- 投稿日:2020-03-21T22:33:11+09:00
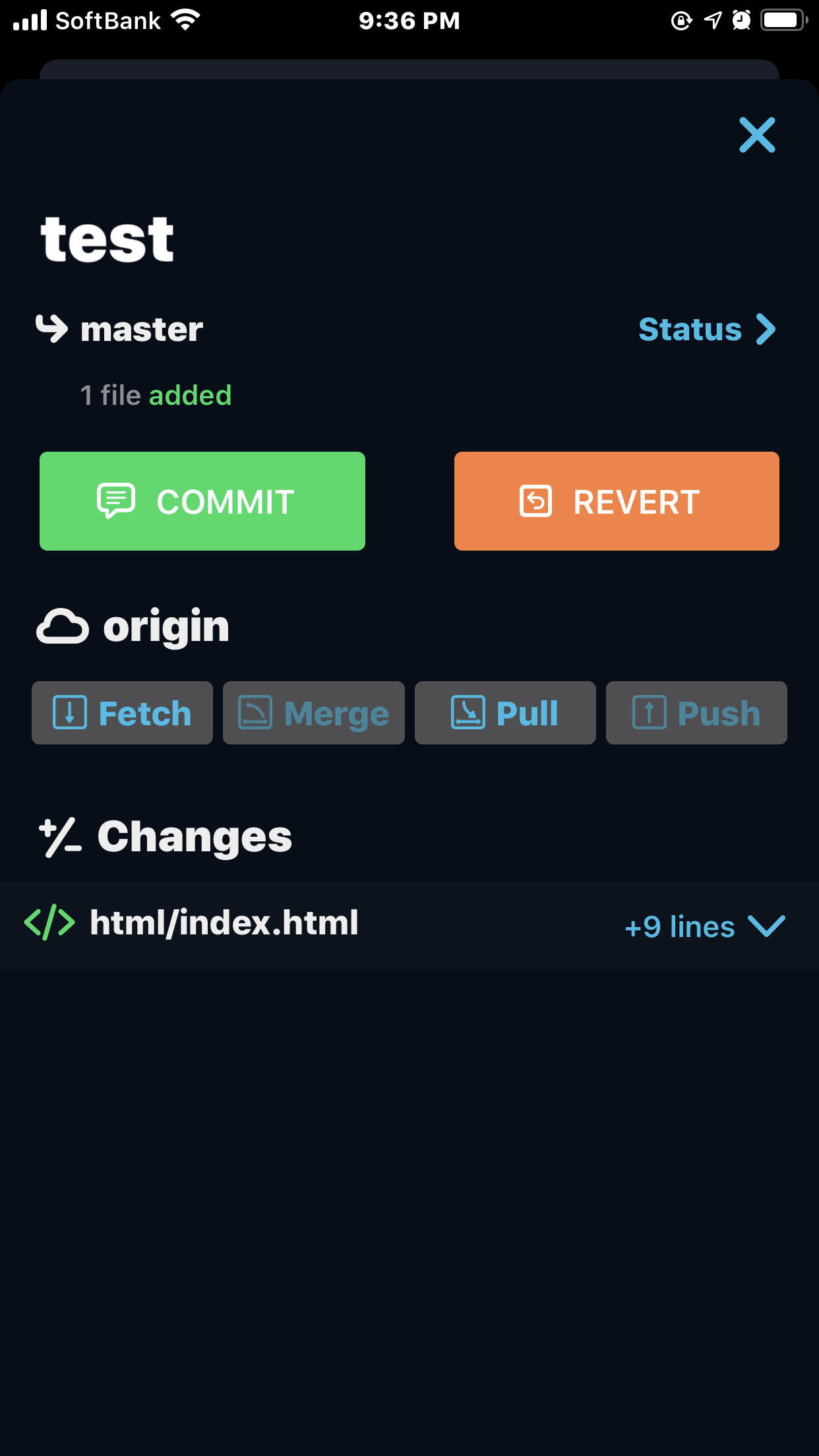
AWS RDSにHeidiSQLでSSHトンネル接続を行う
HeidiSQL(ハイジSQL)で AWS RDS に接続するメモです。
概要
VPCのサブネットで、RDSをPrivateに置いている場合、踏み台EC2を作成して、SSHトンネル接続を行います。RDSはPrivate で、Webはpublicです。DBに直接にアクセスできないようにしています。
社内 ⇔ パブリック ⇔ プライベート PC 22 SSH
3307 仮踏み台EC2 3306 MySQL RDS 踏み台EC2の作成
- AWS EC2 を作成します(Linuxのt2.microでOK)
- 踏み台 EC2 の Security Groups(3307は他でもOK)
- AWS RDS の Security Groups に追加します(SourceはIPでなくsgでもOK)
Type Protocol Port range Source SSH TCP 22 グローバルIP Custom TCP TCP 3307 グローバルIP
Type Protocol Port range Source MYSQL/Aurora TCP 3306 sg-1234xxxx (test-tunnel-ssh) HeidiSQLの設定
- plink.exe をダウンロードします。DLページはSSHトンネルのリンクを押します。
- pem から ppk を作成します。plink.exe と同じサイトから puttygen.exe をDLします。Load で pem を選んで、Save private を押します。
- HeidiSQLで接続。plink のタイムアウトを40秒に変更します。
ポイント
- SQL Error (2003) のとき、HeidiSQL のバージョンが古いです(←ハマりました)
- RDS側のSecurity Groupsで、踏み台のsgを登録すれば、IPの登録は不要です(知らなかった)
まとめ
結果的に HeidiSQL をバージョンアップをするだけでした。以前のものは接続できて、作成したものは接続できないという中途半端な状態になり、1日くらいハマりました。





- 投稿日:2020-03-21T21:28:19+09:00
AWS Identity and Access Management (IAM)
概要
- AWSでIAM管理に最低限必要な知識をざっくりと解説
- 対象読者はIAM入門者向けとなっています
ルートユーザー
- ルートユーザーはemailとパスワードでログインでき、全てのAWSサービスとリソースにアクセスできる
- 日々のタスクをルートユーザですることは推奨されない
- ルートユーザを作成した後は、個人用のIAMアドミンユーザとグループを作成することが推奨される
- AWSアカウントのルートユーザーのアクセスキーは作成、更新、無効化、削除できる
- パスワードを変更することもできる
- ルートユーザーの認証情報を持っていれば、誰でも請求情報を含むアカウントの全てのリソースに無制限にアクセスできる
- アクセスキーを作成するときは、アクセスキーIDとシークレットアクセスキーをセットで作成する
- シークレットアクセスキーの表示およびダウンロードは一回のみ
- IAMユーザもルートユーザも最大2つのアクセスキーを割り当てることができる
- アクセスキーを無効にした場合、APIコールに使用することはできず、無効なキーは制限に対してカウントされる
- 一度アクセスキーを削除した場合、永久に削除されて、回復することはできない
ルートアカウントのMFAを有効化
- ルートユーザーのMFAを有効にすると、ルートユーザー認証情報のみが影響を受ける
- アカウントのIAMユーザーは固有の認証情報を持つ独立したIDであり、各IDには固有のMFA設定がある
- MFAの認証方法は「仮想MFAデバイス」「U2Fセキュリティキー」「ハードウェアMFAデバイス」「SMSテキストメッセージベースMFA」の4種類がある
- SMS MFAのサポートはまもなく終了
IAMユーザー
- Identity and Access Management (IAM) ユーザーはAWSとやり取りするために使用するユーザーまたはアプリケーションを表す
- AWSのユーザは名前と認証情報で構成される
IAMの識別
- ユーザーのフレンドリ名(AWS マネジメントコンソール に表示される名前)
- ユーザーの Amazonリソースネーム(ARN)(AWS全体でユーザーを一意に識別する必要がある場合は、ARNを使用)
ユーザーと認証情報
- AWS には、ユーザーの認証情報に応じてさまざまな方法(コンソールパスワード,アクセスキー,CodeCommitで使用するSSHキー,サーバー証明書)でアクセスできる
- AWSマネジメントコンソールを使用してユーザーを作成するときは、少なくともコンソールパスワードまたはアクセスキーを含める選択をする必要がある
- デフォルトでは、AWS CLIまたはAWS APIを使用して作成された新しいIAMユーザーには、どのような種類の認証情報も提供されていない
- パスワード、アクセスキー、およびMFAデバイスを管理するために、次のオプションが重要
- IAMユーザーのパスワード管理
- IAMユーザーのアクセスキー管理
- 認証情報のセキュリティ強化のためのMFAの有効化
- 使用されていないパスワードおよびアクセスキーの発見
- アカウント認証情報レポートのダウンロード
ユーザーとアクセス許可
- デフォルトでは、新しいIAMユーザーには、アクセス許可がない
- IAMユーザーを持つ利点は、アクセス許可を各ユーザーに個別に割り当てることができること
ユーザーとアカウント
- 各IAMユーザーが関連付けられるAWSアカウントは1つだけ
- AWS アカウントに作成できるIAMユーザーの数には制限がある
ユーザーとサービスアカウント
- 認証情報を使用してAWSリクエストを行う人物またはアプリケーションをサービスアカウントと呼ぶ
- アプリケーションコードに直接アクセスキーを埋め込んではいけない
- ベストプラクティスとして、長期的なアクセスキーの代わりに一時的な認証情報(IAMロール)を使用することが推奨される
IAMユーザーの作成
- AWSマネジメントコンソール、AWS CLI、Tools for Windows PowerShell、またはAWS APIオペレーションを使用してユーザーを作成
- AWSマネジメントコンソールでユーザーを作成する場合は、選択内容に基づいてステップ1~4が自動的に処理される
- ユーザーに必要なアクセスのタイプに応じてユーザーの認証情報を作成
- プログラムによるアクセス(API コール、AWS CLI、Tools for Windows PowerShellのいずれか)
- AWSマネジメントコンソールアクセス(該当ユーザーのパスワード作成)
- ユーザーを1つ以上のグループに追加することで、必要なタスクを実行するアクセス権限を付与
- ユーザーをグループに配置し、アクセス権限の管理は、グループにアタッチされているポリシーを通して行うことが推奨される
- アクセス許可の境界を利用してユーザのアクセス許可を制限できる(これは一般的ではない)
- タグをアタッチして、メタデータをユーザーに追加(オプション)
- 必要なサインイン情報をユーザーに提供(オプション)
- ユーザーのMFAを設定(オプション)
- ユーザーに自分の認証情報を管理する権限を与える(オプション)
IAMグループ
IAMグループ
* IAMユーザーの集合
* 複数のユーザーに対してアクセス許可を指定でき、それらのユーザーのアクセス許可を容易に管理することができる
* グループとIAMユーザーの関係は多対多
* グループ同士はネストできない
* デフォルトのグループは存在しない(作成が必要)
* 1人のIAMユーザーが持てるグループの数、および1つのグループが持てるユーザーの数には制限があるパスワードポリシーの設定
IAM ユーザー用のアカウントパスワードポリシーの設定
* パスワードの最小の長さを設定できる
* 大文字、小文字、数値、およびアルファベット以外の文字を含む特定の文字型を要求できる
* すべてのIAMユーザーが自分のパスワードを変更できるようにできる
* 期間を指定し、IAMユーザーにパスワードを変更するように要求できる
* IAMユーザーが(1~24回前までの)以前のパスワードを再利用できないようにできる
* IAMユーザーがパスワードの失効を許可したときに、アカウント管理者への連絡を強制できる
- 投稿日:2020-03-21T21:25:07+09:00
CloudFormationテンプレートを1からしっかり理解しながらECS on Fargateなアプリを自動構築する(前編)
前提条件
「CFn?IaC?何それ美味しいの?」な超初心者向け。
とは言え、AWSの機能を使おうって言うんだから、当然AWS BlackBeltオンラインセミナーのCloudFormation編くらいは見ていると読みやすいと思う。
あと、CFnは知らなくても同じことをマネジメントコンソールでポチポチできるくらいの理解度は前提。
文中後半で動かしているアプリは、8080ポートで待ち受けるHTTPサーバ。
SpringBootなWebアプリと考えてもらえれば。記事中には、備忘のためにリファレンスに書かれていないデフォルト値を整理しておくが、2020年3月時点の情報であり、後でAWSが仕様を変えたとしても追従する予定はないので、挙動が違ったらリファレンスを見直してほしい。あと、今回の構成(ECS on FargateのBlue/Greenデプロイメント)以外の構成以外のデフォルト値まで調査はしていないのであしからず。
環境を整える
1から理解しながら書くので、力技でいく。
基本の流れは、「リファレンス見ながら書く→構文チェック→動かしてみる→修正する→…」の繰り返し。というわけで、以下の記事を参考に構文チェッカをインストールしておく。
【Qiita】cfn-python-lint
pipのインストールは以下の記事を見ながら。
【AWS公式】Linux で Python、pip、EB CLI をインストールする
cfn-lintは、↓こんな感じで間違っている箇所を教えてくれる。便利!
$ cfn-lint createALB.yml E0000 Null value at line 13 column 22 createALB.yml:13:22とりあえず空っぽのALBを作ってみる
スタックの作成
まずは、ALBを作ってみる。最初はEC2じゃないのかよ!というツッコミがあるのは重々承知しているが、とりあえずALBで。
こういうことをやっているサイトは探してみれば色々とあるものの、結局最後に頼るのはAWS公式のユーザーガイドのリファレンスなのである。これを見ながらしっかり理解していく。
リファレンスでAWS::ElasticLoadBalancingV2::LoadBalancerを選択して、プロパティを設定していく。「必須: いいえ」になっているプロパティがたくさんあるので、そういったものはとりあえずザクザク削っていってみよう。削った場合のデフォルト値が書いてないから不安になるけど、気にしない。createALB.ymlAWSTemplateFormatVersion: "2010-09-09" Description: ALB Create Resources: # ------------------------------------------------------------# # ALB # ------------------------------------------------------------# ALB: Type: AWS::ElasticLoadBalancingV2::LoadBalancer Properties: Name: CFn-test-ALB Subnets: - [自分のサブネットID①] - [自分のサブネットID②] - [自分のサブネットID③]えっ、こんなにシンプルでいいの?と思いつつ、マネコンのCloudFormationの「スタック」で「スタックの作成」ボタンを押す。選択肢が出るので「新しいリソースを使用(標準)」を選択する。
こんな感じでYAMLのファイルをアップロードをする。
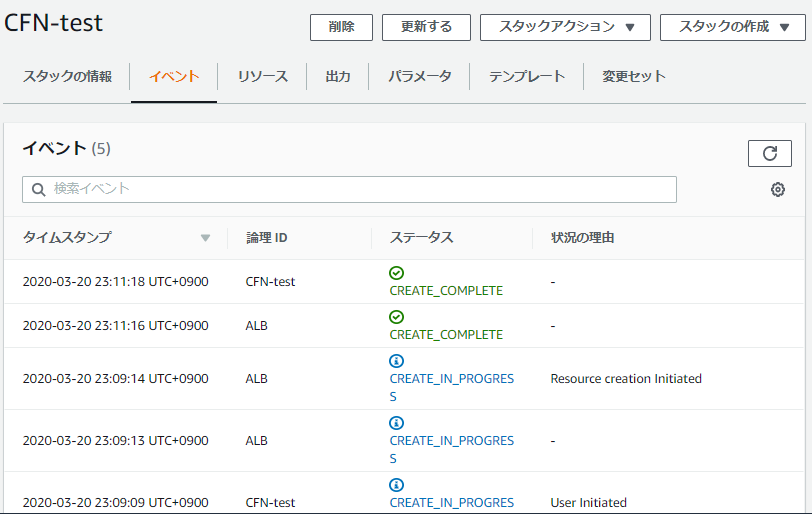
あとは、「次へ」で進みまくる。細かい設定は今は気にしなくてOK。スタックの名前は「CFn-test」とか適当につけておく。流し終わると↓こんな感じになる。
ちゃんとCREATE_COMPLETEされているので、ALBを見に行くと、
ちゃんとできてる!すごい!
ちなみに、省略したプロパティのデフォルト値でリファレンスに書いていない値は、ALBの場合は↓こんな感じになるようである。「ALBの場合は」と書いてあるのは、NLBの場合はデフォルト値が違う可能性があるから。試していないので分からない。
リファレンスに書いておいてほしい…。
プロパティ デフォルト値 IpAddressType ipv4 LoadBalancerAttributes なし? SecurityGroups default VPC security group SubnetMappings/Subnets 省略不可。省略すると cfn-lint で E2523 Only one of [SubnetMappings, Subnets] should be specified for Resources/ALB/PropertiesのエラーになるTags なし 作成したスタックを修正する
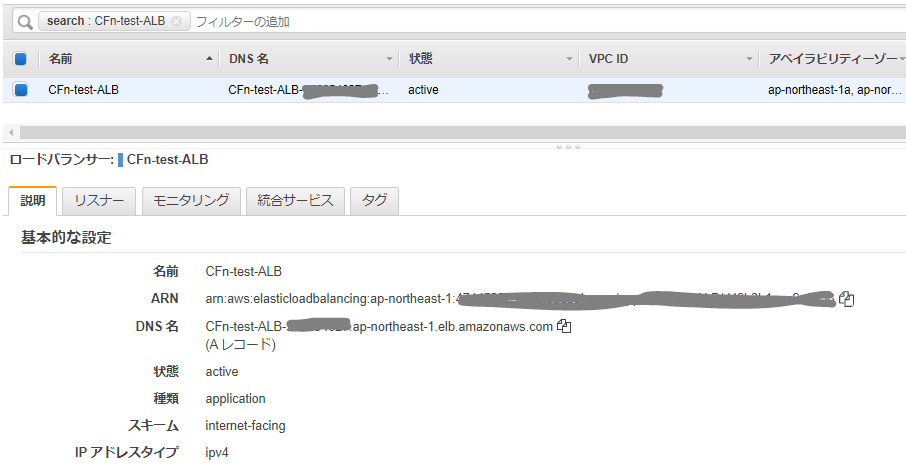
さて、作られたALBを見てみると、セキュリティグループがデフォルトになっている。
さすがにこれはちょっとセキュリティ的にアレなので、テンプレートのYAMLのALBのプロパティに以下を追加する。SecurityGroups: - [セキュリティグループID]セキュリティグループは、新規で作るか、既存のを持ってくるか。
今回は、インバウンドの80, 8080ポートを開放している既存のセキュリティグループをアタッチする。テンプレートを修正したら、スタックの詳細画面で「更新」を押して、テンプレートを差し替えていく。
ステータスが UPDATE_COMPLETE になったら、もう一度ALBの設定を見てみると、
無事、設定が反映されている。
作成したスタックを削除する
これも簡単で、スタックの詳細画面から「削除」すれば良い。
CloudFormationで作成したスタックのリソースは、スタックの削除に紐付けてまとめて掃除してくれるらしい。便利!ちなみに、マネジメントコンソールから先回りしてALBを削除をしておいたらどうなるか実験したが、問題なく DELETE_COMPLETE のステータスになった。最終結果が合えば良いらしい。
ALBのリスナー・ターゲットグループを設定する
このセクションでは、空っぽのALBを完成品にして、80ポートで待ち受けしているEC2インスタンスにフォワードするところまで。待ち受けするEC2インスタンスを立てる手順をここで書くのは本筋とは違うので、分からなければこの記事で
docker run -p 80:8080 ...しているあたりまでやっておく。テンプレートの中で作ってもいいけど、それも面倒なので今回は有り物を使うということで。今回の完成品のテンプレートのYAMLは以下。ALBのリソース部分は前回と同じ。
createALB_TG.ymlAWSTemplateFormatVersion: "2010-09-09" Description: ALB Create Resources: # ------------------------------------------------------------# # ALB # ------------------------------------------------------------# ALB: Type: AWS::ElasticLoadBalancingV2::LoadBalancer Properties: Name: CFn-test-ALB SecurityGroups: - [セキュリティグループID] Subnets: - [自分のサブネットID①] - [自分のサブネットID②] - [自分のサブネットID③] ALBLISTENER: Type: AWS::ElasticLoadBalancingV2::Listener Properties: DefaultActions: - TargetGroupArn: !Ref ALBTG Type: forward LoadBalancerArn: !Ref ALB Port: 80 Protocol: HTTP ALBTG: Type: AWS::ElasticLoadBalancingV2::TargetGroup Properties: Name: CFn-test-ALB-TG Targets: - Id: [EC2インスタンスID] Port: 80 Port: 80 Protocol: HTTP VpcId: [VPCID]ALBのターゲットグループ
ALBのリソースとほぼ同じような記述方法なので、特に目新しい部分は無いと思う。
ターゲットグループのプロパティで、リファレンスにALBの場合のデフォルト値が明記されていないものは以下。
なお、PortとProtocolはリファレンスで「必須: いいえ」と書いてあったし cfn-lint でも引っかからなかったので指定をしなかったら、CREATE の際にエラーになったので指定した。
プロパティ デフォルト値 Matcher HttpCode: "200" Name AWS払い出しの名前 TargetGroupAttributes それぞれの属性のプロパティのデフォルト値(リファレンスに書いてある) Targets なし ALBのリスナー
ここはデフォルト値がリファレンスに明記されているので分かりやすかった。
ポイントは以下の部分。
DefaultActions: - TargetGroupArn: !Ref ALBTG Type: forward LoadBalancerArn: !Ref ALBリスナーの定義には、ALBのARNとターゲットグループのARNが必須パラメータになっているが、どちらもこのテンプレート内でリソースを作成しているので、あらかじめ作っておいたリソースのARNをマネジメントコンソールから転記することができない。なので、同一テンプレート内で作成したリソースのARNを参照するためのCloudFormationの機能を使うのである。
※そういう意味では、ターゲットグループのVPCやインスタンスなんかも、同じテンプレート内でリソース定義してRefすれば全部ひっくるめてコード化できるけど、今回はやらなかった。各リソースに対して
!Refした場合に何が取得できるかは、ユーザーガイドの各リファレンスの「戻り値」に 記載されている。ECSでサービスを起動する
ECSで起動するためのALBの設定の見直し
最終的にBlue/GreenデプロイメントできるECSの起動を行いたいので、ALBはBlue用とGreen用の2つの待ち受けをできるようにする。つまり、ターゲットとリスナーをそれぞれ2つ定義すれば良い。
また、Blue/Greenデプロイメント環境にするのであれば、ターゲットグループのタイプ指定をipにしておく必要がある。Outputsは、テンプレートファイルを分けるなら必要。
ALB作成のテンプレートのアウトプットをエクスポートして、次のECS作成してインポートすることが可能。ALBLISTENER1: Type: AWS::ElasticLoadBalancingV2::Listener Properties: DefaultActions: - TargetGroupArn: !Ref ALBTG1 Type: forward LoadBalancerArn: !Ref ALB Port: 80 Protocol: HTTP ALBLISTENER2: Type: AWS::ElasticLoadBalancingV2::Listener Properties: DefaultActions: - TargetGroupArn: !Ref ALBTG2 Type: forward LoadBalancerArn: !Ref ALB Port: 8080 Protocol: HTTP ALBTG1: Type: AWS::ElasticLoadBalancingV2::TargetGroup Properties: Name: CFn-test-ALB-TG1 Port: 80 Protocol: HTTP TargetType: ip VpcId: [VPCID] ALBTG2: Type: AWS::ElasticLoadBalancingV2::TargetGroup Properties: Name: CFn-test-ALB-TG2 Port: 8080 Protocol: HTTP TargetType: ip VpcId: [VPCID] Outputs: TargetGroupArn1: Description: ALB Target Group Arn 1 Value: !Ref ALBTG1 Export: Name: !Sub ${AWS::StackName}-TargetGroupArn1 TargetGroupArn2: Description: ALB Target Group Arn 2 Value: !Ref ALBTG2 Export: Name: !Sub ${AWS::StackName}-TargetGroupArn2ECSクラスターの作成
これは悩むことはないはず。適当に名前を付ければOK。
ECSCLUSTER: Type: AWS::ECS::Cluster Properties: ClusterName: CFn-test-Clusterロググループの作成
最悪無くても良いのだが、CloudWatch Logsにコンテナのログを出力しておかないと、何かあった時に手も足も出なくなってしまうので、新規のロググループをリソースに追加しておくことをオススメする。
LOGGROUP: Type: AWS::Logs::LogGroup Properties: LogGroupName: /ecs/CFn-test-Containerタスク定義
ここはプロパティが大量。
今回は Fargate でコンテナ起動をすることを前提にしているので、Fargate対象外のプロパティのデフォルト値調査は割愛。
プロパティ デフォルト値 IpcMode よく分からない… NetworkMode host ProxyConfiguration AppMeshのプロキシ設定無効 Tags 無し タスク定義の中のコンテナ定義(
ContainerDefinitions)も色々と設定項目がある。
ただ、ここはそもそものコンテナ定義の理解が必要なのと、その理解にはかなり時間がかかりそうなので、今回は必要な設定のみを考える。
プロパティ デフォルト値 Family AWS払い出しの名前 最終的に、タスク定義のリソースについては↓こんなイメージ。
ARNの指定については、!Sub ${AWS::AccountId}や!Sub ${AWS::Region}などを使ってなるべくベタ書きをしないようにした方が良い。
LogConfiguration は↑で作成したロググループをコンテナに紐付けるプロパティ。ログ出力しないのであれば不要。ECSTASKDEFINITION: Type: AWS::ECS::TaskDefinition Properties: RequiresCompatibilities: - FARGATE Cpu: "256" ExecutionRoleArn: !Sub arn:aws:iam::${AWS::AccountId}:role/ecsTaskExecutionRole Family: CFn-test-task Memory: "512" NetworkMode: awsvpc TaskRoleArn: !Sub arn:aws:iam::${AWS::AccountId}:role/ecsTaskExecutionRole ContainerDefinitions: - Name: CFn-test-Container Image: !Sub ${AWS::AccountId}.dkr.ecr.${AWS::Region}.amazonaws.com/my-greeting-web:52c324b Memory: 512 PortMappings: - ContainerPort: 8080 HostPort: 8080 Protocol: HTTP LogConfiguration: LogDriver: awslogs Options: awslogs-group: !Ref LOGGROUP awslogs-region: !Sub ${AWS::Region} awslogs-stream-prefix: ecsECSサービスの作成
ここもプロパティがたくさんあって大変。
これ、死ぬほど悩んだのだが、日本語ドキュメントで翻訳されていない
DeploymentControllerというプロパティがあって、これがマネジメントコンソール上でサービスを作成するときの「デプロイメントタイプ」に該当する。デフォルトがECSなので、Blue/Greenデプロイメントができないように思えてしまうけど、実際には指定したら作れた。
プロパティ デフォルト値 DeploymentConfiguration MinimumHealthyPercent: 100, MaximumPercent: 200 DeploymentController ECS EnableECSManagedTags よく分からない… HealthCheckGracePeriodSeconds 0 LaunchType EC2 LoadBalancers 無し PlacementConstraints 制約無し PlacementStrategies 戦略無し PropagateTags よく分からない… SchedulingStrategy REPLICA ServiceName AWS払い出しの名前 ServiceRegistries 無し Tags 無し サービスの設定については最終的に以下のような感じになる。
ここで、ALBの設定のときにエクスポートした値を!ImportValue CFn-test-TargetGroupArn1して取り込んでいる。ECSSERVICE: Type: AWS::ECS::Service Properties: Cluster: !Ref ECSCLUSTER ServiceName: CFn-test-ECSService LaunchType: FARGATE DesiredCount: 1 DeploymentController: Type: CODE_DEPLOY LoadBalancers: - ContainerName: CFn-test-Container ContainerPort: 8080 TargetGroupArn: !ImportValue CFn-test-TargetGroupArn1 NetworkConfiguration: AwsvpcConfiguration: AssignPublicIp: ENABLED SecurityGroups: - [セキュリティグループID] Subnets: - [自分のサブネットID①] - [自分のサブネットID②] - [自分のサブネットID③] TaskDefinition: !Ref ECSTASKDEFINITIONここまでやると、Blue/GreenデプロイメントするためのECS on Fargateが1アクションないし2アクションで起動する。
さて、ここからCI/CDパイプラインまで自動構築してみよう!というところで中編に続く。


- 投稿日:2020-03-21T21:25:07+09:00
CloudFormationテンプレートを1からしっかり理解しながらECS on Fargateなアプリを自動構築する
前提条件
「CFn?IaC?何それ美味しいの?」な超初心者向け。
とは言え、AWSの機能を使おうって言うんだから、当然AWS BlackBeltオンラインセミナーのCloudFormation編くらいは見ていると読みやすいと思う。
あと、CFnは知らなくても同じことをマネジメントコンソールでポチポチできるくらいの理解度は前提。
文中後半で動かしているアプリは、8080ポートで待ち受けるHTTPサーバ。
SpringBootなWebアプリと考えてもらえれば。環境を整える
1から理解しながら書くので、力技でいく。
基本の流れは、「リファレンス見ながら書く→構文チェック→動かしてみる→修正する→…」の繰り返し。というわけで、以下の記事を参考に構文チェッカをインストールしておく。
【Qiita】cfn-python-lint
pipのインストールは以下の記事を見ながら。
【AWS公式】Linux で Python、pip、EB CLI をインストールする
cfn-lintは、↓こんな感じで間違っている箇所を教えてくれる。便利!
$ cfn-lint createALB.yml E0000 Null value at line 13 column 22 createALB.yml:13:22とりあえず空っぽのALBを作ってみる
スタックの作成
まずは、ALBを作ってみる。最初はEC2じゃないのかよ!というツッコミがあるのは重々承知しているが、とりあえずALBで。
こういうことをやっているサイトは探してみれば色々とあるものの、結局最後に頼るのはAWS公式のユーザーガイドのリファレンスなのである。これを見ながらしっかり理解していく。
リファレンスでAWS::ElasticLoadBalancingV2::LoadBalancerを選択して、プロパティを設定していく。「必須: いいえ」になっているプロパティがたくさんあるので、そういったものはとりあえずザクザク削っていってみよう。削った場合のデフォルト値が書いてないから不安になるけど、気にしない。createALB.ymlAWSTemplateFormatVersion: "2010-09-09" Description: ALB Create Resources: # ------------------------------------------------------------# # ALB # ------------------------------------------------------------# ALB: Type: AWS::ElasticLoadBalancingV2::LoadBalancer Properties: Name: CFn-test-ALB Subnets: - [自分のサブネットID①] - [自分のサブネットID②] - [自分のサブネットID③]えっ、こんなにシンプルでいいの?と思いつつ、マネコンのCloudFormationの「スタック」で「スタックの作成」ボタンを押す。選択肢が出るので「新しいリソースを使用(標準)」を選択する。
こんな感じでYAMLのファイルをアップロードをする。
あとは、「次へ」で進みまくる。細かい設定は今は気にしなくてOK。スタックの名前は「CFn-test」とか適当につけておく。流し終わると↓こんな感じになる。
ちゃんとCREATE_COMPLETEされているので、ALBを見に行くと、
ちゃんとできてる!すごい!
ちなみに、省略したプロパティのデフォルト値でリファレンスに書いていない値は、ALBの場合は↓こんな感じになるようである。「ALBの場合は」と書いてあるのは、NLBの場合はデフォルト値が違う可能性があるから。試していないので分からない。
リファレンスに書いておいてほしい…。
プロパティ デフォルト値 IpAddressType ipv4 LoadBalancerAttributes なし? SecurityGroups default VPC security group SubnetMappings/Subnets 省略不可。省略すると cfn-lint で E2523 Only one of [SubnetMappings, Subnets] should be specified for Resources/ALB/PropertiesのエラーになるTags なし 作成したスタックを修正する
さて、作られたALBを見てみると、セキュリティグループがデフォルトになっている。
さすがにこれはちょっとセキュリティ的にアレなので、テンプレートのYAMLのALBのプロパティに以下を追加する。SecurityGroups: - [セキュリティグループID]セキュリティグループは、新規で作るか、既存のを持ってくるか。
今回は、インバウンドの80, 8080ポートを開放している既存のセキュリティグループをアタッチする。テンプレートを修正したら、スタックの詳細画面で「更新」を押して、テンプレートを差し替えていく。
ステータスが UPDATE_COMPLETE になったら、もう一度ALBの設定を見てみると、
無事、設定が反映されている。
作成したスタックを削除する
これも簡単で、スタックの詳細画面から「削除」すれば良い。
CloudFormationで作成したスタックのリソースは、スタックの削除に紐付けてまとめて掃除してくれるらしい。便利!ちなみに、マネジメントコンソールから先回りしてALBを削除をしておいたらどうなるか実験したが、問題なく DELETE_COMPLETE のステータスになった。最終結果が合えば良いらしい。
ALBのリスナー・ターゲットグループを設定する
このセクションでは、空っぽのALBを完成品にして、80ポートで待ち受けしているEC2インスタンスにフォワードするところまで。待ち受けするEC2インスタンスを立てる手順をここで書くのは本筋とは違うので、分からなければこの記事で
docker run -p 80:8080 ...しているあたりまでやっておく。テンプレートの中で作ってもいいけど、それも面倒なので今回は有り物を使うということで。今回の完成品のテンプレートのYAMLは以下。ALBのリソース部分は前回と同じ。
createALB_TG.ymlAWSTemplateFormatVersion: "2010-09-09" Description: ALB Create Resources: # ------------------------------------------------------------# # ALB # ------------------------------------------------------------# ALB: Type: AWS::ElasticLoadBalancingV2::LoadBalancer Properties: Name: CFn-test-ALB SecurityGroups: - [セキュリティグループID] Subnets: - [自分のサブネットID①] - [自分のサブネットID②] - [自分のサブネットID③] ALBLISTENER: Type: AWS::ElasticLoadBalancingV2::Listener Properties: DefaultActions: - TargetGroupArn: !Ref ALBTG Type: forward LoadBalancerArn: !Ref ALB Port: 80 Protocol: HTTP ALBTG: Type: AWS::ElasticLoadBalancingV2::TargetGroup Properties: Name: CFn-test-ALB-TG Targets: - Id: [EC2インスタンスID] Port: 80 Port: 80 Protocol: HTTP VpcId: [VPCID]ALBのターゲットグループ
ALBのリソースとほぼ同じような記述方法なので、特に目新しい部分は無いと思う。
ターゲットグループのプロパティで、リファレンスにALBの場合のデフォルト値が明記されていないものは以下。
なお、PortとProtocolはリファレンスで「必須: いいえ」と書いてあったし cfn-lint でも引っかからなかったので指定をしなかったら、CREATE の際にエラーになったので指定した。
プロパティ デフォルト値 Matcher HttpCode: "200" Name AWS払い出しの名前 TargetGroupAttributes それぞれの属性のプロパティのデフォルト値(リファレンスに書いてある) Targets なし ALBのリスナー
ここはデフォルト値がリファレンスに明記されているので分かりやすかった。
ポイントは以下の部分。
DefaultActions: - TargetGroupArn: !Ref ALBTG Type: forward LoadBalancerArn: !Ref ALBリスナーの定義には、ALBのARNとターゲットグループのARNが必須パラメータになっているが、どちらもこのテンプレート内でリソースを作成しているので、あらかじめ作っておいたリソースのARNをマネジメントコンソールから転記することができない。なので、同一テンプレート内で作成したリソースのARNを参照するためのCloudFormationの機能を使うのである。
※そういう意味では、ターゲットグループのVPCやインスタンスなんかも、同じテンプレート内でリソース定義してRefすれば全部ひっくるめてコード化できるけど、今回はやらなかった。各リソースに対して
!Refした場合に何が取得できるかは、ユーザーガイドの各リファレンスの「戻り値」に 記載されている。ECSでサービスを起動する
ECSで起動するためのALBの設定の見直し
最終的にBlue/GreenデプロイメントできるECSの起動を行いたいので、ALBはBlue用とGreen用の2つの待ち受けをできるようにする。つまり、ターゲットとリスナーをそれぞれ2つ定義すれば良い。
また、Blue/Greenデプロイメント環境にするのであれば、ターゲットグループのタイプ指定をipにしておく必要がある。Outputsは、テンプレートファイルを分けるなら必要。
ALB作成のテンプレートのアウトプットをエクスポートして、次のECS作成してインポートすることが可能。ALBLISTENER1: Type: AWS::ElasticLoadBalancingV2::Listener Properties: DefaultActions: - TargetGroupArn: !Ref ALBTG1 Type: forward LoadBalancerArn: !Ref ALB Port: 80 Protocol: HTTP ALBLISTENER2: Type: AWS::ElasticLoadBalancingV2::Listener Properties: DefaultActions: - TargetGroupArn: !Ref ALBTG2 Type: forward LoadBalancerArn: !Ref ALB Port: 8080 Protocol: HTTP ALBTG1: Type: AWS::ElasticLoadBalancingV2::TargetGroup Properties: Name: CFn-test-ALB-TG1 Port: 80 Protocol: HTTP TargetType: ip VpcId: [VPCID] ALBTG2: Type: AWS::ElasticLoadBalancingV2::TargetGroup Properties: Name: CFn-test-ALB-TG2 Port: 8080 Protocol: HTTP TargetType: ip VpcId: [VPCID] Outputs: TargetGroupArn1: Description: ALB Target Group Arn 1 Value: !Ref ALBTG1 Export: Name: !Sub ${AWS::StackName}-TargetGroupArn1 TargetGroupArn2: Description: ALB Target Group Arn 2 Value: !Ref ALBTG2 Export: Name: !Sub ${AWS::StackName}-TargetGroupArn2ECSクラスターの作成
これは悩むことはないはず。適当に名前を付ければOK。
ECSCLUSTER: Type: AWS::ECS::Cluster Properties: ClusterName: CFn-test-Clusterロググループの作成
最悪無くても良いのだが、CloudWatch Logsにコンテナのログを出力しておかないと、何かあった時に手も足も出なくなってしまうので、新規のロググループをリソースに追加しておくことをオススメする。
LOGGROUP: Type: AWS::Logs::LogGroup Properties: LogGroupName: /ecs/CFn-test-Containerタスク定義
ここはプロパティが大量。
今回は Fargate でコンテナ起動をすることを前提にしているので、Fargate対象外のプロパティのデフォルト値調査は割愛。
プロパティ デフォルト値 IpcMode よく分からない… NetworkMode host ProxyConfiguration AppMeshのプロキシ設定無効 Tags 無し タスク定義の中のコンテナ定義(
ContainerDefinitions)も色々と設定項目がある。
ただ、ここはそもそものコンテナ定義の理解が必要なのと、その理解にはかなり時間がかかりそうなので、今回は必要な設定のみを考える。
プロパティ デフォルト値 Family AWS払い出しの名前 最終的に、タスク定義のリソースについては↓こんなイメージ。
ARNの指定については、!Sub ${AWS::AccountId}や!Sub ${AWS::Region}などを使ってなるべくベタ書きをしないようにした方が良い。
LogConfiguration は↑で作成したロググループをコンテナに紐付けるプロパティ。ログ出力しないのであれば不要。ECSTASKDEFINITION: Type: AWS::ECS::TaskDefinition Properties: RequiresCompatibilities: - FARGATE Cpu: "256" ExecutionRoleArn: !Sub arn:aws:iam::${AWS::AccountId}:role/ecsTaskExecutionRole Family: CFn-test-task Memory: "512" NetworkMode: awsvpc TaskRoleArn: !Sub arn:aws:iam::${AWS::AccountId}:role/ecsTaskExecutionRole ContainerDefinitions: - Name: CFn-test-Container Image: !Sub ${AWS::AccountId}.dkr.ecr.${AWS::Region}.amazonaws.com/my-greeting-web:52c324b Memory: 512 PortMappings: - ContainerPort: 8080 HostPort: 8080 Protocol: HTTP LogConfiguration: LogDriver: awslogs Options: awslogs-group: !Ref LOGGROUP awslogs-region: !Sub ${AWS::Region} awslogs-stream-prefix: ecsECSサービスの作成
ここもプロパティがたくさんあって大変。
これ、死ぬほど悩んだのだが、日本語ドキュメントで翻訳されていない
DeploymentControllerというプロパティがあって、これがマネジメントコンソール上でサービスを作成するときの「デプロイメントタイプ」に該当する。デフォルトがECSなので、Blue/Greenデプロイメントができないように思えてしまうけど、実際には指定したら作れた。
プロパティ デフォルト値 DeploymentConfiguration MinimumHealthyPercent: 100, MaximumPercent: 200 DeploymentController ECS EnableECSManagedTags よく分からない… HealthCheckGracePeriodSeconds 0 LaunchType EC2 LoadBalancers 無し PlacementConstraints 制約無し PlacementStrategies 戦略無し PropagateTags よく分からない… SchedulingStrategy REPLICA ServiceName AWS払い出しの名前 ServiceRegistries 無し Tags 無し サービスの設定については最終的に以下のような感じになる。
ここで、ALBの設定のときにエクスポートした値を!ImportValue CFn-test-TargetGroupArn1して取り込んでいる。ECSSERVICE: Type: AWS::ECS::Service Properties: Cluster: !Ref ECSCLUSTER ServiceName: CFn-test-ECSService LaunchType: FARGATE DesiredCount: 1 DeploymentController: Type: CODE_DEPLOY LoadBalancers: - ContainerName: CFn-test-Container ContainerPort: 8080 TargetGroupArn: !ImportValue CFn-test-TargetGroupArn1 - ContainerName: CFn-test-Container ContainerPort: 8080 TargetGroupArn: !ImportValue CFn-test-TargetGroupArn2 NetworkConfiguration: AwsvpcConfiguration: AssignPublicIp: ENABLED SecurityGroups: - [セキュリティグループID] Subnets: - [自分のサブネットID①] - [自分のサブネットID②] - [自分のサブネットID③] TaskDefinition: !Ref ECSTASKDEFINITIONここまでやると、Blue/GreenデプロイメントするためのECS on Fargateが1アクションないし2アクションで起動する。
さて、ここからCI/CDパイプラインまで自動構築してみよう!というところで後編に続く。
- 投稿日:2020-03-21T20:55:00+09:00
AWSでDjangoサーバーを立ててみる
Python3、djangoのインストール
以下の場合、/usr/local/bin/にインストールされるのでパスを通しておく。インストール yum install python3 python3 -m pip install Django python3 -m django --version プロジェクト作成 /usr/local/bin/ django-admin startproject mysiteDjangoのチュートリアル通りに進めると「python manage.py runserver」でSQLiteを使用していてもバージョンエラーが発生するのでバージョンを上げる。
SQLiteのバージョンアップ
https://www.sqlite.org/download.htmlパッケージの取得 yum install wget tar gzip gcc make wget https://www.sqlite.org/2020/sqlite-autoconf-3310100.tar.gz インストール tar xvfz sqlite-autoconf-3310100.tar.gz cd sqlite-autoconf-3310100/ ./configure --prefix=/usr/local make make install 新バージョンへのシンボリックリンクの作成 mv /usr/bin/sqlite3 /usr/bin/sqlite3_old ln -s /usr/local/bin/sqlite3 /usr/bin/sqlite3 共有ライブラリへパスを通す vi ~/.bashrc export LD_LIBRARY_PATH="/usr/local/lib" source .bashrcサーバー起動
DEBUGモード時はALLOWED_HOSTSの設定が必要になるsettings.pyDEBUG = True ALLOWED_HOSTS = ["www.example.com"]python manage.py migrate ローカルで起動 python3 manage.py runserver グローバルで起動 python3 manage.py runserver 0:80
- 投稿日:2020-03-21T18:51:27+09:00
GCPのほうのIoTCoreを使ってみる
はじめに
こんにちは
RHEMS技研荒木です。
無人島に漂流しすぎて寝不足です。島の名前はI/O島にしました。備忘録がてらIoTCoreを用いたセンサデータの収集についてまとめました。
2020/03/21現在の情報です。1~2ヶ月のうちに情報が古くなると思いますのでご注意ください。構成図
センサデータを収集するためのスタンダードな構成だと思います。
CloudFunctionはデータ到達確認のため置いています。 ここでは解説しません。IoTCore
これはAWSでいうIoTCoreと似たサービスになります。そりゃそうなんですけど。
大きく違う点はレジストリ単位でトピックが決まっている等点になります。AWSではエンドポイントは固定でトピックはデバイスごとに選択できるのですが、GCPではレジストリに属しているデバイスはすべて同じトピックへの送信になります。設定をしていきます。
まずプロジェクトを作成します。
今回はqiita-akijin-testという名前にしました。
組織や場所は環境によります。
問題なければ作成してしまいます。次はIoTCoreを有効にします。
左のナビゲーションメニューよりIoTCoreを探します。
初回では画像のような画面になるので有効にするを選択してAPIを有効にします。
有効になると下画像の用になりますので上の
レジストリを作成を選択。
すると、レジストリの設定が出るので設定をしていきます。
今回は画像の通りの設定をしました。
MQTTでしか通信する予定がないのでHTTPのチェックは外しておきましょう。
次にデバイスの登録をするのですが先に証明書関係をクリアしておきましょう。
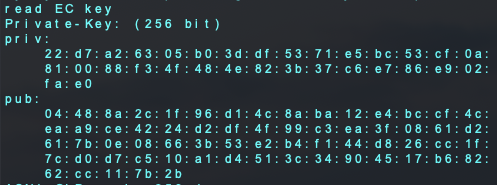
$ openssl ecparam -genkey -name prime256v1 -noout -out ec_private.pem$ openssl ec -in ec_private.pem -pubout -out ec_public.pem$ openssl ec -in ec_private.pem -noout -text上2つのコマンドでサーバー側とデバイス側の証明書を作成、3つ目でデバイスに書き込む用の証明書を書き出しています。
書き出すと画像のように出るのでprivの方を後ほど使うのでコピーしておきます。
また、先頭が00だった場合は00を抜かしてコピーします。
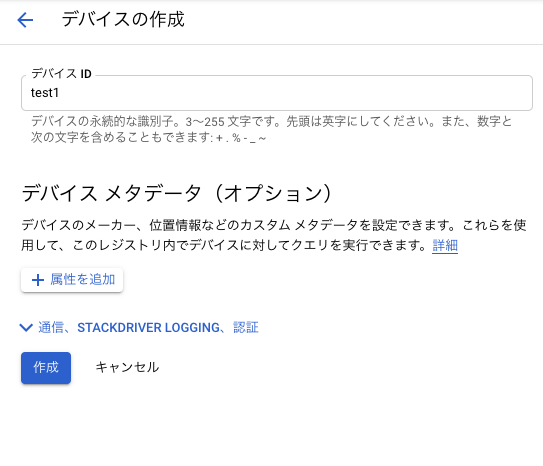
ではデバイスの登録をしていきます。
左のメニューよりデバイスを選択してデバイスを作成を選択します。
デバイスの設定は画像の通りです。
証明書は公開鍵の形式をES256にしてec_public.pemの中身をペーストします。
各種設定が終わったら作成してしまいましょう。
これでIoTCoreの設定は終了になります。
Pub/Sub
これはIoTCoreに届いたリクエストを他のGCPのサービスに割り振るために使用します。基本的にIoTCoreを使用する際はPub/Subは必ず使用します。
ここでの設定は特にないです。
IoTCoreのレジストリからPub/Subのページに飛びます。先程作成したトピックで作られているかを確認します。
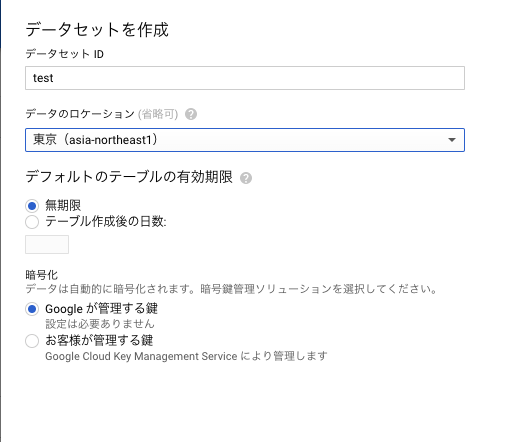
BigQuery
先にBigQueryのテーブルを作成します。
左メニューよりBigQueryを選択。プロフェクト名がリソースに追加されているので選択して右側にあるデータセットを作成を選択します。
作成したらテーブルを作成します。今回は画像のように設定しました。
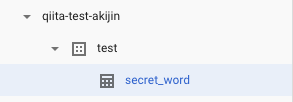
作成するとリソースに画像のようなツリーができていることを確認します。
テーブルが作成されていることも確認しましょう。
これでBigQueryの設定は終わりです。
Dataflow
これはサービスとサービスとの間に入れるものになります。テンプレートが予め用意されているので簡単に使用することができます。
使用するテンプレートはPub/Subの指定したトピックに届いたデータをBigQueryに追加してくれるものになります。
今回では、test-akijinに届いたメッセージをBigQueryへと送ります。Storage
AWSで言うところのS3がこれに当たります。
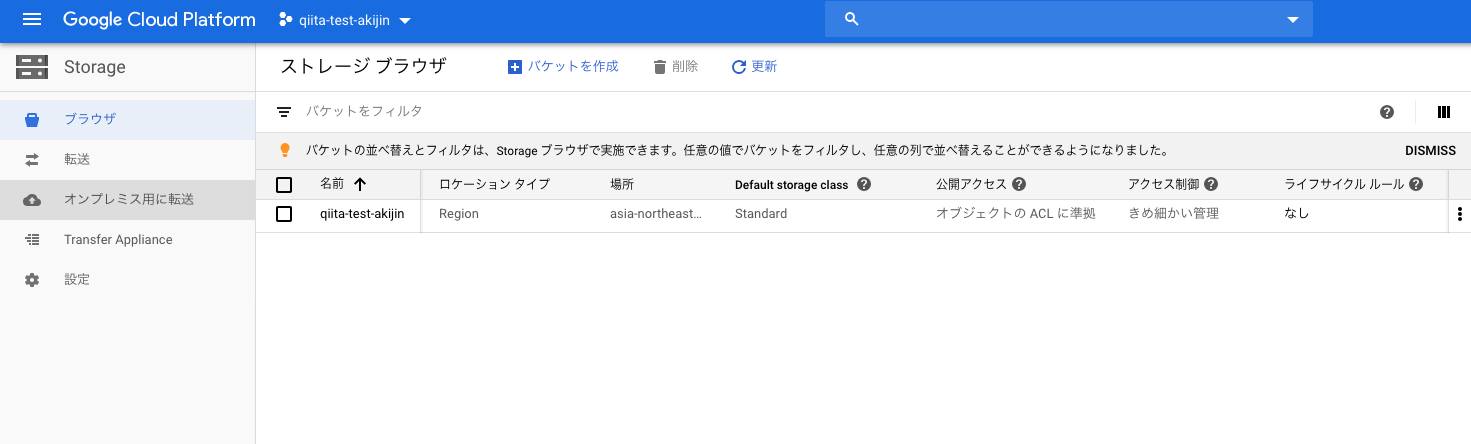
Dataflowはデータを処理するのにバッファリングをします。なのでバッファを作成する必要があり、Storageにバッファを作成するようになっています。
左のメニューよりStorage-ブラウザを選択。
バケットの作成よりバケットを作成していきます。設定は画像のとおりです。
バケット内にフォルダを一つ作成しておきます。このフォルダがDataflowで使用するバッファになります。
これでバッファは用意されました。Dataflowの設定に戻ります。
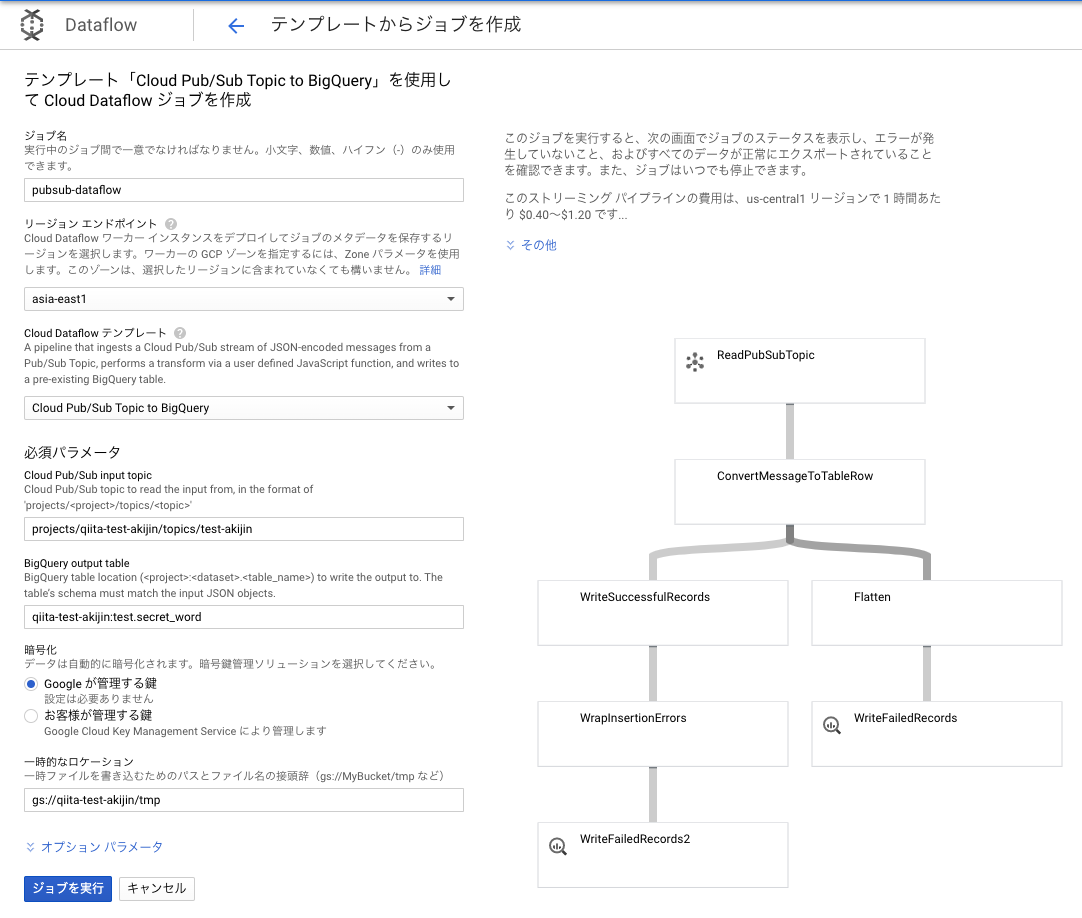
Pub/SubのメニューよりBIBQUERYにエクスポートを選択。
するとDataflowの設定に飛ぶので画像のように設定します。
リージョンエンドポイントはDataflowの元であるComputeEngineが置かれるリージョンを指定します。なるべく近いリージョンを選ばないと他のサービスとの地理的距離が大きくなってしまうので料金がかさむ要因になります。
BigQuery output tableでは書き込むBigQuery先を選択します。<プロジェクト名>:<データセット名>.<テーブル名>の形式で入力するので、qiita-test-akijin:test.secret_wordとなります。
一時的なロケーションには先程作成したStorageのバッファの場所を入力します。
設定し終えたらDataflowの設定は終わりです。
GCP側での設定も終了です。デバイスの設定
デバイスはESP32を使い、ArduinoIDEで進めていきます。他のエディタでも同様に進めることができると思います。
IoTCoreでの設定の通り、通信にはHTTPではなくMQTTで通信をしていきます。
通信用のコード・ライブラリも用意されているものを使用します。
https://github.com/GoogleCloudPlatform/google-cloud-iot-arduino
をクローンして通常のライブラリを入れる要領で追加します。使いしたらサンプル例より、
Esp32-lwmqttを開きます。
開くとinoファイルとヘッダーファイルが2つが開かれます。
ciotc_config.hがWiFiやGCP,MQTTの設定用ファイルになりますので編集していきます。
17行目以下のところを編集します。// Wifi network details. const char *ssid = "SSID"; const char *password = "PASSWORD"; // Cloud iot details. const char *project_id = "qiita-test-akijin"; const char *location = "asia-east1"; const char *registry_id = "akijin-test"; const char *device_id = "test1";WiFiの設定は飛ばします。
GCPの設定は変数名を参考にして書き換えます。42行目以下は証明書を貼り付けていきます。
// is probably wrong with your key. const char *private_key_str = "22:d7:a2:63:05:b0:3d:df:53:71:e5:bc:53:cf:0a:" "81:00:88:f3:4f:48:4e:82:3b:37:c6:e7:86:e9:02:" "fa:e0";
esp32-mqtt.hの中身も少し書きえます。
setupWifiが名前の通りWiFiの設定なのですが、中身を以下のように書き換えます。
書き換えることによってライブラリのインクルードが必要になるので追加・継承までします。#include <Client.h> #include <WiFiManager.h> #include <WiFiClientSecure.h> WiFiClientSecure client; WiFiManager wifiManager;void setupWifi() { Serial.println("Starting wifi"); Serial.println(wifiManager.autoConnect()); IPAddress ipadr = WiFi.localIP(); Serial.println(ipadr); Serial.println(WiFi.SSID()); configTime(0, 0, ntp_primary, ntp_secondary); Serial.println("Waiting on time sync..."); while (time(nullptr) < 1510644967) { delay(10); } }こうすることによってWiFiの設定を書き込まずともPCやスマホで設定ができるようになりました。詳細は僕の他の記事や
autoconnectについて検索してください。最後に
Esp32-lwmqtt.inoを編集してきます。
loopを以下のように変更します。void loop() { mqtt->loop(); delay(10); // <- fixes some issues with WiFi stability if (!mqttClient->connected()) { connect(); } publishTelemetry("{\"Hello\":\"World\"}"); delay(10000); }
publishTelemetry();の引数が送信するデータになります。
BigQueryは追加するデータをJsonで指定するので"{\"Hello\":\"World\"}"を引数にします。
10秒に一回送信され、BigQueryのDataflowで設定したテーブルのHelloの列に文字列のWorldが追加されます。
Dataflowの方でバッファリングするので10秒に一回追加されるわけではないので注意が必要です。BigQueryに戻り、プレビューで追加されていることを確認します。
無事に追加されているはずです。
これでセンサデータの収集は終わりです。料金
これが一番気になるところです。AWSと比較してみます。
AWSはIoTCoreとDynamoDBを使用したとして比較します。
台数は1台で1時間に12回(5分おき)の送信で1ヶ月での運用と仮定して考えます。
また15分おきにPingを送ります。
メッセージ数12*24*31= 8640が一ヶ月のメッセージ数になります。
一ヶ月は44640分です。
リージョンはいずれも東京です。AWS
まずAWSです。
IoTCore
https://aws.amazon.com/jp/iot-core/pricing/?nc=sn&loc=4ここを参考にします。
0.096/1000000*44640 = 0.0042...が接続しているための料金
1.20/1000000*86400 = 0.10368 がメッセージ送信のための料金
0.18/1000000*86400*2 = 0.031...がルールの料金(DynamoDBへのインサート)
合計して0.01388USDがIoTCoreの一ヶ月あたりの料金です。
DynamoDB
https://aws.amazon.com/jp/dynamodb/pricing/on-demand/より、書き込みだけを想定します。
100 万単位あたり 1.4269USDなので、1.4269/1000000*8640 = 0.0123...がDynamoDBの料金になります。各サービスの合計で0.1511USDが一ヶ月あたりの料金になります。
GCP
IoTCore
https://cloud.google.com/iot/pricing?hl=ja#overviewの例から計算します。
4*24*30*1024 =294.9120kB
250MBまで無料なのでIoTCoreでは料金はかからないみたいです。Pub/Sub
送受信するデータが10GBに満たないので無料になります。
Dataflow
DataflowではCompute Engineという他のサービスで料金計算になります。
ここのサイトを参考にします。
今回はストリーミング処理なので1時間あたり約0.35\$かかります。したがって、0.35*24*31=260.6$となります。
これが一番やばい。
これはテンプレートを使用した際ストリーミング処理になってしまうので1台で運用する際はバッチ処理が適切だと思います。
そうした際はテンプレートを使用しないのでJavaもしくはPythonでコードを書くことになります。BigQuery
料金計算が複雑なため公式のサイトを御覧ください。
https://cloud.google.com/bigquery/pricing?hl=ja#on_demand_pricing合計で260.6~USDになります。
Dataflowが主に占めています。台数が少ないならCloudFunctionとかで代用したほうがかなりコストが削減できそう。さいごに
プログラムもほぼ書かないでデータの収集までできました。
このぐらいなら初学者の方でも簡単にできそうなのでお試しください。














- 投稿日:2020-03-21T18:34:16+09:00
Elasticsearchで類似ベクトル探索 / 類似画像検索 [TensorFlowでDeep Learning 20]
(目次はこちら)
はじめに
3年ほど前に、Deep FeaturesとFaissというタイトルで画像検索に関して書いたが、2020年3月AWSから、Build k-Nearest Neighbor (k-NN) similarity search engine with Amazon Elasticsearch Serviceが発表されたことを教えてもらい飛びついた。しかもただただサポートされているだけじゃなくて、HNSWで実装されているとのこと。
Built using the lightweight and efficient Non-Metric Space Library (NMSLIB), k-NN enables high scale, low latency nearest neighbor search on billions of documents across thousands of dimensions with the same ease as running any regular Elasticsearch query.
類似ベクトル探索/類似画像検索をElasticsearchで、しかもマネージドサービスで提供できるのは非常にメリットが大きくて、いろいろな用途で使いたい。この記事は、このサービスがすぐにでも実用できるものなのか確認したときの記録です。
(Python: 3.6.8, Tensorflow: 2.1.0で動作確認済み)
前提条件
この条件で、1クエリあたり、10ms〜20msで返ってくるなら、いろいろ用途がありそう
- ベクトル次元: 1,000〜
- ベクトル数: 1,000,000〜
- サーバスペック: AWS ec2 r5.large (2コア, 16GBメモリ) 1台
データ
若干重複はあるもののDeepFashionとDeepFashion2を合わせると約百万件(991,257)
特徴ベクトル抽出
簡単に、MobileNetV2のImageNetのPre-trained modelを使う。ベクトルは1,280次元。
import struct import glob import numpy as np import tensorflow as tf from tensorflow.keras.applications.mobilenet_v2 import preprocess_input import tensorflow.keras.layers as layers from tensorflow.keras.models import Model def preprocess(img_path, input_shape): img = tf.io.read_file(img_path) img = tf.image.decode_jpeg(img, channels=input_shape[2]) img = tf.image.resize(img, input_shape[:2]) img = preprocess_input(img) return img def main(): batch_size = 100 input_shape = (224, 224, 3) base = tf.keras.applications.MobileNetV2(input_shape=input_shape, include_top=False, weights='imagenet') base.trainable = False model = Model(inputs=base.input, outputs=layers.GlobalAveragePooling2D()(base.output)) fnames = glob.glob('deepfashion*/**/*.jpg', recursive=True) list_ds = tf.data.Dataset.from_tensor_slices(fnames) ds = list_ds.map(lambda x: preprocess(x, input_shape), num_parallel_calls=-1) dataset = ds.batch(batch_size).prefetch(-1) with open('fvecs.bin', 'wb') as f: for batch in dataset: fvecs = model.predict(batch) fmt = f'{np.prod(fvecs.shape)}f' f.write(struct.pack(fmt, *(fvecs.flatten()))) with open('fnames.txt', 'w') as f: f.write('\n'.join(fnames)) if __name__ == '__main__': main()事前検証
Faissにも、HNSWが実装されているので、パラメータ選定の意味も含めて動作検証を行う。
Amazon Elasticsearch Serviceでは、コサイン類似度でスコアが返ってくるので、ここでも、normalize()して、L2をコサイン類似度に変換している。import os import time import math import random import numpy as np import json from sklearn.preprocessing import normalize import faiss def dist2sim(d): return 1 - d / 2 def get_index(index_type, dim): if index_type == 'hnsw': m = 48 index = faiss.IndexHNSWFlat(dim, m) index.hnsw.efConstruction = 128 return index elif index_type == 'l2': return faiss.IndexFlatL2(dim) raise def populate(index, fvecs, batch_size=1000): nloop = math.ceil(fvecs.shape[0] / batch_size) for n in range(nloop): s = time.time() index.add(normalize(fvecs[n * batch_size : min((n + 1) * batch_size, fvecs.shape[0])])) print(n * batch_size, time.time() - s) return index def main(): dim = 1280 fvec_file = 'fvecs.bin' index_type = 'hnsw' #index_type = 'l2' index_file = f'{fvec_file}.{index_type}.index' fvecs = np.memmap(fvec_file, dtype='float32', mode='r').view('float32').reshape(-1, dim) if os.path.exists(index_file): index = faiss.read_index(index_file) if index_type == 'hnsw': index.hnsw.efSearch = 256 else: index = get_index(index_type, dim) index = populate(index, fvecs) faiss.write_index(index, index_file) print(index.ntotal) q_idx = [random.randint(0, fvecs.shape[0]) for _ in range(100)] k = 10 s = time.time() dists, idxs = index.search(normalize(fvecs[q_idx]), k) print((time.time() - s) / len(q_idx)) print(idxs[0], dist2sim(dists[0])) s = time.time() for i in q_idx: dists, idxs = index.search(normalize(fvecs[i:i+1]), k) print((time.time() - s) / len(q_idx)) if __name__ == '__main__': main()検索時間
HNSWすばらしい。これがElasticsearchで実現できるとステキ。
Batch Search Single Query Search IndexFlatL2 110 ms/image 530 ms/image IndexHNSWFlat 0.9 ms/image 5 ms/image 類似画像検索結果
最左列がクエリ画像で、右側の列が、類似度が高い順に10画像。
上記、HNSWのパラメータ(m=48, efConstruction=128, efSearch=256)で、今回の検証に耐えうるReallが出てると判断(厳密な検証はしていない)。
ImageNetのPre-trained modelでここまでいけるんだと感心。
Amazon Elasticsearch Service
AWSのコンソールからポチポチやって、10分くらい待つとインスタンスが立ち上がる。
データ挿入
import time import math import numpy as np import json import certifi from elasticsearch import Elasticsearch, helpers from sklearn.preprocessing import normalize dim = 1280 fvecs = np.memmap('fvecs.bin', dtype='float32', mode='r').view('float32').reshape(-1, dim) idx_name = 'imsearch' es = Elasticsearch(hosts=['https://vpc-xxxxxxxxxxx.us-west-2.es.amazonaws.com'], ca_certs=certifi.where()) mapping = { "settings" : { "index" : { "knn": True, "knn.algo_param" : { "ef_search" : "256", "ef_construction" : "128", "m" : "48" } } }, 'mappings': { 'properties': { 'fvec': { 'type': 'knn_vector', 'dimension': dim } } } } res = es.indices.create(index=idx_name, body=mapping, ignore=400) print(res) bs = 200 nloop = math.ceil(fvecs.shape[0] / bs) for k in range(nloop): rows = [{'_index': idx_name, '_id': f'{i}', '_source': {'fvec': normalize(fvecs[i:i+1])[0].tolist()}} for i in range(k * bs, min((k + 1) * bs, fvecs.shape[0]))] s = time.time() helpers.bulk(es, rows, request_timeout=30) print(k, time.time() - s)1時間くらい待つと、Searchable Documentsがデータ件数と同じに。
res = es.cat.indices(v=True) print(res)health status index uuid pri rep docs.count docs.deleted store.size pri.store.size yellow open imsearch 2fvSq3doQ5-4EHhpI_NfhA 5 1 991257 0 24.8gb 24.8gb検索
k = 10 res = es.search(request_timeout=30, index=idx_name, body={'size': k, '_source': False, 'query': {'knn': {'fvec': {'vector': normalize(fvecs[0:1])[0].tolist(), 'k': k}}}}) print(json.dumps(res, indent=2))目を疑う結果に。。。Warmupしても同じ。。。 1クエリあたり15s
サーバ台数を3台にしても現実的なレスポンス時間は得られず。
Faissを使った検証と同じドキュメントが返ってきていることは確認できた。{ "took": 15471, "timed_out": false, "_shards": { "total": 5, "successful": 5, "skipped": 0, "failed": 0 }, "hits": { "total": { "value": 1203, "relation": "eq" }, "max_score": 1.0, "hits": [ { "_index": "imsearch", "_type": "_doc", "_id": "340460", "_score": 1.0 }, { "_index": "imsearch", "_type": "_doc", "_id": "355432", "_score": 0.6760856 }, ...あとがき
Amazon Elasticsearch Serviceにデータを入れるところまではよかったが、現実的なレスポンス時間を得ることはできず。何か間違っているんだろうか、、、わからない。。。


- 投稿日:2020-03-21T17:39:52+09:00
オブジェクトロック設定をしているS3バケットをConfigのスナップショット配信先にはできない
結論
まずは結論から。
タイトル通りなのですが、
オブジェクトロック設定をしているS3をConfigのスナップショット配信先にはできません(2020/03/21時点)。
以下、詳細について書いていきます。AWSサービス概要
登場するAWSサービスの概要を説明します。
AWS Config
AWSリソースの構成情報の記録を行います。
リソースカットで特定時間にどういった設定になっていたか、どういった変更が行われたかが分かります。
そのため、構成管理・変更管理の目的でConfigを利用することがあります。
設定スナップショットの配信機能を用いることで、特定時間のリソース情報をS3に保存することができます。また、Configルールという機能もあり、AWSリソースが定義したルールに準拠しているかをチェックすることができます。
例えば、全IP,portでインバウンド許可されているセキュリティグループが無いかどうかを簡単にチェックすることができます。
構成管理の目的よりも、こういったセキュリティチェックの目的でConfigを利用する人の方が多い印象です。Amazon S3 オブジェクトロック
みなさんご存知のS3にはオブジェクトロックという機能があります。
オブジェクトロックを設定すると、一度S3に保存したオブジェクトを一定期間削除したり上書きできなくすることができます。
そのため、削除されたり、上書きされたりすると困るオブジェクトを保管するのにもってこいの機能です。Configが配信したスナップショット情報は削除されたくない
配信する情報を構成管理の目的で利用する場合は、これらを削除されると困ります。
そのため、オブジェクトロック設定をしているS3を配信先としておけば一定期間削除されないし安心じゃない?と思い始めます。オブジェクトロック設定をしているS3をConfigのスナップショット配信先にはできません
はい。そうなんですよ。。
Configの配信情報こそオブジェクトロックしたいのに対応してないんです(2020/03/21時点)。
しかも、ドキュメントにはそんなこと記載されてないので、注意が必要です。
(AWSサポートには機能改善とドキュメント修正の要望を出してます。)そのため、これらの情報をオブジェクトロックしたい場合はオブジェクトロック設定をしているS3バケットを別途用意して、移してあげる必要があります。
CloudTrailのログ保管先はオブジェクトロック設定のS3バケットでも可能
実はCloudTrailのログ保管先にオブジェクトロック設定のS3バケットを指定することはできなかったのですが、記事を書くにあたって再度確認したら設定できるようになってました!
Configも後々格納できるようなることを願ってます。
- 投稿日:2020-03-21T14:24:42+09:00
Amazon ECS の Volumes と Bind Mount の仕組み
1.Volumes
/var/lib/docker/volumes/↔️/var/www/html
管理者権限でログイン
sudo su
/var/lib/docker/volumes/に移動。cd /var/lib/docker/volumes/ ll drwxr-xr-x 3 root root 4096 Mar 21 04:47 80a6b074bf3171ef09d22cfdc17c950986315ec71498fe2c10fe364573a3dcff
80a〜に移動`cd 80a6b074bf3171ef09d22cfdc17c950986315ec71498fe2c10fe364573a3dcff ll drwxr-xr-x 2 root root 4096 Mar 21 04:47 _data
_dataに移動。cd _data -rw-rw-r-- 1 root root 111 Mar 9 09:36 index.html
index.htmlを適当に編集し、変更が表示されるか確認する。index.html<html> <head><title>ecs volumes demo</head></title> <body> this is ecs volumes demo </body> </html>2.Bind Mount
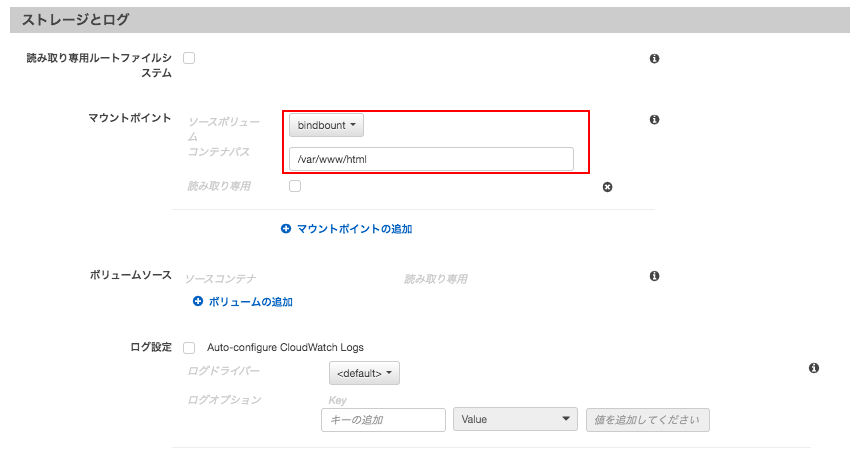
/root/Volume01↔️/var/www/html
Volume01ができているか確認。sudo su cd ll drwxr-xr-x 2 root root 4096 3月 21 05:14 Volume01
Volume01に適当なindex.htmlを開き、反映されるか確認。cd Volume01index.html<html> <head><title>ecs bind mount demo</head></title> <body> this is ecs bind mount demo </body> </html>3.リンク


- 投稿日:2020-03-21T11:24:52+09:00
Serverless Frameworkのアプリにカスタムドメインを付与する
前回作成したLaravelのサーバレスアプリにカスタムドメインでアクセスできるようにします。
ACMで証明書を取得します。Route53経由の方はDNS経由で簡単に取得できます。サブドメインはワイルドカードで申請するのみです。
Lambda関数がEdgeの場合は、us-east-1(バージニア北部)のACMである必要があります。東京のACMは関係ありません。
発行済になったら
serverless-domain-managerのインストールします。a4e6e25d$ npm install serverless-domain-manager --save-dev
serverless.ymlを編集します。8c313fafserverless.yml+ custom: + customDomain: + domainName: laravel-demo.umihi.co + certificateName: umihi.co + basePath: '' + stage: ${self:provider.stage} + createRoute53Record: true + endpointType: 'edge' + securityPolicy: tls_1_2 provider: name: aws region: ap-northeast-1 runtime: provided plugins: - ./vendor/bref/bref + - serverless-domain-manager最後に
sls create_domainしてsls deployしますが、create_domain実行後は最大40分待つ必要があります。$ sls create_domain Serverless: Custom domain laravel-demo.umihi.co was created. New domains may take up to 40 minutes to be initialized. $ sls deploy Serverless: Packaging service... Serverless: Excluding development dependencies... Serverless: Uploading CloudFormation file to S3... Serverless: Uploading artifacts... Serverless: Uploading service laravel-demo.zip file to S3 (14.2 MB)... Serverless: Validating template... Serverless: Updating Stack... Serverless: Checking Stack update progress... .............. Serverless: Stack update finished... Service Information service: laravel-demo stage: dev region: ap-northeast-1 stack: laravel-demo-dev resources: 12 api keys: None endpoints: ANY - https://td3rzowchc.execute-api.ap-northeast-1.amazonaws.com/dev ANY - https://td3rzowchc.execute-api.ap-northeast-1.amazonaws.com/dev/{proxy+} functions: website: laravel-demo-dev-website layers: None Serverless: Created basepath mapping. Serverless Domain Manager Summary Domain Name laravel-demo.umihi.co Distribution Domain Name Target Domain: aaaaabbbbbcccc.cloudfront.net Hosted Zone Id: XXXXYYYYYZZZZZ Serverless: Run the "serverless" command to setup monitoring, troubleshooting and testing.https://laravel-demo.umihi.co にアクセスできるようになりました。
カスタムドメイン+証明書+サーバレス+Laravelの完成です。Cloudfrontの文字が見えますが、当該IDは、 https://console.aws.amazon.com/cloudfront
には無く、API Gateway配下の https://ap-northeast-1.console.aws.amazon.com/apigateway/main/publish/domain-names
で確認できます。
- 投稿日:2020-03-21T09:25:31+09:00
Lambda@edgeを完全に理解する?♀️
何者だお前は
2017年7月17日に正式リリースされたサービス。
Lambda@Edge の一般提供を開始AWS Lambda にコードをアップロードし、Amazon CloudFront イベント (ビューワーリクエスト、ビューワーレスポンス、オリジンリクエスト、オリジンリクエストなど) によってトリガーされるように設定するだけです。関連するリクエストが CloudFront によって受信されると、ビューワーに近い最適な AWS のロケーションに実行のためルーティングされます。次に、Lambda@Edge はコードを実行し、CloudFront のグローバルなネットワーク間のリクエストのボリュームに応じてスケールします。Lambda@Edge により、コードを実行して各個別のリクエストに基づいてウェブページをカスタマイズし、グローバルに実行されるカスタム認証ロジックを作成して、安全なカスタムヘッダーの配信を簡略化できます。
Lambdaとはどういう関係なの?
継承関係で言うところの、
Lambda@edge is a Lambda.Lambda@Edge とは、AWS Lambda の拡張機能で、CloudFront が配信するコンテンツをカスタマイズする関数を実行できるコンピューティングサービスです。
コードをアップロードして実行してくれるサーバーレスなコンピューティング環境という点では同じだが、Lambda@edgeには色々と制約がある。
Node.jsとPythonのみをサポート
リリース時はNode.js一択だった。
2年後の2019年8月1日に、Python3.7が追加。
Lambda@Edge が Python 3.7 のサポートを追加今後も追加の要望や計画があるのかもしれないが、これで十分だと思う。
後述するが、使い道が限られているので、いろんな言語が使えることのうまみがLambdaほどない。
us-east-1リージョンでしか作れないこれは制約といえば制約なのだが、そもそもリージョンという概念は必要ない。
最適なエッジロケーションで実行するために、あらゆるリージョンに置かれるので、
最初にどこで作成しようが関係ない。まあ便宜上
us-east-1になっているのだろう。
CloudFront, S3系はそういうルールがちょくちょくあるな。いつも通り ap-northeast-1 で作業してるとつまづいたりするので困るが。
CloudFrontと紐づけて使う必要がある
この表現は半分正解で半分間違い。
必要がある、というよりは、CloudFrontに紐づけたLambdaがLambda@edgeなのだ。CloudWatch Event から定期的に Lambda@edge をキックしよう、
みたいなことはできないし、そういう考え方自体が間違っている。Lambda@edge を呼び出すのは CloudFront であり、
ユーザーからのリクエストなしには処理するべきものが存在しない。
どうやって作るのか
普通にLambdaの関数を作る。
先述の通り、とりわけ Lambda@edge を作るみたいなインターフェースは存在しない。
バージニア北部 で、サポートされている言語で作るだけである。
作った関数は、CloudFront の [Behavior] の設定で使う。
イベントタイプを指定して、バージョン番号を含めたARNを入力するだけ。
イベントタイプは後述する。
ハマりどころ1: サービスプリンシパルが異なる
関数の実行ロールにLambda@edgeを追加しないといけない。
自動で生成されるIAMロールにはlambdaしか含まれていないので、
edgelambda.amazonaws.comを追加する。{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": [ "lambda.amazonaws.com", "edgelambda.amazonaws.com" ] }, "Action": "sts:AssumeRole" } ] }動作の仕組み
Lambda 関数をトリガーできる CloudFront イベント
リンク先のこの画像がわかりやすい。
イベントには4種類あり、
- ビューワーリクエスト
- オリジンリクエスト
- オリジンレスポンス
- ビューワーレスポンス
そろぞれをトリガーとして Lambda@edge の処理を挟み込める。
どのイベントが適しているかはユースケースに応じて適切に判断する必要がある。
例えば、リクエストされたパスやリファラに応じて一部をリダイレクトさせたい場合、
オリジンサーバーにアクセスさせる必要はないので、
ビューワーリクエストのイベントを拾ってレスポンスを返してしまえばよい。
Lambda@Edgeを使ってリファラによってリダイレクトさせるS3の静的Webホスティングにもリダイレクト機能はあるが、
こちらの方が迅速にエッジロケーションからレスポンスを返せる。逆に、オリジンリクエストで処理すべきケースもある。
CloudFrontはキャッシュが効くので、オリジンリクエストが発生しない可能性がある。
その分無駄に Lambda@edge がコールされないで済むのでコスト削減に役立つ。ハマりどころ2: イベントが発生しないことがある
上述のキャッシュのケース以外にも、リクエストはされているが、
Lambda@edge がコールされないケースがいくつか存在する。ビューアープロトコルポリシーでHTTPをHTTPSにリダイレクトしていた場合や、
CloudFrontが400系のエラーレスポンスを生成する場合は Lambda@edge は無視される。オリジンレスポンス
CloudFront がオリジンからのレスポンスを受け取った後、レスポンス内のオブジェクトをキャッシュする前に関数が実行されます。関数は、オリジンからエラーが返された場合でも実行されることに注意してください。以下の場合、関数は実行されません。
リクエストされたファイルが CloudFront キャッシュ内にあり、その有効期限が切れていない場合。
オリジンリクエストイベントによってトリガーされた関数からレスポンスが生成された場合。
ビューワーレスポンス
リクエストされたファイルがビューワーに返される前に関数が実行されます。ファイルが CloudFront キャッシュ内にすでに存在するかどうかに関係なく、関数が実行されることに注意してください。以下の場合、関数は実行されません。
オリジンが HTTP ステータスコードとして 400 以上を返した場合。
カスタムエラーページが返された場合。
ビューワーリクエストイベントによってトリガーされた関数からレスポンスが生成された場合。
CloudFront が HTTP リクエストを自動的に HTTPS にリダイレクトする場合 (ビューアープロトコルポリシー の値が [Redirect HTTP to HTTPS (HTTP を HTTPS にリダイレクトする)] の場合)。
ハマりどころ3: ログがリージョンごとに吐かれる
Lambdaの実行ログは CloudWatch に記録されるが、
様々なエッジロケーションで実行される Lambda@edge は、
実行されたリージョンにそれぞれログを吐く。AWS Lambda@Edgeのログはどこ?AWS Lambda@Edgeのログ出力先について
結構めんどくさい。
どういう使い方をするものなのか
- ABテスト(A/B testing on AWS CloudFront with Lambda@Edge)
- ユーザーのデバイスの解像度に最適な画像の配信(Lambda@Edgeを利用して画像リサイズ機能を実装した)
- 認証(S3 + CloudFront + Lambda@Edge でBasic認証)
- サブディレクトリのルートオブジェクト設定(CloudFront + S3 でのディレクトリアクセス)
- i18n(Lambda@Edgeでアクセス元の国を判別してリダイレクト)
- セキュリティヘッダーの付与(CloudFront+S3環境でLambda@Edgeを用いてHTTPセキュリティヘッダーを付与する方法)
- SSR(SSRをやめる。OGP対応はLambda@Edgeでダイナミックレンダリングする。)
他に覚えておきたい仕様
不正にヘッダーをいじれな
できたらやばいのだが。
追加不可能、読み取り専用のヘッダーが以下にリストされている。
ブラックリストに記載されているヘッダー現在サポートされているランタイム
Python3.7 と Node.js 10 のみ。
Node.js 8 と Node.js 6 については、すでにサポートが切れている。
すでに関連づけられている関数は引き続き動作し続けるが、新規で関連づけることはできない。環境変数は使えない
Lambdaとは異なる部分。
まあ、使うユースケースはあまりないと思うが、
やるとしたらパラメータストアから引っこ抜くとかかな笑タイムアウトは厳しめ
非同期的な使い方は想定外なので、Lambdaに比べてだいぶ制限されている。
他にもメモリやコードのサイズに制限が追加されている。
ボディの取り扱い
Include Body オプションを有効にすると、ボディの内容が Lambda@edge に送られる。
GETなんだからいらねー気もするが、深く追求しないでおこう。以下の2点注意が必要。
本文は公開される前、常に Lambda@Edge で Base64 エンコードされています。
リクエストボディが大きい場合は、次のように、公開する前に Lambda@Edge によって切り捨てられます。
・ビューワーリクエストの場合、本文は 40 KB で切り捨てられます。
・オリジンリクエストの場合、本文は 1 MB で切り捨てられます。所感
S3+CloudFrontでWebを配信することも増えてきたし、
なんかかゆいところに手が届くいいソリューションが出てきたなという感じですね。
Dynamoとかにも接続できちゃうしSSR的な使い方もやろうと思ったらできてしまう。Lambdaっていう名前はややこしいから変えてほしいなあとは思う。
サーバーレスコンピューティング環境っていうよりは、Webサーバーの設定の上位互換みたいなイメージだし、CloudFrontとがっつり絡んでるのだからCloudFront側の機能として立て付けられてた方がわかりやすい気がするんだがな。
裏側のリソースの関係でLambdaに寄せたほうが都合よかったのかな
以上です。
最後まで読んだ人は「Lambda@edge完全に理解した」って言って良いです。






- 投稿日:2020-03-21T09:25:31+09:00
Lambda@Edgeを完全に理解する?♀️
何者だお前は
2017年7月17日に正式リリースされたサービス。
Lambda@Edge の一般提供を開始AWS Lambda にコードをアップロードし、Amazon CloudFront イベント (ビューワーリクエスト、ビューワーレスポンス、オリジンリクエスト、オリジンリクエストなど) によってトリガーされるように設定するだけです。関連するリクエストが CloudFront によって受信されると、ビューワーに近い最適な AWS のロケーションに実行のためルーティングされます。次に、Lambda@Edge はコードを実行し、CloudFront のグローバルなネットワーク間のリクエストのボリュームに応じてスケールします。Lambda@Edge により、コードを実行して各個別のリクエストに基づいてウェブページをカスタマイズし、グローバルに実行されるカスタム認証ロジックを作成して、安全なカスタムヘッダーの配信を簡略化できます。
Lambdaとはどういう関係なの?
継承関係で言うところの、
Lambda@Edge is a Lambda.Lambda@Edge とは、AWS Lambda の拡張機能で、CloudFront が配信するコンテンツをカスタマイズする関数を実行できるコンピューティングサービスです。
コードをアップロードして実行してくれるサーバーレスなコンピューティング環境という点では同じだが、Lambda@Edgeには色々と制約がある。
Node.jsとPythonのみをサポート
リリース時はNode.js一択だった。
2年後の2019年8月1日に、Python3.7が追加。
Lambda@Edge が Python 3.7 のサポートを追加今後も追加の要望や計画があるのかもしれないが、これで十分だと思う。
後述するが、使い道が限られているので、いろんな言語が使えることのうまみがLambdaほどない。
us-east-1リージョンでしか作れないこれは制約といえば制約なのだが、そもそもリージョンという概念は必要ない。
最適なエッジロケーションで実行するために、あらゆるリージョンに置かれるので、
最初にどこで作成しようが関係ない。まあ便宜上
us-east-1になっているのだろう。
CloudFront, S3系はそういうルールがちょくちょくある気がする。いつも通り
ap-northeast-1で作業してるとつまづいたりするので困る。CloudFrontと紐づけて使う必要がある
この表現は半分正解で半分間違い。
必要がある、というよりは、CloudFrontに紐づけたLambdaがLambda@Edgeなのだ。CloudWatch Event から定期的に Lambda@Edge をキックしよう、
みたいなことはできないし、そういう考え方自体が間違っている。Lambda@Edge を呼び出すのは CloudFront であり、
ユーザーからのリクエストなしには処理するべきものが存在しない。
どうやって作るのか
普通にLambdaの関数を作る。
先述の通り、特別 Lambda@Edge を作るみたいなインターフェースは存在しない。
バージニア北部で、サポートされている言語で作るだけである。
作った関数は、CloudFront の [Behavior] の設定で使う。
イベントタイプを指定して、バージョン番号を含めたARNを入力するだけ。
イベントタイプは後述する。
ハマりどころ1: サービスプリンシパルが異なる
関数の実行ロールにLambda@Edgeを追加しないといけない。
自動で生成されるIAMロールにはLambdaしか含まれていないので、
edgelambda.amazonaws.comを追加する。{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": [ "lambda.amazonaws.com", "edgelambda.amazonaws.com" ] }, "Action": "sts:AssumeRole" } ] }動作の仕組み
Lambda 関数をトリガーできる CloudFront イベント
リンク先のこの画像がわかりやすい。
イベントには4種類あり、
- ビューワーリクエスト
- オリジンリクエスト
- オリジンレスポンス
- ビューワーレスポンス
そろぞれをトリガーとして Lambda@Edge の処理を挟み込める。
どのイベントが適しているかはユースケースに応じて適切に判断する必要がある。
例えば、リクエストされたパスやリファラに応じて一部をリダイレクトさせたい場合、
オリジンサーバーにアクセスさせる必要はないので、
ビューワーリクエストのイベントを拾ってレスポンスを返してしまえばよい。
Lambda@Edgeを使ってリファラによってリダイレクトさせるS3の静的Webホスティングにもリダイレクト機能はあるが、
こちらの方が迅速にエッジロケーションからレスポンスを返せる。逆に、オリジンリクエストで処理すべきケースもある。
CloudFrontはキャッシュが効くので、オリジンリクエストが発生しない可能性がある。
その分無駄に Lambda@Edge がコールされないで済むのでコスト削減に役立つ。ハマりどころ2: イベントが発生しないことがある
上述のキャッシュのケース以外にも、リクエストはされているが、
Lambda@Edge がコールされないケースがいくつか存在する。ビューアープロトコルポリシーでHTTPをHTTPSにリダイレクトしていた場合や、
CloudFrontが400系のエラーレスポンスを生成する場合は Lambda@Edge は無視される。オリジンレスポンス
CloudFront がオリジンからのレスポンスを受け取った後、レスポンス内のオブジェクトをキャッシュする前に関数が実行されます。関数は、オリジンからエラーが返された場合でも実行されることに注意してください。以下の場合、関数は実行されません。
リクエストされたファイルが CloudFront キャッシュ内にあり、その有効期限が切れていない場合。
オリジンリクエストイベントによってトリガーされた関数からレスポンスが生成された場合。
ビューワーレスポンス
リクエストされたファイルがビューワーに返される前に関数が実行されます。ファイルが CloudFront キャッシュ内にすでに存在するかどうかに関係なく、関数が実行されることに注意してください。以下の場合、関数は実行されません。
オリジンが HTTP ステータスコードとして 400 以上を返した場合。
カスタムエラーページが返された場合。
ビューワーリクエストイベントによってトリガーされた関数からレスポンスが生成された場合。
CloudFront が HTTP リクエストを自動的に HTTPS にリダイレクトする場合 (ビューアープロトコルポリシー の値が [Redirect HTTP to HTTPS (HTTP を HTTPS にリダイレクトする)] の場合)。
ハマりどころ3: ログがリージョンごとに吐かれる
Lambdaの実行ログは CloudWatch に記録されるが、
様々なエッジロケーションで実行される Lambda@Edge は、
実行されたリージョンにそれぞれログを吐く。AWS Lambda@Edgeのログはどこ?AWS Lambda@Edgeのログ出力先について
結構めんどくさい。
どういう使い方をするものなのか
- ABテスト(A/B testing on AWS CloudFront with Lambda@Edge)
- 画像のリサイズ・最適化(Lambda@Edgeを利用して画像リサイズ機能を実装した)
- 認証(S3 + CloudFront + Lambda@Edge でBasic認証)
- サブディレクトリのルートオブジェクト設定(CloudFront + S3 でのディレクトリアクセス)
- i18n(Lambda@Edgeでアクセス元の国を判別してリダイレクト)
- セキュリティヘッダーの付与(CloudFront+S3環境でLambda@Edgeを用いてHTTPセキュリティヘッダーを付与する方法)
- SSR(SSRをやめる。OGP対応はLambda@Edgeでダイナミックレンダリングする。)
他に覚えておきたい仕様
不正にヘッダーをいじれない
できたらやばいのだが。
追加不可能、読み取り専用のヘッダーが以下にリストされている。
ブラックリストに記載されているヘッダー現在サポートされているランタイム
Python3.7 と Node.js 10 のみ。
Node.js 8 と Node.js 6 については、すでにサポートが切れている。
すでに関連づけられている関数は引き続き動作し続けるが、新規で関連づけることはできない。環境変数は使えない
Lambdaとは異なる部分。
まあ、使うユースケースはあまりないと思うが、
やるとしたらパラメータストアから引っこ抜くとかかな笑タイムアウトは厳しめ
非同期的な使い方は想定外なので、Lambdaに比べてだいぶ制限されている。
他にもメモリやコードのサイズに制限が追加されている。
ボディの取り扱い
Include Body オプションを有効にすると、ボディの内容が Lambda@Edge に送られる。
GETなんだからいらねー気もするが、深く追求しないでおこう。以下の2点注意が必要。
本文は公開される前、常に Lambda@Edge で Base64 エンコードされています。
リクエストボディが大きい場合は、次のように、公開する前に Lambda@Edge によって切り捨てられます。
・ビューワーリクエストの場合、本文は 40 KB で切り捨てられます。
・オリジンリクエストの場合、本文は 1 MB で切り捨てられます。所感
S3+CloudFrontでWebを配信することも増えてきたし、
なんかかゆいところに手が届くいいソリューションが出てきたなという感じですね。
Dynamoとかにも接続できちゃうしSSR的な使い方もやろうと思ったらできてしまう。Lambdaっていう名前はややこしいから変えてほしいなあとは思う。
サーバーレスコンピューティング環境っていうよりは、Webサーバーの設定の上位互換みたいなイメージだし、CloudFrontとがっつり絡んでるのだからCloudFront側の機能として立て付けられてた方がわかりやすい気がするんだがな。
裏側のリソースの関係でLambdaに寄せたほうが都合よかったのかな以上です。
最後まで読んだ人は「Lambda@Edge完全に理解した」って言って良いです。
- 投稿日:2020-03-21T09:10:56+09:00
iOSデバイスでプログラミング環境構築
今時机やPCの前だけで作業できる環境はナンセンスでしょ?!
スキマ時間の有効活用や職場にラップトップ、タブレットを持ち込めないとき、旅行などのための環境構築です。
PCが壊れても別の端末ですぐ作業開始できる環境が大事。
布団の中でゴロゴロしながらもプログラミングできますし
旅先で重たいラップトップなんか持ちたくない
用意するアイテム
- iOSデバイス
- モバイルキーボード(なくても可)
- Working Copy(GitHub用)
- Textastic (テキストエディタ GoCoEditよりiOSライク )
- GoCoEdit (これもいいらしい)
- Blink Shell(SSH)
- AWSアカウント
- GitHubアカウント
参考:エディタのreviewはこちら
私はTextasticとGoCoEdit 両方買いました。Textasticのほうが使いやすいかな?
どちらもIDEエディタ並みのショートカットはありません。
アプリをインストール
- AppStoreからBlink Shell Textastic Working Copyをインストール
- Blink ShellはMACを持っていれば自分でビルドして無料で使えます。(私はビルドがメンドウなので、買いました)
- Working Copyはpush機能が課金対象です。(pushできないのは意味ないので課金しました。) push機能以外は無料で使えます
AWSアカウント作成
現在新規登録すると1年間は無料で使えます。詳細はオフィシャルサイトで確認してください。
GitHubアカウント作成
はじめは無料アカウントで十分です。
今はPrivateリポジトリも使えるしね
github
Working Copyの作業
このアプリからGitHubにあるリポジトリをcloneしたりpullしたりpushしたりします。
すでにGitHubにあるリポジトリはclone repositoryrepositoryを新規作成 ちょっと悩みました(-_-;)
アプリ内でInitialize new repository
repository名を入力->create
ファイルやディレクトリを作成
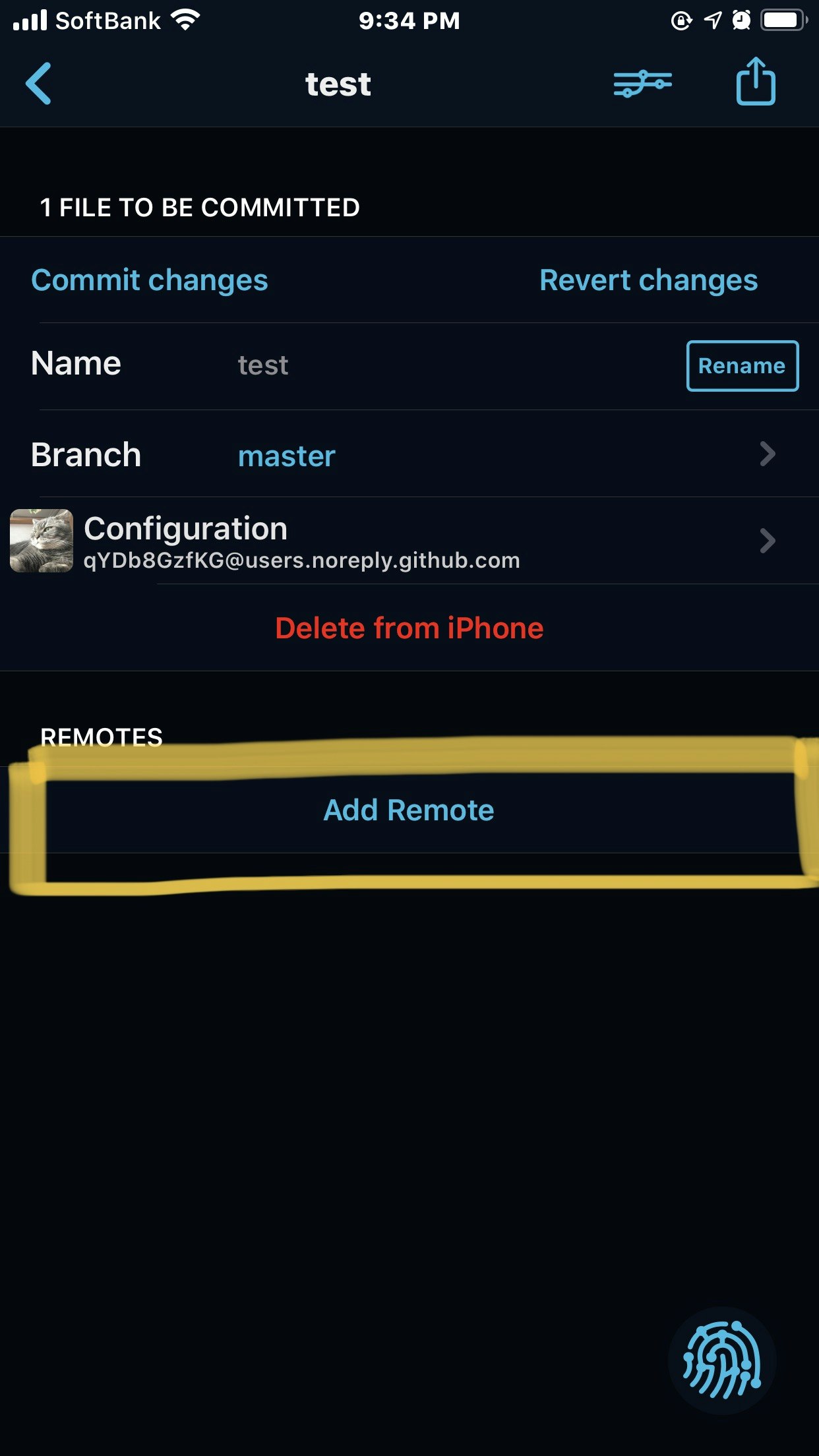
Repositoryをタップ
Add Remote->Create Repository->Confirm Create
これでGitHubに反映されます
(この階層にiphoneからdeleteもあります。)
commitのしかた
repositoryをフリックしたり、右下の指紋マークをタップでcommit画面に遷移します。
GitHub上
Textasticの作業
かんたんなサンプルページを作ります
emmetで作成します
(ファイルを新規作成するときにtemplateを選択して作成できます。)
IDE並みにカンタンに入力できます。















- 投稿日:2020-03-21T09:10:24+09:00
Laravelのサーバレス用ライブラリbrefを使い、lambdaでhello world
プロジェクトを作ってから少し手を加えるだけで、Laravelのサーバレス化ができました。
AWS上のデプロイはServerless Frameworkが全てやってくれます。composer create-project --prefer-dist laravel/laravel laravel-demo #プロジェクト作成 cd laravel-demo composer require bref/bref #肝のbrefインストール以下の編集を加えます。b508b15
.env- SESSION_DRIVER=file + SESSION_DRIVER=array + VIEW_COMPILED_PATH=/tmp/storage/framework/viewsconfig/logging.php'stack' => [ 'driver' => 'stack', - 'channels' => ['single'], + 'channels' => ['stderr'], 'ignore_exceptions' => false, ],/app/Providers/AppServiceProvider.phppublic function boot() { - // + if (!is_dir(config('view.compiled'))) { + mkdir(config('view.compiled'), 0755, true); + } } }最後に
serverless.ymlを追加します。007fb31serverless.ymlservice: laravel-demo provider: name: aws region: ap-northeast-1 runtime: provided plugins: - ./vendor/bref/bref package: exclude: - node_modules/** - public/storage - storage/** - tests/** functions: website: handler: public/index.php timeout: 28 # in seconds (API Gateway has a timeout of 29 seconds) layers: - ${bref:layer.php-73-fpm} events: - http: 'ANY /' - http: 'ANY /{proxy+}' # artisan: # handler: artisan # timeout: 120 # in seconds # layers: # - ${bref:layer.php-73} # PHP # - ${bref:layer.console} # The "console" layer本家の
artisanコマンド用関数ですが、私はローカルでしか実行しないのでコメントアウトしています。デプロイコマンドは
php artisan config:clearとsls deployのセットです。
以下のアウトプットになりました。$ php artisan config:clear Configuration cache cleared! $ sls deploy Serverless: Packaging service... Serverless: Excluding development dependencies... Serverless: Creating Stack... Serverless: Checking Stack create progress... ........ Serverless: Stack create finished... Serverless: Uploading CloudFormation file to S3... Serverless: Uploading artifacts... Serverless: Uploading service laravel-demo.zip file to S3 (14.19 MB)... Serverless: Validating template... Serverless: Updating Stack... Serverless: Checking Stack update progress... ................................. Serverless: Stack update finished... Service Information service: laravel-demo stage: dev region: ap-northeast-1 stack: laravel-demo-dev resources: 12 api keys: None endpoints: ANY - https://td3rzowchc.execute-api.ap-northeast-1.amazonaws.com/dev ANY - https://td3rzowchc.execute-api.ap-northeast-1.amazonaws.com/dev/{proxy+} functions: website: laravel-demo-dev-website layers: None Serverless: Run the "serverless" command to setup monitoring, troubleshooting and testing.さっそく https://td3rzowchc.execute-api.ap-northeast-1.amazonaws.com/dev にアクセスしてみましょう。
以上です。以下の課題に対しても記事投稿予定です。
- URLにあるステージのパスが外せないことによる不具合が多いので、カスタムドメインを導入する
- public配下が参照されず、jsとcssが参照できない。
- slsコマンドと同期して.envを環境毎に使い分けたい。
- セッション含めDB接続したいがサーバレスはコネクションプール問題がある。

- 投稿日:2020-03-21T04:23:56+09:00
【#awscli】管理者権限を持たないWindows環境に「AWSコマンドラインインターフェイス(AWS CLI v2)」をインストールする #AWS #awscliv2 #jawsug #環境構築 #環境設定
AWS CLI v2では「Pythonがなくてもインストールできるようになった!」というのがウリなのですが、 相変わらずWindows MSI インストーラ形式で提供されているので管理者権限を持たないWindows端末にインストールすることができません。
というわけで管理者権限を持たないWindows端末に「AWSコマンドラインインターフェイス(AWS CLI v2)」をインストールした際の内容を自分用のメモとしてまとめました。
環境情報
OS/ソフトウェア バージョン 入手元 Windows 10 pro バージョン1903(May 2019) Microsoft Corporation Python3 3.8.2 https://www.python.org/downloads/windows/ pip 20.0.2 botocore 2.0.0dev6 https://github.com/boto/botocore/archive/v2.tar.gz aws-cli 2.0.2 https://github.com/aws/aws-cli/archive/v2.tar.gz 1. Python3 のインストール
まず「Python3」をインストールします。
□手順 1-1: 公式URLからPythonの
executable installerをダウンロードします■URL
https://www.python.org/downloads/windows/■ファイル名
python-3.8.2-amd64.exe□手順 1-2: ダウンロードした
executable installerを実行します□手順 1-3:
Add Python 3.8 to PATHチェックボックスにチェックを入れた後Customize installationをクリックします[ ] Install launcher for all users(recommended) [✔] Add Python 3.8 to PATH
□手順 1-4: 次の Optional Features にチェックを入れて
Nextボタンをクリックします[✔] Documentaion [✔] pip [✔] tcl/tk and IDLE [✔] py launcher [ ] for for all users(requires elevation)
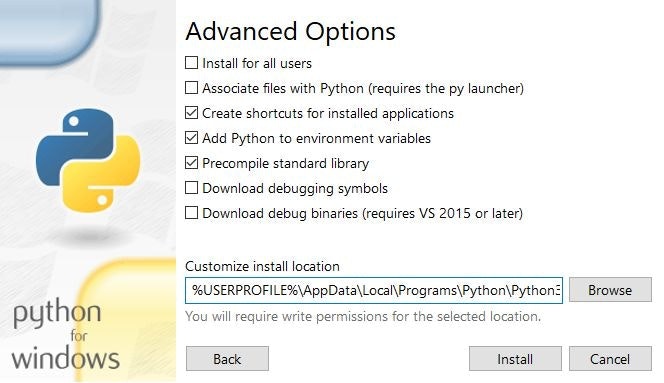
□手順 1-5: 次の Advanced Options にチェックを入れて
Installボタンをクリックします[ ] Install for all users [ ] Associate files with Python (requires the py launcher) [✔] Create shortcuts for installed applications [✔] Add Python to environment variables [✔] Precompile standard library [ ] Download debugging symbols [ ] Download debug binaries (requires VS 2015 or later)
□手順 1-6:
Closeボタンをクリックしexecutable installerを終了します
□手順 1-7: スタートメニューから
Powershellを起動し次のコマンドを実行、Pythonがインストールされて、パスが通っていることを確認しますPS C:\> & python --version Ptyhon 3.8.22. botocore と aws-cli のインストール
AWS CLI v1 の時は、Python3 インストール後は pip で比較的に簡単にインストールできたのですが、
v2 になってから意図的に PyPI 上にも公開しないことになったようで、少し工夫が必要です。
https://github.com/aws/aws-cli/issues/4947Not publishing CLI v2 to PyPI has been a conscious decision and for the time being we have no plans to publish to PyPI. In the long term we want the fact that the AWS CLI is written in Python to be more of an implementation detail than a feature.□手順 2-1: まず
pipを最新バージョンにアップグレードしますPS C:\> & easy_install.exe -U pip□手順 2-2: 次に
pipを使ってGitHubレポジトリ上からbotocoreをインストールしますPS C:\> & pip install --trusted-host pypi.org --trusted-host files.pythonhosted.org --trusted-host github.com --trusted-host codeload.github.com https://github.com/boto/botocore/archive/v2.tar.gz Collecting https://github.com/boto/botocore/archive/v2.tar.gz Downloading https://github.com/boto/botocore/archive/v2.tar.gz | 5.1 MB 43 kB/s Collecting jmespath<1.0.0,>=0.7.1 Downloading jmespath-0.9.5-py2.py3-none-any.whl (24 kB) Collecting docutils<0.16,>=0.10 Downloading docutils-0.15.2-py3-none-any.whl (547 kB) |████████████████████████████████| 547 kB 6.8 MB/s Collecting python-dateutil<3.0.0,>=2.1 Downloading python_dateutil-2.8.1-py2.py3-none-any.whl (227 kB) |████████████████████████████████| 227 kB 6.4 MB/s Collecting urllib3<1.26,>=1.20 Downloading urllib3-1.25.8-py2.py3-none-any.whl (125 kB) |████████████████████████████████| 125 kB 6.4 MB/s Collecting six>=1.5 Downloading six-1.14.0-py2.py3-none-any.whl (10 kB) Installing collected packages: jmespath, docutils, six, python-dateutil, urllib3, botocore Running setup.py install for botocore ... done Successfully installed botocore-2.0.0.dev6 docutils-0.15.2 jmespath-0.9.5 python-dateutil-2.8.1 six-1.14.0 urllib3-1.25.8試した環境ではプロキシの影響で
--trusted-hostオプションを付与せずに実行すると次のエラーメッセージが出力されてしまいましたPS C:\> & pip install https://github.com/boto/botocore/archive/v2.tar.gz Collecting https://github.com/boto/botocore/archive/v2.tar.gz WARNING: Retrying (Retry(total=4, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: self signed certificate in certificate chain (_ssl.c:1108)'))': /boto/botocore/archive/v2.tar.gz WARNING: Retrying (Retry(total=3, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: self signed certificate in certificate chain (_ssl.c:1108)'))': /boto/botocore/archive/v2.tar.gz WARNING: Retrying (Retry(total=2, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: self signed certificate in certificate chain (_ssl.c:1108)'))': /boto/botocore/archive/v2.tar.gz WARNING: Retrying (Retry(total=1, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: self signed certificate in certificate chain (_ssl.c:1108)'))': /boto/botocore/archive/v2.tar.gz WARNING: Retrying (Retry(total=0, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: self signed certificate in certificate chain (_ssl.c:1108)'))': /boto/botocore/archive/v2.tar.gz ERROR: Could not install packages due to an EnvironmentError: HTTPSConnectionPool(host='github.com', port=443): Max retries exceeded with url: /boto/botocore/archive/v2.tar.gz (Caused by SSLError(SSLCertVerificationError(1, '[SSL: CERTIFICATE_VERIFY_FAILED] certificate verify failed: self signed certificate in certificate chain (_ssl.c:1108)')))□手順 2-3: 次に
aws-cliをGitHubレポジトリからインストールしますPS C:\> & pip install --trusted-host pypi.org --trusted-host files.pythonhosted.org --trusted-host github.com --trusted-host codeload.github.com https://github.com/aws/aws-cli/archive/v2.tar.gz Collecting https://github.com/aws/aws-cli/archive/v2.tar.gz Downloading https://github.com/aws/aws-cli/archive/v2.tar.gz - 3.0 MB 15 kB/s Requirement already satisfied: botocore==2.0.0dev6 in c:\users\kukita\appdata\local\programs\python\python38\lib\site-packages (from awscli==2.0.2) (2.0.0.dev6) Collecting colorama<0.4.4,>=0.2.5 Downloading colorama-0.4.3-py2.py3-none-any.whl (15 kB) Requirement already satisfied: docutils<0.16,>=0.10 in c:\users\kukita\appdata\local\programs\python\python38\lib\site-packages (from awscli==2.0.2) (0.15.2) Collecting cryptography<=2.9.0,>=2.8.0 Downloading cryptography-2.8-cp38-cp38-win_amd64.whl (1.5 MB) |████████████████████████████████| 1.5 MB 3.2 MB/s Collecting s3transfer<0.4.0,>=0.3.0 Downloading s3transfer-0.3.3-py2.py3-none-any.whl (69 kB) |████████████████████████████████| 69 kB 4.5 MB/s Collecting ruamel.yaml<0.16.0,>=0.15.0 Downloading ruamel.yaml-0.15.100.tar.gz (318 kB) |████████████████████████████████| 318 kB 6.4 MB/s Collecting prompt-toolkit<3.0.0,>=2.0.0 Downloading prompt_toolkit-2.0.10-py3-none-any.whl (340 kB) |████████████████████████████████| 340 kB 6.4 MB/s Requirement already satisfied: jmespath<1.0.0,>=0.7.1 in c:\users\kukita\appdata\local\programs\python\python38\lib\site-packages (from botocore==2.0.0dev6->awscli==2.0.2) (0.9.5) Requirement already satisfied: python-dateutil<3.0.0,>=2.1 in c:\users\kukita\appdata\local\programs\python\python38\lib\site-packages (from botocore==2.0.0dev6->awscli==2.0.2) (2.8.1) Requirement already satisfied: urllib3<1.26,>=1.20 in c:\users\kukita\appdata\local\programs\python\python38\lib\site-packages (from botocore==2.0.0dev6->awscli==2.0.2) (1.25.8) Requirement already satisfied: six>=1.4.1 in c:\users\kukita\appdata\local\programs\python\python38\lib\site-packages (from cryptography<=2.9.0,>=2.8.0->awscli==2.0.2) (1.14.0) Collecting cffi!=1.11.3,>=1.8 Downloading cffi-1.14.0-cp38-cp38-win_amd64.whl (177 kB) |████████████████████████████████| 177 kB 6.8 MB/s Collecting wcwidth Downloading wcwidth-0.1.8-py2.py3-none-any.whl (17 kB) Collecting pycparser Downloading pycparser-2.20-py2.py3-none-any.whl (112 kB) |████████████████████████████████| 112 kB 3.2 MB/s Installing collected packages: colorama, pycparser, cffi, cryptography, s3transfer, ruamel.yaml, wcwidth, prompt-toolkit, awscli Running setup.py install for ruamel.yaml ... done Running setup.py install for awscli ... done Successfully installed awscli-2.0.2 cffi-1.14.0 colorama-0.4.3 cryptography-2.8 prompt-toolkit-2.0.10 pycparser-2.20 ruamel.yaml-0.15.100 s3transfer-0.3.3 wcwidth-0.1.8□手順 2-4:
aws --versionコマンドを実行し正常にインストールされていることを確認できれば完了ですPS C:\> & aws --version 拡張子 .py のファイルの関連付けが見つかりません aws-cli/2.0.2 Python/3.8.2 Windows/10 botocore/2.0.0dev6おまけ:
拡張子 .py のファイルの関連付けが見つかりませんという警告メッセージへの対応管理者権限を有しているアカウントで下記コマンドを実行してもらうことができれば解決できるはずです。。。
PS C:\> & assoc .py=Python.File PS C:\> & ftype Python.File="%USERPROFILE%\AppData\Local\Programs\Python\Python37\python.exe" "%1" %*おまけ(その2): 「AWS CLI v2」実行時のMFA(Multi-Factor Authentication:多要素認証)の有効化
「AWS CLI」を使用するためにはアクセスキー(アクセスキーIDとシークレットキーのキーペア)が必要になるのですが、このアクセスキーが漏洩すると怖いことが起こるので、ちゃんとMFA(Multi-Factor Authentication:多要素認証)を有効にしましょう ↓
【#awscli】あらかじめ指定した接続元IPアドレス以外からの「AWS CLI v2」実行時はMFA(ワンタイムパスワードでの認証)が必要になるようIAMを設定する #AWS #awscliv2 #jawsug #環境構築 #環境設定
https://qiita.com/kukita/items/1a4f9c35a956eb37003d
以上、管理者権限を持たないWindows端末に「AWSコマンドラインインターフェイス(AWS CLI v2)」をインストールする手順でした。



- 投稿日:2020-03-21T03:58:19+09:00
時々忘れるので「MFA前提でAWS CLI を使う方法」をメモ
概要
MFAを有効にしている前提でAWS CLIを使うときの方法を忘れて、ハマる事象の回避のためのメモとリンク
要するに
- aws sts get-session-tokenでキーを取得
- exportでキーを設定
- aws xxを打てる状態に
手順
AWS公式ページを見て実行するのみ。
https://aws.amazon.com/jp/premiumsupport/knowledge-center/authenticate-mfa-cli/
- 投稿日:2020-03-21T03:53:44+09:00
【#awscli】特定の接続元IPアドレス以外からの「AWS CLI v2」実行時のみMFA(ワンタイムパスワードでの認証)が必要になるようIAMを設定する #AWS #awscli2 #jawsug #環境構築 #環境設定
特定の接続元IPアドレス以外からの「AWSコマンドラインインターフェイス(AWS CLI v2)」実行時のみMFA(Multi-Factor Authentication)が必要になるようにIAMの設定をしたので、その際の手順を自分用のメモとしてまとめました。
MFA(Multi-Factor Authentication:多要素認証)とは
参考: Wikipedia - 多要素認証
https://ja.wikipedia.org/wiki/多要素認証簡単に説明すると次の4つの要素のうち2要素以上を使用して認証を行うことです
1.知る要素
2.持つ要素
3.備える要素
4.場所の要素認証を多段階で実施しても(多段階認証をしても)、同じ要素での認証ではセキュアではないとされています(例: ”印鑑”と”通帳”など)
ちなみに、
天空の城ラピュタにおける崩壊の呪文は、
- ”バルス” という呪文を【←知る要素】
- 飛行石の結晶 を持った状態で【←持つ要素】
- 王族の人間 が【←備える要素】
- ラピュタ内の聖域と呼ばれる場所 で【←場所の要素】
唱えた場合のみ発動するので四要素認証になっています∑d(゚∀゚d)イカス!!
MFA(Multi-Factor Authentication)を設定しないとどうなるのか?
「AWS CLI」を使用するためにはアクセスキー(アクセスキーIDとシークレットキーのキーペア)が必要になるのですが、このアクセスキーが漏洩すると怖いことが起こります。
参考: 初心者がAWSでミスって不正利用されて$6,000請求、泣きそうになったお話。
https://qiita.com/mochizukikotaro/items/a0e98ff0063a77e7b694参考: GitHub に AWS キーペアを上げると抜かれるってほんと???試してみよー!
https://qiita.com/saitotak/items/813ac6c2057ac64d5fefAWSではどういった対策ができるのか?
[AWSマネージメントコンソールへのアクセス]時に ”スマーフォンデバイス(TOTP:Time-based One-Time Password)” での認証を有効にする↓というのは比較的知られていますが、「AWS CLI」でも同様に設定することが可能です。
少し違う点は、「AWS CLI」の場合、1コマンド実行するごとにワンタイムパスワード認証を求められるのはツライので、
「AWS Security Token Service (AWS STS)」より払い出された有効期限付き(デフォルト1時間)のセッショントークンを使用するという点です。まず、前半の部分で「AWS STS」のセッショントークンを払い出す際はMFAを必要とする設定を行います。
加えて、後半の部分で、特定の接続IPアドレスからのアクセス時のみは、ワンタイムパスワードの入力なしでアクセスキー(アクセスキーIDとシークレットキーのキーペア)だけで実行できるようにする設定を行います。
1. IAMグループとIAMユーザーの作成 (「管理者」側手順)
まず、AWS CLI を実行する際に使用するIAMユーザーを作成します。
設定はIAMポリシーで制御するのですが、AWSのベストプラクティスに従って、IAMユーザーに直接ポリシーをアタッチするのではなく、IAMグループを作成して、作成したIAMグループに対してMFAを有効化するためのポリシーをアタッチしていきます
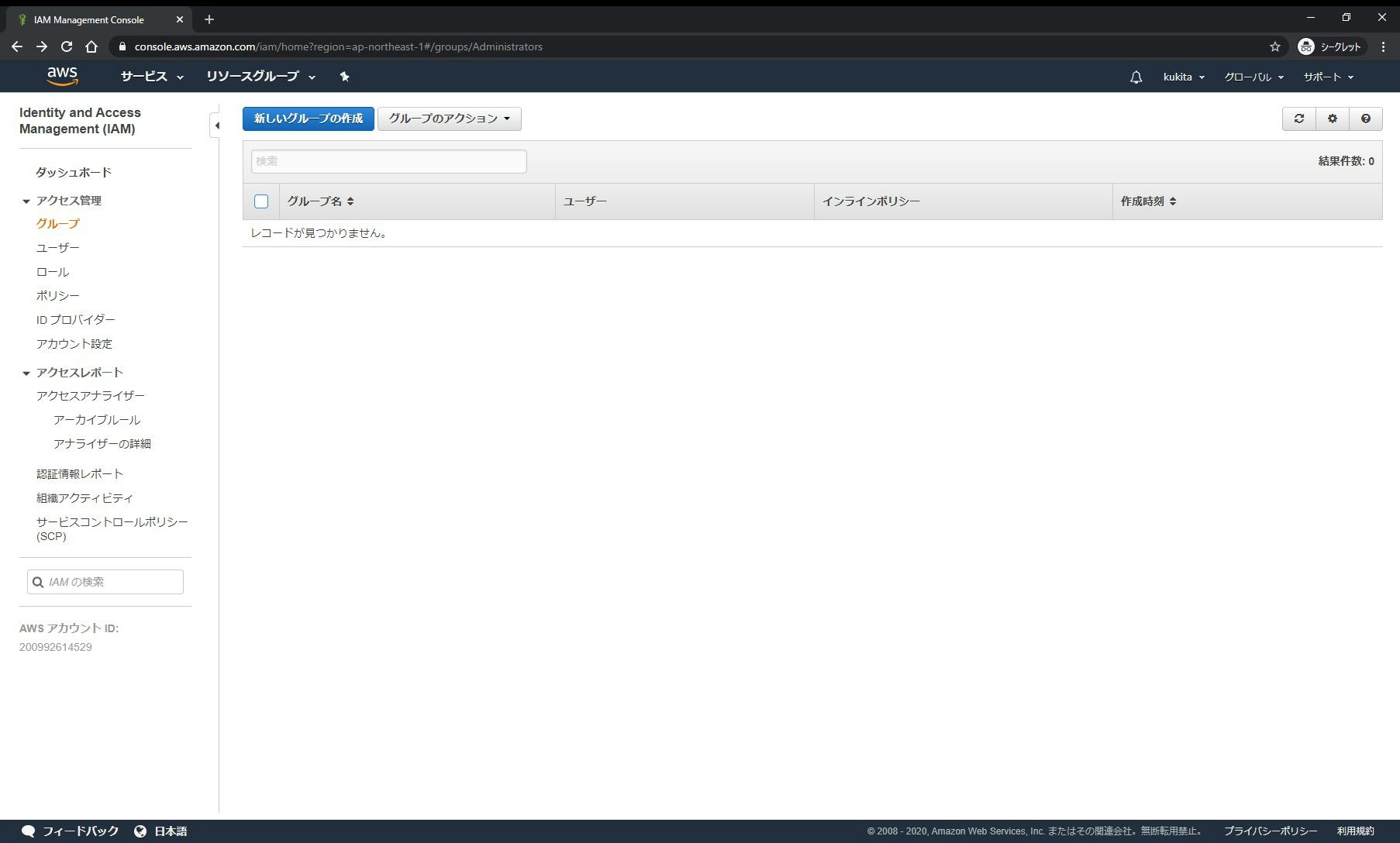
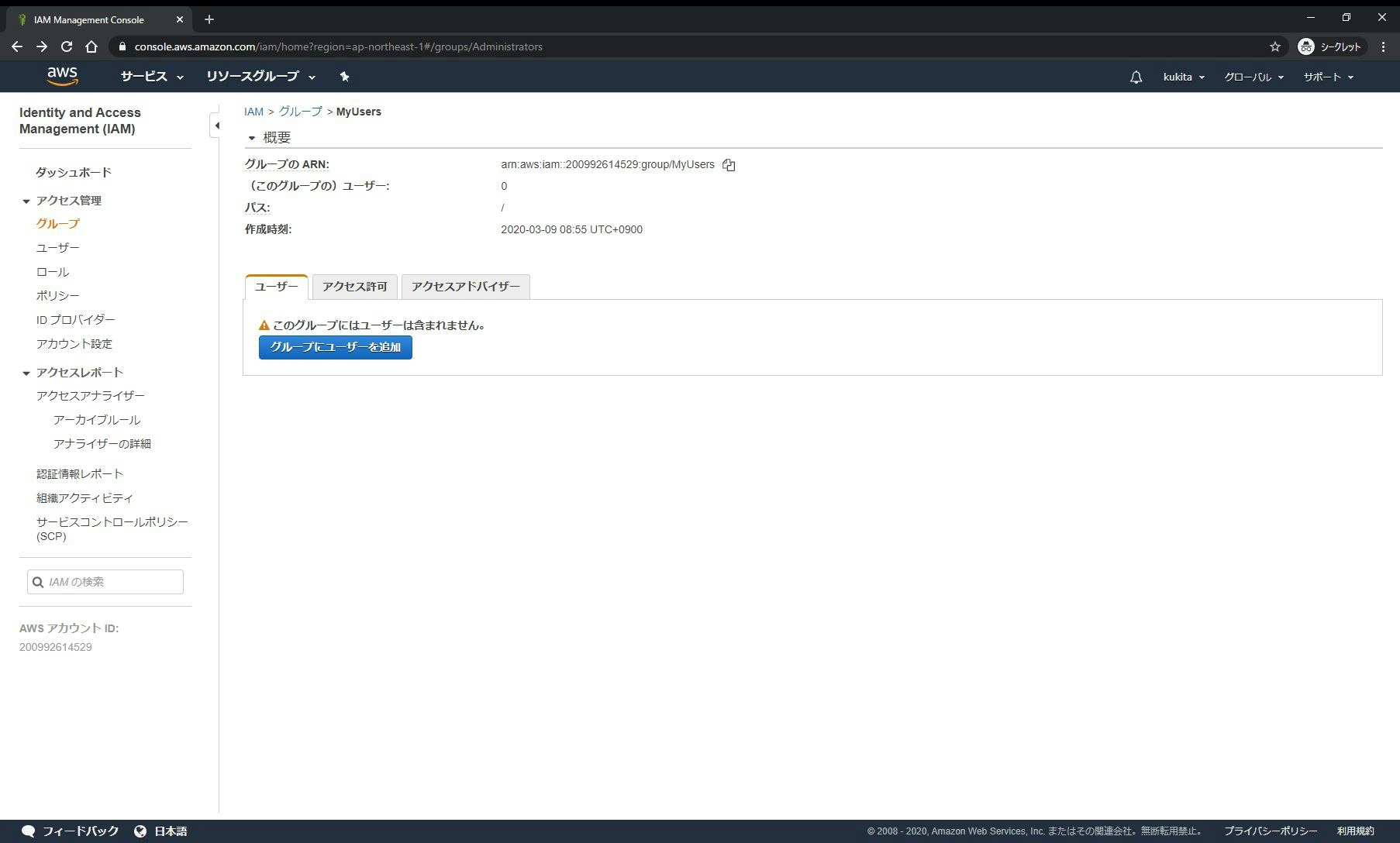
□手順 1-1: [Identity and Access Management(IAM)]サービスの[グループ]メニュー画面で[新しいグループの作成]をクリックします
□手順 1-2: [グループ名]に任意の名前(ここでは
MyUsers)を入力し[次のステップ]をクリックします
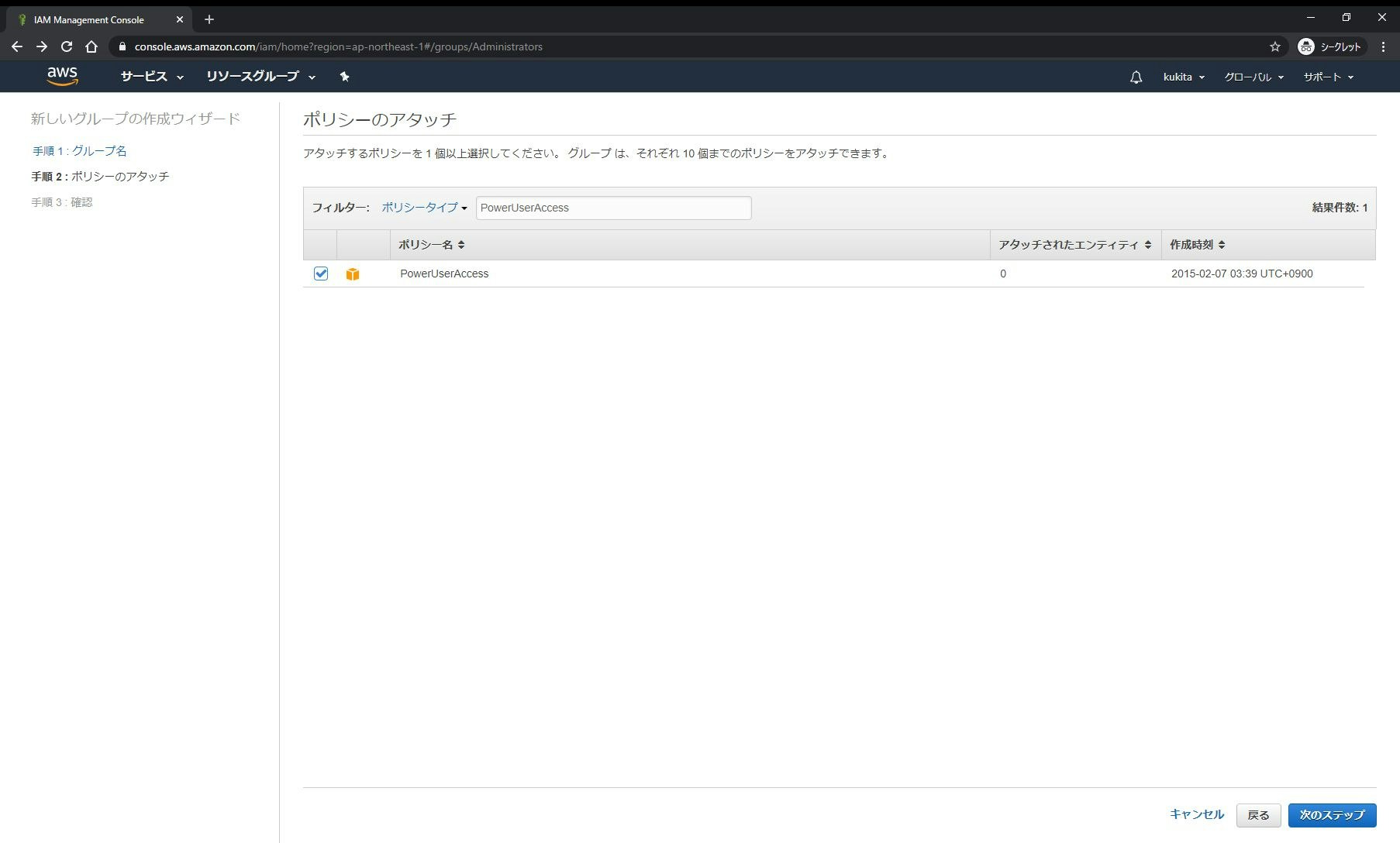
□手順 1-3: [ポリシーのアタッチ]画面で、任意のAWS管理ポリシー(ここでは
PowerUserAccessポリシー)を選択し[次のステップ]をクリックします
□手順 1-4: 内容を確認し[グループの作成]をクリックします
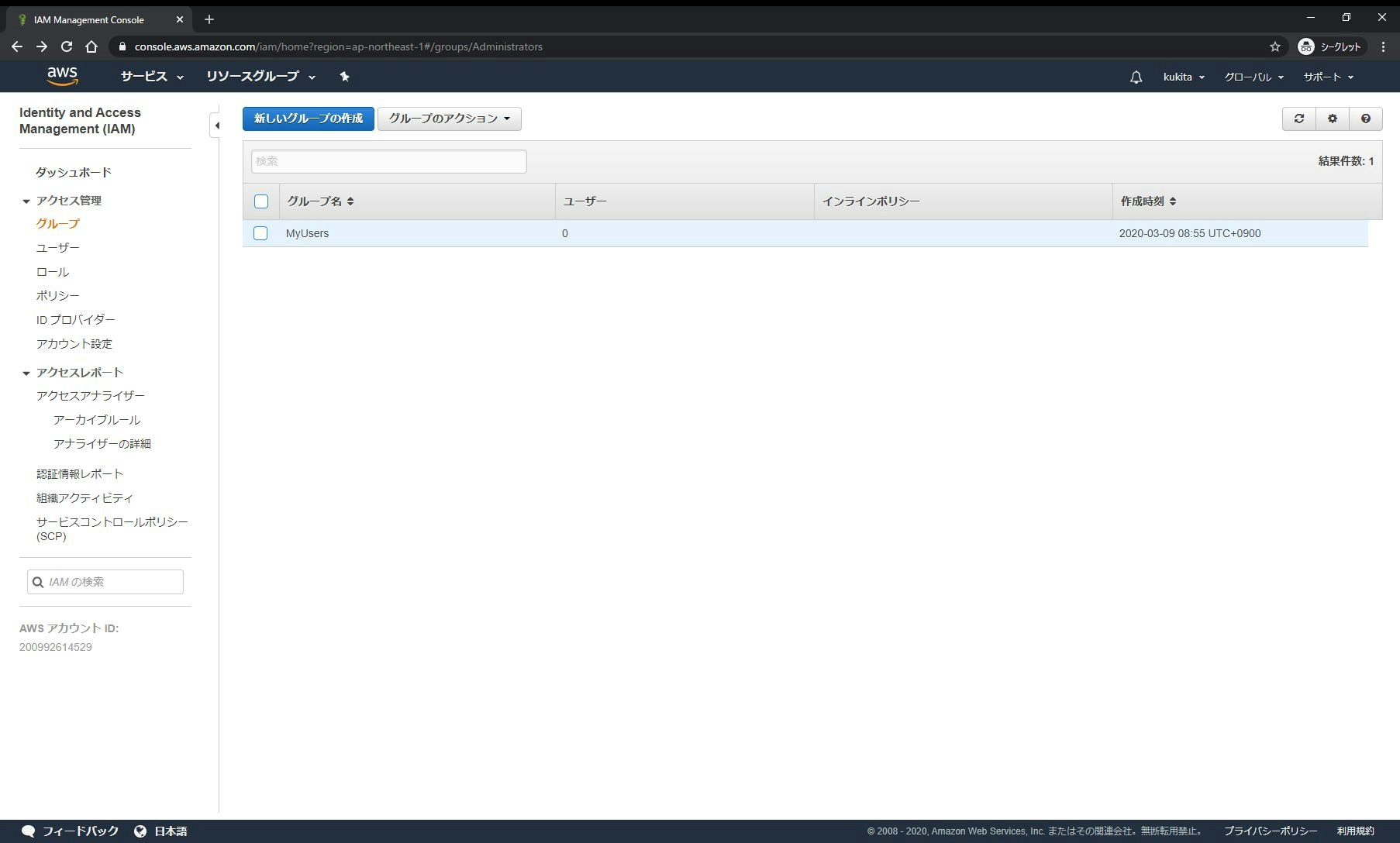
□手順 1-5: IAMグループ(
MyUsers)が作成されたことを確認します
□手順 1-6: 続いて[Identity and Access Management(IAM)]サービスの[ユーザー]メニュー画面に移り[ユーザーを追加]をクリックします
□手順 1-7: [ユーザー名]に任意の名前(ここでは
cli-user)を入力し[プログラムによるアクセス]にチェックを入れて[次のステップ:アクセス権限]をクリックします※必要ではないのでチェックを入れていませんが[AWSマネージメントコンソールへのアクセス]にチェックを入れても問題はないと思います
□手順 1-8: [ユーザーをグループに追加]で先ほど作成したIAMグループを選択し[次のステップ:タグ]をクリックします
□手順 1-9: 必要に応じてタグを設定し(ここでは何も設定せずに)[次のステップ:確認]をクリックします
□手順 1-10: 内容を確認し[ユーザーの作成]をクリックします
□手順 1-11: "成功"のメッセージを確認し[.csvのダウンロード]をクリックして完了です
※ダウンロードした CSVファイル は後ほど使用します
2. 「スマートフォンデバイス」(←持つ要素)によるMFA(多要素認証)の有効化 (「管理者」側手順)
AWSでは「仮想MFAデバイス」と「AWS Security Token Service (AWS STS)」の仕組みを使う事で「AWS CLI」でも「スマートフォンデバイス」(←持つ要素)でのMFA(多要素認証)を実現することができます
□手順 2-1: 作成したIAMグループ(
MyUsers)をクリックします
□手順 2-2: [アクセス許可]タブをクリックします
□手順 2-3: [インラインポリシー]の”ここをクリックしてください”部分をクリックします
□手順 2-4: [カスタムポリシー]にチェックを入れます
□手順 2-5: [ポリシー名]に任意の名前(ここでは
MyUsersPolicy)、[ポリシードキュメント]に次の「AWSユーザーガイド」記載の内容を入力して[ポリシー]の適用をクリックしますAWSユーザーガイド - IAM: IAM ユーザーに MFA デバイスの自己管理を許可する
https://docs.aws.amazon.com/ja_jp/IAM/latest/UserGuide/reference_policies_examples_iam_mfa-selfmanage.htmlMyUsersPolicy{ "Version": "2012-10-17", "Statement": [ { "Sid": "AllowListActions", "Effect": "Allow", "Action": [ "iam:ListUsers", "iam:ListVirtualMFADevices" ], "Resource": "*" }, { "Sid": "AllowIndividualUserToListOnlyTheirOwnMFA", "Effect": "Allow", "Action": [ "iam:ListMFADevices" ], "Resource": [ "arn:aws:iam::*:mfa/*", "arn:aws:iam::*:user/${aws:username}" ] }, { "Sid": "AllowIndividualUserToManageTheirOwnMFA", "Effect": "Allow", "Action": [ "iam:CreateVirtualMFADevice", "iam:DeleteVirtualMFADevice", "iam:EnableMFADevice", "iam:ResyncMFADevice" ], "Resource": [ "arn:aws:iam::*:mfa/${aws:username}", "arn:aws:iam::*:user/${aws:username}" ] }, { "Sid": "AllowIndividualUserToDeactivateOnlyTheirOwnMFAOnlyWhenUsingMFA", "Effect": "Allow", "Action": [ "iam:DeactivateMFADevice" ], "Resource": [ "arn:aws:iam::*:mfa/${aws:username}", "arn:aws:iam::*:user/${aws:username}" ], "Condition": { "Bool": { "aws:MultiFactorAuthPresent": "true" } } }, { "Sid": "BlockMostAccessUnlessSignedInWithMFA", "Effect": "Deny", "NotAction": [ "iam:CreateVirtualMFADevice", "iam:EnableMFADevice", "iam:ListMFADevices", "iam:ListUsers", "iam:ListVirtualMFADevices", "iam:ResyncMFADevice" ], "Resource": "*", "Condition": { "BoolIfExists": { "aws:MultiFactorAuthPresent": "false" } } } ] }このインラインポリシーを適用することによりユーザーは後述するMFAデバイスの登録作業などを以外のオペレーションはMFAなしでは実行できないようになります
□手順 2-6: 「管理者」側手順はこれで終了です
4. 仮想MFAデバイスの作成 (「ユーザー」側手順)
ここから「AWS CLI v2」を使用する「ユーザー」側の手順です
□手順 4-1: 「AWS CLI v2」の新機能である
aws configure importコマンドを使ってIAMユーザー作成時にダウンロードしたCSVファイルからクレデンシャル情報(アクセスキーの情報)を読み取ります実行コマンドaws configure import --csv file://<CSVファイル名>実行例[user@workstaion ~]$ aws configure import --csv file://credentials.csv Successfully imported 1 profile(s)□手順 4-2: この状態でコマンドを実行してお
Access Deniedとなってしまうことを確認します実行例[user@workstaion ~]$ aws s3 ls --proflie "cli-user" An error occurred (AccessDenied) when calling the ListBuckets operation: Access Denied□手順 4-3:
aws iam create-virtual-mfa-deviceコマンドを実行して仮想MFAデバイスと共有鍵情報が保存されたQRコードを生成します
--virtual-mfa-device-nameパラメーターに設定する名前はIAMユーザーと同じにしてください実行コマンドaws iam create-virtual-mfa-device --virtual-mfa-device-name "<任意の仮想MFAデバイス名>" --outfile <QRコードを出力する任意のパス> --bootstrap-method "QRCodePNG" --profile "<IAMユーザープロファイル名>"実行例[user@workstaion ~]$ aws iam create-virtual-mfa-device --virtual-mfa-device-name "cli-user" --outfile .\QRCode.png --bootstrap-method "QRCodePNG" --profile "cli-user" { "VirtualMFADevice": { "SerialNumber": "<作成された仮想MFAデバイスのリソースネーム(ARN)>" } }ここで出力される”仮想MFAデバイスのリソースネーム(ARN)"の値は後ほど使用するのでメモしておきます
AWS管理コンソールからも確認可能です(該当IAMユーザーの[認証情報]タブ)↓
□手順 4-4: 「Google 認証システム(Google Authenticator)」などをスマートフォンにインストールして先ほど生成した共有鍵情報が保存されたQRコードを読み取ります
App Store - Google Authenticator
https://apps.apple.com/jp/app/google-authenticator/id388497605Google Play - Google 認証システム
https://play.google.com/store/apps/details?id=com.google.android.apps.authenticator2□手順 4-5:
aws iam enable-mfa-deviceコマンドを実行して作成した仮想MFAデバイスの有効化(スマートフォンデバイスとの同期)を行います実行コマンドaws iam enable-mfa-device --user-name "<IAMユーザー名>" --serial-number "<仮想MFAデバイスのリソースネーム(ARN)>" --authentication-code1 "<MFAデバイスに表示されている6桁の数字>" --authentication-code2 "<`--authentication-code1`に設定した値の次に表示される6桁の数字>" --profile "<IAMユーザープロファイル名>"実行例[user@workstaion ~]$ aws iam enable-mfa-device --user-name "cli-user" --serial-number "<仮想MFAデバイスのリソースネーム(ARN)>" --authentication-code1 "123456" --authentication-code2 "234567" --profile "cli-user"□手順 4-6:
aws sts get-session-tokenコマンドを実行することで有効期限付き(デフォルト1時間)のセッショントークンを取得することができます実行コマンドaws sts get-session-token --serial-number "<仮想MFAデバイスのリソースネーム(ARN)>" --token-code <MFAデバイスに表示されている6桁の数字> --profile "<IAMユーザープロファイル名>"実行例[user@workstaion ~]$ aws sts get-session-token --serial-number "<仮想MFAデバイスのリソースネーム(ARN)>" --token-code <MFAデバイスに表示されている6桁の数字> --profile "cli-user" { "Credentials": { "AccessKeyId": "<アクセスキーID>", "SecretAccessKey": "<シークレットアクセスキー>", "SessionToken": "<セッショントークン>", "Expiration": "<セッショントークンの有効期限(yyyy-MM-ddTHH:mm:ss+00:00)>" } }□手順 4-7:
aws sts get-session-tokenコマンドで得られた値を次の環境変数に設定します
環境変数名 設定する値 説明 AWS_ACCESS_KEY_ID Credentials.AccessKeyIdの値 アクセスキーID AWS_SECRET_ACCESS_KEY Credentials.SecretAccessKeyの値 シークレットアクセスキー AWS_SESSION_TOKEN Credentials.SessionTokenの値 セッショントークン [MacOSやLinux環境での実行例]
jqコマンドが使える環境であれば次のようなスクリプトを作成して実行しますBashの場合virtualMFADevice = "<仮想MFAデバイスのリソースネーム(ARN)>" profileName = "cli-user" echo "MFAデバイスに表示されている6桁の数字を入力してください" read tokenCode sessionToken=$(aws sts get-session-token --serial-number "$virtualMFADevice" --token-code "$tokenCode" --profile "$profileName") export AWS_ACCESS_KEY_ID=$(echo $sessionToken | jq -r .Credentials.AccessKeyId) export AWS_SECRET_ACCESS_KEY=$(echo $sessionToken | jq -r .Credentials.SecretAccessKey) export AWS_SESSION_TOKEN=$(echo $sessionToken | jq -r .Credentials.SessionToken)[Windows環境での実行例]PowerShellの
ConvertFrom-Jsonコマンドレットを使えばJSONのパースが可能なので次のようなスクリプトを作成して実行しますPowerShellの場合$virtualMFADevice = "<仮想MFAデバイスのリソースネーム(ARN)>" $profileName = "cli-user" $tokenCode = Read-Host "MFAデバイスに表示されている6桁の数字を入力してください" $sessionToken = $(& aws sts get-session-token --serial-number "$virtualMFADevice" --token-code "$tokenCode" --profile "$profileName" | ConvertFrom-Json) $env:AWS_ACCESS_KEY_ID=$sessionToken.Credentials.AccessKeyID $env:AWS_SECRET_ACCESS_KEY=$sessionToken.Credentials.SecretAccessKey $env:AWS_SESSION_TOKEN=$sessionToken.Credentials.SessionToken□手順 4-8: この状態で「AWS CLI」を実行し Access Denied などのエラーメッセージが表示されなくなっていれば成功です
※この時
--profileオプションの付与は不要です実行例[user@workstaion ~]$ aws s3 ls yyyy-MM-dd HH:mm:ss xxxx :
5. 特定の接続IPアドレスからのアクセス時はMFAなしでアクセスできるように設定 (「管理者」側手順)
続いて、特定の接続IPアドレスからのアクセス時のみは、ワンタイムパスワードの入力なしでアクセスできるように設定します。
□手順 5-1: 作成したIAMグループ(
MyUsers)をクリックします
□手順 5-2: [アクセス許可]タブをクリックします
□手順 5-3: [インラインポリシー]の”ポリシーの編集”部分をクリックします
□手順 5-4: ポリシードキュメントの ”Condition” 句を次のように修正して[ポリシーの適用]をクリックします
修正前"Condition": { "BoolIfExists": { "aws:MultiFactorAuthPresent": "false" } }修正後"Condition": { "BoolIfExists": { "aws:MultiFactorAuthPresent": "false" }, "NotIpAddress": { "aws:SourceIp": [ "xxx.xxx.xxx.xxx", "yyy.yyy.yyy.yyy" ] } }□手順 5-5: 「管理者」側手順はこれで終了です
6. 「AWS CLI」の実行(「ユーザー」側手順)
再び「AWS CLI」を使用する「ユーザー」側の手順です
□手順 6-1:
--profileオプションを付与して「AWS CLI」を実行し、問題なく実行できれば成功です実行例[user@workstaion ~]$ aws s3 ls --proflie "cli-user" yyyy-MM-dd HH:mm:ss xxxx :
以上、特定の接続元IPアドレス以外から「AWSコマンドラインインターフェイス(AWS CLI v2)」を実行した際のみMFA(Multi-Factor Authentication)が必要になるようにIAMの設定をした際の手順でした。












- 投稿日:2020-03-21T03:53:44+09:00
【#awscli】特定の接続元IPアドレス以外からの「AWS CLI v2」実行時のみMFA(ワンタイムパスワードでの認証)が必要になるようIAMを設定する #AWS #awscliv2 #jawsug #環境構築 #環境設定
特定の接続元IPアドレス以外からの「AWSコマンドラインインターフェイス(AWS CLI v2)」実行時のみMFA(Multi-Factor Authentication)が必要になるようにIAMの設定をしたので、その際の手順を自分用のメモとしてまとめました。
MFA(Multi-Factor Authentication:多要素認証)とは
参考: Wikipedia - 多要素認証
https://ja.wikipedia.org/wiki/多要素認証簡単に説明すると次の4つの要素のうち2要素以上を使用して認証を行うことです
1.知る要素
2.持つ要素
3.備える要素
4.場所の要素認証を多段階で実施しても(多段階認証をしても)、同じ要素での認証ではセキュアではないとされています(例: ”印鑑”と”通帳”など)
ちなみに、
天空の城ラピュタにおける崩壊の呪文は、
- ”バルス” という呪文を【←知る要素】
- 飛行石の結晶 を持った状態で【←持つ要素】
- 王族の人間 が【←備える要素】
- ラピュタ内の聖域と呼ばれる場所 で【←場所の要素】
唱えた場合のみ発動するので四要素認証になっています∑d(゚∀゚d)イカス!!
MFA(Multi-Factor Authentication)を設定しないとどうなるのか?
「AWS CLI」を使用するためにはアクセスキー(アクセスキーIDとシークレットキーのキーペア)が必要になるのですが、このアクセスキーが漏洩すると怖いことが起こります。
参考: 初心者がAWSでミスって不正利用されて$6,000請求、泣きそうになったお話。
https://qiita.com/mochizukikotaro/items/a0e98ff0063a77e7b694参考: GitHub に AWS キーペアを上げると抜かれるってほんと???試してみよー!
https://qiita.com/saitotak/items/813ac6c2057ac64d5fefAWSではどういった対策ができるのか?
[AWSマネージメントコンソールへのアクセス]時に ”スマーフォンデバイス(TOTP:Time-based One-Time Password)” での認証を有効にする↓というのは比較的知られていますが、「AWS CLI」でも同様に設定することが可能です。
少し違う点は、「AWS CLI」の場合、1コマンド実行するごとにワンタイムパスワード認証を求められるのはツライので、
「AWS Security Token Service (AWS STS)」より払い出された有効期限付き(デフォルト1時間)のセッショントークンを使用するという点です。まず、前半の部分で「AWS STS」のセッショントークンを払い出す際はMFAを必要とする設定を行います。
加えて、後半の部分で、特定の接続IPアドレスからのアクセス時のみは、ワンタイムパスワードの入力なしでアクセスキー(アクセスキーIDとシークレットキーのキーペア)だけで実行できるようにする設定を行います。
1. IAMグループとIAMユーザーの作成 (「管理者」側手順)
まず、AWS CLI を実行する際に使用するIAMユーザーを作成します。
設定はIAMポリシーで制御するのですが、AWSのベストプラクティスに従って、IAMユーザーに直接ポリシーをアタッチするのではなく、IAMグループを作成して、作成したIAMグループに対してMFAを有効化するためのポリシーをアタッチしていきます
□手順 1-1: [Identity and Access Management(IAM)]サービスの[グループ]メニュー画面で[新しいグループの作成]をクリックします
□手順 1-2: [グループ名]に任意の名前(ここでは
MyUsers)を入力し[次のステップ]をクリックします
□手順 1-3: [ポリシーのアタッチ]画面で、任意のAWS管理ポリシー(ここでは
PowerUserAccessポリシー)を選択し[次のステップ]をクリックします
□手順 1-4: 内容を確認し[グループの作成]をクリックします
□手順 1-5: IAMグループ(
MyUsers)が作成されたことを確認します
□手順 1-6: 続いて[Identity and Access Management(IAM)]サービスの[ユーザー]メニュー画面に移り[ユーザーを追加]をクリックします
□手順 1-7: [ユーザー名]に任意の名前(ここでは
cli-user)を入力し[プログラムによるアクセス]にチェックを入れて[次のステップ:アクセス権限]をクリックします※必要ではないのでチェックを入れていませんが[AWSマネージメントコンソールへのアクセス]にチェックを入れても問題はないと思います
□手順 1-8: [ユーザーをグループに追加]で先ほど作成したIAMグループを選択し[次のステップ:タグ]をクリックします
□手順 1-9: 必要に応じてタグを設定し(ここでは何も設定せずに)[次のステップ:確認]をクリックします
□手順 1-10: 内容を確認し[ユーザーの作成]をクリックします
□手順 1-11: "成功"のメッセージを確認し[.csvのダウンロード]をクリックして完了です
※ダウンロードした CSVファイル は後ほど使用します
2. 「スマートフォンデバイス」(←持つ要素)によるMFA(多要素認証)の有効化 (「管理者」側手順)
AWSでは「仮想MFAデバイス」と「AWS Security Token Service (AWS STS)」の仕組みを使う事で「AWS CLI」でも「スマートフォンデバイス」(←持つ要素)でのMFA(多要素認証)を実現することができます
□手順 2-1: 作成したIAMグループ(
MyUsers)をクリックします
□手順 2-2: [アクセス許可]タブをクリックします
□手順 2-3: [インラインポリシー]の”ここをクリックしてください”部分をクリックします
□手順 2-4: [カスタムポリシー]にチェックを入れます
□手順 2-5: [ポリシー名]に任意の名前(ここでは
MyUsersPolicy)、[ポリシードキュメント]に次の「AWSユーザーガイド」記載の内容を入力して[ポリシー]の適用をクリックしますAWSユーザーガイド - IAM: IAM ユーザーに MFA デバイスの自己管理を許可する
https://docs.aws.amazon.com/ja_jp/IAM/latest/UserGuide/reference_policies_examples_iam_mfa-selfmanage.htmlMyUsersPolicy{ "Version": "2012-10-17", "Statement": [ { "Sid": "AllowListActions", "Effect": "Allow", "Action": [ "iam:ListUsers", "iam:ListVirtualMFADevices" ], "Resource": "*" }, { "Sid": "AllowIndividualUserToListOnlyTheirOwnMFA", "Effect": "Allow", "Action": [ "iam:ListMFADevices" ], "Resource": [ "arn:aws:iam::*:mfa/*", "arn:aws:iam::*:user/${aws:username}" ] }, { "Sid": "AllowIndividualUserToManageTheirOwnMFA", "Effect": "Allow", "Action": [ "iam:CreateVirtualMFADevice", "iam:DeleteVirtualMFADevice", "iam:EnableMFADevice", "iam:ResyncMFADevice" ], "Resource": [ "arn:aws:iam::*:mfa/${aws:username}", "arn:aws:iam::*:user/${aws:username}" ] }, { "Sid": "AllowIndividualUserToDeactivateOnlyTheirOwnMFAOnlyWhenUsingMFA", "Effect": "Allow", "Action": [ "iam:DeactivateMFADevice" ], "Resource": [ "arn:aws:iam::*:mfa/${aws:username}", "arn:aws:iam::*:user/${aws:username}" ], "Condition": { "Bool": { "aws:MultiFactorAuthPresent": "true" } } }, { "Sid": "BlockMostAccessUnlessSignedInWithMFA", "Effect": "Deny", "NotAction": [ "iam:CreateVirtualMFADevice", "iam:EnableMFADevice", "iam:ListMFADevices", "iam:ListUsers", "iam:ListVirtualMFADevices", "iam:ResyncMFADevice" ], "Resource": "*", "Condition": { "BoolIfExists": { "aws:MultiFactorAuthPresent": "false" } } } ] }このインラインポリシーを適用することによりユーザーは後述するMFAデバイスの登録作業などを以外のオペレーションはMFAなしでは実行できないようになります
□手順 2-6: 「管理者」側手順はこれで終了です
4. 仮想MFAデバイスの作成 (「ユーザー」側手順)
ここから「AWS CLI v2」を使用する「ユーザー」側の手順です
□手順 4-1: 「AWS CLI v2」の新機能である
aws configure importコマンドを使ってIAMユーザー作成時にダウンロードしたCSVファイルからクレデンシャル情報(アクセスキーの情報)を読み取ります実行コマンドaws configure import --csv file://<CSVファイル名>実行例[user@workstaion ~]$ aws configure import --csv file://credentials.csv Successfully imported 1 profile(s)□手順 4-2: この状態でコマンドを実行してお
Access Deniedとなってしまうことを確認します実行例[user@workstaion ~]$ aws s3 ls --proflie "cli-user" An error occurred (AccessDenied) when calling the ListBuckets operation: Access Denied□手順 4-3:
aws iam create-virtual-mfa-deviceコマンドを実行して仮想MFAデバイスと共有鍵情報が保存されたQRコードを生成します
--virtual-mfa-device-nameパラメーターに設定する名前はIAMユーザーと同じにしてください実行コマンドaws iam create-virtual-mfa-device --virtual-mfa-device-name "<任意の仮想MFAデバイス名>" --outfile <QRコードを出力する任意のパス> --bootstrap-method "QRCodePNG" --profile "<IAMユーザープロファイル名>"実行例[user@workstaion ~]$ aws iam create-virtual-mfa-device --virtual-mfa-device-name "cli-user" --outfile .\QRCode.png --bootstrap-method "QRCodePNG" --profile "cli-user" { "VirtualMFADevice": { "SerialNumber": "<作成された仮想MFAデバイスのリソースネーム(ARN)>" } }ここで出力される”仮想MFAデバイスのリソースネーム(ARN)"の値は後ほど使用するのでメモしておきます
AWS管理コンソールからも確認可能です(該当IAMユーザーの[認証情報]タブ)↓
□手順 4-4: 「Google 認証システム(Google Authenticator)」などをスマートフォンにインストールして先ほど生成した共有鍵情報が保存されたQRコードを読み取ります
App Store - Google Authenticator
https://apps.apple.com/jp/app/google-authenticator/id388497605Google Play - Google 認証システム
https://play.google.com/store/apps/details?id=com.google.android.apps.authenticator2□手順 4-5:
aws iam enable-mfa-deviceコマンドを実行して作成した仮想MFAデバイスの有効化(スマートフォンデバイスとの同期)を行います実行コマンドaws iam enable-mfa-device --user-name "<IAMユーザー名>" --serial-number "<仮想MFAデバイスのリソースネーム(ARN)>" --authentication-code1 "<MFAデバイスに表示されている6桁の数字>" --authentication-code2 "<`--authentication-code1`に設定した値の次に表示される6桁の数字>" --profile "<IAMユーザープロファイル名>"実行例[user@workstaion ~]$ aws iam enable-mfa-device --user-name "cli-user" --serial-number "<仮想MFAデバイスのリソースネーム(ARN)>" --authentication-code1 "123456" --authentication-code2 "234567" --profile "cli-user"□手順 4-6:
aws sts get-session-tokenコマンドを実行することで有効期限付き(デフォルト1時間)のセッショントークンを取得することができます実行コマンドaws sts get-session-token --serial-number "<仮想MFAデバイスのリソースネーム(ARN)>" --token-code <MFAデバイスに表示されている6桁の数字> --profile "<IAMユーザープロファイル名>"実行例[user@workstaion ~]$ aws sts get-session-token --serial-number "<仮想MFAデバイスのリソースネーム(ARN)>" --token-code <MFAデバイスに表示されている6桁の数字> --profile "cli-user" { "Credentials": { "AccessKeyId": "<アクセスキーID>", "SecretAccessKey": "<シークレットアクセスキー>", "SessionToken": "<セッショントークン>", "Expiration": "<セッショントークンの有効期限(yyyy-MM-ddTHH:mm:ss+00:00)>" } }□手順 4-7:
aws sts get-session-tokenコマンドで得られた値を次の環境変数に設定します
環境変数名 設定する値 説明 AWS_ACCESS_KEY_ID Credentials.AccessKeyIdの値 アクセスキーID AWS_SECRET_ACCESS_KEY Credentials.SecretAccessKeyの値 シークレットアクセスキー AWS_SESSION_TOKEN Credentials.SessionTokenの値 セッショントークン [MacOSやLinux環境での実行例]
jqコマンドが使える環境であれば次のようなスクリプトを作成して実行しますBashの場合virtualMFADevice = "<仮想MFAデバイスのリソースネーム(ARN)>" profileName = "cli-user" echo "MFAデバイスに表示されている6桁の数字を入力してください" read tokenCode sessionToken=$(aws sts get-session-token --serial-number "$virtualMFADevice" --token-code "$tokenCode" --profile "$profileName") export AWS_ACCESS_KEY_ID=$(echo $sessionToken | jq -r .Credentials.AccessKeyId) export AWS_SECRET_ACCESS_KEY=$(echo $sessionToken | jq -r .Credentials.SecretAccessKey) export AWS_SESSION_TOKEN=$(echo $sessionToken | jq -r .Credentials.SessionToken)[Windows環境での実行例]PowerShellの
ConvertFrom-Jsonコマンドレットを使えばJSONのパースが可能なので次のようなスクリプトを作成して実行しますPowerShellの場合$virtualMFADevice = "<仮想MFAデバイスのリソースネーム(ARN)>" $profileName = "cli-user" $tokenCode = Read-Host "MFAデバイスに表示されている6桁の数字を入力してください" $sessionToken = $(& aws sts get-session-token --serial-number "$virtualMFADevice" --token-code "$tokenCode" --profile "$profileName" | ConvertFrom-Json) $env:AWS_ACCESS_KEY_ID=$sessionToken.Credentials.AccessKeyID $env:AWS_SECRET_ACCESS_KEY=$sessionToken.Credentials.SecretAccessKey $env:AWS_SESSION_TOKEN=$sessionToken.Credentials.SessionToken□手順 4-8: この状態で「AWS CLI」を実行し Access Denied などのエラーメッセージが表示されなくなっていれば成功です
※この時
--profileオプションの付与は不要です実行例[user@workstaion ~]$ aws s3 ls yyyy-MM-dd HH:mm:ss xxxx :
5. 特定の接続IPアドレス(←場所の要素)によるMFA(多要素認証)の有効化 (「管理者」側手順)
続いて、特定の接続IPアドレスからのアクセス時のみは、ワンタイムパスワードの入力なしでアクセスできるように設定します。
□手順 5-1: 作成したIAMグループ(
MyUsers)をクリックします
□手順 5-2: [アクセス許可]タブをクリックします
□手順 5-3: [インラインポリシー]の”ポリシーの編集”部分をクリックします
□手順 5-4: ポリシードキュメントの ”Condition” 句を次のように修正して[ポリシーの適用]をクリックします
修正前"Condition": { "BoolIfExists": { "aws:MultiFactorAuthPresent": "false" } }修正後"Condition": { "BoolIfExists": { "aws:MultiFactorAuthPresent": "false" }, "NotIpAddress": { "aws:SourceIp": [ "xxx.xxx.xxx.xxx", "yyy.yyy.yyy.yyy" ] } }□手順 5-5: 「管理者」側手順はこれで終了です
6. 「AWS CLI」の実行(「ユーザー」側手順)
再び「AWS CLI」を使用する「ユーザー」側の手順です
□手順 6-1:
--profileオプションを付与して「AWS CLI」を実行し、問題なく実行できれば成功です実行例[user@workstaion ~]$ aws s3 ls --proflie "cli-user" yyyy-MM-dd HH:mm:ss xxxx :
以上、特定の接続元IPアドレス以外から「AWSコマンドラインインターフェイス(AWS CLI v2)」を実行した際のみMFA(Multi-Factor Authentication)が必要になるようにIAMの設定をした際の手順でした。
- 投稿日:2020-03-21T03:53:44+09:00
【#awscli】あらかじめ指定した接続元IPアドレス以外からの「AWS CLI v2」実行時はMFA(ワンタイムパスワードでの認証)が必要になるようIAMを設定する #AWS #awscliv2 #jawsug #環境構築 #環境設定
特定の接続元IPアドレス以外からの「AWSコマンドラインインターフェイス(AWS CLI v2)」実行時のみMFA(Multi-Factor Authentication)が必要になるようにIAMの設定をしたので、その際の手順を自分用のメモとしてまとめました。
MFA(Multi-Factor Authentication:多要素認証)とは
参考: Wikipedia - 多要素認証
https://ja.wikipedia.org/wiki/多要素認証簡単に説明すると次の4つの要素のうち2要素以上を使用して認証を行うことです
1.知る要素
2.持つ要素
3.備える要素
4.場所の要素認証を多段階で実施しても(多段階認証をしても)、同じ要素での認証ではセキュアではないとされています(例: ”印鑑”と”通帳”など)
ちなみに、
天空の城ラピュタにおける崩壊の呪文は、
- ”バルス” という呪文を【←知る要素】
- 飛行石の結晶 を持った状態で【←持つ要素】
- 王族の人間 が【←備える要素】
- ラピュタ内の聖域と呼ばれる場所 で【←場所の要素】
唱えた場合のみ発動するので四要素認証になっています∑d(゚∀゚d)イカス!!
MFA(Multi-Factor Authentication)を設定しないとどうなるのか?
「AWS CLI」を使用するためにはアクセスキー(アクセスキーIDとシークレットキーのキーペア)が必要になるのですが、このアクセスキーが漏洩すると怖いことが起こります。
参考: 初心者がAWSでミスって不正利用されて$6,000請求、泣きそうになったお話。
https://qiita.com/mochizukikotaro/items/a0e98ff0063a77e7b694参考: GitHub に AWS キーペアを上げると抜かれるってほんと???試してみよー!
https://qiita.com/saitotak/items/813ac6c2057ac64d5fefAWSではどういった対策ができるのか?
[AWSマネージメントコンソールへのアクセス]時に ”スマーフォンデバイス(TOTP:Time-based One-Time Password)” での認証を有効にする↓というのは比較的知られていますが、「AWS CLI」でも同様に設定することが可能です。
少し違う点は、「AWS CLI」の場合、1コマンド実行するごとにワンタイムパスワード認証を求められるのはツライので、
「AWS Security Token Service (AWS STS)」より払い出された有効期限付き(デフォルト1時間)のセッショントークンを使用するという点です。まず、前半の部分で「AWS STS」のセッショントークンを払い出す際はMFAを必要とする設定を行います。
加えて、後半の部分で、特定の接続IPアドレスからのアクセス時のみは、ワンタイムパスワードの入力なしでアクセスキー(アクセスキーIDとシークレットキーのキーペア)だけで実行できるようにする設定を行います。
1. IAMグループとIAMユーザーの作成 (「管理者」側手順)
まず、AWS CLI を実行する際に使用するIAMユーザーを作成します。
設定はIAMポリシーで制御するのですが、AWSのベストプラクティスに従って、IAMユーザーに直接ポリシーをアタッチするのではなく、IAMグループを作成して、作成したIAMグループに対してMFAを有効化するためのポリシーをアタッチしていきます
□手順 1-1: [Identity and Access Management(IAM)]サービスの[グループ]メニュー画面で[新しいグループの作成]をクリックします
□手順 1-2: [グループ名]に任意の名前(ここでは
MyUsers)を入力し[次のステップ]をクリックします
□手順 1-3: [ポリシーのアタッチ]画面で、任意のAWS管理ポリシー(ここでは
PowerUserAccessポリシー)を選択し[次のステップ]をクリックします
□手順 1-4: 内容を確認し[グループの作成]をクリックします
□手順 1-5: IAMグループ(
MyUsers)が作成されたことを確認します
□手順 1-6: 続いて[Identity and Access Management(IAM)]サービスの[ユーザー]メニュー画面に移り[ユーザーを追加]をクリックします
□手順 1-7: [ユーザー名]に任意の名前(ここでは
cli-user)を入力し[プログラムによるアクセス]にチェックを入れて[次のステップ:アクセス権限]をクリックします※必要ではないのでチェックを入れていませんが[AWSマネージメントコンソールへのアクセス]にチェックを入れても問題はないと思います
□手順 1-8: [ユーザーをグループに追加]で先ほど作成したIAMグループを選択し[次のステップ:タグ]をクリックします
□手順 1-9: 必要に応じてタグを設定し(ここでは何も設定せずに)[次のステップ:確認]をクリックします
□手順 1-10: 内容を確認し[ユーザーの作成]をクリックします
□手順 1-11: "成功"のメッセージを確認し[.csvのダウンロード]をクリックして完了です
※ダウンロードした CSVファイル は後ほど使用します
2. 「スマートフォンデバイス」(←持つ要素)によるMFA(多要素認証)の有効化 (「管理者」側手順)
AWSでは「仮想MFAデバイス」と「AWS Security Token Service (AWS STS)」の仕組みを使う事で「AWS CLI」でも「スマートフォンデバイス」(←持つ要素)でのMFA(多要素認証)を実現することができます
□手順 2-1: 作成したIAMグループ(
MyUsers)をクリックします
□手順 2-2: [アクセス許可]タブをクリックします
□手順 2-3: [インラインポリシー]の”ここをクリックしてください”部分をクリックします
□手順 2-4: [カスタムポリシー]にチェックを入れます
□手順 2-5: [ポリシー名]に任意の名前(ここでは
MyUsersPolicy)、[ポリシードキュメント]に次の「AWSユーザーガイド」記載の内容を入力して[ポリシー]の適用をクリックしますAWSユーザーガイド - IAM: IAM ユーザーに MFA デバイスの自己管理を許可する
https://docs.aws.amazon.com/ja_jp/IAM/latest/UserGuide/reference_policies_examples_iam_mfa-selfmanage.htmlMyUsersPolicy{ "Version": "2012-10-17", "Statement": [ { "Sid": "AllowListActions", "Effect": "Allow", "Action": [ "iam:ListUsers", "iam:ListVirtualMFADevices" ], "Resource": "*" }, { "Sid": "AllowIndividualUserToListOnlyTheirOwnMFA", "Effect": "Allow", "Action": [ "iam:ListMFADevices" ], "Resource": [ "arn:aws:iam::*:mfa/*", "arn:aws:iam::*:user/${aws:username}" ] }, { "Sid": "AllowIndividualUserToManageTheirOwnMFA", "Effect": "Allow", "Action": [ "iam:CreateVirtualMFADevice", "iam:DeleteVirtualMFADevice", "iam:EnableMFADevice", "iam:ResyncMFADevice" ], "Resource": [ "arn:aws:iam::*:mfa/${aws:username}", "arn:aws:iam::*:user/${aws:username}" ] }, { "Sid": "AllowIndividualUserToDeactivateOnlyTheirOwnMFAOnlyWhenUsingMFA", "Effect": "Allow", "Action": [ "iam:DeactivateMFADevice" ], "Resource": [ "arn:aws:iam::*:mfa/${aws:username}", "arn:aws:iam::*:user/${aws:username}" ], "Condition": { "Bool": { "aws:MultiFactorAuthPresent": "true" } } }, { "Sid": "BlockMostAccessUnlessSignedInWithMFA", "Effect": "Deny", "NotAction": [ "iam:CreateVirtualMFADevice", "iam:EnableMFADevice", "iam:ListMFADevices", "iam:ListUsers", "iam:ListVirtualMFADevices", "iam:ResyncMFADevice" ], "Resource": "*", "Condition": { "BoolIfExists": { "aws:MultiFactorAuthPresent": "false" } } } ] }このインラインポリシーを適用することによりユーザーは後述するMFAデバイスの登録作業などを以外のオペレーションはMFAなしでは実行できないようになります
□手順 2-6: 「管理者」側手順はこれで終了です
4. 仮想MFAデバイスの作成 (「ユーザー」側手順)
ここから「AWS CLI v2」を使用する「ユーザー」側の手順です
□手順 4-1: 「AWS CLI v2」の新機能である
aws configure importコマンドを使ってIAMユーザー作成時にダウンロードしたCSVファイルからクレデンシャル情報(アクセスキーの情報)を読み取ります実行コマンドaws configure import --csv file://<CSVファイル名>実行例[user@workstaion ~]$ aws configure import --csv file://credentials.csv Successfully imported 1 profile(s)□手順 4-2: この状態でコマンドを実行すると
Access Deniedとなってしまうことを確認します実行例[user@workstaion ~]$ aws s3 ls --proflie "cli-user" An error occurred (AccessDenied) when calling the ListBuckets operation: Access Denied□手順 4-3:
aws iam create-virtual-mfa-deviceコマンドを実行して仮想MFAデバイスと共有鍵情報が保存されたQRコードを生成します
--virtual-mfa-device-nameパラメーターに設定する名前はIAMユーザーと同じにしてください実行コマンドaws iam create-virtual-mfa-device --virtual-mfa-device-name "<任意の仮想MFAデバイス名>" --outfile <QRコードを出力する任意のパス> --bootstrap-method "QRCodePNG" --profile "<IAMユーザープロファイル名>"実行例[user@workstaion ~]$ aws iam create-virtual-mfa-device --virtual-mfa-device-name "cli-user" --outfile .\QRCode.png --bootstrap-method "QRCodePNG" --profile "cli-user" { "VirtualMFADevice": { "SerialNumber": "<作成された仮想MFAデバイスのリソースネーム(ARN)>" } }ここで出力される”仮想MFAデバイスのリソースネーム(ARN)"の値は後ほど使用するのでメモしておきます
AWS管理コンソールからも確認可能です(該当IAMユーザーの[認証情報]タブ)↓
□手順 4-4: 「Google 認証システム(Google Authenticator)」などをスマートフォンにインストールして先ほど生成した共有鍵情報が保存されたQRコードを読み取ります
App Store - Google Authenticator
https://apps.apple.com/jp/app/google-authenticator/id388497605Google Play - Google 認証システム
https://play.google.com/store/apps/details?id=com.google.android.apps.authenticator2□手順 4-5:
aws iam enable-mfa-deviceコマンドを実行して作成した仮想MFAデバイスの有効化(スマートフォンデバイスとの同期)を行います実行コマンドaws iam enable-mfa-device --user-name "<IAMユーザー名>" --serial-number "<仮想MFAデバイスのリソースネーム(ARN)>" --authentication-code1 "<MFAデバイスに表示されている6桁の数字>" --authentication-code2 "<`--authentication-code1`に設定した値の次に表示される6桁の数字>" --profile "<IAMユーザープロファイル名>"実行例[user@workstaion ~]$ aws iam enable-mfa-device --user-name "cli-user" --serial-number "<仮想MFAデバイスのリソースネーム(ARN)>" --authentication-code1 "123456" --authentication-code2 "234567" --profile "cli-user"□手順 4-6:
aws sts get-session-tokenコマンドを実行することで有効期限付き(デフォルト1時間)のセッショントークンを取得することができます実行コマンドaws sts get-session-token --serial-number "<仮想MFAデバイスのリソースネーム(ARN)>" --token-code <MFAデバイスに表示されている6桁の数字> --profile "<IAMユーザープロファイル名>"実行例[user@workstaion ~]$ aws sts get-session-token --serial-number "<仮想MFAデバイスのリソースネーム(ARN)>" --token-code <MFAデバイスに表示されている6桁の数字> --profile "cli-user" { "Credentials": { "AccessKeyId": "<アクセスキーID>", "SecretAccessKey": "<シークレットアクセスキー>", "SessionToken": "<セッショントークン>", "Expiration": "<セッショントークンの有効期限(yyyy-MM-ddTHH:mm:ss+00:00)>" } }□手順 4-7:
aws sts get-session-tokenコマンドで得られた値を次の環境変数に設定します
環境変数名 設定する値 説明 AWS_ACCESS_KEY_ID Credentials.AccessKeyIdの値 アクセスキーID AWS_SECRET_ACCESS_KEY Credentials.SecretAccessKeyの値 シークレットアクセスキー AWS_SESSION_TOKEN Credentials.SessionTokenの値 セッショントークン [MacOSやLinux環境での実行例]
jqコマンドが使える環境であれば次のようなスクリプトを作成して実行しますBashの場合virtualMFADevice = "<仮想MFAデバイスのリソースネーム(ARN)>" profileName = "cli-user" echo "MFAデバイスに表示されている6桁の数字を入力してください" read tokenCode sessionToken=$(aws sts get-session-token --serial-number "$virtualMFADevice" --token-code "$tokenCode" --profile "$profileName") export AWS_ACCESS_KEY_ID=$(echo $sessionToken | jq -r .Credentials.AccessKeyId) export AWS_SECRET_ACCESS_KEY=$(echo $sessionToken | jq -r .Credentials.SecretAccessKey) export AWS_SESSION_TOKEN=$(echo $sessionToken | jq -r .Credentials.SessionToken)[Windows環境での実行例]PowerShellの
ConvertFrom-Jsonコマンドレットを使えばJSONのパースが可能なので次のようなスクリプトを作成して実行しますPowerShellの場合$virtualMFADevice = "<仮想MFAデバイスのリソースネーム(ARN)>" $profileName = "cli-user" $tokenCode = Read-Host "MFAデバイスに表示されている6桁の数字を入力してください" $sessionToken = $(& aws sts get-session-token --serial-number "$virtualMFADevice" --token-code "$tokenCode" --profile "$profileName" | ConvertFrom-Json) $env:AWS_ACCESS_KEY_ID=$sessionToken.Credentials.AccessKeyID $env:AWS_SECRET_ACCESS_KEY=$sessionToken.Credentials.SecretAccessKey $env:AWS_SESSION_TOKEN=$sessionToken.Credentials.SessionToken□手順 4-8: この状態で「AWS CLI」を実行し Access Denied などのエラーメッセージが表示されなくなっていれば成功です
※この時
--profileオプションの付与は不要です実行例[user@workstaion ~]$ aws s3 ls yyyy-MM-dd HH:mm:ss xxxx :
5. 特定の接続IPアドレス(←場所の要素)によるMFA(多要素認証)の有効化 (「管理者」側手順)
続いて、特定の接続IPアドレスからのアクセス時のみは、ワンタイムパスワードの入力なしでアクセスできるように設定します。
□手順 5-1: 作成したIAMグループ(
MyUsers)をクリックします
□手順 5-2: [アクセス許可]タブをクリックします
□手順 5-3: [インラインポリシー]の”ポリシーの編集”部分をクリックします
□手順 5-4: ポリシードキュメントの ”Condition” 句を次のように修正して[ポリシーの適用]をクリックします
修正前"Condition": { "BoolIfExists": { "aws:MultiFactorAuthPresent": "false" } }修正後"Condition": { "BoolIfExists": { "aws:MultiFactorAuthPresent": "false" }, "NotIpAddress": { "aws:SourceIp": [ "xxx.xxx.xxx.xxx", "yyy.yyy.yyy.yyy" ] } }□手順 5-5: 「管理者」側手順はこれで終了です
6. 「AWS CLI」の実行(「ユーザー」側手順)
再び「AWS CLI」を使用する「ユーザー」側の手順です
□手順 6-1:
--profileオプションを付与して「AWS CLI」を実行し、問題なく実行できれば成功です実行例[user@workstaion ~]$ aws s3 ls --proflie "cli-user" yyyy-MM-dd HH:mm:ss xxxx :
以上、特定の接続元IPアドレス以外から「AWSコマンドラインインターフェイス(AWS CLI v2)」を実行した際のみMFA(Multi-Factor Authentication)が必要になるようにIAMの設定をした際の手順でした。
- 投稿日:2020-03-21T02:39:24+09:00
CloudFront×S3で403 Access Deniedが出るときに確認すべきこと
前提
- S3をオリジンとしたCloudFrontディストリビューションを作成している
- HTMLや画像ファイルをCloudFront経由で配信したい
- 独自ドメインのCNAMEを登録している
CloudFrontのドメイン、またはCNAMEで登録している独自ドメインにアクセスすると以下のような画面が表示される
これをアクセスできるようにすることがゴールです。
確認すべきこと
バケット内のオブジェクトが公開されているかどうか
まずCloudFront抜きのS3単体で考えます。
特に制限をかけておらず、バケットのパブリックアクセスが可能になっている状態であれば、
パブリックという黄色のラベルが表示されているはずです。
もしついていなければとりあえず以下のバケットポリシーを設定しましょう。
{ "Version": "2008-10-17", "Id": "PublicRead", "Statement": [ { "Sid": "1", "Effect": "Allow", "Principal": "*", "Action": "s3:GetObject", "Resource": "arn:aws:s3:::{your bucket name}/*" } ] }これは、制限なしで誰でもバケット内のオブジェクトにアクセスできる状態を作ります。
※ブロックパブリックアクセスをオンにしている場合、設定がうまくいかないことがあります。
下記画像の4つの設定のどれがオンになっているのか、バケットポリシーが新規なのか既存なのか等々、
ユースケースに応じて原因が異なるので、以下の公式ドキュメントを参考にしてください。
Amazon S3 ブロックパブリックアクセスの使用
これでひとまずS3のREST API エンドポイントを叩いてアクセスができる確認してみましょう。
https://your_bucket_name.s3.amazonaws.com/hoge.htmlバケット内のオブジェクトがCloudFrontに対して公開されているかどうか
アクセスができたら、今度はアクセス元を制限します。
直接バケットへのアクセスが可能になっているのはセキュリティ上好ましくないですし、
CloudFrontの恩恵も受けられないので、CloudFrontからのアクセスのみ可能な形にします。まずは OAI(Origin access identity)を作成します。
ディストリビューションの作成時に一緒に作成する方法と、
既存のディストリビューションのOrigin編集時に作成してアタッチする方法と、
CloudFrontのマネジメントコンソールから作成して、既存のディストリビューションにアタッチする方法があります。これはマネジメントコンソールからの作成。
コメントはヒューマンリーダブルなものを適当につけましょう。
作成したOAIを [Your Identities] に指定します。
後述しますが、[Grant Read Permission on Bucket]のYesにチェックを入れると後々楽です。
バケットポリシーの編集に戻ります。
アタッチしたOAIのIDのみ許可するようにします。{ "Version": "2008-10-17", "Id": "PolicyForCloudFrontPrivateContent", "Statement": [ { "Sid": "1", "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::cloudfront:user/CloudFront Origin Access Identity {your oai id}" }, "Action": "s3:GetObject", "Resource": "arn:aws:s3:::{your bucket name}/*" } ] }先ほどの [Grant Read Permission on Bucket] にチェックを入れていると、
作成したOAIでバケットポリシーを自動で更新してくれるのでこの作業は不要です。これで先ほどの S3 REST API エンドポイントで今度は Access Denied が出るようになります。
バケット内のオブジェクトにアクセスできるのは、該当のOAIを付与したディストリビューションだけになったからです。試しにディストリビューションの Domain Name でアクセスしてみましょう。
http://hohge.cloudfront.net/hoge.htmlバケットポリシーで Denied を設定してたりしないかどうか
バケットポリシーには明示的にアクセスを拒否するステートメントも記述することができます。
そのような設定がなされている場合は削除したり、削除した後もキャッシュが残っていることがあるので5分待つ必要があります(Invalidations で無効にするも可)。注: CloudFront は、Access Denied エラーの結果を最大 5 分間キャッシュします。バケットポリシーから拒否ステートメントを削除した後、ディストリビューションに対して無効化を実行してオブジェクトをキャッシュから削除できます。
オブジェクトが存在するかどうか
根本的な確認になりますが、意外とこういうケアレスミスがあります。ファイル名のタイポとか。
ややこしいのは、存在しないオブジェクトにアクセスした場合でも403 Access Denied が返ってくる仕様になっていることです。
404 Not Found が隠蔽されることがしれっとドキュメントに書いてあります。オブジェクトがバケット内にない場合は、アクセス拒否エラーは「404 Not Found」エラーを隠します。
注: セキュリティ上のベストプラクティスではないため、s3:ListBucket の公開を有効にすることはお勧めしません。s3:ListBucket を付与すれば404になるんでしょうね。
バケット内の状態が不可視になっているために、
オブジェクトが存在しないのか、権限がなくて不可視になっているだけなのか、判別できないとうことなんでしょう。デフォルトのルートオブジェクトが定義されているかどうか
先述のオブジェクトの存在チェックとも絡んできますが、
ディストリビューションのルートオブジェクトを設定しましょう。ディストリビューションにデフォルトのルートオブジェクトが定義されておらず、リクエスタが s3:ListBucket アクセス許可を持っていない場合、リクエスタはアクセス拒否エラーを受け取ります。ディストリビューションのルートをリクエストするとき、リクエスタは 404 Not Found エラーの代わりにこのエラーを受け取ります。
動作が異なるので、S3の静的ウェブサイトホスティングに慣れている人は特に注意してください。
CloudFrontのデフォルトルートオブジェクトとS3の静的ウェブサイトホスティングのインデックスドキュメントの動作の違いバケットを作成してから24時間以上経っているかどうか
ブラウザ上で確認していると気付きにくいが、403ではなく、307でリダイレクトされ結果403になっていることがあります。
リダイレクト先はS3のREST API エンドポイントです。
適切にアクセス元が絞られていれば、S3への直アクセスは Denied になるので、結果的に403という状態になっています。これは、リージョンの伝播に時間がかかるためです。
Amazon S3 バケットを作成後、そのバケット名がすべての AWS リージョンに伝達されるまで、最大で 24 時間ほどかかる場合があります。その間に、S3 バケットと同じリージョンにないリージョンのエンドポイントにリクエストすると、「307 Temporary Redirect」レスポンスが返る場合があります
どういうことかというと、
バケットのエンドポイントにはリージョンが含まれます。
ap-northeast-1 で作成したバケット内のオブジェクトのエンドポイントは以下のようになります。
https://your-bucket-name.s3-ap-northeast-1.amazonaws.com/hoge.htmlしかし、ディストリビューションを作成する際に Origin として候補に出てくるのは、
S3のデフォルトのエンドポイント(your_bucket_name.s3.amazonaws.com)です。
リージョンがついてませんが、こいつの実態はus-east-1です。つまり、
us-east-1以外のバケットにおいては、
このエンドポイントが使用できるまでに遅延が発生する可能性があるということです。Amazon S3 オリジンで Amazon CloudFront ディストリビューションを使用する場合、CloudFront はリクエストをデフォルトの S3 エンドポイント (s3.amazonaws.com) に転送します。このエンドポイントは、us-east-1 リージョンにあります。バケットを作成後 24 時間以内に Amazon S3 にアクセスする必要がある場合は、バケットのリージョンのエンドポイントが含まれるように、このディストリビューションのオリジンドメイン名を変更します。たとえば、バケットが us-west-2 にある場合は、オリジンドメイン名を bucketname.s3.amazonaws.com から bucketname.s3-us-west-2.amazonaws.com に変更することができます。
解消方法は24時間待つか、 Originにリージョン込みのエンドポイントを設定することです。
選択式のため入力できないかと思いがちですが、別にそんなことはありません。
リージョン込みのエンドポイントを指定すればすぐに使えるようになります。
だいたい原因はこんなところかなーと思います。
僕は最後のでちょっとハマりました。
バケット名がなんか気にくわないから別のバケットを作って切り替えるみたいなことをしていたら踏みました。他にもこんなのでハマったとかあれば教えてください??




- 投稿日:2020-03-21T00:46:17+09:00
AWS で無料のサーバーを 30 分で立てる
しばらく前に AWS の知識をゲットしたはずだったんだが、記憶力が悪いせいですっかり忘れた。
インターネット上に自分用の Linux サーバーが欲しかったので、AWS を使おうとしたのだが、ほとんど何も覚えてない。ゼロから始めてサーバーを立てるまで、を復習がてら記事にする。
AWS はユーザー登録から 1 年間の無料枠があるとはいえ、ユーザー登録にクレジットカード番号が必要。これは済んでいることとする。
まずはじめに
トップサイトからログインすると、画面遷移して「AWS マネジメントコンソール」に連れていかれる。ここが異世界の入口だ。タダでもらえる初期装備はなかなか豪華で、小さいサーバーならタダで使わせてもらえる。マネジメントコンソールのメニューを探して「Billing」と「VPC」と「EC2」とを確認する。この 3 つが主な活動場所だ。
Billing
課金の状況を知るところ。
まず最初はここを知らないと安心して使えない。ここには「今月はいくらかかったか」の金額が表示されている。無料枠の中で使っていれば $0 と表示されているはず。
VPC ダッシュボード
「VPC を作る」のはリアル世界で例えれば「サーバールームを確保して環境整備する」ことにあたる。
VPC をクリックして「VPC ダッシュボード」に入る。
VPC の作成
VPC というリンクをクリックすると VPC を作成する画面に移る。最初から「デフォルト VPC」というのが用意されているが、たしか、こいつを消すのはやめたほうがいい。あとあと面倒なことになる。
新しい VPC を作成していく。「VPC の作成」を押すと作成が始まる。IPv4 CIDR ブロックは
10.0.0.0/16とする。10.0.xx.xx のアドレスを使えるようになる。IPv6 は使わないので、IPv6 CIDR ブロックは無しを選ぶ。無料枠で済ませたいので「テナンシー」はデフォルトを選ぶ。名前はあとで参照することになるので、分かりやすい名前を付けておくのが吉だ。これで、リアルでいえば「サーバールームを陣取った」ことになる。
サブネットの作成
「サブネット」というリンクをクリックすると、サブネットを作成する画面に移る。「サブネットの作成」を押すと作成が始まる。VPC は先ほど作成したものを選択。アベイラビリティゾーンは ap-northeast-1a など、東京リージョンのものを選ぶ。海外のを選んでも遅くなるだけだ。「IPv4 CIDR ブロック」は
10.0.1.0/24とする。これでサブネット内で10.0.1.xxのアドレスを使えるようになる。これで「サーバールームのイーサネットの配線」が完了。
ルートテーブルの確認
「ルートテーブル」というリンクをクリックすると、ルートテーブルの設定画面に移る。VPC を作成したときに、セットでルートテーブルも作成されている。他にはデフォルト VPC 用のルートテーブルも最初からあるが、これも消さないようにする。「ルート」というタブをクリックすると、送信先が
10.0.0.0/16でターゲットがlocalになっているはず。変更は要らない。「タグ」というタブで名前をつけられるので、やっといた方がいい。これで「ルーターの設置」が完了。
インターネットゲートウエイの作成
「インターネットゲートウエイ」というリンクをクリックすると作成画面にうつる。ルーターと外部のネットをつなぐことにあたる。「インターネットゲートウエイの作成」を押せば作成できる。例によって名前は付けておいた方がいい。「アクション」から「VPC にアタッチ」を選んで、いま作成中の VPC につなぐ。
ルートテーブルの設定(その2)
「ルート」タブを押すと、ルートテーブルの編集ができる。ルートの編集を押して、いま作成中の VPC のルートを追加する。
0.0.0.0/0をinternet gatewayに対応付ける。これで VPC 内部は内部でルーティング、それ以外はインターネットに流すようになる。これでインターネットに接続できた。サーバールームの建設は終了だ。
EC2
「EC2 を起動する」のは、リアルでは「コンピュータを買ってきてサーバールームに据え付けて起動する」ことにあたる。
EC2 ダッシュボード
「EC2 ダッシュボード」に移動する。「インスタンス」をクリックし「インスタンスの作成」を押すと、インスタンス(仮想のコンピュータにあたる)を選ぶ画面になる。
Amazon Linux 2 AMI (HVM), SSD Volume Typeを選ぶ。次に進んで無料枠の t2-micro を選ぶ。「ネットワーク」はいま作成した VPC を、「サブネット」もいま作成したサブネットを選択。「自動割り当てパブリック IP」はデフォルトで無効になっているのを有効に変更する。次の「ストレージの追加」を選んで先に進むが、追加のストレージは不要。
作成して起動すると、キーペアの作成ダイアログが立ち上がるので作成してダウンロードしておく。このファイルは RSA 鍵というやつで、このコンピュータにログインするときに必要となる。
インスタンスの一覧を表示する画面を表示すると、いま起動したコンピュータが見える。IPv4 パブリック IP アドレスも表示されている。この IP アドレスのコンピュータは、もうインターネット上に存在する。SSH などで接続が可能だ。
確認
たったこれだけのことで、インターネット上に本当にサーバーが存在するのか。TeraTerm で確認する。
TeraTerm を起動し、接続先にさっきの IPv4 パブリック IP アドレスを入力して SSH2 で接続する。ユーザー名は ec2-uesr で、パスワード欄は何も入れなくていい。その代わりに「RSA 鍵を使う」を選び、秘密鍵に先ほどダウンロードしたファイルを選ぶ。
「接続」を押せば、確かにつながっていることが分かる。
TeraTermLast login: Fri Mar 20 15:18:50 2020 __| __|_ ) _| ( / Amazon Linux AMI ___|\___|___| https://aws.amazon.com/amazon-linux-ami/2018.03-release-notes/ 7 package(s) needed for security, out of 11 available Run "sudo yum update" to apply all updates. [ec2-user@ip-10-0-1-156 ~]$おわり