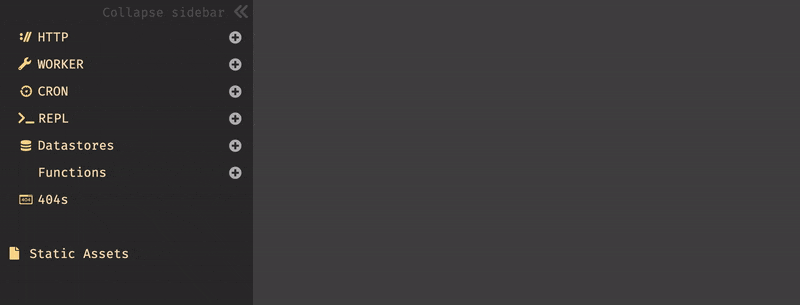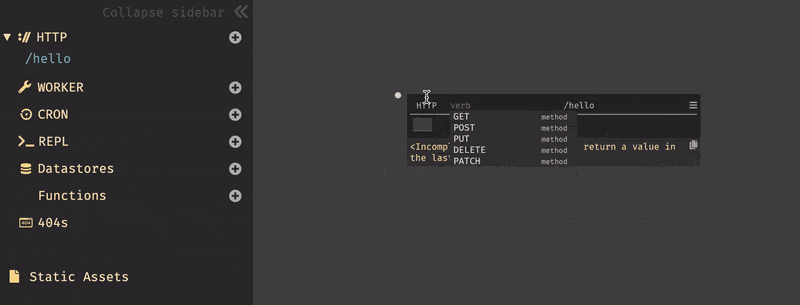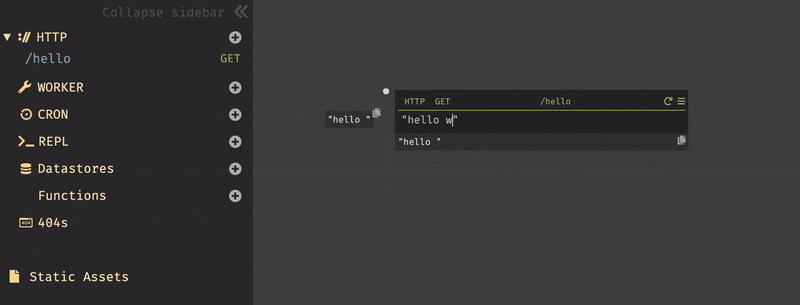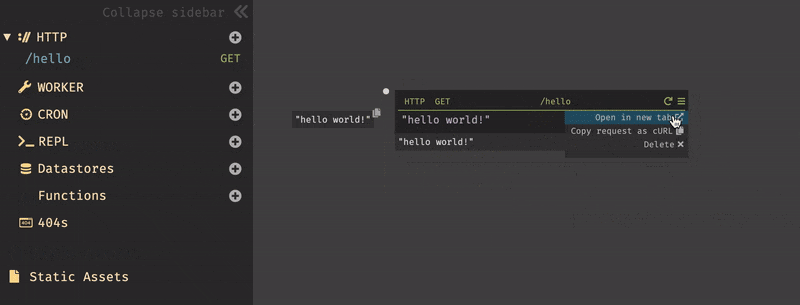- 投稿日:2020-03-22T22:17:11+09:00
CloudFormationテンプレートを1からしっかり理解しながらECS on Fargateなアプリを自動構築する(中編)
前提条件
前編で作ったECSのサービスに対してCodePipelineを使ってCI/CDパイプラインを作るので、前編を理解しておく。
記事中には、備忘のためにリファレンスに書かれていないデフォルト値を整理しておくが、2020年3月時点の情報であり、後でAWSが仕様を変えたとしても追従する予定はないので、挙動が違ったらリファレンスを見直してほしい。あと、今回の構成(ECS on FargateのBlue/Greenデプロイメント)以外の構成以外のデフォルト値まで調査はしていないのであしからず。
CodeDeployでBlue/Greenデプロイメントのアプリケーションを作る
アプリケーションの設定
ここはそんなに悩むことはない。以下のような感じで設定しておけばOK。
APPLICATION: Type: AWS::CodeDeploy::Application Properties: ApplicationName: CFn-test-Application ComputePlatform: ECS各プロパティのデフォルト値は以下。
プロパティ デフォルト値 ApplicationName AWS払い出しの名前 ※リファレンス記載 ComputePlatform EC2/オンプレミス デプロイメントグループの準備
ちなみに、デフォルト値の確認をしていたところ、DeploymentStyle のプロパティを設定しないと、なぜか
For ECS deployment group, ec2TagFilters can not be specified (Service: AmazonCodeDeploy; Status Code: 400; Error Code: InvalidEC2TagException; Request ID: ...)なエラーが出た。謎。
BLUE_GREENを設定すれば解消するので深く追跡はしない。例によって各プロパティのデフォルト値は以下。
プロパティ デフォルト値 AlarmConfiguration 無し AutoRollbackConfiguration よく分からない… AutoScalingGroups 無し Deployment よく分からない… DeploymentConfigName なし? DeploymentGroupName AWS払い出しの名前 ※リファレンス記載 Ec2TagFilters Fargateでは対象外 Ec2TagSet Fargateでは対象外 LoadBalancerInfo ECSのBlue/Greenデプロイメントでは必須 OnPremisesInstanceTagFilters Fargateでは対象外 OnPremisesTagSet Fargateでは対象外 TriggerConfigurations なし ここで問題が……
ここから先、どう頑張ってもエラーが出てしまう。
なんと、ユーザーガイドを見るとBlue/Green デプロイタイプでは、AWS CloudFormation は、Lambda コンピューティングプラットフォームでのデプロイのみをサポートします。
とか書いてある。ガーン……このままではCloudFormationによる全自動化ができないのか……。
ここまでやって諦めてしまうのは勿体ないので、一部だけ半自動にする。
作りたかったアプリケーションとデプロイメントグループの定義をCLIをラップしたシェルにして…#!/bin/sh APPLICATION_NAME=CFn-test-Application DEPLOYMENT_GROUP_NAME=CFn-test-DeploymentGroup DEPLOYMENT_GROUP_JSON=./CLI_createDeploymentGroup.json aws deploy create-application --application-name ${APPLICATION_NAME} --compute-platform ECS aws deploy create-deployment-group --application-name ${APPLICATION_NAME} --deployment-group-name ${DEPLOYMENT_GROUP_NAME} --cli-input-json file://${DEPLOYMENT_GROUP_JSON}{ "applicationName": "CFn-test-Application", "deploymentGroupName": "CFn-test-DeploymentGroup", "serviceRoleArn": "arn:aws:iam::[アカウントID]:role/ecsCodeDeployRole", "deploymentStyle": { "deploymentType": "BLUE_GREEN", "deploymentOption": "WITH_TRAFFIC_CONTROL" }, "blueGreenDeploymentConfiguration": { "terminateBlueInstancesOnDeploymentSuccess": { "action": "TERMINATE", "terminationWaitTimeInMinutes": 30 }, "deploymentReadyOption": { "actionOnTimeout": "CONTINUE_DEPLOYMENT", "waitTimeInMinutes": 0 } }, "loadBalancerInfo": { "targetGroupPairInfoList": [ { "targetGroups": [ { "name": "CFn-test-ALB-TG1" }, { "name": "CFn-test-ALB-TG2" } ], "prodTrafficRoute": { "listenerArns": [ "[CFn-test-ALBの本番用リスナーのArn]" ] }, "testTrafficRoute": { "listenerArns": [ "[CFn-test-ALBテスト用リスナーのArn]" ] } } ] }, "ecsServices": [ { "serviceName": "CFn-test-ECSService", "clusterName": "CFn-test-ECSCluster" } ] }こうだ!このシェルを実行して、アプリケーションを作成してからCodeDeployでデプロイを作成してみると、ちゃんとテストポートを使ったBlue/Greenデプロイメントが発動する!
あとは、これをCodePipelineに組み込むのみ!
ということで、後編に続く。
- 投稿日:2020-03-22T22:10:40+09:00
AWS認定ソリューションアーキテクト - アソシエイト 1回落ちて2回目で合格
AWS認定ソリューションアーキテクト - アソシエイト 受験の感想です。
はじめに
今まで、AWSを使う機会は全く無かったのですが、
転職を機会きっかけにAWSに関わることが増えたため、知識の底上げとして受験することにしました。実は、半年くらい前に一度受験したのですが、その時は落ちてしまい、再受験の機会を伺っていました。
そんな時、新しいバージョン(SAA-C02)が、2020/3/23から始まるとのことで、急遽受験することにしました。1回目(落ちた)
勉強
みなさまの合格記録を参考に勉強をはじめました。
- 黒本を3〜4周
- 公式のサンプル問題
- 公式の模擬試験
模擬試験は、問題をキャプチャ、正解はわからないので、黒本で確認、わからなければググる。
不安はあったものの、大枠、理解出来てる感はあったので、受験してみました。振り返り
サービス名と内容の把握は出来ているものの、
具体的なアプリケーションやシステム構成に落とし込んだ場合についての理解が甘かったのだと思います。
実際、回答にかなりの時間を要し、見直す時間はない状況でした。2回目(受かった)
勉強
1回目の振り返りを元に、各サービス/機能を
- どのように使用するのか
- どう選ぶのか
を理解するため、以下に頼りました。
ハンズオンで使い方のイメージを固めつつ、試験問題で復習するという形で進めていきました。
うちの会社は、AWSが使い放題なので、そこは非常に助かりました。勉強に対する支援、ホント素晴らしいです!!当初、1ヶ月後に再受験と考えていたものの、予定が合わず一旦キャンセル、いつ受けようか悩んでいたところ、
新バージョンの話が出てきて、急遽、2週間後に再受験することにしました。
ハンズオンは一通り終わっていたので、2週間は、ひたすら試験を解いて過ごしました。振り返り
1回目と違い、半分ほどの時間を残して回答が終わり、残りは全て見直しに使うことが出来ました。
慣れもあるかもしれませんが、今回は、問題が求めているものをしっかり読み取り、スムーズに回答出来ました。おまけ
2回目の勉強期間中、社内の勉強会で「ABD(アクティブ・ブック・ダイアローグ)で黒本を読む」という機会があり、
非常に良い復習になりました。最初にこの機会があれば、機能理解はもっとスムーズ進んだことと思います。最後に
資格が全てではないものの、やっぱり合格出来て嬉しいです。
資格を持っているだけにならないよう、学んだ知識を仕事で活用していこうと思います(使わないと忘れちゃう)。
- 投稿日:2020-03-22T21:43:19+09:00
DjangoアプリをローカルからAWSに上げたらCSSが適用されなくなった話
経緯
DjangoやAWSの学習のため、以下の記事を元にローカルでDjangoアプリを作成したあと、githubからAWSにclone。
Django(Python)でシステム開発できるようになる記事_入門編
【20分でデプロイ】AWS EC2にDjango+PostgreSQL+Nginx環境を構築してササッと公開AWS上で
python3 manage.py runserverした後、ローカルでは管理画面に適用されていたCSSが適用されていないことに気づく。
解決方法
Nginxのログを確認した結果、CSSのパスが通っていないというエラーが発生しているのを確認。
$ tail -F /var/log/nginx/error.log (中略) 2020/03/21 01:18:04 [error] 23086#23086: *197 open() "/home/ubuntu/repository/mysite/static/admin/css/base.css" failed (2: No such file or directory), client: XXX.XXX.XXX.XXX, server: XXX.XXX.XXX.XXX, request: "GET /static/admin/css/base.css HTTP/1.1", host: "XXX.XXX.XXX.XXX", referrer: "http://XXX.XXX.XXX.XXX/admin/login/?next=/admin/"Djangoにおける静的ファイル(static file)の取り扱いによると、パスを通すには
collectstaticコマンドを使えば良い模様。
settings.pyの静的コンテンツ取り扱いの設定値を以下の通り設定した後、python3 manage.py collectstaticを実行settings.py# 静的ファイルの呼び出し設定を1番下に追加 BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) PROJECT_NAME = os.path.basename(BASE_DIR) #STATICFILES_DIRS = [os.path.join(BASE_DIR, 'static')] STATIC_ROOT = os.path.join(BASE_DIR, 'static')$ python3 manage.py collectstatic You have requested to collect static files at the destination location as specified in your settings: /home/ubuntu/repository/mysite/static This will overwrite existing files! Are you sure you want to do this? Type 'yes' to continue, or 'no' to cancel: yes 119 static files copied to '/home/ubuntu/repository/mysite/static'.staticディレクトリ配下に管理画面の静的ファイル(
~/.local/lib/python3.5/site-packages/django/contrib/admin/static/配下にあるもの)がコピーされる。$ ls ~/repository/mysite/static admin css images js (css,image,jsはmkdirで作成) $ ls ~/repository/mysite/static/admin css fonts img jsこれによって管理画面のCSSのパスが通った。

- 投稿日:2020-03-22T18:59:21+09:00
【AWS初心者】×【対策本1冊のみ】×【 平日+休日2日のみ(50時間)】でSAA(ソリューションアーキテクト アソシエイト)を取得する方法
この記事の構成
▶合格するのに必要なもの3点(無駄を究極にそぎ落としました)
①:対策本1冊
②:"受けるからには 絶対に 受かる"という強い意志
③:50時間
▶これから始める人へのエール①:対策本
本屋に並んでる対策本全部見て、以下の観点で決めました。
ポイントは1冊に絞ること。複数冊買いたくなりますが、
9割以上重複してるので学習効率が悪いです。
- ページ数が少ない(重要!量より質を大事に)
- 図解が好み(超重要!色とかテイストは集中力に直結)
- 模擬試験の解説が教科書とリンクしている(最重要!!学習効率が爆上がり)
②:"受けるからには 絶対に 受かる"という強い意志
なんのために試験を受けるか?
なんとなく勉強するのであれば時間の無駄です。
受かる ことから逆算して攻略方法を考えるべきです。
意志次第で同じ1時間でも密度が全く異なります。③:50時間
具体的な学習方法について記述します。
1冊を 教科書・模擬試験・試験解説 に分解して考えます。
1冊を極めることを意識して学習に臨みます。1.教科書
所要時間 学習方法 1周目 8時間 [慣れる] 流し読み。言葉に慣れるだけでOK 2周目 5時間 [慣れる] 言葉に慣れきることを意識 3-5周目 各3時間 [理解する] 書かれてる内容を理解しようとする。ネットを少し活用して調べるのも可 6-10周目 各2時間 [極める] 模擬試験の内容とリンクさせる。必要に応じて書き込み 合計 32時間 2.模擬試験
所要時間 学習方法 1周目 2時間 [慣れる] ほとんど解けない。一番しんどいですが我慢です 2周目 1時間 [解ける] 間違えたところと自信がなかったところだけ重点的に 3周目 1時間 [理解して解ける] 解説に書かれている内容を思い出しながら 合計 4時間 3.試験解説
所要時間 学習方法 1周目 5時間 [知識吸収] 出題されることしか書いてないです。貪欲に頭に叩き込みます 2周目 4時間 [解き方の理解] 選択肢の中で正答と誤答の違いを 人に説明する つもりで理解します 3周目 1時間 [理解して解ける] 間違ったところだけもう一度理解 合計 10時間 →合計で46時間です。残り4時間は自身で不足箇所の学習にあてます
3週間でやるとすると
所要時間 やること 1週目 13時間 教科書2周 2週目 19時間 教科書2周、(模擬試験+試験解説理解)×2周 3週目 18時間 教科書6周、試験解説理解1周 平日+休日2日のみ で時間を捻出する
- 通勤で1時間
- 昼休みで30分
- 定時後に1時間
→これで平日に2時間半確保。3週間で37時間半- 休日に6時間~7時間を2日
私の場合、自宅では集中効率が悪いのでやらないと決めました。
定時後や休日はカフェやコ・ワーキングスペース(AWS Loft TokyoやNagatacho GRiD)を利用しました。これから始める人へのエール
ここまで読んでいただきありがとうございます。
人生80年で考えると50時間はたったの0.007%ほどです。
これからの時代を考えるとかけた時間に対して得られる果実が圧倒的に大きいです。それから、試験は選択式です。
- 4択で正答1つを選択
- 5択で正答2つを選択
の2パターンです。問題数は65問なので50問以上(正答率77%)の正解を目指しましょう。
単に知識を問うだけの問題も多いので、35問は自信を持って答えられるレベルであれば
残り30問の50%(15問)を正解すればよいだけです。
4択で正答1つを選択のパターンであれば2択まで絞り込めれば合格できる計算です。ぜひ頑張ってください!!

- 投稿日:2020-03-22T17:55:30+09:00
[入門] AWS Systems Managerでパッチ管理(チュートリアル)
AWS Systems Manager とは
世はまさに大マネージドサービス時代。
「この世の全てがそこにある」と言われています(?)。今回お話させていただくSystems Managerにはシステム管理におけるたくさんの機能があります。
※全体像を把握しにくいのですが、多分AWS裏側で構成管理/自動構築(ChefやAnsibleなど)を利用しており
それらによってインフラ管理するサービスと捉えています。今回はパッチ管理に関する部分だけお話をさせていただきます。
この記事で書くこと
- パッチ管理の考え方
- サブ機能「メンテナンスウィンドウ」について
- サブ機能「パッチマネージャー」について
- 実装方法
1.パッチ管理の考え方
パッチの自動適用が許容できない(逐一パッチ内容を精査する必要がある)場合に
本記事が役に立つのではないかと思います。2.サブ機能「メンテナンスウィンドウ」について
スケジュール実行のタイミング等を定義するものです。
また、パッチ管理においては「スキャン」or「スキャン&インストール」を決めます。
※今回は自動パッチ適用を許容しないためスキャンのみです。3.サブ機能「パッチマネージャー」について
どのパッチ適用をするか「PatchBaseline」というルールで設定します。
以下はできることサマリです。※2020/4/13時点
対象EC2の制御
- 特定のタグ設定しているものだけ自動で適用
- (パッチグループという括りに事前に参加し)グループでまとめて指定
- 手動でインスタンスを一つ一つ指定
様々なOSが対応
- Amazon Linux
- Amazon Linux2
- CentOS
- Red Hat Enterprise Linux
- SUSE
- Ubuntu
- Windows
※より細かいOSの指定も可能です。
Windowsの場合は、Win7~10/Win10LTSB/WinsServer2012R2~2019など。
パッチ分類を指定することが可能です。
- CriticalUpdate
- Driver
- SecurityUpdates
- FeaturePacks
- etc...
パッチの重要度を指定することができます。
- Critical~Low / Unspecified
その他
- パッチがリリースされてからパッチマネージャーの対象にするまでの待機日数を指定可能です。
- アプリケーションのパッチ適用も自動化できます。
- OfficeやADなど ※AWSはライセンスの問題でOffice自体ほぼ使えないですけどね。
- 明示的に対象/非対称のパッチを指定可能です※WindowsはKB、Linuxはパッケージ名
4.実装方法
1. マネージドインスタンス対応
□ SSMエージェントインストール
WinServer2012R2(2016年以降公開)、Amazon Linux2などはデフォルトでインストール済みです。
※手動インストールはリンクのとおり□ EC2インストールへのSSMエージェント用権限付与
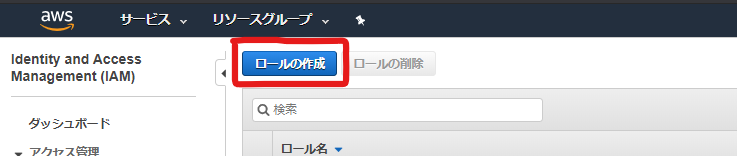
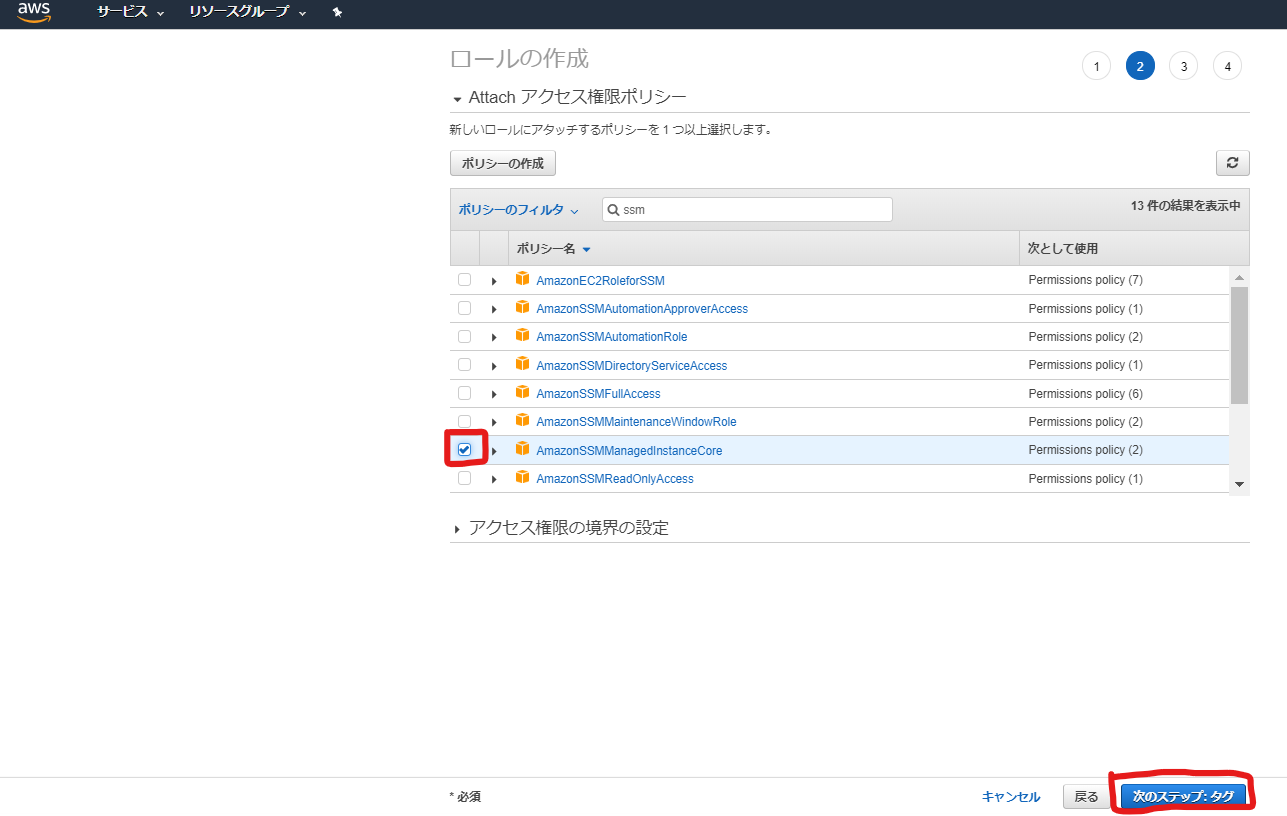
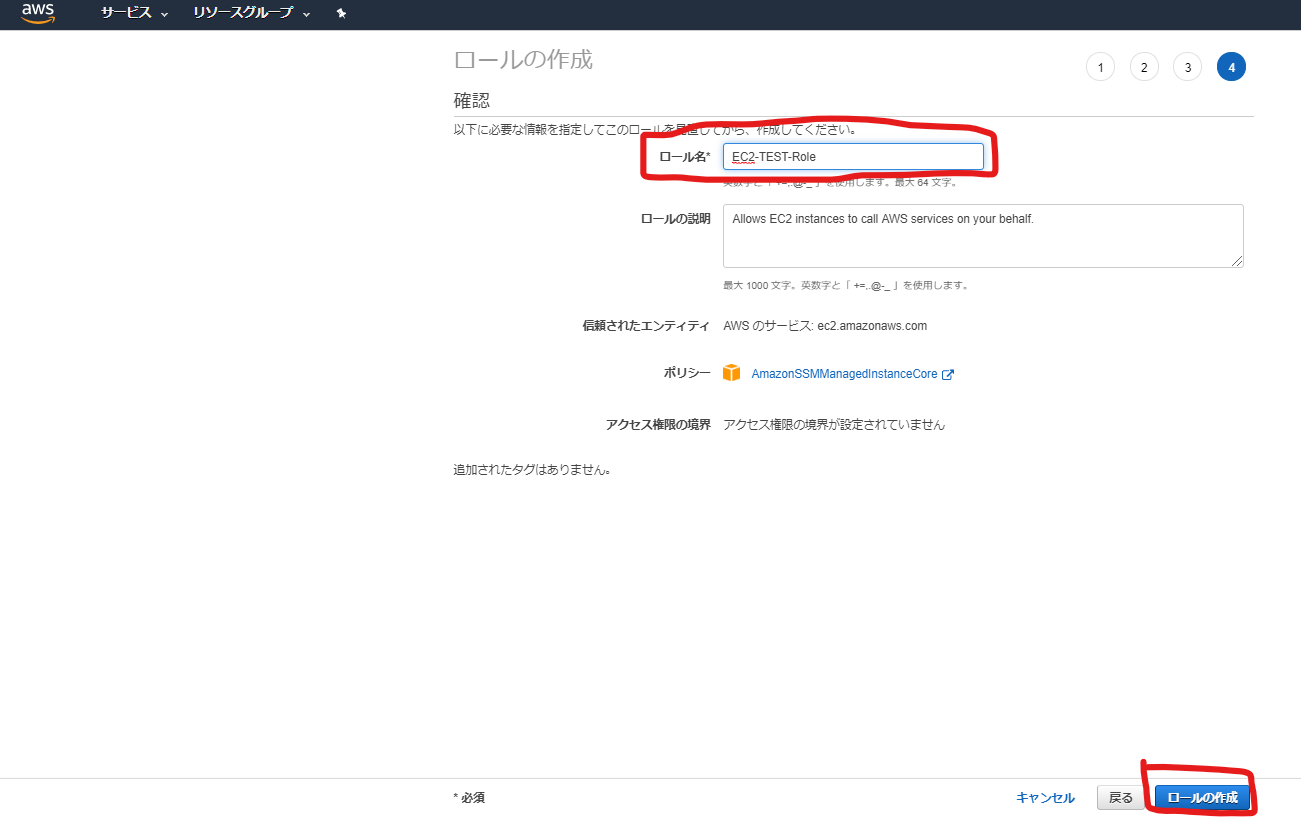
サービス[IAM]のページで、EC2用のIAM Roleを作成し、
SSMエージェント用のポリシー(AmazonSSMManagedInstanceCore)を当てます。
サービス[EC2]のページで、上記で作成したIAM Roleを使用してEC2をデプロイします。※手順割愛
□ SSMエージェント再起動
EC2デプロイ後、エージェントサービスを再起動することでActive状態になります。
EC2起動直後の状態をコマンドで確認してみます。systemctl status amazon-ssm-agent.service -l以下は結果です。
● amazon-ssm-agent.service - amazon-ssm-agent Loaded: loaded (/usr/lib/systemd/system/amazon-ssm-agent.service; enabled; vendor preset: enabled) Active: active (running) since Mon 2020-03-16 04:36:46 UTC; 6min ago Main PID: 3163 (amazon-ssm-agen) CGroup: /system.slice/amazon-ssm-agent.service mq3163 /usr/bin/amazon-ssm-agent Mar 16 04:36:46 *** systemd[1]: Started amazon-ssm-agent. Mar 16 04:36:46 *** systemd[1]: Starting amazon-ssm-agent... Mar 16 04:36:46 *** amazon-ssm-agent[3163]: 2020/03/16 04:36:46 Failed to load instance info from vault. RegistrationKey does not exist. Mar 16 04:36:46 *** amazon-ssm-agent[3163]: Error occurred fetching the seelog config file path: open /etc/amazon/ssm/seelog.xml: no such file or directory Mar 16 04:36:46 *** amazon-ssm-agent[3163]: Initializing new seelog logger Mar 16 04:36:46 *** amazon-ssm-agent[3163]: New Seelog Logger Creation Complete Mar 16 04:38:55 *** amazon-ssm-agent[3163]: 2020-03-16 04:38:55 INFO Entering SSM Agent hibernate - RequestError: send request failed Mar 16 04:38:55 *** amazon-ssm-agent[3163]: caused by: Post https://ssm.ap-northeast-1.amazonaws.com/: dial tcp 52.119.222.76:443: i/o timeout Mar 16 04:38:55 *** amazon-ssm-agent[3163]: 2020-03-16 04:38:55 INFO Agent is in hibernate mode. Reducing logging. Logging will be reduced to one log per backoff periodサービス再起動コマンドを実行します。
sudo systemctl restart amazon-ssm-agent.service確認コマンドを実行します。
systemctl status amazon-ssm-agent.service -l以下は結果です。
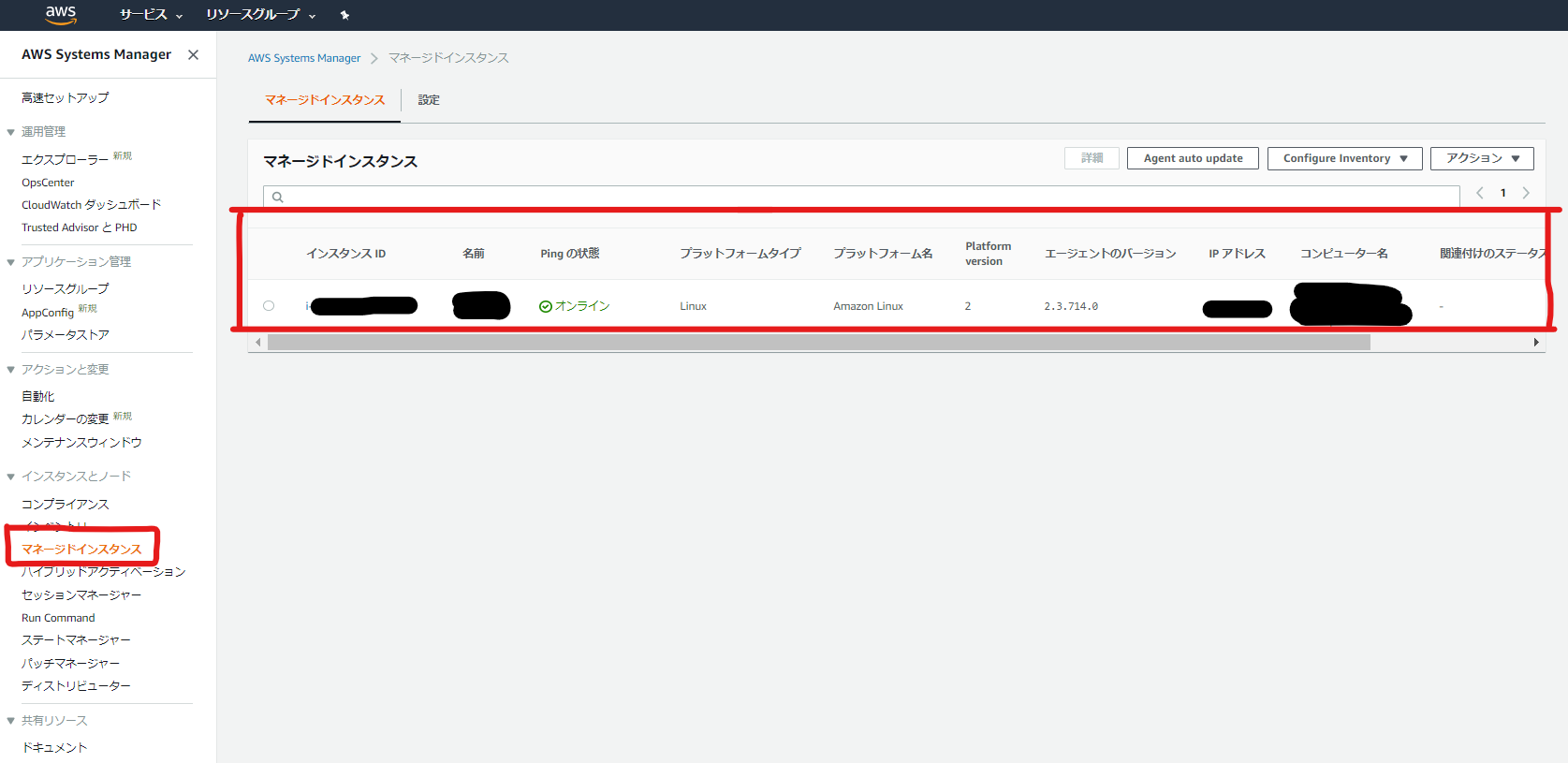
● amazon-ssm-agent.service - amazon-ssm-agent Loaded: loaded (/usr/lib/systemd/system/amazon-ssm-agent.service; enabled; vendor preset: enabled) Active: active (running) since Mon 2020-03-16 04:43:36 UTC; 3s ago Main PID: 3440 (amazon-ssm-agen) CGroup: /system.slice/amazon-ssm-agent.service mq3440 /usr/bin/amazon-ssm-agent Mar 16 04:43:39 *** amazon-ssm-agent[3440]: 2020-03-16 04:43:37 INFO [LongRunningPluginsManager] There are no long running plugins currently getting executed - skipping their healthcheck Mar 16 04:43:39 *** amazon-ssm-agent[3440]: 2020-03-16 04:43:37 INFO [MessageGatewayService] listening reply. Mar 16 04:43:39 *** amazon-ssm-agent[3440]: 2020-03-16 04:43:37 INFO [StartupProcessor] Executing startup processor tasks Mar 16 04:43:39 *** amazon-ssm-agent[3440]: 2020-03-16 04:43:37 INFO [StartupProcessor] Write to serial port: Amazon SSM Agent v2.3.714.0 is running Mar 16 04:43:39 *** amazon-ssm-agent[3440]: 2020-03-16 04:43:37 INFO [StartupProcessor] Write to serial port: OsProductName: Amazon Linux Mar 16 04:43:39 *** amazon-ssm-agent[3440]: 2020-03-16 04:43:37 INFO [StartupProcessor] Write to serial port: OsVersion: 2 Mar 16 04:43:39 *** amazon-ssm-agent[3440]: 2020-03-16 04:43:37 INFO [MessageGatewayService] Opening websocket connection to: wss://ssmmessages.ap-northeast-1.amazonaws.com/v1/control-channel/i-***?role=subscribe&stream=input Mar 16 04:43:39 *** amazon-ssm-agent[3440]: 2020-03-16 04:43:37 INFO [MessageGatewayService] Successfully opened websocket connection to: wss://ssmmessages.ap-northeast-1.amazonaws.com/v1/control-channel/i-***?role=subscribe&stream=input Mar 16 04:43:40 *** amazon-ssm-agent[3440]: 2020-03-16 04:43:37 INFO [MessageGatewayService] Starting receiving message from control channel Mar 16 04:43:40 *** amazon-ssm-agent[3440]: 2020-03-16 04:43:37 INFO [MessageGatewayService] [EngineProcessor] Initial processingサービス[Systems Manager]のページで、マネージドインスタンス画面に対象EC2が表示されることを確認します。
2. PatchBaselineの作成
□ 作成
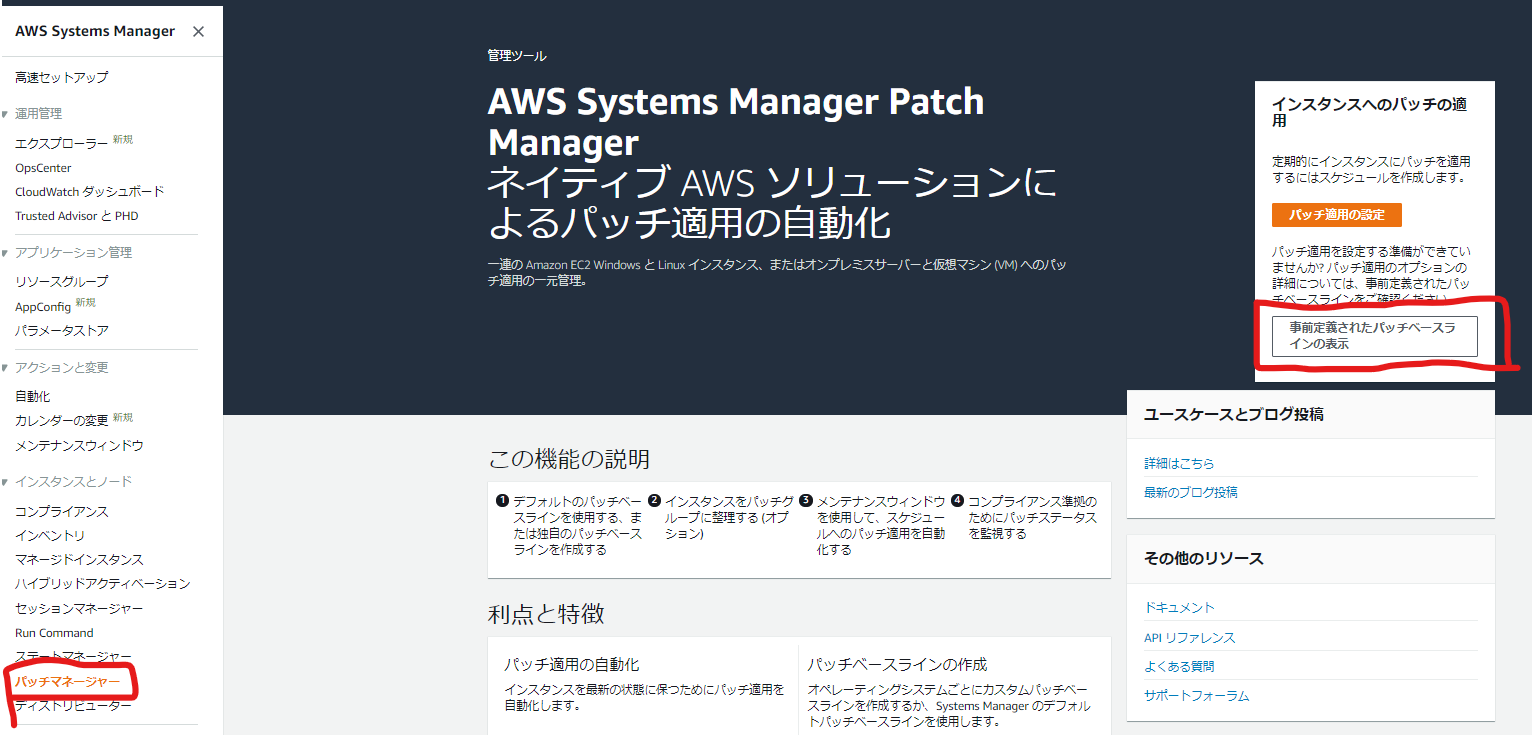
「パッチマネージャー」画面を表示しようとすると、はじめての場合に以下の画面が表示されます。
「事前定義されたパッチベースラインの表示」を選択します。
「パッチベースラインの作成」を選択します。
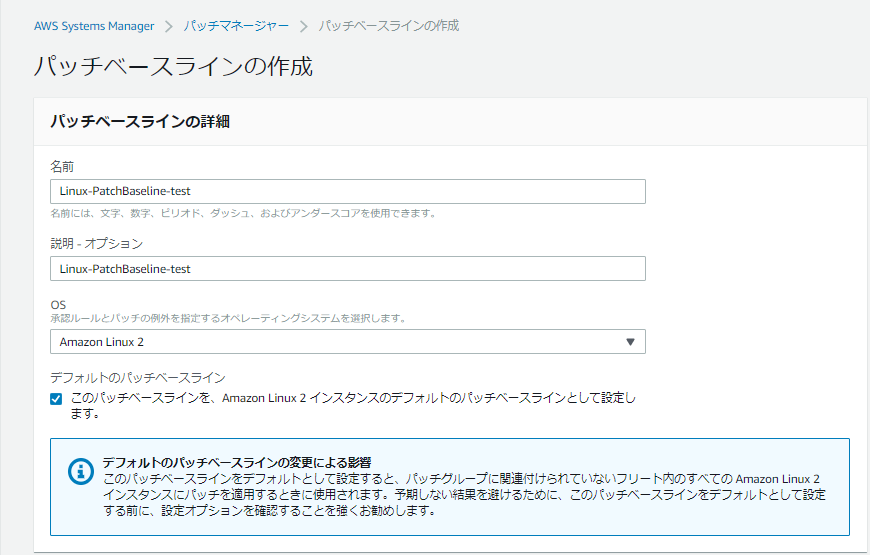
「名前」など必要項目を入力します。
※今回はOSをAmazonLinux2にしていますが、Windows系OSでも殆ど設定項目が変わりません。
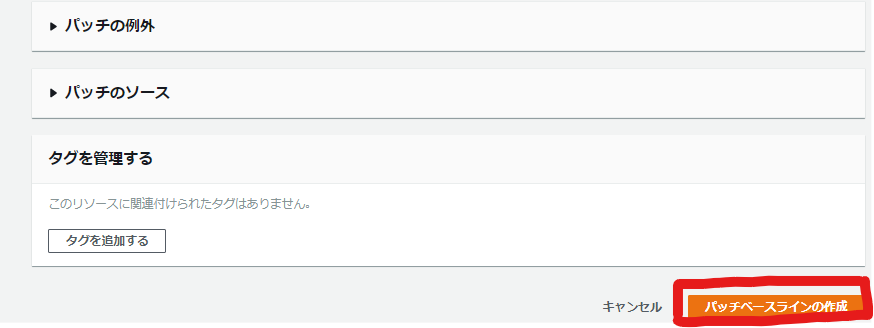
必要項目を入力し終わったら、画面下部の「パッチベースラインの作成」を選択します。
すると、パッチベースラインの一覧画面に戻るかと思います。
3. メンテナンスウィンドウの作成
□ 作成
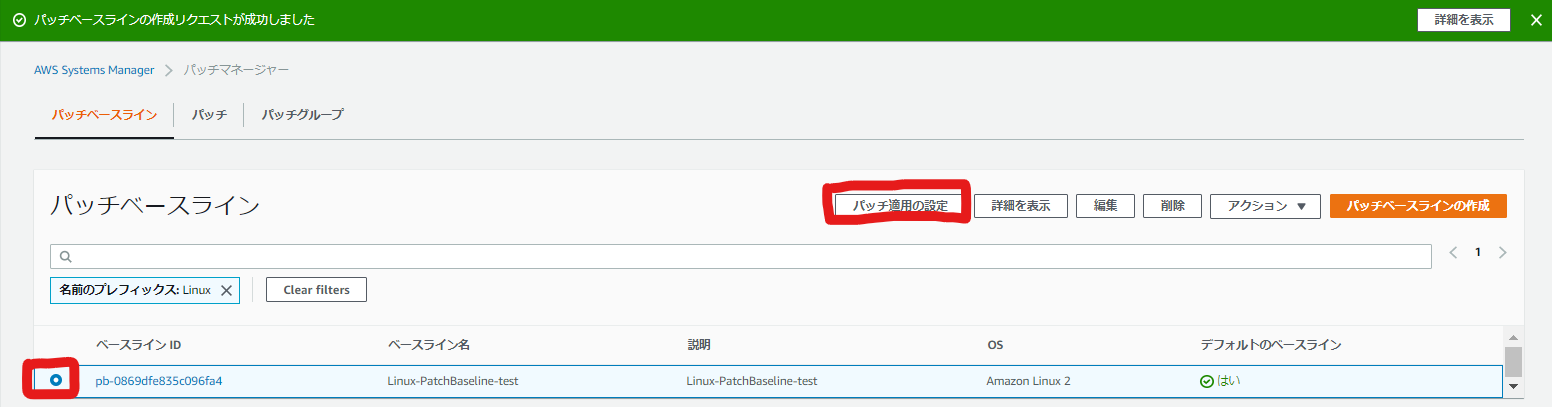
先程作成したパッチベースラインにチェックを入れ、「パッチ適用の設定」を選択します。
パッチ管理を自動化する対象のEC2インスタンスをどのように決めるか設定します。
今回はEC2の「インスタンスタグを入力する」を選択します。
※Tag Keyに「PatchGroup」、Tag Valueに「Linux-PatchBaseline」を入力し、
「Add」を選択すると以下の画像のように表示されます。
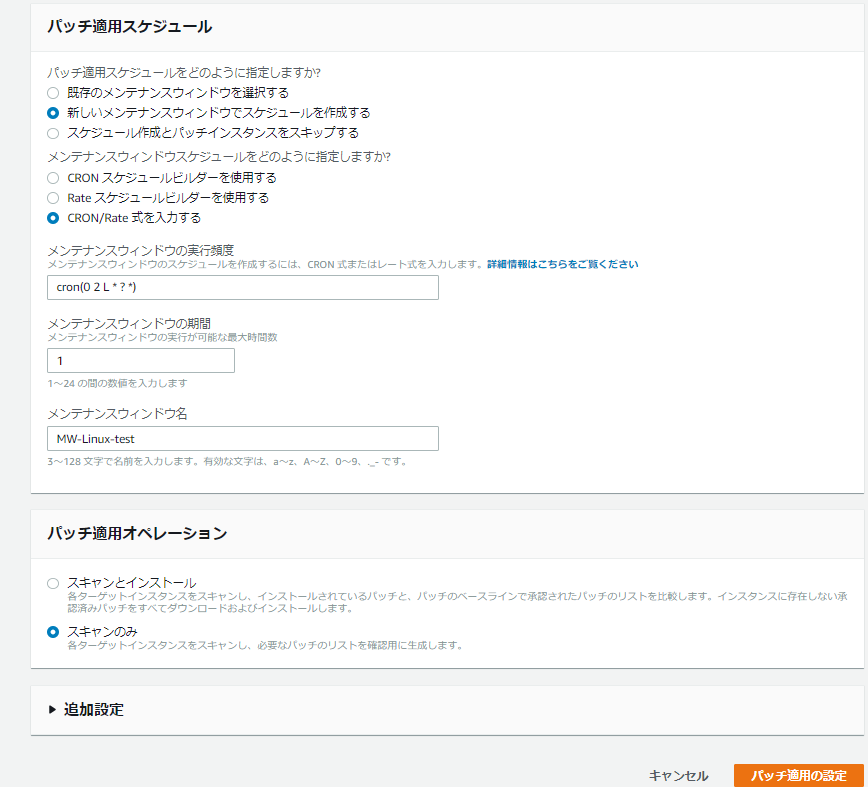
「新しいメンテナンスウィンドウでスケジュールを作成する」にチェックを入れます。
スケジュールの設定方法は「CRON/Rate式を入力する」にしました。
※画面で表示されるCronスケジュールは毎月最終日の午前2時に実行を意味しています。
Cron構文の参考ページ「メンテナンスナンスウィンドウ名」を入力、「パッチ適用オペレーション」を
「スキャンのみ」にチェックを入れ、最後に「パッチ適用の設定」を選択します。
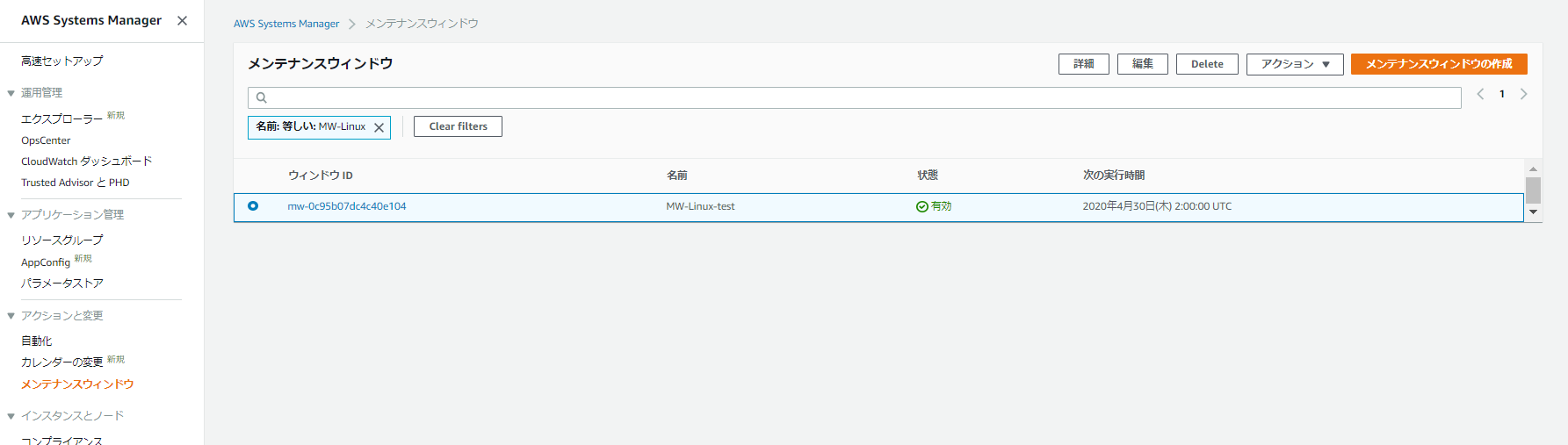
メンテナンスウィンドウ一覧画面に推移するので、
作成したメンテナンスウィンドウが表示されることを確認します。
4. スキャン実行
パッチスキャンはスケジュール実行のみで手動実行はできません。
※検証用に短めの時間で設定をしてすぐに結果がでるように変更しましょう。5. スキャン後、パッチ情報をリストしてみる
今回は、先程SSM AgentをインストールしたサーバからAWS CLIを実行します。
AWS CLIリファレンス※LambdaからPythonやJAVAの言語で実行してもいいです。
□ 権限付与
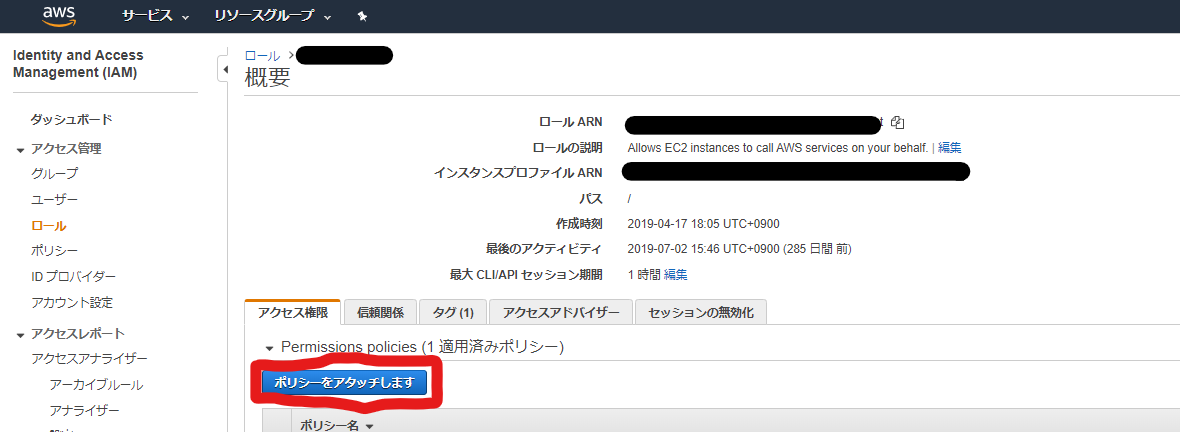
AWS CLIで実行する際には、EC2のIAM Roleに対してPolicyを付与してあげる必要があります。
IAM画面で、4-1で作成したRoleの詳細画面を開きます。
「ポリシーをアタッチします」を選択します。
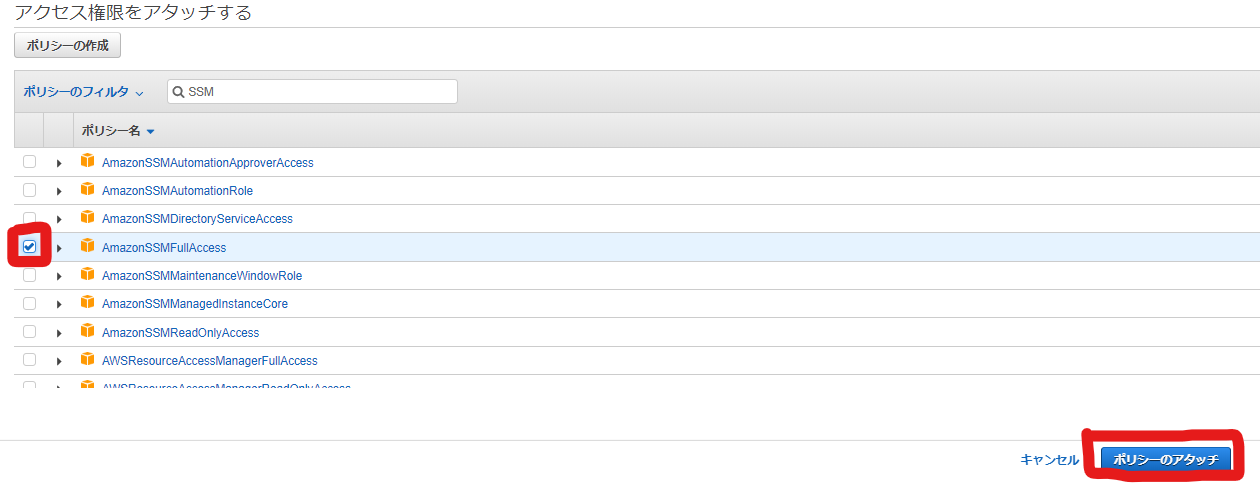
「AmazonSSMReadOnlyAccess」か「AmazonSSMFullAccess」を設定する必要があります。
Policyにチェックを入れ、「ポリシーをアタッチ」を選択します。
□未適用パッチの確認コマンド
サーバにログインし、以下のコマンドを実行すると未適用パッチを一覧で表示してくれます。
[ec2-user@*** ~]$ aws ssm describe-instance-patches --instance-id i-*** --filters Key=State,Values=Missing実行結果は以下のように表示されます。
{ "Patches": [ { "KBId": "curl.x86_64", "Severity": "Medium", "Classification": "Security", "Title": "curl.x86_64:0:7.61.1-12.93.amzn1", "State": "Missing", "InstalledTime": 0.0 }, ・ ・ ・5.あとがき
いかがでしょうか。
かんたんな管理であればSystems Managerで十分だと思います。作り込み次第では、以下のような構成も可能です。
◎未適用パッチスキャンの自動化
1.CloudWatchEventsでメンテナンスウィンドウの終了を検知
2.Lambdaでパッチ未適用リストを作成&S3にアップロード
Amazon CloudWatch Events による Systems Manager イベントのモニタリング◎セベリティでセキュリティのみ自動適用
1.パッチベースラインの作成時に、分類で「Security」を選択
2.メンテナンスウィンドウの作成時に、パッチ適用オペレーションで
「スキャンとインストール」を選択
スケジュール実行時に常にセキュリティ関連のパッチのみインストールしてくれます。
※インストールが失敗する可能性を考慮した実装、運用が必要となります。





- 投稿日:2020-03-22T17:40:51+09:00
EC2で稼働するECSのタスクにFirelensを適用する
Firelensとは
- ECSタスクのログ出力を管理する仕組み
- サイドカーとしてFluent Bit、またはFluentdのコンテナをタスクに追加する
- サイドカーのためアプリケーションに変更を加える必要がない
- EC2、Fargateどちらのタスクでも使用可能
- ログの出力先はCloudwatch LogsやKinesis Data Firehoseなどのマネージドサービスはもちろんのこと、PapertrailやDatadogなどのSaaSの製品にも適用できる
目標
- ログの出力先をCloudWatch LogsからPapetrailに変更する
前提
- EC2で稼働するECSタスクを使用する
- Container Instanceで稼働するECS Agentのバージョンは、1.30以降である必要があります
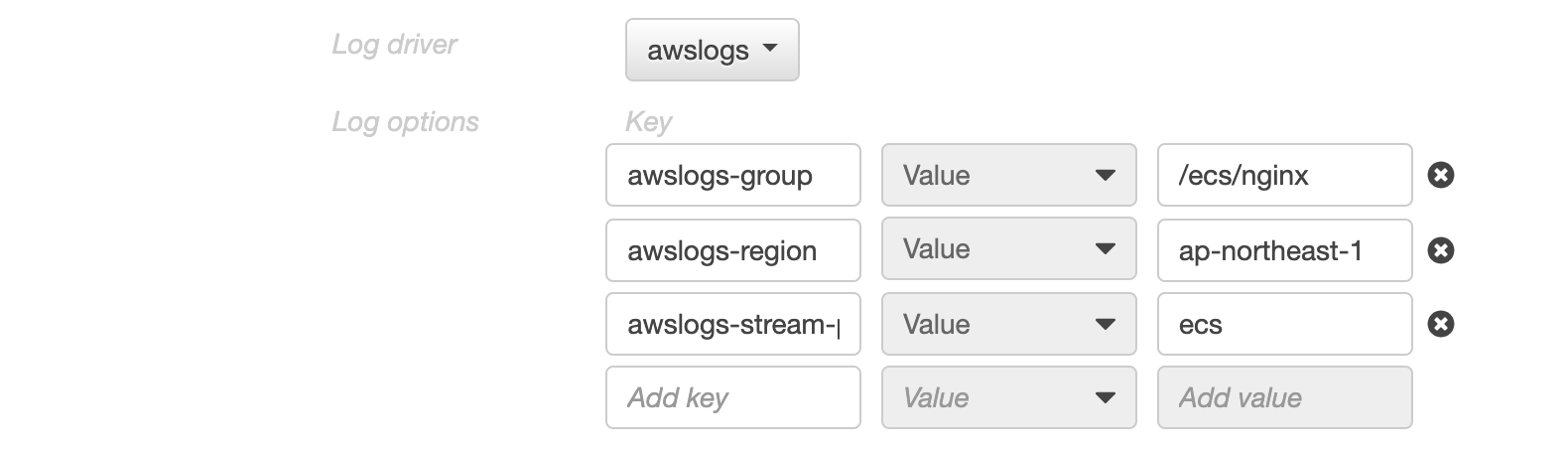
Firelensを使用せずにCloudWatch Logsへ出力する
- これはTask Definitionの設定のみで行えます
- Containerの「Log Configuration」の項目で「awslogs」を指定し、指定したlog groupを作成するのみです
Firelensを使用してPapertrailへ出力する
サイドカーコンテナの追加
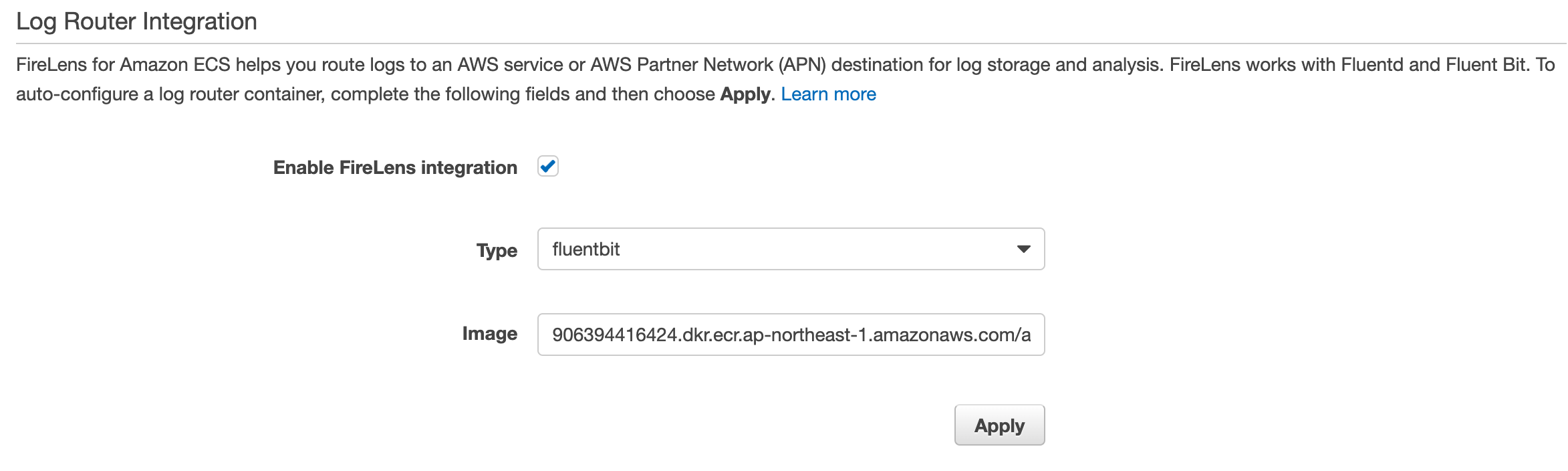
- 先ほど使用したTask Definitionを更新します
- Task Definitionの設定画面の下部に、「Log Router Integration」という項目があるのでチェックを入れます
- Typeはfluentbitとfluentdから指定できます
- ここではfluentbitを使用します
- ImageにはAWSが提供しているImageが自動的に入力されます
- このイメージはCloudWatch Logsと Kinesis Data Firehose用のプラグインが追加されたものです
- Applyを押下することでfluentbitのサイドカーコンテナが追加されます
Firelensの適用
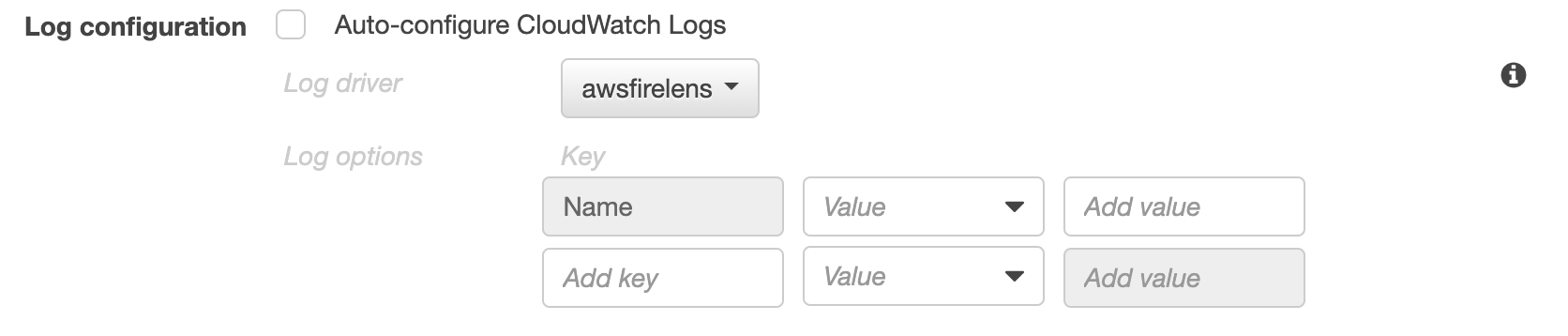
- ログを出力させるコンテナのLog Configurationを変更します
- Log driverをawsfirelensに設定します
ログの出力先を設定
出力先の設定方法は以下の3通りの方法があります
- ログ出力を行うコンテナのLog Configurationに記載する
- 設定を記載したファイルをコンテナに埋め込み、fluentbitのfirelensConfigurationにパスを指定する
- 設定を記載したファイルをS3に保存し、fluentbitのfirelensConfigurationにキーを指定する
ここでは最も簡単な1の方法で実行してみますが、2と3のようにファイルに記載するときには何点か注意事項があります(後述)
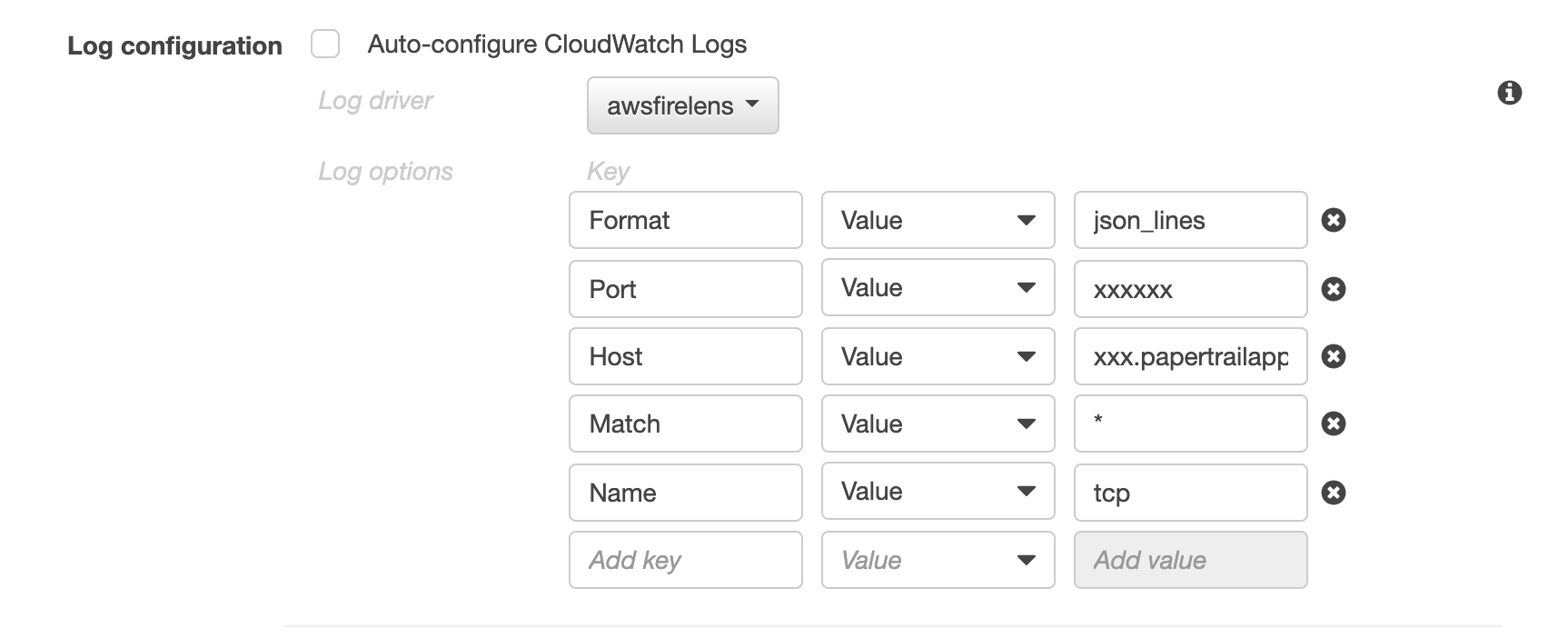
コンテナのLog Configurationに以下のような設定をします
- HostとPortにはPapertrail上で割り当てられた情報を記載
サービスの更新
ECSのServiceから、先ほど作成したTaskDefinionのRevisionを指定します
更新が終わると、無事にPaperTrailにログが出力されます
- 上図のように、Cluster名やTask DefinitionとそのRevision、コンテナ名のメタデータが送付されます
ファイルに出力先を指定する際の注意点
- firelensConfigurationはコンソールから変更できません(2020/3/22時点)
- JSONの編集画面を開いて直接書き込みます
- S3にファイルを配置する場合はTaskExecutionRoleにGetObjectとGetBucketLocationの権限が必要になります
- ファイルの形式はFluent Bitの公式ページを参照
- 今回の設定の場合は以下のようになります
[OUTPUT] Name tcp Match * Host xxxx.papertrailapp.com Port xxxx Format json_lines
- おまけ
- ファイルで記載する場合にはコンテナに含めるよりもS3に配置する方がベターかと思います
- コンテナに含めるには、ログを出力するコンテナまたはFluent Bitのイメージに含める必要があります
- 前者の場合は既存のアプリに変更加える必要がある
- 後者の場合は公式イメージが提供されているにも関わらず手を加えてしまうことで管理するべきDockerイメージが増えてしまう
- 以上の点から、S3に配置した方が手間も少なく、運用コストを減らせると思います
参考


- 投稿日:2020-03-22T17:09:16+09:00
AWS障害は全て通知されると思ってた話
結論からいうと
アカウント固有のリソース障害であっても、全ては通知されません。
背景
EC2のシステムステータスチェック失敗や、VPNのトンネルステータスがダウン時に、Personal Health Dashboardやメールにて通知されていないことに気づいたので、サポートに問い合わせてみた。
問合せ結果
以下、問合せ結果の抜粋です。
Personal Health DashboardにはAWSアカウント固有のリソースに対するメンテナンス情報や、お客様が影響を受ける可能性のあるAWS大規模障害の情報などが通知されます。
あらかじめ予定されているイベント情報や事前に予兆を検知することのできた障害情報、および広範囲に渡って発生した障害情報などは適宜通知されますが、現時点では個別のリソースにおいて一時的に発生した障害情報などは通知されません。障害に対してどうすべきか
今回のようなEC2やVPNの障害については、Cloudwatchのメトリクスを監視するアラームを作成し、Amazon SNS トピックへの通知、EC2アクション、EC2 AutoScalingアクションによる、ユーザ側での対応が可能です。
まとめ
障害通知はAWS頼りにするのではなく、重要な箇所についてはユーザ側で監視するようにしましょう。
- 投稿日:2020-03-22T16:50:04+09:00
EC2上でvue+expressの環境構築からAPI通信実装まで
バックエンド
EC2インスタンス上でexpressを動かし、アプリケーションのbackend環境を構築する。
ここでは例としてアプリケーションappを作る環境構築
AMI:Ubuntu18.04、IP:x.x.x.x の場合
$ sudo apt-get update $ sudo apt-get install nodejs $ sudo apt-get install npm $ sudo update-alternatives --install /usr/bin/node node /usr/bin/nodejs 10 $ sudo npm install -g express $ sudo npm install -g express-generator $ express --view=pug app $ cd app $ npm install $ npm start > app@0.0.0 start /home/ubuntu/app > node ./bin/wwwAMI:AmazonLinux2、IP:x.x.x.x の場合
$ curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.34.0/install.sh | bash $ . ~/.nvm/nvm.sh $ nvm install node $ sudo npm install -g express $ sudo npm install -g express-generator $ express --view=pug app $ cd app $ npm install $ npm start > app@0.0.0 start /home/ubuntu/app > node ./bin/wwwapp/bin/wwwファイルでポート番号を指定できる。デフォルトではポート3000なので、ブラウザからアクセスして確認できる。
APIの作成
app下に
index.jsを作成し、以下を記述。GET// expressモジュールを読み込む const express = require('express'); // expressアプリを生成する const app = express(); // ルート(http://x.x.x.x:3000/)にアクセスしてきたときに「Hello」を返す app.get('/', (req, res) => res.send('Hello')); // ポート3000でサーバを立てる app.listen(3000, () => console.log('Listening on port 3000'));POSTconst express = require('express'); const bodyParser = require('body-parser'); const app = express(); // urlencodedとjsonは別々に初期化する app.use(bodyParser.urlencoded({ extended: true })); app.use(bodyParser.json()); app.post('/', function(req, res) { console.log(req.body); res.send('POST request to the homepage'); }) // ポート3000でサーバを立てる app.listen(3000, () => console.log('Listening on port 3000'));$ node index.js # 実行 Listening on port 3000POSTメソッドでは、
body-parserモジュールを用いてJSONで取得する。テスト
APIを叩く。
ブラウザから(GET)
x.x.x.x:3000/にアクセス。コンソールから(POST)
POST$ curl -X POST http://x.x.x.x:3000/ -H "Accept: application/json" -H "Content-type: application/json" -d '{ "name" : "tanaka" }'フロントエンド
環境構築
vueの環境構築はこちらの記事で書いた通りなので省略。
フロントエンドから外部APIを叩く
デフォルトのAboutページにボタンをつくり、押したら非同期で外部API(httpbin)を叩くようにしてみる。
必要なものをいれる。
$ npm install axios vue-axiosmain.tsimport Vue from 'vue' import App from './App.vue' import './registerServiceWorker' import router from './router' import store from './store' import axios from 'axios' //追記 import VueAxios from 'vue-axios' //追記 Vue.config.productionTip = false Vue.use(VueAxios, axios) //追記 new Vue({ router, store, render: h => h(App) }).$mount('#app')About.vue<template> <div class="about"> <h1>This is an about page</h1> <button @click="clicked" >Call API</button> </div> </template> <script lang="ts"> import { Component, Prop, Vue, Emit } from 'vue-property-decorator'; @Component export default class About extends Vue { private clicked():void { this.axios.get('https://httpbin.org/get') .then((response) => { console.log(response); }) .catch((e) => { console.log(e); }); } } </script>consoleにデータが来てれば成功。
フロントエンドからexpressの内部APIを叩く
上のコードのURLをそのまま
http://x.x.x.x:3000とすると以下のCORSのエラーが出る。Access to XMLHttpRequest at
http://x.x.x.x:3000/from originhttp://x.x.x.x:8080has been blocked by CORS policy: No 'Access-Control-Allow-Origin' header is present on the requested resource.CORS(Cross-Origin Resource Sharing)とは何か?
あるオリジンで動いている Web アプリケーションに対して、別のオリジンのサーバーへのアクセスをオリジン間 HTTP リクエストによって許可できる仕組み
引用) https://qiita.com/att55/items/2154a8aad8bf1409db2b
どうしたらいいか
index.js(CORS設定版)const express = require('express'); const bodyParser = require('body-parser'); const app = express(); // CORSを許可する app.use(function(req, res, next) { res.header("Access-Control-Allow-Origin", "*"); res.header("Access-Control-Allow-Headers", "Origin, X-Requested-With, Content-Type, Accept"); // OPTIONSでメソッドがバレないようにする。 (?) if ('OPTIONS' === req.method) { res.send(200) } else { next() } }); app.use(bodyParser.urlencoded({ extended: true })); app.use(bodyParser.json()); // POST app.post('/', function(req, res) { console.log(req.body); res.send('Hello'); }) // GET app.get('/', (req, res) => res.send('Hello')); app.listen(3000, () => console.log('Listening on port 3000'));上記のコードにしてフロントとバックを起動後、GETでコールしてみる。
$ cd app $ node index.js #バックエンド起動 $ cd front $ npm run serve #フロントエンド起動コンソールに以下が得られたら成功。
{data: "Hello", status: 200, statusText: "OK", headers: {…}, config: {…}, …}Appendix
EC2インスタンスに置いたvueファイルを更新するのにいちいち
scpとかviとかしてるのはだるすぎるのでVSCodeから直接SSHでいじるための方法。VSCode拡張機能である
remote developmentを入れるて以下に設定ファイルを書いておく。.ssh/configHost 任意の接続名 //configには何個も接続先とキーとかの情報を書けるのでそれらを区別する名前。 HostName x.x.x.x User ec2-user Port 22 IdentityFile /Users/xxx/.ssh/hoge.pem
参考
- Amazon Linux2 への nvm と npm のインストール
https://qrunch.net/@dr3mms/entries/66FDqVNl3CoNvvCH- Node.jsとExpressでWeb APIを作ってみよう
https://sbfl.net/blog/2018/08/25/nodejs-express-webapi/- Ubuntu でapt を使用してNode.js をインストールする3 つの方法(Ubuntu 15.04, Ubuntu 14.04.2 LTS)
https://qiita.com/TsutomuNakamura/items/7a8362efefde6bc3c68b- NodeJSでWebアプリケーション開発 – Express編
https://avinton.com/en/academy-2/webapp-with-node-express/- node.js + expressでPOSTを受け取る & POSTパラメータをJSONで取得する
https://qiita.com/ktanaka117/items/596febd96a63ae1431f8- vue-cliでaxiosを使用する(設定から使用方法まで)
https://qiita.com/right1121/items/092ac7ff747e1c47b2b1- なんとなく CORS がわかる...はもう終わりにする。
https://qiita.com/att55/items/2154a8aad8bf1409db2b- express.jsのcors対応
https://qiita.com/chenglin/items/5e563e50d1c32dadf4c3- expressにてCORSを許可する
https://qiita.com/tomoya_ozawa/items/feca4ffc6217d585b037
- 投稿日:2020-03-22T16:13:05+09:00
EC2の起動設定と起動テンプレートの違い
そもそも起動設定って何?
EC2インスタンスを起動するために、AutoScalingグループで使用される設定です。
よくあるユースケースとしてAutoHealingと呼ばれる、インスタンス障害発生時に障害インスタンスを削除し、新規インスタンスの起動で使用されます。起動テンプレートと何が違うの?
起動テンプレートは起動設定の後継となるサービスとなります。
AWS公式ユーザガイドにも、以下のように記載されております。Amazon EC2 の最新機能を確実に使用できるようにするために、起動設定ではなく起動テンプレートを使用することをお勧めします。
起動設定と比較すると設定可能な項目が多いため、詳細なユースケースに対応することが可能です。
また、起動テンプレート単体でEC2起動が可能なので、AMIからの手動展開が楽になります。小ネタ
AWSマネジメントコンソールにて、作成済みのEC2インスタンスをチェックし、アクションから「Create Template From Instance」をクリックすると、自動で起動テンプレートが作成されるのでオススメです。
参照
- 投稿日:2020-03-22T15:14:54+09:00
EC2インスタンスでWindowsServerの日本語版を選択する方法
はじめに
EC2の作成時にWindow Server 2016を入れた際に英語版OSを入れた為に、日本語版で作成してくれという事で丸ッと作り直しになってしまったので備忘録的に残していく。
日本語版を選択する方法
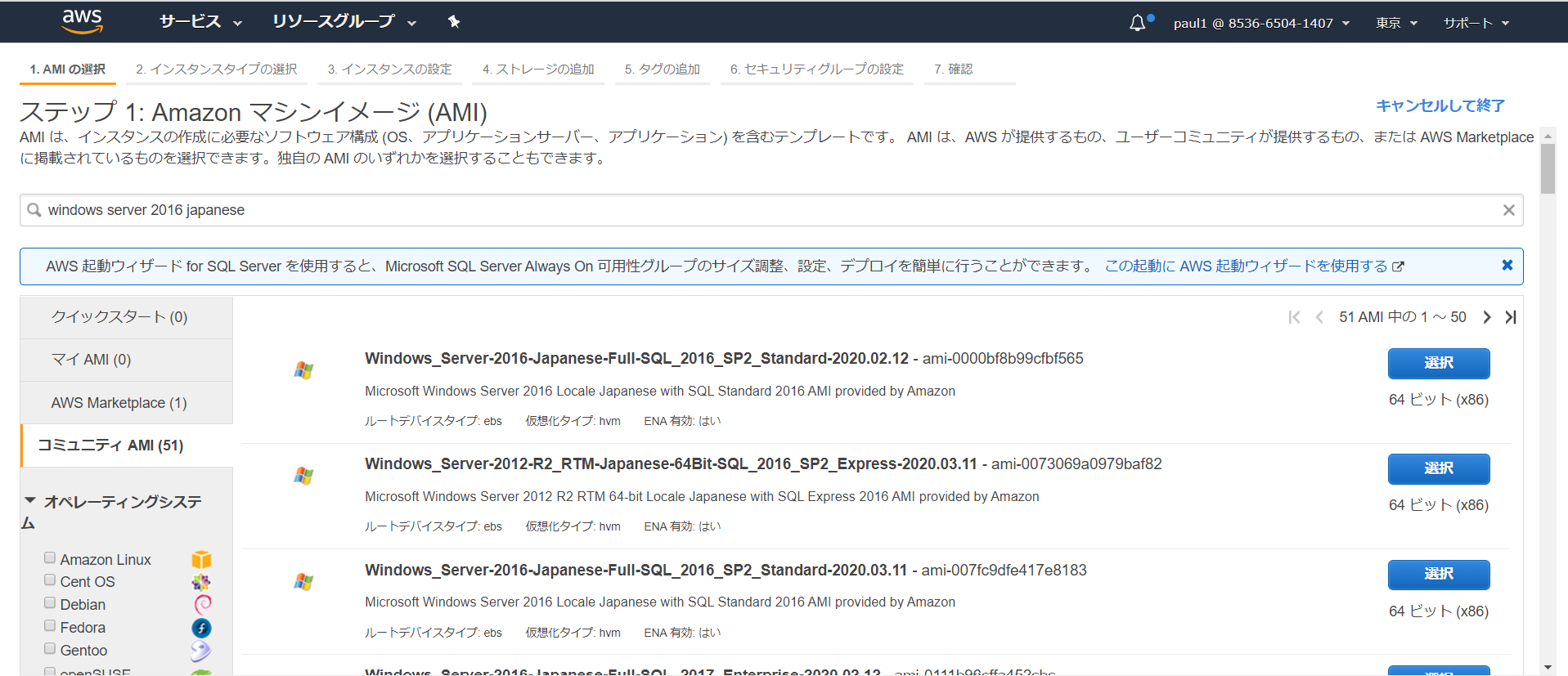
AWSマネジメントコンソール⇒EC2⇒インスタンス⇒インスタンス作成⇒
検索欄でWindows server 2016 Japaneseと入力
※Windows japanese等でもOKAWS使い始めで指定のAMIを探すのに選択欄の「クイックスタート」から探しがちになるが、
選択肢としてはそれほど多くは無く、見つからない場合が多い。コミュニティAMIを確認
コミュニティAMIは公式を見てみると・・・
「AMI を作成したら、自分だけがそれを使用できるようにプライベートとして保存したり、AWS アカウントの指定リストと共有したりできます。コミュニティで利用できるように、カスタム AMI を公開することもできます。」
・・・とあり、日本語版を見つけたは良いものの、自由に個人がAMIを作成して放流できるようなので信頼性としてどうなのと思っていたが、
ここにもAWS側から提供しているAMIがあるのでそれを使用できる。
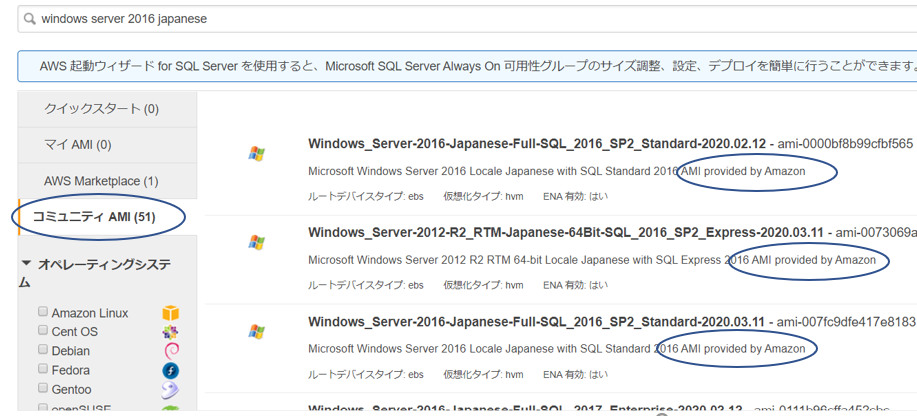
確認方法は、AMIの名称にAMI provided by Amazonとの記載がある。
念のため調べてみた
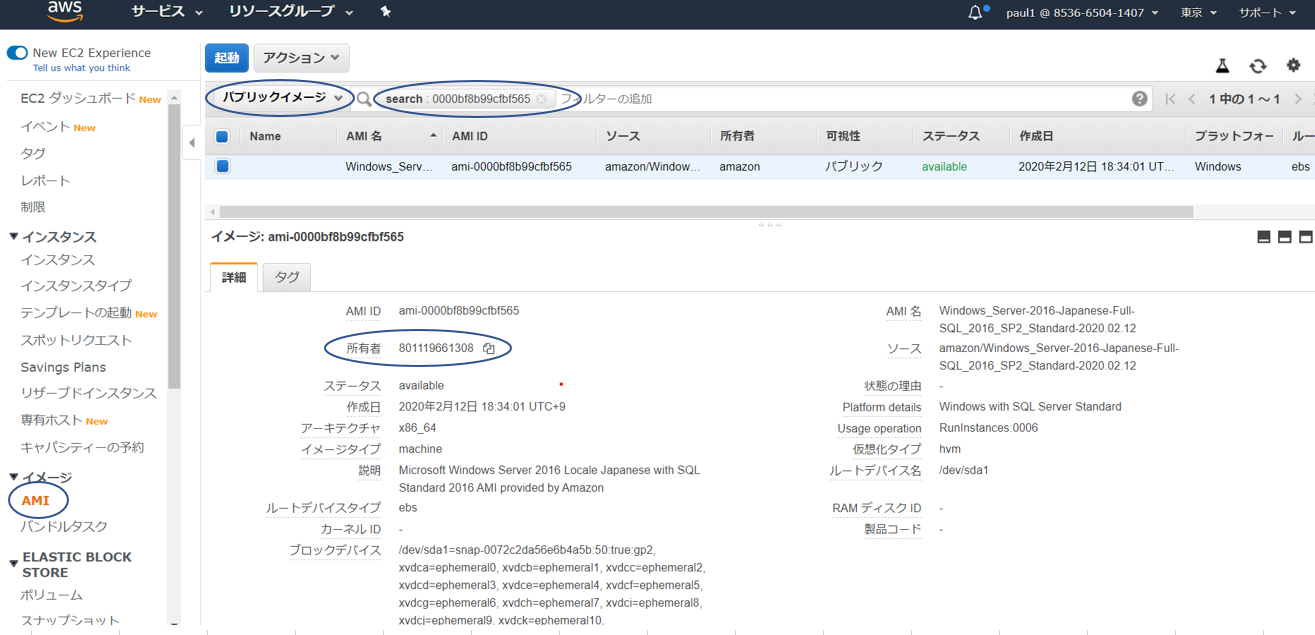
カスタムAMIとして自由に提供出来るのであれば、
名称の中にprovided by Amazonと入れてしまえば偽る事も可能なのではないかと勘繰ってみた。
・EC2⇒AMI⇒選択欄で「パブリックイメージ」を選択、対象のAWS名を入力⇒所有者を確認
こちらの所有者801119661308がAWS公式の配布元であることが確認出来た。
マネージド AWS Windows AMI
AWS公式を見てみると、提供しているAMIの紹介、更新情報等が記載されている。
困った時の参照元はここを見ればよいのかも。
インスタンスユーザーガイド AWS Windows AMI終わりに
今回は日本語版を入れてくれという要望だったが、
別に英語版を入れても日本語設定してしまえばいいのではと思った。。
またそれは別途調べてみるとする。
- 投稿日:2020-03-22T15:01:42+09:00
AWS Lambdaの例外処理の仕方(同期実行・非同期実行・ストリームベース実行)
前置き
本記事は、AWS Lambda(以下、Lambda)のコード内で起きた例外処理の仕方を書きます。つまり、以下で紹介するものは、Lambdaの起動には成功しているという前提なので、起動自体に失敗しているちう人は、別の記事を参照してください。
概要
Lambdaに限らず、例外処理というのはプログラムにつきものです。何等かの不具合で例外が発生させる場合や、意図して例外を発生させる場合があります。
Lambdaでも同じように例外処理をするわけですが、Lambdaはイベントトリガーによって例外処理の仕方を変える必要があります! Lambdaのイベントトリガーについては、以下のようなものがあります。[参考]
AWS Black Belt の AWS Lambda Part1
https://d1.awsstatic.com/webinars/jp/pdf/services/20190402_AWSBlackbelt_AWSLambda%20Part1%262.pdf以下で Pythonプログラムを用いて、簡単例外処理の仕方を紹介したいともいます。
同期実行
例えば、event引数に "key" というプロパティにあるデータを取得するというプログラムがあったとします。しかし、そこに "key" というプロパティがない場合、後続の処理ができないので、例外終了させます。
# -*- coding: encoding -*- def lambda_handler(event,context): print(event) if "key" in event: raise KeyError("event does not have key propertry")非同期実行
同期実行の場合、"key"がない場合、例外終了(異常終了)させましたが、非同期実行の場合、最大6時間の間に、3回実行します(初回は通常実行、2回目と3回目はリトライ実行)。3回実行しても失敗した場合、DLQといって、SQS (Simple Queue Service) を使って、イベント引数の内容を保存しておくことも可能です。 lambda_handlerのeventの内容がすべてそのまま保存されるので、4回目以降のリトラインの可能になります。contextの内容は入ってきません。
[参考]
AWS Lambda が非同期呼び出しの最大イベント経過時間と最大再試行回数をサポートするようになりました
https://aws.amazon.com/jp/about-aws/whats-new/2019/11/aws-lambda-supports-max-retry-attempts-event-age-asynchronous-invocations/ここで問題なのが、リトライするときは、イベント引数が全く同じで来るため、"key" プロパティがないということが分かれば、2回目も同じように自動リトライさせても例外終了します。例外が発生すると変わっているものを、あえてリトライさせる必要はなく、プログラムとしてもおかしいと思うので、正常終了させます。
# -*- coding: encoding -*- def lambda_handler(event,context): try: print(event) if "key" in event: raise KeyError("event does not have key propertry") except KeyError as e: print(f"type = {type(e)} , message = {e}")ストリームベース実行
ストリームベース実行も、例外処理は非同期実行と同じです。ストリームベース実行は、Kinesis Data StreamsとDynamoDB をトリガーとする場合です(それしか知りません)。ストリームベース実行の場合、データの有効期限(Kinesis Data Streamsはデフォルトで24時間、最大7日間。DynamoDBは24時間)がきれるまでリトライを行います。
# -*- coding: encoding -*- def lambda_handler(event,context): try: print(event) if "key" in event: raise KeyError("event does not have key propertry") except KeyError as e: print(f"type = {type(e)} , message = {e}")まとめ
以上、Lambdaの例外処理についてでした。なお、例外処理は、要件定義等によって当然変わってくるので、それぞれに応じた処理にカスタマイズしてください。
- 投稿日:2020-03-22T07:19:04+09:00
Rails アプリを EC2 にデプロイしよう!(デプロイ編)
Rails アプリを Amazon Web Service を使ってデプロイするまでの手順をまとめました。
次の順番でデプロイまで持っていきます。1, 準備編
2, サーバー構築編
3, 環境構築編
4, デプロイ編今回は「デプロイ編」です。
1 ~ 3 を読んでない方は先に読んでください。
Rails アプリを EC2 にデプロイしよう!(準備編)
Rails アプリを EC2 にデプロイしよう!(サーバー構築編)
Rails アプリを EC2 にデプロイしよう!(環境構築編)Gem のインストール
前回までに、アプリのクローンを完了しました。
今回の最初の作業は、gem のインストールです。まずは bundler を設定しましょう。
bundler は本アプリ使用している bundler とバージョンが一致しているものを選択しましょう。[minato@ip-192-168-10-49 ~]$ /var/www/rails/sample_app [minato@ip-192-168-10-49 sample_app]$ gem install bundler 2.1.4 Fetching bundler-2.1.4.gem Successfully installed bundler-2.1.4 Parsing documentation for bundler-2.1.4 Installing ri documentation for bundler-2.1.4 Done installing documentation for bundler after 3 seconds 1 gem installed次に、Gemfile の中身を確認しましょう。
今回は次の gem を想定しています。Gemfilegem 'rails', '~> 5.2.2' gem 'bootsnap', require: false gem 'puma', '~> 3.7' gem 'mysql2', '>= 0.4.10', '< 0.5'確認したら
bundle installを行いましょう。[minato@ip-192-168-10-49 sample_app]$ bundle _2.1.4_ install --path vendor/bundle --without development:test無事にインストールできれば OK です。
アプリの secret_key_base の設定
次に secret_key_base の設定を行います。
今回はRails 5.2なので、config/credentials.yml.encを読み込むために
config/master.keyをEC2でも作成しましょう。
これがないと本番環境で起動することができません。
- ローカル環境 にある
config/master.keyの中身をコピーします。- サーバー環境 で
config/master.keyを新規作成して先ほどコピーした内容をペーストします。次のコマンドで secret_key_base が確認できれば OK です。
[minato@ip-192-168-10-49 sample_app]$ EDITOR="vim" bundle exec rails credentials:editPuma の設定
次は Puma の設定を行います。
Puma はアプリケーションサーバーの一種です。早速設定していきます。
config/puma.rbcase ENV['RAILS_ENV'] when "production" environment "production" port 3000 threads 16, 16 daemonize true # sample_app の部分は自身のアプリケーションの名前に変更してください。 app_dir = File.expand_path("/var/www/rails/sample_app", __FILE__) bind "unix://#{app_dir}/tmp/sockets/puma.sock" pidfile "#{app_dir}/tmp/pids/puma.pid" state_path "#{app_dir}/tmp/pids/puma.state" stdout_redirect nil, "#{app_dir}/log/puma.stderr.log", true plugin :tmp_restart else environment "development" port 3000 threads 5, 5 pidfile "tmp/pids/puma.pid" state_path "tmp/pids/puma.state" stdout_redirect nil, "log/puma.stderr.log", true plugin :tmp_restart endここら辺は設定ファイルなので、詳細には追いません。
また、設定ファイルの記述が終わったら、次のコマンドも実行してください。[minato@ip-192-168-10-49 sample_app]$ mkdir tmp/sockets
puma.sockを作成先のディレクトリを作成しています。
これで Puma の設定が完了です。Nginx の設定
お次は Nginx です。「エンジンエックス」と読むそうです。
この Nginx は Web サーバーにあたります。早速下記コマンドを打ち込んでください。
[minato@ip-192-168-10-49 ~]$ cd ~ [minato@ip-192-168-10-49 ~]$ sudo yum install nginx [minato@ip-192-168-10-49 ~]$ sudo vim /etc/nginx/conf.d/sample_app.confvim コマンドで作成した nginx の設定ファイルを次のように記述します。
/etc/nginx/conf.d/sample_app.conf# アクセスログ・エラーログの出力先を設定する # sample_app の部分は自身のアプリケーションの名前に変更してください error_log /var/www/rails/sample_app/log/nginx.error.log; access_log /var/www/rails/sample_app/log/nginx.access.log; upstream puma { # puma.sock の場所を指定する # sample_app の部分は自身のアプリケーションの名前に変更してください server unix:///var/www/rails/sample_app/tmp/sockets/puma.sock; } server { listen 80; # server_name を設定します。自身のパブリックDNSに変更してください。 server_name ec2-52-198-194-39.ap-northeast-1.compute.amazonaws.com; client_max_body_size 500M; keepalive_timeout 5; # パブリックページの場所をここで設定します。 # sample_app の部分は自身のアプリケーションの名前に変更してください root /var/www/rails/sample_app/public; location / { try_files $uri $uri/index.html $uri.html @app; } location @app { proxy_read_timeout 300; proxy_connect_timeout 300; proxy_redirect off; client_max_body_size 1G; proxy_set_header Host $http_host; proxy_set_header X-Forwarded-Proto $http_x_forwarded_proto; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Real-IP $remote_addr; proxy_pass http://puma; } # Rails のエラーページを表示する # sample_app の部分は自身のアプリケーションの名前に変更してください error_page 500 502 503 504 /500.html; location = /500.html { root /var/www/rails/sample_app/public; } }ここも設定ファイルなので詳細には追いません。
また、AWSが生成するドメイン名が
ec2-52-198-194-39.ap-northeast-1.compute.amazonaws.com
と大変長いので、次のコマンドを実行して設定を変えます。$ sudo cp /etc/nginx/nginx.conf /etc/nginx/nginx.conf.old $ sudp vim /etc/nginx/nginx.confnginx.conf# ... http { # ... sendfile on; tcp_nopush on; tcp_nodelay on; keepalive_timeout 65; types_hash_max_size 2048; server_names_hash_bucket_size 128; # これを追記 # ... }最後に、次のコマンドを実行してください。
[minato@ip-192-168-10-49 conf.d]$ cd /var/lib [minato@ip-192-168-10-49 lib]$ sudo chmod -R 775 nginxpost メソッドでもエラーが出ないようにするためのものです。
これにて Nginx の設定完了です。MySQLの設定
次は DB です。
アプリケーションの DB が MySQL で作成されている前提で話を進めていきます。まずは database の設定を行います。
[minato@ip-192-168-10-49 sample_app]$ vim config/database.yml設定内容は次のとおりです。
config/database.ymlproduction: <<: *default adapter: mysql2 port: 3306 database: sample_app_production username: root password: encoding: utf8 charset: utf8 collation: utf8_general_ci保存したら次のコマンドを実行していきましょう。
# mysql を起動 [minato@ip-192-168-10-49 sample_app]$ sudo service mysqld start # mysql.sock を /tmp に移動する [minato@ip-192-168-10-49 sample_app]$ ln -s /var/lib/mysql/mysql.sock /tmp/mysql.sock # 本番環境用の db を作成する [minato@ip-192-168-10-49 sample_app]$ RAILS_ENV=production bundle exec rake db:create # 本番環境用の db の migrate を実行する [minato@ip-192-168-10-49 sample_app]$ RAILS_ENV=production bundle exec rake db:migrate
seedを予め設定する場合はこのタイミングで実行してください。Rails アプリの起動
このコマンドで puma を起動しましょう。
これで Rails アプリが起動します。[minato@ip-192-168-10-49 sample_app]$ RAILS_ENV=production bundle exec pumaインターネットからアクセス出来る様に
次のコマンドで nginx を起動します。[minato@ip-192-168-10-49 sample_app]$ sudo service nginx start自身のパブリックDNSを使用してブラウザからアクセスしてみましょう
http://ec2-52-198-194-39.ap-northeast-1.compute.amazonaws.com/無事にアクセスできれば OK です。
停止方法
最後に停止方法について記述しておきます。
$ sudo service nginx stop$ bundle exec pumactl halt最後に
これでデプロイを完了することができました。
でも、まだアクセス出来てない方もいるかと思います。
そんな方はググったり、質問したりして問題解決を頑張ってください。
当たりが強いエンジニアもいますが、優しく教えてくれるエンジニアもいます。自分は大学一回生でこのデプロイ作業を初めて行いましたが、完了するのに1週間もかかりました。
それでも大学の先輩に質問したり、頑張って英語の公式ドキュメントを読んだり、
ひたすらググったりすることでなんとかデプロイを完了しました。このデプロイ経験で多くの知識や経験を得ました。
特に、根気よく問題解決する精神は鍛えられました。根気よく、適度に休憩をとりながら、デプロイ作業を頑張ってください。
- 投稿日:2020-03-22T03:23:52+09:00
参考にならないAWSソリューションアーキテクト・アソシエイト合格までの道のり
はじめに
思い立って12日、約10時間でAWSソリューションアーキテクト・アソシエイトを取得した日記
バックグラウンドが同じ人はいないので、参考にならないな。。。多分。スペック
- 学生時代
- 趣味のプログラミング 10年
- 社会人(下の2つは同時稼働)
- 銀行・証券関連プログラマ 5年
- ゲームプログラマ 5年
- サーバーサイドプログラマ 1年
- インフラエンジニア(サーバー/ネットワーク) 15年
- DBA 10年
などなど
つまりかなりのオッサン- AWS
- 趣味でAlexaスキルを作るためにLambdaとかCloud9とかは
2年くらい前から使っていた- Alexaスキル公開しているので毎月AWSの無料枠+$100使える
→Alexa AWSプロモーションクレジットのご紹介- なので、ちょこちょこと実験しているけど課金されたことはない
- 会社がAWSJに近いのでセミナーとかハンズオンに時々行く
- ここ1年業務でAWSをつかったいくつかの案件に首を突っ込んだ。(突っ込んだだけ)
- AWSの営業さんとかSAさんに知り合いがいるw
- 2019/8 (認定者ラウンジに入ってグッズを貰うためため)クラウドプラクティショナー取得
→認定試験50%OFFと模擬試験100%OFFのバウチャーゲット- 2019/12 re:Invent2019参加
→目論見通り、認定者ラウンジでマッタリしたり、グッズゲット!試験まで
2020/3/8 (1日目 0.5時間)
もともとKindle Unlimited会員で、なにかUnlimitedで面白い本がないか探していたら
ソリューションアーキテクト本を発見↓
この1冊で合格! AWS認定ソリューションアーキテクト - アソシエイト テキスト&問題集
初めの数ページを読んで、チョット憧れるw
まぁ試験を受ける受けないは置いておいて、もっとAWSサービスを知るために読んでみるか!
明日からね!!2020/3/9 〜 3/12(2日目〜5日目 各0.5時間)
読みこみ Now Loding...
2020/3/13 (6日目 1時間)
巻末の模擬試験以外、読み終わる
大丈夫そうな気がする なんか、そんな気がする
とりあえず試験予約ページをみてみよう
ん?2020/3/23から新しい問題?になるらしい
この手の試験って新しくなると難しくなるっていうしな〜
取るなら今なのか?今なのか???
クラウドプラクティショナーの時の50%バウチャーを使ったら税込8,250円か。
試験日はできるだけ遅く...横浜の試験会場は19日だった
22日を狙っていたんだけどねw
まぁいいや、なんとかなるでしょ
ポチッとな2020/3/14 (7日目 1.5時間)
巻末の模擬試験をやってみる
……う、いろいろわからない。。。わからないので試験が早く終わるw
正解率60%…
AWSのサンプル問題やってみよう
正解率70%…
コレはマズいのでわ、マズいよな、マズい
ここにきて、本は読んだけど細かいところまで理解していないことに気がつくw
どうしよう…おやすみなさい2020/3/15 (8日目 2時間)
間違えた問題について、本の見直し、Webで調べる
疲れた…2020/3/16 (9日目 1時間)
クラウドプラクティショナーの時のバウチャーで公式模擬試験を無料受けてみる
自宅でできるのでラクだわー
なんか難しいぞ 日本語が変なところもあるし「〜を使用するある」とか 神楽かw
とりあえず30分位で終了 さてさて答え合わせ〜って、
本番の時と同じように何があっていて何が間違っているかわからんじゃないかwこんなメールが来た
Tsuzuki Hiroyuki様
AWS Certified Solutions Architect - Associate - Practice (Retires March 22, 2020) を受験いただき誠にありがとうございました。本試験受験前の準備対策のご参考まで、以下の情報をご確認ください。
総合スコア: 76%
トピックレベルスコア
1.0 Design Resilient Architectures: 100%
2.0 Define Performant Architectures: 71%
3.0 Specify Secure Applications and Architectures: 66%
4.0 Design Cost-Optimized Architectures: 0%
5.0 Define Operationally-Excellent Architectures: 100%0%ってw
でも100%が2つあるから2勝1敗ということにしておこう
合格ラインギリギリすぎて危ないなコレ
一つ問題間違えたら死亡パターン2020/3/17 (10日目 2時間)
世の中には無料でサンプル問題をたくさん公開してくれている親切な人がいる
で、ひたすらWeb巡回して問題を解く、解く!
無断でURL貼ると怒られるかも知れないので、
google[AWS ソリューションアーキテクト サンプル問題]とかで2020/3/18 (11日目 0.5時間)
本を流し読み。何となく間違えたサービスとキーワードを紙に書いて安心するw
2020/3/19 (12日目 試験当日)
勉強は何もしない
学生の頃から当日勉強で得たで知識で間違えることが多かったのでさわらない
認定試験
試験まで
- 横浜テストセンターの場合
- 受付到着するまでにスタッフからお名前は?と聞かれるw
- 受験する内容を聞かれる 今回はAWSの試験ですね?
- 確認書類 免許とクレカなど2種類
- 誓約書にサイン
- 写真撮影
- ロッカーに荷物、時計などをしまう カギ、ハンカチなんかもしまう
- メモ用にペン2本とラミネート加工されたメモ用紙?をわたされる
- 簡単な説明と注意事項
- 貴方の机は何番です
- ユーザIDとパスワードは打ってあるのでそのまま進めてください
- 回答が終わったらログアウトするまで進めて、会場を出てください
- 試験時間に+10分してあるので、初めの5分は誓約関係、終わりの5分はアンケートに使っててください
- レポートは紙では出ませんので、試験終了後メールやWebで確認してください
- 準備できたら中に入って始めてください
- 指定された机に座る
- さっき言われたとおりID,PASSは入力済みなので、Loginボタンをクリック
- しばし待つと人の名前がずらーっと出てくるので、自分の名前を選択
- またまたしばらく待つ この時間が長くてスタッフを呼び出そうかと思ったw
- 誓約関連
- いきなり1問目Start!w
試験の状況
- 全部で65問。
読むのが面倒な問題、答えがわからない問題、不安な問題は
「後で見直し」フラグをたててジャカジャカ進め、残り1時間くらいで最後まで到達- 見直し一覧を見ると10問ほど
残り1時間、アンケートを入れると5分/問くらいはあるな。。。- 不安だった問題を確定させる
- 読むのが面倒な問題を考える
- 答えが全くわからない問題 →
上に書いたように2択にはなっていたけど考えてもわからないので、
その時の残り時間の秒数が偶数か奇数かでw- この時点で残り30分くらい
- 1問目からサラッと見直し
- 残り10分
- 試験を終わらせる 戻れないですけどいいですか?が2回くらい
- アンケート 適当に答える
- アンケート終わらせる 答えてない質問がありますけど終了していいですか???
ページ戻っても答えていないところがない。。。
仕方がないので終了させる- いきなり結果発表!
全体の流れはクラウドプラクティショナーの時と同じで、合否だけは会場を出る前にわかる
試験内容を書くと怒られちゃうので、概要だけ
- ウワサには聞いていたが全体的に問題集や模擬試験より難しい
- 問題文と選択肢1つ1つの文章が長い。特に問題文は3行4行は当たり前
- 直訳文章が難解。日本語でおkとツッコミを入れたくなる問題あり
- AWSのこんなサービスは何?みたいな問題はない
「あなたはソリューションアーキテクトです。今度会社でこんな事やることになりました。 こんな条件でAWSサービスを選ぶとしたらどれ?」みたいな感じ- 四者択一が多く、五者択二?はあまりなかった
- ほとんどの場合、四者のうち二者は明らかに違うので残り二つのウチどっちかw
- 疎結合で SQS/SNS
- コンテナで EC2/Fargate
- EBSで プロビジョンド/スループット
- S3で IA/Glacier迅速取り出し
- Cloudwatchで alarm/event
みたいな感じ 問題文をよ〜く読むと何をしたいかが書いてあることが多い- 横浜テストセンターの場合、日本語ネイティブではない外国人が監視カメラ越しに見ているということはなかった(少なくとも前回のクラウドプラクティショナーの時と今回は)
というわけでふりかえりなどなど
- 点数は852点だった
例によってどの問題が間違っていたのかは不明w
まぁ何点でも受かればOKOK- 試験勉強の時間はkindle本の初めにを読んだ日から試験前日までの11日、約10.5時間
ただし大雑把ではあるけど業務や趣味でAWSサービスを使った構築設定や利用経験あり- 金銭的な支出は受験費用8,250円だけ
(バウチャーやkindle unlimitedは利用した)- 有償の何とかdemyとか会員登録しての問題とかは、さらさらやる気なし
- 何十万もするAWSの有償セミナーももちろんなし
- WhitePaperは。。。字が多いのはニガテなのだ。。。w
- 本は読むだけではダメ
サービス名称やデフォルト設定、制限、利用場面などを覚えないとw- クラウドプラクティショナー受験で流れを知っていたので少し気が楽
- 引きずられてクラウドプラクティショナーの認定期間が延長された
- LinkedInのシークレットグループへのリンクが来た
- Professionalは受ける気なしw(サンプル問題みたらさらに長文で愕然とした)
基本的にテスト勉強や暗記は嫌い 受験費用高いし
もちろんお金があったところでスキルなし
このページも字しかないので後で写真を貼るかも
- 投稿日:2020-03-22T02:40:22+09:00
Rails アプリを EC2 にデプロイしよう!(環境構築編)
Rails アプリを Amazon Web Service を使ってデプロイするまでの手順をまとめました。
次の順番でデプロイまで持っていきます。1, 準備編
2, サーバー構築編
3, 環境構築編
4, デプロイ編今回は「環境構築編」です。
「準備編」と「サーバー構築編」を読んでない方は先に読んでください。EC2 にログインする
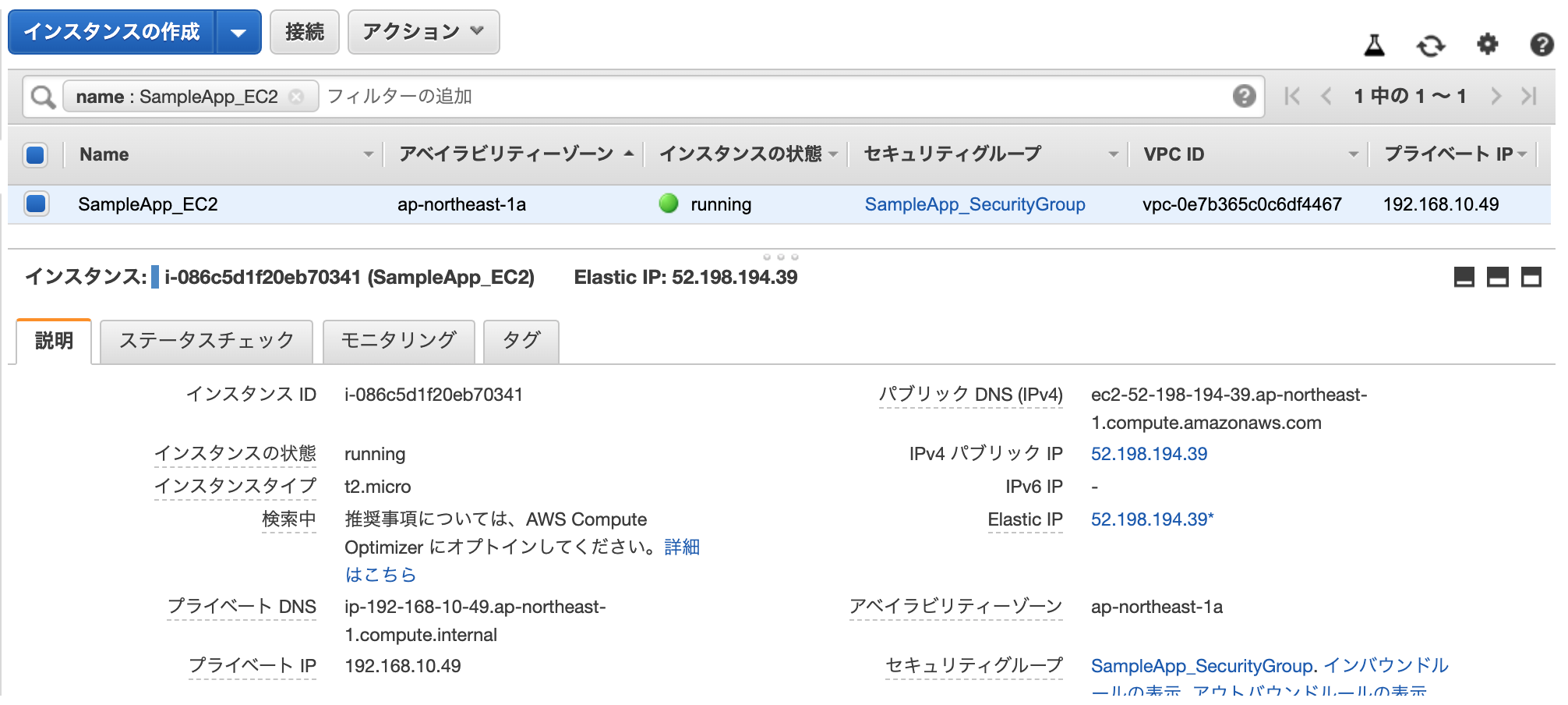
まずは、作成したインスタンスが起動しているのを確認してください。
下記画像の欄が緑文字で「running」となっていればOKです。
このインスタンスにアクセスしましょう。
アクセスするにはパブリックDNSを使用します。パブリックDNSとは、インターネットを通じてアクセスするための住所といったイメージです。
例えば http://yahoo.co.jp と打ち込むと「Yahoo Japan!」のページに飛ぶことができますが、
http://118.151.235.191/ と打ち込んでも、同様のページにアクセスすることができます。これは何故かというと、DNS(Domain Name System)というものが
118.151.~~~.~~~というIPアドレスとyahoo.co.jpというドメインを紐付けているからです。つまり、一旦ドメインでのアクセスをDNSが受け付けて、受け付けたドメインと対応するIPアドレスを探して表示させているという流れになります。このDNSの場所が上記に記載されているといった形です。
パブリック DNS が表示されていない場合
パブリックDNSが割り当てられていないとインスタンスにアクセスできないので、
次の手順で解決を行ってください。
1. コンソール画面から検索するなりして「VPC」をクリックしてください。
2. 左のメニューバーから「VPC」をクリックしてください。
3. 左上辺りにある「アクション」から「DNS ホスト名の編集」を選択してください。
4. 「DNS ホスト名」にチェックを入れて「有効化」してください。参考元:AWSでPublic DNS(パブリックDNS)が割り当てられない時の解決法
ここでやっと、ターミナル画面を使っていきます(長かった)...
今回は Mac を想定して記述していきます。下準備
今回は
opensshを使用するので、インストールしていない方はインストールしましょう。~$ brew install opensshSSH? という方は次の記事を一読ください。
初心者がSSHについて学ぶ(´・ω・`)今回はSSHを簡素に使用するので、よりセキュアに設定したい(しなければならない)方は
こちらの記事を一読するなどして、勉強しましょう。
インフラエンジニアじゃなくても押さえておきたいSSHの基礎知識インスタンスへのログイン設定
先ほど作成したインスタンスにログインをしていきます。
EC2インスタンスにログインできるユーザーとして、
AWSでは、デフォルトでec2-userという名のユーザーが用意されています。次の流れで進めていきたいと思います。
1. ec2-userでログイン
2. 新たなユーザーの作成
3. 作成したユーザーにec2-userと同様の権限を付与
4. 新たなユーザーで再度ログイン打ち込むコマンドは次の通りです。
~# 前回作成した公開鍵を .ssh ディレクトリに移動する $ mv Downloads/SampleApp_ConsoleKeyRsa.pem ~/.ssh # .ssh ディレクトリに移動 $ cd ~/.ssh~/.ssh# 公開鍵に600番で定義されたアクセス権を付与する $ chmod 600 SampleApp_ConsoleKeyRsa.pem # 公開鍵を利用してec2-userとしてログイン $ ssh -i SampleApp_ConsoleKeyRsa.pem ec2-user@52.198.194.39 # 信頼性について警告を受けますが「yes」と入力しましょう。 The authenticity of host '52.198.194.39 (52.198.194.39)' can't be established. ECDSA key fingerprint is SHA256:**************************************************. Are you sure you want to continue connecting (yes/no/[fingerprint])? yes※ アクセス権について知っておきたい方は、次の URL を参考にするなどして予習しましょう
chmod? chown? よくわからんって人のための、ファイル権限系まとめこれでEC2にアクセスすることができました。
~/.sshWarning: Permanently added '52.198.194.39' (ECDSA) to the list of known hosts. __| __|_ ) _| ( / Amazon Linux AMI ___|\___|___| https://aws.amazon.com/amazon-linux-ami/2018.03-release-notes/ 7 package(s) needed for security, out of 11 available Run "sudo yum update" to apply all updates. [ec2-user@ip-192-168-10-49 ~]$新たなユーザーの作成
続いて、新たなユーザーを作成し、作成したユーザーにマスター権限を与えていきます。
# 新規ユーザー名の登録 [ec2-user@ip-192-168-10-49 ~]$ sudo adduser minato # 新規ユーザー名のパスワードを登録 [ec2-user@ip-192-168-10-49 ~]$ sudo passwd minato Changing password for user minato. New password: Retype new password: passwd: all authentication tokens updated successfully. # 作成したユーザーに root 権限を追加する # 1. rootに関する権限の記述箇所 # root ALL=(ALL) ALL # を探す。 # 2. 「i」を入力することで「-- INSERT --」(入力)モードに移行する # 3. その下に「作成したユーザーに権限を追加する」記述 # minato ALL=(ALL) ALL # を追加する # 4. esc を押して Input モードを終了 # 5. 「:wq」で保存&編集完了 [ec2-user@ip-192-168-10-49 ~]$ sudo visudo
$ sudo visudoでは Vim というものを使用しています。
Vim とは主にコンソールから文字列を扱うviというテキストエディタを拡張したものです。
Amazon Linux においてはviコマンドを使用するとvimを使用するようにエイリアス設定がされています。[ec2-user@ip-192-168-10-49 ~]$ which vi alias vi='vim' /usr/bin/vimvim の使い方については次の記事が非常に参考になります。
Vim初心者に捧ぐ実践的入門編集が完了したら、次のコマンドでユーザーの切り替えを行ってください。
[ec2-user@ip-192-168-10-49 ~]$ sudo su - minato [minato@ip-192-168-10-49 ~]$無事に
ec2-userがminato(作成したユーザー名)と切り替わればOKです。SSH通信によるインスタンスへのログイン
続いては、先ほど作成したユーザーを使用してインスタンスにログインしていきます。
次の流れで進めていきたいと思います。
1. ローカルで鍵の生成
2. その鍵をどの通信の認証時に使用するか設定
3. サーバーとの認証処理を行う。
4. 実際に新ユーザーでログインでは早速作業していきますが、
ここからしばらくは、ローカル(あなたが使っているパソコン)での作業になるので、
次のコマンドでローカル環境に戻りましょう。
(別のターミナルを立ち上げて作業を行ってもOKです)[minato@ip-192-168-10-49 ~]$ exit logout [ec2-user@ip-192-168-10-49 ~]$ exit logout Connection to 52.198.194.39 closed.次のコマンドで、ローカルで鍵の生成を行います。
~/.ssh配下などで作業を行ってください。~/.ssh# 秘密鍵と公開鍵を作成 # 「Enter file in which to save the key」 # で、秘密鍵ファイルと公開鍵ファイルの名前を記述する $ ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/Users/minato/.ssh/id_rsa): SampleApp_MinatoKeyRsa Enter passphrase (empty for no passphrase): # そのままエンター Enter same passphrase again: # そのままエンター Your identification has been saved in SampleApp_MinatoKeyRsa. Your public key has been saved in SampleApp_MinatoKeyRsa.pub. The key fingerprint is: SHA256:************************************************** The key's randomart image is: ********** ********** ********** ********** ********** # 秘密鍵と公開鍵が生成されたことを確認 $ ls SampleApp_MinatoKeyRsa SampleApp_MinatoKeyRsa.pem # Vim を起動して設定ファイルを編集する # 以下を追記します。 # ######################################## # Host SampleApp_MinatoKeyRsa # Hostname 52.198.194.39 # Elastic IP # Port 22 # ポート番号 # User minato # サーバーで作成したユーザー名 # IdentityFile ~/.ssh/SampleApp_MinatoKeyRsa # 秘密鍵の場所 # ######################################## $ vim config # 公開鍵の中身をターミナル上に出力して、出力されたもの全てコピーしておく $ cat SampleApp_MinatoKeyRsa.pub ssh-rsa **************************************************上記により、
1. ローカルで鍵の生成
2. その鍵をどの通信の認証時に使用するか設定
ここまでが完了しました。次はサーバー側で作業を進めます。
~/.ssh$ ssh -i SampleApp_ConsoleKeyRsa.pem ec2-user@52.198.194.39 [ec2-user@ip-192-168-10-49 ~]$ sudo su - minatoサーバーに公開鍵を登録します。
# 鍵を入れるためのディレクトリを作成、権限の付与を行い、 # そのディレクトリに移動する [minato@ip-192-168-10-49 ~]$ mkdir .ssh [minato@ip-192-168-10-49 ~]$ chmod 700 .ssh [minato@ip-192-168-10-49 ~]$ cd .ssh # 公開鍵ファイルを作成する # 公開鍵の中身をコピペしましょう [minato@ip-192-168-10-49 .ssh]$ vim authorized_keys # 権限を設定する [minato@ip-192-168-10-49 .ssh]$ chmod 600 authorized_keys # ログアウトする [minato@ip-192-168-10-49 .ssh]$ exit [ec2-user@ip-192-168-10-49 ~]$ exitこれで新ユーザーでログインできるようになりました。
ローカルで下記コマンドを入力して、実際にログインできるか試してみましょう。~$ ssh SampleApp_MinatoKeyRsa Last login: Sat Mar 21 16:54:32 2020 __| __|_ ) _| ( / Amazon Linux AMI ___|\___|___| https://aws.amazon.com/amazon-linux-ami/2018.03-release-notes/ 7 package(s) needed for security, out of 11 available Run "sudo yum update" to apply all updates. [minato@ip-192-168-10-49 ~]$ログインできれば、無事ユーザー設定は終了です。
EC2インスタンスの環境構築
次は、作成したEC2インスタンス内で
Rubyやその他の環境が動くよう設定していきます。
「自身のPCで開発を始めるときに環境構築を行う」要領で、AWS内に新しく作成したパソコン(=EC2インスタンス)でも同様に環境構築を行なっていく感じです。yum を使って環境を構築
まずは
yumを使って幾つかの実行環境を構築していきます。
yumは「Yellowdog Updater Modified」の略で、環境を構築するときに使用する「パッケージ」を管理・運用することができるものです。
これを使って環境構築していきます。EC2 には既に
yumが入っているので、
まずはyumでインストールされているパッケージを最新の状態に更新しましょう。# yum 内のパッケージを更新する # パスワードが要求された際は入力する # 「これだけインストールしますけど大丈夫ですか?」というような警告が出てきますが、 # 「y」を入力して承認してください。 [minato@ip-192-168-10-49 ~]$ sudo yum update次に、今回使用するパッケージを一気にインストールしていきます。
# 今回使用するパッケージを一気にインストール。 # 各パッケージの説明は割愛しますが、 # C++、openssl、mysql、ImageMagick などをインストールしています。 [minato@ip-192-168-10-49 ~]$ sudo yum install \ git make gcc-c++ patch \ openssl-devel \ libyaml-devel libffi-devel libicu-devel \ libxml2 libxslt libxml2-devel libxslt-devel \ zlib-devel readline-devel \ mysql mysql-server mysql-devel \ ImageMagick ImageMagick-devel \ epel-release
Complete!が最後に表示されればOKです。Ruby の実行環境
次に、EC2インスタンスに
Rubyの実行環境を作成していきます。
Rubyをインストールするのにrbenvを使用します。
rbenvとは、簡単にRubyのバージョンの切り替えを行うためのツールです。次の手順で
rbenvをインストールしていきます。# rbenv をインストール [minato@ip-192-168-10-49 ~]$ git clone https://github.com/sstephenson/rbenv.git ~/.rbenv # ~/.bash_profile に bin の位置を登録する [minato@ip-192-168-10-49 ~]$ echo 'export PATH="$HOME/.rbenv/bin:$PATH"' >> ~/.bash_profile # ~/.bash_profile に rbenv コマンドが使えるように登録する [minato@ip-192-168-10-49 ~]$ echo 'eval "$(rbenv init -)"' >> ~/.bash_profile # 先ほど設定したものを再読み込みする [minato@ip-192-168-10-49 ~]$ exec $SHELL -l # rbenv のバージョンを確認する [minato@ip-192-168-10-49 ~]$ rbenv --version rbenv 1.1.2-28-gc2cfbd1 # ruby-build をインストール [minato@ip-192-168-10-49 ~]$ git clone https://github.com/sstephenson/ruby-build.git ~/.rbenv/plugins/ruby-build # rehash を行う [minato@ip-192-168-10-49 ~]$ rbenv rehashそしていよいよ、
Rubyのインストールです。# rbenv のバージョンのリストを確認する [minato@ip-192-168-10-49 ~]$ rbenv install --list 1.8.5-p52 1.8.5-p113 1.8.5-p114 ... # 2.6.5 をインストールする(バージョンは適宜変更してください) [minato@ip-192-168-10-49 ~]$ rbenv install -v 2.6.5 # 2.6.5 を使用するように設定する [minato@ip-192-168-10-49 ~]$ rbenv global 2.6.5 # rehash を行う [minato@ip-192-168-10-49 ~]$ rbenv rehash # ruby のバージョンを確認する [minato@ip-192-168-10-49 ~]$ ruby -v ruby 2.6.5p114 (2019-10-01 revision 67812) [x86_64-linux]しっかりと
Rubyのバージョンが表示されれば成功です。Node.js の実行環境
次に、EC2インスタンスに
Node.jsの実行環境を作成していきます。
Node.jsをインストールするのにnvmを使用します。
nvmは、簡単にNode.jsのバージョンの切り替えを行うためのツールです。
rbenvと同じ立ち位置ですが、次の手順で
nvmをインストールしていきます。# nvm をインストール [minato@ip-192-168-10-49 ~]$ git clone https://github.com/creationix/nvm.git ~/.nvm # ~/.bash_profile に nvm.sh を読み込むように設定する [minato@ip-192-168-10-49 ~]$ echo -e "if [[ -s ~/.nvm/nvm.sh ]]; then \nsource ~/.nvm/nvm.sh\nfi" >> ~/.bash_profile # インストール可能な Node.js バージョンの確認 [minato@ip-192-168-10-49 ~]$ nvm --versionそしていよいよ、
Node.jsのインストールです。# インストール可能な Node.js バージョンの確認 [minato@ip-192-168-10-49 ~]$ nvm ls-remote # v12.16.1 をインストールする(バージョンは適宜変更してください) [minato@ip-192-168-10-49 ~]$ nvm install v12.16.1 # Node.js のバージョンを確認する [minato@ip-192-168-10-49 ~]$ node -vしっかりと
Node.jsのバージョンが表示されれば成功です。別のバージョンをデフォルトで使用するよう設定する場合は次のコマンドを使用してください。
$ nvm alias default v12.16.1Rails アプリのクローン
今回の最後に、作成したアプリを git からクローンしてEC2インスタンス内に配置していきます。
git の設定ファイルを作成
まずは
vimコマンドで.gitconfigという git に関する設定ファイルを生成します。[minato@ip-192-168-10-49 ~]$ vim .gitconfig次のように設定しましょう。
~/.gitconfig# git のユーザー情報 [user] name = minato # git に登録した自分の名前 email = hoge@hoge.com # git に登録した自分のメールアドレス # 色付け [color] ui = true # githubの場合 # pull と push のための設定 [url "github:"] InsteadOf = https://github.com/ InsteadOf = git@github.com: # bitbucketの場合 [url "bitbucket:"] InsteadOf = https://minato@bitbucket.org/ # minato はあなたのユーザー名に置き換えてください InsteadOf = git@bitbucket.org:完了したらファイルを保存しましょう
アプリを配置するディレクトリの作成
次は、アプリを配置するディレクトリを作成していきます。
# / に移動 [minato@ip-192-168-10-49 ~]$ cd / # var ディレクトリの所有者を minato にする [minato@ip-192-168-10-49 /]$ sudo chown minato var [sudo] password for minato: # var 配下に www ディレクトリを作成し、所有者を minato にする [minato@ip-192-168-10-49 /]$ cd var; sudo mkdir www; sudo chown minato www # www 配下に rails ディレクトリを作成し、所有者を minato にする [minato@ip-192-168-10-49 var]$ cd www; sudo mkdir rails; sudo chown minato railsmkdirコマンドでフォルダを作成し、chownコマンドで作成したフォルダの所有者を変更しています。
git と連携
いよいよ git と連携していきます。
まずは次のコマンドを打ち込んで、
git と連携する用の秘密鍵と公開鍵を作成しましょう。[minato@ip-192-168-10-49 www]$ cd ~ [minato@ip-192-168-10-49 ~]$ chmod 700 .ssh [minato@ip-192-168-10-49 ~]$ cd .ssh [minato@ip-192-168-10-49 .ssh]$ ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/home/minato/.ssh/id_rsa): SampleApp_GitKeyRsa Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in SampleApp_GitKeyRsa. Your public key has been saved in SampleApp_GitKeyRsa.pub. The key fingerprint is: SHA256:************************************************** The key's randomart image is: ********** ********** ********** ********** ********** [minato@ip-192-168-10-49 .ssh]$ ls authorized_keys SampleApp_GitKeyRsa SampleApp_GitKeyRsa.pub秘密鍵と公開鍵が作成されているか確認できればOKです。
次は
vimを起動して設定ファイルを編集しましょう。[minato@ip-192-168-10-49 .ssh]$ vim config次のように設定してください。
~/.ssh/config# github の場合 Host github Hostname github.com User git IdentityFile ~/.ssh/SampleApp_GitKeyRsa # bitbucket の場合 Host bitbucket Hostname bitbucket.org User git IdentityFIle ~/.ssh/SampleApp_GitKeyRsa保存したら config に権限も設定しましょう。
[minato@ip-192-168-10-49 .ssh]$ chmod 600 config次に、公開鍵を出力します。
[minato@ip-192-168-10-49 .ssh]$ cat SampleApp_GitKeyRsa.pub ssh-rsa **************************************************一度インスタンスとの接続で行った鍵の作成の流れなので、大丈夫だと思います。
そして cat で表示させた公開鍵を github または bitbucket に登録します。GitHub の場合
1. GitHubにログインして、右上のメニューから Settings を選択
2. SSH and GPG keys を選択
3. New SSH Key を押す
4. Title(自由)、Key(コピーした内容をペースト)を入力して Add SSH key を押すBitbucket の場合
1. Bitbucket にログインして、左下の自身のアイコンから View Profile を選択
2. メニューから「設定」を選択
3. メニューから「SSH 鍵」を選択
4. 「鍵を追加」を押す
5. Label(自由)、Key(コピーした内容をペースト)を入力して「鍵を追加」を押す登録が完了したら接続を試してみましょう
# github の場合 [minato@ip-192-168-10-49 .ssh]$ ssh -T github Hi MinatoTachibana! You've succwwwessfully authenticated, but GitHub does not provide shell access. # bitbucket の場合 [minato@ip-192-168-10-49 .ssh]$ ssh -T bitbucket The authenticity of host 'bitbucket.org (18.205.93.2)' can't be established. RSA key fingerprint is ******************************. Are you sure you want to continue connecting (yes/no)? yes Warning: Permanently added 'bitbucket.org,18.205.93.2' (RSA) to the list of known hosts. logged in as minato You can use git or hg to connect to Bitbucket. Shell access is disabledこのように表示されれば接続成功です。
登録が済んだら、いよいよクローンです。[minato@ip-192-168-10-49 .ssh]$ cd /var/www/rails [minato@ip-192-168-10-49 rails]$ git clone git@bitbucket.org:minato/sample_app.git [minato@ip-192-168-10-49 rails]$ ls sample_app自身で作成した Rails アプリが表示されていれば OK です。
最後に
今回は「環境構築編」でした。
次回が最終回になります(長い...)それでは最終回「デプロイ編」お楽しみに。
- 投稿日:2020-03-22T01:30:28+09:00
AWS Global AcceleratorでLoadbalancerのPublicIPを固定する
非機能要件概要
外部システムとデータ連携している時、外部システム側がDNS名ではなく、IPを指定した接続のみという非機能要件もあったりします。PublicIPを持つEC2 Instanceでリバースプロキシを作成したり、Network Loadbalancerを使用すればIPを指定した接続という要件は満たせます。しかしながらSSLアクセラレーション機能がなかったり、バックエンドサーバのInboundを0.0.0.0/0にしておく必要があったり、EC2に依存する設定が複数あります。
また、Direct ConnectとVPC endpointを使用して外部システムと同じ閉域網で構築したりもします。
ただし、使用するコンポーネントも多く、外部システムとの作業調整やデータ提供の可用性を高めるためのコストが高くなりがちです。
また、Application LoadbalancerとClassic LoadbalancerにはPublicIPが2つ付きますが、このIPは動的でAWSの任意のタイミングやトラフィック需要によって変動します。そのため、IP変更されたことを検知するためにポーリングして変更を実施する仕組みが必要だったりします。Global Acceleratorを使用すると、LoadBalancerのIPを実質的に固定することが可能になります。複雑になりがちな構成をシンプルにできます。
Global Accelerator?
Global Accerelator を使うと、Load Balancerや EC2 Instanceに対して2つの静的IPアドレスを関連付けることが可能になります。Global Accerelator がアプリケーションサーバのフロントエンドインターフェイスとして機能するため、アプリケーションサーバのIPアドレスを更新せずに、Blue Green deploymentが実行できます。
インターネットに接続された単一のアクセスポイントとして Global Accerelator を使用することで、AWSで実行しているアプリケーションサーバを分散サービス妨害 (DDoS) 攻撃から保護できます。
Global Acceleratorは専用のVPCで稼働しています。VPC間のピア接続でShield Advancedが機能することで分散サービス妨害(DDoS)攻撃から保護されます。
しかも、アプリケーションまでのホップ数が少ないNW経路を使用できるため、理論上はパフォーマンスが向上します。イメージ
設定ファイル
下記は terraform での設定例です。
multiple_provider.tfprovider "aws" { region = "ap-northeast-1" profile = "terraform-user01" } provider "aws" { region = "us-west-2" alias = "oregon" profile = "terraform-user02" }globalaccelerator_accelerator.tfresource "aws_globalaccelerator_accelerator" "xxxxxxxxxx_accelerator" { provider = aws.oregon name = "xxxxxxxxxx" ip_address_type = "IPV4" enabled = true attributes { flow_logs_enabled = true flow_logs_s3_bucket = "xxxxxxxxxx" flow_logs_s3_prefix = "xxxxxxxxxx/" } }globalaccelerator_listener.tfresource "aws_globalaccelerator_listener" "xxxxxxxxxx_listener" { provider = aws.oregon accelerator_arn = aws_globalaccelerator_accelerator.xxxxxxxxxx_accelerator.id client_affinity = "SOURCE_IP" protocol = "TCP" port_range { from_port = 80 to_port = 80 } }globalaccelerator_endpoint_group.tfresource "aws_globalaccelerator_endpoint_group" "xxxxxxxxxx_endpoint_group" { provider = aws.oregon endpoint_group_region = "ap-northeast-1" health_check_interval_seconds = 30 health_check_path = "/" health_check_protocol = "TCP" listener_arn = aws_globalaccelerator_listener.xxxxxxxxxx_listener.id threshold_count = 3 traffic_dial_percentage = 100 endpoint_configuration { endpoint_id = "arn:aws:elasticloadbalancing:ap-northeast-1:xxxxxxxxxx:loadbalancer/app/xxxxxxxxxx" weight = 128 } }確認
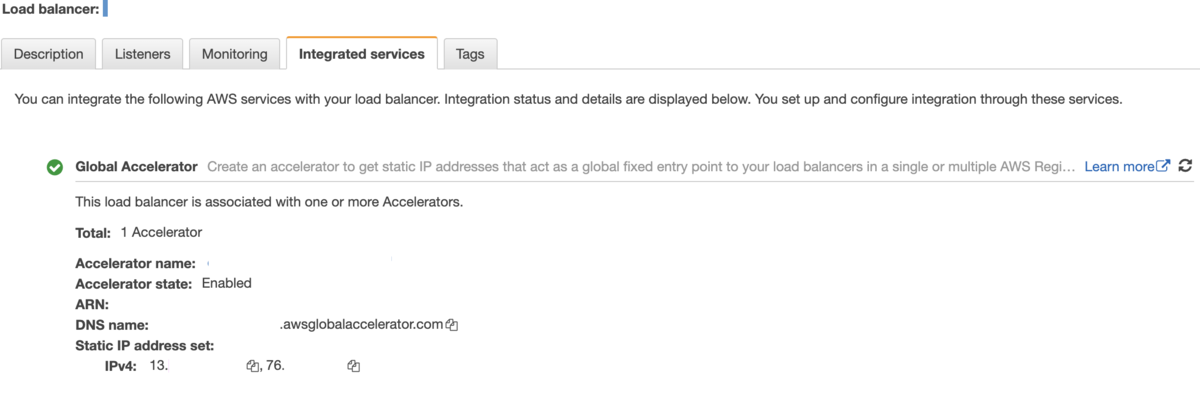
Global Accelerator作成前
ターゲットにALBを指定したGlobal Accelerator作成後、以下の2IPが付与されました
この2つの静的IPアドレスを任意のFQDNのAレコードとして定義すれば作業完了です。
料金
- 固定料金: アクセラレーターが削除されるまで、アカウントでアクセラレーターが稼働している 1 時間 (1 時間未満は繰上げ) 毎に 0.025 USD 課金されます。
- プレミアムデータ転送料金 (DT-Premium): AWS ネットワーク経由で転送されるデータのギガバイトあたりの料金です。
所感
- クライアントから少ないホップ数でアプリケーションに到達できるというのはIPを固定する運用の副産物としのレイテンシ低減などはインパクトがありますが、月に$130くらいかかるので明細と相談しながら運用する必要があります。

- 投稿日:2020-03-22T01:22:09+09:00
Docker を AWS にインストール
200321
注意点
なぜか動かない、という状況は AWS のセキュリティグループの設定が原因かもしれない。AWS の準備
EC2 をたてるまでの手順は、ここでは説明しない。注意が必要なのはセキュリティグループの設定で、デフォルトでは SSH 以外はすべてブロックされる。
AWS に docker をインストール
sudo yum update
sudo yum install -y docker正常にインストールできたか確認できる。バージョンは 1.21.5 のようだ。
docker infosudo がなくてもいいようにする
sudo service docker start
sudo usermod -a -G docker ec2-userdocker-compose インストール
docker-compose
sudo curl -L https://github.com/docker/compose/releases/download/1.21.0/docker-compose-$(uname -s)-$(uname -m) -o /usr/local/bin/docker-composeパーミッション変更が必要
'sudo chmod +x /usr/local/bin/docker-compose'
'docker-compose --version'Django のデプロイ
Docker を使った本番デプロイ
AWS 上でディレクトリ構造などを作ったりする必要はない。そんなことをやっていると手間ばかりかかってミスも連発する。ローカルの開発環境にも Docker を入れて、ここで完成したものをそのまま丸ごとコピーするのが正しい。
セキュリティグループの追加
EC2 のインスタンスを普通に立てただけでは SSH しかできない設定となってる。セキュリティグループに、HTTP プロトコル(ポート 80 または 8000)を通す設定をしておかないと絶対につながらず、時間を溶かすので注意が必要。
ローカルで開発したプロジェクトのデプロイ
ローカル環境で動作確認した django プロジェクトは、ディレクトリごと zip にしてホストに転送する。配置したい場所で unzip すると、そのままファイルができるので、あとは docker-comopose up すれば立ち上がる。
おわり
- 投稿日:2020-03-22T00:10:45+09:00
駆け出しエンジニアが知識ゼロから1ヶ月半でAWSのSAA試験に受かった話
1ヶ月半の学習を経て、AWSソリューションアーキテクトアソシエイト試験に合格したので学習方法等を記録しようと思います。
僕のような駆け出しの方でAWS-SAA受けようという方の参考になればと思います。前提
- SES
- 実務経験は4.5ヶ月程度(学習開始時は3ヶ月程度)
- 現在の職場が初現場、初プロジェクト
- 普段はLaravelやReactを触らせてもらってる
- スキル的にはフロント寄り
- ネットワーク知識はほぼなし
- オンプレミスのインフラの知識もほぼなし
- もちろんその辺の実務経験もなし
受験までの経緯
現在のプロジェクトのメンバーの方でフロント技術を得意としている方がおりまして、普段はその方からReactを教えてもらっています。その方との会話の中で「ネットワークやインフラの知識も大事だよねー、最近だとクラウドだよねー」といった感じになり、気づいたら一緒に1ヶ月後の試験を予約していました。
自分としても徐々にフロント周りの知識がついてきていたので、きっかけがあれば他のことも勉強したいなと思っていました。
勉強始める前に試験を申し込んでしまうのは絶対に必要かなと思います。じゃないと結局やらないので。主に使用した教材
あとは公式サイトやGoogleです。
試験のためにやったこと
- はじめにUdemyの動画講座を購入し、動画を視聴。
- 丁寧な解説で理解しやすいが、僕自身の前提知識がなさすぎてイマイチ頭に残っていないことに気づき、効率が悪いと判断。
- このタイミングでKindleで参考書の購入、Udemyの動画視聴を一旦やめる。
- わからない言葉はGoogleで調べながら、参考書を一通り読む。
- 試験が近くなってきたので、Udemy模擬試験を解いて、気になるところを動画や書籍や公式サイトで見直す。
基本は土日に時間をとって勉強して、平日は通勤時間などにスマホでKindleみたり、模擬試験の解説をみていました。
職場でも昼休みに経験豊富な上司にネットワーク関連の話を質問したりして前提知識を増やしていきました。Udemyの動画講座は他の方の記事にも紹介されており、おすすめです。
ただ、全くの初心者の場合、個人的には先に書籍などで自分のペースで言葉などを調べながらやる方がいいかなと思います。
書籍の場合、概要をつかむのにおすすめですが、情報が古いことがあるので注意です。この段階では22時間あるUdemyの動画は全部は見れず、心残りはあったがそのままの日程で試験を受けました。
初受験スコア
SAA試験は1000点満点の試験です。合格ラインは720点で7割程度の正答率が求められます。問題数は65問、選択式です。
結果は700点で不合格。
後日スコアレポートをみると、セキュリティの問題が弱かったみたいでした。
一発で合格したかったのですが、自分で購入した分の教材すら全てみれていなかったので仕方ないかなという風にも思いました。再び試験が受けられるのは二週間後になりますので、そこでリベンジしようと思いました。期間が空くと勉強しないので。
反省点
- 単純に勉強時間が少なかった。
- ハンズオンをやっていなかったため、細かい設定や各サービスのデフォルト設定などが全くわかっていなかった。
- ネットワークの基礎知識が全然なかったので、問題文自体がすっと入ってこなかった。
- 各サービスでできることの範囲や切り分けが曖昧だった。
- 切り分けが曖昧なので各サービスの連携に関わる問題で迷ってしまった。
再受験までにやったこと
- ネットワークの基礎知識を習得するためマスタリングTCP/IP入門編を購入し読んでみた。読み物として気楽に読めるのでおすすめ。
- 視聴できていなかったUdemy動画を見て、ハンズオンの動画もしっかり見た。(この時には動画の内容も以前より理解しやすくなっていたので1.5倍速でも無理なく学べました)
- 自分のawsアカウントでコンソール画面を触って見たりした。
- 模擬試験問題を解いて、復習を繰り返した。
誘惑に負けてNetflixで鬼滅の刃と約束のネバーランドを全部見てしまったりしましたが、一度試験を受けてイメージが出来ていたので前回よりは気持ちに余裕がありました。試験直前では結局緊張したんですけどね。
再受験スコア
結果は755点で合格。ギリギリでした。
回答終了後すぐに結果出るのは心臓に悪いです。
でも結構嬉しかったです。資格を取ったことなかったので。後日レポートではまたしてもセキュリティの問題が弱かったみたいでした。
サブネット構成、証明書やデータ暗号化周りの復習は必要そうです。よかったこと
- 少し自信がついたこと
- ネットワークやインフラの基礎知識を学べたこと(まだまだこれからだとも思います)
- 学習を通してフロントエンド以外の技術に対する興味関心が生まれたこと
まとめ
学習方法に関しては僕みたいな初心者は本を読むのがおすすめです。そこから動画や公式サイトを見て行くのがいいと思います。
ある程度経験や知識のある方はUdemyの動画だけでも良い気がします。
Udemy模擬試験と解答解説をしっかりみるのはマストだと思います。
コンソール画面も一度触ったり動画でしっかりみるとイメージ湧きやすくなります。図やイメージは大事です。感想としては実務で触るのがきっと1番勉強になるんだろうなと思いました。
個人的にはこの試験だけでは実務でバリバリというのは難しそうな気もします。
ですが知識は絶対に得られるし、学習のきっかけ、AWSなどのクラウドを使った仕事をするきっかけにはなってくれるかもしれませんし、駆け出しの方にとっては多少のアピールにはなるのかなとも思ったりしています。これをとっかかりとして今後も継続的な学習を心がけたいと思います。
以上。
- 投稿日:2020-03-22T00:07:54+09:00
新たな言語 "Dark" を実際に触ってみて
はじめに
先日、私が以前に申請していたDarkのプライベートベータ版に漸く招待されたので、実際に触ってみた感想を述べようと思う。
1. Darkとは?
Darkとは、Ellen Chisa、そしてCircleCIの創業者であるPaul Biggarによって設立された会社で開発されている「偶発的な複雑さ」を無くし、バックエンドWebサービスを構築するための総合的なプログラミング言語であり、エディタであり、インフラストラクチャである。呼称するならば、総合的なソフトウェア開発プラットフォームだろう。Web上にエディタが展開され、そこで全ての開発を行える為、開発ツールやパブリッククラウドと言った多くのテクノロジーを直接触る必要は無い。
また、最大の特徴としてはデプロイレスだろう。デプロイレスとは、入力したものが即座にデプロイされ、本番環境ですぐに使用できる事である。Darkはインタープリタをクラウドで実行する。関数またはHTTP/イベントハンドラで新しいコードを作成すると、抽象構文ツリーの差分(エディターとサーバーが内部で使用するコードの表現)をサーバに送信し、次にそのコードを実行する。その為、デプロイメントはデータベースへの僅かな書き込みで済む為、瞬時且つアトミックである。この様に、デプロイを可能な限り最小化する事で最大50msの高速デプロイを実現している。
※デプロイレスに関する詳細は本記事下部の参考文献に記載
2. どんな開発に向いているのか
Darkは大きな目標として、「ソフトウェアの構築を100倍容易にすることでコーディングを民主化し、次の10億人がコーディングできるようにする」と挙げているが、初期段階では以下のような領域をターゲットにしている。
- モバイルアプリや、React, Vue, Anglarで記述された単一ページのWebアプリ等のクライアントアプリのバックエンド
- 既存のマイクロサービスベースのアーキテクチャで新しいサービスを構築すること
一方で、組み込みシステムや、定理証明、機械学習モデルなどは今後サポートする予定は無いとの事。
3. 実際に動かしてみる
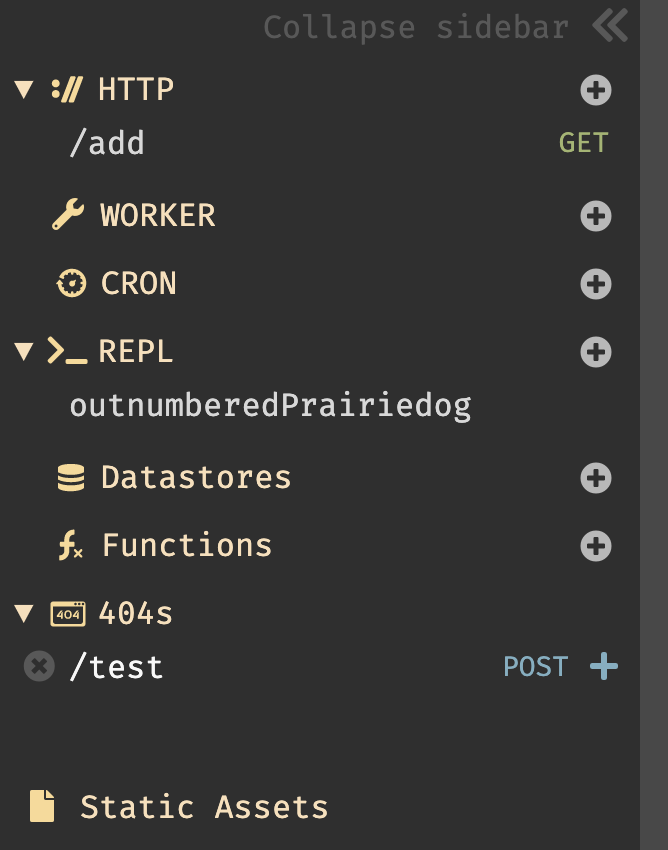
実際にDarkのチュートリアルを参考にして、「日付レポート」のAPIを実装していく。
Darkにログインするとエディタが立ち上がる。画面は非常にシンプルで、サイドバー、ユーザ情報(右上)、ドキュメント(右下)のみである。基本的な操作は画面をクリックすると以下の図の様に機能の選択画面が表示される。開発は、この画面をキャンバスの様に使用して都度、自分の使用したいものを選択・追加してく事で開発していく。
3.1. Hello World
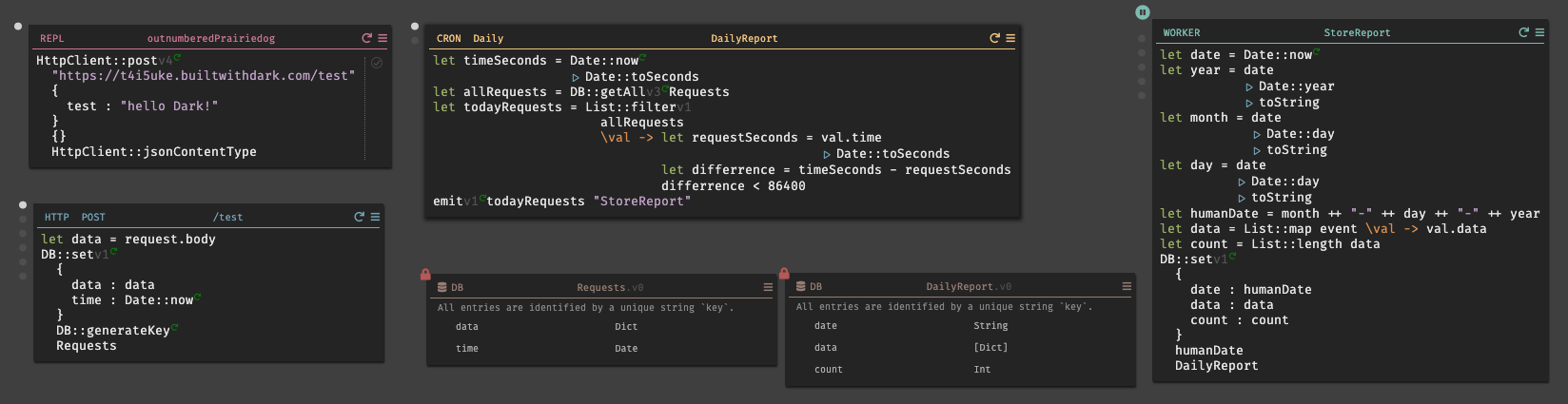
Hello Worldを作成してみる。手順は非常にシンプルである。
画面をクリックし、メニューが開かれた状態で
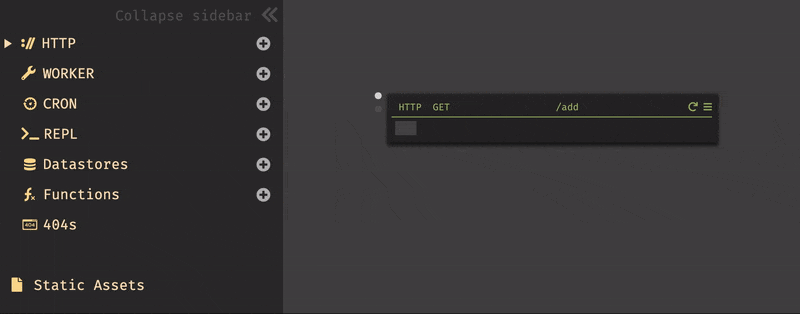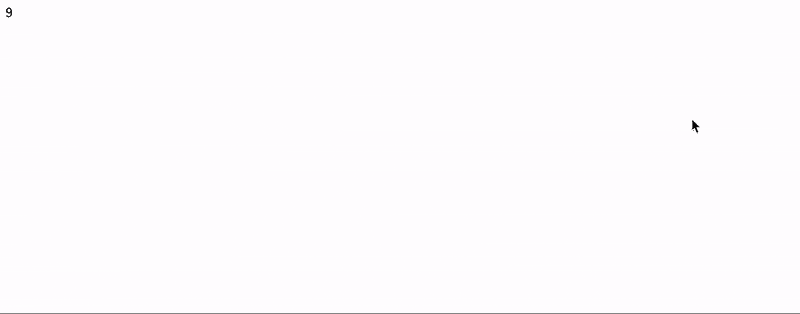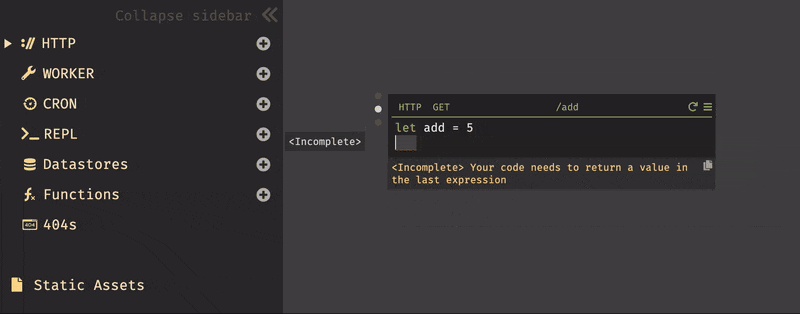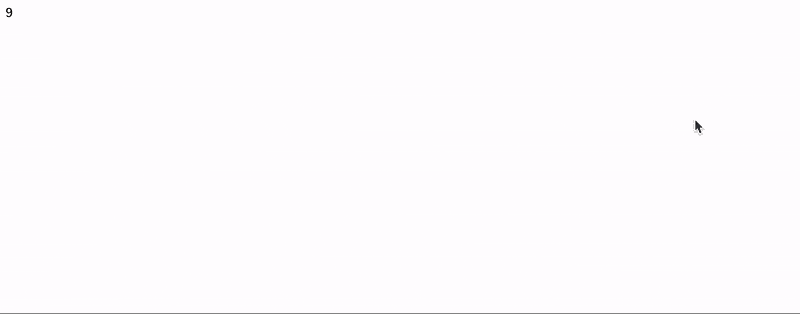
helloと入力すると、New HTTP handler named /helloとメニューに表示されるので、それを選択すると/helloハンドラが作成される。後は、リクエストメソッドと、valueを書くだけで完成である。作成したものは、右上の設定からOpen in new tabで即時に確認する事ができる。また、valueが未記入の場合、
<Incomplete> Your code needs to return a value in the last expressionとエラーが表示される。※エンドポイントは、デフォルトでは
USERNAME-gettingstarted.builtwithdark.comとなるが、USERNAME-.builtwithdark.comの2つ存在した。エンドポイント変更はユーザ画像をクリックし、Account/Canvasから切り換える事ができる。【2020/03/22追記】
エンドポイントを書き換える事でプロジェクトを複数作成する事が可能で、新規プロジェクトを作成する際はエンドポイントを書き換えて更新すると良い。3.2. 演算
次に簡単な演算を行い、演算結果を渡してみる。
先程、同じ様にHTTPハンドラを作成し、リクエストメソッドを
GET、ルートを/addに設定した。演算処理は、演算子を使用して簡単に記述する事も可能だが、変数を宣言して行うことも可能である。
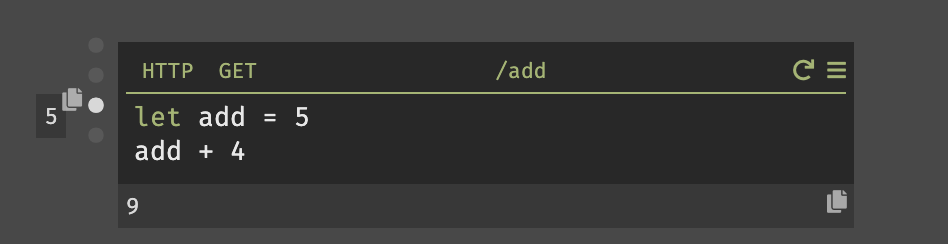
また、Darkではハンドラを作成すると、以下の様に各々の値を瞬時に確認する事ができる。
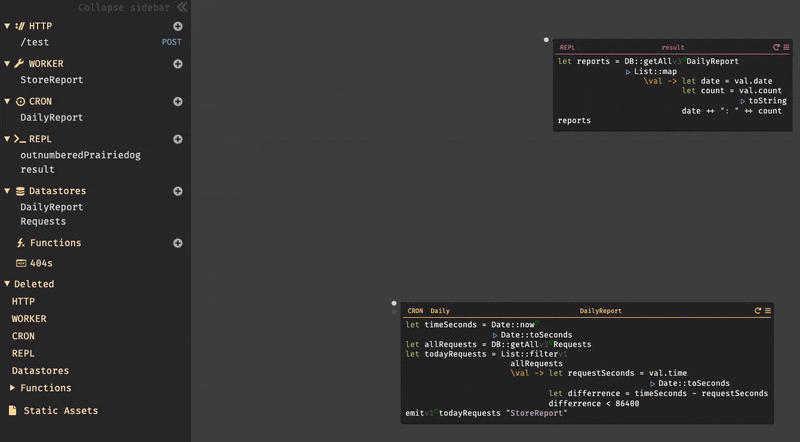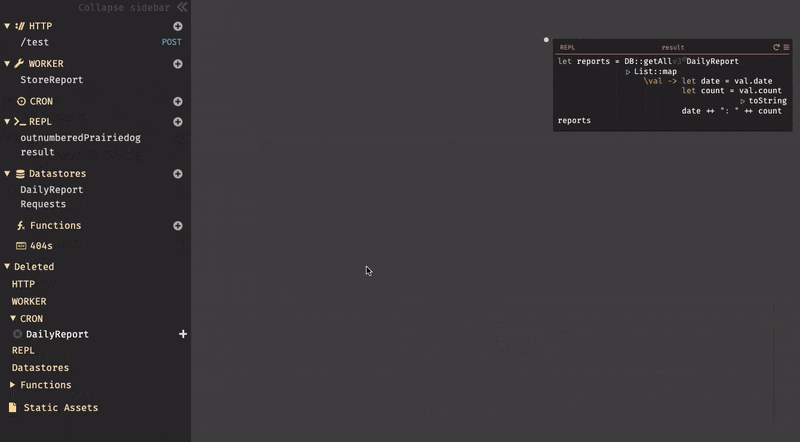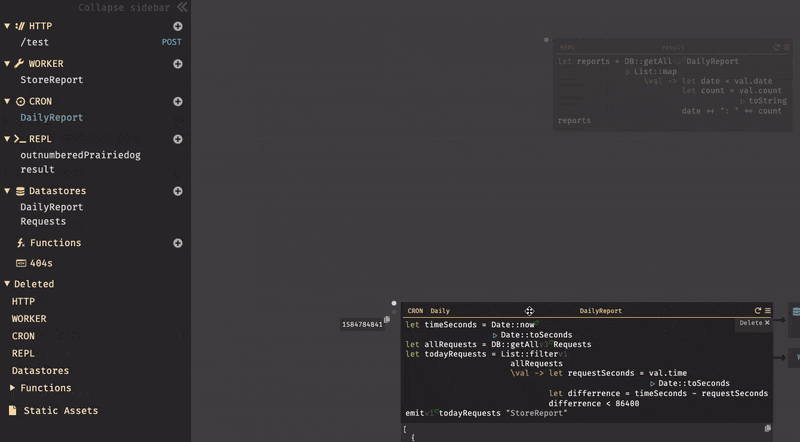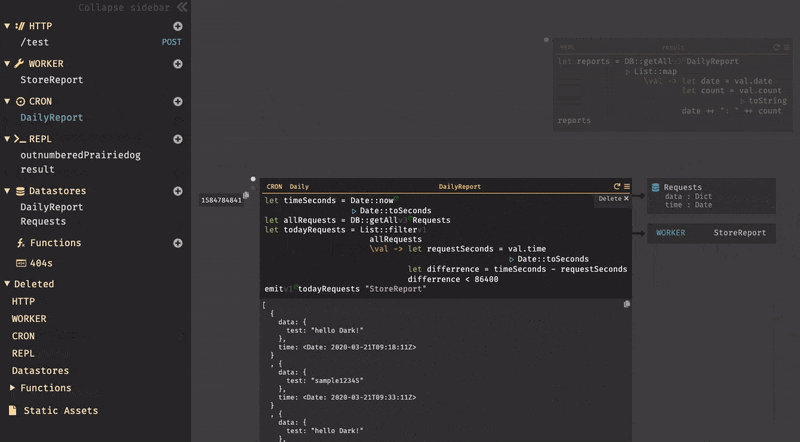
9(画像下部)と出力されている場所は、このハンドラの戻り値である。5(画像左部)はカーソルが置かれている位置の式の結果を表示している。整数の場合では利便性を感じないが、変数の場合は即座に結果を確認できる。3.3. REPL
REPLを作成する際も、同様に選択画面からREPLを選択し作成していく。今回は、敢えてエラーを起こしてその挙動も確認してみる事にする。
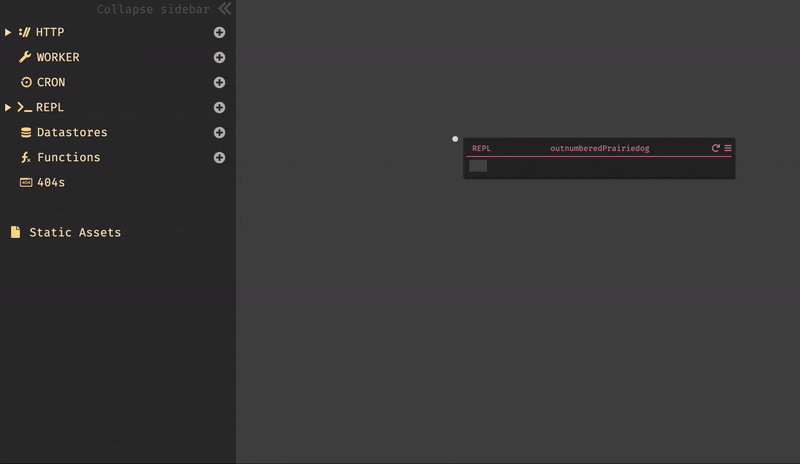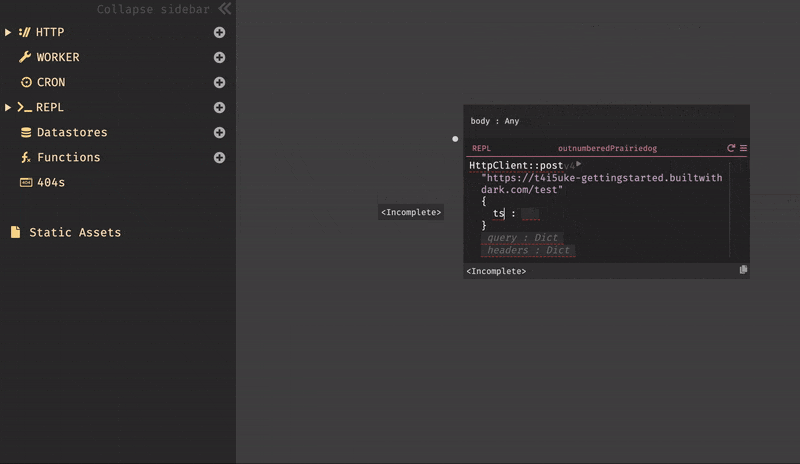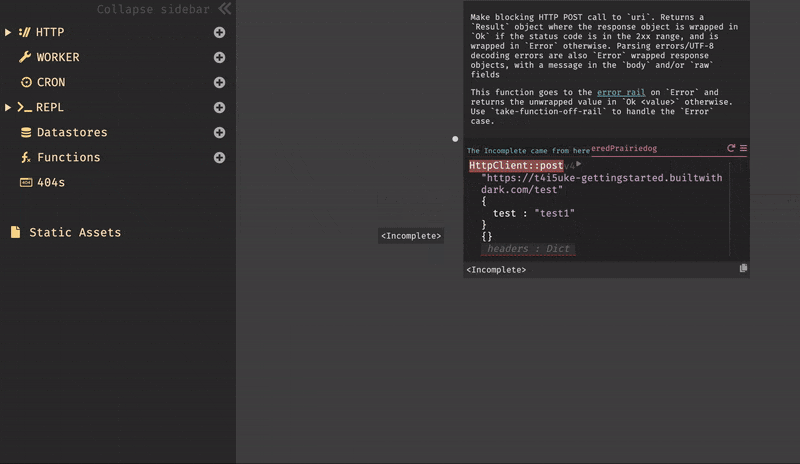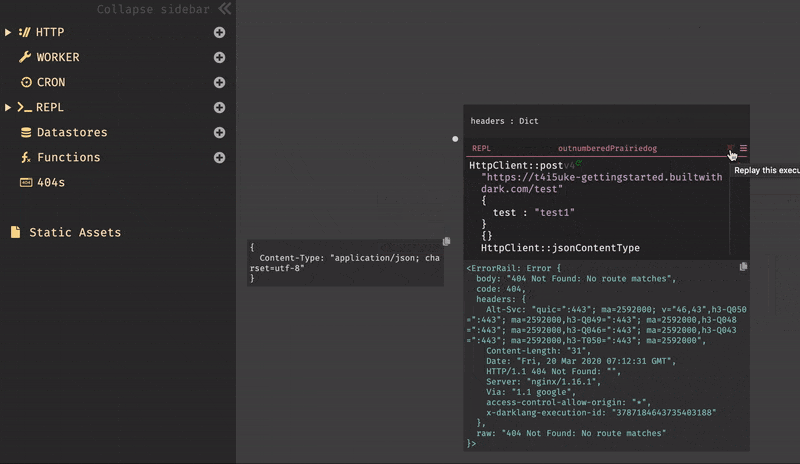
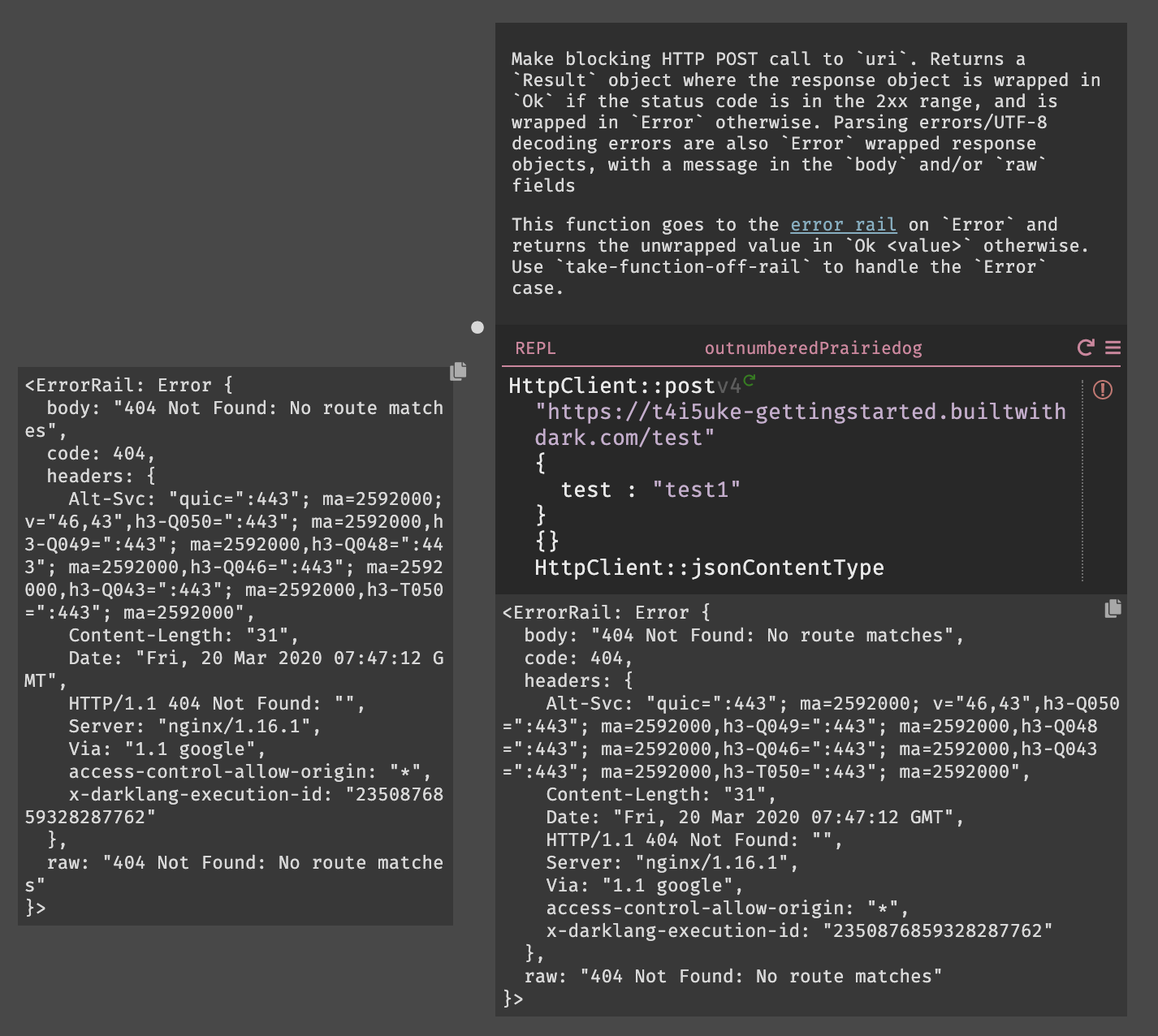
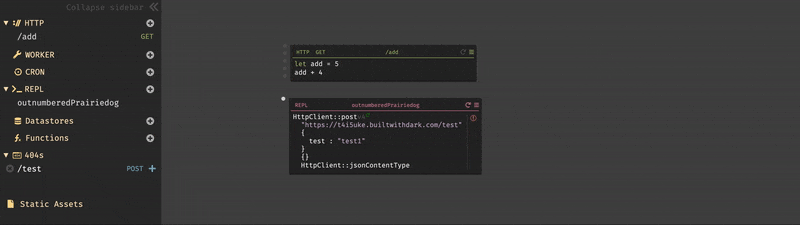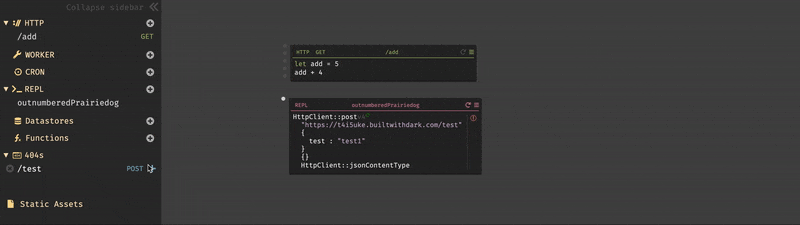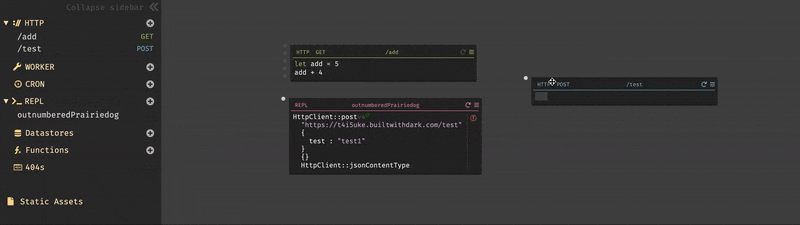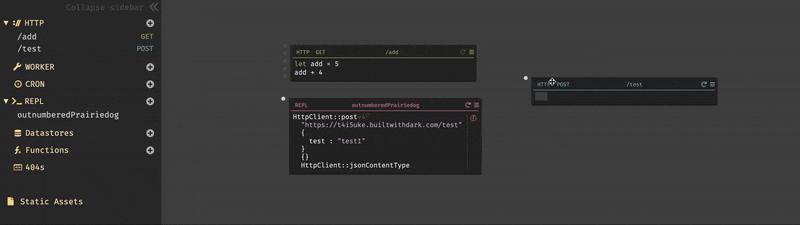
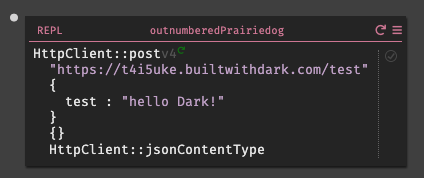
httpclientと入力すると、HTTPClientのすべての標準ライブラリ関数、署名、およびdocstringが表示される。今回は、HTTPClient::postを使用しようと思うので、httpclientpostまで打つと表示された。Darkはオートコンプリートを行ってくれるので、正確なテキストを入力する必要は無い。
HTTPClient::postを選択すると、受け取る為のパラメータ(URI,Body,Query,Headers)を自動的に作成され、それらを全て入力するとエディター内から式を実行できる実行ボタン(HTTPClient::postの右側の灰色の三角形)が表示される。
エンドポイントは今回、
USERNAME.builtwithdark.comを使用したので、以下の様に入力する。https://USERNAME.builtwithdark.com/testその他、パラメータを入力して実行しようとすると
404がレスポンスとして表示される。これは、エンドポイント/testがキャンバス上に存在しない為である。この結果は、サイドバーの404セクションからも確認できる。
一方、キャンバス上ではエラーはこの様に表示される。
3.4. データストア
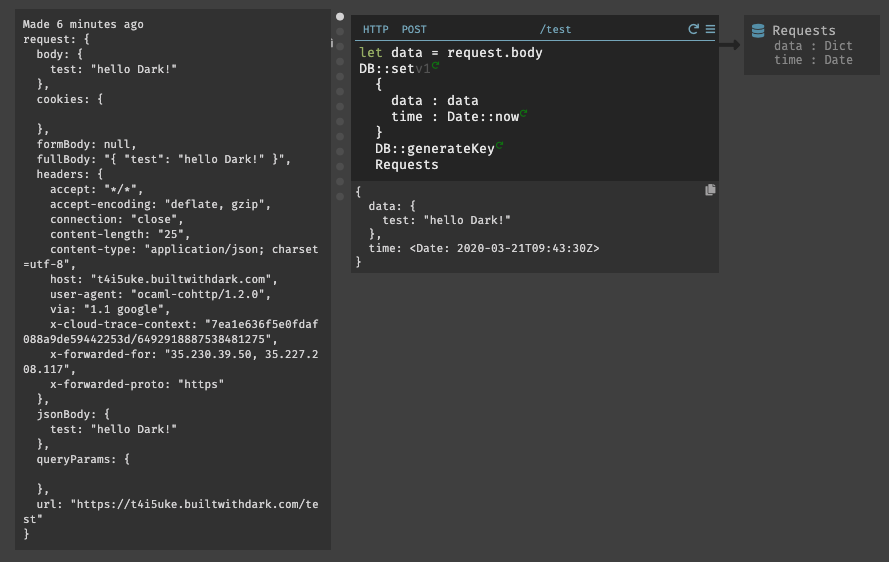
まず、先程のエンドポイントでのエラーを解決する為に、DarkではHTTPリクエストのトレースを使用してエンドポイントを構築する(トレース駆動開発)。404セクションにあるルート
/testの右側にある青色の+ボタンを押すと、POSTメソッドのルート/testが作成される。
作成されたものを確認してみると、
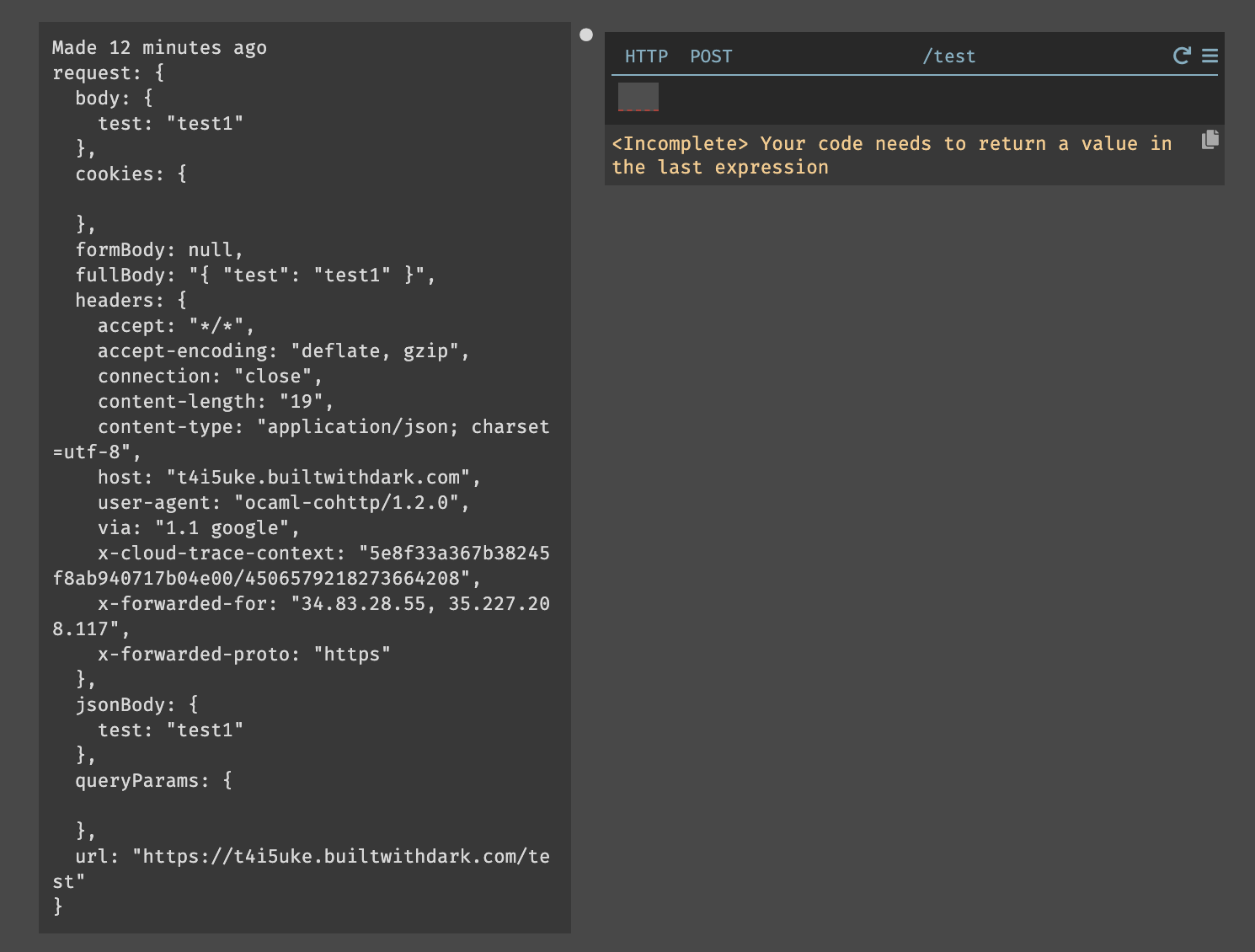
Bodyを含むREPLで設定したリクエスト情報が完全にトレースされている事が確認できる。
このリクエストを直接処理し、
let data = request.bodyを入力して取得した情報をレコードに保存する、ここでも、オートコンプリートを活用して記述していく。
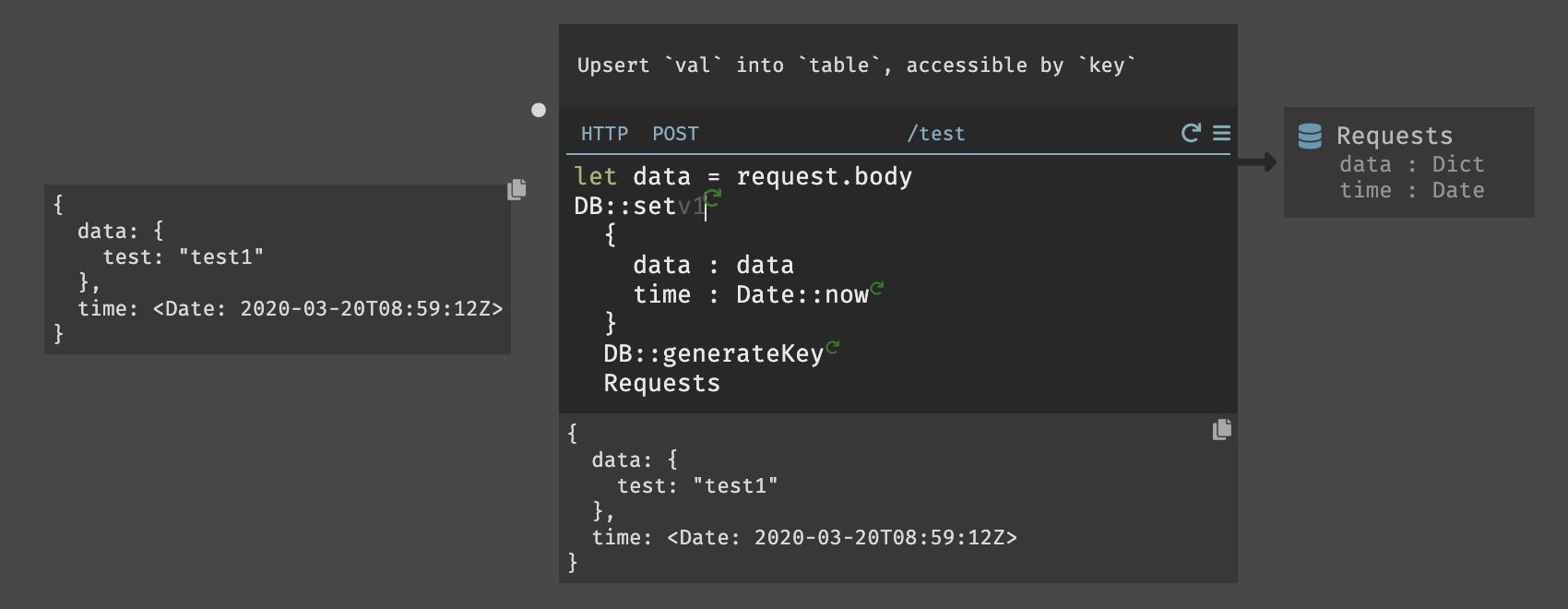
データストアは、HttpClientライブラリと同様に、空白に「DB」と入力すると、すべてのデータストア関数がプルアップされる。今回の場合では、
db::setを使用する。データストアの作成は、サイドバーかキャンバス内をクリックして作成が可能である。今回は、
Requestsと言うデータストアを作成した。(小文字で入力して作成しても、最初の1文字目は大文字に変換してくれる様である)Darkのすべてのデータストアはキー値ベースであり、キーをレコードの一意の識別子として使用する。今回の場合であると、
data、timeのキーを作成した場合は以下の様になる。{ key1: { data: { test: "test2" }, time: }, key2: { data: { test: "test1" }, time: } }最初のパラメータは、挿入するレコードである。これは、日付と時刻のスキーマと一致する。Darkでは、
DB::setのすべてのフィールドを含める必要がある。上記のデータとDate::now関数を挿入して時間を取得している。2つ目はキーであり、各オブジェクトに一意のキーが必要である。この場合、dbと入力すると、組み込みのdb::GenerateKey関数が取得できる。3つ目は、データストア名を指定する。データストアの名前はオートコンプリートで表示される。最後に、
DB::setを実行してみると以下の様にデータストアにレコードが挿入され、スキーマがロックされる。
3.5. CRON
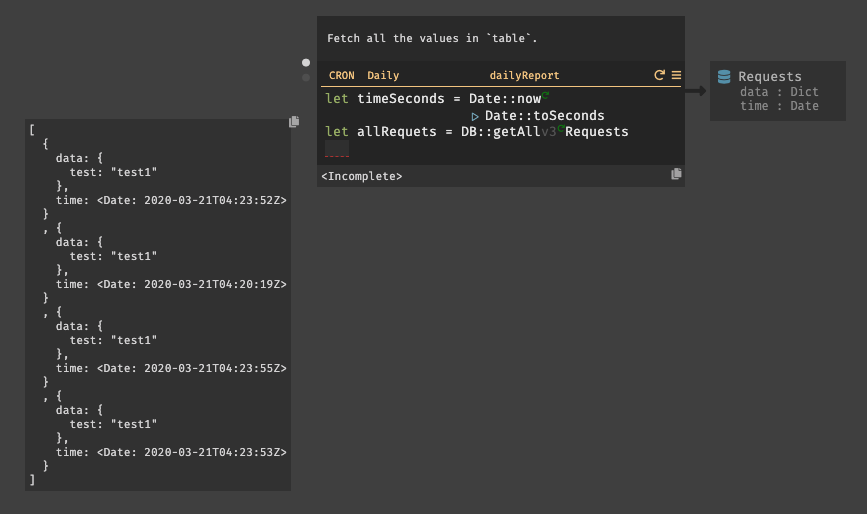
今回は、
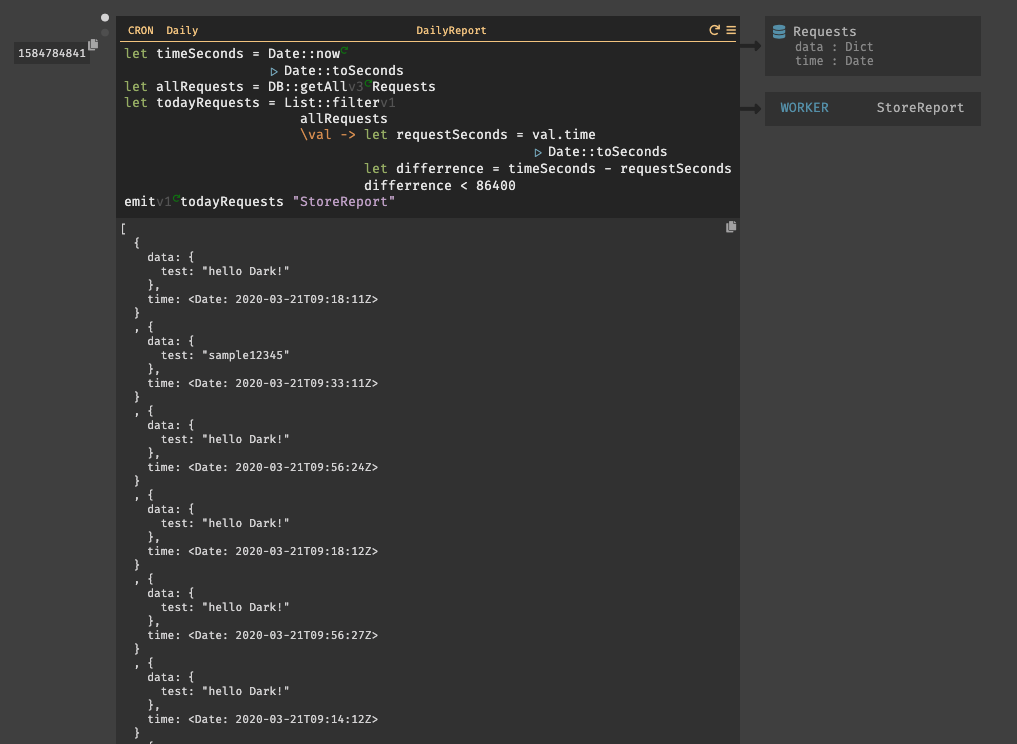
dailyReportと言うの名前のCRONを作成する。日付レポートを作成する為には、現在の時間と比較する必要がある。まず、変数
timeSecondsを用意しDate::nowを設定する。次に、比較の為に秒単位の時間が必要の為、Date::toSecondsも設定する。関数はパイプで繋げる事ができる。(|と入力すると、|>と表示される。)リクエストの取得は、
DB::getAllを使用し、取得したいDBテーブル(Requests)を指定する。リクエストはList型で取得される。入力後に、実行してみると以下の様にリクエストが取得されている事が確認できる。
次に、
List::filterを使用してリクエストのフィルタリングを行う。List::filterでは、フィルタリングするリスト名と、匿名関数を設定する。
匿名関数では、リクエストが今日の情報であるかどうかを確認する。
変数
requestSecondsは、リクエスト内に内包されている時間dateである。リクエストの時間は秒に変換する必要がある為、CRONの最初の行と似ているが、val.timeでリクエストの時間を取得しパイプでDate::toSecondsを繋げて変換している。変数
differenceは、現在の時刻とリクエストの時間の差分を計算している。 そして、差分の結果が24時間以内(86400秒)であるかどうかを判別する。最後に、
emitを使用して、バックグラウンドワーカーにリクエストを送信している。emitでは、イベント名(todayRequests)と、WORKER名(StoreReport)を指定して送信を行う。では、次にWORKERの作成について説明する。3.6. WORKER
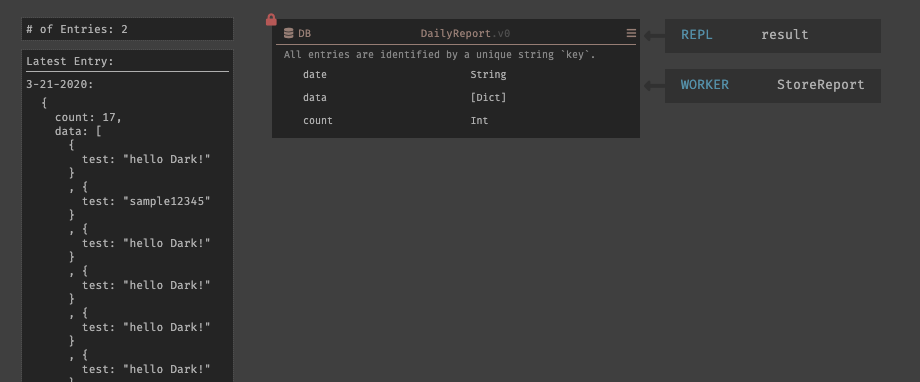
CRONを実行すると、WORKERは存在していないので404セクションに表示される。その為、先程と同じ様に404セクションから
StoreResortを選択すると、既に名前がついた状態で作成される。作成されたWORKERにカーソルを合わせると、CRONによってトリガーされイベントが表示される。
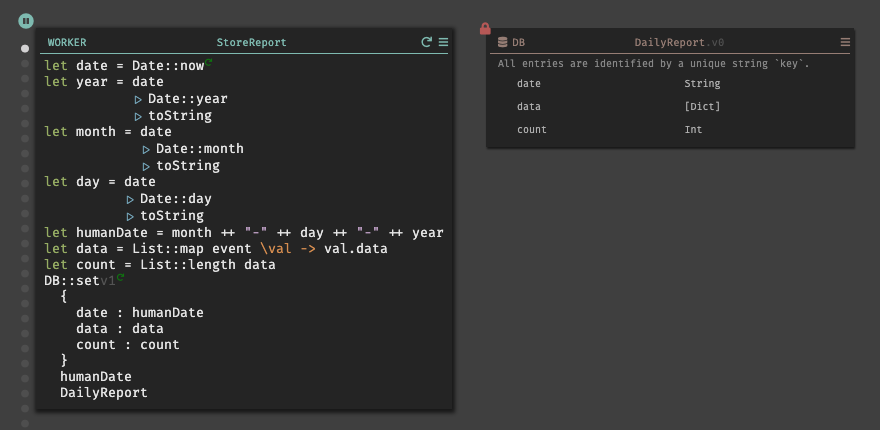
実際に、WORKERの機能を実装すると以下のようになる。
レポートでは、
MM-DD-YYYYの表記でデータを保存する為、現在時刻を取得し、それぞれを分割して変数humanDateでフォーーマット変換を行った。※
+はint型の場合でのみ使用できる様で、String型の場合は++を使用する事で文字列を連結する事ができる。変数
dataでは、リクエストに内包されているdataのみを取得している。List::mapを使用する事で、リスト内のオブジェクトのコレクションに対して操作する事ができる。レポートの保存は、新たに
DailyReportと言うデータストアを作成しているが、外部APIを使用する事も可能である。以上で、実装は終了である。ここまでの実装したものを並べると以下のようになる。
3.7. 動作検証
REPL内で記述した、BODY部分を
test 1から、hello Dark!に変更して実行してみる。
実行すると、
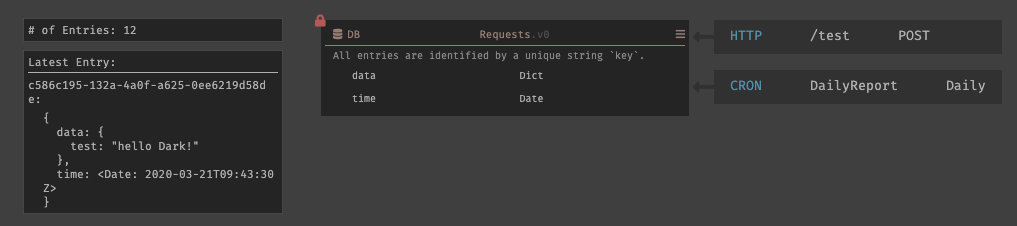
/testハンドラでは新しいトレースドットが表示され、リクエストのBODYが、hello Dark!になっている事が確認できる。
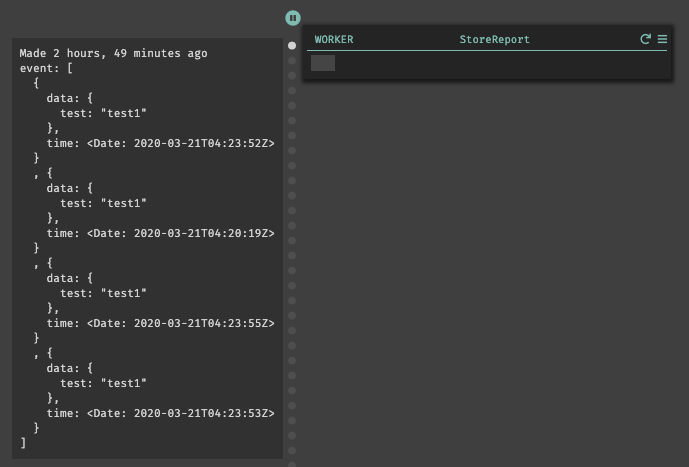
データストアも同じく、DBに追加されたレコードが表示される。
CRONの方も確認してみると、DBのレコードが全て取得できている事が確認できているが、時系列毎にソートして表示されてはいない為探すのに苦労した。筆者が不必要に連打したのが原因でもあるが、レコードが増えていく事が想定されると目を通すのには可読性が悪く、少し労力が掛かるなと感じた。
WORKERも同じ事が言える。しかし、Eventは実行された時系列毎に保存されており、前回との差分の確認や以前のデータの内容を確認する事ができる。
最後に、日付レポートのデータストアも確認すると、日付毎にレコードが登録されている事が確認できる。
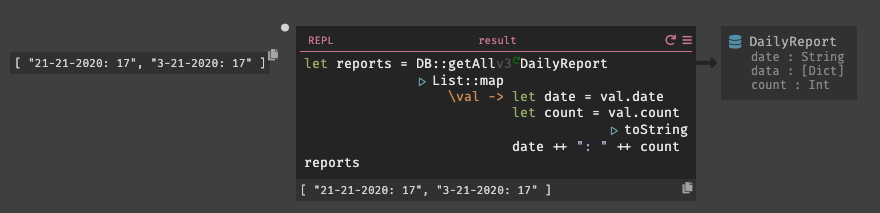
また、新たにREPLを作成し日時レポートとその内部の項目数を取得してみた。実行してみると、
DailyReport
から日付毎にレポートを取得する事ができた。試しに異なる日付のレコードも登録した所、そちらも同じく取得する事ができた。
ハンドラなどを削除すると、Deletedセクションが表示される。Deleteセクションから削除されたハンドラやデータストアを見ることができ、復元すると即座にデプロイし直され元の状態に復元する事ができる。
4. 総評
初めてDarkを触り、直感的操作で開発を行う事ができた。確かに、初期段階ではDarkのツールセットについての学習コストは発生するものの、従来の開発言語を覚える程では現段階は無いと感じる。
また、コードを書くことと並行してトレーシングが行われ、Dark内で作成したものはオートセーブされる為、ウィンドウを閉じても再度立ち上げると以前の状態から再開する事ができるので逐一保存する面倒もない。
デプロイレスと言う指向は、これまでいくつかのサービスで実装しようと試みて来たが、Darkが初めての成功例ではないだろうか。開発者は、アプリケーションのコードを書くだけで良く、書き終わったコードは既にホストされていると言うのは非常に有り難い事である。CircleCIを開発してきたPaul Bigger氏だからこそ、デプロイに深く精通し、その中に存在する課題を解決する策として見出せたのだと思う。
ベータ版ではあるが、既にある程度の開発も可能でReact SPAや、Slackbotの開発もできるようなので今後試しに実装してみる。
しかし、バグもまだ存在しているのでこれからの改善に大きく期待すると共に今後の開発に貢献していけたらと思う。
最後に、本記事を見てDarkを触れてみたいと感じた人が少しでも増えてくれれば幸いである。ベータ版は、Darkの公式サイトから登録が可能で招待されるまでに時間は掛かる(筆者はベータ版開始から大体2,3ヶ月待った)が是非この機会に登録して欲しい。
5. 謝辞
本記事を作成するに至り、快く承諾してくれたCEOのEllen Chisaに深く感謝する。
参考文献