido F., et al. "On the number of linear regions of deep neural networks." Advances in neural information processing systems. 2014. ↩
- 投稿日:2020-04-01T22:55:43+09:00
[CentOS8]Pythonの標準出力をsystemdのログに吐く方法
はじめに
PythonでTwitterのボットを作ったのだが、print関数で出力したログ
systemctl statusコマンドでみることができずはまったので解決方法を覚え書きです。もっといい方法があったら教えていただけると嬉しいです。環境
CentOS Linux release 8.1.1911 (Core)
Unitファイルの記述
etc\systemd\system\におくUnitファイルの記述bot.service[Unit] Description=Python Tweet Collector [Service] ExecStart=実行ファイル(ここではBotを起動するシェルスクリプト)のパス Type=simple StandardOutput=journal #標準出力をjournalctlで見られるようにする StandardError=journal #標準エラーをjournalctlで見られるようにする [Install] WantedBy=multi-user.targetPythonコマンド実行時のオプション
上記の設定だけだとPythonの標準出力がバッファされてprint文の出力が表示されないことがあるらしい...
ということでシェルスクリプトを書き、そこからBotを起動するようにしましたstart_bot.sh#!/bin/bash cd $(dirname $0) #このファイルがあるディレクトリに移動 . venv/bin/activate #Pythonの仮想環境を有効化 python -u bot.py # -u オプションでバッファを無効化最後に
chmod 744 start_bot.shでシェルスクリプトに実行権限を付与Botを起動
systemctl start bot.serviceBotの状態を確認
systemctl status bot.serviceログを確認
journalctl -u bot.servicePythonのプリント文で出力した内容がログに表示されているのが確認できると思います
おわり
Linuxのことはまだまだ初心者なので、不適切な箇所の指摘、アドバイス等ありましたらご教授いただけるととてもうれしいです。
- 投稿日:2020-04-01T21:58:47+09:00
【初心者向け】ある条件式を満たす要素のインデックスを取得したい
背景
プロpythonistからすれば普通のことなのかもしれないんですが、
自分は理解するのに時間がかかり、
理解できたらその強さに感動した。。。ので。。。ndarray[条件式]
行列のままで各要素がある条件を満たすか満たさないかを判別し、
その結果のTrue/Falseを同じ形状の行列として出力してくれます。例
arr = np.array([[0,1,2,3],[0,2,4,6]]) print(arr<3) # [[ True True True False] # [ True True False False]]numpy.nonzero
行列の0でない要素のインデックスを取得してくれ、x,y別のndarray配列として出力されます。
# 例の定義 arr_int = np.array([[3,5,0],[0,4,0]]) arr_bool = np.array([[True,True,False],[False,True, False]]) # np.nonzeroの利用 nonzero_int_row, nonzero_int_column = np.nonzero(arr_int) nonzero_bool_row, nonzero_bool_column = np.nonzero(arr_bool) # 各変数の値 # row: array([0, 0, 1]) # column: array([0, 1, 1]))この例では、0でないのがarr[0,0],arr[0,1],arr[1,1]なのでこういう結果になります。
合体!
arr = np.array([[0,1,2,3],[0,2,4,6]]) arr_bool = arr<3 nonzero_row, nonzero_column = np.nonzero(arr_bool) # row: [0 0 0 1 1] # column: [0 1 2 0 1]
- 投稿日:2020-04-01T21:51:55+09:00
Pythonの基礎を学ぶのにおすすめの教材・方法を紹介(初学者向け)
はじめに
この記事を書く前に簡単な自己紹介をさせてもらいます。
2017年からバルセロナの街クラブにてサッカーのトレーナーをしてる鍼灸師
現在は、AIでスポーツ・医療の発展に貢献をしたくAIエンジニアを目指して勉強中(今年の1月28日から)もう直ぐ日本帰国予定。この記事の対象者
・Pythonを学びたいが勉強方法がわからない方
・色んな教材を試したが上手くスキルがアップしなかった方
・AIエンジニアを目指してる方
・スクールではなく、独学で学びたい方大まかな流れ
とみーさんのロードマップでPythonの基礎を学ぶ
・https://obgynai.com/python-roadmap/
UdemyやYouTube、その他記事で理解不足のところは復習する
【キカガク流】人工知能・機械学習 脱ブラックボックス講座 - 初級編
【世界で21万人が受講】データサイエンティストを目指すあなたへデータサイエンス25時間ブートキャンプ
現役シリコンバレーエンジニアが教えるPython 3 入門 + 応用 +アメリカのシリコンバレー流コードスタイル
ゴール
・ロードマップで記載されてるPythonの基礎の課題をある程度できるようになる
こちらの課題はロードマップで学んだ内容を勉強のために作成したのですが
ロードマップを終了後には、問題を見ただけである程度コーディングすることができるようにまで成長しました。
ロードマップ内の課題・他の教材のPython講座をみてもある程度理解ができるようになる。
【世界で21万人が受講】データサイエンティストを目指すあなたへ〜データサイエンス25時間ブートキャンプ〜
こちらのUdemyの教材に、Pythonの基礎動画だけで3時間あるのですが
小テストが27問あり、ロードマップ終了後は3問ミスだけで講座自体もほとんど理解できました。ロードマップがオススメの理由
私自身1月28日から独学でAIエンジニアを目指し
Python基礎、数学、統計学、機械学習、DeepLearningと自分なりに学んでたのですが
広く浅く、いろいろな教材を学んでは他の教材へ行き、終了すれば他の教材を学ぶを1日平均4-8時間を1ヶ月半ほど繰り返してました。しかし、勉強時間の割りに、できるようなことが少なく初学者には適切なロードマップが必要だと感じました。
その後、こちらのロードマップにしたがって勉強したところ約10日間で、Pythonのコードが少し書けるようになってきており、こちらのロードマップはPython習得基礎への再現性が高いと思い紹介させてもらうことにしました。勉強方法
とみーさんのロードマップでPythonの基礎を学ぶ
・https://obgynai.com/python-roadmap/
主な勉強方法ですが、シンプルでこちらのロードマップにしたがって学んでいくです。
個人的に、理解しにくいところがあれば、先ほど紹介した動画なので学んでからロードマップに戻るとさらに良しです。私は3月21日から昨日までの11日間毎日平均7時間ほど繰り返し4周ほどやりました。(約80時間ほどですね)
同じ教材を繰り返すことによって毎週新たな課題が発見でき前回理解できなかったところも理解できるようになってきます。守るべきルール2つ
1. 1周やったから終了ではなく何周も繰り返す
1周程度では人にもよるかもしれませんが、理解は多少できるようになりますが、ほとんど身につかないかと思います。 (繰り返し大事です)
2. 必ずコーディングする
こちらは思ってるよりも大切で、理解してるからコーディングは必要ないと思ってても実際にコードを書くとなると書けないものです。(以前の私は理解してるからいいやと飛ばしてました)
より効率よく、集中して学びたい方におすすめ
ポモドーロメゾットを紹介します。
クリスさんという方がYouTubeで話しており、
効率化・集中力アップを目的に取り入れてみました。ポモドーロメゾットとは
・25分作業、5分休憩(やり方)
・1つの作業に集中、邪魔されない環境を作る(ルール)
・音楽でプラスアルファールールの2つ
・1つの作業に集中(これはマルチタスクは集中力の低下につながると言われてるから)
・邪魔されない環境を作る(集中すると発生するゾーンに上手く入る為)音楽
脳波は集中してる時は12-18hzと言われております。
ある音楽を聴くと、脳波の波動が集中してる波動に変えてくれるといいます。
脳波を変えるには10分ぐらいかかるそう。
YouTubeで検査可能です。詳しく知りたい方はYoutubeをご覧ください。
こちらのロードマップもオススメです
・米国でデータサイエンティストとして活躍されてるかめさんの記事もとても有益なのでこちらも同時に利用するのもありですね!
DSのためのPython入門講座世の中には無料、有料関わらず、たくさん優良な記事があるので自分にあった教材を選択していきましょう
最後に
今回は私自身AIエンジニアを目指す中で、こちらのロードマップはオススメだと思ったので紹介させてもらいました。
とはいえ、まだPythonを使ってコーディングを完璧に出来るようになったわけではないので、引き続き勉強をしつつ、AIエンジニアに向けて毎日努力していきたいと思います。
私と同じように学ばれてる方。諦めずに一緒にがんばっていきましょう!!
参考文献
・とみーさんのロードマップ
https://obgynai.com/python-roadmap/・ロードマップ内の内容を自作
ロードマップ内の課題【キカガク流】人工知能・機械学習 脱ブラックボックス講座 - 初級編
- 投稿日:2020-04-01T21:51:55+09:00
【文系出身の僕がオススメする】Python初心者のための入門から応用までの学習方法を紹介します【教材紹介】
はじめに
この記事を書く前に簡単な自己紹介をさせてもらいます。
2017年からバルセロナの街クラブにてサッカーのトレーナーをしてる鍼灸師
現在は、AIでスポーツ・医療の発展に貢献をしたくAIエンジニアを目指して勉強中(今年の1月28日から)もう直ぐ日本帰国予定。この記事の対象者
・Pythonを学びたいが勉強方法がわからない方
・色んな教材を試したが上手くスキルがアップしなかった方
・AIエンジニアを目指してる方
・スクールではなく、独学で学びたい方大まかな流れ
とみーさんのロードマップでPythonの基礎を学ぶ
・https://obgynai.com/python-roadmap/
UdemyやYouTube、その他記事で理解不足のところは復習する
【キカガク流】人工知能・機械学習 脱ブラックボックス講座 - 初級編
【世界で21万人が受講】データサイエンティストを目指すあなたへデータサイエンス25時間ブートキャンプ
現役シリコンバレーエンジニアが教えるPython 3 入門 + 応用 +アメリカのシリコンバレー流コードスタイル
ゴール
・ロードマップで記載されてるPythonの基礎の課題をある程度できるようになる
こちらの課題はロードマップで学んだ内容を勉強のために作成したのですが
ロードマップを終了後には、問題を見ただけである程度コーディングすることができるようにまで成長しました。
ロードマップ内の課題
ロードマップ内の課題の回答・他の教材のPython講座をみてもある程度理解ができるようになる。
【世界で21万人が受講】データサイエンティストを目指すあなたへ〜データサイエンス25時間ブートキャンプ〜
こちらのUdemyの教材に、Pythonの基礎動画だけで3時間あるのですが
小テストが27問あり、ロードマップ終了後は3問ミスだけで講座自体もほとんど理解できました。ロードマップがオススメの理由
私自身1月28日から独学でAIエンジニアを目指し
Python基礎、数学、統計学、機械学習、DeepLearningと自分なりに学んでたのですが
広く浅く、いろいろな教材を学んでは他の教材へ行き、終了すれば他の教材を学ぶを1日平均4-8時間を1ヶ月半ほど繰り返してました。しかし、勉強時間の割りに、できるようなことが少なく初学者には適切なロードマップが必要だと感じました。
その後、こちらのロードマップにしたがって勉強したところ約10日間で、Pythonのコードが少し書けるようになってきており、こちらのロードマップはPython習得基礎への再現性が高いと思い紹介させてもらうことにしました。勉強方法
とみーさんのロードマップでPythonの基礎を学ぶ
・https://obgynai.com/python-roadmap/
主な勉強方法ですが、シンプルでこちらのロードマップにしたがって学んでいくです。
個人的に、理解しにくいところがあれば、先ほど紹介した動画なので学んでからロードマップに戻るとさらに良しです。私は3月21日から昨日までの11日間毎日平均7時間ほど繰り返し4周ほどやりました。(約80時間ほどですね)
同じ教材を繰り返すことによって毎週新たな課題が発見でき前回理解できなかったところも理解できるようになってきます。キカガクのいまにゅさんのYouTube動画も有益
実際に私がやってた方法ですが
ロードマップの内容で理解があまりできなかった時は、キカガクのいまにゅさんのYouTubeを見てからロードマップに入るとさらに理解が深まるのでオススメです。また説明もうまく他の動画もオススメなのでぜひ利用してみてください。
中学生でも分かるPython入門シリーズ具体的な例
ロードマップのStep17にあるオブジェクト指向ですが、動画を見る前はあまり理解ができなく、オブジェクト指向とはどういうことなのか。
何のためにあるのかよく理解できませんでしたが、いまにゅさんの3つの動画を見てからロードマップに戻ると驚くほど理解ができ、その後のロードマップの助けになりました。おすすめとしては、まずは動画で概要を理解する方法もありかと思います。
守るべきルール2つ
1. 1周やったから終了ではなく何周も繰り返す
1周程度では人にもよるかもしれませんが、理解は多少できるようになりますが、ほとんど身につかないかと思います。 (繰り返し大事です)
2. 必ずコーディングする
こちらは思ってるよりも大切で、理解してるからコーディングは必要ないと思ってても実際にコードを書くとなると書けないものです。(以前の私は理解してるからいいやと飛ばしてました)
より効率よく、集中して学びたい方におすすめ
ポモドーロメゾットを紹介します。
クリスさんという方がYouTubeで話しており、
効率化・集中力アップを目的に取り入れてみました。ポモドーロメゾットとは
・25分作業、5分休憩(やり方)
・1つの作業に集中、邪魔されない環境を作る(ルール)
・音楽でプラスアルファールールの2つ
・1つの作業に集中(これはマルチタスクは集中力の低下につながると言われてるから)
・邪魔されない環境を作る(集中すると発生するゾーンに上手く入る為)音楽
脳波は集中してる時は12-18hzと言われております。
ある音楽を聴くと、脳波の波動が集中してる波動に変えてくれるといいます。
脳波を変えるには10分ぐらいかかるそう。
YouTubeで検査可能です。詳しく知りたい方はYoutubeをご覧ください。
こちらのロードマップもオススメです
・米国でデータサイエンティストとして活躍されてるかめさんの記事もとても有益なのでこちらも同時に利用するのもありですね!
DSのためのPython入門講座世の中には無料、有料関わらず、たくさん優良な記事があるので自分にあった教材を選択していきましょう
最後に
今回は私自身AIエンジニアを目指す中で、こちらのロードマップはオススメだと思ったので紹介させてもらいました。
とはいえ、まだPythonを使ってコーディングを完璧に出来るようになったわけではないので、引き続き勉強をしつつ、AIエンジニアに向けて毎日努力していきたいと思います。
私と同じように学ばれてる方。諦めずに一緒にがんばっていきましょう!!
参考文献
・とみーさんのロードマップ
https://obgynai.com/python-roadmap/・ロードマップ内の内容を自作
ロードマップ内の課題
ロードマップ内の課題の回答【キカガク流】人工知能・機械学習 脱ブラックボックス講座 - 初級編
【世界で21万人が受講】データサイエンティストを目指すあなたへデータサイエンス25時間ブートキャンプ
現役シリコンバレーエンジニアが教えるPython 3 入門 + 応用 +アメリカのシリコンバレー流コードスタイル
その他オススメの記事
- 投稿日:2020-04-01T21:41:59+09:00
GCP Compute engine でGPUを使ってPythonの実行環境を構築する
経緯とやりたいこと
卒業研究で、
tensorflowで書かれたコードを実行する必要があったのですが、
そのプログラムが中々メモリを消費するもので、研究室のパソコンくんが悲鳴をあげて動いてくれなかったので、泣く泣くGCPを利用して実行環境を構築する必要がありました...ううう....しかも、GCPを使わないと私の卒業に間に合わない疑惑(?!)があったので(大変です)
GCPも使えるようにPythonの実行環境を構築しました...。最初はやり方が全然わからなくで、半泣きになりながらググりまくるという日々を過ごしました(これによって、私の研究の進捗が芳しくなかったことはいうまでもありません
)!!
同じようなことで困っている方々の為に少しでもなれば...ということで始めていきたいと思います!
環境設定
今回は、以下の設定で環境を構築していきます。
- Ubuntu 16.04 LTS
- GCE
- CUDA 9.0
- cuNN 7.4
- TensolFlowGPU 1.12.0
TensolFlowはバージョンによって、CUDAとバージョンを合わせたりする必要があるみたいです...
このバージョンがずれていたりするとうまくGCPが認識できなかったりするみたいなので、
以下から確認することをお勧めします。(ちなみに私は何回かミスりました、はい。)環境構築の手順
0. GCPへの登録
- CCPへアカウント登録
- VMインススタンスの課金の有効化
- VMインスタンスの作成
- vCPU x 24
- メモリ 90 GB
- GPU : NVIDIA Tesla T4
- Boot disk : Ubuntu 16.04 LTS (Size 250GB)
- ZONE : us-west1-b
- HTTPトラフィックを許可
参考サイト: タダでGCPのGPU(NVIDIA Tesla K80)を使ってディープラーニング(NVIDIA DIGITS)する方法
1. CUDAとNVIDIAドライバのインストール
VMインスタンスで以下のcommandを実行し,CUDAとドライバをインストールする
$ curl -O http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/cuda-repo-ubuntu1604_9.0.176-1_amd64.deb $ sudo dpkg -i cuda-repo-ubuntu1604_9.0.176-1_amd64.deb$ sudo apt-key adv --fetch-keys http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1604/x86_64/7fa2af80.pub$ sudo apt-get update $ sudo apt-get install cuda-9-0さらに、GPUのパフォーマンスを最適化するために、以下のcommandを実行します。
$ sudo nvidia-smi -pm 12. cuDNN7.0のインストール
ここからでdeveloperアカウントを作成して、cuDNNの以下の3つのファイルをダウンロードします。
version : ubuntu 16.04 cuda-9.0 version
- libcudnn7_7.6.4.38-1+cuda9.0_amd64.deb
- libcudnn7-dev_7.6.4.38-1+cuda9.0_amd64.deb
- libcudnn7-doc_7.6.4.38-1+cuda9.0_amd64.deb
ダウンロードが完了したら、3つのファイルをStarageへアップロードします。
ここではバケット名はcuda_9とします(お好みで変更してください!)。アップロードが完了したら gsutil command でそのままインスタンスへの転送します。
アップロードするディレクトリはお好みでどうぞ。$ cd {UP_LOAD_PATH} $ gsutil cp gs://cuda_9/libcudnn7_7.6.4.38-1+cuda9.0_amd64.deb . $ gsutil cp gs://cuda_9/libcudnn7-dev_7.6.4.38-1+cuda9.0_amd64.deb . $ gsutil cp gs://cuda_9/libcudnn7-doc_7.6.4.38-1+cuda9.0_amd64.deb .転送が完了したらファイルを展開してインストールしていきます。
$ sudo dpkg -i *.deb3. swap file の設定
swap file がない場合、プログラム実行時にメモリリークする可能性があります。
GCEでLinux仮想マシンを作成するとmUbuntuだろうがCentOSだろうが swap file がない状態で仮想マシンが作成される...らしい...です。(そんなことを1ミリも知らなかった私は、ここで詰みました)ということで、まずはfree commandでswapの有無を確認。
$ free -m以下のようになっていたらSwap:がゼロになっているので、swapファイルを作成する必要があります。
total used free shared buff/cache available Mem: 581 148 90 0 342 336 Swap: 0 0 0swap file の作成。swap file の容量はお好みで(今回は10G)
$ sudo fallocate -l 10G /swapfile $ sudo chmod 600 /swapfile $ sudo mkswap /swapfile $ sudo swapon /swapfileswap file の確認
$ free -mtotal used free shared buff/cache available Mem: 581 148 88 0 344 336 Swap: 1023 0 10023Tips : 再起動時にスワップファイルを自動マウントするには,
/etc/fstabに以下を追加したらいいみたいです。/swapfile none swap sw 0 04. GPU認識確認とCUDAの設定
CUDAの設定を行っていきます。
$ echo "export PATH=/usr/local/cuda-9.0/bin\${PATH:+:\${PATH}}" >> ~/.bashrc $ source ~/.bashrc $ sudo /usr/bin/nvidia-persistencedその後、GPUが認識されているかを確認します。
$ nvidia-smi以下のようなresponseがあれば、GPUの設定は完了です!
+-----------------------------------------------------------------------------+ | NVIDIA-SMI 410.72 Driver Version: 410.72 CUDA Version: 10.0 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 Tesla K80 Off | 00000000:00:04.0 Off | 0 | | N/A 42C P0 65W / 149W | 0MiB / 11441MiB | 100% Default | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| | No running processes found | +-----------------------------------------------------------------------------+5. Python環境の構築
最後に、Python環境をAnadondaで構築していきます。
(普段からAnacondaを使っているのと、他の方法だとなぜがプログラムが動かなかったので今回はAnacondaにしました)
wgetでAnaconda をダウンロードします。$ wget https://repo.anaconda.com/archive/Anaconda3-5.3.1-Linux-x86_64.sh $ sh ./Anaconda3-5.3.1-Linux-x86_64.sh $ echo ". /home/{USER_NAME}/anaconda3/etc/profile.d/conda.sh" >> ~/.bashrc $ source ~/.bashrc次に、Anaondaの仮装環境を構築します。Pythonのversionと
ENV_NAMEはお好みで。
(今回はtensorflow==1.12.0を使いたいので、Python3.6.5)$ conda create -n {ENV_NAME} python=3.6.5 $ conda activate {ENV_NAME}6. tensorflow-gpuのインストール
condaからinstall(ここまでくると安心感ありますね...)
$ conda install tensorflow-gpu==1.12.0以下のプログラムを実行して、
GPUと出てきたらtensorflow-gpuがGPUを認識してくれています。test.pyfrom tensorflow.python.client import device_lib device_lib.list_local_devices()
- OUT
[name: "/device:CPU:0" device_type: "CPU" memory_limit: 268435456 locality { } incarnation: 2319180638018740093 , name: "/device:GPU:0" device_type: "GPU" memory_limit: 11324325888 locality { bus_id: 1 } incarnation: 13854674477442207273 physical_device_desc: "device: 0, name: Tesla K80, pci bus id: 0000:00:04.0, compute capability: 3.7" ]その他、必要なライブラリがあればcondaからinstallしていきます。(↓こんな感じ)
$ conda install numpy==1.15.4 $ conda install scipy==1.1.0 $ conda install scikit-learn==0.20.0これで、conpute engine のインスタンスでGCPを使ってPythonのプログラムを実行できるはず...です!お疲れ様でした...!!
なにか、間違いなどがあればコメントの方宜しくお願いします
- 投稿日:2020-04-01T21:37:37+09:00
Django3で管理者ページにログインできない
概要
タイトルの通り、http://localhost:8000/admin/ からsuper userでログインしようとするとrunserverが落ちて失敗する。
ログインに失敗した環境
macOS Catalina 10.15.3
Django 3.0.5
Python 3.7.0pythonをアップグレードすることで解決
3.7.4と3.8.0で動作することを確認しました。一応referenceでは3.6から対応しているはずですが、なぜか3.7.0では正常に動作しませんでした。
- 投稿日:2020-04-01T21:32:11+09:00
Python&機械学習 勉強メモ③
参考教材
Udemy みんなのAI講座 ゼロからPythonで学ぶ人工知能と機械学習
課題設定
緯度・経度を与えると、東京・神奈川のどちらに属するかを判定するプログラムを作成する.
判定方法
入力層2つ・中間層2つ・出力層1つのニューラルネットワークで判定する。
ニューロンクラス
class Neuron: input_sum = 0.0 output = 0.0 def setInput(self, inp): self.input_sum += inp def getOutput(self): self.output = sigmoid(self.input_sum) return self.output def reset(self): self.input_sum = 0 self.output = 0
setInput入力を合計する。
getOutput入力値を活性化関数で変換した値を出力する。
ニューロンは入力値が閾値を超えると発火する特徴があるが、上記のように活性化関数にシグモイド関数を適用することでそれを模倣する。
reset入力値をリセットする。
ニューラルネットワーク
class NeuralNetwork: input_layer = [0.0, 0.0, 1.0] middle_layer = [Neuron(), Neuron(), 1.0] ouput_layer = Neuron() ...
input_layerとmiddle_layerの3番目の要素はバイアス。
ニューロンクラスを組み合わせて入力形式とファイル読み込み
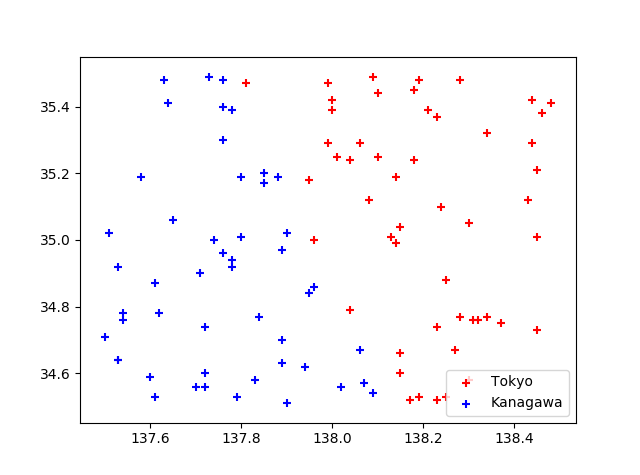
入力ファイル
1行に 経度,緯度 を記載しているファイルを読み込む。
35.48,137.76 35.47,137.81 35.29,138.06 ...得られる結果
複雑な境界線に対して東京・神奈川を区別できている。
きちんと判定するには、各入力の重みづけや閾値を適切に設定する必要があるはず。
その設定方法は次回以降に学習。
- 投稿日:2020-04-01T21:16:56+09:00
【初心者向け】PythonでWebスクレイピング 「ページ内のURLにアクセスして内容を取得する」
はじめに
前回のおさらい
【初心者向け】PythonでWebスクレイピングをやってみるの記事の続きになります。
前回は、日経ビジネス電子版
https://business.nikkei.com/
から、新着記事の見出しとURLを取得しました。しかし、これだけでは、実際にこのURLにアクセスすれば知る事ができます。
今回の目的
ニュースサイトを閲覧した際に、気になったニュースがあればクリックをして、詳細な内容を閲覧すると思います。
日経ビジネスの記事には、全てのニュースでは無いのですが、内容の前に読みたいと思わせるような150文字程度の記事紹介文があります。
この内容も一緒に表示する事で、記事を読むか読まないかの判断材料にします。
いちいち全ての記事にアクセスして、記事の紹介文を読むのは大変です。
Webスクレイピングの良さを、引き出していきます。前回のコードのおさらい
code.pyimport requests from bs4 import BeautifulSoup import re urlName = "https://business.nikkei.com" url = requests.get(urlName) soup = BeautifulSoup(url.content, "html.parser") elems = soup.find_all("span") for elem in elems: try: string = elem.get("class").pop(0) if string in "category": print(elem.string) title = elem.find_next_sibling("h3") print(title.text.replace('\n','')) r = elem.find_previous('a') #記事のURLを取得している print(urlName + r.get('href'), '\n') #この部分にURL先の記事紹介文を取得するプログラムを書く except: pass詳しくは、前回の記事を参照してください。
ニュースをクリックした際に、遷移するURLを表示して前回は終わりました。今回は、そのURLにアクセスして内容を取得します。プログラミング
まず初めに、今回はrequestsとBeautifulSoupの部分を関数にします。
subFunc.pyimport requests from bs4 import BeautifulSoup def setup(url): url = requests.get(url) soup = BeautifulSoup(url.content, "html.parser") return url, soupmain.pyimport re import subFunc urlName = "https://business.nikkei.com" url, soup = subFunc.setup(urlName) elems= soup.find_all("span") for elem in elems: try: string = elem.get("class").pop(0) if string in "category": print('\n', elem.string) title = elem.find_next_sibling("h3") print(title.text.replace('\n','')) r = elem.find_previous('a') nextPage = urlName + r.get('href') print(nextPage) #ここから新しく記述した部分 nextUrl, nextSoup = subFunc.setup(nextPage) abst = nextSoup.find('p', class_="bplead") if len(abst) != 0: print(abst.get_text().replace('\n','')) except: pass正直、やる事は変わりません。
遷移先のURLを、requestsとBeautifulSoupを使って情報を取得します。
記事の紹介文は、classがbpleadの要素にありました。しかし、紹介文が無い記事もあるので、あった場合に表示するようにしました。実行結果は以下の通りです。(省略しています)
共創/競争・スタートアップ 新型コロナは長期戦 xxxxxxxxxxx https://business.nikkei.com/atcl/gen/19/00101/040100009/ 新型コロナウイルスの流行xxxxxxxxxxxxと訴えた。さいごに
調べてみると、他の方法もいくつか紹介されていますが、簡単な方法で遷移先の内容を取得してみました。
- 投稿日:2020-04-01T20:13:00+09:00
TeamsやZoomでカメラ画像を加工する方法 Tensorflowで感情分析の巻
本記事はこちらでも紹介しております。
https://cloud.flect.co.jp/entry/2020/04/01/201158みなさんこんにちは。
前回はTeamsやZoomでカメラ画像を加工する方法をご紹介し、
笑顔を検出してニコニコマークを表示するデモをご紹介いたしました。
https://qiita.com/wok/items/0a7c82c6f97f756bde65今回は、これを少し拡張して、AI(Tensorflow)でリアルタイムに感情分析することに挑戦しましたので、ご紹介いたします。
具体的には、次のように、画像に写った人物の表情から悲しみや怒りと言った感情を読み取り、それに合わせた画像を画面に表示します。これでビデオ会議で言葉を発しなくても感情を伝えることができそうですね。(いや待て、、)
前提
前回の記事を参考に、v4l2loopbackなどを設定しておいてください。
Webカメラのフックの拡張
今回は、カメラで取られた人物の感情を分析して、対応する画像をビデオストリーム上の映像に表示します。
感情分析にはTensorflowを用いますが、次のサイトでトレーニング済みのモデルがMITライセンスで提供されているので、これを利用させてもらいましょう。https://github.com/oarriaga/face_classification
まず、最初に前回と同様に下記のリポジトリから、スクリプトをcloneして、必要なモジュールをインストールしてください。
$ git clone https://github.com/dannadori/WebCamHooker.git $ cd WebCamHooker/ $ pip3 install -r requirements.txt次に、先程のサイトから感情分析用のトレーニング済みのモデルを取得します。
なお、今回は、適切な画像を表示するために、性別判断も同時に行おうと思います。
$ wget https://github.com/oarriaga/face_classification/raw/master/trained_models/emotion_models/fer2013_mini_XCEPTION.110-0.65.hdf5 -P models # 感情分析用のモデル
$ wget https://github.com/oarriaga/face_classification/raw/master/trained_models/gender_models/simple_CNN.81-0.96.hdf5 -P models/ # 性別判定用のモデル
また、画像を再びいらすとやさんからお借りしましょう。$ wget https://4.bp.blogspot.com/-8DirG_alwXo/V5Xc1SMykvI/AAAAAAAA8u4/krI2n_SWimUBGEyMWCw5kZZ-HzoUKrY8ACLcB/s800/pose_sugoi_okoru_woman.png -P images/ $ wget https://4.bp.blogspot.com/-EBpxVigkCCY/V5Xc1CHSeEI/AAAAAAAA8u0/9XIAzDJaQNU3HIiXi4PCPK3aMip3aoGyACLcB/s800/pose_sugoi_okoru_man.png -P images/ $ wget https://4.bp.blogspot.com/-HJ0FUQz67AA/XAnvUxSRsLI/AAAAAAABQnM/3XzIWzvW6L80aGB-geaHvAQETlJTAwkYQCLcBGAs/s800/business_woman2_4_think.png -P images/ $ wget https://3.bp.blogspot.com/-S7iQQCOgfWY/XAnvQWwBGtI/AAAAAAABQmc/z7yIqGjIQr88Brc_QNdOGsrJRLvqY1hcQCLcBGAs/s800/business_man2_4_think.png -P images/ $ wget https://4.bp.blogspot.com/-PQQV4wfGlNI/XAnvQBMeneI/AAAAAAABQmU/lN7zIROor9oi3q-JZOBJiKKzfklzPE1hwCLcBGAs/s800/business_man2_2_shock.png] -P images/ $ wget https://3.bp.blogspot.com/-QcDbWqQ448I/XAnvUT4TMDI/AAAAAAABQnE/_H4XzC4E93AEU2Y7fHMDBjri1drdyuAPQCLcBGAs/s800/business_woman2_2_shock.png -P images/ $ wget https://3.bp.blogspot.com/-dSPRqYvIhNk/XAnvPdvjBFI/AAAAAAABQmM/izfRBSt1U5o7eYAjdGR8NtoP4Wa1_Zn8ACLcBGAs/s800/business_man1_4_laugh.png -P images/ $ wget https://1.bp.blogspot.com/-T6AOerbFQiE/XAnvTlQvobI/AAAAAAABQm8/TYVdIfxQ5tItWgUMl5Y0w8Og_AZAJgAewCLcBGAs/s800/business_woman1_4_laugh.png -P images/ $ wget https://4.bp.blogspot.com/-Kk_Mt1gDKXI/XAnvS6AjqyI/AAAAAAABQm4/LQteQO7TFTQ-KPahPcAqXYannEArMmYfgCLcBGAs/s800/business_woman1_3_cry.png -P images/ $ wget https://4.bp.blogspot.com/-3IPT6QIOtpk/XAnvPCPuThI/AAAAAAABQmI/pIea028SBzwhwqysO49pk4NAvoqms3zxgCLcBGAs/s800/business_man1_3_cry.png -P images/ $ wget https://3.bp.blogspot.com/-FrgNPMUG0TQ/XAnvUmb85VI/AAAAAAABQnI/Y06kkP278eADiqvXH5VC0uuNxq2nnr34ACLcBGAs/s800/business_woman2_3_surprise.png -P images/ $ wget https://2.bp.blogspot.com/-i7OL88NmOW8/XAnvQacGWuI/AAAAAAABQmY/LTzN4pcnSmYLke3OSPME4cUFRrLIrPsYACLcBGAs/s800/business_man2_3_surprise.png -P images/ $ cp images/lN7zIROor9oi3q-JZOBJiKKzfklzPE1hwCLcBGAs/s800/business_man2_2_shock.png] images/lN7zIROor9oi3q-JZOBJiKKzfklzPE1hwCLcBGAs/s800/business_man2_2_shock.png上記のうち、最後のコマンドは、ファイル名にゴミ(末尾のカギカッコ)がついているので取り除いているだけです。
実行は次のように行います。オプションが一つ追加されてます。
- input_video_num には実際のウェブカメラのデバイス番号を入れてください。/dev/video0なら末尾の0を入力します。
- output_video_dev には仮想ウェブカメラデバイスのデバイスファイルを指定してください。
- emotion_mode はTrueにしてください。
なお、終了のさせ方はctrl+cでお願いします。
$ python3 webcamhooker.py --input_video_num 0 --output_video_dev /dev/video2 --emotion_mode True上のコマンドを実行するとffmpegが動き、仮想カメラデバイスに映像が配信されはじめます。
ビデオ会議をしてみよう!
前回と同様に、ビデオ会議をするときにビデオデバイスの一覧にdummy〜〜というものが現れると思うのでそれを選択してください。
これはTeamsの例です。表情に合わせて画面上部の文字列が変化し、合わせて対応する画像が表示されますね。大成功です。
最後に
在宅勤務が長引き、気軽なコミュニケーションがなかなか難しいかもしれませんが、こういった遊び心をビデオ会議に持ち込んで、会話を活性化させるのもいいのではないかと思っています。
もっといろいろできると思いますので、みなさんもいろいろ試してみてください。参考
Tensorflowによる感情分析については次のサイトを参考にさせていただきました。
(このサイトではtensorflowjsでの紹介をされております)

- 投稿日:2020-04-01T19:52:26+09:00
LDAPのことを意識させずに操作できるPYTHON用クラス
はじめに
pythonでLDAPを操作する方法を3回に分けてまとめてきました。複数人で開発する場合は全員がldap3のライブラリやLDAPのことについて理解する必要がありますが、それには時間と労力がかかります。そこでLDAPはツリー構造のデータであるということだけを知っていれば誰でも使えるようにクラスを作成しました。
環境
- python:3.6.5
- ldap3:2.7
- イメージ:osixia/openldap
メリット
- LDAPのことを意識せずに使える
- ルールを加えられる(dc=xxxの後はouにするなど)
- ぱっと見で分かりやすい
今回のクラスを使用した例
まずは、今回のクラスを使用した場合にどのようにLDAPを操作するのかを記載します。使用するときはクラス名を変えるとより分かりやすくなるため、この後の説明で出てくるDomainクラスをAddress、OrganizationをOwner、CommonをPetに変更することでAddress -> Owner -> Petの階層であることが意識できます。
main.pyfrom ldap_obj.Address import Address # 場所の追加 address = Address('localhost', 'LdapPass', 'admin', 'sample-ldap') address.set_item('tokyo') address.save() # 人の追加 owner = address.create_owner() owner.set_item('sato') owner.save() # ペット(たま)の追加 pet_tama = owner.create_pet() pet_tama.set_item('tama') pet_tama.save({'sn': 'sato', 'st': 'tama', 'title': 'cat'}) # ペット(ぽち)の追加 pet_pocho = owner.create_pet() pet_pocho.set_item('pochi') pet_pocho.save({'sn': 'sato', 'st': 'pochi', 'title': 'dog'}) # titleを検索条件にしてdomain層からcnの値を取得する address.set_filter('title') print(address.get_common()) print('***********************') # Addressを生成 address_get = Address('localhost', 'LdapPass', 'admin', 'sample-ldap') address_get.set_item('tokyo') # Address -> Ownerの生成 owner_get = address_get.create_owner() owner_get.set_item('sato') # Address -> Owner -> Petの生成 pet_get = owner_get.create_pet() pet_get.set_item('tama') print(pet_get.get_common())LDAP用クラス
LDAP用クラスは各階層ごとにクラスを作成します。
ディレクトリ構成
\-- |--ldap_obj\ | |--BaseClass.py (基準のクラス) | |--CommonClass.py (cnのクラス) | |--DomainClass.py (dcのクラス) | |--OrganizationClass.py (ouのクラス) | |--main.py基準のクラス
基準のクラスは基本的にldap3のラッパーになります。特に複雑なことはしていません。コントラクタでは接続に必要なクラスの生成をして、get_xxx()では_read_ldap()にオブジェクトクラスを渡してLDAPから情報を取得しています。オブジェクトクラスが増えた場合はこの関数が増えます。
BaseClass.pyfrom ldap3 import Server, Connection, ObjectDef, Reader class BaseClass(object): def __init__(self, host, passwd, user, top_domain, dn=None): self.passwd = passwd self.user = user self.host = host self.top_domain = top_domain self.filter = None if (dn): self.dn = dn else: self.dn = 'dc=' + top_domain self.server = Server(self.host) self.conn = Connection(self.host, 'cn={},dc={}'.format(user, top_domain), password=passwd) def set_filter(self, filter): self.filter = filter def get_domain(self): return self._read_ldap('domain', self.filter) def get_organizational(self): return self._read_ldap('organizationalUnit', self.filter) def get_common(self): return self._read_ldap('inetOrgPerson', self.filter) def get_domain_dict(self): return self._read_ldap_dict('domain', self.filter) def get_organizational_dict(self): return self._read_ldap_dict('organizationalUnit', self.filter) def get_common_dict(self): return self._read_ldap_dict('inetOrgPerson', self.filter) def _read_ldap(self, object_type, search_attr = None): data_list = [] self.conn.bind() obj_dn = ObjectDef(object_type, self.conn) data_reader = Reader(self.conn, obj_dn, self.dn) data_reader.search(search_attr) for data in data_reader: data_list.append(data) data_reader.reset() self.conn.unbind() return data_list def _read_ldap_dict(self, object_type, search_attr = None): data_list = [] self.conn.bind() obj_dn = ObjectDef(object_type, self.conn) data_reader = Reader(self.conn, obj_dn, self.dn) data_reader.search(search_attr) for data in data_reader: data_list.append(data.entry_attributes_as_dict) data_reader.reset() self.conn.unbind() return data_list拡張クラス
上の基準のクラスを継承したクラスをそれぞれの階層ごとに作成していきます。
Domainクラス
dcの値が必要なため
set_item()でdnの文字列にdcの値を追加しています。このself.dnを使用して基準のクラスのget_xxx()で情報を取得したり、save()で追加します。create_organization()はou用のクラスを生成して返却しています。今回の例は、dc=xxx,ou=yyyとしてほしいのでou用の生成関数しかないですがdc=xxx,dc=yyyとしたいときはdc用の生成関数を同じように作成すればできます。DomainClass.pyfrom ldap_obj.BaseClass import BaseClass from ldap_obj.OrganizationClass import OrganizationClass class DomainClass(BaseClass): def set_item(self, item): self.dn = 'dc=' + item + ',' + self.dn def create_organization(self): return OrganizationClass(self.host, self.passwd, self.user, self.top_domain, self.dn) def save(self): self.conn.bind() result = self.conn.add(self.dn, 'domain') self.conn.unbind() return resultOrganizationクラス
Domainクラスから生成したOrganizationクラスにはself.dnにcnまでのパスが入っているので
set_item()でouの値を追加しています。このself.dnを使用して基準のクラスのget_xxx()で情報を取得したり、save()で追加します。create_common()はcn用のクラスを生成して返却しています。今回の例は、dc=xxx,ou=yyy,cn=zzzzとしてほしいのでcn用の生成関数しかないですが他の構成にしたいときはそれ用の生成関数を作成します。OrganizationClass.pyfrom ldap_obj.BaseClass import BaseClass from ldap_obj.CommonClass import CommonClass class OrganizationClass(BaseClass): def set_item(self, item): self.dn = 'ou=' + item + ',' + self.dn def create_common(self): return CommonClass(self.host, self.passwd, self.user, self.top_domain, self.dn) def save(self): self.conn.bind() result = self.conn.add(self.dn, 'organizationalUnit') self.conn.unbind() return resultCommonクラス
Organizationクラスから生成したCommonクラスにはself.dnにouまでのパスが入っているので
set_item()でcnの値を追加しています。このself.dnを使用して基準のクラスのget_xxx()で情報を取得したり、save()で追加します。今回の例は、このcnで最後なので生成関数はありませんがさらに階層が深い場合はそれ用の生成関数を作成します。CommonClass.pyfrom ldap_obj.BaseClass import BaseClass class CommonClass(BaseClass): def set_item(self, item): self.dn = 'cn=' + item + ',' + self.dn def save(self, attr_dict): self.conn.bind() result = self.conn.add(self.dn, 'inetOrgPerson', attr_dict) self.conn.unbind() return result呼び出し元メイン関数
これらのクラスの使い方は、最初にDomainClassを生成してからdcの値を入れます、次に生成したDomainClassの
create_organization()を使用してOrganizationクラスを生成してouの値をいれます。commonの生成は生成したOrganizationクラスのcreate_common()を使用してcnの値をいれます。それぞれの生成クラスで取得関数や追加関数を使用してLDAPの操作をします。main.pyfrom ldap_obj.DomainClass import DomainClass domain = DomainClass('localhost', 'LdapPass', 'admin', 'sample-ldap') domain.set_item('sample-component') domain_item_list = domain.get_domain() for domain_item in domain_item_list: print(domain_item) print("=====================") domain.set_filter('st') domain_item_list = domain.get_common() for domain_item in domain_item_list: print(domain_item) print("=====================") organization = domain.create_organization() organization.set_item('sample-unit') organization_list = organization.get_organizational() for organization_item in organization_list: print(organization_item) print("=====================") common = organization.create_common() common.set_item('sample-name') common_list = common.get_common() for common_item in common_list: print(common_item) print("***********************************") new_domain = DomainClass('localhost', 'LdapPass', 'admin', 'sample-ldap') new_domain.set_item('new-component') print(new_domain.save()) print("=====================") new_organization = new_domain.create_organization() new_organization.set_item('new-organization') print(new_organization.save()) print("=====================") new_common = new_organization.create_common() new_common.set_item('new-common') print(new_common.save({'st':'new-st', 'sn': 'new-sn'})) print("=====================") new_common_list = new_common.get_common() for common_item in new_common_list: print(common_item)おわりに
極力LDAPの要素を排して操作できるようなクラスを作ってみました。ldap3のライブラリを知っているとクラス経由の操作は面倒に思えますが実際にソースを見てみるとぱっと見で何をしているのかがわかりやすくなりました。今回は取得と追加の機能を持たせましたが、削除と移動と更新は基準のクラスにldap3を使用する関数を追加すれば良いと思います。ここまで分かりやすくすればデータの格納の候補として使用にも躊躇がなくなるのではないかと思います。
- 投稿日:2020-04-01T18:53:44+09:00
scikit-learnとpyclusteringのk-means実装例を比較
はじめに
Pythonで機械学習を実装する際のデファクトスタンダードはscikit-learnだが、クラスタリングにおいては一部かゆいところに手が届いていない部分もあるため、pyclusteringが選択肢として入ってくる。
しかし、pyclusteringはscikit-learnと比較すると若干使いにくい部分があるため、利用方法の備忘のため、最も基本的なk-meansにおける実装例をまとめる。
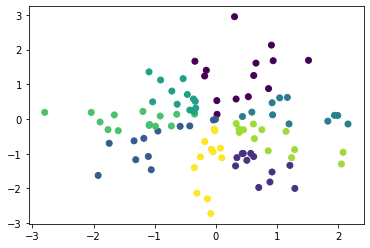
K-meansの実行例
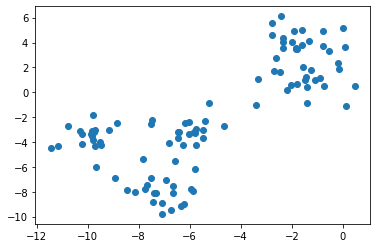
使用データ
データ定義from sklearn.datasets import make_blobs X, _ = make_blobs(n_features=2, centers=5, random_state=1)散布図import matplotlib.pyplot as plt plt.scatter(X[:, 0], X[:, 1])
scikit-learn
scikit-learnを用いたk-meansの実装は以下の通りである。
なお、scikit-learnでの初期値設定方法は
initオプションで設定でき、デフォルトでha
k-means++になっている。scikit-learnでのk-meansfrom sklearn.cluster import KMeans sk_km = KMeans(n_clusters=3).fit(X) plt.scatter(X[:, 0], X[:, 1], c=sk_km.labels_)
pyclustering
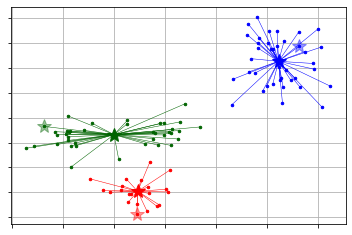
pyclusteringを用いたk-meansの実装は以下の通りである。
scikit-learnとは異なり、初期値設定とその後のクラスタ学習を分けて指定する必要がある。
後、こちらで用意されている可視化用の関数を使うと少し情報がリッチになる。from pyclustering.cluster import kmeans from pyclustering.cluster.center_initializer import kmeans_plusplus_initializer initial_centers = kmeans_plusplus_initializer(X, 3).initialize() # k-means++で初期値設定 pc_km = kmeans.kmeans(X, initial_centers) # kmeansクラスの定義 pc_km.process() # 学習の実行 _ = kmeans.kmeans_visualizer.show_clusters(X, pc_km.get_clusters(), pc_km.get_centers(), initial_centers=initial_centers) # 可視化
pyclusteringで得られたクラスタは、
predictメソッドとget_clustersメソッドで参照できる。
predictでは、scikit-learnと同様に、入力データに対してラベルを返す。
get_clustersは、学習に使ったデータに対するインデックスをクラスタ別に返す。こちらはpandasなどで取り扱うのに適していないので、別途加工する必要がある。(predict使った方が簡単)predictを用いたクラスタ番号の取得(1)labels = pc_km.predict(X)get_clustersを用いたクラスタ番号の取得import numpy as np clusters = pc_km.get_clusters() labels = np.zeros((np.concatenate([np.array(x) for x in clusters]).size, )) for i, label_index in enumerate(clusters): labels[label_index] = iクラスタ数の決定
scikit-learn
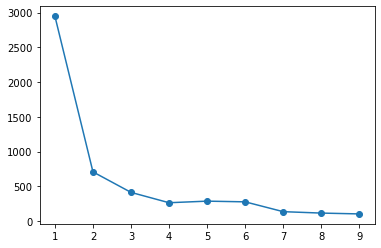
scikit-learnにおけるエルボー法について示す。
シルエット分析も可能だが、pyclusteringと同様に実装が複雑になるため、割愛する。
なお、どちらにおいても自動的にクラスタ数を決定することはできず、分析者が確認した上で決定する必要がある。
エルボー法sse = list() for i in range(1, 11): km = KMeans(n_clusters=i).fit(X) sse.append(km.inertia_) plt.plot(range(1, 11), sse, 'o-')
pyclustering
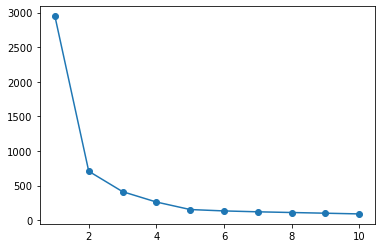
pyclusteringの場合、エルボー法でクラスタ数の決定まで行ってくれる。
なお、クラスタ数は、探索範囲内でクラスタ内誤差平方和が大きく下がったクラスタ数を採用しているようだ。エルボー法from pyclustering.cluster.elbow import elbow kmin, kmax = 1, 10 # 探索する値域 elb = elbow(X, kmin=kmin, kmax=kmax) # 探索範囲は、kmin~kmax-1までなことに注意 elb.process() elb.get_amount() # クラスタ数を参照できる plt.plot(range(kmin, kmax), elb.get_wce())
pyclusteringでは、x-meansやg-meansに対応しているため、それを利用することもできる。
x-meansfrom pyclustering.cluster import xmeans from pyclustering.cluster.kmeans import kmeans_visualizer initial_centers = xmeans.kmeans_plusplus_initializer(X, 2).initialize() # k=2以上で探索 xm = xmeans.xmeans(X, initial_centers=initial_centers, ) xm.process() _ = kmeans_visualizer.show_clusters(X, xm.get_clusters(), xm.get_centers())
g-meansfrom pyclustering.cluster import gmeans from pyclustering.cluster.kmeans import kmeans_visualizer initial_centers = gmeans.kmeans_plusplus_initializer(X, 2).initialize() gm = gmeans.gmeans(X, initial_centers=initial_centers, ) gm.process() _ = kmeans_visualizer.show_clusters(X, gm.get_clusters(), gm.get_centers())
scikit-learnに比べ、pyclusteringが優位な点
敷居の低さで選ぶのであればscikit-learnではあるが、細かくクラスタリングアルゴリズムに調整したい場合はpyclusteringが優位である。
pyclusteringはそもそも対応しているアルゴリズムが多く、細かく処理内容を定義できる。例えば、距離定義をユークリッド距離からマンハッタン距離やユーザが定義した距離指標に変えることが出来る。
以下にコサイン距離でクラスタリンを行う例を示す。
※コサイン距離でやるだけなら、sphereclusterの方が簡単
コサイン距離でk-meansimport numpy as np from pyclustering.cluster import kmeans from pyclustering.cluster.center_initializer import kmeans_plusplus_initializer from pyclustering.utils.metric import distance_metric, type_metric X = np.random.normal(size=(100, 2)) def cosine_distance(x1, x2): if len(x1.shape) == 1: return 1 - np.dot(x1, x2) / (np.linalg.norm(x1) * np.linalg.norm(x2)) else: return 1 - np.sum(np.multiply(x1, x2), axis=1) / (np.linalg.norm(x1, axis=1) * np.linalg.norm(x2, axis=1)) initial_centers = kmeans_plusplus_initializer(X, 8).initialize() pc_km = kmeans.kmeans(X, initial_centers, metric=distance_metric(type_metric.USER_DEFINED, func=cosine_distance)) pc_km.process() plt.scatter(X[:, 0], X[:, 1], c=pc_km.predict(X))
参考

- 投稿日:2020-04-01T18:23:53+09:00
[Python]マルコフ連鎖則で友人っぽいツイートを生成するTwitterのBotを作った
はじめに
大学生の暇な春休み、クローリング&スクレイピングの勉強をとだらだらやってきましたが、ここらでいっちょなんか作るかということでTwitterのBotを作ってみることにしました。
友人Bの協力を得て、友人Bのツイートを分析して友人BっぽいツイートをするBotを作成しました。開発環境
Windows10上のvirtualboxでUbuntuの仮想環境を使用
Ubuntu 18.04.4 LTS使ったものたち
- マルコフ連鎖則
- MeCab
- tweepy
- MySQL
- VPS (Virtual Private Server)
それぞれちょっとずつ説明を書きますね
マルコフ連鎖則
「さて、どうやって生成する文章にその人らしさを出そうかな、っていうかそもそも文章の自動生成ってどうやるの?」っということで調べたところ、マルコフ連鎖則というものを発見。
マルコフ連鎖則についてはこちらの記事にとってもわかりやすく書いてありますのでこちらをご参照ください。Pythonのコードも参考にさせていただきました。マルコフ連鎖則すげーっ!てなります。
[Python]N階マルコフ連鎖で文章生成](https://qiita.com/k-jimon/items/f02fae75e853a9c02127)
MeCab
取得したツイートを分析する手段としてMeCabを使います。
「取得したツイートに対してMeCabを用いて形態素解析を行い単語のリストを作成しマルコフ連鎖則に従って単語を並べる」というのが基本的な文章生成の流れになります。MeCabについての詳しい説明はこちらをご覧ください。
tweepy
ツイッターを自動操作するにはTwitterが公式に提供しているTwitterAPIを使います。
TwitterAPIを使うとアカウントをプログラムから自動操作することができるようになります。PythonからTwitterAPIを操作するときはPythonのライブラリであるtweepyが便利とのことで、この本を参考にしつつネットで調べながら使い方を勉強しました。
MySQL
どうせならデータベースの勉強もしてやろう思い立ち、TwitterAPIで取得したデータの保存をMySQLを使って保存することにしました。MySQLを使うことであとからアプリケーションを拡張しやすいなどのメリットが生まれます。試作時にはテキストファイルにデータを入れてみていましたが少し動作が遅かった印象です。
MySQLについて詳しく知りたい方は下記のリンク先を参照してみてください。イメージがつかめるかと思います。
VPS
Botを運営するためのサーバーが必要だということで、VPSを借りました。常時起動しているパソコンを1台使えるみたいなイメージ。
必要な環境の構築にはLinuxの知識が必要で、サーバー初心者の私にはそこそこハードな作業になりましたが、MySQLやMeCabなど必要なソフトウェアをインストールしました。
CohoHaVPSで手軽に借りることができました。そのうちWebサーバーとしても使っていこうと思います。月880円でサーバーで遊べるなら安いもんです...
Botアプリの構成
やっと本題ですが、図にするとこんな感じ。
各スクリプトの役割は以下のようにしている
@twitter_collector.py(データ収集用スクリプト)
1. TwitterAPIをPythonライブラリであるtweepyで利用して、ツイートデータを取得
2. 取得したデータから必要な要素(本文、投稿日時など)を抜きだし、データベースへ保存
3. ストリーミングAPIを利用して新規ツイートがあれば随時データベースへ追加する@bot.py(Bot本体)
1. データベースからツイート本文を読み出し、処理しやすい形に整形
2. テキストデータをMeCabで形態素解析し、友人Bのツイートの内容の傾向をモデル化
3. 作成したモデルにしたがって友人Bらしいツイートを生成
4. TwitterAPI(Tweepy)で生成したツイートを投稿データを集める部分とツイートを行うBot本体をわけることで管理がしやすくなっていると思います。
Botの自動化
サーバーにCentOS8の環境を用意し、そこにMeCab、MySQL、Pythonなど必要な各ツールをインストールし環境構築を行いました
Pythonスクリプトを実行するためのシェルスクリプトをsystemdによって自動実行することでBotを動かしています。systemdについてはこちらの記事にわかりやすく解説されています。
もっと似せるために
ただマルコフ連鎖則にしたがって文章をつくらせているだけでも結構面白いツイートを生み出してくれたので楽しかったのですが、もっと似せたいなということで現時点で下記2点を工夫しています
- 本人のツイート間隔のパターンを時間帯ごとの分布を調べ、それに従ってツイートさせる
- 本人のツイートの文字数の分布を調べそれに従ってツイートする文字数(の範囲)を確率的に決定する
どちらも、友人Bが実際にしたツイートからデータを取得、リスト化し、その中からランダムに値を選ぶことで実現しています。
感想
さすがに長い文章になるほど文の意味はとおらなくなってしまうが、短いツイートなら本当に本人がいったようなツイートをすることもあるし、本人が過去につぶやいた内容からランダムにワードが選ばれているので、組み合わせによっては思わず笑ってしまうツイートも生成することができました。
アイコンなど全く同じにしてしまえばBotと本人の区別がつかないこともあるのではないかと思っており、チューリングテストしてみたいというお気持ち。
友人B君、協力してくれてありがとう。
おわりに
機械学習でもできるのかなとも思ったんだけど、それは次回以降の課題ということにしよう...もう春休みが終わるし...。オンライン授業だけど。
最後まで読んでいただきありがとうございます。
なにかアドバイス等ありましたらコメントいただけると嬉しいです。

- 投稿日:2020-04-01T18:14:14+09:00
SQLAlchemyでのsessionの扱い方
はじめに
SQLAlchemyでは,sessionを生成したあと,必要に応じて
commit()やrollback(),close()を行う必要がある.
ここでは,DB操作を行うクラスを作成し,sessionの受け渡し方についてまとめる.
以下では,下のようなモデルクラスが存在しているとする.models.pyclass User(Base): __tablename__="user" #テーブル名を指定 id=Column(Integer, primary_key=True) first_name=Column(String(255)) last_name=Column(String(255))sessionの悪い扱い方
以下のソースコードのようにしてしまうと良くない.
wrong_way.pyfrom models import User class FirstName(object): def update_first_name(self, user_id, first_name): session=Session() try: user=session.query(User).filter(User.id==user_id).one() #id=user_idであるobjを取り出す user.first_name=first_name #first_nameを変更 session.commit() except: session.rollback() raise class LastName(object): def update_last_name(self, user_id, last_name): session=Session() try: user=session.query(User).filter(User.id==user_id).one() #id=user_idであるobjを取り出す user.first_name=first_name #last_nameを変更 session.commit() except: session.rollback() raise def run_my_program(): FirstName().update_first_name(1, "update_first_name") LastName().update_last_name(1, "update_last_name")なぜなら,
run_my_program中のupdate_first_nameとupdate_last_nameで,同一sessionが使われていないため,
「first_nameはupdateされたが,last_nameはupdateされなかった」
のようなことが起きてしまうからである.sessionの良い扱い方1
そこで,以下のソースコードのようにすれば解決する.
right_way_1.pyfrom models import User class FirstName(object): def update_first_name(self, user_id, first_name, session): user=session.query(User).filter(User.id==user_id).one() user.first_name=first_name class LastName(object): def update_last_name(self, user_id, last_name, session): user=session.query(User).filter(User.id==user_id).one() user.first_name=first_name def run_my_program(): session = Session() try: FirstName().update_first_name(session) LastName().update_last_name(session) session.commit() except: session.rollback() raise finally: session.close()こうすることで,
update_first_nameとupdate_last_nameで,同一sessionが使われ,
「片方だけが正常に実行された」
のような状況が起こらない.sessionの良い扱い方2
次に,
context managerを用いたsessionの扱い方を紹介する.
なお,context managerについては,以下の記事が大変わかりやすく参考になるのでここでは説明を省略する.
Pythonのコンテキストマネージャってなんなの?と思って調べた話right_way_2.pyfrom models import User from contextlib import contextmanager @contextmanager def session_scope(): session = Session() # def __enter__ try: yield session # with asでsessionを渡す session.commit() # 何も起こらなければcommit() except: session.rollback() # errorが起こればrollback() raise finally: session.close() # どちらにせよ最終的にはclose() class FirstName(object): def update_first_name(self, user_id, first_name, session): user=session.query(User).filter(User.id==user_id).one() user.first_name=first_name class LastName(object): def update_last_name(self, user_id, last_name, session): user=session.query(User).filter(User.id==user_id).one() user.first_name=first_name def run_my_program(): with session_scope() as session: FirstName().update_first_name(session) LastName().update_last_name(session)参考文献
この記事は以下の情報を参考にして執筆しました.
・公式ドキュメント(Session Basics)
・Pythonのコンテキストマネージャってなんなの?と思って調べた話
- 投稿日:2020-04-01T18:09:08+09:00
画像を二値化処理させる。さらに、二領域間の最短距離を算出できるようにした(Ver1.1)。
はじめに
今回は、前回記事二領域間の最短距離を求めるプログラムについて、修正を行った内容です。
前回は、画像サイズをそのまま処理していたことと、必ずしも二領域間の最短距離を求めることができていなかった課題がありました。画像を二値化処理させる。さらに、二領域間の最短距離を算出できるようにした。
https://qiita.com/Fumio-eisan/items/05a6506da8cc88d89e49要点は下記です。
- 画像を小さくして処理しやすくする
- 任意の領域を二値化させる
- 領域間の距離を求め、そこから最短距離を求める
画像を小さくして処理しやすくする
今回はこちらの焼肉画像を用いて二つの肉の最短距離を求めたいと思います。
前回の記事ではそのままの画像サイズで処理を行っていました。この場合、画像サイズが大きくなると領域を囲む処理が重くなってしまいます。従って、画像サイズを小さくして処理しやすくします。
今回は、幅を300ピクセルに固定して同じアスペクト比(幅:高さ比)で縮小させます。
img.ipynbdef scale_to_width(img, width): scale = width / img.shape[1] return cv2.resize(img, dsize=None, fx=scale, fy=scale) img = scale_to_width(img, 300)#300ピクセルに固定画像を二値化させる
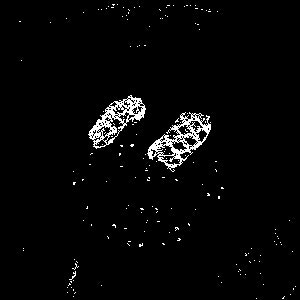
次に、二値化により肉部分だけを色を抽出したいと思います。cv2.inRangeメソッドによって特定の色を白、特定の色を黒とします。
img.ipynbimport numpy as np bgrLower = np.array([0, 0, 130]) # 抽出する色の下限(BGR) bgrUpper = np.array([120,120, 255]) # 抽出する色の上限(BGR) img_mask = cv2.inRange(img, bgrLower, bgrUpper) fig = plt.figure(figsize=(8,8)) ax = fig.add_subplot(1,1,1) ax.imshow(img_mask) ax.axis("off")
見事肉だけ白く表示させることができました。ただ、これは元画像の色合いによって手動で抽出する色を調整する必要があるため、手間になります。この表示させたい色だけを抽出して二値化させる手法は、別途まとめたいと思います。
領域間の距離を求め、そこから最短距離を求める
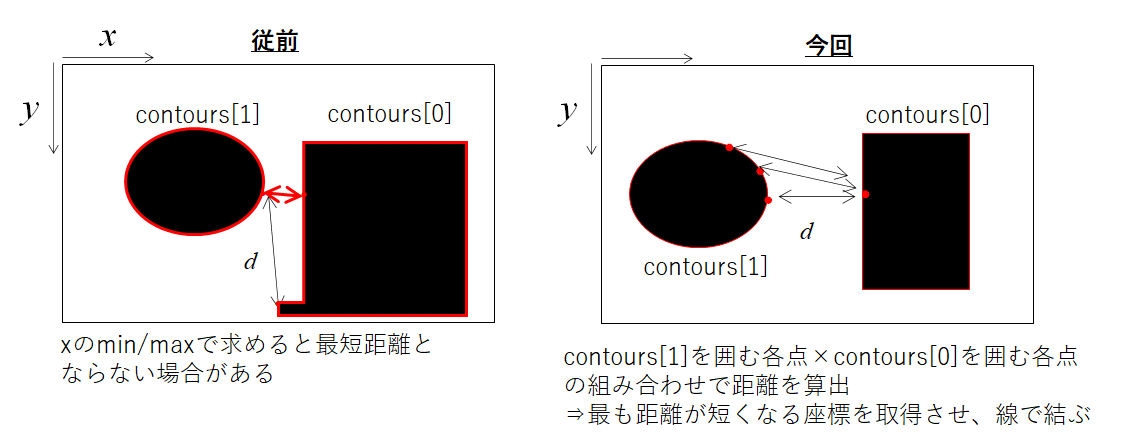
次に、領域間の距離を求めます。前回は、各領域のx座標最大値/最小値を取る座標を取得させてから距離を求めました。しかし、その求め方は必ずしも最短距離をとれるわけではありません(下右図の例)。
対策としては、各領域を囲む点通しの組み合わせによる距離を全て求めて、それが最小値を取る座標を取得することです。
この時、画像サイズを調整しないとかなり計算数が大きくなるため、前に示した画像サイズを縮小化させることが効いてきます。img.ipynbimport numpy as np dd=np.array([300])#空白の配列だとif min(dd)> dでエラーが出るため for i in range(len(contours[0])): x3 = contours[0][i][0][0] y3 = contours[0][i][0][1] for ii in range (len(contours[1])): x4 = contours[1][ii][0][0] y4 = contours[1][ii][0][1] d = get_distance(x3, y3, x4, y4) if min(dd) > d: x3min =x3 y3min =y3 x4min =x4 y4min =y4 dd = np.append(dd,d)26.248809496813376
無事に最短距離を求めることができました。
おわりに
画像ファイルを小さくするだけで、処理がかなり早くなりました。一方、色の抽出は手動で行いますので、ここは改善の余地があります。二値化したいところだけ自在に分けられるような改造を検討したいと思います。
簡単ですが改善しましたので、下記に格納しています(日付が新しいものがバージョンアップしたものです)。

- 投稿日:2020-04-01T17:46:18+09:00
AtCoder Beginner Contest 088 過去問復習
所要時間
感想
以前解いた過去問になりますが、D問題でまた同じミスをしてしまいました。
D問題にてミスの内容については言及しておきたいと思います。A問題
500円通貨は無限に持っているので、nを500で割った余りがaより小さいかどうかを考えます。
answerA1.pyn=int(input()) a=int(input()) print("Yes" if n%500<=a else "No")B問題
大きい順に並べて0-indexedで偶数のインデックスのものをAliceがとり、奇数のインデックスのものをBobがとるのが、二人の自分の得点を最大化する戦略となります。
answerB.pyn=int(input()) a=sorted(list(map(int,input().split())),reverse=True) ans=0 for i in range(n): if i%2==0: ans+=a[i] else: ans-=a[i] print(ans)C問題
i行目について$a_i+b_1,a_i+b_2,a_i+b_3$であり、それぞれの行について(2列目の値-1列目の値)と(3列目の値-2列目の値)はそれぞれ等しいことが高橋君の情報が正しいために必要な条件であり、この条件を満たしている時は適当にaの値を定めれば十分であることも実験をすると明らかになります。(説明が適当ですが、(2列目の値-1列目の値)と(3列目の値-2列目の値)をそれぞれ実際に計算すると明らかです。)
answerC.pyc=[list(map(int,input().split())) for i in range(3)] x=c[0][2]-c[0][1] y=c[0][1]-c[0][0] for i in range(1,3): if c[i][1]-c[i][0]!=y: print("No") break if c[i][2]-c[i][1]!=x: print("No") break else: print("Yes")D問題
この問題は前に解いて印象的だったので解き方は覚えていましたが、最後ミスを多発してしまいました。
すぬけ君はできるだけスコアを伸ばしたいので、できるだけ多くのマス目を黒に変える必要があります。しかし、マス目を多く変えすぎるとけぬす君がゴールにたどり着くことができません。つまり、けぬす君が辿ってゴールにいく際に通るマス目以外の全てを塗りつぶせば良く、最大化するには最短経路で通るところ以外の全てを塗りつぶせば良いです。
したがって、この問題は単純な最短経路問題とみなすことができます。僕はdfsによりコードを書きました。しかし、Pythonの場合は再帰の深さの上限がそれぞれの環境によって設定されているので、sys.setrecursionlimit(x)によって再帰の制限回数をxに設定しました。しかし、このxが大きすぎるとTLEしてしまうので、できるだけ小さくする必要があります。この問題ではHが50でWが50なので2500以上であれば良いかと思ったのですがREになってしまったので再帰回数が2500より多くなるパターンがあるようです(パッと思いつきません…)。
再帰回数をギリギリに設定しようとしましたが、Writerの意向なのかうまくいきませんでした。ここで最後にPyPyで高速化することでうまくいきました。また、最短距離を求める際には幅優先探索の方が有効でWriter解は幅優先探索になります(深さ優先探索だと余計に深く調べ過ぎてしまうので)。answerD.pyimport sys h,w=map(int,input().split()) sys.setrecursionlimit(h*w+10) s=[list(input()) for i in range(h)] inf=1000000000000000 d=[[inf]*w for i in range(h)] def dfs(i,j): global h,w,s nex=[(0,-1),(0,1),(-1,0),(1,0)] for k in range(4): l,m=i+nex[k][0],j+nex[k][1] if 0<=i+nex[k][0]<h and 0<=j+nex[k][1]<w: if s[l][m]=="." and d[l][m]>d[i][j]+1: d[l][m]=d[i][j]+1 dfs(l,m) d[0][0]=0 dfs(0,0) ans=0 for i in range(h): for j in range(w): if s[i][j]==".": ans+=1 if d[h-1][w-1]==inf: print(-1) else: print(ans-d[h-1][w-1]-1)

- 投稿日:2020-04-01T17:00:21+09:00
[Keras] CIFAR10データセットで正確度75%を実現
1.はじめに
今日は、CIFAR10データセットで、正確度75%を達成する内容をご紹介します。
最初は、90%以上を目標としましたので、これからもファインチューニングを続ける予定です。2.やりたいこと
下記の図のように、普段のAIプロジェクトで行われる内容を一通り実行します。
今回のタスクの特徴です。
1. データセットはCIFAR10を利用する。データセットを(Train, Validation, Test) = (0.8, 0.1, 0.1)に分けて利用する。
2. Kerasのgeneratorを利用し、Data Augmentationを利用する。
3. 学習済みモデルVGG16を利用した、転移学習を利用する。
4. ファインチューニングされた学習モデルをh5形式で保存する。
5. 推論部では、モデルを呼び出し、テストを行う。
6. テスト結果を混合行列(Confusion Matrix)でプロットする。
7. 学習と推論の部分を別のPythonファイルにする。3.転移学習内容
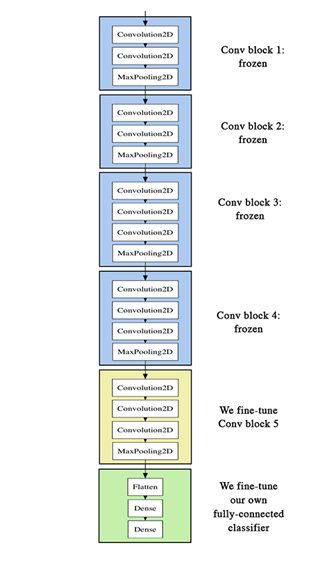
VGG16は、五つのConv Blockと最後のFull Connected Layerで構成されています。
今回は、一つ目から四つ目のConv Blockはそのままにし、五つ目と最後のFull Connected Layerを学習することにします。
4.実行結果
4.1.学習の結果 (train.py)
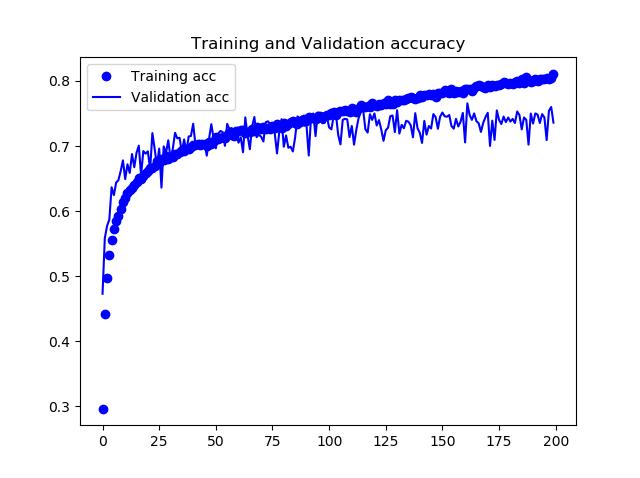
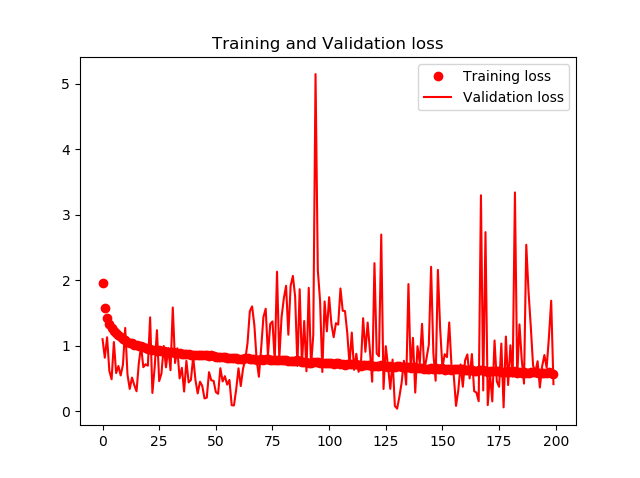
下記の図に学習時の正確度Accuracyと損失関数Lossの推移を示します。200Epochsまでの学習で、75%の正確度が得られました。
ただし、TrainデータとValidaionデータの結果が離れていくので、Overfittingが発生しているようにも見えます。
4.2.推論の結果(Inference.py)
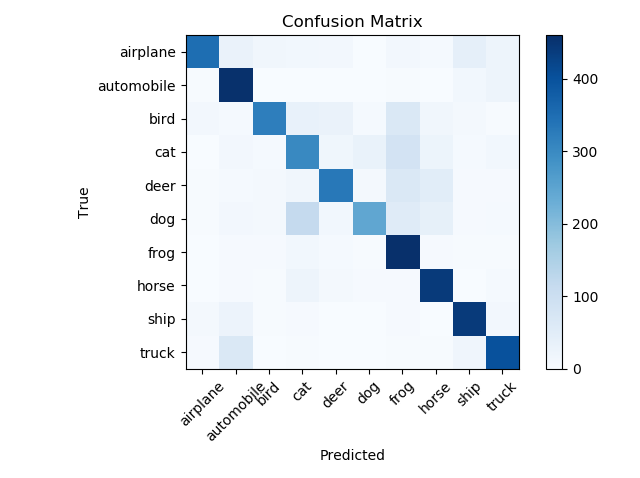
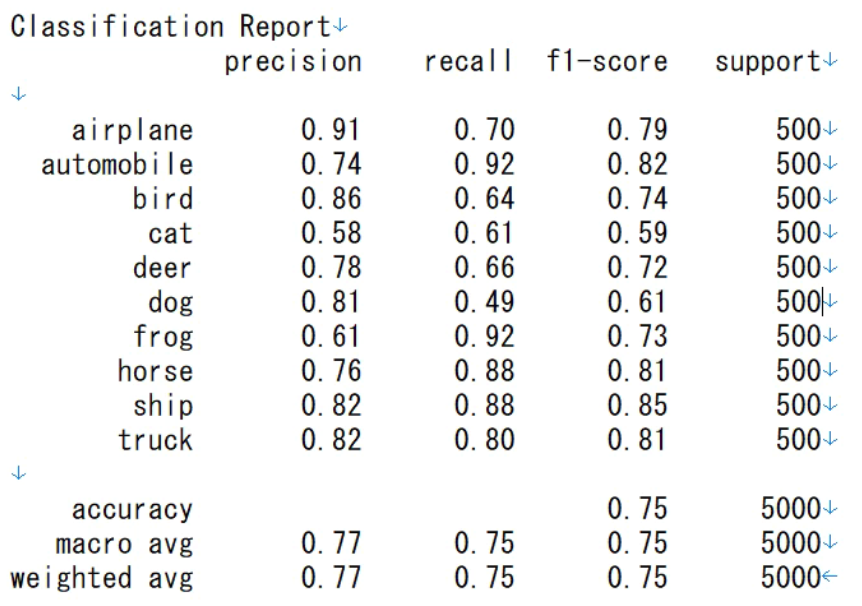
推論の結果です。
テストデータによる正確度は平均で74.5%です。test acc: 0.7450000047683716
Confusion Matrixの処理には、ScikitLearnのConfusion Matrixモジュールを利用しました。5000個のテストデータの推論結果です。(5000個=500個*10クラス)
上記のテキスト形式の混同行列をMatplotlibでプロットします。
そして、各クラスごとのPrecision, Recall、F1-scoreの結果も教えてくれます。
(Precision, Recallの説明は、こちらを参考にしてください。)
5.コード
学習train.py
プログラムの構造
train.py##Import import os import keras from keras.preprocessing.image import ImageDataGenerator from keras import models, layers from keras.applications import VGG16 from keras import optimizers import numpy as np import matplotlib.pyplot as plt from keras.callbacks import EarlyStopping #1.plot loss and accuracy def plot_acc(hist): acc = hist.history['acc'] val_acc = hist.history['val_acc'] epochs = range(len(acc)) plt.plot(epochs, acc, 'bo', label='Training acc') plt.plot(epochs, val_acc, 'b', label='Validation acc') plt.title('Training and Validation accuracy') plt.legend() pass def plot_loss(hist): loss = hist.history['loss'] val_loss = hist.history['val_loss'] epochs = range(len(loss)) plt.plot(epochs, loss, 'ro', label='Training loss') plt.plot(epochs, val_loss, 'r', label='Validation loss') plt.title('Training and Validation loss') plt.legend() def main(): #Initial Setting width_x, width_y = 32, 32 batch_size = 32 num_of_train_samples = 40000 num_of_val_samples = 5000 num_of_test_samples = 5000 #CIFAR100 epochs = 1000 # label_class classes = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'] nb_classes = len(classes) ## 01. Data Input # folder information base_dir = 'E:\\Dataset\CIFAR10\cifar10_keras_training' train_data_dir = os.path.join(base_dir, 'train') val_data_dir = os.path.join(base_dir, 'val') test_data_dir = os.path.join(base_dir, 'test') print(train_data_dir) print(val_data_dir) print(test_data_dir) # Input Data Generation (with Data Augmentation) train_datagen = ImageDataGenerator(rescale=1. / 255, rotation_range=20, width_shift_range=0.1, height_shift_range=0.1, shear_range=0.1, zoom_range=0.1, horizontal_flip=True, fill_mode='nearest') val_datagen = ImageDataGenerator(rescale=1. / 255) test_datagen = ImageDataGenerator(rescale=1. / 255) train_generator = train_datagen.flow_from_directory( train_data_dir, target_size=(width_x, width_y), color_mode='rgb', classes=classes, class_mode='categorical', batch_size=batch_size, shuffle=False) val_generator = val_datagen.flow_from_directory( val_data_dir, target_size=(width_x, width_y), color_mode='rgb', classes=classes, class_mode='categorical', batch_size=batch_size, shuffle=False) test_generator = test_datagen.flow_from_directory( test_data_dir, target_size=(width_x, width_y), color_mode='rgb', classes=classes, class_mode='categorical', batch_size=batch_size, shuffle=False) ##2. CNN Model conv_base = VGG16(weights='imagenet', include_top=False, input_shape=(width_x, width_y, 3)) # conv5 block fine tuning only conv_base.trainable = True set_trainable = False for layer in conv_base.layers: if layer.name == 'block5_conv1': set_trainable = True if set_trainable: layer.trainable = True else: layer.trainable = False model = models.Sequential() model.add(conv_base) model.add(layers.Flatten()) model.add(layers.Dropout(0.5)) model.add(layers.Dense(512, activation='relu')) model.add(layers.Dense(nb_classes, activation='softmax')) model.summary() model.compile(loss='categorical_crossentropy', optimizer=optimizers.RMSprop(lr=1e-5), metrics=['acc']) model.summary() ##3. Training # early_stopping = EarlyStopping(patience=20) history = model.fit_generator( train_generator, epochs=epochs, steps_per_epoch=num_of_train_samples//batch_size, validation_data=val_generator, validation_steps= num_of_val_samples//batch_size, verbose=2) # callbacks=[early_stopping] ##5. Model Save model.save('./Model/CIFAR10_trained03_seq.h5') ##4. Accuracy and Loss Plot plot_acc(history) plt.figure() plot_loss(history) plt.show() ## Run code if __name__=='__main__': main()推論Inference.py
プログラムの構造
Inferenece.py## Import import os import keras from keras.models import load_model from keras.preprocessing.image import ImageDataGenerator from sklearn.metrics import confusion_matrix, accuracy_score from sklearn.metrics import classification_report import numpy as np import matplotlib.pyplot as plt ##Confusion matrix function def plot_confusion_matrix(cm, classes, cmap): ''' confusion_matrixをheatmap表示する関数 Keyword arguments: cm -- confusion_matrix title -- 図の表題 cmap -- 使用するカラーマップ Normalize = True/ False ''' plt.imshow(cm, cmap=cmap) plt.colorbar() plt.ylabel('True') plt.xlabel('Predicted') plt.title('Confusion Matrix') tick_marks = np.arange(len(classes)) plt.xticks(tick_marks, classes, rotation=45) plt.yticks(tick_marks, classes) plt.tight_layout() ##Main Function def main(): #01. Initial Setting width_x, width_y = 32, 32 batch_size = 32 # label_class classes = ['airplane', 'automobile', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck'] #02. load_test data base_dir = 'E:\\Dataset\CIFAR10\cifar10_keras_training' test_data_dir = os.path.join(base_dir, 'test') #02-01. Input Data Generation (with Data Augmentation) test_datagen = ImageDataGenerator(rescale=1. / 255) test_generator = test_datagen.flow_from_directory( test_data_dir, target_size=(width_x, width_y), color_mode='rgb', classes=classes, class_mode='categorical', batch_size=batch_size, shuffle=False) #In case of test generator, Shuffle sholud be turned off. #03. Load Trained model model_dir = './Model/' model_name = 'CIFAR10_trained03_seq.h5' model_dir_name = os.path.join(model_dir, model_name) print(model_dir_name) model=load_model(model_dir_name) #04. Evaluating Test Data test_loss, test_acc = model.evaluate_generator(test_generator, steps=50) print('test acc:', test_acc) #05. Prediction and Confusion Matrix Y_pred = model.predict_generator(test_generator) y_pred = np.argmax(Y_pred, axis=-1) y_true = test_generator.classes print('Confusion Matrix') print(confusion_matrix(y_true, y_pred)) print('Classification Report') print(classification_report(y_true, y_pred, target_names=classes)) cm = confusion_matrix(y_true, y_pred) cmap = plt.cm.Blues plot_confusion_matrix(cm, classes=classes, cmap=cmap) plt.show() ## Run code if __name__=='__main__': main()6.参考資料
1.【Python】多重分類問題のTraining, Validation, Testフォルダーを簡単に作る方法 https://qiita.com/kotai2003/items/293beaf9d79a05cb74b0
2. 【機械学習】分類器の評価(1) https://qiita.com/kotai2003/items/8d5174cbc121e86a797e
3. Confusion Matrix,https://gist.github.com/RyanAkilos/3808c17f79e77c4117de35aa68447045
4. Keras で CNN 実装およびファインチューニングをやってみる at CIFAR-10 http://blog.livedoor.jp/itukano/archives/52139557.html
5. https://github.com/geifmany/cifar-vgg/blob/master/cifar10vgg.py




- 投稿日:2020-04-01T16:32:10+09:00
AtCoder Beginner Contest 092 過去問復習
所要時間
感想
同時にあげるABC088とまとめて解きました。実質70分ですが、二回分のコンテストを合計で120分で解いていてギリギリで解き切れたのでうれしかったです。
D問題はかなりパズルよりで以前解いたAGCの問題に似ていたので思いつくことができました。A問題
乗り放題切符が通常切符より安いことがあり得ないと思い少し時間をかけてしまいました。
answerA1.pya,b,c,d=[int(input()) for i in range(4)] print(min(a,b)+min(c,d))B問題
一人ずつ数えてくのではなく、それぞれの日に参加者がチョコレートを食べているのかを判定していきます。
$1,A_i+1,2A_i+1,…$と食べるので、$A_i$で割った時の余りが1の日かどうかを判定すれば良いのですが、A_iが1の時だけ余りが0になるので、注意が必要です。answerB.pyn=int(input()) d,x=map(int,input().split()) a=[int(input()) for i in range(n)] ans=0 for i in range(1,d+1): for j in range(n): if a[j]==1: ans+=(i%a[j]==0) else: ans+=(i%a[j]==1) print(ans+x)C問題
コンテスト中には気付きませんでしたが、入力の$A_1,A_2,…,A_n$に$A_0=0$と$A_{n+1}=0$を加えると考えやすいです。ここで、それぞれ一つずつ訪れる観光スポットを取りやめることから、元々の旅行での金額の総和から観光スポットを一つ取りやめた時の差額を考えれば良いのではと考えました。
この時、まず全ての観光スポットを順に訪れた時の総和をSとすれば以下の式が立てられます。
さらに、ここから仮にi番目の観光スポットを訪れないとすると、その時の金額の総和は差額を考えて、$S-|A_i-A_{i-1}|-|A_{i+1}-A_i|+|A_{i+1}-A_{i-1}|$になります。
これをi=1~nで考えれば答えを求めることができます。answerC.pyn=int(input()) a=list(map(int,input().split())) base=0 for i in range(n+1): if i==0: base+=abs(a[0]) elif i==n: base+=abs(a[n-1]) else: base+=abs(a[i]-a[i-1]) ans=[] for i in range(n): if i==0: ans.append(base+abs(a[1])-abs(a[0])-abs(a[1]-a[0])) elif i==n-1: ans.append(base+abs(a[n-2])-abs(a[n-1])-abs(a[n-2]-a[n-1])) else: ans.append(base+abs(a[i+1]-a[i-1])-abs(a[i+1]-a[i])-abs(a[i]-a[i-1])) for i in range(n): print(ans[i])answerC_better.pyn=int(input()) a=list(map(int,input().split())) b=[0] b.extend(a) b.append(0) a=b base=0 for i in range(n+1): base+=abs(a[i+1]-a[i]) ans=[] for i in range(1,n+1): ans.append(base+abs(a[i+1]-a[i-1])-abs(a[i+1]-a[i])-abs(a[i]-a[i-1])) for i in range(n): print(ans[i])D問題
一つ出力されるので自分にとって都合の良いものを探すしかありません。こういう問題は良くAGCで出ますが、何をしたいのかはっきりさせないと迷宮入りしそうです。
まず、この問題ではA,Bの二変数があったので、A,Bのどちらかを0にしようとしました。しかし、片方が0の場合、残りは全て連結になってしまうので、A,Bの間に差がない方が良いのではないかと考えました。そこで、A,Bの間に差をなくすために自由にその差を調節出来るような小構造に分けて考えることにしました。さらに、この際にできるだけ広いグリッドで一つの連結成分はできるだけ小さくした方が自分に都合の良いグリッドを作りやすいのではと考え試行錯誤しました。
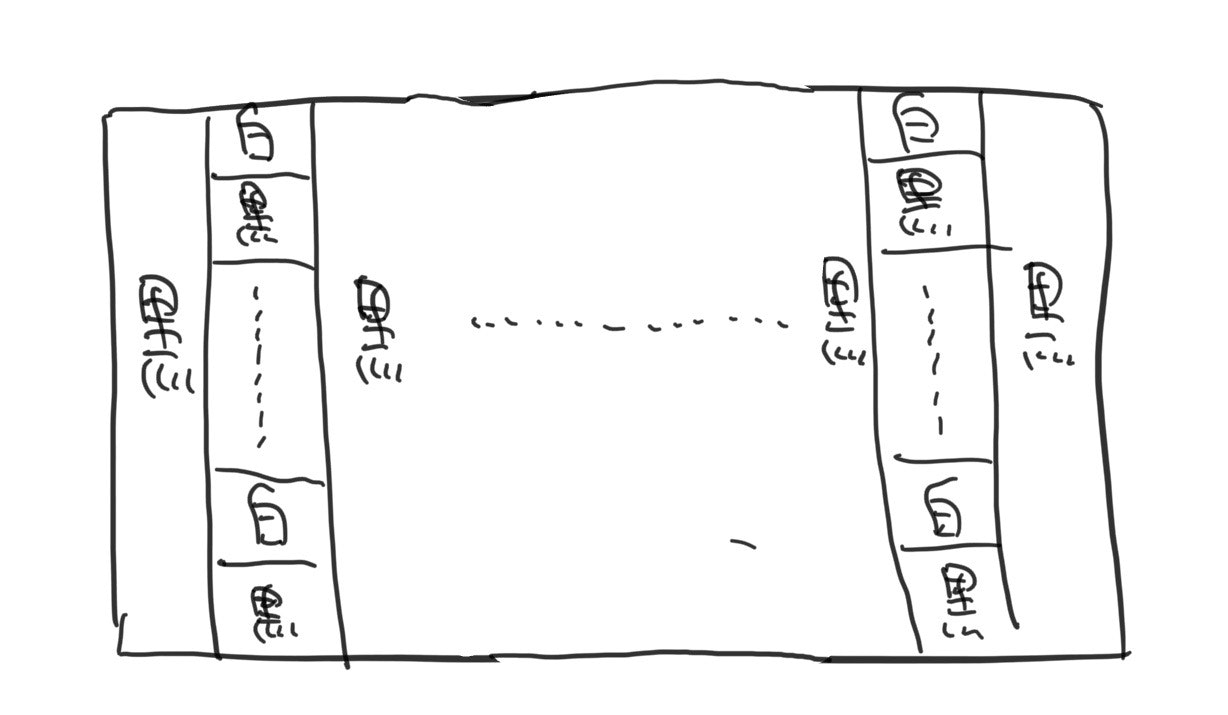
まず初めに思いついたのが以下のような最小構造を組み合わせたものになります。
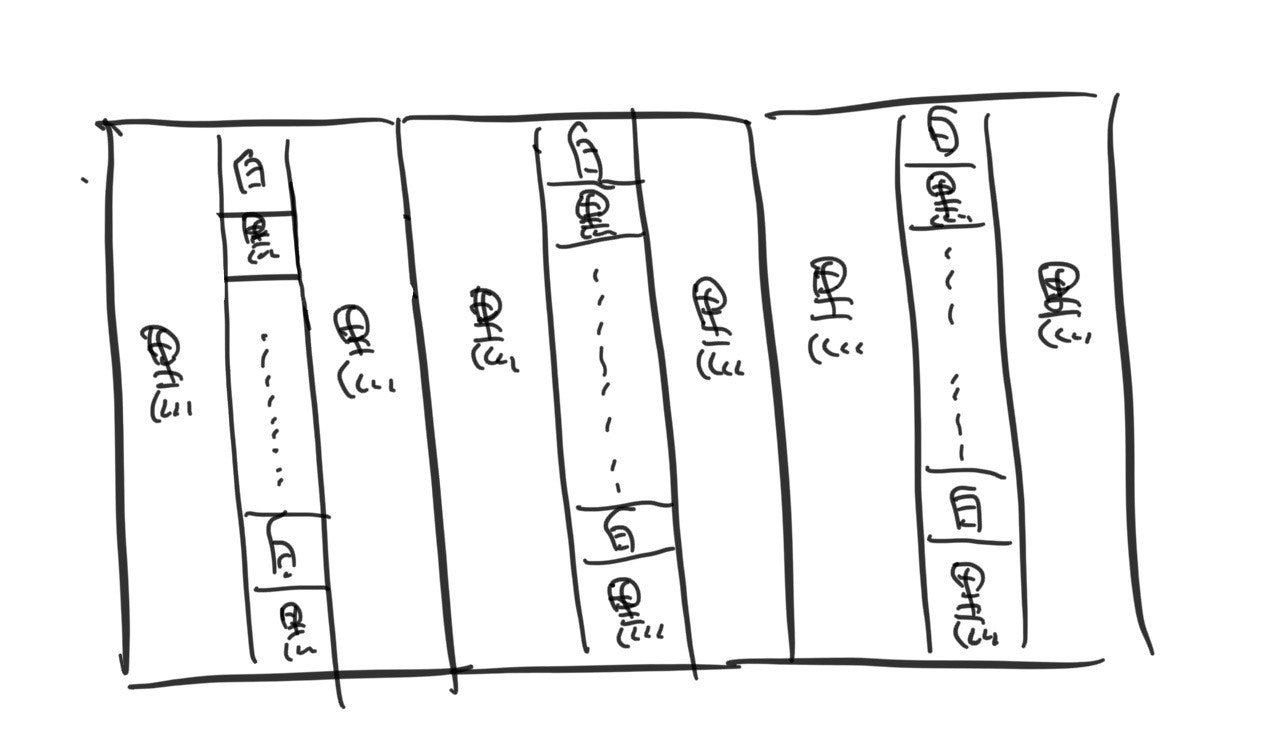
上記の構造を逆パターンが隣り合うように組み合わせてA,Bを満たす構造を作ろうと思い試してみましたが、うまくいきませんでした。しかし、この構造で実験しているうちに同じパターンを組み合わせた場合は以下のようになりました。このパターンの場合、白の連結成分は0~50over、黒の連結成分は1なので、調節が非常にしやすいのではないかと考えました。(逆のパターンは黒の連結成分が0~50over、白の連結成分が1)
上記のパターンには小構造が重なる部分に黒の少し無駄があるので無駄を減らして改善したものが下の構造になります。
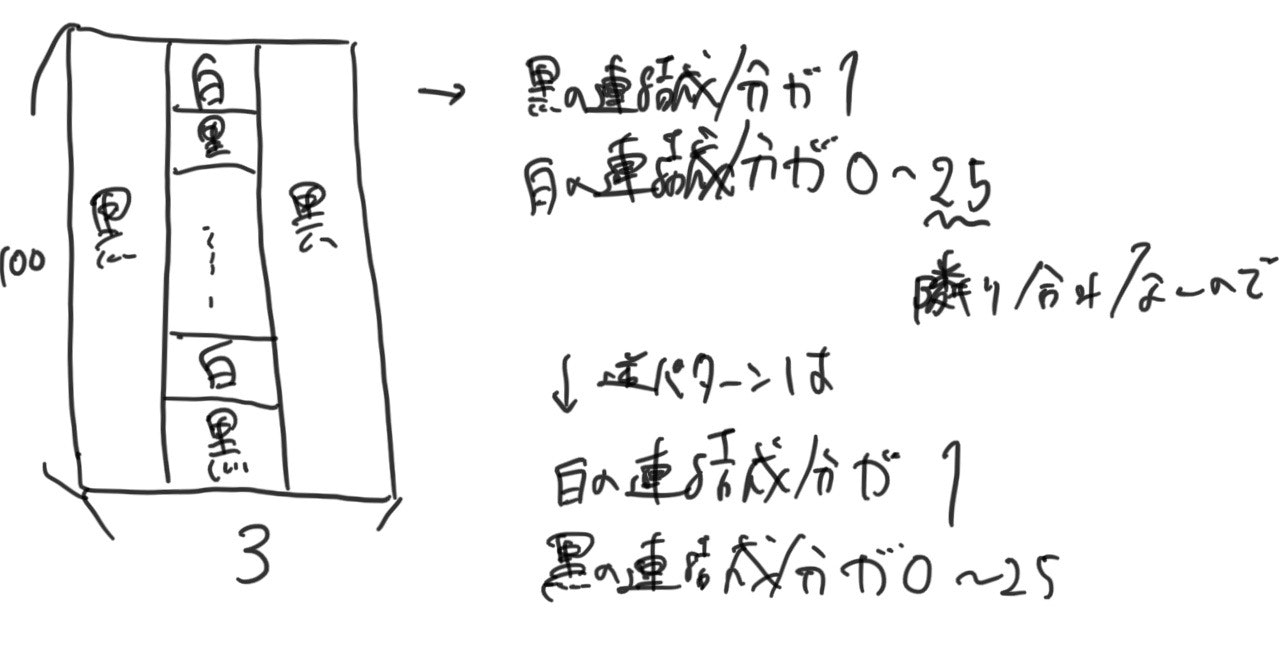
ここで上の構造の縦を100で横を50とし、逆パターンをつなげてみます。すると、上記の構造については、白の連結成分が0~25*50で黒の連結成分が1、逆パターンの構造では白の連結成分が1で黒の連結成分が0~25*50になります。したがって、つなげると、白の連結成分が1~25*50で黒の連結成分が1~25*50になります。したがって、1<=A<=500で1<=B<=500の制限であればこの方法でグリッドを作り出すことができる。
answerD.pya,b=map(int,input().split()) print("100 100") a-=1 b-=1 for i in range(100): if i%2==0: print("."*50+"#"*50) else: for j in range(50): if j%2==0 or j==49: print(".",end="") else: if b>0: print("#",end="") b-=1 else: print(".",end="") for j in range(50): if j%2==0 or j==49: print("#",end="") else: if a>0: print(".",end="") a-=1 else: print("#",end="") print("")

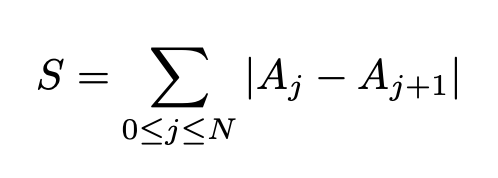
- 投稿日:2020-04-01T15:56:05+09:00
70日目 GCI2019Winter無事修了しました!
12月から始まった東大のデータサイエンティスト講座、無事修了しました!
GCI Online Course 東大のデータサイエンティスト/未来のCMO育成講座のオンラインコースです
3ヶ月でデータサイエンティストを要請するという講座でなんと無料です。●コースの概要 * 大量のデータを自由自在に解析・分析し、隠れた関係性を発見する。そんなスキルを身につけた「データサイエンティスト」に対する需要は、工学分野だけならず、医療・経済・経営・ライフサイエンスなど非常に多くの分野で高まる一方です。 * 本コースでは、あらゆる分野で武器になるデータの解析・分析スキルのコアとなる機械学習およびビッグデータを扱う技術、分析結果を効果的に可視化する技術の基盤を網羅的に身につけ、一人前のデータサイエンティストとして活躍する入り口に立つことを目指します。 * 受講費用は一切発生しません(通信費等は自己負担でお願いします)。とにかく課題の量が多い。この3ヶ月は毎日が機械学習漬けでした。
前年度のテキストが販売されていたので、目を通してみましたが、あまりの難しさにこりゃ無理だと投げそうになりました。東京大学のデータサイエンティスト育成講座 塚本 邦尊
https://www.amazon.co.jp/dp/B07PD237GQ/ref=cm_sw_r_tw_dp_U_x_j1bHEb66RA461ですが、テキストがよく練られていたこと、Slackで随時質問できる事と、チームで参加した事と、サポート体制にずいぶん助けられ、なんとか修了までこぎつけました。
うえっとなったテキストが読めるようになる。これは自信になります。4月からまた受講者を募集しておりますので、これから機械学習をはじめようと思うみなさまにぜひおすすめしたいと思います。
受講テスト(12/7〜12)
受講前にスキルを確認のためのテストがありました。WhirlwindTourOfPythonのような基礎的なレベルですとのこと。リンク先がいきなり英語の解説で面食らいました。Pythonをかじっていたので何とかクリア。
問題は、行列の問題をPythonで解いて出すというもの。数学は中学校で挫折したので問題の意味がさっぱりわからず。数学が得意な人に教えていただきどうにかクリアしました。第1回(12/18) データサイエンスとは、Python基礎、ライブラリ
IT化によりデータが大量にあるのにほとんど分析されていない。 これを分析すると、ビジネスにとんでもなく生かせる事ができる、、、という講義でした。翌日に動画で配信があり面白かったです。それからPython基礎です。
第2回(12/25) Pythonによる科学計算とデータ加工処理の基礎(Numpy,Pandas)
Pythonの表計算を学びました。全部コマンドのExcelみたいなものです。集計、統計、etcこの後めちゃくちゃ使いました。
コンペその1タイタニック号の生死予測。
KaggleのTitanic: Machine Learning from Disasterと同じです。
最初はまったく分からず、映画を見て予測を思いついても、どうやって実装したらいいか暗中模索でした。Kaggleやチーム、Slackで意見交換しながら粘りました。アイデアがスコアに結びつくと面白くなってきます。結果を次の予測に再利用するなんちゃってブースティングでランクインしました。コンペ後に上位のコードが公開されるのですが、ほんと頭のいい人がいるんだなーと感心するばかりです。第3回(1/8) データサイエンスにおけるデータの可視化(Matplotlib)
グラフ、相関行列とヒートマップの作り方を学びました。なかなか思うように表現できないので、最初は美しいグラフを集めて、そのコードをコピペしながら慣れると良いようです。
第4回(1/15) 確率統計の基礎
合計、平均などの統計、散布図、ヒストグラムなどの図の書き方。確率・統計はさっぱり分からず。初心者問題を解くのがやっとでした。
コンペその2 ワインのクオリティ
ポルトガルのワインプロジェクトより、4898本のワインの成分とソムリエによる評価を読み込んで、成分からおいしさを予測するというものです。ワインは大好きなのです。何かというとお店のワインのラベルを読んではあれこれ考えるという楽しいコンペでした。
第5回(1/29) 機械学習の基礎(教師あり学習)
教師あり学習、教師なし学習、強化学習について。タイタニックやワインの予想で使っている手法をもう一度丁寧に解説。重回帰、ロジスティック回帰、ラッソ回帰、リッジ回帰、K-NN、 サポートベクターマシンあたりをチュートリアルに沿ってぽちぽちしていけば、なんとなく使えるようになった・・・気がします。
第6回(2/5) 機械学習の基礎(教師なし学習)
教師なし学習、目的変数がない学習モデルの構築を学びました。ざっくり分類、クラスタリング、主成分分析・・・。正直まだよく理解できていません。事前情報なしにデータをふるい分けできるのは便利なので覚えておく・・・というレベル。要復習ですね。
コンペその3 PUBGの勝者予想
KaggleのPUBG Finish Placement Prediction (Kernels Only)と同じです。
PUBGは100人の参加者が島に送られバトルロワイヤルするというゲームです。やってみましたが討ち死にしてばかり。まずはよく遊ぶ人にゲームをしている所を見せていただきました。アイテム、乗り物、武器の活用、刻々と狭まる安全圏にどう潜り込むかが勝負の決め手のようです。
しかしゲームの強さをどうコードにしたらよいかがさっぱり分かりません。
Kaggleにはどのように予測したかがNotebookとして沢山公開されています。目から鱗のアプローチがたくさんありました。
機械学習がものすごいスピードで発展するわけです。強そうなコードを組み合わせて提出するとそこそこいいスコアがとれました。第7回(2/12) モデルの検証方法とチューニング方法
モデルのパラメータを調整、さまざまなモデルの特徴、複数のモデルを組み合わせての予測を学びました。
ちゃんとやろうとすると前例主義に陥ったり考えすぎで外したりするので、多少アソビを作っておくというイメージです。
それから、バギングというデータをいくつかに分割して学習させあう方法を実装すると、予測精度がぐっと良くなりました。
まだよく理解できていないので、深めたいところです。第8回(3/4) データサイエンティスト中級者への道
第一線で活躍している方をお呼びして現場の話でした。マーケティング、物を売るには、どう思ってもらいたいかなど、データをビジネスの課題に生かす方法について学びました。CMの効果測定の話などすごく面白かったです。それから深層学習、Pythonを高速に実行するためのアルゴリズム、Pyspark、SparkSQL、その他数学的手法の紹介、エンジニアリングツールの紹介でした。
最終課題 Home Credit社への新規事業提案
東南アジアで展開するクレジット会社、Home Credit社のデータを分析して、新たなビジネスを提案しましょうというもの。
昨年おこなわれたKaggleのHome Credit Default Riskのデータを使って、別の切り口を機械学習を知らない経営陣にプレゼンするのです。これもまた見当もつかないところから、8回目の講義を参考に、こんな予測なら喜ばれるかなと考えてどうにか提出しました。修了して
こうして振り返るとよく修了できたなーと我ながら感心してしまいます。講座のみなさまの手厚いサポートに感謝しきりです。
コロナでいろいろな予定がキャンセルになりましたので、ぼちぼち復習していこうと思います。
4月からまたGCI 2020 Summerが始まりますので、機械学習に興味のある方はぜひ。おすすめです!
- 投稿日:2020-04-01T15:56:05+09:00
GCI2019Winter無事修了しました!
12月から始まった東大のデータサイエンティスト講座、無事修了しました!
GCI Online Course 東大のデータサイエンティスト/未来のCMO育成講座のオンラインコースです
3ヶ月でデータサイエンティストを要請するという講座でなんと無料です。●コースの概要 * 大量のデータを自由自在に解析・分析し、隠れた関係性を発見する。そんなスキルを身につけた「データサイエンティスト」に対する需要は、工学分野だけならず、医療・経済・経営・ライフサイエンスなど非常に多くの分野で高まる一方です。 * 本コースでは、あらゆる分野で武器になるデータの解析・分析スキルのコアとなる機械学習およびビッグデータを扱う技術、分析結果を効果的に可視化する技術の基盤を網羅的に身につけ、一人前のデータサイエンティストとして活躍する入り口に立つことを目指します。 * 受講費用は一切発生しません(通信費等は自己負担でお願いします)。とにかく課題の量が多い。この3ヶ月は毎日が機械学習漬けでした。
前年度のテキストが販売されていたので、目を通してみましたが、あまりの難しさにこりゃ無理だと投げそうになりました。東京大学のデータサイエンティスト育成講座 塚本 邦尊
https://www.amazon.co.jp/dp/B07PD237GQ/ref=cm_sw_r_tw_dp_U_x_j1bHEb66RA461ですが、テキストがよく練られていたこと、Slackで随時質問できる事と、チームで参加した事と、サポート体制にずいぶん助けられ、なんとか修了までこぎつけました。
うえっとなったテキストが読めるようになる。これは自信になります。4月からまた受講者を募集しておりますので、これから機械学習をはじめようと思うみなさまにぜひおすすめしたいと思います。
受講テスト(12/7〜12)
受講前にスキルを確認のためのテストがありました。WhirlwindTourOfPythonのような基礎的なレベルですとのこと。リンク先がいきなり英語の解説で面食らいました。Pythonをかじっていたので何とかクリア。
問題は、行列の問題をPythonで解いて出すというもの。数学は中学校で挫折したので問題の意味がさっぱりわからず。数学が得意な人に教えていただきどうにかクリアしました。第1回(12/18) データサイエンスとは、Python基礎、ライブラリ
IT化によりデータが大量にあるのにほとんど分析されていない。 これを分析すると、ビジネスにとんでもなく生かせる事ができる、、、という講義でした。翌日に動画で配信があり面白かったです。それからPython基礎です。
第2回(12/25) Pythonによる科学計算とデータ加工処理の基礎(Numpy,Pandas)
Pythonの表計算を学びました。全部コマンドのExcelみたいなものです。集計、統計、etcこの後めちゃくちゃ使いました。
コンペその1タイタニック号の生死予測。
KaggleのTitanic: Machine Learning from Disasterと同じです。
最初はまったく分からず、映画を見て予測を思いついても、どうやって実装したらいいか暗中模索でした。Kaggleやチーム、Slackで意見交換しながら粘りました。アイデアがスコアに結びつくと面白くなってきます。結果を次の予測に再利用するなんちゃってブースティングでランクインしました。コンペ後に上位のコードが公開されるのですが、ほんと頭のいい人がいるんだなーと感心するばかりです。第3回(1/8) データサイエンスにおけるデータの可視化(Matplotlib)
グラフ、相関行列とヒートマップの作り方を学びました。なかなか思うように表現できないので、最初は美しいグラフを集めて、そのコードをコピペしながら慣れると良いようです。
第4回(1/15) 確率統計の基礎
合計、平均などの統計、散布図、ヒストグラムなどの図の書き方。確率・統計はさっぱり分からず。初心者問題を解くのがやっとでした。
コンペその2 ワインのクオリティ
ポルトガルのワインプロジェクトより、4898本のワインの成分とソムリエによる評価を読み込んで、成分からおいしさを予測するというものです。ワインは大好きなのです。何かというとお店のワインのラベルを読んではあれこれ考えるという楽しいコンペでした。
第5回(1/29) 機械学習の基礎(教師あり学習)
教師あり学習、教師なし学習、強化学習について。タイタニックやワインの予想で使っている手法をもう一度丁寧に解説。重回帰、ロジスティック回帰、ラッソ回帰、リッジ回帰、K-NN、 サポートベクターマシンあたりをチュートリアルに沿ってぽちぽちしていけば、なんとなく使えるようになった・・・気がします。
第6回(2/5) 機械学習の基礎(教師なし学習)
教師なし学習、目的変数がない学習モデルの構築を学びました。ざっくり分類、クラスタリング、主成分分析・・・。正直まだよく理解できていません。事前情報なしにデータをふるい分けできるのは便利なので覚えておく・・・というレベル。要復習ですね。
コンペその3 PUBGの勝者予想
KaggleのPUBG Finish Placement Prediction (Kernels Only)と同じです。
PUBGは100人の参加者が島に送られバトルロワイヤルするというゲームです。やってみましたが討ち死にしてばかり。まずはよく遊ぶ人にゲームをしている所を見せていただきました。アイテム、乗り物、武器の活用、刻々と狭まる安全圏にどう潜り込むかが勝負の決め手のようです。
しかしゲームの強さをどうコードにしたらよいかがさっぱり分かりません。
Kaggleにはどのように予測したかがNotebookとして沢山公開されています。目から鱗のアプローチがたくさんありました。
機械学習がものすごいスピードで発展するわけです。強そうなコードを組み合わせて提出するとそこそこいいスコアがとれました。第7回(2/12) モデルの検証方法とチューニング方法
モデルのパラメータを調整、さまざまなモデルの特徴、複数のモデルを組み合わせての予測を学びました。
ちゃんとやろうとすると前例主義に陥ったり考えすぎで外したりするので、多少アソビを作っておくというイメージです。
それから、バギングというデータをいくつかに分割して学習させあう方法を実装すると、予測精度がぐっと良くなりました。
まだよく理解できていないので、深めたいところです。第8回(3/4) データサイエンティスト中級者への道
第一線で活躍している方をお呼びして現場の話でした。マーケティング、物を売るには、どう思ってもらいたいかなど、データをビジネスの課題に生かす方法について学びました。CMの効果測定の話などすごく面白かったです。それから深層学習、Pythonを高速に実行するためのアルゴリズム、Pyspark、SparkSQL、その他数学的手法の紹介、エンジニアリングツールの紹介でした。
最終課題 Home Credit社への新規事業提案
東南アジアで展開するクレジット会社、Home Credit社のデータを分析して、新たなビジネスを提案しましょうというもの。
昨年おこなわれたKaggleのHome Credit Default Riskのデータを使って、別の切り口を機械学習を知らない経営陣にプレゼンするのです。これもまた見当もつかないところから、8回目の講義を参考に、こんな予測なら喜ばれるかなと考えてどうにか提出しました。修了して
こうして振り返るとよく修了できたなーと我ながら感心してしまいます。講座のみなさまの手厚いサポートに感謝しきりです。
コロナでいろいろな予定がキャンセルになりましたので、ぼちぼち復習していこうと思います。
4月からまたGCI 2020 Summerが始まりますので、機械学習に興味のある方はぜひ。おすすめです!
- 投稿日:2020-04-01T15:47:27+09:00
Pythonで毎日AtCoder #23
はじめに
前回
今日もCです#23
ABC154-C
41diff
len(set(A))=len(A)なら全ての要素が異なるので、setするだけn = int(input()) a = list(map(int,input().split())) a_s = set(a) if len(a) == len(a_s): print('YES') else: print('NO')ABC153-C
36diff
Hをsortする。必殺技は体力が多い順に使った方が攻撃回数は減るのでH[k:]から足していくn, k = map(int,input().split()) h = list(map(int,input().split())) h.sort(reverse=True) ans = 0 for i in range(k,n): ans += h[i] print(ans)ABC152-C
119diff
そのまま(i,j)の組を全部試すとTLEするので、最小値を更新していく。そうすると$P_j \leq P_i$を満すかどうかを判定できる。n = int(input()) p = list(map(int,input().split())) ans = 0 for i in range(n): if i == 0: ans += 1 m = p[0] continue if p[i] <= m: ans += 1 m = p[i] print(ans)ABC151-C
239diff
正解した問題をboolで管理する。WAはACした時に足すだけ。n, m = map(int,input().split()) ps = list(list(map(str,input().split())) for _ in range(m)) check = [True] * (n+1) wa = [0] * (n+1) wa_ans = 0 for i in range(m): if ps[i][1] == 'AC' and check[int(ps[i][0])]: check[int(ps[i][0])] = False wa_ans += wa[int(ps[i][0])] if ps[i][1] == 'WA': wa[int(ps[i][0])] += 1 ans = 0 for i in check: if not i: ans += 1 print(ans,wa_ans)ABC150-C
94diff
itertools神。$N\le 8$なので組合せを全列挙する。import itertools n = int(input()) p = tuple(((map(int,input().split())))) q = tuple(((map(int,input().split())))) num = [] for i in range(1,n+1): num.append(i) ans = [] for i in itertools.permutations(num,n): ans.append(i) print(abs(ans.index(p)-ans.index(q)))まとめ
まだ解ける。では、また
- 投稿日:2020-04-01T15:36:03+09:00
rbenv や pyenv で困っている人のための解説
対象読者: Ruby・Pythonなどの初心者で、こんなエラーメッセージが出てきて困っている人
$ fluentd rbenv: fluentd: command not found The `fluentd' command exists in these Ruby versions: 2.6.3rbenv や pyenv などの、
**envを使っていると、このようなエラーメッセージが出てくることがあります。この問題を解決するには
**envの仕組みを理解する必要があります。
**envの仕組みそもそも、
**envを使っていると、このようにディレクトリを移動しただけで、rubyやpythonのバージョンが自動で切り替わるようになりますが、これはどのように実現されているのでしょう?$ ruby --version ruby 2.3.7p456 (2018-03-28 revision 63024) [universal.x86_64-darwin18] $ cd my-project $ cat .ruby-version 2.4.5 $ ruby --version ruby 2.4.5p335 (2018-10-18 revision 65137) [x86_64-darwin18]実はここで実行している
rubyは、本物のrubyではありません!~/.rbenv/shims/に置かれたスクリプトなのです。$ which ruby /Users/x-xxxxx/.rbenv/shims/ruby $ cat ~/.rbenv/shims/ruby #!/usr/bin/env bash set -e [ -n "$RBENV_DEBUG" ] && set -x program="${0##*/}" if [ "$program" = "ruby" ]; then for arg; do case "$arg" in -e* | -- ) break ;; */* ) if [ -f "$arg" ]; then export RBENV_DIR="${arg%/*}" break fi ;; esac done fi export RBENV_ROOT="/Users/x-xxxxx/.rbenv" exec "/Users/x-xxxxx/.rbenv/libexec/rbenv" exec "$program" "$@"
bundler,gemなどの同梱コマンドや、Gemによって追加されるコマンドも同様です。$ which gem /Users/x-xxxxx/.rbenv/shims/gem $ which bundle /Users/x-xxxxx/.rbenv/shims/bundle $ which fluentd /Users/x-xxxxx/.rbenv/shims/fluentdそして、普通に
rbenv initでセットアップすると、$PATHの先頭に~/.rbenv/shims/が追加されて最優先で使用されます。エラーメッセージが表示されるまでの流れ
~/.rbenv/shims/のスクリプトは現在使用中のバージョンのRuby内の同名のコマンドを実行しようとします。そのため、現在使用中のバージョンのRubyにコマンドがインストールされていなければ、エラーになります;
- あなたが
fluentdを実行する$PATHが先頭から検索され、最初に見つかる~/.rbenv/shims/fluentd実行される~/.rbenv/shims/fluentdは現在のディレクトリから .rbenv-version を検索し、Rubyのバージョンを決定する- そのバージョンのRuby内の
flunetdを実行しようとするがfluentdが見つからない(別バージョンのRubyにはインストールされているが)- 下記のエラーメッセージを表示
$ fluentd rbenv: fluentd: command not found The `fluentd' command exists in these Ruby versions: 2.6.3対策
コマンドを絶対パスで指定する
~/.rbenv/shims/hogeを経由せずに直接実行します。~/.rbenv/versions/2.6.1/bin/ruby$PATHの先頭に追加する
~/.rbenv/shims より先にパスを追加します。
なお、RubyやPythonにはコマンドを、(インタープリターのディレクトリではなく)ホーム直下のディレクトリにインストールする機能があります。そのディレクトリを$PATHに追加すると良いでしょう。
$ export PYTHONUSERBASE=~/.local $ pip3 install --user awscli $ ls ~/.local/bin jupyter-notebook $ ls ~/.local/bin/ jupyter jupyter-bundlerextension jupyter-console jupyter-kernel ...# ~/.bashrc eval "$(pyenv init -)" export PATH=$HOME/.local/bin:$PATHrbenv init を使わない
実は
rbenv initを使わなくても、rbenv installでRubyをビルドすることはできます。人によってはビルドできるだけで十分かもしれません。
pipenv や bundler 経由で使う
RubyやPythonのコマンドをグローバルにインストールして使うというのが、そもそもトラブルの元です。常に pipenv や bundler 経由で使いましょう。
- 投稿日:2020-04-01T15:15:20+09:00
IISでDjangoプロジェクトにあるpydファイルがインポートできない問題への対応
TL;DR
https://qrunch.net/@sugurunatsuno/entries/wF9aXWZ3x3PBarLR
PYTHONPATHに読み込みたいpydファイルがあるディレクトリを追加する。はじめに
IISを使ってDjangoのプロジェクトを実行したときにpydファイルが読み込めなくなった。
結果として環境変数のPYTHONPATHにpydファイルを参照できるディレクトリがなかったことが原因であった。
Djangoのrunserverでの実行時にはpydファイルがインポートできていた。
IISではpydファイルのインポート以外に関しては動作する前提。バージョン
OS/ソフトウェア/ライブラリ名 バージョン Windows 10 IIS 10 Python 3.8.0 Django 2.2.8 Cython 0.29.15 IISで設定する場合
IISかPythonのどちらかで設定できればよい。
IISではweb.configなどで環境変数を設定できる。
セミコロンで区切って複数のパスを設定できるので、pydファイルがあるパスを追加する。<add key="PYTHONPATH" value="project_path;pyd_absolute_path" />この場合のpydファイルのインポートはPYTHONPATHを参照するため、呼び出すpyファイルからの相対パスにならない。
# 相対パスで参照できない # from pyd_relative_path import target # PYTHONPATHに設定しているためそのまま呼び出せる import targetPython上で設定する場合
IISかPythonのどちらかで設定できればよい。
python上でも環境変数は設定できるので、pydファイルがあるディレクトリを設定できる。import os import sys current_dir = os.path.abspath(os.path.dirname(__file__)) sys.path += [os.path.join(current_dir, 'pyd_relative_path')] import target
- 投稿日:2020-04-01T14:47:46+09:00
pythonで2次元リストの置換がうまくいかなかった話
はじめに
pythonの2次元配列の一部を置換しようとしたときに、作成方法をミスして詰まった話です。
ちょっとした備忘録として。。問題の説明
とても簡単ですが、5*4の0から構成された2次元配列があったとして、その一部を1に置換したかったわけです。
#before:こんな感じの2次元配列を [[0,0,0,0,0], [0,0,0,0,0], [0,0,0,0,0], [0,0,0,0,0]] ''''''''''''' | | | \|/ ''''''''''''' #after:こんな風に置換したかった [[0,0,0,0,0], [0,0,1,0,0], [0,0,0,0,0], [0,0,0,0,0]]何が起こったか?
まずは自分がやってしまった過ちから、、
#間違えた例 #初期化された配列を作成 map_list = [[0]*W]*H #map_listのindex指定して置換 map_list[1][2] = 1 #結果を表示してみる for line in map_list: print(line)結果:
[0, 0, 1, 0, 0] [0, 0, 1, 0, 0] [0, 0, 1, 0, 0] [0, 0, 1, 0, 0]どうしてなの!?ちゃんと位置指定したじゃない!?
なぜか全部の列に対して実行されたpythonでは以下の方法でidを確認することができます
print(id(a))先ほどの2次元配列に対して確認すると、、
[1650962624, 1650962624, 1650962656, 1650962624, 1650962624] [1650962624, 1650962624, 1650962656, 1650962624, 1650962624] [1650962624, 1650962624, 1650962656, 1650962624, 1650962624] [1650962624, 1650962624, 1650962656, 1650962624, 1650962624]どうやら列のidがかぶっていることが原因のようですね
解決策
さて、問題となっていたのは配列の作成部分です。
map_list = [[0]*5]*4以下のようにリスト内包表記を用いて作成します
map_list = [[0 for i in range(5)] for r in range(4)]実際に置換してみましょう
#初期化された配列を作成 map_list = [[0 for i in range(5)] for r in range(4)] #map_listのindex指定して置換 map_list[1][2] = 1 #結果を表示してみる for line in map_list: print(line)出力:
[0, 0, 0, 0, 0] [0, 0, 1, 0, 0] [0, 0, 0, 0, 0] [0, 0, 0, 0, 0]まとめ
ということで、2次元配列の初期化の際には気を付けないといけませんねという話でした。
思わぬところに落とし穴があるものですね。
- 投稿日:2020-04-01T14:18:59+09:00
pythonでシリアル通信制御してI2C通信する(GPIO8デバイスを使用します)
本記事について
電子回路経験がありGPIO、I2Cという単語は知っている前提としますのでその辺の用語解説を省きます。
GPIO8とは
シリアル通信でGPIOを制御できるデバイスです
Numato Labs社のUSB GPIO(デジタル入出力)ボードで日本だとエレファイン通販から購入できます。
https://www.elefine.jp/SHOP/USBGPIO8.html
ADコンバータも付いているので各種単体実験に便利です。I2C通信について
http://www.picfun.com/f1/f06.html
こちらの解説がとても分かりやすいです。なにをするか
python でシリアル通信を制御してGPIO8を制御しEEPROMに1バイト書き込み、その後読み込んで書き込まれている事を確認します。
EEPROM は 24LC64 を使用します。
24LC64はこちらの製品です → http://akizukidenshi.com/catalog/g/gI-00194/ハードウェアの準備
GPIO8 の 0番ポートをSDA とします。
GPIO8 の 1番ポートをSCL とします。
各々10kΩでプルアップします。
上記構成でブレッドボード上で接続してます。
GPIO8のコマンドについて
エレファインのサイトや公式からマニュアルがダウンロードできますので詳しくはそちらを参照ください。
最初からプログラム制御ではなくTeraterm等のシリアル端末ソフトから制御実験することをおすすめします。gpio [command] [arg]\rという形式です、arg は有ったり無かったりします、末尾の ¥r を忘れないように注意します。
書き込み系のコマンドを送信すると[送ったコマンド]\n\r> # 例えば gpio set 0\n\r>とコマンドにプロンプトを付けて返ってきます。
また読み込み系コマンドを送信すると[送ったコマンド]\n\r[戻り値]\n\r> # 例えば gpio read 0\n\r1\n\r> # \n\r に挟まれている 1 が戻り値とコマンドに戻り値とプロンプトを付けて返ってきます。
GPIOのLOW-HIGH制御
0番ポートをLOWにするには clear コマンドを使います
SerialInstance = serial.Serial("COM4", 115200, timeout=0.01) SerialInstance.write("gpio clear 0\r".encode())0番ポートをHIGHにするには set コマンドを使います
SerialInstance = serial.Serial("COM4", 115200, timeout=0.01) SerialInstance.write("gpio set 0\r".encode())コマンド
timeout=0.01 としてタイムアウトを設定します、設定しないと一生応答を返さなくなるので設定したほうが良いです
GPIOの読み取り
0番ポートのLOW-HIGH状態を読み取るには
SerialInstance = serial.Serial("COM4", 115200, timeout=0.01) SerialInstance.write("gpio read 0\r".encode())とします
gpio read 0\n\r0\n\r>と応答が返ってくればGPIOの状態は0(LOW)ということになります。
プログラム構造
0=LOW
1=HIGH
2=読み取りクロック
と定義します。
定義に従い配列を作成し、その配列の通りにSCL、SDAを制御します。例
これはEEPROMデバイスのアドレスが0x50、データアドレスが 0xa0、書き込みデータが 0x33 の場合に作られる配列です。[1, 0, 1, 0, 0, 0, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 2, 1, 0, 1, 0, 0, 0, 0, 0, 2, 0, 0, 1, 1, 0, 0, 1, 1, 2] 処理毎に分割するとこうなる [1, 0, 1, 0, 0, 0, 0, 0, 2] [0, 0, 0, 0, 0, 0, 0, 0, 2] [1, 0, 1, 0, 0, 0, 0, 0, 2] [0, 0, 1, 1, 0, 0, 1, 1, 2]各行を解説する
[1, 0, 1, 0, 0, 0, 0, 0, 2] 先頭7ビット 0x50 のアドレスを表し、8ビット目は書き込みフラグ、9ビット目はACKの読み出し
[0, 0, 0, 0, 0, 0, 0, 0, 2] 先頭8ビットは書き込みアドレスの上位バイト、9ビット目はACKの読み出し
[1, 0, 1, 0, 0, 0, 0, 0, 2] 先頭8ビットは書き込みアドレスの下位バイト、9ビット目はACKの読み出し
[0, 0, 1, 1, 0, 0, 1, 1, 2] 先頭8ビットは書き込む1バイトのデータ、9ビット目はACKの読み出しという構成になっている。
上記のようにSDAのパターンを配列化しそれに従いクロックとデータを送信・受信する構造とする。ソースコード
# i2c_byte_write_and_read.py import serial import sys import time SerialInstance = None def SerialInit(comString): global SerialInstance SerialInstance = serial.Serial(comString, 115200, timeout=0.01) #SerialInstance = serial.Serial(comString, 19200, timeout=0.1) def SerialEnd(): SerialInstance.close() def SerialTalk(cmd, response=False): readLen = len(cmd) + 1 # gpio read 0\n\r # 最初から \r が付いているので +2 ではなく +1 する if response == True: readLen += 3 # N\n\r readLen += 1 # > cnt = SerialInstance.write(cmd.encode()) res = SerialInstance.read(readLen) res = res.decode("utf-8").strip() return res # 返される文字数を正確に読み取り切ること、1文字でも過不足があると応答待ち状態が続く事になる def gpioHigh(n): SerialTalk("gpio set {}\r".format(n)) def gpioLow(n): SerialTalk("gpio clear {}\r".format(n)) def gpioRead(n): res = SerialTalk("gpio read {}\r".format(n), response=True) return res def ByteToLH(b): lh = [] for i in range(8): if (b << i & 128) == 0: lh.append(0) else: lh.append(1) return lh def SDA_LOW(): gpioLow(0) def SDA_HIGH(): gpioHigh(0) def SCL_LOW(): gpioLow(1) def SCL_HIGH(): gpioHigh(1) def READ_DATA(): return gpioRead(0) def parseData(all): res = [] for l in all: a = l.split("\n\r") res.append(a[1]) return res # 0 = LOW # 1 = HIGH # 2 = READ # スタートコンディション: SCLがHIGHの間にSDAをLOWにする # ストップコンディション: SCLをHIGHにしてから、SDAをHIGHにする def WriteProc(): ctrlByte = ByteToLH(constDeviceAddress << 1) addrHigh = ByteToLH((constDataAdress >> 8) & 0xff) addrLow = ByteToLH(constDataAdress & 0xff) write1Byte = ByteToLH(constData) cmdWrite = ctrlByte + [2] + addrHigh + [2] + addrLow + [2] + write1Byte + [2] # START CONDITION SCL_HIGH() SDA_LOW() size = len(cmdWrite) data = [] for i in range(size): SCL_LOW() d = cmdWrite[i] if d == 0: SDA_LOW() elif d == 1: SDA_HIGH() SCL_HIGH() if d == 2: response = READ_DATA() data.append(response) SCL_LOW() # LOWに戻す SDA_LOW() # LOWに戻す # STOP CONDITION SDA_LOW() SCL_HIGH() SDA_HIGH() time.sleep(0.1) print(parseData(data)) print("write end") def ReadProc(): # # # set address ctrlByte = ByteToLH(constDeviceAddress << 1) addrHigh = ByteToLH((constDataAdress >> 8) & 0xff) addrLow = ByteToLH(constDataAdress & 0xff) cmdSetAddress = ctrlByte + [2] + addrHigh + [2] + addrLow + [2] # START CONDITION SCL_HIGH() SDA_LOW() size = len(cmdSetAddress) data = [] for i in range(size): SCL_LOW() #print(i) d = cmdSetAddress[i] if d == 0: SDA_LOW() elif d == 1: SDA_HIGH() SCL_HIGH() if d == 2: response = READ_DATA() data.append(response) SCL_LOW() # LOWに戻す SDA_LOW() # LOWに戻す # STOP CONDITION SCL_HIGH() SDA_HIGH() print(parseData(data)) # # # read data ctrlByte = ByteToLH((constDeviceAddress << 1) | 0x01) readByte = [2] * 8 cmdReadByte = ctrlByte + [2] + readByte + [2] # START CONDITION SCL_HIGH() SDA_LOW() size = len(cmdReadByte) data = [] for i in range(size): SCL_LOW() #print(i) d = cmdReadByte[i] if d == 0: SDA_LOW() elif d == 1: SDA_HIGH() SCL_HIGH() if d == 2: response = READ_DATA() data.append(response) SCL_LOW() # LOWに戻す SDA_LOW() # LOWに戻す # STOP CONDITION SCL_HIGH() SDA_HIGH() print(parseData(data)) print("read end") # defines constDeviceAddress = 0x50 # ICの設定に従う constDataAdress = 0xa0 # ICのアドレス範囲内で適当に決める、今回は最大2バイト(0-65535)と想定したコード、3バイトアドレスの場合はコード修正が必要 constData = 0x33 # 0-255 の範囲で適当に決める def run(comString): SerialInit(comString) WriteProc() ReadProc() SerialEnd() if __name__ == "__main__": run(sys.argv[1]) # python i2c_byte_write_and_read.py COM4ソースコード解説
使い方
Linuxの場合
python i2c_byte_write_and_read.py /dev/ttyUSB0Windowsの場合
python i2c_byte_write_and_read.py COM4戻り値の見方
['0', '0', '0', '0'] # コントロールバイトのACK、アドレス上位バイトのACK、アドレス下位バイトのACK、書き込みデータのACK write end ['0', '0', '0'] # コントロールバイトのACK、アドレス上位バイトのACK、アドレス下位バイトのACK ['0', '0', '0', '1', '1', '0', '0', '1', '1', '1'] # コントロールバイトのACK、読み込んだ8ビットの状態、読み込み終了のACK(1だが正常に読み取れている) read end以上です
- 投稿日:2020-04-01T14:18:59+09:00
pythonでシリアル通信制御してI2C通信する(USBGPIO8デバイスを使用します)
本記事について
電子回路経験がありGPIO、I2Cという単語は知っている前提としますのでその辺の用語解説を省きます。
USBGPIO8とは
シリアル通信でGPIOを制御できるデバイスです
Numato Labs社のUSB GPIO(デジタル入出力)ボードで日本だとエレファイン通販から購入できます。
https://www.elefine.jp/SHOP/USBGPIO8.html
ADコンバータも付いているので各種単体実験に便利です。I2C通信について
http://www.picfun.com/f1/f06.html
こちらの解説がとても分かりやすいです。なにをするか
python でシリアル通信を制御してUSBGPIO8を制御しEEPROMに1バイト書き込み、その後読み込んで書き込まれている事を確認します。
EEPROM は 24LC64 を使用します。
24LC64はこちらの製品です → http://akizukidenshi.com/catalog/g/gI-00194/ハードウェアの準備
USBGPIO8 の 0番ポートをSDA とします。
USBGPIO8 の 1番ポートをSCL とします。
各々10kΩでプルアップします。
上記構成でブレッドボード上で接続してます。
USBGPIO8のコマンドについて
エレファインのサイトや公式からマニュアルがダウンロードできますので詳しくはそちらを参照ください。
最初からプログラム制御ではなくTeraterm等のシリアル端末ソフトから制御実験することをおすすめします。gpio [command] [arg]\rという形式です、arg は有ったり無かったりします、末尾の ¥r を忘れないように注意します。
書き込み系のコマンドを送信すると[送ったコマンド]\n\r> # 例えば gpio set 0\n\r>とコマンドにプロンプトを付けて返ってきます。
また読み込み系コマンドを送信すると[送ったコマンド]\n\r[戻り値]\n\r> # 例えば gpio read 0\n\r1\n\r> # \n\r に挟まれている 1 が戻り値とコマンドに戻り値とプロンプトを付けて返ってきます。
GPIOのLOW-HIGH制御
0番ポートをLOWにするには clear コマンドを使います
SerialInstance = serial.Serial("COM4", 115200, timeout=0.01) SerialInstance.write("gpio clear 0\r".encode())0番ポートをHIGHにするには set コマンドを使います
SerialInstance = serial.Serial("COM4", 115200, timeout=0.01) SerialInstance.write("gpio set 0\r".encode())コマンド
timeout=0.01 としてタイムアウトを設定します、設定しないと一生応答を返さなくなるので設定したほうが良いです
GPIOの読み取り
0番ポートのLOW-HIGH状態を読み取るには
SerialInstance = serial.Serial("COM4", 115200, timeout=0.01) SerialInstance.write("gpio read 0\r".encode())とします
gpio read 0\n\r0\n\r>と応答が返ってくればGPIOの状態は0(LOW)ということになります。
プログラム構造
0=LOW
1=HIGH
2=読み取りクロック
と定義します。
定義に従い配列を作成し、その配列の通りにSCL、SDAを制御します。例
これはEEPROMデバイスのアドレスが0x50、データアドレスが 0xa0、書き込みデータが 0x33 の場合に作られる配列です。[1, 0, 1, 0, 0, 0, 0, 0, 2, 0, 0, 0, 0, 0, 0, 0, 0, 2, 1, 0, 1, 0, 0, 0, 0, 0, 2, 0, 0, 1, 1, 0, 0, 1, 1, 2] 処理毎に分割するとこうなる [1, 0, 1, 0, 0, 0, 0, 0, 2] [0, 0, 0, 0, 0, 0, 0, 0, 2] [1, 0, 1, 0, 0, 0, 0, 0, 2] [0, 0, 1, 1, 0, 0, 1, 1, 2]各行を解説する
[1, 0, 1, 0, 0, 0, 0, 0, 2] 先頭7ビット 0x50 のアドレスを表し、8ビット目は書き込みフラグ、9ビット目はACKの読み出し
[0, 0, 0, 0, 0, 0, 0, 0, 2] 先頭8ビットは書き込みアドレスの上位バイト、9ビット目はACKの読み出し
[1, 0, 1, 0, 0, 0, 0, 0, 2] 先頭8ビットは書き込みアドレスの下位バイト、9ビット目はACKの読み出し
[0, 0, 1, 1, 0, 0, 1, 1, 2] 先頭8ビットは書き込む1バイトのデータ、9ビット目はACKの読み出しという構成になっている。
上記のようにSDAのパターンを配列化しそれに従いクロックとデータを送信・受信する構造とする。ソースコード
# i2c_byte_write_and_read.py import serial import sys import time SerialInstance = None def SerialInit(comString): global SerialInstance SerialInstance = serial.Serial(comString, 115200, timeout=0.01) #SerialInstance = serial.Serial(comString, 19200, timeout=0.1) def SerialEnd(): SerialInstance.close() def SerialTalk(cmd, response=False): readLen = len(cmd) + 1 # gpio read 0\n\r # 最初から \r が付いているので +2 ではなく +1 する if response == True: readLen += 3 # N\n\r readLen += 1 # > cnt = SerialInstance.write(cmd.encode()) res = SerialInstance.read(readLen) res = res.decode("utf-8").strip() return res # 返される文字数を正確に読み取り切ること、1文字でも過不足があると応答待ち状態が続く事になる def gpioHigh(n): SerialTalk("gpio set {}\r".format(n)) def gpioLow(n): SerialTalk("gpio clear {}\r".format(n)) def gpioRead(n): res = SerialTalk("gpio read {}\r".format(n), response=True) return res def ByteToLH(b): lh = [] for i in range(8): if (b << i & 128) == 0: lh.append(0) else: lh.append(1) return lh def SDA_LOW(): gpioLow(0) def SDA_HIGH(): gpioHigh(0) def SCL_LOW(): gpioLow(1) def SCL_HIGH(): gpioHigh(1) def READ_DATA(): return gpioRead(0) def parseData(all): res = [] for l in all: a = l.split("\n\r") res.append(a[1]) return res # 0 = LOW # 1 = HIGH # 2 = READ # スタートコンディション: SCLがHIGHの間にSDAをLOWにする # ストップコンディション: SCLをHIGHにしてから、SDAをHIGHにする def WriteProc(): ctrlByte = ByteToLH(constDeviceAddress << 1) addrHigh = ByteToLH((constDataAdress >> 8) & 0xff) addrLow = ByteToLH(constDataAdress & 0xff) write1Byte = ByteToLH(constData) cmdWrite = ctrlByte + [2] + addrHigh + [2] + addrLow + [2] + write1Byte + [2] # START CONDITION SCL_HIGH() SDA_LOW() size = len(cmdWrite) data = [] for i in range(size): SCL_LOW() d = cmdWrite[i] if d == 0: SDA_LOW() elif d == 1: SDA_HIGH() SCL_HIGH() if d == 2: response = READ_DATA() data.append(response) SCL_LOW() # LOWに戻す SDA_LOW() # LOWに戻す # STOP CONDITION SDA_LOW() SCL_HIGH() SDA_HIGH() time.sleep(0.1) print(parseData(data)) print("write end") def ReadProc(): # # # set address ctrlByte = ByteToLH(constDeviceAddress << 1) addrHigh = ByteToLH((constDataAdress >> 8) & 0xff) addrLow = ByteToLH(constDataAdress & 0xff) cmdSetAddress = ctrlByte + [2] + addrHigh + [2] + addrLow + [2] # START CONDITION SCL_HIGH() SDA_LOW() size = len(cmdSetAddress) data = [] for i in range(size): SCL_LOW() #print(i) d = cmdSetAddress[i] if d == 0: SDA_LOW() elif d == 1: SDA_HIGH() SCL_HIGH() if d == 2: response = READ_DATA() data.append(response) SCL_LOW() # LOWに戻す SDA_LOW() # LOWに戻す # STOP CONDITION SCL_HIGH() SDA_HIGH() print(parseData(data)) # # # read data ctrlByte = ByteToLH((constDeviceAddress << 1) | 0x01) readByte = [2] * 8 cmdReadByte = ctrlByte + [2] + readByte + [2] # START CONDITION SCL_HIGH() SDA_LOW() size = len(cmdReadByte) data = [] for i in range(size): SCL_LOW() #print(i) d = cmdReadByte[i] if d == 0: SDA_LOW() elif d == 1: SDA_HIGH() SCL_HIGH() if d == 2: response = READ_DATA() data.append(response) SCL_LOW() # LOWに戻す SDA_LOW() # LOWに戻す # STOP CONDITION SCL_HIGH() SDA_HIGH() print(parseData(data)) print("read end") # defines constDeviceAddress = 0x50 # ICの設定に従う constDataAdress = 0xa0 # ICのアドレス範囲内で適当に決める、今回は最大2バイト(0-65535)と想定したコード、3バイトアドレスの場合はコード修正が必要 constData = 0x33 # 0-255 の範囲で適当に決める def run(comString): SerialInit(comString) WriteProc() ReadProc() SerialEnd() if __name__ == "__main__": run(sys.argv[1]) # python i2c_byte_write_and_read.py COM4ソースコード解説
使い方
Linuxの場合
python i2c_byte_write_and_read.py /dev/ttyUSB0Windowsの場合
python i2c_byte_write_and_read.py COM4戻り値の見方
['0', '0', '0', '0'] # コントロールバイトのACK、アドレス上位バイトのACK、アドレス下位バイトのACK、書き込みデータのACK write end ['0', '0', '0'] # コントロールバイトのACK、アドレス上位バイトのACK、アドレス下位バイトのACK ['0', '0', '0', '1', '1', '0', '0', '1', '1', '1'] # コントロールバイトのACK、読み込んだ8ビットの状態、読み込み終了のACK(1だが正常に読み取れている) read end以上です
- 投稿日:2020-04-01T13:34:02+09:00
Google画像検索の画像をオリジナルサイズで取得する
画像検索の画像をスクレイピングする方法についての記事は既に複数あるが、ちょっとした仕様変更が頻繁なのか、そのまま使えるものはほぼなかったので、どこを変更する可能性があるかも含めて記事を書いておきます。
多分動かないときにやることは、ブラウザのディベロッパーツールを使って必要なclass名やid名を調べればよい、というだけですが、わかる人には自明だけど、知らないと何が間違っている調べるのに結構時間かかる。実行環境
macOS Mojave 10.14.5
Python 3.7.2
Chrome 80.0
date 2020-04-01スクレイピングに必要なモジュールの準備
- Seleniumのインストール
pip install selenium
- webdriverのインストール
- webdriverとはwebブラウザを外部のソフトから実行するためのもので、自動テストなどでよく使われる. 今回はchromeのwebdriverを使う
- chromeのversionをブラウザのヘルプから確認(同じバージョンにしたい場合)
- Downloads - ChromeDriver - WebDriver for Chromeから該当の環境、versionのものをダウンロードする
- [追記]pipでもinstallできる Python/ChromeDriverインストールとパスの通し方
webdriverが使えるかチェック
起動 → google検索 → 終了 をしてみる
from selenium import webdriver # ダウンロードしたwebdriverのpathを指定 DRIVER_PATH = '/User/hoge/1bin/chromedriver' # webブラウザを起動 wd = webdriver.Chrome(executable_path=DRIVER_PATH) # googleにアクセス wd.get('https://google.com') # 検索boxを選択する. 選択する方法は複数ある search_box = wd.find_element_by_name('q') # search_box = wd.find_element_by_css_selector('input.gLFyf') # search_box = wd.find_element_by_class_name('gLFyf') # Qiitaを検索する search_box.send_keys('Qiita') search_box.submit() time.sleep(5) # webブラウザを終了する wd.quit()画像検索をして画像のURLを取得する
サムネイル画像のURLを取得
最初に検索結果のサムネイルのURLを取得する。
# クリックなど動作後に待つ時間(秒) sleep_between_interactions = 2 # ダウンロードする枚数 download_num = 3 # 検索ワード query = "cat" # 画像検索用のurl search_url = "https://www.google.com/search?safe=off&site=&tbm=isch&source=hp&q={q}&oq={q}&gs_l=img" wd = webdriver.Chrome(executable_path=DRIVER_PATH) wd.get(search_url.format(q=query)) # サムネイル画像のリンクを取得(ここでコケる場合はセレクタを実際に確認して変更する) thumbnail_results = wd.find_elements_by_css_selector("img.rg_i")サムネイル画像をクリックして元画像のURLを取得する
取得したサムネイルのURLをwebdriverでクリックし、画像を表示してオリジナル画像のURLを取得する。
また、オリジナル画像URLの取得の際に指定するclass nameは変更されることあるので、適宜ディベロッパーツールを使って調べて変更する。image_urls = set() for img in thumbnail_results[:download_num]: try: img.click() time.sleep(sleep_between_interactions) except Exception: continue # 一発でurlを取得できないので、候補を出してから絞り込む(やり方あれば教えて下さい) # 'n3VNCb'は変更されることあるので、クリックした画像のエレメントをみて適宜変更する url_candidates = wd.find_elements_by_class_name('n3VNCb') for candidate in url_candidates: url = candidate.get_attribute('src') if url and 'https' in url: image_urls.add(url) # 少し待たないと正常終了しなかったので3秒追加 time.sleep(sleep_between_interactions+3) wd.quit()画像URLから画像を取得する
あとはURLから画像をダウンロードするだけで、webdriverは必要ない。
* PILは画像ライブラリimport os from PIL import Image import hashlib image_save_folder_path = 'data' for url in image_urls: try: image_content = requests.get(url).content except Exception as e: print(f"ERROR - Could not download {url} - {e}") try: image_file = io.BytesIO(image_content) image = Image.open(image_file).convert('RGB') file_path = os.path.join(image_save_folder_path,hashlib.sha1(image_content).hexdigest()[:10] + '.jpg') with open(file_path, 'wb') as f: image.save(f, "JPEG", quality=90) print(f"SUCCESS - saved {url} - as {file_path}") except Exception as e: print(f"ERROR - Could not save {url} - {e}")画像リンクを取得するときのelementの探し方
googleの検索窓なら、
search_box = wd.find_element_by_name('q')
画像検索結果のオリジナル画像なら、wd.find_elements_by_class_name('n3VNCb')
などで指定するが、これらはブラウザのディベロッパーツールを使って確認できる。ブラウザの「…」→その他のツール→デベロッパーツール
ショートカットは、Ctrl Shift J (on Windows)orcmd + Option + J (on Mac)指定したい画像があれば、画像を右クリックして"検証"を選択すると、画像に対応するエレメントを表示してくれる。
画像検索のサムネイルなら、以下のようなエレメントになる。
エレメントは選択状態で出てくる'...'をクリックしてコピーできる。<img alt="Dogs | The Humane Society of the United States" class="n3VNCb" src="https://www.humanesociety.org/sites/default/files/styles/1240x698/public/2019/02/dog-451643.jpg?h=bf654dbc&itok=MQGvBmuo" data-noaft="1" jsname="HiaYvf" jsaction="load:XAeZkd;" style="width: 450px; height: 253.306px; margin: 0px;">class="n3VNCb"とあるので、
wd.find_elements_by_class_name('n3VNCb')としたら選択できる。コードまとめ
コピペ用
import os import time from selenium import webdriver from PIL import Image import io import requests import hashlib # クリックなど動作後に待つ時間(秒) sleep_between_interactions = 2 # ダウンロードする枚数 download_num = 3 # 検索ワード query = "cat" # 画像検索用のurl search_url = "https://www.google.com/search?safe=off&site=&tbm=isch&source=hp&q={q}&oq={q}&gs_l=img" # サムネイル画像のURL取得 wd = webdriver.Chrome(executable_path=DRIVER_PATH) wd.get(search_url.format(q=query)) # サムネイル画像のリンクを取得(ここでコケる場合はセレクタを実際に確認して変更する) thumbnail_results = wd.find_elements_by_css_selector("img.rg_i") # サムネイルをクリックして、各画像URLを取得 image_urls = set() for img in thumbnail_results[:download_num]: try: img.click() time.sleep(sleep_between_interactions) except Exception: continue # 一発でurlを取得できないので、候補を出してから絞り込む(やり方あれば教えて下さい) # 'n3VNCb'は変更されることあるので、クリックした画像のエレメントをみて適宜変更する url_candidates = wd.find_elements_by_class_name('n3VNCb') for candidate in url_candidates: url = candidate.get_attribute('src') if url and 'https' in url: image_urls.add(url) # 少し待たないと正常終了しなかったので3秒追加 time.sleep(sleep_between_interactions+3) wd.quit() # 画像のダウンロード image_save_folder_path = 'data' for url in image_urls: try: image_content = requests.get(url).content except Exception as e: print(f"ERROR - Could not download {url} - {e}") try: image_file = io.BytesIO(image_content) image = Image.open(image_file).convert('RGB') file_path = os.path.join(image_save_folder_path,hashlib.sha1(image_content).hexdigest()[:10] + '.jpg') with open(file_path, 'wb') as f: image.save(f, "JPEG", quality=90) print(f"SUCCESS - saved {url} - as {file_path}") except Exception as e: print(f"ERROR - Could not save {url} - {e}")参考にした記事