- 投稿日:2020-02-25T23:44:27+09:00
読書ログ『メタプログラミング Ruby 第2版』3章
3章 火曜日: メソッド
動的メソッド
- メソッドを呼び出すというのは、オブジェクトにメッセージを送ること
Object#send
- メソッドを呼び出すには、ドット記法とObject#sendがある
obj.send(:my_method, 3)- Object#sendを使うと、どんなメソッドでも呼び出せてしまう
- privateメソッドを呼び出せるからこそ、sendを使う
動的ディスパッチ
sendメソッドを使って、呼び出したいメソッド名を引数として、コードの実行時に呼び出すメソッドを決めることメソッドを動的に定義する
Module#define_method
- 実行時にメソッド名を定義できる
- メソッド名とブロックを渡すことで、ブロックがメソッドの本体となる
class MyClass define_method :my_method do |my_arg| my_arg * 3 end end obj = MyClass.new obj.my_method(2) #=> 6手順1: 動的ディスパッチを追加する
手順2: メソッドを動的に生成する
手順3: コードにイントロスペクションをふりかける
method_missing
BasicObjectクラスの、privateインスタンスメソッド
- NoMethodErrorを返すのが役割
指定したメソッドが継承チェーンを遡っても見つからない場合、Rubyは、method_missingを呼び出して負けを認める。
method_missingが呼び出されると
hoge.send :method_missing, :my_method => NoMethodError: undefined method 'my_method' for <...>
- method_missingをオーバーライドすると、実際には存在しないメソッドを呼び出せる
class Lawyer def method_missing(method, *args) puts "呼び出した: #{method}(#{args.join(',')})" puts "(ブロックも渡した)" if block_given? end end bob = Lawyer.new bob.talk_simple('a', 'b') do # ブロック end => 呼び出した: talk_simple(a,b) (ブロックも渡した)ゴーストメソッド
- method_missingを呼び出す際、通常と同様に見えるが、レシーバ側に対応するメソッドが見当たらないこと。
- 「君が理解できないことを頼まれたら、これをやっておいてね」という感じ
動的プロキシ
- ゴーストメソッドを補足して、他のオブジェクトに転送するオブジェクトのこと。
respond_to_missing?
- Rubyが、respond_to?にゴーストメソッドを認識させる仕組み
- method_missingをオーバーライドしたときには、respond_to_missing?もオーバーライドすること。
const_missing
- 存在しない定数を参照すると、Rubyは定数の名前をconst_missingにシンボルとして渡す。
- クラス名は単なる定数なので、不明な参照はModule#const_missingに渡される
ブランクスレート
- 最小限のメソッドしかない状態のクラスのこと
- ブランクスレートが必要であれば、BasicObjectを直接継承する
まとめ
可能であれば動的メソッドを使い、仕方がなければゴーストメソッドを使う
感想
Object#sendを使って、動的にメソッドを呼び出すこと、Module#define_methodを使って、動的にメソッドを定義する、という動的メソッドの存在を知る。
また、BasicObject#method_missingを上書きし、存在しないメソッドをゴーストメソッドとして生成する方法を知る。
一旦は見た際に気づけるかな、という感覚。実際に自分で使うとなると、もう少し慣れや自信が必要かな、という肌感。
- 投稿日:2020-02-25T23:40:49+09:00
Railsの復習
はじめに
標題の通りRailsの復習です。
部分テンプレート
Webアプリケーションにて、各ページに共通する箇所を切り出して1つのファイルにまとめたもの。ファイル名の先頭には「」が付く。ビュー側では部分テンプレートを呼び出しているにも関わらず、部分テンプレートのファイル名に「」が付いていないとエラーになります。実装時にはERBファイルに以下のように書きます。
<%= render partial: "使用する部分テンプレート", locals: {部分テンプレート中の変数: 部分テンプレートで使いたい値} %>わかりづらいと思うので、実例を示します。
<%= render partial: "hoge", locals: {fuga: "test"} %>これで「_hoge.html.erb」という部分テンプレートで"test"という文字列が入った変数”fuga”が使えます。
アソシエーション
モデル間で紐付けを行うことです。ツイッターを例にすると、ユーザー情報を格納するUsersテーブルとツイートを格納するTweetsテーブルがあったとします。どのユーザーがどのツイートをしたのか紐付けを行わなければアプリケーションとして破綻しますので、アソシエーションが必要になってきます。実装時にはモデルにテーブル間の関係を記載します。
・ユーザーモデルの場合
Class User 中略 has_many :tweets end1人のユーザーに対してツイートは0個以上存在するため「has_many :tweets」となります。
・ツイートモデルの場合
Class Tweet 中略 belongs_to :Users end1つのツイートに対して紐づくユーザーは必ず一人になります。そのため、「belongs_to :Users」となります。
バリデーション
データの登録に制限をかけることです。先ほどと同じようにツイッターを例にあげると、ツイート欄が空白のままでは投稿しても意味がありません。なので、ツイート欄が空白の場合はデータベースに登録させないように制限をかけます。これがバリデーションです。モデルに以下のような記述を加えれば実装できます!
class Tweet < ApplicationRecord validates :tweet, presence: true end1つずつ解説。
・validates ApplicationRecordクラスのメソッドらしいです。ApplicationRecordクラスを継承しているためTweetクラスでも使える。
・:tweet クライアントから送られてきたツイートが入っています。
・presence: true 入力値が空でないことを確認します。空でなければバリデーションチェックを通過してDBにデータが登録されます!まとめ
私の頭の中でモヤモヤしていたものをまとめました。某スクールの某試験でカンペに使えるかもしれません。
- 投稿日:2020-02-25T23:22:40+09:00
Ruby/GTK3 - RadioButton
gem install gtk3RadioButton
ラジオボタンは、1つのボタンを押すと他のボタンが押されていない状態になり、常に1つのボタンだけが押された状態になる。
Button 1 was turned off
Button 2 was turned on
Button 2 was turned off
Button 1 was turned on
Button 1 was turned off
Button 3 was turned onrequire 'gtk3' class RadioButtonWindow < Gtk::Window def initialize super set_title 'RadioButton Demo' set_border_width 10 hbox = Gtk::Box.new(:horizontal, 6) add hbox button1 = Gtk::RadioButton.new(label: 'Button 1') button1.signal_connect('toggled') { |b| on_button_toggled b, 1 } hbox.pack_start(button1) button2 = Gtk::RadioButton.new(member: button1, label: 'Button 2') button2.signal_connect('toggled') { |b| on_button_toggled b, 2 } hbox.pack_start(button2) button3 = Gtk::RadioButton.new(member: button1, label: 'B_utton 3', use_underline: true) button3.signal_connect('toggled') { |b| on_button_toggled b, 3 } hbox.pack_start(button3) end def on_button_toggled(button, name) state = button.active? ? 'on' : 'off' puts "Button #{name} was turned #{state}" end end win = RadioButtonWindow.new win.signal_connect('destroy') { Gtk.main_quit } win.show_all Gtk.mainところで、
memberやuse_underlineといったRuby/GTK3に特徴的なオプションはどこで定義されているのだろうか?
https://github.com/ruby-gnome/ruby-gnome/blob/master/gtk3/lib/gtk3/radio-button.rb
を見ると、どうやらこれらは手動で定義されているようである。

- 投稿日:2020-02-25T22:12:27+09:00
【Rails6】param is missing or the value is empty: postで少し詰まったが無事解決
こんにちは!
転職活動用のポートフォリオ作成中のかっちゃんです!今回は「param is missing or the value is empty: post」というエラーの解決方法を皆様に共有したいと思います。
param is missing or the value is empty: postとは?
potsにパラメーターが入ってない、または空ですよという意味
問題箇所
エラー文
画像投稿する際にエラーが発生
pryでデバックしてみた
投稿内容は送信しているが、@postには値が送られておらず「nil(空)」と表示された。
解決するために変更べき箇所
今回の場合はparams.require(:post).permit(:content, :image, :remove_image)の「require(:post)」の部分が不要なのでここを削除する
エラー解決
上記の様にrequire(:post)を削除すると解決!
以上の手順で僕はエラーを解決する事ができました。
ご参考になれば幸いです!参考にした記事↓





- 投稿日:2020-02-25T20:18:17+09:00
RSpec でクラスメソッドとインスタンスメソッドを mock 化する
Overview
この記事ではクラスメソッドとインスタンスメソッドを、
テスト対象に都合の良いデータを返してくれるように mock 化する方法を紹介します。(自動テスト界隈では「本物のふりをしてくれるオブジェクト」をまとめてテストダブルと言い、テスト対象からの出力を受けるのが mock で、テスト対象に都合の良いデータを返してくれるのが stub と言いうのでは?という方がいらっしゃるかと思いますが、この記事ではこれらの用語の定義はややこしいので触れません...
テストを pass するためにテスト中に都合の良いデータを返す方法という観点だけでお読みください)
テスト中のクラスメソッドの返り値を固定する
では、まずはクラスメソッドからです。
こういうクラスがあったとします。class ExampleClass def self.real_method # クラスメソッドは self で定義 'real' end endこの
real_methodの返り値を、テスト中にdummyにしたい場合はこう書きます。require 'spec_helper' describe 'ExampleClass' do it 'return dummy' allow(Example).to receive(:real_method).and_return('dummy') puts Example.real_method # dummy end endテスト中のインスタンスメソッドの返り値を固定する
続いてインスタンスメソッドです。
こういうクラスがあったとします。class ExampleClass def real_method # インスタンスメソッドは self いらない 'real' end endテストはこう書きます。
require 'spec_helper' describe 'ExampleSlass' do it 'return dummy' do allow_any_instance_of(Example).to receive(:real_method).and_return('dummy') puts Example.new.real_method # dummy end end
allow_any_instance_ofを使うところがキモですね。ちなみに、インスタンスメソッドをただの allow で mock しようとすると以下のように Example に real_method というクラスメソッドはないよというエラーを吐かれ、
allow(Example).to receive(:real_method).and_return('dummy') # Example does not implement: real_methodテスト中に new してインスタンスを mock しようとすると、テストで new したインスタンスと実際のコードで new したインスタンスは異なるので mock ができず、
realが返されます。allow(Example.new).to receive(:real_method).and_return('dummy') # ここで new しても、実際のコードは別のインスタンスなので real が返されるまとめ
- クラスメソッド
allow(Class).to receive(:target_method).and_return('mock_value')
- インスタンスメソッド
allow_any_instance_of(Class).to receive(:target_method).and_return('mock_value')
- 投稿日:2020-02-25T18:58:46+09:00
スクリプト言語 KINX/基本編(1) - プログラム基礎・データ型
はじめに
前回の記事から。シリーズ第一弾は普通に基本編。概要は以下の前回の記事を参照してください。
- スクリプト言語 KINX(ご紹介)
- Kinx 基本編(1) - プログラム基礎・データ型(今回)
前回お披露目してみたら★を付けてくださった方がいて、非常に浮かれています。ありがとうございました。温かいお気持ちで行く末を見届けてやってください。
- ここ (https://github.com/Kray-G/kinx) です。「見た目は JavaScript、頭脳(中身)は Ruby、(安定感は AC/DC)」でお届けする スクリプト言語 KINX。オブジェクト指向と C 系シンタックスで C 系プログラマになじむ触感 を目指して。
Kinx 基本編(1) - プログラム基礎・データ型
プログラム基礎
hello, world
プログラムはトップレベルから記述可能。
hello.kxSystem.println("hello, world.");
hello.kxという名前で保存し、以下のように実行.$ ./kinx hello.kx hello, world.コメント
コメントは C/C++ 形式と Perl のような
#形式と両方利用可能。/* Comment */ // Comment# Comment変数宣言
変数宣言は
varで宣言する。var a = 10;初期化子を使って初期化するが、初期化子を書かなかった場合は
nullとなる。ちなみに Kinx においてはnullとundefinedは同じ意味(賛否あると思うが)。どちらもa.isUndefinedが true となる。データ型一覧
Kinx は動的型付け言語だが、内部に型を持っている。
Type CheckProperty Example Meaning Undefined isUndefinednull 初期化されていない値。 Integer isInteger,isBigInteger100, 0x02 整数。演算では自動的に Big Integer と相互変換される。 Double isDouble1.5 実数。 String isString"aaa", 'bbb' 文字列。 Binary isBinary<1,2,3> バイナリ値。バイトの配列。要素は全て 0x00-0xFF に丸められる。 Array isArray,isObject[1,a,["aaa"]] 配列。扱える型は全て保持可能。 Object isObject{ a: 1, b: x } JSON のようなキーバリュー構造。 Function isFunctionfunction(){},
&() => expr関数。
Undefined以外であればisDefinedで true が返る。尚、真偽値としての
true、falseは整数の 1、0 のエイリアスでしかないのに注意。
Boolean 型というのは特別に定義されていないが、オブジェクトとして真偽を表すTrue、Falseという定数が定義されているので、整数値とどうしても区別したい場合はそちらを使用する。System.println(True ? 1 : 0); // 1 System.println(False ? 1 : 0); // 0ブロックとスコープ
ブロックはスコープを持ち、内側で宣言された変数は外側のブロックからは参照不可。同じ名前で宣言した場合、外側ブロックの同名変数は隠蔽される。
var a = 10; { var a = 100; System.println(a); } System.println(a);この辺が「見た目は JavaScript」であっても中身は JavaScript ではない感じの部分。というか、JavaScript のスコープは変態過ぎて使いづらい。
式
式(エクスプレッション)は、以下の優先順位で四則演算、関数呼び出し、オブジェクト操作等が可能。
# 要素 演算子例 評価方向 1 要素 変数, 数値, 文字列, ... - 2 後置演算子 ++,--,[],.,()左から右 3 前置演算子 !,+,-,++,--左から右 4 パターンマッチ =~,!~左から右 5 べき乗 **右から左 6 乗除 *,/,%左から右 7 加減 +,-左から右 8 ビットシフト <<,>>左から右 9 大小比較 <,>,>=,<=左から右 10 等値比較 ==,!=左から右 11 ビットAND &左から右 12 ビットXOR ^左から右 13 ビットOR |左から右 14 論理AND &&左から右 15 論理OR ||左から右 16 三項演算子 ? :,function(){}左から右 17 代入演算子 =,+=,-=,*=./=.%=,&=,|=,^=,&&=,||=右から左 いくつか特徴を以下に示す。
演算
演算結果によって型が自動的に結果に適応していく。
3/2は1.5になる。num = 3 + 2; // 5 num = 3 - 2; // 1 num = 3 * 2; // 6 num = 3 / 2; // 1.5 num = 3 % 2; // 1インクリメント・デクリメント
前置形式・後置形式があり、C と同様。
var a = 10; System.println(a++); // 10 System.println(++a); // 12 System.println(a--); // 12 System.println(--a); // 10データ型
数値
整数、実数
整数、実数は以下の形式。整数では可読性向上のため任意の場所に
_を挿入可能。_は単に無視される。var i = 2; var j = 100_000_000; var num = 1.234;文字列
基本
ダブルクォートとシングルクォートの両方が使えるが、エスケープしなければならないクォート文字が異なるだけでどちらも同じ意味になる。
var a = "\"aaa\", 'bbb'"; var b = '"aaa", \'bbb\''; System.println(a == b ? "same" : "different"); // same内部式
%{...}の形式で内部に式を持つことができる。for (var i = 0; i < 10; ++i) { System.println("i = %{i}, i * 2 = %{i * 2}"); } // i = 0, i * 2 = 0 // i = 1, i * 2 = 2 // i = 2, i * 2 = 4 // i = 3, i * 2 = 6 // i = 4, i * 2 = 8 // i = 5, i * 2 = 10 // i = 6, i * 2 = 12 // i = 7, i * 2 = 14 // i = 8, i * 2 = 16 // i = 9, i * 2 = 18フォーマッタ
文字列に対する
%演算子はフォーマッタ・オブジェクトを作成する。var fmt = "This is %1%, I can do %2%."; System.println(fmt % "Tom" % "cooking");
%1%の1はプレースホルダ番号を示し、%演算子で適用した順に合わせて整形する。適用場所が順序通りであれば、C の printf と同様の指定の仕方も可能。さらに、C の printf と同じ指定子を使いながら同時にプレースホルダも指定したい場合は、$の前に位置指定子を書き、'$' で区切って記述する。例えば、16進数で表示したい場合は以下のようにする。var fmt = "This is %2%, I am 0x%1$02x years old in hex."; System.println(fmt % 27 % "John"); // This is John, I am 0x1b years old in hex.フォーマッタ・オブジェクトに後から値を適用していく場合は、
%=演算子で適用していく。var fmt = "This is %1%, I can do %2%."; fmt %= "Tom"; fmt %= "cooking"; System.println(fmt);実際のフォーマット処理は、
System.println等で表示するとき、文字列との加算等が行われるとき、に実際に実行される。Raw 文字列
文字列内部ではなく、
%{...}で文字列を記載することで Raw 文字列を作成することが可能。%-{...}を使うと、先頭と末尾の改行文字をトリミングする。ヒアドキュメントのようにも使えるので、ヒアドキュメントはサポートしていない。また、%<...>、%(...)、%[...]を使うこともできる。var a = 100; var b = 10; var str = %{ This is a string without escaping control characters. New line is available in this area. { and } can be nested here. }; System.println(str); var str = %-{ This is a string without escaping control characters. New line is available in this area. But newlines at the beginning and the end are removed when starting with '%-'. }; System.println(str);
\でエスケープする必要があるのは、内部式を使う場合%{の%に対するものと、ネストした形にならないケースでのクォート文字である{や}に対するものだけとなる。また、カッコは対応する閉じカッコでクォートするが、以下の文字を使ったクォートも可能である。その場合は、開始文字と終了文字は同じ文字となる。例えば、
%|...|のような形で使用する。
|,!,^,~,_,.,,,+,*,@,&,$,:,;,?,',".正規表現リテラル
正規表現リテラルは
/.../の形式で使う。リテラル内の/は\でエスケープする必要がある。以下が例。var a = "111/aaa/bbb/ccc/ddd"; while (group = (a =~ /\w+\//)) { for (var i = 0, len = group.length(); i < len; ++i) { System.println("found[%2d,%2d) = %s" % group[i].begin % group[i].end % a.subString(group[i].begin, group[i].end - group[i].begin)); } }
/を多用するような正規表現の場合、%mプレフィックスを付け、別のクォート文字を使うことで回避できる。例えば%m(...)といった記述が可能。これを使って上記を書き直すと、以下のようになる。var a = "111/aaa/bbb/ccc/ddd"; while (group = (a =~ %m(\w+/))) { for (var i = 0, len = group.length(); i < len; ++i) { System.println("found[%2d,%2d) = %s" % group[i].begin % group[i].end % a.subString(group[i].begin, group[i].end - group[i].begin)); } }尚、正規表現リテラルを
while等の条件式に入れることができるが注意点があるので補足しておく。例えば以下のように記述した場合、strの文字列に対してマッチしなくなるまでループを回すことができる(groupにはキャプチャ一覧が入る)。その際、最後のマッチまで実行せずに途中でbreak等でループを抜けると正規表現リテラルの対象文字列が次回のループで正しくリセットされない、という状況が発生する。while (group = (str =~ /ab+/)) { /* block */ }正規表現リテラルがリセットされるタイミングは以下の 2 パターン。
- 初回(前回のマッチが失敗して再度式が評価された場合を含む)。
strの内容が変化した場合。将来改善を検討するかもしれないが、現在は上記の制約があることに注意。
配列
配列は任意の要素を保持するリスト。インデックスでアクセスできる。またインデックスに負の数を与えることで末尾からアクセスすることもできる。
var a = [1,2,3]; var b = [a, 1, 2]; System.println(b[0][2]); // 3 System.println(a[-1]); // 3配列構造は左辺値で使用すると右辺値の配列を個々の変数に取り込むことが可能。これを使用して値のスワップも可能。
[a, b] = [b, a]; // Swapスプレッド(レスト)演算子を使っての分割も可能。
[a, ...b] = [1, 2, 3, 4, 5]; // a = 1 // b = [2, 3, 4, 5]尚、以下の書き方はできない。変数は宣言なしで使用できる(最初に代入された時点で生成される)ため、
varを付けない形で直接記述することは可能。ただしその際、外部のスコープで定義されていた場合、外側のスコープの変数の内容が書き換わってしまうことに注意。スコープで変数へのアクセス範囲を閉じたい場合は、予めvar a, b;と宣言してから使うことで回避可能。// var [a, ...b] = [1, 2, 3, 4, 5]; // error. var a = 3, b = [4], x = 3, y = [4]; { var a, b; [a, ...b] = [1, 2, 3, 4, 5]; // a = 1 // b = [2, 3, 4, 5] [x, ...y] = [1, 2, 3, 4, 5]; // x = 1 // y = [2, 3, 4, 5] [z] = [1, 2, 3, 4, 5]; // okay z = 1, but scoped out... } System.println("a = ", a); // 3 System.println("b = ", b[0]); // 4 System.println("x = ", x); // 1 System.println("y = ", y[0]); // 2宣言と同時に使えると便利とは思うので、将来改善するかもしれない。
バイナリ
バイナリはバイト配列であり、
<...>の形式で記述する。全ての要素は 0x00 ~ 0xFF の範囲にアジャストされ、配列のようにアクセス可能。バイナリと配列は相互にスプレッド演算子で分割、結合することが可能。
var bin = <0x01, 0x02, 0x03, 0x04>; var ary = [...bin]; // ary := [1, 2, 3, 4] var ary = [10, 11, 12, 257]; var bin = <...ary>; // bin := <0x0a, 0x0b, 0x0c, 0x01>ただし、バイナリになった瞬間に 0x00-0xFF に丸められるので注意。
オブジェクト
いわゆる JSON。ただし、ソースコード上のキー文字列に対してクォートする必要は無い(しても良い)。
var a = { a: 100 }; a.b = 1_000; a["c"] = 10_000; System.println(a.a); // 100 System.println(a.b); // 1000 System.println(a.c); // 10000内部的に実はオブジェクトと配列は同じであり、両方の値を同時に保持できる。
var a = { a: 100 }; a.b = 1_000; a["c"] = 10_000; a[1] = 10; System.println(a[1]); // 10 System.println(a.a); // 100 System.println(a.b); // 1000 System.println(a.c); // 10000おわりに
今回はここまで。結構疲れた。
非常に一般的な話ばかりで面白くないのだが、まずはこういうところに触れた上で色々な解説しとかないと土台が良く分からなくなりそうなので頑張ってみた。とりあえず、次は制御構造に触れて、一通りのプログラムが構築できるところまでを目指そう。そこまで行ったら関数とかクラスとかクロージャとか個別の解説をしてみる予定。
例によって★が増えるといいな、と宣伝しておく。
そして書きながらバグを見つけ修正するという...。
- 投稿日:2020-02-25T18:24:23+09:00
Ruby/GTK3 - ToggleButton
gem install gtk3ToggleButton
トグルボタンは通常のGTKのボタンとよく似ているが、クリックすると再びクリックされるまでアクティブなまま、押されたままになる。ボタンの状態が変化すると「toggled」シグナルが発生する。
Button 2 was turned on
Button 1 was turned on
Button 2 was turned off
Button 1 was turned offrequire 'gtk3' class ToggleButtonWindow < Gtk::Window def initialize super self.title = "ToggleButton Demo" self.border_width = 10 hbox = Gtk::Box.new(:horizontal, 6) add(hbox) button = Gtk::ToggleButton.new(label: 'Button 1') button.signal_connect('toggled') { |b| on_button_toggled(b, 1) } hbox.pack_start(button) button = Gtk::ToggleButton.new(label: 'Button 2') button.signal_connect('toggled') { |b| on_button_toggled(b, 2) } button.set_active true hbox.pack_start(button) end def on_button_toggled(button, name) state = button.active? ? 'on' : 'off' puts "Button #{name} was turned #{state}" end end win = ToggleButtonWindow.new win.signal_connect('destroy') { Gtk.main_quit } win.show_all Gtk.main

- 投稿日:2020-02-25T17:50:45+09:00
[rails] Modelに紐づく関連テーブル名一覧を取得するメモ
User.reflect_on_all_associations.map(&:name) => [:orders, :address, :payments] # has_one等を指定する事も出来る User.reflect_on_all_associations(:has_one).map(&:name) => [:address]
- 投稿日:2020-02-25T14:16:39+09:00
ruby-build で Homebrew の openssl@1.1 を使う (fish shell の場合)
結論をお急ぎの方は末尾をご覧くださいませ。
背景
2019年の暮れ頃から、ruby-build (rbenv install) で Ruby をインストールする際、Homebrew でインストールしている OpenSSL が使用されず、ダウンロード&ビルドされるようになりました。
$ rbenv install 2.6.4 5.4s Downloading openssl-1.1.1d.tar.gz... -> https://dqw8nmjcqpjn7.cloudfront.net/1e3a91bc1f9dfce01af26026f856e064eab4c8ee0a8f457b5ae30b40b8b711f2 Installing openssl-1.1.1d... Installed openssl-1.1.1d to /Users/foo/.rbenv/versions/2.6.4 Downloading ruby-2.6.4.tar.bz2... -> https://cache.ruby-lang.org/pub/ruby/2.6/ruby-2.6.4.tar.bz2 Installing ruby-2.6.4... ruby-build: using readline from homebrew Installed ruby-2.6.4 to /Users/foo/.rbenv/versions/2.6.4詳細はこちらの PR にある通り:
Don’t look for Homebrew openssl by gfguthrie · Pull Request #1375 · rbenv/ruby-build互換性のないバージョンがインストールされているかもしれないし、ユーザーがどのバージョンをインストールしているかわかっていないかもしれないし、それらをいちいちケアするのが大変だということでしょうか。
一方で、上級者は
RUBY_CONFIGURE_OPTS="--with-openssl-dir=/my-openssl-directory"オプションを指定することで ruby-build がインストールする OpenSSL を使わないようにすることもできる、と。個別に OpenSSL がインストールされるのも別に悪くはないのですが、いちいちダウンロードしてビルドするのもなんだし、ストレージもあまり余裕がないので、どちらかというと Homebrew でインストールした OpenSSL を使いたい。
RUBY_CONFIGURE_OPTS 変数の設定
Homebrew で ruby-build をインストール/アップグレードした際にも、Homebrew の OpenSSL をリンクしたい場合は
RUBY_CONFIGURE_OPTS環境変数を設定せよという補足説明が表示されますが==> Caveats ruby-build installs a non-Homebrew OpenSSL for each Ruby version installed and these are never upgraded. To link Rubies to Homebrew's OpenSSL 1.1 (which is upgraded) add the following to your ~/.config/fish/config.fish: export RUBY_CONFIGURE_OPTS="--with-openssl-dir=$(brew --prefix openssl@1.1)" Note: this may interfere with building old versions of Ruby (e.g <2.4) that use OpenSSL <1.1.いかんせん、上記
export 〜は fish shell ではエラーになりますので、~/.config/fish/config.fishset -x RUBY_CONFIGURE_OPTS --with-openssl-dir=(brew --prefix openssl@1.1)とすれば OK です。
- 投稿日:2020-02-25T12:02:27+09:00
【Rails】複数画像を保存したい時のcarrierwaveとMiniMagickの導入
はじめに
syomaと申します。よろしくお願いいたします。
某プログラミングスクールの最終課題で某フリマアプリのクローンにて、商品出品における画像の複数投稿のための下準備でcarrierwaveとMiniMagickを導入しました。環境
Rails 5.2.4.1
ruby 2.5.1やりたいこと
- carrierwaveの導入
- MiniMagickの導入
↓最終形のイメージ
0.下準備
複数画像を投稿する場合は?対多(画像)になるので、Photoテーブルを作成し、カラム名はimageにしようと思います。※1枚のみであれば保存したいテーブルにimageカラムを追記するだけでOK!
保存先のテーブルを用意しましょう
以下のコマンドを実行してPhotoモデルを作成してください。
ターミナル$ rails g model Photo作成できたら、下記のファイルを記述を変更します。
db/migrate/****_create_photos.rbclass CreatePhotos < ActiveRecord::Migration[5.2] def change create_table :photos do |t| # ==========ここから追加する========== t.string :image, null: false t.references :good, foreign_key: true, null: false # ==========ここまで追加する========== # t.references :good, foreign_key: true, null: falseのgoodは # 紐付けたいテーブル名です。私の場合は商品に紐付けたかったのでGoodテーブルに紐づけております。 # 人によってはテーブル名が異なるかと存じます。 t.timestamps end end endでは、マイグレーションファイルを実行してphotosテーブルを作成します。
ターミナル$ rails db:migrateアソシエーションの設定
モデルを作成したらアソシエーションの設定を行います。
アソシエーションとは、2つのモデル同士のつながりを指します。モデルとモデルの間には関連付けを行う必要があります。GoodモデルとPhotoモデルのアソシエーションを設定します。上記2つのモデルの関係性は以下のようになります。
- 一つの商品は複数の写真を持つことができる
- 写真Aに関して、写真Aに紐づく商品は一つしかない
つまり、GoodモデルとPhotoモデルは「1対多」の関係になります。
では、app/models/good.rbに以下のコードを追加してください。good.rbhas_many :photos, dependent: :destroy次にapp/models/photo.rbに以下のコードを追加してください。
photo.rbbelongs_to :goodこれで、アソシエーションの設定は完了です。
1. carrierwaveの導入
carrierwaveはファイルを簡単かつ柔軟にアップロードする方法を提供するgem。
carrierwaveのGemをインストール
gemfilegem "carrierwave"ターミナル$ bundle installCarrierWaveのアップローダーを作成
ターミナル$ rails g uploader Image上記のコマンドを実行すると以下のファイルが作成されます。
ターミナルcreate app/uploaders/image_uploader.rbimage_uploader.rbでは、ファイルの保存方法(デフォルトはファイル)、保存パス、ファイルのサイズ、拡張子やファイル名の変換などが変更できます。
モデルのカラムにアップローダーを紐付け
Photoモデルのimageカラムと、先ほど作成したアップローダーImageUploaderと紐付けをします。(ImageUploaderはapp/uploaders/image_uploader.rbのクラスの名前です。)
app/models/photo.rbに以下のコードを追加してください。
photo.rbclass Photo < ApplicationRecord belongs_to :good , optional: true # ==========ここから追加する========== mount_uploader :image, ImageUploader # ==========ここまで追加する========== end2.MiniMagickの導入
MiniMagickは画像をリサイズできるgemです。Gemfileの最下部に以下のコードを追加します。
gemfilegem "mini_magick"ターミナル$ bundle installアップローダーの記述を修正
app/uploaders/image_uploader.rbを修正します。
ここで修正するのは以下の3点です。
- 4行目のすでに生成されているコードのコメントを外す
- 「version :middle」というサイズを指定するコードを追加 ※サイズを指定しない場合は不要
- extension_whitelistメソッドのコメントアウトを外す
image_uploader.rbclass ImageUploader < CarrierWave::Uploader::Base # Include RMagick or MiniMagick support: # include CarrierWave::RMagick include CarrierWave::MiniMagick # ここのコメントアウトを外す # Choose what kind of storage to use for this uploader: storage :file # storage :fog # Override the directory where uploaded files will be stored. # This is a sensible default for uploaders that are meant to be mounted: def store_dir "uploads/#{model.class.to_s.underscore}/#{mounted_as}/#{model.id}" end # Provide a default URL as a default if there hasn't been a file uploaded: # def default_url(*args) # # For Rails 3.1+ asset pipeline compatibility: # # ActionController::Base.helpers.asset_path("fallback/" + [version_name, "default.png"].compact.join('_')) # # "/images/fallback/" + [version_name, "default.png"].compact.join('_') # end # Process files as they are uploaded: # process scale: [200, 300] # # def scale(width, height) # # do something # end # Create different versions of your uploaded files: # version :thumb do # process resize_to_fit: [50, 50] # end # ==========ここから追加する========== version :middle do process resize_to_fill: [188, 188] end # ==========ここまで追加する========== # Add a white list of extensions which are allowed to be uploaded. # For images you might use something like this: # ここのコメントアウトを外す def extension_whitelist %w(jpg jpeg gif png) end # Override the filename of the uploaded files: # Avoid using model.id or version_name here, see uploader/store.rb for details. # def filename # "something.jpg" if original_filename # end endimage_uploader.rbversion :middle do process resize_to_fill: [188, 188] endmiddleというバージョンが作成され、画像を188 x 188ピクセルにリサイズします。
最後に
実際の投稿は
【Ajax+Rails+Carrierwave】個別削除可能な画像複数(10枚まで)投稿
https://qiita.com/syoma/items/09a0d7bbadad35771a4d
にてご案内しております。もし、参考になったと思ったら「いいね」よろしくお願いいたします!twitterもやっておりますので是非フォローよろしくお願いいたします。
https://twitter.com/syomabusiness
youtubeも始める予定です。

- 投稿日:2020-02-25T11:58:33+09:00
みんなでしりとり Ruby編
エンジニア目指して一生懸命勉強中です。
ランクBは難しい!調べながらじゃないとクリアできなくて悔しい!
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
みんなでしりとり(Bランク練習問題 Ruby)
https://paiza.jp/works/mondai/skillcheck_archive/word_chain?language_uid=ruby&t=5849f929b8390356d4da2de5cc89575f
参考にした動画(Python3)
https://www.youtube.com/watch?v=ihItHDx9sX0※練習問題はブログやSNS等に掲載することはOKとのことです。
ーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーーline = gets.split.map(&:to_i)
n = line[0] #人数
k = line[1] #単語数
m = line[2] #発言数
word_list = [] #使用可能な単語
siri = [] #入力された単語全部
used_siri = [] #使用した単語単語の格納
k.times do
word_list.push(gets.chomp.to_s)
endm.times do
siri.push(gets.chomp.to_s)
end生きてる人数
alive = Array.new(n,true)
4つのルール
def ruleO(w,s)
return w.include?(s)
enddef ruleT(b,a,ruleT_pass)
return b[-1,1] == a[0,1] ||
ruleT_pass == true
enddef ruleTh(a,b)
return a.include?(b) != true
enddef ruleF(a)
return a[-1,1] != "z"
end次に発言する人の番号を求める
def next_number(alive,now_number)
now_number += 1
until alive[now_number] == true
if now_number >= alive.size
now_number = 0
else
now_number += 1
end
end
return now_number
end初期値
now_number = 0
一番最初の人はルール2免除
ruleT_pass = true
しりとり開始
(1..m).each do |num|
if ruleO(word_list,siri[num - 1]) &&
ruleT(siri[num - 2],siri[num - 1],ruleT_pass) &&
ruleTh(used_siri,siri[num - 1]) && ruleF(siri[num - 1])
used_siri.push(siri[num - 1])
ruleT_pass = false
else
alive[now_number] = false
ruleT_pass = true
end
now_number = next_number(alive,now_number)
if word_list.sort == used_siri.sort
used_siri = []
end
endoutput
p alive.count(true)
alive.size.times do
if alive.find_index(true)
f = alive.find_index(true)
puts (f.to_i + 1)
alive[f] = false
end
end
- 投稿日:2020-02-25T10:58:13+09:00
[自然言語処理 初心者向け] COTOHA API を Ruby で使いたくて gem を作りました
はじめに
COTOHA API というものがあります。
NTTコミュニケーションズが開発した日本最大級の日本語辞書を活用した自然言語処理、音声認識APIプラットフォーム
です。これを使うとカンタンに自然言語処理をすることができます。
この API を Ruby でお手軽に扱えるようにしたいなぁと思い gem を作りました

tanaken0515/cotoha-ruby: COTOHA API client for Rubyこのgemを紹介しつつ COTOHA API でこんなことができるんだよ〜、という話を書いていこうと思います。
想定読者
- 自然言語処理に興味があるけどやったことない方
- Rubyで自然言語処理をやりたい方
僕自身も自然言語処理については疎いので、この記事を書きながら一緒に「こんなことができるんだなぁ〜」と学んでいきます

cotohagem の使い方基本的な使い方を紹介します。
インストール
cotohagem は rubygems に公開してあります。
Gemfileにgem 'cotoha'を記載してbundle installするか、
gem install cotohaでインストールすることができます。認証
- まずは スタートガイド | COTOHA API の通りに COTOHA API のアカウントを作り、ログインしましょう

- ログインすると以下のような
Client IDとClient secretが記載された画面が表示されます

- その情報を使って以下のように認証を行ないます
 require 'cotoha' client_id = 'xxxxx' client_secret = 'xxxxx' client = Cotoha::Client.new(client_id: client_id, client_secret: client_secret) client.create_access_token # => {"access_token"=>"xxxxx", "token_type"=>"bearer", "expires_in"=>"86399", "scope"=>"", "issued_at"=>"1582159764808"}
require 'cotoha' client_id = 'xxxxx' client_secret = 'xxxxx' client = Cotoha::Client.new(client_id: client_id, client_secret: client_secret) client.create_access_token # => {"access_token"=>"xxxxx", "token_type"=>"bearer", "expires_in"=>"86399", "scope"=>"", "issued_at"=>"1582159764808"}
- また、前もってアクセストークンが分かっている場合にはそれを用いて以下のように書くこともできます。
client = Cotoha::Client.new(token: 'xxxxx')使用例
cotohagem では COTOHA API の各種エンドポイントをCotoha::Clientクラスのインスタンスメソッドとして提供しています。例えば「感情分析」のエンドポイント
POST /nlp/v1/sentimentにはsentimentメソッドが対応しています。client.sentiment(sentence: 'ゲームをするのが好きです。') # {"result"=> # {"sentiment"=>"Positive", # "score"=>0.4714220003626205, # "emotional_phrase"=>[{"form"=>"好きです", "emotion"=>"P"}]}, # "status"=>0, # "message"=>"OK"}基本的な使い方の紹介は以上です。
次節では各種エンドポイントをそれぞれ見ていきます。
COTOHA API でできること
cotohagem を使って COTOHA API でできることを紹介します。
自然言語処理をまだあまり知らない方は、この節を読むと「あ、こういうのが自然言語処理というやつなんだ〜」というのがなんとなく分かると思います
公式の APIリファレンス | COTOHA API を見つつ、各種エンドポイントと
Cotoha::Clientクラスのインスタンスメソッドとの対応関係を以下にまとめました。
名称 エンドポイント Cotoha::Client構文解析 POST /nlp/v1/parseparse固有表現抽出 POST /nlp/v1/nenamed_entities照応解析 POST /nlp/v1/coreferencecoreferenceキーワード抽出 POST /nlp/v1/keywordkeywords類似度算出 POST /nlp/v1/similaritysimilarity文タイプ判定 POST /nlp/v1/sentence_typesentence_typeユーザ属性推定(β) POST /nlp/beta/user_attributeuser_attribute言い淀み除去(β) POST /nlp/beta/remove_fillerremove_filler音声認識誤り検知(β) POST /nlp/beta/detect_misrecognitiondetect_misrecognition感情分析 POST /nlp/v1/sentimentsentiment要約(β) POST /nlp/beta/summarysummaryCOTOHA API には上記の他に「固有名詞(企業名)補正」「音声認識」「音声合成」のAPIがありますが、有料の for Enterprise プランに申し込まないと利用できないため、現時点(
cotoha v0.2.0)では対象外としています。それぞれのエンドポイントについて見ていきましょう。
構文解析
公式リファレンスによれば
構文解析APIは、入力として日本語で記述された文を受け取り、文の構造と意味を解析・出力します。入力された文は、文節・形態素に分解され、文節間の係り受け関係や形態素間の係り受け関係、品詞情報などの意味情報などが付与されます。
とのこと。では「吾輩は猫である」という文章を構文解析
parseしてみましょう。response = client.parse(sentence: '吾輩は猫である') pp response # {"result"=> # [{"chunk_info"=> {...} # "tokens"=> [...]}, # {"chunk_info"=> {...} # "tokens"=> [...]}, # {"chunk_info"=> {...} # "tokens"=> [...]}], # "status"=>0, # "message"=>""}レスポンスをそのまま貼り付けると長かったので中身を省略しました。result に
chunk_infoとtokensをキーとする Hash オブジェクトの配列が入っていることがわかりますね。
chunkは「大きなかたまり」という意味で、公式リファレンスの説明文の文脈では(あるいは自然言語処理では一般に?)「文節」を意味しているようです。つまり「吾輩は猫である」という文章は3つの「文節」に分けることができたようです。
tokensは文章を構成する最小単位となっている「字句」を表しています。公式リファレンスの説明文の文脈では「形態素」にあたるのようですね。つまり先ほどの3つの「文節」のそれぞれは、いくつかの「形態素」によって構成されているよ、という意味になりそうです。
responseの全文(クリックして開閉)
{"result"=> [{"chunk_info"=> {"id"=>0, "head"=>2, "dep"=>"D", "chunk_head"=>0, "chunk_func"=>1, "links"=>[]}, "tokens"=> [{"id"=>0, "form"=>"吾輩", "kana"=>"ワガハイ", "lemma"=>"吾輩", "pos"=>"名詞", "features"=>["代名詞"], "dependency_labels"=>[{"token_id"=>1, "label"=>"case"}], "attributes"=>{}}, {"id"=>1, "form"=>"は", "kana"=>"ハ", "lemma"=>"は", "pos"=>"連用助詞", "features"=>[], "attributes"=>{}}]}, {"chunk_info"=> {"id"=>1, "head"=>2, "dep"=>"D", "chunk_head"=>0, "chunk_func"=>1, "links"=>[]}, "tokens"=> [{"id"=>2, "form"=>"猫", "kana"=>"ネコ", "lemma"=>"猫", "pos"=>"名詞", "features"=>[], "dependency_labels"=>[{"token_id"=>3, "label"=>"cop"}], "attributes"=>{}}, {"id"=>3, "form"=>"で", "kana"=>"デ", "lemma"=>"で", "pos"=>"判定詞", "features"=>["連用"], "attributes"=>{}}]}, {"chunk_info"=> {"id"=>2, "head"=>-1, "dep"=>"O", "chunk_head"=>0, "chunk_func"=>1, "links"=> [{"link"=>0, "label"=>"agent"}, {"link"=>1, "label"=>"condition"}], "predicate"=>[]}, "tokens"=> [{"id"=>4, "form"=>"あ", "kana"=>"ア", "lemma"=>"ある", "pos"=>"動詞語幹", "features"=>["R"], "dependency_labels"=> [{"token_id"=>0, "label"=>"nsubj"}, {"token_id"=>2, "label"=>"nmod"}, {"token_id"=>5, "label"=>"aux"}], "attributes"=>{}}, {"id"=>5, "form"=>"る", "kana"=>"ル", "lemma"=>"る", "pos"=>"動詞接尾辞", "features"=>["終止"], "attributes"=>{}}]}], "status"=>0, "message"=>""}↑の「responseの全文」をみつつ、簡単な図にしてみました。
tokenごとに
dependency_labelsがあるので、 token 間の関係性を図にしてみると面白いかもですね。(今回は図を作るのが大変そうなので遠慮しました)固有表現抽出
公式リファレンスによれば
固有表現抽出APIは、入力として日本語で記述された文を受け取り、人名や地名、日付表現(時間、日付)、組織名、量的表現(金額、割合)、人工物の8種類の固有表現と、200種類以上のクラス数を持つ拡張固有表現を出力します。
とのこと。
では試しに「私は犬が好きだ。よく代々木公園の近くを散歩している。」という文章から固有表現を抽出してみます。
response = client.named_entities(sentence: '私は犬が好きだ。よく代々木公園の近くを散歩している。') pp response # {"result"=> # [{"begin_pos"=>10, # "end_pos"=>15, # "form"=>"代々木公園", # "std_form"=>"代々木公園", # "class"=>"LOC", # "extended_class"=>"", # "source"=>"basic"}, # {"begin_pos"=>2, # "end_pos"=>3, # "form"=>"犬", # "std_form"=>"犬", # "class"=>"OTH", # "extended_class"=>"Mammal", # "source"=>"basic"}, # {"begin_pos"=>4, # "end_pos"=>7, # "form"=>"好きだ", # "std_form"=>"好きだ", # "class"=>"ART", # "extended_class"=>"Movie", # "source"=>"basic"}], # "status"=>0, # "message"=>""}「代々木公園」「犬」「好きだ」の3つが抽出されたようです。
「代々木公園」は地名(
"class"=>"LOC")で抽出されているのでたしかに〜、という感じですが、他の2つは意外ですね。「犬」は
"class"=>"OTH", "extended_class"=>"Mammal"で抽出されています。これは「固有表現」としては「その他(OTHER)」に分類され、「拡張固有表現」としては「自然物名>生物名>哺乳類名(Mammal)」に分類されるよ、ということらしいです。「拡張固有表現」すごいですね、生物名、どれくらいいけるのかなぁ。最後に「好きだ」は
"class"=>"ART", "extended_class"=>"Movie"だそうです。いや全然そんなつもりで使ってなかったんで驚きました。「固有表現」としては「固有物名(ART)」に分類され、「拡張固有表現」としては「芸術作品名>映画名(Mammal)」に分類されるよ、ということらしいです。
へ〜、そんな映画あったんですね。調べてみると正式名称は『好きだ、』のようで、宮崎あおいさん、西島秀俊さん、瑛太さんなどが出演している映画なんですね〜。公式サイトはこちら -> su-ki-da,「拡張固有表現」面白いなぁと思ったので、「珍しい生き物の名前」でググって生物名として判定されるか試してみました。
response = client.named_entities(sentence: 'タツノイトコを捕まえた') pp response # {"result"=> # [{"begin_pos"=>0, # "end_pos"=>6, # "form"=>"タツノイトコ", # "std_form"=>"タツノイトコ", # "class"=>"OTH", # "extended_class"=>"Fish", # "source"=>"basic"}], # "status"=>0, # "message"=>""}お〜、「タツノイトコ」をちゃんと「魚類名(Fish)」として判定していますね。
response = client.named_entities(sentence: 'ウッカリカサゴを捕まえた') pp response # {"result"=>[], "status"=>0, "message"=>""} response = client.named_entities(sentence: 'うっかり笠子を捕まえた') pp response # {"result"=>[], "status"=>0, "message"=>""}あ〜、「ウッカリカサゴ」は難しかったみたい。
照応解析
公式リファレンスによれば
照応解析APIは、入力として日本語で記述された複数の文からなるテキストを受け取り、テキスト中の「そこ」「それ」などの指示詞や「彼」「彼女」などの代名詞と対応する先行詞を抽出し、同一のものとしてまとめて出力します。
とのこと。
response = client.coreference(document: '太郎は友人だ。彼は焼き肉を食べた。') pp response # {"result"=> # {"coreference"=> # [{"representative_id"=>0, # "referents"=> # [{"referent_id"=>0, # "sentence_id"=>0, # "token_id_from"=>0, # "token_id_to"=>0, # "form"=>"太郎"}, # {"referent_id"=>1, # "sentence_id"=>0, # "token_id_from"=>5, # "token_id_to"=>5, # "form"=>"彼"}]}], # "tokens"=> # [["太郎", "は", "友人", "だ", "。", "彼", "は", "焼き肉", "を", "食べ", "た", "。"]]}, # "status"=>0, # "message"=>"OK"}「太郎は友人だ。彼は焼き肉を食べた。」という文章について、「太郎 = 彼」であることを特定できています。
複数のモノがある場合はどうなるんだろう、と思ってやってみました。
response = client.coreference(document: '机にノートとペンがある。彼はこれらを手に取った。') pp response # {"result"=> # {"coreference"=> # [{"representative_id"=>0, # "referents"=> # [{"referent_id"=>0, # "sentence_id"=>0, # "token_id_from"=>4, # "token_id_to"=>4, # "form"=>"ペン"}, # {"referent_id"=>1, # "sentence_id"=>0, # "token_id_from"=>11, # "token_id_to"=>11, # "form"=>"これら"}]}], # "tokens"=> # [["机", "に", "ノート", "と", "ペン", "が", "あ", "る", "。", "彼", "は", "これら", "を", "手", "に", "取", "っ", "た", "。"]]}, # "status"=>0, # "message"=>"OK"}「机にノートとペンがある。彼はこれらを手に取った。」という文章について、「ペン = これら」という結果になりました。
キーワード抽出
公式リファレンスによれば
キーワード抽出APIは、入力として日本語で記述された複数の文からなるテキストを受け取り、テキストに含まれる特徴的なフレーズ・単語をキーワードとして抽出します。
テキストから算出される特徴的スコアに基づいて、複数のフレーズ・単語が降順に出力されます。とのこと。
先ほども使った「太郎は友人だ。彼は焼き肉を食べた。」のキーワードを抽出してみます。
response = client.keywords(document: '太郎は友人だ。彼は焼き肉を食べた。') pp response # {"result"=> # [{"form"=>"太郎", "score"=>15.86012}, # {"form"=>"彼", "score"=>15.71654}, # {"form"=>"焼き肉", "score"=>12.8053}, # {"form"=>"友人", "score"=>9.71421}], # "status"=>0, # "message"=>""}動作の主体(「太郎」「彼」)が高いスコアのキーワードとして抽出されるのでしょうか。
類似度算出
公式リファレンスによれば
類似度算出APIは、入力として日本語で記述されたテキストを2つ受け取り、テキスト間の意味的な類似度を算出・出力します。
類似度は0から1の定義域で出力され、1に近づくほどテキスト間の類似性が大きいことを示します。
テキストに含まれる単語の意味情報を用いて類似度を算出しているため、異なった単語を含むテキスト間の類似性も推定することができます。とのこと。
response = client.similarity(s1: '近くのレストランはどこですか?', s2: 'このあたりの定食屋はどこにありますか?') pp response # {"result"=>{"score"=>0.88565135}, "status"=>0, "message"=>"OK"}お〜、なるほど、確かに類似している意味合いの文章はscoreが高くなるんですね。
response = client.similarity(s1: '花粉が多くなってきてつらい。', s2: '森林浴、最高!') pp response # {"result"=>{"score"=>0.05732418}, "status"=>0, "message"=>"OK"}お〜、適当な文章にしてみたら類似度めっちゃ低い。
response = client.similarity(s1: '麻婆豆腐は美味しい。', s2: 'カレーはうまい。') pp response # {"result"=>{"score"=>0.99354756}, "status"=>0, "message"=>"OK"}自明ですが、麻婆豆腐は実質カレーであることを証明することもできました。
文タイプ判定
公式リファレンスによれば
文タイプ判定APIは、入力として日本語で記述された文を受け取り、文の法(叙述/疑問/命令)タイプと発話行為タイプを判定・出力します。
とのこと。
例えば「近くのレストランはどこですか?」の文タイプを判定してみます。
response = client.sentence_type(sentence: '近くのレストランはどこですか?') pp response # {"result"=> # {"modality"=>"interrogative", "dialog_act"=>["information-seeking"]}, # "status"=>0, # "message"=>""}文種別は「質問(interrogative)」で、発話行為種別は「情報獲得(information-seeking)」と判定されました。
「発話行為」という単語を初めて聞きましたが、この論文によると「コミュニケーションを行うために遂行される行為であり、一定の音声や文法上の語句、一定の意味を持つ文を発する行為のことである。」とのことです。
これを踏まえて「発話行為種別」は発話の目的や意味合いの種類、のようなものだと解釈しました。
日々の発言の文タイプを分析・集計してみるとちょっと面白いかもですね。
ユーザ属性推定(β)
公式リファレンスによれば
ユーザ属性推定APIは、入力として日本語で記述された複数の文からなるテキストを受け取り、年代、性別、趣味、職業などの人物に関する属性を推定・出力します。
とのこと。
例えば「渋谷でエンジニアとして働いています。」のユーザ属性を推定してみると、
response = client.user_attribute(document: '渋谷でエンジニアとして働いています。') pp response # {"result"=> # {"civilstatus"=>"既婚", # "hobby"=>["COOKING", "INTERNET", "MOVIE", "SHOPPING"], # "location"=>"関東", # "moving"=>["RAILWAY"], # "occupation"=>"会社員"}, # "status"=>0, # "message"=>"OK"}渋谷のエンジニアは既婚であることが分かります。
より高い精度の推定結果を出すには、単文ではなく複数の文章を入れたほうが良さそうですね。
ここまで説明していませんでしたが COTOHA API は基本的に
sentenceかdocumentを引数に取ります。
前者はstringで、後者はstringまたはstringのArrayを受け取ることができます。なのでこのように使うこともできます。
response = client.user_attribute(document: ['渋谷でエンジニアとして働いています。', 'webアプリケーションを作るのが好きです。']) pp response # {"result"=> # {"age"=>"20-29歳", # "civilstatus"=>"既婚", # "habit"=>["SMOKING"], # "hobby"=> # ["ANIMAL", # "COOKING", # "FISHING", # "FORTUNE", # "GAMBLE", # "INTERNET", # "TVGAME"], # "location"=>"関東", # "moving"=>["CAR", "RAILWAY"]}, # "status"=>0, # "message"=>"OK"}
"habit"=>["SMOKING"]...(喫煙の習慣は無いですが...)例えば、好きなサービスのSNS公式アカウントの「中の人」がどんな人なのかを推定してみると面白いかもですね。
言い淀み除去(β)
公式リファレンスによれば
言い淀み除去APIは、音声認識処理後のテキストに対して、ユーザからの音声入力時に含まれる言い淀みを除去します。
とのこと。
例えば「えーーっと、あの、何時に待ち合わせですっけ。」の言い淀みを除去してみます。
response = client.remove_filler(text: 'えーーっと、あの、何時に待ち合わせですっけ。') pp response # {"result"=> # [{"fillers"=> # [{"begin_pos"=>0, "end_pos"=>5, "form"=>"えーっと、"}, # {"begin_pos"=>5, "end_pos"=>7, "form"=>"あの"}], # "normalized_sentence"=>"えーっと、あの、何時に待ち合わせですっけ。", # "fixed_sentence"=>"、何時に待ち合わせですっけ。"}], # "status"=>0, # "message"=>"OK"}除去した結果は
"fixed_sentence"=>"、何時に待ち合わせですっけ。"ですね。文頭に「、」が残っているは惜しいですが、「えーっと」と「あの」が除去されて無駄のない文章になっています。音声認識したデータを分析する時の前処理として重要そうですね。
あと、自分の発話を音声認識で記録しておけば、このAPIを使って「普段どんな言い淀みをしているのか」を明らかにすることもできそうです。
音声認識誤り検知(β)
公式リファレンスによれば
音声認識誤り検知APIは、音声認識処理後のテキストを受け取り、認識誤りが疑われる箇所をそのスコアと訂正例とともに出力します。入力文全体の誤り度合いについても数値化を行って出力します。
とのこと。
response = client.detect_misrecognition(sentence: '温泉認識は誤りを起こす') pp response # {"result"=> # {"score"=>0.9999968696704667, # "candidates"=> # [{"begin_pos"=>0, # "end_pos"=>2, # "form"=>"温泉", # "detect_score"=>0.9999968696704667, # "correction"=> # [{"form"=>"音声", "correct_score"=>0.7722403968717316}, # {"form"=>"厭戦", "correct_score"=>0.6619857013879067}, # {"form"=>"怨念", "correct_score"=>0.6554196604056673}, # {"form"=>"おんねん", "correct_score"=>0.6554196604056673}, # {"form"=>"モンセン", "correct_score"=>0.654462258316514}]}]}, # "status"=>0, # "message"=>"OK"}この例では「『温泉認識』じゃなくて『音声認識』では?」という提案ができそうです。
YouTubeで「字幕あり」にすると(おそらく)音声認識の結果が表示されるんですが、それらの認識誤りをこのAPIで分析してみると面白そうだなと思いました。
感情分析
公式リファレンスによれば
感情分析APIは、入力として日本語で記述されたテキストを受け取り、そのテキストの書き手の感情(ネガティブ・ポジティブ)を判定します。また、テキスト中に含まれる「喜ぶ」「驚く」「不安」「安心」といった15種類の感情を分類・認識して出力します。
とのこと。
例えば「ゲームをするのが好きです。」はポジティブな文章であることが分かります。
response = client.sentiment(sentence: 'ゲームをするのが好きです。') pp response # {"result"=> # {"sentiment"=>"Positive", # "score"=>0.4714220003626205, # "emotional_phrase"=>[{"form"=>"好きです", "emotion"=>"P"}]}, # "status"=>0, # "message"=>"OK"}では「ゲームをするのが好きです。でも勉強は嫌いです。」はどうでしょう。
response = client.sentiment(sentence: 'ゲームをするのが好きです。でも勉強は嫌いです。') pp response # {"result"=> # {"sentiment"=>"Neutral", # "score"=>0.35432534042635183, # "emotional_phrase"=> # [{"form"=>"嫌いです", "emotion"=>"N"}, {"form"=>"好きです", "emotion"=>"P"}]}, # "status"=>0, # "message"=>"OK"}「Neutral」になりました。ではもう少し勉強嫌い度合いを上げてみます。
response = client.sentiment(sentence: 'ゲームをするのが好きです。でも勉強はめまいがするほど嫌いです。') pp response # {"result"=> # {"sentiment"=>"Negative", # "score"=>0.362639080610924, # "emotional_phrase"=> # [{"form"=>"嫌いです", "emotion"=>"N"}, # {"form"=>"好きです", "emotion"=>"P"}, # {"form"=>"めまい", "emotion"=>"悲しい"}]}, # "status"=>0, # "message"=>"OK"}「Negative」になりました。 「めまい = 悲しい」なんですね。
チャットやSNSの発言から自分や周囲の人の感情を分析してみると面白いかもですね〜。
要約(β)
公式リファレンスによれば
要約APIは、入力として日本語で記述された複数文で構成された文章を受け取り、これを文単位で重要度を算出し、スコアを付与します。そして、入力時に指定された要約文数に応じ、重要文を返します。
とのこと。
document =<<~EOS 前線が太平洋上に停滞しています。 一方、高気圧が千島近海にあって、北日本から東日本をゆるやかに覆っています。 関東地方は、晴れ時々曇り、ところにより雨となっています。 東京は、湿った空気や前線の影響により、晴れ後曇りで、夜は雨となるでしょう。 EOS response = client.summary(document: document, sent_len: 1) pp response # {"result"=>"東京は、湿った空気や前線の影響により、晴れ後曇りで、夜は雨となるでしょう。", "status"=>0}文章の結論がわかりやすくて良いですね。
COTOHA APIの存在を知ったきっかけは、この要約APIを使って書かれた 「メントスと囲碁の思い出」をCOTOHAさんに要約してもらった結果。COTOHA最速チュートリアル付き - Qiitaの記事だったので、「きっかけをありがとうございます〜」という気持ちです。
「要約」というと文章を組み替えていい感じにまとめあげてくれる、というのをイメージしますが、このAPIは与えられた文章の中から重要な文をそのまま返す、というものなのでそこだけ注意が必要ですね。
おわりに
この記事では COTOHA API を Ruby でお手軽に扱えるようにした gem を紹介しました。
tanaken0515/cotoha-ruby: COTOHA API client for Rubyこの記事をきっかけに COTOHA API に興味持ってくれる方やこの gem を使ってくれる方がいたら嬉しいなぁと思います。

- 投稿日:2020-02-25T08:51:47+09:00
progate Rails学習コースⅨ-6の「self」について
本記事の概要
ProgateのRails学習コース内で、インスタンスメソッド内で使用するselfについて、
その仕様を自分なりに噛み砕いてまとめています。誰向けの記事か
selfの使い方について、Progate内の解説が簡素すぎて、よく分からなかった人向け(私がそうでした)
問題の箇所
Postsテーブル:id,content,user_id
Usersテーブル:id, name,emailposts.rbdef user return User.find_by(id: self.user_id) end# ターミナルでrails consoleを実行したのち、以下を実行 post = Post.find_by(id:1) post.user #結果=> id:1, name:hogehoge ~~~スライド内の解説
Postモデル内にその投稿に紐付いたuserインスタンスを戻り値として返すuserメソッドを定義しましょう。
インスタンスメソッド内で、self はそのインスタンス自身を指す「selfはそのインスタンス自身を指す」←?????
自分なりに処理の流れを追ってみた
まず、Progateのスライドでは、Controller内ではなくコンソールで、インスタンスメソッドであるuserを呼び出している点に注意です。
演習では、インスタンスメソッドであるuserの呼び出しは、posts_controllerで行います。
そちらでどう記述するか、を先に見てしまいましょう。以下になります。
posts_controller.rbdef show @post = Post.find_by(id: params[:id]) @user = @post.user endインスタンスメソッドuserを定義しているコードと合わせて、見てみましょう。
以下です。posts.rbdef user return User.find_by(id: self.user_id) endそして、スライドの解説文をもう一度。
インスタンスメソッド内で、self はそのインスタンス自身を指す
インスタンスメソッドuser内の self は、インスタンスメソッドuserを呼び出すインスタンス自身を指している、ということです。
実際にuserが使用されているcontrollerをもう一度見てみましょう。posts_controller.rbdef show @post = Post.find_by(id: params[:id]) @user = @post.user end@user = @post.user
↑↑まさにここで、インスタンスメソッドuserが呼び出されていますね。
そして、呼び出しているインスタンスは、@postです。インスタンスメソッドuser内の self は、
インスタンスメソッドuserを使用するインスタンスである@postを指している、
ということです。では、@postの中身は何かというと、
@post = Post.find_by(id: params[:id])
⇨「Postテーブルの中身を、idで検索して得られた結果」です。
Postsテーブルのカラムは、id,content,user_id であり、それぞれに値が入っています。・インスタンスメソッドuser内の self は、
インスタンスメソッドuserを使用するインスタンスである@postを指している
・@postの中身は、Postテーブルの中身を、idで検索して得られた結果それを踏まえて、再度、インスタンスメソッドuserの中身を見てみましょう。
posts.rbdef user return User.find_by(id: self.user_id) end⇨@postの中身から、user_idを取り出して(参照して、が正しいか?)、
Userテーブルについて、そのuser_idをidとして検索し、
その結果をreturnする
というのが、インスタンスメソッドuserの中身である、ということになります。Userテーブルにはuser_idというカラムは存在しませんが、Postテーブルのuser_idとUserテーブルのidが等しいため、
Userテーブルでの検索条件に@post.user_idを用いることで、PostテーブルとUserテーブルを関連づけた形の検索結果が得られる、ということになります。Progate以外での、selfの使用例
Qiitaの記事で、ズバリな解説をしてくださっているものがありましたので引用いたします。
https://qiita.com/leavescomic1/items/99f32f45cd04035f146c#%E3%82%A4%E3%83%B3%E3%82%B9%E3%82%BF%E3%83%B3%E3%82%B9%E3%83%A1%E3%82%BD%E3%83%83%E3%83%89以下引用ーーーーーーーーーーーーーーーーーーーーーーーーーーーー
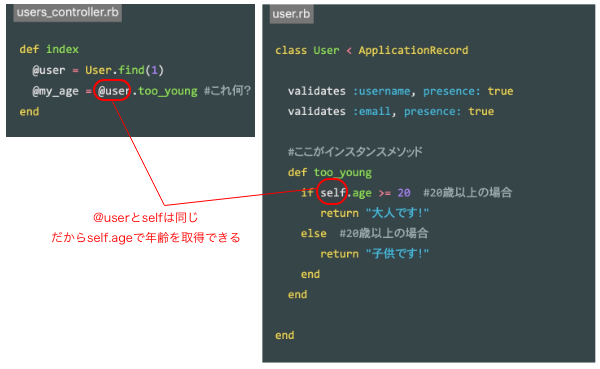
以下のusers_controllerの@userがインスタンスになります。
users_controller.rb@user = User.find(params[:id]) #findはインスタンスを探すメソッド #Userクラスから調べたいidに該当するユーザー情報をデータベースから取得しています。 @my_age = @user.too_young #@userというインスタンスにtoo_youngというメソッドを使っている。ここで、@userというインスタンスに対してtoo_youngというメソッドが使われています。
@userというインスタンスに使うメソッド....これがインスタンスメソッドとなります。もう一度user.rb内に記載されているtoo_youngメソッドを見てみましょう。
user.rbclass User < ApplicationRecord validates :username, presence: true validates :email, presence: true #ここがインスタンスメソッド def too_young if self.age >= 20 #20歳以上の場合 return "大人です!" else #20歳以下の場合 return "子供です!" end end endtoo_youngメソッド内に「self」というものがあります。
この「self」は何かというとusers_controller.rbで定義された@userのことです。
@userというインスタンスに対して「.(ドット)」で繋げてインスタンスメソッドを呼び出す時、インスタンスメソッド内では「self」が使え、self=呼び出し元のインスタンス(@user)となります。
今@userの中身は
user.rb
id: 1, username: "山田太郎", email: "hogehoge@example.com", age: 28
なので、self.ageでageカラムの値が呼びだされ、「28」という数字が返ってきます。引用ここまでーーーーーーーーーーーーーーーーーーーーーーーーーーーーー
おわりに
Progateは、初学者にとって非常に便利な学習サイトですが、解説がシンプルすぎる箇所があります。
理解が曖昧だと感じたときは、その箇所を使ったコードをProgate以外で探して見ると、理解が深まります。
(更に、その部分について自分のローカル環境でコーディングして、改変してエラーを出す、などしてみるのが、最も仕様を理解できる手段です)今回の self がどのくらい重要かは正直今の知識ではよく分からないですが、
色々と調べてみて、「多分こういうことだろう」と理解できたのは自分にとってプラスになったと感じたので、
備忘録的な形で記事として残すこととします。
万が一、同じように詰まっている人がいたら、少しでも参考にしていただければと思います。
- 投稿日:2020-02-25T06:35:02+09:00
PofEAAのユニットオブワークを実装してみた
マーチン・ファウラー著のエンタープライズアーキテクチャーパターン(以下PofEOAA)に載っていた、ユニットオブワーク(UnitOfWork)というパターンを理解するために、Rubyで実装してみたという話です。
ユニットオブワークとは
PofEOAAでは次のように記載されています。
ビジネストランザクションの影響を受けるオブジェクトのリストを保持しつつ、変更点の書き込みと並行性の問題の解決を調整する。
引用: マーチン・ファウラー. エンタープライズアプリケーションアーキテクチャパターン (Japanese Edition)ドメインロジックで、オブジェクトに複数の変更を加えたいとき、トランザクションをどの範囲で設定したらよいか悩むことがあると思いますが、そうした問題に対処できそう、ということでこのユニットオブワークの理解を深めることにしました。
実装方法
オブジェクトの変更を、それぞれ追加、変更、削除を記録しておくコレクションに追加しておき、コミットメソッドが呼ばれたら一気に変更を反映する、というやり方をします。
ソースコード
githubのこちらのリポジトリにも置いてあります。
ユニットオブワークのソースコードrequire 'singleton' # Mapperはサンプルなので何もしません class SomeMapper def self.insert(obj) puts "追加処理をしました" end def self.update(obj) puts "更新処理をしました" end def self.getSomeDomainObject() return SomeDomeinObject.create end end # これがユニットオブワークの実装です class UnitOfWork include Singleton def initialize @newObjects = [] @dirtyObjects = [] # 変更を保存しておく場所。Cleanな状態から変更されたのでDirtyです。 @removedObjects = [] end def registerNew(domainObj) @newObjects << domainObj end def registerDirty(domainObj) @dirtyObjects << domainObj unless @dirtyObjects.include?(domainObj) end def registerRemoved(domainObj) return if @newObjects.delete domainObj @dirtyObjects.delete domainObj @removedObjects << domainObj unless @removedObjects.include?(domainObj) end def registerClean(domainObj) end def commit() insertNew() updateDirty() deleteRemoved() end def insertNew @newObjects.each do |o| SomeMapper.insert o end end def updateDirty @newObjects.each do |o| SomeMapper.update o end end def deleteRemoved # 略 end end # ユニットオブワークに記録されるドメインオブジェクトの基底クラス class DomainObject def markNew UnitOfWork.instance.registerNew self end def markClean UnitOfWork.instance.registerClean self end def markDirty UnitOfWork.instance.registerDirty self end def markRemoved UnitOfWork.instance.registerRemoved self end end # ドメインオブジェクトの実装 class SomeDomeinObject < DomainObject def self.create obj = SomeDomeinObject.new obj.markNew # ここでユニットオブワークに追加を記録している return obj end def setSomeValue(newValue) @some_value = newValue markDirty() # ここでユニットオブワークに変更を記録している end end # ここからは実際にサンプルを実行するところ dobj = SomeMapper.getSomeDomainObject() dobj.setSomeValue("test") UnitOfWork.instance.commit()まとめ
PofEOAAに載っているサンプルは、ただ記録して、それを反映するだけのシンプルなものでした。
実際に並列性の問題を解消するためには、ロックの仕組みを入れていかなければなりませんが、これについては書かれていませんでした。PofEOAAにはこの他に、軽ロックや重ロックなどのパターンが説明されているので、これらと組み合わせて並列性の問題を解決しましょう、ということなのかもしれません。
重ロックというとヘビーメタルみたいですね。
- 投稿日:2020-02-25T06:00:46+09:00
[Rails]NoMethodError の解決例
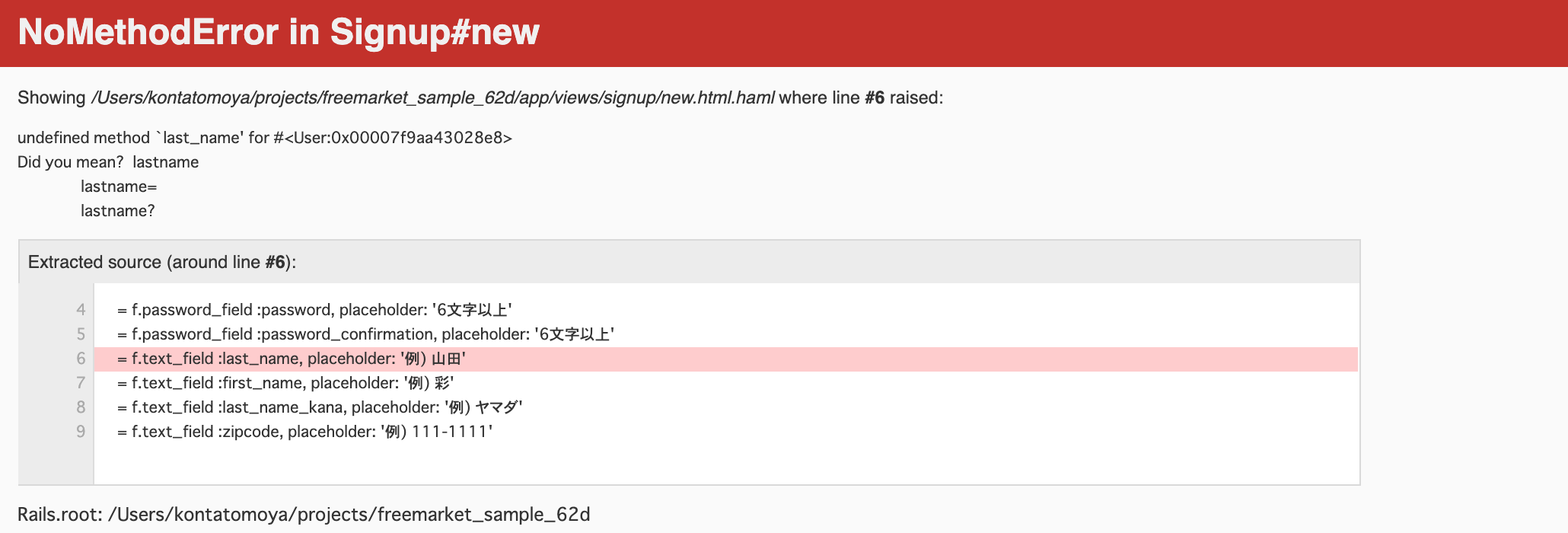
1.エラーの様子
エラー文を読むと下記のように言っています
・定義されていないメソッドがsignupコントローラのnewアクションに関連するファイルの中にあります。
※メソッドとは、正確に表現するとオブジェクトから値を"呼び出す動作"を示したもののことです。噛み砕いていうと配列の一要素を呼び出す動作のこととなります。さらに意訳すると呼び出した値(オブジェクト)と同義とみなすことができるため、そちらで理解すると下記で解説するシンボルと対比で覚えることができるためおすすめです。
例:配列user=[name,age,hair-color]に対しuser.nameとした場合、.nameがメソッドで意味はuser配列のname変数と定義した箇所を呼び出す動作となりますが、こういう塊が出てきたときは「この塊が意味しているのは、配列の中からメソッドがで呼び出してる値のnameだ!」ではなく、「この塊はnameという値だ」と理解するのをおすすめしています・app/view/new.html.hamlファイルに定義されてないメソッドのlsatnameなるものがありました。
・
lastname?ではないですか(シンボルキーではなく数値有無の判定子じゃないですか?)
※判定子は、定義されないことによる数値が入ってこない現象(failse)に対し、rails機能で、エラーではなくnullとして判断するためエラーになりません。なので確かにlastname?にするとこの部分のエラーは解消します。しかし、当初の目的の「数値の出し入れ」の機能は持たせることができません。2.原因とその調べ方
1.原因
シンボルキーの使用許可をし忘れていたことが原因でした(下記の3番目のミス)
2.原因の調べ方
NoMethodErororが出ている時点でルート設定はうまく行っているためrailsの命名規則にしたがっていると判断できます。(例えばusers_controllerと関係があるのはapp/view/usersフォルダの中のファイルのみという決まりがあります。さらに命名規則について詳しく知りたい方は下記のURLからrailsドキュメント(公式)のホームページを読んでみることをお勧めします。(とても説明が少ないため、ある程度railsを理解している方で公式のルールが確認したい方にのみおすすめします。)参考:railsドキュメント https://railsdoc.com/rails_base )
したがって間違っている可能性のあるファイルはsignup_controller、app/view/signupの中のファイル、:last_nameを定義したマイグレーションファイル、:last_nameを含んだ配列を記載したモデルファイルのどこかにあると考えられます。また、一般的な話として、マイグレーションファイルとモデルファイルは記載箇所が少ないためまず間違ってないことがほとんどで実質2択まで絞ることが出来ます。
さらにこのエラーの時は大抵下記の3つの原因に当てはまるため、signup_controllerかapp/view/signupの中のファイルどちらかのファイルで誤りを探してもらえればほとんど解決すると思います。1.コントローラによって定義されていない変数(:nameや@user.nameのようなもの)を媒介して値を入出力しようとしている。(エラー表示はNomethodErrorと出るためややこしいです。)
※例えば@user.nameを使いたければコントローラで@user=user.all(@useはuserテーブル全てのカラムを使用できる)と定義する。または、@user=user.nameで@userとして利用する必要があります2.変数をテーブルに入力したいのに出力用の変数のインスタンス変数(@userなど)を使用している。@userとして使用する変数(インスタンス変数)はviewで"呼びだす"ためのもので、viewで:nameと使用する変数(シンボルキー)は"入力してもらう"変数です。@userはインスタンス(=実体化した)と呼ぶくらいで、変化が終わった後のもの、つまり定義後の引用先(viewファイル)で値の変更はない変数となっていることを理解していると間違えがなくなります
※エラーの様子のところで説明した通り、インスタンス変数の一部をメソッドで呼び出したもの(@users.nameなど)を1つの塊として値(オブジェクト)と見なすと、シンボルも値(オブジェクト)であるため、"出すためのもの"か"入れるためのもの"という対比の関係に落とし込むことができ、viewファイルの記述で記入用の変数に間違ってインスタンス変数を使った(@をつけた)といったミスはなくなります3.悪意のある入力を弾くため(セキュリティを強くするため)、railsではコントローラ以外(=マイグレーションファイル)で定義された変数をそのまま使うためにはその値がコントローラで許可されている必要があるのだが、その過程が抜けてしまっている(ストロングパラメータの指定し忘れ)
3.解決方法
今回は:lastnameの使用許可の記述が抜けていたため、app/controllers/signup_controllerに下記の通りの記載を加えることでこのエラーは解消します
app/controllers/signup_controllerclass SignupController < ApplicationController before_action :user_params #この行を追加 #〜中略〜 private #この行から def user_params params.require(:user).permit(:lastname) end #この行まで追記 end (signup_controllerの全てのアクションで使用する必要があるため、あらかじめ定義しbefore_actionで全てに反映しています)
- 投稿日:2020-02-25T03:20:07+09:00
dockerでsinatraサーバーを起動しよう。
この記事で得られるもの(目的)
- Virtual MachineとDockerの起動方式
- Dockerfileの書き方
- DockerでImageを作る方法
- DockerでContainerを起動する方法
この記事で扱わないこと
- Dockerのインストール
Agenda
- Dockerとは
- Virtual MachineとDockerの起動方式
- SintraサーバーのDocker Imageを作る
- Imageに基づいたContainerを起動させる
Dockerとは
DockerはImageに基づいてContainerを起動したりするプログラムです。
Containerは隔離された空間でProcessを動く技術です。
ImageはどういうContainerを作るかについて記録されている設計図みたいなことです。Virtual MachineとDockerの起動方式
Virtual Machineの起動方式
(出処)Dockerホームページ
例えば、WindowsでLinuxを実行したいとなった場合、
Virtual Machine(Virtual Boxなど)ではHost OS(Windows)の上にGuest OS(Linux)をインストールしてApp Serverを立ち上げることになります。
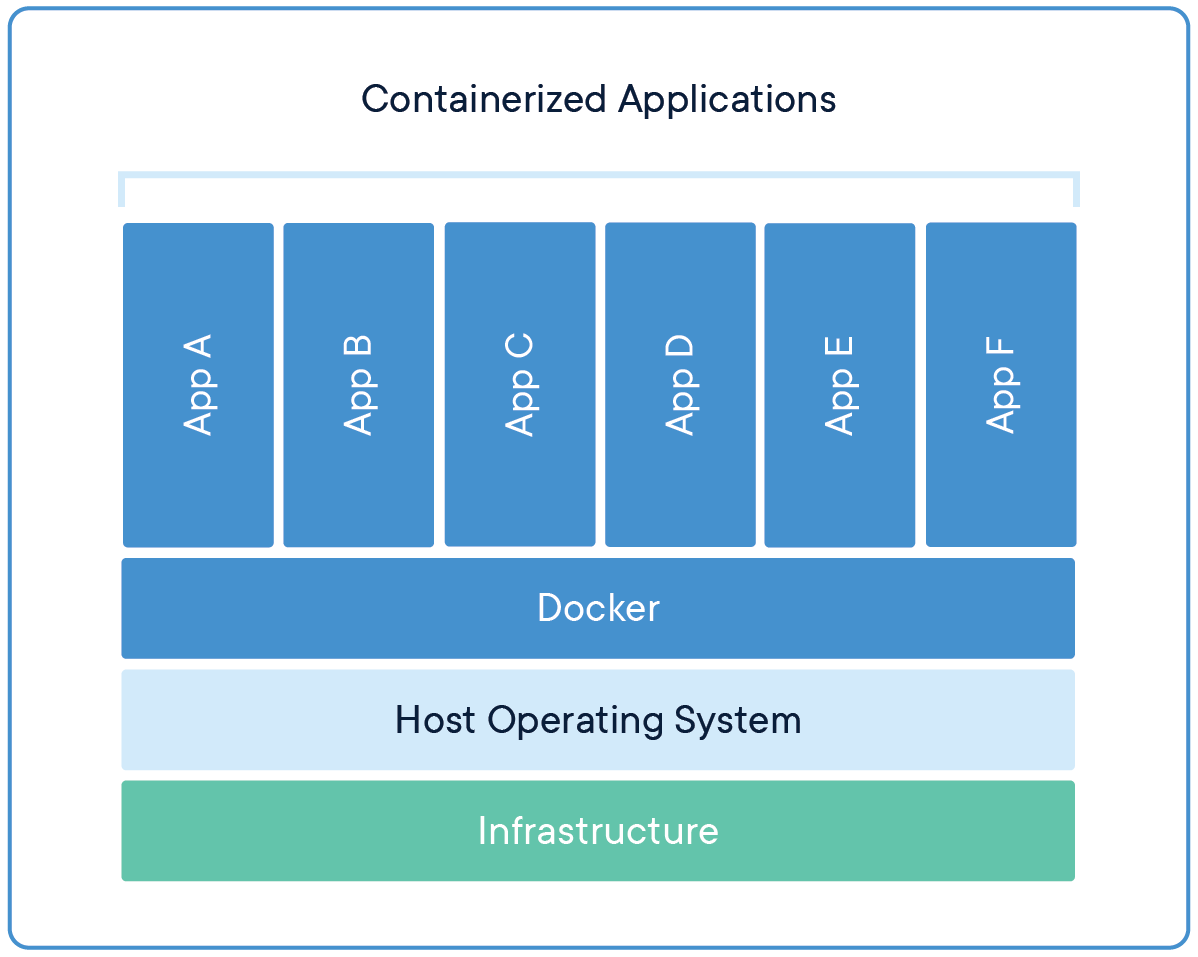
つまりHost OSとは別のResourceを全部作り直します。Dockerの起動方式
(出処)Dockerホームページ
DockerはHost OSのResourceを共有してもらってContainerを起動させる。
だから、VMの方式よりOverheadがかなり少なくなるし、実際使って見ても結構早いですね。SintraサーバーのDocker Imageを作る
まず、DockerがContainerを実行するまでの簡略な順を見ましょう。
DockerはDockerfileに基づいてDocker Imageを作ります。
その後、Docker Imageに基づいてDocker Containerを起動させます。じゃー、SinatraのAppのための環境を作るための書いて見ましょう。
ファイルの位置: /Dockerfile
1 # baseになるimage 2 FROM ruby:2.6.5 3 # このDockerfileを作った人 4 MAINTAINER jinument@gmail.com 5 6 # Docker Containerの環境変数を設定 7 # ENV 環境変数名 環境変数値 8 ENV WORKSPACE /app 9 10 # HostのファイルをContainer内に追加 11 # ADD Hostのファイル経路 Container内の経路 12 # Hostの現在DirectoryにあるGemfileと始まるファイルを 13 # Container内のWorkspace(ここでは/app)に追加 14 ADD ./Gemfile* $WORKSPACE/ 15 # Container内の作業Directoryを変更する 16 # Container内でcd(change directory)コマンドをうつのと同じ 17 WORKDIR $WORKSPACE 18 # Container内で実行するコマンドを定義 19 # このコマンドの意味は 20 # Container内の/app/でbundle installを実行してという意味 21 RUN bundle install 22 23 ADD . $WORKSPACE 24 25 # ContainerのPortを開放する 26 # このコマンドでHostから4567ポートで 27 # Container内の4567にアクセスできるようになる 28 # (参考)Sinatraのサーバーポートが4567だからここで4567を開放する 29 EXPOSE 4567 30 31 # Containerのbuildが出来上がって 32 # Containerが実行するタイミングでこのコマンドが実行される 33 CMD ['ruby', 'app.rb']ファイルの位置: /app.rb
1 require 'sinatra' 2 3 set :bind, '0.0.0.0' 4 5 get '/health_check' do 6 'health check' 7 endファイルの位置: /Gemfile
1 source 'https://rubygems.org' 2 3 gem 'sinatra', '2.0.8'以下のファイルを同じDirectoryに置いておいて以下のコマンドを実行することで、Docker Imageを作る。
docker build -t sinatra_image .
-t sinatra_imageは作るimageの名前を指定すること。
.は現在DirectoryにあるDockerfileを利用してDocker Imageを作るという意味。
docker build -t sinatra_image .このコマンドを打ったら、Dockerは以下のログを吐き出します。
ログを見ると内がDockerfileに書いた部分が一個づつ実行されることが確認できる。
(Layerという概念もあるが、この記事では扱いません。)lee@leeui-MacBookAir ~/workspace/qiita docker build -t make_image . Sending build context to Docker daemon 6.144kB Step 1/9 : FROM ruby:2.6.5 ---> a161c3e3dda8 Step 2/9 : MAINTAINER jinument@gmail.com ---> Running in ce277718c930 Removing intermediate container ce277718c930 ---> b56f7155a807 Step 3/9 : ENV WORKSPACE /app ---> Running in 3869474ae7c2 Removing intermediate container 3869474ae7c2 ---> d17245751687 Step 4/9 : ADD ./Gemfile* $WORKSPACE/ ---> 616bacbaa111 Step 5/9 : WORKDIR $WORKSPACE ---> Running in 0a6fd625644c Removing intermediate container 0a6fd625644c buffers ---> 2ef75a288ed5 Step 6/9 : RUN bundle install ---> Running in df916cdef1f6 Fetching gem metadata from https://rubygems.org/.......... Using bundler 1.17.2 Fetching ruby2_keywords 0.0.2 Installing ruby2_keywords 0.0.2 Fetching mustermann 1.1.1 Installing mustermann 1.1.1 Fetching rack 2.2.2 Installing rack 2.2.2 Fetching rack-protection 2.0.8 Installing rack-protection 2.0.8 Fetching tilt 2.0.10 Installing tilt 2.0.10 Fetching sinatra 2.0.8 Installing sinatra 2.0.8 Bundle complete! 1 Gemfile dependency, 7 gems now installed. Use `bundle info [gemname]` to see where a bundled gem is installed. Removing intermediate container df916cdef1f6 ---> 2ce2af9012c7 Step 7/9 : ADD . $WORKSPACE ---> eec1a89dd292 Step 8/9 : EXPOSE 4567 ---> Running in 4b7d253f9875 Removing intermediate container 4b7d253f9875 ---> fca62715a481 Step 9/9 : CMD ['ruby', 'app.rb'] ---> Running in dd5069206a4a Removing intermediate container dd5069206a4a ---> 41e7c0189e0c Successfully built 41e7c0189e0c Successfully tagged sinatra_image:latestじゃー、Imageがちゃんと作られたか以下のコマンドで確認して見ましょう。
⚙ lee@leeui-MacBookAir ~/workspace/qiita docker images REPOSITORY TAG IMAGE ID CREATED SIZE sinatra_image latest 41e7c0189e0c 32 minutes ago 872MBImageに基づいたContainerを起動させる
⚙ lee@leeui-MacBookAir ~/workspace/qiita docker run -d -p 4567:4567 sinatra_image 023f6c6e7d27a7368a3440163c7faeda406c3e8cc36ee7d254e50c56551200af現状Container化されているものの状況を確認するコマンドは以下になります。
docker ps -a⚙ lee@leeui-MacBookAir ~/workspace/qiita docker ps -a CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 023f6c6e7d27 sinatra_image "/bin/sh -c '['ruby'…" 3 minutes ago Exited (127) 3 minutes ago boring_northcuttlocalhost:4567/health_checkにアクセスして意図通り動いているか確認します。

- 投稿日:2020-02-25T00:34:12+09:00
敢えてRubyで学ぶ「ゼロから作るDeep Learning」偏微分での二層ニューラルネット
CPUがガリガリ回る計算が遅い偏微分での二層ニューラルネットを実装。次回は誤差伝搬法で高速実装の予定
基本関数
数値偏微分
二層のニューラルネット
two_layer_neuralnet.rbrequire 'numo/narray' require './functions' require './numerical_gradient' class TwoLayerNeuralNet # 初期化 def initialize(input_size, hidden_size, output_size, weight_init_std = 0.01) @params = {} @params['w1'] = weight_init_std * Numo::DFloat.new(input_size, hidden_size).rand_norm @params['b1'] = Numo::DFloat.zeros(hidden_size) @params['w2'] = weight_init_std * Numo::DFloat.new(hidden_size, output_size).rand_norm @params['b2'] = Numo::DFloat.zeros(output_size) end # self.paramsで参照できるように def params @params end # ニューラルネットの行列計算 def predict(x) w1, w2 = self.params['w1'], self.params['w2'] b1, b2 = self.params['b1'], self.params['b2'] a1 = x.dot(w1) + b1 z1 = sigmoid(a1) a2 = z1.dot(w2) + b2 softmax(a2) end # 誤差伝搬関数 def loss(x, t) y = self.predict(x) cross_entropy_error(y, t) end # 精度計算 def accuracy(x, t) y = predict(x) y = y.max_index(1) % 10 y.eq(t).cast_to(Numo::UInt32).sum / y.shape[0].to_f end # 該当の数値微分、最適化 def numerical_gradients(x,t) loss_w = lambda {|w| loss(x, t) } grads = {} grads['w1'] = numerical_gradient(loss_w, self.params['w1']) grads['b1'] = numerical_gradient(loss_w, self.params['b1']) grads['w2'] = numerical_gradient(loss_w, self.params['W2']) grads['b2'] = numerical_gradient(loss_w, self.params['b2']) grads end end実行関数
exec_numerical_gradent_neuralnet.rbrequire 'numo/narray' require './functions' require './numerical_gradient' require './two_layer_neural_net' require 'datasets' require 'mini_magick' train_size = 60000 test_size = 10000 batch_size = 100 iters_num = 10000 learning_rate = 0.1 train = Datasets::MNIST.new(type: :train) x_train = Numo::NArray.concatenate(train.map{|t| t.pixels }).reshape(train_size,784) t_train = Numo::NArray.concatenate(train.map{|t| t.label }) test = Datasets::MNIST.new(type: :test) x_test = Numo::NArray.concatenate(test.map{|t| t.pixels }).reshape(test_size,784) t_test = Numo::NArray.concatenate(test.map{|t| t.label }) train_loss_list = [] train_acc_list = [] test_acc_list = [] keys = ['w1', 'b1', 'w2', 'b2'] iter_per_epoch = [train_size / batch_size,1].max network = TwoLayerNeuralNet.new(input_size=784, hidden_size=50, output_size=10) iters_num.times do batch_mask = Array.new(batch_size){ rand test_size } x_batch = x_train[batch_mask, true] t_batch = t_train[batch_mask] grad = network.numerical_gradients(x_batch, t_batch) keys.each do |key| network.params[key] -= learning_rate * grad[key] end loss = network.loss(x_batch, t_batch) train_loss_list.append(loss) if i % iter_per_epoch == 0 train_acc = network.accuracy(x_train, t_train) test_acc = network.accuracy(x_test, t_test) train_acc_list.append(train_acc) test_acc_list.append(test_acc) p "train acc, test acc | " + str(train_acc) + ", " + str(test_acc) end end