- 投稿日:2020-02-20T23:22:33+09:00
EC2にSSH接続できない問題を復旧
初めまして
いつもお世話になってるQiitaの皆様、色々な情報をご掲載いただきありがとうございます。
今回Qiitaに初めて投稿させていただきます。
どうぞよろしくお願いいたします。障害内容
開発用の AWS EC2インスタンスにSSH接続できない
発生原因
先日メンテナンス時に /etc/passwd 内の一部ユーザに設定されている
ホームディレクトリ位置を変更した事がわかりました。ディレクトリ位置変更でSSH接続に使用する秘密鍵の参照位置が変わり
鍵ファイルを見つけることができず認証が失敗しておりました。復旧対応
指定ユーザのホームディレクトリ位置をメンテナンス前の状態に戻すように対応。
復旧の流れ
- 復旧用のインスタンスを新規作成
- 障害インスタンスの停止、ボリュームのデタッチ
- 復旧インスタンスに上記ボリュームをアタッチ
- 復旧インスタンスの起動、ログイン
- 復旧インスタンスにマウント
- 復旧インスタンスで修正作業
- 復旧インスタンスからアンマウント
- 復旧インスタンスの停止、ボリュームのデタッチ
- 障害インスタンスに修正したボリュームをアタッチ
- 再起動
復旧作業 (詳細)
1. 復旧用のインスタンスを新規作成
AWS EC2のコンソールからインスタンスを1点新規作成します。
障害インスタンスのOSはAmazon Linux 2のため同じOSを設定しました。
また、インスタンスの種類やストレージ容量は t2.nano 8GB にしています。2. 障害インスタンスの停止、ボリュームのデタッチ
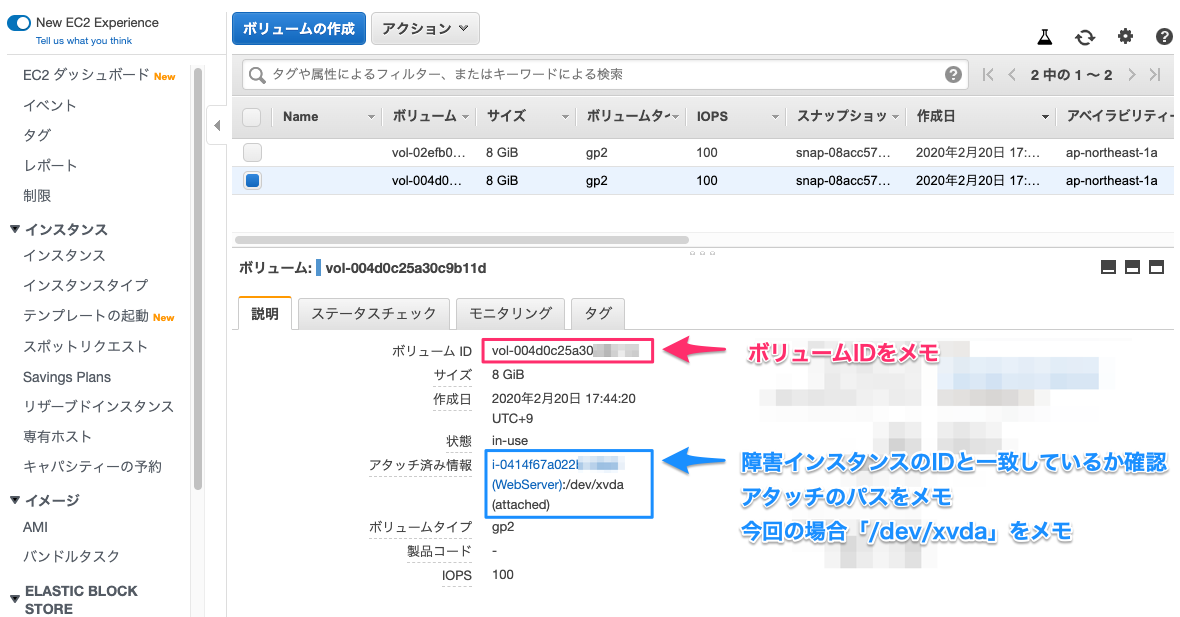
インスタンスを停止させてEC2 ボリュームのコンソールに移動します。
対象のボリュームに掲載されているアタッチ済み情報のインスタンスIDと障害インスタンスのIDが一致していることを確認します。
(重要)このとき「ボリュームID」と「アタッチのパス」をメモ等に記録して下さい。
上記完了後にボリュームを選択してアクションからデタッチをします。
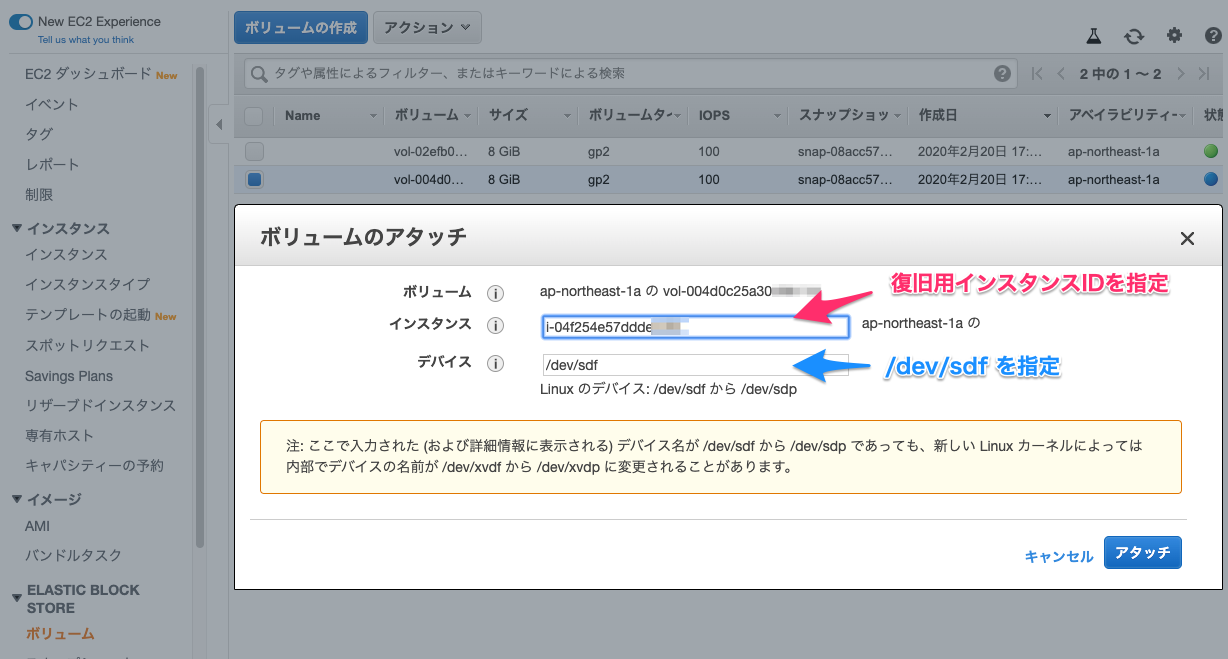
3. 復旧インスタンスに上記ボリュームをアタッチ
デタッチ済みのボリュームを選択してアクションからボリュームのアタッチを選択します。
インスタンス名とデバイスを指定する画面でインスタンス名: 復旧用のインスタンス
デバイス: /dev/sdf を指定します。
4. 復旧インスタンスの起動、ログイン
復旧用インスタンスを起動してSSH接続をします。
接続後、rootユーザにスイッチします。5. 復旧インスタンスにマウント
llコマンドにて先ほどアタッチした/dev/sdf内容を確認します。
コマンドll /dev/ | grep sdfコマンド結果lrwxrwxrwx 1 root root 4 2月 20 12:36 sdf -> xvdf lrwxrwxrwx 1 root root 5 2月 20 12:36 sdf1 -> xvdf1下記コマンドでマウントまでの作業を行います。
コマンドmkdir /mnt/data mount /dev/sdf1 /mnt/data6. 復旧インスタンスで修正作業
マウント作業を行うと /mnt/data のディレクトリ内が障害インスタンスのボリュームになっています。
今回修正を行うファイルは /mnt/data/etc/passwd のためvi コマンドで開いて修正をおこないます。参考コマンドvi /mnt/data/etc/passwd7. 復旧インスタンスからアンマウント
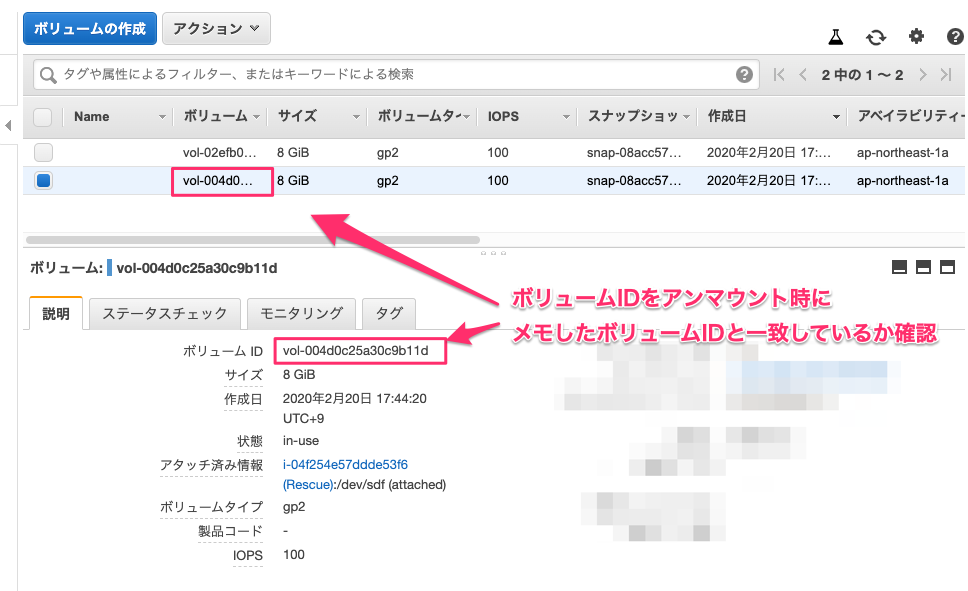
下記コマンドにて障害インスタンスのボリュームをアンマウントします。
コマンドumount /dev/sdf18. 復旧インスタンスの停止、ボリュームのデタッチ
復旧インスタンスを停止します。
停止後、EC2 ボリュームのコンソールに移動します。
(2)の工程でメモした「ボリュームID」のボリュームを見つけて選択後、アクションからデタッチします。
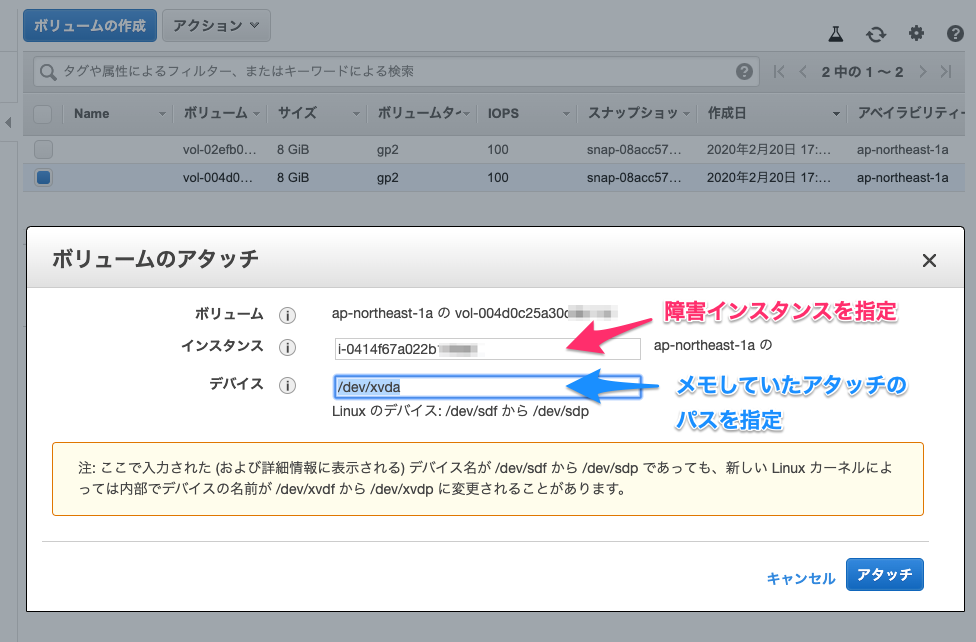
9. 障害インスタンスに修正したボリュームをアタッチ
上記ボリュームを障害インスタンスにアタッチします。
デバイスは(2)の工程でメモした「アタッチのパス」を入力してください。
今回 /dev/xvda になります。
10. 再起動
障害インスタンスを再起動して、SSH接続が正常にできることを確認します。
- 投稿日:2020-02-20T22:56:06+09:00
AWS Amplify フレームワークの使い方Part8〜GraphQL Transform @connection編〜
はじめに
今回は、Amplifyで一対多や多対多を実現するのに必須である
@connectionについて解説していきます。
2019年11月頃?に定義が変わって相当わかりやすくなりました。基本的には新定義を理解するだけで問題有りませんが、参考としてこの記事には旧定義も記載しています。定義
まずは、定義から見ていきましょう。
@connectionについて初めての方は、この定義解説は飛ばしてあとから読むことをおすすめします。新定義
directive @connection(keyName: String, fields: [String!]) on FIELD_DEFINITIONkeyName
@keyで設定したセカンダリインデックスを接続先に指定することができます。keyNameを指定しない場合は、接続するテーブルのプライマリーインデックスが指定されます。fields
fieldsに引数を指定することで、接続先のテーブルから情報を取得することができます。
旧定義
directive @connection(name: String, keyField: String, sortField: String, limit: Int) on FIELD_DEFINITIONname
nameは宣言しなくても自動生成してくれますが、わかりにくい形になることも多いので、命名したほうがベターです。
keyField
keyFieldを指定しない場合は、自動的にそのテーブルのプライマリインデックスが指定されます。keyFieldにの名前を指定することで、セカンダリインデックスを利用したテーブル間の紐付けが可能になります。
sortField
sortFieldを設定することで、レコードのソート方法を設定できます。こちらもDynamoDB上では、ソートキーに設定されることで、ソート検索ができるようになります。createdAtでソートを掛けたい場合は必須です。
limit
1回のget(list)で取得するデータの個数。設定しない場合は自動で10になります。
何ができるのか?
そもそも
@connectionを使って何ができるのか?っていう話を簡潔に。新定義のみ解説していきます。1対1
getUserで所属するTeam情報も同時に取得できます。schema.graphql// 実際にDBに書き込まれるのは、id/teamId/nameの3つteamは取得用。 type User @model { id: ID! teamId: ID! name: String team: Team @connection(fields: ["teamId"]) } type Team @model { id: ID! name: String! }graghql/queries.jsexport const getUser = `query GetUser ($id: ID!) { getUser (id: $id) { id teamId name team { id name } } }以下の記載でも同様のことができます。
その場合、User情報をcreate時に、userTeamIdという項目を作り、そこに所属するチームのIDを与えてあげる必要があります。schema.graphqltype User @model { id: ID! name: String team: Team @connection } type Team @model { id: ID! name: String! }graghql/queries.jsexport const getUser = `query GetUser ($id: ID!) { getUser (id: $id) { id name team { id name } } }1対多
getTeamでチームに所属するUserの情報一覧が取得できます。schema.graphqltype User @model @key(name: "byTeam", fields: ["teamId"]) { id: ID! teamId: ID! name: String team: Team @connection(fields: ["teamId"]) } type Team @model { id: ID! name: String! users: [User] @connection(keyName: "byTeam", fields: ["id"]) }graghql/queries.jsexport const getTeam = `query GetTeam($id: ID!) { getTeam (id: $id) { id name users { items { id name } } } }graghql/queries.jsexport const getUser = `query GetUser ($id: ID!) { getUser (id: $id) { id name team { id name } } }多対多
ユーザーが複数のチームに所属する場合は、以下のようになります。
schema.graphqltype User @model { id: ID! name: String teams: [TeamGroup] @connection(fields: ["id"]) } type TeamGroup @model @key(name: "byTeam", fields: ["teamId"]) @key(name: "byUser", fields: ["userId"]) { id: ID! userId: ID! teamId: ID! user: User @connection(fields: ["userId"]) team: Team @connection(fields: ["teamId"]) } type Team @model { id: ID! name: String! users: [TeamGroup] @connection(fields: ["id"]) }graghql/queries.jsexport const getUser = `query GetUser($id: ID!) { getUser (id: $id) { id name teams { items { id userId teamId team { id name } } } } }graghql/queries.jsexport const getTeam = `query GetTeam($id: ID!) { getTeam (id: $id) { id name users { items { id userId teamId user { id name } } } } }はまりポイント解説
理解するのに時間がかかったけれど大事なところをピックアップ。
@connetionをつけたモデルの削除
@connetionをつけたモデルの削除をする場合は注意が必要です。削除はできますが、戻す時に下記エラーが出ることがあります。REATE_FAILED AnswerquestionResolver AWS::AppSync::Resolver Fri Dec 13 2019 23:00:09 GMT 0900 (GMT 09:00) Only one resolver is allowed per field. (Service: AWSAppSync; Status Code: 400; Error Code: BadRequestException; Request ID: eefe6b89-2664-46a2-bf5a-435567035e15)原因としては、削除したモデルに
@connectionで繋がっていたモデルが存在していた場合、その繋がりの記録がどこかしらに残っており、上書きできないので、エラーです、みたいな内容です。
こうなってしまうと、その両方のモデルを一度削除した上で、もう一度新しくpushし直す必要があり、@connectionがいろんなモデルにクロスしているともはや再生不能に陥るので、モデルの削除には気をつけましょう。
以下でissueで話し合われています。https://github.com/aws-amplify/amplify-cli/issues/682
keyNameのfieldsはnon-null
keyNameのfieldsはnon-nullなので、「!」のつけ忘れに注意が必要です。
@connection関係なく、@keyでGSIを設定する場合は、fieldsに指定するカラムがnullで問題ありません。おわりに
新定義になり、とにかくわかりやすくなりました。初めはわかりづらいかもしれませんが、実践すればすぐになれると思います。
Amplifyは絶賛開発中に現在進行形でどんどん便利になっていっています。公式ドキュメントの定期なチェックは必須です。参考
関連記事
AWS amplify フレームワークの使い方Part1〜Auth設定編〜
AWS Amplify フレームワークの使い方Part2〜Auth実践編〜
AWS Amplify フレームワークの使い方Part3〜API設定編〜
AWS Amplify フレームワークの使い方Part4〜API実践編〜
AWS Amplify フレームワークの使い方Part5〜GraphQL Transform @model編〜
AWS Amplify フレームワークの使い方Part6〜GraphQL Transform @auth編〜
AWS Amplify フレームワークの使い方Part7〜GraphQL Transform @key編〜
- 投稿日:2020-02-20T22:54:42+09:00
Route53をAWS-CLIを使用してコマンドラインで操作する。
前提条件
・Windows端末(著者はwin10)
・Pythonインストール済行う事
AWS-CLIを使用してコマンドラインでRoute53にレコードをセットする
手順
pythonのバージョンの確認
pythonが入っているか確認(画像は3.8.1)
>python --version Python 3.8.1pipを使用して、AWS CLI をインストール
> pip3 install awscliパスの確認
where /R c:\ awsPathの設定
Windowsボタンを押して検索ボックスで「環境変数」と入力して検索し、上で表示されたPathを設定する
【例】表示結果:「c:[userdirectory]\Python\Python37\Scripts\aws」の場合
設定内容: c:[userdirectory]\Python\Python37\Scripts
※pythonインストール時にPATHを設定してくれるオプションもありました。AWS CLIのバージョンの確認
>aws --version aws-cli/1.18.3 Python/3.8.1 Windows/10 botocore/1.15.3IAMでユーザーを作成する
accessKeys.csvをダウンロードする。
認証情報の設定
> aws configure以下を入力する。
> AWS Access Key ID [None]:csvファイルのAccess key IDを入力 > Secret access key:csvファイルのSecret access keyを入力 > Default region name [None]: ap-northeast-1 > Default output format [None]:json実際にレコードセットしてみる
sample.jsonを作成する
{ "Comment": "CREATE/DELETE/UPSERT a record ", "Changes": [{ "Action": "CREATE", "ResourceRecordSet": { "Name": "a.example.com", "Type": "A", "TTL": 300, "ResourceRecords": [{ "Value": "4.4.4.4"}] }}] }コマンド change-resource-record-sets を使用し、ドメインのリソースレコードセットをホストゾーンに作成する。レコードを作成するための値は、sample.json ファイルで指定する。
コマンド実行
aws route53 change-resource-record-sets --hosted-zone-id ZXXXXXXXXXX --change-batch file://sample.jsonJSON ファイルにエラーがなければ、一意の ID とともにステータスとしてPENDING (保留中) が返される。
$ aws route53 change-resource-record-sets --hosted-zone-id ZXXXXXXXXXXX --change-batch file://sample.json { "ChangeInfo": { "Status": "PENDING", "Comment": "optional comment about the changes in this change batch request", "SubmittedAt": "2018-07-10T19:39:37.757Z", "Id": "/change/C3QYC83OA0KX5K" } }変更のステータスを確認するには、API コール get-change で change-resource-record-sets レスポンスの Id 値を使用します。
aws route53 get-change --id /change/C3QYC83OA0KX5K・PENDING (保留中) は、このリクエストの変更が、まだサーバーには伝播済みでないことを示す。
・INSYNC (同期中) は、変更がサーバーに伝播済みであることを示す。
- 投稿日:2020-02-20T21:45:15+09:00
【試験合格記】AWS 認定 DevOps エンジニア – プロフェッショナル
お疲れさまです。
表題の試験に合格したため記録として残したいと思います。結果
合格(760点)
分野 名称 割合 1 SDLC の自動化 22% 2 構成管理およびInfrastructure as Code 19% 3 監視およびロギング 15% 4 ポリシーと標準の自動化 10% 5 インシデントおよびイベントへの対応 18% 6 高可用性、フォールトトレランス、およびディザスタリカバリ 16% 所有資格
AWSに限っては下記の通りです。
SAPからだいぶ間が空きましたが、ようやく旧ホルダー名称である5冠達成で語感が良くなりましたね。
資格名 取得年月日 AWS Certified Solutions Architect - Associate (SAA) 2018-06-14 AWS Certified SysOps Administrator - Associate (SOA) 2018-06-22 AWS Certified Developer - Associate (DVA) 2018-06-25 AWS Certified Solutions Architect - Professional (SAP) 2018-07-19 AWS Certified DevOps Engineer - Professional (DOP) 2020-02-19 事前知識
インフラ寄りの技術者かつまぁまぁ早いうちにパブリッククラウドの世界に身を投じていたため、AWSにフィットさせることができていました。
あとは実際にAWS環境で設計〜運用まで1サイクル回した経験も地力がついた要因だったと思います。所感
試験に備えて準備した勉強箇所(Linux academy, Udemy)をことごとく外していて正答の確証があった問題は2割程度でした。
内容について詳しく書くことは避けますが、全体的にサービス間のパイプラインを使っていかにスマートな問題解決のアーキテクチャを選択できるか、が主軸にあったように感じました。
半分涙目になりながら170分間戦い抜いたことでボーナスポイントが加算されたのだと考えます。受験者に向けたアドバイス
- CodePipeline, CodeBuild, CodeDeployを使って何ができるかを理解すること
- Elastic Beanstalkのダウンタイムを避けるための運用はどうすればいいか理解すること
- gitのあるべき運用方法を実業務に近い形で理解しておくこと
- SAPと同様に可用性を担保するための工夫をパターン別で把握しておくこと
- DynamoDBを多少触っておくこと
まとめ
やはりSAPよりは人道的な設問および選択肢が多かったため、プロフェッショナルの中ではDOPがおすすめです。
そしてDOPを取得することで開発者がAWSを使うために、サービスの取捨選択をどうすればいいのかが学べるため出題範囲を学習するだけでも得るものはあると思いました。個人の目標としては年内に11冠を達成したいので、次はスペシャリティ取得を目指して引き続きがんばります。
- 投稿日:2020-02-20T21:40:32+09:00
イベントレポート(Developers.IO 2019)
AWS関連のイベント、セミナーに参加してきましたので、自分に対する備忘も兼ねて要点を纏めておきたいと思います。
・参加イベント
【11/1(金)東京】国内最大規模の技術フェス!Developers.IO 2019 東京開催!AWS、機械学習、サーバーレス、SaaSからマネジメントまで60を越えるセッション数!毎年開催されているクラスメソッド様のイベントです。
徐々に規模拡大されているようで、今年は1000人以上も参加者がいたそうです。
私は今の現場でCDKを使い始めたこともあって、CloudFormationやCDKなど、IoC関連のセッションをメインに聞いてきました。各セッション内容纏め
1. AWSのすべてをコードで管理する方法〜その理想と現実〜(濱田孝治氏)
https://dev.classmethod.jp/cloud/aws/aws-all-iac/
IaCを理解する
- IACは状態を定義(CLIは処理を定義)
- 手法 CloudFormation、Terraform、CDK
- CloudFormationのテンプレートについて ⇒JSONは古いので、YAMLに変える リソース記述順は関係ない(Parameter、Resources、Outputsは必須)
- CDKは入門編(Workshop)で学習可能
CLIで実行する
- CLIでCloudFormationを実行する(運用効率化) ⇒create-stack使わない、deployを使う ⇒deployはチェンジセット必ず作成、チェックバリデーションもしてくれる ⇒--no-execute-changesetを使う
- 本当にあった怖い話 同じスタック名で作成してスタック消える ⇒対策はチェンジセット見る
- 実行はCLI、結果確認はGUIで良い
複数リソースを作成する
- 典型的な一式を作ると1000行超える
- スタックの分け方 ⇒VPCとセキュリティグループは分ける(セキュリティグループは変更多いのでIaCでなくてもよい)
- スタック間でリソースを参照する方法 ⇒クロススタック参照 ⇒注意点は参照しているスタックがある場合、削除できない ⇒例)ECSのTaskをServiceがクロススタック参照する形だと運用破綻
- ダイナミック参照 ⇒SystemsManagerのパラメータストア ⇒DBのパスワードなど
- シェルで頑張る ⇒ECRのURIなど(CloudFormationでoutputできない)
運用上のつらみ
- スタックの作成が終わらない ⇒EC2に割り当たっているセキュリティグループを削除しようとすると返ってこない サービス定義が誤ったECSの作成
- 新機能に対応しない
- 循環参照
- Conditionsに頼らない ⇒条件分岐はテンプレートに適さない ⇒テンプレートを分けるなどで対応する方がよい
- CloudFormation以外でリソース更新される ⇒スタック更新が正常に働かなくなる ⇒Drift Detection(ドリフト検出)で対応 ⇒AWS Configで自動Drift検知も(cloudformation-stack-drift-detection-check)
パイプラインでインフラ構築
実行場所
⇒個人のクライアントPC、適当なEC2インスタンス、リポジトリからのパイプライン実行パイプライン実行例
⇒CodeCommitにテンプレート
⇒CodeBuild チェンジセットまで
⇒確認、問題なければCodeBuild スタック作成1. Amazon CultureとAWSの設計思想 ~マイクロサービスアーキテクチャとアジャイル開発~
AWS亀田治伸 氏
https://dev.classmethod.jp/report/report-developers-io-2019-tokyo-amazon-culture/AWS CDKの基本と実例
加藤諒氏
AWS構築の歴史
1.手順書(AMC、LambdaのIAMロール自動作成など
2.スクリプト
3.プロビジョニングツール(CloudFormation、Terraform、DOMs、GoFormation、CDK)
4.CDKAWS CDKのメリット
コードで書けると嬉しいのか?
⇒型があり、IDEの支援が受けられる
CDKによる抽象化
cdk.jsonに環境ごとのパラメータを設定できる(--context)AWS CDKでテストを行うべき理由
CDKは頻繁にアップデートされる
CloudFormationコードが変更されたかの検知をしたいテストの種類
Snapshot Tests・・・生成されるCloudFormation差分を確認
Fine-grained tests・・・意図したCloudFormationリソースが存在するか
ValidationTest最近のAuroraのアップデート使いこなし術 〜 ServerlessやMulti-Masterどんな時に利用する? 〜
大栗宗氏
Auroraとは
大量アクセスのスループットが向上する方針で開発
Aurora Serverless
DBインスタンスを意識せずに自動でスケーリングする形態
通常のAuroraより割高最近のAuroraアップデート
・Custom Endpoint
バッチアクセスとスループットが求められるアクセスのリソース分離
・GlobalDatabase
リージョン外にレプリケーションする機能
・Aurora Serverless Data API
インターネットからAPIでAurora ServerlessにAPIアクセスする
IAM機能でセキュリティ担保
HTTPだがトランザクション可能
VPC Lambdaが高速になったため、利用用途がなくなってきている
・Multi-Master Cluster
楽観的な同時実行制御
書き込み競合は発生する所感、自身の仕事に活かせたことなど
インフラのセッションにメインで参加してきましたが、
初心者でも分かるように丁寧に説明してくれています。
インフラエンジニア初心者にもお勧めできるイベントかなと思います。
来年もぜひ参加したいイベントです。
自身の仕事に活かせたこととしては下記が挙げられます。
・CloudFormationをCLIで実行(deployコマンド --no-execute-changeset付き)
・DBのパスワードなどはSSMのパラメータストアで定義する
・cdk.jsonに環境差分を書く
・Python自動テストの利用(これは要検討)
- 投稿日:2020-02-20T21:23:13+09:00
お気に入りのテレビ番組の有無を答えてくれるAlexaスキルを作ってみた
はじめに
日曜日の夜に日本テレビ系列で放送されている「世界の果てまでイッテQ!」見てますか? 面白いですよね。
娘もこの番組大好きで、週末になると毎日「今日イッテQある?」と聞いてきます。だいたい毎週日曜日にはあるのですが、時々特番とかで放送なかったりで、その時の娘のガッカリ感ときたら…。
それはさておき、毎週末聞いてくるので、大好きなアレクサが答えてくれたら娘も喜ぶんじゃないかな、と思って、「今日イッテQある?」と聞いたら答えてくれるアレクサスキルを作ってみました。
要件
以下のようなものを目標にしてみました。
- 「アレクサ、今日イッテQある?」と聞いたら
- WEB上にある番組表から「イッテQ」というキーワードで検索。
- 今日見つかったら「HH:MM〜HH:MMに世界の果てまでイッテQ…があります」と答える。
- 今日はないけど見つかったら「MM/DDのHH:MMにあるようです」と答える。
- 見つからなかったら「ありません」と答える。
実装方針
- スキルの呼び出し名を「今日イッテQある」にする。
- こうすると「アレクサ、今日イッテQあるを開いて」で起動する設定になりますが、「アレクサ、今日イッテQある?」でも起動できたので…。
- たぶんスキル名にもよるのだと思いますが、もしこれで起動できなかった場合は、定型アクションを使うつもりでした。
- いつもPythonの人なので、今回は自分自身の新たな取組としてNode.jsで書いてみる。
- ほぼ初めてのNode.jsなので、お見苦しい点はお許しくださいませ。
- 今回はLambda上で実装するする。
- Alexa-hostedスキルでもできるのかもしれないですが、初めてNode.jsでアレクサスキルを作るということをやる上で、慣れない環境でハマるのもイヤだったので。
実装内容
Alexa Developer Console
※いくつかキャプチャを貼っていますが、作成済みのスキルの編集画面ですので、作成手順に沿っているわけではありません。
呼び出し名
方針に書いたように「今日イッテQある」にしました。
「呼び出し名は2名詞以上である必要があります。」と赤字でエラーっぽく書かれていますが、これで動いています。
※保存したらQが小文字になりました
インテント
今回はスキル呼び出されたらそのまま回答して終了するスキルにするので、インテント用意しなくてもいいのかな…と思っていたのですが、何も設定していない状態だと、ビルドエラーが出てしまいます。
何かしらサンプル発話を登録すればいい、ということなので、今回はビルトインインテントのAMAZON.StopIntentにサンプル発話を設定することで、ビルドが通るようになります。
エンドポイント
ここは普通にLambdaを使ったAlexaスキル一般通り、LambdaのARNを指定してます。
AWS Lambda
Lambda側は以下方針で実装しました。
- ASK ADK for Node.jsを使用。
- 番組を調べるためのWebサービスとしてYahoo!テレビを使用させていただく。
- 検索するのに使い勝手がよかったので…
- スクレイピングするためのHTMLパースにはCheerioを使用。
ということでソースは以下の通りです。コメント入れているので何やっているかはわかるかと思います。
app.jsconst Alexa = require('ask-sdk-core') const Axios = require('axios') const Cheerio = require('cheerio') const Moment = require('moment-timezone') const Moji = require('@eai/moji') Moment.tz.setDefault('Asia/Tokyo') // 最後のa=10が札幌を示している const Url = 'https://tv.yahoo.co.jp/search/?q=%E3%82%A4%E3%83%83%E3%83%86Q&a=10' const Title = '世界の果てまでイッテQ!' // スキル起動ハンドラ const LaunchRequestHandler = { canHandle (handlerInput) { // スキル起動時に反応する return handlerInput.requestEnvelope.request.type === 'LaunchRequest' }, async handle (handlerInput) { const response = await Axios.get(Url) const $ = Cheerio.load(response.data) const programInfos = $('.programlist li').map((index, elm) => { const left = $('div.leftarea', elm) const right = $('div.rightarea', elm) const dateString = $('p:first-of-type > em', left).text() const timeString = $('p:nth-of-type(2) > em', left).text() const titleString = $('p:first-of-type > a', right).text() return { date: dateString, time: timeString, // 番組表の文字列、全角半角の混ざり方が不規則なので、英数は半角、カナは全角に揃える title: Moji(titleString).convert('ZEtoHE').convert('HKtoZK').toString() } }).get().filter(x => x.title.indexOf(Title) === 0) // 特番とかだと違う番組が引っかかることがあるので、番組名先頭に「世界の果てまでイッテQ!」 // と書かれているものを対象番組として扱うことにする // 今日あるかどうかの判断を行う const timestamp = Moment(handlerInput.requestEnvelope.request.timestamp) const dateString = timestamp.format('M/D') const filtered = programInfos.filter(x => x.date === dateString) let speechText if (filtered.length > 0) { // 今日ある場合は、番組詳細まで返す const subStr = filtered.map(x => { const timeString = x.time.replace('~', 'から') const result = timeString + 'に' + x.title + 'が' return result }).join('、') speechText = '今日は' + subStr + 'あります。' } else if (programInfos.length > 0) { // 今日はないけど、明日以降見つかったら、日付と時刻を返す。 const subStr = programInfos.map(x => { const result = x.date.replace('/', '月') + '日' + x.time.replace('~', 'から') return result }).join('と、') speechText = '今日はイッテQはありませんが、' + subStr + 'にあるようです。' } else { // ない speechText = '今日はイッテQはありません。' } return handlerInput.responseBuilder // 最後は全角で返さないとうまく読んでもらえない。 .speak(Moji(speechText).convert('HEtoZE').toString()) .getResponse() } } exports.handler = Alexa.SkillBuilders.custom() .addRequestHandlers( LaunchRequestHandler ) .lambda()ビルド、デプロイはAWS SAMを使いました。
特に特筆する内容はないですが、以下のようなテンプレートを使いました。template.yamlAWSTemplateFormatVersion: '2010-09-09' Transform: AWS::Serverless-2016-10-31 Description: > alexa itteq 今日イッテQがあるか答えるAlexaスキル Globals: Function: Timeout: 30 Resources: AlexaItteqFunction: Type: AWS::Serverless::Function Properties: CodeUri: src/ Handler: app.handler Runtime: nodejs12.x Events: Alexa: Type: AlexaSkillあとは、デザイナー画面の「Alexa Skills Kit」でスキルIDをセット。
スキルIDはAlexa Developers Consoleで確認可能。作ってみての所感など…
今回作ったスキルは期待通り娘にも使ってもらえてよかった〜と感じです。
ただ、スキルを呼び出した後、返答が返ってくるまで少しタイムラグがあるのが気になりますね。
娘には「イッテQある?って聞かれてからアレクサは一所懸命調べたり考えたりしているんだよ〜」って説明して納得してくれていますが、やはりUX的には気になるところ…番組表取得自体はデイリーとかで回してDynamoDBなりS3なりに保存しておいて、Alexaからの要求が来たときはDynamoDBなりS3なりを参照にする方がいいのかなぁ…
いずれにしてもX-RAYを仕掛けて、番組表取得で遅くなっているのか、その後の処理で遅くなっているのかなどを見極めたいと思っています。


- 投稿日:2020-02-20T21:16:05+09:00
ssh先(AWS EC2)でjupyter notebookを立てる方法
- 自分用メモ
- このページに従ってやったら出来た
- AWSのEC2でjupyter notebookをたてた https://ljvmiranda921.github.io/notebook/2018/01/31/running-a-jupyter-notebook/
- 投稿日:2020-02-20T19:57:21+09:00
ECSにおいてdocker runコマンドの-t,--ttyオプションに相当する設定をした話
はじめに
こんにちは。
現在私は社内のデータ分析基盤の刷新に取り組んでおります。今回は検証中のDataSunriseをECSに乗せるべくを試行錯誤を行っていた中で発見した、
docker runコマンドの-t,--ttyオプションに相当するであろう設定をECSで行う方法について記載します。DataSunriseについてはこちらをご参照下さい。
事の起こり
localでできることがECSでできない
検証のためにlocal環境にてコンテナを立てていました。
docker run -itd -p 11000:11000 [datasunrise image id](local環境にて)
この場合は期待通りコンテナが立ち上がり、https://[グローバルIP]:11000で繋ぐことができました。これをECSで実現したかったのですが、ECSのタスクは即時終了し、
CloudWatchLogsに流れてくるのはservice is started.のメッセージのみでした。試しにlocal環境にて、
docker run [datasunrise image id]を実行してみると、
service is started.との表示のみでコンテナは即時終了していました。
(本メッセージはDataSunriseコンテナが起動、即時終了した際に残すログのようです。)結果的にECSにおいて
docker runコマンドの-t,--ttyオプションに相当するようなことを設定しなければならないと判断しました。結論
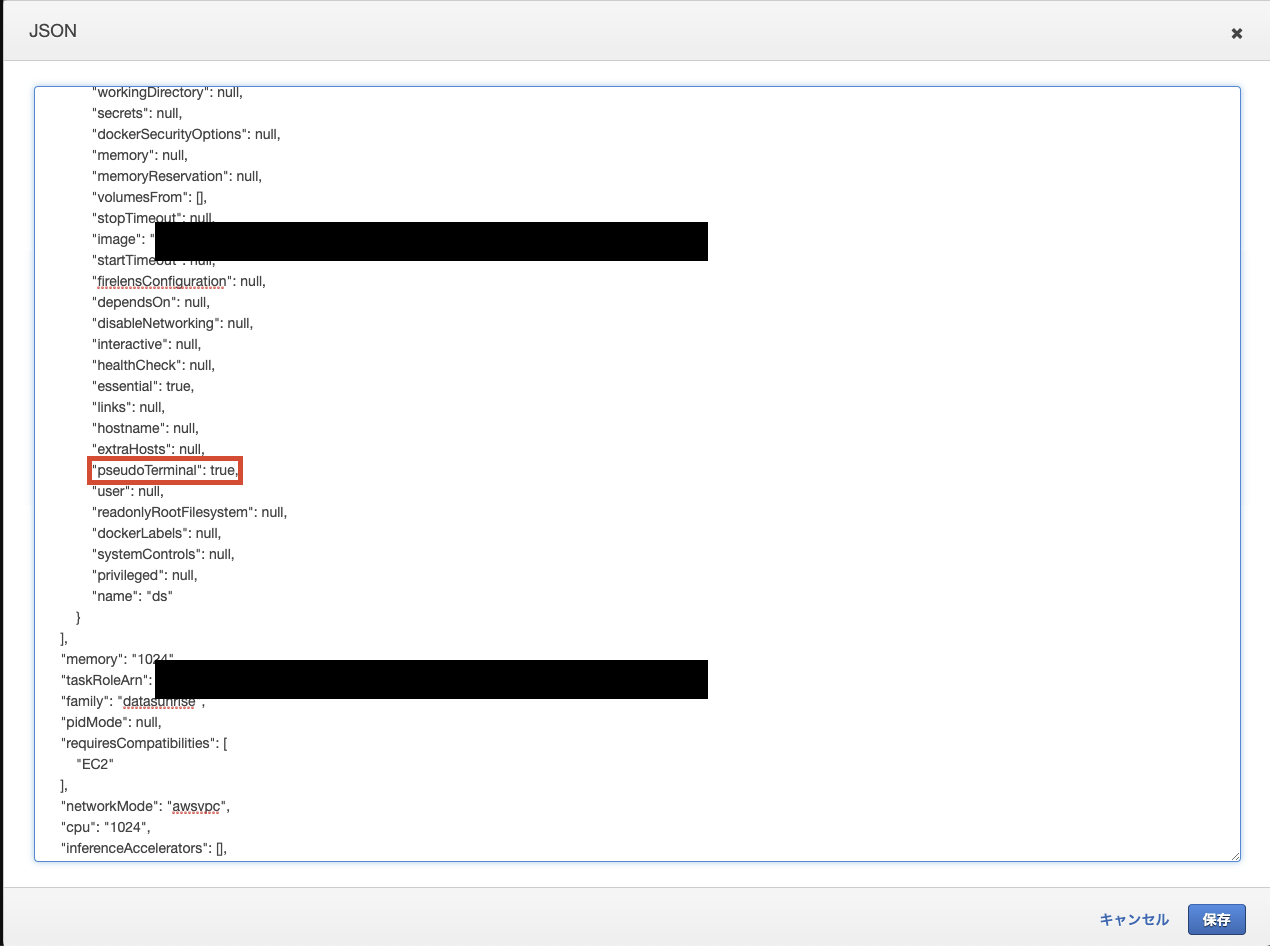
タスク定義において
pseudoTerminalをtrueにすることで、コンテナを起動させ続けることができました。
なお、本問題を解決に導いて下さった記事はこちらのstackoverflowです。具体的な設定方法は次の通りです。
設定方法
GUIでの設定方法を記載します。
最終的にJSONをいじることになるのでCLIで設定する場合も対応可能ではないかと思います。
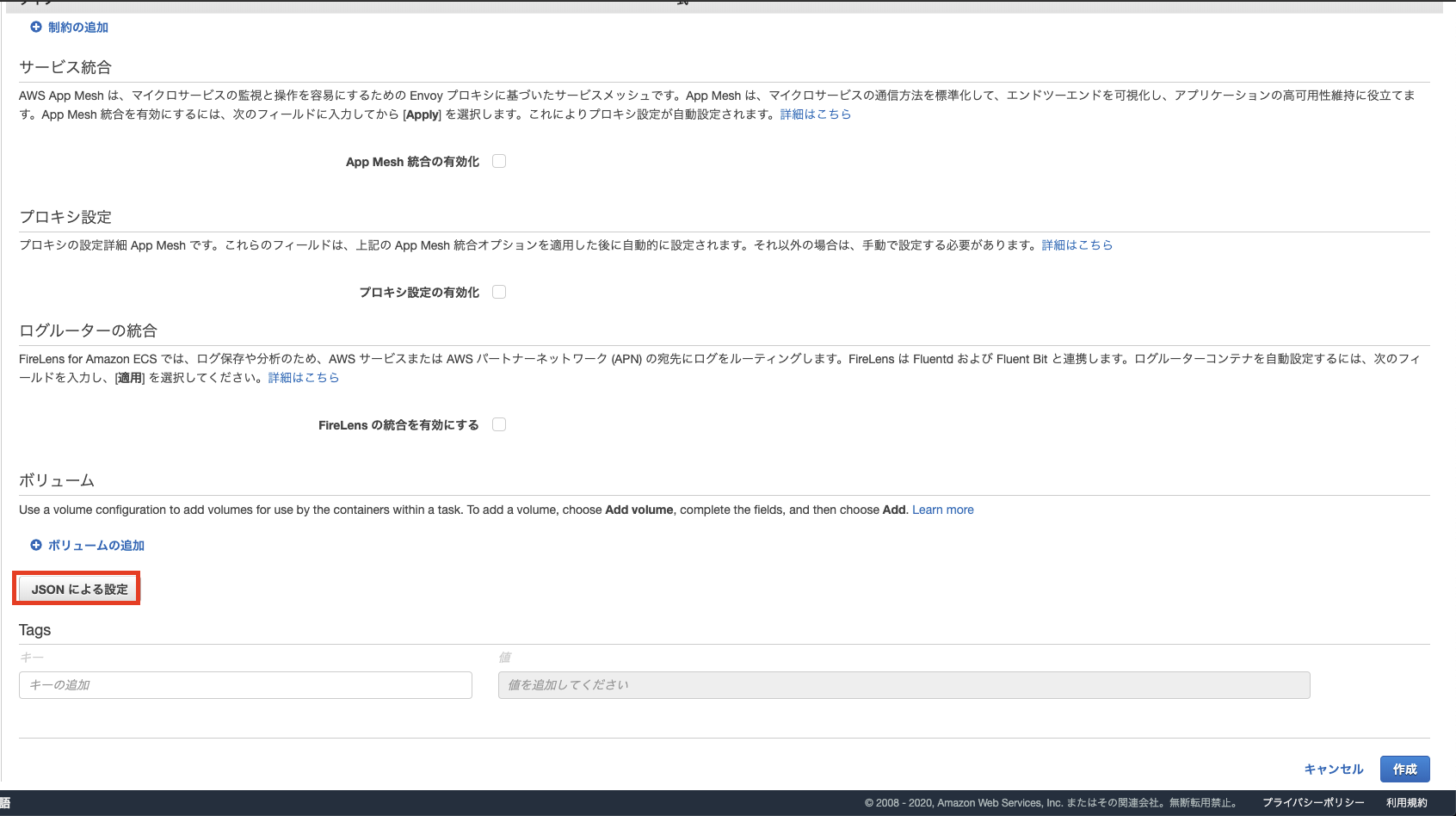
対象のECSタスク定義を開く
JSONによる設定を押下
ページ最下部に存在します。(画像赤枠部分)pseudoTerminalをtrueに変更
初期設定でnullとなっていましたが、trueに書き換えて保存を押せば適用できました。(EC2/Fargateともに適用可能)
*こちらは説明用画像ですので、当該箇所以外は環境に合わせてよしなに設定下さい。念の為。まとめ
ECSにおいて
docker runコマンドの-t,--ttyオプションに相当するであろう設定ができました。
今回は試行錯誤段階において、stackoverflowに行き着いた事によって解決したのですが、
よくよく公式ドキュメントを読んでみるとpseudoTerminal
Type: BooleanRequired: no
When this parameter is true, a TTY is allocated. This parameter maps to Tty in the Create a container section of the Docker Remote API and the --tty option to docker run.
という記載がありました。
ちゃんと公式ドキュメント読みましょうという教訓でした。。。
参考
- DataSunrise公式
- Stack Overflow当該記事 How to enable tty and run interactive console with AWS ECS?
- AWS ECS公式ドキュメント
また、試行錯誤段階にて以下記事も参考にさせて頂きました。ありがとうございます。
Dockerのコンテナを起動したままにする

- 投稿日:2020-02-20T19:34:28+09:00
rails s 起動しない 解決方法の1つ
チーム開発においてエラーが発生!
※ 初心者向けに何か助けになればと思い記述しております。
※ アウトプットの練習も兼ねております。開発環境 rails 5.2.4.1
ruby 2.5.1
クラウドサービスはAWSを使用
現状自動デプロイまで完了5名でフリマアプリの作成
githubアプリより最新のタスクデータを取得のため
masterブランチにブランチを切り替えpullを実行rails sでサーバーを立ち上げた際に起動しない
..... => Rails 5.2.4.1 application starting in development => Run `rails server -h` for more startup options Exiting Traceback (most recent call last): 85: from bin/rails:3:in `<main> .....試した事
PC再起動
bunde linstall
rails db:migrate
rails db:rollback
rails db:drop
rails db:migration:reset
rake db:migrate:reset 等...いずれもエラー表示冷静にエラーの記述を見るとrails sの起動時に下記の内容が
config/initializers/carrierwave.rb:10:in `block in <top (required)>'
指定のファイルconfig/initialize/carriewave.rbの記述に注目
provider: 'AWS', aws_access_key_id: Rails.application.credentials[:aws] [:access_key_id], aws_secret_access_key: Rails.application.credentials[:aws] [:secret_access_key], region: 'ap-northeast-1'
結果awsのマスターkeyをpullでは取得できていないためであったと思われる。
configファイルの参加にmaster.keyのファイルを作成しマスターよりkeyを一旦取得し記述するとエラーは解決。しかしこのままではセキュリティに問題がある為、別の方法を模索中です。
- 投稿日:2020-02-20T19:24:10+09:00
AWSを利用したAtCoderコンテスト追加通知LINE BOTの作成
LINE以外のアプリの通知を切っていますか? 僕は切っています。
AtCoderコンテストの予定が追加されたらLINEで通知してほしいなと思い、Mr JJ と共に LINE BOTを作成しました。作成したもの
毎時00分に予定されたコンテストの検索を行い、新たなコンテストが追加されている場合BOT君が通知してくれます。
一応メッセージを送ると返してくれる機能もあります。(おまけ)
作成したLINE BOTは以下のボタンから友達追加できます。
バックエンドの構成
バックエンドの処理はすべてAWS(Amazon Web Services)上で行っています。
AWS上の動作は以下の2つに分割できます。
- コンテスト通知セクション
- AtCoderコンテストの検索と新たなコンテストの通知を行う
- LINE応答セクション
- BOTに対しメッセージが送信された際に応答を行う
各セクションについて実装した機能を説明します。
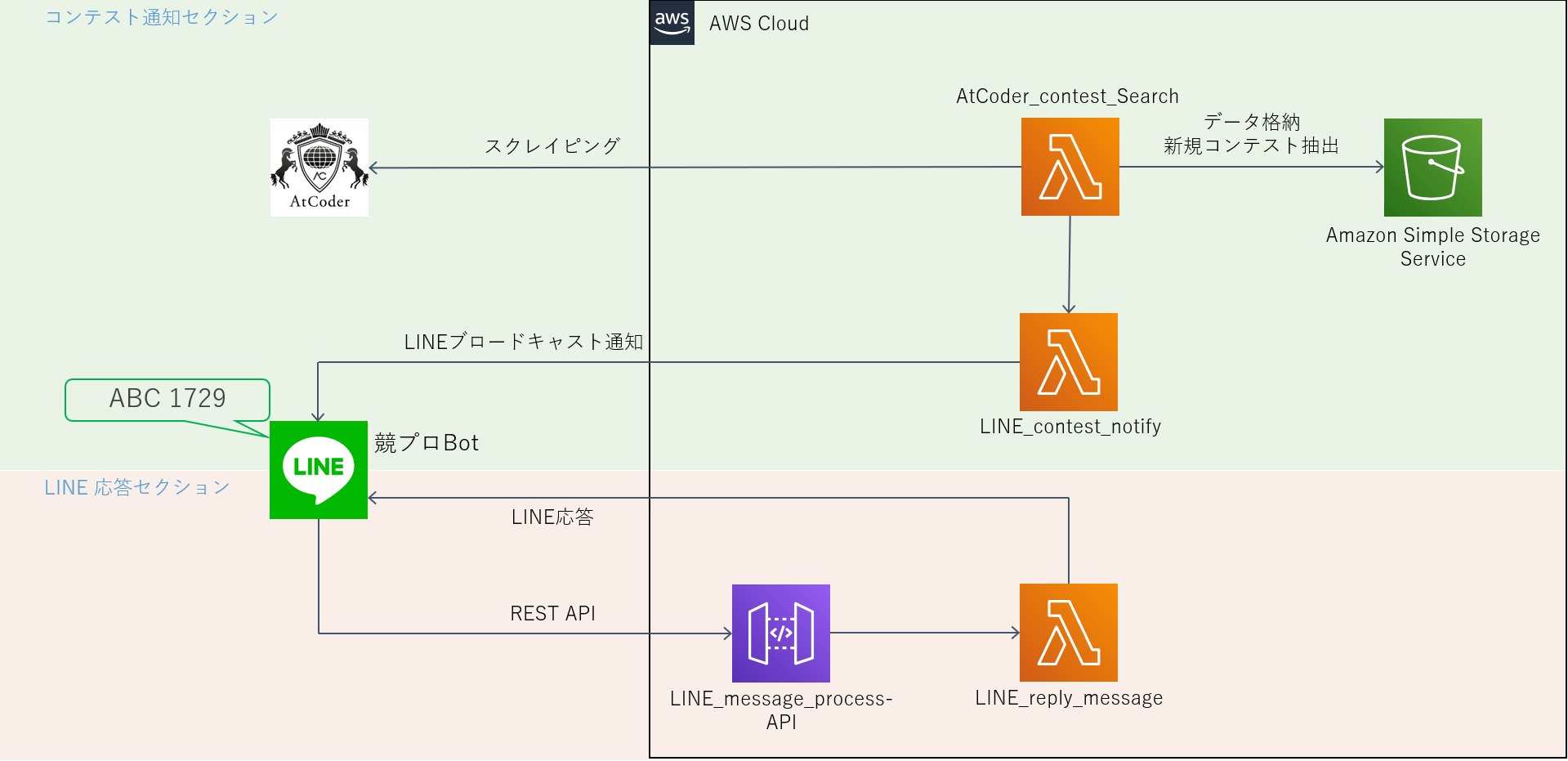
コンテスト通知セクション
コンテスト通知セクションの流れ
- Lambda関数: AtCoder_contest_Search がAtCoderホームページのスクレイピングを行い、予定されたコンテストリストを取得する
- AtCoder_contest_Search が S3 から通知済みコンテスト一覧 JSON ファイルを取得する。
- 差集合を計算し、未通知コンテストを抽出する。未通知コンテストが空なら終了。
- 未通知コンテストデータをLambda関数: LINE_contest_notify に送る。
- LINE_contest_notify が送られたデータを line-bot-sdk を用いてブロードキャスト形式で通知する。
- [1] で得られたコンテストデータを S3 にアップロード
スクレイピング機能
Python3def get_contests(): # URLからデータを取ってくる url = "https://atcoder.jp/home?lang=ja" html_data = requests.get(url) # htmlパース soup = BeautifulSoup(html_data.text, "html.parser") tags = ["upcoming", "recent"] ret_dic = {} for tag in tags: div = soup.find("div", id="contest-table-"+tag) table = div.find("table") times = table.find_all("time") titles = table.find_all("a") ret_list = [] for i in range(len(times)): dic = {} dic["start"] = times[i].text dic["title"] = titles[i*2+1].text dic["url"] = "https://atcoder.jp" + titles[i*2+1].get("href") ret_list.append(dic) ret_dic[tag] = ret_list return ret_dic
データ内容 引数 null 返り値 各コンテストに対してデータ(開始時刻・タイトル・URL)を要素に持つ辞書のリスト 本BOTでは ret_dic["upcoming"] のみ使用。
S3からのファイル取得
Python3def get_data_s3(): # S3上にある通知済みコンテストjsonファイル"contests.json"の読み込み client = boto3.client("s3") try: response = client.get_object(Bucket = "bucket_name", Key = "json_file_name") except Exception as e: print(e) return json.loads(response["Body"].read().decode())
データ内容 引数 null 返り値 S3上のJSONファイルを読み込んだ辞書データ get_object メソッドの返り値は辞書であり、キー"Body"にファイルの内容が含まれる。
S3へのファイルアップロード
Python3def put_data_s3(save_dic): # 新たな通知済みコンテストjsonファイルのS3アップローダー text = json.dumps(save_dic, ensure_ascii = False) s3 = boto3.resource("s3") s3.Object("bucket_name", "json_file_name").put(Body = text)
データ内容 引数 保存対象の辞書データ 返り値 null 辞書をJSON形式のテキストにする際、ensure_ascii の値をFalseにしておくと、
JSONファイル内の日本語が読みやすくなり、ファイルサイズも小さくできる。ブロードキャスト形式のメッセージ送信
Python3def DatetimeToString(date): if not isinstance(date, datetime.datetime): date = datetime.datetime.strptime(date, "%Y-%m-%d %H:%M:%S%z") week_list = "月火水木金土日" return f"{date.strftime('%m/%d')}({week_list[date.weekday()]}){date.strftime('%H:%M')}" def MakeMessageText(event): text = DatetimeToString(event["start"]) + "\n" + event["title"] + "が開催されます!\n" + event["url"] return text def main(event, context): # ***ここでLINE BOTのチャンネルアクセストークン取得しておく*** line_bot_api = LineBotApi("channel_access_token") message = MakeMessageText(event) line_bot_api.broadcast(TextSendMessage(text=message)) # *** main関数を終える処理 ***DatetimeToString 関数でコンテスト開始時間のメッセージフォーマットを作成し、
MakeMessageText 関数で通知するメッセージのフォーマットを作成した。line-bot-sdk の LineBotApi クラス broadcast メソッドを呼び出すだけでBOTの友達全員に通知を行うことができる。
LINE応答セクション
本システムの構成図
LINE応答セクションの流れ
- LINE BOT がLINEメッセージを受け取るとWebhookを利用してAPI Gatewayへメッセージ内容をPOSTする。
- API GatewayへのPOSTがトリガーとなりLambda関数: LINE_reply_message が実行される。
- LINE_reply_message が line-bot-sdk を用いてLINEのリプライメッセージを送信する。
リプライメッセージ送信
Python3def main(event, context): # ***ここでLINE BOTのチャンネルアクセストークン・秘密鍵を取得しておく*** handler = WebhookHandler("channel_secret") line_bot_api = LineBotApi("channel_access_token") body = event["body"] # handlerにリプライ関数を追加 @handler.add(MessageEvent) def SendReply(line_event): message = MakeReplyMessage(line_event.message.text) line_bot_api.reply_message(line_event.reply_token, TextSendMessage(text=message)) try: handler.handle(body, event["headers"]["X-Line-Signature"]) except # エラー処理 # *** main関数を終える処理 ***MakeReplyMessage 関数はBOTが受け取ったメッセージ内容に応じたリプライメッセージを文字列で返す。
ここの部分に関しては特に line-bot-sdkのドキュメント を読むことをおすすめします。終わりに
作成した主な機能について紹介を行いました。
簡単にBOTの操作を行えるline-bot-sdk がとても便利です。
AWSに関する知識が少なく、かなり荒い設計になりましたが、気が向いたら今後機能追加&改善します。(たぶん)

- 投稿日:2020-02-20T19:24:10+09:00
AWSを利用したAtCoderコンテストの追加通知をするLINE BOTの作成
LINE以外のアプリの通知を切っていますか? 僕は切っています。
AtCoderコンテストの予定が追加されたらLINEで通知してほしいなと思い、Mr JJ と共に LINE BOTを作成しました。作成したもの
毎時00分に予定されたコンテストの検索を行い、新たなコンテストが追加されている場合BOT君が通知してくれます。
一応メッセージを送ると返してくれる機能もあります。(おまけ)
作成したLINE BOTは以下のボタンから友達追加できます。
バックエンドの構成
バックエンドの処理はすべてAWS(Amazon Web Services)上で行っています。
AWS上の動作は以下の2つに分割できます。
- コンテスト通知セクション
- AtCoderコンテストの検索と新たなコンテストの通知を行う
- LINE応答セクション
- BOTに対しメッセージが送信された際に応答を行う
各セクションについて実装した機能を説明します。
コンテスト通知セクション
コンテスト通知セクションの流れ
- Lambda関数: AtCoder_contest_Search がAtCoderホームページのスクレイピングを行い、予定されたコンテスト一覧を取得する
- AtCoder_contest_Search が S3 から通知済みコンテスト一覧 JSON ファイルを取得する。
- 差集合を計算し、未通知コンテストを抽出する。未通知コンテストが空なら終了。
- 未通知コンテストデータをLambda関数: LINE_contest_notify に送る。
- LINE_contest_notify が送られたデータを line-bot-sdk を用いてブロードキャスト形式で通知する。
- [1] で得られたコンテストデータを S3 にアップロード
スクレイピング機能
Python3def get_contests(): # URLからデータを取ってくる url = "https://atcoder.jp/home?lang=ja" html_data = requests.get(url) # htmlパース soup = BeautifulSoup(html_data.text, "html.parser") tags = ["upcoming", "recent"] ret_dic = {} for tag in tags: div = soup.find("div", id="contest-table-"+tag) table = div.find("table") times = table.find_all("time") titles = table.find_all("a") ret_list = [] for i in range(len(times)): dic = {} dic["start"] = times[i].text dic["title"] = titles[i*2+1].text dic["url"] = "https://atcoder.jp" + titles[i*2+1].get("href") ret_list.append(dic) ret_dic[tag] = ret_list return ret_dic
データ内容 引数 null 返り値 各コンテストに対してデータ(開始時刻・タイトル・URL)を要素に持つ辞書のリスト 本BOTでは ret_dic["upcoming"] のみ使用。
S3からのファイル取得
Python3def get_data_s3(): # S3上にある通知済みコンテストjsonファイル"contests.json"の読み込み client = boto3.client("s3") try: response = client.get_object(Bucket = "bucket_name", Key = "json_file_name") except Exception as e: print(e) return json.loads(response["Body"].read().decode())
データ内容 引数 null 返り値 S3上のJSONファイルを読み込んだ辞書データ get_object メソッドの返り値は辞書であり、キー"Body"にファイルの内容が含まれる。
S3へのファイルアップロード
Python3def put_data_s3(save_dic): # 新たな通知済みコンテストjsonファイルのS3アップローダー text = json.dumps(save_dic, ensure_ascii = False) s3 = boto3.resource("s3") s3.Object("bucket_name", "json_file_name").put(Body = text)
データ内容 引数 保存対象の辞書データ 返り値 null 辞書をJSON形式のテキストにする際、ensure_ascii の値をFalseにしておくと、
JSONファイル内の日本語が読みやすくなり、ファイルサイズも小さくできる。ブロードキャスト形式のメッセージ送信
Python3def DatetimeToString(date): if not isinstance(date, datetime.datetime): date = datetime.datetime.strptime(date, "%Y-%m-%d %H:%M:%S%z") week_list = "月火水木金土日" return f"{date.strftime('%m/%d')}({week_list[date.weekday()]}){date.strftime('%H:%M')}" def MakeMessageText(event): text = DatetimeToString(event["start"]) + "\n" + event["title"] + "が開催されます!\n" + event["url"] return text def main(event, context): line_bot_api = LineBotApi("channel_access_token") message = MakeMessageText(event) line_bot_api.broadcast(TextSendMessage(text=message)) # *** main関数を終える処理 ***DatetimeToString 関数でコンテスト開始時間のメッセージフォーマットを作成し、
MakeMessageText 関数で通知するメッセージのフォーマットを作成した。line-bot-sdk の LineBotApi クラス broadcast メソッドを呼び出すだけでBOTの友達全員に通知を行うことができる。
LINE応答セクション
本システムの構成図
LINE応答セクションの流れ
- LINE BOT がLINEメッセージを受け取るとWebhookを利用してAPI Gatewayへメッセージ内容をPOSTする。
- API GatewayへのPOSTがトリガーとなりLambda関数: LINE_reply_message が実行される。
- LINE_reply_message が line-bot-sdk を用いてLINEのリプライメッセージを送信する。
リプライメッセージ送信
Python3def main(event, context): handler = WebhookHandler("channel_secret") line_bot_api = LineBotApi("channel_access_token") body = event["body"] # handlerにリプライ関数を追加 @handler.add(MessageEvent) def SendReply(line_event): message = MakeReplyMessage(line_event.message.text) line_bot_api.reply_message(line_event.reply_token, TextSendMessage(text=message)) try: handler.handle(body, event["headers"]["X-Line-Signature"]) except # エラー処理 # *** main関数を終える処理 ***MakeReplyMessage 関数はBOTが受け取ったメッセージ内容に応じたリプライメッセージを文字列で返す。
ここの部分に関しては特に line-bot-sdkのドキュメント を読むことをおすすめします。終わりに
作成した主な機能について紹介を行いました。
簡単にBOTの操作を行えるline-bot-sdk がとても便利です。
AWSに関する知識が少なく、かなり荒い設計になりましたが、気が向いたら今後機能追加&改善します。(たぶん)
- 投稿日:2020-02-20T18:48:32+09:00
【Go】Lambda + RDSをIAM認証で接続する
はじめに
現在、API Gateway + Lambda + RDSを使ってWebアプリケーションを作っています。LambdaとRDSのIAM接続というのを見つけて、Goで試してみたので備忘録です。
IAM認証で接続するメリット・デメリット
メリット
コールドスタート問題の解決
アプリケーションでLambdaとRDSを接続することが避けられていた理由は、とにかく接続に時間がかかるためです。Webアプリを使っていて、DB接続に10秒も20秒も待ってられないですよね。(通称VPC Lambdaの10秒の壁?)
LambdaがVPC内で通信を行うにはENI生成を行う必要があり、コールドスタートとなってしまいます。しかし、IAM認証で接続することで、LambdaをVPC内に設置する必要がなくなるので、問題とされていた10秒の壁が解決できるのです!
【朗報】
Lambda関数のVPC環境でのコールドスタートが改善されたようです?参考 : [発表] Lambda 関数が VPC 環境で改善されます
デメリット
同時接続数が限られる
RDSの同時接続数に上限があり、それ以上は接続できません。RDSのサイズによりますが、db.t2.microの場合、1秒間に10接続まで。
私が今回作っているアプリは20人程度しか使わない、かつ使用頻度も低い、かつ社内のシステムなので、とりあえず大丈夫かなという軽い気持ちで考えていますが、もっと大人数が使うWebアプリだと厳しい制限です…。
【朗報】
2019年末に行われたre:Invent 2019で発表された、RDS Proxyを利用すると、この同時接続数の制限から解放されるかもしれないという朗報が!!(現在はプレビュー版です。)LambdaとRDSを接続するデメリットはなくなったかもしれないです!
手順
LambdaからRDSのIAM認証での接続は下記の流れで進めていきます。
- RDSの構築
- IAM認証用のユーザーの作成
- テーブルの作成
- SSL証明書のダウンロード
- IAMポリシーの作成
- Lambda関数の作成
- ソースコードの実装
- ソースコードのアップロード
- MySQLのIP制限
やってみる
1. RDSの構築
私が使用したMySQLのバージョン:MySQL 5.7.22
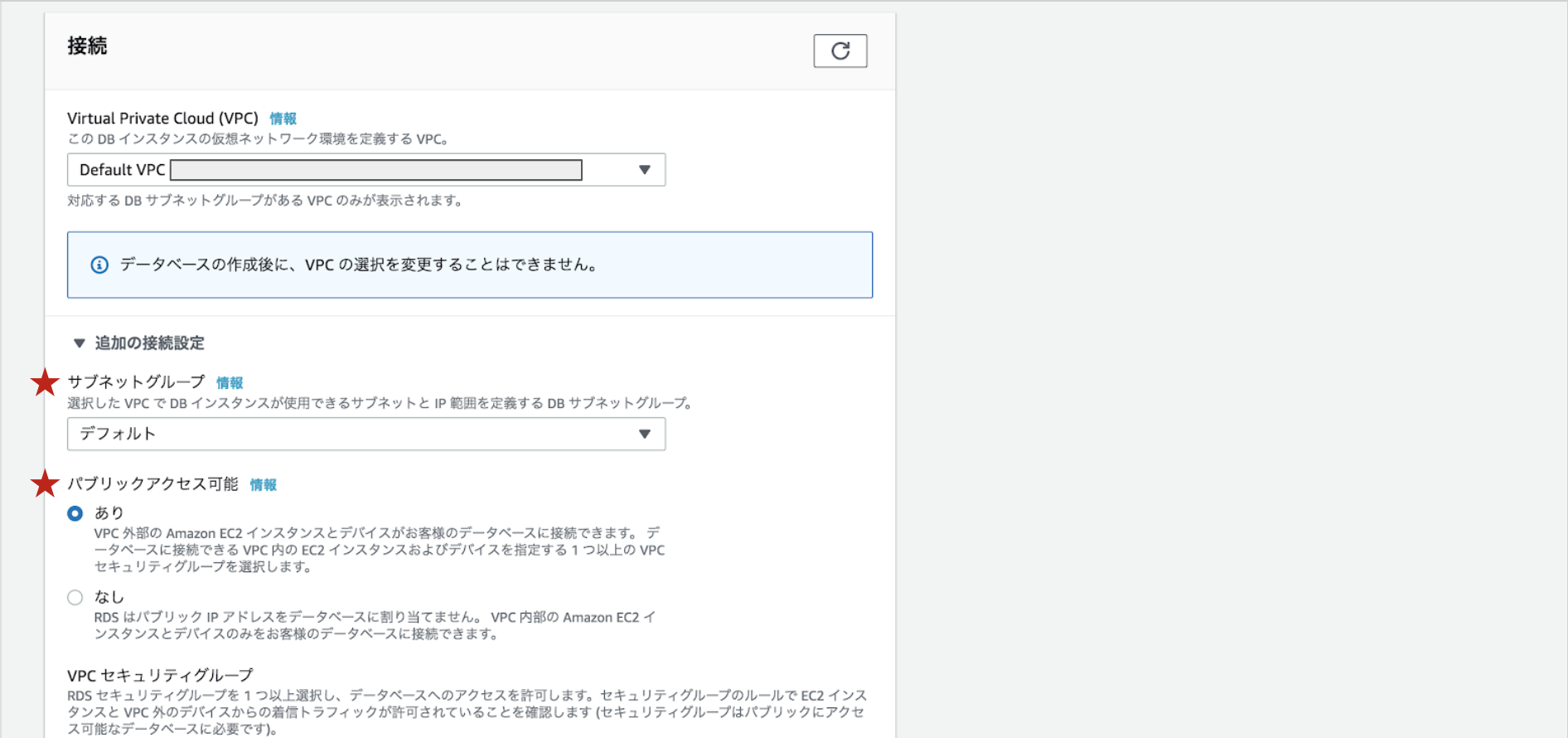
(MySQL 8.0.16ですると、SSL経由でデータベースに接続を許可する設定が後で出てくるんですが、私の力ではできなかったので5.7系で作り直しました…。)設定内容のうち、特別な箇所のみご紹介します。
サブネットグループ:パブリックサブネットでサブネットグループを作成し、選択
パブリックアクセス可能:ありを選択
データベース認証:パスワードと IAM データベース認証を選択
セキュリティグループでIP制限をすると、Lambdaからアクセスできません。ここでも躓いてしまったので、お気をつけください!!
その他は扱いたいデータ量などを鑑みて設定してください!
2. IAM認証用のユーザーの作成
前項で作成したDBにマスターユーザーでログインします。
$ mysql -h [エンドポイント] -u [マスターユーザー名] -pIAM認証用のユーザーを作成します。Hostは % を指定します。
> CREATE USER '[ユーザー名]'@'%' IDENTIFIED WITH AWSAuthenticationPlugin as 'RDS';SSL経由でデータベースに接続を許可します。下記では、SELECT、INSERT、UPDATE、DELETEを許可しています。
> GRANT SELECT,INSERT,UPDATE,DELETE ON [DB名].* to '[ユーザー名]'@'%' REQUIRE SSL;3. テーブルの作成
今回は以下のようなテーブルを作成しました。
> select * from Info; +----+-------------+-----------+------------------+ | ID | Name | Address | TEL | +----+-------------+-----------+------------------+ | 1 | 山田太郎 | 東京都 | 090-0000-0000 | +----+-------------+-----------+------------------+4. SSL証明書のダウンロード
main.goと同じディレクトリにダウンロードしてください。$ wget https://s3.amazonaws.com/rds-downloads/rds-ca-2019-root.pem5. IAMポリシーの作成
以下のポリシーを作成します。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "rds-db:connect" ], "Resource": [ "arn:aws:rds-db:[リージョン]:[アカウントID]:dbuser:[リソースID]/[DBに作成したユーザー名]" ] } ] }6. Lambda関数の作成
Lambda関数は特に複雑な設定をする必要がなく、通常通り作成するため省略します。
前項で作成したポリシーをアタッチし、VPCは非VPCのままにします。7. ソースコードの実装
main.gopackage main import ( "crypto/tls" "crypto/x509" "database/sql" "encoding/json" "fmt" "io/ioutil" "os" "github.com/aws/aws-lambda-go/lambda" "github.com/aws/aws-sdk-go/aws/credentials" "github.com/aws/aws-sdk-go/service/rds/rdsutils" "github.com/go-sql-driver/mysql" ) type Response struct { UserID int `json:"userId"` UserName string `json:"userName"` Address string `json:"address"` TEL string `json:"tel"` } // os.Getenv()でLambdaの環境変数を取得 var pemFile = "rds-ca-2019-root.pem" // SSL証明書 var dbEndpoint = os.Getenv("dbEndpoint") // エンドポイント:ポート番号 var dbUser = os.Getenv("dbUser") // DBに作成したユーザ名 var dbName = os.Getenv("dbName") // テーブルを作ったDB名 var awsRegion = os.Getenv("awsRegion") // RDSのリージョン func RDSConnect() (interface{}, error) { awsCredentials := credentials.NewEnvCredentials() authToken, err := rdsutils.BuildAuthToken( dbEndpoint, awsRegion, dbUser, awsCredentials, ) if err != nil { panic(err.Error()) } connectStr := fmt.Sprintf("%s:%s@tcp(%s)/%s?tls=rds&allowCleartextPasswords=true", dbUser, authToken, dbEndpoint, dbName, ) db, err := sql.Open("mysql", connectStr) if err != nil { panic(err.Error()) } defer db.Close() fmt.Println("--- データの取得") // データの取得 info, err := db.Query("SELECT * FROM Info") defer info.Close() if err != nil { panic(err.Error()) } var UserID int var UserName string var Address string var TEL string for info.Next() { if err := info.Scan(&UserID, &UserName, &Address, &TEL); err != nil { panic(err.Error()) } fmt.Println(UserID, UserName, Address, TEL) } responseMap := Response{} responseMap.UserID = UserID responseMap.UserName = UserName responseMap.Address = Address responseMap.TEL = TEL params, _ := json.Marshal(responseMap) fmt.Println(string(params)) return string(params), nil } func RegisterTLSConfig() { caCertPool := x509.NewCertPool() pem, err := ioutil.ReadFile(pemFile) if err != nil { panic(err.Error()) } if ok := caCertPool.AppendCertsFromPEM(pem); !ok { panic(err.Error()) } mysql.RegisterTLSConfig("rds", &tls.Config{ ClientCAs: caCertPool, InsecureSkipVerify: true, }) } func run() (interface{}, error) { fmt.Println("--- tsl.Configの登録開始") RegisterTLSConfig() fmt.Println("--- tsl.Configの登録終了") fmt.Println("--- RDS接続開始") response, err := RDSConnect() if err != nil { panic(err.Error()) } fmt.Println("--- RDS接続終了") return response, nil } /************************** メイン **************************/ func main() { lambda.Start(run) }8. ソースコードのアップロード
ビルドして
$ GOOS=linux GOARCH=amd64 go build -o mainzipして
$ zip main.zip main rds-ca-2019-root.pemアップロード!!!
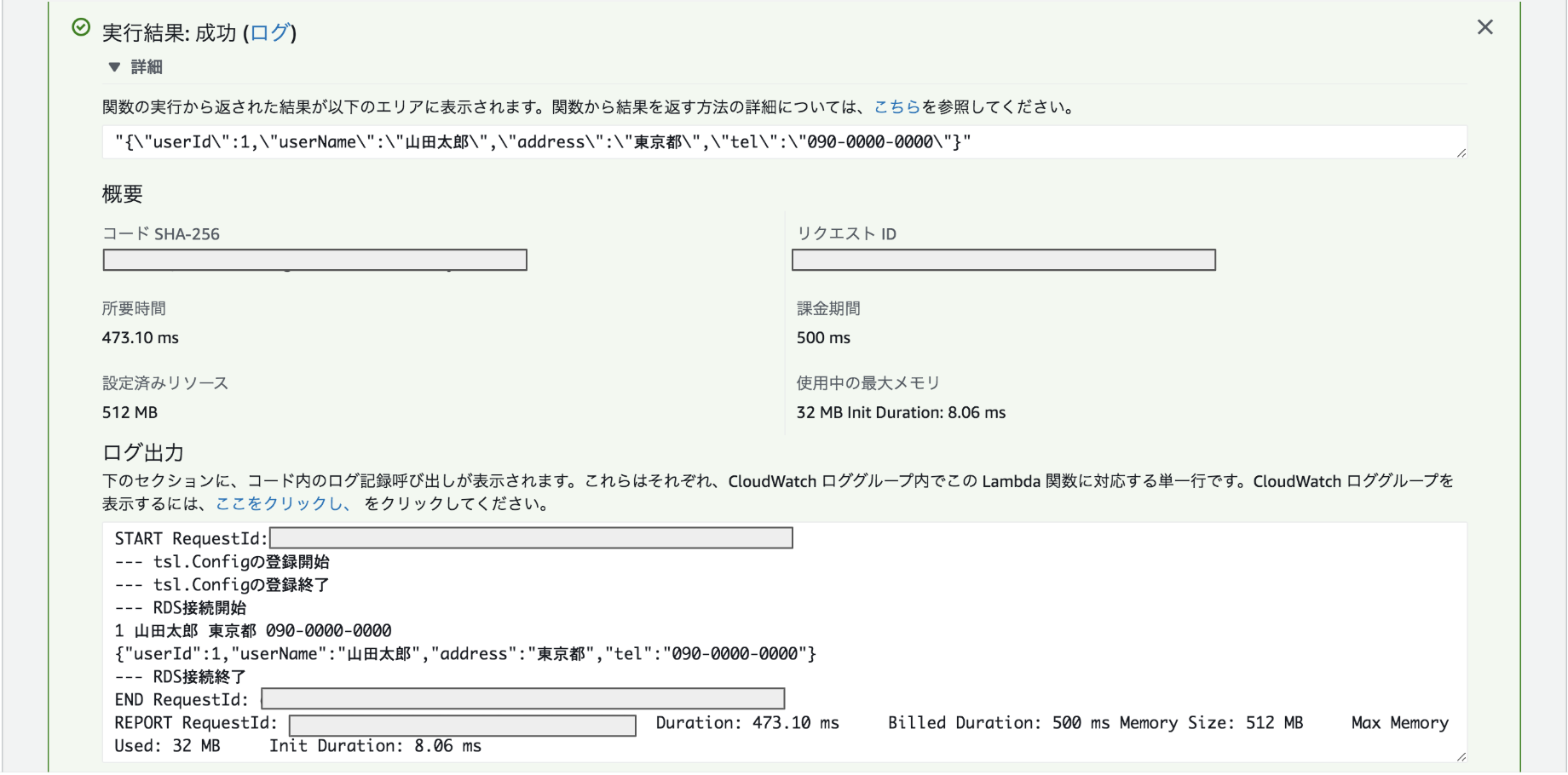
ハンドラはmainに変更します。実行結果
値を取得することができました!
レイテンシーも気になりません!
9. MySQLのIP制限
IAM認証と言えどパブリックサブネットにRDSを置いて、セキュリティグループ全開ってセキュリティどうなんだろう?マスターユーザーはパスワード認証やん!!!って思いますよね。そこで、DBのマスターユーザーのIP制限をしました。
> RENAME USER '[マスターユーザー名]'@'%' TO '[マスターユーザー名]'@'[許可したいIPアドレス]';私は会社のIPアドレスにして、
/32まで書いたらログインできずに焦りました…。お気をつけください。VPC内のIPアドレスに設定して、そのVPCの中に立てたEC2からの接続を許可するっていう方法でもいいですね。複数IPを追加したい!
上記で設定したIPアドレス以外にも、複数の場所からマスターユーザーでアクセスしたく、接続できるIPアドレスを増やす必要があったのですが、
RENAMEだと先ほど指定したIPアドレスに上書きされてしまうので…以下の方法でマスターユーザーを追加(複製)しました!> CREATE USER '[マスターユーザー名]'@'[許可したいIPアドレス]' IDENTIFIED BY '[パスワード]'; > GRANT SELECT, INSERT, UPDATE, DELETE, CREATE, DROP, RELOAD, PROCESS, REFERENCES, INDEX, ALTER, SHOW DATABASES, CREATE TEMPORARY TABLES, LOCK TABLES, EXECUTE, REPLICATION SLAVE, REPLICATION CLIENT, CREATE VIEW, SHOW VIEW, CREATE ROUTINE, ALTER ROUTINE, CREATE USER, EVENT, TRIGGER ON *.* TO '[マスターユーザー名]'@'[許可したいIPアドレス]' WITH GRANT OPTION;おまけ
ローカルからRDSに接続してみた
IAMユーザの作成
LambdaにアタッチしたポリシーをIAMユーザーにアタッチします。
AWS CLIの設定
作成したユーザーで、CLIの設定を行います。
$ aws configure先ほど作成したIAMユーザーのアクセスキーとシークレットキー、リージョンを入力してください。
ターミナルから接続
ターミナルからプログラムアクセスをします。SSL証明書のパスは置いてあるところに変更してください。
$ RDSHOST="[エンドポイント]" $ TOKEN="$(aws rds generate-db-auth-token --hostname $RDSHOST --port 3306 --region [リージョン] --username [IAMユーザー名] )" $ mysql --host=$RDSHOST --port=3306 --ssl-ca=${GOPATH}/src/qiita/rds-ca-2019-root.pem --enable-cleartext-plugin --user=[IAMユーザー名] --password=$TOKEN上記を実行して証明書チェーンを受け入れない場合は、次のコマンドを実行して、古いルート証明書と新しいルート証明書の両方を含む証明書バンドルをダウンロードしてください。
その後、再度上記のコマンドを実行してみてください。(証明書名は変更する。)
$ wget https://s3.amazonaws.com/rds-downloads/rds-combined-ca-bundle.pem実行
実行結果は以下の通りとなりました。先ほどと同じですね!
> select * from Info; +----+-------------+-----------+------------------+ | ID | Name | Address | TEL | +----+-------------+-----------+------------------+ | 1 | 山田太郎 | 東京都 | 090-0000-0000 | +----+-------------+-----------+------------------+おわりに
無事、RDSから取得したデータをLambdaに返すことができました!次回はAPI Gatewayを使ってWebブラウザで表示するところまでいきたいです!
RDS Proxyの発表やLambdaのコールドスタートの改善など、もっとLambda + RDSがこれから利用しやすくなりそうですね!また、RDS Proxyも試してみたいなと思ってます。

- 投稿日:2020-02-20T18:00:08+09:00
ウサギでもわかるAmazon FSx for WindowsのPowerShellによる管理
前回はFSxとは何か、サービスの位置づけ、簡単なチュートリアルをやってみましたが、今回は作成したFSxの各機能の設定に触れてみたいと思います。
共有ポイントを増やす
標準では一つの共有ポイントしかありませんが、増やす方法もドキュメントに記載されてました。
共有ポイントを増やすことができれば、既存ファイルサーバからの移行作業も効率的になったり、管理の手間が省けたりすることもあるので試してみました。
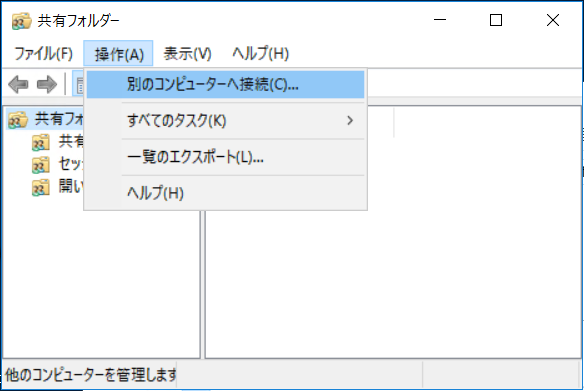
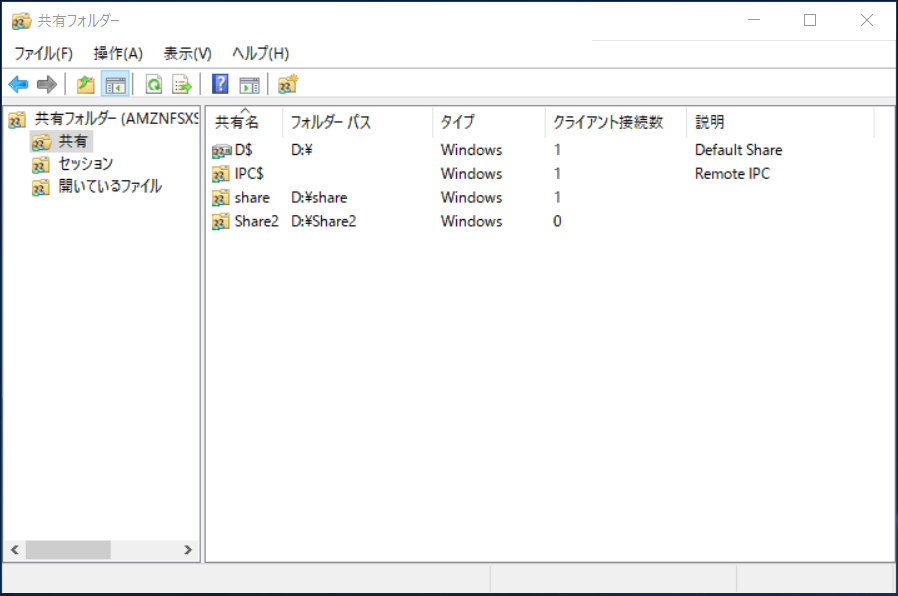
ユーザーセッションとオープンファイルWindowsメニューから「fsmgmt.msc」と検索し、「共有フォルダ管理」を開き、「操作」から「別のコンピューターへ接続」を選択。
ここでDNS名を入力します。
「共有」を開いて右側の空白で右クリックし、「新しい共有」を選択。
既存の「share」があるドライブ(この場合には「D:¥」)に新しい名前を指定し、「見つかりません」といわれるので「はい」を押します。
アクセス権はAdministratorにフルアクセスのみで良い、と思ったら、このAdministratorはローカルのAdministratorなのでアクセス権をカスタマイズして、ドメインユーザーを設定する必要がありました。
できました!
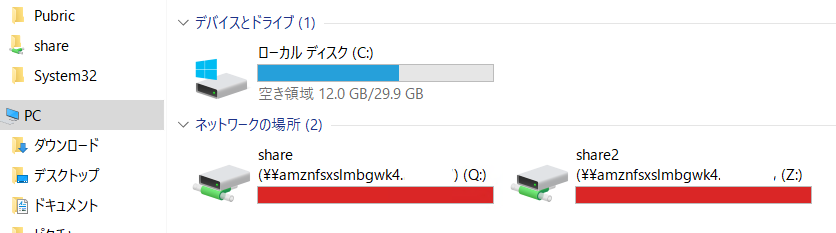
追加した共有ポイントをマウントする
できました。
しかし、クォータ設定が共通らしく、両方のディスクがフルになっています。
内容的には以下のような操作をしたからです。
1MBでハードクォータを設定した上で、Qドライブに1MBのファイルを作ってディスクフルにしました。
その結果、あとから作成したしてZドライブにマウントした別の共有ポイントも、ファイルが一つもない状態であるにもかかわらず、ディスクフルになってしまいました。
共有ポイントは増やせた
FSxにおいては共有ポイントを増やすことはできました。
しかし、ファイルサーバの運用では一般的に、共有ポイントごとにクォータ設定することが多いのではないかと思います。しかし、FSxでは共有ポイントを増やしても、同じエンドポイントの配下になるため、クォータの設定も当然ながら同一の配下になってしまうことがわかりました。
クォータの設定を新たに設定したい場合には、また別のFSxエンドポイントをデプロイしなければならないということがわかりました。なお、共有ポイントの追加は以下のコマンドでも可能なようです。
ファイル共有New-FSxSmbShare -Name "New CA Share" -Path "D:\share\Marketing" -Description "CA share" -ContinuouslyAvailable $TrueAmazon FSx for WindowsをPowerShellで管理する
次に、CLI(PowerShell)で各種設定をしてみます。
FSxはストレージのみなのでRemoteDesktopはできませんが、PowerShellで管理します。しかし、いきなりエラーが発生して凹みます。
PS C:\Users\Administrator> enter-pssession -ComputerName amznfsxslmbgwk4.bx.local -ConfigurationName FsxRemoteAdmin enter-pssession : One or more errors occurred processing the module 'FSxRemoteAdmin' specified in the InitialSessionSta te object used to create this runspace. See the ErrorRecords property for a complete list of errors. The first error wa s: Cannot find the Windows PowerShell data file 'SmbLocalization.psd1' in directory 'C:\Windows\system32\WindowsPowerSh ell\v1.0\Modules\smbshare\ja-JP\', or in any parent culture directories. 発生場所 行:1 文字:1 + enter-pssession -ComputerName amznfsxslmbgwk4.bx.local -Configuration ... + ~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~ + CategoryInfo : OpenError: (:) [Enter-PSSession], RunspaceOpenModuleLoadException + FullyQualifiedErrorId : ErrorLoadingModulesOnRunspaceOpenエラーの解消方法
こちらの情報によると英語OS以外の言語のOSからだとエラーになるそうです。なるほど、バグですか。
そのため以下のようにこのセッションだけ英語に切り替える方法で実行します。(そんなことできるんだ…)
できました!
$usSession = New-PSSessionOption -Culture en-US -UICulture en-US↑これが大切。英語のセッションに切り替えます。
↓そして管理モード?のセッションに入ります。enter-pssession -ComputerName amznfsxslmbgwk4.domain.com -SessionOption $usSession -ConfigurationName FsxRemoteAdminもう一つの実行方法
コマンドの送信方法には二通りあって、上記はコマンドセッションを接続して連続してコマンドを入力できるようにする方法です。プロンプトが異なっているのでわかりますね。
この場合には「exit」でPowerShellに戻ることができます。もう一つの方法は以下のように記述することで、セッションを一行ごとに送信することもできます。
Invoke-Command -ComputerName amznfsxslmbgwk4.domain.com -SessionOption $usSession -ConfigurationName FSxRemoteAdmin -scriptblock {Set-FsxShadowStorage -Default}コマンド実行後に通常のPowerShellプロンプトに戻っていますね。
この場合ももちろん事前に$usSessionの定義は必要です。クォータを設定してみる
早速クォータの設定をしてみましょう。
とはいえ方法がわからないので、まずはAWSのドキュメントを見てみます。
ストレージクォータコマンドの一覧はこちらです。
ユーザーストレージクォータコマンド 説明 Enable-FSxUserQuotas ユーザーストレージクォータの追跡または実施、またはその両方を開始します。 Disable-FSxUserQuotas ユーザーストレージクォータの追跡と適用を停止します。 Get-FSxUserQuotaSettings ファイルシステムの現在のユーザーストレージクォータ設定を取得します。 Get-FSxUserQuotaEntries ファイルシステム上の個々のユーザーおよびグループの現在のユーザーストレージクォータエントリを取得します。 Set-FSxUserQuotas 個々のユーザーまたはグループのユーザーストレージクォータを設定します。 ・・・なるほどわからん。
え?説明これだけ?
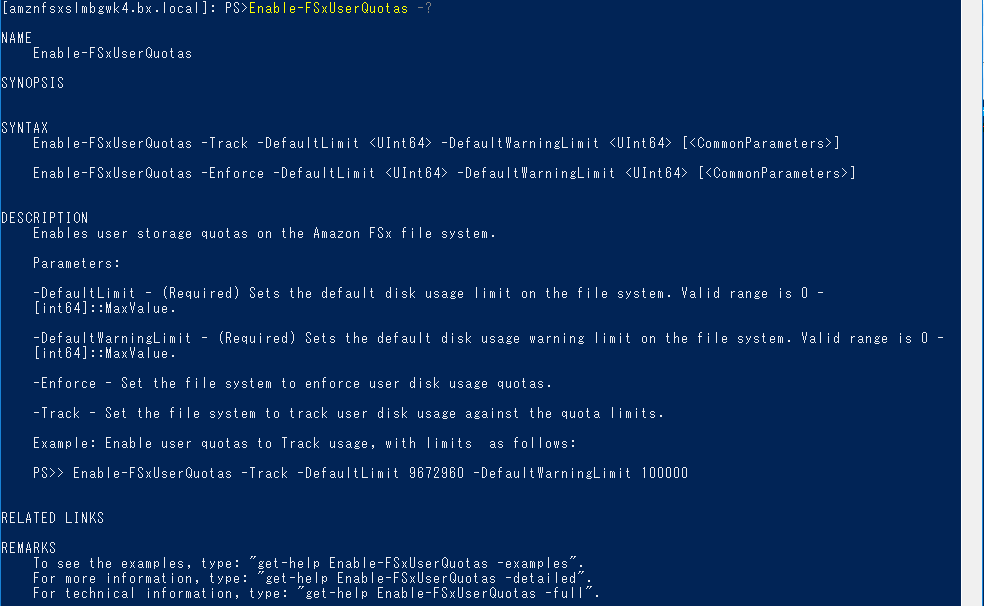
これでは何もわかりません。コマンドのヘルプ
各コマンドの後ろに「-?」をつけて実行すると簡単な説明が出るらしいのでやってみます。
これで少しわかりました。
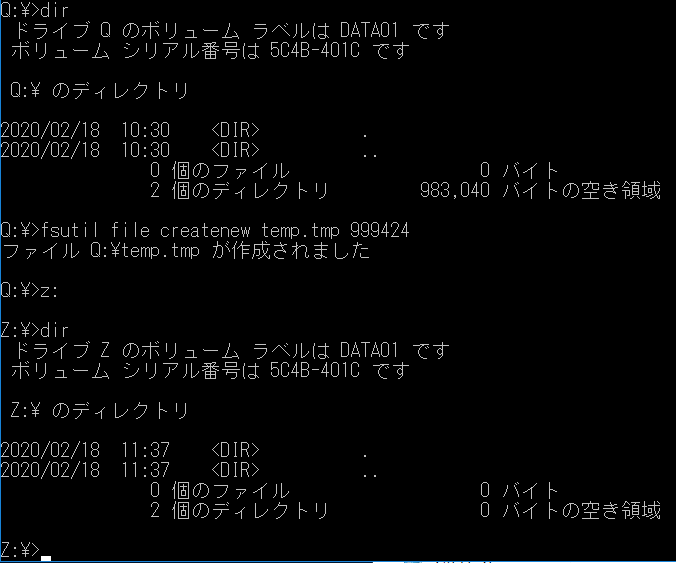
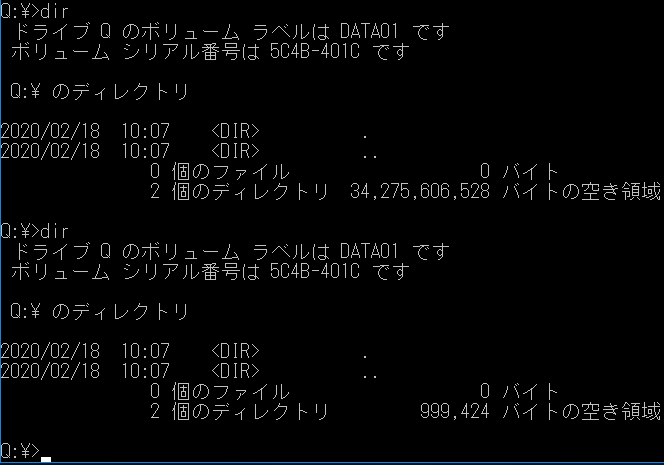
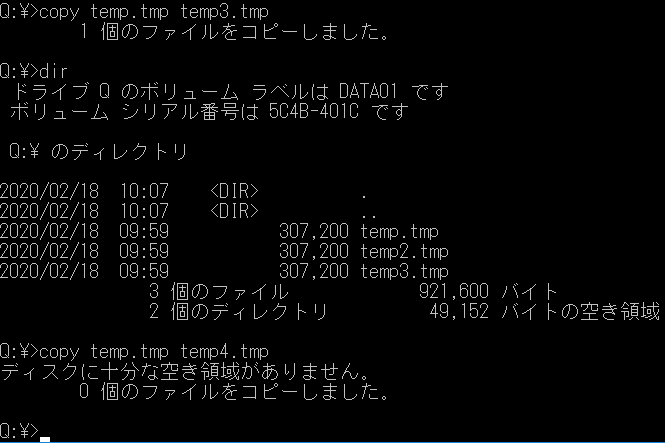
クォータを有効化するコマンドは以下のように入力すればいいようです。Enable-FSxUserQuotas -Enforce -DefaultLimit 1000 -DefaultWarningLimit 500設定する項目の単位は試してみたところ、「キロバイト」のようです。「500」と「1000」と書いたので、警告が「500KB」で、「1MB」を超えたら書き込みができなくなるはずです。
設定できたようです。設定前と設定後で、QドライブにマウントしたFSxの空き容量が変更されました。
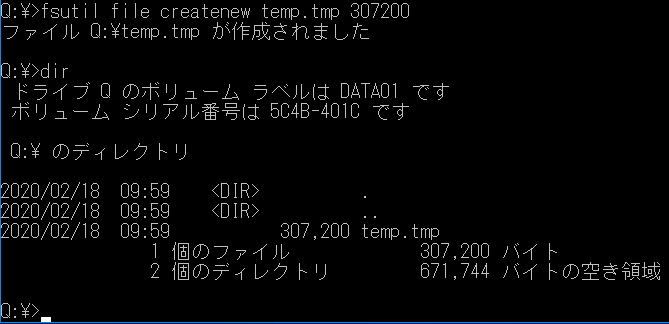
成功です。クォータの動作テスト
300KBのファイルを作ってみました。
正常にできました。
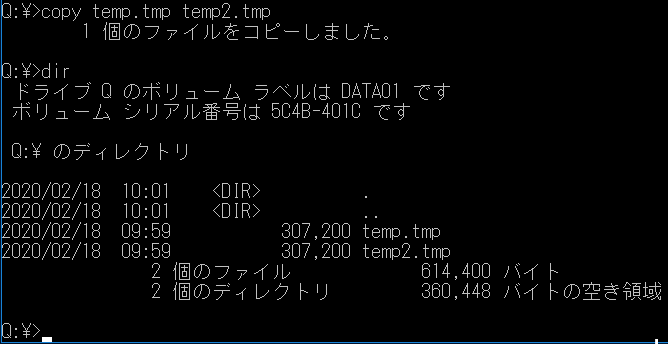
コピーして600KBにしてみます。
こちらも正常です。
ただし、Warningはどこに警告が出るのかわかりませんでした。CloudWatchにも無いようですし、Windowsのイベントログにも出ていませんでした。
謎です。
CloudWatchのアラート画面は以下のように何もありません。
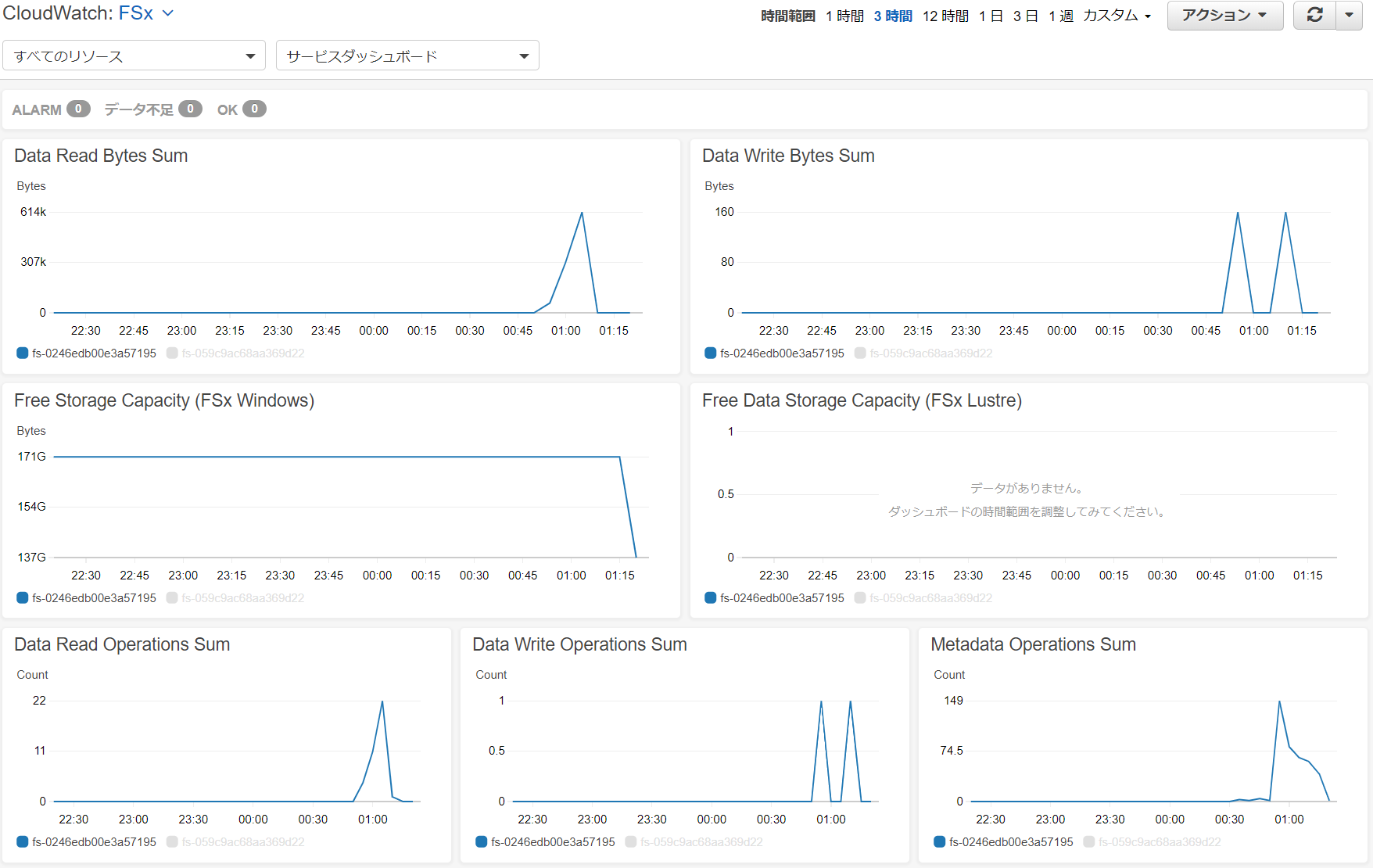
ちなみに、FSxをデプロイすると、標準で以下のようなリソースがCloudWatchで取得されます。
でもこれ、「Free Storage Capacity」がおかしくないですか?
32GBしかないはずなんですが、このFSxエンドポイント。それに1MBの未満データをいじった程度で171GB→103GBへ変化しているのはなぜ?クォータ設定の影響?
不明ですが、とりあえず無視しましょう。ともかく、さらにコピーして4つ目のファイルをコピーしたら、1MBを超えるときにエラーが出ました。ハードクォータの動作確認は成功です。
アラートの設定
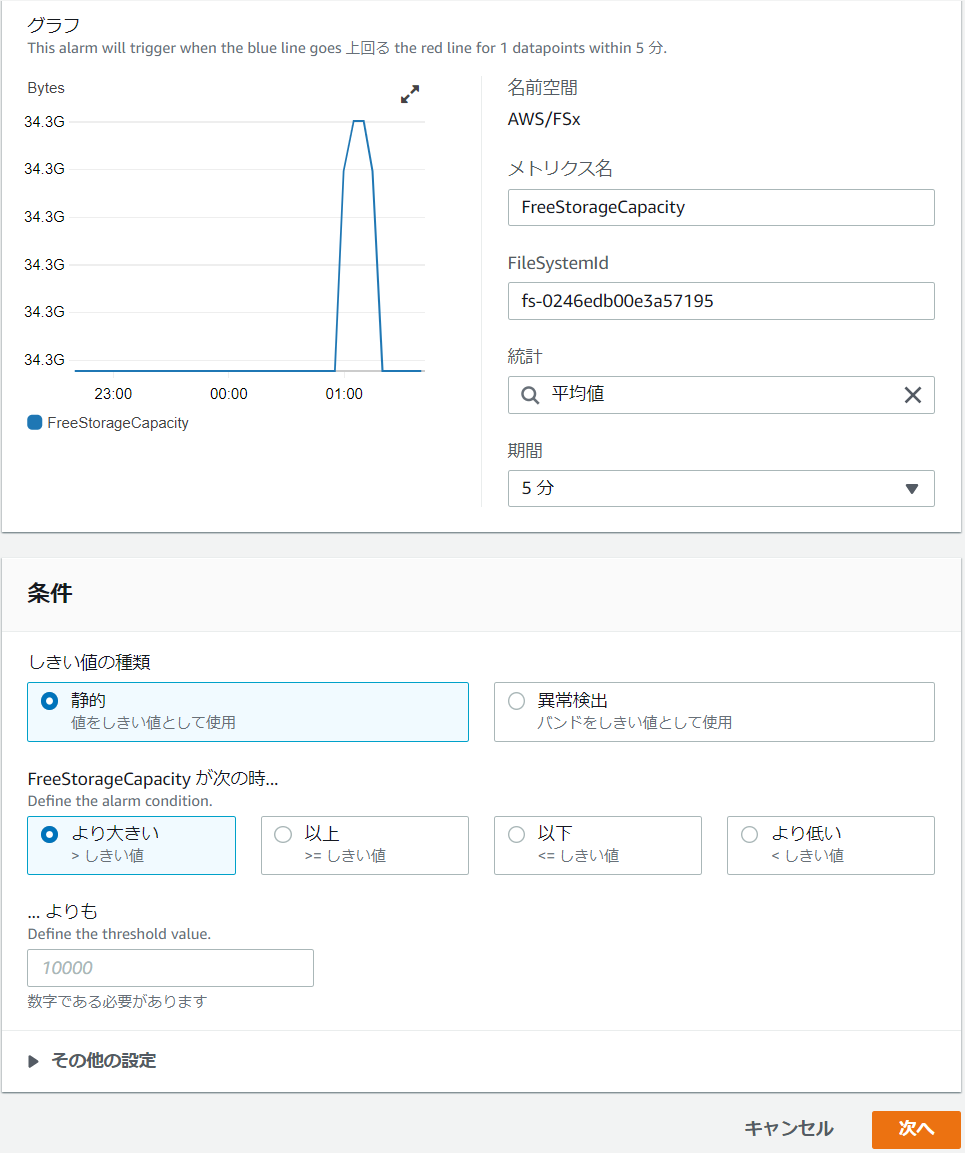
警告の出る場所や手段は結局わかりませんでしたが、CloudWatchでアラートの作成は可能なので、SNSでメール通知なども簡単にできます。
メトリクス名 DataReadOperations MetadataOperations DataWriteOperations DataWriteBytes DataReadBytes FreeStorageCapacity ここにもWarningの文字はありません。「FreeStorageCapacity(空き容量)」もストレージ全体の容量が分母になっているので、クォータの警告とは関連なさそうです。
「FreeStorageCapacity(空き容量)」メトリクスのアラート設定条件は以下の画面で行います。
以下のドキュメントには「追跡にのみ関連」と記載がありますが、これでは追跡もできなさそうです。
ストレージクォータ
とほほ。。。FSxのクォータWarningについては、今後も情報を探していきたいと思います。
シャドーコピー設定
クォータの次はシャドーコピーの設定です。
Windowsでサーバ運用をした経験がある方ならおなじみの、「以前のバージョン」機能です。
Windowsでシャドーコピー機能をONにすると標準で64世代が自動的に取得され、万が一ファイルを誤って上書きしたり消去してしまった場合に、設定した時間に取得した状態に戻すことができる機能です。
AWSのドキュメントはこちらです。
Working with Shadow Copies
Shadow Copiesコマンド一覧
シャドウコピーコマンド 説明 ドキュメントに一覧が・・・なかった
ので、AWSのドキュメントを見て作りました。
シャドウコピーコマンド 説明 Set-FsxShadowStorage シャドウコピーを設定する Get-FsxShadowStorage シャドウコピーの現在の構成を表示 Remove-FsxShadowStorage シャドーコピー領域の削除と無効化 Set-FsxShadowCopySchedule シャドーコピースケジュールの設定 Get-FsxShadowCopySchedule シャドーコピースケジュールの現在の構成を表示 Remove-FsxShadowCopySchedule シャドーコピースケジュールの削除 New-FsxShadowCopy 新しいシャドウコピーの作成 Get-FsxShadowCopies 既存のシャドウコピーの表示 Remove-FsxShadowCopies シャドウコピーの削除 機能を有効化する
WindowsServerと同様に、FSxも標準では機能が有効化されていないので、まずは有効化するところからやってみましょう。
先ほどのクォータ設定と同様にPowerShellを利用します。当然日本語OSでは(以下略)なのでご注意ください。
オプションはいくつかありますが、コマンドは簡単です。
コマンドオプション 説明 -Maxsize 消費できるストレージの最大量 -Default ファイルシステムの最大10%
Maxsizeオプション 説明 2500000000 バイト単位 (2500MB)、(2.5GB) キロ・メガ・ギガバイトなどの単位 "20%" ストレージ全体に対する割合 "UNBOUNDED" 未定義 今回はディフォルトで設定します。
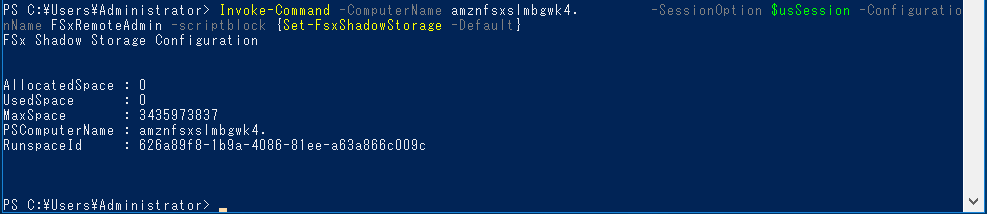
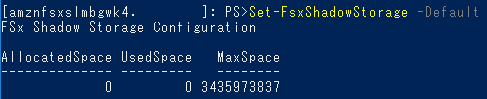
Set-FsxShadowStorage -Default
「-Default」オプションはシャドーコピーで利用する容量をディフォルトの10%に設定するという内容です。
シャドーコピー領域の削除
次に、シャドーコピーの領域を削除してみます。
[Y]の入力が求められます。
もともとデータがありませんでしたので、一瞬で終わりました。Remove-FsxShadowStorage
この状態ではシャドーコピー機能が無効化されてしまうので、また有効化する必要があります。
スケジュールの作成
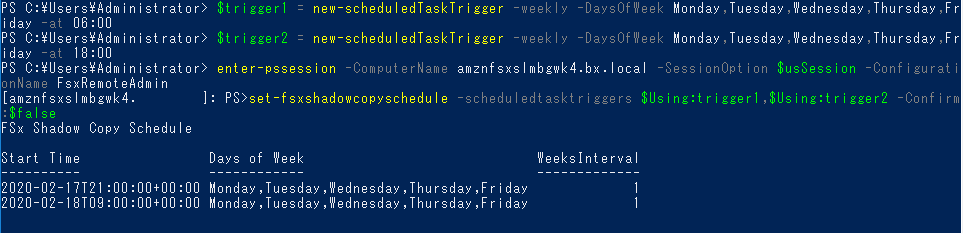
次はシャドーコピーを取得するタイミングを設定してみます。
例としてはありがちな「月~金、6:00」「月~金、18:00」の2パターンを入れてみます。変数を用いますので、一度「exit」してから以下を実行します。
$trigger1 = new-scheduledTaskTrigger -weekly -DaysOfWeek Monday,Tuesday,Wednesday,Thursday,Friday -at 06:00 $trigger2 = new-scheduledTaskTrigger -weekly -DaysOfWeek Monday,Tuesday,Wednesday,Thursday,Friday -at 18:00 enter-pssession -ComputerName amznfsxslmbgwk4.domain.com -SessionOption $usSession -ConfigurationName FsxRemoteAdmin set-fsxshadowcopyschedule -scheduledtasktriggers $Using:trigger1,$Using:trigger2 -Confirm:$false
お!きちんとUTCでセットしてくれました。賢い!
きちんとスケジュールをセットすることができました。シャドーコピーを作成する
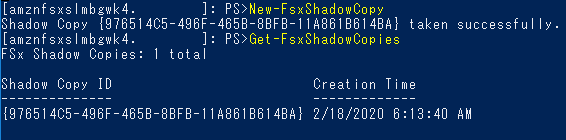
稀に任意のタイミングでシャドーコピーを作成する必要があるかもしれませんが、そのコマンドも用意されています。
実行するとすぐに取得完了しました。
差分の容量によっては時間がかかるかもしれません。
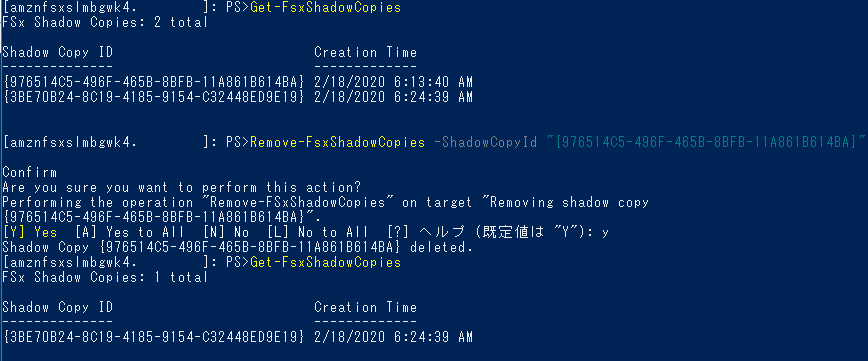
シャドーコピーを削除する
以下のオプションがあります。
コマンドオプション 説明 -Oldest 最も古いシャドウコピーを削除します -All 既存のすべてのシャドウコピーを削除します -ShadowCopyId IDで特定のシャドウコピーを削除します ID指定で消してみます。
消えました。セッション管理
接続しているユーザーや、開いているファイルなどの情報を一覧したり、強制切断したりする機能です。
ドキュメントの記載はこちらです。
ユーザーセッションとオープンファイルコマンド一覧
セッションコマンド 説明 Get-FSxSmbSession ファイルシステムと関連するクライアント間で現在確立されているサーバーメッセージブロック(SMB)セッションに関する情報を取得します。 Close-FSxSmbSession SMBセッションを終了します。 Get-FSxSmbOpenFile ファイルシステムに接続されているクライアントに対して開かれているファイルに関する情報を取得します。 Close-FSxSmbOpenFile SMBサーバーのクライアントの1つに対して開いているファイルを閉じます。 重複排除
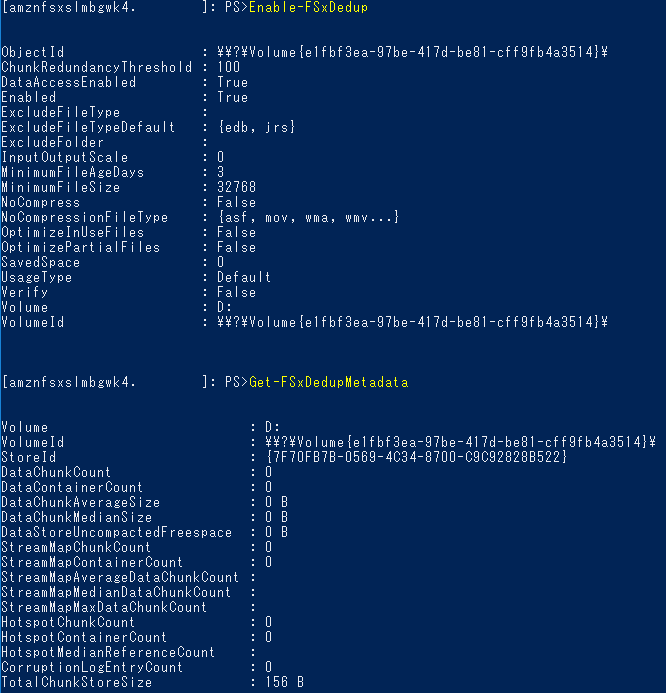
重複排除機能もWindowsServerに標準で利用できる機能でしたが、使用したことはありませんでした。こういったサービス型なら管理の手間を考えることなく試せますね。
コマンド一覧
データ重複排除コマンド 説明 Enable-FSxDedup ファイル共有のデータ重複排除を有効にします。 Disable-FSxDedup ファイル共有のデータ重複排除を無効にします。 Get-FSxDedupConfiguration 最適化のための最小ファイルサイズと保存期間、圧縮設定、除外ファイルの種類とフォルダーなどの重複排除構成情報を取得します。 Set-FSxDedupConfiguration 最適化のための最小ファイルサイズと保存期間、圧縮設定、除外ファイルの種類とフォルダーなど、重複排除の構成設定を変更します。 Get-FSxDedupStatus 重複排除ステータスを取得し、ファイルシステム上の最適化の節約とステータス、時間、およびファイルシステム上の最後のジョブの完了ステータスを記述する読み取り専用プロパティを含めます。 Get-FSxDedupMetadata 重複排除最適化メタデータを取得します。 Update-FSxDedupStatus 更新されたデータ重複排除の節約情報を計算して取得します。 Measure-FSxDedupFileMetadata フォルダーのグループを削除した場合にファイルシステムで再利用できる潜在的なストレージスペースを測定して取得します。多くの場合、ファイルには他のフォルダー間で共有されるチャンクがあり、重複排除エンジンはどのチャンクが一意で削除されるかを計算します。 Get-FSxDedupSchedule 現在定義されている重複排除スケジュールを取得します。 New-FSxDedupSchedule データ重複排除スケジュールを作成およびカスタマイズします。 Set-FSxDedupSchedule 既存のデータ重複排除スケジュールの構成設定を変更します。 Remove-FSxDedupSchedule 重複排除スケジュールを削除します。 Get-FSxDedupJob 現在実行中またはキューに入っているすべての重複排除ジョブのステータスと情報を取得します。 Stop-FSxDedupJob 指定された1つ以上のデータ重複排除ジョブをキャンセルします。 実際に設定してみます。
設定してメタデータを取得しましたが、そもそもデータがほぼカラっぽなのでほとんど何も出ませんね。以上、いろいろな設定を確認してみました。
次は運用を仮定してDFS-Rとの組合せと、VPNを接続してオフィスからの利用を仮定した利用方法を試してみたいと思います。
まとめ
最後にWindowsServerからの移行を検討する際に気になるポイントをまとめてみました。
機能比較表
機能 WindowsServer Amazon SFx 備考 価格 ○ △ サービス改善待ち アクセス権限 ○ ○ NTFSによるアクセス権管理 容量拡張性 ○(EBS) × サービス改善待ち クォータ フォルダ毎に設定可能 エンドポイント毎にのみ設定可能 エンドポイントを増やせば可 シャドーコピー ○ ○ セッション管理 ○ ○ 重複排除 ○ ○ ウィルスチェック ○(別途) × サービス改善待ち ログ監査 ○(別途) × 別の仕組みで解決 ホスト名設定 ○ × エイリアスや名前空間によって変更可 冗長化 ○(別途) ○ MultiAZ対応 DFS-R対応 ○ ○? ちょっと触ったけどできなかった…






- 投稿日:2020-02-20T17:50:38+09:00
AWS Aurora Postgres のレプリケーションについて確認してみた。
公式ドキュメントはこの辺りになります。
https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/aurora-replicas-adding.htmlAWSのRDSでAuroraを運用していますが、これまでそれほど負荷が高くないことも有り、リードレプリカのインスタンスは利用していませんでした。
これを、ちょっと重たい分析などを行いたいという話が出てきたため、リードレプリカのインスタンスを追加すればできるんじゃないかということで、漠然とした利用イメージはあるものの細かな動作や設定をどうすればいいかわかっていなかったので、確認してみたものです。一通り動かして確認したものですが、ツールなどを使って厳密に検証を行ったと言えるものではありませんので、もし誤って理解しているような箇所があればご指摘いただけると幸いです。
結論
とにかく、検証結果確認できた結論から。
- 書込み可能なプライマリーインスタンスと、読み込み専用のリードレプリカは、インスタンスタイプは揃える必要はない。プライマリーより大きいリードレプリカ、プライマリーより小さいリードレプリカのどちらも作成が可能。
- エンドポイントは、クラスターのエンドポイントを指定し、個別インスタンスのエンドポイントは使用しない。個別のインスタンスを指定したい場合は、カスタムエンドポイント機能を使う。
- RDSの停止処理は、クラスター単位。リードレプリカを追加して、レプリカのインスタンスのみを停止させるといったことは不可能。
- プライマリーインスタンスに書き込まれた情報は、ほぼリアルタイムでレプリケーションされる。(タイムラグは通常数十ミリ秒単位)よほどシビアにリアルタイム性が追求されるシステムでもない限り、誤差が発生することを意識する必要なし。
- プライマリーインスタンスのDBに読み込みロックが掛かると、リードレプリカのテーブルも読み込み不可となる。
- Fail-over状態は1分程度で復旧。
0.前提
環境は
AWS RDS Aurora for Postgres でエンジンバージョンは 10.7で確認しました。1.インスタンスタイプについて
検証では、プライマリーインスタンスのタイプを
プライマリーインスタンスタイプ リードレプリカのインスタンスタイプ r5.large t3.medium t3.medium r5.large の両方で検証。いずれも問題なく作成できた。
もちろん、両方のサイズを揃えた状態でも問題なし。2.エンドポイントについて
参考URL
https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/Aurora.Connecting.html#Aurora.Connecting.AuroraPostgreSQL
https://dev.classmethod.jp/cloud/aws/amazon-aurora-custom-endpoints/AruroraのDBを指定するエンドポイントとしては
- クラスターの書き込み用エンドポイント
- クラスターの読み込み用エンドポイント
- カスタムエンドポイント
- インスタンスエンドポイント
の4種類がある。
この内、インスタンスエンドポイントについては基本的に 利用してはいけない 。
一見、インスタンスのエンドポイントを指定しても正常に動作するように見えるが、フェイルオーバーなどの処理によってロールが変更され、書き込み用インスタンスだったものが読み込み専用になるなど、障害等が発生した際に処理が継続できなくなる恐れがある。このため、必ずクラスターのエンドポイントを指定する。
クラスターのエンドポイントは書き込み用と読み込みようが用意されていて、基本は書き込み用にアクセスできるようになっていればすべての処理が実行可能。
読み込み用のエンドポイントの場合は、リードレプリカが複数ある時、どのインスタンスにアクセスするかは自動的に振り分けられる形になる。
リアルタイム分析など、読み込み専用の処理であれば、読み込み用のエンドポイントを利用することで、書き込み用のプライマリーインスタンスに負荷をかけずに処理することができる。
カスタムエンドポイントは、その組み合わせ。例えばリードレプリカを5台用意しているような場合で、分析で大きな負荷がかかるような処理がある場合、書き込み処理を行うメーンの処理はプライマリー1台と2台のリードレプリカを指定し、残りの3台を分析処理専用に使う、といった処理系の大きさに合わせた組み合わせでインスタンスを効率的に利用することが可能となる。[未検証情報] 参考URL: https://readouble.com/laravel/6.x/ja/database.html#read-and-write-connections Laravelを利用する場合は、databaseの設定で、readとwriteのDBを切り分けが可能。 この機能とエンドポイントの指定をうまく組み合わせれば、書き込み処理と読み込み処理の接続先を切り分けることで負荷分散が図れるはず。3.停止・削除処理
RDSの停止処理は通常のRDSインスタンスと同様に1週間の停止後自動起動となる。
ただし、停止できるのはクラスター単位。インスタンス単位での停止は不可。
追加したリードレプリカの削除は随時任意のタイミングで実施可能。
リードレプリカの作成もダウンタイム無しで任意のタイミングで実施可能。
リードレプリカが存在する状態でプライマリーインスタンスを削除すると、ロールが変更され、リードレプリカのインスタンスがプライマリーインスタンスへと昇格する。
ダウンタイムはほとんどなかった(あったとしてもおそらく切り替わる数秒間程度)。4.レプリケーション・ロック
レプリケーションにより発生するタイムラグは、概ね20ミリ秒以下(同一A-Z内)。異なるアベイラビリティゾーンの場合でも30ms程度。
ほぼリアルタイム処理と考えて問題なし。
PostgresのLOCK TABLE機能で確認。
プライマリーインスタンスのテーブルにロックをかけると、クラスターのエンドポイントからも、リードレプリカのエンドポイントからも、該当テーブルを読み込めなくなった。5.Fail-Over
フェイルオーバーをAWS consoleから実行したところ、ダウンタイムあり。
ただし、1分程度で利用可能な状態に復旧する。実際に障害が発生した際も同様と考えられる。
- 投稿日:2020-02-20T17:06:30+09:00
FunctionComputeで実現するDTS(DataTransmissionService)のデータ移行のスケジューリング処理(DTS紹介編)
この記事の目的
DataTransmissionServiceをAPIで操り、
「データ移行」サービスを定期実行(バッチ処理)させるスクリプトをFunctionComputeで実現します。FunctionComputeって何?という方は前回のECSをFunctionComputeで自動停止&起動させる記事を書いているのでご参照ください。Alibaba CloudのFunction Compute(サーバレスアーキテクチャ)を使ってECSインスタンスを自動起動&自動停止させる
https://qiita.com/tnoce/items/453f9a6e2fafdbe61b1fこの記事では、まずDTSを詳しく紹介していきます。
2本目の記事を、FunctionComputeを利用したバッチ処理の実行編とします。Alibaba Cloud DTS(DataTransmissionServiceとは)
- Alibaba Cloudでデータベース間のデータ転送や同期ができるマネージドサービス。 マネージドのため、インスタンスはデフォルトで冗長化されている
- RDBMSやNoSQLを含む、幅広いDBエンジンに対応している。
- SLAは99.95%
- なんと"あの"中国アリババの「独身の日」においての運用に実際使われている。
- おそらく、何万ものアプリケーション向けにリアルタイムにデータ同期する用途で使われている様子...?
- 中国では5年間順調に運用されている信頼できるプロダクトとのこと
DTSのポイント
- 増分データのみを移行させることができる
- ホットマイグレーションが可能(DBがread, writeのステータスにかかわらず影響を与えない)
- それによってデータ移行におけるダウンタイムが発生しない
- 高性能
- DTSがホストされている物理サーバーは高スペックマシンが採用されているため、優れたパフォーマンスが発揮できる
- データ移行においては、ピーク時で毎秒200,000レコードの転送が可能
- データ同期においては、ピーク時で毎秒30,000レコードの転送が可能
DTSにおけるマイグレーションの対応種別(2020-02-20時点)
種別 機能 対応DBエンジン 対応リージョン データ移行が利用できる環境 データ移行(Data Migration) ・スキーマ移行、完全なデータ移行、増分データ移行をサポート
・ダウンタイムを最小限に抑えてデータ移行をするためには、スキーマ移行、完全データ移行、増分データ移行をすべて選択すると良き
・異なるDBエンジン間の以降の場合、DTS側でソースDBのスキーマを読み取り、宛先DBエンジンの構文に変換してくれる
・すべてのデータ構造を移行するにはある程度の時間を要する。このプロセスが走るとき、増分として書き込まれたレコードは継続的に書き込まれる(ホットマイグレーションが可能)
・MySQL
Oracle
PostgreSQL
SQLServer
Redis
MongoDB
DB2
AmazonRDS
AmazonAurora
【Alibaba系】
RDS, PorlaDB, MongoDB
杭州、北京、青島、深セン、上海、シリコンバレー、バージニア、シンガポール、ドバイ、フランクフルト、クアラルンプール、香港、オーストラリア、ジャカルタ、日本、インド、フフホト、ロンドン ①Alibaba Cloud RDS
②オンプレミスデータベース
③AlibabaCloud ECSベースのデータベースデータ同期(Data Synchronization) ・ソースデータベースとターゲットデータベースをリアルタイムに常時同期させることができる
・OLTPデータベースからOLTPデータベースへがサポートされている(※OTPL=オンライントランザクションプロセッシング)
・増分データのリアルタイム同期が可能
・①初回に初期同期 → ②その後増分データの同期という流れ
・【ソースDB】
MySQL
Redis
PolarDB
【ターゲットDB】
MySQL
MaxCompute
ElasticSearch
AnalyticDB for PostgreSQL
PolarDB
AnalyticDB for MySQL【ソースDB】
杭州、北京、青島、深セン、上海、シリコンバレー、バージニア、シンガポール、ドバイ、フランクフルト、クアラルンプール、オーストラリア、インド、日本、ジャカルタ、フフホト、張家口、香港、ロンドン
【ターゲットDB】
杭州、北京、青島、深セン、上海、フフホト①Alibaba Cloud RDS
②オンプレミスデータベース(ただしVPN必須)
③AlibabaCloud ECSベースのデータベースデータサブスクリプション ・データサブスクリプションを利用すると、リアルタイムで増分データを取得することができる。
MySQL 杭州、北京、青島、深セン、上海、シリコンバレー、シンガポール ①Alibaba Cloud RDS
②オンプレミスデータベース
③AlibabaCloud ECSベースのデータベースFunctionComputeを利用する理由
上記表の通り、DTSには3つのサービス(機能)があります。
データ移行サービスが最も対応しているDBエンジンが多く、汎用的に利用できると思われますが、実はデータ移行はバッチ処理のようにスケジューリングできる機能がありません。
そこで、FunctionComputeのタイムトリガー機能を利用することで、バッチ処理でデータ移行サービスを実行させることが可能になります。DTSの従量課金とサブスクリプションの違い
種別 対象サービス 説明 注意点 Pay-As-You-Go(従量課金タイプ) ①データ同期
②データサブスクリプション・実際の使用量に基づいて請求される
・時間単位で課金される
・短期的な利用において活用される
・仕様後のインスンタスをリリースすることで費用節約ができる
・従量課金→サブスクインスタンスへ切り替えることができる- サブスクリプション(月額固定タイプ) ①データ移行
②データ同期
③データサブスクリプション・長期利用においては従量課金よりもコストが安いのでおすすめ ・サブスクリプションインスタンスを従量課金インスタンスへ変更することはできない
・サブスクが切れるまでインスタンスリリースはできない
利用料金の対象
種別 課金対象アイテム 請求ルール 注意点 費用(/時間)※杭州リージョンの場合 データ移行(Data Migration) ①データ移行インスタンス
②インターネットのトラフィック料金①時間課金。また、増分データの移行が進行中の場合(増分データの移行が一時停止されている期間を含む)が請求対象となる。スキーマの行こうと完全なデータ移行については課金されない
②アウトバウンドトラフィックのみ課金がされる。つまり、Alibaba Cloudから外に出るときの通信に課金が発生する。実際のチャージは実際の通信に準じる。・増分データ移行が失敗した時間は、料金発生しない
・アウトバウンドトラフィックは1GBが最低課金単位。500MBの通信であっても1GB分の料金が課金されるsmall:0.158ドル
medium:0.287ドル
large:0.462ドル
xlarge:0.846ドル
2xlarge:1.502ドルデータ同期(Data Synchronization) ①データ同期インスタンス ①時間課金。設定が完了しデータ同期インスタンスが実行されると、請求が開始される。(インスタンスが一時停止されている期間も時間課金が発生)
②サブスクリプション課金- small:0.158ドル
medium:0.287ドル
large:0.462ドル
xlarge:0.846ドル
2xlarge:1.502ドルデータサブスクリプション ①データサブスクリプションインタンス ①時間課金。設定が完了しデータサブスクリプションインスタンスが実行されると、請求が開始される。(インスタンスが一時停止されている期間も時間課金が発生)
②サブスクリプション課金- 0.46ドル DTSのコンソール画面
今回はAlibaba Cloudのインターナショナルサイト(国際サイト)ベースで見ていきます。
データベース系プロダクトの中にあります。
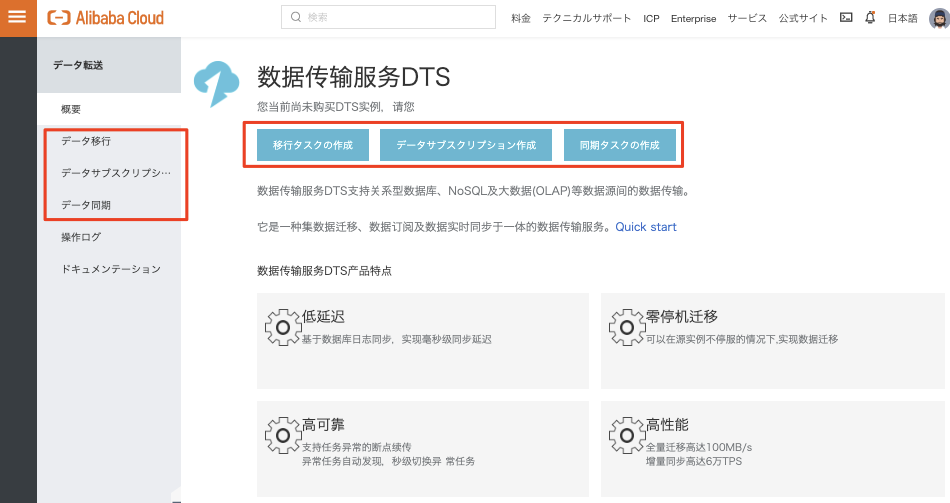
DTSのトップページです。
左のペインでも、真ん中のアイコンどちらからでもそれぞれのサービスページに遷移可能です。
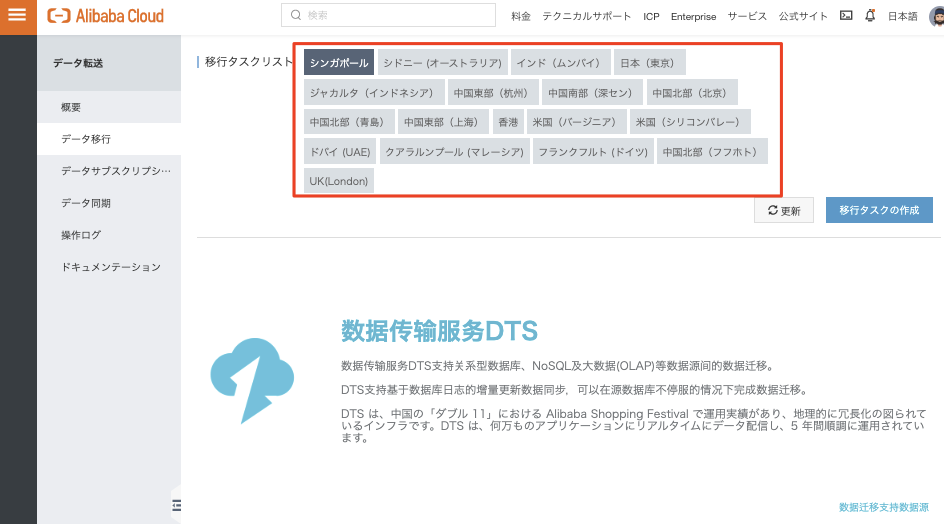
例えばデータ移行サービスに遷移してみると、移行タスクが起動できるリージョン一覧が表示されます。
注意するべきポイントとして、Alibaba Cloud RDSなどをソース or ターゲットインスタンスとして選択したい場合は、RDSが存在するリージョンのタスクインスタンスを作成する必要があります。
操作ログ画面です。
タスクを実行したログなどがここに出ます。
最後に
取り急ぎDTSの説明を行いました。
次は実際にFunctionComputeを使ったDTSのデータ移行サービスのバッチ処理編を投稿しようと思います。

- 投稿日:2020-02-20T17:06:30+09:00
FunctionComputeで実現するDTS(DataTransmissionService)データ移行サービスのスケジューリング(DTS紹介編)
この記事の目的
DTS(DataTransmissionService)をFunctionComputeで操り、
「データ移行」サービスを定期実行(バッチ処理)させるスクリプトをFunctionComputeで実現します。FunctionComputeって何?という方は前回のECSをFunctionComputeで自動停止&起動させる記事を書いているのでご参照ください。Function Computeで実現するECSインスタンスの起動&自動のスケジューリング
この記事では、まずDTSを詳しく紹介していきます。
2本目の記事を、FunctionComputeを利用したバッチ処理の実行編とします。Alibaba Cloud DTS(DataTransmissionServiceとは)
- Alibaba Cloudでデータベース間のデータ転送や同期ができるマネージドサービス。 マネージドのため、インスタンスはデフォルトで冗長化されている
- RDBMSやNoSQLを含む、幅広いDBエンジンに対応している。
- SLAは99.95%
- なんと"あの"中国アリババの「独身の日」においての運用に実際使われている。
- おそらく、何万ものアプリケーション向けにリアルタイムにデータ同期する用途で使われている様子...?
- 中国では5年間順調に運用されている信頼できるプロダクトとのこと
DTSのポイント
- 増分データのみを移行させることができる
- ホットマイグレーションが可能(DBがread, writeのステータスにかかわらず影響を与えない)
- それによってデータ移行におけるダウンタイムが発生しない
- 高性能
- DTSがホストされている物理サーバーは高スペックマシンが採用されているため、優れたパフォーマンスが発揮できる
- データ移行においては、ピーク時で毎秒200,000レコードの転送が可能
- データ同期においては、ピーク時で毎秒30,000レコードの転送が可能
DTSにおけるマイグレーションの対応種別(2020-02-20時点)
種別 機能 対応DBエンジン 対応リージョン データ移行が利用できる環境 データ移行(Data Migration) ・スキーマ移行、完全なデータ移行、増分データ移行をサポート
・ダウンタイムを最小限に抑えてデータ移行をするためには、スキーマ移行、完全データ移行、増分データ移行をすべて選択すると良き
・異なるDBエンジン間の移行の場合、DTS側でソースDBのスキーマを読み取り、宛先DBエンジンの構文に変換してくれる
・すべてのデータ構造を移行するにはある程度の時間を要する。このプロセスが走るとき、増分として書き込まれたレコードは継続的に書き込まれる(ホットマイグレーションが可能)MySQL
Oracle
PostgreSQL
SQLServer
Redis
MongoDB
DB2
AmazonRDS
AmazonAurora
【Alibaba系】
RDS, PorlaDB, MongoDB
杭州、北京、青島、深セン、上海、シリコンバレー、バージニア、シンガポール、ドバイ、フランクフルト、クアラルンプール、香港、オーストラリア、ジャカルタ、日本、インド、フフホト、ロンドン ①Alibaba Cloud RDS
②オンプレミスデータベース
③AlibabaCloud ECSベースのデータベースデータ同期(Data Synchronization) ・ソースデータベースとターゲットデータベースをリアルタイムに常時同期させることができる
・OLTPデータベースからOLTPデータベースへがサポートされている(※OTPL=オンライントランザクションプロセッシング)
・増分データのリアルタイム同期が可能
・①初回に初期同期 → ②その後増分データの同期という流れ
・【ソースDB】
MySQL
Redis
PolarDB
【ターゲットDB】
MySQL
MaxCompute
ElasticSearch
AnalyticDB for PostgreSQL
PolarDB
AnalyticDB for MySQL【ソースDB】
杭州、北京、青島、深セン、上海、シリコンバレー、バージニア、シンガポール、ドバイ、フランクフルト、クアラルンプール、オーストラリア、インド、日本、ジャカルタ、フフホト、張家口、香港、ロンドン
【ターゲットDB】
杭州、北京、青島、深セン、上海、フフホト①Alibaba Cloud RDS
②オンプレミスデータベース(ただしVPN必須)
③AlibabaCloud ECSベースのデータベースデータサブスクリプション(Data Subscription) ・データサブスクリプションを利用すると、リアルタイムで増分データを取得することができる。
MySQL 杭州、北京、青島、深セン、上海、シリコンバレー、シンガポール ①Alibaba Cloud RDS
②オンプレミスデータベース
③AlibabaCloud ECSベースのデータベースFunctionComputeを利用する理由
上記表の通り、DTSには3つのサービス(機能)があります。
データ移行サービスが最も対応しているDBエンジンが多く、汎用的に利用できると思われますが、実はデータ移行はバッチ処理のようにスケジューリングできる機能がありません。
そこで、FunctionComputeのタイムトリガー機能を利用することで、バッチ処理でデータ移行サービスを実行させることが可能になります。DTSの従量課金とサブスクリプションの違い
種別 対象サービス 説明 注意点 Pay-As-You-Go(従量課金タイプ) ①データ移行
②データ同期
③データサブスクリプション・実際の使用量に基づいて請求される
・時間単位で課金される
・短期的な利用において活用される
・仕様後のインスンタスをリリースすることで費用節約ができる
・従量課金→サブスクインスタンスへ切り替えることができる- サブスクリプション(月額固定タイプ) ①データ移行
②データ同期
③データサブスクリプション・長期利用においては従量課金よりもコストが安いのでおすすめ ・サブスクリプションインスタンスを従量課金インスタンスへ変更することはできない
・サブスクが切れるまでインスタンスリリースはできない
利用料金の対象
種別 課金対象アイテム 請求ルール 注意点 費用(/時間)※杭州リージョンの場合 データ移行(Data Migration) ①データ移行インスタンス
②インターネットのトラフィック料金①時間課金。また、増分データの移行が進行中の場合(増分データの移行が一時停止されている期間を含む)が請求対象となる。スキーマの行こうと完全なデータ移行については課金されない
②アウトバウンドトラフィックのみ課金がされる。つまり、Alibaba Cloudから外に出るときの通信に課金が発生する。実際のチャージは実際の通信に準じる。・増分データ移行が失敗した時間は、料金発生しない
・アウトバウンドトラフィックは1GBが最低課金単位。500MBの通信であっても1GB分の料金が課金されるsmall:0.158ドル
medium:0.287ドル
large:0.462ドル
xlarge:0.846ドル
2xlarge:1.502ドルデータ同期(Data Synchronization) ①データ同期インスタンス ①時間課金。設定が完了しデータ同期インスタンスが実行されると、請求が開始される。(インスタンスが一時停止されている期間も時間課金が発生)
②サブスクリプション課金- small:0.158ドル
medium:0.287ドル
large:0.462ドル
xlarge:0.846ドル
2xlarge:1.502ドルデータサブスクリプション ①データサブスクリプションインタンス ①時間課金。設定が完了しデータサブスクリプションインスタンスが実行されると、請求が開始される。(インスタンスが一時停止されている期間も時間課金が発生)
②サブスクリプション課金- 0.46ドル DTSのコンソール画面
今回はAlibaba Cloudのインターナショナルサイト(国際サイト)ベースで見ていきます。
データベース系プロダクトの中にあります。
DTSのトップページです。
左のペインでも、真ん中のアイコンどちらからでもそれぞれのサービスページに遷移可能です。
例えばデータ移行サービスに遷移してみると、移行タスクが起動できるリージョン一覧が表示されます。
注意するべきポイントとして、Alibaba Cloud RDSなどをソース or ターゲットインスタンスとして選択したい場合は、RDSが存在するリージョンのタスクインスタンスを作成する必要があります。
操作ログ画面です。
タスクを実行したログなどがここに出ます。
最後に
取り急ぎDTSの説明を行いました。
次は実際にFunctionComputeを使ったDTSのデータ移行サービスのバッチ処理編を投稿しようと思います。
- 投稿日:2020-02-20T17:06:30+09:00
FunctionComputeで実現するDTS(DataTransmissionService)データ移行サービスのスケジューリング
この記事の目的
DTS(DataTransmissionService)をFunctionComputeで操り、
「データ移行」サービスを定期実行(バッチ処理)させるスクリプトをFunctionComputeで実現します。FunctionComputeって何?という方は前回のECSをFunctionComputeで自動停止&起動させる記事を書いているのでご参照ください。Function Computeで実現するECSインスタンスの起動&自動のスケジューリング
この記事では、まずDTSを詳しく紹介していきます。
2本目の記事を、FunctionComputeを利用したバッチ処理の実行編とします。Alibaba Cloud DTS(DataTransmissionServiceとは)
- Alibaba Cloudでデータベース間のデータ転送や同期ができるマネージドサービス。 マネージドのため、インスタンスはデフォルトで冗長化されている
- RDBMSやNoSQLを含む、幅広いDBエンジンに対応している。
- SLAは99.95%
- なんと"あの"中国アリババの「独身の日」においての運用に実際使われている。
- おそらく、何万ものアプリケーション向けにリアルタイムにデータ同期する用途で使われている様子...?
- 中国では5年間順調に運用されている信頼できるプロダクトとのこと
DTSのポイント
- 増分データのみを移行させることができる
- ホットマイグレーションが可能(DBがread, writeのステータスにかかわらず影響を与えない)
- それによってデータ移行におけるダウンタイムが発生しない
- 高性能
- DTSがホストされている物理サーバーは高スペックマシンが採用されているため、優れたパフォーマンスが発揮できる
- データ移行においては、ピーク時で毎秒200,000レコードの転送が可能
- データ同期においては、ピーク時で毎秒30,000レコードの転送が可能
DTSにおけるマイグレーションの対応種別(2020-02-20時点)
種別 機能 対応DBエンジン 対応リージョン データ移行が利用できる環境 データ移行(Data Migration) ・スキーマ移行、完全なデータ移行、増分データ移行をサポート
・ダウンタイムを最小限に抑えてデータ移行をするためには、スキーマ移行、完全データ移行、増分データ移行をすべて選択すると良き
・異なるDBエンジン間の移行の場合、DTS側でソースDBのスキーマを読み取り、宛先DBエンジンの構文に変換してくれる
・すべてのデータ構造を移行するにはある程度の時間を要する。このプロセスが走るとき、増分として書き込まれたレコードは継続的に書き込まれる(ホットマイグレーションが可能)MySQL
Oracle
PostgreSQL
SQLServer
Redis
MongoDB
DB2
AmazonRDS
AmazonAurora
【Alibaba系】
RDS, PorlaDB, MongoDB
杭州、北京、青島、深セン、上海、シリコンバレー、バージニア、シンガポール、ドバイ、フランクフルト、クアラルンプール、香港、オーストラリア、ジャカルタ、日本、インド、フフホト、ロンドン ①Alibaba Cloud RDS
②オンプレミスデータベース
③AlibabaCloud ECSベースのデータベースデータ同期(Data Synchronization) ・ソースデータベースとターゲットデータベースをリアルタイムに常時同期させることができる
・OLTPデータベースからOLTPデータベースへがサポートされている(※OTPL=オンライントランザクションプロセッシング)
・増分データのリアルタイム同期が可能
・①初回に初期同期 → ②その後増分データの同期という流れ
・【ソースDB】
MySQL
Redis
PolarDB
【ターゲットDB】
MySQL
MaxCompute
ElasticSearch
AnalyticDB for PostgreSQL
PolarDB
AnalyticDB for MySQL【ソースDB】
杭州、北京、青島、深セン、上海、シリコンバレー、バージニア、シンガポール、ドバイ、フランクフルト、クアラルンプール、オーストラリア、インド、日本、ジャカルタ、フフホト、張家口、香港、ロンドン
【ターゲットDB】
杭州、北京、青島、深セン、上海、フフホト①Alibaba Cloud RDS
②オンプレミスデータベース(ただしVPN必須)
③AlibabaCloud ECSベースのデータベースデータサブスクリプション(Data Subscription) ・データサブスクリプションを利用すると、リアルタイムで増分データを取得することができる。
MySQL 杭州、北京、青島、深セン、上海、シリコンバレー、シンガポール ①Alibaba Cloud RDS
②オンプレミスデータベース
③AlibabaCloud ECSベースのデータベースFunctionComputeを利用する理由
上記表の通り、DTSには3つのサービス(機能)があります。
データ移行サービスが最も対応しているDBエンジンが多く、汎用的に利用できると思われますが、実はデータ移行はバッチ処理のようにスケジューリングできる機能がありません。
そこで、FunctionComputeのタイムトリガー機能を利用することで、バッチ処理でデータ移行サービスを実行させることが可能になります。DTSの従量課金とサブスクリプションの違い
種別 対象サービス 説明 注意点 Pay-As-You-Go(従量課金タイプ) ①データ移行
②データ同期
③データサブスクリプション・実際の使用量に基づいて請求される
・時間単位で課金される
・短期的な利用において活用される
・仕様後のインスンタスをリリースすることで費用節約ができる
・従量課金→サブスクインスタンスへ切り替えることができる- サブスクリプション(月額固定タイプ) ①データ移行
②データ同期
③データサブスクリプション・長期利用においては従量課金よりもコストが安いのでおすすめ ・サブスクリプションインスタンスを従量課金インスタンスへ変更することはできない
・サブスクが切れるまでインスタンスリリースはできない
利用料金の対象
種別 課金対象アイテム 請求ルール 注意点 費用(/時間)※杭州リージョンの場合 データ移行(Data Migration) ①データ移行インスタンス
②インターネットのトラフィック料金①時間課金。また、増分データの移行が進行中の場合(増分データの移行が一時停止されている期間を含む)が請求対象となる。スキーマの行こうと完全なデータ移行については課金されない
②アウトバウンドトラフィックのみ課金がされる。つまり、Alibaba Cloudから外に出るときの通信に課金が発生する。実際のチャージは実際の通信に準じる。・増分データ移行が失敗した時間は、料金発生しない
・アウトバウンドトラフィックは1GBが最低課金単位。500MBの通信であっても1GB分の料金が課金されるsmall:0.158ドル
medium:0.287ドル
large:0.462ドル
xlarge:0.846ドル
2xlarge:1.502ドルデータ同期(Data Synchronization) ①データ同期インスタンス ①時間課金。設定が完了しデータ同期インスタンスが実行されると、請求が開始される。(インスタンスが一時停止されている期間も時間課金が発生)
②サブスクリプション課金- small:0.158ドル
medium:0.287ドル
large:0.462ドル
xlarge:0.846ドル
2xlarge:1.502ドルデータサブスクリプション ①データサブスクリプションインタンス ①時間課金。設定が完了しデータサブスクリプションインスタンスが実行されると、請求が開始される。(インスタンスが一時停止されている期間も時間課金が発生)
②サブスクリプション課金- 0.46ドル DTSのコンソール画面
今回はAlibaba Cloudのインターナショナルサイト(国際サイト)ベースで見ていきます。
データベース系プロダクトの中にあります。
DTSのトップページです。
左のペインでも、真ん中のアイコンどちらからでもそれぞれのサービスページに遷移可能です。
例えばデータ移行サービスに遷移してみると、移行タスクが起動できるリージョン一覧が表示されます。
注意するべきポイントとして、Alibaba Cloud RDSなどをソース or ターゲットインスタンスとして選択したい場合は、RDSが存在するリージョンのタスクインスタンスを作成する必要があります。
操作ログ画面です。
タスクを実行したログなどがここに出ます。
最後に
取り急ぎDTSの説明を行いました。
次は実際にFunctionComputeを使ったDTSのデータ移行サービスのバッチ処理編を投稿しようと思います。
- 投稿日:2020-02-20T17:01:02+09:00
AWS Lambda で 日⇨英翻訳する
AWS初心者のものです。
昨日JAWS-初心者支部にて1.AWS Lambda で 日⇨英翻訳する
2.翻訳 Web APIを作る
3.文字起こし+翻訳パイプラインを作るのハンズオン3本立てを実施していただきました。
今回は「1.AWS Lambda で 日⇨英翻訳する」をアウトプットをしていきたいと思います。
そもそもLambdaとは
⇨AWS Lambda を使用することで、サーバーのプロビジョニングや管理をすることなく、コードを実行できます。料金は、コンピューティングに使用した時間に対してのみ発生します。(公式サイト参照)
え?
理解するのに時間がかかりました。。。
僕みたいな初心者の方にわかりやくす説明するとしたら、
アプリケーション実行時には
-WindowsやLinuxの環境を構築
-Webサーバ・APサーバ・DBサーバのインストール・環境構築が発生していました。
この手間を無くしてくれたのが救世主Lambda様。
初心者がつまずきやすい環境構築を取っ払ってくれました。※EC2とLambda結局どっちがいいの?⇨一長一短あるみたいなので適材適所で利用するのが良いみたいです!
概要を理解できたところで早速本題へ移っていきましょう。
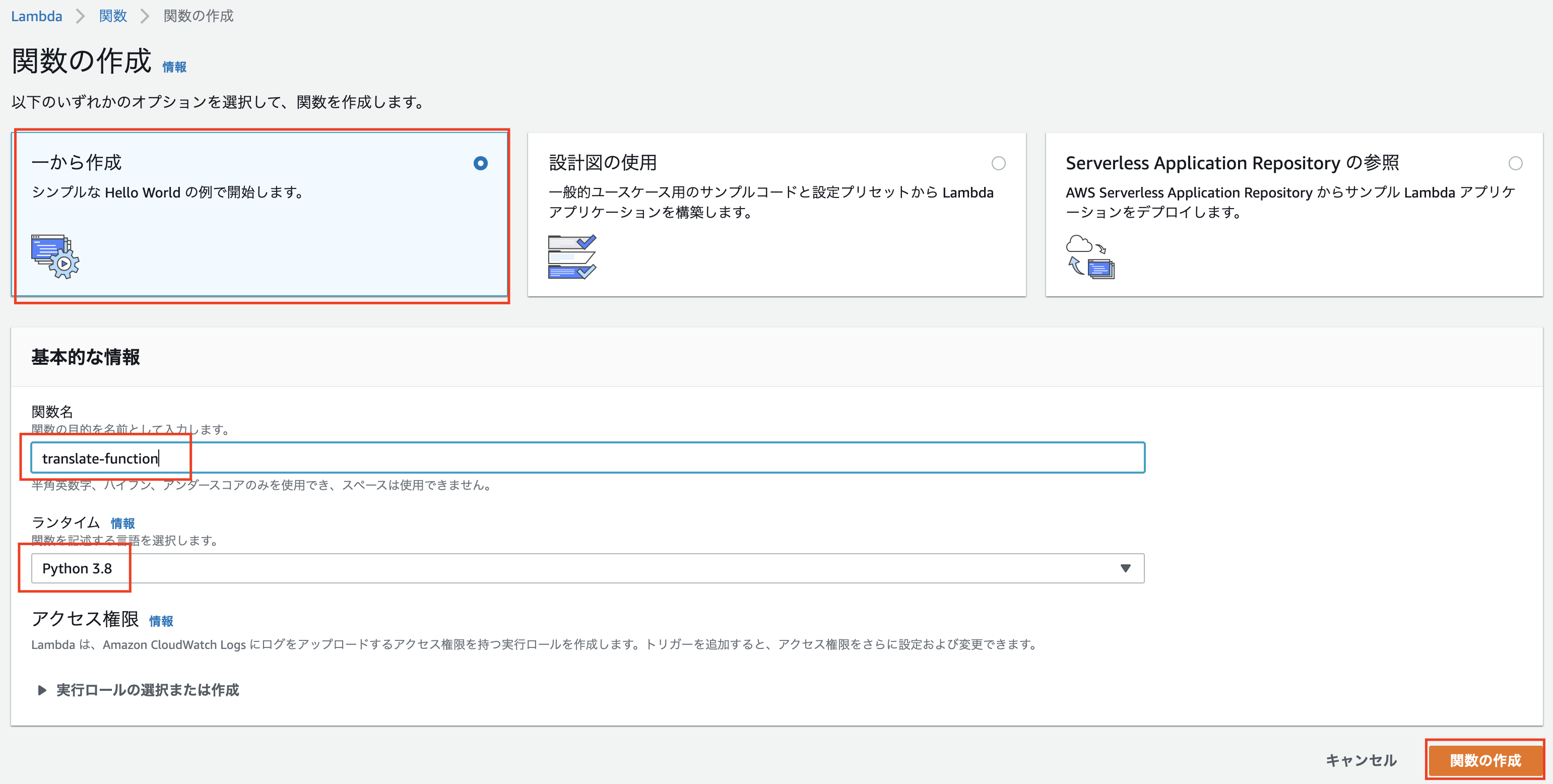
1.Lambda functionを作成し、"Hello World!"を表示する
Lambdaのコンソールに行っていただいて
画面右上にある「関数の作成」をクリック
オプション:「一から作成」
関数名:「translate-function」
ランタイム:「Python3.8」
⇨「関数の作成」をクリック
無事作成できましだでしょうか?
できたらこのポップアップが出現します。
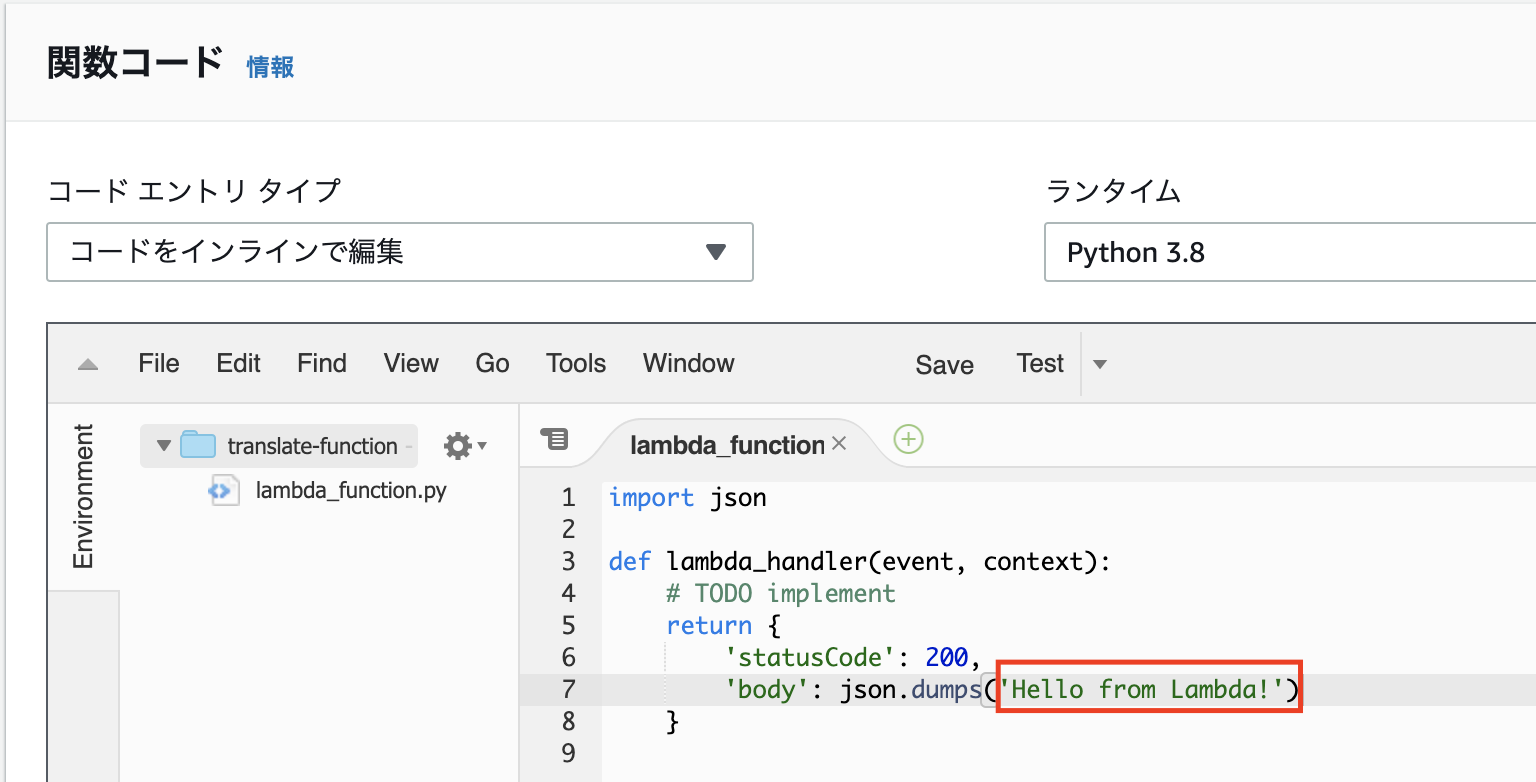
作成したら少し下にスクロールして
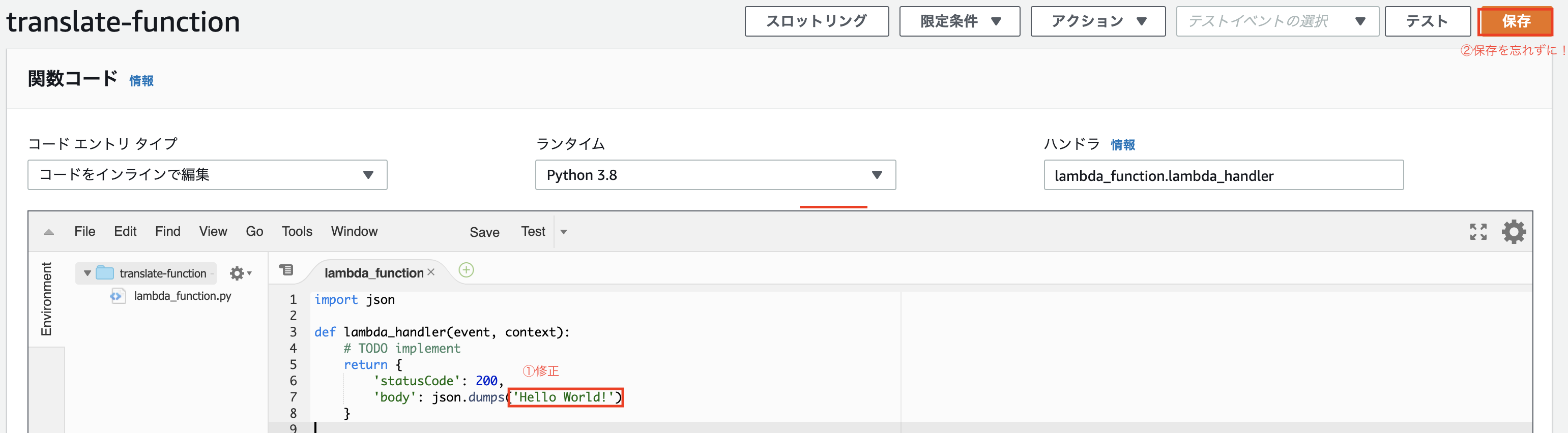
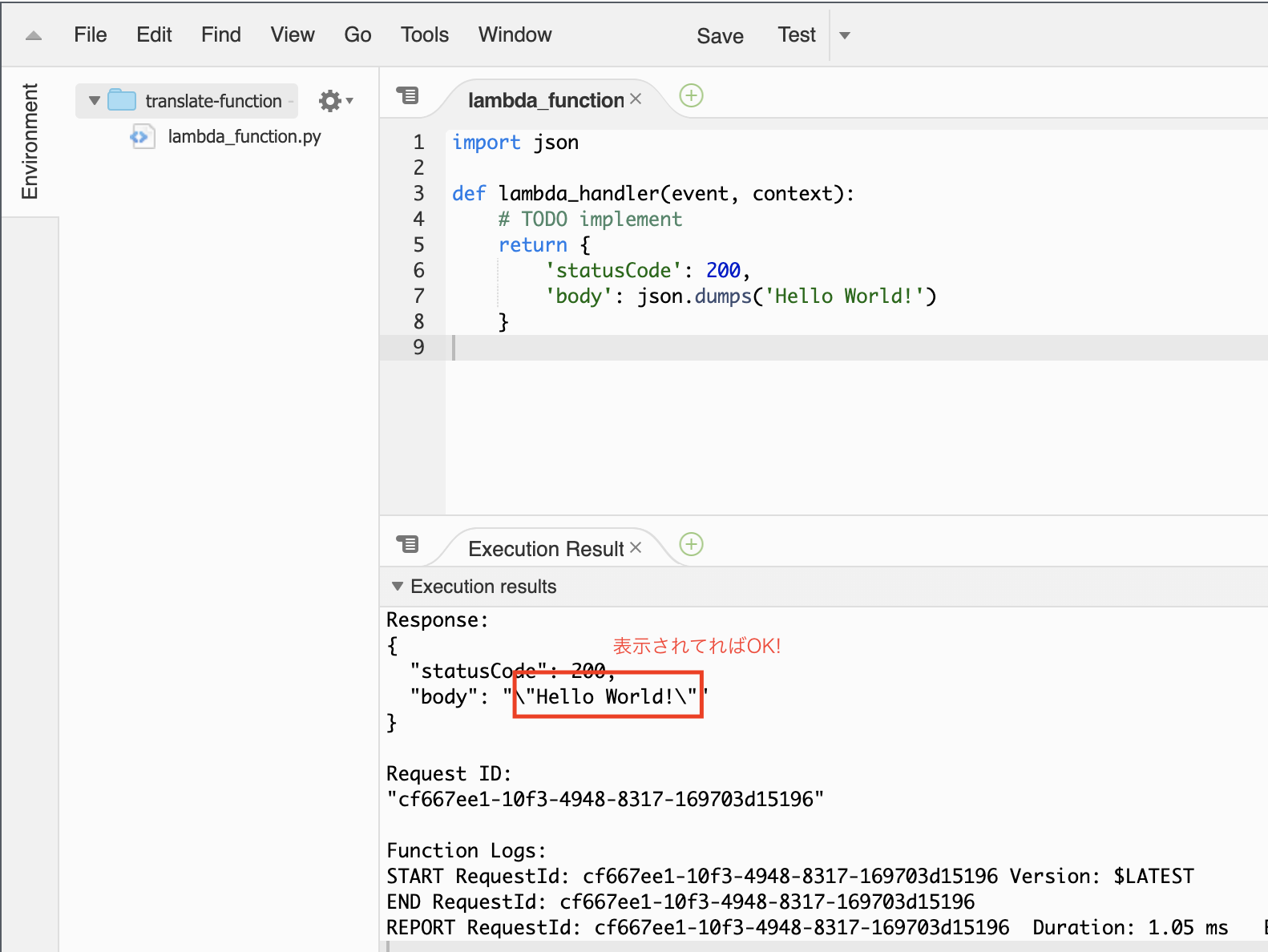
「関数コード」の欄にコードがあります。コードの「"Hello from Lambda"」⇨「"Hello World"」へ修正してみましょう!
↓
修正したら右上の「保存」を忘れずに!右上の「テスト」をクリック
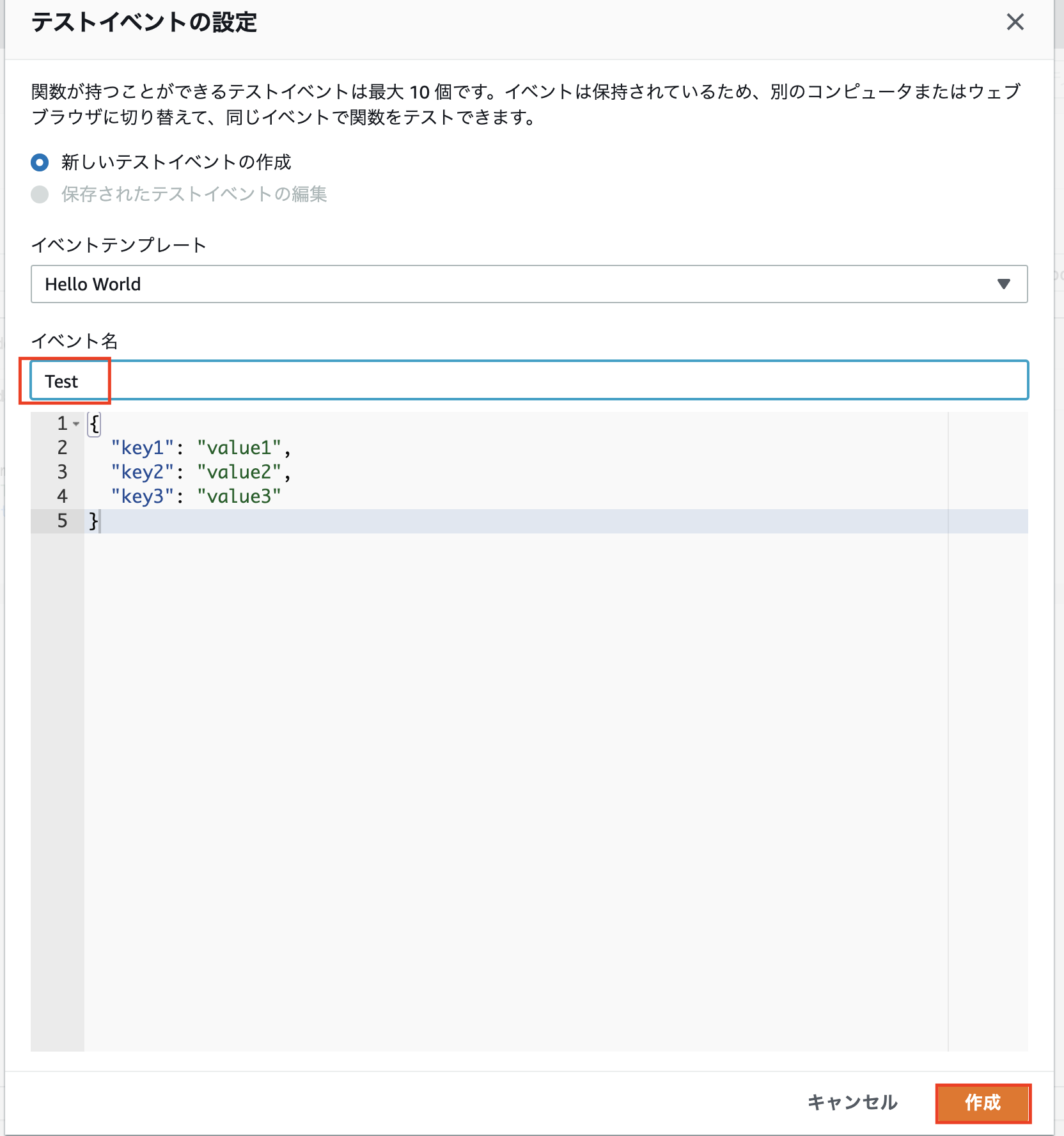
テストイベントの設定で
イベント名:「Test」とし、「作成」をクリック。
もう一回「テスト」をクリックしてみてください!
少しわかりづらいですが「Hello World!」が表示されてれば成功です!
2.Lambda functionを修正し、Amazon Translateと連携する!
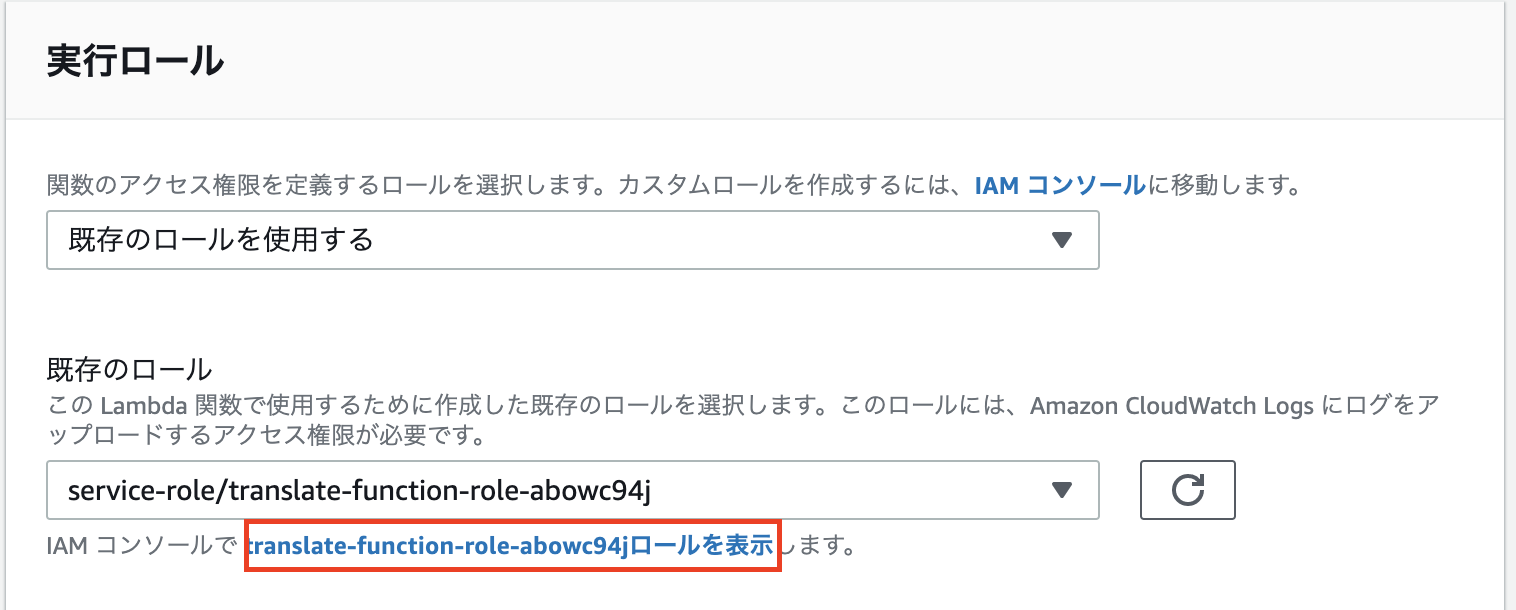
先ほど作成したLambda functionの下部へスクロールし、実行ロール欄の「※※※※ロールを表示」をクリック!
ポリシーをアタッチしていきます! ※おそらく別タブが開きます
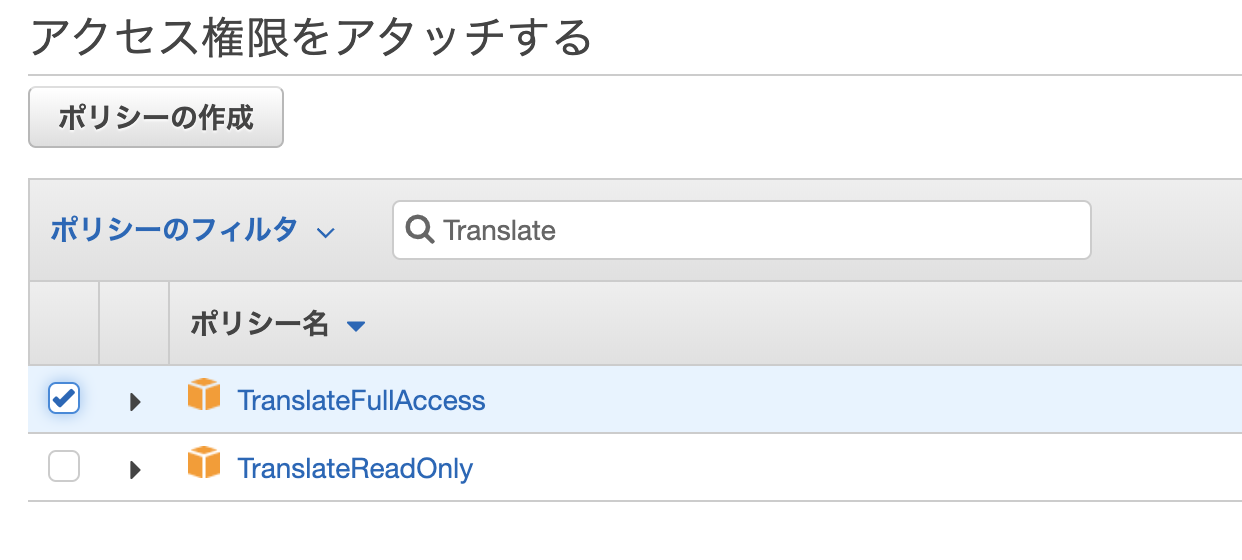
「ポリシーをアタッチします」をクリック
⇨検索窓で「translate」⇨「TranslateFullAccess」にチェックをいれ、「ポリシーのアタッチ」をクリック。
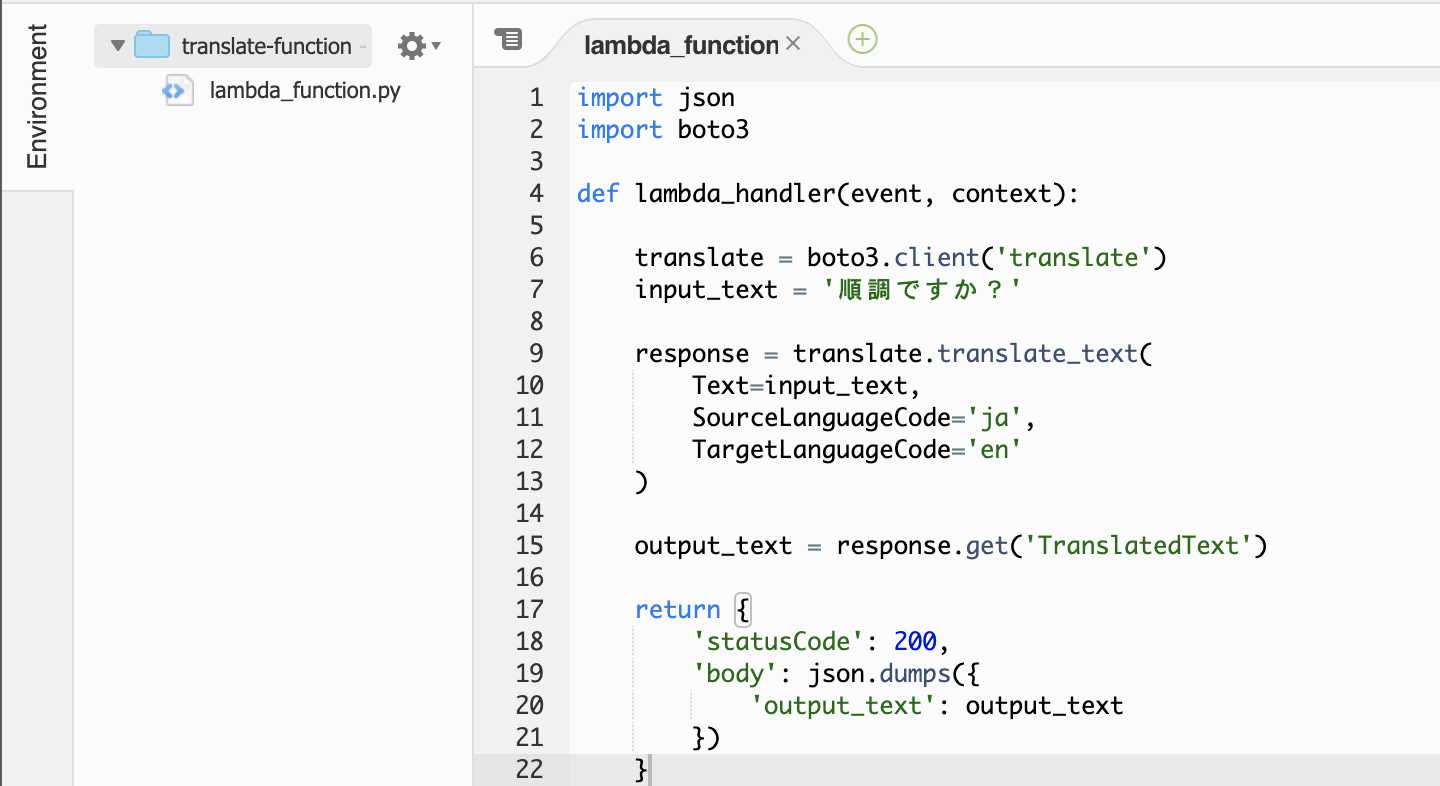
Lambdaコンソールを開いてるタブへいき、ソースコードを修正していきます!
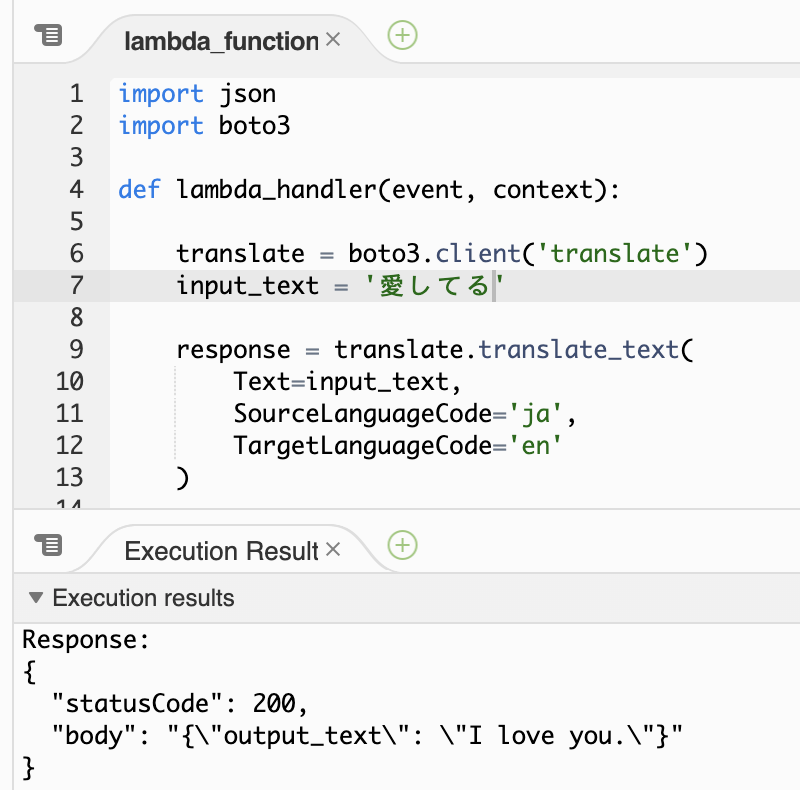
※AWS SDK for Python (boto3) のソースコードを利用しております。import json import boto3 def lambda_handler(event, context): translate = boto3.client('translate') input_text = '順調ですか?' response = translate.translate_text( Text=input_text, SourceLanguageCode='ja', TargetLanguageCode='en' ) output_text = response.get('TranslatedText') return { 'statusCode': 200, 'body': json.dumps({ 'output_text': output_text }) }
「保存」⇨「テスト」
またわかりづらいですが翻訳結果が出ていれば成功です!
テキストを変更して遊んでみます!
「愛してる」
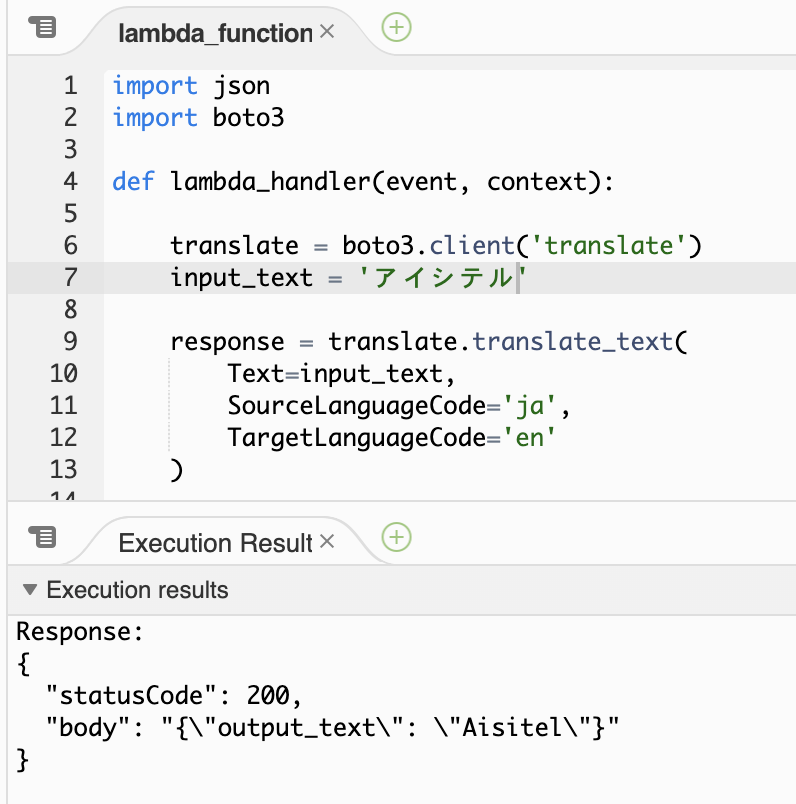
おお〜〜〜じゃ、カタカナは?と思い。
「アイシテル」
カタカナは流石にダメでした。笑
Lambdaについて理解できていませんでしたが、ハンズオンを通し、少しは理解できたと思います。
実務的なテクニカルな部分については理解しておりませんが、これから理解していけるように勉強していきます!ありがとうございました!





- 投稿日:2020-02-20T16:28:56+09:00
AWS EC2 に Linux 立てて VSCode で 接続できるまでの覚書
AWS EC2 に Linux 立てて VSCode で 接続できるまでの覚書
やったこと
EC2インスタンスの作成
- AWSのアカウントを取得
- AWSマネジメントコンソールにログイン
- 東京リージョンに変更(アカウント名の横、デフォルトはオハイオ?)
- サービスからEC2を選択し「EC2ダッシュボードを表示」
- 左側サイドバーメニューから「インスタンス」を選択、インスタンス一覧画面が表示される
- 「インスタンス作成」を押下
- ステップ 1:Amazon マシンイメージ…「Amazon Linux AMI 2018.03.0 (HVM), SSD Volume Type」を選択
- ステップ 2:インスタンスタイプの選択…「無料利用枠の対象」とついた「t2.micro」を選択 => 確認と作成 ※おそらくデフォルト
- ステップ 7:インスタンス作成の確認「[作成] をクリックして、インスタンスにキーペアを割り当て、作成処理を完了します。」とか書いてあるけど「起動」を押下
- 「既存のキーペアを選択するか、新しいキーペアを作成します。」みたいな画面が出てくるので「新しいキーペアの作成」を選択し、「キーペア名」を入力
- 「キーペアのダウンロード」を押下して、キーペアを保存(接続の際に使うので大切に)、「作成」を押下
- 作成まで少しかかるので1,2分放置
パブリックIPアドレスを設定する
パブリックIPアドレスが変化してしまうそうなので固定する手順。
- 現在地:EC2ダッシュボード
- 作成したインスタンスのIPアドレスを確認(確認用)
- 左側サイドバーメニューから「Elastic IP」を選択 => 「Elastic IP アドレス」の一覧画面が表示される
- 「Elastic IP アドレスの割り当て」を押下→次の画面で「割り当て」を押下
- 「Elastic IP アドレス」の一覧画面に戻り、作成したIPアドレスをクリック(パブリックIPv4 アドレスのところ)
- 「Elastic IP アドレスの関連付け」押下
- インスタンス欄をクリックして、先ほど作成したインスタンスを指定、それ以外はデフォルトで「関連付ける」を押下
- インスタンス一覧に戻って確認してみると、IPアドレスが作成したもに変わっているはず
セキュリティグループの設定
なんかやるって書いてあったからやるけど、これなんだよと思ったワシの読んだもの
↓
Linux インスタンスの Amazon EC2 セキュリティグループファイアウォールらしい。
- インスタンス一覧から作成したインスタンスのセキュリティグループをクリック
- インバウンドタブの「編集」を押下
- 「HTTP」と「HTTPS」を追加
- 「保存」を押して完了
VSCode関連のインストールと設定
- VSCode をインストール
- Remote SSH (プラグイン) をインストール
- その後、VSCode再起動
- Ctrl + P => Remote-SSH:Connect To Host => Configure SSH Hosts
- 「C:\Users\XXXXX(ユーザー名).ssh\」に、ダウンロードしておいたキーペアを配置(フォルダが無かったら作ってください)
- C:\Users\XXXXX(ユーザー名).ssh\config に 以下の内容に変更して保存
# Read more about SSH config files: https://linux.die.net/man/5/ssh_config Host aws.ec2-user User ec2-user HostName XX.XX.XX.XX # IPアドレス identityFile ~/.ssh/XXXXXXXXX.pem # キーペア名つなげてみる
- Ctrl + P => Remote-SSH:Connect To Host => aws.ec2-user
- 繋がったらOK!!!
- 投稿日:2020-02-20T16:03:53+09:00
EC2のsecureログにerror: AuthorizedKeysCommandが出力されるようになった
概要
掲題の通りにsecureログに以下のようにerrorが記録されるようになった
原因はec2-instance-connectを1.1-12にアップデートした。1.1-11では出力されない
なお、SSH接続は問題なく接続できるが、監視システムでアラートが発報される可能性があるので対応したほうがいいですね/var/log/secureFeb 20 14:57:29 ec2-user sshd[8046]: Connection from xxx.xxx.xxx.xxx port 17756 on xxx.xxx.xxx.xxx port 22 Feb 20 14:57:30 ec2-user sshd[8046]: error: AuthorizedKeysCommand /opt/aws/bin/eic_run_authorized_keys ec2-user SHA256:xxxxxxxxxxxxxxxxx failed, status 22 Feb 20 14:57:30 ec2-user sshd[8046]: Accepted publickey for ec2-user from xxx.xxx.xxx.xxx port 17756 ssh2: RSA SHA256:xxxxxxxxxxxxxxxxx Feb 20 14:57:30 ec2-user sshd[8046]: pam_unix(sshd:session): session opened for user ec2-user by (uid=0)対策法
以下の2つの方法があります
その1、シンプルにsshd_configの該当箇所をコメントアウトする
/etc/ssh/sshd_config# コメントアウト #AuthorizedKeysCommand /opt/aws/bin/eic_run_authorized_keys %u %f #AuthorizedKeysCommandUser ec2-instance-connectその2、接続ユーザのアクセス許可をポリシーに設定する
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/ec2-instance-connect-set-up.html
- 投稿日:2020-02-20T14:07:26+09:00
AWS知識保存用
Well-Architected
信頼性⇒高可用性
- リソースの冗長化
- 地理的冗長化
- 疎結合
パフォーマンス効率
- 最新技術の導入
- グローバルな環境
- サーバーレスアーキテクチャの使用
- 比較テストの実施
- 適切な技術の利用
セキュリティ
- AWS責任共有モデル
- アイデンティティ管理とアクセス管理
- ネットワークセキュリティ
- セキュリティグループ
- ネットワークACL
- 踏み台サーバー
- データの保護
- 通信SSL/TLS
- データ暗号化⇒SSE、CSE、AWS KMS、CloudHSM)
- セキュリティ監視
コスト最適化
コスト最適化指針
- 必要なリソースを必要な時に必要な分だけ利用する
- 全体的なコスト効果を測定する
- データセンター運用への投資を不要に
- 投資効果の要因分析
- マネージドサービス活用
コスト最適化の四つのベストプラクティス
- コスト効果の高いリソースを選定
- オンデマンドインスタンス
- リザーブドインスタンス(Standard、Convertible)
- スポットインスタンス(スポットブロック、スポットフリート)
- ITリソースの需要とAWSサービスの適切な供給によるコスト最適化
- 全体的なコストの管理
- Consolidated Billing一括請求⇒AWS Organizationsマスターアカウント、メンバーアカウント
- AWS Cost and Usage Report
- Cost Explorer
- AWS Budgets
- Truested Advisor
- 継続的なコスト最適化の活動
運用上の優秀性
- コードによるオペレーション実行
- 定期的に小規模で元に戻すことができる変更を行う
- 運用手順を見直す
- 障害発生を想定する
- 運用の失敗をもとに改善する
サービスの稼働状況監視
- AWS Service Health Dashboard
- AWS Personal Health Dashboard
AWSサポートプラン
- ベーシック⇒標準、技術問合せ不可
- 開発者⇒学習用途、1名のみ
- ビジネス⇒本番環境運用ユーザー、無制限
- エンタープライズ⇒ミッションクリティカルなシステム、無制限
AWSサポートプラン緊急度
- 非常事態⇒15分
- 発生中障害(ビジネスへの影響大)⇒一時間
- 発生中障害⇒4時間
- 障害・開発中急ぎ⇒12時間
- 通常⇒24時間
アクセス制御サービス
IAM
- AWS管理ポリシー(AdministratorAccess、PowerUserAccess)
- カスタマー管理ポリシー
- インラインポリシー
IDフェデレーション
- SAML 2.0/OpenID Connect
- Security Token Service(STS)
Web IDフェデレーションによるソーシャル連携
- OpenID Connect
- Amazon Cognito
Directory ServiceによるMicrosoft AD連携
- Microsoft AD
- Simple AD⇒Sambaサービス
- AD Connector⇒プロキシーサービス
暗号化SSL/TLS
- ELB
- RDS
- CloudFront
- API Gateway
- AWS Certificate Manager(ACM)証明書サービス
Client Site Encryption(CSE)
Server Site Encryption(SSE)
AWS KMS
- S3(SSE)
- EBS(SSE)
- RDS(SSE)
- Redshift(SSE)
- AWS CLI(CSE)
- AWS SDK(CSE)
CloudHSM(Hardware Security Module)
- Redshift
- RDS for Oracle
操作方法
- AWSマネジメントコンソール
- AWS CLI
- AWS SDK
ネットワークサービス
VPC
- サブネット
- IGW(インターネットゲートウェイ)
- ルートテーブル(サブネット単位)
- NATゲートウェイ(NATインスタンス⇒送信元/送信先チェック無効、自身への通信トラフィックを破棄)
- VPCフローログ
- VPCピアリング接続(VPC間、1対1)
- VPCエンドポイント
EIP
セキュリティグループ
ネットワークACL
ELB
- CLB
- ALB
- ELB
Auto Scaling
- クールダウン
- ライフサイクルフック(起動か終了時に実行できる)
Route 53
- シンプルルーティング
- 加重ルーティング
- 位置情報ルーティング
- レイテンシーベースルーティング
- フェイルオーバールーティング
AWS Direct Connect(インターネットVPNと比較)
仮想プライベートゲートウェイ
CloudFront
- エッジロケーション
- リージョン別エッジキャッシュ
コンピューティングサービス
EC2
Lambda
- コンテナ上動作
- SQSでホットスタンバイ⇒低レイテンシー
API Gateway
EMR(Amazon Elastic MapReduce)
ECS(Amazon Container Service)
VM Import/Export
ストレージサービス
S3
- スタンダード
- 標準低頻度アクセス⇒読み込み課金
- 1ゾーン低頻度アクセス
- 低冗長化ストレージ
- Glacier
Amazon Glacier
- Expedited (1-5mins)
- Standard (3-5hours)
- Bulk (5-12hours)
EBS
- 汎用SSD(General Purpose SSD:gp2)
- プロビジョンドIOPS SSD(PIOPS SSD:io1)⇒EBS最適化インスタンス
- スループット最適化HDD(st1)⇒EMR、ビッグデータ
- コールドHDD(sc1)⇒ログ
- マグネティック⇒旧世代EBS
EFS
- スケーラブルな共有ストレージサービス
- 複数EC2インスタンスから共有ファイルストレージとして利用
- オンプレ環境も利用可能
SGW(AWS Storage Gateway)
S3へNFS、SMB,iSCSIといった標準プロトコルでアクセスできるサービス
- キャッシュ型ボリュームゲートウェイ
- 保管型ボリュームゲートウェイ
- テープゲートウェイ
- ファイルゲートウェイAWS Import/Export⇒Snowball
データベースサービス
RDS
- マスタ、スレーブ、リードレプリカ
DynamoDB
- Amazon DynamoDB Accelerator(DAX)⇒インメモリキャッシュ、1秒当たり100万単位のリクエストの応答時間数ミリ秒
Redshift
- ノード⇒リーダーノード、コンピュータノード⇒クラスター
- SQLでデータアクセス可能
- データウェアハウス(BIツール)
- 列志向アーキテクチャ(カラム)
ElastiCache
- キーバリュー型
ElastiCache Memcached
- 一時的なデータのキャッシュ用
- ノード間の複製は行わない
- データベース別途用意
- シンプル
- スケールアウト、スケールイン機能が必要
- データベースのオブジェクトをキャッシュする必要がある
- 永続性が不要
ElastiCache Redis
- マスター・スレーブ型の構成
- データストアとしても使用可能
- 複雑なデータ構造
- 自動的にフェイルオーバー必要がある
- 永続性が必要
データ通知・連携サービス
SES
SNS
- トピック、サブスクライバ
SQS
- ショットポーリング
- ロングポーリング
- 可視性タイムアウト⇒スポットインスタンスと組み合わせ
Data Pipeline
Kinesis Data Streams
- データ処理
Kinesis Data Firehose
- データの配信・保存
Kinesis Data Analytics
- SQLクエリ実行しリアルタイム分析
構成サービス(プロビジョニング、デプロイ)
CloudFormation⇒プロビジョニングのみ
- テンプレート⇒スタック
- 主な項目
- AWSTemplateFormatVersion
- Description
- Type
- Parameters⇒テンプレート実行時に利用できる値を指定
- Resources⇒プロビジョニングしたいAWSリソース、設定記述
- Outputs⇒スタック作成後に出力したい項目
Elastic Beanstalk⇒プロビジョニング、デプロイ
- Webアプリケーションやサービスをサーバーにデプロイでき、また、実行環境の管理も行う
AWS OpsWorks ⇒プロビジョニング、デプロイ
- 構築手順通りにサーバー構築作業を自動化することができる構成管理サービス
AWS CodeDeploy⇒デプロイのみ
運用管理サービス
CloudWatch
- 標準メトリクス、カスタムメトリクス
- アラーム
- イベント
CloudWatch Logs
CloudTrail
- ユーザーレベル
VPCフローログ
- VPC内のネットワークインターフェース間で通信内容をキャプチャする機能、監視・監査に使用
AWS Config
- リソースレベル
AWS System Manager
- AWS内のさまざまなリソースの運用情報を総合的に可視化、および制御するサービス
AWS Trusted Advisor
- コスト最適化
- セキュリティ
- 耐障害性
- パフォーマンス
- サービスの制限
セキュリティ侵入テスト
- EC2
- RDS
- Aurora
- CloudFront
- API Gateway
- Lambda
- Lightsail
- DNS Zone Walking
上限値
IAM
- 1AWSアカウントあたり5000ユーザー
- 1AWSアカウントあたり300グループ
- 1ユーザーあたり10グループ
セキュリティグループ
- 通信ルール最大60
- 投稿日:2020-02-20T12:52:21+09:00
Github ActionsでAssumeRoleする方法
はじめに
ローカル端末にて実施していたServerless FrameworkによるLambda環境のdeployを、GitHubActionsに移行したけど、AssumeRoleの処理で詰まったので備忘録です。
ローカルでのデプロイ方法
複数のAWSアカウントを持ってるので、以下を参考にIAMユーザーには権限を持たせず、
AssumeRoleを利用して各AWS環境のRoleにスイッチロールしてアクセスをしてます。https://dev.classmethod.jp/cloud/aws/aggregate-login-aws-account/
その為、デプロイする時は対象のAWSアカウント用のProfileを指定してデプロイを実行しています。
$ AWS_PROFILE=aws-test sls deploy --verbose~/.aws/credentials
[default] aws_access_key_id = **************** aws_secret_access_key = ***************************************** [aws-test] role_arn = arn:aws:iam::<AcountID>:role/assume-role source_profile = defaultAssumeRoleの実行方法
AWSのブログ「GitHub Actions と AWS CodeBuild テストを使用して Amazon ECS の CI/CD パイプラインを作成する」にも紹介されている、以下の公式のActionを利用してAsume Roleを実行します。
https://github.com/aws-actions/configure-aws-credentials
GitHub Actionsの設定
READMEの記載を参考に以下を定義します。
AssumeRoleのARNもsecretsから取得するようにしてます。- name: Configure AWS Credentials uses: aws-actions/configure-aws-credentials@v1 with: aws-access-key-id: ${{ secrets.AWS_ACCESS_KEY_ID }} aws-secret-access-key: ${{ secrets.AWS_SECRET_ACCESS_KEY }} aws-region: ap-northeast-1 role-to-assume: ${{ secrets.AWS_ASSUME_ROLE_ARN }} role-duration-seconds: 1200secretsには
~/.aws/credentialsと同じ値を設定します。workflowの全文はこちら
https://gist.github.com/dehio3/7f41754e50a39914b01a831383d9a677
GitHub Actionsの実行
そのまま実行すると
Configure AWS Credentialsのステップにて以下のエラーで失敗します。##[error]User: arn:aws:iam::<AcountID>:user/<IAM User Name> is not authorized to perform: sts:TagSession on resource: *** ##[error]Node run failed with exit code 1原因
Actionの処理を確認すると以下の様にAssumeRoleする際にセッションタグを渡していました。
(普段使ってないのでセッションタグの存在を初めて知りました。)https://github.com/aws-actions/configure-aws-credentials/blob/master/index.js#L38-L46
セッションタグについては以下を参照
https://docs.aws.amazon.com/ja_jp/IAM/latest/UserGuide/id_session-tags.html対応
セッションタグの説明のセッションタグの追加に必要なアクセス許可に記載の通り、接続先のロールの信頼ポリシーにセッションタグへのアクセスを許可する必要があります。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::<AcountID>:root" }, "Action": [ "sts:AssumeRole", "sts:TagSession" # "sts:TagSession"をActionに追加する ], "Condition": {} } ] }ロールを作成する時に、コンソールから「信頼されたエンティティの種類」で「別のAWSアカウント」を指定して作成すると、
sts:AssumeRoleしか許可しない為、一旦作成後に信頼ポリシーを編集して追加する必要があります。接続元のアカウントではなく、接続先のアカウントのロールに設定が必要なので注意です。
(接続元のアカウント側で対応してて、小一時間ハマってしまいました・・・)
- 投稿日:2020-02-20T11:30:11+09:00
CodePipelineの自動デプロイを一時停止する手順
CodePipelineを利用して自動デプロイ環境を利用している際、一時的に自動デプロイを停止させたい時があると思います。
簡単にですか書き残しておこうと思います。方法
1.コンソールからトリガーとなるブランチを変更する。
2.コンソールから移行を無効にするを設定する。
3.CLIでコマンドを打つ。 ←手っ取り早い1.コンソールからトリガーとなるブランチを変更する。
1.該当のPipelineを開く
2.右上の編集する→ Sourceのステージを編集する
3.Sourceの鉛筆マークをクリック。
4.ブランチ名を変更する。
5.保存する。戻し作業
ブランチ名を変更前に戻す。2.コンソールから
移行を無効にするを設定する1.該当のPipelineを開く
2.Source と Buildの間にある移行を無効にするをクリック
3.無効にする理由を英語で記載し、保存する。
戻し作業
移行を有効にするを選択し保存する。3.CLIでコマンドを打つ。
以下例文
MyfirstPipelineという名前のPipelineで、Stagingというステージへの遷移を、My reasonという理由で停止させる。aws codepipeline disable-stage-transition \ --pipeline-name MyfirstPipeline \ --stage-name Staging \ --transition-type Inbound \ --reason "My reason"戻し作業
aws codepipeline enable-stage-transition \ --pipeline-name MyFirstPipeline \ --stage-name Staging \ --transition-type Inbound参考




- 投稿日:2020-02-20T11:25:23+09:00
AWSソリューションアーキテクト-アソシエイト合格体験記
2月あたまにAWSソリューションアーキテクトーアソシエイトを受験してきました。スコアは788/1000で、合格ラインは公開されていないですが、720〜750という噂なのでかなりギリギリでした。正直も少し取れると思ってました。。AWSの公式模試を受けた時は正答率9割だったので、本番の試験は難易度1割増しくらいですかね。ちなみに私が受験した試験は2020年3月22日まで受験可能で、それ以降は改定版の試験になるようです。改定後は難しくなるのかな?とりあえず改定前に受けようと思いこのタイミングで受けてきました。このような記事はたくさんありますが、これから受ける方の参考に少しでもなれば幸いです。
受験までにやったこと
- AWSソリューションアーキテークトアソシエイトの黒本を読む(黒本)
- 黒本の購入者特典の模試受験
- AWSの公式模試受験(2,000円)
簡単に私のAWS経験を紹介しておくと、会社の業務でIoTシステムのリフト&シフトや、AWSネイティブのシステム開発などで約2年間程AWSを使ってきたので、前提知識は既にありました。ただ知識が断片的だったため、一度整理し直す為に黒本を読みました。基本的には読んで、章末問題を解く、章末問題でわからなかった部分は読み直す、これだけです。一通り読み終わったあと黒本特典の模擬試験を解き、よく理解できてない部分を重点的に黒本で復習しました。これだけでも十分かなと思ったのですが、試験料金が15,000円と高いこともあり絶対に落ちたくなかったので、念の為公式模試も受験しました。結果的には受けておいて良かったと思います。本番は似たような問題がたくさん出題されました。模試の内容を理解していれば7割くらいは解けるのではないかというレベル。ただ公式模試は、正答の割合しか教えてくれず、どの問題を間違えたのかがわからないため、復習に時間が掛かるのが難点です。その他には、Blackbeltなどは読んでいたのですが、業務で必要に応じて読んだ程度なので試験勉強としてやったことには含めていません。試験のための勉強時間はトータル20時間くらいでした。
試験当日
新宿駅前テストセンターというところで受けました。近くの吉野家でお昼を食べて、15分前に試験会場に行き、運転免許証と保険証を提示、署名や写真撮影などを済ませ(2〜3分)、ロッカーに荷物を預けたら準備完了です。あとはA4くらいのホワイトボードを渡されて試験室に入り、問題を解く。試験会場によっては、試験中に顔を触るだけで怒られる会場があるという噂を聞いていたのでビビっていましたが、この会場は全くそんなことはなくゆったり受けることができました。防音マフも快適でした。ホワイトボードの使い所はありません!1時間弱で解き終わり30分見直しして試験終了です。簡単なアンケートに答えたあとすぐに結果が表示されました。
翌日
ポータルからスコアを確認できますよ、というメールがきたので確認。冒頭にも書きましたがボーダーラインギリギリで結構ショックでした。IPAの某試験とは違い、何故か合格したから良いやという気持ちにはなれませんでした。あと知らなかったのですが、合格すると合格者限定ストアからグッズを買うことができるようです。ノートとか、帽子とかが売っているのですが個人的にあまり欲しいものはなかったです。その他には、別試験の模試がタダで受けられるコードなどの特典もありました。
最後に
業務で触ったことがないサービスも結構ありましたが、その辺は黒本の知識でもなんとかなりました。本を読んで初めて知ったことも多かったので、普段AWSを触っている人でも読んでおくことをおすすめします。知識の体系化にもなるので。次は他のアソシエイト資格を受験しようと思います。最終的に秋までにはソリューションアーキテクトプロフェッショナル取れるように頑張ります。
- 投稿日:2020-02-20T10:06:39+09:00
fluentdでS3に転送しているならば、無駄なGETリクエストに気をつけろ!
概要
FluentdでS3にログ転送している場合で、以下の条件に当てはまると無駄なS3のGETリクエストを消費することがあります
check_objectがtrue(指定なしはtrue)s3_object_key_formatに%{index}を含めている
S3に出力される際に同名のファイルがある時に自動的に枝番を付与される
S3のGETリクエスト単価(
$0.0037/10,000リクエスト)は安いので、なかなか無駄に気づかないことが多い
私も気づくまでに1年かかりましたw
ただ、無駄なものは無駄なのできちんと設定して無駄を無くしましょう!正しい設定
check_objectをfalse%{index}を利用せずに出力するファイル名が必ず一意になるようにs3_object_key_formatを指定する
ファイル名に秒まで含めるのが良いでしょう
※fluent-plugin-s3のリファレンス
※時間フォーマットの詳しい設定はこちらを参照fluent.conf<match pattern> @type s3 path logs/ # 存在確認を無効 check_object false # hms_sliceは時間 s3_object_key_format %{path}%{time_slice}_%{hms_slice}.log # 日時(2020-02-18) time_slice_format %Y-%m-%d </match>※なお、バージョンによっては副作用として上記の
s3_object_key_formatとcheck_objectを併用するとfluentdログにWARNが記録されますなぜ
前述の条件によりS3に同一ファイル名が存在する場合は、自動的に枝番を付与してくれます
ただし、枝番を採番する際に都度GETリクエストを発行して枝番ごとにファイルの存在確認していく処理になっている実際にCloudTrialログを添えて、流れを追っていきます
- S3に
2020-02-19.log_0と2020-02-19.log_1がある前提- さらに同名のログ(
2020-02-19.log)をPUTする2020-02-19.log_0をGETリクエスト(HeadObject)するエラーがなかったので、存在すると判定し、
2020-02-19.log_1でGETリクエストするCloudTrialログ{ "eventVersion": "1.06", "eventTime": "2020-02-19T09:12:01Z", "eventSource": "s3.amazonaws.com", "eventName": "HeadObject", "awsRegion": "ap-northeast-1", "requestParameters": { "bucketName": "hogehoge", "Host": "hogehoge.s3.ap-northeast-1.amazonaws.com", "key": "logs/2020-02-19_0.log" }, "responseElements": null, "readOnly": true, "resources": [ { "type": "AWS::S3::Object", "ARN": "arn:aws:s3:::hogehoge/logs/2020-02-19_0.log" }, { "type": "AWS::S3::Bucket", "ARN": "arn:aws:s3:::hogehoge" } ], "eventType": "AwsApiCall", "managementEvent": false }同様にエラーがなかったので、存在すると判定し、
2020-02-19.log_2でGETリクエストするCloudTrialログ{ "eventVersion": "1.06", "eventTime": "2020-02-19T09:12:01Z", "eventSource": "s3.amazonaws.com", "eventName": "HeadObject", "awsRegion": "ap-northeast-1", "requestParameters": { "bucketName": "hogehoge", "Host": "hogehoge.s3.ap-northeast-1.amazonaws.com", "key": "logs/2020-02-19_1.log" }, "responseElements": null, "readOnly": true, "resources": [ { "type": "AWS::S3::Object", "ARN": "arn:aws:s3:::hogehoge/logs/2020-02-19_1.log" }, { "type": "AWS::S3::Bucket", "ARN": "arn:aws:s3:::hogehoge" } ], "eventType": "AwsApiCall", "managementEvent": false }エラー(
"errorCode": "NoSuchKey")が発生したので、存在しないと判定し、2020-02-19.log_2でPUTリクエストするCloudTrialログ{ "eventVersion": "1.06", "eventTime": "2020-02-19T09:12:02Z", "eventSource": "s3.amazonaws.com", "eventName": "HeadObject", "awsRegion": "ap-northeast-1", "errorCode": "NoSuchKey", "errorMessage": "The specified key does not exist.", "requestParameters": { "bucketName": "hogehoge", "Host": "hogehoge.s3.ap-northeast-1.amazonaws.com", "key": "logs/2020-02-19_2.log" }, "responseElements": null, "readOnly": true, "resources": [ { "type": "AWS::S3::Object", "ARN": "arn:aws:s3:::hogehoge/logs/2020-02-19_2.log" }, { "type": "AWS::S3::Bucket", "ARN": "arn:aws:s3:::hogehoge" } ], "eventType": "AwsApiCall", "managementEvent": false }, { "eventVersion": "1.06", "eventTime": "2020-02-19T09:12:02Z", "eventSource": "s3.amazonaws.com", "eventName": "PutObject", "awsRegion": "ap-northeast-1", "requestParameters": { "bucketName": "hogehoge", "Host": "hogehoge.s3.ap-northeast-1.amazonaws.com", "key": "logs/2020-02-19_2.log" }, "readOnly": false, "resources": [ { "type": "AWS::S3::Object", "ARN": "arn:aws:s3:::hogehoge/logs/2020-02-19_2.log" }, { "type": "AWS::S3::Bucket", "ARN": "arn:aws:s3:::hogehoge" } ], "eventType": "AwsApiCall", "managementEvent": false }という流れになっています
なので枝番が増えれば増えるほどGETリクエスト数も
1+2+3+4+5・・・と増えていきます
ファイル名が被らなくてもcheck_objectが有効な場合は、必ず1回はGETリクエストが発生するので、falseを検討してもよいかもしれない
万が一に上書きの心配があるならば念のために有効のままにしておくのもいいかもしれないちなみに自社のS3の請求欄です
S3にはログしか保存していないのにもかかわらず、GETリクエストがPUTの25倍もある
幸い単価が安いので助かっています( ;∀;)
検証用
検証用にサンプルコードを作成したので、そちらで簡単に動作確認ができるかと思います
手順はReadmeを参照ください
https://github.com/comefigo/fluentd-s3CloudTrial以外にもバケットのメトリックス(CloudWatchの有料メトリックス)でリクエスト数の確認もできますので、必要であればご確認ください

- 投稿日:2020-02-20T01:08:17+09:00
文系出身エンジニアが学ぶMySQLサーバーの構築(AWS)
記事を書く背景
『Amazon Web Services 基礎からのネットワーク&サーバー構築』を読み進める中で、AWSにMySQLサーバーを構築する際のつまずいたところとその対処方法を記載しようと思います。
環境
OS : Amazon Linux release 2 (Karoo)
つまずきポイント1:MySQLをインストールできない
下記コマンドを打つとエラーが発生。
$ sudo yum -y install mysql-server原因
Amazon EC2のyumリポジトリにMySQLのリポジトリが存在していないため。
下記コマンドで確認できます。$ yum list installed | grep mysql対処方法
下記コマンドでAmazon EC2のyumリポジトリにMySQLのリポジトリを追加
$ sudo yum localinstall http://dev.mysql.com/get/mysql57-community-release-el7-7.noarch.rpmこれでめでたくMySQLをインストールする準備が整いました。
そして、下記コマンドでMySQLをインストールします。$ sudo yum -y install mysql-community-server無事にインストールできていることを確認します。
$ mysqld --version mysqld Ver 5.7.29 for Linux on x86_64 (MySQL Community Server (GPL))ちなみに、、、
Amazon EC2にはMySQL派生版のMariaDBがインストール済みだそうです。
こちらは使わないのでアンインストールしました。// MariaDBがインストールされていることを確認 $ sudo yum list installed | grep mariadb // MariaDBの削除 $ sudo yum remove mariadb-libsつまずきポイント2:Passwordの設定ができない
passwordの変更をしようと下記コマンドを打つとエラーが出てしまい、ログインパスワードの変更ができない。
$ mysqladmin -u root password ERROR 1045 (28000): Access denied for user 'ec2-user'@'localhost' (using password: NO)原因
rootユーザの権限設定がされていない
対処方法
1. MySQLを停止させる
$ sudo systemctl stop mysqld2. MySQLの環境変数にオプションを追加
→権限システムを使用しないで起動することが可能になる$ sudo systemctl set-environment MYSQLD_OPTS="--skip-grant-tables"3. MySQLの起動
$ sudo systemctl start mysqld4. MySQLにログイン
$ mysql -u root5. rootユーザーのPasswordを設定
mysql> UPDATE mysql.user SET authentication_string = PASSWORD('設定したいPassword') WHERE User = 'root' AND Host = 'localhost'; mysql> FLUSH PRIVILEGES; mysql> quit以下は環境変数にオプションを追加したのを戻す作業
6. MySQLを停止させる$ sudo systemctl stop mysqld7. MySQLの環境変数にオプションを元に戻す
$ sudo systemctl unset-environment MYSQLD_OPTS8. MySQLの起動
$ sudo systemctl start mysqldつまずきポイント3:Passwordを設定したと思ったらALTER USER statementが使えない
これでようやくPasswordも設定できたと思い、ログインして
CREATE DATABASEしたところまたもエラー発生。ERROR 1820 (HY000): You must reset your password using ALTER USER statement before executing this statement.原因
rootのパスワードを初回設定から変えていないときに表示される
対処方法
下記コマンドで新しいパスワードを設定する
ALTER USER 'root'@'localhost' IDENTIFIED BY '新しいパスワード';つまずきポイント4:MySQLのパスワードポリシーに怒られる
新しいパスワードを設定する際に例えば
passなどの小文字4字で設定しようとするとデフォルトの設定ではMySQLのパスワードポリシーに違反してしまいます。ERROR 1819 (HY000): Your password does not satisfy the current policy requirements原因
ポリシー Passwordに必要な条件 0 または LOW 長さ 1 または MEDIUM 長さ; 数字、小文字/大文字、および特殊文字 2 または STRONG 長さ; 数字、小文字/大文字、および特殊文字。辞書ファイル 現在のポリシーは以下のコマンドで確認できます。
mysql> SHOW VARIABLES LIKE 'validate_password%'; +--------------------------------------+-------+ | Variable_name | Value | +--------------------------------------+-------+ | validate_password_check_user_name | OFF | | validate_password_dictionary_file | | | validate_password_length | 8 | | validate_password_mixed_case_count | 1 | | validate_password_number_count | 1 | | validate_password_policy | MEDIUM| | validate_password_special_char_count | 1 | +--------------------------------------+-------+ 7 rows in set (0.00 sec)対処方法
1. Passwordをポリシーに合わせる。
おとなしくMySQLに従う。。2. ポリシーを変更する
-- 最低限の長さの変更 mysql> SET GLOBAL validate_password_length=4; -- ポリシーの変更 mysql> SET GLOBAL validate_password_policy=LOW; -- 変更の確認 SHOW VARIABLES LIKE 'validate_password%'; +--------------------------------------+-------+ | Variable_name | Value | +--------------------------------------+-------+ | validate_password_check_user_name | OFF | | validate_password_dictionary_file | | | validate_password_length | 4 | | validate_password_mixed_case_count | 1 | | validate_password_number_count | 1 | | validate_password_policy | LOW | | validate_password_special_char_count | 1 | +--------------------------------------+-------+ 7 rows in set (0.00 sec)参考文献
AWSのEC2で行うAmazon Linux2(MySQL5.7)環境構築
AWS Amazon Linux2にMySQL5.7を構築する
Change mysql root password on Centos7
MySQL 5.7.16 でERROR 1820 (HY000): You must reset your passwordの対処法(windows用)
Mysql 5.7* パスワードをPolicyに合わせるとめんどくさい件について
- 投稿日:2020-02-20T01:01:56+09:00
AWSソリューションアーキテクト-アソシエイト合格体験記
2月あたまにAWSソリューションアーキテクトーアソシエイトを受験してきました。スコアは788/1000で、合格ラインが720〜750という噂なのでかなりギリギリでした。。正直も少し取れると思ってました。。AWSの公式模試は正答率9割だったので、難易度1割増しくらいですかね。ちなみに私が受験した試験は2020年3月22日まで受験可能で、それ以降は改定版の試験になるようです。とりあえず改定前に受けようと思いこのタイミングで受けてきました。このような記事はたくさんありますが、これから受ける方に少しでも参考になれば幸いです。
受験までにやったこと
- AWSソリューションアーキテークトアソシエイトの黒本を読む(黒本)
- 黒本の購入者特典の模試受験
- AWSの公式模試受験(2,000円)
簡単に私のAWS経験を紹介しておくと、会社の業務でIoTシステムのリフト&シフトや、AWSネイティブのシステム開発など約2年間程経験してきたので、前提知識は既にありました。ただ、知識が断片的だったため、一度整理し直す為に黒本を読みました。基本的には読んで、章末問題を解く、章末問題でわからなかった部分は読み直す、これだけです。一通り読み終わったあと黒本特典の模擬試験を解き、よく理解できてない部分を重点的に黒本を読み直しました。これだけでも十分かなと思ったのですが、試験料金が15,000円と高いこともあり絶対に落ちたくなかったので、念の為公式模試も受験しました。結果的には受けておいて良かったと思います。本番は似たような問題がたくさんでます。模試の内容を完全に理解していれば6、7割は解けるのではないかというレベル。ただ公式模試は、正答の割合しか教えてくれず、どの問題を間違えたのかがわからないため、復習に時間が掛かるのが難点です。その他には、Blackbeltなどは読んでいたのですが、業務で必要に応じて読んだ程度なので試験勉強としてやったことには含めていません。試験のための勉強時間はトータル15時間くらいでした。
試験当日
新宿駅前テストセンターというところで受けました。近くの吉野家でお昼を食べて、15分前に試験会場に行き、運転免許証と保険証を提示、署名や写真撮影などを済ませ(2〜3分)、ロッカーに荷物を預けたら準備完了です。あとはA4くらいのホワイトボードを渡されて試験室に入り、問題を解く。試験会場によっては、試験中に顔を触るだけで怒られる会場があるという噂を聞いていたのでビビっていましたが、この会場は全くそんなことはなくゆったり受けることができました。防音のヘッドホン?も快適でした。ホワイトボードの使い所はありません。1時間弱で解き終わり30分見直しして試験終了です。簡単なアンケートに答えたあとすぐに結果が表示されました。
翌日
ポータルからスコアを確認できますよ、というメールがきたので確認。冒頭にも書きましたがボーダーラインギリギリで結構ショックでした。IPAの某試験とは違い、何故か合格したから良いやという気持ちにはなれませんでした。あと知らなかったのですが、合格すると合格者限定ストアからグッズを買うことができるようです。ノートとか、帽子とか、個人的にあまり欲しいものはなかったです。その他には、別試験の模試がタダで受けられるコードなどの特典もありました。
その他
業務で触ったことがないサービスも結構ありましたが、その辺は黒本の知識でもなんとかなりました。本を読んで初めて知ったことも多かったので、普段触っている人でも読んでおくことをおすすめします。知識の体系化にもなるので。次は他のアソシエイト資格を受験しようと思います。最終的に秋までにはソリューションアーキテクトプロフェッショナル取れるように頑張ります。