- 投稿日:2020-03-21T23:46:31+09:00
OANDA APIを使用したFXデータ収集
モチベーション
FXを対象とした自動売買botを作成する際に、どのような戦略で自動売買をしようか考える必要があります。
そしてその戦略はどの程度のパフォーマンスであるかを評価されなければいけません。
この記事では戦略のパフォーマンスチェックのためにOANDA REST APIを使用したFXデータの収集方法について、備忘も兼ねて記載します。やりかた
1. OANDAの登録
OandaというFX業者が公開しているAPI群のことを指します。
FXのAPIを公開している業者は非常に少なく、またネット上にある情報量を考慮するとFXに関するAPIはOANDA REST APIを使用するのが良いと思います。
APIを使用するにはOANDAに登録し、APIキーを発行して貰う必要があります。
下記のリンクから5分くらいで登録できます2. oandapyV20のインストール
OANDAに登録し、APIキーが払い出されたら次はAPIを叩く環境を作りましょう。
APIキーは別ファイルに出しておくと便利です。pip install oandapyV20oanda_access_key.py
ACCOUNT_ID = "xxxxxxxxxxx" PERSONAL_ACCESS_TOKEN = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"instruments_candles.py
from oandapyV20.endpoints.instruments import InstrumentsCandles import oandapyV20 import oanda_access_key as oak account_id = oak.ACCOUNT_ID access_token = oak.PERSONAL_ACCESS_TOKEN api = oandapyV20.API(access_token = access_token, environment = "practice")3. データ取得
過去データを取得するにはInstrumentsCandlesを使用します。
公式ドキュメント
oandapyV20のドキュメント
ざっくり、15分足のデータを取得してデータフレームに突っ込むサンプルです↓
あとはDBに突っ込むなりそのままデータを使用するなり、自由に調理できます。ic = InstrumentsCandles( instrument="USD_JPY", # 通貨ペアを選択 params={ "granularity": "M15", # ロウソク足の種類を選択 "alignmentTimezone": "Japan", # タイムゾーン # "count": 5000 # 取得するデータ件数、from-toを指定する場合はcountは指定しない "from": start_datetime.strftime(datetime_format), "to": (start_datetime + relativedelta(days=date_window) - relativedelta(seconds=1)).strftime(datetime_format) } ) api.request(ic) data = [] for candle in ic.response["candles"]: data.append( [ candle['time'], candle['volume'], candle['mid']['o'], candle['mid']['h'], candle['mid']['l'], candle['mid']['c'] ] ) df = pd.DataFrame(data)
- 投稿日:2020-03-21T23:46:31+09:00
OANDA REST APIを使用したFXデータ収集
モチベーション
FXを対象とした自動売買botを作成する際に、どのような戦略で自動売買をしようか考える必要があります。
そしてその戦略はどの程度のパフォーマンスであるかを評価されなければいけません。
この記事では戦略のパフォーマンスチェックのためにOANDA REST APIを使用したFXデータの収集方法について、備忘も兼ねて記載します。やりかた
1. OANDAの登録
OANDA REST APIはOandaというFX業者が公開しているAPI群のことを指します。
FXのAPIを公開している業者は非常に少なく、またネット上にある情報量を考慮するとFXに関するAPIはOANDA REST APIを使用するのが良いと思います。
APIを使用するにはOANDAに登録し、APIキーを発行して貰う必要があります。
下記のリンクから5分くらいで登録できます2. oandapyV20のインストール
OANDAに登録し、APIキーが払い出されたら次はAPIを叩く環境を作りましょう。
APIキーは別ファイルに出しておくと便利です。pip install oandapyV20oanda_access_key.py
ACCOUNT_ID = "xxxxxxxxxxx" PERSONAL_ACCESS_TOKEN = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx"instruments_candles.py
from oandapyV20.endpoints.instruments import InstrumentsCandles import oandapyV20 import oanda_access_key as oak account_id = oak.ACCOUNT_ID access_token = oak.PERSONAL_ACCESS_TOKEN api = oandapyV20.API(access_token = access_token, environment = "practice")3. データ取得
過去データを取得するにはInstrumentsCandlesを使用します。
公式ドキュメント
oandapyV20のドキュメント
ざっくり、15分足のデータを取得してデータフレームに突っ込むサンプルです↓
あとはDBに突っ込むなりそのままデータを使用するなり、自由に調理できます。ic = InstrumentsCandles( instrument="USD_JPY", # 通貨ペアを選択 params={ "granularity": "M15", # ロウソク足の種類を選択 "alignmentTimezone": "Japan", # タイムゾーン # "count": 5000 # 取得するデータ件数、from-toを指定する場合はcountは指定しない "from": start_datetime.strftime(datetime_format), "to": (start_datetime + relativedelta(days=date_window) - relativedelta(seconds=1)).strftime(datetime_format) } ) api.request(ic) data = [] for candle in ic.response["candles"]: data.append( [ candle['time'], candle['volume'], candle['mid']['o'], candle['mid']['h'], candle['mid']['l'], candle['mid']['c'] ] ) df = pd.DataFrame(data)
- 投稿日:2020-03-21T23:42:27+09:00
あさココを自動でChromecast(or Nest Hub)にキャストして目覚まし代わりにする
はじめに
最近、Vtuber界で勢いを増しているホロライブ。
アイドル色が強く、メンバー同士のコラボも多いことから、箱推しの機運が高まりがちですが、全員の配信を追うことはかなり厳しいです。
そんなホロライブの情報を入手する手段として、4期生の桐生ココさんが平日朝6時に放送している「あさココLiveニュース」(以下あさココ)があります。
あさココは、前日のホロライブメンバーの配信で起こった事などをピックアップして20分ほどにまとめられており、非常に見やすい配信となっています。
ですが、朝6時という時間の都合上、寝過ごして見逃してしまうことが多々ありました。
そこで、あさココを自動で再生し、目覚まし代わりにすることで、見逃しを減らします。
具体的には、Youtube Data APIで配信予定情報を取得し、配信開始を監視、配信が始まったらChromecastにキャストします。動作確認環境
- Ubuntu 18.04 LTS 64Bit
- Python 3.6.9
- Chromecast Ultra
- Google Nest Hub
事前準備
- Youtube Data API
- APIキーを取得しておきます。取得方法はここを参照
- Pythonモジュール
- Youtube Data API用のクライアントとChromecast制御用のモジュールをインストールしておきます。
pip3 install pychromecast pip3 install --upgrade google-api-python-client詳細手順
ソースはGithubに置いてあります。以下はざっくりした説明です。
パス名やファイル名は適宜変更してください。配信予定情報を取得する
search:listリクエストを使用して配信予定を探します。配信予定枠が作られていれば、その動画IDを返します。
booking.pydef search_videos(): """あさココの検索結果から配信予定枠を検索して動画IDを返す""" # q=検索クエリ # part=取得する情報種別(snippet:基本情報) # channnelId=検索対象に入れるチャンネルID # maxResults=検索結果として返す最大数 search_response = youtube.search().list( q='あさココ', part='snippet', channelId='UCS9uQI-jC3DE0L4IpXyvr6w', maxResults=5 ).execute() video_id = None for search_result in search_response.get('items', []): if search_result['id']['kind'] == 'youtube#video': if search_result['snippet']['liveBroadcastContent'] == 'upcoming': # 配信予定枠が見つかったらvideoIdを取得する video_id = search_result['id']['videoId'] break return video_id配信予定の動画IDが見つかったら、配信開始予定時刻を取得します。
videos:listリクエストを使用します。booking.pydef get_scheduledtime(video_id): """配信予定枠の動画IDから配信開始予定時間を取得しての5分前の時刻をatコマンドのフォーマットで返す""" # part=liveStreamingDetails(配信情報) # id=動画ID videos_response = youtube.videos().list( part='liveStreamingDetails', id=video_id ).execute() for search_result in videos_response.get('items', []): scheduled = datetime.datetime.strptime(search_result['liveStreamingDetails']['scheduledStartTime'], '%Y-%m-%dT%H:%M:%S.%fZ') scheduled_jst = scheduled + datetime.timedelta(hours=8, minutes=55) return scheduled_jst.strftime('%H:%M %m%d%Y')"scheduledStartTime"が配信開始予定時刻ですが、UTCのため、+9時間した時刻が日本での正しい時刻です。
atコマンドで、配信開始予定時刻の5分前に配信状態監視スクリプトが起動するように設定します。
pythonからatコマンドで予約booking.pyp = subprocess.Popen(['at', start_time], stdin=subprocess.PIPE) command = '%slivestate.py -i %s' % (EXEC_PATH, video_id) p.communicate(command.encode('utf-8'))コマンドライン引数として動画IDを渡しておきます。
配信状態を監視して、配信中であればChromecastにキャストする
atコマンドにより、配信時間5分前になったら、配信状態監視スクリプトが起動します。
コマンドライン引数として渡された動画IDをvideos:listリクエストに渡して配信状態を取得します。livestate.pyvideos_response = youtube.videos().list( part='snippet', id=video_id ).execute() for search_result in videos_response.get('items', []): result = search_result['snippet']['liveBroadcastContent'] return result取得した状態が"upcoming"であればしばらく待って再度取得します。
"live"であれば配信中なので、Chromecastへキャストします。livestate.pydef cast_device(video_id): """指定した動画IDの動画をデバイスにキャストする""" chromecasts = pychromecast.get_chromecasts() cast = next(cc for cc in chromecasts if cc.device.friendly_name == CAST_DEV_NAME) cast.wait() yt = YouTubeController() cast.register_handler(yt) yt.play_video(video_id)参考:pychromecast/examples/youtube_exapmle.py
CAST_DEV_NAMEはキャストするデバイスの名前です。Homeアプリで設定したデバイス名を設定しておきます。Cronに登録して、自動で開始するようにする
このままだと1回目の放送情報取得は手動で行わなければいけないため、Cronに登録して、指定時間に自動で動くようにします。
$ crontab -e # 以下をファイルに追記 0 0 * * 1-5 Python3 [作業パス]/booking.pyこれで月~金曜日の0時に初回が起動するようになりました。
まとめ
Youtube Data APIを使用して配信情報を取得し、配信開始時にChromecastにキャストすることができました。
これを応用すれば、登録チャンネルの配信予定を一覧取得し、視聴予約する というようなことができそうです。
あさココで起きることで、1日のよいスタートが切れそうですね(?)。
最後に、推しの曲を貼ってまとめとさせていただきます。すいちゃんはいいぞ。
comet
天球、彗星は夜を跨いで
- 投稿日:2020-03-21T23:34:59+09:00
Pythonで毎日AtCoder #12
はじめに
前回
今日はAGCがあるから書かなくていいかなと思っていたら、一問も解けなかったので書きます。最近はAGC-Aとかもレコメンドに出てくるので疲れる。#12
問題
1WA。参加したけど解けなかった問題考えたこと
まず考えるのは$B-A$が偶数のときで、偶数のときは$\frac{B-A}{2}$でよい。問題は、$B-A$が奇数のとき。$B-A$が奇数のときはどれだけ近くなっても同卓できることはない。なのでどちらかが1またはNに行って偶奇を調整しなければならない。当然、1、Nに近い方がそれぞれに行った方が同卓するまでの回数は減るので$min(a-1,n-b)$でどちらが近いかを求める。a-1しているのは、卓の数字は1から始まっているから。1、Nまで行くと偶奇を調整するために+1、$B-A-1$が偶数になったので$\frac{B-A-1}{2}$すればよい。n, a, b = map(int,input().split()) d = b - a if d % 2 == 0: print(d//2) else: print(min(a-1,n-b)+1+(b-a-1)//2)ifで偶奇の判断をして、後は上に書いた通りに計算している。
まとめ
AGC-Aは難しい。明日のABCは取り敢えずA~Cの三完を目指す!!
では、また。おやすみなさい。
- 投稿日:2020-03-21T23:12:22+09:00
ツイートの期間を指定して削除
黒歴史は無かったことにしたい
世の中にはいろんなツールが既にあるが、
ツイッターの仕様で最新3200件しか削除できないとか、
大量削除は有料とか。
非常に困る。こちとら2010年から積み上げたゴミのようなつぶやきは優に10万を超える。
探せばQiitaに全ツイートを消すソースもある。
でも全部は困るんだよ。
そもそも全消しするならアカウント作りなおした方が早いだろ…黒歴史だけ消して最近の真人間な自分は残しておきたいんだ。
そんな人向け。
手順
- python3.6環境の構築
- 黒歴史が詰まったアーカイブの取得
- アーカイブの中にあるtweet.jsを編集
- APIキーの取得
- ソースコードの編集
- 実行
- 完了
1. python3.6環境の構築
もちろん使えるよね?
使えなかったらグーグル先生に聞いてくれ2. 黒歴史が詰まったアーカイブの取得
① PCでツイッターにログインして設定画面を開く(https://twitter.com/settings/account)
② 「Twitterデータ」タブを選択(パスワード求められたら入力する)
③ 「Twitterデータをダウンロード」を押す。
※ダウンロードができるようになるまでかなり時間がかかる
過去のツイートやDMを画像も含めてDLするので、Twitterがダウンロードデータを生成するのに時間がかかる
でも新設設計なので、ダウンロード可能になったらダウンロードリンクをメールで送ってくれる。
④ メールに来たリンクをクリックしてダウンロード開始。
⑤ ダウンロードが完了したら適当な場所に解凍する3. tweet.jsを編集
ソースコードでこのファイルを読み込みたいので、ちょこっと手を加える。
① 解凍したフォルダの中の「data」フォルダを開く
② 「tweet.js」という名前のファイルがあるので、適当なテキストエディタで開く。
③ 先頭にある「window.YTD.tweet.part0 = 」という文字列を削除。
④ 保存して閉じる。※保存する際にUTF-8のBOM無しにしておくこと。多分ファイル読み込み時にエラー出る。
※あと、念のためファイルのバックアップは取っておこう。ミスったらまたダウンロードのやり直しだ。4. APIキーの取得
ツイッターのAPIを使用するのにアクセストークンなるものが必要になる。まあ、ただの文字列だ。
下記手順で2つのkeyと2つのtokenを取得しよう。
プログラムで必要なのでメモ帳にでもコピペすればOK① ココにアクセス→https://developer.twitter.com/en/apps
② Appsって中にいくつかあるかもしれないが、ツイッターのアカウントIDが記載されたものの「Details(詳細)」を選択する
③ 「App details」「Keys and tokens」「Permissions」って3つのタブがあるのを確認する④ まずは「Permissions」を選択し、「Edit」ボタンを押して権限を変更する
⑤ 権限は「Read, write, and Direct Messages」てやつ。
⑥ Saveを押して保存。⑦ 「Keys and tokens」を開く
⑧ 「Keys, secret keys and access tokens management.」に記載されている下記をそれぞれメモする
・API key
・API secret key
⑨ 「Access token & access token secret」の情報もコピーする
「Regenerator」的なボタンを押すと
・Access token
・Access token secret
が表示されるのでそれぞれメモするこれでOK
5. ソースコードの編集
ソースサンプルは下記
各々よしなに変更してほしいところはコメントに書いたので好きなようにしてくれimport json import twitter # pip install python-twitter # ====== いい感じに設定書いてね ====== # keyとtokenを下記に記載 api_key = 'ここにコピペ', # メモした「API key」をここにコピペ api_secret_key = 'ここにコピペ', # メモした「API secret key」をここにコピペ access_token = 'ここにコピペ', # メモした「Access token」をここにコピペ access_token_secret = 'ここにコピペ', # メモした「Access token secret」をここにコピペ # tewwt.jsのファイルパスを記載。("\"は必ず2つつけてね) js_file_path = "D:\\sample\\hogehoge\\tweet.js" # 下記に指定したbegin~endの期間のツイートを削除する。(beginとendの日付を含む) begin_year = 2010 # この年の begin_month = 1 # この月の begin_day = 1 # この日から↓ end_year = 2019 # この年の end_month = 12 # この月の end_day = 31 # この日までを削除 # ================================ api = twitter.Api( consumer_key = api_key, consumer_secret = api_secret_key, access_token_key = access_token, access_token_secret = access_token_secret, sleep_on_rate_limit = True ) class date(): def __init__(self, y, m, d): self.y = y self.m = m self.d = d class date_range(): def __init__(self): self.begin = date(begin_year, begin_month, begin_day) self.end = date(end_year, end_month, end_day) # もっと効率良い方法ある気がするが、気にしたら負け def cnv_month_from_str2int(month): if month =='Jan': return 1 elif month =='Feb': return 2 elif month =='Mar': return 3 elif month =='Apr': return 4 elif month =='May': return 5 elif month =='Jun': return 6 elif month =='Jul': return 7 elif month =='Aug': return 8 elif month =='Sep': return 9 elif month =='Oct': return 10 elif month =='Nov': return 11 elif month =='Dec': return 12 else: assert False, "ERROR!! [{}] is not month".format(month) def run(): d_r = date_range() cnt = 0 with open(js_file_path, encoding='utf-8', mode='r') as f: tj=json.load(f) for tweet0 in tj: tweet = tweet0['tweet'] print() print(tweet['id']) date = tweet['created_at'] dow, month, day, time, other, year = date.split() _year = int(year) _day = int(day) _month = cnv_month_from_str2int(month) # out of custum date range. if ( _year > d_r.begin.y and d_r.end.y < _year) \ or (_month > d_r.begin.m and d_r.end.m < _month) \ or (_day > d_r.begin.d and d_r.end.d < _day): continue print("The number that deleted tweet is {}".format(cnt)) print("Now deleting {}/{}/{}".format(_year, _month, _day) ) try: api.DestroyStatus(tweet['id']) cnt += 1 except Exception as e: # Error if already deleted or tweet is RT print(e.args) return cnt if __name__ == '__main__': dl_cnt = run() print() print("Finish!!") print("Deleted {} tweets".format(dl_cnt))6. 実行
実行すると削除が始まる。
自分のアカウント開いて更新連打すればツイート数が減っていくのがわかる。
削除には結構時間がかかるので、気長に待とう。(数万件削除だと1時間とかそういう単位じゃ終わらない)7. 完了。
finishが表示されれば完了しているはず。
これで黒歴史をほぼ綺麗に消せたはずだ。やったぜ。非対応事項
ちなみに、RTの取り消しはできない…
tweet.jsの情報を詳しく見てないけど、多分RTだと判定できるものがあるはず
あとはRTを取り消すAPIを公式ドキュメントから探して叩けばいいはず。調べるのが面倒だった。。画像付きツイートだけ削除とかも、やろうと思えばできるはず。
やりたい人は.jsの中身とAPIを調べて良い感じに自分で書き換えてくれ
参考
- 投稿日:2020-03-21T23:12:22+09:00
指定した期間のツイートを削除
黒歴史は無かったことにしたい
世の中にはいろんなツールが既にあるが、
ツイッターの仕様で最新3200件しか削除できないとか、
大量削除は有料とか。
非常に困る。こちとら2010年から積み上げたゴミのようなつぶやきは優に10万を超える。
探せばQiitaに全ツイートを消すソースもある。
でも全部は困るんだよ。
そもそも全消しするならアカウント作りなおした方が早いだろ…黒歴史だけ消して最近の真人間な自分は残しておきたいんだ。
そんな人向け。
手順
- python3.6環境の構築
- 黒歴史が詰まったアーカイブの取得
- アーカイブの中にあるtweet.jsを編集
- APIキーの取得
- ソースコードの編集
- 実行
- 完了
1. python3.6環境の構築
もちろん使えるよね?
使えなかったらグーグル先生に聞いてくれ2. 黒歴史が詰まったアーカイブの取得
① PCでツイッターにログインして設定画面を開く(https://twitter.com/settings/account)
② 「Twitterデータ」タブを選択(パスワード求められたら入力する)
③ 「Twitterデータをダウンロード」を押す。
※ダウンロードができるようになるまでかなり時間がかかる
過去のツイートやDMを画像も含めてDLするので、Twitterがダウンロードデータを生成するのに時間がかかる
でも新設設計なので、ダウンロード可能になったらダウンロードリンクをメールで送ってくれる。
④ メールに来たリンクをクリックしてダウンロード開始。
⑤ ダウンロードが完了したら適当な場所に解凍する3. tweet.jsを編集
ソースコードでこのファイルを読み込みたいので、ちょこっと手を加える。
① 解凍したフォルダの中の「data」フォルダを開く
② 「tweet.js」という名前のファイルがあるので、適当なテキストエディタで開く。
③ 先頭にある「window.YTD.tweet.part0 = 」という文字列を削除。
④ 保存して閉じる。※保存する際にUTF-8のBOM無しにしておくこと。多分ファイル読み込み時にエラー出る。
※あと、念のためファイルのバックアップは取っておこう。ミスったらまたダウンロードのやり直しだ。4. APIキーの取得
ツイッターのAPIを使用するのにアクセストークンなるものが必要になる。まあ、ただの文字列だ。
下記手順で2つのkeyと2つのtokenを取得しよう。
プログラムで必要なのでメモ帳にでもコピペすればOK① ココにアクセス→https://developer.twitter.com/en/apps
② Appsって中にいくつかあるかもしれないが、ツイッターのアカウントIDが記載されたものの「Details(詳細)」を選択する
③ 「App details」「Keys and tokens」「Permissions」って3つのタブがあるのを確認する④ まずは「Permissions」を選択し、「Edit」ボタンを押して権限を変更する
⑤ 権限は「Read, write, and Direct Messages」てやつ。
⑥ Saveを押して保存。⑦ 「Keys and tokens」を開く
⑧ 「Keys, secret keys and access tokens management.」に記載されている下記をそれぞれメモする
・API key
・API secret key
⑨ 「Access token & access token secret」の情報もコピーする
「Regenerator」的なボタンを押すと
・Access token
・Access token secret
が表示されるのでそれぞれメモするこれでOK
5. ソースコードの編集
ソースサンプルは下記
各々よしなに変更してほしいところはコメントに書いたので好きなようにしてくれimport json import twitter # pip install python-twitter # ====== いい感じに設定書いてね ====== # keyとtokenを下記に記載 api_key = 'ここにコピペ', # メモした「API key」をここにコピペ api_secret_key = 'ここにコピペ', # メモした「API secret key」をここにコピペ access_token = 'ここにコピペ', # メモした「Access token」をここにコピペ access_token_secret = 'ここにコピペ', # メモした「Access token secret」をここにコピペ # tewwt.jsのファイルパスを記載。("\"は必ず2つつけてね) js_file_path = "D:\\sample\\hogehoge\\tweet.js" # 下記に指定したbegin~endの期間のツイートを削除する。(beginとendの日付を含む) begin_year = 2010 # この年の begin_month = 1 # この月の begin_day = 1 # この日から↓ end_year = 2019 # この年の end_month = 12 # この月の end_day = 31 # この日までを削除 # ================================ api = twitter.Api( consumer_key = api_key, consumer_secret = api_secret_key, access_token_key = access_token, access_token_secret = access_token_secret, sleep_on_rate_limit = True ) class date(): def __init__(self, y, m, d): self.y = y self.m = m self.d = d class date_range(): def __init__(self): self.begin = date(begin_year, begin_month, begin_day) self.end = date(end_year, end_month, end_day) # もっと効率良い方法ある気がするが、気にしたら負け def cnv_month_from_str2int(month): if month =='Jan': return 1 elif month =='Feb': return 2 elif month =='Mar': return 3 elif month =='Apr': return 4 elif month =='May': return 5 elif month =='Jun': return 6 elif month =='Jul': return 7 elif month =='Aug': return 8 elif month =='Sep': return 9 elif month =='Oct': return 10 elif month =='Nov': return 11 elif month =='Dec': return 12 else: assert False, "ERROR!! [{}] is not month".format(month) def run(): d_r = date_range() cnt = 0 with open(js_file_path, encoding='utf-8', mode='r') as f: tj=json.load(f) for tweet0 in tj: tweet = tweet0['tweet'] print() print(tweet['id']) date = tweet['created_at'] dow, month, day, time, other, year = date.split() _year = int(year) _day = int(day) _month = cnv_month_from_str2int(month) # out of custum date range. if ( _year > d_r.begin.y and d_r.end.y < _year) \ or (_month > d_r.begin.m and d_r.end.m < _month) \ or (_day > d_r.begin.d and d_r.end.d < _day): continue print("The number that deleted tweet is {}".format(cnt)) print("Now deleting {}/{}/{}".format(_year, _month, _day) ) try: api.DestroyStatus(tweet['id']) cnt += 1 except Exception as e: # Error if already deleted or tweet is RT print(e.args) return cnt if __name__ == '__main__': dl_cnt = run() print() print("Finish!!") print("Deleted {} tweets".format(dl_cnt))6. 実行
実行すると削除が始まる。
自分のアカウント開いて更新連打すればツイート数が減っていくのがわかる。
削除には結構時間がかかるので、気長に待とう。(数万件削除だと1時間とかそういう単位じゃ終わらない)7. 完了。
finishが表示されれば完了しているはず。
これで黒歴史をほぼ綺麗に消せたはずだ。やったぜ。非対応事項
ちなみに、RTの取り消しはできない…
tweet.jsの情報を詳しく見てないけど、多分RTだと判定できるものがあるはず
あとはRTを取り消すAPIを公式ドキュメントから探して叩けばいいはず。調べるのが面倒だった。。画像付きツイートだけ削除とかも、やろうと思えばできるはず。
やりたい人は.jsの中身とAPIを調べて良い感じに自分で書き換えてくれ
参考
- 投稿日:2020-03-21T22:43:45+09:00
ManyToManyFieldのthroughを使ってDjangoで扱いやすいフォローモデルを作る
最近Djangoで改めてフォロー機能のためのモデルを作った際、
through引数を使ってみたところ書きやすいモデルが作れたので記事にしてみました。特別に高度な書き方をしているわけではありませんが、フォロー機能について検索してみたところこの通りのモデルがなかなか見当たらなかったので、近い機能を作る方の参考になれば幸いです。
Djangoにおける多対多の書き方
Djangoでは多対多を表すモデルを作成する際、書き方が大きく分けて3つあります。
ManyToManyFieldのみ使用する
- 基本的な方法です。この場合、中間テーブルは自動生成されます。
- 中間モデルを作成して、
ManyToManyFieldを使用しない
- データ同士の繋がり以外の情報(
created_atなど)を持たせるために用います。- 中間モデルを作成して、
ManyToManyFieldのthrough引数に渡す
- 今回紹介する方法です。
できること
# user1のフォロワー/フォロイー全部の取得 user1.followers.all() user1.followees.all() # user1がフォローしているユーザーのアイテム一覧(Twitterで言うところのタイムライン)取得 Item.objects.filter(user__followers=user1) # user1がuser2をフォローする user1.followee_friendships.create(followee=user2)みたいな書き方が出来るようになります。
実装
中間モデル
class FriendShip(models.Model): follower = models.ForeignKey('User', on_delete=models.CASCADE, related_name='followee_friendships') followee = models.ForeignKey('User', on_delete=models.CASCADE, related_name='follower_friendships') class Meta: unique_together = ('follower', 'followee')フォローの関係性を表す中間モデルです。
Userモデルに対してフォロー、フォロイーとしてそれぞれにForeignkeyを向けています。ユーザーが削除されるとこれらの関係も削除されるべきなので、
on_delete引数はmodels.CASCADEです。これによってForeignkeyの対象データが削除されると、自動でこのデータも削除されます。related_name
同じクラスに対して複数
Foreignkeyを使用する場合はrelated_nameを設定しないとmanage.py makemigrationsコマンドの時点でエラーが出ます。これを設定することで外部キーの接続先からこのモデルに対して、つまり逆向きの参照が出来るようになります。ここで
follower_friendshipsはobjectsのような振る舞いをします。例えば、以下の2行は同じ意味になります。Friendship.objects.create(follower=user1, followee=user2) user1.followee_friendships.create(followee=user2)これらは
user1からuser2へのフォローを表します。unique_together
組み合わせが一意であるという制約を設けるためのものです。
フォロワーに対するフォロイーの組み合わせは必ず一通りであり、複数作成されることは異常な動作であるためこれを設定しておきます。
なお、フォローとフォロイーがそれぞれ逆になったもの(いわゆる相互フォロー)が存在してもがエラーになることは無いようです。
ユーザーモデル
class User(AbstractUser): followees = models.ManyToManyField( 'User', verbose_name='フォロー中のユーザー', through='FriendShip', related_name='+', through_fields=('follower', 'followee') ) followers = models.ManyToManyField( 'User', verbose_name='フォローされているユーザー', through='FriendShip', related_name='+', through_fields=('followee', 'follower') )AbstractUser
AbstractUserはデフォルトのUserを拡張するためのものです。Userがすでに持っているフィールドを上書きしたり、新たに追加する時に用います。これはより良い情報がすでにいくつかあるので、詳細は解説記事または公式ドキュメントを参照のこと。
ManyToManyField
through引数にFriendShipモデルを指定しています。これでfollowees,followersを呼び出すだけで、中間モデルを通したデータが得られるようになります。related_name
+を指定することで逆参照が不要であることを示します。ドキュメントには以下のように書かれています。If you’d prefer Django not to create a backwards relation, set related_name to '+' or end it with '+'. For example, this will ensure that the User model won’t have a backwards relation to this model:
https://docs.djangoproject.com/en/3.0/ref/models/fields/#django.db.models.ForeignKey.related_name
through_fields
ManyToManyFieldにおいてあるデータとこれに紐づく別のデータをソースとターゲットとするとき、through_fields引数には(ソース, ターゲット)を渡します。
user.followeeはあるユーザーのフォロイーを取得したいので('follower', 'followee')を指定し、user.followerはその逆を指定しています。余談
related_nameで逆参照を指定すれば、ManyToManyFieldは1つで済みます。class User(AbstractUser): followers = models.ManyToManyField( 'User', verbose_name='フォローされているユーザー', through='FriendShip', related_name='followees', through_fields=('followee', 'follower') )ただし
verbose_nameを指定できなくなるなど不便が出てきそうなので、2つ宣言しておく方が良さそうです。
- 投稿日:2020-03-21T22:22:46+09:00
googleドライブと連携した単語帳プログラム
はじめに
始めまして。KKと申します。至らないところもあると思いますがよろしくお願いします。
プログラムの概要
概要は以下のようになります。
- 予めGoogleドキュメント上で単語帳を作成しておき、
- 作成した単語帳を読み取り、ランダムな順番で出題する
今回、こういったプログラムを作ろうと思ったわけ
以前私は、TOEICの勉強をする機会がありました。当然単語の勉強にも精を出しており、単語用のノートを買って勉強していました。しかし、大学でPCを使う機会が増えたことによって高校時代は感じることのなかったストレスに苛まれました。
- いちいち手で文字を書くイライラ
- 家に忘れてたら勉強できない・荷物が増える
という紙媒体の非効率性を徐々に感じるようになり、「どうにかGoogleドライブ等クラウドを用いて管理できないか」と考えました。
また、「単語をランダムに、クイズ形式で出題できないものか」と考えました。なぜなら
- 順番通りだとどうしても覚えやすい単語に偏りが生じる
- 同じページに書いてある単語同士で結び付けて覚えてしまう
からです
何らかの情報に結びつけて暗記するという手法は日本史などでは役立つと思います。
しかし英語においては、英単語を見た瞬間に実際のオブジェクトが浮かんでこなければなりません。まして問題数の多い受験英語において、別の単語と結び付けて覚えるのは完全な悪手だと私は考えています。例えば、
- 「apple」という単語を見る
- 『この単語は確か「orange」と同じページにあったよな~~ あ!「リンゴ」だ』と思い出す
- 実際のイメージを浮かべる

ラグがありますよね?ではなく、
- 「apple」という単語を見る
- 実際のイメージを浮かべる
という動作をできるようにならねばなりません。これをマスターするには「単語をランダムに、クイズ形式で出題する機能」で日頃から練習するのが一番と感じました。
実際のコード
あくまで機能の実現を目的としていたので、少ない知識で作っています。
word_practice.pydef main(): Quiz(Make_Data(DLwordnote('指定したURL'))) print("well played!!") import urllib.request as req def DLwordnote(url): response = req.urlopen(url) # URLを指定してHTMLファイルを開く html_data=(str(response.read(),'utf-8_sig'))#html_dataという変数にhtmlを全部ぶち込む response.close() #print(html_data) word_data=''#単語だけのデータをここに作る startwords='DOCS_modelChunk = [{"ty":"is","ibi":'#htmlにおいて単語データはこの文で始まる(はず) while(html_data.find(startwords)!=-1): startpoint = html_data.find(startwords)+len(startwords)#始点が何文字目か html_data=extract(html_data,startpoint,len(html_data))#単語データの始まりまで削る i=0#,"s":"から数えて何番目か while True:#"が見つかるまで if (html_data[html_data.find(',"s":"')+len(',"s":"')+i]=='"'):#"が見つかったらループ抜け break word_data+=str(html_data[html_data.find(',"s":"')+len(',"s":"')+i])#先ほどのhtml_dataから単語だけ抽出したword_dataという変数にぶちこむ #これだと、\nが改行コードとして認識されていない i+=1 dammy="\\"+"n"#改行コードではない\n #print(word_data.replace(dammy,"\n")) return (word_data.replace(dammy,"\n"))#読み取ったcsv文字列を返す import random import csv def Make_Data(csv_data):#ファイルからcsv文字列を読み込み #なるべく少ない配列を使うことを心がけた list_data=csv_data.split("\n")#csv文字列を改行を基準にlistの要素として区切ったのを、list_dataに代入 list_data=[n for n in list_data if (n!='\n') and (n!='') and (n!=' ')]#無効な値を取り除く作業 for i in range(len(list_data)):#list_dataを各要素内でさらにカンマ基準で要素として区切る list_data[i]=list_data[i].split(",") #print(list_data) return list_data#csvが格納されたリストlist_dataを返す def Quiz(list_data): #各問題が出題されたかをメモるcheckというリストを作成(below),0:undo,1:done check=[0]*len(list_data)#とりあえず、dataと同じ長さで要素すべて0のリストを作る total=0#何問出題されたかをメモる while True:#ループ num=random.randint(0,len(list_data)-1)#numに問題番号を代入(ランダム) if(check[num]==0):#それがまだ出題されてないならば print("[%d/%d]" % (total+1,len(list_data)))#画面出力して出題 #press enter key input("%s" % (list_data[num][0])) print("%s\n" % (list_data[num][1]))#画面出力して出題 check[num]=1#既出としてメモし、 total+=1#1カウントアップする if(total==len(list_data)):#全問題出題したようなら break#ループ抜 def extract(data,a,b):#文字列dataのa,bまで抽出 tmp='' for i in range(a,b): tmp+=data[i] return tmp if __name__=="__main__": main()使い方
Googleドライブ上にドキュメントを作成してください(名前は何でもよい)
作成したドキュメントの共有設定で「リンクを知っている全員が閲覧可能」にしてください
作成したドキュメントにcsv形式で単語データを書いていってください
といったように
"英単語" "半角カンマ" "日本語訳"
といった形式で書き込んでもらえれば大丈夫です。
4. ドキュメントのリンクを、上記のコードの2行目の指定欄にペーストしてください
word_practice.pyを実行すると順不同で単語が出題されます。
まとめ
今回のプログラムで
- 予めGoogleドキュメント上で単語帳を作成しておき、
- 作成した単語帳を読み取り、ランダムな順番で出題する
機能を実現しました。機能を実現させることのみを目標にしていたので雑なのはあしからず。
今後の課題としては
- htmlの勉強をし、綺麗に単語データを抜き出すことを実現
- フロントエンド側の勉強をし、実際にアプリとしてリリースしたい
ことが挙げられます。
改善できたら再投稿します!




- 投稿日:2020-03-21T22:22:46+09:00
Googleドキュメントと連携した単語帳プログラム
はじめに
初めまして。KKと申します。至らないところもあると思いますがよろしくお願いします。
プログラムの概要
概要は以下のようになります。
- 予めGoogleドキュメント上で単語帳を作成しておき、
- 作成した単語帳を読み取り、ランダムな順番で出題する
今回、こういったプログラムを作ろうと思ったわけ
以前私は、TOEICの勉強をしていました。当然単語の勉強にも精を出しており、単語用のノートを買って勉強していました。しかし、大学でPCを使う機会が増えたことによって高校時代は感じることのなかったあるストレスに苛まれました。
- いちいち手で文字を書くイライラ
- 荷物が増える・ノートを家に忘れたら勉強できない
という紙媒体の非効率性を徐々に感じるようになり、「どうにかGoogleドキュメント等クラウドを用いて管理できないか」と考えました。
加えて、「単語をランダムに、クイズ形式で出題できないものか」と考えました。なぜなら
- 順番通りだとどうしても覚えやすい単語に偏りが生じる
- 同じページに書いてある単語同士で結び付けて覚えてしまう
からです
何らかの情報に結びつけて暗記するという手法は日本史などでは役立つと思います。
しかし英語においては、英単語を見た瞬間に実際のオブジェクトが浮かんでこなければなりません。まして問題数の多い受験英語において、別の単語と結び付けて覚えるのは完全な悪手だと私は考えています。例えば、
- 「apple」という単語を見る
- 『この単語は確か「orange」と同じページにあったよな~~ あ!「リンゴ」だ』と思い出す
- 実際のイメージを浮かべる
ラグがありますよね?ではなく、
- 「apple」という単語を見る
- 実際のイメージを浮かべる
という動作をできるようにならねばなりません。これをマスターするには「単語をランダムに、クイズ形式で出題する機能」で日頃から練習するのが一番と感じました。
Pythonを用いた実装
あくまで機能の実現を目的としていたので、少ない知識で作っています。
word_practice.pydef main(): Quiz(Make_Data(DLwordnote('指定したURL'))) print("well played!!") import urllib.request as req def DLwordnote(url): response = req.urlopen(url) # URLを指定してHTMLファイルを開く html_data=(str(response.read(),'utf-8_sig'))#html_dataという変数にhtmlを全部ぶち込む response.close() #print(html_data) word_data=''#単語だけのデータをここに作る startwords='DOCS_modelChunk = [{"ty":"is","ibi":'#htmlにおいて単語データはこの文で始まる(はず) while(html_data.find(startwords)!=-1): startpoint = html_data.find(startwords)+len(startwords)#始点が何文字目か html_data=extract(html_data,startpoint,len(html_data))#単語データの始まりまで削る i=0#,"s":"から数えて何番目か while True:#"が見つかるまで if (html_data[html_data.find(',"s":"')+len(',"s":"')+i]=='"'):#"が見つかったらループ抜け break word_data+=str(html_data[html_data.find(',"s":"')+len(',"s":"')+i])#先ほどのhtml_dataから単語だけ抽出したword_dataという変数にぶちこむ #これだと、\nが改行コードとして認識されていない i+=1 dammy="\\"+"n"#改行コードではない\n #print(word_data.replace(dammy,"\n")) return (word_data.replace(dammy,"\n"))#読み取ったcsv文字列を返す import random import csv def Make_Data(csv_data):#ファイルからcsv文字列を読み込み #なるべく少ない配列を使うことを心がけた list_data=csv_data.split("\n")#csv文字列を改行を基準にlistの要素として区切ったのを、list_dataに代入 list_data=[n for n in list_data if (n!='\n') and (n!='') and (n!=' ')]#無効な値を取り除く作業 for i in range(len(list_data)):#list_dataを各要素内でさらにカンマ基準で要素として区切る list_data[i]=list_data[i].split(",") #print(list_data) return list_data#csvが格納されたリストlist_dataを返す def Quiz(list_data): #各問題が出題されたかをメモるcheckというリストを作成(below),0:undo,1:done check=[0]*len(list_data)#とりあえず、dataと同じ長さで要素すべて0のリストを作る total=0#何問出題されたかをメモる while True:#ループ num=random.randint(0,len(list_data)-1)#numに問題番号を代入(ランダム) if(check[num]==0):#それがまだ出題されてないならば print("[%d/%d]" % (total+1,len(list_data)))#画面出力して出題 #press enter key input("%s" % (list_data[num][0])) print("%s\n" % (list_data[num][1]))#画面出力して出題 check[num]=1#既出としてメモし、 total+=1#1カウントアップする if(total==len(list_data)):#全問題出題したようなら break#ループ抜 def extract(data,a,b):#文字列dataのa,bまで抽出 tmp='' for i in range(a,b): tmp+=data[i] return tmp if __name__=="__main__": main()使い方
Googleドライブ上にドキュメントを作成してください(名前は何でもよい)
作成したドキュメントの共有設定で「リンクを知っている全員が閲覧可能」にしてください
作成したドキュメントにcsv形式で単語データを書いていってください
といったように
"英単語" "半角カンマ" "日本語訳"
といった形式で書き込んでもらえれば大丈夫です。
4. ドキュメントのリンクを、上記のコードの2行目の指定欄にペーストしてください
word_practice.pyを実行すると順不同で単語が出題されます。
まとめ
今回のプログラムで
- 予めGoogleドキュメント上で単語帳を作成しておき、
- 作成した単語帳を読み取り、ランダムな順番で出題する
機能を実現しました。機能を実現させることのみを目標にしていたので雑なのはあしからず。
今後の課題としては
- htmlの勉強をし、綺麗に単語データを抜き出すことを実現
- フロントエンド側の勉強をし、実際にアプリとしてリリースしたい
ことが挙げられます。
改善できたら再投稿します!
- 投稿日:2020-03-21T22:22:46+09:00
Googleドキュメントと連携した英単語帳プログラム
はじめに
初めまして。KKと申します。至らないところもあると思いますがよろしくお願いします。また、ブログなど初心者のため編集しまくりますがあしからず。
プログラムの概要
概要は以下のようになります。
- 予めGoogleドキュメント上で英単語帳を作成しておき、
- 作成した英単語帳を読み取り、ランダムな順番で出題する
今回、こういったプログラムを作ろうと思ったわけ
以前私はTOEICの勉強をしていました。当然英単語の勉強にも精を出しており、単語用のノートを買って勉強していました。しかし、大学でPCを使う機会が増えたことによって高校時代は感じることのなかったあるストレスに苛まれました。
- いちいち手で文字を書くイライラ
- 荷物が増える・ノートを家に忘れたら勉強できない
という紙媒体の非効率性を徐々に感じるようになり、「どうにかGoogleドキュメント等クラウドを用いて管理できないか」と考えました。
実現できれば、場所やデバイスを選ばず(スマホからでも、専用のキーボードを使用すれば問題ない)ストレスなく英単語を追加できるようになります。加えて、「単語をランダムに、クイズ形式で出題できないものか」と考えました。なぜなら
- 順番通りだとどうしても覚えやすい単語に偏りが生じる
- 同じページに書いてある単語同士で結び付けて覚えてしまう
からです
何らかの情報に結びつけて暗記するという手法は日本史などでは役立つと思います。
しかし英語においては、英単語を見た瞬間に実際のオブジェクトが浮かんでこなければなりません。まして問題数の多い受験英語において、別の単語と結び付けて覚えるのは完全な悪手だと私は考えています。例えば、
- 「apple」という単語を見る
- 『この単語は確か「orange」と同じページにあったよな~~ あ!「リンゴ」だ』と思い出す
- 実際のイメージを浮かべる
ラグがありますよね?ではなく、
- 「apple」という単語を見る
- 実際のイメージを浮かべる
という動作をできるようにならねばなりません。これをマスターするには「単語をランダムに、クイズ形式で出題する機能」で日頃から練習するのが一番と感じました。
Pythonを用いた実装
Python 3.〇を想定。あくまで機能の実現を目的としていたので、少ない知識で作っています。
word_practice.pydef main(): Quiz(Make_Data(DLwordnote('指定したURL'))) print("well played!!") import urllib.request as req def DLwordnote(url): response = req.urlopen(url) # URLを指定してHTMLファイルを開く html_data=(str(response.read(),'utf-8_sig'))#html_dataという変数にhtmlを全部ぶち込む response.close() #print(html_data) word_data=''#単語だけのデータをここに作る startwords='DOCS_modelChunk = [{"ty":"is","ibi":'#htmlにおいて単語データはこの文で始まる(はず) while(html_data.find(startwords)!=-1): startpoint = html_data.find(startwords)+len(startwords)#始点が何文字目か html_data=extract(html_data,startpoint,len(html_data))#単語データの始まりまで削る i=0#,"s":"から数えて何番目か while True:#"が見つかるまで if (html_data[html_data.find(',"s":"')+len(',"s":"')+i]=='"'):#"が見つかったらループ抜け break word_data+=str(html_data[html_data.find(',"s":"')+len(',"s":"')+i])#先ほどのhtml_dataから単語だけ抽出したword_dataという変数にぶちこむ #これだと、\nが改行コードとして認識されていない i+=1 dammy="\\"+"n"#改行コードではない\n #print(word_data.replace(dammy,"\n")) return (word_data.replace(dammy,"\n"))#読み取ったcsv文字列を返す import random import csv def Make_Data(csv_data):#ファイルからcsv文字列を読み込み #なるべく少ない配列を使うことを心がけた list_data=csv_data.split("\n")#csv文字列を改行を基準にlistの要素として区切ったのを、list_dataに代入 list_data=[n for n in list_data if (n!='\n') and (n!='') and (n!=' ')]#無効な値を取り除く作業 for i in range(len(list_data)):#list_dataを各要素内でさらにカンマ基準で要素として区切る list_data[i]=list_data[i].split(",") #print(list_data) return list_data#csvが格納されたリストlist_dataを返す def Quiz(list_data): #各問題が出題されたかをメモるcheckというリストを作成(below),0:undo,1:done check=[0]*len(list_data)#とりあえず、dataと同じ長さで要素すべて0のリストを作る total=0#何問出題されたかをメモる while True:#ループ num=random.randint(0,len(list_data)-1)#numに問題番号を代入(ランダム) if(check[num]==0):#それがまだ出題されてないならば print("[%d/%d]" % (total+1,len(list_data)))#画面出力して出題 #press enter key input("%s" % (list_data[num][0])) print("%s\n" % (list_data[num][1]))#画面出力して出題 check[num]=1#既出としてメモし、 total+=1#1カウントアップする if(total==len(list_data)):#全問題出題したようなら break#ループ抜 def extract(data,a,b):#文字列dataのa,bまで抽出 tmp='' for i in range(a,b): tmp+=data[i] return tmp if __name__=="__main__": main()使い方(単語帳準備)
Googleドライブ上にドキュメントを作成してください(名前は何でもよい)
作成したドキュメントの共有設定で「リンクを知っている全員が閲覧可能」にしてください
作成したドキュメントにcsv形式で単語データを書いていってください
といったように
"英単語" "半角カンマ" "日本語訳"
といった形式で書き込んでもらえれば大丈夫です。
4. ドキュメントのリンクを、上記のコードの2行目の指定欄にペーストしてください
使い方(実行)
- 実行すると、問題が出題されます

- 頭の中で答えを思い浮かべEnterキーを押すと、現在の問題の答えと次の問題が出てきます

- 最後まで繰り返すと、「well played!!」と表示されます

当然、次に実行する際は前回と違う順番で出題されるはずです!
使い方(iPhoneでの実行)
1.アプリ「モバイルC」をインストールしてください
2.適当なフォルダにファイル作成し、上記のコードをペーストしてください
3.「ラン」で実行、右下の折れ曲がった矢印ボタンを押すと次に進みます。
まとめ
今回のプログラムで
- 予めGoogleドキュメント上で英単語帳を作成しておき、
- 作成した英単語帳を読み取り、ランダムな順番で出題する
機能を実現しました。機能を実現させることのみを目標にしていたので雑なのはあしからず。
今後の課題としては
- htmlの勉強をし、綺麗に単語データを抜き出すことを実現
- フロントエンド側の勉強をし、実際にアプリとしてリリースしたい
ことが挙げられます。
改善できたら再投稿します!





- 投稿日:2020-03-21T22:03:57+09:00
(今さら)GeForce GTX960でGPUのDeep Learning環境構築
はじめに
最近ほとんど使っていなかった自作デスクトップPCに、NVIDIA製のGPU(GeForce GTX960)が入っているのを思い出し、折角なのでこれを活用してDeep Learningが出来る環境を構築してみようと思いやってみました。
5年前に購入したGPUにも関わらず、処理速度が段違いに速くGPUの素晴らしさに驚きました(笑)
msi GeForce GTX960 Gaming 2G MGSV環境
- Windows 10 Pro (Version 1909)
- Python 3.6.4 (Anaconda3 5.1.0)
必要なもの
- NVIDIA製のGPU
- Tensorflow-gpu
- Keras
- Microsoft Visual Studio C++ (MSVC)
- NVIDIA Driver
- CUDA
- cuDNN
バージョン確認
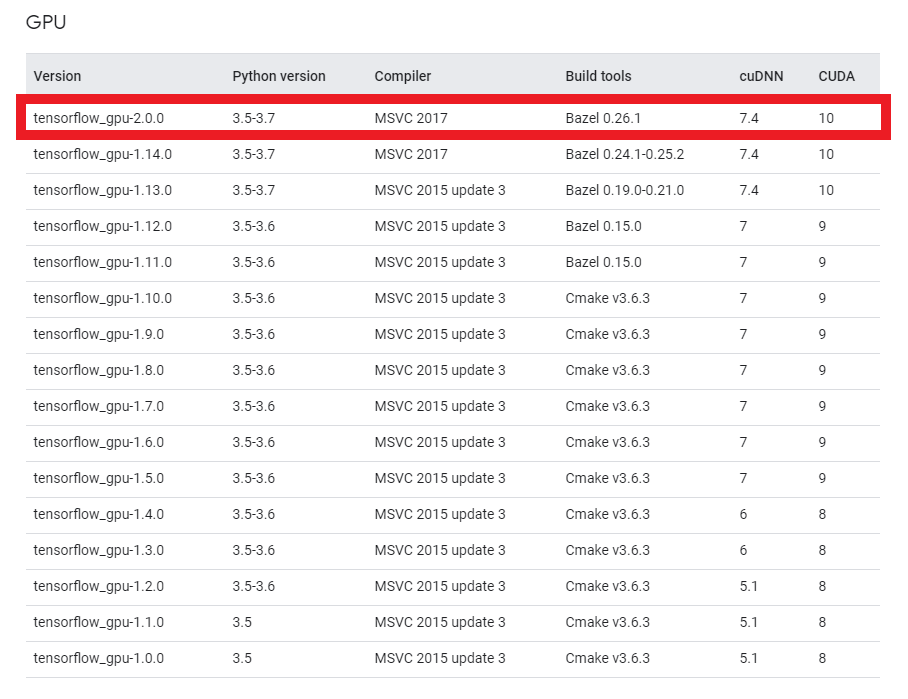
GPU環境でTensorflow/Kerasを使用するには、上記必要なものをそれぞれ対応するバージョンで合わせなければなりません。
Tensorflowのサイトにマッチングテーブルがありますので、必ず確認して下さい。
基本的には、Tensorflowのバージョンに合わせてそれぞれ対応するバージョンをインストールすれば良いと思います。
何か理由があってバージョン指定がなければ最新でOKです。
投稿時点(2020/03/21)では2.0.0が最新なので、2.0.0で構築します。
Conda環境作成&Tensorflow-gpuインストール
TensorflowのCPU版とGPU版が混在していると、CPU版が自動的に選択されるみたいなので新しく環境を作ります。
cmd> conda create -n tf200gpu Python=3.6.4作成完了したら、環境を有効化してTensorflow-gpuをインストールします。
cmd> conda activate tf200gpu (tf200gpu)> pip install tensorflow-gpu==2.0.0↓このエラーが出る場合は以下記事を参照
ERROR: cannot uninstall 'wrapt'. It is a distutils installed project and thus we cannot accurately determine which files belong to it which would lead to only a partial uninstall.インストール完了したら、
pip listで以下内容を確認して下さい。
(この段階でPythonでimport tensorflowを実行しても、CUDA/cuDNNが入っていないのでエラーになります)
- CPU版Tensorflowがインストールされていないか?
- Tensorflow-gpuがインストールされていて、バージョンは2.0.0か?
Kerasのインストール
Kerasは特に問題無くインストール出来ると思います。僕の環境ではバージョン2.3.1が入りました。
cmd(tf200gpu)> pip install kerasTensorflow同様、
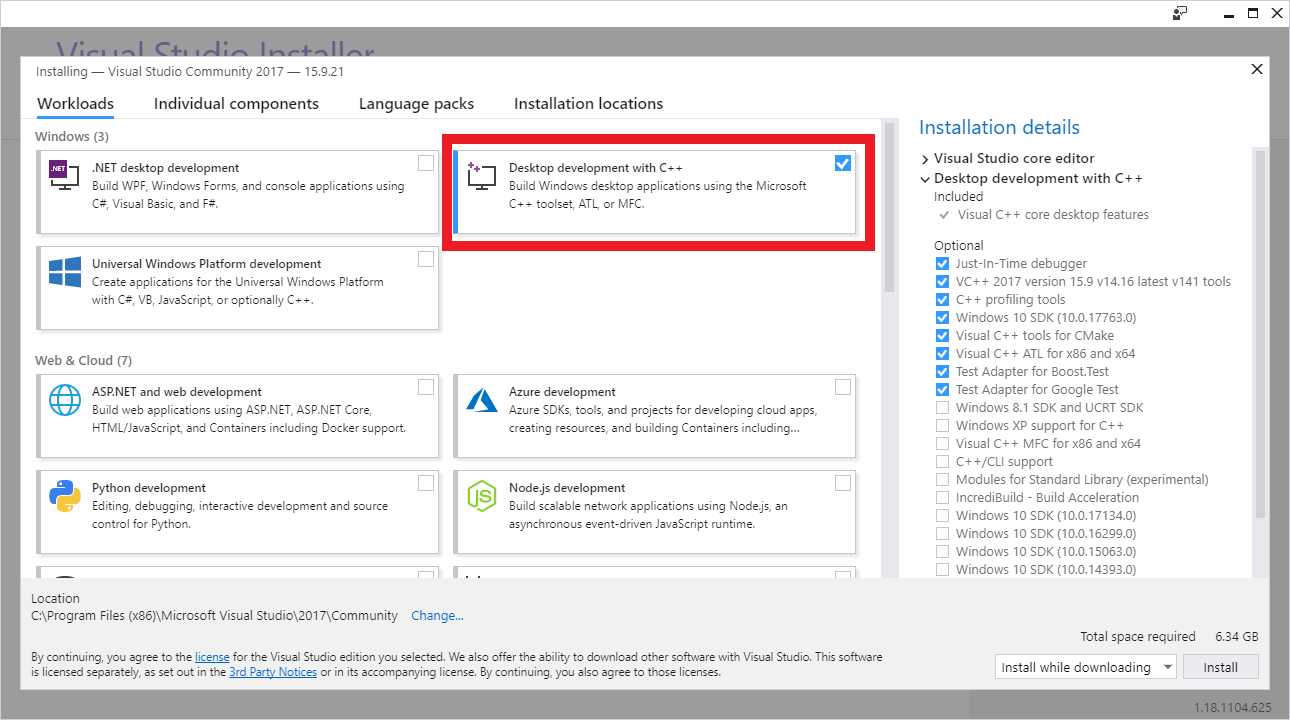
pip listでインストールが出来ているか確認して下さい。Visual Studio C++2017のインストール
TensorflowのバージョンとマッチしたVisual StudioをMicrosoftのダウンロードサイトから入手してインストールします。
今回は2017になりますので、Visual Studio Community 2017をインストール。
インストール時に「C++ ワークロードを使用したデスクトップ開発」にチェックを入れて下さい。
(結構時間かかる…)
NVIDIA Driverのインストール
NVIDIAのダウンロードサイトから、製品を選択してインストーラを入手。他のグラフィックボードの場合は、適宜変えて下さい。
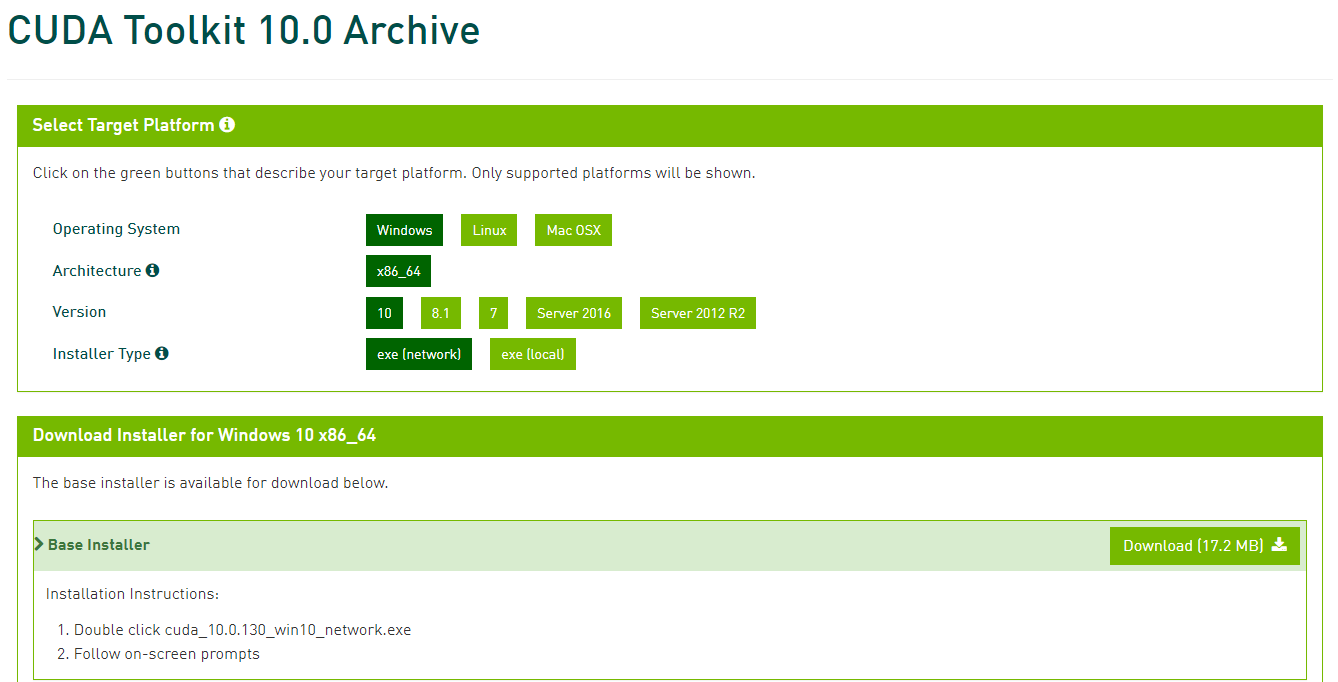
特別なことは何もせず、「次に」を押し続けていれば問題無くインストール完了するはずです。CUDAのインストール
CUDAはNVIDIAが開発・提供している、GPU向けの汎用並列コンピューティングプラットフォームです。
CUDA Toolkitのダウンロードサイトからインストーラを入手してインストールします。
インストーラを入手するのに無料アカウントの作成が必要なので、ちゃちゃっと作ります。
今回はCUDA Toolkit 10.0をインストールします。OSの種類やバージョンを選んで、exe(network)を選択します。
(ネット接続出来ないPCにインストールする場合はlocalを選んで下さい)
ダウンロードが終わったら、インストーラを起動し、Driver同様に「次に」を押し続ければインストール出来ます。
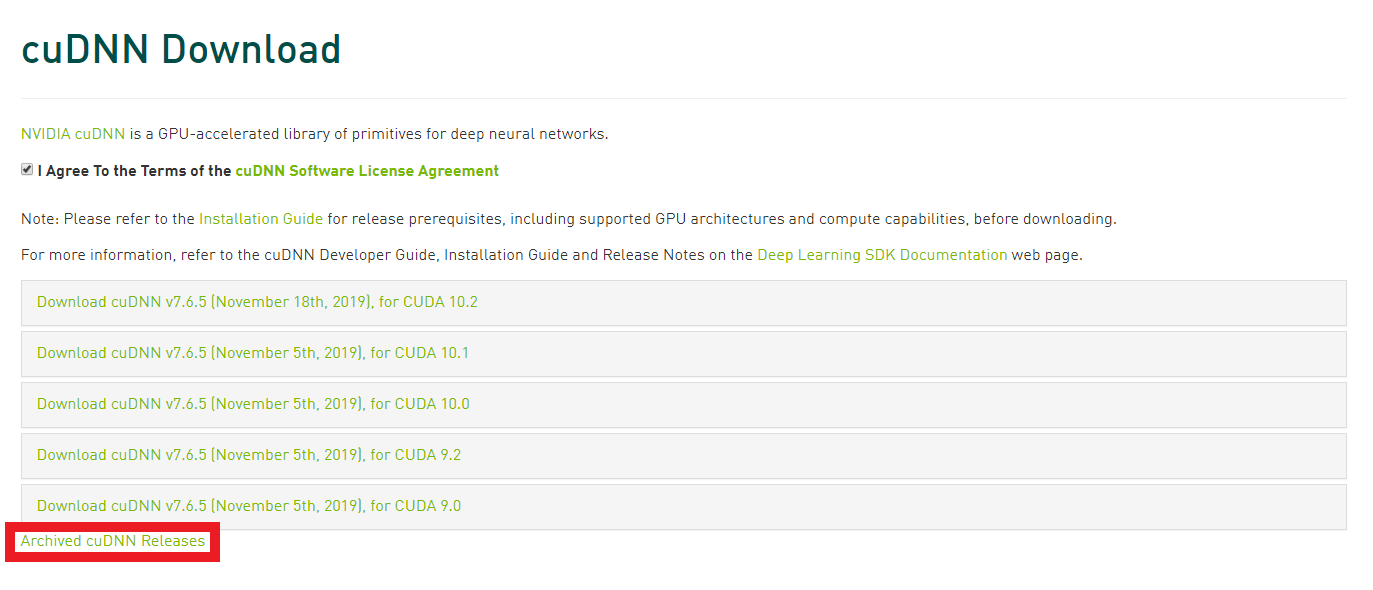
cuDNNのインストール
続いてNVIDAが公開するDeep Learning用のライブラリであるcuDNNをインストールします。
こちらもアカウントが必要になりますので、CUDAの時に作ったアカウントでログインして下さい。
今回は、7.4.2 for CUDA 10をcuDNNのダウンロードサイトから入手します。
「I Agree To the Terms of the cuDNN Software License Agreement」にチェックを入れると、いくつか選択肢が出てきます。この中に欲しいバージョンが無ければ、赤枠の「Archived cuDNN Releases」をクリックすれば過去のリリースが出てきます。
ダウンロードしたzipを解凍すると、bin、include、libの3つのフォルダと、NVIDIA_SLA_cuDNN_Support.txtというテキストファイルがあると思います。
Windows ExplorerでC:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v.10.0を開き、そこにも同様にbin、include、libのフォルダが存在しますので、ダウンロードしたフォルダの中身をそれぞれ同じ名前のフォルダ内にコピペすることでインストール完了です。
管理者権限を求められることがありますので、許可してあげて下さい。GPUが認識されているか確認
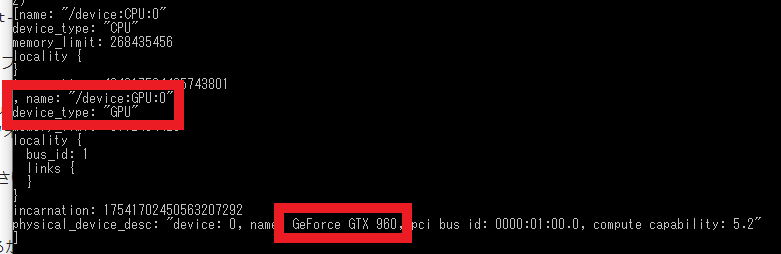
以上でインストール系は完了です。GPUがちゃんと認識されているかを確認するためにコマンドプロンプトで以下を実行してみます。
cmd(tf200gpu)> python -c "from tensorflow.python.client import device_lib;print(device_lib.list_local_devices())"ちゃんと認識されている…!!
いざ実行!
では早速Tensorflow-gpuを使って学習させてみる…も以下エラーに阻まれた。
tensorflow.python.framework.errors_impl.UnknownError: Failed to get convolution algorithm. This is probably because cuDNN failed to initialize, so try looking to see if a warning log message was printed above.こちらの記事を参考にしたところ、cudatooklitもcudnnもcondaのlistに出てこない…
ので、conda install cudnnしてみたら候補が出てきたので、インストールしてみる。
ちなみに、conda install cudnnで、cudatoolkitもcudnnもインストール出来るみたいです。
上記でインストールしたの:
- cudatoolkit 10.2.89
- cudnn 7.6.5
再度学習のコードを実行してみたら、GPUで問題無く動作するようになりました!!
CUDAとcuDNNは2回インストールしているので、これが正しい方法かはわかりませんが(しかもバージョン違うし)とりあえずは動いているので良しとします(笑)
今後何か問題が出たり、正しい方法がわかったら記事更新します!
(詳しい方、コメントで教えて下さい~(´;ω;`))結果
某オンライン研修プログラムで作った以下学習用のPythonコードで測定してみます。
入力された画像をCNNを用いて3つのクラスに分類する画像認識プログラムの学習コードです。
学習用の画像データは、事前に.npy形式で保存してあるものをロードします。
50×50ピクセルの画像を157枚(中途半端)、バッチサイズ32、エポック100で学習させてみたところ…
Processor Time CPU 0:01:22.239975 GPU 0:00:15.542190 GPUの方が約5.4倍速いですね。
(ちなみに搭載CPUはIntel Core i5-6600K @ 3.5GHzです)train.pyimport keras from keras.models import Sequential from keras.layers import Conv2D, MaxPooling2D from keras.layers import Activation, Dropout, Flatten, Dense from keras.utils import np_utils import numpy as np import datetime classes = ["class1", "class2", "class3"] num_classes = len(classes) image_size = 50 def main(): X_train, X_test, y_train, y_test = np.load("./data.npy", allow_pickle=True) X_train = X_train.astype("float") / 256 X_test = X_test.astype("float") / 256 y_train = np_utils.to_categorical(y_train, num_classes) y_test = np_utils.to_categorical(y_test, num_classes) model = model_train(X_train, y_train) model_eval(model, X_test, y_test) def model_train(X, y): model = Sequential() model.add(Conv2D(32, (3, 3), padding='same', input_shape=X.shape[1:])) model.add(Activation('relu')) model.add(Conv2D(32, (3, 3))) model.add(Activation('relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Conv2D(64, (3, 3), padding='same')) model.add(Activation('relu')) model.add(Conv2D(64, (3, 3))) model.add(Activation('relu')) model.add(MaxPooling2D(pool_size=(2, 2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(512)) model.add(Activation('relu')) model.add(Dropout(0.5)) model.add(Dense(3)) model.add(Activation('softmax')) opt = keras.optimizers.adam(lr=0.0001, decay=1e-6) model.compile( loss='categorical_crossentropy', optimizer=opt, metrics=['accuracy'] ) model.fit(X, y, batch_size=32, epochs=100) return model def model_eval(model, X, y): scores = model.evaluate(X, y, verbose=1) print('Test Loss: ', scores[0]) print('Test Accuracy: ', scores[1]) if __name__ == "__main__": start_time = datetime.datetime.now() main() end_time = datetime.datetime.now() print("Time: " + str(end_time - start_time))

- 投稿日:2020-03-21T20:46:15+09:00
プログラミングについて学ぶ
AtCorderに挑戦してみた
以前からコードを書く機会が少ないと思っていたので、
AtCorderで問題を解きながらコードを書いていこうと思います習慣づけるためにQiitaに投稿してみることにしました。
自分が知らなかった知識などについては、記事に書いていこうと思います最初に簡単な問題の実装
文字列と文字の扱い
pythonだと文字列の中の一文字にアクセスしたいときに簡単にできる
下の例では文字列から最初の文字と最後の文字を出力しているsample1.pystr = 'abcdef' print(str[0]) #a print(str[-1]) #fこれからやること
AtCoder Grand Contest 043をやってみようと思います。
- 投稿日:2020-03-21T19:53:57+09:00
自然数ジェネレータ
普段何気なく使っている自然数ですが、数学で扱うためには厳密に定義する必要があります。今回はその方法をご紹介します。
以下、個人的な好みの問題ですが、自然数は$0$から始まるものとしています。自然数の作り方
自然数は$0$(または$1$)から始まり、無限に、かつ一列に並ぶ性質を持っています。当然ですが、どこかで途切れたり、分岐したり、合流したりすることはありません。このような自然数が満たすべき性質は「ペアノの公理」というもので定められています。ペアノの公理に関しては、「高校数学の美しい物語 自然数とは(0を含むこともあるよ)」等を参考にしていただけると良いかと思います。また、「数学ガール ゲーテルの不完全性定理」の中で詳しく、かつ分かりやすく議論されています。
ところが、ペアノの公理では自然数であるための条件にしか触れていません。一応これでも問題はないのですが、これらの条件を満たすものを形式的に定義する、つまり自然数に実体を与えるアルゴリズムの一つが「ノイマンの構成法」です。エンジニアの言葉でいうと、ペアノの公理で自然数の要件定義を行い、ノイマンの構成法でコーディングするイメージでしょうか。ノイマンの構成法では、集合(
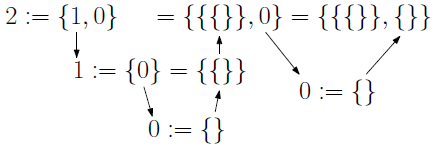
{1, 2, 3}みたいなやつ)を使用して、ペアノの公理を満たすものを生成していきます。ノイマンの構成法では$0$を最初の自然数として、自然数を次のように定義していきます。
\begin{eqnarray} 0 &:=& \{\} \\ 1 &:=& \{0\} = \{\{\}\} \\ 2 &:=& \{1,\ 0\} = \{\{\{\}\},\ \{\}\} \\ 3 &:=& \{2,\ 1,\ 0\} = \{\{\{\{\}\},\ \{\}\},\ \{\{\}\},\ \{\}\} \end{eqnarray}以降は繰り返しです。
アルゴリズムの整理
ノイマンの構成法に従い、自然数を定義するアルゴリズムを作ります。ゴールは$0$以上の整数を入力すると、その定義を文字列で標準出力するプログラムを作ることです。
ノイマンの構成法では、最初に
0 = {}を定義した後、既に定義済みの自然数のみを使用して再帰的に定義していきます。最終的に自然数は{、}、,の3種類の文字だけで表現されます。イメージ図を載せておきます。
あとはこれを左から1文字ずつ出力すればOKです。
実装
ソースコードはこちら。python 3.7を使用しています。
natural_number_generator.pyimport sys # 自然数ジェネレータ def neumann_algorithm(target_num: int): processing = target_num - 1 yield '{' while processing >= -1: # (1) if processing == -1: yield '}' return 0 else: natural_number_generator = neumann_algorithm(processing) yield from natural_number_generator # (2) if processing == 0: yield '}' return 0 else: yield ', ' processing -= 1 return 0 # 入力値を取得 def get_input_num(): args = sys.argv input_num = int(args[1]) return input_num if __name__ == "__main__": target_num = get_input_num() natural_number_generator = neumann_algorithm(target_num) for char in natural_number_generator: print(char, end='')ソースコード解説
ソースコードの
neumann_algorithm関数が自然数を生成するアルゴリズムになります。関数内部では(1)と(2)(ソースコード中のコメントを参照)の2か所で分岐が存在します。簡単に説明した図を載せておきます。
(1)はこれから出力する数値が$0$であるか否か、つまり定義済みであるか否かを判定する部分です。0 = {}は最初に定義されているので直接{}を出力できますが、その他の数は定義されていないので再起的に関数を呼び出すことが必要です。
(2)は再起処理が1個終了するごとに、次は}と,のどちらを出力するかを判定する部分です。なお、自然数の定義は数が大きくなると爆発的に長くなります($O(2^n)$くらい)。そのため、全体を文字列やリストに起こしてしまうとメモリが足りなくなる可能性があります。これを防ぐため、出力する文字を逐一判定し、必要なくなったら破棄できるジェネレータを使用して実装しました。実行する場合は$10$くらいで一度様子見することをお勧めします。
出力結果
$0$から$5$を入力して実行した結果がこちら。
>python natural_number_generator.py 0 {} >python natural_number_generator.py 1 {{}} >python natural_number_generator.py 2 {{{}}, {}} >python natural_number_generator.py 3 {{{{}}, {}}, {{}}, {}} >python natural_number_generator.py 4 {{{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}} >python natural_number_generator.py 5 {{{{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}} >いい感じですね。
ちなみに動かしてみて気付いたのですが、
}は3回以上連続することはないみたいです。分岐の仕方をみれば明確ではあるのですが、アルゴリズムを考える段階では意識していませんでした。新たな発見がありましたね。おまけ
$10$の定義です。
>python natural_number_generator.py 10 {{{{{{{{{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{{{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{{{{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{{{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}}, {{{{}}, {}}, {{}}, {}}, {{{}}, {}}, {{}}, {}} >以上です。ありがとうございました。
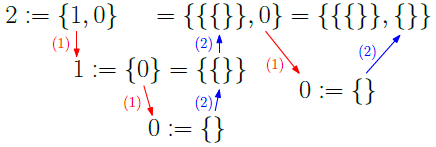
- 投稿日:2020-03-21T19:38:24+09:00
pythonの基本箇所についての復習(FizzBuzz)
はじめに
pythonでfizz-buzz的なアルゴリズムを作ったので投稿します。
前提
2の倍数の時は
〜は偶数です
3の倍数の時は〜は3の倍数です
6の倍数の時は〜は6の倍数です
それ以外は〜はそれ以外の数です
と表示させます。いくつまで判定させるかは、最初に入力できるようにします。
実行
まずは倍数を判定するための関数を作ります。
def sample(x): if (x % 3 == 0 and x % 2 ==0): print(x,"は6の倍数です") elif (x % 3 == 0): print(x,"は3の倍数です") elif (x % 2 == 0): print(x,"は偶数です") else: print(x,"はそれ以外の数です")
ifやelseの行の最後には:がつく事、
elsifではなくelifな事、
&&ではなくandを使っていることに注意が必要ですが、
それ以外はrubyと大きな違いはありません。次に、表示回数を入力するようにします。
print("いくつまで表示しますか?") y = int(input())入力だけなら
y = input()でも良さそうですが、数字として判定されなかったのでこういう書き方です。最後に、入力した回数分、倍数の判定を行うようにします。
for x in range(1, y + 1): sample(x)実行回数は
range(1, y + 1)で決まります。
ここでは、1から先ほど入力したyまでの全ての整数について、sample(x)を行うという処理になります。
sample(x)は、最初に定義した関数を呼び出すということです。全体のコードは次の通りとなります。
# coding:utf-8 import sys def sample(x): if (x % 3 == 0 and x % 2 ==0): print(x,"は6の倍数です") elif (x % 3 == 0): print(x,"は3の倍数です") elif (x % 2 == 0): print(x,"は偶数です") else: print(x,"はそれ以外の数です") print("いくつまで表示しますか?") y = int(input()) for x in range(1, y + 1): sample(x)
- 投稿日:2020-03-21T19:38:24+09:00
Pythonの基本箇所についての復習(FizzBuzz)
はじめに
pythonでfizz-buzz的なアルゴリズムを作ったので投稿します。
前提
2の倍数の時は
〜は偶数です
3の倍数の時は〜は3の倍数です
6の倍数の時は〜は6の倍数です
それ以外は〜はそれ以外の数です
と表示させます。いくつまで判定させるかは、最初に入力できるようにします。
実行
まずは倍数を判定するための関数を作ります。
def sample(x): if (x % 3 == 0 and x % 2 ==0): print(x,"は6の倍数です") elif (x % 3 == 0): print(x,"は3の倍数です") elif (x % 2 == 0): print(x,"は偶数です") else: print(x,"はそれ以外の数です")
ifやelseの行の最後には:がつく事、
elsifではなくelifな事、
&&ではなくandを使っていることに注意が必要ですが、
それ以外はrubyと大きな違いはありません。次に、表示回数を入力するようにします。
print("いくつまで表示しますか?") y = int(input())入力だけなら
y = input()でも良さそうですが、数字として判定されなかったのでこういう書き方です。最後に、入力した回数分、倍数の判定を行うようにします。
for x in range(1, y + 1): sample(x)実行回数は
range(1, y + 1)で決まります。
ここでは、1から先ほど入力したyまでの全ての整数について、sample(x)を行うという処理になります。
sample(x)は、最初に定義した関数を呼び出すということです。全体のコードは次の通りとなります。
# coding:utf-8 import sys def sample(x): if (x % 3 == 0 and x % 2 ==0): print(x,"は6の倍数です") elif (x % 3 == 0): print(x,"は3の倍数です") elif (x % 2 == 0): print(x,"は偶数です") else: print(x,"はそれ以外の数です") print("いくつまで表示しますか?") y = int(input()) for x in range(1, y + 1): sample(x)
- 投稿日:2020-03-21T19:21:42+09:00
pythonで即時関数(うそ)
fizzbuzz
def b(a=([print("fizzbuzz") if i % 15 == 0 else print("fizz") if i % 3 == 0 else print("buzz") if i % 5 == 0 else print(i) for i in range(1, 101)]})): pass
- 投稿日:2020-03-21T19:11:43+09:00
Djangoのインストール
はじめに
pythonをインストールした後にDjangoをインストールしようとして詰まったので、
その際の解決法を書いていきます。実行
ターミナル上で次のコマンドを入力します。
pip install djangoこれでDjangoがインストールされるはずですが、次のエラーが出ました。
-bash: pip: command not found「
pipがインストールされていないのでこのコマンドは使えない」というエラーのようです。
ならばpipをインストールすればいいと、次のコマンドを実行します。python -m pip install -U pipすると今度は次のエラーが出てきます。
/usr/bin/python: No module named pipどうやら「pythonにpipなんてないよ」というエラーのようです。
pythonとpython3が別物だったことを思い出し、次のコマンドを入力しました。python3 -m pip install -U pip今度は上手くいったようで、次のメッセージが表示されました。
Collecting pip Downloading https://files.pythonhosted.org/packages/(中略) (1.4MB) |████████████████████████████████| 1.4MB 1.4MB/s Installing collected packages: pip Found existing installation: pip 19.2.3 Uninstalling pip-19.2.3: Successfully uninstalled pip-19.2.3 Successfully installed pip-20.0.2改めて次のコマンドを入力します。
pip install djangoこれも上手くいき、次のメッセージが表示されました。
Collecting django Downloading Django-3.0.4-py3-none-any.whl (7.5 MB) |████████████████████████████████| 7.5 MB 2.0 MB/s Collecting asgiref~=3.2 Downloading asgiref-3.2.5-py2.py3-none-any.whl (19 kB) Collecting pytz Downloading pytz-2019.3-py2.py3-none-any.whl (509 kB) |████████████████████████████████| 509 kB 46.8 MB/s Collecting sqlparse>=0.2.2 Downloading sqlparse-0.3.1-py2.py3-none-any.whl (40 kB) |████████████████████████████████| 40 kB 701 kB/s Installing collected packages: asgiref, pytz, sqlparse, django Successfully installed asgiref-3.2.5 django-3.0.4 pytz-2019.3 sqlparse-0.3.1これで完了です。
- 投稿日:2020-03-21T19:02:53+09:00
エクセルで範囲選択した内容をPythonのリスト初期化コードに変換するマクロ(VBA)
概要
エクセル上の選択範囲の内容を、Pythonのリスト初期化コードに変換してクリップボードにコピーするVBAコードです。次の図のように選択範囲の先頭行を変数名、以降の行をリストの要素とするPythonプログラムを生成します。
クリップボードにテキストをコピーする方法については「VBA 失敗しない文字列をクリップボードへコピーする方法」で紹介されているコードを、そのまま利用させていただきました。
コード
選択範囲(Range)をPythonのリスト(初期化コード)に変換Sub Range2PythonList() If TypeName(Selection) <> "Range" Then Exit Sub End If sCol = Selection(1).Column '範囲開始列 eCol = Selection(Selection.Count).Column '範囲終了列 sRow = Selection(1).Row '範囲開始行 eRow = Selection(Selection.Count).Row '範囲終了行 If sRow = eRow Then Exit Sub End If pCode = "" For c = sCol To eCol pCode = pCode & Cells(sRow, c).Value & "=[" For r = sRow + 1 To eRow v = Cells(r, c).Value Select Case TypeName(v) Case "String" pCode = pCode & "'" & v & "'" Case "Empty", "Null", "Nothing" pCode = pCode & "None" Case "Date" pCode = pCode & "datetime.datetime(" _ & Year(v) & "," _ & Month(v) & "," _ & Day(v) & "," _ & Hour(v) & "," _ & Minute(v) & "," _ & Second(v) & ")" Case Else pCode = pCode & v End Select pCode = pCode & "," Next r pCode = Left(pCode, Len(pCode) - 1) & "]" & vbCrLf Next c Debug.Print pCode SetClip (pCode) End Sub 'クリップボードにテキストをコピー ' https://info-biz.club/windows/vba/vba-set-clipboard.html Sub SetClip(S As String) With CreateObject("Forms.TextBox.1") .MultiLine = True .Text = S .SelStart = 0 .SelLength = .TextLength .Copy End With End Sub実行方法
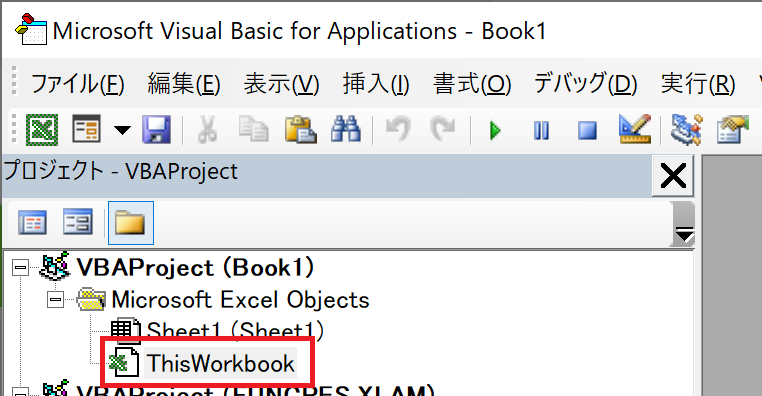
エクセルを起動して「Alt+F11」でVBAコードエディタを起動し、対象のブックをダブルクリックで選択します。
VBAコードを記述するウィンドウが開くので、そこに上記のコードをコピペします。
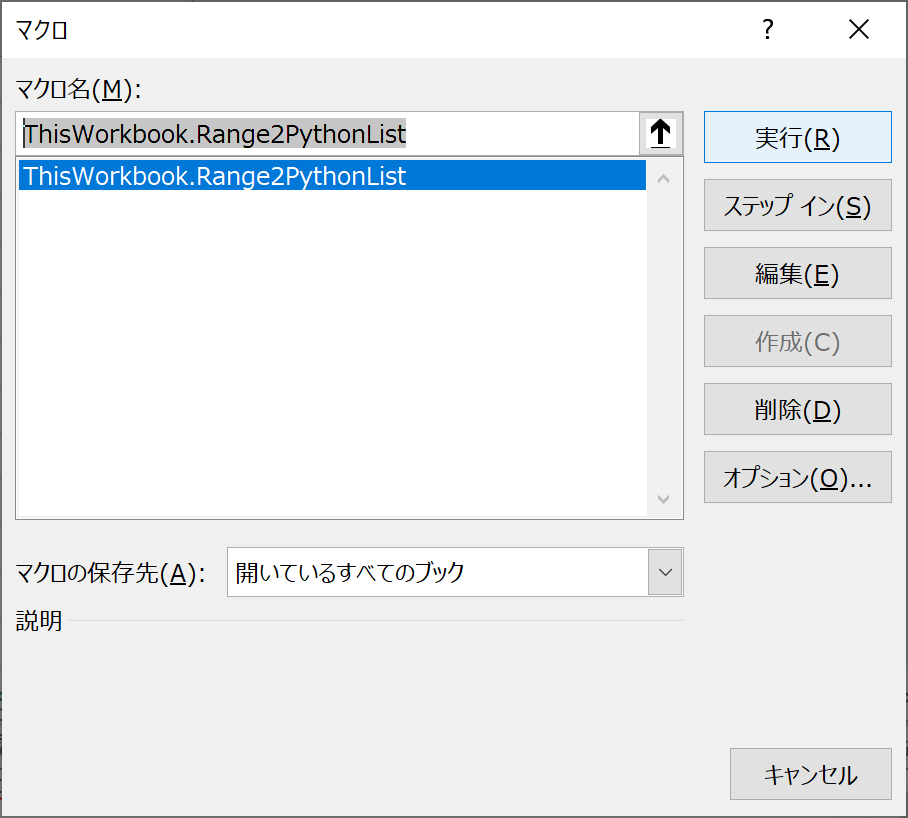
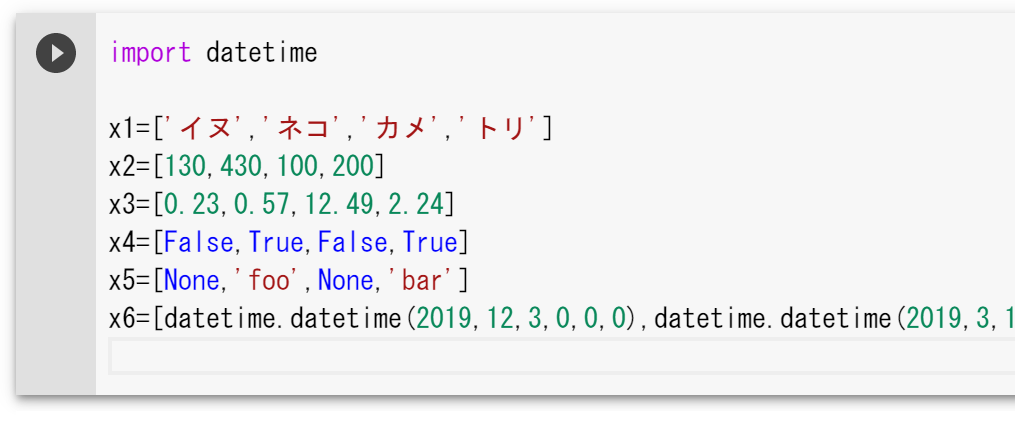
エクセルに戻って、範囲を選択してから「Alt+F8」でマクロを起動、「ThisWorkbook.Range2PythonList」を選択して実行します。
選択範囲の内容が、Pythonのリストの初期化コードに変換されクリップボードにコピーされます。あとは、適当なエディタに貼り付けて利用します(必要に応じて
import datetimeを追記してください)。
参考資料

- 投稿日:2020-03-21T18:55:27+09:00
【Python】データ分析、機械学習実践(Kaggle)〜モデル解析編〜
はじめに
前回の記事
【Python】初めての データ分析・機械学習(Kaggle)
【Python】初めての データ分析・機械学習(Kaggle)〜Part2〜
に引き続き、Kaggleで比較的優しいコンペ「House Prices: Advanced Regression Techniques」に挑戦しました!今回のコンペは、住宅に関する情報の変数をもとに、住宅の価格を推定するというもの。
しかし、この住宅に関する変数が80もあり、いきなり怖気付きました、、(笑)「こんなのできるのか、、?」て思いつつ、今回もしっかり先人の知恵を借りました!笑
参考コード↓↓↓大まかな流れは、以下のようになっています。
- 特徴エンジニアリング
- Imputing missing values 欠損値の穴埋め
- Transforming データ変換(log変換等)
- Label Encoding カテゴリカルデータのエンコード
- Box Cox Transformation : 正規分布に近づけさせるための変換
- Getting dummy variables カテゴリカルデータを数値データへ
- モデリング(スタッキングアンサンブル学習)
- ベースモデル解析
- 第2モデル解析
そして、本記事では、 モデリング に焦点を当てていきます!
ですから、Kaggleのコンペの予測値まで出力するところまで行きます!!前回の特徴エンジニアリングに関する記事はこちら↓↓↓
【Python】データ分析、機械学習実践(Kaggle)〜データ前処理編〜1. ライブラリのインポート
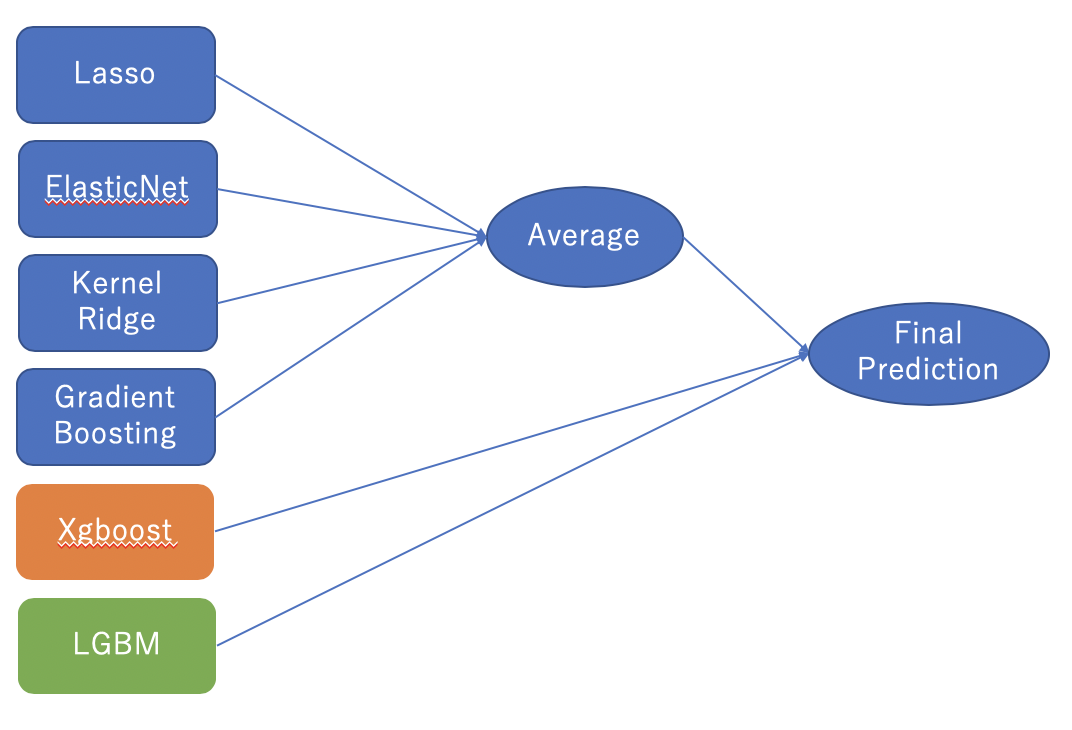
今回もTitanicの時と同様にスタッキングアンサンブル学習で予測する。
使用するモデル
1. LASSO Regression
2. Elastic Net Regression
3. Kernel Ridge Regression
4. Gradient Boosting Regression
5. XGBoost
6. LightGBM学習の流れ
4つのモデルを平均する
- LASSO Regression
- Elastic Net Regression
- Kernel Ridge Regression
- Gradient Boosting Regression
1.で平均したモデルとXGBoostとLightGBMの3つでスタックして最終的な予測を行う
from sklearn.linear_model import ElasticNet, Lasso, BayesianRidge, LassoLarsIC from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor from sklearn.kernel_ridge import KernelRidge from sklearn.pipeline import make_pipeline from sklearn.preprocessing import RobustScaler from sklearn.base import BaseEstimator, TransformerMixin, RegressorMixin, clone from sklearn.model_selection import KFold, cross_val_score, train_test_split from sklearn.metrics import mean_squared_error import xgboost as xgb import lightgbm as lgb2. 交差検証の定義
k=5(データ群を5分割)として
モデルの評価は対数平均二乗誤差(RMSLE)で行います。
スコアが小さいほど精度が高いという見方です!#Validation function n_folds = 5 def rmsle_cv(model): kf = KFold(n_folds, shuffle=True, random_state=42).get_n_splits(train.values) #シャッフル rmse= np.sqrt(-cross_val_score(model, train.values, y_train, scoring="neg_mean_squared_error", cv = kf)) return(rmse) def rmsle(y, y_pred): return np.sqrt(mean_squared_error(y, y_pred))3.平均するモデリング
- 4つのモデルの平均(ベースモデルEnet・KRR・Gboost,メタモデル=lasso)
- XGBoost
- LightGBM
この3つをスタッキングします!
まずは、1. 4つのモデルの平均(ベースモデルEnet・KRR・Gboost,メタモデル=lasso)から!
class StackingAveragedModels(BaseEstimator, RegressorMixin, TransformerMixin): def __init__(self, base_models, meta_model, n_folds=5): self.base_models = base_models self.meta_model = meta_model self.n_folds = n_folds # モデルのクローンにデータをfitさせる def fit(self, X, y): self.base_models_ = [list() for x in self.base_models] self.meta_model_ = clone(self.meta_model) kfold = KFold(n_splits=self.n_folds, shuffle=True, random_state=156) # 学習ベースモデルがフォールド外予測をします # そのフォールド外予測はメタモデルで必要となります out_of_fold_predictions = np.zeros((X.shape[0], len(self.base_models))) for i, model in enumerate(self.base_models): for train_index, holdout_index in kfold.split(X, y): instance = clone(model) self.base_models_[i].append(instance) instance.fit(X[train_index], y[train_index]) y_pred = instance.predict(X[holdout_index]) out_of_fold_predictions[holdout_index, i] = y_pred # フォールド外予測を用いてメタモデルの学習 self.meta_model_.fit(out_of_fold_predictions, y) return self #全てのベースモデルの予測値と予測の平均値をメタ特徴として、メタモデルで最終予測を行います! def predict(self, X): meta_features = np.column_stack([ np.column_stack([model.predict(X) for model in base_models]).mean(axis=1) for base_models in self.base_models_ ]) return self.meta_model_.predict(meta_features)ベースモデルEnet・KRR・Gboost,メタモデル=lassoで適応します。
stacked_averaged_models = StackingAveragedModels(base_models = (ENet, GBoost, KRR), meta_model = lasso) score = rmsle_cv(stacked_averaged_models) print("Stacking Averaged models score: {:.4f} ({:.4f})".format(score.mean(), score.std()))出力Stacking Averaged models score: 0.1085 (0.0074)平均したモデルをrmsle()で評価します!
stacked_averaged_models.fit(train.values, y_train) stacked_train_pred = stacked_averaged_models.predict(train.values) stacked_pred = np.expm1(stacked_averaged_models.predict(test.values)) print(rmsle(y_train, stacked_train_pred))出力0.07815719379164. 平均しないモデリング
平均しないXGBoostとLightGBMのモデルで学習・テスト・評価します!
XGBoost
#学習 model_xgb.fit(train, y_train) xgb_train_pred = model_xgb.predict(train) #テスト xgb_pred = np.expm1(model_xgb.predict(test)) #評価 print(rmsle(y_train, xgb_train_pred))出力0.0785165142425LightGBM
model_lgb.fit(train, y_train) lgb_train_pred = model_lgb.predict(train) lgb_pred = np.expm1(model_lgb.predict(test.values)) print(rmsle(y_train, lgb_train_pred))出力0.07167574688345. 平均モデルとXGBoostとLightGBMをスタッキング
'''RMSE on the entire Train data when averaging''' print('RMSLE score on train data:') print(rmsle(y_train,stacked_train_pred*0.70 + xgb_train_pred*0.15 + lgb_train_pred*0.15 ))出力RMSLE score on train data: 0.0752190464543アンサンブル学習
ensemble = stacked_pred*0.70 + xgb_pred*0.15 + lgb_pred*0.156. Kaggleの提出
sub = pd.DataFrame() sub['Id'] = test_ID sub['SalePrice'] = ensemble sub.to_csv('submission.csv',index=False)最後に
今回参考にしたStacked Regressions : Top 4% on LeaderBoardでは、説得力を増すための補足的なコーディングが多かったので、本記事ではかなりシンプルに書きました!
ただし、人のコードを参考にしただけなので、自分でもまだ消化し切れていない部分があります、、
例えば、
- 各モデルの利用根拠
- 最後にスタッキングする際に、重みを「0.7,0.15,0.15」にした理由
などがよくわかっていませんので、もしもわかる方がいらっしゃいましたらコメントで教えていただきたいです?
おかしな記述があるかもしれませんが、少しでもモデリングについて参考になれば幸いです!!
- 投稿日:2020-03-21T18:45:37+09:00
turicreateを使ったモデルからデータを返却するAPIを作成する
概要
turicreateという Apple製の機械学習のライブラリがある。(machine learning modelsってことなのでそれで良いはず)
こいつを使ったモデルをGCP上で扱う構成を作ったときのメモ
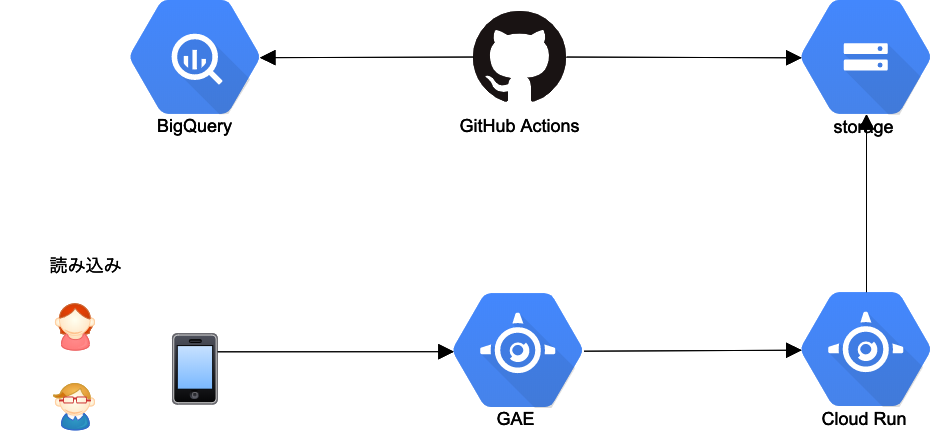
参考: https://cloud.google.com/blog/products/ai-machine-learning/how-to-serve-deep-learning-models-using-tensorflow-2-0-with-cloud-functions構成
*CloudRunって書いてある部分はアイコンがなかったのでGAEのアイコンで代用しています
ユーザはGAEに対してアクセスし、その後ろでCloud Runがstorageからmodelをdownloadしてきて動く。
もちろん毎回storageから持ってくると意味がないのでロードしたモデルはメモリ上にキャッシュする。困ったこと+解消方法
参考の構成では、TensorflowのmodelをCloud FunctionsでloadしてAPIとして、返しているがTuricreateの場合、おそらく依存関係の解消をしようとしている際にbuildができずにエラーになってしまう。(GAEでやっても同じ、Cloud Buildの設定をいじれれば良いのかもしれないがGAEやCloud Functionsからそれが触れるのかがわからなかった)
そのため、自分で実行imageを作ってdeployし動かすことができる、Cloud Runを使うことにした
実装
実装自体は何ということのないもの、ほぼほぼpython+CloudRunの構成に沿っている
main.pyimport turicreate import os from flask import Flask, request, jsonify from google.cloud import storage import zipfile model = None app = Flask(__name__) def download_model(bucket_name, source_blob_name, dest_blob_name): storage_client = storage.Client() bucket = storage_client.get_bucket(bucket_name) blob = bucket.blob(source_blob_name) blob.download_to_filename(dest_blob_name) with zipfile.ZipFile(dest_blob_name) as modelZip: modelZip.extractall('.') @app.route('/') def root(): global model request_json = request.get_json() if request.args and 'userId' in request.args: userId = request.args.get('userId') else: return jsonify({'message': 'userId is not found'}), 400 if 'limit' in request.args: limit = int(request.args.get('limit')) else: limit = 10 if model is None: load_model() result = model.recommend(users=[userId], k=limit) random.shuffle(result) return jsonify({'result': result}) def load_model(): global model os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = './credential.json' download_model("learning-data", "model.zip", "./model.zip") model = turicreate.load_model('./model') if __name__ == '__main__': app.run(host='127.0.0.1', port=int( os.environ.get('PORT', 8080)), debug=False)FROM python:3.7 ENV APP_HOME /app WORKDIR $APP_HOME COPY . . RUN pip install -r requirements.txt CMD [ "python", "main.py" ]requirements.txtturicreate==6.1 flask==1.1.1 gunicorn==20.0.4 google-cloud-storage==1.26.0GAEの方は出来上がったserviceにアクセスしていればOK
課題
- 上記の場合instanceが残り続けた場合どうなるのか、modelの更新のタイミングをみて動くようにしたい
- instanceが増えた場合どうやって更新するか
→ 一旦考えているのは、メモリにあるデータは
key: 時間、 value: modelのようにすることで別途タイミングで先にモデルデータを非同期で読み込むようにしておく方法このあたりが参考になるかも
https://cloud.google.com/run/docs/tips?hl=ja
- 投稿日:2020-03-21T18:25:08+09:00
TCPサーバーをRustで作成したときの記録
RTMPサーバーを作っている途中の記録を残そうと思って書いています。
注意:これらのリポジトリを参考にして作っています。https://github.com/KallDrexx/rust-media-libs/tree/master/examples/mio_rtmp_server
https://github.com/nareix/joy4RTMPとは?
RTMPは,
Real-Time Messaging Protocolのことで,映像や音声,またはそれ以外のデータをストリーム形式で送受信するときに用いるプロトコルのことです。
TCPベースで作られているので,1対1で通信を行います。
TCPベースなので,とりあえずTCPサーバーだけ立ててみようと思います。プロトコル
プロトコルは,ざっくりいうと通信を行う際に決められている手順や規格のことです。
RTMPの処理順序
- Handshake
- 接続
- publish(配信を行う場合)
- play(視聴を行う場合)
つまり,この処理順序で通信を行うサーバーを作ればいいってことですかね!
Handshakeとは
まず
Handshakeというのは,TCP通信を行う際に,接続の前に応答確認やタイムスタンプの交換などを行うことを指します。
今回はThree way handshakeというものを最初に行います。これは図のように,
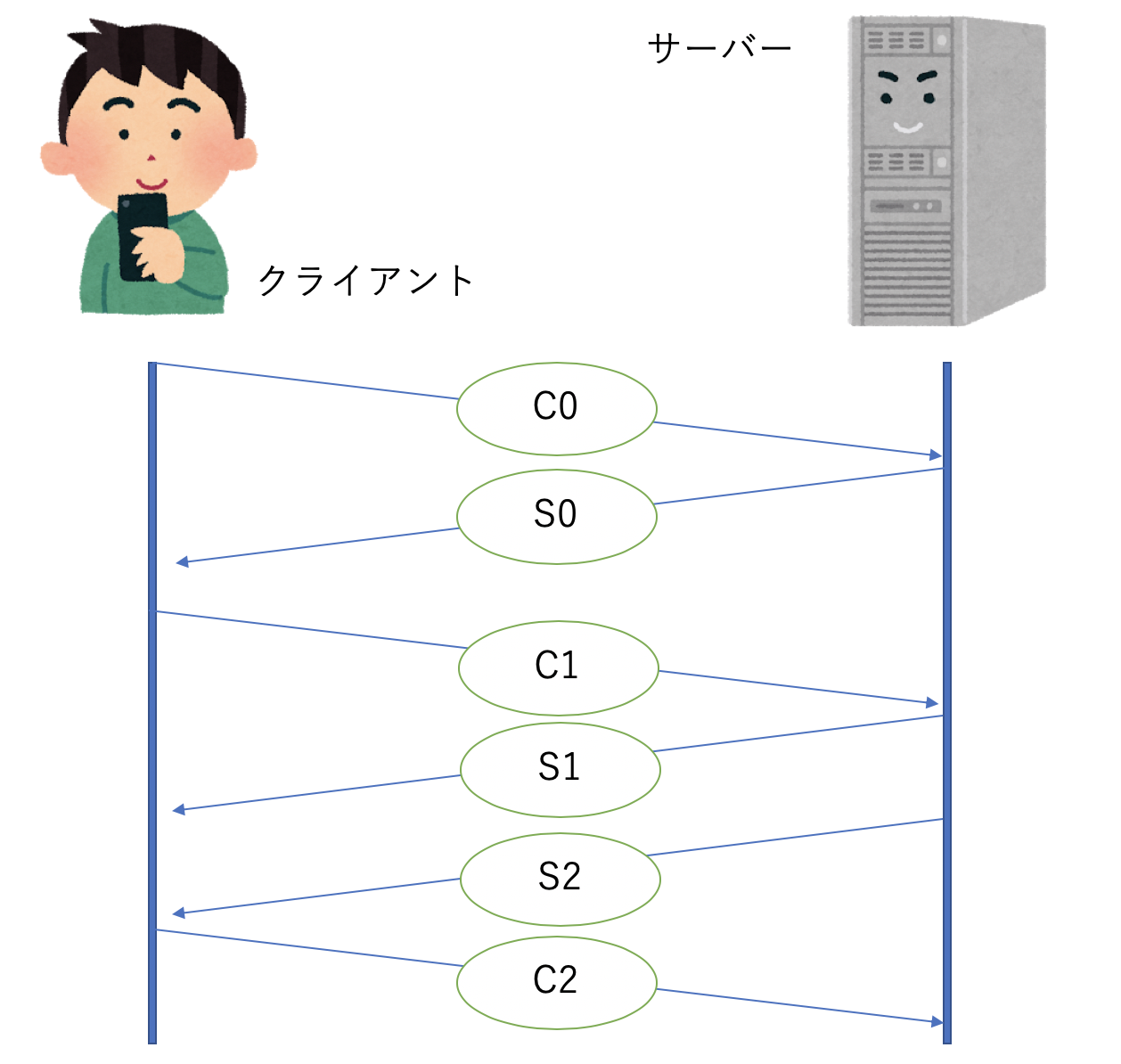
クライアントとサーバー間で3回通信のやり取りを行ってHandshakeを行います。
クライアントからC0, C1を送信し,サーバーからS0, S1, S2を送信し,最後にまたクライアントからC2を送信して完了となります。
このHandshakeを行ってはじめて接続をすることができます。では,とりあえずディレクトリを作成します。
mkdir inferno cd infernoディレクトリの中に
Cargo.tomlを作成し,ワークスペースを作成します。
とりあえずamf0は使うことがわかっているのでライブラリとしてプロジェクトを作成するためにワークスペースに登録しておきます。Cargo.toml[workspace] members = [ "amf0", "inferno-rtmp-engine" ]cargo new inferno-rtmp-engine --bin cargo new amf0 --libこれで最初の準備ができました。
Handshake部分の実装
それではHandshakeの部分を実装していこうと思います。
inferno-rtmp-engine/の方のプロジェクトのsrc/の中に新しくhandshake/フォルダを作成します。その中にerrors.rsとmod.rsを作成します。
すると現在のinferno-rtmp-engineのディレクトリ構成は. ├── Cargo.toml └── src ├── handshake │ ├── errors.rs │ └── mod.rs └── main.rsこのようになっています。
次は中身の部分を書いていきます。
Stage構造体
では,Handshakeの際に自身が実行するべき処理を把握するための構造体
Stageを定義します。
※Rustのインデントはスペース4つらしいです。handshake/mod.rsmod errors; #[derive(Eq, PartialEq, Debug, Clone)] enum Stage { WaitingForC0, WaitingForC1, NeedToSendS2, Complete, }サーバーを立てる際に使うフォルダ
serversを作成します。そしてその中にまたmod.rsを作成しておきます。それと一緒に,errors.rsとresult.rsも作っちゃいます。
さて,RTMPはTCPベースになっているので,TCPサーバーが立たないといけません。
なのでまずはRustでTCPサーバーを立ててみます。TCPサーバーの準備
servers/mod.rsmod errors; mod result; use std::io::{Error, Read, Write}; use std::net::{TcpListener, TcpStream}; use std::thread; pub struct Server { addr: String, } impl Server { // Some methods to handle connection. pub fn listen_and_serve() -> Result<(ServerSession, Vec<ServerSessionResult>), ServerSessionError> { // Build a server } }このように
listen_and_serve()メソッドを使ってTCPサーバーが立つようにしたいと思います。
ServerSessionなどはまだ定義されていないので,result.rsたちの中に書いていきます。(あとで掲載します)
すると,servers/mod.rsmod errors; mod result; use std::io::{Error, Read, Write}; use std::net::{TcpListener, TcpStream}; use std::thread; pub use self::errors::ServerSessionError; pub use self::result::ServerSessionResult; pub struct Server { addr: String, } impl Server { // Some methods to handle connection. pub fn listen_and_serve() -> Result<(Server, Vec<ServerSessionResult>), ServerSessionError> { // Build a server let server = Server { addr: "somewhere".to_string(), }; let mut results = Vec::with_capacity(4); Ok((server, results)) } }とりあえずこんな感じで
listen_and_serve()メソッドを作ることができました。
メソッドの中身はとりあえずテストが通るように書いただけみたいな感じです。では,次はメソッドの中身を埋めていきます。
まずはTCPサーバーを立てる必要があるので,その処理を書いていきます。server/mod.rsmod errors; mod result; #[cfg(test)] mod tests; use std::io::{Error, Read, Write}; use std::net::{TcpListener, TcpStream}; use std::thread; pub use self::errors::ServerSessionError; pub use self::result::ServerSessionResult; pub struct Server { addr: Option<String>, } impl Server { pub fn new() -> Result<(Server, Vec<ServerSessionResult>), ServerSessionError> { let server = Server { addr: Some("somewhere".to_string()), }; let mut results = Vec::with_capacity(4); Ok((server, results)) } pub fn listen_and_serve(self) { // Build a server let listener = TcpListener::bind("127.0.0.1:1935").expect("Error: Failed to bind"); println!("Listening..."); for streams in listener.incoming() { match streams { Err(e) => { eprintln!("error: {}", e) }, Ok(stream) => { thread::spawn(move || { handler(stream).unwrap_or_else(|error| eprintln!("{:?}", error)); }); } } } } } fn handler(mut stream: TcpStream) -> Result<(), Error> { println!("Connection from {}", stream.peer_addr()?); let mut buffer = [0; 1024]; loop { let nbytes = stream.read(&mut buffer)?; if nbytes == 0 { return Ok(()); } stream.write(&buffer[..nbytes])?; stream.flush()?; } }これでTCPサーバーが立つようになったので,PythonのスクリプトでTCPサーバーとして動くかどうかを試してみます。
connection.ini[server] ip = 127.0.0.1 port = 1935 [packet] # [bytes] header_size = 4 # [pixels] image_width = 64 image_height = 64stream.pyimport socket import configparser import logging import time logging.basicConfig(level=logging.DEBUG) config = configparser.ConfigParser() config.read('./connection.ini', 'UTF-8') # Connectino Settings SERVER_IP = config.get('server', 'ip') SERVER_PORT = int(config.get('server', 'port')) IMAGE_WIDTH = int(config.get('packet', 'image_width')) IMAGE_HEIGHT = int(config.get('packet', 'image_height')) IMAGE_SIZE = IMAGE_WIDTH * IMAGE_HEIGHT if __name__ == '__main__': with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as s: s.connect((SERVER_IP, SERVER_PORT)) i = 0 while True: s.send(i.to_bytes(IMAGE_SIZE, 'big')) logging.info(" Send: " + str(i)) time.sleep(1) i = i + 1このスクリプトと,Rustのサーバーを同時に起動すると,
Hello, world! Listening... Connection from 127.0.0.1:50247一応テスト用のコードも出しておくと,
server/test.rsuse super::*; use std::thread; #[test] fn bridge_tcp_server() { let (server, _result) = Server::new().unwrap(); thread::spawn(move || { server.listen_and_serve(); }); }新しくスレッドを作成して
listen_and_serve()を行うことで,テストでたてたTCPサーバーが正常に終了するようにしています。running 1 test test tests::it_works ... ok test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out Running target/debug/deps/inferno_rtmp_engine-d3654c5273df6f45 running 1 test Listening... test servers::tests::bridge_tcp_server ... ok test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out Doc-tests amf0 running 0 tests test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered outまとめ
とりあえず今回はTCPサーバーをたてるところまで進めました。
RTMPサーバーを立てる途中の記録なので,TCPサーバーのコードとしては要らない部分がかなり多いと思います。
この開発の目的はRTMPサーバーを作成することなので,また少しずつ進めていきます。参考リンク
http://blog.hirokikana.com/dev/rtmp-client/
https://www.adobe.com/jp/devnet/rtmp.html
https://www.otsuka-shokai.co.jp/words/protocol.html
http://e-words.jp/w/%E3%83%8F%E3%83%B3%E3%83%89%E3%82%B7%E3%82%A7%E3%82%A4%E3%82%AF.html
https://developers.cyberagent.co.jp/blog/archives/13739/
https://cha-shu00.hatenablog.com/entry/2019/03/02/174532
https://users.rust-lang.org/t/how-to-close-tcpconnection-with-a-function/39367/3参考にしたコード
https://github.com/KallDrexx/rust-media-libs/tree/master/examples/mio_rtmp_server
https://github.com/nareix/joy4/blob/master/format/rtmp/rtmp.go
- 投稿日:2020-03-21T18:14:40+09:00
Pythonで複数のリストを同時にfor文で回す
zipを使います。あるサイトの記事一覧から、
BeautifulSoup4を使いURLとタイトルのリストを取得します。
目的は['url>>>title', 'url>>>title']という、URLとタイトルを>>>で接続したリストを作りたい。以下のようにaタグの要素にタイトルが記載されているタイプのページなら...
import requests, bs4 res = requests.get('https://qiita.com/takuto_neko_like') posts = bs4.BeautifulSoup(res.text, 'html.parser').select('.u-link-no-underline') print(posts)変数
postsには<class 'bs4.element.Tag'>が入っており、posts[0]などとして個別にアクセスするとhtmlのaタグの内容を見られる。aタグの要素にタイトルが記載されている[<a class="u-link-no-underline" href="/takuto_neko_like/items/52c6c52385386544aa62">herokuで悩んだところ</a>, <a class="u-link-no-underline" href="/takuto_neko_like/items/c5791f267e0964e09d03">新着記事を取得するツールを作った</a>, <a class="u-link-no-underline" href="/takuto_neko_like/items/93b3751984e5e3fd3670">fishの動きが遅すぎた gitのトラブル</a>, <a class="u-link-no-underline" href="/takuto_neko_like/items/62aeb4271614f6f0347f">Plotlyで作るグラフをDjangoで使う</a>, <a class="u-link-no-underline" href="/takuto_neko_like/items/c9c80ff453d0c4fad239">【Python】super()を使ってオーバーライドする理由</a>, <a class="u-link-no-underline" href="/takuto_neko_like/items/14e92797fa2b23a64adb">【Python】多重継承で継承するものは何?</a>, <a class="u-link-no-underline" href="/takuto_neko_like/items/6cf9bade3d9515a724c0">【Python】@classmethod及びデコレータとは?</a>, <a class="u-link-no-underline" href="/takuto_neko_like/items/aed9dd5619d8457d4894">【Python】*args **kwrgs って何だろう</a>, <a class="u-link-no-underline" href="/takuto_neko_like/items/bb8d0957347636b5bf4f">【Bootstrap】スクロールしてもnavbarを固定して表示する方法と、その際の留意点及び解決法</a>]それぞれのaタグの内容は
<class 'bs4.element.Tag'>= Tagオブジェクトというものなので、str()で文字列型に変換することで.find()で`タグ名や属性名などを指定して取得したインデックスを使い、URL部分・タイトル部分の文字列だけを抽出できるようになる。urlとtitleを整形for post in posts: # URLを抽出 index_first = int(str(post).find('href=')) + 6 index_end = int(str(post).find('">')) url = (str(post)[index_first : index_end]) # タイトルを抽出 index_first = int(str(post).find('">')) + 2 index_end = int(str(post).find('</a')) title = (str(post)[index_first : index_end].replace('\u3000', ' ')) url_title_set.append(f"{url}>>>{title}")などとすれば、出来上がり。
ただ、aタグの要素としてタイトルが記載されていないタイプのサイトもよくあります。
例えば画像とタイトルから成るカードとして記事情報が表示され、カード全体にリンクが貼ってあるパターン例<div class='card'><a href='#' class='link'> <div class='image'><img src='#'></div> <div class='title'>タイトル</div> </a> </div>このような場合、bs4の
.selectでクラスcardを指定すると、cardクラスが適用されているdivタグ内を取得できます。そこからaタグのhref情報、titleクラスdivの要素を取得したい。実際のコードではより多くの要素が重なっているので、親要素から.findで特定の文字列を探し出そうとすると、若干面倒くさい。
また、bs4には子要素にアクセスする必要方法もがありますが、ドキュメントを見ていたら若干面倒くさそうだったので、以下のようにそれぞれを個別に取得しました。
posts_links = bs4.BeautifulSoup(res.text, 'html.parser').select('.link') posts_titles = bs4.BeautifulSoup(res.text, 'html.parser').select('.title')先程のコード
urlとtitleを整形でpostsリストをfor文で回して`Tagオブジェクトに個別にアクセスしていきますが、今回はリストが2つあります。2つのリストを同時にfor文で回して、それぞれのリストから取得したurlとtitleを結合。その後新たなリストに格納したい。このように、複数のリストを同時にfor文で回したいときは、
zipを使います。now_posts_link_title_set = [] for (posts_link, posts_title) in zip(posts_links, posts_titles): index_first = int(str(posts_link).find('href=')) + 6 index_end = int(str(posts_link).find('">')) posts_link_set = (str(posts_link)[index_first : index_end]) index_first = int(str(posts_title).find('h2')) + 3 index_end = int(str(posts_title).find('</h2')) posts_title_set = (str(posts_title)[index_first : index_end].replace('\u3000', ' ')) # 空白置換 now_posts_link_title_set.append(f"{posts_link_set}>>>{posts_title_set}")2つより多くても大丈夫
for (a, b, c, d) in zip(a_list, b_list, c_list, d_list)リストの要素数に差がある場合は、多い方が無視されます
aa = [1,2,3,4,5] bb = ['a', 'b', 'c'] for (a, b) in zip(aa, bb): print(f'{a} : {b}') # 結果 1 : a 2 : b 3 : cこれは便利だ
- 投稿日:2020-03-21T17:46:27+09:00
PySimpleGUIでMatplotlibのxyグラフを表示する。
はじめに
PySimpleGUIのサンプルプログラムを参考にファイルを読み込んでxyグラフを表示するプログラムを作ってみた。
サンプルプログラム:PySimpleGUI-cookbook-(Recipe-Compare 2 Files), (Matplotlib Window With GUI Window)その他参考
PySimpleGUIでグラフを描く
tkinter(pySimpleGUI)でmatplotlibなしでグラフを書く方法環境
Win10Pro
Anaconda
Python3.7PySimpleGUIのインストールについては、前回の記事PySimpleGUIでQRコード作成GUIを作るを参考にしてください。
作成プログラム
x,yのデータが入ったCSVファイルをアップロードしてグラフを書かせるプログラム
from pathlib import Path import matplotlib.pyplot as plt import pandas as pd import PySimpleGUI as sg sg.theme('Light Blue 2') def draw_plot(x,y): plt.plot(x,y) plt.show(block=False) #block=Falseの指定をしないと、その間コンソールは何も入力を受け付けなくなり、GUI を閉じないと作業復帰できない。 def check_file(file_name): p = Path(file_name) print(p.suffix) if p.suffix == '.csv': df = pd.read_csv(p) x = df.iloc[:,0] y = df.iloc[:,1] return x, y else: print('Wrong data file, data must be CSV') return None, None layout = [[sg.Text('Enter csv data')], [sg.Text('File', size=(8, 1)),sg.Input(key='-file_name-'), sg.FileBrowse()], [sg.Submit()], [sg.Button('Plot'), sg.Cancel()], [sg.Button('Popup')]] window = sg.Window('Plot', layout) while True: event, values = window.read() if event in (None, 'Cancel'): break elif event in 'Submit': print('File name:{}'.format(values['-file_name-'])) x,y = check_file(values['-file_name-']) if x[0] == None: sg.popup('Set file is not CSV') elif event == 'Plot': draw_plot(x,y) elif event == 'Popup': sg.popup('Yes, your application is still running') window.close()プログラムを実行して、ファイル名を指定します。横の'Browse'を押すと、ファイルが選べます。そして'Submit'を押します。
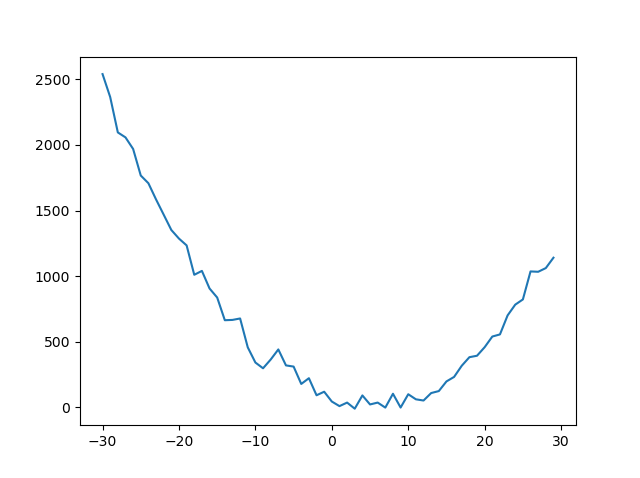
そして'Plot'を押すとグラフがプロットされます。
なお今回使ったCSVデータを作るプログラムはこちら
HDF5へ様々なファイルの格納で作製したものと同じです。import numpy as np import matplotlib.pyplot as plt import pandas as pd def base_func(x,a,b,c): y = c + a*(x - b)**2 return y x = np.arange(-30, 30, 1) para = [2.0,5.0,10.0] np.random.seed(seed=10) y = base_func(x,para[0],para[1],para[2])+np.random.normal(0, 60, len(x)) plt.scatter(x , y) plt.show() #dataをdataframeでcsvにする df = pd.DataFrame({'x':x,'y':y}) df.to_csv('csvdata.csv',index=False)まとめ
やっぱりお手軽に作れます!
- 投稿日:2020-03-21T17:19:17+09:00
測定データの解析-フィッティングの覚書①-
まえがき
或る日、
教「T君、測定器から出てきたデータを送っとくから自分でグラフ作ってきて」
T 「わかりました!」
某日ミーティング・・
T 「これがグラフです」
教「ここの値なんぼだった?計算した?」
(・・・?!)
教「これとおんなじ形式のデータがまだ〇個残ってるから。計算もやっといてね。」
(( ^ω^)・・・オワタ)といった経緯があり、
データ整理を自動化、高速化するためにpythonを学習し始めました。プログラミングに手を出したのはpythonが初めてでした。少しずつ勉強し、修士論文も書き上げたところで一旦、python関連の進捗を記録していこうかと思います。記事を書くのは初で、書き終わるかも不明です(3/18)。
GitHubにもサンプルデータとnotebookがあります。こちらからどうぞ。データを取りました。グラフ起こし頑張ろう。
T 「今からpython勉強しながらプログラム書くのでちょっと待っててもらえますか?」
教「?? 了!」
(後に、"ちょっと"が数カ月まで膨らむ)さて、データを開いてみます。頂いたデータはエクセルでも開くことのできるtxt形式のデータでした。セミコロン区切りなのがちょっといやらしい。以下、データの例です。
初めて触った教科書はpython入門ノートでした。この教科書に従ってAnacondaをインストールした後、spyder上でコードを書いて勉強していました。
ファイルの読み込み
教科書にはnumpyを使ったファイルの読み書きが書かれていました。とりあえず教科通りに読み込みました。
ファイルパスはtkinterを使って通してみました。tkinterよく分かってないですが魔法の呪文のように使っていました。.pyimport tkinter as tk import tkinter.filedialog as fd import numpy as np root=tk.Tk() root.withdraw() path = fd.askopenfilename( title="file---", filetypes=[("csv","csv"),("CSV","csv")]) if path : fileobj=np.genfromtxt(path,delimiter=";",skip_header=3)#セミコロン区切りのデータを3行飛ばして読み込む f=fileobj[:,0]#1列目のデータ・・・といった具合で当時は読み込んでいました。後にpandasという便利なモジュールに出会う。
PythonユーザのためのJupyter[実践]入門 を参考にnotebook環境を立ち上げました。
jupyter notebook とpandasを引っ提げて再出発。.ipynbimport tkinter from tkinter import filedialog import pandas as pd root = tkinter.Tk() root.withdraw() path = filedialog.askopenfilename( title="file___", filetypes=[("txt","txt"),("csv","csv")]) if path: df = pd.read_csv(path,engine="python",header=None,sep=';',skiprows=3,index_col=0)可視化
pandasで読み込むとこんな感じのテーブルデータになります。
pandasのグラフ機能でサクッとグラフ化してみます。今回の実験では1列目と2列目のデータを使います。
DataFrameではインデクサ(loc,iloc)を使ってデータを加工しますが、1行もしくは1列のデータを指定すると返ってくるオブジェクトがSeriesに変わっていることには注意が必要です。.ipnbimport matplotlib.pyplot as plt df=df.iloc[:,[0,1]] df.set_index(0,inplace=True)#インデックスを指定してdfを上書き df.plot() plt.show()
pandasを使ってプロットする場合、インデックスの列を自動的に横軸に取ってくれるようですので.set_inedex(列名)で予めインデックスを指定しています。
画像のような中心あたりに鋭いピークを持つ波形が現れました。端っこの方にはノイズが乗っていました。データ点数にもよりますが、ここまではエクセルでやっていました。scipyを使ってフィッティング
グラフ作成までは順調に進んでいましたが、計算が面倒でした。
今回の課題はピークの鋭さを評価することでした。フィッティングツールとしてはscipyのcurve_fitがググったらすぐに出てきてたので使ってみました。
先ほどのグラフにおける縦軸は入力パワーになっておりまして、単位がデシベル(dBm)で表されていました。mWに単位を直して最大値で規格化すると下図のようになりました。df.index = df.index*pow(10,-9) df.index.rename('freq[GHz]',inplace=True) df['mag'] = pow(10,(df.iloc[:]-df.iloc[:].max())/10) df['mag'].plot() plt.show()
フィットさせたい関数は次の通りです。ローレンツ関数にベースラインを加えたものになります。x以外は全部変数です。。$$f_{\left(x\right)}=A \left(\frac{\gamma}{\left(x-\mu\right)^2+\gamma^2}\right)+Bx+C$$
initはパラメータの初期値です。ざっくりと予測した値で
リストを作りました。
curve_fit(関数名,x,y,パラメータの初期値)で最適なパラメータoptと共分散covが求まります。import scipy.optimize def lorentz(x,A,mu,gamma,B,C):#フィットする関数を定義 return A*x*gamma/((x-mu)**2+gamma**2)+B*x+C A = -np.pi*(df.index.max()-df.index.min())/20 mu = df.index.values.mean() gamma = (df.index.max()-df.index.min())/20 B = 10 C = 0 init = [A,mu,gamma,B,C]#フィットしたいパラメータの初期値 opt, cov = scipy.optimize.curve_fit(lorentz,df.index,df['mag'],init)#フィッティング
結果をプロットします。df [列名]=〇〇で新しく列を作れるのは大変便利。Seriesオブジェクトに追加したいときには、pd.DataFrame(Seriesオブジェクト)か.reset_index()を経てDataFrame型に変換してから。
列名をそのまま凡例にしてくれるのはうれしい点。縦軸は…。。df['fit']=lorentz(df.index,opt[0],opt[1],opt[2],opt[3],opt[4]) df.loc[:,['mag','fit']].plot() plt.show()
いい感じにフィットできています。求まった$\mu$と$\gamma$を使ってピークの鋭さを評価しました。
・$\mu$ : ピークの中心
・$\gamma$ : ピークの深さが半分になるときの2点の幅 の半分(:半値半幅)
になっているのでQ値(ピークの鋭さ)
$$ Q = \frac{\mu}{2\gamma} $$
を求めて課題解決です。続く。まとめ
サンプルデータはとある共振回路の周波数特性を表していました。
独学で触り始めてやっとこさ解析プログラムが完成しました。初めて動いた時はやむごとなき感動。
卒業する頃には数千個のデータを処理していました。恐ろしい。作っておいてヨカッタ…
pandasをもっともっと勉強して自在にデータを扱えるようになりたいです。

- 投稿日:2020-03-21T17:19:17+09:00
測定データの解析-フィッティングの覚書-
まえがき
或る日、
教「T君、測定器から出てきたデータを送っとくから自分でグラフ作ってきて」
T 「わかりました!」
某日ミーティング・・
T 「これがグラフです」
教「ここの値なんぼだった?計算した?」
(・・・?!)
教「これとおんなじ形式のデータがまだ〇個残ってるから。計算もやっといてね。」
(( ^ω^)・・・オワタ)といった経緯があり、
データ整理を自動化、高速化するためにpythonを学習し始めました。プログラミングに手を出したのはpythonが初めてでした。少しずつ勉強し、修士論文も書き上げたところで一旦、python関連の進捗を記録していこうかと思います。記事を書くのは初で、書き終わるかも不明です(3/18)。データを取りました。グラフ起こし頑張ろう。
T 「今からpython勉強しながらプログラム書くのでちょっと待っててもらえますか?」
教「?? 了!」
(後に、"ちょっと"が数カ月まで膨らむ)さて、データを開いてみます。頂いたデータはエクセルでも開くことのできるtxt形式のデータでした。セミコロン区切りなのがちょっといやらしい。以下、データの例です。
初めて触った教科書はpython入門ノートでした。この教科書に従ってAnacondaをインストールした後、spyder上でコードを書いて勉強していました。
ファイルの読み込み
教科書にはnumpyを使ったファイルの読み書きが書かれていました。とりあえず教科通りに読み込みました。
ファイルパスはtkinterを使って通してみました。tkinterよく分かってないですが魔法の呪文のように使っていました。.pyimport tkinter as tk import tkinter.filedialog as fd import numpy as np root=tk.Tk() root.withdraw() path = fd.askopenfilename( title="file---", filetypes=[("csv","csv"),("CSV","csv")]) if path : fileobj=np.genfromtxt(path,delimiter=";",skip_header=3)#セミコロン区切りのデータを3行飛ばして読み込む f=fileobj[:,0]#1列目のデータ・・・といった具合で当時は読み込んでいました。後にpandasという便利なモジュールに出会う。
PythonユーザのためのJupyter[実践]入門 を参考にnotebook環境を立ち上げました。
jupyter notebook とpandasを引っ提げて再出発。.ipynbimport tkinter from tkinter import filedialog import pandas as pd root = tkinter.Tk() root.withdraw() path = filedialog.askopenfilename( title="file___", filetypes=[("txt","txt"),("csv","csv")]) if path: df = pd.read_csv(path,engine="python",header=None,sep=';',skiprows=3,index_col=0)可視化
pandasで読み込むとこんな感じのテーブルデータになります。
pandasのグラフ機能でサクッとグラフ化してみます。今回の実験では1列目と2列目のデータを使います。
DataFrameではインデクサ(loc,iloc)を使ってデータを加工しますが、1行もしくは1列のデータを指定すると返ってくるオブジェクトがSeriesに変わっていることには注意が必要です。.ipnbimport matplotlib.pyplot as plt df=df.iloc[:,[0,1]] df.set_index(0,inplace=True)#インデックスを指定してdfを上書き df.plot() plt.show()
pandasを使ってプロットする場合、インデックスの列を自動的に横軸に取ってくれるようですので.set_inedex(列名)で予めインデックスを指定しています。
画像のような中心あたりに鋭いピークを持つ波形が現れました。端っこの方にはノイズが乗っていました。データ点数にもよりますが、ここまではエクセルでやっていました。scipyを使ってフィッティング
グラフ作成までは順調に進んでいましたが、計算が面倒でした。
今回の課題はピークの鋭さを評価することでした。フィッティングツールとしてはscipyのcurve_fitがググったらすぐに出てきてたので使ってみました。
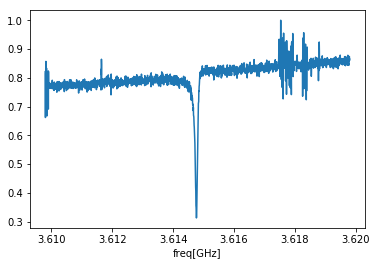
先ほどのグラフにおける縦軸は入力パワーになっておりまして、単位がデシベル(dBm)で表されていました。mWに単位を直して最大値で規格化すると下図のようになりました。df.index = df.index*pow(10,-9) df.index.rename('freq[GHz]',inplace=True) df['mag'] = pow(10,(df.iloc[:]-df.iloc[:].max())/10) df['mag'].plot() plt.show()
フィットさせたい関数は次の通りです。ローレンツ関数にベースラインを加えたものになります。x以外は全部変数です。。$$f_{\left(x\right)}=A \left(\frac{\gamma}{\left(x-\mu\right)^2+\gamma^2}\right)+Bx+C$$
initはパラメータの初期値です。ざっくりと予測した値で
リストを作りました。
curve_fit(関数名,x,y,パラメータの初期値)で最適なパラメータoptと共分散covが求まります。import scipy.optimize def lorentz(x,A,mu,gamma,B,C):#フィットする関数を定義 return A*x*gamma/((x-mu)**2+gamma**2)+B*x+C A = -np.pi*(df.index.max()-df.index.min())/20 mu = df.index.values.mean() gamma = (df.index.max()-df.index.min())/20 B = 10 C = 0 init = [A,mu,gamma,B,C]#フィットしたいパラメータの初期値 opt, cov = scipy.optimize.curve_fit(lorentz,df.index,df['mag'],init)#フィッティング
結果をプロットします。df [列名]=〇〇で新しく列を作れるのは大変便利。Seriesオブジェクトに追加したいときには、pd.DataFrame(Seriesオブジェクト)か.reset_index()を経てDataFrame型に変換してから。
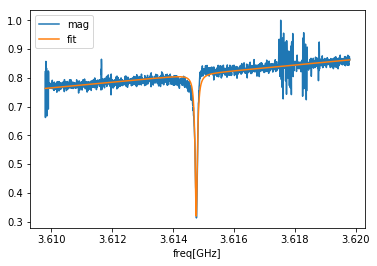
列名をそのまま凡例にしてくれるのはうれしい点。縦軸は…。。df['fit']=lorentz(df.index,opt[0],opt[1],opt[2],opt[3],opt[4]) df.loc[:,['mag','fit']].plot() plt.show()
いい感じにフィットできています。求まった$\mu$と$\gamma$を使ってピークの鋭さを評価しました。
・$\mu$ : ピークの中心
・$\gamma$ : ピークの深さが半分になるときの2点の幅 の半分(:半値半幅)
になっているのでQ値(ピークの鋭さ)
$$ Q = \frac{\mu}{2\gamma} $$
を求めて課題解決です。続く。まとめ
サンプルデータはとある共振回路の周波数特性を表していました。
独学で触り始めてやっとこさ解析プログラムが完成しました。初めて動いた時はやむごとなき感動。
卒業する頃には数千個のデータを処理していました。恐ろしい。作っておいてヨカッタ…
pandasをもっともっと勉強して自在にデータを扱えるようになりたいです。
- 投稿日:2020-03-21T17:00:48+09:00
CharucoBoard出力【OpenCV】
- 投稿日:2020-03-21T16:56:18+09:00
最適化ズブの素人がGEKKOを使って輸送問題を解く
はじめに
皆さんはGEKKOを知っているだろうか?はじめに言っておくとGEKKOは最適化問題を計算機で解くための"ソルバー"と呼ばれるツールを簡単に動かすためのツールである(こういうものをモデラーと呼ぶらしい)。pythonで動くのでインタープリタの強みを活かしてサクサク最適化問題を解くことができる。
僕とGEKKOの出会いは突然だった。それは、会社での出来事。業務の中で最適化問題をかじる事になった時。隣のデスクの最適化おじさん(※最適化問題を愛しているおじさんの事)が呟いた。
「GEKKOってのがあるらしいよ」
なにそれ、かっこいい。。。
僕の脳裏には某ロボアニメのテロリスト集団「ゲッコー○テイト」のメンバーの顔が走馬灯のように駆け抜けた。
実はソルバーやモデラーは他にもいっぱい種類があるのだが、僕はGEKKOを使うことに決めた。理由は名前がかっこいいから。ここには触ってみた感想とかを適当に綴っておく。
制約付き最適化問題と輸送問題
GEKKOの話の前に一般的な制約付き最適化問題やその中の輸送問題について書く。実は素人なので、間違っている内容もあるかもしれない。
制約付き最適化問題とは
簡単にいうと、いくつかの制約条件を満たしつつ、目的関数を最小(あるいは最大)化する変数を探しだす問題である。
線形・非線形、連続・不連続などで多少勝手が変わるが、基本的には以下のように定式化される。minimize~~f(x) \\ subject~to~~x \in X$x \in X$で表現してあるのが制約式にあたる。ここでは、等号や不等号で変数を縛る条件が付与される。
さらに詳しくは、ネットに資料や記事が溢れているので割愛する。最適輸送問題
読んで字の如く、輸送を最適化する。
例えば、上の図のように、東京と大阪にそれぞれ倉庫があり、同種の在庫がストックしてあるとする。福岡のAさんが商品を頼んだ時、単純に考えるなら距離が近い大阪の倉庫から発送されるだろう。これは、輸送コストに応じて輸送を最適化している事になる。
では、輸送元も先も複数ある場合はどうなってくるだろうか。考えられる輸送ルートは輸送元数×輸送先数存在する事になる。そして、各ルートそれぞれが異なる輸送コストを持つ。その上でトータルの輸送コストを最小に抑える輸送量の組み合わせを探さなくてはならない。
仮に、ある輸送先だけに注目するなら話は簡単である。その輸送先に延びるルートのうちコストが一番低いものを選ぶだけでよい。じかし実際には、輸送量には幾つかの制約があるのでこれはできない。例えば、倉庫は無限の在庫を格納できるわけではない。在庫の兼ね合いによっては、少しコストの高いルートも選択されうることになる。最小化したいのはあくまで全体のコストなのだ。
ある条件の基、何かを最小化する。というわけで、輸送問題は条件付き最適化問題に落とし込むことができる。GEKKO
概要
最適化モデラーである。名前がかっこいい。詳しくは公式ドキュメントを参照されたし。
インストール
インストールは簡単で、下の1行で済んだ。
pip install gekko
実はここがGEKKOのいいところ。ソルバーを別でビルドしたりせずに、この1行だけで準備完了となる。実際にやってみた
適当に考えた練習問題をGEKKOで解いてみた。
問題1
倉庫から消費者への米の輸送を考える。
今回は以下のような設定をおく。
- 倉庫はそれぞれキャパが異なる
- 消費者はそれぞれ消費量が異なる
- 倉庫-消費者間の輸送経路は決まっており、輸送コストが与えられる
- 供給の総量=需要の総量とする
その上で、倉庫-消費者間の各ルートに何キロの米を流せばいいかを求めたい。
定式化
この問題は連続変数の線形最適化問題に落とし込める。
まず、各倉庫にある米の量(供給)をベクトル$ \boldsymbol{s} $、消費者が求めている米の量(需要)をベクトル$\boldsymbol{d}$で表す。
そして、$s_i$から$d_j$への輸送量を$\gamma_{ij}$、輸送コストを$c_{ij}$とする。
この問題では、需要と供給の送料は同じとしているので、テーブルにまとめると以下のようになる。ちなみに、輸送量は常に正であることに注意。
ここで、最適化関数をモデリングする。
トータルのコストは単純に輸送量と輸送コストの線形和だと考えて
$$\sum_{i,j} \gamma_{ij} \cdot c_{ij}$$
とする。
以上より、以下の様な最適化問題に定式化される。minimize~~\sum_{i,j} \gamma_{ij} \cdot c_{ij} \\ subject~~to \sum_j \gamma_{ij} = s_i \\ ~~~~~~~~~~~\sum_i \gamma_{ij} = d_j \\ ~~~~~~~~~~~\gamma_{ij} \geq 0実装
GEKKOで実装していく。コード全文はコチラ。
まずは必要なライブラリのインポート。from gekko import GEKKO import numpy as np今回使うのはたったこれだけである
続いて、前提として与えられる定数を定義しておく。数は適当に決めている。
#### 問題設定 #### ware_house_num = 3 # 倉庫の数 shop_num = 2 # 客の数 supry = np.array([10,5,2]) # 倉庫の方の供給 demand = np.array([7,10]) # 客の方の需要 c_npa = np.array([[1.,2.,3.], [4.,5.,6.]]) # 輸送コストさらに、この手順が本当に必要か定かではないが、需要と供給のベクトルをGEKKOのm.Paramという型に変換しておく
supry_pa = m.Array(m.Param,(supry.shape)) for i in range(len(supry)): supry_pa[i].value = supry[i] demand_pa = m.Array(m.Param,(demand.shape)) for j in range(len(demand)): demand_pa[j].value = demand[j]また、コスト行列は定数なので,m.Constという型に変換する
c = m.Array(m.Const,(c_npa.shape)) for i in range(shop_num): for j in range(ware_house_num): c[i,j].value = c_npa[i, j]そして、変数を初期化する。この値も適当。※ところで、上の定式化で使ってる文字とプログラムの変数名が揃ってないのはご容赦を…
#変数の初期化 s = m.Array(m.Var,(shop_num, ware_house_num,)) for i in range(shop_num): for j in range(ware_house_num): s[i,j].value = 2.0 s[i,j].lower = 0.0ここで、変数の値と下限を設定している。この他にも、上限や整数縛り、好きな名前を付けたりすることもできる。
一番重要な目的関数と制約式は次のように書く
# 最適化関数 m.Obj(m.sum([m.sum([s[i,j] * c[i,j] for i in range(shop_num)]) for j in range(ware_house_num)])) # 制約式 for i in range(shop_num): m.Equation(m.sum([s[i,j] for j in range(ware_house_num)]) == demand_pa[i]) for j in range(ware_house_num): m.Equation(m.sum([s[i,j] for i in range(shop_num)]) == supry_pa[j])ここまで書けたらあとは、ワンポチでソルバーが面倒な最適化アルゴを自動で実行してくれる。具体的には次のメソッドを呼ぶ。
m.solve()エラー無くだらだらと計算過程のログなどが出力されていたらおそらく成功である。
ログの下の方のObjective :と書かれた欄には目的関数の値が示されているが、今回注目したいのはどちらかというと、その値を取る時の変数の値なので、それを確認したかったら上で定義した変数を出力するといい。この場合はprint(s)などとすれば確認できる。問題2
さらに少し複雑な問題を考えてみる。米は農家から倉庫、倉庫から消費者へ渡ると想定する。また、倉庫では何故か一定量中抜きが行われているとする。この時の輸送量を最適化する。
定式化
農家の供給量を$\boldsymbol{s}$、消費者の需要量を$\boldsymbol{d}$倉庫での中抜き量を$\boldsymbol{a}$とする。また農家から倉庫への輸送量と輸送コストを$\bar{\gamma_{kj}}, \bar{c_{kj}}$、倉庫から消費者へのそれを$\gamma_{ji}, c_{ji}$とすると以下のように定式化される。
minimize~~\sum_{k,j} \bar{\gamma_{kj}} \cdot \bar{c_{kj}} + \sum_{j,i} \gamma_{ji} \cdot c_{ji} \\ subject~~to \sum_j \bar{\gamma_{kj}} = s_k \\ ~~~~~~~~~~~\sum_i \gamma_{ji} = \sum_k \bar{\gamma_{kj}} - a_j \\ ~~~~~~~~~~~\sum_j \gamma_{ji} = d_i \\ ~~~~~~~~~~~\bar{\gamma_{kj}},\gamma_{ji} \geq 0実装
問題1とそんなに変わらないので説明は省略。コードはコチラを参照されたし
感想
定式化した問題を簡単にコードに落とすことができた。最初は「あんまり使ってる人いなさそうだし、大丈夫か?」と思ったが、なかなかいいおもちゃを手に入れたかもしれない。
さながら『ねだるな、勝ち取れ、さすれば与えられん』といったところか(言いたいだけ)。おわりに
久しぶりに記事を書いた。どうやら前記事を書いた時から3年以上も経過しているらしい、、、3年てやばいな
そして、定式化や実装面で上述の最適化おじさんに大変有益なアドバイスをいくつも頂きました。ありがとう最適化おじさん。。。

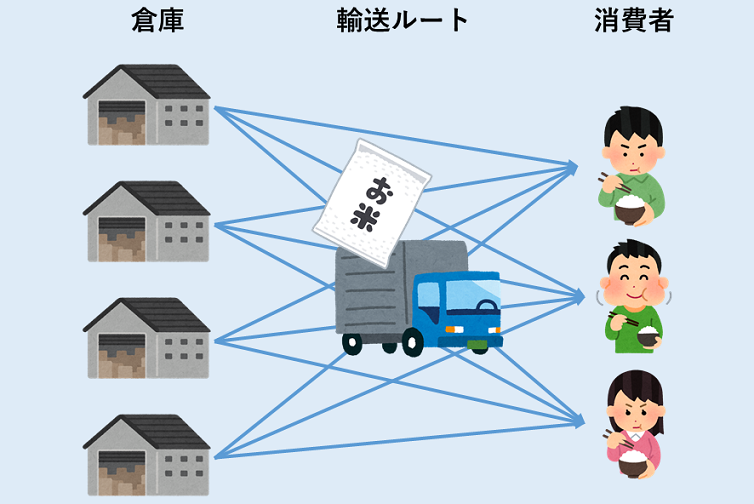

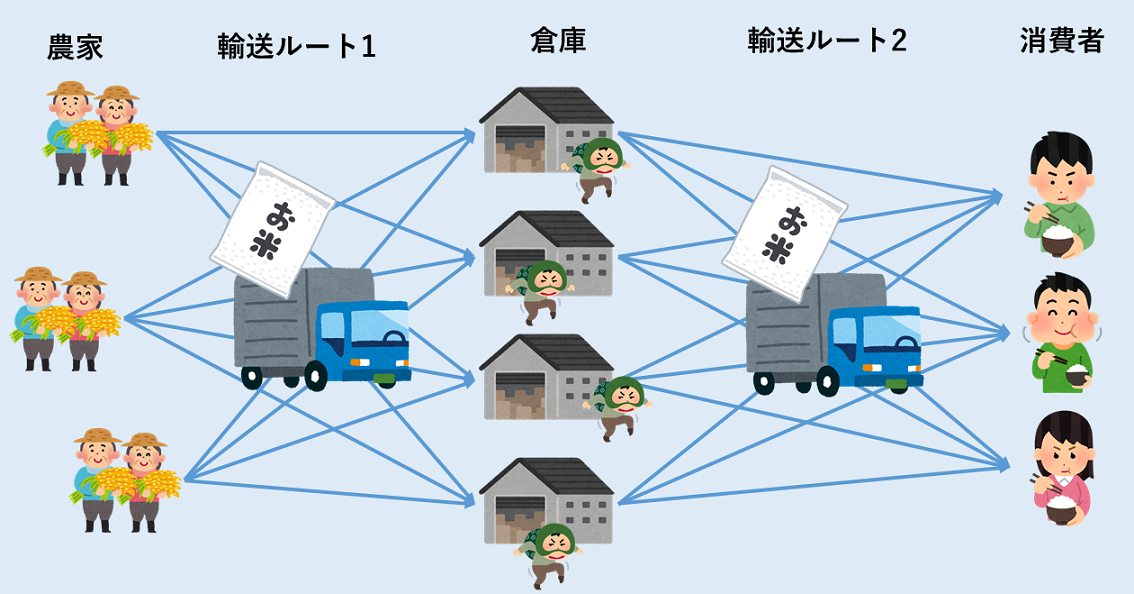
- 投稿日:2020-03-21T16:26:48+09:00
TensorFlow 2.2.0-rc0(CUDA10.2+cuDNN7.6.5)のビルド手順 - Windows10
TensorFlow 2.2.0-rc0(GPU版)をWindows 10でビルドする手順です。
細かい説明は省略して要点だけを記載しているので、もう少し詳しい内容はdev.infohub.ccのBlogなどを参考にしていただければと思います。ビルド環境の準備
ビルドには次の環境を利用します。
CUDAやcuDNN、Pythonなどは事前にPATHを通しておきます。
- CPU: AMD Ryzen Threadripper 3960X
- GPU: NVIDIA TITAN RTX
- Windows 10 Pro 64bit (Ver 1909 build 18363.720)
- CUDA 10.2
- cuDNN 7.6.5
- Visual Studio Community 2019 Ver16.4.6
- Python 3.8.2
- MSYS2
インストールしてC:\msys64\usr\binにパスを通す。- Bazel 2.0.0
ダウンロードしたファイルをbazel.exeにリネームしてパスの通ったフォルダに格納。
※TensorFlow 2.2.0-rc0のビルドに使えるバージョンはBazel 2.0.0だけなので注意!
MSYS2のパッケージ追加
C:\msys64\msys2_shell.cmdを起動して、ビルドに必要なパッケージを追加します。# 必要なパッケージの導入 pacman -S git patch unzip # 以降はMSYS2のコンソールは利用しないので終了 exitTensorFlowのビルド
ビルド用のPython仮想環境
g:\venvs\build_tf2を使ってTensorFlowをビルドしていきます。
パス等はそれぞれの環境に合わせて読み替えてください。以降の操作は、Visual Studio 2019の
x64 Native Tools Command Prompt for VS 2019で起動したコンソール画面を利用します。# 仮想環境を作成して有効化する python -m venv g:\venvs\build_tf2 cd /d g:\venvs\build_tf2 g:\venvs\build_tf2\Scripts\activate.bat # pipのアップグレード(任意) python -m pip install --upgrade pip # ビルドに必要なパッケージを導入 pip install six numpy wheel pip install keras_applications==1.0.8 --no-deps pip install keras_preprocessing==1.1.0 --no-deps # TensorFlow v2.2.0-rc0のソースコードを取得 git clone https://github.com/tensorflow/tensorflow.git cd tensorflow git checkout v2.2.0-rc0 # 不要な環境変数の削除(オプション) # 環境変数全てがパラメータで渡されるため、パラメータの文字列が32768文字を超えると # FATAL: Command line too long (34052 > 32768) というようなエラーが発生する。 # それを防ぐために、ここで不要な環境変数を一時的に削除。 # _OLD_VIRTUAL_PATHは文字数が多くなりがちなので、削除する第一候補。 set _OLD_VIRTUAL_PATH= # ビルド構成の設定 #---------------------------------------------------------------- # <設定例> # Location of Python : (Default) # ROCm support : (Default = N) # CUDA support : Y # CUDA compute capabilities : 7.5 (詳細はhttps://developer.nvidia.com/cuda-gpusを参照) # Optimization flag : /arch:AVX2 # Override eigen... : (Default = Y) #---------------------------------------------------------------- python ./configure.py # ビルド(CUDA向け) # ビルドが完了するまで、数十分~数時間かかります bazel build --config=opt --config=cuda --define=no_tensorflow_py_deps=true --copt=-nvcc_options=disable-warnings //tensorflow/tools/pip_package:build_pip_package # Wheelパッケージの作成 # g:\tensorflow_pkgフォルダにパッケージを作成する(数分かかる) bazel-bin\tensorflow\tools\pip_package\build_pip_package g:\tensorflow_pkg # これでTensorFlowのビルドが完了。exitで終了。 #---------------------------------------------------------------- # <参考> # Bazelのワークファイルは %UserProfile%_bazel_%UserName% に作成されるので # 不要なら、このフォルダを削除してもOK(20GB程度の容量) #---------------------------------------------------------------- exit新規環境にビルドしたTensorFlowを導入
ビルドしたTensorFlowを新しいPythonの仮想環境に導入する方法です。
ここではg:\venvs\tf2に新しい仮想環境を作成する例です。# 仮想環境を作成して有効化 python -m venv g:\venvs\tf2 g:\venvs\tf2\Scripts\activate.bat # pipのアップデート(任意) python -m pip install --upgrade pip # ビルドしたTensorFlowのインストール(作成したwheelファイルを指定するだけ) pip install g:\tensorflow_pkg\tensorflow-2.2.0rc0-cp38-cp38-win_amd64.whl # 動作確認 python -c "import tensorflow as tf; print(tf.__version__); print(tf.keras.__version__)" python -c "import tensorflow as tf; print(tf.reduce_sum(tf.random.normal([1000, 1000])))"備考
TensorFlow 2.2.0-rc0のビルドは、TensorFlow v1の頃に比べると格段に簡単になっている印象を受けます。
今回のビルドでも、python ./configure.pyとしたときに、FATAL: Command line too long (34052 > 32768)というエラーに遭遇しただけで、それ以外は何の問題も発生しませんでした。実行時にDLLが見つからずにエラーになるケースが多くありますが、この場合はCUDA等必要なライブラリへのパスが通っているか確認してみてください。
- 投稿日:2020-03-21T16:07:00+09:00
Python、os操作について
(1)前提
デスクトップにディレクトリtestを作成し、ディレクトリ内にtest.pymとtest.txtを作成。
test.txtは、”テスト完了”と記述。
ディレクトリ内にディレクトリtext2を作成し、test2.txtを作成。
test2.txtは、”テスト2完了と記述。test ├test.py ├test.txt(”テスト完了”と記述) └test2 └test2.txt(”テスト2完了”と記述)(2)pwd
カレントディレクトリを、ターミナルでpwdを入力すると以下の通り
/Users/*******/desktop/test(3)os.getcwd()と__ file__
os.getcwd()でカレントディレクトリの絶対パスを取得し、_file_でカレントディレクトリ内からの相対パスを取得する。
import os print(os.getcwd()) print(__file__)実行結果は以下の通り。
/Users/*******/Desktop/test file_test.py(5)os.path.abspath()
_file_で取得できるのはカレントディレクトリからの相対パスだが、os.path.abspath()で絶対パスに変換できる。ディレクトリも絶対パスで取得可能。
import os print(os.path.abspath(__file__)) print(os.path.dirname(os.path.abspath(__file__)))実行結果は以下の通り。
/Users/*******/Desktop/test/file_test.py /Users/*******/Desktop/test(6)os.path.join
os.path.joinとは、引数に与えられた二つの文字列を結合させ、一つのパスにする事ができる。
まず、ディレクトリtest内にあるtest.txtを読み込む。with open('test.txt',encoding='utf-8') as f: print(f.read())すると、以下のようになる。
テスト完了次に、ディレクトリtest2内にあるtest2.txtを読み込む。
with open('test2/test2.txt',encoding='utf-8') as f: print(f.read())すると、以下のようになる。
テスト2完了次に、os.path.joinを使い、カレントディレクトリまでの絶対パスと、test2.txtへの相対パスを結合したものでtest2を読み込んでみる。
import os target = os.path.join(os.path.dirname(os.path.abspath(__file__)),'test2/test2.txt') with open(target,encoding='utf-8') as f: print(f.read())とすると、以下のようになる。
テスト2完了(7)chdir
chdir [移動先のパス]として使う。ターミナル上でカレントディレクトリを移動する際に使う。
まず、移動先のパスを作成する。import os target2 = os.path.join(os.path.dirname(os.path.abspath(__file__)),'test2')設定した移動先パスを経由してカレントディレクトリを移動する。
os.chdir(target2)念の為、カレントディレクトリを確認し移動てきているかどうかを確認する。
print(os.getcwd())ちゃんとtestから、test2にカレントディレクトリが移動できていることが確認できた。
/Users/*********/Desktop/test/test2test2.txtを直接読み込んでみると(
with open('test2.txt',encoding='utf-8')as f: print(f.read())以下の通り、ちゃんと出力される。
(カレントディレクトリがtestの場合は、with open('test2.txt',encoding='utf-8')の部分を、with open('test2.test2.txt',encoding='utf-8')とする必要がある。)テスト2完了(8)まとめ
test.pyimport os print(os.getcwd()) print(__file__) print(os.path.abspath(__file__)) print(os.path.dirname(os.path.abspath(__file__))) print('------------------------------------') with open('test.txt',encoding='utf-8') as f: print(f.read()) with open('test2/test2.txt',encoding='utf-8') as f: print(f.read()) target = os.path.join(os.path.dirname(os.path.abspath(__file__)),'test2/test2.txt') with open(target,encoding='utf-8') as f: print(f.read()) print('------------------------------------') target2 = os.path.join(os.path.dirname(os.path.abspath(__file__)),'test2') os.chdir(target2) print(os.getcwd()) with open('test2.txt',encoding='utf-8')as f: print(f.read())参考にしたサイト
- 投稿日:2020-03-21T15:53:07+09:00
pandas で 'DataFrame' object has no attribute 'ix' が出てきたとき
困ったこと
pandasを使ってcsvへの書き込みをしようとしたら、以下のようなエラーを吐かれた
現象
'DataFrame' object has no attribute 'ix'原因
pandasの最新バージョン(1.0.2)では無理らしい。詳しくはドキュメント読んでね❤️。
対処法
まずはpandasのバージョン確認して(今回はjupyter notebook使ってたので次のように)
print(pd.__version__)必要に応じて過去のバージョンに戻せばよひ。
pipなりcondaなりでバージョンを指定してなんかコマンド打とう。