- 投稿日:2020-02-25T23:55:10+09:00
Pythonで関数を作る
Pythonでの関数の作り方を自分用のメモとして置いておきます。
定義
関数名をfunctionとする。
def function(): pass #引数なし引数
関数にデータ(int,str,class等)を渡す。
引数(ひきすう)名をargsとする。def function(args): #引数あり print(args) def function2(args1,args2): #引数は何個でも取れる print(args,args2) def function3(args="Hello World"): #引数に初期値を設定できる #呼び出し時に引数がなければargsには"Hello World"が入る print(args)戻り値
関数内の処理の結果を返す。
def function(args): #戻り値あり n = args * 2 #引数を2倍して返す return n def function2(args,args2): a = args + args2 b = args - args2 return (a,b) #タプル型で返す返す型は何でもいい
呼び出し
関数を呼び出すには 関数名() で呼び出せる。
def function(): print("Hello World") function() #------------ #Hello World #------------引数がない場合は()内に何も書かなくていい。
書くとエラーが出る。TypeError: function() takes 0 positional arguments but 1 was given引数
引数は()の中に書く。
def function(args): print(args) function("Hello World") #------------ #Hello World #------------引数を設定しないとTypeErrorが起きる。
TypeError: function() missing 1 required positional argument: 'args'戻り値
戻り値は変数に入れることができる。
def function(args): n = args * 2 return n n = function(5)#function関数の戻り値を変数nに代入 print(n) #-------- #10 #--------その他
関数内から別の関数を呼ぶこともできる。
def function(args): n = function2(args,10)#function関数内からfunction2関数の呼び出し print(n) def function2(args,args2): n = args * args2 return n function(5) #-------- #50 #--------
- 投稿日:2020-02-25T23:10:13+09:00
【Docker】チュートリアル(Python+php)
はじめに
Dockerを勉強するにあたり、素晴らしいチュートリアル動画があったのでそれを元に自分で手を動かして見ました。リンク先の動画は英語ですので、日本語で少し補足をしながら進めていきます。初心者のため認識の誤りがあるかもしれませんので、その際はコメント頂けると幸いです。
事前にdocker、docker-composeのインストールが必要です。
元動画
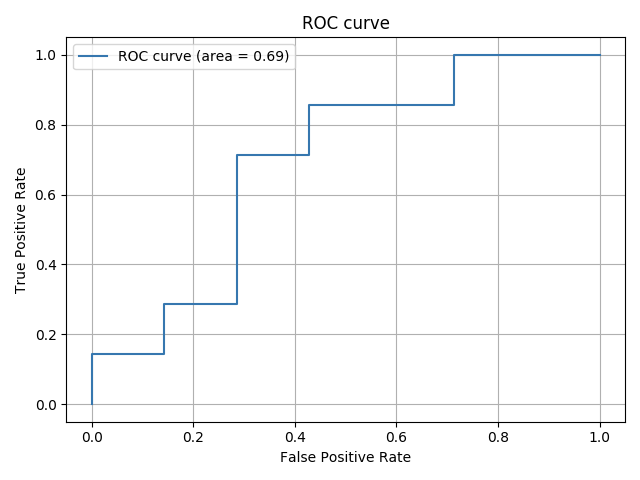
最終的なフォルダ構成は以下のようになります。
productディレクトリにはjsonを返すAPIをpythonで用意します。
websiteディレクトリには画面を描画するphpを用意します。product
まずはdocker_tutorial配下にproductディレクトリを作成します。
$ mkdir productそしてシンプルなPythonコードを作成します。flaskとflask_restfulというライブラリを使用します。
api.pyfrom flask import Flask from flask_restful import Resource, Api app = Flask(__name__) api = Api(app) class Product(Resource): def get(self): return{ 'products': [ 'Ice cream', 'Chocolate', 'Fruit' ] } api.add_resource(Product, '/') if __name__ == '__main__': app.run(host='0.0.0.0', port=80, debug=True)ローカル環境にpythonをインストールしている場合は、pip installなどでライブラリをインストールしますが、Dockerを使用した場合は個別にインストールする必要はありません。その代わりにコンテナ起動時に必要となるライブラリなどを以下のテキストファイルに記載するか、後述のDockerfile内にpip installのコマンドを記載します。バージョンはライブラリの公式サイトなどを参照して使用したいバージョンを記載します。
requirements.txtFlask==0.12 flask-restful==0.3.5次にDockerfileを作成します。
DockerfileはDocker上で動作させるコンテナの構成情報を記述するためのファイルです。FROM python:3-onbuild COPY . /usr/src/app CMD ["python", "api.py"]FROM
FROMにはベースとするDockerイメージを指定します。また「onbuild」を記載することで、Dockerfile を使って docker build をするとき、Dockerfile 内で pip install を書かなくても Dockerfile と同じディレクトリに requirements.txt があると自動的にインストールをするようになっています。COPY
COPYにはローカルファイルをDockerイメージのどこにコピーするかを記載します。今回の場合はproductディレクトリをDocker上の/usr/src/app内にコピーします。CMD
CMDにはコンテナ起動時に実行するコマンドを記載します。次にdocker-compose.ymlを作成します。docker-composeには
- Dockerイメージをビルドするための情報(使用するDockerfile、イメージ名など)
- コンテナ起動するための情報(ホストとの共有ディレクトリ設定やポートフォワードなどの起動オプションなど)
- 使用するDockerネットワーク
などを記載します。
docker-compose.ymlversion: '3' services: product-service: build: ./product volumes: - ./product:/usr/src/app ports: - 5001:80version
docker-composeで使用するバージョンを記載します。現在はバージョン3が最新ですので、3を指定します。services
アプリケーションを動かすための各要素をServiceと読んでいます。各サービスをネストしてこちらに記載します。今回の場合は「product-service」というサービスを起動します。build
指定したディレクトリにあるDockerfileでコンテナを起動します。今回の場合はproductディレクトリのDockerfileでコンテナを起動します。volumes
ローカリのディレクトをコンテナのディレクトにマウントします。今回の場合はproductディレクトリをコンテナ上の/usr/src/appディレクトリにマウントします。ports
Dockerを立ち上げるポート番号を記載します。今回は5001番ポートで立ち上げます。それではDockerを起動
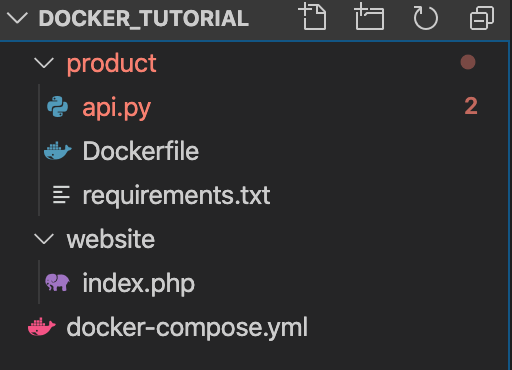
$ docker-compose up起動が完了したら、localhost:5001にアクセスします。
以下のような画面が表示されたら問題なく起動しています。
ここまでで、簡単にPython、Flaskの環境ができることが分かります。
この状態でapi.pyを以下のように変更し、保存します。
api.pyclass Product(Resource): def get(self): return{ 'products': [ 'Ice cream', 'Chocolate', 'Fruit', 'Eggs' ] }再読み込みを行うと、表示内容も更新されます。コンテナを再起動しなくてもマウントしてくれます。
ここまできたらコンソール上で「control+C」を押して、dockerを一旦停止します。
website
次はdocker_tutorial配下にwebsiteというディレクトリを作成します。こちらにはphpのファイルを作成します。
http://product-serviceの結果をループして表示する処理です。
ここでいうproduct-serviceはdocker-composeに記載したサービス名が該当します。index.php<html> <head> <title>My Shop</title> </head> <body> <h1>Welcome to my shop</h1> <ul> <?php $json = file_get_contents('http://product-service'); $obj = json_decode($json); $products = $obj->products; foreach($products as $product) { echo "<li>$product</li>"; } ?> </ul> </body>次にdocker-compose.ymlを以下のように変更します。
docker-compose.ymlversion: '3' services: product-service: build: ./product volumes: - ./product:/usr/src/app ports: - 5001:80 website: image: php:apache volumes: - ./website:/var/www/html ports: - 5000:80 depends_on: - product-servicewebsite
servicesにwebsiteというサービスを追加します。image
imageを記載することで、Docker Hub上に用意されている既存のイメージを使用することができます。buildとimageは同時に指定することはできません。depends_on
サービス同士の依存関係を記載します。今回の場合、websiteが実行されるより前にproduct-serviceが実行されるようになります。docker-compose.ymlにproduct-serviceがない場合はエラーになります。再度Dockerを起動します。
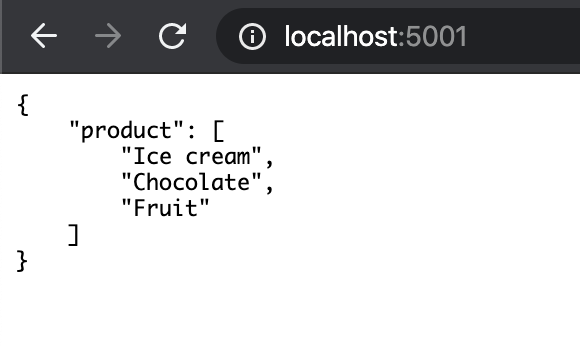
$ docker-compose up起動が完了したらlocalhost:5000にアクセスします。
以下のような画面が表示されていれば成功です。
さいごに
Dockerを使用することで、簡単にPython+phpの環境を作ることができました。私もDocker初心者のためこれからも引き続き学習していきたいと思います。
おまけ
-dをつけることでバックグラウンドでコンテナを立ち上げることができます。
$ docker-compose up -d Starting docker_tutorial_product-service_1 ... done Starting docker_tutorial_website_1 ... donepsコマンドで起動中のコンテナの一覧が確認できます。
$ docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 24de043f94d9 php:apache "docker-php-entrypoi…" 10 minutes ago Up About a minute 0.0.0.0:5000->80/tcp docker_tutorial_website_1 da62924c1154 docker_tutorial_product-service "python api.py" 32 minutes ago Up About a minute 0.0.0.0:5001->80/tcp docker_tutorial_product-service_1stopでコンテナを停止することができます。
$ docker-compose stop Stopping docker_tutorial_website_1 ... done Stopping docker_tutorial_product-service_1 ... done $ docker ps ONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES参考

- 投稿日:2020-02-25T22:59:09+09:00
機械学習のアルゴリズム(線形回帰まとめ&正則化)
はじめに
以前、「機械学習の分類」で取り上げたアルゴリズムについて、その理論とpythonでの実装、scikit-learnを使った分析についてステップバイステップで学習していく。個人の学習用として書いてるので間違いなんかは大目に見て欲しいと思います。
今回は、線形回帰編のまとめとしてガウシアンカーネルを使った線形近似と、過学習やそれを抑えるL1正則化(Lasso)、L2正則化(Ridge)についてまとめてみようと思う。
今回参考にしたのは以下のサイト。ありがとうございます。
- 線形な手法とカーネル法(1. 回帰分析)
- リッジ回帰とラッソ回帰の理論と実装を初めから丁寧に
- 正則化項(LASSO)を理解する
- ラッソ回帰を実装してみよう
- scikit-learnで線形モデルとカーネルモデルの回帰分析をやってみた - イラストで学ぶ機会学習
カーネル近似について
以前、線形回帰の一般化について書いた時に、「基底関数はなんでもよい」と書いた。現実の回帰でも常に直線で近似できるとは限らず、多項式や三角関数のようなクネクネした近似というのも必要になってくる。
例えば$y=-xsin(x)$にノイズを乗せた$y=-xsin(x)+\epsilon$について考える、
import numpy as np import pandas as pd import matplotlib.pyplot as plt %matplotlib inline fig, ax = plt.subplots() t = np.linspace(0, 2*np.pi, 100) y1 = - t * np.sin(t) n=40 np.random.seed(seed=2020) x = 2*np.pi * np.random.rand(n) y2 = - x * np.sin(x) + 0.4 * np.random.normal(loc=0.0, scale=1.0, size=n) ax.scatter(x, y2, color='blue', label="sample(with noise)") ax.plot(t, y1, color='green', label="-x * sin(x)") ax.legend(bbox_to_anchor=(1.05, 1), loc='upper left', borderaxespad=0, fontsize=11) plt.show()
青い点がノイズを乗せたサンプルで、緑の実線が想定する関数を示している。ノイズは乱数で加えたが、毎回同じ結果になるように乱数のシード値は固定した。
今回は目的関数がわかっているのでよいが、サンプルが多項式なのかそれとも別な関数なのかはわからない状態から推定しなければならない。
ガウスカーネルついて
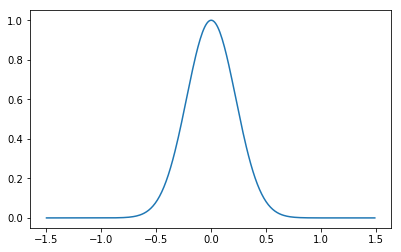
ガウスカーネルは次のように定義されます。
k(\boldsymbol{x}, \boldsymbol{x'})=\exp(-\beta||\boldsymbol{x}-\boldsymbol{x'}||^2)$||\boldsymbol{x}-\boldsymbol{x'}||^2$はベクトル同士の距離で、$\sqrt{\sum_{j=1}^{n}(x_j-x'_j)^2} $とも表されます。
この関数は以下のような形をしており、この関数の中心を移動したり大きさを変えることで目的のデータ列に回帰させます。
ガウスカーネルを使った線形回帰
今、目的の関数を
f({\bf x})=\sum_{i=1}^{N} \alpha k({\bf x}^{(i)}, {\bf x}')とする。標本の値を$\hat{y}$とすると、
\hat{y} = \left(\begin{matrix} k({\bf x}^{(1)}, {\bf x}) & k({\bf x}^{(2)}, {\bf x}) & \cdots & k({\bf x}^{(N)}, {\bf x}) \end{matrix}\right) \left(\begin{matrix} \alpha_0 \\ \alpha_1 \\ \vdots \\ \alpha_N \end{matrix}\right)となり、
{\bf y} = \left(\begin{matrix} y^{(1)} \\ y^{(2)} \\ \vdots \\ y^{(N)} \end{matrix}\right) ,\; K=\left(\begin{matrix} k({\bf x}^{(1)}, {\bf x}^{(1)}) & k({\bf x}^{(2)}, {\bf x}^{(1)}) & \cdots & k({\bf x}^{(N)}, {\bf x}^{(1)}) \\ k({\bf x}^{(1)}, {\bf x}^{(2)}) & k({\bf x}^{(2)}, {\bf x}^{(2)}) & & \vdots \\ \vdots & & \ddots & \vdots \\ k({\bf x}^{(1)}, {\bf x}^{(N)}) & \cdots & \cdots & k({\bf x}^{(N)}, {\bf x}^{(N)}) \end{matrix}\right) ,\; {\bf \alpha} = \left(\begin{matrix} \alpha^{(1)} \\ \alpha^{(2)} \\ \vdots \\ \alpha^{(N)} \end{matrix}\right)という風に展開される(このへんコピペですすいません)。ここで$K$をグラム行列と呼ぶ。$f({\bf x})$と$\hat{y}$の二乗誤差$L$は
L=({\bf y}- K {\bf \alpha})^{\mathrm{T}}({\bf y}- K {\bf \alpha})となり、これを$\alpha$について解くと、$${\bf \alpha} = (K^{\mathrm{T}}K)^{-1}K^{\mathrm{T}}{\bf y} = K^{-1}{\bf y}$$となる。つまり、グラム行列の逆行列が計算できれば$\alpha$を求めることが可能ということになる。観測サンプル数が多すぎる場合、この逆行列を求めることが大変になるので別の方法を選ぶ必要がある。
pythonでの実装
上の式をそのまま使ってKernelRegressionクラスを実装した。
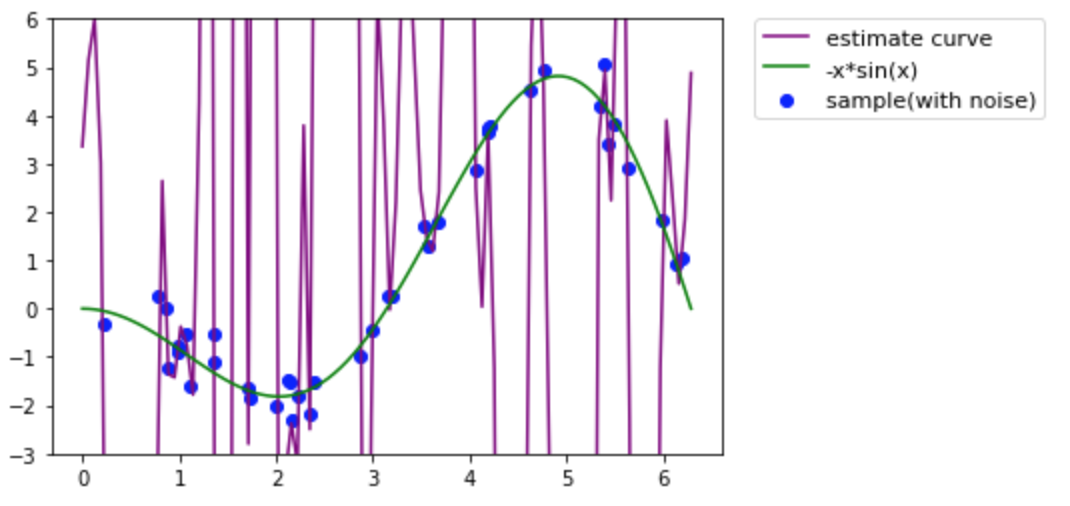
class KernelRegression: #正則化なし def __init__(self, beta=1): self.alpha = np.array([]) self.beta = beta def _kernel(self, xi, xj): return np.exp(- self.beta * np.sum((xi - xj)**2)) def gram_matrix(self, X): N = X.shape[0] K = np.zeros((N, N)) for i in range(N): for j in range(N): K[i][j] = self._kernel(X[i], X[j]) K[j][i] = K[i][j] return K def fit(self, X, Y): K = self.gram_matrix(X) self.alpha = np.linalg.inv(K)@Y def predict(self, X, x): Y = 0 for i in range(len(X)): Y += self.alpha[i] * self._kernel(X[i], x) return Y最初のサンプルを使って近似させてみる。
model = KernelRegression(beta=20) model.fit(x, y2) xp = np.linspace(0, 2*np.pi, 100) yp = np.zeros(len(xp)) for i in range(len(xp)): yp[i] = model.predict(x, xp[i]) fig, ax = plt.subplots() plt.ylim(-3,6) ax.plot(xp, yp, color='purple', label="estimate curve") ax.scatter(x, y2, color='blue', label="sample(with noise)") ax.plot(t, y1, color='green', label="-x*sin(x)") ax.legend(bbox_to_anchor=(1.05, 1), loc='upper left', borderaxespad=0, fontsize=11) plt.show()
確かに与えられたサンプル上を通っているみたいですがグチャグチャです。緑の曲線とは全然違いますね。
過学習(overfitting)について
上のように学習の結果が教師データに対して忠実だが、現実とかけ離れてしまうことを過学習(overfitting)と言います。数学のテストで、教科書と同じ問題が出れば解けるけどちょっとアレンジされるととたんに解けなくなるのと似ているでしょうか。
過学習されたモデルのことを汎化性能がよくないとも言います。予測精度が低い状態です。これを防ぐために、正則化という概念が必要になります。
正則化(regularization)
上の例では、与えられたサンプルの点を無理やり通すために、パラメータ$\bf{\alpha}$が極端に大きくなっていることが原因で激しく暴れる曲線になってしまっています。あとは、データ数が極端に少なかったり、変数が多い場合にこうなってしまうことが多いようです。
これを防ぐためには、$\alpha$を求める際に、カーネル回帰の二乗誤差に正則化項を加えることで$\alpha$の範囲を制限することで実現できます。機械学習ではL1正則化(Lasso)とL2正則化(Ridge)が有名です。両者をミックスさせるとElasticNet正則化と呼ばれます。
L2正則化
L1ではなくL2から始めます。
先ほど$\alpha$を求めた際に目的関数とサンプルの二乗誤差を$L$とおきましたが、$\lambda||{\bf \alpha}||_2^2$を加えたL=({\bf y}- K {\bf \alpha})^{\mathrm{T}}({\bf y}- K {\bf \alpha})+\lambda||{\bf \alpha}||_2^2を最適化します。$\lambda$が大きいほど$\alpha$が制限されるため、よりおとなしい(?)曲線になります。これを$\alpha$で偏微分して0とおき、$\alpha$について解くと、
{\bf \alpha} = (K+\lambda I_N)^{-1}{\bf y}となります。これはグラム行列に単位行列を足して逆行列を計算するだけでよいので変更は簡単ですね。
pythonでの実装
先ほどのKernelRegressionクラスの$\alpha$を求める部分を若干変更しました。あとはほぼ同じです。
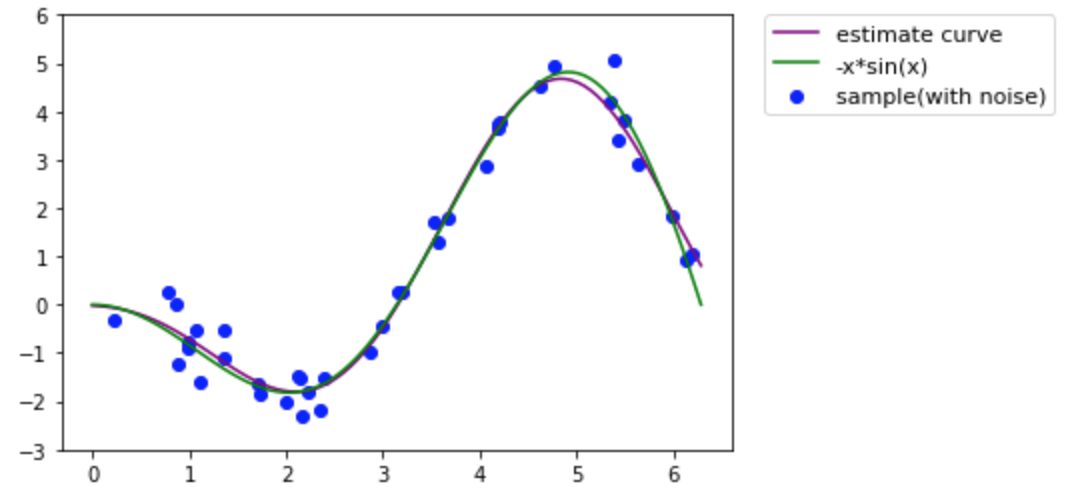
class KernelRegression: # L2正則化 def __init__(self, beta=1, lam=0.5): self.alpha = np.array([]) self.beta = beta self.lam = lam def _kernel(self, xi, xj): return np.exp(- self.beta * np.sum((xi - xj)**2)) def gram_matrix(self, X): N = X.shape[0] K = np.zeros((N, N)) for i in range(N): for j in range(N): K[i][j] = self._kernel(X[i], X[j]) K[j][i] = K[i][j] return K def fit(self, X, Y): K = self.gram_matrix(X) self.alpha = np.linalg.inv(K + self.lam * np.eye(X.shape[0]))@Y def predict(self, X, x): Y = 0 for i in range(len(X)): Y += self.alpha[i] * self._kernel(X[i], x) return Y正則化しなかった場合と同じサンプルを使って近似してみます。$\beta$や$\lambda$の数値は適当に決めました。
model = KernelRegression(beta=0.3, lam=0.1) model.fit(x, y2) xp = np.linspace(0, 2*np.pi, 100) yp = np.zeros(len(xp)) for i in range(len(xp)): yp[i] = model.predict(x, xp[i]) fig, ax = plt.subplots() plt.ylim(-3,6) ax.plot(xp, yp, color='purple', label="estimate curve") ax.scatter(x, y2, color='blue', label="sample(with noise)") ax.plot(t, y1, color='green', label="-x*sin(x)") ax.legend(bbox_to_anchor=(1.05, 1), loc='upper left', borderaxespad=0, fontsize=11) plt.show()
今回は見事に一致しました。実際は表示している範囲外では形が変わってしまうんですが、特定の範囲においてはかなり近い近似曲線がひけることがご理解いただけたと思います。
$\beta$や$\lambda$はハイパーパラメータと呼ばれ、これらを少しずつ変えて損失関数の値を最小化するという最適化も実際には必要になりますね。
L1正則化
L2正則化では、正則化項として、$\lambda ||{\bf \alpha}||^2_{2} $を加えましたが、L2正則化では正則化項として$\lambda||{\bf \alpha}||_1$を加えます。
L1正則化では正則化項が微分できないため、解を求めるのは少し複雑です。scikit-learnでは座標降下法(Coordinate Descent)という手法で実装されているみたいですが、私がまだ理解できていないので、本稿では素直にscikit-learnを使いたいと思います。
L1正則化は、パラメータ$\alpha$のかなりの部分を0にすることができ(スパースな解を得る)、不要なパラメータを削ることに役立ちます。
pythonでの実装
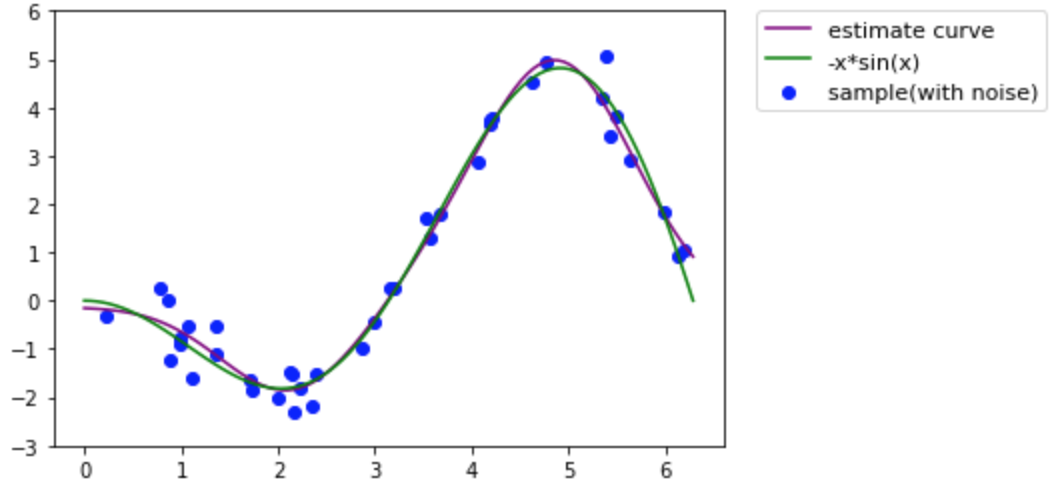
素直にscikit-learnで実装してみます。
from sklearn.metrics.pairwise import rbf_kernel from sklearn.linear_model import Lasso kx = rbf_kernel(x.reshape(-1,1), x.reshape(-1,1)) KX = rbf_kernel(xp.reshape(-1,1), x.reshape(-1,1)) clf = Lasso(alpha=0.01, max_iter=10000) clf.fit(kx, y2) yp = clf.predict(KX) fig, ax = plt.subplots() plt.ylim(-3,6) ax.plot(xp, yp, color='purple', label="estimate curve") ax.scatter(x, y2, color='blue', label="sample(with noise)") ax.plot(t, y1, color='green', label="-x*sin(x)") ax.legend(bbox_to_anchor=(1.05, 1), loc='upper left', borderaxespad=0, fontsize=11) plt.show() print("coef: ", clf.coef_) coef: [-0. 0. 0. -0. -0.79703436 -0. -0. -0. 0. -0. -0. 3.35731837 0. -0. -0.77644607 0. -0. 0. -0. -0.19590705 0. -0. 0. -0. 0. 0. -0. -0. -0. 0. -0. 0. -0. -0. 0. 0.58052561 0.3688375 0. -0. 1.75380012]
こちらも元の関数にだいぶ近似していますね。また、パラメータ(coef)もかなりの部分が0になっているのも確認できます。
Elasticnet
L1正則化とL2正則化はどちらも損失関数に正則化項を加えていますが、それぞれ独立に考えることができ、どちらをどれくらい採用するか決めることができ、これをElasticNetと呼びます。実際、scikit-learnの実装ではElasticNetのパラメータを変えたものをLassoとRidgeとして関数定義していました。
まとめ
線形回帰における基底関数は任意の関数を選ぶことができる。ガウシアンカーネル(に限らない)は、自由度が高く過学習しがちなのでL1正則化やL2正則化によって制限を加えることで、より汎化性能の高い回帰モデルを作ることができる。
数回にわたって回帰シリーズについてまとめてみたが、scikit-learnのチートシートにおけるRegressionの内容はだいたい理解できるようになったのではないだろうか。
割と適当にまとめたので、ツッコミは歓迎します。

- 投稿日:2020-02-25T22:27:48+09:00
QiskitとBlueqatを比較してみた(初心者)
QiskitとBlueqatを比較してみた(初心者)
現在量子コンピュータの学習をしているが、量子コンピュータ用Pythonライブラリである「Qiskit」、「Blueqat」について初心者目線で比較してみた。かなり私見が入っているので、参考程度に読んでください。ちなみに、QiskitはIBM社製、BlueqatはMDR社製となっています。
評価ポイント
今回は以下の評価ポイントで比較してみる。
- 説明が充実しているか
- 実行環境の準備、利用のしやすさ
- 使用感(かなり私見)
今回はこれで評価しますが、何か他にいい評価基準があれば教えてください。
1. 説明が充実しているか
結論から言うと、説明は「Blueqat」の方が分かりやすい。以下にQiskitとBlueqatのAPIドキュメント、チュートリアルのリンクを載せておく。
・Qiskitチュートリアル
・Qiskit APIドキュメント
・Blueqatチュートリアル(英語)
・Blueqatチュートリアル(日本語)
・Blueqat APIドキュメントリンク先を見ていただけると分かるんですが、Qiskitの方はドキュメント体系が分かりにくい。なんか色々な人がパーツを作って合体させた感じがします。あと、地味に大きいのがBlueqatは日本企業ということもあり、チュートリアルが日本語に対応している。
2. 実行環境の準備、利用のしやすさ
実行環境の準備/利用のしやすさで言うと、私の目線では両者さほど変わらない。
まず、「実行環境の準備」についてだが、Pythonを利用する場合は両者「pip」コマンドでライブラリを準備するだけである。ただし、Qiskitは「IBM Q Experience」でインターネット経由でjupyter notebook環境を取り扱うことができます。ただし、Googleが提供している「Google Colaboratory」でも同様の環境が提供されているため、大きなアドバンテージにならないなと感じました。あとちょっと説明が脇道にそれますが、IBMが提供しているIBM Q ExperienceのCircuit Composerを利用するとドラック&ドロップで量子回路を作成することができます。気軽に試してみたいという方にはいいかもしれません。
3. 使用感(かなり私見)
使用感については、今後使っていく上で気づいた所があれば適宜追記/修正してきます。
正直な所「1. 説明が充実しているか」に引きずられる部分が大きい部分が大きく、やりたいことを比較的すぐ実行できるのはBlueqatであり、使用しずらさを感じる場面は今の所ないです。
ただし、Qiskitは計算結果を図で表示するまで簡単に実装できるので、jupyter notebookが視覚的に分かりやすくなる所が利点だと思います。今の所実装速度を求めるならBlueqat、視覚的に分かりやすいものを簡単に実装したいならQiskitって感じかなと考えています。総合評価
ということで、今までの評価を踏まえ総合評価は以下の通りとしました!
Qiskit Blueqat 説明が充実度 △ 〇 実行環境/利用のしやすさ 〇 〇 使用感 〇 〇 総合評価 △ 〇 異論は認めます!なぜなら使用感の評価がガバガバだからです(`・ω・´)
それではまた次の投稿で!
- 投稿日:2020-02-25T22:26:28+09:00
【他プログラミング言語修得者向け】Python 要点キャッチアップ10点
Overvierw
Pythonは、シンプルで習得がしやすいオブジェクト指向言語として有名である。
他言語修得者向けに、Python独自の要素を10点独断で選別したので、それを記載する。1. 改行の ";" が不要
多くの言語の共通ルールである「改行時は;」について、Pythonでは不要。
とはいえ、改行として認識自体はされるため、以下の様なコードを実行してもエラーにはならず、従来通りの挙動をする。>>> print("1"); print("2") 1 22. インデントがブロックを表す
他言語において、インデントはコードの可読性を高めるための要素で、挙動に影響はしなかった。
しかし、Pythonではインデントを使ってブロックを表現する。if x > 0: print("positive") # if文内 print("always") # if文外上記のコードでは、xが0以上の場合は"positive","always"の両方を表示、それ以外の場合でも"always"を出力する。
また、 以下の様に適切なインデントがない場合は
IndentationError: expected an indented blockが発生する。if x > 0: print("positive") # IndentationError発生3. シングルクォーテーション、ダブルクォーテーションが同義
Pythonにおいては、これらの間に違いは存在しない。以下のコードは、いずれも同様に挙動となる。
>>> print('single') single >>> print("double") double仮に文字列中に
'を入れる場合は、表記は異なる。>>> print('It\'s single') # \ でエスケープ It's single >>> print("It's double") # 文字列に含まれるクォーテーション It's double同じコード内で表記を統一する必要もないので、単語の場合はシングル、文章の場合はダブルなど、一定ルールを設けることも可能。
s = 'single' w = "It's a double!4. 変数宣言と型
varや型指定は不要。変数名 = 値の書式で 数値、文字列、真偽値 を格納できる。
ただし、値から型を推測するため、初期値が必要となる。
以下の表記は全てエラー。# 型指定は不要 int a = 1 ^ SyntaxError: invalid syntax # var の記述も不要 var a = 1 ^ SyntaxError: invalid syntax # 初期値がない場合もエラー a NameError: name 'a' is not definedまた、一度宣言した変数に、全く違う型の値を代入することができる。その場合、変数の型も同時に変わる。
>>> a = 100 >>> type(a) <class 'int'> >>> a = "text" >>> type(a) <class 'str'> >>> a = True >>> type(a) <class 'bool'>5. その他よく使うデータ型
Pythonでは数値、文字列、真偽値に加えて、 リスト、タプル、セット、辞書型 がある。
いずれも複数データを格納するデータ型で、特徴は以下の通り。
データ型名 特徴 宣言の仕方 リスト(list) 追加・重複の制限なし [val1, val2, ...] タプル(tuple) 宣言後の追加・更新を許可しない, パフォーマンスが高い (val1, val2, ...) セット(set) 同値の重複を許可しない {val1, val2, ...} 辞書型(dict) key-value 形式 {key1: val1, key2: val2, ...} ### リスト型 list1 = [1,2,3] type(list1) # -> <class 'list'> print(list1) # -> [1, 2, 3] print(list1[0] # -> 0 list1.append(4) print(list1) # -> [1, 2, 3, 4] ### セット型 set1 = {1,2,3,3} type(set1) # -> <class 'set'> print(set1) # -> {1, 2, 3} set1[0] = 9 # -> TypeError: 'set' object does not support item assignment set1.add(4) print(set1) # -> {1, 2, 3, 4} ### タプル型 tuple1 = (1,2,3) type(tuple1) # -> <class 'tuple'> print(tuple1) # -> (1,2,3,3) tuple1[0] = 9 # -> TypeError: 'tuple' object does not support item assignment ### 辞書型 dict1 = {"a": 123, "b": 456, "c": 789} type(dict1) # -> <class 'dict'> print(dict1) # -> {'a': 123, 'b': 456, 'c': 789} dict1["d"] = 0 print(dict1) # -> {'a': 123, 'b': 456, 'c': 789, 'd': 0}タプルの用途としては、統計値などの一度宣言した値や順番を変更したくないとき、または変更する必要がないときに利用する。
メモリを圧迫しないため、パフォーマンス向上につながる。また、これらは相互に変換することも可能。ただし、構成によってはエラーになる。
list1 = [1,2,3] print(tuple(list1)) # -> (1, 2, 3) print(set(list1)) # -> {1, 2, 3} list2 = [["a", 123], ["b", 456], ["c", 789]] print(dict(list2)) # -> {'a': 123, 'b': 456, 'c': 789}6. スライス操作
先のデータ型もそうだが、他言語では「配列」と呼ばれる様な複数要素をまとめて1つの変数で扱えるデータ型を、Pythonでは シーケンス型 と呼ぶ。
具体的には以下が該当。
型 解釈 文字列(string) 連続した文字 レンジ(range) 連続した数値 バイト(bytes) 連続したバイト リスト(list) 連続したデータ, あらゆるデータを扱える タプル(tuple) 要素追加・更新のできない連続したデータ セット(set) 重複を許可しない連続したデータ これらに対して、一部分を切り取ってコピーを返すスライス操作がPythonでは利用できる。
指定の際はseq[start:stop:step]の様に指定する。値を指定しなかった場合はデフォルト値が適用されるが、全て未指定にはできない。
引数 指定する値 デフォルト start 切り取り視点インデックス 0 end 切り取り終点インデックス 要素数に等しい値 step 切り取る際のステップ数
負数の場合は逆順にする1 インデックスは、 Pythonチュートリアル の考え方がわかりやすい。
つまり、「インデックスは要素と要素の境界を指し、最初の要素の左端が0」ということである。
また、マイナス指定インデックスは一番最後の文字を指すインデックスが-1, 以降前に戻る度に負の値が増加する。+---+---+---+---+---+---+ | P | y | t | h | o | n | +---+---+---+---+---+---+ 0 1 2 3 4 5 6 -6 -5 -4 -3 -2 -1上記を踏まえて、以下の様に利用する。
str = "Python" print(str[3:]) # -> "hon" print(str[:3] ) # -> "Pyt" print(str[::-1]) # -> "nohtyP" print(str[::2]) # -> "Pto"6. 制御文全般の留意点
全体的な留意点は以下。
- 条件式で
()は不要- 末尾に
:を記入する例えば、if 文の使い方は以下。他言語と比べて大きな違いはないが、
elifの表記だけやや特殊かも。### if文 if x > 0: print("positive") elif x < 0: print("negative") else: print("zero")7. for文はシーケンスと組み合わせて柔軟に回せる
in 以下で、先に述べたシーケンス型を指定することでその要素を回すことができる。
list1 = [1,2,3] for val in list1: print(val) 1 2 3シーケンス型の変数を事前に使っていない場合は、range関数で連続した数字のシーケンスを生成できるので便利。
# 引数1つの場合は0始まり for i in range(3): print(i) 0 1 2 # 引数2つの場合は始点を変更できる for i in range(1, 4): print(i) 1 2 3 # 引数3つの場合は間隔を変更できる for i in range(1, 8, 2): print(i) 1 3 5 78. 終了を伴う処理をwith文で簡易化できる
Python の特徴的な構文に、with が存在する。
一般的に他言語で「ファイルの読み書き」や「通信処理」を行う場合は、開始と終了を明確に宣言する必要があった。
しかし、Pythonではwith文と同時に開始処理を宣言することで、インデントを抜けた際に自動で終了処理を行ってくれる。ここでは、ファイルの読み書きを例としてみる。
# ファイルの読み込み with open("read.txt", "r") as file1: print(file1.read()) # ファイルの書き込み with open("write.txt", "w") as file2: print(file2.write())もちろん、以下の様に入れ子で宣言することも可能。
# ファイルから読み込んだ内容を別ファイルに書き込む with open("reaad.txt", "r") as file1: with open("write.txt", "w") as file2: file2.write(file1.read())9. 複数の値を返す関数を作成できる
まず、python における関数定義は以下の様に
defを使って行う。def double(x): return x * x print(double(10)) # -> 100この際に、返り値をタプル、またはカンマ区切りで複数指定することができる。カンマ区切りが可能なのは、Python においてカンマで区切られた値は丸括弧を省略したタプルとみなされるため。
このとき、この複数の返り値を異なる変数に格納することも可能。def test(): return "a", 123, True # return ("a", 123, True) と同義 print(test()) # -> ('a', 123, True) a, b, c = test() print(a) # -> 'a' print(b) # -> 123 print(c) # -> True10. ライブラリの利用はimport
Python は、 デフォルトで利用できる組み込み関数に加えて、適宜
importを実行することで各種ライブラリを簡単に利用することができる。
import宣言はプログラムの冒頭で宣言し、以下の順番で記述することがPEP8では望ましいとされている。
1. 標準ライブラリ
2. サードパーティライブラリ
3. ローカルライブラリ(自作のライブラリ)
グループ間は空白行で区切り、同一グループ内はアルファベット順とすることが多い。# 標準ライブラリ import math import os import sys # サードパーティライブラリ import Requests # 自作ライブラリ import my_package1 import my_package2また、
importと一緒にas,fromもよく使われる。
as を使うことで、importしたモジュールやオブジェクトに対して別名をつけることができる。
例えばmath を m, numpy を np とするのはよくある。import math as m import numpy as np print(np,array([1,2], [100,200])) # -> array([[1, 2],[100, 200]]) print(m.pi) # -> 3.141592653589793fromは、大別して以下2種類のいずれかの用法となる。
-from <モジュール名> import <オブジェクト名>
-from <パッケージ名> import <モジュール名>
ここで、ライブラリの階層は パッケージ > モジュール > オブジェクト の構造となっていることを踏まえると、上位階層から下位階層を取得するイメージとなる。めちゃくちゃざっくり言うと、
* パッケージ = ディレクトリ
* モジュール = クラスファイル
* オブジェクト = 各種関数、定数
と置き換えて認識してもよい。例えば、円周率πをよく使うなら、オブジェクトpiを指定してimportするとよい。
from math import pi # math クラスの pi オブジェクトをインポート print(pi) # math 指定なしに、そのまま利用できる。終わりに
10項目もあると結構な量になるが、ここにある内容を理解できればまずはPython初心者卒業といったところだろうか。
あとは各種汎用ライブラリ独自の用法を適宜把握できれば、コーディングはスイスイできるはず!
- 投稿日:2020-02-25T22:21:37+09:00
Pythonでコマンドライン引数の受け取り方
コマンドライン引数とは
コマンドライン引数とは、コンピュータのコマンド入力画面(コマンドライン)からプログラムを起動する際に指定する文字列のこと。また、これをプログラム側で受け取った変数などの値。
コマンドライン引数とはmain 関数の引数のことです。 実行するときに、 コマンドラインからコマンドライン引数に値を与えることができます。
http://www.ritsumei.ac.jp/~mmr14135/johoWeb/cmnds.html
>>> ls -a ↑ココPythonでコマンドライン引数を受け取る
Pythonでコマンドライン引数を受け取るには主に3つの方法があります。
sys.argvを使うargparseを使うclickを使うです。
sys.argv
最も認知されている(と思う)方法です。Pythonの標準ライブラリのsysを使用し取得します。
args.pyimport sys def main() -> None: args = sys.argv print(args) if __name__=='__main__': main()実行
>>> python args.py aaa 123 hoge ['args.py', 'aaa', '123', 'hoge']
メリット デメリット 簡単に記述できる どんな型が来るのかがわからない Python標準ライブラリである helpがない argparse
コマンドライン引数専用のPython標準ライブラリ。
Help機能や型の指定などができる。扱いはクセがある。args2.pyimport argparse def main() -> None: parser = argparse.ArgumentParser(description='説明') parser.add_argument('description', help='引数の説明') # 実行時指定しないとエラーになる。 parser.add_argument('hoge', help='hogehoge') # 順番が決まっている。 parser.add_argument('--foo', help='option') # ハイフンを1~2個つけると実行時指定しなくても良くなる。 args = parser.parse_args() print(args.description) print(args.hoge) print(args.foo) if __name__ == "__main__": main()実行
>>> python args2.py -h usage: aaa.py [-h] [--foo FOO] description hoge 説明 positional arguments: description 引数の説明 hoge hogehoge optional arguments: -h, --help show this help message and exit --foo FOO option >>> python args2.py aaa bbb aaa bbb None >>> python args2.py aaa bbb --foo 123 aaa bbb 123
メリット デメリット 機能が豊富 複雑 Helpがある Python標準ライブラリである click
Pythonのコマンドラインパーサ。別の言い方で、コマンドライン解析用モジュール。
Python標準ライブラリではないため別途インストールが必要だが、わかりやすさと使いやすさで上記2つを抜いている。そのため、これさえおぼえておけばOK
ちなみに、click、Flask、jinjaは同じプロジェクト。# インストール pip install clickargs3.pyimport click @click.command() @click.option('--args', prompt=True, help='説明') @click.option('--hoge', prompt=True, is_flag=True, help='hogehoge') def main(args: str, hoge: bool) -> None: if hoge: print(args) if __name__ == "__main__": main()実行
>>> python args3.py --args foo --hoge foo >>> python args3.py Args: aaaaa Hoge [y/N]: y aaaaa
メリット デメリット 機能が豊富 Python標準ライブラリではない 使いやすい プロンプトに表示できる 進捗バーも表示できる パスワード入力を隠すことができる 複数入力もできる 参考資料
Pythonでコマンドライン引数を扱う方法(sys.argv, argparse)
Pythonでコマンドライン引数を渡す方法
ArgumentParserの使い方を簡単にまとめた
Python: コマンドラインパーサの Click が便利すぎた
- 投稿日:2020-02-25T22:12:19+09:00
S3上ObjectのKeyを普通のdate形式からHive形式に変更する
何を書いた記事か
ぼく「とりあえずアプリのログとか分析用データとかS3に吐き出しとこう!パス?後から考えればいいからとりあえず
yyyy-mm-ddとかで切っておけばいいよ!」〜1年後〜
ぼく「なんでこんな分析かけづらいパス形式でデータが保管されてるんや・・」
という状態になってたのでなんとかしようという話です。何が嬉しいのか
上の例のように、特に運用を考えずに下記のようなKeyでS3上に出力してしまっている場合
s3://BUCKET_NAME/path/to/2020-01-01/log.jsonいざ分析にかけようと思ったとき、ここにおいたファイルに対してAthenaなどでクエリを投げる時、日付に対して適切なPartitionが効かせられないという状況に陥ります。
どういうことかというと、
「2019年1月のデータを横断的に分析しよう!」
と思っても、S3では2019−01-01のような文字列がKeyになっているだけで、2019-01-*のようなクエリをかけることは至難の技です。そこで、S3への保管の仕方をHive形式に変換することを考えます。Hive形式とは下記のような形式です。
s3://BUCKET_NAME/path/to/year=2020/month=01/date=01/log.jsonこのようなKeyでObjectを保管しておいて、Athenaのテーブル上でyyyy/mm/ddに対してPartitionを切ってあげると、SQLのWhere句で特定日付に区切ってクエリを実行することができるようになり、分析もしやすくなります。
ただ、S3はKey-Value形式でObjectを保管する形式のストレージなので、Objectに対するKeyをライトに一括変更することができません。
そこで、指定した期間のObjectに対して一括でKeyをHive形式に変更するスクリプトを作成し、Lambdaから実行しました。作成したLambda関数
早速ですが、作成したLambdaは下記のようなシンプル1ファイルスクリプトです。
import os import boto3 from datetime import datetime, timedelta # Load Environment Variables S3_BUCKET_NAME = os.environ['S3_BUCKET_NAME'] S3_BEFORE_KEY = os.environ['S3_BEFORE_KEY'] S3_AFTER_KEY = os.environ['S3_AFTER_KEY'] S3_BEFORE_FORMAT = os.environ['S3_BEFORE_FORMAT'] FROM_DATE = os.environ['FROM_DATE'] TO_DATE = os.environ['TO_DATE'] DELETE_FRAG = os.environ['DELETE_FRAG'] def date_range(from_date: datetime, to_date: datetime): """ Create Generator Range of Date Args: from_date (datetime) : datetime param of start date to_date (datetime) : datetime param of end date Returns: Generator """ diff = (to_date - from_date).days + 1 return (from_date + timedelta(i) for i in range(diff)) def pre_format_key(): """ Reformat S3 Key Parameter given Args: None Returns: None """ global S3_BEFORE_KEY global S3_AFTER_KEY if S3_BEFORE_KEY[-1] == '/': S3_BEFORE_KEY = S3_BEFORE_KEY[:-1] if S3_AFTER_KEY[-1] == '/': S3_AFTER_KEY = S3_AFTER_KEY[:-1] def change_s3_key(date: datetime): """ Change S3 key from datetime format to Hive format at specific date Args: date (datetime) : target date to change key Returns: None """ before_date_str = datetime.strftime(date, S3_BEFORE_FORMAT) print('Change following date key format : {}'.format(before_date_str)) before_path = f'{S3_BEFORE_KEY}/{before_date_str}/' after_path = "{}/year={}/month={}/date={}".format( S3_AFTER_KEY, date.strftime('%Y'), date.strftime('%m'), date.strftime('%d') ) s3 = boto3.client('s3') response = s3.list_objects_v2( Bucket=S3_BUCKET_NAME, Delimiter="/", Prefix=before_path ) try: for content in response["Contents"]: key = content['Key'] file_name = key.split('/')[-1] after_key = f'{after_path}/{file_name}' s3.copy_object( Bucket=S3_BUCKET_NAME, CopySource={'Bucket': S3_BUCKET_NAME, 'Key': key}, Key=after_key ) if DELETE_FRAG == 'True': s3.delete_object(Bucket=S3_BUCKET_NAME, Key=key) except Exception as e: print(e) return def lambda_handler(event, context): pre_format_key() from_date = datetime.strptime(FROM_DATE, "%Y%m%d") to_date = datetime.strptime(TO_DATE, "%Y%m%d") for date in date_range(from_date, to_date): change_s3_key(date)実行時には下記の設定をLambdaで入れてあげる必要があります。
- 環境変数に下記を設定
環境変数 値 備考 S3_BUCKET_NAME S3バケット名 S3_BEFORE_KEY 変更前S3キー(path/to) S3_AFTER_KEY 変更前S3キー(path/to) キーの移動が不要であれば上と同じ値 S3_BEFORE_FORMAT 変更前日付フォーマット %Y-%m-%dなど、Pythonのdatetimeが認識できる形式FROM_DATE 開始日(yyyymmdd) キー変更を行いたいObjectの始点 TO_DATE 終了日(yyyymmdd) キー変更を行いたいObjectの終点 DELETE_FRAG True/False 元のObjectを削除するかどうか
- Lambdaの実行RoleにS3の対象バケットの操作権限を付与
- 実行時間や割り当てメモリは適宜調整
必要な設定は環境変数化したので、自分の環境に合わせて好きに設定していただければと思います。
また、エラーハンドリングは面倒で実装していません。
一度だけSPOTで実行するスクリプトなので最小限の実装に止めています。気になる方は修正してください。結果
既存のS3 Keyに対して通常のdate形式からHive形式に変更し、無事に分析しやすい形式にすることができました。
追加情報ですが、path/to/のレイヤーでGlue Cralwerを実行すると、Athenaで読み込めるData CatalogがPartition含めて自動的に生成されるので、よりAthenaでの分析ライフが充実したものとなります。
ここの実装がおかしいとか、もっとこうした方がいいとかあれば教えてください!
大した内容ではありませんが、リポジトリも公開しておきます。
https://github.com/kzk-maeda/change-s3-key/blob/master/lambda_function.py
- 投稿日:2020-02-25T22:08:17+09:00
SEIRモデルでコロナウイルスの挙動を予測してみた。
1.はじめに
2019年12月に中国の湖北省の武漢で発生した新型コロナ肺炎(Covid-19)が、日本にも感染者数が増加しています。インフルエンザ, AIDS, SARS,などの感染病がどのプロセスで人間集団の中で拡大していくことを理解することは、予防接種の設定、感染者の隔離などの保健政策の効果を確認するためにも重要であります。
前回の記事では、SIRモデルを説明しましたが、感染病の潜伏期間を考慮したSEIRモデルを紹介します。
このモデルをPythonで計算する過程と、このSEIRモデルを利用しコロナウイルスがどう拡散するか計算結果を紹介します。2.伝染病の予測モデル(SEIRモデル)
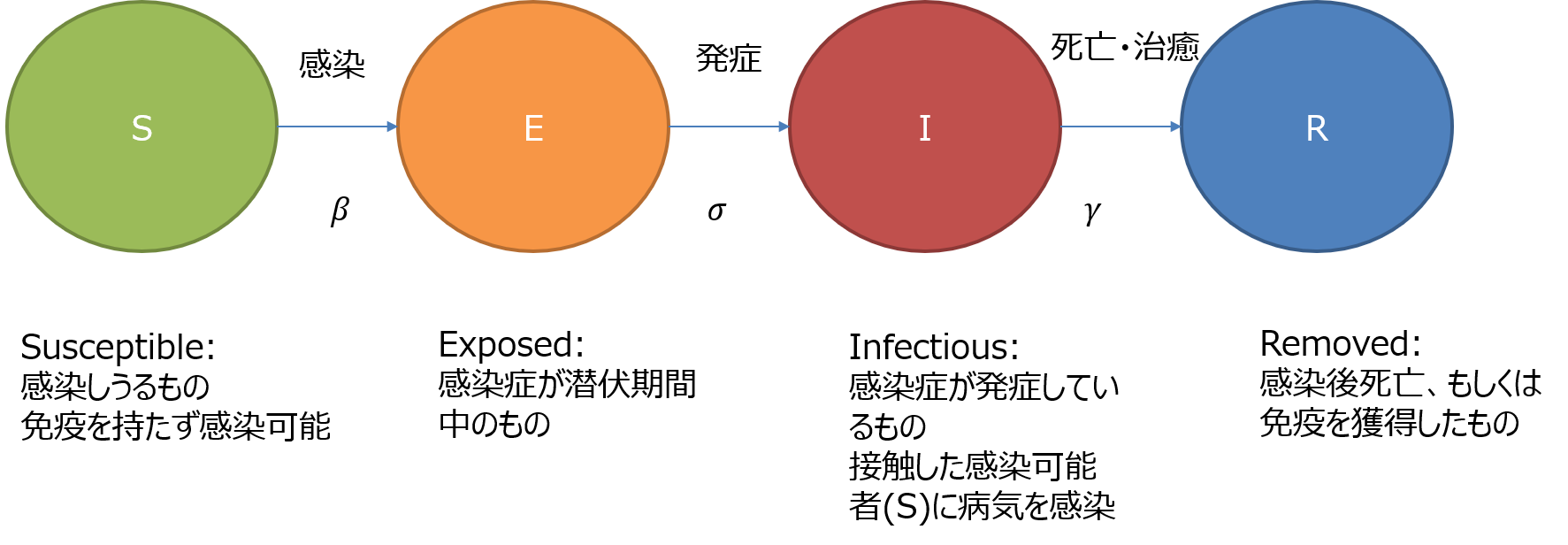
SEIRモデルでは、全体人口を次の集団に分類し、時間に関する各集団の人口増減を微分方程式で表す。
- S(Susceptible) : 伝染病に対する免疫がない。感染可能者
- E(Exposed):感染症が潜伏期間中の者
- I(Infectious):感染により発病し、感染可能者(S)への伝染可能な者。感染者
- R (Removed) : 発病から回復し、免疫を獲得したもの。あるいは発病から回復できず死亡した者。(このモデルのシステムから排除されるため、Removedと言う。)
各集団の人口増減を次の微分方程式で表す。
\begin{align} \frac{dS}{dt} &= -\beta \frac{SI}{N} \\ \frac{dE}{dt} &= \beta \frac{SI}{N} -\sigma E \\ \frac{dI}{dt} &= \sigma E -\gamma I \\ \frac{dR}{dt} &= \gamma I \\ \end{align}\begin{align} S &: 感染しうるもの、免疫を持たず感染可能 \quad \text{(Susceptible)} \\ E &: 感染症が潜伏期間中のもの \quad \text{(Infectious)} \\ I &: 感染症が発症しているもの、接触した感染しうるもの(S)に病気を感染 \quad \text{(Infectious)} \\ R &: 感染後死亡者、もしくは免疫を獲得した者 \quad \text{(Removed)} \\ N &: 全人口, S+E+I+R \end{align}\begin{align} \beta &: 感染率\quad \text{(The infectious rate)} \\ \sigma &: 暴露後に感染症を得る率\quad \text{(The rate at which an exposed person becomes infective)} \quad [1/day] \\ \gamma &:除去率\quad \text{(The Recovery rate)} \quad [1/day] \\ \end{align}\begin{align} \ l_p &: 感染待ち時間 \text{(latency period [day])}\quad \sigma= \frac{1}{l_p} \\ \ i_p &: 感染期間 \text{(Infectious period [day])}\quad \sigma= \frac{1}{i_p} \\ \end{align}このSIRモデルの前提条件
- 一度免疫を獲得した者は2度と感染することなく、免疫を失うこともありません。
- 全体人口で外部からの流入及び流出はありません。なお出生者及び感染以外の原因で死亡する者もいません。3.SEIRモデルの計算
SIRモデルは、数値積分を用いて解きます。ここでは、PythonのScipyモジュールのRunge-Kutta方程式を解くodeint関数を利用します。
import numpy as np from scipy.integrate import odeint import matplotlib.pyplot as plt次に、SIRモデルの微分方程式をodeintで計算できる形に記述します。ここで、v[0], v[1], v[2],v[3]がそれぞれS,E,I,Rに対応します。
# Define differential equation of SEIR model ''' dS/dt = -beta * S * I / N dE/dt = beta* S * I / N - epsilon * E dI/dt = epsilon * E - gamma * I dR/dt = gamma * I [v[0], v[1], v[2], v[3]]=[S, E, I, R] dv[0]/dt = -beta * v[0] * v[2] / N dv[1]/dt = beta * v[0] * v[2] / N - epsilon * v[1] dv[2]/dt = epsilon * v[1] - gamma * v[2] dv[3]/dt = gamma * v[2] ''' def SEIR_EQ(v, t, beta, epsilon, gamma, N ): return [-beta * v[0] * v[2] / N ,beta * v[0] * v[2] / N - epsilon * v[1], epsilon * v[1] - gamma * v[2],gamma * v[2]]そして、数値積分に必要な各パラメータ及び初期条件を定義します。ここでは、人口1,000名の集団に対し、初期の感染症が潜伏期間中の者が1名がいると仮定します。
感染率を1に、感染待ち時間を2日、感染期間を7.4日と設定します。# parameters t_max = 100 #days dt = 0.01 # initial_state S_0 = 99 E_0 = 1 I_0 = 0 R_0 = 0 N_pop = S_0 + E_0 + I_0 + R_0 ini_state = [S_0, E_0, I_0, R_0] # [S[0],E,[0], I[0], R[0]] #感染率 beta_const = 1 #感染率 #暴露後に感染症を得る率 latency_period = 2 #days epsilon_const = 1/latency_period #回復率や隔離率 infectious_period = 7.4 #days gamma_const = 1/infectious_period数値積分結果をresultに格納し、この結果を時間軸に対しプロットします。
# numerical integration times = np.arange(0, t_max, dt) args = (beta_const, epsilon_const, gamma_const, N_pop) # Numerical Solution using scipy.integrate # Solver SEIR model result = odeint(SEIR_EQ, ini_state, times, args) # plot plt.plot(times, result) plt.legend(['Susceptible', 'Exposed', 'Infectious', 'Removed']) plt.title("SEIR model COVID-19") plt.xlabel('time(days)') plt.ylabel('population') plt.grid() plt.show()
このグラフから言えることは、100名の集団に感染症が潜伏期間中の者が1名(Exposed(0))発生することで、最終的に100名(Removed(100))が感染を経験することである。そして、感染者(Infectious)のピークは約18日辺りで発生し、その後は感染が収束することがわかる。
このように感染病に関するパラメータをもって、感染病が人口集団に及ぼす影響を評価することが可能である。4.コロナウイルスの予測
現在、コロナウイルスの発症事例より、SEIRのパラメータを推定する研究論文が多数発表されています。今回は、2月16日に発表された論文に掲載されたパラメータ推定値で、SEIRモデルを計算してみます。(参考文献 2)
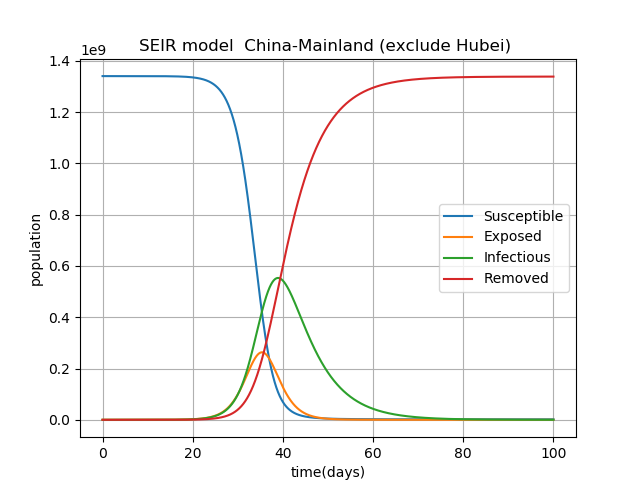
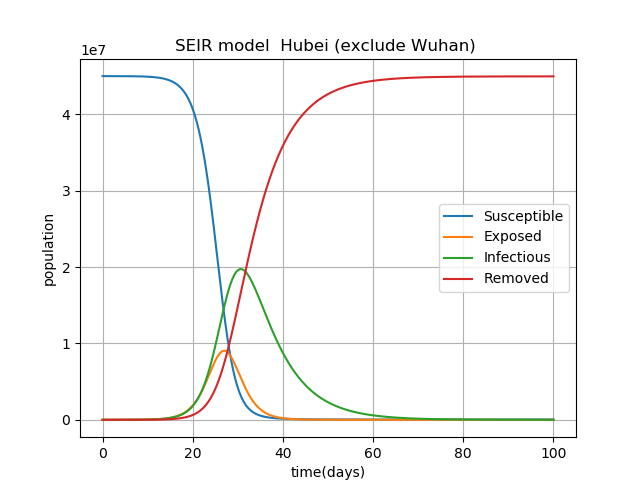
Parameter 中国本土(湖北省除く) 湖北省(武漢除く) 武漢 人口数 N (million) 1340 45 14 感染率 [beta] 1.0 1.0 1.0 Latency period (days) 2 2 2 infectious_period (days) 6.6 7.2 7.4 E_0 696 592 318 I_0 652 515 389 計算結果を示します。それぞれ縦軸の人口の数値が異なることに注意してください。
1番目のグラフは、湖北省を除く中国本土の感染拡大の予測です。
2番目のグラフは、武漢を除く湖北省の感染拡大の予測です。
3番目のグラフは、武漢の感染拡大の予測です。
このパラメータでの予測だと、30日~40日で感染者数はピークを迎えて、最終的にはほぼ100%の人口が感染を経験する(Removed(100))ことになります。正直、驚きました。
恐らくWorst Caseを想定した予測結果になったと思います。今回のコロナウイルスには各段に注意が必要だと思います。5. 参考文献
SEIR and SEIR models https://institutefordiseasemodeling.github.io/Documentation/general/model-seir.html
Epidemic analysis of COVID-19 in China by dynamical modeling https://arxiv.org/abs/2002.06563


- 投稿日:2020-02-25T22:08:17+09:00
感染病の数学予測モデルの紹介: (コロナウイルス、SEIRモデル)
1.はじめに
2019年12月に中国の湖北省の武漢で発生した新型コロナ肺炎(Covid-19)が、日本にも感染者数が増加しています。インフルエンザ, AIDS, SARS,などの感染病がどのプロセスで人間集団の中で拡大していくことを理解することは、予防接種の設定、感染者の隔離などの保健政策の効果を確認するためにも重要であります。
前回の記事では、SIRモデルを説明しましたが、感染病の潜伏期間を考慮したSEIRモデルを紹介します。
このモデルをPythonで計算する過程と、このSEIRモデルを利用しコロナウイルスがどう拡散するか計算結果を紹介します。2.伝染病の予測モデル(SEIRモデル)
SEIRモデルでは、全体人口を次の集団に分類し、時間に関する各集団の人口増減を微分方程式で表す。
- S(Susceptible) : 伝染病に対する免疫がない。感染可能者
- E(Exposed):感染症が潜伏期間中の者
- I(Infectious):感染により発病し、感染可能者(S)への伝染可能な者。感染者
- R (Removed) : 発病から回復し、免疫を獲得したもの。あるいは発病から回復できず死亡した者。(このモデルのシステムから排除されるため、Removedと言う。)
各集団の人口増減を次の微分方程式で表す。
\begin{align} \frac{dS}{dt} &= -\beta \frac{SI}{N} \\ \frac{dE}{dt} &= \beta \frac{SI}{N} -\sigma E \\ \frac{dI}{dt} &= \sigma E -\gamma I \\ \frac{dR}{dt} &= \gamma I \\ \end{align}\begin{align} S &: 感染しうるもの、免疫を持たず感染可能 \quad \text{(Susceptible)} \\ E &: 感染症が潜伏期間中のもの \quad \text{(Infectious)} \\ I &: 感染症が発症しているもの、接触した感染しうるもの(S)に病気を感染 \quad \text{(Infectious)} \\ R &: 感染後死亡者、もしくは免疫を獲得した者 \quad \text{(Removed)} \\ N &: 全人口, S+E+I+R \end{align}\begin{align} \beta &: 感染率\quad \text{(The infectious rate)} \\ \sigma &: 暴露後に感染症を得る率\quad \text{(The rate at which an exposed person becomes infective)} \quad [1/day] \\ \gamma &:除去率\quad \text{(The Recovery rate)} \quad [1/day] \\ \end{align}\begin{align} \ l_p &: 感染待ち時間 \text{(latency period [day])}\quad \sigma= \frac{1}{l_p} \\ \ i_p &: 感染期間 \text{(Infectious period [day])}\quad \sigma= \frac{1}{i_p} \\ \end{align}このSIRモデルの前提条件
- 一度免疫を獲得した者は2度と感染することなく、免疫を失うこともありません。
- 全体人口で外部からの流入及び流出はありません。なお出生者及び感染以外の原因で死亡する者もいません。3.SEIRモデルの計算
SIRモデルは、数値積分を用いて解きます。ここでは、PythonのScipyモジュールのRunge-Kutta方程式を解くodeint関数を利用します。
import numpy as np from scipy.integrate import odeint import matplotlib.pyplot as plt次に、SIRモデルの微分方程式をodeintで計算できる形に記述します。ここで、v[0], v[1], v[2],v[3]がそれぞれS,E,I,Rに対応します。
# Define differential equation of SEIR model ''' dS/dt = -beta * S * I / N dE/dt = beta* S * I / N - epsilon * E dI/dt = epsilon * E - gamma * I dR/dt = gamma * I [v[0], v[1], v[2], v[3]]=[S, E, I, R] dv[0]/dt = -beta * v[0] * v[2] / N dv[1]/dt = beta * v[0] * v[2] / N - epsilon * v[1] dv[2]/dt = epsilon * v[1] - gamma * v[2] dv[3]/dt = gamma * v[2] ''' def SEIR_EQ(v, t, beta, epsilon, gamma, N ): return [-beta * v[0] * v[2] / N ,beta * v[0] * v[2] / N - epsilon * v[1], epsilon * v[1] - gamma * v[2],gamma * v[2]]そして、数値積分に必要な各パラメータ及び初期条件を定義します。ここでは、人口1,000名の集団に対し、初期の感染症が潜伏期間中の者が1名がいると仮定します。
感染率を1に、感染待ち時間を2日、感染期間を7.4日と設定します。# parameters t_max = 100 #days dt = 0.01 # initial_state S_0 = 99 E_0 = 1 I_0 = 0 R_0 = 0 N_pop = S_0 + E_0 + I_0 + R_0 ini_state = [S_0, E_0, I_0, R_0] # [S[0],E,[0], I[0], R[0]] #感染率 beta_const = 1 #感染率 #暴露後に感染症を得る率 latency_period = 2 #days epsilon_const = 1/latency_period #回復率や隔離率 infectious_period = 7.4 #days gamma_const = 1/infectious_period数値積分結果をresultに格納し、この結果を時間軸に対しプロットします。
# numerical integration times = np.arange(0, t_max, dt) args = (beta_const, epsilon_const, gamma_const, N_pop) # Numerical Solution using scipy.integrate # Solver SEIR model result = odeint(SEIR_EQ, ini_state, times, args) # plot plt.plot(times, result) plt.legend(['Susceptible', 'Exposed', 'Infectious', 'Removed']) plt.title("SEIR model COVID-19") plt.xlabel('time(days)') plt.ylabel('population') plt.grid() plt.show()
このグラフから言えることは、100名の集団に感染症が潜伏期間中の者が1名(Exposed(0))発生することで、最終的に100名(Removed(100))が感染を経験することである。そして、感染者(Infectious)のピークは約18日辺りで発生し、その後は感染が収束することがわかる。
このように感染病に関するパラメータをもって、感染病が人口集団に及ぼす影響を評価することが可能である。4.コロナウイルスの予測
現在、コロナウイルスの発症事例より、SEIRのパラメータを推定する研究論文が多数発表されています。今回は、2月16日に発表された論文に掲載されたパラメータ推定値で、SEIRモデルを計算してみます。(参考文献 2)
Parameter 中国本土(湖北省除く) 湖北省(武漢除く) 武漢 人口数 N (million) 1340 45 14 感染率 [beta] 1.0 1.0 1.0 Latency period (days) 2 2 2 infectious_period (days) 6.6 7.2 7.4 E_0 696 592 318 I_0 652 515 389 計算結果を示します。それぞれ縦軸の人口の数値が異なることに注意してください。
1番目のグラフは、湖北省を除く中国本土の感染拡大の予測です。
2番目のグラフは、武漢を除く湖北省の感染拡大の予測です。
3番目のグラフは、武漢の感染拡大の予測です。
このパラメータでの予測だと、30日~40日で感染者数はピークを迎えて、最終的にはほぼ100%の人口が感染を経験する(Removed(100))ことになります。正直、驚きました。
恐らくWorst Caseを想定した予測結果になったと思います。今回のコロナウイルスには各段に注意が必要だと思います。5. 参考文献
SEIR and SEIR models https://institutefordiseasemodeling.github.io/Documentation/general/model-seir.html
Epidemic analysis of COVID-19 in China by dynamical modeling https://arxiv.org/abs/2002.06563
- 投稿日:2020-02-25T21:37:32+09:00
【機械学習】線形重回帰をscikit-learnと数学の両方から理解する
1.目的
機械学習をやってみたいと思った場合、scikit-learn等を使えば誰でも比較的手軽に実装できるようになってきています。
但し、仕事で成果を出そうとしたり、より自分のレベルを上げていくためには
「背景はよくわからないけど何かこの結果になりました」の説明では明らかに弱いことが分かると思います。この記事では、2~3で「理論はいいからまずはscikit-learn使ってみる」こと、4以降で「その背景を数学から理解する」2つを目的としています。
※私は文系私立出身なので、数学に長けていません。可能な範囲で数学が苦手な方にもわかりやすいように説明するよう心がけました。
(とはいえ、今回は線形代数の知識が必要になるので、難しいと感じる方は、そういうものか、と受け流すくらいで大丈夫です。)※「数学から理解する」シリーズとして、同様の記事を投稿していますので、併せてお読みいただけますと幸いです。
【機械学習】線形単回帰をscikit-learnと数学の両方から理解する
【機械学習】ロジスティック回帰をscikit-learnと数学の両方から理解する
【機械学習】SVMをscikit-learnと数学の両方から理解する
【機械学習】相関係数はなぜ-1から1の範囲を取るのか、数学から理解する2. 線形(重)回帰とは
上記の、線形単回帰とも重複する箇所がありますので線形単回帰の記事も併せて参考にしてください。
【機械学習】線形単回帰をscikit-learnと数学の両方から理解する(1) 回帰とは
数値を予測すること。機械学習では、他に「分類」があるが、「●●円」「△Kg」といった数値を予測したい場合は、回帰を使うと考えればよい。
(2) 線形回帰とは
若干の語弊はあるかもしれないですが、
「求めたいもの($=y$)」と、「その求めたいものに影響を与えると思われるもの
($=x$)」に線形の関係がある場合、その線形の特徴を使って$y$を求めるやり方を線形回帰といいます。線形単回帰は$x$は1つでしたが、線形重回帰は$x$が複数あります。
分かりづらいと思うので、具体例を出します。
<具体例>
あなたは自営業でアイスクリーム屋さんを営んでおり、売上の目途を安定的に立てるため、「自分の店のアイスクリームの売上を予測できるようになりたい」と強く思っているとします。
あなたは、自分の店のアイスクリームの売上に影響を与えているのは何だろうかと必死に考えました。
線形単回帰の記事では、アイスクリームの売上に影響を与えているのは「気温」と仮定して話を進めてきましたが、よく考えると、あなたが本当にアイスクリーム屋さんを営んでいたとしたら、売上に影響を与えているのは本当に「気温だけ」という結論をたてるでしょうか。おそらく、気温だけでなく、その日のアイスクリーム屋さんの通りの交通量や、それこそ、一緒に働く従業員の影響も大きいと考えるのではないでしょうか。
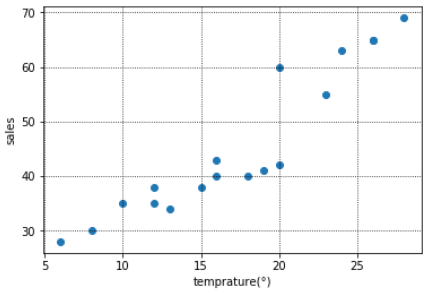
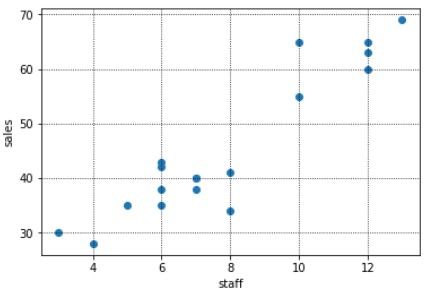
このように、通常は目的変数(アイスクリームの売上)に影響を与えると思われる説明変数は複数あり、場合によっては数万個ある、という場合もあります。そこで、下記のように「いくつかの説明変数($=x$)」と「目的変数(アイスクリームの売上($=y$))」を図示してみると、説明変数と目的変数(アイスクリームの売上)にはおおよそ直線の形(=$ax+b$)が引けそう(=線形である)なものや、あまり関係なさそうなものがあることがわかります。
<売上と気温の散布図>
<売上と交通量の散布図>
<売上とその日にシフトに入っていた従業員数の散布図>
このように図示すると、売上と線形の関係にありそうな「気温」と「従業員数」を説明変数に使用し、「交通量」は使わないという選択もできます。
ここでは、後の例として使うので、「交通量」も説明変数に入れていきます。次から、scikit-learnを使って気温・交通量・従業員数から、アイスクリームの売上を求める機械学習のモデルを構築してみましょう。
3.scikit-learnで線形回帰
(1)必要なライブラリのインポート
線形回帰を行うために必要な下記をインポートしておく。
import numpy as np import pandas as pd from sklearn.linear_model import LinearRegression(2)データの準備
気温、交通量、従業員数とアイスクリームの売上を下記のようにdataとして設定する。
※例えば、下記でいうと気温が8°の日は売上が30万円、10°の日は売上が35万円となる。data = pd.DataFrame({ "temprature":[8,10,6,15,12,16,20,13,24,26,12,18,19,16,20,23,26,28], "car":[100,20,30,15,60,25,40,20,18,30,60,10,8,25,35,90,25,55], "clerk":[3,5,4,6,6,7,12,8,12,10,7,7,8,6,6,10,12,13], "sales(=y)":[30,35,28,38,35,40,60,34,63,65,38,40,41,43,42,55,65,69] })(3)モデル構築
(ⅰ)データ整形
まずはモデル構築をするためにデータの形を整えていきます。
y = data["sales(=y)"].values X = data.drop("sales(=y)", axis=1).values #sales以外の列をXとして定義する、という意味今回はpython文法の記事ではないので詳細は割愛しますが、Xとyをscikit-learnで線形回帰するための形に整えます。
※このあたりもある程度しっかりわかっていないと書けないコードだと思うので、どこかでまとめたいと思っています。(ⅱ)モデル構築
いよいよ、モデル構築のコードです。
regr = LinearRegression(fit_intercept = True) regr.fit(X,y)単純なモデルであればこれで終わりです。
regrという変数にこれから線形回帰モデルを作ります!と宣言のようなことを行い、次の行で、そのregrに準備したXとyをフィット(=学習)させるというイメージです。(ⅲ)直線の傾きと切片を出してみる
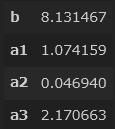
「2. 線形(重)回帰とは」(2)で記載しましたが、先ほどまでのscikit-learnで$y=a_1x_1+ a_2x_2 + a_3x_3 + b$の$a$と$b$を求め、気温、交通量、従業員数から売上を予測する直線の式を裏で求めています。
今のままだと実感がわかないので、実際に傾きと切片を出しておきましょう。b = regr.intercept_ a1 = regr.coef_[0] a2 = regr.coef_[1] a3 = regr.coef_[2] pd.DataFrame([b,a1,a2,a3],index = ["b","a1","a2","a3"])すると、下記のように表示されます。
つまり、今回の線形回帰の式は、$y = 1.074159x_1 + 0.04694x_2 + 2.170663x_3 + 8.131467$で求められることが分かります。
補足になりますが、最初の図示で売上とあまり関係なさそうだった交通量($x_2$)の係数($=a_2$)は0.04694と、他2つの係数に比べて非常に小さいことが、計算からもわかりますね。つまり、交通量は$y$を求める際にあまり影響を与えない(=重要でない)変数であることが、あらためてわかります。
(6)現実世界では・・
モデルを作って終わり、では意味ないですね。現実世界では、この予測モデルを使って、今後の売上を予測していくことが必要です。
あなたは今後の3日分の気温、見込み交通量、従業員数をメモしました。
それを下記のようにzという変数に格納します。z = pd.DataFrame([[20,15,18], [15,60,30], [5,8,12]])やりたいのは、先ほどscikit-learnで求めた直線の式に、上記の今後のデータをあてはめ、売り上げを予測することです。
regr.predict(z)このようにすると、「([69.39068087, 92.18012508, 39.92573722])」と結果が表示されます。
つまり、明日の売上は約69.4万円、明後日は約92.2万円・・というかたちです。
むこう1か月分のデータが取得できれば、売上のおおよその目途が立つということになり、あなたの目標は達成されます。細かいことは他にも様々ありますが、まずはオーソドックスな線形回帰を実装してみるという点では良いのではないでしょうか。
4.線形(重)回帰を数学から理解する
さて、3まではscikit-learnを用いて$y=a_1x_1+ a_2x_2 + ・・・+ a_ix_i +b$の$a$と$b$を算出→今後3日間のデータから売上を予測するという流れを実装してみました。
ここでは、この流れの「$a$と$b$を算出」は、数学的にはどのように計算されているのかを明らかにしていきたいと思います。
※現状はこの知識は必要ないという方は読み飛ばしていただいて結構です。
※今回はベクトル、線形代数が登場してきますので、難しいと感じる方は、「そういうものなのだ」と思っていただく程度で大丈夫です。(1)前提知識(基本的なベクトル、線形代数)
$\frac{∂c}{∂\boldsymbol{x}} = 0 ←定数をxで微分すると0になる$
$\frac{∂(\boldsymbol{c}^T\boldsymbol{x})}{∂\boldsymbol{x}} = \boldsymbol{c}$
$\frac{∂(\boldsymbol{x}^TC\boldsymbol{x})}{∂\boldsymbol{x}} = (C
+ C^T)\boldsymbol{x}$(2)数学的な理解
(ⅰ)重回帰分析の式について
◆重回帰分析の式
前半でも触れましたが、重回帰分析の式は一般に下記のように表されます。$\hat{y} = a_1x_1 + a_2x_2 + ・・ + a_mx_m + a_0・1$
※$a_0・1$は、いわゆる$y = ax + b$でいう$b$のことを指していて、定数の何らかの数値として設定しています。
※今回は詳細は割愛しますが、$a_0・1$はデータ全体を標準化すれば0になります。今回は標準化はしないですが、通常は標準化することも多いので、$a_0・1$を解析的に求めることはしていません。◆今回の例で言うと・・
$x_1$が気温、$x_2$が交通量、$x_3$が従業員数で、それぞれの数値に何らかの係数$a_1,a_2,a_3$を掛けて、最後に定数$a_0・1$を足して売上$\hat{y}$を求めています。(ⅱ)重回帰分析の式をベクトルで表現する
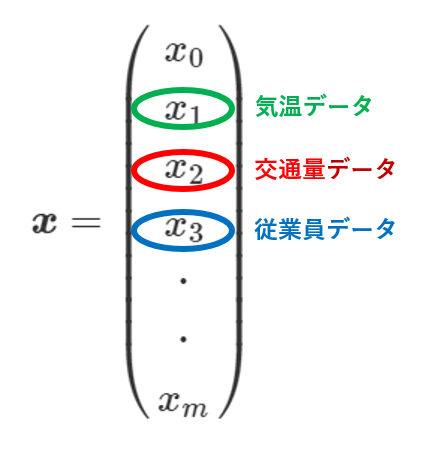
(ⅰ)の重回帰分析の式の$x$をベクトル$x$、すなわち$\boldsymbol{x}$として表すと下記のようになります。
今回は説明変数が3つなので$x_3$までになりますが、一般には上記のように表します。
そして、例えば上記の$x_1$の気温データも、データは1つではなく、その中には複数日程分の気温データが格納されているはずです。
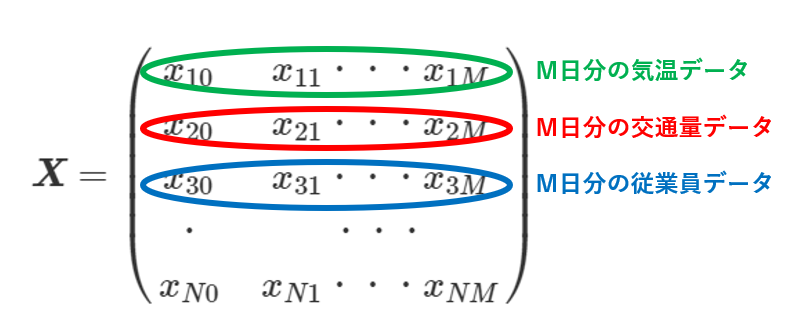
それを行列$X$で表しているのが下記です。
同様にベクトル$a$、すなわち$\boldsymbol{a}$は下記のように表せます。
$
\boldsymbol{a} = \begin{pmatrix}
a_0\\
a_1\\
a_2\\
a_3\\
・\\
・\\
a_m
\end{pmatrix}
$つまり、元の売上を予測する重回帰分析の式が$\hat{y} = a_1x_1 + a_2x_2 + ・・ + a_mx_m + a_0・1$なので、$\hat{y} = \boldsymbol{X}\boldsymbol{a}$と表すことができます。
重要なことは、$\hat{y}$と$\boldsymbol{X}$は自分の手元にあるデータからわかるので、これらを代入して$\boldsymbol{a}$、すなわち重回帰分析の式の各説明変数の係数が計算できるということです。
次から、この式を用いて$\boldsymbol{a}$を解析的(=手計算)に求めていきましょう。
Scikit-learnが裏で行っているのも、これと同じ計算です。(厳密には異なるのですが、後程触れます。)(ⅲ)誤差関数の計算
線形単回帰の記事でも触れていますが、$\hat{y} = a_1x_1 + a_2x_2 + ・・ + a_mx_m + a_0・1$の$a_1$や$a_2$、$a_3$を決めるには、本当の売上$y$と、あくまで予測値の$\hat{y}$の差がなるべく小さくなるように、良さげな$a_1,a_2,a_3$を設定します。
「良さげな」とはどういうことか、$y$と$\hat{y}$の差(誤差関数)を計算しながら見ていきましょう。
$\begin{align}
E &=
\sum_{i=1}^n ({y_i - \hat{y}})^{2}\\
&= (y - \hat{y})^T(y - \hat{y})\\
&= (y - \boldsymbol{X}\boldsymbol{a})^T(y - \boldsymbol{X}\boldsymbol{a}) ←\hat{y}に\boldsymbol{X}\boldsymbol{a}を代入\\
&= (y^T - (\boldsymbol{X}\boldsymbol{a})^T)(y - \boldsymbol{X}\boldsymbol{a})\\
&= (y^T - a^T\boldsymbol{X}^T)(y - \boldsymbol{X}\boldsymbol{a})←(\boldsymbol{X}\boldsymbol{a})^T = a^T\boldsymbol{X}^T\\
&= y^Ty - y^T\boldsymbol{X}\boldsymbol{a} - a^T\boldsymbol{X}^Ty + a^T\boldsymbol{X}^T\boldsymbol{X}\boldsymbol{a}←1つ上の式を展開\\
&= y^Ty - 2y^T\boldsymbol{X}\boldsymbol{a} + a^T\boldsymbol{X}^T\boldsymbol{X}\boldsymbol{a}←a^T\boldsymbol{X}^Ty = y^T\boldsymbol{X}\boldsymbol{a}より
\end{align}$この$E$を最小にするために、$E$を$\boldsymbol{a}$で微分し、0になる$\boldsymbol{a}$を求めます。
(なぜ微分して0になるようにするのかは、線形単回帰の記事を参照してください)$
\begin{align}
\frac{∂E}{∂\boldsymbol{a}} &= \frac{∂}{∂\boldsymbol{a}}(y^Ty) - 2\frac{∂}{∂\boldsymbol{a}}(y^T\boldsymbol{X}\boldsymbol{a}) + \frac{∂}{∂\boldsymbol{a}}(a^T\boldsymbol{X}^T\boldsymbol{X}\boldsymbol{a})←\frac{∂}{∂\boldsymbol{a}}(y^Ty)は0になる\\
&= -2\boldsymbol{X}^Ty + [\boldsymbol{X}^T\boldsymbol{X} + (\boldsymbol{X}^T\boldsymbol{X})^T]\boldsymbol{a}←前提知識の3つ目の式のCはここでいうと\boldsymbol{X}^T\boldsymbol{X}にあたる\\
&= -2\boldsymbol{X}^Ty + 2\boldsymbol{X}^T\boldsymbol{X}\boldsymbol{a}
\end{align}
$この誤差関数が0になるから、
$
\begin{align}
-2\boldsymbol{X}^Ty + 2\boldsymbol{X}^T\boldsymbol{X}\boldsymbol{a} = 0\\
2\boldsymbol{X}^T\boldsymbol{X}\boldsymbol{a} = 2\boldsymbol{X}^Ty\\
\boldsymbol{X}^T\boldsymbol{X}\boldsymbol{a} = \boldsymbol{X}^Ty\\
\end{align}
$つまり、求めたかった$\boldsymbol{a}$は下記のように求められます。
$\boldsymbol{a} = (\boldsymbol{X}^T\boldsymbol{X})^{-1} \boldsymbol{X}^Ty$
(3)発展~pythonで実装してみる~
求めたかった$\boldsymbol{a}$は数式で表現できましたが、これだけ提示されても、重回帰はいまいちぴんとこないかもしれないです(私はきませんでした)。
そこで、ここでは、pythonのnumpyを使って、上記の式から解析的に重回帰分析の式を算出してみたいと思います。
◆データセット
(ⅰ)numpyのインポート
import numpy as np(ⅱ)データセット
少し見づらいかもしれないですが、xの左の縦1列が気温、2列目が交通量、3列目が従業員数です。yは売上です。x = np.matrix([[8,100,3], [10,20,5], [6,30,4], [15,15,6], [12,60,6], [16,25,7], [20,40,12], [13,20,8], [24,18,12], [26,30,10], [12,60,7], [18,10,7], [19,8,8], [16,25,6], [20,35,6], [23,90,10], [26,25,12], [28,55,13]]) y = np.matrix([[30], [35], [28], [38], [35], [40], [60], [34], [63], [65], [38], [40], [41], [43], [42], [55], [65], [69]])(ⅲ)重回帰分析
先ほど示した通り、$\boldsymbol{a} = (\boldsymbol{X}^T\boldsymbol{X})^{-1} \boldsymbol{X}^Ty$なので、下記のように記述します。(x.T * x)**-1 * x.T * yそうすると、このように結果が表示されます。つまり、numpy上で計算すると$a_1 = 1.26, a_2 = 0.09, a_3 = 2.47$ということになります。
matrix([[1.26664688],
[0.09371714],
[2.47439799]])これは、scikit-learnで求めた$a_1,a_2,a_3$と数値が微妙に異なりますが、scikit-learnはこのnumpyの計算に、さらにバイアス(というもの)を考慮しているためです。
そこまで突っ込み始めるとより複雑になってくるので、scikit-learnが裏で行っている基本的な計算を知るという意味では、まずは今回レベルのことを押さえておければいいのではと思います。5.まとめ
以上、いかがでしたでしょうか。
私の思いとして、「最初からものすごい複雑なコードなんて見せられても自分で解釈できないから、精度は一旦どうでもいいのでまずはscikit-learn等で基本的な一連の流れを実装してみる」ことは非常に重要だと思っています。ただ、慣れてきたらそれらを裏ではどのように動かしているのか、数学的な背景から理解していくことも非常に重要だと感じています。
とっつきづらい内容も多いと思いますが、少しでも理解の深化の助けとなりましたら幸いですし、私自身もここはもっとしっかり学ばなければいけないと思っていますので、学習を続けることで、より強化した記事を投稿したいと思います。


- 投稿日:2020-02-25T20:33:47+09:00
「ヤジが飛んでくるマインクラフト」DeepLearningで適当テキスト生成 ~modで動かす~
DeepLearningの力を借りて、マイクラのプレイ中、ゲームに関係のある文章を読み上げてくれるソフトを作った。
↓こんなやつ
1つの記事にまとめるのが困難なため、いくつかの記事に分けます。
ここでは、アプリケーション部分について説明します。↓他の記事
やりたいこと
マインクラフトで、近くにゾンビがいるか判定。
ゾンビがいたら、ゾンビに関連する文章を表示。(文章そのものを用意するところは別の記事へ)
マインクラフトmod
マインクラフトは有志の方が制作した、modというものがある。
mod を使えば、かなり自由にゲームを改造することができる。MCreator を使えば、すぐにmod制作が始められる。
簡単な変更なら、コードすら書く必要がない。Python プログラムを組み込みたい
マインクラフト mod は Java で書かれている。
- Java あまり分からない。
- DeepLearningのモデルも動かしたいので、Python が使いたい。
Raspberry Jam Mod(mcpi)
Pythonからマインクラフトを一部操作できる。
いろんなことができる。
しかし、ゲーム情報を取得する部分は微妙。Python と Java で通信
mcpiのコードを見てみる。
Socket通信でやりとりしているらしい。
ポートを指定してごにょごにょするらしい。
Python側は mcpi の Connectionクラスを改造
Java側は ゴリ押しで書く
近くにゾンビがいるかどうか調べる
ようやく、modの実装。
MCreator1.9.1 を使用した。MCreator で新しいワークスペースを作ると mod の雛形が作成される。
GUIで、新しいコマンドを作れる。空のコマンドを作成。
- hogehogeCommandExecuted みたいなやつの、
executeProcedure関数に書く。やりたいことを別の関数に詰め込む。
- Socketを準備
- 継続して、データを取得・送信・受信
コマンド実行時に、別のプロセスで、作った関数を実行するようにする。
- mod 素人(+Java素人)なので、mod と切り分けたかった。
- 脳死で、Thread とかいうのを使ってみる。
ゲーム内情報取得
Minecraft mc = Minecraft.getMinecraft() WorldClient world = mc.world; List<Entity> entities = world.getEntities(Entity.class, (entity)->!entity.isInvisible());これで、ワールド内で透明でない敵mobや動物mobが取得できる。
Entity player = world.getEntityByID(mc.player.getEntityId());そして、プレイヤーのインスタンスもとる。
String minecraftData; for (Entity e: entities) { if (e.getDistance(player) < 8.0f) { minecraftData += e.getName() + ","; } }
getDistanceで Entity 同士の距離が分かる。
近くにいる Entity の名前をgetNameで取得して、送信用の文字列に加えている。表示
マインクラフト内のチャットに文字を出す。
MinecraftServer mcserv; mcserv.getPlayerList().sendMessage(new TextComponentString("hogehoge"));参考になりそうなサイト
mod で気をつけること
バージョンによって少しずつ、ライブラリの仕様が異なる。
ライブラリのソースは、MCreatorからでも見られる。分かる人は直接読んでみてもいいと思う。文字列を用意する。
あらかじめ、どのオブジェクトに関係のある文か分けてあるので、mod からのデータを元にランダムに選ぶ。
その文章の先頭単語を生成モデルに入れて、文を生成してみた。
詳しくは別記事参照。おまけ
表示するだけでは、味気ない。
ゆっくりに喋らせてみた。
簡単に、こんな感じでやった(windows)。subprocess.call("start C:\hoge\softalk\SofTalk.exe /R: /W: "+"読ませたい文章", shell=True)まとめ
マインクラフトのmodは有名なので、解説記事が充実しているかと思ったが、そうでもなかった。
MCreator を使わない環境構築が面倒で、出来ていない。
ガチガチにコーディングしようと思うと不便な気がするので、どうにかしたい。マインクラフトはかなり可能性を秘めているので、みんなもやってみてほしい。

- 投稿日:2020-02-25T18:58:46+09:00
スクリプト言語 KINX/基本編(1) - プログラム基礎・データ型
はじめに
前回の記事から。シリーズ第一弾は普通に基本編。概要は以下の前回の記事を参照してください。
- スクリプト言語 KINX(ご紹介)
- Kinx 基本編(1) - プログラム基礎・データ型(今回)
前回お披露目してみたら★を付けてくださった方がいて、非常に浮かれています。ありがとうございました。温かいお気持ちで行く末を見届けてやってください。
- ここ (https://github.com/Kray-G/kinx) です。Kinx 基本編(1) - プログラム基礎・データ型
プログラム基礎
hello, world
プログラムはトップレベルから記述可能。
hello.kxSystem.println("hello, world.");
hello.kxという名前で保存し、以下のように実行.$ ./kinx hello.kx hello, world.コメント
コメントは C/C++ 形式と Perl のような
#形式と両方利用可能。/* Comment */ // Comment# Comment変数宣言
変数宣言は
varで宣言する。var a = 10;初期化子を使って初期化するが、初期化子を書かなかった場合は
nullとなる。ちなみに Kinx においてはnullとundefinedは同じ意味(賛否あると思うが)。どちらもa.isUndefinedが true となる。データ型一覧
Kinx は動的型付け言語だが、内部に型を持っている。
Type CheckProperty Example Meaning Undefined isUndefinednull 初期化されていない値。 Integer isInteger,isBigInteger100, 0x02 整数。演算では自動的に Big Integer と相互変換される。 Double isDouble1.5 実数。 String isString"aaa", 'bbb' 文字列。 Binary isBinary<1,2,3> バイナリ値。バイトの配列。要素は全て 0x00-0xFF に丸められる。 Array isArray,isObject[1,a,["aaa"]] 配列。扱える型は全て保持可能。 Object isObject{ a: 1, b: x } JSON のようなキーバリュー構造。 Function isFunctionfunction(){},
&() => expr関数。
Undefined以外であればisDefinedで true が返る。尚、真偽値としての
true、falseは整数の 1、0 のエイリアスでしかないのに注意。
Boolean 型というのは特別に定義されていないが、オブジェクトとして真偽を表すTrue、Falseという定数が定義されているので、整数値とどうしても区別したい場合はそちらを使用する。System.println(True ? 1 : 0); // 1 System.println(False ? 1 : 0); // 0ブロックとスコープ
ブロックはスコープを持ち、内側で宣言された変数は外側のブロックからは参照不可。同じ名前で宣言した場合、外側ブロックの同名変数は隠蔽される。
var a = 10; { var a = 100; System.println(a); } System.println(a);この辺が「見た目は JavaScript」であっても中身は JavaScript ではない感じの部分。というか、JavaScript のスコープは変態過ぎて使いづらい。
式
式(エクスプレッション)は、以下の優先順位で四則演算、関数呼び出し、オブジェクト操作等が可能。
# 要素 演算子例 評価方向 1 要素 変数, 数値, 文字列, ... - 2 後置演算子 ++,--,[],.,()左から右 3 前置演算子 !,+,-,++,--左から右 4 パターンマッチ =~,!~左から右 5 べき乗 **右から左 6 乗除 *,/,%左から右 7 加減 +,-左から右 8 ビットシフト <<,>>左から右 9 大小比較 <,>,>=,<=左から右 10 等値比較 ==,!=左から右 11 ビットAND &左から右 12 ビットXOR ^左から右 13 ビットOR |左から右 14 論理AND &&左から右 15 論理OR ||左から右 16 三項演算子 ? :,function(){}左から右 17 代入演算子 =,+=,-=,*=./=.%=,&=,|=,^=,&&=,||=右から左 いくつか特徴を以下に示す。
演算
演算結果によって型が自動的に結果に適応していく。
3/2は1.5になる。num = 3 + 2; // 5 num = 3 - 2; // 1 num = 3 * 2; // 6 num = 3 / 2; // 1.5 num = 3 % 2; // 1インクリメント・デクリメント
前置形式・後置形式があり、C と同様。
var a = 10; System.println(a++); // 10 System.println(++a); // 12 System.println(a--); // 12 System.println(--a); // 10データ型
数値
整数、実数
整数、実数は以下の形式。整数では可読性向上のため任意の場所に
_を挿入可能。_は単に無視される。var i = 2; var j = 100_000_000; var num = 1.234;文字列
基本
ダブルクォートとシングルクォートの両方が使えるが、エスケープしなければならないクォート文字が異なるだけでどちらも同じ意味になる。
var a = "\"aaa\", 'bbb'"; var b = '"aaa", \'bbb\''; System.println(a == b ? "same" : "different"); // same内部式
%{...}の形式で内部に式を持つことができる。for (var i = 0; i < 10; ++i) { System.println("i = %{i}, i * 2 = %{i * 2}"); } // i = 0, i * 2 = 0 // i = 1, i * 2 = 2 // i = 2, i * 2 = 4 // i = 3, i * 2 = 6 // i = 4, i * 2 = 8 // i = 5, i * 2 = 10 // i = 6, i * 2 = 12 // i = 7, i * 2 = 14 // i = 8, i * 2 = 16 // i = 9, i * 2 = 18フォーマッタ
文字列に対する
%演算子はフォーマッタ・オブジェクトを作成する。var fmt = "This is %1%, I can do %2%."; System.println(fmt % "Tom" % "cooking");
%1%の1はプレースホルダ番号を示し、%演算子で適用した順に合わせて整形する。適用場所が順序通りであれば、C の printf と同様の指定の仕方も可能。さらに、C の printf と同じ指定子を使いながら同時にプレースホルダも指定したい場合は、$の前に位置指定子を書き、'$' で区切って記述する。例えば、16進数で表示したい場合は以下のようにする。var fmt = "This is %2%, I am 0x%1$02x years old in hex."; System.println(fmt % 27 % "John"); // This is John, I am 0x1b years old in hex.フォーマッタ・オブジェクトに後から値を適用していく場合は、
%=演算子で適用していく。var fmt = "This is %1%, I can do %2%."; fmt %= "Tom"; fmt %= "cooking"; System.println(fmt);実際のフォーマット処理は、
System.println等で表示するとき、文字列との加算等が行われるとき、に実際に実行される。Raw 文字列
文字列内部ではなく、
%{...}で文字列を記載することで Raw 文字列を作成することが可能。%-{...}を使うと、先頭と末尾の改行文字をトリミングする。ヒアドキュメントのようにも使えるので、ヒアドキュメントはサポートしていない。また、%<...>、%(...)、%[...]を使うこともできる。var a = 100; var b = 10; var str = %{ This is a string without escaping control characters. New line is available in this area. { and } can be nested here. }; System.println(str); var str = %-{ This is a string without escaping control characters. New line is available in this area. But newlines at the beginning and the end are removed when starting with '%-'. }; System.println(str);
\でエスケープする必要があるのは、内部式を使う場合%{の%に対するものと、ネストした形にならないケースでのクォート文字である{や}に対するものだけとなる。また、カッコは対応する閉じカッコでクォートするが、以下の文字を使ったクォートも可能である。その場合は、開始文字と終了文字は同じ文字となる。例えば、
%|...|のような形で使用する。
|,!,^,~,_,.,,,+,*,@,&,$,:,;,?,',".正規表現リテラル
正規表現リテラルは
/.../の形式で使う。リテラル内の/は\でエスケープする必要がある。以下が例。var a = "111/aaa/bbb/ccc/ddd"; while (group = (a =~ /\w+\//)) { for (var i = 0, len = group.length(); i < len; ++i) { System.println("found[%2d,%2d) = %s" % group[i].begin % group[i].end % a.subString(group[i].begin, group[i].end - group[i].begin)); } }
/を多用するような正規表現の場合、%mプレフィックスを付け、別のクォート文字を使うことで回避できる。例えば%m(...)といった記述が可能。これを使って上記を書き直すと、以下のようになる。var a = "111/aaa/bbb/ccc/ddd"; while (group = (a =~ %m(\w+/))) { for (var i = 0, len = group.length(); i < len; ++i) { System.println("found[%2d,%2d) = %s" % group[i].begin % group[i].end % a.subString(group[i].begin, group[i].end - group[i].begin)); } }尚、正規表現リテラルを
while等の条件式に入れることができるが注意点があるので補足しておく。例えば以下のように記述した場合、strの文字列に対してマッチしなくなるまでループを回すことができる(groupにはキャプチャ一覧が入る)。その際、最後のマッチまで実行せずに途中でbreak等でループを抜けると正規表現リテラルの対象文字列が次回のループで正しくリセットされない、という状況が発生する。while (group = (str =~ /ab+/)) { /* block */ }正規表現リテラルがリセットされるタイミングは以下の 2 パターン。
- 初回(前回のマッチが失敗して再度式が評価された場合を含む)。
strの内容が変化した場合。将来改善を検討するかもしれないが、現在は上記の制約があることに注意。
配列
配列は任意の要素を保持するリスト。インデックスでアクセスできる。またインデックスに負の数を与えることで末尾からアクセスすることもできる。
var a = [1,2,3]; var b = [a, 1, 2]; System.println(b[0][2]); // 3 System.println(a[-1]); // 3配列構造は左辺値で使用すると右辺値の配列を個々の変数に取り込むことが可能。これを使用して値のスワップも可能。
[a, b] = [b, a]; // Swapスプレッド(レスト)演算子を使っての分割も可能。
[a, ...b] = [1, 2, 3, 4, 5]; // a = 1 // b = [2, 3, 4, 5]尚、以下の書き方はできない。変数は宣言なしで使用できる(最初に代入された時点で生成される)ため、
varを付けない形で直接記述することは可能。ただしその際、外部のスコープで定義されていた場合、外側のスコープの変数の内容が書き換わってしまうことに注意。スコープで変数へのアクセス範囲を閉じたい場合は、予めvar a, b;と宣言してから使うことで回避可能。// var [a, ...b] = [1, 2, 3, 4, 5]; // error. var a = 3, b = [4], x = 3, y = [4]; { var a, b; [a, ...b] = [1, 2, 3, 4, 5]; // a = 1 // b = [2, 3, 4, 5] [x, ...y] = [1, 2, 3, 4, 5]; // x = 1 // y = [2, 3, 4, 5] [z] = [1, 2, 3, 4, 5]; // okay z = 1, but scoped out... } System.println("a = ", a); // 3 System.println("b = ", b[0]); // 4 System.println("x = ", x); // 1 System.println("y = ", y[0]); // 2宣言と同時に使えると便利とは思うので、将来改善するかもしれない。
バイナリ
バイナリはバイト配列であり、
<...>の形式で記述する。全ての要素は 0x00 ~ 0xFF の範囲にアジャストされ、配列のようにアクセス可能。バイナリと配列は相互にスプレッド演算子で分割、結合することが可能。
var bin = <0x01, 0x02, 0x03, 0x04>; var ary = [...bin]; // ary := [1, 2, 3, 4] var ary = [10, 11, 12, 257]; var bin = <...ary>; // bin := <0x0a, 0x0b, 0x0c, 0x01>ただし、バイナリになった瞬間に 0x00-0xFF に丸められるので注意。
オブジェクト
いわゆる JSON。ただし、ソースコード上のキー文字列に対してクォートする必要は無い(しても良い)。
var a = { a: 100 }; a.b = 1_000; a["c"] = 10_000; System.println(a.a); // 100 System.println(a.b); // 1000 System.println(a.c); // 10000内部的に実はオブジェクトと配列は同じであり、両方の値を同時に保持できる。
var a = { a: 100 }; a.b = 1_000; a["c"] = 10_000; a[1] = 10; System.println(a[1]); // 10 System.println(a.a); // 100 System.println(a.b); // 1000 System.println(a.c); // 10000おわりに
今回はここまで。結構疲れた。
非常に一般的な話ばかりで面白くないのだが、まずはこういうところに触れた上で色々な解説しとかないと土台が良く分からなくなりそうなので頑張ってみた。とりあえず、次は制御構造に触れて、一通りのプログラムが構築できるところまでを目指そう。そこまで行ったら関数とかクラスとかクロージャとか個別の解説をしてみる予定。
例によって★が増えるといいな、と宣伝しておく。
そして書きながらバグを見つけ修正するという...。
- 投稿日:2020-02-25T18:49:58+09:00
[python]List内の値の順位を昇順/降順で取得する
記事の内容
PythonのListの値の順位を昇順/降順で取得したい。
昇順は調べるとすぐに見つかりましたが、降順は少し工夫が必要だったのでメモとして残します。コード
早速、コードです。
sample.pyfrom scipy.stats import rankdata # 対象のデータ array = [10,30,30,40,20] # rankdataでインデックス毎の順位を取得 asc = rankdata(array) # 昇順の表示 print(type(asc)) print(asc.astype(float)) # 降順の計算 desc = (len(asc) - asc + 1).astype(float) # 降順の表示 print(type(desc)) print(desc)降順はrankdataに降順で取得する処理が実装されていない様なので計算する必要がありました。
色々試してみた結果、これが一番簡単に出来そうな気がします。以下、実行結果です。
<class 'numpy.ndarray'> [1. 3. 5. 4. 2.] <class 'numpy.ndarray'> [5. 3. 1. 2. 4.]astypeをastype(int)に変更すると
<class 'numpy.ndarray'> [1 3 5 4 2] <class 'numpy.ndarray'> [5 3 1 2 4]こうなります。
この状態で同じ値が入っていると・・
# 対象のデータ array = [10,30,30,40,20]<class 'numpy.ndarray'> [1 3 3 5 2] <class 'numpy.ndarray'> [5 2 2 1 4]こうなります。結果が変わってしまいました・。
floatのままだと<class 'numpy.ndarray'> [1. 3.5 3.5 5. 2. ] <class 'numpy.ndarray'> [5. 2.5 2.5 1. 4. ]こうなります。
データに被りがない時、限定のやり方ということで・・。
追記
konandoirusa さんよりご指摘頂いた方法の方が圧倒的に簡単なので追記
sample.pyimport numpy as np from scipy.stats import rankdata # 対象のデータ array = [10,30,30,40,20] # 昇順 print(rankdata(np.array(array))) # 降順 print(rankdata(-np.array(array)))実行結果
[1. 3.5 3.5 5. 2. ] [5. 2.5 2.5 1. 4. ]
- 投稿日:2020-02-25T18:48:07+09:00
pythonで生徒を当てるアプリをつくる-GUI版
はじめに
以前投稿したpythonで生徒を当てるアプリをつくるをGUIソフトにしたってだけの記事.
プログラム
main.py data/ history.txt list.txt list_raw.txt web/ main.html css/ style.css js/ eel.js
main.py
main.pyimport locale import eel import random import pickle import os import sys import datetime from tkinter import filedialog, Tk import platform import copy def main(): eel.init("web") eel.start("main.html") Student_names = [] Student_FILENAME = "./data/list.txt" Student_FILENAME_raw = "./data/list_raw.txt" # Student @eel.expose def Student_load(): with open(select_file(), "r") as f: global Student_names Student_names = f.read().splitlines() Student_save(Student_FILENAME) Student_save(Student_FILENAME_raw) @eel.expose def Student_reset(): Student_names_load(Student_FILENAME_raw) @eel.expose def Student_show(): Student_names_load(Student_FILENAME) name_ls = "" a = 1 for name in Student_names: if a % 5 == 0: name_ls = name_ls + name + "<br>" else: name_ls = name_ls + name + " " a += 1 return name_ls @eel.expose def Student_choice(): Student_names_load(Student_FILENAME) global Student_names_raw Student_names_raw = copy.deepcopy(Student_names) if not Student_names: return global name name = random.choice(Student_names) Student_names.remove(name) if Student_names == []: Student_names_load(Student_FILENAME_raw) History_add(name) Student_save(Student_FILENAME) return name @eel.expose def Student_save(FILENAME): f = open(FILENAME, 'wb') pickle.dump(Student_names, f) @eel.expose def Student_names_load(FILENAME): f = open(FILENAME, "rb") global Student_names Student_names = pickle.load(f) # History History_FILENAME = "./data/history.txt" History_data = [] @eel.expose def History_load(): with open(History_FILENAME, "r") as f: global History_data History_data = f.read().splitlines() @eel.expose def History_save(): with open(History_FILENAME, "w") as f: for history in History_data: print(history, file=f) @eel.expose def History_show(): history_ls = "" History_load() for history in History_data: history_ls = history + "<br>" + history_ls return history_ls locale.setlocale(locale.LC_ALL, '') @eel.expose def History_add(name): now = datetime.datetime.now() History_data.append(f"{now:%m月%d日}:{name}") History_save() @eel.expose def History_cancel(): History_data.pop() History_save() global Student_names Student_names = copy.deepcopy(Student_names_raw) Student_save(Student_FILENAME) @eel.expose def History_clear(): global History_data History_data = [] History_save() # 名簿読み込み # ダイアログ用のルートウィンドウの作成 # (root自体はeelのウィンドウとは関係ないので非表示にしておくのが望ましい) root = Tk() # ウィンドウサイズを0にする root.geometry("0x0") # ウィンドウのタイトルバーを消す root.overrideredirect(1) # ウィンドウを非表示に root.withdraw() system = platform.system() @eel.expose def select_file(): # Windowsの場合withdrawの状態だとダイアログも # 非表示になるため、rootウィンドウを表示する if system == "Windows": root.deiconify() # macOS用にダイアログ作成前後でupdate()を呼ぶ root.update() # ダイアログを前面に # topmost指定(最前面) root.attributes('-topmost', True) root.withdraw() root.lift() root.focus_force() path_str = filedialog.askopenfilename() root.update() if system == "Windows": # 再度非表示化(Windowsのみ) root.withdraw() #path = Path(path_str) return path_str if __name__ == '__main__': main()
main.html
main.html<html> <head> <meta charset="UTF-8"> <title>生徒当てるヤツ</title> <link rel="stylesheet" type="text/css" href="./css/style.css"> <script type="text/javascript" src="/eel.js"></script> <script type="text/javascript"> async function Student_choice() { var demo2 = document.getElementById("div0"); demo2.innerHTML = ""; div0.insertAdjacentHTML('afterbegin', '<div id="name"></div>'); let val = await eel.Student_choice()(); var doc0 = document.getElementById("name"); doc0.innerHTML = val; } async function Student_load() { eel.Student_load(); } async function Student_show() { let val = await eel.Student_show()(); var doc0 = document.getElementById("div0"); doc0.innerHTML = val; } async function History_show() { let val = await eel.History_show()(); var doc0 = document.getElementById("div0"); doc0.innerHTML = val; } async function History_clear() { let val = await eel.History_clear()(); var doc0 = document.getElementById("div0"); doc0.innerHTML = val; } async function History_cancel() { let val = await eel.History_cancel()(); var doc0 = document.getElementById("div0"); doc0.innerHTML = val; } </script> </head> <body> <center> <div id="div0"> </div> <div class="bottom"> <a href="#" onclick="Student_choice()" class="btn-square">生徒を当てる</a> <a href="#" onclick="History_cancel()" class="btn-square">欠席者を飛ばす</a> <a href="#" onclick="Student_show()" class="btn-square">残りの生徒を表示</a> <a href="#" onclick="History_show()" class="btn-square">履歴の表示</a> <a href="#" onclick="History_clear()" class="btn-square">履歴の消去</a> <a href="#" onclick="Student_load()" class="btn-square">名簿を更新</a> </div> </center> <div class='markdown-preview' data-use-github-style> <details> <summary>名簿の更新方法</summary> <div> <h1 id="名簿の更新方法">名簿の更新方法</h1> <h3 id="1">1</h3> <p>任意のファイル名のテキストファイル(*.txt)を作成します.</p> <h3 id="2">2</h3> <p>その中に<br> 1.名前<br> 2.名前<br> ・<br> ・<br> ・<br> と入力します.</p> <h3 id="3">3</h3> <p>名簿を更新をクリックし,テキストファイルを選択する.</p> </div> </details> </div> </html>
style.css
style.css.btn-square { display: inline-block; padding: 0.5em 1em; text-decoration: none; background: #668ad8; /*ボタン色*/ color: #FFF; border-bottom: solid 4px #627295; border-radius: 3px; } .btn-square:active { /*ボタンを押したとき*/ -webkit-transform: translateY(4px); transform: translateY(4px); /*下に動く*/ border-bottom: none; /*線を消す*/ } #div0 { height: 300px; overflow: scroll; } #name { margin-top: 50px; font-size: 100px; } .bottom {} .markdown-preview:not([data-use-github-style]) { padding: 2em; font-size: 1.2em; color: rgb(197, 200, 198); background-color: rgb(29, 31, 33); overflow: auto; } .markdown-preview:not([data-use-github-style])> :first-child { margin-top: 0px; } .markdown-preview:not([data-use-github-style]) h1, .markdown-preview:not([data-use-github-style]) h2, .markdown-preview:not([data-use-github-style]) h3, .markdown-preview:not([data-use-github-style]) h4, .markdown-preview:not([data-use-github-style]) h5, .markdown-preview:not([data-use-github-style]) h6 { line-height: 1.2; margin-top: 1.5em; margin-bottom: 0.5em; color: rgb(255, 255, 255); } .markdown-preview:not([data-use-github-style]) h1 { font-size: 2.4em; font-weight: 300; } .markdown-preview:not([data-use-github-style]) h2 { font-size: 1.8em; font-weight: 400; } .markdown-preview:not([data-use-github-style]) h3 { font-size: 1.5em; font-weight: 500; } .markdown-preview:not([data-use-github-style]) h4 { font-size: 1.2em; font-weight: 600; } .markdown-preview:not([data-use-github-style]) h5 { font-size: 1.1em; font-weight: 600; } .markdown-preview:not([data-use-github-style]) h6 { font-size: 1em; font-weight: 600; } .markdown-preview:not([data-use-github-style]) strong { color: rgb(255, 255, 255); } .markdown-preview:not([data-use-github-style]) del { color: rgb(155, 160, 157); } .markdown-preview:not([data-use-github-style]) a, .markdown-preview:not([data-use-github-style]) a code { color: white; } .markdown-preview:not([data-use-github-style]) img { max-width: 100%; } .markdown-preview:not([data-use-github-style])>p { margin-top: 0px; margin-bottom: 1.5em; } .markdown-preview:not([data-use-github-style])>ul, .markdown-preview:not([data-use-github-style])>ol { margin-bottom: 1.5em; } .markdown-preview:not([data-use-github-style]) blockquote { margin: 1.5em 0px; font-size: inherit; color: rgb(155, 160, 157); border-color: rgb(67, 72, 76); border-width: 4px; } .markdown-preview:not([data-use-github-style]) hr { margin: 3em 0px; border-top: 2px dashed rgb(67, 72, 76); background: none; } .markdown-preview:not([data-use-github-style]) table { margin: 1.5em 0px; } .markdown-preview:not([data-use-github-style]) th { color: rgb(255, 255, 255); } .markdown-preview:not([data-use-github-style]) th, .markdown-preview:not([data-use-github-style]) td { padding: 0.66em 1em; border: 1px solid rgb(67, 72, 76); } .markdown-preview:not([data-use-github-style]) code { color: rgb(255, 255, 255); background-color: rgb(48, 51, 55); } .markdown-preview:not([data-use-github-style]) pre.editor-colors { margin: 1.5em 0px; padding: 1em; font-size: 0.92em; border-radius: 3px; background-color: rgb(39, 41, 44); } .markdown-preview:not([data-use-github-style]) kbd { color: rgb(255, 255, 255); border-width: 1px 1px 2px; border-style: solid; border-color: rgb(67, 72, 76) rgb(67, 72, 76) rgb(53, 57, 60); border-image: initial; background-color: rgb(48, 51, 55); } .markdown-preview[data-use-github-style] { font-family: "Helvetica Neue", Helvetica, "Segoe UI", Arial, freesans, sans-serif; line-height: 1.6; overflow-wrap: break-word; padding: 30px; font-size: 16px; color: rgb(51, 51, 51); background-color: rgb(255, 255, 255); } .markdown-preview[data-use-github-style]> :first-child { margin-top: 0px !important; } .markdown-preview[data-use-github-style]> :last-child { margin-bottom: 0px !important; } .markdown-preview[data-use-github-style] a:not([href]) { color: inherit; text-decoration: none; } .markdown-preview[data-use-github-style] .absent { color: rgb(204, 0, 0); } .markdown-preview[data-use-github-style] .anchor { position: absolute; top: 0px; left: 0px; display: block; padding-right: 6px; padding-left: 30px; margin-left: -30px; } .markdown-preview[data-use-github-style] .anchor:focus { outline: none; } .markdown-preview[data-use-github-style] h1, .markdown-preview[data-use-github-style] h2, .markdown-preview[data-use-github-style] h3, .markdown-preview[data-use-github-style] h4, .markdown-preview[data-use-github-style] h5, .markdown-preview[data-use-github-style] h6 { position: relative; margin-top: 1em; margin-bottom: 16px; font-weight: bold; line-height: 1.4; } .markdown-preview[data-use-github-style] h1 .octicon-link, .markdown-preview[data-use-github-style] h2 .octicon-link, .markdown-preview[data-use-github-style] h3 .octicon-link, .markdown-preview[data-use-github-style] h4 .octicon-link, .markdown-preview[data-use-github-style] h5 .octicon-link, .markdown-preview[data-use-github-style] h6 .octicon-link { display: none; color: rgb(0, 0, 0); vertical-align: middle; } .markdown-preview[data-use-github-style] h1:hover .anchor, .markdown-preview[data-use-github-style] h2:hover .anchor, .markdown-preview[data-use-github-style] h3:hover .anchor, .markdown-preview[data-use-github-style] h4:hover .anchor, .markdown-preview[data-use-github-style] h5:hover .anchor, .markdown-preview[data-use-github-style] h6:hover .anchor { padding-left: 8px; margin-left: -30px; text-decoration: none; } .markdown-preview[data-use-github-style] h1:hover .anchor .octicon-link, .markdown-preview[data-use-github-style] h2:hover .anchor .octicon-link, .markdown-preview[data-use-github-style] h3:hover .anchor .octicon-link, .markdown-preview[data-use-github-style] h4:hover .anchor .octicon-link, .markdown-preview[data-use-github-style] h5:hover .anchor .octicon-link, .markdown-preview[data-use-github-style] h6:hover .anchor .octicon-link { display: inline-block; } .markdown-preview[data-use-github-style] h1 tt, .markdown-preview[data-use-github-style] h2 tt, .markdown-preview[data-use-github-style] h3 tt, .markdown-preview[data-use-github-style] h4 tt, .markdown-preview[data-use-github-style] h5 tt, .markdown-preview[data-use-github-style] h6 tt, .markdown-preview[data-use-github-style] h1 code, .markdown-preview[data-use-github-style] h2 code, .markdown-preview[data-use-github-style] h3 code, .markdown-preview[data-use-github-style] h4 code, .markdown-preview[data-use-github-style] h5 code, .markdown-preview[data-use-github-style] h6 code { font-size: inherit; } .markdown-preview[data-use-github-style] h1 { padding-bottom: 0.3em; font-size: 2.25em; line-height: 1.2; border-bottom: 1px solid rgb(238, 238, 238); } .markdown-preview[data-use-github-style] h1 .anchor { line-height: 1; } .markdown-preview[data-use-github-style] h2 { padding-bottom: 0.3em; font-size: 1.75em; line-height: 1.225; border-bottom: 1px solid rgb(238, 238, 238); } .markdown-preview[data-use-github-style] h2 .anchor { line-height: 1; } .markdown-preview[data-use-github-style] h3 { font-size: 1.5em; line-height: 1.43; } .markdown-preview[data-use-github-style] h3 .anchor { line-height: 1.2; } .markdown-preview[data-use-github-style] h4 { font-size: 1.25em; } .markdown-preview[data-use-github-style] h4 .anchor { line-height: 1.2; } .markdown-preview[data-use-github-style] h5 { font-size: 1em; } .markdown-preview[data-use-github-style] h5 .anchor { line-height: 1.1; } .markdown-preview[data-use-github-style] h6 { font-size: 1em; color: rgb(119, 119, 119); } .markdown-preview[data-use-github-style] h6 .anchor { line-height: 1.1; } .markdown-preview[data-use-github-style] p, .markdown-preview[data-use-github-style] blockquote, .markdown-preview[data-use-github-style] ul, .markdown-preview[data-use-github-style] ol, .markdown-preview[data-use-github-style] dl, .markdown-preview[data-use-github-style] table, .markdown-preview[data-use-github-style] pre { margin-top: 0px; margin-bottom: 16px; } .markdown-preview[data-use-github-style] hr { height: 4px; padding: 0px; margin: 16px 0px; background-color: rgb(231, 231, 231); border: 0px none; } .markdown-preview[data-use-github-style] ul, .markdown-preview[data-use-github-style] ol { padding-left: 2em; } .markdown-preview[data-use-github-style] ul.no-list, .markdown-preview[data-use-github-style] ol.no-list { padding: 0px; list-style-type: none; } .markdown-preview[data-use-github-style] ul ul, .markdown-preview[data-use-github-style] ul ol, .markdown-preview[data-use-github-style] ol ol, .markdown-preview[data-use-github-style] ol ul { margin-top: 0px; margin-bottom: 0px; } .markdown-preview[data-use-github-style] li>p { margin-top: 16px; } .markdown-preview[data-use-github-style] dl { padding: 0px; } .markdown-preview[data-use-github-style] dl dt { padding: 0px; margin-top: 16px; font-size: 1em; font-style: italic; font-weight: bold; } .markdown-preview[data-use-github-style] dl dd { padding: 0px 16px; margin-bottom: 16px; } .markdown-preview[data-use-github-style] blockquote { padding: 0px 15px; color: rgb(119, 119, 119); border-left: 4px solid rgb(221, 221, 221); } .markdown-preview[data-use-github-style] blockquote> :first-child { margin-top: 0px; } .markdown-preview[data-use-github-style] blockquote> :last-child { margin-bottom: 0px; } .markdown-preview[data-use-github-style] table { display: block; width: 100%; overflow: auto; word-break: keep-all; } .markdown-preview[data-use-github-style] table th { font-weight: bold; } .markdown-preview[data-use-github-style] table th, .markdown-preview[data-use-github-style] table td { padding: 6px 13px; border: 1px solid rgb(221, 221, 221); } .markdown-preview[data-use-github-style] table tr { background-color: rgb(255, 255, 255); border-top: 1px solid rgb(204, 204, 204); } .markdown-preview[data-use-github-style] table tr:nth-child(2n) { background-color: rgb(248, 248, 248); } .markdown-preview[data-use-github-style] img { max-width: 100%; box-sizing: border-box; } .markdown-preview[data-use-github-style] .emoji { max-width: none; } .markdown-preview[data-use-github-style] span.frame { display: block; overflow: hidden; } .markdown-preview[data-use-github-style] span.frame>span { display: block; float: left; width: auto; padding: 7px; margin: 13px 0px 0px; overflow: hidden; border: 1px solid rgb(221, 221, 221); } .markdown-preview[data-use-github-style] span.frame span img { display: block; float: left; } .markdown-preview[data-use-github-style] span.frame span span { display: block; padding: 5px 0px 0px; clear: both; color: rgb(51, 51, 51); } .markdown-preview[data-use-github-style] span.align-center { display: block; overflow: hidden; clear: both; } .markdown-preview[data-use-github-style] span.align-center>span { display: block; margin: 13px auto 0px; overflow: hidden; text-align: center; } .markdown-preview[data-use-github-style] span.align-center span img { margin: 0px auto; text-align: center; } .markdown-preview[data-use-github-style] span.align-right { display: block; overflow: hidden; clear: both; } .markdown-preview[data-use-github-style] span.align-right>span { display: block; margin: 13px 0px 0px; overflow: hidden; text-align: right; } .markdown-preview[data-use-github-style] span.align-right span img { margin: 0px; text-align: right; } .markdown-preview[data-use-github-style] span.float-left { display: block; float: left; margin-right: 13px; overflow: hidden; } .markdown-preview[data-use-github-style] span.float-left span { margin: 13px 0px 0px; } .markdown-preview[data-use-github-style] span.float-right { display: block; float: right; margin-left: 13px; overflow: hidden; } .markdown-preview[data-use-github-style] span.float-right>span { display: block; margin: 13px auto 0px; overflow: hidden; text-align: right; } .markdown-preview[data-use-github-style] code, .markdown-preview[data-use-github-style] tt { padding: 0.2em 0px; margin: 0px; font-size: 85%; background-color: rgba(0, 0, 0, 0.04); border-radius: 3px; } .markdown-preview[data-use-github-style] code::before, .markdown-preview[data-use-github-style] tt::before, .markdown-preview[data-use-github-style] code::after, .markdown-preview[data-use-github-style] tt::after { letter-spacing: -0.2em; content: " "; } .markdown-preview[data-use-github-style] code br, .markdown-preview[data-use-github-style] tt br { display: none; } .markdown-preview[data-use-github-style] del code { text-decoration: inherit; } .markdown-preview[data-use-github-style] pre>code { padding: 0px; margin: 0px; font-size: 100%; word-break: normal; white-space: pre; background: transparent; border: 0px; } .markdown-preview[data-use-github-style] .highlight { margin-bottom: 16px; } .markdown-preview[data-use-github-style] .highlight pre, .markdown-preview[data-use-github-style] pre { padding: 16px; overflow: auto; font-size: 85%; line-height: 1.45; background-color: rgb(247, 247, 247); border-radius: 3px; } .markdown-preview[data-use-github-style] .highlight pre { margin-bottom: 0px; word-break: normal; } .markdown-preview[data-use-github-style] pre { overflow-wrap: normal; } .markdown-preview[data-use-github-style] pre code, .markdown-preview[data-use-github-style] pre tt { display: inline; max-width: initial; padding: 0px; margin: 0px; overflow: initial; line-height: inherit; overflow-wrap: normal; background-color: transparent; border: 0px; } .markdown-preview[data-use-github-style] pre code::before, .markdown-preview[data-use-github-style] pre tt::before, .markdown-preview[data-use-github-style] pre code::after, .markdown-preview[data-use-github-style] pre tt::after { content: normal; } .markdown-preview[data-use-github-style] kbd { display: inline-block; padding: 3px 5px; font-size: 11px; line-height: 10px; color: rgb(85, 85, 85); vertical-align: middle; background-color: rgb(252, 252, 252); border-width: 1px; border-style: solid; border-color: rgb(204, 204, 204) rgb(204, 204, 204) rgb(187, 187, 187); border-image: initial; border-radius: 3px; box-shadow: rgb(187, 187, 187) 0px -1px 0px inset; } .markdown-preview[data-use-github-style] a { color: rgb(51, 122, 183); } .markdown-preview[data-use-github-style] code { color: inherit; } .markdown-preview[data-use-github-style] pre.editor-colors { padding: 0.8em 1em; margin-bottom: 1em; font-size: 0.85em; border-radius: 4px; overflow: auto; } .markdown-preview pre.editor-colors { user-select: auto; } .scrollbars-visible-always .markdown-preview pre.editor-colors .vertical-scrollbar, .scrollbars-visible-always .markdown-preview pre.editor-colors .horizontal-scrollbar { visibility: hidden; } .scrollbars-visible-always .markdown-preview pre.editor-colors:hover .vertical-scrollbar, .scrollbars-visible-always .markdown-preview pre.editor-colors:hover .horizontal-scrollbar { visibility: visible; } .markdown-preview .task-list-item input[type="checkbox"] { position: absolute; margin: 0.25em 0px 0px -1.4em; } .markdown-preview .task-list-item { list-style-type: none; } .markdown-preview code { text-shadow: none; } @keyframes RotatingBackground { 0% { background-position-x: 0%; } 100% { background-position-x: 100%; } } .debugger-breakpoint-icon::before, .debugger-shadow-breakpoint-icon::before { font-family: 'Octicons Regular'; font-weight: normal; font-style: normal; display: inline-block; line-height: 1; -webkit-font-smoothing: antialiased; text-decoration: none; font-size: 130%; width: 130%; height: 130%; content: "\f052"; } .debugger-breakpoint-icon, .debugger-breakpoint-icon-disabled, .debugger-breakpoint-icon-unresolved, .debugger-breakpoint-icon-conditional, .debugger-shadow-breakpoint-icon { text-align: center; display: block; width: 0.8em; cursor: pointer; } .debugger-breakpoint-icon-nonconditional { color: #5293d8; } .debugger-breakpoint-icon-conditional { color: #ff982d; } .debugger-breakpoint-icon-disabled { position: relative; top: -4px; left: 2px; } .debugger-breakpoint-icon-disabled::before { font-family: 'Octicons Regular'; font-weight: normal; font-style: normal; display: inline-block; line-height: 1; -webkit-font-smoothing: antialiased; text-decoration: none; font-size: 78%; width: 78%; height: 78%; content: "\f084"; } .debugger-breakpoint-icon-unresolved { position: relative; top: -2px; } .debugger-breakpoint-icon-unresolved::before { font-family: 'Octicons Regular'; font-weight: normal; font-style: normal; display: inline-block; line-height: 1; -webkit-font-smoothing: antialiased; text-decoration: none; font-size: 80%; width: 80%; height: 80%; content: "\f0e8"; } .debugger-shadow-breakpoint-icon { color: rgba(82, 147, 216, 0.4); } .debugger-current-line-highlight { background: linear-gradient(to bottom, rgba(0, 152, 255, 0.8) 0%, rgba(0, 152, 255, 0.8) 5%, rgba(0, 152, 255, 0.3) 5%, rgba(0, 152, 255, 0.3) 95%, rgba(0, 152, 255, 0.8) 95%, rgba(0, 152, 255, 0.8) 100%); } .gutter[gutter-name=diagnostics-gutter] { width: 0.7em; } .diagnostics-gutter-ui-item { display: flex; } .diagnostics-gutter-ui-item .icon { display: flex; width: 0.7em; height: 0.7em; font-size: 0.7em; align-self: center; } .diagnostics-gutter-ui-item .icon::before { width: 1em; height: 1em; font-size: 1em; margin: 0; align-self: center; } .diagnostics-gutter-ui-item.diagnostics-gutter-ui-gutter-info, .diagnostics-gutter-ui-item.diagnostics-gutter-ui-gutter-review { color: #5293d8; } .diagnostics-gutter-ui-item.diagnostics-gutter-ui-gutter-error { color: #c00; } .diagnostics-gutter-ui-item.diagnostics-gutter-ui-gutter-action, .diagnostics-gutter-ui-item.diagnostics-gutter-ui-gutter-warning { color: #ff982d; } .bracket-matcher .region { border-bottom: 1px dotted lime; position: absolute; } .line-number.bracket-matcher.bracket-matcher { color: #c5c8c6; background-color: rgba(255, 255, 255, 0.14); } .spell-check-misspelling .region { border-bottom: 2px dotted rgba(255, 51, 51, 0.75); } .spell-check-corrections { width: 25em !important; } pre.editor-colors { background-color: #1d1f21; color: #c5c8c6; } pre.editor-colors .invisible-character { color: rgba(197, 200, 198, 0.2); } pre.editor-colors .indent-guide { color: rgba(197, 200, 198, 0.2); } pre.editor-colors .wrap-guide { background-color: rgba(197, 200, 198, 0.1); } pre.editor-colors .gutter { background-color: #292c2f; } pre.editor-colors .gutter .cursor-line { background-color: rgba(255, 255, 255, 0.14); } pre.editor-colors .line-number.cursor-line-no-selection { background-color: rgba(255, 255, 255, 0.14); } pre.editor-colors .gutter .line-number.folded, pre.editor-colors .gutter .line-number:after, pre.editor-colors .fold-marker:after { color: #fba0e3; } pre.editor-colors .invisible { color: #c5c8c6; } pre.editor-colors .cursor { border-color: white; } pre.editor-colors .selection .region { background-color: #444; } pre.editor-colors .bracket-matcher .region { border-bottom: 1px solid #f8de7e; margin-top: -1px; opacity: .7; } .syntax--comment { color: #8a8a8a; } .syntax--entity { color: #FFD2A7; } .syntax--entity.syntax--name.syntax--type { text-decoration: underline; color: #FFFFB6; } .syntax--entity.syntax--other.syntax--inherited-class { color: #9B5C2E; } .syntax--keyword { color: #96CBFE; } .syntax--keyword.syntax--control { color: #96CBFE; } .syntax--keyword.syntax--operator { color: #EDEDED; } .syntax--storage { color: #CFCB90; } .syntax--storage.syntax--modifier { color: #96CBFE; } .syntax--constant { color: #99CC99; } .syntax--constant.syntax--numeric { color: #FF73FD; } .syntax--variable { color: #C6C5FE; } .syntax--invalid.syntax--deprecated { text-decoration: underline; color: #FD5FF1; } .syntax--invalid.syntax--illegal { color: #FD5FF1; background-color: rgba(86, 45, 86, 0.75); } .syntax--string .syntax--source, .syntax--string .syntax--meta.syntax--embedded.syntax--line { color: #EDEDED; } .syntax--string .syntax--punctuation.syntax--section.syntax--embedded { color: #00A0A0; } .syntax--string .syntax--punctuation.syntax--section.syntax--embedded .syntax--source { color: #00A0A0; } .syntax--string { color: #A8FF60; } .syntax--string .syntax--constant { color: #00A0A0; } .syntax--string.syntax--regexp { color: #E9C062; } .syntax--string.syntax--regexp .syntax--constant.syntax--character.syntax--escape, .syntax--string.syntax--regexp .syntax--source.syntax--ruby.syntax--embedded, .syntax--string.syntax--regexp .syntax--string.syntax--regexp.syntax--arbitrary-repetition { color: #FF8000; } .syntax--string.syntax--regexp.syntax--group { color: #C6A24F; background-color: rgba(255, 255, 255, 0.06); } .syntax--string.syntax--regexp.syntax--character-class { color: #B18A3D; } .syntax--string .syntax--variable { color: #8A9A95; } .syntax--support { color: #FFFFB6; } .syntax--support.syntax--function { color: #DAD085; } .syntax--support.syntax--constant { color: #FFD2A7; } .syntax--support.syntax--type.syntax--property-name.syntax--css { color: #EDEDED; } .syntax--source .syntax--entity.syntax--name.syntax--tag, .syntax--source .syntax--punctuation.syntax--tag { color: #96CBFE; } .syntax--source .syntax--entity.syntax--other.syntax--attribute-name { color: #FF73FD; } .syntax--entity.syntax--other.syntax--attribute-name { color: #FF73FD; } .syntax--entity.syntax--name.syntax--tag.syntax--namespace, .syntax--entity.syntax--other.syntax--attribute-name.syntax--namespace { color: #E18964; } .syntax--meta.syntax--preprocessor.syntax--c { color: #8996A8; } .syntax--meta.syntax--preprocessor.syntax--c .syntax--keyword { color: #AFC4DB; } .syntax--meta.syntax--cast { color: #676767; } .syntax--meta.syntax--sgml.syntax--html .syntax--meta.syntax--doctype, .syntax--meta.syntax--sgml.syntax--html .syntax--meta.syntax--doctype .syntax--entity, .syntax--meta.syntax--sgml.syntax--html .syntax--meta.syntax--doctype .syntax--string, .syntax--meta.syntax--xml-processing, .syntax--meta.syntax--xml-processing .syntax--entity, .syntax--meta.syntax--xml-processing .syntax--string { color: #8a8a8a; } .syntax--meta.syntax--tag .syntax--entity, .syntax--meta.syntax--tag>.syntax--punctuation, .syntax--meta.syntax--tag.syntax--inline .syntax--entity { color: #FF73FD; } .syntax--meta.syntax--tag .syntax--name, .syntax--meta.syntax--tag.syntax--inline .syntax--name, .syntax--meta.syntax--tag>.syntax--punctuation { color: #96CBFE; } .syntax--meta.syntax--selector.syntax--css .syntax--entity.syntax--name.syntax--tag { text-decoration: underline; color: #96CBFE; } .syntax--meta.syntax--selector.syntax--css .syntax--entity.syntax--other.syntax--attribute-name.syntax--tag.syntax--pseudo-class { color: #8F9D6A; } .syntax--meta.syntax--selector.syntax--css .syntax--entity.syntax--other.syntax--attribute-name.syntax--id { color: #8B98AB; } .syntax--meta.syntax--selector.syntax--css .syntax--entity.syntax--other.syntax--attribute-name.syntax--class { color: #62B1FE; } .syntax--meta.syntax--property-group .syntax--support.syntax--constant.syntax--property-value.syntax--css, .syntax--meta.syntax--property-value .syntax--support.syntax--constant.syntax--property-value.syntax--css { color: #F9EE98; } .syntax--meta.syntax--preprocessor.syntax--at-rule .syntax--keyword.syntax--control.syntax--at-rule { color: #8693A5; } .syntax--meta.syntax--property-value .syntax--support.syntax--constant.syntax--named-color.syntax--css, .syntax--meta.syntax--property-value .syntax--constant { color: #87C38A; } .syntax--meta.syntax--constructor.syntax--argument.syntax--css { color: #8F9D6A; } .syntax--meta.syntax--diff, .syntax--meta.syntax--diff.syntax--header { color: #F8F8F8; background-color: #0E2231; } .syntax--meta.syntax--separator { color: #60A633; background-color: #242424; } .syntax--meta.syntax--line.syntax--entry.syntax--logfile, .syntax--meta.syntax--line.syntax--exit.syntax--logfile { background-color: rgba(238, 238, 238, 0.16); } .syntax--meta.syntax--line.syntax--error.syntax--logfile { background-color: #751012; } .syntax--source.syntax--gfm { color: #999; } .syntax--gfm .syntax--markup.syntax--heading { color: #eee; } .syntax--gfm .syntax--link { color: #555; } .syntax--gfm .syntax--variable.syntax--list, .syntax--gfm .syntax--support.syntax--quote { color: #555; } .syntax--gfm .syntax--link .syntax--entity { color: #ddd; } .syntax--gfm .syntax--raw { color: #aaa; } .syntax--markdown .syntax--paragraph { color: #999; } .syntax--markdown .syntax--heading { color: #eee; } .syntax--markdown .syntax--raw { color: #aaa; } .syntax--markdown .syntax--link { color: #555; } .syntax--markdown .syntax--link .syntax--string { color: #555; } .syntax--markdown .syntax--link .syntax--string.syntax--title { color: #ddd; }eel.jsは公式githubとかから取得してください
(このコードをそのまま使うなら必要ない)参考にしたサイト
CSSで作る!押したくなるボタンデザイン100(Web用)
Python eelでファイル選択ダイアログ動作風景
exeファイル
- 投稿日:2020-02-25T18:37:32+09:00
Open3Dの基本と点群のボクセル化
はじめに
卒業研究でOpen3Dは一通り触れましたが、Open3D触り始めのとき日本語情報が少なすぎて困ったので少しまとめます。
たぶんOpen3Dを触り始めた人の多くがたどり着くであろうサイト→Open3D:http://lang.sist.chukyo-u.ac.jp/classes/Open3D/
こちらは公式チュートリアルの和訳ですが、チュートリアル以外にもたくさんできることがたくさんあります。
やりたいことがある場合は公式ドキュメントを探せば大体できます(英語ですが)。研究で行ったのは「RGB-Dカメラ画像からの点群生成」「外れ値の除去」「点群の位置合わせ」などなど。
他に行ったのは「点群のボクセル化」「RANSACを用いた平面推定」です。今回はOpen3Dの基本と「点群のボクセル化」について書きます(といっても関数の紹介だけですが)。
環境
- Open3D 0.9.0
- Python 3.6
Open3Dはバージョンごとに仕様が大幅に異なるので注意。
本記事ではv0.9.0対応で記述してありますが、自分も研究にはv0.7.0を使用していたので、v0.9.0では最低限の動作確認しか行っていません。Open3Dの基本
RGB-D画像からの点群生成と可視化、pcdファイルへの読み書き
RGB-D画像からの点群生成
右上がRealSenseから取得した画像で左が生成した点群(研究では画像を切り取ってから点群生成を行いました。)import open3d as o3d """ Open3DにRGB-D画像入力 """ color = o3d.Image(color_numpy) # numpy配列から変換 depth = o3d.Image(depth_numpy) rgbd = o3d.geometry.RGBDImage.create_rgbd_image_from_color_and_depth(color, depth, convert_rgb_to_intensity=False) pcd = o3d.geometry.PointCloud.create_point_cloud_from_rgbd_image(rgbd, pinhole_camera_intrinsic) pcd.transform([[1, 0, 0, 0], [0, -1, 0, 0], [0, 0, -1, 0], [0, 0, 0, 1]]) # 見やすくするための回転pinhole_camera_intrinsicの取得方法はRealSenseなら以下の方法で取得可能。
RealSenseの設定などの処理は省いてます。import pyrealsense2 as rs # camera intrinsics取得 intr = profile.get_stream(rs.stream.color).as_video_stream_profile().get_intrinsics() pinhole_camera_intrinsic = o3d.camera.PinholeCameraIntrinsic(intr.width, intr.height, intr.fx, intr.fy, intr.ppx, intr.ppy)点群の可視化
o3d.visualization.draw_geometries([pcd])点群以外にもボクセルやメッシュの可視化にも使います。
pcdファイルへの読み書き
書き込み
# バイナリでの書き込み o3d.io.write_point_cloud("hoge.pcd", pcd) # asciiでの書き込み o3d.io.write_point_cloud("hoge.pcd", pcd, True)pcdファイル以外にも出力可能です。
asciiで出力しておくと見やすいので便利です。読み込み
pcd = o3d.io.read_point_cloud("./hoge.pcd")点群のボクセル化
voxel = o3d.geometry.VoxelGrid.create_from_point_cloud(pcd, 0.03) # ボクセルのサイズ指定 o3d.visualization.draw_geometries([voxel])
Open3D触りたてのときは自分で点群のボクセル化関数を作成しましたが、もともと用意されていたらしい。。。
おわりに
今回はOpen3Dの基本についてまとめました。
時間があれば研究内容やRANSACでの平面推定についてまとめたいですが、たぶんやりません。


- 投稿日:2020-02-25T18:22:30+09:00
returnの使い方
returnとは?
・返り値がない場合とある場合の2種類がある
return(返り値がない場合)
def a(x,y): if x==y: print("same") return print(x,y) else: print("different") a(1,1) a(1,0)実行結果same different・returnの後のprint(x,y)は実行されない
return(返り値がある場合)
def a(x,y): if x==y: return ("{}と{}は等しい").format(x,y) else: return ("{}と{}は等しくない").format(x,y) a(1,1) a(1,0)実行結果'1と1は等しい' '1と2は等しくない'
- 投稿日:2020-02-25T17:47:33+09:00
pythonのクラスへの理解奮闘記(1)とりあえず動かしてみる
クラスって概念難しくないすかね・・・?
クラスってなんぞや。インスタンス?メソッド?関数の宣言だよねそれ。て感じで多分1,2年前この分野で挫折してちょっとプログラミングの勉強から遠ざかっていた気がする。今回、pythonをもう一度学び直しのために勉強してようやくまたクラスの分野に戻ってきたところです。
とりあえず触ってみる
概念とかインスタンスとかオブジェクト指向とかちょっと置いといて、どんなイメージなのか触りながらの手探りで学習スタート。ほかの方のクラスに関する記事を読んでみてイメージしたのは、会社で回ってくる稟議書とかに対して何かしらの処理をするとき便利そうじゃない??ってイメージです。ひとまず理論とかオブジェクト指向とは何なのかというお勉強チックなことは次回に回してここでは自分のイメージしたクラスってこういうときに使ったら便利なんじゃね?というイメージを持って作ったコードを公開してみます。
稟議書に対する処理
当方、文系でとある会社の経理部員です。毎日書類や勘定科目と戦っています。このような身分でクラスが利用できないかと思いついたのが稟議起こして購入する予定の資産に対する処理です。
すなわち、稟議ナンバー、稟議起案者、起案者所属部署、何の資産か、いくらの資産かという属性を持たせて
メール確認の処理、そしてエクセルへの転記で決算時の帳票として利用できるようにしておくことです。
稟議書は毎日ひっきりなしに回ってくるのでプログラム化して効率化するのがよさそう。
この着想をもとにpythonのクラスが使えるのではないかと以下のコードを作成した次第。とりあえずプログラムにやってほしいこと
①メール文の作成
②エクセルへの転記そして作ったのが以下のクラスを交えたコーディング
qiita.rbimport openpyxl import datetime class assets(): def __init__(self,apdnum,apdmen,unitname,assetname,money): self.apdnum=apdnum self.apdmen=apdmen self.unitname=unitname self.assetname=assetname self.money=money #メールにPDFを添付する機能 担当者と担当部署から送り先メールアドレスを拾ってくる作業を追加予定 def when_mail(self): mail=("{}{}様お疲れ様です。経理部の固定資産担当です。稟議書No{}の{}についてですが、\ \n当月の状況について利用開始しているか教えてください。また請求書もあれば請求書の添付も\ \nよろしくお願いいたします。".format(self.unitname,self.apdmen,self.apdnum,self.assetname)) print(mail) def Insert_excel(self): wb=openpyxl.load_workbook("../data/発注固定資産管理表.xlsx") sh=wb.active for dt_row in range(2,50): if sh["A"+str(dt_row)].value!=None: continue else: sh["A"+str(dt_row)].value=self.apdnum sh["B"+str(dt_row)].value=self.unitname sh["C"+str(dt_row)].value=self.apdmen sh["D"+str(dt_row)].value=self.assetname sh["E"+str(dt_row)].value=self.money break wb.save("../data/発注固定資産管理表_{}_johannesrome作成.xlsx".format(datetime.date.today())) #以下実行プログラム print("新しい稟議書Noを入力してください") apdnum_re=input() print("稟議書の起票者を入力してください") apdmen_re=input() print("起票者の所属部署を入力してください") unitname_re=input() print("購入対象の名前を入力してください") assetname_re=input() print("予定調達価格を入力してください") money_re=input() m=assets(apdnum_re,apdmen_re,unitname_re,assetname_re,money_re) m.when_mail() m.Insert_excel()コードの詳細
コードとしては、assetクラスを作り、そこに5つの属性を持たせる。
①稟議ナンバー
②稟議起案者
②起案者所属部署
④購入予定資産の名称
⑤購入金額
プログラムを起動すると上記の5つのインプットを求められ、それに基づきインスタンスが作成。
そしてメール文の作成とエクセルへの転記が行われるという内容。個人的な総括
個人的にはこれでクラスのメリットを享受したプログラムになっているのではないかと思うのだけれど。
どのようなものだろうか。クラスの承継や多重承継なんかは使ってないけれど、クラスのメリット
使いきれてないよ~て意見があればぜひぜひコメントください( ^ω^)。以上、第一回目でした!
- 投稿日:2020-02-25T16:52:32+09:00
python弄ってた時に出たエラー
メモ代わり
これからpython弄ってくしそのメモとして
都度都度追記してくその1
エラーメッセージ
SyntaxError: Non-UTF-8 code starting with 'エラー個所' in file sample.py on line 1, but no encoding declared; see http://python.org/dev/peps/pep-0263/ for details
原因
書いてたpythonのコードがS-JIS(SHIFT-JIS)で書かれてたことが原因(要は文字コード)
手順:[新規作成]→[テキスト ドキュメント]→出来たファイルの拡張子をtxtからpyに変更
オチ
pythonのソースコードをS-JISからUTF-8に変更
terapadの場合:一度コード全文をコピー→[ファイル]→[文字コードしてい再読み込み]→UTF-8を選択→(再読み込み後)ctrl+Aで全文選択→ctrl+Vで貼り付け→ctrl+Sで上書き保存
htmlでも文字化けされまくったし、やはりS-JISは害悪・・・我らがUTF-8神の元に統一しなきゃ・・・(UTF-8教過激派)その2
エラーメッセージ
FileNotFoundError: [Errno 2] No such file or directory: './img.png'
原因
「img.png」なんてファイルが指定しているフォルダ(ディレクトリ)存在しないことが原因
→間違えてimg.jpgを入れてた
オチ
ファイル[img.jpg]を[img.png]にするか、コード中のimg.pngをimg.jpgにするかのどちらか
- 投稿日:2020-02-25T16:36:56+09:00
活性化関数はなぜ非線形関数でなければならないのか
はじめに
ニューラルネットワークでは活性化関数として非線形関数を用いるのですが、「なぜ線形関数ではないのか」ということを説明します.
線形関数とは
出力が入力の定数倍になる関数のことです. つまり、一本の直線の関数のことです.
こんなの.
非線形関数とは
線形ではない、カクカクしてたりぐにゃっと曲がっている線の関数のことです.
こんなの.
ニューラルネットワークでは活性化関数に非線形関数を用いる必要があります. もし、線形関数を使うと、出力は入力の定数倍(直線)になります. これでは層を深くする意味がなくなってしまいます.
どうして?
ひとつ例を考えてみます.
例)活性化関数として、線形関数である $h(x) = ax$ を用いた3層ネットワーク出力$y$は、$y(x) = h(h(h(x)))$ となります. これは $y(x) = kx$(ただし$k=a^3$)の一回のかけ算で表現できます. つまり、隠れ層のないネットワークで表現できるんです. これでは多層にする意味がありません.
だからニューラルネットワークでは線形ではない、非線形関数を用いるのです.
おわりに
こちらの記事おすすめです.
「複雑」をたくさんの「単純」に分解する〜順伝播は「1次関数」と「単純な非線形」の繰り返し


- 投稿日:2020-02-25T16:27:36+09:00
COTOHA APIを触ってみた
はじめに
コトハ アピをはじめ、COTOHA APIを使用した記事をたくさん目にしたので参考にしつつ触ってみることにしました。
APIを使用するにはアカウントが必要になりますので、もし興味がある方は作成してみてください。(それほど時間を掛けずに利用開始できました。)
本記事では、こちらのAPIを使用して形態素解析結果を得るところまで行います。まずは認証
import requests import json BASE_URL = "https://api.ce-cotoha.com/api/dev/nlp/" CLIENT_ID = "CLIENT_ID" #発行されたIDを入力 CLIENT_SECRET = "CLIENT_SECRET" #発行されたsecretを入力 # アクセストークンを取得 def auth(client_id, client_secret): token_url = "https://api.ce-cotoha.com/v1/oauth/accesstokens" headers = { "Content-Type": "application/json", "charset": "UTF-8" } data = { "grantType": "client_credentials", "clientId": client_id, "clientSecret": client_secret } r = requests.post(token_url, headers=headers, data=json.dumps(data)) return r.json()["access_token"] if __name__ == "__main__": access_token = auth(CLIENT_ID, CLIENT_SECRET) # print(access_token)アクセストークンを出力するのはどうかと思います(一応コメントアウトしてあります)が、認証を行い、トークンを取得することでAPIの呼び出しが可能になります。
形態素解析(構文解析)
import requests import json import sys BASE_URL = "https://api.ce-cotoha.com/api/dev/nlp/" CLIENT_ID = "CLIENT_ID" # 発行されたIDを入力 CLIENT_SECRET = "CLIENT_SECRET" # 発行されたsecretを入力 # アクセストークンを取得 def auth(client_id, client_secret): token_url = "https://api.ce-cotoha.com/v1/oauth/accesstokens" headers = { "Content-Type": "application/json", "charset": "UTF-8" } data = { "grantType": "client_credentials", "clientId": client_id, "clientSecret": client_secret } r = requests.post(token_url, headers=headers, data=json.dumps(data)) return r.json()["access_token"] # 形態素解析 def parse(sentence, access_token): base_url = BASE_URL headers = { "Content-Type": "application/json", "charset": "UTF-8", "Authorization": "Bearer {}".format(access_token) } data = { "sentence": sentence, "type": "default" } r = requests.post(base_url + "v1/parse", headers=headers, data=json.dumps(data)) return r.json() if __name__ == "__main__": document = "テスト" args = sys.argv if len(args) >= 2: document = str(args[1]) access_token = auth(CLIENT_ID, CLIENT_SECRET) parse_document = parse(document, access_token) print(parse_document)今回は構文解析のAPIを使用しましたが、こちらに用意されてるものであればすぐに使用できます。
実行
python auth.py 私は鳥です結果
{'result': [{'chunk_info': {'id': 0, 'head': 1, 'dep': 'D', 'chunk_head': 0, 'chunk_func': 1, 'links': []}, 'tokens': [{'id': 0, 'form': '私', 'kana': 'ワタシ', 'lemma': '私', 'pos': '名詞', 'features': ['代名詞'], 'dependency_labels': [{'token_id': 1, 'label': 'case'}], 'attributes': {}}, {'id': 1, 'form': 'は', 'kana': 'ハ', 'lemma': 'は', 'pos': '連用助詞', 'features': [], 'attributes': {}}]}, {'chunk_info': {'id': 1, 'head': -1, 'dep': 'O', 'chunk_head': 0, 'chunk_func': 1, 'links': [{'link': 0, 'label': 'aobject'}], 'predicate': []}, 'tokens': [{'id': 2, 'form': '鳥', 'kana': 'トリ', 'lemma': '鳥', 'pos': '名詞', 'features': [], 'dependency_labels': [{'token_id': 0, 'label': 'nmod'}, {'token_id': 3, 'label': 'cop'}], 'attributes': {}}, {'id': 3, 'form': 'です', 'kana': 'デス', 'lemma': 'です', 'pos': '判定詞', 'features': ['終止'], 'attributes': {}}]}], 'status': 0, 'message': ''}おわりに
アカウントの取得もスムーズで、すぐに利用できて便利でした。
形態素解析は実業務でも触れる機会があり、個人的に興味もある分野です。
現在は無料で登録しているのでfor Developersですが、for Enterpriseの専門用語辞書や拡張も興味があるので機会があれば触ってみたいです。
COTOHA APIでなんかしたいと思っていますが、発想力がないのでアイデアが全く浮かびません…
思いつき次第なにか投稿したいと思います。
- 投稿日:2020-02-25T16:17:13+09:00
Django:MigrationでモデルがDBに反映されない
反映されない
表題の通り、マイグレーションしてもDBに反映されず苦しんだので記録しておきます。
環境
・Windows10 Enterprise
・Docker Desktop for Windows:2.1.0.1
・MySQL:5.7.28(Docker上)
・Django:3.0(Docker上)経緯
models.pyに新モデル(モデルAとします)を追加してマイグレーションを行った所、DBに反映されず。
他モデルの変更は反映されるので、モデルAのみ問題と推定。色々やってみた
下記記事などを参考に色々やってみました。
・DjangoでmigrateしてるのにDBに反映されない時の対処法【Djangoアウトプット】
・DjangoでMigrationsのリセット方法(既存のデータベースを残したまま)
・djangoでmigrateができない
・Djangoのmodels.pyの反映(python manage.py makemigrations/migrate)
・modelにカラムを追加したのにmigrationファイルに追加されない現象
・python manage.py migrationが効かない時の対処法 [Django]大体「python manage.py migrate --fake hoge zero」でマイグレーション履歴削除して、フォルダのファイルも削除後、makemigrationしてmigrateすれば反映されるでしょ、という事でしたが全滅。
おまえだったのか
で、一旦DBドロップして再度マイグレーションしてみると…モデルA以外にもうひとつモデル(モデルBとします)が反映されていない。
「?」と思いよくよく「models.py」を読んでいるとこれら2つのモデルのみ「class Meta:」の中に「managed = False」の文字が。models.pyclass Meta: managed = False db_table = 'temp'試しにこれを削除して再度マイグレーションしたら、出来ました。あっさりと。
モデルBはどこかからかコピーしてきた書式をペーストしていて、これをコピペしてモデルAを作成したので今回のトラップにかかった様です。
「managed = False」と書く事でマイグレーションの管理対象外とするそうな。そりゃ反映されない筈だ。
(「経緯」で他モデルの変更は反映されたと書いていますが、モデルBでは試していませんでした)という訳で
コピー元がなぜこれを含んでいたかは謎ですが、一先ず動いたので…
灯台下暗し。もう少し手前から調べてみようと思いました。また時間できたら纏めたいと思います。
時間できたら…(やるのか…?)
- 投稿日:2020-02-25T16:13:40+09:00
BERTなどの大規模のモデルの課題
自然言語処理の画期的なモデル - BERT
BERT [Bidirectional Encoder Representations from Transformers] は、Googleのチームに2018年の秋に発表された。トランスフォーマーアーキテクチャを使って、大量のデータで非常に大きいネットワークを画期的な方法でモデルを学習した結果である。学習方法と精度についてこの記事をご参照ください。
オープンソース・情報を自由に交換することを大事にしている機械学習のフィールドでは、新しいアイデアを arxiv.org で論文として公開し、github でモデルを共有することが基本的なやり方である。新しいアイデアが公開されたとたんに、世界の機械学習の研究者や開発チームが参考したり、再利用したりできる。
オープンソースの文化の結果、BERTが公開されて数か月たったら、
Open AI、Facebook、NVidia、BaiduなどのすべてのIT大企業がこの新しいアーキテクチャに基づいてモデルを作った。2017年からの進化、特にBERTからの画期的な影響については、このナイス図 をご参照ください。
BERTよりデカイモデルが最近流行
BERTの精度向上の原因は、アーキテクチャや学習データの量だけではなく、パラメータ数でもある。
BERTが大きいです。でかい。というより、デカイ。BERTの「小さい」版は、一番単純なバージョンのパラメータ数は1億である。また、BERTに基づいたほかのモデルはさらに大きくきている。
- Open AI のGPT-2:15 億
- Nvidia の Megatron-ML:83 億 2020年に発表されたGoogleのチャットボット Meena :26 億
- Microsoft の T-NLG:170 億
ディープラーニングでは、データ量とネットワークのサイズが上がることによって、精度もあがる。
ただし、このようのデカイネットワークには、いくつかの課題が発生する。温暖化を防ぐには、転移学習の場合重みを固定したままにしよう
何億パラメータを大量のデータで学習するには、いくるかかったかは公開されていないが、電気代だでけでも何千万円かかったと考えられる。このようのモデルを自分の課題にカスタマイズするには、ゼロで学習させることは現実的ではない。グーグルやマイクロソフトじゃないと、転移学習でやるしかない。家のパソコンを使ってゼロから学習させたら、GPUが暖房の代わりになるでしょう。溶ける可能性もある。
学習はコストが当然かかるけど、Inference [モデルで特定なインプットに対してアウトプットを予測すること] もコストがかかる。最近話題になった AI Dungeon がこの課題を直接に感じて、記事も書いた。この規模のモデルのメモリ要件は数ギガバイト。また、処理にも時間がかかりますので、精度が高くても、スピードが大事な活用の場合では、適切なシステムではない。
まとめると、ITの大企業で最近開発された自然言語処理モデルの精度は確かに高いですが、学習・処理は大変である。クラウドで大変。エッジでさらに大変である。
さらに読む改善方法・解決方法
ハードウェア購入・クラウド型の無限な予算 - 稟議無しで無限な予算を取れたら、お気軽に数万個のTPUでいけると考えらる。グーグルの予算なかったら、どうやってこのようの精度を出すモデルを使えるでしょうか?
一つの解決方法として、DistilBERTのような縮小版のモデル。元のモデルに「教育」される小さ目なモデルを学習させる。この学習方法の結果、精度は元のモデルほどよくはないですが、サイズを何十倍も縮小することができる。「Knowledge Distillation」について、この記事をご参照ください。。
2020年2月の論文でもアマゾンから発表された論文でトランスフォーマーアーキテクチャを縮小する方法が紹介された。精度のニーズが常に上がることによって、このようの課題はなくならない。一般の会社でもこのようなモデルを利用できるように、ハードウェア進化、クラウド費やコスパがいいトランスフォーマーアーキテクチャが必要になる。

- 投稿日:2020-02-25T15:00:47+09:00
趣味としてのプログラミング言語
「趣味」って、日本語ではヒトコトで片付けがちだけど。
— 倉戸みと@3/21マスクフェス (@mitragyna) February 10, 2020
like(ライク:好きなこと)
hobby(ホビー:探究してること)
life work(ライフワーク:人生かけてること)
の「3種類の趣味」を持っておくと、趣味が重層的に楽しめるのでオススメ。上記つぶやきの趣味の三分類に基づいて、自分にとってのプログラミング言語について整理してみます。
like
C++://コメントを始めCの手が届かなかったところに手が届く。Templateはまだ制服できず。life workまでいけてない。
C言語/C++に対する誤解、曲解、無理解、爽快。
https://qiita.com/kaizen_nagoya/items/3f3992c9722c1cee2e3aAutosar Guidelines C++14 example code compile list(1-169)
https://qiita.com/kaizen_nagoya/items/8ccbf6675c3494d57a76C++N4741, 2018 Standard Working Draft on ISO/IEC 14882 sample code compile list
https://qiita.com/kaizen_nagoya/items/3294c014044550896010C++ Templates The Complete Guide(2nd Edition)をclang++とg++でコンパイルしてみた
https://qiita.com/kaizen_nagoya/items/a7065ea839cb33793bdf仮説・検証(52)プログラミング言語教育のXYZ
https://qiita.com/kaizen_nagoya/items/1950c5810fb5c0b07be4hobby
python。50才から毎年1言語勉強を目標にして、一番バズった言語。2つめの記事は、Qiitaで自己最大のviews。教育以外にお金になっていない。
docker(19) 言語処理100本ノックをdockerで。python覚えるのに最適。
https://qiita.com/kaizen_nagoya/items/7e7eb7c543e0c18438c4Windows(MS)にPython(Anaconda)を導入する(5つの罠)
https://qiita.com/kaizen_nagoya/items/7bfd7ecdc4e8edcbd679「ゼロから作るDeep Learning 2自然言語処理編」読書会に参加する前に読んで置くとよい資料とプログラム
https://qiita.com/kaizen_nagoya/items/537b1810265bbbc70e73dockerで機械学習(3) with anaconda(3)「直感Deep Learning」Antonio Gulli、Sujit Pal著
https://qiita.com/kaizen_nagoya/items/483ae708c71c88419c32プログラムは音楽だ
https://qiita.com/kaizen_nagoya/items/33c9f33581e6886f8ad8life work
論理回路(機械語・アセンブラ・Verilog HDL・CPU・量子計算機)
Qiitaで組立語・機械語・CPU<アセンブラへの道>
https://qiita.com/kaizen_nagoya/items/46f2333c2647b0e692b2RTL設計スタイルガイド Verilog HDL編(System Verilog対応版)
https://qiita.com/kaizen_nagoya/items/4c02f1575db1f28310a764bitCPUへの道 and/or 64歳の決意(0)
https://qiita.com/kaizen_nagoya/items/cfb5ffa24ded23ab3f6064bitCPUへの道 and/or 64歳の決意(2)32bitと64bitの違い
https://qiita.com/kaizen_nagoya/items/1763b20c607260ea2c3e量子コンピュータプログラムへの道
https://qiita.com/kaizen_nagoya/items/37c90488c87bbe9f2d71下記、slideshareのviewsのtop10のうち記事数で半分、views数で49%がverilog HDLの記事。
岐阜大学の非常勤の演習のうち1科目はVerilog HDL, もう1科目はC言語だった。
ちなみに、数年前から岐阜大学ではpythonが全学で最初に覚える言語に指定。
like, hobby, life workともそろい踏み。slideshare top 10(views)
https://qiita.com/kaizen_nagoya/items/2035b961adad19b74c17out of scope
Qiitaでいいねが一番多い自分の記事が分類できてない。あ、これは趣味じゃなくて仕事だった。
名刺には、長らく ProgrammerではなくDesignerと記載しています(場合によってはNetwork Designer)プログラマが知っているとよい色使い(JIS安全色)
https://qiita.com/kaizen_nagoya/items/cb7eb3199b0b98904a35post script
40年前だったら、
likeがfortranで
hobyがbasicだったと思う。文書履歴(document history)
ver. 0.01 初稿 20200225 午後2時
ver. 0.02 補足 20200225 午後3時
ver. 0.03 はてなURL追記 20200225 午後4時
ver. 0.04 post script 追記 20200225 午後5時
- 投稿日:2020-02-25T14:58:25+09:00
Python3エンジニア認定基礎試験を受験して
Pythonエンジニア認定基礎試験
Pythonエンジニア認定基礎試験について
様々なqiitaの記事でも説明されているので、割愛します。公式サイトのリンクを貼っておきます。
Python未経験者からすると参考にはならないかもしれないですが、試験や自分の勉強について書こうと思います。
経歴
著者は現在(2019年度現在)2年目の社会人で、1年目から業務で初めてPythonを触れてから今まで2年近く触れています。Pythonは業務で調べながら、独学で学びました。大学時代にプログラミングには触れていたので、苦ではなかったです。
その大学時代はC言語やJavaを授業で勉強していましたが、正直、大学の授業で学んだことはほとんど業務で役に立たないと1年目から実感しました。(小並感)受験経緯
受験経緯は結論から申しますと、汚い話ですが、お金が欲しかったからです。著者の会社では資格の報奨金がありましたので、受けようと思いました。お金は裏切りません。
受験までの勉強
1年以上Pythonを触っているからノー勉で行くほど、度胸はありませんでした。
まずは、qiitaの記事等で勉強の仕方を調べました。目に着いたのは模擬試験。そして無料。
模擬試験
やってみたら、1000点満点中の450点...。ちゃんと勉強しようと決意した瞬間でした。勉強法
まずは、模擬試験の間違えた問題の答えを見て、回答について理解する。できなければ、とにかくわかるまでググる。全部できたら、また模擬試験をする。間違えを理解するを満点とるまで、やります。
ここまで来ると答えだけ見ただけでも、回答がわかります。過学習ですね。
でも試験で、もしかしたら同じ問題が出るかもしれないと思ったので、満点とるまでやりました。
最後に、参考教材のドキュメントを読みました。試験の出題範囲はオライリー・ジャパン「Pythonチュートリアル 第3版」の掲載内容なので、読みました。web上で読むことができます。
Pythonチュートリアル
とりあえず、全部読んで、読みながら疑問に思ったところは実際に手を動かして、動きを確認しました。未経験者
未経験者は教材を読んでから、模擬試験を受けて、もう一度教材を読むのがいいのではないかと思います。
受験して
結果から言うと合格しました。1000点満点中850点でした。なんとかなりました。
個人的には受けて良かったと思います。試験自体は30分以上余りました。簡単な問題が多かったと思います。これは別に覚えてなくてもいいだろうという問題もありました。
受けて良かったと思った理由は、自分の基礎力の無さを自覚できたことです。特に自分が知らなかったメソッドが実際には便利なものがあったりして、基礎の大切さを改めて実感しました。まとめ
この試験自体は模擬試験とドキュメントを読んでおけば、合格できると思います。
基礎はしっかり固めましょう。
- 投稿日:2020-02-25T14:54:49+09:00
poetryでSolverProblemError
1. 環境
(.venv) user$ python --version Python 3.7.6 (.venv) user$ poetry -V Poetry version 1.0.32. 現象
Cythonをインストールする時に以下のような
SolverProblemErrorが発生.(.venv) user$ poetry install Installing dependencies from lock file Warning: The lock file is not up to date with the latest changes in pyproject.toml. You may be getting outdated dependencies. Run update to update them. [SolverProblemError] Because annotator depends on Cython (0.29.15) which doesn't match any versions, version solving failed.Cythonは
0.29.15で指定していた.pyproject.toml... [tool.poetry.dependencies] Cython = "0.29.15" ...3. 解決策
poetry addならいける.(.venv) user$ poetry add Cython Using version ^0.29.15 for Cython Updating dependencies Resolving dependencies... (0.4s) Package operations: 1 install, 0 updates, 0 removals - Installing cython (0.29.15)
poetry addだと自動的にバージョンを^で指定する.pyproject.toml... [tool.poetry.dependencies] Cython = "^0.29.15" ...どうやらこれが必要だった模様.
Cython=0.29.15はpypiにもあるし,ドキュメント
によるとこの方法で指定すると>= 0.29.15 < 1.0.0になるはずなので0.29.15指定でも良さそうなものだが...ちなみに
addじゃなくてもCython = "^0.29.15"で指定してinstallでもいける.(.venv) user$ poetry install Installing dependencies from lock file Package operations: 1 install, 0 updates, 0 removals - Installing cython (0.29.15)
- 投稿日:2020-02-25T14:46:29+09:00
pythonで生徒を当てるアプリをつくる-GUI版
はじめに
以前投稿したpythonで生徒を当てるアプリをつくるをGUIソフトにしたってだけの記事.
プログラム
main.py data/ history.txt list.txt list_raw.txt web/ main.html css/ style.css js/ eel.js
main.py
main.pyimport locale import eel import random import pickle import os import sys import datetime from tkinter import filedialog, Tk import platform import copy def main(): eel.init("web") eel.start("main.html") Student_names = [] Student_FILENAME = "./data/list.txt" Student_FILENAME_raw = "./data/list_raw.txt" # Student @eel.expose def Student_load(): with open(select_file(), "r") as f: global Student_names Student_names = f.read().splitlines() Student_save(Student_FILENAME) Student_save(Student_FILENAME_raw) @eel.expose def Student_reset(): Student_names_load(Student_FILENAME_raw) @eel.expose def Student_show(): Student_names_load(Student_FILENAME) name_ls = "" a = 1 for name in Student_names: if a % 5 == 0: name_ls = name_ls + name + "<br>" else: name_ls = name_ls + name + " " a += 1 return name_ls @eel.expose def Student_choice(): Student_names_load(Student_FILENAME) global Student_names_raw Student_names_raw = copy.deepcopy(Student_names) if not Student_names: return global name name = random.choice(Student_names) Student_names.remove(name) if Student_names == []: Student_names_load(Student_FILENAME_raw) History_add(name) Student_save(Student_FILENAME) return name @eel.expose def Student_save(FILENAME): f = open(FILENAME, 'wb') pickle.dump(Student_names, f) @eel.expose def Student_names_load(FILENAME): f = open(FILENAME, "rb") global Student_names Student_names = pickle.load(f) # History History_FILENAME = "./data/history.txt" History_data = [] @eel.expose def History_load(): with open(History_FILENAME, "r") as f: global History_data History_data = f.read().splitlines() @eel.expose def History_save(): with open(History_FILENAME, "w") as f: for history in History_data: print(history, file=f) @eel.expose def History_show(): history_ls = "" History_load() for history in History_data: history_ls = history + "<br>" + history_ls return history_ls locale.setlocale(locale.LC_ALL, '') @eel.expose def History_add(name): now = datetime.datetime.now() History_data.append(f"{now:%m月%d日}:{name}") History_save() @eel.expose def History_cancel(): History_data.pop() History_save() global Student_names Student_names = copy.deepcopy(Student_names_raw) Student_save(Student_FILENAME) @eel.expose def History_clear(): global History_data History_data = [] History_save() # 名簿読み込み # ダイアログ用のルートウィンドウの作成 # (root自体はeelのウィンドウとは関係ないので非表示にしておくのが望ましい) root = Tk() # ウィンドウサイズを0にする root.geometry("0x0") # ウィンドウのタイトルバーを消す root.overrideredirect(1) # ウィンドウを非表示に root.withdraw() system = platform.system() @eel.expose def select_file(): # Windowsの場合withdrawの状態だとダイアログも # 非表示になるため、rootウィンドウを表示する if system == "Windows": root.deiconify() # macOS用にダイアログ作成前後でupdate()を呼ぶ root.update() # ダイアログを前面に # topmost指定(最前面) root.attributes('-topmost', True) root.withdraw() root.lift() root.focus_force() path_str = filedialog.askopenfilename() root.update() if system == "Windows": # 再度非表示化(Windowsのみ) root.withdraw() #path = Path(path_str) return path_str if __name__ == '__main__': main()
main.html
main.html<html> <head> <meta charset="UTF-8"> <title>生徒当てるヤツ</title> <link rel="stylesheet" type="text/css" href="./css/style.css"> <script type="text/javascript" src="/eel.js"></script> <script type="text/javascript"> async function Student_choice() { var demo2 = document.getElementById("div0"); demo2.innerHTML = ""; div0.insertAdjacentHTML('afterbegin', '<div id="name"></div>'); let val = await eel.Student_choice()(); var doc0 = document.getElementById("name"); doc0.innerHTML = val; } async function Student_load() { eel.Student_load(); } async function Student_show() { let val = await eel.Student_show()(); var doc0 = document.getElementById("div0"); doc0.innerHTML = val; } async function History_show() { let val = await eel.History_show()(); var doc0 = document.getElementById("div0"); doc0.innerHTML = val; } async function History_clear() { let val = await eel.History_clear()(); var doc0 = document.getElementById("div0"); doc0.innerHTML = val; } async function History_cancel() { let val = await eel.History_cancel()(); var doc0 = document.getElementById("div0"); doc0.innerHTML = val; } </script> </head> <body> <center> <div id="div0"> </div> <div class="bottom"> <a href="#" onclick="Student_choice()" class="btn-square">生徒を当てる</a> <a href="#" onclick="History_cancel()" class="btn-square">欠席者を飛ばす</a> <a href="#" onclick="Student_show()" class="btn-square">残りの生徒を表示</a> <a href="#" onclick="History_show()" class="btn-square">履歴の表示</a> <a href="#" onclick="History_clear()" class="btn-square">履歴の消去</a> <a href="#" onclick="Student_load()" class="btn-square">名簿を更新</a> </div> </center> <div class='markdown-preview' data-use-github-style> <details> <summary>名簿の更新方法</summary> <div> <h1 id="名簿の更新方法">名簿の更新方法</h1> <h3 id="1">1</h3> <p>任意のファイル名のテキストファイル(*.txt)を作成します.</p> <h3 id="2">2</h3> <p>その中に<br> 1.名前<br> 2.名前<br> ・<br> ・<br> ・<br> と入力します.</p> <h3 id="3">3</h3> <p>名簿を更新をクリックし,テキストファイルを選択する.</p> </div> </details> </div> </html>
style.css
style.css.btn-square { display: inline-block; padding: 0.5em 1em; text-decoration: none; background: #668ad8; /*ボタン色*/ color: #FFF; border-bottom: solid 4px #627295; border-radius: 3px; } .btn-square:active { /*ボタンを押したとき*/ -webkit-transform: translateY(4px); transform: translateY(4px); /*下に動く*/ border-bottom: none; /*線を消す*/ } #div0 { height: 300px; overflow: scroll; } #name { margin-top: 50px; font-size: 100px; } .bottom {} .markdown-preview:not([data-use-github-style]) { padding: 2em; font-size: 1.2em; color: rgb(197, 200, 198); background-color: rgb(29, 31, 33); overflow: auto; } .markdown-preview:not([data-use-github-style])> :first-child { margin-top: 0px; } .markdown-preview:not([data-use-github-style]) h1, .markdown-preview:not([data-use-github-style]) h2, .markdown-preview:not([data-use-github-style]) h3, .markdown-preview:not([data-use-github-style]) h4, .markdown-preview:not([data-use-github-style]) h5, .markdown-preview:not([data-use-github-style]) h6 { line-height: 1.2; margin-top: 1.5em; margin-bottom: 0.5em; color: rgb(255, 255, 255); } .markdown-preview:not([data-use-github-style]) h1 { font-size: 2.4em; font-weight: 300; } .markdown-preview:not([data-use-github-style]) h2 { font-size: 1.8em; font-weight: 400; } .markdown-preview:not([data-use-github-style]) h3 { font-size: 1.5em; font-weight: 500; } .markdown-preview:not([data-use-github-style]) h4 { font-size: 1.2em; font-weight: 600; } .markdown-preview:not([data-use-github-style]) h5 { font-size: 1.1em; font-weight: 600; } .markdown-preview:not([data-use-github-style]) h6 { font-size: 1em; font-weight: 600; } .markdown-preview:not([data-use-github-style]) strong { color: rgb(255, 255, 255); } .markdown-preview:not([data-use-github-style]) del { color: rgb(155, 160, 157); } .markdown-preview:not([data-use-github-style]) a, .markdown-preview:not([data-use-github-style]) a code { color: white; } .markdown-preview:not([data-use-github-style]) img { max-width: 100%; } .markdown-preview:not([data-use-github-style])>p { margin-top: 0px; margin-bottom: 1.5em; } .markdown-preview:not([data-use-github-style])>ul, .markdown-preview:not([data-use-github-style])>ol { margin-bottom: 1.5em; } .markdown-preview:not([data-use-github-style]) blockquote { margin: 1.5em 0px; font-size: inherit; color: rgb(155, 160, 157); border-color: rgb(67, 72, 76); border-width: 4px; } .markdown-preview:not([data-use-github-style]) hr { margin: 3em 0px; border-top: 2px dashed rgb(67, 72, 76); background: none; } .markdown-preview:not([data-use-github-style]) table { margin: 1.5em 0px; } .markdown-preview:not([data-use-github-style]) th { color: rgb(255, 255, 255); } .markdown-preview:not([data-use-github-style]) th, .markdown-preview:not([data-use-github-style]) td { padding: 0.66em 1em; border: 1px solid rgb(67, 72, 76); } .markdown-preview:not([data-use-github-style]) code { color: rgb(255, 255, 255); background-color: rgb(48, 51, 55); } .markdown-preview:not([data-use-github-style]) pre.editor-colors { margin: 1.5em 0px; padding: 1em; font-size: 0.92em; border-radius: 3px; background-color: rgb(39, 41, 44); } .markdown-preview:not([data-use-github-style]) kbd { color: rgb(255, 255, 255); border-width: 1px 1px 2px; border-style: solid; border-color: rgb(67, 72, 76) rgb(67, 72, 76) rgb(53, 57, 60); border-image: initial; background-color: rgb(48, 51, 55); } .markdown-preview[data-use-github-style] { font-family: "Helvetica Neue", Helvetica, "Segoe UI", Arial, freesans, sans-serif; line-height: 1.6; overflow-wrap: break-word; padding: 30px; font-size: 16px; color: rgb(51, 51, 51); background-color: rgb(255, 255, 255); } .markdown-preview[data-use-github-style]> :first-child { margin-top: 0px !important; } .markdown-preview[data-use-github-style]> :last-child { margin-bottom: 0px !important; } .markdown-preview[data-use-github-style] a:not([href]) { color: inherit; text-decoration: none; } .markdown-preview[data-use-github-style] .absent { color: rgb(204, 0, 0); } .markdown-preview[data-use-github-style] .anchor { position: absolute; top: 0px; left: 0px; display: block; padding-right: 6px; padding-left: 30px; margin-left: -30px; } .markdown-preview[data-use-github-style] .anchor:focus { outline: none; } .markdown-preview[data-use-github-style] h1, .markdown-preview[data-use-github-style] h2, .markdown-preview[data-use-github-style] h3, .markdown-preview[data-use-github-style] h4, .markdown-preview[data-use-github-style] h5, .markdown-preview[data-use-github-style] h6 { position: relative; margin-top: 1em; margin-bottom: 16px; font-weight: bold; line-height: 1.4; } .markdown-preview[data-use-github-style] h1 .octicon-link, .markdown-preview[data-use-github-style] h2 .octicon-link, .markdown-preview[data-use-github-style] h3 .octicon-link, .markdown-preview[data-use-github-style] h4 .octicon-link, .markdown-preview[data-use-github-style] h5 .octicon-link, .markdown-preview[data-use-github-style] h6 .octicon-link { display: none; color: rgb(0, 0, 0); vertical-align: middle; } .markdown-preview[data-use-github-style] h1:hover .anchor, .markdown-preview[data-use-github-style] h2:hover .anchor, .markdown-preview[data-use-github-style] h3:hover .anchor, .markdown-preview[data-use-github-style] h4:hover .anchor, .markdown-preview[data-use-github-style] h5:hover .anchor, .markdown-preview[data-use-github-style] h6:hover .anchor { padding-left: 8px; margin-left: -30px; text-decoration: none; } .markdown-preview[data-use-github-style] h1:hover .anchor .octicon-link, .markdown-preview[data-use-github-style] h2:hover .anchor .octicon-link, .markdown-preview[data-use-github-style] h3:hover .anchor .octicon-link, .markdown-preview[data-use-github-style] h4:hover .anchor .octicon-link, .markdown-preview[data-use-github-style] h5:hover .anchor .octicon-link, .markdown-preview[data-use-github-style] h6:hover .anchor .octicon-link { display: inline-block; } .markdown-preview[data-use-github-style] h1 tt, .markdown-preview[data-use-github-style] h2 tt, .markdown-preview[data-use-github-style] h3 tt, .markdown-preview[data-use-github-style] h4 tt, .markdown-preview[data-use-github-style] h5 tt, .markdown-preview[data-use-github-style] h6 tt, .markdown-preview[data-use-github-style] h1 code, .markdown-preview[data-use-github-style] h2 code, .markdown-preview[data-use-github-style] h3 code, .markdown-preview[data-use-github-style] h4 code, .markdown-preview[data-use-github-style] h5 code, .markdown-preview[data-use-github-style] h6 code { font-size: inherit; } .markdown-preview[data-use-github-style] h1 { padding-bottom: 0.3em; font-size: 2.25em; line-height: 1.2; border-bottom: 1px solid rgb(238, 238, 238); } .markdown-preview[data-use-github-style] h1 .anchor { line-height: 1; } .markdown-preview[data-use-github-style] h2 { padding-bottom: 0.3em; font-size: 1.75em; line-height: 1.225; border-bottom: 1px solid rgb(238, 238, 238); } .markdown-preview[data-use-github-style] h2 .anchor { line-height: 1; } .markdown-preview[data-use-github-style] h3 { font-size: 1.5em; line-height: 1.43; } .markdown-preview[data-use-github-style] h3 .anchor { line-height: 1.2; } .markdown-preview[data-use-github-style] h4 { font-size: 1.25em; } .markdown-preview[data-use-github-style] h4 .anchor { line-height: 1.2; } .markdown-preview[data-use-github-style] h5 { font-size: 1em; } .markdown-preview[data-use-github-style] h5 .anchor { line-height: 1.1; } .markdown-preview[data-use-github-style] h6 { font-size: 1em; color: rgb(119, 119, 119); } .markdown-preview[data-use-github-style] h6 .anchor { line-height: 1.1; } .markdown-preview[data-use-github-style] p, .markdown-preview[data-use-github-style] blockquote, .markdown-preview[data-use-github-style] ul, .markdown-preview[data-use-github-style] ol, .markdown-preview[data-use-github-style] dl, .markdown-preview[data-use-github-style] table, .markdown-preview[data-use-github-style] pre { margin-top: 0px; margin-bottom: 16px; } .markdown-preview[data-use-github-style] hr { height: 4px; padding: 0px; margin: 16px 0px; background-color: rgb(231, 231, 231); border: 0px none; } .markdown-preview[data-use-github-style] ul, .markdown-preview[data-use-github-style] ol { padding-left: 2em; } .markdown-preview[data-use-github-style] ul.no-list, .markdown-preview[data-use-github-style] ol.no-list { padding: 0px; list-style-type: none; } .markdown-preview[data-use-github-style] ul ul, .markdown-preview[data-use-github-style] ul ol, .markdown-preview[data-use-github-style] ol ol, .markdown-preview[data-use-github-style] ol ul { margin-top: 0px; margin-bottom: 0px; } .markdown-preview[data-use-github-style] li>p { margin-top: 16px; } .markdown-preview[data-use-github-style] dl { padding: 0px; } .markdown-preview[data-use-github-style] dl dt { padding: 0px; margin-top: 16px; font-size: 1em; font-style: italic; font-weight: bold; } .markdown-preview[data-use-github-style] dl dd { padding: 0px 16px; margin-bottom: 16px; } .markdown-preview[data-use-github-style] blockquote { padding: 0px 15px; color: rgb(119, 119, 119); border-left: 4px solid rgb(221, 221, 221); } .markdown-preview[data-use-github-style] blockquote> :first-child { margin-top: 0px; } .markdown-preview[data-use-github-style] blockquote> :last-child { margin-bottom: 0px; } .markdown-preview[data-use-github-style] table { display: block; width: 100%; overflow: auto; word-break: keep-all; } .markdown-preview[data-use-github-style] table th { font-weight: bold; } .markdown-preview[data-use-github-style] table th, .markdown-preview[data-use-github-style] table td { padding: 6px 13px; border: 1px solid rgb(221, 221, 221); } .markdown-preview[data-use-github-style] table tr { background-color: rgb(255, 255, 255); border-top: 1px solid rgb(204, 204, 204); } .markdown-preview[data-use-github-style] table tr:nth-child(2n) { background-color: rgb(248, 248, 248); } .markdown-preview[data-use-github-style] img { max-width: 100%; box-sizing: border-box; } .markdown-preview[data-use-github-style] .emoji { max-width: none; } .markdown-preview[data-use-github-style] span.frame { display: block; overflow: hidden; } .markdown-preview[data-use-github-style] span.frame>span { display: block; float: left; width: auto; padding: 7px; margin: 13px 0px 0px; overflow: hidden; border: 1px solid rgb(221, 221, 221); } .markdown-preview[data-use-github-style] span.frame span img { display: block; float: left; } .markdown-preview[data-use-github-style] span.frame span span { display: block; padding: 5px 0px 0px; clear: both; color: rgb(51, 51, 51); } .markdown-preview[data-use-github-style] span.align-center { display: block; overflow: hidden; clear: both; } .markdown-preview[data-use-github-style] span.align-center>span { display: block; margin: 13px auto 0px; overflow: hidden; text-align: center; } .markdown-preview[data-use-github-style] span.align-center span img { margin: 0px auto; text-align: center; } .markdown-preview[data-use-github-style] span.align-right { display: block; overflow: hidden; clear: both; } .markdown-preview[data-use-github-style] span.align-right>span { display: block; margin: 13px 0px 0px; overflow: hidden; text-align: right; } .markdown-preview[data-use-github-style] span.align-right span img { margin: 0px; text-align: right; } .markdown-preview[data-use-github-style] span.float-left { display: block; float: left; margin-right: 13px; overflow: hidden; } .markdown-preview[data-use-github-style] span.float-left span { margin: 13px 0px 0px; } .markdown-preview[data-use-github-style] span.float-right { display: block; float: right; margin-left: 13px; overflow: hidden; } .markdown-preview[data-use-github-style] span.float-right>span { display: block; margin: 13px auto 0px; overflow: hidden; text-align: right; } .markdown-preview[data-use-github-style] code, .markdown-preview[data-use-github-style] tt { padding: 0.2em 0px; margin: 0px; font-size: 85%; background-color: rgba(0, 0, 0, 0.04); border-radius: 3px; } .markdown-preview[data-use-github-style] code::before, .markdown-preview[data-use-github-style] tt::before, .markdown-preview[data-use-github-style] code::after, .markdown-preview[data-use-github-style] tt::after { letter-spacing: -0.2em; content: " "; } .markdown-preview[data-use-github-style] code br, .markdown-preview[data-use-github-style] tt br { display: none; } .markdown-preview[data-use-github-style] del code { text-decoration: inherit; } .markdown-preview[data-use-github-style] pre>code { padding: 0px; margin: 0px; font-size: 100%; word-break: normal; white-space: pre; background: transparent; border: 0px; } .markdown-preview[data-use-github-style] .highlight { margin-bottom: 16px; } .markdown-preview[data-use-github-style] .highlight pre, .markdown-preview[data-use-github-style] pre { padding: 16px; overflow: auto; font-size: 85%; line-height: 1.45; background-color: rgb(247, 247, 247); border-radius: 3px; } .markdown-preview[data-use-github-style] .highlight pre { margin-bottom: 0px; word-break: normal; } .markdown-preview[data-use-github-style] pre { overflow-wrap: normal; } .markdown-preview[data-use-github-style] pre code, .markdown-preview[data-use-github-style] pre tt { display: inline; max-width: initial; padding: 0px; margin: 0px; overflow: initial; line-height: inherit; overflow-wrap: normal; background-color: transparent; border: 0px; } .markdown-preview[data-use-github-style] pre code::before, .markdown-preview[data-use-github-style] pre tt::before, .markdown-preview[data-use-github-style] pre code::after, .markdown-preview[data-use-github-style] pre tt::after { content: normal; } .markdown-preview[data-use-github-style] kbd { display: inline-block; padding: 3px 5px; font-size: 11px; line-height: 10px; color: rgb(85, 85, 85); vertical-align: middle; background-color: rgb(252, 252, 252); border-width: 1px; border-style: solid; border-color: rgb(204, 204, 204) rgb(204, 204, 204) rgb(187, 187, 187); border-image: initial; border-radius: 3px; box-shadow: rgb(187, 187, 187) 0px -1px 0px inset; } .markdown-preview[data-use-github-style] a { color: rgb(51, 122, 183); } .markdown-preview[data-use-github-style] code { color: inherit; } .markdown-preview[data-use-github-style] pre.editor-colors { padding: 0.8em 1em; margin-bottom: 1em; font-size: 0.85em; border-radius: 4px; overflow: auto; } .markdown-preview pre.editor-colors { user-select: auto; } .scrollbars-visible-always .markdown-preview pre.editor-colors .vertical-scrollbar, .scrollbars-visible-always .markdown-preview pre.editor-colors .horizontal-scrollbar { visibility: hidden; } .scrollbars-visible-always .markdown-preview pre.editor-colors:hover .vertical-scrollbar, .scrollbars-visible-always .markdown-preview pre.editor-colors:hover .horizontal-scrollbar { visibility: visible; } .markdown-preview .task-list-item input[type="checkbox"] { position: absolute; margin: 0.25em 0px 0px -1.4em; } .markdown-preview .task-list-item { list-style-type: none; } .markdown-preview code { text-shadow: none; } @keyframes RotatingBackground { 0% { background-position-x: 0%; } 100% { background-position-x: 100%; } } .debugger-breakpoint-icon::before, .debugger-shadow-breakpoint-icon::before { font-family: 'Octicons Regular'; font-weight: normal; font-style: normal; display: inline-block; line-height: 1; -webkit-font-smoothing: antialiased; text-decoration: none; font-size: 130%; width: 130%; height: 130%; content: "\f052"; } .debugger-breakpoint-icon, .debugger-breakpoint-icon-disabled, .debugger-breakpoint-icon-unresolved, .debugger-breakpoint-icon-conditional, .debugger-shadow-breakpoint-icon { text-align: center; display: block; width: 0.8em; cursor: pointer; } .debugger-breakpoint-icon-nonconditional { color: #5293d8; } .debugger-breakpoint-icon-conditional { color: #ff982d; } .debugger-breakpoint-icon-disabled { position: relative; top: -4px; left: 2px; } .debugger-breakpoint-icon-disabled::before { font-family: 'Octicons Regular'; font-weight: normal; font-style: normal; display: inline-block; line-height: 1; -webkit-font-smoothing: antialiased; text-decoration: none; font-size: 78%; width: 78%; height: 78%; content: "\f084"; } .debugger-breakpoint-icon-unresolved { position: relative; top: -2px; } .debugger-breakpoint-icon-unresolved::before { font-family: 'Octicons Regular'; font-weight: normal; font-style: normal; display: inline-block; line-height: 1; -webkit-font-smoothing: antialiased; text-decoration: none; font-size: 80%; width: 80%; height: 80%; content: "\f0e8"; } .debugger-shadow-breakpoint-icon { color: rgba(82, 147, 216, 0.4); } .debugger-current-line-highlight { background: linear-gradient(to bottom, rgba(0, 152, 255, 0.8) 0%, rgba(0, 152, 255, 0.8) 5%, rgba(0, 152, 255, 0.3) 5%, rgba(0, 152, 255, 0.3) 95%, rgba(0, 152, 255, 0.8) 95%, rgba(0, 152, 255, 0.8) 100%); } .gutter[gutter-name=diagnostics-gutter] { width: 0.7em; } .diagnostics-gutter-ui-item { display: flex; } .diagnostics-gutter-ui-item .icon { display: flex; width: 0.7em; height: 0.7em; font-size: 0.7em; align-self: center; } .diagnostics-gutter-ui-item .icon::before { width: 1em; height: 1em; font-size: 1em; margin: 0; align-self: center; } .diagnostics-gutter-ui-item.diagnostics-gutter-ui-gutter-info, .diagnostics-gutter-ui-item.diagnostics-gutter-ui-gutter-review { color: #5293d8; } .diagnostics-gutter-ui-item.diagnostics-gutter-ui-gutter-error { color: #c00; } .diagnostics-gutter-ui-item.diagnostics-gutter-ui-gutter-action, .diagnostics-gutter-ui-item.diagnostics-gutter-ui-gutter-warning { color: #ff982d; } .bracket-matcher .region { border-bottom: 1px dotted lime; position: absolute; } .line-number.bracket-matcher.bracket-matcher { color: #c5c8c6; background-color: rgba(255, 255, 255, 0.14); } .spell-check-misspelling .region { border-bottom: 2px dotted rgba(255, 51, 51, 0.75); } .spell-check-corrections { width: 25em !important; } pre.editor-colors { background-color: #1d1f21; color: #c5c8c6; } pre.editor-colors .invisible-character { color: rgba(197, 200, 198, 0.2); } pre.editor-colors .indent-guide { color: rgba(197, 200, 198, 0.2); } pre.editor-colors .wrap-guide { background-color: rgba(197, 200, 198, 0.1); } pre.editor-colors .gutter { background-color: #292c2f; } pre.editor-colors .gutter .cursor-line { background-color: rgba(255, 255, 255, 0.14); } pre.editor-colors .line-number.cursor-line-no-selection { background-color: rgba(255, 255, 255, 0.14); } pre.editor-colors .gutter .line-number.folded, pre.editor-colors .gutter .line-number:after, pre.editor-colors .fold-marker:after { color: #fba0e3; } pre.editor-colors .invisible { color: #c5c8c6; } pre.editor-colors .cursor { border-color: white; } pre.editor-colors .selection .region { background-color: #444; } pre.editor-colors .bracket-matcher .region { border-bottom: 1px solid #f8de7e; margin-top: -1px; opacity: .7; } .syntax--comment { color: #8a8a8a; } .syntax--entity { color: #FFD2A7; } .syntax--entity.syntax--name.syntax--type { text-decoration: underline; color: #FFFFB6; } .syntax--entity.syntax--other.syntax--inherited-class { color: #9B5C2E; } .syntax--keyword { color: #96CBFE; } .syntax--keyword.syntax--control { color: #96CBFE; } .syntax--keyword.syntax--operator { color: #EDEDED; } .syntax--storage { color: #CFCB90; } .syntax--storage.syntax--modifier { color: #96CBFE; } .syntax--constant { color: #99CC99; } .syntax--constant.syntax--numeric { color: #FF73FD; } .syntax--variable { color: #C6C5FE; } .syntax--invalid.syntax--deprecated { text-decoration: underline; color: #FD5FF1; } .syntax--invalid.syntax--illegal { color: #FD5FF1; background-color: rgba(86, 45, 86, 0.75); } .syntax--string .syntax--source, .syntax--string .syntax--meta.syntax--embedded.syntax--line { color: #EDEDED; } .syntax--string .syntax--punctuation.syntax--section.syntax--embedded { color: #00A0A0; } .syntax--string .syntax--punctuation.syntax--section.syntax--embedded .syntax--source { color: #00A0A0; } .syntax--string { color: #A8FF60; } .syntax--string .syntax--constant { color: #00A0A0; } .syntax--string.syntax--regexp { color: #E9C062; } .syntax--string.syntax--regexp .syntax--constant.syntax--character.syntax--escape, .syntax--string.syntax--regexp .syntax--source.syntax--ruby.syntax--embedded, .syntax--string.syntax--regexp .syntax--string.syntax--regexp.syntax--arbitrary-repetition { color: #FF8000; } .syntax--string.syntax--regexp.syntax--group { color: #C6A24F; background-color: rgba(255, 255, 255, 0.06); } .syntax--string.syntax--regexp.syntax--character-class { color: #B18A3D; } .syntax--string .syntax--variable { color: #8A9A95; } .syntax--support { color: #FFFFB6; } .syntax--support.syntax--function { color: #DAD085; } .syntax--support.syntax--constant { color: #FFD2A7; } .syntax--support.syntax--type.syntax--property-name.syntax--css { color: #EDEDED; } .syntax--source .syntax--entity.syntax--name.syntax--tag, .syntax--source .syntax--punctuation.syntax--tag { color: #96CBFE; } .syntax--source .syntax--entity.syntax--other.syntax--attribute-name { color: #FF73FD; } .syntax--entity.syntax--other.syntax--attribute-name { color: #FF73FD; } .syntax--entity.syntax--name.syntax--tag.syntax--namespace, .syntax--entity.syntax--other.syntax--attribute-name.syntax--namespace { color: #E18964; } .syntax--meta.syntax--preprocessor.syntax--c { color: #8996A8; } .syntax--meta.syntax--preprocessor.syntax--c .syntax--keyword { color: #AFC4DB; } .syntax--meta.syntax--cast { color: #676767; } .syntax--meta.syntax--sgml.syntax--html .syntax--meta.syntax--doctype, .syntax--meta.syntax--sgml.syntax--html .syntax--meta.syntax--doctype .syntax--entity, .syntax--meta.syntax--sgml.syntax--html .syntax--meta.syntax--doctype .syntax--string, .syntax--meta.syntax--xml-processing, .syntax--meta.syntax--xml-processing .syntax--entity, .syntax--meta.syntax--xml-processing .syntax--string { color: #8a8a8a; } .syntax--meta.syntax--tag .syntax--entity, .syntax--meta.syntax--tag>.syntax--punctuation, .syntax--meta.syntax--tag.syntax--inline .syntax--entity { color: #FF73FD; } .syntax--meta.syntax--tag .syntax--name, .syntax--meta.syntax--tag.syntax--inline .syntax--name, .syntax--meta.syntax--tag>.syntax--punctuation { color: #96CBFE; } .syntax--meta.syntax--selector.syntax--css .syntax--entity.syntax--name.syntax--tag { text-decoration: underline; color: #96CBFE; } .syntax--meta.syntax--selector.syntax--css .syntax--entity.syntax--other.syntax--attribute-name.syntax--tag.syntax--pseudo-class { color: #8F9D6A; } .syntax--meta.syntax--selector.syntax--css .syntax--entity.syntax--other.syntax--attribute-name.syntax--id { color: #8B98AB; } .syntax--meta.syntax--selector.syntax--css .syntax--entity.syntax--other.syntax--attribute-name.syntax--class { color: #62B1FE; } .syntax--meta.syntax--property-group .syntax--support.syntax--constant.syntax--property-value.syntax--css, .syntax--meta.syntax--property-value .syntax--support.syntax--constant.syntax--property-value.syntax--css { color: #F9EE98; } .syntax--meta.syntax--preprocessor.syntax--at-rule .syntax--keyword.syntax--control.syntax--at-rule { color: #8693A5; } .syntax--meta.syntax--property-value .syntax--support.syntax--constant.syntax--named-color.syntax--css, .syntax--meta.syntax--property-value .syntax--constant { color: #87C38A; } .syntax--meta.syntax--constructor.syntax--argument.syntax--css { color: #8F9D6A; } .syntax--meta.syntax--diff, .syntax--meta.syntax--diff.syntax--header { color: #F8F8F8; background-color: #0E2231; } .syntax--meta.syntax--separator { color: #60A633; background-color: #242424; } .syntax--meta.syntax--line.syntax--entry.syntax--logfile, .syntax--meta.syntax--line.syntax--exit.syntax--logfile { background-color: rgba(238, 238, 238, 0.16); } .syntax--meta.syntax--line.syntax--error.syntax--logfile { background-color: #751012; } .syntax--source.syntax--gfm { color: #999; } .syntax--gfm .syntax--markup.syntax--heading { color: #eee; } .syntax--gfm .syntax--link { color: #555; } .syntax--gfm .syntax--variable.syntax--list, .syntax--gfm .syntax--support.syntax--quote { color: #555; } .syntax--gfm .syntax--link .syntax--entity { color: #ddd; } .syntax--gfm .syntax--raw { color: #aaa; } .syntax--markdown .syntax--paragraph { color: #999; } .syntax--markdown .syntax--heading { color: #eee; } .syntax--markdown .syntax--raw { color: #aaa; } .syntax--markdown .syntax--link { color: #555; } .syntax--markdown .syntax--link .syntax--string { color: #555; } .syntax--markdown .syntax--link .syntax--string.syntax--title { color: #ddd; }eel.jsは公式githubとかから取得してください
参考にしたサイト
CSSで作る!押したくなるボタンデザイン100(Web用)
Python eelでファイル選択ダイアログ動作風景
exeファイル
- 投稿日:2020-02-25T14:19:12+09:00
Quantx Factoryでアルゴリズムを実装する時に頻繁に用いるpandas, talibのメソッドまとめ
自己紹介
株式会社SmartTradeでインターンをしている、M大学理工学部2年の益川と申します。機械学習勉強中です。
QuantX Factoryとは?
株式会社Smart Tradeが
金融の民主化
を理念に、トレードアルゴリズムを誰もが簡単に開発することのできるプラットフォーム"QuantX Factory"を開発しました。
強み
- 初心者の挫折しがちな環境構築が不要
- 各銘柄の終値や高値、出来高などの各種データが用意されていて,データセットの用意が不要
- 開発したトレードアルゴリズムは審査を通過すればQuantX Storeで販売可能
- 上級者の方にはQuantX Labといった開発環境も (引用元:公式ドキュメント)
本題
当社インターン一ヶ月目ということで、自分が今まで作成してきたアルゴリズムを例に、アルゴリズム作成において頻繁に使うpandasやtalibのメソッドの使い方を解説していこうと思います。
(注:このコードの内容を今完全に理解しなくて大丈夫です)
# ライブラリーのimport # 必要ライブラリー # バックテストエンジン「maron」をインポート import maron import maron.signalfunc as sf import maron.execfunc as ef # 追加ライブラリー # 追加で必要なライブラリーがある場合は以下の例に倣って追加して下さい # データ分析ツール「pandas」をインポートし「pd」という名前で使用 import pandas as pd # 金融系関数セット「talib」をインポートし「ta」という名前で使用 import talib as ta import numpy as np # 「」をインポートし「」という名前で使用 # import as # オーダ方法(目的の注文方法に合わせて以下の3つの中から一つだけコメントアウトを外して下さい) # ot = maron.OrderType.MARKET_CLOSE # シグナルが出たた翌日の終値のタイミングでオーダー ot = maron.OrderType.MARKET_OPEN # シグナルが出たた翌日の始値のタイミングでオーダー # ot = maron.OrderType.LIMIT # 指値によるオーダー def initialize(ctx): # 初期化部分 ctx.logger.debug("initialize() called") # ログ出力 ctx.target = 0.1 ctx.loss_cut = -0.02 ctx.plofit = 0.05 ctx.configure( channels={ "jp.stock": { "symbols": [ "jp.stock.2914", #JT(日本たばこ産業) "jp.stock.8766", #東京海上ホールディングス "jp.stock.8031", #三井物産 "jp.stock.8316", #三井住友フィナンシャルグループ "jp.stock.8411", #みずほフィナンシャルグループ "jp.stock.9437", #NTTドコモ "jp.stock.4502", #武田薬品工業 "jp.stock.8058", #三菱商事 "jp.stock.9433", #KDDI "jp.stock.9432", #日本電信電話 "jp.stock.7267", #ホンダ(本田技研工業) "jp.stock.8306", #三菱UFJフィナンシャル・グループ "jp.stock.4503", #アステラス製薬 "jp.stock.4063", #信越化学工業 "jp.stock.7974", #任天堂 "jp.stock.6981", #村田製作所 "jp.stock.3382", #セブン&アイ・ホールディングス "jp.stock.9020", #東日本旅客鉄道 "jp.stock.8802", #三菱地所 "jp.stock.9022", #東海旅客鉄道 "jp.stock.9984", #ソフトバンクグループ "jp.stock.6861", #キーエンス "jp.stock.6501", #日立製作所 "jp.stock.6752", #パナソニック "jp.stock.6758", #ソニー "jp.stock.6954", #ファナック "jp.stock.7203", #トヨタ自動車 "jp.stock.7751", #キヤノン "jp.stock.4452", #花王 "jp.stock.6098", #リクルートホールディングス ], #⑥ "columns": ["close_price_adj", # 終値(株式分割調整後) ]}}) def _my_signal(data): # 売買シグナル生成部分 # dataの中身を確認したい場合は以下のコメントアウトを外してください # ctx.logger.debug(data) syms = data.minor_axis # 銘柄リストの作成 dates = data.major_axis # 日付リストの作成 '''↓ロジックの計算に必要なデータを3次元構造のdataから取得するコードを書いて下さい↓''' cp = data["close_price_adj"].fillna("ffill") '''↑ロジックの計算に必要なデータを3次元構造のdataから取得するコードを書いて下さい↑''' '''↓売買条件を定義するために必要なロジックの計算をするコードを書いて下さい↓''' movave5 = cp.rolling(window = 5, center = False).mean() movave25 = cp.rolling(window = 25, center = False).mean() '''↑売買条件を定義するために必要なロジックの計算をするコードを書いて下さい↑''' # 売買シグナルを定義(bool値で返す) buy_sig = (movave5 > movave25) & (movave5.shift(1) < movave25.shift(1)) sell_sig = (movave5 < movave25) & (movave5.shift(1) > movave25.shift(1)) # market_sigという全て0.0が格納されている「横:銘柄名、縦:日付」のデータフレームを作成 market_sig = pd.DataFrame(data=0.0, columns=syms, index=dates) # buy_sigがTrueのとき1.0、sell_sigがTrueのとき-1.0、どちらもTrueのとき0.0とおく market_sig[buy_sig == True] = 1.0 market_sig[sell_sig == True] = -1.0 market_sig[(buy_sig == True) & (sell_sig == True)] = 0.0 # market_sigの中身を確認したい場合は以下のコメントアウトを外してください # ctx.logger.debug(market_sig) return { "buy:sig":buy_sig, "sell:sig": sell_sig, "market:sig": market_sig, # 以下にバックテスト結果のチャートで表示したいデータを追加して下さい } ctx.regist_signal("my_signal", _my_signal) # シグナル登録 def handle_signals(ctx, date, current): # 日ごとの処理部分 ''' current: pd.DataFrame ''' # initializeの_my_signalで生成したシグナルをmarket_sigに格納 market_sig = current["market:sig"] done_syms = set([]) # 利益確定及び損切りが行われた銘柄を格納するset型 none_syms = set([]) # portfolio.positionsに存在しない銘柄を格納するset型 # portfolio.positions(保有している銘柄)に対象銘柄(sym)が存在するかのチェック for (sym, val) in market_sig.items(): if sym not in ctx.portfolio.positions: none_syms.add(sym) # portfolio.positions(保有している銘柄)のそれぞれの銘柄(sym)の保有株数が0ではないかのチェック for (sym, val) in ctx.portfolio.positions.items(): if val["amount"] == 0: none_syms.add(sym) # 損切り、利益確定(利確)の設定 # 所有している銘柄を1つずつ確認する繰り返し処理 for (sym, val) in ctx.portfolio.positions.items(): # 損益率の取得 returns = val["returns"] if returns < -0.03: # 損益率が-3%未満(絶対値で3%より大きい損)の場合 # 損切りのための売り注文 sec = ctx.getSecurity(sym) sec.order(-val["amount"], comment="損切り(%f)" % returns) # 利益確定及び損切りが行われた銘柄を格納するset型にsymに代入されている銘柄を追加 done_syms.add(sym) elif returns > 0.05: # 損益率が+5%より大きい場合 # 利益確定(利確)のための売り注文 sec = ctx.getSecurity(sym) sec.order(-val["amount"], comment="利益確定売(%f)" % returns) # 利益確定及び損切りが行われた銘柄を格納するset型にsymに代入されている銘柄を追加 done_syms.add(sym) buy = market_sig[market_sig > 0.0] # 買いシグナル for (sym, val) in buy.items(): # 買いシグナルが出ている銘柄を1つずつ処理 # done_symsまたはnone_symsにsymがある場合 if sym in done_syms: continue # 処理をスキップ # 買い注文 sec = ctx.getSecurity(sym) sec.order(sec.unit() * 1, orderType=ot, comment="SIGNAL BUY") # 買い注文のログを下に出力したい場合は以下のコメントアウトを外してください(長期間注意) #ctx.logger.debug("BUY: %s, %f" % (sec.code(), val)) sell = market_sig[market_sig < 0.0] # 売りシグナル for (sym, val) in sell.items(): # 売りシグナルが出ている銘柄を1つずつ処理 # done_symsまたはnone_symsにsymがある場合 if (sym in done_syms) | (sym in none_syms): continue # 処理をスキップ # 売り注文 sec = ctx.getSecurity(sym) sec.order(sec.unit() * -1,orderType=ot, comment="SIGNAL SELL")図1:移動平均線のゴールデンクロス、デッドクロスを用いたアルゴリズム(参照:https://factory.quantx.io/developer/149d79a8cf744f059af0e96918913a9f/coding)
pandas系
rollingメソッド
pd.DataFrame.rolling(window)
- DataFrame、Seriesなどのpandasの基本的なデータ構造に窓関数をに適用するときに用いるメソッドで、rollingオブジェクトを返す。
- 主に用いる引数は窓数を設定するwindow
- 窓関数:ある有限区間以外で0となる関数。 - ある関数や信号(データ)に窓関数が掛け合わせられると、区間外は0になり、有限区間内だけが残るので、数値解析が容易になる。(参照:Weblio 「窓関数とは」)
- 使い道:移動平均線、出来高移動平均線等のテクニカル指標を実装するときに用いる。
例:25日移動平均線を実装する
図1の82行目において
movave25 = cp.rolling(window = 25).mean()
とありますが、これが25日移動平均線を定義しているものです。
- 各銘柄の各日付の終値を格納したDataFrameである
cpにcp.rolling(window = 25)で窓数25の窓関数を適用し、rollingオブジェクトが返されます。- 返されたrollingオブジェクトにmeanメソッドを適用して、25日分の平均値の格納されている新たなDataFrame型オブジェクトが返されます。
これで、25日分の移動平均を格納したDataFrameである、movave25を得ることができました。
shiftメソッド
pandas.DataFrame.shift(periods)
- データフレームに格納されているデータをperiods分だけ移動(シフト)させるメソッド、DataFrameオブジェクトを返す
- 使い道:短期線と長期線の二つの移動平均線の大小関係の前日からの変化を検知する。
例: ゴールデンクロス、デッドクロスの判定
図1の87行目において
buy_sig = (movave5 > movave25) & (movave5.shift(1) < movave25.shift(1))
とありますが、このコードは「当日の5日移動平均の方が25日移動平均よりも大きく、前日5日移動平均の方が25日移動平均よりも小さい」こと、つまりゴールデンクロスしたことを示しています。88行目はその逆です。shiftメソッドはこのような形で利用します。
talib系
そもそもtalibとは
テクニカル指標などを簡単に実装できるライブラリ。
実装できる指標については下記URLを参考にしてください。
https://mrjbq7.github.io/ta-lib/funcs.htmltalibを用いた例
# Sample Algorithm # ライブラリーのimport # 必要ライブラリー import maron import maron.signalfunc as sf import maron.execfunc as ef # 追加ライブラリー # 使用可能なライブラリに関しましては右画面のノートをご覧ください① import pandas as pd import talib as ta import numpy as np # オーダ方法(目的の注文方法に合わせて以下の2つの中から一つだけコメントアウトを外してください) # オーダー方法に関しましては右画面のノートをご覧ください② #ot = maron.OrderType.MARKET_CLOSE # シグナルがでた翌日の終値のタイミングでオーダー ot = maron.OrderType.MARKET_OPEN # シグナルがでた翌日の始値のタイミングでオーダー #ot = maron.OrderType.LIMIT # 指値によるオーダー # 銘柄、columnsの取得 # 銘柄の指定に関しては右画面のノートをご覧ください③ # columnsの取得に関しては右画面のノートをご覧ください④ def initialize(ctx): # 設定 ctx.logger.debug("initialize() called") ctx.configure( channels={ # 利用チャンネル "jp.stock": { "symbols": [ "jp.stock.2914", #JT(日本たばこ産業) "jp.stock.8766", #東京海上ホールディングス "jp.stock.8031", #三井物産 "jp.stock.8316", #三井住友フィナンシャルグループ "jp.stock.8411", #みずほフィナンシャルグループ "jp.stock.9437", #NTTドコモ "jp.stock.4502", #武田薬品工業 "jp.stock.8058", #三菱商事 "jp.stock.9433", #KDDI "jp.stock.9432", #日本電信電話 "jp.stock.7267", #ホンダ(本田技研工業) "jp.stock.8306", #三菱UFJフィナンシャル・グループ "jp.stock.4503", #アステラス製薬 "jp.stock.4063", #信越化学工業 "jp.stock.7974", #任天堂 "jp.stock.6981", #村田製作所 "jp.stock.3382", #セブン&アイ・ホールディングス "jp.stock.9020", #東日本旅客鉄道 "jp.stock.8802", #三菱地所 "jp.stock.9022", #東海旅客鉄道 "jp.stock.9984", #ソフトバンクグループ "jp.stock.6861", #キーエンス "jp.stock.6501", #日立製作所 "jp.stock.6752", #パナソニック "jp.stock.6758", #ソニー "jp.stock.6954", #ファナック "jp.stock.7203", #トヨタ自動車 "jp.stock.7751", #キヤノン "jp.stock.4452", #花王 "jp.stock.6098", #リクルートホールディングス ], "columns": [ "close_price", # 終値 "close_price_adj", # 終値(株式分割調整後) #"volume_adj", # 出来高 #"txn_volume", # 売買代金 ] } } ) # シグナル定義 def _my_signal(data): #終値のデータを取得 cp=data["close_price_adj"].fillna(method="ffill") syms = data.minor_axis # 銘柄リストの作成 dates = data.major_axis # 日付リストの作成 #データを格納する場所 macd = pd.DataFrame(data=0.0, columns=syms, index=dates) macdsignal = pd.DataFrame(data=0.0, columns=syms, index=dates) macdhist = pd.DataFrame(data=0.0, columns=syms, index=dates) rsi = pd.DataFrame(data = 0.0, columns = syms, index = dates) #TA-LibによるMACDの計算 for (sym,val) in cp.items(): macd[sym],macdsignal[sym],macdhist[sym] = ta.MACD(cp[sym]) rsi[sym] = ta.RSI(cp[sym].values.astype(np.double), timeperiod = 10) macd_golden = (macd > macdsignal) & (macd.shift(1) < macdsignal.shift(1)) macd_dead = (macd < macdsignal) & (macd.shift(1) > macdsignal.shift(1)) #売買シグナル生成部分 buy_sig = macd_golden | (rsi < 30) sell_sig = macd_dead | (rsi > 70) #market_sigという全て0が格納されているデータフレームを作成 market_sig = pd.DataFrame(data=0.0, columns=syms, index=dates) #buy_sigがTrueのとき1.0、sell_sigがTrueのとき-1.0とおく market_sig[buy_sig == True] = 1.0 market_sig[sell_sig == True] = -1.0 market_sig[(buy_sig == True) & (sell_sig == True)] = 0.0 # ctx.logger.debug(market_sig) return { "MACD:g2": macd, "MACDSignal:g2": macdsignal, "MACDHist": macdhist, "market:sig": market_sig, } # シグナル登録 ctx.regist_signal("my_signal", _my_signal) def handle_signals(ctx, date, current): # 日ごとの処理部分 ''' current: pd.DataFrame ''' # initializeの_my_signalで生成したシグナルをmarket_sigに格納 market_sig = current["market:sig"] done_syms = set([]) # 利益確定及び損切りが行われた銘柄を格納するset型 none_syms = set([]) # portfolio.positionsに存在しない銘柄を格納するset型 # portfolio.positions(保有している銘柄)に対象銘柄(sym)が存在するかのチェック for (sym, val) in market_sig.items(): if sym not in ctx.portfolio.positions: none_syms.add(sym) # portfolio.positions(保有している銘柄)のそれぞれの銘柄(sym)の保有株数が0ではないかのチェック for (sym, val) in ctx.portfolio.positions.items(): if val["amount"] == 0: none_syms.add(sym) # 損切り、利益確定(利確)の設定 # 所有している銘柄を1つずつ確認する繰り返し処理 for (sym, val) in ctx.portfolio.positions.items(): # 損益率の取得 returns = val["returns"] if returns < -0.03: # 損益率が-3%未満(絶対値で3%より大きい損)の場合 # 損切りのための売り注文 sec = ctx.getSecurity(sym) sec.order(-val["amount"], comment="損切り(%f)" % returns) # 利益確定及び損切りが行われた銘柄を格納するset型にsymに代入されている銘柄を追加 done_syms.add(sym) elif returns > 0.05: # 損益率が+5%より大きい場合 # 利益確定(利確)のための売り注文 sec = ctx.getSecurity(sym) sec.order(-val["amount"], comment="利益確定売(%f)" % returns) # 利益確定及び損切りが行われた銘柄を格納するset型にsymに代入されている銘柄を追加 done_syms.add(sym) buy = market_sig[market_sig > 0.0] # 買いシグナル for (sym, val) in buy.items(): # 買いシグナルが出ている銘柄を1つずつ処理 # done_symsまたはnone_symsにsymがある場合 if sym in done_syms: continue # 処理をスキップ # 買い注文 sec = ctx.getSecurity(sym) sec.order(sec.unit() * 1, orderType=ot, comment="SIGNAL BUY") # 買い注文のログを下に出力したい場合は以下のコメントアウトを外してください(長期間注意) #ctx.logger.debug("BUY: %s, %f" % (sec.code(), val)) sell = market_sig[market_sig < 0.0] # 売りシグナル for (sym, val) in sell.items(): # 売りシグナルが出ている銘柄を1つずつ処理 # done_symsまたはnone_symsにsymがある場合 if (sym in done_syms) | (sym in none_syms): continue # 処理をスキップ # 売り注文 sec = ctx.getSecurity(sym) sec.order(sec.unit() * -1,orderType=ot, comment="SIGNAL SELL")図2:RSIとMACDのゴールデンクロス、デッドクロスを用いたアルゴリズム(参照:https://factory.quantx.io/developer/6ba1eb1b748d46a18ce128fea3156282/coding)
RSI
talib.RSI(close, timeperiod = 14)
- RSIとは、「買われすぎ」、「売られすぎ」を判別するテクニカル指標です
- 終値を示すnp.double型のnp.arraysオブジェクトcloseと、期間を示すtimeperiodを引数にとります。
例:図2のコードの82行目において
rsi = pd.DataFrame(data = 0.0, columns = syms, index = dates)各銘柄のRSIを格納するDataFrameを定義して
85行目のfor文
for (sym,val) in cp.items(): rsi[sym] = ta.RSI(cp[sym].values.astype(np.double), timeperiod = 10)において各銘柄のRSIを格納しています。
cp[sym]はDataFrame型のオブジェクトですので、cp[sym].valuesでarray型のオブジェクトに変換します。- そして
cp[sym].values.astype(np.double)でarrayの中身をnp.double型に変換しています。- 今回は10日分のRSIを取るのでtimeperiod = 10にします
- 「売られすぎ」か「買われすぎ」かを参考に売買を判断します
MACD
ta.MACD(close)
- 移動平均線を応用したテクニカル指標で、MACDラインとMACDシグナルラインの日本の線の組み合わせて売買のタイミングを測ります。
- 銘柄の終値を格納したSeriesオブジェクトcloseを引数にとります。
- 三つのDataFrame型のオブジェクトを返します
例:図2のコード79〜81行目において、
macd = pd.DataFrame(data=0.0, columns=syms, index=dates) macdsignal = pd.DataFrame(data=0.0, columns=syms, index=dates) macdhist = pd.DataFrame(data=0.0, columns=syms, index=dates)返り値を格納するDataFrameを定義します。
85行目のfor文for (sym,val) in cp.items(): macd[sym],macdsignal[sym],macdhist[sym] = ta.MACD(cp[sym])において各銘柄のmacd, macdsignal, macdhistをとります。
90,91行目でMACDラインとMACDシグナルラインのゴールデンクロス、デッドクロスを判断しています。
macd_golden = (macd > macdsignal) & (macd.shift(1) < macdsignal.shift(1)) macd_dead = (macd < macdsignal) & (macd.shift(1) > macdsignal.shift(1))MACD、RSIから、買いシグナル、売りシグナルを定める
buy_sig = macd_golden | (rsi < 30) #ゴールデンクロスかつ売られすぎ sell_sig = macd_dead | (rsi > 70) #デッドクロスかつ買われすぎこのように、talibを用いることでMACD、RSIなどの有名なテクニカル指標を簡単に実装することができます。
まとめ
以上でこの記事を終えたいと思います。今回はtalibやpandasのアルゴ作成において頻繁に使うメソッドをピックアップしてきました。これを読んで少しでも他のインターン生の方々のアルゴリズムへの理解が深まったら幸いです。最後まで拙い文章をお読みいただきありがとうございました。
免責注意事項
このコード・知識を使った実際の取引で生じた損益に関しては一切の責任を負いかねますので御了承下さい。
- 投稿日:2020-02-25T14:19:12+09:00
Quantx Factoryで基本的なアルゴ実装をするときによく使うメソッドをまとめてみた
自己紹介
株式会社SmartTradeでインターンをしている、M大学理工学部2年の益川と申します。機械学習勉強中です。
QuantX Factoryとは?
株式会社Smart Tradeが
金融の民主化
を理念に、トレードアルゴリズムを誰もが簡単に開発することのできるプラットフォーム"QuantX Factory"を開発しました。
強み
- 初心者の挫折しがちな環境構築が不要
- 各銘柄の終値や高値、出来高などの各種データが用意されていて,データセットの用意が不要
- 開発したトレードアルゴリズムは審査を通過すればQuantX Storeで販売可能
- 上級者の方にはQuantX Labといった開発環境も (引用元:公式ドキュメント)
本題
当社インターン一ヶ月目ということで、MACDや移動平均線、RSIといった基本的なテクニカル指標を実装するためのアルゴリズム作成において頻繁に使うpandasやtalibのメソッドの使い方を解説していこうと思います。
(注:このコードの内容を今完全に理解しなくて大丈夫です)
# ライブラリーのimport # 必要ライブラリー # バックテストエンジン「maron」をインポート import maron import maron.signalfunc as sf import maron.execfunc as ef # 追加ライブラリー # 追加で必要なライブラリーがある場合は以下の例に倣って追加して下さい # データ分析ツール「pandas」をインポートし「pd」という名前で使用 import pandas as pd # 金融系関数セット「talib」をインポートし「ta」という名前で使用 import talib as ta import numpy as np # 「」をインポートし「」という名前で使用 # import as # オーダ方法(目的の注文方法に合わせて以下の3つの中から一つだけコメントアウトを外して下さい) # ot = maron.OrderType.MARKET_CLOSE # シグナルが出たた翌日の終値のタイミングでオーダー ot = maron.OrderType.MARKET_OPEN # シグナルが出たた翌日の始値のタイミングでオーダー # ot = maron.OrderType.LIMIT # 指値によるオーダー def initialize(ctx): # 初期化部分 ctx.logger.debug("initialize() called") # ログ出力 ctx.target = 0.1 ctx.loss_cut = -0.02 ctx.plofit = 0.05 ctx.configure( channels={ "jp.stock": { "symbols": [ "jp.stock.2914", #JT(日本たばこ産業) "jp.stock.8766", #東京海上ホールディングス "jp.stock.8031", #三井物産 "jp.stock.8316", #三井住友フィナンシャルグループ "jp.stock.8411", #みずほフィナンシャルグループ "jp.stock.9437", #NTTドコモ "jp.stock.4502", #武田薬品工業 "jp.stock.8058", #三菱商事 "jp.stock.9433", #KDDI "jp.stock.9432", #日本電信電話 "jp.stock.7267", #ホンダ(本田技研工業) "jp.stock.8306", #三菱UFJフィナンシャル・グループ "jp.stock.4503", #アステラス製薬 "jp.stock.4063", #信越化学工業 "jp.stock.7974", #任天堂 "jp.stock.6981", #村田製作所 "jp.stock.3382", #セブン&アイ・ホールディングス "jp.stock.9020", #東日本旅客鉄道 "jp.stock.8802", #三菱地所 "jp.stock.9022", #東海旅客鉄道 "jp.stock.9984", #ソフトバンクグループ "jp.stock.6861", #キーエンス "jp.stock.6501", #日立製作所 "jp.stock.6752", #パナソニック "jp.stock.6758", #ソニー "jp.stock.6954", #ファナック "jp.stock.7203", #トヨタ自動車 "jp.stock.7751", #キヤノン "jp.stock.4452", #花王 "jp.stock.6098", #リクルートホールディングス ], #⑥ "columns": ["close_price_adj", # 終値(株式分割調整後) ]}}) def _my_signal(data): # 売買シグナル生成部分 # dataの中身を確認したい場合は以下のコメントアウトを外してください # ctx.logger.debug(data) syms = data.minor_axis # 銘柄リストの作成 dates = data.major_axis # 日付リストの作成 '''↓ロジックの計算に必要なデータを3次元構造のdataから取得するコードを書いて下さい↓''' cp = data["close_price_adj"].fillna("ffill") '''↑ロジックの計算に必要なデータを3次元構造のdataから取得するコードを書いて下さい↑''' '''↓売買条件を定義するために必要なロジックの計算をするコードを書いて下さい↓''' movave5 = cp.rolling(window = 5, center = False).mean() movave25 = cp.rolling(window = 25, center = False).mean() '''↑売買条件を定義するために必要なロジックの計算をするコードを書いて下さい↑''' # 売買シグナルを定義(bool値で返す) buy_sig = (movave5 > movave25) & (movave5.shift(1) < movave25.shift(1)) sell_sig = (movave5 < movave25) & (movave5.shift(1) > movave25.shift(1)) # market_sigという全て0.0が格納されている「横:銘柄名、縦:日付」のデータフレームを作成 market_sig = pd.DataFrame(data=0.0, columns=syms, index=dates) # buy_sigがTrueのとき1.0、sell_sigがTrueのとき-1.0、どちらもTrueのとき0.0とおく market_sig[buy_sig == True] = 1.0 market_sig[sell_sig == True] = -1.0 market_sig[(buy_sig == True) & (sell_sig == True)] = 0.0 # market_sigの中身を確認したい場合は以下のコメントアウトを外してください # ctx.logger.debug(market_sig) return { "buy:sig":buy_sig, "sell:sig": sell_sig, "market:sig": market_sig, # 以下にバックテスト結果のチャートで表示したいデータを追加して下さい } ctx.regist_signal("my_signal", _my_signal) # シグナル登録 def handle_signals(ctx, date, current): # 日ごとの処理部分 ''' current: pd.DataFrame ''' # initializeの_my_signalで生成したシグナルをmarket_sigに格納 market_sig = current["market:sig"] done_syms = set([]) # 利益確定及び損切りが行われた銘柄を格納するset型 none_syms = set([]) # portfolio.positionsに存在しない銘柄を格納するset型 # portfolio.positions(保有している銘柄)に対象銘柄(sym)が存在するかのチェック for (sym, val) in market_sig.items(): if sym not in ctx.portfolio.positions: none_syms.add(sym) # portfolio.positions(保有している銘柄)のそれぞれの銘柄(sym)の保有株数が0ではないかのチェック for (sym, val) in ctx.portfolio.positions.items(): if val["amount"] == 0: none_syms.add(sym) # 損切り、利益確定(利確)の設定 # 所有している銘柄を1つずつ確認する繰り返し処理 for (sym, val) in ctx.portfolio.positions.items(): # 損益率の取得 returns = val["returns"] if returns < -0.03: # 損益率が-3%未満(絶対値で3%より大きい損)の場合 # 損切りのための売り注文 sec = ctx.getSecurity(sym) sec.order(-val["amount"], comment="損切り(%f)" % returns) # 利益確定及び損切りが行われた銘柄を格納するset型にsymに代入されている銘柄を追加 done_syms.add(sym) elif returns > 0.05: # 損益率が+5%より大きい場合 # 利益確定(利確)のための売り注文 sec = ctx.getSecurity(sym) sec.order(-val["amount"], comment="利益確定売(%f)" % returns) # 利益確定及び損切りが行われた銘柄を格納するset型にsymに代入されている銘柄を追加 done_syms.add(sym) buy = market_sig[market_sig > 0.0] # 買いシグナル for (sym, val) in buy.items(): # 買いシグナルが出ている銘柄を1つずつ処理 # done_symsまたはnone_symsにsymがある場合 if sym in done_syms: continue # 処理をスキップ # 買い注文 sec = ctx.getSecurity(sym) sec.order(sec.unit() * 1, orderType=ot, comment="SIGNAL BUY") # 買い注文のログを下に出力したい場合は以下のコメントアウトを外してください(長期間注意) #ctx.logger.debug("BUY: %s, %f" % (sec.code(), val)) sell = market_sig[market_sig < 0.0] # 売りシグナル for (sym, val) in sell.items(): # 売りシグナルが出ている銘柄を1つずつ処理 # done_symsまたはnone_symsにsymがある場合 if (sym in done_syms) | (sym in none_syms): continue # 処理をスキップ # 売り注文 sec = ctx.getSecurity(sym) sec.order(sec.unit() * -1,orderType=ot, comment="SIGNAL SELL")図1:移動平均線のゴールデンクロス、デッドクロスを用いたアルゴリズム(参照:https://factory.quantx.io/developer/149d79a8cf744f059af0e96918913a9f/coding)
pandas系
rollingメソッド
pd.DataFrame.rolling(window)
- DataFrame、Seriesなどのpandasの基本的なデータ構造に窓関数をに適用するときに用いるメソッドで、rollingオブジェクトを返す。
- 主に用いる引数は窓数を設定するwindow
- 窓関数:ある有限区間以外で0となる関数。 - ある関数や信号(データ)に窓関数が掛け合わせられると、区間外は0になり、有限区間内だけが残るので、数値解析が容易になる。(参照:Weblio 「窓関数とは」)
- 使い道:移動平均線、出来高移動平均線等のテクニカル指標を実装するときに用いる。
例:25日移動平均線を実装する
図1の82行目において
movave25 = cp.rolling(window = 25).mean()
とありますが、これが25日移動平均線を定義しているものです。
- 各銘柄の各日付の終値を格納したDataFrameである
cpにcp.rolling(window = 25)で窓数25の窓関数を適用し、rollingオブジェクトが返されます。- 返されたrollingオブジェクトにmeanメソッドを適用して、25日分の平均値の格納されている新たなDataFrame型オブジェクトが返されます。
これで、25日分の移動平均を格納したDataFrameである、movave25を得ることができました。
shiftメソッド
pandas.DataFrame.shift(periods)
- データフレームに格納されているデータをperiods分だけ移動(シフト)させるメソッド、DataFrameオブジェクトを返す
- 使い道:短期線と長期線の二つの移動平均線の大小関係の前日からの変化を検知する。
例: ゴールデンクロス、デッドクロスの判定
図1の87行目において
buy_sig = (movave5 > movave25) & (movave5.shift(1) < movave25.shift(1))
とありますが、このコードは「当日の5日移動平均の方が25日移動平均よりも大きく、前日5日移動平均の方が25日移動平均よりも小さい」こと、つまりゴールデンクロスしたことを示しています。88行目はその逆です。shiftメソッドはこのような形で利用します。
talib系
そもそもtalibとは
テクニカル指標などを簡単に実装できるライブラリ。
実装できる指標については下記URLを参考にしてください。
https://mrjbq7.github.io/ta-lib/funcs.htmltalibを用いた例
# Sample Algorithm # ライブラリーのimport # 必要ライブラリー import maron import maron.signalfunc as sf import maron.execfunc as ef # 追加ライブラリー # 使用可能なライブラリに関しましては右画面のノートをご覧ください① import pandas as pd import talib as ta import numpy as np # オーダ方法(目的の注文方法に合わせて以下の2つの中から一つだけコメントアウトを外してください) # オーダー方法に関しましては右画面のノートをご覧ください② #ot = maron.OrderType.MARKET_CLOSE # シグナルがでた翌日の終値のタイミングでオーダー ot = maron.OrderType.MARKET_OPEN # シグナルがでた翌日の始値のタイミングでオーダー #ot = maron.OrderType.LIMIT # 指値によるオーダー # 銘柄、columnsの取得 # 銘柄の指定に関しては右画面のノートをご覧ください③ # columnsの取得に関しては右画面のノートをご覧ください④ def initialize(ctx): # 設定 ctx.logger.debug("initialize() called") ctx.configure( channels={ # 利用チャンネル "jp.stock": { "symbols": [ "jp.stock.2914", #JT(日本たばこ産業) "jp.stock.8766", #東京海上ホールディングス "jp.stock.8031", #三井物産 "jp.stock.8316", #三井住友フィナンシャルグループ "jp.stock.8411", #みずほフィナンシャルグループ "jp.stock.9437", #NTTドコモ "jp.stock.4502", #武田薬品工業 "jp.stock.8058", #三菱商事 "jp.stock.9433", #KDDI "jp.stock.9432", #日本電信電話 "jp.stock.7267", #ホンダ(本田技研工業) "jp.stock.8306", #三菱UFJフィナンシャル・グループ "jp.stock.4503", #アステラス製薬 "jp.stock.4063", #信越化学工業 "jp.stock.7974", #任天堂 "jp.stock.6981", #村田製作所 "jp.stock.3382", #セブン&アイ・ホールディングス "jp.stock.9020", #東日本旅客鉄道 "jp.stock.8802", #三菱地所 "jp.stock.9022", #東海旅客鉄道 "jp.stock.9984", #ソフトバンクグループ "jp.stock.6861", #キーエンス "jp.stock.6501", #日立製作所 "jp.stock.6752", #パナソニック "jp.stock.6758", #ソニー "jp.stock.6954", #ファナック "jp.stock.7203", #トヨタ自動車 "jp.stock.7751", #キヤノン "jp.stock.4452", #花王 "jp.stock.6098", #リクルートホールディングス ], "columns": [ "close_price", # 終値 "close_price_adj", # 終値(株式分割調整後) #"volume_adj", # 出来高 #"txn_volume", # 売買代金 ] } } ) # シグナル定義 def _my_signal(data): #終値のデータを取得 cp=data["close_price_adj"].fillna(method="ffill") syms = data.minor_axis # 銘柄リストの作成 dates = data.major_axis # 日付リストの作成 #データを格納する場所 macd = pd.DataFrame(data=0.0, columns=syms, index=dates) macdsignal = pd.DataFrame(data=0.0, columns=syms, index=dates) macdhist = pd.DataFrame(data=0.0, columns=syms, index=dates) rsi = pd.DataFrame(data = 0.0, columns = syms, index = dates) #TA-LibによるMACDの計算 for (sym,val) in cp.items(): macd[sym],macdsignal[sym],macdhist[sym] = ta.MACD(cp[sym]) rsi[sym] = ta.RSI(cp[sym].values.astype(np.double), timeperiod = 10) macd_golden = (macd > macdsignal) & (macd.shift(1) < macdsignal.shift(1)) macd_dead = (macd < macdsignal) & (macd.shift(1) > macdsignal.shift(1)) #売買シグナル生成部分 buy_sig = macd_golden | (rsi < 30) sell_sig = macd_dead | (rsi > 70) #market_sigという全て0が格納されているデータフレームを作成 market_sig = pd.DataFrame(data=0.0, columns=syms, index=dates) #buy_sigがTrueのとき1.0、sell_sigがTrueのとき-1.0とおく market_sig[buy_sig == True] = 1.0 market_sig[sell_sig == True] = -1.0 market_sig[(buy_sig == True) & (sell_sig == True)] = 0.0 # ctx.logger.debug(market_sig) return { "MACD:g2": macd, "MACDSignal:g2": macdsignal, "MACDHist": macdhist, "market:sig": market_sig, } # シグナル登録 ctx.regist_signal("my_signal", _my_signal) def handle_signals(ctx, date, current): # 日ごとの処理部分 ''' current: pd.DataFrame ''' # initializeの_my_signalで生成したシグナルをmarket_sigに格納 market_sig = current["market:sig"] done_syms = set([]) # 利益確定及び損切りが行われた銘柄を格納するset型 none_syms = set([]) # portfolio.positionsに存在しない銘柄を格納するset型 # portfolio.positions(保有している銘柄)に対象銘柄(sym)が存在するかのチェック for (sym, val) in market_sig.items(): if sym not in ctx.portfolio.positions: none_syms.add(sym) # portfolio.positions(保有している銘柄)のそれぞれの銘柄(sym)の保有株数が0ではないかのチェック for (sym, val) in ctx.portfolio.positions.items(): if val["amount"] == 0: none_syms.add(sym) # 損切り、利益確定(利確)の設定 # 所有している銘柄を1つずつ確認する繰り返し処理 for (sym, val) in ctx.portfolio.positions.items(): # 損益率の取得 returns = val["returns"] if returns < -0.03: # 損益率が-3%未満(絶対値で3%より大きい損)の場合 # 損切りのための売り注文 sec = ctx.getSecurity(sym) sec.order(-val["amount"], comment="損切り(%f)" % returns) # 利益確定及び損切りが行われた銘柄を格納するset型にsymに代入されている銘柄を追加 done_syms.add(sym) elif returns > 0.05: # 損益率が+5%より大きい場合 # 利益確定(利確)のための売り注文 sec = ctx.getSecurity(sym) sec.order(-val["amount"], comment="利益確定売(%f)" % returns) # 利益確定及び損切りが行われた銘柄を格納するset型にsymに代入されている銘柄を追加 done_syms.add(sym) buy = market_sig[market_sig > 0.0] # 買いシグナル for (sym, val) in buy.items(): # 買いシグナルが出ている銘柄を1つずつ処理 # done_symsまたはnone_symsにsymがある場合 if sym in done_syms: continue # 処理をスキップ # 買い注文 sec = ctx.getSecurity(sym) sec.order(sec.unit() * 1, orderType=ot, comment="SIGNAL BUY") # 買い注文のログを下に出力したい場合は以下のコメントアウトを外してください(長期間注意) #ctx.logger.debug("BUY: %s, %f" % (sec.code(), val)) sell = market_sig[market_sig < 0.0] # 売りシグナル for (sym, val) in sell.items(): # 売りシグナルが出ている銘柄を1つずつ処理 # done_symsまたはnone_symsにsymがある場合 if (sym in done_syms) | (sym in none_syms): continue # 処理をスキップ # 売り注文 sec = ctx.getSecurity(sym) sec.order(sec.unit() * -1,orderType=ot, comment="SIGNAL SELL")図2:RSIとMACDのゴールデンクロス、デッドクロスを用いたアルゴリズム(参照:https://factory.quantx.io/developer/6ba1eb1b748d46a18ce128fea3156282/coding)
RSI
talib.RSI(close, timeperiod = 14)
- RSIとは、「買われすぎ」、「売られすぎ」を判別するテクニカル指標です
- 終値を示すnp.double型のnp.arraysオブジェクトcloseと、期間を示すtimeperiodを引数にとります。
例:図2のコードの82行目において
rsi = pd.DataFrame(data = 0.0, columns = syms, index = dates)各銘柄のRSIを格納するDataFrameを定義して
85行目のfor文
for (sym,val) in cp.items(): rsi[sym] = ta.RSI(cp[sym].values.astype(np.double), timeperiod = 10)において各銘柄のRSIを格納しています。
cp[sym]はDataFrame型のオブジェクトですので、cp[sym].valuesでarray型のオブジェクトに変換します。- そして
cp[sym].values.astype(np.double)でarrayの中身をnp.double型に変換しています。- 今回は10日分のRSIを取るのでtimeperiod = 10にします
- 「売られすぎ」か「買われすぎ」かを参考に売買を判断します
MACD
ta.MACD(close)
- 移動平均線を応用したテクニカル指標で、MACDラインとMACDシグナルラインの日本の線の組み合わせて売買のタイミングを測ります。
- 銘柄の終値を格納したSeriesオブジェクトcloseを引数にとります。
- 三つのDataFrame型のオブジェクトを返します
例:図2のコード79〜81行目において、
macd = pd.DataFrame(data=0.0, columns=syms, index=dates) macdsignal = pd.DataFrame(data=0.0, columns=syms, index=dates) macdhist = pd.DataFrame(data=0.0, columns=syms, index=dates)返り値を格納するDataFrameを定義します。
85行目のfor文for (sym,val) in cp.items(): macd[sym],macdsignal[sym],macdhist[sym] = ta.MACD(cp[sym])において各銘柄のmacd, macdsignal, macdhistをとります。
90,91行目でMACDラインとMACDシグナルラインのゴールデンクロス、デッドクロスを判断しています。
macd_golden = (macd > macdsignal) & (macd.shift(1) < macdsignal.shift(1)) macd_dead = (macd < macdsignal) & (macd.shift(1) > macdsignal.shift(1))MACD、RSIから、買いシグナル、売りシグナルを定める
buy_sig = macd_golden | (rsi < 30) #ゴールデンクロスかつ売られすぎ sell_sig = macd_dead | (rsi > 70) #デッドクロスかつ買われすぎこのように、talibを用いることでMACD、RSIなどの有名なテクニカル指標を簡単に実装することができます。
まとめ
今回はtalibやpandasのアルゴ作成において頻繁に使うメソッドをピックアップしてみました。これを読んで少しでQuantX Factoryのアルゴリズムへの理解が深まったら幸いです。最後まで拙い文章をお読みいただきありがとうございました。
免責注意事項
このコード・知識を使った実際の取引で生じた損益に関しては一切の責任を負いかねますので御了承下さい。
- 投稿日:2020-02-25T14:12:21+09:00
LINE botの作成 〜作成・デプロイ・起動まで〜
はじめに
LINE botを作りたくなったので練習がてら、オウム返しのLINE botに挑戦。
その時のメモ、日記。環境
- Ubuntu 18.04.3 LTS
- Python 3.6.8
- Flask==1.1.1
- line-bot-sdk==1.15.0
- Heroku
必要なパッケージのインストール
$ pip3 install flask $ pip3 install line-bot-sdk目標
出来上がりはこのようになります。
LINEのQRコードリーダーで以下のQRコードを読み込んでください。
なにかコメントするとオウム返ししてくれます。
登録
LINE Developers
LINE botのアカウントを作成するため、LINE Developersに登録する。
1.今すぐ始めようをクリック。
2.ログイン
ログインをする。既に持っているIDでも問題ない。
他の人に自分のLINEが知られることはない。あくまでもLINE botと利用するためのログイン。
3.LINE botアカウント作成
ログインするとこのような画面になる。
3-1.チャネルの種類はbotなので「Messagin API」を選択
3-2.botの提供元であるプロバイダ名を設定
なんでもOK.
3.3.その他の設定
下の項目を設定して「作成」ボタンをクリック。
- チャネルアイコン
- チャネル名
- チャネル説明
- 大業種
- 小業種
- メールアドレス
4.チャネルシークレットとチャネルアクセストークンの取得
4.1. 「チャネル基本設定」タブを選択
4.2.「チャネルシークレット」欄から「発行」ボタンを押し、IDを取得。後ほど[YOUR_CHANNEL_SECRET]として利用。
4.3. 次に、「Messaging API設定」タブを選択
4.4. 「チャネルアクセストークン」欄から「発行」ボタンを押し、IDを取得。後ほど[YOUR_CHANNEL_ACCESS_TOKEN]として利用。
Heroku
1. アカウント登録
こちらのリンクからHerokuのアカウント登録をする。
2. Set up
Heroku CLIのSet upをする。
端末で以下のコマンドを打ち込む。
参考はこちら。$ sudo snap install heroku --classicログインをする。以下のコマンドを実行するとブラウザが立ち上がるのでそこでHerokuにログイン。以下のような感じのメッセージがでれば成功。
$ heroku login heroku: Press any key to open up the browser to login or q to exit › Warning: If browser does not open, visit › https://cli-auth.heroku.com/auth/browser/*** heroku: Waiting for login... Logging in... done Logged in as me@example.com実装
オウムがえしのコード作成
line-bot-sdk-pythonにあるコードを使用します。
["YOUR_CHANNEL_ACCESS_TOKEN"]と["YOUR_CHANNEL_SECRET"]はここでは自分のものに置き換えず、そのままで大丈夫です。main.pyfrom flask import Flask, request, abort from linebot import ( LineBotApi, WebhookHandler ) from linebot.exceptions import ( InvalidSignatureError ) from linebot.models import ( MessageEvent, TextMessage, TextSendMessage, ) import os app = Flask(__name__) #環境変数取得 # not should be chnged chracters. YOUR_CHANNEL_ACCESS_TOKEN = os.environ["YOUR_CHANNEL_ACCESS_TOKEN"] YOUR_CHANNEL_SECRET = os.environ["YOUR_CHANNEL_SECRET"] line_bot_api = LineBotApi(YOUR_CHANNEL_ACCESS_TOKEN) handler = WebhookHandler(YOUR_CHANNEL_SECRET) @app.route("/callback", methods=['POST']) def callback(): # get X-Line-Signature header value signature = request.headers['X-Line-Signature'] # get request body as text body = request.get_data(as_text=True) app.logger.info("Request body: " + body) # handle webhook body try: handler.handle(body, signature) except InvalidSignatureError: abort(400) return 'OK' @handler.add(MessageEvent, message=TextMessage) def handle_message(event): line_bot_api.reply_message( event.reply_token, TextSendMessage(text=event.message.text)) if __name__ == "__main__": # app.run() port = int(os.getenv("PORT", 5000)) app.run(host="0.0.0.0", port=port)Herokuへのデプロイ
必要なファイルの準備
Herokuで必要となるファイルは以下の3つです。
- Procfile (Herokuで実行するコマンド)
- requirements.txt (main.pyを動かす上で必要なパッケージ)
- runtime.txt (使用する言語とバージョン)
Procfileweb: python3 main.pyrequirements.txtFlask==1.1.1 line-bot-sdk==1.15.0runtime.txtpython-3.6.8ログイン
端末からHerokuへ、ログインしてください。
$ heroku login heroku: Press any key to open up the browser to login or q to exit › Warning: If browser does not open, visit › https://cli-auth.heroku.com/auth/browser/*** heroku: Waiting for login... Logging in... done Logged in as me@example.comアプリの作成
Herokuにアプリを作成します。
$ heroku create <app_name> Creating ⬢ <app_name>... done https://<app_name>.herokuapp.com/ | https://git.heroku.com/<app_name>環境変数の設定
「4.チャネルシークレットとチャネルアクセストークンの取得」で取得したチャネルアクセストークン[YOUR_CHANNEL_ACCESS_TOKEN]とチャネルシークレット[YOUR_CHANNEL_SECRET]をHerokuの環境変数として設定する。
# LINE botのチャネルアクセストークンを使用 $ heroku config:set YOUR_CHANNEL_ACCESS_TOKEN="<Access Token>" --app <app_name> # LINE botのチャネルシークレットを使用 $ heroku config:set YOUR_CHANNEL_SECRET="<Channel Secret>" --app <app_name>Webhookの設定
「3.LINE botアカウント作成」で作成したアカウントページに戻って、Messagin API設定タブをクリック。
Webhook設定欄のWebhookの利用をオンにする。
さらに、WebhookURLに以下を記載。Webhook URL:https://<app_name>.herokuapp.com/callbackデプロイの実行
Pythonプログラム(main.py)と設定ファイルデプロイします。
# 初期化(initialize) $ git init # commitするファイルを追加 $ git add . # commit $ git commit -m "new commit" # deploy $ git push heroku masterLINE botでの実行結果
いい感じに返してくれました。
[番外編]つまづいたところ
git commitで「Please tell me who you are.」
git commitでお前誰だと怒られる。
gitの初期設定ができていないようです。$ git commit -m "new commit" *** Please tell me who you are. Run git config --global user.email "you@example.com" git config --global user.name "Your Name" to set your account's default identity. Omit --global to set the identity only in this repository. fatal: unable to auto-detect email address (got '○@○Air2.(none)')メールアドレスとアカウント名を設定してあげるとエラーが無くなる。
私の場合は、Githubで作成したメールアドレスとアカウント名を使用しました。$ git config --global user.email "you@example.com" $ git config --global user.name "Your Name"設定した、メールアドレスとアカウント名等はこのコマンドから確認できます。
$ git config --listpush時にdoes not appear to be a git repository
デプロイするさいに、repositoryがないと怒られました。
gitがリモートのリポジトリを探せていないようです。$ git push heroku master fatal: 'heroku' does not appear to be a git repository fatal: Could not read from remote repository. Please make sure you have the correct access rights and the repository exists.リモートリポジトリ先を確認すると、ところが"heroku create "で作成したものと異なっていた。
$ git remote -v heroku https://git.heroku.com/<app_name>.git (fetch) heroku https://git.heroku.com/<app_name>.git (push)リモートリポジトリ先の変更は以下のコマンドでできる。
$ git remote set-url heroku {ここに変更するURLを貼り付け} # ex.) git remote set-url heroku https://git.heroku.com/<app_name>.git「メッセージありがとうございます...」という自動返信がついてくる。
オウムがえしと共に自動返信のメッセージがついてくる。
こちらは、LINE botアカウントの「Massaging API設定」タブから応答メッセージの編集から変更できる。
「Massaging API設定」タブから応答メッセージの編集を押す。
詳細設定から応答メッセージの応答メッセージ設定を選択。
不要な応答メッセージのステータスをオフにする。
main.pyを編集したときの更新
オウムがえしのコードを書き換えてmain.pyを更新した場合。デプロイし直す必要がある。
1.main.pyの更新。$ git status ブランチ master Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git checkout -- <file>..." to discard changes in working directory) modified: main.py no changes added to commit (use "git add" and/or "git commit -a")2.git addする。
$ git add .3.git commitする。
# -aでGit 管理下のファイルをすべてをコミットする $ git commit -am "modified main.py" [master d3cfd15] modified main.py and git add. 1 file changed, 1 insertion(+)4.デプロイする
$ git push heroku masterまとめ
LINE botを作成するために、種々の登録から、ファイルの作成、Herokuでデプロイをした。
将来的には、株価予測AIが判定した結果を定期的にLINEで通知するシステムを構築したい。



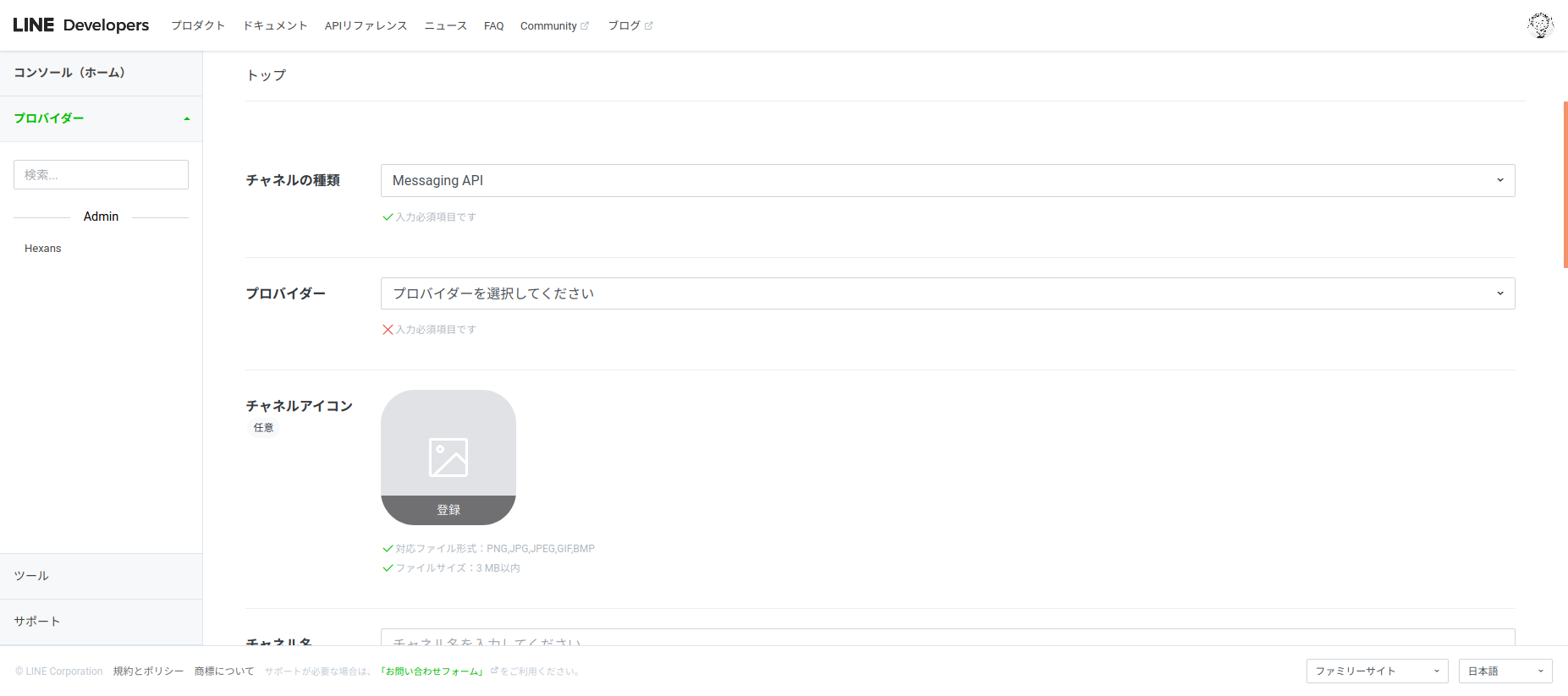






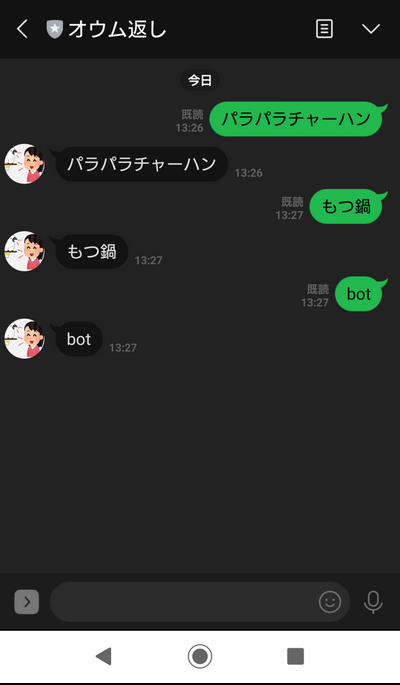
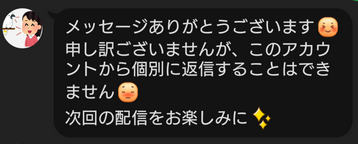

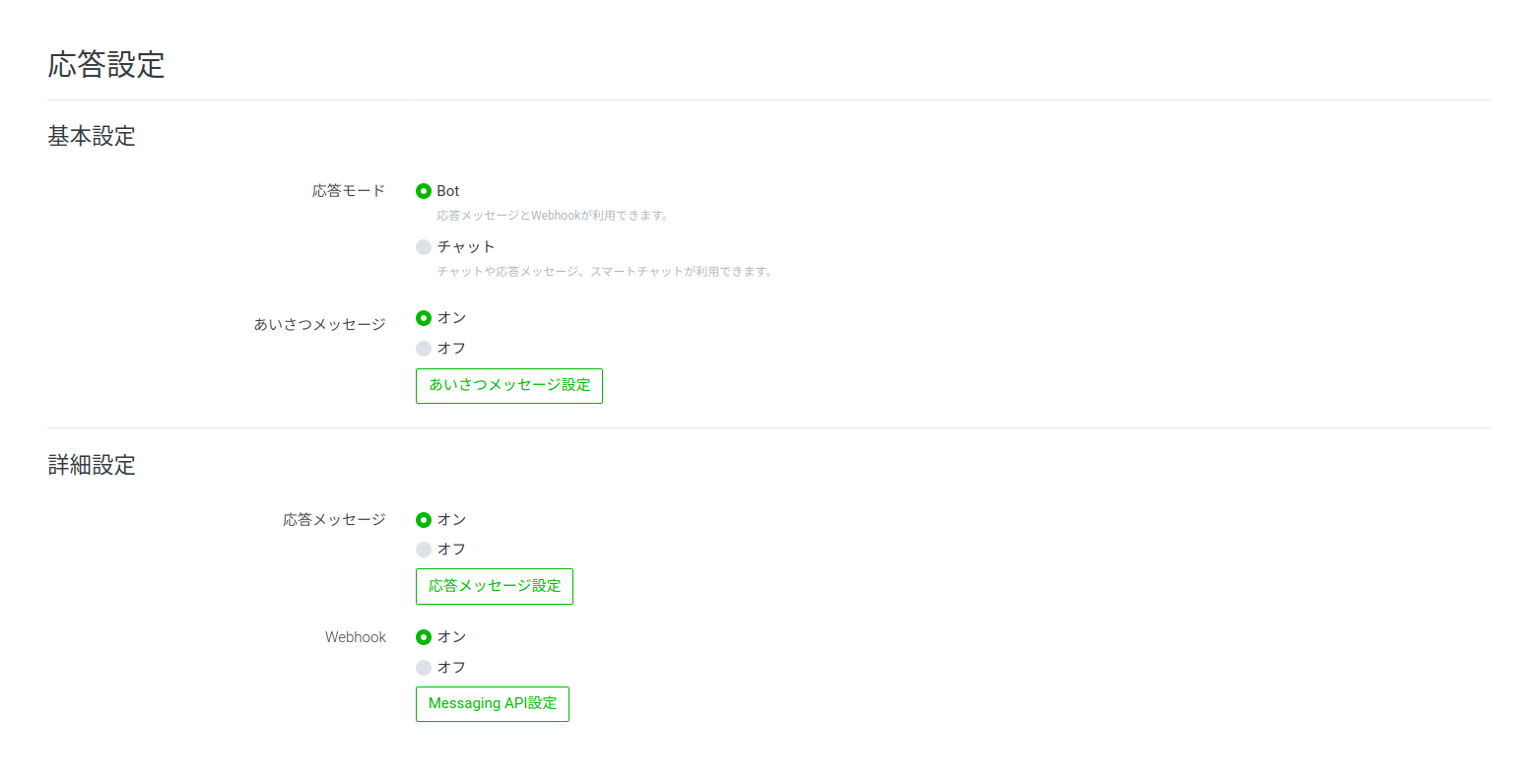
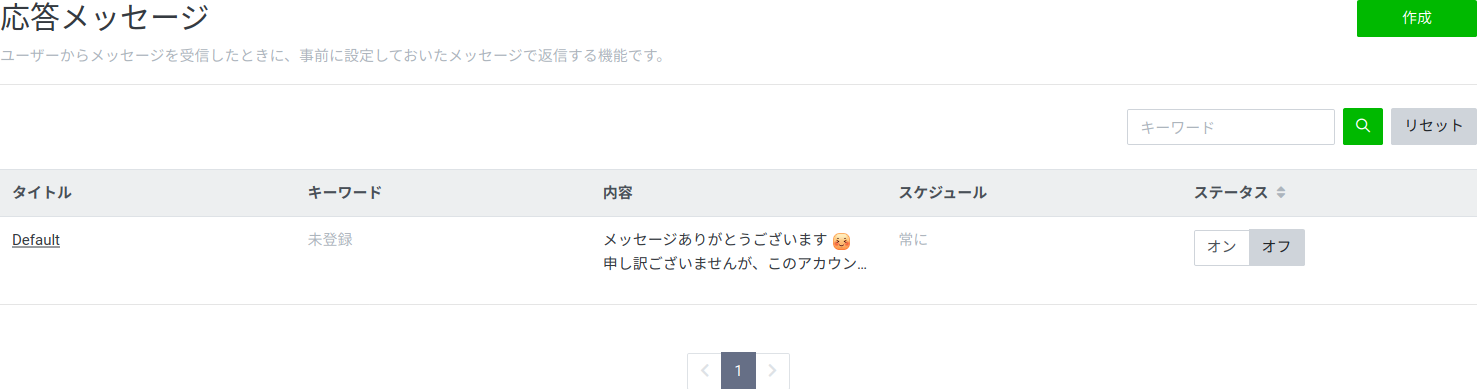
- 投稿日:2020-02-25T13:59:35+09:00
Factorization MachinesをfastFMでサクッと試すサンプル
- 近年、レコメンド技術等で注目されているFactorization Machinesアルゴリズムをライブラリを使ってささっと試してみる導入記事です。
- 理論的な解説ではなくて動かすための記事です。
- 基本、チュートリアルをなぞって行く+補足です。
参考資料いろいろ
今回fastFMというライブラリを使用しました。またこのライブラリの説明&性能に関してはarXivにて公開されています。
- fastFM
Factorization Machinesの概要や動向を知りたい方はQiita内外に参考記事がありますので一部貼っておきます。また下記の書籍もfastFM扱ってます。
すごく乱暴に言うと、「行列分解を利用してて、スパースなデータに強い、回帰や分類・ランク付けができる」アルゴリズムです。本編
導入
注意点あり。自身の環境の場合、以下の感じでした。
Python 3.6.10の場合
pip install fastFMで導入可能Python 3.7.6の場合
- pipのインストールではエラーが発生。
- GitHub記載のソースからインストールで動作可能。
なので新しめの環境の方はソースからインストールするか、pyenvなどの複数のpythonを動作させられる環境を構築して3.6系を導入するか、Dockerなどで何かしら3.6な環境作るか、、、といった感じになると思います。
サンプルデータ
Factorization Machines(以下FM)系のサンプルですと、辞書型のものをサンプルデータに使う場合が多いように感じます。
[ {user:A, item:X, ...}, {user:B, item:Y, ...}, ... ]みたいな。
スパースなデータだと確かにこういうデータを入力にすることが多い気がしますが、今回はシンプルなcsvを想定して扱ってみたいと思います。サンプルのダミーデータカテゴリ,rating,is_A,is_B,is_C,is_X,is_Y,is_Z A,5,0,0,1,0,1,0 A,1,1,0,0,0,0,1 B,2,0,1,0,0,0,0 B,5,0,0,0,0,1,0 C,1,1,0,0,0,0,1 C,4,0,0,0,0,1,0 ...一番下に全部バージョンを載せておきます。
値は適当に作ったダミーですが、
- カテゴリ情報の入った
カテゴリ列- 1〜5までの5段階評価が入った
rating列- フラグ情報が入った
is_?列
- 商品を買ったフラグとか、ユーザ属性を示すフラグとかをイメージしていただければ
を想定しています。
処理の流れ確認 with 回帰分析
ライブラリの使い方自体はシンプルで、scikit-learn等を使ったことのある方ならおなじみの感じです。
まずはシンプルな回帰分析のロジックで処理の流れを作ってみます。
詳細は端折りますが、一般的なモデル作成は以下のような流れになると思われます。
- データの読み込み
- 前処理(モデルに合う形式にデータを変換)
- 「学習データ」(、「バリデーションデータ」)、「テストデータ」に分割
- 学習データでモデル作成
- テストデータにモデル適用
- 性能評価指標を定義して評価
今回は ratingを当てる ことをテーマに回帰モデルを作ってみます。
(わかりやすさのため、つどつどimportしてますが、一番上で全部importしちゃっても良いです。)データ読み込み
import numpy as np import pandas as pd # csvデータ読み込み raw = pd.read_csv('fm_sample.csv') # ターゲットの列とその他の情報を分けます target_label = "rating" data_y = raw[target_label] data_X = raw.drop(target_label, axis=1)前処理〜データ分割
# 前処理 ## 便利なカテゴリデータ処理ライブラリ、scikit-learnの便利機能をバンバン使います import category_encoders as ce ## 指定の列をone-hotエンコードします enc = ce.OneHotEncoder(cols=['カテゴリ']) X = enc.fit_transform(data_X) y = data_y # データ分割 from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=810)モデル作成〜評価
評価はMAE(平均絶対誤差)にしていますが、MSEなどもささっと計算できます。
from sklearn import linear_model from sklearn.metrics import mean_squared_error, mean_absolute_error # モデル作成 reg = linear_model.LinearRegression() reg.fit(X_train, y_train) # 評価 ## 学習データへの当てはまり具合 mean_absolute_error(y_train, reg.predict(X_train)) ## テストデータの誤差 mean_absolute_error(y_test, reg.predict(X_test))こんな流れになるかと思います。
評価部分はもちろん、算出された回帰線引いてみたり、誤差の外れ方見てみたりと本来ならもっとやるんですが、今回は動かすまで。FMによる回帰
上の流れができれば、あとは計算部分を今回利用するfastFM仕様にしてしまえばもう完成です。1点注意なのは DataFrameをそのままは扱えないのでcsr_matrixを使う というところです。
モデル作成〜評価
from fastFM import als from scipy.sparse import csr_matrix # モデル作成 fm = als.FMRegression(n_iter=1000, init_stdev=0.1, rank=8, l2_reg_w=0.5, l2_reg_V=0.5, random_state=810) fm.fit(csr_matrix(X_train), y_train) # 評価 ## 学習データへの当てはまり具合 mean_absolute_error(y_train, fm.predict(csr_matrix(X_train))) ## テストデータの誤差 mean_absolute_error(y_test, fm.predict(csr_matrix(X_test)))疎行列、csr_matrix
ここで
csr_matrixというものが出てきます。これはスパースなデータを扱うものです。
イメージとしてはシンプルで、DataFrameや通常のmatrixが以下のように2次元データを扱うとするとmatrixarray([ [0, 0, 1], [0, 0, 0], [0, 3, 0] ])データが入っている部分だけ扱おうというもの
疎なデータの扱い大きさ:3 x 3 データあるところ: ([0,2]地点に 1) ([2,1]地点に 3)みたいなイメージです。
いくつか扱い方に種類があり、csr_matrix, coo_matrix, csc_matrix, lil_matrixなどがあり扱い方や処理速度が異なるようですので気になる方は「scipy sparse行列」等で検索ください。
note.nkmk.meさんとか詳しく載っています。今回覚えておくものとしては
- DataFrameから変換例:
csr_matrix(df)- csr_matrixを行列に変換するtodense例:
csr_matrix(X_train).todense()ぐらいかなと。
FMによる分類
2値分類もできるのでやってみます。
今回は ratingが4以上か未満かの2クラスを当てる というタスクを行ってみます。
前処理〜データ分割の部分の後にratingが4以上か否かという回答データを作るところを挟んでからモデル作成と評価を実施します。
また、fastFMの分類では0 or 1ではなく-1 or 1で値を作ることに注意です。from fastFM import sgd from sklearn.metrics import roc_auc_score # 前処理続き ## 4以上なら1 それ以外なら-1とする y_ = np.array([1 if r > 3 else -1 for r in y]) ## 学習データ・テストデータ作成 X_train, X_test, y_train, y_test = train_test_split(X, y_, random_state=810) # モデル作成 fm = sgd.FMClassification(n_iter=5000, init_stdev=0.1, l2_reg_w=0, l2_reg_V=0, rank=2, step_size=0.1) fm.fit(csr_matrix(X_train), y_train) ## 2種類の予測値の出し方ができるようです y_pred = fm.predict(csr_matrix(X_test)) y_pred_proba = fm.predict_proba(csr_matrix(X_test)) # 評価 ## AUCの値を評価とした例 roc_auc_score(y_test, y_pred_proba)ROC曲線を書く
note.nkmk.meさんのページをがっつり参考にさせていただいて、ROC曲線も書いてみます。
fpr, tpr, thresholds = metrics.roc_curve(y_test, y_pred_proba, drop_intermediate=False) auc = metrics.auc(fpr, tpr) # ROC曲線をプロット plt.plot(fpr, tpr, label='ROC curve (area = %.2f)'%auc) plt.legend() plt.title('ROC curve') plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plt.grid(True) plt.show()
できたー。
他
以下、サンプルデータを貼り付け。
適当に作ったものなので面白いデータでもなんでもないです。動作確認等にどうぞ。fm_sample.csvカテゴリ,rating,is_A,is_B,is_C,is_X,is_Y,is_Z A,5,0,0,1,0,1,0 A,1,1,0,0,0,0,1 A,3,0,0,1,0,1,0 A,2,1,0,0,0,0,1 A,4,0,0,0,0,0,1 A,5,1,0,0,1,1,0 A,1,0,1,0,0,0,1 A,2,0,0,0,0,0,1 B,2,0,1,0,0,0,0 B,5,0,0,0,0,1,0 B,3,1,1,0,0,1,0 B,2,0,0,1,0,0,0 B,1,0,0,0,0,0,1 B,3,0,0,1,0,0,1 B,4,0,1,0,0,0,0 B,1,0,0,0,0,0,1 B,2,0,1,0,0,0,1 C,1,1,0,0,0,0,1 C,4,0,0,0,0,1,0 C,2,1,0,1,0,1,0 C,4,0,0,0,0,0,0 C,5,0,0,1,1,1,0 C,2,0,1,0,0,0,1 C,5,1,0,0,0,1,0 C,3,0,0,1,1,1,0 C,2,0,0,0,0,0,1 C,3,0,0,0,0,1,0 A,2,0,0,0,0,0,1 A,4,1,0,0,0,1,0 A,3,0,0,0,0,0,0 A,1,0,0,0,0,0,1 A,3,1,0,0,0,0,0 A,4,0,0,1,0,1,0 A,5,1,1,0,0,1,0 A,3,1,0,0,1,0,0 B,4,0,0,0,0,1,0 B,1,0,0,0,0,0,1 B,5,0,0,0,0,1,0 B,3,0,0,0,0,0,0 B,1,0,0,0,1,0,1 B,3,0,0,1,0,0,0 B,2,0,1,0,0,0,1 B,5,1,0,0,0,1,0 B,4,0,0,0,1,1,1 C,1,0,0,0,0,0,0 C,2,0,0,0,0,0,1 C,3,0,0,1,0,0,0 C,4,0,1,0,0,1,0 C,1,0,0,1,0,0,1 C,1,0,0,0,0,0,0 C,3,0,0,1,0,0,0 C,3,0,0,1,0,1,0 C,5,0,0,0,1,1,0 C,3,0,0,1,0,1,0