- 投稿日:2020-03-27T23:58:19+09:00
デプロイ
GithubにSSH鍵を登録
アプリケーションのコードをGithubからEC2サーバへクローンします。全世界に公開できるIPアドレスを持ったEC2サーバ上でアプリを動かすためです。
現状、EC2サーバにアプリケーションのコードをクローンしようとしてもpermission deniedとエラーが出てしまいます。
これは、Githubから見てこのEC2インスタンスが何者かわからないためです。
EC2インスタンスからGithubにアクセスするためには、作成したEC2インスタンスのSSH公開鍵をGithubに登録する必要があります。
SSH鍵をGithubに登録すると、Githubはそれを認証に利用し、コードのクローンを許可してくれるようになります。
EC2インスタンスからGithubにアクセスするためには、作成したEC2インスタンスのSSH公開鍵をGithubに登録します。
SSH鍵をGithubに登録すると、Githubはそれを認証に利用し、コードのクローンを許可してくれるようになります。
これからターミナル(ローカル)とターミナル(EC2サーバ)を使いますので、ターミナルでcommand T で2つ使えるようにしましょう。
ターミナル(EC2サーバ)に入るためには以下のことを実行してください。
ターミナル(ローカル)$ cd .ssh/ $ ssh -i ダウンロードした鍵の名前.pem ec2-user@作成したEC2インスタンスと紐付けたElastic IP途中で passphrase など3段階ほど入力を求められることがありますが、全て何も入力せずにEnterキーで進んでください。
ターミナル(EC2サーバ)[ec2-user@ip-172-31-23-189 ~]$ ssh-keygen -t rsa -b 4096次に、以下のコマンドで生成されたSSH公開鍵を表示し、値をコピーします。
ターミナル(EC2サーバ)[ec2-user@ip-172-31-23-189 ~]$ cat ~/.ssh/id_rsa.pubcatで表示させた公開鍵を、Githubにアクセスして登録していきます。
以下のURLにアクセスしてください。
https://github.com/settings/keys
タイトルはなんでもOKです。
keyは公開鍵をペーストしてください。
Add SSH keyで保存します。
Githubに鍵を登録できたら、SSH接続できるか以下のコマンドで確認できます。
ターミナル(EC2サーバ)[ec2-user@ip-172-31-23-189 ~]$ ssh -T git@github.com途中でこのまま続けるかどうかYes/Noで聞かれることがありますが、Yesで進んでください。
Permission denied (publickey). と表示された場合は、SSH鍵の設定が間違っているので、作業を確認をしてください。アプリケーションサーバの設定
まず、アプリケーションサーバとは、ブラウザからの「リクエスト」を受け付けRailsアプリケーションを実際に動作させるソフトウェアのことです。rails sコマンドのことです。
ローカル環境でRuby on Railsのアプリケーションの動作を確認する際は
①ターミナルからrails sコマンドを打つ
②ブラウザでlocalhost:3000にアクセス
の順番になります。
①の操作で「アプリケーションサーバの起動」を行なっています。
つまり、環境開発の場合
①rails sコマンドでappサーバを起動
②ブラウザからlocalhostにアクセス
となります。
アプリケーションサーバが動いていれば、ブラウザからのリクエストを受け付けてRailsアプリケーションが動作します。
なので、全世界に公開するEC2サーバ上でもアプリケーションサーバを動かす必要があります。Unicorn
全世界に公開されるサーバ上で良く利用されるアプリケーションサーバです。rails sコマンドの代わりにunicorn_railsコマンドで起動することができます。
本番環境の場合
①unicorn_railsコマンドでUnicorn(appサーバ)を起動
②ブラウザからドメインにアクセス
Unicornを理解するために必要な重な概念がプロセスです。プロセス
PC(サーバ)上で動く全てのプログラムの実行時の単位です。ここで言うプログラムとは、ブラウザや音楽再生ソフト、ExcelといったGUIや、Rubyなどのスクリプト言語の実行などが含まれます。
プログラムが動いている数だけ、プロセスが存在しています。例えばテキストエディタを起動する時、テキストエディタ用のプロセスが生み出されます。
PCがMacの場合、アクティビティモニタというアプリケーションでプロセスを確認することができます。
アクティビティモニタは、現在MacPC上で動いているプログラムの状況をモニタリングするアプリです。
「PID(プロセスアイディー)」というに数字が入っていますが、これはプロセスを識別するための一意の数字になります。PIDがあることで、あるプログラムから別のプロセスを指定して操作したり、プロセスからプログラムを停止したりできます。
Unicornなどのアプリケーションサーバを起動するとアプリケーションサーバのプロセスが生まれます。アプリケーションサーバのプロセスがあれば、リクエストを受け付けブラウザにレスポンスを返すことができます。Unicornをインストール
Gemfile
group :production do gem 'unicorn', '5.4.1' endターミナル(ローカル)
$ bundle installこのgroup :production do ~ endの間に記述されたgemは本番環境のみで読み込まれます。
次に、config/unicorn.rbを作成します。config/unicorn.rb#サーバ上でのアプリケーションコードが設置されているディレクトリを変数に入れておく app_path = File.expand_path('../../', __FILE__) #アプリケーションサーバの性能を決定する worker_processes 1 #アプリケーションの設置されているディレクトリを指定 working_directory app_path #Unicornの起動に必要なファイルの設置場所を指定 pid "#{app_path}/tmp/pids/unicorn.pid" #ポート番号を指定 listen 3000 #エラーのログを記録するファイルを指定 stderr_path "#{app_path}/log/unicorn.stderr.log" #通常のログを記録するファイルを指定 stdout_path "#{app_path}/log/unicorn.stdout.log" #Railsアプリケーションの応答を待つ上限時間を設定 timeout 60 #以下は応用的な設定なので説明は割愛 preload_app true GC.respond_to?(:copy_on_write_friendly=) && GC.copy_on_write_friendly = true check_client_connection false run_once = true before_fork do |server, worker| defined?(ActiveRecord::Base) && ActiveRecord::Base.connection.disconnect! if run_once run_once = false # prevent from firing again end old_pid = "#{server.config[:pid]}.oldbin" if File.exist?(old_pid) && server.pid != old_pid begin sig = (worker.nr + 1) >= server.worker_processes ? :QUIT : :TTOU Process.kill(sig, File.read(old_pid).to_i) rescue Errno::ENOENT, Errno::ESRCH => e logger.error e end end end after_fork do |_server, _worker| defined?(ActiveRecord::Base) && ActiveRecord::Base.establish_connection endworker(ワーカー)
Unicornは、プロセスを分裂させることができます。この分裂したプロセス全てをworkerと呼びます。プロセスを分裂させることで、リクエストに対してのレスポンスを高速にすることができます。後述するworker_processesという設定項目で、workerの数を決定します。
ブラウザなどからリクエストが来ると、UnicornのworkerがRailsアプリケーションを動かします。Railsは、リクエストの内容とルーティングを照らし合わせ最終的に適切なビュー(HTML)もしくはJSONをレスポンスします。レスポンスを受け取ったUnicornは、それをブラウザに返します。一連の動きはおよそ0.1 ~ 0.5秒程度で行われます。常にそれ以上のスピードでリクエストが頻発するようなアプリケーションだと、1つのworkerだけでは処理が追いつかず、レスポンスまで長い時間がかかってしまったり最悪サーバがストップしてしまいます。そんな時、worker_processesの数を 2,3,4と増やすことでアプリケーションからのレスポンスを早くすることができます。Unicornの設定
設定項目 詳細 worker_processes リクエストを受け付けレスポンスを生成するworker(ワーカー)の数を決めます。 working_directory UnicornがRailsのコードを動かす際、ルーティングなど実際に参照するファイルを探すディレクトリを指定します。 pid Unicornは、起動する際にプロセスidが書かれたファイルを生成します。その場所を指定します。 listen どのポート番号のリクエストを受け付けることにするかを決定します。今回は、3000番ポートを指定しています。 ここまで変更できたら、いったんファイルをコミットしておきましょう。Githubにpushしてください。ブランチを切っている場合は、masterブランチにmergeもしておきましょう。
デプロイ時にエラーの原因となる記述の対策
Uglifierというgemがあり、これはJavaScriptを軽量化するためのものです。しかし、ChatSpaceのJavaScriptで使用しているテンプレートリテラル記法(`)に対応していません。そのため、デプロイ時にエラーの原因となります。
そこで、この部分をコメントアウトすることで対策できます。config/environments/production.rb(修正前)config.assets.js_compressor = :uglifierconfig/environments/production.rb(修正後)# config.assets.js_compressor = :uglifier変更修正したらGitHub Desktopからコミットしてプッシュしましょう。この時必ず、masterブランチで行うようにしてください。もし、別ブランチでコミット&プッシュした場合は、リモートリポジトリでプルリクエストを作成し、ブランチをmasterへマージしてください。
Githubからコードをクローン
Unicornの設定を済ませたコードをEC2インスタンスにクローンします。
まず、以下のコマンドを入力して、ディレクトリを作成します。今回は、ここで作成したディレクトリにアプリケーションを設置することにします。/var/wwwディレクトリを作成し、権限をec2-userに変更
ターミナル(EC2サーバ)
#mkdirコマンドで新たにディレクトリを作成 [ec2-user@ip-172-31-23-189 ~]$ sudo mkdir /var/www/ #作成したwwwディレクトリの権限をec2-userに変更 [ec2-user@ip-172-31-23-189 ~]$ sudo chown ec2-user /var/www/Githubから「リポジトリURL」を取得
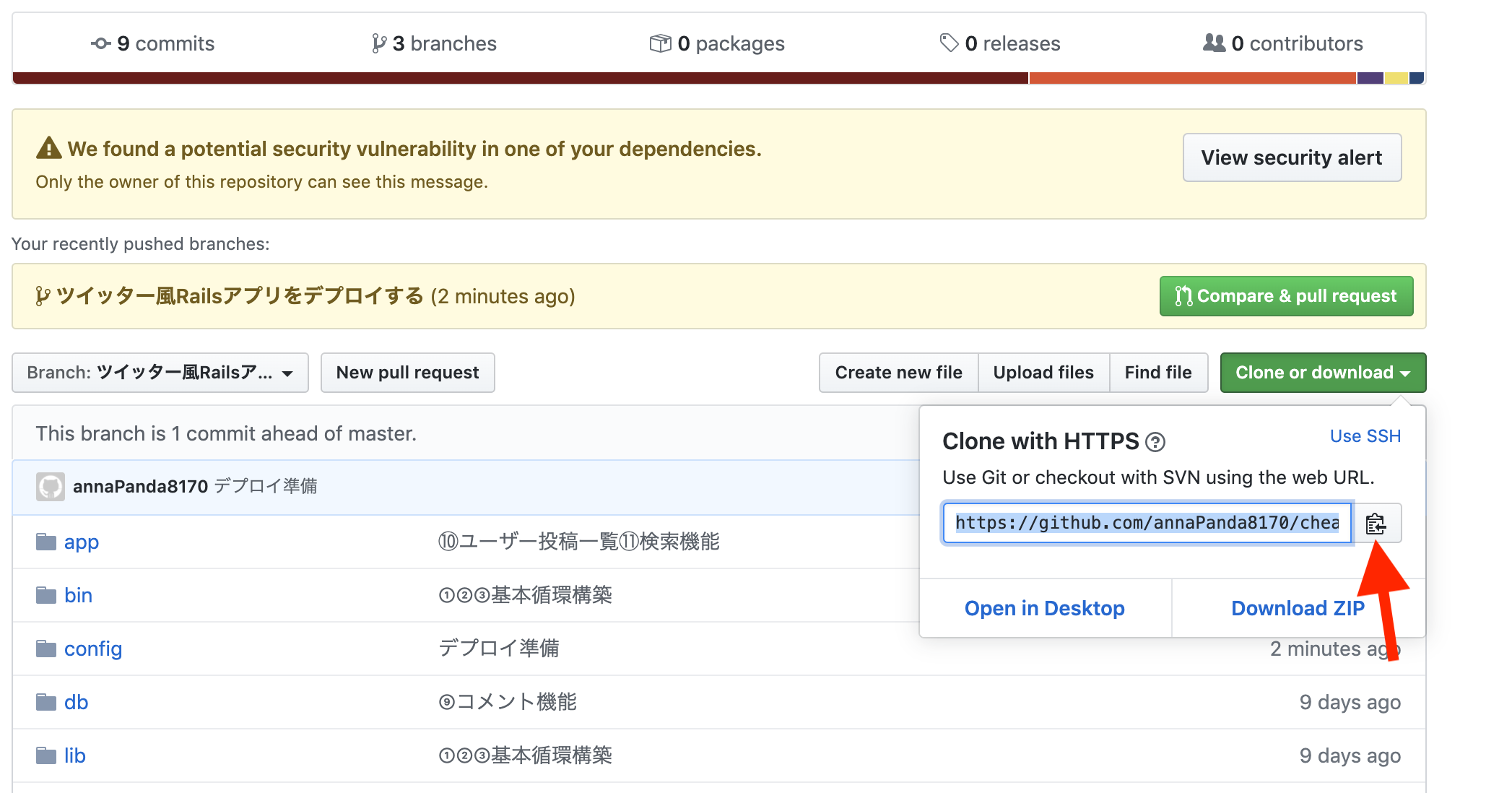
clone or downloadをクリックし、URLをコピーしてください。
取得した「リポジトリURL」を使って、コードをクローン
ターミナル(EC2サーバ)
[ec2-user@ip-172-31-23-189 ~]$ cd /var/www/ [ec2-user@ip-172-31-23-189 www]$ git clone https://github.com/<ユーザー名>/<リポジトリ名>.git本番環境での設定
アプリケーションのコードをEC2サーバにクローンすることができました。続いて、サービスを公開するための設定を行なっていきます。
※これ以降基本的には、作業は /var/www/アプリ名 で行います。EC2の能力を拡張
現状動かしているEC2のインスタンスではコンピューターの能力が足りず、Gemのインストール時などにエラーが発生する可能性があります。具体的には、コンピューターの処理能力に関係するメモリというものが足りません。
そこで、今後の設定を行う前にメモリを増強する処理を行います。Swap(スワップ)領域
コンピュータが処理を行う際、メモリと呼ばれる場所に処理内容が一時的に記録されます。メモリは容量が決まっており、容量を超えてしまうとエラーで処理が止まってしまいます。Swap領域は、メモリが使い切られそうになった時にメモリの容量を一時的に増やすために準備されるファイルです。
EC2はデフォルトではSwap領域を用意していないため、これを準備することでメモリ不足の処理エラーを防ぎます。
Swap領域の用意です。
ターミナル(EC2サーバ)#ホームディレクトリに移動 [ec2-user@ip-172-31-25-189 ~]$ cd#処理に時間がかかる可能性があるコマンドです [ec2-user@ip-172-31-25-189 ~]$ sudo dd if=/dev/zero of=/swapfile1 bs=1M count=512 # しばらく待って、以下のように表示されれば成功 512+0 レコード入力 512+0 レコード出力 536870912 バイト (537 MB) コピーされました、 7.35077 秒、 73.0 MB/秒[ec2-user@ip-172-31-25-189 ~]$ sudo chmod 600 /swapfile1[ec2-user@ip-172-31-25-189 ~]$ sudo mkswap /swapfile1 # 以下のように表示されれば成功 スワップ空間バージョン1を設定します、サイズ = 524284 KiB ラベルはありません, UUID=74a961ba-7a33-4c18-b1cd-9779bcda8ab1[ec2-user@ip-172-31-25-189 ~]$ sudo swapon /swapfile1[ec2-user@ip-172-31-25-189 ~]$ sudo sh -c 'echo "/swapfile1 none swap sw 0 0" >> /etc/fstab'これで、Swap領域を確保することができました。
次に、クローンしたアプリケーションを起動するために必要なgemを以下のコマンドでインストールします。
クローンしたディレクトリに移動し、rbenvでインストールされたRubyが使われているかチェックします。
ターミナル(EC2サーバ)[ec2-user@ip-172-31-23-189 www]$ cd /var/www/リポジトリ名 [ec2-user@ip-172-31-23-189 <リポジトリ名>]$ ruby -v ruby 2.5.1p112 (2016-04-26 revision 54768) [x86_64-linux]ruby 2.5.1 ... となっていれば成功です。そうでない場合は、もともと用意されているRubyが利用されているので、Rubyのインストールが成功しているか確認してください。
確認できたら本番環境でgemを管理するためのbundlerをインストールして、bundle installを実行します。
まず今まで開発環境(ローカル)で開発してきたアプリにおいて、どのバージョンのbundlerが使われていたのか確認します。
ターミナル(ローカル)#アプリ名のディレクトリで以下を実行 $ bundler -v Bundler version 2.0.1 # 開発環境によってバージョンは異なります。開発環境で仕様しているbundlerのバージョンがわかったので、同じバージョンのものをEC2サーバ側にも導入します。上記の場合では、bundler 2.0.1のバージョンを導入して bundle install を実行します。
ターミナル(EC2サーバ)[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ gem install bundler -v 2.0.1 # ローカルで確認したbundlerのバージョンを導入する [ec2-user@ip-172-31-23-189 <リポジトリ名>]$ bundle install # 上記コマンドは、数分以上かかる場合もあります。環境変数の設定
データベースのパスワードなどセキュリティのためにGithubにアップロードすることができない情報は、環境変数というものを利用して設定します。
環境変数は、Railsからは ENV['<環境変数名>'] という記述でその値を利用することができます。
今、config/secrets.yml と config/database.yml を確認すると、例えばですが <%= ENV["SECRET_KEY_BASE"] %> と書かれている部分は、 SECRET_KEY_BASE という環境変数の値になります。secret_key_base
Cookieの暗号化に用いられる文字列です。Railsアプリケーションを動作させる際は必ず用意する必要があります。また、外部に漏らしてはいけない値であるため、こちらも環境変数から参照します。
secret_key_baseは以下のコマンドを打つことで生成できます。
ターミナル(EC2サーバ)[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ rake secret長い英数の羅列が出てきます。この後利用するのでコピーしておいてください。
環境変数は /etc/environment というファイルに保存することで、サーバ全体に適用されます。環境変数の書き込みはvimコマンドを使用して行います。
ターミナル(EC2サーバ)[ec2-user@ip-172-31-23-189 ~]$ sudo vim /etc/environment何もない画面になると思います。iと打ち込んで入力モードに切り替えた後、下記の記述を打ち込みます。=の前後にスペースは入れません。
/etc/environment#設定したMySQLのrootユーザーのパスワードを入力 DATABASE_PASSWORD='MySQLのrootユーザーのパスワード' SECRET_KEY_BASE='先程コピーしたsecret_key_base'書き込みができたら esc(エスケープキー)を押下後、:wqと入力して内容を保存します。保存できたら環境変数を適用するために一旦ログアウトします。
ターミナル(EC2サーバ)[ec2-user@ip-172-31-23-189 ~]$ exitexitでログアウトすると、ローカル環境となります。再度SSHし直します。
ターミナル(ローカル)$ ssh -i [ダウンロードした鍵の名前].pem ec2-user@[作成したEC2インスタンスと紐付けたElastic IP] (ダウンロードした鍵を用いて、ec2-userとしてログイン)SSHし直したら、 env というコマンドと grep を組み合わせて、先程設定した環境変数が適用されているか確認します。
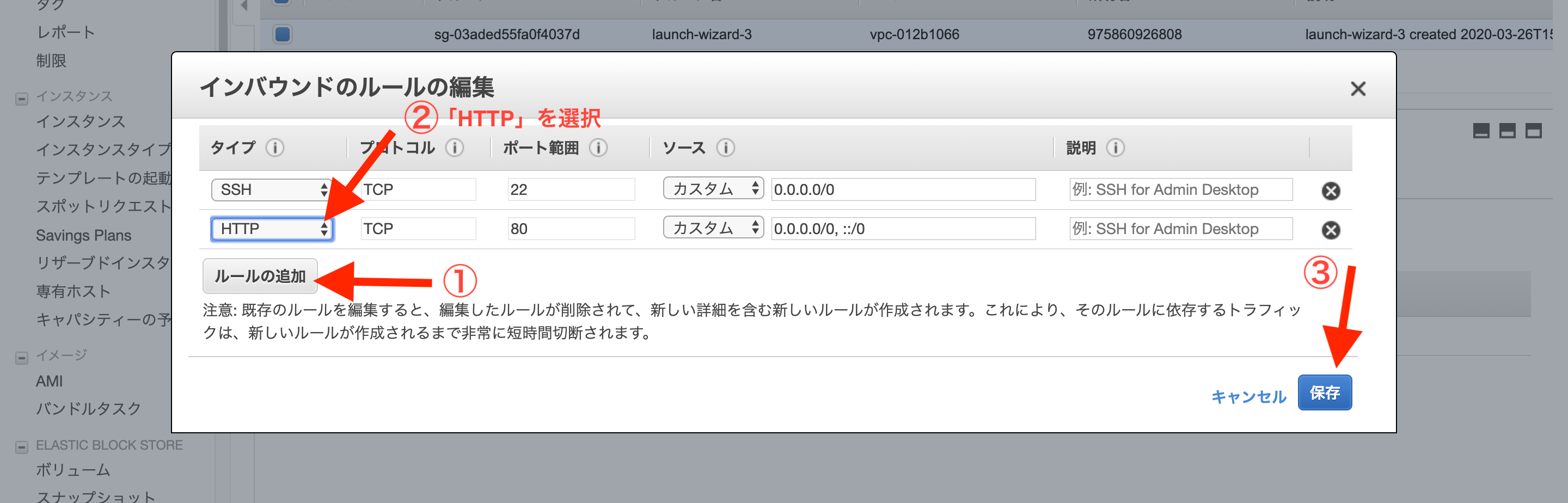
ターミナル(EC2サーバ)[ec2-user@ip-172-31-23-189 ~]$ env | grep SECRET_KEY_BASE SECRET_KEY_BASE='secret_key_base' [ec2-user@ip-172-31-23-189 ~]$ env | grep DATABASE_PASSWORD DATABASE_PASSWORD='MySQLのrootユーザーのパスワード'立ち上げたばかりのEC2インスタンスはSSHでアクセスすることはできますが、HTTPなどの他の通信方法ではつながりません。そのため、WEBサーバとして利用するEC2インスタンスは事前にHTTPがつながるように「ポート」を開放します。
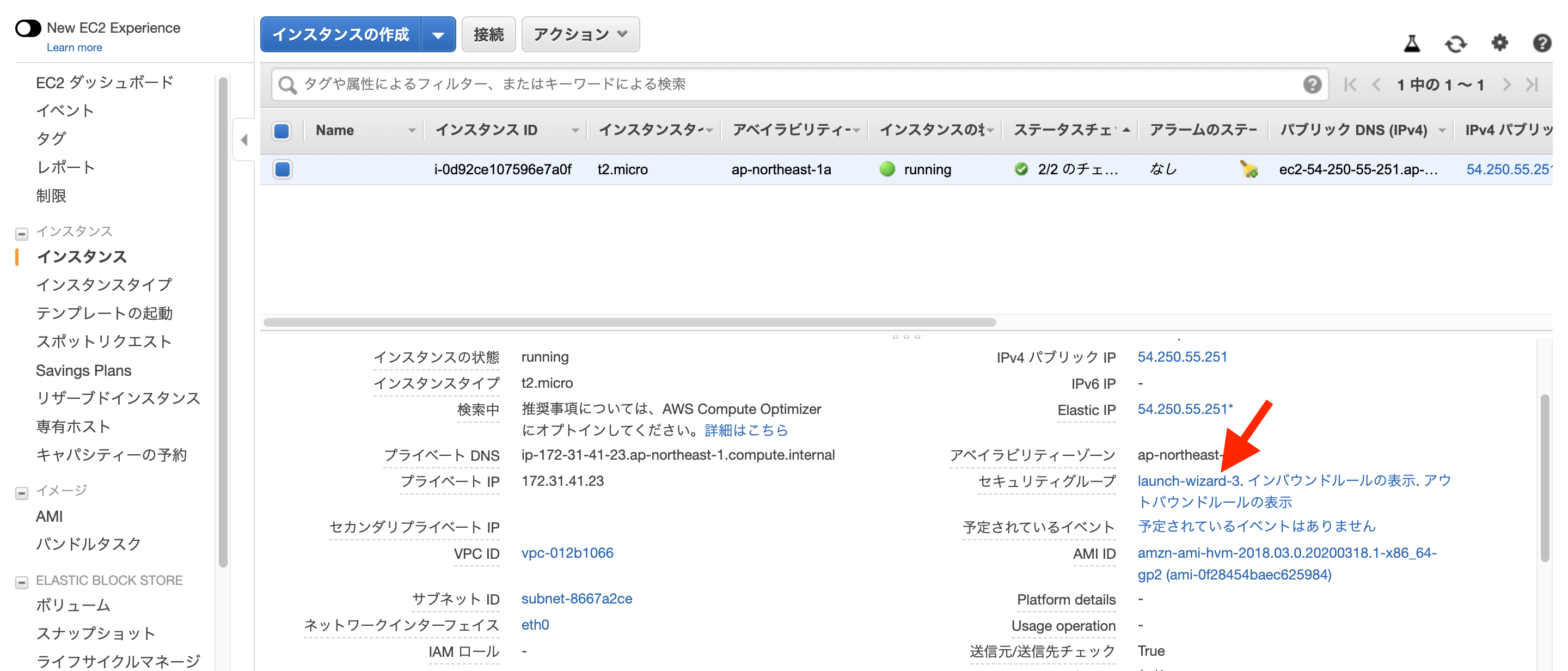
ポートの設定をするためにはEC2の「セキュリティグループ」という設定を変更します。
セキュリティグループとは、EC2サーバが属するまとまりのようなもので、複数のEC2インスタンスのネットワーク設定を一括で行うためのものです。セキュリティグループのポートを設定
まずは、AWSのEC2インスタンス一覧画面から、対象のインスタンスを選択し、「セキュリティグループ」のリンクをクリックします。
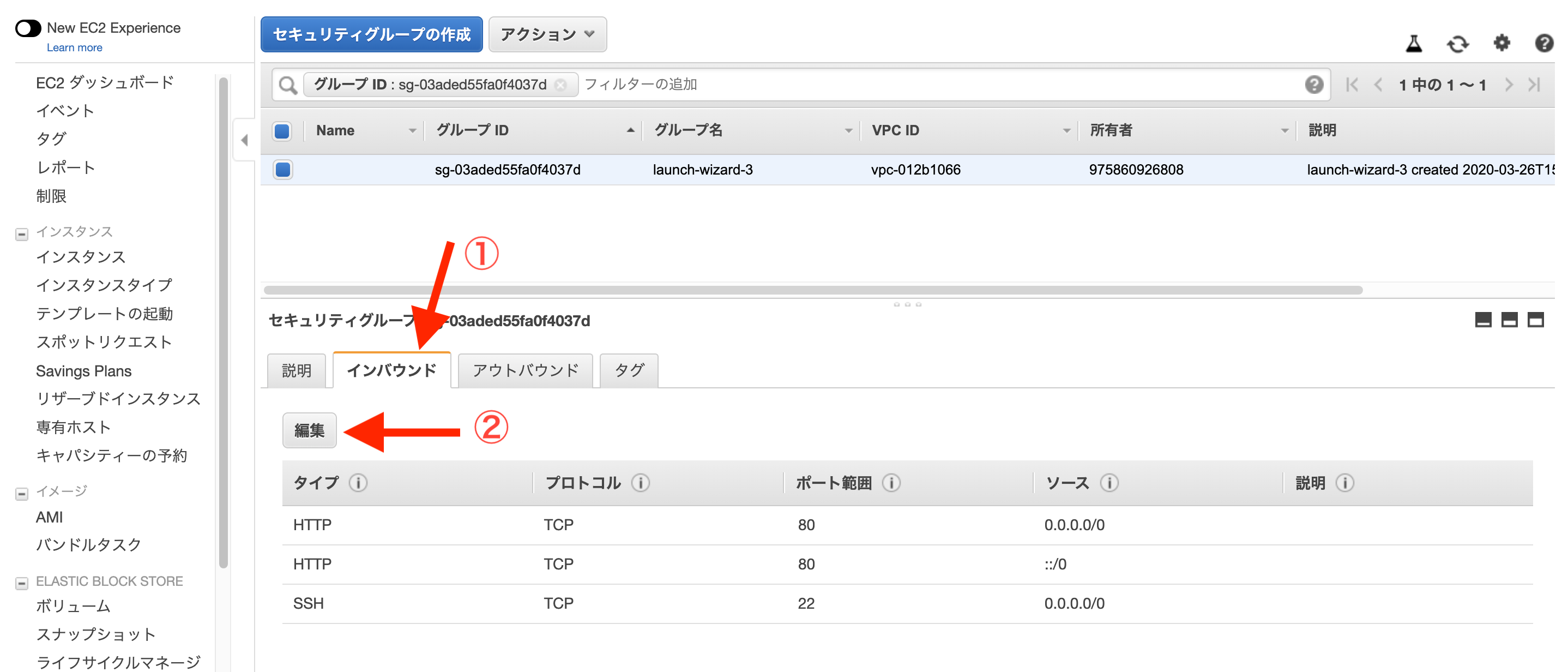
次に、インスタンスの属するセキュリティグループの設定画面に移動するので、「インバウンド」タブの中の「編集」をクリックします。
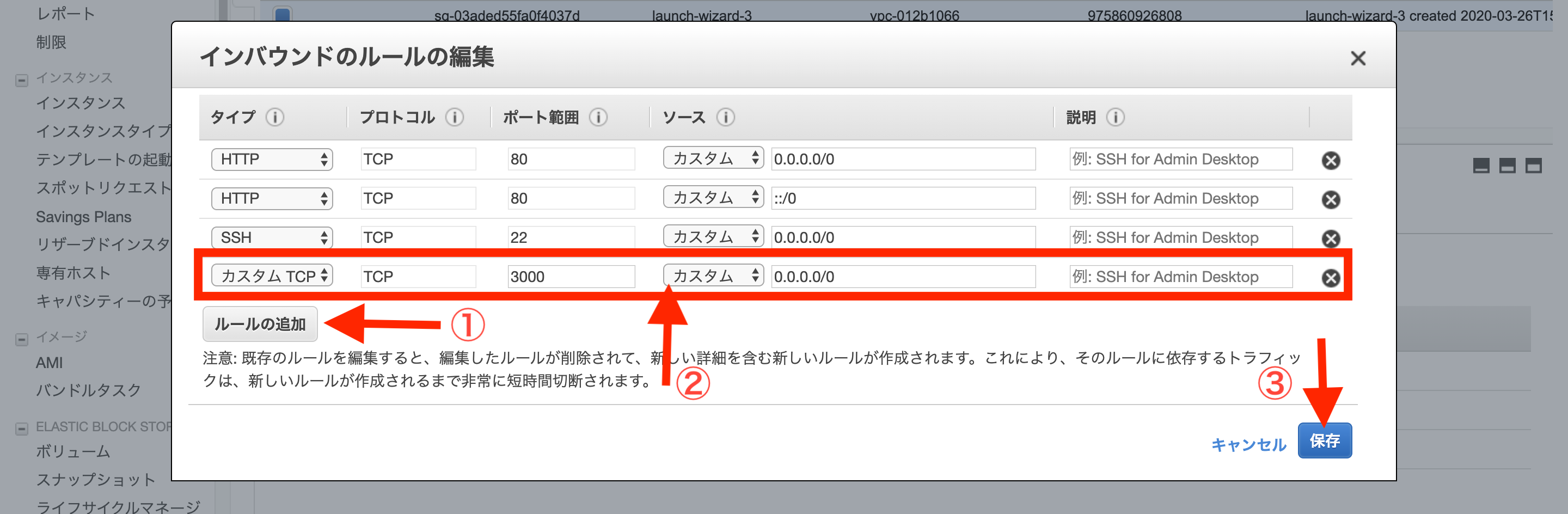
モーダルが開くので、「ルールの追加」をクリックします。
タイプを「カスタムTCPルール」、プロトコルを「TCP」、ポート範囲を「3000」、送信元を「カスタム」「0.0.0.0/0」に設定します。
「0.0.0.0」は「全てのアクセスを許可する」という意味です。
以上で、ポートの開放が完了です。
この作業が終わっていないと、起動したRailsにアクセスできません。本番環境でRailsを起動
unicorn_railsコマンド
-c config/unicorn.rb は設定ファイルの指定、 -E production は環境を「本番モードとして動作させる」ことを示します。
-Dで、プログラムを起動させつつターミナルで別のコマンドを打てるようにするオプションです。
unicorn のgemをインストールしていると unicorn_rails というコマンドが使えるようになります。
ローカル環境でrails s と同じように使います。
ターミナル(EC2サーバ)[ec2-user@ip-172-31-23-189 ~]$ cd /var/www/[リポジトリ] [ec2-user@ip-172-31-23-189 <リポジトリ名>]$ bundle exec unicorn_rails -c config/unicorn.rb -E production -D master failed to start, check stderr log for detailsまだこの状態だとエラーが出てしましいます。エラーログの確認をします。
先程の config/unicorn.rb をもう一度確認してみると、 stderr_path "#{app_path}/log/unicorn.stderr.log" という記述があります。これは、「Unicorn関係で起きたエラーをlog/unicorn.stderr.log」に記録するという指定になっています。
なので log/unicorn.stderr.log を確認します。ターミナル(EC2サーバ)
[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ less log/unicorn.stderr.log I, [2016-12-21T04:01:19.135154 #18813] INFO -- : Refreshing Gem list I, [2016-12-21T04:01:20.732521 #18813] INFO -- : listening on addr=0.0.0.0:3000 fd=10 E, [2016-12-21T04:01:20.734067 #18813] ERROR -- : Can't connect to local MySQL server through socket '/tmp/mysql.sock' (2) /home/ec2-user/.rbenv/versions/2.5.1/lib/ruby/gems/2.5.0/gems/activerecord-5.0.0.1/lib/active_record/connection_adapters/mysql2_adapter.rb:29:in `rescue in 〜省略〜 /home/ec2-user/.rbenv/versions/2.5.1/lib/ruby/gems/2.5.0/gems/unicorn-5.1.0/bin/unicorn_rails:209:in `<top (required)>' /home/ec2-user/.rbenv/versions/2.5.1/bin/unicorn_rails:23:in `load' /home/ec2-user/.rbenv/versions/2.5.1/bin/unicorn_rails:23:in `<main>'このERRORという行を見ると、これは本番環境でインストールするmysqlの設定がローカルとは異なるため、mysqlへ接続できなくなっている状態です。
なので、本番環境のmysqlの設定に合わせるため、ローカルのdatabase.ymlを以下のように編集します。
config/database.yml(ローカル)roduction: <<: *default database: それぞれのアプリケーション名 username: root password: <%= ENV['DATABASE_PASSWORD'] %> socket: /var/lib/mysql/mysql.sockリモートリポジトリが更新されたため、サーバ上のアプリケーションにも反映させます。
先ほどはgit cloneコマンドを利用しましたが、今回はすでにEC2とGithubは接続できているため、git pullコマンドを利用します。
※別にブランチを切っている場合は、masterブランチにmergeしてから以下のコマンドを実行してください。
ターミナル(EC2サーバ)[ec2-user@ip-172-31-23-189 <リポジトリ名>] git pull origin masterデータベースを作成しマイグレーションを実行し直します。
ターミナル(EC2サーバ)[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ rails db:create RAILS_ENV=production Created database '<データベース名>' [ec2-user@ip-172-31-23-189 <リポジトリ名>]$ rails db:migrate RAILS_ENV=productionもしここでMysql2::Error: Can't connect to local MySQL server through socket '/var/lib/mysql/mysql.sock'というエラーが起こった場合、mysqlが起動していない可能性があります。sudo service mysqld startというコマンドをターミナルから打ち込み、mysqlの起動を試してください。
データベースの準備ができたので、再びRailsの起動
ターミナル(EC2サーバ)[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ bundle exec unicorn_rails -c config/unicorn.rb -E production -Dブラウザで http://<サーバに紐付けたElastic IP>:3000/ にアクセスしてみて、ブラウザにCSSの反映されていない(ビューが崩れている)画面が表示されていれば成功です。
本番モードでは、事前にアセットをコンパイルする必要があります。
ターミナル(EC2サーバ)[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ rails assets:precompile RAILS_ENV=productionUnicornのプロセスの確認
コンパイルが成功したら反映を確認するため、Railsを再起動するんですが、まずは今動いているUnicornをストップします。そのために、Unicornのプロセスを確認し、プロセスを止めます。ターミナルからプロセスを確認するにはpsコマンドを利用します。
psコマンド
psコマンドは、現在動いているプロセスを確認するためのコマンドです。
aux は、psコマンドのオプションです。表示結果を見やすくしてくれます。また、| grep unicornとしているのはpsコマンドの結果からunicorn関連のプロセスのみを抽出するためです。
ターミナル(EC2サーバ)[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ ps aux | grep unicorn以下のようにプロセスが表示されます。
ターミナル(EC2サーバ)ec2-user 17877 0.4 18.1 588472 182840 ? Sl 01:55 0:02 unicorn_rails master -c config/unicorn.rb -E production -D ec2-user 17881 0.0 17.3 589088 175164 ? Sl 01:55 0:00 unicorn_rails worker[0] -c config/unicorn.rb -E production -D ec2-user 17911 0.0 0.2 110532 2180 pts/0 S+ 02:05 0:00 grep --color=auto unicorn大事なのは左から2番目の列です。ここに表示されるのがプロセスのid、つまりPIDになります。
「unicorn_rails master」と表示されているプロセスがUnicornのプロセス本体です。この時のPIDは、17877となります。
ターミナルからプロセスをストップするにはkillコマンドを利用します。killコマンド
killコマンドは、現在動いているプロセスを停止させるためのコマンドです。
ターミナル(EC2サーバ)
[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ kill <確認したunicorn rails masterのPID>
```
プロセスを表示させ終了できているかの確認
ターミナル(EC2サーバ)[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ ps aux | grep unicorn ... ec2-user 17911 0.0 0.2 110532 2180 pts/0 S+ 02:05 0:00 grep --color=auto unicorn実行結果が上記のようになっていればUnicornを停止が完了です。ローカルの ctrl + cでサーバをストップするという作業と同じことです。
プロセスが終了できない場合
下記の2行が表示が消えていない場合はプロセスが終了できていないことになります。
ターミナル(EC2サーバ)ec2-user 17877 0.4 18.1 588472 182840 ? Sl 01:55 0:02 unicorn_rails master -c config/unicorn.rb -E production -D ec2-user 17881 0.0 17.3 589088 175164 ? Sl 01:55 0:00 unicorn_rails worker[0] -c config/unicorn.rb -E production -Dそのような場合は、プロセスを強制終了します。オプション-9をkillコマンドにつけると強制終了を実行できます。通常のkillコマンドで削除できない場合はこちらを使用します。
$ kill -9 [プロセスID] #プロセスIDはpsコマンドで検索した結果の数字に置き換えてください。上記であれば17877です。再びunicornを起動します。このとき RAILS_SERVE_STATIC_FILES=1 という指定を先頭に追加します。これは、コンパイルされたアセットをRailsが見つけられるような指定になります。
ターミナル(EC2サーバ)[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ RAILS_SERVE_STATIC_FILES=1 unicorn_rails -c config/unicorn.rb -E production -Dもう一度、ブラウザで http://<Elastic IP>:3000/ にアクセスしてみて、レイアウト崩れも無くサイトが正常に表示されていれば成功です。
ちなみに、以下のようにコマンドを実行する事で正常に動いている際のログも確認することができます。
ターミナル(EC2サーバ)[ec2-user@ip-172-31-23-189 <リポジトリ名>]$tail -f log/production.logtail コマンド
指定したファイルの最後の行を表示するコマンドです。-fオプションを追加することで、そのままリアルタイムに更新されるようになります。
tail -fコマンドによる表示を終了したい場合は、ctrl + cで中断できます。Railsの起動がうまくできなかった時
上記のコマンドを実行してもRailsが起動しないときや、起動できてもIPアドレス:3000にアクセスするとエラーが表示されないときに考えられるのは
pushのし忘れ、またはEC2サーバ側でのpullのし忘れは無いか
EC2サーバ側で、/var/www/<リポジトリ名>/log/unicorn.stderr.logをlessまたはcatコマンドで確認し、エラーが出ていないか確認する(下に行くほど最新のログです。時刻表記がUTCであることに注意してください)
ローカルでの編集のpushやEC2でのgit pullを忘れていないか
mysqlの起動は正しく行えているか
EC2サーバ側のSECRET_KEY_BASE等は正しく設定できているか
EC2インスタンスの再起動を行ってみる
などを確認してみてください。
- 投稿日:2020-03-27T23:06:33+09:00
AWS SSOで発行されるIAMRoleを使ってEKSのRBACを認証する
はじめに
社内でAWS SSOが導入されたことで、EKSの管理者権限の管理方法についての記事を見てくださった社内の方から、SSOで発行されるIAMロールでRBACの認証をすることはできますか、と問い合わせをもらったので調べました。
結論としてはできます、むしろすごく運用が楽になったので是非ともやるべき、とお勧めできるのですが、ハマりポイントがあったので備忘を兼ねて記事にします。やったこと(うまくいかなかったパターン)
成功したパターンを書く前にうまくいかなかったパターンから紹介します。
手順1 aws-authにIAMRoleを追加
AWS SSOから発行されたIAMRoleをRBACで認証するためにConfigMapのaws-authを更新するためのマニフェストファイルを作成します。作成後、
kubectl applyコマンドで適用します。apiVersion: v1 kind: ConfigMap metadata: name: aws-auth namespace: kube-system data: mapRoles: | - rolearn: arn:aws:iam::000000000000:role/hogehoge username: system:node:{{EC2PrivateDNSName}} groups: - system:bootstrappers - system:nodes - rolearn: arn:aws:iam::000000000000:role/aws-reserved/sso.amazonaws.com/AWSReservedSSO_AdministratorAccess_0123456789abcdefg username: sso-eks-operator groups: - system:masters手順2 AWS Profileのセットアップ
AWSCLIv2を利用している場合は
aws configure ssoコマンドでProfileをセットアップします。今回はsso-profileという名前で作成しました。
余談ですが、AWSCLIv2は最近使い始めたのですが、最初はインターフェースがかなり変わっていて驚いたのですが、補完機能やSSO連携など機能が充実していてかなり良いですね。
SSO連携時のProfileはどうやって発行するの??という方もいるかと思いますので、発行時のキャプチャを貼っておきます。
AWSCLIv1の場合は、AWS SSOのコンソールからアクセスキー、シークレットキーを取得し、従来の方法でProfileを設定します。こちらの記事が参考になるかと思います。
手順3 kube configの更新
以下のコマンドを実行し、
~/.kube/configを更新します。$ aws eks update-kubeconfig --name [cluster_name] --profile sso-profile手順4 アクセス確認
ここまでくればあとはEKSを操作するだけとなります。kubectlコマンドを実行し、操作できるかを確認します。
$ kubectl get pod error: You must be logged in to the server (Unauthorized)k8sを触ったことがある人は全員目にしたことがある(はずの)RBACで弾かれてそうなエラーが出ました。設定を見直してもおかしそうなところはなく、原因がわからなかったのでサポートケースを起票することにしました。
ハマりポイント
サポートケースをチャット形式で起票し、状況を伝えるなど対話を重ねる中で、一つのブログ記事を紹介していただきました。ブログ記事はこちらになります。
この記事を読み進めると、以下のように言及されています。
- For the rolearn be sure to remove the /aws-reserved/sso.amazonaws.com/ from the rolearn url, otherwise the arn will not be able to authorize as a valid user.
かいつまんで直訳すると、 rolearnから「/aws-reserved/sso.amazonaws.com/」を削除する です。
早速やってみました。
上記の「手順1 aws-authにIAMRoleを追加」で作成したConfigMapを編集し、 /aws-reserved/sso.amazonaws.com/を削除 し、kubectl applyします。apiVersion: v1 kind: ConfigMap metadata: name: aws-auth namespace: kube-system data: mapRoles: | - rolearn: arn:aws:iam::000000000000:role/hogehoge username: system:node:{{EC2PrivateDNSName}} groups: - system:bootstrappers - system:nodes - rolearn: arn:aws:iam::000000000000:role/AWSReservedSSO_AdministratorAccess_0123456789abcdefg username: sso-eks-operator groups: - system:mastersこれを適用したことで、無事にEKSを操作できるようになりました。
さいごに
AWS SSOやAWSCLIv2のSSO連携など、SREとして運用負荷の下がる機能のリリースが次々とあり、ありがたいと感じている一方で、私自身AWSCLIv2がリリースされてから実際に利用するまでにラグがあったように、使ってみればすごくいいものでも、キャッチアップして使うまでが大変ということをつくづく感じました。
ただ、今回はサポートケースを頼らせてもらいましたが、最近ではサポートケースをチャット形式で利用させてもらっており、対話形式の中で状況確認を適切に行なって頂いているためか、短時間で芯を食った回答を得られることが増えており非常に助かっています。今回この件を調べることになったきっかけは別チームの方からの問い合わせでしたが、良いアイデアをもらったので、感謝しつつ弊チームでも利用させていただくこととします。

- 投稿日:2020-03-27T23:06:33+09:00
EKSのRBACによる認証にAWS SSOで発行されるIAMRoleを使用する
はじめに
社内でAWS SSOが導入されたことで、EKSの管理者権限の管理方法についての記事を見てくださった社内の方から、SSOで発行されるIAMロールでRBACの認証をすることはできますか、と問い合わせをもらったので調べました。
結論としてはできます、むしろすごく運用が楽になったので是非ともやるべき、とお勧めできるのですが、ハマりポイントがあったので備忘を兼ねて記事にします。やったこと(うまくいかなかったパターン)
成功したパターンを書く前にうまくいかなかったパターンから紹介します。
手順1 aws-authにIAMRoleを追加
AWS SSOから発行されたIAMRoleをRBACで認証するためにConfigMapのaws-authを更新するためのマニフェストファイルを作成します。作成後、
kubectl applyコマンドで適用します。apiVersion: v1 kind: ConfigMap metadata: name: aws-auth namespace: kube-system data: mapRoles: | - rolearn: arn:aws:iam::000000000000:role/hogehoge username: system:node:{{EC2PrivateDNSName}} groups: - system:bootstrappers - system:nodes - rolearn: arn:aws:iam::000000000000:role/aws-reserved/sso.amazonaws.com/AWSReservedSSO_AdministratorAccess_0123456789abcdefg username: sso-eks-operator groups: - system:masters手順2 AWS Profileのセットアップ
AWSCLIv2を利用している場合は
aws configure ssoコマンドでProfileをセットアップします。今回はsso-profileという名前で作成しました。
余談ですが、AWSCLIv2は最近使い始めたのですが、最初はインターフェースがかなり変わっていて驚いたのですが、補完機能やSSO連携など機能が充実していてかなり良いですね。
SSO連携時のProfileはどうやって発行するの??という方もいるかと思いますので、発行時のキャプチャを貼っておきます。
AWSCLIv1の場合は、AWS SSOのコンソールからアクセスキー、シークレットキーを取得し、従来の方法でProfileを設定します。こちらの記事が参考になるかと思います。
手順3 kube configの更新
以下のコマンドを実行し、
~/.kube/configを更新します。$ aws eks update-kubeconfig --name [cluster_name] --profile sso-profile手順4 アクセス確認
ここまでくればあとはEKSを操作するだけとなります。kubectlコマンドを実行し、操作できるかを確認します。
$ kubectl get pod error: You must be logged in to the server (Unauthorized)k8sを触ったことがある人は全員目にしたことがある(はずの)RBACで弾かれてそうなエラーが出ました。設定を見直してもおかしそうなところはなく、原因がわからなかったのでサポートケースを起票することにしました。
ハマりポイント
サポートケースをチャット形式で起票し、状況を伝えるなど対話を重ねる中で、一つのブログ記事を紹介していただきました。ブログ記事はこちらになります。
この記事を読み進めると、以下のように言及されています。
- For the rolearn be sure to remove the /aws-reserved/sso.amazonaws.com/ from the rolearn url, otherwise the arn will not be able to authorize as a valid user.
かいつまんで直訳すると、 rolearnから「/aws-reserved/sso.amazonaws.com/」を削除する です。
早速やってみました。
上記の「手順1 aws-authにIAMRoleを追加」で作成したConfigMapを編集し、 /aws-reserved/sso.amazonaws.com/を削除 し、kubectl applyします。apiVersion: v1 kind: ConfigMap metadata: name: aws-auth namespace: kube-system data: mapRoles: | - rolearn: arn:aws:iam::000000000000:role/hogehoge username: system:node:{{EC2PrivateDNSName}} groups: - system:bootstrappers - system:nodes - rolearn: arn:aws:iam::000000000000:role/AWSReservedSSO_AdministratorAccess_0123456789abcdefg username: sso-eks-operator groups: - system:mastersこれを適用したことで、無事にEKSを操作できるようになりました。
さいごに
AWS SSOやAWSCLIv2のSSO連携など、SREとして運用負荷の下がる機能のリリースが次々とあり、ありがたいと感じている一方で、私自身AWSCLIv2がリリースされてから実際に利用するまでにラグがあったように、使ってみればすごくいいものでも、キャッチアップして使うまでが大変ということをつくづく感じました。
ただ、今回はサポートケースを頼らせてもらいましたが、最近ではサポートケースをチャット形式で利用させてもらっており、対話形式の中で状況確認を適切に行なって頂いているためか、短時間で芯を食った回答を得られることが増えており非常に助かっています。今回この件を調べることになったきっかけは別チームの方からの問い合わせでしたが、良いアイデアをもらったので、感謝しつつ弊チームでも利用させていただくこととします。
- 投稿日:2020-03-27T22:40:42+09:00
DBとAPIサーバのパフォーマンスチューニングの調査
はじめに
- 業務で、DBとAPIサーバのパフォーマンスチューニングを行う予定なのですが、全く行ったことがなかったので、どのような手順や方法で進めていくのか調べてみました。
目次
- パフォーマンスチューニングとは
- パフォーマンスチューニングの種類
- SQLチューニング
- indexチューニング
- auroraについて
- APIサーバ側のチューニングについて
1. パフォーマンスチューニングとは
パフォーマンスチューニングの説明として、一番しっくりきました。
システムの処理性能や信頼性を高めるために,システムの動作環境を最適化することです。パフォーマンスチューニングを実施することで,システムの性能を最大限に生かし,安定稼働させられるようになります。
一般的には、
SQLやDBのチューニングを指しているようでした。
パフォーマンスチューニング ≒ SQLやDBのチューニング2. パフォーマンスチューニングの種類
今回は、バックエンド側のみです。主なパフォーマンスチューニングは、以下の通りでした。
SQLチューニングDBチューニングAPIサーバ側のチューニング具体的には、以下のようなチューニングを行うことが可能です。
SQLチューニング
- indexの追加・削除 - SQLを書き換える - データ型の見直しDBチューニング
- MySQLパフォーマンスチューニング -my.cnfの見直しAPIサーバ側のチューニング
- 不要なクエリ - APIサーバとDBのロジックの比率の修正3. SQLチューニング
やればやるだけ性能が良くなります。チューニングの手順は以下のようになります。
- スロークエリを探す
- explainを使用し実行計画を確認する
- チューニングを行う
具体的なチューニング方法は、以下の3つになります。
[SQLを書き換える]
- サブクエリをできる限りJOIN句に置き換える
- ループ回数を少なくする(N+1問題があれば絶対に修正する)
- 大量データを更新する際は、バルクインサートを行う
[indexの追加・削除]
テーブルの情報を探す時に検索の対象としてよく使用するカラムの値だけを取り出して検索しやすいようにしておいたものです。
indexとはindexを貼る際のポイント
- カーディナリティの高い(不特定多数のデータが想定される)カラムを選択します。
- 複合インデックスのカラムの順に注意が必要です。順によってインデックスの内容が変わります。
- 更新性能・キャッシュ効率が低下するので、必要なものだけ貼ります。無闇に貼ってはいけません。
[データ型の見直し]
- テーブルに設定したデータ型と入力したデータ型が一致しているか確認が必要です。 型が異なっていた場合、本来は必要のない無駄な型変換処理が行われてしまいます。
- この型変換の処理は、暗黙的に行われてしまうので、発見が少し難しいです。
4. DBチューニング
以下の記事がとても参考になりました。
DBには、MySQLを始めとする様々なものが存在しますが、どのDBでも似たような設定を行うことが可能です。今回は、開発環境で使用しているMySQLを中心に調査しました。
MySQLパフォーマンスチューニング -my.cnfの見直し
チューニングのポイントは以下の通りです。
- スロークエリが発生していないか?
- mysqlのメモリが正しく割り当てられていないか?
- mysqlのログ設定が適切であるか?
- max_connectionの設定が適切であるか?
Mysqlのmy.cofがデフォルトの設定であれば、これらを設定するだけで大幅な改善が可能です。
初期の設定や運用が大変...
- 上記の設定を行うことにより、性能改善は十分に見込まれます。
- しかし、プロダクトの状況に応じ、ベストなパフォーマンスを継続的に維持する方法としては、あまり現実的ではありません...
- もっと楽な良い方法はないのかと.....
と思い調べていたら、
AWS Auroraにたどり着きました。ちょうど、本番環境ではAuroraを使用するようなので少し調べてみました。5. auroraについて
Amazon Aurora は、MySQL および PostgreSQL と互換性のあるクラウド向けのリレーショナルデータベースであり、従来のエンタープライズデータベースのパフォーマンスと可用性に加え、オープンソースデータベースのシンプルさとコスト効率性も兼ね備えています。
auroraとは
- クラウド向けRDB
- MySQLおよびPostgreSQLと互換性あり
- 標準的なMySQLと比べ、最大5倍の性能差、PostgreSQLと比べ、最大3倍の性能差
- 従来の商用DBと同様なセキュリティ、可用性、信頼性を10分の1のコストで実現
費用面以外で悪く書いてある記事が全く見当たらなかったです....笑
Amazonさんが本気を出したみたいです。記事によっては、「Auroraに合わせて設計を行った方が良い」とまで書かれている記事もありました。メリット
主なメリットは以下の通りです。
[クエリのスループットの向上]
- CPUを効率的に利用 - 分散ロック機構やQueryChacheの改善による性能向上[ディスクの可用性の向上]
- オートスケーリング機能 - 容易にバックアップが可能[複数サーバにシャーディング]
- 複数の小さいDBを1つにまとめるチューニング方法
[前提]
- デフォルトのパラメータグループを使用することで、十分な高パフォーマンスを実現することができます。
- さらに、高パフォーマンスを実現するためには、主に以下の2つの方法があります。
[方法]
1. 適切なインスタンスタイプを選択
サービスの規模に合わせた適切なインスタンスタイプを選択することで、よりパフォーマンスが最大化されます。
2. 一つのトランザクションで大量の更新や削除を行なったり、大量のデータのシーケンシャルリードを行う場合
auroraのアーキテクチャに合わせてクエリを実行することで性能を向上させることができます。
トランザクションが並列に実行されるワークロード向けにチューニングされているため、クエリを分割することで、並列実行が可能になり性能が向上します。6. APIサーバ側のチューニングについて
開発を進めていきますと、最初の設計時に想定できなかった大きな仕様変更やバグの発生などが必ず発生します。その際に、パフォーマンスの低下に繋がるようなボトルネックも必ず生まれます。そのため、決まったチューニング方法はありません。SQLやDBチューニングとは異なり、泥臭いものになりやすいです。
チューニングというより、性能改善を目的としたリファクタリングに近いかと思います。
APIサーバとDBのロジックの比率
- 設計段階で議論すべき問題の一つだと思います。
- 全体の設計を考慮しないといけないため、他のチューニングと比較すると、とても難しいです。
[判断材料] - 仕様 - 開発チームの技術レベル - プロダクトフェーズ - 好み ...など簡単に書き出してみましたが、これらをパフォーマンス面と天秤に掛けて判断するのは、今の自分ではなかなか難しそうです....
不要なクエリを削除
システム上で不要なクエリを発行していないか確認し削除します。
- SQLチューニングと並行して行うことになると思っています。地道で特別な知識は必要ないですが、開発規模が大きくなればなるほど必要になるはずです。
- 特に、ORMを使用している際には、時間をかけて行う価値はあると思います!!実装する際に、想定外のクエリばかり発行されたので......
まとめ
- DBとAPIサーバのパフォーマンスチューニングを行う際のイメージが着きました。
- また、パフォーマンスチューニングには終わりがないため、短時間で効果的なチューニングが大切であることが分かりました。
- 次はフロント側のパフォーマンスチューニングについてもまとめてみたいと思います。
参考URL
- 投稿日:2020-03-27T22:02:23+09:00
ツイッター風Railsアプリをデプロイする(前編:unicornのみで取り急ぎ繋げよう)
この記事の基本的な方針
この記事は、過去記事で作ったアプリをEC2でデプロイします。
手を動かしながら読みたいようでしたら、以下でこのアプリを手に入れてください。Terminal$ git clone https://github.com/annaPanda8170/cheaptweet.git $ bundle install $ bundle exec rake db:create $ bundle exec rake db:migrateこれ自体の作り方は、こちら。
Rails5.2.4.2_でのみ動作確認しています。
基本解説はしません。手順のみ示します。想定する読み手
既に一度Railsアプリをチュートリアルやスクール等で作りデプロイしたこのある方を想定しています。
Mac使用で、パソコンの環境構築は完了し、AWSのアカウントを持っていることが前提です。具体的な手順
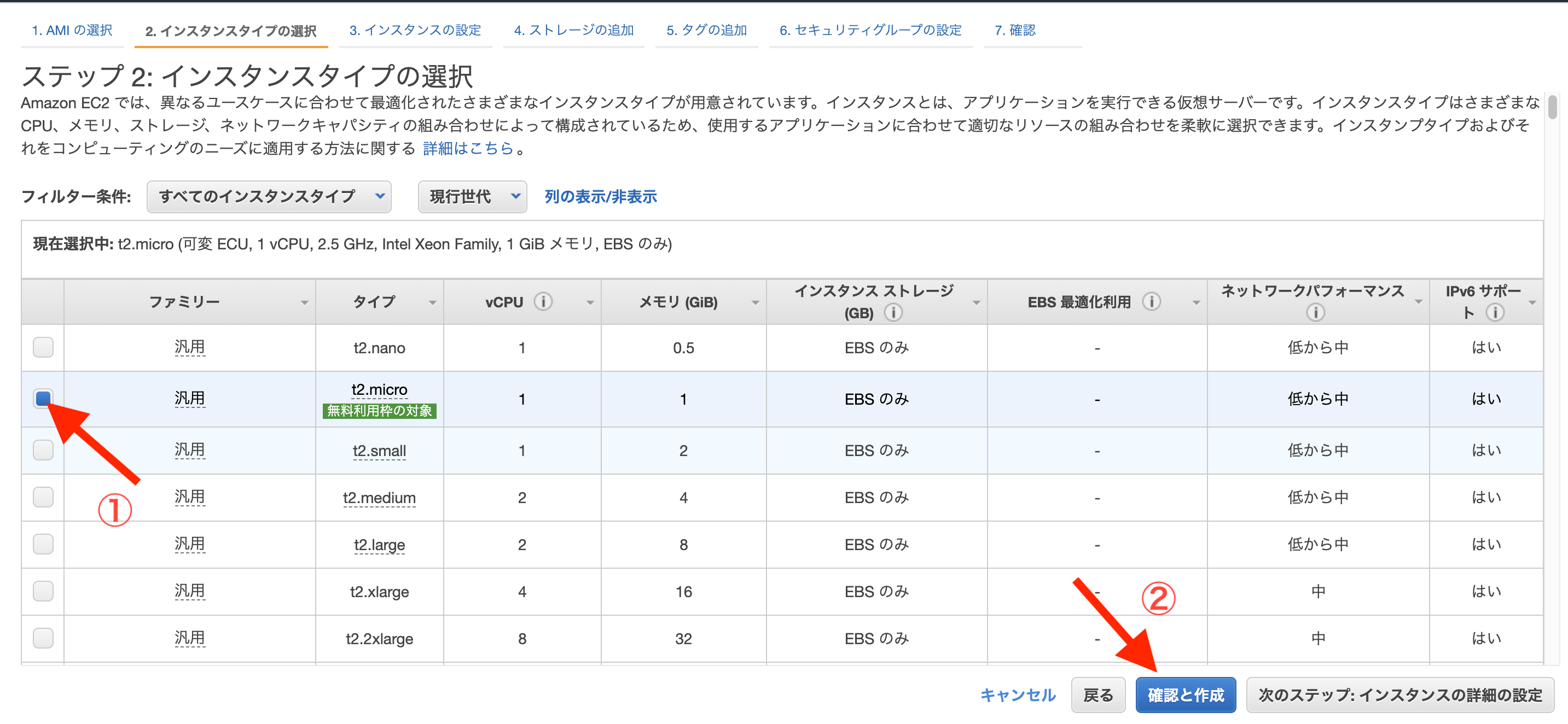
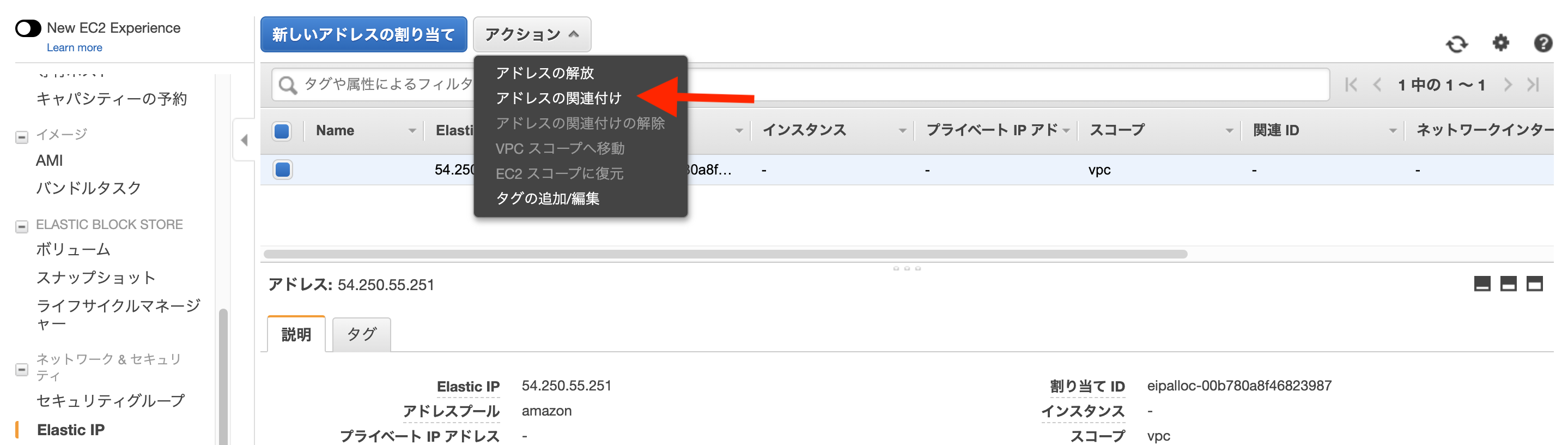
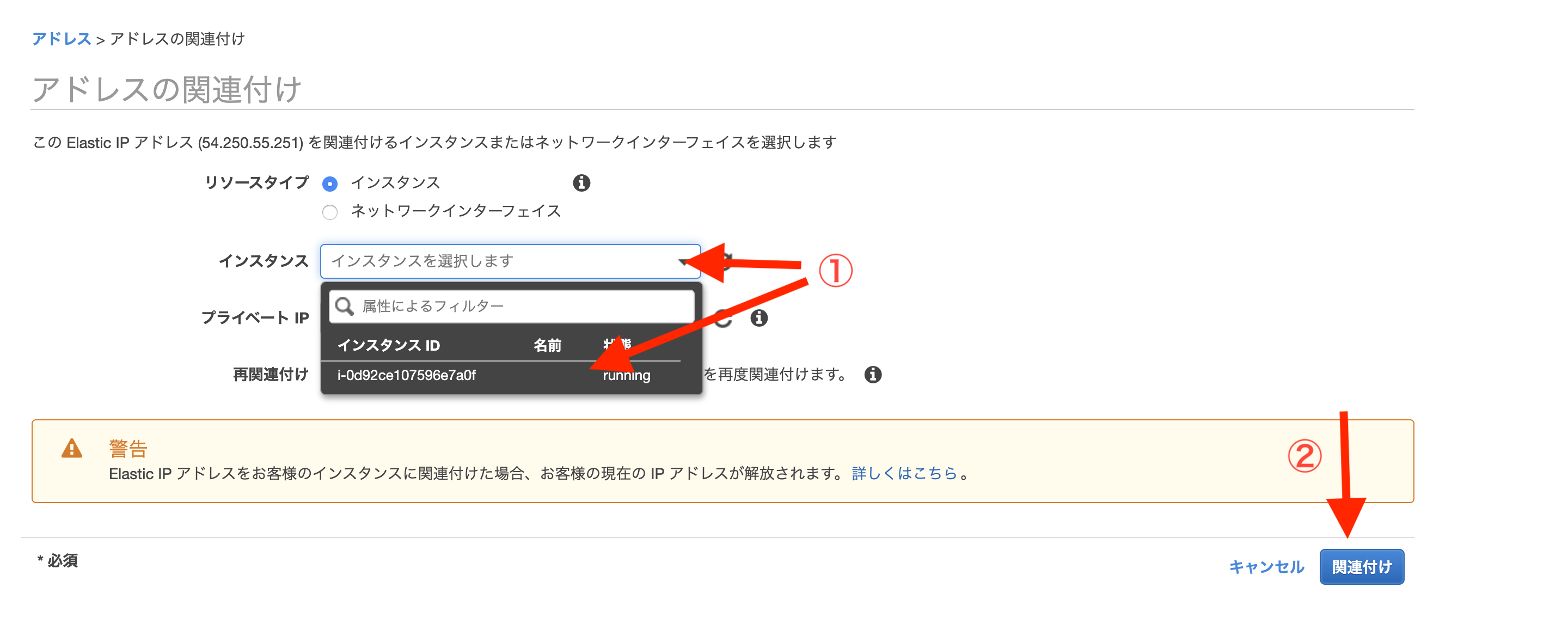
①インスタンスを作り、ssh接続でログインする
Terminal(ローカル)# ホームディレクトリ直下に.ssh/隠しディレクトリを事前に作ってます $ cd # 別に移動しなくても問題ないが、隠しディレクトリに入れといた方が無難 $ mv Downloads/****鍵の名前****.pem .ssh/ $ cd .ssh/ # ****鍵の名前****.pemのファイルに関して所有者のみ読み出し・書き込みの権限を与える意 # (所有者も実行権限がなく、所有者グループとその他はなんの権限もない) $ chmod 600 ****鍵の名前****.pem # ログイン $ ssh -i ****鍵の名前****.pem ec2-user@****ここはElasticIP****OutputAre you sure you want to continue connecting (yes/no)?Terminal(ローカル)yesOutputWarning: Permanently added '54.250.55.251' (ECDSA) to the list of known hosts. __| __|_ ) _| ( / Amazon Linux AMI ___|\___|___| https://aws.amazon.com/amazon-linux-ami/2018.03-release-notes/②諸々インストールと、GitHub連携
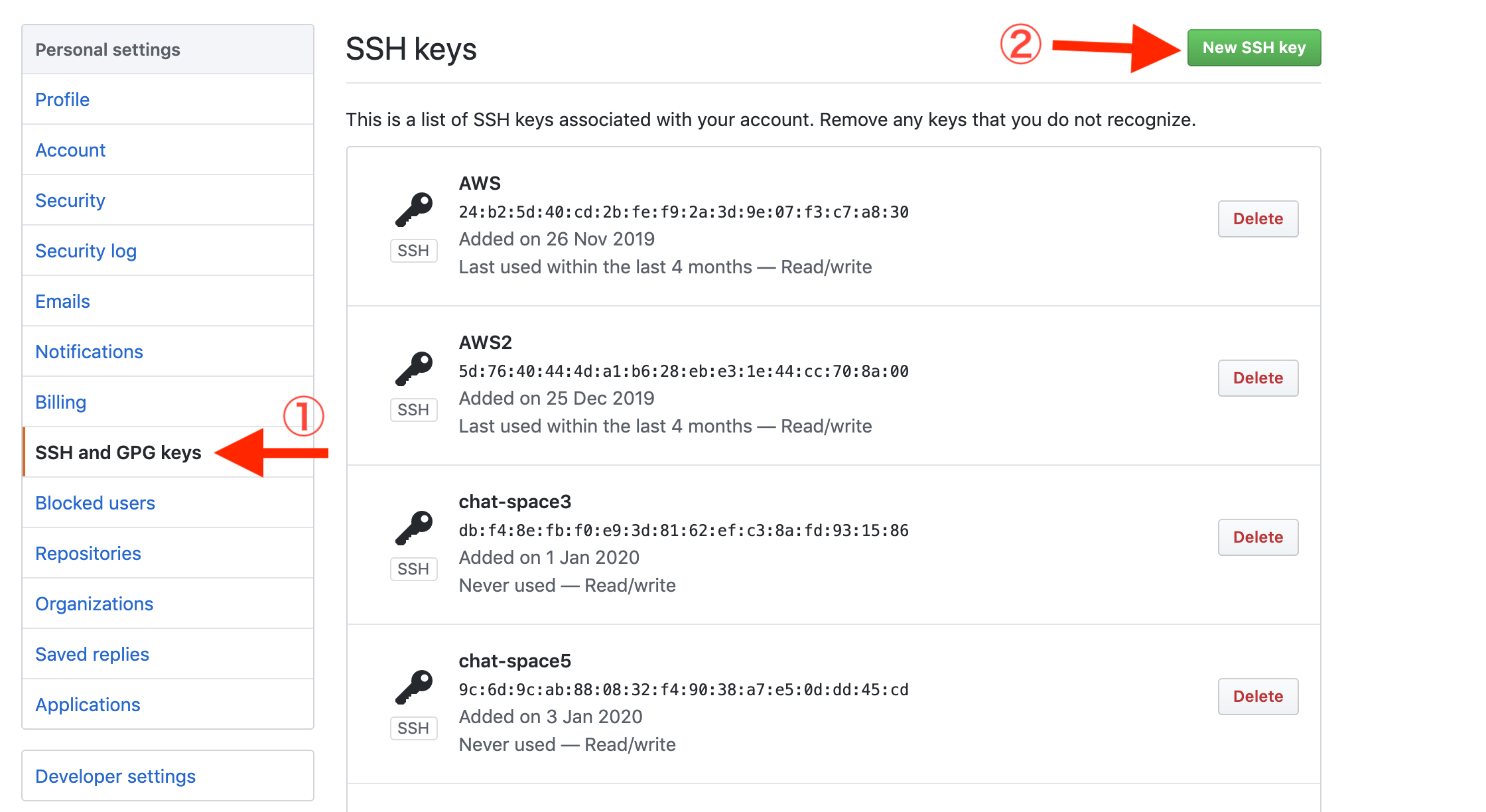
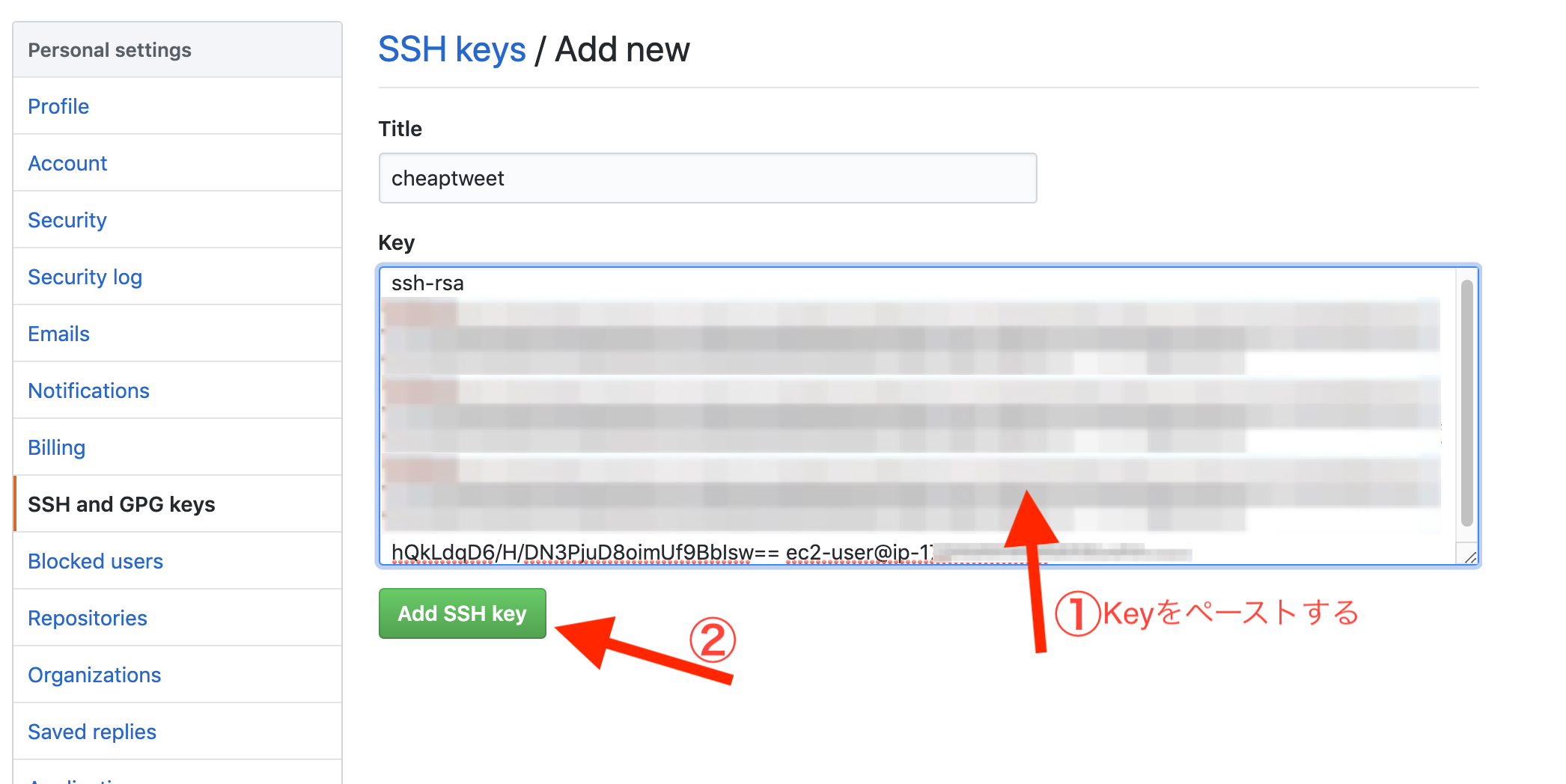
Terminal(EC2)# もしアップデートしろと言われたら以下を実行 # アップデートしろと言われてなくてやっても問題ないので一応やってもいいかも $ sudo yum -y update # 諸々基本インストール $ sudo yum -y install git make gcc-c++ patch libyaml-devel libffi-devel libicu-devel zlib-devel readline-devel libxml2-devel libxslt-devel ImageMagick ImageMagick-devel openssl-devel libcurl libcurl-devel curl $ sudo curl -sL https://rpm.nodesource.com/setup_6.x | sudo bash - $ sudo yum -y install nodejs # 今回はJSは使ってないが一応 # 諸々Ruby・Rails関係インストール $ git clone https://github.com/sstephenson/rbenv.git ~/.rbenv $ echo 'export PATH="$HOME/.rbenv/bin:$PATH"' >> ~/.bash_profile $ echo 'eval "$(rbenv init -)"' >> ~/.bash_profile $ source .bash_profile $ git clone https://github.com/sstephenson/ruby-build.git ~/.rbenv/plugins/ruby-build $ rbenv rehash # 自身のRubyのバージョンを確認して以下。結構時間かかります $ rbenv install 2.5.1 $ rbenv global 2.5.1 $ rbenv rehash # 確認は # ruby -v # MySQLインストール $ sudo yum -y install mysql56-server mysql56-devel mysql56 # MySQL起動 $ sudo service mysqld start # 確認は # sudo service mysqld status # MySQLパスワード設定 $ sudo /usr/libexec/mysql56/mysqladmin -u root password # 確認は # mysql -u root -p # SSH鍵ペア関連 # 鍵ペア作成 $ ssh-keygen -t rsa -b 4096 # この後何も入力せずにEnter三回 # 鍵ペア表示 $ cat ~/.ssh/id_rsa.pub # 表示された値を ssh-rsa から最後までまるまるコピーwebBrowserhttps://github.com/
Terminal(EC2)$ ssh -T git@github.comOutputAre you sure you want to continue connecting (yes/no)?Terminal(EC2)yes③unicorn導入
Gemfile# 省略 group :production do gem 'unicorn', '5.4.1' end # 省略Terminal(ローカル)$ bundle install
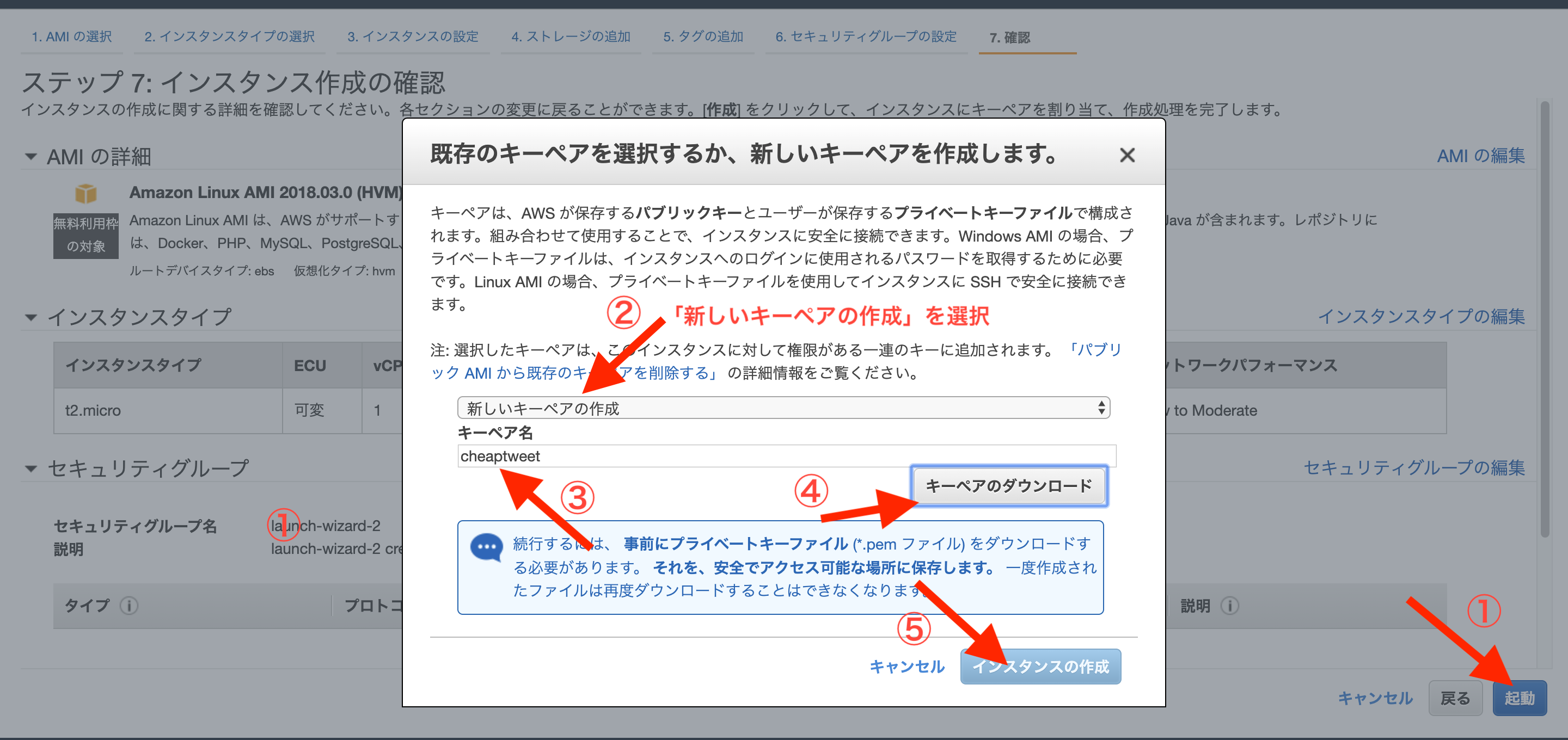
config/unicorn.rbを作成config/unicorn.rbapp_path = File.expand_path('../../', __FILE__) worker_processes 1 working_directory app_path pid "#{app_path}/tmp/pids/unicorn.pid" listen 3000 stderr_path "#{app_path}/log/unicorn.stderr.log" stdout_path "#{app_path}/log/unicorn.stdout.log" timeout 60 preload_app true GC.respond_to?(:copy_on_write_friendly=) && GC.copy_on_write_friendly = true check_client_connection false run_once = true before_fork do |server, worker| defined?(ActiveRecord::Base) && ActiveRecord::Base.connection.disconnect! if run_once run_once = false end old_pid = "#{server.config[:pid]}.oldbin" if File.exist?(old_pid) && server.pid != old_pid begin sig = (worker.nr + 1) >= server.worker_processes ? :QUIT : :TTOU Process.kill(sig, File.read(old_pid).to_i) rescue Errno::ENOENT, Errno::ESRCH => e logger.error e end end end after_fork do |_server, _worker| defined?(ActiveRecord::Base) && ActiveRecord::Base.establish_connection endconfig/environments/production.rb# 以下をコメントアウトする # config.assets.js_compressor = :uglifierconfig/database.yml#production: # <<: *default # database: ***名前***_production # username: ***名前*** # password: <%= ENV['***名前***_DATABASE_PASSWORD'] %> # | # V production: <<: *default database: '***名前***'_production username: root password: <%= ENV['DATABASE_PASSWORD'] %> socket: /var/lib/mysql/mysql.sockプッシュしてmasterにマージする
Terminal(EC2)$ cd $ sudo mkdir /var/www/ $ sudo chown ec2-user /var/www/ $ cd /var/www/
Terminal(EC2)$ git clone ***上でコピーしたGitHubのURL***④Swap領域の追加
Terminal(EC2)$ cd $ sudo dd if=/dev/zero of=/swapfile1 bs=1M count=512 $ sudo chmod 600 /swapfile1 $ sudo mkswap /swapfile1 $ sudo swapon /swapfile1 $ sudo sh -c 'echo "/swapfile1 none swap sw 0 0" >> /etc/fstab'Terminal(EC2)$ cd /var/www/***アプリ名*** # ローカルでバンドラーのバージョンを確認 $ gem install bundler -v ***確認したバージョン*** $ bundle install $ rake secret #出てきたキーをコピー $ sudo vim /etc/environment/etc/environmentDATABASE_PASSWORD='***MySQLのパスワード***' SECRET_KEY_BASE='***先程コピーしたキー***'Terminal# 再ログイン $ exit $ ssh -i ****鍵の名前****.pem ec2-user@***ここはElasticIP*** #上の環境変数の確認は # env | grep SECRET_KEY_BASE # env | grep DATABASE_PASSWORD
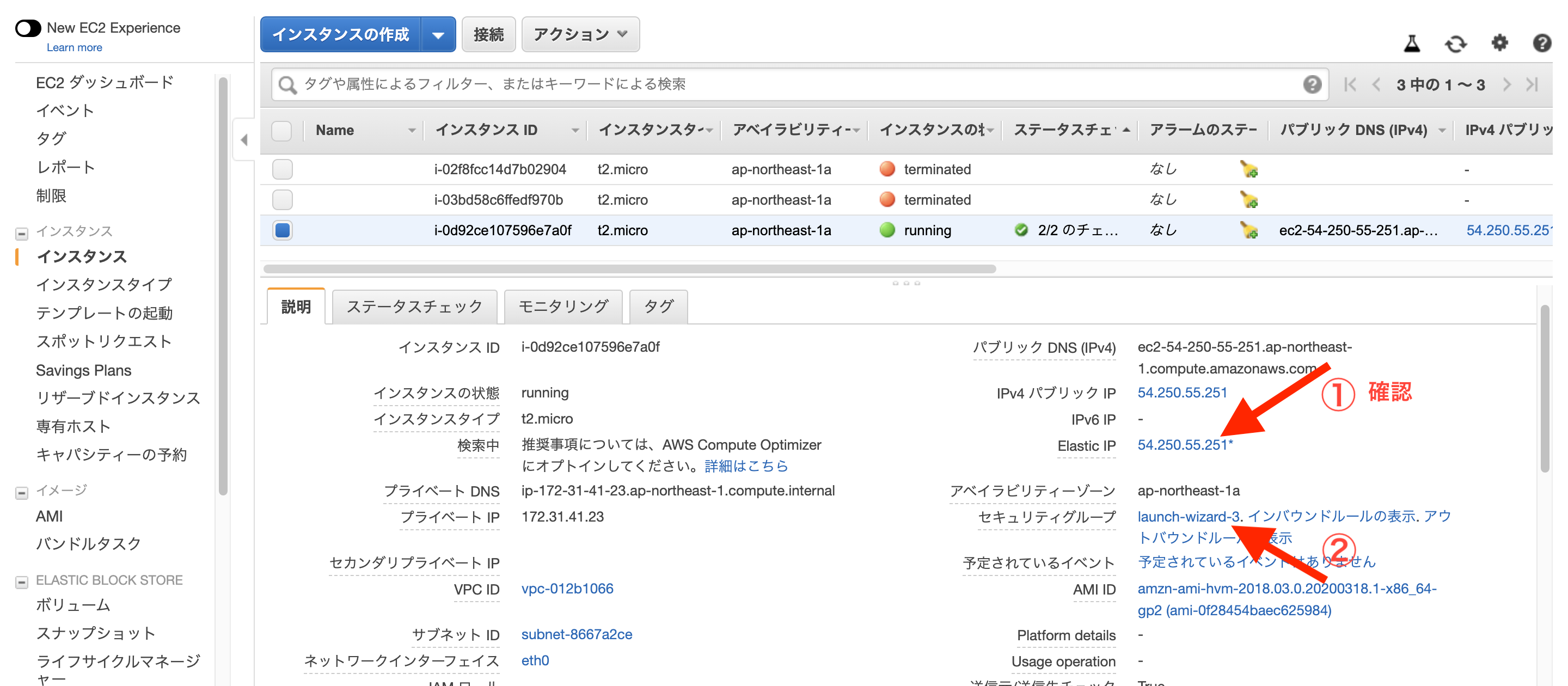
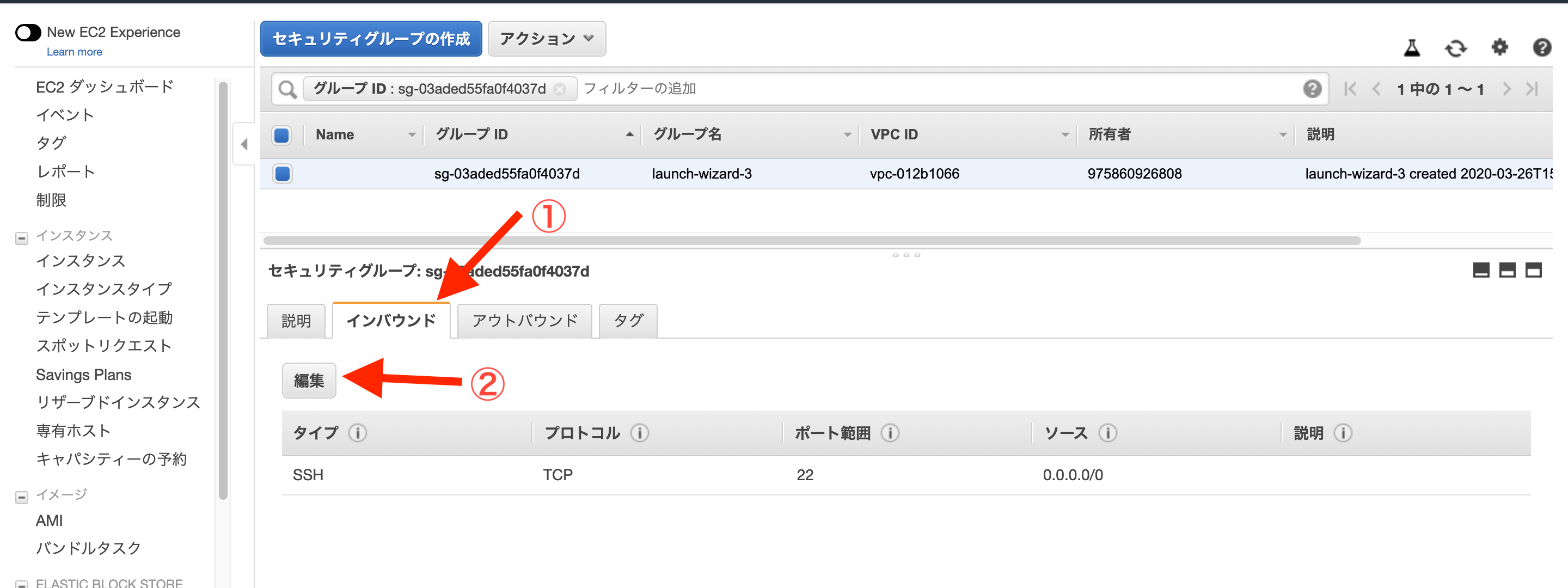
ポート範囲が
3000、ソースが0.0.0.0/0で
Terminal(EC2)$ cd /var/www/***アプリ名*** $ rails db:create RAILS_ENV=production $ rails db:migrate RAILS_ENV=production $ bundle exec unicorn_rails -c config/unicorn.rb -E production -D $ rails assets:precompile RAILS_ENV=production # 起動 $ RAILS_SERVE_STATIC_FILES=1 unicorn_rails -c config/unicorn.rb -E production -DwebBrowserhttp://***ここはElasticIP***:3000以上でとりあえず、繋がるはずです。
ただ、非常に遅いですね。パワーアップして通常のアプリとして動作させるにはNginxが必要です。
マージをコマンド一つで本番環境まで反映させるにはCapistranoが必要です。
これらの導入は後編で。もし困ったら
①ログ確認
/var/www/***アプリ名***/log/unicorn.stderr.logをtailかcatかlessかvimあたりのコマンドで確認する。②unicornの再起動
Terminal(EC2)$ ps aux | grep unicorn $ kill ***ユニコーンのPID*** $ RAILS_SERVE_STATIC_FILES=1 unicorn_rails -c config/unicorn.rb -E production -D
- 投稿日:2020-03-27T20:50:32+09:00
AWS CLI で EC2 インスタンスプロファイルを作成する方法
はじめに
よくインスタンスプロファイルと IAM ロールを同じものと考えている人がいますが、厳密には異なります。
マネージメントコンソールを使用して EC2 インスタンスに IAM ロールを設定すると、自動的に IAM ロール名と同じインスタンスプロファイルが作成されるので、あまり意識していない人が多いのだと思います。
AWS CLI で EC2 インスタンスに IAM ロールを設定したい場合、インスタンスプロファイルを明示的に作成する必要があります。
イメージとしては以下となります。
検証
各設定値を予め環境変数に設定
マネージメントコンソールで作成されるインスタンスプロファイルと同様に、IAM ロールと同じ名前のインスタンスプロファイルを作成します。
InstanceProfileName=S3AdministratorForEC2 RoleName=$InstanceProfileName PolicyArn=arn:aws:iam::aws:policy/AmazonS3FullAccessIAM ロールを作成
assume-role-policy-document.json{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "ec2.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }aws iam create-role \ --role-name $RoleName \ --assume-role-policy-document file://assume-role-policy-document.json { "Role": { "Path": "/", "RoleName": "S3AdministratorForEC2", "RoleId": "XXXXXXXXXXXXXXXXXXXX", "Arn": "arn:aws:iam::XXXXXXXXXXX:role/S3AdministratorForEC2", "CreateDate": "2020-03-27T01:43:30Z", "AssumeRolePolicyDocument": { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "ec2.amazonaws.com" }, "Action": "sts:AssumeRole" } ] } } }IAM ロールにポリシーをアタッチ
aws iam attach-role-policy \ --role-name $RoleName \ --policy-arn $PolicyArn確認
aws iam list-attached-role-policies \ --role-name $RoleName { "AttachedPolicies": [ { "PolicyName": "AmazonS3FullAccess", "PolicyArn": "arn:aws:iam::aws:policy/AmazonS3FullAccess" } ] }インスタンスプロファイルを作成
aws iam create-instance-profile \ --instance-profile-name $InstanceProfileName { "InstanceProfile": { "Path": "/", "InstanceProfileName": "S3AdministratorForEC2", "InstanceProfileId": "XXXXXXXXXXXXXXXX", "Arn": "arn:aws:iam::XXXXXXXXXXXXXXXXX:instance-profile/S3AdministratorForEC2", "CreateDate": "2020-03-27T01:43:59Z", "Roles": [] } }インスタンスプロファイルに IAM ロールをアタッチする
aws iam add-role-to-instance-profile \ --instance-profile-name $InstanceProfileName \ --role-name $RoleName結果
aws iam get-instance-profile \ --instance-profile-name $InstanceProfileName { "InstanceProfile": { "Path": "/", "InstanceProfileName": "S3AdministratorForEC2", "InstanceProfileId": "XXXXXXXXXXXXXXXXXXX", "Arn": "arn:aws:iam::XXXXXXXXXXXXXX:instance-profile/S3AdministratorForEC2", "CreateDate": "2020-03-27T01:43:59Z", "Roles": [ { "Path": "/", "RoleName": "S3AdministratorForEC2", "RoleId": "XXXXXXXXXXXXXXXXX", "Arn": "arn:aws:iam::XXXXXXXXXXXXXX:role/S3AdministratorForEC2", "CreateDate": "2020-03-27T01:43:30Z", "AssumeRolePolicyDocument": { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "ec2.amazonaws.com" }, "Action": "sts:AssumeRole" } ] } } ] } }まとめ
上記のようにして、AWS CLI でインスタンスプロファイルを作成することが出来ます。
作成したインスタンスプロファイルは、もちろん EC2 インスタンス起動時に指定することも可能ですし、マネージメントコンソールや AWS CLI で既存の EC2 インスタンスにアタッチすることも可能です。
「EC2 インスタンスに設定したい IAM ロールが、EC2 インスタンスに設定する IAM ロールの選択肢に表示されない」という場合は、インスタンスプロファイルが作成されていない可能性があります。
上記を参考にインスタンスプロファイルを作成して、状況が改善しないか試してみてください。参考ドキュメント

- 投稿日:2020-03-27T18:31:56+09:00
AWS EC2からFTP アクティブモードでファイル転送する
昨今では使われることもなくなってきたと思われるFTPですが、このFTPは環境によって微妙に使いにくいプロトコルであります。
その原因としてはアクティブとパッシブの2つのモードの存在があります
違いは以下のページが分かりやすいです。
https://www.infraexpert.com/study/tcpip20.htmlアクティブモードは環境によって使えないケースが多く(特に所謂NAT越えの場合)、AWS EC2インスタンスからインターネット上のFTPサーバーに通信する時もうまくいきません。
パッシブモードで使えればいいのですが、アクティブモードしか受け付けていないサーバーというのもあるので、どんな状態になっているかちょっと調べてみました。EC2インスタンスにログイン
まずは普通にログインします。その後、FTPの通信を確認する為にtcpdumpを実行
sudo tcpdump -A -p host xxx.xxx.xxx.xxxオプション -A はAsciiで出力。文字列で読めるところは文字列になります。
-p は自ホストに関連する通信のみ出力。
host でターゲットのIPを指定。
そうするとこんな表示が出てくるところがあります。PORT 192,168,1,1,228,200前半4個の数字がIPアドレス、後ろ2つがポート番号。
ポート番号は最初の数字に256をかけて次の数字と足したものになる。
この場合は
228 * 256 + 200 = 58568今回の問題はIPアドレスの方です。
EC2インスタンスに割り当てられたプライベートIPを送っているのですが、AWSがこの辺りをよしなに変換してくれるということはなく、相手側は送られたプライベートIPに接続しようとします。
その結果、当然接続できないので通信が正常に行えないという事になるのでした。PORTコマンドのIPを外に出て行くときのグローバルIPに変更すれば接続できそうですが、よく入っているFTPクライアントでは変更ができません。
この状態でFTP転送する場合、コマンドレベルであればlftpというコマンドを使うのが便利です。
インストールはyumで可能です。sudo yum install lftp使い方はこんな感じ
# まずは接続先を指定 lftp example.jp # userコマンドでユーザー指定 user hogehoge # パスワードを聞かれるので入力 Password: # パッシブモードをオフにする set ftp:passive-mode off # 相手に送るグローバルIPを指定 set ftp:port-ipv4 xx.xx.xx.xxこれでアクティブモードで使えました。
- 投稿日:2020-03-27T17:40:04+09:00
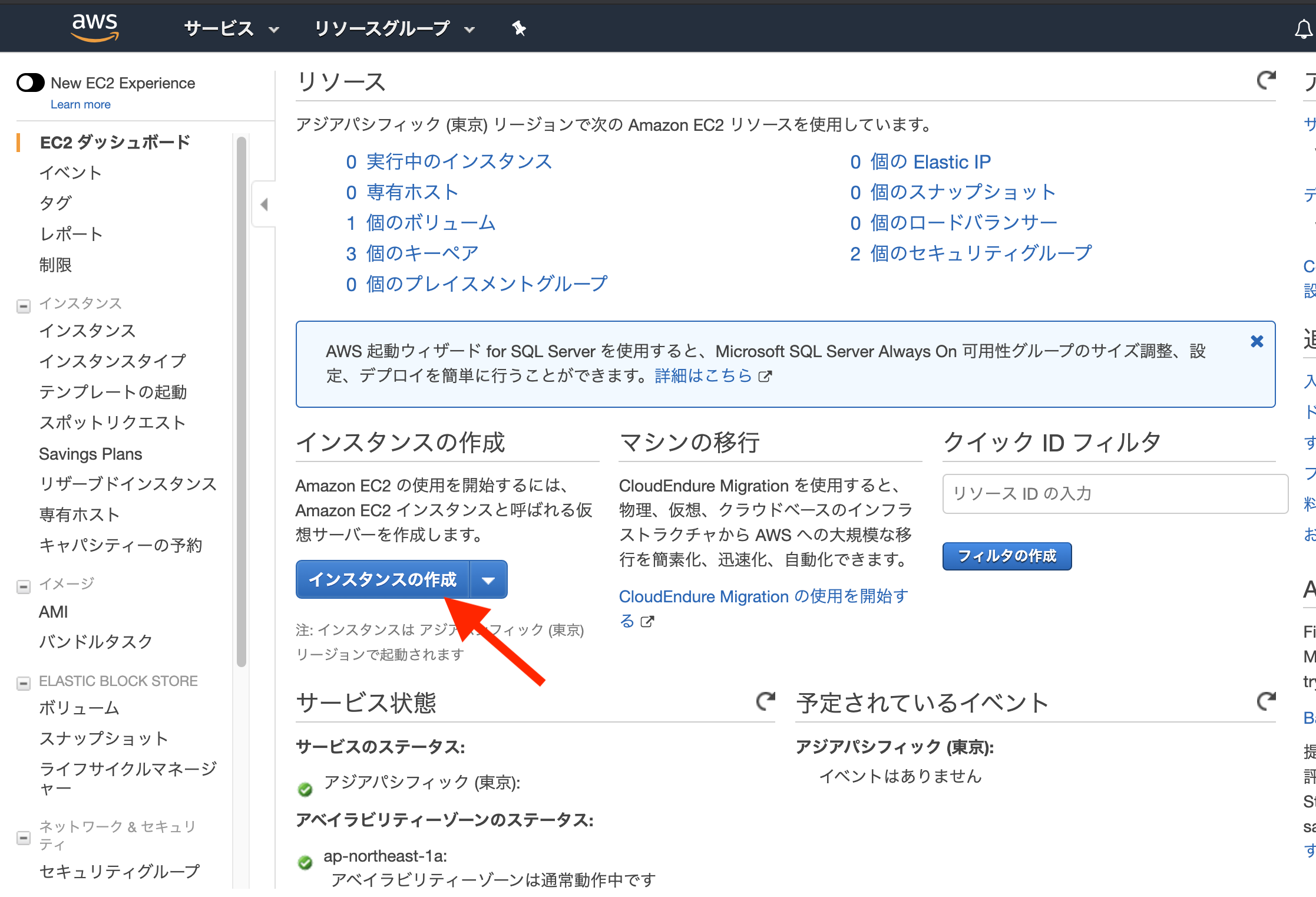
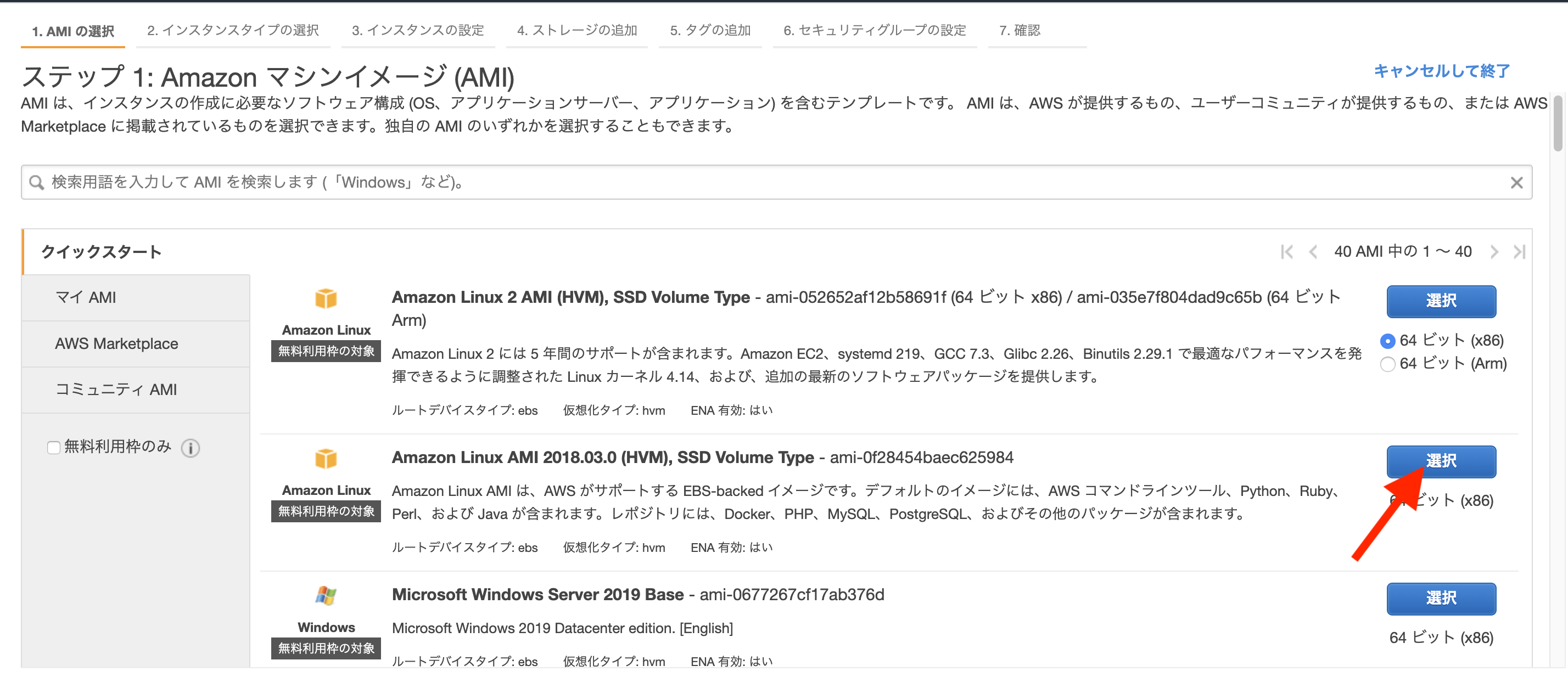
特定のEC2インスタンスを起動停止するだけのアカウントをもっと簡単に作成する
AWSで特定のEC2インスタンスの起動停止だけ出来るIAMアカウントを作成する で特定のEC2インスタンスだけ起動停止できるアカウントの作り方をご紹介しましたが、アカウント作成までの手順をCloudFromationで自動化しました。
https://ap-northeast-1.console.aws.amazon.com/cloudformation/home?region=ap-northeast-1#/stacks/create/review?templateURL=https://s3-ap-northeast-1.amazonaws.com/static.bmscr.com/qiita/ec2boot.template&stackName=EC2Boot
を開くと CloudFormation のテンプレートが既にセットされた状態でスタックの作成画面が表示されます。
ログインパスワードを入力しIAMリソースが作成されることの同意のチェックを入れ、スタックの作成をクリックするだけでポリシーとユーザが作成できます。
注:テンプレートは https://s3-ap-northeast-1.amazonaws.com/static.bmscr.com/qiita/ec2boot.template で確認することが出来ます。
改竄等されないように万全を期しますが改竄の無いことを保証は出来ません。
万一このページや上記テンプレートが改竄され悪意のあるCloudFormationテンプレートを適用してしまった場合アカウントが乗っ取られる等の恐れがありますが私は一切責任を負いません。
EC2Bootの名前でユーザーが作成されます。
ユーザー作成以降のEC2インスタンスの設定、アカウントID確認、ログイン後の操作等は AWSで特定のEC2インスタンスの起動停止だけ出来るIAMアカウントを作成する を参考に設定を行ってください。CloudFormationのスタックにEC2Bootというスタックが作成されるのでこれを削除すると作成されたポリシーとユーザーも削除されます。


- 投稿日:2020-03-27T17:02:00+09:00
CloudTrailで操作ログを設定する






- 投稿日:2020-03-27T16:20:05+09:00
【SRE/S3】まあまあ便利!削除してしまったオブジェクトを復元
手順
- バージョニングを有効にする
- オブジェクトを削除する
- 削除マーカーを削除する
下記を主に参考にします。
削除した S3 オブジェクトを復元する方法またS3の全体像に関しては下記が参考になります。
AWS再入門 Amazon S3編 | Developers.IOバージョニングを有効にする
Bucketのプロパティを開き、「バージョニング」を有効にします。
オブジェクトを削除する
該当のオブジェクトを選択し、削除します。
削除結果
削除マーカーを削除する
表示を選択
バケット内のオブジェクトのバージョン一覧を表示させます。
下記のように表示を選択します。
こうすることで、削除されたオブジェクトの削除マーカーを表示することができます。
この削除マーカーでされているオブジェクトを削除することで復元することが可能です。
削除マーカーの削除
該当のオブジェクトを選択し、削除します。
結果
復元できていることがわかります。







- 投稿日:2020-03-27T16:03:38+09:00
AutoScaling の導入 - Nextcloud 環境の構築を通じて AWS での環境構築を体験する⑦ [終]
「Nextcloud 環境の構築を通じて AWS での環境構築を体験する」 の第 7 回 兼 最終回となります。
これまでの記事は下記からどうぞ。
- 【第 1 回】EC2 と RDS を利用した Nextcloud 環境の構築
- 【第 2 回】ElastiCache サービスの導入
- 【第 3 回】EFS ファイルサーバーへの移行
- 【第 4 回】ALB を利用したサーバー負荷分散、可用性向上に向けた取り組み
- 【第 5 回】分散した EC2 インスタンスのログの集約
- 【第 6 回】Cron の外部実行とメール送信の追加
はじめに
前回記事 までで、可用性も考慮した Nextcloud の構成がひととおり完了しました。
最終回は、 AutoScaling を追加して、何らかのトラブルで EC2 が死んでも勝手に新たな EC2 が起動されるようにします。AutoScaling っていかにもクラウドっぽいサービスで私が好きなサービスの一つです。今回構築する Nextcloud on AWS 環境
次のような構成となります。基本的な構成は前回から変わりません。 EC2 の起動を AutoScaling で制御していきます。
今回追加で利用する AWS サービス
サービス名 役割 AutoScaling EC2 の稼働台数維持や、必要に応じて EC2 の自動スケールアウト/スケールインを行うことができるサービス。サービス自体は無料。今回は、稼働台数維持を目的として利用します。 設定手順
Nextcloud サーバーのマシンイメージ取得
Nextcloud サーバーの EC2 を停止し、現時点でののマシンイメージを取得します。
AWS マネジメントコンソールにログインし、EC2 サービスを選択します。「インスタンス」をクリックします。
Nextcloud サーバーの EC2 インスタンスを選択し、「アクション」-「インスタンスの状態」-「停止」の順にクリックします。
※起動している Nextcloud サーバーの EC2 インスタンスすべてに対して同じように実施します。
Nextcloud サーバーの EC2 インスタンスを 1 つ選択し、「アクション」-「イメージ」-「イメージの作成」の順にクリックします。
「イメージ名」に適当なマシンイメージの名前を入力し、「イメージの作成」をクリックします。
# どうでもいいところですが、画面イメージでは "Snapshot-・・・" としていますが、スナップショットとはちょっと違いますね・・・
マシンイメージの作成が開始されます。「保留中のイメージ ami-*** の表示」のリンクをクリックします。
「ステータス」が「available」になったら作成完了です。引き続き、「AUTO SCALING」の「起動設定」をクリックします。
AutoScaling の起動設定
まず AutoScaling でどのような EC2 インスタンスを作成するのかを定義していきます。EC2 インスタンスの作成イメージによく似てるのでわかりやすいと思います。
「起動設定の作成」をクリックします。
先ほど作成したマシンイメージを探し「選択」をクリックします。
AutoScaling で起動する際のインスタンスタイプを選択します。これまでは "t3.small" を利用していましたが、ここでは "t3.small" よりも時間単価が安い "t3a.small" を選択し、「次の手順: 詳細設定」をクリックします。
※ "t3.small" と "t3a.small" の違いは、CPU の種別となります。
起動設定の名前を適当に入力して「次の手順: ストレージの追加」をクリックします。
ストレージの設定です。そのまま「次の手順: セキュリティグループの設定」をクリックします。
セキュリティグループの設定です。「既存のセキュリティグループを選択する」をクリックし、これまで EC2 インスタンスに設定していたセキュリティグループを選択して、「確認」をクリックします。
これまでの設定内容を確認し、「起動設定の作成」をクリックします。
EC2 のキーペアは、これまで EC2 インスタンスに設定したキーペアを選択して「起動設定の作成」をクリックします。
AutoScaling の起動設定の作成が完了しました。引き続き「この起動設定を使用して Auto Scaling グループを作成する」をクリックします。
AutoScaling グループの作成
AutoScaling グループは、自動的にスケーリングしたり管理の目的で論理グループとして扱われる EC2 インスタンスの集合です。先ほど作成した起動設定の EC2 のインスタンスを「どこに」「いくつ」作成するかなどを定義します。
まずは下記のように設定します。
項目 設定内容 グループ名 AutoScaling グループ名を適当に入力。 グループサイズ 開始時にいくつの EC2 インスタンスを起動するか。ここでは 2 を入力。 ネットワーク これまで構築を行っている VPC を選択。 サブネット 選択した VPC のパブリックサブネットをすべて選択。 さらに「高度な詳細」をクリックすると追加の設定メニューが表示されますので、以下のとおり設定します。
項目 設定内容 ロードバランシング 「ひとつまたは複数のロードバランサーからトラフィックを受信する」をチェック。 ターゲットグループ ロードバランサ (ALB) 設定時に定義したターゲットグループを選択。 ヘルスチェックのタイプ 「 ELB 」を選択。 サブネット 選択した VPC のパブリックサブネットをすべて選択。 設定したら「次の手順: スケーリングポリシーの設定」をクリックします。
今回は、当初起動した EC2 の起動数をそのまま維持する形とするので「このグループを初期のサイズに維持する」を選択し、「次の手順: 通知の設定」をクリックします。
AutoScaling でインスタンスが起動した等のイベントが発生した場合の通知設定です。ここでは特に何も設定しないので「次の手順: タグの設定」をクリックします。
AutoScaling グループへのタグ設定です。必要に応じてタグを追加して「確認」をクリックします。
これまでの設定を確認し、「Auto Scaling グループの作成」をクリックします。
AutoScaling グループの作成が完了しました。引き続きこの設定に基づいて EC2 インスタンスが起動してきます。
7. しばらくして EC2 インスタンスの一覧画面を確認すると下の画面のように EC2 インスタンスが 2 つ起動されることが確認できます。
これまでの EC2 インスタンスをロードバランサから外す
引き続き左ペインの「ターゲットグループ」をクリックします。
先ほど選択したターゲットグループを選択し「ターゲット」タブをクリックすると「登録済みターゲット」にこれまで作成していた EC2 インスタンスと、AutoScaling で新たに作成された EC2 インスタンスの計 4 インスタンスが登録されています。これまで作成していた EC2 インスタンスは不要となりますのでこの登録を解除します。「編集」をクリックします。
これまで作成していた EC2 インスタンスを選択して「削除」をクリックします。
削除対象とした EC2 インスタンスのステータスが「 draining 」となり登録解除処理が開始されます。しばらくするとこれらは登録済みターゲットからなくなります。
登録解除した EC2 インスタンスは不要となります。忘れずにインスタンスの「終了」をしておきましょう。
お疲れさまでした! これで完了です。
あとがき
今回の設定作業により、 万が一 EC2 インスタンスが障害などで終了しても自動的に新たな EC2 インスタンスが起動してくるようになります。またロードバランサののヘルスチェックと連動させておりますので、例えば、どちらかの EC2 インスタンスの Web サーバにアクセスできない状態 (=Nginx を停止するなど) となると、新たな EC2 インスタンスが起動し、アクセスできない EC2 インスタンスは自動的に終了します。また起動数も設定変更で簡単に制御できますのでいろいろ試してみてください。
7 回にわたって連載形式で様々な AWS サービスを試してきました。私自身、ほとんど触ってこなかったサービスをこの連載を通じて学ぶことができ、とても大きな収穫でした。
最後までお付き合いいただき、ありがとうございました!



























- 投稿日:2020-03-27T15:25:05+09:00
AWS Elemental Media Convertで、動画を一括変換する方法
はじめに
AWS Elemental Media Convertで動画を変換する際、GUIでは1つずつしか変換できないので、APIを使って一括変換する仕組みを作る必要があります
詳細
S3に動画を置くのをトリガーに、Lambdaでリクエストして変換したい場合は、公式で公開されている下記のLambdaサンプルソースを使えばいけると思います
https://github.com/aws-samples/aws-media-services-vod-automation/tree/master/MediaConvert-WorkflowWatchFolderAndNotification今回は変換を任意で実行したかったのと、取得先・保存先をわけたかったので、下記のように実装しました
- S3に、変換前と変換後の保存先オブジェクトを作る
- LambdaのテストイベントのJsonに、上記のオブジェクトを設定
- Lambdaサンプルコードを流用し、テストイベントJsonで設定したオブジェクトを見に行くよう修正
- Lambdaのテストボタンを押下して、変換を実行する
おわりに
AWSすごく便利でよく使わせてもらってますが、時々かゆいところに手が届かない感がありますね
今回の1つずつ変換できない件もそうですが、変換するファイル名にも謎の制約がありました(半角ハイフンが使えないなど)今回「一括変換する方法はありますか」というのをフォーラムに投げたら、2日で公式から案内してもらえました。
ここで、上記のサンプルソースのリンクがある、下記のAWS公式ブログを教えてもらったのですが、日本版サイトからは行けないっぽいし、調査していたときにはGoogleからも見つけられなかったので、今後はここも見ていきたいと思います
https://aws.amazon.com/blogs/media/vod-automation-part-1-create-a-serverless-watchfolder-workflow-using-aws-elemental-mediaconvert/
- 投稿日:2020-03-27T14:38:19+09:00
ポートフォリオ公開
学習期間3ヶ月の初学者がポートフォリオを公開してみる。
なぜ書いたか?
ふとダウンロードしたアプリによって余命を知りこのままではまずいと焦った。(現在28歳あと51年の余命だそうです。)
余命タイマーAWSの漫画を読んでいたところ「アウトプットしないのは知的な便秘」という話から便秘は嫌だなーと思いたち急遽この記事を書いております。
最初の記事で何を書こうか迷ったのですが、いきなりすごい記事は書けないので、プログラミングスクールに3ヶ月通い、そこで得た知見と自己学習の成果を発表することで、今からプログラミングを学び始める方の参考になればいいなと思い書かせていただきます。
自己紹介
初めまして。いつもQiitaの記事にはお世話になっております。私の経歴からお話しさせていただくと、もともと消防士を4年ほどしていまして、今はエンジニア転職を目指す28歳です。
元々コンピューターには疎く仕事でもそれほどパソコンは触らないので、タッチタイピングもできない状態でmac?何それ美味しいの?あーポテト食べたくなってきた。からのスタートでした。
本格的にプログラミングを学び始めたのは2019年の12月からです。これから発信活動もしていけたらと思っています!はじめに
いきなりですがポートフォリオを実際に見てもらった方が早いと思うので一部公開します。
またプログラミングにこれから触れる方向けに記事を書いておりますので用語の説明をなるべく噛み砕いてさせていただいてます。つよつよエンジニアのみなさん、間違っているところありましたらコメントしていただけると幸いです。概要
メンターマッチングサイトMENTAのクローン(模倣)サイトです。
開発環境
- Docker 19.03.5 (コンテナという技術を用いてアプリを立ち上げるための環境構築が楽になる)
- CircleCI 2.0 (自動でテストを行う。githubというサービスを用いてインターネットに自分のソースコードをあげたときに自動的にテストを行う仕組み)
- Ruby on Rails 5.2.4.1 (Rubyをもちいてアプリを簡単に作れるようにしたもの。フレームワークと呼ばれる)
- Ruby 2.5.1 (日本人のまつもとさんが作った偉大なプログラミング言語)
- MySQL 5.6 (データベース、いろいろなデータが入っているエクセルみたいなもの)
- unicorn 5.4.1 (アプリケーションサーバー、動きがある画面を返すパソコンみたいなもの)
- nginx 1.16.1 (webサーバー、文字だけなど静的な画面を返すパソコンみたいなもの)
環境仕様
- Dockerによる開発環境構築
- CircleCIによる自動テスト(rubocop,siderによる自動コードレビュー、ソースコードを綺麗にしてくれるもの)
- CapistranoによるAWSへの自動デプロイ (デプロイ・・・インターネットに自分のサイトを公開すること、AWS・・・アマゾンがやっているサーバーのサービス)
アプリケーション仕様
- ユーザーサインイン・ログイン機能
- ユーザー編集、削除(退会)機能
- プラン投稿、編集、削除機能
- メッセージ送受信機能、返信機能
- ユーザーフォロー機能
- タグ機能
- 記事投稿、編集、削除機能
- メンター検索機能、タグ検索機能
制作期間
3週間から1ヶ月
DEMO
TOPページ
メインページ
プラン作成画面
メンター一覧画面
メンタースキル絞り込み画面
プラン詳細画面
プロフィール画面
退会確認画面
やったこと
- 3ヶ月間、毎日10時間はパソコンの画面を見つめました。(おかげで視力が悪くなったかも笑)
- スクールの友人とアウトプットをする(説明できないことは理解が足りていない)
- ひたすらググる。(ただググるだけではなく仮説を立ててからググる)
こうすればよかったこと
コピペは辞める。(理解してコピペならいいが思考停止でコピペは本当によくない。)
アプリを作ってみて
- 筋トレと一緒で頭を悩ましている(脳みそに負荷をかけている)時が一番成長している気がする。
- 最初は辛いけど徐々にできることが増えていき楽しくなってくる...はず笑
- あるあるだと思いますが、プログラミングを知らない人にアプリを見せてもあまり興味を持ってくれない
(家族に見せてもへーくらいの感想しかもらえない。でもそれが本当のユーザーの反応なのである笑)
- まだまだ全然完成してないんですが、就活始めなきゃということで僕の実力ではここまででした。
3ヶ月間毎日少しずつでも学習すれば優秀なみなさんならもっといいものが作れると思います。これからプログラミングを始める方の参考になれば幸いです。
最後までみていただきありがとうございます!
もしソースコードを公開してほしいというリクエストがありましたらコメントよろしくお願いします!
- 投稿日:2020-03-27T14:38:19+09:00
学習期間3ヶ月の初学者がポートフォリオを公開してみる。
なぜ書いたか?
いつもと変わらぬ1日が始まり、なんとなしに携帯をいじっていると余命診断アプリなるものを見つけました。面白そうだなと思い、ダウンロードして余命を診断してみるとなんとあと51年しか生きられないというではありませんか。
人によってはあと51年もあると考えるのかもしれませんが、なんとなくあと70年くらいは生きられるとのほほんと考えていた私にとってこの51年というのはあまりに少ない。何か後世に残さなければということで筆を...じゃなくてキーボードを叩いているのです。
余命タイマーまた個人的にAWSの勉強をし始めたのですが、とっかかりにAWSの漫画を読んでいたところ「アウトプットしないのは知的な便秘」というフレーズから便秘は嫌だなーと思い急遽この記事を書いております。
最初の記事で何を書こうか迷ったのですが、いきなりすごい記事は書けないので、プログラミングスクールに3ヶ月通い、そこで得た知見と自己学習の成果を発表することで、今からプログラミングを学び始める方の参考になればいいなと思い書かせていただきます。
自己紹介
初めまして。いつもQiitaの記事にはお世話になっております。私の経歴からお話しさせていただくと、もともと消防士を4年ほどしていまして、今はエンジニア転職を目指す28歳です。
元々コンピューターには疎く仕事でもそれほどパソコンは触らないので、タッチタイピングもできない状態でmac?何それ美味しいの?あーポテト食べたくなってきた。からのスタートでした。
本格的にプログラミングを学び始めたのは2019年の12月からです。これから発信活動もしていけたらと思っています!はじめに
いきなりですがポートフォリオを実際に見てもらった方が早いと思うので一部公開します。
またプログラミングにこれから触れる方向けに記事を書いておりますので用語の説明をなるべく噛み砕いてさせていただいてます。つよつよエンジニアのみなさん、間違っているところありましたらコメントしていただけると幸いです。概要
メンターマッチングサイトMENTAのクローン(模倣)サイトです。
開発環境
- Docker 19.03.5 (コンテナという技術を用いてアプリを立ち上げるための環境構築が楽になる)
- CircleCI 2.0 (自動でテストを行う。githubというサービスを用いてインターネットに自分のソースコードをあげたときに自動的にテストを行う仕組み)
- Ruby on Rails 5.2.4.1 (Rubyをもちいてアプリを簡単に作れるようにしたもの。フレームワークと呼ばれる)
- Ruby 2.5.1 (日本人のまつもとさんが作った偉大なプログラミング言語)
- MySQL 5.6 (データベース、いろいろなデータが入っているエクセルみたいなもの)
- unicorn 5.4.1 (アプリケーションサーバー、動きがある画面を返すパソコンみたいなもの)
- nginx 1.16.1 (webサーバー、文字だけなど静的な画面を返すパソコンみたいなもの)
環境仕様
- Dockerによる開発環境構築
- CircleCIによる自動テスト(rubocop,siderによる自動コードレビュー、ソースコードを綺麗にしてくれるもの)
- CapistranoによるAWSへの自動デプロイ (デプロイ・・・インターネットに自分のサイトを公開すること、AWS・・・アマゾンがやっているサーバーのサービス)
アプリケーション仕様
- ユーザーサインイン・ログイン機能
- ユーザー編集、削除(退会)機能
- プラン投稿、編集、削除機能
- メッセージ送受信機能、返信機能
- ユーザーフォロー機能
- タグ機能
- 記事投稿、編集、削除機能
- メンター検索機能、タグ検索機能
制作期間
3週間から1ヶ月
DEMO
TOPページ
メインページ
プラン作成画面
メンター一覧画面
メンタースキル絞り込み画面
プラン詳細画面
プロフィール画面
退会確認画面
やったこと
- 3ヶ月間、毎日10時間はパソコンの画面を見つめました。(おかげで視力が悪くなったかも笑)
- スクールの友人とアウトプットをする(説明できないことは理解が足りていない)
- ひたすらググる。(ただググるだけではなく仮説を立ててからググる)
こうすればよかったこと
コピペは辞める。(理解してコピペならいいが思考停止でコピペは本当によくない。)
アプリを作ってみて
- 筋トレと一緒で頭を悩ましている(脳みそに負荷をかけている)時が一番成長している気がする。
- 最初は辛いけど徐々にできることが増えていき楽しくなってくる...はず笑
- あるあるだと思いますが、プログラミングを知らない人にアプリを見せてもあまり興味を持ってくれない
- まだまだ全然完成してないんですが、就活始めなきゃということで僕の実力ではここまででした。
3ヶ月間毎日少しずつでも学習すれば優秀なみなさんならもっといいものが作れると思います。これからプログラミングを始める方の参考になれば幸いです。
最後までみていただきありがとうございます!
- 投稿日:2020-03-27T14:18:29+09:00
S3とCloudFrontを使ったサイトを公開するために最低限行うべき手順
前提
- 公開するドメインを取得していること。説明上、<ドメイン名>と表記。
- 以下に挙げるサービスが利用できるアカウントを持っていること
利用するAWSサービス
- S3
- CloudFront
- Route53
- Certificate Manager
手順
1. 静的サイトホスティング用のバケットを作成
S3を開き、バケットを作成します。
項目 値 バケット名 <ドメイン名> 作成したバケットを選択し、「プロパティ」タブを開く。
「Static website hosting」を選択する。
以下の内容を設定後、保存する。
項目 値 このバケットを使用してウェブサイトをホストする 選択 インデックスドキュメント index.html エラードキュメント (任意) 2. ホストゾーンを作成
Route 53を開き、ホストゾーンを作成する。
項目 値 ドメイン名 <ドメイン名> コメント (任意) タイプ パブリックホストゾーン 3. SSL証明を取得
Certificate Managerを開き、証明書をリクエストする。
項目 値 証明書タイプ パブリック証明書のリクエスト ドメイン名 *.<ドメイン名> 検証方法 DNSの検証 作成されたリクエストを選択し、「Route53でのレコードの作成」を押下する。
ステータスが「発行済み」になるまで待つ。
4. ディストリビューションの作成
CloudFrontを開き、「Web」のディストリビューションを作成する。
項目 値 Origin Domain Name 1.で作成したバケット Restrict Bucket Access Yes Origin Access Identity Create a new identity Grant Read Permissions on Bucket Yes, Update Bucket Policy Viewer Protocol Policy Redirect HTTP to HTTPS Alternate Domain Names <ドメイン名> SSL Certificate Custom SSL Certificate(3.で発行された証明書) Default Root Object index.html Stateが「Enabled」になるまで待つ。
5. コンテンツアップロード
作成したバケットにindex.htmlをアップロードする。
ブラウザから、「https://<ドメイン名>」にアクセスすると表示される。
参考サイト
- 投稿日:2020-03-27T13:45:59+09:00
Amazon Comprehendの感情分析をAWS CLIで行ってみた。
Amazon Comprehendの感情分析をAWS CLIで行ってみた。
Amazon Comprehendでできるらしい。
DetectSentimentのところを参照
https://docs.aws.amazon.com/comprehend/latest/dg/API_DetectSentiment.html今回PythonでやってみるのでPython用のを見る。
https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/comprehend.html#Comprehend.Client.detect_sentiment一番上に何をインポートすればいいか書いてある。
https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/comprehend.htmlコードはこんな感じ。
import boto3 client = boto3.client('comprehend') response = client.detect_sentiment( Text='東京オリンピックが延期になるなんて、まさにアキラの世界みたいだ。', LanguageCode='ja' ) print(response)結果はこんな感じ。
{'Sentiment': 'NEUTRAL', 'SentimentScore': {'Positive': 0.12571793794631958, 'Negative': 0.006899271160364151, 'Neutral': 0.8673694729804993, 'Mixed': 1.3250895790406503e-05}, 'ResponseMetadata': {'RequestId': 'e458bcfd-c85e-4314-bb01-f11b8e72ec8f', 'HTTPStatusCode': 200, 'HTTPHeaders': {'x-amzn-requestid': 'e458bcfd-c85e-4314-bb01-f11b8e72ec8f', 'content-type': 'application/x-amz-json-1.1', 'content-length': '164', 'date': 'Fri, 27 Mar 2020 04:44:21 GMT'}, 'RetryAttempts': 0}}
- 投稿日:2020-03-27T12:09:55+09:00
2020年 AWS 認定 DevOps エンジニア – プロフェッショナル に効率的に合格する方法
「AWS 認定 DevOps エンジニア – プロフェッショナル」を2020年03月に受験し、合格できましたのでまとめます。
試験結果
試験の結果は、800/1000点でした。
合格基準は750/1000点なのでギリギリでした。
AWS経験
実務ではほぼ触ったことはありませんが、2019年夏ごろから少しずつ学習を進めてきました。
会社の部署でAWS資格取得が推奨されていたため、部署のAWSアカウントを利用してある程度自由(費用が多少かかってもよい)にAWS環境に触れられる学習環境でした。
AWS環境を触って具体的に動かしてみた内容は下記のような感じです。
No. やった内容 使った主なAWSサービス 1 EC2とRDSで3層Webアプリケーション構築 EC2,RDS,EIP 2 CodeCommitへのコード登録/管理 CodeCommit 3 API GatewayとLambdaでAPI作成 API Gateway,Lambda 4 S3で静的Webホスティング S3 5 3と4でSingle Page Apllication CloudFront,S3,API Gateway,Lambda,DynamoDB 6 GitHubコミットを契機としたFargate環境へのWebアプリケーション自動デプロイ ECS Fargate,Codepipeline,CodeBuild,ECR,ELB 7 Elastic BeanstalkへのWebアプリケーションデプロイ Elastic Beanstalk 資格取得の状況は下記の通りです。
No. 資格名 取得時期 1 AWS 認定 ソリューションアーキテクト – アソシエイト 2019/09/17 2 AWS 認定 デベロッパー – アソシエイト 2020/01/30 3 AWS 認定 DevOps エンジニア – プロフェッショナル 2020/03/16 実際にAWS環境でいろいろ動かしてみたことと2つのアソシエイト資格で基礎知識を得られていたことが、経験として活かせたと考えています。
学習リソース
- 公式E-Learning
- サンプル問題
- 模擬試験
- Udemy
公式E-Learning
動画で試験の概要や各分野の出題傾向と問題の問われ方を知ることができます。
この試験では、どんな分野のどんな知識が必要かといった全体感と長文の問題からキーワードを素早く抽出して適切な回答を選択する必要があることがわかりました。
公式ページにある"コースの概要"は下記の通りです。
- コースと試験の概要
- 分野1: SDLC の自動化
- 分野2: 設定管理と Infrastructure as Code
- 分野3: モニタリングとロギング
- 分野4: ポリシーと標準の自動化
- 分野5: インシデントとイベントレスポンス
- 分野6: 高可用性、耐障害性、災害対策
サンプル問題
「AWS 認定 DevOps エンジニア – プロフェッショナル」から"サンプル問題"をダウンロードできます。
サンプル問題は英語ですが日本語で解説してくださっている方が居られました。(AWS 認定 DevOps エンジニア – プロフェッショナル サンプル問題の解説)
回答の意味と考え方を理解できるまで実施しました。模擬試験
前回合格した際の特典で無料で模擬試験を受験しました。
結果は40%でした。。。
試験時にスクリーンショットを撮っておき復習しましたが、正答や解説がないためいろいろ調べても確信を持てる回答かどうかは最後まで定かではありませんでした。Udemy
Udemyで模擬試験を購入しました。
購入したコースは「AWS Certified DevOps Engineer Professional Practice Exams」です。
私は英語がわかりませんが、google chromeの翻訳ツールを利用して理解することができました。
当初は、翻訳文がわかりにくいことと知識不足で問題の内容が理解できないことのダブルパンチで問題を解き進めることが困難な状態でしたが、解いては解説を確認してをわからないサービスや内容を確認するといったことを繰り返していくうちにある程度解き進める状態になることができました。
(本番の試験でも翻訳文のような日本語で問われるため、翻訳文の模擬試験でキーワードを素早く抽出して適切な回答を選択することを鍛えておいたことも役立ったような気がします。)解説にはAWSの各種ドキュメントへのリンクが貼ってあるので、その内容を読んで理解を深めることができました。
学習方法
上述の学習リソースを以下の順序&方法で実施しました。
No. 学習リソース 方法 1 公式E-Learning 動画を見て、設問を解く 2 サンプル問題 自力で解いて、解説を確認して回答の意味と考え方を理解する 3 模擬試験 解いてみる(解説がないので振り返りは少なめ) 4 Udemy 1問毎に解く→解説の確認を繰り返す(全問解けるレベルではなくとも何となく全体的に迷いなく解ける程度まで)

- 投稿日:2020-03-27T12:03:10+09:00
【AWS】Amazon Linux 2にMavenをインストールする方法
概要
AWS EC2(AMI: Amazon Linux 2)にMavenをインストールして
mvnコマンドが使えるようにする環境
- AWS EC2
- OS: Amazon Linux 2
- AMI ID: amzn2-ami-hvm-2.0.20200304.0-x86_64-gp2
構築手順
1. JDK8をインストールする
- Amazon Linux 2にはデフォルトでJavaが入っていないのでインストールする
- Apache Maven 3.3以降はJDK 1.7以上が必要
$ sudo yum install -y java-1.8.0-openjdk-devel.x86_64 $ sudo alternatives --config java $ java -version openjdk version "1.8.0_242" OpenJDK Runtime Environment (build 1.8.0_242-b08) OpenJDK 64-Bit Server VM (build 25.242-b08, mixed mode)2. Mavenをダウンロードする
- ダウンロード先: Downloading Apache Maven
Binary tar.gz archiveのLinkのURLをコピーしてwgetでダウンロード$ cd /usr/local/lib/ $ sudo wget http://ftp.meisei-u.ac.jp/mirror/apache/dist/maven/maven-3/3.6.3/binaries/apache-maven-3.6.3-bin.tar.gz Saving to: ‘apache-maven-3.6.3-bin.tar.gz’ 2020-03-27 11:23:54 (23.6 MB/s) - ‘apache-maven-3.6.3-bin.tar.gz’ saved [9506321/9506321]3. Mavenを展開して配置する
- ダウンロードしたファイルを解凍して
/opt/に配置- 展開した
apache-maven-3.6.3にapache-mavenのシンボリックリンクを貼る$ sudo tar -xzvf apache-maven-3.6.3-bin.tar.gz $ sudo mv apache-maven-3.6.3 /opt/ $ cd /opt/ $ sudo ln -s /opt/apache-maven-3.6.3 apache-maven $ ls -l lrwxrwxrwx 1 root root 23 Mar 27 11:36 apache-maven -> /opt/apache-maven-3.6.3 drwxr-xr-x 6 root root 99 Mar 27 11:28 apache-maven-3.6.34. MavenへのPATHを追加する
.bash_profileにMVN_HOMEを追加するPATHにMVN_HOME/binを追加する.bash_profileを反映する$ cd $ vi .bash_profile MVN_HOME=/opt/apache-maven PATH=$MVN_HOME/bin:$PATH:$HOME/.local/bin:$HOME/bin $ source .bash_profile5.mvnコマンドが使えることを確認する
$ mvn --version Apache Maven 3.6.3 (cecedd343002696d0abb50b32b541b8a6ba2883f) Maven home: /opt/apache-maven Java version: 1.8.0_242, vendor: Oracle Corporation, runtime: /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.242.b08-0.amzn2.0.1.x86_64/jre Default locale: en_US, platform encoding: UTF-8 OS name: "linux", version: "4.14.171-136.231.amzn2.x86_64", arch: "amd64", family: "unix"感想
Maven homeをどこにすべきかちょっと迷った
参考
- 投稿日:2020-03-27T11:45:59+09:00
Rails5 AWS EC2とRDS、S3、paperclipを使用したデプロイ
デプロイ覚書
基本的に下記記事を参考にさせて頂きました。
https://qiita.com/naoki_mochizuki/items/f795fe3e661a3349a7ce
https://qiita.com/Yuki_Nagaoka/items/975b7598806d6ae0c0b2上記記事の中では説明がなく自分がハマった箇所について。
まず
・画像投稿のストレージにS3を使用していた為その設定。
・あとRDSでデータベースを作成する際の文字コードの設定。
・デプロイ終わった後に大幅な修正を見つけてしまった際のやり方S3使用時の設定について
https://qiita.com/nakki/items/6df87756ef4119cc3e68
コチラの記事を参考に実装しました。
デプロイ時にハマったのはunicornが起動しなかった。。。
ログを調べると
Cannot load Rails.config.active_storage.service
undefined method fetch for nilclass
コチラのエラーは同じエラー文での記事が見つけられませんでした。
デプロイの参考サイトと違う環境はS3を使っていることだし、active storageのエラーが出ていると言うことはやっぱりS3関係のエラーだろうと考えて調べる。。
ローカルではS3にちゃんと接続できて写真投稿も問題なくできていました。
ここのエラーに一日かかりました。。。
原因は、、、
config/environments/production.rbの設定でした。
config.require_master_key = trueこのコードがデフォルトfalseでコメントアウトされているのですがtrueにして有効化。
これでproduction環境でS3に接続する環境変数が読み込まれるようになったようです。
確かにマスターキーがないと環境変数読み込めないですもんね。
これでunicorn問題なく起動OK。RDSの文字コード
デプロイ終わってよっしゃー。会員ログインして動かしてみよ!
「ログイン」!→「エラー」え?!
log/production.logを調べるとデータベースにレコード保存しようとしたときに文字コードが合わなくて弾かれた、と言うことらしい。
と言うことで下記記事参考に対応
https://qiita.com/kijitora-neko/items/aab58b4c1f684353e075パッチ当てて再起動したんですがデータベース削除して作り直しても文字コードが変わらない。。。
3回くらいやったらやっと反映されました。。パッチが適用されるのにタイムラグがあるのかな?
同じ問題に当たった方は焦らずに設定確認して時間を置くことも必要かと。
もちろんそもそもRDSのデータベース作成時にパッチを作成して適用しておけばこのようなエラーは出ないかと。
次からは気をつけよう。デプロイ後のアプリ修正
まあ、コチラはデプロイする前にちゃんとテストしとけよって話ですが。。。
デプロイしてからあれ?ここのリンク飛ばない?
あれ?問合せフォームから送信できない?
など等結構大幅に修正することがあったのでその時のやり方。ちょっとした修正ならvimでコード修正してすぐ終わるかと思います。
でもいくつものファイルの修正や移動、削除など多くなってくるとコンソールからだと時間がかかる。。。そこで一旦アプリ削除することにしました。
EC2インスタンスの/var/www/rails/アプリフォルダ
このアプリフォルダをコンソールで強制削除します。
nignx,unicorn,mysqlなどはこの上階層でインストールしているので影響なし。
アプリフォルダ削除後に再度git cloneして設定し直し。
と言っても作業量は大したことないです。
その後プリコンパイル、nignx,unicorn,mysqlの再起動して終わり。以上です。
- 投稿日:2020-03-27T11:00:41+09:00
デプロイ時 よく使ったコマンドメモ 自分用
unicorn
起動
bundle exec unicorn_rails -c config/unicorn.rb
unicorn_rails -c /var/www/rails/(アプリの名前)/config/unicorn.conf.rb -D -E production状態確認
ps -ef | grep unicorn | grep -v grepmysql
起動
sudo service mysqld startproduction環境でのDB削除
RAILS_ENV=production DISABLE_DATABASE_ENVIRONMENT_CHECK=1 bundle exec rake db:drop接続
mysql -h エンドポイント -P 3306 -u root -pDBの文字コードチェック
show variables like "chara%";nignx
再起動
sudo nginx -s reloadvimコマンド
強制書き込み
$ sudo vim <ファイル名>
:w !sudo tee %
:q!
- 投稿日:2020-03-27T10:15:34+09:00
AWSで特定のEC2インスタンスの起動停止だけ出来るIAMアカウントを作成する
- テスト用にEC2を建てたけど24時間稼働させる必要は無く必要になったときに誰でも起動できるようにしたい。
- でもチーム内に協力会社のひとも居るような状況でルートアカウントを共有はしたくない。
- 個別にIAMアカウントを作る運用が望ましいのはわかっては居るけどそんなコストはかけれないしスキルも無い。
という状況で最低限EC2のインスタンスの起動停止だけ出来るアカウントを作ってそれを共有する方法をご紹介します。
概要
インスタンスの一覧の表示、特定のインスタンスだけ起動停止が出来る権限をもつアカウントを作成します。
インスタンスの特定はkeyがBootable、値がyesのタグが設定されているかで行います。方法
IAMの設定
ポリシーの作成
IAMの管理画面を開き、カスタマー管理ポリシーの作成を選択する。
JSON を選び以下の内容を貼り付ける。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "ec2:StartInstances", "ec2:StopInstances" ], "Resource": "*", "Condition": { "StringEquals": { "ec2:ResourceTag/Bootable": "yes" } } }, { "Sid": "VisualEditor1", "Effect": "Allow", "Action": [ "ec2:DescribeInstances", "ec2:DescribeInstanceStatus" ], "Resource": "*" } ] }適当な名前を付けて作成する。
ユーザーを追加
IAM のユーザーから ユーザーを追加を選択する。
アクセスの種類は AWS マネジメントコンソールへのアクセス にチェックする。
他はお好みで。
既存のポリシーを直接アタッチ を選択し先ほど作成したポリシーを選択する。
タグの設定は特にせず次へすすむ。
確認画面が出るので「ユーザーの作成」ユーザーの作成が完了します。
パスワードを自動生成にした場合、この画面でメモっておかないと他の所で確認することは出来ません。
間違って閉じてしまった場合ユーザーを削除し、作成をやり直す必要があります。
EC2インスタンスの設定
EC2のインスタンス一覧から該当のインスタンスを右クリックして インスタンスの設定>タグの追加/編集 を選択する。
タグの作成をクリックし、、キーに
Bootable、値yesを設定する。
アカウントID確認
ログイン時に必要になるのでアカウントIDを確認しておきます。
右上の名前が表示されている所のメニューからマイアカウントを開くとアカウント設定が表示され、アカウントIDを確認できます。
動作確認
ログアウトされた状態(もしくはプライベートモード)でログイン画面を開きIAMを選択し、アカウントIDを入力する。
先ほど作成したアカウントのユーザ名とパスワードを入力しサインインする。
ec2のコンソールに入るとインスタンスの状態はタグの設定にかかわらず全て確認できます。
※テスト用にBootableタグの値を「
yesを設定してあるもの」「noを設定してあるもの」「tagを設定していないもの」の3種類を用意しています。tagに
yesを設定したインスタンスを起動してみると
正常に起動できます。
yes以外の値が設定されていたりタグが無いインスタンスも権限が無いと言われ起動できません。
起動停止以外(終了とかインスタンスのタイプの変更等)も出来なくなっています。
もちろんインスタンスの作成とかは出来ません。
EC2以外も何も出来ません。(S3のバケット一覧が見れない)





















- 投稿日:2020-03-27T10:10:43+09:00
AWS S3 で AccessDeniedが出ることのデバッグ
今までVagrantで動かしていた、Railsをdockerに移したところ、何故かs3にホストしてある画像が取得出来なくなったのでその確認をしました。
1. dockerにaws-cliをインストールしてみる
- ruby:2.6.5-slim-stretch イメージをベースにしていたことがありそもそもpythonが入っていなかったので色々とインストールしてみた
> docker-compose exec web bash # curl "https://bootstrap.pypa.io/get-pip.py" -o "get-pip.py" # python get-pip.py bash: python: command not found → インストールされていなかったので、apt install l-y pythonでまずpythonを導入 # apt install -y python # python get-pip.py # pip install awscli2. s3の一覧を取得する
# aws s3 ls s3://[[バケットのURL]] An error occurred (RequestTimeTooSkewed) when calling the ListObjectsV2 operation: The difference between the request ti me and the current time is too large.3. RequestTimeTooSkewed って?
https://qiita.com/sadakan5/items/4c0a394fd1d6be34efb2
を参照。サーバーとAWSの時間がずれているとエラーになるとのことで date で時間を確認してみた
# date Wed Mar 25 23:39:24 UTC 2020ちなみに、EC2にホストしているサーバーで実行すると。。
# date Thu Mar 26 23:11:39 UTC 2020確かにずれています。。
ホストがずれているの?と見てみてもそんなことはないです。。
(ホストは日本時刻)> date 2020年3月27日 8:12:11システムを休止状態(Hybernate)にするとずれることがあると
https://docs.docker.com/docker-for-mac/troubleshoot/#known-issuesで、こうすればいいみたい
(ホスト側で) > docker run --rm --privileged alpine hwclock -s > docker-compose exec web bash # date Fri Mar 27 08:28:29 UTC 2020でなおった... って、ホストの時刻をそのまま時差を考えずに同期していた!
一旦、ホストの方をUTCにして再度時間を合わせてみる
> Get-Timezone Id : Tokyo Standard Time ... > Set-Timezone -Id "UTC"(ホスト側で) > docker run --rm --privileged alpine hwclock -s > docker-compose exec web bash # date Fri Mar 27 08:28:29 UTC 2020直らなかったです。再度docker for windowsを再起動しました
> Start-Process PowerShell.exe -Verb runas > restart-service *docker*
- 投稿日:2020-03-27T09:00:16+09:00
AWS Step Functions+Amazon ECS(Fargate)をイベントトリガーで実行するときにハマるポイント
AWS Step FunctionsでAmazon S3のイベントをトリガーにしたときにいろいろとハマったのでメモ。
ハマる構成
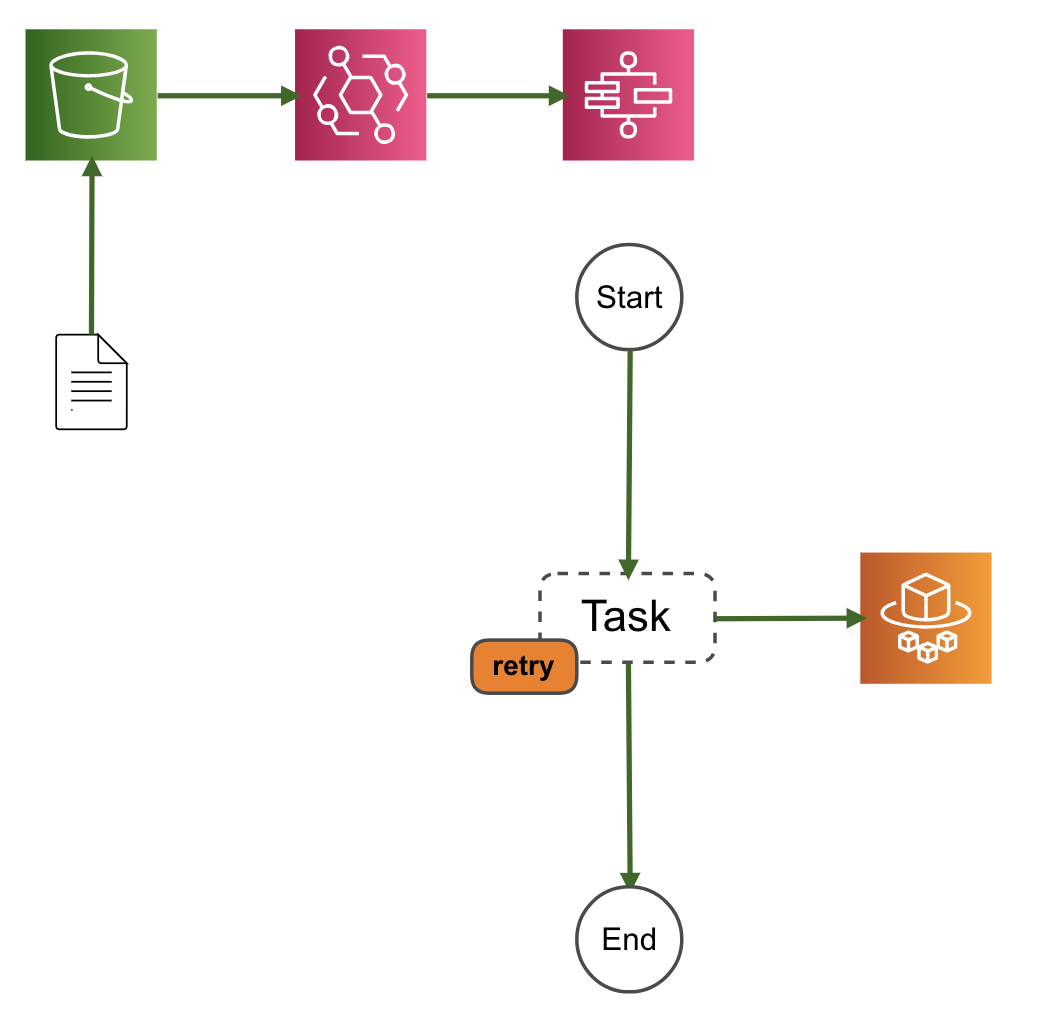
下記を参考にAmazon S3(S3)イベントをトリガーにAWS Step Functions(Step Functions)のステートマシンが実行される構成を作ってみました。
Amazon S3 イベント発生時にステートマシンの実行を開始する - AWS Step Functions
https://docs.aws.amazon.com/ja_jp/step-functions/latest/dg/tutorial-cloudwatch-events-s3.html構成はこんな感じです。
ステートマシンからAmazon ECS(Fargate)のタスクを起動してなにかしらの処理を行います。
ハマるポイント
上記構成でも利用頻度が低ければ問題ありませんが、もし大量に処理を行うのであればいろいろとハマることになります。
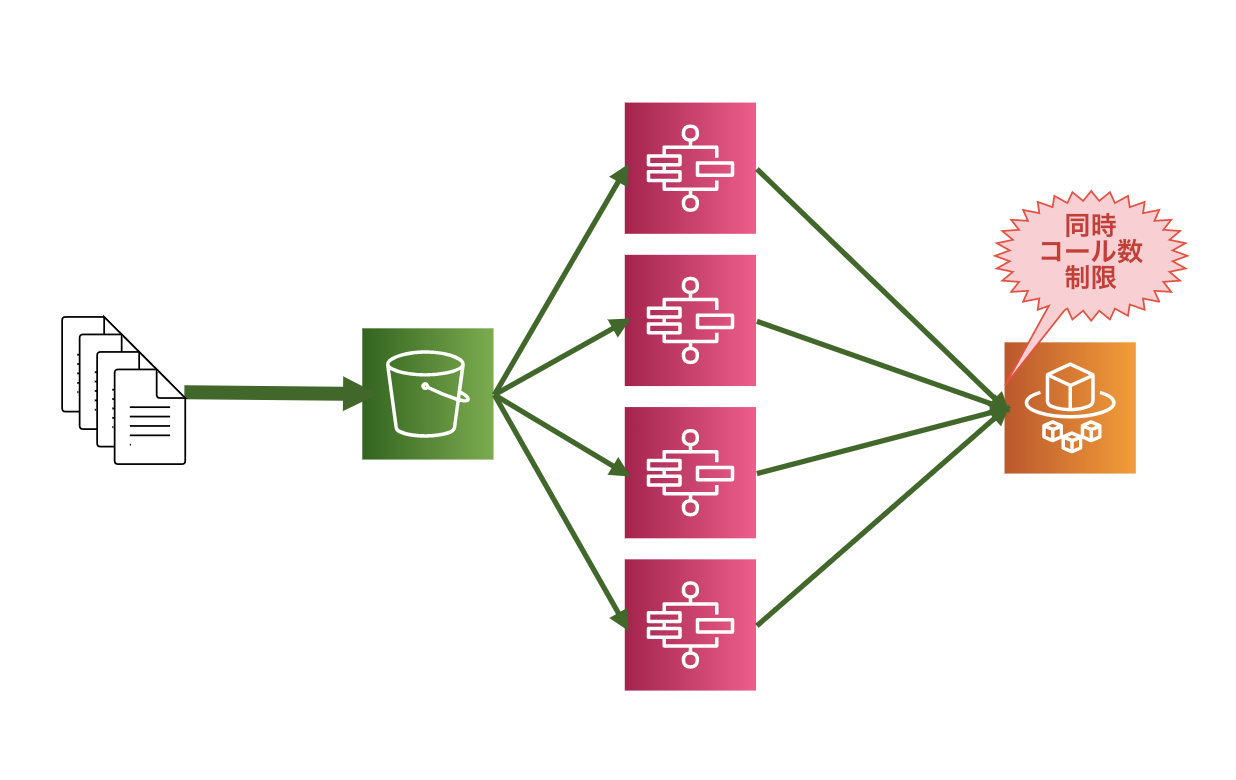
ECS(Fargate)のタスク同時実行数制限
Amazon ECS Endpoints and Quotas - AWS General Reference
https://docs.aws.amazon.com/general/latest/gr/ecs-service.html#limits_ecsFargateの場合、同時実行数に制限があります。制限値は
100です。
引っかかるとステートマシンの状態でECS.AmazonECSException (ThrottlingException)の例外が発生します。Tasks using the Fargate launch type, per Region, per account: 100
The maximum number of tasks using the Fargate launch type, per Region.Public IP addresses for tasks using the Fargate launch type: 100
The maximum number of public IP addresses used by tasks using the Fargate launch type, per Region.これら制限は上限緩和申請が可能なので必要であれば、申請するのもありです。
ECS(Fargate)のRunTask APIの同時コール数制限
ECS(Fargate)のRunTask APIの同時コール数制限に引っかかる可能性があります。制限値は
10です。
これも引っかかるとステートマシンの状態でECS.AmazonECSException (ThrottlingException)の例外が発生します。
Amazon ECS Endpoints and Quotas - AWS General Reference
https://docs.aws.amazon.com/general/latest/gr/ecs-service.html#limits_ecsTasks launched (count) per run-task: 10
The maximum number of tasks that can be launched per RunTask API action.この制限は上限緩和申請の対象となっていないみたいなので、何かしらの制限回避を考える必要があります。
対策を考える
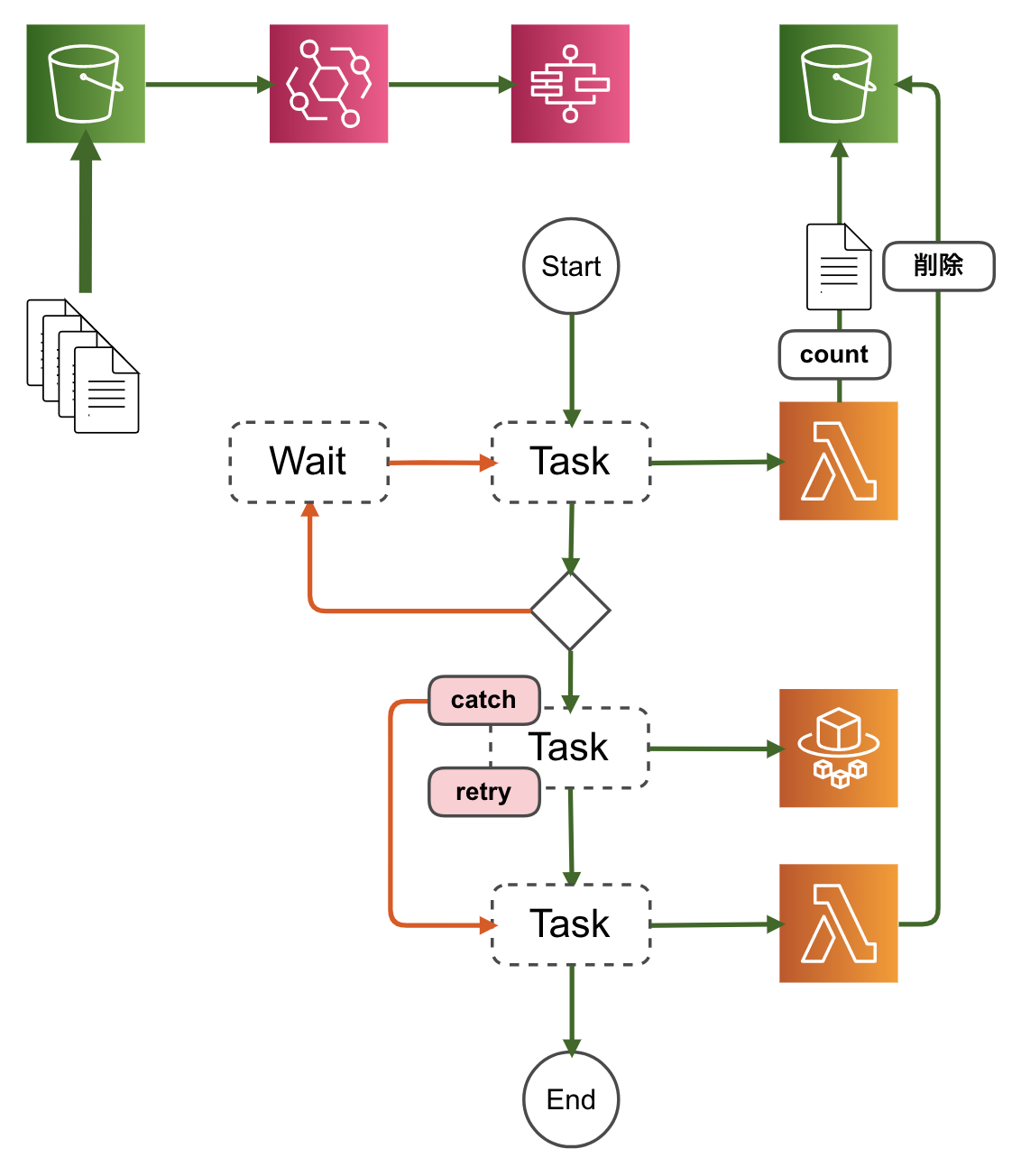
ステートマシンにエラー処理を追加する
こちらの記事でも同じにようにハマっておられてリトライ設定で回避されていました。記事中には
ECS APIコール数が秒間1回までとありますが、おそらくはAPIの同時コール数制限のことだと思われます。Step Functions & Fargate バッチでやらかしたこと - Qiita
https://qiita.com/a_sh_blue/items/8ccf7502d1512933d226調べてみると、どうもECSタスク起動のためのECS APIコール数が秒間1回までという制限にひっかかっていたらしく、
リトライ設定をしても結構な確率で再衝突しました。結果リトライ上限に達し無事死亡……。
ErrorEqualsにECS.AmazonECSException、待機時間(IntervalSeconds)とリトライの最大回数(MaxAttempts)、バックオフのレート(BackoffRate)を指定します。
下記の例だと、リトライ回数が3回で待機時間が3秒、6秒、12秒となります。
同時実行数制限に対応するにはECSタスクの処理時間に応じて待機時間やリトライ回数を調整する必要があります。Step Functions でのエラー処理 - AWS Step Functions
https://docs.aws.amazon.com/ja_jp/step-functions/latest/dg/concepts-error-handling.html#error-handling-retrying-after-an-error"Retry": [ { "ErrorEquals": [ "ECS.AmazonECSException" ], "IntervalSeconds": 3, "MaxAttempts": 3, "BackoffRate": 2.0 } ]
これで多少イベント数が増えても耐えることができます。ただし相当数のイベントがあると、リトライ対応だけでは耐えることができません(でした)。同時実行数制限の場合、ECSタスクの実行前に対策をいれたいところです。
Lambda関数で実装して制御する
Step Functionsのステートマシンに同時実行数を制御するLambda関数を追加してみました。
Lambda関数でイベント発生元のS3バケットとは別のS3バケットにファイルを置き、それをカウントして同時実行数を制御します。
イベント発生元のS3バケットにファイルを置くと無限ループにハマって無事にタヒ亡することができるのでご注意ください。
同時実行数を超える場合は、
Waitに遷移して待機します。ファイル削除するのに、ECSタスクの処理の後続にLambda関数を追加して処理します。
欠点として、ロック機構がないのでLambda関数が同時に実行されるとカウントがうまくさせない点があります。
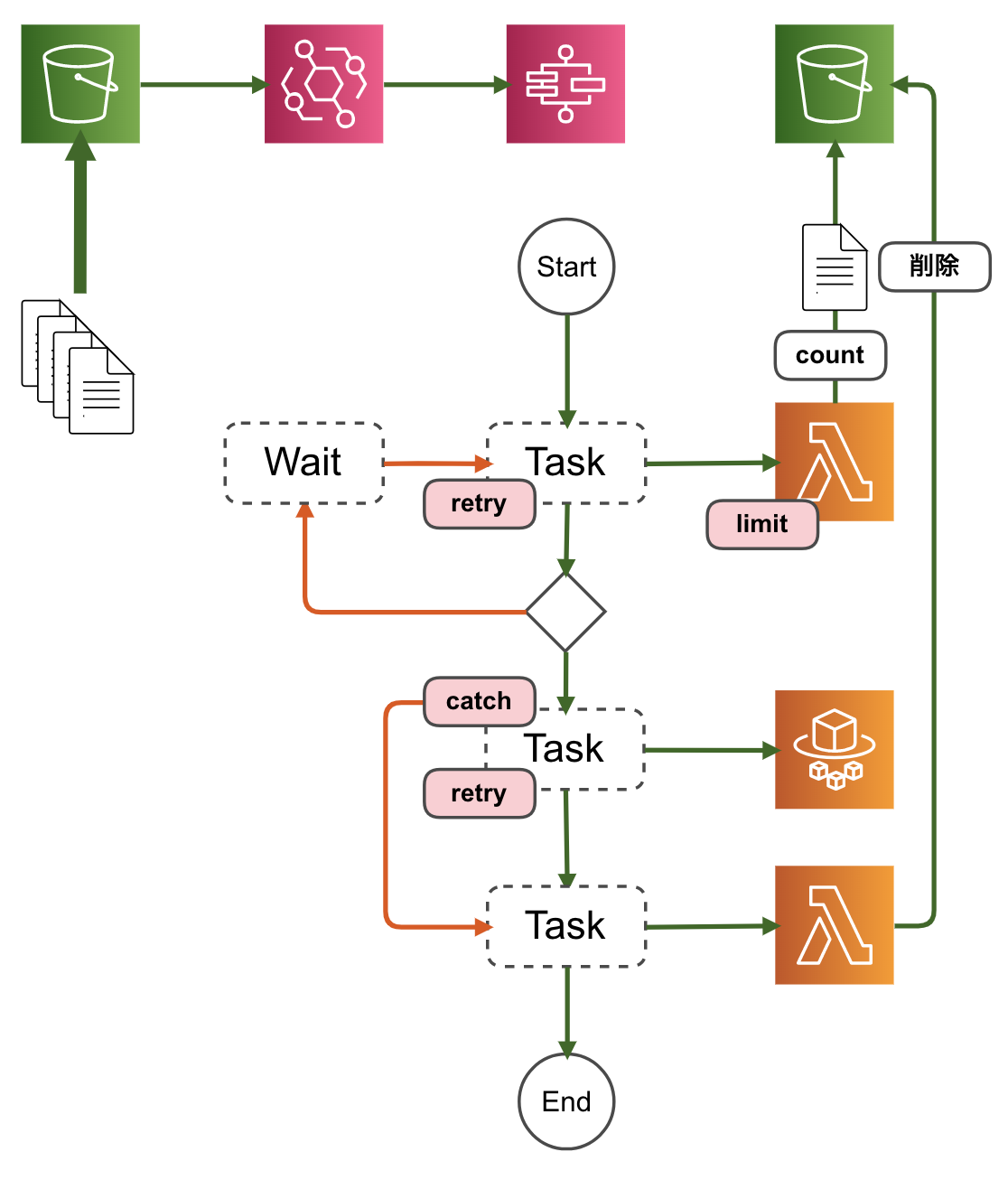
Lambda関数の同時実行数を制限する
同時実行数を制限することでカウントの精度を高めてみました。Lambda関数の同時実行数は標準設定だと
1,000になっているはずなので値を小さくします。注意点はLambda関数の同時実行数を制限すると、大量のLambda関数呼び出しがあった場合に、
Lambda.TooManyRequestsExceptionが発生することです。こちらはECSタスクの呼び出しでも利用したリトライ設定で回避します。"Retry": [ { "ErrorEquals": ["Lambda.TooManyRequestsException"], "IntervalSeconds": 3, "MaxAttempts": 3, "BackoffRate": 2.0 } ],
これでもLambda関数の同時実行数分は同時にカウントする可能性があるので、ランダムな秒数待ち受けるなどの小細工をするともう少し制御の精度が上がります。
Step Functionsの上限にひっかかる可能性もある
Step Functionsにも制限があるため、それを超えるようなイベント数になる可能性があるならば、Amazon SQSなどを間に挟むなどの対策が必要になると思います。
標準ワークフローのクォータ - AWS Step Functions
https://docs.aws.amazon.com/ja_jp/step-functions/latest/dg/limits.htmlAPI アクションのスロットリングに関連するクォータ
一部の Step Functions API アクションは、サービスの帯域幅を維持するため、トークンのバケットスキームを使用してスロットリングされます。
[新機能] CloudWatch EventsがAmazon SQSのQueueをターゲット指定できるようになりました | Developers.IO
https://dev.classmethod.jp/cloud/aws/cloudwatch-events-support-sqs/Amazon SQSからLambdaを実行できるようになったので試して見た。 - Qiita
https://qiita.com/keni_w/items/dc651c9fc794f5a8ad64おわりに
いろいろと検討したものの、まだバシッとハマる(ポジティブ)構成が思い浮かびません。
よいプラクティスがあれば教えてください!参考
Amazon S3 イベント発生時にステートマシンの実行を開始する - AWS Step Functions
https://docs.aws.amazon.com/ja_jp/step-functions/latest/dg/tutorial-cloudwatch-events-s3.htmlAmazon ECS Endpoints and Quotas - AWS General Reference
https://docs.aws.amazon.com/general/latest/gr/ecs-service.html#limits_ecsStep Functions & Fargate バッチでやらかしたこと - Qiita
https://qiita.com/a_sh_blue/items/8ccf7502d1512933d226Step Functions でのエラー処理 - AWS Step Functions
https://docs.aws.amazon.com/ja_jp/step-functions/latest/dg/concepts-error-handling.html#error-handling-retrying-after-an-error標準ワークフローのクォータ - AWS Step Functions
https://docs.aws.amazon.com/ja_jp/step-functions/latest/dg/limits.html[新機能] CloudWatch EventsがAmazon SQSのQueueをターゲット指定できるようになりました | Developers.IO
https://dev.classmethod.jp/cloud/aws/cloudwatch-events-support-sqs/Amazon SQSからLambdaを実行できるようになったので試して見た。 - Qiita
https://qiita.com/keni_w/items/dc651c9fc794f5a8ad64

- 投稿日:2020-03-27T03:20:51+09:00
AWS Solution Architect Professional 持ちは GCP Associate Cloud Engineer もすぐに取れます!(個人の感想です)
AWS Solution Architect Professional (SAP) を持っていれば、GCP ほぼ未経験でも GCP Associate Cloud Engineer は知識の流用で何とかなると感じたので、取得までの過程をご紹介します。
もちろん保証はしないし前提もあります
- 「すぐに」≠「ノー勉で」
- Kubernetes の基礎は知っていること
- あくまで「資格を取る」だけの話です
勉強したこと
- まずは、公式ドキュメントから「AWS プロフェッショナルのための Google Cloud」を熟読しましょう
- IAM は個別にドキュメントを確認しておきましょう
- 「概要」と「ベストプラクティス」だけで十分です
- IAM は AWS を知っているがゆえに混乱する部分もあります。まっさらな気持ちで読みましょう
- AWS の Auto Scaling に相当する部分は個別にドキュメントを確認しておきましょう
- その流れでネットワークロードバランサと HTTP(S)ロードバランサは見ておきましょう
- あとは実際に触ることが重要!アカウントを作って、GCPを使えるようにしましょう
- 始め方はググればなんぼでも出てきます。十分な無償枠があります
- 同じことをコンソールでの操作とCLIの両方でやってみましょう
- CLIは、個別のサービスを網羅する必要はありませんが、文型は押さえておきましょう。あと、デフォルトリージョン/ゾーンの設定
- Cloud Shell でコンソールからお手軽にCLIが使えます
- プロジェクトを作って、VPCを作って、サブネットを作って、VMを立てて、ファイアウォールルールを作って、VMにアクセスしてみましょう
- VMへのアクセスの仕方はLinuxとWindows両方を押さえておきましょう
- サードパーティツールではなく、コンソール or CLI 経由でより安全に!
- GKE もクラスタを作って、Deployment 作って、Service 作って、外部に公開くらいのベーシックな操作はやっておきましょう
- IAM も試しに操作してみましょう。深堀りはしなくて大丈夫です。
- 最低、これくらい触っておけば、イメージはつくはず(AWSに慣れ親しんでいる人は)です
- 最後に模擬試験はMUSTでやりましょう
- これだけで何とかなります!(たぶん)
- セキュリティや可用性は AWS の常識と同じ感覚を持ち込めば、大きく外すことはないです
おまけ(個人的に印象に残った AWS との差異をピックアップ)
- ネットワーク
- VPC はグローバルリソース。CIDRは持たない
- AWS ではリージョンリソース。CIDR を付与
- サブネットはリージョンリソース。ゾーンをまたげる
- AWS では AZリソース
- ファイアウォールはVPCに割当。ネットワークアドレス/リソースに「タグ」を付与してタグベースで制御
- AWS では セキュリティグループをリソースに割当、ネットワークアドレス/セキュリティグループを指定して制御
- AWS の「タグ」に相当するのは GCP では「ラベル」
- 外向けのHTTP(S)ロードバランサはグローバルに展開可能
- AWS では、複数リージョンへの負荷分散はDNSベース
- 管理系
- プロジェクト(AWSでいうAWSアカウントに相当)の組織構造において、上位階層でつけた許可ルールは下位階層の権限と和集合で効く(上位階層で許可すると権限がガバガバになる)
- AWS では、Organizations の SCP はフィルタとして機能。AWSアカウントの IAM と積集合で効く(SCP で許可していても IAM で許可されていなければ許可されないし、逆もしかり)
- VM
- スナップショットはグローバルリソース
- AWSではリージョンリソース
- オブジェクトストレージ
- GCS は強整合性
- AWS S3 は結果整合性
- GCS は複数リージョンへの冗長化がバケットのタイプとして選べる。ユーザはどのリージョンに書き込んだか、どのリージョンから読みだしたか意識しない(できない)
- AWS では別リージョンに作った別バケットにクロスリージョンレプリケートを設定。リージョンを意識する
以上
- 投稿日:2020-03-27T02:56:41+09:00
AWS Solution Architect Professional 持ちは GCP Associate Cloud Engineer もすぐに取れます!(個人の感想です)
AWS Solution Architect Professional (SAP) を持っていれば、GCP ほぼ未経験でも GCP Associate Cloud Engineer は知識の流用で取れるなと感じたので、取得までの過程をご紹介します。
もちろん保証はしないし前提もあります
- 「すぐに」≠「ノー勉で」
- Kubernetes の基礎は知っていること
- 試験でも Google Kubernetes Engine (GKE) 推しです
- あくまで「資格を取る」だけの話です
勉強したこと
- まずは、公式ドキュメントから「AWS プロフェッショナルのための Google Cloud」を熟読しましょう
- IAM は個別にドキュメントを確認しておきましょう
- 「概要」と「ベストプラクティス」だけで十分です
- IAM は AWS を知っているがゆえに混乱する部分もあります。まっさらな気持ちで読みましょう
- AWS の Auto Scaling に相当する部分は個別にドキュメントを確認しておきましょう。試験に出ます(たぶん)
- その流れでネットワークロードバランサと HTTP(S)ロードバランサは見ておきましょう
- あとは実際に触ることが重要!アカウントを作って、GCPを使えるようにしましょう
- 始め方はググればなんぼでも出てきます。十分な無償枠があります
- 重要ポイント:同じことをコンソールでの操作とCLIの両方でやってみましょう
- CLIはテストに出ます。個別のサービスを網羅する必要はありませんが、文型は押さえておきましょう。あと、デフォルトリージョン/ゾーンの設定
- Cloud Shell でコンソールからお手軽にCLIが使えます
- プロジェクトを作って、VPCを作って、サブネットを作って、VMを立てて、ファイアウォールルールを作って、VMにアクセスしてみましょう
- VMへのアクセスの仕方、テストに出ます!LinuxとWindows両方!(たぶん)
- サードパーティツールではなく、コンソール or CLI 経由でより安全に!
- GKE もクラスタを作って、Deployment 作って、Service 作って、外部に公開くらいのベーシックな操作はやっておきましょう
- IAM も試しに操作してみましょう。深堀りはしなくて大丈夫です。
- 最低、これくらい触っておけば、イメージはつくはず(AWSに慣れ親しんでいる人は)です
- 最後に模擬試験はMUSTでやりましょう
- これだけで何とかなります!(たぶん)
- セキュリティや可用性は AWS の常識と同じ感覚を持ち込めば、大きく外すことはないです
おまけ(個人的に印象に残った AWS との差異をピックアップ)
- ネットワーク
- VPC はグローバルリソース。CIDRは持たない
- AWS ではリージョンリソース。CIDR を付与
- サブネットはリージョンリソース。ゾーンをまたげる
- AWS では AZリソース
- ファイアウォールはVPCに割当。ネットワークアドレス/リソースに「タグ」を付与してタグベースで制御
- AWS では セキュリティグループをリソースに割当、ネットワークアドレス/セキュリティグループを指定して制御
- AWS の「タグ」に相当するのは GCP では「ラベル」
- 外向けのHTTP(S)ロードバランサはグローバルに展開可能
- AWS では、複数リージョンへの負荷分散はDNSベース
- 管理系
- プロジェクト(AWSでいうAWSアカウントに相当)の組織構造において、上位階層でつけた許可ルールは下位階層の権限と和集合で効く(上位階層で許可すると権限がガバガバになる)
- AWS では、Organizations の SCP はフィルタとして機能。AWSアカウントの IAM と積集合で効く(SCP で許可していても IAM で許可されていなければ許可されないし、逆もしかり)
- VM
- スナップショットはグローバルリソース
- AWSではリージョンリソース
- オブジェクトストレージ
- GCS は強整合性
- AWS S3 は結果整合性
- GCS は複数リージョンへの冗長化がバケットのタイプとして選べる。ユーザはどのリージョンに書き込んだか、どのリージョンから読みだしたか意識しない(できない)
- AWS では別リージョンに作った別バケットにクロスリージョンレプリケートを設定。リージョンを意識する
以上
- 投稿日:2020-03-27T02:30:46+09:00
Darkを使用して、Slack App作成する
はじめに
本書では、Darkを使用したSlack Appの作成を行う。Darkに関しては、「新たな開発プラットフォーム "Dark/Darklang" を実際に触ってみて」を参考して頂ければと思う。
Darkでは、トレース駆動開発を駆使する事で、ビジネスロジックのみを記述するだけで開発が可能であるので、その点も注目して貰えたらと思う。
1. Slackアプリケーションの開発
Slack Appの開発を始めていく。アプリケーション名は
sampleAppとした。今回は、簡単にスラッシュコマンド
/testを入力するとワニの画像が返されるようにする。1.1. キャンバスの作成
開発する為にキャンバスを新規作成する。
アカウントには、
darklang.com/a/USERNAME-CANVASNAMEからアクセスできる。今回は、Slack Appを作成するので、darklang.com/a/USERNAME-slackappと名付けた。入力後にアクセスすると、キャンバスが立ち上がる。
1.2. Slackコマンドの追加
次に、Slack APIからSlack Appを新規作成する。
アプリケーションをワークスペースにインストールする為には権限が必要である。その為、筆者は独自のワークスペースを作成し、その中にSlack Appをセットアップする事にした。
Slackコマンドに
/testコマンドを追加し、USERNAME-CANVASNAME.builtwithdark.com/testでリクエストURLを指定する。今回は以下の様に設定した。
必要に応じて、ここでSlackbot等の他の機能を追加できるが、今回はこれをベースに開発していく。
1.3. OAuthのセットアップ
1.3.1 リダイレクトURLの設定
アプリを配布できるようにする為、OAuthをセットアップする。Slack APIの
OAuth & Permissionsから、リダイレクトURLを追加する。
DarkではOAuthの使用する際は以下の形式でURLを指定する必要があるので、それに則って記述する。
https://USERNAME-CANVASNAME.builtwithdark.com/OAUTH-REDIRECTURLを保存後、
Settings/Manage Distributionから共有可能なURLをブラウザのアドレスバーにコピーする。アクセスするとアプリケーションをインストールできるのでインストールする。この段階ではアクセスしてもバックエンドのロジックは何も記述していない為、以下の様なエラーが表示される。404 Not Found: No route matchesしかし、この様な振る舞いを行う事でDarkは痕跡を確認する事ができ、それをトレースする事で開発を行う。
筆者自身、このトレース駆動開発にはまだ慣れていない部分もあるが、敢えてこの様に異常検知を起こす事でアクセスに必要な情報をトレースして開発を行う事がDarkを使用する上での1つのメリットである。
Darkのキャンバス(
https://darklang.com/a/USERNAME-slackapp)に戻り、セクションを確認してみると404セクションに/oauth-redirectが表示されている事が確認できる。
この404にある
/oauth-redirectをプロダクショントレースしてバックエンドを構築していく。+をクリックすると、GETメソッドのOAuthリクエストに応答するHTTPハンドラを作成する。
作成したものを確認してみると、SlackがDarkアプリに対して行ったリクエストを示すトレースが表示されている。ここには、Slackに返答する際に必要なコードが含まれる。(一部個人情報を含む為、加工している)
1.3.2. トークンの取得
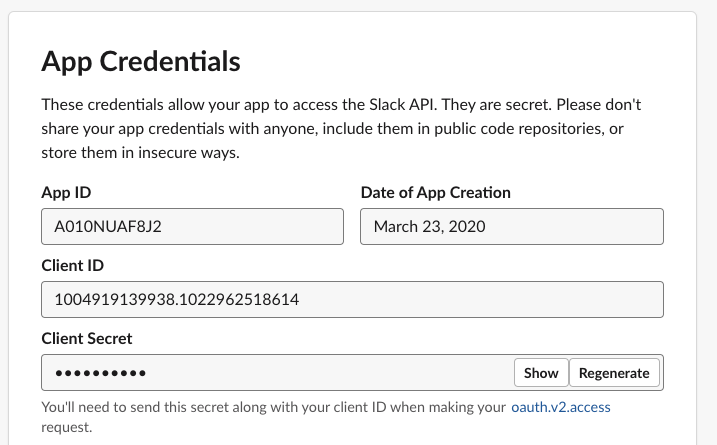
Slackアプリに送信する為には
client_idとclient_secretが必要である。これらの情報は、SlackのSettings/App Credentialsから確認する事ができる。
確認後、作成した
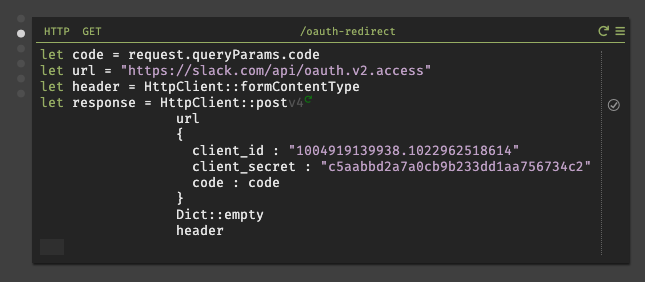
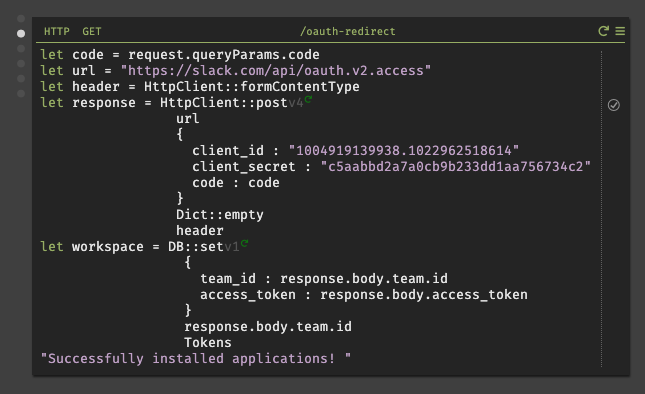
/oauth-redirectハンドラにコードを記述していく。ここで、client_id、client_secretをペーストする際は最初に文字リテラル"を入力してからでないと、Darkではフロート型の様に扱われ、全ての文字列がペーストされない。
また、実行すると偶に
oauth_authorization_url_mismatchと返される場合があるが、それはOAuthの認証URLが異なるからである。どちらのURLを使用するかは、Settings/App CredentialsのClient IDを見ると右下に小さく書いているので、それで判断する事が可能である。# どちらかのURLを使用する https://slack.com/api/oauth.access https://slack.com/api/oauth.v2.access※ 今回、筆者は
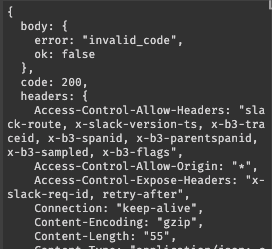
oauth.v2.accessを使用しているが、oauth.v2.accessからレスポンスで返されるJSONの仕様が変更されている。その為、oauth.accessを使用する場合は、後述で説明するトークン保存時のパラメータの指定方法が異なるので注意して欲しい。これにより、Slack APIの一部(oauth.v2.access)が呼び出され、リクエストされたSlackにアクセス可能になる。実行すると、正しくレスポンスが返されれば
team.id、access_tokenが取得できる。しかし、コードの有効期限が切れると以下の様なエラーが表示される。その場合は、面倒だが再度ブラウザから共有リンクを開き、認証を行う必要がある。
1.3.2. トークンの保存
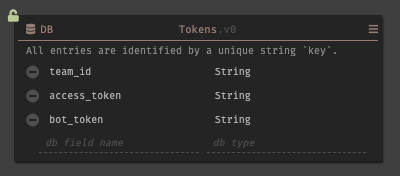
次に、取得したトークンとデータストアに保存する。アドレスバーから新しいデートストアを作成し、保存するフィールドにスキーマを設定する。
bot_tokenはoauth.v2.accessを使用する場合は不要である。
データストアの作成が完了すれば、
/oauth-redirectにロジックを記述していく。
1.4. アプリケーション機能の構築
ワークスペースにアプリケーションをインストールしたので、Slackを起動して確認してみる。設定したスラッシュコマンド
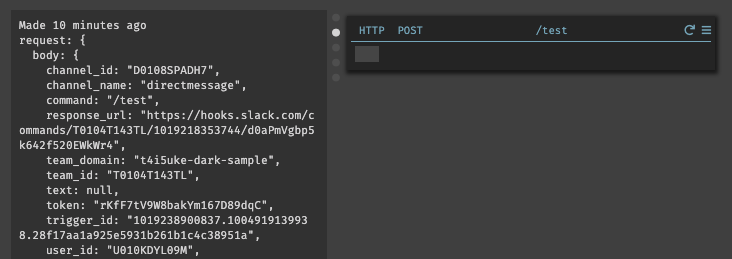
/testを入力してもまだロジックが実装されていない為、エラーが表示される。
しかし、このトリガーからDarkの404セクションにルートが表示されるので、それをトレースして機能を構築していく。404セクションからエンドポイントを作成するとトレースを操作可能である。
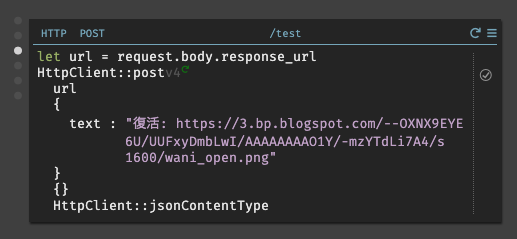
今回のアプリケーションでは以下の様に実装した。リクエストURLを取得し、そのリクエストに対してテキストを返す。
1.5. 動作検証
実際にSlack側で動作させてみる。
/testと入力すると、Darkで設定したテキストと成功した事を証明するJSONが出力された事が確認できる。
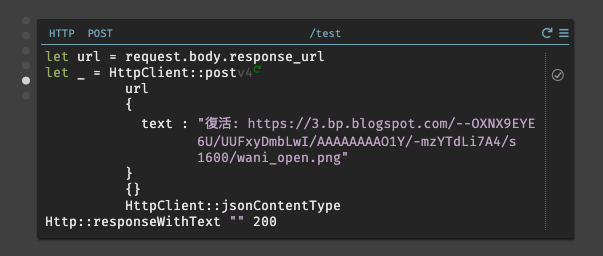
JSONの出力を非表示にしたい場合は、
Http::respondWithTextを使用して200コードに対して空白を指定すると表示されなくなる。
以上で、DarkでSlack Appの実装する事ができた。
2. データストアを活用したアプリケーションの実装
応用として、データストアに保存された50音を行ごとにランダムに出力する様に実装してみる。
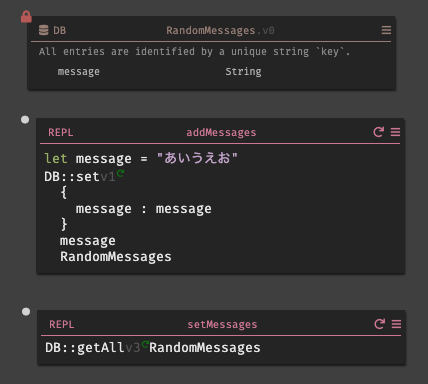
まず、
RandomMessagesと言うデータストアを用意し、フィールドにmessageと言うスキーマを用意する。そこにREPLでデータストアに対して登録を行うaddMessagesを用意する。続けて、データストアに登録された情報を確認する為にREPLでsetMessagesも用意した。
次に、先程使用した
/testのロジックを一部修正し、その結果をSlack側に送信する。
追加した変数の概要は以下の通りである。
変数名 内容 allMessages RandomMessagesに保存されている情報を全て取得し、配列に保存する。messageCount 配列の長さを取得する。 messageCountLessOne 配列は0から始まる為、 1除算する。index ランダム値を取得する。範囲として 0からmessageCountLessOneを指定する。message indexの値に該当する情報をデータストアから取得する。 実際に動かしてみると、以下の様にランダムに結果が表示される事がわかる。先程、実装した
Http::respondWithTextによりJSONが出力されない事も併せて見て貰うと良い。
3. 最後に
今回は、DarkでSlack Appの実装を行った。筆者は、Slack Appの開発は初めてであった為、Dark以外でいくつか躓く点が多かったのだが、開発した事のある方であれば比較的容易に開発できるのではないだろうか。実際に今回開発した全体図を見ると、非常に少ないコードで開発できている事がわかる。
また、Darkでは定義した変数名をクリックすると即座に値を確認できるので、意図した値が返ってきているかどうかを知ることができる。これにより、コードを記述している間も修正箇所に気づきやすいので、逐一デバッグを行い確認する必要はない。
最後に開発を通して発見した事だが、Darkで日本語文字列を入力しようとすると変換をする際にスペースも誤入力されてしまう様である。この点に関しては、今後の改善希望として報告しておこうと思う。
【2020/03/27 03:43追記】
ベータ版と言う事もあり、現段階ではテキスト構成のサポートがまだ十分ではないとの事。回避策として、もし日本語入力を行いたい際はコピー&ペーストを使用して入力して欲しい。





- 投稿日:2020-03-27T01:34:34+09:00
Amplify+ReactでCRUDアプリ作成RTA(Any%)Part.1
amplify+reactでアプリ作成RTAやっていきます。
当方基盤エンジニアです。(ただ、ハッカソンでアプリ作成経験ありです。)
はい、よーいスタートレギュレーション(又の名を前提)
- AWSに乗っかるのでamplify利用(前も使ったから)
- 面倒なので認証なし(前はCognitoとか実装した)
- GraphQLを使いたい(バックエンド考えるの大変だからね。)
- 必要機能はCRUD(わかりやすさ重視)
- 計測期間はreactの雛形作成からデプロイして初回アクセスまで
- Google先生は多用する。
- 失踪しない
イメージ図
1.Create画面
2.一覧表示
それでは、イクゾー!(デッデッデデデデ カーン)
初期設定
1.いつも通りreactの雛形作成
詳細は以下を参考にしてください。丁寧丁寧丁寧に記載されているのでおすすめです。
https://qiita.com/G-awa/items/a5b2cc7017b1eceeb002npx create-react-app <アプリ名> cd <アプリ名>2.色々インストール
いろんなUI使ってみたいので今回はevergreen-uiを利用してみました。
(大胆なチャート変更)yarn add react-dom evergreen-ui yarn add aws-amplify aws-amplify-react3.amplify設定
amplify init4.GraphQLスキーマ作成
amplify add api amplify pushgraphqlのスキーマは入力速度を考慮して以下としました。ほぼ変えてないです;;
(Postの方が良かったですね、、、複数形にするとPostssになってしまいますた。)/amplify/backend/api/~~~AppName~~~/schema.graphqltype posts @model { id: ID! name: String! url: String! description: String }コーディング準備
気持ちよくアプリを作成していくために準備をしていきます。
あちなみに、筆者の環境はVSCodeです。ちなみにVimmerです。(宗教戦争)0.GitHubのリポジトリ登録しておく
リポジトリ作成は割愛します。適当でもOKですgit remote add origin git@github.com:aion0721/ozadoc.git1.不要ファイル削除
以下ファイルはフヨウラ!
ただ普通に消すとgitの管理もありややこしくなるのでgitコマンドで消します。git rm logo.svg git rm App.css2.index.js
変更点とかだけ抜き出します。全文はgithub参照してください。
(え、URLはどこかだって?ヒントをあげているので自分で考えてください。)index.jsimport * as serviceWorker from "./serviceWorker"; import Amplify from "aws-amplify"; import config from "./aws-exports"; Amplify.configure(config);3.app.js
師匠の教えを守りcomponentsフォルダを作りますので、以下の記載にします。
(正直ファイル分ける必要なかったのでここ600fpsぐらいロスですね。)App.jsimport Top from "./components/Top"; function App() { return ( <div> <Top /> </div> ); }4.Top.js作成
メインディッシュです。mkdir ./components touch ./components/Top.jsTop.jsimport React from "react"; function Top(){ return( <div> Hello, World!!!~素晴らしきこの世界~ </div> ); } export default Top;5.起動確認
とりあえず起動してみます。yarn start文字が出たらOK
次回へ続く
短いですがPart.1としてはここまでにします。
区間ラップは1.5時間です。ほぼ、UI選ぶ時間でした。勉強も兼ねてるから仕方ないね(レ)
(更新部分を残す走者の鑑)


- 投稿日:2020-03-27T00:04:32+09:00
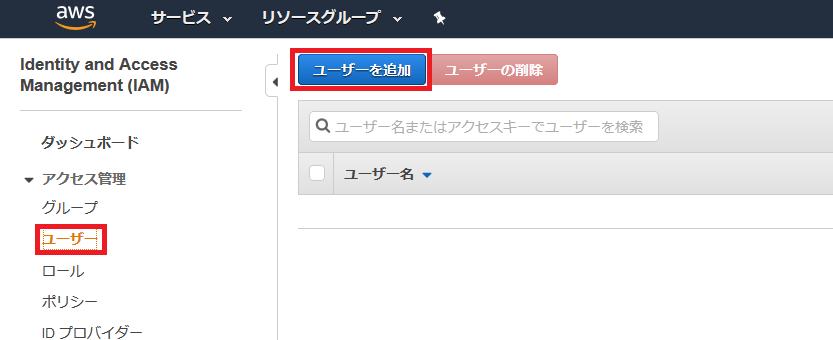
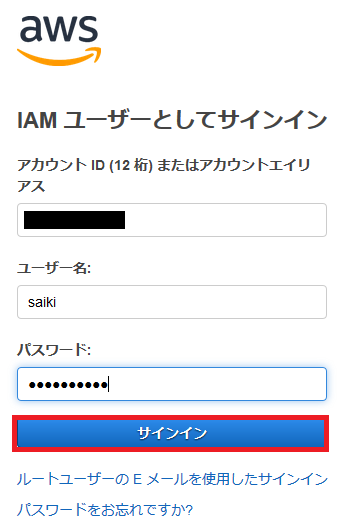
IAMでユーザー作成
今回は学習用の作業ユーザーをIAM(Identity and Access Management)を使って作る。
作業ユーザー作成
AWSマネジメントコンソールで「IAM」を検索。
IAM画面の左側のメニューからユーザーを選択し、ユーザー追加を選択。
ユーザー名、アクセスの種類、パスワードを設定。
パスワードのリセットは複数ユーザーが使う場合にしか使わないので、チェックを外す。
「次のステップ:アクセス権限」を選択。
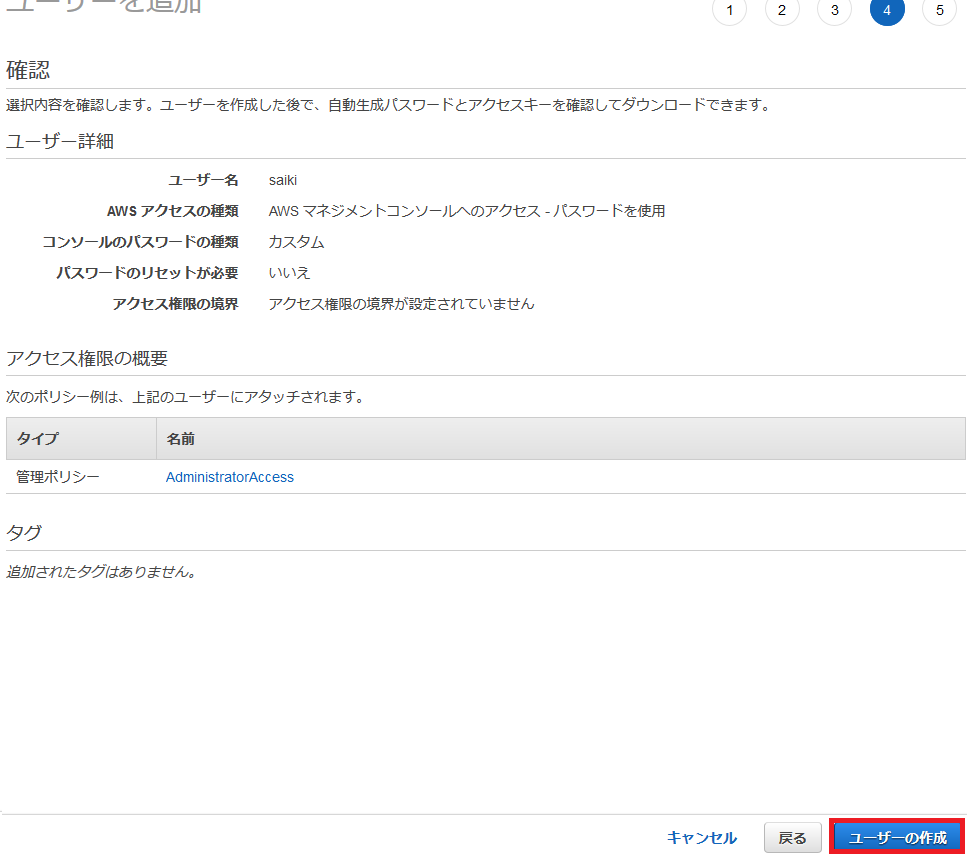
ユーザーの権限を設定する。今回はAWSがある程度設定してくれている権限のテンプレートを使う。
しばらく学習でいろいろ触りたいので、強めの権限を設定。
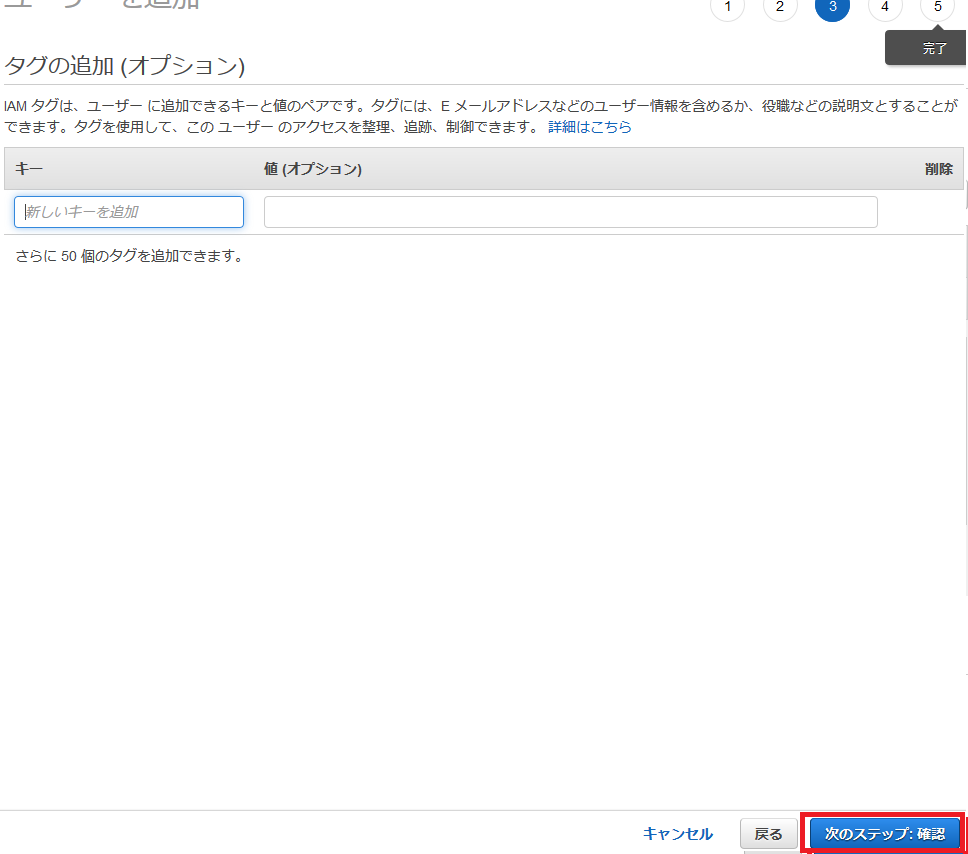
「次のステップ:タグ」を選択。
タグは何もせず次へ。
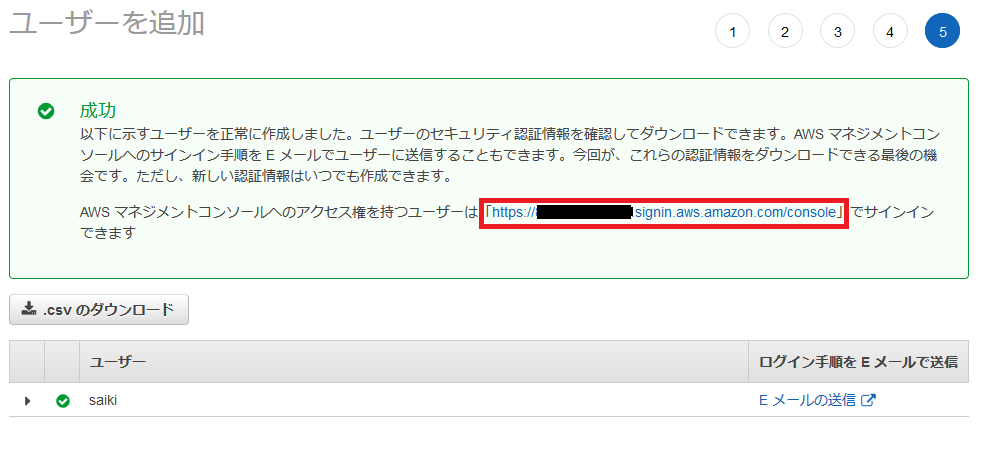
確認画面で確認して、ユーザー作成を選択。
ユーザーの追加が完了したので、URLにアクセスしてサインインしてみる。
サインイン
追加したユーザーでサインインしてみる。
サインイン成功!