- 投稿日:2020-03-22T23:37:00+09:00
【minimize入門】SEIRモデルでデータ解析する♬
COVID-19のデータ解析する準備として、以下のグラフを出力するまでの解説をする。
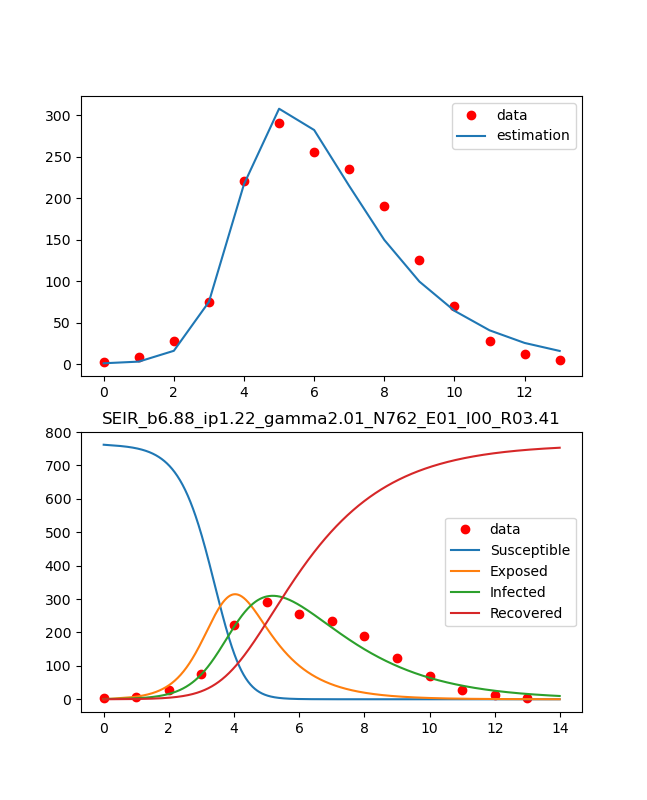
この図は、与えられたdataに対して感染症のSEIRモデルにminimize@scipyを利用してフィッティングした図である。
手法は、ほぼ以下の参考のとおりです。どちらもいろいろな意味で参考になりました。
【参考】
①感染症数理モデル事始め PythonによるSEIRモデルの概要とパラメータ推定入門
②感染病の数学予測モデル (SIRモデル):事例紹介(1)
③SEIRモデルで新型コロナウイルスの挙動を予測してみた。やったこと
・コード解説
・SIRモデルとSEIRモデルでフィッティングしてみる
・その他のモデル・コード解説
コード全体は以下に置いた。
・collective_particles/minimize_params.py
解説は上記の参考に譲り、ここでは今回利用したコードの解説をする。なお、データは参考②から利用させていただいた。また、minimizeのコードは参考①を参考にさせていただいた。
利用するLibは以下のとおりである。
今回はWindows10のconda環境のkeras-gpu環境で実施しているが、scipyも含めて以前インストール済である。#include package import numpy as np from scipy.integrate import odeint from scipy.optimize import minimize import matplotlib.pyplot as plt以下にSEIRモデルの微分方程式を定義している。
ここでNをどうするかは適宜判断することになるが、今回の命題では参考②の掲出論文からN=763人であり、固定とした。
SEIRモデルの微分方程式は以下のとおり
ここで、参考①ではNを変数betaに押し込めてしまって、陽には表していないが、ウワン的には以下の式の方が分かりやすい。
以下は、参考③から引用させていただいた。{\begin{align} \frac{dS}{dt} &= -\beta \frac{SI}{N} \\ \frac{dE}{dt} &= \beta \frac{SI}{N} -\epsilon E \\ \frac{dI}{dt} &= \epsilon E -\gamma I \\ \frac{dR}{dt} &= \gamma I \\ \end{align} }上記を見ながら以下を見ると、まんまなので理解できると思う。
#define differencial equation of seir model def seir_eq(v,t,beta,lp,ip): N=763 a = -beta*v[0]*v[2]/N b = beta*v[0]*v[2]/N-(1/lp)*v[1] c = (1/lp)*v[1]-(1/ip)*v[2] d = (1/ip)*v[2] return [a,b,c,d]まず、通常の微分方程式として初期値に基づいて解を求めている。
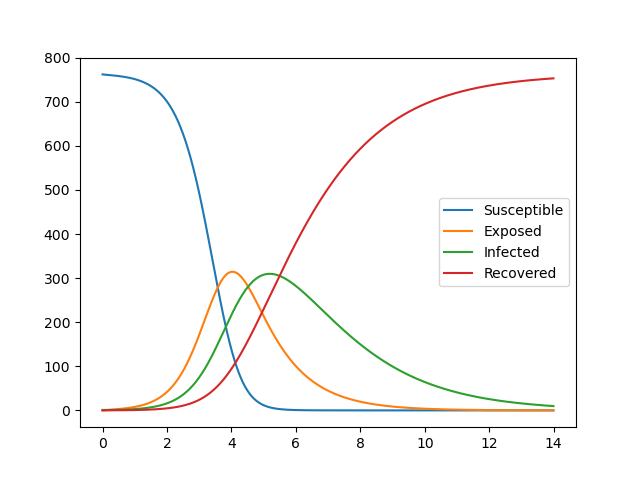
#solve seir model N,S0,E0,I0=762,0,1,0 ini_state=[N,S0,E0,I0] beta,lp,ip=6.87636378, 1.21965986, 2.01373496 #2.493913 , 0.95107715, 1.55007883 t_max=14 dt=0.01 t=np.arange(0,t_max,dt) plt.plot(t,odeint(seir_eq,ini_state,t,args=(beta,lp,ip))) #0.0001,1,3 plt.legend(['Susceptible','Exposed','Infected','Recovered']) plt.pause(1) plt.close()結果は以下のとおり、ここでパラメータを推定して変化させていけば大体のフィッティングはできるが複雑なものでは難しい。
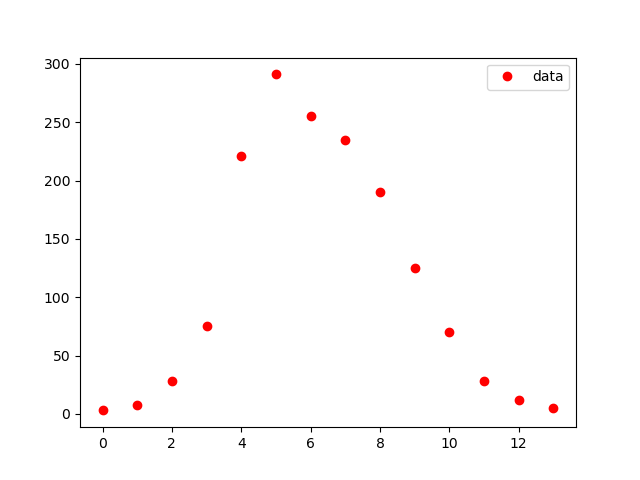
データは参考②のとおり、代入して以下のようにグラフに出力する。#show observed i #obs_i=np.loadtxt('fitting.csv') data_influ=[3,8,28,75,221,291,255,235,190,125,70,28,12,5] data_day = [1,2,3,4,5,6,7,8,9,10,11,12,13,14] obs_i = data_influ plt.plot(obs_i,"o", color="red",label = "data") plt.legend() plt.pause(1) plt.close()結果は以下のとおり、これは途中の確認のための出力なので見出しなどは省略している。
さて、次が推定部分である。この評価関数は引数の値を使って微分方程式で計算し、評価結果を返している。#function which estimate i from seir model func def estimate_i(ini_state,beta,lp,ip): v=odeint(seir_eq,ini_state,t,args=(beta,lp,ip)) est=v[0:int(t_max/dt):int(1/dt)] return est[:,2]対数尤度関数を以下のように定義する。
※参考①を参照
基本はパラメータを変更して、この対数尤度関数の最大値を求める問題になる。(実際はマイナスを取って最小化問題にしている)
※ここでlogの引数が負になるのを防ぐために絶対値を取っている#define logscale likelihood function def y(params): est_i=estimate_i(ini_state,params[0],params[1],params[2]) return np.sum(est_i-obs_i*np.log(np.abs(est_i)))最大値を求めるために以下のScipyのminimize関数を利用する。
#optimize logscale likelihood function mnmz=minimize(y,[beta,lp,ip],method="nelder-mead") print(mnmz)出力は以下のとおり
>python minimize_params.py final_simplex: (array([[6.87640764, 1.21966435, 2.01373196], [6.87636378, 1.21965986, 2.01373496], [6.87638203, 1.2196629 , 2.01372646], [6.87631916, 1.21964456, 2.0137297 ]]), array([-6429.40676091, -6429.40676091, -6429.40676091, -6429.4067609 ])) fun: -6429.406760912483 message: 'Optimization terminated successfully.' nfev: 91 nit: 49 status: 0 success: True x: array([6.87640764, 1.21966435, 2.01373196])計算結果から以下のようにbeta_const,lp,gamma_constを取り出し、以下でR0を計算する。これが基本再生産数であり、感染拡大の目安でありR0<1なら拡大しないが、R0>1なら拡大し、その程度を示す指標である。
#R0 beta_const,lp,gamma_const = mnmz.x[0],mnmz.x[1],mnmz.x[2] #感染率、感染待時間、除去率(回復率) print(beta_const,lp,gamma_const) R0 = beta_const*(1/gamma_const) print(R0)今回は以下のとおりとなり、R0=3.41なので感染拡大したわけですね。
6.876407637532918 1.2196643491443309 2.0137319643699927 3.4147581501415165こうして求めたものをグラフに表示します。
#plot reult with observed data fig, (ax1,ax2) = plt.subplots(2,1,figsize=(1.6180 * 4, 4*2)) lns1=ax1.plot(obs_i,"o", color="red",label = "data") lns2=ax1.plot(estimate_i(ini_state,mnmz.x[0],mnmz.x[1],mnmz.x[2]), label = "estimation") lns_ax1 = lns1+lns2 labs_ax1 = [l.get_label() for l in lns_ax1] ax1.legend(lns_ax1, labs_ax1, loc=0) lns3=ax2.plot(obs_i,"o", color="red",label = "data") lns4=ax2.plot(t,odeint(seir_eq,ini_state,t,args=(mnmz.x[0],mnmz.x[1],mnmz.x[2]))) ax2.legend(['data','Susceptible','Exposed','Infected','Recovered'], loc=0) ax2.set_title('SEIR_b{:.2f}_ip{:.2f}_gamma{:.2f}_N{:d}_E0{:d}_I0{:d}_R0{:.2f}'.format(beta_const,lp,gamma_const,N,E0,I0,R0)) plt.savefig('./fig/SEIR_b{:.2f}_ip{:.2f}_gamma{:.2f}_N{:d}_E0{:d}_I0{:d}_R0{:.2f}_.png'.format(beta_const,lp,gamma_const,N,E0,I0,R0)) plt.show() plt.close()結果は上記のとおりです。
・その他のモデル
この計算をやっていたら、もう少し簡単なSIRモデルと少し複雑なモデルがあったのでまとめておきます。
SIRモデルは、S-E-I-RからExposureを無視したモデルなので以下のとおりです。{\begin{align} \frac{dS}{dt} &= -\beta \frac{SI}{N} \\ \frac{dI}{dt} &= \beta \frac{SI}{N} -\gamma I \\ \frac{dR}{dt} &= \gamma I \\ \end{align} }以下のように書き換えると$R_0$の意味が理解できる。
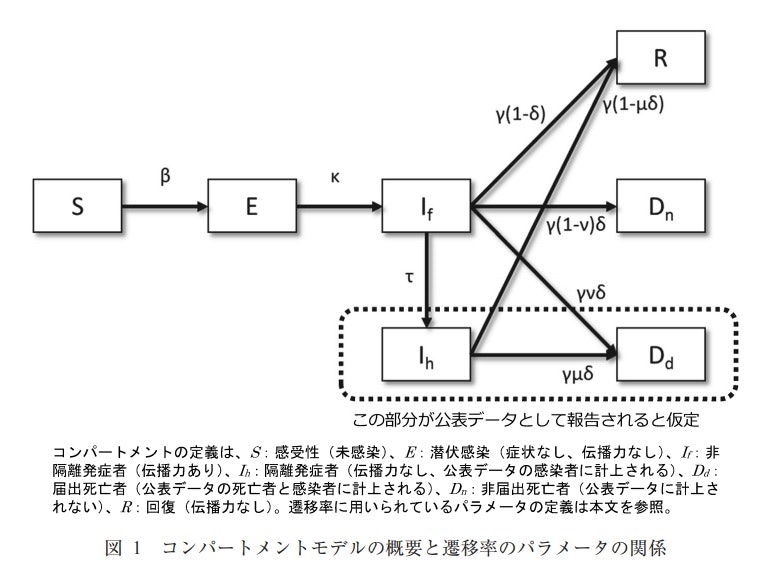
{\begin{align} \frac{dS}{dt} &= -R_0 \frac{S}{N} \frac{dR}{dt} \\ R_0 &= \frac{beta}{gamma}\\ \end{align} }一方、例えば死亡する遷移があり、届け出無しの死亡とかあるなど複雑な状況だと以下のようになります。なお、死亡者は感染には寄与しないという仮定です。
※COVID-19はこんな感じかもしれない
図は参考①の以下の文献より
・数理モデルを用いたエボラウイルス感染症の流行の解析
まとめ
・minimize@scipyにより自動的にデータフィッティングできるようになった
・SEIRモデルで実際のデータをフィッティング出来た・次回はCOVID-19の各国のデータを分析したいと思う

- 投稿日:2020-03-22T23:27:54+09:00
LineNotifyを使ってメッセージ、画像を送信する
LineNotifyを使って Fortniteの画像とメッセージを送ってみる。
まず、LINE Notifyのサイトでログインしてトークンを発行する。
https://notify-bot.line.me/ja/・Mac
・python(1)ディレクトリ構成
imagesの中に、gazo.jpegを保存。test ├test.py └images └gazo.img(2)test.pyを記述
コードは以下の通り。test.py#coding:UTF-8 import requests,os #------画像を送る場合---------------------------- def main_gazo(): url = "https://notify-api.line.me/api/notify" token = "*********************************" headers = {"Authorization" : "Bearer "+ token} message = 'Fortnite!' payload = {"message" : message} #imagesフォルダの中のgazo.jpg files = {"imageFile":open('images/gazo.jpeg','rb')} #rbはバイナリファイルを読み込む post = requests.post(url ,headers = headers ,params=payload,files=files) #------メッセージを送る場合---------------------------- def main(): url = "https://notify-api.line.me/api/notify" token = "*********************************" headers = {"Authorization" : "Bearer "+ token} message = 'Fortnite!' payload = {"message" : message} r = requests.post(url ,headers = headers ,params=payload) if __name__ == '__main__': main_gazo()#画像を送るmain_gazo()を動かしてみる(メッセージの場合はmain())
- 投稿日:2020-03-22T23:26:48+09:00
Pythonで毎日AtCoder #13
はじめに
今まではAtCoderProblemsのレコメンド問題を解いていましたが、より基礎的な力が足りないと思ったのでこれをやります。
#13
さすがにA問題1題だけだと物足りないので、A問題をふたつ解きます。
考えたこと
ABC086-Aは$a*b mod(2)$するだけa, b = map(int,input().split()) if a*b % 2 != 0: print('Odd') else: print('Even')ABC081-Aはsの中の'1'をcountするだけ
s = list(str(input())) print(s.count('1'))まとめ
今日のABCで悔しい思いをしたのでとりあえず過去問精選を解く。
では、また
- 投稿日:2020-03-22T23:06:15+09:00
AtCoder Beginner Contest 159 参戦記
AtCoder Beginner Contest 159 参戦記
ABC159A - The Number of Even Pairs
3分半で突破. 奇数のペアか、偶数のペアが答えになる. kC2 = k(k-1)/2 が分かっていればあとは書くだけなのだが、A問題にしては難しいね、これ.
N, M = map(int, input().split()) print(N * (N - 1) // 2 + M * (M - 1) // 2)ABC159B - String Palindrome
12分で突破. 時間かかりすぎた orz. 回分チェックルーチンを書いて、後は 1-indexed を 0-indexed に変換しながら、言われたとおりにチェックしていくだけ. B問題にしては難しいね、これ.
S = input() def is_palindrome(s): return s == s[::-1] N = len(S) if not is_palindrome(S): print('No') exit() if not is_palindrome(S[:(N - 1) // 2]): print('No') exit() if not is_palindrome(S[(N + 3) // 2 - 1:]): print('No') exit() print('Yes')ABC159C - Maximum Volume
2分で突破. A問題の間違いじゃないの、これ?
L = int(input()) print((L / 3) ** 3)ABC159D - Banned K
10分で突破. 当然 k 番目のボールを除いた場合の数を毎回全部計算し直していたら TLE. とりあえず抜かない場合の数を計算して、k 番目の値の場合の数だけ調整して答える.
N = int(input()) A = list(map(int, input().split())) d = {} for a in A: if a in d: d[a] += 1 else: d[a] = 1 s = 0 for k in d: s += d[k] * (d[k] - 1) // 2 for i in range(N): t = d[A[i]] print(s - t * (t - 1) // 2 + (t - 1) * (t - 2) // 2)ABC159E - Dividing Chocolate
敗退. 累積和でホワイトチョコの数え上げを O(HW) から O(H) に軽減して、再帰関数で総当りしたが、TLE & WA でした. 総当たりなのに WA なのでどこか実装がバグってますね…….
- 投稿日:2020-03-22T23:02:54+09:00
ブラックジャックの戦略を強化学習で作ってみる(①ブラックジャックの実装)
はじめに
Pythonと強化学習の勉強を兼ねて,ブラックジャックの戦略作りをやってみました.
ベーシックストラテジーという確率に基づいた戦略がありますが,それに追いつけるか試してみます.こんな感じで進めていきます
1. ブラックジャック実装 ← 今回はここ
2. OpenAI gymの環境に登録
3. 強化学習でブラックジャックの戦略を学習なぜブラックジャック?
- プログラミングの勉強によさそう(プログラミング入門者からの卒業試験は『ブラックジャック』を開発すべし)
- 学習後の戦略をベーシックストラテジーと比較できる(ベンチマークがある)
- ブラックジャックうまくなりたい
開発環境
- Windows 10
- Python 3.6.9
- Anaconda 4.3.0 (64-bit)
ブラックジャックのルール
ブラックジャックはカジノの中でも人気のテーブルゲームです.
簡単にルールを紹介します.基本ルール
- ディーラー対プレーヤーでカードを配布
- 手札の合計が21点に近い方が勝ち
- 手札の合計点が22点を超えると負け(バースト)
- ポイントの数え方
- 2~9・・・そのまま2~9点
- 10と絵札・・・10点
- A(エース)・・・1点または11点
実装するブラックジャックのルール
こんな感じのブラックジャックを作ります.
- トランプ6組を使用
- BET機能あり(ただし額は固定で$100.リターンは強化学習の報酬にします.)
- 初期の所持金は$1000
- Playerの選択肢
- スタンド(Stand)・・・カードを引かず勝負する
- ヒット(Hit)・・・もう一枚カードを引く
- ダブルダウン(Double Down)・・・BETを2倍にしてもう1枚だけカードを引く
- サレンダー(Surrender)・・・BETの半分を放棄してプレイを降りる
- 実装しないこと
- スプリット(Split)・・・配られた2枚のカードが同じ数字の場合,はじめのBETと同じ額を追加し2つに分けてプレイする
- インシュランス(Insurance)・・・ディーラーの表向きカードがAの時,BETの半分を追加して保険をかける
- ブラックジャック(BlackJack)・・・A+絵札or10の2枚で21点になること
実装
コード全体は末尾に記載します.
Cardクラス
トランプのカードを生成します.
ブラックジャックの特殊な絵札の点数の数え方はここで定義します.
Aも特殊なのですが,ここでは1点として生成します.
Aの点数はHandクラス内で他の手札の点数を考慮して決定します.class Card: ''' カードを生成 数字:A,2~10,J,Q,K スート:スペード,ハート,ダイヤ,クラブ ''' SUITS = '♠♥♦♣' RANKS = range(1, 14) # 通常のRank SYMBOLS = "A", "2", "3", "4", "5", "6", "7", "8", "9", "10", "J", "Q", "K" POINTS = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 10, 10, 10] # BlackJack用のポイント def __init__(self, suit, rank): self.suit = suit self.rank = rank self.index = suit + self.SYMBOLS[rank - self.RANKS[0]] self.point = self.POINTS[rank - self.RANKS[0]] def __repr__(self): return self.indexDeckクラス
NUM_DECK = 6と定義して,6組のトランプを使ったデッキを生成します.
デッキ生成と同時にシャッフルまでやってしまいます.class Deck: ''' カードがシャッフルされたデッキ(山札を生成) ''' def __init__(self): self.cards = [Card(suit, rank) \ for suit in Card.SUITS \ for rank in Card.RANKS] if NUM_DECK > 1: temp_cards = copy.deepcopy(self.cards) for i in range(NUM_DECK - 1): self.cards.extend(temp_cards) random.shuffle(self.cards) ・・・略Handクラス
手札へのカード追加やポイントの計算をします.
ソフトハンド(Aを含む手札)の判定も入れました.class Hand: """ 手札クラス """ def __init__(self): self.hand = [] self.is_soft_hand = False def add_card(self, card): # 手札にカードを加える処理. ・・・略 def check_soft_hand(self): # ソフトハンド(Aを含む手札)かチェックする ・・・略 def sum_point(self): # 手札のポイントを計算. # ソフトハンドなら,Aが1の場合と11の場合,両方計算する ・・・略 def calc_final_point(self): # Dealerと勝負するときのポイントを計算する # BUSTしていない最終的なポイントを返す ・・・略 def is_bust(self): # 手札がBUST(21を超えている)かどうか判定する ・・・略 def deal(self, card): # Deal時の処理 ・・・略 def hit(self, card): # Hit時の処理 ・・・略Playerクラス
StandやHitといった選択はここで定義します.
未実装のSplitやInsuranceも追記するならここへ.
おまけで自動プレイモードをつけました.後述の適当AIでプレイできます.class Player: def __init__(self): self.hand = Hand() self.chip = Chip() self.done = False # Playerのターン終了を示すフラグ self.hit_flag = False # Player が Hit を選択済みかどうか示すフラグ self.is_human = False # True:人がプレイ,False:自動プレイ def init_player(self): # 手札や各フラグを初期化する ・・・略 def deal(self, card): # Stand時の処理 ・・・略 def hit(self, card): # Hit時の処理 ・・・略 def stand(self): # Stand時の処理 ・・・略 def double_down(self, card): # Double down時の処理 ・・・略 def surrender(self): # Surrender時の処理 ・・・略Dealerクラス
Playerクラスと一緒でよかったかもしれません.
ディーラーならではのメソッドが必要かと思って作りましたが特にありませんでした.Chipクラス
勝負の後のチップのやり取り.
勝ったら賭けた額の2倍がもらえ,負けたら全額没収.引き分けなら賭けた分がそのままPlayerに戻ります.class Chip: def __init__(self): self.balance = INITIAL_CHIP self.bet = 0 def bet_chip(self, bet): self.balance -= bet self.bet = bet def pay_chip_win(self): self.balance += self.bet * 2 def pay_chip_lose(self): self.balance = self.balance def pay_chip_push(self): self.balance += self.betAIクラス
自動プレイ用の適当なAIが入っています.おまけ程度.
強化学習をする前のテスト用です.class AI: ・・・略 def select_random3(self, hand, n): if hand < 11: selection = 'h' # hit elif hand == 11 and n == 2: selection = 'd' # double down elif hand == 16 and n == 2: selection = 'r' # surrender elif hand > 17: selection = 's' # stand else: r = random.randint(0, 1) if r > 0.5: selection = 'h' # hit else: selection = 's' # stand return selectionGameクラス
ブラックジャックのメイン機能です.
表示関係のメソッドが混在していて見にくいかも.改善の余地ありです.
player_step関数は,gymのstep関数でも使います.class Game: def __init__(self): self.game_mode = 0 # 0:開始待ち,1:ゲーム中, 2:ゲーム終了 self.deck = Deck() self.player = Player() self.dealer = Dealer() self.judgment = 0 # 1:勝ち,0:引き分け, -1:負け self.game_count = 0 self.start() self.message_on = True #self.player.is_human # True:コンソールにメッセージ表示する,False:コンソールにメッセージ表示しない def start(self): # デッキをシャッフル,Player, Dealerを初期化 ・・・略 def reset_game(self): # Player, Dealerの手札をリセット ・・・略 def bet(self, bet): # PlayerがBETする ・・・略 def deal(self, n=2): # Player, Dealerにカードを配る ・・・略 def player_turn(self): # Playerのターン.行動をコンソールから入力する or 適当AIで自動決定する ・・・略 def player_step(self, action): # Stand, Hit, Double down, Surrenderに応じた処理 ・・・略 def show_card(self): # カードを表示.Dealerの伏せられているカードは「?」表示 ・・・略 def dealer_turn(self): # Dealerのターン.ポイントが17以上になるまでカードを引く ・・・略 def open_dealer(self): # Dealerの伏せられていたカードをオープンする ・・・略 def judge(self): # 勝敗の判定 ・・・略 def pay_chip(self): # Chipの精算 ・・・略 def check_chip(self): # Playerの所持額がMinimum Bet(最低限賭けなければいけない額)を下回っていないかチェック # 下回っていたらゲームを終了する ・・・略 def show_judgement(self): # 勝敗の結果を表示 ・・・略 def ask_next_game(self): # ゲームを続けるか尋ねる ・・・略 def check_deck(self): # カードの残り枚数をチェックし,少なければシャッフルする ・・・略main関数
main関数にゲームの流れに沿った処理を書きます.
これを実行するとブラックジャックで遊べます.
ちなみに,
・ NUM_DECK = 6 # デッキ数
・ INITIAL_CHIP = 1000 # 初期チップ
・ MINIMUM_BET = 100 # 最低限賭けなければいけない額
としています.def main(): game = Game() game.start() while game.game_mode == 1: game.reset_game() # いろいろをリセットする game.bet(bet=100) # 賭ける game.deal() # カードを配る game.player_turn() # プレイヤーのターン game.dealer_turn() # ディーラーのターン game.judge() # 勝敗の判定 game.pay_chip() # チップの精算 game.check_chip() # プレイヤーの残額を確認 game.ask_next_game() # ゲームを続けるか尋ねる game.check_deck() # 残りカード枚数の確認 print("BlackJackを終了します") print(str(game.game_count) + "回ゲームをしました") return game.player.chip, game.game_count実行結果
Hit(h) or Stand(s) or Double down(d) or Surrender(r):の後に,
キーボードから文字を入力してPlayerの選択を決めます.$100 賭けました 残りは $900 Playerのターン Player : [♠A, ♦9] = [10, 20], soft card : True Dealer : ♣6, ? = 6 Hit(h) or Stand(s) or Double down(d) or Surrender(r): s Dealerのターン Player : [♠A, ♦9] = 20 Dealer : [♣6, ♥K] = 16 Dealerのターン Player : [♠A, ♦9] = 20 Dealer : [♣6, ♥K, ♥3] = 19 Playerの勝ち Playerの所持チップは $1100 続けますか? y/n: y 残りカード枚数は 307 $100 賭けました 残りは $1000 Playerのターン Player : [♠2, ♥K] = [12], soft card : False Dealer : ♥3, ? = 3 Hit(h) or Stand(s) or Double down(d) or Surrender(r): h Playerのターン Player : [♠2, ♥K, ♥2] = [14], soft card : False Dealer : ♥3, ? = 3 Hit(h) or Stand(s) or Double down(d) or Surrender(r): h Playerのターン Player : [♠2, ♥K, ♥2, ♠Q] = [24], soft card : False Dealer : ♥3, ? = 3 Player BUST Playerの負け Playerの所持チップは $1000 続けますか? y/n: y 残りカード枚数は 301 $100 賭けました 残りは $900 Playerのターン Player : [♥7, ♥5] = [12], soft card : False Dealer : ♠8, ? = 8 Hit(h) or Stand(s) or Double down(d) or Surrender(r): d Playerのターン Player : [♥7, ♥5, ♠8] = [20], soft card : False Dealer : ♠8, ? = 8 Double down が選択されました.掛け金を倍にしました 残りは $800 Dealerのターン Player : [♥7, ♥5, ♠8] = 20 Dealer : [♠8, ♥2] = 10 Dealerのターン Player : [♥7, ♥5, ♠8] = 20 Dealer : [♠8, ♥2, ♣7] = 17 Playerの勝ち Playerの所持チップは $1200 続けますか? y/n: n 残りカード枚数は 295 BlackJackを終了します 3回ゲームをしましたコード
記録用に置いておきます.
以下コード(クリックで展開)
blackjack.pyimport random import copy # 定数 NUM_DECK = 6 # デッキ数 NUM_PLAYER = 1 # プレイヤー数 INITIAL_CHIP = 1000 # 初期チップ MINIMUM_BET = 100 class Card: ''' カードを生成 数字:A,2~10,J,Q,K スート:スペード,ハート,ダイヤ,クラブ ''' SUITS = '♠♥♦♣' RANKS = range(1, 14) # 通常のRank SYMBOLS = "A", "2", "3", "4", "5", "6", "7", "8", "9", "10", "J", "Q", "K" POINTS = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 10, 10, 10] # BlackJack用のポイント def __init__(self, suit, rank): self.suit = suit self.rank = rank self.index = suit + self.SYMBOLS[rank - self.RANKS[0]] self.point = self.POINTS[rank - self.RANKS[0]] def __repr__(self): return self.index class Deck: ''' カードがシャッフルされたデッキ(山札を生成) ''' def __init__(self): self.cards = [Card(suit, rank) \ for suit in Card.SUITS \ for rank in Card.RANKS] if NUM_DECK > 1: temp_cards = copy.deepcopy(self.cards) for i in range(NUM_DECK - 1): self.cards.extend(temp_cards) random.shuffle(self.cards) def draw(self, n=1): ''' デッキから指定した枚数分だけ引く関数 ''' cards = self.cards[:n] del self.cards[:n] # 引いたカードを山札から削除 return cards def shuffle(self): ''' デッキをシャッフルする ''' random.shuffle(self.cards) return def count_cards(self): """ デッキの残り枚数を返す """ count = len(self.cards) return count class Hand: """ 手札クラス """ def __init__(self): self.hand = [] self.is_soft_hand = False def add_card(self, card): self.hand.append(card) def check_soft_hand(self): """ ソフトハンド(Aを含むハンド)かチェックする """ hand_list = [] for i in range(len(self.hand)): hand_list.append(self.hand[i].point) hand_list.sort() # 手札を昇順にソート if hand_list[0] == 1 and sum(hand_list[1:]) < 11: # ソフトハンドなら self.is_soft_hand = True else: self.is_soft_hand = False def sum_point(self): """ ポイントの合計値を返す """ self.check_soft_hand() hand_list = [] for i in range(len(self.hand)): hand_list.append(self.hand[i].point) hand_list.sort() # 手札を昇順にソート s1 = 0 # Aを1とカウントする場合の初期値 for i in range(len(self.hand)): s1 += self.hand[i].point if self.is_soft_hand == True: # ソフトハンドなら s2 = 11 # 1枚目のAを11としてカウント for i in range(len(hand_list)-1): s2 += hand_list[i+1] s = [s1, s2] else: s = [s1] return s def calc_final_point(self): """ BUSTしていない最終的なポイントを返す """ temp_point = self.sum_point() if max(temp_point) > 22: p = temp_point[0] # ポイントの大きい方がBUSTなら小さい方 else: p = max(temp_point) return p def is_bust(self): """ BUSTかどうか判定する """ if min(self.sum_point()) > 21: # ポイントの小さい方が21を超えていたら return True else: return False def deal(self, card): """ Dealされたカードを手札に加える """ for i in range(len(card)): self.add_card(card[i]) def hit(self, card): # 1枚ずつHitする if len(card) == 1: self.add_card(card[0]) else: print("カードの枚数が正しくありません") class Player: def __init__(self): self.hand = Hand() self.chip = Chip() self.done = False # Playerのターン終了を示すフラグ self.hit_flag = False # Player が Hit を選択済みかどうか示すフラグ self.is_human = True # True:人がプレイ,False:自動プレイ def init_player(self): self.hand = Hand() self.done = False self.hit_flag = False def deal(self, card): self.hand.deal(card) def hit(self, card): # カードを1枚手札に加える self.hand.hit(card) self.hit_flag = True def stand(self): # ターン終了 self.done = True def double_down(self, card): # betを2倍にして一度だけHitしてターン終了 self.chip.balance -= self.chip.bet self.chip.bet = self.chip.bet * 2 self.hand.hit(card) self.done = True # double down後は一度しかhitできないルールとする def surrender(self): # Betを半分にして(betの半分を手持ちに戻して)ターン終了 # self.chip.balance += int(self.chip.bet / 2) self.chip.bet = int(self.chip.bet / 2) self.chip.balance += self.chip.bet self.done = True def insurance(self): # 未実装 pass def split(self): # 未実装 pass class Dealer: def __init__(self): self.hand = Hand() def init_dealer(self): self.hand = Hand() def deal(self, card): self.hand.deal(card) def hit(self, card): self.hand.hit(card) class Chip: def __init__(self): self.balance = INITIAL_CHIP self.bet = 0 def bet_chip(self, bet): # Chipを掛けたら手持ちから減らす self.balance -= bet self.bet = bet def pay_chip_win(self): # 勝った時,BETの2倍を得る self.balance += self.bet * 2 def pay_chip_lose(self): # 負けた時,BETを全額失う self.balance = self.balance def pay_chip_push(self): # 引き分けのとき,BETした分だけ戻る self.balance += self.bet class AI: def select_random1(self): r = random.randint(0, 1) if r > 0.5: selection = 'h' # hit else: selection = 's' # stand return selection def select_random2(self, hand): if hand <= 11: selection = 'h' else: r = random.randint(0, 1) if r > 0.5: selection = 'h' # hit else: selection = 's' # stand return selection def select_random3(self, hand, n): if hand < 11: selection = 'h' # hit elif hand == 11 and n == 2: selection = 'd' # double down elif hand == 16 and n == 2: selection = 'r' # surrender elif hand > 17: selection = 's' # stand else: r = random.randint(0, 1) if r > 0.5: selection = 'h' # hit else: selection = 's' # stand return selection class Game: def __init__(self): self.game_mode = 0 # 0:開始待ち,1:ゲーム中, 2:ゲーム終了 self.deck = Deck() self.player = Player() self.dealer = Dealer() self.judgment = 0 self.game_count = 0 self.start() self.message_on = True #self.player.is_human # True:コンソールにメッセージ表示する,False:コンソールにメッセージ表示しない def start(self): self.deck.shuffle() self.game_mode = 1 self.player = Player() self.dealer = Dealer() self.game_count = 0 def reset_game(self): self.player.init_player() self.dealer.init_dealer() self.game_count += 1 def bet(self, bet): self.player.chip.bet_chip(bet=bet) if self.message_on: print("$" + str(self.player.chip.bet) + " 賭けました") print("残りは $" + str(self.player.chip.balance)) # カードを配る def deal(self, n=2): ''' カードを配る ''' card = self.deck.draw(n) self.player.deal(card) # print(self.player.hand.hand) card = self.deck.draw(n) self.dealer.deal(card) # print(self.dealer.hand.hand) self.judgment = 0 # 勝敗の判定 self.player.done = False self.show_card() # Playerのターン def player_turn(self): ''' プレーヤーのターン ''' if self.player.hand.calc_final_point() == 21: # 合計が21だったらすぐにDealerのターンへ self.player.done = True while not self.player.done and not self.player.hand.is_bust(): if self.player.is_human is True: action = input("Hit(h) or Stand(s) or Double down(d) or Surrender(r): ") elif self.player.is_human is True and self.player.hit_flag: action = input("Hit(h) or Stand(s): ") # Hitの後はhit/standのみ else: action = AI().select_random3(hand=self.player.hand.calc_final_point(), n=len(self.player.hand.hand)) self.player_step(action=action) def player_step(self, action): if action == 'h': # Hit card = self.deck.draw(1) self.player.hit(card) self.show_card() if self.player.hand.calc_final_point() == 21: # 合計点が21になったらこれ以上Hitはできない self.player.done = True if self.player.hand.is_bust(): self.player.done = True self.judgment = -1 # PlayerがBUSTしたら即負け if self.message_on: print("Player BUST") elif action == 's': # Stand self.player.stand() elif action == 'd' and self.player.hit_flag is False: # Double down. Hit選択していない場合に可 card = self.deck.draw(1) if self.player.chip.balance >= self.player.chip.bet: # 残額が賭けた額以上にあればDouble Down可 self.player.double_down(card) self.show_card() if self.message_on: print("Double down が選択されました.掛け金を倍にしました") print("残りは $" + str(self.player.chip.balance)) if self.player.hand.is_bust(): self.player.done = True self.judgment = -1 # PlayerがBUSTしたら即負け if self.message_on: print("Player BUST") else: # 残額が賭けた額未満ならばHitとする print("チップが足りないためHitします") self.player.hit(card) self.show_card() if self.player.hand.calc_final_point() == 21: # 合計点が21になったらこれ以上Hitはできない self.player.done = True if self.player.hand.is_bust(): self.player.done = True self.judgment = -1 # PlayerがBUSTしたら即負け if self.message_on: print("Player BUST") elif action == 'r' and self.player.hit_flag is False: # Surrender. Hit選択していない場合に可 self.player.surrender() self.judgment = -1 # Surrenderを選択したので負け if self.message_on: print("Surrender が選択されました") else: if self.message_on: print("正しい選択肢を選んでください") def show_card(self): ''' プレーヤーのカードを表示 ''' if self.message_on: print("Playerのターン") print("Player : " + str(self.player.hand.hand) + " = " + str(self.player.hand.sum_point()) + ", soft card : " + str(self.player.hand.is_soft_hand)) print("Dealer : " + str(self.dealer.hand.hand[0].index) + ", ? = " + str(self.dealer.hand.hand[0].point)) else: pass def dealer_turn(self): ''' ディーラーのターン ''' if self.judgment == -1: return self.open_dealer() while self.dealer.hand.calc_final_point() < 17 and self.judgment == 0: card = self.deck.draw(1) self.dealer.hit(card) self.open_dealer() if self.dealer.hand.calc_final_point() > 21: self.judgment = 1 if self.message_on: print("Dealer BUST") def open_dealer(self): ''' hole cardをオープンする ''' if self.message_on: print("Dealerのターン") print("Player : " + str(self.player.hand.hand) + " = " + str(self.player.hand.calc_final_point())) print("Dealer : " + str(self.dealer.hand.hand) + " = " + str(self.dealer.hand.calc_final_point())) else: pass def judge(self): ''' 勝敗の判定 ''' if self.judgment == 0 and self.player.hand.calc_final_point() > \ self.dealer.hand.calc_final_point(): self.judgment = 1 elif self.judgment == 0 and self.player.hand.calc_final_point() < \ self.dealer.hand.calc_final_point(): self.judgment = -1 elif self.judgment == 0 and self.player.hand.calc_final_point() == \ self.dealer.hand.calc_final_point(): self.judgment = 0 if self.message_on: self.show_judgement() def pay_chip(self): previous_chip = self.player.chip.balance if self.judgment == 1: # Player win self.player.chip.pay_chip_win() elif self.judgment == -1: # Player lose self.player.chip.pay_chip_lose() elif self.judgment == 0: # Push self.player.chip.pay_chip_push() if self.message_on: print("Playerの所持チップは $" + str(self.player.chip.balance)) reward = self.player.chip.balance - previous_chip # このゲームで得た報酬 return reward def check_chip(self): if self.player.chip.balance < MINIMUM_BET: self.game_mode = 2 if self.message_on: print("チップがMinimum Betを下回ったのでゲームを終了します") def show_judgement(self): ''' 勝敗の表示 ''' if self.message_on: print("") if self.judgment == 1: print("Playerの勝ち") elif self.judgment == -1: print("Playerの負け") elif self.judgment == 0: print("引き分け") print("") else: pass def ask_next_game(self): ''' ゲームを続けるか尋ねる ''' if self.player.is_human == True: while self.game_mode == 1: player_input = input("続けますか? y/n: ") if player_input == 'y': break elif player_input == 'n': self.game_mode = 2 break else: print('y/nを入力してください') else: pass # 自動プレイなら継続する print('残りカード枚数は ' + str(self.deck.count_cards())) print("") def check_deck(self): ''' カードの残り枚数をチェックし,少なければシャッフルする ''' if self.deck.count_cards() < NUM_PLAYER * 10 + 5: self.deck = Deck() if self.message_on: print("デッキを初期化しました") print('残りカード枚数は ' + str(self.deck.count_cards())) print("") def main(): game = Game() game.start() while game.game_mode == 1: game.reset_game() # いろいろをリセットする game.bet(bet=100) # 賭ける game.deal() # カードを配る game.player_turn() # プレイヤーのターン game.dealer_turn() # ディーラーのターン game.judge() # 勝敗の判定 game.pay_chip() # チップの精算 game.check_chip() # プレイヤーの残額を確認 game.ask_next_game() # ゲームを続けるか尋ねる game.check_deck() # 残りカード枚数の確認 print("BlackJackを終了します") print(str(game.game_count) + "回ゲームをしました") return game.player.chip, game.game_count if __name__ == '__main__': main()終わりに
Pythonでブラックジャックを作ってみました.
ベーシックストラテジーになるべく近づけるため,Double downとSurrenderの実装にも挑戦してみました.
Splitもいつか入れたいです.
学習することを想定してBET機能を入れましたが,所持金がゼロなのにDouble downしてしまうなど,
バグが多々発見され,修正が大変でした.(まだバグがあったらご指摘ください)次は今回作ったブラックジャックを自作の環境として, OpenAI のgymに登録します.
参考にさせていただいたサイト
- 投稿日:2020-03-22T23:00:52+09:00
PythonでABC159を解きたかった
はじめに
今回は問題が簡単だったのでA~Cは解けましたが、Dまで解けるべきでした。
A問題
考えたこと
偶数を作るには、偶数+偶数、奇数+奇数しかないのでNとMのそれぞれで$_nC _r$、$_mC _r$しています。コンビネーションの計算は自分で実装してもいいですが、scipyにあるのでそれを使いました。from scipy.misc import comb n, m = map(int,input().split()) ans = comb(n,2,exact=True) + comb(m,2,exact=True) #exact=Trueで整数値が返される print(ans)B問題
考えたこと
回文の問題が苦手でA解いた後に放置していました。Sが回文であるのなら、s.reverse()==sになることを利用して解きました。強い回文の条件はsをスライスして、上と同じことをしました。ns = list(str(input())) checker = 0 n = len(s) new_s = list(reversed(s)) if s == new_s: checker += 1 split_s = s[0:(n-1)//2] new_s = list(reversed(split_s)) if new_s == split_s: checker += 1 split_s = s[(n+2)//2:n] new_s = list(reversed(split_s)) if new_s == split_s: checker += 1 if checker == 3: print('Yes') else: print('No')C問題
考えたこと
体積が最大になるのは、立方体になるときなので$(L/3)^3$で終わり。精度が怖かったけどなにもしなくても通った。l = int(input()) print((l/3)**3)D問題
問題
1WA、4TLE考えたこと
解けなかった
for文で$A_i$を抜いたAでコンビネーションを計算しようとしたけど、TLEが出て死んだ。from scipy.misc import comb n = int(input()) a = list(map(int,input().split())) a_s = set(a) for i in range(n): l = a[i] a[i] = 'X' ans = 0 for j in a_s: ans += comb(a.count(j),2,exact=True) print(ans) a[i] = lまとめ
勉強不足なのとBを解くことをあきらめてしまったことが敗因。
おやすみなさい。
- 投稿日:2020-03-22T23:00:51+09:00
Python の lambda の使い方
はじめに
lambda と聞くと AWS の lambda を思い付くかと思いますが、
今回はお話しするのは Python の無名関数を意味する lambda についてです。Python の lambda とは
ざっくり一言で表すと、def 文を使用せずに関数を定義できるものです。
def 文では以下のような構成になっているかと思います。
def function(引数): return 式lambda では以下のように記述することができます。
function = lambda 引数: 式使い方
この lambda の使い方について記述します。
def 文
まずは lambda を使用せずに def 文でプログラムを作成したいと思います。
内容としては小文字、大文字のアルファベットが入ったリストを用意して、
capitalize関数を用いて、全て大文字に修正するといったものです。l = ['A', 'b', 'C', 'd', 'e', 'F', 'g'] def change_words(words, func): for word in words: print(func(word)) def sample_func(word): return word.capitalize() change_words(l, sample_func)
change_words関数では
引数には words と function を渡す func を設定しています。
中の処理では words を for ループで回してあげてその値を func() の中に入れています。
funcの定義にしたがって、 word を変更するといった内容になります。
sample_func関数では
word を引数にしていて、中では capitalize() という文字列の先頭を
大文字にするメソッドを使用して返すといった処理になっています。実際に実行してみると全て大文字になって出力されることが確認できます。
A B C D E F Glambda
上記のプログラムを lambda を使用して記述してみます。
l = ['A', 'b', 'C', 'd', 'e', 'F', 'g'] def change_words(words, func): for word in words: print(func(word)) #def sample_func(word): # return word.capitalize() sample_func = lambda word: word.capitalize() change_words(l, sample_func)このように一行で記述することが可能になります。
実行してみると同様の結果が出力されると思います。lambda式には名前を付けない方がいい
今回はわかりやすいように lambda の式に
sample_funcと名前をつけましたが、Python のコーディング規約PEP8では
名前を付けて関数を定義する場合はdefを使うべきと推奨されています。そこで名前を付けずに、直接記述して関数として渡すことが可能です。
l = ['A', 'b', 'C', 'd', 'e', 'F', 'g'] def change_words(words, func): for word in words: print(func(word)) # def sample_func(word): # return word.capitalize() # sample_func = lambda word: word.capitalize() change_words(l, lambda word: word.capitalize())この記述だと関数をいちいち定義せずに使用でき、
キレイなプログラムになると思います。より効率的に
より lambda の効果を実感するために
今度はアルファベットを小文字に修正する関数を追加してみます。def 文
まずは def 文で記述してみます。
l = ['A', 'b', 'C', 'd', 'e', 'F', 'g'] def change_words(words, func): for word in words: print(func(word)) def sample_func(word): return word.capitalize() def sample_func2(word): return word.lower() change_words(l, sample_func) change_words(l, sample_func2)
sample_func2という名前で新たに関数を増やしました。実際に実行してみると小文字のアルファベットも出力されます。
A B C D E F G a b c d e f g
sample_func2関数の内容としては
capitalize()がlower()に変更しただけです。しかし、いちいち関数を定義してから記述しなければならないのは面倒に感じます。
lambda
そこで lambdaを使用して1行で記述した方が楽になります。
l = ['A', 'b', 'C', 'd', 'e', 'F', 'g'] def change_words(words, func): for word in words: print(func(word)) change_words(l, lambda word: word.capitalize()) change_words(l, lambda word: word.lower())こちらを実行しても同じ結果が出力されます。
おわりに
function を引数にするものは lambda を使用して()内で定義すれば
あえて def で関数を定義しなくてもよくなるため
とても効率のよいプログラムを記述することが可能になります。
- 投稿日:2020-03-22T22:42:45+09:00
Splunkでカスタムサーチコマンドを作成する
Splunkのサーチバーで使うコマンドが自作できると聞いたので試してみました。ちなみに、Splunkでは自作したコマンドを「カスタムサーチコマンド」と呼ぶらしい。
作成するカスタムサーチコマンドのイメージ
今回作成するカスタムサーチコマンドは、新規フィールド
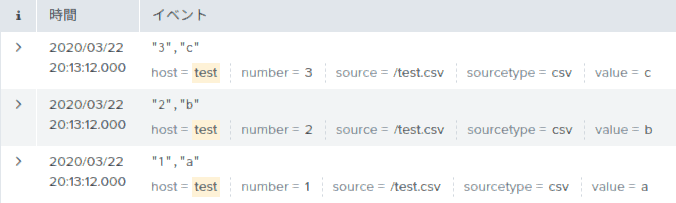
new_numberを作成して、その値に「別フィールドnumberに書かれている値に1を加えた数」を入れる、というものにしました。今回使用する元データを下に示します。
カスタムサーチコマンドを登録する
プログラムを作成する前にまず登録を行います。登録するには、
/opt/splunk/etc/apps/search/local/commands.confに以下のような文を追加します。Splunkの初回インストールの直後は、
/opt/splunk/etc/apps/search/配下にlocalフォルダすらないので、localフォルダを作成しcommands.confも新規作成します。/opt/splunk/etc/apps/search/local/commands.conf[hoge] filename = test.py streaming = true[ ]で囲まれた中の文字がサーチバーで記載するカスタムサーチコマンド名になり、このコマンドが呼び出されると
filename=で書かれているプログラム名を実行します。カスタムサーチコマンドの本体の作成
プログラムの本体は
/opt/splunk/etc/apps/search/bin/のフォルダに作成します。プログラム名はcommands.confに記入したプログラム名test.pyと同じにします。/opt/splunk/etc/apps/search/bin/test.pyimport splunk.Intersplunk data,dummy1,dummy2 = splunk.Intersplunk.getOrganizedResults(input_str=None) for tmp in data: tmp['new_number'] = int(tmp['number']) + 1 splunk.Intersplunk.outputResults(data)作成が完了したら、splunkの設定からSplunkを再起動します。
test.pyは再起動しなくても変更が反映されますが、commands.confは再起動しないと変更が反映されません。プログラムの実行
下のSPLを実行すると、
host = test | hoge | table number new_number無事、新規フィールド
new_numberが出てきました。
ちなみにカスタムサーチコマンドは、前のSPLの結果を50件くらいに小分けして受け取っているようです。つまり、プログラムを起動し最初の50件を処理し終了したら、またプログラムを起動し次の50件を処理し終了する・・・を繰り返しているみたいです。だから、出力結果がビロビロ〜ンと伸びていくんですね。
おわりに
ちょこっとだけ調べたのですが、関数
splunk.Intersplunk.getOrganizedResultsで受け取るデータはpython標準のリスト型で、そのリスト型の中身はsplunk.util.OrderedDictで、標準の辞書型ではありませんでした。もう少し詳しく調べましたら、また投稿したいと思います。
動作環境
Ubuntu 18.04.4 LTS
Splunk 8.0.2.1

- 投稿日:2020-03-22T22:42:07+09:00
「〇〇で歌ってみた」動画のパワポ素材をpythonで生成する
概要
「〇〇で歌ってみた」動画の素材として用いることを想定し、本来の歌詞、替え歌歌詞、対応する画像を決まった場所に配置した画像をPowerPointのスライドとして生成するpythonコードを書きました。
背景
特定ジャンルの名詞だけで本来の歌詞を再現するように歌った替え歌を、通称「〇〇で歌ってみた」シリーズとよびます。
「〇〇で歌ってみた」動画では、本来の歌詞、替え歌歌詞、対応する画像を決まった場所に配置した下記のような画像を、紙芝居形式で流す事が多いです。
替え歌歌詞に登場する名詞数が多いときは対応する動画素材を手動で作るのが大変なので、プログラムで自動化したいと思いました。
またプログラムで生成したものを人が微調整できるようしておけば更に便利だと思ったので、PowerPointのスライドとして、作ることにしました。
このために、python-pptxというpythonからpptxファイルを生成できるライブラリを使いました。環境
macOS Catalina バージョン10.15.3
python3.8.0またはpython3.7.0用意するもの
画像ファイル
パワーポイントに挿入する画像を用意します。
今回はこちらの方法で入手した国旗画像を使います。名詞と画像ファイル名の対応表
名詞IDと対応する画像ファイル名をカンマ区切りで下記のように記入したcsvファイルを用意します。名詞IDは後述の歌詞定義ファイル中で使用します。
img_file_names.csvアイスランド,Flag_of_Iceland.png アイルランド,Flag_of_Ireland.png アゼルバイジャン,Flag_of_Azerbaijan.png アフガニスタン,Flag_of_Afghanistan.png アブハジア,Flag_of_the_Republic_of_Abkhazia.png アメリカ合衆国,Flag_of_the_United_States.png アラブ首長国連邦,Flag_of_the_United_Arab_Emirates.png アルジェリア,Flag_of_Algeria.png ...歌詞定義ファイル
本来の歌詞、替え歌歌詞、表示する画像の名詞IDをカンマ区切りで1行に1つずつ記入した下記のようなcsvを用意します。
名詞IDの部分はファイル名をいちいち書くのが手間だと感じたので、名詞IDをファイル名に置き換える対応表を別途用意する形式にしました。
画像ファイル名を直接書くのでも構わない場合は、対応表なしでも構いません。lyric.csv風の中のスバル,カザフスタン ツバル,カザフスタン 風の中のスバル,カザフスタン ツバル,ツバル 砂の中の銀河,スワジランド ギニア,スワジランド 砂の中の銀河,スワジランド ギニア,ギニア みんなどこへ行った,インドネシア インド,インドネシア みんなどこへ行った,インドネシア インド,インド 見守られることもなく,マリ モナコ レソト モナコ,マリ共和国 見守られることもなく,マリ モナコ レソト モナコ,モナコ 見守られることもなく,マリ モナコ レソト モナコ,レソト 見守られることもなく,マリ モナコ レソト モナコ,モナコ ...ファイル構成
画像ファイルを格納するフォルダ名をpictures、名詞と画像ファイル名の対応表をimg_file_names.csv、歌詞定義ファイルをlyric.csvとします。
またパワポを生成するpythonスクリプトをgenerate_pptx.pyとします。
これらのファイルを下記のように配置してください。. ├── generate_pptx.py ├── pitcures │ ├── Flag_of_Afghanistan.png │ ├── Flag_of_Albania.png │ └── ... ├── img_file_names.csv ├── lyric.csvコード
前述のファイル構成において、「〇〇で歌ってみた」動画の素材となるパワーポイントファイルを出力するpythonスクリプトについて説明します。コード全体は末尾に載せておきます。本コードを基本として編集することで、文字や画像の追加、配置の変更などもできます。必要に応じてpython-pptxの公式ドキュメントも参照してください。
ライブラリのインストール
python-pptxとPillowを使いますので、必要に応じて下記コマンド等によりインストールしてください。
pip install python-pptx pip install Pillowimportと各種定数の設定
ライブラリのimportと各種定数の設定をします。
スライドサイズは単位がEnglish Metric Unit (EMU; 1 cm = 360,000 emu) であることに注意してください。
(参考:python-pptxでスライドのサイズを変えたい)from pptx import Presentation from pptx.util import Inches, Pt from pptx.enum.text import PP_ALIGN from PIL import Image from pptx.dml.color import RGBColor #スライドサイズ #4:3 (default) 9144000x6858000 #16:9 12193200x6858000 SLIDE_WIDTH = 12193200 SLIDE_HEIGHT = 6858000 BACKGROUD_RGB = RGBColor(0,0,0) FONT_RGB = RGBColor(255,255,255) OUTPUT_FILE_PATH = "test.pptx" #替え歌歌詞テキストボックスの左上座標の高さ (左右方向は中央揃えするので不要) IMG_FILE_PATH = "img_file_names.csv"#1行につきidと画像パスがひとつずつ書かれたcsvファイル IMG_DIR = "./picture/" LYRIC_FILE_PATH = "lyric.csv"#1行につき本来の歌詞、替え歌歌詞、画像ファイルIDが一つずつ書かれたcsvファイル PARODY_LYRIC_HEIGHT = Inches(5.5) PARODY_LYRIC_FONTSIZE = Pt(36) ORIGINAL_LYRIC_HEIGHT = Inches(6.5) ORIGINAL_LYRIC_FONTSIZE = Pt(28) IMG_DISPLAY_HEIGHT = Inches(3) #スライドに表示するときの画像の高さ。とりあえず3インチとしておく。 IMG_CENTER_X, IMG_CENTER_Y = SLIDE_WIDTH/2, SLIDE_HEIGHT/2 #画像の中心座標```設定ファイルの情報を取得
対応表の情報をname2path(dict型)、歌詞定義ファイルの情報をlyrics(list型)という変数に代入します。
name2path = {} with open(IMG_FILE_PATH,"r") as f: text = [v.split(',') for v in f.read().split("\n")] for v in text: if len(v) == 2: name2path[v[0]]=IMG_DIR+v[1] lyrics=[] with open(LYRIC_FILE_PATH,"r") as f: lyrics = [v.split(',') for v in f.read().split("\n") if len(v.split(','))==3]プレゼンテーションオブジェクトの生成とサイズ指定
スライドサイズはPresentation.slide_width、Presentation.slide_heightに値を代入することで変更できます。
#スライドオブジェクトの定義 prs = Presentation() #スライドサイズの指定 prs.slide_width = SLIDE_WIDTH prs.slide_height = SLIDE_HEIGHTfor文でlyricsの各要素に対応するスライドを追加する
ここからfor文でlyricsの各要素に対応するスライドを追加していく処理について説明します。まずlyricの0、1、2番めの要素がそれぞれ本来の歌詞(original_text)、替え歌歌詞(parody_text)、画像ID(img_id)に対応しているので、取得します。
画像IDが対応表に存在しない場合は、continueします。存在する場合は、ファイルパス(img_file)を取得します。for index,lyric in enumerate(lyrics): original_text = lyric[0] parody_text = lyric[1] img_id = lyric[2] if img_id not in name2path: print("img_id",img_id,"does not exist") print("line",index,":",lyric,"is ignored") continue img_file = name2path[img_id]白紙スライドを追加する
白紙のスライドをPresentationオブジェクトにadd_slideします。
#白紙スライドの追加 blank_slide_layout = prs.slide_layouts[6] slide = prs.slides.add_slide(blank_slide_layout)スライドの背景を黒くする
#背景を黒くする shapes = slide.shapes left, top, width, height = 0, 0, SLIDE_WIDTH, SLIDE_HEIGHT shape = shapes.add_textbox(left,top,width,height) fill = shape.fill fill.solid() fill.fore_color.rgb = BACKGROUD_RGBスライドと同じサイズのtextBoxを追加し、黒く塗りつぶします。
画像の挿入
画像をIMG_CENTER_X, IMG_CENTER_Yを中心とする位置に挿入します。
本来、python-pptxによるadd_pictureでは左上の座標位置しか指定できませんが、「〇〇で歌ってみた」動画では絵が切り替わる前後で画像中心が揃ってたほうが見栄えがいいので、画像サイズを別途取得した上で、センタリングで挿入します。
詳しいやり方はpython-pptxで画像をセンタリングするにまとめたので参考にしてください。#画像サイズを取得してアスペクト比を得る im = Image.open(img_file) im_width, im_height = im.size aspect_ratio = im_width/im_height #表示された画像のサイズを計算 img_display_height = IMG_DISPLAY_HEIGHT img_display_width = aspect_ratio*img_display_height #センタリングする場合の画像の左上座標を計算 left = IMG_CENTER_X - img_display_width / 2 top = IMG_CENTER_Y - img_display_height / 2 #画像をスライドに追加 slide.shapes.add_picture(img_file, left, top, height = IMG_DISPLAY_HEIGHT)替え歌歌詞の挿入
替え歌歌詞を追加します。
テキストボックスの幅をスライド幅と同じに指定した上で、PP_ALIGN.CENTERで左右方向のセンタリングをすることで、歌詞が真ん中に表示されるようにします。
文字色、文字サイズはそれぞれfont.size、font.color.rgbに値を代入して指定します。#テキストボックスを追加 left, top, width, height = 0, PARODY_LYRIC_HEIGHT, SLIDE_WIDTH, Inches(1) txBox = slide.shapes.add_textbox(left, top, width, height) tf = txBox.text_frame tf.text = parody_text paragraph = tf.paragraphs[0] font = paragraph.font font.size = PARODY_LYRIC_FONTSIZE font.color.rgb = FONT_RGB paragraph.alignment = PP_ALIGN.CENTER #左右方向のセンタリング本来の歌詞の挿入
本来の歌詞を挿入します。やり方は替え歌歌詞の挿入と同じです。
#テキストボックスを追加 left, top, width, height = 0, ORIGINAL_LYRIC_HEIGHT, SLIDE_WIDTH, Inches(1) txBox = slide.shapes.add_textbox(left, top, width, height) tf = txBox.text_frame tf.text = original_text paragraph = tf.paragraphs[0] font = paragraph.font font.size = ORIGINAL_LYRIC_FONTSIZE font.color.rgb = FONT_RGB paragraph.alignment = PP_ALIGN.CENTER出力
for文を終えたら、Presentation.saveでpptxファイルを出力します。
prs.save(OUTPUT_FILE_PATH)コード全体
コード全体は下記です。
generate_pptx.pyfrom pptx import Presentation from pptx.util import Inches, Pt from pptx.enum.text import PP_ALIGN from PIL import Image from pptx.dml.color import RGBColor #スライドサイズ #4:3 (default) 9144000x6858000 #16:9 12193200x6858000 SLIDE_WIDTH = 12193200 SLIDE_HEIGHT = 6858000 BACKGROUD_RGB = RGBColor(0,0,0) FONT_RGB = RGBColor(255,255,255) OUTPUT_FILE_PATH = "test.pptx" #替え歌歌詞テキストボックスの左上座標の高さ (左右方向は中央揃えするので不要) IMG_FILE_PATH = "img_file_names.csv"#1行につきidと画像パスがひとつずつ書かれたcsvファイル IMG_DIR = "./picture/" LYRIC_FILE_PATH = "lyric.csv"#1行につき本来の歌詞、替え歌歌詞、画像ファイルIDが一つずつ書かれたcsvファイル PARODY_LYRIC_HEIGHT = Inches(5.5) PARODY_LYRIC_FONTSIZE = Pt(36) ORIGINAL_LYRIC_HEIGHT = Inches(6.5) ORIGINAL_LYRIC_FONTSIZE = Pt(28) IMG_DISPLAY_HEIGHT = Inches(3) #スライドに表示するときの画像の高さ。とりあえず3インチとしておく。 IMG_CENTER_X, IMG_CENTER_Y = SLIDE_WIDTH/2, SLIDE_HEIGHT/2 #画像の中心座標 name2path = {} with open(IMG_FILE_PATH,"r") as f: text = [v.split(',') for v in f.read().split("\n")] for v in text: if len(v) == 2: name2path[v[0]]=IMG_DIR+v[1] lyrics=[] with open(LYRIC_FILE_PATH,"r") as f: lyrics = [v.split(',') for v in f.read().split("\n") if len(v.split(','))==3] #スライドオブジェクトの定義 prs = Presentation() #スライドサイズの指定 prs.slide_width = SLIDE_WIDTH prs.slide_height = SLIDE_HEIGHT for index,lyric in enumerate(lyrics): original_text = lyric[0] parody_text = lyric[1] img_id = lyric[2] if img_id not in name2path: print("img_id",img_id,"does not exist") print("line",index,":",lyric,"is ignored") continue img_file = name2path[img_id] #白紙スライドの追加 blank_slide_layout = prs.slide_layouts[6] slide = prs.slides.add_slide(blank_slide_layout) #背景を黒くする shapes = slide.shapes left, top, width, height = 0, 0, SLIDE_WIDTH, SLIDE_HEIGHT shape = shapes.add_textbox(left,top,width,height) fill = shape.fill fill.solid() fill.fore_color.rgb = BACKGROUD_RGB #画像サイズを取得してアスペクト比を得る im = Image.open(img_file) im_width, im_height = im.size aspect_ratio = im_width/im_height #表示された画像のサイズを計算 img_display_height = IMG_DISPLAY_HEIGHT img_display_width = aspect_ratio*img_display_height #センタリングする場合の画像の左上座標を計算 left = IMG_CENTER_X - img_display_width / 2 top = IMG_CENTER_Y - img_display_height / 2 #画像をスライドに追加 slide.shapes.add_picture(img_file, left, top, height = IMG_DISPLAY_HEIGHT) #テキストボックスを追加 left, top, width, height = 0, PARODY_LYRIC_HEIGHT, SLIDE_WIDTH, Inches(1) txBox = slide.shapes.add_textbox(left, top, width, height) tf = txBox.text_frame tf.text = parody_text paragraph = tf.paragraphs[0] font = paragraph.font font.size = PARODY_LYRIC_FONTSIZE font.color.rgb = FONT_RGB paragraph.alignment = PP_ALIGN.CENTER #テキストボックスを追加 left, top, width, height = 0, ORIGINAL_LYRIC_HEIGHT, SLIDE_WIDTH, Inches(1) txBox = slide.shapes.add_textbox(left, top, width, height) tf = txBox.text_frame tf.text = original_text paragraph = tf.paragraphs[0] font = paragraph.font font.size = ORIGINAL_LYRIC_FONTSIZE font.color.rgb = FONT_RGB paragraph.alignment = PP_ALIGN.CENTER prs.save(OUTPUT_FILE_PATH)おわりに
pptxファイルが出力されたら、微調整をして、書き出し機能でpngなどに書き出すことで、動画編集ソフトの素材として使えると思います。
上記のコードでできあがるのはシンプルなスライドですが、歌詞や画像の挿入位置、文字色や背景色を変えるなどして、好みのデザインにしてみてください。


- 投稿日:2020-03-22T22:36:16+09:00
Docker Compose でWebアプリケーションを開発する環境(NGINX + uWSGI + PostgreSQL)を構築する。
はじめに
Docker Composeを使って、NGINX、uWSGI、PostgreSQLが動作するDocker コンテナを構築し、
Django(Python)で開発したWebアプリケーションをブラウザで動作確認するまでの手順を記載します。
※ 本投稿は、Mac OSを前提としています。
macOS Catalina 10.15.3で作業しています。
No. 項目 説明 1 Docker Compose 複数のDocker コンテナを一元管理するツールです。
本投稿では、NGINX、uWSGI、PostgreSQLが動作するDocker コンテナを
構築します。2 NGINX Webサーバです。
本投稿では、ここに静的ファイルを配置します。3 uWSGI アプリケーションサーバです。
Pythonで作成したWebアプリケーションを配置します。4 PostgreSQL DBサーバです。
Webアプリケーションで利用するデータを保持します。5 Django PythonのWebフレームワークです。 前提条件
Docker for Macをダウンロードする際、Dockerの公式サイトにログインする必要があります。
Dockerの公式サイトにログインするためのユーザを作成して下さい。1. Docker for Mac
最初にDocker for Macのインストールを行います。
Docker Composeは、Docker for Macに含まれています。1-1. ダウンロード
以下のサイトからダウンロードします。
https://docs.docker.com/docker-for-mac/install/(1) 「Download from Docker Hub」ボタンを押下します。
(2) 「Download Docker Desktop for Mac」ボタンを押下します。
Docker.dmg がダウンロードされます。
1-2. インストール
(1) Docker.dmgの実行
ダウンロードした Docker.dmg を実行して下さい。(2) Applicationsに移動
DockerをApplicationsに移動させます。
(3) Dockerの実行
アプリケーションからDockerを実行して下さい。1-3. 確認
(1) ターミナルを開き、"docker --version"を実行します。
インストールしたDockerのバージョンを確認します。$ docker --version Docker version 19.03.5, build 633a0ea(2) 次に、"docker-compose --version"を実行します。
Docker Composeのバージョンを確認します。$ docker-compose --version docker-compose version 1.25.4, build 8d51620a2. Docker コンテナの構築
NGINX、uWSGI、PostgreSQLが動作するDocker コンテナを構築します。
2-1. 作業ディレクトリの作成
任意の作業ディレクトリを作成して下さい。
本投稿では、"django"を作成します。$ mkdir django2-2. ファイル/ディレクトリの準備
Docker Composeの実行に必要なファイル、Webアプリケーションのソースコードを
配置するディレクトリなどを準備します。(1) 作業ディレクトリへの移動
$ cd django(2) requirements.txt の作成
$ touch requirements.txt(3) Dockerfile の作成
$ touch Dockerfile(4) docker-compose.yml の作成
$ touch docker-compose.yml(5) nginx ディレクトリの作成
$ mkdir nginx(6) nginx/conf ディレクトリの作成
$ mkdir nginx/conf(7) nginx/conf/mainproject_nginx.conf の作成
$ touch nginx/conf/mainproject_nginx.conf(8) nginx/uwsgi_params の作成
$ touch nginx/uwsgi_params(9) src ディレクトリの作成
$ mkdir src(10) src/static ディレクトリの作成
$ mkdir src/static(11) dbdata ディレクトリの作成
$ mkdir dbdata[ファイル/ディレクトリの説明]
No. 名称 説明 1 requirements.txt 利用するPythonのパッケージ(ライブラリ)を指定するファイル 2 Dockerfile Docker コンテナの構成情報を記述するためのファイル 3 docker-compose.yml アプリケーションを動かすための処理を記述するファイル 4 nginx NGINXのルートディレクトリ 5 nginx/conf NGINXの設定ファイルを配置するディレクトリ 6 nginx/conf/mainproject_nginx.conf NGINXの設定を記述するためのファイル
※ ファイル名は任意です、拡張子は".conf"にして下さい。7 nginx/uwsgi_params NGINXとuWSGIを連携させるためのファイル 8 src Webアプリケーションを配置するディレクトリ 9 src/static css、JavaScript、画像などの静的ファイルを配置するディレクトリ 10 dbdata PostgreSQLのデータファイルを保持するディレクトリ [ここまでのファイル構成]
$ tree . . ├── Dockerfile ├── dbdata ├── docker-compose.yml ├── nginx │ ├── conf │ │ └── mainproject_nginx.conf │ └── uwsgi_params ├── requirements.txt └── src └── static 5 directories, 5 files2-3. requirements.txtの設定
requirements.txtを開き、以下の内容を記述して保存します。
requirements.txtは、次に説明するDockerfileの中で利用しています。
("RUN pip install -r requirements.txt"の箇所)Django django-bootstrap4 uwsgi psycopg2[説明]
① Django
PythonのWebフレームワークのDjangoをインストールします。
② django-bootstrap4
DjangoでBootstrap4を利用するためのパッケージをインストールします。
※ Bootstrap4を利用しない場合、インストールする必要はありません。
最後にDjangoで作成したページにBootstrap4を適用する方法を参考に紹介します。
③ uwsgi
アプリケーションサーバをインストールします。
④ psycopg2
PythonからPostgreSQLに接続するためのドライバをインストールします。2-4. Dockerfileの設定
Dockerfileを開き、以下の内容を記述して保存します。
Dockerfileは、次に説明するdocker-compose.ymlの中で利用しています。
("build: ."の箇所)FROM python:3.7 ENV PYTHONUNBUFFERED 1 RUN mkdir /code WORKDIR /code COPY requirements.txt /code/ RUN pip install --upgrade pip RUN pip install -r requirements.txt COPY . /code/[説明]
① FROM python:3.7
Docker のベースイメージに"python3.7"を指定
"Docker Hub"のイメージから作成します。
② ENV PYTHONUNBUFFERED 1
Python の標準出力、標準エラー出力をバッファに溜め込まない設定となります。
バッファが有効になっていると、標準出力の途中経過が表示されず、
全てのタスクが終わった後に纒めて表示されます。
③ RUN mkdir /code
コンテナ上にcodeディレクトリを作成します。
④ WORKDIR /code
コンテナの作業ディレクトリにcodeディレクトリを指定します。
⑤ COPY requirements.txt /code/
ローカルマシンのrequirements.txtをコンテナのcodeディレクトリに追加します。
⑥ RUN pip install --upgrade pip
コンテナ上のpipを最新のバージョンにします。
⑦ RUN pip install -r requirements.txt
requirements.txtに記載しているPythonのパッケージ(ライブラリ)を
コンテナ上インストールします。
⑧ ローカルマシンのカレントディレクトリの内容をコンテナのcodeディレクトリに追加します。
2-5. docker-compose.ymlの設定
docker-compose.ymlを開き、以下の内容を記述して保存します。
version: '3.7' volumes: pgdata: driver_opts: type: none device: $PWD/dbdata o: bind services: nginx: image: nginx container_name: container.nginx ports: - "8000:8000" volumes: - ./nginx/conf:/etc/nginx/conf.d - ./nginx/uwsgi_params:/etc/nginx/uwsgi_params - ./src/static:/static - ./nginx/log:/var/log/nginx depends_on: - web web: build: . container_name: container.uwsgi command: uwsgi --ini /code/mainproject/django.ini volumes: - ./src:/code expose: - "8001" depends_on: - db db: image: postgres restart: always container_name: container.postgres ports: - "5432:5432" environment: POSTGRES_DB: "postgresdb" POSTGRES_USER: "admin" POSTGRES_PASSWORD: "test" POSTGRES_INITDB_ARGS: "--encoding=UTF-8 --locale=C" volumes: - pgdata:/var/lib/postgresql/data hostname: postgres[説明]
① version: '3.7'
docker-composeで使用するバージョンとなります。
バージョンによって、docker-compose.ymlの書き方が異なります。
※ Docker 本体のバージョンとの関連は「Compose file version 3 reference」を参照して下さい。
② volumes:
トップレベルのvolumesは、名前付きvolumeとなります。
ここでは、"pgdata"という名前付きvolumeを指定しています。
"device: $PWD/dbdata"は、ローカルマシンの作業ディレクトリ配下のdbdataディレクトリを表します。
③ services:
構築するコンテナを記述します。
ここでは、"nginx"、"web"、"db"を記述しています。
この名前は任意で指定が可能です。
例えば、"db"は、"database"などでも問題ありません。
③-1 nginx:
③-1-1 image: nginx
NGINXが動作するコンテナは、"Docker Hub"のイメージから作成します。
③-1-2 container_name: container.nginx
"container.nginx"という任意のコンテナ名を付けます。
③-1-3 ports:
NGINXのポート番号に8000ポートを指定します。
③-1-4 volumes:
ローカルマシンの作業ディレクトリ配下の各ファイル/ディレクトリと
NGINXのコンテナのファイル/ディレクトリのマウントを設定します。
a) ./nginx/conf:/etc/nginx/conf.d
これにより、"nginx/conf/mainproject_nginx.conf"が"/etc/nginx/conf.d"にマウントされます。
"/etc/nginx/conf.d"に配置した拡張子".conf"のファイルは、
親の設定ファイルにあたる"/etc/nginx/nginx.conf"によって読み込まれます。
* "/etc/nginx/nginx.conf"は、nginxのコンテナにデフォルトで存在します。
b) ./nginx/uwsgi_params:/etc/nginx/uwsgi_params
"/etc/nginx/uwsgi_params"は、次に説明する"nginx/conf/mainproject_nginx.conf"の中で利用しています。
("include /etc/nginx/uwsgi_params;"の箇所)
c) ./src/static:/static
静的ファイルを配置するディレクトリをマウントします。
cssなどをNGINXから配信するための設定となります。
d) ./nginx/log:/var/log/nginx
ログファイルを配置するディレクトリをマウントします。
これにより、ローカル上でログを確認できるようになります。
③-1-5 depends_on:
"web"、つまりuWSGIのコンテナが起動された後に、NGINXのコンテナを起動するという指定です。
③-2 web:
③-2-1 build: .
uWSGIが動作するコンテナは、Dockerfileに記述したコンテナの構成情報で作成します。
"build: ."は、ビルドに使用するDockerfileのパスを表します。
つまり、このコンテナは、Dockerfileに記載したコンテナの構成情報で作成します。
③-2-2 container_name: container.uwsgi
"container.uwsgi"という任意のコンテナ名を付けます。
③-2-3 command: uwsgi --ini /code/mainproject/django.ini
コンテナが起動した後に、uWSGIを設定ファイル"/code/mainproject/django.ini"の
内容に従って、起動させるということを表します。
③-2-4 volumes:
ローカルマシンの作業ディレクトリ配下の各ディレクトリと
uWSGIのコンテナのディレクトリのマウントを設定します。
③-2-5 expose:
uWSGIのポート番号に8001ポートを指定します。
③-2-6 depends_on:
"db"、つまりPostgreSQLのコンテナが起動された後に、uWSGIのコンテナを起動するという指定です。
③-3 db:
③-3-1 image: postgres
PostgreSQLが動作するコンテナは、"Docker Hub"のイメージから作成します。
③-3-2 restart: always
ホストOSを起動したタイミングでコンテナを自動起動するという指定です。
③-3-3 container_name: container.postgres
"container.postgres"という任意のコンテナ名を付けます。
③-3-4 ports:
PostgreSQLのポート番号に5432ポートを指定します。
③-3-5 environment:
a) POSTGRES_DB: "postgresdb"
コンテナ起動時に作成するデフォルトのDBの名称を指定します。
指定しない場合、POSTGRES_USERの値が使われます。
b) POSTGRES_USER: "admin"
スーパユーザの名称を指定します。
指定しない場合、"postgres"が使われます。
c) POSTGRES_PASSWORD: "test"
スーパユーザのパスワードを指定します。
指定しない場合、POSTGRES_USERの値が使われます。
d) POSTGRES_INITDB_ARGS: "--encoding=UTF-8 --locale=C"
DBを作成するコマンド(postgres initdb)を実行する際に渡す引数を指定します。
エンコーディングに"UTF-8"、ロケールに"C"を指定しています。
※ environmentの詳細は、「Supported tags and respective Dockerfile links 」を参照して下さい。
③-3-6 volumes:
名前付きvolumeの"pgdata"と
PostgreSQLコンテナの"/var/lib/postgresql/data"のマウントを設定します。
この設定により、DBのデータが永続化されます。
(コンテナを削除してもデータがローカルマシン上に残ります。)
③-3-7 hostname:
"postgres"という任意のホスト名を付けます。2-6. nginx/conf/mainproject_nginx.confの設定
nginx/conf/mainproject_nginx.confを開き、以下の内容を記述して保存します。
# the upstream component nginx needs to connect to upstream django { ip_hash; server web:8001; } # configuration of the server server { # the port your site will be served on listen 8000; # the domain name it will serve for server_name 127.0.0.1; # substitute your machine's IP address or FQDN charset utf-8; # max upload size client_max_body_size 75M; # adjust to taste location /static { alias /static; } # Finally, send all non-media requests to the Django server. location / { uwsgi_pass django; include /etc/nginx/uwsgi_params; # the uwsgi_params file you installed } }[説明]
① upstream django
細かい設定方法は割愛しますが、"server web:8001;"については、
docker-compose.ymlに記載したweb(ポート番号は、8001)を指しています。
つまり、uWSGIを指しています。
② server
こちらも細かい設定方法は割愛しますが、"location / {"については、
NGINXのルートにアクセスがあった場合、①で説明したuWSGIに処理を渡すという設定になります。
また、③-1-4で説明した/etc/nginx/uwsgi_paramsの設定ファイルに基づいて連携しています。
"location /static {"については、
静的ファイルについては、NGINXのstaticディレクトリに配置したものを使用するという設定です。2-7. nginx/uwsgi_paramsの設定
nginx/uwsgi_paramsを開き、以下の内容を記述して保存します。
uwsgi_param QUERY_STRING $query_string; uwsgi_param REQUEST_METHOD $request_method; uwsgi_param CONTENT_TYPE $content_type; uwsgi_param CONTENT_LENGTH $content_length; uwsgi_param REQUEST_URI $request_uri; uwsgi_param PATH_INFO $document_uri; uwsgi_param DOCUMENT_ROOT $document_root; uwsgi_param SERVER_PROTOCOL $server_protocol; uwsgi_param REQUEST_SCHEME $scheme; uwsgi_param HTTPS $https if_not_empty; uwsgi_param REMOTE_ADDR $remote_addr; uwsgi_param REMOTE_PORT $remote_port; uwsgi_param SERVER_PORT $server_port; uwsgi_param SERVER_NAME $server_name;2-9. Djangoプロジェクトの作成
以下のコマンドを実行し、Djangoプロジェクトを作成します。
プロジェクト名は任意です。(ここでは、"mainproject"という名前にしました。)$ docker-compose run --rm web django-admin.py startproject mainproject .下記のようなWARNINGが出力されますが、「イメージが存在していなかったので、ビルドした」という
警告なので、問題ありません。WARNING: Image for service web was built because it did not already exist. To rebuild this image you must use `docker-compose build` or `docker-compose up --build`.[実行結果の確認①(ファイル構成)]
ファイル構成は以下の構成となります。
※ dbdata配下には、マウントしたPostgreSQLのデータ(/var/lib/postgresql/data)が
大量に作成されるので、省略しています。$ tree . . ├── Dockerfile ├── dbdata │ ├── PG_VERSION │ ├── base │ │ └── ・・・ 省略 │ │ └── ・・・ 省略 │ └── ・・・ 省略 ├── docker-compose.yml ├── nginx │ ├── conf │ │ └── mainproject_nginx.conf │ └── uwsgi_params ├── requirements.txt └── src ├── mainproject │ ├── __init__.py │ ├── asgi.py │ ├── settings.py │ ├── urls.py │ └── wsgi.py ├── manage.py └── static[実行結果の確認②(Docker コンテナの状態)]
"docker ps -a"コマンドを実行し、Docker コンテナの状態を確認して下さい。
以下のようにPostgreSQLのコンテナが起動しています。
※ uWSGIのDocker コンテナについては、次に説明するuWSGIのiniファイルを作成していない為、
起動していません。(docker-compose.ymlの"command: uwsgi --ini /code/mainproject/django.ini"の箇所)
※ NGINXのDocker コンテナについては、uWSGIのDocker コンテナの起動が
前提条件となっていますので、こちらもまだ起動していません。$ docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 9d68d40adee0 postgres "docker-entrypoint.s…" 25 hours ago Up 25 hours 0.0.0.0:5432->5432/tcp container.postgres2-10. uWSGIのiniファイルを作成します。
src/mainproject/django.iniを新規に作成し、以下の内容を記述します。
[uwsgi] socket = :8001 module = mainproject.wsgi wsgi-file = /code/mainproject/wsgi.py logto = /code/mainproject/uwsgi.log py-autoreload = 1[説明]
① socket = :8001
uWSGIを起動するポート番号を指定します。
② module = mainproject.wsgi
loadするwsgiモジュールを指定します。
③ wsgi-file = /code/mainproject/wsgi.py
loadするwsgiファイルを指定します。
④ logto = /code/mainproject/uwsgi.log
ログを出力する場所を指定します。
アプリケーションのエラーが発生した時などに確認するログとなります。
⑤ py-autoreload = 1
オートリロード機能の間隔を指定します。
この設定では、1秒ごとにリクエストがあればリロードするという設定になります。
※ 詳細は、「uWSGI Options 」を参照して下さい。2-11. ALLOWED_HOST、DB及び静的ファイルの設定を行う。
src/mainproject/settings.pyを開き、以下の修正を行い保存します。
(1) ALLOWED_HOSTの設定
下記の修正を行います。
公開するドメイン名を設定します。
※ Django 1.5以降のsettings.pyに、ALLOWED_HOSTSという項目が追加されました。
これを設定しない場合、デバックモードがtrueの時にエラーとなります。(修正前)
ALLOWED_HOSTS = [](修正後)
ALLOWED_HOSTS = ["*"](2) DBへの接続設定
下記の修正を行います。
docker-compose.ymlのdbのenvironmentに合わせます。
(修正前)DATABASES = { 'default': { 'ENGINE': 'django.db.backends.sqlite3', 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'), } }(修正後)
DATABASES = { 'default': { 'ENGINE': 'django.db.backends.postgresql', 'NAME': 'postgresdb', 'USER': 'admin', 'PASSWORD': 'test', 'HOST': 'db', 'PORT': 5432, } }(3) 静的ファイルの設定
下記の修正を行います。(修正前)
# Static files (CSS, JavaScript, Images) # https://docs.djangoproject.com/en/3.0/howto/static-files/ STATIC_URL = '/static/'(修正後)
# Static files (CSS, JavaScript, Images) # https://docs.djangoproject.com/en/3.0/howto/static-files/ # All applications can use Static files of this directory STATICFILES_DIRS = ( os.path.join(BASE_DIR, "mainproject/static/"), ) # Collectstatic command put STATICFILES_DIRS and each application's Static files together into this directory STATIC_ROOT = os.path.join(BASE_DIR, 'static/') # Django template files read this directory to use Static files(example {% static 'style.css' %}) STATIC_URL = '/static/'[説明]
① STATICFILES_DIRS
パスの指定先は任意です。
ここでは、「2-9. Djangoプロジェクトの作成」で説明した
Djangoプロジェクト(mainproject)配下のstaticディレクトリを指定しています。
このディレクトリには、各アプリケーションで共通の静的ファイルを配置します。
後術しますが、本投稿では、faviconを配置します。
② STATIC_ROOT
後術するCollectstaticコマンドを実行した際に、
STATICFILES_DIRSで指定した共通の静的ファイルと
各アプリケーション配下のstaticディレクトリの静的ファイルを
収集し、配置するディレクトリを指定します。
BASE_DIRは、作業ディレクトリ(src)のことなので、STATIC_ROOTは、src/staticとなります。
「2-5. docker-compose.ymlの設定」で説明したNGINXの静的ファイルのマウント元と一致します。
("- ./src/static:/static"の./src/staticの箇所)
③ STATIC_URL
後術するDjangoのテンプレートファイルが静的ファイルを読み込むディレクトリ先となります。
「2-5. docker-compose.ymlの設定」で説明したNGINXの静的ファイルのマウント先と一致します。
("- ./src/static:/static"の/staticの箇所)※ 「Django Static Files 」を合わせて見ると理解しやすいと思います。
2-12. Docker コンテナを起動します。
以下のコマンドを実行します。
$ docker-compose up -d[実行結果の確認①(Docker コンテナの状態)]
"docker ps -a"コマンドを実行し、Docker コンテナの状態を確認して下さい。
以下のようにNGINX、uWSGI、PostgreSQLのコンテナが起動しています。$ docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES f41f7a5b634d nginx "nginx -g 'daemon of…" 10 minutes ago Up 10 minutes 80/tcp, 0.0.0.0:8000->8000/tcp container.nginx c12eee7ac189 django_web "uwsgi --ini /code/m…" 10 minutes ago Up 10 minutes 8001/tcp container.uwsgi 9d68d40adee0 postgres "docker-entrypoint.s…" 27 hours ago Up 27 hours 0.0.0.0:5432->5432/tcp container.postgres2-13. 動作確認
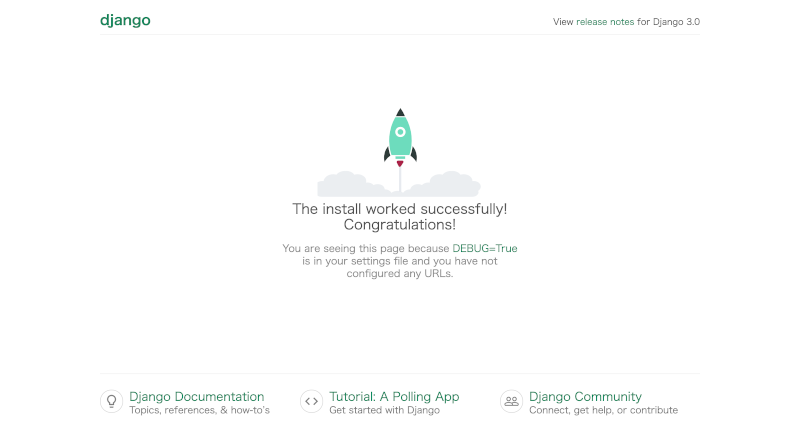
ブラウザを開き、"http://0.0.0.0:8000"にアクセスし、
Djangoのデフォルトのページが表示されることを確認します。
ここまでの手順で、NGINX、uWSGI、PostgreSQLが動作するDocker コンテナの構築が完了しました。
3. Django Webアプリケーションの作成
Djangoで"Hello world."を出力するWebアプリケーションを作成します。
3-1. Djangoアプリケーションの作成
以下のコマンドを実行し、Djangoアプリケーションを作成します。
アプリケーション名は任意です。(ここでは、"app"という名前にしました。)$ docker-compose run --rm web python manage.py startapp app[実行結果の確認①(ファイル構成)]
srcディレクトリ配下にappディレクトリが作成されます。$ tree src src ├── app │ ├── __init__.py │ ├── admin.py │ ├── apps.py │ ├── migrations │ │ └── __init__.py │ ├── models.py │ ├── tests.py │ └── views.py ├── mainproject │ ├── __init__.py │ ├── __pycache__ │ │ ├── __init__.cpython-37.pyc │ │ ├── settings.cpython-37.pyc │ │ ├── urls.cpython-37.pyc │ │ └── wsgi.cpython-37.pyc │ ├── asgi.py │ ├── django.ini │ ├── settings.py │ ├── urls.py │ ├── uwsgi.log │ └── wsgi.py ├── manage.py └── static 5 directories, 19 files3-2. ビューの作成
"Hello world."を出力するファイルです。
src/app/views.pyを開き、以下の修正を行い保存します。(修正前)
from django.shortcuts import render # Create your views here.(修正後)
from django.http import HttpResponse def index(request): return HttpResponse("Hello world.")3-3. URLの対応付け
作成したビューをブラウザからアクセスするために、 URLの対応付けを行う必要があります。
(1) appディレクトリの配下にurls.pyを新規作成します。
urls.pyを作成することで、URLの対応付けに必要なURLconfが作成されます。
以下の内容を記述します。from django.urls import path from . import views urlpatterns = [ path('', views.index, name='index'), ](2) mainprojectディレクトリの配下のurls.pyを更新します。
ルート(プロジェクト)のURLconfにapp.urlsモジュールの記述を反映させます。
具体的には、
① django.urls.includeのimportを追加
② urlpatternsのリストにinclude('app.urls')を挿入
を行います。
※ 以下の修正前後のファイルは、文頭のコメント部分は省略しています。
※ include()関数は他のURLconfへの参照が可能になります。
修正後の"path('app/', include('app.urls'))"の箇所は、
app/にアクセスがあった場合、app配下のURLconfを参照するということを表します。(修正前)
from django.contrib import admin from django.urls import path urlpatterns = [ path('admin/', admin.site.urls), ](修正後)
from django.contrib import admin from django.urls import include, path urlpatterns = [ path('app/', include('app.urls')), path('admin/', admin.site.urls), ]3-4. 動作確認
ブラウザを開き、"http://0.0.0.0:8000/app/"にアクセスし、
画面に"Hello world."が表示されることを確認します。4. Databaseの設定
DjangoでDatabase(PostgreSQL)を利用するための設定を行います。
※ 私がCafe好きなので、Cafeの情報を例に説明します。4-1. モデルの作成
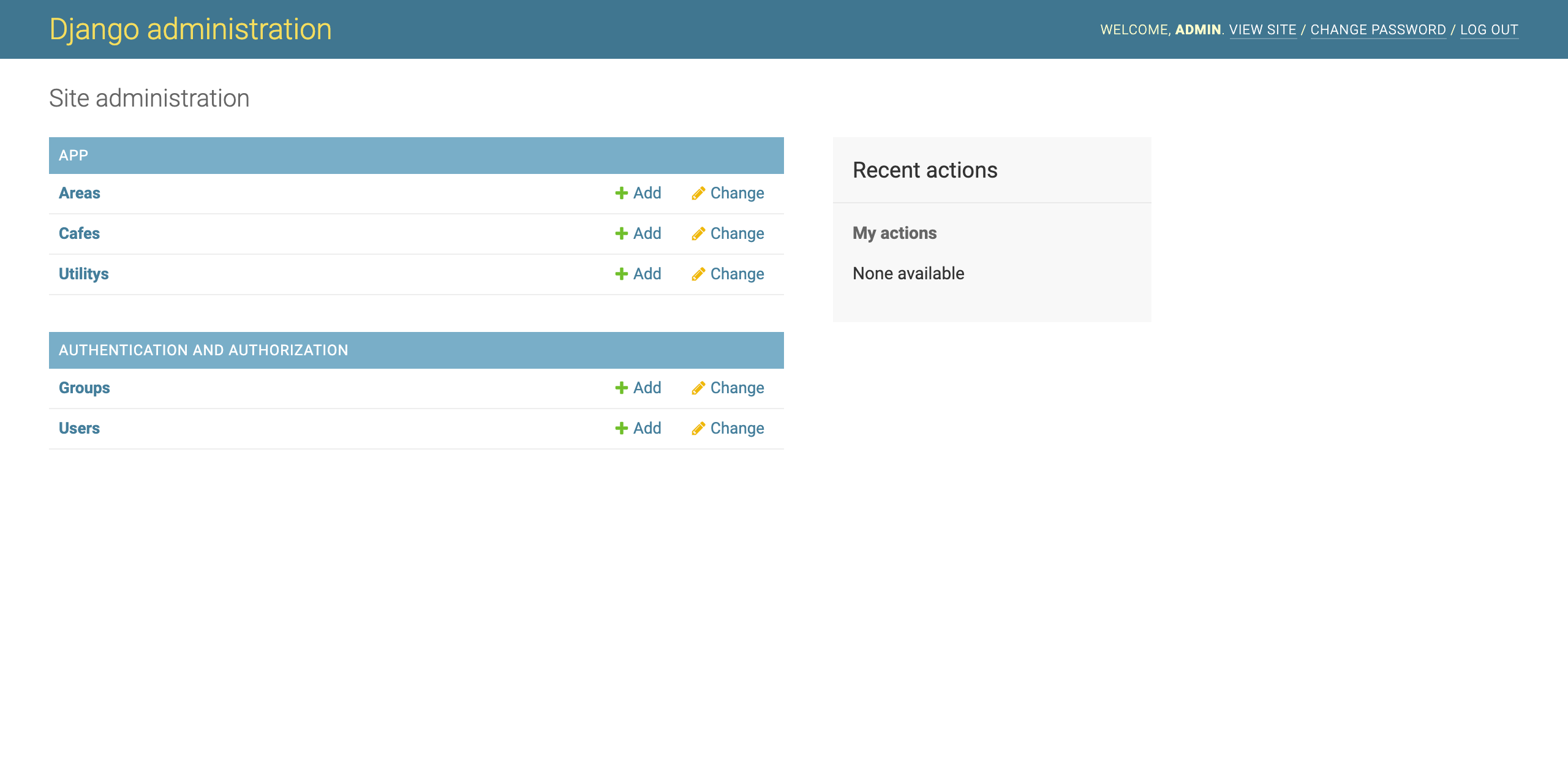
Webアプリケーションで利用するモデルを最初に定義します。
ここでは、Area、Cafe、Utilityの3つのモデルを作成します。
src/app/models.pyを開き、以下の内容を記述して保存します。(修正前)
from django.db import models # Create your models here.(修正後)
from django.db import models class Area(models.Model): name = models.CharField(max_length=100) create_date = models.DateTimeField('date published') def __str__(self): return self.name; class Cafe(models.Model): area = models.ForeignKey(Area, on_delete=models.CASCADE) name = models.CharField(max_length=100) memo = models.CharField(max_length=400) website = models.URLField() image_path = models.CharField(max_length=400) create_date = models.DateTimeField('date published') def __str__(self): return self.name; class Utility(models.Model): key = models.CharField(max_length=100) value = models.CharField(max_length=100) create_date = models.DateTimeField('date published') def __str__(self): return self.key;[説明]
① Area
Cafeのエリア情報(場所)を管理するマスタです。
② Cafe
Cafeの情報を保持するテーブルです。
※ ForeignKeyを使用してリレーションシップを定義しています。
各Cafeが1つのAreaに関連付けられています。
③ Utility
汎用的なデータを保持するマスタです。
今回は、表示方法の切り替えに利用します。
データの変更で、制御することで、毎回プログラムの変更を行う必要がなくなります。4-2. モデルを有効にする。
(1) モデル有効化の準備
src/mainproject/settings.pyを開き、INSTALLED_APPSに「'app.apps.AppConfig',」を追加します。
後術するmigrateコマンドを実行すると、INSTALLED_APPSに記述されている
アプリケーションに対し、各アプリケーションに必要なテーブルを作成します。
※ app.apps.AppConfigは、src/app/apps.pyのAppConfigクラスを表します。(修正前)
INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', ](修正後)
INSTALLED_APPS = [ 'app.apps.AppConfig', 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', ](2) マイグレーションファイルの作成
以下のコマンドを実行し、モデルの変更内容が記述されたマイグレーションファイルを作成します。$ docker-compose run --rm web python manage.py makemigrations app下記のようなメッセージが出力され、src/app/migrations/0001_initial.pyが作成されます。
※ src/app/migrations/0001_initial.pyは、手動で調整することも可能です。$ docker-compose run --rm web python manage.py makemigrations app Starting container.postgres ... done Migrations for 'app': app/migrations/0001_initial.py - Create model Area - Create model Utility - Create model Cafe(3) テーブルの作成
マイグレーションファイルを元にモデルのテーブルを作成する。
以下のコマンドを実行します。$ docker-compose run --rm web python manage.py migrate下記のようなメッセージが出力され、テーブルが作成されます。
$ docker-compose run --rm web python manage.py migrate Starting container.postgres ... done Operations to perform: Apply all migrations: admin, app, auth, contenttypes, sessions Running migrations: Applying contenttypes.0001_initial... OK Applying auth.0001_initial... OK Applying admin.0001_initial... OK Applying admin.0002_logentry_remove_auto_add... OK Applying admin.0003_logentry_add_action_flag_choices... OK Applying app.0001_initial... OK Applying contenttypes.0002_remove_content_type_name... OK Applying auth.0002_alter_permission_name_max_length... OK Applying auth.0003_alter_user_email_max_length... OK Applying auth.0004_alter_user_username_opts... OK Applying auth.0005_alter_user_last_login_null... OK Applying auth.0006_require_contenttypes_0002... OK Applying auth.0007_alter_validators_add_error_messages... OK Applying auth.0008_alter_user_username_max_length... OK Applying auth.0009_alter_user_last_name_max_length... OK Applying auth.0010_alter_group_name_max_length... OK Applying auth.0011_update_proxy_permissions... OK Applying sessions.0001_initial... OK(4) テーブルの確認
作成したテーブルをDBeaverというSQLクライアントツールを使って確認します。
DBeaverを使ったことがない方は、「DBeaverのインストールとPostgreSQLへの接続」を参考にして下さい。① DBeaverを起動します。
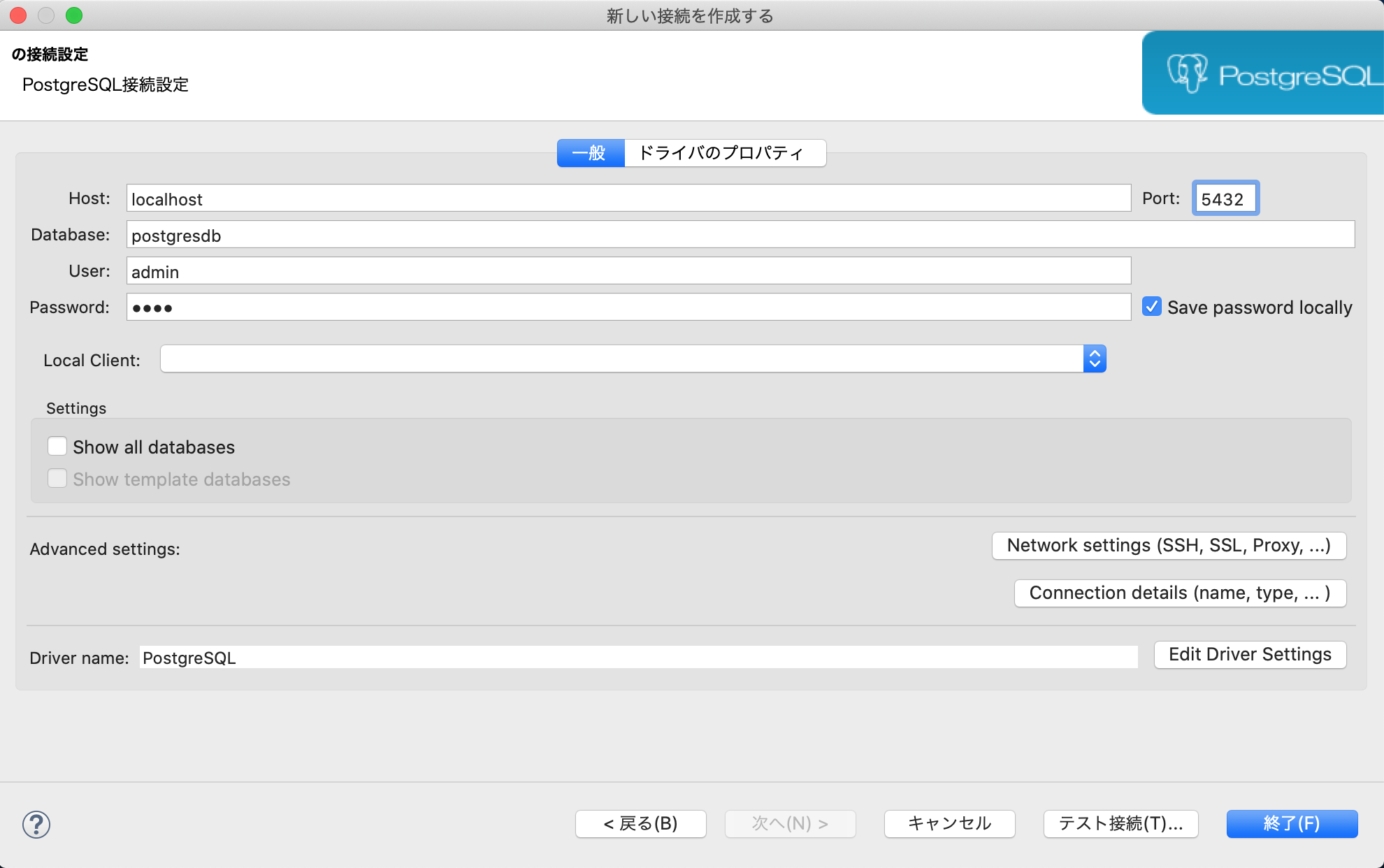
② 新しい接続を作成します。
以下の画面で、PostgreSQLに接続するDatabase、User、Password、Portの入力を行います。
※ 「2-11. ALLOWED_HOSTの設定、DBへの接続設定を行う。」の(2)で設定した内容を入力します。
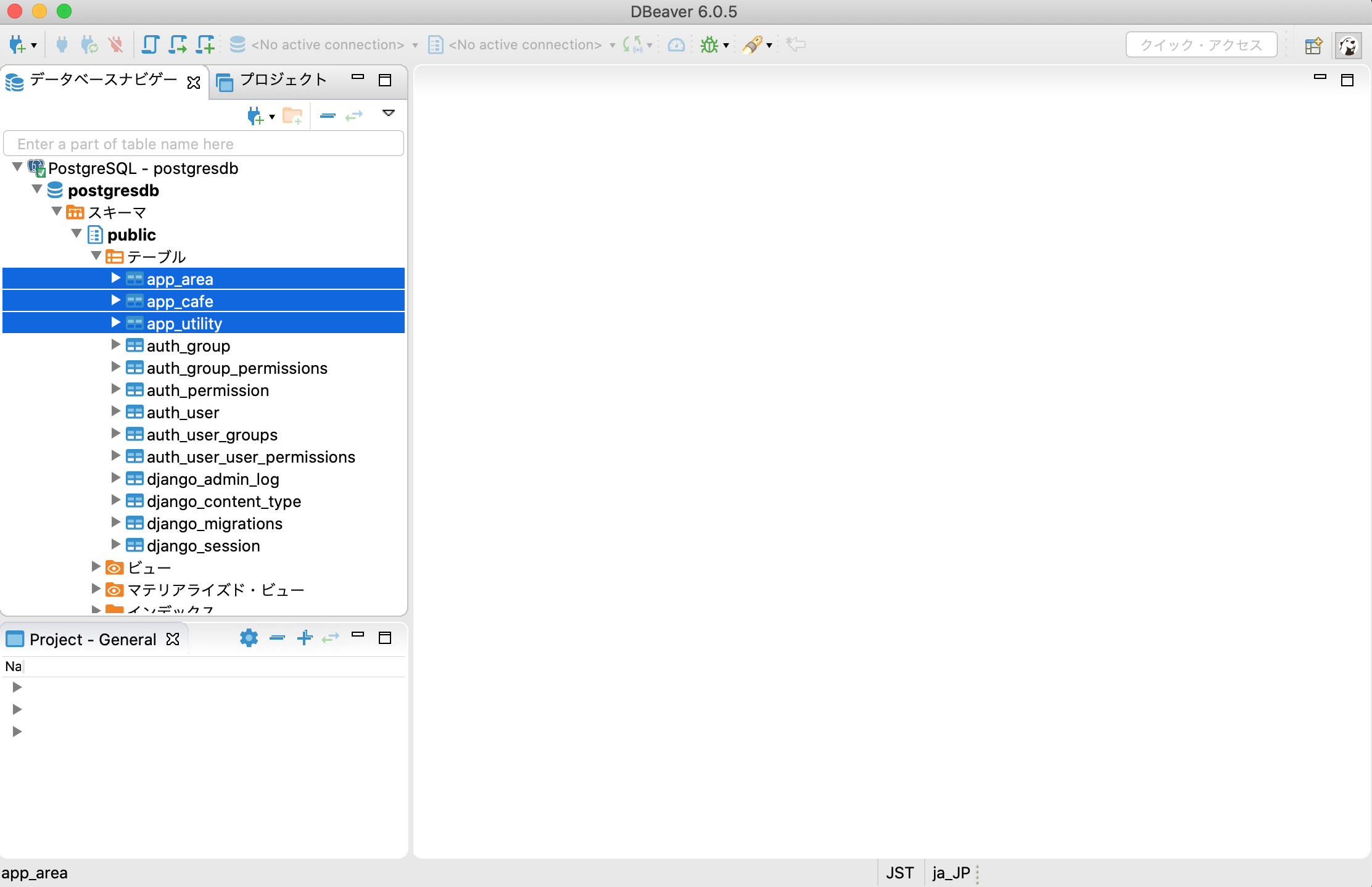
③ テーブルの確認
下記の通り、app_area、app_cafe、app_utilityテーブルが作成されています。
(5) データの登録
下記のようなSQLを実行し、初期データを登録して下さい。insert into app_area (name, create_date) values ('清澄白河', now()); insert into app_area (name, create_date) values ('神保町', now()); insert into app_area (name, create_date) values ('代々木公園', now()); insert into app_cafe (name, memo, website, image_path, create_date, area_id) values ('ブルーボトルコーヒー', 'カフェモカはここが一番美味しい。', 'https://bluebottlecoffee.jp/', 'bluebottlecoffee_IMG.jpg', now(), '1'); insert into app_cafe (name, memo, website, image_path, create_date, area_id) values ('iki ESPRESSO', 'オセアニアンスタイルのカフェ。フードもコーヒーも美味しい。', 'https://www.ikiespresso.com/', 'ikiespresso_IMG.jpg', now(), '1'); insert into app_cafe (name, memo, website, image_path, create_date, area_id) values ('GLITCH COFFEE', 'コーヒーが好きになったきっかけのカフェ。一番好きです。', 'https://glitchcoffee.com/', 'glitchcoffee_IMG.jpg', now(), '2'); insert into app_cafe (name, memo, website, image_path, create_date, area_id) values ('DIXANS', 'とてもオシャレなカフェ。デザートが絶品です。', 'http://www.dixans.jp/', 'dixans_IMG.jpg', now(), '2'); insert into app_cafe (name, memo, website, image_path, create_date, area_id) values ('Fuglen Tokyo', 'コーヒーがとても美味しいです。代々木公園で遊んだ時は必ず寄ります。', 'https://fuglencoffee.jp/', 'fuglencoffee_IMG.jpg', now(), '3'); commit;5. 画面の作成
Databaseに保持した情報を出力するWebアプリケーションを作成します。
簡単な一覧画面と詳細画面を作成します。5-1. 一覧画面の作成
(1) src/appの配下に"templates"ディレクトリを作成し、
"templates"ディレクトリ配下に""list.html"を作成します。$ mkdir -p src/app/templates $ touch src/app/templates/list.html(2) src/app/templates/list.htmlを開き、以下の内容で保存します。
{% load static %} <html lang="ja"> <head> <meta charset="utf-8"> <link rel="stylesheet" type="text/css" href="{% static 'app_css/style.css' %}"> <link rel="shortcut icon" href="{% static 'pj_image/armx8-1ibhc-001.ico' %}" type="image/vnd.microsoft.icon"> </head> <body> <table border="1"> <thead> <tr> <th>カフェ</th> <th>特徴</th> <th>エリア</th> <th>サイト</th> </tr> </thead> <tbody> {% for cafe in cafe_list %} <tr> <td><a href="{% url 'app:detail' cafe.id %}">{{ cafe.name }}</a></td> <td>{{ cafe.memo }}</td> <td>{{ cafe.area.name }}</td> <td><a href="{{ cafe.website }}">{{ cafe.website }}</a></td> </tr> {% endfor %} </tbody> </table> </body> </html>5-2. 詳細画面の作成
(1) src/app/templatesの配下に"detail.html"を作成します。
$ touch src/app/templates/detail.html(2) src/app/templates/detail.htmlを開き、以下の内容で保存します。
{% load static %} <html lang="ja"> <head> <meta charset="utf-8"> <link rel="stylesheet" type="text/css" href="{% static 'app_css/style.css' %}"> <link rel="shortcut icon" href="{% static 'pj_image/armx8-1ibhc-001.ico' %}" type="image/vnd.microsoft.icon"> </head> <body> <h1>{{ cafe.name }}</h1> <h2><img src="{% static 'app_image/' %}{{ cafe.image_path }}" alt="{{ cafe.name }}のイメージ" title="{{ cafe.name }}のイメージ" width="384" height="384"></h2> <h2>特徴:{{ cafe.memo }}</h2> <h2>エリア:{{ cafe.area.name }}</h2> <h2>サイト:<a href="{{ cafe.website }}">{{ cafe.website }}</a></h2> <a href="{% url 'app:list' %}">戻る</a> </body> </html>5-3. ビューの編集
3-2.で作成した"Hello world."を出力するファイルを編集します。
src/app/views.pyを開き、以下の修正を行い保存します。(修正前)
from django.http import HttpResponse def index(request): return HttpResponse("Hello world.")(修正後)
from django.http import HttpResponse, HttpResponseRedirect from django.shortcuts import get_object_or_404, render from django.urls import reverse from django.views import generic from .models import Area, Cafe, Utility class IndexView(generic.ListView): template_name = 'list.html' context_object_name = 'cafe_list' def get_queryset(self): """Return the last five published records.""" return Cafe.objects.order_by('name')[:5] class DetailView(generic.DetailView): model = Cafe template_name = 'detail.html'5-4. URLの対応付け
3-3.で作成したURLを対応付けするファイルを編集します。
src/app/urls.pyを開き、以下の修正を行い保存します。
※ path()を追加し、新しいviewを app.urls モジュールと結びつけます。(修正前)
from django.urls import path from . import views urlpatterns = [ path('', views.index, name='index'), ](修正後)
from django.urls import path from django.contrib.auth.views import LoginView from . import views app_name = 'app' urlpatterns = [ path('', views.IndexView.as_view(), name='list'), path('<int:pk>/', views.DetailView.as_view(), name='detail'), ]5-5. 静的ファイルの設置
(1) appアプリケーションの静的ファイルのディレクトリを作成します。
$ mkdir -p src/app/static/app_css $ mkdir -p src/app/static/app_image $ mkdir -p src/app/static/app_js(2) appアプリケーションのcssを作成します。
src/app/static/app_css/style.cssを新規に作成し、以下の内容を記述します。table { background-color: #ffffff; border-collapse: collapse; /* セルの線を重ねる */ } th { background-color: #000080; color: #ffffff; /* 文字色指定 */ } th, td { border: solid 1px; /* 枠線指定 */ padding: 10px; /* 余白指定 */ }(3) DBに登録したCafeの画像ファイルをsrc/app/static/app_imageに配置します。
※ 画像ファイルは何でも良いので用意して下さい。
無くても、画像ファイルが表示されないだけなのでスキップしても問題ありません。
(4) mainprojectプロジェクトの静的ファイルのディレクトリを作成します。$ mkdir -p src/mainproject/static/pj_css $ mkdir -p src/mainproject/static/pj_image $ mkdir -p src/mainproject/static/pj_js
(5) faviconをsrc/mainproject/static/pj_imageに配置します。
※ faviconは何でも良いので用意して下さい。
無くても、faviconが表示されないだけなのでスキップしても問題ありません。
(6) 静的ファイルの収集を行う。
以下のコマンドを実行します。$ docker-compose run web ./manage.py collectstatic下記のようなメッセージが出力され、
「2-11. ALLOWED_HOST、DB及び静的ファイルの設定を行う。」で説明した通り、
STATICFILES_DIRSで指定した共通の静的ファイルと
各アプリケーション配下のstaticディレクトリの静的ファイルを収集します。
→ src/app/static/app_css/style.cssと
src/app/static/app_imageに配置した画像ファイルと
src/mainproject/static/pj_imageのfaviconが
src/staticにコピーされます。$ docker-compose run web ./manage.py collectstatic Starting container.postgres ... done 137 static files copied to '/code/static'.5-6. 動作確認
ブラウザを開き、"http://0.0.0.0:8000/app/"にアクセスし、
一覧画面と詳細画面が下記のように表示されていることを確認します。
(1) 一覧画面
(2) 詳細画面
NGINX、uWSGI、PostgreSQLが動作するDocker コンテナで、
DjangoのWebアプリケーションを動作確認するまでの手順が完了です。
Webアプリケーションを作る上で、基本的なことは紹介できたと思いますので、
本投稿が役に立てば幸いです。6. 参考情報(Django Admin)
本投稿では、DBeaverを使ってデータの登録を行いましたが、Django Adminという
Djangoに用意されている管理画面を使ってデータを登録することも可能です。6-1. 管理ユーザの作成
以下のコマンドを実行します。
$ docker-compose run --rm web python manage.py createsuperuserコマンドプロンプトで以下のように任意の情報を入力します。
Username:admin
Email address:admin@example.com
Password:admin$ docker-compose run --rm web python manage.py createsuperuser Starting container.postgres ... done Username (leave blank to use 'root'): admin Email address: admin@example.com Password: Password (again): The password is too similar to the username. This password is too short. It must contain at least 8 characters. This password is too common. Bypass password validation and create user anyway? [y/N]: y Superuser created successfully.6-2. モデルをDjango Adminに登録
「4-1. モデルの作成」で作成したモデルをDjango Adminで編集できるようにします。
src/app/admin.pyを開き、以下の修正を行い保存します。
(修正前)
from django.contrib import admin # Register your models here.(修正後)
from django.contrib import admin from .models import Area from .models import Cafe from .models import Utility admin.site.register(Area) admin.site.register(Cafe) admin.site.register(Utility)6-3. 動作確認
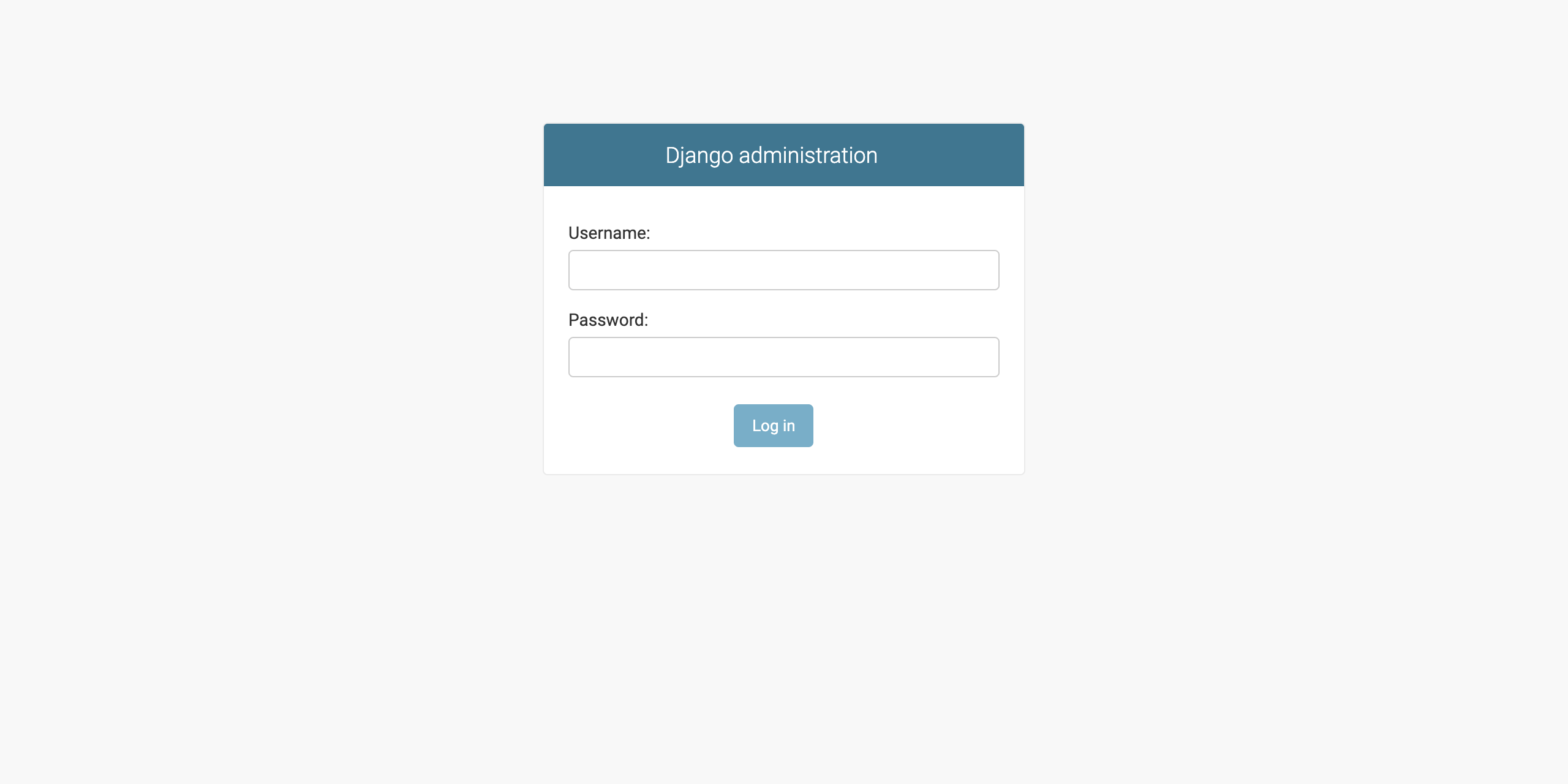
ブラウザを開き、"http://0.0.0.0:8000/admin/"にアクセスします。
Django Adminのログイン画面が開くので、
「6-1. 管理ユーザの作成」で作成した管理ユーザでログインして下さい。
ログイン後、Area、Cafe、Utilityのモデルの参照、追加、更新が出来ることを確認して下さい。(1) ログイン画面
(2) 管理画面
7. 参考情報(Bootstrap4)
Bootstrap4を使用する方法を説明します。
「2-3. requirements.txtの設定」で説明した通り、
DjangoでBootstrap4を利用するためのパッケージをインストールしていますので、
以下の手順を行うことで、Bootstrap4のcss、Javascriptの利用が可能です。7-1. django-bootstrap4の設定
src/mainproject/settings.pyを開き、以下の修正を行い保存します。
(1) INSTALLED_APPSにdjango-bootstrap4を追加します。
(修正前)
INSTALLED_APPS = [ 'app.apps.AppConfig', 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', ](修正後)
INSTALLED_APPS = [ 'app.apps.AppConfig', 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', 'bootstrap4', ](2) TEMPLATESのbuiltinsにbootstrap4.templatetags.bootstrap4を追加します。
※ これを追加することで、各htmlに{% load bootstrap4 %}を記述する必要がなくなります。(修正前)
TEMPLATES = [ { 'BACKEND': 'django.template.backends.django.DjangoTemplates', 'DIRS': [], 'APP_DIRS': True, 'OPTIONS': { 'context_processors': [ 'django.template.context_processors.debug', 'django.template.context_processors.request', 'django.contrib.auth.context_processors.auth', 'django.contrib.messages.context_processors.messages', ], }, }, ](修正後)
TEMPLATES = [ { 'BACKEND': 'django.template.backends.django.DjangoTemplates', 'DIRS': [], 'APP_DIRS': True, 'OPTIONS': { 'context_processors': [ 'django.template.context_processors.debug', 'django.template.context_processors.request', 'django.contrib.auth.context_processors.auth', 'django.contrib.messages.context_processors.messages', ], 'builtins':[ 'bootstrap4.templatetags.bootstrap4', ], }, }, ]7-2. Utilityテーブルに制御フラグを追加(おまけ①)
UtilityテーブルにBootstrap4のcssを利用するかしないかを制御するデータを追加します。
このデータを使って、一覧画面のhtmlでBootstrap4のcssを読み込むか読み込まないか判別します。
* 使用しない場合、value列の値を”1”以外に設定します。insert into app_utility (key, value, create_date) values ('bootstrap_flg', '1', now()); commit;7-3. 一覧画面の修正
(1) src/mainproject/settings.pyを開き、以下の修正を行い保存します。(おまけ②)
get_context_dataを使って、「7-2. Utilityテーブルに制御フラグを追加」で
追加したデータをhtmlで利用できるようにしています。(修正前)
from django.http import HttpResponse, HttpResponseRedirect from django.shortcuts import get_object_or_404, render from django.urls import reverse from django.views import generic from .models import Area, Cafe, Utility class IndexView(generic.ListView): template_name = 'list.html' context_object_name = 'cafe_list' def get_queryset(self): """Return the last five published records.""" return Cafe.objects.order_by('name')[:5] class DetailView(generic.DetailView): model = Cafe template_name = 'detail.html'(修正後)
from django.http import HttpResponse, HttpResponseRedirect from django.shortcuts import get_object_or_404, render from django.urls import reverse from django.views import generic from .models import Area, Cafe, Utility class IndexView(generic.ListView): template_name = 'list.html' context_object_name = 'cafe_list' def get_queryset(self): """Return the last five published records.""" return Cafe.objects.order_by('name')[:5] def get_context_data(self, **kwargs): context = super().get_context_data(**kwargs) context["bootstrap_flg"] = Utility.objects.all().filter(key='bootstrap_flg').first() return context class DetailView(generic.DetailView): model = Cafe template_name = 'detail.html'(2) src/app/templates/list.htmlを開き、以下の修正を行い保存します。
bootstrap_flg.value == "1"の時に、{% bootstrap_css %}を読み込むように記述しています。
今回、おまけ①②をすることで、テーブルのデータによって、
Bootstrap4のcssを読み込むか制御できるように対応しましたが、
単純に使用したい場合は、おまけ①②は飛ばし、{% bootstrap_css %}を
htmlに追加するだけで使用が可能です。
(修正前){% load static %} <html lang="ja"> <head> <meta charset="utf-8"> <link rel="stylesheet" type="text/css" href="{% static 'app_css/style.css' %}"> <link rel="shortcut icon" href="{% static 'pj_image/armx8-1ibhc-001.ico' %}" type="image/vnd.microsoft.icon"> </head> <body> <table border="1"> <thead> <tr> <th>カフェ</th> <th>特徴</th> <th>エリア</th> <th>サイト</th> </tr> </thead> <tbody> {% for cafe in cafe_list %} <tr> <td><a href="{% url 'app:detail' cafe.id %}">{{ cafe.name }}</a></td> <td>{{ cafe.memo }}</td> <td>{{ cafe.area.name }}</td> <td><a href="{{ cafe.website }}">{{ cafe.website }}</a></td> </tr> {% endfor %} </tbody> </table> </body> </html>(修正後)
{% load static %} <html lang="ja"> <head> <meta charset="utf-8"> <link rel="stylesheet" type="text/css" href="{% static 'app_css/style.css' %}"> {% if bootstrap_flg.value == "1" %} {% bootstrap_css %} {% endif %} <link rel="shortcut icon" href="{% static 'pj_image/armx8-1ibhc-001.ico' %}" type="image/vnd.microsoft.icon"> </head> <body> <table border="1"> <thead> <tr> <th>カフェ</th> <th>特徴</th> <th>エリア</th> <th>サイト</th> </tr> </thead> <tbody> {% for cafe in cafe_list %} <tr> <td><a href="{% url 'app:detail' cafe.id %}">{{ cafe.name }}</a></td> <td>{{ cafe.memo }}</td> <td>{{ cafe.area.name }}</td> <td><a href="{{ cafe.website }}">{{ cafe.website }}</a></td> </tr> {% endfor %} </tbody> </table> </body> </html>7-4. 動作確認
ブラウザを開き、"http://0.0.0.0:8000/app/"にアクセスし、
一覧画面にBootstrap4のcssが使用されていることを確認します。
参考元
Compose file version 3 reference
Docker Composeチュートリアル: herokuのPostgresをローカルにさくっとコピーする
Supported tags and respective Dockerfile links
はじめての Django アプリ作成、その 1
SQLのSELECT文を、DjangoのQuerySet APIで書いてみた
Djangoにおけるクラスベース汎用ビューの入門と使い方サンプル



- 投稿日:2020-03-22T22:35:17+09:00
Fortniteの画像を100枚スクレイピングする
Fortniteの画像を、Yahooから100枚スクレイピングしてみた。
・Mac
・python3(1)環境構築、ディレクトリ構成
デスクトップにディレクトリfortniteを作成。
ディレクトリ内にimagesフォルダ(画像保存用)と、scraping.pyを作成。fortnite ├scraping.py └imagesディレクトリ内で仮想環境構築。
python3 -m venv . sorce bin/activate必要なパッケージ、モジュールをインストール
pip install beautifulsoup4 pip install requests pip install lxml(2)scraping.pyを記述
Fortniteの画像スクレイピングは、Yahooの画像検索結果を使う。
https://search.yahoo.co.jp/image/search?p=%E3%83%95%E3%82%A9%E3%83%BC%E3%83%88%E3%83%8A%E3%82%A4%E3%83%88&ei=UTF-8&b=1
1ページあたり10枚画像あり、次ページ以降を合わせると100枚以上はあることが確認できる。
ここからスクレピングして、imagesフォルダに格納する。scraping.pyfrom bs4 import BeautifulSoup import lxml import requests import os import time def main(): #1ページあたり20個の画像、次ページをスクレイピングするための変数 page_key=0 #保存した画像をナンバリングするための変数 num_m = 0 for i in range(6): URL = "https://search.yahoo.co.jp/image/search?p=%E3%83%95%E3%82%A9%E3%83%BC%E3%83%88%E3%83%8A%E3%82%A4%E3%83%88&ei=UTF-8&b={}".format(page_key + 1) res = requests.get(URL) res.encoding = res.apparent_encoding html_doc = res.text soup = BeautifulSoup(html_doc,"lxml") list = [] _list = soup.find_all("div",class_="gridmodule") for i in _list: i2 = i.find_all('img') for i3 in i2: i4 = i3.get('src') list.append(i4) for i in list: i2 = requests.get(i) #絶対パスを指定して保存 with open(os.path.dirname(os.path.abspath(__file__)) + '/images' + '/{}'.format(num_m)+'.jpeg','wb')as f: f.write(i2.content) num_m += 1 #画像が101枚目となったら保存処理を停止(for文停止) if num_m == 101: break #保村処理のfor文が停止した場合、for文を停止する処理 else: continue break #サーバー負荷防止のため1秒間隔を開ける time.sleep(1) page_key+=20 if __name__ == '__main__': main()補足説明
・GoogleChromeの”検証”を使い、画像URLのありそうな場所を探した結果、divタグのclassがgridmoduleの部分にあることを確認。そこからimgタグの部分をスクレイピング。
・get('src')で、imgタグのsrc属性の値を取得する。
・取得したimgタグのsrc属性はurlではあるものの、str型となっているので、requestsでレスポンス情報を格納したレスポンスオブジェクトを取得する。レスポンスオブジェクトには、text、encoding、status_code、contentが含まれる。contentはレスポンスボディをバイナリ形式で取得するために必要。(参考)Requests の使い方 (Python Library)
・ファイルで絶対パスを指定して、wbモードで書き込む(参考)
Python、os操作について
・for文で100枚保存したら内側のfor文と外側のfor文を中止する。Pythonのforループのbreak(中断条件)実行すると、imagesフォルダに画像を保存できたことが確認できる。
- 投稿日:2020-03-22T22:15:04+09:00
Splunkでカスタムサーチコマンドを作成する
Splunkのサーチバーで使うコマンドが自作できると聞いたので試してみました。ちなみに、Splunkでは自作したコマンドを「カスタムサーチコマンド」と呼ぶらしい。
作成するカスタムサーチコマンドのイメージ
今回作成するカスタムサーチコマンドは、新規フィールド
new_numberを作成して、その値に「別フィールドnumberに書かれている値に1を加えた数」を入れる、というものにしました。今回使用する元データを下に示します。
カスタムサーチコマンドを登録する
プログラムを作成する前にまず登録を行います。登録するには、
/opt/splunk/etc/apps/search/local/commands.confに以下のような文を追加します。Splunkの初回インストールの直後は、
/opt/splunk/etc/apps/search/配下にlocalフォルダすらないので、localフォルダを作成しcommands.confも新規作成します。/opt/splunk/etc/apps/search/local/commands.conf[hoge] filename = test.py streaming = true[ ]で囲まれた中の文字がサーチバーで記載するカスタムサーチコマンド名になり、このコマンドが呼び出されると
filename=で書かれているプログラム名を実行します。なお、Streamingの値により動作が多少変わります。
streamingの値 動作 True 前のSPLの結果を50件づつ区切ってプログラムに渡す False 前のSPLの全結果をプログラムを渡す カスタムサーチコマンドの本体の作成
プログラムの本体は
/opt/splunk/etc/apps/search/bin/のフォルダに作成します。プログラム名はcommands.confに記入したプログラム名test.pyと同じにします。/opt/splunk/etc/apps/search/bin/test.pyimport splunk.Intersplunk data,dummy1,dummy2 = splunk.Intersplunk.getOrganizedResults(input_str=None) for tmp in data: tmp['new_number'] = int(tmp['number']) + 1 splunk.Intersplunk.outputResults(data)作成が完了したら、splunkの設定からSplunkを再起動します。
test.pyは再起動しなくても変更が反映されますが、commands.confは再起動しないと変更が反映されません。プログラムの実行
下のSPLを実行すると、
host = test | hoge | table number new_number無事、新規フィールド
new_numberが出てきました。
おわりに
ちょこっとだけ調べたのですが、関数
splunk.Intersplunk.getOrganizedResultsで受け取るデータはpython標準のリスト型で、そのリスト型の中身はsplunk.util.OrderedDictで、標準の辞書型ではありませんでした。もう少し詳しく調べましたら、また投稿したいと思います。
動作環境
Ubuntu 18.04.4 LTS
Splunk 8.0.2.1
- 投稿日:2020-03-22T22:06:04+09:00
Pythonで食品のリコール情報をスクレイピングして、pandasデータフレームを作ってみた
pythonの学習記録をつけてみようと思い、Qittaを始めてみました。
仕事は非IT企業なので、、pythonは本当に趣味・・・というか、興味本位で学習しています。今は、食品衛生に関わる仕事をしているので、pythonを使って何か出来ないかな〜と思い、食品のリコール情報をデータ分析してみよう!と思い立ちました。
その第一段階として、スクレイピングで食品リコール情報のデータフレームを作ってみました。データの元はリコールプラスというサイト。
food_recall_info.pyfrom bs4 import BeautifulSoup import requests import re import csv import time import pandas as pd def recalls(url): res = requests.get(url) soup = BeautifulSoup(res.text, 'html.parser') recall_soup = soup.findAll("tr",{"class":{"return","info","apology"}}) campany_list = [] recall_list = [] action_list = [] recall_date = [] for j in range(len(recall_soup)): #会社名を取得 campany_list.append(recall_soup[j].find("a", href=re.compile("/company/*")).get_text()) #リコール内容 recall_list.append(recall_soup[j].find("a", {"style":"float:left"}).get_text()) #対応方法 keyword = re.compile(r'回収|回収&返金|回収&返金/交換|回収&交換|返金|交換|点検&交換|お知らせ|景品表示法違反|お詫び|返金/交換|送付') action_list.append(re.search(keyword, str(recall_soup[j])).group()) #発生日 recall_date.append(recall_soup[j].find("td", {"class":"day"}).get_text().replace("\n ","20")) return campany_list,recall_list,action_list,recall_date campany_lists = [] recall_lists = [] action_lists = [] recall_dates = [] for i in range(1,20): resl = recalls("https://www.recall-plus.jp/category/1?page={}".format(i)) campany_lists.extend(resl[0]) recall_lists.extend(resl[1]) action_lists.extend(resl[2]) recall_dates.extend(resl[3]) recall_df = pd.DataFrame({'会社名':campany_lists,'リコール内容':recall_lists,'対応':action_lists,'発生日':recall_dates})実行結果
recall_df.head() 会社名 リコール内容 対応 発生日 0 神戸物産 業務スーパー ほしいもスティック一部商品に樹脂片の混入 回収 2020/03/17 1 丸文 丸文 国産大豆使用よせ豆腐 消費期限誤表示 回収 2020/03/17 2 イオン常陸大宮店... 豚肉ロース味付トンテキ用 アレルゲン(乳)表示欠落 お詫び 2020/03/18 3 ツルヤ 軽井沢店 おいしい白身魚フライ アレルゲン乳成分表示欠落 回収 2020/03/16 4 畑中鯉屋 畑中鯉屋 鯉甘煮 アレルゲン「小麦」の表示欠落 回収 2020/03/13見た目上は、pandasのデータフレームに収納出来た・・・と思います。
はじめは、データフレームにその都度上場を書き込もうかと思ったけれど、やり方がわからずに断念。一先ず、それぞれの列のリストを作ってから、pandasに取り込む格好にしてみました。
ど素人なので、なんかの一つ覚えではじめはappend()で値を追加していました。しかし、それだとリスト形式で追加されてしまい、うまくpandasに取り込めませんでした。
色々調べてみると、リストの中の値だけを追加するには、extend()を使えばよいと分かりました。
一つ勉強になりました。
無事データも作れたので、データ分析をしてみたいと考えています。
今このデータで、分析出来そうな事は、
①リコールが起きた時の回収や返品の割合
②リコールが起きやすい時期はあるのか?でしょうか。
色々試行錯誤してみたいと思います。
- 投稿日:2020-03-22T21:50:37+09:00
Web スクレイピングで河川水位データを自動で取得する
はじめに
本記事の目的は、国土交通省が公開している「水文水質データベース」から観測データを自動取得する方法を紹介することです。国土交通省や気象庁といった公機関は、天気・河川水位といった計測データを一般公開しており、「水文水質データベース」はその1つです。(サイトurl: http://www1.river.go.jp/)
データによっては数十年もの蓄積があり、気候変動の調査やビジネスへの活用が期待できると考えています。
水文水質データベースの概要をサイトから引用しますこのデータベースは水文水質にかかわる国土交通省水管理・国土保全>局が所管する観測所における観測データを公開することを目的として> います。掲載対象としているデータは、雨量、水位、流量、水質、底質、地下水位、地下水質、積雪深、ダム堰等の管理諸量、海象です。
しかし、水文水質データベースは有益なデータが豊富に揃っていながらも、CSV形式等でのダウンロードが不可であるなど少し利用が難しいです。そこで、PythonによるWebスクレイピングの方法をソースコード共に紹介し、水文水質データベースを有効活用ができる様にしたいと考えました。今回は「河川の水位」をターゲットにSeleniumとBeautifulSoupを用いてWebからデータ取得を行い、機械学習などに利用しやすい様にPandasのDataFrameで扱える様にします。
水文水質データベースからデータを取得する手順
Webスクレイピングは以下の手順で進めます。
1.HTMLのソースを取得
2.データ記載された表の部分を取得
3.データ値を切り出す
本章でその概要をします。また、今回は東京都と神奈川を分ける多摩川の「田園調布(下)」観測所のデータを取得します。自動取得するHTMLソース
データの取得対象である水位観測局を検索します。図1の「水系単位の観測所一覧検索」をクリックし観測局検索画面に遷移します。
続いて観測局を検索するために図2の観測局検索画面で、河川名欄に「多摩川」と入力し「田園調布(下)」をクリックし観測局の詳細情報
を表示します。
図3の観測所情報画面に観測局IDという項目がありますが、これはスクレイピングをする上で必須の情報ですので控えておきます。また、「任意期間水位検索」ボタンをクリックすることで水位データの検索画面に遷移します。図4で示すデータ検索画面で期間を入力し水位データを取得します。ここで注意が必要なのは検索の期間は31日までです。
図4の下方に取得可能期間が記載されていますが、1930年代からデータが取れるという恐ろしい内容になっています。
図5が検索結果の画面です。注目すべき点はURLを見ると検索のクエリは観測局IDと開始日付と終了日付から構成されるということと、データ取得を行う表の部分はiframeタグであることです(ブラウザの開発者ツールで確認してください)。したがって、検索条件を付加したURLでリクエストを行い、表の部分だけを取得すれば所望の処理が実現できます。▪️図1: 水文水質データベース トップ画面
▪️図2: 水位観測局の検索
▪️図3: 水位観測所情報画面
▪️図4: 水位データ検索画面
▪️図5: データ取得を行う対象の画面
SeleniumとBeautifulSoupを用いたWebスクレイピング
前章で紹介した手順に沿って実際にデータを取得するプログラムを記載します。ソースの取得にはSeleniumを、HTMLを解析した必要なデータだけを抽出する操作をBeautifulSoupを用い、PandasのDataFrameの型でデータを扱います。
Seleniumのセットアップ
SeleniumはWebブラウザの操作を自動化するためのフレームワークです。環境構築や使い方は次の記事を参考にしました。わかりやすいく書かれているのでご参照ください!
https://qiita.com/Chanmoro/items/9a3c86bb465c1cce738aHTMLソースの取得
検索条件に合致する河川水位データが記載されたHTMLのソースを取得します。
まずは本記事において必要なパッケージのインポート宣言
from bs4 import BeautifulSoup from selenium import webdriver import pandas as pd import datetime import matplotlib.pyplot as pltSeleniumによるWebブラウザのドライバーを生成し、GETメソッドでHTMLのソースを取得します。
## Driverの生成 # Chrome のオプションを設定する options = webdriver.ChromeOptions() options.add_argument('--headless') # Selenium Server に接続する driver = webdriver.Remote( command_executor='http://localhost:4444/wd/hub', desired_capabilities=options.to_capabilities(), options=options)検索条件である観測所ID、検索開始・終了日付を宣言しURLを生成します
## 検索条件の定義 # ※水文水質データベースでは一回に30日までのデータしか取得できません station_id = 303051283310020 start_date_test = '20200101' end_date_test = '20200120' ## リクエストURLの生成 url_base = 'http://www1.river.go.jp/cgi-bin/DspWaterData.exe?KIND=1&ID={0}&BGNDATE={1}&ENDDATE={2}&KAWABOU=NO' url_request = url_base.format(station_id, start_date_test, end_date_test)以下でSeleniumを用いてURLでリクエストを送信し、
iframe部のHTMLソースを取得してからBeautifulSoupでHTMLの解析を行います。
解析ではtableタグの要素を取得します。# URLからソースを取得 driver.get(url_request) # 水位データを取得するためにifrmaを取得 iframe = driver.find_element_by_tag_name('iframe') driver.switch_to.frame(iframe) # ここでiframeの操作に切り替える # iframeのソースを取得し表データの'tr'タグを全て取得する soup = BeautifulSoup(driver.page_source, 'html.parser') table = soup.findAll("table")[0] rows = table.findAll("tr")ここで注意が必要なのは6行目の
driver.switch_to.frame(iframe)
の部分です。このメソッドを呼ぶことでiframeの操作ができるようになります。取得したrowsの中身を確認します
print(rows)[<tr> </tr>, <tr> <td align="left" height="10" width="40%">2020/01/01</td> <td align="left" height="10" width="30%"> 01:00</td> <td align="left" height="10" width="30%"><font color="#0000ff"> 1.56</font></td> </tr>, <tr> 〜中略〜 <td align="left" height="10" width="40%">2020/01/20</td> <td align="left" height="10" width="30%"> 24:00</td> <td align="left" height="10" width="30%"><font color="#0000ff"> 1.52</font></td> </tr>]配列形式でtableタグ内の要素が取得できています。
データの抽出と変換
続いてタグから値だけを取り出しDataFrameの形式に変換していきます。
# tdタグから値を取得し配列に格納する wl_data_list = [] for row in rows: list_tmp = [] td_list = row.findAll(['td']) for td in td_list: list_tmp.append(td.get_text().replace('\u3000', '')) wl_data_list.append(list_tmp)取得したrowsの中身を確認します
print(wl_data_list)[[], ['2020/01/01', '01:00', '1.56'], ['2020/01/01', '02:00', '1.56'], ['2020/01/01', '03:00', '1.56'], ['2020/01/01', '04:00', '1.55'], ['2020/01/01', '05:00', '1.55'], ... ['2020/01/20', '22:00', '1.53'], ['2020/01/20', '23:00', '1.52'], ['2020/01/20', '24:00', '1.52']]欲しいデータのみが配列で取得できています。
取得したデータから日付と時間を結合しDataFrameに変換します。
# 配列をPandasに変換し日付と時刻を結合する df_wl = pd.DataFrame(wl_data_list,columns=['date', 'time', 'water_lev']) df_wl.loc[:,'date'] = df_wl.loc[:,'date'] + ' ' + df_wl.loc[:,'time'] df_wl.drop('time', axis=1, inplace=True) df_wl.dropna(how='all', inplace=True) # 'time'をdatetime型に'水位'をfloat型に変換する df_wl['date'] = df_wl['date'].astype('str').apply(str2datetime) df_wl['water_lev'] = pd.to_numeric(df_wl['water_lev'], errors='coerce') df_wl.set_index('date', inplace=True) df_wl.sort_index(inplace=True)8行目の
df_wl['date'] = df_wl['date'].astype('str').apply(str2datetime)
では文字列の日時をdatetimeに変換しています。
水文水質データベースの時刻は01:00-24:00の表記になっている一方で、
Pandasは時刻を00:00-23:00の範囲で扱っています。
その変換は自前で定義したstr2datetimeの関数を用いています。
その関数を以下に示します。def str2datetime(string): """ Stringの日時データをdatetime型に変換する。 'YYYY/MM/DD 24:00'表記の日時を'YYYY/MM/DD+1 00:00'に変換する。 Args: string (String): 日時の文字列。'YYYY/MM/DD HH:mm'の表記を前提とする。 Returns: date (datetime.datetime): 日時のdatetime変換後の形式 """ if string[-5:] == '24:00': string = string[:-5] + ' ' + '00:00' date = datetime.datetime.strptime(string, "%Y/%m/%d %H:%M") date += datetime.timedelta(days=1) else: date = datetime.datetime.strptime(string, "%Y/%m/%d %H:%M") return dateこうして出来上がったDataFrameを可視化します
df_wl.plot()
思った通りにデータが取得できていそうです!まとめ
Webスクレイピングを用いて水文水質データベースから河川水位データを自動取得する方法を紹介しました。Selenium、BeautifulSoupを活用しています。記事では20日分のデータしか取得していませんが、githubにさらに長期間に渡ってデータを取得可能なコードをアップしていますので興味のある方はご覧ください。
以下がgithubのURLです
https://github.com/Sampeipei/qiita/blob/master/Web_scraping_river_water_level.ipynb
また、スクレイピングでこんなデータを取得したい!というのがありましたら是非コメントお願いいたします。


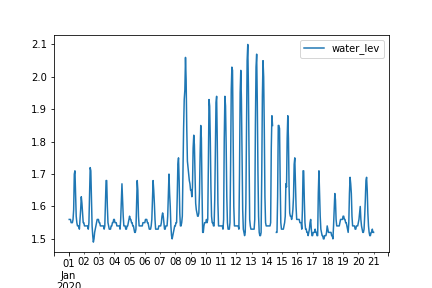
- 投稿日:2020-03-22T21:43:19+09:00
DjangoアプリをローカルからAWSに上げたらCSSが適用されなくなった話
経緯
DjangoやAWSの学習のため、以下の記事を元にローカルでDjangoアプリを作成したあと、githubからAWSにclone。
Django(Python)でシステム開発できるようになる記事_入門編
【20分でデプロイ】AWS EC2にDjango+PostgreSQL+Nginx環境を構築してササッと公開AWS上で
python3 manage.py runserverした後、ローカルでは管理画面に適用されていたCSSが適用されていないことに気づく。
解決方法
Nginxのログを確認した結果、CSSのパスが通っていないというエラーが発生しているのを確認。
$ tail -F /var/log/nginx/error.log (中略) 2020/03/21 01:18:04 [error] 23086#23086: *197 open() "/home/ubuntu/repository/mysite/static/admin/css/base.css" failed (2: No such file or directory), client: XXX.XXX.XXX.XXX, server: XXX.XXX.XXX.XXX, request: "GET /static/admin/css/base.css HTTP/1.1", host: "XXX.XXX.XXX.XXX", referrer: "http://XXX.XXX.XXX.XXX/admin/login/?next=/admin/"Djangoにおける静的ファイル(static file)の取り扱いによると、パスを通すには
collectstaticコマンドを使えば良い模様。
settings.pyの静的コンテンツ取り扱いの設定値を以下の通り設定した後、python3 manage.py collectstaticを実行settings.py# 静的ファイルの呼び出し設定を1番下に追加 BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) PROJECT_NAME = os.path.basename(BASE_DIR) #STATICFILES_DIRS = [os.path.join(BASE_DIR, 'static')] STATIC_ROOT = os.path.join(BASE_DIR, 'static')$ python3 manage.py collectstatic You have requested to collect static files at the destination location as specified in your settings: /home/ubuntu/repository/mysite/static This will overwrite existing files! Are you sure you want to do this? Type 'yes' to continue, or 'no' to cancel: yes 119 static files copied to '/home/ubuntu/repository/mysite/static'.staticディレクトリ配下に管理画面の静的ファイル(
~/.local/lib/python3.5/site-packages/django/contrib/admin/static/配下にあるもの)がコピーされる。$ ls ~/repository/mysite/static admin css images js (css,image,jsはmkdirで作成) $ ls ~/repository/mysite/static/admin css fonts img jsこれによって管理画面のCSSのパスが通った。

- 投稿日:2020-03-22T21:27:56+09:00
Pythonの -i フラグでスクリプト実行後にインタラクティブモードに入る
- 投稿日:2020-03-22T20:59:09+09:00
【PyTorch】Transformerを用いた日本語文章生成
はじめに
この記事では、小説のタイトルと本文のペアを用いて、任意のタイトルを入力することで小説を自動生成するモデルを構築することを目指します。
事前準備
- Google Colaboratory
- PyDrive
- janome
- mojimoji
分析のインフラにはGoogle Colaboratoryを利用します。
Google Colaboratoryは、Googleが提供しているクラウドノートブック環境で、Googleアカウントさえあれば誰でも無償で利用することが可能です。
データ分析に必要なライブラリが事前に準備されているだけでなく、GPUまで利用できるため、手元のノートPCで何か気軽に試したいときには非常にオススメです。
Google Colaboratoryのセットアップは、こちらの記事が詳しいです。セットアップ後、今回の分析用のノートブックを開き、以下のコマンドを実行することで、事前にインストールされていないライブラリをインストールしておきます。
!pip install -U -q PyDrive !pip install janome !pip install mojimojiデータの取得
小説データは青空文庫のGithubから取得します。
まずは、対象のリポジトリを自身のGoogle Driveにコピーします。下記コマンドの実行もGoogle Colaboratoryから可能です。!git clone --branch master --depth 1 https://github.com/aozorabunko/aozorabunko.git "drive/My Drive/任意のディレクトリ"続いて、コピーしたファイル群からモデル構築に利用するデータを抽出し、整形します。今回は、本文の文字数が3,000文字以内の小説を利用することにします。
なお、コード内の「drive上のid」は対象ディレクトリのURLに含まれるfolders/以下の文字列を指します。#---------------------- # 対象ファイル一覧の取得 #---------------------- from pydrive.auth import GoogleAuth from pydrive.drive import GoogleDrive from google.colab import auth from oauth2client.client import GoogleCredentials import pandas as pd # Google driveへのアクセスを許可 auth.authenticate_user() gauth = GoogleAuth() gauth.credentials = GoogleCredentials.get_application_default() drive = GoogleDrive(gauth) # 全作品のタイトルとdrive上のidを取得 def get_list_file_recursively(parent_id, l=None): if l is None: l = [] file_list = drive.ListFile({'q': '"{}" in parents and trashed = false'.format(parent_id)}).GetList() l += [f for f in file_list if f['mimeType'] != 'application/vnd.google-apps.folder'] for f in file_list: if f['mimeType'] == 'application/vnd.google-apps.folder': get_list_file_recursively(f['id'], l) return l listed = [] for f in get_list_file_recursively('コピーしたリポジトリの最上位ディレクトリのdrive上のid'): print(f['title']) if 'html' in f['title'] and 'card' not in f['title']: list = [f['title'], f['id']] listed.append(list) listed = pd.DataFrame(listed) #---------------------- # タイトル・本文の取得 #---------------------- from bs4 import BeautifulSoup # リストのhtmlファイルを読込 Stories = [] for i in range(0, len(listed)): if i % 100 == 0: print('{} / {}'.format(i, len(listed))) # リストのidからファイルを特定 file_data = drive.CreateFile({'id': listed.iloc[i, 2]}) file_data.GetContentFile(listed.iloc[i, 1]) with open(listed.iloc[i, 1], 'rb') as html: soup = BeautifulSoup(html, 'lxml') # タイトル・本文を取得 title = soup.find("h1", class_='title') main_text = soup.find("div", class_='main_text') # タイトルか本文が欠損の場合は飛ばす if title == None or main_text == None: continue # ルビを削除 for yomigana in main_text.find_all(["rp", "h4", "rt"]): yomigana.decompose() # 整形して文字列化 title = [line.strip() for line in title.text.strip().splitlines()] main_text = [line.strip() for line in main_text.text.strip().splitlines()] title = ''.join(title) text=''.join(main_text) # 本文が3,000文字以内の作品に絞込み if len(text) <= 3000: Stories.append([title, text]) # csvとして保存 Stories = pd.DataFrame(Stories) Stories.to_csv('drive/My Drive/Stories.csv', index=False, header=False)最後に、データの80%を学習用、20%をテスト用としてランダムに分割したものも保存しておきます。
#---------------------- # データの分割 #---------------------- from sklearn.model_selection import KFold kf = KFold(n_splits=5, shuffle=True, random_state=12345) tr_idx, te_idx = list(kf.split(df))[0] train = df.iloc[tr_idx, :] test = df.iloc[te_idx, :] train.to_csv('drive/My Drive/train.csv', index=False, header=False) test.to_csv('drive/My Drive/test.csv', index=False, header=False)学習用データの準備
データの読込にはtorchtextを利用します。torchtextの基本的な解説はこちらの記事が詳しいです。
前処理の定義
まずは、torchtextでデータを読み込んだ際に適用する前処理用の関数を定義します。形態素解析にはjanomeを利用します。
#---------------------- # 前処理の定義 #---------------------- from torchtext import data from janome.tokenizer import Tokenizer import re import mojimoji # 文字列処理定義 def preprocessing(text): # 改行、半角スペース、全角スペースを削除 text = re.sub('\r', '', text) text = re.sub('\n', '', text) text = re.sub(' ', '', text) text = re.sub(' ', '', text) # 数字文字の一律「0」化 text = re.sub(r'[0-9 0-9]', '0', text) # 全角化 text = mojimoji.han_to_zen(text) return text # Tokenizer定義 j_t = Tokenizer() def tokenizer(text): return [tok for tok in j_t.tokenize(text, wakati=True)] # 文字列処理 + Tokenizer def tokenizer_with_preprocessing(text): text = preprocessing(text) text = tokenizer(text) return texttorchtextの設定
続いて、torchtextによる読込方法の設定を行います。
#---------------------- # Fieldの定義 #---------------------- TEXT = data.Field( sequential=True, init_token='<sos>', eos_token='<eos>', tokenize=tokenizer_with_preprocessing, lower=True, use_vocab=True, batch_first=True )データの読込
学習用、テスト用として分割したcsvファイルを読み込み、ボキャブラリー辞書を作成します。
#---------------------- # データの読込 #---------------------- train_ds, test_ds = data.TabularDataset.splits( path='drive/My Drive', train='train.csv', test='test.csv', format='csv', skip_header=False, fields=[('title', TEXT), ('text', TEXT)] ) # 確認 train_ds[0].__dict__.keys() test_ds[0].__dict__.keys() for i in range(0, 10): print(vars(train_ds[i])) print(vars(test_ds[i])) # 辞書作成 TEXT.build_vocab(train_ds, test_ds, min_freq=2) # 単語カウント print(TEXT.vocab.freqs) print('語彙数:{}'.format(len(TEXT.vocab))) # イテレータの作成 device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') # --> 事前に「ランタイムのタイプを変更」からGPUを選択しておく。 train_iter = data.Iterator(train_ds, batch_size=16, shuffle=True, device=device) test_iter = data.Iterator(test_ds, batch_size=16, shuffle=False, device=device) # 確認 batch = next(iter(train_iter)) print(batch.title) print(batch.text) batch = next(iter(test_iter)) print(batch.title) print(batch.text)モデル構築
ネットワークの定義
Transformerの実装を行います。本稿ではTransformerの仕組みについて解説は行いませんが、日本語ではこちらの記事、英語ではこちらの記事が非常に分かりやすいと思います。
また、実装はこちらを参考にさせていただきました。各処理の意味についても詳しく解説されているため、試される前にぜひご一読ください。まずは、小説のタイトルをベクトル化するEncoderを定義します。
import torch from torch import nn class Encoder(nn.Module): def __init__(self, input_dim, hid_dim, n_layers, n_heads, pf_dim, dropout, device, max_length=100): super().__init__() self.device = device self.tok_embedding = nn.Embedding(input_dim, hid_dim) self.pos_embedding = nn.Embedding(max_length, hid_dim) self.layers = nn.ModuleList([EncoderLayer(hid_dim, n_heads, pf_dim, dropout, device) for _ in range(n_layers)]) self.dropout = nn.Dropout(dropout) self.scale = torch.sqrt(torch.FloatTensor([hid_dim])).to(device) def forward(self, src, src_mask): #src = [batch size, src len] #src_mask = [batch size, src len] batch_size = src.shape[0] src_len = src.shape[1] pos = torch.arange(0, src_len).unsqueeze(0).repeat(batch_size, 1).to(self.device) #pos = [batch size, src len] src = self.dropout((self.tok_embedding(src) * self.scale) + self.pos_embedding(pos)) #src = [batch size, src len, hid dim] for layer in self.layers: src = layer(src, src_mask) #src = [batch size, src len, hid dim] return src class EncoderLayer(nn.Module): def __init__(self, hid_dim, n_heads, pf_dim, dropout, device): super().__init__() self.layer_norm = nn.LayerNorm(hid_dim) self.self_attention = MultiHeadAttentionLayer(hid_dim, n_heads, dropout, device) self.positionwise_feedforward = PositionwiseFeedforwardLayer(hid_dim, pf_dim, dropout) self.dropout = nn.Dropout(dropout) def forward(self, src, src_mask): #src = [batch size, src len, hid dim] #src_mask = [batch size, src len] #self attention _src, _ = self.self_attention(src, src, src, src_mask) #dropout, residual connection and layer norm src = self.layer_norm(src + self.dropout(_src)) #src = [batch size, src len, hid dim] #positionwise feedforward _src = self.positionwise_feedforward(src) #dropout, residual and layer norm src = self.layer_norm(src + self.dropout(_src)) #src = [batch size, src len, hid dim] return src class MultiHeadAttentionLayer(nn.Module): def __init__(self, hid_dim, n_heads, dropout, device): super().__init__() assert hid_dim % n_heads == 0 self.hid_dim = hid_dim self.n_heads = n_heads self.head_dim = hid_dim // n_heads self.fc_q = nn.Linear(hid_dim, hid_dim) self.fc_k = nn.Linear(hid_dim, hid_dim) self.fc_v = nn.Linear(hid_dim, hid_dim) self.fc_o = nn.Linear(hid_dim, hid_dim) self.dropout = nn.Dropout(dropout) self.scale = torch.sqrt(torch.FloatTensor([self.head_dim])).to(device) def forward(self, query, key, value, mask = None): batch_size = query.shape[0] #query = [batch size, query len, hid dim] #key = [batch size, key len, hid dim] #value = [batch size, value len, hid dim] Q = self.fc_q(query) K = self.fc_k(key) V = self.fc_v(value) #Q = [batch size, query len, hid dim] #K = [batch size, key len, hid dim] #V = [batch size, value len, hid dim] Q = Q.view(batch_size, -1, self.n_heads, self.head_dim).permute(0, 2, 1, 3) K = K.view(batch_size, -1, self.n_heads, self.head_dim).permute(0, 2, 1, 3) V = V.view(batch_size, -1, self.n_heads, self.head_dim).permute(0, 2, 1, 3) #Q = [batch size, n heads, query len, head dim] #K = [batch size, n heads, key len, head dim] #V = [batch size, n heads, value len, head dim] energy = torch.matmul(Q, K.permute(0, 1, 3, 2)) / self.scale #energy = [batch size, n heads, seq len, seq len] if mask is not None: energy = energy.masked_fill(mask == 0, -1e10) attention = torch.softmax(energy, dim = -1) #attention = [batch size, n heads, query len, key len] x = torch.matmul(self.dropout(attention), V) #x = [batch size, n heads, seq len, head dim] x = x.permute(0, 2, 1, 3).contiguous() #x = [batch size, seq len, n heads, head dim] x = x.view(batch_size, -1, self.hid_dim) #x = [batch size, seq len, hid dim] x = self.fc_o(x) #x = [batch size, seq len, hid dim] return x, attention class PositionwiseFeedforwardLayer(nn.Module): def __init__(self, hid_dim, pf_dim, dropout): super().__init__() self.fc_1 = nn.Linear(hid_dim, pf_dim) self.fc_2 = nn.Linear(pf_dim, hid_dim) self.dropout = nn.Dropout(dropout) def forward(self, x): #x = [batch size, seq len, hid dim] x = self.dropout(torch.relu(self.fc_1(x))) #x = [batch size, seq len, pf dim] x = self.fc_2(x) #x = [batch size, seq len, hid dim] return x次に、タイトルのベクトルを受け取って、小説の本文を生成するDecoderを定義します。
class Decoder(nn.Module): def __init__(self, output_dim, hid_dim, n_layers, n_heads, pf_dim, dropout, device, max_length=1000): super().__init__() self.device = device self.tok_embedding = nn.Embedding(output_dim, hid_dim) self.pos_embedding = nn.Embedding(max_length, hid_dim) self.layers = nn.ModuleList([DecoderLayer(hid_dim, n_heads, pf_dim, dropout, device) for _ in range(n_layers)]) self.fc_out = nn.Linear(hid_dim, output_dim) self.dropout = nn.Dropout(dropout) self.scale = torch.sqrt(torch.FloatTensor([hid_dim])).to(device) def forward(self, trg, enc_src, trg_mask, src_mask): #trg = [batch size, trg len] #enc_src = [batch size, src len, hid dim] #trg_mask = [batch size, trg len] #src_mask = [batch size, src len] batch_size = trg.shape[0] trg_len = trg.shape[1] pos = torch.arange(0, trg_len).unsqueeze(0).repeat(batch_size, 1).to(self.device) #pos = [batch size, trg len] trg = self.dropout((self.tok_embedding(trg) * self.scale) + self.pos_embedding(pos)) #trg = [batch size, trg len, hid dim] for layer in self.layers: trg, attention = layer(trg, enc_src, trg_mask, src_mask) #trg = [batch size, trg len, hid dim] #attention = [batch size, n heads, trg len, src len] output = self.fc_out(trg) #output = [batch size, trg len, output dim] return output, attention class DecoderLayer(nn.Module): def __init__(self, hid_dim, n_heads, pf_dim, dropout, device): super().__init__() self.layer_norm = nn.LayerNorm(hid_dim) self.self_attention = MultiHeadAttentionLayer(hid_dim, n_heads, dropout, device) self.encoder_attention = MultiHeadAttentionLayer(hid_dim, n_heads, dropout, device) self.positionwise_feedforward = PositionwiseFeedforwardLayer(hid_dim, pf_dim, dropout) self.dropout = nn.Dropout(dropout) def forward(self, trg, enc_src, trg_mask, src_mask): #trg = [batch size, trg len, hid dim] #enc_src = [batch size, src len, hid dim] #trg_mask = [batch size, trg len] #src_mask = [batch size, src len] #self attention _trg, _ = self.self_attention(trg, trg, trg, trg_mask) #dropout, residual connection and layer norm trg = self.layer_norm(trg + self.dropout(_trg)) #trg = [batch size, trg len, hid dim] #encoder attention _trg, attention = self.encoder_attention(trg, enc_src, enc_src, src_mask) #dropout, residual connection and layer norm trg = self.layer_norm(trg + self.dropout(_trg)) #trg = [batch size, trg len, hid dim] #positionwise feedforward _trg = self.positionwise_feedforward(trg) #dropout, residual and layer norm trg = self.layer_norm(trg + self.dropout(_trg)) #trg = [batch size, trg len, hid dim] #attention = [batch size, n heads, trg len, src len] return trg, attention最後に、EncoderとDecoderをつなぎ合わせてTransformerの完成です。
class Seq2Seq(nn.Module): def __init__(self, encoder, decoder, src_pad_idx, trg_pad_idx, device): super().__init__() self.encoder = encoder self.decoder = decoder self.src_pad_idx = src_pad_idx self.trg_pad_idx = trg_pad_idx self.device = device def make_src_mask(self, src): #src = [batch size, src len] src_mask = (src != self.src_pad_idx).unsqueeze(1).unsqueeze(2) #src_mask = [batch size, 1, 1, src len] return src_mask def make_trg_mask(self, trg): #trg = [batch size, trg len] trg_pad_mask = (trg != self.trg_pad_idx).unsqueeze(1).unsqueeze(3) #trg_pad_mask = [batch size, 1, trg len, 1] trg_len = trg.shape[1] trg_sub_mask = torch.tril(torch.ones((trg_len, trg_len), device = self.device)).bool() #trg_sub_mask = [trg len, trg len] trg_mask = trg_pad_mask & trg_sub_mask #trg_mask = [batch size, 1, trg len, trg len] return trg_mask def forward(self, src, trg): #src = [batch size, src len] #trg = [batch size, trg len] src_mask = self.make_src_mask(src) trg_mask = self.make_trg_mask(trg) #src_mask = [batch size, 1, 1, src len] #trg_mask = [batch size, 1, trg len, trg len] enc_src = self.encoder(src, src_mask) #enc_src = [batch size, src len, hid dim] output, attention = self.decoder(trg, enc_src, trg_mask, src_mask) #output = [batch size, trg len, output dim] #attention = [batch size, n heads, trg len, src len] return output, attention今回は行っていませんが、返り値のattentionを利用することで、学習後のattention weightの視覚化も可能です。
モデルの学習
モデルを学習します。
なお、参考スクリプトではバリデーションデータの精度を見てエポックを止めていますが、今回の試行では1エポック目から学習が進むほどバリデーションデータの精度が低下したため、オーバーフィットは無視して最終エポック後のモデルを採用しています。#---------------------- # 学習準備 #---------------------- # パラメータの設定 INPUT_DIM = len(TEXT.vocab) OUTPUT_DIM = len(TEXT.vocab) HID_DIM = 256 ENC_LAYERS = 3 DEC_LAYERS = 3 ENC_HEADS = 8 DEC_HEADS = 8 ENC_PF_DIM = 512 DEC_PF_DIM = 512 ENC_DROPOUT = 0.1 DEC_DROPOUT = 0.1 # Encoderの初期化 enc = Encoder(INPUT_DIM, HID_DIM, ENC_LAYERS, ENC_HEADS, ENC_PF_DIM, ENC_DROPOUT, device) # Decoderの初期化 dec = Decoder(OUTPUT_DIM, HID_DIM, DEC_LAYERS, DEC_HEADS, DEC_PF_DIM, DEC_DROPOUT, device) # padding用のIDの指定 PAD_IDX = TEXT.vocab.stoi[TEXT.pad_token] # モデルの初期化 model = Seq2Seq(enc, dec, PAD_IDX, PAD_IDX, device).to(device) # 重みの初期化 def initialize_weights(m): if hasattr(m, 'weight') and m.weight.dim() > 1: nn.init.xavier_uniform_(m.weight.data) model.apply(initialize_weights) # オプティマイザーの設定 LEARNING_RATE = 0.0005 optimizer = torch.optim.Adam(model.parameters(), lr=LEARNING_RATE) # 損失関数の設定 criterion = nn.CrossEntropyLoss(ignore_index=PAD_IDX) # 学習用関数の定義 def train(model, iterator, optimizer, criterion, clip): model.train() epoch_loss = 0 for i, batch in enumerate(iterator): src = batch.title trg = batch.text optimizer.zero_grad() output, _ = model(src, trg[:,:-1]) #output = [batch size, trg len - 1, output dim] #trg = [batch size, trg len] output_dim = output.shape[-1] output = output.contiguous().view(-1, output_dim) trg = trg[:,1:].contiguous().view(-1) #output = [batch size * trg len - 1, output dim] #trg = [batch size * trg len - 1] loss = criterion(output, trg) loss.backward() torch.nn.utils.clip_grad_norm_(model.parameters(), clip) optimizer.step() epoch_loss += loss.item() return epoch_loss / len(iterator) # 評価用関数の定義 def evaluate(model, iterator, criterion): model.eval() epoch_loss = 0 with torch.no_grad(): for i, batch in enumerate(iterator): src = batch.title trg = batch.text output, _ = model(src, trg[:,:-1]) #output = [batch size, trg len - 1, output dim] #trg = [batch size, trg len] output_dim = output.shape[-1] output = output.contiguous().view(-1, output_dim) trg = trg[:,1:].contiguous().view(-1) #output = [batch size * trg len - 1, output dim] #trg = [batch size * trg len - 1] loss = criterion(output, trg) epoch_loss += loss.item() return epoch_loss / len(iterator) # 処理時間測定用関数の定義 def epoch_time(start_time, end_time): elapsed_time = end_time - start_time elapsed_mins = int(elapsed_time / 60) elapsed_secs = int(elapsed_time - (elapsed_mins * 60)) return elapsed_mins, elapsed_secs # 文章生成用関数の定義 def translate_sentence(sentence, src_field, trg_field, model, device, max_len=1000): model.eval() tokens = [token.lower() for token in sentence] tokens = [src_field.init_token] + tokens + [src_field.eos_token] src_indexes = [src_field.vocab.stoi[token] for token in tokens] src_tensor = torch.LongTensor(src_indexes).unsqueeze(0).to(device) src_mask = model.make_src_mask(src_tensor) with torch.no_grad(): enc_src = model.encoder(src_tensor, src_mask) trg_indexes = [trg_field.vocab.stoi[trg_field.init_token]] for i in range(max_len): trg_tensor = torch.LongTensor(trg_indexes).unsqueeze(0).to(device) trg_mask = model.make_trg_mask(trg_tensor) with torch.no_grad(): output, attention = model.decoder(trg_tensor, enc_src, trg_mask, src_mask) pred_token = output.argmax(2)[:,-1].item() trg_indexes.append(pred_token) if pred_token == trg_field.vocab.stoi[trg_field.eos_token]: break trg_tokens = [trg_field.vocab.itos[i] for i in trg_indexes] return trg_tokens[1:], attention #---------------------- # モデルの学習 #---------------------- import time import math N_EPOCHS = 100 CLIP = 1 # サンプル1作品を取得 example_idx = 8 src_sample = vars(train_ds.examples[example_idx])['title'] trg_sample = vars(train_ds.examples[example_idx])['text'] # タイトルと本文を表示 print(f'src = {src_sample}') print(f'trg = {trg_sample}') best_valid_loss = float('inf') for epoch in range(N_EPOCHS): start_time = time.time() train_loss = train(model, train_iter, optimizer, criterion, CLIP) valid_loss = evaluate(model, test_iter, criterion) end_time = time.time() epoch_mins, epoch_secs = epoch_time(start_time, end_time) #if valid_loss < best_valid_loss: # best_valid_loss = valid_loss # torch.save(model.state_dict(), 'drive/My Drive/trained_model.pt') # 参考スクリプトではバリデーションデータの精度を指標にしているが、今回の試行では学習が進むほどバリデーションデータの精度が低下したため、オーバーフィットは無視して最終エポック後のモデルを採用(途中終了も考慮して各エポック後に保存) torch.save(model.state_dict(), 'drive/My Drive/trained_model.pt') # エポックごとに学習用・バリデーション用データの精度を表示 print(f'Epoch: {epoch+1:02} | Time: {epoch_mins}m {epoch_secs}s') print(f'\tTrain Loss: {train_loss:.3f} | Train PPL: {math.exp(train_loss):7.3f}') print(f'\t Val. Loss: {valid_loss:.3f} | Val. PPL: {math.exp(valid_loss):7.3f}') # 10エポックごとにサンプル1作品のタイトルから本文を生成した結果を表示 if epoch % 10 == 0: translation, attention = translate_sentence(src_sample, TEXT, TEXT, model, device) print(f'predicted trg = {translation}')テスト
以下に好きなタイトルを入れることで、小説を生成することができます。
translation, attention = translate_sentence(['任意のタイトル'], TEXT, TEXT, model, device) print(f'predicted trg = {translation}')いくつか試してみました。
上の2つは学習用データに含まれるタイトル、下の2つは含まれないタイトルです(正確には、辞書に含まれている(=学習用データまたはテスト用データのタイトルか本文に2回以上登場する)単語の組み合わせのうち、学習用データのタイトルではないもの)。
入力タイトル 生成文章 思い出 二十代の時鴎外先生には五、六回お目にかかった。その後二、三度陸軍省の(unk)局に校正を届けた際お目にかゝったが、いずれも簡単で、(unk)談を語るほどの資料はもっていない。そのころ、与謝野寛、生田長江、永井荷風氏らが鴎外先生の門人で、私は先生の孫のようなものだった。そうした縁故で私は先生と直接の関係はないが、先生の文学的事業から尊敬している。先生は世間から気むずかし屋と思われることを苦にして、いつも相手に窮屈な思いをさせぬように気をつかっておられたようであるが、それが却ってこちらには窮屈であった。思出といえば、いつか「我等」という雑誌の出版祝いに、…(以下省略) 足跡 ずつと昔のこと一匹の狐が河岸の粘土層を走つていつたそれから何万年かたつたあとにその粘土層が化石となつて足跡が残つたその足跡を見ると、むかし狐が何を考えて走つていつたのかがわかる 髪 ああきみは情慾のにほふ月ぐさ、われははた憂愁の瀬川の螢、(unk)ふ舟ばたの光をみれば、ゆふぐれのおめがの瞳にて、たれかまたあるはをしらむ、さ(unk)、くち(unk) 音楽 (unk)は(unk)は(unk)太陽が落ちて太陽の世界が始つた[#「始つた」は底本では「始まつた」](unk)は戸袋(unk)は(unk)太陽が上つて夜の世界が始つた(unk)は妖怪下痢は(unk)と日暮が直径を描いてダダの世界が始つた(それを(unk)が眺めてそれをキリストが感心する 学習用データに対しては、タイトルから本文がかなり高精度に再現できているようです。
一方で、学習用データに含まれないタイトルは、意味が通らない文章になってしまっています。おわりに
Transformerを用いることで、小説のタイトルから本文を生成できることが確認できました。
とはいえ、学習用データにないタイトルに対してはまともな生成ができなかったため、次回は今回放棄したバリデーションデータを活用し、より汎用的なモデルを目指したいと思います。参照
- 投稿日:2020-03-22T20:24:20+09:00
【Python】OpenCVで画像を読み込む (初心者向け)
はじめに
最近Pythonが何かと話題になっています。PythonではOpenCVと呼ばれるライブラリを使うことで、簡単な画像処理ができます。本記事では、OpenCVで画像を読み込んで、色々処理する方法を解説します。
環境
MacOS Mojave
Python 3.7.6下準備
opencvとmatplotlibと呼ばれるライブラリをインストールします。matplotlibはグラフを書くためのライブラリで画像の表示などでも使用できます。以下のコマンドをそれぞれターミナルに打ち込んで、実行してください。
$pip install opencv-python$pip install matplotlib"opencv"だけではインストールできないので注意してください。Requirement already satisfiedと表示されて入れば、既にインストールされているので、問題ありません。
画像を読み込んでみよう
今回は以下の猫 (neko.jpg) の画像を使用します。
以下のコードを実行します。
opencv_read_img.py#ライブラリの読み込み import cv2 import matplotlib.pyplot as plt #neko.jpgを読み込んで、imgオブジェクトに入れる img = cv2.imread("neko.jpg") #imgオブジェクトをmatlotlibを用いて表示する plt.imshow(img) plt.show()最初のimportの部分でopencv (cv2) とmatplotlibのpyplot (matplotlib.pyplot) を読み込んでいます。as pltというのはmatplotlib.pylotを長いから、pltに省略してこれから使いますよーていう意味です。
以上のコードを実行して、以下のような画面が出てくれば成功です。
ただ、猫ちゃんが変な色になってしまいましたね? これはopencvではGBR (緑・青・赤) 、matplotlibではRGB (赤・緑・青) と色の表現方法が異なることが原因で起こります。なので、元の色で表現する為には、色の変換が必要です。
色の変換方法
画像を読み込んだ後に、cv2.cvtColor()を使います。
opencv_read_img.py#ライブラリの読み込み import cv2 import matplotlib.pyplot as plt #neko.jpgを読み込んで、imgオブジェクトに入れる img = cv2.imread("neko.jpg") #画像の色の順序をBGRからRGBに変換する img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB) #imgオブジェクトをmatlotlibを用いて表示する plt.imshow(img) plt.show()以上のコードを実行すると、以下の画面が出力されます。
もとの画像が表示されましたね!
次回は簡単な画像処理を行って保存する方法を解説します。トラブルシューティング
python: can't open file 'opencv_read_img.py': [Errno 2] No such file or directoryこれは、ファイルがないよというエラーです。この場合は以下の手順を行ってください。
①作成したpythonファイルと同じ位置に画像をおく。
②ターミナルでpythonファイルが置いてあるフォルダに移動する。
もしディスクトップのqiita_pythonというフォルダの中にpythonファイルと画像が入ってるとしたら以下のコマンドを実行してください。$cd /Users/ユーザー名/Desktop/qiita_python $python opencv_read_img.pyTwitterやってます
もしよろしければフォローお願いします!
https://twitter.com/ryuji33722052

- 投稿日:2020-03-22T19:07:04+09:00
キャプチャボードからの入力映像を画像で保存
はじめに
キャプチャボードからの入力映像を定期的に画像として保存するスクリプトです。
ゲーム映像(Nitendo Switch)のスクショを定期的に取得したかったので作成しました。
環境
- Windows 10
- Python 3.7
- GC550 PLUS(キャプチャボード)
スクリプト
OpenCVでキャプチャボードからの映像を取得
1秒おきにキャプチャ画像を取得
-> Switchは 60fps(1/60秒おき)なので、
countが60の倍数のときに画像を保存
- 取得したフレームをHDサイズにリサイズして保存
-> Full HDで映像が出力されますが、HDのキャプチャ画像が欲しかったため
capture.pyimport cv2 import datetime # VideoCapture オブジェクトを取得 # キャプボの他にWebカメラなど接続している場合は他の数字を指定する必要があるかも capture = cv2.VideoCapture(0) print(capture.isOpened()) capture.set(3, 1920) capture.set(4, 1080) count = 0 while(True): ret, frame = capture.read() cv2.imshow('frame', frame) count += 1 print(count) if count % 60 == 0: dt_now = datetime.datetime.now() # 1280 * 720のキャプチャ画像に変換、保存 resized = cv2.resize(frame, (1280, 720)) # 所定のフォルダにjpgで保存 cv2.imwrite('H:/capture/'+ dt_now.strftime('%Y%m%d-%H%M%S')+'.jpg', resized) # "q"キー または ctrl + C でキャプチャ停止 if cv2.waitKey(1) & 0xFF == ord('q'): break capture.release() cv2.destroyAllWindows()
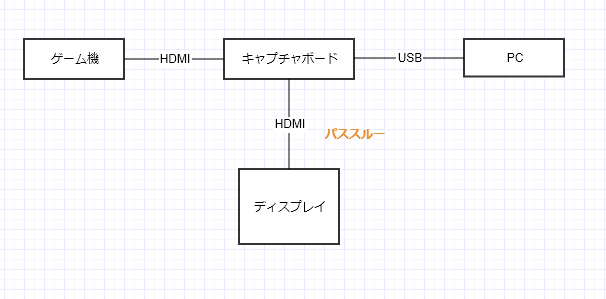
- 投稿日:2020-03-22T19:06:06+09:00
Pythonでスクレイピング、TwitterBotで投稿、Herokuで定期実行
Pythonでスクレイピングし、 TwitterBotへの投稿を、Herokuで定期実行するところまでをやってみた。
・耳鳴りに悩まされているので、”耳鳴り”に関する情報を定期的にツイートするボット。
・Mac
・Python3
・具体的には、以下の2つを実行するアプリを作成した。
[1] Yahooニュースから”耳鳴り”、”めまい”の検索結果をスクレイピングし、定期的にツイート
[2] 耳鳴り改善”や、”耳鳴り原因”などのツイートを、定期的にリツイート(イイねも)※環境構築、ディレクトリ構成
デスクトップにディレクトリmiminariを作成し、scraping.pyを作成。
以下の通り、仮想環境を構築し起動する。python3 -m venv . source bin/activate必要なモジュールをインストール。
pip install requests pip install beautifulsoup4 pip install lxmlディレクトリ構成
miminari ├scraping.py ├date_list.txt ├source_list.txt ├text_list.txt ├title_list.txt ├url_list.txt ├twitter.py ├Procfile ├requirements.txt └runtime.txt[1]Yahooニュースから”耳鳴り”、”めまい”をスクレイピングし、定期的にツイート
(1)scraping.pyを作成する
①ニュースタイトルとURLをスクレイピングする
Yahooニュースから、”耳鳴り”、”めまい”を検索し、urlをコピー。
サイトには、ニュースが10個表示されている。タイトルとURLのありそうな場所を探す。
GoogleChromeの”検証”を見ると、h2タグのclass=tにあることがわかる。
これを踏まえてコードを書いていく。
scraping.pyfrom bs4 import BeautifulSoup import lxml import requests URL = "https://news.yahoo.co.jp/search/?p=%E8%80%B3%E9%B3%B4%E3%82%8A+%E3%82%81%E3%81%BE%E3%81%84&oq=&ei=UTF-8&b=1" res = requests.get(URL) res.encoding = res.apparent_encoding html_doc = res.text soup = BeautifulSoup(html_doc,"lxml") list = soup.find_all("h2",class_="t") print(list)とすると、以下のようにリスト形式で取得できる。
[<h2 class="t"><a href="https://headlines.yahoo.co.jp/hl?a=20200320-00000019-nkgendai-hlth">misonoも闘病中メニエール病 根本治療が見つかっていないがどう付き合う?</a></h2>, <h2 class="t"><a href="https://headlines.yahoo.co.jp/article?a=20200316-00010000-flash-ent">相田翔子、突発性難聴とメニエール病で苦しんだ過去「<em>耳鳴り</em>が…」</a></h2>, <h2 class="t"><a href="https://headlines.yahoo.co.jp/article?a=20200315-00000004-nikkeisty-hlth">グルテンで不調、治療法は食の見直し 指導なしは危険</a></h2>, <h2 class="t"><a href="https://headlines.yahoo.co.jp/hl?a=20200313-00000243-spnannex-ent">相田翔子、芸能界引退考えた病魔を初告白 名医の“心のケア”に感謝</a></h2>, <h2 class="t"><a href="https://headlines.yahoo.co.jp/article?a=20200310-00000011-pseven-life">「難聴」は認知症の危険因子 うつ病リスク2.4倍とのデータも</a></h2>, <h2 class="t"><a href="https://headlines.yahoo.co.jp/hl?a=20200309-00010009-nishispo-spo">五輪代表大野の同級生が病に打ち勝ち大舞台へ 81キロ級で無差別挑戦</a></h2>, <h2 class="t"><a href="https://headlines.yahoo.co.jp/article?a=20200226-00010011-newsweek-int">米軍を襲ったイラン謎の衝撃波、解明には数年かかる</a></h2>, <h2 class="t"><a href="https://headlines.yahoo.co.jp/article?a=20200223-00986372-jspa-life">持病と妊活でウツ状態に…アラフォー妻に夫がかけた言葉に涙</a></h2>, <h2 class="t"><a href="https://headlines.yahoo.co.jp/hl?a=20200215-00001569-fujinjp-life">熱エネルギー不足?血巡り停滞?「冷え」のタイプを知って、寒さに負けない体に</a></h2>, <h2 class="t"><a href="https://headlines.yahoo.co.jp/article?a=20200214-00010009-jisin-soci">医師が推奨!不眠や生理痛、頭痛も…「平熱36.5度」が不調を防ぐ</a></h2>]補足説明
・encodingとは、サーバーから返されるレスポンスの文字エンコーディング。この文字エンコーディングにしたがってコンテンツを変換する。
・apparent_encodingとは、文字化けなどが起こらないようにコンテンツを取得できるようにするための処理を意味する。
・lxmlは、HTMLの字句解析をして、タグなどを判断してデータ構造として取得するHTMLパーサーのうちの一つ。通常はhtml.parserを使うが。より高速なパーサーとしてlxmlを今回は使う。lxmlは別途インストールしてインポートが必要。
・GoogleChromeの検証から、タイトルとURLはh2タグのclass=tにあることがわかるため、find_all("h2",class_="t")とした。②ニュースタイトルとURLをスクレイピングする(ファイルに保存する)
scraping.pyfrom bs4 import BeautifulSoup import lxml import requests URL = "https://news.yahoo.co.jp/search/?p=%E8%80%B3%E9%B3%B4%E3%82%8A+%E3%82%81%E3%81%BE%E3%81%84&oq=&ei=UTF-8&b=1" res = requests.get(URL) html_doc = res.text soup = BeautifulSoup(html_doc,"lxml") #タイトルとurlを取得------------------------------ _list = soup.find_all("h2",class_="t") title_list = [] url_list = [] for i in _list: a_tag = i.find_all('a') for _tag in a_tag: #タイトルを抽出、get_text()は、タグで囲まれた文字列を抽出する href_text = _tag.get_text() #タイトルを抽出したリストを作成 title_list.append(href_text) #get("href")は、タグで囲まれたurlを抽出する url_text = _tag.get("href") #タイトルを抽出したリストを作成 url_list.append(url_text) #text形式で保存 with open('title_data'+'.txt','a',encoding='utf-8') as f: for i in title_list: f.write(i + '\n') with open('url_data'+'.txt','a',encoding='utf-8') as f: for i in url_list: f.write(i + '\n')補足説明
・get.text()は、タグで囲まれた文字列を抽出できる。
・get("href")は、その属性値を取得できる。③ニュースの概要(text)と日時、ソースをスクレイピングする
ニュースの概要と日時も同様にスクレイピングして、それぞれを保存する。
scraping.pyfrom bs4 import BeautifulSoup import lxml import requests URL = "https://news.yahoo.co.jp/search/?p=%E8%80%B3%E9%B3%B4%E3%82%8A+%E3%82%81%E3%81%BE%E3%81%84&oq=&ei=UTF-8&b=1" res = requests.get(URL) html_doc = res.text soup = BeautifulSoup(html_doc,"lxml") #タイトルとurlを取得------------------------------ _list = soup.find_all("h2",class_="t") title_list = [] url_list = [] for i in _list: a_tag = i.find_all('a') for _tag in a_tag: #タイトルを抽出、get_text()は、タグで囲まれた文字列を抽出する href_text = _tag.get_text() #タイトルを抽出したリストを作成 title_list.append(href_text) #get("href")は、タグで囲まれたurlを抽出する url_text = _tag.get("href") #タイトルを抽出したリストを作成 url_list.append(url_text) with open('title_data'+'.txt','a',encoding='utf-8') as f: for i in title_list: f.write(i + '\n') with open('url_data'+'.txt','a',encoding='utf-8') as f: for i in url_list: f.write(i + '\n') #textを取得----------------------------------------- _list2 = soup.find_all("p",class_="a") text_list = [] for i in _list2: text_text = i.get_text() text_list.append(text_text) with open('text_list'+'.txt','a',encoding='utf-8')as f: for i in text_list: f.write(i + '\n') #日時、--------------------------------------------------------------- _list3 = soup.find_all("span",class_="d") date_list = [] for i in _list3: _date_text = i.get_text() _date_text = _date_text.replace('\xa0','') date_list.append(_date_text) with open('date_list'+'.txt','a',encoding='utf-8') as f: for i in date_list: f.write(i + '\n') #ソース--------------------------------------------------------------- _list4 = soup.find_all("span",class_="ct1") source_list = [] for i in _list4: _source_text = i.get_text() source_list.append(_source_text) with open('source_list'+'.txt','a',encoding='utf-8') as f: for i in source_list: f.write(i + '\n')補足説明
・日時であるが、そのまま抽出すると、” ”という余計な文字も抽出してしまうため、replaceを使ってブランクにしている(スクレピングすると、” ”は、”\xa0”と表記されているため、replace('\xa0','')とした。
④次ページ以降もスクレイピングする
このままだと1ページ分の10個のニュースのみスクレイピング対象としいるため、これを4ページ分まわす(4ページまわすとは、”耳鳴り”、”めまい”のニュース検索結果が4ページのみであったため)。
コードを以下のように修正。scraping.pyfrom bs4 import BeautifulSoup import lxml import requests mm = 0 for i in range(4): URL = "https://news.yahoo.co.jp/search/?p=%E8%80%B3%E9%B3%B4%E3%82%8A+%E3%82%81%E3%81%BE%E3%81%84&oq=&ei=UTF-8&b={}".format(mm*10 + 1) res = requests.get(URL) html_doc = res.text soup = BeautifulSoup(html_doc,"lxml") #タイトルとurlを取得------------------------------ _list = soup.find_all("h2",class_="t") title_list = [] url_list = [] for i in _list: a_tag = i.find_all('a') for _tag in a_tag: #タイトルを抽出、get_text()は、タグで囲まれた文字列を抽出する href_text = _tag.get_text() #タイトルを抽出したリストを作成 title_list.append(href_text) #get("href")は、タグで囲まれたurlを抽出する url_text = _tag.get("href") #タイトルを抽出したリストを作成 url_list.append(url_text) with open('title_list'+'.txt','a',encoding='utf-8') as f: for i in title_list: f.write(i + '\n') with open('url_list'+'.txt','a',encoding='utf-8') as f: for i in url_list: f.write(i + '\n') #textを取得----------------------------------------- _list2 = soup.find_all("p",class_="a") text_list = [] for i in _list2: text_text = i.get_text() text_list.append(text_text) with open('text_list'+'.txt','a',encoding='utf-8')as f: for i in text_list: f.write(i + '\n') #日時、--------------------------------------------------------------- _list3 = soup.find_all("span",class_="d") date_list = [] for i in _list3: _date_text = i.get_text() _date_text = _date_text.replace('\xa0','') date_list.append(_date_text) with open('date_list'+'.txt','a',encoding='utf-8') as f: for i in date_list: f.write(i + '\n') #ソース--------------------------------------------------------------- _list4 = soup.find_all("span",class_="ct1") source_list = [] for i in _list4: _source_text = i.get_text() source_list.append(_source_text) with open('source_list'+'.txt','a',encoding='utf-8') as f: for i in source_list: f.write(i + '\n') #mm------------------------------------------------------------------- mm += 1補足説明
追加したのは、以下の箇所。URLの末尾が1ページ毎に1、11、21、31となっているためfor文とformatを使って処理した。
mm = 0 for i in range(4): 〜〜〜〜 〜〜〜〜 q=&ei=UTF-8&b={}".format(mm*10 + 1) 〜〜〜〜 mm += 1ここまでで、スクレイピングにより、それぞれのニュースのタイトル(title_list)、URL(url_list)、概要(text_list)、日時(date_list)、ソース(source_list)が作成できた。以降、Twitterへの投稿作業を進めるが、使用するのは、日時(date_list)、ソース(source_list)、URL(url_list)のみとした。
(2)Twitterへ投稿
今回、TwitterBotの詳しい作成方法は割愛する。Botを作成する上で、TwitterAPIへの登録やTwitterへのツイートの方法は以下を参考にした。
Twitter API 登録 (アカウント申請方法) から承認されるまでの手順まとめ
TweepyでTwitterに投稿する
TweepyでTwitterの検索, いいね, リツイートディレクトリmiminari内に、twitter.pyを作成して、Tweepyをインストール。
pip install tweepstwitter.pyを以下の通り作成
twitter.pyimport tweepy from random import randint import os auth = tweepy.OAuthHandler(os.environ["CONSUMER_KEY"],os.environ["CONSUMER_SECRET"]) auth.set_access_token(os.environ["ACCESS_TOKEN"],os.environ["ACCESS_TOKEN_SECERET"]) api = tweepy.API(auth) twitter_source =[] twitter_url = [] twitter_date = [] with open('source_list.txt','r')as f: for i in f: twitter_source.append(i.rstrip('\n')) with open('url_list.txt','r')as f: for i in f: twitter_url.append(i.rstrip('\n')) with open('date_list.txt','r')as f: for i in f: twitter_date.append(i.rstrip('\n')) #randint、len関数で、リストの0番目から nー1番目の範囲からランダムに記事を抽出 i = randint(0,len(twitter_source)-1) api.update_status("<耳鳴り関連のニュース>" + '\n' + twitter_date[i] + twitter_source[i] + twitter_url[i])補足説明
・Herokuへのデプロイを踏まえ、CONSUMER_KEY等は環境変数とした。
・記事はランダムにツイートされるようにした。[2]”耳鳴り改善”や、”耳鳴り原因”などのツイートを定期的にリツイート(イイねも)
twitter.pyにコードを追加
twitter.pyimport tweepy from random import randint import os #auth = tweepy.OAuthHandler(config.CONSUMER_KEY,config.CONSUMER_SECRET) #auth.set_access_token(config.ACCESS_TOKEN,config.ACCESS_TOKEN_SECERET) auth = tweepy.OAuthHandler(os.environ["CONSUMER_KEY"],os.environ["CONSUMER_SECRET"]) auth.set_access_token(os.environ["ACCESS_TOKEN"],os.environ["ACCESS_TOKEN_SECERET"]) api = tweepy.API(auth) #-Yahoo_news(耳鳴り、めまい)ツイート処理---------------------------------------------- twitter_source =[] twitter_url = [] twitter_date = [] with open('source_list.txt','r')as f: for i in f: twitter_source.append(i.rstrip('\n')) with open('url_list.txt','r')as f: for i in f: twitter_url.append(i.rstrip('\n')) with open('date_list.txt','r')as f: for i in f: twitter_date.append(i.rstrip('\n')) #randint、len関数で、リストの0番目から nー1番目の範囲からランダムに記事を抽出 i = randint(0,len(twitter_source)-1) api.update_status("<耳鳴り関連のニュース>" + '\n' + twitter_date[i] + twitter_source[i] + twitter_url[i]) #-(以下が追加)リツイート処理---------------------------------------------------------------------- search_results_1 = api.search(q="耳鳴り 改善", count=10) search_results_2 = api.search(q="耳鳴り ひどい", count=10) search_results_3 = api.search(q="耳鳴り ピー", count=10) search_results_4 = api.search(q="耳鳴り 薬", count=10) search_results_5 = api.search(q="耳鳴りとは", count=10) search_results_6 = api.search(q="耳鳴り 原因", count=10) search_results_7 = api.search(q="耳鳴り 漢方", count=10) search_results_8 = api.search(q="耳鳴り ツボ", count=10) search_results_9 = api.search(q="耳鳴り 頭痛", count=10) search_results_10 = api.search(q="#耳鳴り", count=10) search_results_11 = api.search(q="耳鳴り", count=10) the_list = [search_results_1, search_results_2, search_results_3, search_results_4, search_results_5, search_results_6, search_results_7, search_results_8, search_results_9, search_results_10, search_results_11 ] for i in range(10): for result in the_list[i]: tweet_id = result.id # 例外処理をする。重複して処理するとエラーが起こるようなので, # 例外処理にしておくとプログラム途中で止まることが無い。 try: api.retweet(tweet_id)#リツイート処理 api.create_favorite(tweet_id) #いいね処理 except Exception as e: print(e)[3]Herokuへデプロイ
(1)デプロイ
デプロイに必要なProcfile、runtime.txt、requirements.txtを作成する。
runtime.txtは、自身のpythonのバージョンを確認の上作成する。runtime.txtpython-3.8.0Procfileは以下を記述。
Prockfileweb: python twitter.pyrequirements.txtは以下をターミナルで入力して記述。
pip freeze > requirements.txt次に以下の要領でデプロイ。
gitを初期化、Herokuとgitを紐つけて、addして、the-firstという名前でcommitする。
最後にHerokuにプッシュ。git init heroku git:remote -a testlinebot0319 git add . git commit -m'the-first' git push heroku master定期実行する前に以下をターミナルに入力し、Twitterに投稿されていれば、ひとまず成功。
(2)定期実行
ターミナルで以下を実行し、ブラウザ上で直接Herokuの定期実行の設定を行う。
heroku adding:add scheduler:standard heroku adding:open scheduler
上記のように設定すれば完了(上記は10分毎にツイート設定)
おわりに
よろしければ、フォローしてください
Twitter@MiminariBot

- 投稿日:2020-03-22T18:29:00+09:00
新型コロナウイルスの実効再生産数の世界動向から収束時期を検討してみる
はじめに
新型コロナウイルス感染症(COVID-19)に関連して、実効再生産数1を都道府県別に分析したり、ランキングして来ましたが、今回、世界のデータに目を向けて、実効再生産数の推移から、収束時期が予測できないか検討して見ました。特に、7月に東京オリンピック2020が開催できるかどうかの瀬戸際ですので、日本だけでなく、世界的にも一刻も早い収束が望まれます。
結論
まず、結論から簡潔に述べますと、
- 欧州では3月21日ころに感染ピークを迎え、実効再生産数が$R \leq 1$となった可能性があるが、それが観測されるのは4月上旬ごろと思われます。
- 米国、豪州、東南アジア(マレーシア、インドネシア)、中東(トルコ、イスラエル)では、$R$が10付近の高い水準で推移して収束傾向が見られないため、予断を許さない状況。
- 比較的拡大が抑えられている国(台湾、香港、シンガポール、日本)でも、時折$R$が跳ね上がることがあるため、国外からの流入に注意が必要。
前提
基本的な計算式は、前回の記事の内容と同一です。パラメータも変えていません。また、データは新型コロナウイルスデータセットを使用させて頂きました。このような公開データを提供されている努力に敬意を表します。
潜伏期間や感染期間を経て、検査陽性が判明するというタイムラグがあるため、直近2週間以前の結果は出ていません。Pythonで計算してみる
今回のコードは、GitHubで公開しています。Jupyter Notebook形式で保存してあります。(ファイル名:03_R0_estimation-WLD-02b.ipynb)
コード
特に、前回の記事を踏襲しているため、あまり変更点はありません。
強いて言うなら、累積値のデータを日々の確定データに変えるため、差分をとっています。def readCsvOfWorldArea(area : None): # 下記URLよりダウンロード # https://hackmd.io/@covid19-kenmo/dataset/https%3A%2F%2Fhackmd.io%2F%40covid19-kenmo%2Fdataset fcsv = u'World-COVID-19.csv' df = pd.read_csv(fcsv, header=0, encoding='sjis', parse_dates=[u'日付']) # 日付, 対象国を抽出 if area is not None: df1 = df.loc[:,[u'日付',area]] else: df1 = df.loc[:,[u'日付',u'世界全体の感染者']] df1.columns = ['date','Psum'] ## 累積⇒日次に変換 df2 = df1.copy() df2.columns = ['date','P'] df2.iloc[0,1] = 0 ## 文字列⇒数値 getFloat = lambda e: float('{}'.format(e).replace(',','')) ## 差分計算 for i in range(1,len(df1)): df2.iloc[i, 1] = getFloat(df1.iloc[i, 1]) - getFloat(df1.iloc[i-1, 1] ) ## return df2また、軸を見やすくするため、対数軸で表示しています。
def showResult3(dflist, title): # R0=1 dfs = dflist[0][0] ptgt = pd.DataFrame([[dfs.iloc[0,0],1],[dfs.iloc[len(dfs)-1,0],1]]) ptgt.columns = ['date','target'] ax = ptgt.plot(title='COVID-19 R0', x='date',y='target',style='r--', figsize=(10,8)) ax.set_yscale("symlog", linthreshy=1) # for df, label in dflist: showResult2(ax, df, label) # ax.grid(True) ax.set_ylim(0,) plt.show() fig = ax.get_figure() fig.savefig("R0_{}.png".format(title))元のコードをあまり変えずに対応できたので、助かりました。
計算結果
それでは、いよいよ計算結果を見てみましょう。$R_0 >1$であれば感染拡大傾向、$R_0<1$であれば感染収束傾向、と言えるでしょう。
爆発的感染が観測された地域
中国本土、イタリア、米国、スペイン、イラン、韓国の結果がこちらです。
- グラフの形状として、一気にRが増加したあと、段々と漸減していく傾向があるようです。
- アメリカだけ、やや特異な形状に見えます。
- 中国本土と韓国はほぼ収まっている印象です。
ヨーロッパ
イタリアをはじめ、ヨーロッパでも感染者の多い国を集めた結果がこちらです。
- イタリアは2月25日付近までは漸減傾向にあったものの、2月26日~3月1日あたりに一気にぶり返しています。
- 最近はイタリアの代わりにスペインが$R$のトップに置き換わっているようです。
- その他のヨーロッパ諸国の傾向はかなり似ています。
アジア周辺で比較的感染が抑制されている地域
台湾、日本、香港、シンガポールの結果がこちらです。
- 台湾、香港、シンガポールは1を切ることも多く、よく抑えられているようですが、3月に入ってピークが見られ、海外からの流入が懸念されます。
- 日本は、シンガポールと香港あたりによく似ています。ここから、継続的に1を割っていければ収束が見えてきます。
今後感染拡大が懸念される地域
全てではありませんが、グラフを見ながら、$R$が高い水準で推移しており、収束傾向が見られない国を集めた結果がこちらです。
- 3月22日現在、感染者の比較的多い国で、$R$の収束傾向が確認できない国です。
- おおむね$R=10$付近で推移しており、ヨーロッパのように漸減していないように見えます。
- 共通点は、良くわかりません((+_+))。
ヨーロッパの結果をもとに、実効再生産数の近似式を引いてみる
実効再生産数の推移を見ますと、急激に上がったあとは、指数的に漸減していく傾向が見られます。特に、ヨーロッパの結果を見ますと、国によらず同じような収束傾向が見られます。そこで、以下の近似式で当てはめてみました。
R(t) = R(t_0) \cdot 2^{-\frac{t-t_0}{T}}つまり、$R(t)$の半減期が$T$である、というモデルです。
実際、$T=7.5[days]$として、ヨーロッパ地域のグラフに合わせてみると、以下のようになります(図中の点線が推定式)。
ここから、具体的に$R(t)$に日付を代入してみると、
- 2020-03-01に、$R(t)=6.23$
- 2020-03-21に、$R(t)=0.98$
- 2020-04-15に、$R(t)=0.097$
- 2020-04-30に、$R(t)=0.024$
- 2020-05-15に、$R(t)=0.0061$
という結果になります。もちろん、近似ですので、この通りにならない可能性があります。しかし、直近の3月21日に$R<1$になっているとすれば、新規感染者の増加が一定に収まっているという傾向が、13日後の4月4日ごろに観測されるはずです。そうであれば、入院患者数がどんどん減っていき収束が見えてくるのではないでしょうか。
さらに言えば・・・
- 3月22日現在、南米地域はエクアドルの532名、アフリカ地域はエジプトの294名が最多のようですが、今後増加していく可能性があり、注視していく必要があるでしょう。
- 今後感染拡大が懸念される地域、特にアメリカの動向が心配です。ワシントン州、ニューヨーク州、カリフォルニア州などで非常事態宣言がなされ、ロックダウンも始まっているようですが、まだ、$R$の減少傾向は数字に現れていません。
- 当然、日本も引き続き警戒をしていく必要があります。
参考リンク
下記のページを参考にさせて頂きました。
- 新型コロナウイルスデータセット
- 「新型コロナウイルス感染症対策の状況分析・提言」(2020年3月19日)
- 新型コロナウイルスの都道府県別の基本再生産数の推移を計算してみる
- 新型コロナウイルスの都道府県別の効果的再生産数のランキングを出してみる
本記事では、(ある時刻tにおける,一定の対策下での)1人の感染者による2次感染者数と定義します。 ↩
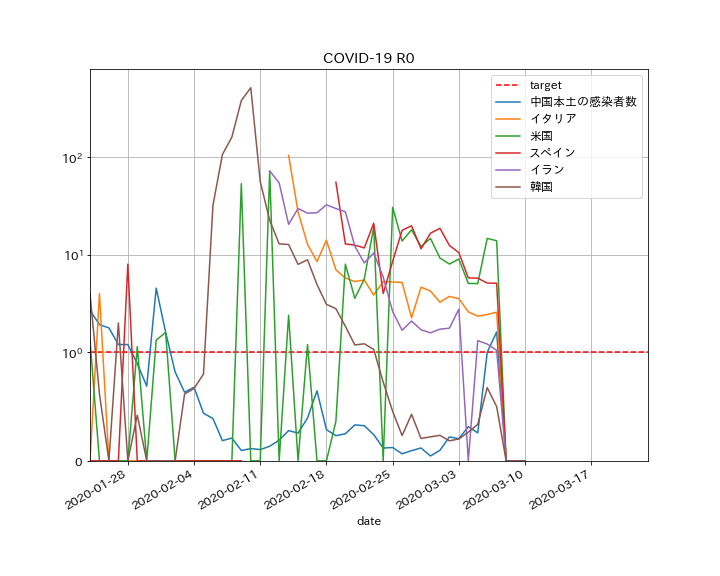
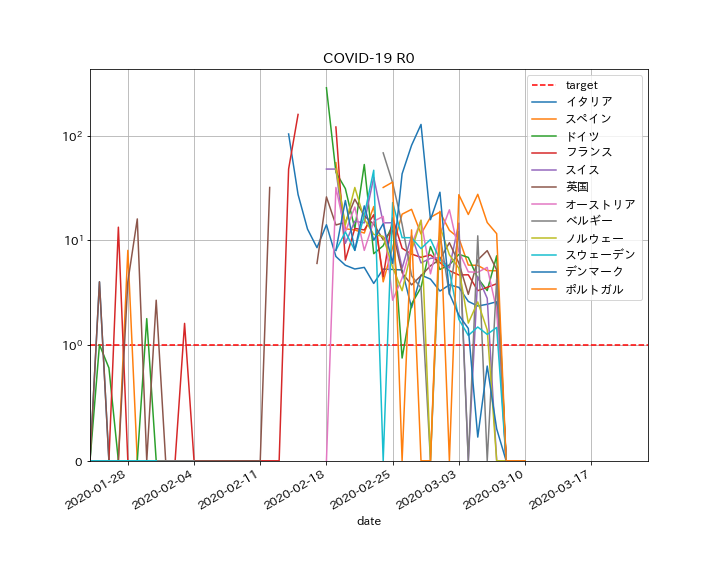
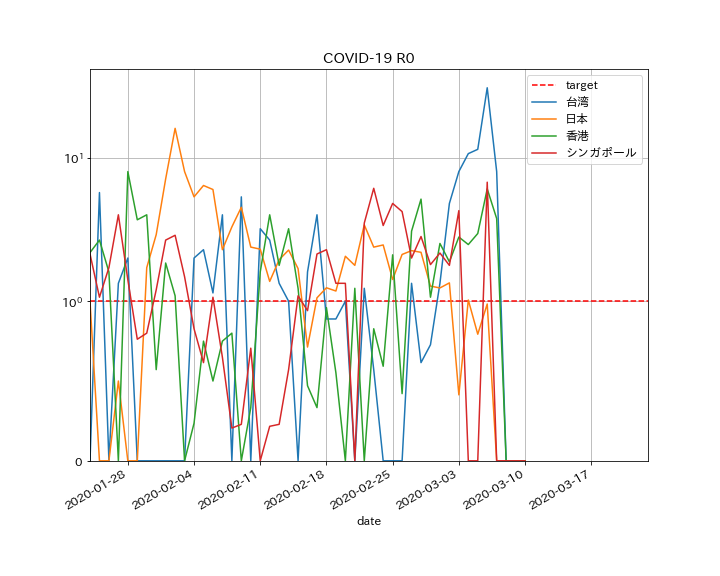
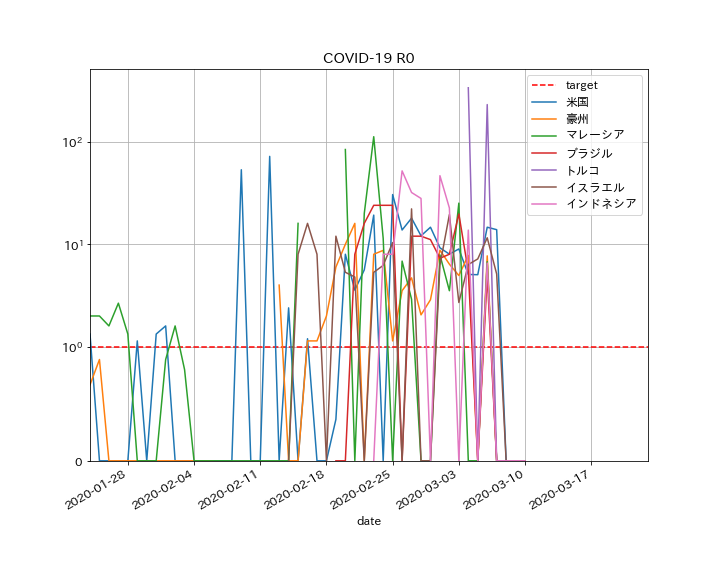
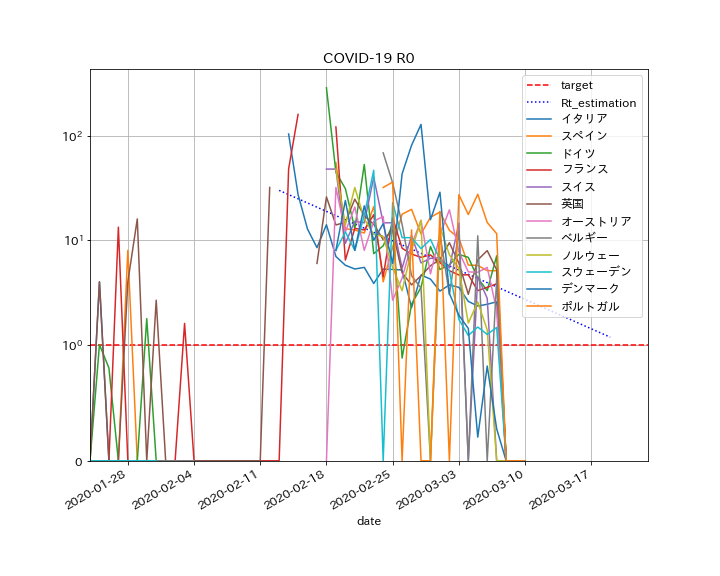
- 投稿日:2020-03-22T18:17:27+09:00
新型コロナは本当に脅威か? Stan で検証した (続編)
前回投稿した「新型コロナは本当に脅威か? Stan で検証した (かった)」は、次の二点で消化不良でした:
- 結局 COVID-19 の致死率がどんなもんなのか分からない
- 最終的に Stan がうまく使えていない
という訳で、今回はそのリベンジとして、 Stan を使って「真の致死率」を求めるという試みをやってみます。
前回の記事で説明したことに関しては繰り返し説明していないので、そちらもご参照ください
免責
筆者はベイズモデリングや Stan の専門家ではないため、この記事の内容には誤りや、よりよい手法が存在する可能性があります。
また、間違っている箇所を見つけたら、ご教示いただけると幸いです。
仮定
前回の投稿では、ダイヤモンド・プリンセス号に於ける感染調査 1 が、世界で最も正確であるという前提のものに議論を展開しました。今回もその方針を踏襲します。
しかしながら、ダイヤモンド・プリンセス号だけでは症例数が少なくて、年齢ごとの致死率を知ることができません。そこで、中国疾病預防控制中心のデータ 2 を利用します。
この2つのデータは母集団がぜんぜん違うので、えいやで仮定を設定してなんとか統合します。ここでは、中国のデータの感染数は、真の感染者全体から、年齢層や致死率に関わらず一定の確率 $c$ で補足され得られたものであると仮定を用いました。
年齢層により症状の傾向が変わり、結果、捕捉された感染者の割合は異なると考えられるため、この仮定は明らかに不正確です。したがって、この記事の結論には、この仮定に起因する誤差が発生します。しかし、国立感染症研究所のデータ 1 によれば、症状がある場合 (Symptomatic confirmed cases) に対する症状がない場合 (Asymptomatic confirmed cases) の割合はむしろ若年層の方が低くなっています。また、若年層の重症率が意外と高いという報告 3 も存在します。このことから、直感よりは荒唐無稽な仮定ではないのではないかと思います。
ダイヤモンド・プリンセス号に於ける致死率は、ここで仮定した捕捉率 $c$ を用いて計算した年齢層ごとの致死率に従うものとすることで、この2つのデータを結合します。
一方、死亡者の捕捉については、中国の統計に於いてももれなく行われていると仮定します。
次に、ダイヤモンド・プリンセス号に於ける死亡者は 6 人としました。3月7日に 7 人目の死亡者が確認されていますが、国立感染症研究所のデータ 1 から2週間以上経過していることから、その時点で感染者でなかった可能性も高いことと、 COVID-19 に関連する死亡かどうかは公表されていないこと、3月7日の時点を基準にするならば感染者の方もデータの時点より増えていたことが根拠です。
最後に、人種による差や、感染者分布の違い (本当は、中国の感染者分布と世界の感染者分布は違うはず) を考慮しないことにしました。ただし、中国とダイヤモンド・プリンセス号に於ける感染者数分布の違いは例外的に考慮しています。
仮定内容をまとめると、以下のようになります。
- 中国に於ける感染者の捕捉率 $c$ は、年齢層に関わらず一定である
- 中国に於ける死亡者の捕捉率は 100% とする
- ダイヤモンド・プリンセス号の統計は正確である (= 捕捉率 100%)
- ダイヤモンド・プリンセス号での致死率は、年齢層ごとに、中国での致死率に捕捉率 $c$ を乗じて計算したものに一致する
- ダイヤモンド・プリンセス号に於ける死亡者を 6 人とする
- 致死率の計算に際して、人種による差・感染者分布による差を考慮しなくてよい
モデル
以下、 $N$ を感染者数、 $D$ を死亡者数、 $p$ を致死率とします。特に断りがない場合、上付き文字で年齢層、下付き文字で場所 ( ${\rm dp}$ = ダイヤモンド・プリンセス号、 ${\rm ch}$ = 中国 ) を示します。上付き文字がないことで全年齢層を表現します。
例えば、 $N_{{\rm dp}}^{60-69}$ は「ダイヤモンド・プリンセス号で確認された 60-69 歳の感染者数」を示します。(実際には、以後、特定の年齢層について言及せず、 $N_{{\rm dp}}^{a}$ と書いて、「ダイヤモンド・プリンセス号で確認された 年齢層 $a$ の感染者数」を表すような使い方をしています。)
推定対象として、仮定が正しい場合の推定致死率を $p$ とし、それと中国の調査によって得られた致死率との比率 $c$ (= $p \over p_{{\rm ch}}$) とします。また、この推定致死率 $p$ を年齢層ごとに分けたものを $p^{60-69}$ のように (下付き文字なしで) 表現します。
中国に於ける年齢層 $a$ の感染者に占める死亡者数は二項分布に従い、
$$ D_{{\rm ch}}^a \sim {\rm binomial}(N_{{\rm ch}}^a, p_{{\rm ch}}^a) $$
とモデル化できます。
また、ダイヤモンド・プリンセス号に於ける、感染者に占める死亡者数も同様に、
$$ D_{{\rm dp}} \sim {\rm binomial}(N_{{\rm dp}}, p_{{\rm dp}}) $$
となります。ダイヤモンド・プリンセス号の死亡者の年齢分布が手元にないため、こちらは年齢層ごとにモデリングしていないことに注意してください。
このふたつを捕捉率 $c$ でつなぎ合わせます。
捕捉率に関してはなんの情報もないので、一様分布を仮定します。
$$ c \sim {\rm uniform}(0, 1) $$
$c$ は年齢層や致死率に関わらず一定と仮定したので、 $p_{{\rm ch}}^a$ に対して独立です。だから、年齢層 $a$ の推定致死率は、
$$ p^a = c \times p_{{\rm ch}}^a $$
全年齢では、
$$ p = c \times {1 \over N_{{\rm ch}}} \sum_a{p_{{\rm ch}}^a \times N_{{\rm ch}}^a} = {1 \over N_{{\rm ch}}} \sum_a{p^a \times N_{{\rm ch}}^a} $$
となります。
また、ダイヤモンド・プリンセス号の致死率は推定致死率に従う ($p_{{\rm dp}}^a = p^a$) と仮定したので、 $p_{{\rm dp}}$ は
$$ p_{{\rm dp}} = {1 \over N_{{\rm dp}}} \sum_a{p^a \times N_{{\rm dp}}^a} $$
となります。
実装
役者が揃ったので、 Stan で実装していきます。
入力データ
変数名は、年齢層を 60-69 歳なら
_6x(i.e. $N_{{\rm ch}}^{60-69}$ =N_ch_6x)、 80 歳以上を_80_up(i.e. $N_{{\rm ch}}^{80-}$ =N_ch_80_up) と表現していること以外は概ねモデルの章の記号と同様です。ダイヤモンド・プリンセス号のデータ 1 は 90 代に関してのデータがありますが、中国のデータ 2 は 80 歳以上でまとめられている点に注意してください。
data { // ダイヤモンド・プリンセス号に於ける死者数 int D_dp; // ダイヤモンド・プリンセス号に於ける年齢層ごとの感染者数 int N_dp_0x; int N_dp_1x; int N_dp_2x; int N_dp_3x; int N_dp_4x; int N_dp_5x; int N_dp_6x; int N_dp_7x; int N_dp_8x; int N_dp_9x; // 中国に於ける年齢層ごとの死亡者数 int D_ch_0x; int D_ch_1x; int D_ch_2x; int D_ch_3x; int D_ch_4x; int D_ch_5x; int D_ch_6x; int D_ch_7x; int D_ch_80_up; // 中国に於ける年齢層ごとの感染者数 int N_ch_0x; int N_ch_1x; int N_ch_2x; int N_ch_3x; int N_ch_4x; int N_ch_5x; int N_ch_6x; int N_ch_7x; int N_ch_80_up; }Stan では便利のために加工したデータを定義しておけるので、全年齢の値を計算しておきます。
transformed data { // ダイヤモンド・プリンセス号に於ける感染者数 int N_dp; // 中国に於ける感染者数 int N_ch; N_dp = N_dp_0x + N_dp_1x + N_dp_2x + N_dp_3x + N_dp_4x + N_dp_5x + N_dp_6x + N_dp_7x + N_dp_8x + N_dp_9x; N_ch = N_ch_0x + N_ch_1x + N_ch_2x + N_ch_3x + N_ch_4x + N_ch_5x + N_ch_6x + N_ch_7x + N_ch_80_up; }推定対象パラメータ
推定対象のパラメータを指定します。
parameters { // 捕捉率 c real<lower=0, upper=1> c; // 中国に於ける致死率 real<lower=0, upper=1> p_ch_0x; real<lower=0, upper=1> p_ch_1x; real<lower=0, upper=1> p_ch_2x; real<lower=0, upper=1> p_ch_3x; real<lower=0, upper=1> p_ch_4x; real<lower=0, upper=1> p_ch_5x; real<lower=0, upper=1> p_ch_6x; real<lower=0, upper=1> p_ch_7x; real<lower=0, upper=1> p_ch_80_up; }改めてこう書いてみると、中国に於ける致死率は普通に $D_{{\rm ch}} \over N_{{\rm ch}}$ で計算できるから推定対象ではないかと思われる方もいらっしゃると思います。
実は、中国に於ける致死率はまだこのモデルでは確定していません。例えばサイコロを 2 回振って 2 回とも 6 が出たとして、そのサイコロは 6 が 100% 出るサイコロだとは言えないように、感染者数と死亡者数が与えられても直ちに致死率を確定することはできないのです。
こういう不確定のものを不確定のまま簡単に扱えるのがベイズモデリングの良さであり、 Stan の良さですね。
さて、データと同じように、
parametersも値の変換を行えるので、やっておきます。transformed parameters { // 年齢ごとの推定致死率 real<lower=0, upper=1> p_0x; real<lower=0, upper=1> p_1x; real<lower=0, upper=1> p_2x; real<lower=0, upper=1> p_3x; real<lower=0, upper=1> p_4x; real<lower=0, upper=1> p_5x; real<lower=0, upper=1> p_6x; real<lower=0, upper=1> p_7x; real<lower=0, upper=1> p_80_up; // 推定致死率 real<lower=0, upper=1> p; // ダイヤモンド・プリンセス号に於ける致死率 real<lower=0, upper=1> p_dp; p_0x = c * p_ch_0x; p_1x = c * p_ch_1x; p_2x = c * p_ch_2x; p_3x = c * p_ch_3x; p_4x = c * p_ch_4x; p_5x = c * p_ch_5x; p_6x = c * p_ch_6x; p_7x = c * p_ch_7x; p_80_up = c * p_ch_80_up; p = (p_0x * N_ch_0x + p_1x * N_ch_1x + p_2x * N_ch_2x + p_3x * N_ch_3x + p_4x * N_ch_4x + p_5x * N_ch_5x + p_6x * N_ch_6x + p_7x * N_ch_7x + p_80_up * N_ch_80_up ) / N_ch; p_dp = (p_0x * N_dp_0x + p_1x * N_dp_1x + p_2x * N_dp_2x + p_3x * N_dp_3x + p_4x * N_dp_4x + p_5x * N_dp_5x + p_6x * N_dp_6x + p_7x * N_dp_7x + p_80_up * (N_dp_8x + N_dp_9x) ) / N_dp; }モデル
モデルの章で書いたままなので特に言うことがないですね。この表現力が Stan の良さです。
model { c ~ uniform(0, 1); D_ch_0x ~ binomial(N_ch_0x, p_ch_0x); D_ch_1x ~ binomial(N_ch_1x, p_ch_1x); D_ch_2x ~ binomial(N_ch_2x, p_ch_2x); D_ch_3x ~ binomial(N_ch_3x, p_ch_3x); D_ch_4x ~ binomial(N_ch_4x, p_ch_4x); D_ch_5x ~ binomial(N_ch_5x, p_ch_5x); D_ch_6x ~ binomial(N_ch_6x, p_ch_6x); D_ch_7x ~ binomial(N_ch_7x, p_ch_7x); D_ch_80_up ~ binomial(N_ch_80_up, p_ch_80_up); D_dp ~ binomial(N_dp, p_dp); }実行
データ
以下のデータを入力しました。
これらは仮定の章で記載したデータに基づきます。data = { # ダイヤモンド・プリンセス号に於ける死者数 'D_dp': 6, # ダイヤモンド・プリンセス号に於ける年齢層ごとの感染者数 'N_dp_0x': 1, 'N_dp_1x': 5, 'N_dp_2x': 28, 'N_dp_3x': 34, 'N_dp_4x': 27, 'N_dp_5x': 59, 'N_dp_6x': 177, 'N_dp_7x': 234, 'N_dp_8x': 52, 'N_dp_9x': 2, # 中国に於ける死者数 'D_ch_0x': 0, 'D_ch_1x': 1, 'D_ch_2x': 7, 'D_ch_3x': 18, 'D_ch_4x': 38, 'D_ch_5x': 130, 'D_ch_6x': 309, 'D_ch_7x': 312, 'D_ch_80_up': 208, # 中国に於ける年齢層ごとの感染者数 'N_ch_0x': 416, 'N_ch_1x': 549, 'N_ch_2x': 3619, 'N_ch_3x': 7600, 'N_ch_4x': 8571, 'N_ch_5x': 10008, 'N_ch_6x': 8583, 'N_ch_7x': 3918, 'N_ch_80_up': 1408, }ソースコード
結果
parametersをたくさん設定したので、実行するとなにやら長大な結果が得られます。mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat c 0.21 8.7e-4 0.08 0.08 0.15 0.2 0.25 0.38 7792 1.0 p_ch_0x 2.4e-3 3.0e-5 2.3e-3 7.1e-5 7.1e-4 1.7e-3 3.2e-3 8.3e-3 5850 1.0 p_ch_1x 3.6e-3 3.3e-5 2.6e-3 4.3e-4 1.7e-3 3.0e-3 4.9e-3 0.01 6364 1.0 p_ch_2x 2.2e-3 9.7e-6 8.0e-4 9.5e-4 1.6e-3 2.1e-3 2.7e-3 4.0e-3 6894 1.0 p_ch_3x 2.5e-3 6.3e-6 5.7e-4 1.5e-3 2.1e-3 2.5e-3 2.9e-3 3.7e-3 8234 1.0 p_ch_4x 4.6e-3 8.7e-6 7.4e-4 3.2e-3 4.1e-3 4.5e-3 5.0e-3 6.1e-3 7259 1.0 p_ch_5x 0.01 1.3e-5 1.1e-3 0.01 0.01 0.01 0.01 0.02 7562 1.0 p_ch_6x 0.04 2.4e-5 2.0e-3 0.03 0.03 0.04 0.04 0.04 7096 1.0 p_ch_7x 0.08 5.2e-5 4.3e-3 0.07 0.08 0.08 0.08 0.09 6650 1.0 p_ch_80_up 0.15 1.1e-4 9.2e-3 0.13 0.14 0.15 0.15 0.17 7552 1.0 p_0x 4.8e-4 7.1e-6 5.3e-4 1.2e-5 1.3e-4 3.1e-4 6.5e-4 1.9e-3 5530 1.0 p_1x 7.4e-4 8.5e-6 6.3e-4 7.0e-5 3.0e-4 5.8e-4 9.8e-4 2.4e-3 5462 1.0 p_2x 4.5e-4 3.2e-6 2.4e-4 1.3e-4 2.8e-4 4.0e-4 5.7e-4 1.1e-3 5637 1.0 p_3x 5.2e-4 2.7e-6 2.3e-4 1.8e-4 3.4e-4 4.8e-4 6.4e-4 1.1e-3 7336 1.0 p_4x 9.4e-4 4.6e-6 3.9e-4 3.6e-4 6.5e-4 8.8e-4 1.2e-3 1.9e-3 7248 1.0 p_5x 2.7e-3 1.2e-5 1.0e-3 1.1e-3 1.9e-3 2.5e-3 3.3e-3 5.0e-3 7484 1.0 p_6x 7.4e-3 3.1e-5 2.8e-3 3.0e-3 5.4e-3 7.0e-3 9.0e-3 0.01 7796 1.0 p_7x 0.02 6.9e-5 6.1e-3 6.6e-3 0.01 0.02 0.02 0.03 7770 1.0 p_80_up 0.03 1.3e-4 0.01 0.01 0.02 0.03 0.04 0.06 7937 1.0 p 4.7e-3 2.0e-5 1.8e-3 1.9e-3 3.5e-3 4.5e-3 5.8e-3 8.6e-3 7853 1.0 p_dp 0.01 4.7e-5 4.2e-3 4.5e-3 8.3e-3 0.01 0.01 0.02 7865 1.0 lp__ -4215 0.06 2.35 -4220 -4216 -4214 -4213 -4211 1641 1.0重要なところを抜き出すと
mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat c 0.21 8.7e-4 0.08 0.08 0.15 0.2 0.25 0.38 7792 1.0 p 4.7e-3 2.0e-5 1.8e-3 1.9e-3 3.5e-3 4.5e-3 5.8e-3 8.6e-3 7853 1.0となります。
すなわち、仮定が正しいならば、中国での感染者の捕捉率は 20% くらいで、それを考慮した致死率は 0.5% くらいであり、 95% 信頼区間においては 0.19% 〜 0.86% と推定されました。
前述の通り、実際にはこの仮定は正確ではないため、 95% 信頼区間なんて何も信頼できないのですが、乗客の過半が 60 歳以上だったダイヤモンド・プリンセス号に於ける致死率が実測 1% くらいなので、この推定は大きく外してはいないんじゃないかと期待しています。
まとめ
今回は前回と違って Stan を使って新型コロナウイルスの致死率を推定することができました。
前よりは Stan の良さも表現できたんじゃないかと思います。 (前ができてなさすぎた)
結果として、強めの仮定を置いたので眉に唾を塗っておく必要があるものの、中国の感染状況に対応する推定致死率として 0.19% 〜 0.86% を得ました。
余談
前回の投稿で、二項分布をベータ分布に変換して推定を行いましたが、今回も、中国に於ける年齢層 $a$ の感染者に占める死亡者数のモデリングを
$$ D_{{\rm ch}}^a \sim {\rm binomial}(N_{{\rm ch}}^a, p_{{\rm ch}}^a) $$
ではなく、
$$ p_{{\rm ch}}^a \sim {\rm beta}(D_{{\rm ch}}^a + 1, N_{{\rm ch}}^a - D_{{\rm ch}}^a + 1) $$
に置き換えて、同じように推論できます。興味がある方は試してみてください。
- 投稿日:2020-03-22T18:17:27+09:00
[続編] 新型コロナは本当に脅威か? Stan で致死率を計算した
前回投稿した「新型コロナは本当に脅威か? Stan で検証した (かった)」は、次の二点で消化不良でした:
- 結局 COVID-19 の致死率がどんなもんなのか分からない
- 最終的に Stan がうまく使えていない
という訳で、今回はそのリベンジとして、 Stan を使って「真の致死率」を求めるという試みをやってみます。
前回の記事で説明したことに関しては繰り返し説明していないので、そちらもご参照ください
免責
筆者はベイズモデリングや Stan の専門家ではないため、この記事の内容には誤りや、よりよい手法が存在する可能性があります。
また、間違っている箇所を見つけたら、ご教示いただけると幸いです。
仮定
前回の投稿では、ダイヤモンド・プリンセス号に於ける感染調査 1 が、世界で最も正確であるという前提のものに議論を展開しました。今回もその方針を踏襲します。
しかしながら、ダイヤモンド・プリンセス号だけでは症例数が少なくて、年齢ごとの致死率を知ることができません。そこで、中国疾病預防控制中心のデータ 2 を利用します。
この2つのデータは母集団がぜんぜん違うので、えいやで仮定を設定してなんとか統合します。ここでは、中国のデータの感染数は、真の感染者全体から、年齢層や致死率に関わらず一定の確率 $c$ で補足され得られたものであると仮定を用いました。
年齢層により症状の傾向が変わり、結果、捕捉された感染者の割合は異なると考えられるため、この仮定は明らかに不正確です。したがって、この記事の結論には、この仮定に起因する誤差が発生します。しかし、国立感染症研究所のデータ 1 によれば、症状がある場合 (Symptomatic confirmed cases) に対する症状がない場合 (Asymptomatic confirmed cases) の割合はむしろ若年層の方が低くなっています。また、若年層の重症率が意外と高いという報告 3 も存在します。このことから、直感よりは荒唐無稽な仮定ではないのではないかと思います。
ダイヤモンド・プリンセス号に於ける致死率は、ここで仮定した捕捉率 $c$ を用いて計算した年齢層ごとの致死率に従うものとすることで、この2つのデータを結合します。
一方、死亡者の捕捉については、中国の統計に於いてももれなく行われていると仮定します。
次に、ダイヤモンド・プリンセス号に於ける死亡者は 6 人としました。3月7日に 7 人目の死亡者が確認されていますが、国立感染症研究所のデータ 1 から2週間以上経過していることから、その時点で感染者でなかった可能性も高いことと、 COVID-19 に関連する死亡かどうかは公表されていないこと、3月7日の時点を基準にするならば感染者の方もデータの時点より増えていたことが根拠です。
最後に、人種による差や、感染者分布の違い (本当は、中国の感染者分布と世界の感染者分布は違うはず) を考慮しないことにしました。ただし、中国とダイヤモンド・プリンセス号に於ける感染者数分布の違いは例外的に考慮しています。
仮定内容をまとめると、以下のようになります。
- 中国に於ける感染者の捕捉率 $c$ は、年齢層に関わらず一定である
- 中国に於ける死亡者の捕捉率は 100% とする
- ダイヤモンド・プリンセス号の統計は正確である (= 捕捉率 100%)
- ダイヤモンド・プリンセス号での致死率は、年齢層ごとに、中国での致死率に捕捉率 $c$ を乗じて計算したものに一致する
- ダイヤモンド・プリンセス号に於ける死亡者を 6 人とする
- 致死率の計算に際して、人種による差・感染者分布による差を考慮しなくてよい
モデル
以下、 $N$ を感染者数、 $D$ を死亡者数、 $p$ を致死率とします。特に断りがない場合、上付き文字で年齢層、下付き文字で場所 ( ${\rm dp}$ = ダイヤモンド・プリンセス号、 ${\rm ch}$ = 中国 ) を示します。上付き文字がないことで全年齢層を表現します。
例えば、 $N_{{\rm dp}}^{60-69}$ は「ダイヤモンド・プリンセス号で確認された 60-69 歳の感染者数」を示します。(実際には、以後、特定の年齢層について言及せず、 $N_{{\rm dp}}^{a}$ と書いて、「ダイヤモンド・プリンセス号で確認された 年齢層 $a$ の感染者数」を表すような使い方をしています。)
推定対象として、仮定が正しい場合の推定致死率を $p$ とします。また、この推定致死率 $p$ を年齢層ごとに分けたものを $p^{60-69}$ のように (下付き文字なしで) 表現します。
中国に於ける年齢層 $a$ の感染者に占める死亡者数は二項分布に従い、
$$ D_{{\rm ch}}^a \sim {\rm binomial}(N_{{\rm ch}}^a, p_{{\rm ch}}^a) $$
とモデル化できます。
また、ダイヤモンド・プリンセス号に於ける、感染者に占める死亡者数も同様に、
$$ D_{{\rm dp}} \sim {\rm binomial}(N_{{\rm dp}}, p_{{\rm dp}}) $$
となります。ダイヤモンド・プリンセス号の死亡者の年齢分布が手元にないため、こちらは年齢層ごとにモデリングしていないことに注意してください。
このふたつを仮定の章で言及した捕捉率 $c$ でつなぎ合わせます。
捕捉率に関してはなんの情報もないので、一様分布を仮定します。
$$ c \sim {\rm uniform}(0, 1) $$
$c$ は年齢層や致死率に関わらず一定と仮定したので、 $p_{{\rm ch}}^a$ に対して独立です。だから、年齢層 $a$ の推定致死率は、
$$ p^a = c \times p_{{\rm ch}}^a $$
全年齢では、
$$ p = c \times {1 \over N_{{\rm ch}}} \sum_a{p_{{\rm ch}}^a \times N_{{\rm ch}}^a} = {1 \over N_{{\rm ch}}} \sum_a{p^a \times N_{{\rm ch}}^a} $$
となります。
また、ダイヤモンド・プリンセス号の致死率は推定致死率に従う ($p_{{\rm dp}}^a = p^a$) と仮定したので、 $p_{{\rm dp}}$ は
$$ p_{{\rm dp}} = {1 \over N_{{\rm dp}}} \sum_a{p^a \times N_{{\rm dp}}^a} $$
となります。
実装
役者が揃ったので、 Stan で実装していきます。
入力データ
変数名は、年齢層を 60-69 歳なら
_6x(i.e. $N_{{\rm ch}}^{60-69}$ =N_ch_6x)、 80 歳以上を_80_up(i.e. $N_{{\rm ch}}^{80-}$ =N_ch_80_up) と表現していること以外は概ねモデルの章の記号と同様です。ダイヤモンド・プリンセス号のデータ 1 は 90 代に関してのデータがありますが、中国のデータ 2 は 80 歳以上でまとめられている点に注意してください。
data { // ダイヤモンド・プリンセス号に於ける死者数 int D_dp; // ダイヤモンド・プリンセス号に於ける年齢層ごとの感染者数 int N_dp_0x; int N_dp_1x; int N_dp_2x; int N_dp_3x; int N_dp_4x; int N_dp_5x; int N_dp_6x; int N_dp_7x; int N_dp_8x; int N_dp_9x; // 中国に於ける年齢層ごとの死亡者数 int D_ch_0x; int D_ch_1x; int D_ch_2x; int D_ch_3x; int D_ch_4x; int D_ch_5x; int D_ch_6x; int D_ch_7x; int D_ch_80_up; // 中国に於ける年齢層ごとの感染者数 int N_ch_0x; int N_ch_1x; int N_ch_2x; int N_ch_3x; int N_ch_4x; int N_ch_5x; int N_ch_6x; int N_ch_7x; int N_ch_80_up; }Stan では便利のために加工したデータを定義しておけるので、全年齢層の値を計算しておきます。
transformed data { // ダイヤモンド・プリンセス号に於ける感染者数 int N_dp; // 中国に於ける感染者数 int N_ch; N_dp = N_dp_0x + N_dp_1x + N_dp_2x + N_dp_3x + N_dp_4x + N_dp_5x + N_dp_6x + N_dp_7x + N_dp_8x + N_dp_9x; N_ch = N_ch_0x + N_ch_1x + N_ch_2x + N_ch_3x + N_ch_4x + N_ch_5x + N_ch_6x + N_ch_7x + N_ch_80_up; }推定対象パラメータ
推定対象のパラメータを指定します。
parameters { // 捕捉率 c real<lower=0, upper=1> c; // 中国に於ける致死率 real<lower=0, upper=1> p_ch_0x; real<lower=0, upper=1> p_ch_1x; real<lower=0, upper=1> p_ch_2x; real<lower=0, upper=1> p_ch_3x; real<lower=0, upper=1> p_ch_4x; real<lower=0, upper=1> p_ch_5x; real<lower=0, upper=1> p_ch_6x; real<lower=0, upper=1> p_ch_7x; real<lower=0, upper=1> p_ch_80_up; }改めてこう書いてみると、中国に於ける致死率は普通に $D_{{\rm ch}} \over N_{{\rm ch}}$ で計算できるから推定対象ではないかと思われる方もいらっしゃると思います。
実は、中国に於ける致死率はまだこのモデルでは確定していません。例えばサイコロを 2 回振って 2 回とも 6 が出たとして、そのサイコロは 6 が 100% 出るサイコロだとは言えないように、感染者数と死亡者数が与えられても直ちに致死率を確定することはできないのです。
こういう不確定のものを不確定のまま簡単に扱えるのがベイズモデリングの良さであり、 Stan の良さですね。
さて、データと同じように、
parametersも値の変換を行えるので、やっておきます。transformed parameters { // 年齢ごとの推定致死率 real<lower=0, upper=1> p_0x; real<lower=0, upper=1> p_1x; real<lower=0, upper=1> p_2x; real<lower=0, upper=1> p_3x; real<lower=0, upper=1> p_4x; real<lower=0, upper=1> p_5x; real<lower=0, upper=1> p_6x; real<lower=0, upper=1> p_7x; real<lower=0, upper=1> p_80_up; // 推定致死率 real<lower=0, upper=1> p; // ダイヤモンド・プリンセス号に於ける致死率 real<lower=0, upper=1> p_dp; p_0x = c * p_ch_0x; p_1x = c * p_ch_1x; p_2x = c * p_ch_2x; p_3x = c * p_ch_3x; p_4x = c * p_ch_4x; p_5x = c * p_ch_5x; p_6x = c * p_ch_6x; p_7x = c * p_ch_7x; p_80_up = c * p_ch_80_up; p = (p_0x * N_ch_0x + p_1x * N_ch_1x + p_2x * N_ch_2x + p_3x * N_ch_3x + p_4x * N_ch_4x + p_5x * N_ch_5x + p_6x * N_ch_6x + p_7x * N_ch_7x + p_80_up * N_ch_80_up ) / N_ch; p_dp = (p_0x * N_dp_0x + p_1x * N_dp_1x + p_2x * N_dp_2x + p_3x * N_dp_3x + p_4x * N_dp_4x + p_5x * N_dp_5x + p_6x * N_dp_6x + p_7x * N_dp_7x + p_80_up * (N_dp_8x + N_dp_9x) ) / N_dp; }モデル
モデルの章で書いたままなので特に言うことがないですね。この表現力が Stan の良さです。
model { c ~ uniform(0, 1); D_ch_0x ~ binomial(N_ch_0x, p_ch_0x); D_ch_1x ~ binomial(N_ch_1x, p_ch_1x); D_ch_2x ~ binomial(N_ch_2x, p_ch_2x); D_ch_3x ~ binomial(N_ch_3x, p_ch_3x); D_ch_4x ~ binomial(N_ch_4x, p_ch_4x); D_ch_5x ~ binomial(N_ch_5x, p_ch_5x); D_ch_6x ~ binomial(N_ch_6x, p_ch_6x); D_ch_7x ~ binomial(N_ch_7x, p_ch_7x); D_ch_80_up ~ binomial(N_ch_80_up, p_ch_80_up); D_dp ~ binomial(N_dp, p_dp); }実行
データ
以下のデータを入力しました。
これらは仮定の章で記載したデータに基づきます。data = { # ダイヤモンド・プリンセス号に於ける死者数 'D_dp': 6, # ダイヤモンド・プリンセス号に於ける年齢層ごとの感染者数 'N_dp_0x': 1, 'N_dp_1x': 5, 'N_dp_2x': 28, 'N_dp_3x': 34, 'N_dp_4x': 27, 'N_dp_5x': 59, 'N_dp_6x': 177, 'N_dp_7x': 234, 'N_dp_8x': 52, 'N_dp_9x': 2, # 中国に於ける死者数 'D_ch_0x': 0, 'D_ch_1x': 1, 'D_ch_2x': 7, 'D_ch_3x': 18, 'D_ch_4x': 38, 'D_ch_5x': 130, 'D_ch_6x': 309, 'D_ch_7x': 312, 'D_ch_80_up': 208, # 中国に於ける年齢層ごとの感染者数 'N_ch_0x': 416, 'N_ch_1x': 549, 'N_ch_2x': 3619, 'N_ch_3x': 7600, 'N_ch_4x': 8571, 'N_ch_5x': 10008, 'N_ch_6x': 8583, 'N_ch_7x': 3918, 'N_ch_80_up': 1408, }ソースコード
結果
parametersをたくさん設定したので、実行するとなにやら長大な結果が得られます。mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat c 0.21 8.7e-4 0.08 0.08 0.15 0.2 0.25 0.38 7792 1.0 p_ch_0x 2.4e-3 3.0e-5 2.3e-3 7.1e-5 7.1e-4 1.7e-3 3.2e-3 8.3e-3 5850 1.0 p_ch_1x 3.6e-3 3.3e-5 2.6e-3 4.3e-4 1.7e-3 3.0e-3 4.9e-3 0.01 6364 1.0 p_ch_2x 2.2e-3 9.7e-6 8.0e-4 9.5e-4 1.6e-3 2.1e-3 2.7e-3 4.0e-3 6894 1.0 p_ch_3x 2.5e-3 6.3e-6 5.7e-4 1.5e-3 2.1e-3 2.5e-3 2.9e-3 3.7e-3 8234 1.0 p_ch_4x 4.6e-3 8.7e-6 7.4e-4 3.2e-3 4.1e-3 4.5e-3 5.0e-3 6.1e-3 7259 1.0 p_ch_5x 0.01 1.3e-5 1.1e-3 0.01 0.01 0.01 0.01 0.02 7562 1.0 p_ch_6x 0.04 2.4e-5 2.0e-3 0.03 0.03 0.04 0.04 0.04 7096 1.0 p_ch_7x 0.08 5.2e-5 4.3e-3 0.07 0.08 0.08 0.08 0.09 6650 1.0 p_ch_80_up 0.15 1.1e-4 9.2e-3 0.13 0.14 0.15 0.15 0.17 7552 1.0 p_0x 4.8e-4 7.1e-6 5.3e-4 1.2e-5 1.3e-4 3.1e-4 6.5e-4 1.9e-3 5530 1.0 p_1x 7.4e-4 8.5e-6 6.3e-4 7.0e-5 3.0e-4 5.8e-4 9.8e-4 2.4e-3 5462 1.0 p_2x 4.5e-4 3.2e-6 2.4e-4 1.3e-4 2.8e-4 4.0e-4 5.7e-4 1.1e-3 5637 1.0 p_3x 5.2e-4 2.7e-6 2.3e-4 1.8e-4 3.4e-4 4.8e-4 6.4e-4 1.1e-3 7336 1.0 p_4x 9.4e-4 4.6e-6 3.9e-4 3.6e-4 6.5e-4 8.8e-4 1.2e-3 1.9e-3 7248 1.0 p_5x 2.7e-3 1.2e-5 1.0e-3 1.1e-3 1.9e-3 2.5e-3 3.3e-3 5.0e-3 7484 1.0 p_6x 7.4e-3 3.1e-5 2.8e-3 3.0e-3 5.4e-3 7.0e-3 9.0e-3 0.01 7796 1.0 p_7x 0.02 6.9e-5 6.1e-3 6.6e-3 0.01 0.02 0.02 0.03 7770 1.0 p_80_up 0.03 1.3e-4 0.01 0.01 0.02 0.03 0.04 0.06 7937 1.0 p 4.7e-3 2.0e-5 1.8e-3 1.9e-3 3.5e-3 4.5e-3 5.8e-3 8.6e-3 7853 1.0 p_dp 0.01 4.7e-5 4.2e-3 4.5e-3 8.3e-3 0.01 0.01 0.02 7865 1.0 lp__ -4215 0.06 2.35 -4220 -4216 -4214 -4213 -4211 1641 1.0重要なところを抜き出すと
mean se_mean sd 2.5% 25% 50% 75% 97.5% n_eff Rhat c 0.21 8.7e-4 0.08 0.08 0.15 0.2 0.25 0.38 7792 1.0 p 4.7e-3 2.0e-5 1.8e-3 1.9e-3 3.5e-3 4.5e-3 5.8e-3 8.6e-3 7853 1.0となります。
すなわち、仮定が正しいならば、中国での感染者の捕捉率は 20% くらいで、それを考慮した致死率は 0.5% くらいであり、 95% 信頼区間においては 0.19% 〜 0.86% と推定されました。
前述の通り、実際にはこの仮定は正確ではないため、 95% 信頼区間なんて何も信頼できないのですが、乗客の過半が 60 歳以上だったダイヤモンド・プリンセス号に於ける致死率が実測 1% くらいなので、この推定は大きく外してはいないんじゃないかと期待しています。
まとめ
今回は前回と違って Stan を使って新型コロナウイルスの致死率を推定することができました。
前よりは Stan の良さも表現できたんじゃないかと思います。 (前ができてなさすぎた)
結果として、強めの仮定を置いたので眉に唾を塗っておく必要があるものの、中国の感染状況に対応する推定致死率として 0.19% 〜 0.86% を得ました。
余談
前回の投稿で、二項分布をベータ分布に変換して推定を行いましたが、今回も、中国に於ける年齢層 $a$ の感染者に占める死亡者数のモデリングを
$$ D_{{\rm ch}}^a \sim {\rm binomial}(N_{{\rm ch}}^a, p_{{\rm ch}}^a) $$
ではなく、
$$ p_{{\rm ch}}^a \sim {\rm beta}(D_{{\rm ch}}^a + 1, N_{{\rm ch}}^a - D_{{\rm ch}}^a + 1) $$
に置き換えて、同じように推論できます。興味がある方は試してみてください。
- 投稿日:2020-03-22T17:39:19+09:00
化合物生成をディープラーニングで?
はじめに
過去に書いたものを再掲しています。
雑記に近いかもしれません。あしからず。新規分子生成?
新しい分子を生成する。特に「欲しい物性を持つ有用な新規分子」の設計について、今までどうしてきたのでしょうか?例えば、創薬の分野では化学の基礎理論は勿論のこと、経験則、Tanimoto係数 、量子化学計算 etc....(他にもあると思いますが、)を用いて創出していると思われます(自分調べ)。
最近、機械学習に上記のことを行わせようという大きな動きがあるようです。
その中で今回注目したのが、引用数が213と多く、ハーバード大のAspuru-Guzikグループが発表した
「Automatic Chemical Design Using a Data-Driven Continuous Representation of Molecules」(1)
という論文とこれを元に作られたプログラム
「Chemical VAE」(2)です。
Chemical VAEって何?
これは、SMILES2vecというword2vec(Seq2Seq)を利用した技術です。これについては前回の私の記事を見ていただければ幸いです。
以下は論文を読んで、自分なりに考えた新規分子生成の流れです。
まず、化合物の表す文字列をエンコーダーでベクトル化し、潜在空間(ベクトル空間)を生成させます。このベクトル空間の位置1点1点はSMILESの文字列であり、位置(後にzと表されます。)が近いほど構造が近いものが存在するそうです。それをデコーダーでできるだけ、同じような文字列に戻します。また、エンコードとデコードがうまく行くように、エンコーダーとデコーターを学習をさせていきます。
その後、(「同時に」と言ってもいいかもしれません。)ベクトル空間と対応する分子の物性値をニューラルネットワークで学習することで、下図のようにf(z)を生成します。
(注)ここからは特に読解が難しかったため、予想に近いものになります。
新規分子と言っても欲しい物性がもたなければ意味がありませんよね?
今回紹介した技術は新規分子生成ではあるものの、
「物性の良い既知の分子に近い構造の分子は同様に物性が良い場合がある(多い?)」という薬学的経験則?のような考えがあるようです。
つまり、この学習した潜在空間中に物性の良い既知の分子をエンコードして、その分子の潜在空間中の位置周辺を探して新規分子を探すという過程をとるようです。その後、学習させたデコーダでその分子のSMILES生成します。最後に生成する際、分子として成り立つかどうかをRDkitで判別させます。
下図はその結果のようです。四角で囲んでいるものが中心分子です。そこから潜在空間の位置関係が表されています。
ここまでの流れが私の理解内です。
実際にGitHubのExampleをやってみた。
Exampleをやる際は、chemical_vaeをcondaやpipで入れてください。
まずは、import部分
intro_to_chemvae.ipynb# tensorflow backend from os import environ environ['KERAS_BACKEND'] = 'tensorflow' # vae stuff from chemvae.vae_utils import VAEUtils from chemvae import mol_utils as mu # import scientific py import numpy as np import pandas as pd # rdkit stuff from rdkit.Chem import AllChem as Chem from rdkit.Chem import PandasTools # plotting stuff import matplotlib.pyplot as plt import matplotlib as mpl from IPython.display import SVG, display %config InlineBackend.figure_format = 'retina' %matplotlib inlineデータセットはzincのデータセットを使います。このデータセットは、SMILESと物性(QED(薬らしさ評価),SAS(synthetic accessibility score),logP(オクタノール係数))の数値が入っています。
また、
・smiles_1は中心分子を指定します。
・noiseは潜在空間中の中心分子からの距離(z)です。
・z範囲内でランダムサンプリングをしており、SMILESが成り立つものが試行1回だけでは、みつからない場合があるため、500回for文で回してみました。
・Reconstructionは中心分子を学習したエンコーダーでベクトル化したものを学習したデコーダーで出力したものです。(下の結果はうまくいってなさそうですが、学習の仕方、パラメーターを変えるべきでしょう。)vae = VAEUtils(directory='../models/zinc_properties') smiles_1 = mu.canon_smiles('CSCC(=O)NNC(=O)c1c(C)oc(C)c1C') for i in range(500): X_1 = vae.smiles_to_hot(smiles_1,canonize_smiles=True) z_1 = vae.encode(X_1) X_r= vae.decode(z_1) print('{:20s} : {}'.format('Input',smiles_1)) print('{:20s} : {}'.format('Reconstruction',vae.hot_to_smiles(X_r,strip=True)[0])) print('{:20s} : {} with norm {:.3f}'.format('Z representation',z_1.shape, np.linalg.norm(z_1))) print('Properties (qed,SAS,logP):') y_1 = vae.predict_prop_Z(z_1)[0] print(y_1) noise=3.0 print('Searching molecules randomly sampled from {:.2f} std (z-distance) from the point'.format(noise))・出力結果
Using TensorFlow backend. Standarization: estimating mu and std values ...done! Input : CSCC(=O)NNC(=O)c1c(C)oc(C)c1C Reconstruction : CH1nCNc1Cs)Nccccc(CCc1)c3 Z representation : (1, 196) with norm 9.901 Properties (qed,SAS,logP): [0.72396696 2.1183593 2.1463375 ] Searching molecules randomly sampled from 3.00 std (z-distance) from the point最後は、見つけてきた、ユニークかつRDkitに判別されたものを取得してきます。
df = vae.z_to_smiles( z_1,decode_attempts=100,noise_norm=noise) print('Found {:d} unique mols, out of {:d}'.format(len(set(df['smiles'])),sum(df['count']))) print('SMILES\n',df.smiles) if sum(df['count']) !=0: df1=pd.DataFrame(df.smiles) df1.to_csv("result1.csv",mode='a',index=False,header=False)以下出力結果
result1.csvON cCO=COCC(O)ccN2cs2c CCCCCCNc-1cO-SCOCCcccc1 CC1CCcC(-nOcc1ccccCCC1)c1 O OC (C)C(=Occc3cccccccc)CB CCC1oNCc2cCcccccc2cccc1 1 1 CO CC(1c(O=O1O(1cO)nC))1 C=C1nn(=O)SnNccccccocc1C CC C@Cs(=CN=11cccc2cc1Cc)2c1 C OcCCc(CO)c1nccc=Occccc1C O1Cc(c1CCO)CNCC=BBOCCCN CC ON(FCNN(C)ccc(Ocn1)1)l C1ccnccnccccccccncccscc1 CC(CScc(c1cOn1nc1CCl)C)1 CCCCc(-ncccc21nc1c1c2)1CCC C cnc(Cnncncc(C())Cl)Cl1 1RDkitを通したにも関わらず、おそらく分子にならないものもちらほら。。。
しかし、多くのSyntax errorを回避しているようです。RDkit有能。。以上
参考
1)Automatic Chemical Design Using a Data-Driven Continuous Representation of Molecules
https://pubs.acs.org/doi/abs/10.1021/acscentsci.7b00572
2)chemical_vae
https://github.com/aspuru-guzik-group/chemical_vae
3)DeepLearningによる化合物生成(薬、有機発光分子)
https://ritsuan.com/blog/8480/

- 投稿日:2020-03-22T17:29:22+09:00
CLI で csv を tsv に変換する方法
Python が使える環境で
csvkitをインストールする。brew install csvkit # or pip install csvkit
csvformatというコマンドが使えるようになるので下記の要領で実行する。csvformat -T input.csv > output.tsv
- 投稿日:2020-03-22T17:25:16+09:00
pythonからthingspeakを使う
import requests APIKEY = '******' baseURL = 'https://api.thingspeak.com/update?api_key={}&'.format(myAPI) data = 10 response = requests.get(baseURL+'field1={}'.format(data))
- 投稿日:2020-03-22T16:55:23+09:00
macOS Catalina で python の開発環境を作るメモ
メモ随時更新予定
狙いとしては python の開発環境の構築
Mojave から Catalina に上げた環境で、普通にやってるとバージョンの違いで
python3とかpip3で期待通りに動かなかったのでpyenvあたりを利用してうまいこと動かないか試す。本当は Docker とか使った方が良さそうだけどひとまず・・・
homebrew
ここからスタート。
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/master/install.sh)"pyenv インストール
$ brew install pyenv $ pyenv -v pyenv 1.2.17設定
$ echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bash_profile $ echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bash_profile $ echo -e 'if command -v pyenv 1>/dev/null 2>&1; then\n eval "$(pyenv init -)"\nfi' >> ~/.bash_profilehttps://github.com/pyenv/pyenv
反映
$ source ~/.bash_profileインストール可能なバージョンを確認
$ pyenv install -l使いたいバージョンをインストール
$ pyenv install 3.7.7インストールの確認
$ pyenv versions * system (set by /Users/ykinomt/.pyenv/version) 3.7.7バージョン切り替え
現状確認
$ python -V Python 2.7.16切り替え
$ pyenv global 3.7.7 $ python -V Python 3.7.7そのディレクトリ単位で切り替えるなら local を使う。
$ python -V Python 2.7.16 $ pyenv local 3.7.7 $ python -V Python 3.7.7localを使った場合、そのディレクトリに
.python-versionというファイルが作成され、そのディレクトリでは指定されたバージョンで動く。
アプリケーションを作成する様な場合は local で指定した方が良いかも。vscode の設定
特に必要ないが、インタープリタの設定で出てくるバージョンは VSCode 起動までにインストールされたモノみたいなので、上記の設定で新規にインストールした場合には一度 vscode を再起動しないと選択できないかも。
- 投稿日:2020-03-22T16:48:57+09:00
【python】日付のフォーマット(表示書式)を変更する方法
pythonで日付のフォーマット(表示書式)を変更する方法
日付の型を文字列として出力するとデフォルトは、「yyyy-mm-dd」の形になる。
これを「yyyy/mm/dd」や「yyyy年m月d日」のように任意の書式に変更する。※list形式は「yyyy-mm-dd」となる。書式を変えられるのは文字列のみ。
日付のデフォルト表示例
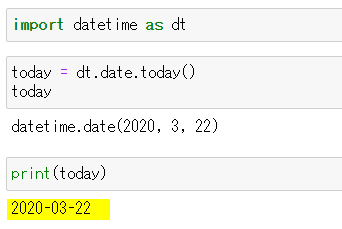
2020-03-22(文字列|str)目次
日付変更の「2つ」の方法
①strptimeメソッドを使う
②formatメソッドを使う
[1]日付書式の変更(例:yyyy/mm/dd)
0埋めありパターン
(1-1)strptimeメソッドで変更する
.strftime('%Y/%m/%d')
└ 例:「today.strftime("%Y/%m/%d")」
└ 「%Y」:西暦 (4桁) の 10進数(※%yは2桁)
└ 「%m」:0埋めした10進数の月(※%Mは分)
└ 「%d」:0埋めした10進数の日にち(%Dはmm/dd/yy)ソースコードimport datetime as dt today = dt.date.today() #出力:datetime.date(2020, 3, 22) today.strftime("%Y/%m/%d") #出力結果 #'2020/03/22'タイプは文字列
「type(today.strftime("%Y/%m/%d"))」:str
(1-2)formatメソッドで変更する
'{0:%Y/%m/%d}'.format()
└ 例:'{0:%Y/%m/%d}'.format(today)
└ 「0:」何番目の要素に適用するか指定(※省略不可)
※上記例ではtodayの1つしか存在しないソースコードimport datetime as dt today = dt.date.today() #出力:datetime.date(2020, 3, 22) '{0:%Y/%m/%d}'.format(today) #出力結果 #'2020/03/22'タイプは文字列
「type('{0:%Y/%m/%d}'.format(today))」:str
■インデックス番号の適用例
'{0:%Y/%m/%d}'.format()
└ 「0:」で0以外を指定する場合・format()の引数の中に複数の日付がある場合に使う
インデクス番号の使用例#3つの日付を作成 today = dt.date.today() past = dt.date(2015,1,1) future = dt.date(2030,1,1) #インデックス番号を変更(0~2) '{0:%Y/%m/%d}'.format(today,past,future) #出力:'2020/03/22' '{1:%Y/%m/%d}'.format(today,past,future) #出力:'2015/01/01' '{2:%Y/%m/%d}'.format(today,past,future) #出力:'2030/01/01'
[2]日付書式の変更(例:yyyy年m月d日)
0埋めなしパターン
(2-1)strptimeメソッドで変更する
.strftime('%Y/%#m/%#d')
└ 例:「today.strftime("%Y/%#m/%#d")」
└ 「%Y」:西暦 (4桁) の 10進数(※%yは2桁)
└ 「%#m」:0埋めなし10進数の月(※%Mは分)
└ 「%#d」:0埋めなし10進数の日にち(%Dはmm/dd/yy)▼0埋めなしにする方法
※windows:「#」をつける(例:「%#m」)
※Mac:「-」をつける(例:「%-m」)ソースコード(windows)today = dt.date.today() today.strftime("%Y年%#m月%#d日") #出力結果 #'2020年3月22日
(2-2)formatメソッドで変更する
'{0:%Y年%#m月%#d日}'.format()
└ 例:'{0:%Y年%#m月%#d日}'.format(today)
└ 「0:」何番目の要素に適用するか指定(※省略不可)ソースコードtoday = dt.date.today() '{0:%Y年%#m月%#d日}'.format(today) #出力結果 #'2020年3月22日
(2-3)year, month, dayメソッドを使う
str(today.year)+"年"+str(today.month)+"月"+str(today.day)+"日"
└ 「.year」:西暦4桁(型:int)
└ 「.month」:0埋めなしの月(型:int)
└ 「.day」:0埋めなしの日付(型:int)
└ 「+」:intとstrはつなげない⇒ intをstrに変換ソースコードtoday = dt.date.today() str(today.year)+"年"+str(today.month)+"月"+str(today.day)+"日" #出力結果 #'2020年3月22日
(2-4)replaceメソッドを使う
y = today.strftime("%Y年")
md = today.strftime("%m月%d日").replace("0","")
y+mdソースコードtoday = dt.date.today() y = today.strftime("%Y年") md = today.strftime("%m月%d日").replace("0","") y+md #出力結果 #'2020年3月22日
方法は他にもたくさんあると思いますが、いったんこんなもので。いい方法ありましたら教えてください。
- 投稿日:2020-03-22T16:40:36+09:00
Wikipediaの国旗画像をpythonで一括ダウンロードする
概要
Wikipediaの国旗の一覧に載っている国旗画像をpythonでダウンロード(スクレイピング)しました。
参考
環境
macOS Catalina
python3.8.0ライブラリのインストール
pip install beautifulsoup4 pip install requests pip install urllib実装
from bs4 import BeautifulSoup import requests import urllib import os import time #wikipedia「国旗の一覧」のurl wiki_url = "https://ja.wikipedia.org/wiki/%E5%9B%BD%E6%97%97%E3%81%AE%E4%B8%80%E8%A6%A7" #htmlソースの取得とパース html_text = requests.get(wiki_url).text soup = BeautifulSoup(html_text,"lxml") #imgタグの取得 imgs = soup.find_all("img") #国旗画像URLの取得 flag_urls = [] for tag in imgs: #国旗画像のimgタグはalt属性が"〇〇の旗"という形式になっているので(2020年3月22日現在)、"旗"が含まれるものだけ処理する。 if "旗" not in tag.get("alt"): continue url = tag.get("src") #src属性(urlの相対パス)を取得 url = "https:"+url #https:を先頭につけて絶対URLにする flag_urls.append(url) for url in flag_urls: #ダウンロード先のパスの指定 #各URLの末尾は"125px-Flag_of_国名.svg.png"のようになっている。ここから"Flag_of_国名.png"をダウンロード後のファイル名にする png_name = url.split("px-")[-1].split(".")[0]+".png" #figsというディレクトリの下に保存する。figsは予め作っておく png_name = os.path.join("./figs",png_name) #ファイルが存在しない場合のみダウンロードする if os.path.exists(png_name): print("File",png_name,"already exists") continue urllib.request.urlretrieve(url,png_name) print("File",png_name,"downloaded") #サーバに負荷を与えないため待機 time.sleep(1)ファイル名が一部文字化けしていましたが、ダウンロードは無事できました。
- 投稿日:2020-03-22T16:30:45+09:00
フォルダ内のすべてのxlsxファイルを、CSVファイルに一括変換する
背景・前提・仕様とか
仕事用Excel操作ツール作成用メモ。
これ↓の派生。
フォルダ内のすべてのxlsxファイル名を自然順のリストで取得して、絶対パスを構築する使い方
デスクトップ上に新しいフォルダを2つ、"folder1", "folder2"という名前で作る。
"folder1"内に、変換したいxlsxのファイルをすべて放り込む。
動かす。
"folder2"内に、csvファイルに変換されて保存。
実行環境
実行環境と各ライブラリのバージョンは下記の通り。
- Windows10 pro
- Python 3.7.3
- natsort 7.0.1
- openpyxl 3.0.3
フォルダ内のすべてのxlsxファイルを、CSVファイルに一括変換する。
all_xlsx_to_csv.pyimport os import csv import openpyxl from natsort import natsorted # デスクトップに作った任意のフォルダ名称 folder_name = "folder1" folder_2_name = "folder2" # 定数 desktop_path = os.getenv("HOMEDRIVE") + os.getenv("HOMEPATH") + "\\Desktop" folder_path = os.path.join(desktop_path, folder_name) folder_2_path = os.path.join(desktop_path, folder_2_name) # Excelファイル名リストを自然順で取得 files = natsorted(os.listdir(folder_path)) #ファイル名リストをfor文でまわして各ファイルの絶対パスを構築 for filename in files: filepath = os.path.join(folder_path, filename) # xlsxファイルにアクセス→先頭シートのオブジェクトを取得 wb = openpyxl.load_workbook(filepath) ws_name = wb.sheetnames[0] ws = wb[ws_name] # csvに変換して、folder2に保存 savecsv_path = os.path.join(folder_2_path, filename.rstrip(".xlsx")+".csv") with open(savecsv_path, 'w', newline="") as csvfile: writer = csv.writer(csvfile) for row in ws.rows: writer.writerow([cell.value for cell in row])