- 投稿日:2020-02-21T21:22:29+09:00
DICOMから被験者の情報を一括自動収集
はじめに
200件ちかいMRIのDICOMから被験者の
- 名前
- ID
- 生年月日
- 性別
- 年齢
- 検査日
を表にまとめる。
手作業では、いつまで経っても終わらないのとコピペのミス等のHuman Errorが出る可能性があるのでPCにまかせるプログラムを作成した。
dcmdumpを使うととても便利。作業環境
$ cat /etc/os-release NAME="Ubuntu" VERSION="18.04.4 LTS (Bionic Beaver)" ID=ubuntu ID_LIKE=debian PRETTY_NAME="Ubuntu 18.04.4 LTS" VERSION_ID="18.04" HOME_URL="https://www.ubuntu.com/" SUPPORT_URL="https://help.ubuntu.com/" BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/" PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy" VERSION_CODENAME=bionic UBUNTU_CODENAME=bionicdcmdump
DICOMのヘッダー情報を吐き出すことができる。
インストール
$ apt-get install dcmtk使い方
使い方は、dcmdumpのあとにDICOM fileを指定するだけです。
タグごとに情報が吐き出されます。$ dcmdump <DICOM file>準備
フォルダ構造はこのような感じ。
200人分のフォルダがあり、それぞれの中に複数の画像が入っている。$tree . ├── 1 │ ├── Tensor_diffusion_30dir_4mm_DFC_MIX - 10 │ │ ├── IM-0001-0001-0001.dcm │ │ ├── IM-0001-0002-0001.dcm │ │ ├── IM-0001-0003-0001.dcm ・ ・ ・ │ │ └── IM-0001-0062-0001.dcm │ └── t1_mprage_sag_p2_iso - 9 │ ├── IM-0001-0001-0001.dcm │ ├── IM-0001-0002-0001.dcm │ ├── IM-0001-0003-0001.dcm ・ ・ ・ │ └── IM-0001-0176-0001.dcm ├── 2 ・ ・ ・ └── 200実行
大人の事情でヘッダーの吐き出しているところを実際に見せられませんが雰囲気を掴んで貰えれば幸いです(汗)。
1. 被験者一人ひとりのフォルダ名が1,2,3,・・・200となっていたので"ls |sort -n" で1,2,3,・・・100,・・・200とリスト化して変数kに順次代入。(仮に"ls"のみだと1,100,200,・・・99と頭の数字順にsortされる)
2. 各被験者ごとに大量のDICOMがあるがどれか一つでもあれば情報は取得できる。ということで、"find <被験者フォルダ> -type f(ファイルのみ探す) | head -n 1"をつかって各被験者ごとに1枚DICOMを取り出す。
3. 2.で得られたDICOMファイルのパス・ファイル名をもとに、"dcmdump"でヘッダー吐き出し
4. 3.のうち必要なものだけをとりだす(grep <必要なタグ>)。
5. それぞれのタグは(tag ID) tag type [tag info] tag nameからなる。ほしいのは [tag info]なので"[]"の中身をとりだすようにして”cut -d [ -f2| cut -d ] -f1”を使う。
6. それぞれのほしいタグごとにtmp?にリダイレクトし最後にpasteでまとめる。
7. tmp?ファイルは必要ないので削除(汚物は除去)。
8. 1列目に被験者フォルダ名、続いて名前、ID、生年月日、性別、年齢、検査日がまとまったテキストがdcm_info.txtに保存される。get_dcminfo.shfor k in $(\ls |sort -n);do # 被験者フォルダ名 echo $k >> tmp1 # 名前(PatientName) find $k -type f | head -n 1 | xargs -i dcmdump {} \ | grep PatientName \ | cut -d [ -f2| cut -d ] -f1 >> tmp2 # ID(PatientID) find $k -type f | head -n 1 | xargs -i dcmdump {} \ | grep PatientID \ | cut -d [ -f2| cut -d ] -f1 >> tmp3 # 生年月日(PatientBirthDate) find $k -type f | head -n 1 | xargs -i dcmdump {} \ | grep PatientBirthDate \ | cut -d [ -f2| cut -d ] -f1 >> tmp4 # 性別(PatientSex) find $k -type f | head -n 1 | xargs -i dcmdump {} \ | grep PatientSex \ | cut -d [ -f2| cut -d ] -f1 >> tmp5 # 年齢(PatientAge) find $k -type f | head -n 1 | xargs -i dcmdump {} \ | grep PatientAge \ | cut -d [ -f2| cut -d ] -f1 >> tmp6 # 検査日(PerformedProcedureStepStartDate) find $k -type f | head -n 1 | xargs -i dcmdump {} \ | grep PerformedProcedureStepStartDate \ | cut -d [ -f2| cut -d ] -f1 >> tmp7 done # tmp1, tmp2, tmp3,...tmp7を左詰めでpasteし一つのファイルに paste tmp* >> dcm_info.txt # tmpファイルの削除 rm tmp*まとめ
大量の被験者情報をDICOMから自動で一括収集するプログラムを作成した。
正直、処理の速さとか効率はなにも考えれていない回りくどいかんじだけどコードの中身は単純で理解しやすいのかな?
これならHuman Errorも無くなるし時間も有効に使えそう!
特に、AIをやっている人であれば必須のスキルかもしれません。
(過去にKaggleのチャレンジで100万近くのDICOMを相手にしました...)
- 投稿日:2020-02-21T20:55:24+09:00
Raspberry4BでSLAMロボットを自作してみる(序章)
はじめに
息抜き()にROSでSLAMしていて、最近ようやく(まだまだ未完成ながらも)形になってきたので、まとめとして記事にしてみます。
記事書いてる中の人は元々情報系は全く詳しくありません。RaspberryPiのことをお菓子だと思っていたほどです。なので記事には間違いや勘違い等が多々あると思いますので、ご指摘や批評等を遠慮なくオナシャス!
クローラ型の駆動ロボットを使いました。使用したハードウェアとかお世話になった参考書
まずはハードウェアから
・RaspberryPi4B(Ubuntu18.04)もしくはRaspberryPi3B+(Ubuntu16.04)
3B+の方は3Bでも大丈夫です。・SanDisk Extreme PRO 64GB
ラズパイのOS入れる用のSDカードです。ほんとは16か32GBの容量のやつがよかったけど、A2規格のカードでは見当たらなかったのでこれでいいやーみたいな。店頭で買うとamazonとかよりも4倍近く値段が上がるのはどういうことなの…?・ArduinoMega2560
エンコーダからのパルスをカウントしたりモータを回したりする用、UNOでも問題ないと思います。・Pololu Dual VNH5019 Motor Driver SHield for Arduino(https://www.switch-science.com/catalog/1747/)
Arduinoで使えるモータドライバシールド、Arduinoに載せるだけで簡単に使えるだけでなく、様々な保護回路が組み込まれているので、多少雑に扱っても(丁寧に扱え)滅多ことでは壊れない。ピンをつける際は半田こてが必要です。・クローラロボット(https://www.vstone.co.jp/robotshop/index.php?main_page=product_info&products_id=4008)
研究室で埃をかぶってたので使用。まぁエンコーダがついているモータが目当てなので。機体は何でもよかったです。はい。・URG-04LX-UG01(https://www.hokuyo-aut.co.jp/search/single.php?serial=17)
色んな書籍にもたびたび登場する測域センサ、ROS対応で実に使いやすい。・RT-USB-9axisIMU2(https://www.rt-net.jp/products/9axisimu2)
いわゆる9軸センサ、キャリブレーションやファームウェアの書き直しなどクッソ楽なうえにROS対応。・DualShock3
入力用デバイス。いわずと知れたプレステ3のコントローラ。長年放置された影響かボタンの入力判定がガバガバだったので、例に倣ってティッシュを潜影蛇手してるわ…あとは、RaspberryPi用にUSBマウスとUSBキーボード、HDMIモニターを準備してください
ここからは参考書を紹介
・RaspberryPiで学ぶROSロボット入門(https://www.rt-shop.jp/index.php?main_page=product_info&products_id=3655)
打つべきコマンドや、デモコードにも細かな解説がなされていて、ROSの仕組みについてが丁寧丁寧丁寧に記されています。ただ、この本を最大限生かすためには
Raspberry Pi Mouse(https://www.rt-shop.jp/index.php?main_page=product_info&products_id=3419)
が必要(お高い)。えぇ、買いましたともおかげさまでとても勉強になったよ。
後で知ったことですが、RaspberryPiMouseにはシュミュレーターが用意されているので、機体を買う必要はありませんでしたね。・実用ロボット開発のためのROSプログラミング(https://www.morikita.co.jp/books/book/3240)
今回のような電子工作レベルのロボットを作る際には必要ないかもしれません。
シュミュレーションで使うモデルの作り方、シュミレーションソフトの使い方等を調べる際にお世話になりました。・ROSロボットプログラミングバイブル(https://www.ohmsha.co.jp/book/9784274221965/)
今回のようにSLAMをやる。という場合には、この本が一番良いと個人的には思います。ArduinoをROSで使うための環境構築の記述もあるので、この記事のロボットを作るにあたって最も役立つ一冊でした。次回
砕け散る地図

- 投稿日:2020-02-21T19:45:36+09:00
Azure DevOps で Azure Pipelies のビルドを Linux のセルフホスト環境で実行する
本記事は Azure DevOps で自前で用意した仮想マシンでビルドする、セルフホスト・エージェントの環境を構築する方法について記述します。
Azure DevOps とは何か?あるいは何ができるか?については、他の方が詳しく書かれているので、ここでは割愛して本題のみに触れます。
なぜセルフホストなのか?
Azure DevOps において、ビルドを行うサービスは Azure Pipelines です。デフォルトでは、Microsoft がホスト(Microsoft-hosted)する環境でビルドが行われます。しかも、それらは無料で提供されます。
では、なぜわざわざ仮想マシンの料金まで払って自前のセルフホスト環境を用意するのか?
それは、Microsoft がホストする環境では、以下のような制限があるからです。(2020/02/20 現在)
- ソースファイルおよびビルド出力に "少なくとも" 10 GB のストレージ
- 時間制限
- オープンソースなプロジェクト
- 毎回最大 6 時間実行できる 10 個の並列の無料ジョブ
- 月あたりの上限は特になし
- 制限を引き上げる場合は、Microsoft に問い合わせる
- クローズドソースなプロジェクト
- 毎回最大 1 時間実行できる並列の無料ジョブ
- 月あたり最大 30 時間
- 上限引き上げは有料になる
- 実行マシンは `DS2_v2' 仮想マシン
- 2 vCPU
- 7 GiB Memory
- 14 GiB SSD
- など
- など
このような制約がありますが、オープンソースなプロジェクトで使用する場合は、よほど大きなプロジェクトで無い限り、Microsoft がホストするエージェントでビルドを行えるはずです。
しかし、エンタープライズシステムでは、クローズドなソースでシステム開発が行われる事がほとんどで、毎回 1 時間の制約ではビルドおよびテストには時間が足りないことはよくあります。
このような場合には、セルフホストが現実的な選択肢となります。さらに、セルフホストは仮想マシンのサイズは自由に設定できる ため、ビルドマシンに大きなサイズの仮想マシンを使用し、全体のビルドおよびテスト時間を短縮する事が可能です。
何をセルフホスト環境で実現したいか?
今回、実現したいことは単純で、こちらでセットアップした仮想マシンで実行されるエージェントを、Azure Pipelines から呼び出せるようにします。
全体像は次の図のようになります。
一連のフローは、図の番号順に実行されます。
- 開発者はソースコードを master ブランチにプッシュする
- Azure Repos はプッシュされたことをトリガーとして、Azure Pipelines のビルドシーケンスを起動する
- Azure Pipelines は、仮想マシン上にセルフホストされたエージェントにビルドを依頼する
- 仮想マシン上のエージェントは、ソースコードをビルドする
- 仮想マシン上のエージェントは、ビルドの結果が成功または失敗にかかわらず、Azure Pipelines に結果を通知する
- Azure Pipelines は開発者にビルドの結果をメールで通知する
前提条件
さて、ここからセルフホスト環境の設定を行うのですが、話を簡単にするためにいくつかの前提条件を設けます。
まず、作業を行うユーザーの権限について、以下の条件を満たしている必要があります。
- Azure AD のユーザーおよびグループの作成権限があること
- Azure DevOps のプロジェクト管理者のロールを持っていること
- Ubuntu 18.04 の仮想マシンを作成する権限があること
次に、Azure リソースについても、ある程度の準備をしていることを前提とします。
- すでに Azure DevOps 上の組織を作成していること
- すでに Azure DevOps のプロジェクトを作成していること
- すでに Azure Repos にビルド用のリポジトリを用意してあること
- すでに セルフホスト用のリソースグループおよび仮想マシンのセットアップをしていること
- Ubuntu Server 18.04 にログインできる状態であること
- Git 2.9.0 以降のインストールを済ませていること
- ユーザーに sudo の権限があること
- エージェントのインストールについては必要ありません
以下は必須ではありませんが、あれば後々のために楽ができるかもしれません。
- Key Vault をリソースグループに作成し、作業するユーザーにシークレットの作成権限があること
作業の概観
個別の作業に入る前に、作業の一連の流れを把握しておくことは将来の自動化のために重要です。
また、作業する際に設定すること、あるいはしないことについて理解しておいた方が、作業の意味がよく理解でき、何を自動化するべきかの取捨選択および作業の分担が捗ると思います。ここで行う作業は、次のように大きく3つに分けることができます。
- 各 Azure リソースの設定および関連付け
- 仮想マシンに対するエージェントのセットアップ
- 新しいパイプラインの作成
最後のビルドおよびテストのための
azure-pipelines.ymlについては、Dev に記述してもらっても良いかも知れません。各 Azure リソースの設定および関連付け
主に Azure DevOps で必要なものを作成します。
作成するのは次のようなものです。
- Azure Active Directory ユーザー
- パーソナルアクセストークン
- Agent Pool
では、順を追って説明していきます。
エージェントを実行するユーザーの作成
今回の最重要な作業は、Azure Pipelines とセルフホスト環境のエージェントを関連付けることです。
そうしないと、Azure Pipelines はどのエージェントを呼び出していいか判断がつかず、エージェントもなんのタスクを実行していいか判断のつかない状態になります。今回は新しいユーザーを作成して、Azure Pipelines のエージェント管理者として登録します。
なお、既存のユーザーにエージェント管理者を関連付ける場合は、この手順をスキップできます。ただし、エージェント管理者のパーソナルアクセストークンを使用する都合上、専用のユーザーを用意したほうがトークンの管理が楽になる(かも知れません)
蛇足ですが、スクリーンショットのテーマがいろいろ変わってるのは気にしないで下さい…
Azure Active Directory ユーザーの作成
まず、Agent Queue を管理するユーザーが必要なので、以下の情報で Azure AD ユーザーを作成します。
設定項目 設定値 ユーザー名 Azure-Pipelines-Agent-Queue-Admin-001 名前 Azure Pipelines Queue Admin 001 名 Admin - 001 性 Azure Pipelines Agent Queue パスワード 任意のパスワード 利用場所 日本 さらに、認証の連絡先情報を編集し、Azure AD 管理者あるいは管理者メーリングリストのメールアドレスを入力します。
Azure DevOps へのユーザーの追加
Azure Active Directory で作成したユーザーを Azure DevOps に追加します。
Azure DevOps の管理権限を持ったユーザーが、Azure DevOps にサインインし、次の図のOrganization settingsをクリックし、組織の設定画面を開きます。
次に、左ペインの
Usersを選択します。
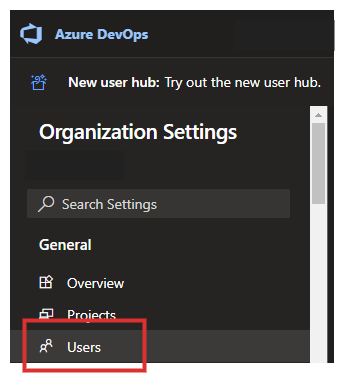
最後に、ユーザーの情報を入力して
Addをクリックします。
設定項目 設定値 Users 先ほど作成した Azure AD ユーザー Access level Basic Add to projects 追加するプロジェクト名 Azure DevOps Groups Project Contributors
エージェント管理ユーザーのパーソナルアクセストークンの作成
先程、作成したユーザーで Azure DevOps にサインインします。
サインインした後は、プロファイルを編集して、メールアドレスを有効な値にしておきます。サインイン後にプロジェクトを選択し、画面右上のプロファイルから
Personal access tokensをクリックします。
次に、今の段階では何もアクセストークンは発行されていないはずなので、右ペインの
New Tokenをクリックします。
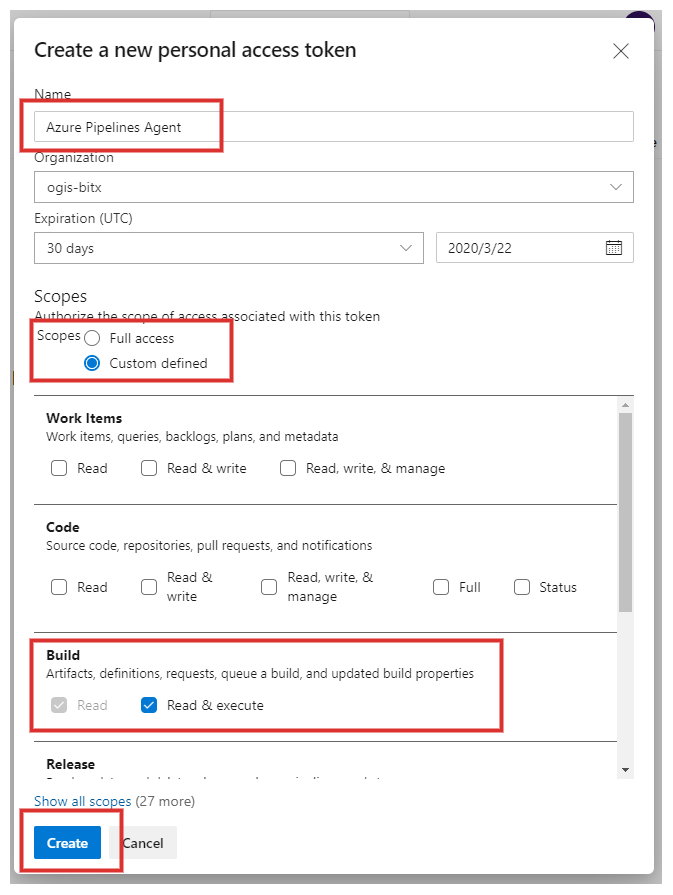
画面右側に入力ダイアログが開くので、必要な情報を入力します。
以下のスコープに、権限を設定します。
スコープ 設定値 Agent Pools Read & manage Build Read & execute Packaging Read, write, & manage Release Read, write, execute, & manage Test Management Read & write
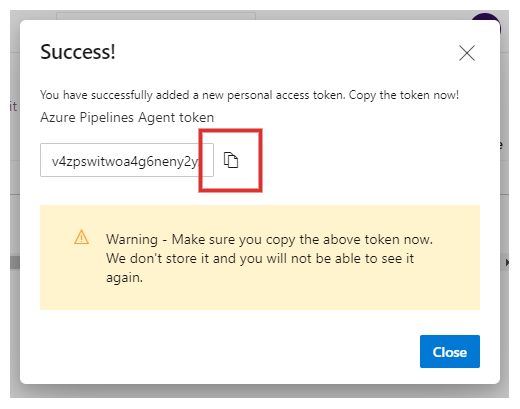
Createをクリックすると、次のようにパーソナルアクセストークンが表示されるので、コピーアイコンをクリックしてどこかに保管しておきましょう。
Azure DevOps はこのパーソナルアクセストークンを保存しない ことに注意して下さい。忘れても大丈夫なように、必ずどこかに保存しましょう。
ここで Tips ですが、先程のパスワードもパーソナルアクセストークンも Key Vault のシークレットとして管理することをお勧めします。
これに Key Vault の有効期限をチェックするカスタムポリシーを関連付けて監査すれば、パーソナルアクセストークンの有効期限が切れる前に、新たにパーソナルアクセストークンを発行して、常に有効なトークンを使用できるようになります。実は作成時にしかパーソナルアクセストークンが必要としないのではないか…?
Agent Pool の作成
さて、ここからが今回のポイントである Agent Pool の作成です。
プロジェクトを選択し、
Project settingsをクリックします。
左ペインの
Agent poolsをクリックします。
右ペインの右上にある
Add poolをクリックします。
必要な情報を入力し
Createをクリックします。今回はHosted Agent Poolという名前にします。
Agent Pool が作成されたのでクリックします。
右ペインの
New Agentをクリックします。
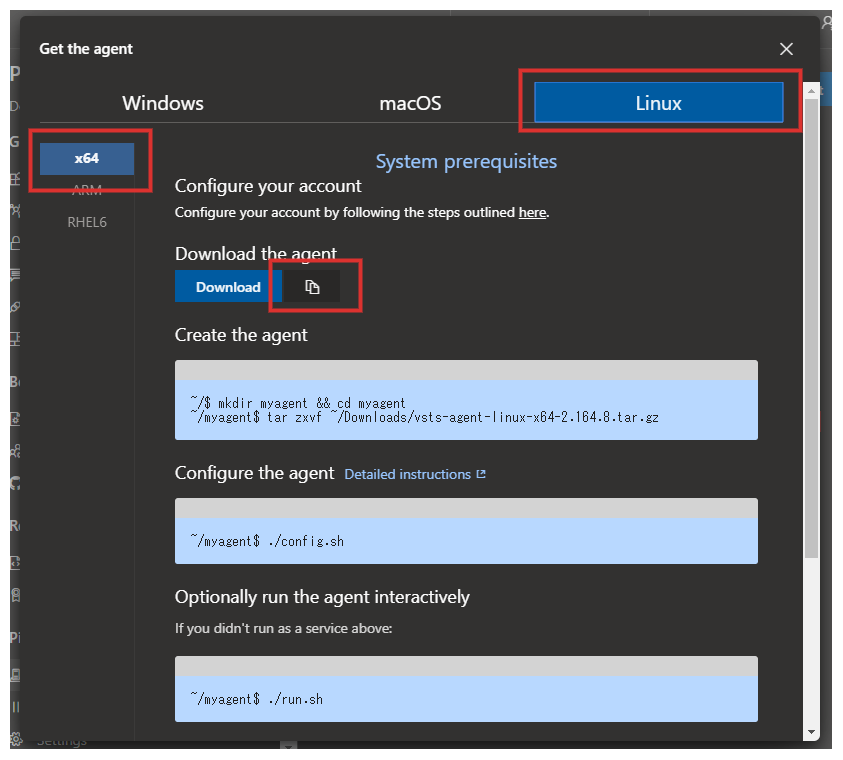
Agent のためのダイアログが表示されるのでので、
Linuxタブをクリックし、プラットフォームがx64になっていることを確認し、コピーアイコンをクリックしダウンロードリンクを保存します。
仮想マシンに対するエージェントのセットアップ
先程のエージェントをダウンロードする手順は次のとおりです。
- すでに準備していた仮想マシンにログインします。
myagentというディレクトリを作成します。- ダウンロードリンクを使用して、エージェントをダウンロードし、圧縮ファイルを展開します。
コマンドは次のとおりです。
mkdir myagent && cd myagent wget https://vstsagentpackage.azureedge.net/agent/2.164.8/vsts-agent-linux-x64-2.164.8.tar.gz tar zxvf vsts-agent-linux-x64-2.164.8.tar.gz次に、エージェントを構成します。
./config.sh次のようなプロンプトが表示されます。
___ ______ _ _ _ / _ \ | ___ (_) | (_) / /_\ \_____ _ _ __ ___ | |_/ /_ _ __ ___| |_ _ __ ___ ___ | _ |_ / | | | '__/ _ \ | __/| | '_ \ / _ \ | | '_ \ / _ \/ __| | | | |/ /| |_| | | | __/ | | | | |_) | __/ | | | | | __/\__ \ \_| |_/___|\__,_|_| \___| \_| |_| .__/ \___|_|_|_| |_|\___||___/ | | agent v2.164.8 |_| (commit 99c93e1) >> 使用許諾契約書: TFVC リポジトリからソースを構築するには、Team Explorer Everywhere の使用許諾契約書に同意する必要があります。この手順は、Git リポジトリからソースを構築する場合は必要ありません。 Team Explorer Everywhere ライセンス契約のコピーはこちらでご確認いただけます: /home/hayashi_toshiki/myagent/externals/tee/license.html (Y/N) 今すぐ Team Explorer Everywhere ライセンス契約に同意しますか? を入力する (N の場合は、Enter キーを押します) >入力手順は次のとおりです。
Yを入力し、Enterキーを押します。- サーバーの URL を入力します。値は
https://dev.azure.com/{組織の名前}です。入力したらEnterキーを押します。- 認証の種類を入力します。パーソナルアクセストークンを使用するので、そのまま
Enterキーを押します。- エージェント プールを入力します。
Hosted Agent Poolと入力して、Enterキーを押します。- エージェント名を入力します。デフォルトを使用するので、そのまま
Enterキーを押します。- 作業フォルダを入力します。デフォルトを使用するので、そのまま
Enterキーを押します。サービスの登録
仮想マシンのエージェントが自動的に実行できるようにサービス(Daemon)として登録します。
サービスを登録するコマンドは次のとおりです。
cd ~/myagent sudo ./svc.sh install次に、コマンドを入力してサービスを起動します。
sudo ./svc.sh startこれで、仮想マシン上のエージェントのセットアップは完了しました。
なお、サービスの状態を取得するコマンドは次のとおりです。
sudo ./svc.sh status新しいパイプラインの作成
Azure Pipelines とセルフホストのエージェントがちゃんと関連付けできているかを検証するために、新しいパイプラインを作成します。
Azure DevOps で左ペインの
PipelinesよりBuildsをクリックします。
右ペインの
New pipelineをクリックします。
今回は Azure Repos のリポジトリを参照するので、
Azure Repos Gitをクリックします。
次に、リポジトリを選択するページが表示されます。任意のリポジトリを選んで下さい。
次に、
azure-pipelines.ymlを新規で作るか?あるいは既存のものを使用するか?について選択します。今回は、シンプルな YAML ファイルを作成するので、Starter pipelineを選択します。
最後に、YAML ファイルの編集ページが現れるので、以下のように編集して下さい。
# Starter pipeline # Start with a minimal pipeline that you can customize to build and deploy your code. # Add steps that build, run tests, deploy, and more: # https://aka.ms/yaml trigger: - master # ---------------------------------------------------- # ここで Agent Pool の名前を指定しているのが重要です。 # ---------------------------------------------------- pool: Hosted Agent Pool steps: - script: echo Hello, world! displayName: 'Run a one-line script' - script: | echo Add other tasks to build, test, and deploy your project. echo See https://aka.ms/yaml displayName: 'Run a multi-line script'
Save and runをクリックし、YAML を保存しパイプラインを実行します。
編集した YAML ファイルのコミットメッセージを入力するダイアログが表示されます。
このままSave and runをクリックします。
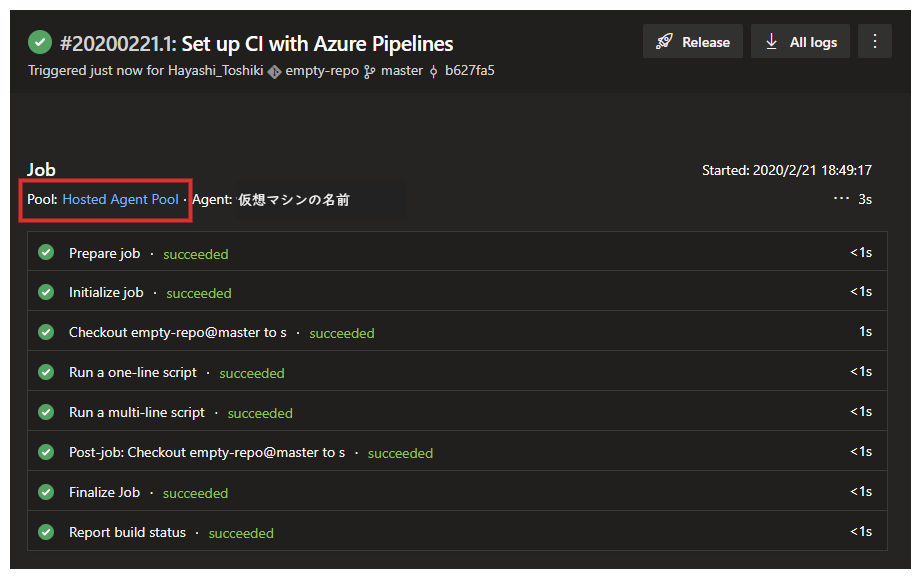
しばらくすると、Job が実行され、以下のようなページが表示され、Hosted Agent Pool でビルドが成功したことがわかります。
これで、セルフホスト環境のエージェントと Azure Pipelines が連携していることを確認できました。
最後に
今回は、セルフホスト環境でエージェントを設定し、自前のビルド環境を使用することについて説明しました。
本記事の説明を簡単にするため、以下のトピックには触れていません。
- Windows のセルフホスト環境
azure-pipelines.ymlの書き方- デプロイの方法
- テストの方法
- セットアップの自動化
それらについては、また機会がありましたら記事にしたいと思います。
Azure DevOps を試してみようと思っている皆様の、ご参考になれば幸いです。




- 投稿日:2020-02-21T17:51:06+09:00
初心者がLinuxでディスク追加をする(´・ω・`)
この記事について
対象
対象:IT初心者「しょぼん君」(´・ω・`)
▶︎ 初心者向け、イメージを掴むキッカケになることが目的の記事
▶︎ 砕いた理解で、一部正確ではない場合があります。
しょぼん君のぼやき
しょぼん君:(´・ω・`)『挿せばいいだけじゃないの』目次
- [Linuxでディスク追加をする]
ファイルシステムについて
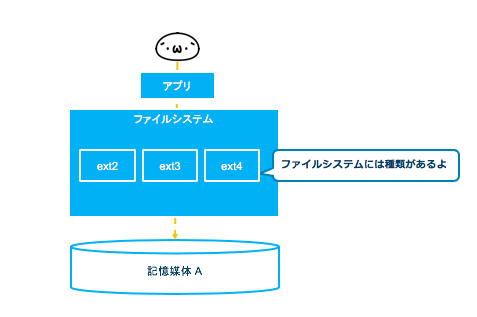
Linuxでディスクを追加するとは、大抵の場合ファイルシステムとして利用するという意味になるかと思います。ファイルシステムは、HDDなどの記憶媒体を効率的に管理して、ファイルとして利用するための手段を提供する基本的なOSのサービスの1つです。
しょぼん君:(´・ω・`)『データをファイルとしてい扱えるのは、ファイルシステムのおかげとな』
普段、ファイルシステムの種類について触れる機会はありませんが、Linuxだけでも「ext2,ext3,ext4,xfs...」などがあります。現在、Linuxでのデファクトスタンダードは、ext3の拡張である ext4 です。
ext4
最大ファイルサイズは16TiB, 最大ボリュームサイズは1EiB
日付範囲は、1901年12月14日から2514年4月25日まで
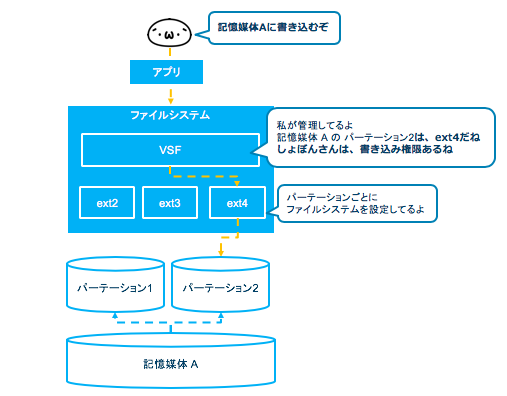
ファイルシステムでは、ベースとなるVFS(Virtual File System:仮想ファイルシステム)という仕組みで、記憶媒体のパーテーションをどのファイルシステムで管理しているのか判断してコントロールしています。また、バックグラウンドでのアクセス権確認や書き込み待ち判断などのファイル処理も行っています。
パーテーションは、物理的な記憶媒体の領域を論理的な領域に分割した中の1つの領域のことです。
しょぼん君:(´・ω・`)『パーテーションごとにファイルシステムで管理しているのかぁ』
ディスクの追加などで新たな記憶媒体をファイルシステムとして利用するには、パーテーションを割り当てて、フォーマットをする必要があります。
パーテーションの割り当て
パーテーションを割り振るために、追加した記憶媒体が認識されてデバイス名が割り振られていることを確認してみましょう。
Linuxでは、ハードディスクのデバイス名は、/dev/sd* のように認識されます。
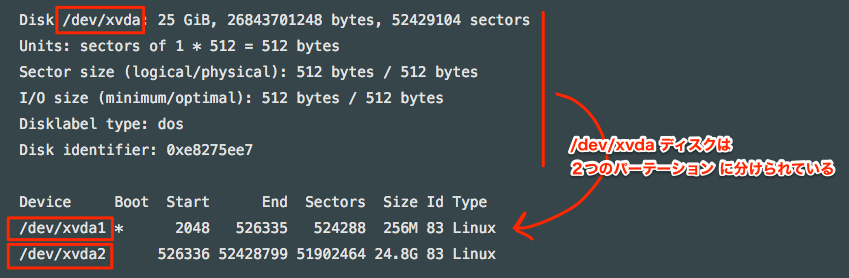
パーテーション情報の確認.$ sudo fdisk -l Disk /dev/xvdb: 2 GiB, 2147483648 bytes, 4194304 sectors Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disklabel type: dos Disk identifier: 0x00025cdb Device Boot Start End Sectors Size Id Type /dev/xvdb1 63 4192964 4192902 2G 82 Linux swap / Solaris Disk /dev/xvda: 25 GiB, 26843701248 bytes, 52429104 sectors Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disklabel type: dos Disk identifier: 0xe8275ee7 Device Boot Start End Sectors Size Id Type /dev/xvda1 * 2048 526335 524288 256M 83 Linux /dev/xvda2 526336 52428799 51902464 24.8G 83 Linux Disk /dev/xvdc: 100 GiB, 107374182400 bytes, 209715200 sectors Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytesファイルシステムとして利用されているディスクには、パーテーション情報が存在します。
/dev/xvda を例にすると、以下です。
これら情報がないディスクが今回追加したディスクになるため、上記の例では一番下の Disk /dev/xvdc が新たに認識されたディスクのデバイス名になります。追加したディスクサイズも合わせて参照し、同ディスクであることを確認しましょう。今回は100GBのディスクを追加しました。
現在利用しているディスクのデバイス名は以下コマンドでも確認出来ます。以下に含まれないことも確認したら良いかもしれませんね。
ディスクの空き領域確認.$ df -h新たに追加したディスクをファイルシステムとして利用するためには、まずパーテーションを設定する必要があります。
しょぼん君:(´・ω・`)『ファイルシステムはパーテーションごとだからだね』
パーテーションの作成は以下コマンドから対話型で設定します。
パーテーションの作成.$ sudo fdisk /dev/xvdc ### 以下が表示されたタイミングでキーを入力。どんなキーがあるかは m でhelpが見られる Command (m for help):m Help: DOS (MBR) a toggle a bootable flag b edit nested BSD disklabel c toggle the dos compatibility flag Generic d delete a partition l list known partition types n add a new partition p print the partition table t change a partition type v verify the partition table Misc m print this menu u change display/entry units x extra functionality (experts only) Save & Exit w write table to disk and exit q quit without saving changes Create a new label g create a new empty GPT partition table G create a new empty SGI (IRIX) partition table o create a new empty DOS partition table s create a new empty Sun partition table ### 設定前のパーテーション情報を表示 Command (m for help): p Disk /dev/xvdc: 100 GiB, 107374182400 bytes, 209715200 sectors Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disklabel type: dos Disk identifier: 0x144852f7 ### パーテーションの作成( n add a new partition ) Command (m for help): n Partition type p primary (0 primary, 0 extended, 4 free) e extended (container for logical partitions) ### パーテーションのタイプを選択(今回はデフォルトのpromary) Select (default p): p ###パーテーションの数を選択(デフォルトのままEnter) Partition number (1-4, default 1): ###サイズの設定(デフォルトのままEnter) First sector (2048-209715199, default 2048): Last sector, +sectors or +size{K,M,G,T,P} (2048-209715199, default 209715199): ### パーテーション情報を確認 Command (m for help): p Disk /dev/xvdc: 100 GiB, 107374182400 bytes, 209715200 sectors Units: sectors of 1 * 512 = 512 bytes Sector size (logical/physical): 512 bytes / 512 bytes I/O size (minimum/optimal): 512 bytes / 512 bytes Disklabel type: dos Disk identifier: 0x144852f7 Device Boot Start End Sectors Size Id Type /dev/xvdc1 209715199 209715199 1 512B 83 Linux ### 終了 Command (m for help): qこれで追加ディスクを、1つの領域で利用するパーテーションを作成出来ました。
フォーマット(論理)
続いて、フォーマットを行ってパーティション上にファイルシステムを適用します。これを論理フォーマットと言います。記憶媒体を記憶媒体として利用するためのフォーマットを物理フォーマットと言いますが、これとは異なります。
論理フォーマットではデータを消すのではなくファイルシステムの管理情報を書き直します。
論理フォーマット.$ mkfs -t ext4 /dev/xvdc1しょぼん君:(´・ω・`)『追加したディスクをファイルシステムとして利用する準備が出来た訳だね。』
マウント
実際にファイルシステムとして利用するためには、作成したパーテーションをマウントする必要があります。
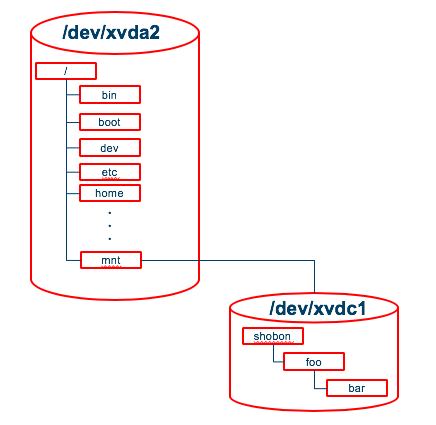
Linux は、/ (ルート) ディレクトリを頂点としたツリー構造のディレクトリ構成をしていますが、マウントとは、基本的にはファイルシステムとして利用可能なパーテーションを / ディレクトリの一部となるようにすることを言います。
イメージが湧きづらいかと思うので図にしてみました。
例えば、/mntに今回追加したディスクをマウントするイメージは以下です。
マウントのコマンドは以下です。
一時マウントでマウント可能か確認し、永続マウントの設定をしてみました。一時マウント.$ sudo mount /dev/xvdc1 /mnt --types=ext4 --option=rwマウントの確認.$ df -hTしょぼん君:(´・ω・`)『ファイルシステムとして追加ディスクが使えるようになった!』
再起動されてもマウントされるように /etc/fstab に追記をします。
永続マウント.$ sudo vi /etc/fstab ### 以下を追記 /dev/xvdc1 /mnt ext4 defaults 0 0fstabの書き方の例
しょぼん君:(´・ω・`)『今まで意識していなかったけど、今後は今どこのパーテーションを使ってるのか意識出来そうな気がする』
END

- 投稿日:2020-02-21T17:04:05+09:00
【黒い画面恐怖症向け】Linuxとかシェルとかざっくり知りたいのでゆるく図解した
はじめに
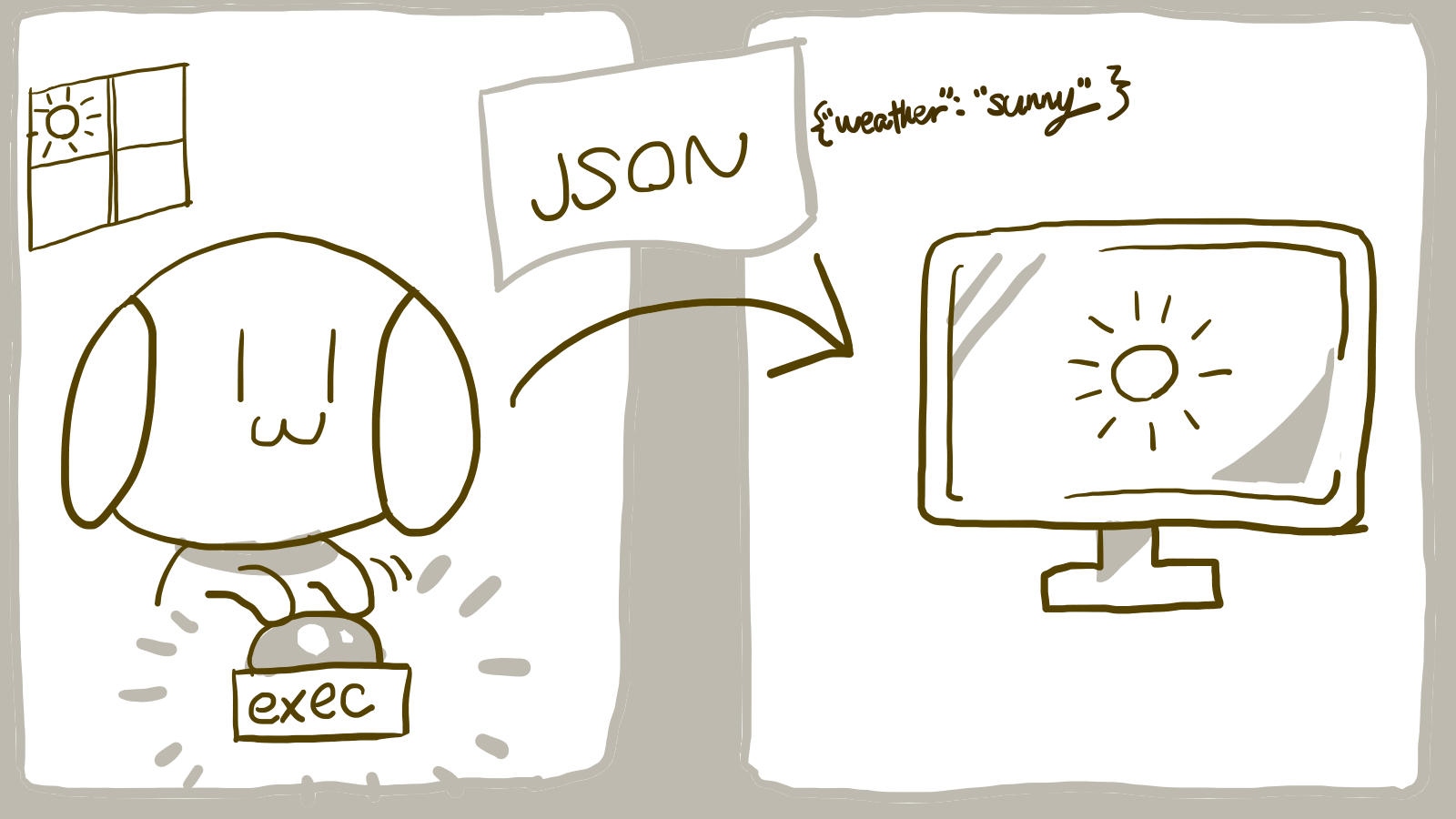
今回作成したいのはこんなファイルです。
「実行されるとアプリサーバーにJSONを送るだけのバッチ」です。
curlコマンド使うといいよ!とのことだったのですが、自分はcurlコマンドはおろか、バッチ(→シェルファイル)を作るのも初めてだったので、シェルやLinuxコマンドの触りの部分を勉強しました。
今までHTMLやCSS、ちょこっとJavaを触っていた人間なので、Linuxコマンドは超初心者です!
勝手が違っていろいろびっくりしたので、備忘録としてまとめておきます。ログディレクトリを無邪気に
-rm -rして以来黒い画面は死ぬほど苦手なのですが、バッチ作ったら少しだけ和解できた気がしないでもないので、黒い画面に親を殺された・村を焼かれた皆さんの理解の一助になれれば幸いです。この記事では、カーネルやシェルと聞いてもピンとこない人類向けに、ざっくり下記内容を説明します。
- Linuxカーネル
- シェル
- シェルスクリプト
- バッチとシェル
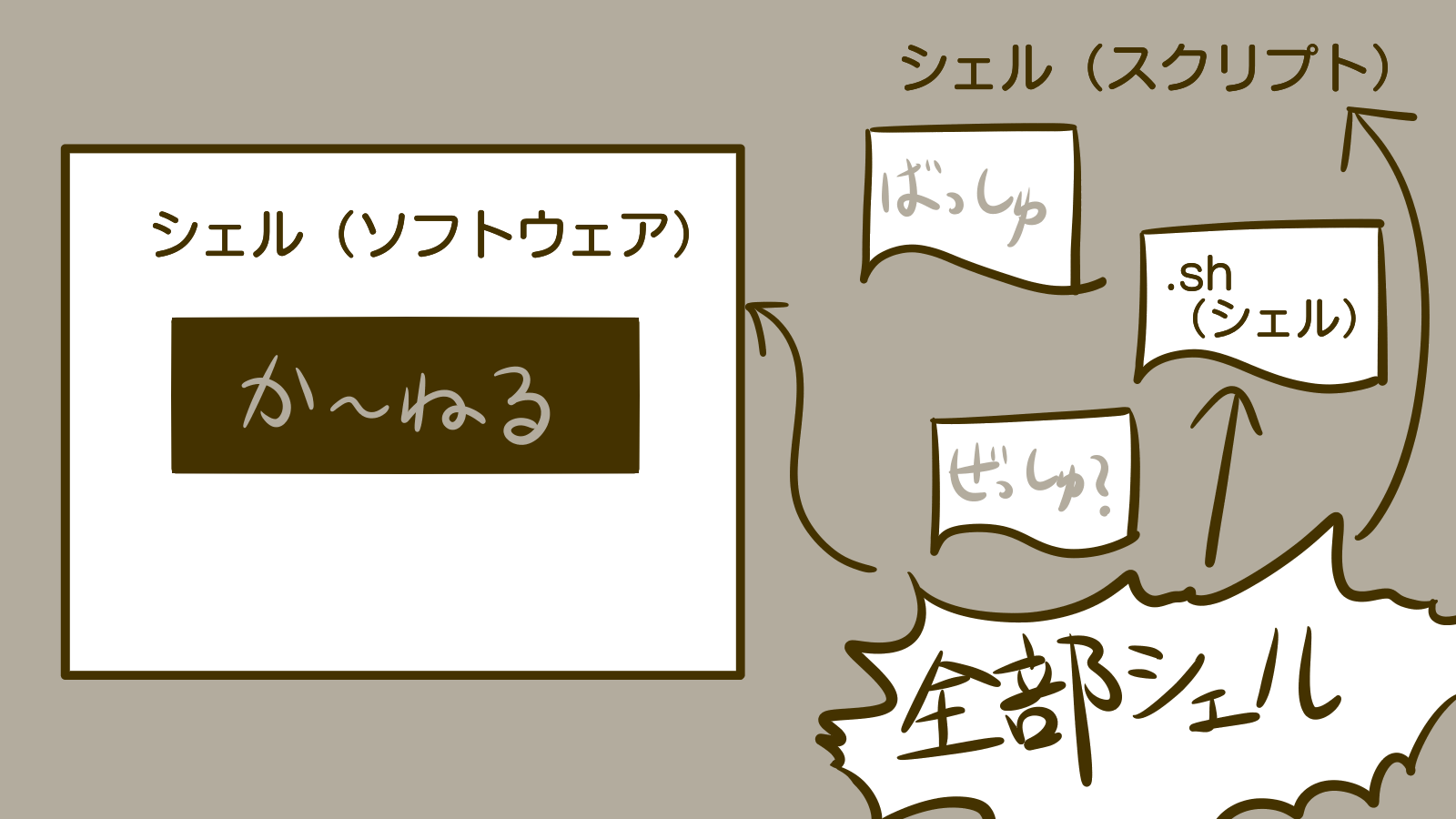
シェルを学ぶ前に : カーネルとシェルとは?
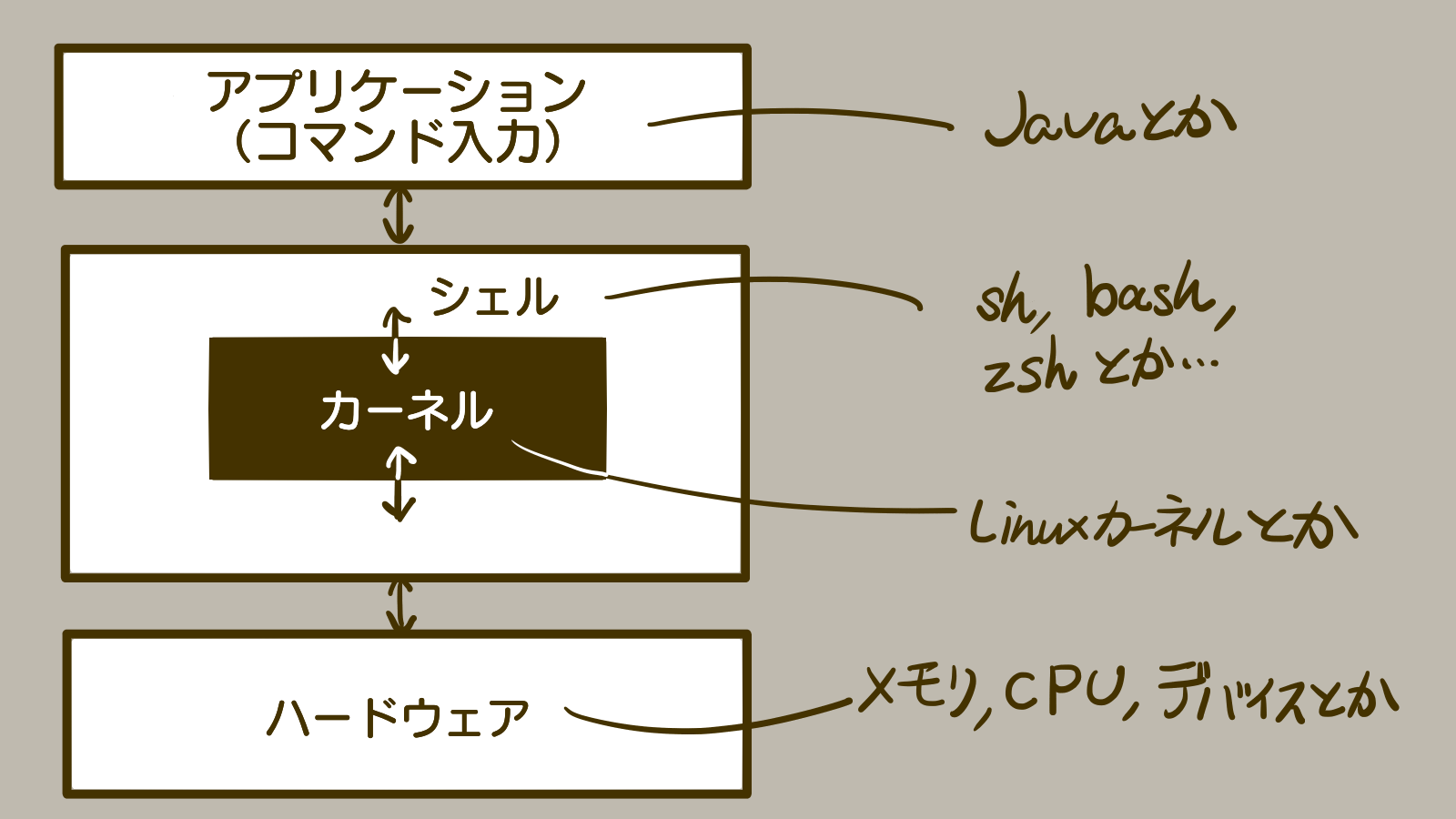
シェルとは、Linuxカーネルのインターフェースとなっているソフトウェアのことです。
…Linuxカーネル?
==========
→「Linuxカーネル? CPUなどのハードウェア管理やコマンド実行などのプロセス管理をする、LinuxOSの核の部分でしょ?」と思った人はAを読む。
→「Linuxカーネル? 何それさんだーす?」と思った人はBを読む。
==========
A:Linuxカーネルのことなんか分かってるよ!という人はこの先3000文字を読む時間がもったいないので、ブラウザバックするか、コメ欄に美味しいラーメン屋の情報でも書いておいてください!
B:ぜひこの記事を読んで一緒に勉強しましょう!!!!
==========
再掲になりますがLinuxカーネルは、CPUなどのハードウェア管理やコマンド実行などのプロセス管理をする、LinuxOSの核の部分です。
(Linux以外のOSにもカーネルやシェルはあると思いますが、今回はLinuxOSの本を読んだのでLinux前提で話します…!)
Linuxカーネルは直接コマンド入力で操作できるものではありません。コマンド実行や入出力先の指定などのユーザーインターフェースとしてシェルが存在するのです。
例えばmacOSのターミナル(黒い画面)を開くと、デフォルトで以下のような文言が表示されています。
Last login: Sun Feb 16 15:49:26 on hogehoge hoge@localhost ~ %これは、シェルが表示しているプロンプトです。シェルというソフトウェアがコマンド入力を待っている状態になっています。
(上記はmacOS Catalinaを使用しました。デフォルトシェルはzshです。
プロンプト表示はbashの場合~ $だったり、ユーザー名ホスト名の部分は端末によって異なります)シェルスクリプトとは?
macOSのターミナルや、フリーの端末エミュレータ(Tera Termなど)の「黒い画面」を用いると、コマンドラインから直接シェルに指示を与えることができます(対話型操作、インタラクティブ操作)。
一方、多くのプログラミング言語同様、シェルコマンドもあらかじめファイルに記述しておいて、そのファイルをシェルが読み込むことで起動する、という使い方もできます。そのように用意しておいたファイルをシェルスクリプトといいます。
先ほどの図に例示したように、シェルにはsh, bash, csh, dash, zshなど様々な種類があります。
『新しいLinuxの教科書』では、現在シェルスクリプトとして用いられるのは主にshかbashですが、以下の理由からbashがおすすめとのことです。
- shはLinuxのディストリビューション1ごとに実装が微妙に違う
- shは古くからあるため、シェルスクリプトを書くうえで必須機能が少ない
- 1の足し算でさえ外部コマンドexprを使用する必要がある
また、今回使用したいcurlコマンドも、shだとevalコマンドを挟む必要があるようです。もどかしいので、手軽に始めるならbashの方がいいんじゃないかなと思います!
バッチとシェル
すっかりシェルシェル言っておりますが、
「そういえば自分、冒頭で「バッチ」作った言うたやないか。バッチどこ行ったんや? バッチとシェルは同じものなんか?」
と心の中の誰かからツッコミが入りました。そういえば、自分も「バッチ」を作ってくれ、と言われましたが、実際に作ったのはシェル(bashを用いたシェルスクリプト)だったので、はて?となりました。
ここまで見てきたところ、「シェル」には以下のような意味がありました。
- カーネルを包むインターフェースソフトウェア
- シェルスクリプトの省略形(shとかbashとかzshとかの総称)
- シェルの種類の一つである「sh」(省略せずにいうとBourne Shellというそうです)
同じように、「バッチ」にも様々な意味があります。
1. バッチ処理
コンピュータで1つの流れのプログラム群(ジョブ)を順次に実行すること。
あらかじめ定めた処理を一度に行うことを示すコンピュータ用語。
反対語は対話処理・インタラクティブ処理またはリアルタイム処理。
バッチ処理 - Wikipedia先ほど出てきた、「「黒い画面」から直接シェルにコマンドを打ち込む」行為は対話型操作だったのに対し、バッチ処理はあらかじめ定めた処理を一度に行うことを指します。
つまり、シェルスクリプトをあらかじめ定められた条件で起動させ処理を行うことも、「バッチ処理」です。
(あくまで図はイメージです。普通はバラバラの拡張子でジョブ作らないんじゃないかな…)
2. バッチファイル
MS-DOS、OS/2、Windowsでのコマンドプロンプト(シェル)に実行させたい命令列をテキストファイルに記述したもの。
バッチファイル - Wikipediaこれは機能としてはシェルスクリプトにそっくりですね。スクリプト言語としては仲間ですが、バッチファイル≠シェルスクリプトファイルです。
例として、ごくごく単純なHello Worldで見比べてみましょう。バッチファイルのHello World
@echo off echo Hello World pause > nulシェルスクリプト(bash)のHello World
#!/bin/bash echo "Hello World" exit 0echoコマンドなど、いくつか類似のコマンドはありますが、基本的に別形式の言語であることが分かりますね。
自分もコマンドプロンプトでlsしてキィィってなること、よくあります。超簡単に見分ける方法としては、拡張子が違います。
- バッチファイル:.bat
- シェルスクリプトファイル:.sh
ね?簡単でしょ?(これ以上詳しく聞かないでください泣いてしまいます、の意)
おわりに
o(・_・ = ・_・)o < アレ〜?curlコマンドどこ〜?
本当はこの後、よく使うLinuxコマンドを説明して、curlコマンドを説明して、オプションをいくつか説明して、実際に作ってみてハマったところの紹介…と行きたかったのですが、
既にここまでで文字数がだいぶ増えてしまったので、今回はここまでとします!
これでもUNIXとかディストリビューションとかだいぶ端折って書いたので、興味がある人はリンク先に飛んでみるなどしてみてください!
お読みいただきありがとうございました。
ここでは詳しく説明しませんが、Linuxのパッケージのことです。Linuxカーネルの他に、最初から使えるコマンド群やアプリケーションなどが同梱されており、それぞれ少しずつ異なります。同じ漫画を買っても、購入店舗によって特典でついてくるポストカードやシールやフィギュアなどが少しずつ異なる…というイメージでしょうか? よく聞く具体名は、UbuntuやCentOSなど。 ↩

- 投稿日:2020-02-21T15:36:37+09:00
[RHEL7/CentOS7] yumコマンドでPerlをインストールした環境でLWP実行エラー
エラーが発生
yumコマンドでPerlをインストールした環境でLWPの実行エラーが発生する。
※LWP は Library for WWW in Perl の略で、PerlからWebアクセスを実現するライブラリHTTPの場合
$ perl test.pl 501 Attempt to reload IO/Socket.pm aborted. Compilation failed in requireHTTPSの場合
$ perl test.pl LWP will support https URLs if the LWP::Protocol::https module is installed.該当Perlスクリプト
test.pl#!/usr/bin/perl use LWP::UserAgent; my $url = "https://www.example.com"; my $request = HTTP::Request->new(GET => $url); my $useragent = LWP::UserAgent->new; my $response = $useragent->request($request); my $result = $response->content; print $result;原因と対策
yum コマンドは Perl のライブラリの依存関係チェックが不十分のようで、必要なライブラリが不足することがあり、個別にインストールする必要があるようです。
今回は下記のパッケージをインストールすることで解決できたが、実行エラー出力に不足なライブラリを示す情報がなかったため perl- の名前が付く中で関係ありそうなパッケージを勘で入れてみるという試行錯誤を繰り返した。
※Socket は不要かもしれない$ sudo yum install perl-Socket $ sudo yum install perl-NetAddr-IP事前に構築していたPerl環境
LWP のインストールは行っているのだが…
$ sudo yum install perl $ sudo yum install perl-Net-SSLeay $ sudo yum install perl-Crypt-SSLeay $ sudo yum install perl-IO-Socket-SSL $ sudo yum install perl-IO-stringy $ sudo yum install perl-URI $ sudo yum install perl-LWP-Protocol-https
- 投稿日:2020-02-21T15:21:08+09:00
システム運用改善業務への三歩目
はじめに
- 前回、可視化 / モニタリング / 標準化/リファクタリングのタスク(案)を列挙したところまで整理しました。
- 今回は、
モニタリングにフォーカスした内容を書きます。
- 弊社が利用しているアーキテクチャの情報が載っていますが、適宜ご自分の環境に読み替えていただけますと幸いです
前提条件
- 弊社では、業務管理のツールとして、
Atlassian社のJIRA Softwareを利用している。
- システムのモニタリングはDatadog、コミュニケーションツールはslackを利用
- 弊社ではm
作業というくくりで、以下を包括する。
- 依頼作業
- インシデント対応
- 課題対応
- セキュリティ対応
- 業務改善
弊社における作業の流れ
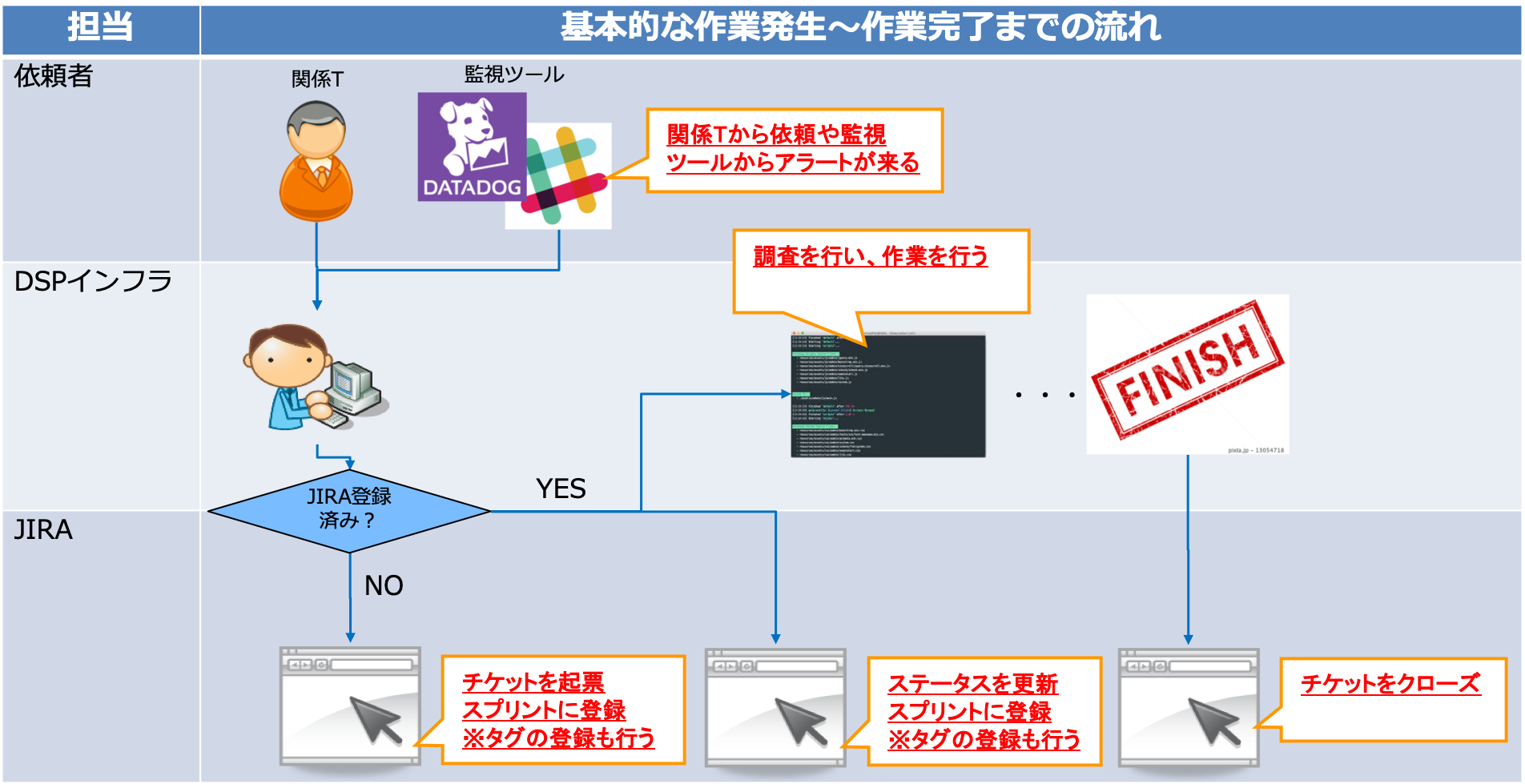
- 基本的な作業発生から作業完了までの流れは以下の図の通り。
モニタリングの一例
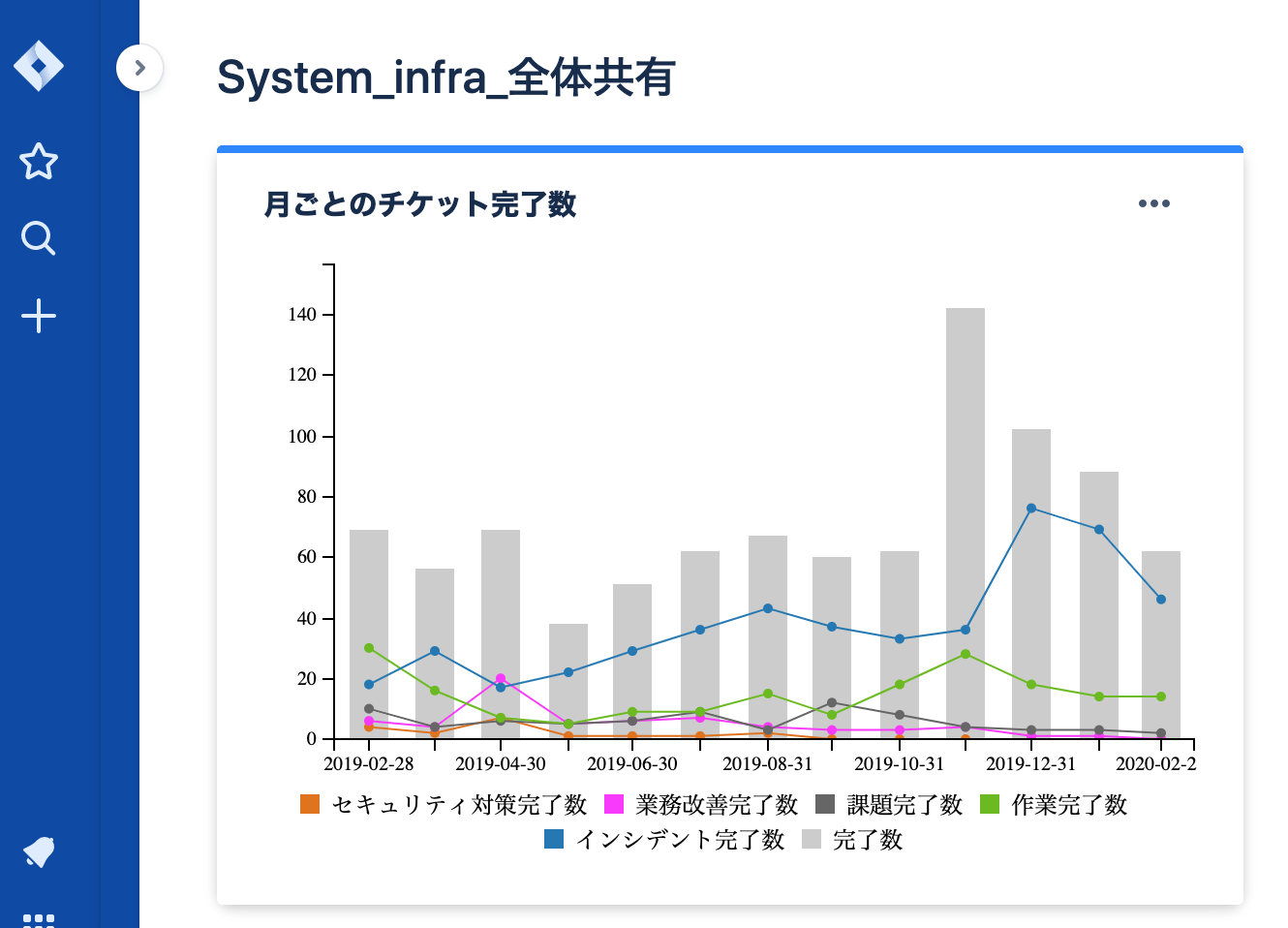
JIRAのダッシュボード機能を用いて、月単位の各作業区分におけるチケット数を集計し、トレンドを把握する。
- 上記の例で言うと、例えば以下を読み取ることができる。
- 2019年12月のインシデント数が急激に増えている
- 調査したところ、
Hadoopクラスタの停止が12月に頻発していた- 2020年に入ってからはインシデント数が減少傾向にある
- 長期休暇の前後は依頼作業が増える傾向にある
- 多角的に数値分析を可能にするために各作業区分に対応した
フィルターを用意する。
- ステータスで分類する
- 完了
- 着手中
- 未着手
- 未解決
苦労・工夫した点
- 業務内容を全てJIRAチケット化するという文化を根付かせることからスタート。
- 過去はslackに依頼事項やインシデント情報が書かれるのみで、集計や分析ができる状態ではなかった
- このままでは
誰が何をしているのか?が可視化・共有できておらず、課題と捉えて改善を実施- ダッシュボードのモニタリングのみでは課題・懸案を吸い上げることができない。
- 週次でJIRAチケットの状況を確認する会議体を設け、チケットベースでの進捗や課題・懸案事項を吸い上げる場を設定している
- Datadogが通知するアラートをトリガーにJIRAチケット起票を自動化した。
- インシデントの集計・分析ができないとプロアクティブな対策が取れず、ナレッジも残っていなかった
- 設定等は別で整理します

- 投稿日:2020-02-21T13:26:26+09:00
Linuxの演習用環境を手軽に準備する方法のメモ
Linuxコマンドを叩いたことのない人向けに、Linuxコマンドの演習用環境を用意した時のメモ
主な要件と状況
・手軽に用意したい
・別途費用が発生して欲しくない(純粋なマシン利用料含め、準備にかかるコスト)
・手元にあるLinuxマシンが1台だけ使える
常用しているマシンのため荒らして欲しくない結論
DockerコンテナでLinux環境を用意することで、一部の特権的操作を除き作業できる環境を用意する。
下記のようなdocker-composeファイルを作り、centosを使用できるコンテナを用意する。
centos/tools:latestイメージは、centosに基本的なツールを入れてあるイメージです。
普通のcentosイメージの場合、minimalな状態のため別途ツールを入れる必要があるため、こちらを利用する。
※ただ、このイメージを使ってもnetstatなどのコマンドが入らないため別途精査する必要はある。docker-compose.ymlservices: cent: image: centos/tools:latest container_name: cent tty: trueあとは適当なLinuxユーザを作成して、dockerグループへ所属させる。
あとはコンテナへアクセスするためのdocker execコマンドを叩いてもらうだけ。docker グループを明け渡すことも若干抵抗があるので、コンテナのsshポートを開けて接続してもらう方がいいかもしれない。
特権が必要なコマンドを実行する方法(未調査)
下記のようにprivilegedや/sbin/initなどを使うことで特権コマンドも使えるようになるっぽい。
今回のケースでは、ホストマシン側の影響を少なくしたかったので使用は避けたが、どうでもいいマシンならこの方法を取りたい。
docker run -it -d --privileged --name centos7 centos:7 /sbin/init
- 投稿日:2020-02-21T02:50:06+09:00
Windows→linux データ持ち込みの勘所
はじめに
一般人がWindowsマシン上でエクセルやらワードやらで作ったファイルをもらって、linux上で情報処理を行うシチュエーションは少なからずあるだろう。その際に必要となるであろうデータ変換手順の基本的なところをまとめてみた。
日本語名ファイルをwindowsからlinuxに持ってくる
ここで日本語名ファイルとは、いわゆる全角文字がファイル名に使われているファイルのことである。
windows環境下で作ったzipファイルをLinux環境下で展開
unzip -O cp932 日本語名ファイルを含むアーカイブ.zipcp932とは、シフトJISにmicrosoftによって拡張が施された文字コード規格である。
参考:
本当は怖くないCP932シフトJISで書かれたファイル名をUTF-8に変換
convmv -f cp932 -t utf-8 * --notestubuntuの場合
convmvコマンドはデフォルトでは導入されていないので、事前にapt install convmvしておく必要がある。日本語名のファイルがzipからlinux上で「標準的な」手順で展開されてしまうと、不適切に文字化けした状態でUTF-8化されてしまうようで、そのあとでconvmvしようとしても「処理済み」と素気無く断られてしまう。あきらめて元zipファイルから上記手順で展開をやり直すしかない。
文字コードと改行を変換する(シフトjis→UTF-8およびCRLF→LF)
シフトjisのテキストをUTF-8に変換し、さらに改行コードをwindowsの標準であるCR/LFからLFに変換し、結果を新しいファイルに書き出す。
iconv -f cp932 -t utf-8 対象ファイル名 | sed 's/\r//g' > 出力先ファイル名カレントディレクトリ中の全ファイルを一度に処理する方法も考えてみた。変換後の内容はサブディレクトリ
utf8に同名のファイルを作って書き出すことにしよう。bashのループ処理を利用する。#!/bin/bash [ -d utf8 ] || mkdir utf8 for a in * do iconv -f cp932 -t utf-8 $a | sed 's/\r//g' > utf8/$a done