- 投稿日:2020-02-21T23:54:52+09:00
機械学習で画像の高画質化を試みる(備忘録)- Python3
1.はじめに
最近、Twitterで「謎の技術で高画質化された画像」なるものがタイムラインにいくつか流れてきて興味が湧いたので、機械学習の勉強がてら画像の高画質化の方法を僕のように「理屈無しで手っ取り早く機械学習に触れたい!」という人に向けて備忘録としてここに残しておくことにしました。
謎の技術でこれを高画質にするのは草 pic.twitter.com/HeBB7J8Q7D
— koboのようなもの (@cinnamon_kobot) February 14, 2020
謎の解像度をあげる技術で僕らのぼっさんが高解像度に!!! pic.twitter.com/cjB0MM8Oqu
— ろありす (@roaris) February 15, 20202.実行環境の構築
今回、この手の機械学習でよく用いられる「pix2pix」を使用しました。pix2pixはGANを用いた画像生成アルゴリズムで、2枚の対になった画像から相互間の関係を学習し、1枚の元画像に対して学習結果に基づいて画像を生成することができます。pix2pixはPyTorchやKerasなどのライブラリを用いて実行することができますが、今回はtensorflowを用いた実行環境を構築しました。
以下に僕が今回使用したライブラリなどをリスト化しておきます。・Python 3.7.6
・pix2pix-tensorflow [https://github.com/affinelayer/pix2pix-tensorflow]
・tensorflow 1.14.0(最新バージョンだと実行できないので注意)
・OpenCV 4.2.0.32tensorflowの最新バージョンは現時点で2.1.0ですが、このバージョンでは実行できないので、pipでインストールする際に以下のようにバージョンを指定します。
pip install tensorflow==1.14.0OpenCVはpix2pixの実行とは直接関係しないのですが、後述の学習データの作成で使用します。今の所最新バージョンで問題なさそうですが、もし実行できないのであれば同じようにバージョンを指定してインストールを行ってください。
3.学習データの作成
pix2pixには予め学習用データセットが用意されていますが、今回の目的は画像の高画質化なので、それに適した学習データを自作することにします。
前述したとおり、pix2pixは以下のような2枚の対になった画像を繋げて1枚にしたものを学習データとして用います。(256px × 256pxを2枚繋げた512px × 256pxの画像)
この画像を作成するためには
1. 大きな画像を256px × 256pxに切り分ける
2. 切り分けたそれぞれの画像にぼかしを入れる
3. 切り分けた画像とぼかしを入れた画像を結合する
の3つの処理を行う必要があります。そのためのコード(pix2pix_util.py)を作成したのでコピペして使用してください。
※追記にこの3つの処理を一気にやってくれるコードを載せていますpix2pix_util.pyimport cv2 import numpy as np from argparse import ArgumentParser import glob import os if __name__ == "__main__": arg = ArgumentParser() arg.add_argument('-md', '--mode', help='select mode [split|blur|margin]', required=True) arg.add_argument('-id', '--inputdir', help='select input directory', required=True) arg.add_argument('-id2', '--inputdir2', help='select second input directory(margin)') arg.add_argument('-od', '--outputdir', help='select output directory', required=True) args = arg.parse_args() #画像を切り分ける if args.mode == "split": os.makedirs(args.outputdir, exist_ok=True) #アウトプット先が存在しなければ作成 if os.path.exists(args.inputdir) == True: files = glob.glob(args.inputdir+"\\*") #ファイル一覧をリスト形式で返す print("SPLIT: Processing...") for i in files: file_name = os.path.basename(i) #この関数でファイル名部分だけを返すことができる img = cv2.imread(i) #画像の読み込み if type(img) == np.ndarray: #OpenCVは画像をnumpy.ndarrayの型で読み込んでいるのでこの条件文 height, width = img.shape[:2] for j in range(int(height / 256)): for k in range(int(width / 256)): splited_image = img[256 * j : 256 * j + 256, 256 * k : 256 * k + 256] cv2.imwrite("{0}\\{1}_{2}_{3}.jpg".format(args.outputdir, file_name[:-4], str(j), str(k)), splited_image) #画像の書き出し else: print("ERROR: {0} is not supported type".format(file_name)) #ファイルが画像じゃなかった場合のエラー print("SPLIT: Completed") #完了のメッセージ else: print("ERROR: No such directory \"{0}\"".format(args.inputdir)) #インプットディレクトリが存在しない場合のエラー #画像をぼかす elif args.mode == "blur": os.makedirs(args.outputdir, exist_ok=True) if os.path.exists(args.inputdir) == True: files = glob.glob(args.inputdir+"\\*") print("BLUR: Processing...") for i in files: file_name = os.path.basename(i) img = cv2.imread(i) if type(img) == np.ndarray: blur_image = cv2.blur(img, (10, 10)) #OpenCVのBlur関数 cv2.imwrite(args.outputdir+"\\"+file_name, blur_image) else: print("ERROR: {0} is not supported type".format(file_name)) print("BLUR: Completed") else: print("ERROR: No such directory \"{0}\"".format(args.inputdir)) #画像を繋げる elif args.mode == "margin": if args.inputdir2 != None: os.makedirs(args.outputdir, exist_ok=True) if os.path.exists(args.inputdir) == True and os.path.exists(args.inputdir2) == True: files1 = glob.glob(args.inputdir+"\\*") files2 = glob.glob(args.inputdir2+"\\*") print("MARGIN: Processing...") for i in files1: file_name = os.path.basename(i) if args.inputdir2+"\\"+file_name in files2: image_1, image_2 = cv2.imread(i), cv2.imread(args.inputdir2+"\\"+file_name) if type(image_1) == np.ndarray and type(image_2) == np.ndarray: margined_image = cv2.hconcat([image_1, image_2]) #OpenCVの画像結合関数 cv2.imwrite(args.outputdir+"\\"+file_name, margined_image) else: print("ERROR: {0} is not supported type".format(file_name)) else: print("ERROR: \"{0}\" is not in \"{1}\"".format(file_name, args.outputdir)) print("MARGIN: Completed") else: print("ERROR: No such directory \"{0}\" or \"{1}\"".format(args.inputdir, args.inputdir2)) else: print("ERROR: Select second inputdir (-id2/--inputdir2)") else: print("ERROR: Select a mode from \"split\", \"blur\", \"margin\"")使用方法
pix2pix_util.pyはコマンドライン上で実行します。
まず、大きな画像を切り分ける(ここで切り分ける画像は幅、高さともに256px以上である必要があります。また、形式はOpenCVが対応している形式なら問題ないと思いますが、ファイル名に日本語が入っているとエラーが発生するようです。)
$ python pix2pix_util.py --mode "split" --inputdir <切り分けたい画像があるディレクトリ> --outputdir <切り分けた画像の保存先>次に、切り分けられた画像にぼかしを入れる
$ python pix2pix_util.py --mode "blur" --inputdir <切り分けた画像があるディレクトリ> --outputdir <ぼかしを入れた画像の保存先>最後に、切り分けられた画像とそれにぼかしを入れた画像を結合する
$ python pix2pix_util.py --mode "margin" --inputdir <切り分けた画像があるディレクトリ> --inputdir2 <ぼかしを入れた画像があるディレクトリ> --outputdir <切り分けた画像の保存先>この結合された画像を用いて学習を行いますが、学習後に学習結果のテストも行うため、学習データとテストデータを2つのフォルダにに分けておきましょう。(一応pix2pix-tensorflow内にあるsplit.pyで同じことができますが、手動でも問題ないと思います。)
4.実際に学習してみる
pix2pix-tensorflowの中に「pix2pix.py」というファイルがあり、これを実行することによって学習やテストを行うことができます。学習を行うにはコマンドライン上で以下のコマンドを実行します。
$ python pix2pix.py --mode train --output_dir <学習結果の保存先> --max_epochs <最大の世代数> --input_dir <学習データがあるディレクトリ> --which_direction BtoAmax_epochsで最大の世代を指定することができますが、あまりこの値が大きすぎると(GPUを搭載していないパソコンでは特に)膨大な時間を要するので、この値を小さくするか、学習データを減らす必要があります。ここはそれぞれの環境によってうまく調節しましょう。
学習が終了したら学習で使用した画像とは別の画像(テストデータ)を用いて学習結果のテストを行います。
$ python pix2pix.py --mode test --output_dir <生成データの保存先> --input_dir <テストデータがあるディレクトリ> --checkpoint <学習結果のディレクトリ>output_dirで指定したディレクトリに生成されたデータが保存されます。checkpointでは学習時に指定した学習結果を保存したディレクトリを指定してください。
5.学習結果を見てみる
500枚の学習データを第5世代まで学習させた結果です。(左からぼかし画像、生成画像、元画像)
パソコンの性能と時間の都合上それほど学習量は多くありませんが、それでもぼかし画像と比べて輪郭がくっきりしているのが確認できます。学習データの数や世代数をもっと大きくすればさらに良い結果を期待できると思われます。6.まとめ
今回はpix2pixを用いて機械学習によって画像の高画質化を試みました。自分自身、機械学習に実際に触れるのは初めてだったので、どんなものなのかと試行錯誤しながらこのテーマに望みましたが、改めて機械学習の潜在能力の高さに感銘を受けました。
(Qiitaでの投稿も初めてだが上手くできただろうか...)追記
学習データ作成で3つの処理を行ったが、「手っ取り早く」という点でこのコードは向いていないと思い、先ほど作成したpix2pix_util.pyを改変しました。これで1回のコマンド実行で一気に学習データの画像まで作成してくれます。容量も圧迫するのでね...
pix2pix_util.pyimport cv2 import numpy as np from argparse import ArgumentParser import glob import os if __name__ == "__main__": arg = ArgumentParser() arg.add_argument('-id', '--inputdir', help='select input directory', required=True) arg.add_argument('-od', '--outputdir', help='select output directory', required=True) args = arg.parse_args() os.makedirs(args.outputdir, exist_ok=True) #アウトプット先が存在しなければ作成 if os.path.exists(args.inputdir) == True: files = glob.glob(args.inputdir+"\\*") #ファイル一覧をリスト形式で返す print("PIX2PIX_UTIL: Processing...") for i in files: file_name = os.path.basename(i) #この関数でファイル名部分だけを返すことができる img = cv2.imread(i) #画像の読み込み if type(img) == np.ndarray: #OpenCVは画像をnumpy.ndarrayの型で読み込んでいるのでこの条件文 height, width = img.shape[:2] for j in range(int(height / 256)): for k in range(int(width / 256)): splited_image = img[256 * j : 256 * j + 256, 256 * k : 256 * k + 256] blurred_image = cv2.blur(splited_image, (10, 10)) margined_image = cv2.hconcat([splited_image, blurred_image]) #OpenCVの画像結合関数 cv2.imwrite("{0}\\{1}_{2}_{3}.jpg".format(args.outputdir, file_name[:-4], str(j), str(k)), margined_image) #画像の書き出し else: print("ERROR: {0} is not supported type".format(file_name)) #ファイルが画像じゃなかった場合のエラー print("PIX2PIX_UTIL: Completed") #完了のメッセージ else: print("ERROR: No such directory \"{0}\"".format(args.inputdir)) #インプットディレクトリが存在しない場合のエラー$ python pix2pix_util.py -id <画像があるディレクトリ> -od <保存先>前と同じく、元画像は幅、高さともに256px以上のファイル名は半角英数字でお願いします。



- 投稿日:2020-02-21T23:35:21+09:00
東京都内病院の緯度経度データ約200件
東京都内病院200件ほどのjsonおよびTSVのデータです。
対象病院(日本病院会リスト):
http://www.hospital.or.jp/shibu_kaiin/?sw=13&sk=1JSONおよびtsvデータ:
https://github.com/HirotakaAseishi/tokyo_hospitalgeodata/tree/masterリストに関して、都内は病院600件のようですが、取り急ぎ病院会のリストにある200件についてwww.geocoding.jpから手作業で緯度経度をまとめてます。病院会のリストは、地理的なばらつきがあり、公立は少なくともありそうでしたので一旦これで十分だと思いここに投稿しています。
***
現在、都内でコロナウイルスの流行が顕在化している状態です。
あらゆるケースにおいて、医療機関(および医療従事者)は重要ですので、
d3.jsなどで各種データと重ねられるように取り急ぎ上記の緯度経度を調べました。現在都内において新型コロナウイルスが流行していますが、2週間前の感染データばかりが集まっても現時点での全体像は見えませんし、頻度論の流儀で証明を待っていても遅すぎます。
各医療機関の要望に沿った検査が実行できれば、現時点に近い状態が見えてくると思います。ランダムサンプリングではありませんが、全体像を見渡すのに効率的だと思います。また、致死率の高い医療従事者や患者を守ることにもなります。
検査が出来なくても各種間接的でもっと不確かなデータの収集は様々な形で可能だと思います。
[ { "id": 1, "type": "独立行政法人国立病院機構", "name": "東京医療センター", "url": "http://www.ntmc.go.jp/", "beds": 741, "address": "目黒区東が丘2-5-1", "lat": 35.626448, "lon": 139.666459 }, { "id": 2, "type": "独立行政法人国立病院機構", "name": "東京病院", "url": "http://www.hosp.go.jp/~tokyo/", "beds": 522, "address": "清瀬市竹丘3-1-1", "lat": 35.767834, "lon": 139.50523 }, { "id": 3, "type": "独立行政法人国立病院機構", "name": "村山医療センター", "url": "http://www.murayama-hosp.jp/", "beds": 303, "address": "武蔵村山市学園2-37-1", "lat": 35.747259, "lon": 139.399031 }, { "id": 4, "type": "国立大学法人", "name": "東京医科歯科大学医学部附属病院", "url": "http://www.tmd.ac.jp/medhospital/", "beds": 753, "address": "文京区湯島1-5-45", "lat": 35.70143, "lon": 139.764363 }, { "id": 5, "type": "国立大学法人", "name": "東京大学医学部附属病院", "url": "http://www.h.u-tokyo.ac.jp/", "beds": 1228, "address": "文京区本郷7-3-1", "lat": 35.714163, "lon": 139.762102 }, { "id": 6, "type": "独立行政法人労働者健康安全機構", "name": "東京労災病院", "url": "http://www.tokyoh.johas.go.jp/", "beds": 400, "address": "大田区大森南4-13-21", "lat": 35.565611, "lon": 139.747214 }, { "id": 7, "type": "国立研究開発法人", "name": "国立がん研究センター中央病院", "url": "http://www.ncc.go.jp/jp/ncch/", "beds": 578, "address": "中央区築地5-1-1", "lat": 35.665005, "lon": 139.767583 }, { "id": 8, "type": "国立研究開発法人", "name": "国立国際医療研究センター病院", "url": "http://www.ncgm.go.jp/index.html", "beds": 763, "address": "新宿区戸山1-21-1", "lat": 35.702292, "lon": 139.716664 }, { "id": 9, "type": "国立研究開発法人", "name": "国立成育医療研究センター病院", "url": "http://www.ncchd.go.jp/", "beds": 460, "address": "世田谷区大蔵2-10-1", "lat": 35.633399, "lon": 139.611529 }, { "id": 10, "type": "独立行政法人地域医療機能推進機構", "name": "東京蒲田医療センター", "url": "http://kamata.jcho.go.jp/", "beds": 230, "address": "大田区南蒲田2-19-2", "lat": 35.55437, "lon": 139.7238 }, { "id": 11, "type": "独立行政法人地域医療機能推進機構", "name": "東京城東病院", "url": "http://joto.jcho.go.jp/", "beds": 130, "address": "江東区亀戸9-13-1", "lat": 35.695177, "lon": 139.846095 }, { "id": 12, "type": "独立行政法人地域医療機能推進機構", "name": "東京新宿メディカルセンター", "url": "http://shinjuku.jcho.go.jp/", "beds": 520, "address": "新宿区津久戸町5-1", "lat": 35.703432, "lon": 139.742135 }, { "id": 13, "type": "独立行政法人地域医療機能推進機構", "name": "東京高輪病院", "url": "http://takanawa.jcho.go.jp/", "beds": 247, "address": "港区高輪3-10-11", "lat": 35.631341, "lon": 139.732021 }, { "id": 14, "type": "独立行政法人地域医療機能推進機構", "name": "東京山手メディカルセンター", "url": "http://yamate.jcho.go.jp/", "beds": 418, "address": "新宿区百人町3-22-1", "lat": 35.704759, "lon": 139.699067 }, { "id": 15, "type": "国(その他)", "name": "自衛隊中央病院", "url": "http://www.mod.go.jp/gsdf/chosp/", "beds": 500, "address": "世田谷区池尻1-2-24", "lat": 35.64481, "lon": 139.683125 }, { "id": 16, "type": "都道府県", "name": "東京都立大塚病院", "url": "http://www.byouin.metro.tokyo.jp/ohtsuka/", "beds": 508, "address": "豊島区南大塚2-8-1", "lat": 35.72526, "lon": 139.732543 }, { "id": 17, "type": "都道府県", "name": "東京都立駒込病院", "url": "http://www.cick.jp/", "beds": 815, "address": "文京区本駒込3-18-22", "lat": 35.729843, "lon": 139.756393 }, { "id": 18, "type": "都道府県", "name": "東京都立小児総合医療センター", "url": "http://www.byouin.metro.tokyo.jp/shouni/", "beds": 561, "address": "府中市武蔵台2-8-29", "lat": 35.691802, "lon": 139.462225 }, { "id": 19, "type": "都道府県", "name": "東京都立神経病院", "url": "http://www.byouin.metro.tokyo.jp/tmnh/", "beds": 304, "address": "府中市武蔵台2-6-1", "lat": 35.690557, "lon": 139.461285 }, { "id": 20, "type": "都道府県", "name": "東京都立多摩総合医療センター", "url": "http://www.fuchu-hp.fuchu.tokyo.jp/", "beds": 789, "address": "府中市武蔵台2-8-29", "lat": 35.691802, "lon": 139.462225 }, { "id": 21, "type": "都道府県", "name": "東京都立広尾病院", "url": "http://www.byouin.metro.tokyo.jp/hiroo/", "beds": 426, "address": "渋谷区恵比寿2-34-10", "lat": 35.646828, "lon": 139.721688 }, { "id": 22, "type": "都道府県", "name": "東京都立松沢病院", "url": "http://www.byouin.metro.tokyo.jp/matsuzawa/", "beds": 898, "address": "世田谷区上北沢2-1-1", "lat": 35.66678, "lon": 139.620278 }, { "id": 23, "type": "都道府県", "name": "都立墨東病院", "url": "http://bokutoh-hp.metro.tokyo.jp/", "beds": 765, "address": "墨田区江東橋4-23-15", "lat": 35.694594, "lon": 139.818958 }, { "id": 24, "type": "市町村", "name": "稲城市立病院", "url": "http://www.hospital.inagi.tokyo.jp/", "beds": 290, "address": "稲城市大丸1171", "lat": 35.646872, "lon": 139.485143 }, { "id": 25, "type": "市町村", "name": "青梅市立総合病院", "url": "http://www.mghp.ome.tokyo.jp/", "beds": 529, "address": "青梅市東青梅4-16-5", "lat": 35.782502, "lon": 139.28118 }, { "id": 26, "type": "市町村", "name": "公立阿伎留医療センター", "url": "http://www.akiru-med.jp/", "beds": 305, "address": "あきる野市引田78-1", "lat": 35.732189, "lon": 139.272619 }, { "id": 27, "type": "市町村", "name": "公立昭和病院", "url": "http://www.kouritu-showa.jp/", "beds": 518, "address": "小平市花小金井8-1-1", "lat": 35.731464, "lon": 139.503033 }, { "id": 28, "type": "市町村", "name": "公立福生病院", "url": "http://www.fussahp.jp/", "beds": 316, "address": "福生市加美平1-6-1", "lat": 35.746974, "lon": 139.326844 }, { "id": 29, "type": "市町村", "name": "町田市民病院", "url": "http://machida-city-hospital-tokyo.jp/", "beds": 447, "address": "町田市旭町2-15-41", "lat": 35.556913, "lon": 139.438796 }, { "id": 30, "type": "地方独立行政法人", "name": "東京都健康長寿医療センター", "url": "http://www.tmghig.jp/", "beds": 550, "address": "板橋区栄町35-2", "lat": 35.751787, "lon": 139.703303 }, { "id": 31, "type": "日赤", "name": "大森赤十字病院", "url": "http://omori.jrc.or.jp/", "beds": 344, "address": "大田区中央4-30-1", "lat": 35.578907, "lon": 139.717896 }, { "id": 32, "type": "日赤", "name": "葛飾赤十字産院", "url": "http://katsushika.jrc.or.jp/", "beds": 113, "address": "葛飾区立石5-11-12", "lat": 35.742572, "lon": 139.846624 }, { "id": 33, "type": "日赤", "name": "日本赤十字社医療センター", "url": "http://www.med.jrc.or.jp/", "beds": 708, "address": "渋谷区広尾4-1-22", "lat": 35.654524, "lon": 139.717985 }, { "id": 34, "type": "日赤", "name": "武蔵野赤十字病院", "url": "http://www.musashino.jrc.or.jp/", "beds": 611, "address": "武蔵野市境南町1-26-1", "lat": 35.697696, "lon": 139.547536 }, { "id": 35, "type": "済生会", "name": "東京都済生会中央病院", "url": "http://www.saichu.jp/", "beds": 535, "address": "港区三田1-4-17", "lat": 35.654062, "lon": 139.74357 }, { "id": 36, "type": "済生会", "name": "東京都済生会向島病院", "url": "http://www.saiseikai-mkj.jp/", "beds": 102, "address": "墨田区八広1-5-10", "lat": 35.720687, "lon": 139.822228 }, { "id": 37, "type": "共済組合及び連合会", "name": "関東中央病院", "url": "http://www.kanto-ctr-hsp.com/", "beds": 403, "address": "世田谷区上用賀6-25-1", "lat": 35.636835, "lon": 139.626088 }, { "id": 38, "type": "共済組合及び連合会", "name": "九段坂病院", "url": "http://www.kudanzaka.com/", "beds": 231, "address": "千代田区九段南1-6-12", "lat": 35.693798, "lon": 139.752063 }, { "id": 39, "type": "共済組合及び連合会", "name": "立川病院", "url": "http://www.tachikawa-hosp.gr.jp/", "beds": 493, "address": "立川市錦町4-2-22", "lat": 35.69256, "lon": 139.422365 }, { "id": 40, "type": "共済組合及び連合会", "name": "東京共済病院", "url": "http://www.tkh.meguro.tokyo.jp/", "beds": 350, "address": "目黒区中目黒2-3-8", "lat": 35.641571, "lon": 139.704112 }, { "id": 41, "type": "共済組合及び連合会", "name": "虎の門病院", "url": "http://www.toranomon.gr.jp/", "beds": 868, "address": "港区虎ノ門2-2-2", "lat": 35.669009, "lon": 139.746173 }, { "id": 42, "type": "共済組合及び連合会", "name": "三宿病院", "url": "http://www.mishuku.gr.jp/", "beds": 253, "address": "目黒区上目黒5-33-12", "lat": 35.642356, "lon": 139.68526 }, { "id": 43, "type": "国民健康保険組合", "name": "総合病院厚生中央病院", "url": "http://kohseichuo.jp/", "beds": 320, "address": "目黒区三田1-11-7", "lat": 35.641464, "lon": 139.712549 }, { "id": 44, "type": "公益法人", "name": "愛誠病院", "url": "http://www.aisei-byouin.or.jp/", "beds": 441, "address": "板橋区加賀1-3-1", "lat": 35.753788, "lon": 139.721035 }, { "id": 45, "type": "公益法人", "name": "板橋区医師会病院", "url": "http://www.itabashi-med.jp/", "beds": 192, "address": "板橋区高島平3-12-6", "lat": 35.786955, "lon": 139.658041 }, { "id": 46, "type": "公益法人", "name": "永寿総合病院", "url": "http://www.eijuhp.com/index.html", "beds": 400, "address": "台東区東上野2-23-16", "lat": 35.7097, "lon": 139.779703 }, { "id": 47, "type": "公益法人", "name": "永寿総合病院 柳橋分院", "url": "http://www.yanagibashihp.com/", "beds": 80, "address": "台東区柳橋2-20-4", "lat": 35.698941, "lon": 139.789649 }, { "id": 48, "type": "公益法人", "name": "荏原病院", "url": "http://www.ebara-hp.ota.tokyo.jp/", "beds": 506, "address": "大田区東雪谷4-5-10", "lat": 35.593755, "lon": 139.693208 }, { "id": 49, "type": "公益法人", "name": "大久保病院", "url": "http://www.ohkubohospital.jp/", "beds": 304, "address": "新宿区歌舞伎町2-44-1", "lat": 35.696697, "lon": 139.701143 }, { "id": 50, "type": "公益法人", "name": "がん研究会有明病院", "url": "http://www.jfcr.or.jp/hospital/", "beds": 700, "address": "江東区有明3-8-31", "lat": 35.634222, "lon": 139.794691 }, { "id": 51, "type": "公益法人", "name": "杏雲堂病院", "url": "http://www.kyoundo.jp/", "beds": 198, "address": "千代田区神田駿河台1-8", "lat": 35.698015, "lon": 139.763245 }, { "id": 52, "type": "公益法人", "name": "榊原記念病院", "url": "http://www.hospital.heart.or.jp/", "beds": 320, "address": "府中市朝日町3-16-1", "lat": 35.66635, "lon": 139.520228 }, { "id": 53, "type": "公益法人", "name": "三楽病院", "url": "http://www.sanraku.or.jp/", "beds": 270, "address": "千代田区神田駿河台2-5", "lat": 35.699416, "lon": 139.761351 }, { "id": 54, "type": "公益法人", "name": "心臓血管研究所付属病院", "url": "https://www.cvi.or.jp/", "beds": 74, "address": "港区西麻布3-2-19", "lat": 35.658924, "lon": 139.727265 }, { "id": 55, "type": "公益法人", "name": "新山手病院", "url": "http://www.shinyamanote.jp/", "beds": 180, "address": "東村山市諏訪町3-6-1", "lat": 35.770348, "lon": 139.462541 }, { "id": 56, "type": "公益法人", "name": "第三北品川病院", "url": "http://kcmi.or.jp/daisankitashinagawa/", "beds": 114, "address": "品川区北品川3-3-7", "lat": 35.621322, "lon": 139.73886 }, { "id": 57, "type": "公益法人", "name": "玉川病院", "url": "http://www.tamagawa-hosp.jp/", "beds": 389, "address": "世田谷区瀬田4-8-1", "lat": 35.620442, "lon": 139.624341 }, { "id": 58, "type": "公益法人", "name": "多摩南部地域病院", "url": "http://www.tamanan-hp.com/", "beds": 287, "address": "多摩市中沢2-1-2", "lat": 35.622822, "lon": 139.414982 }, { "id": 59, "type": "公益法人", "name": "多摩北部医療センター", "url": "http://www.tamahoku-hp.jp/", "beds": 344, "address": "東村山市青葉町1-7-1", "lat": 35.76074, "lon": 139.493331 }, { "id": 60, "type": "公益法人", "name": "東部地域病院", "url": "http://www.tobu-hp.or.jp/", "beds": 314, "address": "葛飾区亀有5-14-1", "lat": 5.766202, "lon": 139.844142 }, { "id": 61, "type": "公益法人", "name": "豊島病院", "url": "http://www.toshima-hp.jp/", "beds": 470, "address": "板橋区栄町33-1", "lat": 35.752819, "lon": 139.701277 }, { "id": 62, "type": "公益法人", "name": "練馬総合病院", "url": "http://www.nerima-hosp.or.jp/", "beds": 224, "address": "練馬区旭丘1-24-1", "lat": 35.733526, "lon": 139.67714 }, { "id": 63, "type": "公益法人", "name": "複十字病院", "url": "http://www.fukujuji.org/", "beds": 334, "address": "清瀬市松山3-1-24", "lat": 35.771558, "lon": 139.512278 }, { "id": 64, "type": "医療法人", "name": "あきる台病院", "url": "http://www.akirudai-hp.or.jp/", "beds": 100, "address": "あきる野市秋川6-5-1", "lat": 35.729343, "lon": 139.291708 }, { "id": 65, "type": "医療法人", "name": "あけぼの病院", "url": "http://www.akebono-hospital.jp/", "beds": 98, "address": "町田市中町1-23-3", "lat": 35.549597, "lon": 139.445112 }, { "id": 66, "type": "医療法人", "name": "小豆沢病院", "url": "http://www.kenbun.or.jp/", "beds": 134, "address": "板橋区小豆沢1-6-8", "lat": 35.772988, "lon": 139.700755 }, { "id": 67, "type": "医療法人", "name": "池上総合病院", "url": "http://www.ikegamihosp.jp/", "beds": 384, "address": "大田区池上6-1-19", "lat": 35.572714, "lon": 139.704387 }, { "id": 68, "type": "医療法人", "name": "池袋病院", "url": "http://www.ikebukuro-hp.com/", "beds": 96, "address": "豊島区東池袋3-5-4", "lat": 35.731029, "lon": 139.717187 }, { "id": 69, "type": "医療法人", "name": "石川島記念病院", "url": "http://ishikawajima.gr.jp/", "beds": 47, "address": "中央区佃2-5-2", "lat": 35.667554, "lon": 139.785431 }, { "id": 70, "type": "医療法人", "name": "板橋中央総合病院", "url": "http://www.ims-itabashi.jp/", "beds": 579, "address": "板橋区小豆沢2-12-7", "lat": 35.775599, "lon": 139.69709 }, { "id": 71, "type": "医療法人", "name": "一心病院", "url": "http://www.isshin.net/", "beds": 111, "address": "豊島区北大塚1-18-7", "lat": 35.732796, "lon": 139.730151 }, { "id": 72, "type": "医療法人", "name": "医療法人社団博栄会 赤羽中央総合病院", "url": "http://www.hakueikai.or.jp/", "beds": 150, "address": "北区赤羽南2-5-12", "lat": 35.773201, "lon": 139.723185 }, { "id": 73, "type": "医療法人", "name": "岩井整形外科内科病院", "url": "http://www.iwai.com/iwai-seikei/", "beds": 56, "address": "江戸川区南小岩8-17-2", "lat": 35.733745, "lon": 139.884947 }, { "id": 74, "type": "医療法人", "name": "浮間中央病院", "url": "http://www.hakueikai.or.jp/ukima/", "beds": 95, "address": "北区赤羽北2-21-19", "lat": 35.784255, "lon": 139.703236 }, { "id": 75, "type": "医療法人", "name": "永生病院", "url": "http://www.eisei.or.jp/", "beds": 595, "address": "八王子市椚田町583-15", "lat": 35.639563, "lon": 139.305 }, { "id": 76, "type": "医療法人", "name": "扇大橋病院", "url": "http://ougioohashi-hp.webmedipr.jp/", "beds": 96, "address": "足立区扇1-55-28", "lat": 35.76555, "lon": 139.771681 }, { "id": 77, "type": "医療法人", "name": "荻窪病院", "url": "https://www.ogikubo-hospital.or.jp/", "beds": 252, "address": "杉並区今川3-1-24", "lat": 35.715238, "lon": 139.607275 }, { "id": 78, "type": "医療法人", "name": "織本病院", "url": "http://www.orimoto.or.jp/", "beds": 92, "address": "清瀬市旭が丘1-261", "lat": 35.79091, "lon": 139.534074 }, { "id": 79, "type": "医療法人", "name": "葛西中央病院", "url": "http://kasai-central-hospital.or.jp/", "beds": 57, "address": "江戸川区船堀7-10-3", "lat": 35.67671, "lon": 139.868744 }, { "id": 80, "type": "医療法人", "name": "金地病院", "url": "http://www.kanaji.jp/", "beds": 38, "address": "北区中里1-5-6", "lat": 35.67671, "lon": 139.868744 }, { "id": 81, "type": "医療法人", "name": "要町病院", "url": "http://www.kanamecho-hp.jp/", "beds": 150, "address": "豊島区要町1-11-13", "lat": 35.733669, "lon": 139.699126 }, { "id": 82, "type": "医療法人", "name": "上板橋病院", "url": "http://www.jiseikai.or.jp/kamiitabashi.html", "beds": 150, "address": "板橋区常盤台4-36-9", "lat": 35.765361, "lon": 139.676413 }, { "id": 83, "type": "医療法人", "name": "神尾記念病院", "url": "http://www.kamio.org/", "beds": 30, "address": "千代田区神田淡路町2-25", "lat": 35.697004, "lon": 139.766688 }, { "id": 84, "type": "医療法人", "name": "亀有病院", "url": "http://www.kameari-hp.com/", "beds": 127, "address": "葛飾区亀有3-36-3", "lat": 35.763345, "lon": 139.849613 }, { "id": 85, "type": "医療法人", "name": "河北前田病院", "url": "http://www.maeda-jp.or.jp/", "beds": 117, "address": "杉並区本天沼1-2-1", "lat": 35.712694, "lon": 139.633064 }, { "id": 86, "type": "医療法人", "name": "嬉泉病院", "url": "http://www.kisen.or.jp/", "beds": 60, "address": "葛飾区東金町1-35-8", "lat": 35.773007, "lon": 139.871156 }, { "id": 87, "type": "医療法人", "name": "グレイス病院", "url": "http://www.mcs.or.jp/", "beds": 120, "address": "日野市大字宮248", "lat": 35.669998, "lon": 139.406451 }, { "id": 88, "type": "医療法人", "name": "敬愛病院", "url": "http://www.keiai-hospital.jp/", "beds": 54, "address": "板橋区向原3-10-23", "lat": 35.744127, "lon": 139.681518 }, { "id": 89, "type": "医療法人", "name": "京葉病院", "url": "http://www.keiyo-hp.jp/", "beds": 60, "address": "江戸川区松江2-43-12", "lat": 35.702681, "lon": 139.87572 }, { "id": 90, "type": "医療法人", "name": "糀谷病院", "url": "http://koujiya-hospital.jp/", "beds": 88, "address": "大田区南蒲田3-3-15", "lat": 35.553765, "lon": 139.728676 }, { "id": 91, "type": "医療法人", "name": "小林病院", "url": "http://www.kobayashibyoin.com/", "beds": 115, "address": "板橋区成増3-10-8", "lat": 35.778451, "lon": 139.633981 }, { "id": 92, "type": "医療法人", "name": "桜台病院", "url": "http://www.keiseikai-group.com/sakuradai/", "beds": 86, "address": "練馬区豊玉南1-20-15", "lat": 35.728608, "lon": 139.659167 }, { "id": 93, "type": "医療法人", "name": "山王病院", "url": "http://www.sannoclc.or.jp/hospital/", "beds": 79, "address": "港区赤坂8-10-16", "lat": 35.669683, "lon": 139.727256 }, { "id": 94, "type": "医療法人", "name": "下井病院", "url": "http://www.shimoi.or.jp/", "beds": 60, "address": "足立区綾瀬3-28-8", "lat": 35.765277, "lon": 139.828982 }, { "id": 95, "type": "医療法人", "name": "荘病院", "url": "http://www.suginami-reha-tokyo.jp/", "beds": 60, "address": "板橋区板橋1-41-14", "lat": 35.748716, "lon": 139.715659 }, { "id": 96, "type": "医療法人", "name": "杉並リハビリテーション病院", "url": "http://www.suginami-reha-tokyo.jp/", "beds": 101, "address": "杉並区西荻北2-5-5", "lat": 35.704325, "lon": 139.60221 }, { "id": 97, "type": "医療法人", "name": "スズキ病院", "url": "http://www.suzuki-hospi.or.jp/", "beds": 99, "address": "練馬区栄町7-1", "lat": 35.737031, "lon": 139.670766 }, { "id": 98, "type": "医療法人", "name": "誠志会病院", "url": "http://www.seisikai.or.jp/", "beds": 152, "address": "板橋区坂下1-40-2", "lat": 35.779627, "lon": 139.681044 }, { "id": 99, "type": "医療法人", "name": "世田谷中央病院", "url": "http://setagaya-hp.or.jp/", "beds": 131, "address": "世田谷区世田谷1-32-18", "lat": 35.641196, "lon": 139.65054 }, { "id": 100, "type": "医療法人", "name": "セントラル病院", "url": "http://www.central-hospital.or.jp/", "beds": 92, "address": "渋谷区松涛2-18-1", "lat": 35.658885, "lon": 139.689644 }, { "id": 101, "type": "医療法人", "name": "総合東京病院", "url": "http://www.tokyo-hospital.com/", "beds": 451, "address": "中野区江古田3-15-2", "lat": 35.727936, "lon": 139.663919 }, { "id": 102, "type": "医療法人", "name": "相武病院", "url": "http://www.sobu-hosp.or.jp/", "beds": 326, "address": "八王子市戸吹町323-1", "lat": 35.709661, "lon": 139.294614 }, { "id": 103, "type": "医療法人", "name": "高山整形外科病院", "url": "http://www.takayamaseikei.or.jp/", "beds": 48, "address": "葛飾区金町3-4-5", "lat": 35.766435, "lon": 139.871646 }, { "id": 104, "type": "医療法人", "name": "竹丘病院", "url": "http://www.takeoka.or.jp/", "beds": 164, "address": "清瀬市竹丘2-3-7", "lat": 35.765141, "lon": 139.508916 }, { "id": 105, "type": "医療法人", "name": "竹川病院", "url": "http://www.takekawa.gr.jp/", "beds": 151, "address": "板橋区桜川2-19-1", "lat": 35.758806, "lon": 139.679136 }, { "id": 106, "type": "医療法人", "name": "立川中央病院", "url": "http://www.tactis.or.jp/", "beds": 115, "address": "立川市柴崎町2-17-14", "lat": 35.695744, "lon": 139.407122 }, { "id": 107, "type": "医療法人", "name": "田中脳神経外科病院", "url": "http://www.tanaka-nrsg-hp.or.jp/", "beds": 58, "address": "練馬区関町南3-9-23", "lat": 35.721865, "lon": 139.581916 }, { "id": 108, "type": "医療法人", "name": "多摩丘陵病院", "url": "http://www.tamakyuryo.or.jp/hospital/", "beds": 316, "address": "町田市下小山田町1491", "lat": 35.604829, "lon": 139.421785 }, { "id": 109, "type": "医療法人", "name": "多摩リハビリテーション病院", "url": "http://www.wafukai.or.jp/tamarb/", "beds": 199, "address": "青梅市長渕9-1412-4", "lat": 35.764746, "lon": 139.269703 }, { "id": 110, "type": "医療法人", "name": "調布東山病院", "url": "http://www.touzan.or.jp/", "beds": 83, "address": "調布市小島町2-32-17", "lat": 35.652173, "lon": 139.542202 }, { "id": 111, "type": "医療法人", "name": "同愛会病院", "url": "http://www.douaikai.jp/", "beds": 149, "address": "江戸川区松島1-42-21", "lat": 35.705578, "lon": 139.867613 }, { "id": 112, "type": "医療法人", "name": "東京衛生アドベンチスト病院", "url": "http://www.tokyoeisei.com/", "beds": 186, "address": "杉並区天沼3-17-3", "lat": 35.708108, "lon": 139.619395 }, { "id": 113, "type": "医療法人", "name": "東京蒲田病院", "url": "http://www.hospital.or.jp/shibu_kaiin/www.t-kamata-hosp.or.jp", "beds": 180, "address": "大田区西蒲田7-10-1", "lat": 35.564248, "lon": 139.71195 }, { "id": 114, "type": "医療法人", "name": "東京天使病院", "url": "http://www.angelcourt.or.jp/", "beds": 122, "address": "八王子市上壱分方町50-1", "lat": 35.684396, "lon": 139.28056 }, { "id": 115, "type": "医療法人", "name": "東都文京病院", "url": "http://www.tohtobunkyo-hp.com/", "beds": 126, "address": "文京区湯島3-5-7", "lat": 35.704205, "lon": 139.767849 }, { "id": 116, "type": "医療法人", "name": "東立病院", "url": "http://www.touritsu-hosp.com/pc/index.html", "beds": 57, "address": "葛飾区立石6-38-13", "lat": 35.743571, "lon": 139.854213 }, { "id": 117, "type": "医療法人", "name": "東和病院", "url": "http://www.towa-hp.jp/", "beds": 299, "address": "足立区東和4-7-10", "lat": 35.772636, "lon": 139.843787 }, { "id": 118, "type": "医療法人", "name": "常盤台外科病院", "url": "http://tokiwadai-geka.jp/", "beds": 99, "address": "板橋区常盤台2-25-20", "lat": 35.76253, "lon": 139.690034 }, { "id": 119, "type": "医療法人", "name": "としま昭和病院", "url": "http://www.toshimashowa.or.jp/", "beds": 46, "address": "豊島区南長崎5-17-9", "lat": 35.728864, "lon": 139.682263 }, { "id": 120, "type": "医療法人", "name": "成増厚生病院", "url": "http://narimasukosei-hospital.jp/", "beds": 530, "address": "板橋区三園1-19-1", "lat": 35.788676, "lon": 139.639942 }, { "id": 121, "type": "医療法人", "name": "ニューハート・ワタナベ国際病院", "url": "https://newheart.jp/", "beds": 44, "address": "杉並区浜田山3-19-11", "lat": 35.683092, "lon": 139.629733 }, { "id": 122, "type": "医療法人", "name": "野村病院", "url": "https://www.nomura.or.jp/", "beds": 133, "address": "三鷹市下連雀8-3-6", "lat": 35.685147, "lon": 139.56805 }, { "id": 123, "type": "医療法人", "name": "八王子消化器病院", "url": "http://www.hachiojisyokaki.com/", "beds": 98, "address": "八王子市万町177-3", "lat": 35.650727, "lon": 139.332914 }, { "id": 124, "type": "医療法人", "name": "浜田病院", "url": "http://www.obatakai.or.jp/", "beds": 22, "address": "千代田区神田駿河台2-5", "lat": 35.699416, "lon": 139.761351 }, { "id": 125, "type": "医療法人", "name": "半蔵門病院", "url": "http://www.hanzomon.com/", "beds": 44, "address": "千代田区麹町1-10", "lat": 35.685123, "lon": 139.742368 }, { "id": 126, "type": "医療法人", "name": "聖ヶ丘病院", "url": "http://www.hijirigaoka.or.jp/", "beds": 48, "address": "多摩市連光寺2-69-6", "lat": 35.639492, "lon": 139.453343 }, { "id": 127, "type": "医療法人", "name": "日の出ヶ丘病院", "url": "http://www.hinodehp.com/", "beds": 170, "address": "西多摩郡日の出町大久野310番地", "lat": 35.742972, "lon": 139.246224 }, { "id": 128, "type": "医療法人", "name": "平塚胃腸病院", "url": "http://www.ichou.gr.jp/", "beds": 40, "address": "豊島区西池袋3-2-16", "lat": 35.728831, "lon": 139.706096 }, { "id": 129, "type": "医療法人", "name": "藤﨑病院", "url": "http://www.fujisaki-hp.com/", "beds": 119, "address": "江東区南砂1-25-11", "lat": 35.676565, "lon": 139.826747 }, { "id": 130, "type": "医療法人", "name": "富士病院", "url": "http://fujihospital.com/", "beds": 92, "address": "北区西ヶ原3-33-11", "lat": 35.745024, "lon": 139.738606 }, { "id": 131, "type": "医療法人", "name": "富士見病院", "url": "http://www.fujimi-hp.or.jp/", "beds": 108, "address": "板橋区大和町14-16", "lat": 35.760756, "lon": 139.705298 }, { "id": 132, "type": "医療法人", "name": "府中恵仁会病院", "url": "http://www.fuchu-keijinkai.or.jp/", "beds": 217, "address": "府中市住吉町5-21-1", "lat": 35.657102, "lon": 139.455508 }, { "id": 133, "type": "医療法人", "name": "平成立石病院", "url": "http://www.heisei-tateishi.net/", "beds": 203, "address": "葛飾区立石5-1-9", "lat": 35.742205, "lon": 139.842137 }, { "id": 134, "type": "医療法人", "name": "右田病院", "url": "http://www.migitahosp.or.jp/", "beds": 82, "address": "八王子市暁町1-48-18", "lat": 35.668842, "lon": 139.340657 }, { "id": 135, "type": "医療法人", "name": "三鷹中央病院", "url": "http://eiju.webmedipr.jp/", "beds": 122, "address": "三鷹市上連雀5-23-10", "lat": 35.694986, "lon": 139.552407 }, { "id": 136, "type": "医療法人", "name": "南多摩病院", "url": "http://www.minamitama.jp/", "beds": 170, "address": "八王子市散田町3-10-1", "lat": 35.655339, "lon": 139.312865 }, { "id": 137, "type": "医療法人", "name": "みなみ野病院", "url": "http://www.eisei.or.jp/minamino", "beds": 205, "address": "八王子市みなみ野5-30-3", "lat": 35.63102, "lon": 139.318712 }, { "id": 138, "type": "医療法人", "name": "武蔵野中央病院", "url": "http://www.musashino-chuou.com/", "beds": 306, "address": "小金井市東町1-44-26", "lat": 35.693836, "lon": 139.529988 }, { "id": 139, "type": "医療法人", "name": "武蔵野徳洲会病院", "url": "https://www.musatoku.com/", "beds": 246, "address": "西東京市向台町3-5-48", "lat": 35.717483, "lon": 139.53324 }, { "id": 140, "type": "医療法人", "name": "目黒病院", "url": "http://www.meguro-hospital.com/", "beds": 60, "address": "目黒区中央町2-12-6", "lat": 35.631921, "lon": 139.691134 }, { "id": 141, "type": "医療法人", "name": "目白病院", "url": "http://mejirohp.jp/", "beds": 100, "address": "新宿区下落合3-22-23", "lat": 35.722402, "lon": 139.698952 }, { "id": 142, "type": "医療法人", "name": "安田病院", "url": "http://www.yasudahosp.jp/", "beds": 46, "address": "板橋区成増1-13-9", "lat": 35.775359, "lon": 139.632883 }, { "id": 143, "type": "医療法人", "name": "代々木病院", "url": "http://www.tokyo-kinikai.com/yoyogi/", "beds": 150, "address": "渋谷区千駄ヶ谷1-30-7", "lat": 35.680855, "lon": 139.709679 }, { "id": 144, "type": "医療法人", "name": "ロイヤル病院", "url": "http://www.mck.or.jp/", "beds": 198, "address": "杉並区下高井戸4-6-2", "lat": 35.670342, "lon": 139.627927 }, { "id": 145, "type": "特定医療法人", "name": "北多摩病院", "url": "https://www.kitatamahospital.net/", "beds": 269, "address": "調布市調布ヶ丘4-1-1", "lat": 35.659608, "lon": 139.54386 }, { "id": 146, "type": "特定医療法人", "name": "武蔵野陽和会病院", "url": "http://www.hospital.or.jp/shibu_kaiin/?sw=13&sk=1", "beds": 103, "address": "武蔵野市緑町2-1-33", "lat": 35.716516, "lon": 139.565313 }, { "id": 147, "type": "社会医療法人", "name": "いずみ記念病院", "url": "http://www.izumikinen.or.jp/", "beds": 144, "address": "足立区本木1-3-7", "lat": 35.76099, "lon": 139.786346 }, { "id": 148, "type": "社会医療法人", "name": "大田病院", "url": "http://othp.c-pronet.jp/", "beds": 189, "address": "大田区大森東4-4-14", "lat": 35.569193, "lon": 139.737833 }, { "id": 149, "type": "社会医療法人", "name": "河北総合病院", "url": "http://kawakita.or.jp/", "beds": 331, "address": "杉並区阿佐谷北1-7-3", "lat": 35.706801, "lon": 139.638856 }, { "id": 150, "type": "社会医療法人", "name": "社会医療法人社団 森山医会 森山記念病院", "url": "http://mk.moriyamaikai.or.jp/", "beds": 275, "address": "江戸川区北葛西四丁目3番1号", "lat": 35.672199, "lon": 139.861665 }, { "id": 151, "type": "社会医療法人", "name": "第一病院", "url": "http://www.daiichi.or.jp/", "beds": 136, "address": "葛飾区東金町4-2-10", "lat": 35.772367, "lon": 139.876405 }, { "id": 152, "type": "社会医療法人", "name": "立川相互病院", "url": "http://www.t-kenseikai.jp/tachisou/", "beds": 287, "address": "立川市緑町4-1", "lat": 35.703575, "lon": 139.413365 }, { "id": 153, "type": "社会医療法人", "name": "長汐病院", "url": "http://www.nagashio.jp/", "beds": 302, "address": "豊島区池袋1-5-8", "lat": 35.735391, "lon": 139.713124 }, { "id": 154, "type": "社会医療法人", "name": "東大和病院", "url": "http://www.yamatokai.or.jp/higasiyamato/", "beds": 284, "address": "東大和市南街1-13-12", "lat": 35.7412, "lon": 139.431966 }, { "id": 155, "type": "社会医療法人", "name": "牧田総合病院", "url": "http://www.makita-hosp.or.jp/", "beds": 284, "address": "大田区大森北1-34-6", "lat": 35.586089, "lon": 139.727256 }, { "id": 156, "type": "社会医療法人", "name": "牧田総合病院 蒲田分院", "url": "http://www.makita-hosp.or.jp/kamata/", "beds": 120, "address": "大田区西蒲田4-22-1", "lat": 35.568822, "lon": 139.715384 }, { "id": 157, "type": "社会医療法人", "name": "武蔵村山病院", "url": "http://www.yamatokai.or.jp/musasimurayama/", "beds": 300, "address": "武蔵村山市榎1-1-5", "lat": 35.743826, "lon": 139.387676 }, { "id": 158, "type": "私立学校法人", "name": "北里大学北里研究所病院", "url": "http://www.kitasato-u.ac.jp/hokken-hp/", "beds": 329, "address": "港区白金5-9-1", "lat": 35.6448, "lon": 139.725733 }, { "id": 159, "type": "私立学校法人", "name": "慶應義塾大学病院", "url": "http://www.hosp.keio.ac.jp/", "beds": 960, "address": "新宿区信濃町35", "lat": 35.681433, "lon": 139.71916 }, { "id": 160, "type": "私立学校法人", "name": "国際医療福祉大学三田病院", "url": "http://mita.iuhw.ac.jp/", "beds": 291, "address": "港区三田1-4-3", "lat": 35.653698, "lon": 139.742477 }, { "id": 161, "type": "私立学校法人", "name": "順天堂大学医学部附属順天堂医院", "url": "http://www.juntendo.ac.jp/hospital/", "beds": 1032, "address": "文京区本郷3-1-3", "lat": 35.702405, "lon": 139.762606 }, { "id": 162, "type": "私立学校法人", "name": "順天堂大学医学部附属順天堂東京江東高齢者医療センター", "url": "http://www.juntendo.gmc.ac.jp/", "beds": 404, "address": "江東区新砂3-3-20", "lat": 35.665352, "lon": 139.83364 }, { "id": 163, "type": "私立学校法人", "name": "順天堂大学医学部附属練馬病院", "url": "https://www.juntendo.ac.jp/hospital_nerima/", "beds": 400, "address": "練馬区高野台3-1-10", "lat": 35.742156, "lon": 139.614761 }, { "id": 164, "type": "私立学校法人", "name": "昭和大学病院", "url": "http://www.showa-u.ac.jp/SUH/", "beds": 815, "address": "品川区旗の台1-5-8", "lat": 35.608364, "lon": 139.703623 }, { "id": 165, "type": "私立学校法人", "name": "聖路加国際病院", "url": "http://hospital.luke.ac.jp/", "beds": 520, "address": "中央区明石町9番1号", "lat": 35.667309, "lon": 139.777298 }, { "id": 166, "type": "私立学校法人", "name": "帝京大学医学部附属病院", "url": "http://www.teikyo-hospital.jp/", "beds": 1078, "address": "板橋区加賀2-11-1", "lat": 35.759005, "lon": 139.713899 }, { "id": 167, "type": "私立学校法人", "name": "東京医科大学八王子医療センター", "url": "http://hachioji.tokyo-med.ac.jp/", "beds": 610, "address": "八王子市館町1163", "lat": 35.631318, "lon": 139.288055 }, { "id": 168, "type": "私立学校法人", "name": "東京医科大学病院", "url": "http://hospinfo.tokyo-med.ac.jp/", "beds": 1015, "address": "新宿区西新宿6-7-1", "lat": 35.693258, "lon": 139.691659 }, { "id": 169, "type": "私立学校法人", "name": "東京慈恵会医科大学附属病院", "url": "http://www.jikei.ac.jp/hospital/honin/", "beds": 1075, "address": "港区西新橋3-19-18", "lat": 35.663568, "lon": 139.751326 }, { "id": 170, "type": "私立学校法人", "name": "東京女子医科大学病院", "url": "http://www.twmu.ac.jp/info-twmu/", "beds": 1379, "address": "新宿区河田町8-1", "lat": 35.69702, "lon": 139.719905 }, { "id": 171, "type": "私立学校法人", "name": "東邦大学医療センター大森病院", "url": "http://www.omori.med.toho-u.ac.jp/", "beds": 934, "address": "大田区大森西6-11-1", "lat": 35.568931, "lon": 139.724109 }, { "id": 172, "type": "私立学校法人", "name": "日本歯科大学附属病院", "url": "http://dent-hosp.ndu.ac.jp/nduhosp/", "beds": 42, "address": "千代田区富士見2-3-16", "lat": 35.700011, "lon": 139.744994 }, { "id": 173, "type": "私立学校法人", "name": "日本医科大学付属病院", "url": "http://www.hospital.or.jp/shibu_kaiin/?sw=13&sk=1", "beds": 897, "address": "文京区千駄木1丁目1番5号", "lat": 35.721143, "lon": 139.758969 }, { "id": 174, "type": "私立学校法人", "name": "日本大学医学部附属板橋病院", "url": "http://www.med.nihon-u.ac.jp/hospital/itabashi/", "beds": 1025, "address": "板橋区大谷口上町30-1", "lat": 35.749564, "lon": 139.691647 }, { "id": 175, "type": "私立学校法人", "name": "日本大学病院", "url": "http://www.nihon-u.ac.jp/hospital/", "beds": 320, "address": "千代田区神田駿河台1-6", "lat": 35.697346, "lon": 139.762752 }, { "id": 176, "type": "社会福祉法人", "name": "あそか病院", "url": "http://hp.asokakai.or.jp/", "beds": 254, "address": "江東区住吉1-18-1", "lat": 35.689926, "lon": 139.811889 }, { "id": 177, "type": "社会福祉法人", "name": "江戸川病院", "url": "http://www.edogawa.or.jp/", "beds": 418, "address": "江戸川区東小岩2-24-18", "lat": 35.728473, "lon": 139.893084 }, { "id": 178, "type": "社会福祉法人", "name": "江戸川病院高砂分院", "url": "http://www.takasago-hp.jp/t_top/takasago_top.html", "beds": 99, "address": "葛飾区西水元4-5-1", "lat": 35.793662, "lon": 139.845542 }, { "id": 179, "type": "社会福祉法人", "name": "江戸川メディケア病院", "url": "http://www.hospital.or.jp/shibu_kaiin/www.katayama-hospital.com/", "beds": 150, "address": "江戸川区東松本2-14-12", "lat": 35.720265, "lon": 139.881562 }, { "id": 180, "type": "社会福祉法人", "name": "久我山病院", "url": "http://www.kugayama-hp.org/", "beds": 199, "address": "世田谷区北烏山2-14-20", "lat": 35.681475, "lon": 139.598969 }, { "id": 181, "type": "社会福祉法人", "name": "桜町病院", "url": "http://www.seiyohanekai.or.jp/sakuramachi-hp/", "beds": 199, "address": "小金井市桜町1-2-20", "lat": 35.70989, "lon": 139.511593 }, { "id": 182, "type": "社会福祉法人", "name": "心身障害児総合医療療育センター", "url": "http://www.ryouiku-net.com/", "beds": 256, "address": "板橋区小茂根1-1-10", "lat": 35.747385, "lon": 139.682685 }, { "id": 183, "type": "社会福祉法人", "name": "聖母病院", "url": "https://www.seibokai.or.jp/", "beds": 154, "address": "新宿区中落合2-5-1", "lat": 35.719919, "lon": 139.694364 }, { "id": 184, "type": "社会福祉法人", "name": "総合母子保健センター愛育病院", "url": "http://www.aiiku.net/", "beds": 160, "address": "港区芝浦1-16-10", "lat": 35.645958, "lon": 139.752468 }, { "id": 185, "type": "社会福祉法人", "name": "同愛記念病院", "url": "http://www.doai.jp/", "beds": 403, "address": "墨田区横網2-1-11", "lat": 35.699569, "lon": 139.794168 }, { "id": 186, "type": "社会福祉法人", "name": "東京白十字病院", "url": "http://www.t-hakujuji.or.jp/", "beds": 125, "address": "東村山市諏訪町2-26-1", "lat": 35.770984, "lon": 139.463579 }, { "id": 187, "type": "社会福祉法人", "name": "日暮里上宮病院", "url": "http://www.jyogu.com/nippori/", "beds": 81, "address": "荒川区東日暮里2-29-8", "lat": 35.728676, "lon": 139.785086 }, { "id": 188, "type": "社会福祉法人", "name": "三井記念病院", "url": "http://www.mitsuihosp.or.jp/", "beds": 482, "address": "千代田区神田和泉町1", "lat": 35.699084, "lon": 139.778469 }, { "id": 189, "type": "社会福祉法人", "name": "南台病院", "url": "http://minamidaihp.jp/", "beds": 140, "address": "小平市小川町1-485", "lat": 35.728184, "lon": 139.440266 }, { "id": 190, "type": "社会福祉法人", "name": "有隣病院", "url": "http://tokyoyurin-hospital.com/", "beds": 251, "address": "世田谷区船橋2-15-38", "lat": 35.650992, "lon": 139.61914 }, { "id": 191, "type": "社会福祉法人", "name": "緑風荘病院", "url": "http://ryokufuusou.com/", "beds": 199, "address": "東村山市萩山町3-31-1", "lat": 35.74425, "lon": 139.46754 }, { "id": 192, "type": "医療生協", "name": "王子生協病院", "url": "http://oujiseikyo-hp.jp/", "beds": 159, "address": "北区豊島3-4-15", "lat": 35.760226, "lon": 139.744192 }, { "id": 193, "type": "医療生協", "name": "東京健生病院", "url": "http://thoken.or.jp/kensei/", "beds": 126, "address": "文京区大塚4-3-8", "lat": 35.724521, "lon": 139.736004 }, { "id": 194, "type": "医療生協", "name": "新渡戸記念中野総合病院", "url": "http://www.nakanosogo.or.jp/", "beds": 296, "address": "中野区中央4-59-16", "lat": 35.702504, "lon": 139.667103 }, { "id": 195, "type": "会社", "name": "いすゞ病院", "url": "http://isuzu-hospital.jp/", "beds": 20, "address": "品川区南大井6-21-10", "lat": 35.589575, "lon": 139.732681 }, { "id": 196, "type": "会社", "name": "NTT東日本関東病院", "url": "http://www.ntt-east.co.jp/kmc/", "beds": 594, "address": "品川区東五反田5-9-22", "lat": 35.631307, "lon": 139.72558 }, { "id": 197, "type": "会社", "name": "JR東京総合病院", "url": "http://www.jreast.co.jp/hospital/index.html/", "beds": 448, "address": "渋谷区代々木2-1-3", "lat": 35.685464, "lon": 139.700149 }, { "id": 198, "type": "会社", "name": "東急病院", "url": "http://www.tokyu-hospital.jp/", "beds": 135, "address": "大田区北千束3-27-2", "lat": 35.607532, "lon": 139.685963 }, { "id": 199, "type": "会社", "name": "東京逓信病院", "url": "http://www.hospital.japanpost.jp/tokyo/", "beds": 461, "address": "千代田区富士見2-14-23", "lat": 35.697582, "lon": 139.743255 }, { "id": 200, "type": "その他法人", "name": "赤羽リハビリテーション病院", "url": "http://www.akabane-rh.jp/", "beds": 234, "address": "北区赤羽西6-37-12", "lat": 35.770318, "lon": 139.706138 }, { "id": 201, "type": "その他法人", "name": "蒲田リハビリテーション病院", "url": "http://www.kamata-rh.net/index.php", "beds": 180, "address": "大田区大森西4-14-5", "lat": 35.572496, "lon": 139.720587 }, { "id": 202, "type": "その他法人", "name": "救世軍清瀬病院", "url": "http://kiyosehp.salvationarmy.or.jp/", "beds": 142, "address": "清瀬市竹丘1-17-9", "lat": 35.769926, "lon": 139.506669 }, { "id": 203, "type": "その他法人", "name": "救世軍ブース記念病院", "url": "http://boothhp.salvationarmy.or.jp/", "beds": 199, "address": "杉並区和田1-40-5", "lat": 35.690519, "lon": 139.66021 }, { "id": 204, "type": "その他法人", "name": "クリニカルリサーチ東京病院", "url": "http://www.crht.jp/", "beds": 50, "address": "新宿区原町3-87-4 NTビル3F", "lat": 35.69773, "lon": 139.723412 }, { "id": 205, "type": "その他法人", "name": "厚生荘病院", "url": "http://www.kouseisou.jp/", "beds": 243, "address": "多摩市和田1547", "lat": 35.646735, "lon": 139.431725 }, { "id": 206, "type": "その他法人", "name": "小金井リハビリテーション病院", "url": "http://www.koganei-rh.net/", "beds": 220, "address": "小金井市前原町1-3-2", "lat": 35.688937, "lon": 139.512298 }, { "id": 207, "type": "その他法人", "name": "五反田リハビリテーション病院", "url": "http://www.gotanda-reha.com/", "beds": 240, "address": "品川区西五反田8-8-20", "lat": 35.621657, "lon": 139.720723 }, { "id": 208, "type": "その他法人", "name": "駒沢病院", "url": "http://www.komazawa-hp.jp/", "beds": 95, "address": "世田谷区駒沢2-2-15", "lat": 35.633942, "lon": 139.660436 }, { "id": 209, "type": "その他法人", "name": "至誠会第二病院", "url": "http://www.shiseikai-daini-hosp.jp/", "beds": 305, "address": "世田谷区上祖師谷5-19-1", "lat": 35.656429, "lon": 139.591587 }, { "id": 210, "type": "その他法人", "name": "城西病院", "url": "http://www.johsai-hp.or.jp/", "beds": 99, "address": "杉並区上荻2-42-11", "lat": 35.70796, "lon": 139.614559 }, { "id": 211, "type": "その他法人", "name": "仁和会総合病院", "url": "http://www.jinwakai.jp/", "beds": 157, "address": "八王子市明神町4-8-1", "lat": 35.658252, "lon": 139.341521 }, { "id": 212, "type": "その他法人", "name": "東京警察病院", "url": "http://www.keisatsubyoin.or.jp/", "beds": 415, "address": "中野区中野四丁目22-1", "lat": 35.709121, "lon": 139.659359 }, { "id": 213, "type": "その他法人", "name": "東京武蔵野病院", "url": "http://www.tmh.or.jp/", "beds": 619, "address": "板橋区小茂根4-11-11", "lat": 35.747142, "lon": 139.674687 }, { "id": 214, "type": "その他法人", "name": "原宿リハビリテーション病院", "url": "http://www.harajuku-reha.com/", "beds": 332, "address": "渋谷区神宮前6-26-1", "lat": 35.666874, "lon": 139.702473 }, { "id": 215, "type": "その他法人", "name": "立正佼成会附属佼成病院", "url": "http://www.kosei-hp.or.jp/", "beds": 340, "address": "杉並区和田2-25-1", "lat": 35.690181, "lon": 139.655795 } ]
- 投稿日:2020-02-21T23:33:31+09:00
計算ドリルを作りました
//qiita-image-store.s3.ap-northeast-1.amazonaws.com/0/569373/3e8c7176-ca7f-b9b3-37d4-866bfe98146b.png)import random ichi = random.sample([1,2,3,4,5,6,7,8,9], 9) ni = random.sample([1,2,3,4,5,6,7,8,9], 9) #1〜9のリストからランダムに被り無しで9回取り出す for ICHI in ichi: for NI in ni: kaitou = int(input(str(ICHI) + '+' + str(NI) + '=')) #ランダムに出力された計算式をinputで回答を入力できるようにする while (kaitou != ICHI + NI): print('?ぜんぜんちがう?') kaitou = int(input(str(ICHI) + '+' + str(NI) + '=')) #while文でICHI + NIが成立しない時はループ if kaitou == ICHI + NI: print('?あってるよ?') ```
- 投稿日:2020-02-21T23:22:10+09:00
[python, multiprocessing] multiprocessing使用時の例外に対する挙動
Pythonで並列処理などのために
multiprocessingを使うが、multiprocessingで子プロセスを生成した時の挙動は、通常の関数呼び出しの挙動と異なる点がいくつかある。準備
今回は簡単のため関数
sleep_bug()を用いる。これは実行中に途中でわざとエラーを発生させるために,i==5の時に1/0を実行しエラーを発生するようにした関数である。import time def sleep_bug(): for i in range(10): print('sleeping %d' % i) if i == 5: 1/0 time.sleep(1) return i sleep_bug() # output ''' sleeping 0 sleeping 1 sleeping 2 sleeping 3 sleeping 4 sleeping 5 --------------------------------------------------------------------------- ZeroDivisionError Traceback (most recent call last) <ipython-input-44-d9f02a4cf7f3> in <module> ----> 1 sleep_bug() <ipython-input-41-26bb27998e63> in sleep_bug() 12 print('sleeping %d' % i) 13 if i==5: ---> 14 1/0 15 time.sleep(1) 16 ZeroDivisionError: division by zero '''子プロセスがエラーを起こしても、親プロセスはそのまま動き続ける。
通常の関数呼び出しでは、呼び出した関数にエラーが生じると、プログラムはそこで止まる。しかし、Poolを用いて生成した子プロセスに
sleep_bug()を実行させると、子プロセスはエラーが発生して止まるが、親プロセスではエラーは発生せずに最後まで進んでしまう。from multiprocessing import Pool p = Pool(1) r = p.apply_async(sleep_bug) p.close() p.join() #子プロセスが終了するまで待つ。 print('Done') # output ''' sleeping 0 sleeping 1 sleeping 2 sleeping 3 sleeping 4 sleeping 5 Done '''子プロセスにエラーが生じて止まった時に、親プロセスにもエラーが伝わるようにするには、
r.get()を用いる。r.get()は通常時には子プロセスが終了するのを待ち、子プロセスの戻り値を出力する関数であるが、子プロセスでエラーが起こった場合には、r.get()は例外を送出し、親プロセスもそこで止まるようになる。from multiprocessing import Pool p = Pool(1) r = p.apply_async(sleep_bug) p.close() output = r.get() print('Done %d' % output) # 出力 ''' sleeping 0 sleeping 1 sleeping 2 sleeping 3 sleeping 4 sleeping 5 --------------------------------------------------------------------------- RemoteTraceback Traceback (most recent call last) RemoteTraceback: """ Traceback (most recent call last): File "/opt/local/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/multiprocessing/pool.py", line 121, in worker result = (True, func(*args, **kwds)) File "<ipython-input-41-26bb27998e63>", line 14, in sleep_bug 1/0 ZeroDivisionError: division by zero """ The above exception was the direct cause of the following exception: ZeroDivisionError Traceback (most recent call last) <ipython-input-50-fb8f5892e1a7> in <module> 3 r = p.apply_async(sleep_bug) 4 p.close() ----> 5 output = r.get() 6 print('Done %d' % output) /opt/local/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/multiprocessing/pool.py in get(self, timeout) 655 return self._value 656 else: --> 657 raise self._value 658 659 def _set(self, i, obj): ZeroDivisionError: division by zero '''
Processを用いた場合には、エラーは表示されるが、親プロセスは最後まで進む。from multiprocessing import Process p = Process(target=sleep_bug) p.start() p.join() print('Done') #出力 ''' sleeping 0 sleeping 1 sleeping 2 sleeping 3 sleeping 4 sleeping 5 Process Process-35: Traceback (most recent call last): File "/opt/local/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/multiprocessing/process.py", line 297, in _bootstrap self.run() File "/opt/local/Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/multiprocessing/process.py", line 99, in run self._target(*self._args, **self._kwargs) File "<ipython-input-41-26bb27998e63>", line 14, in sleep_bug 1/0 ZeroDivisionError: division by zero Done '''親プロセスが止まっても子プロセスは動き続ける
下のスクリプトは、子プロセスが実行中2秒待ち、親プロセスは
sys.exit()でそこで自分自身を終了させるものである。以下の実行例のように、親プロセスは途中で止まっても、子プロセスは動き続ける。from multiprocessing import Pool p = Pool(1) r = p.apply_async(sleep) p.close() r.wait(2) #子プロセスを2秒待つ sys.exit() #出力 ''' sleeping 0 sleeping 1 An exception has occurred, use %tb to see the full traceback. SystemExit sleeping 2 sleeping 3 sleeping 4 sleeping 5 sleeping 6 sleeping 7 sleeping 8 sleeping 9 '''
- 投稿日:2020-02-21T21:48:27+09:00
Qiskit: 量子フーリエ変換
概要
量子フーリエ変換とは,離散フーリエ変換を量子回路上に実装したものです.
詳しい解説は参考書や他のサイトに任せて,ここではQiskitでの実装を行っていきたいと思います.
なお,完全に備忘録的な感じなので細かいところは気にしないでください.
今後はこのcodeを用いて他のアルゴリズム等を実装していきたいですね.code
# coding: utf-8 from qiskit import QuantumRegister, QuantumCircuit, ClassicalRegister from math import log2, pi import numpy as np class QFT: def __init__(self, numQubit): self.numQubit = numQubit def construct_circuit(self, circuit=None, inverse=False): if circuit is None: circuit = QuantumCircuit(range(self.numQubit)) if not inverse: self._input_initial_state(circuit) self._qft(circuit) self._swap_registers(circuit) return circuit elif inverse: self._swap_registers(circuit) self._qft(circuit, inverse=True) self._input_initial_state(circuit, inverse=True) return circuit def _input_initial_state(self, circuit, inverse=False): if not inverse: for j in range(self.numQubit): circuit.h(j) circuit.u1(-pi / float(2 ** j), j) elif inverse: for j in range(self.numQubit): circuit.u1(-pi / float(2 ** j), j) circuit.h(j) def _qft(self, circuit, inverse=False): if not inverse: for j in range(self.numQubit): circuit.h(j) for k in range(j + 1, self.numQubit): circuit.cu1(pi / float(2 ** (k - j)), k, j) elif inverse: for j in range(self.numQubit).__reversed__(): for k in range(j + 1, self.numQubit).__reversed__(): circuit.cu1(pi / float(2 ** (k - j)), k, j) circuit.h(j) circuit.barrier() def _swap_registers(self, circuit): for j in range(int(np.floor(self.numQubit / 2.))): circuit.swap(j, self.numQubit - j - 1)参考文献
- 投稿日:2020-02-21T20:59:12+09:00
競馬データスクレイピングの流れ
まずは前回の記事ですが、意外にも多くの閲覧といいねを頂きまして、
大変感謝するとともに、震えております
今回から、具体的にどんなコードを書いたかを簡略に記事にしていきます。競馬データといっても大きく分けてレース全体の情報とそのレースに出走した馬の情報があります。
いきなり目的の部分だけを切り抜かず、おおきなくくりで一度みてみる。.textなどもまだつけない例えば以下のページの場合
(netkeiba.com様より)赤枠の部分にコースの種類、走行距離、馬場状態が書いてあるので、取得したいとします。
beautifulsuopを用いてもってくるとするとscr1.pyfrom bs4 import BeautifulSoup id = '201806010101'#データ取得したいレースID url = ('https://db.netkeiba.com/race/%s/' % (id)) response = request.urlopen(url) bs = BeautifulSoup(response, 'html.parser') raceinfo = bs.select("span")[6] print(raceinfo) #<span>ダ右1200m / 天候 : 晴 / ダート : 良 / 発走 : 09:55</span>となるので、ここで初めて.textとか.splitとかをつける
scr2.pyimport re racetype = raceinfo.text.split()[0][:1] length = re.sub("\\D", "", raceinfo.text.split()[0]) conde = raceinfo.text.split()[8] print(racetype,length,conde) #ダ 1200 良目的の情報である、コースの種類、走行距離、馬場状態を取得できました。
こうするメリットは、ループさせる際に最初の大きなくくりの部分に変数を使えば他は
そのままでもスムーズにデータ取得できること、リストの数字のアタリがつけやすいことでしょうか。
他のレースの情報や、馬毎の情報も同じ要領で取得すれば良いでしょう。あと、過去10年ものデータを一度にスクレイピングするのはやめたほうが良いです。
何回かにわけて、データが揃ったら.concatとか.appendとかでくっつける。
1年毎にやると良い感じ(寝る時や出勤時にRUNさせると、大体タイムアウトしてますので…)また取得した時点で何かしら計算を加えたものを保存したくなりますが、後にしましょう。ただでさえ時間がかかる作業なので…
以上のような流れでレースと馬のデータをわけて取得しました。
今回は短めですが、情報を取ってくるだけですし特別なことはしていませんので、これくらいで。
次はデータの整理、レースや馬の評価の仕方について書こうと思ってます。
次の記事からはどうしても競馬用語が多めになりますが、出来るだけ解説していきます。

- 投稿日:2020-02-21T20:19:38+09:00
PythonのFlaskで学ぶWebアプリケーション制作講座 第2部1章 〜JSONのやりとり〜
WebAPIとは
今回からWebAPI編となる。今までは人がブラウザで閲覧し、操作するという前提でWebアプリケーションを作ってきた。しかし、現代においてはブラウザ以外のアプリケーションからの利用、例えばスマホアプリなど、も一般的となってきている。また、公式のアプリ以外にも一般に機能を公開し、プログラムから利用してもらうようなことが考えられる。こういった場合に一定のルールに則ってWebアプリケーションとプログラムの間にはいる、つまりWebアプリケーションとプログラムのインターフェイスとなるものがWebAPIである。また、通常のWebアプリケーションにおいてもクライアントサイドのアプリケーションからWebAPIを利用してWebアプリケーションを作るということが可能である。この場合はサーバ側の機能とクライアント側の機能が分離しよりプログラムの見通しがよくなる。
JSONとは
今まではリクエストに対してhtmlを返却するという処理を行なってきた。htmlは一般にブラウザで表示させ人が操作することを意図され設計されている。そのため、WebAPIでもhtmlを使うことは可能だが、プログラムで使う上では面倒で非効率であることがおおい。そのため、多くの1WebAPIではJSON(JavaScript Object Notation)というフォーマットがよく利用されている。JSONの正確なフォーマットについてはRFC 8259で定義されている。基本的にはPythonでいうところの数値と文字列、bool値(true, false)、nullを入れられるリストとディクショナリという理解で良い。書き方もほぼ同一である。以下にjsonの一例を示す。
{ "id": 3, "name": "hoge", "ref": [1, 2, 4], }この例ではidをkeyとして数値3、name対して文字列hoge、"ref"に配列[1, 2, 3]を割り当てている。
JSONを返却する
Flaskから上記の内容のjsonを返却するには下記のようにする。
from flask import Flask, jsonify app = Flask(__name__) # 日本語を使えるように app.config['JSON_AS_ASCII'] = False books = [{'name': 'EffectivePython', 'price': 3315}, {'name': 'Expert Python Programming', 'price': 3960}] @app.route('/') def get_json(): data = { "id": 3, "name": "hoge", "ref": [1, 2, 4], } return jsonify(data) if __name__ == '__main__': app.run()まずは
app.config['JSON_AS_ASCII'] = FalseでJSONで日本語を使えるようにしている(今回は関係ないが入れておいたほうがよい)。
次に返却するオブジェクトを構築する。data = { "id": 3, "name": "hoge", "ref": [1, 2, 4], }これはPythonのディクショナリとリストを使っている。
そしてこのdataをjsonに変換して返却する。
return jsonify(data)このためにjsonify関数を利用する。
以上をまとめると通常のPythonのディクショナリとリストを使ってJSONを表現し、それをjsonify関数を用いて実際にJSONに変換すればよい。
PyCharmからのWebAPIのデバッグ法
今まではブラウザからWebページを確認してデバッグしていた。しかし、WebAPIをデバッグする際にはPyCharm等からデバッグできたほうが便利である。特にPOSTに関しては今まではフォームを使っていたが、WebAPIの場合は直にPOSTするためブラウザからの操作は困難である。PyCharm(のProfessional版)にはPyCharm上でHTTPリクエストを作成し送信する機能(HTTPクライアント)が備わっている。その機能について紹介する。PyCharm以外のIDEでもおそらくできると思われる。また、cURLというツールを使うという手もある。PyCharm以外を使う人は各自調べてほしい。
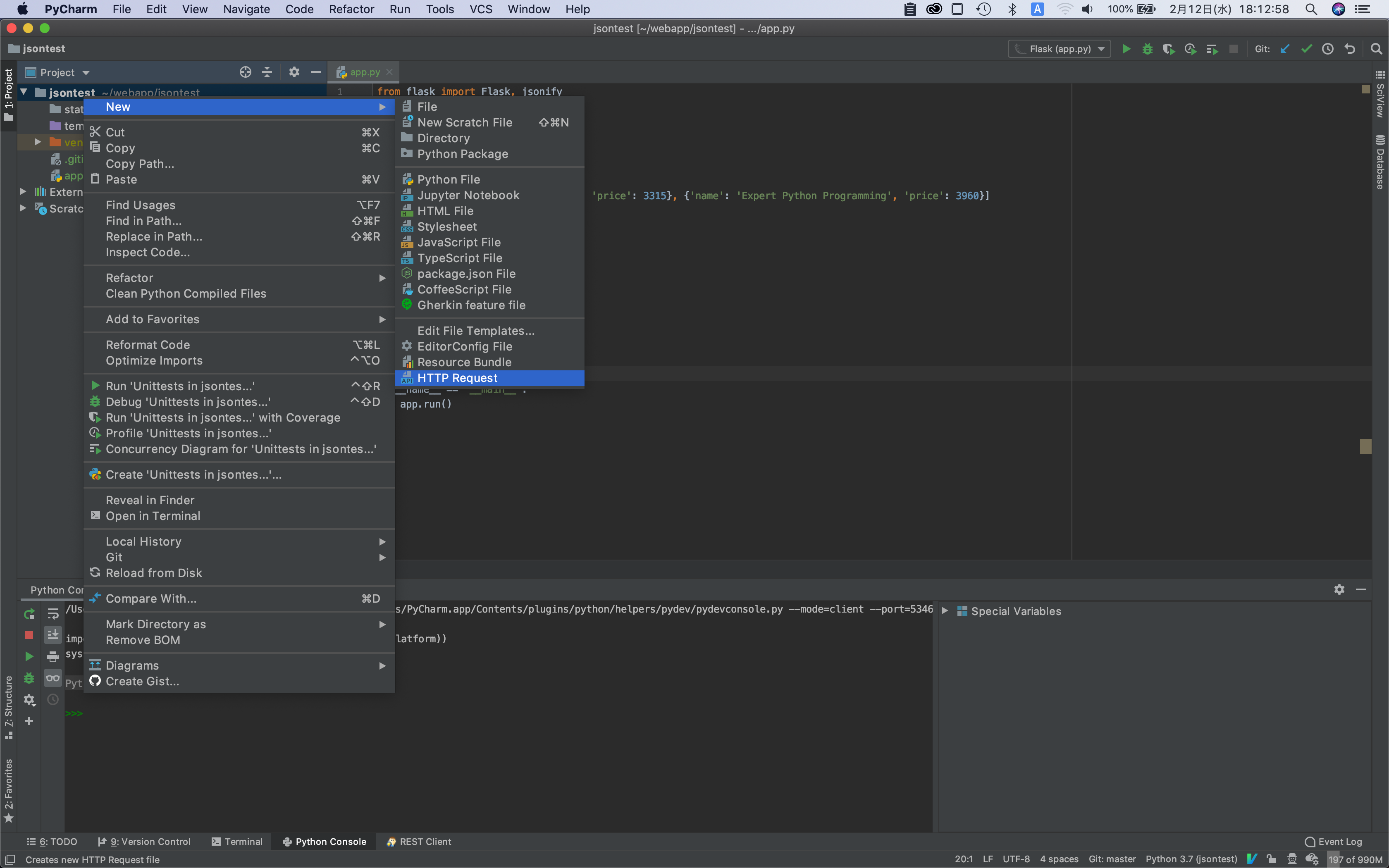
PyCharmのHTTPクライアントはその場かぎりのHTTPリクエストを送信する方法とファイルにHTTPリクエストをファイルに保存しそれを送信する方法の2つの方法が提供されている。今回は使い回しがきくHTTPリクエストをファイルに保存する方法を紹介する。
まずはファイルメニューからNewを選択いs、HTTP Requestをクリックする(下図)。
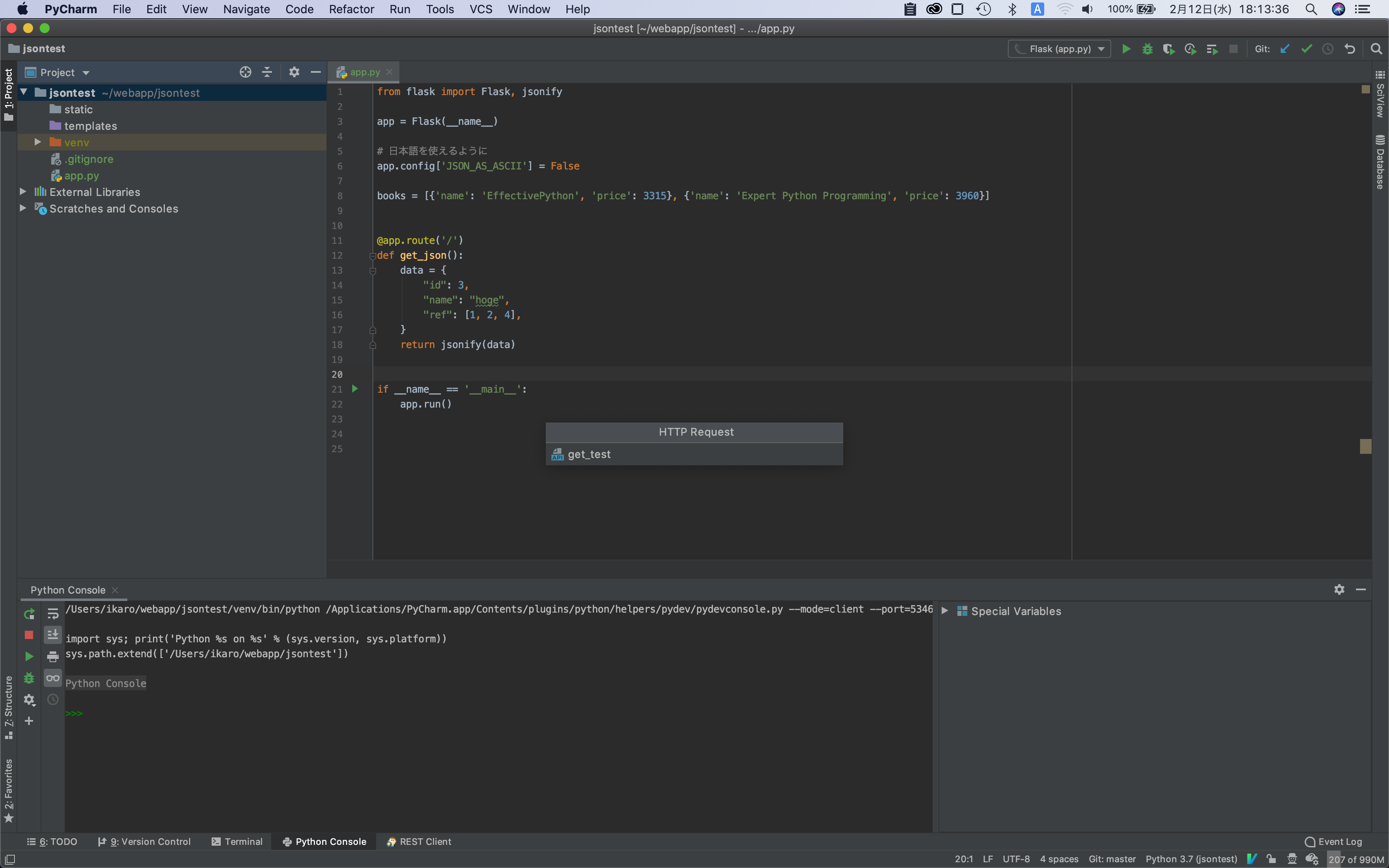
そうするとファイル名の記入を求められるので適当な名前を記入する(かきれいではget_test)。
今回はGETリクエストを送信するので右上の「Add Request」から「GET Request」を選択する(下図)。
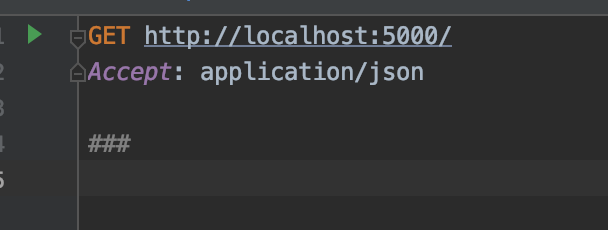
これでGETリクエストのテンプレートが挿入される。挿入されたテンプレートを今回にあわせて下記のように書き換える。
GET http://localhost:5000/ Accept: application/json ###これの意味はまず
GET http://localhost:5000/でGETリクエストを「http://localhost:5000/」に送ることを示している。
Accept: application/jsonは送るコンテンツタイプが「application/json」であることを示している(定型文なのであまり気にしなくても良い)。
###はPyCharmのHTTPClient独特の記法で複数のHTTPリクエストを書く場合のリクエストの区切りを示している。他にも色々と書くことができるが最低限は以上だ。他の機能については基本的にはHTTPヘッダの文法に則っている。各自調べてほしい。
次はこのリクエストを実際に送信してみよう。まずは先程のサンプルプログラムを実行する。その後、HTTPClientに戻り、エディタのGETの左にある緑色の▶(下図)をクリックすることでリクエストを送信できる。
そうすると下に実行結果が表示される。
POSTリクエストでJSONを受け取る
ここまではGETリクエストに対してJSONを送り返すという処理をしてきた。次はPOSTリクエストとそれに含まれるjsonを受け取るという処理を紹介する。
本体のプログラム(app.py)は下記のようにする。
from flask import Flask, request, jsonify app = Flask(__name__) # 日本語を使えるように app.config['JSON_AS_ASCII'] = False books = [{'name': 'EffectivePython', 'price': 3315}, {'name': 'Expert Python Programming', 'price': 3960}] @app.route('/books', methods=['POST']) def post_json(): # JSONを受け取る json = request.get_json() # JSONをパースする name = json['name'] price = json['price'] book = {'name': name, 'price': price} book_id = len(books) books.append(book) # 返却用ディクショナリを構築 book['id'] = book_id return jsonify(book) # JSONをレスポンス @app.route('/books/<book_id>', methods=['GET']) def get_json_from_dictionary(book_id): return jsonify(books[int(book_id)]) if __name__ == '__main__': app.run()また、リクエストのサンプルは下記である。
POST http://localhost:5000/books Content-Type: application/json { "name": "hoge", "price": 1000 } ### GET http://localhost:5000/books/2 Content-Type: application/json ###POSTリクエストを受け取った後、下記のようにget_jsonをつかうことでJSONをPythonのオブジェクトに変換することができる。
request.get_json()get_jsonで変換したオブジェクトはPythonのディクショナリやリストのように扱える(下記部分)。
# JSONをパースする name = json['name'] price = json['price']また、今まで解説してこなかったが同名であるもの、HTTPのメソッド(ここでのGETとPOST)が異なるURLを定義できる。WebAPI(とくにREST APIと呼ばれるもの)ではこのようなことをよく行う。これはGETの場合は取得する、POSTの場合は送信することを明示する意味がある。
問題
第1部5章の問題では商品の在庫管理システムを考えた。これの機能をWebAPIとして実装したい。商品の追加・削除・取得のためのWebAPIを実装せよ。DBを利用すること。今回は誘導のためほぼ第1部5章の問題と共通の部分が存在する。回答を流用しても良い。
- (商品ID,商品名,価格)をcolumとしてもつテーブルを作成せよ
- 商品の取得APIを実装せよ(/api/1.0/items/id)。取得なのでGETメソッドを利用すること。またidは可変である。商品ID,商品名,価格を含むJSONを返却すること。
- 商品の追加APIを実装せよ(/api/1.0/items)。追加なのでPOSTメソッドを利用すること。商品名,価格を含むJSONを送信したら、商品ID、商品名,価格を含むJSONを返却すること。
発展
- 商品の修正APIを作成せよ(/api/1.0/items/id)。更新であるのでPUTメソッドを利用すること。
- 商品の削除ページを作成せよ(/api/1.0/items/id)。削除であるのでDELETEメソッドを利用すること。
"多くの"であるだけですべてではない。過去にはhtmlに近いXMLというフォーマットが利用されていた。最近はより高速に通信が可能なgRPCというプロトコルも出てきている。 ↩

- 投稿日:2020-02-21T19:48:45+09:00
QRコード認識プログラム
はじめに
このページは,
の1ページです.
全体を見たい場合は上記ページへお戻りください.概要
OpenCVを使ってARマーカーを認識させたように,QRコードを認識させることもできます.
今回は,zbarライブラリを使ってQRコードを認識させ,Telloを制御します.
具体的には,以下の動画の様になります.
離着陸や移動などのコマンドをQRコードに変換して、Telloに見せるとそれ通りに動くプログラム。#tello pic.twitter.com/UJIBWog5rI
— hsgucci404 (@hsgucci404) October 30, 2019QRコードを生成するアプリを使って簡単なテキストメッセージを作り,それをTelloに見せると,その通りに動きます.
公式サンプル「Single_Tello_Test」ではcommand.txtを編集して飛行プランを作成しましたが,あれのQRコードバージョンになりますね.前提条件
ホームフォルダにTello-Pythonがインストールされているという前提で話を進めます.
Linuxマシンであれば
/home/(ユーザー名)/に,Tello-Pythonというフォルダがあることになります.詳しくは Tello-Pythonのダウンロード を御覧ください.
スマートフォン用QRコード生成アプリのインストール
一般的なQRコード関連のアプリは,カメラで「読み取る」機能しか持たないので,「QRコード生成」機能のあるアプリをインストールしましょう.
- QRコードリーダー”QRQR(クルクル)”
- QRコードの開発元である,デンソーウェーブ公式のアプリ.
- Clipbox QR
- 背景に画像を入れられるカラフルQRコードも作れるアプリ.
アプリの使い方 QRコードリーダー"クルクル"
1)アプリを起動したら,右下の[QRコードを作成]ボタンを押します.
2)[テキスト]を押します.
3)エディットボックスにQRコードにしたい文字を入力し,[QRコード生成]ボタンを押します.
4)例えば"TWbL"と入力すると,こんなQRコードが出来上がります.
アプリの使い方 Clipbox QR
1)アプリを起動したら,右下の[作成]ボタンを押します.
2)[新規作成]を押します.
3)[QRにしたいテキストを入力]の下のボックスにテキストを打ち込み,右上の[つくる]ボタンを押します.タイトルは不要です.
全角文字を入れると,Pythonプログラム側では文字化けしていました.文字コードの違いかな?
4)すると,この様なQRコードが生成されます.色を変える,背景画像を入れるなどのカスタマイズもできますが,認識率が下がります.
PythonでQRコードを読むライブラリの導入
Tello-PythonはPython2のプログラムなので,Python2で動作するQRコード読込ライブラリを使う必要があります.pyzbarはPython3用なので,今回はzbarを使用しました.
参考: OpenCVとZbarでバーコード・QRコード認識(Python)
ライブラリは,一般的な
pipではなくaptでインストールします.zbarライブラリの導入$ sudo apt install python-zbar作業ディレクトリの作成
まずは,Tello-CV-coreをコピーして,新しいプロジェクト(ディレクトリ)Tello-CV-qrを作ります.
Tello-CV-coreをディレクトリごとコピー$ cd ~/Tello-Python/ $ cp -R Tello-CV-core Tello-CV-qr $ cd Tello-CV-qrtello.pyとlibh264decoder.soのコピーの手間など考えると,フォルダごとコピーが一番楽ですね.
TelloでQRコードを読むだけのプログラム
まずは,Telloのカメラに写ったQRコードを検出し,コンソール画面にprintするだけのプログラムを作ります.
QRライブラリ「zbar」の動作確認,です.main_qr_read.py
プログラムはmain.pyに書き加える形で作成しました.別名で保存しています.
書き加えの手間を省くなら,以下のコードをコピー&ペーストするか,
ここ を右クリックして[名前を付けて保存]機能でファイル保存してください.main_qr_read.py#!/usr/bin/env python # -*- coding: utf-8 -*- import tello # tello.pyをインポート import time # time.sleepを使いたいので import cv2 # OpenCVを使うため import zbar # QRコードの認識 import numpy as np # 四角形ポリゴンの描画のために必要 # メイン関数 def main(): # Telloクラスを使って,droneというインスタンス(実体)を作る drone = tello.Tello('', 8889, command_timeout=1.0) time.sleep(0.5) # 通信が安定するまでちょっと待つ # zbarによるQRコード認識の準備 scanner = zbar.ImageScanner() scanner.parse_config('enable') current_time = time.time() # 現在時刻の保存変数 pre_time = current_time # 5秒ごとの'command'送信のための時刻変数 #Ctrl+cが押されるまでループ try: while True: # (A)画像取得 frame = drone.read() # 映像を1フレーム取得 if frame is None or frame.size == 0: # 中身がおかしかったら無視 continue # (B)ここから画像処理 image = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR) # OpenCV用のカラー並びに変換する small_image = cv2.resize(image, dsize=(480,360) ) # 画像サイズを半分に変更 # QRコード認識のための処理 gray_image = cv2.cvtColor(small_image, cv2.COLOR_BGR2GRAY) # zbarで認識させるために,グレイスケール画像にする rows, cols = gray_image.shape[:2] # 画像データから画像のサイズを取得(480x360) image = zbar.Image(cols, rows, 'Y800', gray_image.tostring()) # zbarのイメージへ変換 scanner.scan(image) # zbarイメージをスキャンしてQRコードを探す # スキャン結果はimageに複数個入っているので,for文でsymbolという名で取り出して繰り返す for symbol in image: qr_type = symbol.type # 認識したコードの種別 qr_msg = symbol.data # QRコードに書かれたテキスト qr_positions = symbol.location # QRコードを囲む矩形の座標成分 print('QR code : %s, %s, %s'%(qr_type, qr_msg, str(qr_positions)) ) # 認識結果を表示 # 認識したQRコードを枠線で囲む pts = np.array( qr_positions ) # NumPyのarray形式にする cv2.polylines(small_image, [pts], True, (0,255,0), thickness=3) # ポリゴンを元のカラー画像に描画 del image # zbarイメージの削除 # (X)ウィンドウに表示 cv2.imshow('OpenCV Window', small_image) # ウィンドウに表示するイメージを変えれば色々表示できる # (Y)OpenCVウィンドウでキー入力を1ms待つ key = cv2.waitKey(1) if key == 27: # k が27(ESC)だったらwhileループを脱出,プログラム終了 break elif key == ord('t'): drone.takeoff() # 離陸 elif key == ord('l'): flag = 0 drone.land() # 着陸 # (Z)14秒おきに'command'を送って、死活チェックを通す current_time = time.time() # 現在時刻を取得 if current_time - pre_time > 14.0 : # 前回時刻から14秒以上経過しているか? drone.send_command('command') # 'command'送信 pre_time = current_time # 前回時刻を更新 except( KeyboardInterrupt, SystemExit): # Ctrl+cが押されたら離脱 print( "SIGINTを検知" ) # telloクラスを削除 del drone # "python main.py"として実行された時だけ動く様にするおまじない処理 if __name__ == "__main__": # importされると"__main__"は入らないので,実行かimportかを判断できる. main() # メイン関数を実行プログラムの実行
プログラム本体はmain_qr_read.pyです.
プログラムの実行$ python main_qr_read.py今までと同様に
ctrl+cを押すことで,プログラムを終了することもできますが,
OpenCVが作ったウィンドウでESCキーを押して終了するのが良いでしょう.QRコードの読込テストは,飛ばす必要がありません.
Telloを手で持ってQRコードを見せてあげましょう.実行結果
前述のQRコード生成アプリで, TWbWfWL というテキストのQRコードを作り,Telloに見せてみました.
問題なく動作すれば,以下の様になるはずです.
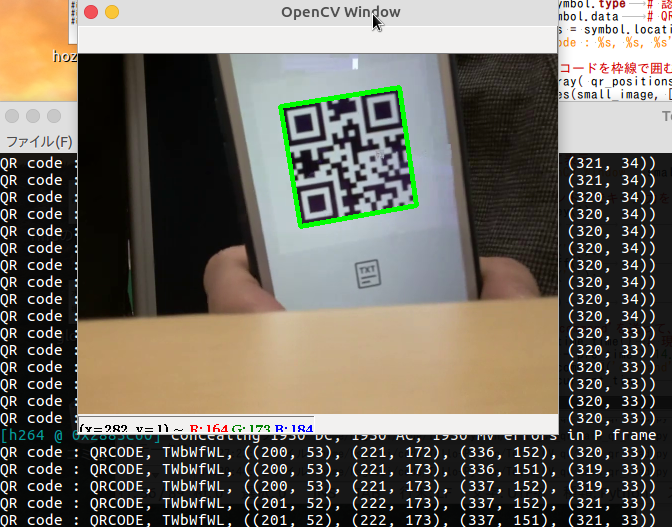
QRコードを認識すると,OpenCVの画像ウィンドウでは,緑色の枠で囲んでいます.
また,後ろのウィンドウでは,バーコードの種類:QRCODE
中身のテキスト:TWbWfWL
バーコードの座標:四隅の座標が表示されているのがわかります.
この TWbWfWL というテキストは,
離陸(TakeoffのT),ウェイト(WaitのW)などの意味に対応させています.
次のサンプルプログラムの際に説明します.main_qr_read.pyの解説
スケルトンプログラムに肉を付ける形で書いているので,スケルトンと同じ部分は割愛します.
import部分
まずはインポート部分です。
インポートimport tello # tello.pyをインポート import time # time.sleepを使いたいので import cv2 # OpenCVを使うため import zbar # QRコードの認識 import numpy as np # 四角形ポリゴンの描画のために必要zbarとnumpyが増えています.
QRコードの認識のためにzbarをインポートしています.
numpyはnpというニックネームで使います(numpyでよくある書き方).
numpyは,QRコードを認識した四角形を色線で囲む際に使用しただけです.メイン関数
メイン関数の中身は大きく分けて3つの部分に分かれています.
「初期化」「ループ」「終了処理」です.メイン関数# メイン関数本体 def main(): 初期化部 ループ部 終了処理部それぞれ解説していきます.
初期化部
初期化処理部# Telloクラスを使って,droneというインスタンス(実体)を作る drone = tello.Tello('', 8889, command_timeout=1.0) time.sleep(0.5) # 通信が安定するまでちょっと待つ # zbarによるQRコード認識の準備 scanner = zbar.ImageScanner() scanner.parse_config('enable') current_time = time.time() # 現在時刻の保存変数 pre_time = current_time # 5秒ごとの'command'送信のための時刻変数Telloクラスの呼び出し時の引数を
command_timeout=1.0としました.(デフォルト値は0.3秒)
ジョイスティック操作のときは.01にして,Telloの応答を待たずにすぐ次のコマンドを送信できるようにしていました.
今回は逆に「移動完了するまで,ゆっくり待つ」という意図で1.0秒と長くしています.また,5秒おきに
commandを送信する機能も付けました.
今回はQRコードの認識画面を出すだけのプログラムなので,Telloの15秒ルールを回避する必要があります.ループ部
while Trueで永久ループを作り,ctrl+cの検知をtry exceptでやるのは今までと同様です.Tello-CV-coreスケルトンと異なる点は,永久ループ内の(B),(Y)ブロックのみです.
まずは(B)ブロックから解説します.永久ループ内 (B)ブロック# (B)ここから画像処理 image = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR) # OpenCV用のカラー並びに変換する small_image = cv2.resize(image, dsize=(480,360) ) # 画像サイズを半分に変更 # QRコード認識のための処理 gray_image = cv2.cvtColor(small_image, cv2.COLOR_BGR2GRAY) # (1)zbarで認識させるために,グレイスケール画像にする rows, cols = gray_image.shape[:2] # 画像データから画像のサイズを取得(480x360) image = zbar.Image(cols, rows, 'Y800', gray_image.tostring()) # (2)zbarのイメージへ変換 scanner.scan(image)Tello-CV-coreスケルトンと異なる点は,永久ループ内の(B),(Y)ブロックのみです. まずは(B)ブロックから解説します. # (3)zbarイメージをスキャンしてQRコードを探す # (4)スキャン結果はimageに複数個入っているので,for文でsymbolという名で取り出して繰り返す for symbol in image: qr_type = symbol.type # 認識したコードの種別 qr_msg = symbol.data # QRコードに書かれたテキスト qr_positions = symbol.location # QRコードを囲む矩形の座標成分 print('QR code : %s, %s, %s'%(qr_type, qr_msg, str(qr_positions)) ) # 認識結果を表示 # 認識したQRコードを枠線で囲む pts = np.array( qr_positions ) # NumPyのarray形式にする cv2.polylines(small_image, [pts], True, (0,255,0), thickness=3) # ポリゴンを元のカラー画像に描画 del image # zbarイメージの削除zbarでQRコードを認識させる場合,以下の手続きを毎回行うだけです.
(1)グレイスケール画像を作る
(2)zbarイメージを作る
(3)scannerにzbarイメージを放り込んで解析
(4)解析結果をsymbolとして処理(1)はOpenCVの関数cv2.cvtColorでBGR画像をグレイスケールに変換しています.
なので引数はcv2.COLOR_BGR2GRAYです.(2)では,zbar用のイメージを作る際に画像サイズが必要です.
まずはrows, cols = gray_image.shape[:2]で画像から情報を取り出しています.
shape配列の左から2つ分の要素を,rowsとcolsにそれぞれ代入する,という意味です.
Python & OpenCVでは,よく使われるテクニックです.
参考:Python + OpenCVでの画像サイズ取得方法その後,
image = zbar.Image(cols, rows, 'Y800', gray_image.tostring())でzbarイメージに変換し,imageへ代入しています.
Y800は,8ビットグレイスケール画像を意味しています.
輝度・色差画像のYUVから,輝度のYが8ビット(256段階)でY8,色差のUとVがゼロなので00,という概念です.
参考:データフォーマット(3)では,定型文で
scanner.scan(image)と書くだけで解析を開始してくれます.
解析結果はimageに格納されて,次の工程で使います.(4)では,解析結果がimageの中に入っているので,for文でsymbolという名前を付けて取り出しています.
画像中に複数個のQRコードがある可能性もあるので,forで複数回ループを回す必要があるのです.symbolの中には,バーコードの種類を示す
type,書き込まれているテキストメッセージを示すdata,画像中のどこにバーコードがあったかの座標データlocationなどの情報が入っています.参考:OpenCV、Python、およびzbarを使用して単一のQRコードを検出する方法
今回はそれぞれの情報を
実行結果を見てもらうと分かるように,Telloから来た画像を毎回(毎ループ)QRコード認識にかけているので,認識結果がズラーーーーーっと連続出力されています.
最後に,作ったzbarイメージクラスをdelで殺しています.
次は(Y)ブロックの解説です.永久ループ内 (Y)ブロック# (Y)OpenCVウィンドウでキー入力を1ms待つ key = cv2.waitKey(1) if key == 27: # k が27(ESC)だったらwhileループを脱出,プログラム終了 break elif key == ord('t'): drone.takeoff() # 離陸 elif key == ord('l'): flag = 0 drone.land() # 着陸これは簡単ですね.離陸と着陸だけに減らしました.飛ばす必要がないので.
QRコードに書かれた文字に従って飛行するプログラム
前述のプログラムで,QRコードに含まれたテキストを抽出することができるようになりました.
次は,テキストに書かれた内容を理解してTelloを動かす処理を行います.
具体的には,以下の文字を使います.
文字 略語 意味 T Takeoff 離陸 L Land 着陸 f forward 前進 b back 後進 r right 右移動 l left 左移動 u up 上昇 d down 下降 w clock-wise(cw) 時計回り(右旋回) c counter-clock-wise(ccw) 反時計回り(左旋回) W Wait 待ち時間 書き方ルール
- 半角文字で書くこと.全角は禁止
- 空白などの無関係な文字は入れないこと.
- 最後にLを必ず書くこと.着陸で終わらないとエラーになります.
例えば,このQRコードのテキストの意味がわかるでしょうか.
T(離陸) - W(ウェイト) - b(後進) - W(ウェイト) - f(前進) - W(ウェイト) - L(着陸)という,一連の動きを書いています.
もう1つ例を.
T(Takeoff) - b(back) - u(up) - f(forward) - d(down) - l(left) - u(up)
- r(right) - d(down) - c(ccw) - f(forward) - w(cw) - b(back) - L(Land)
-
です.イメージできたでしょうか?これは,Tello-Pythonのサンプル「Single_Tello_Test」 で記述するテキストファイルと同じような発想です.
こうやってQRコードを作り,Telloに見せることで,一連の動作を実施させるわけです.
main_qr_control.py
プログラムはmain_qr_read.pyに書き加える形で作成しました.別名で保存しています.
書き加えの手間を省くなら,以下のコードをコピー&ペーストするか,
ここ を右クリックして[名前を付けて保存]機能でファイル保存してください.main_qr_control.py#!/usr/bin/env python # -*- coding: utf-8 -*- import tello # tello.pyをインポート import time # time.sleepを使いたいので import cv2 # OpenCVを使うため import zbar # QRコードの認識 # メイン関数 def main(): # Telloクラスを使って,droneというインスタンス(実体)を作る drone = tello.Tello('', 8889, command_timeout=10.0) time.sleep(0.5) # 通信が安定するまでちょっと待つ # zbarによるQRコード認識の準備 scanner = zbar.ImageScanner() scanner.parse_config('enable') pre_qr_msg = None # 前回見えたQRコードのテキストを格納 count = 0 # 同じテキストが見えた回数を記憶する変数 commands = None # 認識したQRコードをTelloのコマンドとして使う command_index = 0 # 実行するコマンドの番号 flag = 0 # 自動制御のフラグは初期0 current_time = time.time() # 現在時刻の保存変数 pre_time = current_time # 5秒ごとの'command'送信のための時刻変数 #Ctrl+cが押されるまでループ try: while True: # (A)画像取得 frame = drone.read() # 映像を1フレーム取得 if frame is None or frame.size == 0: # 中身がおかしかったら無視 continue # (B)ここから画像処理 image = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR) # OpenCV用のカラー並びに変換する small_image = cv2.resize(image, dsize=(480,360) ) # 画像サイズを半分に変更 # 自動制御フラグが0FF(=0)のときには,QRコード認識処理を行う if flag == 0: # QRコード認識のための処理 gray_image = cv2.cvtColor(small_image, cv2.COLOR_BGR2GRAY) # zbarで認識させるために,グレイスケール画像にする rows, cols = gray_image.shape[:2] # 画像データから画像のサイズを取得(480x360) image = zbar.Image(cols, rows, 'Y800', gray_image.tostring()) # zbarのイメージへ変換 scanner.scan(image) # zbarイメージをスキャンしてQRコードを探す # 一度に2つ以上のQRコードを見せるのはNG for symbol in image: qr_msg = symbol.data # 50回同じQRコードが見えたらコマンド送信する処理 try: if qr_msg != None: # qr_msgが空(QRコードが1枚も認識されなかった)場合は何もしない if qr_msg == pre_qr_msg: # 今回認識したqr_msgが前回のpre_qr_msgと同じ時には処理 count+=1 # 同じQRコードが見えてる限りはカウンタを増やす if count > 50: # 50回同じQRコードが続いたら,コマンドを確定する print('QR code 認識 : %s' % (qr_msg) ) commands = qr_msg command_index = 0 flag = 1 # 自動制御を有効にする count = 0 # コマンド送信したらカウント値をリセット else: count = 0 pre_qr_msg = qr_msg # 前回のpre_qr_msgを更新する else: count = 0 # Telloクラスを使って,droneというインスタンス(実体)を作る drone = tello.Tello('', 8889, command_timeout=.01) current_time = time.time() # 現在時刻の保存変数 pre_time = current_time # 5秒ごとの'command'送信のための時刻変数 time.sleep(0.5) # 通信が安定するまでちょっと待つ # 何も見えなくなったらカウント値をリセット except ValueError, e: # if ids != None の処理で時々エラーが出るので,try exceptで捕まえて無視させる print("ValueError") del image # 自動制御フラグがON(=1)のときは,コマンド処理だけを行う if flag == 1: print commands[command_index] key = commands[command_index] # commandsの中には'TLfblrudwcW'のどれかの文字が入っている if key == 'T': drone.takeoff() # 離陸 time.sleep(5) elif key == 'L': flag = 0 drone.land() # 着陸 time.sleep(4) elif key == 'u': drone.move_up(0.5) # 上昇 elif key == 'd': drone.move_down(0.5) # 下降 elif key == 'c': drone.rotate_ccw(20) # 左旋回 elif key == 'w': drone.rotate_cw(20) # 右旋回 elif key == 'f': テキストdrone.move_forward(0.5) # 前進 elif key == 'b': drone.move_backward(0.5) # 後進 elif key == 'l': drone.move_left(0.5) # 左移動 elif key == 'r': drone.move_right(0.5) # 右移動 elif key == 'W': time.sleep(5) # ウェイト command_index += 1 pre_time = time.time() # (X)ウィンドウに表示 cv2.imshow('OpenCV Window', gray_image) # ウィンドウに表示するイメージを変えれば色々表示できる # (Y)OpenCVウィンドウでキー入力を1ms待つ key = cv2.waitKey(1) if key == 27: # k が27(ESC)だったらwhileループを脱出,プログラム終了 break elif key == ord('t'): drone.takeoff() # 離陸 elif key == ord('l'): flag = 0 drone.land() # 着陸 # (Z)14秒おきに'command'を送って、死活チェックを通す current_time = time.time() # 現在時刻を取得 if current_time - pre_time > 14.0 : # 前回時刻から14秒以上経過しているか? drone.send_command('command') # 'command'送信 pre_time = current_time # 前回時刻を更新 except( KeyboardInterrupt, SystemExit): # Ctrl+cが押されたら離脱 print( "SIGINTを検知" ) テキスト # telloクラスを削除 del drone # "python main.py"として実行された時だけ動く様にするおまじない処理 if __name__ == "__main__": # importされると"__main__"は入らないので,実行かimportかを判断できる. main() # メイン関数を実行プログラムの実行
プログラム本体はmain_qr_control.pyです.
プログラムの実行$ python main_qr_control.py今までと同様に
ctrl+cを押すことで,プログラムを終了することもできますが,
OpenCVが作ったウィンドウでESCキーを押して終了するのが良いでしょう.実行結果
QRコードを作ってTelloに見せれば,以下の動画のようになるはずです.
離着陸や移動などのコマンドをQRコードに変換して、Telloに見せるとそれ通りに動くプログラム。#tello pic.twitter.com/UJIBWog5rI
— hsgucci404 (@hsgucci404) October 30, 2019main_qr_control.pyの解説
前回のmain_qr_read.pyと異なる部分だけ解説します.
import部分
まずはインポート部分です。
インポートimport tello # tello.pyをインポート import time # time.sleepを使いたいので import cv2 # OpenCVを使うため import zbar # QRコードの認識今回はNumPyを使わないので,インポートしていません.
メイン関数
メイン関数の中身は大きく分けて3つの部分に分かれています.
「初期化」「ループ」「終了処理」です.メイン関数# メイン関数本体 def main(): 初期化部 ループ部 終了処理部それぞれ解説していきます.
初期化部
初期化処理部# Telloクラスを使って,droneというインスタンス(実体)を作る drone = tello.Tello('', 8889, command_timeout=10.0) time.sleep(0.5) # 通信が安定するまでちょっと待つ # zbarによるQRコード認識の準備 scanner = zbar.ImageScanner() scanner.parse_config('enable') pre_qr_msg = None # 前回見えたQRコードのテキストを格納 count = 0 # 同じテキストが見えた回数を記憶する変数 commands = None # 認識したQRコードをTelloのコマンドとして使う command_index = 0 # 実行するコマンドの番号 flag = 0 # 自動制御のフラグは初期0 current_time = time.time() # 現在時刻の保存変数 pre_time = current_time # 5秒ごとの'command'送信のための時刻変数Telloクラスの呼び出し時の引数を
command_timeout=10.0としました.(先ほどは1.0秒)
長距離の移動をする場合もあるので「もっとゆっくり待つ」という意図で10.0秒と長くしています.
これを短くし過ぎると,上昇や移動が終わる前に次の動作を行ってしまいます.また,コマンドを理解して制御を行うための変数が増えています.
各変数の使いみちは,ループ部で解説します.ループ部
while Trueで永久ループを作り,ctrl+cを検知をtry exceptでやるのは今までと同様です.main_qr_read.pyと異なる点は,永久ループ内の(B)ブロックのみです.
(B)ブロックは,Telloの画像を取り込んだ後,大きく分けて2つの流れが存在しています.フラグによる処理の分岐# (B)ここから画像処理 image = cv2.cvtColor(frame, cv2.COLOR_RGB2BGR) # OpenCV用のカラー並びに変換する small_image = cv2.resize(image, dsize=(480,360) ) # 画像サイズを半分に変更 # 自動制御フラグが0FF(=0)のときには,QRコード認識処理を行う if flag == 0: (QRコードからテキストを抽出し,flag=1とする) # 自動制御フラグがON(=1)のときは,コマンド処理だけを行う if flag == 1: (テキストに従ってコマンドを実行し,着陸するとflag=0とする)以上のように,「QRコードの認識」と「一連のコマンドの実行」が交互に行われていることがわかると思います.
次は,それぞれの中身を解説します.
QRコード認識部# 自動制御フラグが0FF(=0)のときには,QRコード認識処理を行う if flag == 0: # QRコード認識のための処理 gray_image = cv2.cvtColor(small_image, cv2.COLOR_BGR2GRAY) # zbarで認識させるために,グレイスケール画像にする rows, cols = gray_image.shape[:2] # 画像データから画像のサイズを取得(480x360) image = zbar.Image(cols, rows, 'Y800', gray_image.tostring()) # zbarのイメージへ変換 scanner.scan(image) # zbarイメージをスキャンしてQRコードを探す # 一度に2つ以上のQRコードを見せるのはNG for symbol in image: qr_msg = symbol.data # 50回同じQRコードが見えたらコマンド送信する処理 try: if qr_msg != None: # qr_msgが空(QRコードが1枚も認識されなかった)場合は何もしない if qr_msg == pre_qr_msg: # 今回認識したqr_msgが前回のpre_qr_msgと同じ時には処理 count+=1 # 同じQRコードが見えてる限りはカウンタを増やす if count > 50: # 50回同じQRコードが続いたら,コマンドを確定する print('QR code 認識 : %s' % (qr_msg) ) commands = qr_msg command_index = 0 flag = 1 # 自動制御を有効にする count = 0 # コマンド送信したらカウント値をリセット else: count = 0 pre_qr_msg = qr_msg # 前回のpre_qr_msgを更新する else: count = 0 # 何も見えなくなったらカウント値をリセット except ValueError, e: # if ids != None の処理で時々エラーが出るので,try exceptで捕まえて無視させる print("ValueError") del imageQRコードの解析処理を行い,
symbolという変数で処理するまでは,main_qr_read.pyと同じです.
その後は,ARマーカー でやったのと同様に,「同じQRコードが50回見えたらコマンドを実行する」ようにしました.
「1回見えたら即実行」も試しましたが,Telloに見せてすぐに動き始めるのが少し怖かったので,
「Telloに見せて1呼吸おいたら動き始める」という動作にしました.
心の準備用です(^_^;同じテキストを50回認識すると,以下の手続きを行って,自動制御モードへ移行します.
必要な情報をセットするcommands = qr_msg # QRコードのテキストをcommands変数にコピー command_index = 0 # コマンド読込位置は最初(0)から flag = 1 # 自動制御を有効にする自動制御モードでは,commandsに書かれた一連の動作処理を都度実行していきます.
一連のコマンドの実行# 自動制御フラグがON(=1)のときは,コマンド処理だけを行う if flag == 1: print commands[command_index] key = commands[command_index] # commandsの中には'TLfblrudwcW'のどれかの文字が入っている if key == 'T': drone.takeoff() # 離陸 time.sleep(5) elif key == 'L': flag = 0 drone.land() # 着陸 time.sleep(4) elif key == 'u': drone.move_up(0.5) # 上昇 elif key == 'd': drone.move_down(0.5) # 下降 elif key == 'c': drone.rotate_ccw(20) # 左旋回 elif key == 'w': drone.rotate_cw(20) # 右旋回 elif key == 'f': drone.move_forward(0.5) # 前進 elif key == 'b': drone.move_backward(0.5) # 後進 elif key == 'l': drone.move_left(0.5) # 左移動 elif key == 'r': drone.move_right(0.5) # 右移動 elif key == 'W': time.sleep(5) # ウェイト command_index += 1 pre_time = time.time()
key = commands[command_index]で一文字取り出し,その文字に従ってTelloにコマンドを送ります.
その後command_index += 1するので,次回このループに入ったときは,次のコマンドが実行されるのです.自動制御モードの終了条件は,
着陸コマンドで,フラグを倒し自動制御を終了するelif key == 'L': flag = 0 drone.land() # 着陸 time.sleep(4)着陸コマンドの実行時になっているので,QRコードには必ずLを書く必要があります.
この問題は,
commandsの文字列の長さを調べて,その長さまでcommand_indexがきたらflag=0にする処理を書けば解決できます.
これをやれば,飛行中に次のQRコードを見せることができますね.おわりに
今回は,zbarを使ってQRコードを認識し,そこに書かれた飛行計画テキストに従ってTelloを動かしました.
このようなちょっと変わった使い方も面白いですね.一般的に移動ロボットやドローンでQRコードを使う例は,「ロボットの自己位置の検出」です.
(x,y)を意味する"A1"(A,1)や"D8"(D,8)といったテキストを埋め込んだQRコードを,部屋や廊下に貼ります.
それを見たロボットは,自分が今どこにいるのかを認識できます.
近年は,レーザースキャナーやデプスカメラを使って自己位置を推定する「SLAM」がセオリーですが,
一昔前はQRコードを貼りまくる時代もあったのです.






- 投稿日:2020-02-21T19:05:32+09:00
RealSenseD400シリーズでキャプチャした点群を.plyとして保存する
はじめに
TouchDesingerで点群が使えるようになったらしい。
Point File In TOP, you can read data from a large number of supported file formats (.xyz .obj .exr .pts .ply .FITS/.FIT .csv .txt)
Point Cloudだよ @sotongshi さん。次のTouchDesignerもくもく会はこれだね! #kuma_td / 2020 Official Update | Derivative https://t.co/dusiV23hdH
— まこらぎ (@makoragi) February 20, 2020
作れるよ!
PythonでRealSenseD400シリーズ入門(Windows10、Python3.6)のexport_ply_example.pyでも可能です。
開発環境
ハードウェア
- Windows 10 PC
- RealSense D435
ソフトウェア
- Python 3.6
- pyrealsense2 2.26.0.1053
- open3d-python 0.7.0.0
- opencv-contrib-python 4.1.2.30
- opencv-python 4.1.0.25
- numpy 1.16.4
- open3d 0.9.0.0 (追記)
ソースコード
open3d-python 0.7.0.0を用いた場合。※追記のopen3d 0.9.0.0を用いたほうがよさそう。
$ pip install open3d-pythonexport_ply_example_2.py# First import the library import pyrealsense2 as rs # Import Numpy for easy array manipulation import numpy as np # Import OpenCV for easy image rendering import cv2 # Import Open3D for easy 3d processing from open3d import * # Create a pipeline pipeline = rs.pipeline() #Create a config and configure the pipeline to stream # different resolutions of color and depth streams config = rs.config() config.enable_stream(rs.stream.depth, 640, 480, rs.format.z16, 30) config.enable_stream(rs.stream.color, 640, 480, rs.format.bgr8, 30) # Start streaming profile = pipeline.start(config) # Getting the depth sensor's depth scale (see rs-align example for explanation) depth_sensor = profile.get_device().first_depth_sensor() depth_scale = depth_sensor.get_depth_scale() print("Depth Scale is: " , depth_scale) # We will be removing the background of objects more than # clipping_distance_in_meters meters away clipping_distance_in_meters = 1 #1 meter clipping_distance = clipping_distance_in_meters / depth_scale # Create an align object # rs.align allows us to perform alignment of depth frames to others frames # The "align_to" is the stream type to which we plan to align depth frames. align_to = rs.stream.color align = rs.align(align_to) # Getting camera intrinsics intr = profile.get_stream(rs.stream.color).as_video_stream_profile().get_intrinsics() pinhole_camera_intrinsic = PinholeCameraIntrinsic(intr.width, intr.height, intr.fx, intr.fy, intr.ppx, intr.ppy) # Streaming loop num = 0 try: while True: # Get frameset of color and depth frames = pipeline.wait_for_frames() # Align the depth frame to color frame aligned_frames = align.process(frames) # Get aligned frames color_frame = aligned_frames.get_color_frame() depth_frame = aligned_frames.get_depth_frame() # Validate that both frames are valid if not depth_frame or not color_frame: continue color_image = np.asanyarray(color_frame.get_data()) color = Image(color_image) depth_image = np.asanyarray(depth_frame.get_data()) depth_image = (depth_image < clipping_distance) * depth_image depth = Image(depth_image) # Remove background - Set pixels further than clipping_distance to grey grey_color = 153 depth_image_3d = np.dstack((depth_image,depth_image,depth_image)) #depth image is 1 channel, color is 3 channels bg_removed = np.where((depth_image_3d > clipping_distance) | (depth_image_3d <= 0), grey_color, color_image) # Generate the pointcloud and texture mappings rgbd = create_rgbd_image_from_color_and_depth(color, depth, convert_rgb_to_intensity = False) pcd = create_point_cloud_from_rgbd_image(rgbd, pinhole_camera_intrinsic) # Render images depth_colormap = cv2.applyColorMap(cv2.convertScaleAbs(depth_image, alpha=0.03), cv2.COLORMAP_JET) images = np.hstack((bg_removed, depth_colormap)) cv2.namedWindow('aligned_frame', cv2.WINDOW_AUTOSIZE) cv2.imshow('aligned_frame', images) key = cv2.waitKey(1) # Press 's' to save the point cloud if key & 0xFF == ord('s'): print("Saving to {0}.ply...".format(num)) write_point_cloud('{0}.ply'.format(num), pcd) print("Done") num += 1 # Press esc or 'q' to close the image window elif key & 0xFF == ord('q') or key == 27: cv2.destroyAllWindows() break finally: pipeline.stop()実行
's'キーを押すとキャプチャして.plyで保存します。
'q'キーかescで終了します。RealSenseでキャプチャして.plyでエクスポートするやつ #RealSense #D435 #3D #Python #OpenCV #Open3D pic.twitter.com/vj3jdQx7Bu
— 藤本賢志(ガチ本)@HoloLens2 Ready (@sotongshi) February 21, 2020お疲れ様でした。
追記(メッシュで保存してみた)
RealSense D435iで3Dスキャナもどきの実装を参考にします。
open3D 0.9.0.0を用います。open3dとopen3d-python... ややこしいですね。open3dで統一したほうがよさそう。
$ pip install open3dexport_ply_examples_3.py# First import the library import pyrealsense2 as rs # Import Numpy for easy array manipulation import numpy as np # Import OpenCV for easy image rendering import cv2 # Import Open3D for easy 3d processing import open3d as o3d # Create a pipeline pipeline = rs.pipeline() #Create a config and configure the pipeline to stream # different resolutions of color and depth streams config = rs.config() config.enable_stream(rs.stream.depth, 640, 480, rs.format.z16, 30) config.enable_stream(rs.stream.color, 640, 480, rs.format.bgr8, 30) # Start streaming profile = pipeline.start(config) # Getting the depth sensor's depth scale (see rs-align example for explanation) depth_sensor = profile.get_device().first_depth_sensor() depth_scale = depth_sensor.get_depth_scale() print("Depth Scale is: " , depth_scale) # We will be removing the background of objects more than # clipping_distance_in_meters meters away clipping_distance_in_meters = 1 #1 meter clipping_distance = clipping_distance_in_meters / depth_scale # Create an align object # rs.align allows us to perform alignment of depth frames to others frames # The "align_to" is the stream type to which we plan to align depth frames. align_to = rs.stream.color align = rs.align(align_to) # Getting camera intrinsics intr = profile.get_stream(rs.stream.color).as_video_stream_profile().get_intrinsics() pinhole_camera_intrinsic = o3d.camera.PinholeCameraIntrinsic(intr.width, intr.height, intr.fx, intr.fy, intr.ppx, intr.ppy) # Streaming loop num = 0 try: while True: # Get frameset of color and depth frames = pipeline.wait_for_frames() # Align the depth frame to color frame aligned_frames = align.process(frames) # Get aligned frames color_frame = aligned_frames.get_color_frame() depth_frame = aligned_frames.get_depth_frame() # Validate that both frames are valid if not depth_frame or not color_frame: continue color_image = np.asanyarray(color_frame.get_data()) color = o3d.geometry.Image(color_image) depth_image = np.asanyarray(depth_frame.get_data()) depth_image = (depth_image < clipping_distance) * depth_image depth = o3d.geometry.Image(depth_image) # Remove background - Set pixels further than clipping_distance to grey grey_color = 153 depth_image_3d = np.dstack((depth_image,depth_image,depth_image)) #depth image is 1 channel, color is 3 channels bg_removed = np.where((depth_image_3d > clipping_distance) | (depth_image_3d <= 0), grey_color, color_image) # Generate the pointcloud and texture mappings rgbd = o3d.geometry.RGBDImage.create_from_color_and_depth(color, depth, convert_rgb_to_intensity = False) pcd = o3d.geometry.PointCloud.create_from_rgbd_image(rgbd, pinhole_camera_intrinsic) # Rotate pcd.transform([[1, 0, 0, 0], [0, -1, 0, 0], [0, 0, -1, 0], [0, 0, 0, 1]]) # Estimate Normal pcd.estimate_normals() # Voxel voxel = pcd.voxel_down_sample(voxel_size=0.01) dist = np.mean(voxel.compute_nearest_neighbor_distance()) radius = 1.5 * dist # Mesh mesh = o3d.geometry.TriangleMesh.create_from_point_cloud_ball_pivoting(voxel, o3d.utility.DoubleVector([radius, radius * 2])) # Render images depth_colormap = cv2.applyColorMap(cv2.convertScaleAbs(depth_image, alpha=0.03), cv2.COLORMAP_JET) images = np.hstack((bg_removed, depth_colormap)) cv2.namedWindow('aligned_frame', cv2.WINDOW_AUTOSIZE) cv2.imshow('aligned_frame', images) key = cv2.waitKey(1) # Press 's' to save the point cloud if key & 0xFF == ord('s'): print("Saving to {0}.ply...".format(num)) o3d.io.write_point_cloud('pcd-{0}.ply'.format(num), pcd) o3d.io.write_triangle_mesh('mesh-{0}.ply'.format(num), mesh) print("Done") num += 1 # Press esc or 'q' to close the image window elif key & 0xFF == ord('q') or key == 27: cv2.destroyAllWindows() break finally: pipeline.stop()
- 投稿日:2020-02-21T18:50:04+09:00
SublimeText3でLaTeXとR(ちょこっとPython)の環境構築
SublimeText3でLaTeXとR(ちょこっとPython)
を使いやすくするはじめに
自分のメモ用です。意外にSublimeでのTeXについてまとめられているサイトを見ないと思ったので、
自分が設定した環境(友人Jの丸パクリ)について書いてみようと思いました。SublimeText3で、LaTeXとR (ちょっとPython) を使いやすくするための一連の設定手順を記載します。
Sublimeは適宜再起動するようにしてください。準備するソフトウェア
- Sublime Text 3
- TeXLive 2019
- SumatraPDF
- R-3.6.2
ソフトウェアの準備手順
TeXLive 2019
TeX Live - TeX Wiki を参考にしながらTeX Liveをインストールします。
Windowsの場合、 TeX Live/Windows - TeX Wiki を参考に、インストーラをダウンロードします。
著者はネットワークインストーラの場合を参考に、 Installing TeX Live over the Internet のinstall-tl-windows.exeを利用してTeXLive 2019をインストールしました。正常にインストールできているかの確認として、
Windowsキー + Rを押し、cmdと入力、コマンドプロンプトを起動します。コマンドラインにlatexmkと入力した際、以下のような反応があればインストールは成功です。C:\Users\(User名)>latexmk Latexmk: This is Latexmk, John Collins, 26 Dec. 2019, version: 4.67. Latexmk: No file name specified, and I couldn't find any Use latexmk -help to get usage information C:\texlive\2019\bin\win32\runscript.tlu:907: command failed with exit code 10: perl.exe c:\texlive\2019\texmf-dist\scripts\latexmk\latexmk.plSublime Text 3
公式HP Sublime Text 3 の
DOWNLOAD FOR WINDOWSよりダウンロードし、
Sublime Text Build 3211 x64 Setup.exeよりインストールを行います。SumatraPDF
TeX WikiのDownload SumatraPDFを参考に、
公式HP SumatraPDF の
Installer : SumatraPDF-3.1.2-64-install.exeよりインストーラをダウンロードし、
Sublime Text Build 3211 x64 Setup.exeを実行してインストールを行います。R-3.6.2
The Comprehensive R Archive Network
(Download R for Windows -> base)
R-3.6.2 for Windows のDownload R 3.6.2 for Windowsよりインストーラをダウンロードし、
R-3.6.2-win.exeよりインストールを行います。設定手順
まずはじめに、Sublime Textを開き
Ctrl+Shift+Pを押し、Command Paletteを開き、
install Package installerとPaletteに入力、決定。
これでPackage Controlのインストールは完了です。次に、以下3つのPackageをインストールします。
- LaTeXTools
- R-Box
- SendCode
LaTeXTools
Package Controlの手順と同様に、
Ctrl+Shift+Pを押し、Command Paletteを開きます。
次に、Package Control: Install PackageとPaletteに入力し決定します。
出てきたPaletteにLaTeXToolsと入力、決定すればLaTeXToolsがインストールされます。
(インストールが完了するとSublime Text上でメッセージが表示されます。)次にLaTeXToolsの設定をします。Sublime Textの上欄のメニュー、
右から2つ目の[Preferences]から
[Preferences]-> [Package Settings] -> [LaTeXTools] -> [Settings-User]
と選択します。
\Sublime Text 3\Packages\User\LaTeXTools.sublime-settingsが存在しない場合には、You do not currently have a personalized LaTeXTools.sublime-setting file. Create a copy of the default settings file in your User directory?上記のようなメッセージが表示されるので
[OK]をクリックします。Sublime Text上で表示された
LaTeXTools.sublime-settingsに対して、Ctrl + Fを押し、
出てきた検索欄にbuilder_settingsと入力し、(398行目)の"builder_settings"を見つけます。そして、
(398行目) "builder_settings"から
(406行目) // General settings:の間に、以下の内容を追加します。\User\LaTeXTools.sublime-settings398 "builder_settings" : { "command" : ["latexmk", "-cd", "-e", "$latex = 'uplatex %O -no-guess-input-enc -kanji=utf8 -interaction=nonstopmode -synctex=1 %S'", "-e", "$biber = 'biber %O --bblencoding=utf8 -u -U --output_safechars %B'", "-e", "$bibtex = 'upbibtex %O %B'", "-e", "$makeindex = 'upmendex %O -o %D %S'", "-e", "$dvipdf = 'dvipdfmx %O -o %D %S'", "-f", "-%E", "-norc", "-gg", "-pdfdvi"], 406 // General settings:上記の内容を追加した後
Ctrl + Sで保存を行います。LaTeXのコンパイルができるかどうかを確認します。以下の内容の
text.texをSublime Text上で作成した後、Ctrl + Bを押します。
初回はBuildの方法を聞いてくるのでBuild With LaTeX - Traditionalを選びます。
[Tool]->[Build With...]からもビルド方法の選択は可能です。Buildingの動作(画面下のバーに動作状況が表示されます)が終了した後、自動的にSumatraPDFが起動され、内容が正常に表示されていれば、確認は完了です。
test.tex\documentclass[a4j]{ujarticle} \title{ {\LaTeX} testファイル } \author{ほげ-やま-ふが} \date{\today} \begin{document} \maketitle \section{はじめに} Hell \subsection*{おわりに} World \end{document}!!!注意!!!
\documentclass[a4j]{jarticle} ではなく
\documentclass[a4j]{ujarticle} を使ってください!documentclassがjarticleとなっている場合、正常にコンパイル出来ないようです...
理由が分かる方は、助言をよろしくお願いします。環境変数を通して便利にしよう!
この記事の中で一番ややこしい所だと思われます。
環境変数を通すことで、SumatraPDF上で文章をダブルクリックすると、
Sublime Textで該当部分のソースコードを開くことができるようになります。
Windowsキー + Rを押し、controlと入力、コントロールパネルを開きます。
右上の検索欄に環境変数と入力し表示された一覧から、
[システム - システム環境変数の編集] -> 環境変数(N)を選択します。
[システム環境変数(S)]の一覧から[Path]を選択し、ダブルクリックもしくは[編集(I)]を押します。
[環境変数名の編集] -> [新規(N)]から以下のPathを追加します。C:\Program Files\Sublime Text 3\SumatraPDFを起動して、左上の一覧をクリックして
[設定(S)]->[オプション(O)]を選択します。
逆順検索コマンドラインの設定を以下の内容にします。sublime_text %f:%l以上で環境変数の設定は完了です。
確認をするために、
test.texをSumatraPDfで開き、
そしてSumatraPDF上の文章で[1 はじめに]の部分をダブルクリックして、
Sublime Textで(10行目) \section{はじめに}を開くようになっていたら成功です。!!!注意!!!
.texファイルを置いているフォルダ名にはスペースを入れないようにしてください!!
例hoge fugaフォルダに置いたtest.texで上記の確認を行ってみるとわかります。R-Box
LaTeXToolの手順と同様に、
Package Control: Install PackageからR-Boxをインストールします。R-Boxに関しては特に設定する必要はありません。
SendCode
LaTeXToolの手順と同様に、
Package Control: Install PackageからSendCodeをインストールする。SendCodeの設定を行います。こちらもLaTeXToolの設定、の手順と同様に、
[Preferences] -> [Package Settings] -> [SendCode] -> [Settings]を選択します。その後設定が表示されるので、その設定欄の右側に以下の内容を記載します。
\User\SendCode.sublime-settings{ "prog": "r", "r": { "prog": "r" }, }上記の内容を追加すれば、Sublime Text上で書いたRのコードを
Ctrl + EnterでRGuiに送信できるようになります。
但し、あらかじめRGuiを立ち上げておく必要があるので注意してください。正常に動作するかどうかを確認します。
R.rcurve(dnorm(x) , -5, 5)この行を入力した状態で
Ctrl+Enterを押せば、RGuiに送信されます。
RGui上に正規分布のグラフが現れれば成功です。Pythonのためのシンタックス設定
Pythonのインデントについて
Pythonのコード内において、インデントはブロックを区別する役割があり、
主に半角space 4つ , Tab , 半角space 2つの流儀があります。(space 2つ は殆ど見ませんが)
Sublime Textの、Pythonのシンタックス設定において、Tab = space 4つ分としておけば、
tabを使ってもspace 4つのコードと混同しないようにします。
(混同することは推奨されていないため)まず、はじめに何でもいいので
.pyのファイルをSublime Textで開きます。
(適当にメモ帳を作って、拡張子を.pyに変えたものを開いたら大丈夫です)後は、LaTeXTool等の設定、と同様におこないます。
[Preferences] -> [Settings-Syntax Specific]を選択します。その後設定が表示されるので、その設定欄の右側に以下の内容を記載します。
\User\Python.sublime-settings// These settings override both User and Default settings for the Python syntax { "tab_size": 4, "translate_tabs_to_spaces": true }
Tabを押して、半角space 4つが出力されていれば設定完了です。使い方まとめ
LaTeX
Ctrl + Bでビルドができる。SumatraPDF上で文章をダブルクリックすると、
Sublime Textで該当部分のソースコードを開くことができる。R
- RGuiを起動したのち、Sublime Textにおいて、
Ctrl + Enterを押すことで、コードの送信、および実行ができる。Python
Tabを押せば半角space 4つを出力することができる。Sublimeに入れたら便利そうなもの
以上で基本的な環境構成は完了ですが、
ほかに加えたら便利だと思われるPackageを以下に記載します。
Japanize
Sublime Textを日本語化してくれます。
細かい設定等が英語だと困ることがあると思ったので入れました。ConvertToUTF8
文字コード関連の問題を解決してくれる(らしい)Packageです。
UTF-8を基準にするなら入れていて悪いことはないかと思います。Alignment
とても便利なPackageです。例えば、以下のようなコードについて。
sample.cint x = 0; double y = 1; int z = 10;このコードの全範囲を選択し、
Ctrl + Alt + Aと入力することにより、sample.cint x = 0; double y = 1; int z = 10;
=を基準にして、インデントを調節してくれます。Alignmentの設定Settings-UserをSettings-User{ "alignment_space_chars": ["=","-"], }上記のように設定することにより、
-も基準に調節してくれるようになり、
Rを使うにあたって便利になります。
また、Alignmentの設定Key Bindings-Userを
設定することにより、コマンドを変更することができます。
(私はCtrl + Shift + Aに変更しています。)参考文献
- 投稿日:2020-02-21T18:50:04+09:00
SublimeText3でLaTeXとR(ちょこっとPython)の環境構築(Windows)
SublimeText3でLaTeXとR(ちょこっとPython)
を使いやすくするはじめに
自分のメモ用です。意外にSublimeでのTeXについてまとめられているサイトを見ないと思ったので、
自分が設定した環境(友人Jの丸パクリ)について書いてみようと思いました。SublimeText3で、LaTeXとR (ちょっとPython) を使いやすくするための一連の設定手順を記載します。
Sublimeは適宜再起動するようにしてください。準備するソフトウェア
- Sublime Text 3
- TeXLive 2019
- SumatraPDF
- R-3.6.2
ソフトウェアの準備手順
TeXLive 2019
TeX Live - TeX Wiki を参考にしながらTeX Liveをインストールします。
Windowsの場合、 TeX Live/Windows - TeX Wiki を参考に、インストーラをダウンロードします。
著者はネットワークインストーラの場合を参考に、 Installing TeX Live over the Internet のinstall-tl-windows.exeを利用してTeXLive 2019をインストールしました。正常にインストールできているかの確認として、
Windowsキー + Rを押し、cmdと入力、コマンドプロンプトを起動します。コマンドラインにlatexmkと入力した際、以下のような反応があればインストールは成功です。C:\Users\(User名)>latexmk Latexmk: This is Latexmk, John Collins, 26 Dec. 2019, version: 4.67. Latexmk: No file name specified, and I couldn't find any Use latexmk -help to get usage information C:\texlive\2019\bin\win32\runscript.tlu:907: command failed with exit code 10: perl.exe c:\texlive\2019\texmf-dist\scripts\latexmk\latexmk.plSublime Text 3
公式HP Sublime Text 3 の
DOWNLOAD FOR WINDOWSよりダウンロードし、
Sublime Text Build 3211 x64 Setup.exeよりインストールを行います。SumatraPDF
TeX WikiのDownload SumatraPDFを参考に、
公式HP SumatraPDF の
Installer : SumatraPDF-3.1.2-64-install.exeよりインストーラをダウンロードし、
Sublime Text Build 3211 x64 Setup.exeを実行してインストールを行います。R-3.6.2
The Comprehensive R Archive Network
(Download R for Windows -> base)
R-3.6.2 for Windows のDownload R 3.6.2 for Windowsよりインストーラをダウンロードし、
R-3.6.2-win.exeよりインストールを行います。設定手順
まずはじめに、Sublime Textを開き
Ctrl+Shift+Pを押し、Command Paletteを開き、
install Package installerとPaletteに入力、決定。
これでPackage Controlのインストールは完了です。次に、以下3つのPackageをインストールします。
- LaTeXTools
- R-Box
- SendCode
LaTeXTools
Package Controlの手順と同様に、
Ctrl+Shift+Pを押し、Command Paletteを開きます。
次に、Package Control: Install PackageとPaletteに入力し決定します。
出てきたPaletteにLaTeXToolsと入力、決定すればLaTeXToolsがインストールされます。
(インストールが完了するとSublime Text上でメッセージが表示されます。)次にLaTeXToolsの設定をします。Sublime Textの上欄のメニュー、
右から2つ目の[Preferences]から
[Preferences]-> [Package Settings] -> [LaTeXTools] -> [Settings-User]
と選択します。
\Sublime Text 3\Packages\User\LaTeXTools.sublime-settingsが存在しない場合には、You do not currently have a personalized LaTeXTools.sublime-setting file. Create a copy of the default settings file in your User directory?上記のようなメッセージが表示されるので
[OK]をクリックします。Sublime Text上で表示された
LaTeXTools.sublime-settingsに対して、Ctrl + Fを押し、
出てきた検索欄にbuilder_settingsと入力し、(398行目)の"builder_settings"を見つけます。そして、
(398行目) "builder_settings"から
(406行目) // General settings:の間に、以下の内容を追加します。\User\LaTeXTools.sublime-settings398 "builder_settings" : { "command" : ["latexmk", "-cd", "-e", "$latex = 'uplatex %O -no-guess-input-enc -kanji=utf8 -interaction=nonstopmode -synctex=1 %S'", "-e", "$biber = 'biber %O --bblencoding=utf8 -u -U --output_safechars %B'", "-e", "$bibtex = 'upbibtex %O %B'", "-e", "$makeindex = 'upmendex %O -o %D %S'", "-e", "$dvipdf = 'dvipdfmx %O -o %D %S'", "-f", "-%E", "-norc", "-gg", "-pdfdvi"], 406 // General settings:上記の内容を追加した後
Ctrl + Sで保存を行います。LaTeXのコンパイルができるかどうかを確認します。以下の内容の
text.texをSublime Text上で作成した後、Ctrl + Bを押します。
初回はBuildの方法を聞いてくるのでBuild With LaTeX - Traditionalを選びます。
[Tool]->[Build With...]からもビルド方法の選択は可能です。Buildingの動作(画面下のバーに動作状況が表示されます)が終了した後、自動的にSumatraPDFが起動され、内容が正常に表示されていれば、確認は完了です。
test.tex\documentclass[a4j]{ujarticle} \title{ {\LaTeX} testファイル } \author{ほげ-やま-ふが} \date{\today} \begin{document} \maketitle \section{はじめに} Hell \subsection*{おわりに} World \end{document}!!!注意!!!
\documentclass[a4j]{jarticle} ではなく
\documentclass[a4j]{ujarticle} を使ってください!documentclassがjarticleとなっている場合、正常にコンパイル出来ないようです...
理由が分かる方は、助言をよろしくお願いします。環境変数を通して便利にしよう!
この記事の中で一番ややこしい所だと思われます。
環境変数を通すことで、SumatraPDF上で文章をダブルクリックすると、
Sublime Textで該当部分のソースコードを開くことができるようになります。
Windowsキー + Rを押し、controlと入力、コントロールパネルを開きます。
右上の検索欄に環境変数と入力し表示された一覧から、
[システム - システム環境変数の編集] -> 環境変数(N)を選択します。
[システム環境変数(S)]の一覧から[Path]を選択し、ダブルクリックもしくは[編集(I)]を押します。
[環境変数名の編集] -> [新規(N)]から以下のPathを追加します。C:\Program Files\Sublime Text 3\SumatraPDFを起動して、左上の一覧をクリックして
[設定(S)]->[オプション(O)]を選択します。
逆順検索コマンドラインの設定を以下の内容にします。sublime_text %f:%l以上で環境変数の設定は完了です。
確認をするために、
test.texをSumatraPDfで開き、
そしてSumatraPDF上の文章で[1 はじめに]の部分をダブルクリックして、
Sublime Textで(10行目) \section{はじめに}を開くようになっていたら成功です。!!!注意!!!
.texファイルを置いているフォルダ名にはスペースを入れないようにしてください!!
例hoge fugaフォルダに置いたtest.texで上記の確認を行ってみるとわかります。R-Box
LaTeXToolの手順と同様に、
Package Control: Install PackageからR-Boxをインストールします。R-Boxに関しては特に設定する必要はありません。
SendCode
LaTeXToolの手順と同様に、
Package Control: Install PackageからSendCodeをインストールする。SendCodeの設定を行います。こちらもLaTeXToolの設定、の手順と同様に、
[Preferences] -> [Package Settings] -> [SendCode] -> [Settings]を選択します。その後設定が表示されるので、その設定欄の右側に以下の内容を記載します。
\User\SendCode.sublime-settings{ "prog": "r", "r": { "prog": "r" }, }上記の内容を追加すれば、Sublime Text上で書いたRのコードを
Ctrl + EnterでRGuiに送信できるようになります。
但し、あらかじめRGuiを立ち上げておく必要があるので注意してください。正常に動作するかどうかを確認します。
R.rcurve(dnorm(x) , -5, 5)この行を入力した状態で
Ctrl+Enterを押せば、RGuiに送信されます。
RGui上に正規分布のグラフが現れれば成功です。Pythonのためのシンタックス設定
Pythonのインデントについて
Pythonのコード内において、インデントはブロックを区別する役割があり、
主に半角space 4つ , Tab , 半角space 2つの流儀があります。(space 2つ は殆ど見ませんが)
Sublime Textの、Pythonのシンタックス設定において、Tab = space 4つ分としておけば、
tabを使ってもspace 4つのコードと混同しないようにします。
(混同することは推奨されていないため)まず、はじめに何でもいいので
.pyのファイルをSublime Textで開きます。
(適当にメモ帳を作って、拡張子を.pyに変えたものを開いたら大丈夫です)後は、LaTeXTool等の設定、と同様におこないます。
[Preferences] -> [Settings-Syntax Specific]を選択します。その後設定が表示されるので、その設定欄の右側に以下の内容を記載します。
\User\Python.sublime-settings// These settings override both User and Default settings for the Python syntax { "tab_size": 4, "translate_tabs_to_spaces": true }
Tabを押して、半角space 4つが出力されていれば設定完了です。使い方まとめ
LaTeX
Ctrl + Bでビルドができる。SumatraPDF上で文章をダブルクリックすると、
Sublime Textで該当部分のソースコードを開くことができる。R
- RGuiを起動したのち、Sublime Textにおいて、
Ctrl + Enterを押すことで、コードの送信、および実行ができる。Python
Tabを押せば半角space 4つを出力することができる。Sublimeに入れたら便利そうなもの
以上で基本的な環境構成は完了ですが、
ほかに加えたら便利だと思われるPackageを以下に記載します。
Japanize
Sublime Textを日本語化してくれます。
細かい設定等が英語だと困ることがあると思ったので入れました。ConvertToUTF8
文字コード関連の問題を解決してくれる(らしい)Packageです。
UTF-8を基準にするなら入れていて悪いことはないかと思います。Alignment
とても便利なPackageです。例えば、以下のようなコードについて。
sample.cint x = 0; double y = 1; int z = 10;このコードの全範囲を選択し、
Ctrl + Alt + Aと入力することにより、sample.cint x = 0; double y = 1; int z = 10;
=を基準にして、インデントを調節してくれます。Alignmentの設定Settings-UserをSettings-User{ "alignment_space_chars": ["=","-"], }上記のように設定することにより、
-も基準に調節してくれるようになり、
Rを使うにあたって便利になります。
また、Alignmentの設定Key Bindings-Userを
設定することにより、コマンドを変更することができます。
(私はCtrl + Shift + Aに変更しています。)参考文献
- 投稿日:2020-02-21T18:48:20+09:00
来るPython3.7に備えてMaya(Python2.7)でpathlibを使う
はじめに
2020年に入りpythonclockのタイマーが停止しましたね。
しかし、CG業界は未だPython2.7を使い続けています。
(だってMayaとか3dsMAXとかHoudiniとかがまだ移行完了してないからしょうがないじゃん...DCCツールはまだまだ
Python2.7なんですが、スタンドアロンのPythonツールはPython2.7である必要は無いのでPython3.7を使ってます。
Python3.7を使っててpathlibが便利だなあと思って使ってるんですが、調べたらPython2.7用にパッケージが用意されてたのでMayaにも入れて使ってみようと思います。インストール
Python2.7でpathlibを使いたい場合は
pip install pathlibするだけでOK
Mayaで使う場合は-tフラグでMayaが認識するPYTHONPATHにインストール私の場合は
%USERPROFILE%\Documents\maya\scriptsにsite-packagesフォルダを作成してそこにインストールしてます。
moduleファイルでPYTHONPATHを認識するようにしてある。
インストールしやすいようにbatを用意してたりします。pip.batecho off set PIP_INSTALL_PACKAGE= set /P PIP_INSTALL_PACKAGE="enter the package to install:" py -2.7 -m pip install %PIP_INSTALL_PACKAGE% -t site-packages pause使ってみる
インストール完了したので使ってみようと思います。
import pathlib pathlib.Path # Result: <class 'pathlib.Path'> #問題なくインポート出来てる!!
pathlib.Path(os.getenv("MAYA_LOCATION")).parent # Result: WindowsPath('C:/Program Files/Autodesk') # list(pathlib.Path(os.getenv("MAYA_LOCATION")).iterdir()) # Result: [WindowsPath('C:/Program Files/Autodesk/Maya2020/assets'),WindowsPath('C:/Program Files/Autodesk/Maya2020/bin'),WindowsPath('C:/Program Files/Autodesk/Maya2020/brushImages'),WindowsPath('C:/Program Files/Autodesk/Maya2020/brushShapes'),WindowsPath('C:/Program Files/Autodesk/Maya2020/cmake'),WindowsPath('C:/Program Files/Autodesk/Maya2020/devkit'),WindowsPath('C:/Program Files/Autodesk/Maya2020/docs'),WindowsPath('C:/Program Files/Autodesk/Maya2020/Examples'),WindowsPath('C:/Program Files/Autodesk/Maya2020/ExternalWebBrowser'),WindowsPath('C:/Program Files/Autodesk/Maya2020/icons'),WindowsPath('C:/Program Files/Autodesk/Maya2020/include'),WindowsPath('C:/Program Files/Autodesk/Maya2020/lib'),WindowsPath('C:/Program Files/Autodesk/Maya2020/mkspecs'),WindowsPath('C:/Program Files/Autodesk/Maya2020/modules'),WindowsPath('C:/Program Files/Autodesk/Maya2020/plug-ins'),WindowsPath('C:/Program Files/Autodesk/Maya2020/plugins'),WindowsPath('C:/Program Files/Autodesk/Maya2020/presets'),WindowsPath('C:/Program Files/Autodesk/Maya2020/Python'),WindowsPath('C:/Program Files/Autodesk/Maya2020/PYTHON_LICENSE'),WindowsPath('C:/Program Files/Autodesk/Maya2020/PYTHON_README'),WindowsPath('C:/Program Files/Autodesk/Maya2020/qml'),WindowsPath('C:/Program Files/Autodesk/Maya2020/resources'),WindowsPath('C:/Program Files/Autodesk/Maya2020/scripts'),WindowsPath('C:/Program Files/Autodesk/Maya2020/support'),WindowsPath('C:/Program Files/Autodesk/Maya2020/synColor'),WindowsPath('C:/Program Files/Autodesk/Maya2020/translations')] #
parentで親階層、iterdirでディレクトリの中身を見つけられるlist(pathlib.Path(os.getenv("MAYA_LOCATION")).glob("Python/DLLs/*.pyd")) # Result: [WindowsPath('C:/Program Files/Autodesk/Maya2020/python/dlls/bz2.pyd'),WindowsPath('C:/Program Files/Autodesk/Maya2020/python/dlls/pyexpat.pyd'),WindowsPath('C:/Program Files/Autodesk/Maya2020/python/dlls/select.pyd'),WindowsPath('C:/Program Files/Autodesk/Maya2020/python/dlls/unicodedata.pyd'),WindowsPath('C:/Program Files/Autodesk/Maya2020/python/dlls/winsound.pyd'),WindowsPath('C:/Program Files/Autodesk/Maya2020/python/dlls/_bsddb.pyd'),WindowsPath('C:/Program Files/Autodesk/Maya2020/python/dlls/_ctypes.pyd'),WindowsPath('C:/Program Files/Autodesk/Maya2020/python/dlls/_ctypes_test.pyd'),WindowsPath('C:/Program Files/Autodesk/Maya2020/python/dlls/_elementtree.pyd'),WindowsPath('C:/Program Files/Autodesk/Maya2020/python/dlls/_hashlib.pyd'),WindowsPath('C:/Program Files/Autodesk/Maya2020/python/dlls/_msi.pyd'),WindowsPath('C:/Program Files/Autodesk/Maya2020/python/dlls/_multiprocessing.pyd'),WindowsPath('C:/Program Files/Autodesk/Maya2020/python/dlls/_socket.pyd'),WindowsPath('C:/Program Files/Autodesk/Maya2020/python/dlls/_sqlite3.pyd'),WindowsPath('C:/Program Files/Autodesk/Maya2020/python/dlls/_ssl.pyd'),WindowsPath('C:/Program Files/Autodesk/Maya2020/python/dlls/_testcapi.pyd')] #globも使える!
おわりに
無事
pathlibが使えたので社内のライブラリに追加して積極的に使ってみようと思います。
Maya2021が出るころにはPython3.7になっていると良いのですが、移行したら移行したで既存のツール群のテコ入れ祭りが始まると思うので億劫ですね...来る
Python3.7に備えて少しでも慣れておこうと思います。
- 投稿日:2020-02-21T18:26:53+09:00
PythonによるDiffusion MRIのbvec fileの極性変更
はじめに
diffusion MRIで重要なMPGのGradient Tableであるbvecの極性がMRI装置と解析ソフトウェアで互換性がない。
被験者は200人以上いるため、一人ひとり手直しするのは困難である。
そこで、Pythonでbvec fileの中の極性を任意に変更できるスクリプトを作成した。コードの中身
モジュールのインポート
import pandas as pd import numpy as np from argparse import ArgumentParserコマンドライン引数の設定
argparseを使うとこのPythonプログラムに必要な種々の引数を設定することがきる。
今回の場合だと、
-i : inputするbvec file
-o : outputするbvec file
-x : x軸の1(極性を反転しない) or -1(極性を反転,default)
-y : y軸の1(極性を反転しない) or -1(極性を反転,default)
-z : z軸の1(極性を反転しない) or -1(極性を反転,default)def get_option(): argparser = ArgumentParser(usage='reorient_bvec.py -i <Input bvec file> -o <Output bvec file> [options]') argparser.add_argument('-i', type=str, help='Specify <Input bvec file>') argparser.add_argument('-o', type=str, help='Specify <Output bvec file>') argparser.add_argument('-x', type=int, default=1,help='Specify whether x axis is <1 or -1>') argparser.add_argument('-y', type=int, default=1,help='Specify whether y axis is <1 or -1>') argparser.add_argument('-z', type=int, default=1,help='Specify whether z axis is <1 or -1>') return argparser.parse_args()極性の変更
- "open()"でbvec fileを開く
- "readlines()"ですべてを読み出し一行づつ処理と約束
- "close()"でbvec fileを閉じる
- for文を使って一行ずつ読み出して値の間の空白をカンマ(,)に置換
- values変数に一行づつ追加。ただしこのとき、values変数の中身(dtype)はfloatに指定
- valuesをデータフレームに変換
- 受け取ったx_pol, y_pol, z_polに従ってx,y,zの極性を変更
- "to_csv()"でテキストとして保存。ただしタブ区切り(seq='\t')でheaderとindexはFalseにしてつけない。
def reorient(input,output,x_pol,y_pol,z_pol): f = open(input) line = f.readlines() f.close() values =[] for raw in line: values.append(raw.split()) values = np.array(values, dtype=float) df = pd.DataFrame({'x':values[0,:],'y':values[1,:],'z':values[2,:]}) # change x to -x df['x'] = df['x'] * x_pol df['x'][0] = 0 # change y to -y df['y'] = df['y'] * y_pol df['y'][0] = 0 # change z to -z df['z'] = df['z'] * z_pol df['z'][0] = 0 df.T.to_csv(output,header=False,index=False,sep ='\t')実行
最後に以下を実行。
args = get_option() reorient(args.i,args.o,args.x,args.y,args.z)使ってみた
help画面
$reorient_bvec.py -h usage: reorient_bvec.py -i <Input bvec file> -o <Output bvec file> [options] optional arguments: -h, --help show this help message and exit -i I Specify <Input bvec file> -o O Specify <Output bvec file> -x X Specify whether x axis is <1 or -1> -y Y Specify whether y axis is <1 or -1> -z Z Specify whether z axis is <1 or -1>bvec fileの中身
1行目から順にx,y,zに対応したMPGのベクトルファイルです。
0 -0.217930346727371 0.183526918292046 0.383256644010544 -0.410334378480911 -0.202136784791946 -0.852467894554138 -0.736984968185425 -0.424142956733704 -0.743488430976868 -0.642241656780243 -0.314430356025696 -0.303920179605484 -0.635029315948486 -0.975241184234619 -0.842172503471375 0.02119112201035 0.017083311453462 0.669762194156647 0.350858598947525 -0.176277682185173 0.225432544946671 0.662433862686157 0.334164470434189 0.20159624516964 0.396999925374985 0.717438399791718 0.722378551959991 0.856116056442261 0.868275225162506 0.982918977737427 0 -0.217930346727371 0.183526918292046 0.383256644010544 -0.410334378480911 -0.202136784791946 -0.852467894554138 -0.736984968185425 -0.424142956733704 -0.743488430976868 -0.642241656780243 -0.314430356025696 -0.303920179605484 -0.635029315948486 -0.975241184234619 -0.842172503471375 0.02119112201035 0.017083311453462 0.669762194156647 0.350858598947525 -0.176277682185173 0.225432544946671 0.662433862686157 0.334164470434189 0.20159624516964 0.396999925374985 0.717438399791718 0.722378551959991 0.856116056442261 0.868275225162506 0.982918977737427 0 -0.412680119276047 -0.409769654273987 -0.058996170759201 -0.659401714801788 -0.901793777942657 -0.511457681655884 -0.465032130479813 -0.066757045686245 -0.098933920264244 -0.75407212972641 -0.949280381202698 -0.609742164611816 -0.585166573524475 -0.193069934844971 -0.237830027937889 -0.804597735404968 -0.9742192029953 -0.571449518203735 -0.603594779968262 -0.288592159748077 -0.28386327624321 -0.741296827793121 -0.942338287830353 -0.896425783634186 -0.651651620864868 -0.084958553314209 -0.45000359416008 -0.494898587465286 -0.220817357301712 -0.173311769962311 0 -0.412680119276047 -0.409769654273987 -0.058996170759201 -0.659401714801788 -0.901793777942657 -0.511457681655884 -0.465032130479813 -0.066757045686245 -0.098933920264244 -0.75407212972641 -0.949280381202698 -0.609742164611816 -0.585166573524475 -0.193069934844971 -0.237830027937889 -0.804597735404968 -0.9742192029953 -0.571449518203735 -0.603594779968262 -0.288592159748077 -0.28386327624321 -0.741296827793121 -0.942338287830353 -0.896425783634186 -0.651651620864868 -0.084958553314209 -0.45000359416008 -0.494898587465286 -0.220817357301712 -0.173311769962311 0 -0.884421586990356 -0.89353609085083 -0.921755850315094 -0.629932701587677 -0.381979912519455 -0.108210533857346 -0.490508288145065 -0.903131365776062 -0.661390364170074 0.137480318546295 0.000462443917058 0.73201584815979 0.504299402236938 0.107836477458477 0.483923941850662 0.59344208240509 0.224955901503563 0.474198371171951 0.715941071510315 0.941084921360016 0.931988179683685 0.107983581721783 -0.01824214681983 -0.394689381122589 -0.646329164505005 -0.691421866416931 -0.525039196014404 -0.148797869682312 0.444227457046509 0.061913453042507 0 -0.884421586990356 -0.89353609085083 -0.921755850315094 -0.629932701587677 -0.381979912519455 -0.108210533857346 -0.490508288145065 -0.903131365776062 -0.661390364170074 0.137480318546295 0.000462443917058 0.73201584815979 0.504299402236938 0.107836477458477 0.483923941850662 0.59344208240509 0.224955901503563 0.474198371171951 0.715941071510315 0.941084921360016 0.931988179683685 0.107983581721783 -0.01824214681983 -0.394689381122589 -0.646329164505005 -0.691421866416931 -0.525039196014404 -0.148797869682312 0.444227457046509 0.061913453042507 y軸の極性変更
このケースだとy軸の極性のみを変更すればよかったので、bval file(bvals.bval)のy軸だけ極性を変更する。
input(-i) : bvals.bval
output(-o) : reorient_bvals.bval
y軸(-y) : -1を記載し極性変更$python3 reorient_bval.py -i bvals.bval -o reorient_bvals.bval -y -1実行した結果がこちら。2行目のy軸のみの極性が変更されている。
あとは、このスクリプトを被験者分、for文で回すだけ。
0 -0.217930346727371 0.183526918292046 0.383256644010544 -0.410334378480911 -0.202136784791946 -0.852467894554138 -0.736984968185425 -0.424142956733704 -0.743488430976868 -0.642241656780243 -0.314430356025696 -0.303920179605484 -0.635029315948486 -0.975241184234619 -0.842172503471375 0.02119112201035 0.017083311453462 0.669762194156647 0.350858598947525 -0.176277682185173 0.225432544946671 0.662433862686157 0.334164470434189 0.20159624516964 0.396999925374985 0.717438399791718 0.722378551959991 0.856116056442261 0.868275225162506 0.982918977737427 0 -0.217930346727371 0.183526918292046 0.383256644010544 -0.410334378480911 -0.202136784791946 -0.852467894554138 -0.736984968185425 -0.424142956733704 -0.743488430976868 -0.642241656780243 -0.314430356025696 -0.303920179605484 -0.635029315948486 -0.975241184234619 -0.842172503471375 0.02119112201035 0.017083311453462 0.669762194156647 0.350858598947525 -0.176277682185173 0.225432544946671 0.662433862686157 0.334164470434189 0.20159624516964 0.396999925374985 0.717438399791718 0.722378551959991 0.856116056442261 0.868275225162506 0.982918977737427 0 0.412680119276047 0.409769654273987 0.058996170759201 0.659401714801788 0.901793777942657 0.511457681655884 0.465032130479813 0.066757045686245 0.098933920264244 0.75407212972641 0.949280381202698 0.609742164611816 0.585166573524475 0.193069934844971 0.237830027937889 0.804597735404968 0.9742192029953 0.571449518203735 0.603594779968262 0.288592159748077 0.28386327624321 0.741296827793121 0.942338287830353 0.896425783634186 0.651651620864868 0.084958553314209 0.45000359416008 0.494898587465286 0.220817357301712 0.173311769962311 0 0.412680119276047 0.409769654273987 0.058996170759201 0.659401714801788 0.901793777942657 0.511457681655884 0.465032130479813 0.066757045686245 0.098933920264244 0.75407212972641 0.949280381202698 0.609742164611816 0.585166573524475 0.193069934844971 0.237830027937889 0.804597735404968 0.9742192029953 0.571449518203735 0.603594779968262 0.288592159748077 0.28386327624321 0.741296827793121 0.942338287830353 0.896425783634186 0.651651620864868 0.084958553314209 0.45000359416008 0.494898587465286 0.220817357301712 0.173311769962311 0 -0.884421586990356 -0.89353609085083 -0.921755850315094 -0.629932701587677 -0.381979912519455 -0.108210533857346 -0.490508288145065 -0.903131365776062 -0.661390364170074 0.137480318546295 0.000462443917058 0.73201584815979 0.504299402236938 0.107836477458477 0.483923941850662 0.59344208240509 0.224955901503563 0.474198371171951 0.715941071510315 0.941084921360016 0.931988179683685 0.107983581721783 -0.01824214681983 -0.394689381122589 -0.646329164505005 -0.691421866416931 -0.525039196014404 -0.148797869682312 0.444227457046509 0.061913453042507 0 -0.884421586990356 -0.89353609085083 -0.921755850315094 -0.629932701587677 -0.381979912519455 -0.108210533857346 -0.490508288145065 -0.903131365776062 -0.661390364170074 0.137480318546295 0.000462443917058 0.73201584815979 0.504299402236938 0.107836477458477 0.483923941850662 0.59344208240509 0.224955901503563 0.474198371171951 0.715941071510315 0.941084921360016 0.931988179683685 0.107983581721783 -0.01824214681983 -0.394689381122589 -0.646329164505005 -0.691421866416931 -0.525039196014404 -0.148797869682312 0.444227457046509 0.061913453042507 まとめ
diffusion MRIで出力されるGradient Tableであるbvecの極性を一括変更するためのスクリプトを作成した。
ここでは、
- argparseの扱い
- list, array, DataFrameの行き来
- DataFrameでの一部の値の変更の仕方
を取得できればいいと思う。使用したコード
reorient_bvec.pyimport glob import pandas as pd import numpy as np from argparse import ArgumentParser def get_option(): argparser = ArgumentParser(usage='reorient_bvec.py -i <Input bvec file> -o <Output bvec file> [options]') argparser.add_argument('-i', type=str, help='Specify <Input bvec file>') argparser.add_argument('-o', type=str, help='Specify <Output bvec file>') argparser.add_argument('-x', type=int, default=1,help='Specify whether x axis is <1 or -1>') argparser.add_argument('-y', type=int, default=1,help='Specify whether y axis is <1 or -1>') argparser.add_argument('-z', type=int, default=1,help='Specify whether z axis is <1 or -1>') return argparser.parse_args() def reorient(input,output,x_pol,y_pol,z_pol): f = open(input) line = f.readlines() f.close() values =[] for raw in line: values.append(raw.split()) values = np.array(values, dtype=float) df = pd.DataFrame({'x':values[0,:],'y':values[1,:],'z':values[2,:]}) # change x to -x df['x'] = df['x'] * x_pol df['x'][0] = 0 # change y to -y df['y'] = df['y'] * y_pol df['y'][0] = 0 # change z to -z df['z'] = df['z'] * z_pol df['z'][0] = 0 df.T.to_csv(output,header=False,index=False,sep ='\t') args = get_option() reorient(args.i,args.o,args.x,args.y,args.z)
- 投稿日:2020-02-21T17:52:14+09:00
Python備忘録
この記事は, python初心者の学習の記録です.
自分のわからなかったところを主に書いてます.
なので順序はごちゃごちゃです. 参考までにどうぞ,,,NumPy
np.array
# -*- coding: utf-8 -*- import numpy as np # 2次元配列の宣言・初期化 A = np.array([[1, 2], [3, 4], [5, 6]]) # 行列の大きさ print("行列Aの大きさ:", A.shape) print("行列Aの行数:", A.shape[0]) print("行列Aの列数:", A.shape[1]) """ 行列Aの大きさ:(3, 2) 行列Aの行数:3 行列Aの列数:2 """np.reshape
shape[0]は行数表示, shape[1]は列数表示.
import numpy as np a = np.arange(24) print(a) # [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23] print(a.shape) # (24,) print(a.ndim) # 1 a_4_6 = a.reshape([4, 6]) print(a_4_6) # [[ 0 1 2 3 4 5] # [ 6 7 8 9 10 11] # [12 13 14 15 16 17] # [18 19 20 21 22 23]] print(a_4_6.shape) # (4, 6) print(a_4_6.ndim) # 2np.ndimでは, 簡単に書くと, 要素の数がわかる. reshapeは上記のコードの通り.
[:, 0]
全ての0列目. 2x2の配列なら省略せずに書くと, a[0:2, 0]となる.
A[a:b, c:d]はa~bまでの行でc~dまで(b, d含まない)の列を抜き出す意味.np.where
import numpy as np a = np.arange(9).reshape((3, 3)) print(a) # [[0 1 2] # [3 4 5] # [6 7 8]] print(np.where(a < 4, -1, 100)) # [[ -1 -1 -1] # [ -1 100 100] # [100 100 100]] print(np.where(a < 4, True, False)) # [[ True True True] # [ True False False] # [False False False]] print(a < 4) # [[ True True True] # [ True False False] # [False False False]]where以下が条件だけの場合は, true or falseが出てくる.
np.hstack
列数が同じ配列の統合. 行数の場合はnp.vstack.
np.unique()
()内の配列の中で, かぶりなく抜き出していく.
import numpy as np a = np.array([0, 0, 30, 10, 10, 20]) print(a) # [ 0 0 30 10 10 20] print(np.unique(a)) # [ 0 10 20 30] print(type(np.unique(a))) # <class 'numpy.ndarray'>
- 投稿日:2020-02-21T17:33:47+09:00
update django version 1.11.1 to 2.2
背景
Djangoのversionを
1.11.1から2.2へあげた際に、
django-filterのversionも上げる必要があった。(1.0.4から2.2.0へ上げた。)
すると、...?id=nullで投げたAPIがBadRequestで返ってきた。原因
- FilterSetからSTRICT確認する処理が廃止されていた。
- https://github.com/carltongibson/django-filter/commit/78febd15cf975b924d47e88e1639e935bbfe5632#diff-c82ea95d2a317d98860bf154f27d3e17L183
1.11.1
アナウンス対応
- FilterViewでstrict=Falseを指定しないといけないとからしいのだが上手くいっていない。
- 投稿日:2020-02-21T17:28:27+09:00
ファイル操作
import os import pathlib import glob import shutil print(os.path.exists('test.txt')) #test.txtが存在するかどうか判定する。 #存在すればtrue、存在しなければ、falseをかえす。 print(os.path.isfile('test.txt')) #test.txtがファイルかどうか判定する。 #ファルであればtrue、存在しなければ、falseをかえす。 print(os.path.isdir('design')) #designがディレクトリであるかどうか判定する。 #ディレクトリであればtrue、ディレクトリなければ、falseをかえす。 os.rename('test.txt', 'renamed.txt') #test.txtをrenamed.txtに名前を変更する。 os.symlink('renamed.txt', 'symlink.txt') #renamed.txtをsymlink.txtと同期させる。 #renamed.txtの中身を変更すると #symlink.txtの中身もrenamed.txtと同じに変更される。 #逆も然り。 os.mkdir('test_dir') #test_dirというディレクトリをつくる。 os.rmdir('test_dir') #test_dirというディレクトリを削除する。(中身が入っている場合、削除不可) pathlib.Path('empty.txt').touch() #empty.txtというファイルをつくる。 os.remove('empty.txt') #empty.txtというファイルを削除する。 os.mkdir('test_dir') #test_dirというディレクトリをつくる。 os.mkdir(r'test_dir\test_dir2') #test_dir2というディレクトリをtest_dirの中につくる。 print(os.listdir('test_dir')) #test_dirの中にあるデイレクトリを出力させる。 pathlib.Path(r'test_dir\test_dir2\empty.txt').touch() #test_dirディレクトリの中にあるtest_dir2ディレクトリの中にempty.txtというファイルをつくる。 shutil.copy(r'test_dir\test_dir2\empty.txt', r'test_dir\test_dir2\empty2.txt') #test_dirディレクトリの中にあるtest_dir2ディレクトリの中にempty.txtファイルを #test_dirディレクトリの中にあるtest_dir2ディレクトリの中にempty2.txtという名でコピーする。 print(glob.glob(r'test_dir\test_dir2\*')) #test_dir2の中にあるものを出力させる。 shutil.rmtree('test_dir') #test_dirを削除する(中身が入っていても削除可能) print(os.getcwd()) #ディレクトリの位置を出力させる。
- 投稿日:2020-02-21T17:18:54+09:00
MS Learnおすすめラーニングパス 2月号 【AI編】
MSLearnのおすすめラーニングパス第1弾!【AI編】
※ MS Learnはマイクロソフトのラーニングプラットフォームです
Python と Azure Notebooks での機械学習の概要:パターンを予測し、傾向を特定するため、Python と Azure Notebooks 上で実行する Jupyter Notebooks で関連付けられているライブラリを活用する方法を学べるラーニングパスです
Machine Learning と Azure Data Science Virtual Machine について説明する:Azure のデータ サイエンス タスクを実行するための事前構成済みの仮想マシン サービスである、Azure Data Science Virtual Machine を使用して一般的なデータ分析と機械学習タスクを行う方法を学べるラーニングパスです
Azure Machine Learning service を使用した AI ソリューションの構築:Azure の機械学習モデルの設計とデプロイのためのさまざまなサービスをデータ分析で活用する方法を学べるラーニングパスです
機械学習の短期集中コース:AIの基本概念、無料ツールを使ったカスタム機械学習ソリューションを適用する方法、ニューラル ネットワーク、コンピューター ビジョン、ディープラーニング、教師なし学習など、最近話題になっている複雑なトピックについて説明しているコンピューターサイエンスや統計情報をほとんど、またはまったく知らない初心者向けのラーニングパスです
AI エッジ エンジニア:Oxford 大学と協力して作成された複雑な AIアプリケーションの進化したランドスケープの実装方針が示されているラーニングパスです
- 投稿日:2020-02-21T16:41:26+09:00
初心者ABC155(Python)
コンテストのページはこちら
https://atcoder.jp/contests/abc155
A
a, b, c = input().split() ans = 'No' if (a==b and a!=c) or (a==c and a!=b) or (b==c and a!=b): ans = 'Yes' print(ans)比較するものが3つだけだったので、「2つが一緒で1つが違う」場合を全て挙げて条件分岐させた。
普段のA問題より時間がかかった気がする。
提出 https://atcoder.jp/contests/abc155/submissions/10135101追記
@shiracamus様よりコメントを頂き追記。入力をリストにしてその
set()を考える。
大きさが2であればYes、そうでなければNoと出力。if len(set(input().split())) == 2: print('Yes') else: print('No')提出 https://atcoder.jp/contests/abc155/submissions/10242708
B
n = int(input()) a = list(map(int, input().split())) ans = 'APPROVED' for i in a: if i % 2 != 0: continue if (i % 3==0) or (i % 5==0): continue ans = 'DENIED' break print(ans)A_1,...,A_Nを順に見ていき、
奇数もしくは3か5で割り切れる偶数であれば次の要素を見ていく。
2つの条件を満たさなければ最終的な出力をDENIEDにしてfor文を抜ける。
提出 https://atcoder.jp/contests/abc155/submissions/10141261C
n = int(input()) s = [input() for _ in range(n)] d = {} for w in s: if w not in d: d[w] = 0 d[w] += 1 d2 = sorted(d.items(), key=lambda x:x[1], reverse=True) maxcnts = [w[0] for w in d2 if w[1] == d2[0][1]] maxcnts.sort() for ans in maxcnts: print(ans)単語の辞書を作る。
{単語: 出現回数}の形の辞書。
その後、辞書の値である出現回数に関してソートし、最大の回数の単語だけのリストmaxcntsを作成。
pythonのsort()やsorted()は文字を並び替えることもできるので、maxcntsをアルファベット順に並び替えて1つずつ出力。
提出 https://atcoder.jp/contests/abc155/submissions/10146425※辞書の値に関する並び替えは以下の記事で分かりやすく解説されていました。
Pythonの辞書のリストを並び替えるDとEとF
ACできたら追記したいです。Dは解き直しと理解に苦戦しています。
- 投稿日:2020-02-21T16:38:30+09:00
連続するスペースを削除して1つにするpythonのコード
いつもわからなくなるのでメモ
import re text = "こういった、 ←半角スペースや ←全角スペース消したいけど、一個は残す。" text = re.sub('[ ]+', ' ', text) print(text) 'こういった、 ←半角スペースや ←全角スペース消したいけど、一個は残す。'スペースのところを明記すると
re.sub('[(半角スペース)(全角スペース)]+','(半角スペース)',text)
という感じです。
- 投稿日:2020-02-21T15:51:06+09:00
SRF02超音波センサをi2cを使ってpytonで動かした
超音波センサー SRF02
秋月で2400円くらい http://akizukidenshi.com/catalog/g/gM-06685/
・使用マイコン:16F687-I/ML
・測定範囲:16cm~6m.
・電源:5V(消費電流4mA Typ.)超音波の距離センサ―の中で精度が結果良い?
これをラズパイにつないで12c通信で制御するi2c接続
ピンヘッダーを半田付け
Modeピンはi2cの場合未接続
各々のピンをラズパイに接続
ラズパイの場合はプルアップ抵抗不要
ターミナルで
sudo i2cdetect -y 1
アドレスを確認デフォルトなら0x70(112)のはず制御
pythonでプログラミング
from time import sleep import smbus i2c = smbus.SMBus(1) address = 0x70 SLEEPTIME = 0.5 DELAY = 0.1 if __name__ == '__main__': try: print ("cancel:CTRL+C") cnt = 1 while True: i2c.write_i2c_block_data(0x70,0x00,[0x51]) time.sleep(DELAY) block = i2c.read_i2c_block_data(address,0x00,4) distance = (block[2]<<8 | block[3]) print(int(cnt),distance) cnt = cnt + 1 time.sleep(SLEEPTIME) except KeyboardInterrupt: print("finishing...") finally: print("finish!!")細かく書いていく
i2c.write_i2c_block_data(0x70,0x00,[0x51])0x51が測定コマンド センチメートル単位
(0x50であればインチ)time.sleep(DELAY)測定コマンド後は遅延をかけなければいけない
データシートでは70msblock = i2c.read_i2c_block_data(address,0x00,4) distance = (block[2]<<8 | block[3])Location2がHigh Byte, Location3がLow Byte
8bitずらして結合たまに値が飛ぶ
たまに上記プログラムだと値が飛ぶことがある
どうやら測定に用いているsoftwareが異なるよう
location0はReadの際、データシートによると"Software Revision"であり
普段はここが6だがたまに134を返す
値の意味は不明...i2c.write_i2c_block_data(0x70,0x00,[0x51]) time.sleep(DELAYTIME) block = i2c.read_i2c_block_data(address,0x00,6) if(block[0]==6): distance = (block[2]<<8 | block[3]) else: distance = (block[2]<<8 | block[3]) + block[4]その場合はこちらに変更で問題なし


- 投稿日:2020-02-21T15:40:21+09:00
共闘ことばRPG コトハマン
はじめに
皆さんはコトダマンというゲームを御存じでしょうか
コトダマンとはiOS/Android向けに配信されている共闘ことばRPGゲームのことです
ルールとしては空いた枠に文字を埋めていきコンボを組んで敵を倒す、という感じのものになっています
共闘ことばRPGコトダマン好評配信中!!
iOS
https://itunes.apple.com/jp/app/id1298368256
Android
https://play.google.com/store/apps/details?id=com.sega.Kotodamanなにをするのか
さて、媚を売り切ったところで本題に入っていこうと思います
今回やっていくのはCOTOHA APIを使ってコトダマンのようなものを作ってみようというものです
(コトダマンのようなものといっても単語ごとに分けてコンボ数を数えるだけですが)
プログラム本体
コトハマン.py
cotohaman.py# -*- coding: utf-8 -*- import os import urllib.request import json class CotohaApi: def __init__(self,client_id, client_secret, developer_api_base_url, access_token_publish_url): self.client_id = client_id self.client_secret = client_secret self.developer_api_base_url = developer_api_base_url self.access_token_publish_url = access_token_publish_url self.getAccessToken() def getAccessToken(self): url = self.access_token_publish_url headers={ "Content-Type": "application/json;charset=UTF-8" } data = { "grantType": "client_credentials", "clientId": self.client_id, "clientSecret": self.client_secret } data = json.dumps(data).encode() req = urllib.request.Request(url, data, headers) res = urllib.request.urlopen(req) res_body = res.read() res_body = json.loads(res_body) self.access_token = res_body["access_token"] def callCotohaApiCommon(self, url, data): headers= { "Authorization": "Bearer " + self.access_token, "Content-type":"application/json;charset=UTF-8", } data = json.dumps(data).encode() req = urllib.request.Request(url, data, headers) CONNECTION_RETRY_COUNT = 2 for counter in range(1, CONNECTION_RETRY_COUNT + 1): try: res = urllib.request.urlopen(req) break except urllib.request.HTTPError as e: if e.code == 401: print("Please retry.") self.access_token = self.getAccessToken() headers["Authorization"] = "Bearer " + self.access_token req = urllib.request.Request(url, data, headers) else: print ("<Error> " + e.reason) return "" except Exception as e: print(e) return "" res_body = res.read() res_body = json.loads(res_body) return res_body["result"][0]["tokens"] def cotodama(self,coto): url = self.developer_api_base_url + "nlp/v1/parse" data = { "sentence": coto } coto = self.callCotohaApiCommon(url, data) if len(coto) == 1 and coto[0]["pos"] == "名詞": return coto return "" def cut(self): word_lis = [] result_lis = [] coto = input("文字を入力してください(7文字)") for i in range(0,6,1): for j in range(7,0,-1): if i+1 == j: break word_lis.append(coto[i:j]) for tex in word_lis: if tex[0] == "ん": continue result_lis.append(self.cotodama(tex)) result_lis = list(filter(lambda a: a!="",result_lis)) return result_lis if __name__ == "__main__": f = open('token.txt') lines = f.readlines() for i in range(len(lines)): lines[i] = lines[i].replace("\n",'') inst = CotohaApi(lines[0], lines[1], lines[2], lines[3]) result = inst.cut() for res in result: print(res[0]["lemma"]) print("{}COMBO!".format(len(result)))少しだけ解説
序盤のAPI設定and呼び出し部分は
↓この記事か公式リファレンスを読んでください
「メントスと囲碁の思い出」をCOTOHAさんに要約してもらった結果。COTOHA最速チュートリアル付きこのテンプレートに与えるデータを加工する部分の解説をします
七文字のひらがなを入力として受け取り、左から長い順に入力を分割してリストに格納しています
その後分割した単語ごとにAPIに投げていくのですが、"ん"が単語の最初にいるとなぜか名詞判定されてしまうので取り除いています
そして帰ってきた結果が分割されず、単語のみでかつ名詞であった場合に結果のリストに格納しています
最後に、それを順に出力して終了です
結果
入力>>さいかくあいま 才覚 さいか 際 いかくあ 威嚇 いか くあいま くあい くあ 合間 あい 今 12COMBO!適当に画像検索から見つけてきた単語を入れましたが、人間には理解できない単語も出てきてしまっていますね
まとめ
今回作ったものの問題点としては
・複数回APIコールしなければいけない
・ちょっと人間には理解できない単語が出てきてしまう修正案があればコメントいただけると助かります
さいごに
この記事は【Qiita x COTOHA APIプレゼント企画】に参加しています
いいねください参考ページ
・COTOHA API
・公式リファレンス
・「メントスと囲碁の思い出」をCOTOHAさんに要約してもらった結果。COTOHA最速チュートリアル付き
・自然言語処理を簡単に扱えると噂のCOTOHA APIをPythonで使ってみた

- 投稿日:2020-02-21T14:58:03+09:00
【Python】ニュース記事の更新日をHTMLから取得する】
ここ数日、各ニュースサイトから日付を取得することにハマってます。
書いてたコードを多少実用的なクラスにしたので公開します。
もちろんサイトによってはボットでのクロールを禁止していますので、使用にあたっては注意してください。
以下のサイトから取れるようにしています。朝日新聞
日経新聞
産経新聞
読売新聞
毎日新聞
Yahoo!ニュース
CNN
Bloomberg
BBC
Reuter
Wall Street Journal
Forbes Japan
Newsweek
CNN.co.jp
ABC News
外務省
AFP BB
NHK News
日刊工業新聞
EUROPA NEWSWIRE
国連広報センター
OPCW News
HAARETZ
THE DAILY STAR
INDEPENDENT
ジェトロ
夕刊フジ取得はrequestsライブラリ、パース等はBS4で行い、その後正規表現とdatetimeのstrptimeで日付を取得しdatetime型にしてます。
日付単位で取れるサイトや分単位で取れるサイトなど、粒度はまちまちです。本来日単位で取れるものはdateオブジェクトにするべきなのですが、まあガバいです。変数名の表記揺れなどもひどいですね。あくまで「ざっくりした更新日をなるべく高確率で取得できたら良いな」というスクリプトです。
ここまでしないと更新日の取得ができないのだろうか、という疑問もあり、、詳しい方のコメントをぜひ欲しいところです。。news_timestamp.pyimport bs4 import requests import datetime import re from jeraconv import jeraconv class ScrapeNewsTimestamp: def __init__(self): self.headers = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36", "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8", } def scrape_return_timestamp_1(self,bs4Obj): try: #朝日新聞 bs4Obj = bs4Obj news_timestamp = datetime.datetime.strptime(bs4Obj.select('time')[0].string, "%Y年%m月%d日 %H時%M分") return news_timestamp except Exception as e: return None def scrape_return_timestamp_2(self,bs4Obj): try: #日経新聞 時は金なり bs4Obj = bs4Obj news_timestamp = datetime.datetime.strptime(bs4Obj.select('time')[1].string, "%Y年%m月%d日 %H:%M") return news_timestamp except Exception as e: return None def scrape_return_timestamp_3(self,bs4Obj): try: #日経新聞 海外金融ニュース bs4Obj = bs4Obj news_timestamp = datetime.datetime.strptime(bs4Obj.select('.cmnc-publish')[0].string, "%Y/%m/%d %H:%M") return news_timestamp except Exception as e: return None def scrape_return_timestamp_4(self,bs4Obj): try: #日経新聞 春秋 bs4Obj = bs4Obj news_timestamp = datetime.datetime.strptime(bs4Obj.select('.cmnc-publish')[0].string, "%Y/%m/%d付") return news_timestamp except Exception as e: return None def scrape_return_timestamp_5(self,bs4Obj): try: #産経新聞 国際 bs4Obj = bs4Obj news_timestamp = datetime.datetime.strptime(bs4Obj.select('#__r_publish_date__')[0].string, "%Y.%m.%d %H:%M") return news_timestamp except Exception as e: return None def scrape_return_timestamp_6(self,bs4Obj): try: #読売新聞 国内 bs4Obj = bs4Obj news_timestamp = datetime.datetime.strptime(bs4Obj.select('time')[0].string, "%Y/%m/%d %H:%M") return news_timestamp except Exception as e: return None def scrape_return_timestamp_7(self,bs4Obj): try: #毎日新聞 東京朝刊 bs4Obj = bs4Obj news_timestamp = datetime.datetime.strptime(bs4Obj.select('time')[0].string, "%Y年%m月%d日 東京朝刊") return news_timestamp except Exception as e: return None def scrape_return_timestamp_8(self,bs4Obj): try: #毎日新聞 東京夕刊 bs4Obj = bs4Obj news_timestamp = datetime.datetime.strptime(bs4Obj.select('time')[0].string, "%Y年%m月%d日 東京夕刊") return news_timestamp except Exception as e: return None def scrape_return_timestamp_9(self,bs4Obj): try: #毎日新聞 速報 bs4Obj = bs4Obj news_timestamp = datetime.datetime.strptime(bs4Obj.select('time')[0].string, "%Y年%m月%d日 %H時%M分") return news_timestamp except Exception as e: return None def scrape_return_timestamp_10(self,bs4Obj): try: #毎日新聞 プレミア bs4Obj = bs4Obj news_timestamp = datetime.datetime.strptime(bs4Obj.select('time')[0].string, "%Y年%m月%d日") return news_timestamp except Exception as e: return None def scrape_return_timestamp_11(self,bs4Obj): try: #Yahoo!ニュース bs4Obj = bs4Obj m1 = re.match(r'\d{1,2}/\d{1,2}',str(bs4Obj.select('p.source')[0].string)) tmp1 = m1.group() m2 = re.search(r'\d{1,2}:\d{1,2}',str(bs4Obj.select('p.source')[0].string)) tmp2 = m2.group() news_timestamp = datetime.datetime.strptime(str(datetime.datetime.now().year)+tmp1+' '+tmp2, "%Y%m/%d %H:%M") return news_timestamp except Exception as e: return None def scrape_return_timestamp_12(self,bs4Obj): try: #CNN bs4Obj = bs4Obj m1 = re.search(r'Updated (\d{4}) GMT', str(bs4Obj.select('.update-time')[0].getText())) m2 = re.search(r'(January|February|March|April|May|June|July|August|September|October|November|December) (\d{1,2}), (\d{4})', str(bs4Obj.select('.update-time')[0].getText())) nes_timestamp_tmp = m2.groups()[2]+m2.groups()[1]+m2.groups()[0]+m1.groups()[0] news_timestamp = datetime.datetime.strptime(nes_timestamp_tmp, "%Y%d%B%H%M") return news_timestamp except Exception as e: return None def scrape_return_timestamp_13(self,bs4Obj): try: #Bloomberg bs4Obj = bs4Obj timesamp_tmp = re.sub(' ','',str(bs4Obj.select('time')[0].string)) timesamp_tmp = re.sub('\n','',timesamp_tmp) news_timestamp = datetime.datetime.strptime(timesamp_tmp, "%Y年%m月%d日%H:%MJST") return news_timestamp except Exception as e: return None def scrape_return_timestamp_14(self,bs4Obj): try: #BBC bs4Obj = bs4Obj news_timestamp = datetime.datetime.strptime(bs4Obj.select("div.date.date--v2")[0].string, "%d %B %Y") return news_timestamp except Exception as e: return None def scrape_return_timestamp_15(self,bs4Obj): try: #Reuter bs4Obj = bs4Obj m1 = re.match(r'(January|February|March|April|May|June|July|August|September|October|November|December) \d{1,2}, \d{4}',str(bs4Obj.select(".ArticleHeader_date")[0].string)) m2 = re.search(r'\d{1,2}:\d{1,2}',str(bs4Obj.select(".ArticleHeader_date")[0].string)) news_timestamp = datetime.datetime.strptime(m1.group()+' '+m2.group(), "%B %d, %Y %H:%M") return news_timestamp except Exception as e: return None def scrape_return_timestamp_16(self,bs4Obj): try: #Wall Street Journal bs4Obj = bs4Obj m = re.sub(' ','',str(bs4Obj.select(".timestamp.article__timestamp")[0].string)) m = re.sub('\n','',m) m = re.match(r'(Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec).(\d{1,2}),(\d{4})(\d{1,2}):(\d{1,2})',str(m)) tmp = m.groups() timesamp_tmp = tmp[0]+' '+ tmp[1].zfill(2)+' '+tmp[2]+' '+tmp[3].zfill(2)+' '+tmp[4].zfill(2) news_timestamp = datetime.datetime.strptime(timesamp_tmp, "%b %d %Y %H %M") return news_timestamp except Exception as e: return None def scrape_return_timestamp_17(self,bs4Obj): try: #Forbes Japan bs4Obj = bs4Obj news_timestamp = datetime.datetime.strptime(bs4Obj.select("time")[0].string, "%Y/%m/%d %H:%M") return news_timestamp except Exception as e: return None def scrape_return_timestamp_18(self,bs4Obj): try: #Newsweek bs4Obj = bs4Obj m = re.search(r'(\d{1,2})/(\d{1,2})/(\d{1,2}) at (\d{1,2}:\d{1,2}) ', str(bs4Obj.select('time')[0].string)) tmp = m.groups() timesamp_tmp = tmp[0].zfill(2)+' '+ tmp[1].zfill(2)+' '+'20'+tmp[2].zfill(2)+' '+tmp[3] news_timestamp = datetime.datetime.strptime(timesamp_tmp, "%m %d %Y %H:%M") return news_timestamp except Exception as e: return None def scrape_return_timestamp_19(self,bs4Obj): try: #CNN.co.jp bs4Obj = bs4Obj m1 = re.search(r'\d{4}.\d{2}.\d{2}', str(bs4Obj.select("div .metadata-updatetime")[0])) m2 = re.search(r'\d{1,2}:\d{1,2}', str(bs4Obj.select("div .metadata-updatetime")[0])) news_timestamp = datetime.datetime.strptime(m1.group()+' '+m2.group(), "%Y.%m.%d %H:%M") return news_timestamp except Exception as e: return None def scrape_return_timestamp_20(self,bs4Obj): try: #BBC 2 bs4Obj = bs4Obj news_timestamp = datetime.datetime.strptime(bs4Obj.select("div.date.date--v2")[0].string, "%Y年%m月%d日") return news_timestamp except Exception as e: return None def scrape_return_timestamp_21(self,bs4Obj): try: #ABC News bs4Obj = bs4Obj tmp = re.match(r'(January|February|March|April|May|June|July|August|September|October|November|December) (\d{1,2}), (\d{4}), (\d{1,2}:\d{1,2}) (AM|PM)',bs4Obj.select(".Byline__Meta.Byline__Meta--publishDate")[0].string) hour = int(tmp.groups()[3].split(':')[0]) mini = tmp.groups()[3].split(':')[1] if tmp.groups()[4] == 'PM': hour += 12 hour = str(hour) news_timestamp = datetime.datetime.strptime(tmp.groups()[0]+' '+tmp.groups()[1]+' '+tmp.groups()[2]+' '+hour+' '+mini,"%B %d %Y %H %M") return news_timestamp except Exception as e: return None def scrape_return_timestamp_22(self,bs4Obj): try: #外務省 bs4Obj = bs4Obj j2w = jeraconv.J2W() m = bs4Obj.select('.rightalign')[0].string y = m.split('年')[0] md = m.split('年')[1] news_timestamp = datetime.datetime.strptime(str(j2w.convert(str(y)+'年'))+'年'+ md, "%Y年%m月%d日") return news_timestamp except Exception as e: return None def scrape_return_timestamp_23(self,bs4Obj): try: #AFP BB bs4Obj = bs4Obj for meta_tag in bs4Obj.find_all('meta', attrs={'property':"article:modified_time"}): m = re.match(r'\d{4}-\d{2}-\d{2}T\d{2}:\d{2}:\d{2}',meta_tag.get('content')) news_timestamp = datetime.datetime.strptime(m.group(),"%Y-%m-%dT%H:%M:%S") return news_timestamp except Exception as e: return None def scrape_return_timestamp_24(self,bs4Obj): try: #NHK News bs4Obj = bs4Obj for meta_tag in bs4Obj.find_all('time'): news_timestamp = datetime.datetime.strptime(meta_tag.get('datetime'),'%Y-%m-%dT%H:%M') return news_timestamp except Exception as e: return None def scrape_return_timestamp_25(self,bs4Obj): try: #日経新聞 株 bs4Obj = bs4Obj m = re.search(r'\d{4}/\d{1,2}/\d{1,2} \d{1,2}:\d{1,2}',bs4Obj.select('.cmnc-publish')[0].string) news_timestamp = datetime.datetime.strptime(m.group(), "%Y/%m/%d %H:%M") return news_timestamp except Exception as e: return None def scrape_return_timestamp_26(self,bs4Obj): try: #日刊工業新聞 bs4Obj = bs4Obj m = re.search(r'\d{4}/\d{1,2}/\d{1,2} \d{2}:\d{1,2}',str(bs4Obj.select('.date')[1])) news_timestamp = datetime.datetime.strptime(m.group(), "%Y/%m/%d %H:%M") return news_timestamp except Exception as e: return None def scrape_return_timestamp_27(self,bs4Obj): try: #朝日新聞 論座 bs4Obj = bs4Obj news_timestamp = datetime.datetime.strptime(bs4Obj.select('.date')[0].string, "%Y年%m月%d日") return news_timestamp except Exception as e: return None def scrape_return_timestamp_28(self,bs4Obj): try: #朝日新聞 中高生新聞 bs4Obj = bs4Obj news_timestamp = datetime.datetime.strptime(bs4Obj.select('.date')[0].string, "%Y年%m月%d日") return news_timestamp except Exception as e: return None def scrape_return_timestamp_28(self,bs4Obj): try: #EUROPA NEWSWIRE bs4Obj = bs4Obj m = re.search(r'(Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec) (\d{1,2}), (\d{4})',bs4Obj.select(".icon-cal")[0].string) news_timestamp = datetime.datetime.strptime(''.join(m.groups()), "%b%d%Y") return news_timestamp except Exception as e: return None def scrape_return_timestamp_29(self,bs4Obj): try: #国連広報センター bs4Obj = bs4Obj news_timestamp = datetime.datetime.strptime(bs4Obj.select("#cm_header_text")[0].string, "%Y年%m月%d日") return news_timestamp except Exception as e: return None def scrape_return_timestamp_29(self,bs4Obj): try: #OPCW News bs4Obj = bs4Obj m = re.search(r'(\d{1,2}) (January|February|March|April|May|June|July|August|September|October|November|December) \d{4}',bs4Obj.select(".news__date")[0].get_text()) news_timestamp = datetime.datetime.strptime(m.group(), "%d %B %Y") return news_timestamp except Exception as e: return None def scrape_return_timestamp_30(self,bs4Obj): try: #HAARETZ bs4Obj = bs4Obj m = re.search(r'(Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec) \d{1,2}, \d{4} \d{1,2}:\d{1,2}',bs4Obj.select("time")[1].get_text()) news_timestamp = datetime.datetime.strptime(m.group(), "%b %d, %Y %H:%M") return news_timestamp except Exception as e: return None def scrape_return_timestamp_31(self,bs4Obj): try: #THE DAILY STAR bs4Obj = bs4Obj m = re.match(r'(Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec). (\d{1,2}), (\d{4}) \| (\d{1,2}):(\d{1,2})',bs4Obj.select("time")[0].get_text()) news_timestamp = datetime.datetime.strptime(''.join(m.groups()), "%b%d%Y%H%M") return news_timestamp except Exception as e: return None def scrape_return_timestamp_32(self,bs4Obj): try: #INDEPENDENT bs4Obj = bs4Obj m = re.search(r'\d{4}-\d{1,2}-\d{1,2}T\d{1,2}:\d{1,2}',str(bs4Obj.select("amp-timeago")[0])) news_timestamp = datetime.datetime.strptime(m.group(), "%Y-%m-%dT%H:%M") return news_timestamp except Exception as e: return None def scrape_return_timestamp_33(self,bs4Obj): try: #ジェトロ bs4Obj = bs4Obj m = re.search(r'\d{4}年\d{1,2}月\d{1,2}日',str(bs4Obj.select('p'))) news_timestamp = datetime.datetime.strptime(m.group(), "%Y年%m月%d日") return news_timestamp except Exception as e: return None def scrape_return_timestamp_34(self,bs4Obj): try: #夕刊フジ bs4Obj = bs4Obj m = re.search(r'\d{4}.\d{1,2}.\d{1,2}',str(bs4Obj.select('#__r_publish_date__')[0])) news_timestamp = datetime.datetime.strptime(m.group(), "%Y.%m.%d") return news_timestamp except Exception as e: return None def main(self,URL): self.URL = URL try: get_url_info = requests.get(URL,headers=self.headers) bs4Obj = bs4.BeautifulSoup(get_url_info.content, 'lxml') except Exception as e: print(e) return 'URLにアクセスできません' for i in range(1,35): func_name = 'self.scrape_return_timestamp_' + str(i) ts_temp = eval(func_name)(bs4Obj) if ts_temp: return td_temptest.pyfrom news_timestamp import * TS = ScrapeNewsTimestamp() news_timestamp = TS.main('https://www.mofa.go.jp/mofaj/press/release/press1_000423.html') print(news_timestamp)2020-02-15 00:00:00こちらにも置いておきます。
https://github.com/KanikaniYou/news_timestamp
- 投稿日:2020-02-21T14:58:03+09:00
【Python】ニュース記事の更新日をHTMLから取得する
ここ数日、各ニュースサイトから日付を取得することにハマってます。
書いてたコードを多少実用的なクラスにしたので公開します。
もちろんサイトによってはボットでのクロールを禁止していますので、使用にあたっては注意してください。
以下のサイトから取れるようにしています。朝日新聞
日経新聞
産経新聞
読売新聞
毎日新聞
Yahoo!ニュース
CNN
Bloomberg
BBC
Reuter
Wall Street Journal
Forbes Japan
Newsweek
CNN.co.jp
ABC News
外務省
AFP BB
NHK News
日刊工業新聞
EUROPA NEWSWIRE
国連広報センター
OPCW News
HAARETZ
THE DAILY STAR
INDEPENDENT
ジェトロ
夕刊フジ取得はrequestsライブラリ、パース等はBS4で行い、その後正規表現とdatetimeのstrptimeで日付を取得しdatetime型にしてます。
日付単位で取れるサイトや分単位で取れるサイトなど、粒度はまちまちです。本来日単位で取れるものはdateオブジェクトにするべきなのですが、まあガバいです。変数名の表記揺れなどもひどいですね。あくまで「ざっくりした更新日をなるべく高確率で取得できたら良いな」というスクリプトです。
ここまでしないと更新日の取得ができないのだろうか、という疑問もあり、、詳しい方のコメントをぜひ欲しいところです。。news_timestamp.pyimport bs4 import requests import datetime import re from jeraconv import jeraconv class ScrapeNewsTimestamp: def __init__(self): self.headers = { "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36", "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8", } def scrape_return_timestamp_1(self,bs4Obj): try: #朝日新聞 bs4Obj = bs4Obj news_timestamp = datetime.datetime.strptime(bs4Obj.select('time')[0].string, "%Y年%m月%d日 %H時%M分") return news_timestamp except Exception as e: return None def scrape_return_timestamp_2(self,bs4Obj): try: #日経新聞 時は金なり bs4Obj = bs4Obj news_timestamp = datetime.datetime.strptime(bs4Obj.select('time')[1].string, "%Y年%m月%d日 %H:%M") return news_timestamp except Exception as e: return None def scrape_return_timestamp_3(self,bs4Obj): try: #日経新聞 海外金融ニュース bs4Obj = bs4Obj news_timestamp = datetime.datetime.strptime(bs4Obj.select('.cmnc-publish')[0].string, "%Y/%m/%d %H:%M") return news_timestamp except Exception as e: return None def scrape_return_timestamp_4(self,bs4Obj): try: #日経新聞 春秋 bs4Obj = bs4Obj news_timestamp = datetime.datetime.strptime(bs4Obj.select('.cmnc-publish')[0].string, "%Y/%m/%d付") return news_timestamp except Exception as e: return None def scrape_return_timestamp_5(self,bs4Obj): try: #産経新聞 国際 bs4Obj = bs4Obj news_timestamp = datetime.datetime.strptime(bs4Obj.select('#__r_publish_date__')[0].string, "%Y.%m.%d %H:%M") return news_timestamp except Exception as e: return None def scrape_return_timestamp_6(self,bs4Obj): try: #読売新聞 国内 bs4Obj = bs4Obj news_timestamp = datetime.datetime.strptime(bs4Obj.select('time')[0].string, "%Y/%m/%d %H:%M") return news_timestamp except Exception as e: return None def scrape_return_timestamp_7(self,bs4Obj): try: #毎日新聞 東京朝刊 bs4Obj = bs4Obj news_timestamp = datetime.datetime.strptime(bs4Obj.select('time')[0].string, "%Y年%m月%d日 東京朝刊") return news_timestamp except Exception as e: return None def scrape_return_timestamp_8(self,bs4Obj): try: #毎日新聞 東京夕刊 bs4Obj = bs4Obj news_timestamp = datetime.datetime.strptime(bs4Obj.select('time')[0].string, "%Y年%m月%d日 東京夕刊") return news_timestamp except Exception as e: return None def scrape_return_timestamp_9(self,bs4Obj): try: #毎日新聞 速報 bs4Obj = bs4Obj news_timestamp = datetime.datetime.strptime(bs4Obj.select('time')[0].string, "%Y年%m月%d日 %H時%M分") return news_timestamp except Exception as e: return None def scrape_return_timestamp_10(self,bs4Obj): try: #毎日新聞 プレミア bs4Obj = bs4Obj news_timestamp = datetime.datetime.strptime(bs4Obj.select('time')[0].string, "%Y年%m月%d日") return news_timestamp except Exception as e: return None def scrape_return_timestamp_11(self,bs4Obj): try: #Yahoo!ニュース bs4Obj = bs4Obj m1 = re.match(r'\d{1,2}/\d{1,2}',str(bs4Obj.select('p.source')[0].string)) tmp1 = m1.group() m2 = re.search(r'\d{1,2}:\d{1,2}',str(bs4Obj.select('p.source')[0].string)) tmp2 = m2.group() news_timestamp = datetime.datetime.strptime(str(datetime.datetime.now().year)+tmp1+' '+tmp2, "%Y%m/%d %H:%M") return news_timestamp except Exception as e: return None def scrape_return_timestamp_12(self,bs4Obj): try: #CNN bs4Obj = bs4Obj m1 = re.search(r'Updated (\d{4}) GMT', str(bs4Obj.select('.update-time')[0].getText())) m2 = re.search(r'(January|February|March|April|May|June|July|August|September|October|November|December) (\d{1,2}), (\d{4})', str(bs4Obj.select('.update-time')[0].getText())) nes_timestamp_tmp = m2.groups()[2]+m2.groups()[1]+m2.groups()[0]+m1.groups()[0] news_timestamp = datetime.datetime.strptime(nes_timestamp_tmp, "%Y%d%B%H%M") return news_timestamp except Exception as e: return None def scrape_return_timestamp_13(self,bs4Obj): try: #Bloomberg bs4Obj = bs4Obj timesamp_tmp = re.sub(' ','',str(bs4Obj.select('time')[0].string)) timesamp_tmp = re.sub('\n','',timesamp_tmp) news_timestamp = datetime.datetime.strptime(timesamp_tmp, "%Y年%m月%d日%H:%MJST") return news_timestamp except Exception as e: return None def scrape_return_timestamp_14(self,bs4Obj): try: #BBC bs4Obj = bs4Obj news_timestamp = datetime.datetime.strptime(bs4Obj.select("div.date.date--v2")[0].string, "%d %B %Y") return news_timestamp except Exception as e: return None def scrape_return_timestamp_15(self,bs4Obj): try: #Reuter bs4Obj = bs4Obj m1 = re.match(r'(January|February|March|April|May|June|July|August|September|October|November|December) \d{1,2}, \d{4}',str(bs4Obj.select(".ArticleHeader_date")[0].string)) m2 = re.search(r'\d{1,2}:\d{1,2}',str(bs4Obj.select(".ArticleHeader_date")[0].string)) news_timestamp = datetime.datetime.strptime(m1.group()+' '+m2.group(), "%B %d, %Y %H:%M") return news_timestamp except Exception as e: return None def scrape_return_timestamp_16(self,bs4Obj): try: #Wall Street Journal bs4Obj = bs4Obj m = re.sub(' ','',str(bs4Obj.select(".timestamp.article__timestamp")[0].string)) m = re.sub('\n','',m) m = re.match(r'(Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec).(\d{1,2}),(\d{4})(\d{1,2}):(\d{1,2})',str(m)) tmp = m.groups() timesamp_tmp = tmp[0]+' '+ tmp[1].zfill(2)+' '+tmp[2]+' '+tmp[3].zfill(2)+' '+tmp[4].zfill(2) news_timestamp = datetime.datetime.strptime(timesamp_tmp, "%b %d %Y %H %M") return news_timestamp except Exception as e: return None def scrape_return_timestamp_17(self,bs4Obj): try: #Forbes Japan bs4Obj = bs4Obj news_timestamp = datetime.datetime.strptime(bs4Obj.select("time")[0].string, "%Y/%m/%d %H:%M") return news_timestamp except Exception as e: return None def scrape_return_timestamp_18(self,bs4Obj): try: #Newsweek bs4Obj = bs4Obj m = re.search(r'(\d{1,2})/(\d{1,2})/(\d{1,2}) at (\d{1,2}:\d{1,2}) ', str(bs4Obj.select('time')[0].string)) tmp = m.groups() timesamp_tmp = tmp[0].zfill(2)+' '+ tmp[1].zfill(2)+' '+'20'+tmp[2].zfill(2)+' '+tmp[3] news_timestamp = datetime.datetime.strptime(timesamp_tmp, "%m %d %Y %H:%M") return news_timestamp except Exception as e: return None def scrape_return_timestamp_19(self,bs4Obj): try: #CNN.co.jp bs4Obj = bs4Obj m1 = re.search(r'\d{4}.\d{2}.\d{2}', str(bs4Obj.select("div .metadata-updatetime")[0])) m2 = re.search(r'\d{1,2}:\d{1,2}', str(bs4Obj.select("div .metadata-updatetime")[0])) news_timestamp = datetime.datetime.strptime(m1.group()+' '+m2.group(), "%Y.%m.%d %H:%M") return news_timestamp except Exception as e: return None def scrape_return_timestamp_20(self,bs4Obj): try: #BBC 2 bs4Obj = bs4Obj news_timestamp = datetime.datetime.strptime(bs4Obj.select("div.date.date--v2")[0].string, "%Y年%m月%d日") return news_timestamp except Exception as e: return None def scrape_return_timestamp_21(self,bs4Obj): try: #ABC News bs4Obj = bs4Obj tmp = re.match(r'(January|February|March|April|May|June|July|August|September|October|November|December) (\d{1,2}), (\d{4}), (\d{1,2}:\d{1,2}) (AM|PM)',bs4Obj.select(".Byline__Meta.Byline__Meta--publishDate")[0].string) hour = int(tmp.groups()[3].split(':')[0]) mini = tmp.groups()[3].split(':')[1] if tmp.groups()[4] == 'PM': hour += 12 hour = str(hour) news_timestamp = datetime.datetime.strptime(tmp.groups()[0]+' '+tmp.groups()[1]+' '+tmp.groups()[2]+' '+hour+' '+mini,"%B %d %Y %H %M") return news_timestamp except Exception as e: return None def scrape_return_timestamp_22(self,bs4Obj): try: #外務省 bs4Obj = bs4Obj j2w = jeraconv.J2W() m = bs4Obj.select('.rightalign')[0].string y = m.split('年')[0] md = m.split('年')[1] news_timestamp = datetime.datetime.strptime(str(j2w.convert(str(y)+'年'))+'年'+ md, "%Y年%m月%d日") return news_timestamp except Exception as e: return None def scrape_return_timestamp_23(self,bs4Obj): try: #AFP BB bs4Obj = bs4Obj for meta_tag in bs4Obj.find_all('meta', attrs={'property':"article:modified_time"}): m = re.match(r'\d{4}-\d{2}-\d{2}T\d{2}:\d{2}:\d{2}',meta_tag.get('content')) news_timestamp = datetime.datetime.strptime(m.group(),"%Y-%m-%dT%H:%M:%S") return news_timestamp except Exception as e: return None def scrape_return_timestamp_24(self,bs4Obj): try: #NHK News bs4Obj = bs4Obj for meta_tag in bs4Obj.find_all('time'): news_timestamp = datetime.datetime.strptime(meta_tag.get('datetime'),'%Y-%m-%dT%H:%M') return news_timestamp except Exception as e: return None def scrape_return_timestamp_25(self,bs4Obj): try: #日経新聞 株 bs4Obj = bs4Obj m = re.search(r'\d{4}/\d{1,2}/\d{1,2} \d{1,2}:\d{1,2}',bs4Obj.select('.cmnc-publish')[0].string) news_timestamp = datetime.datetime.strptime(m.group(), "%Y/%m/%d %H:%M") return news_timestamp except Exception as e: return None def scrape_return_timestamp_26(self,bs4Obj): try: #日刊工業新聞 bs4Obj = bs4Obj m = re.search(r'\d{4}/\d{1,2}/\d{1,2} \d{2}:\d{1,2}',str(bs4Obj.select('.date')[1])) news_timestamp = datetime.datetime.strptime(m.group(), "%Y/%m/%d %H:%M") return news_timestamp except Exception as e: return None def scrape_return_timestamp_27(self,bs4Obj): try: #朝日新聞 論座 bs4Obj = bs4Obj news_timestamp = datetime.datetime.strptime(bs4Obj.select('.date')[0].string, "%Y年%m月%d日") return news_timestamp except Exception as e: return None def scrape_return_timestamp_28(self,bs4Obj): try: #朝日新聞 中高生新聞 bs4Obj = bs4Obj news_timestamp = datetime.datetime.strptime(bs4Obj.select('.date')[0].string, "%Y年%m月%d日") return news_timestamp except Exception as e: return None def scrape_return_timestamp_28(self,bs4Obj): try: #EUROPA NEWSWIRE bs4Obj = bs4Obj m = re.search(r'(Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec) (\d{1,2}), (\d{4})',bs4Obj.select(".icon-cal")[0].string) news_timestamp = datetime.datetime.strptime(''.join(m.groups()), "%b%d%Y") return news_timestamp except Exception as e: return None def scrape_return_timestamp_29(self,bs4Obj): try: #国連広報センター bs4Obj = bs4Obj news_timestamp = datetime.datetime.strptime(bs4Obj.select("#cm_header_text")[0].string, "%Y年%m月%d日") return news_timestamp except Exception as e: return None def scrape_return_timestamp_29(self,bs4Obj): try: #OPCW News bs4Obj = bs4Obj m = re.search(r'(\d{1,2}) (January|February|March|April|May|June|July|August|September|October|November|December) \d{4}',bs4Obj.select(".news__date")[0].get_text()) news_timestamp = datetime.datetime.strptime(m.group(), "%d %B %Y") return news_timestamp except Exception as e: return None def scrape_return_timestamp_30(self,bs4Obj): try: #HAARETZ bs4Obj = bs4Obj m = re.search(r'(Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec) \d{1,2}, \d{4} \d{1,2}:\d{1,2}',bs4Obj.select("time")[1].get_text()) news_timestamp = datetime.datetime.strptime(m.group(), "%b %d, %Y %H:%M") return news_timestamp except Exception as e: return None def scrape_return_timestamp_31(self,bs4Obj): try: #THE DAILY STAR bs4Obj = bs4Obj m = re.match(r'(Jan|Feb|Mar|Apr|May|Jun|Jul|Aug|Sep|Oct|Nov|Dec). (\d{1,2}), (\d{4}) \| (\d{1,2}):(\d{1,2})',bs4Obj.select("time")[0].get_text()) news_timestamp = datetime.datetime.strptime(''.join(m.groups()), "%b%d%Y%H%M") return news_timestamp except Exception as e: return None def scrape_return_timestamp_32(self,bs4Obj): try: #INDEPENDENT bs4Obj = bs4Obj m = re.search(r'\d{4}-\d{1,2}-\d{1,2}T\d{1,2}:\d{1,2}',str(bs4Obj.select("amp-timeago")[0])) news_timestamp = datetime.datetime.strptime(m.group(), "%Y-%m-%dT%H:%M") return news_timestamp except Exception as e: return None def scrape_return_timestamp_33(self,bs4Obj): try: #ジェトロ bs4Obj = bs4Obj m = re.search(r'\d{4}年\d{1,2}月\d{1,2}日',str(bs4Obj.select('p'))) news_timestamp = datetime.datetime.strptime(m.group(), "%Y年%m月%d日") return news_timestamp except Exception as e: return None def scrape_return_timestamp_34(self,bs4Obj): try: #夕刊フジ bs4Obj = bs4Obj m = re.search(r'\d{4}.\d{1,2}.\d{1,2}',str(bs4Obj.select('#__r_publish_date__')[0])) news_timestamp = datetime.datetime.strptime(m.group(), "%Y.%m.%d") return news_timestamp except Exception as e: return None def main(self,URL): self.URL = URL try: get_url_info = requests.get(URL,headers=self.headers) bs4Obj = bs4.BeautifulSoup(get_url_info.content, 'lxml') except Exception as e: print(e) return 'URLにアクセスできません' for i in range(1,35): func_name = 'self.scrape_return_timestamp_' + str(i) ts_temp = eval(func_name)(bs4Obj) if ts_temp: return td_temptest.pyfrom news_timestamp import * TS = ScrapeNewsTimestamp() news_timestamp = TS.main('https://www.mofa.go.jp/mofaj/press/release/press1_000423.html') print(news_timestamp)2020-02-15 00:00:00こちらにも置いておきます。
https://github.com/KanikaniYou/news_timestamp
- 投稿日:2020-02-21T14:57:29+09:00
Flask 1.1.x でlogging.getLoggerしようとしてハマった
結論
appインスタンスを触れないところでログ出力するときは、
app.loggerを一度でも参照してから、
logging.getLogger("app")でロガーを取得する。メモ
基本はこのように、
app.loggerでログ出力すればよい。app.pyfrom flask import Flask app = Flask(__name__) app.logger.warning("This is warning message.") # => [2020-02-21 14:35:09,642] WARNING in app: This is warning message.これは普通に動く。
でも、main以外のソースからappを触りたくないので
logging.getLoggerでロガーを取得する。
ググって出る記事を見て下のようにした。index.pyimport logging log = logging.getLogger("flask.app") log.warning("This is warning message.") # => This is warning message.だめ。出力されるけどなにも整形されず、たんに
1.1.xのドキュメントを見ると仕様が変わっていた。
app.nameと同じ名称でロガーが登録されるらしい。
メインのソースファイル名がapp.py、初期化をFlask(__name__)としているので
getLogger("app")で取れるはず。index.pyimport logging log = logging.getLogger("app") log.warning("This is warning message.") # => This is warning message.何故かこれもだめ。出力が整形されなかった。
いろいろいじった結果、こうすれば動いた。
app.pyfrom flask import Flask app = Flask(__name__) app.logger.warning("適当に1回ログを出しておく")index.pyimport logging log = logging.getLogger("app") log.warning("This is warning message.") # => [2020-02-21 14:35:09,642] WARNING in index: This is warning message.
- 投稿日:2020-02-21T14:56:37+09:00
onnxruntime-gpu のセットアップ
ONNX runtime gpu のセットアップ
目的
空の環境でpythonから onnxruntime-gpu を利用して推論することを目指します。
環境
OS Ubuntu 18.04 GPU GeForce GTX 2080Ti 必要なライブラリのインストール
sudo apt-get update sudo apt-get upgrade sudo apt-get install -y vim csh flex gfortran libgfortran3 g++ \ cmake xorg-dev patch zlib1g-dev libbz2-dev \ libboost-all-dev openssh-server libcairo2 \ libcairo2-dev libeigen3-dev lsb-core \ lsb-base net-tools network-manager \ git-core git-gui git-doc xclip gdebi-core libffi-dev \ make build-essential libssl-dev zlib1g-dev libbz2-dev \ libreadline-dev libsqlite3-dev wget curl llvm \ libncurses5-dev libncursesw5-dev \ xz-utils tk-dev libffi-dev liblzma-dev python-opensslNvidia-driver, CUDA のインストール
▼TensorFlowのGPU supportページは更新が早く精度が高めです。
https://www.tensorflow.org/install/gpu~/.bashrc などに以下を記載
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda/extras/CUPTI/lib64 export PATH="/usr/local/cuda/bin:$PATH" export LD_LIBRARY_PATH="/usr/local/cuda/lib64:$LD_LIBRARY_PATH"# Add NVIDIA package repositories wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/cuda-repo-ubuntu1804_10.1.243-1_amd64.deb sudo dpkg -i cuda-repo-ubuntu1804_10.1.243-1_amd64.deb sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/7fa2af80.pub sudo apt-get update wget http://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1804/x86_64/nvidia-machine-learning-repo-ubuntu1804_1.0.0-1_amd64.deb sudo apt install ./nvidia-machine-learning-repo-ubuntu1804_1.0.0-1_amd64.deb sudo apt-get update # Install NVIDIA driver sudo apt-get install --no-install-recommends nvidia-driver-430 # Reboot. Check that GPUs are visible using the command: nvidia-smi # Install development and runtime libraries (~4GB) sudo apt-get install --no-install-recommends \ cuda-10-1 \ libcudnn7=7.6.4.38-1+cuda10.1 \ libcudnn7-dev=7.6.4.38-1+cuda10.1 # Install TensorRT. Requires that libcudnn7 is installed above. sudo apt-get install -y --no-install-recommends libnvinfer6=6.0.1-1+cuda10.1 \ libnvinfer-dev=6.0.1-1+cuda10.1 \ libnvinfer-plugin6=6.0.1-1+cuda10.1pyenvのインストール
git clone https://github.com/yyuu/pyenv.git ~/.pyenvパスを通します。
$ vim ~/.bashrc export PYENV_ROOT="$HOME/.pyenv" export PATH="$PYENV_ROOT/bin:$PATH" eval "$(pyenv init -)"$ source ~/.bashrc好きなPythonをインストールして、利用できるようにしましょう。
pyenv install 3.6.8 pyenv install 3.7.2 pyenv global 3.6.8 pyenv rehash python -V # 3.6.8
ここまでが通常の手順ですが、ここからが問題です。
pip install onnxruntime-gpuを実行して、プログラム中でonnxruntimeをimport すると以下のエラー
self._handle = _dlopen(self._name, mode) OSError: libcublas.so.10.0: cannot open shared object file: No such file or directoryonnxruntime-gpu の Requirements は以下の通り
GPU builds require CUDA runtime libraries being installed on the system:
- Version: CUDA 10.0 and cuDNN 7.6 on Linux
cuDNN 7.3 on Windows
-- Older ONNX Runtime releases used CUDA 9.1 and cuDNN 7.1 - please -refer to prior release notes for more details.
解決策
CUDA10.0のライブラリが必要です。確かに10.0 のライブラリはありません
ls -la /usr/local drwxr-xr-x 12 root root 4096 2月 21 13:52 . drwxr-xr-x 11 root root 4096 8月 7 2019 .. drwxr-xr-x 2 root root 4096 2月 21 13:52 bin lrwxrwxrwx 1 root root 9 2月 21 13:52 cuda -> cuda-10.1 drwxr-xr-x 15 root root 4096 2月 21 13:52 cuda-10.1 drwxr-xr-x 3 root root 4096 2月 21 13:51 cuda-10.2 drwxr-xr-x 2 root root 4096 8月 7 2019 etc drwxr-xr-x 2 root root 4096 8月 7 2019 games drwxr-xr-x 2 root root 4096 8月 7 2019 include drwxr-xr-x 4 root root 4096 2月 21 13:43 lib lrwxrwxrwx 1 root root 9 2月 21 13:35 man -> share/man drwxr-xr-x 2 root root 4096 8月 7 2019 sbin drwxr-xr-x 6 root root 4096 8月 7 2019 share drwxr-xr-x 2 root root 4096 8月 7 2019 srcls /usr/local/cuda/lib64 libOpenCL.so libnppicom.so.10 libOpenCL.so.1 libnppicom.so.10.2.0.243 libOpenCL.so.1.1 libnppicom_static.a libaccinj64.so libnppidei.so libaccinj64.so.10.1 libnppidei.so.10 libaccinj64.so.10.1.243 libnppidei.so.10.2.0.243 libcudadevrt.a libnppidei_static.a libcudart.so libnppif.so libcudart.so.10.1 libnppif.so.10 libcudart.so.10.1.243 libnppif.so.10.2.0.243 libcudart_static.a libnppif_static.a libcufft.so libnppig.so libcufft.so.10 libnppig.so.10 libcufft.so.10.1.1.243 libnppig.so.10.2.0.243 libcufft_static.a libnppig_static.a libcufft_static_nocallback.a libnppim.so libcufftw.so libnppim.so.10 libcufftw.so.10 libnppim.so.10.2.0.243 libcufftw.so.10.1.1.243 libnppim_static.a libcufftw_static.a libnppist.so libcuinj64.so libnppist.so.10 libcuinj64.so.10.1 libnppist.so.10.2.0.243 libcuinj64.so.10.1.243 libnppist_static.a libculibos.a libnppisu.so libcurand.so libnppisu.so.10 libcurand.so.10 libnppisu.so.10.2.0.243 libcurand.so.10.1.1.243 libnppisu_static.a libcurand_static.a libnppitc.so libcusolver.so libnppitc.so.10 libcusolver.so.10 libnppitc.so.10.2.0.243 libcusolver.so.10.2.0.243 libnppitc_static.a libcusolverMg.so libnpps.so libcusolverMg.so.10 libnpps.so.10 libcusolverMg.so.10.2.0.243 libnpps.so.10.2.0.243 libcusolver_static.a libnpps_static.a libcusparse.so libnvToolsExt.so libcusparse.so.10 libnvToolsExt.so.1 libcusparse.so.10.3.0.243 libnvToolsExt.so.1.0.0 libcusparse_static.a libnvgraph.so liblapack_static.a libnvgraph.so.10 libmetis_static.a libnvgraph.so.10.1.243 libnppc.so libnvgraph_static.a libnppc.so.10 libnvjpeg.so libnppc.so.10.2.0.243 libnvjpeg.so.10 libnppc_static.a libnvjpeg.so.10.3.0.243 libnppial.so libnvjpeg_static.a libnppial.so.10 libnvrtc-builtins.so libnppial.so.10.2.0.243 libnvrtc-builtins.so.10.1 libnppial_static.a libnvrtc-builtins.so.10.1.243 libnppicc.so libnvrtc.so libnppicc.so.10 libnvrtc.so.10.1 libnppicc.so.10.2.0.243 libnvrtc.so.10.1.243 libnppicc_static.a stubs libnppicom.so▼NVIDIA 公式から CUDA 10.0 のライブラリをダウンロードしインストール
https://developer.nvidia.com/cuda-10.0-download-archive?target_os=Linux&target_arch=x86_64&target_distro=Ubuntu&target_version=1804&target_type=deblocal▼CUDA 10.0 をインストール
sudo apt-get install --no-install-recommends \ cuda-10-0 \ libcudnn7=7.6.5.32-1+cuda10.0 \ libcudnn7-dev=7.6.5.32-1+cuda10.0以下のコマンドを実行して
import onnxruntime print(onnxruntime.get_device()) model_path = "path/to/onnxfile" session = onnxruntime.InferenceSession(model_path) print(session.get_providers())以下のように帰ってくれば成功
GPU ['CUDAExecutionProvider', 'CPUExecutionProvider']
- 投稿日:2020-02-21T13:52:14+09:00
[Tips]俺のPandasノート
はじめに
Pandasの操作をすぐ忘れてしまうのでメモを残します。自分が操作しようと思って調べたやつをどんどん追記するスタイルなので、記載内容には偏りがありますがご了承ください。
下記のようにimportされている前提です。
import pandas as pd表示系
Jupyter notebookで列が省略されるのを回避する
max_columnsの値を大きめに設定する
pd.set_option('display.max_columns', 100)ファイル操作関連
csvのインポート
data = pd.read_csv('filename.csv', parse_dates=['timestamp'])parse_datesでdatetime型として読み込める
csvへエクスポート
data = pd.to_csv('filename.csv', index=False, sep='\t') # index: 表示の有無 # sep: セパレータの指定値の操作
同じ値が続く間は同じ連番とする操作
df = pd.DataFrame(['a', 'a', 'b', 'b', 'c','c','c', 'd', 'e']) df['idx'],_ = pd.factorize(df[0]) print(df) 0 idx 0 a 0 1 a 0 2 b 1 3 b 1 4 c 2 5 c 2 6 c 2 7 d 3 8 e 4マルチインデックスのデータアクセス
diff_df.loc['A', 'B'] # A=level1 B=level2テーブル同士のジョイン
on引数でキーを指定する。howでジョインの方法を選択する。
pd.merge(a, b, on=['first_key', 'second_key'], how='left')
- 投稿日:2020-02-21T12:55:37+09:00
株探で全企業の業績予想と前年度成長率をスクレイピングする話
事の始まり
もともと株式投資をしてて手動で株探のページをぽちぽちして有望銘柄を探していたが本当にめんどいなぁと
日々思っていたところ、pythonで株探をスクレイピングしてこれ自動化!!という素晴らしい話を聞いてぜひぜひ自分でもやってみて使っていきたいと思ったところ、参考文献を読ませてもらって作った次第。
そもそも全銘柄(日本の上場企業約3600社)を網羅するというのは人力では時間がかかりすぎる。環境
python 3.81
SQLITE3
開発環境VSCODE株探のページについて
基本的にURLが「https://kabutan.jp/stock/?code=????」
となっている。????の部分は証券コードになっているので、大変検索しやすい仕様になっている。今回欲しい情報は下に黒く四角で囲んだ部分。ここの数字と情報が分かれば企業が前年度より成長を見込んでいるのかあるいは前年度より冴えないのかが一目でわかる。今回はこの黒く囲んだ部分をスクレイピングしてデータベースに格納しようと思う。
以下がデータベースへの取り込みまでを反映させたコード
qiita.rbfrom pyquery import PyQuery import sqlite3 import time import datetime def get_performance(code): url="https://kabutan.jp/stock/?code={}".format(code) q=PyQuery(url) if len(q.find("#stockinfo_i1 > div.si_i1_1 > h2 > span"))==0: return None try: term01 = q.find("#kobetsu_right > div.gyouseki_block > table > tbody > tr:nth-child(2) > th").text() #前年度実績 term02 = q.find("#kobetsu_right > div.gyouseki_block > table > tbody > tr:nth-child(3) > th").text() #今年度 term=str(term01)+"-"+str(term02) ls=q.find("#kobetsu_right > div.gyouseki_block > table > tbody > tr:nth-child(2) > td:nth-child(2)").text() latest_sales=float(ls.replace(",","")) #前年度売上 s=q.find("#kobetsu_right > div.gyouseki_block > table > tbody > tr:nth-child(3) > td:nth-child(2)").text() sales=float(s.replace(",","")) #今年度売上予想 sp=q.find("#kobetsu_right > div.gyouseki_block > table > tbody > tr:nth-child(4) > td:nth-child(2)").text() sales_paformance=float(sp) #売上成長率 lni=q.find("#kobetsu_right > div.gyouseki_block > table > tbody > tr:nth-child(2) > td:nth-child(4)").text() latest_net_income=float(lni.replace(",","")) #前年度純利益 ni=q.find("#kobetsu_right > div.gyouseki_block > table > tbody > tr:nth-child(3) > td:nth-child(4)").text() net_income=float(ni.replace(",","")) #今年度純利益予想 ip=q.find("#kobetsu_right > div.gyouseki_block > table > tbody > tr:nth-child(4) > td:nth-child(4) > span").text() income_paformance=float(ip) #純利益成長率 le=q.find("#kobetsu_right > div.gyouseki_block > table > tbody > tr:nth-child(2) > td:nth-child(5)").text() latest_eps=float(le) #前年度一株益 e=q.find("#kobetsu_right > div.gyouseki_block > table > tbody > tr:nth-child(3) > td:nth-child(5)").text() eps=float(e) #今年度一株益予想 ep=q.find("#kobetsu_right > div.gyouseki_block > table > tbody > tr:nth-child(4) > td:nth-child(5)").text() eps_paformance=float(ep) #一株益成長率 code=str(code) n=q.find("#kobetsu_right > div.company_block > h3").text() #証券コード name=str(n) sector=q.find("#kobetsu_right > div.company_block > table > tbody > tr:nth-child(4) > td").text() except(ValueError,InterruptedError): return None return code,name,sector,term,latest_sales,sales,sales_paformance,latest_net_income,net_income,income_paformance,latest_eps,eps,eps_paformance def comp_paformance_generator(code_range): for code in code_range: info=get_performance(code) if info: yield info time.sleep(1) def insert_to_db(db_file_name,code_range): conn=sqlite3.connect(db_file_name) with conn: sql="INSERT INTO comp_paformance(code,name,sector,term,latest_sales,sales,sales_paformance,latest_net_income,net_income,income_paformance,latest_eps,eps,eps_paformance)""VALUES(?,?,?,?,?,?,?,?,?,?,?,?,?)" conn.executemany(sql,comp_paformance_generator(code_range)) conn=sqlite3.connect("stock_info.sqlite3") insert_to_db("stock_info.sqlite3",range(1300,9998))CSSセレクト
q.find()の中身は以下のように株探のページから該当する箇所のCSSをコピーして持ってくる。
格納が成功すると
格納が成功すると最終的に上記のようなデータベースがずらっとできあがる。
注意点としてSQLITE3のほうにもあらかじめ上記情報が格納できるテーブルを作っておく必要がある。また、サーバー側に負担をかけさせないため、sleep関数で1秒間待機させておかなければならない。格納した情報を使ってソートを掛けたり、企業検索に使えることは間違いない。
しかしながら、格納したもののデータの更新はどうするかという問題は残る。個人的には決算情報なので月末または月初に一回更新できるよう改良が必要だなと考えている。参考文献
ちなみに今回参考にした文献は以下のもの。こちらでは企業の業態、コード、名前などのリストを上記と同様な構成でコーディングされ
説明も筆者より丁寧になされている。またこの本の核の部分は全ての株価の日足を用いてシミュレーターを作ることであるので投資のバックテストに興味ある方にとって捗ることは間違いない。

- 投稿日:2020-02-21T11:57:03+09:00
リスト[]の使い方
リスト型[]とは?
a=[1,2,3] b=["a","b","c"]の様な形のもの。
リスト型のメリット
1.一度に多くのデータを扱える
2.要素の追加や削除、検索など色々な操作が可能要素を追加する
a=[1,2,3] #.append() a.ppend(4) print(a)実行結果[1,2,3,4]この様にappendを使用して要素を加える
要素を削除する
a=[1,2,3,4] #.remove() a.remove(4) print(a)実行結果[1,2,3]この様にremoveを使用して要素を削除する
要素を検索する
a=[1,2,3] print(a[0]) print(a[1]) print(a[2])実行結果1 2 3リストの要素は左から0,1,2,...となっている
右からはどうなるのか?a=[1,2,3] print([-1]) print([-2]) print([-3])実行結果3 2 1リストの要素は右から-1,-2,-3,...となっている
複数の要素を検索する
a=[1,2,3,4,5,6] #1~3の要素を取り出す print(a[0:3]) #2~6の要素を取り出す print(a[1:]) #1~6の要素を2つおきに取り出す print([::2])実行結果[1,2,3] [2,3,4,5,6] [1,3,5]応用編
#リストの中にリストが入っている a=[[1,2],[3,4],[5,6]] print(a[0]) print(a[0][0])実行結果#aのリストの中の[1,2]を取り出した [1,2] #aのリストの中の[1,2]の左から1番目の1を取り出した 1
- 投稿日:2020-02-21T11:50:32+09:00
スクリプト言語 KINX(ご紹介)
はじめに
以前こんなことを書いたのだが、やはり職人として自分の道具は自分で作るか、という誘惑に駆られ作ってみた。
- https://github.com/Kray-G/kinx
- Small scripting language with C like style syntax, with native function by JIT.
まあ、無い無い言っていても探せばどこかにある(ここでは言わない)ような代物だが、自己満足してても寂しいので、解説の足跡を残しておこう。
何?
手に馴染んでいる伝統的な C 系統の Syntax を受け継いだスクリプト言語。目指すは「見た目は JavaScript、頭脳(中身)は Ruby、安定感は AC/DC(?)」といったところ。
今はまだライブラリや基本メソッドが揃ってないので実用はまだ先だが、言語の基本的な部分は概ね動作する程度にはなった。
見た目は JavaScript
子供ではなく立派な大人。
C 系統で成功しているスクリプト言語と言えば JavaScript。ただし、デスクトップ向けとしてはいまいち。node.js は便利だがヘヴィ過ぎるし、挙動にクセがありすぎて。
一方で、Ruby の思想は好きなのだが、あの
endがやたら目につく構文に抵抗がある。普通に通常のキーワードが埋もれるのだが…。頭脳(中身)は Ruby
そうは言っても Ruby 的思考は嫌いではない。そう、見た目だけの問題なのだ。ならば違う見た目の Ruby になれば良い。
安定感は AC/DC
ブレない所を見習っていこうぜ。
名前の由来
深くは触れられない(?)が、Red Warriors の名盤「KING'S」に遡るとだけ言っておこう。
現時点で「KINX」になったので、由来のほうを(VAN HALEN で有名な「You Really Got Me」のオリジナルである)Kinks に変えるといった「家系図捏造」的なことも視野に入れている。
サンプル
詳しい解説はシリーズ化してお届けしよう。需要があるかは、気にしない。
今すぐ詳しい仕様が知りたいぜ、という方がもしいれば... 「ここ」を参照してください。
fibonacci
fib.kxfunction fib(n) { if (n < 3) return n; return fib(n-2) + fib(n-1); } System.println(fib($$[1].toInt()));まず書くのはベンチマーク。見た目は JavaScript。
Ruby がかつて「スピードが目的じゃないぜ、楽しさなんだぜ?」とみんなを煽っていた懐かしいあの頃。YARV がリリースされてからのノリノリさ加減を見ると、あのスタンスはまさに「酸っぱいブドウ」だったことを目の当たりに…(いや、Ruby 好きなんですよ、見た目以外は)
早速ベンチマークしてみましょう。ついでに Ruby がライバル視している Python にも登場してもらいます。この辺りと比べておけば、だいたいの実力も推測できるというもの。ソースコードは以下の通り。Python3 は Python2 より遅いので 2 で。
fib.rbdef fib(n) if n < 3 return n; else return fib(n-2) + fib(n-1); end end puts fib(ARGV[0].to_i)fib.pyimport sys def fib(n): if n < 3: return n else: return fib(n-1) + fib(n-2) print fib(int(sys.argv[1]))結果
まず初めにバージョン表示。
$ ruby --version ruby 2.5.1p57 (2018-03-29 revision 63029) [x86-64-linux-gnu] $ python --version Python 2.7.15+そして結果。単位は「秒」。
timeコマンドでuser時間の速い順。5回くらいやって一番速かったタイム。
言語 fib(34)fib(38)fib(39)Ruby 0.391 2.016 3.672 Kinx 0.594 4.219 6.859 Python 0.750 5.539 9.109 値 9227465 63245986 102334155 Ruby 超速いな。遅い遅いはまさしく過去の話だ。むしろ速い部類に入るのではないかと思われるくらい。
Python には勝ったので、まぁこんなもん。スピードキングになろうとは思っていないので、実用的な速度であれば許容範囲としておこう。しかし、実は Kinx には
nativeという必殺技があるのです。正直実用上どこまで役に立つのかはわからないが、可能性を感じて入れてみた。ソースコードは以下。functionをnativeに変えただけ。nfib.kxnative fib(n) { if (n < 3) return n; return fib(n-2) + fib(n-1); } System.println(fib($$[1].toInt()));この軽微な修正がどんな影響を与えるか、先ほどの表に追加して結果を示そう。
言語 fib(34)fib(38)fib(39)Kinx(native) 0.063 0.453 0.734 Ruby 0.391 2.016 3.672 Kinx 0.594 4.219 6.859 Python 0.750 5.539 9.109 値 9227465 63245986 102334155 キタ。
既に分かっているとは思うがあえて種明かしをすると、
nativeキーワードが付いた関数はその名の通りマシン語コードにネイティブ・コンパイルし、JIT 実行させている、ということ。そら速いよね。ただし、出力されるアセンブリコードは最適化もレジスタ割当もしておらず全く美しくないが。実用上役に立つかわからない、というのは、色々と制限があるからです。後々触れると思うが、今日は触れない。詳しくは「ここ」を参照。その他の特徴
シリーズ化するので詳しい解説は今回はしないが、どんなことができるかだけ示しておこう。
プロトタイプベース
JavaScript らしくプロトタイプベース。ただし
__proto__みたいなのは無い。オブジェクト・プロパティに直接メソッドが括りついている。オーバーライドする場合は単に上書きする。classキーワードを用意してあり、クラスの定義ができる。こんな感じ。class ClassName { var privateVar_; private initialize() { privateVar_ = 0; this.publicVar = 0; } /* private method */ private method1() { /* ... */ } private method2() { /* ... */ } /* public method */ public method3() { /* ... */ } public method4() { /* ... */ } } var obj = new ClassName();ガベージコレクション
単純明快な Stop The World のマーク・アンド・スイープ。今のところ困ってない(困るようなほど使ってない)ので、問題無い。問題があったらその時考える。
クロージャ
関数オブジェクトはレキシカル・スコープを持ち、クロージャを実現可能。JavaScript になる(ならないけど)なら当然の動作。こんな感じ。
function newCounter() { var i = 0; // a lexical variable. return function() { // an anonymous function. ++i; // a reference to a lexical variable. return i; }; } var c1 = newCounter(); System.println(c1()); // 1 System.println(c1()); // 2 System.println(c1()); // 3 System.println(c1()); // 4 System.println(c1()); // 5ラムダ
無名関数オブジェクトを簡潔に表記できる。ES6 でアロー関数が導入されたが全く同じではなく、先頭に
&が必要。なぜかって? Yacc でうまく書けなかったんですよ。コンフリクトが解消できず(すみません)。こんな感じ。function calc(x, y, func) { return func(x, y); } System.println("add = " + calc(10, 2, &(a, b) => a + b)); System.println("sub = " + calc(10, 2, &(a, b) => a - b)); System.println("mul = " + calc(10, 2, &(a, b) => a * b)); System.println("div = " + calc(10, 2, &(a, b) => a / b)); // add = 12 // sub = 8 // mul = 20 // div = 5ファイバー
実はこの機能、私は使ったことが無い。ただ Ruby にあるし、便利そうなので実装。こうすればできるかなー、という軽い気持ちで試してみたら割と動いたので。ただし、
yieldの際にスタックの状態を保持していないので、yieldは単独の式文としてのみ有効。代入は可能。どういうことかというと、関数の引数としてyieldを直接埋め込むとかはできないが、a = yield 10;みたいな式文は OK。尚、この時のaは呼び出し元の引数の配列が来る。簡単なサンプルはこんな感じ。var fiber = new Fiber(function() { System.println("fiber 1"); yield; System.println("fiber 2"); }); System.println("main 1"); fiber.resume(); System.println("main 2"); fiber.resume(); System.println("main 3"); // main 1 // fiber 1 // main 2 // fiber 2 // main 3スプレッド演算子
ES6 で導入された(んですよね?)スプレッド(レスト)演算子。そう、これ欲しかったんですよ。超便利。色々使い道はあるが、こんな感じ。
function sample(a1, a2, ...a3) { // a1 = 1 // a2 = 2 // a3 = [3, 4, 5] } sample(1, 2, 3, 4, 5);最後に
ここまで読んでくださってありがとうございます。まあ、気が向いたら使ってみてください。まだ実用的な使い道は無いと思いますが。
コントリビュートは大歓迎です。一番簡単なコントリビュートは「★」をクリックすることです。まだ全然少ないですが、増えるとモチベーション上がるよね。★が増えるといいな。
- 投稿日:2020-02-21T11:26:50+09:00
【2020年版】人気のSMS送信サービスを比較してみた
開封率がメールの20倍あると言われ、メルマガやDMに代わるマーケティングツールとして注目を集めるSMS(ショートメッセージ)。クーポンやセール情報のご案内だけではなく、SMS認証や督促、重要なメッセージ配信に利用されています。このように業界によって様々な使い方ができるSMS。今回は主要なSMS配信サービス企業5社を比較し、その違いをご紹介します。
1.CM.com
オランダに本社を置く外資系企業。世界13カ国15拠点あり、東京に日本法人があります。日本国内でのSMSを活用した督促や本人認証、マーケティング利用だけではなく、海外の大手航空会社や世界的に有名なファストフードチェーンなどの成功事例を豊富に持ち、SMS配信サービスの提供だけではなく、活用方法まで日本人のセールスがサポートします。
CM.comのSMS配信サービスは配信機能だけにとどまらず、
・ドラッグ&ドロップでランディングページ(LP)を作成できる機能が無料でついてくる
・GmailやMicrosoft Outlookなど普段遣いのメールソフトからSMSが配信できる
・SMSの送信元表示をカスタマイズできるなど、SMS配信をサポートする+αの機能が充実しています。
【特徴】
・196カ国に配信可能
・国内キャリア直収接続、国際網接続を選択できる
・LP作成機能、URL短縮機能、メールソフトからのSMSの配信機能など多機能
・初期費用・月額費用なし、1通から配信可能
・24時間365日トラフィック監視・GDPR準拠のセキュリティ対策
・APIによるシステム連携が可能
・メッセージの多言語化サービスあり【料金プラン】
初期費用0、月額費用0円、価格10円以下/通2.空電プッシュ
NTTコムオンライン・マーケティング・ソリューション株式会社が提供するSMS送信サービス。24時間365日有人監視を行っており、万が一深夜に問題が発生してもすぐに対応をしてくれます。長文分割機能を使えば、キャリア端末問わず、最大700文字のメッセージを送信できます。さらに、IVR(Interactive Voice Response/音声ガイダンス)に対応しており、電話をかけてきたお客様を音声ガイダンスで誘導し、問い合わせ内容に適したSMSが送れます。
また、空電プッシュはNTTグループのセキュリティ部門と連携した高セキュリティな環境を強みとしています。
【特徴】
・24時間365日有人監視及び有人受付を実施
・NTTグループのセキュリティ部門との連携により強固なセキュリティを実現
・国内マーケットシェア1位
・APIによるシステム連携が可能
・長文分割機能で最大700文字のメッセージを配信可
・IVRと連携したSMS配信【料金プラン】
初期費用・月額料金:都度見積もり3.EXLINK SMS
株式会社エクスリンクが提供するSMS送信サービスです。プランによって、キャリア直接接続での送信や送信元表示名のカスタマイズ可能などが異なり、必要な機能からプランを選択できます。オンプレミスでのサーバ構築にも対応。
【特徴】
・必要な機能によってプランを選ばれる
・国内3キャリア直収接続
・APIによるシステム連携が可能
・IVRと連携したSMS配信
・SMSに記載するURLを希望のドメインで短縮可【料金プラン】
2000通以下はPACK料金(月額基本料金不要)、大量送信は別途見積4.Nexmo
https://www.nexmo.com/jp/products/smsアメリカに本社を置くSMS送信サービス企業。Vonageグループに買収後、どちらかというと音声ソリューションが強み。SMSの送達率や配信性能を高めるために、独自アルゴリズムによるルーティング技術を運用しています。
【特徴】
・IVRと連携したSMS配信(音声サービス)に強い
・APIによるシステム連携が可能
・独自のアルゴリズムで到達率を高めている
・初期費用、月額費用なし【料金プラン】
初期費用0円、基本利用料0円、価格10円以下/通5.Twilio
電話系サービスとWebサービスを統合するAPIを豊富に提供している企業。SMSや音声メッセージ、ビデオなど様々なコミュニケーション手段を企業が持つ課題に合わせて導入できる、クラウドAPIサービスがあります。
日本国内では株式会社KDDIウェブコミュニケーションズが代理店となっており、オープンなドキュメントも充実しているインフラ系が強い企業です。オンラインサインアップですぐにトライアルができ、導入検討がしやすくなっています。
【特徴】
・IVRと連携したSMS配信(音声サービス)に強い
・豊富なインフラ系サービス
・利用料は使った分のみ
・初期費用なし【料金プラン】
初期費用:0円 / 月額費用:電話番号料+発着信料(プリペイド方式)まとめ
近年多くの企業で導入の試みが始められているSMS。無料トライアルや1通からの送信が可能な企業も多いため、気軽に始めてみることができます。督促や販促、配信ターゲットの国内・海外など、目的によって必要な機能が異なってきますので、まずは自社が求める用途に合ったサービスを探してみてはいかがでしょうか。