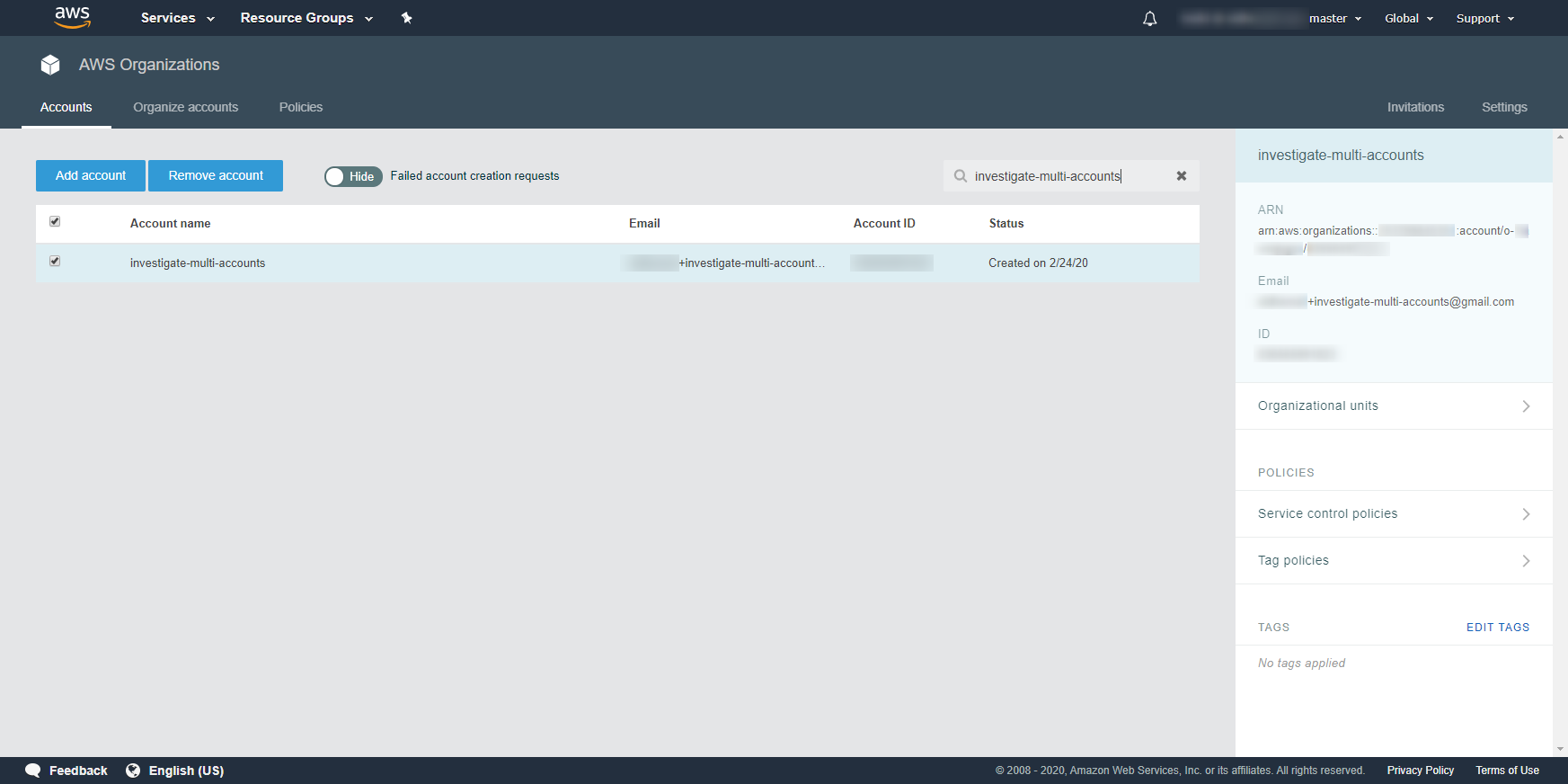
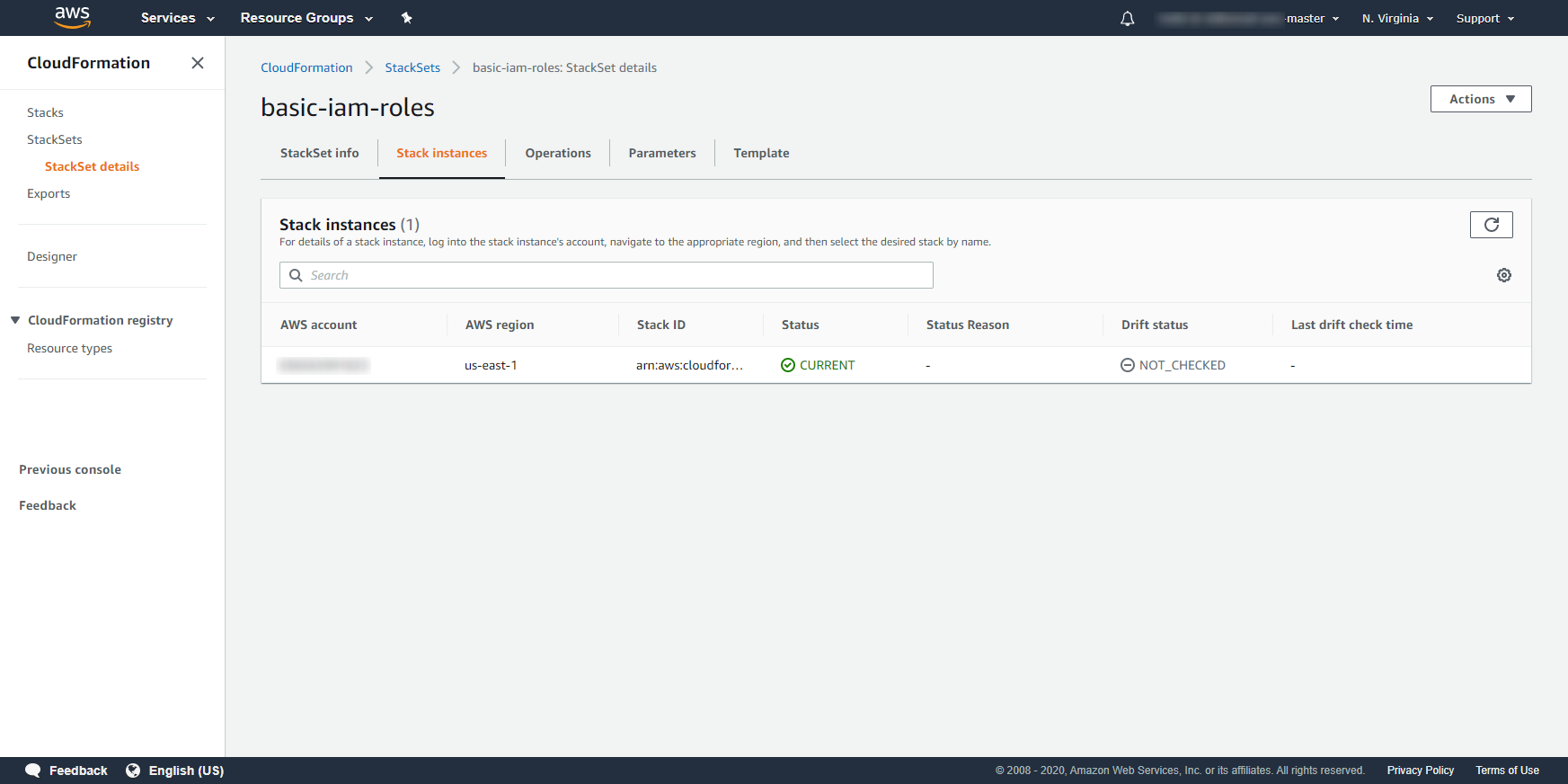
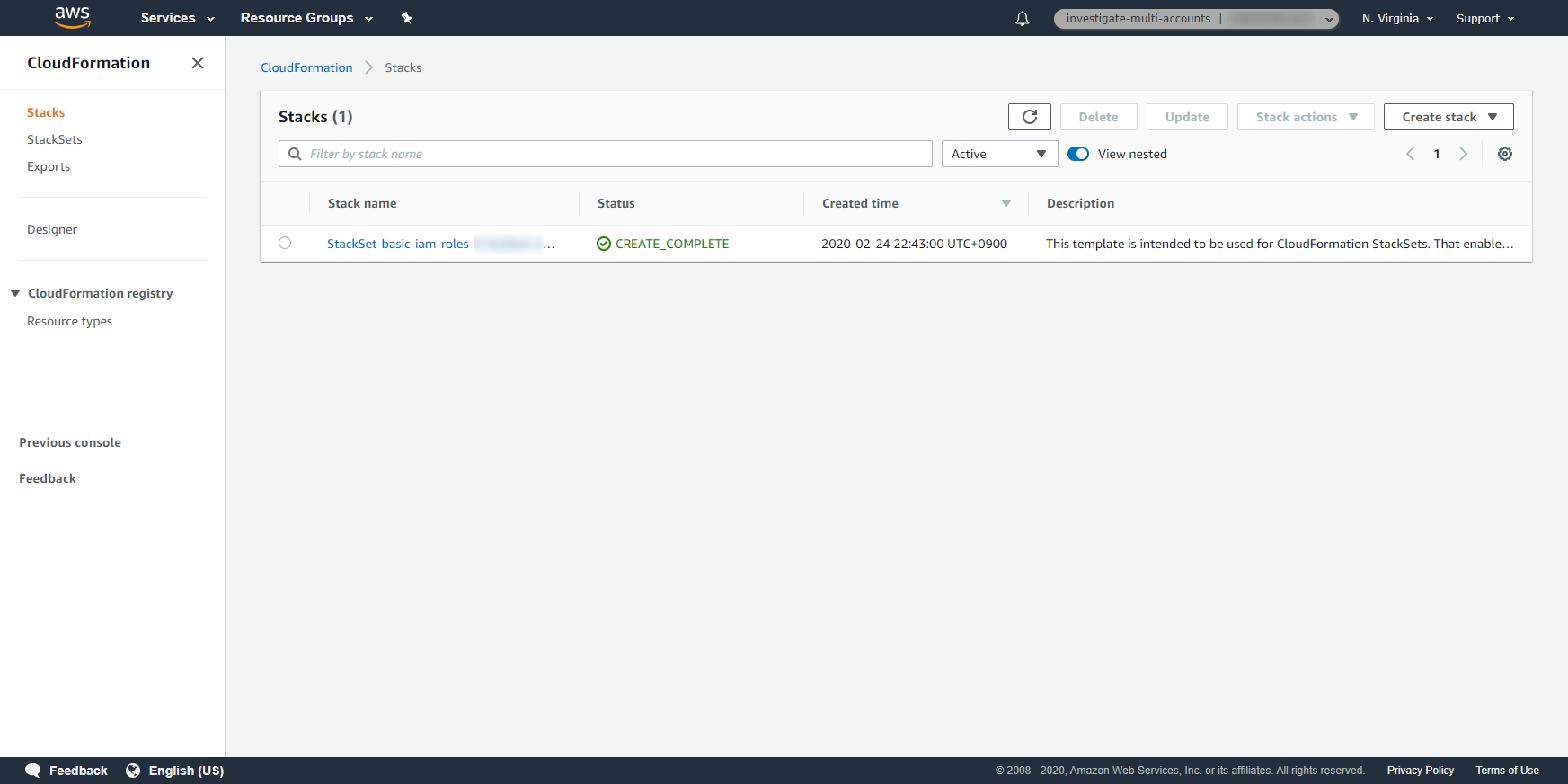
- 投稿日:2020-02-25T23:57:20+09:00
Lambda入門#2 はじめてのLambda関数作成 S3との連携
参考URL
昨日に続いて、クラスメソッドさんの記事を見て勉強を続けていきます。
https://dev.classmethod.jp/cloud/aws/lambda-my-first-step/オブジェクト情報の取得
昨日の記事で実施した部分はオブジェクトが所定の場所に置かれることで起動するトリガーについて触れました。
今回はそこからさらに進んで、昨日、定義したLambdaのハンドラーで指定した引数eventに含まれている「バケット名」とか、「パス」の情報を取得してみます。コードを以下のものに差し替えます。
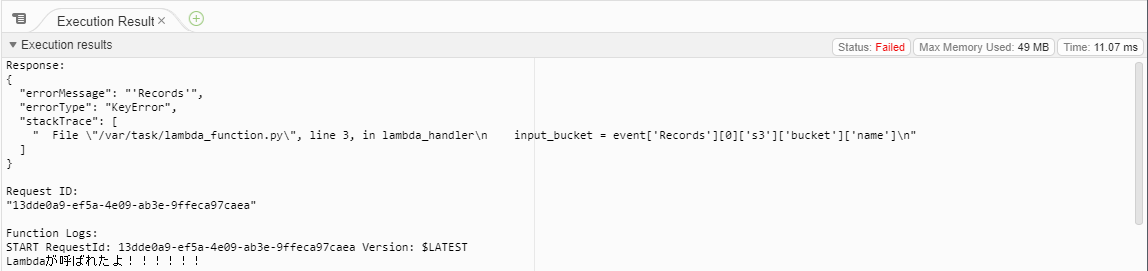
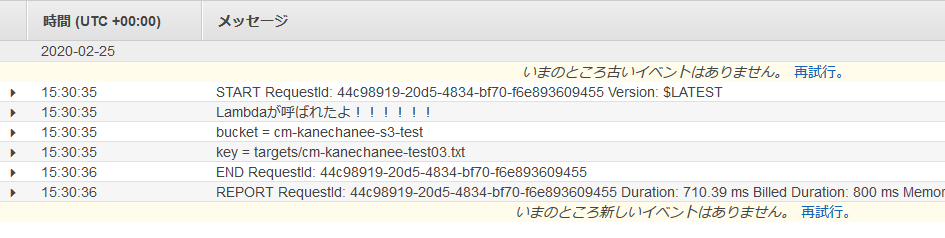
テストコード1def lambda_handler(event, context): print("Lambdaが呼ばれたよ!!!!!!") input_bucket = event['Records'][0]['s3']['bucket']['name'] input_key = event['Records'][0]['s3']['object']['key'] print("bucket =", input_bucket) print("key =", input_key)
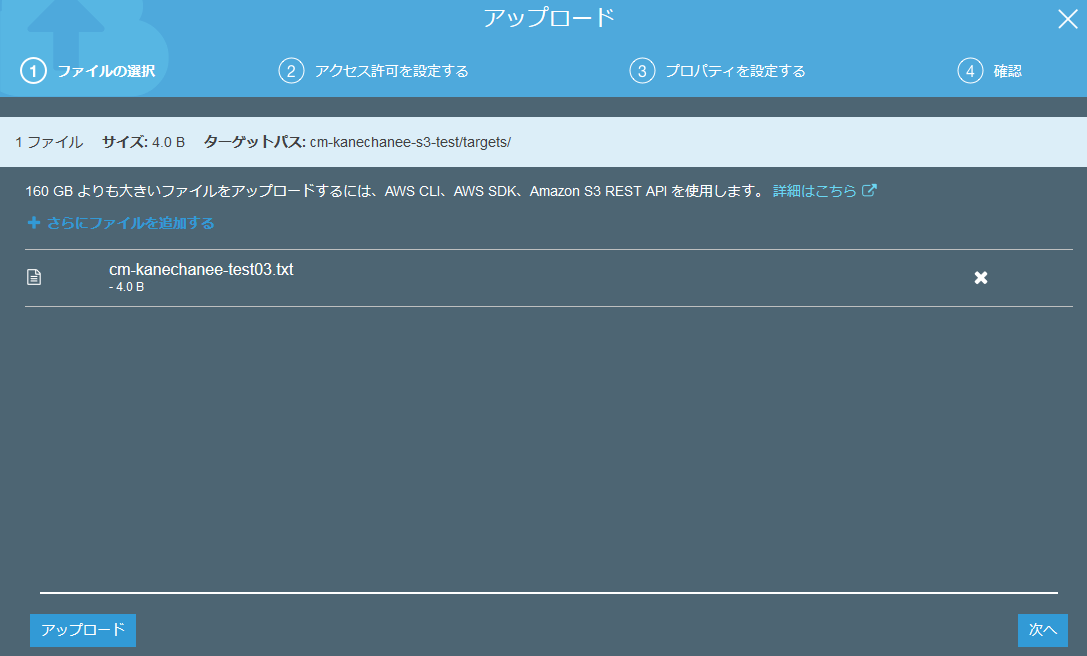
差し替えが終わって、コードを保存したら、またS3上の所定フォルダにテキストファイルをアップしてみます。
また、例のごとく、Cloud Watchにログインして、ログを確認してみます。
おっ!ログが増えてます。
ログ結果を確認すると確かにバケット名とアップロードしたテキストファイル名を取得できています。
テストの実行
記事によりますと、昨日までで用意していた空のjsonファイルだとエラーが出力されるとのことでした。
実際に実行してみますと、確かにエラーが出力されました。
エラーを出力させないためには「バケット」と「ファイルパス」の情報を渡してやればよいとのことです。
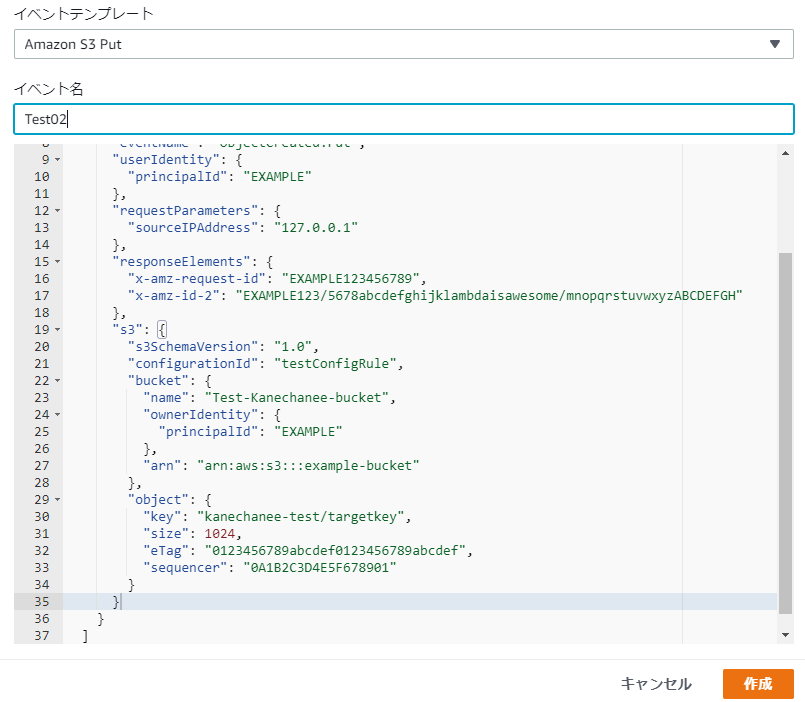
実際に渡してみたら、エラーが解消するのか確認してみました。↓のような感じでテンプレートをベースにバケット名、ファイルパス(key)の情報を入力してテストを実行してみます。
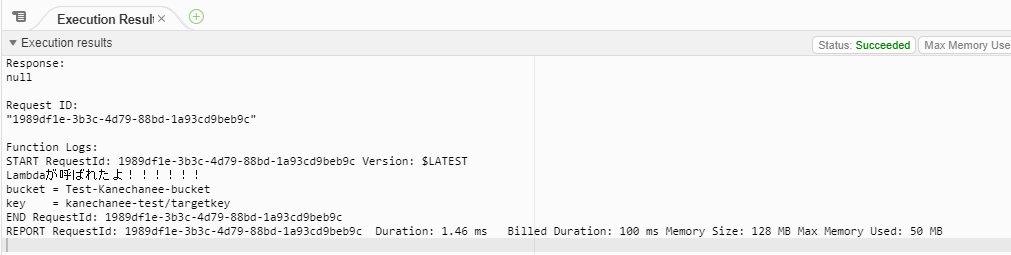
おっ!エラーは出ずに、私が適当に突っ込んだ値を無事に取得することができました!
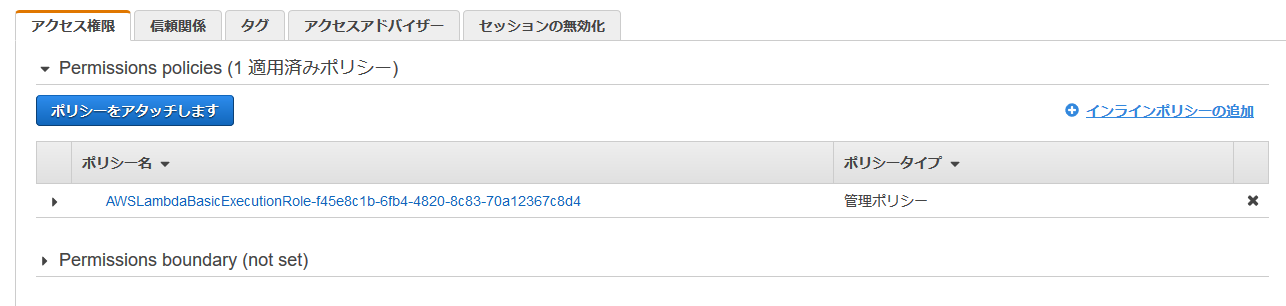
記事にも記載されているのですが、この時点で現段階のLambdaで使用しているロールにはS3に対するアクセス権は設定されていない状態です。
なのにも関わらず、バケット名とファイルパスを取得できているのはトリガーイベントから受け取っている情報だからになるそうです。
ロールの制限を受けることなく、トリガーイベントとして取得している情報はLambdaデフォルトのロール権限で無制限に取得可能だということを理解しました。ファイルコピーする関数の作成
また、コードを差し替えます。
テストコード2import boto3 s3 = boto3.client('s3') def read_file(bucket_name, file_key): response = s3.get_object(Bucket=bucket_name, Key=file_key) return response[u'Body'].read().decode('utf-8') def upload_file(bucket_name, file_key, bytes): out_s3 = boto3.resource('s3') s3Obj = out_s3.Object(bucket_name, file_key) res = s3Obj.put(Body = bytes) return res def lambda_handler(event, context): print("Lambdaが呼ばれたよ!!!!!!") input_bucket = event['Records'][0]['s3']['bucket']['name'] input_key = event['Records'][0]['s3']['object']['key'] print("bucket =", input_bucket) print("key =", input_key) # S3からファイルを読み込み text = read_file(input_bucket, input_key) # outputのキーを設定 output_key = "outputs/" + input_key # ファイルをS3に出力 upload_file(input_bucket, output_key, bytes(text, 'UTF-8'))上記の処理は
lambda_handlerって関数で取得したバケット名、ファイルパス名をread_fileとupload_fileって関数でそれぞれ、流用する形で別ファイルの形で別のバケットへアップロードするものになるようです。先頭の
import boto3が気になったのですが、こちらはAWSをPythonから利用するためのライブラリとのことです。※詳細は以下に。Python boto3 でAWSを自在に操ろう ~入門編~
https://qiita.com/kimihiro_n/items/f3ce86472152b2676004では昨日、自動的に作成されたLambdaのロールにS3へのアクセス権を付与してみます。
まずはIAMへアクセスし、先日、作成したロールを選択します。
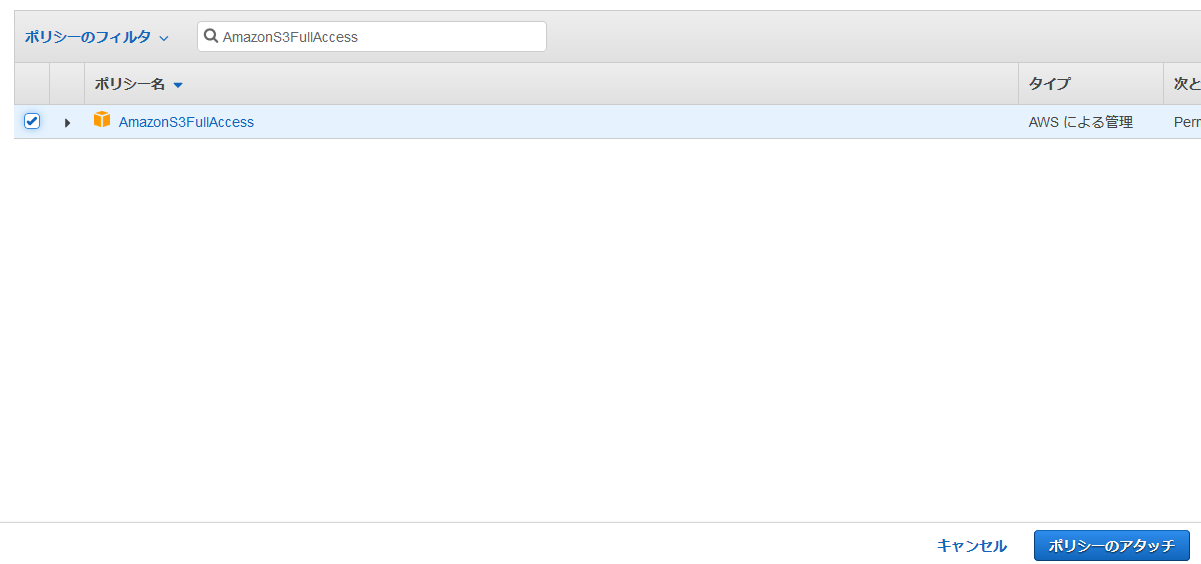
記事で紹介されている通り、ここは何も考えず、
AmazonS3FullAccessを付与しておきます。
IAMとは別に、Lambda上でもアクセス権が増えていることが確認できました。
ではこのパワーアップした関数が動作するのか、確認してみます。
動作確認
実際にS3上にファイルをアップロードしてみます。
そして、例のごとく、Cloud Watchへ飛んでみると、
おっ!また、新しいログが出てます!
えっ、ただ、ログには前回までと同じような内容しか出てないなー(汗
ただ、「何か間違ってたのかなー」とちょっとあきらめ気味にS3バケット内のフォルダを確認してみたところ、なんと!「outputs」フォルダが出来ているではありませんか!
「outputs」フォルダの中には「targets」フォルダが!
おー、ちゃんとファイルがコピーされてますね!
ログの出力だけ疑問が残ったので、よくよく考えたら、print処理している内容変わってなかっただけでした笑
ひとまず出来ましたー!というわけで、今回、参考にさせていただいた記事はここまででしたので、
明日もまた、別の記事をベースに勉強したいと思います。








- 投稿日:2020-02-25T22:35:14+09:00
S3へのput権限エラー
SEC7139: [CORS] 送信元 'https://xxxxx.jp' で、'https://cognito-identity.ap-northeast-1.amazonaws.com/' に対する cross-origin 要求について、指定された値がこの値を超えていたため、Access-Control-Max-Age の最大値 '172800' が使用されました。
上記エラーはCognitoがS3にput権限を持っていないことを意味する。Cognitoにロールをつけてあげましょう。
crossドメインの設定をしていると権限で引っかかることが多いので注意。
(多分、同じエラー見たの3回目だから簡易的ですが、投稿します。)
- 投稿日:2020-02-25T22:28:14+09:00
AWSかんたんWordPress導入(個人利用)
動画
注意!
動画の中で作成したEC2インスタンスはインターネットに面した構成になっています。
セキュリティグループで制限を掛けたとは言え、何があるか分からないので、
ひとしきり楽しんだ後は忘れずに停止or終了することを心がけてください。手順
1,既存パッケージのアップデート
$ sudo su - # yum update2,Apacheのインストール
# yum install httpd3,PHP7.3のインストール
# amazon-linux-extras install php7.34,mariadbのインストール
# yum search mariadb | more # yum install mariadb.x86_64 mariadb-server.x86_64 mariadb-devel.x86_64 mariadb-libs.x86_645,Apacheとmariadbの起動
# systemctl start httpd # systemctl start mariadb6,mariadb上の作業
6-1,ログイン
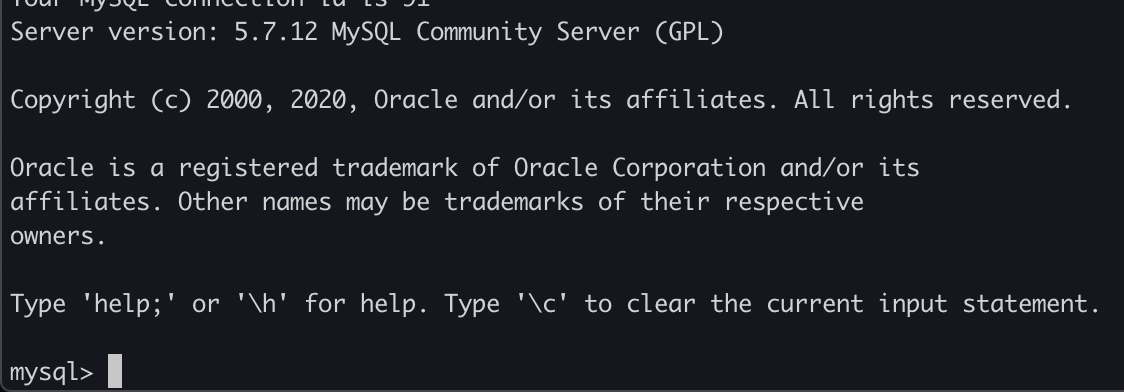
# mysql -uroot -p6-2,データベース作成
mysql> create database wordpress;6-3,ユーザー作成&確認
mysql> grant all on *.* to wpuser@localhost identified by 'wppasswd'; mysql> select user, host from mysql.user;6-4,ユーザー権限の適用
mysql> flush privileges;6-5,作成したデータベースの確認
mysql> show databases;7,wordpress用ユーザーとパスワードでのDB接続確認
# mysql -uwpuser -pwppasswd8,WordPressの解凍と設置
# mv /var/www/html{,_old} # cd ~ec2-user/ # tar zxf wordpress-5.3.2-ja.tar.gz # mv wordpress /var/www/html # chown apache:apache -R /var/www/html以上です。

- 投稿日:2020-02-25T22:12:19+09:00
S3上ObjectのKeyを普通のdate形式からHive形式に変更する
何を書いた記事か
ぼく「とりあえずアプリのログとか分析用データとかS3に吐き出しとこう!パス?後から考えればいいからとりあえず
yyyy-mm-ddとかで切っておけばいいよ!」〜1年後〜
ぼく「なんでこんな分析かけづらいパス形式でデータが保管されてるんや・・」
という状態になってたのでなんとかしようという話です。何が嬉しいのか
上の例のように、特に運用を考えずに下記のようなKeyでS3上に出力してしまっている場合
s3://BUCKET_NAME/path/to/2020-01-01/log.jsonいざ分析にかけようと思ったとき、ここにおいたファイルに対してAthenaなどでクエリを投げる時、日付に対して適切なPartitionが効かせられないという状況に陥ります。
どういうことかというと、
「2019年1月のデータを横断的に分析しよう!」
と思っても、S3では2019−01-01のような文字列がKeyになっているだけで、2019-01-*のようなクエリをかけることは至難の技です。そこで、S3への保管の仕方をHive形式に変換することを考えます。Hive形式とは下記のような形式です。
s3://BUCKET_NAME/path/to/year=2020/month=01/date=01/log.jsonこのようなKeyでObjectを保管しておいて、Athenaのテーブル上でyyyy/mm/ddに対してPartitionを切ってあげると、SQLのWhere句で特定日付に区切ってクエリを実行することができるようになり、分析もしやすくなります。
ただ、S3はKey-Value形式でObjectを保管する形式のストレージなので、Objectに対するKeyをライトに一括変更することができません。
そこで、指定した期間のObjectに対して一括でKeyをHive形式に変更するスクリプトを作成し、Lambdaから実行しました。作成したLambda関数
早速ですが、作成したLambdaは下記のようなシンプル1ファイルスクリプトです。
import os import boto3 from datetime import datetime, timedelta # Load Environment Variables S3_BUCKET_NAME = os.environ['S3_BUCKET_NAME'] S3_BEFORE_KEY = os.environ['S3_BEFORE_KEY'] S3_AFTER_KEY = os.environ['S3_AFTER_KEY'] S3_BEFORE_FORMAT = os.environ['S3_BEFORE_FORMAT'] FROM_DATE = os.environ['FROM_DATE'] TO_DATE = os.environ['TO_DATE'] DELETE_FRAG = os.environ['DELETE_FRAG'] def date_range(from_date: datetime, to_date: datetime): """ Create Generator Range of Date Args: from_date (datetime) : datetime param of start date to_date (datetime) : datetime param of end date Returns: Generator """ diff = (to_date - from_date).days + 1 return (from_date + timedelta(i) for i in range(diff)) def pre_format_key(): """ Reformat S3 Key Parameter given Args: None Returns: None """ global S3_BEFORE_KEY global S3_AFTER_KEY if S3_BEFORE_KEY[-1] == '/': S3_BEFORE_KEY = S3_BEFORE_KEY[:-1] if S3_AFTER_KEY[-1] == '/': S3_AFTER_KEY = S3_AFTER_KEY[:-1] def change_s3_key(date: datetime): """ Change S3 key from datetime format to Hive format at specific date Args: date (datetime) : target date to change key Returns: None """ before_date_str = datetime.strftime(date, S3_BEFORE_FORMAT) print('Change following date key format : {}'.format(before_date_str)) before_path = f'{S3_BEFORE_KEY}/{before_date_str}/' after_path = "{}/year={}/month={}/date={}".format( S3_AFTER_KEY, date.strftime('%Y'), date.strftime('%m'), date.strftime('%d') ) s3 = boto3.client('s3') response = s3.list_objects_v2( Bucket=S3_BUCKET_NAME, Delimiter="/", Prefix=before_path ) try: for content in response["Contents"]: key = content['Key'] file_name = key.split('/')[-1] after_key = f'{after_path}/{file_name}' s3.copy_object( Bucket=S3_BUCKET_NAME, CopySource={'Bucket': S3_BUCKET_NAME, 'Key': key}, Key=after_key ) if DELETE_FRAG == 'True': s3.delete_object(Bucket=S3_BUCKET_NAME, Key=key) except Exception as e: print(e) return def lambda_handler(event, context): pre_format_key() from_date = datetime.strptime(FROM_DATE, "%Y%m%d") to_date = datetime.strptime(TO_DATE, "%Y%m%d") for date in date_range(from_date, to_date): change_s3_key(date)実行時には下記の設定をLambdaで入れてあげる必要があります。
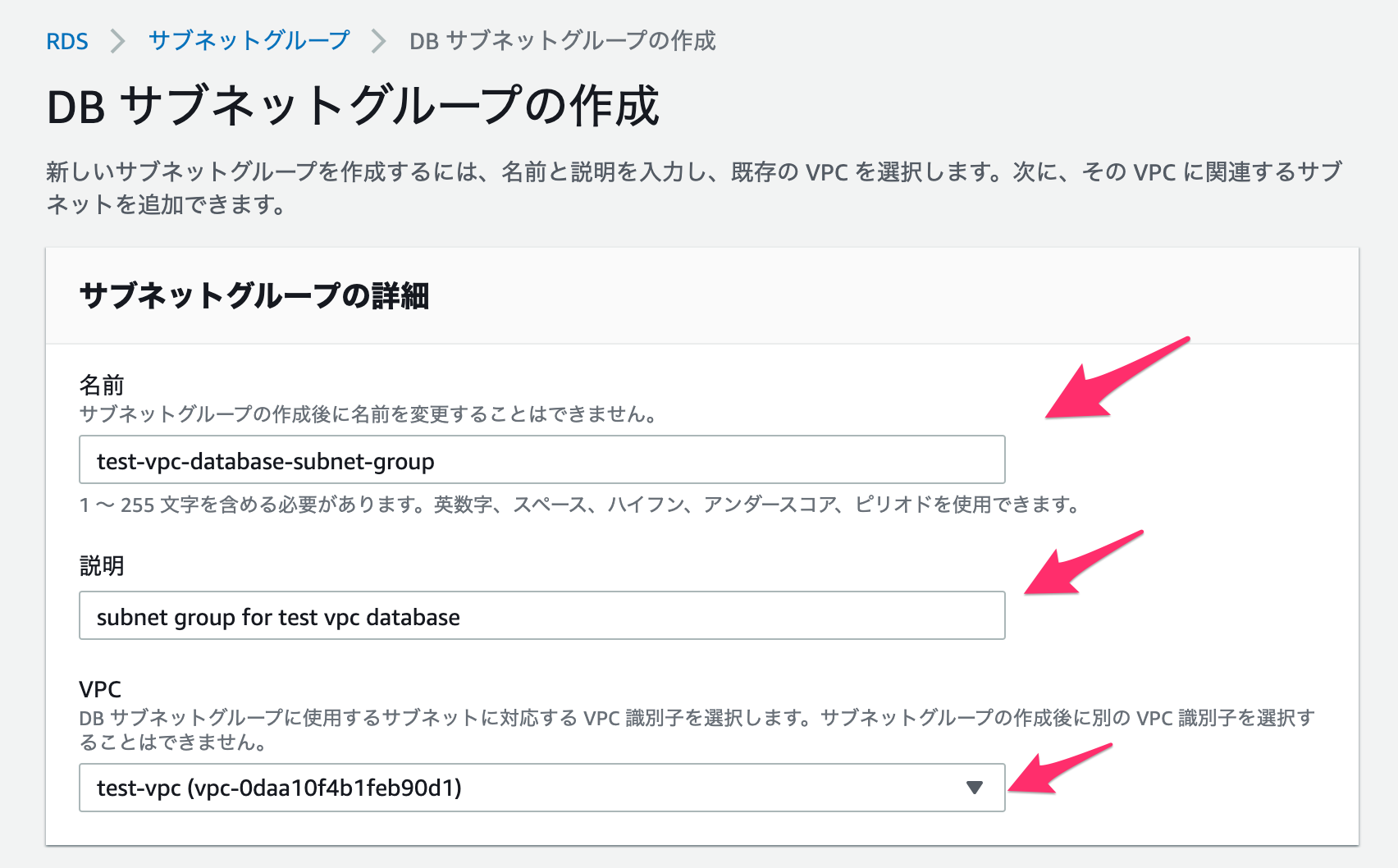
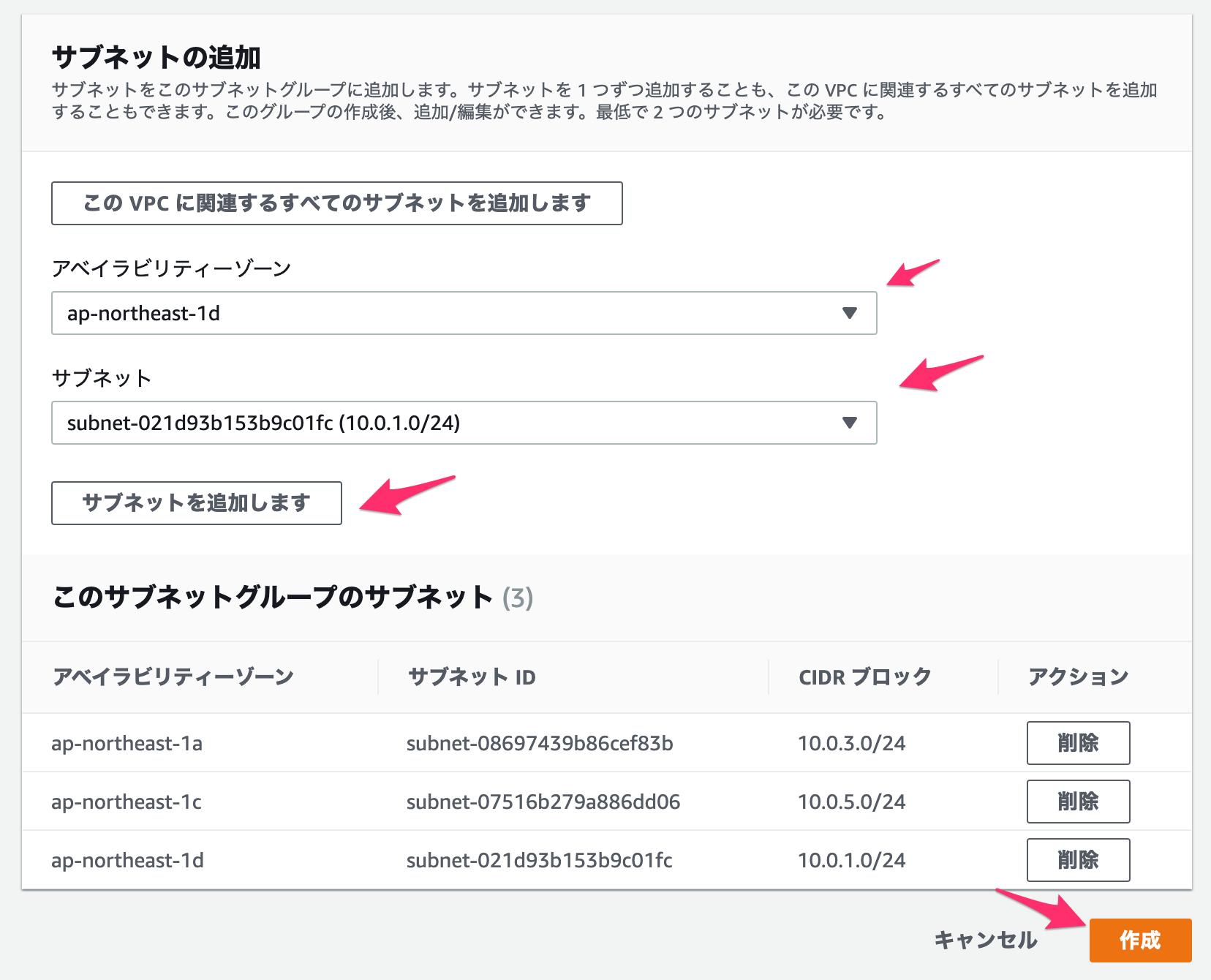
- 環境変数に下記を設定
環境変数 値 備考 S3_BUCKET_NAME S3バケット名 S3_BEFORE_KEY 変更前S3キー(path/to) S3_AFTER_KEY 変更前S3キー(path/to) キーの移動が不要であれば上と同じ値 S3_BEFORE_FORMAT 変更前日付フォーマット %Y-%m-%dなど、Pythonのdatetimeが認識できる形式FROM_DATE 開始日(yyyymmdd) キー変更を行いたいObjectの始点 TO_DATE 終了日(yyyymmdd) キー変更を行いたいObjectの終点 DELETE_FRAG True/False 元のObjectを削除するかどうか
- Lambdaの実行RoleにS3の対象バケットの操作権限を付与
- 実行時間や割り当てメモリは適宜調整
必要な設定は環境変数化したので、自分の環境に合わせて好きに設定していただければと思います。
また、エラーハンドリングは面倒で実装していません。
一度だけSPOTで実行するスクリプトなので最小限の実装に止めています。気になる方は修正してください。結果
既存のS3 Keyに対して通常のdate形式からHive形式に変更し、無事に分析しやすい形式にすることができました。
追加情報ですが、path/to/のレイヤーでGlue Cralwerを実行すると、Athenaで読み込めるData CatalogがPartition含めて自動的に生成されるので、よりAthenaでの分析ライフが充実したものとなります。
ここの実装がおかしいとか、もっとこうした方がいいとかあれば教えてください!
大した内容ではありませんが、リポジトリも公開しておきます。
https://github.com/kzk-maeda/change-s3-key/blob/master/lambda_function.py
- 投稿日:2020-02-25T18:52:01+09:00
AWS Backup EC2 を実運用へ導入したときのあれやこれや
はじめに
2020年1月、ようやく EC2 の バックアップ/リストア を支援する AWS Backup EC2 が リリースされた。
AWS Backup を使った EC2 のバックアップは、スケジュールしたタイミングあるいは即座に、タグあるいはインスタンスIDで指定した EC2 の AMI を取得する。
取得した AMI をライフサイクル管理(期限が切れたAMIを削除、あるいはコールドストレージへ移行(費用削減のため))したり、DR用途で異なるリージョンへコピーしたりといったバックアップ管理をしてくれる。
- スケジュールしたタイミングでバックアップ・・・バックアッププランを作成する
- 即座にバックアップ・・・オンデマンドバックアップを作成する
ただ、リストア機能はちょっと微妙(というか「復元」という定義は人それぞれ違うからそう思うのかな・・)。
リストア機能はさておき、バックアップ機能はすばらしいので、AWS Backup EC2 がリリースされる前は自作したもの(AMI を定期的に取得して世代管理する)を使っていたけど、すべて入れ替えた。
費用に関して(AWSサポート確認済み)
AWS Backup では、その月に使用したバックアップストレージ量および復元したバックアップデータの量に対してのみ料金が発生する。最低料金および初期費用は発生しない。
AWS Backup を利用して EC2をバックアップすると、AMIとEBSスナップショットが作成される。EBSスナップショットは、最初のバックアップとしてデータの完全コピーが保存され、その後は変更部分のみの増分バックアップとなる。毎回完全コピーが保存されるわけではない。そのため、課金対象のストレージ領域の量は次になる。
「最初に取得したEBSの実質容量+2番目に取得したEBSの増分量」AWS Backup EC2 バックアップ・リストアで使われたバックアップストレージの料金は、リソースタイプが 「Amazon EBS ボリュームスナップショット」と同様になる。
My 実運用設定
運用ポリシー
毎朝6時(JST)に、次のタグが付いている EC2 の AMI を取得する。
- EC2タグ
- キー: AWSBackup
- 値: EC2
有効期限は30日とし、30日後は破棄する。
リージョンコピーはしない(大阪リージョンが開通したら大阪にコピーしようかな・・)
AWS Backup EC2 は次の順に作成・設定する
(1) バックアップボールト
- バックアップボールト名: 「EC2」という名前で作成する
- KMS 暗号化マスターキー: デフォルトの「aws/backup」を使う
(2) バックアッププラン
- バックアッププラン名: 「EC2」という名前で作成する
- バックアップルール:
- ルール名:「EC2」
- 頻度:カスタム cron 式: cron(0 21 * * ? *) ← 日本時間で 毎朝6時
- 次の時間以内に開始:1時間
- ライフサイクル:コールドストレージに移行しない、1ヶ月後に失効(削除)
- バックアップボールト:「EC2」
- 送信先リージョン: なし
- リソースの割り当て:
- リソース割り当て名: 「Tag-AWSBackup-EC2」
- IAM ロール: AWS管理ポリシー「AWSBackupServiceRolePolicyForBackup」をアタッチしたもの
- 割り当て単位: タグ
- キー: AWSBackup
- 値: EC2
(3) バックアップ対象の EC2 にタグを付加する
付加するEC2がたくさんあったので、タグエディターで一括設定
EC2タグ
- キー: AWSBackup
- 値: EC2
My 実運用設定を Terraform で作成
- 構成
anyservice/ └── anyenv ├── backup │ ├── backend.tf │ ├── ec2.tf │ ├── provider.tf -> ../../../provider.tf │ └── terraform_remote_state.tf -> ../../../terraform_remote_state.tf └── iam ├── backend.tf ├── policy-document_backup-assume-role-policy.tf ├── role_aws-backup.tf └── terraform_remote_state.tf -> ../../../terraform_remote_state.tf
- AWS Backup EC2
※現時点で aws_backup_plan にはリージョンコピーの設定項目がない
ec2.tfresource "aws_backup_vault" "EC2" { name = "EC2" } resource "aws_backup_plan" "EC2" { name = "EC2" rule { rule_name = "EC2" target_vault_name = aws_backup_vault.EC2.name schedule = "cron(0 21 * * ? *)" lifecycle { delete_after = 30 } } } resource "aws_backup_selection" "EC2" { iam_role_arn = data.terraform_remote_state.IAM.outputs.AWSBackupServiceRole_arn name = "Tag-AWSBackup-EC2" plan_id = aws_backup_plan.EC2.id selection_tag { type = "STRINGEQUALS" key = "AWSBackup" value = "EC2" } }
- aws_backup_selection の iam_role_arn は Required なので、iam role も terraform で作成する。。
policy-document_backup-assume-role-policy.tfdata "aws_iam_policy_document" "backup-assume-role-policy" { statement { actions = ["sts:AssumeRole"] principals { type = "Service" identifiers = ["backup.amazonaws.com"] } } }role_aws-backup.tfresource "aws_iam_role" "AWSBackupServiceRole" { name = "AWSBackupServiceRole" assume_role_policy = data.aws_iam_policy_document.backup-assume-role-policy.json path = "/service-role/" tags = { Name = "AWSBackupServiceRole" ManagedBy = "Terraform" Environment = "anyenv" } } resource "aws_iam_role_policy_attachment" "aws-backup_AWSBackupServiceRolePolicyForBackup" { role = aws_iam_role.AWSBackupServiceRole.name policy_arn = "arn:aws:iam::aws:policy/service-role/AWSBackupServiceRolePolicyForBackup" } output "AWSBackupServiceRole_arn" { value = aws_iam_role.AWSBackupServiceRole.arn }バックアップ確認
バックアップジョブ
AWS Backup のダッシュボードから確認する
バックアップジョブの詳細
↓
- リソースIDは、取得したEC2のインスタンスID
- 作成時間は、06:14 になっている
- バックアップルールのcron式で毎朝6時に指定しているけど、6時ちょうどに取得するわけではない。
- 6時から7時(=「次の時間以内に開始:1時間」)までの間のどこかで取得する。
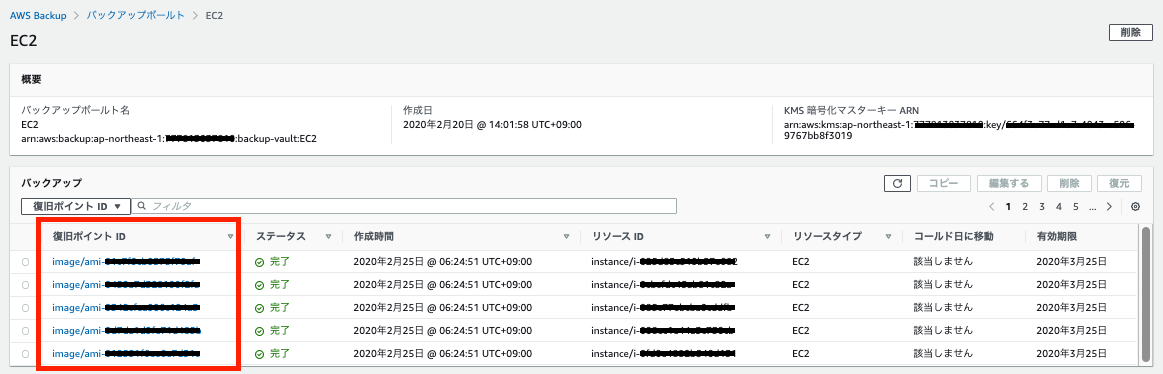
バックアップボールト
- AWS Backup では、取得した AMI を 「復旧ポイントID」 と言うらしい。
バックアップされたAMI
- Nameは、バックアップ元の EC2 の Nameタグの値が付く
- AMI名は、次の命名規則になる
- AWSBackup_インスタンスID_バックアップジョブID
- 作成日は、バックアップジョブの作成時間(06:14)ではなく、AMI作成時間(6:23)になっている
- AMIの削除(登録解除)は、「バックアップボールト」ページの「復旧ポイントID」の削除で行う。
リストアについて
復元時に使う IAM Role について
- EC2 を他のAWSサービスと連携させるなどで、何かしらのIAMロールを割り当てている。
- 何かしらのIAMロールが割り当てられたEC2を AWS Backup EC2 でバックアップして作成された AMI(復旧ポイントID)を復元する場合、デフォルトの IAMロール(AWS管理ポリシー「AWSBackupServiceRolePolicyForRestores」)を使うとエラーが出る。
- なので、次のポリシーを追加する必要がある。IAMの基本方針としてインラインポリシーは使わないのがベストなので、次のポリシーを作成して、デフォルトの IAM ロールにアタッチさせる。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "", "Effect": "Allow", "Action": "iam:PassRole", "Resource": "*" } ] }
- リストア用の IAMロールを Terraform で作成する
role_aws-backup-ec2-restor.tfdata "aws_iam_policy_document" "AWSBackupServiceRolePolicyForEC2Restore" { version = "2012-10-17" statement { sid = "" effect = "Allow" actions = ["iam:PassRole"] resources = ["*"] } } resource "aws_iam_policy" "AWSBackupServiceRolePolicyForEC2Restore" { name = "AWSBackupServiceRolePolicyForEC2Restore" policy = data.aws_iam_policy_document.AWSBackupServiceRolePolicyForEC2Restore.json } data "aws_iam_policy_document" "backup-assume-role-policy" { statement { actions = ["sts:AssumeRole"] principals { type = "Service" identifiers = ["backup.amazonaws.com"] } } } resource "aws_iam_role" "AWSBackupServiceEC2Restore" { name = "AWSBackupServiceEC2Restore" path = "/service-role/" assume_role_policy = data.aws_iam_policy_document.backup-assume-role-policy.json tags = { Name = "AWSBackupServiceEC2Restore" ManagedBy = "Terraform" Environment = "anyenv" } } resource "aws_iam_role_policy_attachment" "AWSBackupServiceRolePolicyForEC2Restore" { role = aws_iam_role.AWSBackupServiceEC2Restore.name policy_arn = aws_iam_policy.AWSBackupServiceRolePolicyForEC2Restore.arn } resource "aws_iam_role_policy_attachment" "AWSBackupServiceRolePolicyForRestores" { role = aws_iam_role.AWSBackupServiceEC2Restore.name policy_arn = "arn:aws:iam::aws:policy/service-role/AWSBackupServiceRolePolicyForRestores" } output "role_AWSBackupServiceEC2Role_arn" { value = aws_iam_role.AWSBackupServiceEC2Restore.arn }復元したEC2に割り当てられるキーペアについて(AWSサポート確認済み)
- 現時点では、AWS Backup EC2 の復元時に キーペアを指定することはできない。
- EC2のダッシュボード上ではキーペアが表示されないが、キーペア自体は元のインスタンスに指定されたものと同様のものがインスタンス内部では保持されているので、そのキーを使えばSSH 接続が可能。
パブリックIPアドレスについて(AWSサポート確認済み)
- バックアップを復元するサブネットで「パブリック IPv4 アドレスの自動割り当て」が「いいえ」と設定されている場合は、復元されたEC2にパブリックIPアドレスは付加されない。



- 投稿日:2020-02-25T18:21:52+09:00
JAWS−UG サーバーレスクイックスタート
JAWS−UG サーバーレスクイックスタート
先日仕事帰りに[JAWS−UG初心者支部]の90分でサーバーレスの基本をクイックで学ぶハンズオン勉強会に参加しましたので簡単にまとめて記載しました。
ハンズオンの前提条件が、ハンズオン用のAWSアカウントを持っていることだったので事前にAWS個人用アカウントを作成し、AWSサービス操作権限のある IAMユーザーでログインできるか確認も済ませました。
下記は勉強会のアジェンダです。
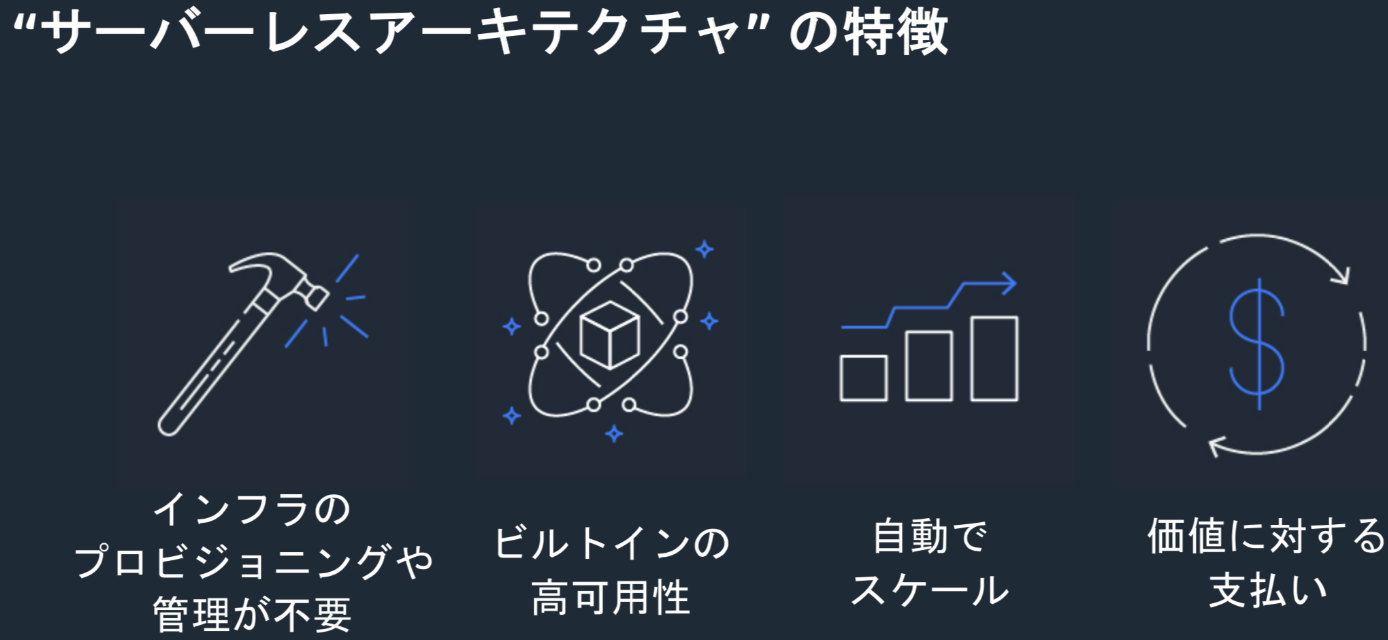
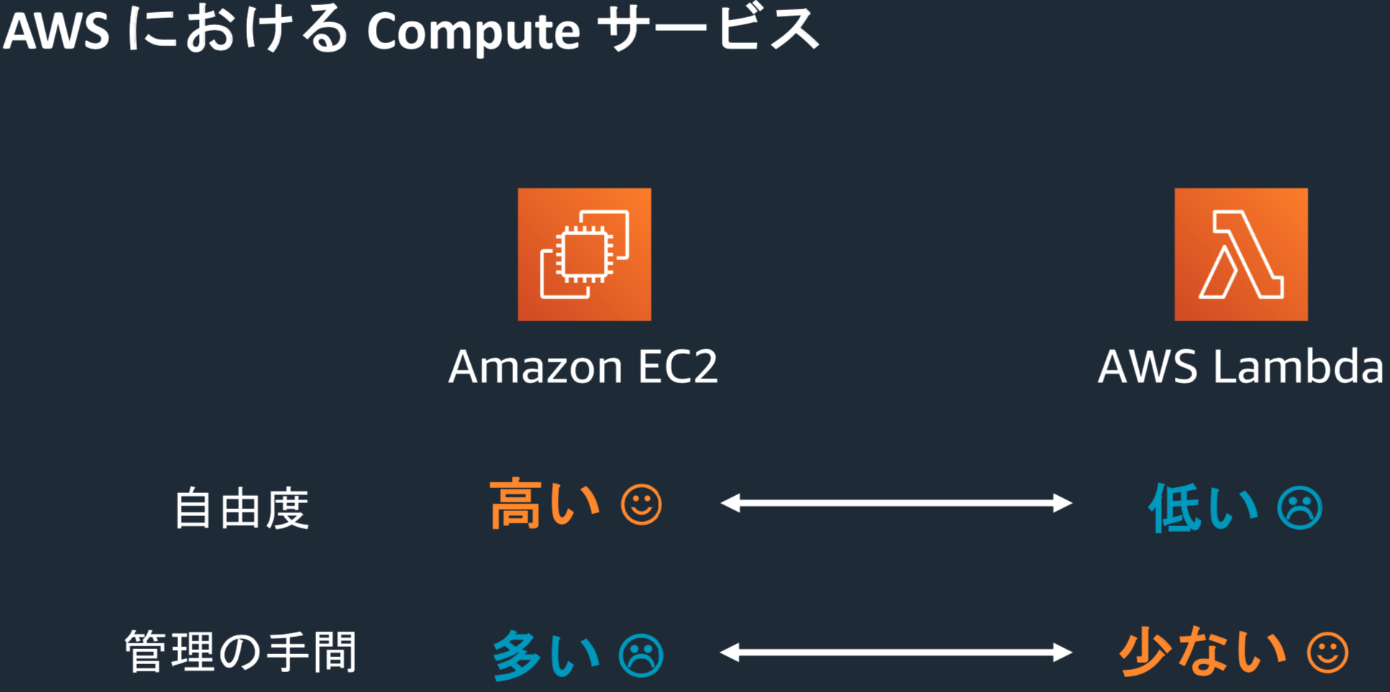
”サーバーレス”とは何か?何が嬉しいのか?
ハンズオン1:AWSLambdaで日=>英翻訳する
ハンズオン2:翻訳Web APIを作る
ハンズオン3:文字起こし+翻訳パイプラインを作る”サーバーレス”とは何か?何が嬉しいのか?
ハンズオン1:AWSLambdaで日=>英翻訳する
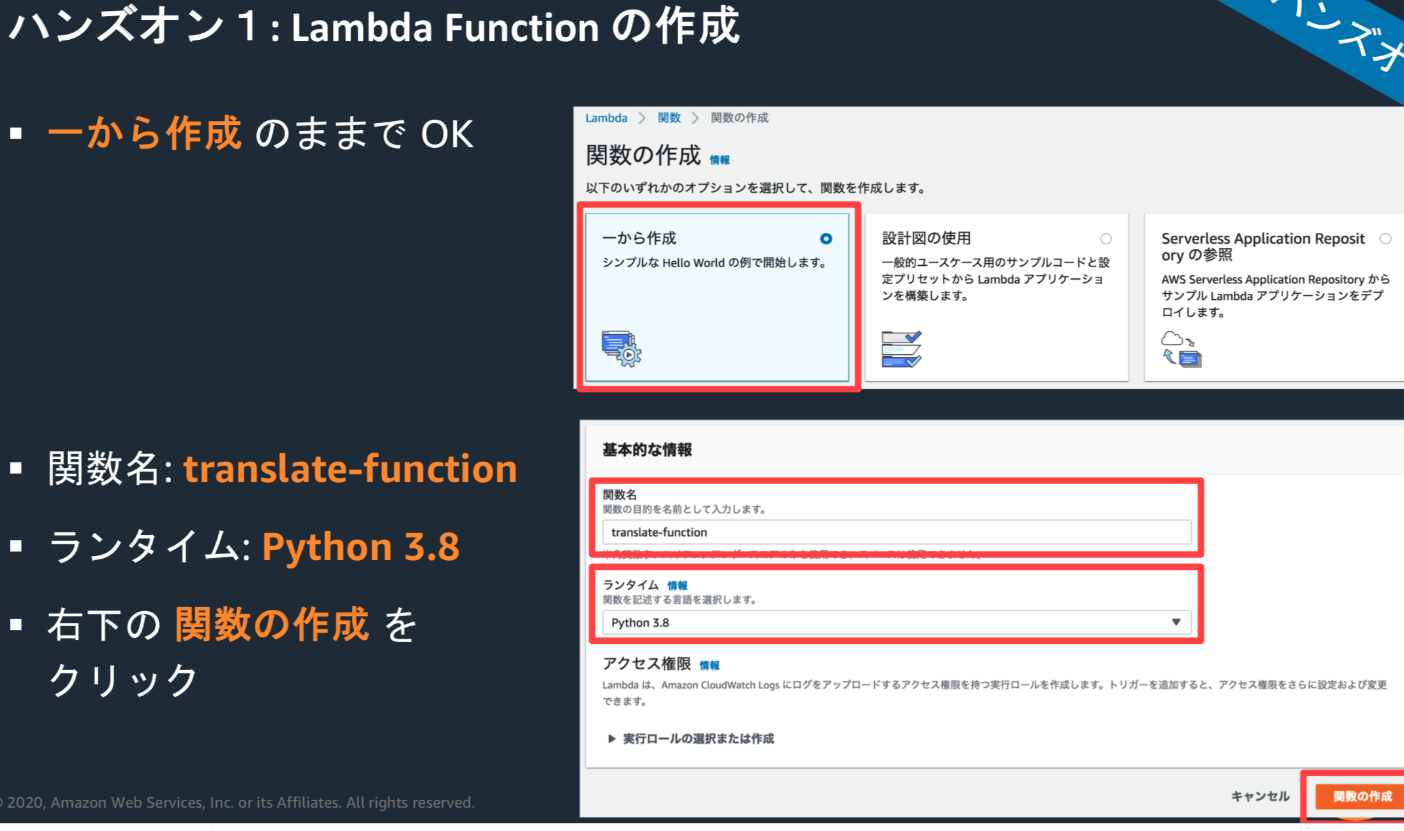
Lambda Functionを作成し、”Hello World” と表示する
・IAMユーザーでログイン後、東京リージョン、日本語を選択。
・AWS Lambda画面でLambda Functionを作成
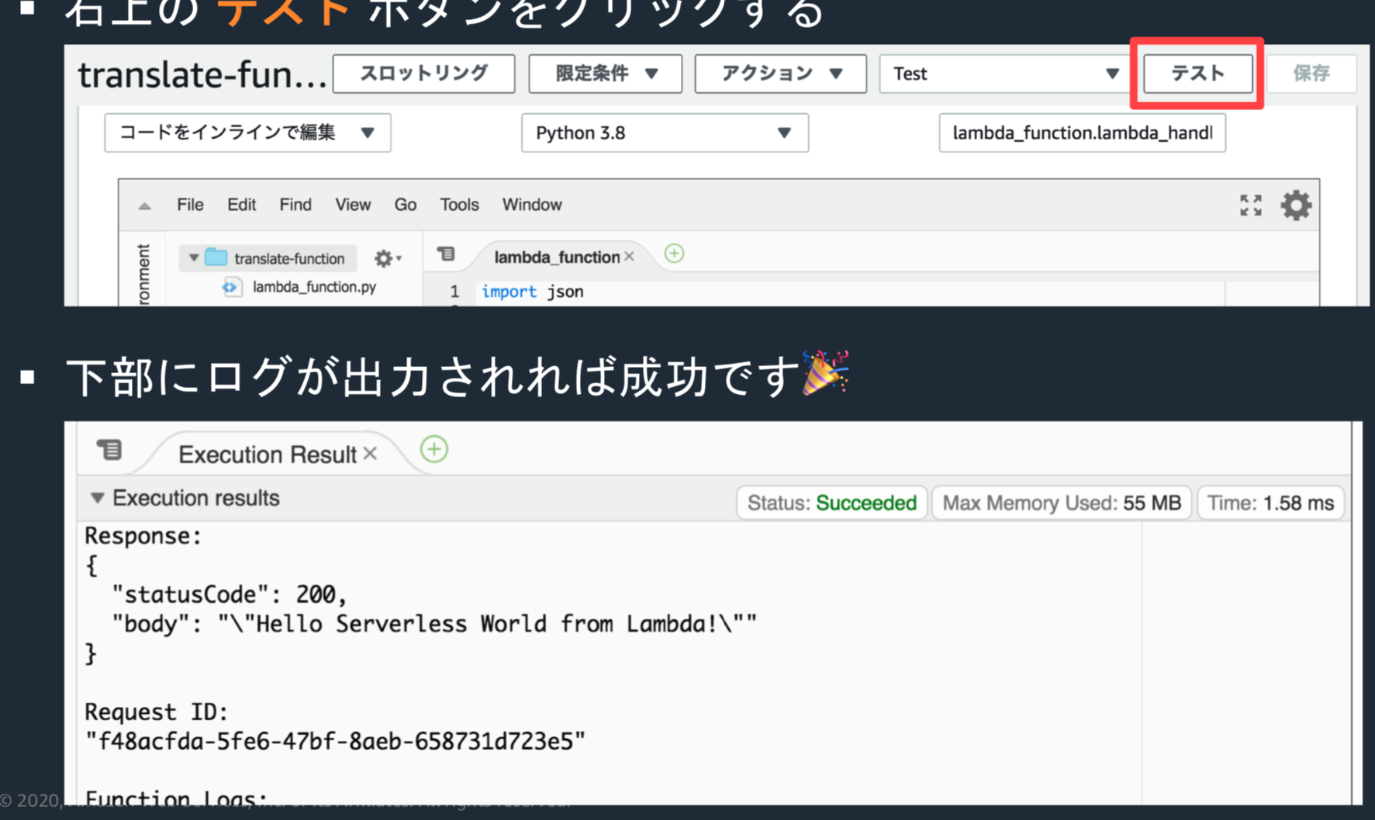
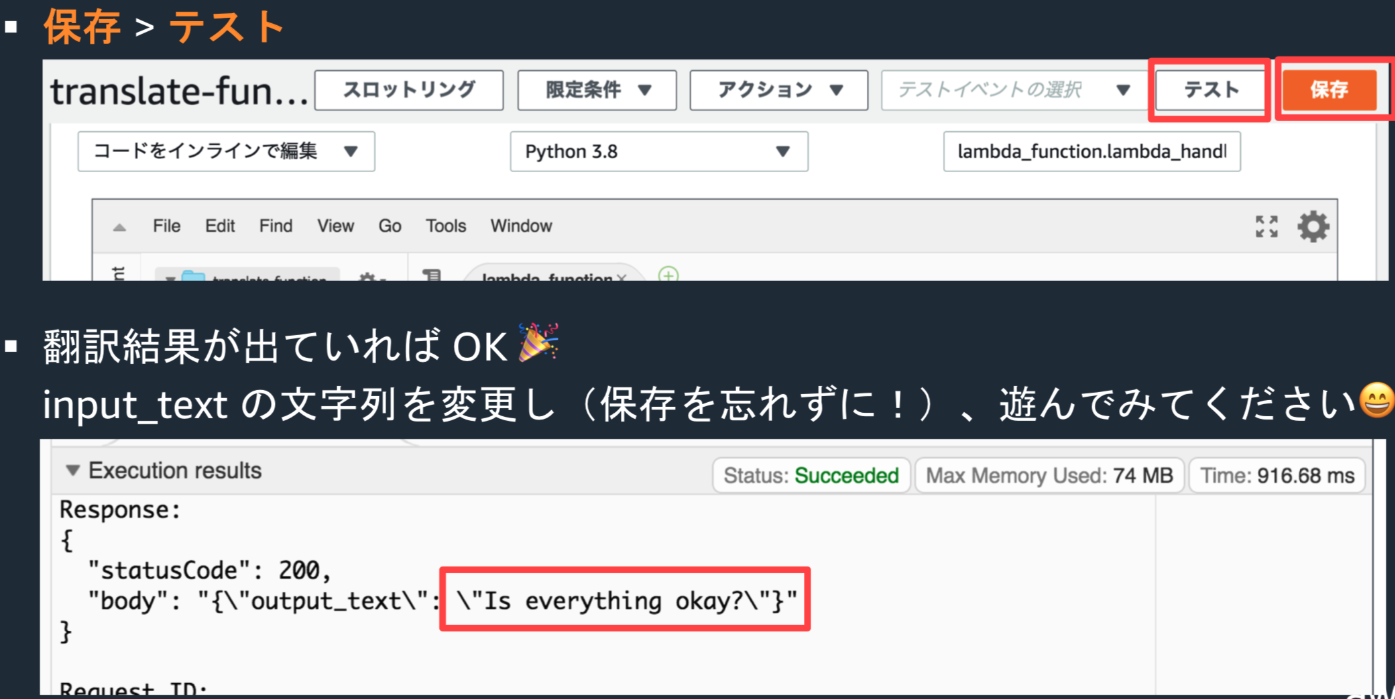
ソースの7行目を修正し、保存ボタンで保存後、テストボタンクリックすると、ゲブにログが出力される。
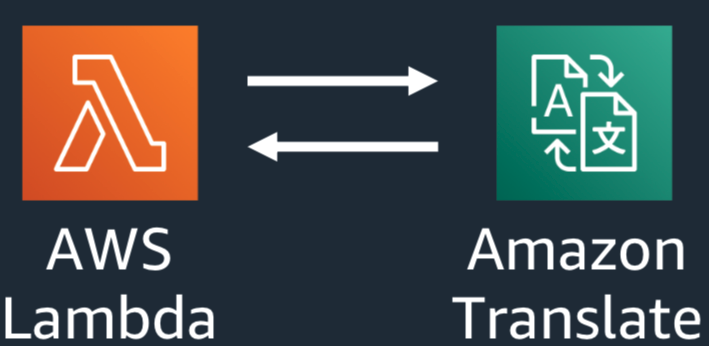
Lambda Functionを修正し、Amazon Translateと連携する
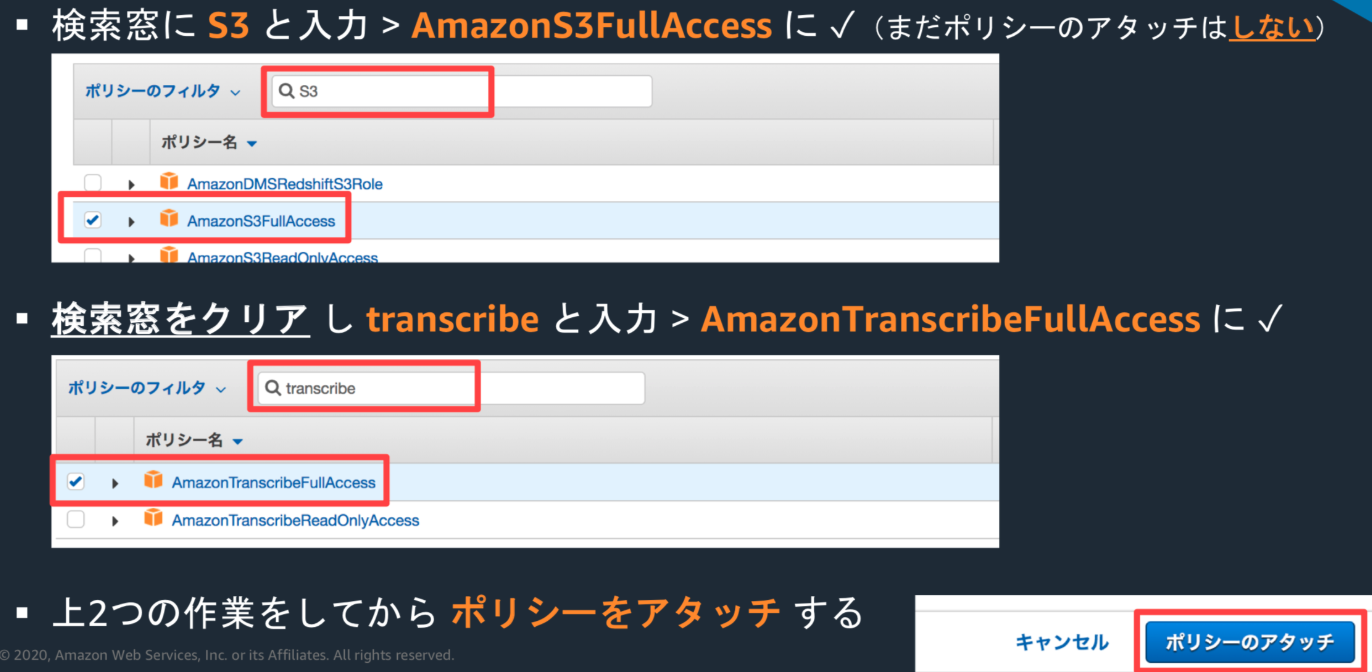
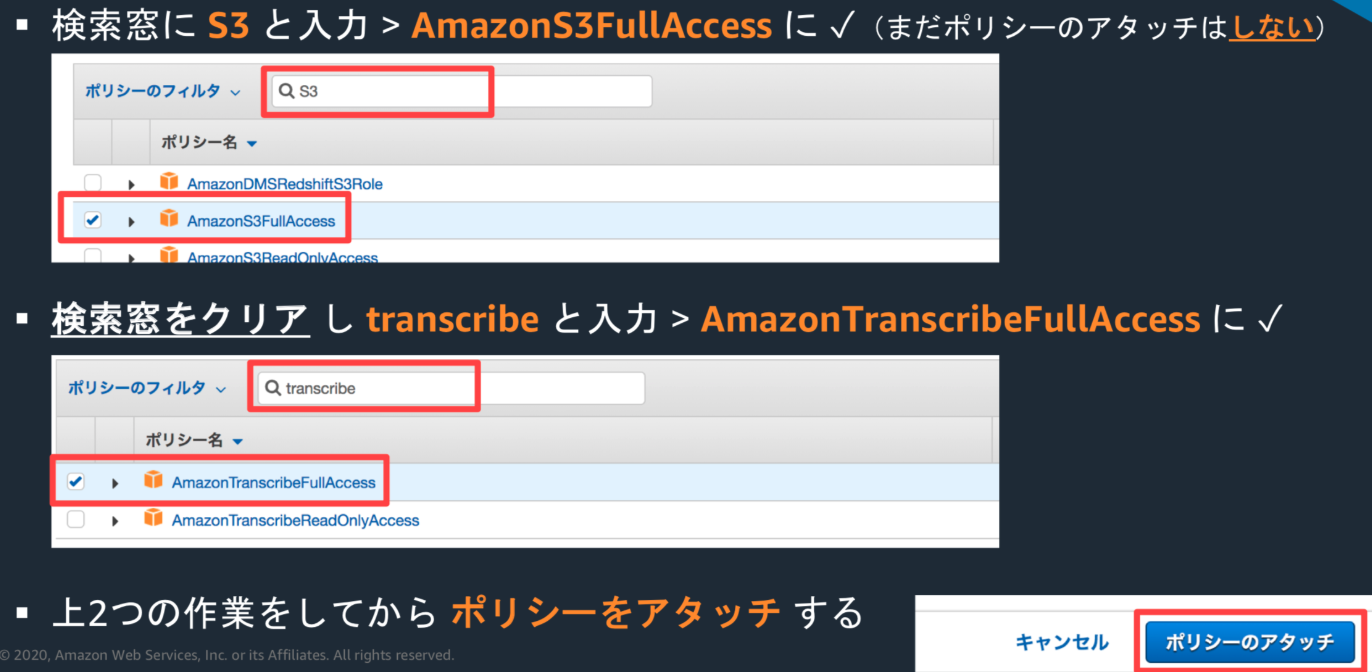
・Lambda Function画面の下の方にスクロールし、「xxxロールを表示」をクリック(IAMロールの画面が別タブで開く)
・「ポリシーをアタッチします」をクリック
・検索窓にtranslateと入力し、TranslateFullAccessの方にチェックを入れる
・その後、右下の「ポリシーのアタッチ」をクリック
・Lambda画面に戻りソースコードを下記のURLのように修正する
https://github.com/ketancho/aws-serverless-quick-start-hands-on/blob/master/src/translate-function.py
・修正後、保存、テスト
ハンズのオン2:翻訳Web APIを作る
Amazon API Gateway の特徴
・サーバーのプロビジョニングや管理なしでAPIを作成・管理できるマネージメントサービス
・可溶性の担保、スケーリングなどのAPI管理で必要なことをAPI Gatewayに任せる
・料金体系はリクエストベース(REST APIの場合)
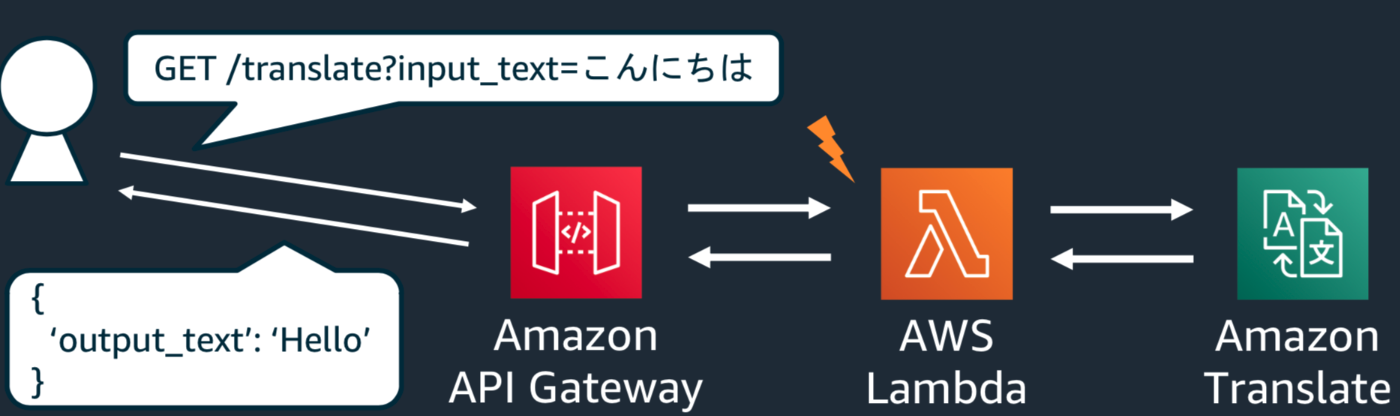
Amazon API Gateway とAWS Lambdaを組み合わせて外部から叩けるWeb APIを作る
Lambda Functionソースの修正
下記のリンクのソースのように、input_textの部分をAPI Gatewayから渡される、クエリストリンクパラメータを受け取る形に修正→保存
https://github.com/ketancho/aws-serverless-quick-start-hands-on/blob/master/src/translate-function-with-apigw.py
・API Gateway画面の下部に遷移し、REST APIの「構築」ボタンをクリック
・プロトコルはRESTのまま、新しいAPIを選択し、API名をtranslate-apiとし、API作成
・アクションタブから「リソースの作成」を選択し、リソース名をtranslateとし、リソース作成
・/translateが選ばれている状態で、アクションタブから「メソッドの作成」を選択し、
/translateのプルダウンから「GET」を選択、☑️をクリックしてメソッドの作成
・「Lambdaプロキシ統合の使用」を☑️した後、Lambda関数にtranslate-function を指定し、保存をクリック
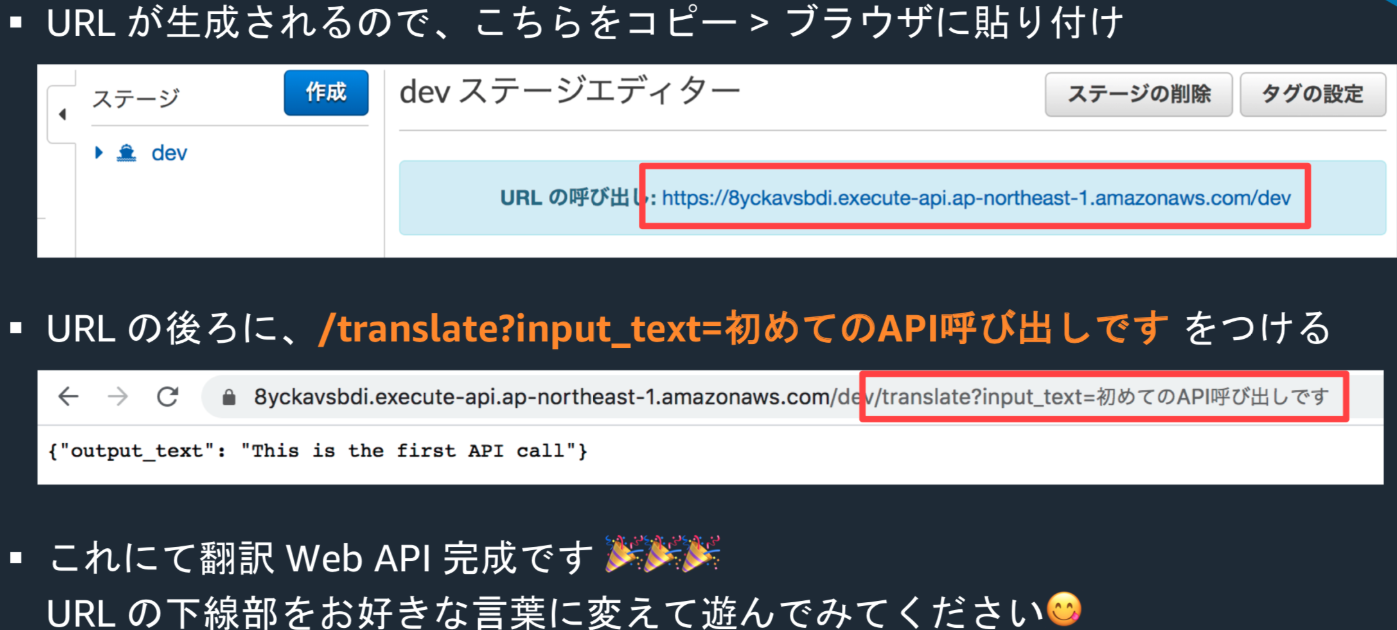
・アクションタブから「APIデプロイ」を選択し、デプロイされるステージは「新しいステージ」を選択し、
ステージ名に「dev」と入力し、デプロイをクリック
・左側のメニューで「ステージ」を選び、「dev」をクリック するとURLガクリックされる。
ハンズオン3:文字起こし+翻訳パイプラインを作る
Amazon Transcribe 特徴
音声をテキストに変換する文字起こしサービス
AWS Lambda とAmazon Transcribe を組み合えあせて、音声データを文字起こしするパイプラインを作る
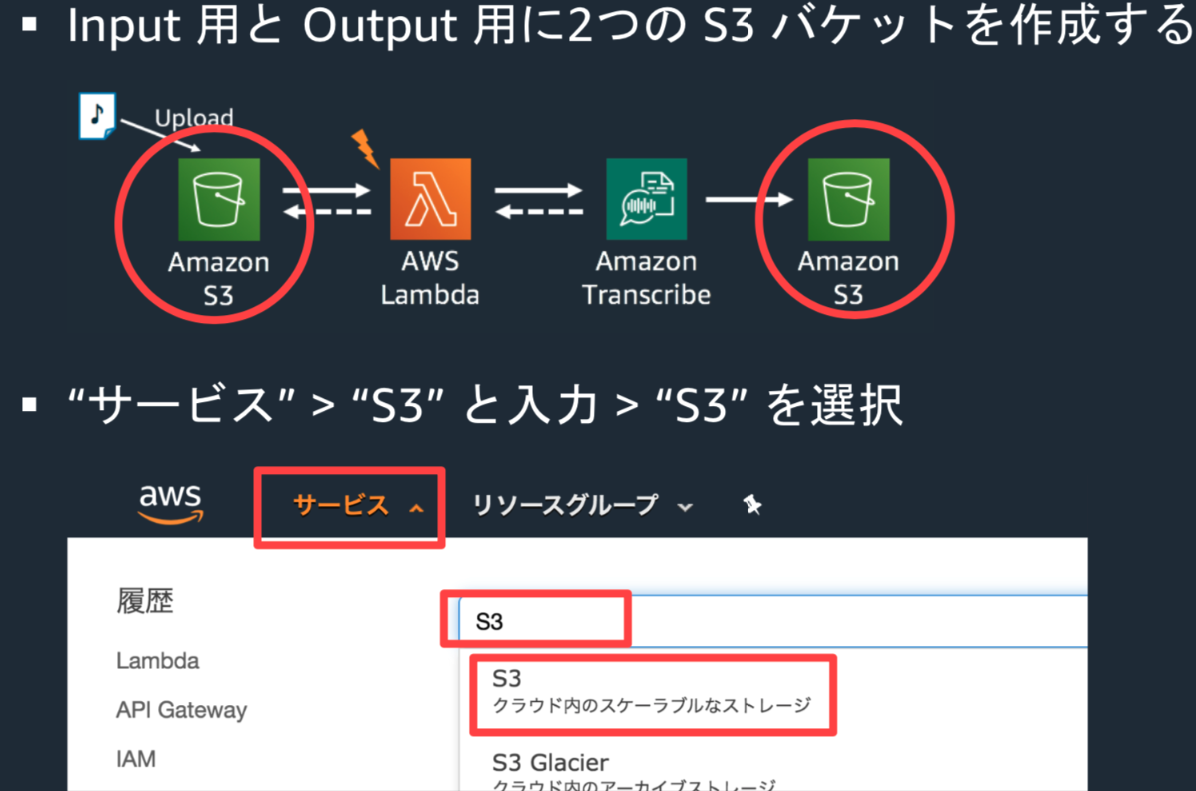
下記のパケットを作成
yyyymmdd-transcribe-input-yourname
yyyymmdd-transcribe-output-yourname・AWS Lambdaの画面へ:サービス > lambdaと入力 > Lambdaを選択 > 関数を作成
・設計図の使用 >検索窓にS3と入力し、Enter
・s3-get-object-pythonを選択肢、右下の設定をクリック
・Function 名: transcribe-function, Role名: transcribe-function-roleとし
・S3トリガーの対象なるバケットを指定(inputの方を選択)
・トリガーの有効化に☑️し、「関数の作成」ボタンクリック
・IAMロールを修正:Lambda Function の下部から xxx ロールを表示をクリック
・「ポリシーをアタッチします」をクリック
ソースコードを下記のリンクのように修正し、保存
https://github.com/ketancho/aws-serverless-quick-start-hands-on/blob/master/src/transcribe-function.py下記リンクより音声ファイルをダウンロードする
https://d1.awsstatic.com/product-marketing/Polly/HelloEnglish-Joanna.0aa7a6dc7f1de9ac48769f366c6f447f9051db57.mp3S3にmp3ファイルをアップロードする。input側のS3バケットでアップロードをクリックしアップする
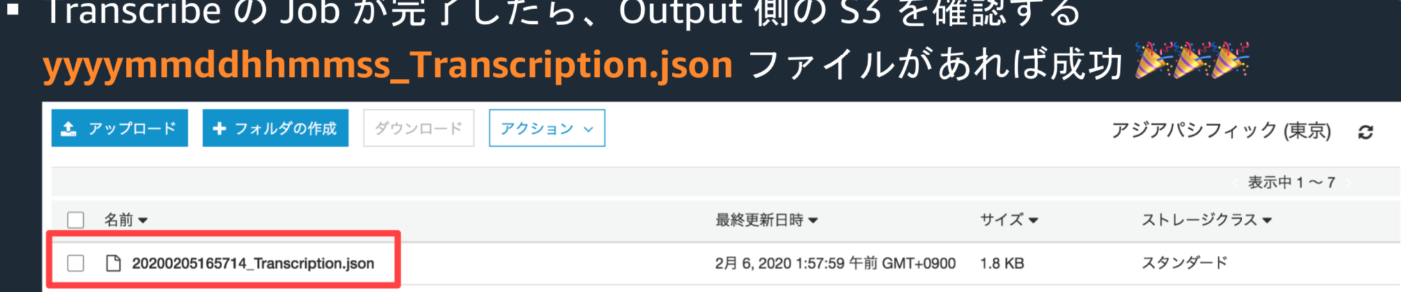
・サービス -> transcribeと入力 > Amazon Transcribeを選択
・左上のハンバーガーメニュークリック > Transcription jobsをクリック
・Job StatusがInprogressであることを確認し、Completeになるまで待つ
感想:
ハンズオンでしかも数人のチューターがいて、質問すると丁寧に指導して頂けて短時間で効率良い勉強ができて良かったです。





- 投稿日:2020-02-25T17:40:16+09:00
【AWS/S3】C#でS3バケット内に特定のフォルダが存在するか確認する
はじめに
開発環境
- Windows10
- VisualStudio2017
- AWSSDK.S3のバージョンは3.3.104.39開発言語
- C#
やりたかったこと
S3にファイルをアップロードする際に、既にディレクトリがアップロードされているものは警告を表示するようにしたかった。
やり方
ソースコードは以下の通り。
既に存在するとtrue,存在しないとfalseが返ります。bool isDirExist(string Buketname ,string Path) { basiccredentials = new BasicAWSCredentials(アクセスキーID,シークレットアクセスキー); using (var S3Client = new AmazonS3Client(basiccredentials, this.wwRegion)) { ListObjectsRequest request = new ListObjectsRequest(); request.BucketName = Buketname ; request.Prefix = Path; var response =S3Client.ListObjects(request); if (response.S3Objects.Count!=0) return true; else return false; // 存在なし } }Buketname :S3バケット名
Path:検索したいディレクトリのパス(ex. main/20200225/log1/ など)ListObjectsのPrefix に確認したいディレクトリパスを指定しListObjectsを呼び出すと
指定したディレクトリパス配下に格納されているオブジェクトのリストを取得できます。ディレクトリの中にファイルが存在しないのにディレクトリが作成されている・・・
という事は無いはずなので、このS3Objects.Countが0以外であればディレクトリパスが存在している ということです。
- 投稿日:2020-02-25T17:31:46+09:00
AWS IoT Device SDK PythonをベースにしてSORACOM Beam経由でAWS IoT CoreへMQTT接続できるか認確
目的
開発量を減らしたいなどの理由やサービスの実装部分を減らしたいと考えれば、メタにPahoで実装したくないとか、サービスアップデート部分もSDKアップデートで対応したいなどの理由でSDKを使いたいケースは多いと思います。一方でデバイスやGatewayのケーパビリティやバッテリーなどの物理的な制約でデバイス側はセキュリティ実装は軽くしたいという相反する希望もあるかと思います。
じゃってことでAWS IoT Device SDKを使ってMQTT -> SORACOM Beam経由で MQTTS -> AWS IoT Coreな通信ができるのかをPython SDKをもとに確認してみます。AWS IoT Core と SORACOM Beamの仕様差分を確認
MQTT client視点で見る差分は以下となります。
AWS IoT Core SORACOM Beam endpoint {prefix}-ats.iot.{region}.amazonaws.com beam.soracom.io port 8883 1883 Protocl MQTTS MQTT ということは、デバイス側のBeam MQTTクライアントとしては、
beam.soracom.io:1883へMQTTが投げられればよいということになります。AWS IoT Device SDKの変更点を見てみる
AWS IoT Device SDK pythonにおけるMQTTインスタンスの生成は以下の記述があります。
# Import SDK packages from AWSIoTPythonSDK.MQTTLib import AWSIoTMQTTClient # For certificate based connection myMQTTClient = AWSIoTMQTTClient("myClientID") # For Websocket connection # myMQTTClient = AWSIoTMQTTClient("myClientID", useWebsocket=True) # Configurations # For TLS mutual authentication myMQTTClient.configureEndpoint("YOUR.ENDPOINT", 8883) myMQTTClient.configureCredentials("YOUR/ROOT/CA/PATH", "PRIVATE/KEY/PATH", "CERTIFICATE/PATH") # For Websocket, we only need to configure the root CA # myMQTTClient.configureCredentials("YOUR/ROOT/CA/PATH") myMQTTClient.configureOfflinePublishQueueing(-1) # Infinite offline Publish queueing myMQTTClient.configureDrainingFrequency(2) # Draining: 2 Hz myMQTTClient.configureConnectDisconnectTimeout(10) # 10 sec myMQTTClient.configureMQTTOperationTimeout(5) # 5 secインスタンス設定用の関数にエンドポイント、ポートが自分で設定できるようになっているので、どうやら変更できそうです。
では上記の差分に従って変更してみると、以下になります。from AWSIoTPythonSDK.MQTTLib import AWSIoTMQTTClient # For certificate based connection myMQTTClient = AWSIoTMQTTClient("myClientID") # For Websocket connection # myMQTTClient = AWSIoTMQTTClient("myClientID", useWebsocket=True) # Configurations # ソラコムの設定にエンドポイント、ポート設定を変更 myMQTTClient.configureEndpoint("beam.soracom.io", 1883) # 証明書によるTLSは不要なので、証明書の設定をコメントアウト #myMQTTClient.configureCredentials("YOUR/ROOT/CA/PATH", "PRIVATE/KEY/PATH", "CERTIFICATE/PATH") # For Websocket, we only need to configure the root CA # myMQTTClient.configureCredentials("YOUR/ROOT/CA/PATH") myMQTTClient.configureOfflinePublishQueueing(-1) # Infinite offline Publish queueing myMQTTClient.configureDrainingFrequency(2) # Draining: 2 Hz myMQTTClient.configureConnectDisconnectTimeout(10) # 10 sec myMQTTClient.configureMQTTOperationTimeout(5) # 5 secShadow packageからshadowインスタンスを作るときにも同じ変更点です。
SORACOM BeamのAWS IoT MQTT接続の設定
詳細はSOARCOMのサイトをご参照ください。後半のmosquittoやAmazon SNSは設定を省略しても構いません。
sampleで提供されているbasicPubSubを使ってみる
basicPubSub
不要かつ動いてしまう証明書依存部分をコメントアウトして以下の様になりました。basicPubSub_beam.py''' /* * Copyright 2010-2017 Amazon.com, Inc. or its affiliates. All Rights Reserved. * * Licensed under the Apache License, Version 2.0 (the "License"). * You may not use this file except in compliance with the License. * A copy of the License is located at * * http://aws.amazon.com/apache2.0 * * or in the "license" file accompanying this file. This file is distributed * on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either * express or implied. See the License for the specific language governing * permissions and limitations under the License. */ ''' from AWSIoTPythonSDK.MQTTLib import AWSIoTMQTTClient import logging import time import argparse import json AllowedActions = ['both', 'publish', 'subscribe'] # Custom MQTT message callback def customCallback(client, userdata, message): print("Received a new message: ") print(message.payload) print("from topic: ") print(message.topic) print("--------------\n\n") # Read in command-line parameters parser = argparse.ArgumentParser() parser.add_argument("-e", "--endpoint", action="store", required=True, dest="host", help="Your AWS IoT custom endpoint") #parser.add_argument("-r", "--rootCA", action="store", required=True, dest="rootCAPath", help="Root CA file path") #parser.add_argument("-c", "--cert", action="store", dest="certificatePath", help="Certificate file path") #parser.add_argument("-k", "--key", action="store", dest="privateKeyPath", help="Private key file path") parser.add_argument("-p", "--port", action="store", dest="port", type=int, help="Port number override") parser.add_argument("-w", "--websocket", action="store_true", dest="useWebsocket", default=False, help="Use MQTT over WebSocket") parser.add_argument("-id", "--clientId", action="store", dest="clientId", default="basicPubSub", help="Targeted client id") parser.add_argument("-t", "--topic", action="store", dest="topic", default="sdk/test/Python", help="Targeted topic") parser.add_argument("-m", "--mode", action="store", dest="mode", default="both", help="Operation modes: %s"%str(AllowedActions)) parser.add_argument("-M", "--message", action="store", dest="message", default="Hello World!", help="Message to publish") args = parser.parse_args() host = args.host #rootCAPath = args.rootCAPath #certificatePath = args.certificatePath #privateKeyPath = args.privateKeyPath port = args.port useWebsocket = args.useWebsocket clientId = args.clientId topic = args.topic if args.mode not in AllowedActions: parser.error("Unknown --mode option %s. Must be one of %s" % (args.mode, str(AllowedActions))) exit(2) ''' if args.useWebsocket and args.certificatePath and args.privateKeyPath: parser.error("X.509 cert authentication and WebSocket are mutual exclusive. Please pick one.") exit(2) if not args.useWebsocket and (not args.certificatePath or not args.privateKeyPath): parser.error("Missing credentials for authentication.") exit(2) ''' # Port defaults if args.useWebsocket and not args.port: # When no port override for WebSocket, default to 443 port = 443 if not args.useWebsocket and not args.port: # When no port override for non-WebSocket, default to 8883 port = 8883 # Configure logging logger = logging.getLogger("AWSIoTPythonSDK.core") #logger.setLevel(logging.DEBUG) streamHandler = logging.StreamHandler() formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') streamHandler.setFormatter(formatter) logger.addHandler(streamHandler) # Init AWSIoTMQTTClient myAWSIoTMQTTClient = None if useWebsocket: myAWSIoTMQTTClient = AWSIoTMQTTClient(clientId, useWebsocket=True) myAWSIoTMQTTClient.configureEndpoint(host, port) #myAWSIoTMQTTClient.configureCredentials(rootCAPath) else: myAWSIoTMQTTClient = AWSIoTMQTTClient(clientId) myAWSIoTMQTTClient.configureEndpoint(host, port) #myAWSIoTMQTTClient.configureCredentials(rootCAPath, privateKeyPath, certificatePath) # AWSIoTMQTTClient connection configuration myAWSIoTMQTTClient.configureAutoReconnectBackoffTime(1, 32, 20) myAWSIoTMQTTClient.configureOfflinePublishQueueing(-1) # Infinite offline Publish queueing myAWSIoTMQTTClient.configureDrainingFrequency(2) # Draining: 2 Hz myAWSIoTMQTTClient.configureConnectDisconnectTimeout(10) # 10 sec myAWSIoTMQTTClient.configureMQTTOperationTimeout(5) # 5 sec # Connect and subscribe to AWS IoT myAWSIoTMQTTClient.connect() if args.mode == 'both' or args.mode == 'subscribe': myAWSIoTMQTTClient.subscribe(topic, 1, customCallback) time.sleep(2) # Publish to the same topic in a loop forever loopCount = 0 while True: if args.mode == 'both' or args.mode == 'publish': message = {} message['message'] = args.message message['sequence'] = loopCount messageJson = json.dumps(message) myAWSIoTMQTTClient.publish(topic, messageJson, 1) if args.mode == 'publish': print('Published topic %s: %s\n' % (topic, messageJson)) loopCount += 1 time.sleep(1)標準のbasicPubSubとdiffをとるとこのくらいの差分
$ diff basicPubSub_soracom.py basicPubSub.py 38,40c38,40 < #parser.add_argument("-r", "--rootCA", action="store", required=True, dest="rootCAPath", help="Root CA file path") < #parser.add_argument("-c", "--cert", action="store", dest="certificatePath", help="Certificate file path") < #parser.add_argument("-k", "--key", action="store", dest="privateKeyPath", help="Private key file path") --- > parser.add_argument("-r", "--rootCA", action="store", required=True, dest="rootCAPath", help="Root CA file path") > parser.add_argument("-c", "--cert", action="store", dest="certificatePath", help="Certificate file path") > parser.add_argument("-k", "--key", action="store", dest="privateKeyPath", help="Private key file path") 54,56c54,56 < #rootCAPath = args.rootCAPath < #certificatePath = args.certificatePath < #privateKeyPath = args.privateKeyPath --- > rootCAPath = args.rootCAPath > certificatePath = args.certificatePath > privateKeyPath = args.privateKeyPath 65c65 < ''' --- > 73c73 < ''' --- > 82c82 < #logger.setLevel(logging.DEBUG) --- > logger.setLevel(logging.DEBUG) 93c93 < #myAWSIoTMQTTClient.configureCredentials(rootCAPath) --- > myAWSIoTMQTTClient.configureCredentials(rootCAPath) 97c97 < #myAWSIoTMQTTClient.configureCredentials(rootCAPath, privateKeyPath, certificatePath) --- > myAWSIoTMQTTClient.configureCredentials(rootCAPath, privateKeyPath, certificatePath)動作確認するだけなので、引数を以下として起動します。
python basicPubSub_beam.py -e beam.soracom.io -p 1883AWS IoT consoleでみるとPubの成功、また本スクリプトがdefaultで自分自身のpubしたtopicをsubscribeしているので、起動したコンソール上にもメッセージが表示されます。
これでまず、Beamを通してpubsubが問題なく行われていることがわかります。動作確認できたもの
ざっと私の方で動作確認できたものとして、
- shadow instaceを生成しての AWS IoT Shadowの操作
- deltaの受信、shadow updateは問題なくできました
- basic ingest: これも問題なし
ということで$awsで始まるような予約topicも問題なくやり取りできました。
SDKを使う上で大事なこと
ここまで説明してきたとおり、Endpoint、TLS設定なし、ポートの変更ができればSDKをつかってBeamを使うことは可能でした。
Javascript版もBeam接続できそうです。JavaはTLSが必須になっている模様。など、SDKの実装に大きく依存しておりますので、皆様にてご確認ください。SORACOM Beamを使う上でのセキュリティレベルは変わるのか?
AWS IoTにおいては、各デバイス/GWなどAWS IoTと通信するものに個別の証明書を入れることを推奨としていると思います。SORACOMを利用する場合同じく通信するデバイス/GWにSORACOM SIMがついており、このSIMが個別証明書相当になります。この違いは、AWS側の考えている通信の前提とSORACOMを利用する場合で前提が異なるということになります。
SORACOMの通信の場合、世の中の携帯のSIM認証のセキュリティレベルがあります。Beamを使う場合はデバイス個別鍵をSIMとしてAWS IoTへの認証をSORACOM側が行うことになり、AWSIoTと皆様のSIM groupが正しく/セキュアに通信するためにBeamの設定としてAWS IoTの証明書を設定することになります。
ということで、通信の前提の違いによる考え方はあるもののSOARCOM Beamを使うからセキュリティレベルが落ちるということにはならないと思います。SORACOM Beamで気にすること
AWS IoTのいう、デバイスごとの証明書を発行する場合、 Policyを証明書を対(1:1)に発行することでPolicyの記載レベルを証明書単位で変えることができます。一方でBeamの場合、グループ単位で一つの証明書になるので、MQTTの設計および、Thing Attributeなどをうまく設計し、Policy変数をうまく使うなどを検討する必要があるかと思います。
SORACOM Beamが解決すること
導入でもいくつか例をあげましたが、
- セキュリティのオフロード
- 証明書ストアの集約
- B2B IoTでお客様ネットワークに相乗りすると問題になるProxy/port問題
などが考えられます。まとめ
いずれにしてもMQTTデザインとpolicyデザイン、証明書発行フロー(SORACOM Beam を使う場合はグループのデザイン)は初期に設計した上で、想定されている最大に拡大したときにも破綻しないデザインを検討することは重要です。
クラウドアーキテクチャや、デバイス側プログラミングが楽しいので、忘れがちにあるのですが、このあたりを初期に担保すると後々困ることは減るはずです。免責
本投稿は、個人の意見で、所属する企業や団体は関係ありません。
また掲載しているsampleプログラムの動作に関しても保障いたしませんので、参考程度にしてください。
- 投稿日:2020-02-25T17:31:46+09:00
AWS IoT Device SDK PythonをベースにしてSORACOM Beam経由でAWS IoT CoreへMQTT接続できるか確認
目的
開発量を減らしたいなどの理由やサービスの実装部分を減らしたいと考えれば、メタにPahoで実装したくないとか、サービスアップデート部分もSDKアップデートで対応したいなどの理由でSDKを使いたいケースは多いと思います。一方でデバイスやGatewayのケーパビリティやバッテリーなどの物理的な制約でデバイス側はセキュリティ実装は軽くしたいという相反する希望もあるかと思います。
じゃってことでAWS IoT Device SDKを使ってMQTT -> SORACOM Beam経由で MQTTS -> AWS IoT Coreな通信ができるのかをPython SDKをもとに確認してみます。AWS IoT Core と SORACOM Beamの仕様差分を確認
MQTT client視点で見る差分は以下となります。
AWS IoT Core SORACOM Beam endpoint {prefix}-ats.iot.{region}.amazonaws.com beam.soracom.io port 8883 1883 Protocl MQTTS MQTT ということは、デバイス側のBeam MQTTクライアントとしては、
beam.soracom.io:1883へMQTTが投げられればよいということになります。AWS IoT Device SDKの変更点を見てみる
AWS IoT Device SDK pythonにおけるMQTTインスタンスの生成は以下の記述があります。
# Import SDK packages from AWSIoTPythonSDK.MQTTLib import AWSIoTMQTTClient # For certificate based connection myMQTTClient = AWSIoTMQTTClient("myClientID") # For Websocket connection # myMQTTClient = AWSIoTMQTTClient("myClientID", useWebsocket=True) # Configurations # For TLS mutual authentication myMQTTClient.configureEndpoint("YOUR.ENDPOINT", 8883) myMQTTClient.configureCredentials("YOUR/ROOT/CA/PATH", "PRIVATE/KEY/PATH", "CERTIFICATE/PATH") # For Websocket, we only need to configure the root CA # myMQTTClient.configureCredentials("YOUR/ROOT/CA/PATH") myMQTTClient.configureOfflinePublishQueueing(-1) # Infinite offline Publish queueing myMQTTClient.configureDrainingFrequency(2) # Draining: 2 Hz myMQTTClient.configureConnectDisconnectTimeout(10) # 10 sec myMQTTClient.configureMQTTOperationTimeout(5) # 5 secインスタンス設定用の関数にエンドポイント、ポートが自分で設定できるようになっているので、どうやら変更できそうです。
では上記の差分に従って変更してみると、以下になります。from AWSIoTPythonSDK.MQTTLib import AWSIoTMQTTClient # For certificate based connection myMQTTClient = AWSIoTMQTTClient("myClientID") # For Websocket connection # myMQTTClient = AWSIoTMQTTClient("myClientID", useWebsocket=True) # Configurations # ソラコムの設定にエンドポイント、ポート設定を変更 myMQTTClient.configureEndpoint("beam.soracom.io", 1883) # 証明書によるTLSは不要なので、証明書の設定をコメントアウト #myMQTTClient.configureCredentials("YOUR/ROOT/CA/PATH", "PRIVATE/KEY/PATH", "CERTIFICATE/PATH") # For Websocket, we only need to configure the root CA # myMQTTClient.configureCredentials("YOUR/ROOT/CA/PATH") myMQTTClient.configureOfflinePublishQueueing(-1) # Infinite offline Publish queueing myMQTTClient.configureDrainingFrequency(2) # Draining: 2 Hz myMQTTClient.configureConnectDisconnectTimeout(10) # 10 sec myMQTTClient.configureMQTTOperationTimeout(5) # 5 secShadow packageからshadowインスタンスを作るときにも同じ変更点です。
SORACOM BeamのAWS IoT MQTT接続の設定
詳細はSOARCOMのサイトをご参照ください。後半のmosquittoやAmazon SNSは設定を省略しても構いません。
sampleで提供されているbasicPubSubを使ってみる
basicPubSub
不要かつ動いてしまう証明書依存部分をコメントアウトして以下の様になりました。basicPubSub_beam.py''' /* * Copyright 2010-2017 Amazon.com, Inc. or its affiliates. All Rights Reserved. * * Licensed under the Apache License, Version 2.0 (the "License"). * You may not use this file except in compliance with the License. * A copy of the License is located at * * http://aws.amazon.com/apache2.0 * * or in the "license" file accompanying this file. This file is distributed * on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either * express or implied. See the License for the specific language governing * permissions and limitations under the License. */ ''' from AWSIoTPythonSDK.MQTTLib import AWSIoTMQTTClient import logging import time import argparse import json AllowedActions = ['both', 'publish', 'subscribe'] # Custom MQTT message callback def customCallback(client, userdata, message): print("Received a new message: ") print(message.payload) print("from topic: ") print(message.topic) print("--------------\n\n") # Read in command-line parameters parser = argparse.ArgumentParser() parser.add_argument("-e", "--endpoint", action="store", required=True, dest="host", help="Your AWS IoT custom endpoint") #parser.add_argument("-r", "--rootCA", action="store", required=True, dest="rootCAPath", help="Root CA file path") #parser.add_argument("-c", "--cert", action="store", dest="certificatePath", help="Certificate file path") #parser.add_argument("-k", "--key", action="store", dest="privateKeyPath", help="Private key file path") parser.add_argument("-p", "--port", action="store", dest="port", type=int, help="Port number override") parser.add_argument("-w", "--websocket", action="store_true", dest="useWebsocket", default=False, help="Use MQTT over WebSocket") parser.add_argument("-id", "--clientId", action="store", dest="clientId", default="basicPubSub", help="Targeted client id") parser.add_argument("-t", "--topic", action="store", dest="topic", default="sdk/test/Python", help="Targeted topic") parser.add_argument("-m", "--mode", action="store", dest="mode", default="both", help="Operation modes: %s"%str(AllowedActions)) parser.add_argument("-M", "--message", action="store", dest="message", default="Hello World!", help="Message to publish") args = parser.parse_args() host = args.host #rootCAPath = args.rootCAPath #certificatePath = args.certificatePath #privateKeyPath = args.privateKeyPath port = args.port useWebsocket = args.useWebsocket clientId = args.clientId topic = args.topic if args.mode not in AllowedActions: parser.error("Unknown --mode option %s. Must be one of %s" % (args.mode, str(AllowedActions))) exit(2) ''' if args.useWebsocket and args.certificatePath and args.privateKeyPath: parser.error("X.509 cert authentication and WebSocket are mutual exclusive. Please pick one.") exit(2) if not args.useWebsocket and (not args.certificatePath or not args.privateKeyPath): parser.error("Missing credentials for authentication.") exit(2) ''' # Port defaults if args.useWebsocket and not args.port: # When no port override for WebSocket, default to 443 port = 443 if not args.useWebsocket and not args.port: # When no port override for non-WebSocket, default to 8883 port = 8883 # Configure logging logger = logging.getLogger("AWSIoTPythonSDK.core") #logger.setLevel(logging.DEBUG) streamHandler = logging.StreamHandler() formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s') streamHandler.setFormatter(formatter) logger.addHandler(streamHandler) # Init AWSIoTMQTTClient myAWSIoTMQTTClient = None if useWebsocket: myAWSIoTMQTTClient = AWSIoTMQTTClient(clientId, useWebsocket=True) myAWSIoTMQTTClient.configureEndpoint(host, port) #myAWSIoTMQTTClient.configureCredentials(rootCAPath) else: myAWSIoTMQTTClient = AWSIoTMQTTClient(clientId) myAWSIoTMQTTClient.configureEndpoint(host, port) #myAWSIoTMQTTClient.configureCredentials(rootCAPath, privateKeyPath, certificatePath) # AWSIoTMQTTClient connection configuration myAWSIoTMQTTClient.configureAutoReconnectBackoffTime(1, 32, 20) myAWSIoTMQTTClient.configureOfflinePublishQueueing(-1) # Infinite offline Publish queueing myAWSIoTMQTTClient.configureDrainingFrequency(2) # Draining: 2 Hz myAWSIoTMQTTClient.configureConnectDisconnectTimeout(10) # 10 sec myAWSIoTMQTTClient.configureMQTTOperationTimeout(5) # 5 sec # Connect and subscribe to AWS IoT myAWSIoTMQTTClient.connect() if args.mode == 'both' or args.mode == 'subscribe': myAWSIoTMQTTClient.subscribe(topic, 1, customCallback) time.sleep(2) # Publish to the same topic in a loop forever loopCount = 0 while True: if args.mode == 'both' or args.mode == 'publish': message = {} message['message'] = args.message message['sequence'] = loopCount messageJson = json.dumps(message) myAWSIoTMQTTClient.publish(topic, messageJson, 1) if args.mode == 'publish': print('Published topic %s: %s\n' % (topic, messageJson)) loopCount += 1 time.sleep(1)標準のbasicPubSubとdiffをとるとこのくらいの差分
$ diff basicPubSub_soracom.py basicPubSub.py 38,40c38,40 < #parser.add_argument("-r", "--rootCA", action="store", required=True, dest="rootCAPath", help="Root CA file path") < #parser.add_argument("-c", "--cert", action="store", dest="certificatePath", help="Certificate file path") < #parser.add_argument("-k", "--key", action="store", dest="privateKeyPath", help="Private key file path") --- > parser.add_argument("-r", "--rootCA", action="store", required=True, dest="rootCAPath", help="Root CA file path") > parser.add_argument("-c", "--cert", action="store", dest="certificatePath", help="Certificate file path") > parser.add_argument("-k", "--key", action="store", dest="privateKeyPath", help="Private key file path") 54,56c54,56 < #rootCAPath = args.rootCAPath < #certificatePath = args.certificatePath < #privateKeyPath = args.privateKeyPath --- > rootCAPath = args.rootCAPath > certificatePath = args.certificatePath > privateKeyPath = args.privateKeyPath 65c65 < ''' --- > 73c73 < ''' --- > 82c82 < #logger.setLevel(logging.DEBUG) --- > logger.setLevel(logging.DEBUG) 93c93 < #myAWSIoTMQTTClient.configureCredentials(rootCAPath) --- > myAWSIoTMQTTClient.configureCredentials(rootCAPath) 97c97 < #myAWSIoTMQTTClient.configureCredentials(rootCAPath, privateKeyPath, certificatePath) --- > myAWSIoTMQTTClient.configureCredentials(rootCAPath, privateKeyPath, certificatePath)動作確認するだけなので、引数を以下として起動します。
python basicPubSub_beam.py -e beam.soracom.io -p 1883AWS IoT consoleでみるとPubの成功、また本スクリプトがdefaultで自分自身のpubしたtopicをsubscribeしているので、起動したコンソール上にもメッセージが表示されます。
これでまず、Beamを通してpubsubが問題なく行われていることがわかります。動作確認できたもの
ざっと私の方で動作確認できたものとして、
- shadow instaceを生成しての AWS IoT Shadowの操作
- deltaの受信、shadow updateは問題なくできました
- basic ingest: これも問題なし
ということで$awsで始まるような予約topicも問題なくやり取りできました。
SDKを使う上で大事なこと
ここまで説明してきたとおり、Endpoint、TSL設定なし、ポートの変更ができればSDKをつかってBeamを使うことは可能でした。
Javascript版もBeam接続できそうです。JavaはTSLが必須になっている模様。など、SDKの実装に大きく依存しておりますので、皆様にてご確認ください。SORACOM Beamを使う上でのセキュリティレベルは変わるのか?
AWS IoTにおいては、各デバイス/GWなどAWS IoTと通信するものに個別の証明書を入れることを推奨としていると思います。SORACOMを利用する場合同じく通信するデバイス/GWにSORACOM SIMがついており、このSIMが個別証明書相当になります。この違いは、AWS側の考えている通信の前提とSORACOMを利用する場合で前提が異なるということになります。
SORACOMの通信の場合、世の中の携帯のSIM認証のセキュリティレベルがあります。Beamを使う場合はデバイス個別鍵をSIMとしてAWS IoTへの認証をSORACOM側が行うことになり、AWSIoTと皆様のSIM groupが正しく/セキュアに通信するためにBeamの設定としてAWS IoTの証明書を設定することになります。
ということで、通信の前提の違いによる考え方はあるもののSOARCOM Beamを使うからセキュリティレベルが落ちるということにはならないと思います。SORACOM Beamで気にすること
AWS IoTのいう、デバイスごとの証明書を発行する場合、 Policyを証明書を対(1:1)に発行することでPolicyの記載レベルを証明書単位で変えることができます。一方でBeamの場合、グループ単位で一つの証明書になるので、MQTTの設計および、Thing Attributeなどをうまく設計し、Policy変数をうまく使うなどを検討する必要があるかと思います。
SORACOM Beamが解決すること
導入でもいくつか例をあげましたが、
- セキュリティのオフロード
- 証明書ストアの集約
- B2B IoTでお客様ネットワークに相乗りすると問題になるProxy/port問題
などが考えられます。まとめ
いずれにしてもMQTTデザインとpolicyデザイン、証明書発行フロー(SORACOM Beam を使う場合はグループのデザイン)は初期に設計した上で、想定されている最大に拡大したときにも破綻しないデザインを検討することは重要です。
クラウドアーキテクチャや、デバイス側プログラミングが楽しいので、忘れがちにあるのですが、このあたりを初期に担保すると後々困ることは減るはずです。免責
本投稿は、個人の意見で、所属する企業や団体は関係ありません。
また掲載しているsampleプログラムの動作に関しても保障いたしませんので、参考程度にしてください。
- 投稿日:2020-02-25T16:45:10+09:00
全部AWSでRedmineをサクッと構築する
はじめに
とあるプロジェクトに途中から参画することになりました。
そこではあらゆるタスク・課題・バグがExcelの一覧で管理され、添付メールでやりとりする世界が広がってました。。
当然ながら資料のデグレは不可避。そこで、みんなで共同利用できるRedmineを立てて少しは効率化しようとしたお話です。
本題
以下の内容をハンズオン形式で書いていきます。
- EC2でRedmineを構築
- Route53でドメイン取得
- ACMで証明書発行
- ELBを使ってHTTPS化
- SESでのメール送信
- AWS BackupでのEC2バックアップ自動化
Redmineを立てることを目的にしてますが、Redmineに限らず各AWSのサービスの使い方として参考になる記事になってると思います。
EC2のマーケットプレイスでBitnami Redmineを作る
EC2のAWSマーケットプレイスからBitnamiのRedmineインストール済みのイメージを使うことにします。
インスタンスタイプやEBSサイズを環境に合わせて決めます。
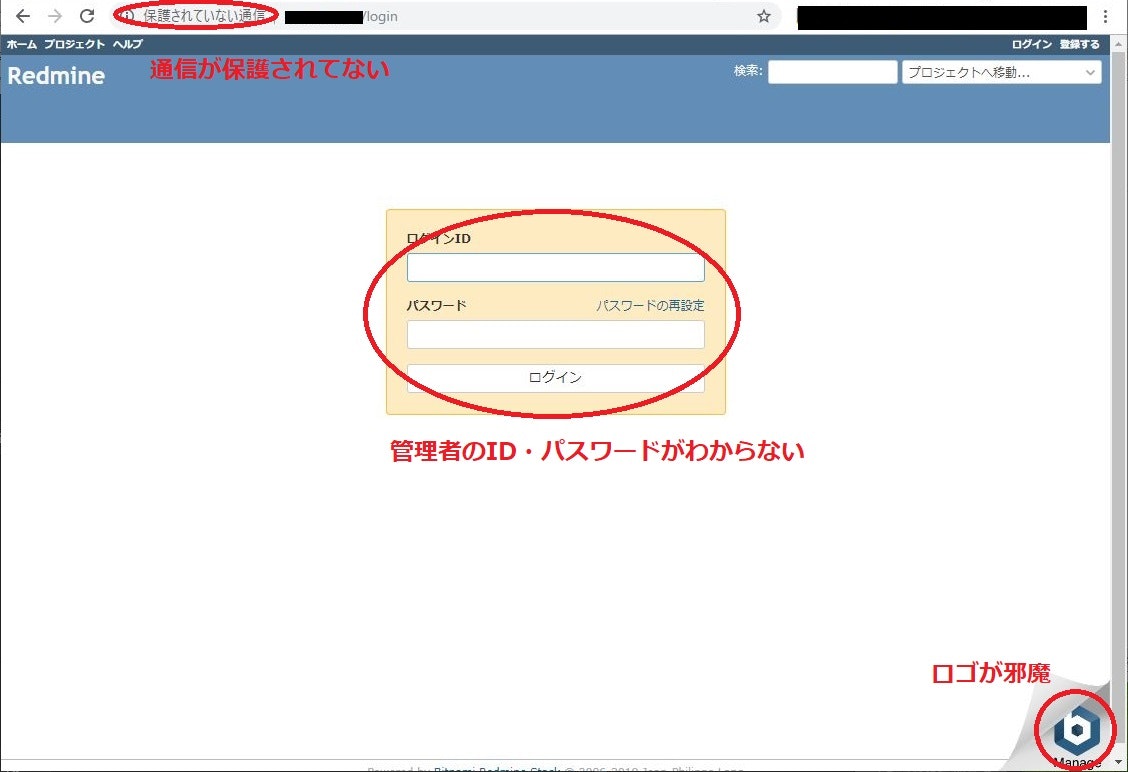
EC2が起動したらブラウザにパブリックIPを入力してアクセスします。
とりあえずRedmineにはアクセスできました。
が、いろいろとなんとかしたい点があるのでこのあと対処していきます。
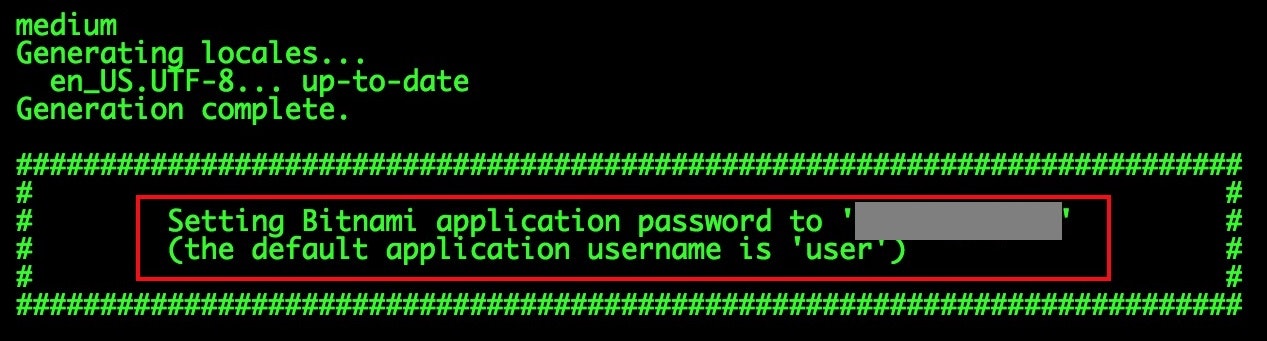
管理者のID・パスワードを調べる
BitnamiのWebサイトに調べ方が載ってました。
マネージメントコンソールから「システムログの取得」で確認できるようです。
ユーザー名は「user」、パスワードは任意の文字列が書いてあるのでそれを入力すると無事ログインできました。
ちなみにSSHでログインして、以下のファイルを確認する方法でもOKです。$ cat /home/bitnami/bitnami_credentialsBitnamiのロゴを消す
これは以前も似たようなことをやって記事にしたことがありました。
基本的には設定ファイルのディレクトリが違うくらいです。
まずSSHでEC2に接続します。ユーザーは「ubuntu」で、鍵はEC2作成時のpemを指定します。
そして以下のコマンドを打ちます$ sudo /opt/bitnami/apps/redmine/bnconfig --disable_banner 1これで邪魔なロゴが消えました。
通信を保護する(HTTPSにする)
これにはいろいろと手順が必要です。
次のようなステップで進めていきます。
- Route53でドメインを取得
- AWS Certificate Managerで証明書を発行
- EC2の手前にELBを置いて、ELBに証明書を導入
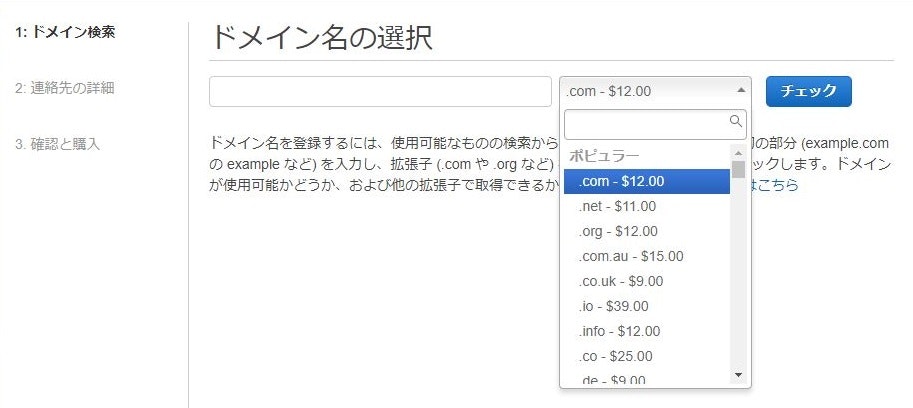
Route53でドメインを取得する
Route53はAWSのDNSのサービスなのですが、ドメインを購入することもできます。
ドメインはいろいろ選べますが、.comドメインで年12ドルです。
当たり前ですが、世の中で使われてないドメイン名にする必要があります。
購入手続きをすすめると、連絡先として入力したメールアドレス宛に「[Action required] Verify your email address to register a domain with Route 53」というメールが送られてきますので、リンクをクリックして認証を完了させます。
自分の場合は認証してから17分後に、「*****.com was successfully registered with Route 53」というメールが来て、ホストゾーンにレコード(NSレコードとSOAレコード)が登録されていました。ACMで証明書を発行する。
AWS Certificate Manager(ACM)で証明書を発行します。
これはあとで作るELBに導入するためです。
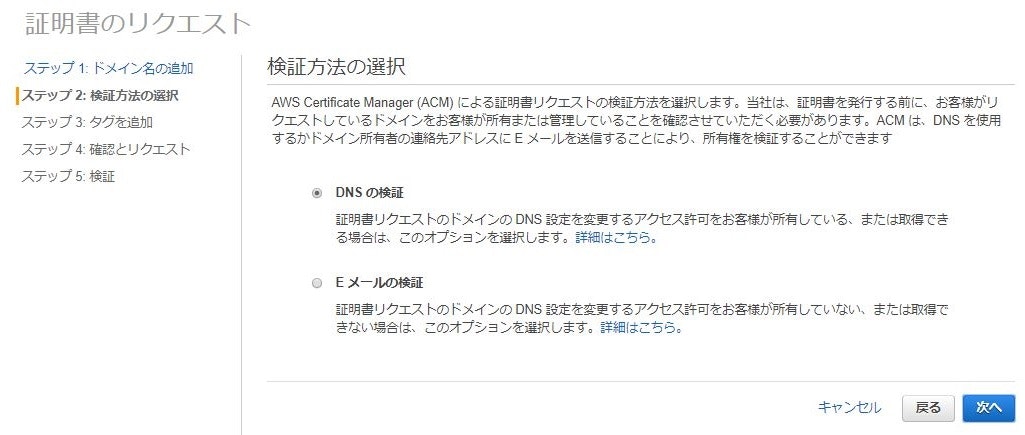
ここでは例として「redmine.*****.com」で発行することにします。
証明書の検証方法として、「DNSの検証」と「Eメールの検証」が選べます。
今回はRoute53で自分でDNSを管理しているので「DNSの検証」を選びます。
ウィザードを進めていくと、証明書発行のためのCNAMEレコードが表示されます。
このCNAMEレコードをRoute53に登録すると、検証が完了して証明書が発行されます。ELBの設定をする
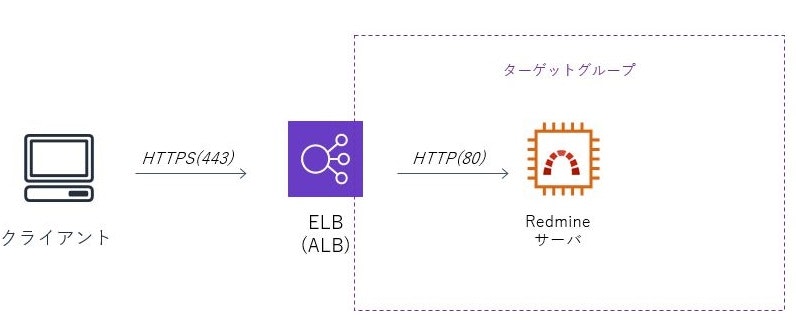
次はELBを設定します。
なんでELBが必要かというと、AWSではACMで発行した証明書をEC2に入れることができません。
そのため、手前にELBを置いて、ELBでSSLを終端させる構成にするからです。
以下の図のイメージです。
EC2の画面からELB(今回はHTTP、HTTPSを使うのでApplication Load Balancer)を設定します。
ELBはHTTPS(443)をリスナーとして、さきほど発行したACMの証明書を選択します。
Security GroupはHTTPS(443)を通すように設定します。次にターゲットグループですが、こちらはHTTP(80)にします。
最初に作ったRedmineのEC2インスタンスをターゲットとして登録します。
ここでELB→EC2のヘルスチェックがOKになる必要があります。
ヘルスチェック用のコンテンツを置くのが望ましいと思いますが、ここではパスとしてログイン画面を示す「/login」、HTTPの応答コードで「200」にします。(ヘルスチェックが通るようにSecurity Groupは設定してください)
これでステータスが「healthy」になりました。
Route53にAレコードを追加する。
ここまできたら、Route53で「redmine.*****.com」のAレコードを登録します。
エイリアスを「はい」にして、エイリアス先として、さきほど設定したELBを指定してします。
登録しても反映されるまで30分ほどかかりました。
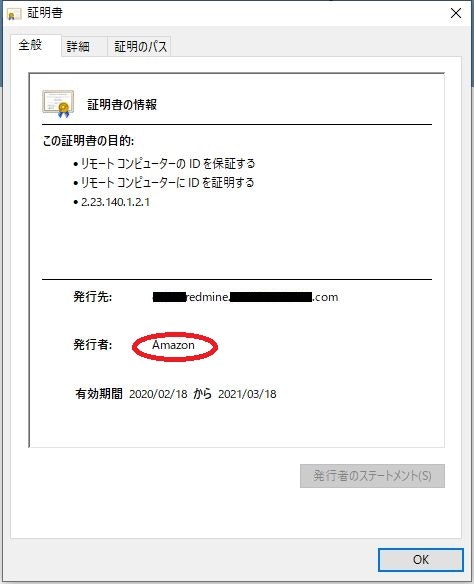
その後、ブラウザから「https:// redmine.*****.com/login」にアクセスすると、保護された通信となりHTTPSでRedmineにアクセスできました。証明書を確認すると、Amazonが発行した証明書であることがわかります。
SESでメールを飛ばせるようにする
Redmineを使い始めたら、チケットの作成・更新があった場合に、メール通知するようにしたくなると思います。
ここではメール送信の仕組みとして、Simple Email Service(SES)を使います。
2020年2月時点でSESは東京リージョンで提供されていないので、ここではオレゴンリージョンにします。送信先メールアドレス制限の解除(サンドボックス環境の外へ)
SESはそのままだとサンドボックス環境となっていて、認証された宛先メールアドレスにしか送信できません。
認証されたメールアドレス以外に送信するには、AWSサポートセンターにサービス制限緩和のリクエストを送る必要があります。
参考までに自分が送ったサポートケースのリクエストを載せておきます。日本語でOKです。
AWS側で承認されると、認証されたメールアドレス以外にも送信できるようになります。
自分の場合は、リクエストしてからサービス制限緩和がされるまで1日以上かかりました。SMTPクレデンシャルの作成
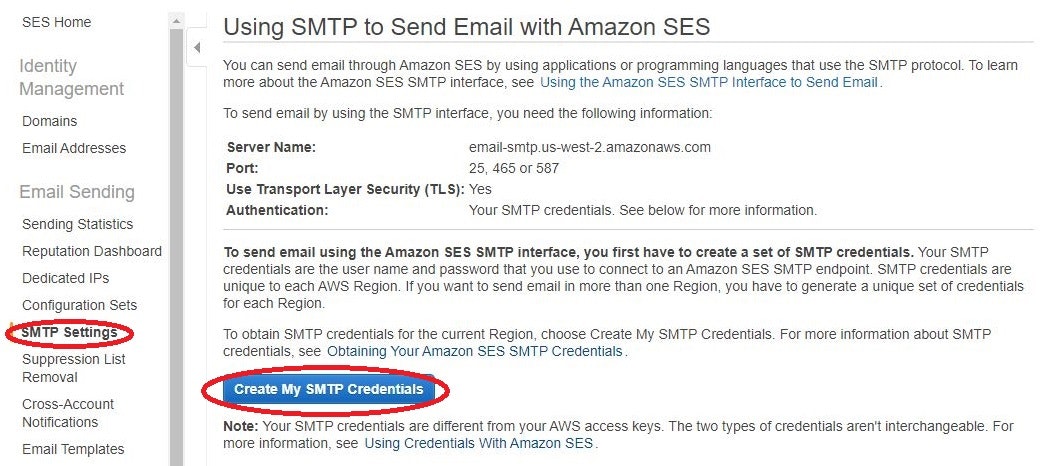
SESの画面から、SMTPクレデンシャルを作成します。
以下の画面から作成を進めると、「Smtp Username」と「Smtp Password」が書かれたCSVがダウンロードできます。
これはあとから確認することができないので、忘れないように残してください。
Redmineの設定ファイル(configuration.yml)を設定する。
Redmine側にメールサーバの設定をします。
設定ファイルを開きます。$ vi /opt/bitnami/apps/redmine/htdocs/config/configuration.ymlこれに以下のように認証情報を記載します。
configuration.yml-configuration email_delivery: delivery_method: :smtp smtp_settings: enable_starttls_auto: true address: "email-smtp.us-west-2.amazonaws.com" # SESのメールサーバ名を書く port: 587 domain: "*****.com" # 送信するメールアドレスに使うドメインを書く authentication: :plain user_name: 'xxxxxxxxxxxxxxx' # smtp usernameを書く password: 'xxxxxxxxxxxxxxx' # smtp passwordを書く設定を反映させるためnginxを再起動します。
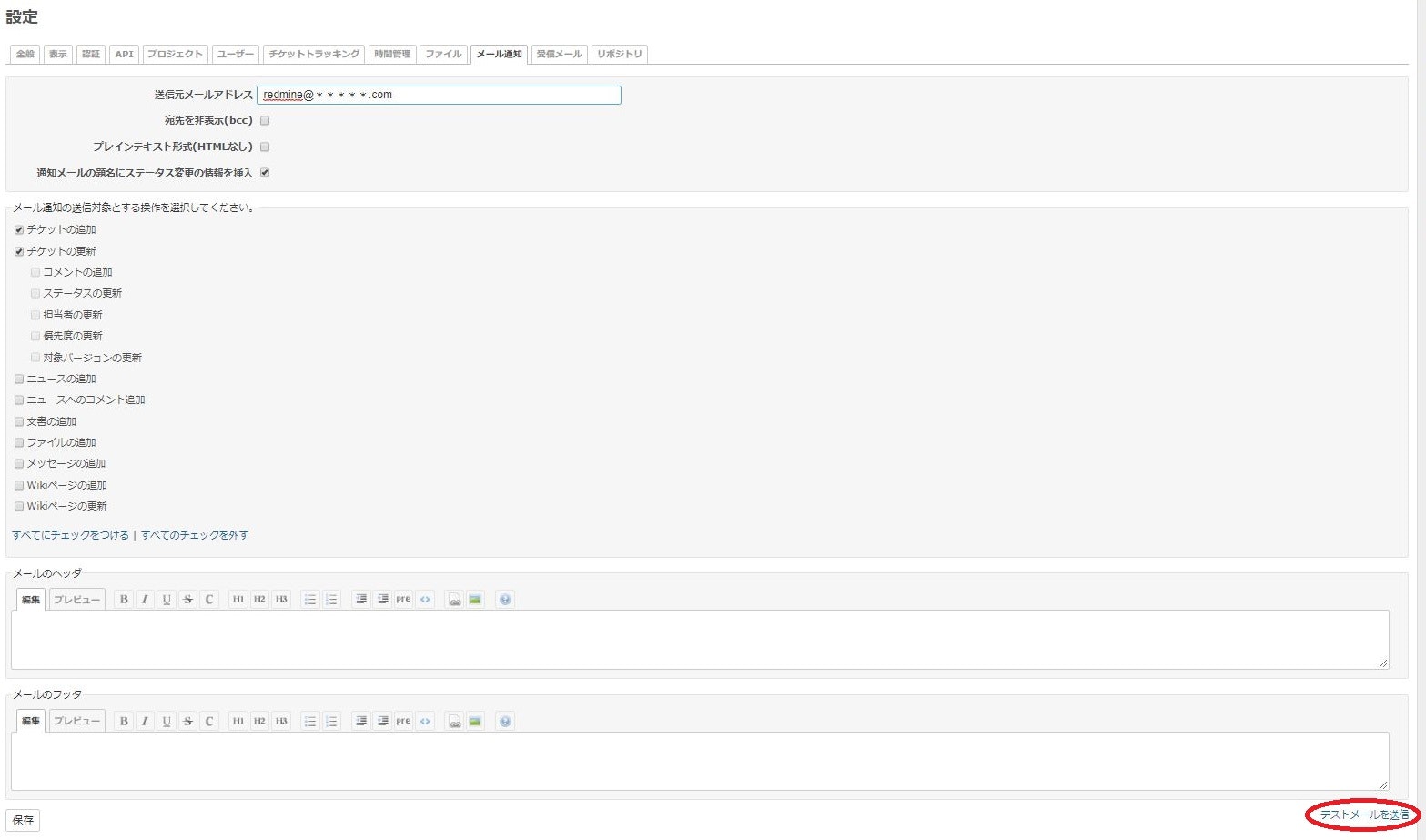
$ sudo /opt/bitnami/ctlscript.sh restart nginxこれでメールが飛ぶようになったので、Redmineの管理画面からテストメールを送ってみましょう。
(おまけ)AWS BackupでEC2丸ごとバックアップ
AWS BackupでのEC2丸ごとバックアップは2020年1月にローンチされました。
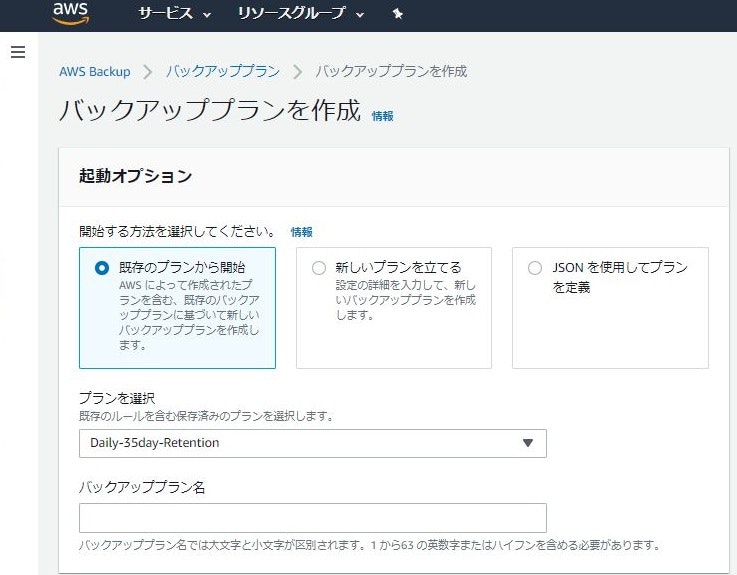
これで簡単にバックアップをスケジュールすることが可能です。まずバックアッププランを作成していきます。
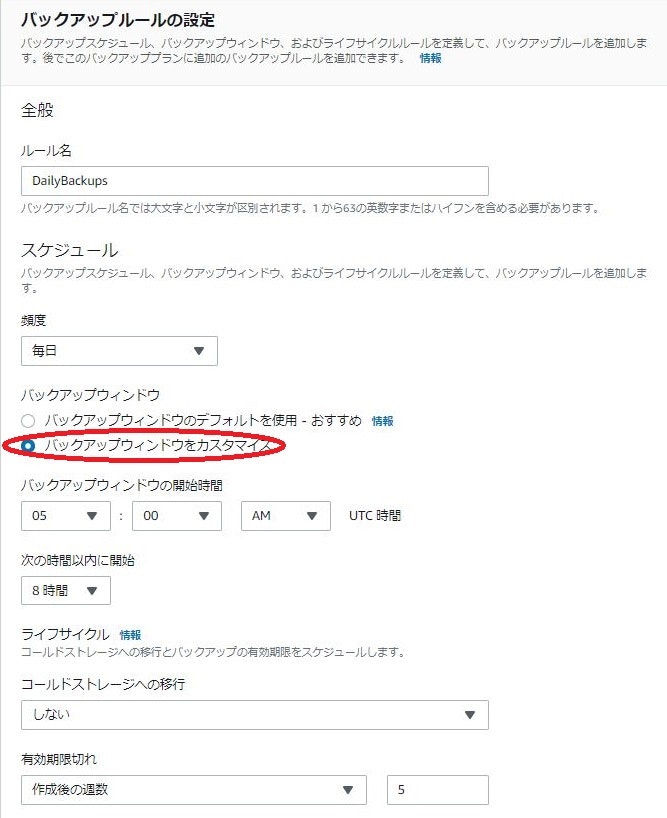
既存のプランで日次バックアップ、35日後に破棄というルールがあるのでこれを選びます。
次にバックアップルールを見ます。
DailyBackupsで「バックアップルールのデフォルトを使用 - おすすめ」と書いてありますが、自分はおすすめしません。
なぜならデフォルトだとUTC時間のAM5:00頃にバックアップが取得されます。
これは日本時間だと14:00なので真っ昼間です。
日本時間のAM5:00(UTC時間にすると20:00)くらいにしたほうが無難でしょう。
バックアップ開始時間の幅もデフォルトだと8時間なので、ここは短く1時間にするほうがよいと思います。
バックアップの有効期限も35日(=5週)も要件によって変更してよいと思います。
リソースの割り当てでは、作成したEC2を指定します。
これで指定した時間になればバックアップが始まり、AMIが作成されていると思います。さいごに
以上、オールAWSでRedmineを構築した話でした。
誰かの役に立てば幸いです。



- 投稿日:2020-02-25T16:45:10+09:00
オールAWSでRedmineをサクッと構築する
はじめに
とあるプロジェクトに途中から参画することになりました。
そこではあらゆるタスク・課題・バグがExcelの一覧で管理され、添付メールでやりとりする世界が広がってました。。
当然ながら資料のデグレは不可避。そこで、みんなで共同利用できるRedmineを立てて少しは効率化しようとしたお話です。
本題
以下の内容をハンズオン形式で書いていきます。
- EC2でRedmineを構築
- Route53でドメイン取得
- ACMで証明書発行
- ELBを使ったHTTPS化
- SESでのメール送信
- AWS BackupでのEC2バックアップ自動化
EC2のマーケットプレイスでBitnami Redmineを作る
EC2のAWSマーケットプレイスからBitnamiのRedmineインストール済みのイメージを使うことにします。
インスタンスタイプやEBSサイズを環境に合わせて決めます。
EC2が起動したらブラウザにパブリックIPを入力してアクセスします。
とりあえずRedmineにはアクセスできました。
が、いろいろとなんとかしたい点があるのでこのあと対処していきます。
管理者のID・パスワードを調べる
BitnamiのWebサイトに調べ方が載ってました。
マネージメントコンソールから「システムログの取得」で確認できるようです。
ユーザー名は「user」、パスワードは任意の文字列が書いてあるのでそれを入力すると無事ログインできました。
ちなみにSSHでログインして、以下のファイルを確認する方法でもOKです。$ cat /home/bitnami/bitnami_credentialsBitnamiのロゴを消す
これは以前も似たようなことをやって記事にしたことがありました。
基本的には設定ファイルのディレクトリが違うくらいです。
まずSSHでEC2に接続します。ユーザーは「ubuntu」で、鍵はEC2作成時のpemを指定します。
そして以下のコマンドを打ちます$ sudo /opt/bitnami/apps/redmine/bnconfig --disable_banner 1これで邪魔なロゴが消えました。
通信を保護する(HTTPSにする)
これにはいろいろと手順が必要です。
次のようなステップで進めていきます。
- Route53でドメインを取得
- AWS Certificate Managerで証明書を発行
- EC2の手前にELBを置いて、ELBに証明書を導入
Route53でドメインを取得する
Route53はAWSのDNSのサービスなのですが、ドメインを購入することもできます。
ドメインはいろいろ選べますが、.comドメインで年12ドルです。
当たり前ですが、世の中で使われてないドメイン名にする必要があります。
購入手続きをすすめると、連絡先として入力したメールアドレス宛に「[Action required] Verify your email address to register a domain with Route 53」というメールが送られてきますので、リンクをクリックして認証を完了させます。
自分の場合は認証してから17分後に、「*****.com was successfully registered with Route 53」というメールが来て、ホストゾーンにレコード(NSレコードとSOAレコード)が登録されていました。ACMで証明書を発行する。
AWS Certificate Manager(ACM)で証明書を発行します。
これはあとで作るELBに導入するためです。
ここでは例として「redmine.*****.com」で発行することにします。
証明書の検証方法として、「DNSの検証」と「Eメールの検証」が選べます。
今回はRoute53で自分でDNSを管理しているので「DNSの検証」を選びます。
ウィザードを進めていくと、証明書発行のためのCNAMEレコードが表示されます。
このCNAMEレコードをRoute53に登録すると、検証が完了して証明書が発行されます。ELBの設定をする
次はELBを設定します。
なんでELBが必要かというと、AWSではACMで発行した証明書をEC2に入れることができません。
そのため、手前にELBを置いて、ELBでSSLを終端させる構成にするからです。
以下の図のイメージです。
EC2の画面からELB(今回はHTTP、HTTPSを使うのでApplication Load Balancer)を設定します。
ELBはHTTPS(443)をリスナーとして、さきほど発行したACMの証明書を選択します。
Security GroupはHTTPS(443)を通すように設定します。次にターゲットグループですが、こちらはHTTP(80)にします。
最初に作ったRedmineのEC2インスタンスをターゲットとして登録します。
ここでELB→EC2のヘルスチェックがOKになる必要があります。
ヘルスチェック用のコンテンツを置くのが望ましいと思いますが、ここではパスとしてログイン画面を示す「/login」、HTTPの応答コードで「200」にします。(ヘルスチェックが通るようにSecurity Groupは設定してください)
これでステータスが「healthy」になりました。
Route53にAレコードを追加する。
ここまできたら、Route53で「redmine.*****.com」のAレコードを登録します。
エイリアスを「はい」にして、エイリアス先として、さきほど設定したELBを指定してします。
登録しても反映されるまで30分ほどかかりました。
その後、ブラウザから「https:// redmine.*****.com/login」にアクセスすると、保護された通信となりHTTPSでRedmineにアクセスできました。証明書を確認すると、Amazonが発行した証明書であることがわかります。
SESでメールを飛ばせるようにする
Redmineを使い始めたら、チケットの作成・更新があった場合に、メール通知するようにしたくなると思います。
ここではメール送信の仕組みとして、Simple Email Service(SES)を使います。
2020年2月時点でSESは東京リージョンで提供されていないので、ここではオレゴンリージョンにします。送信先メールアドレス制限の解除(サンドボックス環境の外へ)
SESはそのままだとサンドボックス環境となっていて、認証された宛先メールアドレスにしか送信できません。
認証されたメールアドレス以外に送信するには、AWSサポートセンターにサービス制限緩和のリクエストを送る必要があります。
参考までに自分が送ったサポートケースのリクエストを載せておきます。日本語でOKです。
AWS側で承認されると、認証されたメールアドレス以外にも送信できるようになります。
自分の場合は、リクエストしてからサービス制限緩和がされるまで1日以上かかりました。SMTPクレデンシャルの作成
SESの画面から、SMTPクレデンシャルを作成します。
以下の画面から作成を進めると、「Smtp Username」と「Smtp Password」が書かれたCSVがダウンロードできます。
これはあとから確認することができないので、忘れないように残してください。
Redmineの設定ファイル(configuration.yml)を設定する。
Redmine側にメールサーバの設定をします。
設定ファイルを開きます。$ vi /opt/bitnami/apps/redmine/htdocs/config/configuration.ymlこれに以下のように認証情報を記載します。
configuration.yml-configuration email_delivery: delivery_method: :smtp smtp_settings: enable_starttls_auto: true address: "email-smtp.us-west-2.amazonaws.com" # SESのメールサーバ名を書く port: 587 domain: "*****.com" # 送信するメールアドレスに使うドメインを書く authentication: :plain user_name: 'xxxxxxxxxxxxxxx' # smtp usernameを書く password: 'xxxxxxxxxxxxxxx' # smtp passwordを書く設定を反映させるためnginxを再起動します。
$ sudo /opt/bitnami/ctlscript.sh restart nginxこれでメールが飛ぶようになったので、Redmineの管理画面からテストメールを送ってみましょう。
(おまけ)AWS BackupでEC2丸ごとバックアップ
AWS BackupでのEC2丸ごとバックアップは2020年1月にローンチされました。
これで簡単にバックアップをスケジュールすることが可能です。まずバックアッププランを作成していきます。
既存のプランで日次バックアップ、35日後に破棄というルールがあるのでこれを選びます。
次にバックアップルールを見ます。
DailyBackupsで「バックアップルールのデフォルトを使用 - おすすめ」と書いてありますが、自分はおすすめしません。
なぜならデフォルトだとUTC時間のAM5:00頃にバックアップが取得されます。
これは日本時間だと14:00なので真っ昼間です。
日本時間のAM5:00(UTC時間にすると20:00)くらいにしたほうが無難でしょう。
バックアップ開始時間の幅もデフォルトだと8時間なので、ここは短く1時間にするほうがよいと思います。
バックアップの有効期限も35日(=5週)も要件によって変更してよいと思います。
リソースの割り当てでは、作成したEC2を指定します。
これで指定した時間になればバックアップが始まり、AMIが作成されていると思います。さいごに
以上、オールAWSでRedmineを構築した話でした。
誰かの役に立てば幸いです。
- 投稿日:2020-02-25T15:40:02+09:00
(メモ)AWSにWordPressを構築する手順
- 投稿日:2020-02-25T15:08:10+09:00
【AWS】構成図作成サービス一覧
構成図作成をサポートしてくれるサービスについてまとめてみました。
・Amazon Cloud Formationデザイナー
・Cloud Craft
・Hava
・Draw.ioAmazon Cloud Formationデザイナー(無料?)
・AWS公式が出しているサービス。
・Cloud FormationというAmazonのインフラサービスの構成、デプロイをコード化して自動化するサービスの付加機能で現在稼働中のAWS環境を図示してくれる便利なサービス。
Cloud Craft(無料版、有料版:月49USドル)
・3rd partyが出しているAWSの機能を3Dに可視化できる機能。
・AWSから構成をインポートして、自動的に図を作り上げる機能。
Hava(登録から2週間無料→有料版:$39~$1,999(月額))
・Cloud Craft同様、3rd partyのサービス。
・Cloud Craftは3Dで表示してくれるが、こちらは2Dで表示してくれる!(AWS公式の描画に近い印象)
・AWSから構成のインポート、自動生成もサポートしてくれる。
※対応しているAWSサービスは以下のとおり、数はそこまで多くない様子。
・VPC(Subnet, Route Table, Security Group)
・ELB
・EC2
・RDS
・Elasticache
Draw.io(無料!)
・Draw.io にアクセスするだけで利用できる無料のフローチャート作成ツール。
・Visio に近い操作感。
- 投稿日:2020-02-25T14:29:15+09:00
AWSで1からWebサイトのインフラ構成を構築してみた
こんにちは。
Web・iOSエンジニアの三浦です。今回は、業務で使ったことのまとめも兼ねて、AWSを使ったWebサイトのインフラ構成を1から構築してみます。
なおここでは、ドメインの取得まではしないのであらかじめご了承ください。構成
まずは構成を考えていきます。
今回は以下のような構成とします。
説明していきます。
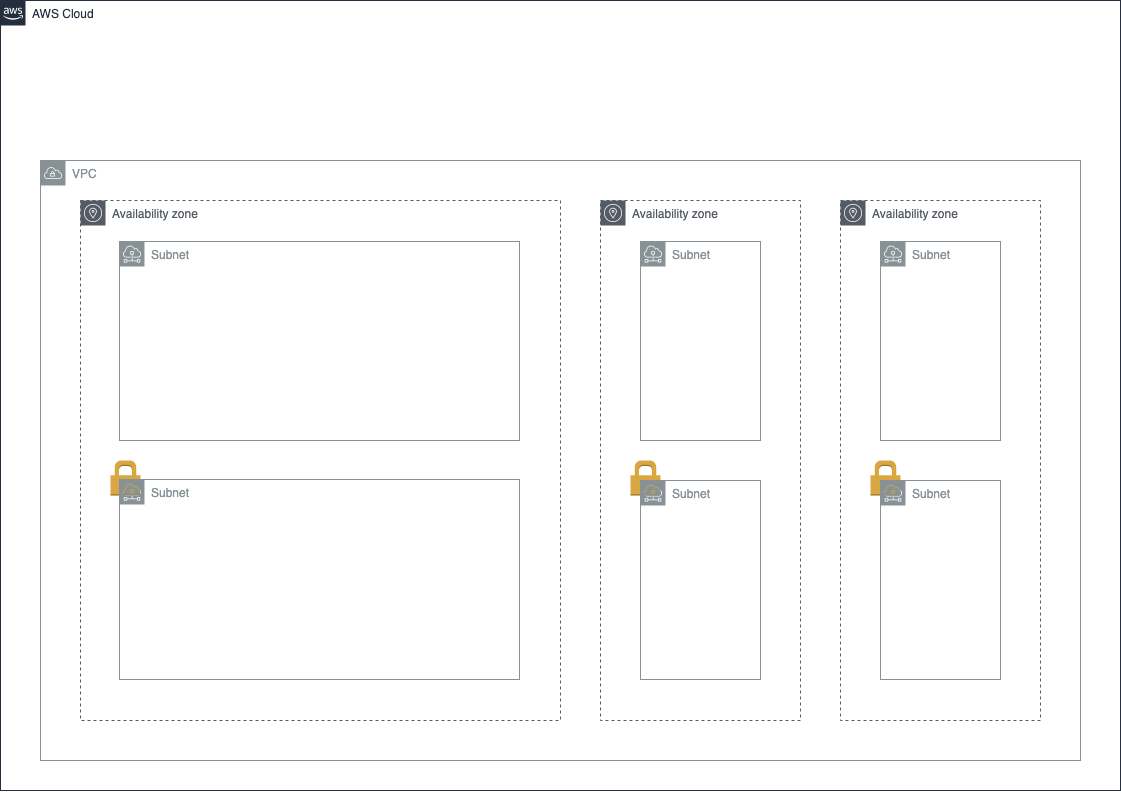
VPC
サーバーやDBなどのAWSのサービスは、そのまま使うこともできますが、例えるならそれは雑居ビルのランダムな部屋を使用しているようなものです。
それでも問題があるわけではありませんが、セキュリティ周りをより厳密に設定するなどしたい場合は、VPC(Virtual Private Cloud)というサービスを使うことができます。
このサービスは、例えるならビルの1フロアを丸々借り上げるようなものです。
さらに
VPCの中をサブネットという形で分けることができます。
これは借り上げたフロアの中を更に区切るもので、基本的にはこのサブネットの中にサーバーやDBを作っていくことになります。
サブネットには、外部からインターネットでアクセスできるパブリックサブネットと、直接インターネットからアクセスできないプライベートサブネットがあり、外部とつながる必要のないサービスをプライベートサブネットに入れ、直接ユーザーがアクセスする必要のあるサービスをパブリックサブネットの中に入れる、といった使い方をします。ちなみに
VPCを作成する際は、「リージョン」というものを選択します。
リージョンには「東京」や「オハイオ(アメリカ)」など様々な地域があり、物理的にAWSの施設がある地域のことです。
例えば日本で使うのであれば「東京」リージョンのほうが「オハイオ(アメリカ)」リージョンよりも物理的に距離が近いので、通信時間が短くなります。
またリージョンの中にはアベイラビリティゾーン(AZ)というものがあります。
東京リージョンには3つのAZがあり、このAZの住所に実際にAWSの施設が存在します。
AZが複数存在するのは、地震や停電などでいずれかのAZの機能が停止したとしても、他のAZでサービスを停止させることなく続けられるようにする、などの可用性の向上のためです。
サブネットを作成する際は、どのAZにサブネットを作成するかを選択します。
ちなみに
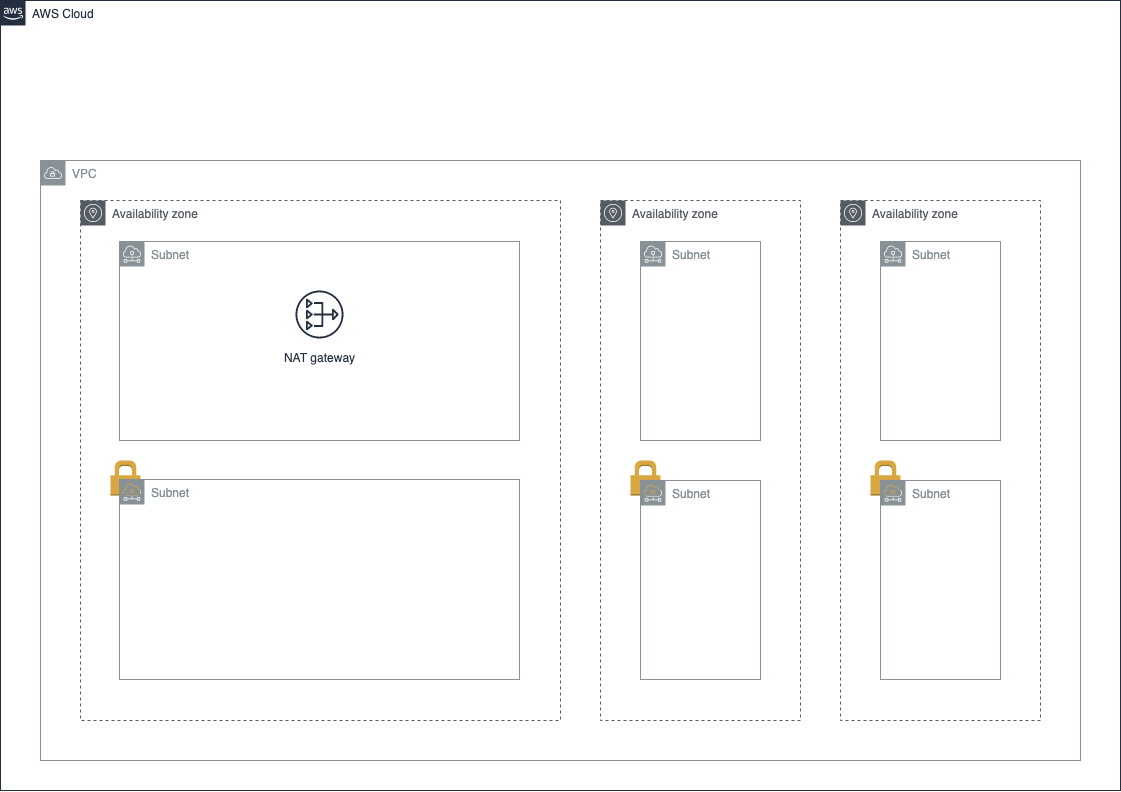
プライベートサブネットが直接インターネットからアクセスできないとは言っても、サーバーへ必要な設定をダウンロードするなどインターネットとつながっている必要があります。
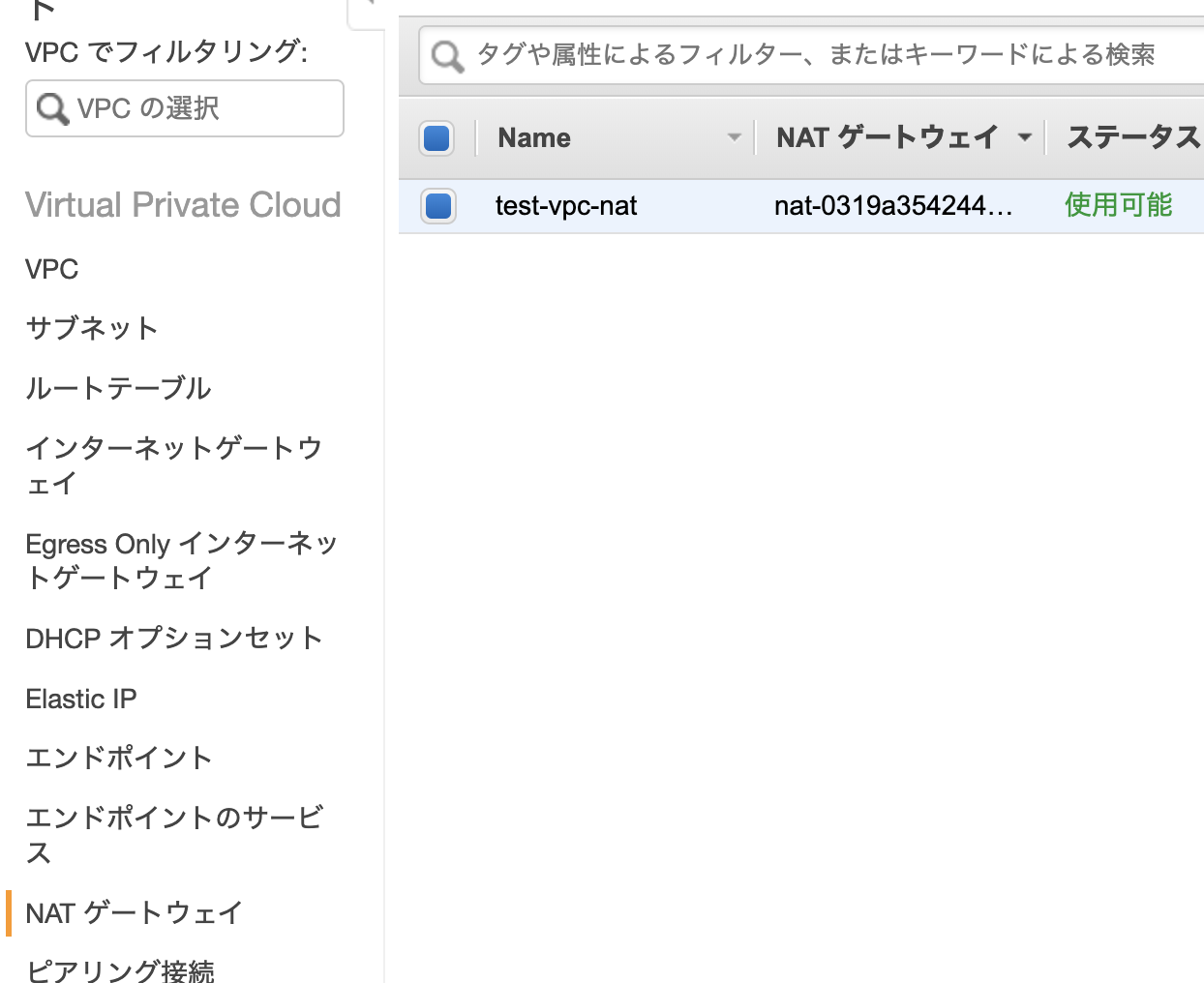
「インターネットからはアクセスできない」が「インターネットとつながっている」状態を実現するため、NATゲートウェイ(Network Address Translation Gateway)という、VPC内部のIPアドレス(プライベートIPアドレス)とインターネットのIPアドレス(グローバルIPアドレス)を相互に変換してくれるサービスを使用します。
NAT ゲートウェイをパブリックサブネット内に配置し、プライベートサブネットがインターネットと何らかのやり取りをする際にそれを経由することで、セキュリティを保ったままインターネットに接続することができるようになります。
NAT ゲートウェイはすべてのパブリックサブネットにおいてもいいのですが、今回は1つのパブリックサブネットにのみ置きます。
これは、実際に今回使用するサブネットはパブリックサブネットとプライベートサブネットそれぞれ1つずつのためです。
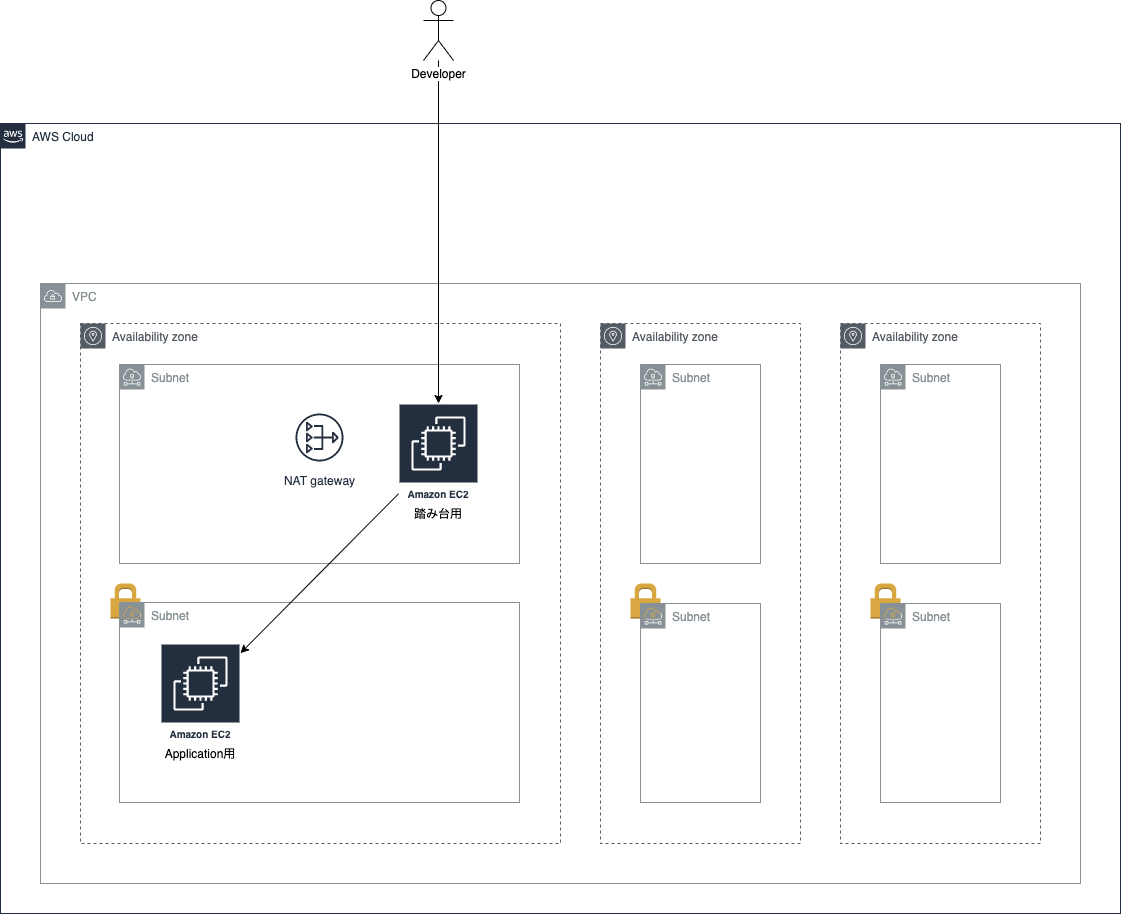
今回使用しないサブネットを作るのは、後述するRDSやALBを使用するためには最低でも2つのAZにサブネットが存在する必要があるためです。EC2
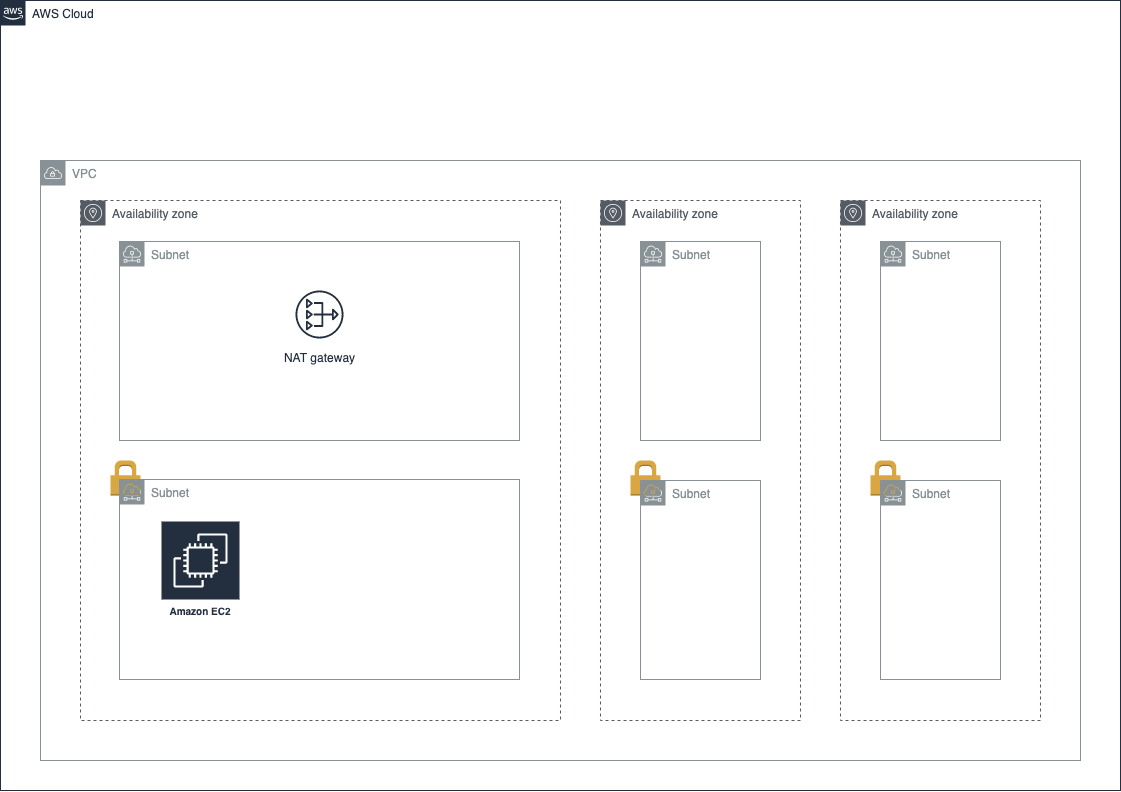
Webサイトを作成するには、サーバーが必要です。
AWSのサーバーはEC2(Elastic Compute Cloud)と呼ばれます。
先程の説明だと、この
EC2は直接ユーザーがアクセスするものなのでパブリックサブネットに置くはずだ、と思うかもしれませんが、今回はALBというサービス(後で説明します)を使うため、EC2はプライベートサブネットに入れます。またもう一つ、サーバーに開発者が直接ログインするため、ログイン中継用の
EC2を作成しておきます。
こういったサーバーは「踏み台サーバー」と呼ばれます。
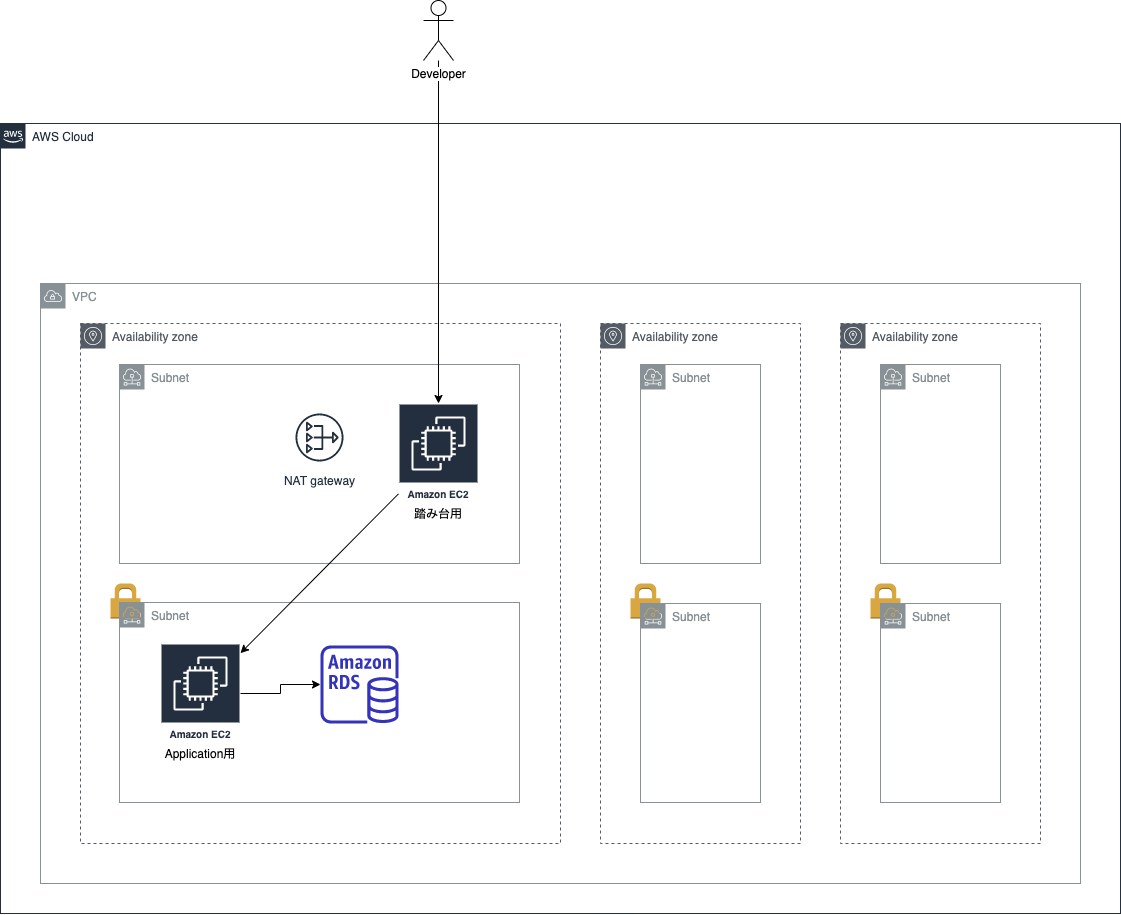
RDS
Webサイトを構築する場合、DBを使用することも多いでしょう。
このとき、EC2の中にDBを構築してもいいですが、AWS側が管理してくれるRDS(Relational Database Service)を使うという手もあります。
こちらに関してはユーザーが直接アクセスする必要がないので、
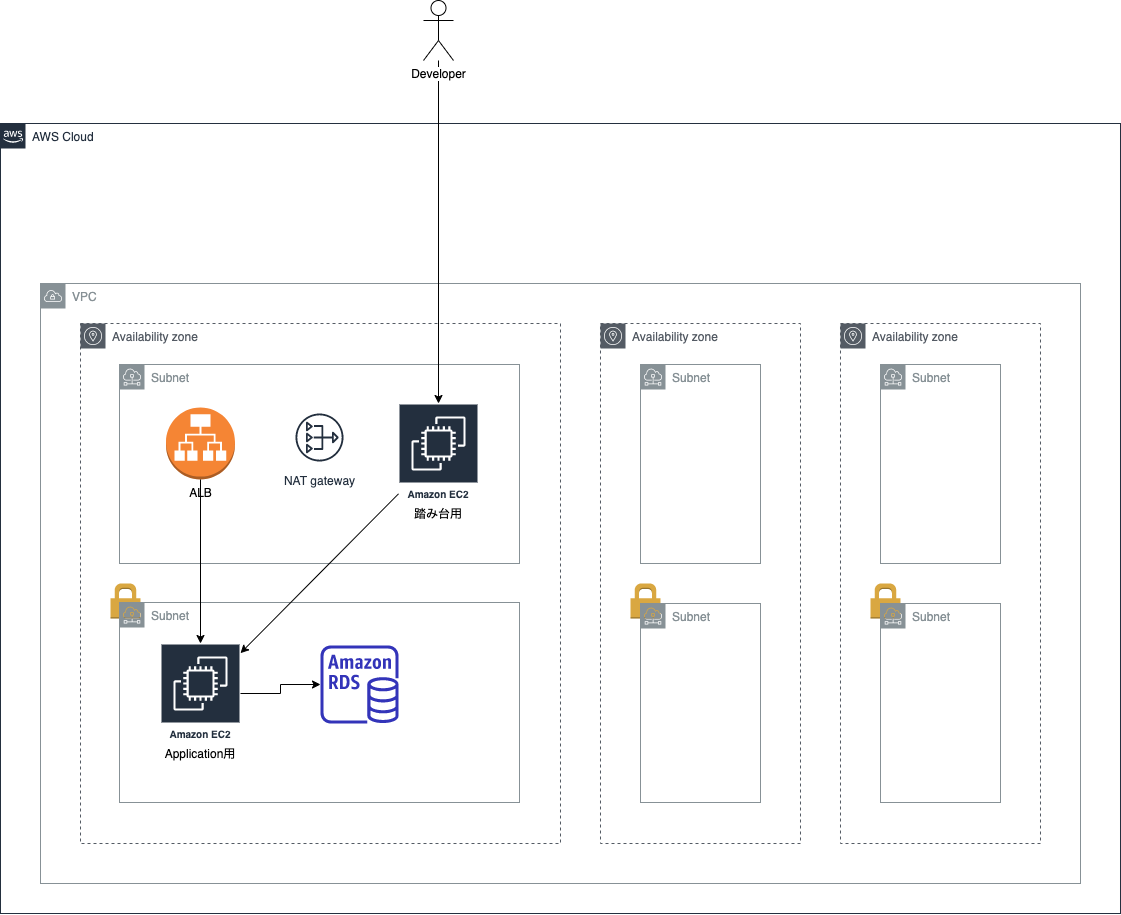
プライベートサブネットの中に入れます。ALB
ユーザーが自分のPCからWebサイトにアクセスする場合、そのアクセスを受け付けるものが必要になります。
EC2をパブリックサブネットに置き、それで直接アクセスを受け付けることもできますが、ここではALB(Application Load Balancer)というものを使います。
ALBは Load Balancer 、すなわち負荷均衡化のためのサービスで、複数のサーバーをALBに紐付けることでアクセスの流し先を自動的に分散し、サーバーごとの負荷を減らすことができます。
またそれだけでなく、ACM(AWS Certificate Manager)というサービスを使うことで、自動で更新される証明書を使ってWebサイトをHTTPSにすることができます。Route 53
最後に、ユーザーがこちらで指定するURLからアクセスできるようにするため、
Route 53を使用します。
Route 53は、ドメイン名(URLがhttps://***/index.phpのような形だった場合、***の部分)を購入したり、そのドメインをALBやEC2に紐付けることができます。
ここまでできれば、あとは
EC2やRDSに必要な設定をすればWebサイトを構築することができます!
それでは実際にAWS上で構築してみましょう。手順
1. アカウント作成
まずはこちらからアカウントを作成します。
アカウントの作成が完了したらこちらの「コンソールにサインイン」からログインしてください。
先程作成したアカウントを使用します。
無事コンソールに入ることができました!
なお右上に出ているように、デフォルトでは「オハイオ」リージョンのEC2などを使用するようになっていますが、「東京」リージョンが良ければ変更してください。
2. VPC
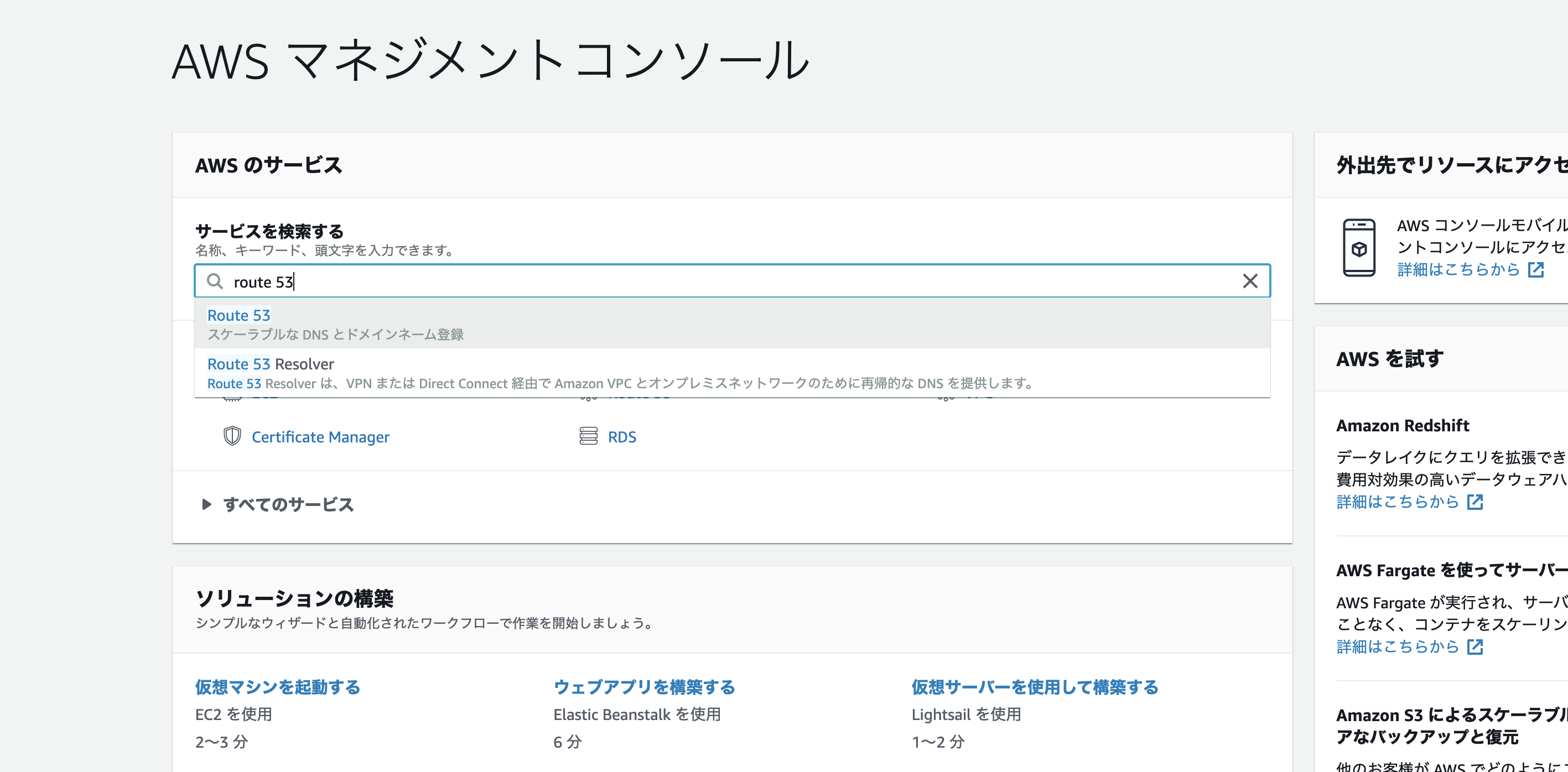
では、VPCを作っていきます。
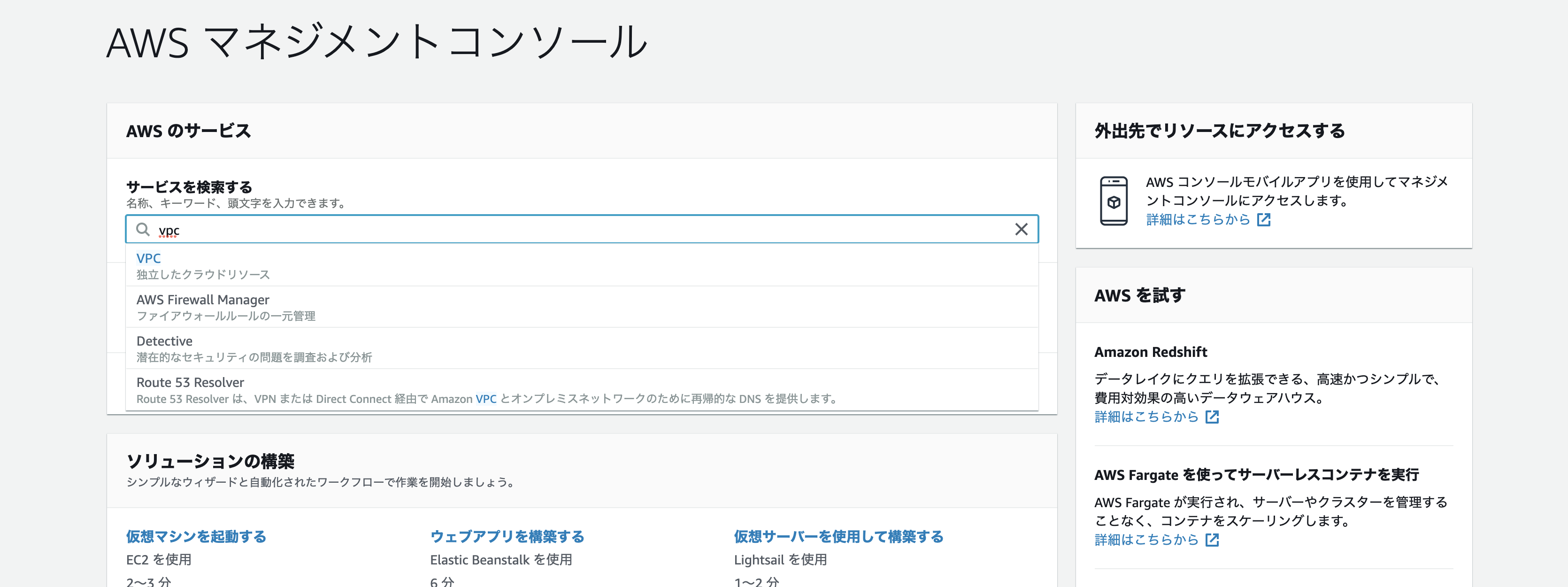
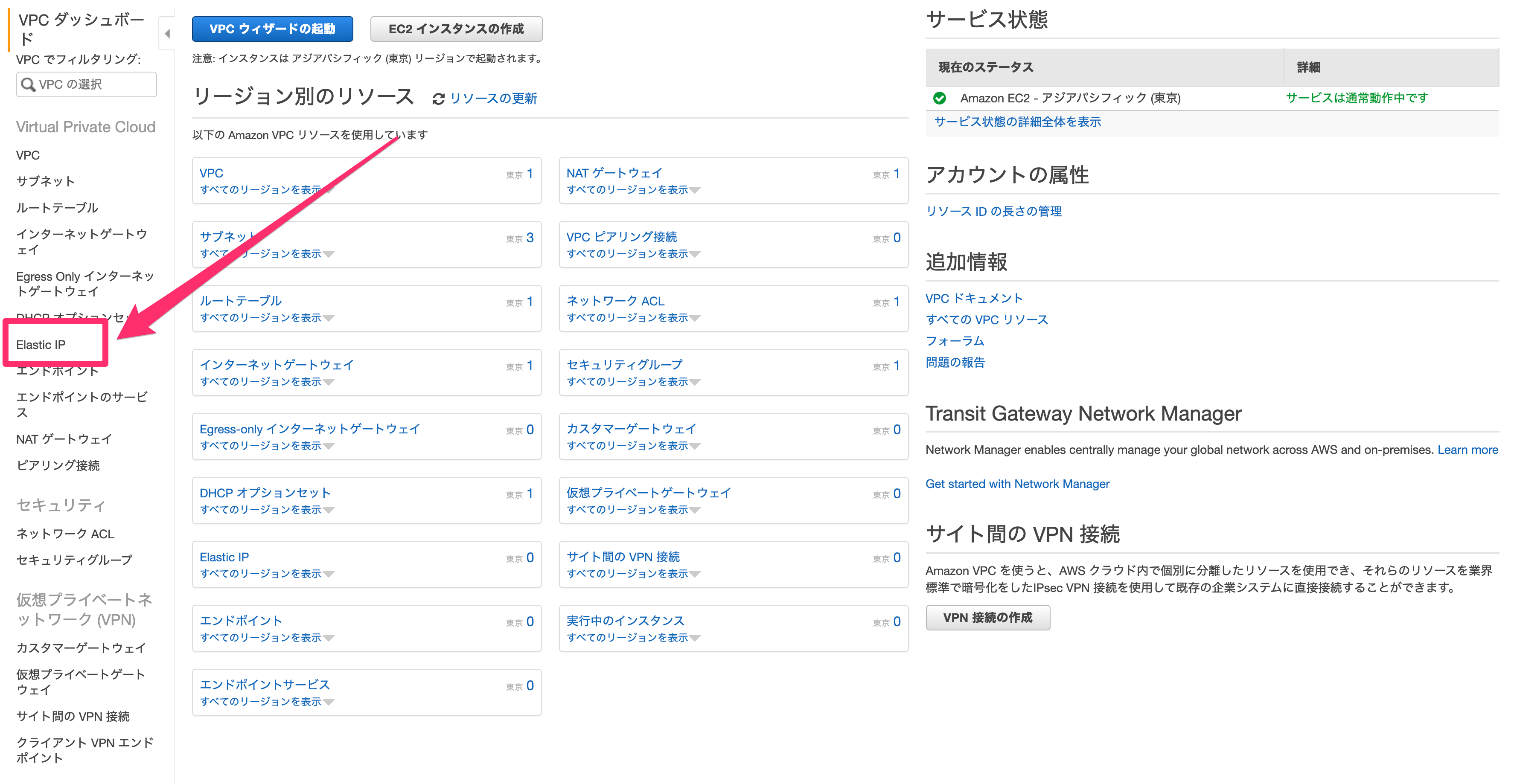
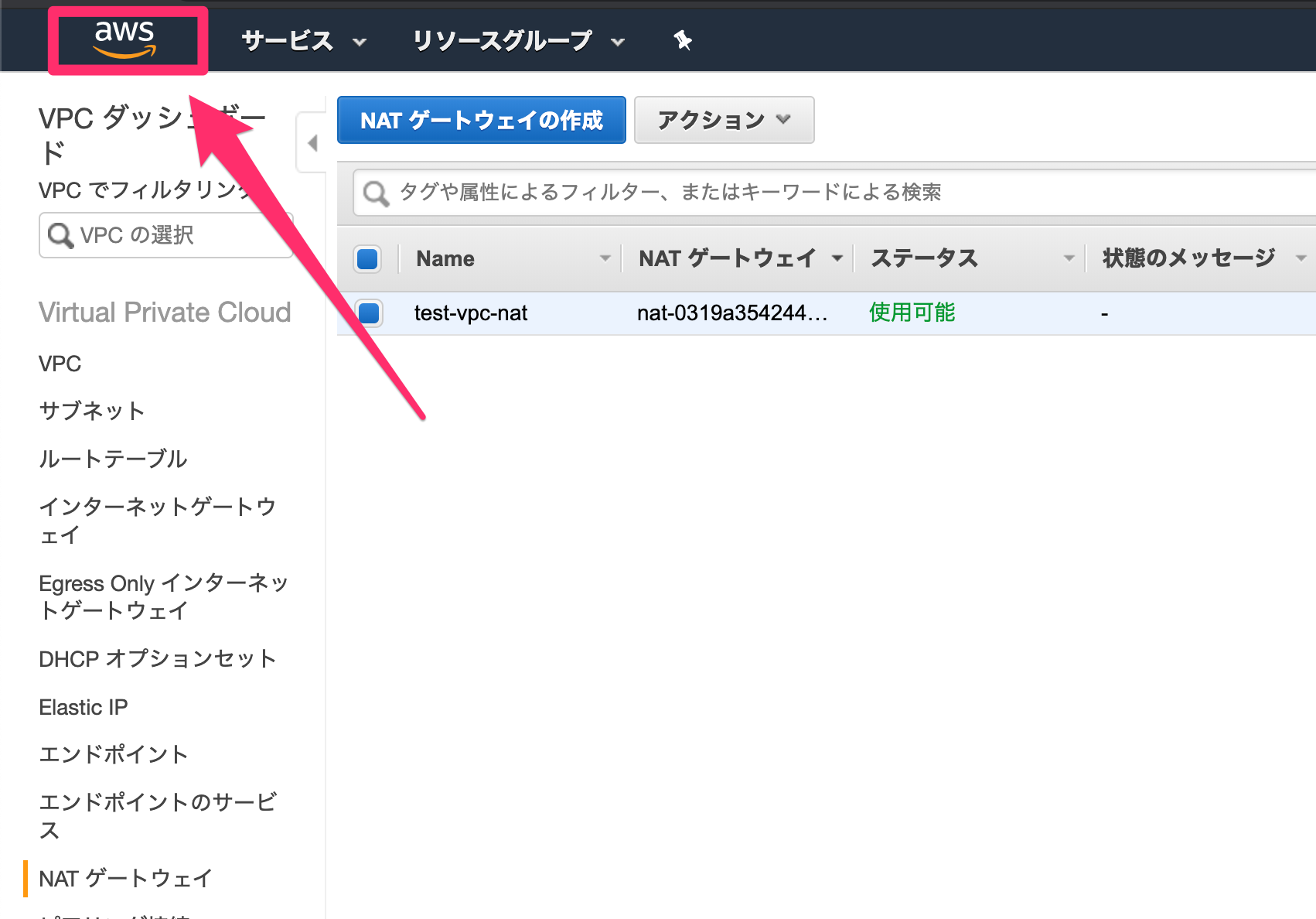
まずはコンソール画面の検索ボックスに「VPC」を打ち込み、クリックします。
VPCの画面に行ったら、まずは左下にある「Elastic IP」に進みます。
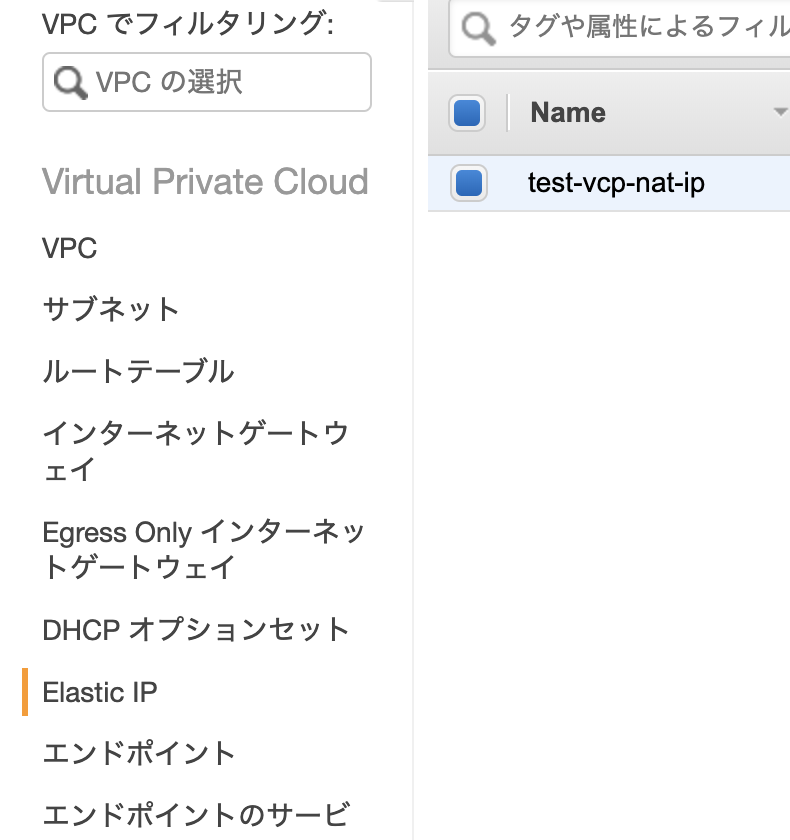
Elastic IPとは、AWSから取得できるグローバルIPアドレスです。
今回はNAT ゲートウェイに必要なため作成します。
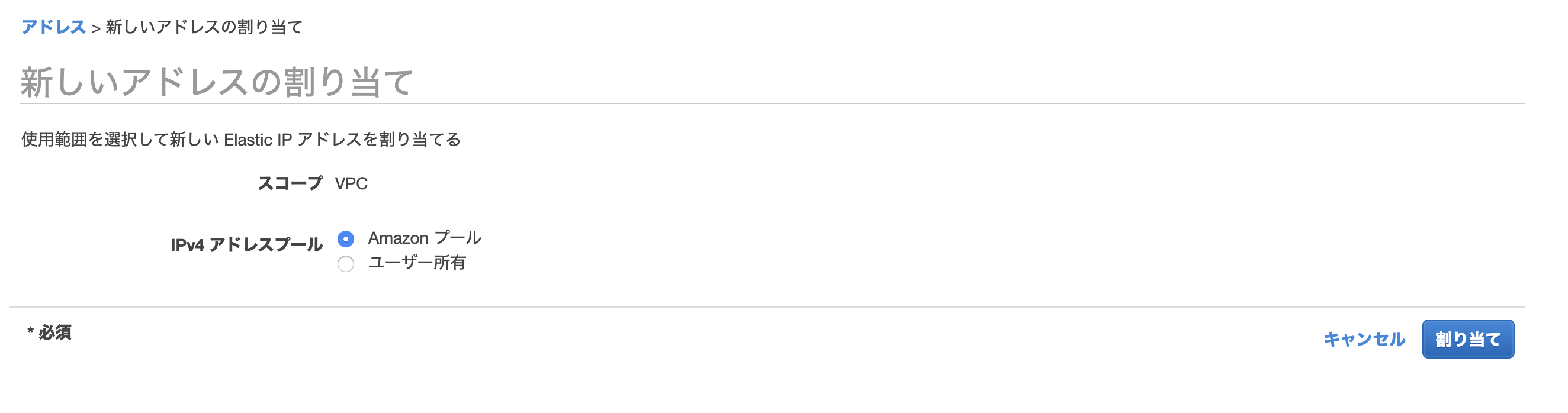
「新しいアドレスの割当」からIPアドレスを作成しましょう。
IPアドレスの作成が完了したら、以下のような画面が表示されるはずです。
「閉じる」で画面を戻します。
続いて、VPCを作っていきます。
画面左上の「VPCダッシュボード」をクリックします。
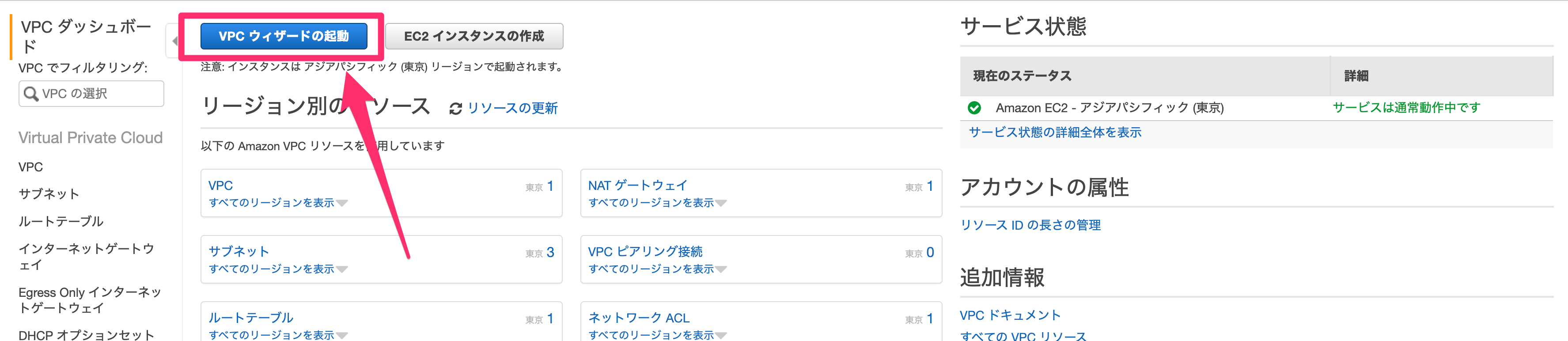
ダッシュボード画面から「VPC ウィザードの起動」に進みましょう。
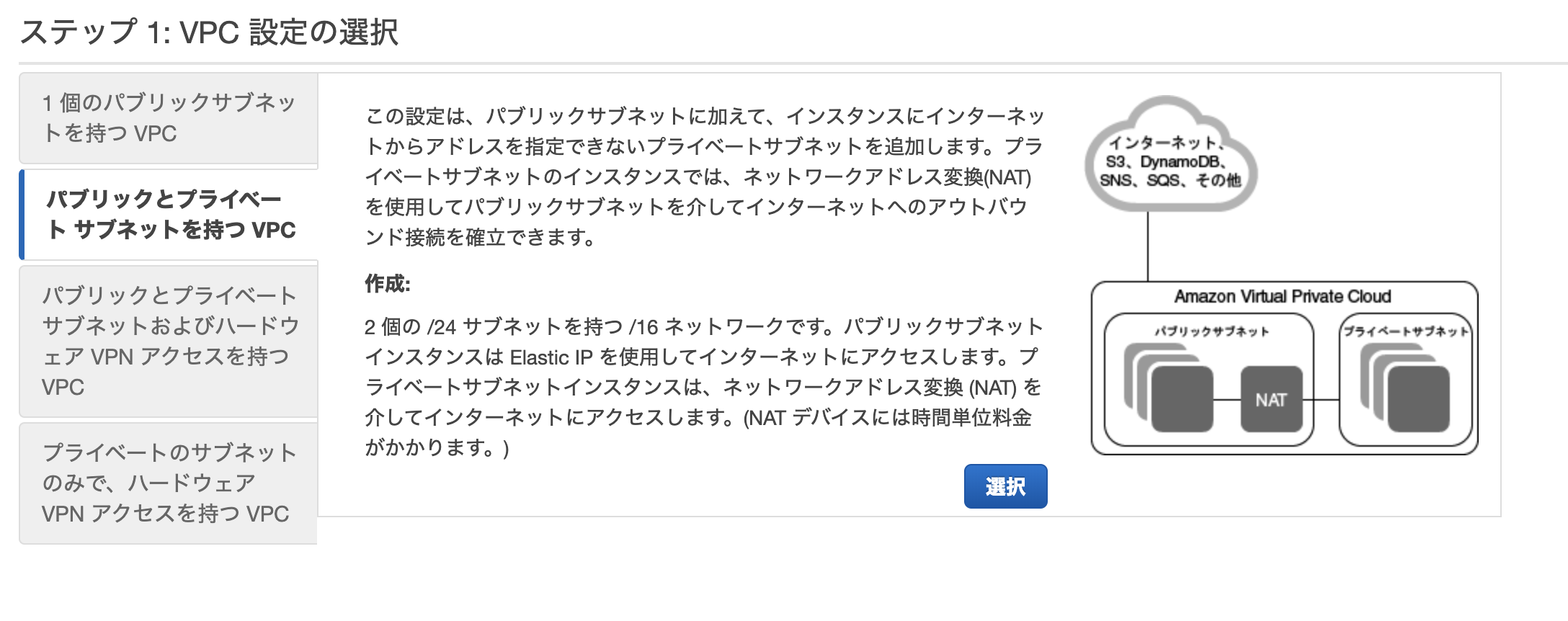
ステップ1では、「パブリックとプライベートサブネットを持つVPC」を選択します。
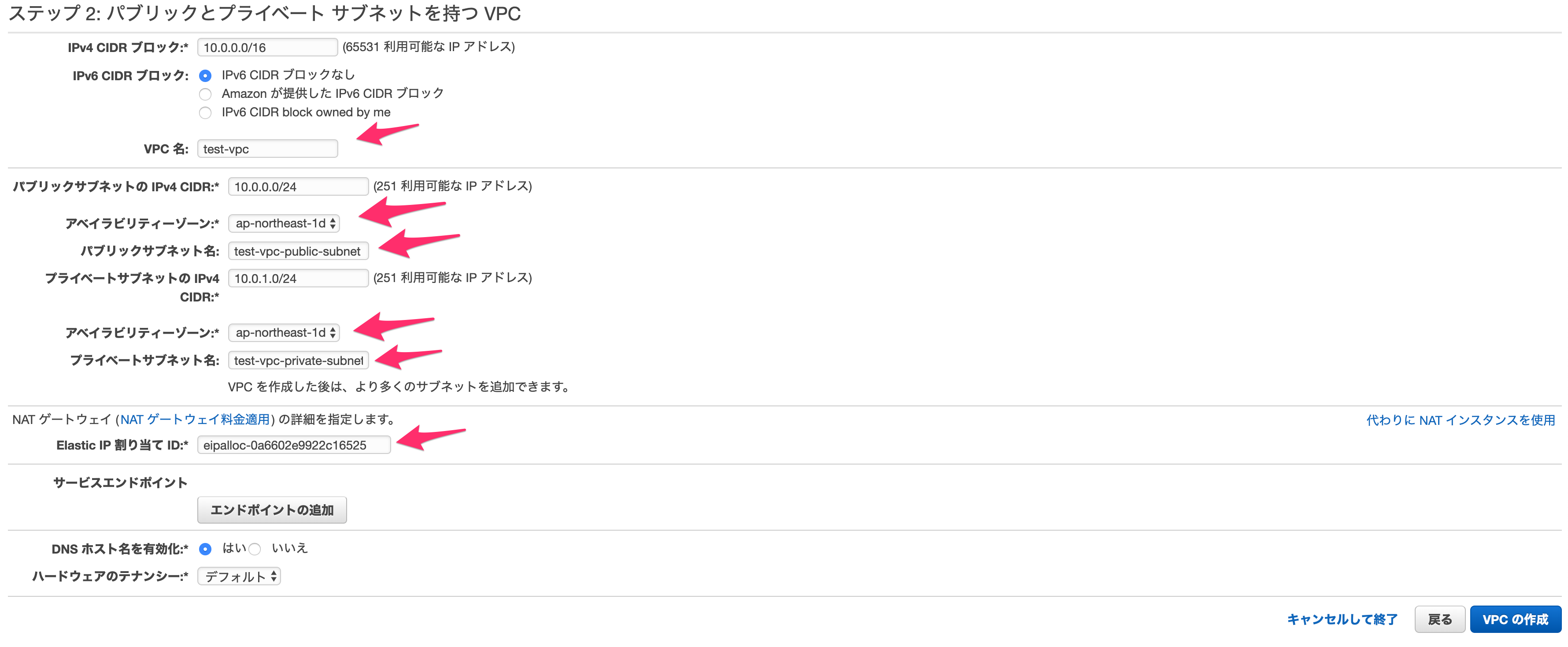
ステップ2では、以下のものを設定していきます。
VPC名
VPCにつける名前です。
なんでも良いですが、わかりやすいものにしましょう。パブリックサブネットのアベイラビリティゾーン
パブリックサブネットを入れるAZです。
こちらはどこでも大丈夫です。パブリックサブネット名
こちらもなんでもいいですが、「public」などの文字やAZのタイプ(a,c,d)などを入れるとわかりやすいです。
プライベートサブネットのAZ
プライベートサブネットを入れるAZです。
こちらもなんでもいいですが、パブリックサブネットと同じAZに入れることで、通信時間やコストをわずかでも減らすことができます。プライベートサブネット名
こちらもなんでもいいですが、「private」などの文字やAZのタイプ(a,c,d)などを入れるとわかりやすいです。
Elastic IP 割当 ID
先ほど作成したElastic IPのIDを入力します。
その他はそのままで大丈夫です。
入力完了後に「VPCの作成」を押せば、VPCが作られます!
少し待つと、こんな画面が表示されます。
作成が完了したら、続いて残りのAZ用のパブリック・プライベートサブネットを作成します。
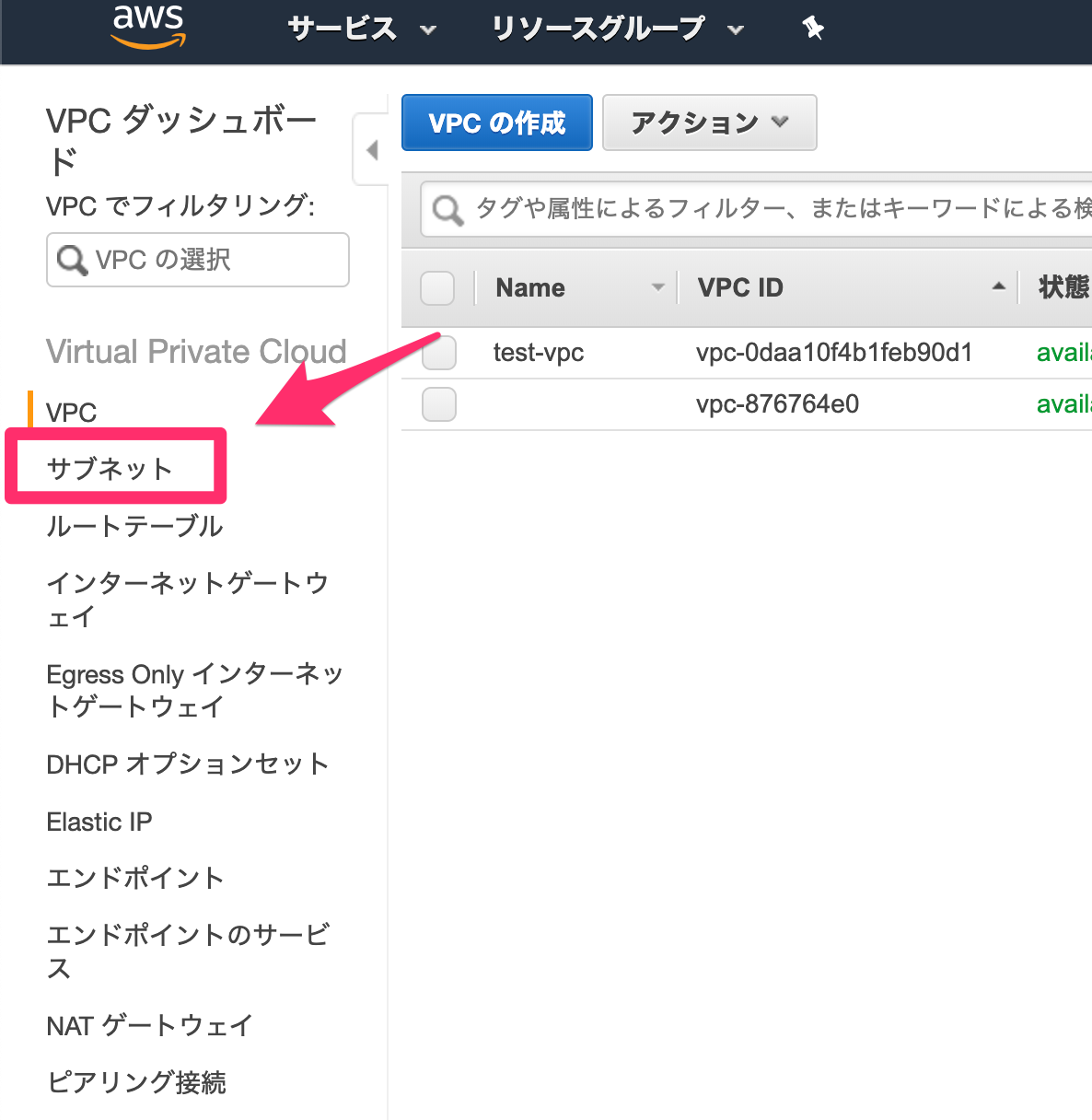
まずは「サブネット」へと行きます。
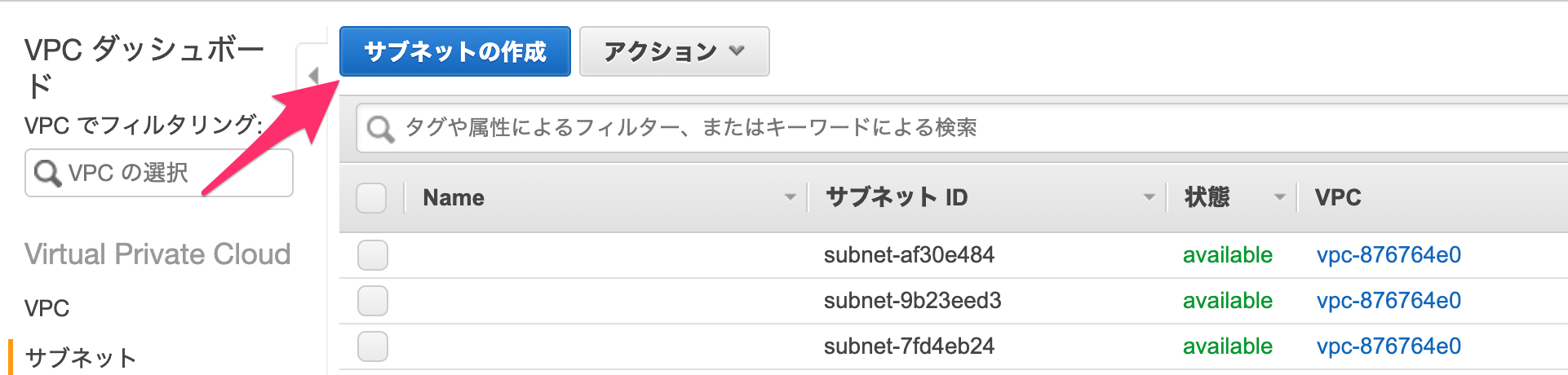
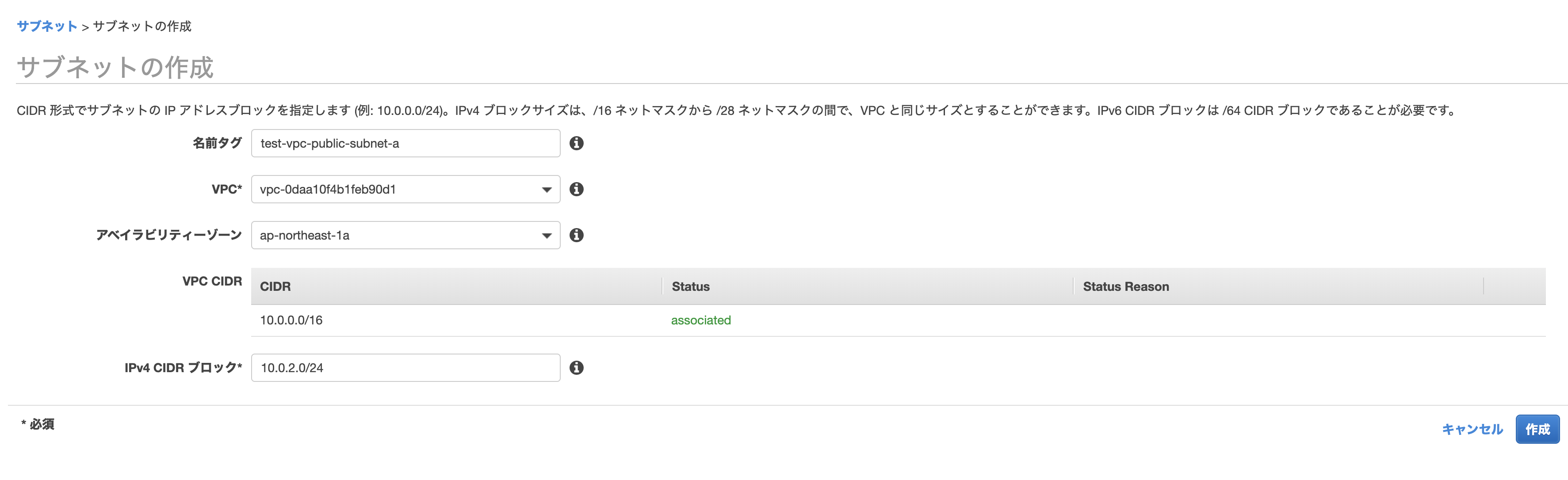
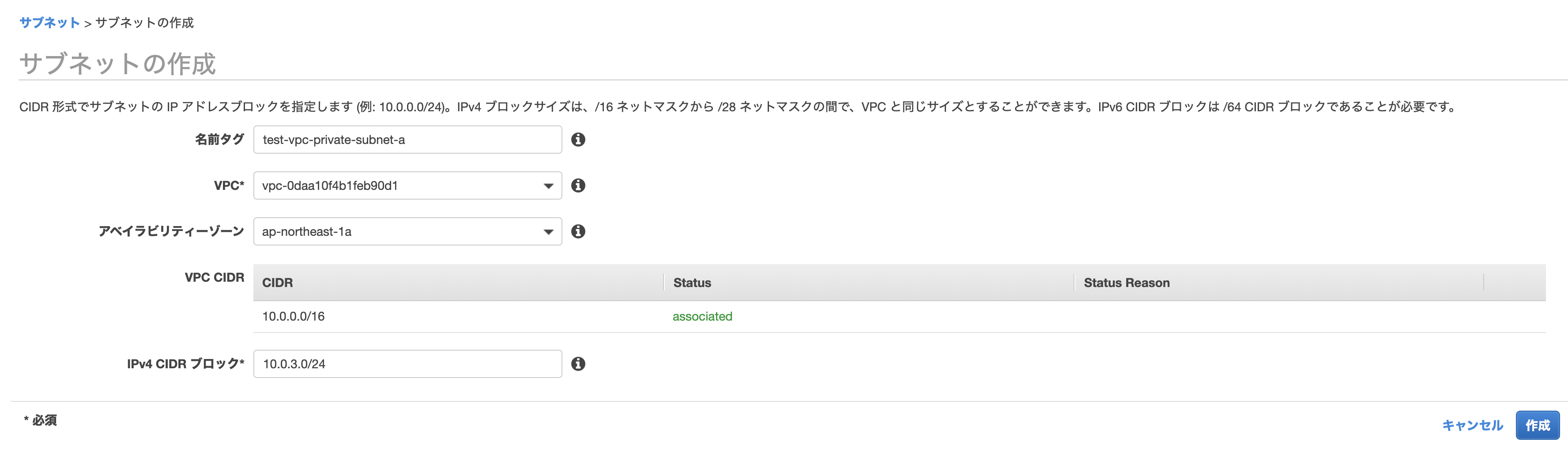
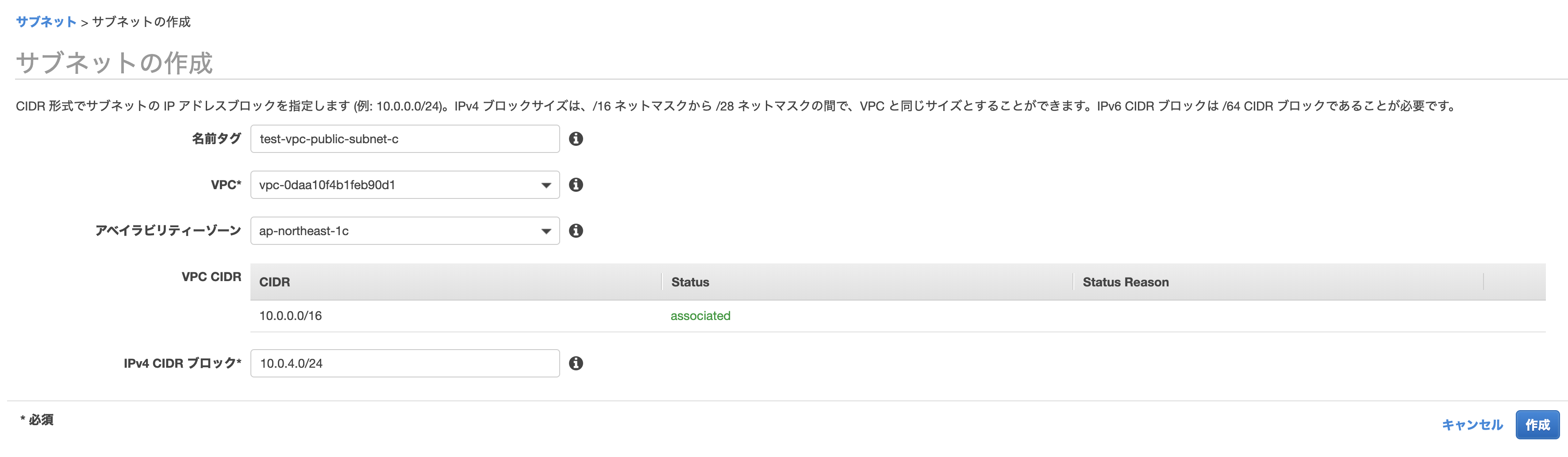
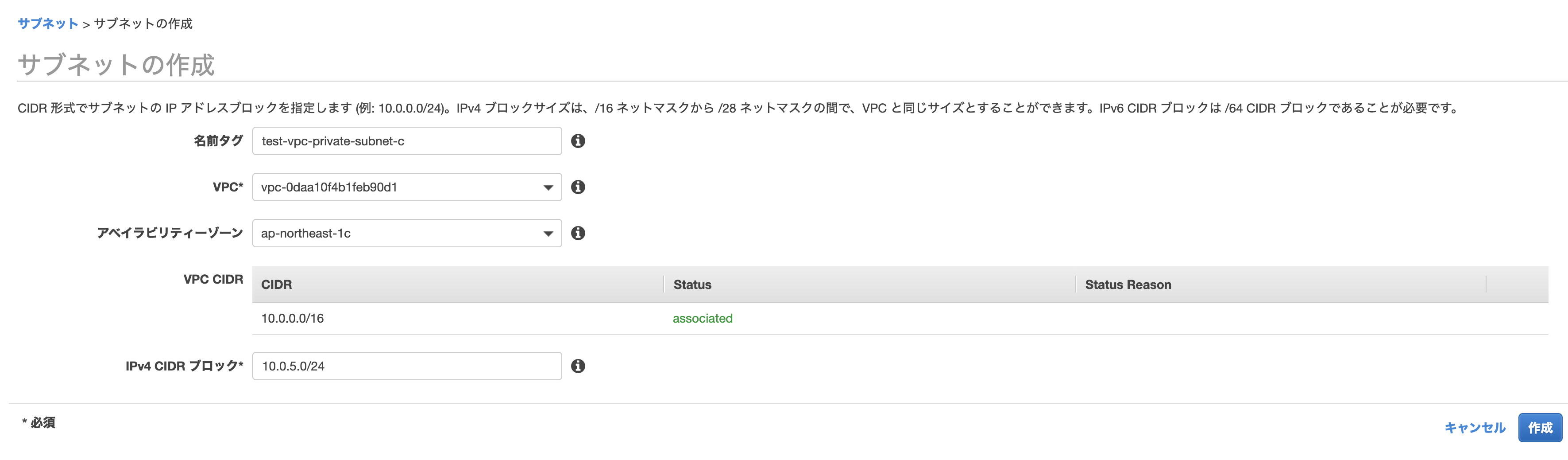
サブネットで「サブネットの作成」をします。
以下のように作っていきます。
名前タグ
何でも大丈夫ですが、先程のように「public/private」や「a/c/d」が入っているとわかりやすいです。
VPC
先程作ったものを選びます。
アベイラビリティゾーン
パブリック・プライベートサブネットで1つずつ選ぶようにします。
IPv4 CIDR ブロック
何でも大丈夫ですが、他のものとかぶらないようにしましょう。
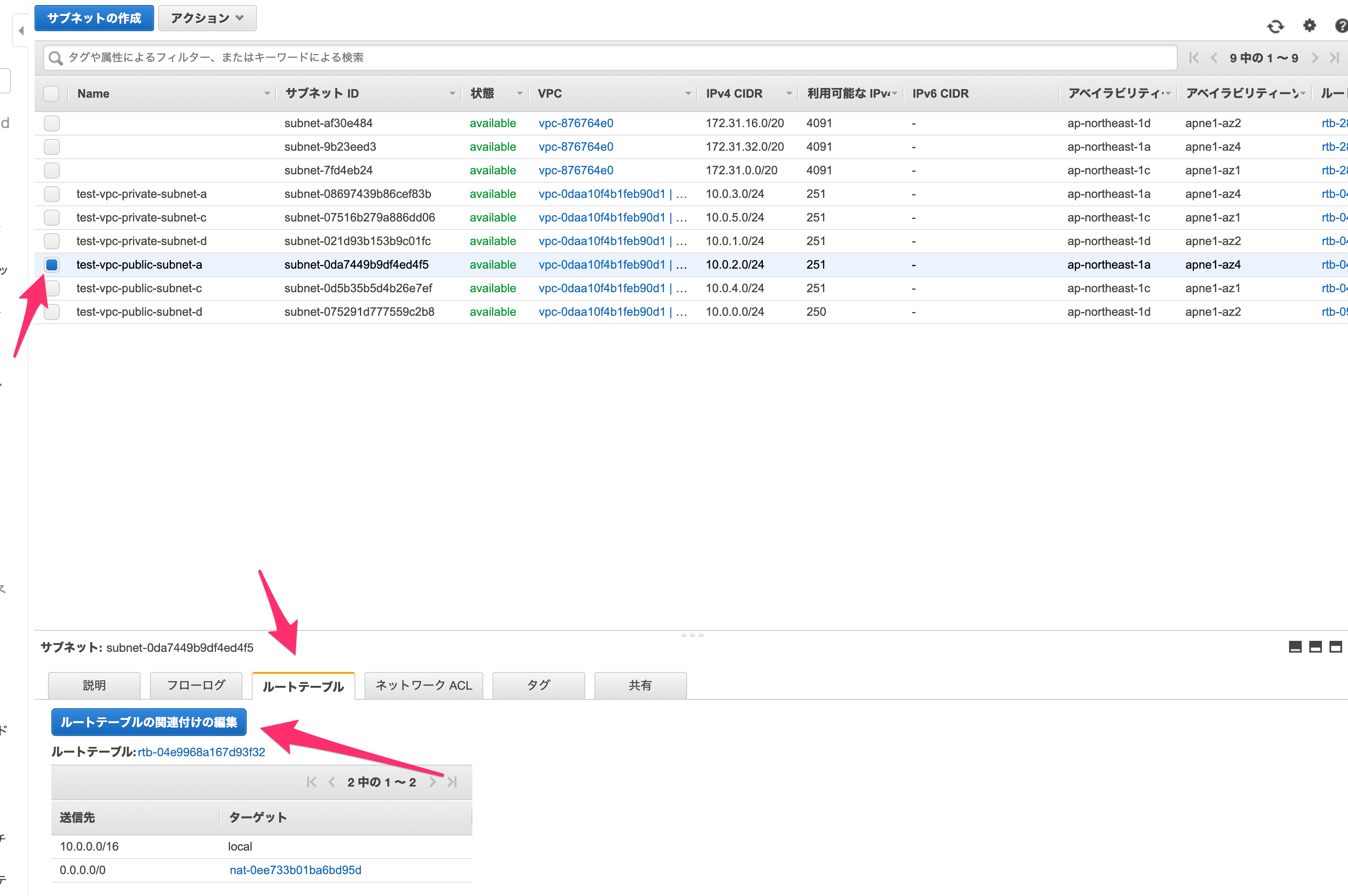
作成が完了したら、パブリックサブネットのみルートテーブルを変更します。
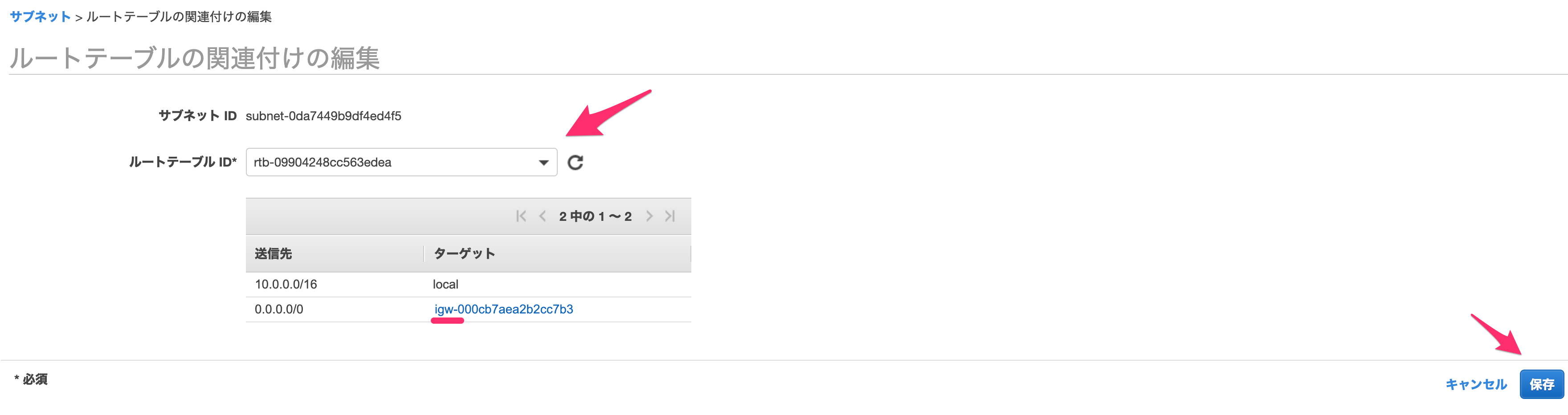
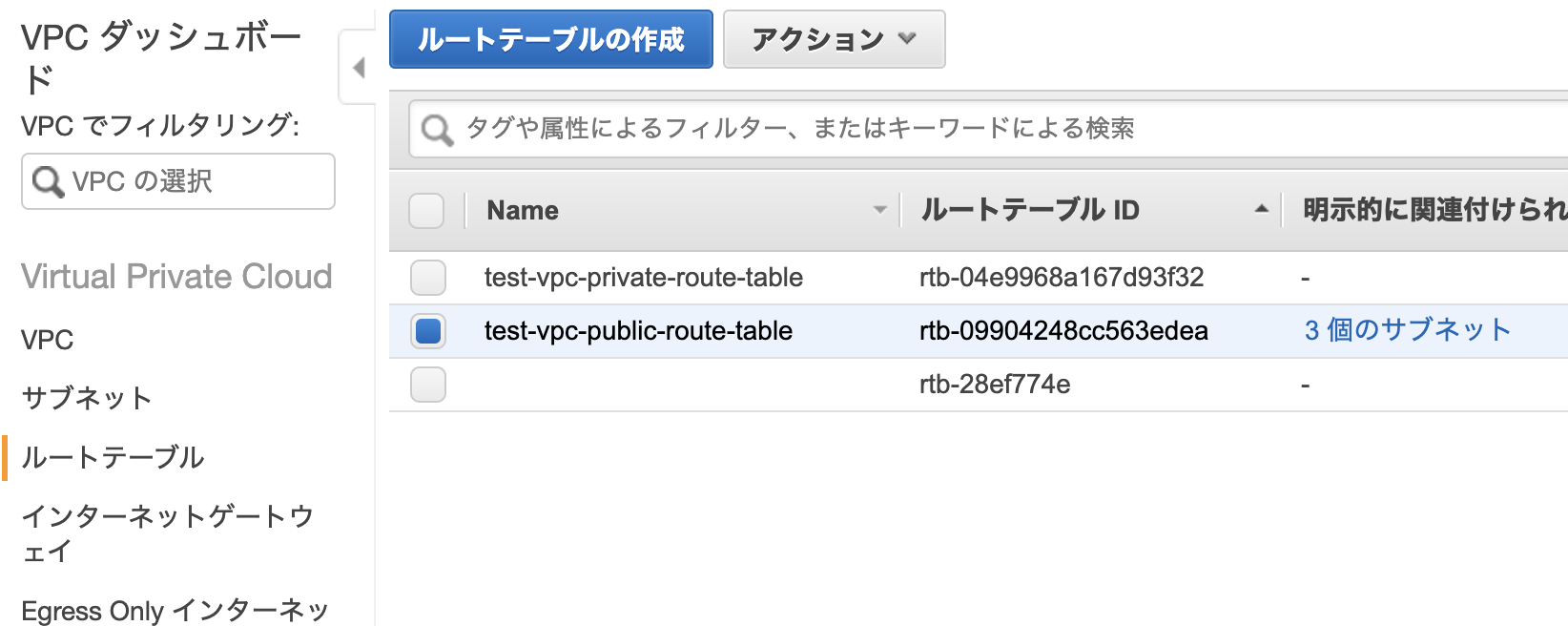
パブリックサブネットの一つを選択し、下の「ルートテーブル」を押して、「ルートテーブルの関連付けの編集」をします。
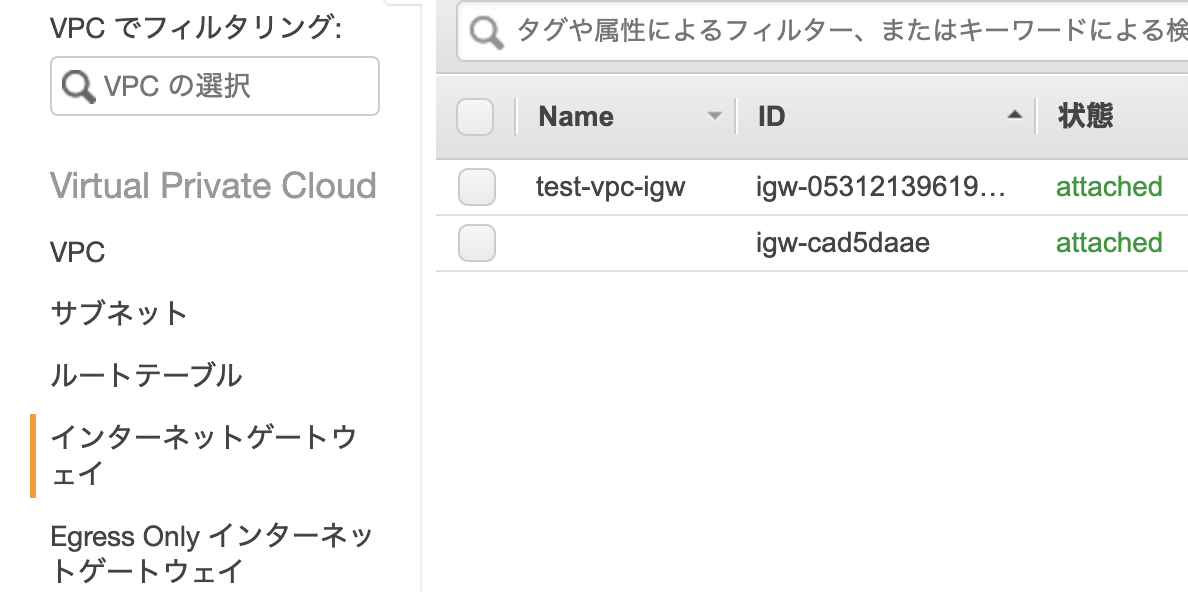
igw-***が表示される方のルートテーブルIDを選択し、「保存」します。
なおigw-***はインターネットゲートウェイと呼ばれるもので、パブリックサブネットに必要なゲートウェイとなっています。
他のパブリックサブネットについても同様に設定してください(なお、最初にVPCと一緒に作成したパブリックサブネットは最初から正しい設定になっています)。
設定が完了したら、「ルートテーブル」「インターネットゲートウェイ」「Elastic IP」「NAT ゲートウェイ」に移り、作成したVPCに紐付いた各データに名前をつけると良いでしょう。
デフォルトのものもあるので、紐付いているVPC IDを見て判断してください。
こちらも適当な名前で大丈夫です。
これでVPCの作成は完了です!
3. EC2
では次に、EC2を作成します。
まずは踏み台サーバーを作りましょう。まずは左上のAWSのロゴからコンソール画面に戻ります。
コンソール画面でEC2を入力し、移動します。
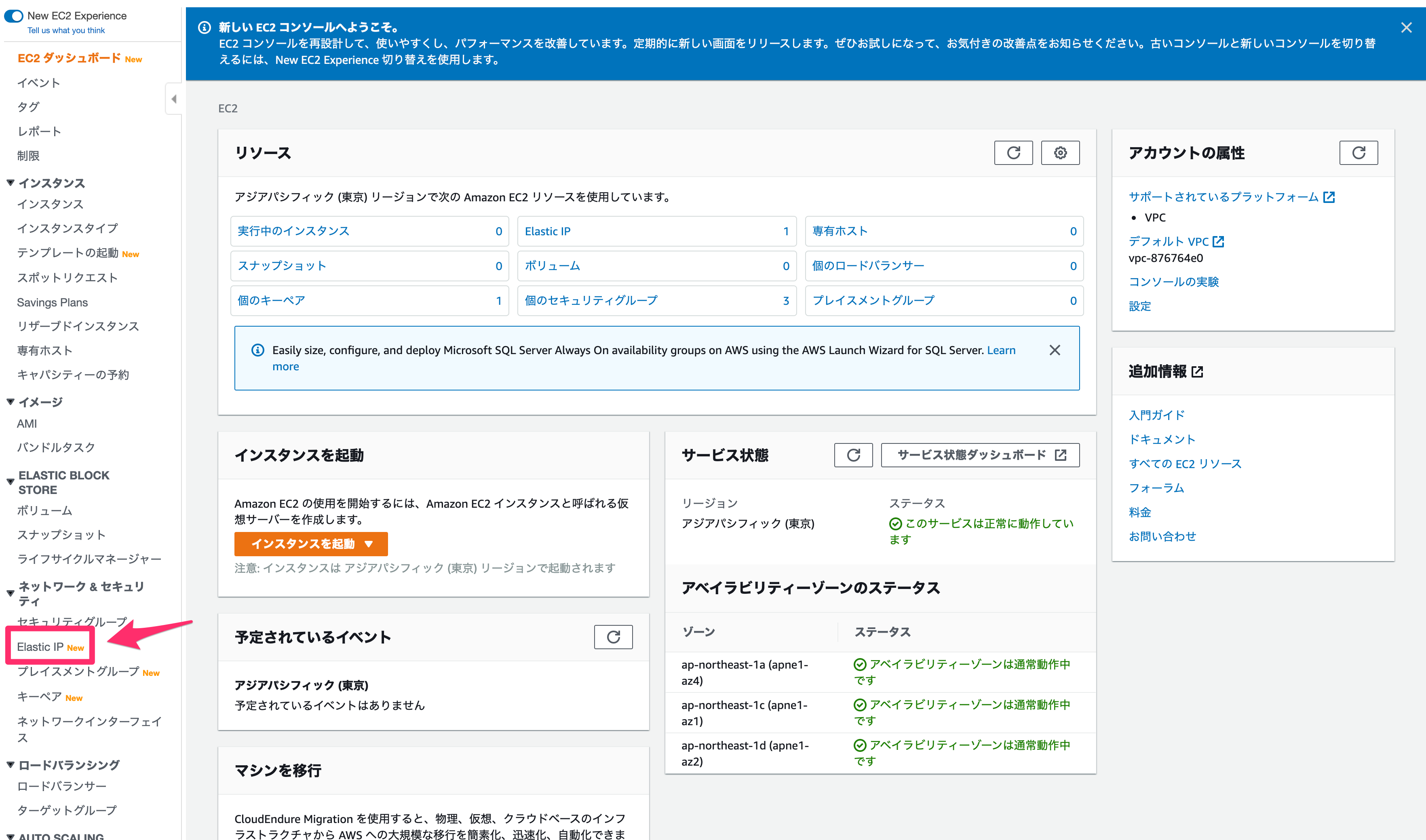
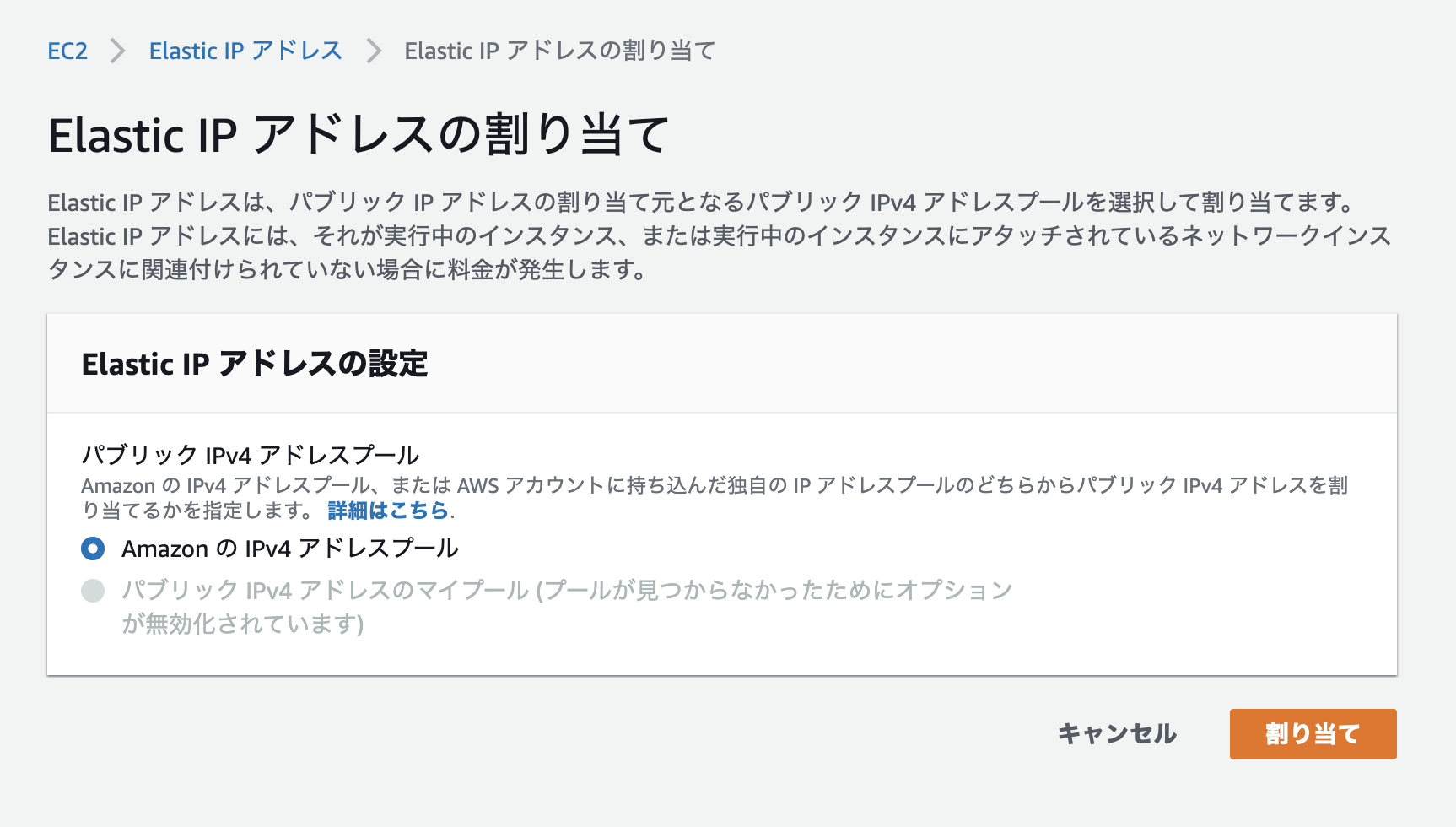
踏み台サーバーには外部からアクセスする必要があるので、まずはElastic IPを作成します。
「Elastic IPアドレスの割り当て」から作成します。
そのまま「割り当て」をクリックしてください。
以下のようになるはずです。
作成が完了したら、EC2を作っていきましょう。
まずは「インスタンス」の画面へ行きます(ちなみにAWSでは、サーバーのことをEC2インスタンス、インスタンスなどと言ったりします)。
インスタンスの画面にて、「インスタンスの作成」を行います。
まずはAMI(Amazon Machine Image)を選択していきます。
これによってサーバーのOSなどが決まってきます。
必要性に応じて選べば問題ありませんが、ここは一番上にある「Amazon Linux 2 AMI (HVM), SSD Volume Type」を選択します。
次にインスタンスタイプを選びます。
インスタンスタイプは、サーバーのCPUやメモリなどのスペックに関わってきます。
サーバーにかかる負荷によって選択する必要がありますが、もしまだアカウントを作って1年以内であればt2.microが無料枠で使用できるので、今回はそちらを選びます。
選択後は、「次のステップ:インスタンスの詳細の設定」をクリックします。
インスタンスの詳細設定では、以下を設定します。
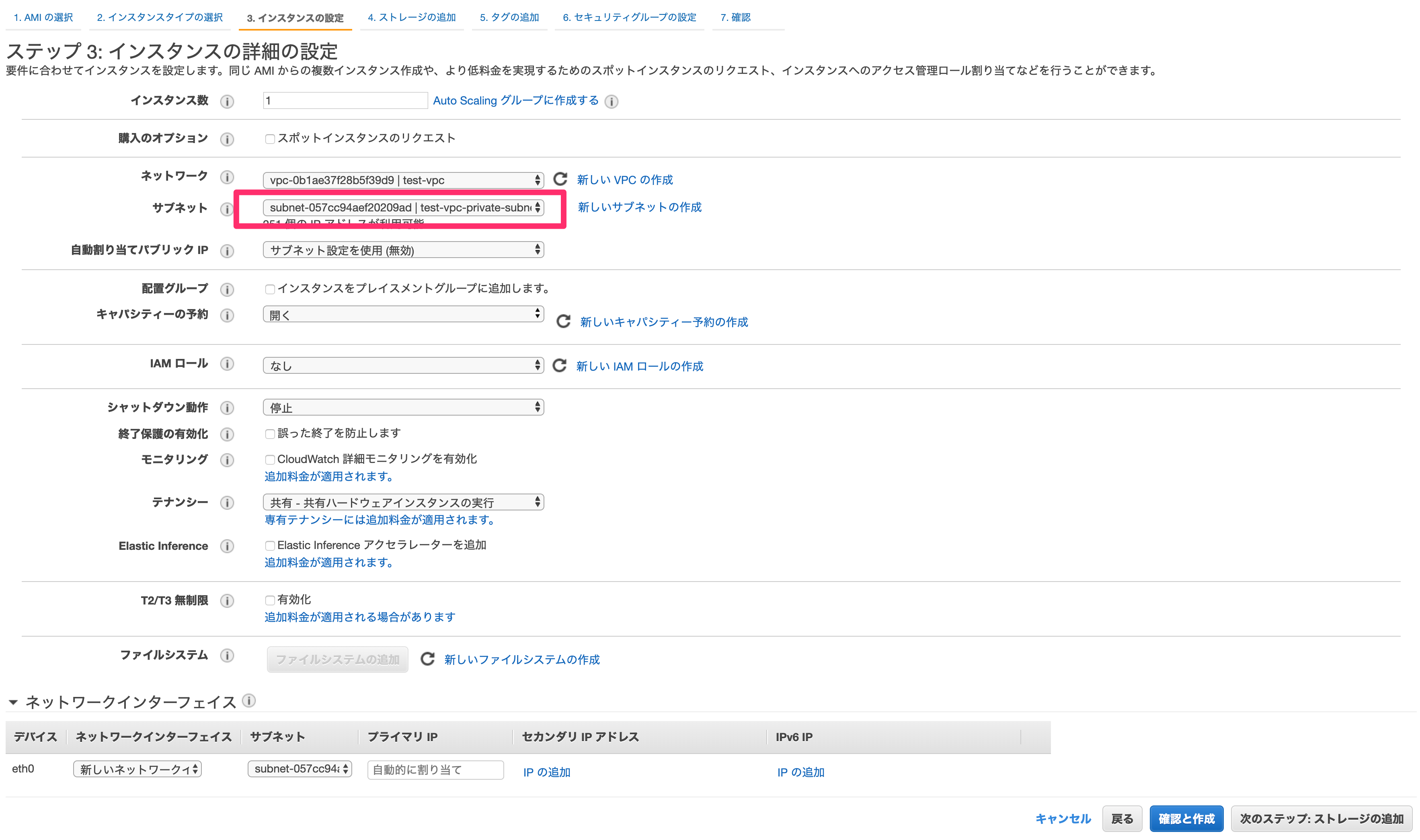
ネットワーク
最初に作成したVPCを選択します。
サブネット
パブリックサブネットのどれかを選択します。
なお今回はすべてのサービスを同じAZのサブネットで作成するので、どのAZで作ったかを覚えておいてください。ちなみに、より詳細にサーバーの属性を設定できるIAMと呼ばれるものもありますが、今回は簡易的に行うため設定しません。
選択後、「次のステップ:ストレージの追加」をクリックします。
ストレージの追加では、サーバーのストレージを決定します。
今回は何もせず、「次のステップ:タグの追加」を選択します。
タグの追加では、作成するインスタンスにタグを追加できます。
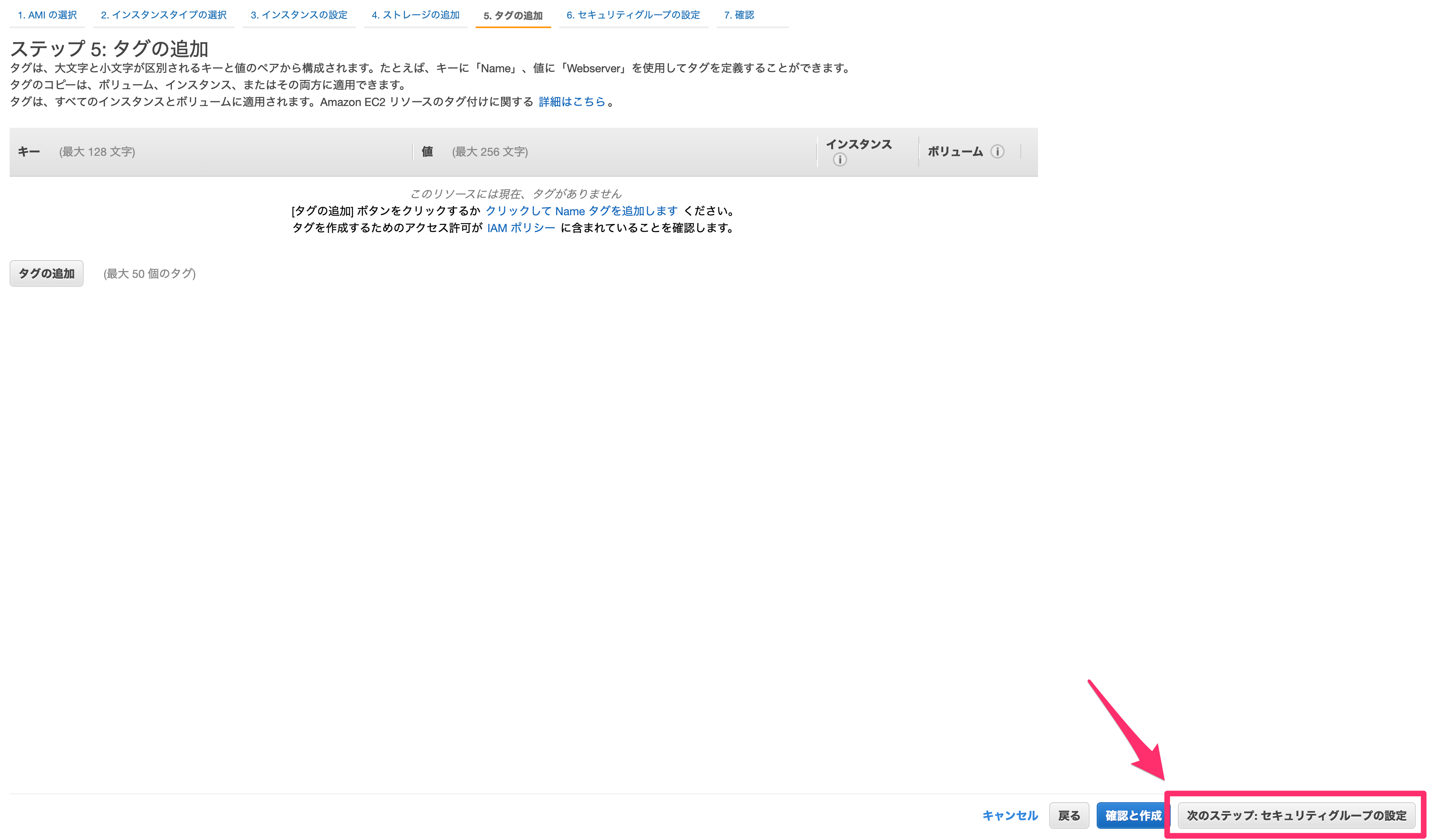
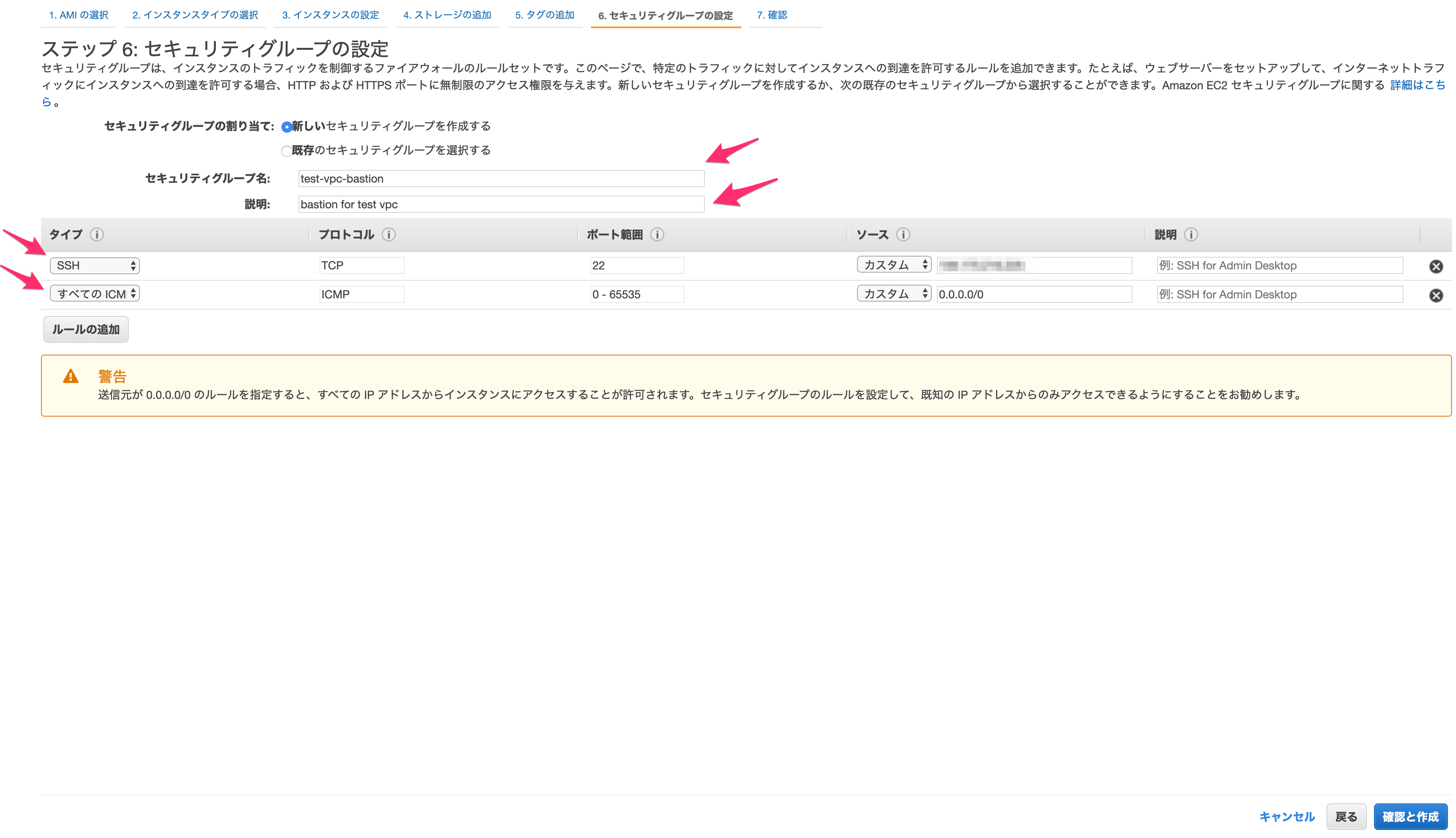
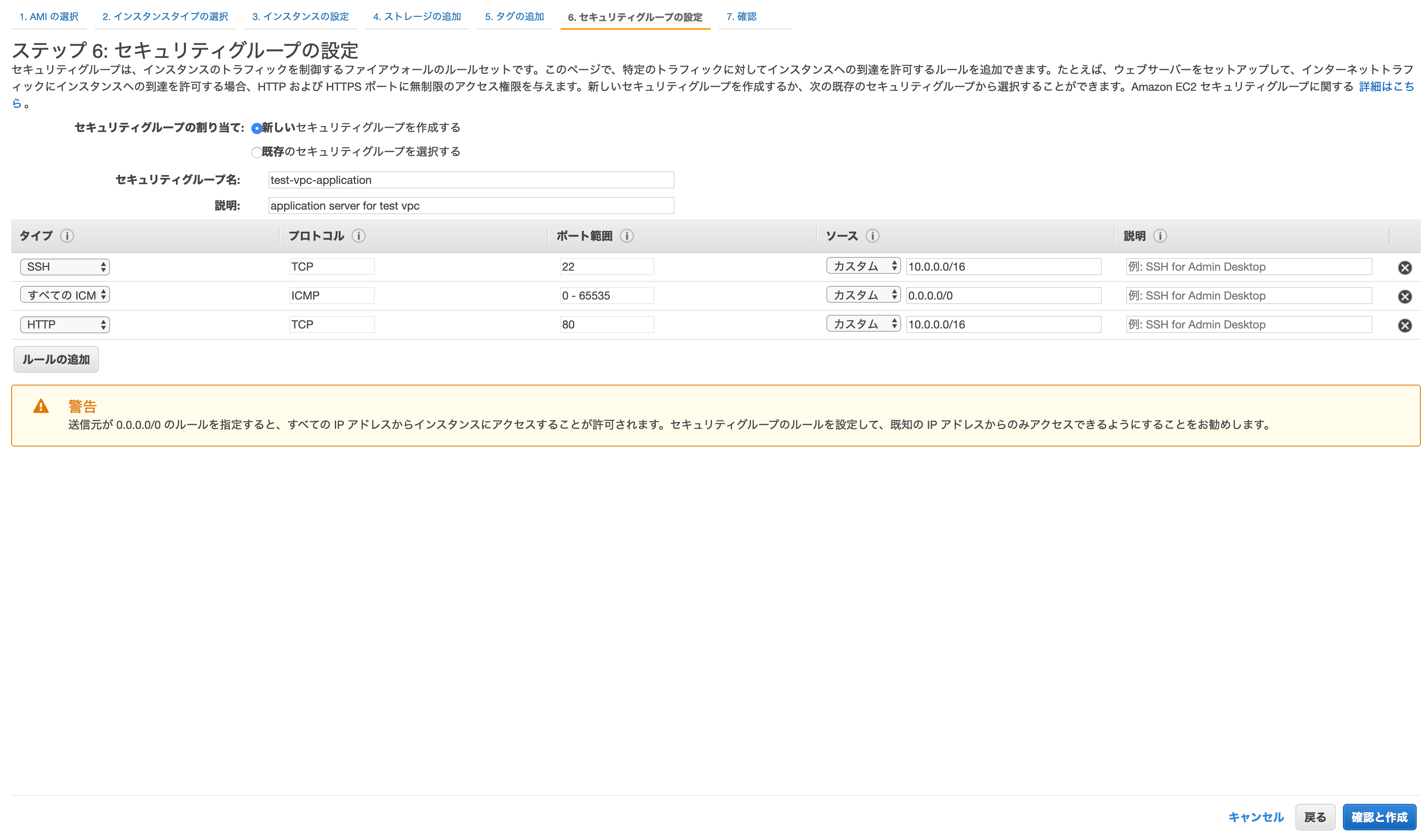
これによりコスト確認などがより便利にできるようになりますが、今回は何もせず「次のステップ:セキュリティグループの確認」を選択します。
セキュリティグループは、インスタンスのセキュリティを担保するファイアウォールです。
以下を設定します。セキュリティグループの割当
「新しいセキュリティグループ」を作成します。
セキュリティグループ名
適当なものを設定します。
説明
適当なものを設定します。
SSH
SSHでサーバーにログインするために必要な設定です。
自分のPCのIPアドレスを「ソース」に設定することで、自分のPCのIPアドレス以外からはSSHでアクセスできなくなります。すべてのICMP - IPv4
pingコマンドなどで確認できるようにするための設定です。
今回は0.0.0.0/0でどこからでも確認できるようにしていますが、ここのIPアドレスを絞っても良いかもしれません。踏み台であれば以上で十分でしょう。
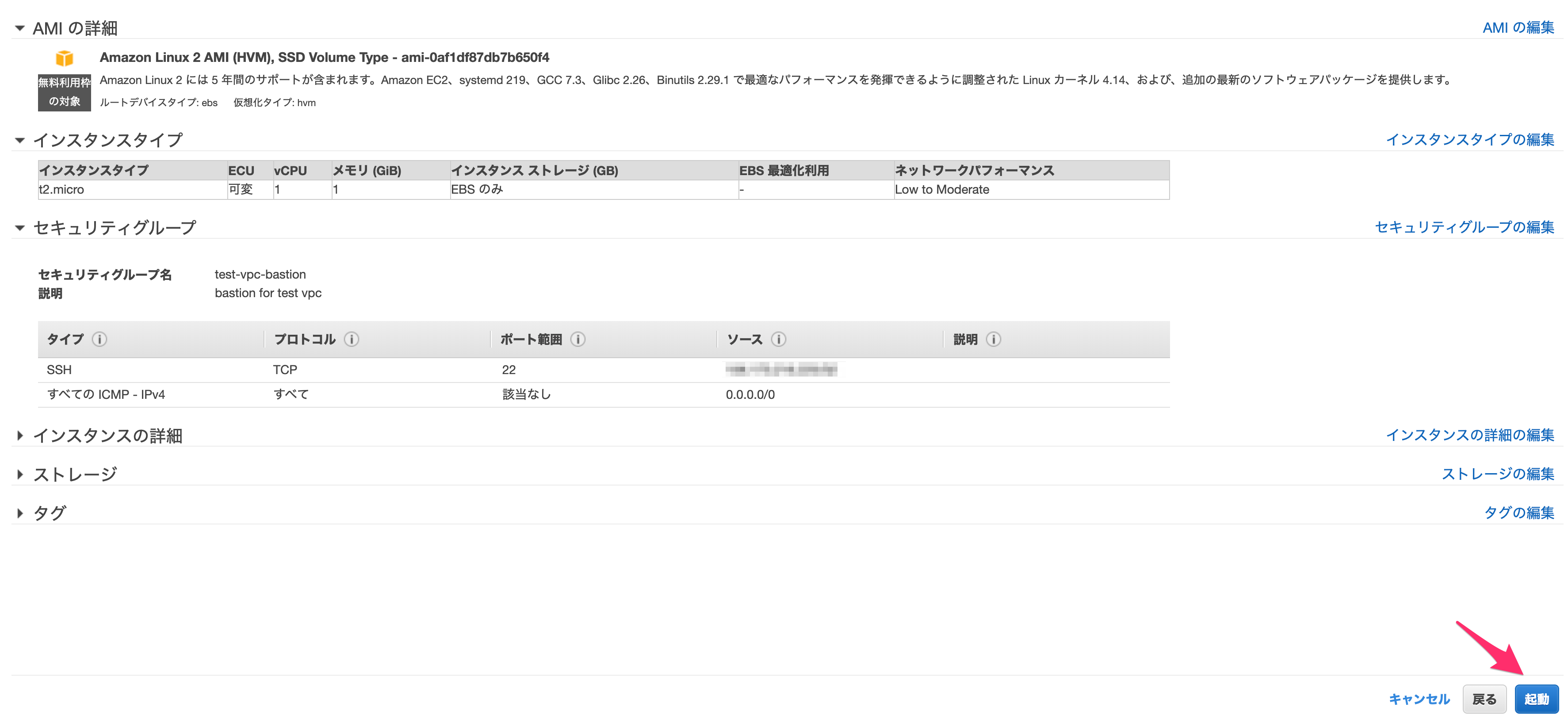
入力後、「確認と作成」を押します。
確認画面が問題なければ「起動」します。
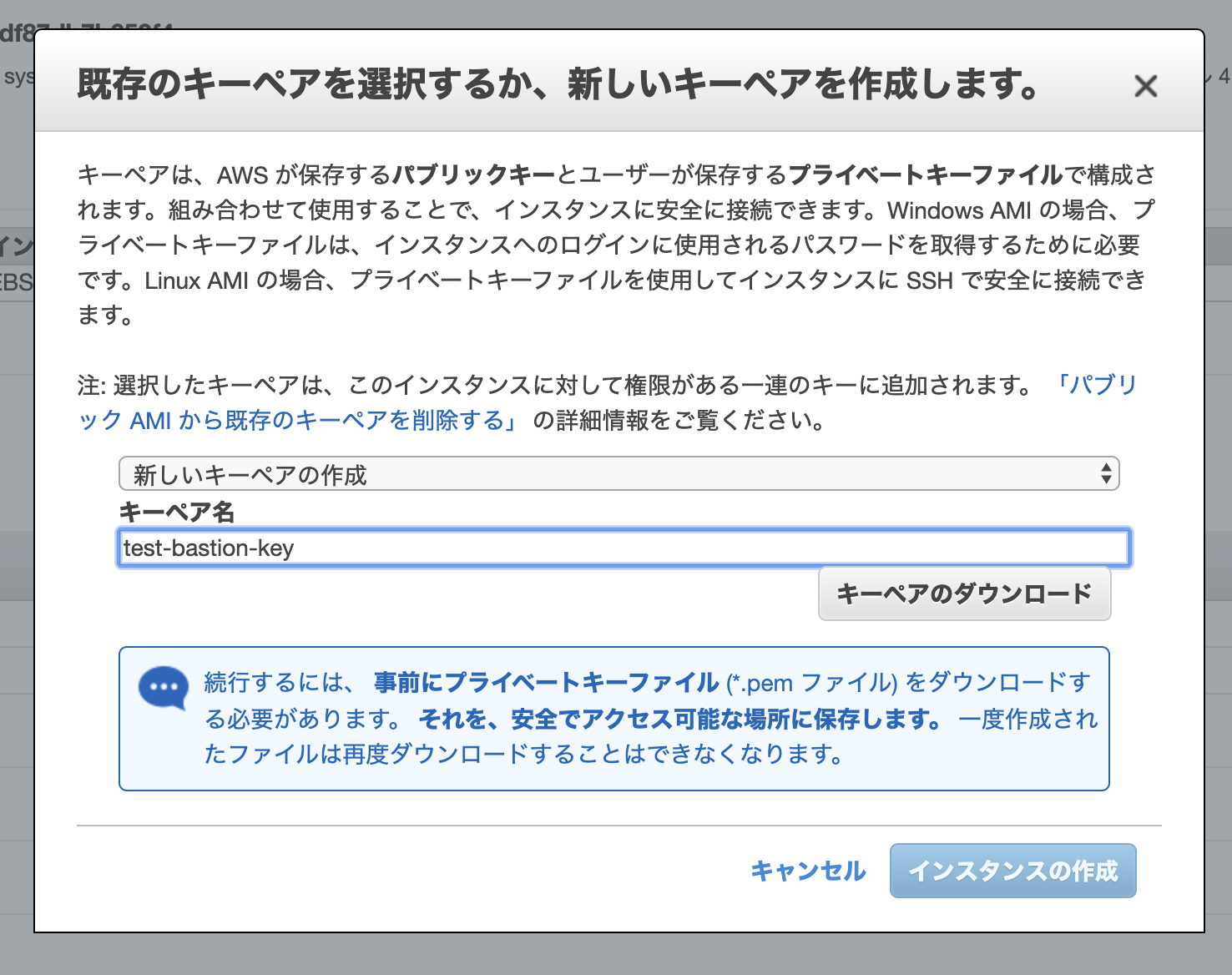
起動するとキーペアについて尋ねられるので、ここでは「新しいキーペアの作成」をします。
名前は適当なものを設定し、ダウンロードしてください。
ダウンロードすると「インスタンスの作成」ができるようになります。
なおここでダウンロードしたキーペアをなくすとサーバーにログインできなくなるので、注意してください。
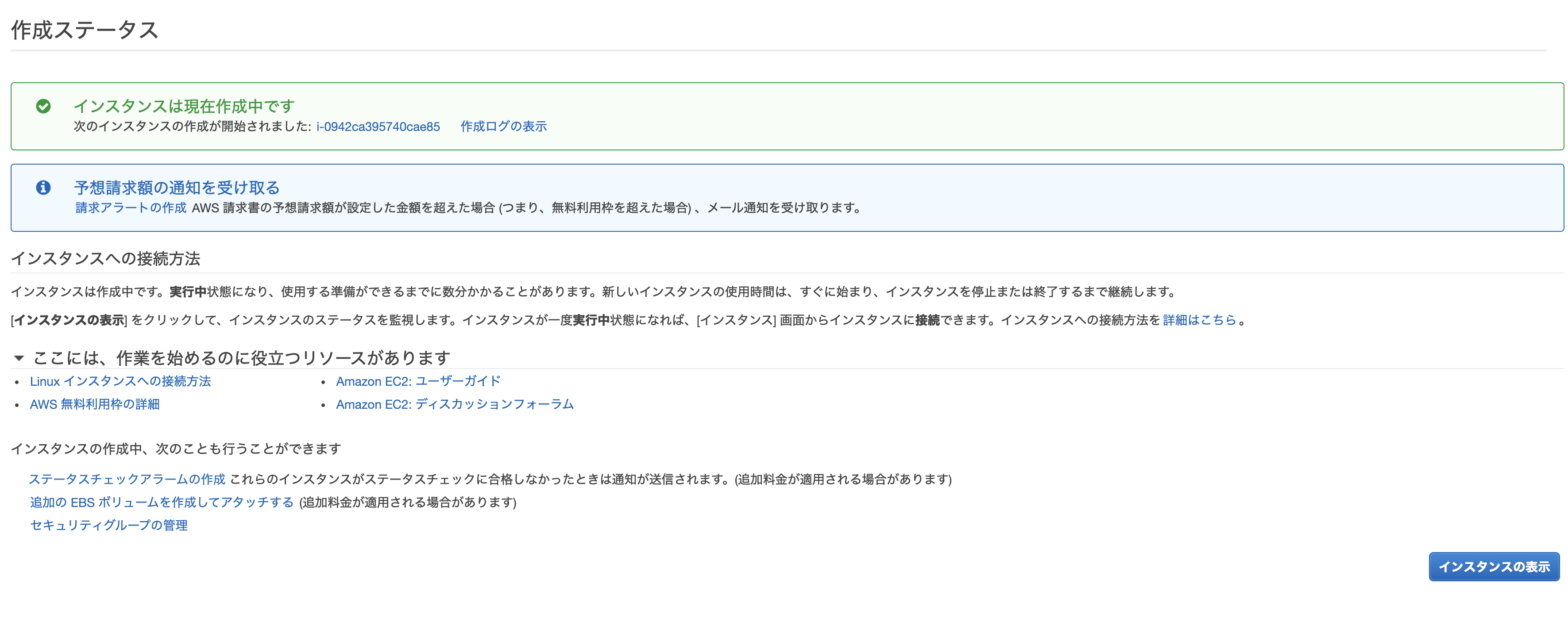
作成すると以下のような画面になります。必要に応じて「請求アラートの作成」をしてもいいでしょう。
問題なければ「インスタンスの表示」をします。
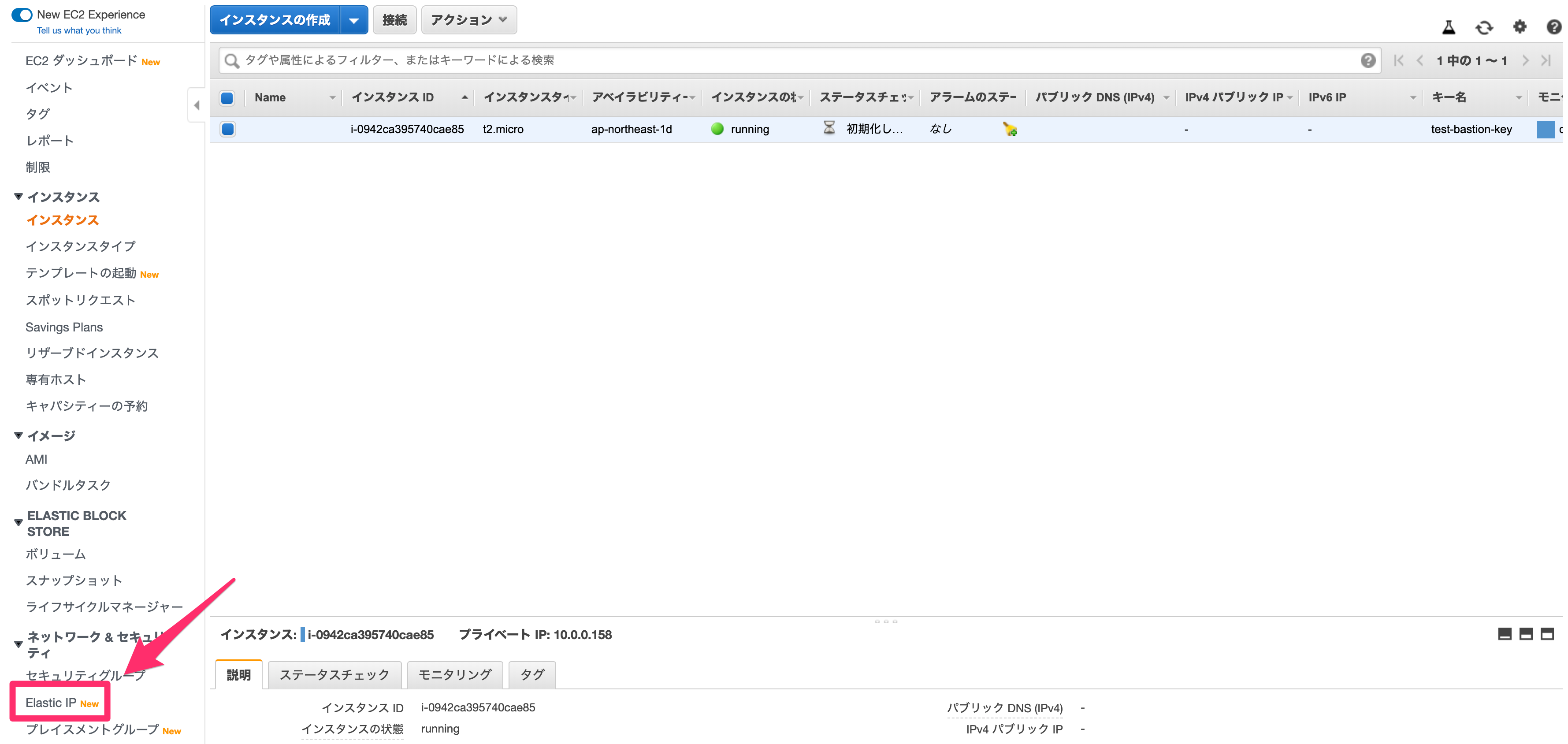
インスタンスを作成したら、先程のVPCのときと同じように名前をつけると良いでしょう。
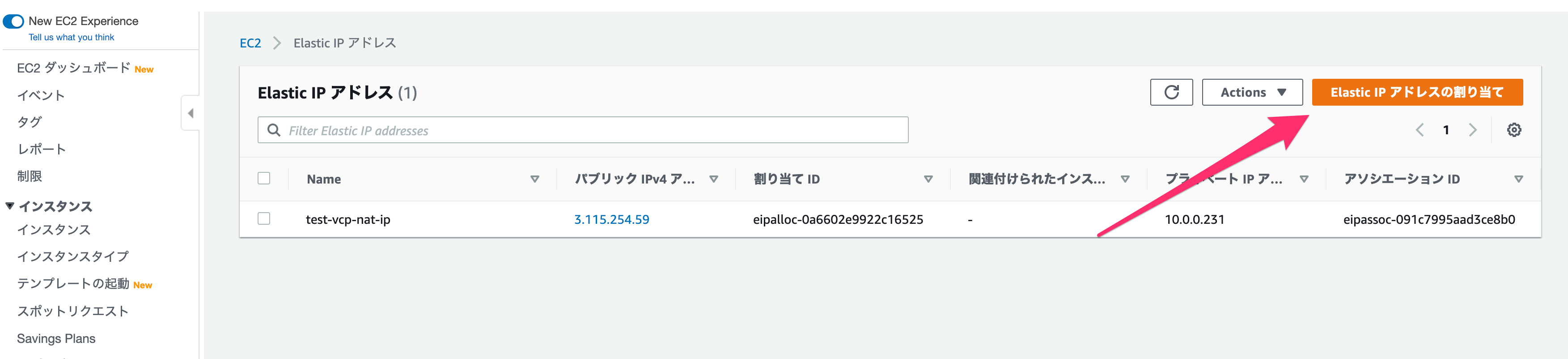
また、Elastic IPとの紐付けで使うので、インスタンスIDとプライベートIPをメモなどに保存しておきます。
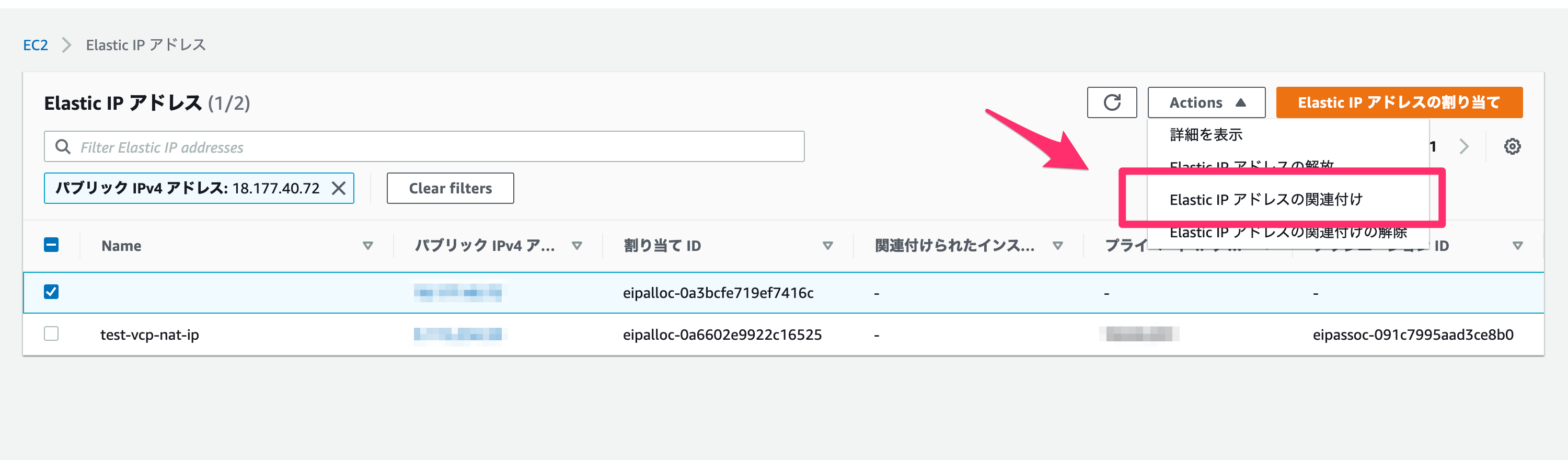
その後、Elastic IPへ進みます。
先程作成したIPにチェックをし、「Actions」から「Elastic IPアドレスの関連付け」を選んでください。
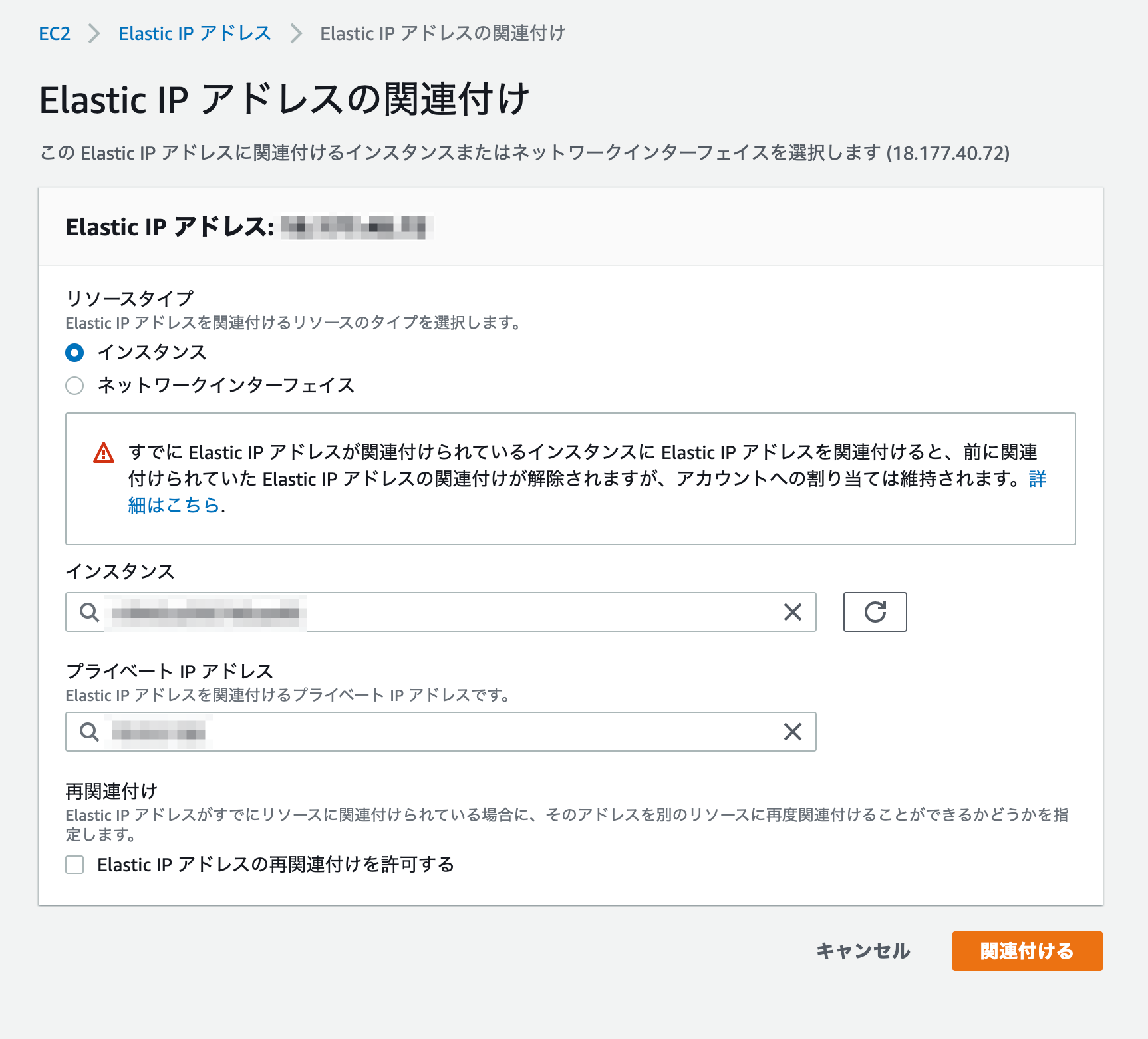
Elastic IPアドレスの関連付けでは、以下のように設定します。
リソースタイプ
EC2に紐付けるので、「インスタンス」を設定してください。
インスタンス
先程作成したEC2を選択してください。
プライベートIPアドレス
先程作成したEC2のプライベートIPアドレスを選択してください。
入力後、「関連付ける」を押してください。
これでサーバーの作成は完了です!
実際にログインしてみましょう。まずは先ほどダウンロードした鍵(秘密鍵)を、秘密鍵が通常存在するディレクトリへ移動させます。
mv ~/Downloads/test-bastion-key.pem ~/.ssh/続いて、権限を変更します。
chmod 600 ~/.ssh/test-bastion-key.pem準備ができたら、先程作成したElastic IP先に、今の秘密鍵を使ってログインしてみます。
ちなみにユーザー名はec2-userです。ssh -i ~/.ssh/test-bastion-key.pem ec2-user@{先程のElastic IP}これで無事ログインできるはずです!
なおユーザーについてはec2-userを使いまわしたりせず、ちゃんと各ユーザー用のものを作成しましょう。では次に、Webサイト用のEC2を作成します。
とは言っても、今の手順のうち一部を変更するのみです。
変更する手順は、1. Elastic IP周りを設定しない
2. パブリックサブネット内に作成するAZは踏み台サーバーと同じところにしてください。
3. セキュリティグループは、VPC内からのみを考える
HTTPで受けるので、セキュリティグループは80番ポートを開けます。
4. 名前を適切につける
です。
これにてアプリケーションサーバーが作成され、踏み台サーバー経由でアプリケーションサーバーに入れるようになったはずです。
ダウンロードした秘密鍵を踏み台サーバーに入れることで踏み台サーバーからSSHログインしてもいいですが、ここでは~/.ssh/configにSSH設定ファイルをおいてログインしてみましょう。
なお今回の秘密鍵はtest-application-keyという名前で作成しました。Host test-bastion HostName {踏み台サーバーのグローバルIPアドレス} User ec2-user Port 22 IdentityFile ~/.ssh/test-bastion-key.pem Host test-application HostName {アプリケーションサーバーのプライベートIPアドレス} User ec2-user Port 22 IdentityFile ~/.ssh/test-application-key.pem ProxyCommand ssh -W %h:%p test-bastionこうして、
ssh test-applicationとすることでアプリケーションサーバーにログインできるはずです!
これにて、EC2の作成は完了しました。
4. RDS
では続いて、RDSの作成に移ります。
最初にRDS用のセキュリティグループを作ります。
EC2の画面から、そのまま「セキュリティグループ」に移動してください。
「セキュリティグループの作成」をします。
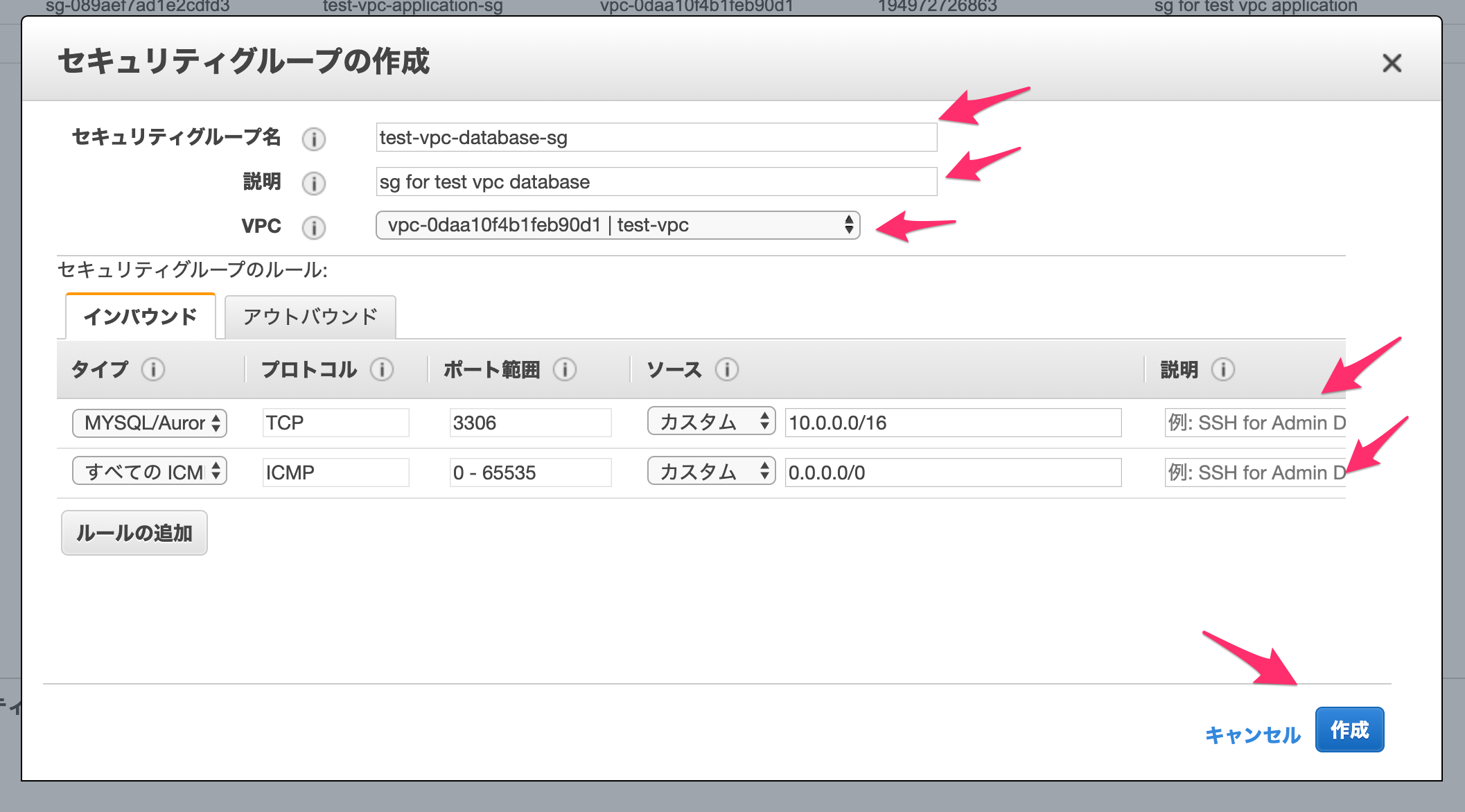
以下を設定します。
セキュリティグループ名
適当に設定します。
説明
適当に設定します。
VPC
作成したVPCを設定します。
セキュリティグループのルール:インバウンド
「MYSQL/Aurora」タイプ(3306番ポート)について、VPCのIPアドレスの範囲からのアクセスを許可します。
また、「ICMP」タイプは全許可します。入力が完了したら「作成」をクリックしてください。
続いてコンソール画面から、RDSの画面に移ってください。
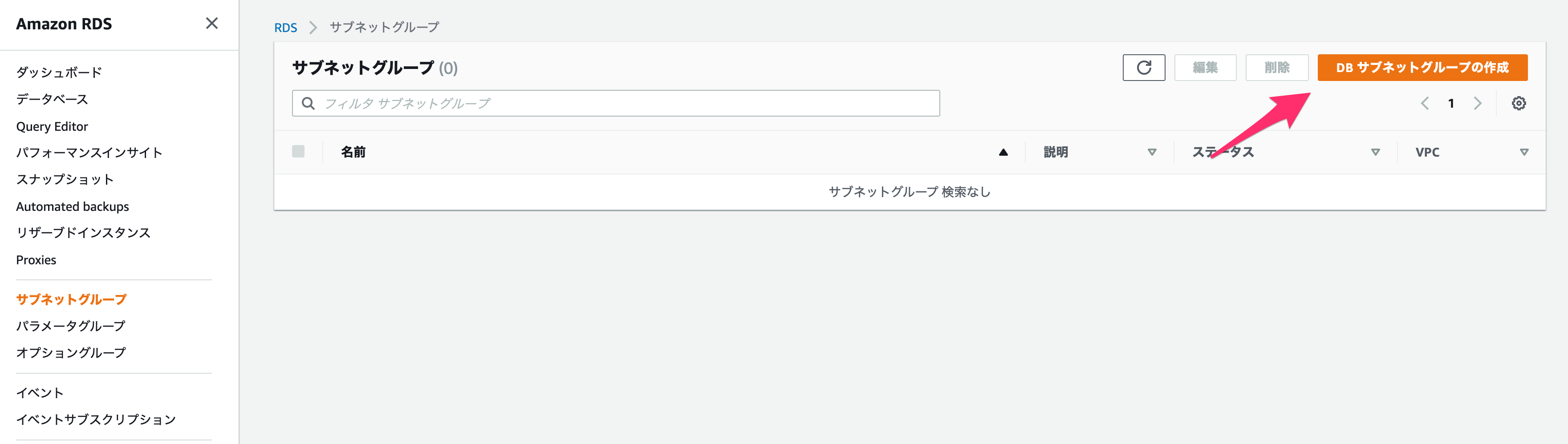
まずは「サブネットグループ」を作成します。
サブネットグループとは、RDSが存在しうるサブネットをまとめたものです。
以下を設定してください。
名前
適当に設定します。
説明
適当に設定します。
VPC
作成したVPCを設定します。
サブネットの追加
プライベートサブネットをすべて「サブネットを追加します」で追加してください。
完了したら「作成」を押します。
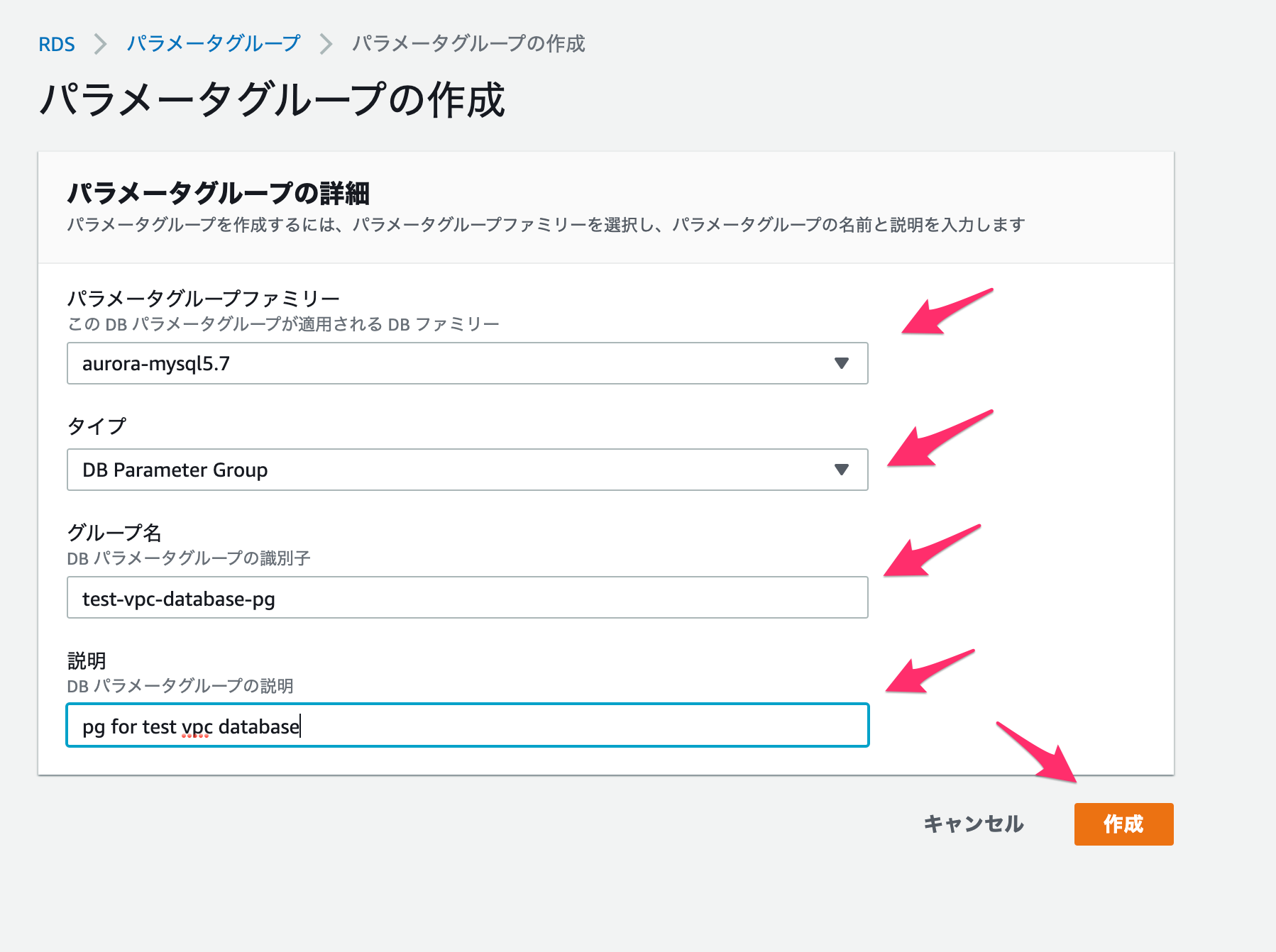
続いてパラメーターグループを作成します。
以下を設定してください。
パラメータグループファミリー
今回は
Amazon Aurora MySQL(AWSで開発されたクラウドに最適化されたDBで、MySQLと互換性があるもの)を使用する予定なので、aurora-mysql5.7とします。タイプ
DB Parameter Groupとします。グループ名
適当に設定します。
説明
適当に設定します。
完了したら「作成」を押します。
ここまでできたら、ダッシュボード画面から「データベースの作成」を選択してください。
以下のように設定します。
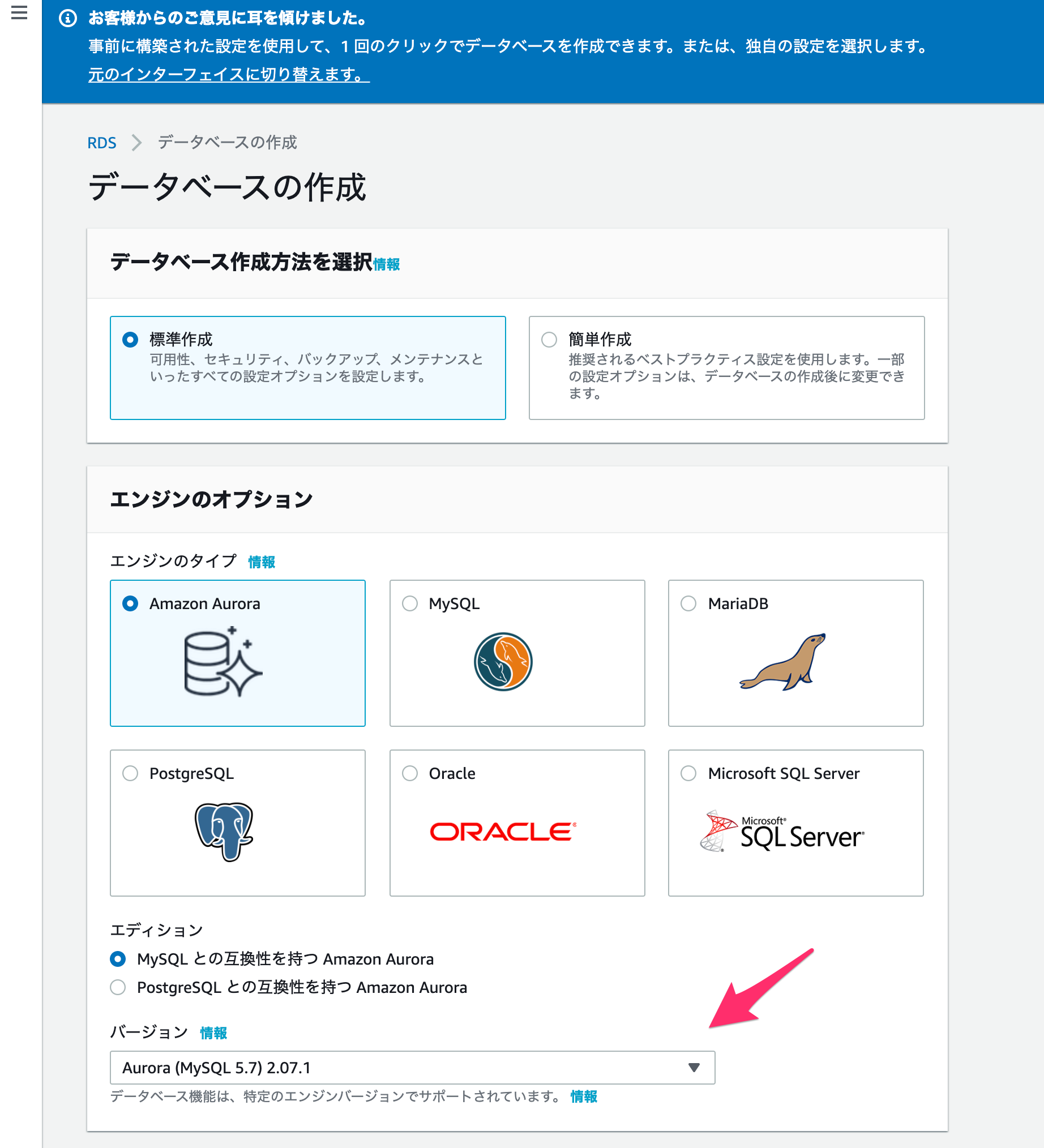
エンジンのタイプ
何でも大丈夫ですが、ここでは
Amazon Auroraの、MySQLと互換性のあるものを選びます。バージョン
好きなもので良いですが、ここでは最新のものにします。
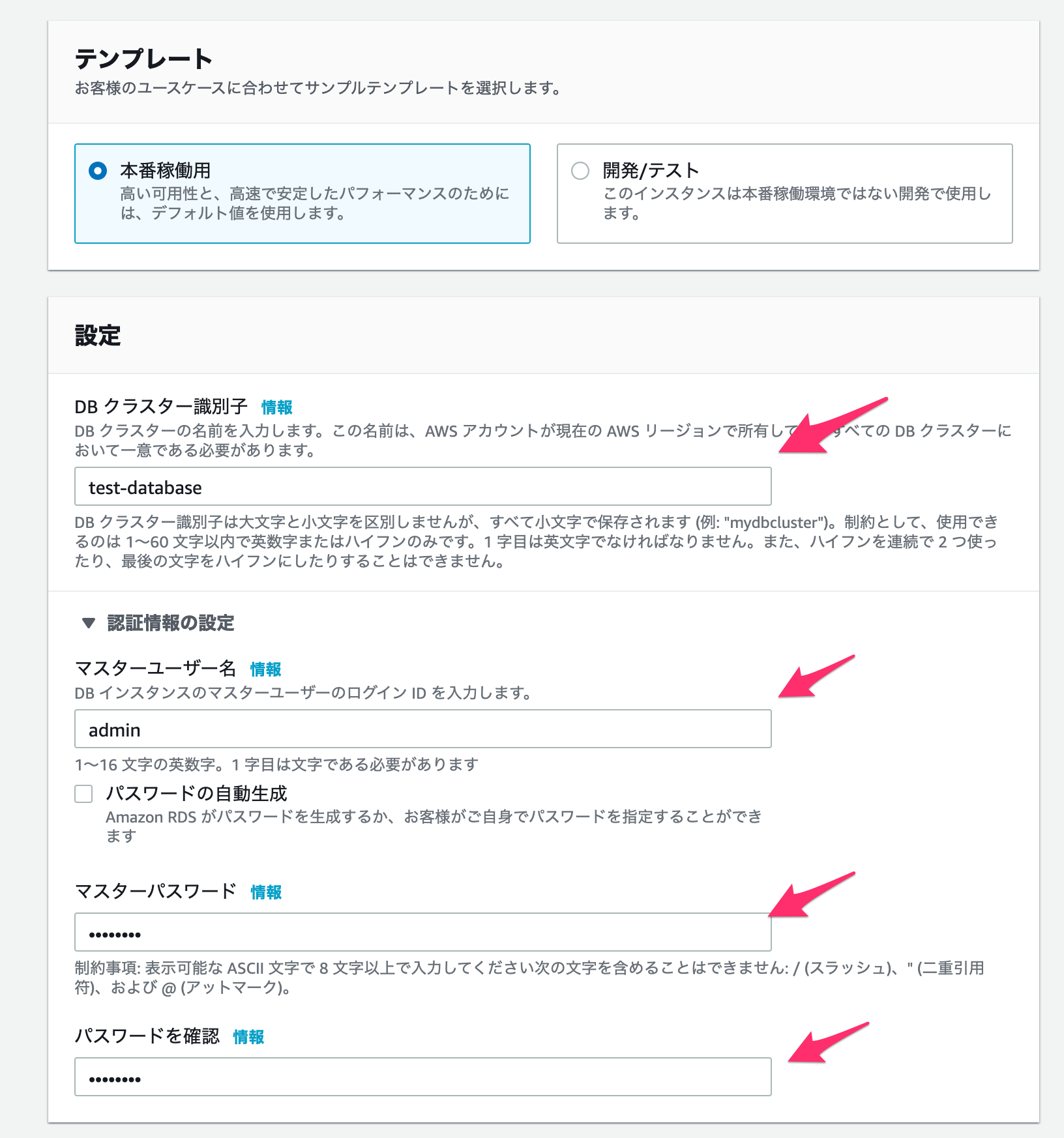
DBクラスター識別子
名前なので、適当につけてください。
マスターユーザー名
デフォルトのユーザー名です
マスターパスワード
ユーザーのパスワードとなります。
最初にログインするために必要なので、設定後は忘れないようにしましょう。
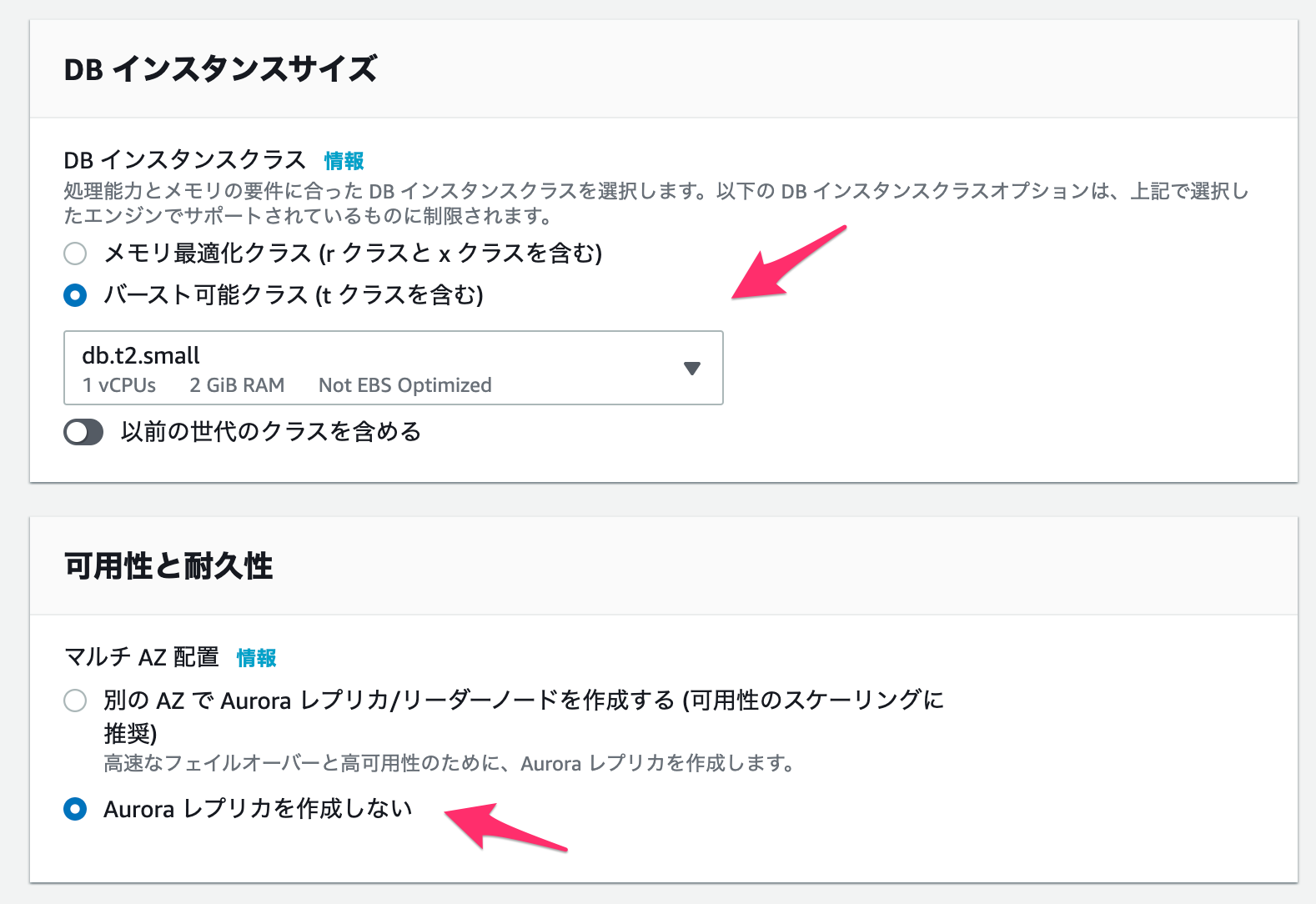
インスタンスサイズ
とりあえず料金が最も安いdb.t2.smallを選びます。
可能性と耐久性
今回は「Auroraレプリカを作成しない」を選択します。
なお「別のAZでAuroraレプリカ/リーダーノードを作成する」にした方が安全性は増しますが、複数台のDBを作成する必要があります。
Virtual Private Cloud (VPC)
作成したVPCを選択します。
その後「追加の接続設定」をクリックします。
サブネットグループ
先程作成したサブネットグループを選択します。
VPCセキュリティグループ
先ほど作成した、RDS用のセキュリティグループを選択します。
アベイラビリティゾーン
EC2を作成したのと同じAZを選択します。
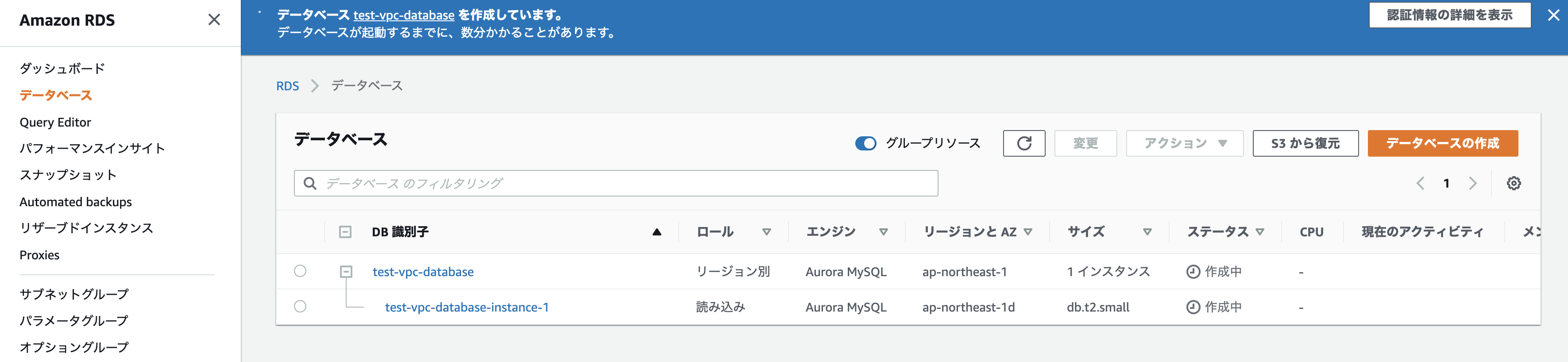
完了したら、一番下の「データベースの作成」をクリックします。しばらくするとDBが作成されます!
では、アプリケーションサーバーから接続してみましょう。
まずはアプリケーションサーバーにログインします。ssh test-applicationデフォルトではサーバーでmysqlコマンドが使えないので、インストールします。
sudo yum localinstall https://dev.mysql.com/get/mysql80-community-release-el7-1.noarch.rpm -y sudo yum-config-manager --disable mysql80-community sudo yum-config-manager --enable mysql57-community sudo yum install mysql-community-client.x86_64これでログインできるようになりました!
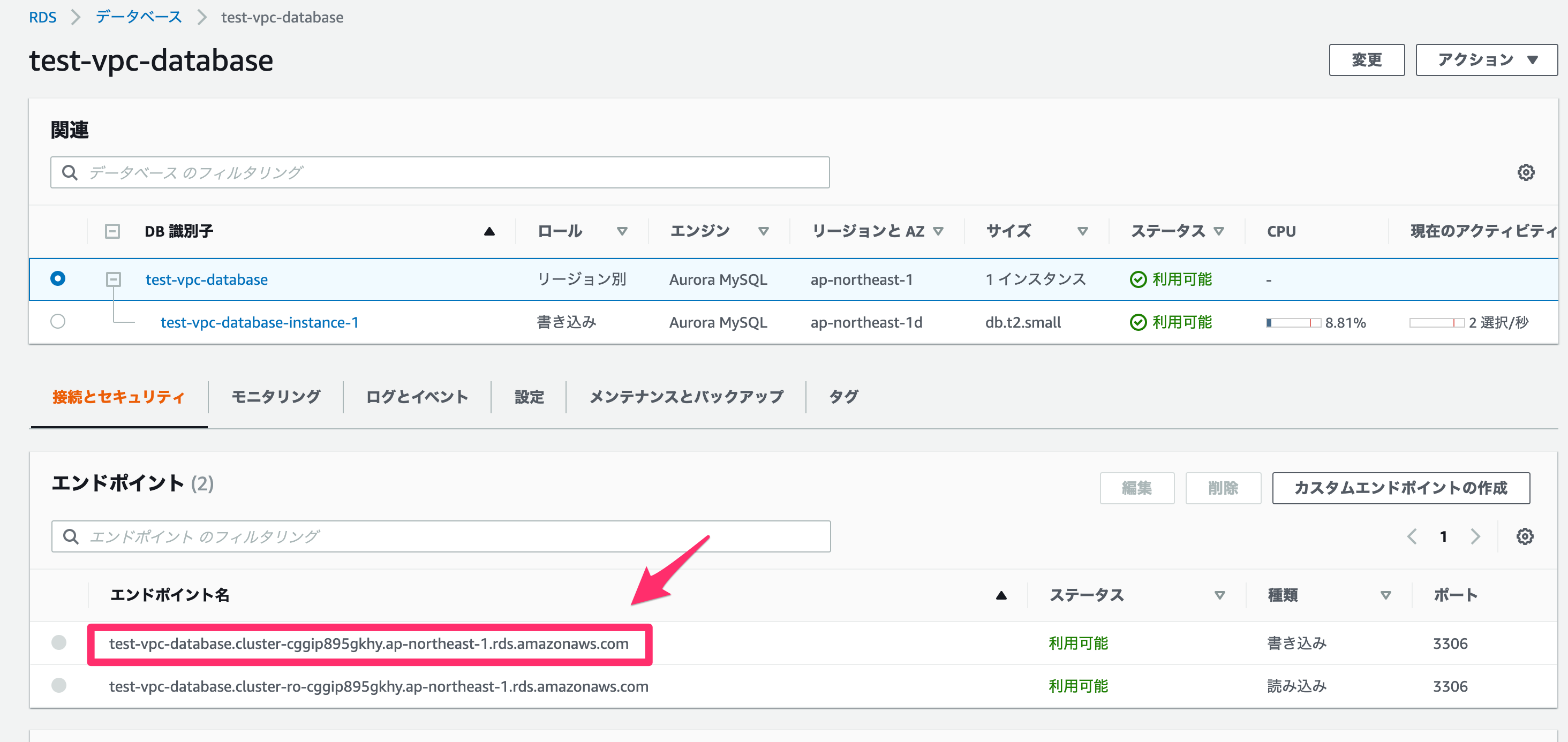
mysql -u {ユーザー名} -p -h {RDSのエンドポイント}ちなみに、RDSのエンドポイントは以下から確認できます。
無事入れました!
5. ALB
次にALBを作成します。
コンソール画面から、またEC2の画面に飛びます。
「ロードバランサー」へ進みます。
「ロードバランサーの作成」をしましょう。
今回はApplication Load Balancer(ALB)を「作成」します。
以下を設定していきます。
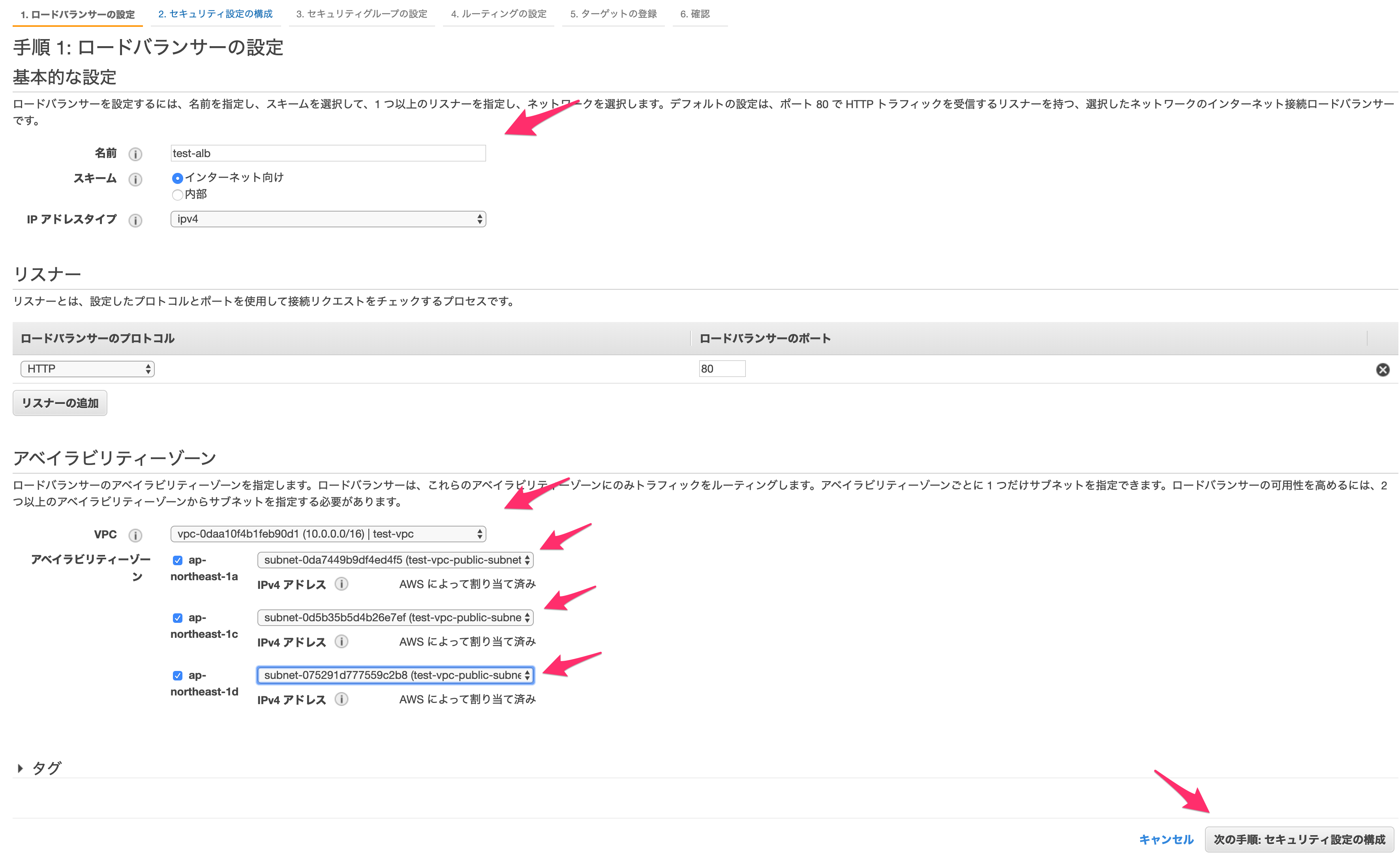
名前
適当に設定します。
VPC
作成したVPCを選択します。
アベイラビリティゾーン
すべてのAZに対してサブネットを作ったはずなので、すべてチェックを入れます。
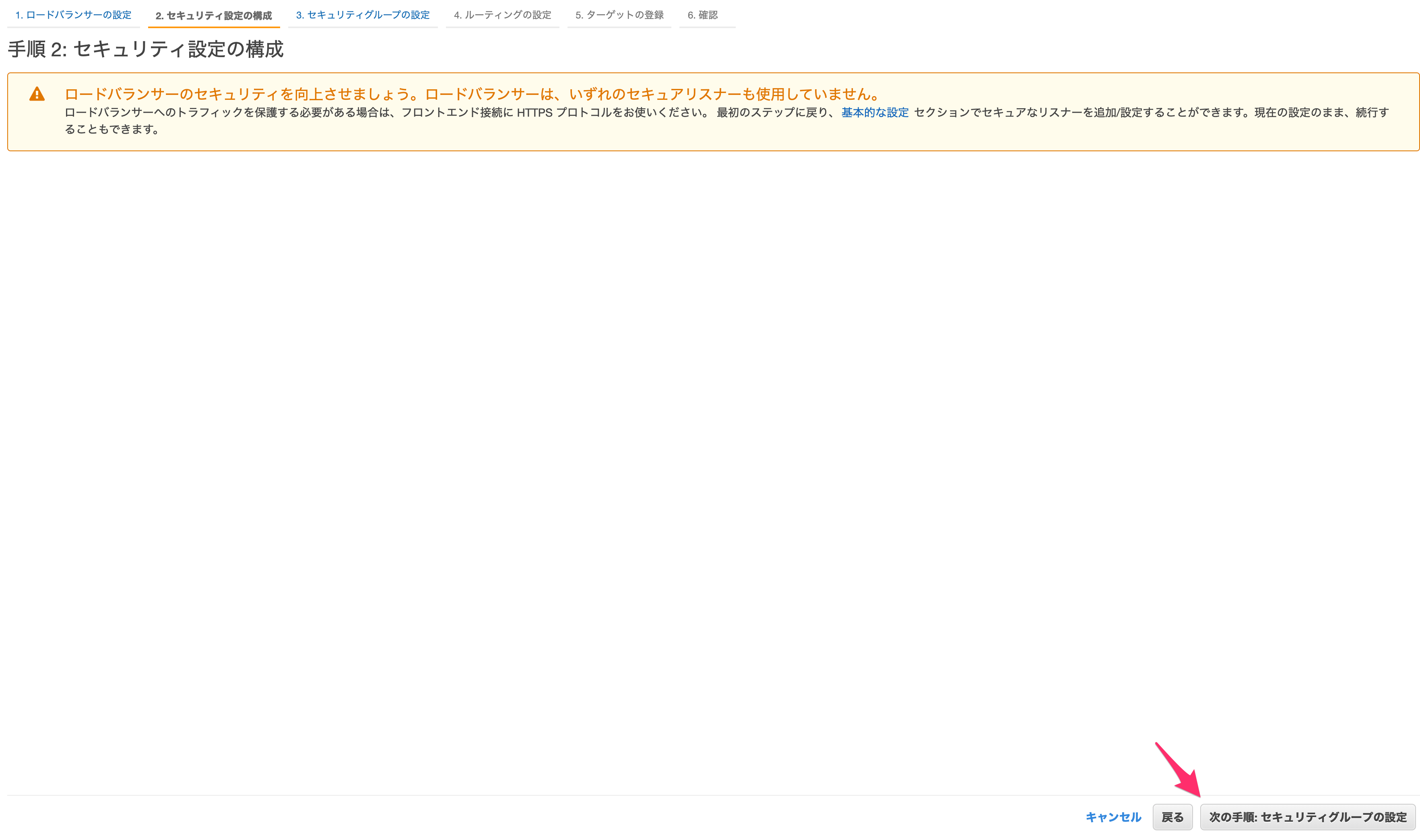
ALBはインターネットから直接アクセスできる必要があるので、パブリックサブネットとします。完了したら「セキュリティ設定」へ進みます。
今回は先程の画面でHTTPSを選ばなかったのでここでは何もできませんが、もし選択した場合はこちらでいくつか設定をします。
Route 53などでドメインを作成して所有しているとACMというサービスで証明書を獲得でき、それを利用すればここでWebサイトをHTTPS化できます。
そのまま「次の手順:セキュリティグループの設定」に進みます。
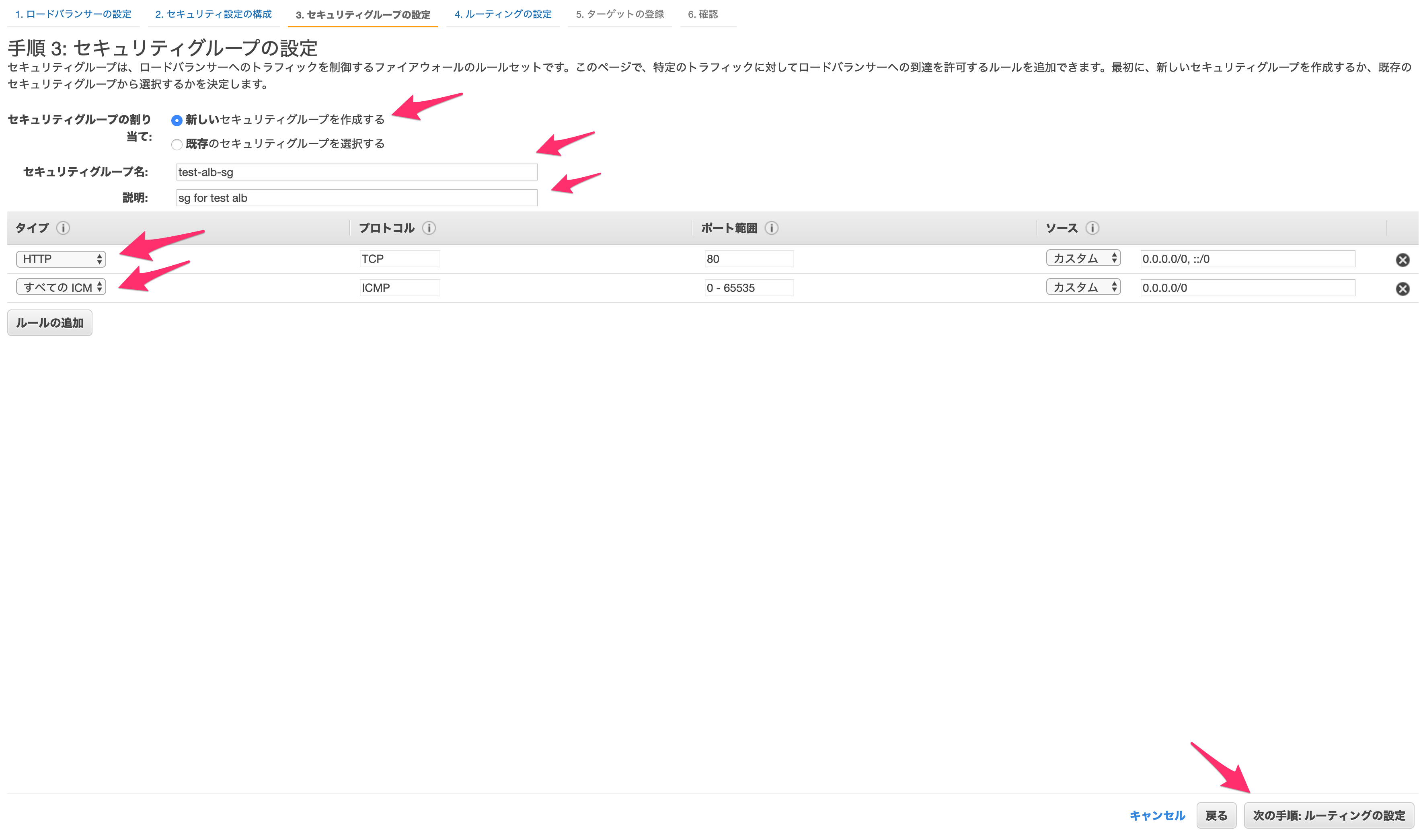
セキュリティグループの設定では、以下の設定をします。
セキュリティグループの割当
新しいセキュリティグループを作成します。
セキュリティグループ名
適当に設定します。
説明
適当に設定します。
ルール
HTTPとICMPの設定をします。
なお今回はALBがユーザーのアクセスを受け付けるところになるため、全IPアドレスから80番ポートへのアクセスを受け付けるようにします。すべての設定が完了したら「次の手順:ルーティングの設定」へ進みます。
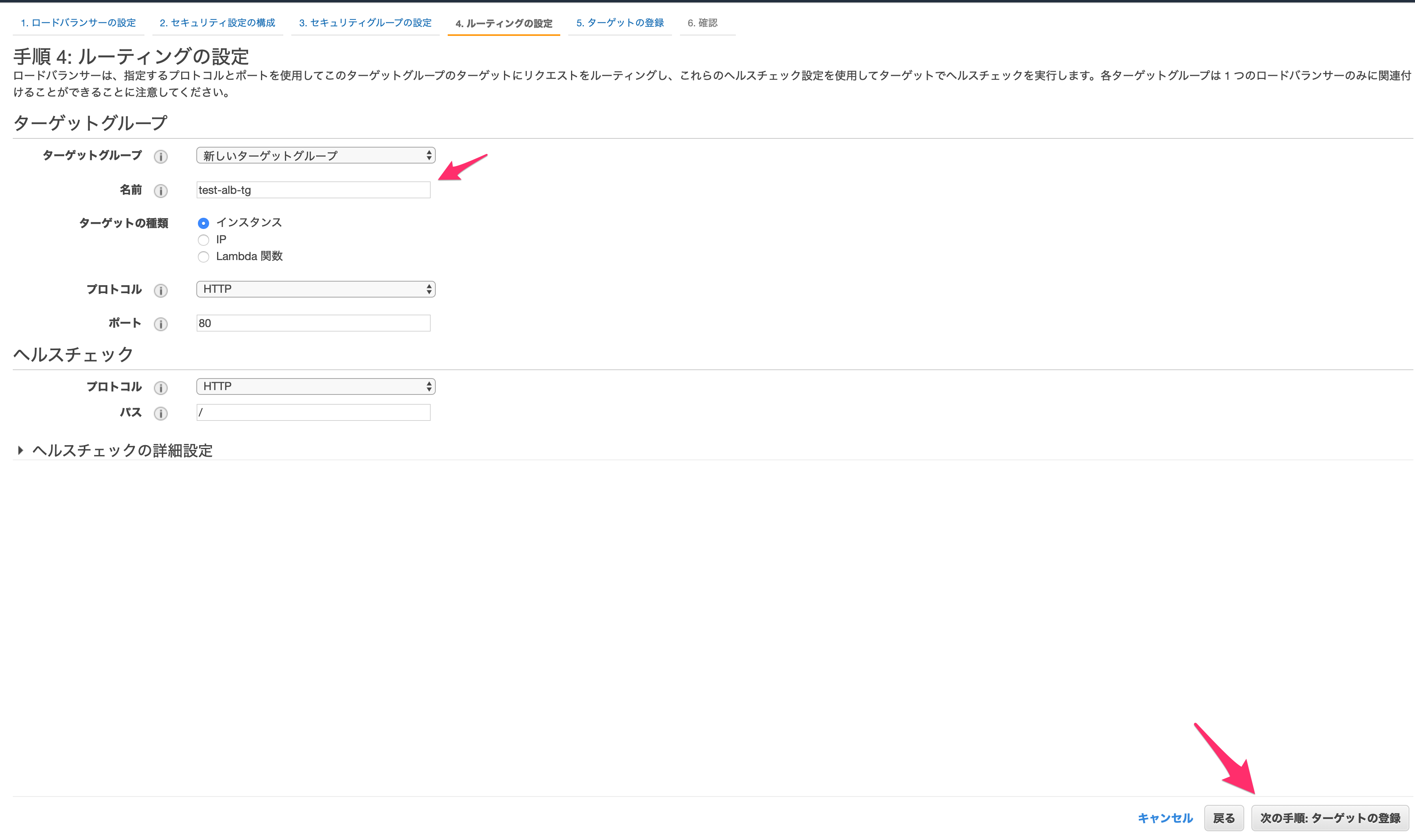
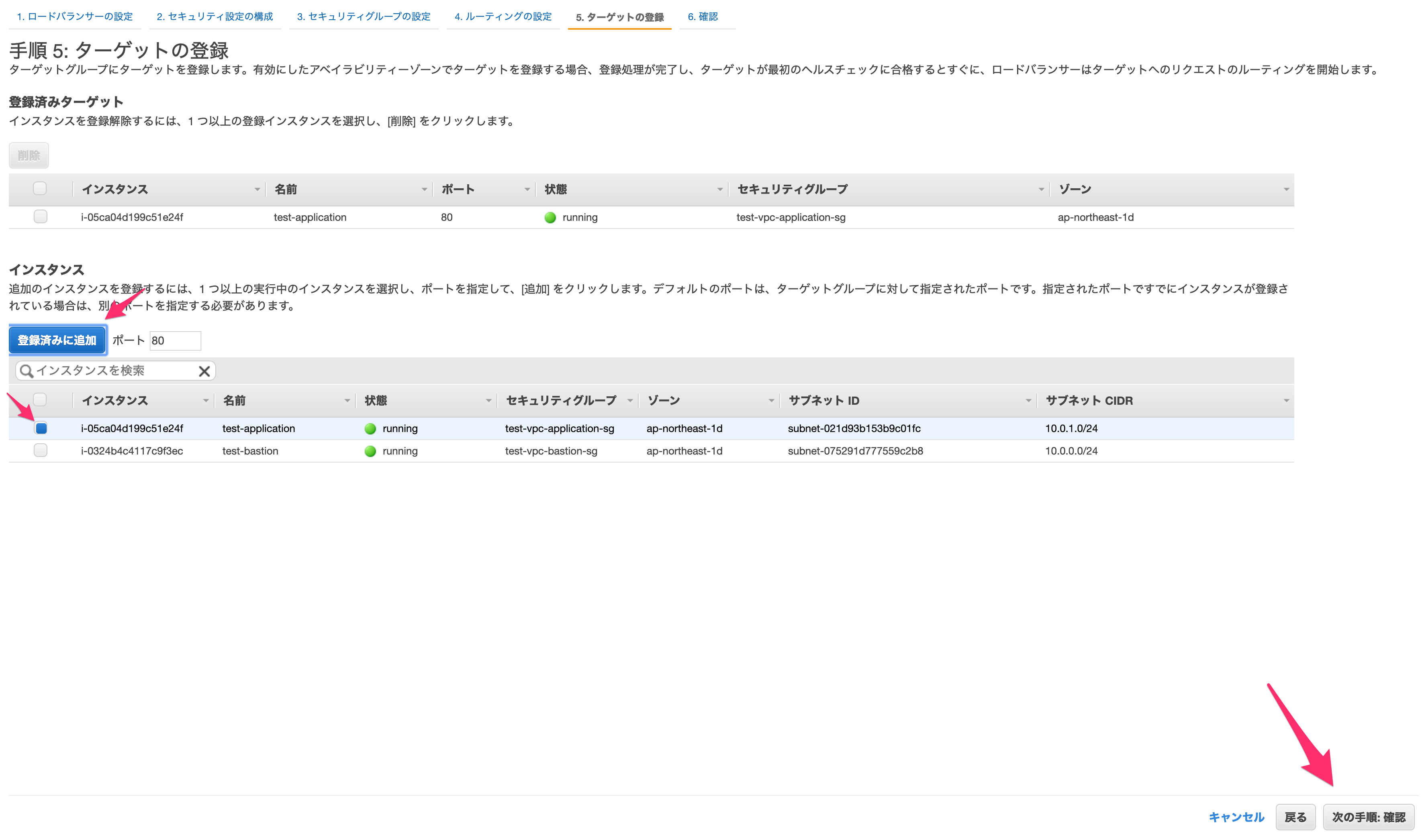
ルーティングの設定では、新しいターゲットグループを作成します。
名前は適当に設定してください。
その他はそのままで「次の手順:ターゲットの登録」に進みます。
ターゲットの選択では、先程作成したアプリケーションサーバーを選択し、「登録済みに追加」を押します。
これにより、このALBへのアクセスが指定したEC2へ流れるようになります。
なおここに複数台のサーバーを設定すれば、自動で分散してアクセスを流してくれます。
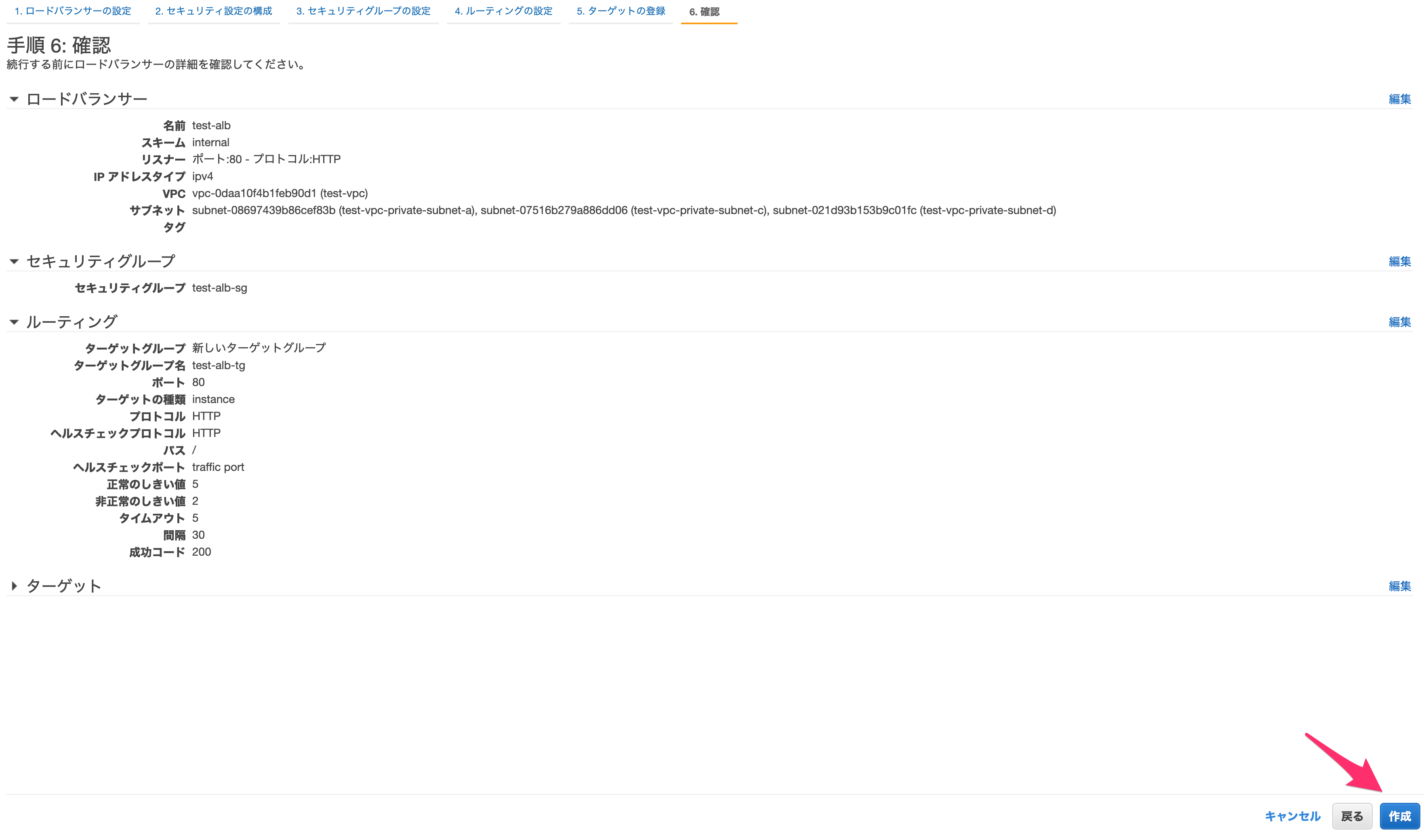
設定が完了したら「次の手順:確認」へ進みます。
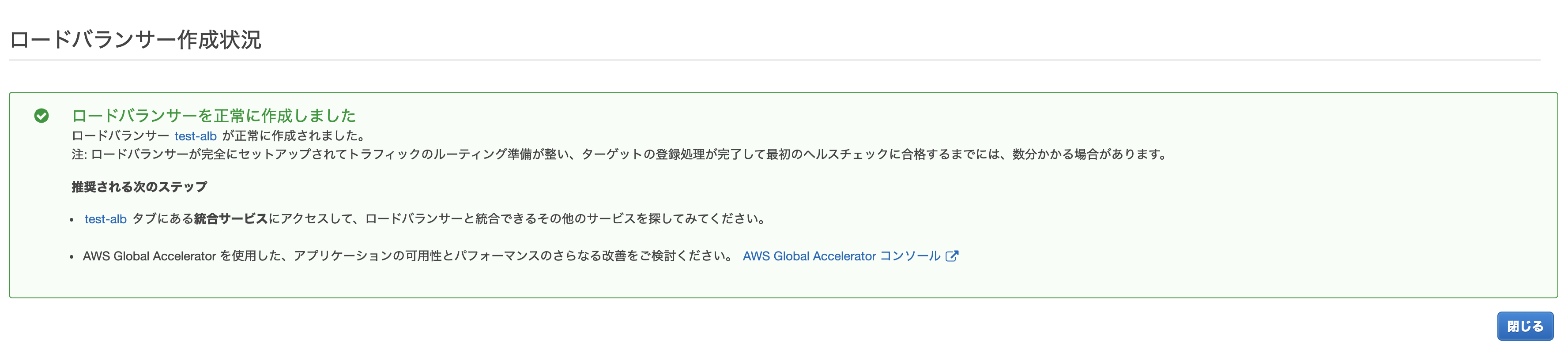
問題なければ作成します。
ALBができました!
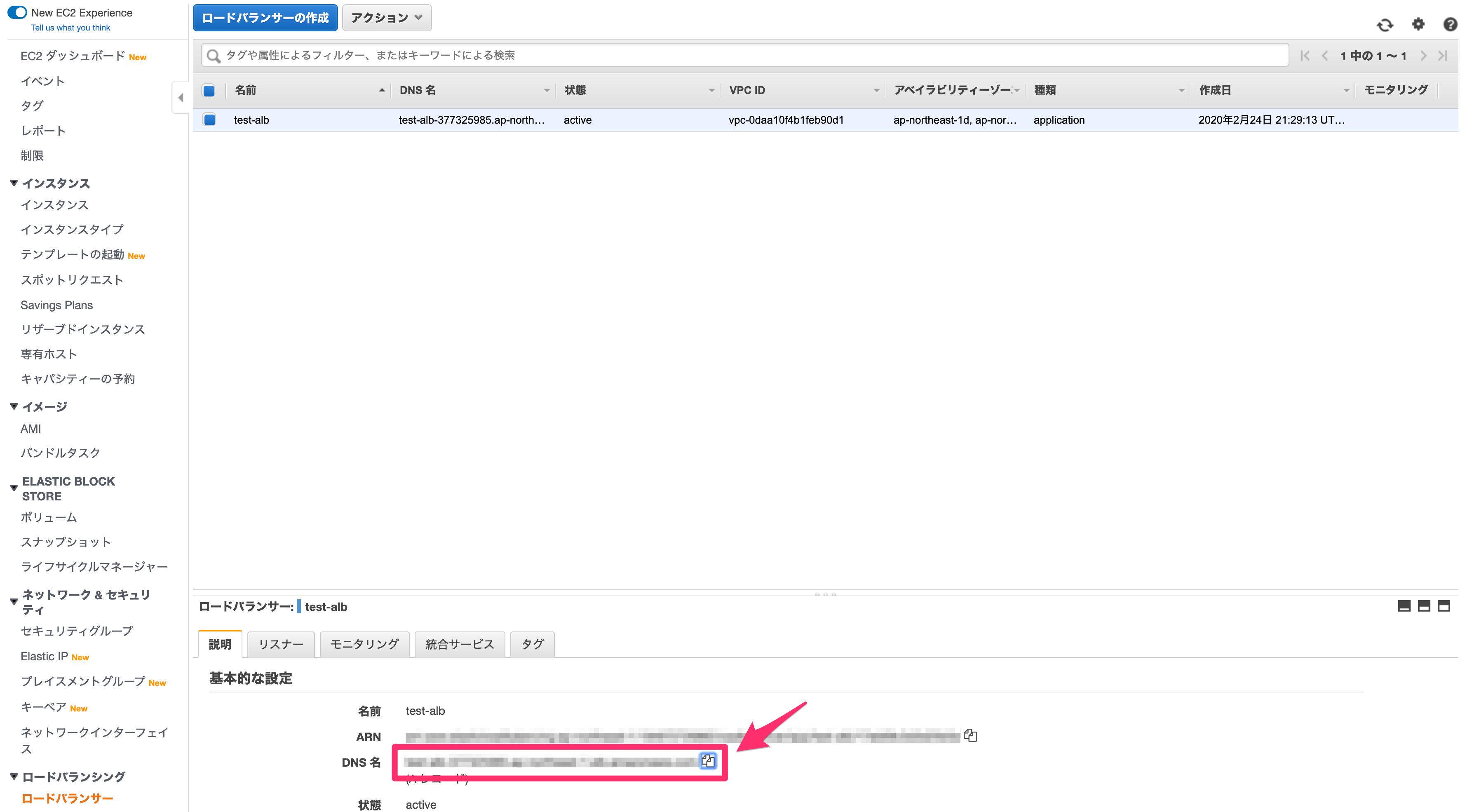
実際にできているか確認してみましょう。
以下のDNS名を
hostコマンドで確認して、IPアドレスが確認できれば問題ありません!
6. Route 53
最後にRoute 53を使ってホストゾーンを指定します。
まずはコンソール画面からRoute 53の画面へ行きます。
ドメイン取得をしたい場合は「ドメインの登録」をしますが、今回は「DNS管理」をします。
「今すぐ始める」を押してください。
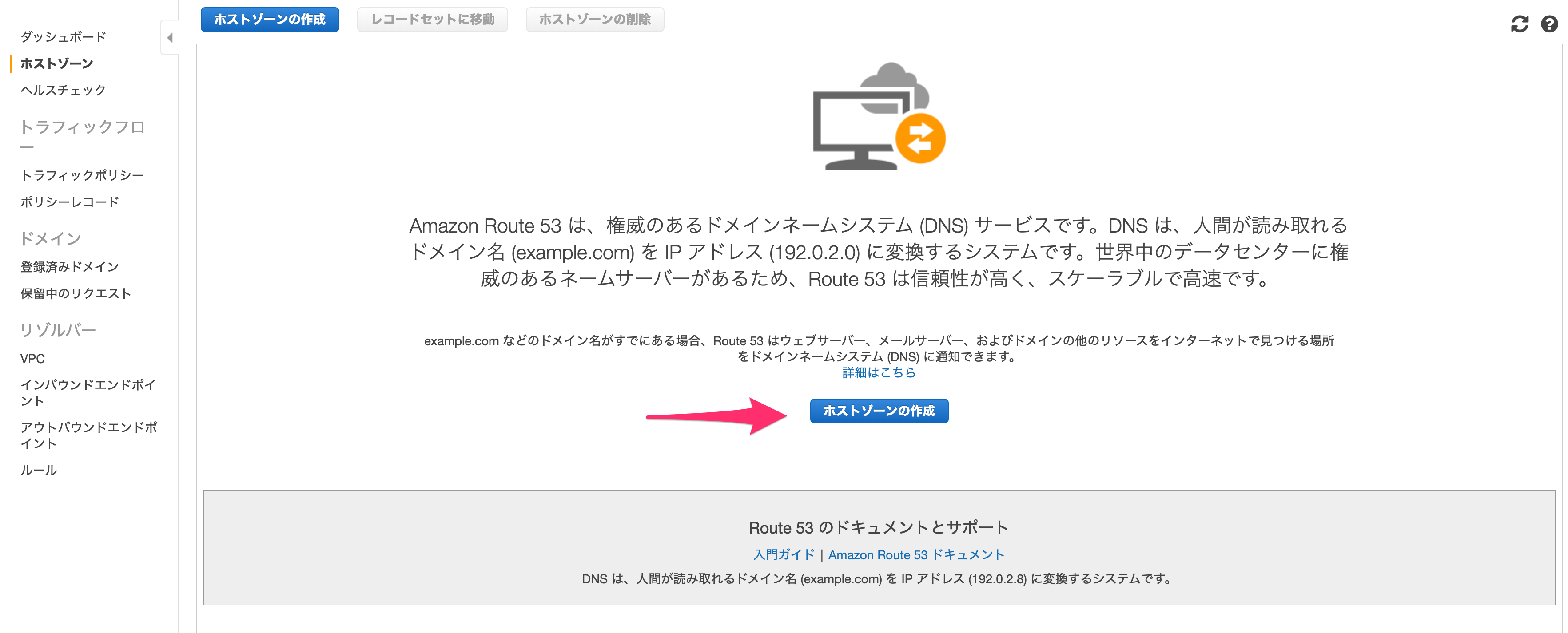
「ホストゾーンの作成」を行います。
遷移先で更に「ホストゾーンの作成」をクリックします。
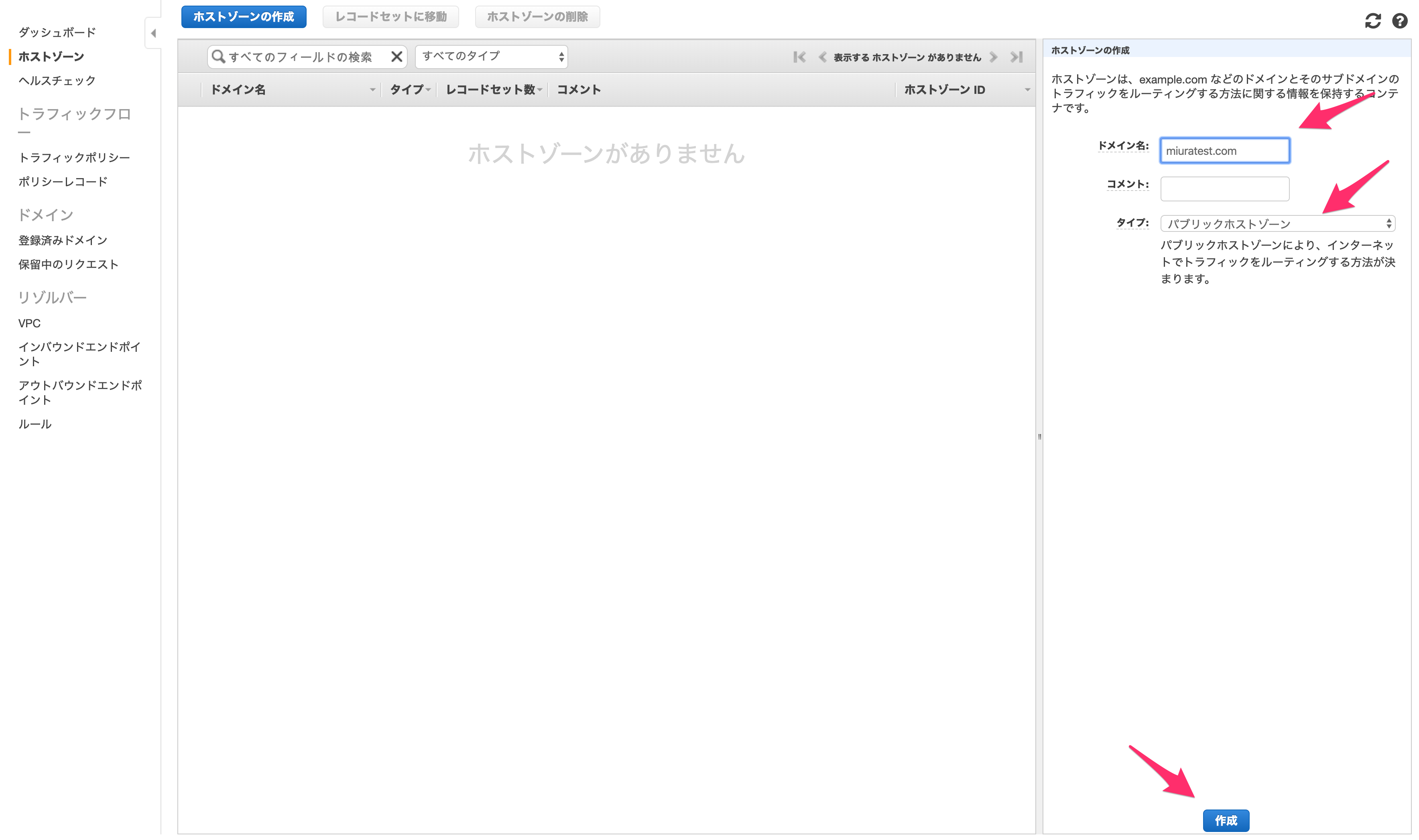
「ドメイン名」には自分のサイトのドメイン名を、タイプには「パブリックホストゾーン」を選択します。
今回はドメイン名を取得していないので意味はありませんが、もしACMなどで取得していればここから指定したドメイン名に対するアクセスを制御できます。
入力したら「作成」します。
これでドメイン名に対するアクセスを制御する準備ができました。
次に、(もしドメイン名を取得していたら)ドメインにアクセスが来た際にアクセスを流す先を指定します。
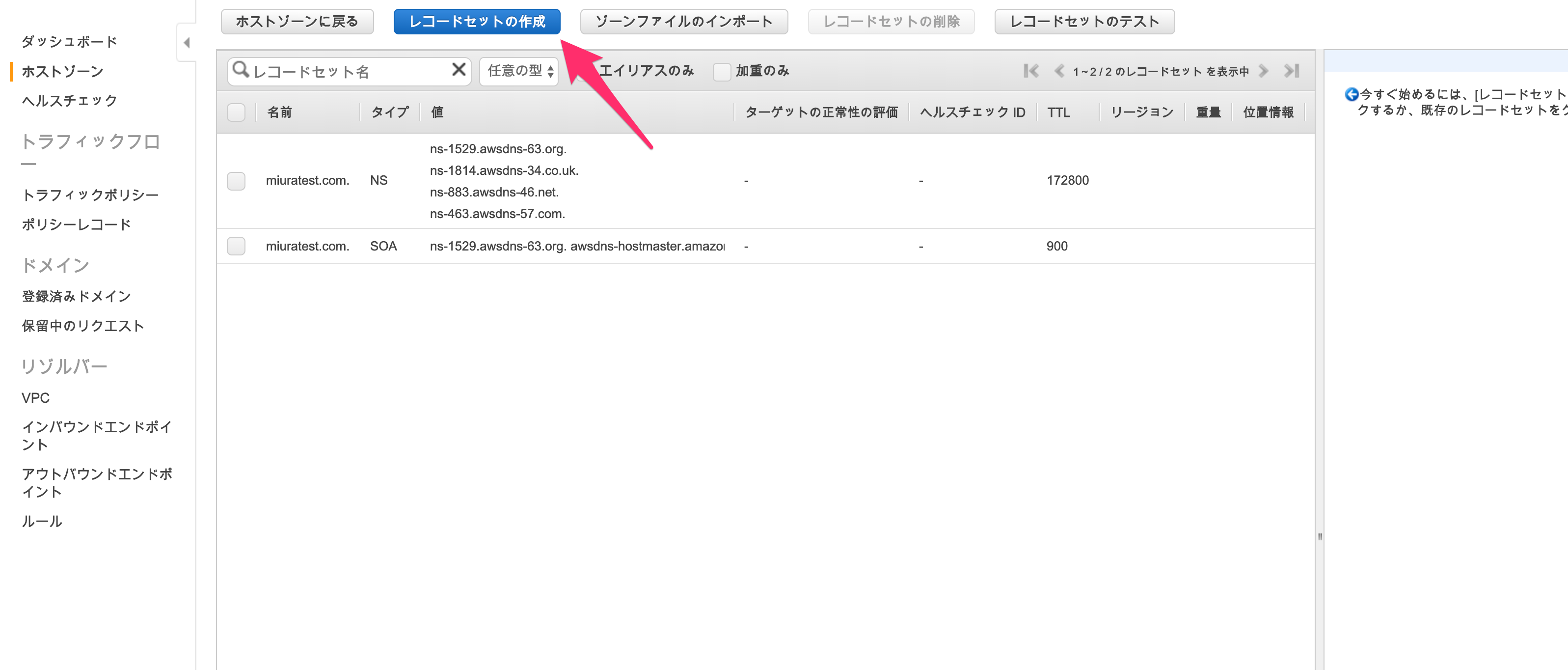
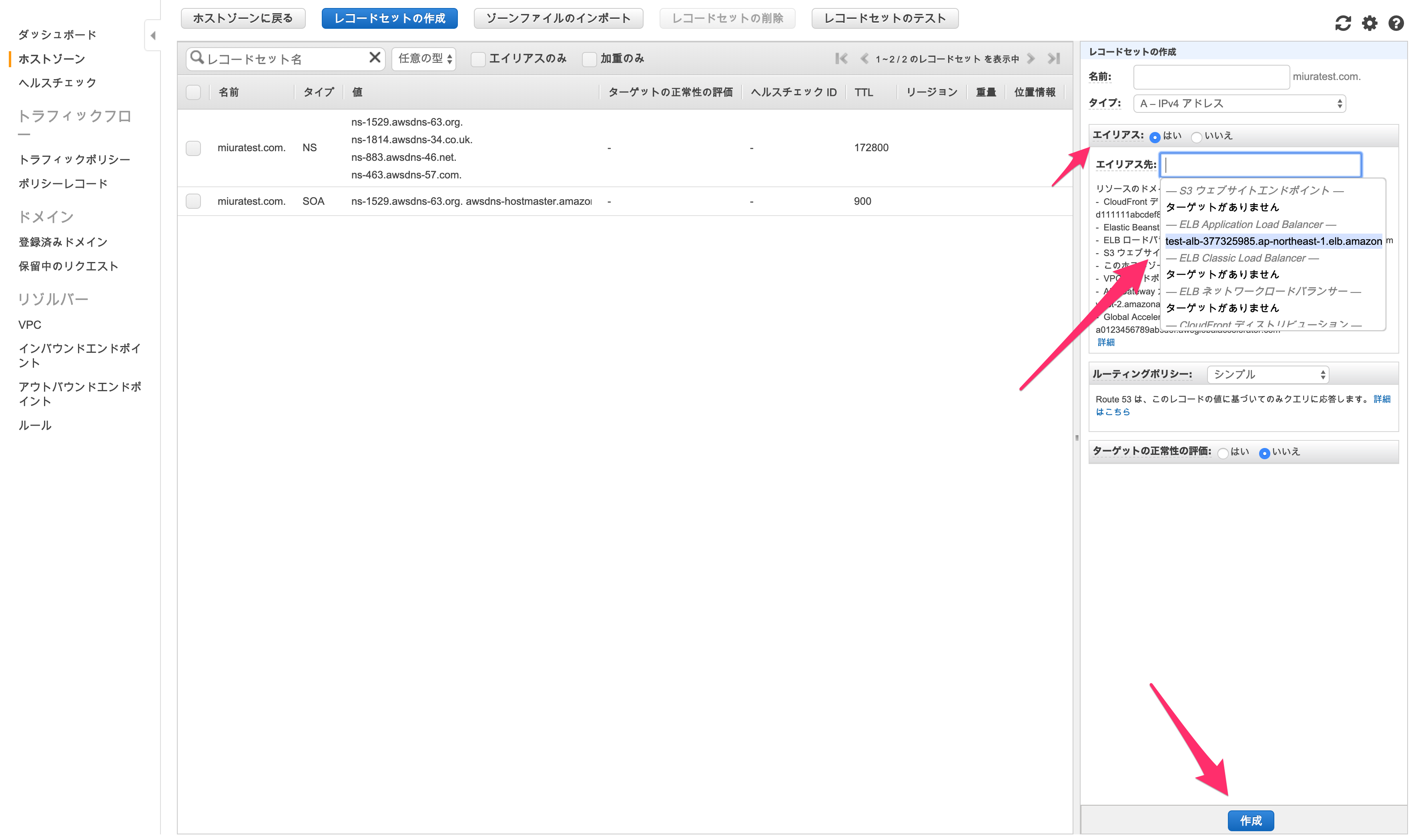
「レコードセットの作成」をクリックします。
「名前」や「タイプ」はそのまま、「エイリアス」を「はい」にし、「エイリアス先」を先程作成したALBとして「作成」します。
これにより、ドメイン名を取得していれば、ドメイン名に対するアクセスが作成したALBに流れます。
これで今回の構成は完了です!
おわりに
業務ではほとんどTerraformというインフラ構成ツールを用いてAWSの構成を行っていたので、改めてコンソール上で構築していくのは逆に新鮮で、かつより深く理解することができました。
今回はIAMなどは使わなかったのでこれがベストプラクティスではないと思いますが、セキュリティグループなども用いてそれなりにセキュアには作れたかなと考えています。
AWSは今後も使っていく機会が多いと思いますので、色々と学んでいきたいです。参考文献
以下のサイトを参考にさせていただきました。
ありがとうございました!AWSでWebサーバー構築!VPC設計に必要なIPアドレスとサブネットの基礎知識(第1回)
こちらの第1回 ~ 第5回




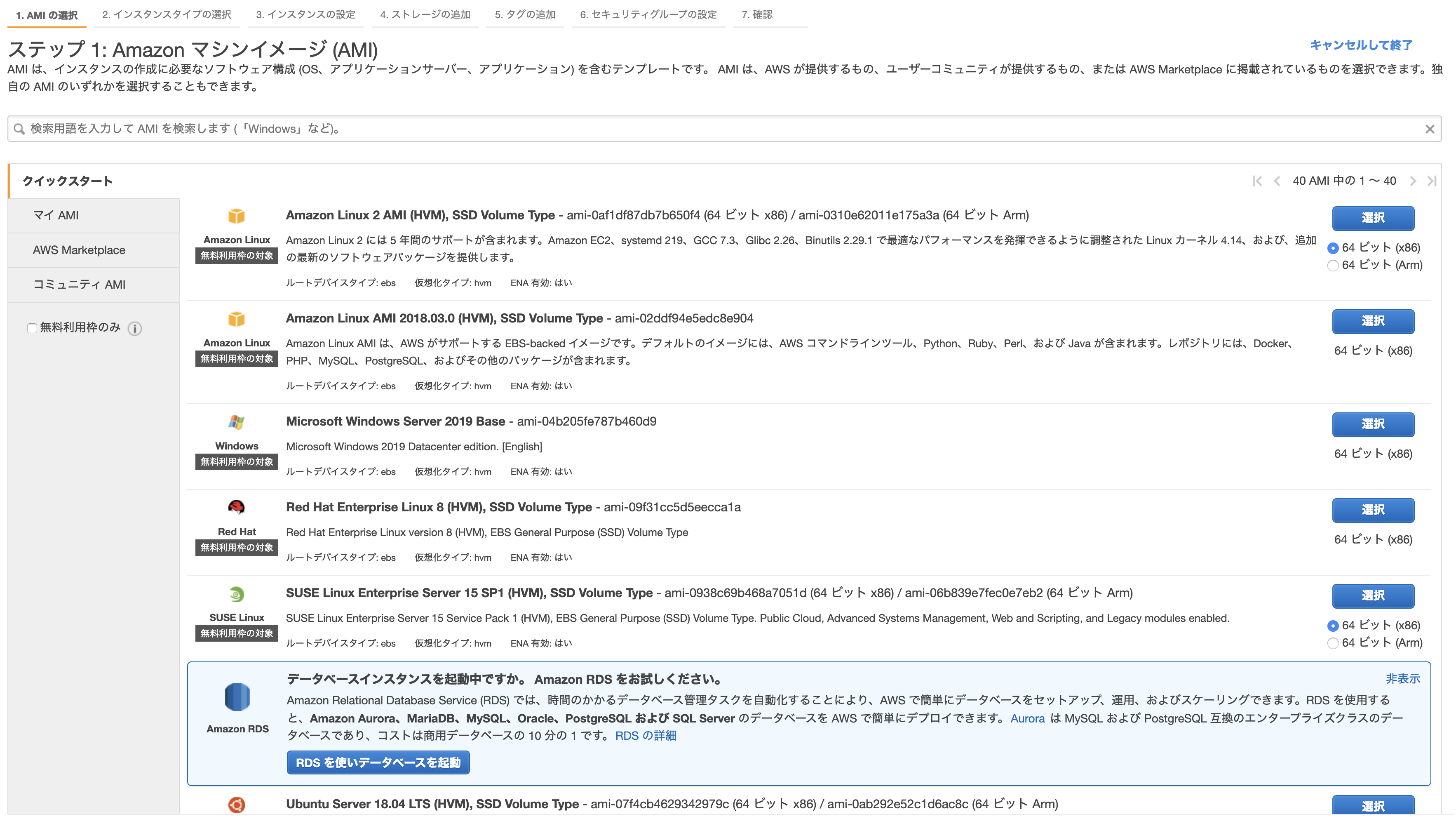
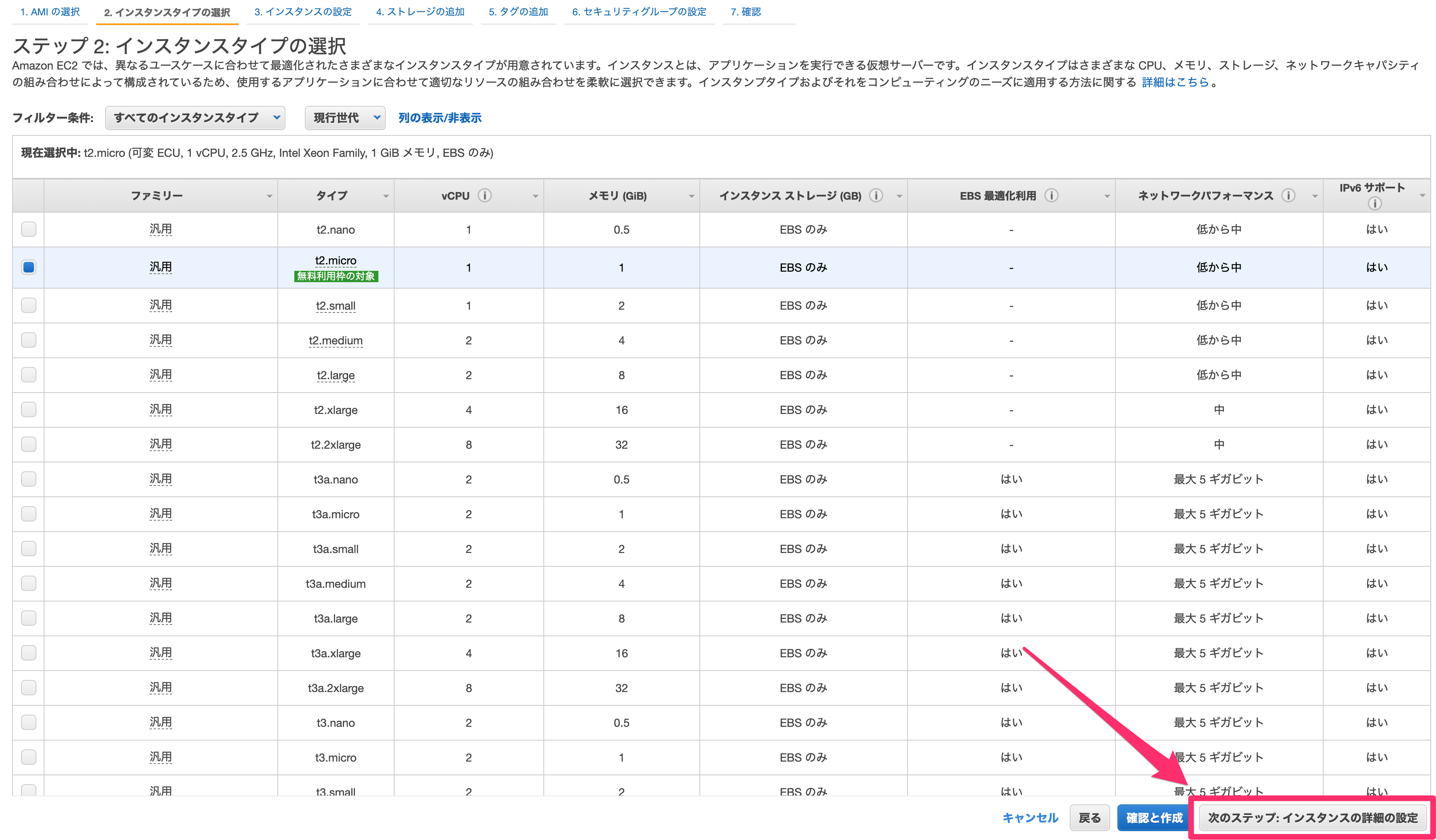
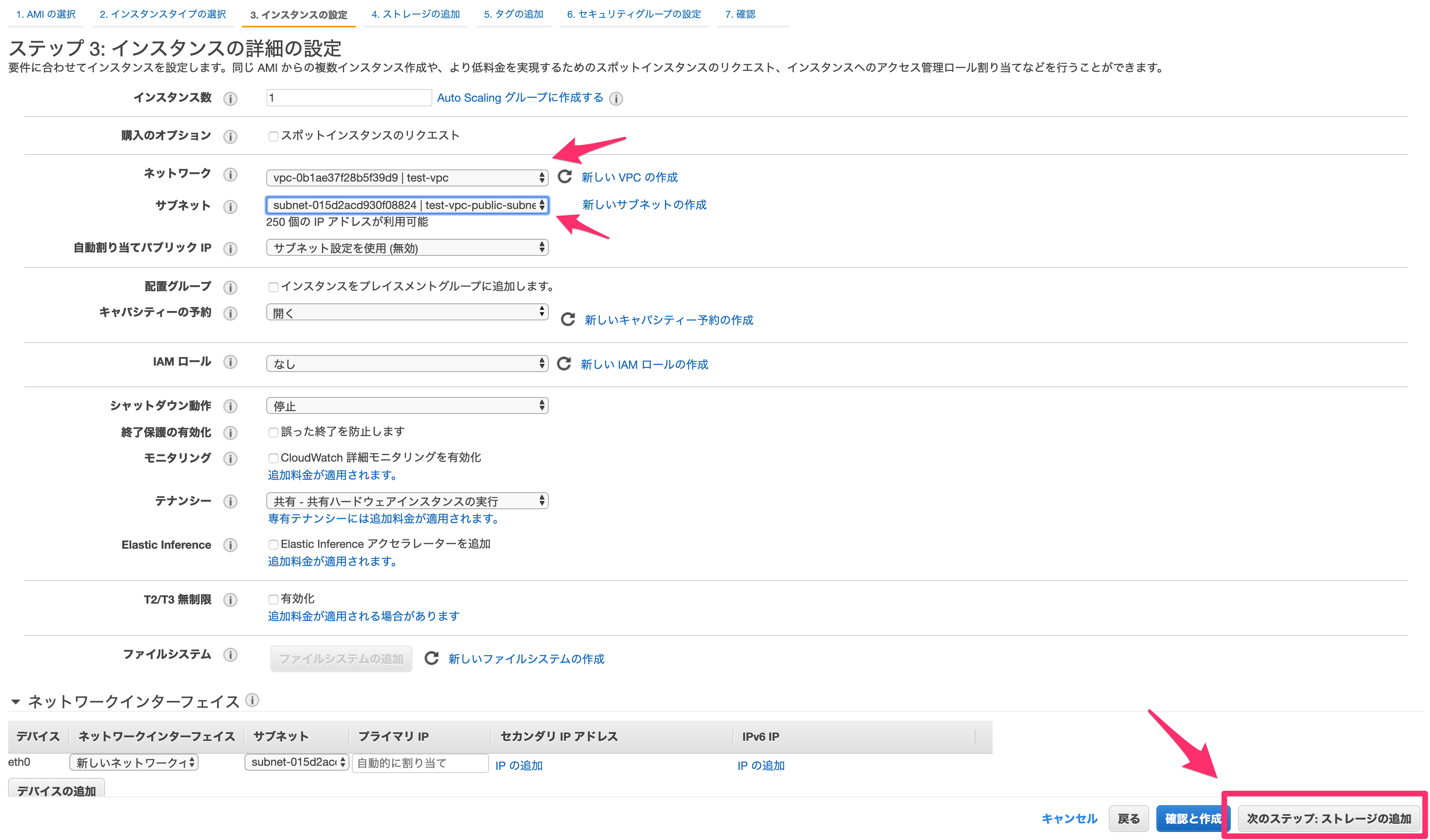
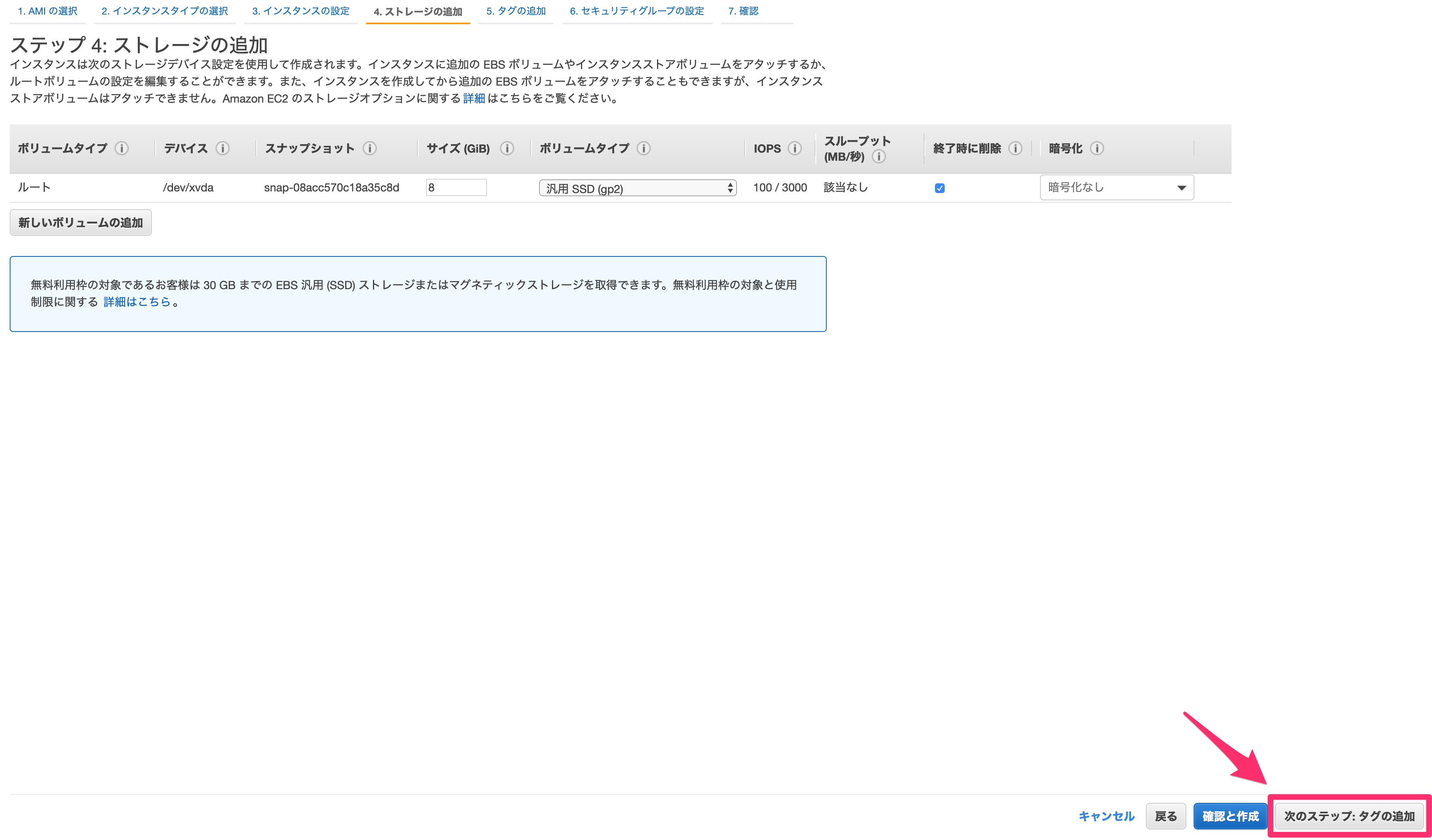


- 投稿日:2020-02-25T14:07:50+09:00
DynamoDBのプロビジョニングモードでのRCUとWCUの算出
プロビジョニングされたキャパシティー
Dynamo DBはテーブルにスループットキャパシティーを割り当てることで性能を指定することができます。「キャパシティーユニット」という単位で指定します。アプリからDBへの読み取り回数と書き込み回数が予め想定できる場合は、プロビジョンモデルでDynamo DBを作成するとコスト管理がしやすくなるメリットがあります。
キャパシティの算出シナリオ1
シナリオ:5,000,000回/日の書き込み、5,000,000回/日の結果整合性の読み取り、1項目のサイズは1KBの場合
書き込みキャパシティ(WCU):
まずは日の書き込み回数を秒に換算します。5000000回/日 = 5000000/(24*60*60) = 58回/秒
書き込みは1キャパシティーユニットで、最大1KBに対して、書き込みの実行が1秒当たり1回ですので、最終的にWCUは58必要になります。結果整合性の読み取りキャパシティ(RCU):
同様に、読み取りも58回/秒になります
結果整合性の読み込み1キャパシティーユニットで、読み込みの実行が1秒当たり2回ですので、RCUは29必要になります。
更に、RCUは1回で最大4KBの読み取りであることから、シナリオ1のの項目(1KB)は1回で読み取れるので、最終的にRCUは29必要になります。キャパシティの算出シナリオ2
シナリオ:5,000,000回/日の書き込み、5,000,000回/日の強い結果整合性の読み取り、1項目のサイズは5.5KBの場合
書き込みキャパシティ(WCU):
秒に換算:5000000回/日 = 5000000/(24*60*60) = 58回/秒
書き込みは1キャパシティーユニットで、最大1KBが可能なので、1項目の書き込みに必要なWCUは6。最終的にWCUは6*58 = 348必要になります強い結果整合性の読み取りキャパシティ(RCU):
上と同様に、読み取りも58回/秒になります
強い結果整合性の読み込み1キャパシティーユニットで、読み込みの実行が1秒当たり1回ですので、RCUは58必要になります。
更に、RCUは1回で最大4KBの読み取りであることから、シナリオ2の5.5KBを読み取るのに2が必要となるため、最終的にRCUは58*2=116必要になります。キャパシティの算出シナリオ3
シナリオ: 1回/日の書き込み、1回/日の結果整合性の読み取り、1項目のサイズは1KBの場合
書き込みキャパシティ(WCU):
秒間の回数に換算して、1回/秒。
書き込みは1キャパシティーユニットで、最大1KBが可能なので、1項目の書き込みに必要なWCUは1。最終的にWCUは1必要になります結果整合性の読み取りキャパシティ(RCU):
秒間の回数書き込みと同様に読み取りも1回/秒になります
結果整合性の読み込み1キャパシティーユニットで、読み込みの実行が1秒当たり2回ですので、RCUは0.5必要になります。
更に、RCUは1回で最大4KBの読み取りであることから、シナリオ3の項目は1回で読み取りことができるので、RCUは0.5が必要になります。
ただし、WCUとRCUの設定は1 以上の正数にする必要があるので、この場合の最終的にRCUは1必要になりますメモ
AWSの無料枠は月間25RCU/秒と25WCU/秒が提供されています。シナリオ1の場合(58WCU と29RCUに設定した場合)33WCUと4RCU分が課金される(はず)。また半月しかDynamoDBを利用しない場合は実質50WCUと50RCUになるので、シナリオ1における課金は8WCUと0RCUに対して発生されます。
- 投稿日:2020-02-25T12:08:53+09:00
MFAを設定するときは別の手段で復旧できることを確認しよう
先日ふとしたきっかけでスマートフォンを初期化したのですが、仮想MFAデバイスの「Google認証」が入っているにもかかわらず何も準備せずに初期化してしまったため、(SMS以外の)MFAが設定してあるすべてのサービスにログインできなくなってしまいました
TL;DR
- MFA設定時には、紛失したときに復旧できる手段が正しく動くことを確認する
- 入力時にverifyのチェックが入らない連絡情報は注意する
- AWSの連絡先情報の電話番号は国コード付きのものにする
Googleアカウントは自力で復旧できた
Googleアカウントは復旧用に電話番号の設定をしバックアップコードを控えていたので安心です。
まず電話番号による認証を試したところ、かかってきた電話で読み上げられたPINコードを入力することによって復旧できました。
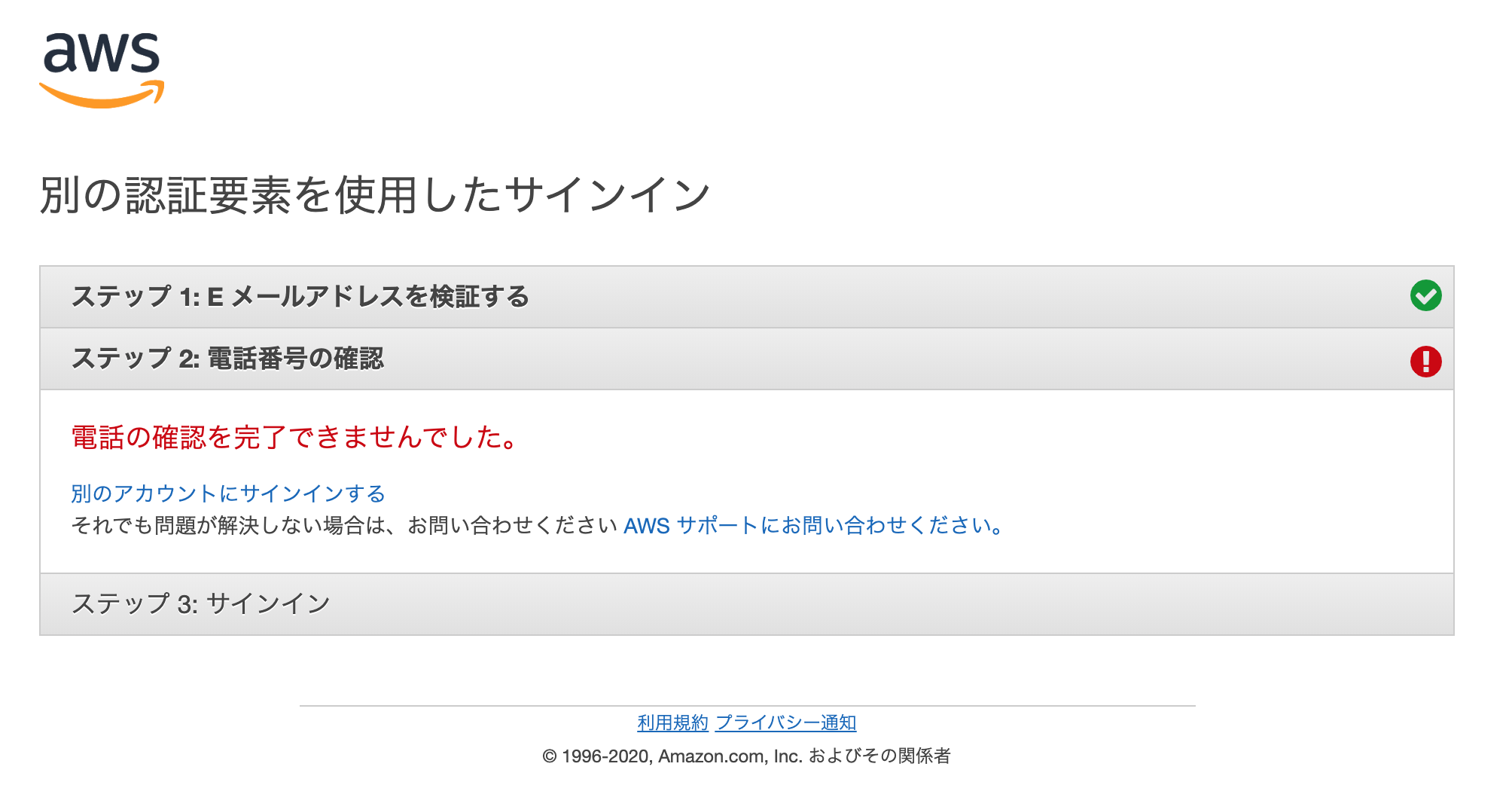
もし何かしらの事情で電話番号が使えなくなってもバックアップコードによる復旧ができます。AWSアカウントは自力で復旧できなかった
AWSはMFA紛失時にメールアドレスと電話番号の2ステップによる認証で復旧できるのですが、なぜか電話番号認証のステップがうまく動かず電話がかかってきません。
AWSアカウント復旧への道のり
「これはまさか噂に聞く公証人コースか?ほとんど使ってないアカウントだからお金をかけてまで復旧するのは嫌だな…」と思いながら、まずはMFA紛失専用お問合せフォームから紛失の旨を申請します。
このとき「Country associated with your phone number」という項目があり、なぜ電話番号認証のステップがうまく動かないのか何となく想像がつきました。電話でMFAを解除してもらう
ベーシックサポートプランだったので、申請は休日に行ったのですが電話は連休明けの平日の午前中にかかってきました。
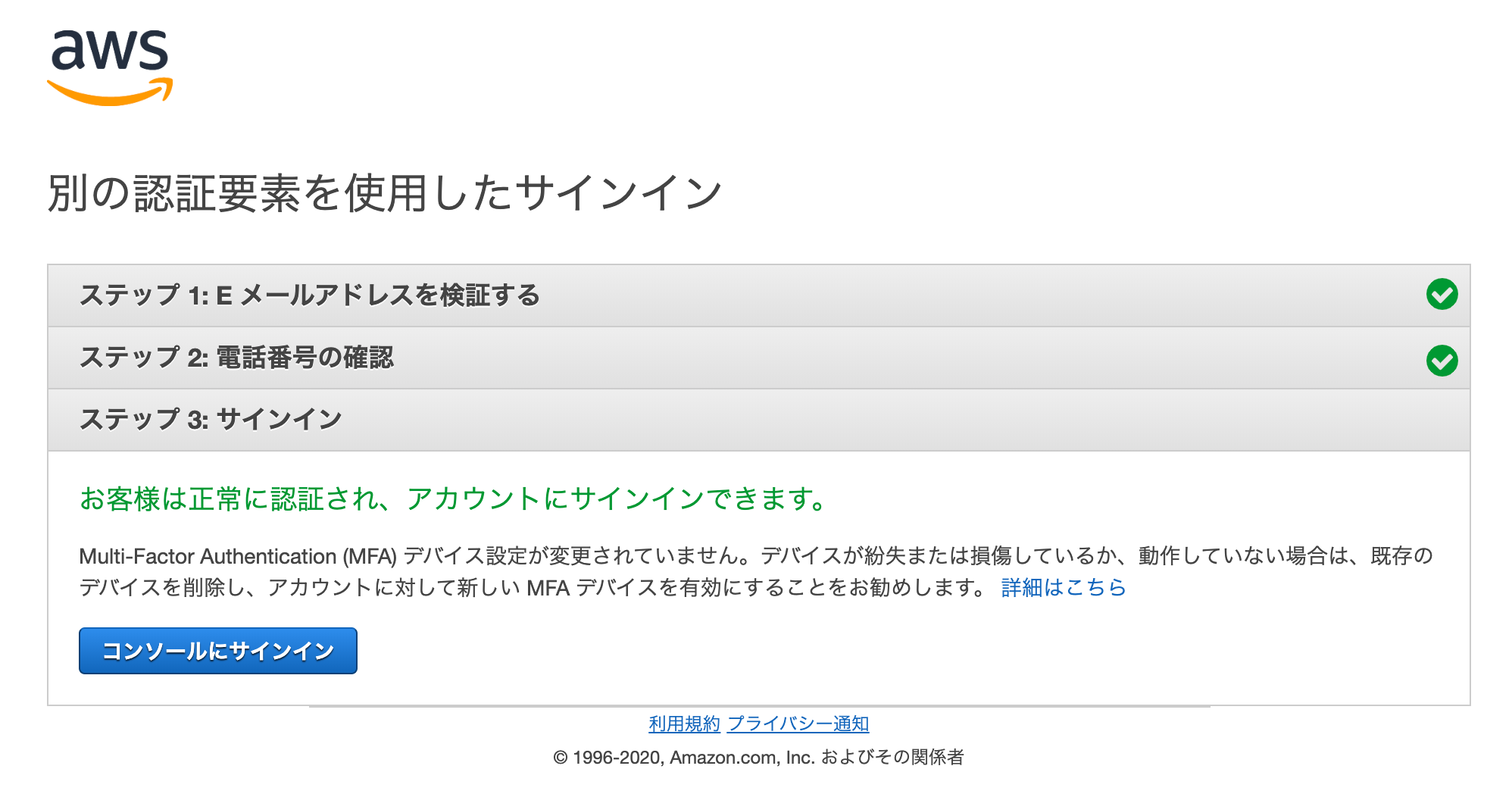
解除のステップはセキュリティ上の事情で省略しますが、メールアドレスさえ生きていれば復旧できるようでした。
窓口は通常のアマゾンのコールセンターのようで、電話番号認証が動かない理由などテクニカルな部分は不明とのこと。AWSの連絡先情報を確認する
無事MFAが解除され再びログインできるようになったので、MFAを再設定した後に「マイアカウント」ページの「連絡先情報」を確認します。
メールアドレスは問題ないのですが、電話番号は「090XXXXYYYY」と入力されていました。
紛失申請時にアタリをつけていた通り「+8190XXXXYYYY」と国コード付きの電話番号に修正してログアウト、再ログイン時にMFA紛失時と同じフローをなぞってみたところ、今回は電話番号認証が期待通りに動作しました。
反省
「バックアップは復旧できることを確認して初めてバックアップになる」という基本をログイン手段に当てはめられていなかったのが失敗でした。
まとめ
大事なことなので2回書きます。
- MFA設定時には、紛失したときに復旧できる手段が正しく動くことを確認する
- 入力時にverifyのチェックが入らない連絡情報は注意する
- AWSの連絡先情報の電話番号は国コード付きのものにする
- 投稿日:2020-02-25T12:02:51+09:00
AWS SAAに合格しました(2年目エンジニア)
はじめに
AWS ソリューションアーキテクト アソシエイト に合格するために行ったことを投稿します。
前提
AWSについての知識
ここ2ヶ月でDynamoDB,Lambda,SES,ElastiCacheを使用した、サーバレス開発を担当。
VPC,APIゲートウェイ,S3を設定している上司の様子を横で見ていた。
EC2は立ち上げや再起動したことある。
S3はアップロードとダウンロードはやったことある。くらいです。
やったこと
参考書を読む
とりあえず知識が無さすぎるので、参考書を通読しました。
徹底攻略 AWS認定 ソリューションアーキテクト – アソシエイト教科書この時点では、主要なサービスの役割について、答えられるくらいで、
細かい機能(Route53のルーティングとか)については、あまり理解できませんでした。Udemyの動画を見る
触ったことが無いサービスばかりなので、
タイトルを見て、勉強したいと思ったところだけ、ハンズオンまで実行しました。説明がとても丁寧で、料金のかかるサービスを毎回講座が終わる時にクローズするように促してくれるので、優しいです。
これだけでOK! AWS認定ソリューションアーキテクト – アソシエイト試験突破講座(初心者向けの22時間完全コース) | Udemyブラックベルトを読む(最重要)
私が一番やったほうがいいと思うところです。
ブラックベルト参考書やUdemyでは、基礎の基礎までなので、実際の業務とかでどうやって使うんだろう・・。
と思っていたところで、点と点を繋げてくれ、理解がとても進みました。1回1時間くらいなので1.3倍速にして、私はお風呂に入りながらぽけーっと見てましたが、それでも効果は十分でした。
見た記憶のある講座を下にまとめておきます。(情報は古いかもしれません)
サービス名 リンク VPC Youtube CloudFront Youtube CloudWatch Youtube CloudWatch Youtube Route 53 Youtube Route 53 Youtube EC2 Youtube ECS Youtube Elastic Beanstalk Lambda Youtube EBS Youtube S3 Youtube EFS Youtube DynamoDB Youtube RDS Youtube Redshift Youtube CloudFormation Youtube Config Youtube Systems Manager Youtube Management Console OpsWorks SlideShare Trusted Advisor Youtube IAM Youtube Key Management Service Youtube EMR Youtube Redshift API Gateway Youtube SQS Youtube 公式の模擬試験について
私は受けませんでした。
Udemyに3回分、模擬試験があるので、そちらで対応しました。その他
ホワイトペーパーをおすすめする方もいらっしゃいましたが、
ちょっと量が多すぎて、見る気になれなかったので、何もしていません。試験当日
ピアソンVUEで受験しました。
外国人と英語でやり取りするとかって記事で見たので、びびりまくっていましたが、
そんなことは一切ありませんでした5年前くらいに受験したITパスポートと同じような感じでした。
結果もすぐ出ます。点数は数時間後にWeb上で確認できます。
結果
合格
スコア820検討もつかない問題が5問くらいだったので、もう少し高いかなあと思っていましたが、
とりあえず合格できてよかったです。感想
情報処理技術者試験みたいに過去問配ってたりしないので、なかなか勉強方法が分かりませんでしたが、
合格できてよかったです。会社でもどんどんAWSを推していくようなので、もっと使ってみたいです(特にサーバレス)

- 投稿日:2020-02-25T11:40:22+09:00
[CloudFront, S3, ALB] “独自ドメインを使用した静的ウェブサイト”の拡張
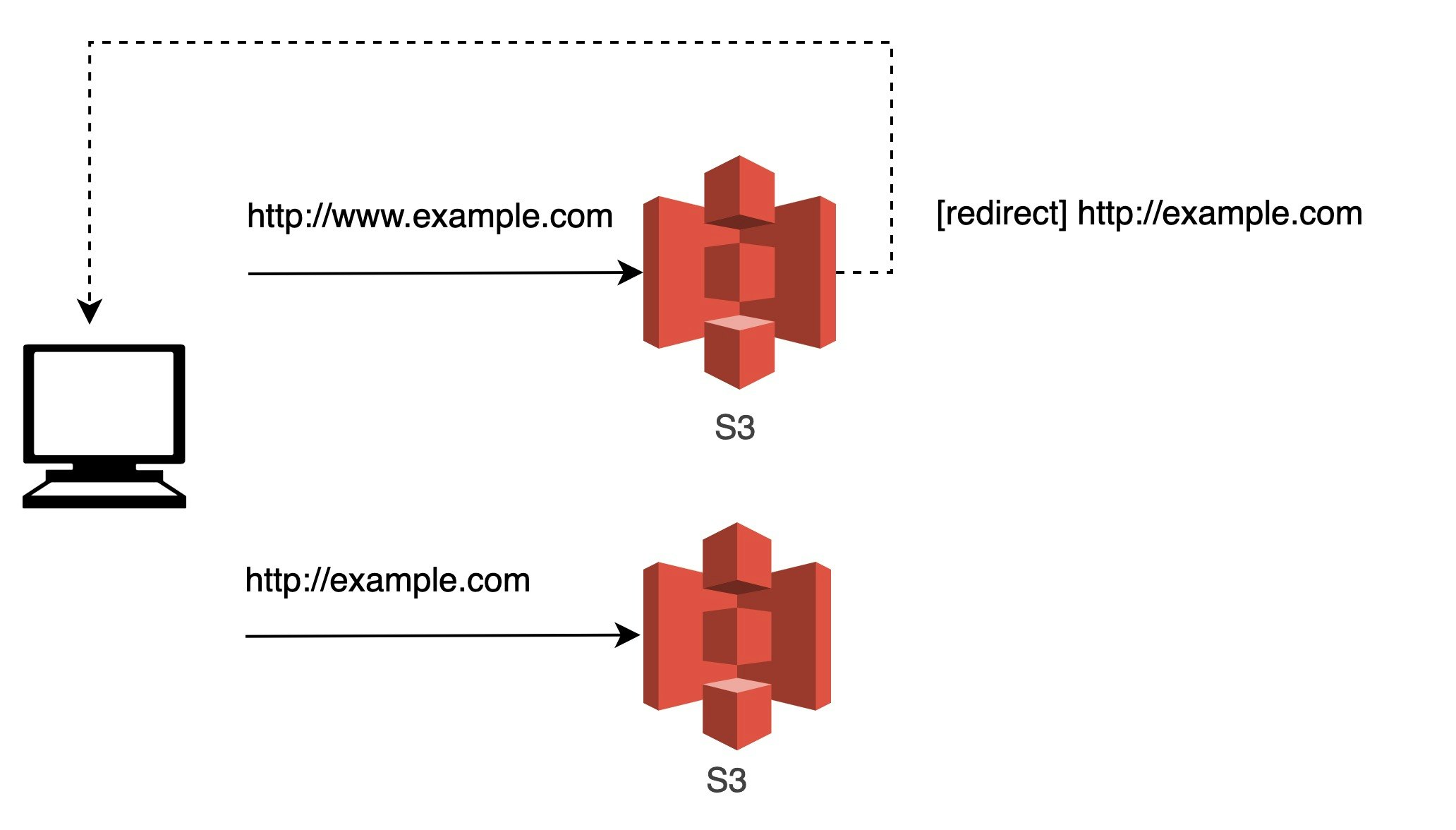
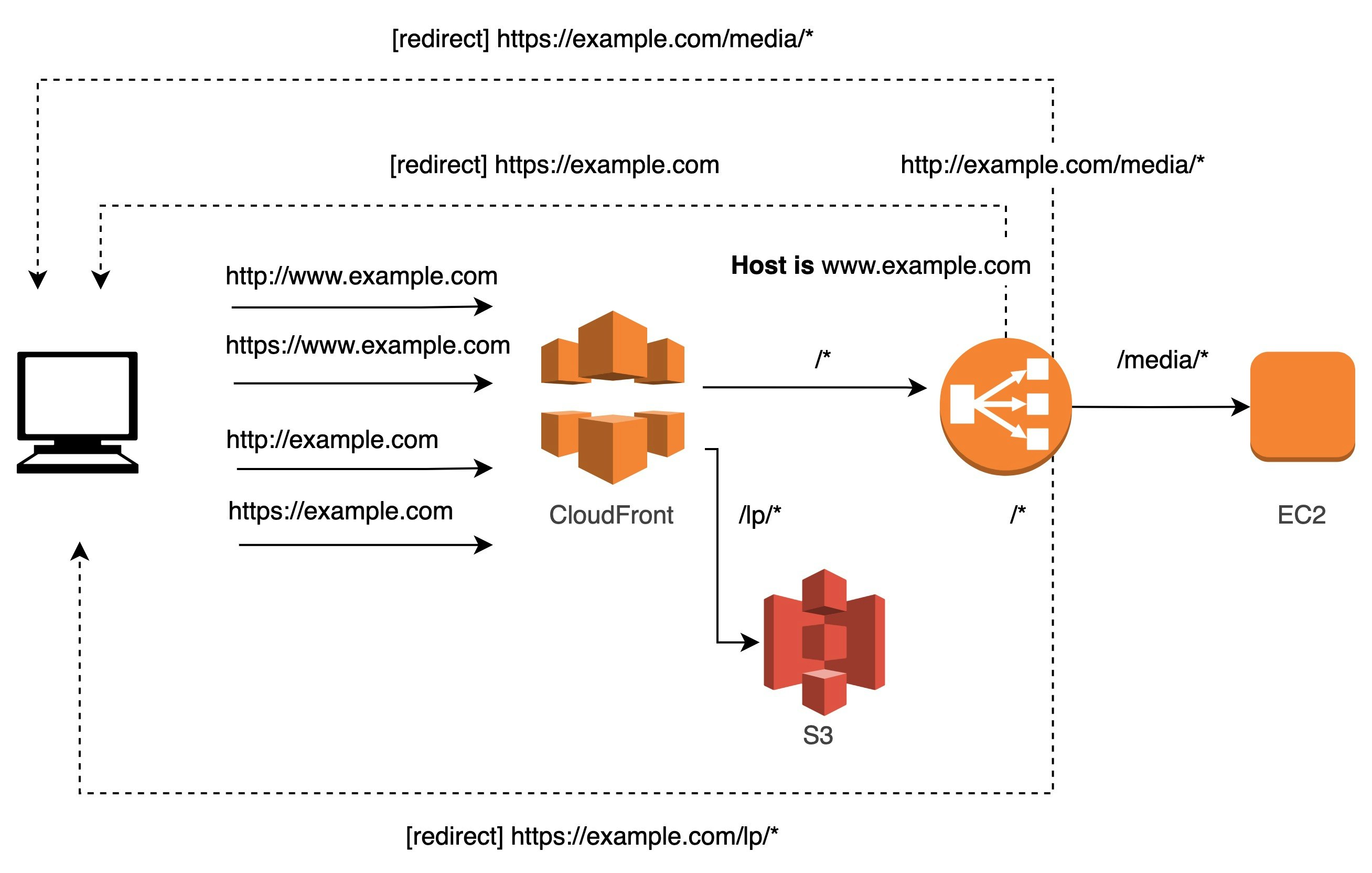
AWSを使った静的サイトの制作において、以下のケースを想定します。
- ルートドメイン(example.com)とサブドメイン(www.example.com)のどちらからアクセスがあっても、ルートドメインにリダイレクトし検索インデックスを統一させたい
- http,https を区別せずに目的のサイトに到達させたい
- 特定のパスのみ、別のバックエンドを参照したい
このとき、Amazon S3のウェブサイトホスティングを使う方法が、サーバーレスで組むのに最も良い方法であり、AWSの公式ドキュメントでも紹介があります。
例: 独自ドメインを使用して静的ウェブサイトをセットアップする一見、直感的な構築方法ではないように思えたため、こちらを深掘りしていきたいと思います。
1. ドメインのリダイレクト設定
公式ドキュメントを要約すると
S3バケットを2つ用意して、片方はリダイレクトのみを担当、もう片方にコンテンツを配置するという方法を紹介しています。
リダイレクト用のS3は空のバケット、つまりコンテンツを置く必要がないというのが珍しい使い方のようにみえるのですが、サーバーレスでの環境構築と考えるととても有用でした。
S3の各設定は以下です。
Route53上での、S3バケットへのaliasレコードの発行、S3のリダイレクトの挙動詳細については、こちらのqiitaがとても参考になりましたのでリンクしておきます。
Route53 で S3 バケットへ alias レコードを作った際のリダイレクトのふるまい
2. http, httpsのリダイレクト設定
ここからが拡張その1です。
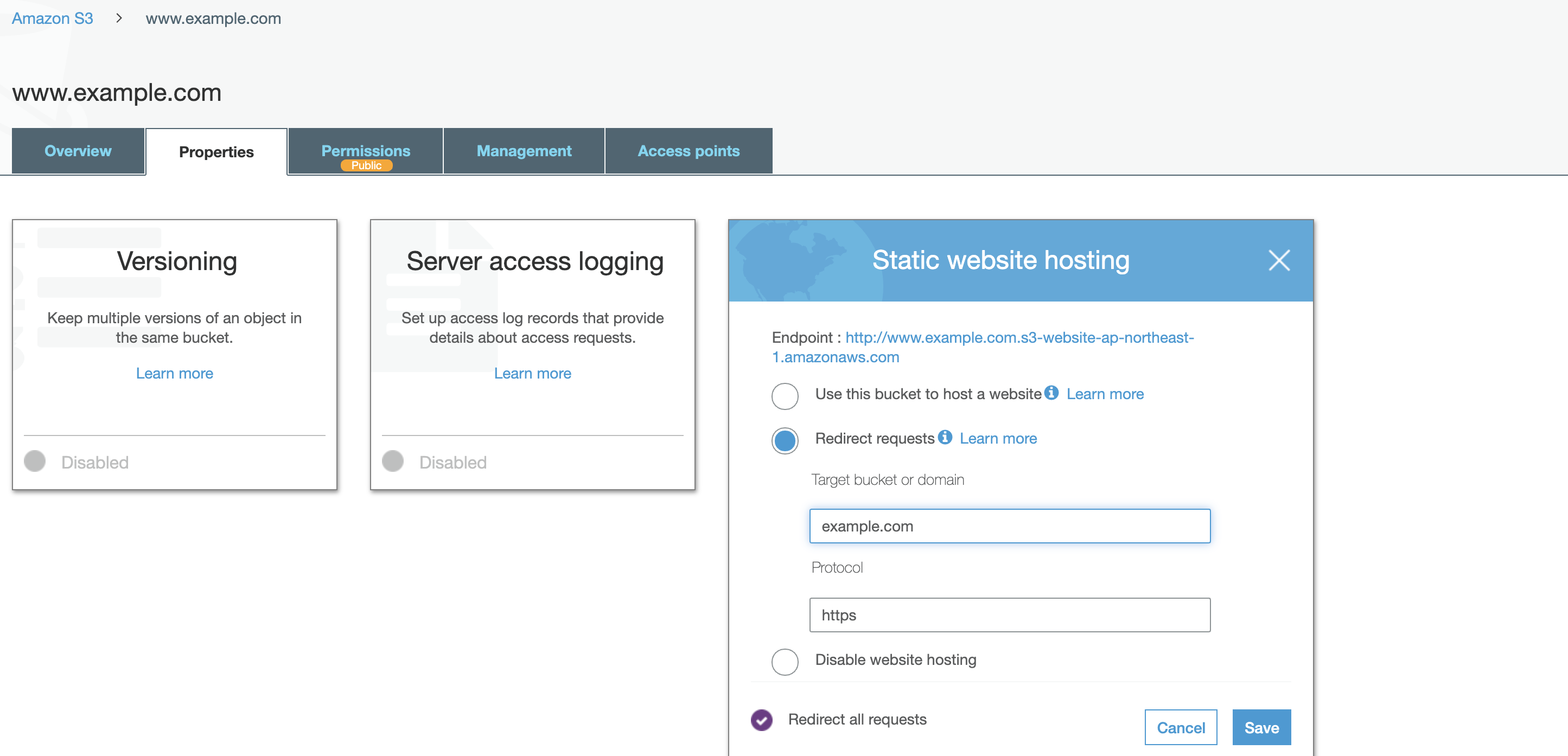
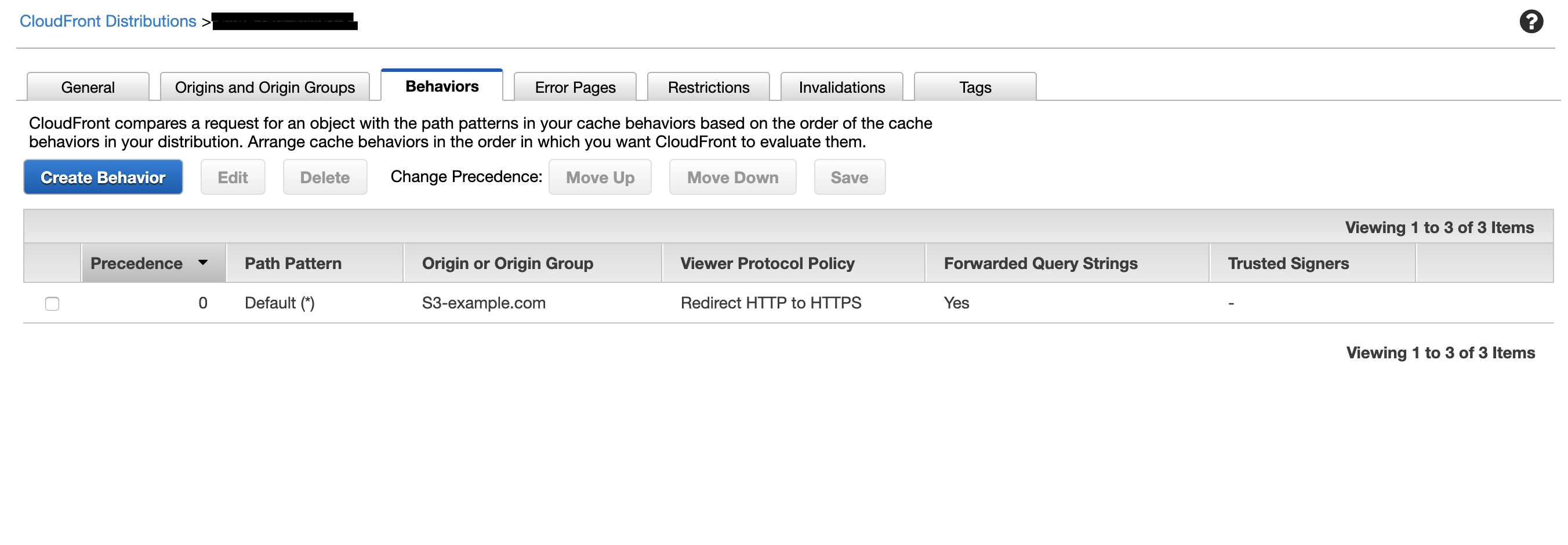
S3のウェブサイトホスティングは、httpのみしかサポートしないため、https化するためにはそのフロントにリダイレクト役が必要になります。
ここでは、CloudFrontを使用したパターンを考えてみました。
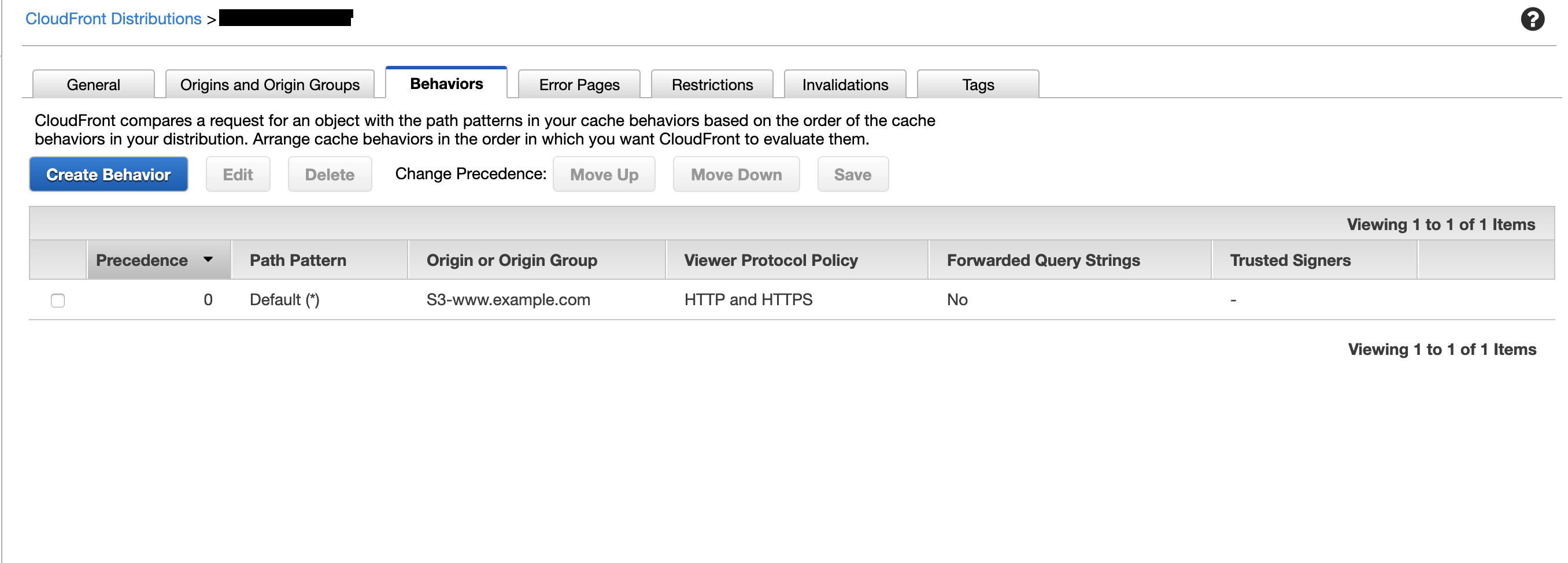
ポイントは、CloudFrontの
Viewer Porotocol Policyで、サブドメイン側のCFはHTTP and HTTPSを許容し、ルートドメイン側のCFではRedirect HTTP to HTTPSにより、リダイレクトをかけることです。
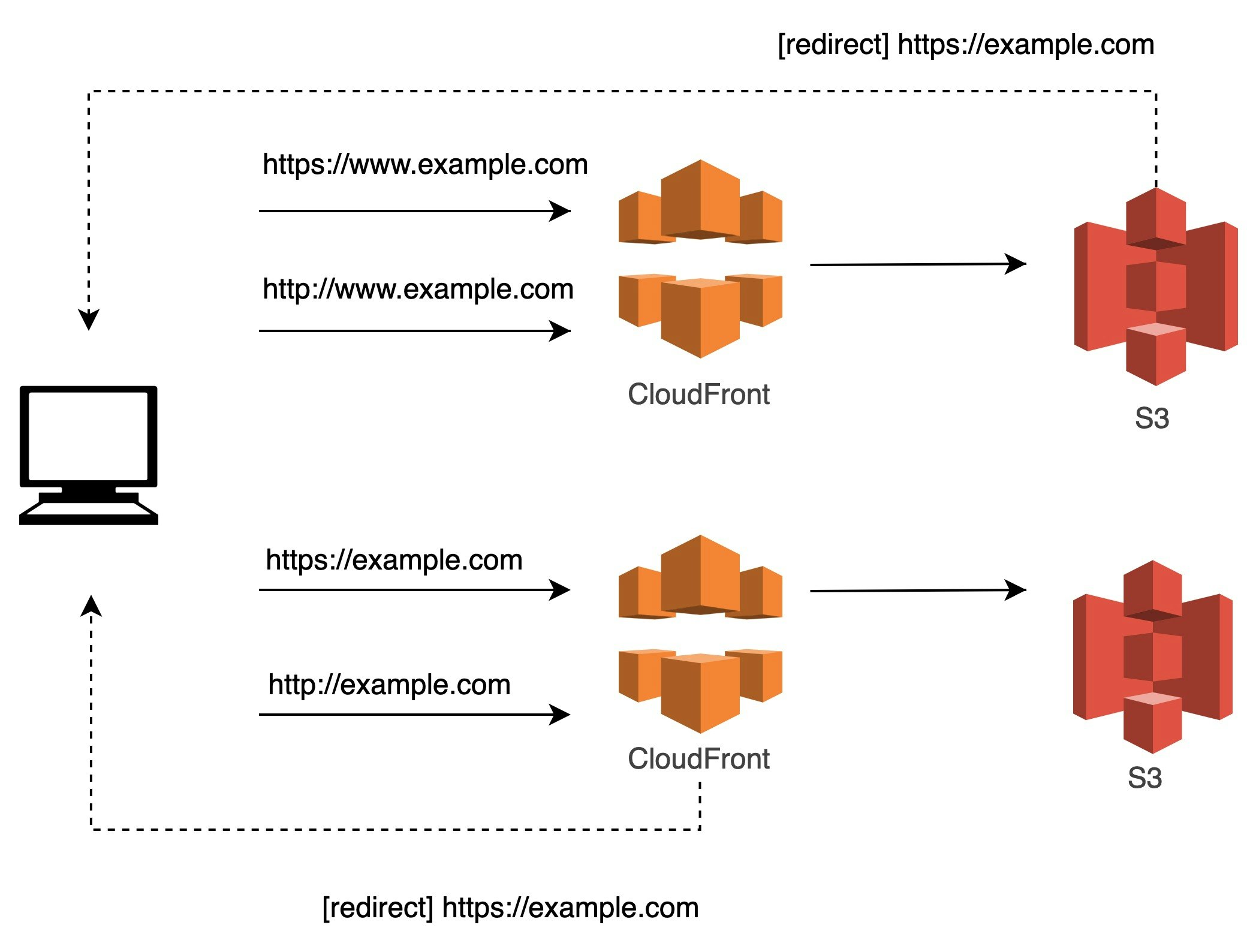
3. 特定のパスのみ、別のバックエンドを参照
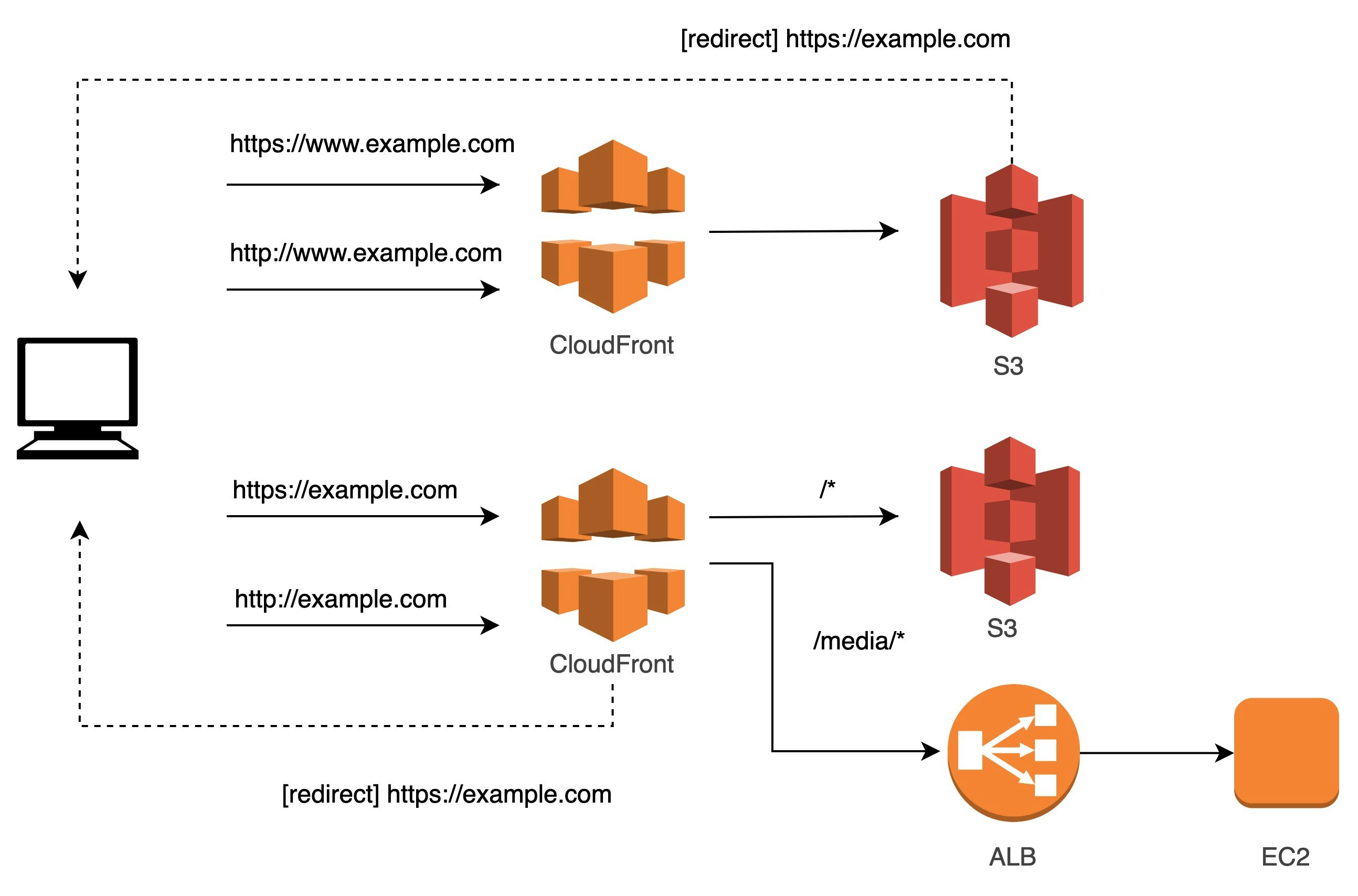
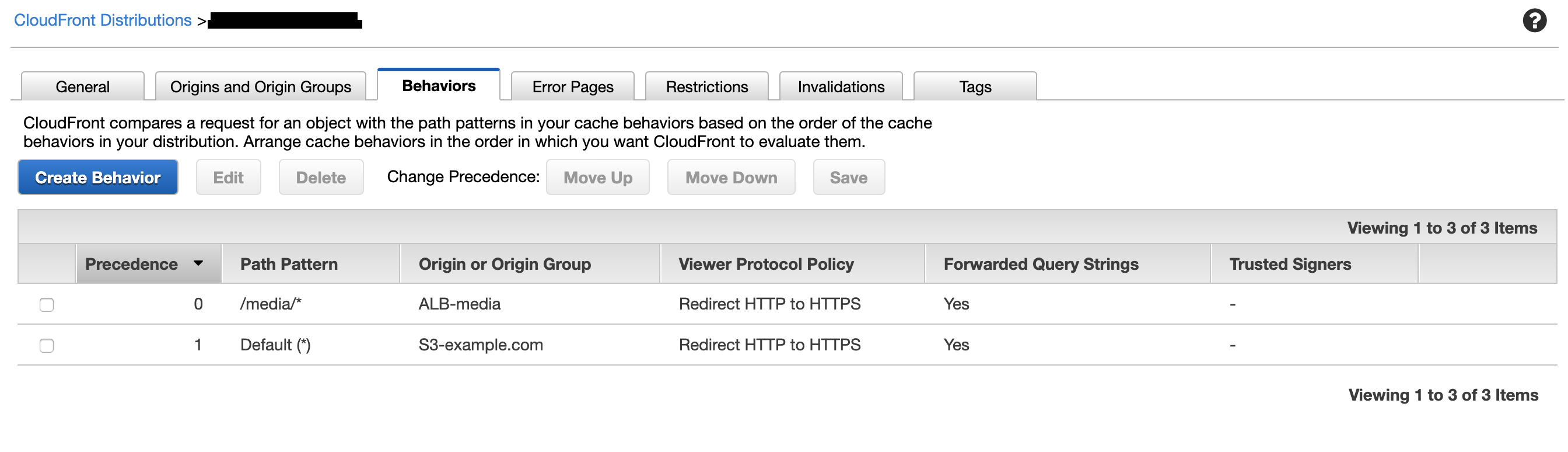
仮に、
/media/*のパスのみEC2のインスタンスを参照したいケースを考えます。
2の延長で、フロントのCFのパスパターン振り分けにより、特定パスのみALBを参照します。
といいつつ冗長な気もする...
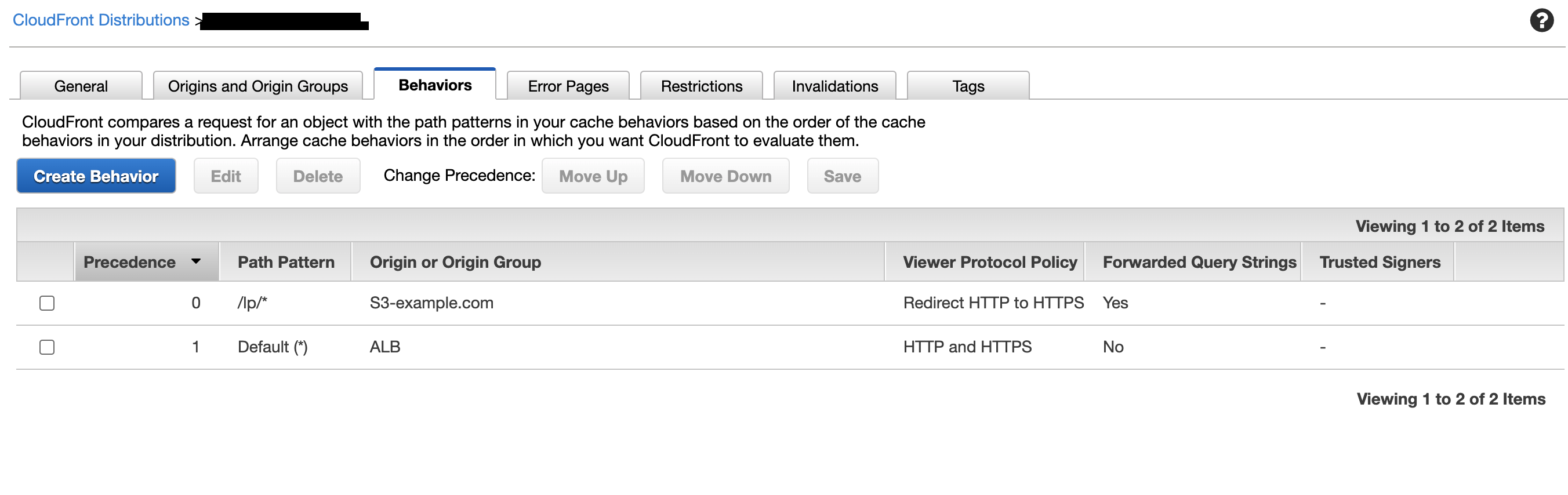
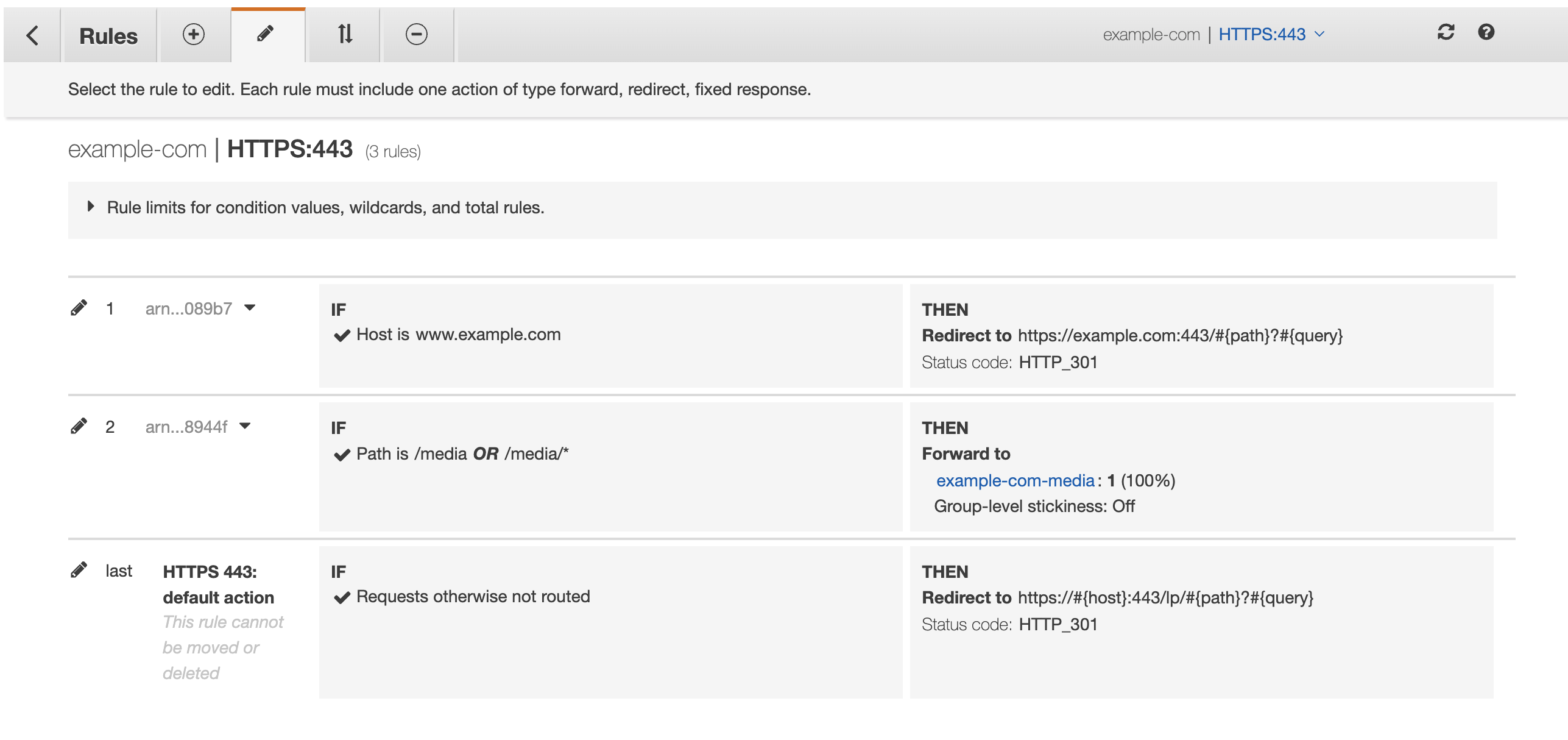
サブドメインおよびプロトコルのリダイレクト処理をフロントに任せているため、ALBがいるにも関わらずS3,CFともに2つずつ必要なのがtoo muchな気もします。アクセスが増えれば増えるほど、リダイレクト時の転送量も大きくなります。
そこで、ALBにリダイレクト処理を一任する方法も考えてみました。
こうすることにより、S3,CFを1つずつ減らすことができました。
1つ注意点は、
ALBの振り分けバックエンドとしてS3のaliasを指定できないことにより、新たに/lp/*の振り分けをCFで指定し、S3へと飛ばす必要がある点です。
S3のディレクトリ構成に多少変更が必要なのと、パスが変わってしまうことを許容できるのであれば、この方法のほうがよさそうです。
まとめ
ランディングページやオウンドメディア を1つのドメインで提供する際の、振り分け設定を考えてみました。
CloudFrontは1つ設定を変えるだけで浸透に数分~数十分かかるため、なかなかトライアンドエラーに時間がかかるため、図示してよく考えてから設定することをおすすめします。
- 投稿日:2020-02-25T09:14:39+09:00
GSuiteのアカウントがあればAWSのユーザーは不要だった件
表題の通り、GSuiteのアカウントがあればAWSのユーザーは不要だったことに気がつきました。
SAMLを使ったシングルサインオンを使えば、GSuiteのアカウントでAWSにログインすることができます。
設定方法は実は全てこちらのページに書いてあるのですが、いくつか分かりづらい点があったので補足します。
G Suite アカウントを用いた AWS へのシングルサインオン | AWS Startup ブログ
Step2の5番の属性のマッピング設定について
SessionDurationは指示通りhttps://aws.amazon.com/SAML/Attributes/SessionDurationと入力します。他のRoleSessionNameとRoleは既定のURLで大丈夫です。Step5の2番のAWSの項目の入力について
Roleの項目が一つ余分に出てきますが、指示通りカンマ区切りで1つの項目に入力すればOKです。
複数項目あるからと言ってRole ARNとIDプロバイダーのARNをそれぞれ分けて入力したところエラーとなってしまいました。CLIからのアクセス(アクセスキー)について
これもこちらの記事に書かれていますが補足があります。
saml2awsでSAML認証を用いたaws cliの利用を簡単にした - Qiita設定時にSAML認証用のURLが必要で、パラメータに
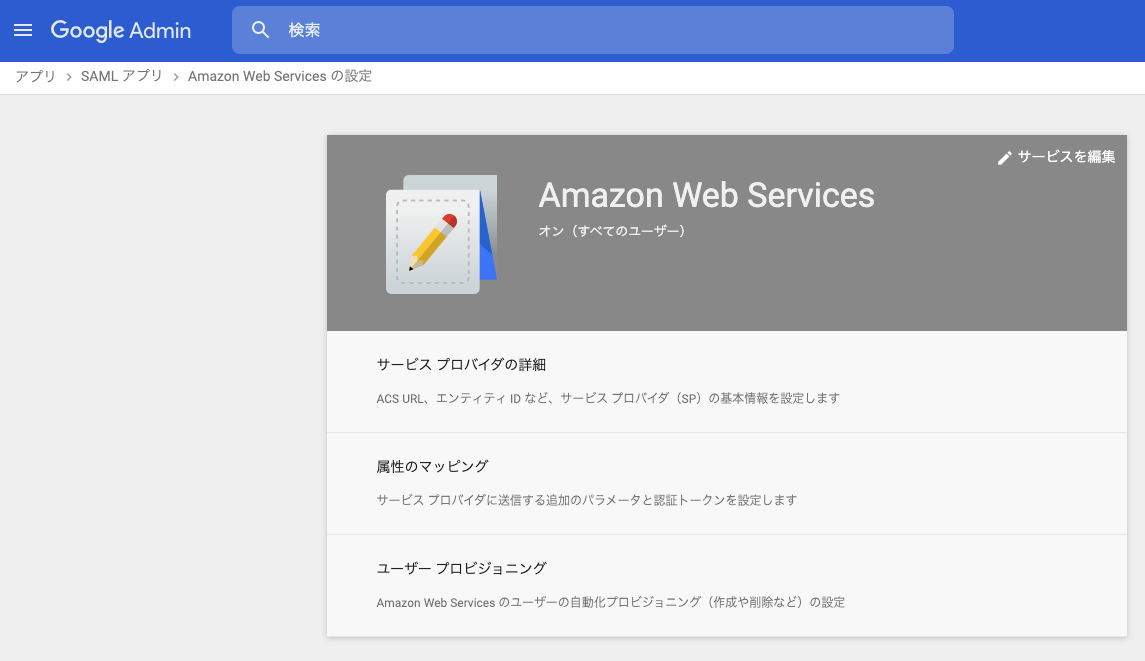
idpidとspidがあります。
少し迷ったのですが、idpidはAWSにアップロードする際のファイルの中に書いてあります。
spidについてはSAMLアプリ設定画面(下記画像)のURLにあるservice=のあとに続く数字のようでした。
- 投稿日:2020-02-25T08:29:16+09:00
Cloud formationについて
Cloudformationの概要についてまとめたいと思います。
テクニカルな部分じゃなくてすみません。Cloudformationとは
⇨AWS CloudFormation は、クラウド環境で AWS とサードパーティ製アプリケーションリソースのモデリングおよびプロビジョニングをする際の、共通的な手法を提供します。AWS CloudFormation では、プログラミング言語またはシンプルなテキストファイルを使用して、あらゆるリージョンとアカウントでアプリケーションに必要とされるすべてのリソースを、自動化された安全な方法でモデル化し、プロビジョニングできます。これは、AWS とサードパーティ製のリソースに真に単一のソースを与えます。
https://aws.amazon.com/jp/cloudformation/
要はコード(JSON,YAML形式)で書くことによってEC2やRDS,S3、VPCなどリソースを自動で構築できるサービス。
[infrastructure as code]⇨インフラ環境をコード化する考え。
「インフラの自動化」という技術に繋がります。※初心者が憧れるやつです。なぜCloudformationを利用するのか
インフラ環境の再現性!!!!
機器を導入したり、ツール、アプリケーションをポチポチとインストールしたりと、
一から環境を作り込んでいくため、かなり手間!一度作ったテンプレートを利用してしまえば同じ環境が構築でき、管理の手間、スピードは断然と上がり、
最終的にはコスト削減へとつなります。この流れに沿って自動化、運用ができる技術者が必要になってきているとのこと。
Cloudformation:スタックとは
⇨テンプレートによって作成された環境群をスタックという。
プラモデルのパーツを想像していただければと。↓テンプレート例
AWSTemplateFormatVersion: 2010-09-09
Resources:
FirstVPC:
Type: 'AWS::EC2::VPC'
Properties:
CidrBlock: 10.0.0.0/16
テンプレートを用いることで
環境が構築されます。一度作ってしまえば次利用するときも同じテンプレートを使えば同じ環境が作れるというわけです。
少し仕様を付け足したい、変更したいという場合でもコードを書き加えるだけで実現できます。最後に
ちょっとだけ概要をまとめましたが「習うより慣れろ」
手を動かして一度作ってしまう方が理解します。僕は始めにこの記事を参考にしました。
https://dev.classmethod.jp/cloud/aws/cloudformation-beginner01/Udemyの教材も試してみます!
あ〜ガシガシ行かねば!!!
- 投稿日:2020-02-25T02:02:58+09:00
GolangのAPIサーバをAWS Lambdaへ移植してみた
背景
現在Golang + Nginxで動いているAPIをLambda関数へ移行したい。
API仕様
- おみくじAPI
/fortuneへのアクセスで大吉・中吉・小吉のどれかをjsonとして返してくれる/listでおみくじで得ることが出来る結果一覧をJSONで取得できる/versionでプレーンテキストとしてAPIのバージョンを取得できる- 無効なパスへのアクセスは404を返す
環境
OS: Ubuntu 18.04
バージョン
$ go version go version go1.10.3 gccgo (Ubuntu 8.3.0-6ubuntu1~18.04.1) 8.3.0 linux/amd64実際に移植してみる!
ざっくりやること
- Lambda関数作成
- ALBとターゲットグループを作成
- ビルドしてLambdaへデプロイ
移植前のソース
下記のコードをLambdaで動くように修正します。
移植前ソース
package main import ( "encoding/json" "fmt" "log" "math/rand" "net/http" ) var fortune = []string{"大吉", "中吉", "小吉"} func fortuneHandler(w http.ResponseWriter, r *http.Request) { res, err := json.Marshal(fortune[rand.Intn(3)]) if err != nil { http.Error(w, err.Error(), http.StatusInternalServerError) return } w.Header().Set("Content-Type", "application/json") fmt.Fprint(w, string(res)) } func versionHandler(w http.ResponseWriter, r *http.Request) { w.Header().Set("Content-Type", "text/plane; charset=utf-8") fmt.Fprint(w, string("version 1.0.0")) } func listHandler(w http.ResponseWriter, r *http.Request) { w.Header().Set("Content-Type", "application/json") fmt.Fprint(w, fortune) } func notFoundHandler(w http.ResponseWriter, r *http.Request) { w.Header().Set("Content-Type", "text/plain; charset=utf-8") w.WriteHeader(404) fmt.Fprint(w, "404 not found") } func main() { http.HandleFunc("/fortune", fortuneHandler) http.HandleFunc("/version", versionHandler) http.HandleFunc("/list", listHandler) http.HandleFunc("/", notFoundHandler) log.Fatal(http.ListenAndServe(":8080", nil)) }Lambda環境作成
Lambda関数の作成
ランタイムが
Go 1.xになっていることを確認し、関数を作成します。
ALBとターゲットグループを作成
EC2の画面を開き、左のメニューからロードバランサーを選択
画面上位の
ロードバランサーの作成を押下
Application Load Balancerの作成を押下
ロードバランサーの設定は各々の環境に合わせて設定してください
ターゲットグループを新規作成し、
ターゲットの種類がLambdaになっていることを確認し、ターゲットの登録ボタンを押下
リストからターゲットにしたいLambdaを選択し、確認を押下
確認して問題なければ作成ボタンを押下
動作確認
作成したALBのDNS名をコピーして、実際にアクセスしてみて確認
Hello from Lambda!と表示されればOK$ curl <ALBのDNS名> -D - HTTP/1.1 200 OK Server: awselb/2.0 Date: Mon, 24 Feb 2020 12:47:12 GMT Content-Type: application/octet-stream Content-Length: 18 Connection: keep-alive Hello from Lambda!Lambda関数として動くようにする
- やること
- サーバとしてではなく関数として動作するようにする
*http.Requestとhttp.ResponseWriterをALBTargetGroupRequestとevents.ALBTargetGroupResponseへ置き換える置き換え後
置き換え後ソース
package main import ( "encoding/json" "fmt" "math/rand" "context" "github.com/aws/aws-lambda-go/events" "github.com/aws/aws-lambda-go/lambda" ) var fortune = []string{"大吉", "中吉", "小吉"} func fortuneHandler() (events.ALBTargetGroupResponse, error) { res, err := json.Marshal(fortune[rand.Intn(3)]) if err != nil { return events.ALBTargetGroupResponse { StatusCode: 500, Body: fmt.Sprintf("%s", err), }, err } return events.ALBTargetGroupResponse { Headers: map[string]string{ "content-type": "application/json", }, Body: fmt.Sprintf("%s", string(res)), }, nil } func versionHandler() (events.ALBTargetGroupResponse, error) { return events.ALBTargetGroupResponse { Headers: map[string]string{ "content-type": "text/plane; charset=utf-8", }, Body: fmt.Sprintf("%s", string("version 1.0.0")), }, nil } func listHandler() (events.ALBTargetGroupResponse, error) { return events.ALBTargetGroupResponse { Headers: map[string]string{ "content-type": "application/json", }, Body: fmt.Sprintf("%s", fortune), }, nil } func notFoundHandler() (events.ALBTargetGroupResponse, error) { return events.ALBTargetGroupResponse { StatusCode: 404, Headers: map[string]string{ "content-type": "text/plain; charset=utf-8", }, Body: fmt.Sprintf("404 not found\n"), }, nil } func main() { lambda.Start(handleRequest) } func handleRequest(ctx context.Context, request events.ALBTargetGroupRequest) (events.ALBTargetGroupResponse, error) { switch request.Path { case "/fortune": return fortuneHandler() case "/version": return versionHandler() case "/list": return listHandler() default: return notFoundHandler() } }
修正差分
6d5 < "log" 8c7,9 < "net/http" --- > "context" > "github.com/aws/aws-lambda-go/events" > "github.com/aws/aws-lambda-go/lambda" 13c14 < func fortuneHandler(w http.ResponseWriter, r *http.Request) { --- > func fortuneHandler() (events.ALBTargetGroupResponse, error) { 17,18c18,21 < http.Error(w, err.Error(), http.StatusInternalServerError) < return --- > return events.ALBTargetGroupResponse { > StatusCode: 500, > Body: fmt.Sprintf("%s", err), > }, err 21,22c24,29 < w.Header().Set("Content-Type", "application/json") < fmt.Fprint(w, string(res)) --- > return events.ALBTargetGroupResponse { > Headers: map[string]string{ > "content-type": "application/json", > }, > Body: fmt.Sprintf("%s", string(res)), > }, nil 25,27c32,38 < func versionHandler(w http.ResponseWriter, r *http.Request) { < w.Header().Set("Content-Type", "text/plane; charset=utf-8") < fmt.Fprint(w, string("version 1.0.0")) --- > func versionHandler() (events.ALBTargetGroupResponse, error) { > return events.ALBTargetGroupResponse { > Headers: map[string]string{ > "content-type": "text/plane; charset=utf-8", > }, > Body: fmt.Sprintf("%s", string("version 1.0.0")), > }, nil 30,32c41,47 < func listHandler(w http.ResponseWriter, r *http.Request) { < w.Header().Set("Content-Type", "application/json") < fmt.Fprint(w, fortune) --- > func listHandler() (events.ALBTargetGroupResponse, error) { > return events.ALBTargetGroupResponse { > Headers: map[string]string{ > "content-type": "application/json", > }, > Body: fmt.Sprintf("%s", fortune), > }, nil 35,38c50,57 < func notFoundHandler(w http.ResponseWriter, r *http.Request) { < w.Header().Set("Content-Type", "text/plain; charset=utf-8") < w.WriteHeader(404) < fmt.Fprint(w, "404 not found") --- > func notFoundHandler() (events.ALBTargetGroupResponse, error) { > return events.ALBTargetGroupResponse { > StatusCode: 404, > Headers: map[string]string{ > "content-type": "text/plain; charset=utf-8", > }, > Body: fmt.Sprintf("404 not found\n"), > }, nil 42,46c61,64 < http.HandleFunc("/fortune", fortuneHandler) < http.HandleFunc("/version", versionHandler) < http.HandleFunc("/list", listHandler) < http.HandleFunc("/", notFoundHandler) < log.Fatal(http.ListenAndServe(":8080", nil)) --- > lambda.Start(handleRequest) > } > > func handleRequest(ctx context.Context, request events.ALBTargetGroupRequest) (events.ALBTargetGroupResponse, error) { 47a66,71 > switch request.Path { > case "/fortune": return fortuneHandler() > case "/version": return versionHandler() > case "/list": return listHandler() > default: return notFoundHandler() > }差分解説
func main() { lambda.Start(handleRequest) } func handleRequest(ctx context.Context, request events.ALBTargetGroupRequest) (events.ALBTargetGroupResponse, error) { switch request.Path { case "/fortune": return fortuneHandler() case "/version": return versionHandler() case "/list": return listHandler() default: return notFoundHandler() } }
lambda.Start
lambda.Start(HandleRequest) を追加すると、Lambda 関数が実行されます。
ALBTargetGroupRequest
- ここにリクエストのパスなどが入ってきます
- golangの
*http.Request相当
func listHandler() (events.ALBTargetGroupResponse, error) { return events.ALBTargetGroupResponse { Headers: map[string]string{ "content-type": "application/json", }, Body: fmt.Sprintf("%s", fortune), }, nil }
- ALBTargetGroupResponse
- この構造体をLambdaからreturnする事で任意のレスポンスを返すことが出来ます
- 基本的に、
http.ResponseWriterをALBTargetGroupResponseへ置き換えるだけで任意のレスポンスを返すように出来ますビルド&動作確認
ビルド
ここでのポイントはクロスコンパイルするところです
$ GOOS=linux GOARCH=amd64 go build -o fortuneここで作ったバイナリをLambdaへアップロードして、動作確認をします!
動作確認
ここで大吉・中吉・小吉のどれかが出力されればOKです
$ curl <ALBのDNS名>/fortune -D - HTTP/1.1 000 Server: awselb/2.0 Date: Mon, 24 Feb 2020 16:18:30 GMT Content-Type: application/json Content-Length: 8 Connection: keep-alive "小吉"記事外で関数に移植する際に困ったところ
条件によって特定のヘッダーを付与してALBTargetGroupResponseを返したい
ALBTargetGroupResponseを一度変数に入れて変数値を操作したものをreturnすればいい
下記コードだとif err {の部分response := events.ALBTargetGroupResponse { StatusCode: http.StatusInternalServerError, Body: fmt.Sprintf("%d", http.StatusInternalServerError), Headers: map[string]string{}, } if err { response.Headers["X-Error-Message"] = fmt.Sprintf("error: %v", err) } response.StatusCode = statusCode response.Headers["Content-Type"] = "text/plane; charset=utf-8" response.Body = http.StatusInternalServerError return responseおわりに
置き換えはLambdaのお作法に従うだけで意外と簡単に移植できるみたいです。
参考資料
AWS Lambda で Go が使えるようになったので試してみた
Go の AWS Lambda 関数ハンドラー
README_ALBTargetGroupEvents.md
type ALBTargetGroupResponse
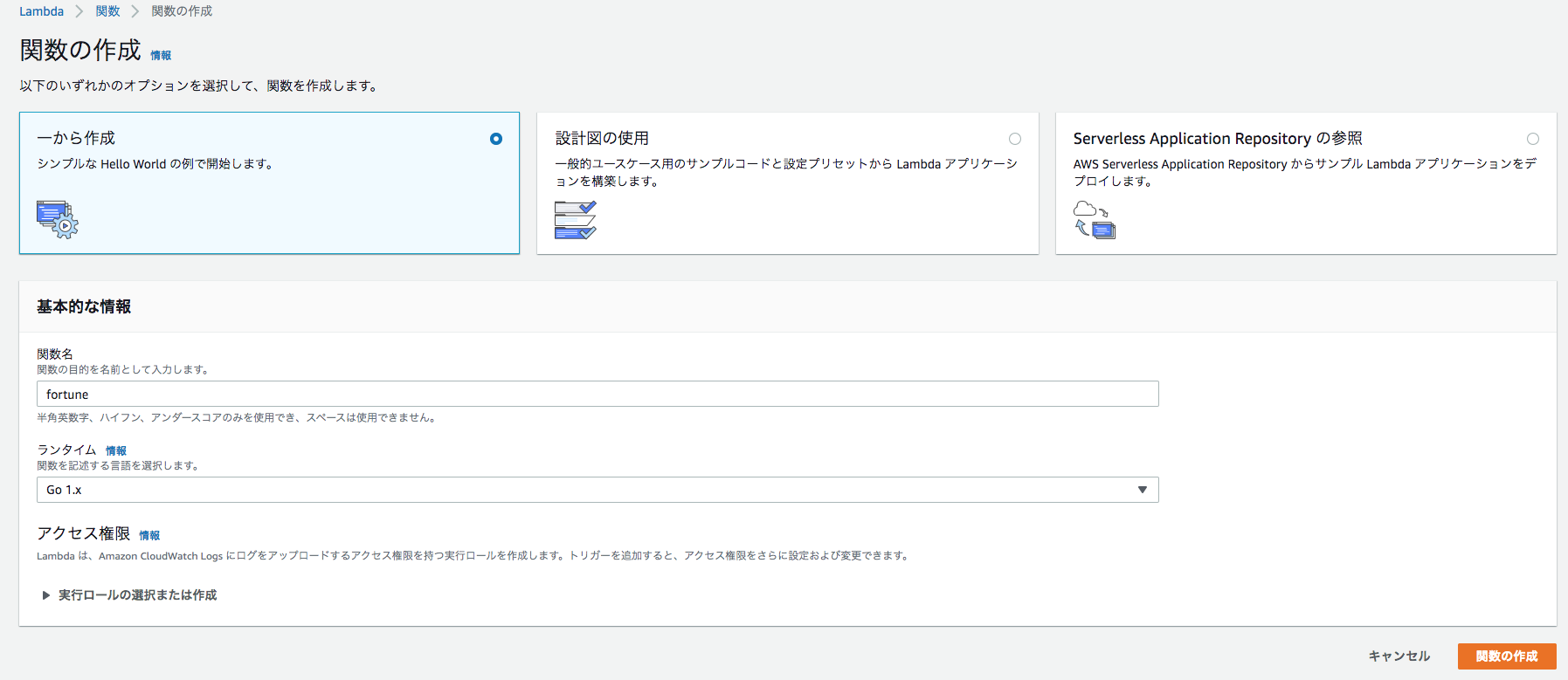
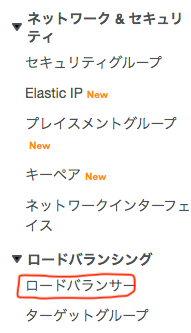
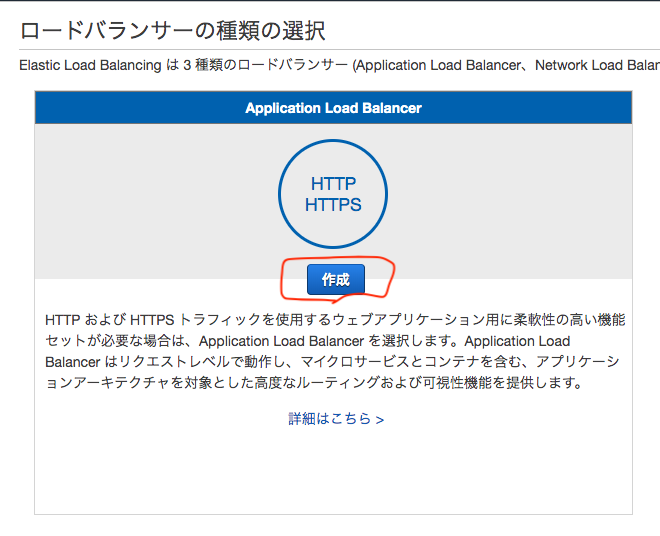
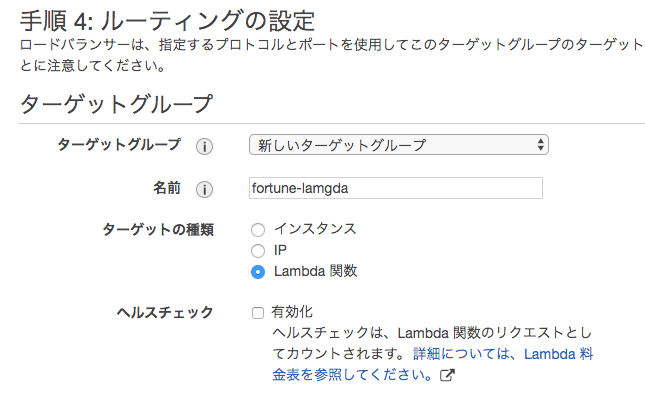

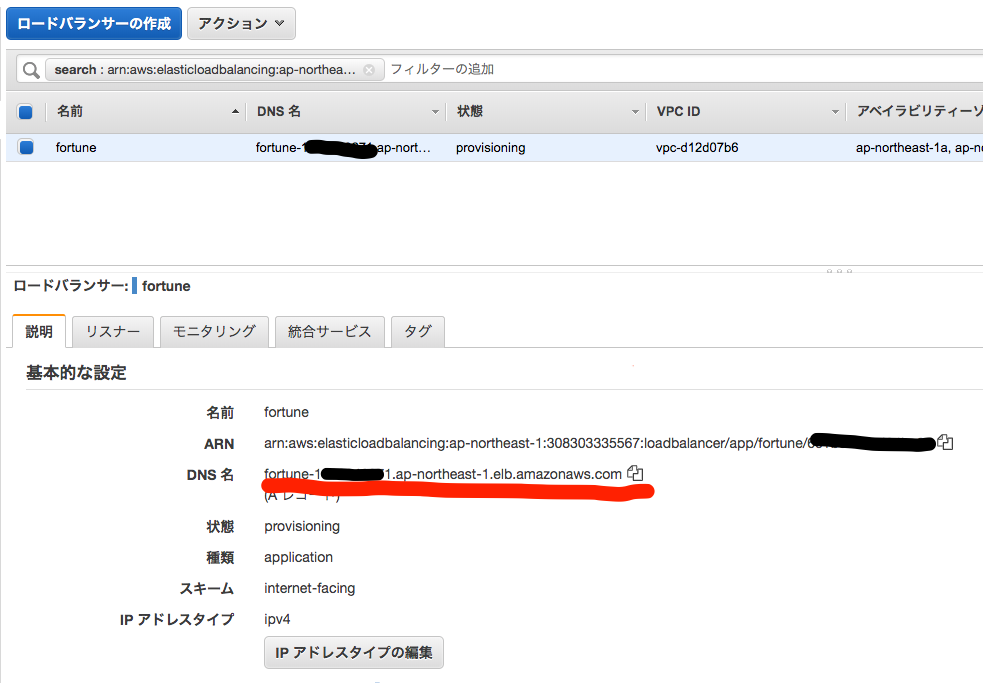
- 投稿日:2020-02-25T01:49:50+09:00
SAAで学ぶAWS -VPC編-
AWS Solutions Architect Associate を取得する際に、VPCについて知りたいときに見るドキュメント。
目次
- 概要
- 作ってみる
- 動作確認
- メモ書き
概要
AWSのインスタンスを生成するようなサービスを利用する際に必要になる土台のネットワーク部分を作成する。
1つのアカウントで複数プロジェクトを管理する場合は、サービスごとにVPCを作ってリソースの管理をするのが望ましいそうな。今回作るのは以下の構成。
大枠のVPCの中に2種類のサブネットを合計6個作成する。
- リージョン (ap-northeast-1)
- VPC (saa-vpc)
- プライベートサブネット
- AZ a, b, c
- パブリックサブネット
- AZ a, b, c
サブネットはIGWへのルーティングの有無によって2種類に分解できる。
- パブリックサブネット
- IGWへのルーティングがあるサブネット
- パブリックIPが付与されていればインターネットに接続できる
- インターネットに公開されるwebサーバなどを配置する
- プライベートサブネット
- IGWへのルーティングがないサブネット
- 基本的にインターネットに接続できない
- インターネットに接続する場合はNAT GWを経由してアクセスする
- インターネットからはアクセスされたくないDBサーバなどを配置する
これから色々構築する (予定な) ので下準備としてこんな感じのネットワークを作成する。
また、リージョンは東京リージョンに作成するのでリージョンを確認しておくこと。
作ってみる
VPCの作成
AWSにログイン後
VPCを検索してメニューを選択する
左メニューから
VPCを選択してVPCの作成を選択する
名前タグに
saa-vpcを入力する
IPv4 CIDR ブロックに34.0.0.0/16を入力する
IPv6 CIDR ブロックは今回は使わないのでIPv6 CIDR ブロックなしを選択する
マシンを専有する必要はないので、テナンシーはデフォルトを選択する
これでVPCが作成された。
VPCフローログ
+ VPC内部のネットワークトラフィックのログをCloudWatchLogsに保存できる
+ CloudWatchLogsでログフィルタをしてLambda連携やアラートの送信も可能
+ CloudWatchLogsの料金が気になる場合はS3に直接出力してコストを抑えることも可能次にこのVPCにインターネットゲートウェイをアタッチする。
インターネットゲートウェイの作成
インターネットに接続するためのIGW(Internet Gate Way)を作成、設定する。
左メニューから
インターネットゲートウェイを選択してインターネットゲートウェイの作成を選択する
名前タグに
saa-vpc-igwを入力して作成
IGW一覧に戻って
saa-vpc-igwを選択 > アクション > VPCにアタッチ
VPCに
saa-vpcのVPC-IDを入力 > アタッチ
これで
saa-vpcにIGWがアタッチされた。
次にこのVPC内にサブネットを作成する。サブネットの作成
各AZにパブリックサブネットとプライベートサブネットを作成する。
- 左メニューから
サブネットを選択してサブネットの作成を選択する
- ap-northeast-1a のパブリックサブネットを作成
- 名前タグに
saa-pubsub-1aを入力する- VPCに先程作成した
saa-vpcのVPC-IDを入力する- アベイラビリティーゾーンに
ap-northeast-1aを入力する- IPv4 CIDR に
34.0.10.0/24を入力する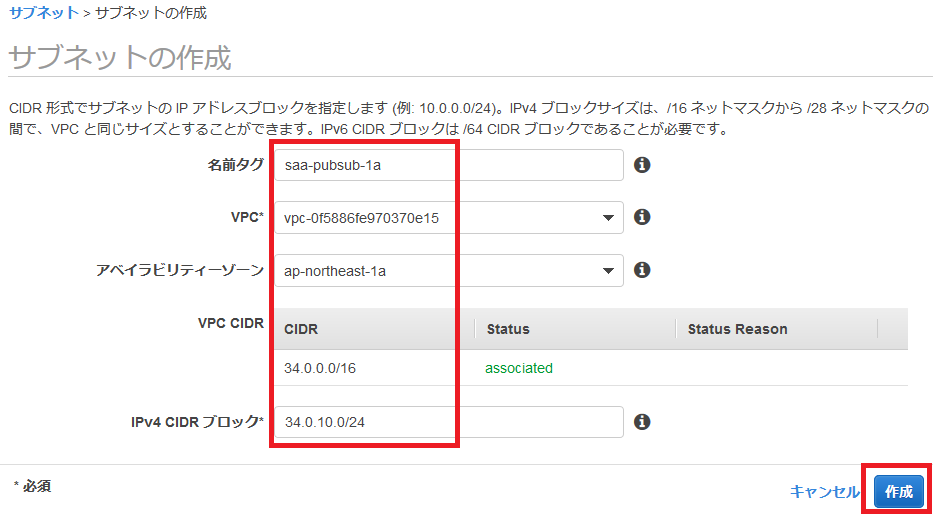
- サブネット一覧から
saa-pubsub-1aを選択して アクション > 自動割り当て IP 設定の変更 を選択する- パブリック IPv4 アドレスの自動割り当てを有効にする をチェックして保存
- ap-northeast-1a のプライベートサブネットを作成
- 名前タグに
saa-prisub-1aを入力する- VPCに先程作成した
saa-vpcのVPC-IDを入力する- アベイラビリティーゾーンに
ap-northeast-1aを入力する- IPv4 CIDR に
34.0.1.0/24を入力する- 他 c, d のAZでも同じ要領で値を置き換えて作成する
saa-pubsub-1cの IPv4 CIDR :34.0.20.0/24saa-prisub-1cの IPv4 CIDR :34.0.2.0/24saa-pubsub-1dの IPv4 CIDR :34.0.30.0/24saa-prisub-1dの IPv4 CIDR :34.0.3.0/24これでサブネットが作成された。
次にNAT Gateway を作成、設定する。
NAT Gatewayの作成、設定
プライベートサブネットからインターネットに接続するためのNAT Gateway を作成、設定する。
左メニューから
NAT ゲートウェイを選択してNATゲートウェイの作成を選択する
サブネットに
saa-pubsub-1aを入力する
Elastic IP 割り当て ID は新しいEIPの作成で自動入力してNATゲートウェイの作成
※ パブリックサブネットであればどこでもOK
これで saa-pubsub-1a のサブネットにNATゲートウェイが作成された。
次にサブネットの種類ごとにルートテーブルを作成、設定する。ルートテーブルの作成
パブリックサブネット向けのルートテーブルと、プライベートサブネット用のルートテーブルを作成する。
- 左メニューから
ルートテーブルを選択してルートテーブルの作成を選択する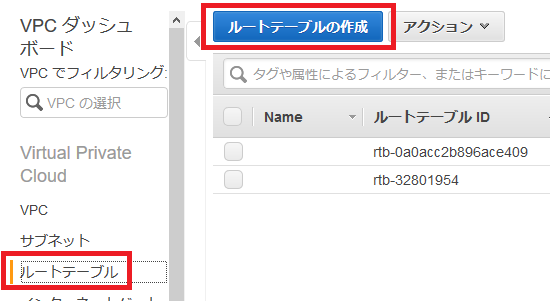
- パブリックサブネット向けルートテーブルの作成、設定
- 名前タグに
saa-public-route-tableを入力する VPCにsaa-vpcのVPC-IDを入力して作成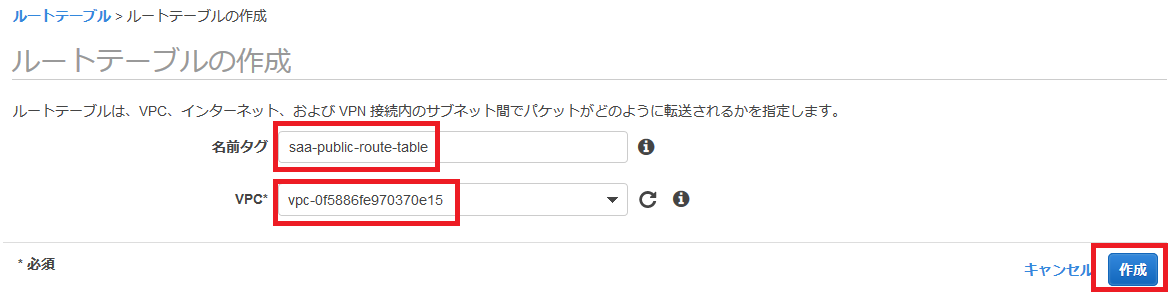
- ルートテーブル一覧に戻り
saa-public-route-tableを選択 > アクション > サブネットの関連付けの編集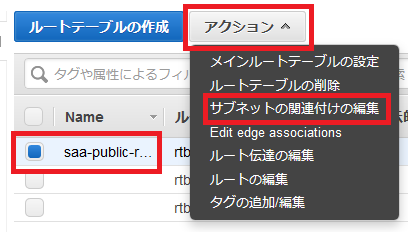
saa-pubsub-1a,saa-pubsub-1c,saa-pubsub-1dを選択し保存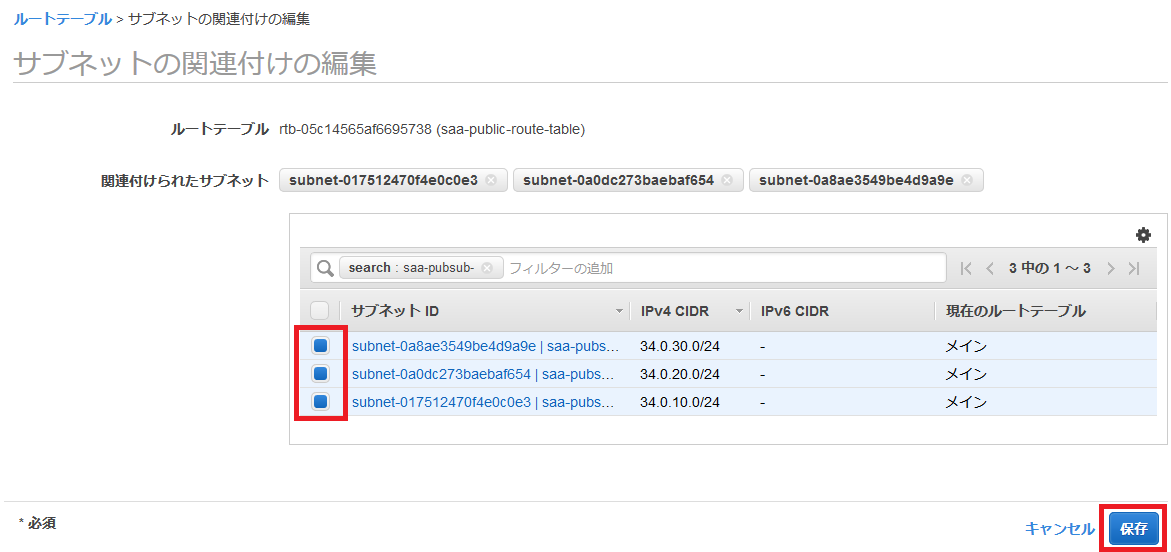
- ルートテーブル一覧に戻り
saa-public-route-tableを選択 > アクション > ルートの編集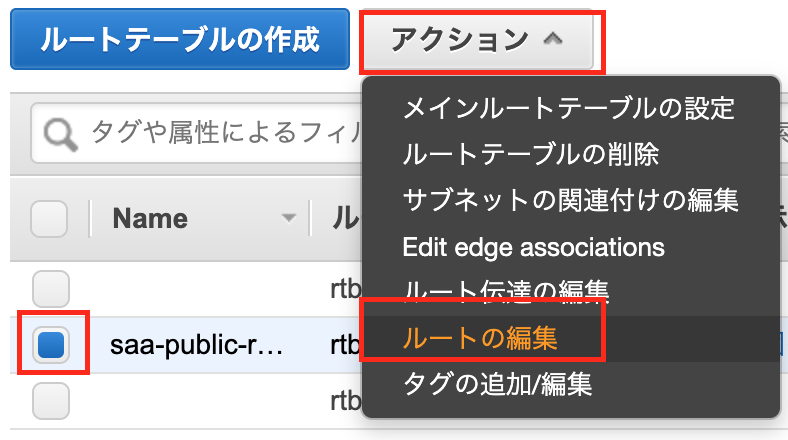
- ルートの追加 > 送信先に
0.0.0.0/0を、ターゲットにInternet Gateway>saa-vpc-igwを選択しルートの保存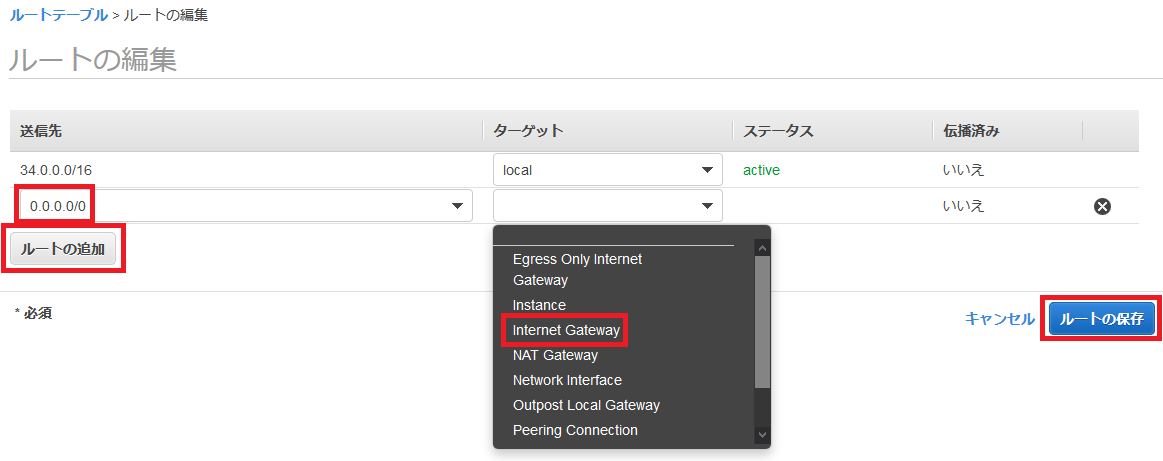
- プライベートサブネット向けルートテーブルの作成
- 名前タグに
saa-private-route-tableを入力する VPCにsaa-vpcのVPC-IDを入力して作成- ルートテーブル一覧に戻り
saa-private-route-tableを選択 > アクション > サブネットの関連付けの編集saa-prisub-1a,saa-prisub-1c,saa-prisub-1dを選択し保存- ルートテーブル一覧に戻り
saa-private-route-tableを選択 > アクション > ルートの編集- ルートの追加 > 送信先に
0.0.0.0/0を、ターゲットにNAT Gateway> 先程作成したNATゲートウェイのIDを選択しルートの保存これでルートテーブルの作成、設定が完了した。
動作確認
想定した動作になっているか確認する。
- 想定
- パブリックサブネットのインスタンス
- パブリックIPでアクセスできること
- インターネットに接続できること
- プライベートサブネットのインスタンスにアクセスできること
- プライベートサブネットのインスタンス
- NAT GateWay 経由でインターネットにアクセスできること
こんな感じで試してみる。
インスタンスの作成
- saa-pubsub-1c にインスタンスを作成する
EC2を検索してメニューを選択し左メニューからインスタンスを選択してインスタンスの作成を選択する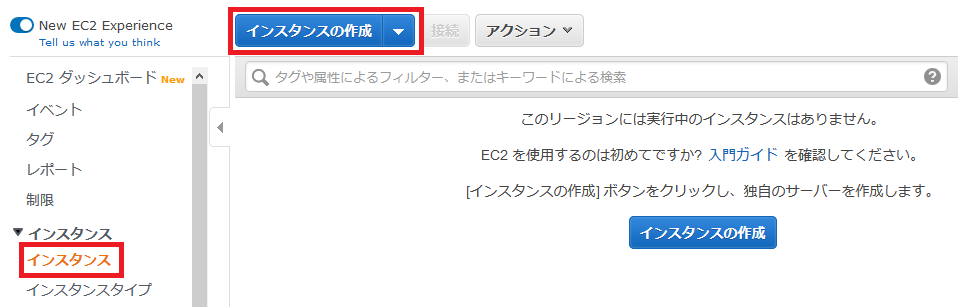
- Amazon マシンイメージに
Amazon Linux 2 AMI (HVM), SSD Volume Typeを選択する
- インスタンスタイプに
t2.microを選択する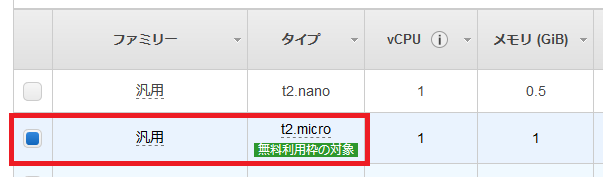
- インスタンスの詳細のネットワークに
saa-vpcを入力する サブネットにsaa-pubsub-1cを入力する その他はデフォルトで次のステップへ進む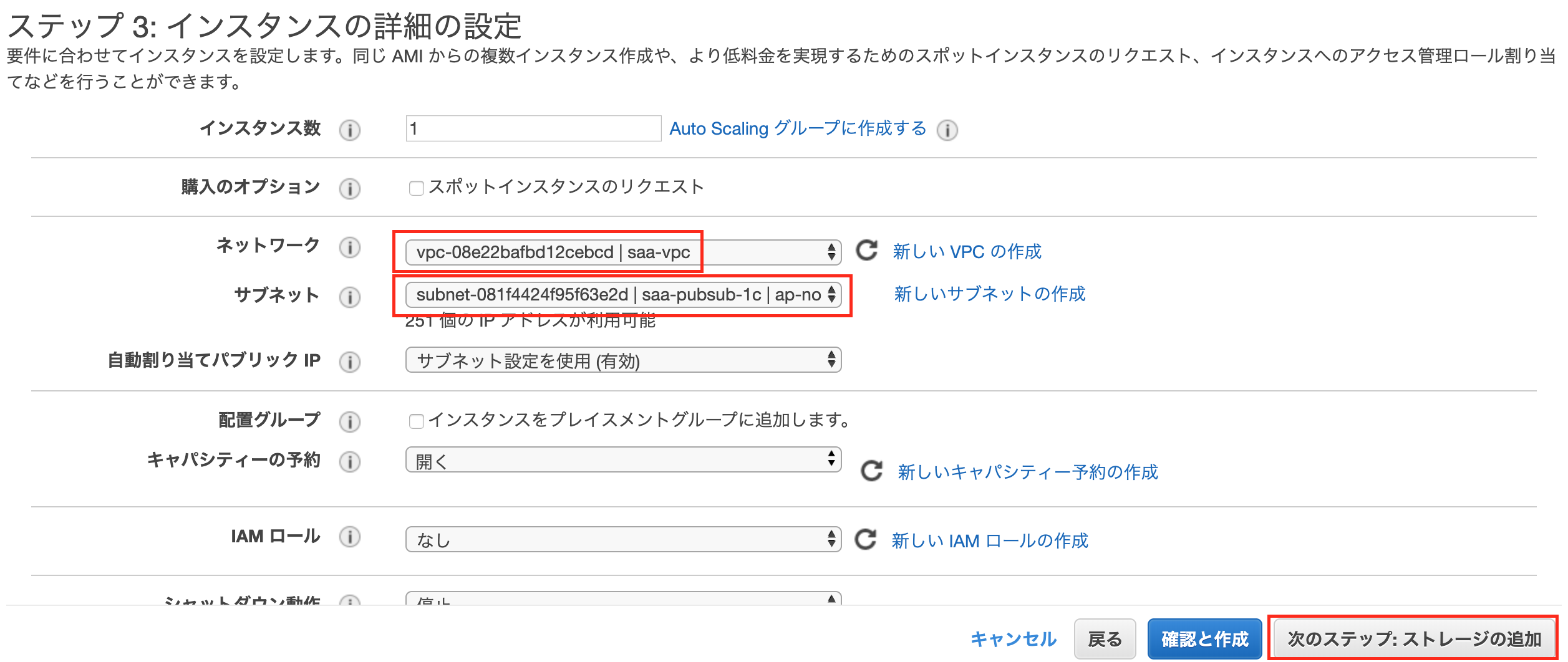
- ストレージはデフォルトで次のステップへ進む
- タグに キー:
Name値:pub-cを入力し次のステップへ進む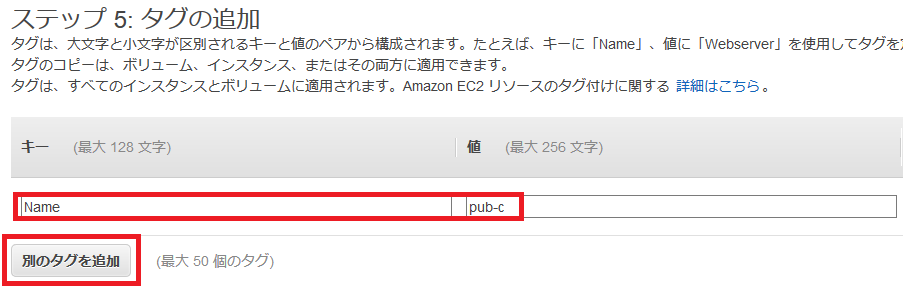
- セキュリティグループ名に
saa-ec2-webを入力する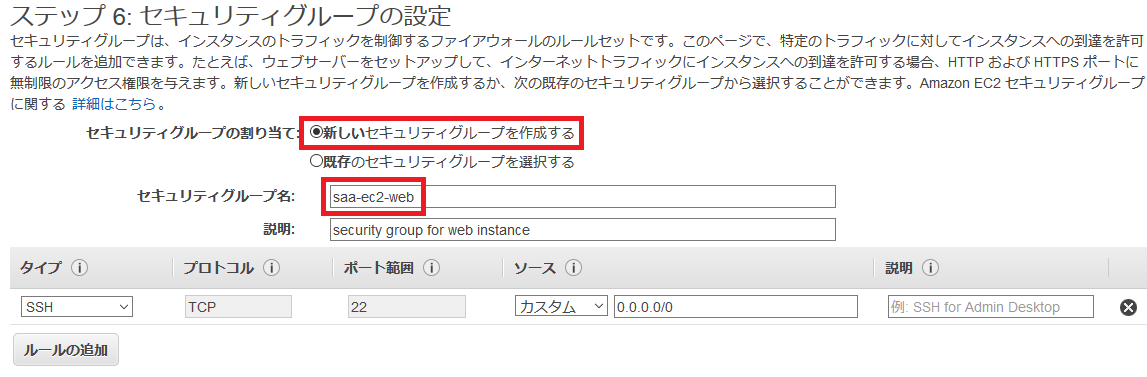
- 内容を確認して起動し、
新しいキーペアの作成キーペア名saa-keypairを入力しダウンロードする ※ キーペアはとても大切なものなのでなくさないこと!!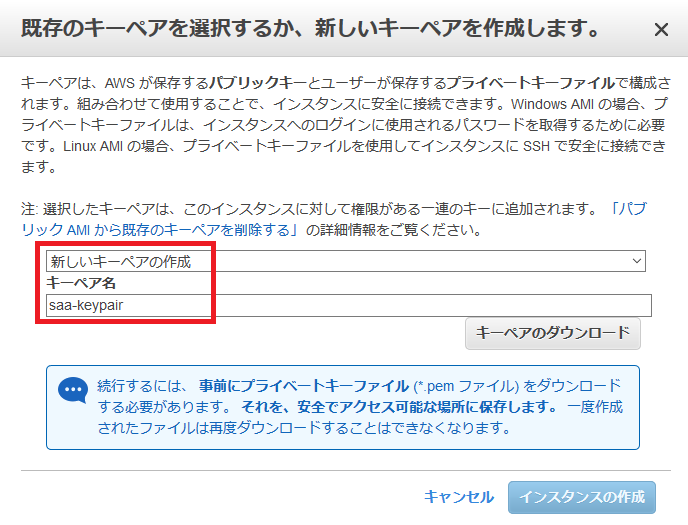
- saa-prisub-1c にインスタンスを作成する
pub-cと同様に作成する。ただし、サブネットはsaa-prisub-1cでタグはName:pri-cに置き換えて作成するこれでEC2インスタンスが作成できた。
接続の確認
pri-cはそもそもパブリックIPがないのでアクセスできない。
まずはpub-cにアクセスして、そこ経由でpri-cにアクセスできることを確認する。
pub-cのパブリックIPアドレスを確認しておく。
pri-cに接続するためにpub-cに鍵を送信しておく。
コマンドラインから以下を実行する。# pub-c のIPアドレスを設定する PUBC=<pub-cのパブリックIPアドレス> # キーペアの鍵を pub-c に転送する scp -i ./saa-keypair.pem ./saa-keypair.pem ec2-user@$PUBC:/home/ec2-user/ # pub-c に接続する ssh -i ./saa-keypair.pem -l ec2-user $PUBC接続できたら
pub-cからインターネットに接続できることを確認してみる。# Google のページにアクセスしてみる curl www.google.co.jpアクセスできたら
pri-cに接続できることを確認するためにpri-cのIPアドレスを確認する。
pub-cからpri-cに接続する。# pri-c のIPアドレスを環境変数に設定する PRIC=<pri-cのIPアドレス> # pri-c へ接続する ssh -i ./saa-keypair.pem ec2-user@$PRIC接続できた。次にNATゲートウェイ経由でインターネットに接続できることを確認する。
# pri-c から Google のページにアクセスしてみる curl www.google.co.jp接続できた。
これで図の構成の構築が完了した。
課金が発生してしまうので、不要なインスタンスやNAT Gatewayは削除しましょう。お疲れ様でした!
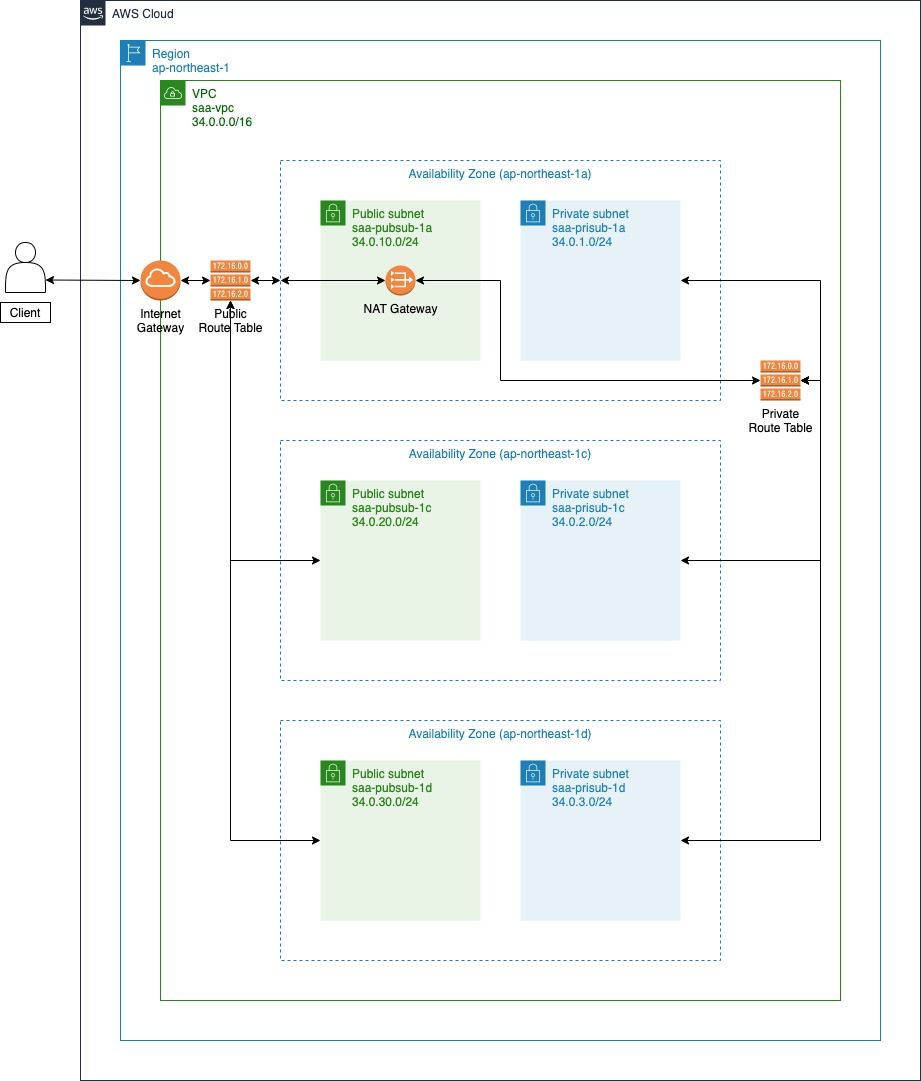
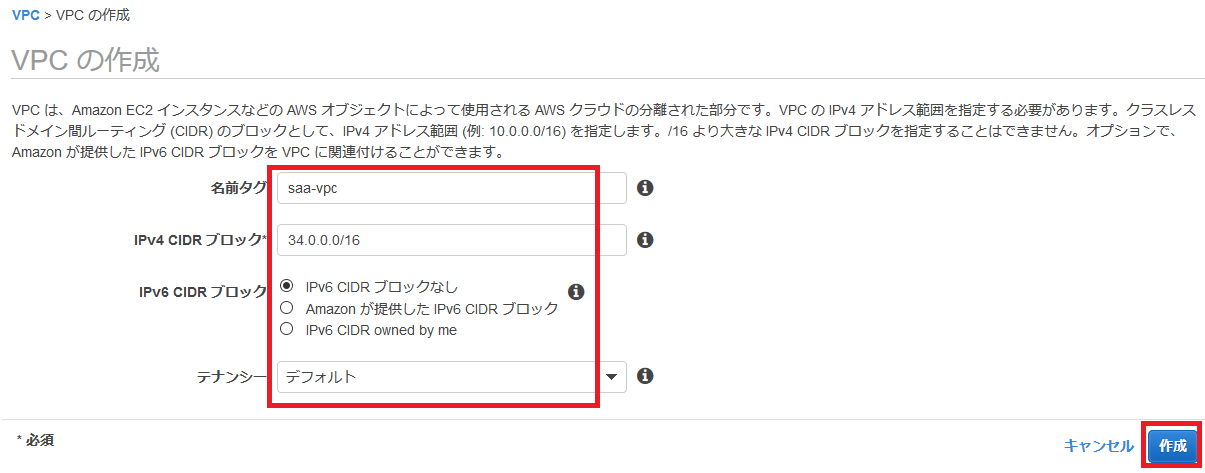
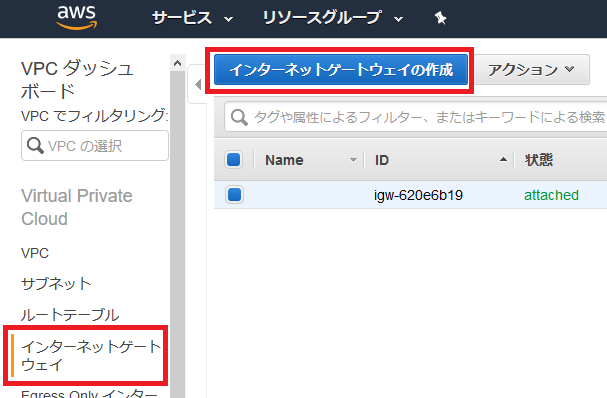
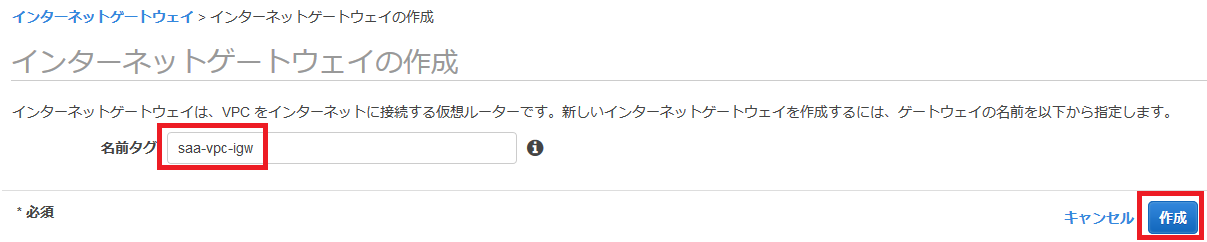
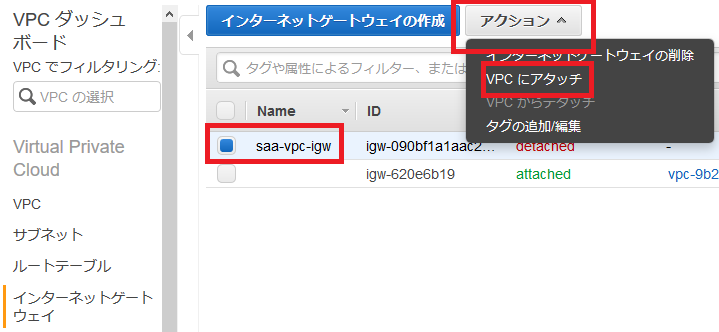
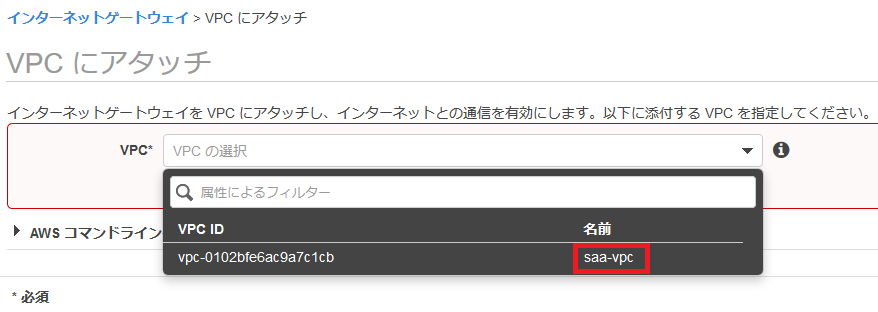
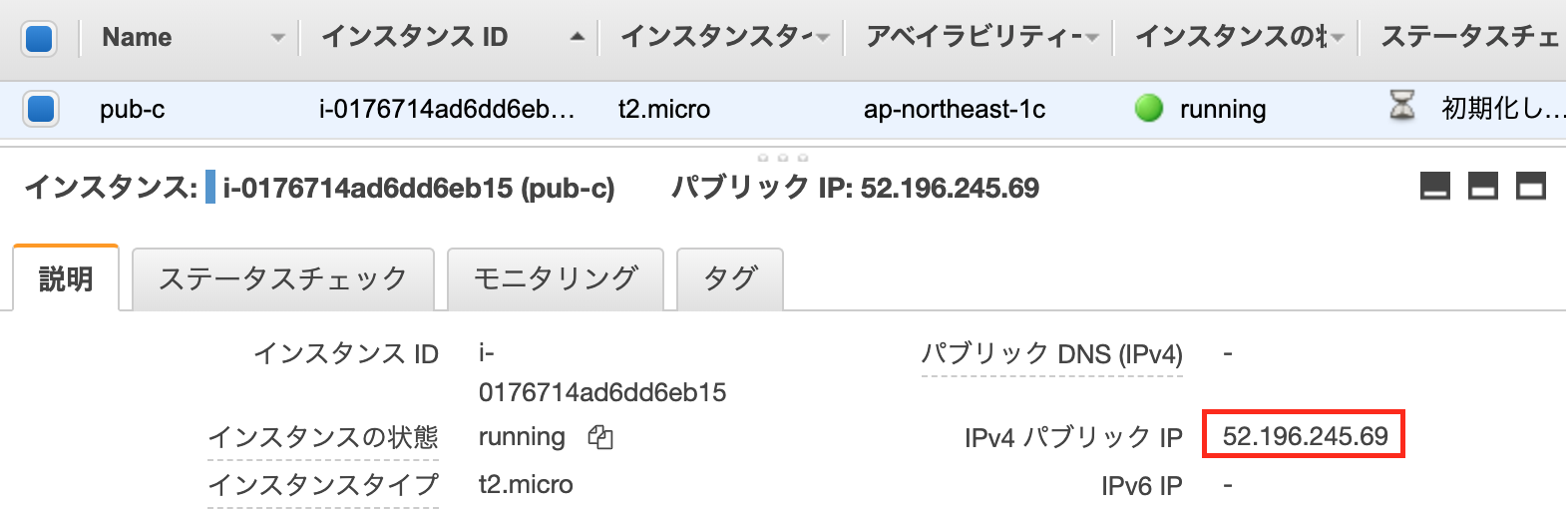
- 投稿日:2020-02-25T01:39:37+09:00
クラウド用語集
概要
・AWS 認定ソリューションアーキテクト – アソシエイト試験で出題されそうな用語を参考書籍よりまとめました。
用語
■アベイラビリティゾーン
・リージョン(東京リージョンなど)という地域の中、独立し異なる場所にある1つ以上のデータセンターのこと。
・データセンターはコンピューター、ストレージ、通信といったIT設備を設置運用する冗長化された施設。■インスタンス
・仮想化の用語として、物理的なコンピューター上で稼働する仮想的なサーバーのこと。
■エッジロケーション
・利用者から見て近くにあるデータセンターで、低レイテンシー(応答時間を短くする)実現の目的で利用。CloudFrontなどで利用される。
■オンプレミス
・ITシステムを利用企業の設備内に設置し、自前で運用する形態。サービスを借りて利用するクラウドとは対になる言葉。
■クエリ
・データの検索や更新、削除、抽出などの要求をデータベースに送信すること。
■コンテナ
・仮想化の1つでアプリケーション、ライブラリ、ミドルウェアなどをパッケージ化し、1つのOS上で実行プロセスとして独立して稼働するもの。
■シャード
・DBの負荷分散のためにインデックスを分け、複数のノードに分散して格納したまとまり。
■スケーリング
・規模を拡大、縮小する処理。水平分散で台数を増やす処理をスケールアウト(縮小はスケールイン)、垂直に能力向上させる処理をスケールアップ(縮小はスケールダウン)という。
■スナップショット
・ある時点でのファイルやデータベースなどの状態を丸ごとコピーしたもの。
■スループット
・単位時間あたりに処理できる量。単位時間内に実行出来る処理件数や通信上の実効伝送量。
■静的コンテンツ
・index.htmlなどのように、リクエストされたHTMLなどのデータを、サーバーのプログラムで処理などをせずにそのまま応答データとして送信する方式のWebページ。
■デプロイ
・開発工程の中で、開発したアプリケーションやサービスを利用できる状態にする作業。
■トランザクション
・複数の処理を、業務上一連の処理としてまとめたもの。この一連の処理は途中で処理を分離することができない。ある業務における一管理単位。
■トリガ
・何らかのきっかけによって、動作すること。引き金となること。
■バージョニング
・同時に複数バージョンが存在出来ること。S3では同じパケット内で複数オブジェクトのバージョンをもたせることが出来る。これにより、意図しない削除から復旧可能。
■バケット
・S3の用語。S3にデータをアップロードするには、S3バケットを作成する必要がある。
■ピアリング
・VPCでの用語。2つのVPC間でプライベートなトラフィックを可能にするネットワーキング接続。
■フルマネージド
・インフラへの変更リクエスト、モニタリング、パッチ管理、セキュリティ、バックアップなどが自動化され、運用負担とリスクの軽減が可能なサービス形態。
■プロビジョニング
・必要に応じたネットワークやコンピューター設備等のリソースを予測して、準備すること。
■プロプライエタリ
・ある特定の開発元のソフトウェア製品(例:Windows,Macなど)。オープンソースの反意語。
■ヘルスチェック
・システムなどの正常稼働を外部の別の機能から監視あるいは検査すること。ELBなどで実施。
■ホストされる
・間貸しする。ホスティングする。
■リージョン
・完全に独立して、地理的に離れた領域で構成されたAWSサービスを提供するエリア。リージョンの中に少なくとも2つ以上のアベイラビリティゾーンがある。
■リスナー
・ネットワークでは外部からの接続要求を待ち続けるプログラム。TCPのポート等で待ち受ける。
■リファクタリング
・プログラムの動作/振る舞いを変更せず、内部の設計やコードを見直し変更すること。
■レガシーアプリケーション
・現行OSのバージョンではサポートされていないアプリケーション。クラウドのオープン技術上で動作しないアプリケーションという意味でも使用される。
■ローカルリポジトリ
・ファイルやディレクトリの状態を記録する場所で、自分の手元のマシン上に配置しているもの。
■ロードバランサ
・サーバーにかかる負荷をある設定されたパターンによって振り分けるための装置。
■ワークロード
・OS、ミドルウェア、アプリケーションソフト、データ等、実行状態にあるソフトウェアの全体。
■DR(Disaster Recovery)
・ITシステムが自然災害等で深刻な被害を受けた時に、損害の軽減、回復・復旧すること。
■NAT
・ネットワークアドレス変換の1つ。プライベートIPのアドレスをグローバルIPアドレスへ変換。プライベートからパブリックに出る時に必要。
■RPO(Recovery Point Objective)
・目標復旧時点。失われたデータを復元する際に、過去のどの時点まで遡ることを許容するか表す目標値。
■RTO(Recovery Time Objective)
・目標復旧時間。業務が停止後、一定レベルに復旧するまでの目標時間。
参考書籍情報
一夜漬け AWS認定ソリューションアーキテクト アソシエイト 直前対策テキスト :山内 貴弘 (著)
https://www.amazon.co.jp/%E4%B8%80%E5%A4%9C%E6%BC%AC%E3%81%91-AWS%E8%AA%8D%E5%AE%9A%E3%82%BD%E3%83%AA%E3%83%A5%E3%83%BC%E3%82%B7%E3%83%A7%E3%83%B3%E3%82%A2%E3%83%BC%E3%82%AD%E3%83%86%E3%82%AF%E3%83%88-%E3%82%A2%E3%82%BD%E3%82%B7%E3%82%A8%E3%82%A4%E3%83%88-%E7%9B%B4%E5%89%8D%E5%AF%BE%E7%AD%96%E3%83%86%E3%82%AD%E3%82%B9%E3%83%88-%E5%B1%B1%E5%86%85/dp/4798059463
- 投稿日:2020-02-25T01:05:11+09:00
(メモ)VPCEについて
VPCE(VPCエンドポイント)とは?
・DynamoDB、S3、Route53といったリージョンサービスに対してVPCからプライベート接続出来る仮想ネットワークサービスのことだよ!
Point
・VPC内のENIからプライベートにリンク(接続)することをプライベートリンクと言うよ!VPCEは2種類ある?
・ゲートウェイ型 と インターフェース型が存在するよ!
<ゲートウェイ型の特徴>
・S3、DynamoDBがサービス対象!
・ルートテーブルに設定して使用!
・安価<インターフェース型の特徴>
・実体はENI(仮想ネットワークカード)
・セキュリティグループにアタッチして使用!
・サービス対象の更新スピードが早いので公式ページを要チェックだ!Point
・インターフェース型に対応したAWSサービスをプライベートリンク対応したAWSサービスと呼ぶこともあるよ!
- 投稿日:2020-02-25T01:05:11+09:00
【AWS】VPCEについて
VPCE(VPCエンドポイント)とは?
・DynamoDB、S3、Route53といったリージョンサービスに対してVPCからプライベート接続出来る仮想ネットワークサービスのことだよ!
Point
・VPC内のENIからプライベートにリンク(接続)することをプライベートリンクと言うよ!VPCEは2種類ある?
・ゲートウェイ型 と インターフェース型が存在するよ!
<ゲートウェイ型の特徴>
・S3、DynamoDBがサービス対象!
・ルートテーブルに設定して使用!
・安価<インターフェース型の特徴>
・実体はENI(仮想ネットワークカード)
・セキュリティグループにアタッチして使用!
・サービス対象の更新スピードが早いので公式ページを要チェックだ!Point
・インターフェース型に対応したAWSサービスをプライベートリンク対応したAWSサービスと呼ぶこともあるよ!
- 投稿日:2020-02-25T00:57:26+09:00
(メモ)NATゲートウェイとENIについて
NATゲートウェイとは?
・NATゲートウェイはプライベートサブネットのインスタンスをElasticIPやプライベートIPを持つことなくインターネットに接続させる為に必要だよ!
<使用上の注意>
・NATゲートウェイはパブリックサブネットにアタッチしよう!
・NATゲートウェイはプライベートIPをElasticIPに変換してインターネットゲートウェイに接続するので、ElasticIPがインターネットゲートウェイに向くようにルーティングが必要だよ!
・インターネットからプライベートサブネットのインスタンスへはアクセス出来ないよ!
・NATゲートウェイにはENI(後述)が自動でアタッチされているよ!
・NATゲートウェイ作成時に必ずENIにElasticIPを割り振らないと作成出来ないよ!ENIとは?
・Elastic Network Interface のこと。
・VPC内の仮想NIC(ネットワークカード)が実現出来るよ!
・ENIにはサブネットのIPレンジより自動でプライベートIPがアタッチされているよ!
- 投稿日:2020-02-25T00:57:26+09:00
【AWS】NATゲートウェイとENIについて
NATゲートウェイとは?
・NATゲートウェイはプライベートサブネットのインスタンスをElasticIPやプライベートIPを持つことなくインターネットに接続させる為に必要だよ!
<使用上の注意>
・NATゲートウェイはパブリックサブネットにアタッチしよう!
・NATゲートウェイはプライベートIPをElasticIPに変換してインターネットゲートウェイに接続するので、ElasticIPがインターネットゲートウェイに向くようにルーティングが必要だよ!
・インターネットからプライベートサブネットのインスタンスへはアクセス出来ないよ!
・NATゲートウェイにはENI(後述)が自動でアタッチされているよ!
・NATゲートウェイ作成時に必ずENIにElasticIPを割り振らないと作成出来ないよ!ENIとは?
・Elastic Network Interface のこと。
・VPC内の仮想NIC(ネットワークカード)が実現出来るよ!
・ENIにはサブネットのIPレンジより自動でプライベートIPがアタッチされているよ!
- 投稿日:2020-02-25T00:47:43+09:00
(メモ)VPCでネットワークと通信する為に必要なこと
1.VPCにIGWをアタッチしよう!
・IGW(※1)をVPCにアタッチすることでEC2インスタンスからインターネットへ接続することが可能になるよ!
※1・・・IGW(インターネットゲートウェイ)とは?
・VPCにアタッチして使用するネットワークコンポーネント(ネットワーク接続に必要なソフトウェア)2.ルートテーブルの設定をIGWに向けた設定にルーティングしよう!
・サブネットのルートテーブルの設定でIGWに向けた設定をルーティングすることでVPC内の通信はローカルルートを通り、それ以外の通信はIGWを通る用になるよ!
Point
・デフォルトゲートウェイについて
→サブネットに設定されているルートテーブル内のIGWのIPアドレスがワイルドカード(全て0)で全てのIPアドレスを示しているルールのこと。
・パブリックサブネットとプライベートサブネットについて
→AWSではデフォルトゲートウェイにIGWが設定されているサブネットをパブリックサブネットと言うよ!逆にデフォルトゲートウェイが設定されていないサブネットのことをプライベートサブネットと言うよ!3.EC2インスタンスにIPアドレスをアタッチしよう!
・インスタンスに ElasticIP(※1) か PublicIP(※2) をアタッチしよう!
※1・・・ElasticIPとは?
・インスタンスにアタッチ/デタッチ可能な静的IPアドレスのこと。
(インスタンスが停止、再起動、終了した場合でも同じIPアドレスとなる)
注意:どこにもアタッチしていないと1時間当たり1円掛かるので注意!※2・・・PublicIPとは?
・AWSのIPアドレスプールより割り当てられるインターネットへ接続出来るIPアドレスのこと。4.セキュリティグループとネットワークACLを設定しよう!
<セキュリティグループ>
・インスタンス単位でアタッチして使用するよ!
・IPアドレスの接続範囲や他のセキュリティグループを指定して使用することも出来るよ!<ネットワークACL>
・サブネット単位にアタッチするファイヤーウォールのことだよ!
・設定したルールは上から適応されていくよ!
- 投稿日:2020-02-25T00:47:43+09:00
【AWS】VPCでネットワークと通信する為に必要なこと
1.VPCにIGWをアタッチしよう!
・IGW(※1)をVPCにアタッチすることでEC2インスタンスからインターネットへ接続することが可能になるよ!
※1・・・IGW(インターネットゲートウェイ)とは?
・VPCにアタッチして使用するネットワークコンポーネント(ネットワーク接続に必要なソフトウェア)2.ルートテーブルの設定をIGWに向けた設定にルーティングしよう!
・サブネットのルートテーブルの設定でIGWに向けた設定をルーティングすることでVPC内の通信はローカルルートを通り、それ以外の通信はIGWを通る用になるよ!
Point
・デフォルトゲートウェイについて
→サブネットに設定されているルートテーブル内のIGWのIPアドレスがワイルドカード(全て0)で全てのIPアドレスを示しているルールのこと。
・パブリックサブネットとプライベートサブネットについて
→AWSではデフォルトゲートウェイにIGWが設定されているサブネットをパブリックサブネットと言うよ!逆にデフォルトゲートウェイが設定されていないサブネットのことをプライベートサブネットと言うよ!3.EC2インスタンスにIPアドレスをアタッチしよう!
・インスタンスに ElasticIP(※1) か PublicIP(※2) をアタッチしよう!
※1・・・ElasticIPとは?
・インスタンスにアタッチ/デタッチ可能な静的IPアドレスのこと。
(インスタンスが停止、再起動、終了した場合でも同じIPアドレスとなる)
注意:どこにもアタッチしていないと1時間当たり1円掛かるので注意!※2・・・PublicIPとは?
・AWSのIPアドレスプールより割り当てられるインターネットへ接続出来るIPアドレスのこと。4.セキュリティグループとネットワークACLを設定しよう!
<セキュリティグループ>
・インスタンス単位でアタッチして使用するよ!
・IPアドレスの接続範囲や他のセキュリティグループを指定して使用することも出来るよ!<ネットワークACL>
・サブネット単位にアタッチするファイヤーウォールのことだよ!
・設定したルールは上から適応されていくよ!
- 投稿日:2020-02-25T00:37:22+09:00
【AWS】複数のAWSアカウントを管理するためにStackSetを活用する #2/2【Multi Accounts】
はじめに
この記事は全部で2部構成となります。
【AWS】複数のAWSアカウントを管理するためにStackSetを活用する #1/2【Multi Accounts】
【AWS】複数のAWSアカウントを管理するためにStackSetを活用する #2/2【Multi Accounts】 ←いまココ本稿では、AWS OrganizationsとCloudFormation StackSetを利用し、複数AWSアカウント管理のための最低限の基盤を作ります。
最終的に、新規で作成されるAWSアカウントに対し、下記のAWSリソースが作成されます。
- 新規AWSアカウント上に作成されるAWSリソース
- AWS Organizationsで作成されるIAM Role
- PermissionsはAdministratorAccessと同等のPolicyを持つ
- Trust Relationshipsは、OrganizationsのmasterアカウントのPrincipalであれば誰でもAssumeRole出来る
- CloudFormation StackSetで作成する、各権限用のIAM Role
- それぞれ、管理者、経理部門などの権限に応じたPermissionsが付与されている
- すべての子AWSアカウントに対して同等のIAM Roleを作成できる
前提条件/検証環境
- masterアカウント
- AWSアカウントID: 123456789012
- AWS CLIのプロファイル名: master
- AWS Organizationsを有効にしておく
- 子AWSアカウント(新規作成するAWSアカウント)
- AWSアカウントID: 987654321098
- AWSアカウントのエイリアス名: investigate-multi-accounts
- AWS CLIのプロファイル名: investigate-multi-accounts
- 管理用のIAM Role: OrganizationAccountAccessRole
- StackSet構成
- masterアカウント
- StackSet用のIAM Role: AWSCloudFormationStackSetAdministrationRole
- 子AWSアカウントに、StackSetを利用して追加するAWSリソース
- IAM Role
- FullAdministratorRole
- AccountingRole
手順の概要
- masterアカウントに、CloudFormation StackSet用のRoleを作成する
- AWS Organizationsを利用して、新規にAWSアカウントを作成する
- 作業用環境にSwitch Roleの設定をする
- AWS CLI
- AWS Management Console
- masterアカウントにStackSetを作る
- 子AWSアカウントに作成するAWSリソースを定義したCloudFormation Templateを作る
- masterアカウントにStackSetを作る
- 子AWSアカウントにStack Instanceを作り、必要なAWSリソースを作成する
- masterアカウント上でStack Instance作成操作を実行する
- 子AWSアカウントで、作成されたStack Instanceを確認する
- Stack Instanceの確認
- 作成されたIAM Roleの確認
手順詳細
masterアカウントに、CloudFormation StackSet用のRoleを作成する
CloudFormationサービスが子AWSアカウントのCFn Stack Instanceを作る際のIAM Roleが必要となりますので、これをまず作成します。
Role名は「AWSCloudFormationStackSetAdministrationRole」となります。CloudFormationサービスが利用するIAM Role、AssumeRoleの順序については下記にまとめてあります。
https://qiita.com/tmiki/items/6a72b9ce67ed0a85e243#cfn-stackset%E3%81%AB%E3%82%88%E3%82%8Btarget-account%E3%81%B8%E3%81%AEstack%E4%BD%9C%E6%88%90%E3%81%AE%E4%BB%95%E7%B5%84%E3%81%BF以下のPermissions、Trust Relationshipsを持つIAM Roleを、「AWSCloudFormationStackSetAdministrationRole」という名称で作成します。
Permissions{ "Version": "2012-10-17", "Statement": [ { "Action": [ "sts:AssumeRole" ], "Resource": [ "arn:aws:iam::*:role/OrganizationAccountAccessRole" ], "Effect": "Allow" } ] }Trust Relationships{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "Service": "cloudformation.amazonaws.com" }, "Action": "sts:AssumeRole" } ] }同等のIAM Roleを作成できるCFn templateを下記にも置いておきます。
https://github.com/tmiki/cloud-formation-templates/blob/master/stack-sets/cfn-stack-set-01-administrator-account.ymlAWS Organizationsを利用して、新規にAWSアカウントを作成する
まずAWS CLIの設定を行い、masterアカウントに対して各APIが実行できることを確認します。
aws sts get-caller-identity$ aws --profile master sts get-caller-identity { "Account": "123456789012", "UserId": "AIDA.................", "Arn": "arn:aws:iam::123456789012:user/tmiki" }次にmasterアカウントでorganizations create-accountを実行し、子となるAWSアカウントを作ります。
新規作成対象のAWSアカウントには、「OrganizationAccountAccessRole」という名称のIAM Roleが併せて作成されます。これはAdministrators権限を持ち、masterアカウントからのAssumeRoleを許可するTrustRelationshipを持ちます。
このIAM Role名は「--role-name」オプションで変更することが可能です。create-account — AWS CLI 1.18.5 Command Reference
https://docs.aws.amazon.com/cli/latest/reference/organizations/create-account.htmlaws organizations create-account$ aws --profile master organizations create-account \ --email youremail+investigate-multi-accounts@gmail.com \ --account-name investigate-multi-accounts \ --iam-user-access-to-billing ALLOW { "CreateAccountStatus": { "RequestedTimestamp": 1582527438.181, "State": "IN_PROGRESS", "Id": "car-e5..............................", "AccountName": "investigate-multi-accounts" } }上記のレスポンスからは、新規作成したAWSアカウントのIDが分からないので、organizations list-accountsを実行し、AWSアカウントIDを確認します。
queryオプションを指定し、Nameが「investigate-multi-accounts」となっているもののみを抽出します。list-accounts — AWS CLI 1.18.5 Command Reference
https://docs.aws.amazon.com/cli/latest/reference/organizations/list-accounts.htmlaws organizations list-accounts$ aws --profile master organizations list-accounts \ --query "Accounts[?Name=='investigate-multi-accounts']" [ { "Status": "ACTIVE", "Name": "investigate-multi-accounts", "Email": "youremail+investigate-multi-accounts@gmail.com", "JoinedMethod": "CREATED", "JoinedTimestamp": 1582527440.143, "Id": "987654321098", "Arn": "arn:aws:organizations::123456789012:account/o-**********/987654321098" } ]なお、AWSアカウントIDがすでに分かっていれば、organizations describe-accountでも同等の結果を得られます。
describe-account — AWS CLI 1.18.5 Command Reference
https://docs.aws.amazon.com/cli/latest/reference/organizations/describe-account.htmlaws organizations describe-account$ aws --profile master organizations describe-account \ --account-id 987654321098 { "Account": { "Status": "ACTIVE", "Name": "investigate-multi-accounts", "Email": "youremail+investigate-multi-accounts@gmail.com", "JoinedMethod": "CREATED", "JoinedTimestamp": 1582527440.143, "Id": "987654321098", "Arn": "arn:aws:organizations::123456789012:account/o-**********/987654321098" } }AWS Management Consoleからも、新規作成したAWSアカウントを確認できます。
作業用環境にSwitch Roleの設定をする
作成した子AWSアカウントの操作をするため、AWS CLI、AWS Management ConsoleにSwitch Roleの設定を追加します。
AWS CLI
AWS CLIの設定に、新規作成したAWSアカウントのIAM RoleをAssumeRoleするための設定を追加します。
予め「master」という名称のprofileを設定済みであるものとします。~/.aws/config$ cat ~/.aws/config [profile master] aws_account_id = your-aws-master-account output = json~/.aws/credentials$ cat ~/.aws/credentials [master] aws_access_key_id = AKIA************* aws_secret_access_key = ****************************************AWS CLIの設定ファイルに以下の内容を追記します。
vi ~/.aws/config$ vi ~/.aws/config ### 下記を追記する [profile investigate-multi-accounts] source_profile = master role_arn = arn:aws:iam::987654321098:role/OrganizationAccountAccessRolests get-caller-identityを発行し、AssumeRole出来ることを確認します。
get-caller-identity — AWS CLI 1.18.5 Command Reference
https://docs.aws.amazon.com/cli/latest/reference/sts/get-caller-identity.htmlaws --profile investigate-multi-accounts sts get-caller-identity$ aws --profile investigate-multi-accounts sts get-caller-identity { "Account": "987654321098", "UserId": "AROA*****************:botocore-session-1582532666", "Arn": "arn:aws:sts::987654321098:assumed-role/OrganizationAccountAccessRole/botocore-session-1582532666" }AWS Management Console
必要に応じて、AWS Management Consoleから、新規作成したAWSアカウントにAssumeRole出来るよう設定します。
Chromeを利用しているのであれば、AWS Extend Switch Rolesというプラグインを利用すると便利です。https://github.com/tilfin/aws-extend-switch-roles
これはAWS CLIと同一のフォーマット(i.e. 上記で追加した~/.aws/configの内容そのまま)で設定を追加できます。
masterアカウントにStackSetを作る
次から、いよいよCloudFormation StackSetを利用して、Stackを作っていきます。
子AWSアカウントに作成するAWSリソースを定義したCloudFormation Templateを作る
子AWSアカウントには、とりあえず管理者用IAM Role「FullAdministratorRole」と、財務部門向けIAM Role「AccountingRole」を作ることとします。
以下のCFnテンプレートを「iam-roles-in-the-target-account.yaml」というファイル名で作成します。下記+αを記載したCFnテンプレートを、GitHubにも置いておきます。
https://github.com/tmiki/cloud-formation-templates/blob/master/stack-sets/cfn-stack-set-11-resources.ymliam-roles-in-the-target-account.yamlAWSTemplateFormatVersion: '2010-09-09' # ------------------------------------------------------------ # Parameters section # ------------------------------------------------------------ Parameters: AdministratorAwsAccountId: Description: An AWS account id where all IAM users created in and they will be principals placed into each Role's trust relationship policy. Type: Number Default: 123456789012 FullAdministratorRoleName: Description: The IAM Role name of Full Administrators. Type: String Default: FullAdministratorRole AccountingRoleName: Description: The IAM Role name of Accountants. Type: String Default: AccountingRole # ------------------------------------------------------------ # Resources section # ------------------------------------------------------------ Resources: # AWS::IAM::Role - AWS CloudFormation # https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-iam-role.html FullAdministratorRole: Type: AWS::IAM::Role Properties: RoleName: !Ref FullAdministratorRoleName AssumeRolePolicyDocument: Version: "2012-10-17" Statement: - Effect: "Allow" Principal: AWS: - !Ref AdministratorAwsAccountId Action: - sts:AssumeRole Description: This role allows IAM users in the administrator account to perform AssumeRole to obtain the privileges of this AWS account Path: '/' Policies: - PolicyName: AllowAdministratorAccess PolicyDocument: Version: "2012-10-17" Statement: - Effect: "Allow" Action: "*" Resource: "*" Tags: - Key: Name Value: !Ref FullAdministratorRoleName - Key: EnvName Value: All # AWS::IAM::Role - AWS CloudFormation # https://docs.aws.amazon.com/AWSCloudFormation/latest/UserGuide/aws-resource-iam-role.html AccountingRole: Type: AWS::IAM::Role Properties: RoleName: !Ref AccountingRoleName AssumeRolePolicyDocument: Version: "2012-10-17" Statement: - Effect: "Allow" Principal: AWS: - !Ref AdministratorAwsAccountId Action: - sts:AssumeRole Description: This role allows IAM users in the administrator account to invoke billing-related actions within the target AWS account. Path: '/' ManagedPolicyArns: - arn:aws:iam::aws:policy/job-function/Billing Tags: - Key: Name Value: !Ref AccountingRoleName - Key: EnvName Value: AllmasterアカウントにStackSetを作る
AWS CLIから以下のように実行してStackSetを作ります。
この時点では、masterアカウントにStackSetが作成されたのみで、子AWSアカウントには何も作成されていません。create-stack-instances — AWS CLI 1.18.5 Command Reference
https://docs.aws.amazon.com/cli/latest/reference/cloudformation/create-stack-instances.htmlaws --profile master cloudformation create-stack-set$ aws --profile master cloudformation create-stack-set \ --region us-east-1 \ --stack-set-name basic-iam-roles \ --template-body file://iam-roles-in-the-target-account.yaml \ --parameters ParameterKey=AdministratorAwsAccountId,ParameterValue=123456789012 \ --execution-role-name OrganizationAccountAccessRole \ --capabilities CAPABILITY_NAMED_IAM { "StackSetId": "basic-iam-roles:********-****-****-****-************" }なお今回、StackSetの作成先として、 us-east-1 (North Virginia)を明示的に指定しています。
これはAWSアカウント/AWSリソース管理のポリシー上の問題となりますが、GlobalなAWSリソースを作成するためのCloudFormation Stack/StackSetは、us-east-1に集約する方が管理しやすい、との判断です。
実際にGlobalなAWSリソース用のStack/StackSetをどのリージョンに作るかは、各組織のポリシーと判断に任されると思います。実行後、成功すると上記のようにStackSetIdが出力されます。
作成されたStackSetを確認します。describe-stack-set — AWS CLI 1.18.5 Command Reference
https://docs.aws.amazon.com/cli/latest/reference/cloudformation/describe-stack-set.htmlaws --profile master cloudformation describe-stack-set$ aws --profile master cloudformation describe-stack-set \ --region us-east-1 \ --stack-set-name basic-iam-roles ### ※出力結果省略上記StackSetに紐づくStack Instanceを確認します。まだ何も存在していないことが分かります。
aws --profile master cloudformation list-stack-instances$ aws --profile master cloudformation list-stack-instances \ --region us-east-1 \ --stack-set-name basic-iam-roles { "Summaries": [] }子AWSアカウントにStack Instanceを作り、必要なAWSリソースを作成する
masterアカウント上でStack Instance作成操作を実行する
masterアカウント上で、cloudformation create-stack-instancesを実行します。
指定するパラメータは、masterアカウントのものなのか、子AWSアカウントのものなのか混乱しやすいので注意が必要です。
- region: masterアカウント側の指定。どこのRegionのStackSetが操作対象となるかを指定する。今回はus-east-1で作成している。
- stack-set-name: masterアカウント側の指定。上記までに作成したStackSetの名前。
- accounts: 子AWSアカウントID。複数の子AWSアカウントIDを指定することもできる。
- regions: 子AWSアカウント側の指定。Stack InstanceをどこのRegionに作成するかを指定する。今回はus-east-1を指定する。
create-stack-instances — AWS CLI 1.18.5 Command Reference
https://docs.aws.amazon.com/cli/latest/reference/cloudformation/create-stack-instances.html$ aws --profile master cloudformation create-stack-instances \ --region us-east-1 \ --stack-set-name basic-iam-roles \ --accounts 987654321098 \ --regions us-east-1 ### OperationIdが出力される { "OperationId": "abcd1234-aaaa-bbbb-cccc-ddddeeeeffff" }出力されたOperationIdをもとに、Stack Instanceの作成状況を確認することができます。--operation-idオプションに、先ほど出力された値を指定します。
Statusが「RUNNING」であれば、Stack Instance作成中のようです。aws --profile master cloudformation describe-stack-set-operation$ aws --profile master cloudformation describe-stack-set-operation \ --region us-east-1 \ --stack-set-name basic-iam-roles \ --operation-id abcd1234-aaaa-bbbb-cccc-ddddeeeeffff { "StackSetOperation": { "Status": "RUNNING", "AdministrationRoleARN": "arn:aws:iam::123456789012:role/AWSCloudFormationStackSetAdministrationRole", "OperationPreferences": { "RegionOrder": [] }, "ExecutionRoleName": "OrganizationAccountAccessRole", "Action": "CREATE", "CreationTimestamp": "2020-02-24T13:42:53.125Z", "StackSetId": "basic-iam-roles:12345678-9999-aaaa-bbbb-ccccddddeeee", "OperationId": "abcd1234-aaaa-bbbb-cccc-ddddeeeeffff" } }Statusが「SUCCEEDED」になれば、Stack Instance作成完了です。
aws --profile master cloudformation describe-stack-set-operation$ aws --profile master cloudformation describe-stack-set-operation \ --region us-east-1 \ --stack-set-name basic-iam-roles \ --operation-id abcd1234-aaaa-bbbb-cccc-ddddeeeeffff { "StackSetOperation": { "Status": "SUCCEEDED", "AdministrationRoleARN": "arn:aws:iam::123456789012:role/AWSCloudFormationStackSetAdministrationRole", "OperationPreferences": { "RegionOrder": [] }, "ExecutionRoleName": "OrganizationAccountAccessRole", "Action": "CREATE", "CreationTimestamp": "2020-02-24T13:42:53.125Z", "StackSetId": "basic-iam-roles:12345678-9999-aaaa-bbbb-ccccddddeeee", "OperationId": "abcd1234-aaaa-bbbb-cccc-ddddeeeeffff" } }AWS Management ConsoleからもStackSetが作成されたことを確認できます。
子AWSアカウントで、作成されたStack Instanceを確認する
Stack Instanceの確認
子AWSアカウント上には、通常のCloudFormation Stackとして作成されます。
子AWSアカウント側でcloudformation list-stacksを実行することで確認できます。
作成されたStack Instanceは、「StackSet-[StackSet名]-[ランダムなUID]」という名称で作成されます。$ aws --profile investigate-multi-accounts cloudformation list-stacks \ --region us-east-1 \ --query "StackSummaries[?starts_with(StackName, 'StackSet-basic-iam-roles-')]" [ { "StackId": "arn:aws:cloudformation:us-east-1:987654321098:stack/StackSet-basic-iam-roles-98765432-abcd-ef12-3456-7890abcd1234/abcd0123-9876-5432-10fe-1234abcd5678", "DriftInformation": { "StackDriftStatus": "NOT_CHECKED" }, "TemplateDescription": "This template is intended to be used for CloudFormation StackSets. That enables you to create fundamental IAM roles into each target AWS accounts. Those are used for AssumeRole by IAM users in your master AWS account.\nPlease notice this template requires the \"CAPABILITY_NAMED_IAM\" capability to create a CloudFormation stack. In addition, since this template creates an IAM Role with fixed name, I recommend you to create a CFn stack in the N.Virginia(us-east-1) region.\nA sample command line with necessary parameters is below. $ aws cloudformation create-stack-set --region us-east-1 --stack-name <stack name> \\ --template-body file://<this file name> \\ --parameters ParameterKey=AdministratorAwsAccountId,ParameterValue=123456789012 \\ --capabilities CAPABILITY_NAMED_IAM \\\n", "CreationTime": "2020-02-24T13:43:00.500Z", "StackName": "StackSet-basic-iam-roles-98765432-abcd-ef12-3456-7890abcd1234", "StackStatus": "CREATE_COMPLETE" } ]AWS Management Consoleからも下記のように確認できます。(下記は子AWSアカウントにSwitch Roleして確認しています。)
作成されたIAM Roleの確認
念のため、子AWSアカウント上に必要なAWSリソースが作成されていることを確認しておきます。
今回作成したのはIAM Roleが2つ、「AccountingRole」「FullAdministratorRole」となりますので、iam list-rolesで確認できます。list-roles — AWS CLI 1.18.5 Command Reference
https://docs.aws.amazon.com/cli/latest/reference/iam/list-roles.html$ aws --profile investigate-multi-accounts iam list-roles \ --query "Roles[?contains(['AccountingRole', 'FullAdministratorRole'], RoleName)]" [ { "Description": "This role allows IAM users in the administrator account to invoke billing-related actions within the target AWS account.", "AssumeRolePolicyDocument": { "Version": "2012-10-17", "Statement": [ { "Action": "sts:AssumeRole", "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::123456789012:root" } } ] }, "MaxSessionDuration": 3600, "RoleId": "AROA*****************", "CreateDate": "2020-02-24T13:43:05Z", "RoleName": "AccountingRole", "Path": "/", "Arn": "arn:aws:iam::987654321098:role/AccountingRole" }, { "Description": "This role allows IAM users in the administrator account to perform AssumeRole to obtain the privileges of this AWS account", "AssumeRolePolicyDocument": { "Version": "2012-10-17", "Statement": [ { "Action": "sts:AssumeRole", "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::123456789012:root" } } ] }, "MaxSessionDuration": 3600, "RoleId": "AROA*****************", "CreateDate": "2020-02-24T13:43:05Z", "RoleName": "FullAdministratorRole", "Path": "/", "Arn": "arn:aws:iam::987654321098:role/FullAdministratorRole" } ]おわりに
CloudFormation StackSetを利用して、子となるAWSアカウント上に任意のCloudFormation Stackを作成することができました。
AWS CLI実行時に指定するパラメータがどのAWSアカウントに対するものなかが分かりにくかったり、masterアカウント側の準備が少し面倒だったりしますが、上手く使えば複数AWSアカウントの管理作業を大幅に軽減することができます。