- 投稿日:2020-02-24T23:43:28+09:00
AWS CLI インストール(Windows)
内容
Windows PCにAWS CLIをインストールして使用可能にするまでを記載。
手順
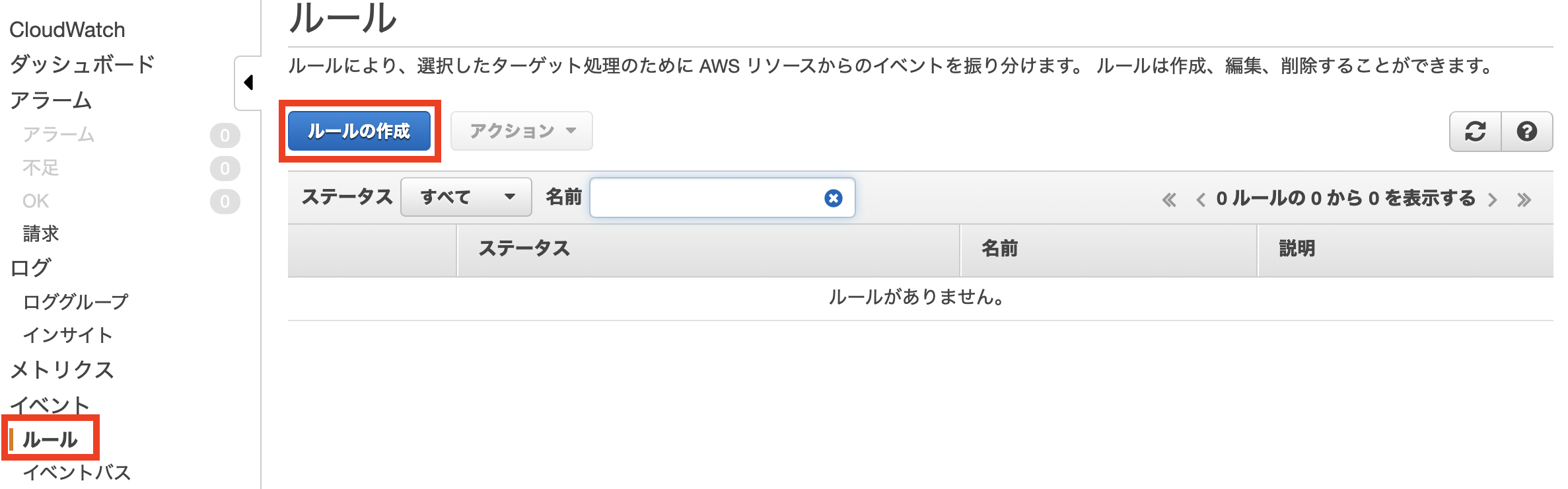
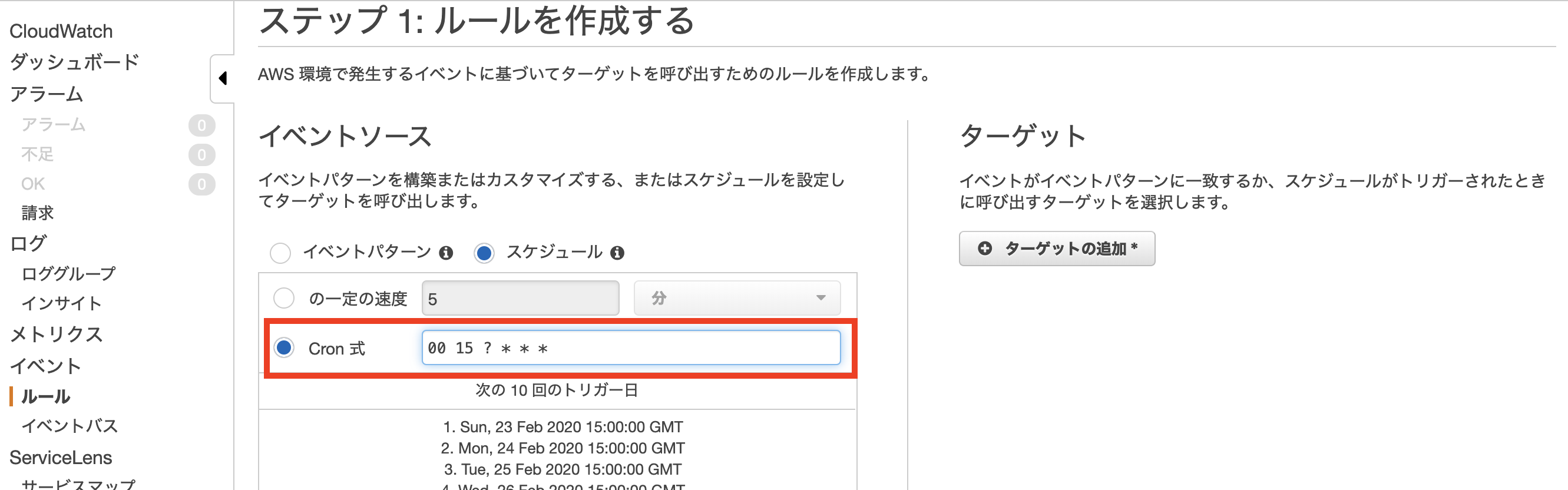
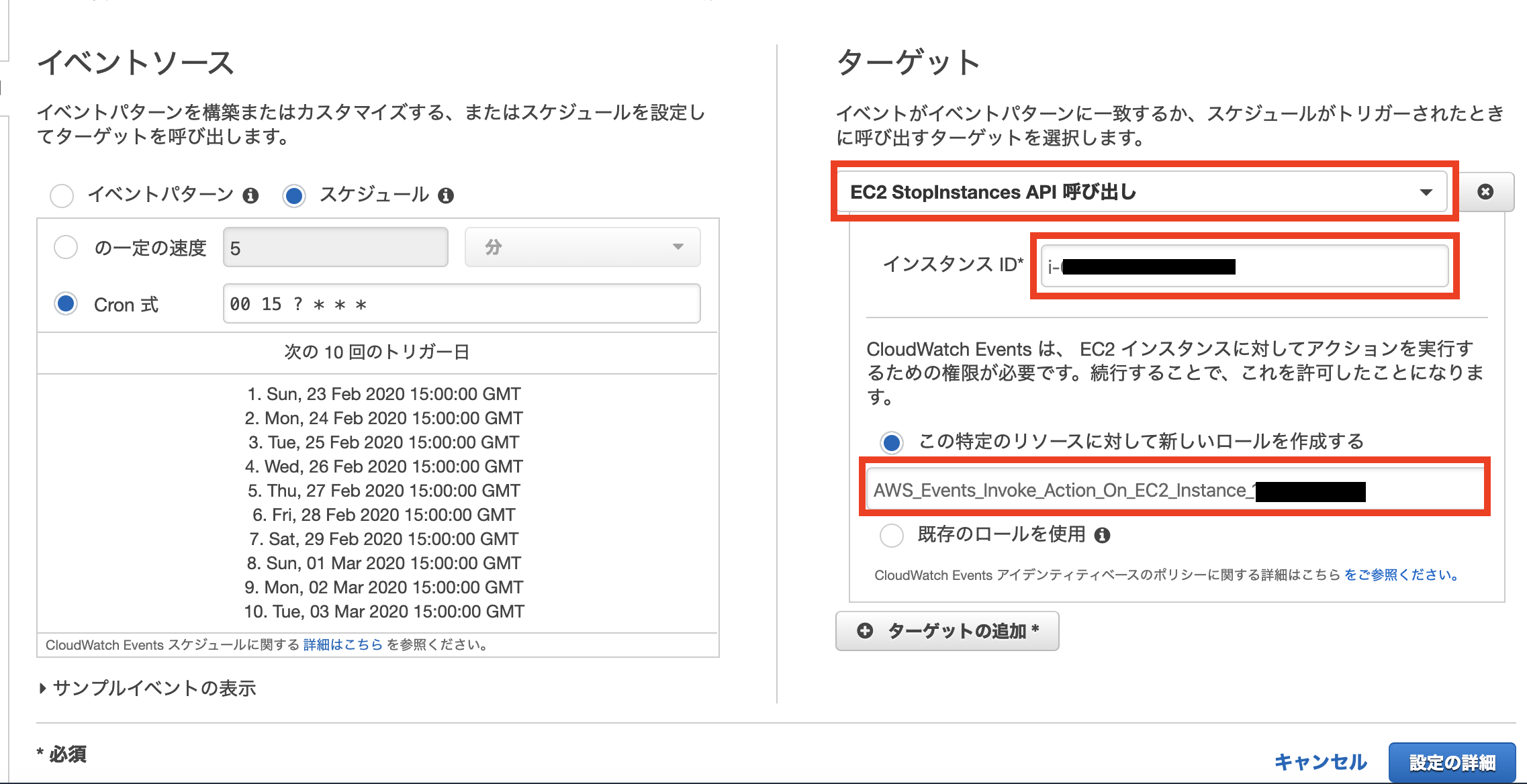
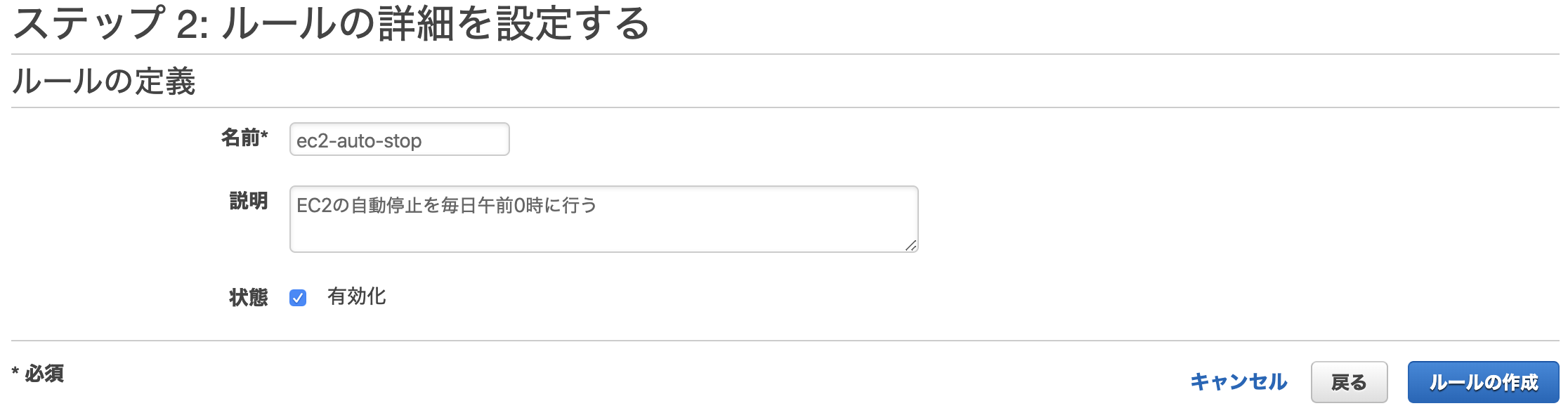
AWS CLIインストール
AWS公式よりインストーラをダウンロード
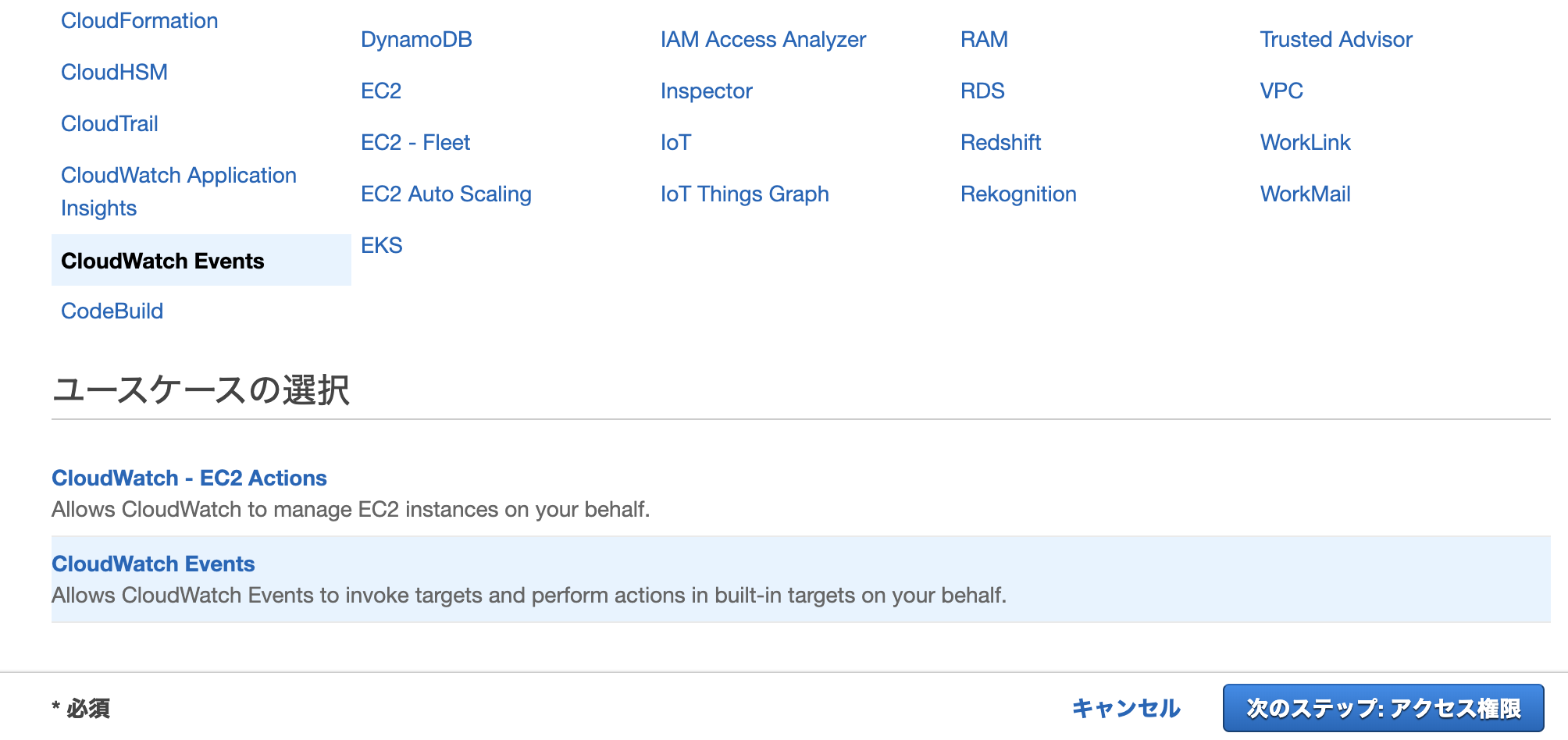
AWS CLI のインストールより、AWS CLI バージョン 1またはAWS CLI バージョン 2のいずれかを選択し、インストーラをダウンロードします。
AWS CLIバージョン1-Windows 64bitの場合は"AWSCLI64PY3.msi"がダウンロードされます。AWS CLIのインストール
先ほどダウンロードしたインストーラ"AWSCLI64PY3.msi"を実行してただひたすらポチポチします。
CLI インストールの確認
コマンドプロンプトを起動し、"aws --version"を入力します。
以下のように返ってくれば問題なくインストールされていることを確認できます。
C:> aws --version
aws-cli/1.16.273 Python/3.7.3 Windows/10 botocore/1.13.0設定
アクセスキー/シークレットキーの取得
※既に取得済みの場合はこの作業は不要。
AWSコンソールへログインし、[セキュリティ、ID、およびコンプライアンス]⇒[IAM]を選択します。
IAMのダッシュボードへ移動後、左側より[アクセス管理]⇒[ユーザー]を選択します。
対象のユーザーを選択します。今回であればTEST_Aになります。
対象ユーザーの概要画面より[認証情報タブ]⇒[アクセスキー]⇒[アクセスキーの作成]を選択します。
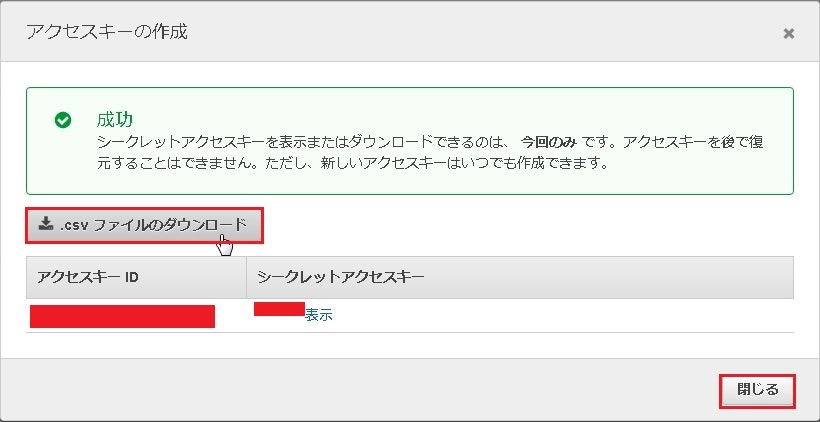
問題なく作成されると✓成功と表示されるので、[.csvファイルのダウンロード]を選択し、閉じるを選択します。
※アクセスキーIDとシークレットアクセスキーが記載されているcsvは無くさないよう任意の場所へ保存します。
CLIの設定
コマンドプロンプトを起動して、"aws configure"と入力します。
その後、先ほど作成したアクセスキーIDとシークレットアクセスキー、リージョン、C:\>aws configure AWS Access Key ID [None]:アクセスキーIDを入力 AWS Secret Access Key [None]:シークレットアクセスキーを入力 Default region name [None]:使用するリージョンを入力 ※東京リージョンであればap-northeast-1を入力します。 Default output format [None]:"text","JSON","table"いずれかを入力以上でAWS CLIの初期設定が完了となります。
CLIが使用できるかの確認
AWS CLIのインストールと初期設定だけでは本当に使えるのかが分からないので取り敢えず、以下のどれかを実行して確認してみてください。
IAMユーザの確認C:\>aws iam list-users { "Users":[ { ...ここに作成済みのユーザが表示されます。 } ] }S3 バケットの確認
C:\>aws s3 ls 作成済みのS3 バケットが表示されます。以上でCLIが使用できることを確認できます。




- 投稿日:2020-02-24T22:28:24+09:00
AWS認定SAA(ソリューションアーキテクトアソシエイト)に合格できたお話を忘れる前に書いてみようと思う
AWS認定合格したお話
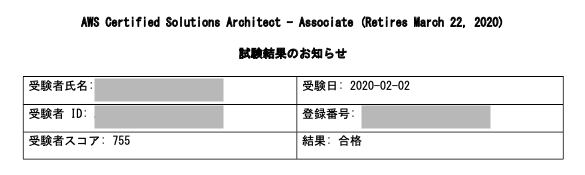
2020年2月にAWS認定SAA 合格しました。
私の受けたものは バージョンC01 になりますが、2020/02/23からは新バージョン C02 になりました。
この記事はC01に滑り込んだ人の感想です。私は社内の年度目標に資格取得を書いたのもあって、滑り込む形で受けてきました。
結果
試験は100-1000のスコアで、合格に必要な最低スコアは720
ということで結構ギリギリなスコアでした。
ギリギリなスコアですが、 全セクション十分な知識を有すると 評価されているため
全体的に平均ラインを少し上回っているということでしょうか。経験
20代後半
AWSは業務で半年ほど利用したことがある(2018年度)
他IT資格保有 なし
仕事は開発からスタート、現在はインフラ使った教材と時間
勉強日数:6日
参考書:一夜漬け AWS認定ソリューションアーキテクト アソシエイト 直前対策テキスト
Udemy:これだけでOK! AWS 認定ソリューションアーキテクト – アソシエイト試験突破講座(初心者向け22時間完全コース) ※ほぼ模試のみ使用日) 参考書購入
月) 参考書 3h
火) 参考書 1h
水) 参考書 3h + 試験申し込み (参考書1周目)
木) 参考書 4h (参考書2周目)
金) 参考書 1h + Udemy 模試 1h
土) 参考書 1h + Udemy 模試 3h
日) 参考書 1h + Udemy 模試 1h + 受験参考書に関して
この参考書を選んだ理由は、当時(2020/01)ある参考書の中では一番新しかったため。
「新バージョンの情報も掲載」と記載されていたのはこの本だけでした。この本の特徴としては、AWSサービス単位で説明が書いてるのではなく、試験のセクションごとにまとめられていることです。
例えば、S3の説明が一括で書かれているのではなく、
信頼性をまとめた章で、CRR(クロスリージョンレプリケーション)の話
パフォーマンスをまとめた章で、Storage Gatewayを利用したパフォーマンス、拡張性などの話
という、試験のセクションに沿った形でまとめられています。欠点としては、索引がないため、S3ってどこにあったっけ?ってなると、探すのに苦労します。
見つけても、他になかったっけ?という疑問からまたページ漁ったりしますからね..
なので私は、色付き付箋で印付けをしてました。(ちょっと写真だと色がわかりにくいかもしれませんが)
個人的には、「8時間集中」、「一夜漬け」と書いているだけあって、試験で問われることをうまくまとめ上げられていたと思います。短時間で合格目指すなら、ひとまずこれでいいと思いました。
一番試験対策としてよかったと思っているのは、ストレージ選定に関する問題で「スループットといった場合はHDDタイプ」、「IOPSといった場合はSSD」とあったことです。
こうしたテクニックは、時間や脳を使うのを抑える事ができるので、個人的にgoodなところでした。Udemyに関して
軽く見てみましたが、初学者向けのコースで、AWSサービスとネットワークの基礎などを確認ができると思います。
ただ私は模試しか使いませんでした。
AWS SAAのコースは、他にも模試だけのもありますし、それでも良かったのかも。
単純に受講生が多かったのと、セールで目についたので選択しました。
模試は1問解いて解説確認、とできたので私にこのスタイルはあっていました。ベンダー系の資格全般に言えるかもしれませんが、模試(手に入るなら過去問)を解いて安心していたほうがいいと思います。
そっくりなものは出ませんが、似ている問題は多かったです。
Udemyはセールも多いので、セールで買っておくのもいいと思います。私もセールで買いました。試験後の感想
DynamoDBに関する問題が多かった
Udemyでやった模試が本番問題と似ている
おかしい日本語はなかった
すぐに結果でるから思わずガッツポーズした勉強振り返り
業務での利用経験はありましたが、マネージドサービスとして利用するよりは、単にEC2インスタンスにアプリをインストールした使い方でした。
本で記載のあるサービスの6割くらいは単語知ってて、だいたいこんなサービスだったなーというのはわかっていましたが、はじめましてーのサービスも結構ありました。実際に勉強してみて、業務的に触ったサービスでも全然理解がない部分も多かったです。
- DB周り(RDS, DynamoDB, RedShift)
- EBSのボリュームタイプ(gp2)
- S3のストレージクラス(S3標準-IA)
また、私がAWSを最後に触ったのは2018年だったので、アップデートされた内容も多いと感じました。
ALBの説明で、下記は衝撃でした。
「ALBと対になるサーバー側の接続相手としてコンテナが使われることが多い」
つまりALB->ECSですよね、僕の頭にあったのはALB->EC2接続だったので、2年で全然変わってるじゃんって思いました。
ガンガン新しいものが出てきて、技術ってどんどんアップデートされているんですね。
正直勉強してよかったと思ってます。次は仕事で関わりたい。次の目標
最初に書きましたが、IT系の保有資格がAWS SAA以外にはないんですよね。
車とバイク(大自二)はあるんですけど基本的に資格って受けたことないんです..はい
こうしたベンダー系の資格を受けてみて、やっぱり合格することでの達成感を得ました(今更かもですが
前からWantedlyに登録してたのですが、資格を更新しただけでオファーを何通かいただきました。やっぱ資格って強い。
今年の目標としてCCNA/CCNP/LPIC1,2/基本情報/応用情報 は取得したいと強く思いましたね。
資格は受験料、参考書共に結構お金かかりますが、来年か再来年には給料上げていけるエンジニア目指してます。実は
CCNAの勉強を初めているのですが、ボリュームがSAAの4倍くらいありますね....oh..no..
これも1週間でやり遂げたいと思いましたが、無理だとわかりました。
3月中に取りたいです。受かっても落ちても別で記事を書きます!
最後まで読んでくださりありがとうございました!それでは!


- 投稿日:2020-02-24T22:13:40+09:00
AWS LambdaでPython外部ライブラリのLayerを作る前に
結論
先人によって既に作られてないか、いったん確認してみましょう。
keithrozario/Klayers使い方
なぜかAWS公式でLayerが提供されていないライブラリ、pandasを例として使います。
(Numpy + Scipyがあるなら、pandasもあってくれていい気がしています)0. 前準備
AWS Lambdaにアクセスして、[関数の作成]を押し、適当な名前の関数を作ります。
「ランタイム」はPython3.8を選びます。「アクセス権限」はノータッチでOKです。1. pandasをインポートし、テストを作成
import pandasを追加し、[保存]を押します。
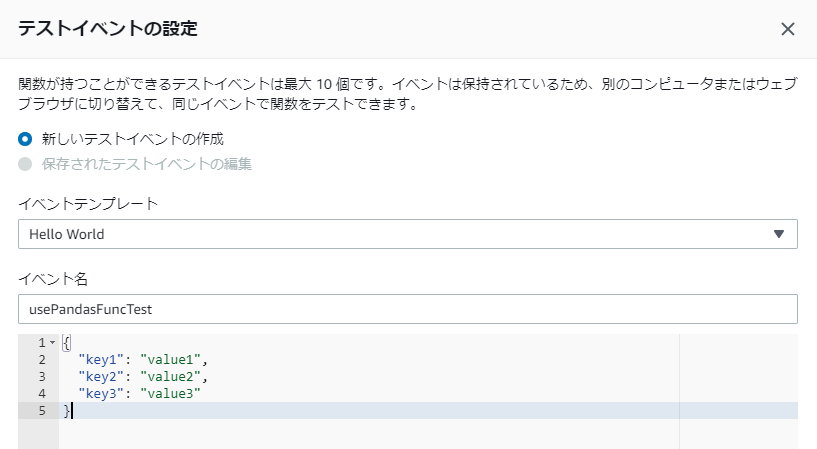
[テスト]を押し、「イベント名」に適当な名前を入れます。
下のJSONは特にいじらなくてOKです。
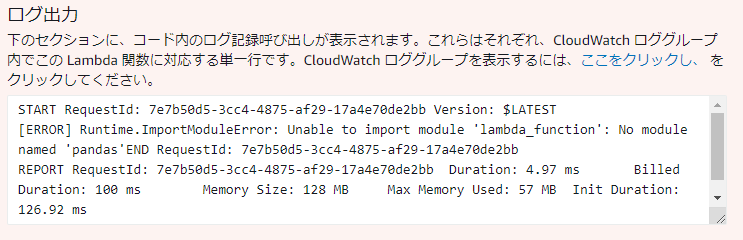
この時点でもう一度[テスト]を押すと失敗します。pandasが無いよと言われています。
それはそうという感じですね。
2. pandasのLayerのARNを調べ、Layerを追加
必要な情報は以下の2つです。
- Lambda実行環境のPythonのバージョン
- Lambda関数が所属しているリージョン
いま、自分の実行環境は
Python3.8でリージョンはus-east-1です。(リージョンが異なる場合は、適宜自分のものに読み替えてください。)
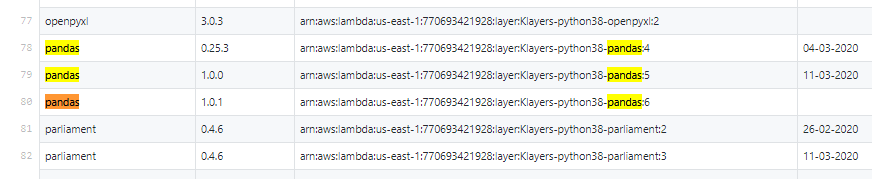
keithrozario/Klayersにアクセスし、[deployments] -> [python3.8] -> [arns] -> [us-east-1.csv]と辿ります。
pandas があるので、該当行のARNをコピーします。pandasのように、複数バージョンのLayerが提供されているライブラリもあります。
ここではpandas1.0.1を選択しました。ほかのバージョンでも特に問題ないです。
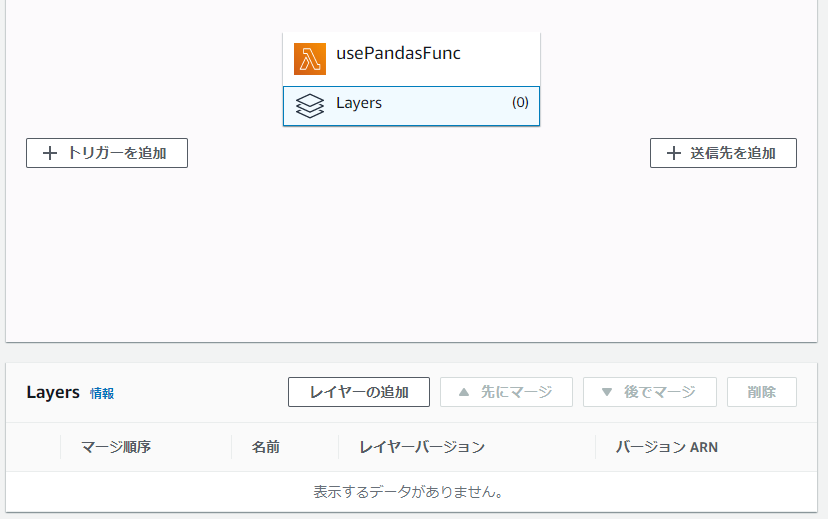
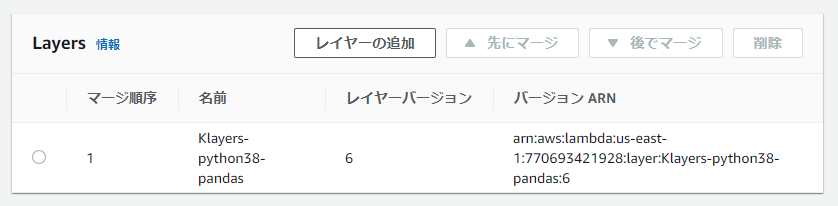
Lambdaに戻り、「Designer」の中の[Layers]を選択します。下に「Layers」というカードが出てくるので、[Layerの追加]を押します。
[レイヤーバージョン ARN を提供]を選択し、「レイヤーバージョン ARN」に先ほどのARNを貼り付けます。
[追加]を押して関数の設定ページに戻ります。
きちんと追加されていれば、「Layer」に反映されます。
[保存]を押します。
3. 確認
さて、これでレイヤーの追加ができたので、pandasを使えるようになっているはずです。
先ほど設定したテストを実行してみましょう。
pandasがインポートされている状態で、関数が正常終了したことが分かります。
Layerが用意されているライブラリ一覧
- aiobotocore
- aiohttp
- ansible
- aws-lambda-powertools (Python3.8 only)
- arrow
- aws-xray-sdk
- bcrypt
- beautifulsoup4
- boltons
- boto3
- construct
- dynamodb-encryption-sdk (Python3.8 only)
- elasticsearch
- envelopes
- ffmpeg-python
- flashtext
- google-auth
- google-auth-oauthlib
- grpcio
- gspread
- idna
- itsdangerous
- kafka-python
- nltk
- numpy
- opencv-python-headless
- openpyxl
- pandas
- parliament (Python3.8 only)
- Pillow
- pulp
- pycryptodome (Python3.8 only)
- PyJWT
- pymongo
- PyMUPDF
- PyMySQL
- PyNaCl
- pyOpenSSL
- pyparsing
- pyqldb
- pytesseract
- python-docx
- python-Levenshtein
- pytz
- PyYAML
- reportlab (Python3.8 only)
- requests
- simplejson
- slackclient
- spacy
- SQLAlchemy
- textdistance
- tinydb
- tldextract
- twilio
終わりに
OS依存の関数があったりすると、Lambdaの実行環境と同じOSでzipを作らなければならないのでちょっと面倒です。
外部ライブラリをサクッとLambdaで使いたいだけなら、ありがたく先人が開いてくれた道を通らせていただきましょう。Lambdaで使える他の言語で、類似のgithubリポジトリ等があれば教えていただければ幸いです。
(ざっと探しましたが見つかりませんでした)



- 投稿日:2020-02-24T21:09:36+09:00
AWSで証明書を発行してみた
はじめに
個人開発で証明書が必要になったのでACM(AWS Certificate Manager)で証明書を作成してみた
手順
①ドメインの取得
Route53コンソールのナビゲーションペインからドメイン > 登録済みドメインを開く。
「ドメインの登録」をクリック
使用したいドメインを選択し「続行」をクリック
Who-is情報を入力し「続行」をクリック
入力内容を確認し、ページ下部の「AWS ドメイン名の登録契約を読んで同意します」にチェックをつけて「注文を完了」をクリック
しばらくすると、登録したメールアドレスにメールが届くので開いてリンクをクリックする
自分の場合は2通メールが届きましたが、2通目の英語のメールの方が本命でした。
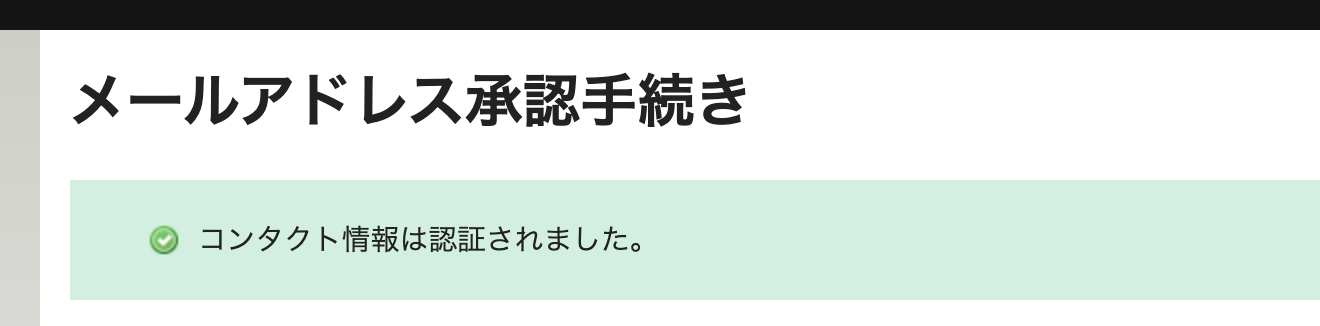
メールを開き、真ん中の長いリンクをクリックしてverificationを完了させる
awsっぽくない完了画面が表示されて一瞬ドキッとするが、これでドメイン取得の手続きが完了
念の為ナビゲーションペインの「登録済みドメイン」を確認し、ドメインが利用可能になっていることを確認
②証明書の登録
Certificate Managerコンソールを開く
左の「証明書のプロビジョニング」を選択
「パブリック証明書のリクエスト」を選択し、「証明書のリクエスト」をクリック
取得したドメインを入力し、「次へ」をクリック
DNSの検証を選択し、「次へ」をクリック
必要に応じてタグを指定し、「確認」をクリック
入力内容を確認し、「確定とリクエスト」をクリック
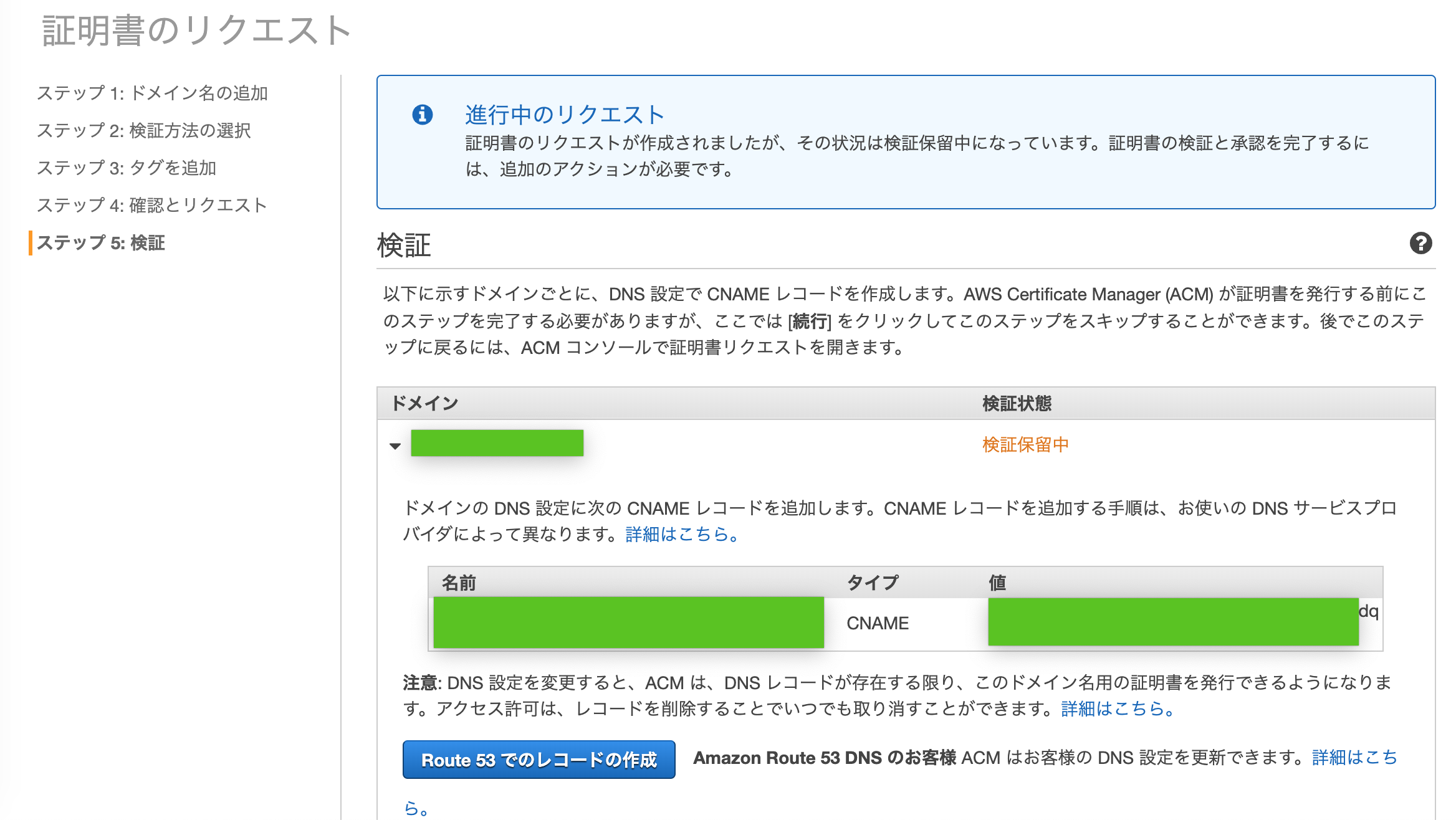
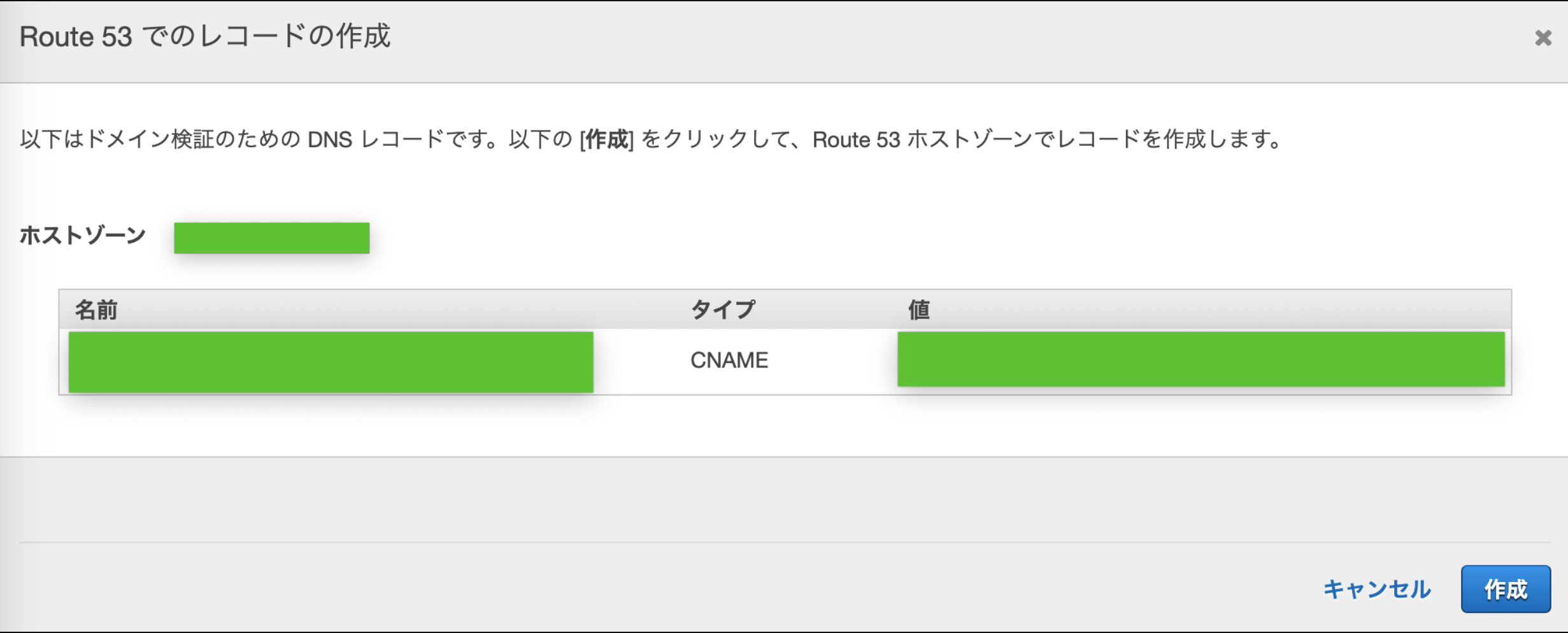
DNSレコードの登録が求められるので「Route53でのレコードの作成」をクリック
「作成」をクリック
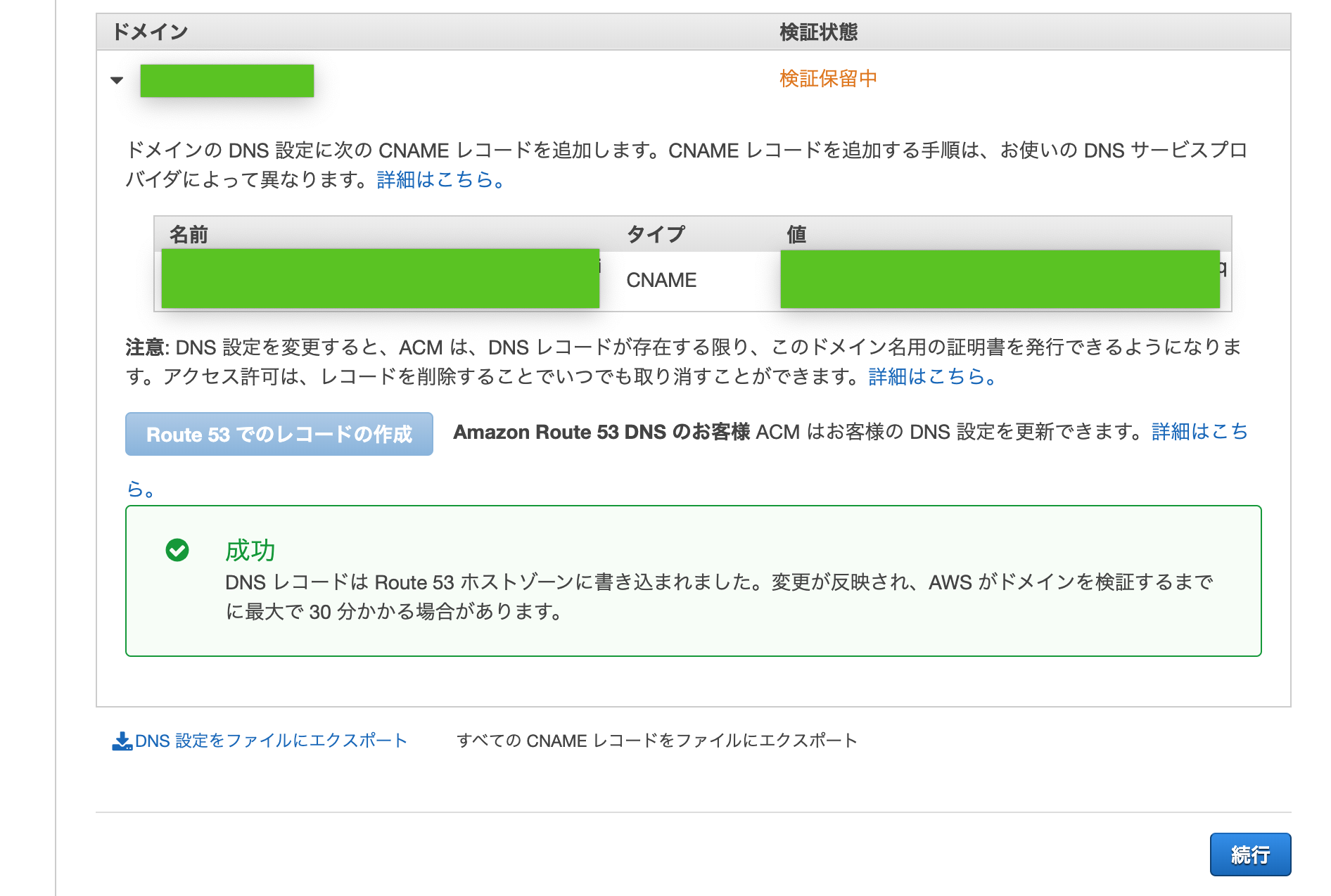
成功が表示されたことを確認し、「続行」をクリック
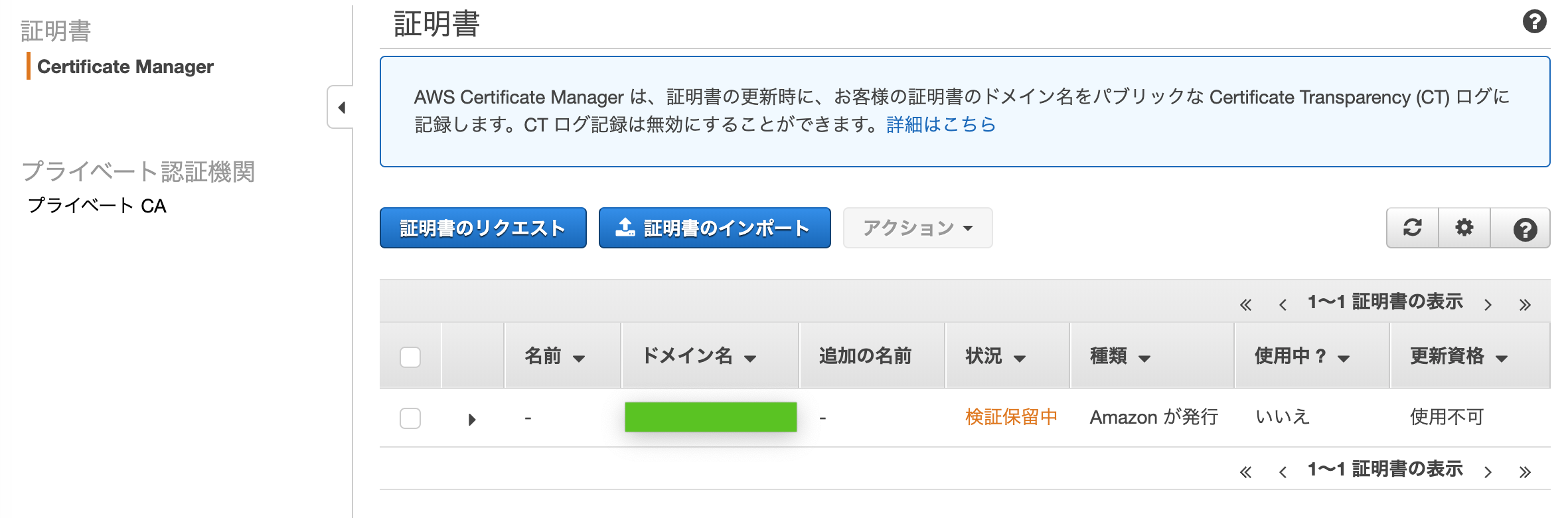
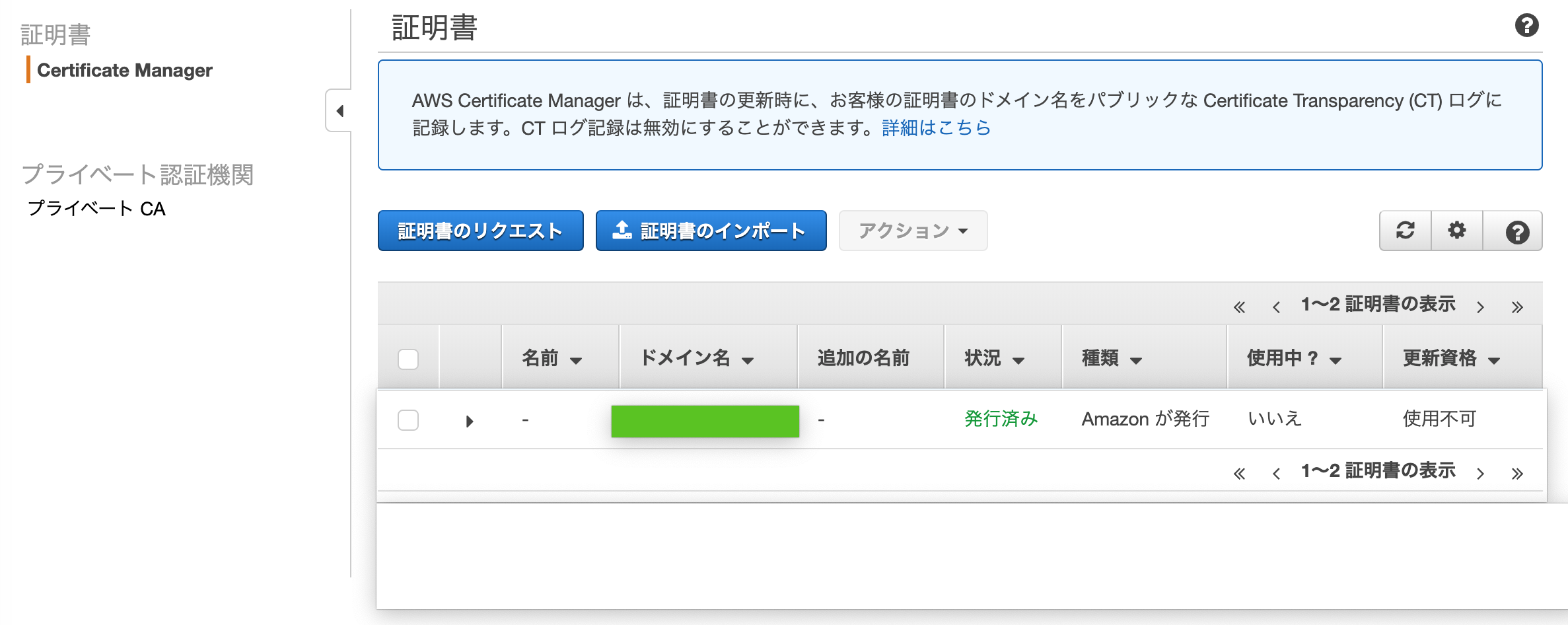
Certificate Managerコンソール内ナビゲーションペインの証明書 > Certificate Managerでステータスが「検証保留中」から「発行済み」になるまでしばらく待つ(10分くらい?)
↓
これで証明書が使える







- 投稿日:2020-02-24T20:27:09+09:00
【EC2】Linuxを触れる程度のエンジニアが唐突にAWS界に放り込まれたときの横文字ガイド
EC2
AWS版VPS。
普通にSSHして、環境構築して使うコンピュータRegion/リージョン
国レベルのAWSの拠点の分け方。
国外のアクセスからの速度を気にする必要があるなら検討する。
関係ないなら、とりあえず東京リージョンAZ/アベイラビリティーゾーン
インスタンスをデプロイするDC(データセンター)を選ぶ。物理的な分け方
複数のAZを選択しておくと、障害が起きてDCが落ちたときにパケットが残りのAZにあるインスタンスへ回される。VPC/仮想プライベートクラウド
AZと異なりこちらは論理的な区分。AWS内で自分専用のネットワークを構築するのに必要。EC2を作成しても、VPCを定義しないと設置できない。
また、インターネットゲートウェイ(WAN)を設置しないとインターネットに出れない。サブネット
VPC内でサブネットを定義できる。
セキュリティグループ
ファイアウォール
EC2以外にもロードバランサーなどにも割り当てられる。ELB/ElasticLoadBalancer
ロードバランサー。EC2などのインスタンスはプライベートサブネット(WAN未割り当て)に配置して、ロードバランサーはパブリックサブネット(WAN割り当て済み)に配置するのが通常のやり方。
ターゲットグループ
ロードバランサーに対する、転送候補先をまとめたもの。
ロードバランスするときに、ターゲットグループ内のインスタンスに対しアルゴリズムに応じて転送される。リスナー
ロードバランサーの受信ポート。ルールを設定でき、URLのパスに応じた転送先を指定できる。
- 投稿日:2020-02-24T19:13:27+09:00
【Rails5.2】credentials.yml.encでmaster key設定
初めに
設定方法は様々あるが、今回はVSCodeで編集出来る様にして設定を行う。
ターミナルでもいいのだが、インデントが分かりにくく、無駄な時間を費やした経験があるからです。VSCodeでcredentialsを編集できるようにする。
1,VSCodeで、「Command + Shift + P」を同時に押してコマンドパレットを開く。
2,「shell」と入力
3,「PATH内に'code'コマンドをインストールします」という項目が表示されるので、それをクリック。
上記の操作でターミナルから「code」と打つことでVSCodeを起動できるようになる。編集の仕方
ターミナル$ EDITOR='code --wait' rails credentials:edit「 rails credentials:edit」が、credentialsファイルを編集するためのコマンド。
使用するエディタにcodeすなわち今回はVSCodeを指定。
下記の様に復号化された内容が表示される。credentilals.yml# aws: # access_key_id: 123 # secret_access_key: 345 # Used as the base secret for all MessageVerifiers in Rails, including the one protecting cookies. secret_key_base: dcb9317dcd2d42d9e045a2cd00c20df0b8109・・・そして、下記の様に編集
credentilals.ymlaws: access_key_id: (ここにはダウンロードしたAccess key IDを入力) secret_access_key: (ここにはダウンロードしたSecret access keyを入力) # Used as the base secret for all MessageVerifiers in Rails, including the one protecting cookies. secret_key_base: dcb9317dcd2d42d9e045a2cd00c20df0b8109・・・値の確認
ターミナル$ rails c $ Rails.application.credentials[:secret_key_base] $ Rails.application.credentials[:aws][:access_key_id]これで、先ほど見た設定の中身が表示される。
CarrierWaveの設定
CarrierWavenに「aws_access_key_id」と「aws_secret_access_key」を設定。
carrierwave.rbCarrierWave.configure do |config| config.fog_credentials = { provider: 'AWS', aws_access_key_id: Rails.application.credentials[:aws][:access_key_id], aws_secret_access_key: Rails.application.credentials[:aws][:secret_access_key], region: 'ap-northeast-1' } endmaster keyがプッシュされない様に.gitignoreに記載
これで設定OK。
これでローカル環境の設定は完了。
あとは本番環境にも同じ設定をしたら終了。.gitignore# Ignore master key for decrypting credentials and more. /config/master.key本番環境の環境変数にマスターキーをセットする
本番環境で環境変数を使用するために、/etc/environmentsファイルで設定を行いため、sshで本番環境にログインする。
ターミナル$ ssh -i ~/.ssh/(pemファイル名) ec2-user@(EC2のElastic IP)リモートのターミナル$ [ec2-user]$ sudo vim /etc/environmentここで「i」キーを押して編集。
/etc/environment(前略) RAILS_MASTER_KEY='master.keyの値'これで設定終了。exit抜ける。
EC2を一回ログインし直して、下記のコマンドで確認して設定されていればOK。/etc/environment(前略) [ec2-user]$ env | grep RAILS_MASTER_KEY
- 投稿日:2020-02-24T17:59:51+09:00
AWSのアカウント作った直後の状態からECS+Fargateでコンテナを起動する
超・初心者向け、AWSのアカウント作った直後の状態からECS+Fargateでコンテナを起動するまで。
最低限、AWSのマネジメントコンソールをちょこちょこでも触ったことがあるくらいが前提。全体の流れ。
1. EC2の起動
2. Dockerのインストール
3. セキュリティグループの設定
4. Tomcatの起動
5. CLIの設定
6. DockerコンテナのイメージをECRに登録
7. IAMポリシーとロールの設定
8. ECS on FargateでECRに登録したDockerコンテナのイメージを起動1. EC2の起動 ~ 2. Dockerのインストール
↓この辺の記事を参考にして、EC2でインスタンスを起動してDockerをインストールする
【Qiita】AWSのEC2でDockerを試してみる3. セキュリティグループの設定 ~ 4. DockerでTomcatの起動
↓この辺の記事を参考にして、DockerでTomcatを起動する。
【Qiita】Docker上でnginx+tomcat を構築してみる。当たり前だが、セキュリティグループでこの辺で使うポートを開放しておかないと通らない。
5. CLIの設定
さてDockerコンテナをレジストリに登録するぞ!と思ってもまだ早い。まずはCLIを使えるようにしておかないと、aws ecr のコマンドが実行できない。
今回は、AWS標準のAMIからEC2インスタンスを起動しているので、CLIはデフォルトでインストール済み。↓これを参考にしながら、初期設定を行う。IAMユーザの登録もこの中で説明されている。
【AWS公式】AWS CLI の設定6. DockerコンテナのイメージをECRに登録
↓を見ながら作ってきたDockerコンテナのイメージをECRにPUSHする。
【Qiita】AWS ECRにdockerイメージを登録する7. IAMポリシーとロールの設定
さて、いよいよECS on Fargateでデプロイだ!と思ったけどちょっと待って。
ECSを実行するためのIAMポリシーとロールを設定しないと、コンテナを起動することができないのである。
【AWS公式】Amazon ECS タスク実行 IAM ロール8. ECS on FargateでECRに登録したDockerコンテナのイメージを起動
↓この辺を参考にしながら、タスク定義→クラスタ作成→サービス作成をしてする。
【Qiita】Amazon Fargate でコンテナを動かすやったーこれで動くはずだ!と思ったら、ALBからコンテナへのヘルスチェックが上手く通らず、Bad Gatewayになってしまう。うーむ、よく分からない……。ここからもう少し改善をしてみたかったのだが……。
その他
Dockerのログ確認
試行錯誤しているうちに docker run してもコンテナが起動しない(正確には、おそらく起動後にexitしていたのだと思う)ことがあり、↓この辺をテキトーにやって調べたり直したりはした。
【Qiita】dockerでコンテナが立ち上がらないときやってみることタスク定義の削除
ECSのタスク定義を登録すると、簡単に消すことができなくなる。
↓これで消せる。厳密にはINACTIVEにして見えなくしているだけのようだ。完全に消し去ることはできなそう?
【Qiita】タスク定義の登録解除サービスディスカバリからのサービス名の削除
どうにも、サービスディスカバリに登録したサービスが上手く削除できず、次に同じサービス名でサービス起動しようと思うと重複エラーになってしまう。ちゃんと全部掃除しているはずなのだが、一覧の取得の仕方も分からず……
- 投稿日:2020-02-24T17:59:51+09:00
AWSのアカウント作った直後の状態からECS+FargateでTomcatのDockerコンテナを起動する
超・初心者向け、AWSのアカウント作った直後の状態からECS+FargateでTomcatのDockerコンテナを起動するまで。
最低限、AWSのマネジメントコンソールをちょこちょこでも触ったことがあるくらいが前提。全体の流れ。
1. EC2の起動
2. Dockerのインストール
3. セキュリティグループの設定
4. Tomcatの起動
5. CLIの設定
6. DockerコンテナのイメージをECRに登録
7. IAMポリシーとロールの設定
8. ECS on FargateでECRに登録したDockerコンテナのイメージを起動1. EC2の起動 ~ 2. Dockerのインストール
↓この辺の記事を参考にして、EC2でインスタンスを起動してDockerをインストールする
【Qiita】AWSのEC2でDockerを試してみるEC2へのTelnetログインどうやんねん、って人は↓これを読む。
【AWS公式】PuTTY を使用した Windows から Linux インスタンスへの接続3. セキュリティグループの設定 ~ 4. DockerでTomcatの起動
↓この辺の記事を参考にして、DockerでTomcatを起動する。
【Qiita】Docker上でnginx+tomcat を構築してみる。当たり前だが、セキュリティグループでこの辺で使うポートを開放しておかないと通らない。
5. CLIの設定
さてDockerコンテナをレジストリに登録するぞ!と思ってもまだ早い。まずはCLIを使えるようにしておかないと、aws ecr のコマンドが実行できない。
今回は、AWS標準のAMIからEC2インスタンスを起動しているので、CLIはデフォルトでインストール済み。↓これを参考にしながら、初期設定を行う。IAMユーザの登録もこの中で説明されている。
【AWS公式】AWS CLI の設定6. DockerコンテナのイメージをECRに登録
↓を見ながら作ってきたDockerコンテナのイメージをECRにPUSHする。
【Qiita】AWS ECRにdockerイメージを登録する7. IAMポリシーとロールの設定
さて、いよいよECS on Fargateでデプロイだ!と思ったけどちょっと待って。
ECSを実行するためのIAMポリシーとロールを設定しないと、コンテナを起動することができないのである。
【AWS公式】Amazon ECS タスク実行 IAM ロール8. ECS on FargateでECRに登録したDockerコンテナのイメージを起動
↓この辺を参考にしながら、タスク定義→クラスタ作成→サービス作成をする。
【Qiita】Amazon Fargate でコンテナを動かす気を付けなければいけないのは「ポートマッピングの設定」で、Tomcatは80番ポートを起動することができないので、ポートマッピングでコンテナ側のポートを8080にしないといけない。
やったーこれでTomcat起動したぞー!あとは、応用すれば色々起動できるようになるはず。
その他
Dockerのログ確認
試行錯誤しているうちに docker run してもコンテナが起動しない(正確には、おそらく起動後にexitしていたのだと思う)ことがあり、↓この辺をテキトーにやって調べたり直したりはした。
【Qiita】dockerでコンテナが立ち上がらないときやってみることDockerイメージの掃除
色々と docker run とかやってると、docker images したときに謎のイメージが増殖したりしているので、↓これを参考にキレイにした。別にVMなんだから後生大事にせず潰せばいいんだけどね…。
【Qiita】Dockerイメージとコンテナの削除方法タスク定義の削除
ECSのタスク定義を登録すると、簡単に消すことができなくなる。
↓これで消せる。厳密にはINACTIVEにして見えなくしているだけのようだ。完全に消し去ることはできなそう?
【Qiita】タスク定義の登録解除サービスディスカバリからのサービス名の削除
どうにも、サービスディスカバリに登録したサービスが上手く削除できず、次に同じサービス名でサービス起動しようと思うと重複エラーになってしまう。ちゃんと全部掃除しているはずなのだが、一覧の取得の仕方も分からず……
- 投稿日:2020-02-24T17:23:36+09:00
セッションタグによるAttribute-based access control (ABAC)を試してみた
セッションタグによるAttribute-based access control (ABAC)を試してみました。
https://docs.aws.amazon.com/ja_jp/IAM/latest/UserGuide/id_session-tags.html
https://docs.aws.amazon.com/ja_jp/IAM/latest/UserGuide/introduction_attribute-based-access-control.html必要なもの
AWSアカウント
手順
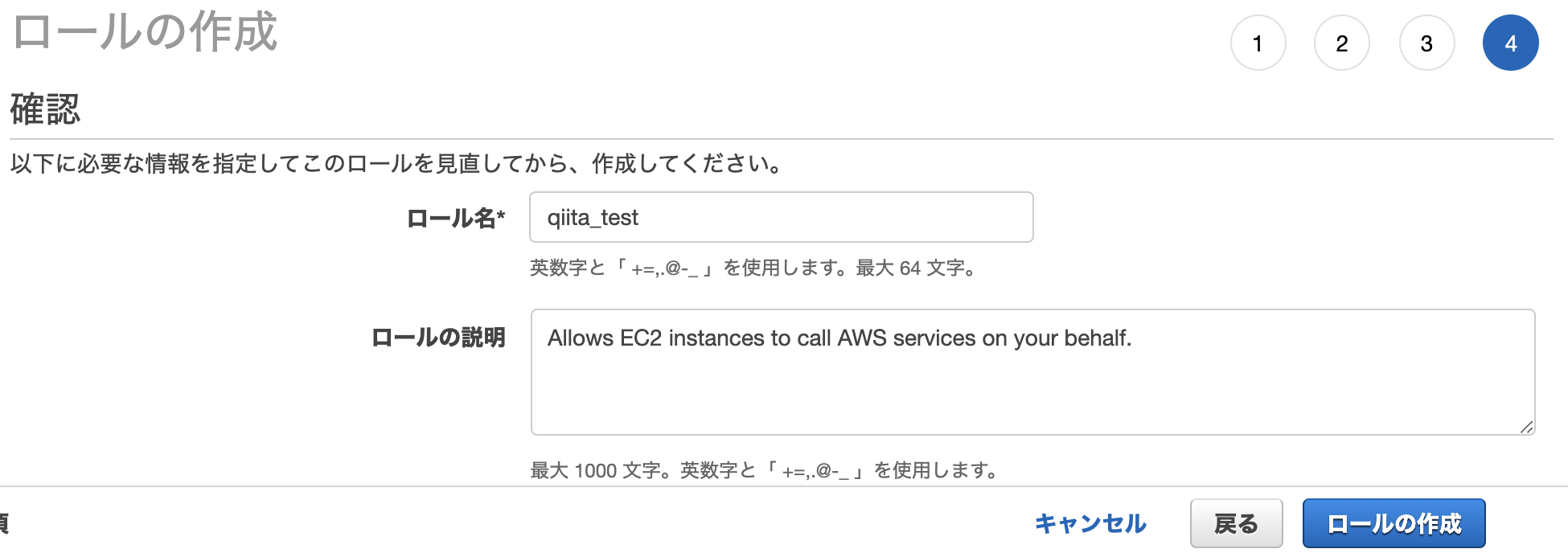
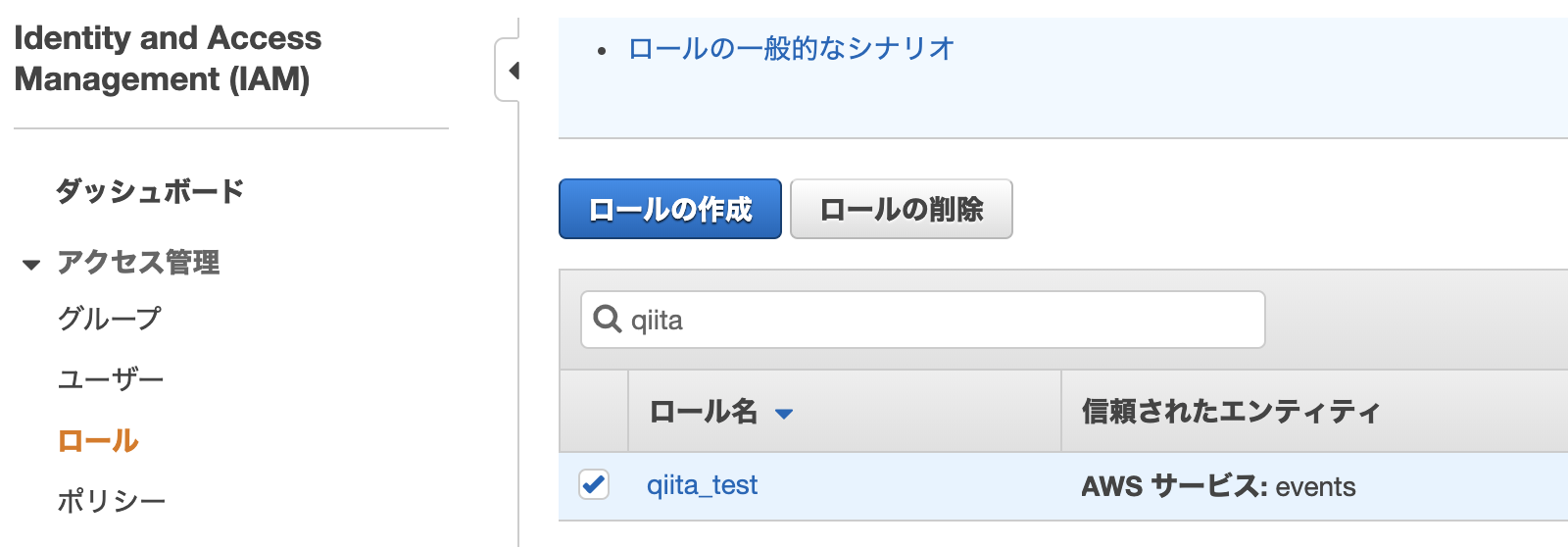
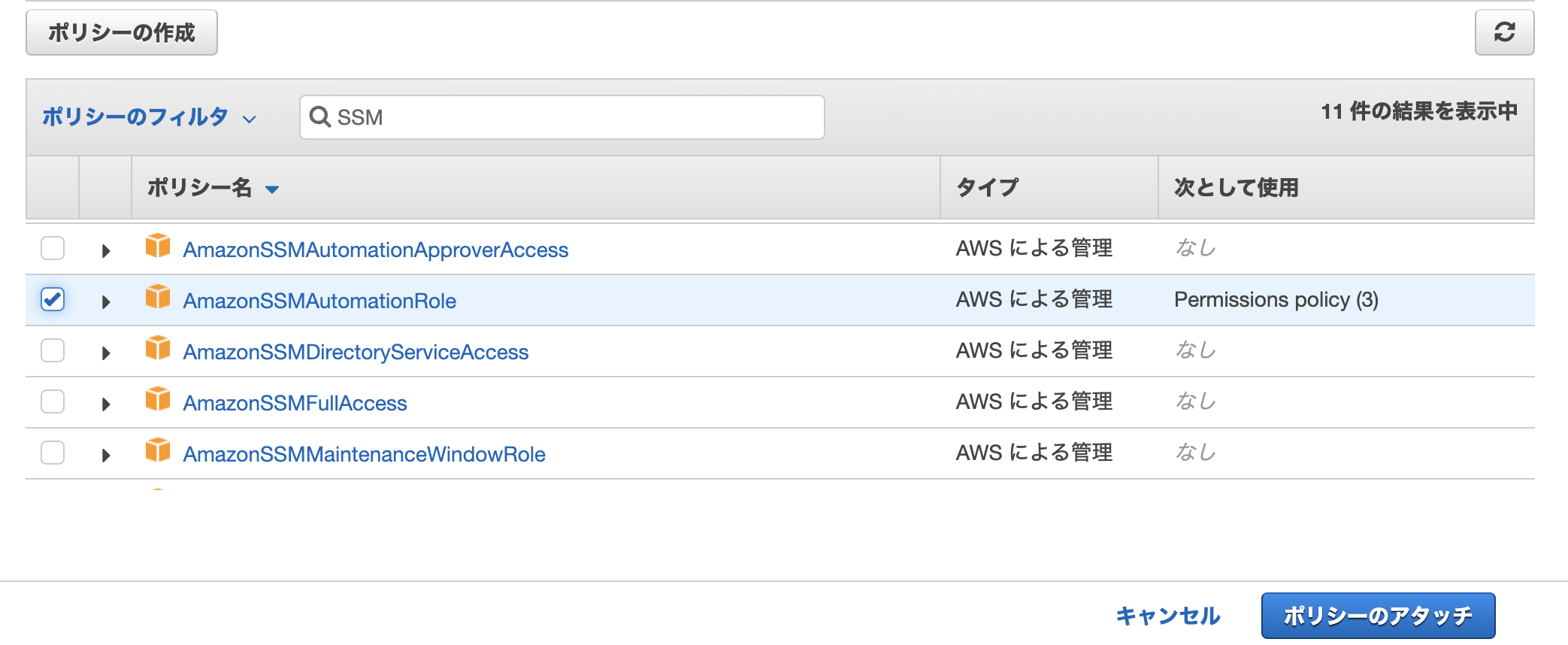
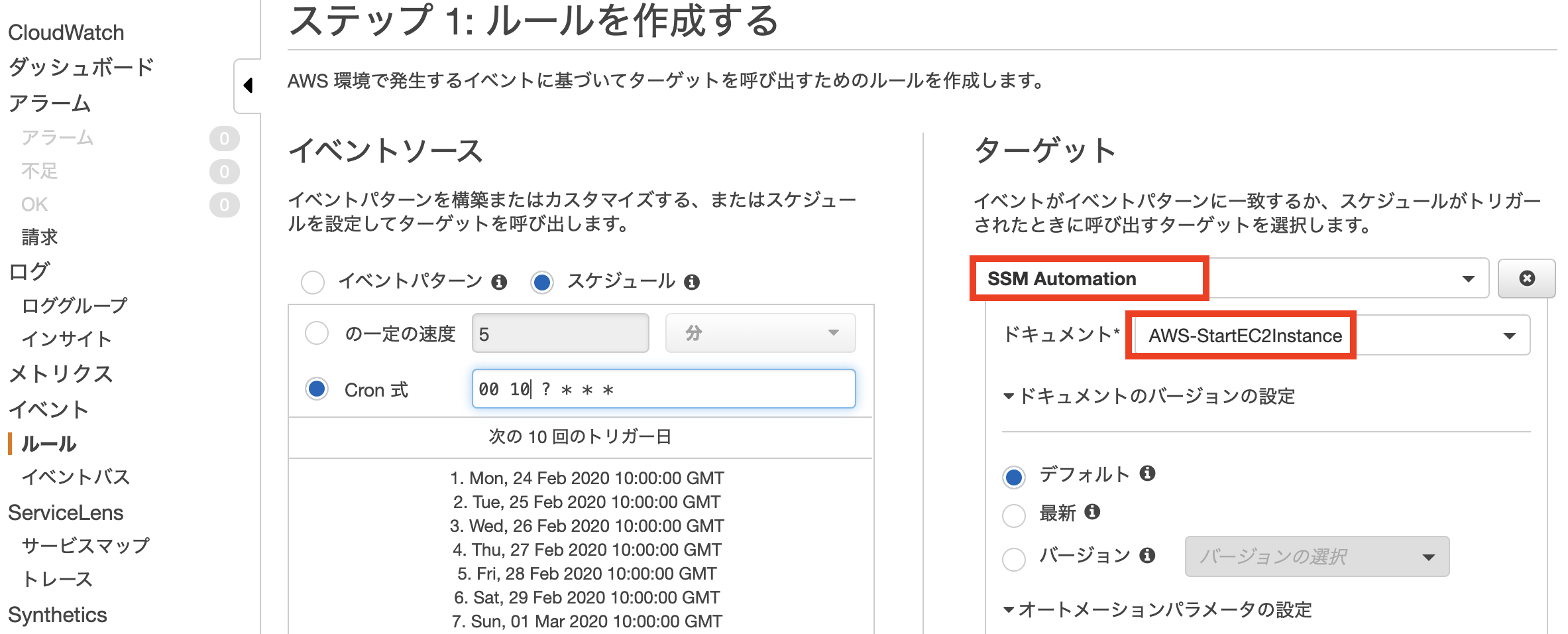
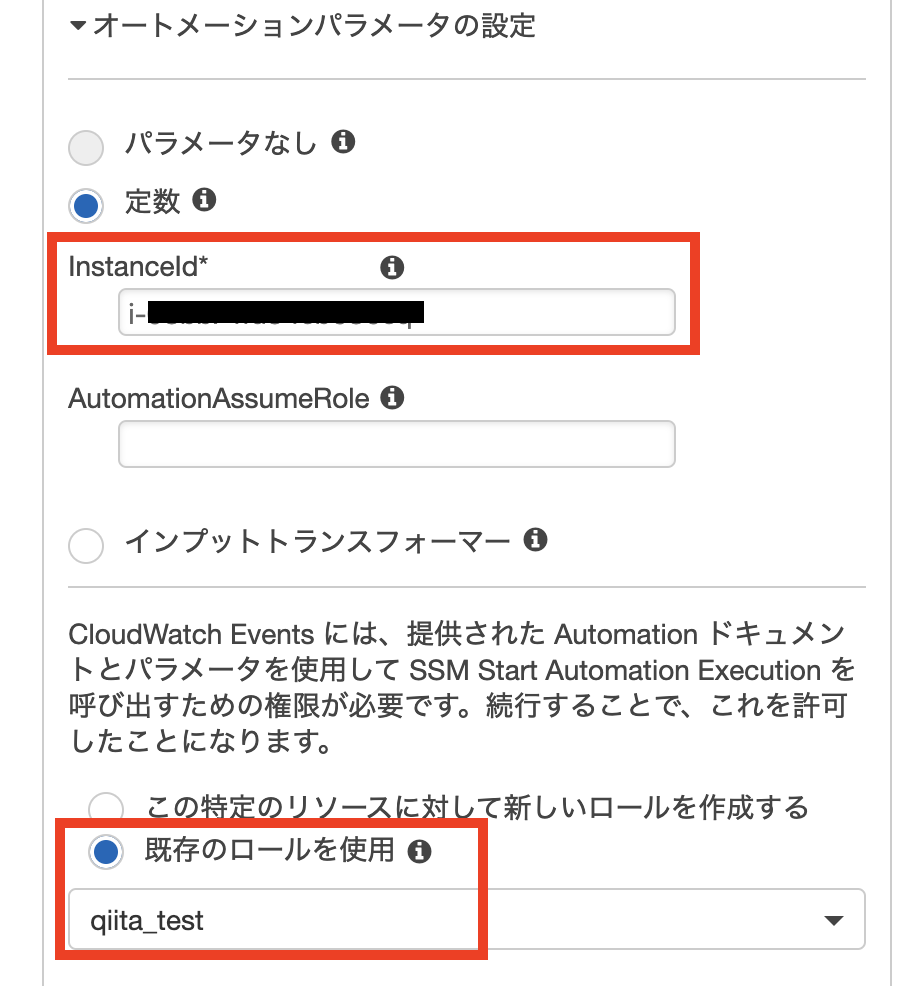
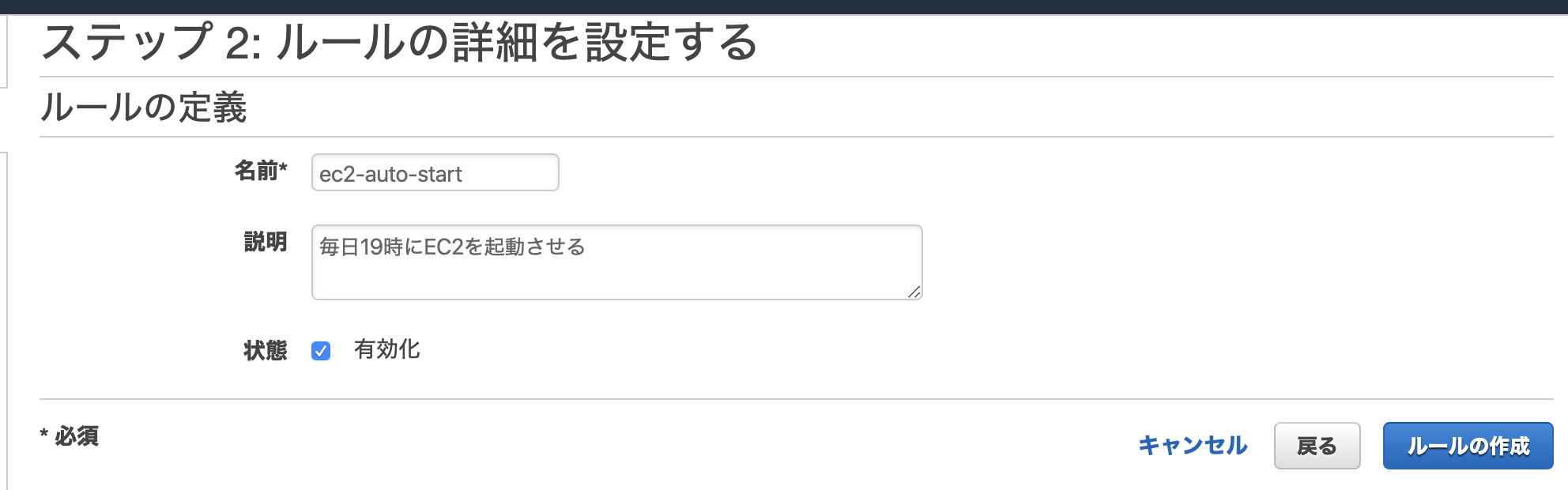
- Roleを作成する
- IAM Userを作成する
- Pamameter storeを作成する
- テスト結果
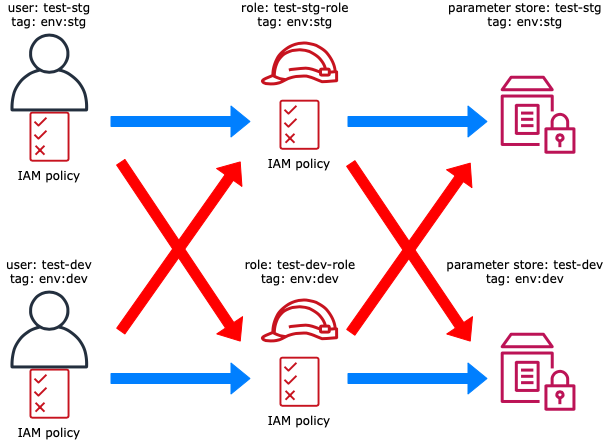
今回試した構成
- IAM UserのポリシーでIAM Userのタグ(aws:PrincipalTag)とIAMロールのタグ(aws:ResourceTag)を比較し、同じならロールへのスイッチを許可する
- IAM RoleのポリシーでIAM Roleのタグ(aws:PrincipalTag)とSSM Parameter storeのタグ(aws:ResourceTag)を比較し、同じならParameter storeへのアクセスを許可する。
1. Roleを作成する
Role
role policy tag test-stg-role test-role-policy env:stg test-dev-role test-role-policy env:dev Role用Policy
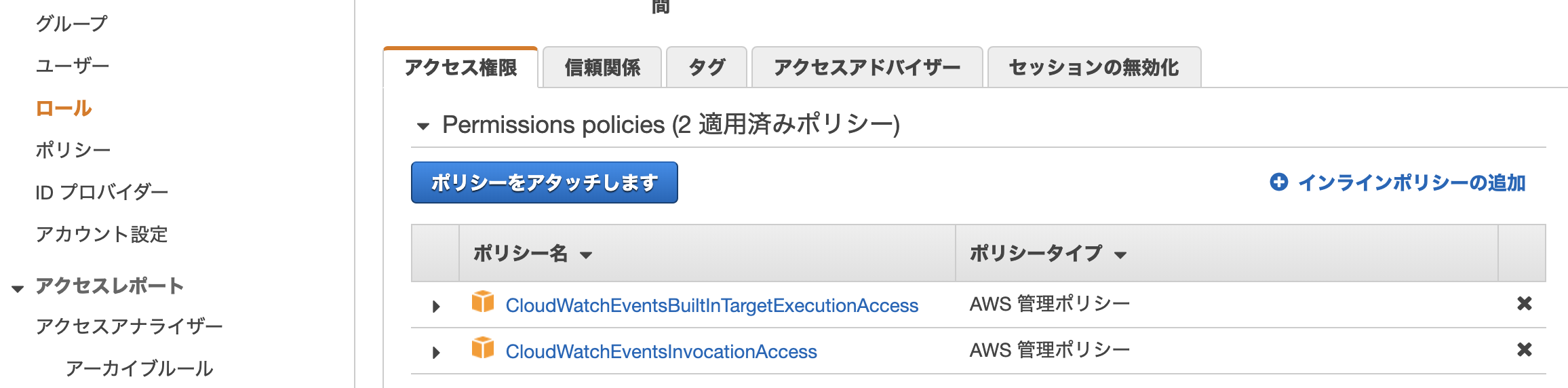
test-role-policy.json{ "Version": "2012-10-17", "Statement": [ { "Sid": "TestAccessSSM", "Effect": "Allow", "Action": [ "ssm:*" ], "Resource": "*", "Condition": { "StringEquals": { "aws:ResourceTag/env": "${aws:PrincipalTag/env}" } } } ] }Role用Trust relationship
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::XXXXXXXXXXXX:root" }, "Action": "sts:AssumeRole", "Condition": {} } ] }2. IAM Userを作成する
IAM User
role policy tag test-stg test-user-policy env:stg test-dev test-user-policy env:dev IAM User用Policy
test-user-policy.json{ "Version": "2012-10-17", "Statement": [ { "Sid": "TestAssumeRole", "Effect": "Allow", "Action": "sts:AssumeRole", "Resource": [ "arn:aws:iam::XXXXXXXXXXXX:role/test-stg-role", "arn:aws:iam::XXXXXXXXXXXX:role/test-dev-role" ], "Condition": { "StringEquals": { "aws:ResourceTag/env": "${aws:PrincipalTag/env}" } } } ] }3. Parameter storeを作成する
Parameter store
name tag value test-stg env:stg 任意 test-dev env:dev 任意 4. テスト結果
4-1. テスト結果(ロールのスイッチ)
No From(User) To(Role) Result 1 test-stg test-stg-role OK 2 test-stg test-dev-role NG 3 test-dev test-stg-role NG 4 test-dev test-dev-role OK 1. IAM User: test-stg → Role: test-stg-role
$ aws sts assume-role \ > --role-arn arn:aws:iam::XXXXXXXXXXXX:role/test-stg-role \ > --role-session-name my-session \ > --profile test-stg { "Credentials": { "AccessKeyId": "XXXXXX", "SecretAccessKey": "XXXXXX", "SessionToken": "XXXXXX", "Expiration": "2020-02-24T09:08:55+00:00" }, "AssumedRoleUser": { "AssumedRoleId": "XXXXXX:my-session", "Arn": "arn:aws:sts::XXXXXXXXXXXX:assumed-role/test-stg-role/my-session" } }2. IAM User: test-stg → Role: test-dev-role
$ aws sts assume-role \ > --role-arn arn:aws:iam::XXXXXXXXXXXX:role/test-dev-role \ > --role-session-name my-session \ > --profile test-stg An error occurred (AccessDenied) when calling the AssumeRole operation: User: arn:aws:iam::XXXXXXXXXXXX:user/test-stg is not authorized to perform: sts:AssumeRole on resource: arn:aws:iam::XXXXXXXXXXXX:role/test-dev-role3. IAM User: test-dev → Role: test-stg-role
$ aws sts assume-role \ > --role-arn arn:aws:iam::XXXXXXXXXXXX:role/test-stg-role \ > --role-session-name my-session \ > --profile test-dev An error occurred (AccessDenied) when calling the AssumeRole operation: User: arn:aws:iam::XXXXXXXXXXXX:user/test-dev is not authorized to perform: sts:AssumeRole on resource: arn:aws:iam::XXXXXXXXXXXX:role/test-stg-role4. IAM User: test-dev → Role: test-dev-role
$ aws sts assume-role \ > --role-arn arn:aws:iam::XXXXXXXXXXXX:role/test-dev-role \ > --role-session-name my-session \ > --profile test-dev { "Credentials": { "AccessKeyId": "XXXXXX", "SecretAccessKey": "XXXXXX", "SessionToken": "XXXXXX", "Expiration": "2020-02-24T09:09:52+00:00" }, "AssumedRoleUser": { "AssumedRoleId": "XXXXXX:my-session", "Arn": "arn:aws:sts::XXXXXXXXXXXX:assumed-role/test-dev-role/my-session" } }4-2. テスト結果(リソースアクセス)
No From(User) To(Parameter store) Result 1 test-stg test-stg OK 2 test-stg test-dev NG 3 test-dev test-stg NG 4 test-dev test-dev OK 1. IAM User: test-stg → Parameter Store: test-stg
$ aws ssm get-parameter --name test-stg --profile test-stg-role { "Parameter": { "Name": "test-stg", "Type": "String", "Value": "test", "Version": 1, "LastModifiedDate": "2020-02-24T15:35:40.814000+09:00", "ARN": "arn:aws:ssm:us-east-1:XXXXXXXXXXXX:parameter/test-stg" } }2. IAM User: test-stg → Parameter Store: test-dev
$ aws ssm get-parameter --name test-dev --profile test-stg-role An error occurred (AccessDeniedException) when calling the GetParameter operation: User: arn:aws:sts::XXXXXXXXXXXX:assumed-role/test-stg-role/botocore-session-XXXXXXXXXX is not authorized to perform: ssm:GetParameter on resource: arn:aws:ssm:us-east-1:XXXXXXXXXXXX:parameter/test-dev3. IAM User: test-dev → Parameter Store: test-stg
$ aws ssm get-parameter --name test-stg --profile test-dev-role An error occurred (AccessDeniedException) when calling the GetParameter operation: User: arn:aws:sts::XXXXXXXXXXXX:assumed-role/test-dev-role/botocore-session-XXXXXXXXXX is not authorized to perform: ssm:GetParameter on resource: arn:aws:ssm:us-east-1:XXXXXXXXXXXX:parameter/test-stg4. IAM User: test-dev → Parameter Store: test-dev
$ aws ssm get-parameter --name test-dev --profile test-dev-role { "Parameter": { "Name": "test-dev", "Type": "String", "Value": "test", "Version": 1, "LastModifiedDate": "2020-02-24T15:27:07.440000+09:00", "ARN": "arn:aws:ssm:us-east-1:XXXXXXXXXXXX:parameter/test-dev" } }感想
- タグに基づく承認が利用できるサービスが少なく、まだまだといった感じです。
- スイッチ先のポリシーでも、スイッチ元のタグから条件判断してスイッチの許可・拒否を判定する条件を記述できればよかったのに。
- aws:RequestTagの概念が難しい。。。
- 投稿日:2020-02-24T17:09:23+09:00
AWS SDK を使わずにAPIを実行する (SigV4 / PHP版)
概要
日頃からAWSの各サービスを使うにあたり、SDKの恩恵を受けているが、自分自身内部でどの様にAPIを実行しているかをあまり理解していなかった。そこで今回は、技術的な好奇心のためSDKの力を使わずにAPIを実行するところまでを行ってみたので、その備忘録として残す。
なお、本記事では PHP の場合での実装を示す。SigV4
AWS側に各種APIリクエストを実行する場合に、AWS側からどのクライアントからの送信かを判別できるように署名をして送信している。
AWSで提供している署名のバージョンは SigV2 と SigV4 の2種類が存在しており、現在では SigV4 が推奨されている。https://docs.aws.amazon.com/ja_jp/general/latest/gr/signing_aws_api_requests.html
署名してリクエストするには次のステップを踏む必要がある
- Step1. 正規リクエストの作成
- Step2. SigV4にあった署名の作成
- Step3. SigV4署名の計算
- Step4. HTTP header に付加
- Step5. curl などのクライアントでリクエストを実行
なお、本記事では Step2,3,4 を一つのステップとして扱い、3つのステップとして記載した。
また、各ステップで行っていることは後述しているが、より細かく確認したい場合はこちらを確認されたい。
https://docs.aws.amazon.com/ja_jp/general/latest/gr/sigv4_signing.html実装
ある程度ステップにそって、わかりやすく実装すると以下のような形になる。
function send_api_request($url, $params, $service, $region, $method) { $credentials = Array( 'AccessKeyId' => 'access_key', 'SecretKey' => 'access_secret', 'SecurityToken' => 'security_token' // 一時的に発行した TOKEN であれば必須 ); $request_headers = signature_request_v4($method, $url, $service, $region, $params, $credentials); $ch = curl_init($url); $header = array(); foreach( $request_headers as $param => $value ) { $header[] = $param . ": " . $value; } curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, REQUEST_TIME_OUT); curl_setopt($ch, CURLOPT_TIMEOUT, REQUEST_TIME_OUT); curl_setopt($ch, CURLOPT_CUSTOMREQUEST, $method); curl_setopt($ch, CURLOPT_HTTPHEADER, $header); curl_setopt($ch, CURLOPT_POSTFIELDS, json_encode($params)); $response = curl_exec($ch); $response_info = curl_getinfo($ch); if ($response === false) { return false; } $response_data = [ 'status_code' => $response_info['http_code'], 'body' => $response ]; return $response_data; } function signature_request_v4($method, $url, $service, $region, $request, $credentials){ $now = time(); $long_date = date("Ymd\THis\Z", strtotime( '-9 Hours', $now)); $short_date = date("Ymd", strtotime( '-9 Hours', $now)); $credential_scope = "{$short_date}/{$region}/{$service}/aws4_request"; $host = parse_url($url, PHP_URL_HOST); $path = parse_url($url, PHP_URL_PATH); $payload = json_encode($request); $headers = []; $headers['Content-type'] = 'application/json'; $headers['host'] = $host; $headers['x-amz-date'] = $long_date; if ($token = $credentials['SecurityToken'] { $headers['x-amz-security-token'] = $token; } // the signing key $key_secret = 'AWS4' . $credentials['SecretKey']; $key_date = hash_hmac('sha256', $short_date, $key_secret, true); $key_region = hash_hmac('sha256', $region, $key_date, true); $key_service = hash_hmac('sha256', $service, $key_region, true); $key_signing = hash_hmac('sha256', 'aws4_request', $key_service, true); $canonical_request = $this->create_canonical_request($headers, $payload, $method, $host, $path); $signed_request = hash('sha256', $canonical_request); $sign_string = "AWS4-HMAC-SHA256\n{$long_date}\n{$credential_scope}\n" .$signed_request; $signature = hash_hmac('sha256', $sign_string, $key_signing, true); $headers['authorization'] = "AWS4-HMAC-SHA256 Credential={$credentials['AccessKeyId']}/{$credential_scope}, " . "SignedHeaders=" . implode(";", array_keys($headers)) . ", " . "Signature=" . bin2hex($signature); return $headers; } function create_canonical_request( Array $headers, $payload, $method, $host, $path) { $canonical_request = array(); $canonical_request[] = $method; $canonical_request[] = $path; $canonical_request[] = ''; foreach($headers as $key => $value) $canonical_headers[ strtolower($key) ] = trim($value); uksort($canonical_headers, 'strcmp'); foreach($canonical_headers as $key => $value) { $canonical_request[] = $key . ':' . $value; } $canonical_request[] = ''; $canonical_request[] = implode(';', array_keys($canonical_headers)); $canonical_request[] = hash('sha256', $payload); $canonical_request = implode("\n", $canonical_request); return $canonical_request; }詳細
準備
まずはヘッダ情報を作成するために準備を行う。
署名やリクエストを作成するにあたり必要なパラメータを定義する。
- 認証スコープ(
credential_scope)や日時(long_date,short_date)の部分はSigV4の署名の文字列作成や計算の部分で使用する- それ以外の情報に関しては正規のリクエストを作成するときに使用する
$now = time(); $long_date = date("Ymd\THis\Z", strtotime( '-9 Hours', $now)); $short_date = date("Ymd", strtotime( '-9 Hours', $now)); $credential_scope = "{$short_date}/{$region}/{$service}/aws4_request"; $host = parse_url($url, PHP_URL_HOST); $path = parse_url($url, PHP_URL_PATH); $payload = json_encode($request); $headers = []; $headers['Content-type'] = 'application/json'; $headers['host'] = $host; $headers['x-amz-date'] = $long_date; if ($token = $credentials['SecurityToken'] { $headers['x-amz-security-token'] = $token; }Step1. SigV4の正規リクエストを作成する
SigV4で用いる正規のリクエストを作成する。
正規リクエストを作成することで、クライアント側で作成したリクエストとAWS側で作成したリクエスト情報で同一の値として計算を行える。
正規化されたリクエストは以下の形式で示されている。HTTPRequestMethod // リクエストメソッド (POST, GET) CanonicalURI // URI (httpエンコードされた絶対パス) CanonicalQueryString // クエリ値 CanonicalHeaders // ヘッダ(各要素の値を前後のスペースを削除して、連続したスペースを1つのみに置き換えした上、キーを小文字に変換。並び順をアルファベット順にしたもの) SignedHeaders // ヘッダのkeyを ; で羅列したもの HexEncode(Hash(RequestPayload)) // ペイロード
CanonicalQueryStringに関しては一定のルールのもとでURIエンコードをした上で生成する
- キーは文字コードベースで昇順にソートを行う
A ~ Z、a ~ z、0 ~ 9、-、_、.、~は変換しない- キーと値にある上記以外の文字列に関してはURIエンコードを行う
ペイロードの内容やURLのホスト、パス、メソッドなどの情報を追加する必要があるため、ある程度ヘッダを作成したうえでそのヘッダ情報に追加する形で作成すると分かりやすくなる。
そこで、本記事では、メソッド化をして、ヘッダ作成後に正規リクエストを作成できるような形にした。function create_canonical_request( Array $headers, $payload, $method, $host, $path) { $canonical_request = array(); $canonical_request[] = $method; $canonical_request[] = $path; $canonical_request[] = ''; foreach($headers as $key => $value) $canonical_headers[ strtolower($key) ] = trim($value); uksort($canonical_headers, 'strcmp'); foreach($canonical_headers as $key => $value) { $canonical_request[] = $key . ':' . $value; } $canonical_request[] = ''; $canonical_request[] = implode(';', array_keys($canonical_headers)); $canonical_request[] = hash('sha256', $payload); $canonical_request = implode("\n", $canonical_request); return $canonical_request; }Step2. SigV4の署名文字列を作成し計算・追加する
署名文字列を作成する場合には以下の形式で作成する必要がある
Algorithm + \n + RequestDateTime + \n + CredentialScope + \n + HashedCanonicalRequest上記実装では各変数を1行単位で実装しているが以下の3行で上記文字列を作成することが出来る。
$canonical_request = create_canonical_request($headers, $payload, $method, $host, $path); $signed_request = hash('sha256', $canonical_request); $sign_string = "AWS4-HMAC-SHA256\n{$long_date}\n{$credential_scope}\n" .$signed_request;
$sign_stringで先に示した形式に沿った形で連結をしているAWS4-HMAC-SHA256\n // アルゴリズム {$long_date}\n // Ymd\THis\Z の形式での時間 {$credential_scope}\n // {$short_date(Ymd形式での時間)}/{$region}/{$service}/aws4_request $signed_request //正規リクエストを sha256 でハッシュ化したもの。次に作成した署名を計算するが、
hash_hmacを用いて生成するため、必要な秘密鍵を生成する。
作成方法に関しては AWS 側のドキュメントを引用した。kSecret = your secret access key kDate = HMAC("AWS4" + kSecret, Date) kRegion = HMAC(kDate, Region) kService = HMAC(kRegion, Service) kSigning = HMAC(kService, "aws4_request")https://docs.aws.amazon.com/ja_jp/general/latest/gr/sigv4-calculate-signature.html
// the signing key $key_secret = 'AWS4' . $credentials['SecretKey']; $key_date = hash_hmac('sha256', $short_date, $key_secret, true); $key_region = hash_hmac('sha256', $region, $key_date, true); $key_service = hash_hmac('sha256', $service, $key_region, true); $key_signing = hash_hmac('sha256', 'aws4_request', $key_service, true);作成した秘密鍵を用いて、署名文字列を計算する、結果はバイナリ形式で出力されるため hex 形式に変換をする。
authorization のヘッダに先ほど作成した情報を使用してヘッダを追加する。
ヘッダ形式は AWS側で以下の様に指定されている。Authorization: algorithm Credential=access key ID/credential scope, SignedHeaders=SignedHeaders, Signature=signature上記の形をphp に落とし込むと以下のような形にする。
$signature = hash_hmac('sha256', $sign_string, $key_signing, true); $headers['authorization'] = "AWS4-HMAC-SHA256 Credential={$credentials['AccessKeyId']}/{$credential_scope}, " . "SignedHeaders=" . implode(";", array_keys($headers)) . ", " . "Signature=" . bin2hex($signature); return $headers;Step3. cURL で実行する
最後にphpで cURL を実行して取得されたレスポンスを成形する
$request_headers = signature_request_v4($method, $url, $service, $region, $params, $credentials); $ch = curl_init($url); $header = array(); foreach( $request_headers as $param => $value ) { $header[] = $param . ": " . $value; } curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1); curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, REQUEST_TIME_OUT); curl_setopt($ch, CURLOPT_TIMEOUT, REQUEST_TIME_OUT); curl_setopt($ch, CURLOPT_CUSTOMREQUEST, $method); curl_setopt($ch, CURLOPT_HTTPHEADER, $header); curl_setopt($ch, CURLOPT_POSTFIELDS, json_encode($params)); $response = curl_exec($ch); $response_info = curl_getinfo($ch); if ($response === false) { return false; } $response_data = [ 'status_code' => $response_info['http_code'], 'body' => $response ]; return $response_data; }参考
AWSAPI リクエストの署名
https://docs.aws.amazon.com/ja_jp/general/latest/gr/signing_aws_api_requests.html[ PHP ] AWS 署名バージョン 4
https://memo.abridge-lab.com/?p=173
- 投稿日:2020-02-24T17:00:53+09:00
AWS S3にデプロイしたら自動的にCloudFrontのキャッシュを無効化(invalidation)するNode.js Lambda
概要
静的コンテンツをAWS S3に置いて、CloudFrontを前段に立てる構成になっている状態で、S3を更新してもCloudFrontのエッジサーバーのキャッシュは自動で更新されずキャッシュの有効期限中は反映されない
そのキャッシュを手動で無効化する運用フローになっているのを自動化する手順のメモ
ロールを作るところからnode.jsのLambdaでやる構成での記事がなかったように思うので、残しておく構成
最初はデプロイスクリプトから CloudFrontのAPIを直に叩いて実現しようかと思った
しかしLambdaがS3の追加削除イベントをトリガーにできるようなので、タイミングとしてそちらのほうが適切であり、更にAWS SDKを使った方が楽だと分かったのでそのように構成した
スクリプトはフロントエンド エンジニアが管理しやすいようにNode.js javascriptにした手順
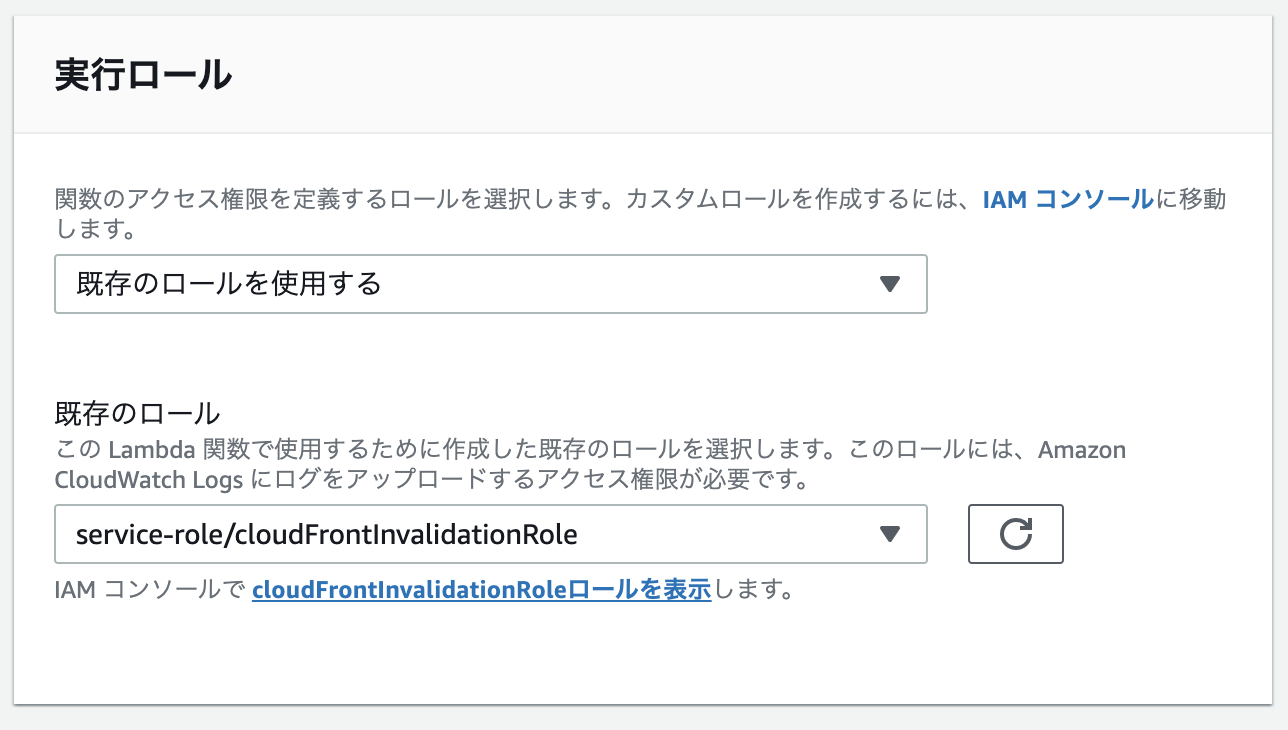
IAM ロールを作る
LambdaがCloudFrontのCreateInvalidationを叩けるように適当な名前でIAM Roleを作る
{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": [ "logs:CreateLogGroup", "logs:CreateLogStream", "logs:PutLogEvents" ], "Resource": "arn:aws:logs:*:*:*" }, { "Sid": "VisualEditor1", "Effect": "Allow", "Action": "cloudfront:CreateInvalidation", "Resource": "*" } ] }Lambdaのロールに適用する
上で作ったロールを適用
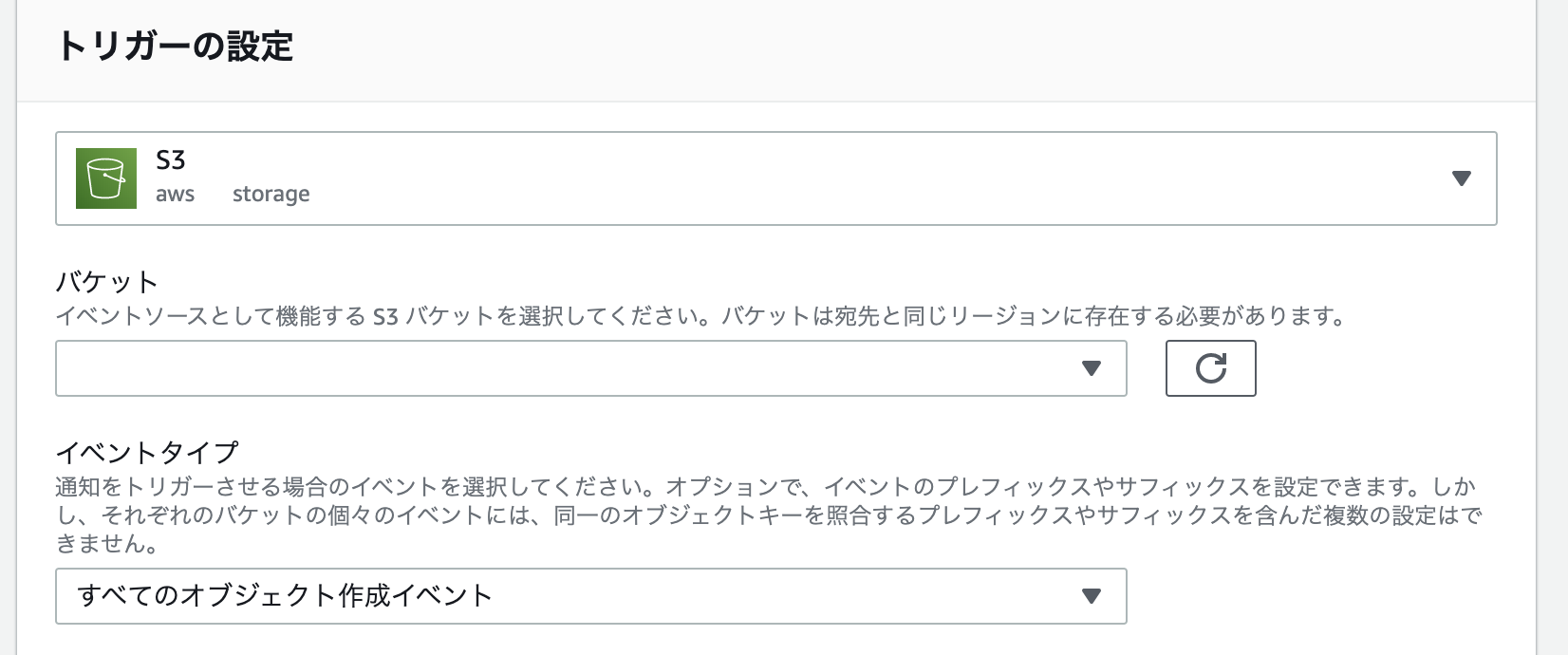
Lambdaのトリガーを追加する
反応させたいS3 Bucketごとに、
すべてのオブジェクト作成イベントとオブジェクトの削除(すべて)の2つのトリガーを作る
Lambdaのコードを書く
インライン編集、Node.jsを選ぶ
const AWS = require("aws-sdk"); const cloudfront = new AWS.CloudFront({ apiVersion: "2019-03-26" }); // @see https://kotororo.net/2018/07/%E9%9D%99%E7%9A%84%E3%82%B3%E3%83%B3%E3%83%86%E3%83%B3%E3%83%84%E3%82%92%E6%9B%B4%E6%96%B0%E3%81%97%E3%81%9F%E3%81%A8%E3%81%8D%E3%81%AB%E5%8D%B3%E6%99%82%E5%8F%8D%E6%98%A0%E3%81%95%E3%82%8C%E3%82%8B%E3%82%88%E3%81%86%E3%81%ABcloudfront%E3%81%AEinvalidation%E3%82%92%E8%B5%B0%E3%82%89%E3%81%9B%E3%82%8Blambda%E9%96%A2%E6%95%B0/ exports.handler = async event => { const paths = getPathsFromEvent(event); const s3BucketToCloudFrontDistributionId = { "S3のバケット名": "CloudFront Distribution ID", }; const distributionId = s3BucketToCloudFrontDistributionId[getS3BucketFromEvent(event)]; const params = { DistributionId: distributionId, InvalidationBatch: { CallerReference: new Date().getTime().toString(), Paths: paths } }; // @see https://docs.aws.amazon.com/AWSJavaScriptSDK/latest/AWS/CloudFront.html#createInvalidation-property await cloudfront .createInvalidation(params, function(err, data) { if (err) { console.log(err, err.stack); } else { console.log(data); } }) .promise(); console.log("invalidate: " + paths.Items[0]); }; function getPathsFromEvent(event) { console.log(JSON.stringify(event)); return { Quantity: 1, Items: ["/" + event.Records[0].s3.object.key] }; } function getS3BucketFromEvent(event) { return event.Records[0].s3.bucket.name; }※ 複数の開発環境に反応させるために、
s3BucketToCloudFrontDistributionIdというマッピングにしてあるので、自分の環境の内容を入れる動作確認
S3に追加削除して、そのパスがInvalidationされていたら成功
いくつまで一度に無効化できるのか?
もともと
*でinvalidationしていたのだが、今回の変更でS3のイベントが各々のオブジェクトの追加削除ごとに発生し、invalidationも1パスずつリクエストされるようになった
もし大量のイベントが発生したときに問題なく動くのか気になり、いくつまで一度にinvaidationできるのか調べたFAQ によると以下の通りなので、通常の使用であれば問題なさそうだった
Q.無効リクエスト数には制限がありますか?
オブジェクトを個別に無効にする場合は、進行中のディストリビューションごとに最大 3,000 個のオブジェクトまで、一度に無効化リクエストを作成できます。これは、最大 3,000 個のオブジェクトに対する 1 つの無効化リクエスト、1 つのオブジェクトに対する最大 3,000 個のリクエスト、または 3,000 個のオブジェクトを超えないその他の任意の組み合わせとすることができます。
*ワイルドカードを使用している場合、最大 15 個の無効化パスのリクエストを一度に作成できます。また、進行中のディストリビューションごとに最大 3,000 個の個別のオブジェクトを同時に作成することができます。ワイルドカードの無効化リクエストの制限は、オブジェクトの個別の無効化の制限とは無関係です。この限度を超過すると、以前のリクエストが終了するまで、余分な無効リクエストはエラーを返します。困ったこと
- handlerでもらえるEventの型の定義がどう調べても分からず、console.logで見てみるしかなかった
- 「イベント構造はサービスによって異なります」という記述しか見当たらなかった
保留したこと
- Lambdaのインラインコードをgit・S3管理すること
- 請求への注意・請求アラームをつけること
静的コンテンツ自体をそんなに頻繁に更新しないので保留した
参考
- https://blog.miguelangelnieto.net/posts/Automatic_Cloudfront_invalidation_with_Amazon_Lambda.html
- https://qiita.com/kskinaba/items/dcf9693dd034517e114a
- https://kotororo.net/2018/07/%E9%9D%99%E7%9A%84%E3%82%B3%E3%83%B3%E3%83%86%E3%83%B3%E3%83%84%E3%82%92%E6%9B%B4%E6%96%B0%E3%81%97%E3%81%9F%E3%81%A8%E3%81%8D%E3%81%AB%E5%8D%B3%E6%99%82%E5%8F%8D%E6%98%A0%E3%81%95%E3%82%8C%E3%82%8B%E3%82%88%E3%81%86%E3%81%ABcloudfront%E3%81%AEinvalidation%E3%82%92%E8%B5%B0%E3%82%89%E3%81%9B%E3%82%8Blambda%E9%96%A2%E6%95%B0/


- 投稿日:2020-02-24T16:45:40+09:00
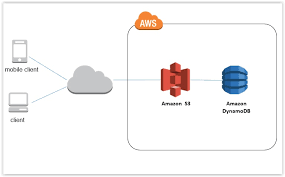
Logstashが実装するS3プラグイン(input/output)の活用について
目的
LogstashにはS3内のデータを抽出(Input)したり、データを出力(Output)するプラグインが存在します。Logstashプラグインのサポートについての記事にて解説した通り、両プラグイン供にTier1のプラグインであり、Elastic社の有償サポートに加入している場合はプロダクト保証があります。Inputプラグインの最新バージョンは
version: v3.4.1であリ、Outputプラグインの最新バージョンはversion: v3.4.1であります。
本投稿では、それらプラグインの基本的な利用方法について解説します。Elastic社のマニュアルから、基本的な設定方法をピックアップして設定の勘所を記載します。それぞれのマニュアルは以下を参考にしました。
S3 input plugin
Main Parameter
S3 input pluginで利用する主要パラメータについて、以下で解説します。基本的にはこれらのパラメータを設定するだけで良いですが、より応用的な使い方をしたい場合は、S3 input-plugin official document by Elasticを参照してください。
- access_key_id: [string]
secret_access_key: [string]
- S3にアクセスするためのcredential情報を記載します。コンフィグレーションファイルに、これらの情報を記載したくない場合は、credential情報が記載された別ファイルをパラメータで指定することも可能です。具体的には、
aws_credentials_fileの値を設定します。aws_credentials_file [string]
- AWS credential情報が格納されたyamlファイルのpath情報です。このパラメータは、
access_key_idとsecret_access_keyのパラメータが設定されていない場合にのみ、読み込まれます。bucket [string]
- S3 bucketの名前。Logstashインスタンスからアクセス可能なS3 bucketを指定する必要があります。
region [string]
- S3 bucketのRegion。デフォルト値は
us-east-1のため、必要に応じて変更する必要があります。delete [boolean]
trueに設定することで、データ抽出後にS3内のオリジナルデータを削除することができます。temporary_directory [string]
- S3から取得したデータを一時的に保管するディレクトリ。デフォルトのディレクトリパスは、
/tmp/logstashです。watch_for_new_files [boolean]
- S3に格納される新規ファイルを継続的に取得し続けるかどうかを設定します。
interval [number]
- LogstashがS3にデータ取得するインターバル。デフォルトは60秒。
include_object_properties [boolean]
- S3のオブジェクトプロパティをデータ取得対象にするか否かを決定します。
prefix [string]
- データ取得対象のプレフィックス長を設定する。もし、設定されている場合、プレフィックスがマッチしたファイルに限り、Lostashのデータ取得対象となります。
Setting Example
以下にS3 input pluginの設定例を示します。
input_plugin_exampleinput { s3 { access_key_id => "<your-access_key_id>" secret_access_key => "<your-access_secret_access_key>" region => "<your-region>" bucket => "<your-bucket>" prefix => "Logs" interval => "10" delete => false watch_for_new_files => true include_object_properties => false } }S3 output plugin
Main Parameter
S3 output pluginで利用する主要パラメータについて、以下で解説します。基本的にはこれらのパラメータを設定するだけで良いですが、より応用的な使い方をしたい場合は、S3 output-plugin official document by Elasticを参照してください。
- access_key_id: [string]
secret_access_key: [string]
- S3にアクセスするためのcredential情報を記載します。コンフィグレーションファイルに、これらの情報を記載したくない場合は、credential情報が記載された別ファイルをパラメータで指定することも可能です。具体的には、
aws_credentials_fileの値を設定します。bucket [string]
- S3 bucketの名前。Logstashインスタンスからアクセス可能なS3 bucketを指定する必要があります。
region [string]
- S3 bucketのRegion。デフォルト値は
us-east-1のため、必要に応じて変更する必要があります。temporary_directory [string]
- S3へデータ出力する前に使用する一時保管用のディレクトリ。デフォルトのディレクトリパスは、
/tmp/logstashです。このディレクトリにS3へ格納する前のファイルが格納され、rotation_strategyなどで設定したローテーション方針に従い処理されることになります。canned_acl [string]
- 格納ファイルに対するアクセス制限。
private, public-read, public-read-write, authenticated-read, aws-exec-read, bucket-owner-read, bucket-owner-full-control, log-delivery-writeから1つ選択します。デフォルト値は、privateです。encoding [string]
- 格納ファイルに対する圧縮方式。
none, gzipから1つ選択する。デフォルト値は、nodeです。upload_queue_size [number]
- S3へアップロードする前にLogstashインスタンスのキュー内に保持する最大メッセージ数。デフォルト値は
4です。storage_class [string]
- 格納ファイルのデータ保持方式。
STANDARD, REDUCED_REDUNDANCY, STANDARD_IA, ONEZONE_IAから1つ選択します。デフォルト値は、STANDARDです。restore [boolean]
- Logstash異常終了時の回復機能利用有無を指定します。trueの場合、
temporary_directory内のログファイルがrecoverされてuploadされます。デフォルト値は、trueです。rotation_strategy [string]
- 出力するファイルをローテーションするアルゴリズムを指定します。
size_and_time, size, timeから1つ選択します。デフォルト値は、size_and_timeです。size_file [number]
- ローテーションするファイルサイズ(byte)を指定します。デフォルト値は、
5242880bytesです。time_file [number]
- ローテーションするタイミング(分)を指定します。デフォルト値は、
15分です。prefix [string]
- ファイル名のprefixを設定します。prefixで指定したオブジェクト名称で格納されます。
Setting Example
以下にS3 output pluginの設定例を示します。
output_plugin_exampleoutput { s3{ access_key_id => "<your-access_key_id>" secret_access_key => "<your-access_secret_access_key>" region => "<your-region>" bucket => "<your-bucket>" prefix => "test/%{+YYYY}/%{+MM}/%{+dd}" encoding => "gzip" rotation_strategy => "time" time_file => 1 } }以上です。
- 投稿日:2020-02-24T16:41:02+09:00
【初心者向け】Alexaカスタムスキルを作成してCognitoのユーザープールとアカウントリンクする手順
1.Lambdaで関数を作成
AWS Lamdaで関数の作成手順
1-1.AWSのサービス一覧から「Lambda」を選択
1-2.Lambdaトップ画面より「関数の作成」を押下
1-3.関数の基本情報を設定
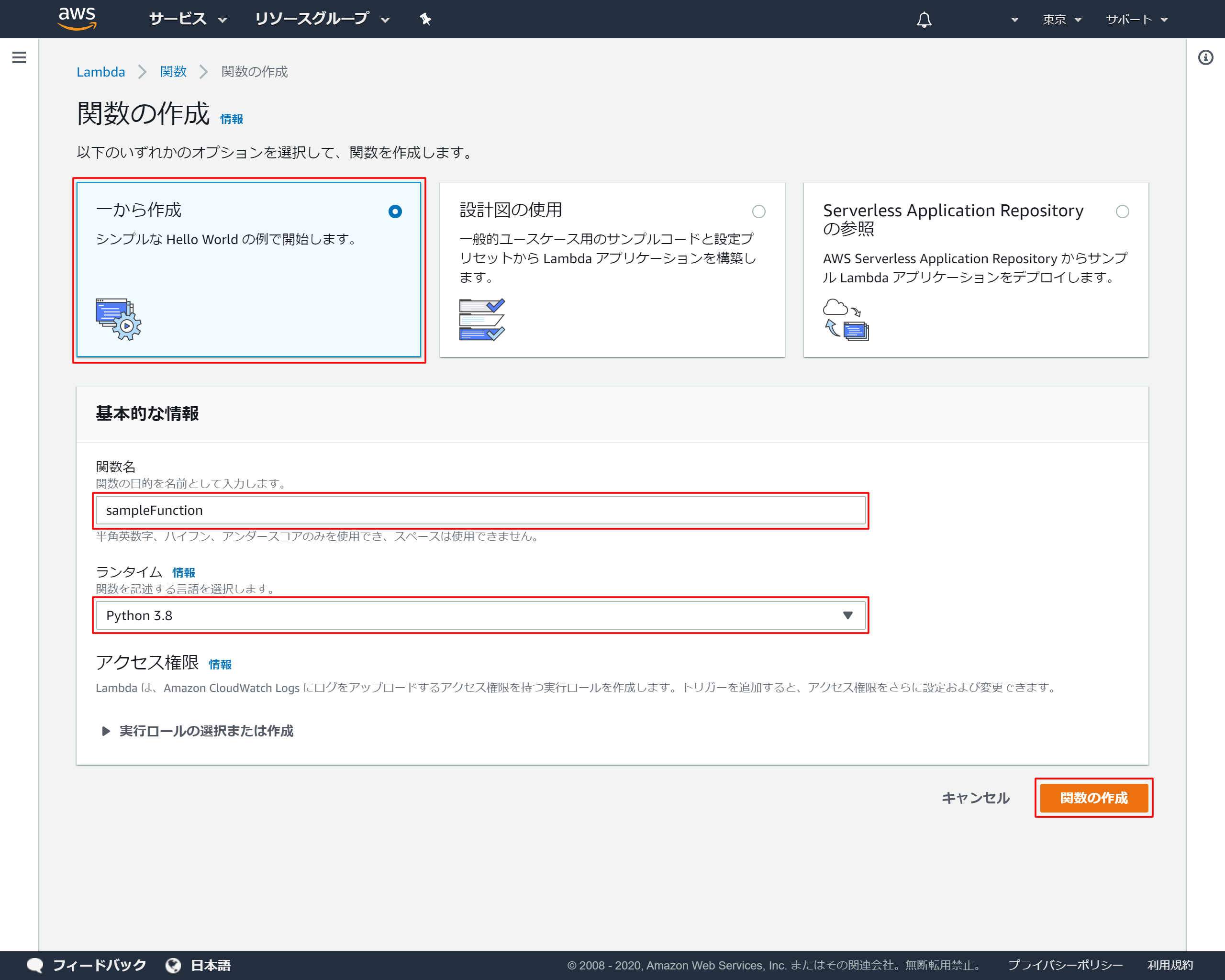
- 「一から作成」を選択
- 「関数名」を入力 →今回は"sampleFunction"としました
- 「ランタイム」では「Python3.8」を選択
- 「関数の作成」を押下
1-4.作成成功メッセージ
作成が成功すると上部にメッセージが表示され、コード入力画面が表示されます
1-5.関数を作成
関数コードに動作が確認可能なサンプルコードを入力します
lambda_function.pyimport json import base64 def lambda_handler(event, context): if event['request']['type'] == "IntentRequest": # トークンを取得してピリオドで分割 token = event['session']['user']['accessToken'].split('.') # トークンをデコードしてjson形式へ payload =json.loads(base64.urlsafe_b64decode(token[1] + '=' * (-len(token[1]) % 4)).decode(encoding='utf-8')) session_attributes = {} card_title = "こんにちは。あなたのIDは" + payload['username'] + "です" speech_output = "こんにちは。あなたのIDは" + payload['username'] + "です" reprompt_text = "こんにちは。あなたのIDは" + payload['username'] + "です" should_end_session = True return build_response(session_attributes, build_speechlet_response( card_title, speech_output, reprompt_text, should_end_session)) else: session_attributes = {} card_title = "サンプルスキルを開きました" speech_output = "サンプルスキルを開きました" reprompt_text = "サンプルスキルを開きました" should_end_session = False return build_response(session_attributes, build_speechlet_response( card_title, speech_output, reprompt_text, should_end_session)) def build_response(session_attributes, speechlet_response): return { 'version': '1.0', 'sessionAttributes': session_attributes, 'response': speechlet_response } def build_speechlet_response(title, output, reprompt_text, should_end_session): return { 'outputSpeech': { 'type': 'PlainText', 'text': output }, 'card': { 'type': 'Simple', 'title': "SessionSpeechlet - " + title, 'content': "SessionSpeechlet - " + output }, 'reprompt': { 'outputSpeech': { 'type': 'PlainText', 'text': reprompt_text } }, 'shouldEndSession': should_end_session }
2.Cognitoでユーザープールを作成
AWS Cognitoでユーザープールの作成手順
2-1.AWSのサービス一覧から「Cognito」を選択
「Cognito」はセキュリティ、ID、およびコンプライアンスのカテゴリです
2-2.Cognitoトップ画面より「ユーザープールの管理」を押下
2-3.ユーザープールトップ画面より「ユーザープールを作成する」を押下
2-4.ユーザープールの基本情報を入力する
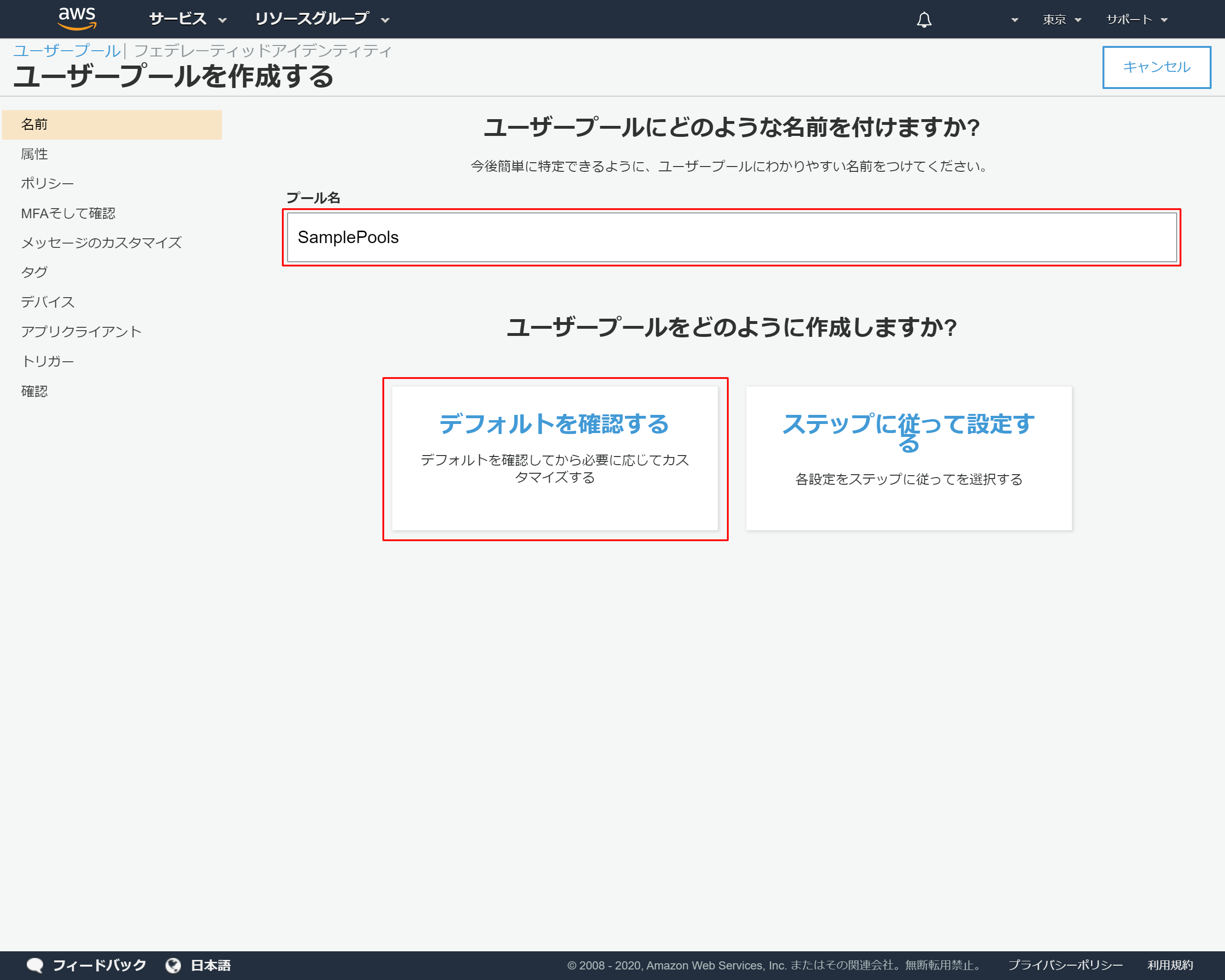
- 「プール名」を入力 →今回はSamplePoolsと入力しました
- 「デフォルトを確認する」を押下
2-5.ユーザープールの情報が表示されたら左側メニューの「属性」を押下
プールの作成はまだ押下しないでください
2-6.属性情報を設定する
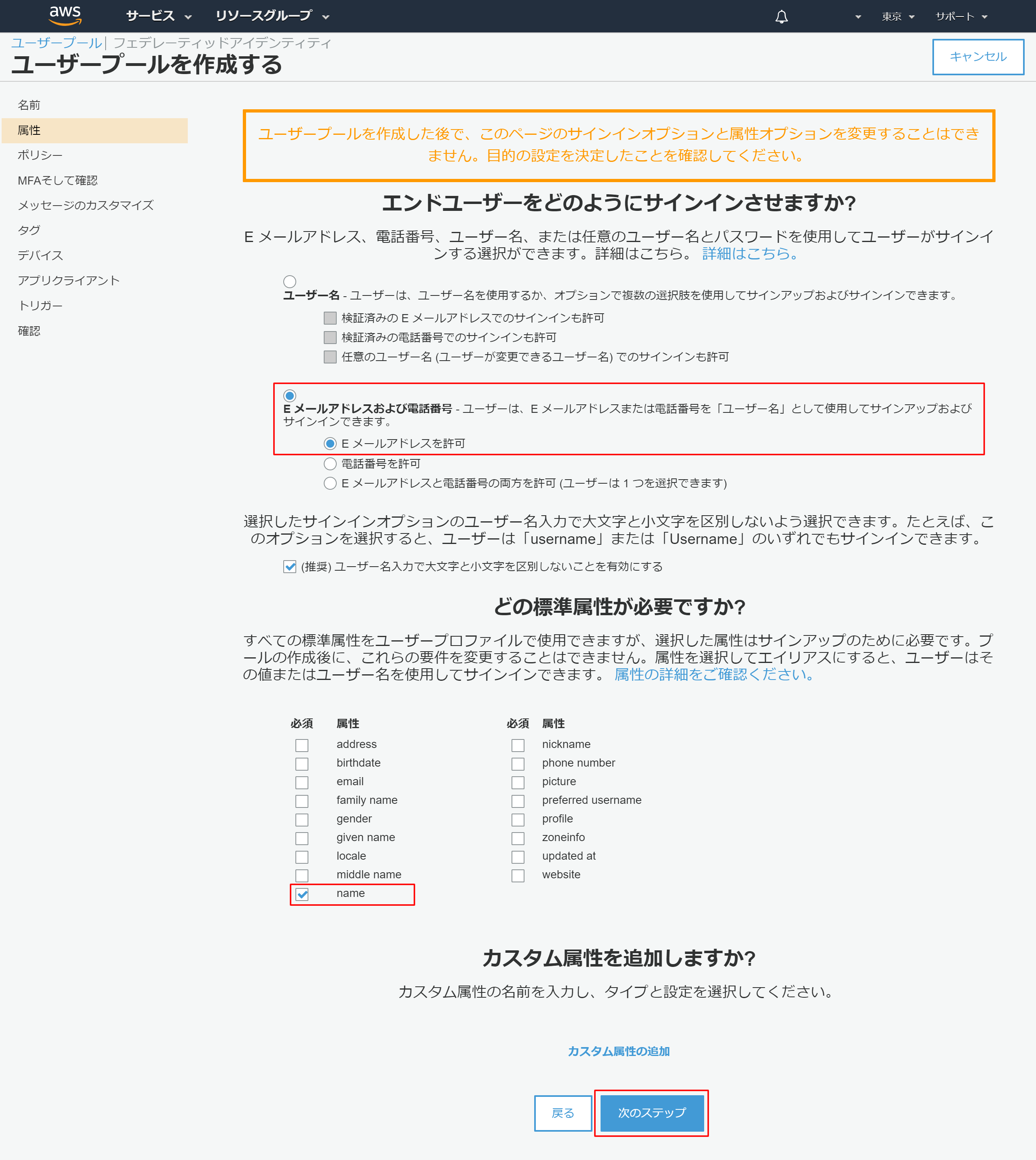
- 「Eメールアドレスおよび電話番号」を選択
- 「Eメールアドレスを許可」を選択
- 必要な必須属性を選択 →今回はnameのみ設定しました
- 「次のステップ」を押下
2-7.ポリシーの設定
今回はデフォルトの設定としますので、左側のメニューより「確認」を押下します
2-8.「プールの作成」を押下
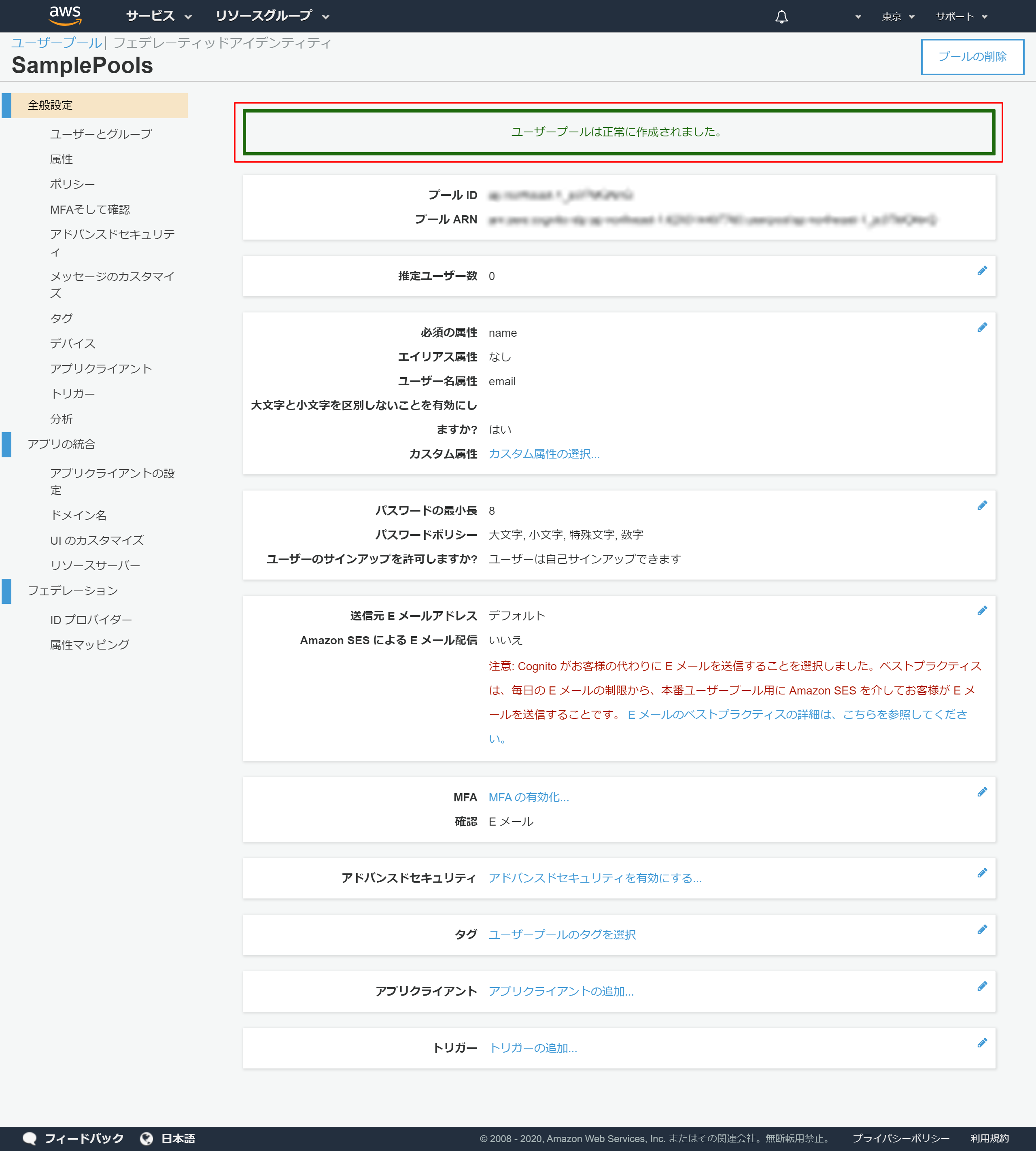
2-9.プールが作成されたメッセージが表示される
2-10.アプリクライントの設定
左側のメニューより「アプリクライアント」を押下
2-11.「アプリクライアントの追加」を押下
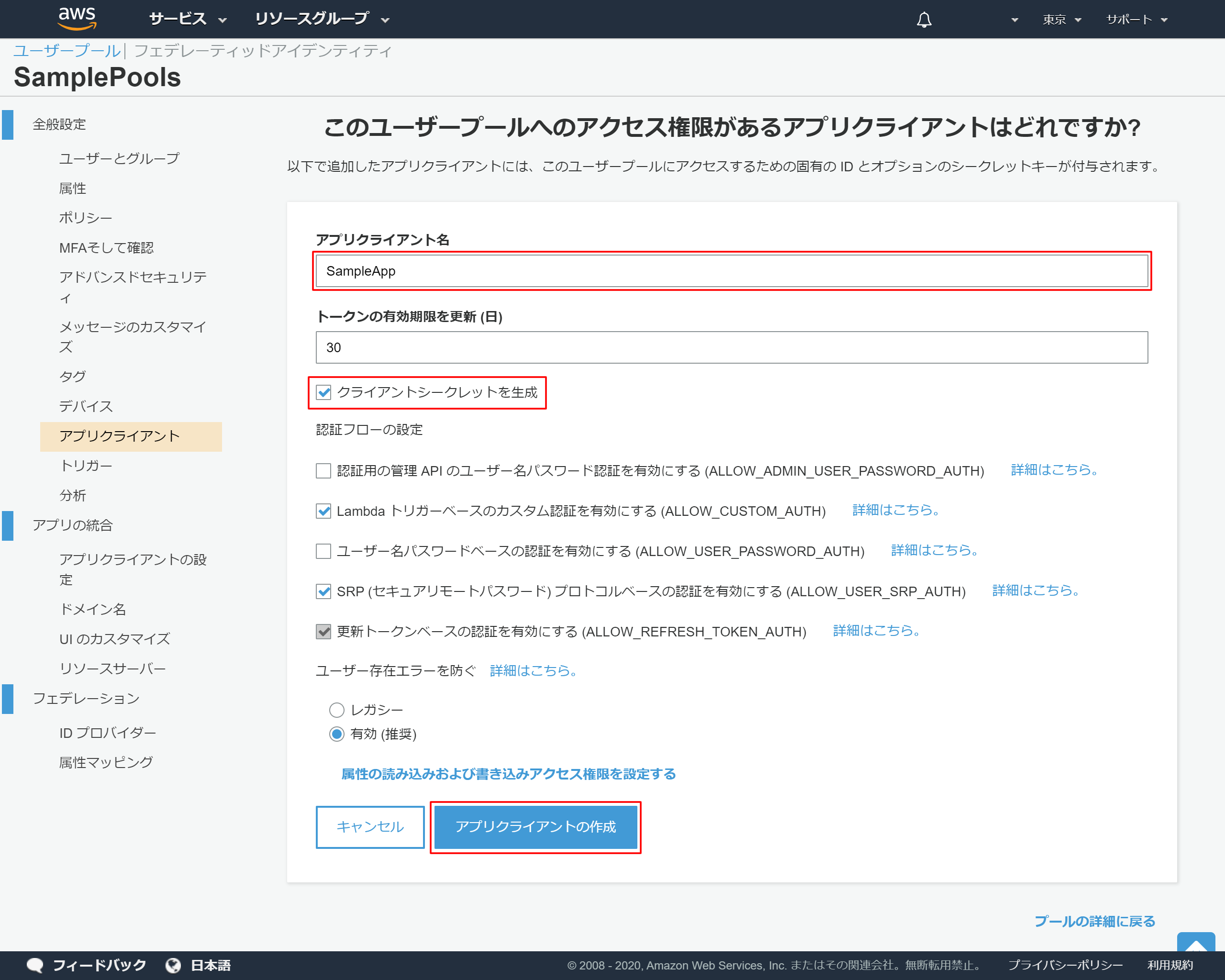
2-12.アプリクライアントの詳細設定
- 「アプリクライアント名」を入力 →今回は「SampleApp」としました
- 「クライアントシークレットを生成」のチェックは入れておく
- 「アプリクライアントの作成」を押下
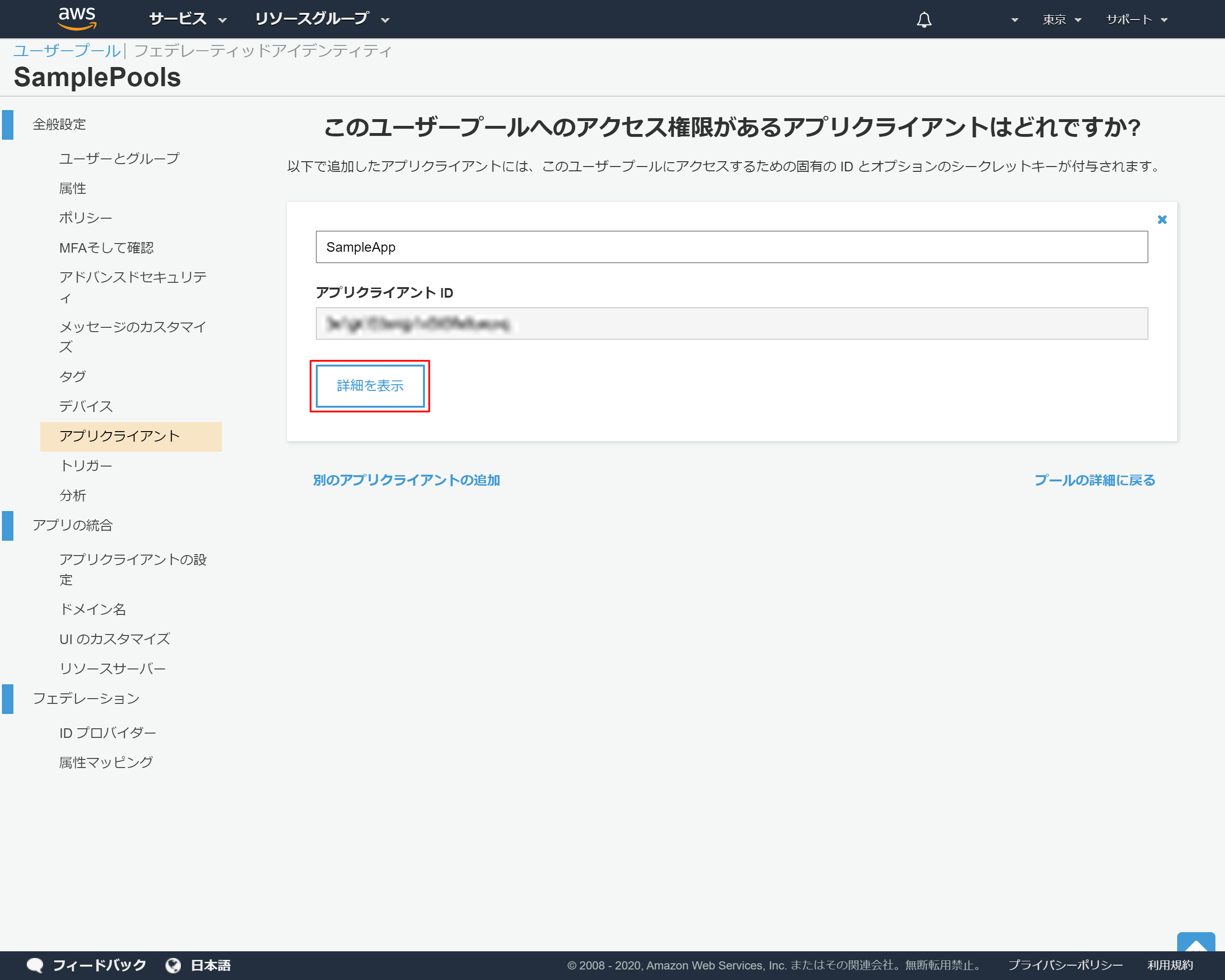
2-13.アプリクライントのIDが発行される
「詳細を表示」を押下
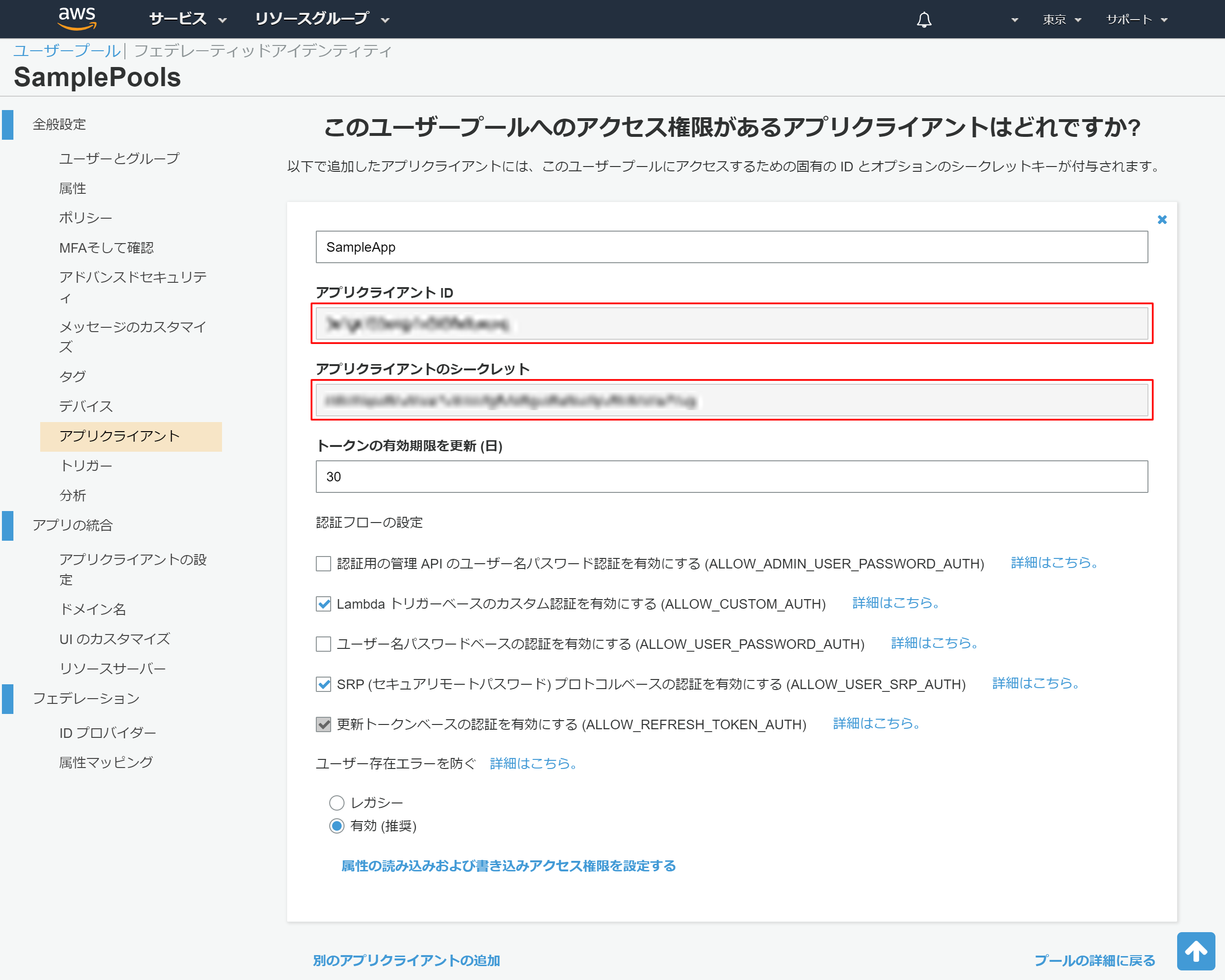
2-14.アプリクライアントの詳細情報の表示
後ほど利用するため、以下情報をメモ帳などにコピーしておく
- アプリクライアントID
- アプリクライアントのシークレット
3.alexa developer consoleでスキルを作成
カスタムスキルの作成手順
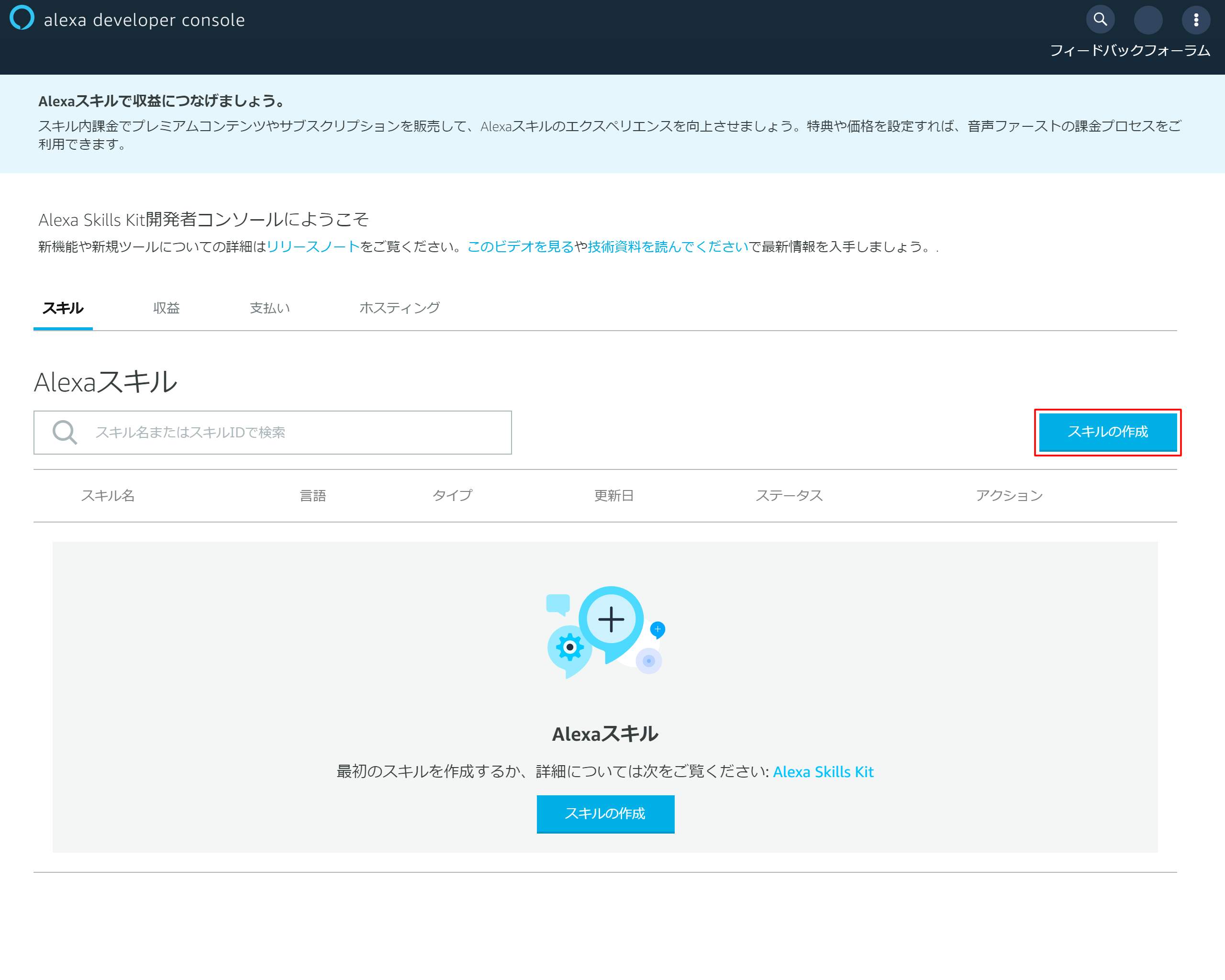
3-1.「スキルの作成」を押下
3-2.スキルの基本情報を入力
- 「スキル名」を入力 →今回はサンプルスキルとしました
- 「カスタム」を選択
- 「ユーザー定義のプロビジョニング」を選択
- 右上の「スキルを作成」を押下
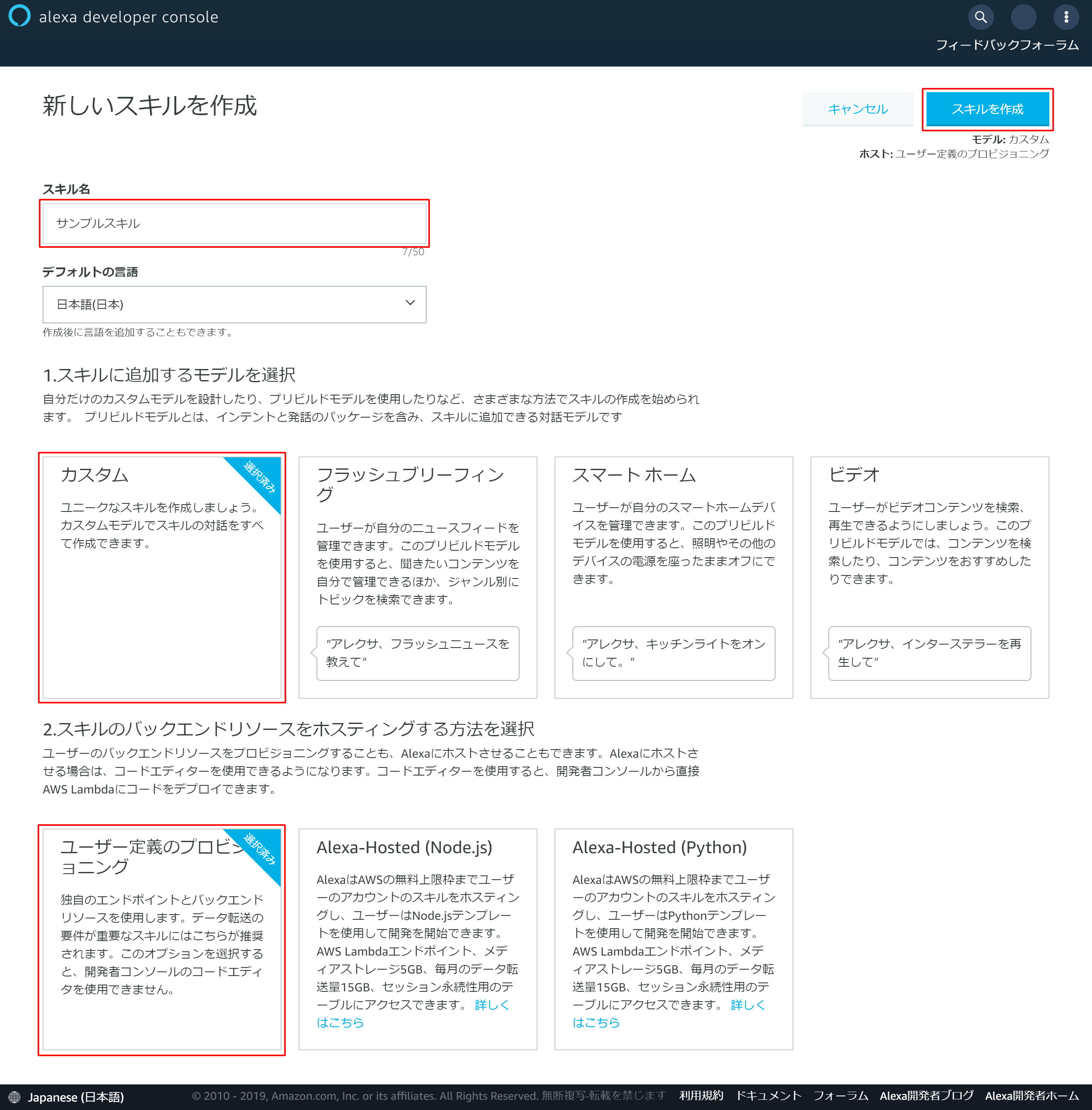
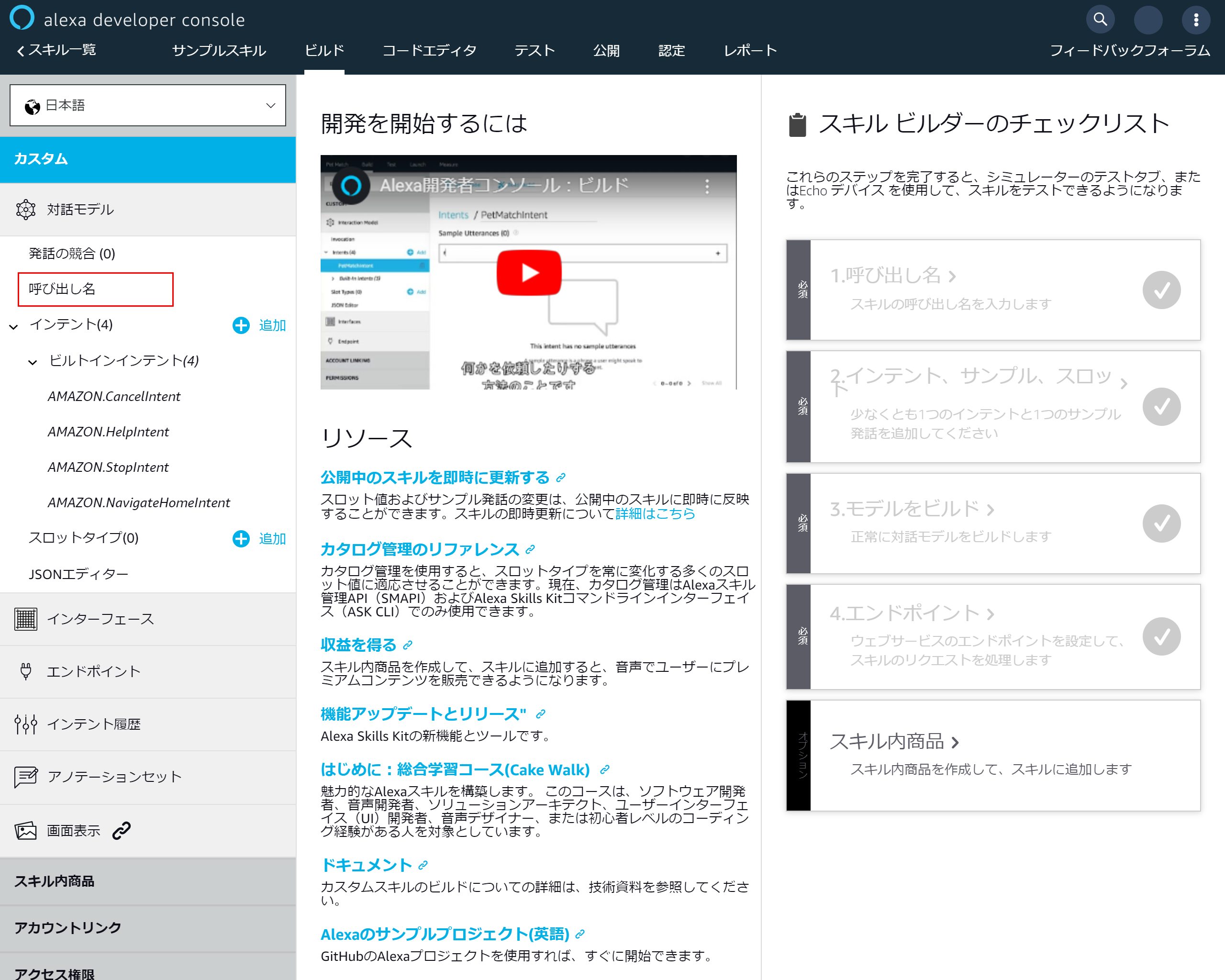
3-3.スキル作成画面
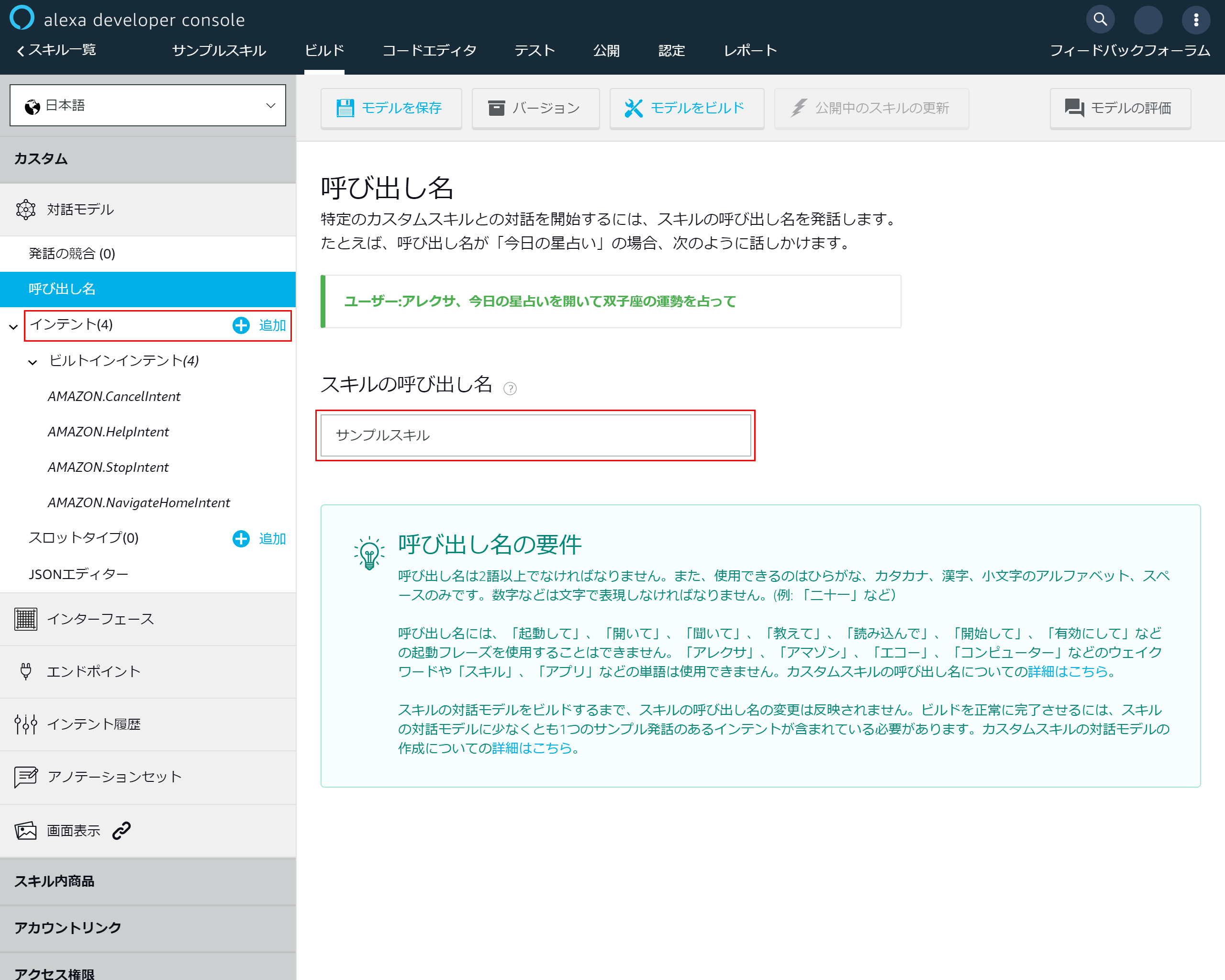
「呼び出し名」を押下
3-4.スキルの基本設定を入力する
- 「呼び出し名」を入力 →今回はサンプルスキルにしました
- 左側メニューのインテントにある「追加」を押下
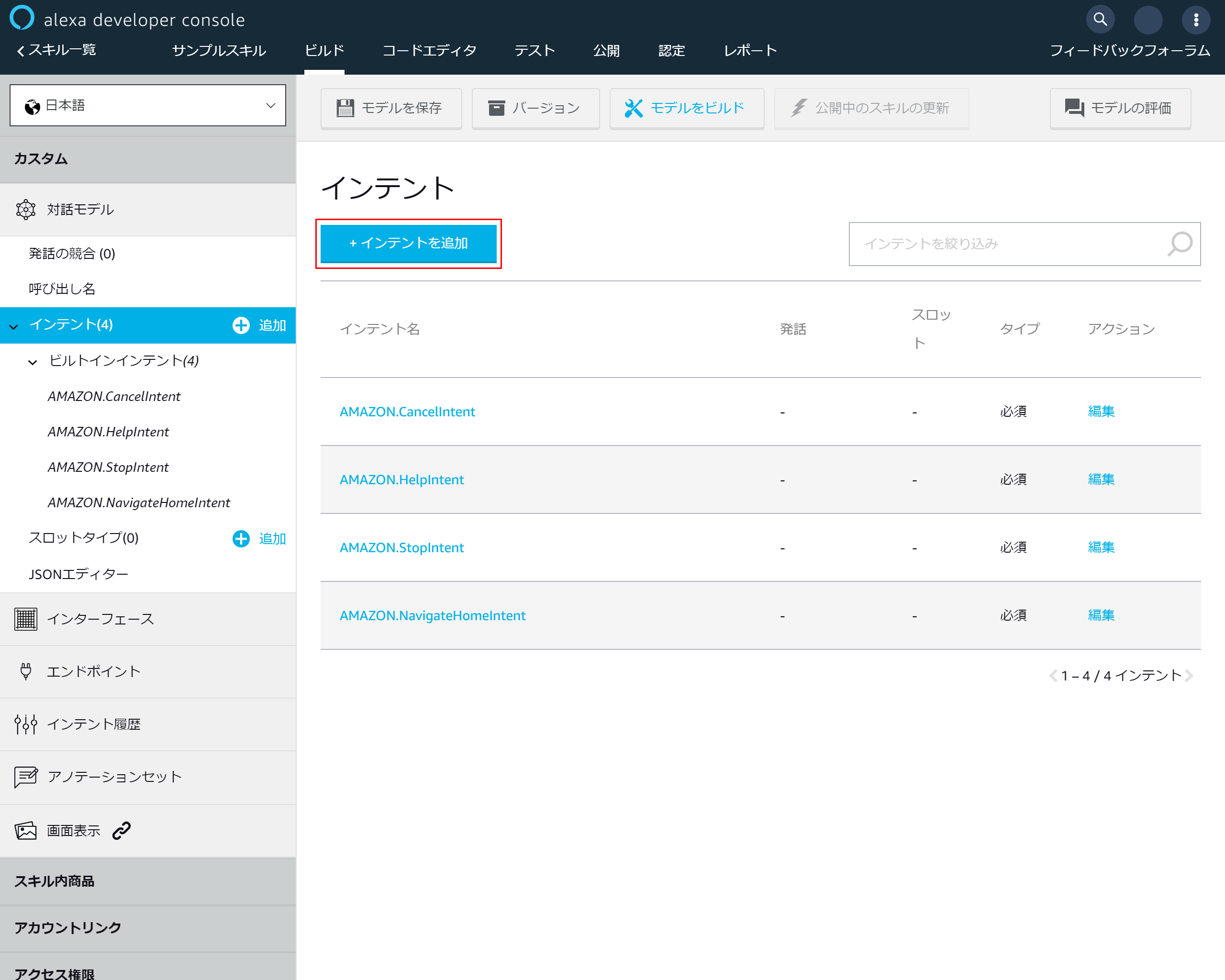
3-5.「インテントを追加」を押下
3-6.インテント設定画面
- インテント名を入力 →今回はtestにしました
- 「カスタムインテントを作成」を押下

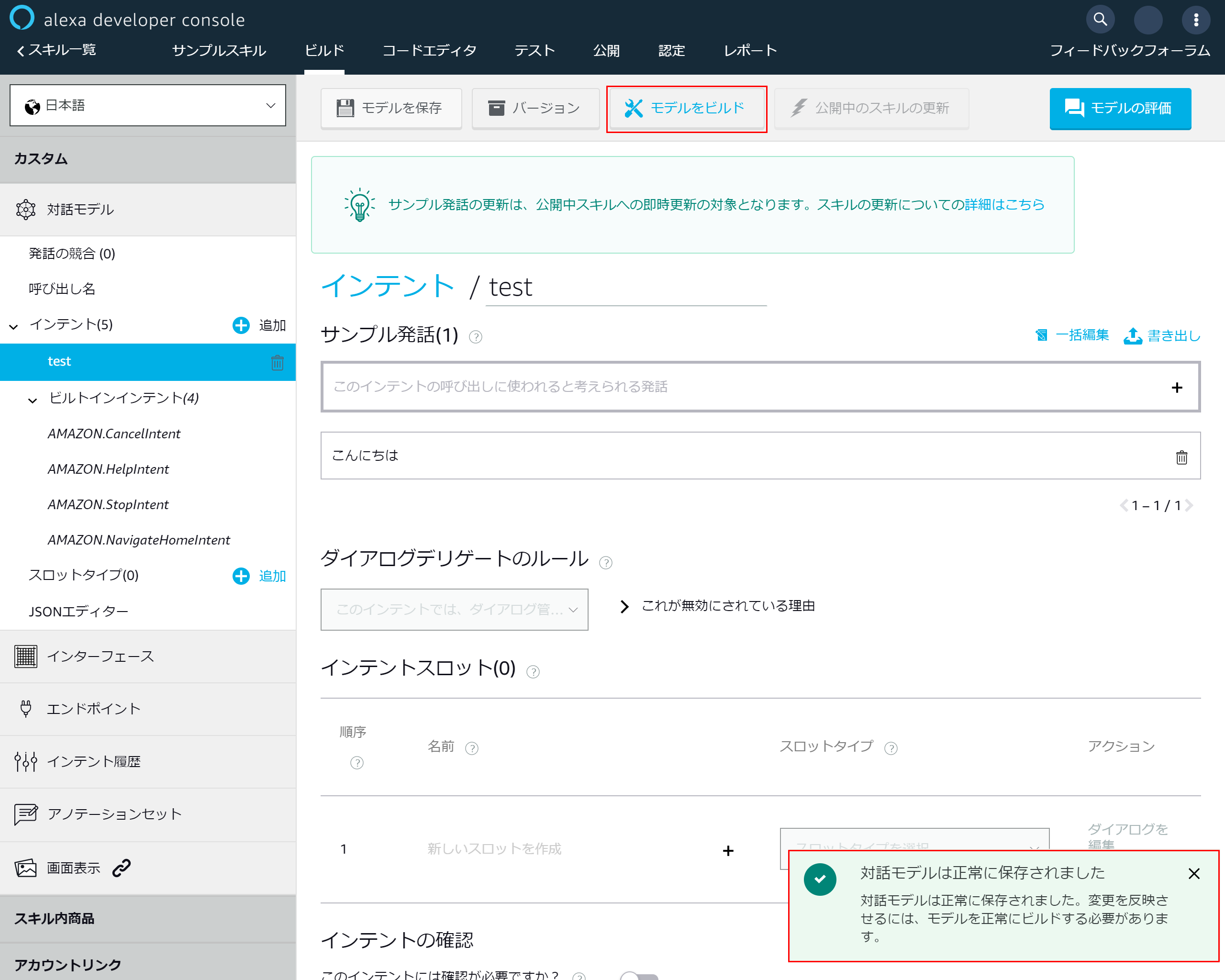
3-7.インテント追加画面
サンプル発話に「こんにちは」と入力して「+」ボタンを押下
3-8.モデルを保存する
サンプル発話が追加されたら「モデルを保存」を押下する
3-9.モデルが保存されたらモデルをビルドする
対話モデルが保存されたら「モデルをビルド」を押下
3-10.ビルド完了
ビルド成功メッセージが出たら基本設定は完了
4.Lambdaとalexaスキルの連携設定
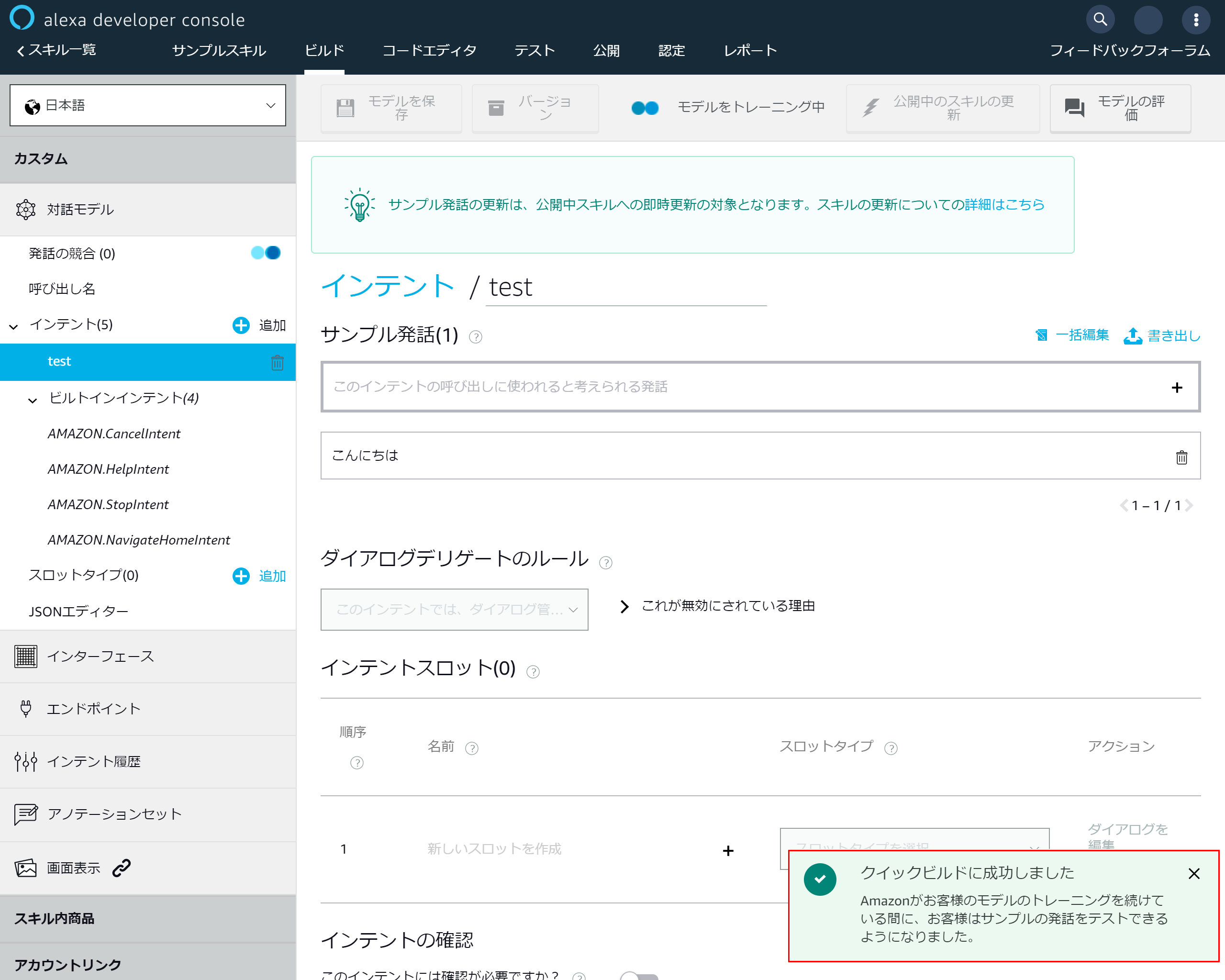
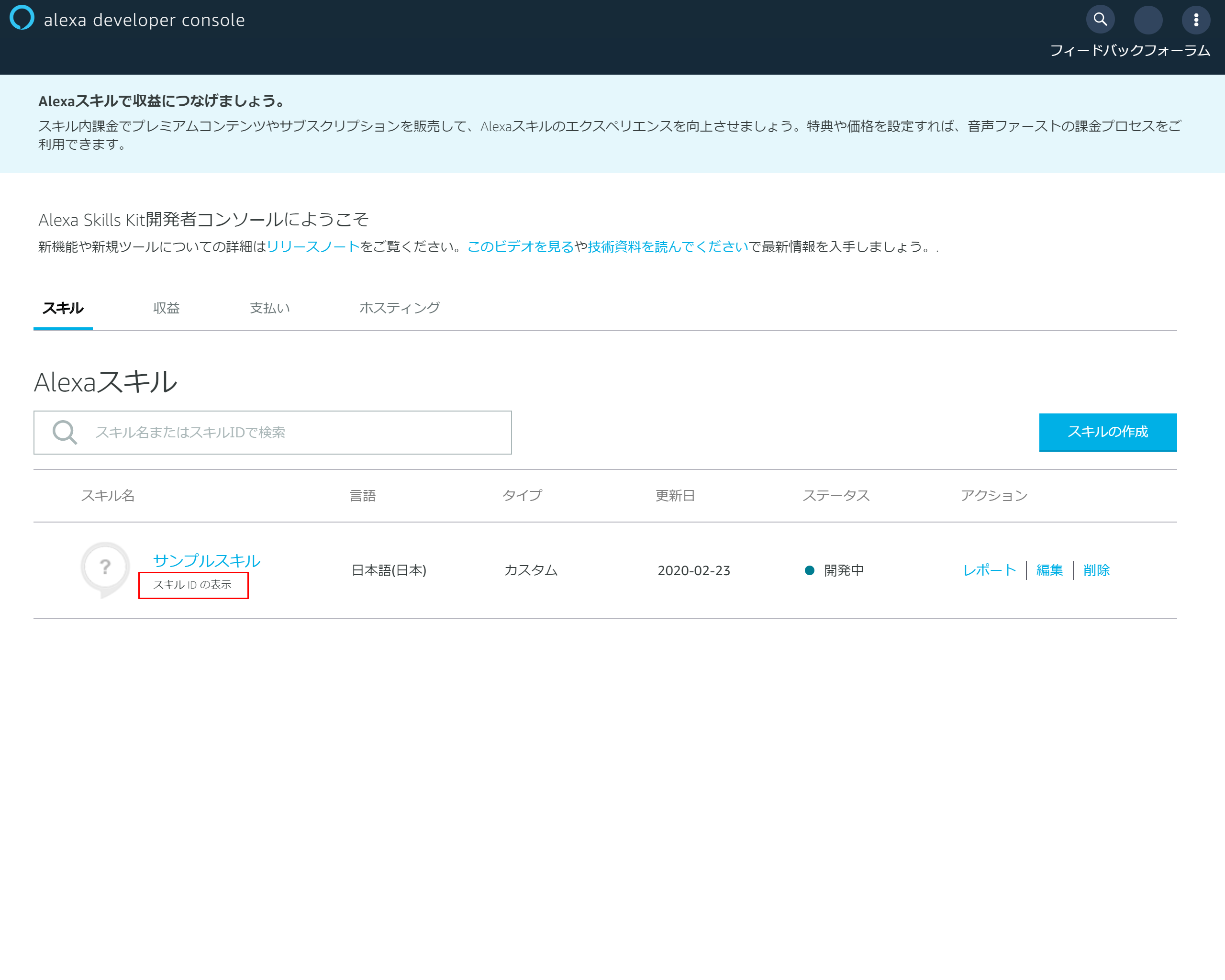
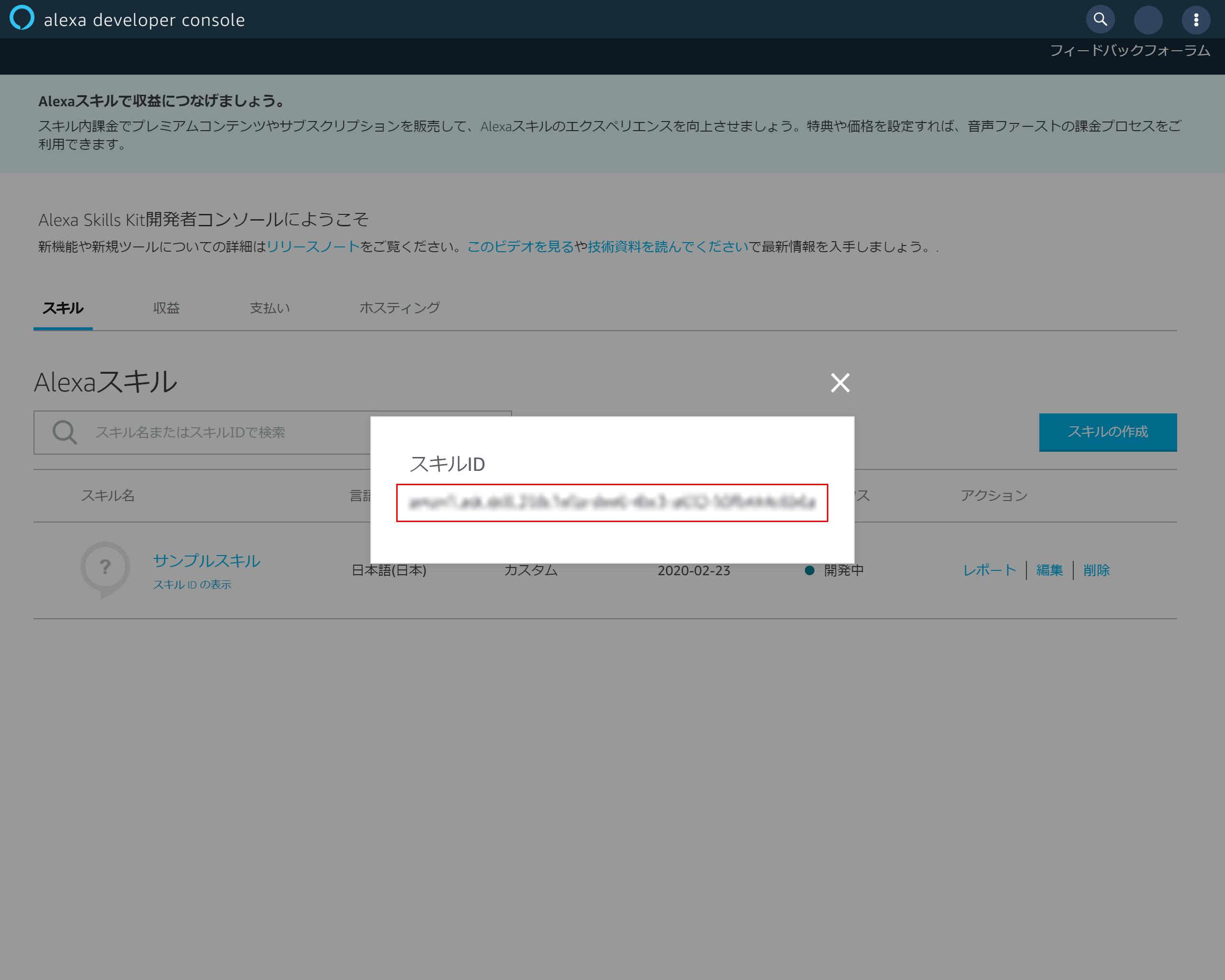
4-1.スキルIDの表示
スキルの一覧に戻り該当スキルの「スキルIDの表示」を押下する
4-2.スキルIDのコピー
表示されたスキルIDをコピーしておく
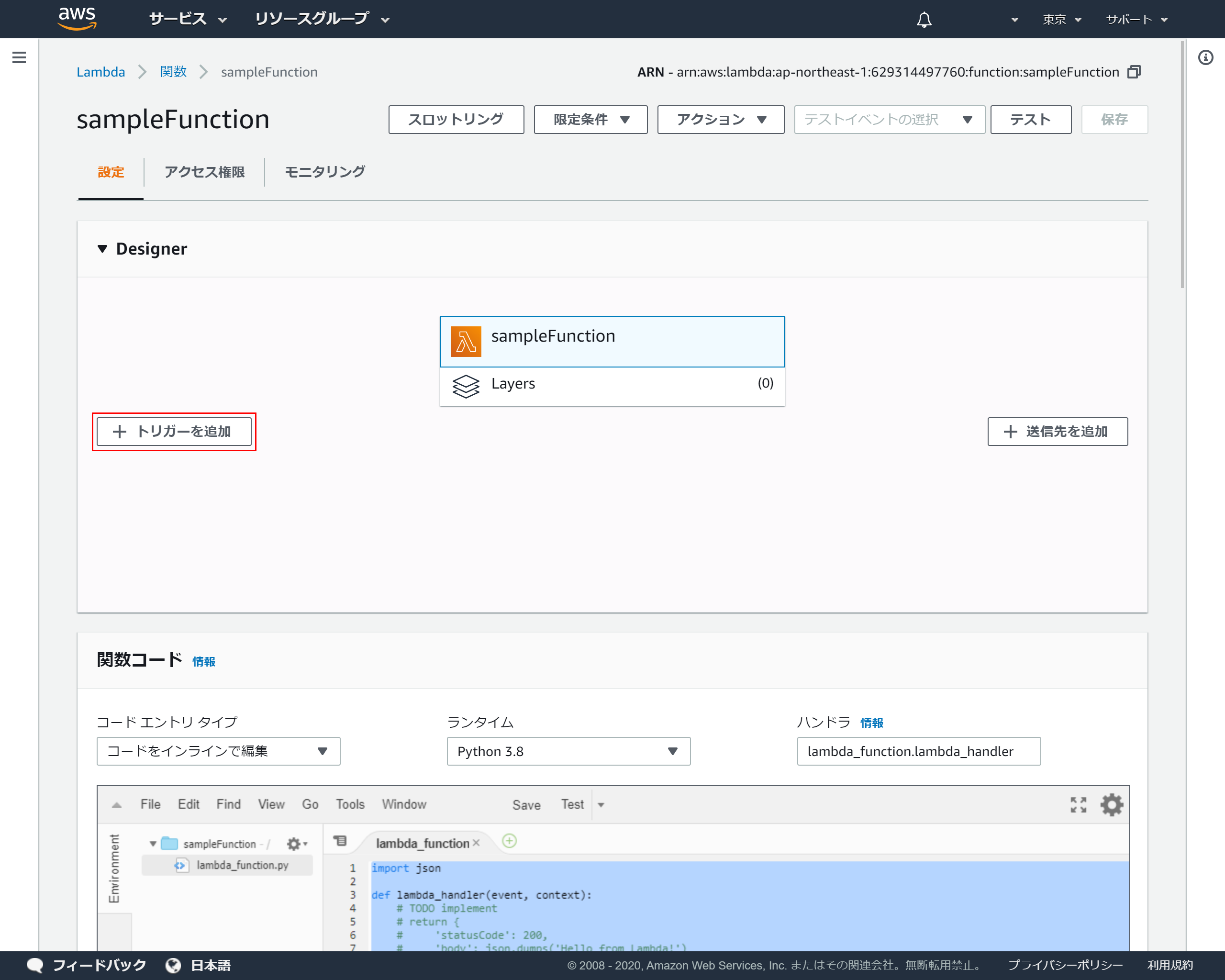
4-3.Lambdaトリガーの設定
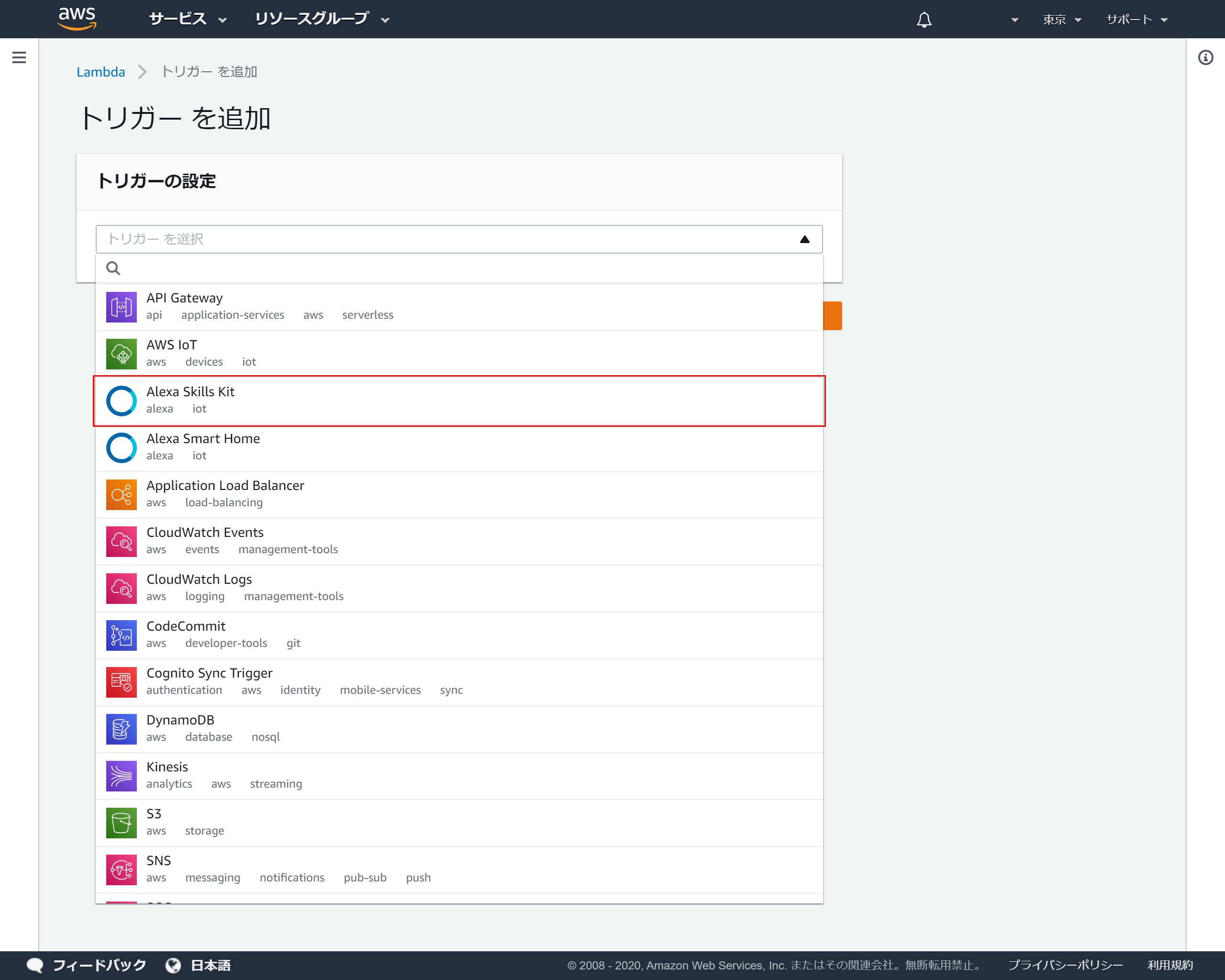
Lambdaに戻り「Designer」を開き「トリガーを追加」を押下
4-4.トリガーの追加
トリガーの設定のプルダウンより「Alexa Skills Kit」を選択
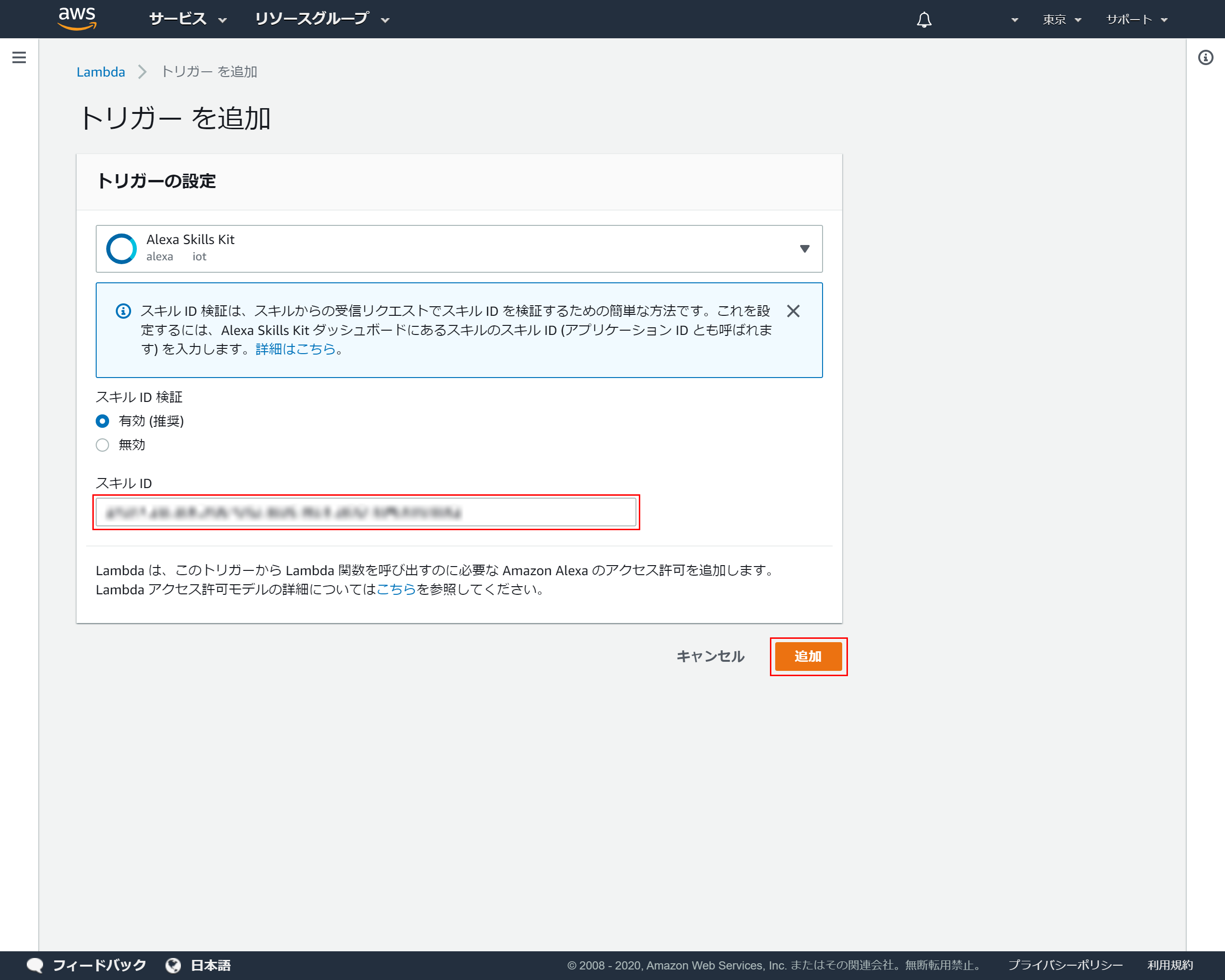
4-5.スキルIDの登録
トリガーの設定の「スキルID」に先ほど4-2でコピーしたスキルIDを貼り付け「追加」を押下
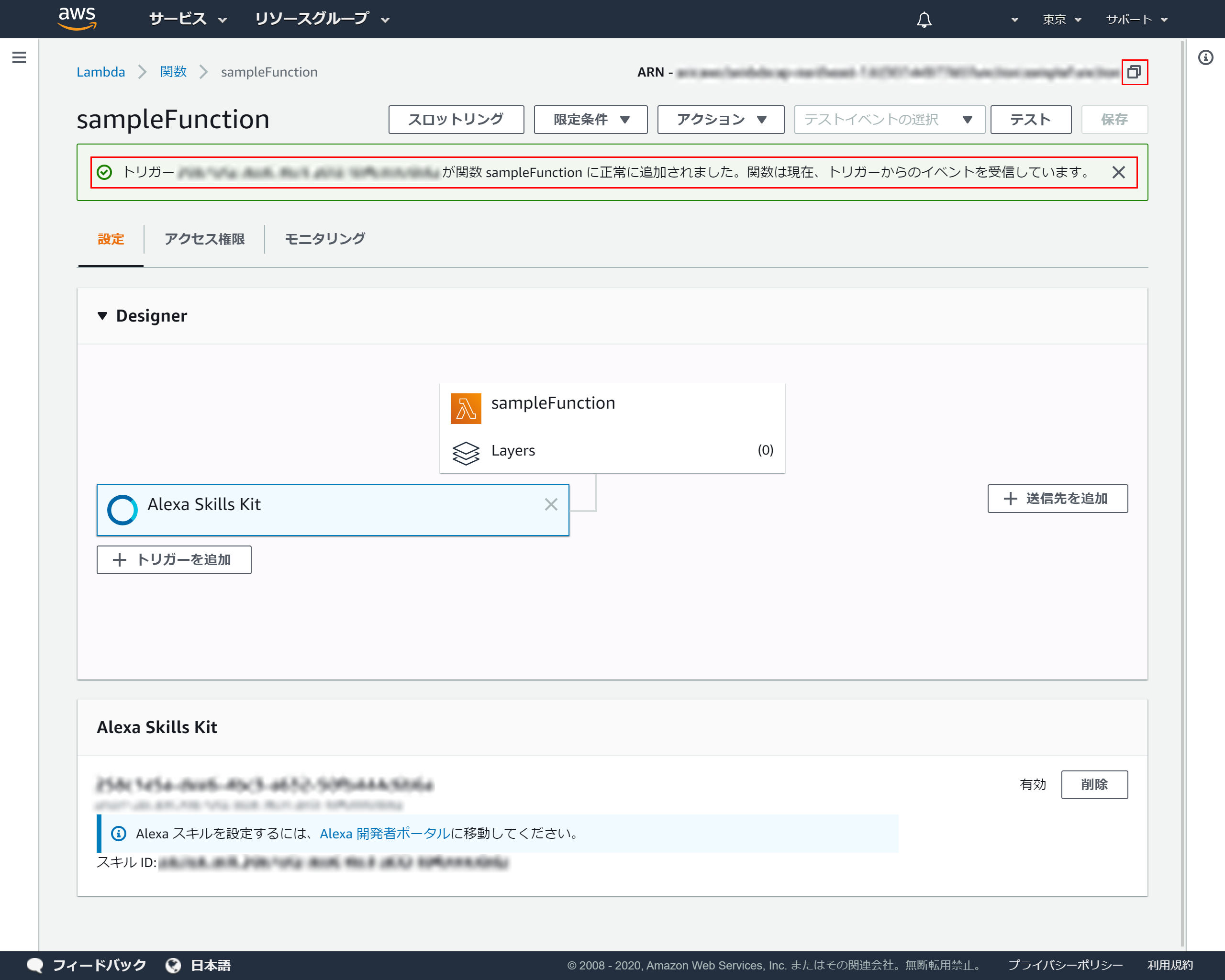
4-6.トリガーがの設定完了
トリガーが正常に登録できれば以下画面が表示されます
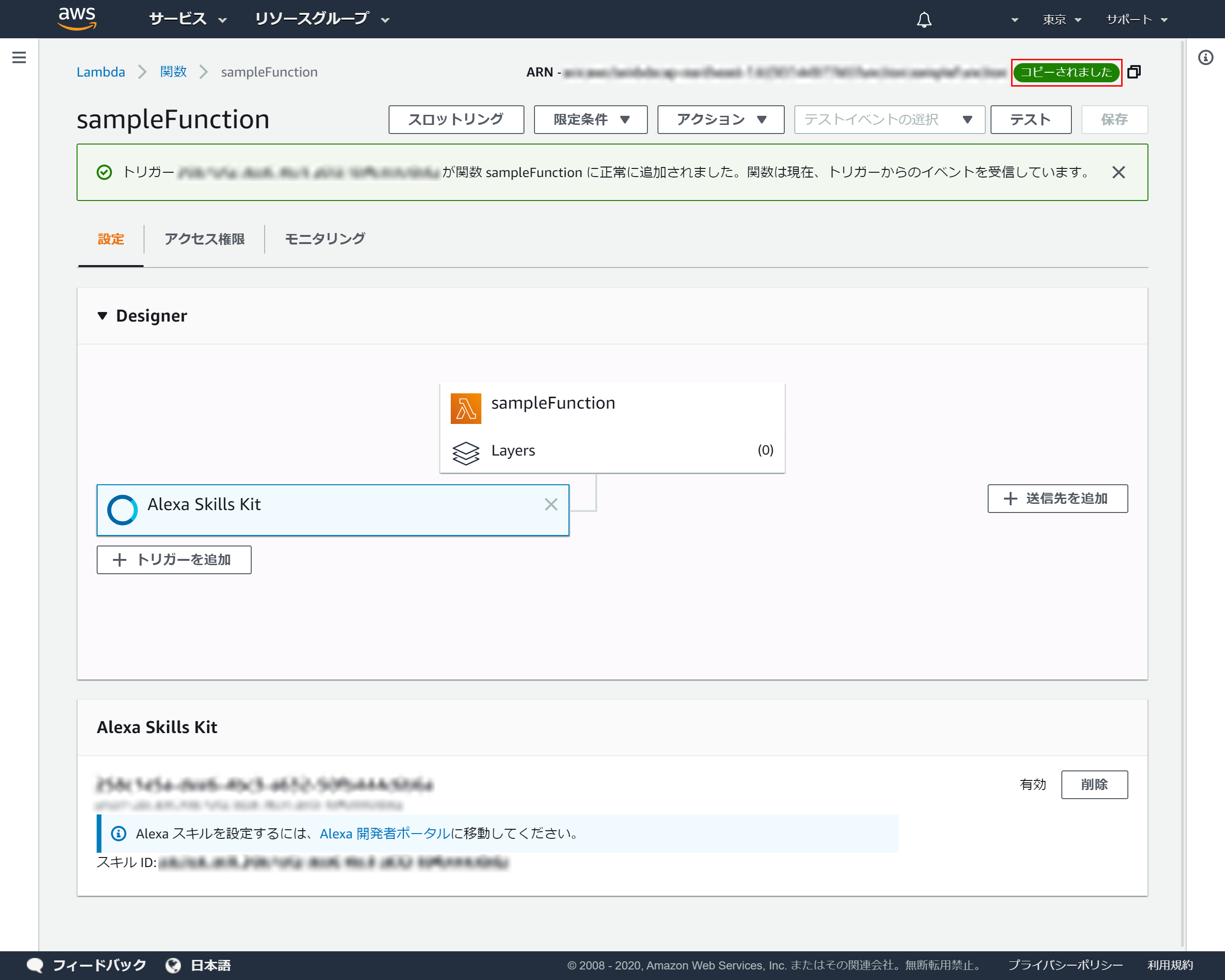
右上のコピーアイコンをクリックしてARNをコピーしてください
4-7.ARNのコピー
成功メッセージが表示されるとクリップボードにARNがコピーされます
4-8.エンドポイントの設定
alexaに戻り左側のメニューより「エンドポイント」を選択
「AWS LambdaのARN」を選択
4-9.エンドポイントの追加
- 「デフォルトの地域」に先ほどコピーしたARNを貼り付け
- 上部にある「エンドポイントを保存」を押下し、Lambdaとalexaの連携を完了させます
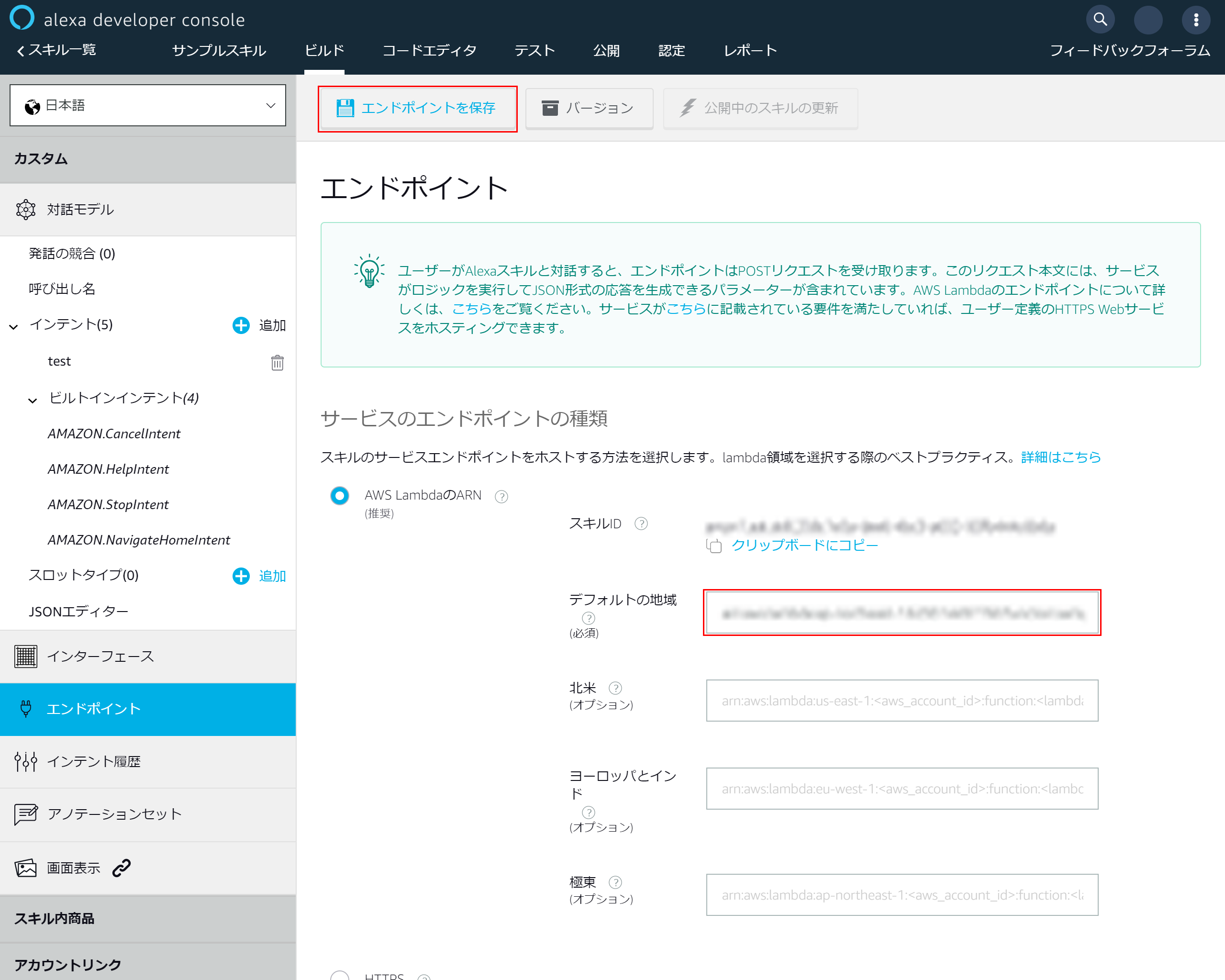
4-10.マニュフェストの保存成功メッセージが表示されます
5.alexaとCognitoをアカウントリンクで連携させる
5-1.ドメインの設定
Cognitoを表示して、左側のメニューより「ドメイン名」を押下
ドメインのプレフィックスに任意のドメインを入力 →このサンプルではalexa-sampleにしました
「変更を保存」を押下
5-2.ドメイン名のコピー
ドメインのURLをコピーしておいてください
5-3.アカウントリンクの設定
alexaに戻り左側のメニューから「アカウントリンク」を押下
5-4.アカウントリンクの詳細設定
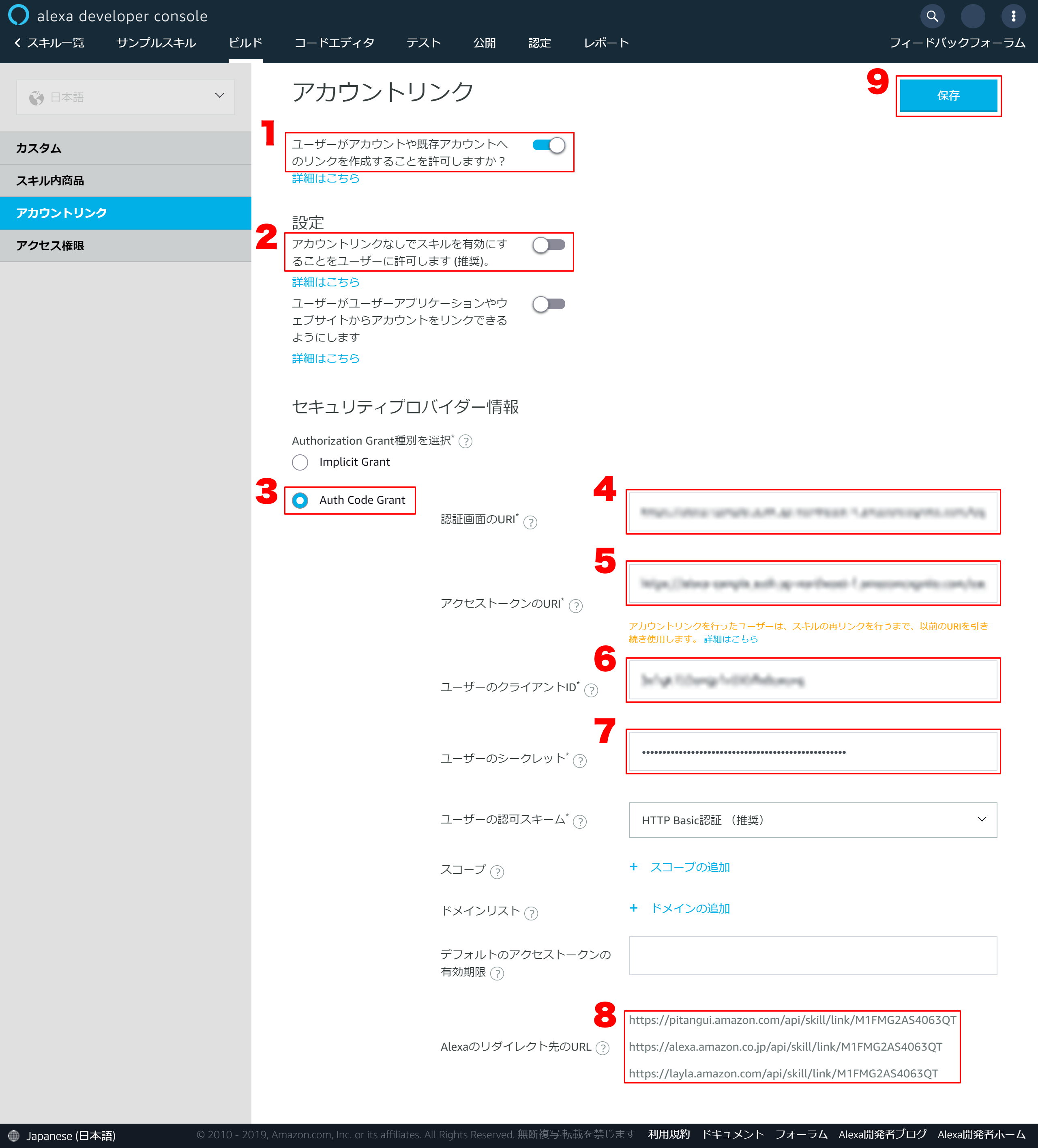
1.「ユーザーがアカウントや既存アカウントへのリンクを作成することを許可しますか?」をONにする
2.「アカウントリンクなしでスキルを有効にすることをユーザーに許可します (推奨)。」をOFFにする
3.「Auth Code Grant」を選択する
4. 「認証画面のURI」を以下フォーマットで設定するhttps://{Amazon Cognito ドメイン}/login?client_id={アプリクライアントID}&response_type=code&scope=aws.cognito.signin.user.admin&redirec ※{Amazon Cognito ドメイン}は5-2で保存したドメインのURL ※{アプリクライアントID}は2-14で保存していた「アプリクライアントID」5.「アクセストークのURI」を以下フォーマットで設定する
https://{Amazon Cognito ドメイン}/oauth2/token ※{Amazon Cognito ドメイン}は5-2で保存したドメインのURL6.「ユーザーのクライアントID」に2-14で保存していた「アプリクライアントID」を入力する
7.「ユーザーのシークレット」に2-14で保存していた「アプリクアライアントのシークレット」を入力する
8.Alexaのリダイレクト先のURLはコピーしておく
9.最後に「保存」を押下
5-5.保存の成功メッセージが表示される
5-6.アプリクライアントの設定
Cognitoに戻り左側のメニューから「アプリクライアントの設定」を押下
5-7.アプリクライアントの詳細設定
- 「Cognito User Pool」を選択
- 「コールバックURL」は5-4の8でコピーしたAlexaのリダイレクト先のURLをカンマでつないで登録する
- 「サインアウトURL」は「https://alexa.amazon.co.jp」を入力
- 「許可されている OAuth フロー」で「Authorization code grant」を選択
- 「許可されている OAuth スコープ」で「aws.cognito.signin.user.admin」
- 「変更の保存」を押下

5-8.登録完了
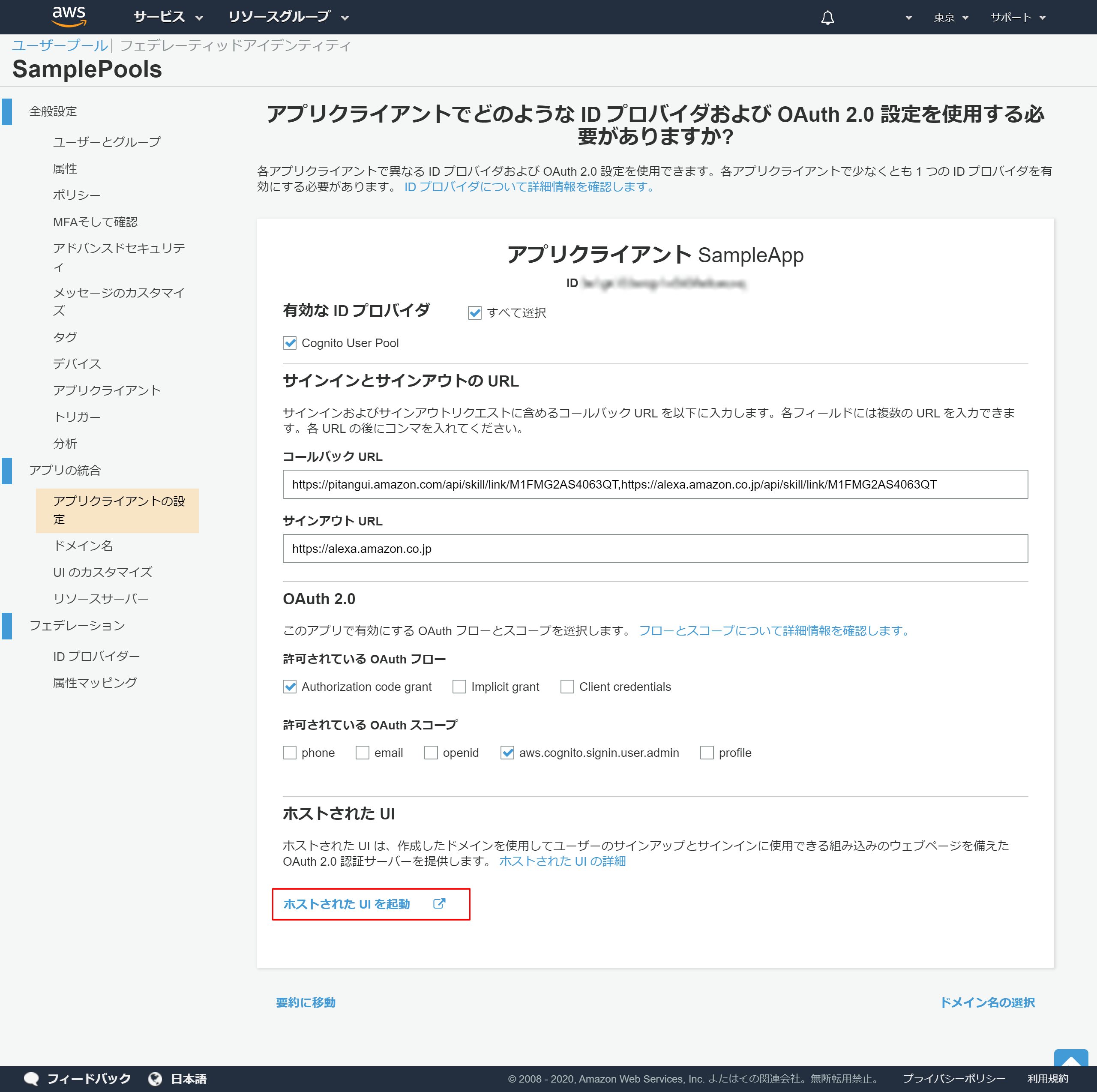
「ホストされたUIを起動」のリンクが表示されれば登録は成功しています
6.alexaとCognitoをアカウントリンクで連携させる
6-1.alexa公開設定
alexaに戻り上部の「公開」メニューを押下
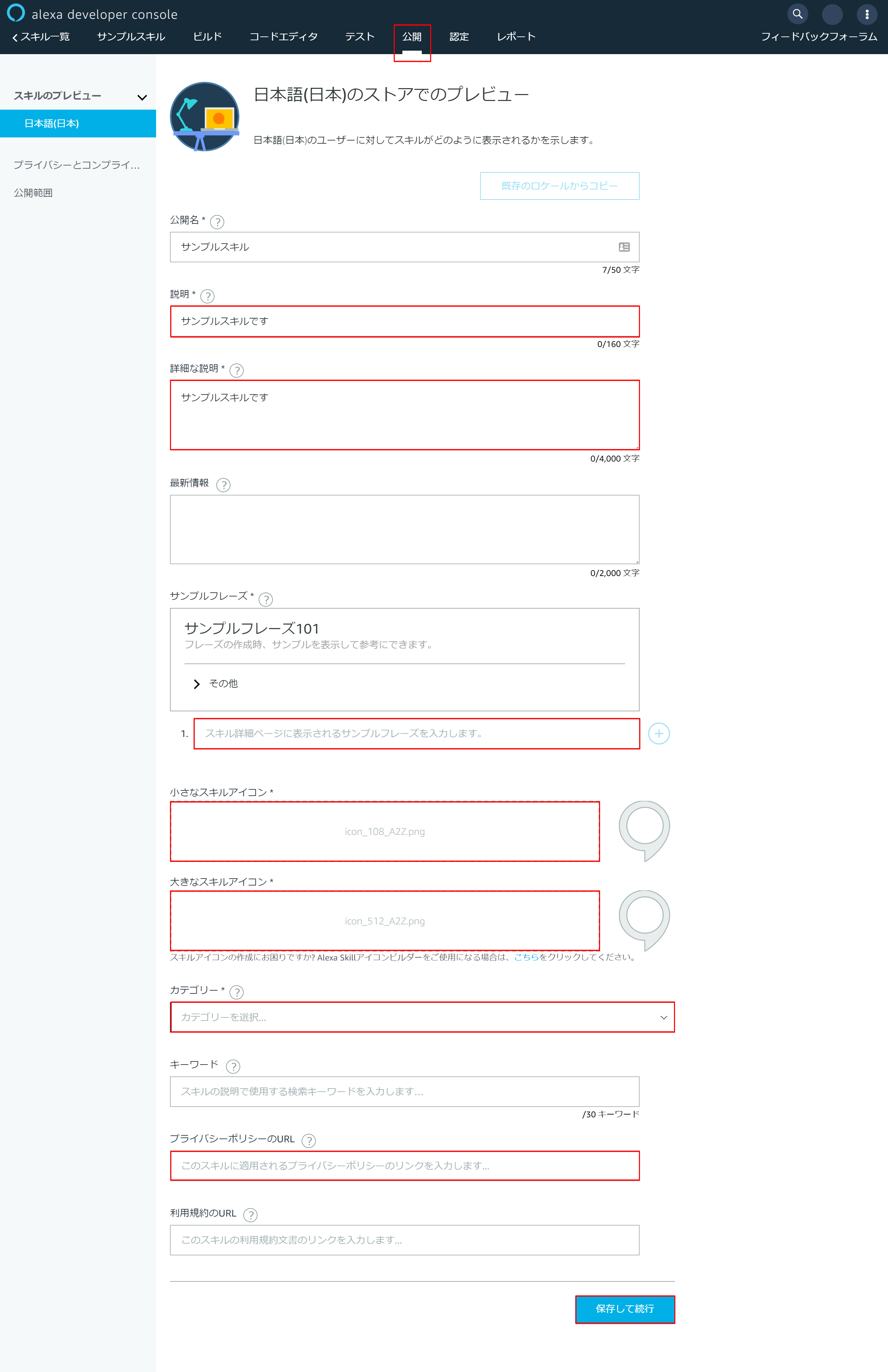
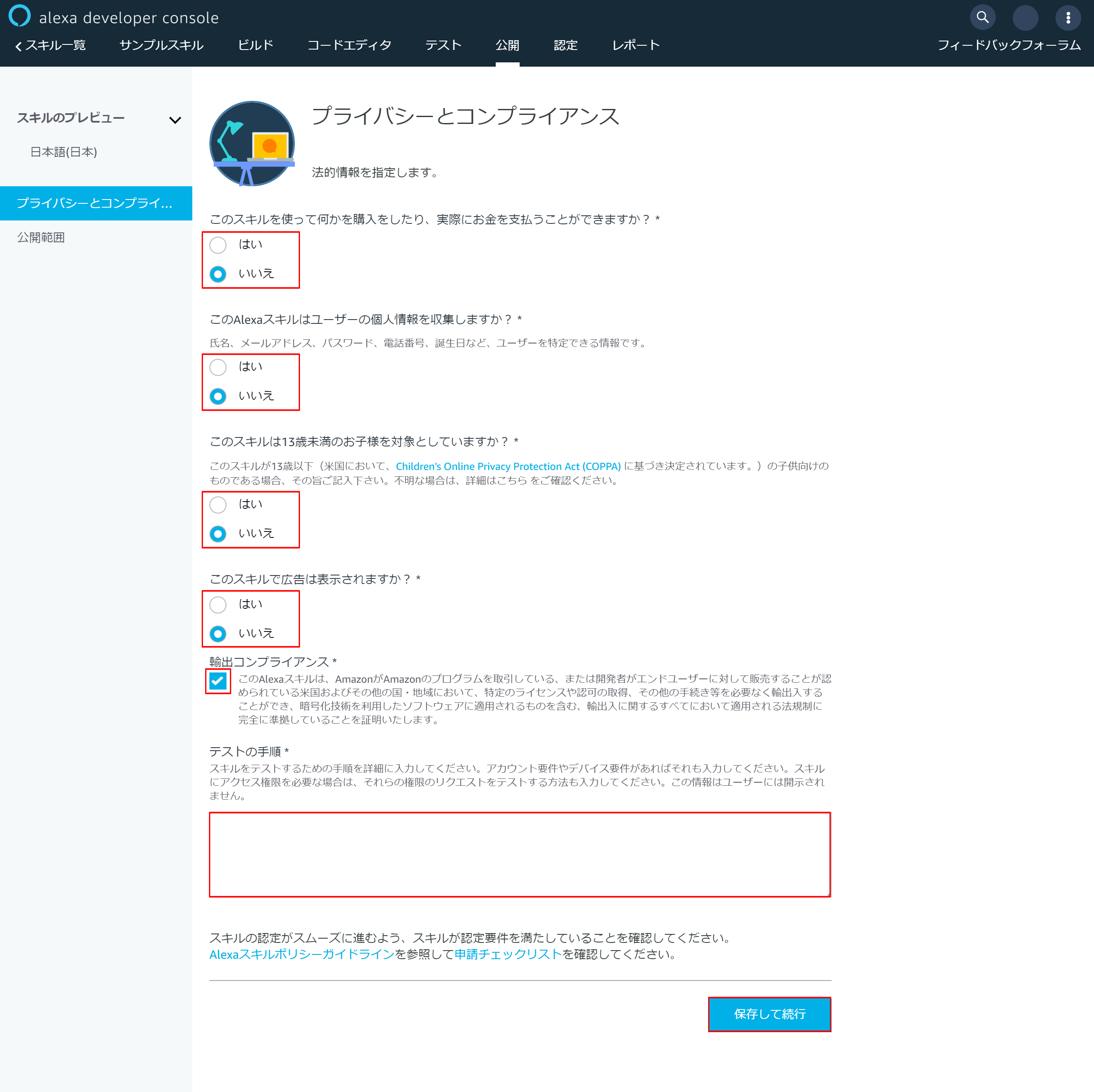
以下赤枠の部分を入力して最後に「保存して続行」を押下
6-2.プライバシーとコンプライアンス設定
赤枠を入力して最後に「保存して続行」を押下
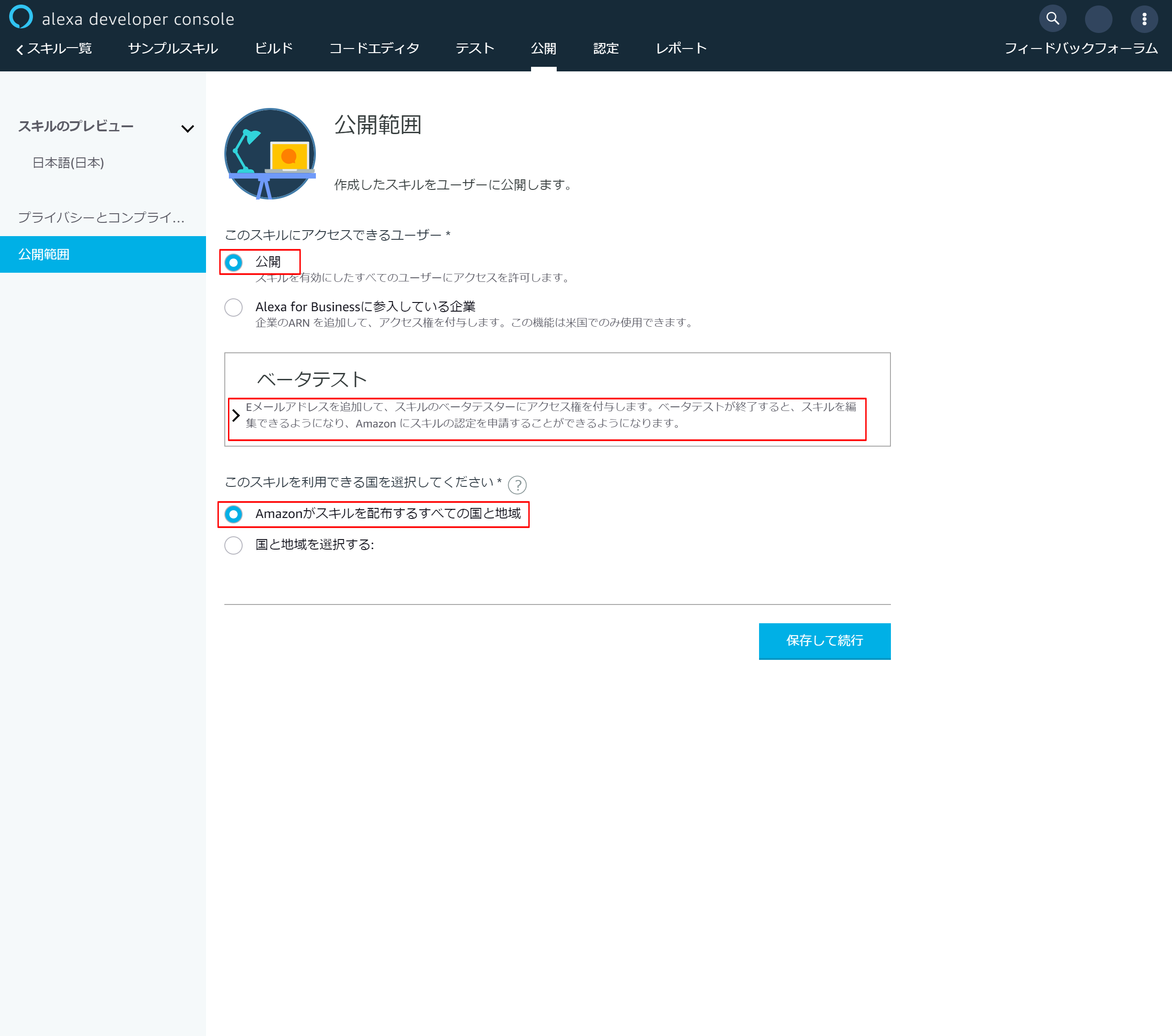
6-3.公開範囲設定
赤枠部分を設定する
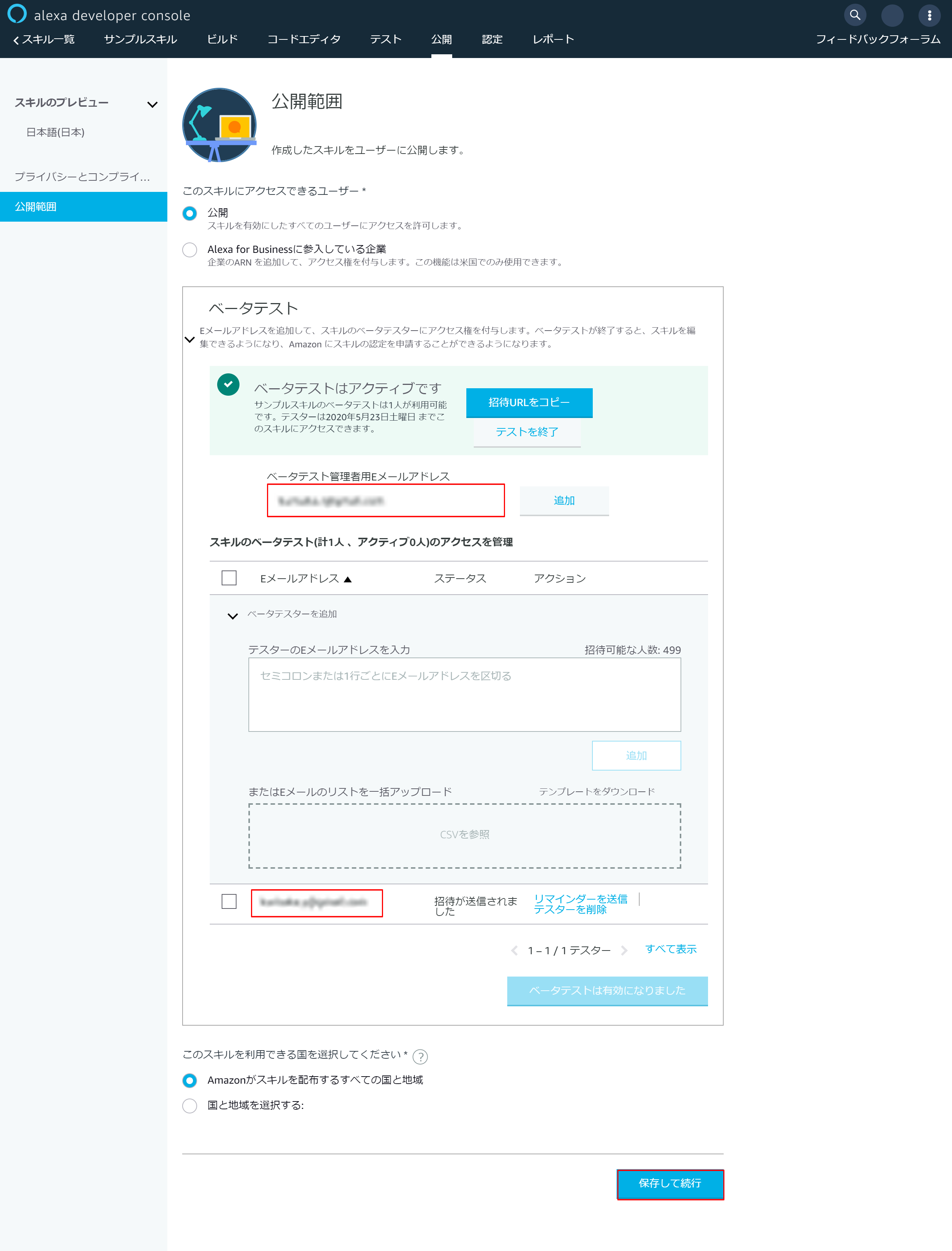
6-4.ベータテスト設定
- 「ベータテスト管理者用Eメールアドレス」を設定
- 「テスターのEメールアドレス」を設定
- 「保存して続行」を押下
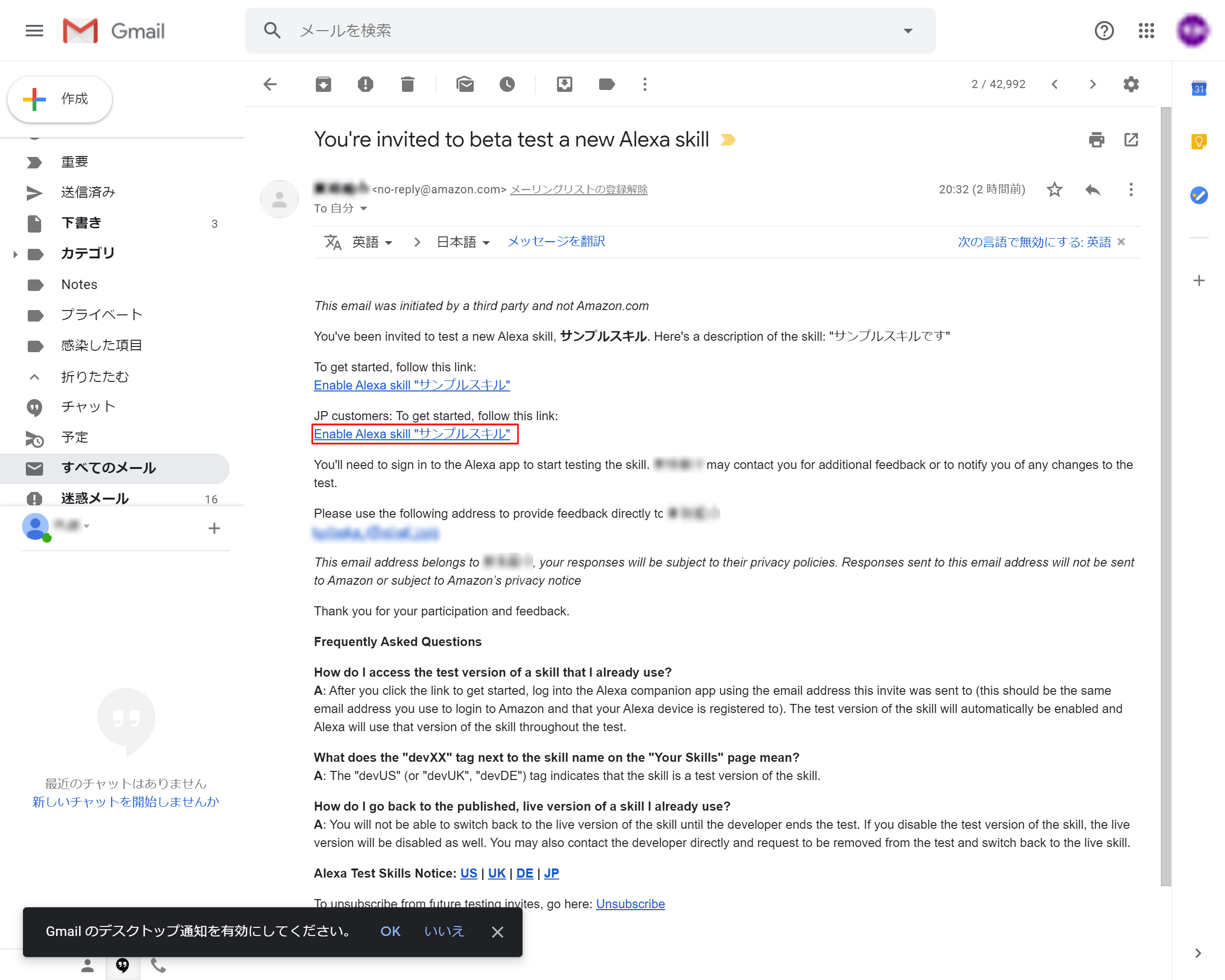
6-5.招待メールのリンクを押下
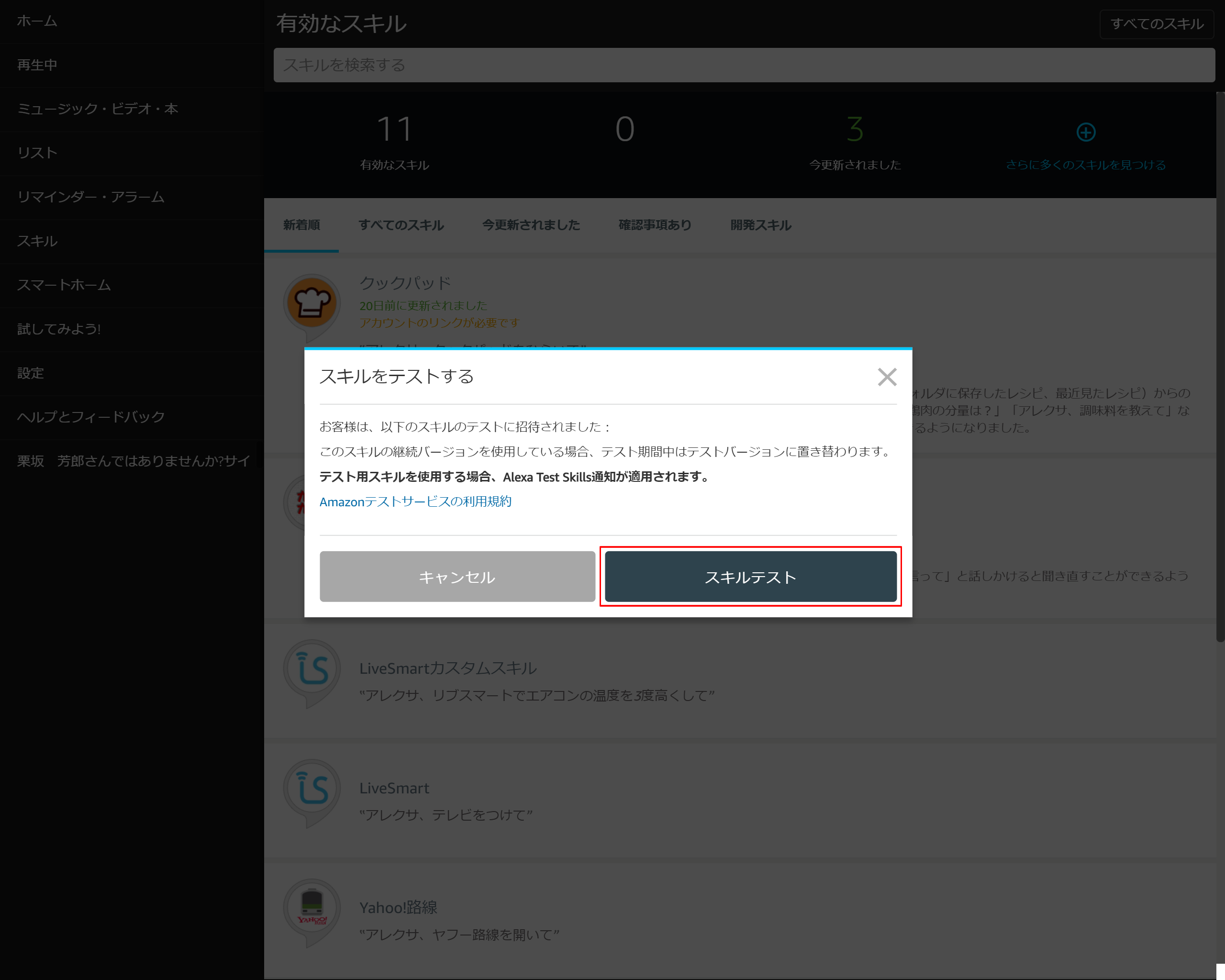
赤枠のリンクを押下する
6-6.「スキルテスト」を押下する
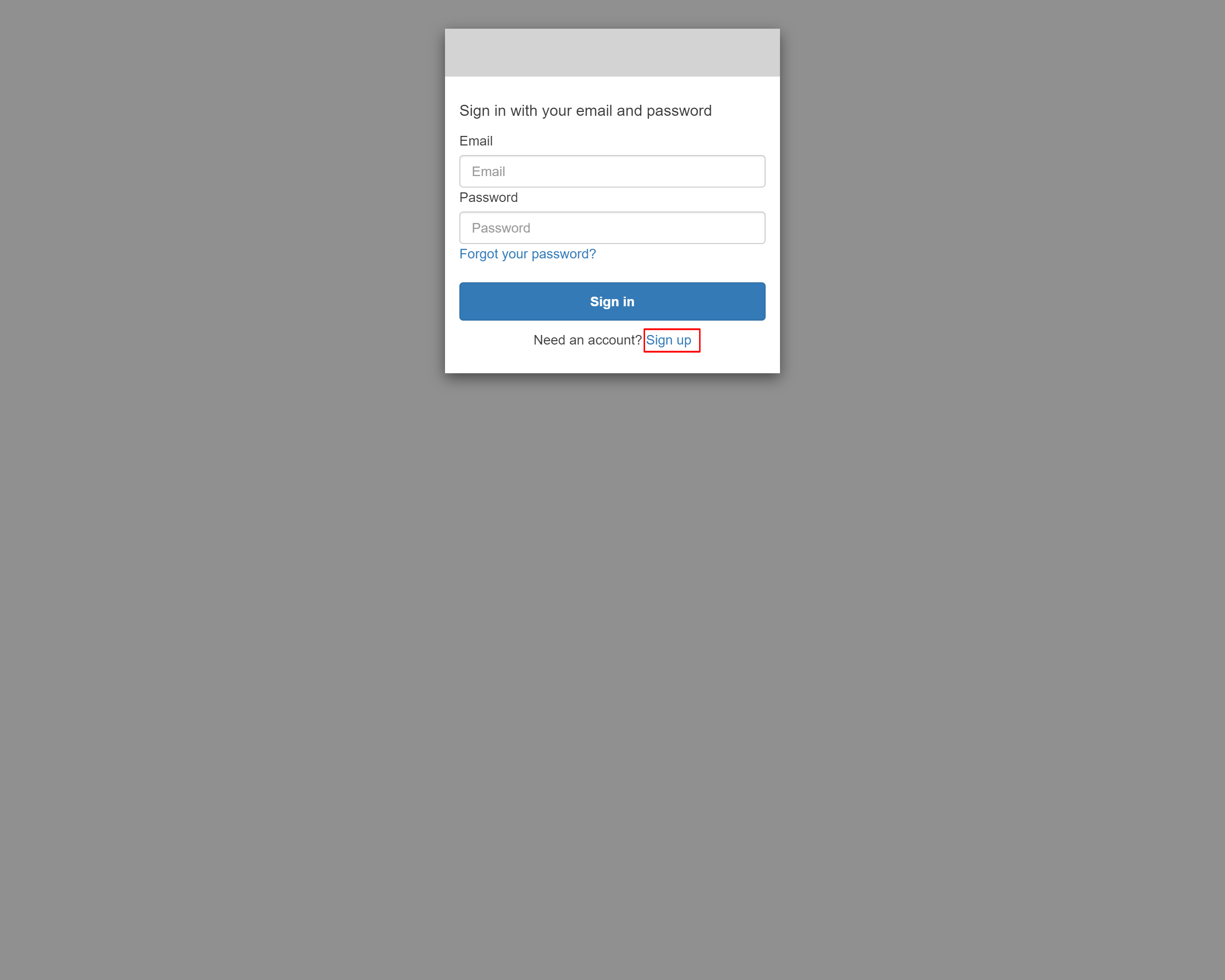
6-7.「有効にする」を押下する
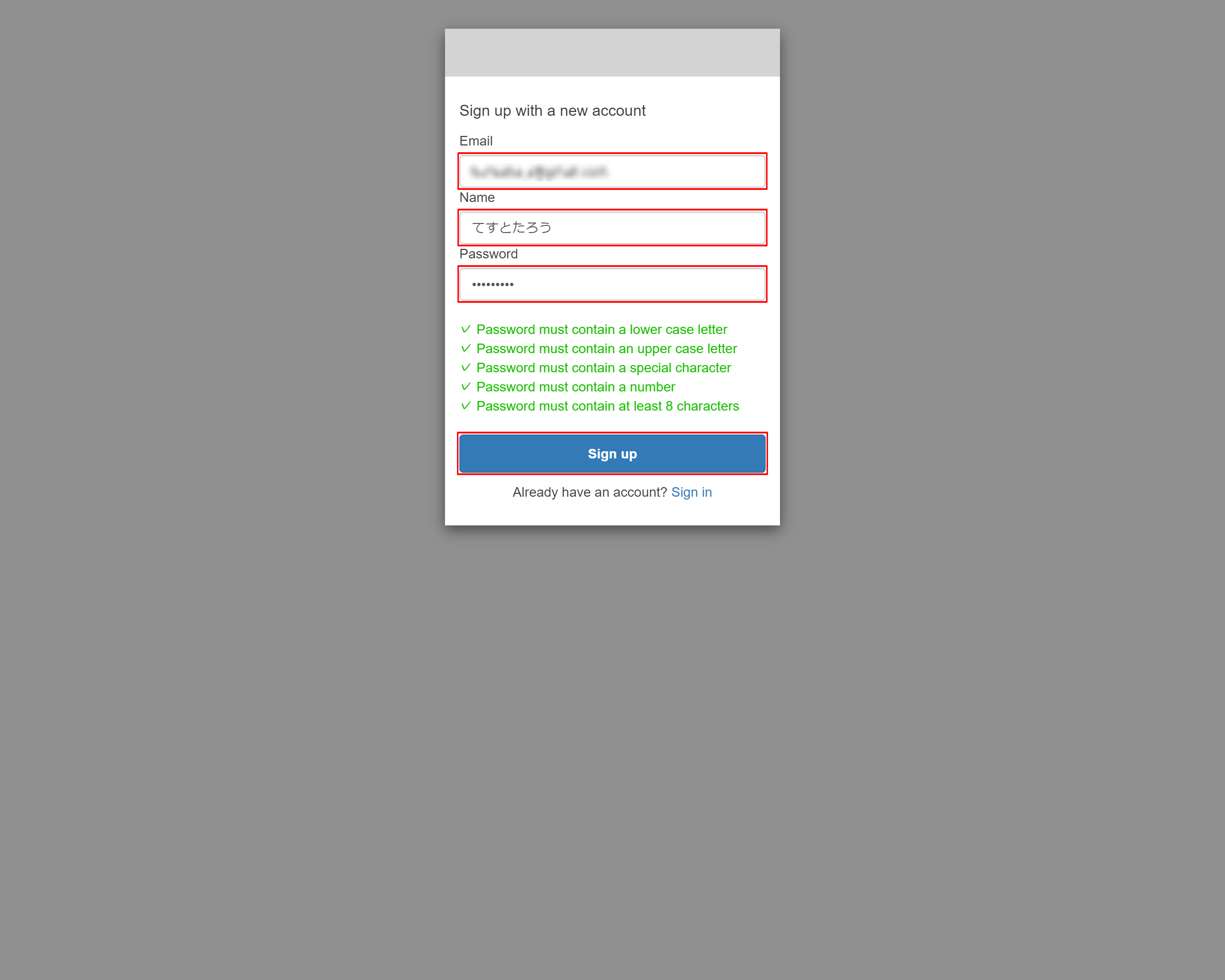
6-8.Sign in画面が表示されたら、Sign upリンクを押下する
6-9.Sign up画面にアカウント情報を入力します
最後に「Sign up」を押下します
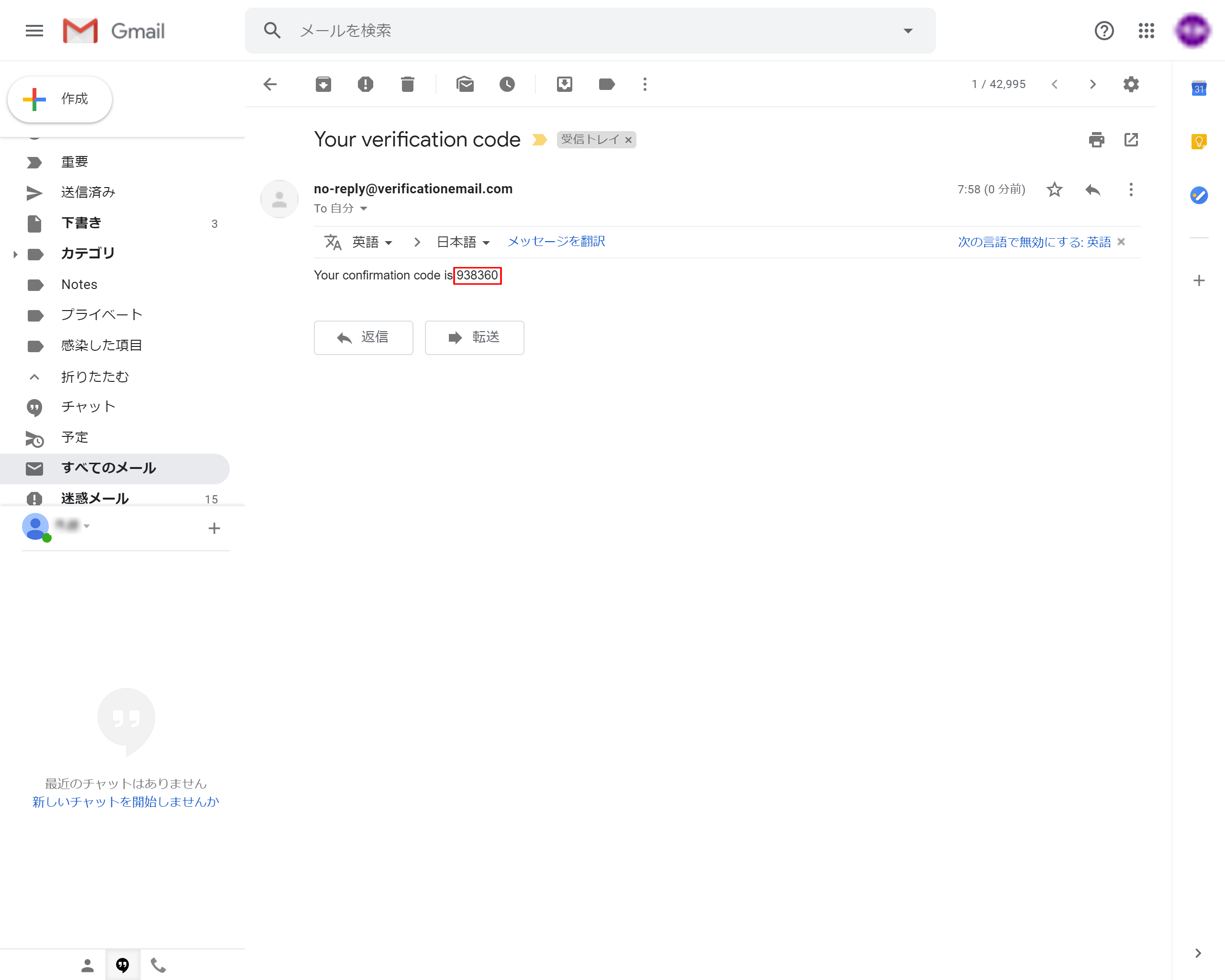
6-10.設定したEmailにverification Codeが送られてきます
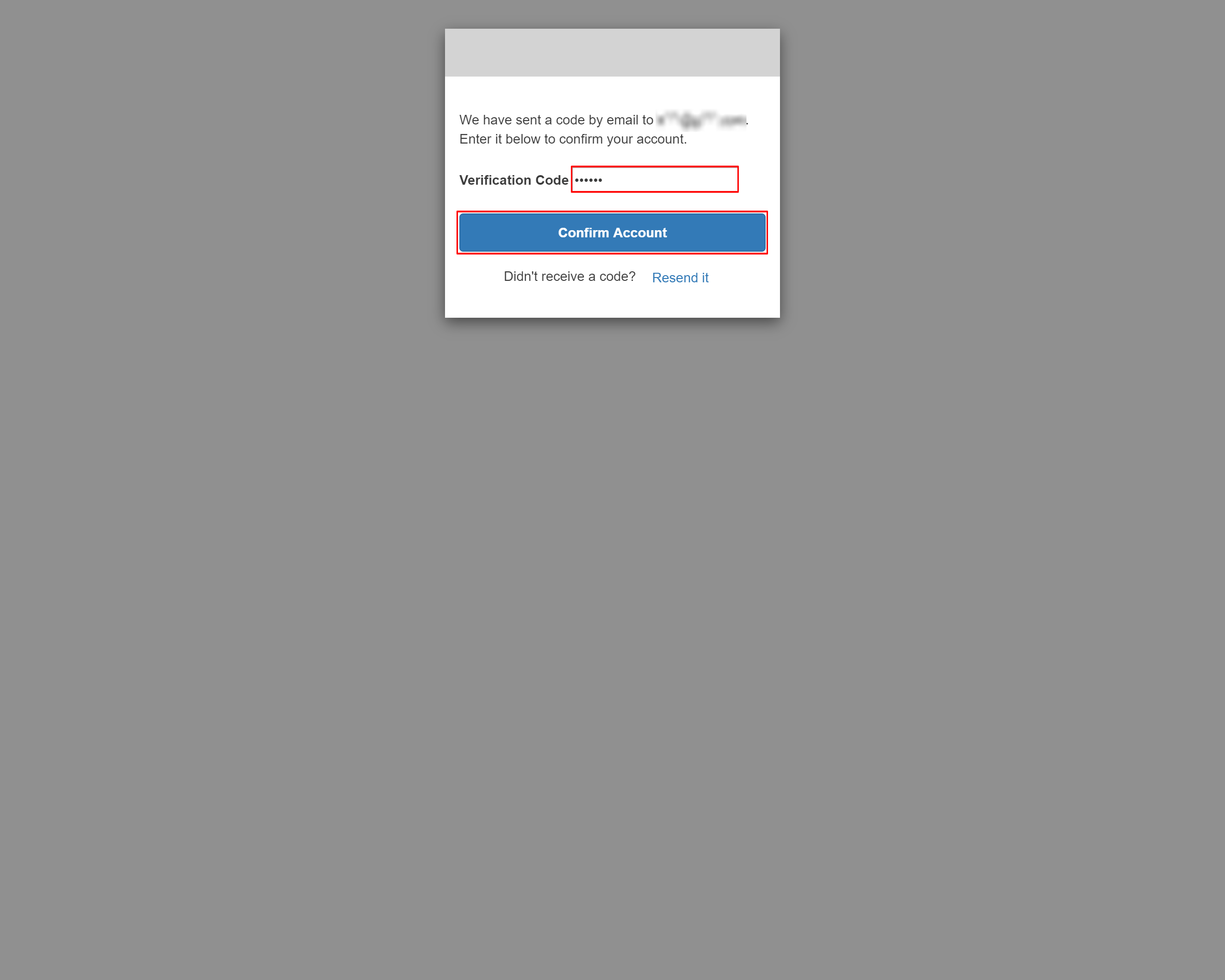
6-11.表示された画面にverification Codeを入力して「Confirm Account」を押下します
6-12.アカウントリンク成功のメッセージが表示される
7.動作確認
7-1.iPhoneアプリから動作を確認
1.「サンプルスキルを開いて」と発話する
2.「こんにちは」と発話する
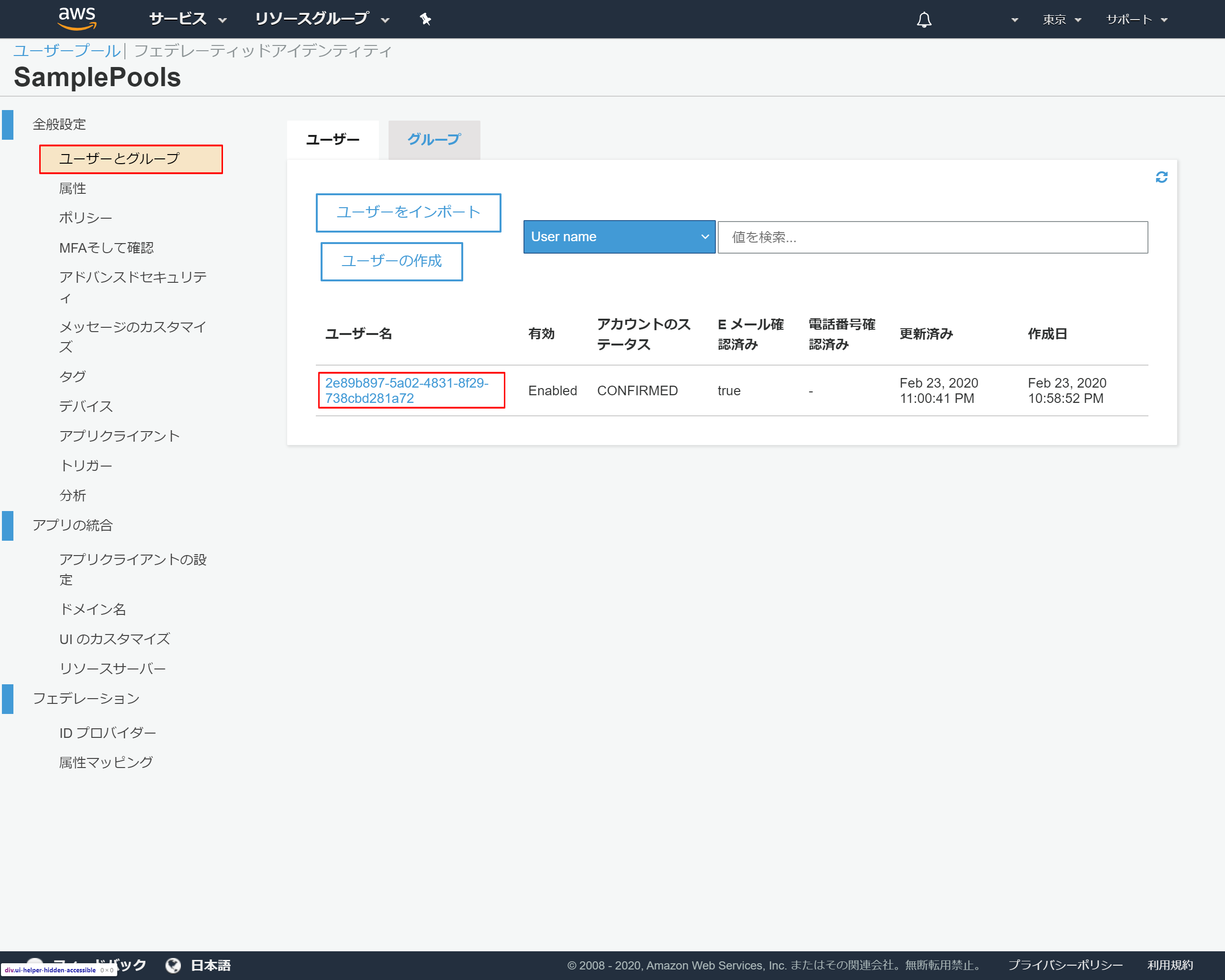
7-2.Cognitoの登録状況を確認
左側のメニューより「ユーザーとグループ」を押下
ユーザー名のリンクを押下
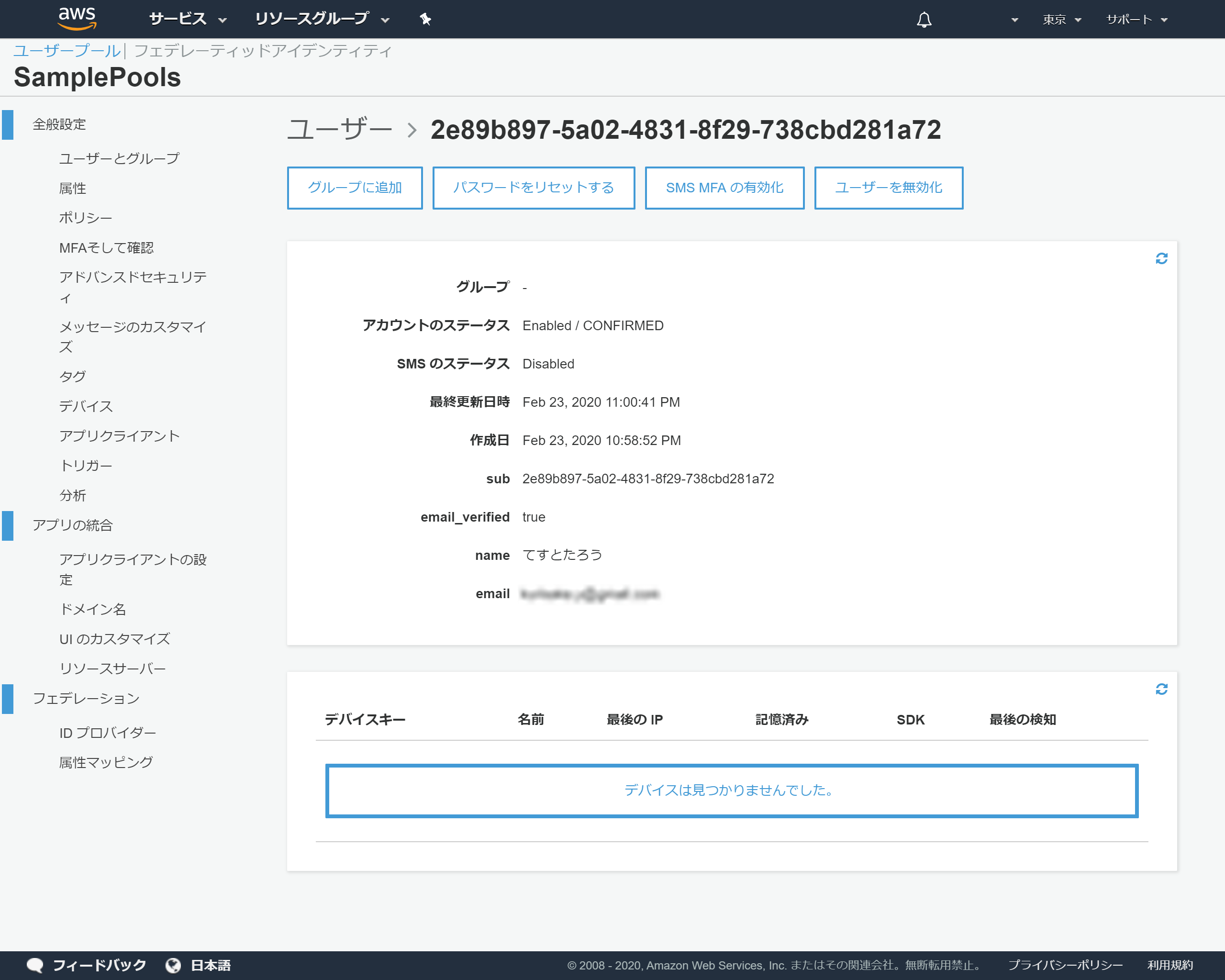
詳細情報が表示される











- 投稿日:2020-02-24T16:21:56+09:00
そろそろaws初めてみよか#6~Elastic Beanstalkによるlaravel~
はじめに
前回まででCodeStar、EC2、RDSによるlaravel環境が整ったわけですので
次はElastic Beanstalkにチャレンジしてみます。Elastic Beanstalkの環境構築
まずはPHPのサンプル環境を作成してみようと思います。
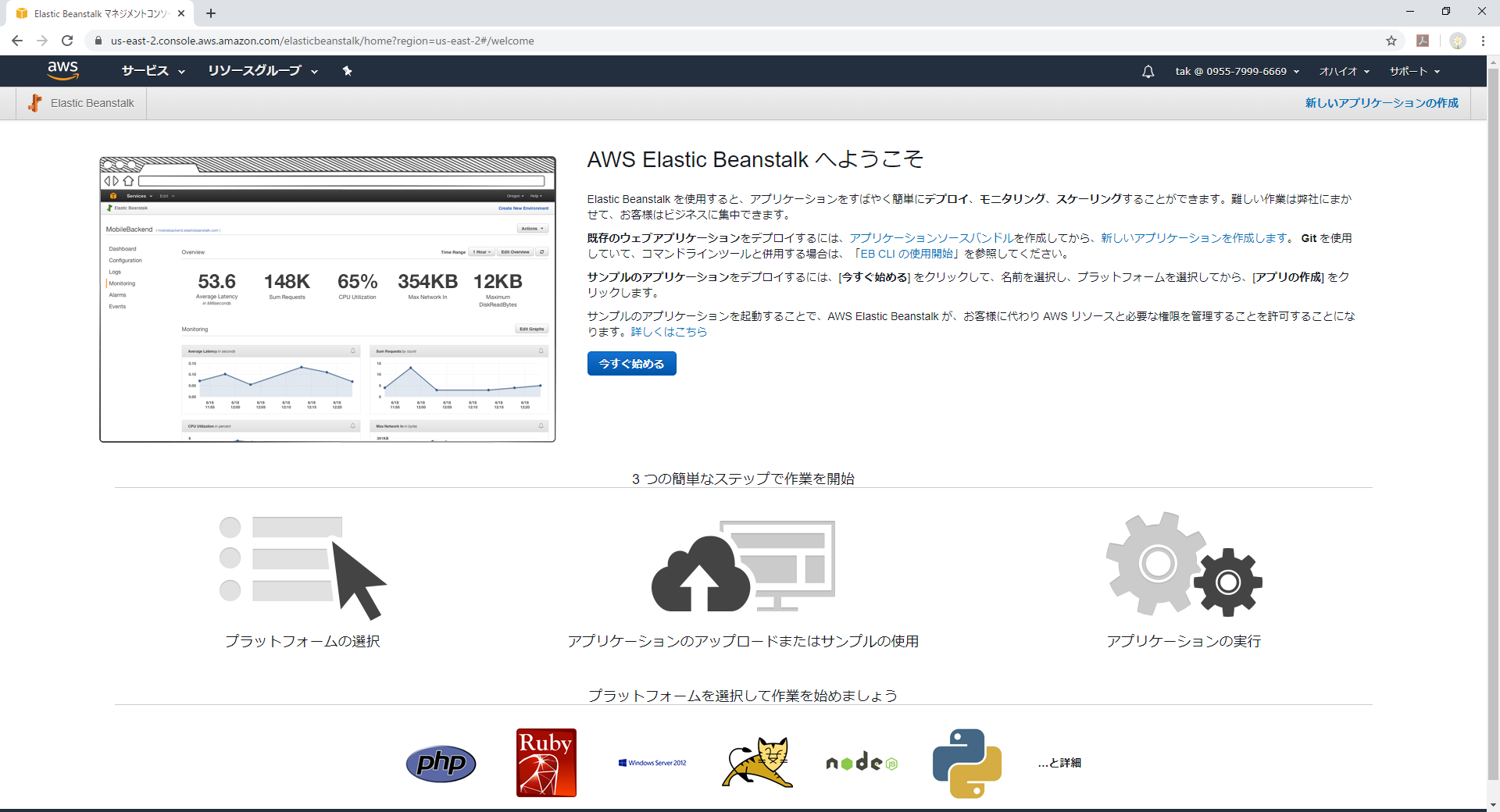
そこからlaravel色に染めましょう(^^♪Elastic Beanstalkのコンソールから[今すぐ始める]をクリック
アプリケーション名はlaravel、プラットフォームはphp、アプリケーションコードはサンプルを選択します。
数分すると環境が出来上がります。
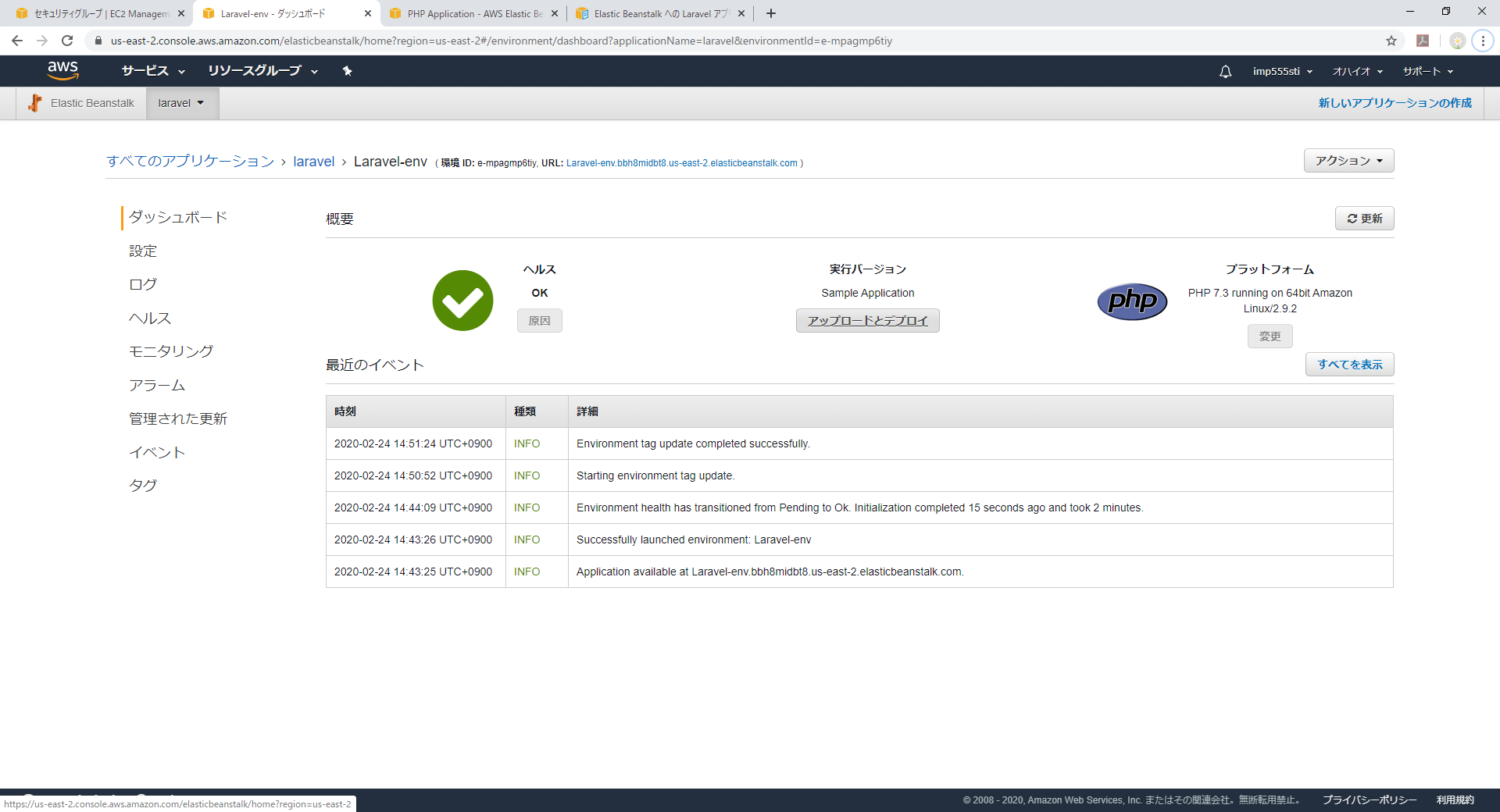
ダッシュボードのURL欄のURLをクリックするとデプロイされたアプリケーションにアクセスできます。
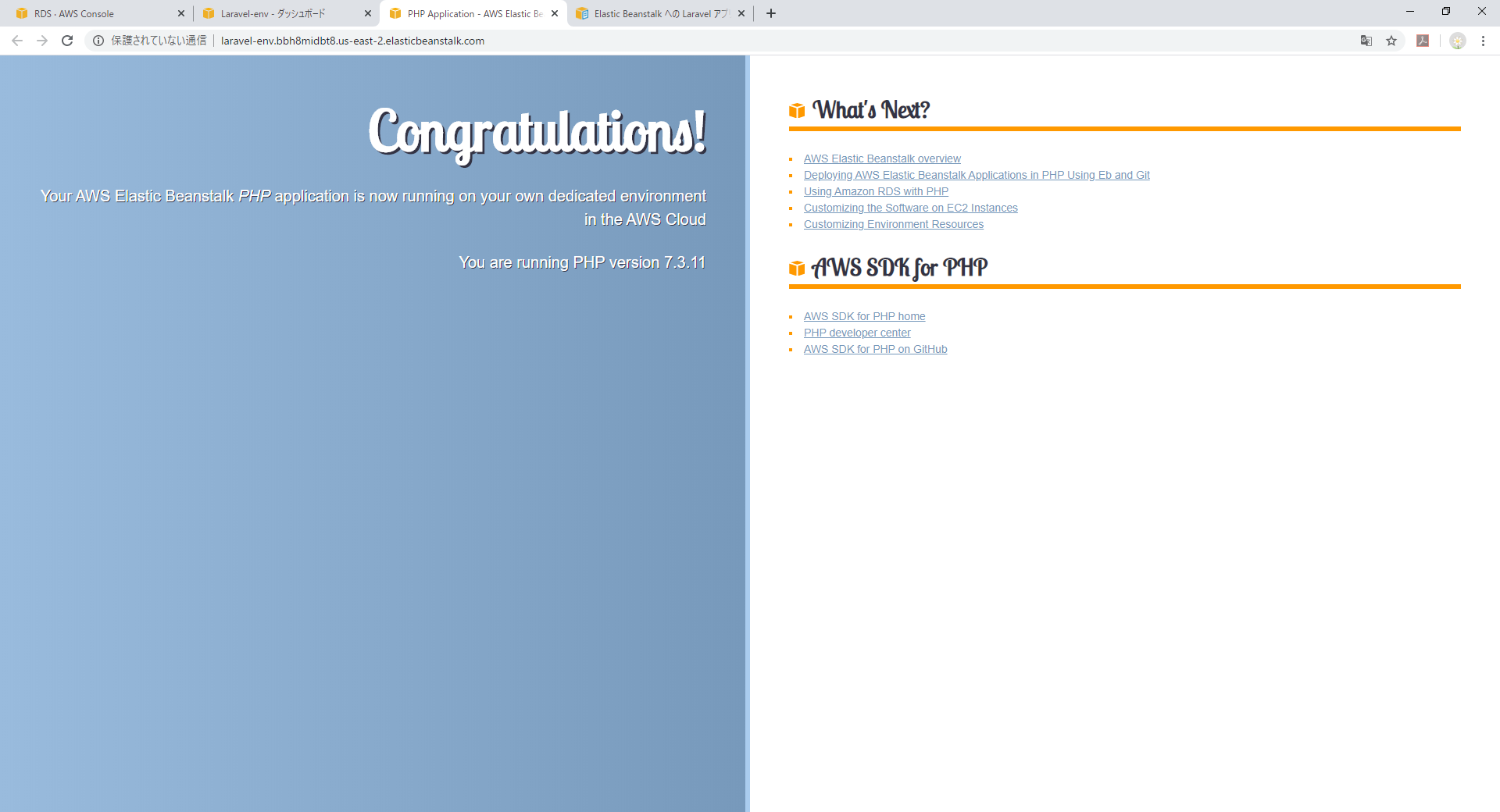
PHP7.3.11らしいです。
ほぼクリックだけで実行環境ができました。
Laravelアプリケーションの作成
さてLaravelにするにはどうしたらよいかと言うと、Vendor配下以外のファイルをZIPに固めてアップロードするとデプロイされます。
せっかくなのでチュートリアルに沿った形で進めたいと思います。
Elastic Beanstalk への Laravel アプリケーションのデプロイまずは既存のEC2 Laravel環境(前回作成した環境ね)に新規にLaravelプロジェクトを作成します。
[ec2-user@ip-172-31-29-127 ~]$ composer create-project --prefer-dist laravel/laravel eb-laravel環境設定ファイル
.envをいじります。
変更したのはDB_HOST,DB_DATABASE,DB_USERNAME,DB_PASSWORDです。[ec2-user@ip-172-31-29-127 eb-laravel]$ cat .env : DB_CONNECTION=mysql DB_HOST=database.culgyynq9ap1.us-east-2.rds.amazonaws.com DB_PORT=3306 DB_DATABASE=laravel_eb DB_USERNAME=admin DB_PASSWORD=******** :次にDB接続を手軽に試すためチュートリアルにあるようindex.phpを修正します。
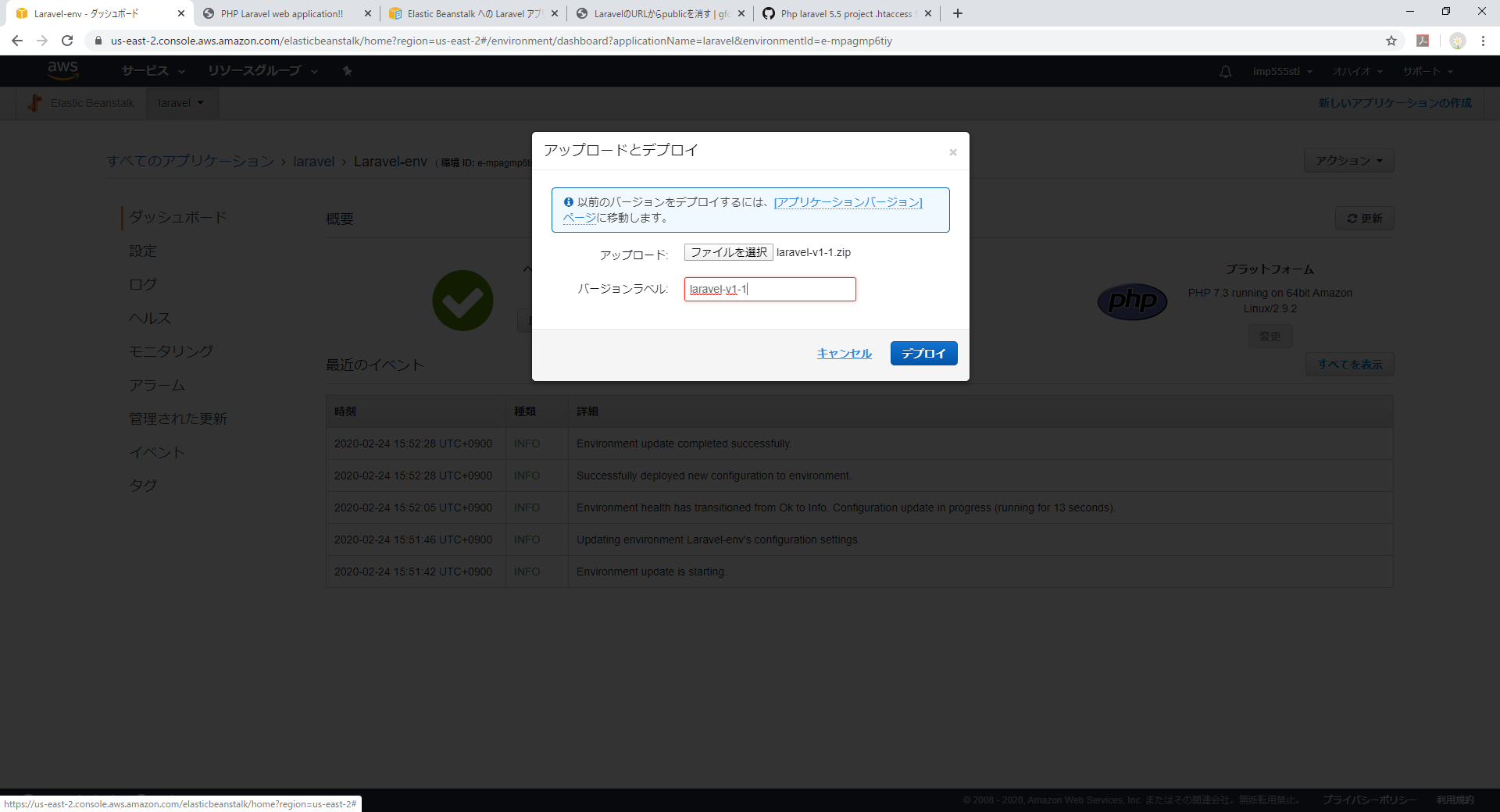
// DB Connection Testのところから3行分です。eb-laravel/public/index.php$kernel = $app->make(Illuminate\Contracts\Http\Kernel::class); $response = $kernel->handle( $request = Illuminate\Http\Request::capture() ); // DB Connection Test if(DB::connection()->getDatabaseName()){ echo "Connected to database ".DB::connection()->getDatabaseName(); } $response->send(); $kernel->terminate($request, $response);修正したらElastic Beanstalk用にソースをZIPに固めます。
[ec2-user@ip-172-31-29-127 eb-laravel]$ zip ~/laravel-v1-1.zip -r * .[^.]* -x "vendor/*"これをTeraTermならSSH SCPなどで取得します。
Elastic BeanstalkのLaravel向け環境設定
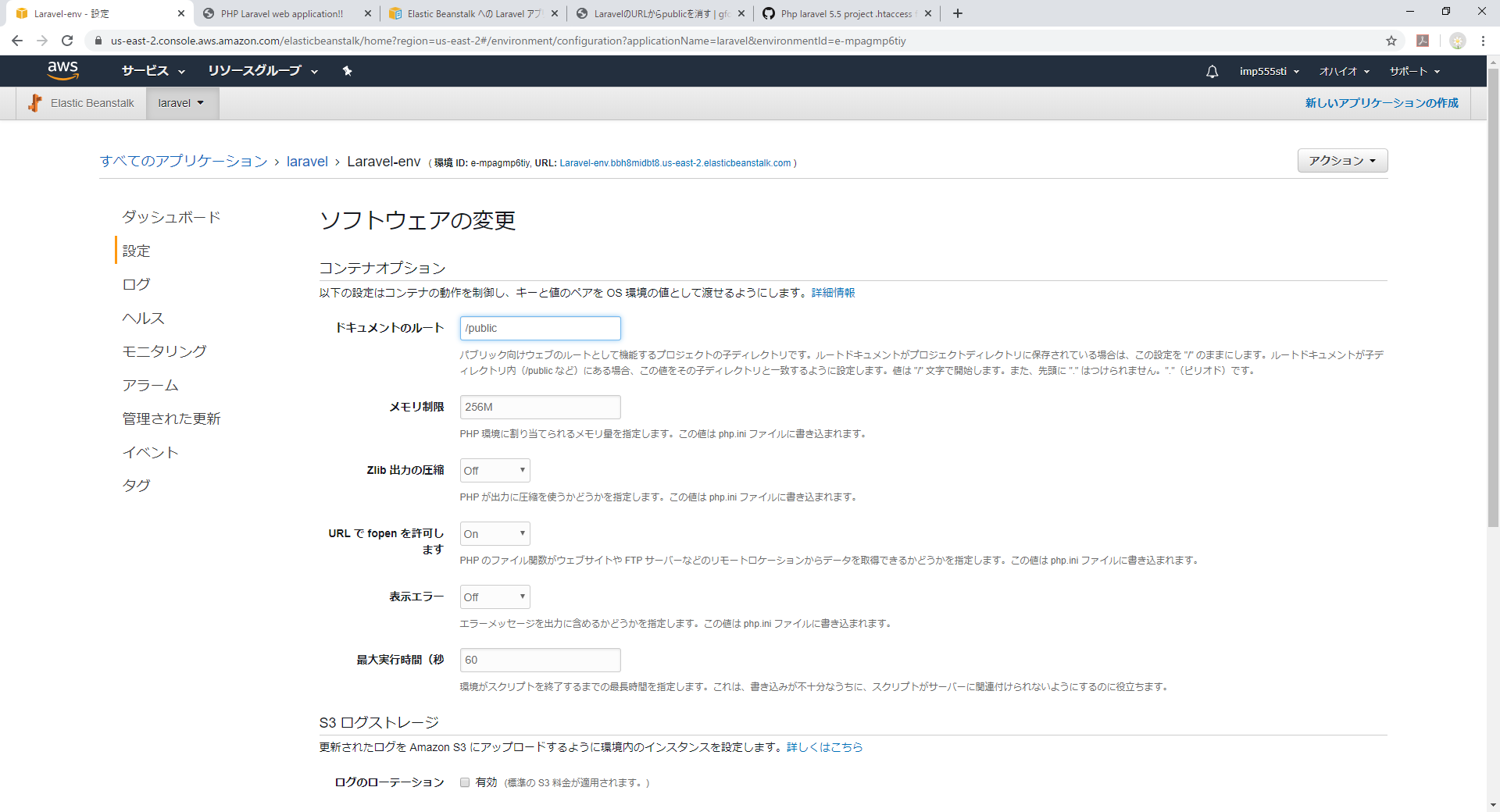
Laravelはご存じの通りdocument_rootはpublic配下です。
これをElastic Beanstalkにも定義します。ダッシュボードの設定からソフトウェアの[変更]ボタンをクリックし
TOPにあるドキュメントのルートを/publicに変更し保存します。
保存するとElastic Beanstalkが環境変更の取り込みを行うのでしばし待ちます。
これでElastic Beanstalk側の準備が整ったので、[アップロードとデプロイ]ボタンより
先ほどZIP化したソースをアップロードしデプロイします。
しばし処理が走ったのちにURLにアクセスすると御覧の通り
Laravelの初期Home画面と左上に仕込んだDBConnectionのサンプルコードの実行結果が表示されます。
最後に
あくまで実行環境ですので、artisan migrateなどは他のEC2インスタンスから実行した後にこちらにリリースするイメージでしょうか


- 投稿日:2020-02-24T15:43:19+09:00
AWS試験対策(⑬移行とコスト管理のサービス)
ラストです。
移行のためのサービス
TCO Calculatorによってオンプレ上で実行されているアプリケーションとAWSにおけるアプリケーションのTCOを比較できる。TCOは総所要コストのこと。
ADSによって現行オンプレの状況把握ができる。
サーバ移行にはMigration Hubで状況確認できたり、VM Import/ExportやSMSでVMの移行がそのままできたりする。SMSはVM Import/Exportの多機能バージョン的な。VMware vSphereとHyper-Vをサポートしている。
DB移行にはRDBを移すならDMS、大容量であるならSnowballを使う。標準的移行としてストレージGWを使用する方法もある。
Snowballはハードウェア送ることで物理的な転送ができる。Amazonすげえ。これによってペタバイト級でもオンラインで転送するより早く転送できる。コスト管理
Cost ExplorerとTrusted Advisorがある。
Cost Explorerではリソースの使用量を時系列のグラフで確認できる。また、過去の実績から参照して、今後3か月のコストを予測してくれる。
Trusted Advisorでは節約できるところを探してコスト最適化のための項目を推奨してくれる。簡単だが以上。模試を受けて問題解いて試験を受けてこようと思う!!
- 投稿日:2020-02-24T15:14:12+09:00
AWS試験対策(⑫分析サービス)
分析サービス編です。RedshiftはDBでやったんで省略します。
分析のためのサービス概要
流れとしては、AWS SnowballやKinesisでデータを収集し、S3に保存。その後EMRやData PipelineやGlueで抽出/加工し、RedshiftやAthenaで分析する。それをQuickSightで可視化するっていった流れ。
AmazonKinesisの各種サービス
よっつある。Kinesis Data Streams、Kinesis Data Firehose、Kinesis Data Analytics、Kinesis Video Streamsの四つ。データを大量に保存する機能はS3やEMRにもあるが、これらはIOの処理能力が低いのでKinesisを使う。
Kinesis Data Streams
数千、数万のデバイスから継続的に生成されるデータ(ストリーミングデータ)を収集するサービス。
アプリケーションはここからデータをリアルタイムに取り出て分析処理を行う。Kinesis Data Firehose
S3/Redhift/Elasticsearch Service/Splunkにストリーミングデータをロードする機能を持つ。
こいつらに受け渡したいときはFirehoseを使おう!Kinesis Data Analytics
ストリーミングデータに対して標準的なSQlクエリを行って分析できるサービス。
要するにデータをほかのDBなどに受け渡さなくてもいいため、リアルタイム分析ができる。Kinesis Video Streams
アプリで動画を解析する際に使う。例えば防犯カメラのデータを取り込んで犯罪防止の解析に使ったり。まとめると、アプリに渡し、リアルタイムな分析をしたいときはData Streams、S3/Redshift/Elasticsearch Service/splunkへ渡したいときはFirehose、DB的な使い方をしたいけどDBへ渡さずにリアルタイムな分析をしたいならAnalytics、動画ならVideo Streams。
EMR
Hadoopのマネージドサービス。といっても当方Hadoopを知らんので簡単にまとめ。
大量のデータを処理する分散処理フレームワークであり、様々な非構造化/構造化データをデータウェアハウスや機械学習のアプリが使用できる構造に変換するサービス。要するにデータの変換をしてくれる?
従量課金制。Data Pipeline
AWSサービスやオンプレのサービスのデータソースについてデータの転送とかETL(抽出、変換、格納の略)を定義し、処理を自動化できるサービス。これだけだと何言ってるかわからないが、要するに、WebサーバからS3へ毎日ログを送り、それを週一でEMRに変換してもらって、それを解析に使用する場合、それらの流れをスケジューリングして自動的に行ってくれる。
Glue
ETLとデータカタログのマネージドサービス。S3に保存されたデータをRedshiftで使用できる形に変換する。スクリプトをPythonまたはScalaで自動生成できる。Apache Spark以外の様々なエンジンで実行されるETL処理が必要な場合はPipelineのほうがいい。Apache Spark専用か。
Athena
S3のデータに対してテーブルを作り、標準的なSQLを直接発行できるサービス。従来はS3のデータをRedshiftへロードしてからクエリ発行していたが、それが不要になった。
Kinesis Data Analyticsと違うのはS3からのデータってこと。QuickSighht
BIツール。AWS以外にも接続できるらしい。よーわからん。
あとは移行とコスト管理のサービスをやってよくある質問読んで模試受けて本番へ行こうかと。
- 投稿日:2020-02-24T15:01:54+09:00
aws sdk goでAPIスロットリングした時のリトライ回数を指定する
aws-sdk-go を利用してAPIから
ThrottlingException: Rate exceededが発生した際のデバッグ方法とリトライ試行回数の指定方法package main import ( "context" "fmt" "log" "sync" "time" "github.com/aws/aws-sdk-go/aws" "github.com/aws/aws-sdk-go/aws/awserr" "github.com/aws/aws-sdk-go/aws/request" "github.com/aws/aws-sdk-go/aws/session" "github.com/aws/aws-sdk-go/service/cloudwatchlogs" "github.com/aws/aws-sdk-go/service/ec2" ) func main() { mySession := session.Must(session.NewSession()) loop := 10 var wg sync.WaitGroup wg.Add(loop) // 意図的にスロットリングを発生させるために並列実行している for i := 0; i < loop; i++ { go func() { getLogs(mySession) wg.Done() }() } wg.Wait() } func getLogs(sess *session.Session) { svc := cloudwatchlogs.New(sess, aws.NewConfig().WithMaxRetries(10)) // リトライ試行回数を指定 t := time.Now().Add(-time.Hour).Unix() * 1000 ctx := context.Background() for i := 0; i < 100; i++ { res, err := svc.FilterLogEventsWithContext(ctx, &cloudwatchlogs.FilterLogEventsInput{ FilterPattern: aws.String(""), LogGroupName: aws.String("/aws/apigateway/welcome"), StartTime: aws.Int64(t), }, request.WithLogLevel(aws.LogDebugWithRequestErrors), // リクエストエラーのデバッグ表示(リトライの度に表示される) ) if err != nil { e, ok := err.(awserr.Error) if ok { log.Printf("i=%d FilterLogEvents code:%s message:%s", i, e.Code(), e.Message()) return } log.Printf("i=%d FilterLogEvents err:%s", i, err) return } if len(res.Events) > 0 { log.Printf("len(events)=%d", len(res.Events)) } } }
- 投稿日:2020-02-24T14:16:13+09:00
AWS Lightsailで構築したWordPressをSSL化する方法
はじめに
AWS LightsailでWordPressを構築したのですが、SSL化にかなり苦戦したので成功した方法をメモしておきます。
私の場合は、日々の生活ブログ(メインドメイン)と旅行者向けのトラベルガイド(サブドメイン)を公開しているので、メインとサブのそれぞれの設定方法なんかも苦戦する原因となりました。
この記事で書くこと
ACMのパブリック証明書とCloudFrontを用いて、閲覧者とCloudFrontの間でHTTPSを要求するように設定する方法を書きます。
参考にしたのは以下の記事です。
・AmazonのVPSサービス(Lightsail)を使い、独自ドメイン・SSL対応したWordPressを構築($3.50〜/月)
・AWSでWebサイトをHTTPS化 その7:CloudFront(+証明書)→EC2編
・CloudFront経由の配信でWordPressのビジュアルエディタが使えない場合この記事で書かないこと
- ロードバランサーを用いる方法
- letsencryptを用いる方法
ロードバランサーは月額18ドルと高コストですし、letsencryptはネットで調べながら導入を試みたのですが上手くいきませんでした。
ACMでSSL証明書の取得
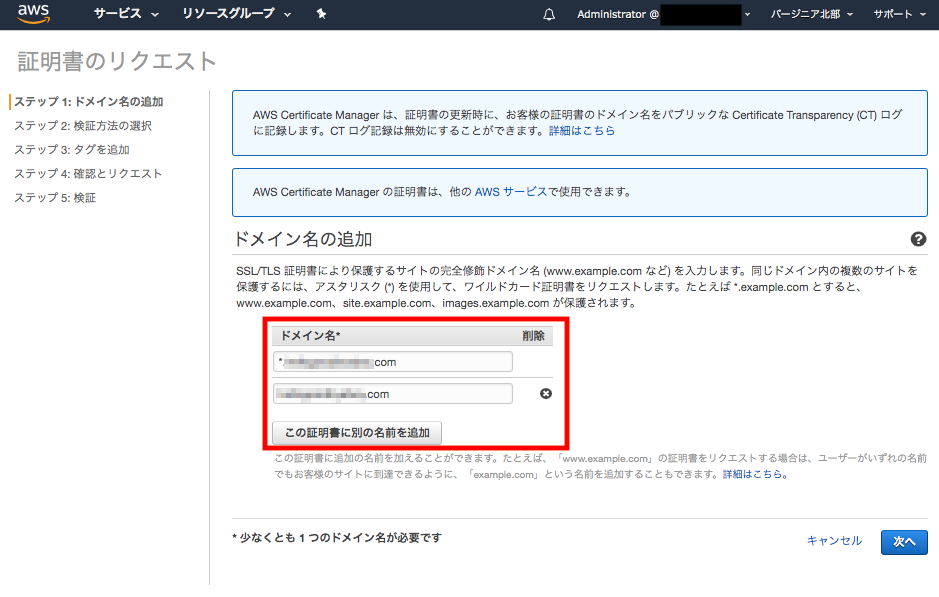
まずはSSL証明書を作成します。
私の場合はプライマリとサブの2つのドメインがありますが、証明書は以下のように名前を追加することで1つで大丈夫です。上段にサブドメイン、下段にプライマリドメインを登録しています。(順不同です。)
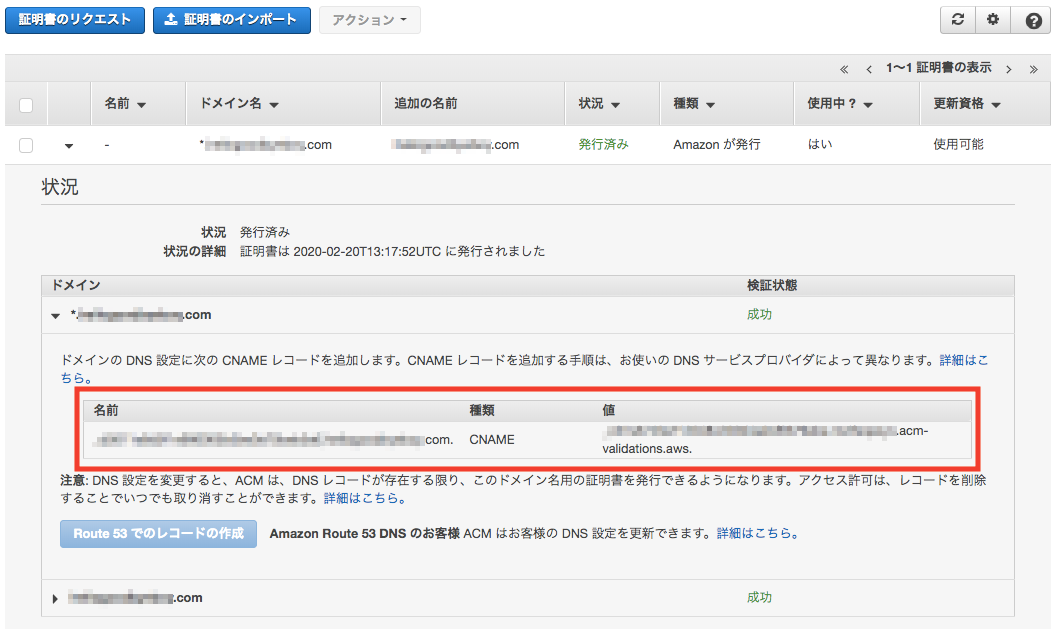
登録してしばらく待つと、以下のようにステータスが「発行済み」となりますので、これで完了です。後程、赤枠で囲ったCNAMEレコードの名前と値をRoute 53で登録します。
CloudFrontの構築
次にCloudFrontの設定をします。
まずはCreate Distributionのボタンを押します。
続いてWebの方のGet Startedを押します。
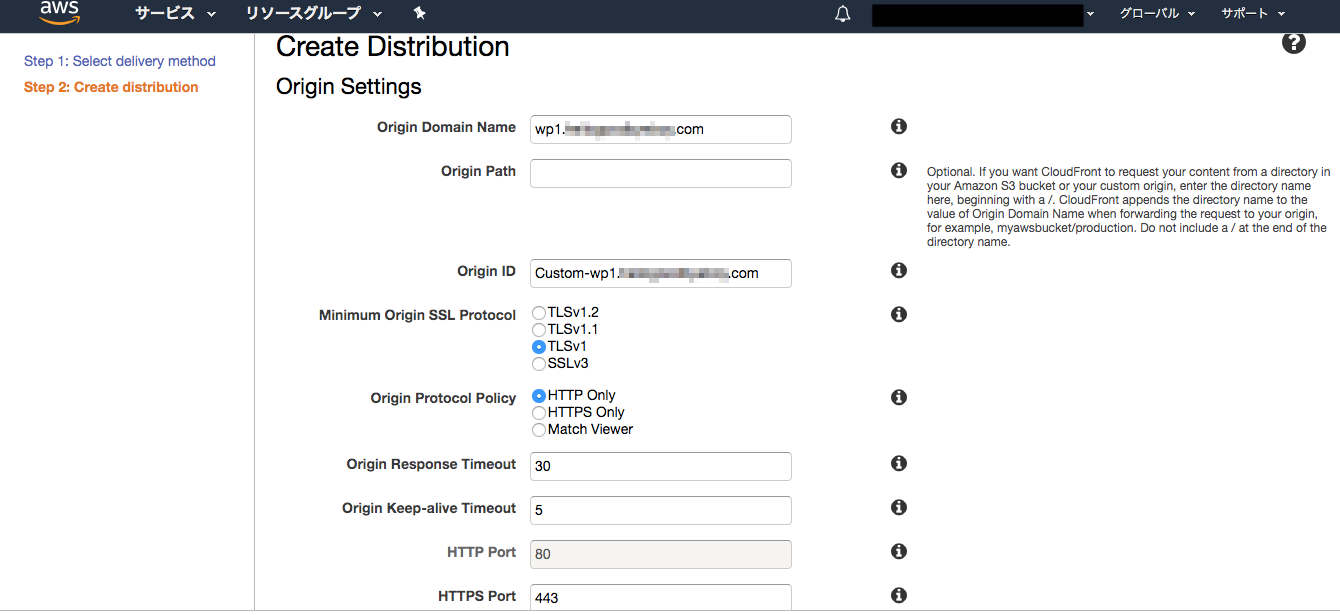
それではプライマリドメインを例にDistributionを作っていきます。Origin Domain Nameは何でも良いのですがここでは「wp1.ドメイン名」としています。サブドメインの場合は「wp2.ドメイン名」などにすると分かりやすいかと思います。
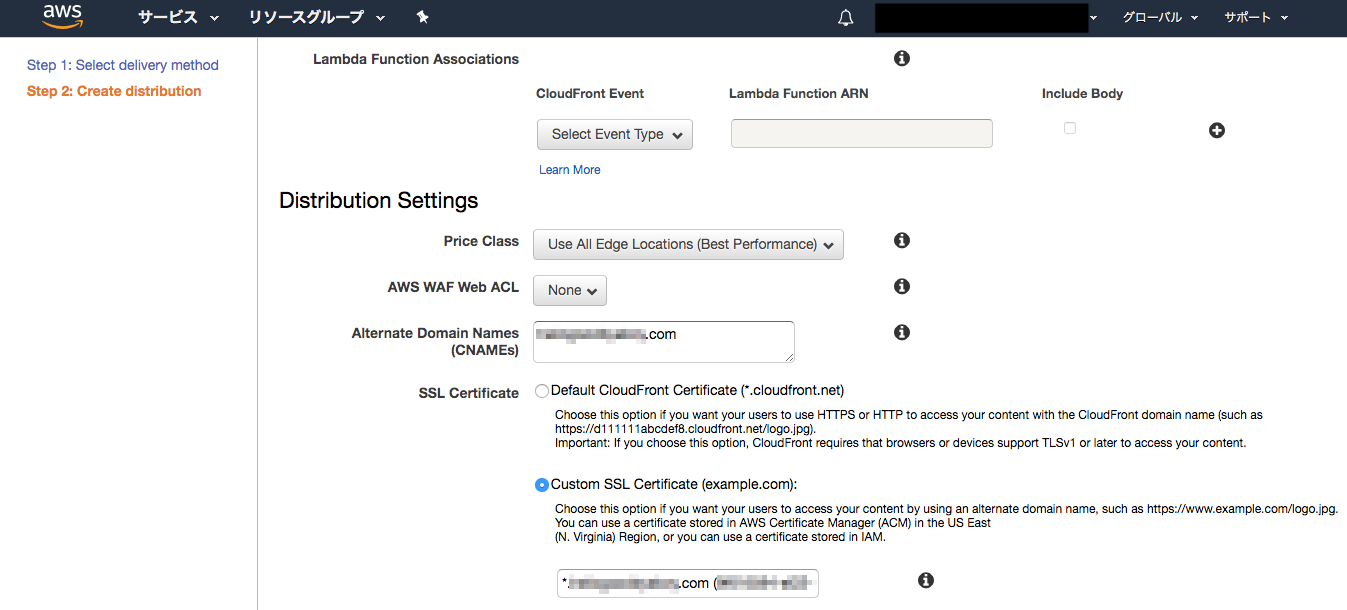
Alternate Domain Name(CNAMEs)にはプライマリドメイン名を入力します。サブドメインの場合は「*.ドメイン名」とします。SSL Certificateでは先ほどACMで登録した証明書を選択します。
その他の項目はデフォルトでOKです。
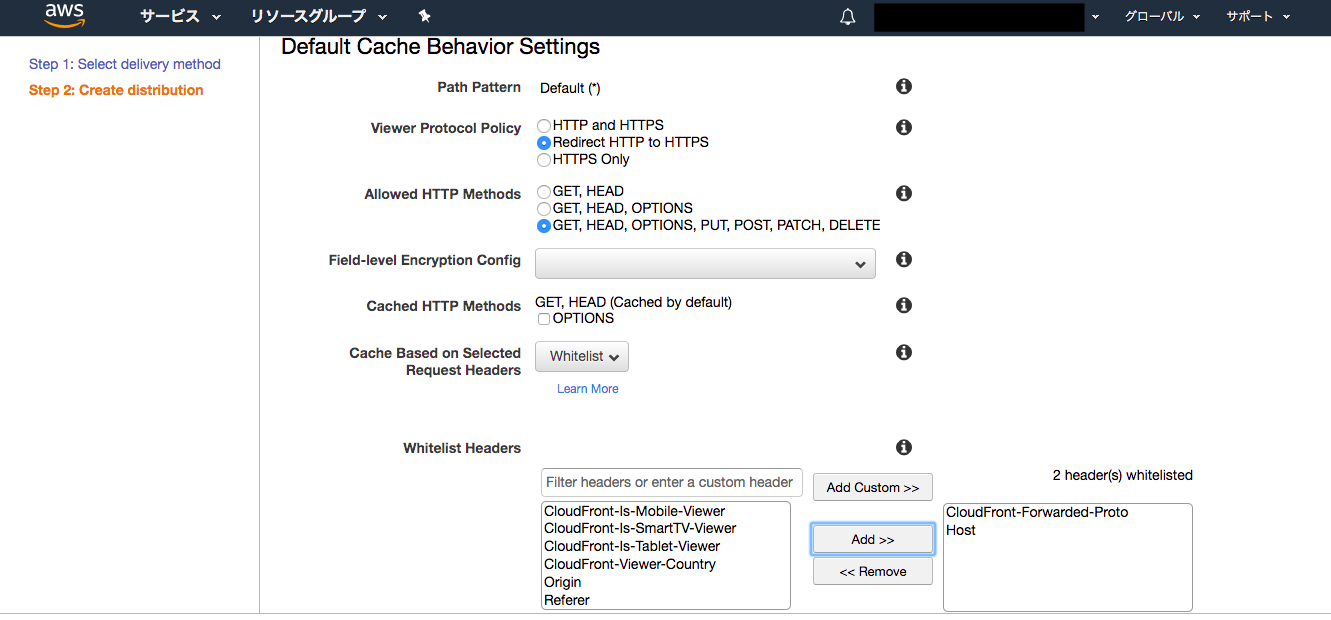
続いて作成したDistributionに、path-Patternが「/wp-login.php*」と「/wp-admin/*」の場合のBehaviorsを設定します。
作成したDistributionにチェックを入れてDistribution Settingsボタンを押します。
Create Behaviorボタンを押します。
設定内容は「Default(*)」とほぼ同じですが、マイナーチェンジを加えます。以下、変化点だけ表示します。
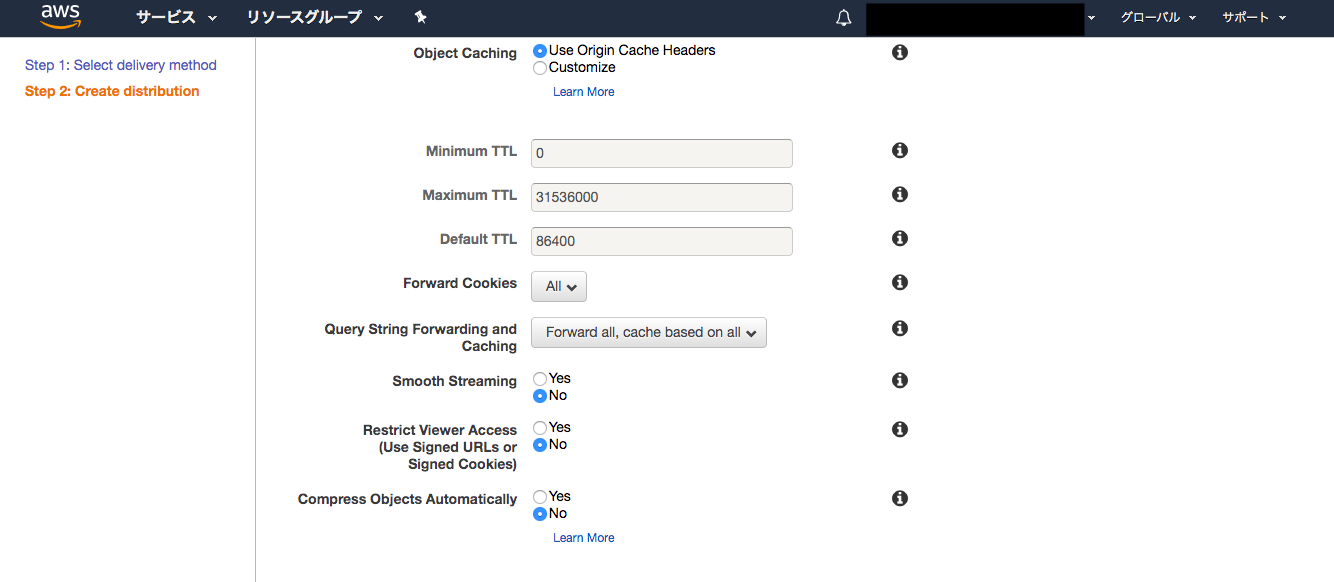
「/wp-login.php*」のBehaviorsの設定では、Object CachingをCustomizeに設定し、その下にある3つのキャッシュ時間をすべて0にします。
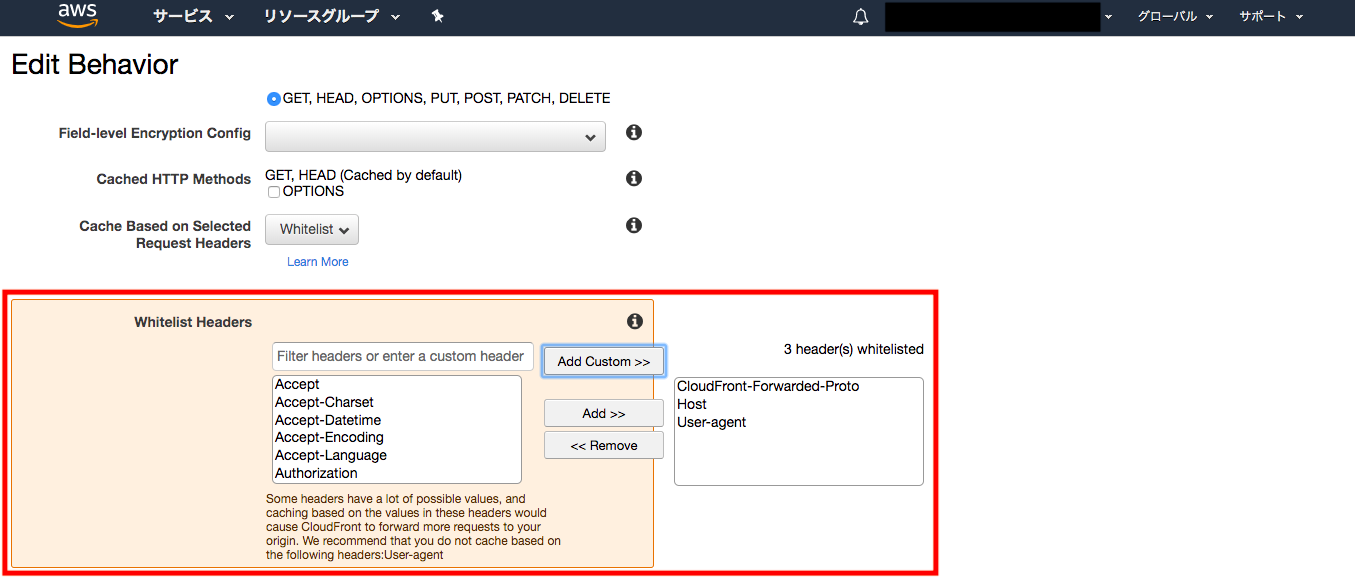
「/wp-admin/*」のBehaviorsの設定では、Whitelist Headersに「User-agent」を追加します。
CloudFront経由の配信にするとなぜかWordPressのエディタが変になってしまい、この設定をしないと↓のようになってしまいます。
これでプライマリドメイン用Distributionの設定は完了です。
僕の場合はサブドメイン用にも同様にDistributionの設定をしました。細かい設定内容はプライマリドメインと同じなのですが、Origin Domain Nameだけサブ用は「wp2.ドメイン名」に変更しました。
最終的には以下のように2つのDistributionが登録されます。
Route 53の設定変更
最後にRoute 53の設定変更をします。
まずは閲覧者からのサイトドメインへのアクセスをCloudFrontのドメインで解決するようにします。
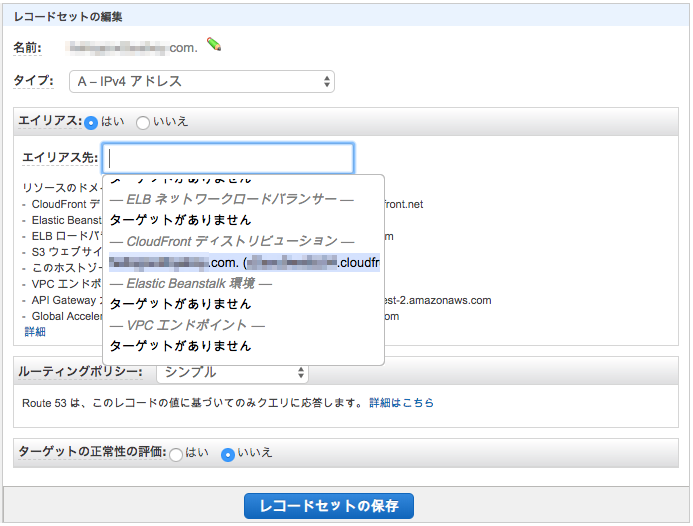
Aレコードを作成します。名前にはドメイン名を入力し、タイプはAレコードを選択します。ポイントはエイリアスの部分で、デフォルトでは「いいえ」となっているところを「はい」に変更し、エイリアス先でCloudFrontで作成したDistributionのDomain Nameを選択します。
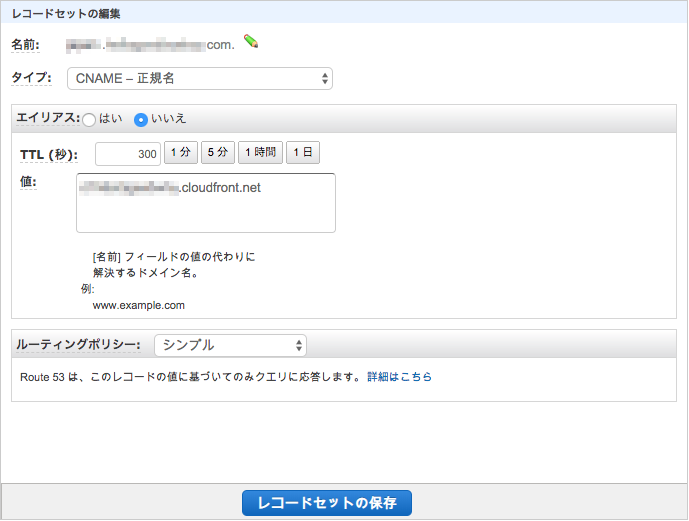
サブドメインがある場合はその設定も追加します。タイプはCNAMEレコードを選び、値にはサブドメイン用DistributionのDomain Nameを入力します。
次にCloudFrontからLightsailインスタンスへの接続を設定します。
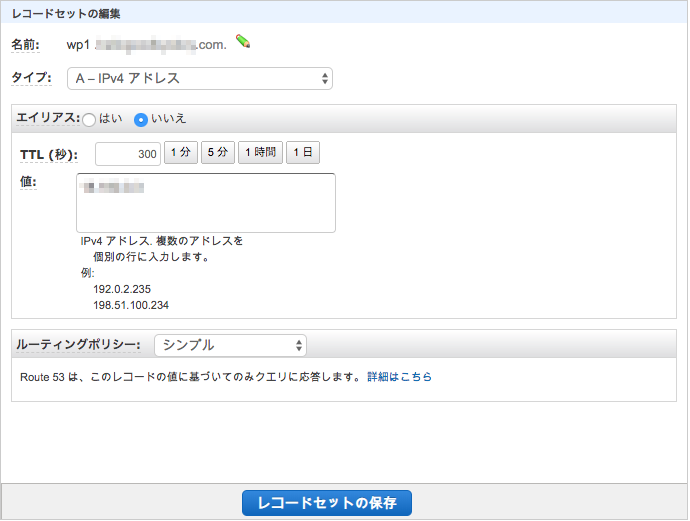
名前にはCloudFrontで作成したDistributionのOrigin Domain Nameを入力します。タイプはAレコードを選び、値にはIPアドレスを入力します。
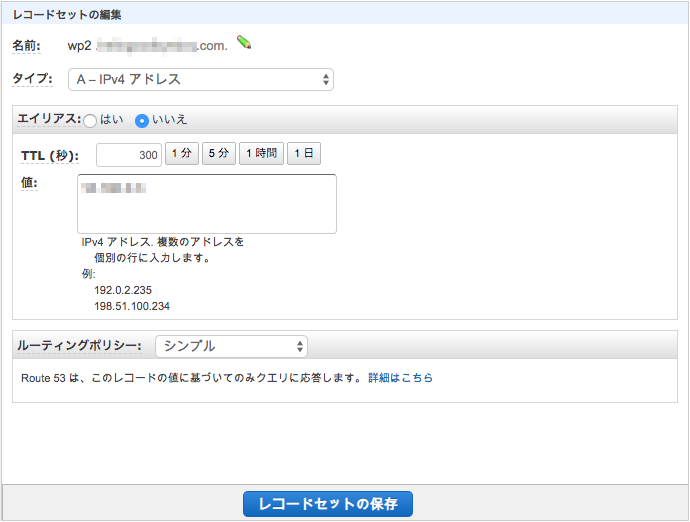
サブドメインがある場合には同じようにAレコードを登録します。
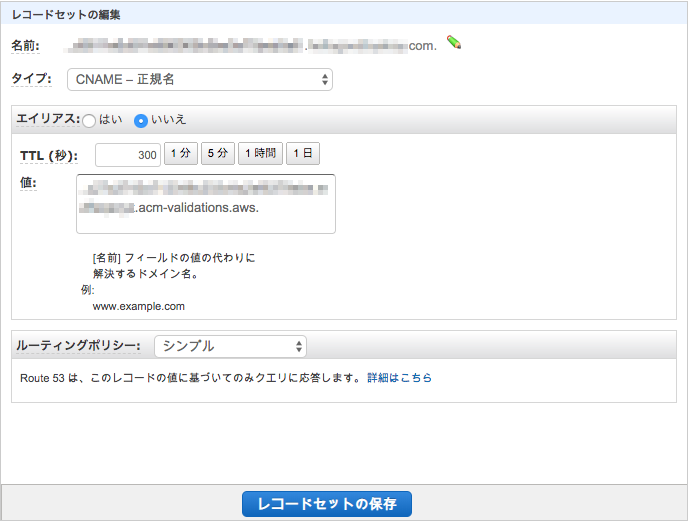
最後にSSL証明書のCNAMEレコードを登録します。
「ACMでSSL証明書の取得」の最後のところで確認したCNAMEレコードの名前を値をそれぞれ入力します。
これで完了です!




- 投稿日:2020-02-24T13:46:03+09:00
AWS試験対策(⑪アプリケーション統合)
アプリケーション統合編。
とりあえずこのまとめるシリーズが終わったら、よくある質問とか読んでみて、明日くらいに模擬試験を受けてみようと思う。SQS
Simple Queue Serviceの略。設計時点ではトラフィックの量を想定できないとき、メッセージをここに一時的に受け入れ、それを後から処理する。普通にキューですね。
あとは、めっちゃ負荷がかかる処理が来た際に、それを一時的に受け入れるのはもちろん、CloudWatchで閾値を超えればオートスケールしてくれたりする。
標準キューとFIFOキューがある。標準キューなら配信は配信しやすい順になる。少なくとも一回以上行われる。
FIFOはメッセージの送信の順序通りに配信される。一回限りで確実に処理する。送受信の順序指定が必要な場合はこっち。SNS
Simple Notification Serviceの略。通知。メールとかSMSとかに通知できる。
パブリッシャ
メッセージ送信者。サブスクライバ
メッセージ受信者。トピック
論理的なアクセスポイント及び通信チャネル。要するにサブスクライバのグループ?順番は
①パブリッシャがトピック(グループ)を作成する
②トピック(グループ)にサブスクライバを登録する。サブスクライバは受信方法を指定する(Eメールとか)
③パブリッシャがトピックにメッセージ送信SNSとSQSの連携
SQSだけだったら、三つのタスクがあった場合、直列処理しかできないが、SNSと組み合わせることにより、SNSが振り分けを実施してくれるので処理を並列で行うことができる。
SES
Eメールサービス。出荷通知や注文状況、広告、ニュースレターなどのマーケティングメッセージなどを顧客に自動配信できる。
また、逆に、受信したメールをもとにS3へメール配信したり、lambdaを呼び出したりできる。メール送信方法にはHTTP REST APIとSMTPエンドポイントの二種類がある。
HTTP REST APIでは各種言語のSDKからAPI経由で呼び出される。
SMTPエンドポイントではSMTPサーバポートでSMTPリクエストを受け付ける。
覚え方はAPIがつくのはAPI、その他はSMTPでいいかな。。。SWF
Simple Workflow Serviceの略。分散している非同期/同期のタスクを一連のフローとして設計し、耐障害性を高めれる。要するにフローをこいつが自動処理してくれるってことかな
あんましよくわからないし重要度低そうなので割愛。。。とりあえずここまで。もうそろおわり!!
- 投稿日:2020-02-24T11:59:27+09:00
Terraformことはじめ
最低限TerraformでAWSのリソースへの操作を行えるようになるためのまとめ
Terraformとは?
- HashiCorpという会社が出してるOSSで、クラウドインフラのリソースをコードとして管理できるツール
- AWSだけでなくてGCPやDataDogなどにも幅広く対応してるので、インフラのコード化を進めるにあたってデファクトのツールとなってる(と思う)
Terraformのリポジトリ構成
- Terraformを使ってクラウドインフラのリソースを管理するには以下のようにいくつかのやり方がある
- 自分は時間の関係上、検証環境やデモ環境はworkspacesを使った
- 本番環境作ったり、環境単位で必要なリソースが異なるものは別の構造で管理する予定
1. Workspaces
- TerraformにはWorkspacesという機能があり、workspaceを使うことで環境を切り替えられる(dev, demo, stg, prdみたいに)
- 環境を切り替えることで、一度書いたリソースを使い回すことができる
- 記述量を減らせる一方で、環境単位で構成が違う場合の対処が厄介
2. ディレクトリ分割
- 環境毎にディレクトリを切ってそれぞれの中でterraform initする
- パラメータが違うが構成が同じ定義が氾濫するが、一般的によく使われてる
├── environments/ ├── prod/ ├── stage/ └── dev/3. module
- 以下のようにディレクトリ単位でリソースを分ける
├── modules/ ├── ecs_service/ ├── iam_role/ └── rds使い方
- Workspacesを例に解説
環境構築
- AWS CLIの準備
$ pip3 install awscli --upgrade $ aws --version # --> awscliのバージョンが返されることを確認する
AWSでアクセス用のIAMユーザーを作成する
- Terraformでリソースを操作する際にはユーザー設定が必要なので作る
- アクセスの種類を
プログラムによるアクセスにして、管理ポリシーをAdministratorAccessにしたユーザーを作るAWSのアクセスキーを環境変数で設定する
- 先ほど作成したユーザーの情報を使う
$ export AWS_ACCESS_KEY_ID=$AWS_ACCESS_KEY_ID $ export AWS_SECRET_ACCESS_KEY=$AWS_SECRET_ACCESS_KEY $ export AWS_DEFAULT_REGION=ap-northeast-1
- TerraformのAWSアカウントを指定して、ローカルからAWS CLIを使えることを確認する
$ aws sts get-caller-identity --query Account --output text # --> 10101010101010 (AWSアカウントIDが出力されればOK!)
- Terraformをインストールする
- Terraformはバージョン管理がダルイのでtfenvを使う
$ brew install tfenv $ tfenv installWorkspacesを作る
- デフォルトでは
defaultというWorkspaceに居るので、適当に別のWorkspaceを作る$ terraform workspace new hoge Created and switched to workspace "hoge"! You're now on a new, empty workspace. Workspaces isolate their state, so if you run "terraform plan" Terraform will not see any existing state for this configuration. $ terraform workspace list default * hogeリソースの追加・編集
- 基本的には
xxx.tfファイルに定義を追加/編集する(以下、例)main.tf# バージョンを縛る呪い provider "aws" { region = "ap-northeast-1" version = "= 2.49.0" } # バージョンを縛る呪い terraform { required_version = "= 0.12.20" } # VPCの定義 resource "aws_vpc" "my-vpc" { cidr_block = "10.0.0.0/16" enable_classiclink = false enable_classiclink_dns_support = false enable_dns_hostnames = false instance_tenancy = "default" enable_dns_support = "true" tags = { Name = "my-vpc-${terraform.workspace}" } }
terraform plan -target=${resource}で対象のリソースの実行計画を見て差分が意図通りか確認する(以下、例)
terraform planはDRY RUN- 以下の感じで構築/変更があるところを出してくれる
$ terraform plan -target=aws_vpc.my-vpc Refreshing Terraform state in-memory prior to plan... The refreshed state will be used to calculate this plan, but will not be persisted to local or remote state storage. ------------------------------------------------------------------------ An execution plan has been generated and is shown below. Resource actions are indicated with the following symbols: + create Terraform will perform the following actions: # aws_vpc.my-vpc will be created + resource "aws_vpc" "my-vpc" { + arn = (known after apply) + assign_generated_ipv6_cidr_block = false + cidr_block = "10.0.0.0/16" + default_network_acl_id = (known after apply) + default_route_table_id = (known after apply) + default_security_group_id = (known after apply) + dhcp_options_id = (known after apply) + enable_classiclink = false + enable_classiclink_dns_support = false + enable_dns_hostnames = false + enable_dns_support = true + id = (known after apply) + instance_tenancy = "default" + ipv6_association_id = (known after apply) + ipv6_cidr_block = (known after apply) + main_route_table_id = (known after apply) + owner_id = (known after apply) + tags = { + "Name" = "my-vpc-hoge" } } Plan: 1 to add, 0 to change, 0 to destroy. Warning: Resource targeting is in effect You are creating a plan with the -target option, which means that the result of this plan may not represent all of the changes requested by the current configuration. The -target option is not for routine use, and is provided only for exceptional situations such as recovering from errors or mistakes, or when Terraform specifically suggests to use it as part of an error message. ------------------------------------------------------------------------ Note: You didn't specify an "-out" parameter to save this plan, so Terraform can't guarantee that exactly these actions will be performed if "terraform apply" is subsequently run.
terraform apply -target=${resource}で対象のリソースをAWS環境に反映させる
- 例:
terraform apply -target=aws_vpc.my-vpcterraform.tfstate.d/hoge(workspace名)/terraform.tfstateファイルに実行結果が記録される
tfstateファイルはterraformコマンドを通じてのみ変更を反映するもの(マイグレーションでいうスキーマみたいなやつ)であり、絶対に手動で変更しないこと!リソースの削除
- 削除したいリソースを指定してplanを実行し、削除したい内容と合致するか確認する (以下、例)
$ terraform plan -destroy -target=aws_rds_cluster_instance.my-rds-instance Refreshing Terraform state in-memory prior to plan... The refreshed state will be used to calculate this plan, but will not be persisted to local or remote state storage. ... ------------------------------------------------------------------------ An execution plan has been generated and is shown below. Resource actions are indicated with the following symbols: - destroy Terraform will perform the following actions: # aws_rds_cluster_instance.my-rds-instance[0] will be destroyed - resource "aws_rds_cluster_instance" "my-rds-instance" { - arn = "arn:aws:rds:ap-northeast-1:xxxxxxxx:my-rds-instance-1" -> null - auto_minor_version_upgrade = true -> null - availability_zone = "ap-northeast-1a" -> null - ca_cert_identifier = "rds-ca-2019" -> null - cluster_identifier = "my-rds" -> null - copy_tags_to_snapshot = false -> null - db_parameter_group_name = "default.aurora-postgresql11" -> null - db_subnet_group_name = "terraform-11111xxxxxxxxxxxxxxxxxx" -> null - dbi_resource_id = "db-xxxxxxxxxxxxxxxxxxxxxx" -> null - endpoint = "xxxxxxxxxxx.ap-northeast-1.rds.amazonaws.com" -> null - engine = "aurora-postgresql" -> null - engine_version = "11.4" -> null - id = "my-rds-instance-1" -> null - identifier = "my-rds-instance-1" -> null - instance_class = "db.t3.medium" -> null - monitoring_interval = 60 -> null - monitoring_role_arn = "arn:aws:iam::xxxxxxxxxxxxxxx:role/rds-xxx-role" -> null - performance_insights_enabled = false -> null - port = 5432 -> null - preferred_backup_window = "18:29-18:59" -> null - preferred_maintenance_window = "thu:15:16-thu:15:46" -> null - promotion_tier = 2 -> null - publicly_accessible = false -> null - storage_encrypted = false -> null - tags = {} -> null - writer = true -> null } Plan: 0 to add, 0 to change, 1 to destroy. Warning: Resource targeting is in effect You are creating a plan with the -target option, which means that the result of this plan may not represent all of the changes requested by the current configuration. The -target option is not for routine use, and is provided only for exceptional situations such as recovering from errors or mistakes, or when Terraform specifically suggests to use it as part of an error message. ------------------------------------------------------------------------ Note: You didn't specify an "-out" parameter to save this plan, so Terraform can't guarantee that exactly these actions will be performed if "terraform apply" is subsequently run.
terraform apply -destroy -target=${resource}で対象のリソースをAWS環境に反映させる
- 例:
terraform apply -destroy -target=aws_vpc.my-vpcterraform.tfstate.d/hoge(workspace名)/terraform.tfstateファイルに実行結果が記録される
tfstateファイルはterraformコマンドを通じてのみ変更を反映するもの(マイグレーションでいうスキーマみたいなやつ)であり、絶対に手動で変更しないこと!既存リソースをTerraformに落とし込む
- import機能を使うことで既にクラウドインフラで構築済みのリソース定義をTerraformに落とし込むことができる
- 例:
terraform import aws_vpc.my-vpc my-vpc-dev公式ドキュメントの一番下に書いてあるので、
terraform ${リソース名}で調べるのが良さげ
- リソースによって最後の引数が違ったりする(ARNだったり、リソース名だったり..)ので、公式読むのが無難...
- 例: Resource: aws_vpc

importで指定などを間違えた場合には
terraform state rm ${resource}で.tfstateファイル上の定義だけ削除できる(クラウドインフラのリソースは削除しない)注意点
terraform planでうまくいっても、必ずしもterraform applyが成功するとは限らない
- planの際には問題なく通ってるが、apply時に実は設定が足りなかったりでコケることがたまにある...
参考
- 投稿日:2020-02-24T09:45:27+09:00
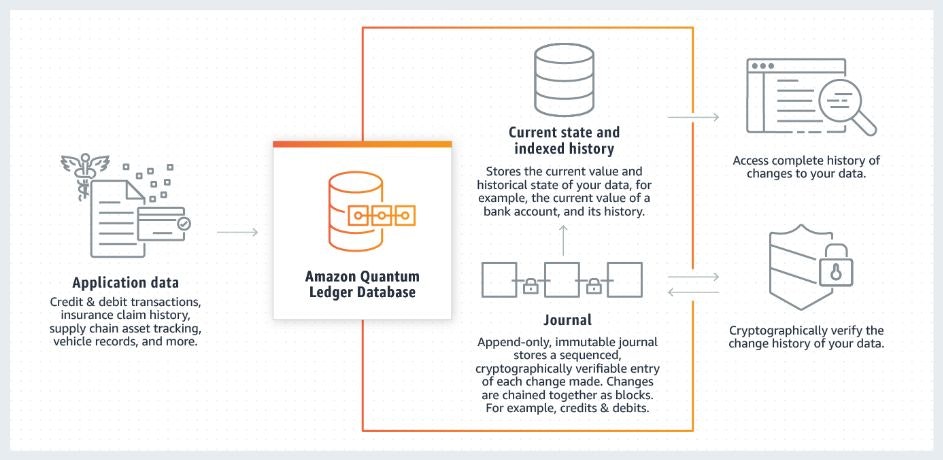
Amazon QLDBで台帳データベースを構築する
Amazon QLDBを触ってみた。
全体構成
- QLDBはテーブルとジャーナルで構成される
- テーブル
- データとメタデータを過去の状態を含めてもつ
- selectの実行先
- ジャーナル
- 変更履歴をもつ
- insert、update、deleteの実行先
ジャーナル
- ドキュメントに行ったすべての変更の完全で不変な履歴全体をもつ
- 追加していくだけで、変更削除はできない
- データだけでなく実行されたクエリも記録する
ブロック
- ジャーナルにコミットされたオブジェクト
- トランザクション:ブロック = 1:n
- エントリ、ブロックハッシュを含む
エントリ
- ドキュメントリビジョン、それらをコミットした PartiQL ステートメントを含む
テーブル
- ドキュメントリビジョンのコレクション
- ドキュメントの最新のリビジョンだけでなく、過去のイテレーションもすべて含まれる
ドキュメント
- データのこと
- Amazon Ionというフォーマットで表す
- 構造化データと非構造化データの両方を一緒に保存できる抽象データモデル
- JSONの拡張フォーマット
- 1レコードに1つのドキュメントIDがメタデータとして付与されている
例
Vehicle.json{ VIN: "1N4AL11D75C109151", Type: "Sedan", Year: 2011, Make: "Audi", Model: "A5", Color: "Silver" }ネストして保持も可能
VehicleRegistration.json{ VIN: "KM8SRDHF6EU074761", LicensePlateNumber: "CA762X", State: "WA", City: "Kent", PendingPenaltyTicketAmount: 130.75, ValidFrom: 2017-09-14T, ValidTo: 2020-06-25T, Owners: { PrimaryOwner: { PersonId: "IN7MvYtUjkp1GMZu0F6CG9" }, SecondaryOwners: [] } }ドキュメントリビジョン
- ドキュメントの更新を表す仕組み
- ドキュメントIDと0から始めるバージョン番号で表す
- ドキュメントとドキュメントIDとバージョン番号を含むメタデータで構成される
例
data:{ VIN: "KM8SRDHF6EU074761", LicensePlateNumber: "CA762X", State: "WA", City: "Kent", PendingPenaltyTicketAmount: 130.75, ValidFrom: 2017-09-14T, ValidTo: 2020-06-25T, Owners: { PrimaryOwner: { PersonId: "IN7MvYtUjkp1GMZu0F6CG9" }, SecondaryOwners: [] } }, metadata:{ id:"JOzfB3lWqGU727mpPeWyxg", version:0, txTime:2019-06-05T20:53:321d-3Z, txId:"HgXAkLjAtV0HQ4lNYdzX60" }ユーザーテーブル、カレントビュー、ユーザービュー
- 削除されていない最新の各ドキュメントが格納される
- 最新かどうかはジャーナルにコミットされたトランザクションに基づく
システムテーブル、コミット済みビュー
- 各ドキュメントとそのシステム生成メタデータを格納する
- ユーザーテーブル作成時にシステムによって作成されるテーブル
- ユーザーテーブルと1対1の関係
- 「_ql_committed_」+ユーザーテーブル名で命名される
- 過去のイテレーションは履歴として保存される
blockAddress
- ドキュメントリビジョンがコミットされた台帳のジャーナルのブロックの場所
- strandId:ブロックを含むジャーナルストランドの一意の ID
- sequenceNo:ストランド内でブロックの場所を指定するインデックス番号
hash
- ドキュメントリビジョンを一意に表す SHA-256 値
- ハッシュは data フィールドと metadata フィールドを対象とする
- 暗号検証に使用
data
- 最新のドキュメント
metadata
- システムによって生成される各ドキュメントごとのメタデータ
- id:システムによって割り当てられたドキュメント ID
- version:ドキュメントリビジョンごとに増えていく 0 から始まる整数
- txTime:ジャーナルにドキュメントリビジョンがコミットされたときのタイムスタンプ
- txId:ドキュメントリビジョンをコミットしたトランザクションの一意の ID
例
{ blockAddress:{ strandId:"JdxjkR9bSYB5jMHWcI464T", sequenceNo:14 }, hash:{{wPuwH60TtcCvg/23BFp+redRXuCALkbDihkEvCX22Jk=}}, data:{ VIN: "KM8SRDHF6EU074761", LicensePlateNumber: "CA762X", State: "WA", City: "Kent", PendingPenaltyTicketAmount: 130.75, ValidFrom: 2017-09-14T, ValidTo: 2020-06-25T, Owners: { PrimaryOwner: { PersonId: "IN7MvYtUjkp1GMZu0F6CG9" }, SecondaryOwners: [] } }, metadata:{ id:"JOzfB3lWqGU727mpPeWyxg", version:0, txTime:2019-06-05T20:53:321d-3Z, txId:"HgXAkLjAtV0HQ4lNYdzX60" } }information_schema
- ユーザーテーブルのメタデータをもつ
- tableId:テーブル ID
- name:テーブル名
- indexes:テーブルのインデックスのリスト
- status:テーブルの現在のステータス (ACTIVE または INACTIVE)
例
{ tableId: "5PLf9SXwndd63lPaSIa0O6", name: "VehicleRegistration", indexes: [{ expr: "[VIN]" }, { expr: "[LicensePlateNumber]" }], status: "ACTIVE" }チュートリアル
Amazon QLDB でのデータと履歴の使用をなぞってみた
台帳作成
「台帳の作成」ボタンを押下
任意の台帳名を入力し、「台帳の作成」ボタンを押下
1分くらいで作成完了
データ投入
今回はサンプルデータでテーブルとドキュメントを挿入
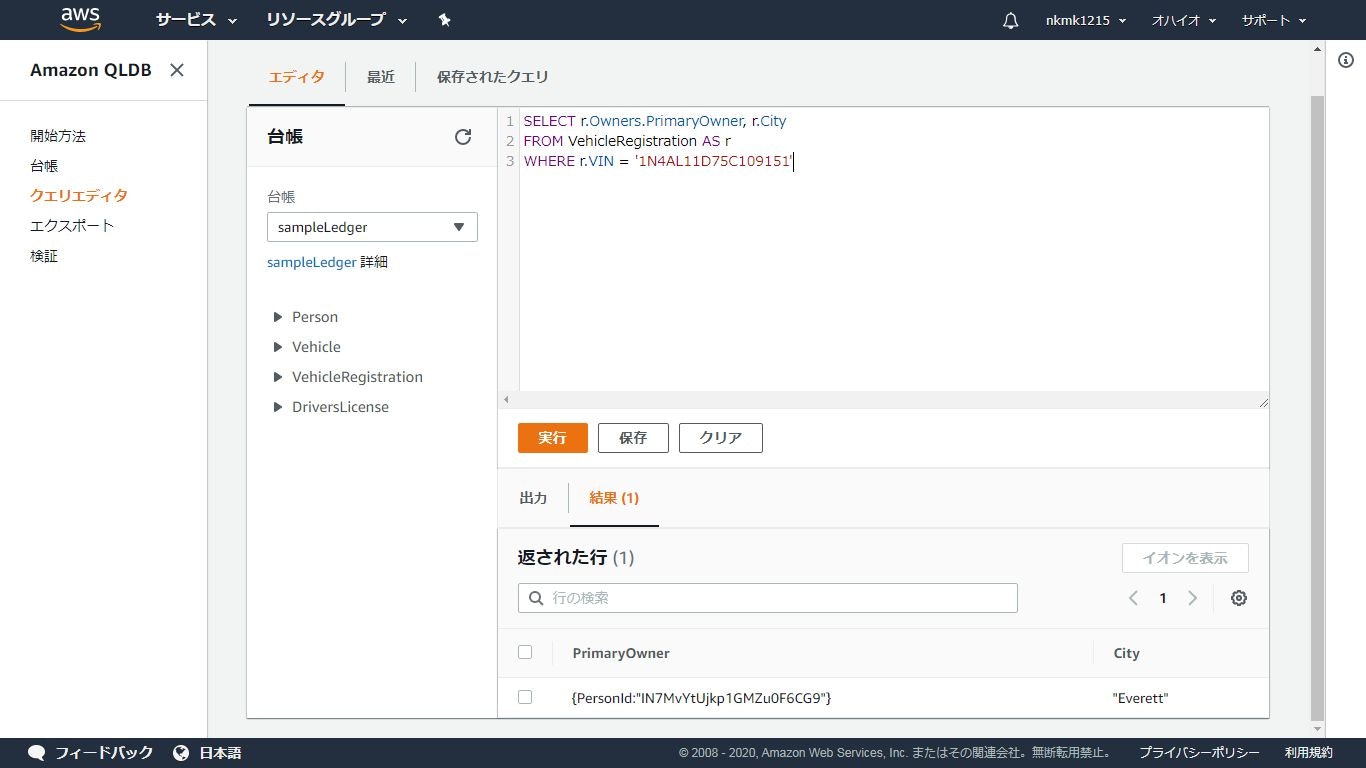
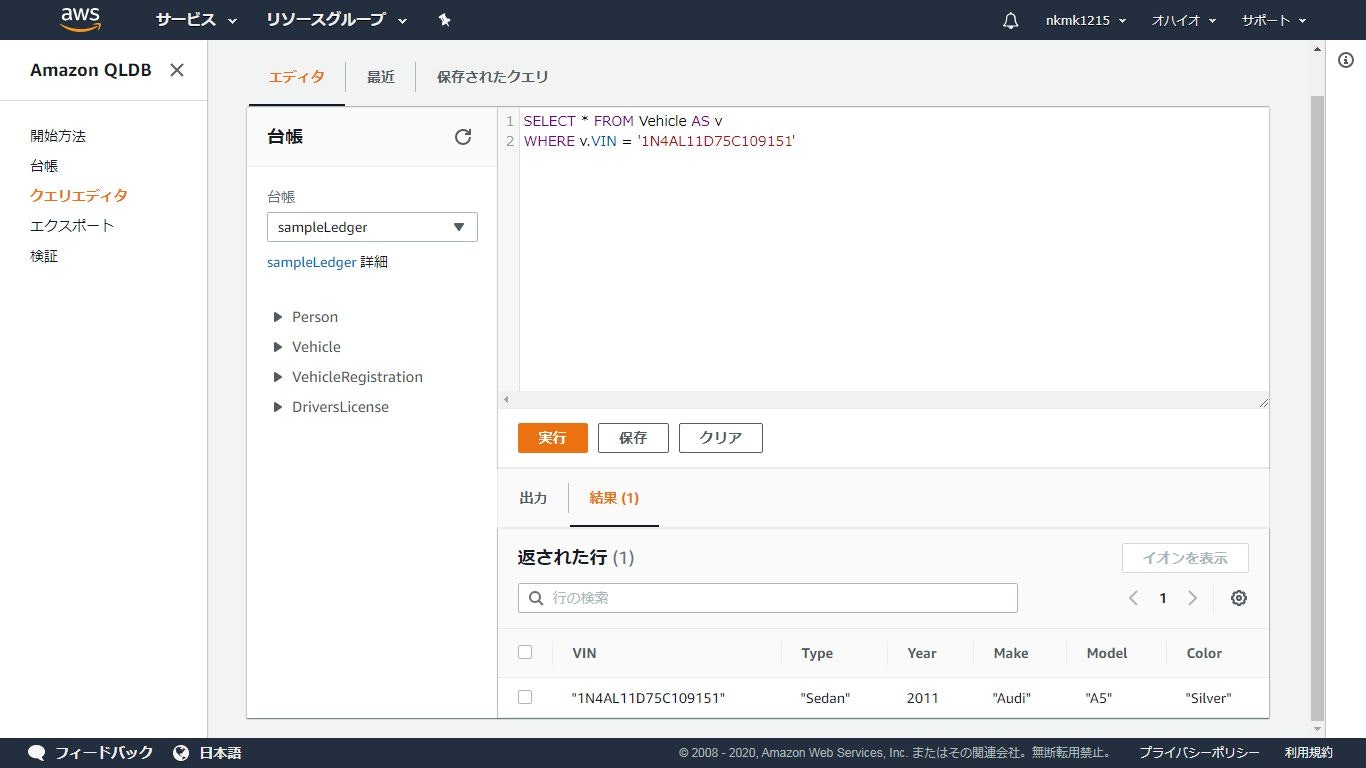
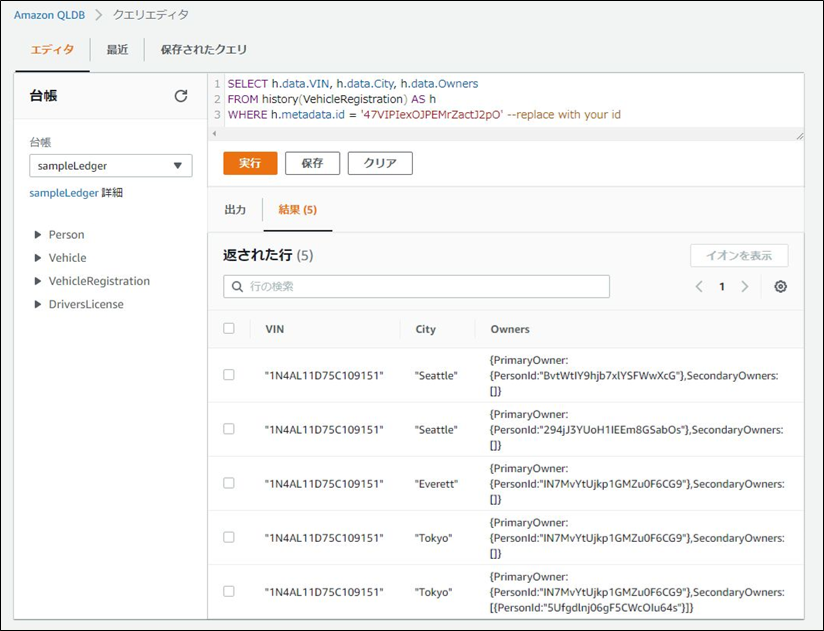
「Vehicle」テーブルのドキュメントをselect
クエリ
- 基本的なSQLは投げられる
- ネストされたデータもSQLで取得可能
取得元.json{ VIN: "1N4AL11D75C109151", LicensePlateNumber: "LEWISR261LL", State: "WA", City: "Tokyo", PendingPenaltyTicketAmount: 90.25, ValidFromDate: 2017-08-21T, ValidToDate: 2020-05-11T, Owners: { PrimaryOwner: { PersonId: "IN7MvYtUjkp1GMZu0F6CG9" }, SecondaryOwners: [{PersonId:"5Ufgdlnj06gF5CWcOIu64s"}] } }実行SQL.sqlSELECT r.VIN, o.PersonId FROM VehicleRegistration AS r, @r.Owners.PrimaryOwner AS o WHERE r.VIN = '1N4AL11D75C109151'取得したデータ.json{ VIN: "1N4AL11D75C109151", PersonId: "IN7MvYtUjkp1GMZu0F6CG9" }更新
- 更新自体はRDSと同様
- 更新前ドキュメント
 実行SQL.sqlUPDATE VehicleRegistration AS r SET r.Owners.PrimaryOwner.PersonId = 'IN7MvYtUjkp1GMZu0F6CG9', r.City = 'Tokyo' WHERE r.VIN = '1N4AL11D75C109151'
実行SQL.sqlUPDATE VehicleRegistration AS r SET r.Owners.PrimaryOwner.PersonId = 'IN7MvYtUjkp1GMZu0F6CG9', r.City = 'Tokyo' WHERE r.VIN = '1N4AL11D75C109151'
更新後ドキュメント
更新前のドキュメントを履歴テーブルから取得できる
メタデータも同様に履歴テーブルから取得できる
検証
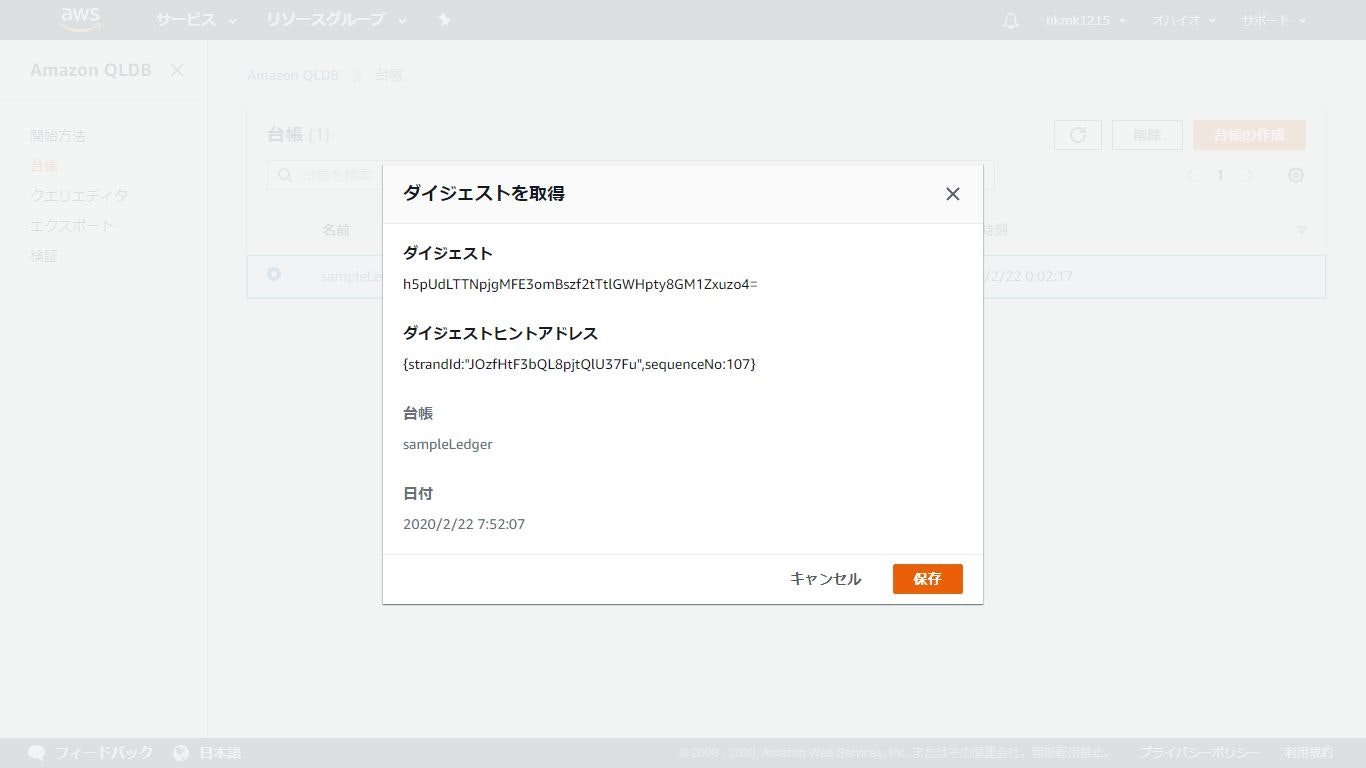
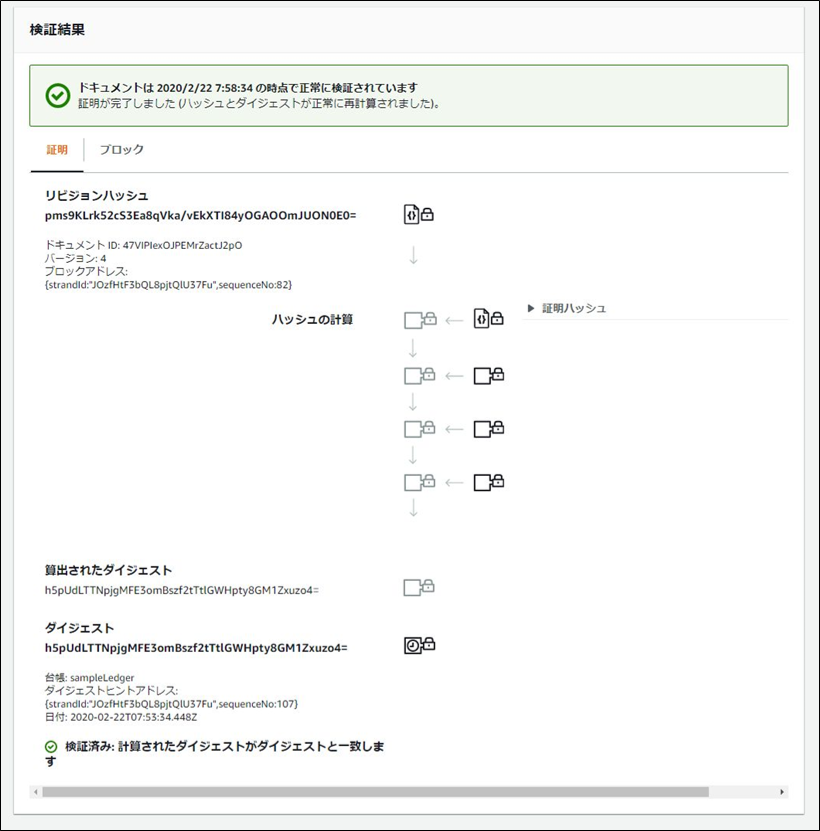
「ダイジェストを取得」ボタンにて現在の台帳のダイジェストを取得
「保存」ボタンを押下し、ファイルとしてダウンロード
sampleLedger-2020-02-22.ion.txt{ "digest":"h5pUdLTTNpjgMFE3omBszf2tTtlGWHpty8GM1Zxuzo4=", "digestTipAddress":"{strandId:\"JOzfHtF3bQL8pjtQlU37Fu\",sequenceNo:107}", "ledger":"sampleLedger", "date":"2020-02-22T07:53:34.448Z" }
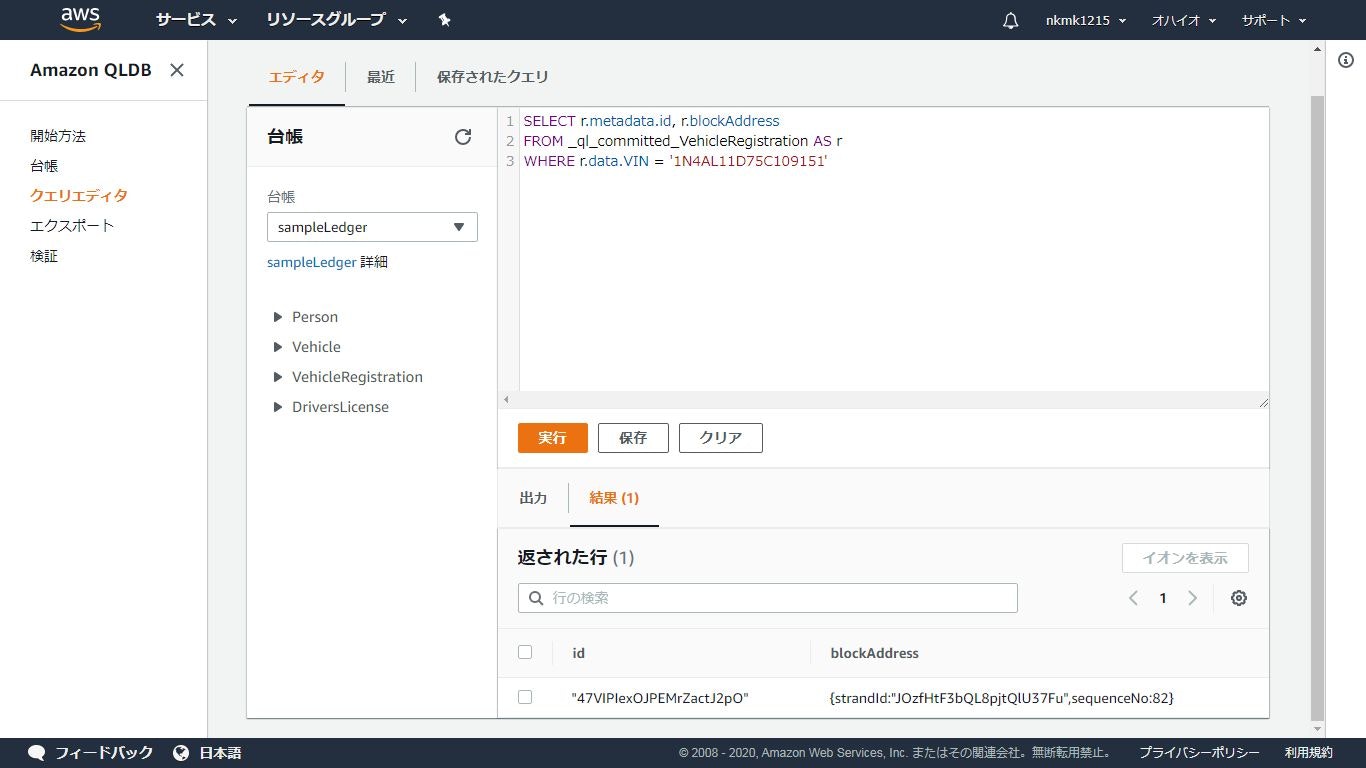
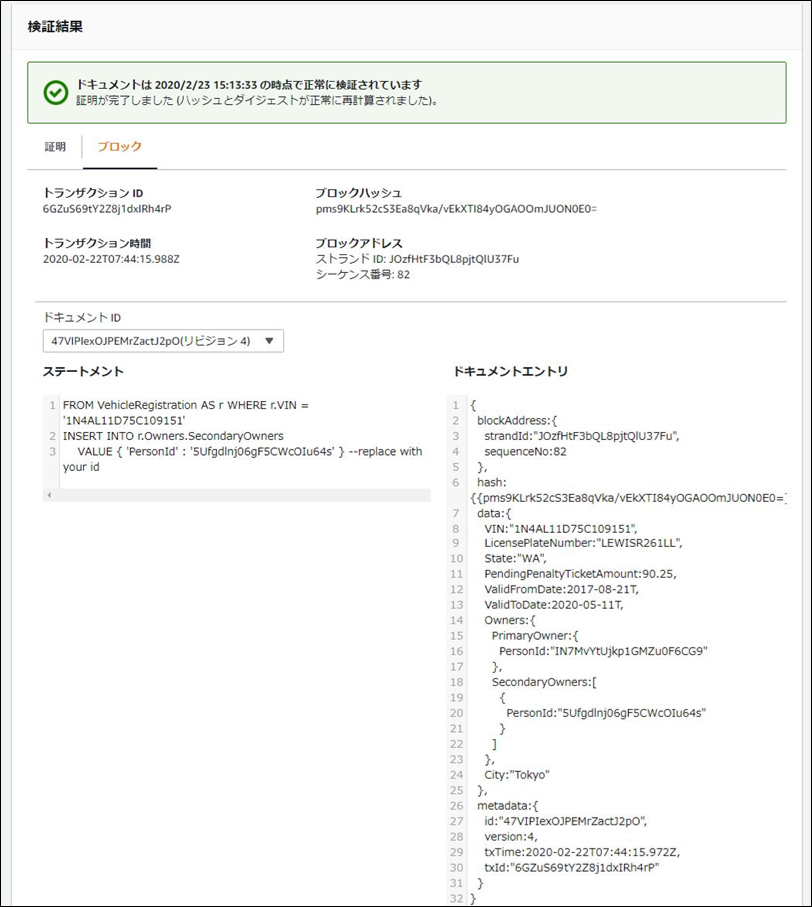
検証したいドキュメントのidとblockAddressを取得
「検証」ボタンを押下
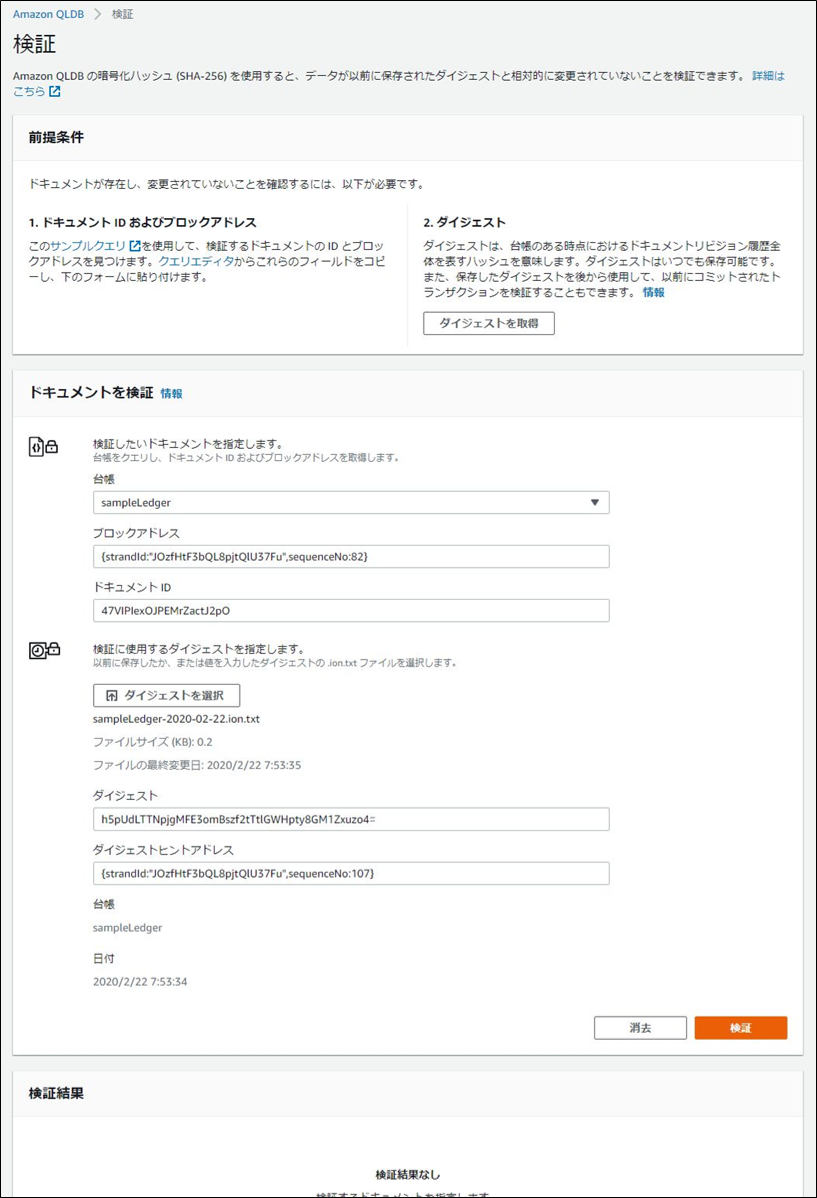
ハッシュのチェーンを確認し検証結果を表示
リビジョンハッシュと証明ハッシュの1つ目を連結し、ハッシュ化した値を
さらに2つ目と連結しハッシュ化し、繰り返す
最終的に出たダイジェストがドキュメントのダイジェストと一致するかを検証している
ブロック情報も確認できる
感想
- 台帳作成がマネジメントコンソール上で完結していてすごく楽
- 数クリック作成されるのはこれまでのブロックチェーンサービスと違って良い体験
- RDSのSQLのように半構造のドキュメントを扱えるのは良い
- 更新履歴の持ち方や整合性を考える必要がなくなるのはすごく良い
- 検証するユースケースはよく分からない…………





- 投稿日:2020-02-24T04:20:21+09:00
無人コンビニ「AmazonGo」を実現している技術について、詳しく調べてみた
記事の概要
巷で話題になっている無人店舗「Amazon Go」。「コンビニの店員いらなくなるんちゃう?」と話題になっているので、技術者の端くれとして、それを可能にしている技術について知るべく、日本語でいろいろ調べてみたのですが、参考になる記事が全く出てきませんでした。
なので、英語・日本語、さまざまな技術系記事を参考に、解説記事を書いてみました。(引用記事は一番下にあります)
技術系の話ですが、細かいことは端に置いて、大枠だけ理解できるように書いたので、ぜひ最後まで読んでみてください。
※重要
記事内の情報は、あくまでAmazon Goの外部の人間が発信してくださった情報をもとに推測したものです。誤りがある可能性が十分にありますので、ご承知おきください。また、著作権には最大限注意して執筆しましたが、もし万が一修正が必要な点がありましたら、お手数ですがご連絡いただけると幸いです。
AmazonGoとは
Amazonが2016年にオープンした「無人コンビニ」で、「レジに並ばず、商品を手にとってお店を出るだけで決済ができる」というのが特徴です。
具体的には、
1. Amazon Goアプリをダウンロードする
2. アプリ内にあるQRコードをかざして入店する
3. 普段の買い物と同じように、店内を回り、ほしい商品を手にする
4. そのままゲートを出る
5. Amazonのアカウントに紐付けられたクレジットカードに自動で請求、決済完了という流れで利用できるみたいです。Amazonはこれを、「Just Walk out Technology」というふうに評しています。
実際に利用している様子は、こちらの動画がすごくわかりやすいです↓
このまさに魔法のような店舗AmazonGo。利用するのは簡単ですが、実際にこの店舗を実現するためには、ディープラーニング、コンピュータビジョン、センサー・フュージョンなど、最先端かつとても高度な技術が必要になります。
ここからは、実際にどのようにしてこのような魔法の店舗が実現されているのか、その詳細な技術について追っていきたいと思います。
"Just walk out" を実現するための6つの技術的課題
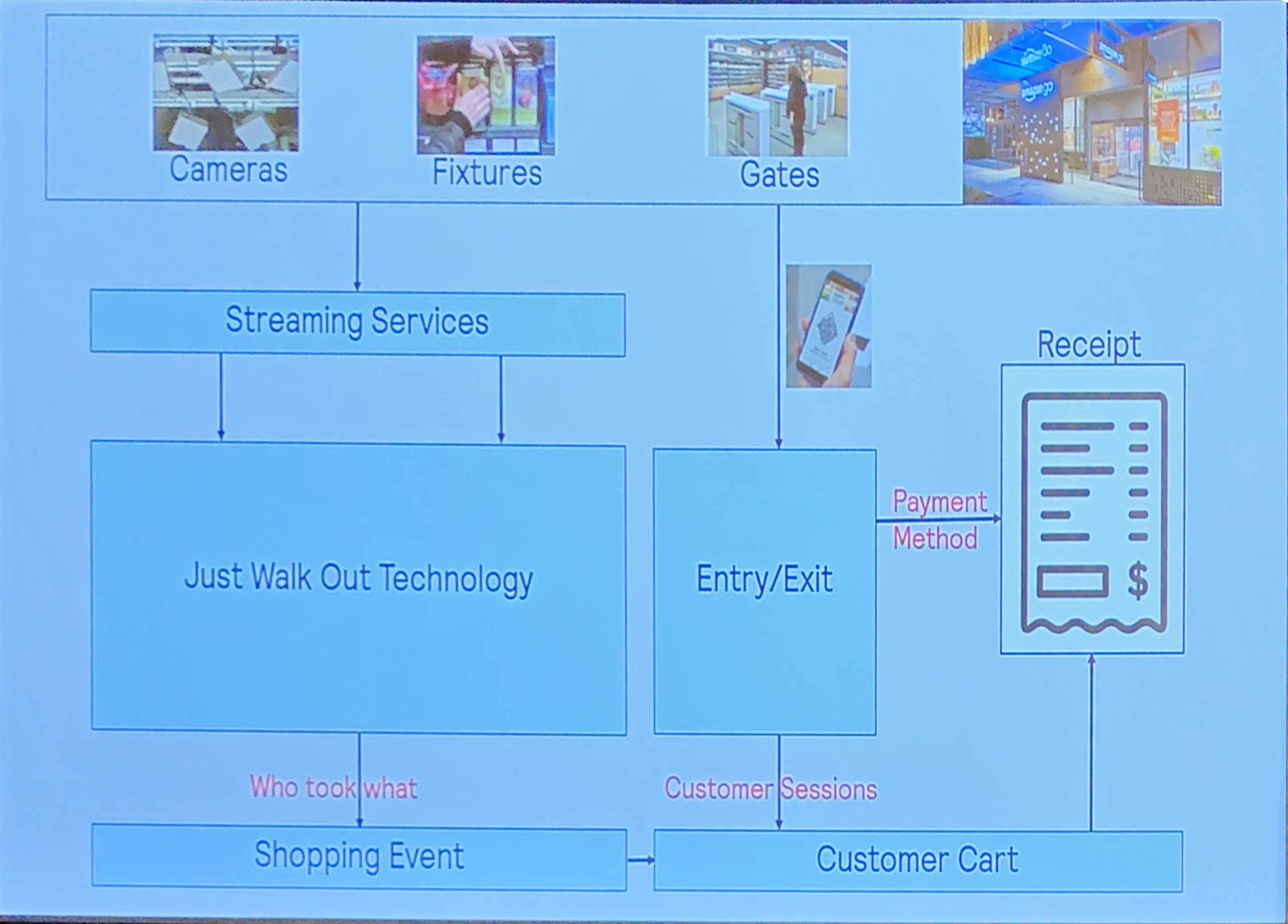
まずはじめに、このJust Walk outにはどのような技術が必要なのか、AmazonGoの全体の作り(アーキテクチャ)を確認してみます。
顧客の行動と、その際に必要なシステムをまとめた図が以下のものになります。
ここから、大きく
・誰が何を手に取ったかの解析
・顧客の映像データと決済アカウントの紐付け
・決済
の大きく3つの問題を解決しなければいけないことがわかります。
Amazon Go のシステムアーキテクチャ1(*1参照)
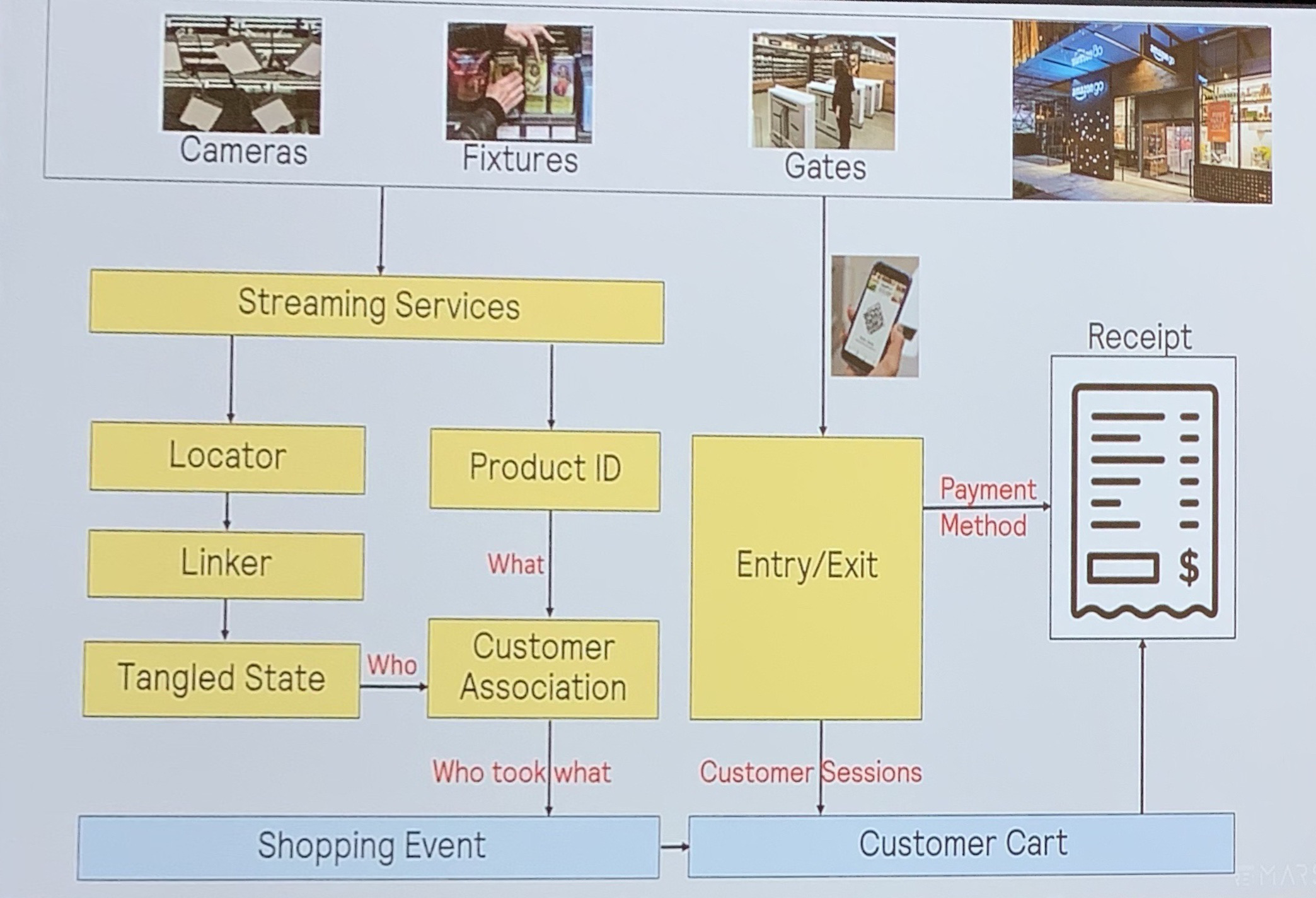
この問題を、もう少し細かくしてみたものがこちら。
「誰が何(商品)を手に取ったか」を特定するためには、個人と商品を別々に特定し、それらの情報を紐付ける必要があることがわかります。
Amazon Go のシステムアーキテクチャ2(*1参照)これらの情報から、AmazonGoの”Just Walk Out ”を実現するためには、大きく6つの課題を解決する必要があることがわかります。それがこちら。
Just Walk Outを実現するための6つの技術課題(*1参照)英語でなにを言っているのかわからないので、以下1つずつ詳しく見ていきます。
個人識別
まず重要なのは、ストア内で行動をする顧客一人一人を、別々に認識し追跡することです。
Amazon Goでは、この課題を解決するために、天井に無数のカメラが搭載されています。
天井にある黒いボックスのようなものがすべてカメラ(*2参照)この無数のカメラによって、店舗のあらゆる場所を、あらゆる方向から撮影しています。
そして、この個別のカメラが撮影した映像は1つに統合され、店舗内での顧客の行動データをマッピングします。
最終的には、以下のように、店舗内での顧客の行動をまとめて認識することができるようになります。
店舗内の顧客ログデータのマッピング(*1参照)アイテムの識別
次に重要なのは、どんな商品を、いくつ手に取ったかです。Amazon Goでは、天井のカメラ、棚の奥に設置してあるカメラ、棚に設置してる重量センサーを用いて、アイテムの識別を行っているようです。
まず商品の識別(どのアイテムが手に取られたか)について。こちらは、天井に付けられたカメラの画像処理によって、アイテムが認識されているようです。(商品バーコードを使用しているという記事もありましたが、詳しくはわかりませんでした)
次に個数について。こちらは、天井のカメラに加えて、棚の奥に設置してあるカメラや棚に設置してある重量センサーを用いて識別を行っているようです。
システムは各アイテムの正確な重量を把握しており、重量の変化量を比較することで、商品が何個手に取られたかを検知するというわけです。
これらの情報を機械学習によって処理することで、どの商品が、いくつ取られたかを解析しているようです。(*2参照)
棚に付けられた重量センサー(*3参照)
棚の奥に設置されたカメラ(*4参照)Who took what?(誰が何を取ったか)
「誰が」「何を」とったか、これらの情報を組み合わせることで、最も重要な「Who took what?」、すなわち、誰が何を取ったのかを認識することができます。
実際に、「誰が」が「何を」取ったのか、その両者の情報を紐付けるためには、商品と顧客の間の関係、すなわち「腕」をトレースする必要があります。
そこでAmazon Goでは、人間を棒人間のように見立てて行動を解析する、「スティックフィギュアモデル」によって、「誰が何を取ったか」を認識しているようです。
顧客が商品を取るときの姿勢(ポーズ)について、膨大な量のデータにて学習を行い、実際に商品が取られたのか、正しく解析できるようにしたそうです。
スティックフィギュアモデルによる購買行動の推定(*1参照)この解析によって、顧客情報と商品情報を紐付けることができ、「誰が何を取ったか?」を認識することができるようになります。
データ転送
これらの個別のカメラによってキャプチャされた映像や、重量センサーにてキャッチしたデータは、店舗からクラウドに転送され、統合して処理される必要があります。
これを可能にするために、
・個別のカメラでの基本的な前処理と、データ量の削減
・ビデオのデータを正しくクラウドに転送するための、ネットワークやデータ形式
・ビデオデータを保存するためのクラウド上のビデオサーバーなど、さまざまな技術がAmazon Goでは活用されているようです。これらの技術によって、通信障害を適切に処理し、店舗内のデータをクラウドと通信させることが可能になっています。
AWSの代表的なストレージ・データベースサービスである、S3とDyanamo出入り検知
次の課題は、どのように顧客の出入りを検知し、ショッピングの決済処理を行うかどうかです。
Amazon Goでは前述の通り、QRコードによってこれを実現しています。顧客が店舗に入店したと同時にカメラにて顧客の行動を捉え、入り口にてQRコードがスキャンされた際に、カメラ上の顧客とアカウントの情報を関連付けます。
また、家族連れ等、複数人で入店するが決済者が1人の場合に対処するために、決済者が同じ場合には同じQRコードで入店する仕様になっているようです。
QRコードのスキャンによる、アカウント情報の紐付け(*4参照)カード、支払い、領収書
ここまでできれば、あとはECのAmazonと同様に決済を行うだけです。実際には、店舗を出た瞬間ではなく、出たあと10-15分経ってからアプリ上にレシートが表示されるようです。
まとめ
このように、Amazon Goのような画期的な、魔法とも思えるような世界を実現するためには、センサー、カメラ、ネットワーク、クラウド、ディープラーニング、コンピュータビジョン、センサー・フュージョン等、本当に様々な技術が必要で、それらが適切に組み合わされることで実現されているみたいです。
イノベーションは1人では起こせない、チームが必要であるということを、Amazon Goから強く学びました。
以上、なにか参考になれば幸いです!
※補足
誤り・修正が必要な点があれば、お手数ですがご連絡いただけると幸いです。
資料一覧








- 投稿日:2020-02-24T04:20:21+09:00
無人コンビニ「AmazonGo」を実現している技術について、どの日本語記事よりも詳しく調べてみる
記事の概要
巷で話題になっている無人店舗「Amazon Go」。「コンビニの店員いらなくなるんちゃう?」と話題になっているので、技術者の端くれとして、それを可能にしている技術について知るべく、日本語でいろいろ調べてみたのですが、参考になる記事が全く出てきませんでした。
なので、Re:MARSというAmazonのカンファレンスイベントの記事や、その他英語・日本語、さまざまな技術系記事を参考に、解説記事を書いてみました。(引用記事は一番下を参照)
技術系の話ですが、細かいことは端に置いて、大枠だけ理解できるように書いたので、ぜひ最後まで読んでみてください。
※重要
記事内の情報は、Amazon Goの内外の方が発信してくださった情報をもとに僕が推測したものです。誤りがある可能性が十分にありますので、ご承知おきください。また、著作権には最大限注意して執筆しましたが、もし万が一修正が必要な点がありましたら、お手数ですがご連絡いただけると幸いです。
AmazonGoとは
Amazonが2016年にオープンした「無人コンビニ」で、「レジに並ばず、商品を手にとってお店を出るだけで決済ができる」というのが特徴です。
具体的には、
1. Amazon Goアプリをダウンロードする
2. アプリ内にあるQRコードをかざして入店する
3. 普段の買い物と同じように、店内を回り、ほしい商品を手にする
4. そのままゲートを出る
5. Amazonのアカウントに紐付けられたクレジットカードに自動で請求、決済完了という流れで利用できるみたいです。Amazonはこれを、「Just Walk out Technology」というふうに評しています。
実際に利用している様子は、こちらの動画がすごくわかりやすいです↓
このまさに魔法のような店舗AmazonGo。利用するのは簡単ですが、実際にこの店舗を実現するためには、ディープラーニング、コンピュータビジョン、センサー・フュージョンなど、最先端かつとても高度な技術が必要になります。
ここからは、実際にどのようにしてこのような魔法の店舗が実現されているのか、その詳細な技術について追っていきたいと思います。
"Just walk out" を実現するための6つの技術的課題
まずはじめに、このJust Walk outにはどのような技術が必要なのか、AmazonGoの全体の作り(アーキテクチャ)を確認してみます。
顧客の行動と、その際に必要なシステムをまとめた図が以下のものになります。
ここから、大きく
・誰が何を手に取ったかの解析
・顧客の映像データと決済アカウントの紐付け
・決済
の大きく3つの問題を解決しなければいけないことがわかります。
Amazon Go のシステムアーキテクチャ1(*1参照)
この問題を、もう少し細かくしてみたものがこちら。
「誰が何(商品)を手に取ったか」を特定するためには、個人と商品を別々に特定し、それらの情報を紐付ける必要があることがわかります。
Amazon Go のシステムアーキテクチャ2(*1参照)これらの情報から、AmazonGoの”Just Walk Out ”を実現するためには、大きく6つの課題を解決する必要があることがわかります。それがこちら。
Just Walk Outを実現するための6つの技術課題(*1参照)英語でなにを言っているのかわからないので、以下1つずつ詳しく見ていきます。
個人識別
まず重要なのは、ストア内で行動をする顧客一人一人を、別々に認識し追跡することです。
Amazon Goでは、この課題を解決するために、天井に無数のカメラが搭載されています。
天井にある黒いボックスのようなものがすべてカメラ(*2参照)この無数のカメラによって、店舗のあらゆる場所を、あらゆる方向から撮影しています。
そして、この個別のカメラが撮影した映像は1つに統合され、店舗内での顧客の行動データをマッピングします。
最終的には、以下のように、店舗内での顧客の行動をまとめて認識することができるようになります。
店舗内の顧客ログデータのマッピング(*1参照)Amazon Goで非常に優れている点は、この個人識別の技術を、"「顔認識」なし"で実現しているところです。
プライバシーの観点から、顔認識を用いる危険性を理解していたため、顔認識を用いないという制約条件の中で個人識別の技術を確立した技術者の方の能力の高さが垣間見れます。
アイテムの識別
次に重要なのは、どんな商品を、いくつ手に取ったかです。Amazon Goでは、天井のカメラ、棚の奥に設置してあるカメラ、棚に設置してる重量センサーを用いて、アイテムの識別を行っているようです。
まず商品の識別(どのアイテムが手に取られたか)について。こちらは、天井に付けられたカメラの画像処理によって、アイテムが認識されているようです。(商品バーコードを使用しているという記事もありましたが、詳しくはわかりませんでした)
次に個数について。こちらは、天井のカメラに加えて、棚の奥に設置してあるカメラや棚に設置してある重量センサーを用いて識別を行っているようです。
システムは各アイテムの正確な重量を把握しており、重量の変化量を比較することで、商品が何個手に取られたかを検知するというわけです。
これらの情報を機械学習によって処理することで、どの商品が、いくつ取られたかを解析しているようです。(*2参照)
棚に付けられた重量センサー(*3参照)
棚の奥に設置されたカメラ(*4参照)Who took what?(誰が何を取ったか)
「誰が」「何を」とったか、これらの情報を組み合わせることで、最も重要な「Who took what?」、すなわち、誰が何を取ったのかを認識することができます。
実際に、「誰が」が「何を」取ったのか、その両者の情報を紐付けるためには、商品と顧客の間の関係、すなわち「腕」をトレースする必要があります。
そこでAmazon Goでは、人間を棒人間のように見立てて行動を解析する、「スティックフィギュアモデル」によって、「誰が何を取ったか」を認識しているようです。
顧客が商品を取るときの姿勢(ポーズ)について、膨大な量のデータにて学習を行い、実際に商品が取られたのか、正しく解析できるようにしたそうです。
スティックフィギュアモデルによる購買行動の推定(*1参照)この解析によって、顧客情報と商品情報を紐付けることができ、「誰が何を取ったか?」を認識することができるようになります。
最終的には、以下のように、顧客の行動と、商品の出し入れの様子を統合して可視化することに成功しています。
顧客の移動だけでなく、「腕」までキャプチャされている、非常に感動する視覚データなので、ぜひ見てみてください!(8:27からです)
顧客の行動ログと商品の出し入れのリアルタイム可視化データ(*5参照)データ転送
これらの個別のカメラによってキャプチャされた映像や、重量センサーにてキャッチしたデータは、店舗からクラウドに転送され、統合して処理される必要があります。
これを可能にするために、
・個別のカメラでの基本的な前処理と、データ量の削減
・ビデオのデータを正しくクラウドに転送するための、ネットワークやデータ形式
・ビデオデータを保存するためのクラウド上のビデオサーバーなど、さまざまな技術がAmazon Goでは活用されているようです。これらの技術によって、通信障害を適切に処理し、店舗内のデータをクラウドと通信させることが可能になっています。
AWSの代表的なストレージ・データベースサービスである、S3とDyanamo出入り検知
次の課題は、どのように顧客の出入りを検知し、ショッピングの決済処理を行うかどうかです。
Amazon Goでは前述の通り、QRコードによってこれを実現しています。顧客が店舗に入店したと同時にカメラにて顧客の行動を捉え、入り口にてQRコードがスキャンされた際に、カメラ上の顧客とアカウントの情報を関連付けます。
また、家族連れ等、複数人で入店するが決済者が1人の場合に対処するために、決済者が同じ場合には同じQRコードで入店する仕様になっているようです。
QRコードのスキャンによる、アカウント情報の紐付け(*4参照)カード、支払い、領収書
ここまでできれば、あとはECのAmazonと同様に決済を行うだけです。実際には、店舗を出た瞬間ではなく、出たあと10-15分経ってからアプリ上にレシートが表示されるようです。
まとめ
このように、Amazon Goのような画期的な、魔法とも思えるような世界を実現するためには、センサー、カメラ、ネットワーク、クラウド、ディープラーニング、コンピュータビジョン、センサー・フュージョン等、本当に様々な技術が必要で、それらが適切に組み合わされることで実現されているみたいです。
不可能にも思える「レジなしコンビニ」という全く新しい概念を、意志と多様性の力で数多くの壁を乗り越えて実現したAmazonの技術者の方々に深く感動した、そんなまとめでした。
以上、なにか参考になれば幸いです!
※補足
誤り・修正が必要な点があれば、お手数ですがご連絡いただけると幸いです。
資料一覧

- 投稿日:2020-02-24T03:05:48+09:00
HelmでデプロイしたGitLabのバックアップをする際Podがevictされるときの対応策
環境情報
EKS: 1.13
kubectl: v1.13.11-eks-5876d6
Helm: 2.14.3
GitLab Helm Chart: 2.3.0 (appVersion: 12.3.0)事象
CronJobでtask-runner Podを立ててGitLabのアプリケーションバックアップを行う際に、このPodが途中でevictされてバックアップに失敗してしまう。
task-runner Podが立っていたNodeを
kubectl describeした結果は次のようになる。$ kubectl describe node ip-10-10-101-14.ap-northeast-1.compute.internal ... ... Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Starting 56m kubelet, ip-10-10-101-14.ap-northeast-1.compute.internal Starting kubelet. Normal NodeHasSufficientMemory 56m (x2 over 56m) kubelet, ip-10-10-101-14.ap-northeast-1.compute.internal Node ip-10-10-101-14.ap-northeast-1.compute.internal status is now: NodeHasSufficientMemory Normal NodeHasNoDiskPressure 56m (x2 over 56m) kubelet, ip-10-10-101-14.ap-northeast-1.compute.internal Node ip-10-10-101-14.ap-northeast-1.compute.internal status is now: NodeHasNoDiskPressure Normal NodeHasSufficientPID 56m (x2 over 56m) kubelet, ip-10-10-101-14.ap-northeast-1.compute.internal Node ip-10-10-101-14.ap-northeast-1.compute.internal status is now: NodeHasSufficientPID Normal NodeAllocatableEnforced 56m kubelet, ip-10-10-101-14.ap-northeast-1.compute.internal Updated Node Allocatable limit across pods Normal Starting 56m kube-proxy, ip-10-10-101-14.ap-northeast-1.compute.internal Starting kube-proxy. Normal NodeReady 56m kubelet, ip-10-10-101-14.ap-northeast-1.compute.internal Node ip-10-10-101-14.ap-northeast-1.compute.internal status is now: NodeReady Warning FreeDiskSpaceFailed 11m kubelet, ip-10-10-101-14.ap-northeast-1.compute.internal failed to garbage collect required amount of images. Wanted to free 17639540326 bytes, but freed 0 bytes Warning FreeDiskSpaceFailed 6m52s kubelet, ip-10-10-101-14.ap-northeast-1.compute.internal failed to garbage collect required amount of images. Wanted to free 23642674790 bytes, but freed 0 bytes Warning ImageGCFailed 6m52s kubelet, ip-10-10-101-14.ap-northeast-1.compute.internal failed to garbage collect required amount of images. Wanted to free 23642674790 bytes, but freed 0 bytes Warning EvictionThresholdMet 3m55s kubelet, ip-10-10-101-14.ap-northeast-1.compute.internal Attempting to reclaim ephemeral-storage Normal NodeHasDiskPressure 3m46s kubelet, ip-10-10-101-14.ap-northeast-1.compute.internal Node ip-10-10-101-14.ap-northeast-1.compute.internal status is now: NodeHasDiskPressure
FreeDiskSpaceFailedというメッセージから大体憶測がつきます。原因
GitLabのアプリケーションバックアップに仕組みとしてGitリポジトリデータ、ユーザデータ、画像データなどを全てまとめて1つのtarにしてS3に転送することになっています。
この過程で生成される一時的なデータはtask-runner Podのファイルシステムに格納されます。
つまり、十分なディスク容量がない場合はevictされることになるわけです。対応策
task-runner PodにPersistentVolumeを紐づけることにします。
GitLab Helm Chartのvaluesを下記のように
gitlab.task-runner.cron.persitenceの項目を追加すればよいです。my-values.yamlgitlab: task-runner: backups: cron: enabled: true schedule: "0 19 * * *" + persistence: + enabled: true + size: 50Giこの項目を加えることでPersistentVolumeが作成されます。
気をつけないといけないのはバックアップが終わるとPersistentVolumeが削除されるわけではなく、ずっと立ち続けるということです。
料金を気にする人は、バックアップ成功時にPersistentVolumeを削除するロジックを組み込む必要があります。リリースを更新するために
helm upgradeします。リリース名はdev-gitlabとしています。$ helm upgrade \ --namespace default \ --values my-values.yaml \ --version 2.3.0 \ dev-gitlab gitlab/gitlab参考
https://docs.gitlab.com/charts/backup-restore/#pod-eviction-issues
- 投稿日:2020-02-24T02:27:16+09:00
Route53のDNSクエリログをAmazonESに取り込んでみた
はじめに
Amazon Route53で作成したホストゾーンに対するDNSクエリログを
Amazon Elasticsearch Serviceに取り込んみました。【参考】
・ Amazon Route53とは
・ DNSクエリのログ記録利用環境
product version logstash 7.5.2 Java 11.0.6 OS(EC2) Amazon Linux2 (t3.small) AMI ID ami-011facbea5ec0363b Amazon ES 7.1 (latest) Region us-east-1 ※投稿時点における最新版を採用しています。
【構成図】
前提条件
- Elasticsearchへのログ出力にはElastic社のETLツールであるLogstashを利用しています。
- Amazon Elasticsearch Service(以下、Amazon ES)は、パブリックアクセスとしています。
(IPアドレスによるホワイトリスト制御)【参考】
・ Logstashとは実施内容
- IAM Role作成
- クエリログ記録の設定
- Amazon ESのドメイン作成
- Logstashの構築
- Kibanaでの各設定
1. IAM Role作成
- EC2として構築するLogstashに割り当てるIAM Roleを作成します。
- logatashに割り当てるIAM Roleとして
logstashinputというロールを作成し、
CloudWatchLogsReadOnlyAccessというIAM Policyを割り当てます。
CloudWatchLogsReadOnlyAccess{ "Version": "2012-10-17", "Statement": [ { "Action": [ "logs:Describe*", "logs:Get*", "logs:List*", "logs:StartQuery", "logs:StopQuery", "logs:TestMetricFilter", "logs:FilterLogEvents" ], "Effect": "Allow", "Resource": "*" } ] }2. クエリログ記録の設定
- [Route53] > [ホストゾーン]をクリックします。
ログ出力したいドメイン名を選択し、
クエリログ記録の設定をクリックします。
下記の内容で
CloudWatchログのロググループの設定を行います。【CloudWatchログのロググループの設定】
項目 値 ホストゾーン <指定したドメイン名> *にクエリログを送信する 米国東部(バージニア北部)に新しいロググループ 新しいロググループ /aws/route53/<ドメイン名> ※新しいロググループ名は任意で好きなように設定可能です。
※クエリログの出力先CloudWatchLogsリージョンは、米国東部(バージニア北部)のみです。
- 下記の内容で
アクセス権限の付与とクエリログ記録の設定を行います。【アクセス権限の付与とクエリログ記録の設定】
項目 値 CloudWatchログのロググループ /aws/route53/<ドメイン名> CloudWatchログのリソースポリシー 米国東部(バージニア北部)に新しいリソースポリシーを作成 リソースポリシーの名前 route53-query-logging-policy リソースポリシーを適用するロググループ /aws/route53/*
ポリシーとテストのアクセス権限の作成をクリックし、下記の成功メッセージが表示されればOKです。
クエリログ記録コンフィグの作成をクリックします。
DNSクエリがあると、CloudWatch Logsの作成したロググループ内に
Route53のホストゾーンID名のログストリームが作成されていきます。
DNSクエリログのフォーマットは以下の通りです。
項目 フィールド名 説明 値 ログ形式バージョン log_version クエリログのバージョン番号 1.0 クエリのタイムスタンプ timestamp Route53がリクエストに応答した日時(ISO8601形式) 2020-02-23T15:50:46Z ホストゾーンID hostzone_id Route53のホストゾーンID Z1CV60OKBEMYL2 クエリ名 query_name リクエストで指定されたドメインまたはサブドメイン xxxxxx.name クエリタイプ query_type リクエストで指定されたDNSレコードタイプ MX レスポンスコード response_code Route53が返すDNSレスポンスコード NOERROR レイヤー 4 プロトコル protocol クエリの送信に使用されたプロトコル (TCP/UDP) UDP Route 53 エッジロケーション edge_location クエリに応答したRoute 53エッジロケーション ORD52-C2 リゾルバー IP アドレス resolver_ipaddress DNSリゾルバーのIPアドレス xxx.215.xx.87 EDNS クライアントサブネット client_subnet DNSリゾルバーのサブネット - 【参考】
・ Route53でクエリログが取得できるようになりました3. Amazon ESのドメイン作成
- 下記内容でAmazon ESのドメインを作成します。
項目 値 リージョン us-east-1 デプロイタイプ 開発およびテスト Elasticsearchのバージョン 7.1 (latest) Elasticsearchのドメイン loganalytics-dev インスタンスタイプ c5.large.elasticsearch ノードの数 1 データノードのストレージタイプ EBS EBS ボリュームタイプ 汎用(SSD) EBS ボリュームサイズ 10 GiB 自動スナップショットの開始時間 00:00 UTC (デフォルト) ネットワークアクセス パブリックアクセス 細かいアクセスコントロールを有効化 無効 Amazon Cognito認証を有効化 無効 ドメインアクセスポリシー カスタムアクセスポリシー (IPv4アドレス) ドメインへのすべてのトラフィックにHTTPSを要求 有効 ノード間の暗号化 無効 保管時のデータの暗号化の有効化 無効 ※アクセスポリシーに追加するIPは、Amazon ESにアクセスする外部IPとLogstashのIPになります。
4. Logstashの構築
- LogstashをEC2 Amazon Linux2 (t3.small)で構築します。
- 下記のパイプライン構成ファイル(
/etc/logstash/conf.d/logstash.conf)の設定を行います。
(このタイミングではLogstashは起動しません。)logstash.confinput { cloudwatch_logs { log_group => [ "/aws/route53/<ドメイン名>" ] region => "us-east-1" interval => 5 } } filter { ### dissect filterでフィールドを抽出 dissect { mapping => { "message" => "%{log_version} %{timestamp} %{hostzone_id} %{query_name} %{query_type} %{response_code} %{protocol} %{edge_location} %{resolver_ipaddress} %{client_subnet}" } } ### dateフィールドから@timestampを抽出 date { match => [ "timestamp", "ISO8601" ] timezone => "Asia/Tokyo" target => "@timestamp" } ### @timstampから日本時間を抽出 ruby { code => "event.set('[@metadata][local_time]',event.get('[@timestamp]').time.localtime.strftime('%Y-%m-%d'))" } ### グローバルIPから国などをマッピングするために指定 geoip { source => "resolver_ipaddress" target => "src_geoip" tag_on_failure => "src_geoip_lookup_failure" } ### document_idに利用する一意のIDを作成 fingerprint { source => "message" target => "[@metadata][fingerprint]" method => "MURMUR3" } ### デフォルトの型がstringのため、フィールド定義で定義した型に変換 mutate { ### typeフィールドを追加 add_field => { "type" => "route53" } ### 不要なフィールドを削除 remove_field => [ "timestamp" ] } } output { ### 出力先のAmazonESのIndexを指定 elasticsearch { hosts => [ "https://search-loganalytics-dev-xxxxxxxxxxxxxxxxxxxxxx.us-east-1.es.amazonaws.com:443" ] index => "%{type}-%{[@metadata][local_time]}" document_id => "%{[@metadata][fingerprint]}" ilm_enabled => false } }【参考】
・ cloudwatch-logs input
・ dissect filter
・ date filter
・ ruby filter
・ geoip filter
・ fingerprint filter
・ mutate filter
・ elasticsearch output5. Kibanaでの各設定
Amazon ESの
KibanaのURLをクリックします。
[Dev Tools]のConsoleからRoute53のIndex Templateを追加します。
上記で張り付けたIndex Templateは以下の通りです。
index_templete_route53PUT _template/route53 { "index_patterns": ["route53-*"], "settings": { "number_of_shards": 1, "number_of_replicas" : 1 }, "mappings": { "properties": { "@timestamp": { "type": "date" }, "@version" : { "type" : "keyword" }, "log_version" : { "type" : "keyword" }, "hostzone_id" : { "type" : "keyword" }, "query_name" : { "type" : "keyword" }, "query_type" : { "type" : "keyword" }, "response_code" : { "type" : "keyword" }, "protocol" : { "type" : "keyword" }, "edge_location" : { "type" : "keyword" }, "resolver_ipaddress" : { "type" : "ip" }, "client_subnet" : { "type" : "keyword" }, "type" : { "type" : "keyword" }, "tags" : { "type" : "keyword" }, "message" : { "type" : "text" }, "cloudwatch_logs" : { "properties" : { "event_id" : { "type" : "keyword" }, "ingestion_time" : { "type" : "date" }, "log_group" : { "type" : "keyword" }, "log_stream" : { "type" : "keyword" } } }, "src_geoip" : { "properties" : { "city_name" : { "type" : "keyword" }, "continent_code" : { "type" : "keyword" }, "country_code2" : { "type" : "keyword" }, "country_code3" : { "type" : "keyword" }, "country_name" : { "type" : "keyword" }, "dma_code" : { "type" : "long" }, "ip" : { "type" : "ip" }, "latitude" : { "type" : "float" }, "location" : { "properties" : { "lat" : { "type" : "float" }, "lon" : { "type" : "float" } } }, "longitude" : { "type" : "float" }, "postal_code" : { "type" : "keyword" }, "region_code" : { "type" : "keyword" }, "region_name" : { "type" : "keyword" }, "timezone" : { "type" : "keyword" } } } } } }
- Logstashを起動します。
logstash_start$ sudo systemctl start logstash $ sudo systemctl status logstash ● logstash.service - logstash Loaded: loaded (/etc/systemd/system/logstash.service; disabled; vendor preset: disabled) Active: active (running) since Sun 2020-02-23 17:11:21 UTC; 4min 42s ago Main PID: 32168 (java) CGroup: /system.slice/logstash.service └─32168 /bin/java -Xms1g -Xmx1g -XX:+UseConcMarkSweepGC -XX:CMSInitiatingOccupancyFraction=75 -XX:+UseCMSInitiatingOccupancyOnly -Djava.awt.h... Feb 23 17:12:00 ip-172-31-37-204.ec2.internal logstash[32168]: [2020-02-23T17:12:00,242][INFO ][logstash.outputs.elasticsearch][main] New Elastic...:443"]} Feb 23 17:12:00 ip-172-31-37-204.ec2.internal logstash[32168]: [2020-02-23T17:12:00,282][INFO ][logstash.filters.geoip ][main] Using geoip data....mmdb"} Feb 23 17:12:00 ip-172-31-37-204.ec2.internal logstash[32168]: [2020-02-23T17:12:00,332][INFO ][logstash.outputs.elasticsearch][main] Using defau...emplate Feb 23 17:12:00 ip-172-31-37-204.ec2.internal logstash[32168]: [2020-02-23T17:12:00,396][INFO ][logstash.outputs.elasticsearch][main] Attempting ...field"= Feb 23 17:12:00 ip-172-31-37-204.ec2.internal logstash[32168]: [2020-02-23T17:12:00,460][WARN ][org.logstash.instrument.metrics.gauge.LazyDelegatingGaug... Feb 23 17:12:00 ip-172-31-37-204.ec2.internal logstash[32168]: [2020-02-23T17:12:00,467][INFO ][logstash.javapipeline ][main] Starting pipeline {:pip... Feb 23 17:12:01 ip-172-31-37-204.ec2.internal logstash[32168]: [2020-02-23T17:12:01,418][INFO ][logstash.javapipeline ][main] Pipeline started..."main"} Feb 23 17:12:01 ip-172-31-37-204.ec2.internal logstash[32168]: [2020-02-23T17:12:01,497][INFO ][logstash.agent ] Pipelines running {:co...es=>[]} Feb 23 17:12:01 ip-172-31-37-204.ec2.internal logstash[32168]: [2020-02-23T17:12:01,736][INFO ][logstash.agent ] Successfully started L...=>9600} Feb 23 17:12:14 ip-172-31-37-204.ec2.internal logstash[32168]: /usr/share/logstash/vendor/bundle/jruby/2.5.0/gems/logstash-filter-fingerprint-3.2...recated Hint: Some lines were ellipsized, use -l to show in full.
- Kibanaの [Management] > [Index Patterns]で
Create index patternをクリックします。
route53-*という名前でIndex Patternを作成します。
@timestampを指定します。
[Discover]を開き、Index Patternに
route53-*を指定します。デフォルトでは直近15分間のログが表示されます。表示されていればOKです。
取り込んだログは以下のような感じです。
route53_log{ "_index": "route53-2020-02-23", "_type": "_doc", "_id": "1366418581", "_version": 2, "_score": null, "_source": { "src_geoip": { "country_code3": "RU", "country_code2": "RU", "continent_code": "EU", "longitude": 100, "ip": "2a00:xxxxxxx:1", "location": { "lon": 100, "lat": 60 }, "latitude": 60, "country_name": "Russia", "timezone": "Asia/Krasnoyarsk" }, "type": "route53", "protocol": "UDP", "query_type": "MX", "response_code": "NOERROR", "@version": "1", "resolver_ipaddress": "2a00:xxxxxxx:1", "log_version": "1.0", "edge_location": "CDG3-C2", "message": "1.0 2020-02-23T17:08:41Z Z1CV60OKBEMYL2 xxxxxxx.name MX NOERROR UDP CDG3-C2 2a00:xxxxxxx:1 -", "hostzone_id": "Z1CV60OKBEMYL2", "client_subnet": "-", "query_name": "xxxxxxx.name", "cloudwatch_logs": { "ingestion_time": "2020-02-23T17:09:08.462Z", "log_stream": "Z1CV60OKBEMYL2/CDG3-C2", "event_id": "35290432438372433059640402101280473034952869042615484416", "log_group": "/aws/route53/xxxxxxx.name" }, "@timestamp": "2020-02-23T17:08:41.000Z" }, "fields": { "cloudwatch_logs.ingestion_time": [ "2020-02-23T17:09:08.462Z" ], "@timestamp": [ "2020-02-23T17:08:41.000Z" ] }, "sort": [ 1582477721000 ] }まとめ
いかがでしたでしょうか。
公開しているWebサービスに対する不審なDNSクエリログを監視することで
攻撃の偵察行為を見つけたり、どこの国からのアクセスがあるのか分析すると
また違った情報が得られるかもしれませんね!
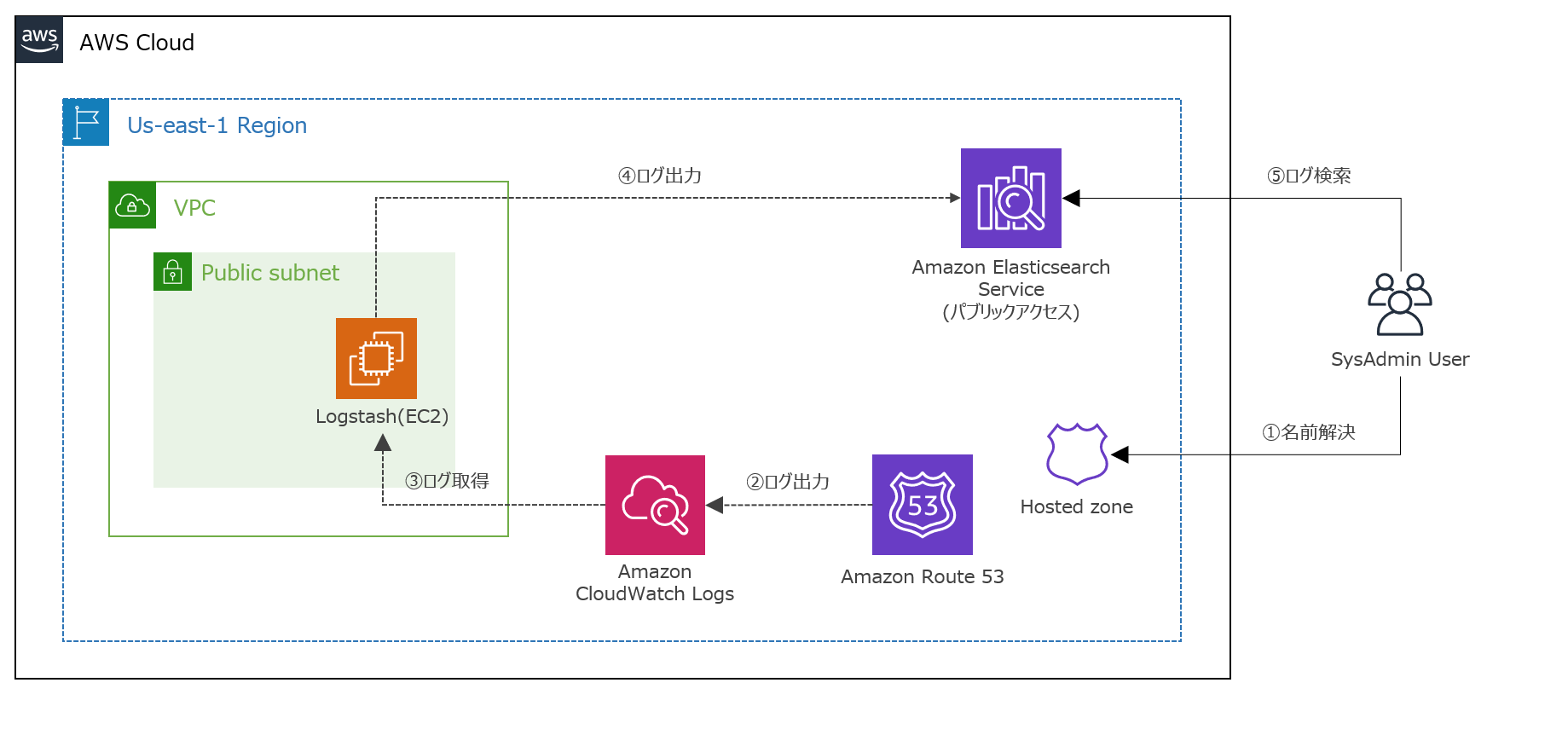
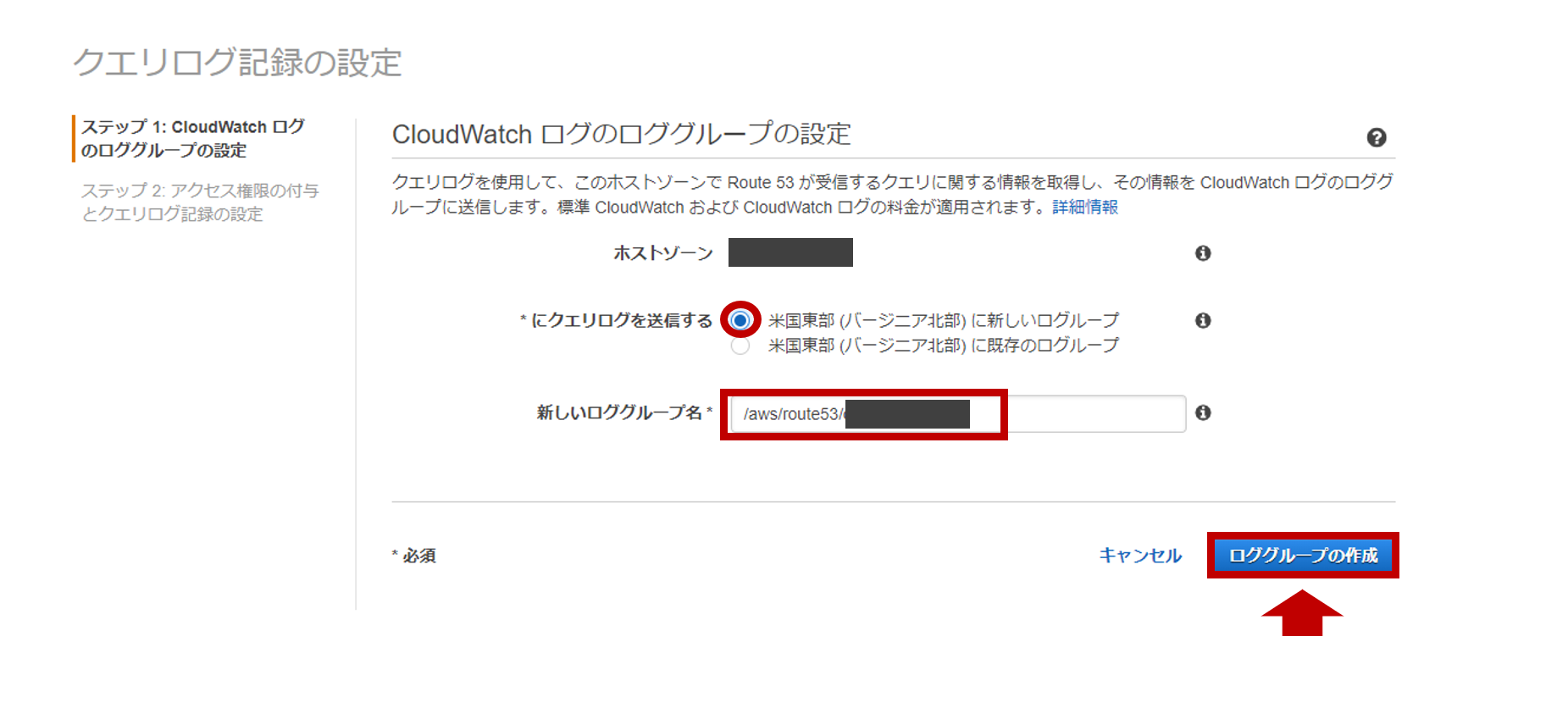
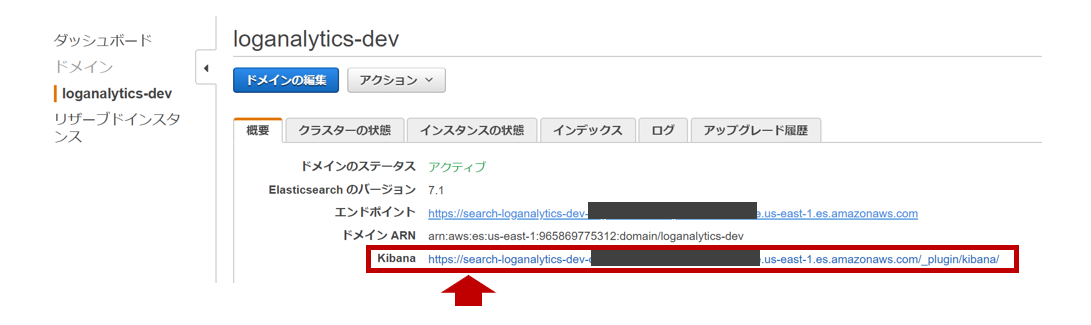


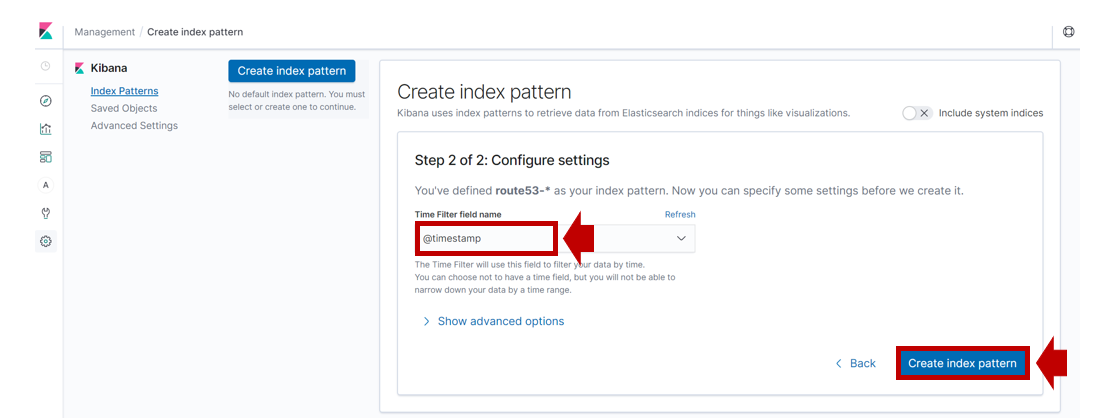

- 投稿日:2020-02-24T00:28:53+09:00
AWS CloudWatch EventsでEC2の自動起動・停止ルールをサクッと作って料金を節約する
EC2を使っていない時は停止させておきたい、特定の時間に起動させたい
個人開発とか勉強のためにawsでEC2を使っていると、起動しっぱなしのEC2があったりして、放っておくと存外に課金されかねない。なので、CloudWatchを使ってEC2の自動停止・起動を設定して、特定の時間に停止させたり、利用したい特定の時間に起動しておくようにする。
自動停止の設定
停止の方がサクッとできるのでこちらから。ルール作成のみでサクッとできます。
ルールの作成(自動停止)
マネジメントコンソールにログインし、上部メニューの「サービス」から「CloudWatch」を検索する。左サイドメニューの「ルール」→「ルールの作成」ボタンを押す。
Cronの設定
Cronを使ってサクッと行う。「スケジュール」を選択し、「Cron式」を選ぶ。
今回はサクッと行きたいので、コピペで済ます。
「毎日午前0時」のCron式
00 15 ? * * *
(※必要に応じて時間は変えてください。GMTなので、日本時間から-9時間(24-9=15時)を指定します。)↑をCron式のところに入力。
ターゲットの設定
「ターゲット」の欄から「ターゲットの追加」を押す。
そこから「EC2 StopInstances API 呼び出し」を選択する。
「インスタンスID」を入力する。(インスタンスIDは「サービス」→「EC2」からEC2の一覧から見れます。)
ルールの詳細を設定する
適当に名前をつける。「
ec2-auto-stop」とか。「説明」も適当に。「ルールの作成」を押下して完了。
自動起動の設定
特定の時間にEC2を起動させるルールを作成する。こちらも時間をかけずサクッと作成する。
・流れ
①IAMロールの作成
②ルールの作成ロールの作成
EC2起動用のロールを作成する。
上部メニューの「サービス」から「IAM」を検索して遷移する。
左サイドバーから「ロール」を選択し、「ロールの作成」ボタンを押下する。
「ロールの作成」を押下し、下の方にある「CloudWatch Events」を選択し、「ユースケースの選択」から
CloudWatch Eventsを選び、「次のステップ」を押下する。
一旦、ポリシーはそのままで、必要に応じてキー、タグ、ロール名をつけ、「ロールの作成」を押下してロールを作成する。(ここではロール名を
qiita_testとしている)
ポリシーのアタッチ
「サービス」→「IAM」→「ロール」から先ほど作成したロールを選択する。
「ポリシーをアタッチします」を押下し、
検索欄にSSMと入力し、AmazonSSMAutomationRoleを選択して「ポリシーのアタッチ」を押下する。
一旦、ロールはこれでOK(のはず)ルールの作成(自動起動)
自動停止のルールを作った時と同様に、「CloudWatch」→「ルール」→「ルールの作成」→「スケジュール」を選択し、「Cron式」を選ぶ。
毎日19時に起動させるようにしてみる。
「毎日19時」のCron式
00 10 ? * * *
これをコピペする。「ターゲット」は
SSM Automationを選択する。「ドキュメント」に、AWS-StartEC2Instanceを選ぶ。
(その他設定はそのままで。必要に応じて変更してください。)
「定数」を選び、
InstanceId*に起動させたいEC2インスタンスのIDを入力する。ロールに「既存のロールを使用」を選び、先ほど作成したロールを選ぶ。
「設定の詳細」を押下してルール名、説明を適当に入力すれば自動起動のルールも完了。
サクッとできました。