- 投稿日:2020-02-21T22:28:08+09:00
【Rails】多対多の関連付け
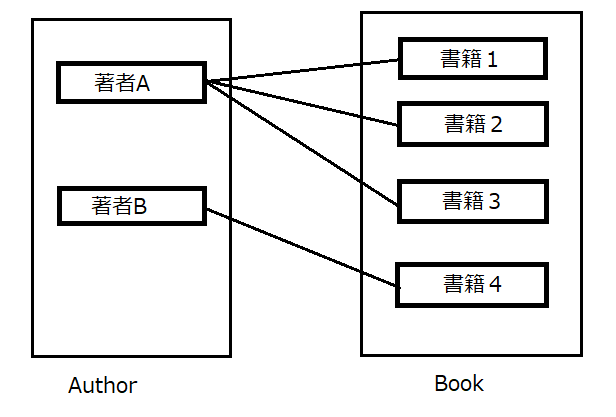
1体多関連の復習
まずは1体多の関連を復習し、それからどのような場合に多対多の関連を付けるべきなのかを見ていきましょう。
関連ですので、二つモデルを用意します。一つはAuthorもう一つはBookにしましょう。
それぞれ著者と書籍を表すクラスです。書籍は一人の著者に書かれており、一人の著者は複数の書籍を出版しているとします。
この時、1体多の関連を作成するには、Bookクラスにauthor_idというカラムを定義し、次のようにクラスを記述するのでした。
class Author < ApplicationRecord has_many :books end class Book < ApplicationRecord belongs_to :author endこのように定義することで、次のようなメソッドを使うことができます。
author = Author.find(id) # ある著者が書いた書籍の配列 # author_idがauthorのidと同じ値であるbookを取得 author.books book = Book.find(id) # ある書籍の著者 # bookが持つauthor_idと同じ値をidに持つauthorを取得 book.authorしかし、実際には一つの書籍に複数の著者がいるという状況の方が一般的です。
ですので、
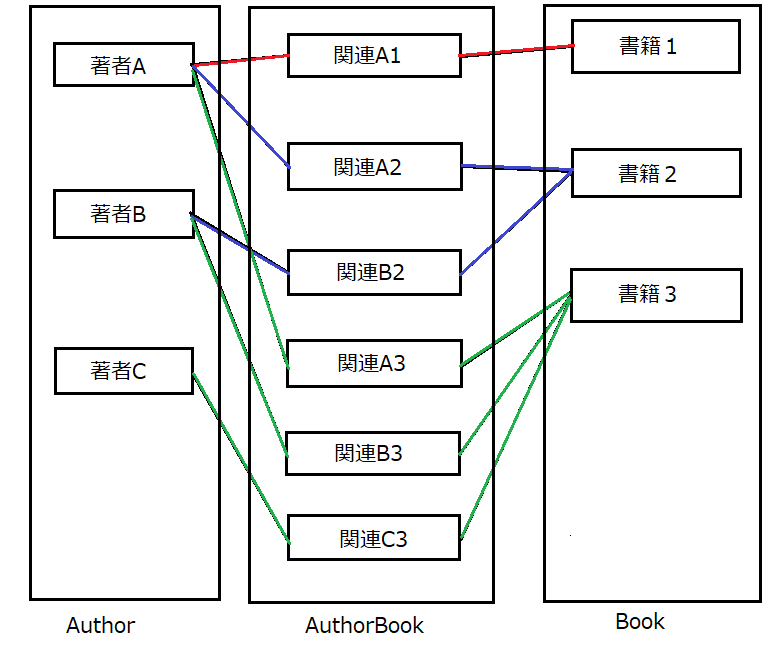
book.authorsとauthor.booksの双方向で複数の値を取得できるのが理想的です。現状、bookには一つのauthor_idを持つことしかできないので、何かしらの改修が必要になります。多対多の実装
そこで多対多の関連が必要となってきます。
多対多の関連にはAuthor,Bookの他に中間クラスと言われるAuthorBookクラスを追加します。
このAuthorBookクラスはauthor_idとbook_idを持っており、著者と書籍の関連1つに付き1レコード生成されます。ではモデルを作っていきましょう。
rails g model author_book author:references book:references rake db:migrateauthor:references,book:referencesと書くことでそれぞれのクラスと紐付けがされます。
次に各クラスを修正していきます。
class Author < ApplicationRecord has_many :author_books has_many :books, through: :author_books end class Book < ApplicationRecord has_many :author_books has_many :authors, through: :author_books end class AuthorBook < ApplicationRecord belongs_to :book belongs_to :author end
これで準備は整いました。では実験してみましょう
book = Book.create author1 = Author.create author2 = Author.create book.authorsこの時点ではまだ中間クラスによる関連付けが存在しないので、書籍に関連する著者は表示されないはずです。
AuthorBook.create(author_id: author1.id, book_id: Book.id) AuthorBook.create(author_id: author2.id, book_id: Book.id) book.authorsでは次はどうでしょうか?
設定がちゃんと出来れいれば2つのauthorインスタンスが表示されているはずです。簡単ですが多対多の関連付けの説明は以上になります。
多対多の関連は例えば、投稿に対するイイね機能や俳優と出演作品の関連などに用いられます。
複数のモデルが出てきて複雑になってきましたが、使いこなして複雑なデータ構造も扱えるようにしましょう。
- 投稿日:2020-02-21T22:01:43+09:00
【if文での論理演算(演算子の優先順位とついでに短絡評価)】
本日プログラミング学習で、if 文について理解度が高まったので備忘録のために記事にしてみました。
下記条件を満たすコードを記述しなさい(Ruby)
- aとbには true または false が入る
- aとb両方とも true または false なら True を表示
- それ以外は False を表示
回答例
judgement.rbdef judge(a, b) if a && b || !a && !b puts "True" else puts "False" end end a = false b = false judge(a, b)演算子の前知識
true && true ⇒ true
true && false ⇒ false
false && true ⇒ false
false && false ⇒ false
true || true ⇒ true
true || false ⇒ true
false || true ⇒ true
false || false ⇒ false
!true ⇒ false
!false ⇒ true考え方
正直メソッドの意味が理解できませんでした。
分解して考えていきます!judgement.rba = false b = false judge(a, b)今回はa、bともに false を代入します。
それらを引数に渡し、メソッドを実行していきます。judgement.rbif a && b || !a && !b puts "True" elseまず優先順位について、「&&」は「||」より優先順位が高いので、以下のように解釈されます。
(Ruby 2.7.0 リファレンスマニュアルより)judgement.rbif (a && b) || (!a && !b) puts "True" elseaとbを代入します。
judgement.rbif (false && false) || (true && true) puts "True" elsetrue && true ⇒ true
false && false ⇒ false
であるため下記のようになります。judgement.rbif false || true puts "True" else||の場合は
false || true ⇒ true
であるため下記のようになります。judgement.rbif true puts "True" elseつまり今回の if の中身は true になるので、else は実行されず True が表示されます。
他の条件の場合でも上記の考え方で理解ができました!
短絡評価とは
簡潔に答えると、左辺のみで評価できるもの(例えばfalse && true ⇒ false)は右辺を評価せずに結果を返す事。Ruby 2.7.0 リファレンスマニュアルでは下記のように書いてありました。
- && 左辺を評価し、結果が偽であった場合はその値(つまり nil か false) を返します。左辺の評価結果が真であった場合には右辺を評価しその結果を返します。
- || 左辺を評価し、結果が真であった場合にはその値を返します。左辺の評価結果が偽であった場合には右辺を評価しその評価結果を返します。
- ! 式の値が真である時偽を、偽である時真を返します。
まとめ
! がついている理由は両方 false だった場合、if 文の結果が false となり else が実行されてしまうのを避けるためだったんですね!
結局どんな if 文も今回のように実行されてるんですよね、、、
「 if 文は true か false で条件分岐を全てを判断している」という点をより深く理解することができました!参考文献
- 投稿日:2020-02-21T21:35:05+09:00
Debian だって日本語入力したい
問題
環境
- ruby の docker image:
2.7-slim-buster(DockerHub の公式のもの)docker-compose使ってる事象
ruby 環境を docker で立ち上げて
irb, pry から 日本語入力しようとしたらできない。(日本語を受け付けない)最初に結果
docker-compose.ymlweb: image: ruby: environment: ... LANG: C.UTF-8 # これを追加する ...これで日本語入力ができるようになりました。
詳細
0. ググる
こちら にたどり着く。
なるほど、OSによって対処が異なるのか。1. 使用しているOSの確認
こちら を参考に使っている docker image のOSを確認した。
どうやら起動している ruby コンテナのOSはDebianらしい。では、
Debianの locale (ロケール) の設定の方法が簡単には見つからず…。2. locale とは
言語_国.文字コード
3. locale コマンド
Linux には
localeコマンドがあるとのこと。
fyi: https://www.atmarkit.co.jp/ait/articles/1812/06/news038.html# コンテナのコンソール開く $ docker-compose exec web bash # 利用可能なロケール名を表示する root@hogehoge# locale -a C C.UTF-8 POSIX4. コンテナのENVに言語を設定
先程のサイトによると
C,POSIX システム標準な英語
utf8(ja_JP.UTF-8) 日本語UTF-8とのことなので、日本語入力が使えそうなのは
C.UTF-8!これを
docker-compose.ymlでENVに設定してみる。↓docker-compose.yml# 上部のコードの再掲 services: web: image: hoge environment: ... LANG: C.UTF-8 # これを追加する ...5. いざ
日本語を入力してみる。↓
# コンテナのコンソール開く $ docker-compose exec web bash # ENVが設定されているか一応確認しておく root@hogehoge# echo $LANG C.UTF-8 # irb 開いて日本語入力してみる root@hogehoge# irb irb(main):001:0> あああ Traceback (most recent call last): 4: from /usr/local/bin/irb:23:in `<main>' 3: from /usr/local/bin/irb:23:in `load' 2: from /usr/local/lib/ruby/gems/2.7.0/gems/irb-1.2.1/exe/irb:11:in `<top (required)>' 1: from (irb):1 NameError (undefined local variable or method `あああ' for main:Object)入力できるようになりました。
最後に
いろいろと間違っているかもしれません。
その際はご指摘いただけますと幸いです。
- 投稿日:2020-02-21T21:17:08+09:00
rails s できない場合の原因事例
※初心者向け
アウトプットの練習の為記述しております。rails sできなかったケースの1つ
かなりイージミスですので初心者の方のみ参考にしてください。
ターミナルでrails sを記述し実行したのですがエラーが発生しました。
下記のメッセージ内容です。=> Booting Puma => Rails 5.2.4.1 application starting in development => Run `rails server -h` for more startup options Puma starting in single mode... * Version 3.12.2 (ruby 2.5.1-p57), codename: Llamas in Pajamas * Min threads: 5, max threads: 5 * Environment: development Exiting Traceback (most recent call last): 44: from bin/rails:3:in `<main>' 43: from bin/rails:3:in `load' .....
これは結果から言いますと、別のローカルサーバーが既に立ち上がっていた為、エラーとなりました。
解決策して、使用していないローカルサーバーをcontrolボタン+Cボタンで切り再びrails s
これで解決しました。もしかしたらと思ったら試してください。
- 投稿日:2020-02-21T18:53:27+09:00
ruby 破壊の話⑤dup編
前回までで、破壊的メソッドを無意識に作らない方法について書いてきました。
その一つとしてdupを使った方法が知られていますが、どうしてdupを使うと回避できるのか、dupを使っても回避できない場合があること、完全に断ち切る方法について書いていこうと思います。
ruby 破壊の話シリーズ ruby 破壊の話①「=」のふるまい ruby 破壊の話②メソッド編 ruby 破壊の話③関数編 ruby 破壊の話④破壊的なメソッド編 ruby 破壊の話⑤dup編 dupの動き
まずはdupとはどんな動きをするのかを検証します。
irb(main):001:0> a=['a','b','c'] => ["a", "b", "c"] irb(main):002:0> b=['a','b','c'] => ["a", "b", "c"] irb(main):003:0> c=a => ["a", "b", "c"] irb(main):004:0> d=a.dup => ["a", "b", "c"] irb(main):005:0> a.__id__ => 47190903357720 irb(main):006:0> b.__id__ => 47190903332260 irb(main):007:0> c.__id__ => 47190903357720 irb(main):008:0> d.__id__ => 47190903309860abcdどれも中身は同じ配列ですが、idはaとcが同じだけで、全部で3つの別々のオブジェクトが生成されていることがわかると思います。
aとcが同じなのは003で参照先を揃えたからですね。今回の主役dupは004で使われています。
dupはコピーした新しいオブジェクトを参照するので、全部で3つになったわけです。
なのでaをもとに生成されたものの、オブジェクト自体は異なるので、好き勝手に操作してもaに影響を与えないわけです。
irb(main):011:0> a<<'d' => ["a", "b", "c", "d"] irb(main):012:0> a => ["a", "b", "c", "d"] irb(main):013:0> c => ["a", "b", "c", "d"] irb(main):014:0> d => ["a", "b", "c"] irb(main):015:0> d<<'ee' => ["a", "b", "c", "ee"] irb(main):016:0> a => ["a", "b", "c", "d"] irb(main):017:0> d.pop => "ee" irb(main):018:0> d.pop => "c" irb(main):019:0> d => ["a", "b"] irb(main):020:0> a => ["a", "b", "c", "d"]新しいオブジェクトなのでこのように好き勝手に扱えますが、今回書きたいのは、完全な複製ではないという点です。
なので好き勝手に扱えるかというと実はそうでもありません。
むしろ中途半端な複製なので、私はあまり使いたくありません。irb(main):001:0> a=["abc","def","ghi"] => ["abc", "def", "ghi"] irb(main):002:0> b=a.dup => ["abc", "def", "ghi"] irb(main):003:0> a => ["abc", "def", "ghi"] irb(main):004:0> b => ["abc", "def", "ghi"] irb(main):005:0> b[0].reverse! => "cba" irb(main):006:0> b => ["cba", "def", "ghi"] irb(main):007:0> a #dupしたはずなのにaも変わっている => ["cba", "def", "ghi"]このように破壊的メソッドの影響がコピー前の配列にも及んでしまいました。
破壊的なメソッドで起こるということは、=でも当然起こります。irb(main):001:0> a=["abc","def","ghi"] => ["abc", "def", "ghi"] irb(main):002:0> b=a => ["abc", "def", "ghi"] irb(main):003:0> obj1=[a,b] => [["abc", "def", "ghi"], ["abc", "def", "ghi"]] irb(main):004:0> obj2=obj1.dup => [["abc", "def", "ghi"], ["abc", "def", "ghi"]] irb(main):005:0> obj2[0][0]="aaa"#obj2の最初の要素だけ書き換えたい => "aaa" irb(main):006:0> obj2 => [["aaa", "def", "ghi"], ["aaa", "def", "ghi"]] irb(main):007:0> obj1 #obj1の最初の要素も書き換えられてしまった => [["aaa", "def", "ghi"], ["aaa", "def", "ghi"]] irb(main):008:0> obj2[0].reverse!#obj2の最初の配列すべてを反転させると => ["ghi", "def", "aaa"] irb(main):009:0> obj2 => [["ghi", "def", "aaa"], ["ghi", "def", "aaa"]] irb(main):010:0> obj1 => [["ghi", "def", "aaa"], ["ghi", "def", "aaa"]] #もれなく全部反転されます。 irb(main):011:0> obj1[0].__id__ => 46991556482860 irb(main):012:0> obj1[1].__id__ => 46991556482860 irb(main):013:0> obj2[0].__id__ => 46991556482860 irb(main):014:0> obj2[1].__id__ => 46991556482860 irb(main):015:0> #みんな同じものを見ていたらそりゃそう何が起こっているか
察しの良い方はお気づきかもしれませんが、関数に渡したときと似たような事象が起こっています。
ローカル変数という概念はここではありませんが、dupはローカル変数を作るときと同じようなふるまいをしています。
ここではobj2というオブジェクトをobj1の複製としているので、obj2を変更する限りは複製前に影響を与えません。
しかしその先、例えばobj2[0]やobj[0][0]は、全く同じものを指しているのでもろに影響が出るわけですね。解決策
実際ここまでやる必要があるかは場合によりますが、少なくとも完全に断ち切る方法位マスターしたいですよね・・・??少なくとも僕はしたいですね。
どこか壊さないか恐れながら実装したくないので。以下の方法で複製元との関係をすべて断ち切った完全な複製が作れます。
irb(main):001:0> a=["abc","def","ghi"] => ["abc", "def", "ghi"] irb(main):002:0> b=a => ["abc", "def", "ghi"] irb(main):003:0> obj1=[a,b] => [["abc", "def", "ghi"], ["abc", "def", "ghi"]] irb(main):004:0> obj3 = Marshal.load(Marshal.dump(obj1)) #obj1の完全な複製としてobj3を作成する => [["abc", "def", "ghi"], ["abc", "def", "ghi"]] irb(main):005:0> obj1 => [["abc", "def", "ghi"], ["abc", "def", "ghi"]] irb(main):006:0> obj3[0][0].reverse! => "cba" irb(main):007:0> obj3[0].reverse! => ["ghi", "def", "cba"] irb(main):008:0> obj3 => [["ghi", "def", "cba"], ["ghi", "def", "cba"]] irb(main):009:0> obj1 => [["abc", "def", "ghi"], ["abc", "def", "ghi"]] #無傷 irb(main):010:0> Marshal.dump(obj1) => "\x04\b[\a[\bI\"\babc\x06:\x06ETI\"\bdef\x06;\x00TI\"\bghi\x06;\x00T@\x06" irb(main):012:0> obj3[0].__id__ => 46956196664760 irb(main):013:0> obj3[1].__id__ => 46956196664760 irb(main):014:0> obj1[1].__id__ => 46956196746500仕組みは簡単で、複製の過程で一回単なる文字列になってます。
そこからもう一度オブジェクトを作り直すので、完全なる独立した複製が出来るわけです。
面白いのが、obj3[0]とobj3[1]の関係性は保持されているところ。
マーシャルデータ自体はオブジェクト内の関係性を保持する仕様の様です。
なので断ち切られる関係性はあくまで複製前と複製後の関係だけ。素晴らしい。
- 投稿日:2020-02-21T18:44:58+09:00
Ruby のクラスメソッドを委譲したい時は SingleForwardable を使おう
Ruby 2.7.0 リファレンスマニュアル > ライブラリ一覧 > forwardableライブラリ > SingleForwardableモジュール より。
結論
クラスメソッドの委譲には
SingleForwardableが使える(というのが調べてもパッと出てこなかったのでメモ)。
例require 'forwardable' class Implementation def self.service puts "serviced!" end end module Facade extend SingleForwardable def_delegator :Implementation, :service end Facade.service # => serviced!具体例
例えば、
Bugsnaggem を使いたいが、そのまま直で使うと後で Sentry に乗り換えづらいので、BugReportモジュールを用意してきちんとラップしておこうと思った場合などに、クラスメソッドの委譲が行きます。Bugsnagの例module BugReport extend SingleForwardable def_delegator :Bugsnag, :notify end BugReport.notify # Bugsnag.notify が実行されるRails 使ってる場合は
ActiveSupportのdelegate使っても良いと思います。delegateの例module BugReport class << self delegate :notify, to: :Bugsnag end end BugReport.notify # Bugsnag.notify が実行される委譲、便利ですね

- 投稿日:2020-02-21T18:44:12+09:00
【初心者向け】Railsで投稿される日時を日本時間に変更する(タイムゾーンの修正)
タイムゾーンを日本に変更するにはconfig/application.rbを修正する
参考
伊藤さんいつも参考にしています、ありがとうございます。
https://qiita.com/jnchito/items/831654253fb8a958ec25どのように記述するのか
module hogehoge class Application < Rails::Application config.time_zone = 'Tokyo' config.active_record.default_timezone = :local end end上記2文を追加するだけ。
追加した記述の2文を解説
config.time_zone = 'Tokyo'↑実際の表示を修正する記述
config.active_record.default_timezone = :local↑DBに保存する際にどの時間帯で保存するかの記述
伊藤さんが推奨されているlメソッドが便利でした!!しかも設定簡単
module hogehoge class Application < Rails::Application config.time_zone = 'Tokyo' config.active_record.default_timezone = :local end endこの設定を下記のように修正します。
module hogehoge class Application < Rails::Application config.i18n.default_locale = :ja config.active_record.default_timezone = :local end endconfig.time_zone = 'Tokyo'を書き換えただけですね。
config/localesにja.ymlファイルを作成
ja: time: formats: default: "%Y/%m/%d %H:%M:%S"と記述しました。
このあと、必ずサーバーを再起動(再起動しないと反映されないっぽい)
あとは、時間を表示させたいviewに
<%= l post.created_at %>っといった形式にするだけ。
ここは違う、こうした方が良い等々ございましたらご指摘いただけますと幸いです。
最後までみていただき、ありがとうございます。
- 投稿日:2020-02-21T18:29:16+09:00
rails でのドラクエ再現挑戦(モンスターのデータ)
はじめに
ドラゴンクエストシリーズをRuby,Ruby on railsで作る場合はどうするのか?という事を色々試してみたいと思います。
実行
ドラゴンクエストシリーズ(以下ドラクエ)には色んな要素がありますが
まずはモンスターのデータです。
サンプルでスライムのデータを記述しています。monsters.rbmonsters = [] monster = {name: "スライム", species_id: 1, HP: 5, MP: 0, attack: 4, defence: 4, speed: 5, pattern: [1,1,1,1,1,1,1,1], exp: 1, gold, 2} monsters << monster (後略)種族は別テーブルで保存しておいて、idで呼び出すことにします。
種族テーブルは次にような感じです。species.rbspecies = ["スライム","ドラキー","ゴースト",(後略)]行動パターンには配列を置いて、別テーブルに保存しておいた値をidで呼び出します。
patterns.rbpatterns = [] pattern = {name: "攻撃", target: 0, value: attack / 2, message: "#{monster.name}のこうげき"} patterns << pattern
targetは効果対象で、0が相手・1が味方、となります。valueはダメージ計算式です。messageは行動時にどんなメッセージが表示されるかを表します。そのモンスターの名前が表示されるように、#{monster.name}を記述しています。モンスター関連のデータはこんな感じで良いかと思います。
- 投稿日:2020-02-21T18:17:41+09:00
Slackのカスタム絵文字の数を数える(ElixirとRubyを使って)
はじめに
- はてな社内のSlackには、カスタム絵文字が2028個! 連携アプリ46個で、飲み会ダッシュボタンも爆誕!
- あなたが参加しているワークスペースには何個のカスタム絵文字がありますでしょうか?
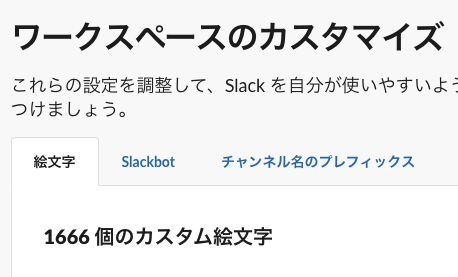
カスタム絵文字数
- 1,667個ありました
カウント方法
- SlackのAPI emoji.listを使います
- tokenが必要になります
- トークンの取得方法は、Slack API 推奨Tokenについて の記事が詳しいです
- ありがとうございます

- 必要なスコープは、
emoji:readが必要になります- 以下、RubyとElixirを使って書いてみます
Ruby
slack_emoji_list_count.rbrequire 'open-uri' require 'json' TOKEN = "xoxp-...secret..." body = URI.open("https://slack.com/api/emoji.list?token=#{TOKEN}", &:read) puts JSON.parse(body)["emoji"].reject { |k, v| v.start_with?('alias:') }.size()実行結果
% ruby -v ruby 2.7.0p0 (2019-12-25 revision 647ee6f091) [x86_64-darwin19] % ruby slack_emoji_list_count.rb 1667Elixir
lib/sandbox/slack_emoji_list.exdefmodule Sandbox.SlackEmojiList do @token "xoxp-...secret..." def run do url() |> HTTPoison.get!() |> Map.get(:body) |> Jason.decode!() |> Map.get("emoji") |> Enum.reject(fn {_key, value} -> String.starts_with?(value, "alias:") end) |> Enum.count() |> IO.puts() end defp url do "https://slack.com/api/emoji.list?token=#{@token}" end end以下、Elixirの環境が整っていない方向けに説明をします。
1. インストール
- Installing Elixir
- macOSの方は、asdf-vmがオススメです
- とりあえず試したい場合にはHomebrewを使って、
brew install elixirでのインストールでもよいとおもいます2. プロジェクト作成
% mix new sandbox % cd sandbox3. 依存ライブラリを追加
- HTTPクライアントのHTTPoison
- A blazing fast JSON parser and generator in pure ElixirのJasonをmix.exsに追加します
- (意訳) 純なElixirで書かれた爆速でHot! Hot!なJSON パーサー、ジェネレーター
mix.exsdefp deps do [ {:httpoison, "~> 1.6"}, {:jason, "~> 1.1"} ] end
- 依存ライブラリのダウンロード
% mix deps.get4. ソースコードを追加
- lib/sandbox/slack_emoji_list.ex (前述)を作る
5. 実行
% iex -S mix Erlang/OTP 22 [erts-10.5.3] [source] [64-bit] [smp:4:4] [ds:4:4:10] [async-threads:1] [hipe] Interactive Elixir (1.10.0) - press Ctrl+C to exit (type h() ENTER for help) iex> Sandbox.SlackEmojiList.run 1667 :okありがとうございます
おまけ
同僚に、https://${workspace}.slack.com/customize/emoji にアクセスしたときに表示される画面に数がてているとおしえてもらいました
ただ上の結果と1個ずれています
少し調査したところ、画像URLの先頭かの文字列が2種類あることがわかりました
%{"https://a.slack-edge.com/" => 1, "https://emoji.slack-edge.com/" => 1666}
- "https://a.slack-edge.com/" で始まるほうが無効なカスタム絵文字になっているのかなとおもいましたが、ふつうに使えていました
- これが使えなければ、ああ、これがだめなやつでカウントされていないのだなと納得したわけですが、そうではありませんでしたので謎だけが残りました
- 投稿日:2020-02-21T17:50:53+09:00
LeetCode - 104. Maximum Depth of Binary Tree
問題
04. Maximum Depth of Binary Tree - こんな感じのツリーが与えられて、これの深さ(高さ)を求める
3 / \ 9 20 / \ 15 7テストデータ
問題には Given binary tree
[3,9,20,null,null,15,7]って配列っぽく書かれているが、実際はこんなTreeNodeオブジェクト#<TreeNode:0x00000000011105e8 @val=3, @left=#<TreeNode:0x00000000011104a8 @val=9, @left=nil, @right=nil>, @right=#<TreeNode:0x0000000001110458 @val=20, @left=#<TreeNode:0x0000000001110408 @val=15, @left=nil, @right=nil>, @right=#<TreeNode:0x00000000011103b8 @val=7, @left=nil, @right=nil>>>なので、テストデータはこんな感じで作ってみた
Definition for a binary tree node. class TreeNode attr_accessor :val, :left, :right def initialize(val) @val = val @left, @right = nil, nil end end # t - top, l - left, r - right t = TreeNode.new(3) tl = TreeNode.new(9) tr = TreeNode.new(20) trl = TreeNode.new(15) trr = TreeNode.new(7) t.left = tl t.right = tr tr.left = trl tr.right = trr p t # => #<TreeNode:0x00000000011105e8 @val=3, @left=#<TreeNode:0x00000000011104a8 @val=9, @left=nil, @right=nil>, @right=#<TreeNode:0x0000000001110458 @val=20, @left=#<TreeNode:0x0000000001110408 @val=15, @left=nil, @right=nil>, @right=#<TreeNode:0x00000000011103b8 @val=7, @left=nil, @right=nil>>>解答
再帰を使って解くことになる。再帰、もうちょっと慣れないとな...
# Definition for a binary tree node. # class TreeNode # attr_accessor :val, :left, :right # def initialize(val) # @val = val # @left, @right = nil, nil # end # end # @param {TreeNode} root # @return {Integer} def max_depth(root) if !root.nil? ld = max_depth(root.left) rd = max_depth(root.right) 1 + [ld, rd].max else 0 end end
- ノードが
nilじゃなければ、その次のノードroot.leftroot.rightを再帰的によび、左右のノードがエッジかどうかを調べる1 + recursive_func()で呼ばれた回数(ツリーを降りた回数)を数える- この
if !root.nil?はif rootでもいけるようだ
if objecttests ifobjectisn't eithernilorfalse.!object.nil?tests ifobjectisn'tnil. So whenobjectisfalse, they have different values.つまりこれでいいのか...
def max_depth(root) if root 1 + [max_depth(root.left), max_depth(root.right)].max else 0 end endスコア
Runtime: 40 ms, faster than 52.11% of Ruby online submissions for Maximum Depth of Binary Tree. Memory Usage: 9.8 MB, less than 100.00% of Ruby online submissions for Maximum Depth of Binary Tree.
- 投稿日:2020-02-21T17:44:13+09:00
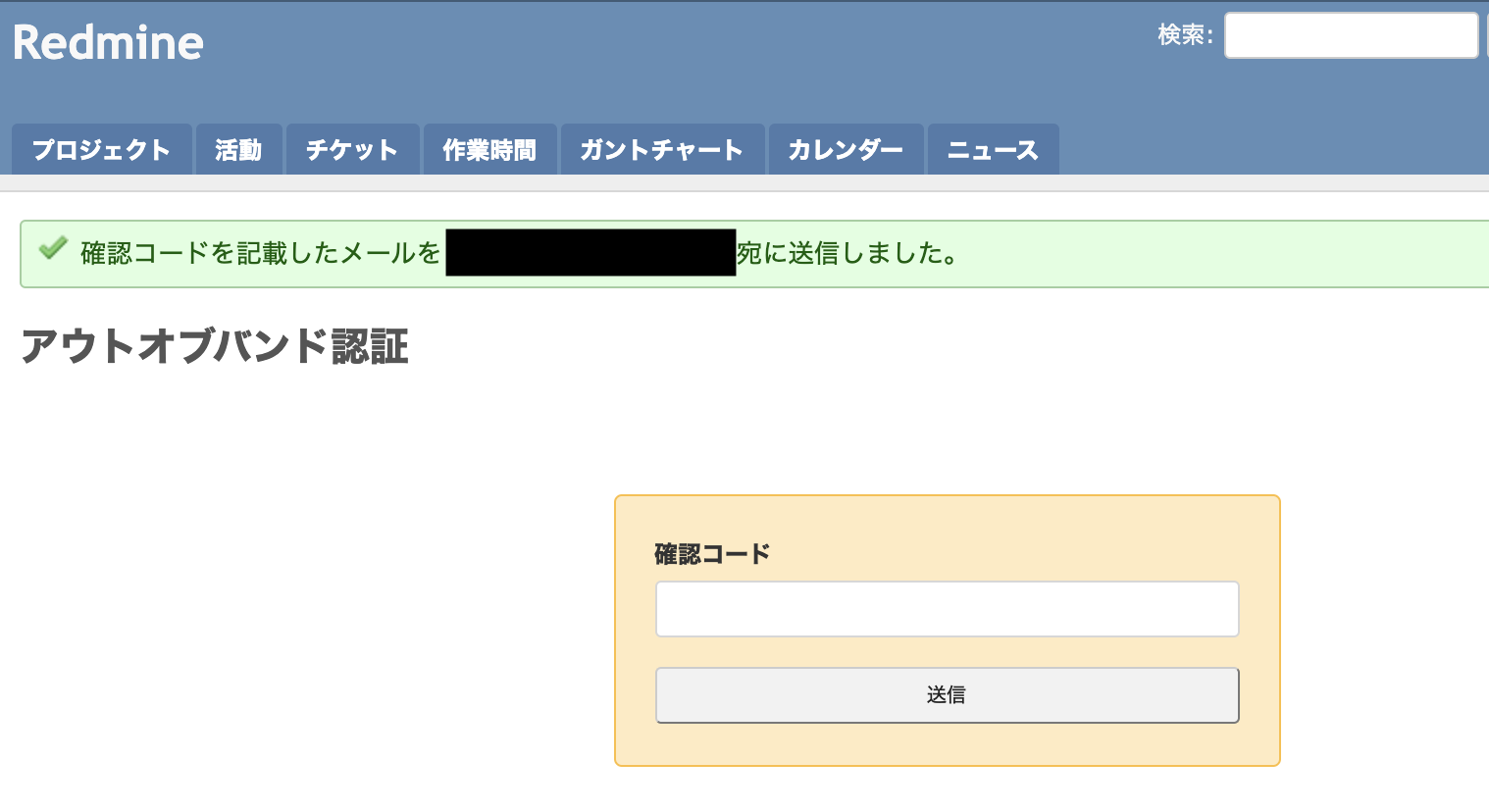
Redmine�に2段階認証プラグインを導入する
概要
- Redmineのセキュリティを高める為にプラグインを導入しました https://www.redmine.org/plugins/redmine_out_of_band_auth
- アウトオブバンド認証(Gmail経由でユーザのメールアドレスにワンタイムパスワードを送る)
- プラグインの導入手順とかをまとめています
実行環境
- EC2(AmazonLinux)
- Redmine 4.1.0
- ruby 2.7.0
- Rails 5.2.4.1
- gem 3.1.2
- mysql 5.7.29
実施したこと
- プラグインのインストール
- 送信元Gmailアカウントの設定
- Redmineサーバの設定
- Redmine利用ユーザの設定
手順
1. プラグインのインストール
一般的なRedmineプラグインインストールの手順です
Railsのバージョンによりつまずきますcd /path/to/redmine/plugin git clone https://www.redmine.org/plugins/redmine_out_of_band_auth cd /path/to/redmine bundle install bundle exec rake redmine:plugins:migrate NAME=redmine_out_of_band_auth RAILS_ENV=productionここでエラー。
StandardError: An error has occurred, all later migrations canceled: Directly inheriting from ActiveRecord::Migration is not supported. Please specify the Rails release the migration was written for: class CreateAuthSourceOutOfBands < ActiveRecord::Migration[4.2] ~~略~~以下の記事によるとRails4で作られたmigrationファイルをRails5で実行すると発生するらしい。
プラグイン内のファイルを編集。
vim /path/to/redmine/plugins/redmine_out_of_band_auth/db/migrate/001_create_auth_source_out_of_bands.rb 前: class CreateAuthSourceOutOfBands < ActiveRecord::Migration 後: class CreateAuthSourceOutOfBands < ActiveRecord::Migration[4.2]もう一度実行して解消。
bundle exec rake redmine:plugins:migrate NAME=redmine_out_of_band_auth RAILS_ENV=production2. メール送信用Googleアカウントの設定
- ワンタイムパスワードをユーザに送るためのGoogleアカウントを作成(既存で持っているものでもOKです)
- 他のアプリからGoogleのサービスを利用する場合、アカウントのパスワードではなくアプリ用のパスワードを作成して利用する必要があります
Googleでアカウント作成後、「アカウント管理」→「セキュリティ」から2段階認証設定をする
アプリパスワードから、Redmineメール送信用のアプリパスワードを作成する(名前は適当でOK)
16桁のパスワードは作成時しか確認できないためどこかにメモること
3. Redmineサーバの設定
configファイルに記載してRedmineを再起動します
vim /path/to/redmine/config/configuration.yml以下を記載します
default: email_delivery: delivery_method: :smtp smtp_settings: enable_starttls_auto: true address: "smtp.gmail.com" port: 587 domain: "smtp.gmail.com" authentication: :plain user_name: "作成したGoogleアカウントのメールアドレス" password: "で作成したアプリパスワード"Redmineを再起動します
service httpd restartRedmineが問題なくアクセスできればOKです
4. Redmine利用ユーザの設定
- メール通知を設定し、そもそもRedmineでメール通知ができるかを確認します
- ユーザのメール認証を有効にします
Redmineに管理者ユーザでログイン
「管理」→「設定」→「メール通知」から、送信元メールアドレスにメール送信用Googleアカウントのアドレスを記載
右下の「テストメール送信」からログインしたユーザのアドレスにテストメールが送信されれば、メール通知の設定はOK
「534-5.7.14 ~~~~」のようなエラーが出たら、アプリパスワードの設定ミスを疑ってください「管理」→「ユーザ」→「メール通知」から、利用ユーザのアドレスとアウトオブバンド認証を有効にする
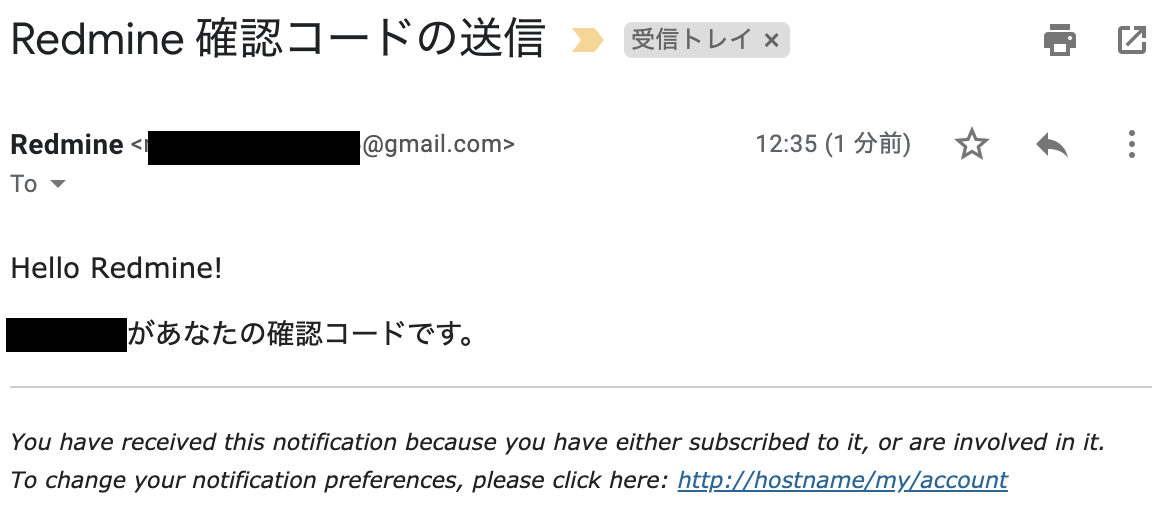
実際にログインし、以下の画面が出てログインできれば設定完了です。
おわりに
- Redmineのインストール手順は今後できたらまとめます
- Rubyの知識なしにとりあえず入れてみたのでbundle?gem?な状態です。少し勉強します
ありがとうございました。

- 投稿日:2020-02-21T17:39:14+09:00
ruby 破壊の話④破壊的なメソッド編
前回までの内容を簡単にまとめると、
- =や破壊的メソッドはデータの中身を壊す危険がある
- 破壊的関数かどうか見極められると良い
- 関数の中で破壊的メソッドを使うと破壊的になる
破壊的なメソッドの判別として、一番ハマりやすい破壊的=についての話を扱う。
ruby 破壊の話シリーズ ruby 破壊の話①「=」のふるまい ruby 破壊の話②メソッド編 ruby 破壊の話③関数編 ruby 破壊の話④破壊的なメソッド編 ruby 破壊の話⑤dup編 単に=を使っても破壊されない
関数に引数として渡しても同じidだから、どうやったら関係を断ち切れるの。。。と思っていましたが、そういう心配はありませんでした。
irb(main):001:0> def overWrite(obj) irb(main):002:1> p obj.__id__ irb(main):003:1> obj='over' irb(main):004:1> return obj.__id__ irb(main):005:1> end => :overWrite irb(main):006:0> a='abc' => "abc" irb(main):007:0> b=:abc => :abc irb(main):008:0> a.__id__ => 47211306018060 irb(main):009:0> b.__id__ => 1162588 irb(main):010:0> overWrite(a) 47211306018060 #書き換え前のidは同じ => 47211305688140 #書き換え後は異なる irb(main):011:0> a #書き換えられていない => "abc" irb(main):012:0> a.__id__ #idも書き換えられてない => 47211306018060 irb(main):013:0> overWrite(b) 1162588 #書き換え前のidは同じ => 47211305656840 #書き換え後は異なる irb(main):014:0> b.__id__ #書き換えられていない => 1162588 irb(main):015:0>このoverWrite関数は破壊的に作ったつもりでしたが、実は破壊的ではなかったようです。
=でidを書き換えているのは前に書いた通りなのですが、実は関数のスコープの問題で渡したaやbは書き換えを逃れています。
書き換えているobjは関数overWriter内でのみ有効なので、idを書き換えているのも、関数内でのみ有効なローカル変数objのidが書き換えられているだけなんですよね。よくよく考えるとプログラミング言語ってそうあるべきだよなって一安心。
結局=を使っても関係は断ち切れているから大丈夫なのね。安心安心。とは言い切れないので安心もできない
ここまで述べたことが間違っているわけではありませんが、ちょっと拡大解釈するとすぐに落とし穴にはまってしまいます。
前回の問題のコードを再掲します。
irb(main):001:0> def judge(hoge) irb(main):002:1> hoge[:point]=hoge[:name].length() irb(main):003:1> return hoge[:point]>2 ? true : nil irb(main):004:1> end => :judge irb(main):005:0> a={:name=>'test'} => {:name=>"test"} irb(main):006:0> b={:name=>'t'} => {:name=>"t"} irb(main):007:0> a => {:name=>"test"} irb(main):008:0> b => {:name=>"t"} irb(main):009:0> judge(a) => true irb(main):010:0> judge(b) => nil irb(main):011:0> a => {:name=>"test", :point=>4} irb(main):012:0> b => {:name=>"t", :point=>1}judge関数は破壊的という話をしましたが、002の=が実は破壊的な=なんですよね。
上で述べたローカル変数objと同じように、引数として受け取ったhogeも確かにローカル変数です。
しかしローカル変数なのはhogeのみです。
例えばhoge[0]やhoge[:name]はローカル変数ではありません。
hogeとhoge[0]は違うオブジェクトですからね。ここがハマりやすいところです。hogeが参照している値は引数として与えられたものと同じです。
hoge自体の参照先を変える「hoge=」という=はローカル変数を変更するものなので破壊的ではないですが、hogeの[:point]が参照している先はローカル変数ではないので、hoge[:point]=という=は破壊的な=になってしまうんですよね。irb(main):001:0> def overZense(obj) irb(main):002:1> obj[:name]='千' #名前は変えてしまう irb(main):003:1> obj={:name=>"千",:mind =>"社畜"} #心まで全部変える irb(main):004:1> return obj irb(main):005:1> end => :overZense irb(main):006:0> a={:name=> '千尋'} => {:name=>"千尋"} irb(main):007:0> overZense(a) => {:name=>"千", :mind=>"社畜"} irb(main):008:0> a #名前は変えられたけど心までは変えられない => {:name=>"千"}主にArrayやHashで出てくる例ですが、条件さえそろえば文字列とかその他mutableなオブジェクト全般で現れる例です。
よくわからないまま適当に=でつないでも、ひたすらにエイリアスなので意味がないです。
irb(main):001:0> def test(obj) irb(main):002:1> dummy=obj irb(main):003:1> dummy[:name]='千' irb(main):004:1> end => :test irb(main):005:0> a={:name=>'宮崎'} => {:name=>"宮崎"} irb(main):006:0> test(a) => "千" irb(main):007:0> a => {:name=>"千"}やるなら「ローカル変数=」の形にする必要があります
irb(main):001:0> def test(obj) irb(main):002:1> dummy_name=obj[:name] irb(main):003:1> dummy_name=dummy_name+'千' irb(main):004:1> p dummy_name irb(main):005:1> end => :test irb(main):006:0> a={:name=>'宮崎'} => {:name=>"宮崎"} irb(main):007:0> test(a) "宮崎千" => "宮崎千" irb(main):008:0> a => {:name=>"宮崎"}あまり直観的でないふるまいですが、ロジックがわかればなるほど納得の仕様でした。
まとめ
破壊的なメソッドは、以下の場合に作られる。
- 破壊的メソッドを使った場合
{ローカル変数}=以外の形で=を使う場合これを回避する方法として、dupを使った方法がありますが、これも盲目的に使っては意味がないことが分かったので、最後にdup編を用意しました。
- 投稿日:2020-02-21T16:15:09+09:00
ruby 破壊の話③関数編
前回までの内容を簡単にまとめると、
- =でidが変えられる。idが変わると参照する値ももちろん変わる。
- 破壊的な関数はidを変えずに参照する値を変える。
このように変数の値の変更手段について見てきた。
しかし実際の実装で困るのは変更方法よりもむしろ変更しない方法だろう。
破壊的メソッドを使わないことは出来るかもしれないが、=を使わないでコードを書くのは難しいと思う。
=を使う限り、常に気をつけねばならないので、今回はその話をする。
ruby 破壊の話シリーズ ruby 破壊の話①「=」のふるまい ruby 破壊の話②メソッド編 ruby 破壊の話③関数編 ruby 破壊の話④破壊的なメソッド編 ruby 破壊の話⑤dup編 簡単な例
まずは問題提起から。実際に困るのはこういう場合である。
irb(main):001:0> def judge(hoge) irb(main):002:1> hoge[:point]=hoge[:name].length() irb(main):003:1> return hoge[:point]>2 ? true : nil irb(main):004:1> end => :judge irb(main):005:0> a={:name=>'test'} => {:name=>"test"} irb(main):006:0> b={:name=>'t'} => {:name=>"t"} irb(main):007:0> a => {:name=>"test"} irb(main):008:0> b => {:name=>"t"} irb(main):009:0> judge(a) => true irb(main):010:0> judge(b) => nil irb(main):011:0> a => {:name=>"test", :point=>4} irb(main):012:0> b => {:name=>"t", :point=>1}judge関数は例えば面接の合否を返す関数だとして、対象はtestさん(a)とtさん(b)だとする。
名前を書いてjudgeすると、trueかnilが返ってくると。
testさんが合格でtさんが不合格なのですが、返り値に注目。pointが格納されて帰ってきています。
なんだ名前の長さのみで評価されるのかよって話になってしまいます。
だいぶ意味不明な例になりましたが、言いたいことは伝わったかなと思います。judge関数自体は合否のみを返しているつもりですが、もらった引数自体を書き換えてしまっているんですよね。
今回は追加だったので情報漏洩ですが、削除してしまうことももちろん出来てしまいます。
破壊的と聞くと削除だけを指すイメージもありますが、削除はもとより追加、変更など、少しでも変化がある場合全般について破壊と呼びます。破壊的な関数を使わない/作らない
先のコードの問題点はただ一つ。judge関数が破壊的であることです。
もしも情報漏洩が正しい(望んでいる)仕様ならば、動きとしては期待通りです。
しかし、一目でjudge関数が破壊的であることがわかる様に"!"をつけ、judge!関数にするべきと言えます。
これならaやbを渡す段で、どんな状態で(名前が消えたり)帰ってきてもある程度は覚悟できているはず。ただそもそも破壊的な関数自体危険性が高いので、実装は必要最低限にとどめるべきと考えます。
もっと言うと、実際の仕様はさておき、どう書いたら破壊的で、どうすれば破壊的でなくなるのかを判断できるようになることは重要だと思います。
関数の基本
では実際にidを確認して、どのように書けばよいのか、まずは仕様を理解してみます。
irb(main):001:0> def get_id(obj) irb(main):002:1> return obj.__id__ irb(main):003:1> end => :get_id irb(main):004:0> a='abc' => "abc" irb(main):005:0> a.__id__ => 47110191884680 irb(main):006:0> b=:abc => :abc irb(main):007:0> b.__id__ => 1162588 irb(main):008:0> get_id(a) #aと同じid => 47110191884680 irb(main):009:0> get_id(b) #bと同じid => 1162588 irb(main):010:0> a => "abc" irb(main):011:0>get_id関数に引数として渡してみましたが、中で評価してもやはりidは同じようですね。
シンボルはidも変わらなさそうでしたが、文字列も変わらないみたいです。実はrubyの関数が引数として受け取るのは値ではなくidのようで、これこそがrubyの仕様っぽいですね。
irb(main):001:0> def reverser(obj) irb(main):002:1> p obj.__id__ irb(main):003:1> obj.reverse! irb(main):004:1> p obj.__id__ irb(main):005:1> obj irb(main):006:1> end => :reverser irb(main):007:0> a='abc' => "abc" irb(main):008:0> reverser(a) 47215576028320 47215576028320 => "cba" irb(main):009:0> a => "cba"うーんしっかり破壊されている。(reverser関数も!を付けるべきですね。)
関数に引数として渡しても同じidだから、破壊的メソッドを使うと破壊されちゃうわけです。
これだけ聞くと困っちゃうんですよね。
破壊的メソッドはともかく、=も関数の先で破壊しないで運用するのって難しい。。。どうやったら関係を断ち切れるの。。。という話が次の記事に続きます。
- 投稿日:2020-02-21T16:05:28+09:00
Rails"モデル"は不倫とガチ恋をする
はじめに
添野です。プログラミングを勉強中です。
今日はRails苦戦中の方向けの記事で、モデルについてです。
RailsのMVCの"M"、"モデル"がよく分かりません、という声をよく耳にします。モデルとは
結論をいいます、モデルとは「メンヘラPretender」です。
Pretender→https://www.youtube.com/watch?v=TQ8WlA2GXbk
※Pretenderをdisっている訳ではないです。筆者はかなり髭男ファンです。Pretenderを歌いたいがために月に4回ボイトレに行っています。モデルの役割
2つです。
・他のモデルとの人間関係を暴露する(アソシエーション)
・データベースとイチャイチャする下記はモデルファイルの一例です。
tweet.rbclass Tweet < ApplicationRecord belongs_to :user has_many :comments def self.search(search) return Tweet.all unless search Tweet.where('text LIKE(?)', "%#{search}%") end end一行ずつ、順番に解説していきます。
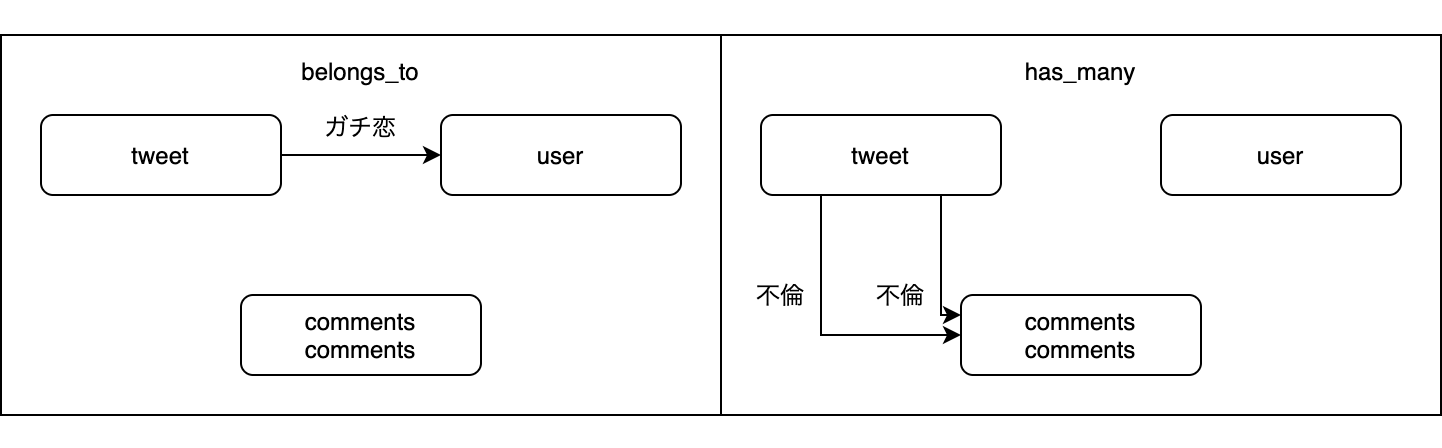
他のモデルとの人間関係を暴露する 「アソシエーション」
belongs_to :user has_many :comments
日本語訳「私はuserモデルにガチ恋しています」「私はcommentsモデルたちと不倫しています」
まず、belongs_to = ガチ恋 has_many = 不倫を覚えてください。下記の図は、tweetモデルさんの人間関係を表しています。
tweetさんが主役です。tweetさんはuserさんに対し秘めたる思いを抱えており、つまりガチ恋をしています。
しかしこれは叶わぬ恋であり、想いは一方通行なのです。美しいですね。君の運命の人は僕じゃないんですね。辛いけど否めないんです。つまりPretenderです。ところが、tweetさんはOfficial髭男dismのように綺麗な心を持っていません。
tweetさんはメンヘラであり、commentsさんたちにN股不倫をかけています。
そしてmodelファイルのなかでtweetさんはこれを堂々と宣言しています。tweetさんはかなりヤバイです。データベースとイチャイチャする
tweetさんはメンヘラであり他のモデル達とイチャイチャしたがると上に書きましたが、データベースともイチャイチャしたがります。最高ですね。
def self.search(search)
日本語訳「メソッドを定義しろ Tweetクラスのsearchメソッドで 引数はsearch」
カレーの話をします。searchメソッドはルーティングとコントローラに定義したカレールーの隠し味です。index,new,show...みたいなのが7種類あったと思いますが、これらはカレールーです。この7種類の他にも隠し味としてリンゴ(searchメソッド)をカレールーにブチ込んだ、みたいな感じです。引数searchは、検索ワードです。return Tweet.all unless search
日本語訳「返り値をよこせ Tweetモデルの全てを 検索ワードが空っぽなら」
入力欄に何も入れずに検索したら、ツイートを全部表示しろという意味です。Tweet.where('text LIKE(?)', "%#{search}%")
日本語訳「Tweetモデルの中身を取得しろ(含んでいれば,"検索ワード"に)」
記号だらけでゴチャゴチャしてますが、中身は簡単です。".where"は値を取得できます。取得する時の条件も設定できる優れものです。
'text LIKE(?)',"%#{search}%"は見た目の通り呪文であり、「引数searchを含んでいれば」という意味です。
引数searchは検索ワードです。この行は、一行前のunlessの影響を受けており、検索ワードが空じゃない時だけ仕事をします。
end
日本語訳「グッバイ」
ここからサビか!と思いきや、終わります。書いていて思いましたが、サビの初っ端が「グッバイ」ってセンスありすぎですよね。
一番盛り上がるところで「グッバイ」て。そんなことあります?逆に、終わりの歌詞は
「たったひとつ確かなことがあるとするのならば 君は綺麗だ」
エェェッッッッッモ...
そんな悲しいことある...?さとっちゃん、センスありすぎアリス議員です。
まとめ
モデルの役割は2つありました。
・他のモデルとの人間関係を暴露する(アソシエーション)
・データベースとイチャイチャする他にも空っぽのツイートを禁止するバリデーション機能などもありますが、とりあえず今回の2つを覚えればOKです。モデルがやっていることは、モデルのコードに書いてあることが全てです。「○○がよく分からん」と感じたら○○に書かれているコードを読みましょう。コードは、そのコードに書かれていること以外のことはしません。
以上がRails"モデル"の説明になります。
他にもRailsの疑問を解消するための記事がありますので、ご活用ください。共にTECH::EXPERTを駆け抜けましょう。
おすすめ記事
Rails消化のコツ
Railsは"5つの属性"を意識しろ
Rails用語集 基礎
- 投稿日:2020-02-21T15:39:14+09:00
ruby 破壊の話②メソッド編
前回の内容を簡単にまとめると、
- =でidが変わる。(=はidを変える働きがある)
- idが変わることにより結果的に参照する値も変わる。
今回は=を使わなくても参照先の値が変わってしまう例を見ていく。
ruby 破壊の話シリーズ ruby 破壊の話①「=」のふるまい ruby 破壊の話②メソッド編 ruby 破壊の話③関数編 ruby 破壊の話④破壊的なメソッド編 ruby 破壊の話⑤dup編 破壊的メソッド
mutableの例
=なしでidは変えられない。
idを変えずに参照先が変わってしまうというのはすなわち、そもそもidが対応している値自体が変わってしまう事象を指す。
こういったメソッドを破壊的メソッドと呼び、"!"が付いているのが特徴である。irb(main):001:0> a='abc' #aを文字列abcを指すよう設定する => "abc" irb(main):002:0> a.__id__ #aのidを確認しておく => 47064986806140 irb(main):003:0> a.reverse #reverseは元の文字列を逆さにする普通のメソッド => "cba" irb(main):004:0> a #aの値自体は変わらない => "abc" irb(main):005:0> a.__id__ #もちろんidも変わらない => 47064986806140 irb(main):006:0> a=a.reverse #左辺aを右辺aの逆さ文字列を参照するように設定 => "cba" irb(main):007:0> a.__id__ #=で異なるものを設定しなおしているのでidも変更される => 47064986914720 irb(main):008:0> a.reverse! #reverse!は元の文字列を逆さにし、上書きしてしまう破壊的メソッド => "abc" irb(main):009:0> a #006で設定した値と異なる => "abc" irb(main):010:0> a.__id__ #しかしidは007で確認したものと同じ => 47064986914720このように、idを変えずidが指す値自体を変更するのが破壊的メソッドである。
値が変わってしまう危険性があるので、自分で破壊的なメソッドを作る場合にも!を付けることが推奨される。
ただしここで言う破壊的なメソッドとは、reverse!などの破壊的メソッドとは少し性質が異なる。
そのため私は、「破壊的メソッド」とはあらかじめ用意されているreverse!やsort!などを指すこととし、自作した破壊的なメソッドのことは「破壊的"な"メソッド」と呼ぶようにしている。immutableの例
immuttableの例というより、そもそもimmutableとは不変という意味で、破壊することは不可能である。
以下で、シンボルがimmutableであることがわかる。irb(main):001:0> a=:abc #aをシンボルabcに設定 => :abc irb(main):002:0> a.reverse #reverseは文字列のメソッドなので NoMethodError: undefined method `reverse' for :abc:Symbol from (irb):2 from /usr/local/rbenv/versions/2.4.2/bin/irb:11:in `<main>' irb(main):003:0> a.reverse! #もちろん破壊できない NoMethodError: undefined method `reverse!' for :abc:Symbol from (irb):3 from /usr/local/rbenv/versions/2.4.2/bin/irb:11:in `<main>' irb(main):004:0> a #シンボルは不変 => :abc irb(main):005:0> a.__id__ #idを確認 => 1162268 irb(main):006:0> a.to_s.reverse! #to_sを使って破壊しようとすると表示は成功 => "cba" irb(main):007:0> a.__id__ #to_sは破壊的メソッドではないのでa自体は無傷 => 1162268 irb(main):008:0>まとめ
破壊的メソッドは、idに紐付けられる値自体を変更する。
続きは次の記事で
余談 rubyで i++ が出来ない話
統計を取ったわけではないが、i=i+1やi+=iの意味で、i++という記法が使えない言語は少ないのではないだろうか。
rubyは使えないようで、最初ちょっと驚いた。c出身ということもあり、まあcの方がもっと全然実装されてないことあるわって思って気にせずi=i+1と書いていたが、rubyについて理解を深めると、納得の理由だった。
理由は数字がimmutableであることと=のふるまいで説明できる。
例1
i=1
i++
p i2が表示されてほしいところだが、=に注目してよくよく考えると、これで2が表示されるわけがない。
=はこのコードに一つ。最初の行だけ。1はimuttable
なのでiは1と同じidということ。その後には=が無いので、最後までiは1と同じidである。
これが2を指しているわけがない。例2
i=1
i=i+1
p i同じようでもこれは2になる。
なぜなら2行目でiのidを変更しているからだ。まとめると、数字をimmutableに設定し、=なしではidを変えられない言語仕様上、i++という表現を許すわけにはいかなかったのだ。
とても理にかなっていて美しいなと思った。
- 投稿日:2020-02-21T14:38:55+09:00
【Rails】SwitchPoint利用時にSchemaCacheを設定しSHOW FULL FIELDSを防ぐ
SwitchPointとは?
https://github.com/eagletmt/switch_point
DBの書き込み接続と読み込み接続を切り替えることができるgemです。SchemaCacheについて
Railsでは
rake db:schema:cache:dumpを使うことでdb/schema_cache.ymlにテーブルやカラムの情報が書き出されます。
このキャッシュを使うことでActiveRecordが型情報などを特定する手助けになします。SwitchPointによりSchemaCacheが使えなくなる
SwitchPointを使うと
ActiveRecord::Baseとは別のConnectionPoolを保持してしまうため、SchemaCacheが自動で読み込まれません。
これによる、SQL実行時にSHOW FULL FIELDS FROM some_tableが実行され不要な遅延を発生させてしまいます。対策
config/initializers/switch_point.rbActiveSupport.on_load(:after_initialize) do ApplicationRecord.switch_point_proxy.connection.pool.schema_cache = ActiveRecord::Base.connection.schema_cache ApplicationRecord.switch_point_proxy.connection.schema_cache = ActiveRecord::Base.connection.schema_cache endinitializer内で
switch_point_proxyのもつConnectionPoolにActiveRecord::Baseと同様のschema_cacheを設定してあげることで対策できます。※ただしこのコールバックより適当な実行タイミングがあるかは未確認
- 投稿日:2020-02-21T14:28:36+09:00
ruby 破壊の話①「=」のふるまい
rubyの破壊するとかしないの話
はじめに
rubyを初めて書いてみて破壊するしないみたいな話題が出てきた際、いまいち想像できなかったので、ちょっと調べてみました。
調べていくうちに次第に興味がわいてきたので、一通り試したり調査して理解したことをまとめました。
全五回に分割してありますが、短くまとめてあるので、是非とも通して読んでいただきたいなと思います。
ruby 破壊の話シリーズ ruby 破壊の話①「=」のふるまい ruby 破壊の話②メソッド編 ruby 破壊の話③関数編 ruby 破壊の話④破壊的なメソッド編 ruby 破壊の話⑤dup編 全部読むと
- 破壊とはどのように行われるか
- =と破壊的メソッドの違い
- 完全な複製の作り方
などが理解できると思います。
環境
$ ruby -v ruby 2.5.1p57 (2018-03-29 revision 63029) [x86_64-linux-gnu] $ irb irb(main):001:0>"="
これをこれまで代入と呼んでいたけど、rubyだと代入とは違う気もする。
一番近いのは「エイリアス」かなと。
ちなみに"=="や”===”は全く関係ない。あくまで"="のふるまいの話をする。
突き詰めると"="のふるまいを理解してからrubyがかなり好きになったと思う。rubyの=は代入ではない(と思う)。
これが他の言語と違っていて、最初は戸惑ったけど慣れるとむしろすごく良いシステムだった。rubyの=は「左辺は右辺のオブジェクトを参照してね」という命令と理解している。idの代入じゃないかと言われるとまあ確かに代入かもしれない・・・
一回だけ使う場合
まずはわかりやすいmutableの例から。
mutableとかimutableの話はまた別の記事で書きます。mutableの例
irb(main):001:0> a='aaa' #変数aが文字列aaaを指すように設定(文字列aaaはこの世界にたくさん存在する) => "aaa" irb(main):002:0> a.__id__ #変数aのobject_id => 47197188120260 irb(main):003:0> a.__id__ #変数aはこの世界に一つしか存在しないので、何度確認しても変わらない => 47197188120260 irb(main):004:0> 'aaa'.__id__ #文字列aaaのobject_id => 47197187994020 irb(main):005:0> 'aaa'.__id__ #同じ文字列でも評価のたびに異なるobjectであることが => 47197187807940 irb(main):006:0> 'aaa'.__id__ #object_idを確認すればわかる => 47197187768200 irb(main):007:0> 'aaa'.__id__=='aaa'.__id__ #評価のたびに異なるからfalse => false irb(main):008:0> a.__id__=='aaa'.__id__ #参照してねという命令であり、この'aaa'はさっき(001)の'aaa'とは異なるのでfalce => falseimmutableの例
muttableとだいぶ異なることがわかる
irb(main):001:0> a=:aaa #変数aがシンボルaaaを指すように設定(シンボルaaaはこの世界に一つしか存在しない) => "aaa" irb(main):002:0> a.__id__ #変数aのobject_id => 1162268 irb(main):003:0> a.__id__ #変数aはこの世界に一つしか存在しないので、何度確認しても変わらない => 1162268 irb(main):004:0> :aaa.__id__ #シンボルaaaのobject_idはaに割り当てられたidと同じ => 1162268 irb(main):005:0> :aaa.__id__ #同じシンボルなら常に同じidであることが => 1162268 irb(main):006:0> :aaa.__id__ #object_idを確認すればわかる => 1162268 irb(main):007:0> a.__id__==:aaa.__id__ #世界に一つの変数aとシンボルaaaの参照先を001でそろえたので => true irb(main):008:0> a.__id__===:aaa.__id__ #これら二つはどこまでも同じ => true複数回使う場合
mutableの例
irb(main):001:0> a='abc' #変数aが文字列abcを指すように設定 => "abc" irb(main):002:0> a.__id__ #変数aのid => 46923898737600 irb(main):003:0> a="abc" #一見意味のないコード => "abc" irb(main):004:0> a.__id__ # 003で新たな参照先に変わったのでidも変わる => 46923898698140 irb(main):005:0> a="cba" # もちろん異なる文字列に設定すると => "cba" irb(main):006:0> a.__id__ #idも変わる => 46923898682240 irb(main):007:0> a=a #左辺aの参照先を右辺aの参照先に設定する => "cba" irb(main):008:0> a.__id__ #右辺aの参照先は006の値だから設定しなおしても変わらない => 46923898682240 irb(main):009:0> a=a+"x" #左辺aの参照先を右辺aにxをつなげたオブジェクトに設定する => "cbax" irb(main):010:0> a.__id__ #右辺aにxをつなげたオブジェクトはaとは異なるオブジェクトなのでidも異なる => 46923898381420immutableの例
こちらもかなり異なる
irb(main):001:0> a=:abc #変数aがシンボルabcを指すように設定 => :abc irb(main):002:0> a.__id__ #変数aのid => 1162268 irb(main):003:0> :abc.__id__ #シンボルabcのidと一致する => 1162268 irb(main):004:0> a=:abc #一見意味のないコード => :abc irb(main):005:0> a.__id__ #immutableの場合は本当に意味が無い => 1162268 irb(main):006:0> a=:cba #aの参照先をシンボルcbaに変更 => :cba irb(main):007:0> a.__id__ #参照先が変わったのでidも変更 => 1162588 irb(main):008:0> :cba.__id__ #参照先はシンボルcbaと一致 => 1162588ざっくり"="は参照先idを更新する命令だという理解で良いと思う。
逆に=が無ければidは変わらないし、値も変わらない。。。わけではない。
実は=なしで値は変えられる。
続きは次の記事で。まとめ
rubyにおける「=」の働きは、object_idを上書きすることである。
- 投稿日:2020-02-21T13:16:50+09:00
RailsでHamlを使う方法⭐︎
RailsでHamlを使えるようにする方法
復習がてらにhamlを使ってコーディングしていたのでこの際アウトプットしておきます。
手順↓
- hamlのgemをインストールする
- 拡張子をerbからhamlにする
以上。超簡単
Hamlのgemをインストールする
Gemfilegem 'haml-rails'Gemfileに以上の記載をして
ターミナルで必ずbundle installを実行しましょう。$ bundle installこの時点でhamlは使えるようになりますが拡張子も一気にerbからhamlに変更しておくと便利なので実行します。
拡張子の変更をターミナルで実行する
$ rails haml:erb2haml実行するとターミナル上で何か聞かれますが
yコマンドを押しておくとオッケーです。以上。簡単
- 投稿日:2020-02-21T12:14:02+09:00
slackAPIを使って各ユーザー・チャンネルごとの絵文字使用回数ランキングを出す
TL;DR (Too Long, Didn't Read)
slackで使ってる絵文字の使用回数を各ユーザー・チャンネルごとにランキング化してくれるスクリプトを
rubyで書きました。
リポジトリはこちら
slackAppを作成してtokenを取得するだけなので、ぜひ使ってみてください。
はじめに
- 仕事でslackを使っていたとき、チーム内でオッケー?という肯定の返事をする際に、男性→女性の場合は女性ok?♀️、女性→男性の場合には男性ok?♂️という記号が使われる傾向があるのに気づきました(ちなみにチーム内の男女比はほぼ均等)。
- オッケー?しているのは本人なのに、相手側の性別で?♀️?♂️を返すという文化が不思議でした(そして自分もなんとなくその慣習に従っています)。 この使い分けは特にマナーとして定義はされていません。
- 相手に対する気遣いか、単になんとなく(無意識)か、いずれにせよslackで使っている絵文字の記号選定には、その人の個性だったり、あるいは無意識だったりが関係していると思います。 そこで、どんな傾向があるのかをちょっと調べてみたくなりました。
- とはいえ、別に細かく統計的なデータを出して全部分析したいとかじゃ全然無いです(研究かよ..)。 普段なんの絵文字を使ってるんだろう、このチャンネルって普段どの絵文字が流行ってるの?とかをチャチャっと出せないものか調べてみました。
- その結果、2016年〜2019年にかけて自分と同様にslackでの絵文字コミュニケーション文化に関心を持った先人達がいたので、参考にしながら自分もやってみることにしました。
やりたいこと
- 絵文字の使用率ランキングが見たい
- チャンネルごとに知りたい
- ユーザーごとに知りたい
実装方針
- ユーザー名かチャンネル名を入力
- 対象ユーザーのreactions(反応データ)を取得
- 対象チャンネルのreactions(反応データ)を取得
- reactionsから絵文字と使用回数を抽出してランキングをチャンネルに投稿
(ランキング化と投稿は別々に分けたほうがよかったですね。)
実装
リポジトリはこちら
使い方や構築手順などは、READMEに詳しく書いたのでぜひ見てください。コードを一部のみ紹介します。
1. user名かchannel名を入力
標準入力から値を受け取ってuser名かchannel名かを判別しました。
BOT化するときは、チャンネルを監視しといて投稿された文字列をここに入れるとよさそうです。
p '調べたいのはどっち?入力してね user or channel' target = gets.chomp! # reactionsを取得 if target == "user" reactions = get_reactions_from_user elsif target == "channel" reactions = get_reactions_from_channel else puts "user or channelのどっちかを入力してください" return end post_emoji_ranking(reactions, target)
2. userからreactions(反応データ)を取得
reactions(反応データ)を取得するために、slackAPImethodの公式リファレンスからよさげなメソッドを探します。
次に、slackAppを新規作成して該当するpermissonを付与したあと、tokenの値を取得します。
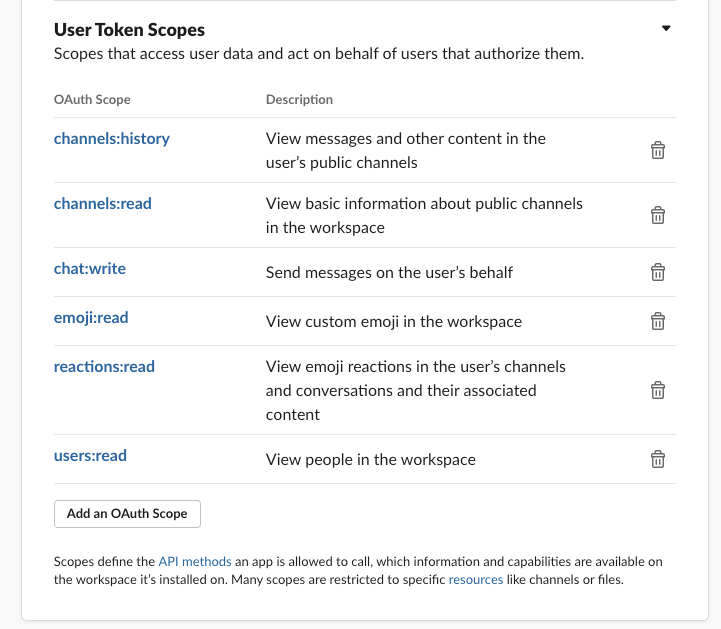
今回は下記の
permissionを付与しました
-channels:history:チャンネルの履歴データを取得
-channels:read:チャンネル名とチャンネルIDを取得
-chat:write:チャンネルに投稿
-emoji:read:カスタム絵文字を読み取る
-reactions:read:反応データを取得
-users:read:ユーザー名とユーザーIDを取得
ユーザーの行った絵文字による反応は、slackAPIの
reactions.listを使うと取得できます。
user_idをクエリパラメータとして渡すことで、該当userのreactions(反応)のjsonデータが取得できます。
このデータの中に、emoji(絵文字)とcount(数)とusers(押した人)の値が入ってます。
(なお、slackAPI制限のため1000レコードまでしか取得できません。)
2.1. 標準入力で受け取ったuser名をuserIDに変換する処理
p '絵文字使用率を調べたいユーザー名を入力してください。' $target_name = gets.chomp! # SlackAPI:users.list res = Net::HTTP.get(URI.parse("https://slack.com/api/users.list?token=#{SLACK_API_TOKEN}&pretty=1")) hash = JSON.parse(res) members = hash["members"] # ユーザー名を知ってればすぐ調べられるようにuserIDとuser名のハッシュを作っておく member_lists = {} members.each do |member| member_lists[member["name"].to_sym] = member["id"] end if member_lists[$target_name.to_sym].nil? puts "#{$target_name}は存在しません" return end # 該当ユーザーのIDを取得する user_id = member_lists[$target_name.to_sym]
2.2. user_idを使って該当userのreactionsを取得する処理
# SlackAPI:reaction.list res = Net::HTTP.get(URI.parse("https://slack.com/api/reactions.list?token=#{SLACK_API_TOKEN}&count=#{COUNT}&user=#{user_id}&pretty=1")) hash = JSON.parse(res) items = hash["items"] messages = [] items.each do |item| messages << item["message"] end reactions = [] messages.each do |message| reactions << message["reactions"] end reactions.flatten
3. 対象チャンネルからreactions(反応データ)を取得
チャンネル内で行われた絵文字による反応は、slackAPIの
channels.historyを使って取得してきます。
channel_idをクエリに渡すことで、該当channelの履歴データが取得できます。
そこから投稿メッセージ(messages)を抜き出して、その中のreactions(反応)のjsonデータを取得します。
(なお、slackAPIの制限のため投稿は1000レコードまでしか取得できません。)
(latest,oldestなどtimestampを指定すれば1000件ずつ取得できるようなので、取得期間をずらして複数回リクエストすれば全件取得できなくもないかもです..)
3.1. 標準入力で受け取ったchannel名をchannel_idに変換する処理
p '絵文字使用率を調べたいチャンネル名を入力してください。' $target_name = gets.chomp! # チャンネルリスト取得 res = Net::HTTP.get(URI.parse("https://slack.com/api/channels.list?token=#{SLACK_API_TOKEN}")) hash = JSON.parse(res) channels = hash["channels"] # チャンネル名だけ知ってればすぐ調べられるように、チャンネルIDとチャンネル名のハッシュを作っておく channel_lists = {} messages = [] channels.each do |channel| channel_lists[channel["name"].to_sym] = channel["id"] messages << channel["messages"] end if channel_lists[$target_name.to_sym].nil? puts "#{$target_name}は存在しません" return end # 該当チャンネルのIDを取得する channel_id = channel_lists[$target_name.to_sym]
3.2. channelIDを使って該当userのreactionsを取得する処理
# SlackAPI:channels.history res = Net::HTTP.get(URI.parse("https://slack.com/api/channels.history?inclusive=true&count=#{COUNT}&channel=#{channel_id}&token=#{SLACK_API_TOKEN}")) hash = JSON.parse(res) messages = hash["messages"] reactions = [] messages.each do |message| reactions << message["reactions"] end # 整形 reactions.compact.flatten
4. reactionsから絵文字と使用回数をランキング化してチャンネルに投稿
対象ユーザーorチャンネルのreactions(反応データ)が取得できました。
これを使ってemojiとcount数の良い感じのhashを作り、降順にソートしてランキング化します。
そのデータをslackAPIの
chat.postに渡してチャンネルに投稿します。
絵文字と使用回数のデータはattachmentsを使って表示しようかなぁと思ったんですが、うまく動かなかったんでやめました。
改行できれば十分なことに気づいたので改行文字列(\n)をつけて保存し、全部まとめてcontentカラムに突っ込んでます。
絵文字(emoji)は、:emoji:のようにコロンで囲ってあげるとslackに投稿した時に文字列がアイコン化されます。
4.1. 投稿用のpostリクエストはnet/httpを使って実装
gemの用意
require 'net/http' require 'uri'
def post_emoji_ranking(reactions, target_type) #取得したreactionsをランキング化して投稿 # あとでcount数を加算するために初期値0でハッシュを作っておく results = Hash.new(0) #ユーザーを対象にした場合はcountは使用せず単に1プラスする。チャンネルを対象にした場合はcountを加算する。 if target_type == "user" reactions.each do |reaction| name = reaction["name"] results[name.to_sym] += 1 end else reactions.each do |reaction| name = reaction["name"] results[name.to_sym] += reaction["count"] end end # コンソール結果表示用 puts "#{$target_name}の絵文字使用率ランキング1〜10位" result_data = [] results.sort_by { |_, v| -v }.to_a.first(10).each do |result| result_data << result puts "#{result[0].to_s.rjust(30, " ")}:#{result[1]}回" end # 該当チャンネルに投稿をするAPIを叩く post_api_url = "https://slack.com/api/chat.postMessage" uri = URI.parse(post_api_url) req = Net::HTTP::Post.new(uri) # 後でjoinして配列内の文字列を全て結合する contents = ["#{$target_name}の絵文字使用率ランキング1〜10位\n"] result_data.each.with_index(1) do |data, n| contents << "#{n}位 :#{data[0]}:は#{data[1]}回です\n" end post_data = { token: "#{SLACK_API_TOKEN}", channel: "#{POST_CHANNEL_NAME}", text: contents.join, } req.set_form_data(post_data) req_options = { use_ssl: uri.scheme == "https" } response = Net::HTTP.start(uri.hostname, uri.port, req_options) do |http| http.request(req) end end
4.2. 環境が変わっても使えるように
dotenvを導入.envファイルを作成
SLACK_API_TOKEN = "your_token" POST_CHANNEL_NAME = "post_channel_name"
.envを読み込む
require 'dotenv' Dotenv.load SLACK_API_TOKEN = ENV['SLACK_API_TOKEN'] # slackAPI用に取得したtoken POST_CHANNEL_NAME = ENV['POST_CHANNEL_NAME'] # 通知対象チャンネル名
結果
こちらは筆者の絵文字使用率ランキング1~10位です。
即レスでリアクションを返してるためか、デフォルトの絵文字データセットの中から無難で使いやすいものばかりを選択しています。
その傾向をはっきり確認することができました(なんてつまらない奴...)。
あと、最初に言ったとおり謎の慣習にとらわれているせいか?♀️の使用率が高いですね。
こちらは筆者が仕事で使ってる分報チャンネル(分報とは、作業ログやつぶやきなどを垂れ流すことで、タスクの見える化、早期の知見共有、助け合いを目指したもの。が、一見仕事に関係なさそうな話題もバンバン投下してる。)における絵文字使用率ランキング1~10位です。
1位:eys(目)
明らかにeye、目が多い。つまり、既読ということですね..。
目はlineの既読機能を代替してくれる大変有能な絵文字記号だと思います。
筆者の投稿は、周囲にとって「お、おう...」となるものが多いために目が多く使われるのかなと思いました。
見てもらえているだけ感謝しています。
2位:+1(親指)、3位:wakaru(わかる)、4位:naruhodo(なるほど)
次に、親指、わかる、なるほど等の納得系の絵文字使用回数が多いです。
これは、筆者が困ったことやわからないことがあったときに、同僚や先輩からの返信やリンク共有などの情報提供に対して、筆者自身が返している絵文字じゃないかと思います。
分報が機能しているといえるので、これは朗報です。
5位:heart(ハート)
筆者はハート絵文字に複雑な評価を抱いてるので、これを使用することはあり得ないです。
よって、これは自分の投稿に対して誰かがつけたものです。
小さなチャンネルなのですぐにわかってしまうんですが、犯人は筆者と仲の良い同僚の男性です。
(そういえば、noteのいいねボタンはチェックマークなの良いですね。)
ちなみにconsoleのログ出力はこんな感じ
"調べたいのはどっち?入力してね user or channel" channel "絵文字使用率を調べたいチャンネル名を入力してください。" _asakawa _asakawaの絵文字使用率ランキング1〜10位 eyes:28回 +1:10回 wakaru:6回 naruhodo:6回 heart:6回 congratulations:5回 kusa:5回 rolling_on_the_floor_laughing:5回 innocent:4回 heart_eyes:4回
考察
- 複数の大きめのチャンネルを対象に結果を表示してみると、チームごとのちょっとした文化の違いが確認できました(例えば、お祝い絵文字(祝:congratulations)が多いチームと、だれかを労る絵文字(お大事に:odaijini2)が多いチームなど)。
- slack導入企業では業務コミュニケーションのほとんどがslackでのやりとりだと思うので、そこで行われているやりとりのダイナミズムを分析することはHR的な職場改善やメンタルヘルスケア等にも応用出来るかもと思います(筆者はこの路線にはあまり関心はない)。
- 一方で、絵文字の使用状況がチームのカルチャー(コミュニケーション文化)の違いを示しているなら、逆説的には使用する絵文字の種類をコントロールすることでカルチャーを意図的に生成したり育てることもできるといえそうです(筆者はこの路線には少し関心がある)。
- その延長でさらに考えると、slack側がデフォルトで用意している絵文字のデータセットだけを使っていたら、カルチャーの育成に限界を生んでしまっているのかもしれません。
- コミュニケーションコストの最小化だけを目的にするのなら、使用する絵文字のデータセットは最小限のほうが良いです。
- しかし、絵文字は自分の表明したかった気持ちを記号に簡略化してしまうので、誰かの意見に対して本当は多様な反応を持っていたはずなのに、いつの間にかそれが画一化してしまっている危険性もあります。
- カスタム絵文字はそれらに抵抗するために存在しているのかもしれません。
- これらを踏まえてコミュニケーションコストの最小化とカルチャーの育成には、トレードオフの関係があると思いました。
所感
- うーん、最初にやりたかったことは実現できたけど、いざ結果を出して眺めてみると期待してたほど面白い結果は出ませんでした(何の成果も得られませんでしたぁぁぁッッ!)。
- このスクリプトは毎回slackAPIを叩きにいくので、ルーティンワーク的にちょこっと分析に使えるのが利点かなと思います。
- なのでBOT化して月ごとに集計してチャンネルに通知するのが現実的な運用かなと思いました。
- とりあえず、もう少しカスタム絵文字を使ったほうがよさそうです。
- これを使ってみた人は、ぜひ感想コメントなどお待ちしています。
参考
・slackAPImethod公式リファレンス
APIの仕様とかはここに全部載ってます。
・社内で使われているSlackの人気絵文字を調査してみた
筆者のやりたかったことはこの人がほぼ実現していたのでおおいに参考にさせてもらいました。使用言語はpythonです。
・社内Slackの絵文字事情を調査する Part 1. 下準備編
この人は全slack履歴データを落としたあとrubyで整形したのち、pythonを使って統計分析してます。筆者のできなかった大規模データの統計分析からコミュニケーション文化の考察を試みています。
・社内Slackでどんな絵文字リアクションがよく使われているかをGoで集計してみた
この人はGOでスクリプトを書いてます。実装方針を考えてるときに参考にさせてもらいました。
・TL;DRの意味を勘違いして使っていたら顰蹙を買ったので気をつけて使おう!
筆者は初見でTL;DRの意味がよくわからずちょっと困惑した経験があるので(セミコロンがちょっとね..)、省略前の英文も付与しました。TL;DR自体はユーザーフレンドリーでとても良いと思うし、nerd(おたく)な表現とのことなので採用しました。
・15,000個のカスタム絵文字を支える、Slack絵文字登録術
カスタム絵文字を用いたコミュニケーションの利点に関する説明は、納得できる部分が多かったです。
・Markdown記法 サンプル集
めちゃ見やすくて助かりました。


- 投稿日:2020-02-21T11:52:23+09:00
if文を用いて出力メソッドを一呼び出し
※初心者向け
※アウトプット練習の為開発環境
rails 5.2.4.1
ruby 2.5.1問題内容
20時から翌朝7時までにオウムに喋られると問題があるのでその場合は「NG」、
それ以外は「OK」と出力するメソッドを作成します。
オウムが喋る時をture、喋らない時をfalseと入力することにし、時刻も同時に入力します。
呼び出し方:
parrot_trouble(talking, hour)def parrot_trouble(talking, hour) if (talking && (hour < 7 || hour > 20)) puts "NG" else puts "OK" end end
- 投稿日:2020-02-21T11:50:32+09:00
スクリプト言語 KINX(ご紹介)
はじめに
以前こんなことを書いたのだが、やはり職人として自分の道具は自分で作るか、という誘惑に駆られ作ってみた。
- https://github.com/Kray-G/kinx
- Small scripting language with C like style syntax, with native function by JIT.
まあ、無い無い言っていても探せばどこかにある(ここでは言わない)ような代物だが、自己満足してても寂しいので、解説の足跡を残しておこう。
何?
手に馴染んでいる伝統的な C 系統の Syntax を受け継いだスクリプト言語。目指すは「見た目は JavaScript、頭脳(中身)は Ruby、安定感は AC/DC(?)」といったところ。
今はまだライブラリや基本メソッドが揃ってないので実用はまだ先だが、言語の基本的な部分は概ね動作する程度にはなった。
見た目は JavaScript
子供ではなく立派な大人。
C 系統で成功しているスクリプト言語と言えば JavaScript。ただし、デスクトップ向けとしてはいまいち。node.js は便利だがヘヴィ過ぎるし、挙動にクセがありすぎて。
一方で、Ruby の思想は好きなのだが、あの
endがやたら目につく構文に抵抗がある。普通に通常のキーワードが埋もれるのだが…。頭脳(中身)は Ruby
そうは言っても Ruby 的思考は嫌いではない。そう、見た目だけの問題なのだ。ならば違う見た目の Ruby になれば良い。
安定感は AC/DC
ブレない所を見習っていこうぜ。
名前の由来
深くは触れられない(?)が、Red Warriors の名盤「KING'S」に遡るとだけ言っておこう。
現時点で「KINX」になったので、由来のほうを(VAN HALEN で有名な「You Really Got Me」のオリジナルである)Kinks に変えるといった「家系図捏造」的なことも視野に入れている。
サンプル
詳しい解説はシリーズ化してお届けしよう。需要があるかは、気にしない。
今すぐ詳しい仕様が知りたいぜ、という方がもしいれば... 「ここ」を参照してください。
fibonacci
fib.kxfunction fib(n) { if (n < 3) return n; return fib(n-2) + fib(n-1); } System.println(fib($$[1].toInt()));まず書くのはベンチマーク。見た目は JavaScript。
Ruby がかつて「スピードが目的じゃないぜ、楽しさなんだぜ?」とみんなを煽っていた懐かしいあの頃。YARV がリリースされてからのノリノリさ加減を見ると、あのスタンスはまさに「酸っぱいブドウ」だったことを目の当たりに…(いや、Ruby 好きなんですよ、見た目以外は)
早速ベンチマークしてみましょう。ついでに Ruby がライバル視している Python にも登場してもらいます。この辺りと比べておけば、だいたいの実力も推測できるというもの。ソースコードは以下の通り。Python3 は Python2 より遅いので 2 で。
fib.rbdef fib(n) if n < 3 return n; else return fib(n-2) + fib(n-1); end end puts fib(ARGV[0].to_i)fib.pyimport sys def fib(n): if n < 3: return n else: return fib(n-1) + fib(n-2) print fib(int(sys.argv[1]))結果
まず初めにバージョン表示。
$ ruby --version ruby 2.5.1p57 (2018-03-29 revision 63029) [x86-64-linux-gnu] $ python --version Python 2.7.15+そして結果。単位は「秒」。
timeコマンドでuser時間の速い順。5回くらいやって一番速かったタイム。
言語 fib(34)fib(38)fib(39)Ruby 0.391 2.016 3.672 Kinx 0.594 4.219 6.859 Python 0.750 5.539 9.109 値 9227465 63245986 102334155 Ruby 超速いな。遅い遅いはまさしく過去の話だ。むしろ速い部類に入るのではないかと思われるくらい。
Python には勝ったので、まぁこんなもん。スピードキングになろうとは思っていないので、実用的な速度であれば許容範囲としておこう。しかし、実は Kinx には
nativeという必殺技があるのです。正直実用上どこまで役に立つのかはわからないが、可能性を感じて入れてみた。ソースコードは以下。functionをnativeに変えただけ。nfib.kxnative fib(n) { if (n < 3) return n; return fib(n-2) + fib(n-1); } System.println(fib($$[1].toInt()));この軽微な修正がどんな影響を与えるか、先ほどの表に追加して結果を示そう。
言語 fib(34)fib(38)fib(39)Kinx(native) 0.063 0.453 0.734 Ruby 0.391 2.016 3.672 Kinx 0.594 4.219 6.859 Python 0.750 5.539 9.109 値 9227465 63245986 102334155 キタ。
既に分かっているとは思うがあえて種明かしをすると、
nativeキーワードが付いた関数はその名の通りマシン語コードにネイティブ・コンパイルし、JIT 実行させている、ということ。そら速いよね。ただし、出力されるアセンブリコードは最適化もレジスタ割当もしておらず全く美しくないが。実用上役に立つかわからない、というのは、色々と制限があるからです。後々触れると思うが、今日は触れない。詳しくは「ここ」を参照。その他の特徴
シリーズ化するので詳しい解説は今回はしないが、どんなことができるかだけ示しておこう。
プロトタイプベース
JavaScript らしくプロトタイプベース。ただし
__proto__みたいなのは無い。オブジェクト・プロパティに直接メソッドが括りついている。オーバーライドする場合は単に上書きする。classキーワードを用意してあり、クラスの定義ができる。こんな感じ。class ClassName { var privateVar_; private initialize() { privateVar_ = 0; this.publicVar = 0; } /* private method */ private method1() { /* ... */ } private method2() { /* ... */ } /* public method */ public method3() { /* ... */ } public method4() { /* ... */ } } var obj = new ClassName();ガベージコレクション
単純明快な Stop The World のマーク・アンド・スイープ。今のところ困ってない(困るようなほど使ってない)ので、問題無い。問題があったらその時考える。
クロージャ
関数オブジェクトはレキシカル・スコープを持ち、クロージャを実現可能。JavaScript になる(ならないけど)なら当然の動作。こんな感じ。
function newCounter() { var i = 0; // a lexical variable. return function() { // an anonymous function. ++i; // a reference to a lexical variable. return i; }; } var c1 = newCounter(); System.println(c1()); // 1 System.println(c1()); // 2 System.println(c1()); // 3 System.println(c1()); // 4 System.println(c1()); // 5ラムダ
無名関数オブジェクトを簡潔に表記できる。ES6 でアロー関数が導入されたが全く同じではなく、先頭に
&が必要。なぜかって? Yacc でうまく書けなかったんですよ。コンフリクトが解消できず(すみません)。こんな感じ。function calc(x, y, func) { return func(x, y); } System.println("add = " + calc(10, 2, &(a, b) => a + b)); System.println("sub = " + calc(10, 2, &(a, b) => a - b)); System.println("mul = " + calc(10, 2, &(a, b) => a * b)); System.println("div = " + calc(10, 2, &(a, b) => a / b)); // add = 12 // sub = 8 // mul = 20 // div = 5ファイバー
実はこの機能、私は使ったことが無い。ただ Ruby にあるし、便利そうなので実装。こうすればできるかなー、という軽い気持ちで試してみたら割と動いたので。ただし、
yieldの際にスタックの状態を保持していないので、yieldは単独の式文としてのみ有効。代入は可能。どういうことかというと、関数の引数としてyieldを直接埋め込むとかはできないが、a = yield 10;みたいな式文は OK。尚、この時のaは呼び出し元の引数の配列が来る。簡単なサンプルはこんな感じ。var fiber = new Fiber(function() { System.println("fiber 1"); yield; System.println("fiber 2"); }); System.println("main 1"); fiber.resume(); System.println("main 2"); fiber.resume(); System.println("main 3"); // main 1 // fiber 1 // main 2 // fiber 2 // main 3スプレッド演算子
ES6 で導入された(んですよね?)スプレッド(レスト)演算子。そう、これ欲しかったんですよ。超便利。色々使い道はあるが、こんな感じ。
function sample(a1, a2, ...a3) { // a1 = 1 // a2 = 2 // a3 = [3, 4, 5] } sample(1, 2, 3, 4, 5);最後に
ここまで読んでくださってありがとうございます。まあ、気が向いたら使ってみてください。まだ実用的な使い道は無いと思いますが。
コントリビュートは大歓迎です。一番簡単なコントリビュートは「★」をクリックすることです。まだ全然少ないですが、増えるとモチベーション上がるよね。★が増えるといいな。
- 投稿日:2020-02-21T11:46:18+09:00
erb拡張子をhaml拡張子に変更する
※初心者向け
※アウトプット練習の為、記述しております。今回は拡張子の変換について記述しております。
開発環境
rails 5.2.4.1
ruby 2.5.1やりたい事下記のファイルの拡張子(.erb)をファイルの内容も含め全てhamlへ変換したい。
/view/_form.html.erb /item.html.erb /new.html.erbまずはGemファイルに記述
gem 'erb2haml'ターミナル
bundle install rails haml:erb2haml
実行結果拡張子
/view/_form.html.haml /item.html.haml /new.html.haml以上で変換完了です
- 投稿日:2020-02-21T11:21:14+09:00
simple_format で textデータに改行を反映させる
text_areaでデータを入力してそのまま表示させると改行が反映されずに読みづらい文章になってしまいます。
<%= form_with model: @post, local: true do |f| %> <%= f.label :text %> <%= f.text_area :description, rows: 5, class: 'form-control', id: 'post_description' %> <% end %>みたいなformに
hello.
hello.
hello.と入力して
<%= @post.description %>みたいな感じで普通に表示させると
hello.hello.hello.改行が反映されずにくっついています。
調べると
simple_formatを使うのがいいようです。<%= simple_format(@post.description) %>hello. hello. hello.になるはずです。長い文章の入力でも大丈夫そうです。
- 投稿日:2020-02-21T11:14:51+09:00
Google Spreadsheet API v4 Pivot Table (ピボットテーブル)のサンプルコードをコピペしても動かないし、エラーも吐かない件
Pivot Tables
下の方にあるコードサンプル
問題
適当なデータを用意して、適当なsource範囲なりで設定して実行すると
Success - #<Google::Apis::SheetsV4::BatchUpdateSpreadsheetResponse:0x00005567c9a9e490などと返ってくるが、実際にはPivotテーブルが作られていない。
原因
Pivotテーブルを作るにはbatchUpdateのupdateCellsを使って更新するが、パラメータのネストが深い。そしてサンプルコードが間違っている。
UpdateCellsRequest
- rows <= ここが深い
- fields
- start / range (union fieldという事で、どちらかいずれか)
rows
まず、配列だ
rows: [RowData, RowData, RowData ...]
RowData
valuesが配列
values: [CellData, CellData, CellData ...]
CellData
pivotTable要素がある
総合すると
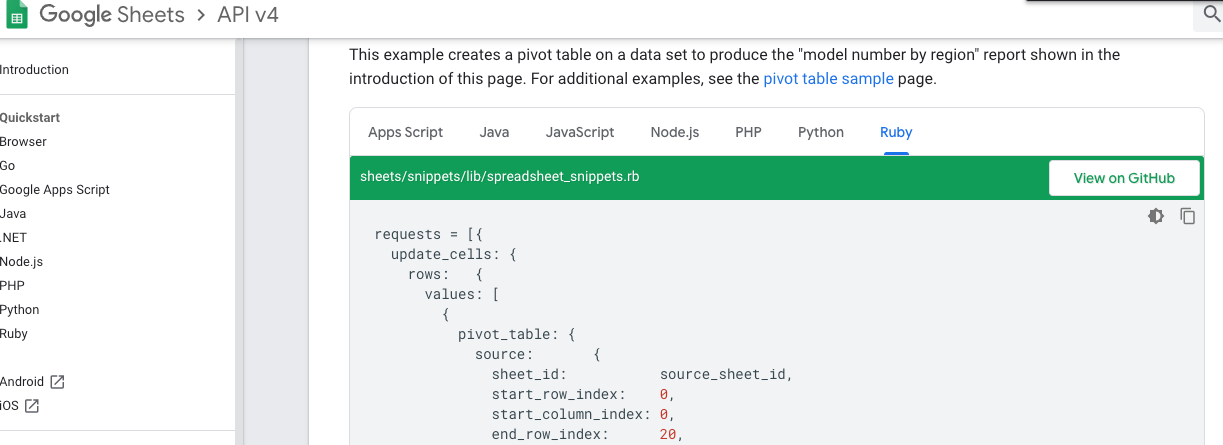
requests = [] requests.push( { update_cells: { # 配列 rows: [ { # 配列 values: [ { # PivotTableの内容 pivot_table: { source: { ... ... }, rows: [ ... ... ], values: [ ... ... ] } } ] } ], # pivotTableを指定 # https://developers.google.com/slides/how-tos/field-masks?utm_campaign=gsuite_series_slidesapi_041317&utm_source=gdev&utm_medium=yt-desc#updating_with_a_field_mask fields: "pivotTable", start: { ... } } } ) request_object = Google::Apis::SheetsV4::BatchUpdateSpreadsheetRequest.new request_object.requests = requests # request_objectを {requests: requests} で渡すとなぜかエラー # ArgumentError: unknown keyword: requests response = GoogleApi.sheet_service.batch_update_spreadsheet( your_spreadsheet_id, request_object )サンプルコードは
rowsが配列になっていないので(invalid)、Pivotテーブルは作られない(が、エラーも出ない)。Method: spreadsheets.batchUpdate
Each request is validated before being applied. If any request is not valid then the entire request will fail and nothing will be applied.
1個でも変なのがあれば、全部取り止めって書いてあるように読めるが...
- 投稿日:2020-02-21T10:10:54+09:00
microsoftgraph/msgraph-sdk-ruby を読む
動機と概要
Microsoft Graph を利用する機会があり、公式rubyライブラリ microsoftgraph/msgraph-sdk-ruby を使う上で生じた疑問をソースコードを読んでスッキリした際の備忘録。
- Gemは microsoft_graph
- リーディング時のコミットID e5408c4096a826ba96a802aef25ee91bf7e11894
TL;DR
Q1. なぜ?ソース内で定義されていない機能が使えるの?(例:
graph.me)
- A1. メタプログラミングのテクニックを用いて metadataファイルを元に動的に定義しているから。
Q2.
graph.meの他にオブジェクト経由でアクセスできる機能はどこを見ればわかるの?
- A2. metadataファイル内の
NavigationPropertyを見るか、:navigation_propertiesメソッドで確認可能。Q3. オブジェクト経由でAPI呼び出しする際にクエリオプション(
$filter,$top...等)って渡せる?
- A3. サポートされていないようなので、自前でURL生成しリクエストする処理を実装する必要あり。
Microsoft Graph は ODataプロトコルを採用
Microsoft Graphは Open Data Protocol (OData) というWebAPIのプロトコルを採用しており、
これにより、多様なクライアントでも一貫した方法でのデータアクセスに寄与しています。公開されているリソースの形式は、APIのルートURLに
$metadataを付与したURLで確認可能です。
Microsoft Graph v1.0 であれば以下がメタデータのURLになります。(XML形式)https://graph.microsoft.com/v1.0/$metadata
"user"型のデータ定義を抜粋。
<EntityType Name="user" BaseType="graph.directoryObject" OpenType="true"> <Property Name="accountEnabled" Type="Edm.Boolean"/> <Property Name="ageGroup" Type="Edm.String"/> <Property Name="assignedLicenses" Type="Collection(graph.assignedLicense)" Nullable="false"/> <Property Name="assignedPlans" Type="Collection(graph.assignedPlan)" Nullable="false"/> <Property Name="businessPhones" Type="Collection(Edm.String)" Nullable="false"/> <Property Name="city" Type="Edm.String"/> <Property Name="companyName" Type="Edm.String"/> <Property Name="consentProvidedForMinor" Type="Edm.String"/> <Property Name="country" Type="Edm.String"/> <Property Name="creationType" Type="Edm.String"/> <Property Name="department" Type="Edm.String"/> <Property Name="displayName" Type="Edm.String"/> <Property Name="employeeId" Type="Edm.String"/> <Property Name="faxNumber" Type="Edm.String"/> <Property Name="givenName" Type="Edm.String"/> ...略... </EntityType>OData形式については以下記事が理解の助けになりました。
- 参考
(本題) gem: microsoft_graph を利用する上での疑問
Microsoft Graph の公式Rubyライブラリ microsoftgraph/msgraph-sdk-ruby のREADMEより
callback = Proc.new { |r| r.headers["Authorization"] = "Bearer #{tokens.access_token}" } graph = MicrosoftGraph.new(base_url: "https://graph.microsoft.com/v1.0", cached_metadata_file: File.join(MicrosoftGraph::CACHED_METADATA_DIRECTORY, "metadata_v1.0.xml"), api_version: '1.6', # Optional &callback ) me = graph.me # get the current user puts "Hello, I am #{me.display_name}." me.direct_reports.each do |person| puts "How's it going, #{person.display_name}?" end疑問1:
graph.meは、直接定義されていないのになぜ動くのか?
graph.meで自身のプロフィール情報を取得できるが、
ソースコードをgrepしてもMicrosoftGraphのインスタンスメソッドにmeメソッドは直接的に定義されていなかった。
どのように動いているのか?ソースコードを追ってみた。ライブラリの大元の
MicrosoftGraphよりlib/microsoft_graph.rbclass MicrosoftGraph attr_reader :service BASE_URL = "https://graph.microsoft.com/v1.0/" def initialize(options = {}, &auth_callback) @service = OData::Service.new( api_version: options[:api_version], auth_callback: auth_callback, base_url: BASE_URL, metadata_file: options[:cached_metadata_file] ) @association_collections = {} unless MicrosoftGraph::ClassBuilder.loaded? MicrosoftGraph::ClassBuilder.load!(service) end end # ... 略 ...MicrosoftGraph::ClassBuilder.load!(service)
結論としては、この
load!メソッドの処理でRubyのオブジェクト定義をしていた。このメソッドでは、metadata(XML)の
EntityType,ComplexType,EntitySet,Action,Functionタグを順にメタプログラミングのテクニックでクラス化し、
メソッドの最後にSingletonタグで定義されている内容 (me等)を、MicrosoftGraphのインスタンスメソッドとして定義しているからgraph.meで呼び出し可能になっていた。
ClassBuilder.load!よりlib/microsoft_graph/class_builder.rbclass MicrosoftGraph class ClassBuilder @@loaded = false def self.load!(service) if !@@loaded @service_namespace = service.namespace service.entity_types.each do |entity_type| create_class! entity_type end service.complex_types.each do |complex_type| create_class! complex_type end service.entity_sets.each do |entity_set| add_graph_association! entity_set end service.actions.each do |action| add_action_method! action end service.functions.each do |function| add_function_method! function end service.singletons.each do |singleton| class_name = classify(singleton.type_name) MicrosoftGraph.instance_eval do resource_name = singleton.name define_method(OData.convert_to_snake_case(resource_name)) do MicrosoftGraph .const_get(class_name) .new( graph: self, resource_name: resource_name, parent: self ).tap(&:fetch) end end end MicrosoftGraph.instance_eval do define_method(:navigation_properties) do service.entity_sets .concat(service.singletons) .map { |navigation_property| [navigation_property.name.to_sym, navigation_property] }.to_h end end @@loaded = true end endmetadataの具体例と合わせて、class_builder.rb の処理内容を追ってみる
以下はmetadataの EntityType のUser型の抜粋。metadata_v1.0.xml<EntityType Name='user' BaseType='microsoft.graph.directoryObject' OpenType='true'> <Property Name='companyName' Type='Edm.String' Unicode='false'/> <Property Name='displayName' Type='Edm.String' Unicode='false'/> ... 略 ... <NavigationProperty Name='calendar' Type='microsoft.graph.calendar' ContainsTarget='true'/> <NavigationProperty Name='calendars' Type='Collection(microsoft.graph.calendar)' ContainsTarget='true'/> <NavigationProperty Name='events' Type='Collection(microsoft.graph.event)' ContainsTarget='true'/> ... 略 ... </EntityType>メソッド内でクラス定義している
create_class!メソッドにて
指定のクラス名(User)とベースクラス(BaseEntity)を指定して、MicrosoftGraph::<クラス名>でクラス化。lib/microsoft_graph/class_builder.rbdef self.create_class!(type) superklass = get_superklass(type) klass = MicrosoftGraph.const_set(classify(type.name), Class.new(superklass)) klass.const_set("ODATA_TYPE", type) klass.instance_eval do def self.odata_type const_get("ODATA_TYPE") end end create_properties(klass, type) create_navigation_properties(klass, type) if type.respond_to? :navigation_properties end def self.get_superklass(type) if type.base_type.nil? (type.class == OData::ComplexType) ? MicrosoftGraph::Base : MicrosoftGraph::BaseEntity else Object.const_get("MicrosoftGraph::" + classify(type.base_type)) end endその後の
create_propertiesで、
metadata内のProperty(companyName,displayName等)分、ゲッターセッターを動的に定義し、
graph.me.display_nameのように、プロパティにアクセスできるようになっていた。
また、:propertiesメソッドで自身のプロパティ一覧が参照できる。lib/microsoft_graph/class_builder.rbdef self.create_properties(klass, type) property_map = type.properties.map { |property| define_getter_and_setter(klass, property) [ OData.convert_to_snake_case(property.name).to_sym, property ] }.to_h klass.class_eval do define_method(:properties) do super().merge(property_map) end end end def self.define_getter_and_setter(klass, property) klass.class_eval do property_name = OData.convert_to_snake_case(property.name) define_method(property_name.to_sym) do get(property_name.to_sym) end define_method("#{property_name}=".to_sym) do |value| set(property_name.to_sym, value) end end endその後の
create_navigation_propertiesで、
metadata内のNavigationProperty(calendar,events等)分、クラスのインスタンスメソッドとしてを動的に定義し、
graph.me.calendarのように、オブジェクトをチェインする形で容易に関連リソースにアクセスできるようになっていた。
また、:navigation_propertiesメソッドで自身のナビゲーションプロパティ一覧が参照できる。lib/microsoft_graph/class_builder.rbdef self.create_navigation_properties(klass, type) klass.class_eval do type.navigation_properties.each do |navigation_property| navigation_property_name = OData.convert_to_snake_case(navigation_property.name).to_sym define_method(navigation_property_name.to_sym) do get_navigation_property(navigation_property_name.to_sym) end unless navigation_property.collection? define_method("#{navigation_property_name}=".to_sym) do |value| set_navigation_property(navigation_property_name.to_sym, value) end end end define_method(:navigation_properties) do type.navigation_properties.map { |navigation_property| [ OData.convert_to_snake_case(navigation_property.name).to_sym, navigation_property ] }.to_h end end end
load!メソッドの後方のSingleton定義処理をSingletonタグ(Name='me')の具体例と共に追ってみる。lib/microsoft_graph/class_builder.rbservice.singletons.each do |singleton| class_name = classify(singleton.type_name) MicrosoftGraph.instance_eval do resource_name = singleton.name define_method(OData.convert_to_snake_case(resource_name)) do MicrosoftGraph .const_get(class_name) .new( graph: self, resource_name: resource_name, parent: self ).tap(&:fetch) end end endmetadata_v1.0.xml<Singleton Name='me' Type='microsoft.graph.user'> <NavigationPropertyBinding Path='ownedDevices' Target='directoryObjects'/> <NavigationPropertyBinding Path='registeredDevices' Target='directoryObjects'/> <NavigationPropertyBinding Path='manager' Target='directoryObjects'/> <NavigationPropertyBinding Path='directReports' Target='directoryObjects'/> <NavigationPropertyBinding Path='memberOf' Target='directoryObjects'/> <NavigationPropertyBinding Path='createdObjects' Target='directoryObjects'/> <NavigationPropertyBinding Path='ownedObjects' Target='directoryObjects'/> </Singleton>ここでは、すべての
SingletonタグのName(me等)をMicrosoftGraphクラスのインスタンスメソッドとして
指定クラス(meであれば、MicrosoftGraph::User)のインスタンスを初期化する処理を定義している。
メソッドの最後のtap(&:fetch)処理で該当リソースの情報をAPIで取得する処理を行っていた。
これにより me メソッドが利用できるようになっていた。APIアクセスしている処理は以下
lib/base_entity.rbdef fetch @persisted = true initialize_serialized_properties(graph.service.get(path)[:attributes]) endlib/odata/service.rbdef get(path, *select_properties) camel_case_select_properties = select_properties.map do |prop| OData.convert_to_camel_case(prop) end if ! camel_case_select_properties.empty? encoded_select_properties = URI.encode_www_form( '$select' => camel_case_select_properties.join(',') ) path = "#{path}?#{encoded_select_properties}" end response = request( method: :get, uri: "#{base_url}#{path}" ) {type: get_type_for_odata_response(response), attributes: response} end def request(options = {}) uri = options[:uri] if @api_version then parsed_uri = URI(uri) params = URI.decode_www_form(parsed_uri.query || '') .concat(@api_version.to_a) parsed_uri.query = URI.encode_www_form params uri = parsed_uri.to_s end req = Request.new(options[:method], uri, options[:data]) @auth_callback.call(req) if @auth_callback req.perform endコードを読む際にメタプログラミングの理解に以下記事が参考になった。
疑問2:
graph.meの他にオブジェクト呼び出しができるメソッドはどこを見ればわかるの?metadataの
<NavigationProperty>を参考にするか、
該当オブジェクトで、:navigation_propertiesメソッドにて確認可能graph.me.navigation_properties.keys => [:owned_devices, :registered_devices, :manager, :direct_reports, :member_of, :created_objects, :owned_objects, :messages, :mail_folders, :calendar, :calendars, :calendar_groups, :calendar_view, :events, :contacts, :contact_folders, :photo, :drive]なお、参照できるプロパティ一覧は
:propertiesメソッドで確認可能me.properties.keys => [:id, :account_enabled, :assigned_licenses, :assigned_plans, :business_phones, :city, :company_name, :country, :department, :display_name, :given_name, :job_title, :mail, :mail_nickname, :mobile_phone, :on_premises_immutable_id, :on_premises_last_sync_date_time, :on_premises_security_identifier, :on_premises_sync_enabled, :password_policies, :password_profile, :office_location, :postal_code, :preferred_language, :provisioned_plans, :proxy_addresses, :state, :street_address, :surname, :usage_location, :user_principal_name, :user_type, :about_me, :birthday, :hire_date, :interests, :my_site, :past_projects, :preferred_name, :responsibilities, :schools, :skills]疑問3: クエリオプションってオブジェクト呼び出し時に渡せるの?
ODataプロトコルでは、
$filter,$count,$orderby,$skip,$top,$expand,$select
などの クエリオプション がサポートされているが、オブジェクト呼び出し時には指定できるの?例えば、大量のカレンダーイベントを取得するときに
$topを使えば、1リクエストで取得するアイテム数を増やすことが可能なので、
リクエスト数を減らすチューニングが可能になるが、コードを見る限りクエリオプションは渡せないようだ。ライブラリの思想として、ユーザが容易に利用できることに重きを入れているのを感じとれた。(個人の感想)
カレンダーイベントなどの複数リソースを取得する処理(ページネーション)は、ライブラリの中でよしなにラップしてくれている。lib/microsoft_graph/collection_association.rbdef fetch_next_page @next_link ||= query_path result = begin @graph.service.get(@next_link) rescue OData::ClientError => e if matches = /Unsupported sort property '([^']*)'/.match(e.message) raise MicrosoftGraph::TypeError.new("Cannot sort by #{matches[1]}") elsif /OrderBy not supported/.match(e.message) if @order_by.length == 1 raise MicrosoftGraph::TypeError.new("Cannot sort by #{@order_by.first}") else raise MicrosoftGraph::TypeError.new("Cannot sort by at least one field requested") end else raise e end end @next_link = result[:attributes]['@odata.next_link'] @next_link.sub!(MicrosoftGraph::BASE_URL, "") if @next_link result[:attributes]['value'].each do |entity_hash| klass = if member_type = specified_member_type(entity_hash) ClassBuilder.get_namespaced_class(member_type.name) else default_member_class end @internal_values.push klass.new(attributes: entity_hash, parent: self, persisted: true) end @loaded = @next_link.nil? endクエリオプションを使いたい場合、自前でクエリオプションを連結したURLを生成してHTTPリクエスト処理を実装する必要があるようだ。
URL生成の際には、pathメソッドは役に立ちそう。me.path => "users/xxx-xxx-xxx-xxx" >> me.calendar.path => "users/xxx-xxx-xxx-xxx/calendars/yyyy_yyyy" >> me.calendars.path => "users/xxx-xxx-xxx-xxx/calendars"まとめ
microsoft_graph のソースコードを読んで、Rubyのメタプログラミングの技法や、ODataプロトコルの思想に触れて、コードを読める範囲が広がった気がする。とてもエレガントなライブラリでした。
- 投稿日:2020-02-21T09:36:30+09:00
bundle install時に起きたmysql2のgemエラー
注意
自分用のメモ書き&同じ状況のエラーに遭遇した初学者のための投稿になっていますので記事内容が読みづらく雑であったり間違えている箇所があるかと思いますが大目に見てくださると助かります。
間違えている箇所についてはコメント欄にて指摘していただけると助かります。内容
既存のrailsプロジェクトを久しぶりに修正しようとした際にbundle installをしたら下記のエラーが出ました。
An error occurred while installing mysql2 (0.5.3), and Bundler cannot continue. Make sure that `gem install mysql2 -v '0.5.3' --source 'https://rubygems.org/'` succeeds before bundling.???
何もいじっていなかったので戸惑いながらエラー文を読み三行目のgem install mysql2 -v '0.5.3' --source 'https://rubygems.org/'を実行。
解決できずで何も変わらず、、、解決
まずエラー時は赤くなっている箇所のみではなくとりあえず遡ってちゃんと読むのが大事と改めて学びました。
この時はこんなことが書いてある箇所が少し遡ったところに書いてありました。。。mysql client is missing. You may need to 'brew install mysql' or 'port install mysql', and try again.MySQLが見当たらない、、これをしてくれと書いてあるではないか!!と思い、
brew install mysqlをまず実行、、、そしたら無事解決しbundle installができました!!
もう一方のport in stall mysqlはMacPortsという、macOSおよびDarwin OS上のソフトウェアの導入を単純化するパッケージ管理システムのひとつでmysqlを導入できるものらしいです。
- 投稿日:2020-02-21T09:18:00+09:00
Rails Unicorn起動時のエラー
本記事投稿のいきさつ
最近Railsの勉強を始めたが、その中でエラー対応に苦戦したためメモ代わりにここに残したいと思います。
また、不慣れのため表現や書き方など、分かりづらい部分があるかと思います。
優しい目で見ていただければ幸いです。エラー
Capistranoでデプロイ後にunicornを再起動をしたかったのですが、EC2でunicorn接続をした際上手く接続ができずlessコマンドでエラーログを確認。
ArgumentError: Already running on PID:~~との表示がされていました。
仮説
エラー文から以前のunicorn接続のプロセスが残っていると思い
ps aux | grep unicorn入力し確認したところどうやら余分なプロセスは確認できませんでした。
もしプロセスが表示されていればkill プロセスidで解決できます。しかし他に原因があるようです。
ネットで調べたところ unicorn.rb に問題がある場合にもこのエラーが発生するとのことでした。原因と対策
unicorn.rbを確認したところ
unicorn.rbpid "#{app_path}tmp/pids/unicorn.pid"の設定を発見しました。
Capistranoの導入でディレクトリの構造が変わるのですが、それに伴う設定の変更を一箇所出来ていませんでした。
そのため記述を以下に変更unicorn.rbpid "#{app_path}/shared/tmp/pids/unicorn.pid"これで無事動くようになりました。
エラー文だけで判断せず調べることも重要ということを改めて再認識した事象でした。
- 投稿日:2020-02-21T09:06:05+09:00
Elastic Beanstalk で Railsアプリをデプロイする時にハマったとこ
Elastic Beanstalk で Railsアプリをデプロイする時にハマったとこ
まとめ
Elastic Beanstalk へデプロイした経験から、ハマりやすいポイントをまとめました。
詳細については、以下の1回目と2回目のところを参照してみてください。
- セキュリティグループ
- MySQL エンコード
- .ebextension 設定
- 各gemの対応
1回目
- 文字コード(日本語の場合、utf8 へ変更必要)
- セキュリティグループ (Mysql2::Error: Can't connect to MySQL server on '**********.*****.ap-northeast-1.rds.amazonaws.com' (4))
- EC2 と RDS を同じVPC/サブネット上に置く方法
- RDS のセキュリティグループに EC2 からのアクセスを許可する。
rails db:createをやってくれない?
(Mysql2::Error: Unknown Databese'**********')
- 下記コマンドにて、自分でMySQLに接続して、DB作成。
- MySQL への接続(EC2上で(eb ssh))
- mysql -h **************.***.ap-northeast-1.rds.amazonaws.com -P 3306 -u ** -p
- DB作成
- create database ***********;
- utf8 へ変更されているかコマンドを実行して確認
initializers/carrierwave.rb 用に beanstalk へS3設定を追記
2回目
- eb init
- eb create
- RDS 作成
- ebに環境変数を格納
.ebextensionを記述
eb deploy
EC2 cd /var/app/ondeck/ 内で
- bundle update --bundler
- gem install bundler:2.0.2
local上の Ruby のversionを上げることでglobal環境のversionと合わせる
# install可能なversionを表示 $ rbenv install -l # versionを指定してinstall $ rbenv install 2.6.5 # インストールしたversionを使用可能な状態にする⇒shimsへの反映 $ rbenv rehash $ rbenv local 2.6.5 $ rbenv global 2.6.5
- bundler のバージョンがあっていない?
(参照:Gem::GemNotFoundExceptionと出てきたときの対処法 - Qiita)
$ gem install bundler -v '1.17.3'$ bundle install
- MySQLのインストールでエラーが出る。 mysql2 gemインストール時のトラブルシュート - Qiita
$ gem install mysql2 -v '0.5.3' --source 'https://rubygems.org/' -- --with-cppflags=-I/usr/local/opt/openssl/include --with-ldflags=-L/usr/local/opt/openssl/lib
nodeのversionが古いとかいうエラーがでた、mini-racer っていうgemを追加すれば直るって記述があった
(ruby on rails - ERROR: ServiceError - Failed to deploy application. on ElasticBeanstalk - Stack Overflow)mini-racer入れたら直った??
- .ebextension に rails db:create を追加
RDS のセキュリティグループを変更
Sequel Pro から MySQLに接続できるかどうかを確認。→ できなかった
EC2 に入って、コマンドで接続できるか
$ mysql -h *****RDSインスタンス*****.ap-northeast-1.rds.amazonaws.com -P 3306 -u **DB名** -p→ 接続できた。
つまり、他の問題?
EC2内から直接、DB(-)を作成するコマンドを打ったところ、ハイフンは使えないということを言われる。
→ 環境設定の ***-*** を _** へ変更。再度、eb deployしたところ、同じエラーが出る。
→ わからないので、MySQLの中から _** を作成してしまって、再度 eb deployエラーコードが変わって、MySQLのエンコードが問題っぽい。
[AWS][RDS][MySQL] 文字コードをutf8mb4にする - Qiita【MySQL】Mysql2::Error: Incorrect string value 【エラー】 - Qiita
対象のRDSのパラメーターグループをさっき変更したものに指定する。
作ったDBを一旦削除して、作成し直す。
これも意味がなく、過去のEBではまったところが確認し直したところ、以下の記事を見つける。
RDSに作成したMySqlのDatabaseに日本語が登録出来ない問題 - QiitaALTER DATABASE データベース名 default character set utf8;
- 下記エラーコードが出たので、crontabのコードを削除して、再度デプロイしてみる。
container_command 06-crontab in .ebextensions/02_setup_app.configようやくデプロイ完了!!
- 投稿日:2020-02-21T08:42:34+09:00
Railsは"5つの属性"を意識しろ
はじめに
TECH::EXPERT 72期生の添野です。短期集中Aチームです。
今日も、Rails苦戦中の方におすすめの記事です。○○メソッドを単体で覚えてもキリがない
急ですが、皆さんは下記3つの呪文を詳細に説明できるでしょうか。
・ paramsメソッド
・ AcctiveRecordクラス
・ newメソッド私は無理です。しかし、次のように一言添えることはできます。
「paramsは、ビューやコントローラで使うよね」
「AcctiveRecordは主にコントローラで使うよね」
「newメソッドはAcctiveRecordクラス自体が持ってる属性みたいな感じ」いかがでしょうか?字面ではピンとこないかもですが、同期生との対面でコレを唱えると、「うお、コイツめっちゃ理解してやがる」と思われたりします。実際のところ、ふんわりとですが、内容を理解しています。
ポケモンはなぜ覚えやすいのか
突然ですが、皆さんはポケモンをやったことがあるでしょうか。
ピカチュウがどんなのか、って言われたら大半の人が「黄色いポケモン」もしくは「でんきタイプだよね」とか言うと思います。ポケモンって890種類いるらしいのですが、どうしてこんなに覚えやすいのでしょうか?「属性」があるからです。ピカチュウは、「でんき」「黄色い」「ねずみ」などの属性を持っています。
メソッドはポケモン
頭のいい方は、私が何を言いたいか分かってしまったかもです。
上記3つの呪文について、私は「属性」を使って覚えています。「paramsは、ビューやコントローラで使うよね」
「AcctiveRecordは主にコントローラで使うよね」
「newメソッドはAcctiveRecord クラス自体が持ってる属性みたいな感じ」Railsの属性は5つしかない
実は、Railsの属性はめちゃくちゃ少ないです。下記5つだけです。
1. D属性 "データベース"
2. M属性 "モデル"
3. R属性 "ルーティン"
4. C属性 "コントローラ"
5. V属性 "ビュー"基本はこれだけ覚えれば十分です。
これらの5属性は、それぞれファイルが分かれており、記述もクセがあります。属性分けできることを知っていれば覚えやすくなります。まとめ
私は、Railsレッスンで度々出現する呪文を5つの属性で覚えています。
皆さんも、明日から是非使ってみてください。他にも、皆さんの役に立ちたいと思い作成した記事がありますので、是非ご活用ください。
・Rails用語集 基礎
・TECH::EXPERTはカレーづくり教室だった話
・Rails消化のコツ使えるものは何でも使っていきましょう。
それでは。
- 投稿日:2020-02-21T08:41:50+09:00
Rails用語集 基礎
はじめに
これはRails用語集です。"GET"って何だ?!ってなったら"command+F"を押して、"GET"で検索してみてください。ゲームの攻略本みたいに、箸休めに流し見するのも、アリ。
D "データベース"
・テーブル データが入ってる表
・カラム テーブルの縦軸
・レコード テーブルの横軸
・マイグレーションファイル テーブル設定を書くファイル
20200218124821~みたいなファイル名 長い
機能追加するとどれがどれなのか分かり難くなるので注意・Sequel Pro データベースを直接弄れるパンケーキ 固そう
M "モデル"
・アソシエーション モデル同士の人間関係
・has_many 1 対 多 不倫関係
・belongs_to 1 対 1かつ一方通行 ガチ恋 Pretender・validates(バリデーション) 空の投稿を禁止する記述
・N+1問題 処理が重くなるので回避すべき問題
・includesメソッド N+1問題を解決できるメソッドR "ルーティング"
・アクション ルーティングに書く指示。7種類
アクション名 Twitterで言うと index 投稿一覧 new 新規ツイート create ツイート投稿 show ツイート詳細 edit ツイート編集 update ツイート編集を反映 destroy ツイート削除 ・resourcesメソッド 上記アクションをまとめた魔法
・only: [:index] "indexだけ使え"という意味
・except: [:index] "indexだけ使うな"という意味・HTTPメソッド リクエストの種類を表す
例 "GETリクエスト"はユーザがURLをクリックした時に"リンク先を表示しろ!"とPCに向けてと言う命令
例 "POSTリクエスト"はユーザがTweetボタンをクリックした時に"ツイート投稿のシステムを起動しろ!"と言う命令
HTTPメソッド いつ使うか Twitterでいうと GET ページ表示 ツイートの投稿/編集画面を表示 POST データ登録 ツイート投稿 PATCH データ変更 ツイート編集 DELETE データ削除 ツイート削除 ・URIパターン ↓"tweets"の部分 URLのようなもの
http://localhost:3000/tweets・Prefix "rails routes"したときに出てくる最初の数文字
URIパターンの変数バージョン。"_path"と組み合わせて使う。
例えばroot _ pathと書くと'/'の代わりに使える。・ルートパス 他全てのページに飛ぶための初期地点。マサラタウン
・rootメソッド ルートパスを変える魔法。トキワシティからゲーム開始できるC "コントローラ"
・アクション コントローラに"def~end"で書く指示。7種類。ルーティングとほぼ一緒
アクション名 Twitterで言うと index 投稿一覧 new 新規ツイート create ツイート投稿 show ツイート表示 edit ツイート編集 update ツイート編集 destroy ツイート削除 ・ActiveRecordクラス テーブルから情報を拾う道具
クラス名 用途 .all テーブルの情報を全部取得 .find レコード内の1つを取得する .new レコードを生成する .save レコードを保存する ・インスタンス変数 @ tweets みたいな奴
・binding.pry 処理を一時停止してデバッグする魔法
・パラメーター 変数、引数、設定値。とにかく"値"のこと
・ストロングパラメーター 指定したカラム名の値だけ受け取る魔法
セキュリティが強固→つよい→ストロング と覚えよう
・プライベートメソッド "private(改行)def~"で書くメソッド
エラーを防いだり読みやすくするために書く
・params 送られてきた値を取得する魔法
・permit.(:カラム名) 指定したカラムの保存を許可する
privateと併用してそれ以外を保存不能にする
・redirect_toメソッド(リダイレクト)
アクション直後にページ移動できる魔法
・current_user.id ユーザidを取得する魔法
・merge 2つのハッシュを合体させる魔法
・before_action 全ての処理の前にアクションを実行させる
未登録ユーザの投稿禁止にも使える
複数メソッドをまとめて呼び出す時にも便利
・configure_permitted_parameters 追加パラメータを許可するV "ビュー"
・ビューファイル ~~.html.erbって名前のファイル HTMLが書いてある
・application.html.erb 本体のファイル
・tweet.html.erb等
・部分テンプレート ビューの一部を切り出したファイル
・renderメソッド 部分テンプレートを召喚する魔法
・partial 上記のテンプレート名を指定する
・locals 上記の変数を召喚できるようにする・ERBタグ HTMLにRubyを書く魔法 2種類ある
<%= %> HTMLに表示される @ tweetsとかを入れよう
<% %> HTMLに表示されない endとかに使おう
・eachメソッド 繰り返し処理 カラムからデータ取り出す時などに使う
・end eachやdefなどの処理を終わらせるのに使う <% %>で括ろう
・scssファイル cssファイルの親戚・<%= yield %> 召喚魔法
application.html.erbなどに書いてあり、主に"ファイルの先頭に<!DOCUTYPE html>って書いてないビューファイルたち"を召喚している
・stylesheet_link_tag CSSを召喚する魔法
・リセットCSS ブラウザ初期設定のCSSの影響で意図せず崩れてしまう表示を元に戻すのに使う奴
・user_signed_in? ユーザがログインしてるかどうかを判定する魔法
Gemfileの末尾にdeviseを入れると使える・ヘルパーメソッド HTMLが楽になるRuby語の魔法
クラス名 用途 form_tag 投稿ページなどの実装 Lesson7でdisられる いらない子 form_with form_tagのほぼ上位互換 form_tagに謝れ link_to リンクにする htmlのaタグみたいな奴 simple_format 表示を整理する ex.ツイートに含まれる<改行>を反映する ・例:form_tagの場合
<%= form_tag('/posts', method: :post) do %> <input type="text" name="content"> <input type="submit" value="投稿する"> <% end %>・例:form_withの場合
<%= form_with model: @post, local: true do |form| %> <%= form.text_field :content %> <%= form.submit '投稿する' %> <% end %>[メリット]
・'/posts'を書かなくていい
・インスタンス変数@ postが使える
・inputタグを使わなくていい
・さよならform_tagその他
・変数型 カラムの中身の種類 合わない物を入れるとエラー
型 中身 用途 integer 整数 回数など string 文字(短) ユーザ名、メルアドなど text 文字(長) 投稿文,画像URLなど boolean true/false 選択肢、いいねの有無など datetime 日付時刻 ・gem Rubyをさらに便利にできる道具
・Gemfile 使いたいgemを書くファイル
・devise ユーザ管理機能
・pry-rails デバッグ機能番外編 railsコマンド集
※ "マイグレ"="マイグレーションファイル"の略
・rails new "アプリ名" -d mysql MySQLに最適化したアプリを生成
・rails db:create データベース生成
・rails s サーバ起動 "control+c"で停止
・rails routes ルーティング確認 文字が沢山出る
・rails g model "モデル名" モデルとマイグレ生成
・rails g controller "コントローラ名" コントローラ生成
・rails d controller "コントローラ名" コントローラ削除
・rails db:migrate マイグレ適用
・rails db:rollback マイグレ差し戻し。マイグレ修正したい時使う
・rails db:migrate:status マイグレのup/down確認する
・rails c コンソール起動 "exit"で停止
・bundle install gemを適用する
・bundle update 同上 バージョン変更も適用するまとめ
コードの意味が分からなくなったら、今あなたがいじってるファイルが上のどのカテゴリなのかを判断して、ここを見ろ。ここにない記述は変数の可能性アリ。これも追加して!というご要望は編集リクエストまでお願いします。
まとめて読んでおきたい記事
Railsは"5つの属性"を意識しろ
カテゴライズを意識するとRailsがさらに捗るそれでは。