- 投稿日:2020-02-24T23:29:02+09:00
__slots__の使い方
Pythonは動的言語であるため、変数の宣言が不要で、インスタンス変数も動的に作成することができる。
class User: pass user1 = User() user1.username = 'kaito'勝手にインスタンス変数を作成させないように、
__slots__を利用して制限をかける。class User: __slots__ = ('username', 'age') user1 = User() user1.username = 'kaito' user1.password = 'aaa'エラーが確認できる。
4 user1 = User() 5 user1.username = 'kaito' ----> 6 user1.password = 'aaa' AttributeError: 'User' object has no attribute 'password'また、Pythonはインスタンス変数を辞書に格納してるが、
__slots__を定義することで、辞書ではなくタプルが使われるため、メモリの節約ができる。
- 投稿日:2020-02-24T23:17:55+09:00
@classmethodと@staticmethod
class Date(object): def __init__(self, day=0, month=0, year=0): self.day = day self.month = month self.year = year @classmethod def from_string(cls, date_as_string): day, month, year = map(int, date_as_string.split('-')) date = cls(day, month, year) return date @staticmethod def is_date_valid(date_as_string): day, month, year = map(int, date_as_string.split('-')) return day <= 31 and month <= 12 and year <= 3999 date1 = Date(11, 9, 2012) date2 = Date.from_string('11-09-2012') is_date = Date.is_date_valid('11-09-2012')
@classmethod
- clsを引数として定義する必要がある
- 上記のコードでは同じクラスDataにおいて、いつもと違うインスタンス化の方法を
@classmethodで実現した。@staticmethod
- clsやselfなどの必須的な引数(obligatory parameter)が不要
- 基本、普通の関数として見ることができる
- クラス内部のあらゆるものにアクセスできない
- 目的はロジックを明白にするため
- 投稿日:2020-02-24T22:58:10+09:00
Pythonのクラスやインスタンスにメソッドをバインドする
Pythonは動的言語であるため、実行時、動的にクラスやインスタンスにメソッドを再定義や追加することができる。
class User: pass user1 = User() user1.set_username('kaito')定義されてないプロパティーやメソッドを呼び出すとエラーが出る。
--------------------------------------------------------------------------- AttributeError Traceback (most recent call last) <ipython-input-30-815371892d44> in <module> 3 4 user1 = User() ----> 5 user1.set_username('kaito') AttributeError: 'User' object has no attribute 'set_username'
MethodTypeを使えば、後からメソッドを追加することが可能。
まずはメソッドを関数として定義する(メソッドのようにselfを引数として定義する必要がある)。def set_username(self, username): self.username = username次に、メソッドをインスタンスにバインドする。
from types import MethodType user1.set_username = MethodType(set_username, user1) user1.set_username('kaito') user1.set_usernameメソッドとしてバインドされてることが確認できる。
<bound method set_username of <__main__.User object at 0x111f55438>>
MethodTypeを使わずに、直接代入するとどうなる?user1.set_username = set_username user1.set_usernameただの関数オブジェクトの参照になってる。
<function __main__.set_username(self, username)>実行してみる。
user1.set_username(user1, 'kaito')メソッドではなく関数なので、selfの割り当てはやってくれない。
--------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-42-70cc4337e082> in <module> ----> 1 user1.set_username('kaito') TypeError: set_username() missing 1 required positional argument: 'username'明示的にselfを与えるで実行できる。
user1.set_username(user1, 'kaito')Userクラスはどうなってる?
User.set_usernameインスタンスにのみ追加したので、クラスのほうは変わらない。
--------------------------------------------------------------------------- AttributeError Traceback (most recent call last) <ipython-input-38-40cdce039232> in <module> ----> 1 User.set_username AttributeError: type object 'User' has no attribute 'set_username'クラスにメソッドを追加したい時は同じやり方でできる。
User.set_username = MethodType(set_username, User) User.set_usernameインスタンスのようにメモリアドレスが表示されないが、ちゃんと追加されている。
<bound method set_username of <class '__main__.User'>>
- 投稿日:2020-02-24T22:36:11+09:00
声に出して読みたい美しいPythonパッケージ(令和版)
背景
冷凍マグロ系スクリプト言語として知られるPythonには、
美しい名前のパッケージが沢山あるようです。
- PyPy(ぱいぱい)
- pypan(ぱいぱん)
- pypants(ぱいぱんつ)
参考: 声に出して読みたい7つのPython用語
http://doloopwhile.hatenablog.com/entry/20120120/1327062714これらの美しい名前のパッケージに魅せられ、
どれくらい美しい名前のパッケージが存在するのか、
本気で調べてみることにしました。参考先の情報は2012年と少し古いですし、
今ならばさらに美しい名前が見つかるに違いありません!!調査の方針と概要
まず、pip対象パッケージは全て
PyPI(ぱいぱい)に登録されています。
https://pypi.org/総数実に「219,370」個!(※2020年2月現在)
とても人手で確認出来る量ではないですね。全く使われていない休眠パッケージは除外したいため、
直近1年間で一回以上のインストールがあるパッケージ
を対象にしたいと思います。
例えば、参考先サイトが掲げている、
Pychinko(ぱいちんこ)
は既にこの世に存在しないようで、除外されますし、
Pyzuri(ぱいずり)
も残念ながら全くダウンロードが無いようで、除外されます。こういった全パッケージ名称と、そのダウンロード情報は、
pypinfoとBigQueryを使うことで取得可能です(詳細後述)。パッケージ名称は英数字であるため、
無理やりカタカナ読みする日本語変換処理を行います。
(パッケージ名は単純な英単語ではないため、
これが結構難しい処理になります)最後に、予め作っておいた「美しい言葉リスト」を用いて
日本語化したパッケージ名称に対して検索をかけます。このような地道な努力によって、
オモシロイ美しい名前のパッケージを
大量に見つけることができました!結果発表!!
捜索用コードの前に、さきに結果の一部をご紹介します。
ぱいそんの美しきネーミングセンスをご堪能ください。
(※読み方は正式な読み方ではなく、
作成したカタカナ読み付与ツールによるものです。)sexmachine(せっくすましん)
直近1年間で、31,001 DL
名前が女性か男性かを判断するツールです。4月になったら新人プログラマーに大声で教えてあげましょう。
例:分からない時は【sexmachine】に聞け!methanal(めすあなる)
直近1年間で、163 DL
仮数フォームおよびユーティリティウィジェットライブラリです。4月になったら職場で叫んでみましょう。
例:休日はずっと【methanal】をいじっていたよthefuck(ざふぁっく)
直近1年間で、64,492 DL
コンソールコマンドのエラーを修正するツールです。
https://github.com/nvbn/thefuckエラー発生時に、とにかく「ファッ〇!!」と
驚きの声を上げてしまう方に、自動対応してくれて人気がある模様。4月になったら兎に角よんでみましょう。
例:【thefuck】【thefuck】【thefuck】!!pyzure(ぱいずり)
直近1年間で、427 DL
Microsoft Azure SQL DBにデータを簡単に送信するPythonパッケージです。
https://github.com/dacker-team/pyzure本家のpyzuriは消えたものの、新たな逸材を発見しました。
4月になったらみんなに話してあげましょう。
例:昨晩【pyzure】にトライして、良かったなあaskocli(あすくおしり)
直近1年間で、78 DL
リモートのAskOmicsにデータを挿入するためのcliツール、とのこと。4月になったら優しく諭しましょう。
例:挿入するときはまず【askocli】だよstockings(すとっきんぐす)
直近1年間で、71 DL
完全なメッセージの送受信を可能にするWindows / Linux、Python 2および3互換のソケットラッパー。4月になったらこっそり打ち明けましょう
例:実はいま【stockings】を使っているんだosex(おせっくす)
直近1年間で、34 DL
詳細不明です。ドキュメントが無いため扱いにくいかもしれません。4月になったら相談してみましょう
例:【osex】にハマって、困ってるんですpypi-cli(ぱいぱい-しり)mypypi(まいぱいぱい)
直近1年間で、488 DL、109 DL
ぱいぱい系は大量にあるため、全量は記載出来ません。
きっと使い勝手の良いパッケージも多いことでしょう。4月になったら絶賛しましょう
例:【mypypi】は最高だ!※pypi-rankings(パイパイ-ランキングス)とかもありました。
例:昨日はずっと【pypi-rankings】を見ていたんだpypants(ぱいぱんつ)pypandas(ぱいぱんだす)
直近1年間で、570 DL、1,114 DL
4月になったら大きな声で宣言しましょう
例:わたしはいつも【pypandas】pants(ぱんつ)fancypants(ふぁんしーぱんつ)
直近1年間で、535 DL、40 DL
4月になったら同僚に紹介してあげましょう
例:ぼくの【fancypants】を見せてあげるよ!doraemon-robotframework(どらえもん-ろぼっとふれーむわーく)
直近1年間で、512 DL
受け入れテストとロボットプロセス自動化(RPA)のための汎用自動化フレームワーク
=「robotframework」を青タヌキの形にしたもののようです?4月になったら宿題を忘れても怖くありません
例:困ったときは【doraemon-robotframework】に頼むことにするねbaka(ばか)
直近1年間で、49 DL
Pyramidのコアを使用するWebアプリケーションフレームワーク?のようです。4月になったら試してみましょう
例:パソコンに【baka】を入れてみたんだhncomments(えっちんこめんつ)
直近1年間で、52 DL
4月になったら何となくつぶやいてみましょう
例:【hncomments】。ふふふsexytime(せくしーたいむ)sexy-fun(せくしーふぁん)
直近1年間で、52 DL、25 DL
4月になったら今後の期待を話しましょう
例:これから【sexytime】をはじめようか!感想(かんそう)
英語からカタカナにするところが一番大変だったのですが、
英語の時点で既にパワーワードが多かったです。今回ご紹介した内容は、4月になったら
ぜひ実際に職場や学校などで実際に読み上げてみてください。
周囲の方はきっと「春の訪れ」を感じると思います。
以下は技術的な詳細なので
多くの人は見なくてよいと思います。
興味のあるかたはぜひご参照ください。美しい名前のパッケージ群を、真面目に紹介しており、
かつ、その取得用コードを解説している本記事が
「検閲/削除」されることは全く心配していません。しかし、心が汚れたオトナが見ると、
本来の意図とは別な意味に受け取ってしまうかもしれません。万が一、心が汚れたオトナによりなんらかの圧力がかかり、
本記事の全部または一部が削除された場合に備えて、
同様のパッケージを探すための技術とコードのポイントを以下に記します。今回ご紹介させていただいた結果は抽出した一部のものですし、
お手元でもぜひお試しいただき、
Python(ぱいそん)の美しい名前をご堪能くださいませ。①パッケージ一覧&ダウンロード数情報取得(pypinfo)
pipのパッケージが登録されているPyPI(ぱいぱい)では、
その統計情報のデータセットを
Google/BigQueryで公開しています。
その情報を容易に取得出来るツールが
pypinfoです。BigQueryを操作するために、
下記のサイトの手順に従って、
https://github.com/ofek/pypinfo
Google Cloud Platform(GCP)のアカウントと、
認証情報(JSONファイル)を作る必要があります。JSONファイルまで作成したら、ブラウザで
Colaboratory(https://colab.research.google.com/?hl=ja)
を立ち上げて、以下のようにコマンドを実行していきましょう。GoogleDriveをマウントします。from google.colab import drive drive.mount('/content/drive')今回の作業フォルダを作ります。!mkdir "drive/My Drive/PYPI" #さきほど作成した認証用のJSONファイルをここにアップロードしましょう。pypinfoをインストールします。pip install pypinfo認証用のJSONファイルのパスを指定して、認証情報を取得します。!pypinfo --auth "/content/drive/My Drive/PYPI/YourGCPProjectName-XXXXXXXXX.json"pypinfoの疎通確認(こんな感じに「request」のダウンロード数が取得出来ます)!pypinfo requests #Served from cache: False #Data processed: 67.70 GiB #Data billed: 67.70 GiB #Estimated cost: $0.34 # #| download_count | #| -------------- | #| 61,319,474 |他にも、国ごと、バージョンごと、インストール先OSごとなど、
様々な情報を取得出来るので、公式サイトの例に従って試してみましょう。ここで重要なのは、上記の中の
「Estimated cost: $0.34」にあるように、
BigQueryでは、クエリを投げるごとに、
その読み取ったデータ量に応じて課金が生じます。
が、1 TB/一か月のAlways Free枠と、
新規GCPユーザ用の300$/年の無料枠があるため、
通常の使い方では大丈夫です。
全量取得系の重いクエリだけは、連射しないように注意しましょう。では、ついに今回の実際のデータ取得用のクエリを投げてみます。
直近1年間を指定してクエリを投げ、結果をファイルに保存。!pypinfo --days 365 --limit 250000 "" project > "drive/My Drive/PYPI/PYPINFO_365_LIST.txt" #Served from cache: False #Data processed: 636.49 GiB #Data billed: 636.49 GiB #Estimated cost: $3.11 #| project | download_count | #| --------------------------------------------------------------------------------- | -------------- | #| urllib3 | 950,108,414 | #| six | 788,263,157 | #| botocore | 693,156,212 | #| requests | 656,942,399 | # ~~以下略~~ご参考までに、
直近1年間の総ダウンロード数は、
約 37,498,000,000 回
パッケージの種類は、約 215,000種類 でした。パッケージの総数が約22万種類なので、
直近1年間レベルで見ると、登録されているものは
ほとんどが「生きている」ことになります。
以前あったと言われているPychinko(ぱいちんこ)が無いことから、
定期的にたなおろしされているのかもしれません。
また、直近30日で見ると13万4千種類ほどでしたので、
実際に多少まともに使われているものは10万種類以下くらいでしょうか?②取得データの加工
先ほど取得したパッケージ名&ダウンロード数のファイルは、
手元で人が閲覧する分には見やすくて便利なのですが、
プログラミング的に扱うには、パースして加工する必要がありますね。冒頭のクエリのコストの行や、表の見出し行/Total行などの除去に注意して、
下記のように加工してLIST形式にします。結果ファイルを加工しながら読み込んでLISTにするf = open('/content/drive/My Drive/PYPI/PYPINFO_365_LIST.txt') line = f.readline() # 1行ずつ読み込む(含:改行文字) pypinfo_list = [] while line: #敷居が三つの場合=見出しと枠とTotalがジャマだが、それ以外はこの条件で判別可能 if line.count('|') != 3: line = f.readline() continue else: #改行コード、カンマ、半角スペースは除去 parsed_line = line.replace('\n', '').replace(' ', '').replace(',', '') one_data = parsed_line.split('|') #['', 'urllib3', '950108414', '']の形の真ん中2個を使う # 備考:数値もいまのところ文字列扱い one_data = one_data[1:3] pypinfo_list.append(one_data) line = f.readline() f.close #最初の2行の見出し行と、最後の合計行は除去 pypinfo_list = pypinfo_list[2:-1]pypinfoが提供していたりしないのかなーと思いながらも、
自作してしまいました。仮に有ったとしても、
一回約3$かかるクエリなので、テキスト版と別に投げるより、
クエリ投入回数の節約にもなるでしょう。
この①と②は、Python関連の「データ分析」を行う際にも有用だと思います。③パッケージ名をカタカナにする技術(alkana.py&頑張る)
さて、パッケージ名の一覧化が出来ましたが、
例えば、urllib ⇒ユーアールエルリブ
python-dateutil ⇒ パイソン-デイトユティル
などのようにパッケージ名をカタカナ化するには
どうしたら良いのでしょうか?今回の方針は4段階です。
1.英単語として存在している言葉をカタカナにする
2.Pythonや、AWS、GITなどのIT特殊用語をカタカナにする
3.「ローマ字変換」を適用出来るだけ適用する
4.残った端数の文字は適当に変換しておく:f⇒フ、など。最初の、「英単語をカタカナに」は、下記の
alkana.py の変換テーブルを使わせていただきました。
https://github.com/cod-sushi/alkana.py/blob/master/README_ja.md2~4については、主にローマ字の規則表から、
330行ほどの変換テーブルを作成しました。
前述のalkana.pyからのデータと足し合わせて、
alkana_listとして変換テーブルを作っておきます。ここでのポイントは、その英語の文字列の長さをキーとして、
alkana_listを降順にソートしておくことです。x[0]の項目にはあらかじめ文字列の長さを入れておくalkana_list = sorted(alkana_list, key=lambda x: x[0], reverse=True) # py ⇒ パイ、や、python ⇒ パイソン など優先度の高いものについては、 # [30, 'py', 'パイ'] などと長さが長いことにして登録すれば優先度が上がる。これで、長い単語から順に変換が適用されることになります。
実際に変換している様子は以下です。
分量があるため、一回50分くらいかかります。
下記のようにtqdmで途中の進捗を表示したり、
処理終了後はpickleで保存しておくと使いやすいでしょう。全モジュールにカタナカ読み情報を付与するfrom tqdm import tqdm pypinfo_jp_list = [] for pypinfo in tqdm(pypinfo_list): #日本語モジュール名格納変数(この時点では英語を格納) jp_module_name = pypinfo[0] for data in alkana_list: #変換テーブルを、順番通りに変換していく。 jp_module_name = jp_module_name.replace(data[1], data[2]) pypinfo_jp_list.append([pypinfo[0], jp_module_name, int(pypinfo[1])]) print(len(pypinfo_jp_list)) print(pypinfo_jp_list[0:10]) import pickle with open('/content/drive/My Drive/PYPI/pypinfo_jp_list.pickle', 'wb') as f: pickle.dump(pypinfo_jp_list, f)特殊だが多少用途もありそうな
自然言語処理ツールになる気もします。④「美しい言葉」が使われているパッケージを探す
最後に、特定のキーワードが含まれているパッケージを探します。
予め「Beautiful_tango_list」にお好みの単語を登録しておき、
ひたすらループするだけです。
「ぱい」などの多数使われている用語を入れると、
結果が膨大になってしまう点は注意しましょう。
Colaboratoryではprint出力は5000行までだと思うので、
1万行くらいいくならば、下記のようにファイルへ出力する方が良いでしょう。Beautiful_tango_listの内容を検索してテキストに書くresult_str = "" for word in Beautiful_tango_list: result_str += "■"+" "+ word + "\n" for data in pypinfo_jp_list: if word in data[1]: result_str += str(data) + "\n" result_str += "\n" with open('/content/drive/My Drive/PYPI/Beautiful_Result.txt', 'w') as f: print(result_str, file=f)おつかれさまでした。
これらの技術&コードを駆使して、前述の結果のような、
美しい名前のパッケージを多数見つけることが出来ました。あとがき
Python(ぱいそん)のネーミングセンスは奥が深いですね。
辞書をひくときに隣の単語もみるように、
このような全く無関係なところ、
名前との巡りあわせだけからでも、
お気に入りのパッケージとの出会いが生じたら素晴らしいことです。PyPI(ぱいぱい)が引き合わせた運命の出会い、
とも言えるでしょう。あと、至って真面目な記事ですので、
心が汚れたオトナのかたは
石を投げないでください。お願いします。さあみなさんも、もっとPyPI(ぱいぱい)が好きになりましたでしょうか?
現場からは以上です。
なお、PyPIをぱいぱいと読むかどうかは流派があるようでして、
本記事の名称は全てツールによる自動付与に依存しています。ところで、個人的にはそろそろ
「本気で自然言語分析系」を「シリーズ化」してもいいんじゃないか、
という気がしてきました。(統一感がかけらも無いですが)
本記事がお好きな人には下記3点もオススメです。
- 投稿日:2020-02-24T22:16:54+09:00
Python練習_仮想環境のセットアップ~Djangoインストール
Python練習中。チュートリアルで仮想環境の構築を行ったので備忘録に。
プロジェクト単位で仮想環境を構築しておくことで限られた範囲内でPythonを実行することができ、フレームワークやライブラリ同士の不要な干渉を避けることができるとのこと。
Django学習サイトをいくつか参照している感じ仮想環境の構築は必須な様子なのでやっておく。
仮想環境を作成
まずデスクトップにフォルダ(今回は[django_girls]と命名)を作成。
$ cd djangogirls
でフォルダに移動し、
$ python3 -m venv myvenv
で仮想環境を作成。※チュートリアルの指示通りに実行した感じだけど、このコマンドで仮想環境が作成されるっぽい。(詳細)
とりあえずこれで、仮想環境(一連のデフォルダとファイル)を含む[myvenv]という名前のフォルダが生成される。
仮想環境を起動
コンソールで
$ source myvenv/bin/activate
を実行して仮想環境を起動。
問題なく起動が完了すると、コンソールでプロンプトの先頭に(myvenv)と表示される。Djangoをインストール
※pipがインストールされていない場合は先にインストールしておく必要あり。ただし、
pipは、Python3.4以上(Python2の場合は2.7.9以上)であれば、プレインストールされていますので、すぐ利用できます。(参照)
とのことなので、今回(3系を使用)はパス。
その後チュートリアルの指示通りに[requirements.txt]というファイルの作成→テキスト(Django~=2.2.4)の記入→
pip install -r requirements.txtの実行
を行い、Djangoをインストール。チュートリアルの指示通りだとバージョンが「2.2.4」で最新ではなかったので、記入するテキストを
Django~=3.0.3に変更して実行すると最新版がインストールできた。使用中のdjangoのバージョンは
$ python -m django --version
で確認可能。(参考)続きはGitのインストールから。
以下、今回のチュートリアルで参照しているサイトはこちらから→(DjangoGirls)
- 投稿日:2020-02-24T22:09:37+09:00
為替の時系列データをクラスタリングしてみた話
本記事内容サマリー
- 為替のデータをクラスタリングしてみました。
- k-means, ユークリッド距離 を用いました。
- 上位足(より長い時間軸の)データを組み合わせると有用そう。
- 上位足を用いると、ラベル(利食い:1、損切り:−1、保有時間による決済:0)の割合の偏りが良化した。
開発環境
- Colaboratory
- scikit-learn
データ準備
2018.01 ~ 2019.04 の USD/JPY を使用し、
5分足での移動平均線のゴールデンクロスのエントリーポイントをサンプルデータとしました。(2482 データ)
* 特徴量:
* エントリーポイント前の約3時間分のデータ(ohlc)
* RSIラベリング
ラベル付けは、以下のルールで行いました。
Result Label Profit 1 Loss -1 保有時間による決済 0 今回は、大体3等分されるように損切りと利食いのラインを設定しました。
クラスタリング
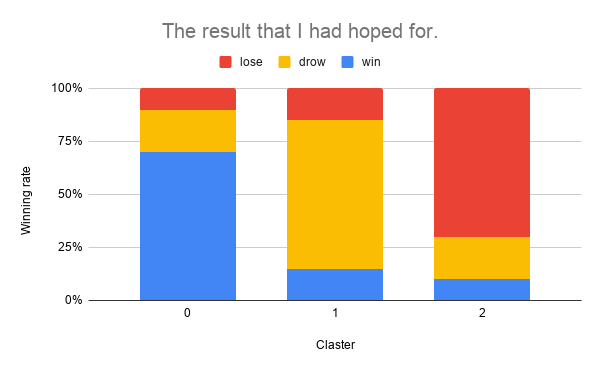
期待した結果
以下のグラフの様に、クラスタ毎に”利食い”/”損切り”/”保有時間による決済”がそれぞれキレイに分かれることを期待しました。
これだと、クラスタ2の場合はダマシと判断して、トレードを見送ることができますね。
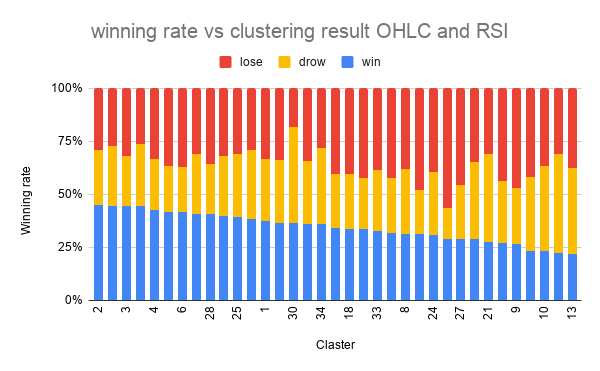
結果
scikit-learn の TimeSeriesKMeans を用いてクラスタリングし、各クラスタのラベルの割合を図示し、勝率順にソートしました。
いまいち。。
勝率最大のクラスタで、45%、最小のクラスタで、22% でした。
元がほぼ3等分(33%)なので、少しは分けれてはいそうですが、もう少しキレイに分かれて欲しいところです。上位足を追加
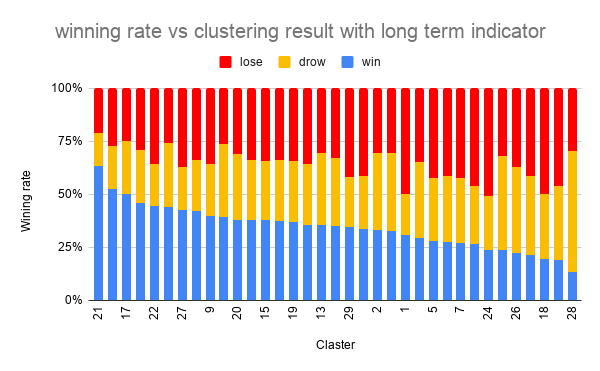
改善を目指し、以下のより長い時間足の情報を特徴量に加えることにしました。
* 30分足でオシレーター系のインジケーター
* 2時間足でトレンドフォロー型のインジケーターその結果が以下です。
勝率最大のクラスタで、63%、最小のクラスタで、14% でした。
上位足の情報を加えることで、大分良化しました。
上位足の情報が有用であることが改めて確認できたので良かったのではないでしょうか。
これくらいの結果であれば、ダマシを回避するのは難しそうですが、ポジションの数量の調整には使えそうだと個人的には思いました。記事を読んでいただきありがとうございました。
参考
- 投稿日:2020-02-24T21:51:42+09:00
【iOS】はじめてのPyto
はじめに
iOSのPython環境で最も有名なのはPythonistaだと思います。個人的にPythonistaは、
- 更新が2年以上無い(2020/2/24現在)
- 対応ライブラリが少ない(Pandasが使えない)
という点が引っかかり、購入を見送っていました。ある日、日経ソフトウェアに「Pyto」というアプリが紹介されており、検索してみるとPythonistaと比較して、以下の点が魅力的だったので購入しました。
- 更新頻度が高い
- Pandasに加え、sklearn、skimage、さらにはOpenCVも使える
- Pythonistaと同様にiOS用のGUIアプリの作成が可能(iOS13以降)
この記事ではPytoの使い方や基本的な機能について説明します。
環境
iPad pro11 64GB (iOS13.3.1)
Pyto(11.4)使い方
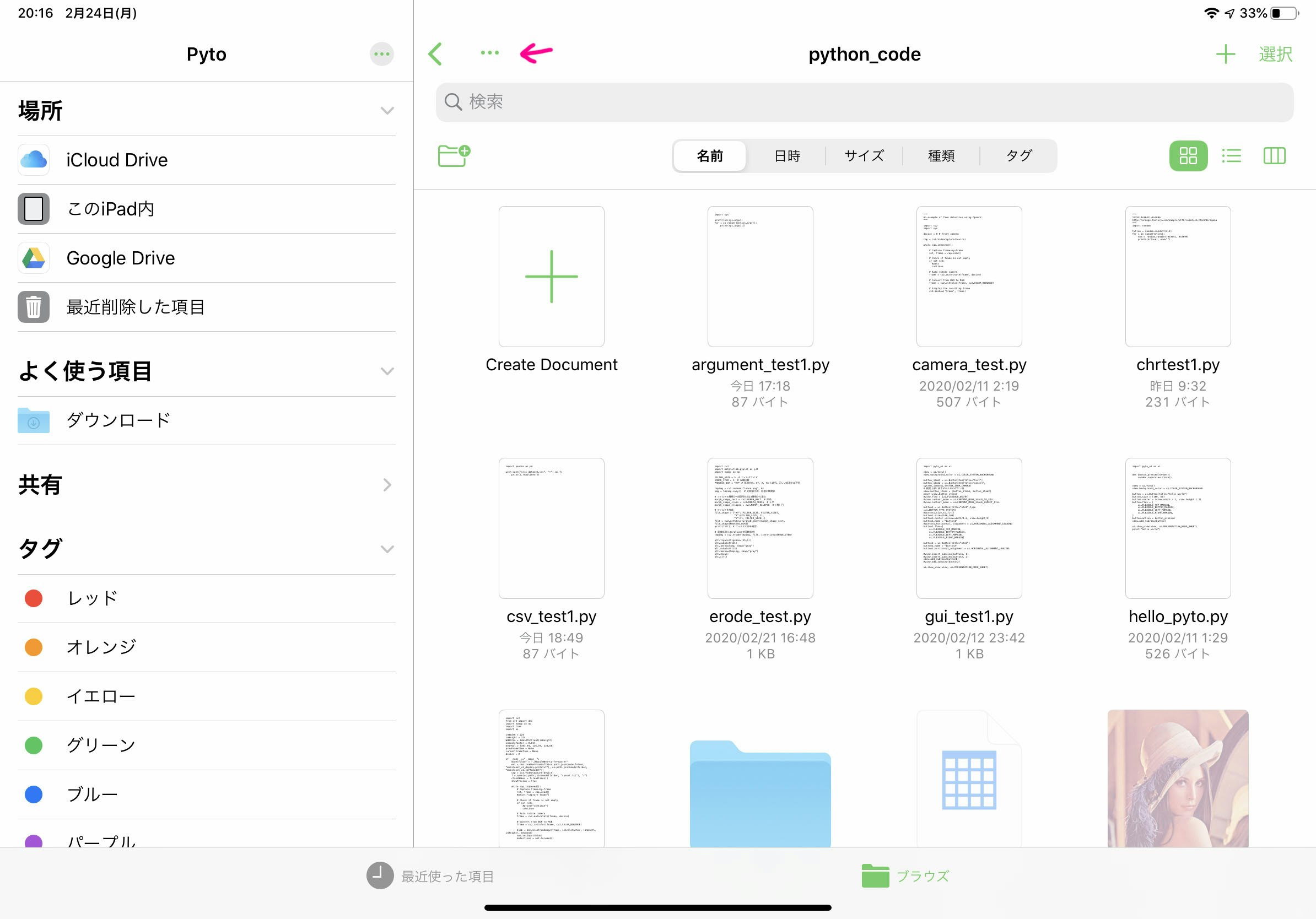
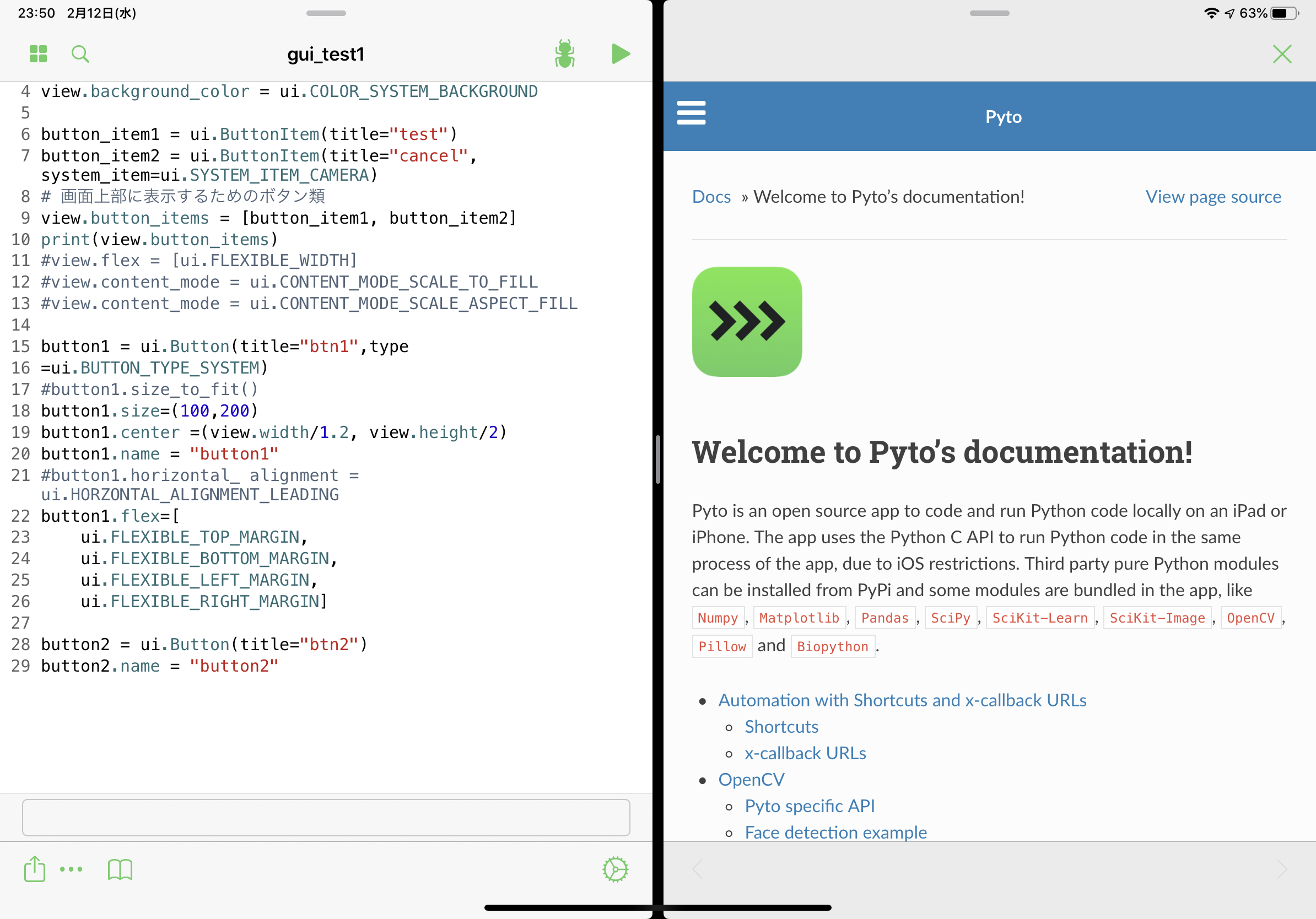
起動画面・ファイル選択画面
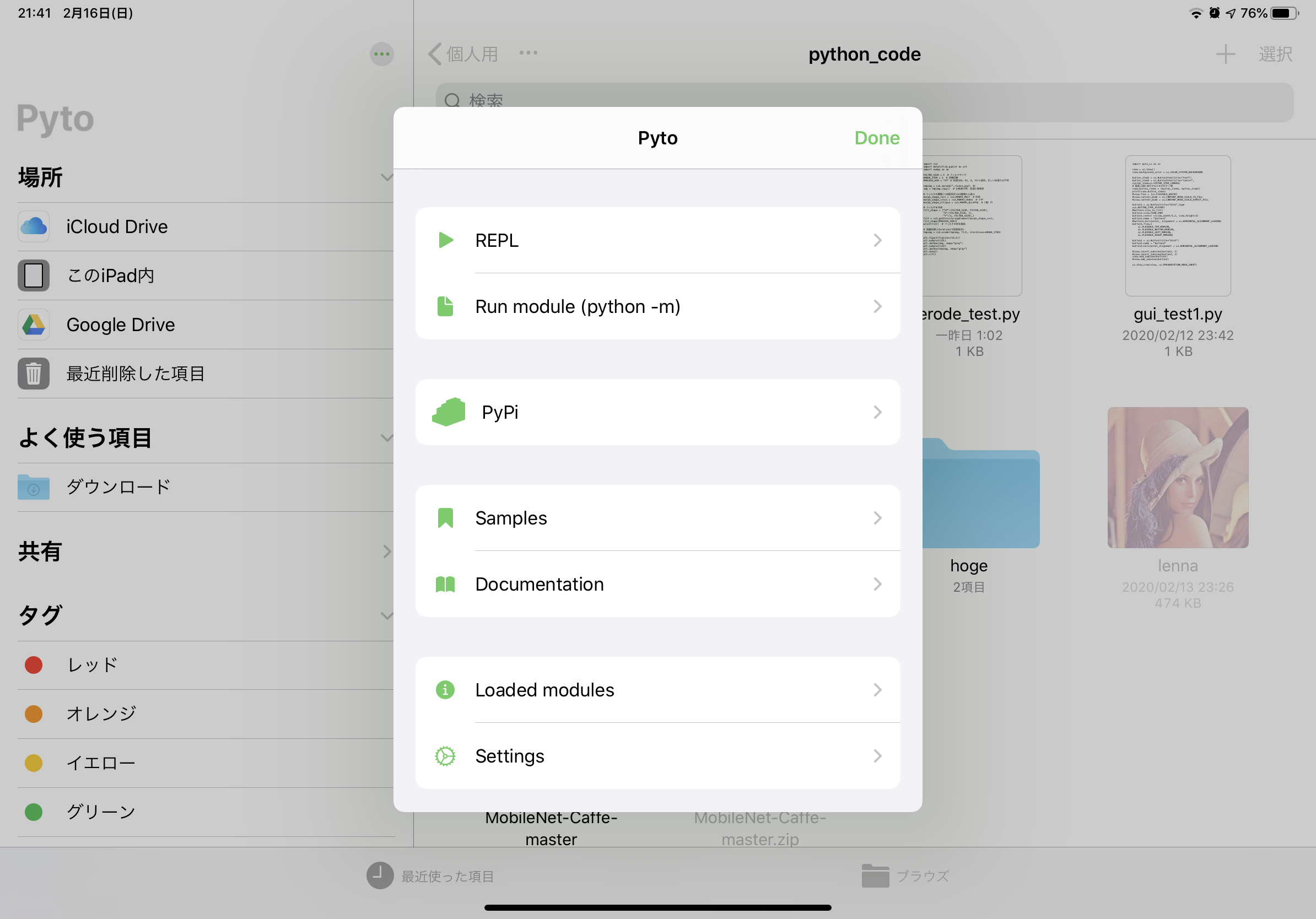
初回はアプリを起動すると、ファイルを選択する画面になります。任意の場所のファイルを開くか、新規作成を行います。また、この画面の「…」のボタン(図のピンクの矢印で示したボタン)がアプリやエディタのメニュー・設定になります。
メニュー・設定
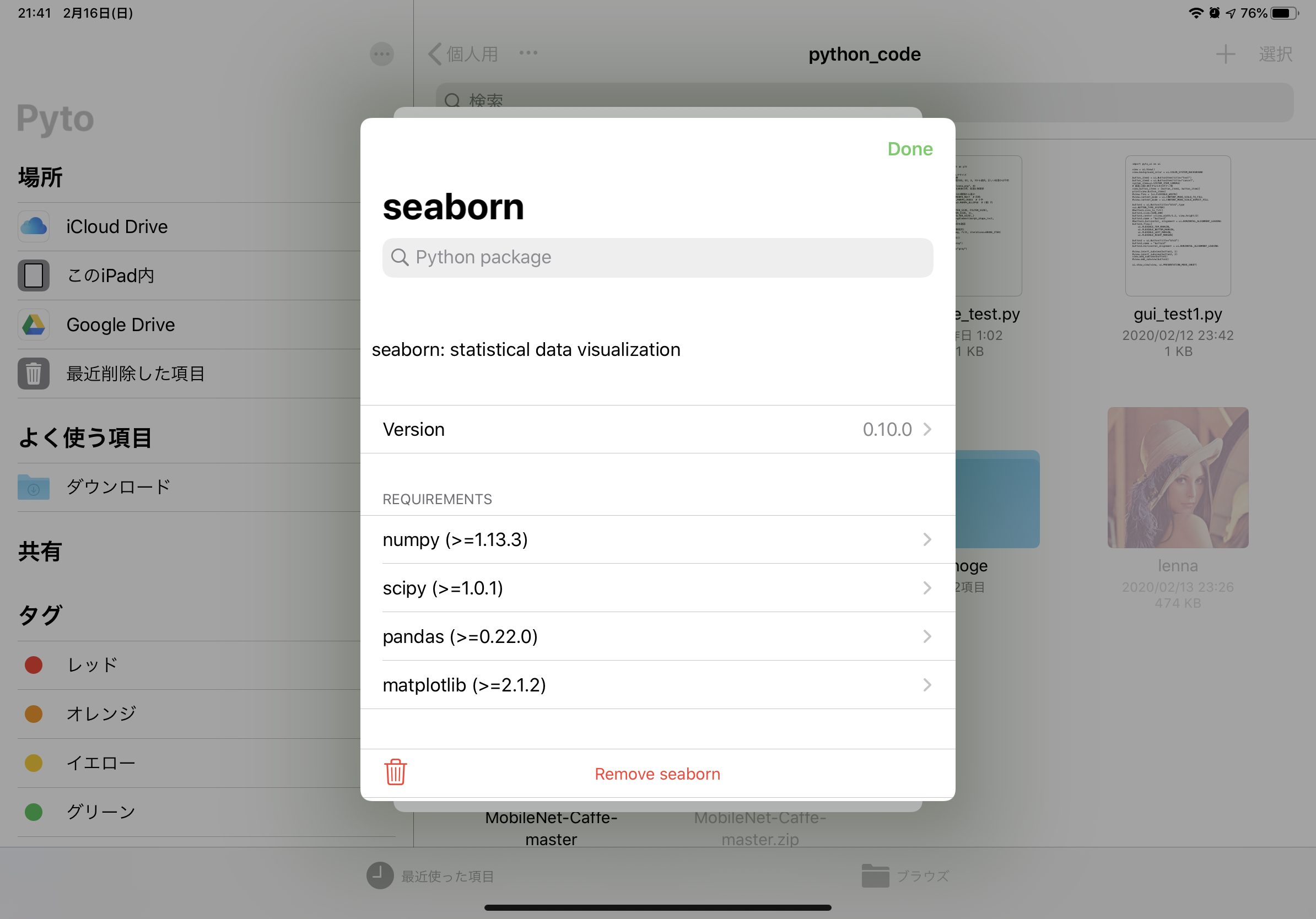
メニューは上図のようになっています。ここでエディタ・外観の設定を行ったり、対話モードを使ったり、PyPiで新たにライブラリを入れることが可能です(追加可能パッケージはpure python限定)。
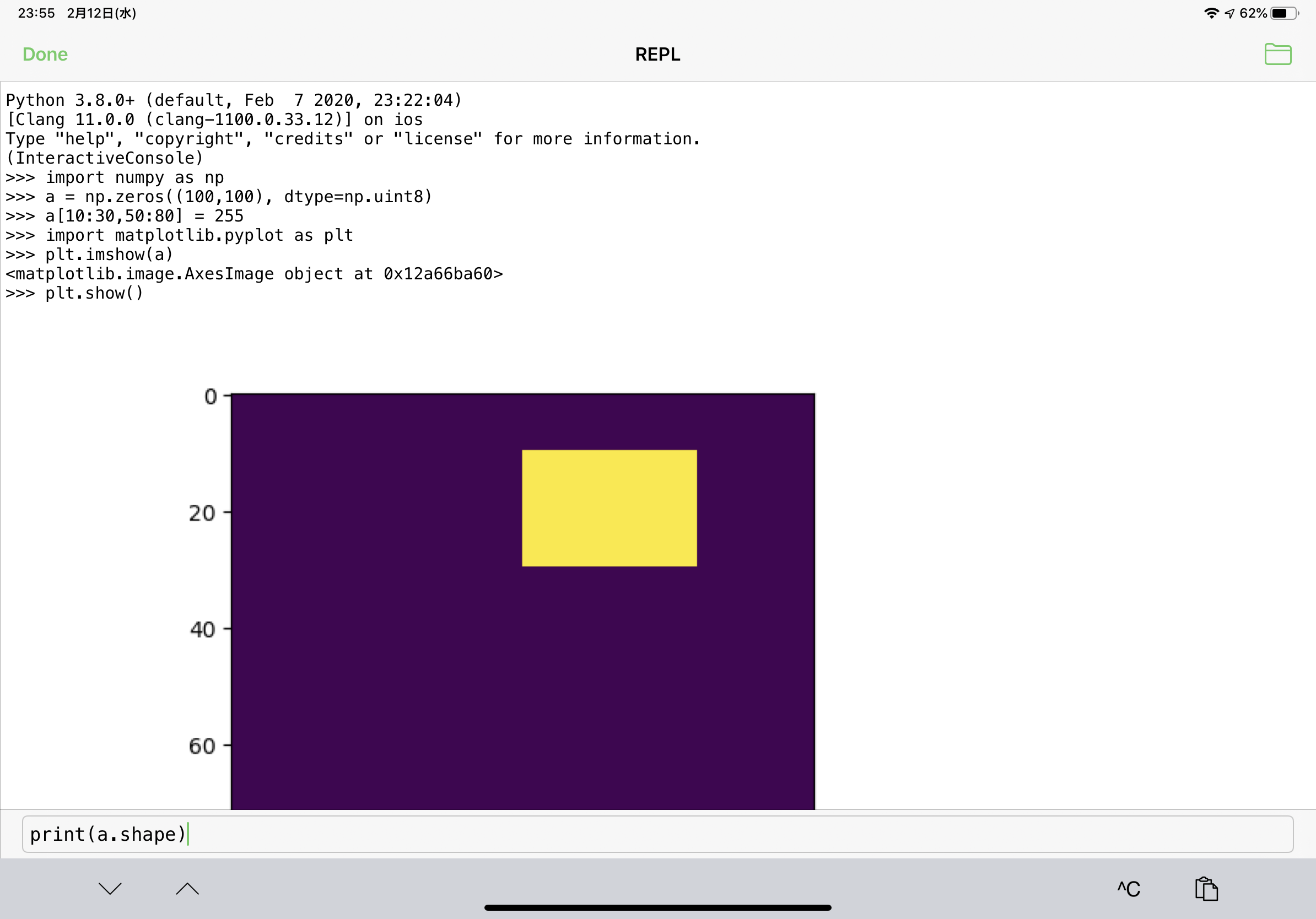
対話モード(REPL)
対話モードです。コードは下のテキストボックスに入力します。対話モードでもmatplotlibのグラフ表示が可能です。Run module (python -m)
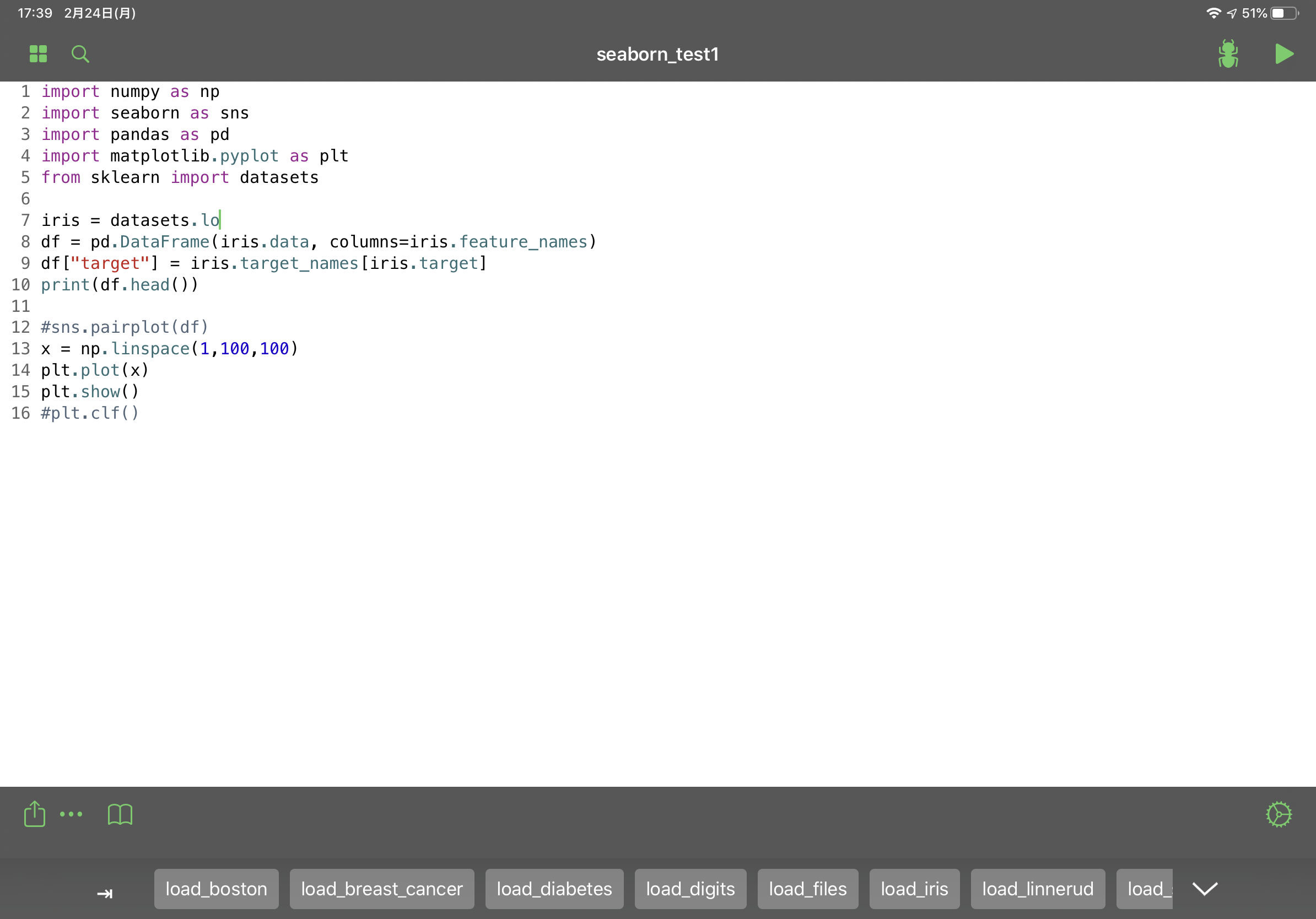
.pyファイルを実行できます。上の画面ではpipを実行していますが、pip showでパッケージの情報を表示することはできませんでした。また、インストール済みのパッケージを確認するためにpip listを実行しましたが、後述するPyPiで後からインストールしたパッケージしか表示されませんでした。PyPi
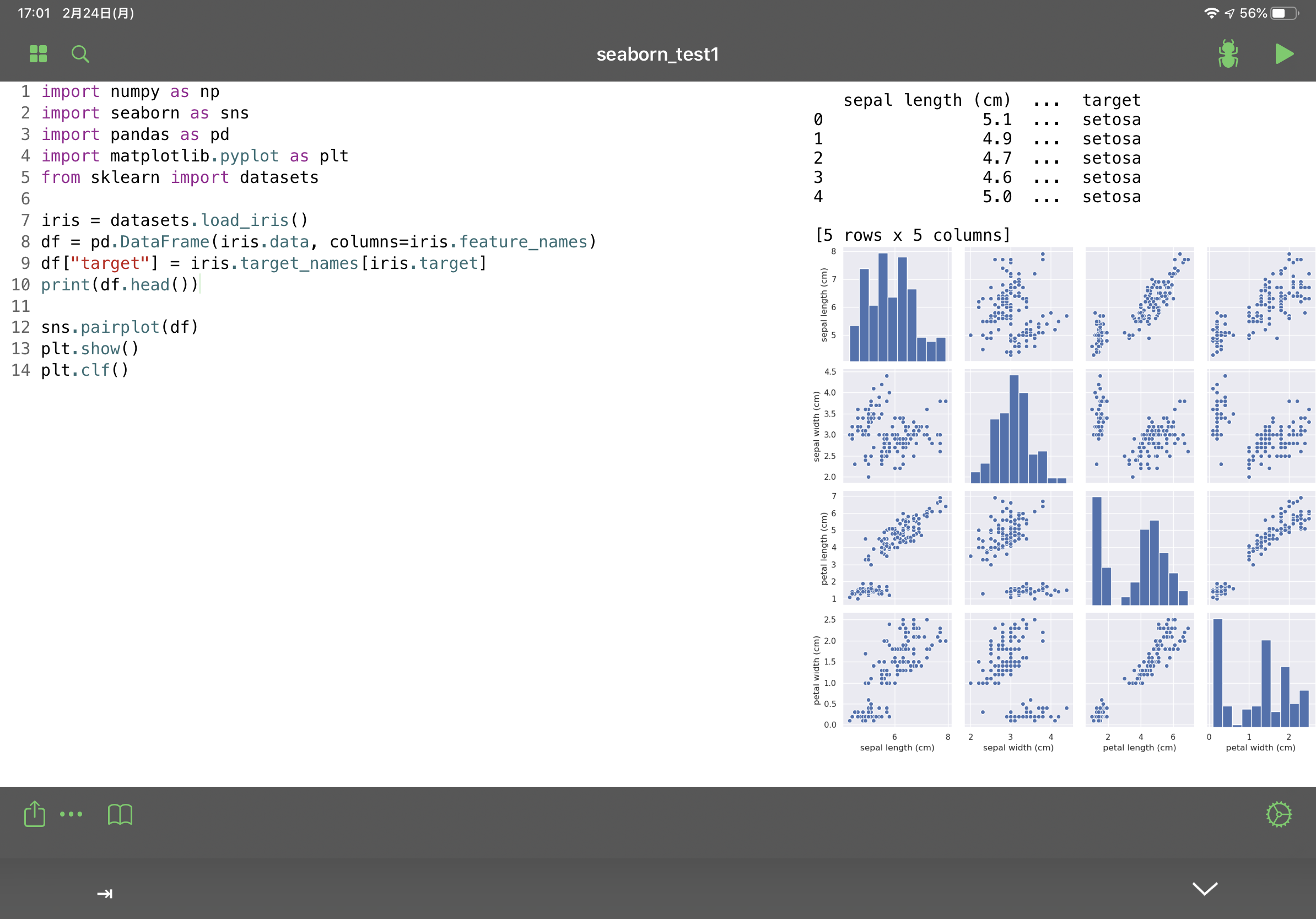
PyPiを使ってインストールされているライブラリのバージョンを確認したり、新たにライブラリを追加することができます。ただし、追加できるのはpure pythonのものに限るそうです。seabornはインストールできましたが、tensorflow、pyaudioはインストールできませんでした。
上の図ではインストールしたseabornを使ってpairplotを実行しています。Pytoでmatplotlibやseabornを使う際は、plt.clf()を最後に記述しないと複数回実行時にグラフが重なってしまいます。サンプルコード
OpenCV, sklearn、GUIモジュール等を使ったサンプルコードが入っています。Loaded modules
読み込んだことのあるモジュールが表示されます。そのモジュールのソースコードも表示できます。何に使うのかはよくわかりません。
Settings
エディタの設定画面です。ソフトタブ(スペースタブ)に対応しています。また、エディタの外観も数種類から選んだり、カスタマイズすることが可能です。
エディタ画面
エディタ画面です。右下に歯車マークがありますが、これはアプリの設定ではありません。Siriに編集中のファイルを登録したり、カレントディレクトリを変更したりできます。左下の…はエディタアクションで、ファイルに対して何か実行できるそうです。その隣のブックマークアイコンはPytoのドキュメントです。Pytoのパッケージ(GUIツールなど)の使い方が書いてあります。このドキュメントはインターネット上に公開されており、こちらから確認できます。
上部のボタンは左の4つの四角形から順に「ファイル選択画面に戻る」、「検索・置換」、「デバッグ(pdb)」、「実行」です。
また、画面右下の「V」のようなボタンを押すと、外部キーボード使用時に入力を終了できます。これにより、split viewでブラウザと同時に使用したときにカーソルをブラウザに移すのが容易になります。
add-to-siri, arguments, current directory
add-to-siri, arguments, current directoryを設定できます。argumentsではプログラム実行時に渡す引数を設定できます。
current directoryではカレントディレクトリを変更することができます。変更すると警告が出ますが、カレントディレクトリ変更後も問題なく実行できます。ここで選択したディレクトリには編集権限がつき、ファイルの参照・変更が可能となります。ローカルのファイルを読み込めない時はここでフォルダ選択すると読み込めるようになるかもしれません。Editor actions
Editor actionsです。デフォルトで2to3とblackが用意されています。ドキュメント
ドキュメントです。公開されているこちらと同じものです。右上の「V」のようなボタンでスプリットビューになります。
ドキュメントをスプリットビューにしたところ。補完
補完が可能です。タップで選択するか、Tabキーで候補から選んでEnterで確定します。フォルダロック
初めて使用するフォルダは初期状態では参照・変更できないようになっています。この場合は右下の鍵マークを押し、現在のディレクトリを選択することで参照・変更が可能となります。キーボード
ソフトウェアキーボードはiOSのデフォルトです。PytoではTabキー以外の拡張キーは用意されていません。そのためiPhoneでプログラムを書くのは少し厳しいです。
外部キーボード(Bluetoothキーボード等)は難なく使えます。コメントアウト、逆インデント、実行等のショートカットキーも使用でき、そこそこ快適です。しかし、複数行を選択した状態で一括コメントアウトを行うことはできませんでした。
おまけ
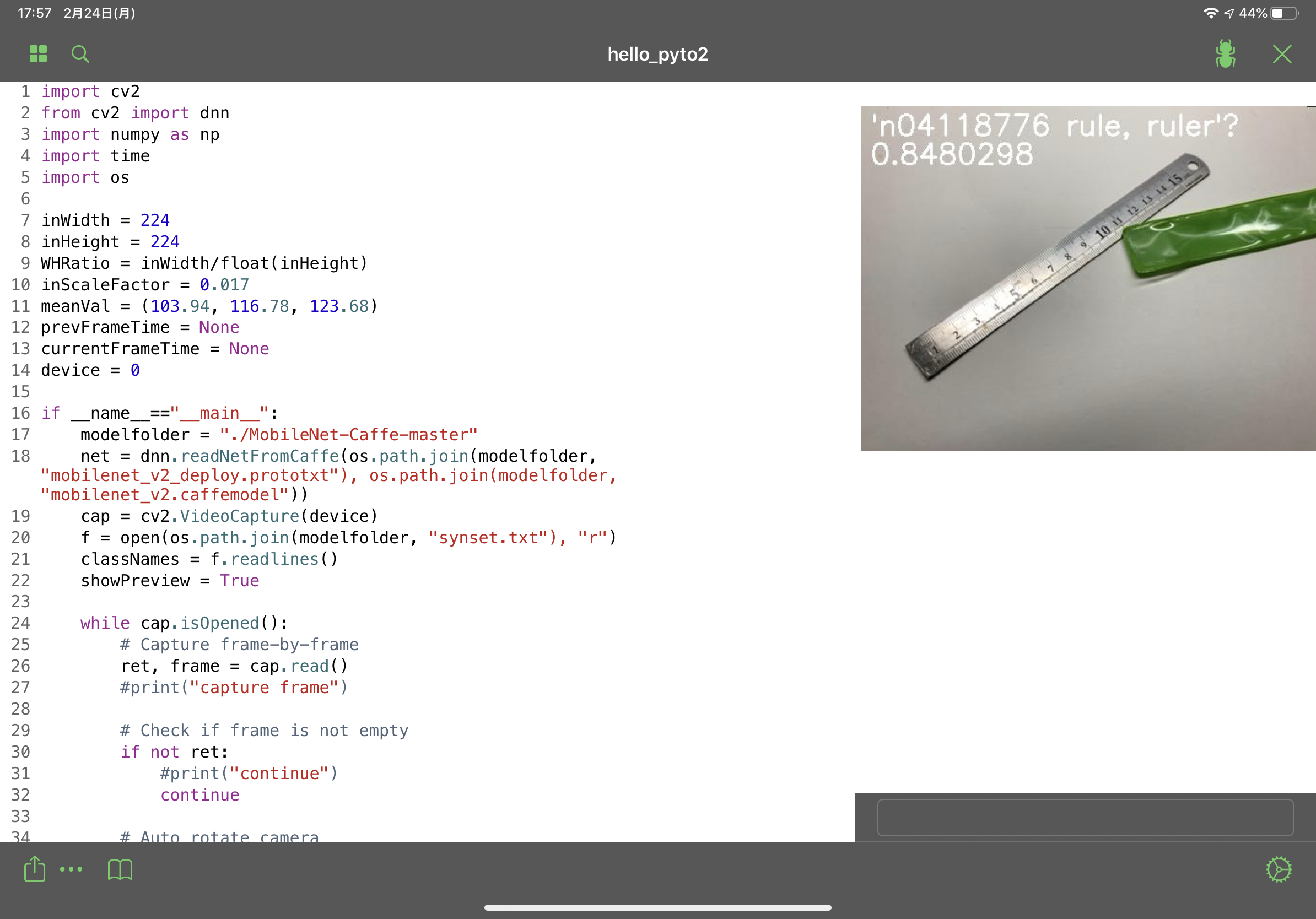
OpenCVにはdnnモジュールが含まれているので、試しにMobilenetを動かしてみました。ソースコードはhttp://asukiaaa.blogspot.com/2018/03/opencvdnnpythonmobilenet.html からお借りし、Pyto用に少し書き直しました。カメラはiPadの外カメラです。
動作は問題無く、フレームレートもカクツキを感じないレベルでした。正直、iOSアプリの上でディープラーニング(の予測)が動くとは思っていなかったので、驚きました。
その他
- ユニバーサルアプリ(iPhone, iPad両対応)である
- デバッガ(pdb)が使える
- csv、画像の読み込みはローカルでも問題なかった
- matplotlibのグラフ重なりは
plt.clf()で解決できる(前述)- PytoのGUIモジュールはpythonistaとほぼ同じ書き方ができる?
- syntax highlightが少しおかしい(「おまけ」の18行目、20行目など)
- 折り返された行は新しい行扱いになる(自動でインデントされなかったり、行の途中なのにコメントアウトできてしまう。バグ?)
- 閉じ括弧「)」を自動で付けてくれるが、自分で書くと2重になってしまう(vscodeみたいに括弧の外に出してくれない)
- pythonistaほどGUIに強くない(GUI作成ツールでパーツ配置できない)
GUIアプリ作成を重視するならPythonista、処理を重視するならPytoといった感じでしょうか。PythonistaにあってPytoに無いライブラリもあるので、ドキュメント等で内蔵ライブラリの比較を行うと良いと思います。
Pytoはこれからも発展していきそうなので、とても期待できるアプリだと感じました。
リンク
Pyto公式サイト:https://pyto.app/
Pytoドキュメント:https://pyto.readthedocs.io/en/latest/




- 投稿日:2020-02-24T20:45:32+09:00
【Python】続・PDFの文章をページ毎にCSVに変換
前回のあと、コレ改修が必要だなと思ったので地味な続きです。
事の発端
PDFのページをCSV出力したはいいけれど、トンデモデータになり申した。
具体的に言うと、サブタイトルが真ん中に来たりしてました。地味につらい。なかなか類似案件が見つからずもだもだしてたところ、以下のサイトを発見。
厚生労働省のブラック企業リストをPythonで解析する(PDFMiner.six)同志がいたことと、座標で何とかできそうなのはわかりました。
のでやってみようと思います。検証-準備-
参考:PDFから文字情報を抽出するには、PDFMiner一択
pdfminerではレイアウトの座標情報も取れるらしいです。
今まではTextConverterで文字データだけを抜いていましたが、
PDFPageAggregatorでは座標と文字データが引っこ抜けるようなのでこちらを使います。とりあえず、どんな座標とれてるかチェックします。
サンプルPDF用意できてなくて申し訳ない…。from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter from pdfminer.converter import TextConverter, PDFPageAggregator from pdfminer.layout import LAParams, LTContainer, LTTextBox, LTTextLine, LTChar from pdfminer.pdfpage import PDFPage def convert_pdf_to_txt(self,p_d_f): fp = open(p_d_f, 'rb') for page in PDFPage.get_pages(fp): rsrcmgr = PDFResourceManager() laparams = LAParams() laparams.detect_vertical = True device = PDFPageAggregator(rsrcmgr, laparams=laparams) interpreter = PDFPageInterpreter(rsrcmgr, device) #PDFから座標と文字データを取得 interpreter.process_page(page) layout = device.get_result() #座標と文字の表示 for node in layout: if isinstance(node, LTTextBox) or isinstance(node, LTTextLine): print(node.get_text()) #文字 word =input(node.bbox) #座標 word =input("---page end---")コマンドプロンプトでぽちぽちチェックする非効率なやつ。
正直LTTextBoxみたいな判定よくわかってないですが、おまじない的に入れてしまっている。
ちゃんと調べよう。検証-結果-
出力結果の抜粋です。
文章はダミーです。---page end--- ポップコーン機について (68.28, 765.90036, 337.2, 779.9403599999999) ぱちぱちはじけてポップコーンを作る機械です。 (67.8, 697.71564, 410.4000000000001, 718.47564) 使うときは安全に気を付けてください。 (67.8, 665.29564, 339.8400000000002, 686.05564) 使い方は以下の通り。 (67.8, 643.69564, 279.3600000000001, 653.65564000) 説明 (67.8, 730.11564, 87.96000000000001, 740.07564)タプルが座標です。順番は(x0,y0,x1,y1)。詳しくは参考サイトへGO!
端的に言うと、y1を見れば一番下からの文字の座標がわかります。
つまり、ページ内のy1が降順であれば上から順番の座標に文字が配置されている=正しい配置形態、です(今回の場合は)。で、この出力結果を見ると最後の行のy1が二番目に大きいので、単純に上から並べるという観点では的外れな結果です。
x0を基準に並び替えられている可能性があります。嘘です何もわかりません。
座標はうまくとれてるっぽいので、このy1を使ってなんとかすることにします。解決方法案
①辞書つくる
②辞書をソート(キー降順)
③それを文字列にする
④改行を一掃するこれでうまくいくはず。
しゃらくせえ人は完成品だけ見てってください。①辞書つくる
d=[] for node in layout: if isinstance(node, LTTextBox) or isinstance(node, LTTextLine): y1 = node.bbox[3] #表ならy1の座標が重複するので文字列結合 if y1 in d: d[y1] += "|" + node.get_text() else: d[y1] = node.get_text()辞書をさくさく作ります。気休め程度に表対策もします。
ですが、正直に言うとこの表ぽくする方法は穴があるので不毛な努力です。
というのも、先ほどの座標って一行ずついい感じに文字を取っているように見えるのですが、仕組みとしてはマージンパディング的な値を設定して、近々の文字の塊を「ブロック」として取っているらしいのです(たしか)。ベタな話、何も設定しなければデフォルトのマージンが適用されて、行間つめつめの文章とか細かめの表なんかは複数行を一つのブロックと認識されます。
なので、同じ座標として複数行の文字がドカッと取得されたら、もうエセ表作戦崩壊です。ならマージンパディング的なのをちゃんと設定しろって話ですけども、今回はそこまで求めてないので特に設定はしません。
表が出たら、「残念だったな!」程度の気持ちでレッツトライ。②辞書のソート(キー降順)
参考:Python sortのまとめ (リスト、辞書型、Series、DataFrame)
d2 = sorted(d.items(), key=lambda x: -x[0])やったぜ! らむだはつよし!
ちなみにこれを実行すると辞書がリストになります。
ソートさえできればいいのであまり気にしません。③それを文字列にする
text = "" for d0 in d2: text += d0[1]ただぐるぐるしてるだけ。
④改行を一掃する
参考:Python, splitでカンマ区切り文字列を分割、空白を削除しリスト化
いつもお世話になってます。space = re.compile("[ ]+") text = re.sub(space, "", text ) l_text = [a for a in text.splitlines() if a != ''] text = '\n'.join(l_text).replace('\n|', '|')空白と改行が多いよ問題の解決案です。
空白は置換、改行はリストにして抹消します。
ついでに表もどきの時に目印にしてた記号の前にある改行も削除します。完成品
from pdfminer.pdfinterp import PDFResourceManager, PDFPageInterpreter from pdfminer.converter import TextConverter, PDFPageAggregator from pdfminer.layout import LAParams, LTContainer, LTTextBox, LTTextLine, LTChar from pdfminer.pdfpage import PDFPage import csv,re,datetime import pandas as pd class converter(object): def convert_pdf_to_txt(self,p_d_f): print("system:pdf【" + p_d_f + "】を読込みます") df = pd.DataFrame(columns=["更新日時","文章","ページ番号"]) cnt = 1 space = re.compile("[ ]+") fp = open(p_d_f, 'rb') #pdfから座標と文字データ引っこ抜く for page in PDFPage.get_pages(fp): rsrcmgr = PDFResourceManager() laparams = LAParams() laparams.detect_vertical = True device = PDFPageAggregator(rsrcmgr, laparams=laparams) interpreter = PDFPageInterpreter(rsrcmgr, device) #PDFから座標と文字データを取得 interpreter.process_page(page) layout = device.get_result() #座標とデータの辞書をつくる d={} for node in layout: if isinstance(node, LTTextBox) or isinstance(node, LTTextLine): y1 = node.bbox[3] #表ならy1の座標が重複するので文字列結合 if y1 in d: d[y1] += "|" + node.get_text() else: d.update({y1 : node.get_text()}) #座標順にソート d2 = sorted(d.items(), key=lambda x: -x[0]) #文字列にぶっこむ text = "" for d0 in d2: text += ddd[1] #空白改行の削除 text = re.sub(space, "", text) l_text = [a for a in text.splitlines() if a != ''] text = '\n'.join(l_text).replace('\n|', '|') df.loc[cnt,["文章","ページ番号"]] = [text,cnt] cnt += 1 fp.close() device.close() dt = datetime.datetime.now() df["更新日時"] = now csv_path = p_d_f.replace('.pdf', '.csv') with open(csv_path, mode='w', encoding='cp932', errors='ignore', newline='\n') as f: df.to_csv(f,index=False) if __name__ == "__main__": p_d_f = "なんちゃか.pdf" con=converter() hoge=con.pdf_to_csv(p_d_f)前回から足し算引き算したのでよく確認してないですが、似たようなものは動きましたメモ。
エラーでたら都度都度自前で直してくださひ。
- 投稿日:2020-02-24T20:44:02+09:00
ゼロで割ったときの警告【invalid value encountered in true_divide】を回避する
はじめに
Pythonの学習メモです。
問題
numpyで作成した配列に0があった場合、0で割ると警告が出ます。(当たり前)
problem.pyimport numpy as np A = np.array([0, 1, 2]) B = np.array([0, 1, 1]) print(A/B)出力> RuntimeWarning: invalid value encountered in true_divide print(A/B) [nan 1. 2.]警告が出て、ゼロで割った箇所がnanになっています。
解決方法
solved.pyimport numpy as np A = np.array([0, 1, 2], dtype=float) B = np.array([0, 1, 1], dtype=float) C = np.divide(A, B, out=np.zeros_like(A), where=B!=0) print(C)出力> [0. 1. 2.]np.zeros_like(A)は、Aと同じ形のゼロで埋められた配列を返します。また、np.divide(A,B)でAをBで割る演算を行えます。ドキュメントによると、outは結果を保存する場所、whereは全入力に対して条件を指定するオプションです。whereが偽となる箇所(この場合はB[0])の計算結果には0が代入されます。
おわりに
確かに警告はなくなりましたが、それに助けられることもあるので、本当に解決して良かったのかは疑問です。
ご覧いただきありがとうございました。ご指摘等ございましたらコメント欄にお願いします。
参考URL
https://stackoverflow.com/questions/26248654/how-to-return-0-with-divide-by-zero (2020年2月24日閲覧)
https://docs.scipy.org/doc/numpy/reference/generated/numpy.divide.html(2020年2月24日閲覧)
https://docs.scipy.org/doc/numpy/reference/generated/numpy.zeros_like.html(2020年2月24日閲覧)
- 投稿日:2020-02-24T19:46:17+09:00
【Pandas】DataFrameで1つ目のrowデータがheaderに入ってしまったら
(Jupyter Notebookを想定した話となります。)
何かしらの理由で、DataFrameの一行目のデータが、header(columns)に入ってしまった場合の対処法。
改めてreadしたり、DataFrameを構築し直すのが簡単だが、
どうにかコードで直したい場合に、DataFrameでゴニョゴニョして直す方法をまとめた。例えば、下記のように本来は1行目のデータがheader部分に入ってしまった場合を考える。
a 0 0 b 1 1 c 2 2 d 3 3 e 4 headerにある[a,0]を、インデックス=0の位置に挿入したいが、pandasでは、そのような関数は用意されていないようなので、次のように処理する。
df = df.shift() #行データを下方向に1つずつずらす df.iloc[0] = df.columns.values #インデックス=0の位置に本来は一行目のデータを代入 df.columns = ["col1", "col2"] #本来のカラム名を設定(結果)
col1 col2 0 a 0 1 b 1 2 c 2 3 d 3 以上。
- 投稿日:2020-02-24T19:05:03+09:00
【Python】構造化配列作成(NumPyで異種型データ格納)
0. 概要
名前、年齢、身長と言った具合に、ある人の情報を一括でまとめたいですよね。
そんなときはNumPyの構造化配列を使用しましょう。複合型の異なるデータを効率的に格納できます。せっかくなので乃木坂メンバーで構成してみました。(2020/02/24現在)1. コード
list.py# -*- coding: utf-8 import numpy as np #4人の情報を各配列に格納 name = ['mai', 'asuka', 'erika', 'yoda'] age = [27, 21, 23, 19] height = [162, 158, 160, 152] #構造化配列の作成(3種類の配列のデータ型を決定) data = np.zeros(4, dtype={'names' : ('name', 'age', 'height'), 'formats': ('U10', 'i4', 'f8')}) #U10 -> Unicode(10文字まで), i4 -> int32, f8 -> float64 #データ型の確認 print(data.dtype) #[('name', '<U10'), ('age', '<i4'), ('height', '<f8')] #構造化配列にデータを格納 data['name'] = name data['age'] = age data['height'] = height #4人の全情報をプリント print(data) #[(u'mai', 27, 162.0) (u'asuka', 21, 158.0) (u'erika', 23, 160.0) (u'yoda', 19, 152.0)] #4人の名前をプリント print(data['name']) #[u'mai' u'asuka' u'erika' u'yoda'] #asukaの全情報をプリント print(data[1]) #(u'asuka', 21, 158.0) #maiのheightをプリント print(data[0]['height']) #162.02. 参考書籍
オライリージャパン : Pythonデータサイエンスハンドブック
- 投稿日:2020-02-24T18:50:32+09:00
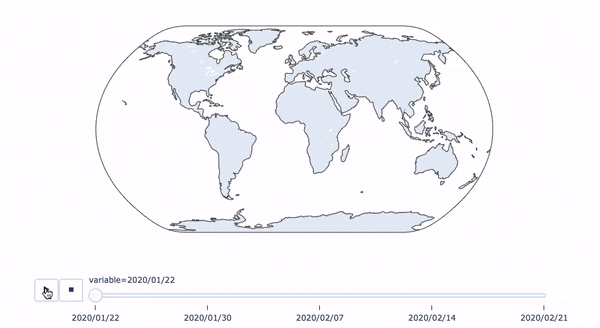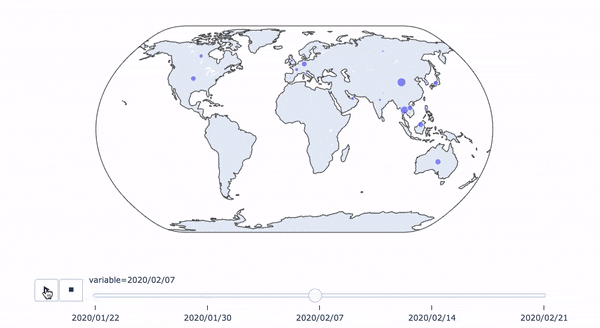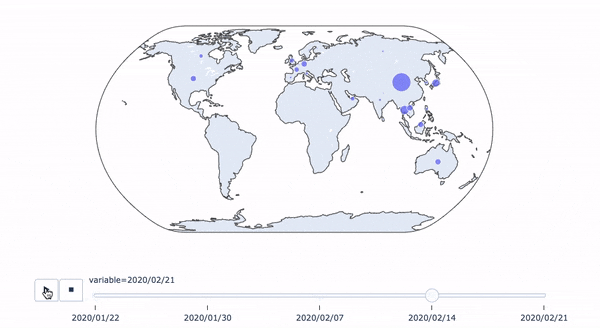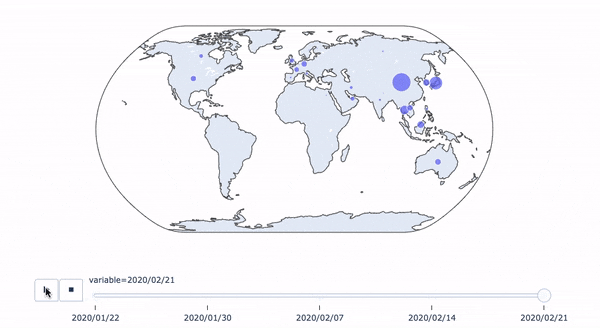
python+plotlyでコロナウイルス感染状況のアニメーション付き時系列マップを作る
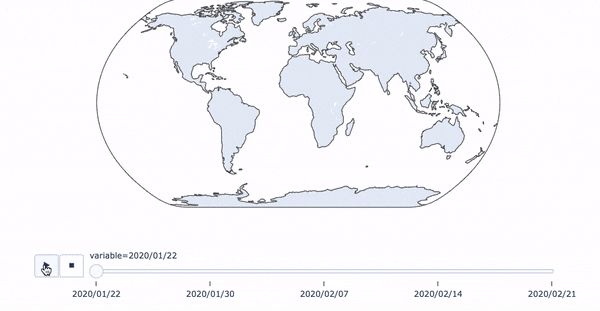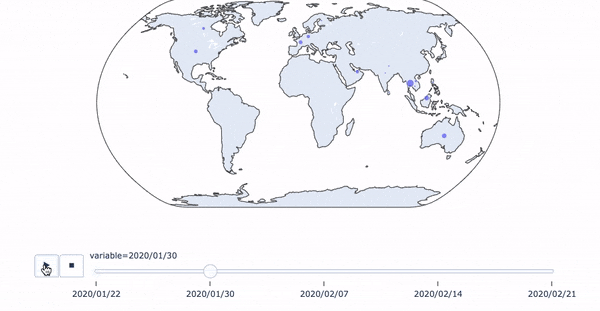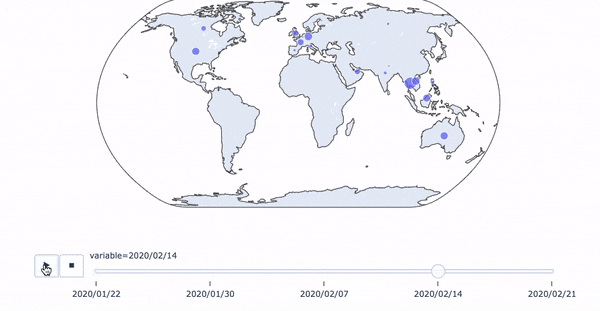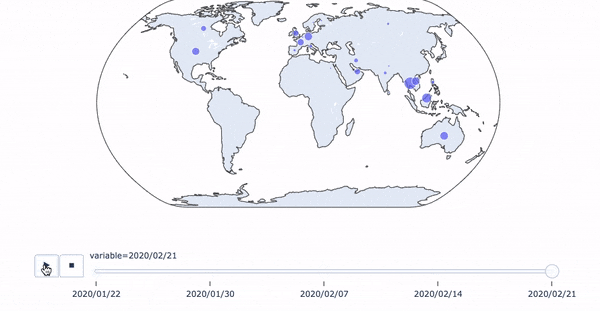
コロナ感染状況のアニメーション付き時系列マップ
簡単なコロナウイルスの感染状況の一週間ごとの時系列マップをplotlyで作ってみました。データはWHOのサイトに掲載されているpdfからひとつずつコピペで持ってきました(大変でした。。。)。
Coronavirus disease (COVID-2019) situation reportsアジア地域の増え方が怖いですね。。。またヨーロッパとアメリカ、カナダにも100人未満ではありますが、ぽつぽついるのも気になります。
【データに関しての注意】
- 中国の感染者は2020/02/21時点で14万人ほどですが、そのままのスケールだと他の国のデータが可視化できなくなるので、100で割って1000人単位にスケールダウンしています
- それでも一部の一桁、二桁台の国は可視化するにはまだ小さすぎるので、10倍にしてスケールアップしています。
- 日本のデータはプリンセスダイヤモンド号の乗客も含んでいるため、600人程度となっています。含まなければ2020/02/21時点では21人です。
作った際のコード
環境:Google Colab
言語:pythonモジュール
plotlyを使って可視化します。plotlyはそのままの国名ではなく、国名コード(JapanだったらJPNなど)を扱うので国名コードに変換するcountry_converterもインポートします。データ処理はpandasで行います。# ない場合 !pip install plotly !pip install country_converter !pip install pandas import country_converter as coco import plotly.express as px import pandas as pdデータの読み取り
これらはすべてWHOのサイトのpdfからコピペ、手打ちしたもののため万が一間違いがあったらすみません。。。もっといいデータベースないのかな。。。
こちらのデータをすべてDataFrameに格納します。
dict_01_22 = {"2020/01/22": {"China": 310, "Japan": 1, "Republic of Korea": 1, "Thailand": 2}} dict_01_30 = {"2020/01/30": {"China": 7737, "Japan": 11, "Republic of Korea": 4, "Vietnam": 2, "Singapore": 10, "Australia": 7, "Malaysia": 7, "Cambodia": 1, "Philippines": 1, "Nepal": 1, "Sri Lanka": 1, "India": 1, "United States of America": 5, "Canada": 3, "France": 5, "Finland": 1, "Germany": 4, "United Arab Emirates": 4, "Thailand": 14}} dict_02_07 = {"2020/02/07": {"China": 31211, "Japan": 91, "Republic of Korea": 24, "Vietnam": 12, "Singapore": 30, "Australia": 15, "Malaysia": 14, "Cambodia": 1, "Philippines": 3, "Nepal": 1, "Sri Lanka": 1, "India": 3, "United States of America": 12, "Canada": 7, "France": 6, "Belgium": 1, "Italy": 3, "Finland": 1, "Spain": 1, "Sweden": 1, "Germany": 13, "The United Kingdom": 3, "United Arab Emirates": 5, "Russia": 2, "Thailand": 25}} dict_02_14 = {"2020/02/14": {"China": 142823, "Japan": 251, "Republic of Korea": 28, "Vietnam": 16, "Singapore": 58, "Australia": 15, "Malaysia": 14, "Cambodia": 1, "Philippines": 3, "Nepal": 1, "Sri Lanka": 1, "India": 3, "United States of America": 15, "Canada": 7, "France": 11, "Belgium": 1, "Italy": 3, "Finland": 1, "Spain": 2, "Sweden": 1, "Germany": 16, "The United Kingdom": 9, "United Arab Emirates": 8, "Russia": 2, "Thailand": 33}} dict_02_21 = {"2020/02/21": {"China": 142823, "Japan": 727, "Republic of Korea": 204, "Vietnam": 16, "Singapore": 85, "Australia": 17, "Malaysia": 22, "Cambodia": 1, "Philippines": 3, "Nepal": 1, "Sri Lanka": 1, "India": 3, "United States of America": 15, "Canada": 8, "France": 12, "Belgium": 1, "Italy": 3, "Finland": 1, "Spain": 2, "Sweden": 1, "Germany": 16, "The United Kingdom": 9, "United Arab Emirates": 9, "Iran": 5, "Egypt": 1, "Russia": 2, "Thailand": 35}} concated = pd.concat([ pd.DataFrame(dict_01_22), pd.DataFrame(dict_01_30), pd.DataFrame(dict_02_07), pd.DataFrame(dict_02_14), pd.DataFrame(dict_02_21)], axis=1, sort=True).fillna(0)
concatedの最初の5行は以下のようになります:
2020/01/22 2020/01/30 2020/02/07 2020/02/14 2020/02/21 Australia 0.0 7.0 15.0 15.0 17 Belgium 0.0 0.0 1.0 1.0 1 Cambodia 0.0 1.0 1.0 1.0 1 Canada 0.0 3.0 7.0 7.0 8 China 310.0 7737.0 31211.0 142823.0 142823 データ処理
国名を国名コードに変換するのと、plotlyではtidy dataを使うことになるので、pd.meltを使って変換します。
time_periods = [column for column in concated.columns] df = concated.reset_index().rename(columns={"index": "country"}) df["ISO"] = df["country"].apply(lambda x: coco.convert(x)) data = pd.melt(df, id_vars=["ISO"], value_vars=time_periods)tidy dataに変換された
dataについてはこのようになります。
ISO variable value 0 AUS 2020/01/22 0.0 1 BEL 2020/01/22 0.0 2 KHM 2020/01/22 0.0 3 CAN 2020/01/22 0.0 4 CHN 2020/01/22 310.0 最後にデータの可視化
ここでデータを可視化したいわけですが、
- 中国が多すぎる
- 一部の国が少なすぎる
問題があるので、そこのスケールを調整します。
- 中国は100で割る
- 日本、中国、韓国以外は10倍にする
ことで地図で見やすくしました(倫理的にいいのかはあまりわかりません。。。)。
data_for_map = data for ind in data[(data["ISO"] != "CHN") & (data["ISO"] != "JPN") & (data["ISO"] != "KOR")].index: data_for_map.at[ind, "value"] = data_for_map.at[ind, "value"] * 10 for ind in data[data["ISO"] == "CHN"].index: data_for_map.at[ind, "value"] = data_for_map.at[ind, "value"] // 100 fig = px.scatter_geo(data_for_map, locations="ISO",size="value", animation_frame="variable", projection="natural earth") fig.show()これで地図が出るはずです。
日本、中国、韓国を除外した場合
======================= 先ほどと一緒 ======================= time_periods = [column for column in concated.columns] df = concated.reset_index().rename(columns={"index": "country"}) df["ISO"] = df["country"].apply(lambda x: coco.convert(x)) data = pd.melt(df, id_vars=["ISO"], value_vars=time_periods) ========================================================== data_for_map = data[(data["ISO"] != "CHN") & (data["ISO"] != "JPN") & (data["ISO"] != "KOR")] fig = px.scatter_geo(data_for_map, locations="ISO",size="value", animation_frame="variable", projection="natural earth") fig.show()とすれば感染者の多い日本、中国、韓国を除外して可視化することができます。その場合の
2020/02/21のデータは以下のようになります。
東南アジア、ヨーロッパ、北アメリカがとくに目立ちます。
一刻も早く収束するといいですね。。。
- 投稿日:2020-02-24T18:43:25+09:00
pytestでflaskの単体テストのパラメータをきれい与える
はじめに
前回はpytestを使用してflaskの単体テストを行いました。しかし、一つのテスト関数の中でflaskのクライアント作成とテストを行っているのでとても見にくいものになりました。今回は、もう少しテストが見やすくなるように色々なpytestの機能を使っていきます。
環境
- python:3.6.5
- flask:1.0.2
- pytest:5.3.5
テストと前処理・後処理の分離
flaskのクライントとテストソースを一つの関数内にまとめていましたが、テスト関数が増えると見にくくなります。また、厳密に言うとクライアント作成はテストではないため、性能テスト時や関数の結果に左右されるのは良くないです。そこでクライアント作成・削除をテストと分離します。
テスト対象のソース
テスト対象のソースは前回のflaskのソースを使用します。
flask_mod.pyfrom flask import Flask, jsonify app = Flask(__name__) @app.route('/') def root(): return "root" @app.route('/sample/<message>') def sample(message): return 'sample_' + message前処理・後処理のソース
前処理と後処理の関数を作成して、その関数を
@pytest.fixtureデコレーションで登録します。この関数のyieldにテスト関数が埋め込まれるイメージです。yieldの前に前処理を記載して、yieldの後ろに後処理を記載します。
例では、テスト用のクライアントを生成してyieldに与えています。その後、deleteでクライアントを削除しています。pytest_flask.py@pytest.fixture def client(): app.config['TESTING'] = True test_client = app.test_client() yield test_client test_client.delete()テスト関数
テスト関数を作成して、前処理・後処理のソースでyieldに与えた値を受け取る引数を指定します。この引数は前処理・後処理の関数と同じ名前にする必要があります。その後は普通にテストのソースを記載します。
例では、test_flask_simple()関数の引数にfixtureで生成したクライアントを受け取る引数を用意してgetを発行してテストしています。pytest_flask.pyimport pytest from flask_mod import app @pytest.fixture def client(): app.config['TESTING'] = True test_client = app.test_client() yield test_client test_client.delete() def test_flask_simple(client): result = client.get('/') assert b'root' == result.data実行結果
テスト対象とテスト方法のソースができたため、実行します。
PS C:\Users\xxxx\program\python> pytest .\pytest_flask.py ======= test session starts ======== platform win32 -- Python 3.6.5, pytest-5.3.5, py-1.8.1, pluggy-0.13.1 rootdir: C:\Users\xxxx\program\python\flask collected 1 item pytest_flask.py . [100%] ======== 1 passed in 0.21s =========結果を見ると先ほど作成したpytest_flaskが100%となり正常に終わっています。テストOKであり、fixtureを使用してクライアントの生成と破棄が正常にできました。
テストソースを複数のパラメータで使い回す。
テストソースを作って別の引数でテストしたいと言うのは往々にしてあると思います。その場合、
@pytest.fixture()デコレーションのparam引数で登録します。テストパラメータの定義
前処理・後処理の関数の
@pytest.fixture()デコレータのparamsにテストパラメータをタプルのリスト形式で記載します。それらのパラメータを受け取る引数を関数に用意してyieldでparamを与えます。
例では、テストされるソースはsample(message)をイメージしているため、タプルの1番目にflaskに与えるパラメータを定義して、2番目には答えを入れています。pytest_flask.py@pytest.fixture(params=[('message', b'sample_message'),('sample', b'sample_sample')]) def client(request): app.config['TESTING'] = True test_client = app.test_client() yield test_client, request.param test_client.delete()テスト関数
テスト関数の引数に、前処理・後処理の関数で
yieldで与えた値がタプルで入っているため、それぞれ必要な要素を抜き出して使用します。
例では、client引数内の1番目にclient、2番目にparamsで与えたタプルの1つが入っているため、それを抜き出してURLと結果確認に使用しています。pytest_flask.pyimport pytest from flask_mod import app @pytest.fixture(params=[('message', b'sample_message'),('sample', b'sample_sample')]) def client(request): app.config['TESTING'] = True test_client = app.test_client() yield test_client, request.param test_client.delete() def test_flask_simple(client): test_client = client[0] test_param = client[1] result = test_client.get('/sample/' + test_param[0]) assert test_param[1] == result.data実行結果
テスト対象とテスト方法のソースができたため、実行します。
PS Users\xxxx\program\python> pytest -v .\pytest_flask.py ======= test session starts ======== platform win32 -- Python 3.6.5, pytest-5.3.5, py-1.8.1, pluggy-0.13.1 -- c:\users\xxxx\appdata\local\programs\python\python36-32\python.exe cachedir: .pytest_cache rootdir: C:\Users\xxxx\program\python\flask collected 2 items pytest_flask.py::test_flask_simple[client0] PASSED [ 50%] pytest_flask.py::test_flask_simple[client1] PASSED [100%] ======== 2 passed in 0.20s =========結果を見ると先ほど作成したtest_flask_simple関数が2回PASSEDになっています。これは、fixtureで与えたタプルが2つなので2回テストして両方OKだったということです。
片方失敗してみる
ちゃんと値が渡っているか確認するため、片方だけ誤りの値を与えてみます。
PS Users\xxxx\program\python> pytest -v .\pytest_flask.py ======= test session starts ======== platform win32 -- Python 3.6.5, pytest-5.3.5, py-1.8.1, pluggy-0.13.1 -- c:\users\xxxx\appdata\local\programs\python\python36-32\python.exe cachedir: .pytest_cache rootdir: C:\Users\xxxx\program\python\flask collected 2 items pytest_flask.py::test_flask_simple[client0] FAILED [ 50%] pytest_flask.py::test_flask_simple[client1] PASSED [100%] ============= FAILURES ============= _______ test_flask_simple[client0] _______ client = (<FlaskClient <Flask 'flask_mod'>>, ('message', b'sample_detail')) def test_flask_simple(client): test_client = client[0] test_param = client[1] result = test_client.get('/sample/' + test_param[0]) > assert test_param[1] == result.data E AssertionError: assert b'sample_detail' == b'sample_message' E At index 7 diff: b'd' != b'm' E Full diff: E - b'sample_detail' E + b'sample_message' pytest_flask.py:17: AssertionError ============= 1 failed, 1 passed in 0.27s =============片方だけ失敗する値を与えてみると関数の片方がFAILEDになり失敗しました。
おわりに
ここでまとめたpytestは、ほんの一部の機能になります。この他にもパラメータの組み合わせを自動で作る機能やデータを保存する機能などさらに便利な機能があります。ただし今回もそうですが使用するのに若干の癖があり初見では使いにくいと感じてしまうかもしれません。しかし、便利で使いやすい機能が豊富なので慣れれば慣れるほど早く多彩なテストが作れるのではないかと思います。
- 投稿日:2020-02-24T17:51:17+09:00
Python「numpy.sum(...)」のaxisオプション指定まとめ
はじめに
numpy.ndarray.sum(...)やnumpy.ndarray.mean(...)などで指定可能な axis オプション についてのまとめです。2次元および3次元のnumpy配列を対象に、図を使って解説します。2次元のnumpy配列の場合
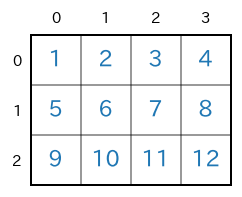
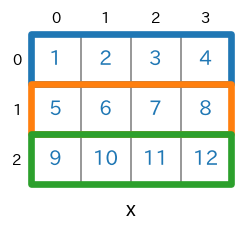
まずは、2次元(ndim=2)のnumpy配列を対象にします。例として、次のような3行4列の2次元のnumpy配列
xを考えます。
この配列
xは次のコードで生成できます。shape=(3,4)のnumpy配列を生成import numpy as np x = np.arange(1,12+1).reshape(3,4) print(x) #print(x.ndim) # -> 2 #print(x.shape) # -> (3, 4)実行結果[ [ 1 2 3 4] [ 5 6 7 8] [ 9 10 11 12] ]
axis=Noneを指定
axis=Noneがデフォルト引数になっているので、x.sum()でもx.sum(axis=None)でも同じ動作をします。numpy.sum(...) / numpy.ndarray.sum(...) のリファレンスsum(axis=None)s = x.sum(axis=None) # print(type(s)) # -> <class 'numpy.int64'> # print(s.ndim) # -> 0 # print(s.shape) # -> () print(s)
axis=Noneを指定すると配列を構成する全ての要素についての合計が求められます。具体的には $1+2+3+\cdots+11+12=$$\bf{78}$ が計算されます。実行結果78
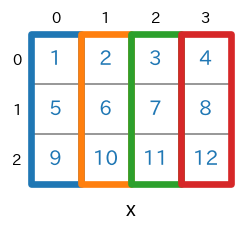
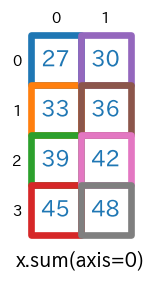
axis=0を指定sum(axis=0)s = x.sum(axis=0) # print(type(s)) # -> <class 'numpy.ndarray'> # print(s.ndim) # -> 1 # print(s.shape) # -> (4,) print(s)実行結果[15 18 21 24]
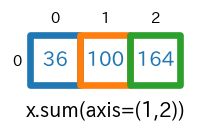
axis=0を指定すると、行方向に要素が合計されます。具体的には、$1+5+9=$$\bf{15}$、$2+6+10=$$\bf{18}$、$3+7+11=$$\bf{21}$、$4+8+12=$$\bf{24}$ が計算され[15 18 21 24]となっています。
【注意】:各行の要素合計ではなくて、行方向(行が 0, 1, 2, 3, ... と大きくなる方向)に要素を合計していることに注意してください(ここを勘違いすると一気に???に陥ります(経験談))。
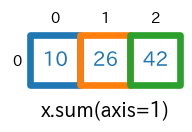
axis=1を指定sum(axis=1)s = x.sum(axis=1) # print(type(s)) # -> <class 'numpy.ndarray'> # print(s.ndim) # -> 1 # print(s.shape) # -> (3,) print(s)実行結果[10 26 42]
axis=1を指定すると、列方向(列が 0, 1, 2, 3, ... と大きくなる方向)に要素が合計されています。具体的には、$1+2+3+4=$$\bf{10}$、$5+6+7+8=$$\bf{26}$、$9+10+11+12=$$\bf{42}$ が計算されて[10 26 42]となっています。
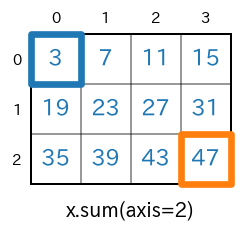
3次元のnumpy配列の場合
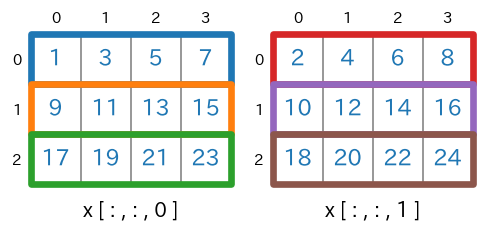
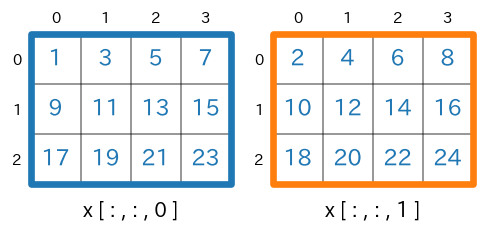
つづいて、3次元のnumpy配列を対象にします。例として、shape が (3,4,2) のnumpy配列
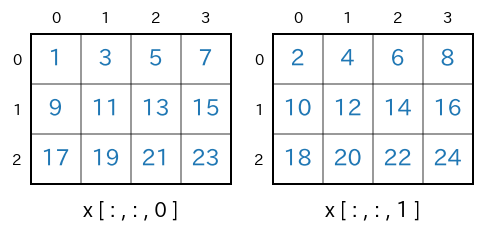
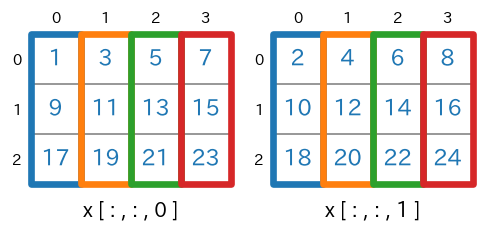
xを扱います。shape=(3,4,2)のnumpy配列を生成import numpy as np x = np.arange(1,24+1).reshape(3,4,2) print(x) # print(x.ndim) # -> 3 # print(x.shape) # -> (3, 4, 2)実行結果(読みやすくするために改行位置などの整形をしています)[ [ [ 1 2] [ 3 4] [ 5 6] [ 7 8] ] [ [ 9 10] [11 12] [13 14] [15 16] ] [ [17 18] [19 20] [21 22] [23 24] ] ]
axis=2で分離して描くと次のようになります。
axis=Noneを指定sum(axis=None)s = x.sum(axis=None) # print(type(s)) # -> <class 'numpy.int64'> # print(s.ndim) # -> 0 # print(s.shape) # -> () print(s)すべての要素についての合計です。具体的には $1+2+3+4+\cdots+22+23+24=300$ が計算されます。
実行結果300
axis=0を指定sum(axis=0)s = x.sum(axis=0) # print(type(s)) # -> <class 'numpy.ndarray'> # print(s.ndim) # -> 2 # print(s.shape) # -> (4, 2) print(s)実行結果[ [27 30] [33 36] [39 42] [45 48] ]
axis=0の指定により、行方向に要素が合計されます。上記の実行結果の最初の要素
[27 30]は、$1+9+17=$$\bf{27}$、$2+10+18=$$\bf{30}$ のように計算された結果です。
shape=(3,4,2) であった
xが、x.sum(axis=0)で shape=(4,2) になります。
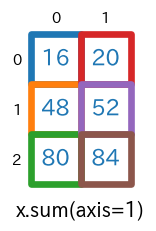
axis=1を指定sum(axis=1)s = x.sum(axis=1) # print(type(s)) # -> <class 'numpy.ndarray'> # print(s.ndim) # -> 2 # print(s.shape) # -> (3, 2) print(s)実行結果[ [16 20] [48 52] [80 84] ]
axis=1の指定により、列方向に要素が合計されます。上記実行結果の最初の要素[16 20]は、$1+3+5+7=$$\bf{16}$、$2+4+6+8=$$\bf{20}$ のように計算された結果です。
shape=(3,4,2) であった
xが、x.sum(axis=1)で shape=(3,2) になります。
axis=2を指定sum(axis=2)s = x.sum(axis=2) # print(type(s)) # -> <class 'numpy.ndarray'> # print(s.ndim) # -> 2 # print(s.shape) # -> (3, 4) print(s)実行結果[ [ 3 7 11 15] [19 23 27 31] [35 39 43 47] ]
axis=2の指定により、画像であればチャンネル方向に要素が合計されます。上記実行結果の最初の左上の要素3は $1+2=$$\bf{3}$、右下の要素47は$23+24=$$\bf{47}$ と計算された結果です。
shape=(3,4,2) であった
xが、x.sum(axis=2)で shape=(3,4) になります。
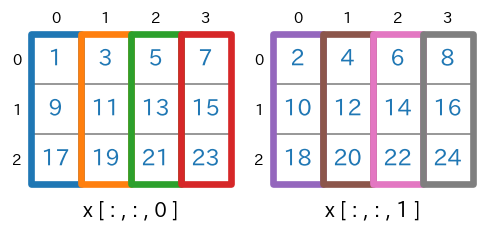
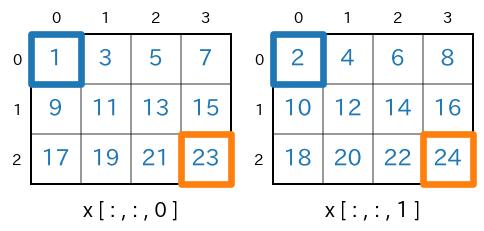
axis=(0,1)を指定NumPy 1.7 以降では、axis をタプルで指定することができます。
axis=(0,1)の指定により、行と列についての合計が求められます。なお、axis=(1,0)としても結果は同じです(順番は関係ありません)。sum(axis=(0,1))s = x.sum(axis=(0,1)) #print(type(s)) # -> <class 'numpy.ndarray'> #print(s.ndim) # -> 1 #print(s.shape) # -> (2,) print(s)実行結果[144 156]実行結果の最初の要素
144は、x[:,:,0]の全要素の合計、つまり $1+3+5+7+\cdots + 19+21+23$ を計算した結果になります。
shape=(3,4,2) であった
xが、x.sum(axis=(0,1))で shape=(2,) になります。
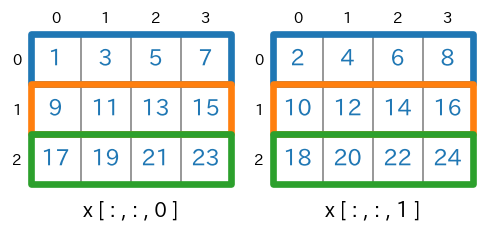
axis=(1,2)を指定
axis=(2,1)としても同じです。sum(axis=(1,2))s = x.sum(axis=(1,2)) # print(type(s)) # -> <class 'numpy.ndarray'> # print(s.ndim) # -> 1 # print(s.shape) # -> (3,) print(s)実行結果[ 36 100 164]実行結果の最初の要素
36は、下図の青枠の要素の合計、つまり、$(1+3+5+7)+(2+4+6+8)$ を計算した結果になります。
shape=(3,4,2) であった
xが、x.sum(axis=(1,2))で shape=(3,) になります。
axis=(0,2)を指定
axis=(2,0)でも同じです。sum(axis=(0,2))s = x.sum(axis=(0,2)) # print(type(s)) # -> <class 'numpy.ndarray'> # print(s.ndim) # -> 1 # print(s.shape) # -> (4,) print(s)実行結果[57 69 81 93]実行結果の最初の要素
57は、下図の青枠の要素の合計、つまり、$(1+9+17)+(2+10+18)$ を計算した結果になります。
shape=(3,4,2) であった
xが、x.sum(axis=(0,2))で shape=(4,) になります。
axis=(0,1,2)を指定
sum(axis=(0,1,2))は、sum(axis=None)またはsum()と同じで全要素の合計が計算されます。sum(axis=(0,1,2))s = x.sum(axis=(0,1,2)) #print(type(s)) # -> <class 'numpy.int64'> #print(s.ndim) # -> 0 #print(s.shape) # -> () print(s)実行結果300shape=(3,4,2) であった
xが、x.sum(axis=(0,1,2))で shape=(0) になります。
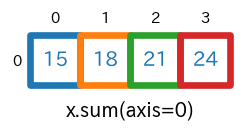
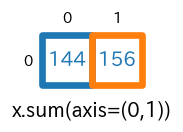
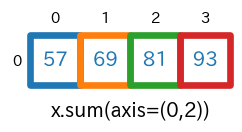
- 投稿日:2020-02-24T17:48:11+09:00
知らなかった用語・概念まとめ
初めて知ることが多すぎる
機械学習周りをちょこっと触っていく中で、そんなの知らなかったよと思ったことが無限にある。知った順に書き足していこうと思う。関連知識が近くなると思うから知った順です
かなり自分用ですHPatches
- 複数の実画像群。様々な測光、幾何学的変化を伴う
- ターゲット画像と、同じ視点で様々な光の当て方をされた5つのソース画像
- ターゲット画像と、異なる視点の5つのソース画像
Ground Truth
- 推論によって提供される情報ではなく、直接観測によって提供される情報のこと
path/to/xxx
- Path to xxx、つまり「xxxへのPath」という意味
- 自分でxxxへのパスに書き換える必要がある
- 最初見たときは何かのパスなんだろうと信じて疑わなかった
実行オプション
- python hoge.pyの後にぐちゃぐちゃ何かが続いているときのぐちゃぐちゃ
- 「実行オプション」であることがわからず、調べ方がわからなかった
- hoge.pyを見ると実行オプションの記述があるはずらしい
- 投稿日:2020-02-24T17:01:37+09:00
scipy の マンホイットニーU検定 の実装が 少サンプル数非対応 なので、代わりに rpy2 を使って R の wilcox.exact を使う
追記(2020/2/25)
マンホイットニーのU検定よりBrunner-Munzel検定の方が良いそうです。
そのため、下の
wilcox.exactをbrunnermunzel.test(片群のサンプルサイズが10程度以下ならbrunnermunzel.permutation.test)に置き換えて利用すると良いはずです。参考
奥村晴彦 先生の解説:
Brunner-Munzel検定他の検定(t検定、Welchのt検定、U検定)との比較:
マイナーだけど最強の統計的検定 Brunner-Munzel 検定 - ほくそ笑む経緯
Jupyter notebook でマンホイットニーのU検定をしようと思いました。U検定を実装しているライブラリを探してみた所、
scipyで実装されていました。具体的にはscipy.stats.mannwhitneyuという名前で実装されています。このライブラリを利用しようと思い、引数等を確認するために公式Docを見た所、
Notesに次の様な注記がありました。Use only when the number of observation in each sample is > 20訳すと、「2群それぞれのサンプルサイズが 20超 の場合のみ利用可能」となります。
なぜこのような条件が付されているのか調べた所、どうやらこのライブラリは「標準正規分布による近似をして検定する方法」のみを実装している事が分かりました。
この事はソースコードとWikipediaを見て分かりました。
そして、scipy の Github を調べると、どうやら片群のサンプルサイズが20以下の場合の実装はプルリク中のようでした。
さて、私は片群のサンプルサイズが20以下の場合の検定を行いたかったので、別のライブラリを探す必要が生まれました。
そこで、Python ライブラリをざっと調べて見たのですが、良さそうなものがパッとは見つかりませんでした。
どうしようか考えた所、「Rの実装を使えばいいのでは」と思いました。
そこで、RでU検定を実装したライブラリを探した所、
wilcox.exactというライブラリが見つかりました。このライブラリは、データ科学便覧で紹介されています。
データ科学便覧の解説によると、サンプルサイズによって自動で「標準正規分布による近似」をするか「p値を正確に計算」するかを決定してくれる事が分かりました。そしてこの機能により、scipyの様なサンプルサイズの制約はない事が分かりました。
この様に、良さそうなライブラリがRで見つかったので、Pythonカーネル上でRを使えるようにするライブラリ
rpy2を使って、wilcox.exactを使う事にしました。方法
1. rpy2を install します
terminalpip install rpy22. exactRankTests を install します
terminal# R を起動します $ RR(teminal上)# exactRankTests を install > install.packages("exactRankTests", repos="http://cran.ism.ac.jp/") # 終了 > q()3. Jupyter notebook 上で次のコードを実行して動作確認をします
Input(Jupyter notebook)# %R が使えるようにする %load_ext rpy2.ipython # U検定が入っているライブラリをロード %R library(exactRankTests) # Python の配列を引数にとる U検定メソッド を作成 def u_test(x, y): # ndarray に変換 # ndarrayなら 「%R -i」 した時に R で 「c()」 した時の形と同じになる x = np.array(x) y = np.array(y) # R側に x と y を読み込む %R -i x %R -i y # U検定 %R output = wilcox.exact(x=x,y=y,paired=F) # Python 側に出力 %R -o output # ListVector型で出力されるので、dictionary 型に変換 result = dict(zip(output.names, map(list,list(output)))) return result # 試してみる x = np.array([0.15165101, 0.47173771, 0.46735185, 0.67045667, 0.17489188]) y = x * 10 u_test(x, y)Output(Jupyter notebook){'statistic': [0.0], 'pointprob': [0.003968253968253968], 'p.value': [0.007936507936507936], 'null.value': [0.0], 'alternative': ['two.sided'], 'method': ['Exact Wilcoxon rank sum test'], 'data.name': ['x and y']}
p.valueがp値です。参考
rpy2の使い方
- 投稿日:2020-02-24T16:43:13+09:00
Diagramsを使用してOCIのアーキテクチャ図を生成
Diagramsとは
DiagramsはPythonでコードを記述することにより、各種アーキテクチャ図のファイルを生成するOSSです。
本記事公開時点のバージョンは0.6.2です。Oracle Cloudはもちろんのこと、オンプレミス、Kubernetes、AWS、Azure、GCP、Alibaba Cloudのアーキテクチャ図や、これらが混在するアーキテクチャ図を生成することが可能です。
本記事はOCIをベースに解説していますが、OCI以外のアーキテクチャ図においてもインポートするパッケージが異なるだけで、基本的な使い方は同様です。
生成されるアーキテクチャ図は各種クラウド標準のそれとは異なるものになりますが、本家サイトでも謳っている"Diagram as Code"、コードベースでのアーキテクチャ図のバージョン管理が実現できる点が大きいと思います。
ライセンスはMITライセンスです。Diagramsの導入
Graphvizの導入
Diagramsは図の描写をGraphvizというOSSに依存しています。
Diagramsを利用するには、先にGraphvizを導入する必要があります。
MacでHomebrewを利用している場合はbrew install graphvizでインストール可能です。
Windowsの場合はGraphvizのサイトからソフトウェアをダウンロード、インストールしてください。
また、インストールパス\binに対してパスを通してください。Diagramsの導入
Python3.6以上の環境にて、
pip install diagramsで導入できます。実行サンプルと解説
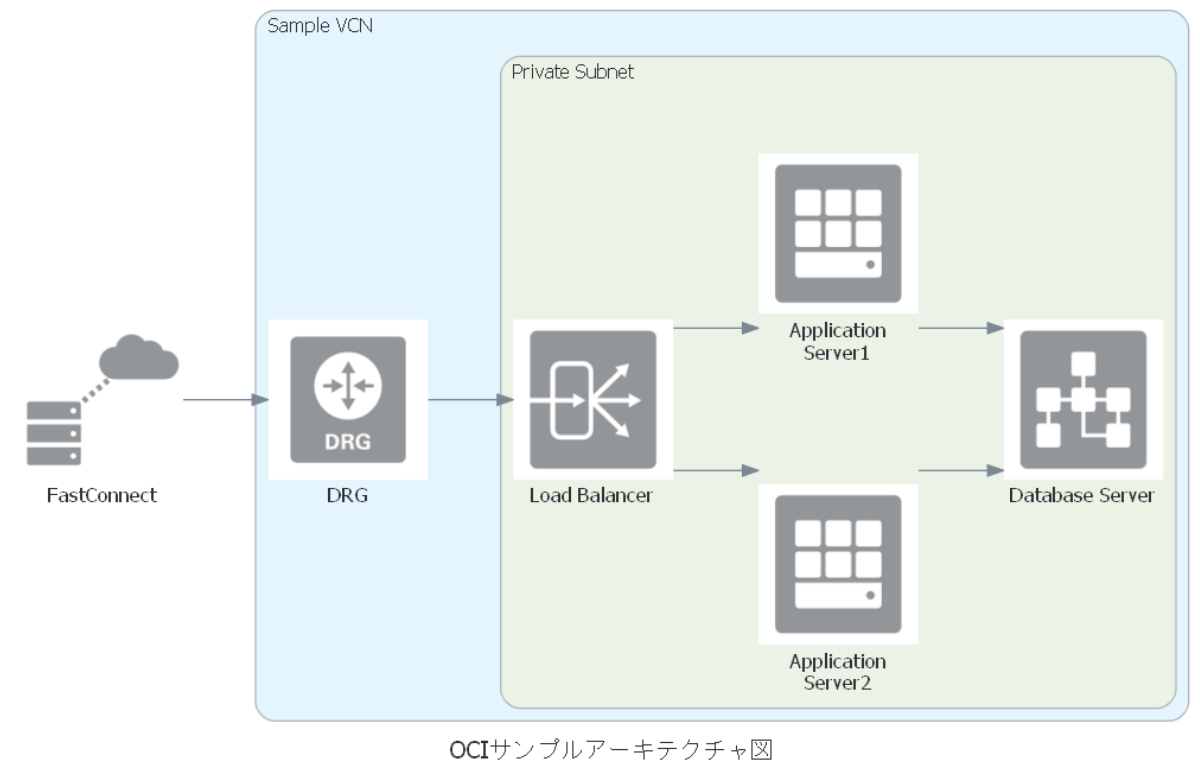
アーキテクチャ図の出力例
今回は以下のようなサンプルを出力してみます。
例のように、日本語も利用可能です。
コーディングサンプル
sample.pyfrom diagrams import Cluster, Diagram from diagrams.oci.compute import Vm as VM from diagrams.oci.database import Databaseservice as DBCS from diagrams.oci.network import Loadbalance as LB, Drg as DRG from diagrams.oci.connectivity import Fastconnect as FC with Diagram("OCIサンプルアーキテクチャ図", outformat="pdf", filename="oci_sample", show=False): with Cluster("Sample VCN"): drg = DRG("DRG") with Cluster("Private Subnet"): lb = LB("Load Balancer") ap = [VM("Application\nServer2"), VM("Application\nServer1")] db = DBCS("Database Server") FC("FastConnect") >> drg >> lb >> ap >> db基本概念
DiagramsにはDiagram, Node, Clusterという基本概念があります。
Diagram
アーキテクチャ図のクラスです。
Diagramクラスはwith文に対応しているので、サンプルのような記述が可能です。
以下、サンプルソースの引数の解説です。
- name : 最初の引数です。サンプルコードでは引数名を省略しています。図のタイトルを指定します。
- outformat : 出力されるファイルのフォーマットを指定します。無指定時のデフォルトはpngです。他にはjpg, svg, and pdfに対応しています。
- filename : 出力ファイル名を指定します。無指定時のデフォルトは、図のタイトルを小文字に変換したものとなります。
- show : 出力したファイルを標準のビューワで表示させるか否かをboolで指定します。デフォルトはTrueです。
サンプルで指定している以外にも、以下の引数が指定可能です。
- direction : フローの方向を指定します。以下の4種類が指定可能です。
- LR : 左から右(デフォルト)
- RL : 右から左
- TB : 上から下
- BT : 下から上
- graph_attr, node_attr, edge_attr : それぞれアーキテクチャ図、Node(後述)、エッジの書式をJSON形式で指定します。指定できる内容はGraphvizがサポートしているものとなります。指定可能な内容の詳細はGraphvizの解説をご確認ください。
Node
ノード(インスタンス、サービス等)のクラスです。
サンプルの図だと「DRG」とか「Database Server」となっている個所などが該当します。
Nodeのオブジェクト名称は「プロバイダ.リソースタイプ.名称」という形式になっています。
Nodeの一覧はこちらを参照してください。
引数はlabelのみとなります。
- label: サンプルコードでは引数名を省略しています。ノードのタイトルを指定します。Cluster
Nodeをグルーピングするクラスです。
サンプルの図では、VCNやサブネットを表現するためにClusterを使用しています。
サンプルの図のようにClusterをネストさせることも可能です。
ネストの階層数に特段の制限はありません。
同一階層に複数のClusterを表示することも可能です。
以下、引数の解説です。
- label: 最初の引数です。サンプルコードでは引数名を省略しています。グルーピングのタイトルを指定します。無指定時は「cluster」と表示されます。
- direction : Diagramのdirection引数と同様です。コーディングの流れ
基本はDiagramクラスのwith文の中で表示させるNodeのインスタンスを作成し、表示順に並べてNodeをつなぐ線の方向を指定するだけです。
必要に応じてClusterを指定し、クラスタに属するNodeはClusterのwith文中で生成します。
線の方向は、以下の3種類となります。
- >> : 前から後への矢印
- >> : 後から前への矢印
- - : 矢印のない線
最後に
全体的には、Pythonに慣れている方であれば、引数の解説以外はコーディングサンプルをしばらく眺めていれば理解できるものと思われます。
記事執筆時点では対応しているサービスの網羅性がやや弱い印象ですが、Diagramsは活発に更新が行われており、より進化することが期待されます。
- 投稿日:2020-02-24T16:41:02+09:00
【初心者向け】Alexaカスタムスキルを作成してCognitoのユーザープールとアカウントリンクする手順
1.Lambdaで関数を作成
AWS Lamdaで関数の作成手順
1-1.AWSのサービス一覧から「Lambda」を選択
1-2.Lambdaトップ画面より「関数の作成」を押下
1-3.関数の基本情報を設定
- 「一から作成」を選択
- 「関数名」を入力 →今回は"sampleFunction"としました
- 「ランタイム」では「Python3.8」を選択
- 「関数の作成」を押下
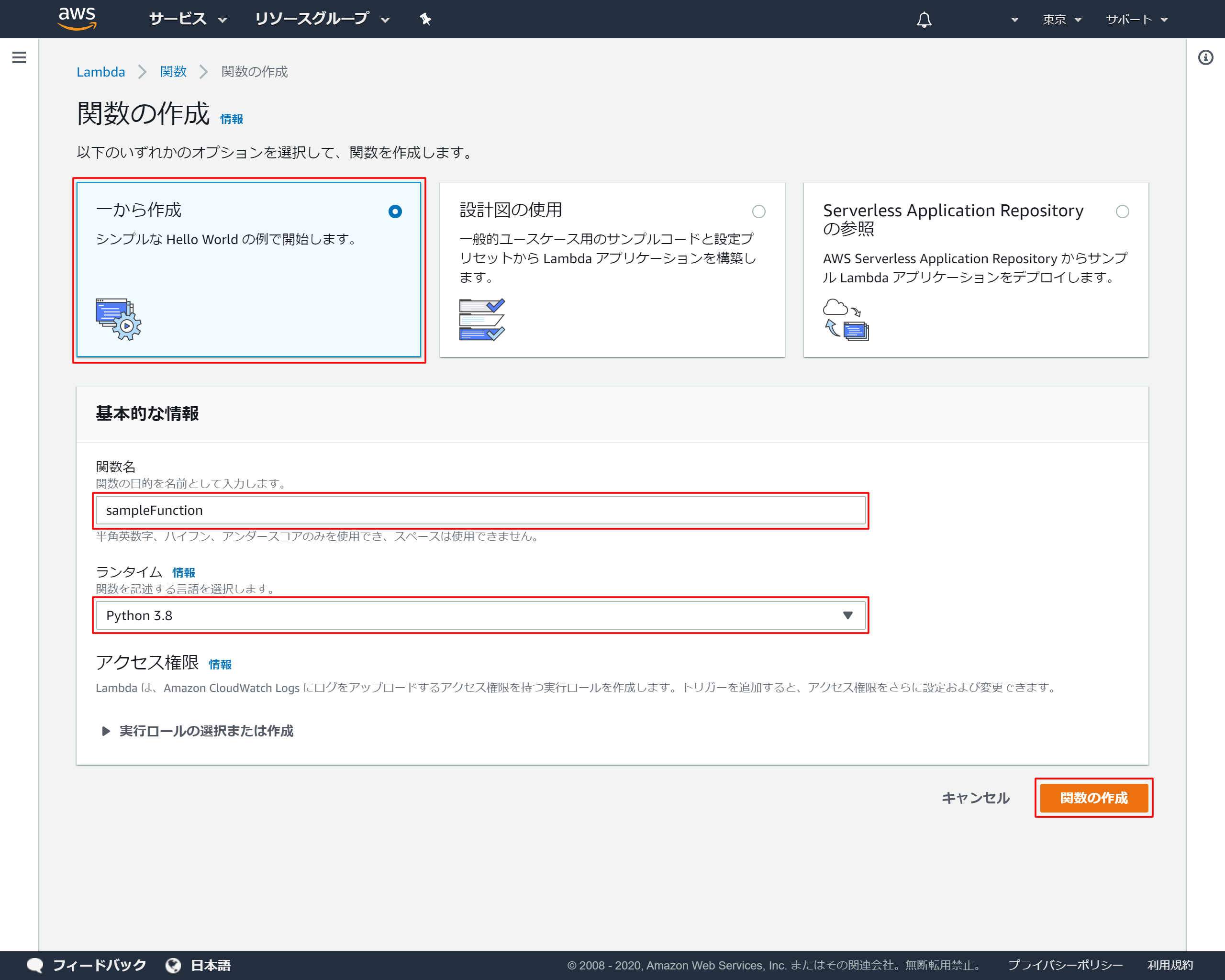
1-4.作成成功メッセージ
作成が成功すると上部にメッセージが表示され、コード入力画面が表示されます
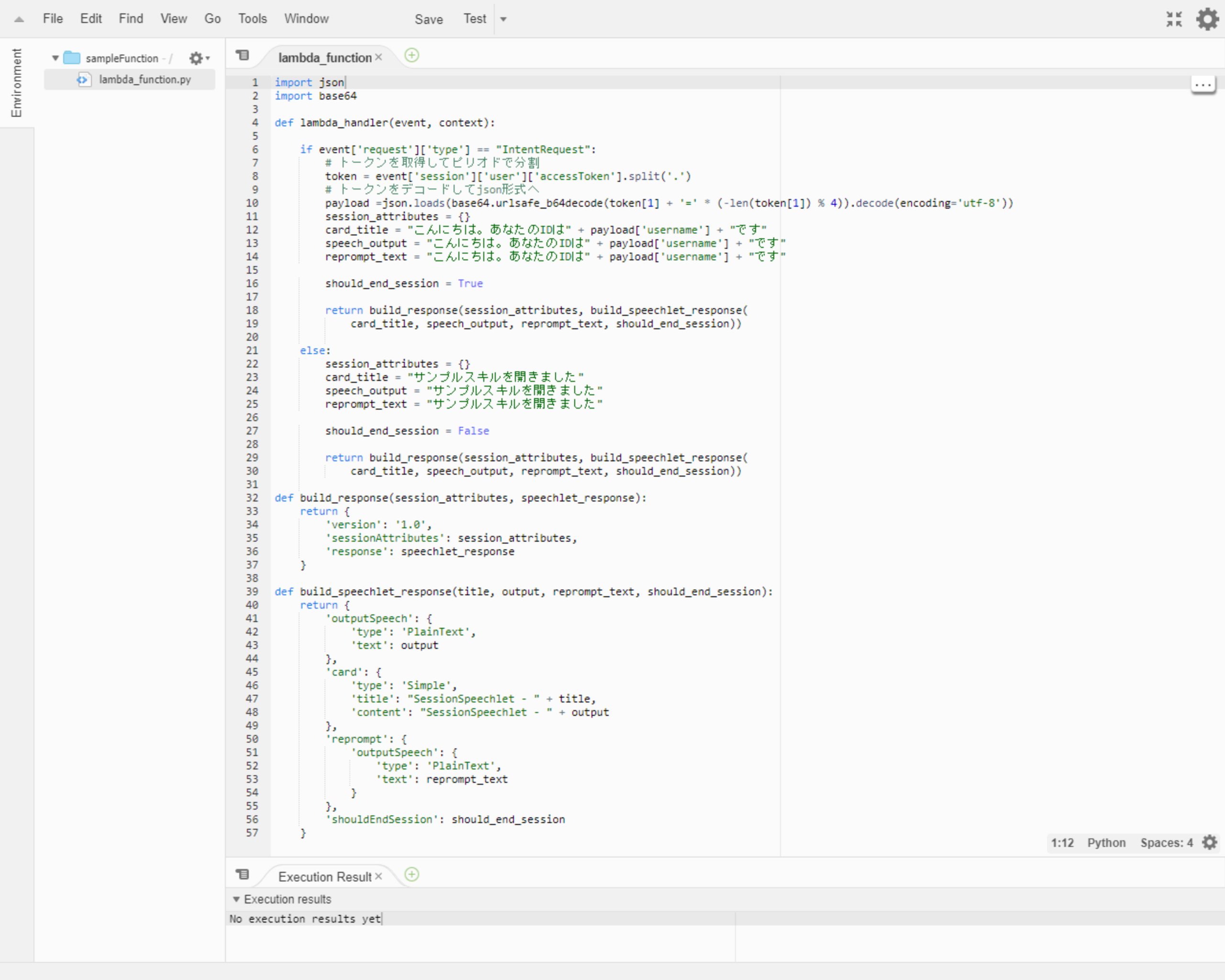
1-5.関数を作成
関数コードに動作が確認可能なサンプルコードを入力します
lambda_function.pyimport json import base64 def lambda_handler(event, context): if event['request']['type'] == "IntentRequest": # トークンを取得してピリオドで分割 token = event['session']['user']['accessToken'].split('.') # トークンをデコードしてjson形式へ payload =json.loads(base64.urlsafe_b64decode(token[1] + '=' * (-len(token[1]) % 4)).decode(encoding='utf-8')) session_attributes = {} card_title = "こんにちは。あなたのIDは" + payload['username'] + "です" speech_output = "こんにちは。あなたのIDは" + payload['username'] + "です" reprompt_text = "こんにちは。あなたのIDは" + payload['username'] + "です" should_end_session = True return build_response(session_attributes, build_speechlet_response( card_title, speech_output, reprompt_text, should_end_session)) else: session_attributes = {} card_title = "サンプルスキルを開きました" speech_output = "サンプルスキルを開きました" reprompt_text = "サンプルスキルを開きました" should_end_session = False return build_response(session_attributes, build_speechlet_response( card_title, speech_output, reprompt_text, should_end_session)) def build_response(session_attributes, speechlet_response): return { 'version': '1.0', 'sessionAttributes': session_attributes, 'response': speechlet_response } def build_speechlet_response(title, output, reprompt_text, should_end_session): return { 'outputSpeech': { 'type': 'PlainText', 'text': output }, 'card': { 'type': 'Simple', 'title': "SessionSpeechlet - " + title, 'content': "SessionSpeechlet - " + output }, 'reprompt': { 'outputSpeech': { 'type': 'PlainText', 'text': reprompt_text } }, 'shouldEndSession': should_end_session }
2.Cognitoでユーザープールを作成
AWS Cognitoでユーザープールの作成手順
2-1.AWSのサービス一覧から「Cognito」を選択
「Cognito」はセキュリティ、ID、およびコンプライアンスのカテゴリです
2-2.Cognitoトップ画面より「ユーザープールの管理」を押下
2-3.ユーザープールトップ画面より「ユーザープールを作成する」を押下
2-4.ユーザープールの基本情報を入力する
- 「プール名」を入力 →今回はSamplePoolsと入力しました
- 「デフォルトを確認する」を押下
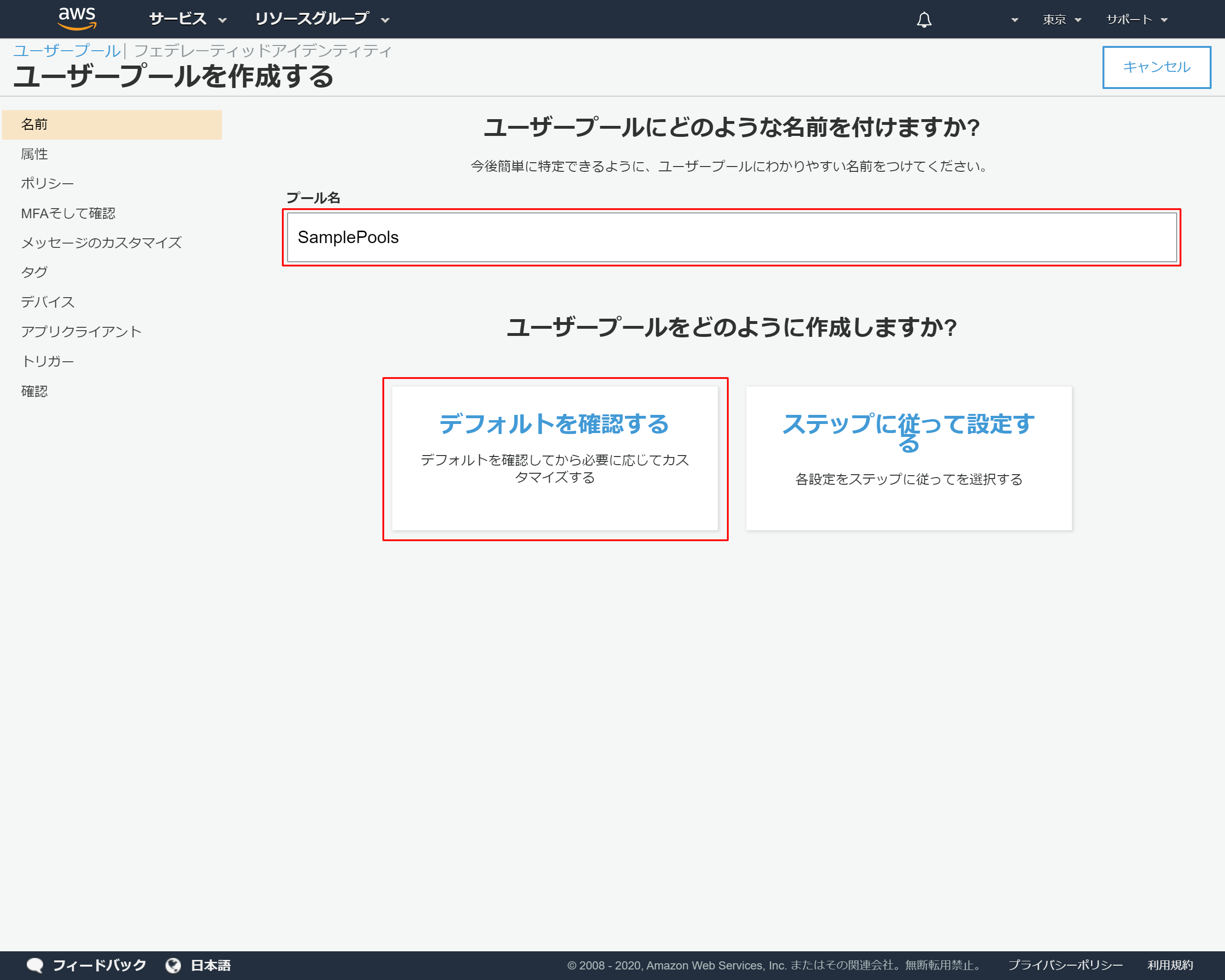
2-5.ユーザープールの情報が表示されたら左側メニューの「属性」を押下
プールの作成はまだ押下しないでください
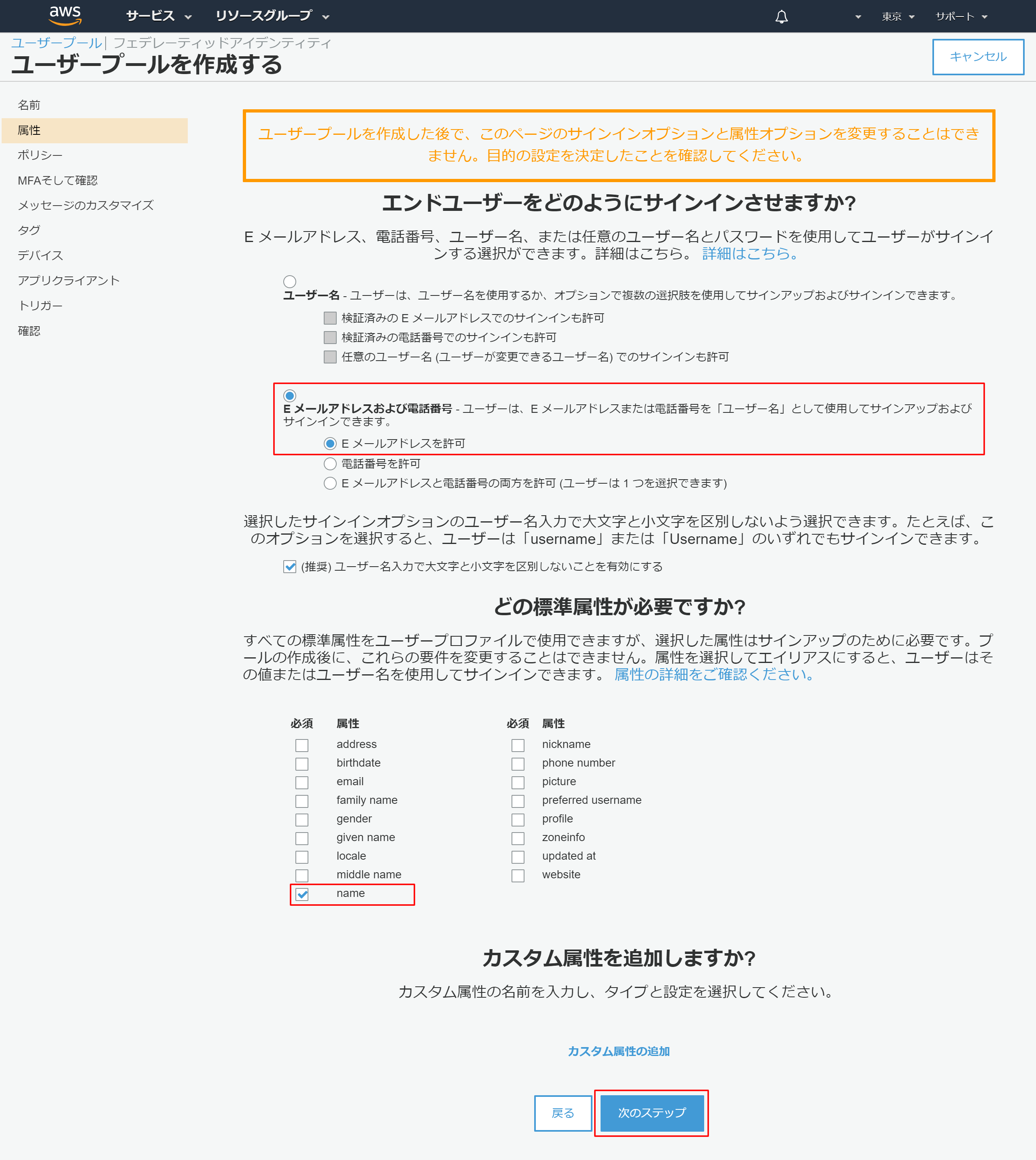
2-6.属性情報を設定する
- 「Eメールアドレスおよび電話番号」を選択
- 「Eメールアドレスを許可」を選択
- 必要な必須属性を選択 →今回はnameのみ設定しました
- 「次のステップ」を押下
2-7.ポリシーの設定
今回はデフォルトの設定としますので、左側のメニューより「確認」を押下します
2-8.「プールの作成」を押下
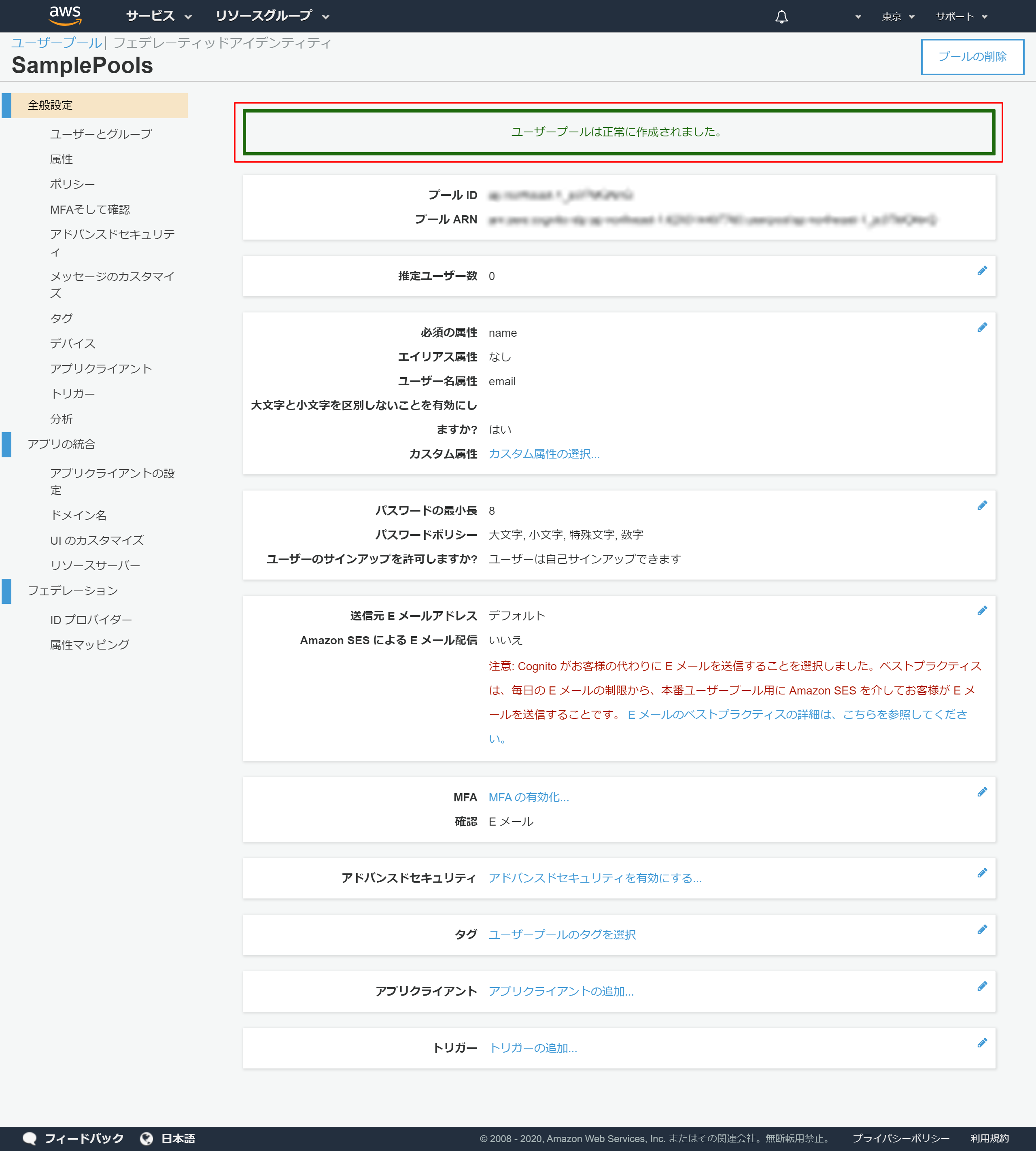
2-9.プールが作成されたメッセージが表示される
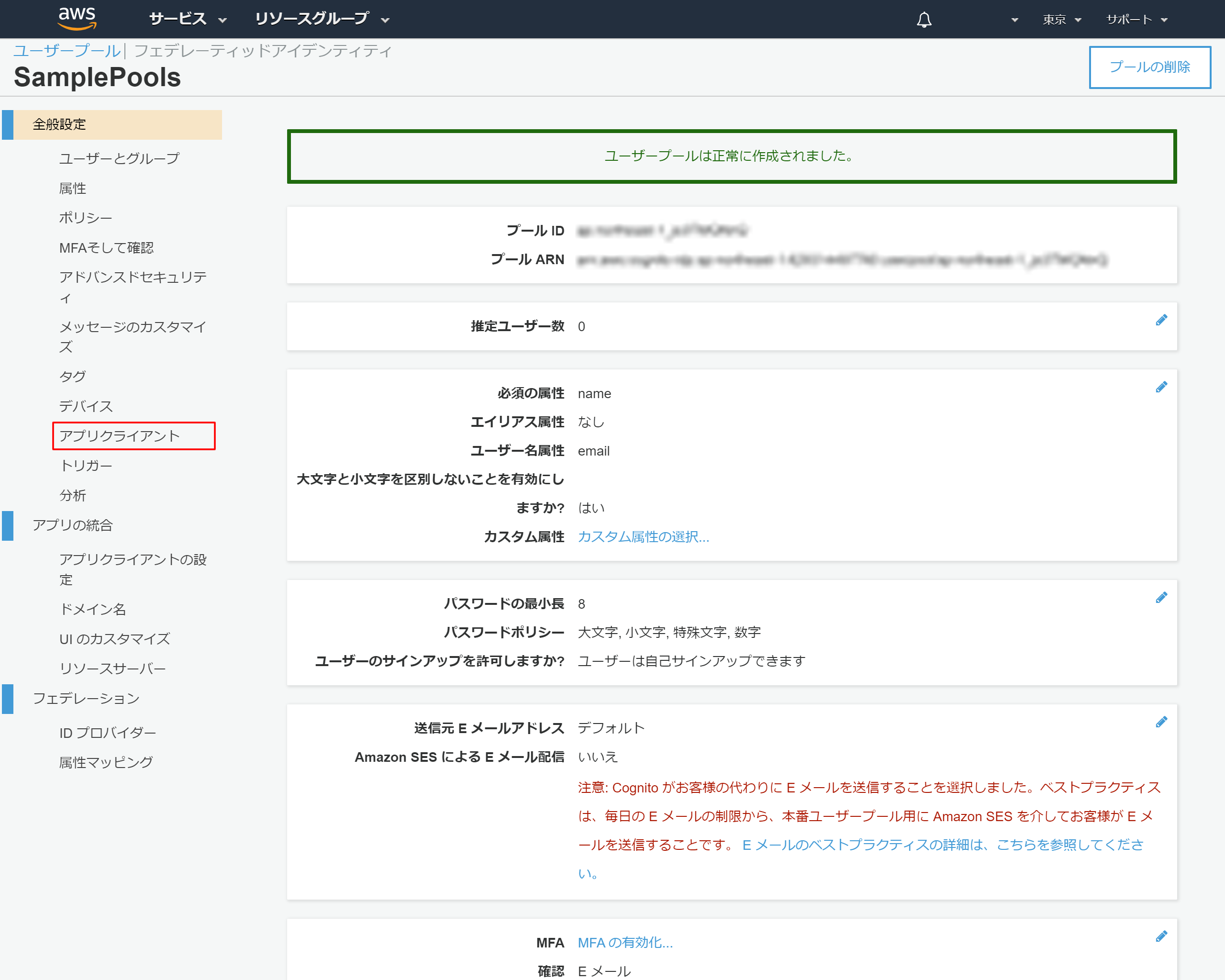
2-10.アプリクライントの設定
左側のメニューより「アプリクライアント」を押下
2-11.「アプリクライアントの追加」を押下
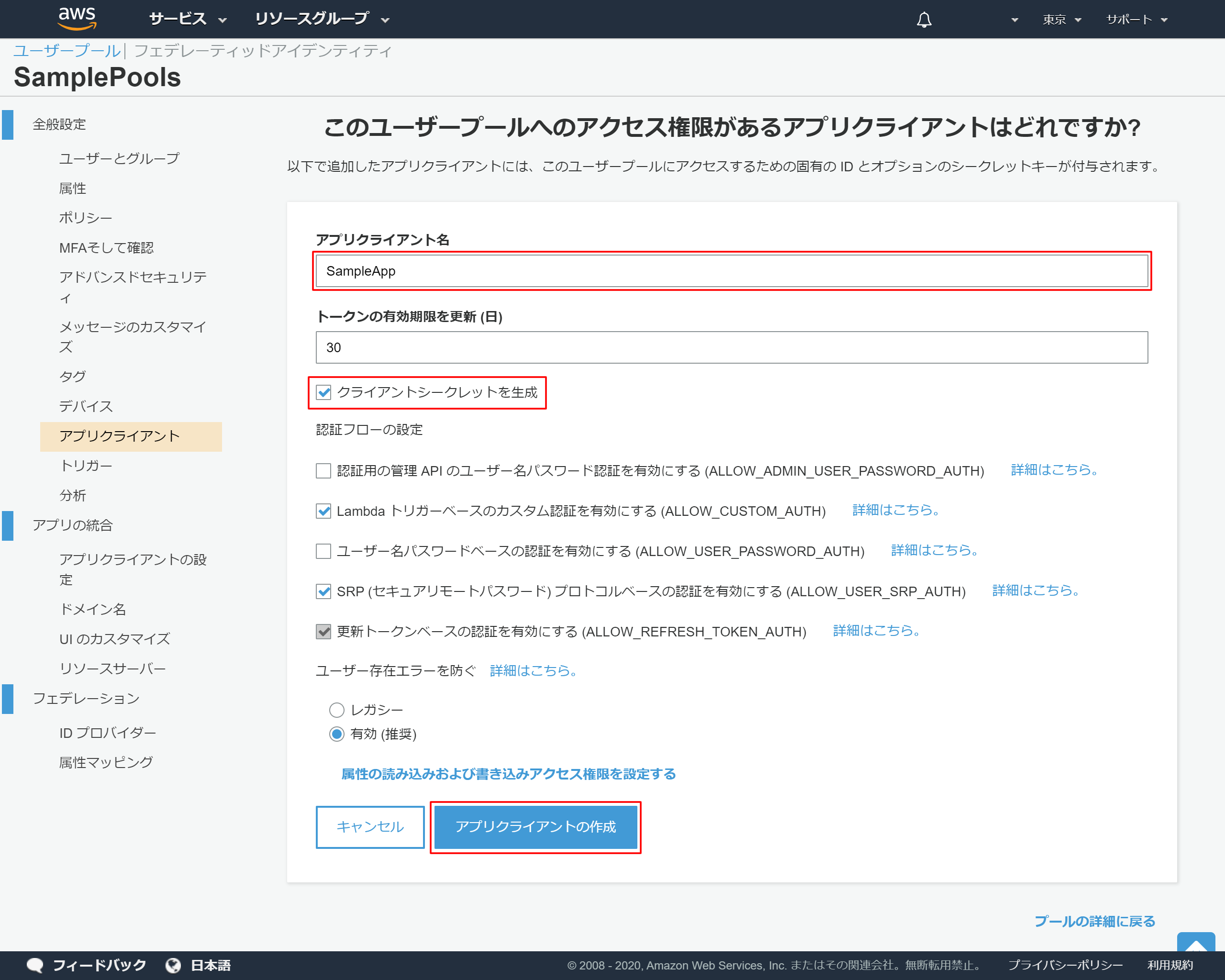
2-12.アプリクライアントの詳細設定
- 「アプリクライアント名」を入力 →今回は「SampleApp」としました
- 「クライアントシークレットを生成」のチェックは入れておく
- 「アプリクライアントの作成」を押下
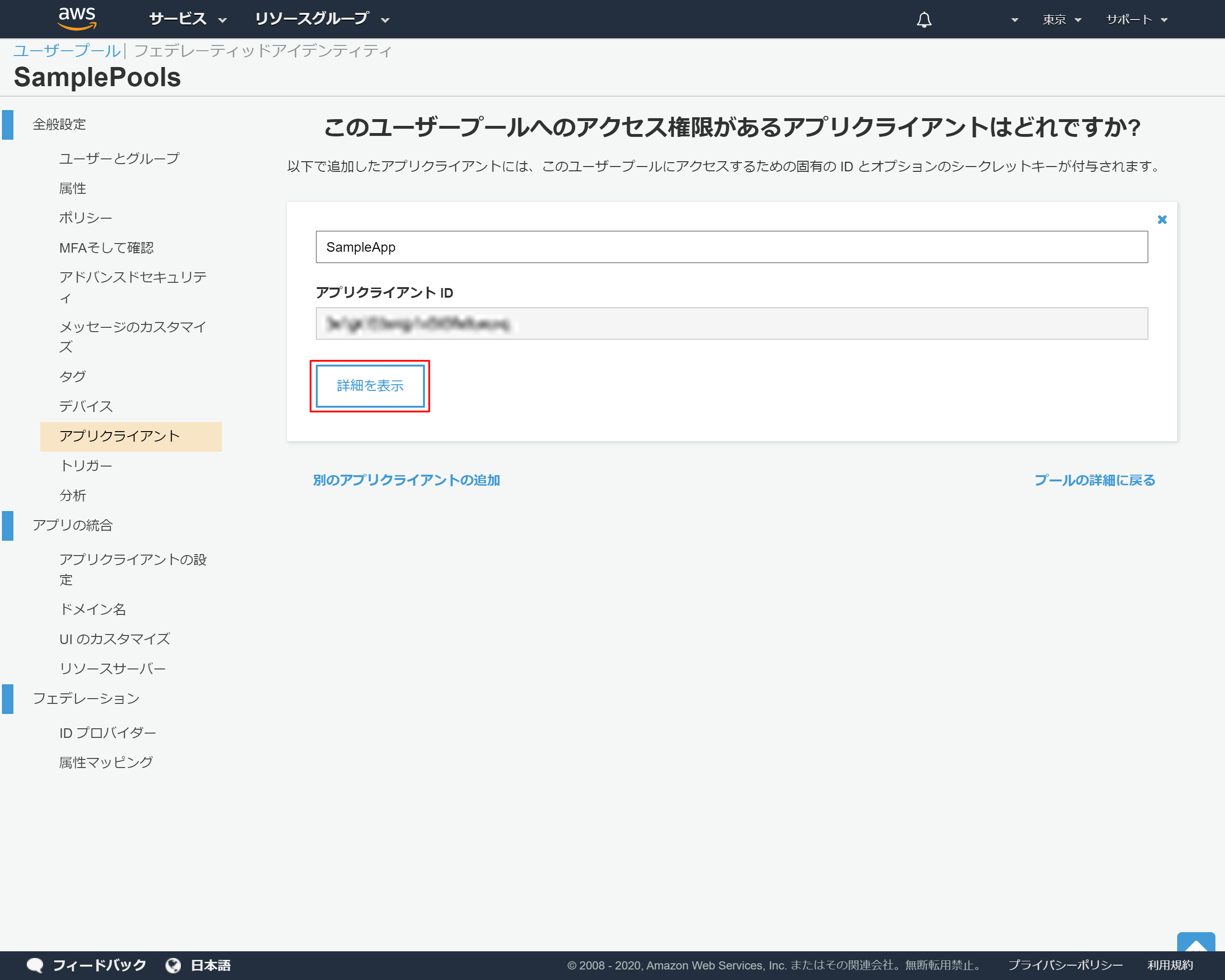
2-13.アプリクライントのIDが発行される
「詳細を表示」を押下
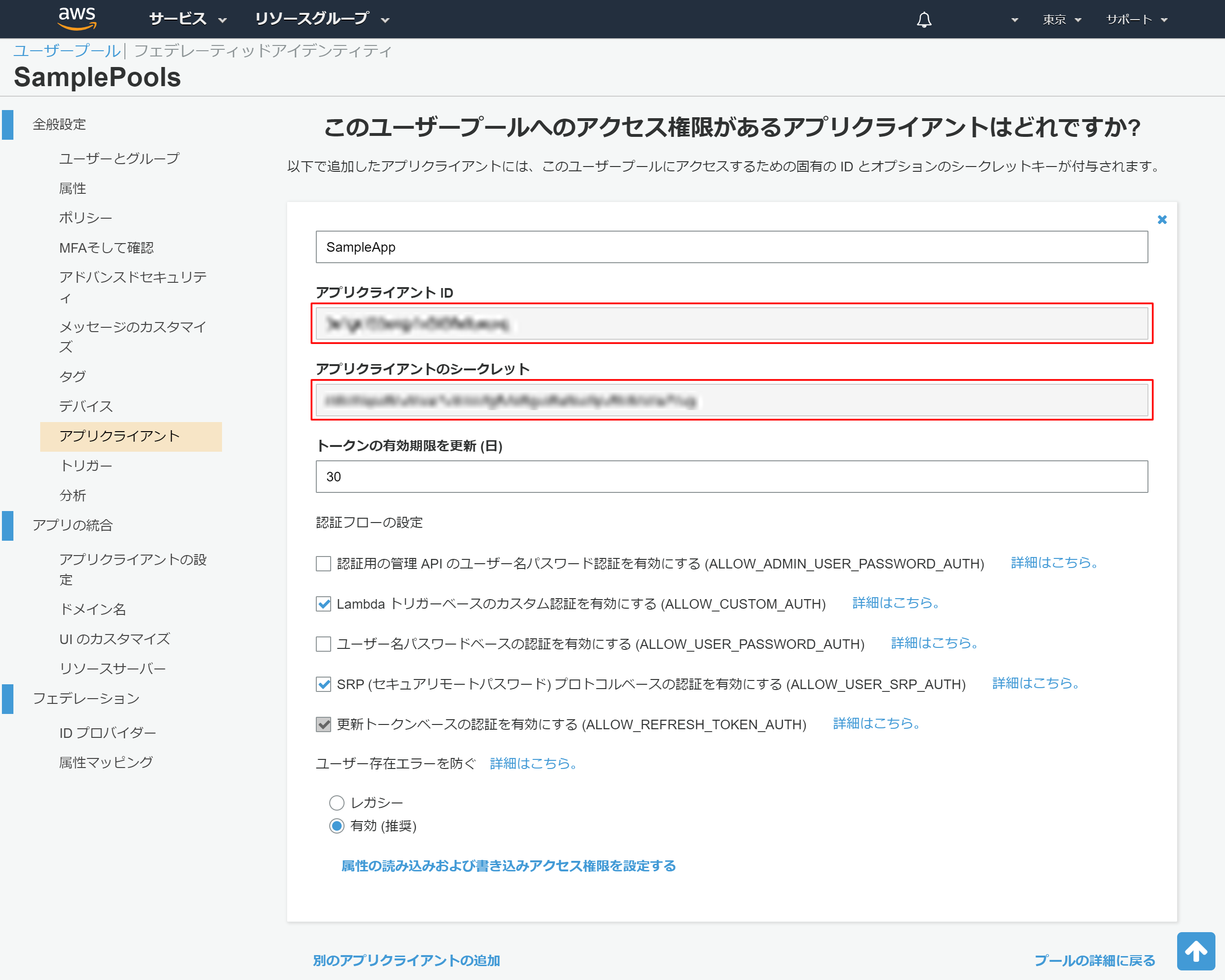
2-14.アプリクライアントの詳細情報の表示
後ほど利用するため、以下情報をメモ帳などにコピーしておく
- アプリクライアントID
- アプリクライアントのシークレット
3.alexa developer consoleでスキルを作成
カスタムスキルの作成手順
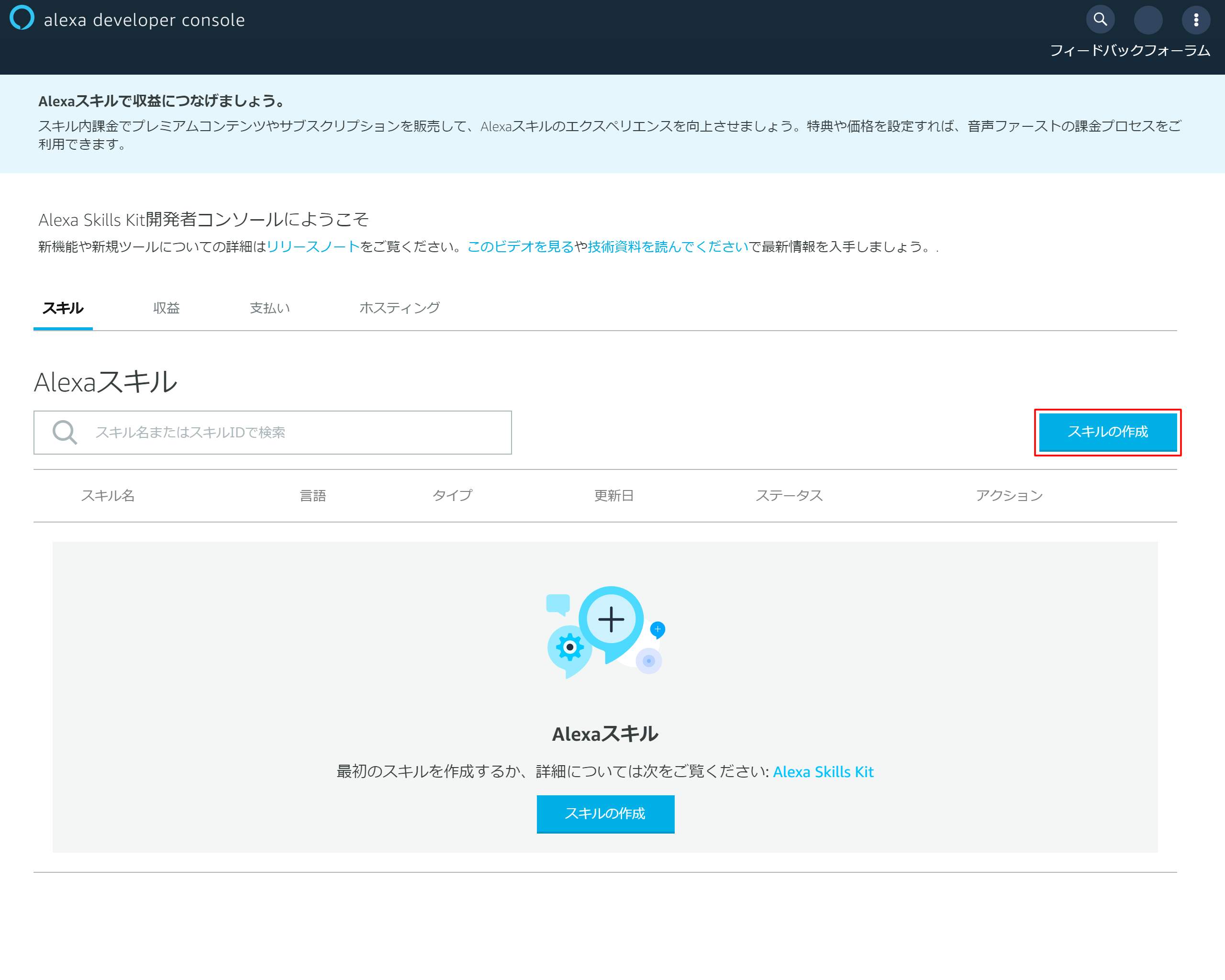
3-1.「スキルの作成」を押下
3-2.スキルの基本情報を入力
- 「スキル名」を入力 →今回はサンプルスキルとしました
- 「カスタム」を選択
- 「ユーザー定義のプロビジョニング」を選択
- 右上の「スキルを作成」を押下
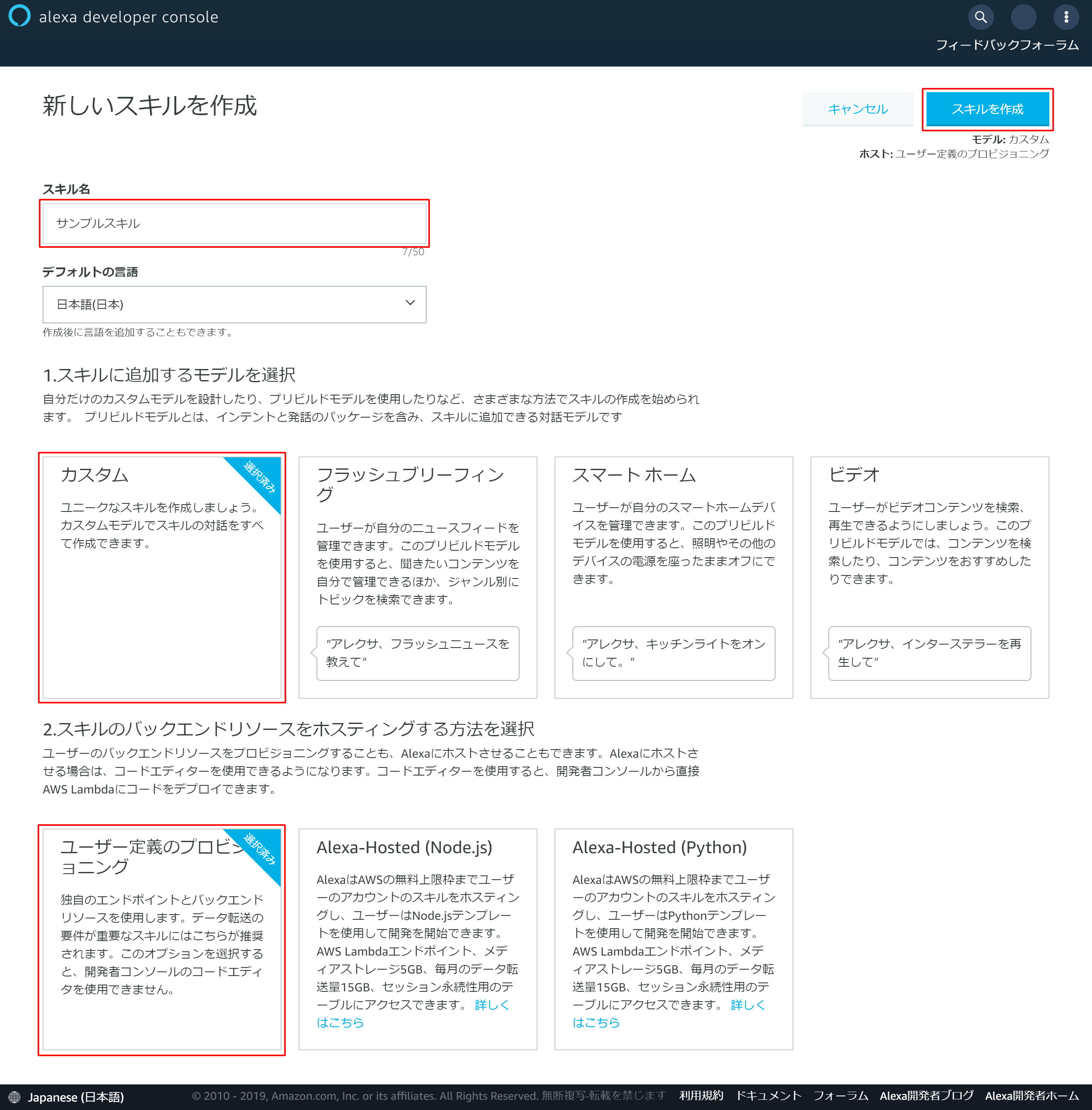
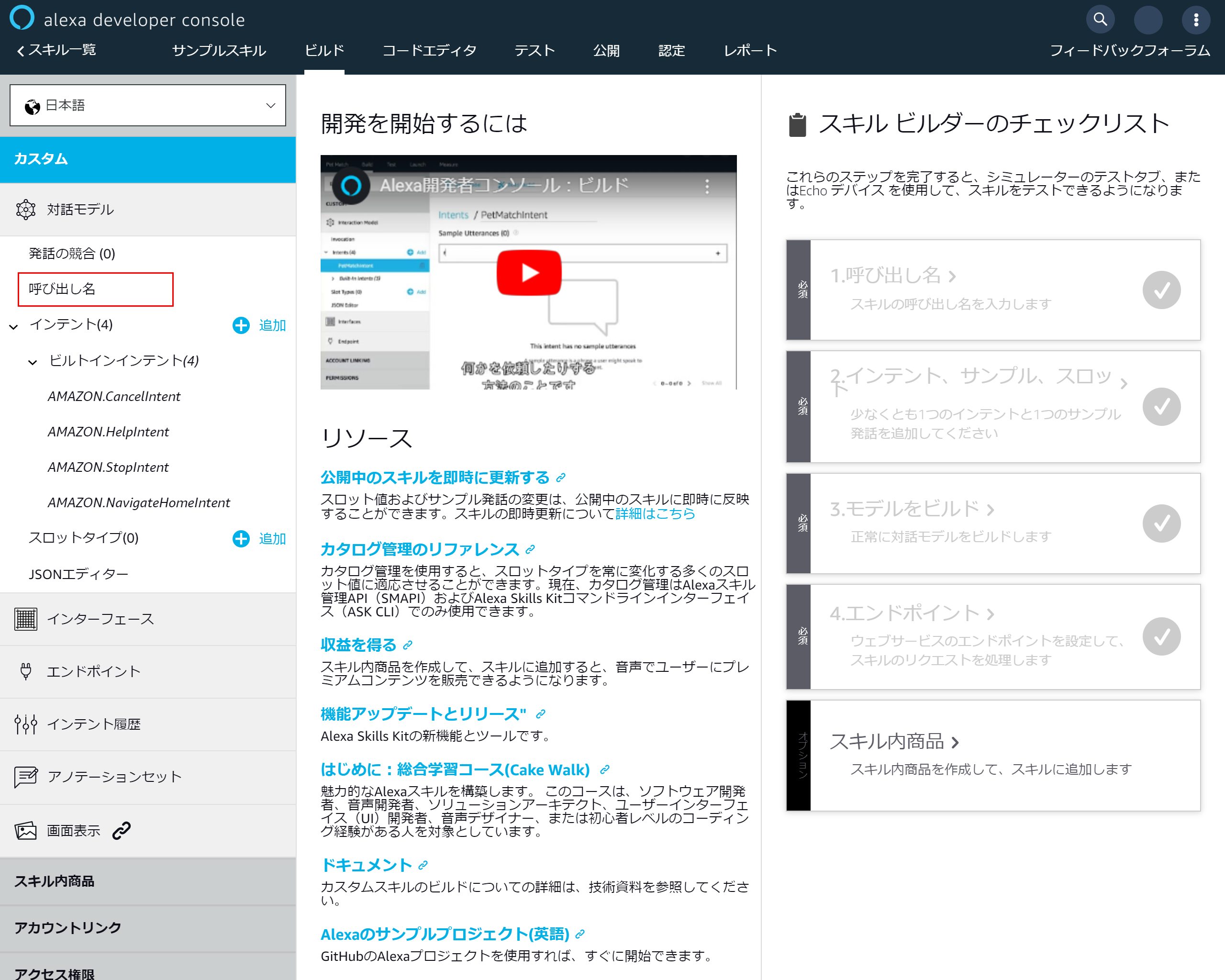
3-3.スキル作成画面
「呼び出し名」を押下
3-4.スキルの基本設定を入力する
- 「呼び出し名」を入力 →今回はサンプルスキルにしました
- 左側メニューのインテントにある「追加」を押下
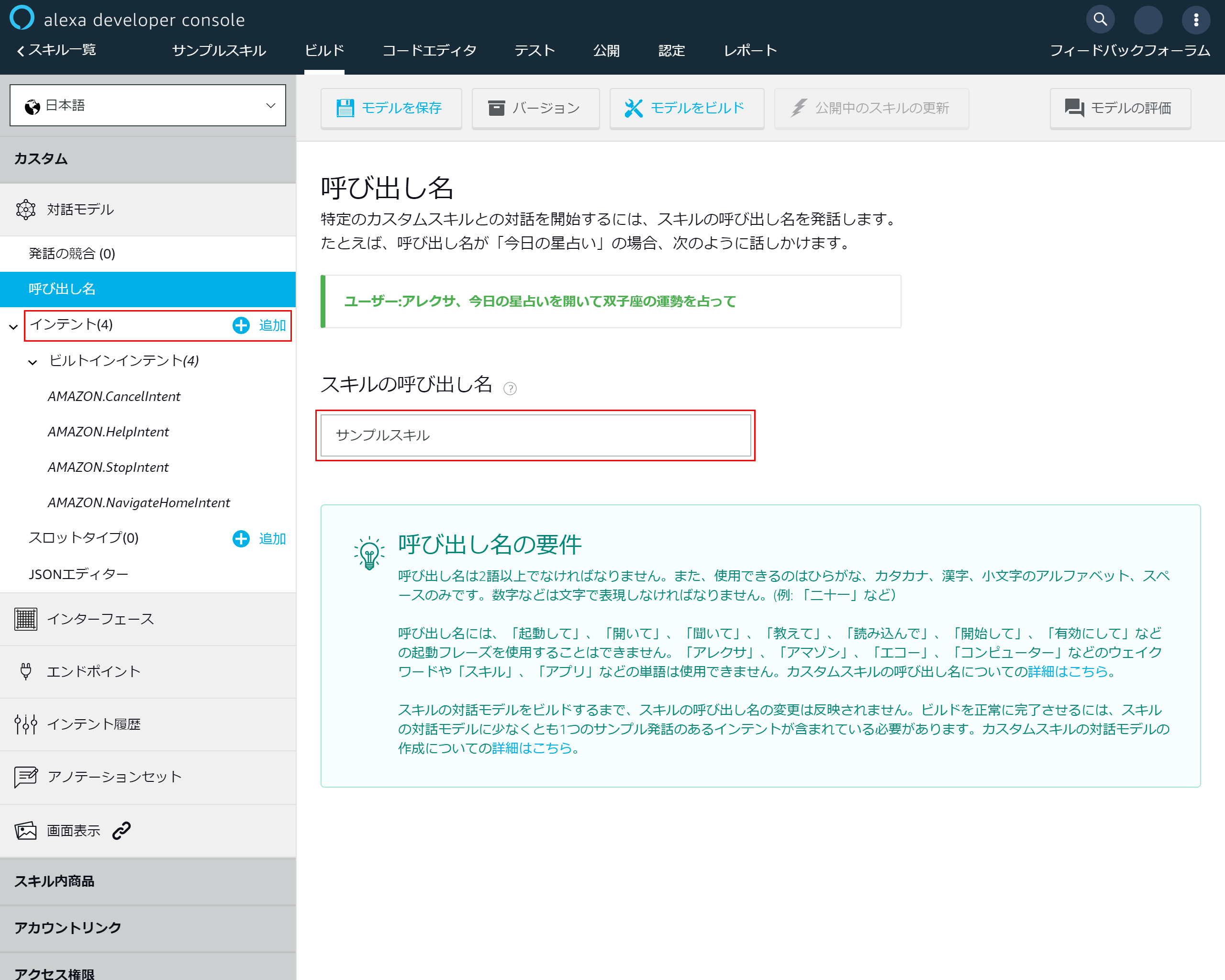
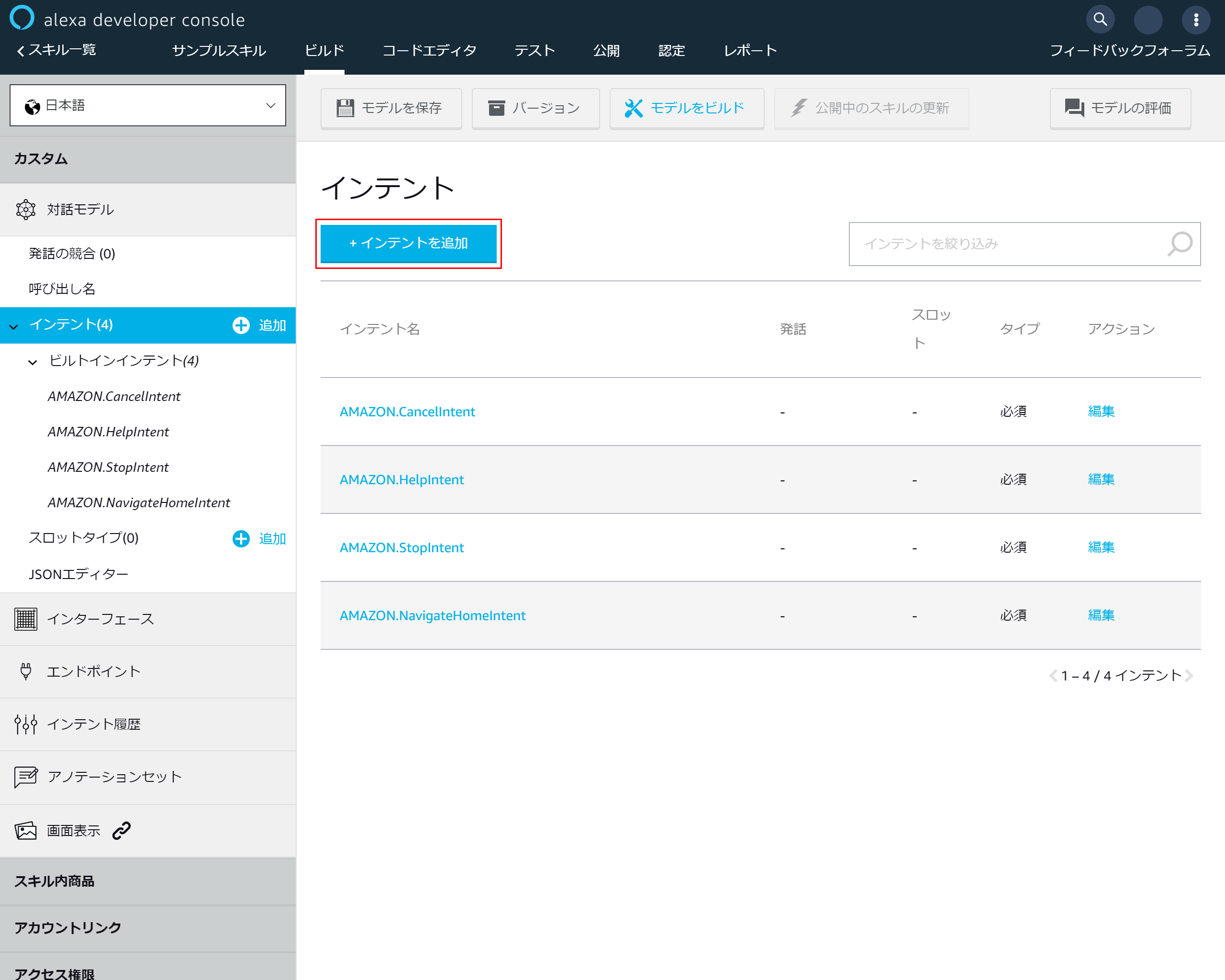
3-5.「インテントを追加」を押下
3-6.インテント設定画面
- インテント名を入力 →今回はtestにしました
- 「カスタムインテントを作成」を押下

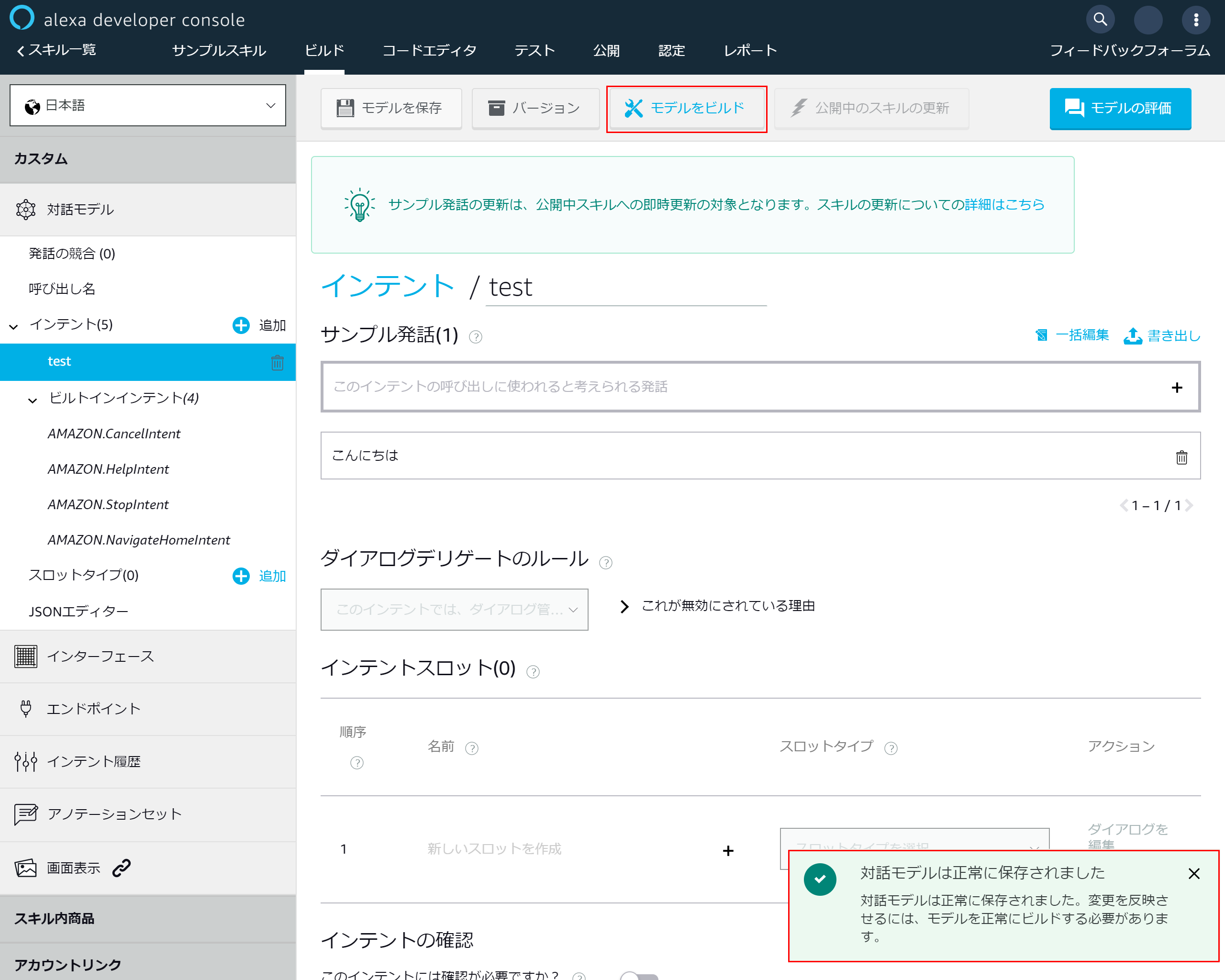
3-7.インテント追加画面
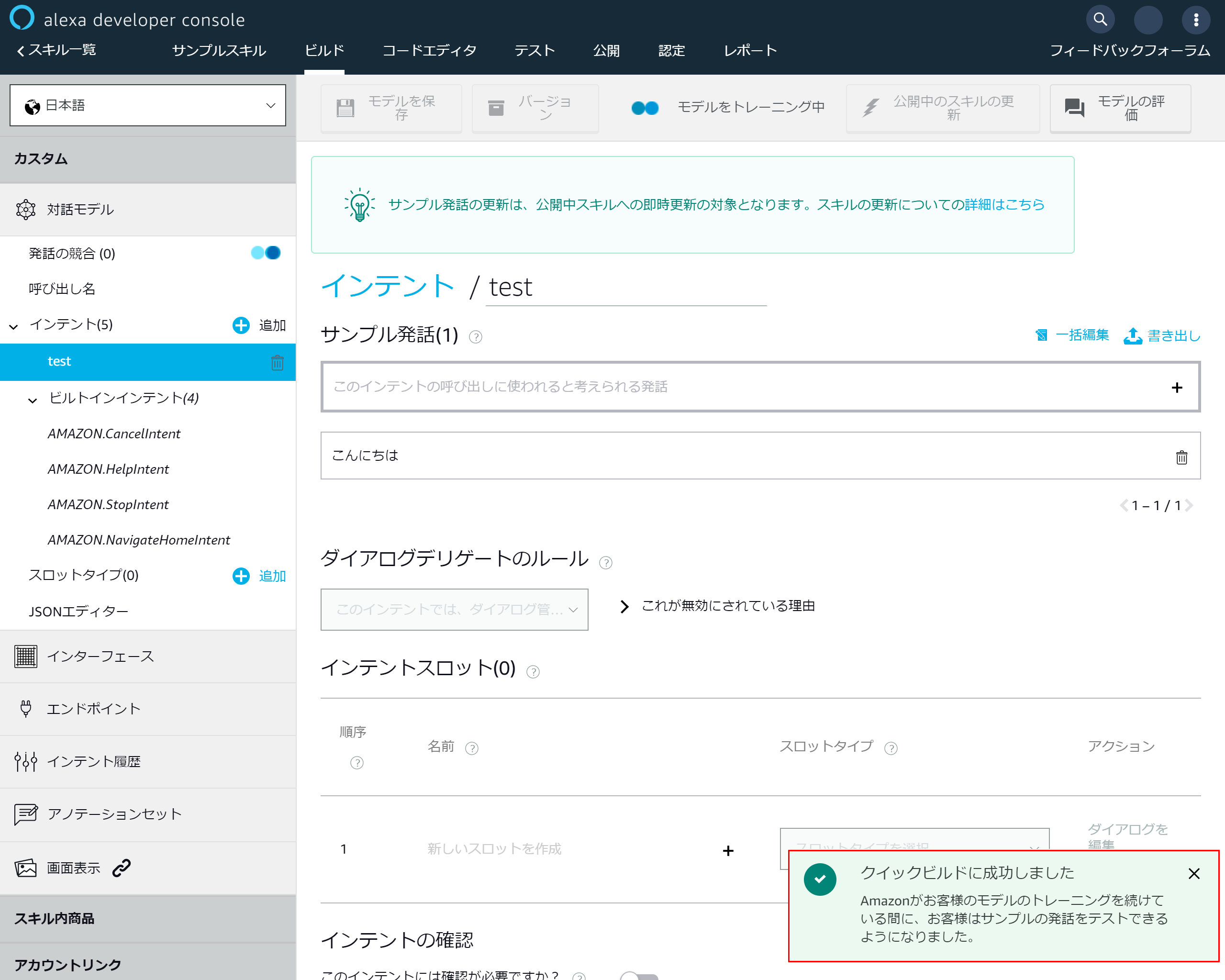
サンプル発話に「こんにちは」と入力して「+」ボタンを押下
3-8.モデルを保存する
サンプル発話が追加されたら「モデルを保存」を押下する
3-9.モデルが保存されたらモデルをビルドする
対話モデルが保存されたら「モデルをビルド」を押下
3-10.ビルド完了
ビルド成功メッセージが出たら基本設定は完了
4.Lambdaとalexaスキルの連携設定
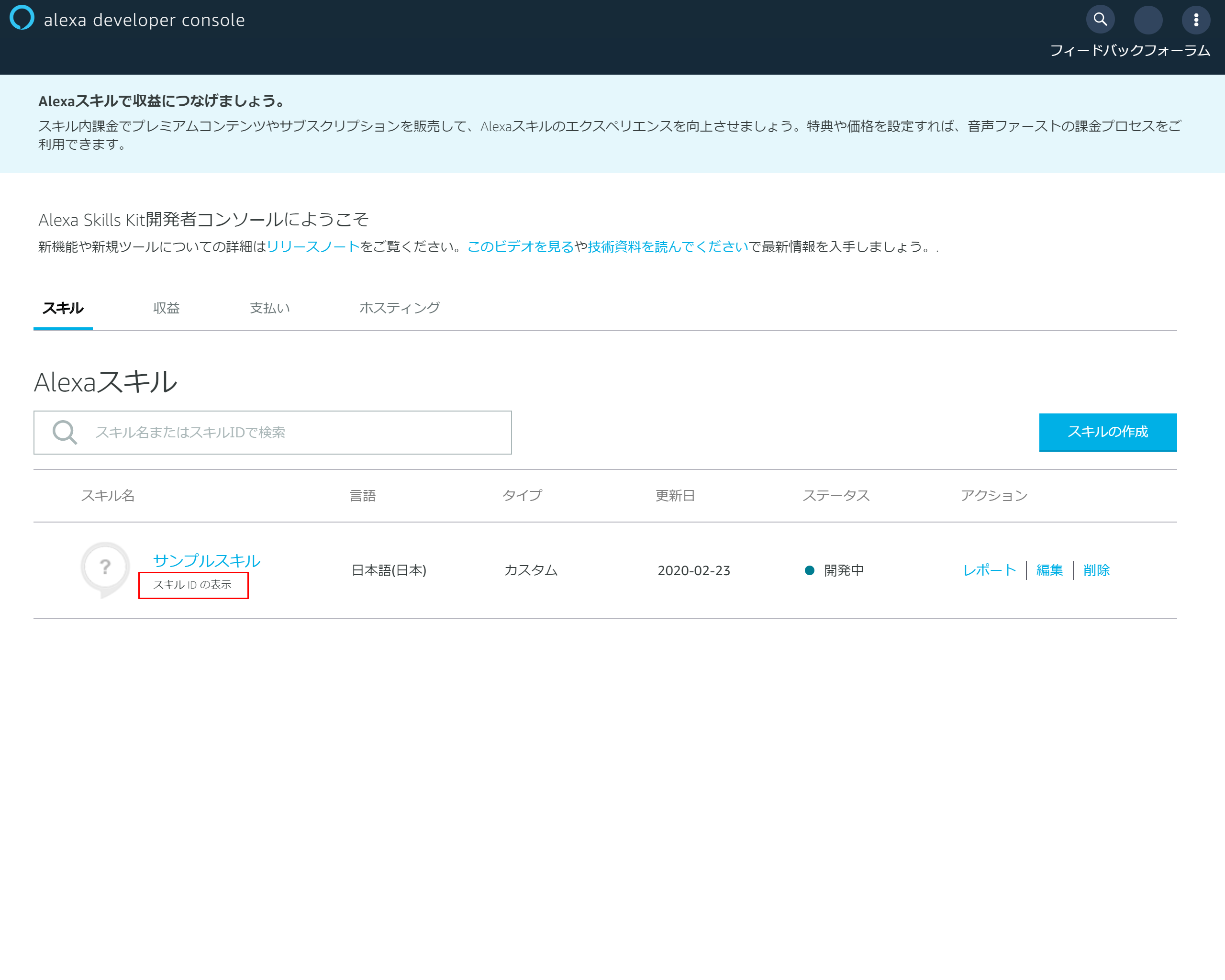
4-1.スキルIDの表示
スキルの一覧に戻り該当スキルの「スキルIDの表示」を押下する
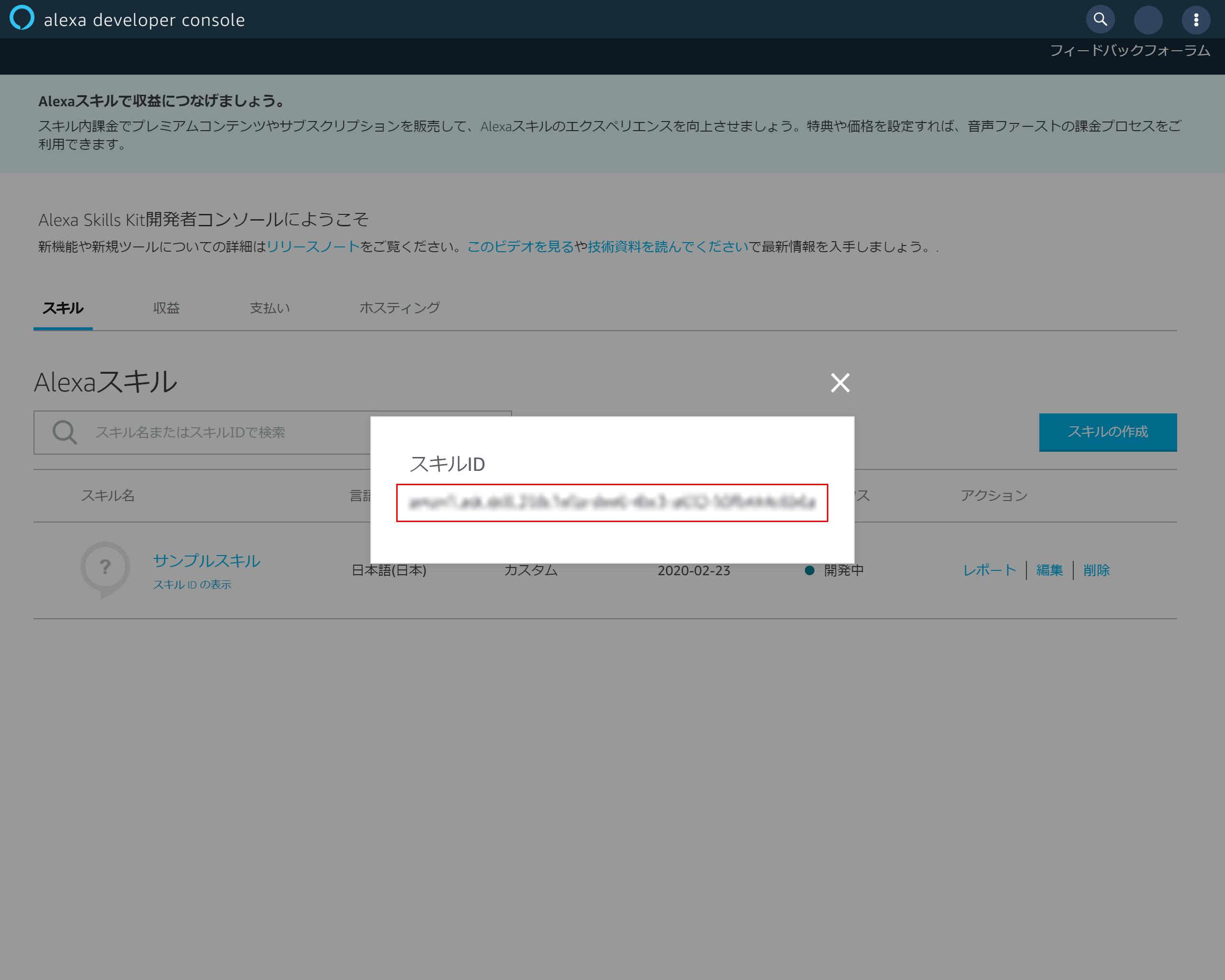
4-2.スキルIDのコピー
表示されたスキルIDをコピーしておく
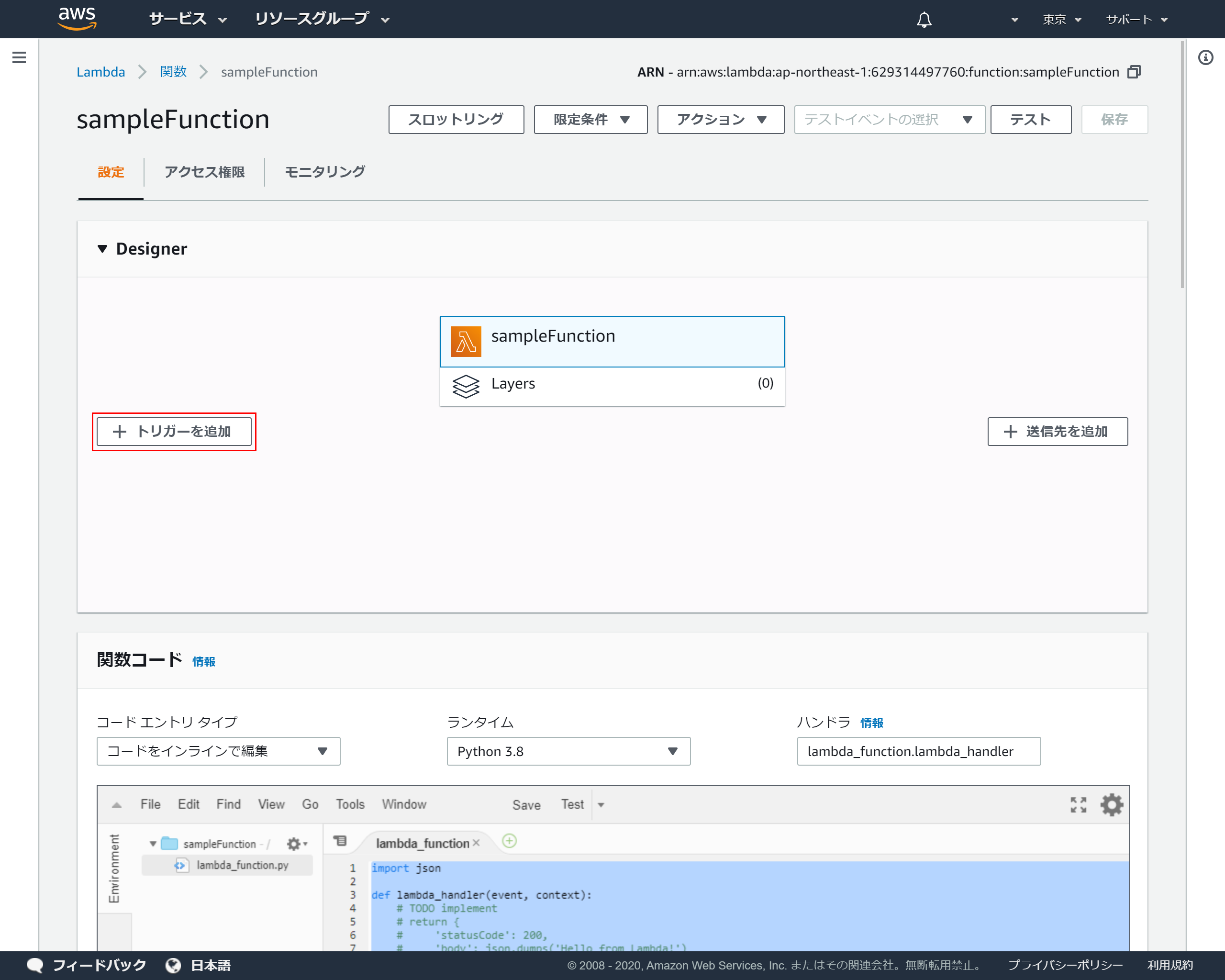
4-3.Lambdaトリガーの設定
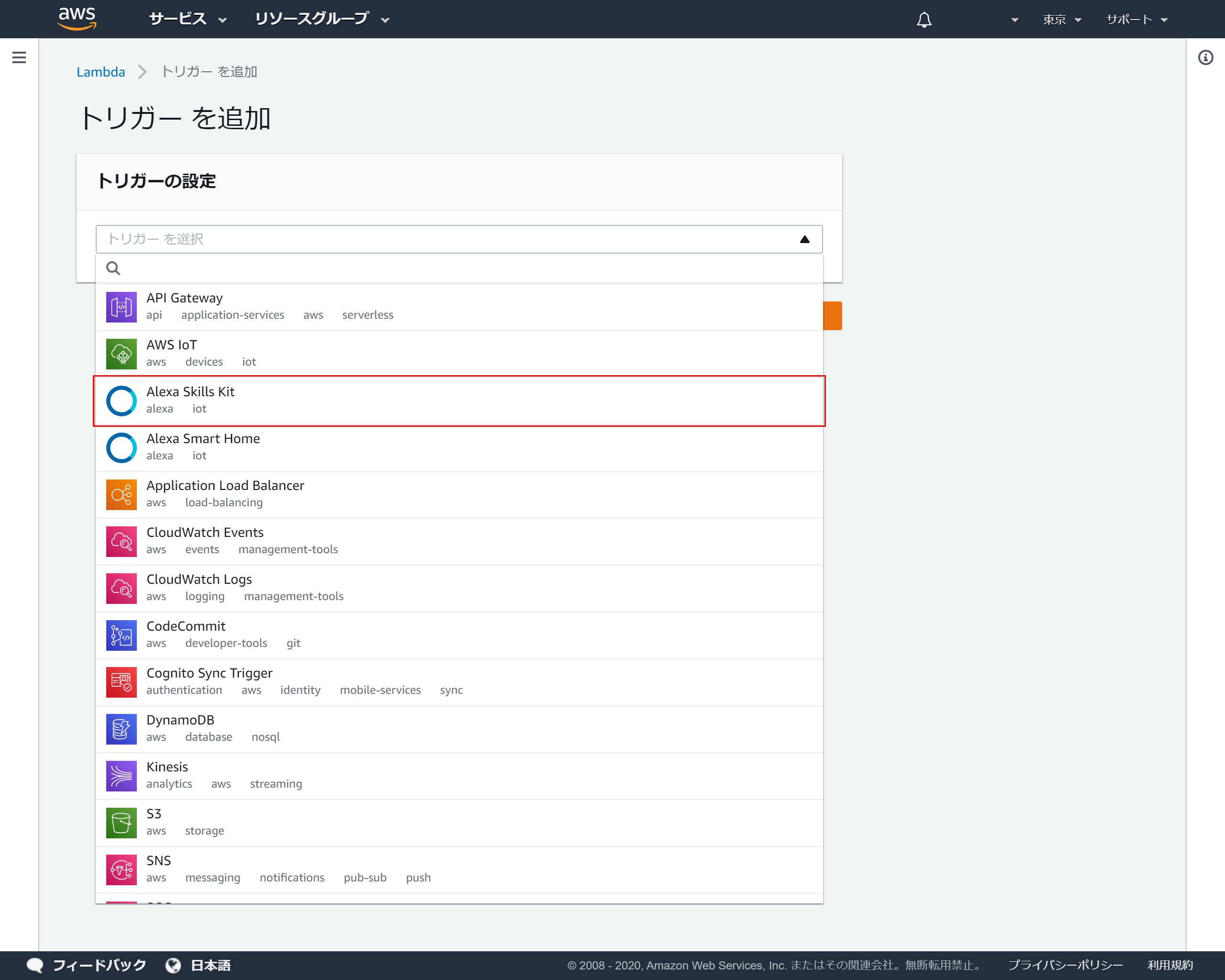
Lambdaに戻り「Designer」を開き「トリガーを追加」を押下
4-4.トリガーの追加
トリガーの設定のプルダウンより「Alexa Skills Kit」を選択
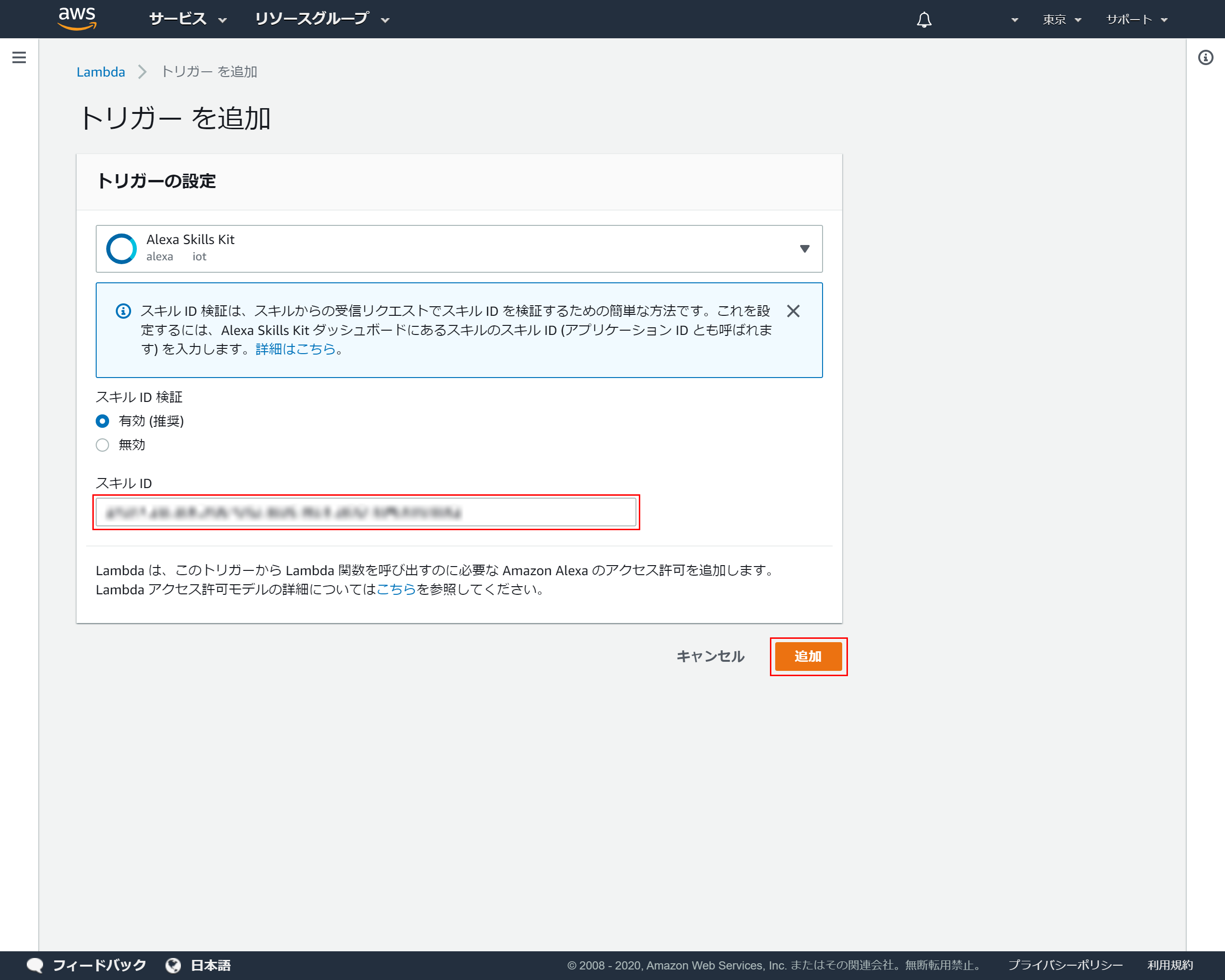
4-5.スキルIDの登録
トリガーの設定の「スキルID」に先ほど4-2でコピーしたスキルIDを貼り付け「追加」を押下
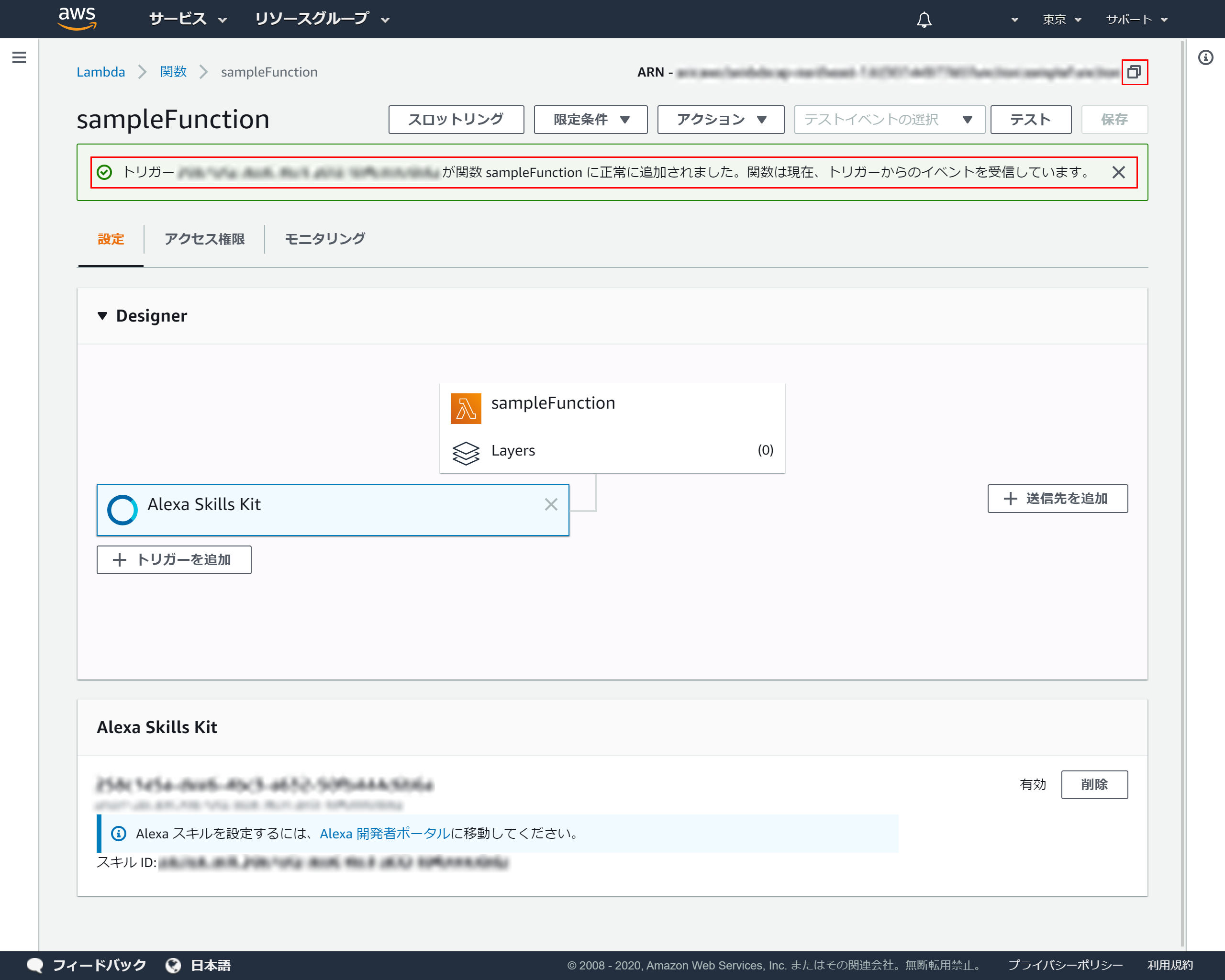
4-6.トリガーがの設定完了
トリガーが正常に登録できれば以下画面が表示されます
右上のコピーアイコンをクリックしてARNをコピーしてください
4-7.ARNのコピー
成功メッセージが表示されるとクリップボードにARNがコピーされます
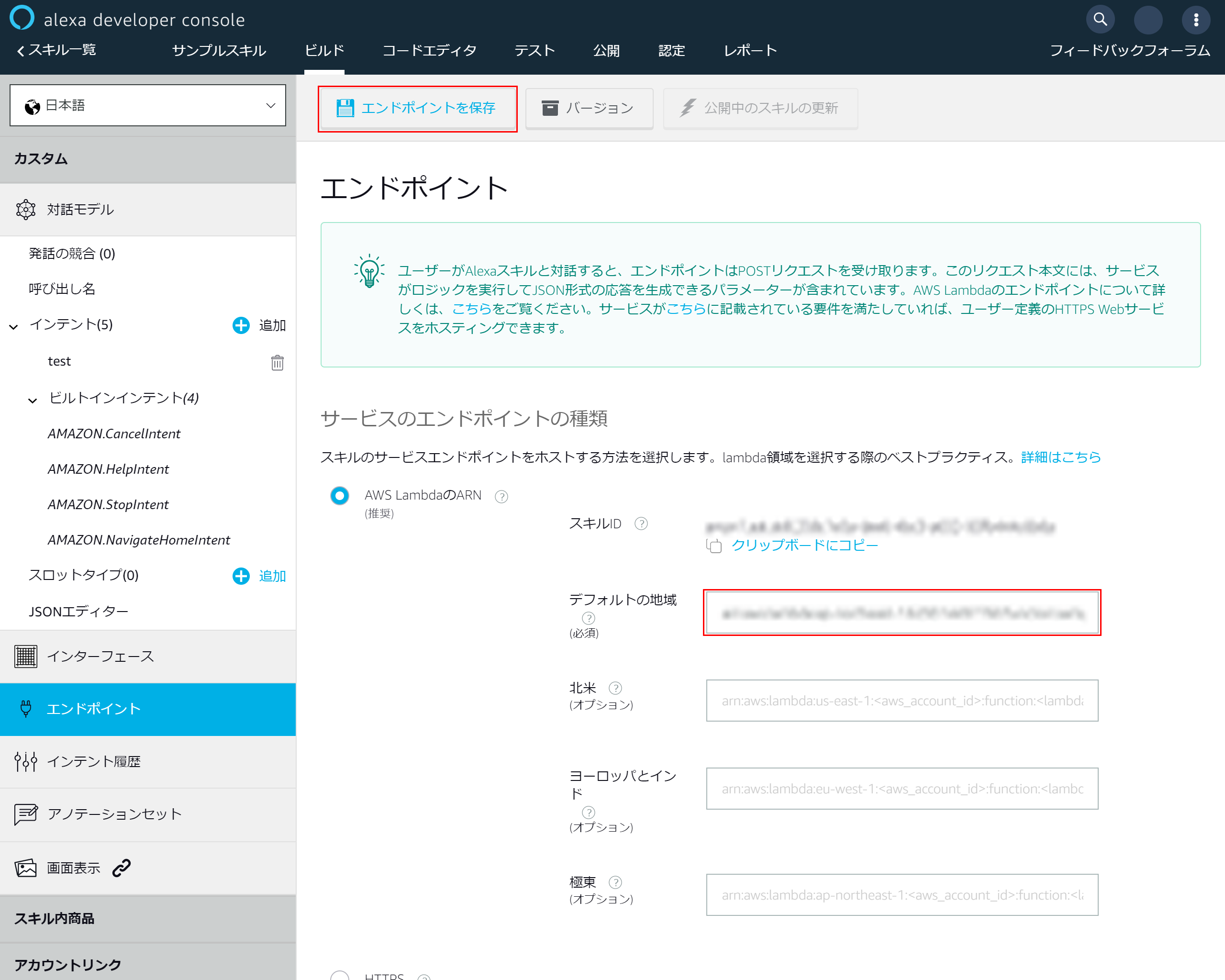
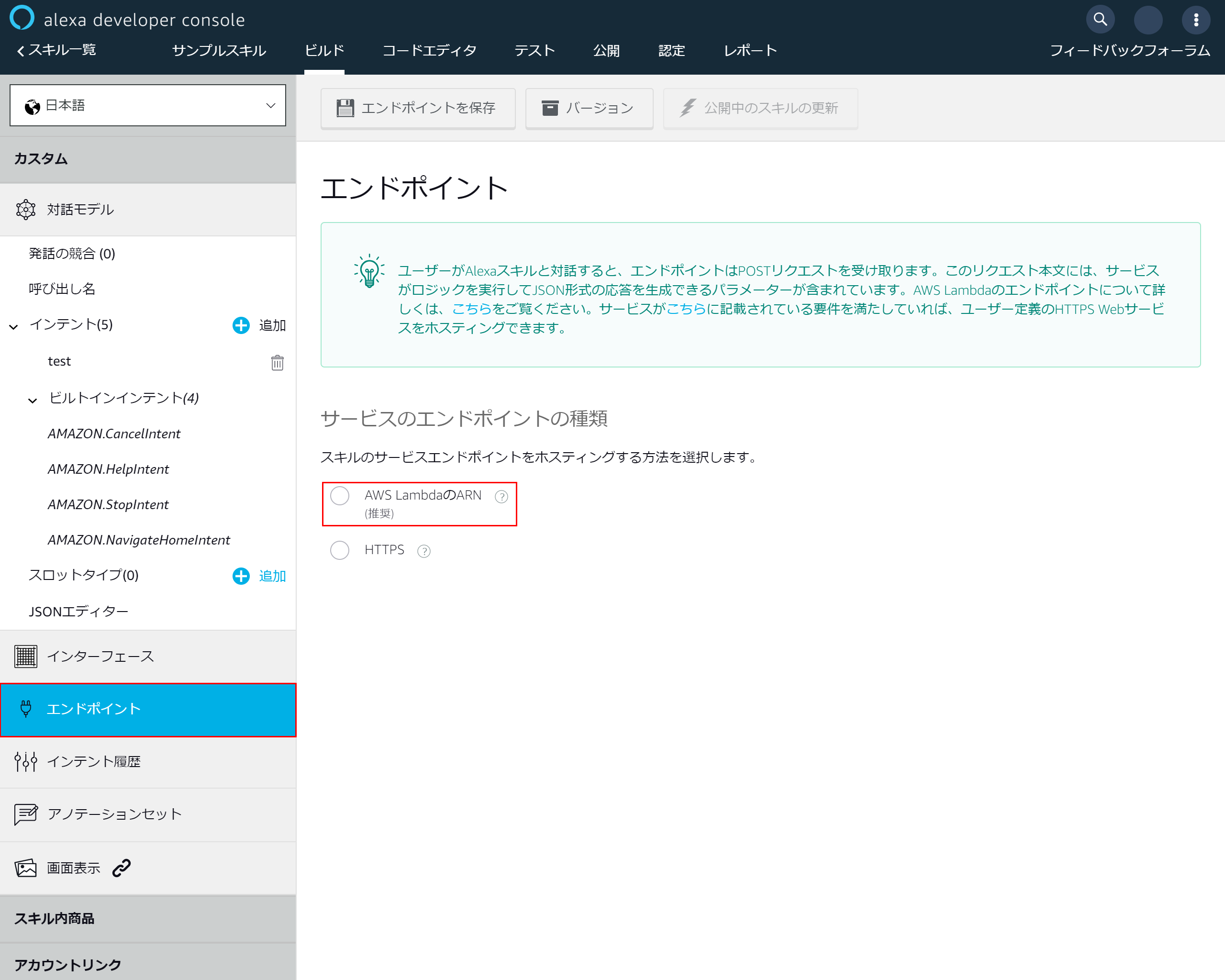
4-8.エンドポイントの設定
alexaに戻り左側のメニューより「エンドポイント」を選択
「AWS LambdaのARN」を選択
4-9.エンドポイントの追加
- 「デフォルトの地域」に先ほどコピーしたARNを貼り付け
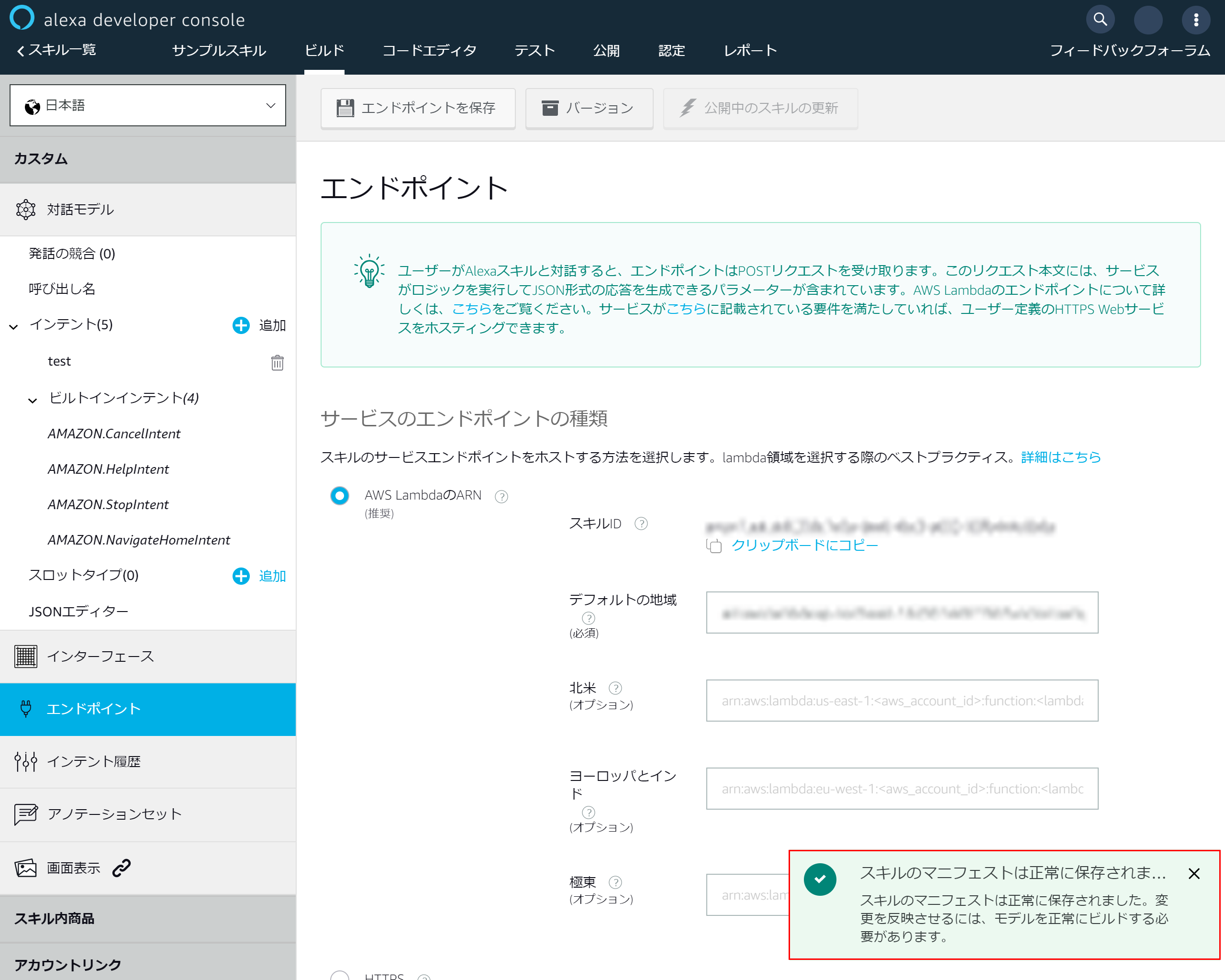
- 上部にある「エンドポイントを保存」を押下し、Lambdaとalexaの連携を完了させます
4-10.マニュフェストの保存成功メッセージが表示されます
5.alexaとCognitoをアカウントリンクで連携させる
5-1.ドメインの設定
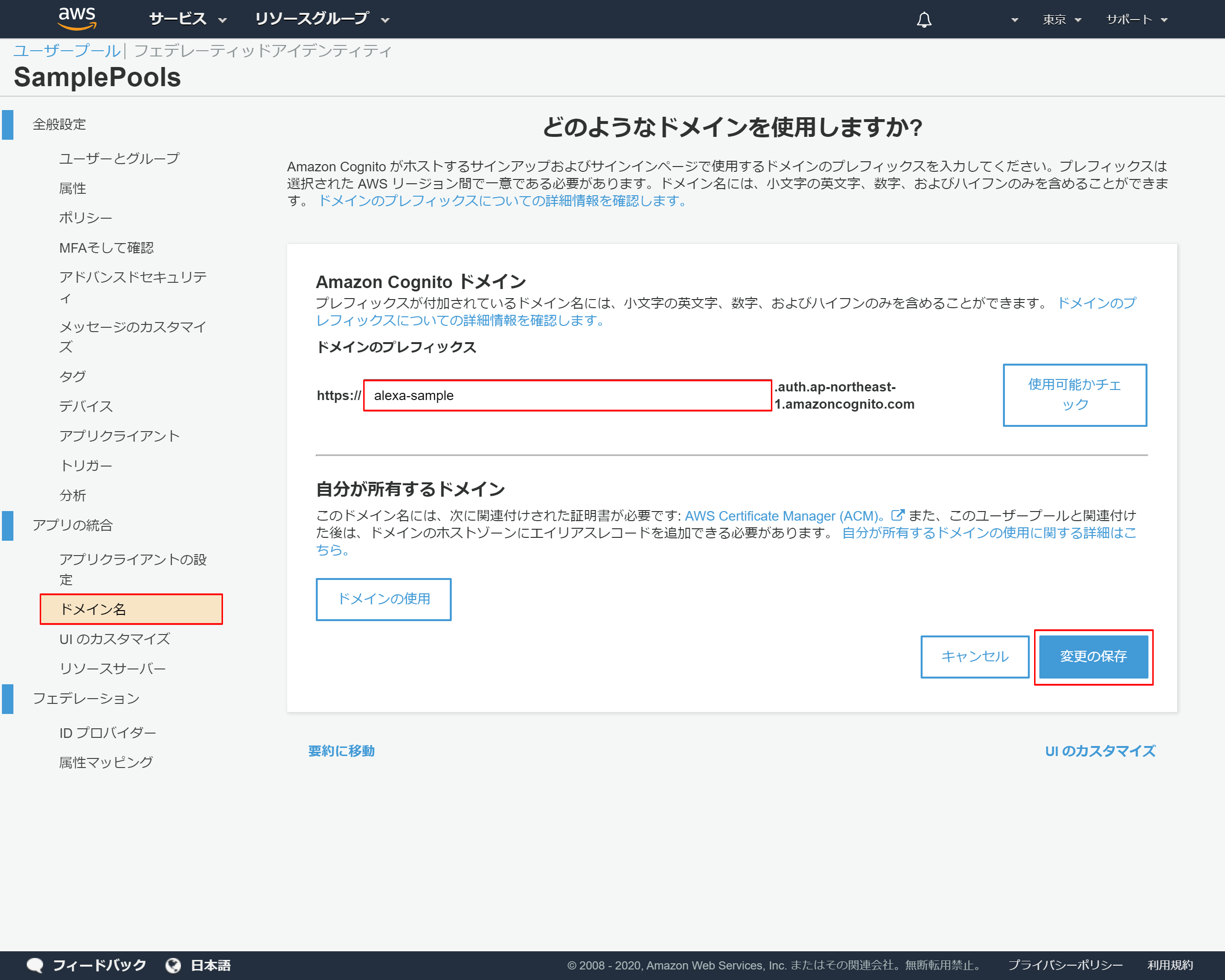
Cognitoを表示して、左側のメニューより「ドメイン名」を押下
ドメインのプレフィックスに任意のドメインを入力 →このサンプルではalexa-sampleにしました
「変更を保存」を押下
5-2.ドメイン名のコピー
ドメインのURLをコピーしておいてください
5-3.アカウントリンクの設定
alexaに戻り左側のメニューから「アカウントリンク」を押下
5-4.アカウントリンクの詳細設定
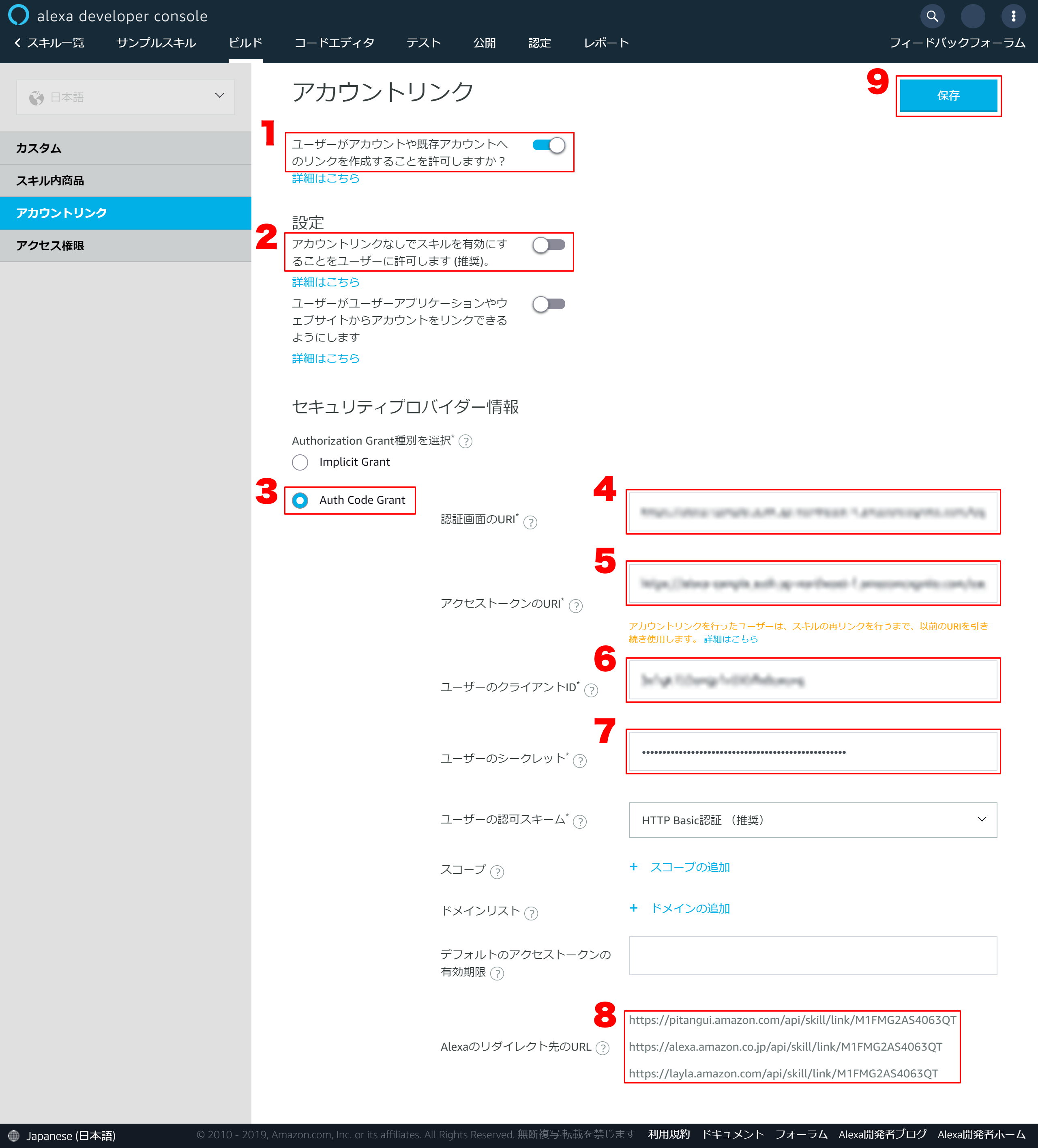
1.「ユーザーがアカウントや既存アカウントへのリンクを作成することを許可しますか?」をONにする
2.「アカウントリンクなしでスキルを有効にすることをユーザーに許可します (推奨)。」をOFFにする
3.「Auth Code Grant」を選択する
4. 「認証画面のURI」を以下フォーマットで設定するhttps://{Amazon Cognito ドメイン}/login?client_id={アプリクライアントID}&response_type=code&scope=aws.cognito.signin.user.admin&redirec ※{Amazon Cognito ドメイン}は5-2で保存したドメインのURL ※{アプリクライアントID}は2-14で保存していた「アプリクライアントID」5.「アクセストークのURI」を以下フォーマットで設定する
https://{Amazon Cognito ドメイン}/oauth2/token ※{Amazon Cognito ドメイン}は5-2で保存したドメインのURL6.「ユーザーのクライアントID」に2-14で保存していた「アプリクライアントID」を入力する
7.「ユーザーのシークレット」に2-14で保存していた「アプリクアライアントのシークレット」を入力する
8.Alexaのリダイレクト先のURLはコピーしておく
9.最後に「保存」を押下
5-5.保存の成功メッセージが表示される
5-6.アプリクライアントの設定
Cognitoに戻り左側のメニューから「アプリクライアントの設定」を押下
5-7.アプリクライアントの詳細設定
- 「Cognito User Pool」を選択
- 「コールバックURL」は5-4の8でコピーしたAlexaのリダイレクト先のURLをカンマでつないで登録する
- 「サインアウトURL」は「https://alexa.amazon.co.jp」を入力
- 「許可されている OAuth フロー」で「Authorization code grant」を選択
- 「許可されている OAuth スコープ」で「aws.cognito.signin.user.admin」
- 「変更の保存」を押下

5-8.登録完了
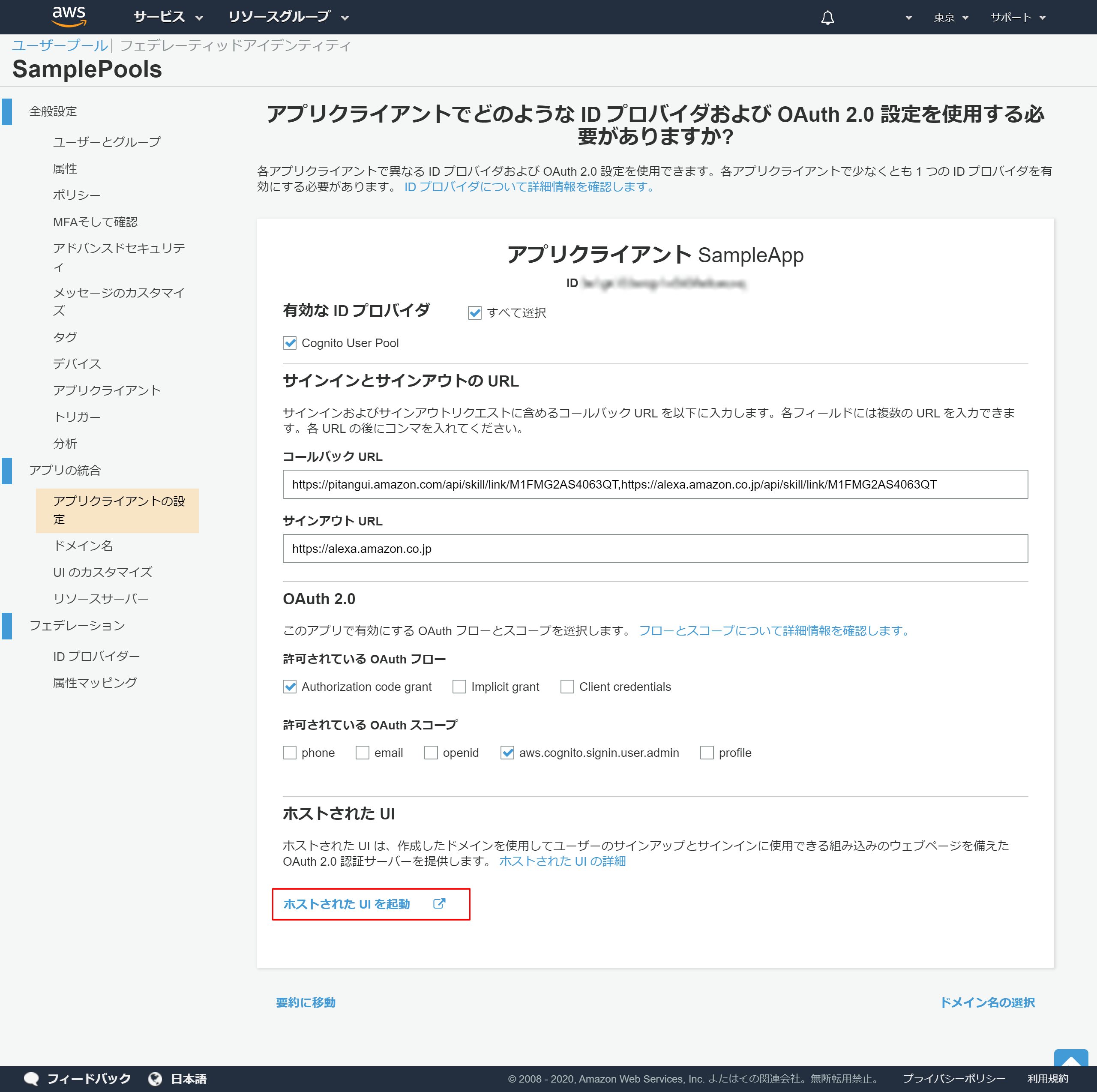
「ホストされたUIを起動」のリンクが表示されれば登録は成功しています
6.alexaとCognitoをアカウントリンクで連携させる
6-1.alexa公開設定
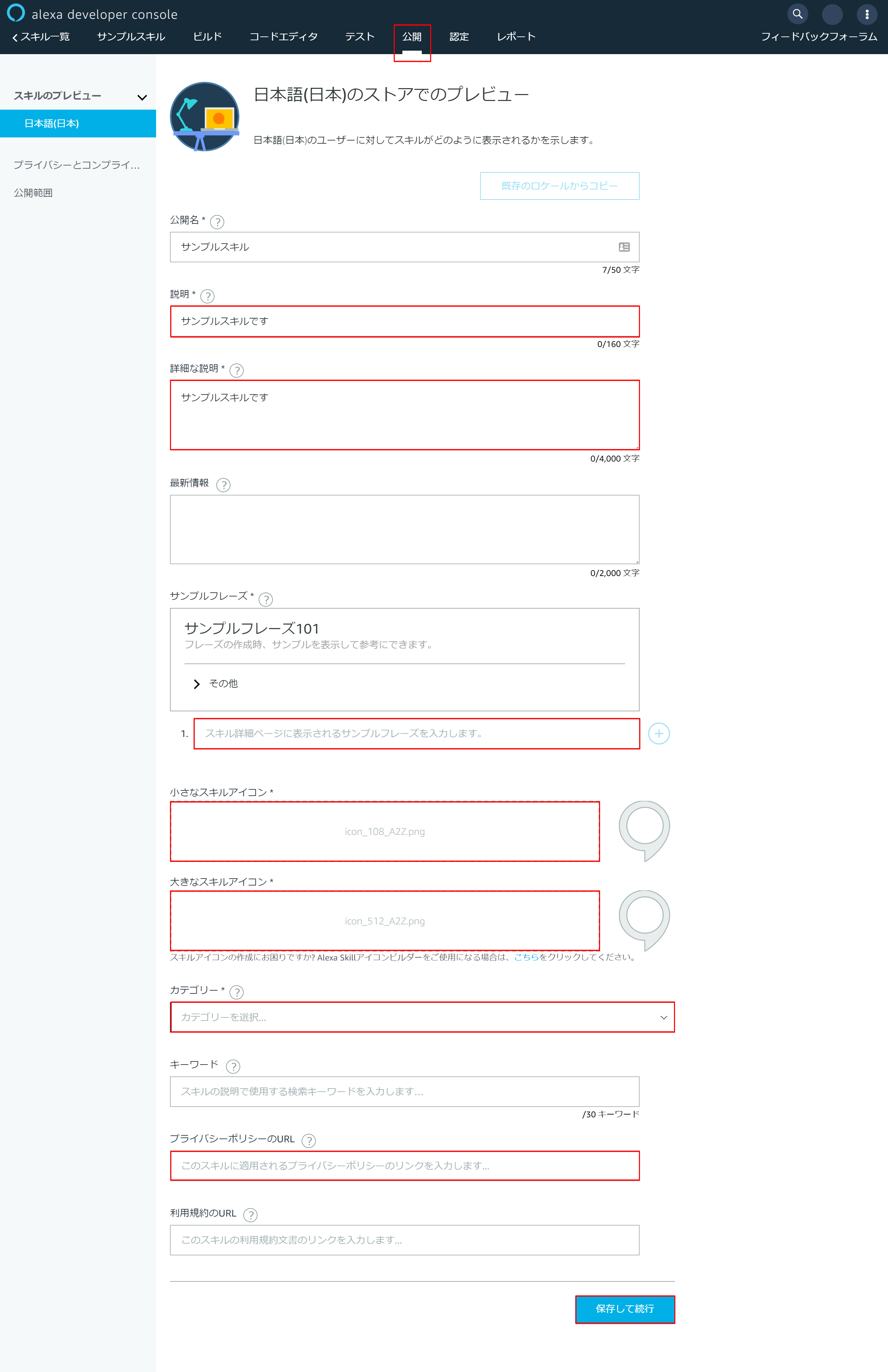
alexaに戻り上部の「公開」メニューを押下
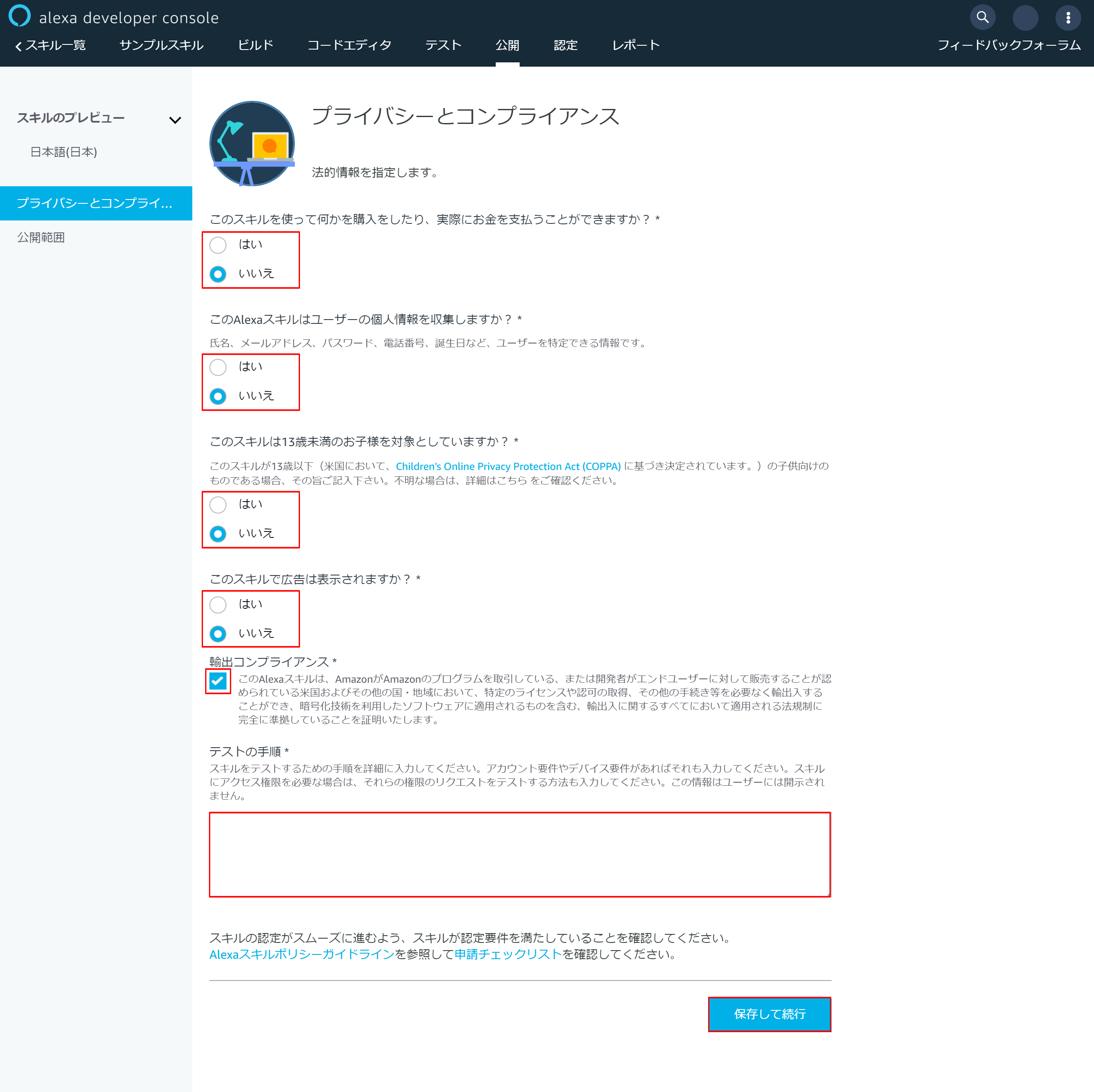
以下赤枠の部分を入力して最後に「保存して続行」を押下
6-2.プライバシーとコンプライアンス設定
赤枠を入力して最後に「保存して続行」を押下
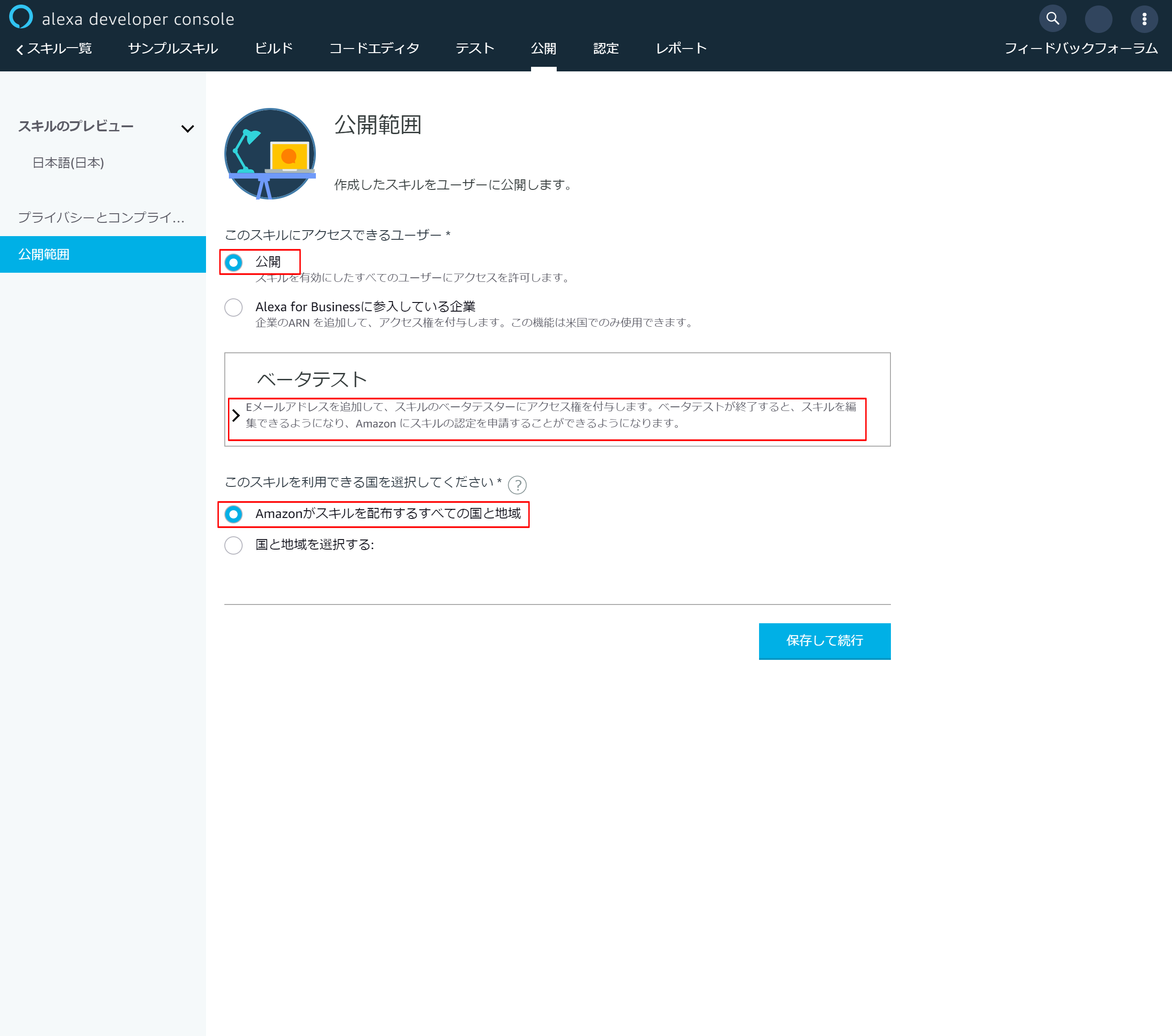
6-3.公開範囲設定
赤枠部分を設定する
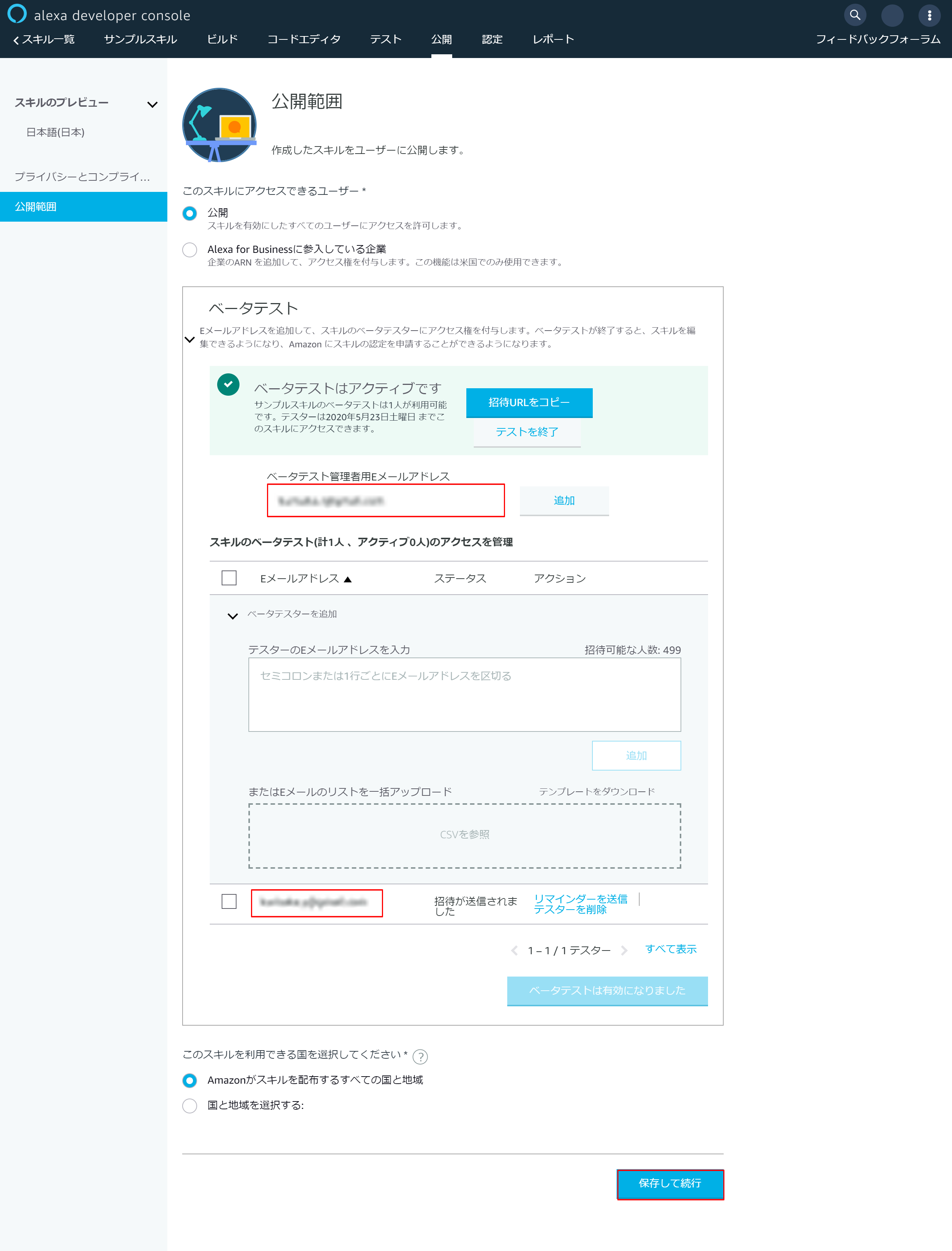
6-4.ベータテスト設定
- 「ベータテスト管理者用Eメールアドレス」を設定
- 「テスターのEメールアドレス」を設定
- 「保存して続行」を押下
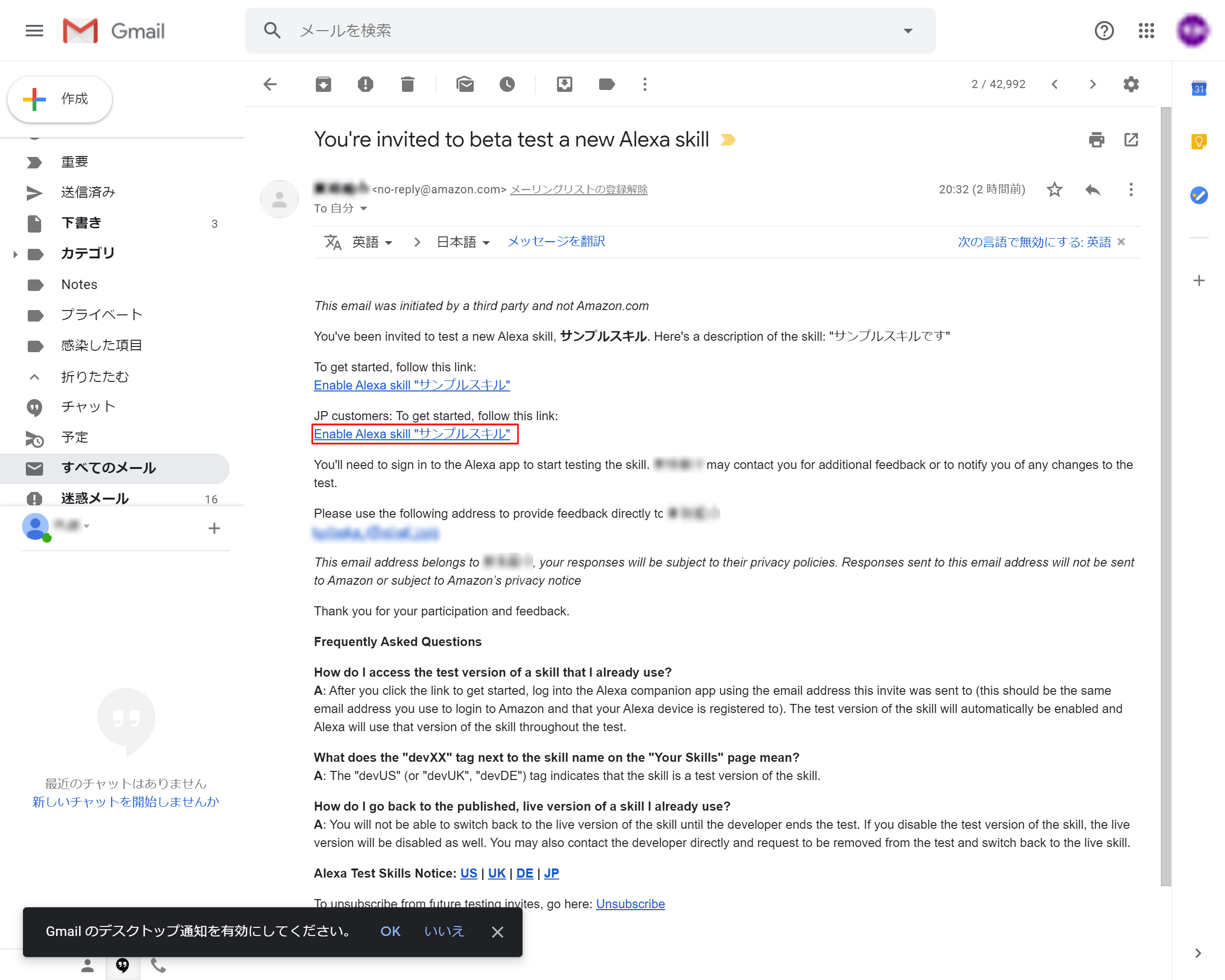
6-5.招待メールのリンクを押下
赤枠のリンクを押下する
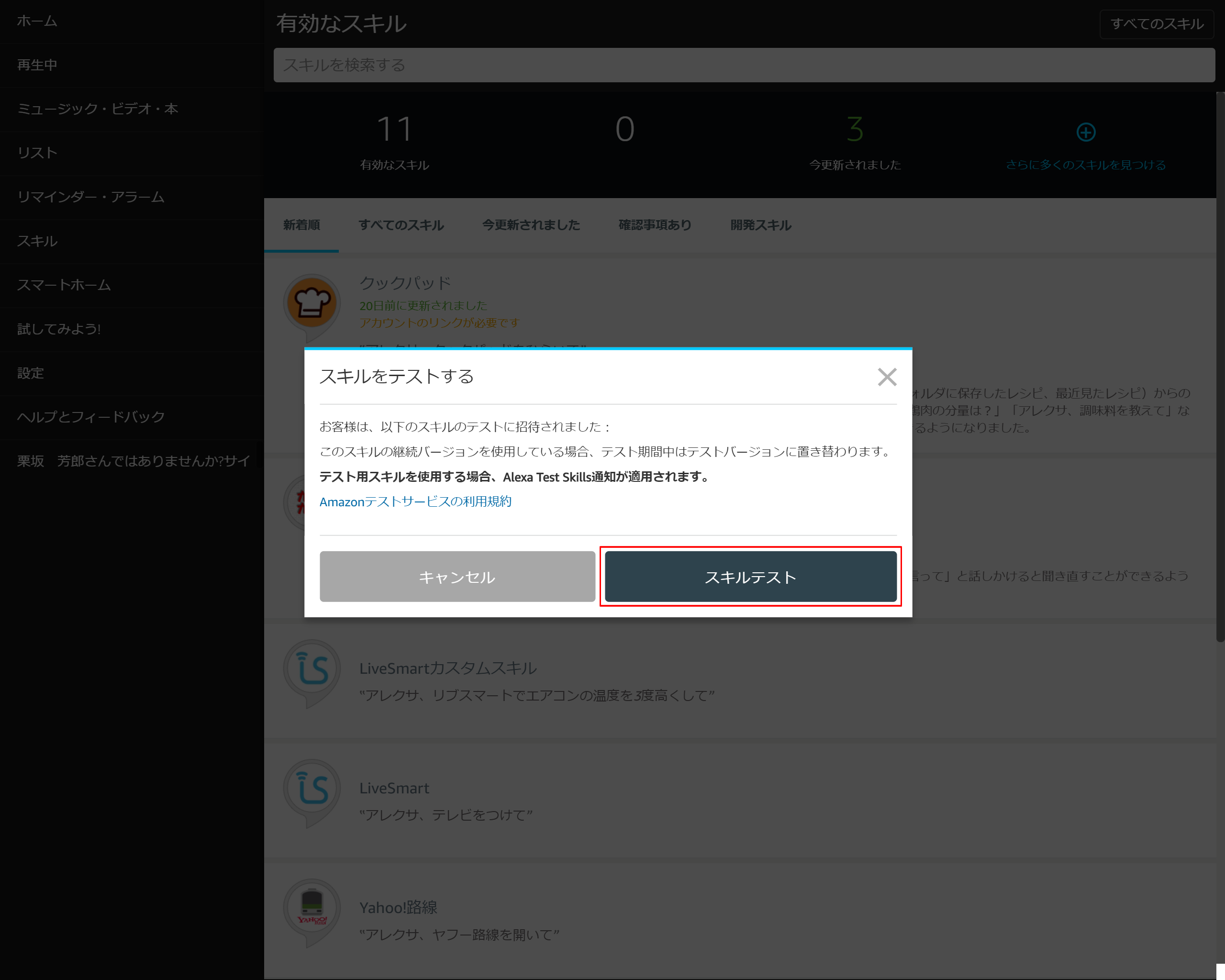
6-6.「スキルテスト」を押下する
6-7.「有効にする」を押下する
6-8.Sign in画面が表示されたら、Sign upリンクを押下する
6-9.Sign up画面にアカウント情報を入力します
最後に「Sign up」を押下します
6-10.設定したEmailにverification Codeが送られてきます
6-11.表示された画面にverification Codeを入力して「Confirm Account」を押下します
6-12.アカウントリンク成功のメッセージが表示される
7.動作確認
7-1.iPhoneアプリから動作を確認
1.「サンプルスキルを開いて」と発話する
2.「こんにちは」と発話する
7-2.Cognitoの登録状況を確認
左側のメニューより「ユーザーとグループ」を押下
ユーザー名のリンクを押下
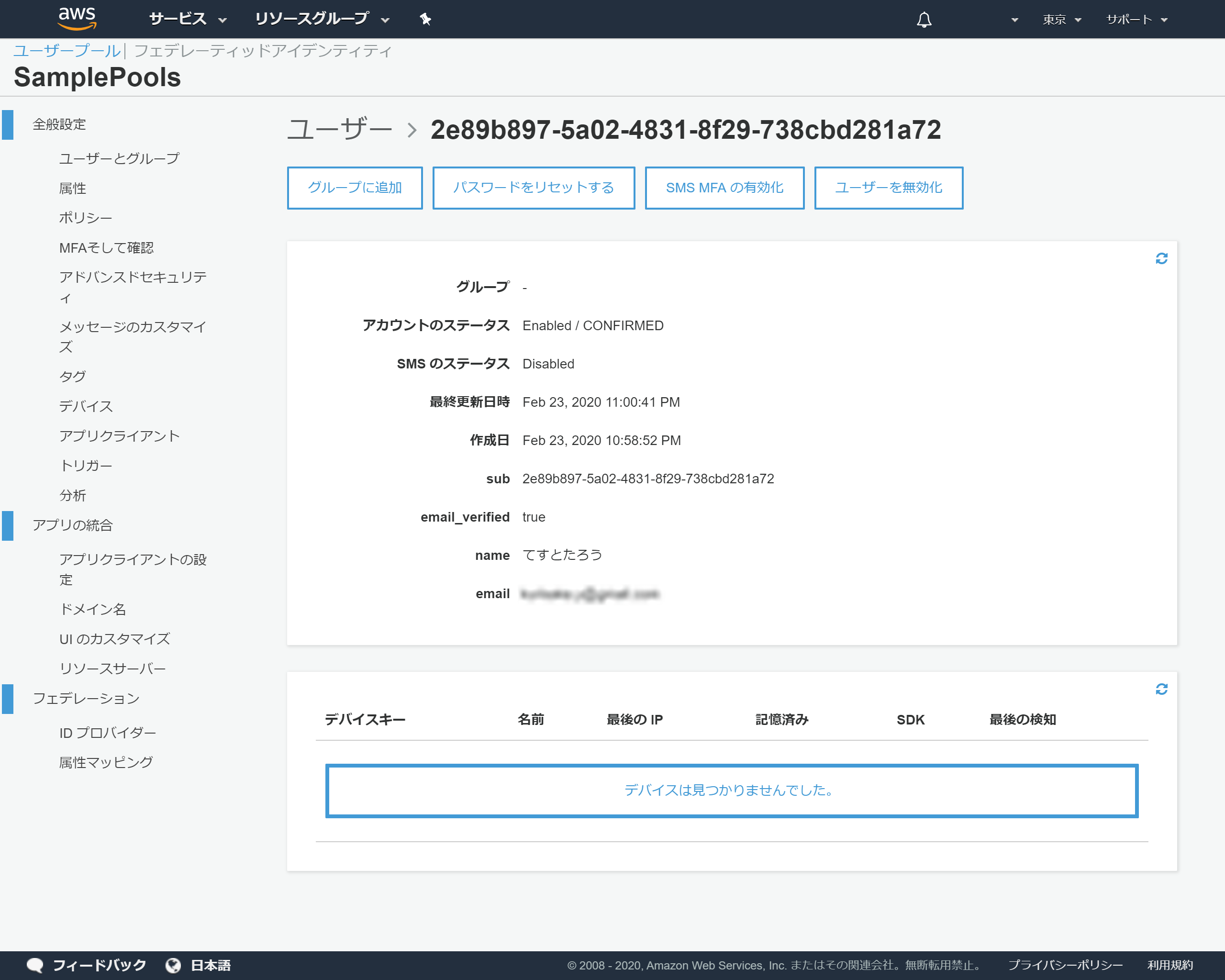
詳細情報が表示される











- 投稿日:2020-02-24T15:47:45+09:00
django-filter/DateFromToRangeFilterのsuffixを変更する
書くこと
django-filterで用意されている
DateFromToRangeFilter()を使うと、デフォルトでは指定したfieldのsuffixに_afterと_beforeがついた物を拾ってその範囲で絞り込んでくれます。ただ、今回自分は
_fromと_toを拾って範囲絞り込みをして欲しかったです。少し時間がかかってしまったので、記録として記事にします。
GitHubにもあげておきました。
準備
created_atカラムを持つBlogModelを作って、そのlistを取得するエンドポイントを作成します。models.pyfrom django.db import models class Blog(models.Model): title = models.CharField(max_length=255) created_at = models.DateTimeField(auto_now_add=True)serializers.pyfrom rest_framework.serializers import ModelSerializer from blogs.models import Blog class BlogSerializer(ModelSerializer): class Meta: model = Blog fields = '__all__'filters.pyfrom django_filters import rest_framework as filters from blogs.models import Blog class BlogFilter(filters.FilterSet): created_at = filters.DateFromToRangeFilter() class Meta: model = Blog fields = ['created_at']views.pyfrom rest_framework.response import Response from rest_framework.viewsets import ViewSet from blogs.filters import BlogFilter from blogs.models import Blog from blogs.serializers import BlogSerializer class BlogViewSet(ViewSet): def list(self, request): queryset = Blog.objects.all() queryset = BlogFilter(data=request.GET, queryset=queryset, request=request).qs serializer = BlogSerializer(queryset, many=True) return Response(serializer.data)urls.pyfrom rest_framework.routers import DefaultRouter from blogs.views import BlogViewSet router = DefaultRouter(trailing_slash=False) router.register( r'^blogs', BlogViewSet, basename='blogs' ) urlpatterns = router.urls最後に
2020年02月24日にBlogテーブルにレコードを作成します。>>> blog1 = Blog.objects.create(title='blog1') <Blog: Blog object (1)> >>> blog1.created_at datetime.datetime(2020, 2, 24, 5, 54, 52, 859528, tzinfo=<UTC>)これで
/blogsにクエリパラメータcreated_at_after,created_at_beforeを渡して範囲指定が出来るようになりました。>>> curl 'http://localhost:18000/blogs?created_at_after=2020-02-01&created_at_before=2020-02-02' [] >>> curl 'http://localhost:18000/blogs?created_at_after=2020-02-01&created_at_before=2020-02-28' [{"id":1,"title":"blog1","created_at":"2020-02-24T05:54:52.859528Z"}]方針
今回したいことは、デフォルトで設定されているsuffixの
_after,_beforeを変更するということです。設定されているところを見つけて可能そうであればオーバーライドする等で対応しようと考えました。
DateFromToRangeFilterの中をのぞいてみます。
DateFromToRangeFilter(GitHub)そうするとDateRangeWidget(GitHub)でこのようにsuffixが設定されていることが分かりました。
class DateRangeWidget(RangeWidget): suffixes = ['after', 'before']これはDateRangeField(GitHub)で使われています。
以上から
1. CustomWidgetを作成
2. CustomDateRangeFieldを作成
3. CustomDateFromToRangeFilterを作成
のように実装することにしました。実装
1. CustomWidgetを作成
suffixが
_from,_toになるようにしますwidgets.pyfrom django_filters.widgets import DateRangeWidget class CustomDateRangeWidget(DateRangeWidget): suffixes = ['from', 'to']2. CustomDateRangeFieldを作成
CustomWidgetを使ってFilterに使用するためのFieldを作ります。
fields.pyfrom django_filters.fields import DateRangeField from blogs.widgets import CustomDateRangeWidget class CustomDateRangeField(DateRangeField): widget = CustomDateRangeWidget3. CustomDateFromToRangeFilterを作成
2で作った
CustomDateRangeFieldを使ってFilterを作成します。filters.pyfrom django_filters import rest_framework as filters from blogs.fields import CustomDateRangeField from blogs.models import Blog class CustomDateRangeFilter(filters.DateFromToRangeFilter): field_class = CustomDateRangeField class BlogFilter(filters.FilterSet): # created_at = filters.DateFromToRangeFilter() created_at = CustomDateRangeFilter() class Meta: model = Blog fields = ['created_at']もちろんデフォルトで用意されている
_after,_beforeは使えなくなります。確認しておきます。
_after,_beforeが使えないことを試す >>> curl 'http://localhost:18000/blogs?created_at_after=2020-02-01&created_at_before=2020-02-02' [{"id":1,"title":"blog1","created_at":"2020-02-24T05:54:52.859528Z"}] >>> curl 'http://localhost:18000/blogs?created_at_after=2020-02-01&created_at_before=2020-02-28' [{"id":1,"title":"blog1","created_at":"2020-02-24T05:54:52.859528Z"}] _from, _toが期待通りに動作することを試す >>> curl 'http://localhost:18000/blogs?created_at_from=2020-02-01&created_at_to=2020-02-02' [] >>> curl 'http://localhost:18000/blogs?created_at_from=2020-02-01&created_at_to=2020-02-28' [{"id":1,"title":"blog1","created_at":"2020-02-24T05:54:52.859528Z"}]以上でsuffixを変更することが出来ました。
最後に
今まで全く使ってこなかった
django-filterですが、非常に便利ですね。「これもっと簡単に解決出来るよ」というのをご存知の方がいれば教えていただけると嬉しいです。
ありがとうございました!
- 投稿日:2020-02-24T15:33:47+09:00
ツール整理:JupyterNotebook
目的
分析コンペでよく使うJupyter Notebook系のテンプレートを整理。
目次
- ライブラリの自動ロード
- 性能プロファイル (%%time / %lprun)
- matplotlib日本語化 (簡単)
- Pandas最大表示数
- Pandasメモリ削減
1.ライブラリの自動ロード
ライブラリを変更した場合でも、実行時に自動ロードしてくれる。
%load_ext autoreload %autoreload 2参考
https://qiita.com/Accent/items/f6bb4d4b7adf268662f42.性能プロフィル
高速化したい場合は、まずボトルネックを見つけることが重要。
JupyterなどのNotebookでの使用を想定。
簡単:セル内の処理時間を知りたい場合は、%%timeが便利。
詳細:各行の詳細処理時間を知りたい場合は、%lprunが便利。2.1 %%time
セルの先頭jにつけること。
セル全体の実行時間を表示してくれる。%%time def func(num): sum = 0 for i in range(num): sum += i return sum out = func(10000)2.2 %lprun
行ごとに、実行時間を出力してくれる。%%prunはモジュール単位のため、わかりにくい場合があるが。%lprunは行ごとでよりわかりやすい。
以下、3ステップ。
Step0. インストール
Step1. ロード
Step2. 実行Step0 インストール
インストール済ならスキップ。
Google Coab、Kaggleクラウド用コマンド!pip install line_profilerStep1 ロード
%load_ext line_profilerStep2 実行
def func(num): sum = 0 for i in range(num): sum += i return sum %lprun -f func out = func(10000)3.matplotlib日本語化 (簡単)
Google Colabなど、クラウドプラットフォームを使っている場合、システムを変更が難しい場合がある。自動で、日本語のフォント事、パッケージをインストールしてくれるので比較的楽。
注意点は、seabornはimport時に、fontも設定してしまうので、最後にsns.setを実行すること。
import seaborn as sns import japanize_matplotlib sns.set(font="IPAexGothic") ### 必ず、最後に実行4. Pandas最大表示数
pandasのDataFrameを表示すると、ある行数/列数以降、省略表示(...)になってしまう。
最大表示数を設定して、省略を制御する。#最大表示行数の指定(ここでは50行を指定) pd.set_option('display.max_rows', 100) pd.set_option('display.max_columns', 50)5. Pandasメモリ削減
データフレームの数値の範囲から、型を自動設定。
参考 by @gemartin
https://www.kaggle.com/gemartin/load-data-reduce-memory-usage# Original code from https://www.kaggle.com/gemartin/load-data-reduce-memory-usage by @gemartin # Modified to support timestamp type, categorical type # Modified to add option to use float16 or not. feather format does not support float16. from pandas.api.types import is_datetime64_any_dtype as is_datetime from pandas.api.types import is_categorical_dtype def reduce_mem_usage(df, use_float16=False): """ iterate through all the columns of a dataframe and modify the data type to reduce memory usage. """ start_mem = df.memory_usage().sum() / 1024**2 print('Memory usage of dataframe is {:.2f} MB'.format(start_mem)) for col in df.columns: if is_datetime(df[col]) or is_categorical_dtype(df[col]): # skip datetime type or categorical type continue col_type = df[col].dtype if col_type != object: c_min = df[col].min() c_max = df[col].max() if str(col_type)[:3] == 'int': if c_min > np.iinfo(np.int8).min and c_max < np.iinfo(np.int8).max: df[col] = df[col].astype(np.int8) elif c_min > np.iinfo(np.int16).min and c_max < np.iinfo(np.int16).max: df[col] = df[col].astype(np.int16) elif c_min > np.iinfo(np.int32).min and c_max < np.iinfo(np.int32).max: df[col] = df[col].astype(np.int32) elif c_min > np.iinfo(np.int64).min and c_max < np.iinfo(np.int64).max: df[col] = df[col].astype(np.int64) else: if use_float16 and c_min > np.finfo(np.float16).min and c_max < np.finfo(np.float16).max: df[col] = df[col].astype(np.float16) elif c_min > np.finfo(np.float32).min and c_max < np.finfo(np.float32).max: df[col] = df[col].astype(np.float32) else: df[col] = df[col].astype(np.float64) else: df[col] = df[col].astype('category') end_mem = df.memory_usage().sum() / 1024**2 print('Memory usage after optimization is: {:.2f} MB'.format(end_mem)) print('Decreased by {:.1f}%'.format(100 * (start_mem - end_mem) / start_mem)) return df
- 投稿日:2020-02-24T15:14:10+09:00
[Pythonで遊ぼう] モノクロとドットに画像加工する
はじめに
SNSアカウントの画像をそろそろ変えたいな、と思ってPythonでやりました。コードを残しておきます。
内容は以下の3つの
- 画像を読み込む
- 画像をモノクロにして出力する
- 画像をドットにして出力する
になります。注意はあまりないのですが、ドット化は多少時間がかかります。(1分程度?PCのスペックによる)
準備
各自実行する場合は以下の点に注意してください。
- もととなる画像をアップロードしておく
- コードにおける画像ファイル名の変更(以下では shiro.jpg としています。)
画像を読み込む
画像を準備して読み込みます。
私はJupiter Notebookでやっています。その場合は画像を準備して、あらかじめNotebookにアップロードしておきます。import numpy as np import matplotlib.pyplot as plt import cv2 #画像の読み込み img = plt.imread('shiro.jpg') type(img) img.sizeplt.imshow(img) #画像の表示 plt.show()元の画像がこれになります。
モノクロ加工をして出力する
次にモノクロ(白黒)加工して出力します。
def img_show(img : np.ndarray, cmap = 'gray', vmin = 0, vmax = 255, interpolation = 'none') -> None: plt.imshow(img, cmap = cmap, vmin = vmin, vmax = vmax, interpolation = interpolation) #画像を表示 plt.show() plt.close() img = plt.imread('shiro.jpg') img_mid_v = np.max(img, axis = 2)/2 +np.min(img, axis = 2)/2 img_show(img_mid_v) img = plt.imread('shiro.jpg')
ドット化する
ドット化します。好みしだいで"dst = pixel_art(img, 0.1, 4)"の数字をいじってみると面白いかもしれません。
実行するとJupiter Notebookに'shiro_mozaiku.jpg'といったファイルが出力されます。# 減色処理 def sub_color(src, K): Z = src.reshape((-1,3)) Z = np.float32(Z) criteria = (cv2.TERM_CRITERIA_EPS + cv2.TERM_CRITERIA_MAX_ITER, 10, 1.0) ret, label, center = cv2.kmeans(Z, K, None, criteria, 10, cv2.KMEANS_RANDOM_CENTERS) center = np.uint8(center) res = center[label.flatten()] return res.reshape((src.shape)) # モザイク処理 def mosaic(img, alpha): h, w, ch = img.shape img = cv2.resize(img,(int(w*alpha), int(h*alpha))) img = cv2.resize(img,(w, h), interpolation=cv2.INTER_NEAREST) return img # ドット絵化 def pixel_art(img, alpha=2, K=4): img = mosaic(img, alpha) return sub_color(img, K)# 入力画像を取得 img = cv2.imread("shiro.jpg") # ドット絵化 画像の粗さ, 色の粗さ dst = pixel_art(img, 0.1, 4) # 結果を出力 cv2.imwrite("shiro_mozaiku.jpg", dst) from PIL import Image mozaiku_shiro = Image.open('shiro_mozaiku.jpg') mozaiku_shiro
雑談
なかなかいいものができたなぁ、という感じです。旅行に行った時の写真ですが、城など建築物はうまくモザイク・ドット化できそうですね。その他、人物や風景などはどうなるかわからないですが試しにやってみると面白いかもしれませんね。



- 投稿日:2020-02-24T14:53:07+09:00
Pythonで日本語を扱う方法
初プログラミングでPython練習中、右も左もわからない状態ですがとりあえず初学備忘録的に。
Atom上でAtom Runner: script.pyを用いてPythonを走らせようとしたところエラーが表示されたため、その解消法。
以下の1行をスクリプトに追加して解決。
# coding: UTF-8日本語をプログラム中で扱う場合には、プログラムの先頭で文字コードを指定し、指定した文字コードでファイルを保存する必要があります。
Pythonプログラムの文字コードを指定し日本語(UTF-8)を扱えるようにするには、プログラムの1行目もしくは2行目に次のように記述します。とのこと。
- 投稿日:2020-02-24T14:51:00+09:00
ExcelVBAを学び、Pythonを学び始める方へ
Pythonを学び始めました。ほぼ独学で勉強していこうと思っています。
見てほしい方はタイトルの通りです。
この記事では参考とした記事やサイトを載せていきたいと思います。(2020/2/24更新)【Python入門】ファイル/フォルダを操作する方法|os・glob | 侍エンジニア塾ブログ(Samurai Blog) - プログラミング入門者向けサイト
- 投稿日:2020-02-24T14:41:32+09:00
PySparkデータ操作
本記事は、
PySparkの特徴とデータ操作をまとめた記事です。PySparkについて
PySpark(Spark)の特徴
- ファイルの入出力
- 入力:単一ファイルでも可
- 出力:出力ファイル名は付与が不可(フォルダ名のみ指定可能)。指定したフォルダの直下に複数ファイルに分かれて出力
- 遅延評価
- ファイル出力時 or 結果出力時に処理が実行
- 通常は実行計画のみが計算
PartitioningとBucketingPySparkの操作において重要な
Apache Hiveの概念
- Partitioning: ファイルの出力先をフォルダごとに分けること。読み込むファイルの範囲を制限できる。
- Bucketing: ファイル内にて、ハッシュ関数によりデータを再分割すること。効率的に読み込むことができる。
PartitioningとBucketingの詳細についてはこちら(英語)をご覧ください。
計算リソース使用状況の確認
データの処理が遅い場合は、Gangliaを使って計算リソースの使用状況を見てみると良いです。
特に、ネットワーク通信量(=データ転送量)が低くて処理に時間がかかることが多いです。
この場合は、以下のような方法で対策を行うと解決する場合があります。
- 単一ファイルよりも分散ファイルを読み込む
- 遅延評価のため、多くの処理を行った結果は出力が遅く、以下のどちらかを利用する
- データフレームのキャッシュを利用:例
df = df.cache()- フォルダに一旦吐き出し、再度出力結果を読み込み、後続の処理を実行
PySparkのコード片
以下の変数は生成済みとしています。
*spark: spark context
*path: なにかしらのファイルパス
* 次項でimportした要素注意
> df.show()で表示される内容は、イメージを掴むことが目的のため、必ずしも正しくない場合があります。- 上記であげた変数以外の変数を突然利用している場合もります。
- AWS上で実行することをイメージしているため、パスは
s3://から始まっています。- 順次追記・修正をしていく予定です。
- 構文や書いていることに間違がある場合はコメントをよろしくおねがいいたします。
import
spark利用時に主にimportするのは以下の項目です。# from pyspark.sql.functions import * とする場合もありますが、 # Fで関数の名前空間を明示した方がわかりやすくて好きです。 # ただ、FだとPEP8に違反していますが。。。 from pyspark.sql import functions as F from pyspark.sql.types import FloatType, TimestampType, StringType from pyspark.sql.window import Window実行環境設定
- AWS上のEMRを利用する場合は、インスタンス上の時刻が
UTCのため、JSTに設定spark.conf.set("spark.sql.session.timeZone", "Asia/Tokyo")initialize spark
EMRのJupyterHub上では必要ありませんが、pythonのscriptで実行する場合は、
sparkのインスタンス初期化が必要です。# spark initialization spark = SparkSession.builder.appName("{your app name here}").getOrCreate()データ読込
- 文字列から読み込む場合
df = spark.read.parquet(path)
*を利用して複数ファイル/フォルダを一度に読み込み可能# dt=2020-01-01/ 以下にあるファイルを全て読み込む df = spark.read.parquet("s3://some-bucket/data/dt=2020-01-01/*.parquet") # dt=2020-01-01/ から dt=2020-01-31/ 以下にあるファイルを全て読み込む df = spark.read.parquet("s3://some-bucket/data/dt=2020-01-*/*.parquet")
- from list: 複数フォルダにまたがる場合はこちらでも可
# pathsリストに含まれるパスにあるファイルを読み込む df = spark.read.parquet(*paths)
- partitionを利用していて、パーティションを読み込んだデータフレームのカラムに入れたい場合
# partitionを列に加えて読み込む df = spark.read.option("basePath", parent_path).parquet(*paths)
- データフレームのキャッシュ保存
遅延評価した結果をメモリに保存しておくことで、高速に処理が可能になります。
よく利用するデータをcache()し、特に処理の後段で利用するのがよいです。# オンメモリのキャッシュ df = df.cache() # または # デフォルトではオンメモリのキャッシュ、オプション引数でキャッシュ先をストレージなどに変更可能 df = df.persist()データ出力
# csv(この場合はheaderが付与されない) df.write.csv(path) # parquet df.write.parquet(path)
- header: csvの場合のみ注意が必要
# csvの場合はheaderの出力設定をしないと付与されない df.write.mode("overwrite").option("header", "True").csv(path) # or df.write.mode("overwrite").csv(path, header=True) # parquetの場合はheaderを指定しなくてもdefaultで出力される df.write.parquet(path)
- compression: 圧縮
# gzip with csv df.write.csv(path, compression="gzip") # snappy with parquet(デフォルトでsnappy圧縮されるはず?) df.write.option("compression", "snappy").parquet(path)
- partitionBy: 出力する際にデータフレームのカラム名でpartitionをしたい場合
以下の例の場合
/dt={dt_col}/count={count_col}/{file}.parquetというフォルダに出力されます。
df.repartition("dt", "count").write.partitionBy("dt", "count").parqeut(path)
- coalesce: 通常は複数ファイルで出力される内容を1つのファイルにまとめて出力可能
複数処理後にcoalesceを行うと処理速度が落ちるため、可能ならば一旦通常にファイルを出力し、再度読み込んだものをcoalesceした方がよいです。
# 複数処理後は遅くなることがある df.coalesce(1).write.csv(path, header=True) # 可能ならばこちらを推奨(出力→読み込み→出力) df.write.parquet(path) alt_df = spark.read.parquet(path) alt_df.coalesce(1).write.csv(path, header=True)
- repartition: 出力するファイルの分割数を指定
df.repartition(20).write.parquet(path)
- write.mode(): 出力時の方法を選択可能
# write.mode()で使用できる引数 'overwrite', 'append', 'ignore', 'error', 'errorifexists' # よく利用するのは overwrite # 通常は出力先のフォルダにファイルが存在した場合はエラーがでる df.write.parquet(path) # 上書き保存したい場合 df.write.mode("overwrite").parquet(path) # 現在のフォルダに追記したい場合 df.write.mode("append").parquet(path)データフレームの生成
ファイル読み込みからではなく、プログラム上でデータフレームを作成する方法です。
- 単一カラムの場合
# 単一カラムのデータフレームを作成 id_list = ["A001", "A002", "B001"] df = spark.createDataFrame(id_list, StringType()).toDF("id")
- 複数カラムの場合
# 中の要素はtuple, 最後にカラムの名前を指定する df = spark.createDataFrame([ ("a", None, None), ("a", "code1", None), ("a", "code2", "name2"), ], ["id", "code", "name"]) > df.show() +---+-----+-----+ | id| code| name| +---+-----+-----+ | a| null| null| | a|code1| null| | a|code2|name2| +---+-----+-----+ # ======================= # rddを一旦利用して作成する場合 rdd = sc.parallelize( [ (0, "A", 223, "201603", "PORT"), (0, "A", 22, "201602", "PORT"), (0, "A", 422, "201601", "DOCK"), (1, "B", 3213, "201602", "DOCK"), (1, "B", 3213, "201601", "PORT"), (2, "C", 2321, "201601", "DOCK") ] ) df_data = spark.createDataFrame(rdd, ["id","type", "cost", "date", "ship"]) > df.show() +---+----+----+------+----+ | id|type|cost| date|ship| +---+----+----+------+----+ | 0| A| 223|201603|PORT| | 0| A| 22|201602|PORT| | 0| A| 422|201601|DOCK| | 1| B|3213|201602|DOCK| | 1| B|3213|201601|PORT| | 2| C|2321|201601|DOCK| +---+----+----+------+----+列の追加(
withColumn())PySparkでは「新しい列を追加する処理」を利用して分析を行うことが多いです。
# new_col_nameという新しい列を作成し、1というリテラル値(=定数)を付与 df = df.withColumn("new_col_name", F.lit(1))
- F.input_file_name(): 読み込んだファイル名を取得
# 読み込んだファイルパスを付与 df = df.withColumn("file_path", F.input_file_name()) # 読み込んだファイルパスからファイル名を取得 df = df.withColumn("file_name", F.split(col("file_path"), "/").getItem({int: 最後のindex値}))
- cast(): 型変換
# 文字列で指定 df = df.withColumn("total_count", F.col("total_count").cast("double")) # PySparkのtypesで指定 df = df.withColumn("value", F.lit("1").cast(StringType()))
- F.when().otherwise(): 条件に応じて追加する値を変更
# 条件に応じた値の列を追加したい場合 # F.when(condtion, value).otherwise(else_value) df = df.withColumn("is_even", F.when(F.col("number") % 2 == 0, 1).otherwise(0))
- isNotNull(): nullかどうか判定
df = df.withColumn("is_touched", F.col("value").isNotNull())
- F.regexp_replace(): 正規表現を利用した文字の置換
df = df.withColumn("replaced_id", F.regexp_replace(F.col("id"), "A", "C"))
- 時間に関する操作
# date time -> epoch time df = df.withColumn("epochtime", F.unix_timestamp("timestamp", "yyyy-MM-dd HH:mm:ssZ")) # epoch time -> date time # 1555259647 -> 2019-04-14 16:34:07 df = df.withColumn("datetime", F.to_timestamp(df["epochtime"])) # datetime -> string # 2019-04-14 16:34:07 -> 2019-04-14 string_format = "yyyy-MM-dd" df = df.withColumn("dt", F.date_format(F.col("datetime"), string_format)) # epoch time: およそ10桁の数字列。1970年1月1日からの秒数 df = df.withColumn("hour", F.hour(F.col("epochtime"))) df = df.withColumn("hour", F.hour(F.col("timestamp"))) # datetimeを、指定した時間幅に切り捨ている df = df.withColumn("hour", F.date_trunc("hour", "datetime")) df = df.withColumn("week", F.date_trunc("week", "datetime"))このほかにもたくたん
withColumnにて利用できる関数はたくさんあります。
参考サイトもご覧ください。データフレームの結合
2つのDataFrameを横/縦に結合するメソッドは
join()/union()です。# onで結合する列を指定する df = left_df.join(right_df, on="id") # data-frameごとに異なる列の場合 df = left_df.join(right_df, left_df.id_1 == right_df.id_2) # 結合方法も指定可能 # how:= inner, left, right, left_semi, left_anti, cross, outer, full, left_outer, right_outer df = left_df.join(right_df, on="id", how="inner")
- 複数カラムで結合
df = left_df.join(right_df, on=["id", "dt"])
- F.broadcast() join: データを各クラスタに効率的に分配し、結合する方法
- 各データフレームのデータサイズが以下のように不均衡の場合に使うと効率が上昇(することがある)
- left_df: データ量:多、例:実データ
- right_df: データ量:少、例:マスターデータ
df = left_df.join(F.broadcast(right_df), on="id")
- union(): データフレームを縦方向に結合
df = upper_df.union(bottom_df)カラム操作 (rename, drop, select)
- withColumnRenamed(before, after): カラム名の変更
よくカラム名のないcsvを読み込んだときに利用することが多いです。
# カラム名がない場合、`_c0`から`_c{n}`というカラム名が与えられる df = df.withColumnRenamed("_c0", "id")
- select("col_1", "col_2", ...): 列単位で取得
df = df.select("id")
- distinct(): 重複削除
df = df.select("id").distinct() # count() と合わせてよく利用する # 例:とあるidのユニーク数 print(df.select("id").distinct().count())
- drop("col_1", "col_2", ...): 列単位で削除
df = df.drop("id")
- drop Null Value
# simple df = df.dropna() # using subset df = df.na.drop(subset=["lat", "lon"])
- collect_list(), collect_set(): 単一のカラムにリストとして値を入力
# 単純な場合 df = df.select("id").select(F.collect_list("id")) id_list = df.first()[0] > id_list => ["A001", "A002", "B001"] # groupByと合わせて使うことも可能 df = df.groupBy("id").agg(F.collect_set("code"), F.collect_list("name")) > +---+-----------------+------------------+ | id|collect_set(code)|collect_list(name)| +---+-----------------+------------------+ | a| [code1, code2]| [name2]| +---+-----------------+------------------+
- collect(): 全ての要素を返す
- take(n): 最初のn個の要素を返す
- first(): 一番最初の要素を返す
# データフレームの値を直接取得する df = df.groupBy().avg() avg_attribute = df.collect()[0] > print(avg_attribute["avg({col_name})"]) {averaged_value}filter
F.col()を利用して特定のカラムに対してフィルタ処理を適用できます# using spark.function df = df.filter(F.col("id") == "A001") # pandas-like df = df.filter(df['id'] == "A001") df = df.filter(df.id == "A001")
- isin(): listの中の要素にある値かどうかを判定
ただ、可能ならばdate_listからsparkのデータフレームを作成し、joinしたほうがよいです。
df = df.filter(F.col("dt").isin(date_list))orderBy
ソートは分散処理では適さない処理のため、あまりしない方が良いです。
# 単一カラムのみ df = df.orderBy("count", ascending=False) # 複数条件ソート df = df.orderBy(F.col("id").asc(), F.col("cound").desc())groupBy (aggregate)
# count() df = df.groupBy("id").count() # multiple # alias() 関数にてカラム名の変更を行なっている # 例:ユーザーの集計 df = df.groupBy("id").agg( F.count(F.lit(1)).alias("count"), F.mean(F.col("diff")).alias("diff_mean"), F.stddev(F.col("diff")).alias("diff_stddev"), F.min(F.col("diff")).alias("diff_min"), F.max(F.col("diff")).alias("diff_max") ) > df.show() (省略) # ======================= # 例:ユーザーの日時ごとの集計 df = df.groupBy("id", "dt").agg( F.count(F.lit(1)).alias("count") ) > df.show() +---+-----------+------+ | id| dt| count| +---+-----------+------+ | a| 2020/01/01| 7| | a| 2020/01/02| 5| | a| 2020/01/03| 4| +---+-----------+------+ # =========================== # 例:ユーザーの日時・場所ごとの集計 df = df.groupBy("id", "dt", "location_id").agg( F.count(F.lit(1)).alias("count") ) > df.show() +---+-----------+------------+------+ | id| dt| location_id| count| +---+-----------+------------+------+ | a| 2020/01/01| A| 2| | a| 2020/01/01| B| 3| | a| 2020/01/01| C| 2| : : : : : +---+-----------+------------+------+
- countDistinct(): 集計時に重複を削除し、countを行う
# 例:日付ごとのユーザユニーク数 df = df.groupBy("dt").agg(countDistinct("id").alias("id_count")) > df.show() +-----------+---------+ | dt| id_count| +-----------+---------+ | 2020/01/01| 7| | 2020/01/02| 5| | 2020/01/03| 4| +-----------+---------+ # =============================== # 例:ユーザごとの接触が1回以上あった日数 df = df.groupBy("id").agg(countDistinct("dt").alias("dt_count")) > df.show() +---+---------+ | id| dt_count| +---+---------+ | a| 10| | b| 15| | c| 4| +---+---------+
- 要素の指定にlistも指定可能
group_columns = ["id", "dt"] df = ad_touched_visit_df.groupBy(*group_columns).count()window関数
- row_number(): 行番号を付与
w = Window().orderBy(F.col("id")) df = df.withColumn("row_num", F.row_number().over(w))
- lag(): 行をずらす
# 前の行のデータをカラムとして追加 w = Window.partitionBy("id").orderBy("timestamp") df = df.withColumn("prev_timestamp", F.lag(df["timestamp"]).over(w))loop処理
分散環境と相性が悪いため、強く非推奨です。
どうしてもforじゃないといけない場合にのみ利用するようにした方がいいです。for row in df.rdd.collect(): do_some_with(row['id'])参考サイト
- 投稿日:2020-02-24T14:08:20+09:00
【ROS2】python形式のlaunchでremapとparameterを記述する方法
はじめに
ROS2からpythonでlaunchファイルを記述できるようになりましたが,まだチュートリアル以外の例があまり見つかりません.そこで,今回はROS2のGithub(ros2/launch_ros)からリマップとパラメータの使い方を探しました.
テスト環境
- Ubuntu 18.04
- ROS Eloquent
remapとparameterの記述方法
import launch import launch_ros.actions def generate_launch_description(): return launch.LaunchDescription([ launch_ros.actions.Node( package='demo_parameters_cpp', node_executable='string_talker', output='screen', node_name='string_talker', remappings=[('string_topic', '/talker')], parameters=[{'string_param':'changed'}] ) ])remap
argumentに
remappingsを指定し,タプルをリストに連ねていきます.タプルは(remap前のtopic名, remap後のtopic名)で記述します.parameter
argumentに
parametersを指定し,辞書をリストの中に置きます.複数のパラメータを指定する場合は[{parameter1:value1, parameter2:value2, ... }]のように記述します.yamlファイルで読み込みたい場合は
parameters=['parameter_dir/parameter.yaml']
のように書くとyamlファイルからparameterを設定できます.参考
関連記事
- 投稿日:2020-02-24T14:01:14+09:00
ツール整理:Google Colaboratory (2020.2.24更新)
目的
SIGNATEやNishikaなどの国内の分析コンペは、計算プラットフォームがないので、自前のノートPCでは辛くなってきた。そこで、GoogleColaboratoryの自分用の使い方メモ。
Kaggleは計算プラットフォームがあるので、問題ない。都度、更新していく予定 2020.2.24
- テンプレート作成
目次
- テンプレート
1. テンプレート
- 「XXX」、「../input/data」を自分のフォルダに、書き換えて使用する。
- 内容
- Google Driveにマウント
- 経過時間表示
import os path = None # プラットフォーム判定 # nt:Windows系 , それ以外Google Colab if os.name == 'nt': # ローカルフォルダ path = '../input/data/' else: # (1)Google Driveにマウント from google.colab import drive drive.mount('/content/drive') !ls drive/My\ Drive/'Colab Notebooks'/XXX/input/data path = "./drive/My Drive/Colab Notebooks/XXX/input/data/" # (2)経過時間確認 (12時間ルール用) !cat /proc/uptime | awk '{print $1 /60 /60 /24 "days (" $1 / 60 / 60 "h)"}' print('os:',os.name) print('path:',path)
- 投稿日:2020-02-24T13:55:31+09:00
ウイイレイベント告知用のBot作成してみた
ウイイレイベント告知用のBot作成してみた
どうもヤジュンです。
今回は、TwitterのBotを作成してみました。※本記事のソフトウェアは、Pythonで作成しています。■参考URL
■背景・導入
2019年から「eスポーツ」市場が急速に成長した.
それに伴い「ウイイレ」のイベントが毎週全国各地で開かれるようになった。
これは、イベントの開催者が、プレイヤーから一般企業や団体に移ったためである。しかし。。。一つの問題が。。。
情報インフラの整備がされていない!!
大会情報がプレイヤーに伝わらない!!
なら、誰かインフラを作るしかない!!
本記事は、世界に誇れるウイイレ民のウイイレ民によるウイイレ民のためのインフラ 「ウイフラ」を作って(ry
■目的
- ウイイレ大会・イベントの開催情報の流れを一元化する。
■方法
- twitterのBOTを作成して、目的を達成します。 ウイイレプレイヤーが好んで使用するからです。
また、大会情報の告知もtwitterで行われるのが主です。▼技術的な話
Botの作成には、Pythonのtweepyを使用します。
twitterが公開しているapiです。
五重羅生門並に、使用許諾申請がだるい!
tweepyでやること自体はシンプル!
- ハッシュタグ「#ウイイレ_イベント告知」をTLから検索
- 該当ツイートをRT
次は、上記のコードが定期的に実行されるようにします。
今回はAWSを使用しました。これもやることはシンプル!
- AWS側から、1分間隔でイベントハンドラ呼び出ししてもらう
■結果
- 出来上がったBotがこいつPES_EVENT_BOT 試しにハッシュタグ「#ウイイレ_イベント告知」付きでツイートしたら、見事RTされました!
■お願い!
お願いは2つ!
①本Botをフォローして下さい
②大会やイベント告知ツイートにハッシュタグを付けてください。ウイイレの大会やイベント開催情報を見つけたら、ハッシュタグ「#ウイイレ_イベント告知」をつけて引用RTしてください。
※そして、もし可能であれば大会主催者側に本Botの存在を教えてください!
次の告知ツイートから主催者側でハッシュタグをつけてもらえるかも??
■終わりに
今回作成したBotで、ウイイレ界をより便利に出来たら嬉しいです!
本活動は、趣味でやっていますが、わがまま言っていいなら私のyoutubeチャンネルを登録してくれると嬉しいです!笑もし増えたら、他のアイディアも実行します♪笑
■参考URL




- 投稿日:2020-02-24T13:54:22+09:00
【制御工学】Pythonによる伝達関数のグラフ化
1.はじめに
・前回書いたqiitaのページ( https://qiita.com/sato235/items/f991411074c578d1640c ) に、波形グラフを出力して考察したら面白いのではというコメントをもらったのがきっかけで、本ページを作成。
2.参考
2.1.図書
[1] 南裕樹 著、オーム社、「Pythonによる制御工学入門」
2.2.ウェブページ
a) [1]の著者サポートページ、https://y373.sakura.ne.jp/minami/pyctrl
b) 前回の自頁、https://qiita.com/sato235/items/f991411074c578d1640c
c) controlモジュールのmatlab関数のグラフ化機能、http://matsulib.hatenablog.jp/entry/2013/04/27/0930083. 伝達関数とグラフ化
まずモジュールのインポート。
import sympy from control import matlab import numpy as np import matplotlib.pyplot as plt伝達関数を作成
Np = [0,1] Dp = [1,2,3] P = matlab.tf(Np, Dp) print(P)伝達関数の出力
1 ------------- s^2 + 2 s + 3上記の伝達関数に、ステップ関数を入力した場合。
t = np.linspace(0, 3, 1000) yout, T = matlab.step(P, t) plt.plot(T, yout,label="test") plt.axhline(1, color="b", linestyle="--") plt.legend(bbox_to_anchor=(1, 0.25), loc='upper right', borderaxespad=0, fontsize=11)
伝達関数Pに、インパルス応答関数を入力した場合。
yout, T = matlab.impulse(P, t) plt.plot(T, yout,label="test") plt.axhline(0, color="b", linestyle="--") plt.xlim(0, 3) plt.legend(bbox_to_anchor=(1, 1), loc='upper right', borderaxespad=0, fontsize=11)
4. 結論
・controlモジュールに、matlab計算機能があることを学んだ。
・同様に、matplotlibの描画機能もあった。
・次は、入力関数を変えて、得られる結果の考察をしたい。
- 投稿日:2020-02-24T13:05:41+09:00
初心者ABC156(Python)
コンテストのページはこちら
https://atcoder.jp/contests/abc156
A
n,r = map(int, input().split()) ans = r if n < 10: ans = r + 100 * (10 - n) print(ans)nが10未満だった場合のみ、内部レートを再計算する。
提出 https://atcoder.jp/contests/abc156/submissions/10269586B
n,k = map(int, input().split()) def base(a, b): if (int(a/b)): return base(int(a/b), b) + str(a % b) return str(a % b) ans = base(n, k) print(len(ans))10進法の数字
aをb進数に変換するには
- aをbで割る
- その余りを1桁目から並べる
この2つをa÷bの商が0になるまで繰り返す(0になったらやめる)方法がある。
(コンテスト中は計算方法を調べて真似して書きました。)
提出 https://atcoder.jp/contests/abc156/submissions/10274589C
n = int(input()) *x, = map(int, input().split()) ans = float('inf') for i in range(min(x), max(x)+1): tmp = 0 for j in x: tmp += (j - i)*(j - i) ans = min(ans, tmp) print(ans)
住人の座標を昇順にソートして、
最小から最大の範囲の中で、それぞれの座標を集会を開く場所とした (iのfor文) 場合の、
各住人の消費体力の合計を計算 (jfor文) しその最小値を考えた。
Nが小さめなので全部調べても大丈夫(途中で気づいた)。
提出 https://atcoder.jp/contests/abc156/submissions/10326967
https://atcoder.jp/contests/abc156/submissions/10281863追記・修正 @c-yan 様よりコメント頂き無駄なソートの部分をなくし修正しました。
DとEとF
ACできたら追記したいです。
- 投稿日:2020-02-24T12:38:10+09:00
今後のエンジニアとしての目標
これまでのわたしのことについて
初めてプログラミングのことについて関心を持ったのは2015年くらいからになります。
その後は多忙で他のことに意識をとられながらPHPやPuby、Webデザイン技術などについて学んできました。本格的にプログラマー、あるいはITエンジニアとして会社で仕事をしたいと思い始めたのは2018年のときでその頃から計画的に業界、業態のことについて色々調べたり、将来のキャリア設計について考えるようになりました。
2019年にエンジニアスクールを修了し、カジュアル面談や実際に面接なども受けて真剣に就職するため努力をしました。そのときはWeb系のエンジニアとして「一つのプロジェクトやアプリに深く携わりたい!」「帰属意識を大切にしたい!」という信念から実務経験のない状態でWeb系の自社内開発での志望をしておりましたが、力が及びませんでした...
今後の展望
わたしはこれから他業種で仕事をしながら「もう一度、望むようなスタイルでエンジニアとして就職をしたい!」という思いから一からやり直すことを決意します!
もともとWeb系に絞っていたことなどはエンジニアスクールの影響などもあり、企業様とお話をしたり、就職活動をしていきながら色々と調べているうちに、本当にやりたいことを探そう!と思うようになり新しくチャレンジすることを探します。AIエンジニア
将来的な目標としてAIエンジニアを目指そうと思っております。
そのためには長期に及ぶ勉強とオンラインでのCS関連学位の得るなどを考えているため、AIエンジニアに関しては長期的な展望になります。Pythonエンジニアとして
近い将来での目標としてこれまでのPHPやRubyなどとは異なるPythonの力をつけていきたいと考えております。
AIエンジニアとして現状一番適した言語であることとこれまでのサーバーサイドでのアプリ制作の経験などが活かされると考えたからです。以前に経験はあるもののPHPやRubyほどではないため、現在は基本構文から取り掛かり、最終的に個人アプリの制作なども行い、今後の就職に活かしていきたいと考えております!