- 投稿日:2020-02-17T23:32:06+09:00
『Kaggle備忘録』One-hotベクトルへの変換
目的
質的変数(カテゴリー変数)をOne-hotベクトルに変換する
使用データ・環境
データ:kaggleのTitanicデータ
環境:kaggle notebook
方法
onehot_encoding.py#モジュールのインポート,osの準備 import numpy as np import pandas as pd import matplotlib as plt import os for dirname, _, filenames in os.walk('/kaggle/input'): for filename in filenames: print(os.path.join(dirname, filename))データを読み込む
onehot_encoding.pytrain_data=pd.read_csv('../input/titanic/train.csv') test_data=pd.read_csv('../input/titanic/test.csv')データを見てみる
onehot_encoding.pytrain.data.head()
カテゴリー変数のデータフレームがいくつかあることがわかる.これらををOne-hotベクトルに変換することを狙う.
とりあえず,文字列のままだと扱いにくいので,各カテゴリーに異なる数値を割り当てる.
Pandasのfactorize()を使う.
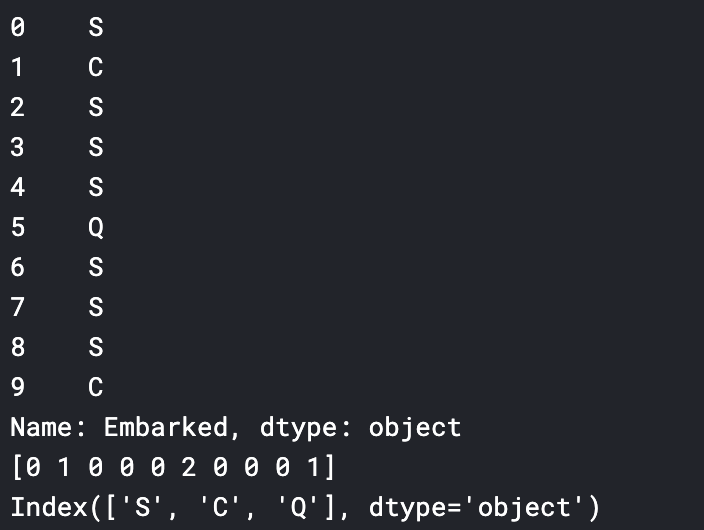
factorize()は,数値のデータ(emb_cat_encoded)とカテゴリーのリスト(emb_categories)の両方を返す.onehot_encoding.pytrain_cat=train_data['Embarked'] train_cat_encoded,train_categories=train_cat.factorize() #見てみる print(train_cat.head()) print(train_cat_encoded[:10]) print(train_categories)
次にone-hotベクトルへの変換
scikit-learnが提供しているOneHotEncoderを用いる.
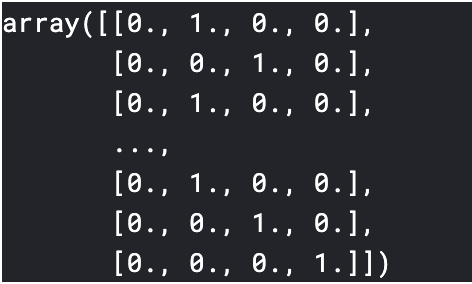
onehot_encoding.py#scikit-learnからOneHotEncoderをインポート from sklearn.preprocessing import OneHotEncoder #one-hotベクトルに変換 oe=OneHotEncoder(categories='auto') train_cat_1hot=oe.fit_transform(train_cat_encoded.reshape(-1,1)) #中を見てみる train_cat_1hot
変換完了.

- 投稿日:2020-02-17T23:23:57+09:00
adversarial validationを実装してみた
この記事は何か
adversarial validationとは何かを説明した後に、試しに実装してみたコードを記載する。
備忘録、知識の整理も兼ねてここに記していく。本記事を投稿するにあたって参考にしたコードはこちら
adversarial validationとは
trainデータの分布がtestデータと異なる場合、validationデータの分布もtrainデータの分布に寄ってしまい、上手くtestデータを予測できないことがある。その時に用いられる手法の一つがadversarial validationである。
adversarial validationとは、trainデータとtestデータを分類するモデルを構築し、それを用いてtestデータになるべく近い分布のvalidationデータを作成することである。
実装
目的変数の作成
trainデータ、testデータに新たな列を作成し、trainデータには0を、testデータには1を入れる。
import pandas as pd train['target'] = 0 test['target'] = 1 train_test = pd.concat([train, test], axis=0).reset_index(drop=True) train_test.head()学習と分類
今回、モデルの構築にはlightgbmを使用した。交差検証を行い、全てのtrainデータに対して、testデータである可能性(probability)を測っている。
import numpy as np import lightgbm as lgb from sklearn.model_selection import StratifiedKFold params = {'objective': 'binary', 'max_depth': 5, 'boosting': 'gbdt', 'metric': 'auc'} features = [col for col in train_test.columns if col not in ('target',)] oof_pred = np.zeros((len(train_test), )) cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42) for fold, (train_idx, val_idx) in enumerate(cv.split(train_test, train_test['target'])): x_train, x_predict = train_test[features].iloc[train_idx], train_test[features].iloc[val_idx] y_train = train_test['target'][train_idx] train_set = lgb.Dataset(x_train, label=y_train) model = lgb.train(params, train_set) oof_pred[val_idx] = model.predict(x_predict).reshape(oof_pred[val_idx].shape)validationデータの作成
probabilityの値を降順にソートし、(testである可能性が)高い順に任意のデータ数取得し、validationデータを作成する
train_test['probability'] = oof_pred train = train_test[train_test.target==0].drop('target', axis=1).sort_values('probability', ascending=False) valid_idx = int(len(train)) / 5 # 今回は決め打ちで上位20%としている validation_data = train.iloc[:valid_idx] train_data = train.iloc[valid_idx:]クラスにしてまとめてみた
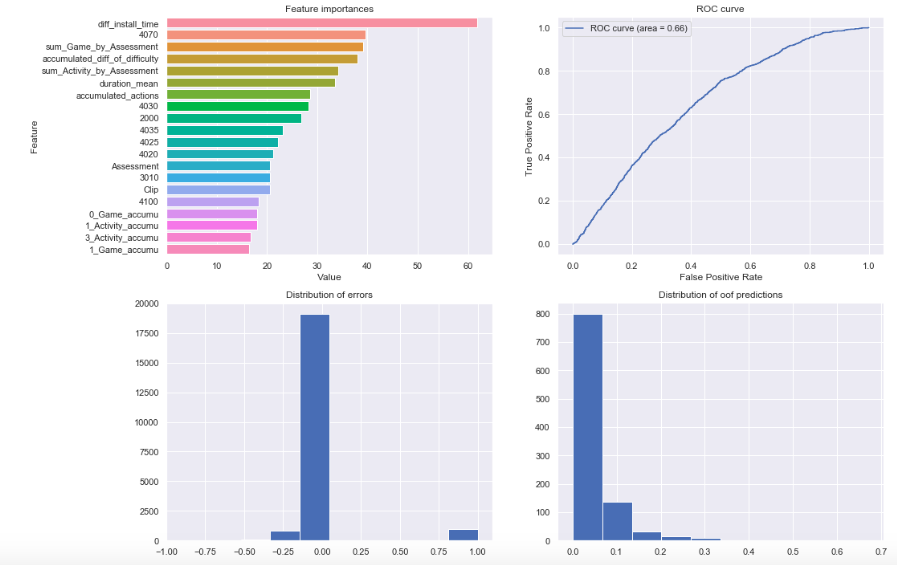
class Adversarial_validator: def __init__(self, train, test, features, categoricals): self.train = train self.test = test self.features = features self.categoricals = categoricals self.union_df = self.train_test_union(self.train, self.test) self.cv = self.get_cv() self.models = [] self.oof_pred = self.fit() self.report_plot() def fit(self): oof_pred = np.zeros((len(self.union_df), )) for fold, (train_idx, val_idx) in enumerate(self.cv): x_train, x_predict = self.union_df[self.features].iloc[ train_idx], self.union_df[self.features].iloc[val_idx] y_train = self.union_df['target'][train_idx] train_set = self.convert_dataset(x_train, y_train) model = self.train_model(train_set) self.models.append(model) oof_pred[val_idx] = model.predict( x_predict).reshape(oof_pred[val_idx].shape) self.union_df['prediction'] = oof_pred return oof_pred def train_test_union(self, train, test): train['target'] = 0 test['target'] = 1 return pd.concat([train, test], axis=0).reset_index(drop=True) def get_cv(self): cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42) return cv.split(self.union_df, self.union_df['target']) def convert_dataset(self, X, y): return lgb.Dataset(X, label=y, categorical_feature=self.categoricals) def train_model(self, train_set): return lgb.train(self.get_params(), train_set) def get_params(self): param = {'num_leaves': 50, 'num_round': 100, 'min_data_in_leaf': 30, 'objective': 'binary', 'max_depth': 5, 'learning_rate': 0.2, 'min_child_samples': 20, 'boosting': 'gbdt', 'feature_fraction': 0.9, 'bagging_freq': 1, 'bagging_fraction': 0.9, 'bagging_seed': 44, 'verbose_eval': 50, 'metric': 'auc', 'verbosity': -1} return param def report_plot(self): fig, ax = plt.subplots(figsize=(16, 12)) plt.subplot(2, 2, 1) self.plot_feature_importance() plt.subplot(2, 2, 2) self.plot_roc_curve() plt.subplot(2, 2, 3) plt.hist(self.union_df['target'] - self.oof_pred) plt.title('Distribution of errors') plt.subplot(2, 2, 4) plt.hist(np.random.choice(self.oof_pred, 1000, False)) plt.title('Distribution of oof predictions') def get_feature_importance(self): n = len(self.models) feature_imp_df = pd.DataFrame() for i in range(n): tmp = pd.DataFrame(zip(self.models[i].feature_importance( ), self.features), columns=['Value', 'Feature']) tmp['n_models'] = i feature_imp_df = pd.concat([feature_imp_df, tmp]) del tmp self.feature_importance = feature_imp_df return feature_imp_df def plot_feature_importance(self, n=20): imp_df = self.get_feature_importance().groupby( ['Feature'])[['Value']].mean().reset_index(False) imp_top_df = imp_df.sort_values('Value', ascending=False).head(n) sns.barplot(data=imp_top_df, x='Value', y='Feature', orient='h') plt.title('Feature importances') def plot_roc_curve(self): fpr, tpr, thresholds = metrics.roc_curve( self.union_df['target'], self.oof_pred) auc = metrics.auc(fpr, tpr) plt.plot(fpr, tpr, label='ROC curve (area = %.2f)' % auc) plt.legend() plt.title('ROC curve') plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') adv = Adversarial_validator(train, test, features, categoricals)
データはkaggleコンペの2019 Data Science Bowlのデータを使用している。
validationデータ作成以外の活用法
- importanceの高い特徴量を削除してtrainデータの分布をtestデータに近づける
- 学習時のデータの重みづけの参考(weight_column)
まとめ
簡単にだがadversarial validationについて紹介してみた。この記事を読んだ方の一助になれば幸いである。
- 投稿日:2020-02-17T23:04:07+09:00
確率分布の漸近的性質をPythonで確かめる
中心極限定理
確率分布$X_i(i=1,\cdots,n)$が,平均$\mu$,分散$\sigma^2$の独立同分布に従うとする。$\frac{\sum_{i=1}^nX_i}{n}$は$n\to \infty$のとき、平均$\mu$,分散$ \frac{\sigma^2}{n}$の正規分布に従う。
実験
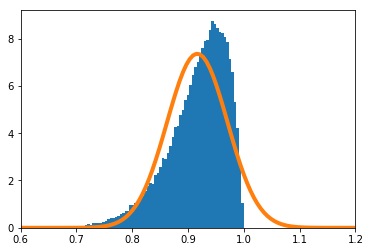
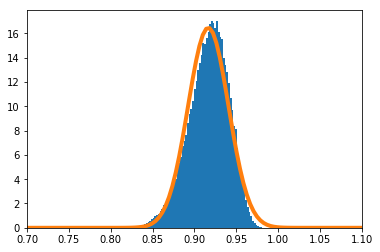
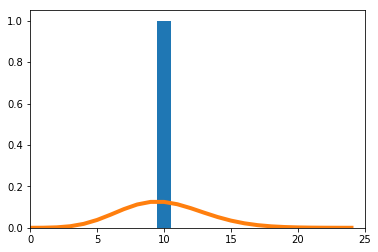
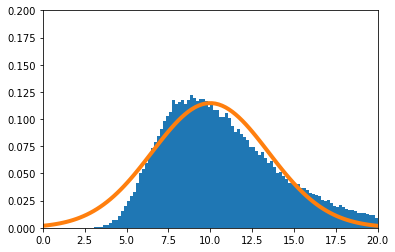
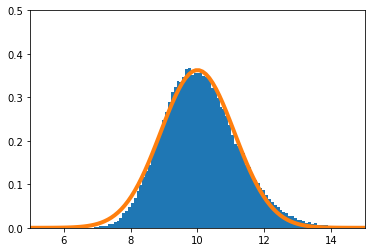
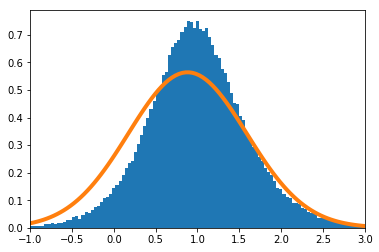
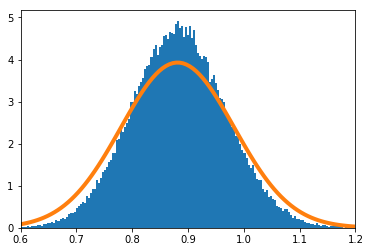
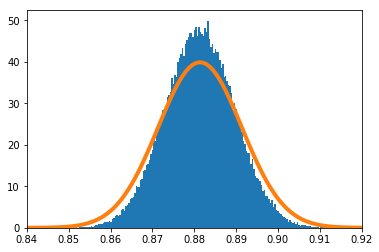
歪んだ分布で実験を実施する。$X_i(i=1,\cdots,n)$の密度関数を
f(x) = 11 x^{10}\ \ \ (0\leq x\leq1)とする。
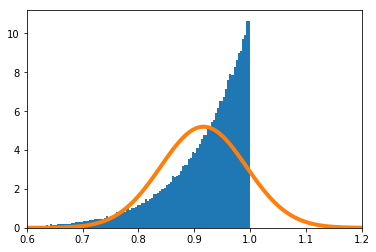
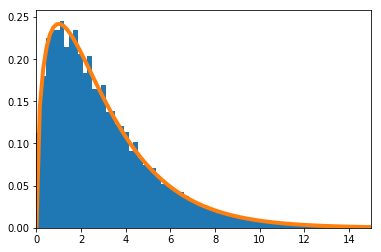
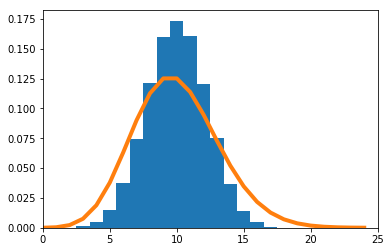
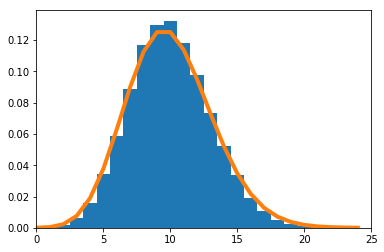
$\frac{\sum_{i=1}^nX_i}{n}$の密度関数を数値的に求めたのが青のヒストグラム、理論上収束するとされる正規分布の密度関数がオレンジの実線である。
$n=1$
$n=2$
$n=10$の場合
$n=1$の場合のPythonソースコードはこちら。
import numpy as np import matplotlib.pyplot as plt from scipy.stats import norm # 確率密度関数 平均11/12, 分散11/13-(11/12)^2 def f(x): return 11 * (x ** 10) mu = 11 / 12 sigma2 = 11 / 13 - (11 / 12) ** 2 # 累積分布関数 def F(x): return x ** 11 # 累積分布関数の逆関数 def F_inv(x): return x ** (1 / 11) n = 1 xmin = 0.6 xmax = 1.2 meanX = [] for _ in range(100000): meanX.append(np.sum(F_inv(np.random.rand(n))) / n) plt.hist(meanX, bins=200, density=True) s = np.linspace(xmin, xmax, 100) plt.plot(s, norm.pdf(s, mu, (sigma2 / n) ** 0.5), linewidth=4) plt.xlim(xmin, xmax)適合度検定の統計検定量(その1)
$(X_1,X_2,\cdots,X_m)$が、試行回数$n$、確率$(p_1,p_2,\cdots,p_m)$の多項分布に従うとする。
\sum_{i=1}^m\frac{(X_i-np_i)^2}{np_i}は、$n\to \infty$のとき自由度$(m-1)$の$\chi^2$分布に従う。
実験
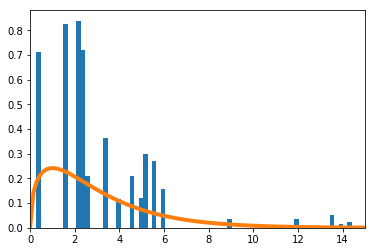
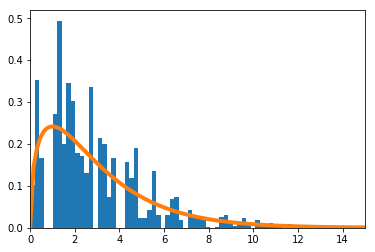
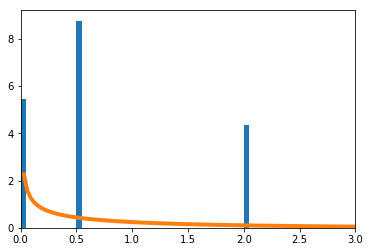
確率が$\big(\frac{1}{16},\frac{1}{4},\frac{1}{4},\frac{7}{16}\big)$の4項分布で考える。数値的に求めた
\sum_{i=1}^4\frac{(X_i-np_i)^2}{np_i}を青のヒストグラムで、理論上収束するとされる自由度3の$\chi^2$分布をオレンジの実線で示す。
$n=4$
$n=16$
$n=400$
$n=4$の場合のPythonソースコードはこちら。
import numpy as np import matplotlib.pyplot as plt from scipy.stats import chi2 p = [1/16, 1/4, 1/4, 7/16] n = 4 xmin = 0 xmax = 15 xx = [] for _ in range(100000): r = np.random.rand(1, n) x = [0] * 4 x[0] = np.sum(r < sum(p[:1])) x[1] = np.sum(np.logical_and(sum(p[:1]) <= r, r < sum(p[:2]))) x[2] = np.sum(np.logical_and(sum(p[:2]) <= r, r < sum(p[:3]))) x[3] = np.sum(sum(p[:3]) <= r) xx.append(sum([(x[i] - n * p[i]) ** 2 / (n * p[i]) for i in range(4)])) plt.hist(xx, bins=int(max(xx))*5, density=True) s = np.linspace(xmin, xmax, 100) plt.plot(s, chi2.pdf(s, 3), linewidth=4) plt.xlim(xmin, xmax)適合度検定の統計検定量(その2)
真の確率$p_i$が未知の場合であるが、$p_i(i=1,2,\cdots,m)$は$l$次元のパラメータ$\boldsymbol{\theta}(l\leq m-2)$で表現できることが分かっているとする。$p_i$の最尤推定量を$\hat{p}_i$とするとき、
\sum_{i=1}^m\frac{(X_i-n\hat{p}_i)^2}{n\hat{p}_i}は、$n\to \infty$のとき自由度$(m-l-1)$の$\chi^2$分布に従う。
実験
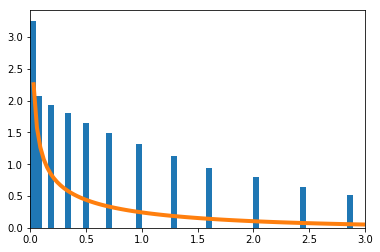
確率が$\big(\frac{1}{16},\frac{1}{4},\frac{1}{4},\frac{7}{16}\big)$の4項分布で考える。真の$p$は未知であるが、$p_1=p_2$だけは既知とする。$p = [q,r,r,1-2r-q]$と表現できる。$q,r$を最尤推定法で求める。
\sum_{i=1}^m\frac{(X_i-n\hat{p}_i)^2}{n\hat{p}_i}を青のヒストグラムで、理論上収束するとされる自由度1の$\chi^2$分布をオレンジで示す。
$n=4$
$n=100$
$n=10000$
$n=4$の場合のPythonソースコードはこちら。
import numpy as np import matplotlib.pyplot as plt from scipy.stats import chi2 n = 4 xmin = 0 xmax = 3 xx = [] for _ in range(100000): r = np.random.rand(1, n) x = [0] * 4 x[0] = np.sum(r < sum(p[:1])) x[1] = np.sum(np.logical_and(sum(p[:1]) <= r, r < sum(p[:2]))) x[2] = np.sum(np.logical_and(sum(p[:2]) <= r, r < sum(p[:3]))) x[3] = np.sum(sum(p[:3]) <= r) p_ = [0] * 4 p_[0] = x[0] / sum(x) p_[1] = (x[1] + x[2]) / (2 * sum(x)) p_[2] = (x[1] + x[2]) / (2 * sum(x)) p_[3] = x[3] / sum(x) xx.append(sum([(x[i] - n * p_[i]) ** 2 / (n * p[i]) for i in range(4)])) plt.hist(xx, bins=int(max(xx))*20, density=True) s = np.linspace(xmin, xmax, 100) plt.plot(s, chi2.pdf(s, 1), linewidth=4) plt.xlim(xmin, xmax)二項分布からポアソン分布
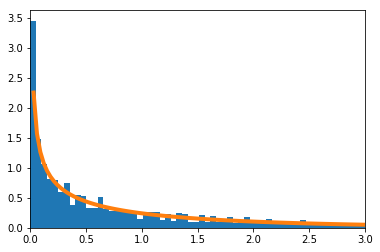
二項分布B$(n,p)$に従う確率変数を$X$とする。$np=\lambda$として、$\lambda$を一定で$n\to \infty$とすると、$X$はPo$(\lambda)$に従う
実験
$\lambda=10$とする。実験的に求めた二項分布を青のヒストグラム、理論上収束するとされるポアソン分布をオレンジで示す。
$n=10$
$n=20$
$n=100$
$n=20$の場合のpythonソースコードはこちら。
import numpy as np import matplotlib.pyplot as plt from scipy.stats import binom, poisson lam = 10 n = 20 xmin = 0 xmax = 25 plt.hist(binom.rvs(n, lam / n, size=100000), density=True, range=(-0.5, n + 0.5), bins=n+1) plt.plot(range(xmin, xmax), poisson.pmf(range(xmin, xmax), lam), linewidth=4) plt.xlim(xmin, xmax)最尤推定量の漸近正規性
パラメータ$\theta$で特徴づけられた確率変数$X_i(i=1,\cdots,n)$について、$\hat\theta$を最尤推定量、フィッシャー情報量を$J_n(\theta)$を
J_n(\theta)=E_\theta\Big[\Big(\frac{\delta}{\delta\theta}\log f(X_1,...,X_n;\theta)\Big)^2\Big]とする。$\hat\theta$は$n\to \infty$のとき平均$\theta$、分散$J_n(\theta)^{-1}$の正規分布に従う。
実験
$X_i(i=1,\cdots,n)$の密度関数を
f(x) = (\theta+1) x^{\theta}\ \ \ (0\leq x\leq1)とする。真の$\theta$を10とする。
実験的に求めた$\hat\theta$の分布を青のヒストグラム、理論上収束するとされる正規分布をオレンジで示す。
$n=1$
$n=10$
$n=100$
$n=1$のときのPythonソースコードはこちら。
import numpy as np import matplotlib.pyplot as plt from scipy.stats import norm # 確率密度関数 平均11/12, 分散11/13-(11/12)^2 def f(x): return 11 * (x ** 10) mu = 11 / 12 sigma2 = 11 / 13 - (11 / 12) ** 2 # 累積分布関数 def F(x): return x ** 11 # 累積分布関数の逆関数 def F_inv(x): return x ** (1 / 11) n = 1 theta_min = -20 theta_max = 40 theta = [] for _ in range(100000): x = F_inv(np.random.rand(n)) theta.append(- n / sum(np.log(x)) - 1) theta = np.array(theta) theta = theta + (theta > theta_max) * (- theta + theta_max + (theta_max - theta_min) * 1 / 100) # theta_max以上のデータをtheta_max + (theta_max - theta_min) * 1 / 100にする。ビン数をプロット範囲内で約100にするため theta = theta + (theta < theta_min) * (- theta - (theta_max - theta_min) * 1 / 100) # theta_minも同様 plt.hist(theta, bins=100, density=True) s = np.linspace(theta_min, theta_max, 100) plt.plot(s, norm.pdf(s, 10, (11 ** 2 / n) ** 0.5), linewidth=4) plt.xlim(theta_min, theta_max) plt.ylim(0.0, 0.1)F分布の近似
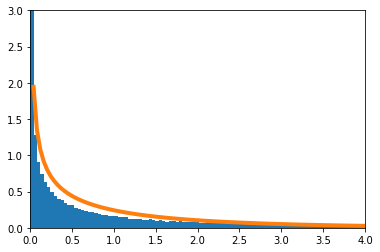
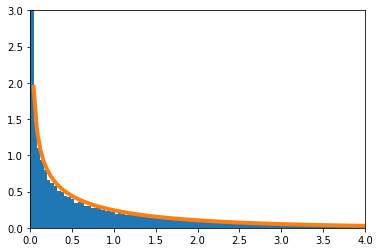
自由度$(1,n)$のF分布は、$n \to \infty$のとき、$\chi^2$分布に収束する。
実験
実験的に求めたF分布を青のヒストグラム、理論上収束するとされる$\chi^2$分布をオレンジで示す。
$n=1$
$n=4$
$n=1$の場合のPythonソースコードはこちら。
import numpy as np import matplotlib.pyplot as plt from scipy.stats import chi2 n = 1 xmin = 0 xmax = 4 x = chi2.rvs(1, size=100000) / (chi2.rvs(n, size=100000) / n) x = x + (x > xmax) * (- x + xmax + (xmax - xmin) * 1 / 100) # xmax以上のデータをxmax + (xmax - xmin) * 1 / 100にする。ビン数をプロット範囲内で約100にするため plt.hist(x, bins=100, density=True) s = np.linspace(xmin, xmax, 100) plt.plot(s, chi2.pdf(s, 1), linewidth=4) plt.xlim(xmin, xmax) plt.ylim(0, 3)相関係数
確率分布$X,Y$の相関係数が$\rho$であるとする。$X,Y$の実現値$x_i,y_i(i=1,\cdots,n)$から求めた相関係数を$\hat\rho$とする。
\frac{1}{2}\log \Big(\frac{1+\hat\rho}{1-\hat\rho}\Big)は、平均$\frac{1}{2}\log \big(\frac{1+\rho}{1 - \rho}\big)$、分散$\frac{1}{n-3}$の正規分布で近似できる。
実験
Y = X + \epsilon\ \ \ (X,\epsilon \sim U(0,1))とする。
実験的に求めた$\frac{1}{2}\log \big(\frac{1+\hat\rho}{1-\hat\rho}\big)$を青のヒストグラム、理論上収束すると正規分布をオレンジで示す。
$n=5$
$n=100$
$n=10000$
$n=5$の場合のPythonソースコードはこちら。
import numpy as np import matplotlib.pyplot as plt from scipy.stats import norm # y = x + epsilon. x, epsilon ~ U(0,1)とする。 mu = 1 / 2 * np.log((1 + 1 / 2 ** 0.5) / (1 - 1 / 2 ** 0.5)) rmin = -1 rmax = 3 rho = [] for _ in range(100000): x = np.random.rand(n) y = x + np.random.rand(n) r = np.corrcoef(x, y)[0, 1] rho.append(1 / 2 * np.log((1 + r) / (1 - r))) plt.hist(rho, density=True, bins=200) s = np.linspace(rmin, rmax, 100) plt.plot(s, norm.pdf(s, mu, (1 / (n - 3)) ** 0.5), linewidth=4) plt.xlim(rmin, rmax)
- 投稿日:2020-02-17T22:51:46+09:00
Dockerで起動したJupyterLabでvimキーバインドを使う
概要
前回Jupyter Notebookでvimのキーバインドが使えるようにしましたが、
JupyterLabの存在を完全に忘れていたので、、同様にDockerでJupyterLabを起動してvimのキーバインドが使えるようなやり方をまとめました。参考:Dockerで起動したJupyter Notebookでvimキーバインドを使う
Jupyter NotebookとJupyterLabの違い
Jupyter notebookの後継機がJupyterLabになってまして、基本的に出来ることはどちらでも同じですが、JupyterLabの方が高機能になっています。
Jupyter notebookの開発は一旦終了して今後はJupyterLabに置き換わるようです。環境
バージョン Mac 10.15.3 Docker 19.03.4 docker-compose 1.24.1 環境構築手順
Dockerfileとdocker-composeを使ってvimのキーバインドが使えるJupyterLabを起動します。
※以下ファイルはGitHubにもまとめているのでご参考ください。
https://github.com/hikarut/Data-Science1. notebook保存用のディレクトリ作成
$ mkdir notebooks2. Dockerfileの作成
DockerfileFROM jupyter/datascience-notebook USER root RUN pip install jupyterlab==1.0 RUN jupyter serverextension enable --py jupyterlab RUN jupyter labextension install jupyterlab_vim EXPOSE 10000 CMD ["bash"]※
jupyterlab_vimがjupyterlab 1.0にしか対応してないようなのでバージョンを指定してインストールしてます
jupyterlab-vim:https://github.com/jwkvam/jupyterlab-vim3. docker-compose.ymlの作成
docker-compose.ymlversion: '3' services: data-science: restart: always build: . container_name: 'data-science' ports: - "10000:10000" working_dir: '/root/' tty: true volumes: - ./notebooks:/root/notebooks/4. コンテナのビルド
$ docker-compose up -d --build5. コンテナにログイン
$ docker-compose exec data-science bash6. Jupyter Notebookの起動
/root# jupyter lab --port 10000 --allow-root表示される
http://127.0.0.1:10000/?token=xxxxxxxxxxxxxxxxにアクセスします。Jupyter Notebookの時のように設定変更する必要もなく、そのままの状態でnotebook上でvimが使えるようになります
最後に
JupyterLabの方がJupyter Notebookよりも気持ちセットアップが楽でした!
(今回もユーザーを全てrootにしちゃったのでその辺は変えた方が良いかもです。。。)
ただjupyterlab-vimのビルドがめちゃくちゃ遅いのが気になりましたが、、今後改善されると嬉しいなと思います。参考
- 投稿日:2020-02-17T22:37:22+09:00
【Djangoシリーズ】基本コマンド
はじめに
今まで使ってきたコマンドのまとめと自分自身で使ったときに学んだことをまとめていきます。
基本コマンドの解説と使用内容
①Djangoでのプロジェクト作成
django-admin startproject configプロジェクトの名前は任意ですが、ややこしくなるのでアプリの大元の設定をするということで「config」という名前にしておきます。
②Djangoでのアプリ作成
python manage.py startapp home次にアプリの作成ですがこちらもアプリの大元を管理するという意味で「home」としておきます。
③サーバの起動と停止
python manage.py runserver ctrl cサーバを起動するときは基本的にはターミナル画面を二つにして行うこと。
エラーが出た際に比較検討できるようにしていく。③データベースの操作
python manage.py makemigrationsデータベースの定義を自動的に作成・管理するコマンド。
変更がない限り無闇に使用はしないこと。python manage.py migrateデータベースの定義したマイグレーションファイルをデータベースに適用するコマンド。
こちらも変更がある場合に適用させるコマンドになっている。この二つについては「Django マイグレーション まとめ」の記事で構造やコマンドについてより詳しく解説されています。
④管理者の作成
python manage.py createsuperuserメールアドレスとパスワードを入れたらアカウントの作成は終りです。
データベースの内容を確認したいときやテストでの確認をするときよく管理者画面を使います。おわりに
今回は簡単に自分が使っているときのコマンドの使い方をまとめました。
公式の情報「Django ドキュメント目次」にはより詳しく記載されているので初心者の方はそちらを参考にしていくといいかもしれません。参考資料
「Django ドキュメント目次」
https://docs.djangoproject.com/ja/3.0/contents/「Django マイグレーション まとめ」
https://qiita.com/okoppe8/items/c9f8372d5ac9a9679396
- 投稿日:2020-02-17T22:24:06+09:00
カスケード分類器を用いた顔検出
1. 背景
現在,私はディープラーニングを用いて,顔を認識するプログラムを作成している.まず,学習データとして,大量の顔画像を用意した.この際,人物が映った画像から,顔を検出し,顔の部分だけを切り取る処理をした.このうち,顔を検出する手法として,カスケード分類器を用いた.この記事では,カスケード分類器について説明する.
2.カスケード分類器とは
カスケード分類器は,複数の単純な分類器によって構成される分類器である.対象画像に対し,これらの単純な分類器が順番に適用される.すべての分類器を通過したら,検出される.一方で,単純な分類器に1回でも拒否されたら,その時点で検出はされない.よって,検出対象に明らかに該当しない画像は初期の段階で拒否されるため,高速である.
OpenCVでは,HAAR-Like特徴量を使ったカスケード分類器が用意されている.OpenCVのcascadeファイル
https://github.com/opencv/opencv/tree/master/data/haarcascadesHAAR-Like特徴量とは,画像の明暗による特徴量である.画像の局所領域における白領域と黒領域の差を特徴としている.よって,画像をグレースケールに変換してから用いるのが一般的である.
3.OpenCVにおけるカスケード分類器
OpenCVにおいては,カスケード分類器が含まれるcascadeファイルを読み込んだ後,detect.MultiScake()によって検出を行う.detect.MultiScake()の返り値はN×4行列となっていてNは検出した数,4は[x,y,width,height]の4要素である.この4要素は,検出した領域を矩形で囲んだ範囲である.xが矩形の左上のx座標,yが矩形の左上のy座標,widthが矩形の幅,heightが矩形の高さである,よって,検出した部分に印を付けたい場合は,OpenCVの描画関数rectangle()を用いて,rectangle(image,(x,y),(x+width,y+height),(255,0,0),2)などと書けば良い.
以下の画像に対して,試してみる.
ソースコードを以下に示す.
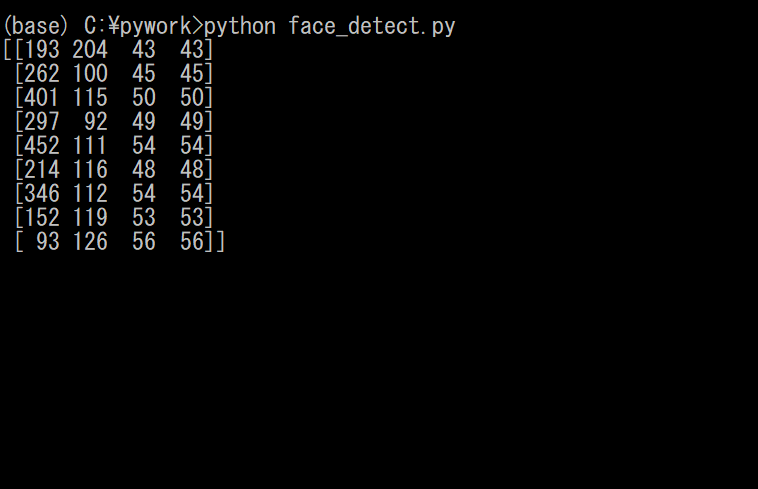
face_detect.pyimport cv2 #画像を読み込む image = cv2.imread('sample.jpg') #画像をグレースケールに変換する image_gray = cv2.cvtColor(image, cv2.COLOR_RGB2GRAY) #ファイルから分類器を読み込む cascade = cv2.CascadeClassifier("/opencv/data/haarcascades/haarcascade_frontalface_alt.xml") #分類器を用いて検出を行う faces = cascade.detectMultiScale(image_gray, scaleFactor=1.1, minNeighbors=1, minSize=(1, 1)) #detectMultiScale()の返り値を出力する(確認用) print(faces) #検出した顔画像の部分を矩形でマークする for (x,y,width,height) in faces: cv2.rectangle(image,(x,y),(x+width,y+height),(255,0,0),2) #画像を表示する cv2.imshow('result',image) cv2.waitKey(0) cv2.destroyAllWindows()実行結果は以下のようになった.1個だけ誤認識があるが,顔は全て検出できている.
ちなみに,detectMultiScale()の返り値を出力したので,出力結果も見てみると...
上のように,検出された領域(矩形)における,左上の座標,幅,高さの情報が返されている.4.余談
前回の記事では,imreadで返される配列を利用して,画像から一部分だけを切り取る手法を学んだ.
[OpenCV]imreadで返される配列について
https://qiita.com/Castiel/items/53ecbee3c06b9d92759eそして,今回は顔を検出する手法を学んだ.これらを利用すれば,ディープラーニングにおける,顔画像の学習データを集められるはずだ.今度は,顔画像の学習データを作成することに取り組もうと思う.


- 投稿日:2020-02-17T22:19:00+09:00
スクレイピングして前処理してpostgreSQLに書き込む
野球のデータを使って分析したいなと思っていつも「サイトの必要な部分をコピーして、excelに張り付けてcsvにして保存」をしていました。がしかし、そろそろ面倒だなと思い、「スクレイピングして前処理してpostgreSQLに書き込む」までをやってみました。
必要なライブラリのインストール
スクレイピングなど
import pandas as pd from bs4 import BeautifulSoup import datetimepostgreSQL書きこみ
import psycopg2 from sqlalchemy import create_engine
- psycopg2
- sqlalchemy
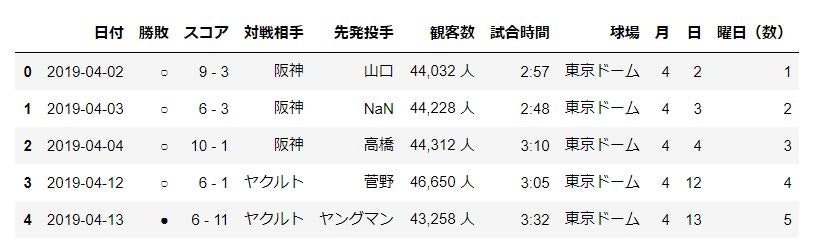
データの取得
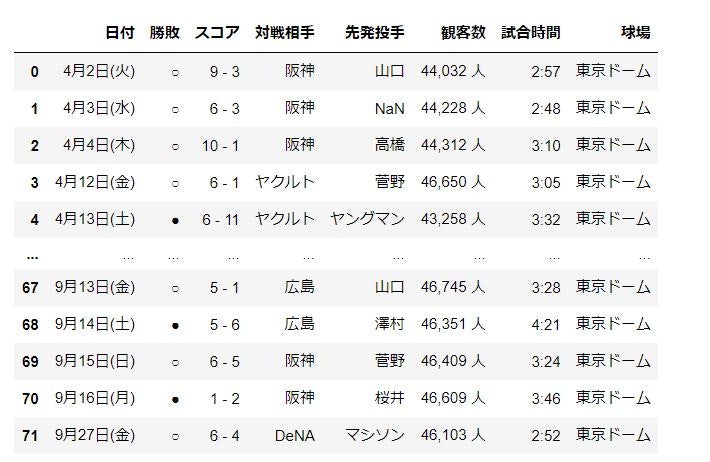
今回は巨人の打者の成績データを「pandas.read_html」で取得します。
ページの表(tableタグ)を順番取ってきてdataframeのリストが返ってくるようです。raw_data = pd.read_html("https://baseball-freak.com/audience/giants.html", flavor="bs4")リストが返ってくるので、こんな感じになります
1つ目のdataframeがこんな感じ。
2つ目に今回ほしいデータが入っているはずなのでそれを確認
data_set = raw_data[1] # ページ内に複数の表があり、今回ほしいのは2つ目の表なので[1]と指定します data_set
データフレームの内容確認
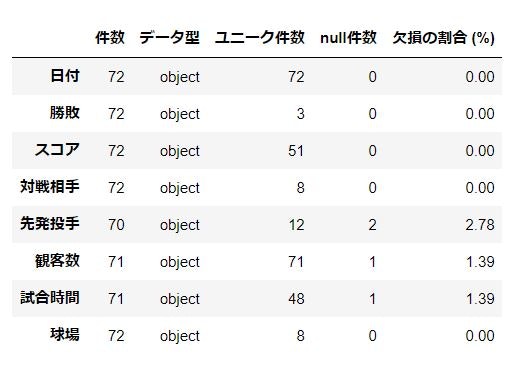
取得したデータの中身を確認します。
pd.concat( [data_set.count().rename('件数'), data_set.dtypes.rename('データ型'), data_set.nunique().rename('ユニーク件数'), data_set.isnull().sum().rename('null件数'), (data_set.isnull().sum() * 100 / data_set.shape[0]).rename('欠損の割合 (%)').round(2)], axis=1 )
全部がobjectになっているのがわかります。また、先発投手、観客数、試合時間はnullが含まれるようです。
この中で日付、スコア、観客数について型変換などをして分析できるようにします。
日付処理
- 日付カラムを月と日のカラムに分ける
- 日付カラムを日付型にする
- 曜日を「dt.dayofweek」で算出する
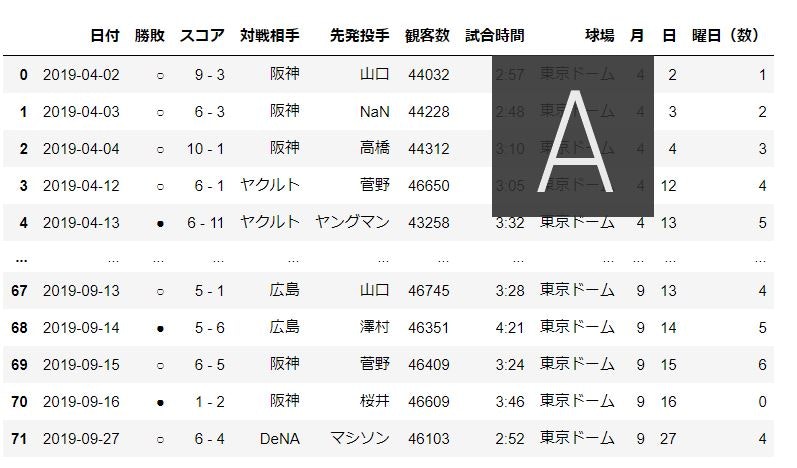
data_set["月"] = data_set["日付"].replace("月.*$", "", regex=True) # regex:正規表現 data_set["日"] = data_set["日付"].replace("日.*$", "", regex=True).replace("^.*月", "", regex=True) for i in range(len(data_set['月'])): data_set['日付'] = "2019/" + data_set["月"] + "/" + data_set["日"] data_set['日付'] = pd.to_datetime(data_set['日付']) data_set['曜日(数)'] = data_set['日付'].dt.dayofweek data_set.head()
観客数の処理
- 「,」と「人」をreplace
- fillnaでNaNを0で埋める
- 型を「int」に変更する
data_set["観客数"] = data_set['観客数'].replace(',', '', regex=True).replace(' 人', '', regex=True).fillna('0').astype(int) data_set
スコアの処理
- str.splitでスコアを二つに分ける
- カラムが2つに分かれるので、カラム名を付けて、int型に変換
data_set_score = pd.concat([data_set, data_set['スコア'].str.split(' - ', expand=True)], axis=1) data_set_score_rename =data_set_score.rename(columns={0:'得点', 1:'失点'}) data_set_score_rename['得点']=data_set_rename['得点'].replace('中止', 0).astype(int) data_set_score_rename['失点']=data_set_rename['失点'].fillna(0).astype(int)postgreSQLへの接続
connection_config = { 'user': '*****', 'password': '*****', 'host': '*****', 'port': '****', # なくてもOK 'database': '*****' } engine = create_engine('postgresql://{user}:{password}@{host}:{port}/{database}'.format(**connection_config))postgreSQLへ保存
- DataFrame.to_sql
data_set_score_rename.to_sql('giants',schema='baseball_2019', con=engine, if_exists='replace', index=False)個人的にはここでつまづきました。何につまづいたのかというと、スキーマ名を指定する方法がわからなかったです。公式ドキュメントを読んですぐに解決しましたが、解決するまで1時間くらいかかりました。わからないときってほんと、わかんないですよねー。
以上になります!記載内容で間違いなどありましたら、優しく教えていただけると嬉しいです!

- 投稿日:2020-02-17T22:18:39+09:00
Pythonのstaticmethodはどう実装されているのか?
同僚と「デコレータの実装って難しい」という話から、「Pythonの組み込みのデコレータ、例えば
staticmethodはどう実装されているの?」という話になりました。私もけっこう長い間Pythonを使っているのですが、そういえば挙動を知らなかったので調べてみることにします。話していた間は、
selfを穴埋めするような実装(このドキュメントにあるような以下の実装)を想定していたのですが、ただオーバーヘッドを作っているだけなので、もっと良い実装をしているはずです。# Using the non-data descriptor protocol, a pure Python version of :func:`staticmethod` would look like this: class StaticMethod: "Emulate PyStaticMethod_Type() in Objects/funcobject.c" def __init__(self, f): self.f = f def __get__(self, obj, objtype=None): return self.fstaticmethodとは
次のコードのように、クラス定義のメソッドの
selfを省略するためのデコレータです。詳しくは公式ドキュメントを読んでください。class C: @staticmethod def f(arg1, arg2, ...): ...ちなみに私自身はあまり
staticmethodは使いません。スタティックメソッドは要らない子?という記事も2010年の時点で書かれている不憫な印象があります?ドキュメントによると
組み込み関数のドキュメントには以下のように記載されています。
静的メソッドについて詳しい情報は 標準型の階層 を参照してください。
リンク先のドキュメントにはこのように書かれています。
静的メソッド (static method) オブジェクト
静的メソッドは、上で説明したような関数オブジェクトからメソッドオブジェクトへの変換を阻止するための方法を提供します。静的メソッドオブジェクトは他の何らかのオブジェクト、通常はユーザ定義メソッドオブジェクトを包むラッパです。静的メソッドをクラスやクラスインスタンスから取得すると、実際に返されるオブジェクトはラップされたオブジェクトになり、それ以上は変換の対象にはなりません。静的メソッドオブジェクトは通常呼び出し可能なオブジェクトをラップしますが、静的オブジェクト自体は呼び出すことができません。静的オブジェクトは組み込みコンストラクタ staticmethod() で生成されます。
どうやら通常のメソッド定義では「クラス内で関数からメソッドに変換」していて、
staticmethodでラップするとその変換が行われないようです。実際に試したところ、現状のPython3.8では次のような挙動になっています。
# メソッドと静的メソッドを持つクラスを定義 class C: def method(self): pass @staticmethod def stmethod(self): pass # クラスの場合は両方ともfunction print(type(C.method)) # => <class 'function'> print(type(C.stmethod)) # => <class 'function'> # インスタンスの場合はメソッドはmethodに変換されていて、静的メソッドはfunctionのまま c = C() print(type(c.method)) # => <class 'method'> print(type(c.stmethod)) # => <class 'function'>ただ、そのすぐ上、「内部型」のドキュメントには以下のようにも書かれています。
これらの定義は将来のインタプリタのバージョンでは変更される可能性がありますが、ここでは記述の完全性のために触れておきます。
実際のコードを見てみようと思ってCPythonのリポジトリを見たのですが、構造体の定義箇所を見つけた以上は読み解けませんでした。ここから実際に初期化されるときに上記のような挙動に実装されているのが確認できたら面白かったのですが…。
まとめ
「(現行のPython3.8では)クラス内で定義された関数が、methodに変換されており、
staticmethodでラップするとその変換処理を打ち消すことができる」ようです。ただ、過去のバージョンや、今後のバージョンでは実装方法が違う可能性があります。CPythonの実装がどうなっているのか、もし詳しく調べられる方がいたらコメントを頂けると嬉しいです。
- 投稿日:2020-02-17T22:13:50+09:00
Visual Studio 2019でnumpyをインストールする
- 投稿日:2020-02-17T21:42:19+09:00
matplotlib.pyplot.scatterの使い方
matplotlob.pyplot.scatterは散布図を描画するためのもの。
matplotlib.pyplot.scatter(x,y,c="色",marker="マーカーの種類",cmap="カラーマップ")。例)
import numpy as np
import matplotlib.pyplot as plt
x=np.random.rand(10)
y=np.random.rand(10)
plt.scatter(x,y,c="Blue",marker="o",cmap="None")
- 投稿日:2020-02-17T21:35:27+09:00
ウイイレのデータ集計自動化してみた! Part2
ウイイレのデータ集計自動化してみた! Part2
どうもヤジュンです!だからお前だれだよ!ってひとはこちら
本記事は、ウイイレのデータ集計自動化してみた!の続きになります。
画像からデータ収集できるようになったので、早速「解析」~「考察」をしてみました。
実装機能の一部をご紹介します。※本ソフトウェアは、pythonで作成しています。参考にしたサイト
■解析のゴール
解析のゴールは、プレイヤーのモデル化としました!
プレイヤーをモデル化するって、美少女やイケメンにするわけじゃないです。(ここ笑うとこ!)
データから、「勝つ時」と「負ける時」のモデルをグラフ等で可視化するのです。
「勝ちモデル」と「負けモデル」のギャップから、課題やプレイヤーの強みを明らかにします!■解析の流れ
- ①各パラメータからグラフを作成
- ②勝敗時のギャップ分析
- ③プレイヤーに対して課題を可視化
- ④次の解析方法の選定
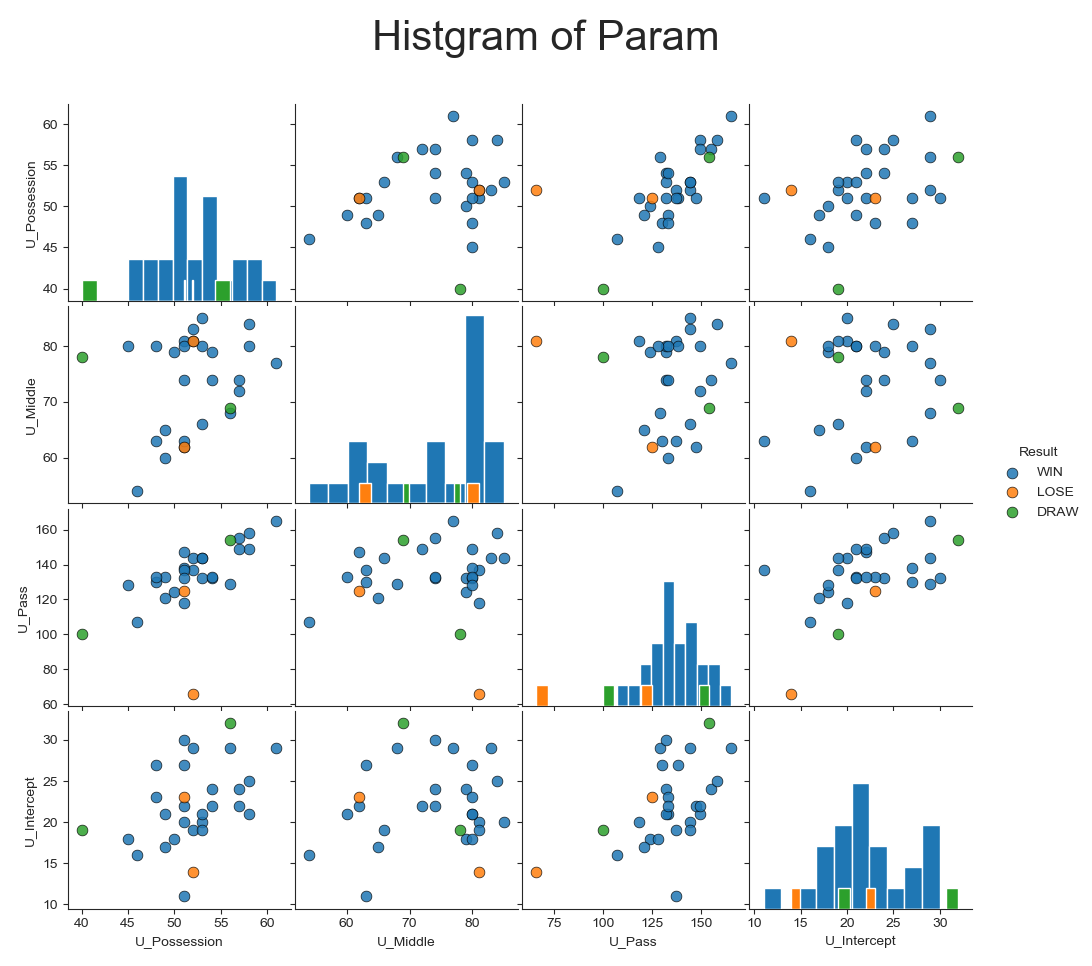
■ヒストグラム & 散布図
【グラフ化】
前回作成したメトリクス収集ソフトウェアで、テスターの30試合分の試合結果を集めました。
(※テスターは匿名としますが、プロプレイヤーです)
取得できるパラメータは80種類以上あります。
全パラメータをグラフ化しても意味が薄いため、今回は例として4つ選択しました。* ポゼッション * 攻撃エリア中央の比率 * パス本数 * ボール奪取数
横軸は以下のパラメータの範囲を示しています。
一番左:「ポゼッション(%)」
二番 :「攻撃エリア中央の比率(%)」
三番 :「パス本数」
一番右:「ボール奪取数」
縦軸も、上から横軸と同じ順番です。色の情報は勝敗結果を示しています。
青色 :「勝ち」
オレンジ:「負け」
緑 :「引き分け」を示しています。
散布図は、各横軸と縦軸の組み合わせ時のデータ分布を示しています。(例)上から2マス目、左から1マス目の散布図は、縦軸「攻撃エリア中央の比率」横軸「ポゼッション」の散布図になります。
※補足
- ヒストグラムと散布図をご存じない方向けに簡単に説明します。
左上の「ポゼッション」のヒストグラムを見ると、ポゼッション「50%~55%」で棒のピークが来ていますよね?
この棒は「該当するX値のデータが何個あったか」を示しています。
「本テスターの試合結果では、ポゼッション50~55%の試合が多かった!」ことが分かります。【考察】
ではグラフを見ていきましょう!
縦軸「ポゼッション」の一番上の行の散布図では綺麗に傾向が出てます。
「攻撃エリア中央」の比率が上がれば、ポゼッションも上がっています。
「パス本数」と「ボール奪取数」も同様の傾向で、分布が右肩上がりになっています。他グラフも傾向見えますが、「勝ちと負け引き分けの差分を明らかにする」のは無理そうです。
2者間の比較では情報量が少ないので、期待する結果が得られないことも多いです。※ただ、今回は30試合分のデータだったので、これが100試合ともなると話は別です。
1パラメータの情報量が増えるので、良い結果が見れたりします。では次!
■ヒートマップ解析
【グラフ化】
ボール奪取 及び ボールロストの情報を可視化していきます。
上図:「エリアごとの平均ボール奪取数」
下図:「エリアごとの平均ボールロスト数」横の並びは勝敗を示しています。
左 :「勝ち」
真ん中:「負け引き分け」
右 :「勝ちvs負け引き分け」
各グラフは、下側が「テスター自陣側」上側が「敵陣側」となっています。【考察】
「勝ち」と「負け引き分け」のギャップを見るなら、一番右のグラフが最適です。
ボール奪取数の「負け引き分け」データは、敵陣内でのボール奪取が全体的に少ないのが分かりますね。(勝ち試合よりもボール奪取数が少ないエリアは青で示されています。)
理由は色々考えられます。フォーメーションの組み合わせか? カウンターターゲットをつけているせいで、後ろで回されている? 守備時にカーソル当ててる選手がいつもとズレている? etc次は、下図の「ボールロスト」を見ていきましょう!
「ボール奪取」とは異なり、エリアによっては「負け引き分け」試合のが良い結果もありますね。
気になったのは、前線のハーフスペース(左から2列目)でのボールロストが多くなっている点です。ハーフスペースでは、サイドも中央も使えて、なおかつ自身でシュートも狙える重要なエリアです。
チャンスにも関わらず、ボールをロストしているということは色々な理由が考えられます。敵が近いにも関わらずスルーパスでビルドアップしている ダッシュボタンを押しぎみ サイドor中央の選択が偏り、相手に読まれている etcこのような仮説を立てて、テスターにヒアリングしたり、試合動画などの追加データをもらって、検証していきます。
次の解析につなげていくのです。では、次!
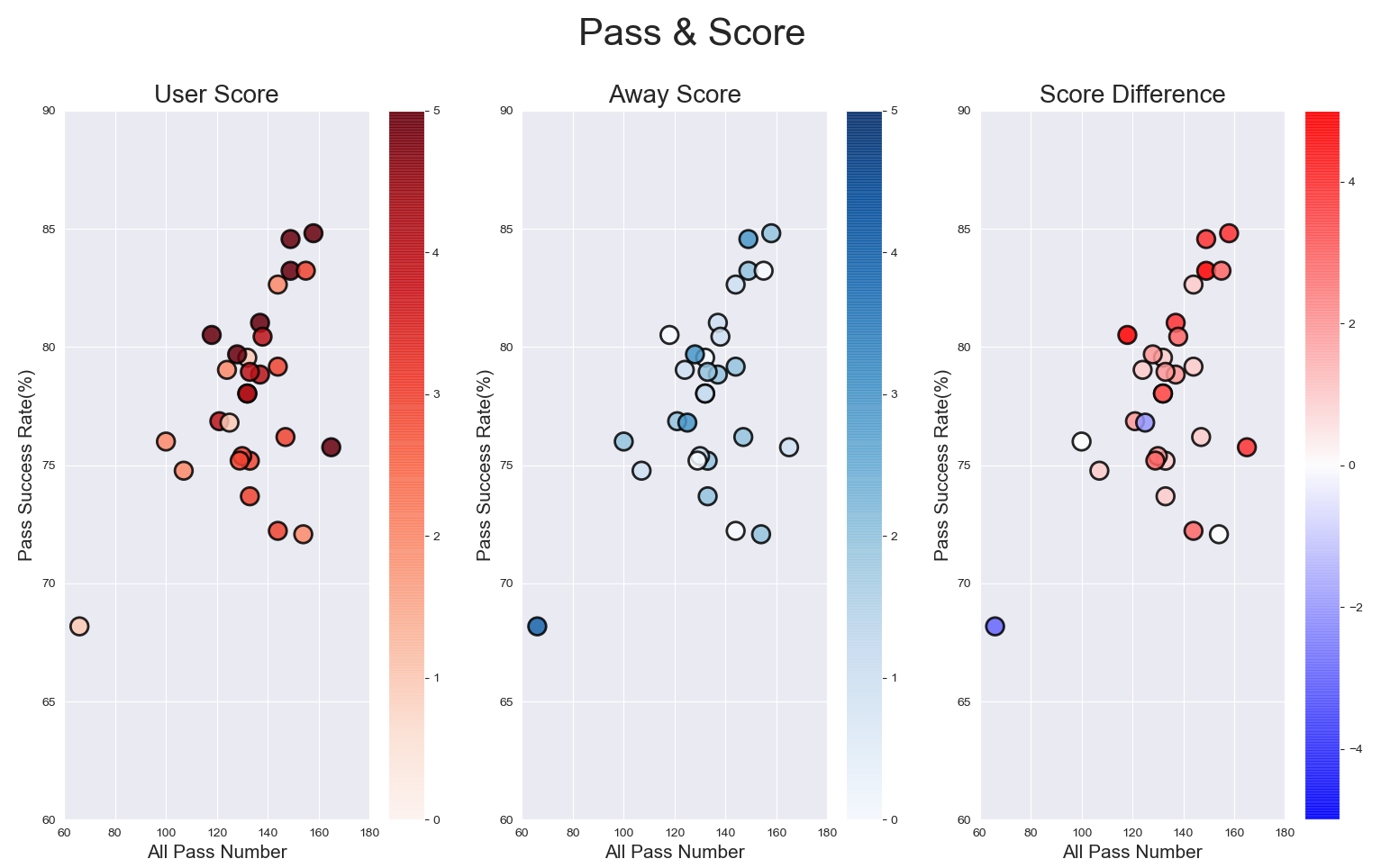
■複数パラメータ解析 (グラフ化)
- 複数のパラメータ情報をまとめてグラフ化します! 選択したのは、「パス本数」「パス成功率」「得点」「失点」の4つのパラメータです。
マップによって、マーカーの示している情報は異なります。
色が濃くなるほど、数値が大きいことを示しています。
左図:「得点」
中図:「失点」
右図:「得失点」軸は、パス情報を示しています。
縦軸:「パス成功率(%)」
横軸:「パス本数」■複数パラメータ解析 (考察)
右図の「得失点」から、得失点0点以下の試合は、「パス成功率80%以下」にしかないことが分かります。 逆にパス本数は影響してなさそうです。
左図の「得点」も同様に、「パス成功率」が高い試合ほど得点が多いことが分かります。
中図の「失点」は面白い結果が出てますね!
パス成功率/パス本数ともに、失点数には影響していなそうです。このテスターにとって、「パス成功率は、攻撃力に影響するが、失点には関係なさそう」という結果得られました。
パス成功率を上げるにはどうすればいいか?
失点数に影響している他のパラメータは何か?
など、次の解析方針が見えてきました!■データ解析のコツ!
- ズバリ!パラメータの依存/内包関係を把握しておくことです! 例えば「ポゼッション」というデータは、いくつもの因子が積みあがって出てくるパラメータです。
▼ポゼッションの因子
* パス本数 パス成功数 ボール奪取数 ボールロスト数 攻撃エリア ドリブル距離 ドリブル成功数 オフサイド数 フォーメーションのギャップ etc ※樹形図で書けよ!って指摘が聞こえるので、後で対応します。
- ん~~たくさん!!笑
ただ、全てのパラメータを細かく見れば良いわけではないです。
「欲しい情報はどの粒度で見るのが一番効率的なのだろう?」
と意味のあるデータの塊を模索することが大切です。
■まとめ
- やはり、最初のヒストグラムなどのチープな図よりも、リッチなグラフの方が価値の高い情報を得られますね。
この記事を見て、プレイヤーの皆さんから「使ってみたい!」と思われたら幸いです。
ニーズとマッチしていないものを作成しても、それはゴミと同じです。
今後もテスターの方にご協力いただき、ソフトウェアの価値を高めていきます。
■今後の予定
すでに、新しい機能拡張をいくつか予定しています。
・フォーメーションと各パラメータの関係
・パラメータの変化量を把握するためのグラフ作成(週毎の成長などを見やすくする狙い)
・テンプレートマッチングを用いた文字認識精度100%化番外編として
・対抗募集を自動リツイートBOT
(TwitterのAPIをいじってみたいだけです笑)part3をお楽しみに!!
■読んでくださった皆様へ
- 私の活動に、ご興味のある方は、気軽にTwitterまでDMしてください♪
「こんなこともお仕事でお願いできませんか?」みたいに、記事内容と関係ないことでも大丈夫です。
今は実績が欲しいですm(__)m■参考URL

- 投稿日:2020-02-17T21:12:10+09:00
機械学習のアルゴリズム(線形回帰の一般化)
はじめに
以前、「機械学習の分類」で取り上げたアルゴリズムについて、その理論とpythonでの実装、scikit-learnを使った分析についてステップバイステップで学習していく。個人の学習用として書いてるので間違いなんかは大目に見て欲しいと思います。
これまで、「単回帰」、「重回帰」と見てきたが、どちらも線形回帰という同じ分野の中で話をしてきた。今回は、線形回帰を一般化した「線形基底回帰モデル」と損失関数を最適化するための「勾配降下法」についてまとめたいと思う。今回参考にしたのは以下のサイトです。
基本
データ列に対する近似曲線を引くために、単回帰モデルは$$y=Ax+B$$重回帰モデルは
y=w_0x_0+w_1x_1+\cdots+w_nx_nで近似させるものだった。さらにいうと、単回帰については、重回帰の式の2項目までを使ったに過ぎないことがわかる。
さて、各項の重み$(w_0,w_1,\cdots,w_n)$とすると、モデルの関数は実はなんでもよくて、これを$y=\phi(x)$とおくと、
y(\boldsymbol{x}, \boldsymbol{w}) = \sum_{j=0}^{M-1}w_j\phi_{j}(\boldsymbol{x})と表される。$\boldsymbol{w}=(w_0,w_1,\cdots,w_{M-1})^T$、$\boldsymbol{\phi}=(\phi_0,\phi_1,\cdots,\phi_{M-1})^T$、とおく。$\phi_0=1$(切片項)とすると、
y(\boldsymbol{x}, \boldsymbol{w}) = \boldsymbol{w}^T\phi(x)になる。この$\phi(x)$を基底関数という。
様々な基底関数
一般化された式の意味するところは、線形回帰というのはつまり、ある基底関数を組み合わせて与えられたデータ列をもっともよく表す係数の列$\boldsymbol{w}$を見つけること、ということです。
- 単回帰、重回帰。回帰直線で近似する際に使う。$$\phi_j(x)=x$$
- 多項式回帰。多項式で近似。$$\phi_j(x)=x^j$$
- ガウス基底関数$$\phi_j(x)=\exp\left\{-\frac{(x-\mu_j)^2}{2s^2}\right\}$$
- シグモイド基底関数。ニューラルネットでよく使われる。$$\phi_j(x)=\sigma(\frac{x-\mu_j}{2s})$$
- フーリエ基底。フーリエ変換で使われる。$$\phi_j(x)=\exp(i\theta)$$
scikit-learnでは回帰に様々な基底関数が使えるようになっています。
回帰係数を求める
単回帰や重回帰では、残差二乗和を最小にするような係数を求めました。単回帰では数学的にwを求めることが可能でしたが、基底関数が複雑な場合や、データの次元が多い場合には解析的に解を求めることが非常に困難な場合が多いです。そういう場合に、近似的に係数を見つける必要があります。その際に用いるのが「勾配降下法」です。文字通り、坂(勾配)を下がっていきながら最適な値を見つける手法です。
数学的に解く方法も含め、係数をどう見つけるか考えてみましょう。なお、以下に詳しく書かれています。
数学的解法
単回帰や重回帰で述べたような式変形で解を探すやり方です。平方完成や偏微分から連立方程式を解くやり方です。数式が簡単なら問題はありませんが、モデルが複雑な場合は解けないケースが出てきます。
勾配降下法
勾配法は、文字通り損失関数の勾配を下っていく方法です。最適なパラメータを求めるためには損失関数の値が小さい必要があるが、小さい値に向かって坂を下っていくイメージです。
よく機械学習のサイトで紹介されるのは最急降下法と確率的勾配降下法だが、ディープラーニングの世界になると、使われる勾配降下法が増えます。ディープラーニングが盛んになってさらに発展している分野と言えるかもしれません。
最急降下法
損失関数$f(x,y)$が与えられた場合に、その勾配ベクトルは$x$と$y$それぞれで偏微分すると、$$ \nabla f(x,y) = \biggl(\frac{\partial f}{\partial x},\frac{\partial f}{\partial y}\biggr) $$なので、初期位置$(x_0,y_0)$を適当に決めて$f[(x_0,y_0)-\eta\nabla f(x_0,y_0)]$を次の点にして結果が収束するまで繰り返します。$\eta$は学習率と呼ばれます。
ただ、この方法の弱点は、損失関数は必ずしも一つではないということです。初期値の取り方を帰ると収束する位置も変わります(局所解に収束する)。
確率的勾配降下法(Stochastic Gradient Descent:SGD)
最急降下法では、参照する点は1つでしたが、確率的勾配降下法では、複数のサンプルを参照します。任意の数のサンプルを抽出しシャッフルしたものを用い、$$ w := w-\eta\sum_{i=1}^n \nabla Q_i(w)$$を計算していきます。
ほとんどの場合はSGDの方が収束が早いらしいですが、最急降下法の方が計算は早いです。ほとんどの場合はSGDを使っていれば問題ないのではないかと思います(Wikipedia談)。
まとめ
単回帰や重回帰を発展させて、一般的な回帰と解法について書きました。これまでの理論を用いることで、いろんなサンプルに対する回帰が求められると思います。
本当はpythonの実装も試してみようと思ったんですが力尽きました。次は、pythonでの実装をいくつか試して見たあとに、過学習(overfitting)や正則化(regularization)についてまとめてみたいと思います。
- 投稿日:2020-02-17T21:10:30+09:00
Windowsで作る初心者向けプログラミング環境
1時間でWindowsでプログラミング環境を作る
対象読者
windowsでプログラミング環境を作成したい初心者
目標
- 一時間以内にC言語とPythonでhello worldを行う
- 可能な限りWindowsの環境を汚さない
- ステップアップしても使い続けられるor環境をリセットできるようにする
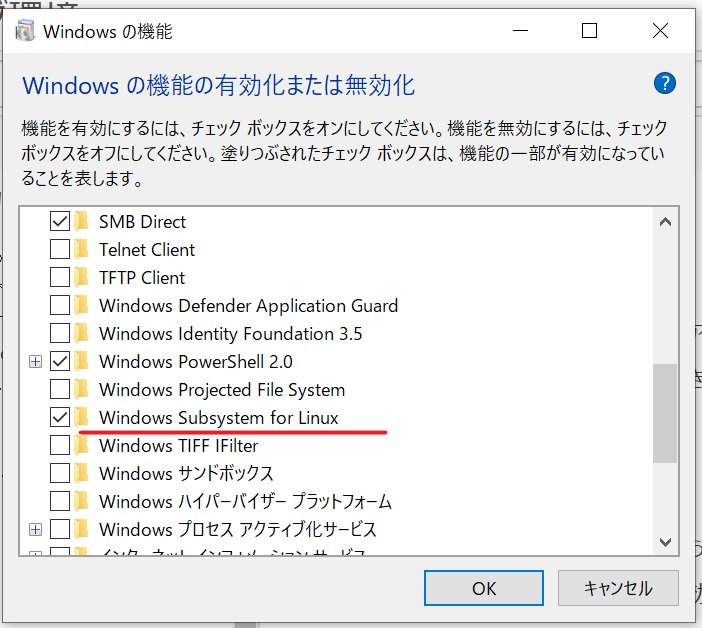
1. WSLの有効化
はじめにWSL(Windows Subsystem for Linux)の有効化を行います。
これはWindows上でLinuxというOSを動かすサービスです。もともとWindowsはプログラミング環境を構築するのがMacOSやLinuxといった他のOSと比べ難しく、WindowsPCしかないけどプログラミングしてみたい!とりあえず大学で習ったC言語でもやってみよう!という初心者(かつての私)のモチベーションを環境構築の段階で折るレベルでした。
一方、Linuxはプログラミング環境を構築するのが非常に簡単なOSですが、LinuxをWindowsPCに入れるという作業はかなり面倒です。嬉しいことにMicrosoftがWSLというサービスを用意してくれているので使いましょう。一昔前では考えられないサービスです。1.1 コントロールパネルを開く
コントロールパネルは左下のWindowsアイコンを右クリックして出てくる「検索」にコントロールパネルと入力すれば開きます。
1.2 WSLの有効化
コントロールパネルにあるメニューのうち、「プログラムと機能」を選択します。右メニューにあるWindowsの機能の有効化または無効化をクリックします。
1.3 WSLの有効化
開いたウィンドウからWindows Subsystem for Linuxを探し、チェックを入れます。
WSLを有効にするため、一度再起動をしましょう。
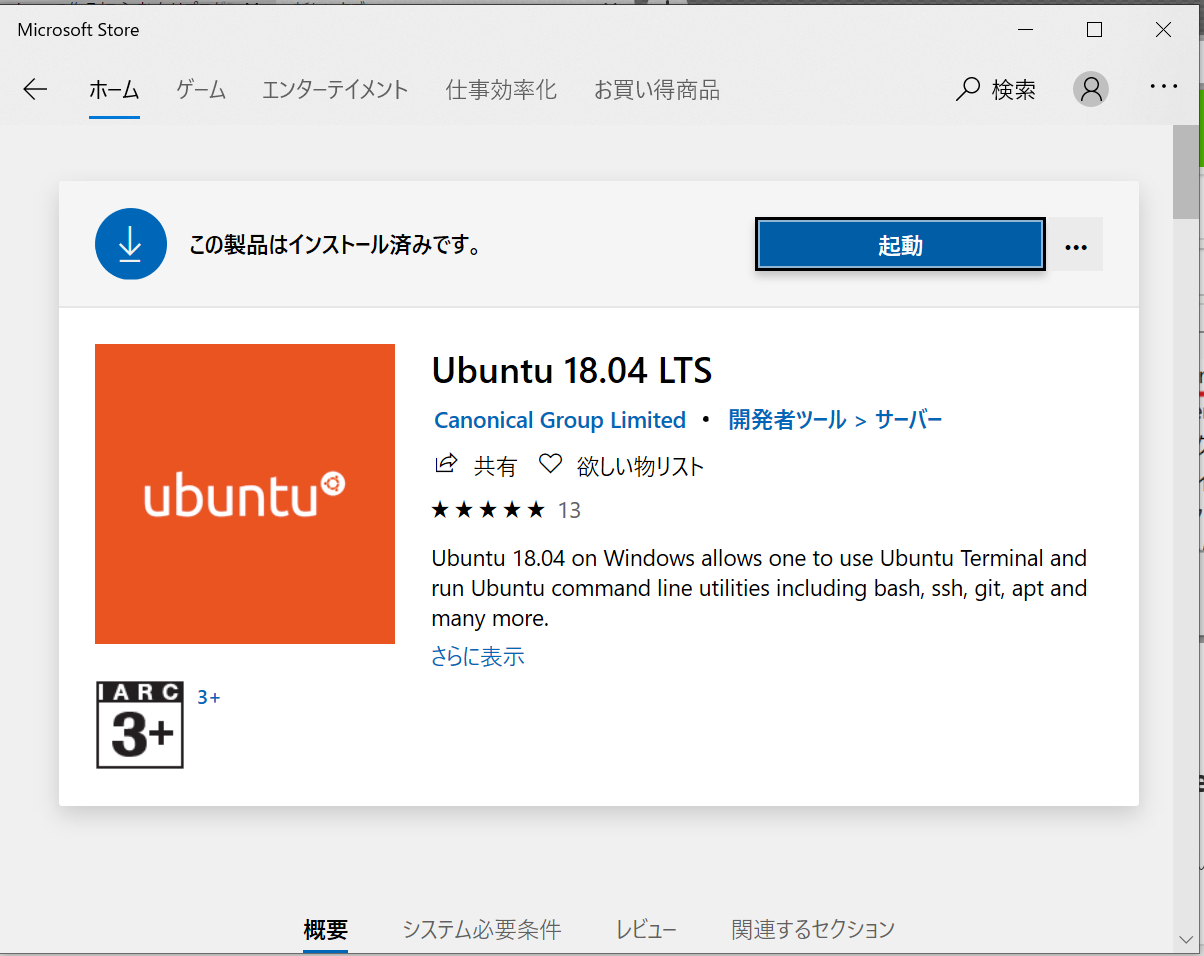
2. WSL用UbuntuとWindows Terminal, VSCodeの入手
Microsoft StoreからUbuntuというアプリを入手します。これはWSL上で動かすOSのイメージです。Ubuntu, Ubutnu18.04, Ubuntu16.04とありますが、ここではUbuntu18.04を選びましょう。あまり違いはありません。ダウンロードしたら起動してください。
黒い画面が表示されて英語でユーザー名とパスワードの設定を求められるので入力してください。
合わせて、Windows Terminalを入手しましょう。Preview版となっていますが特に問題はありません。
また、VSCodeというエディタをダウンロード&インストールしましょう。
https://code.visualstudio.com/Windows Terminalが起動したら、メニューバーにあるセッティングを開いてください。
ここのSettingを開くとVSCodeが立ち上がるはずです。
画面に上側にあるsetting.json"defaultProfile": "{c6eaf9f4-32a7-5fdc-b5cf-066e8a4b1e40}""defaultProfile"の値(c6eaf9f4-32a7-5fdc-b5cf-066e8a4b1e40)を
下スクロールすると現れるUbuntu向けの設定のguid(c6eaf9f4-32a7-5fdc-b5cf-066e8a4b1e40)setting.json{ "guid": "{c6eaf9f4-32a7-5fdc-b5cf-066e8a4b1e40}", "hidden": false, "name": "Ubuntu-18.04", "source": "Windows.Terminal.Wsl" }で置き換え、上書き保存してください。これで、Windows terminalを開くと自動でUbuntuのターミナルが開きます。
3. Ubuntuのアップデート、必要なツールのインストール
Ubuntuのターミナルを開いて以下のコマンドをコピー&ペーストしてください。ターミナルへのペーストにはshift+crtl+Vでペーストできます。パスワードを求められるのでUbuntu初回設定時に入力したパスワードを入れてください
ubuntu.updatesudo apt update sudo apt upgrade sudo apt install build-essential少し時間がかかりますが、Ubuntuの更新だと思って待っていましょう。
4. VS Codeに必要な拡張機能のインストール
VSCodeを開き、メニューバーのFile>Setting>Extensionとクリックしていくと、拡張機能をインストールできるメニューが開きます。
そこで、以下の拡張機能をインストールしてください。Japanese Language Pack for VS Code
Remote - WSL
再度Ubutuターミナルを開き、
openvscodecode .と入力します。これで、VSCodeをUbuntu上で動かすことができるようになります。
また、ターミナルで開いたVSCodeから拡張機能Python
C/C++
を入れてください。これらの拡張機能は対応のプログラミング言語の誤りを指摘してくれたり、コードが見やすくなるようなハイライトを加えてくれます。
以上で最低限の環境構築は終了です。5. プログラムの作成
5.1 C言語
VSCodeでC言語のhello worldファイルを作成し、保存しましょう。今回はDesktop化に保存したとします。
hello_world.c#include <stdio.h> int main(){ printf("Hello World!\n"); return 0; }VSCodeのメニューにあるターミナル>新しいターミナルをクリックすると下側にターミナル画面が開くはずです。そのターミナルに
move_dircd Desktop gcc hello_world.c ./a.outと入力すれば、ターミナルがDesktopフォルダーに移動、hello_world.cファイルをコンパイル、出力したa.outファイルを実行し、ターミナルにHello World!と出力されます。
おめでとうございます!これでC言語の開発環境ができました。どんどんプログラムを作成してコンパイル&実行してみてください。5.2 Python
Pythonの場合はもっと簡単です。
hello_world.pyprint("Hello World!")を作成し、同様にターミナルから
move_dircd Desktop python hello_world.pyとするだけです。おめでとうございます!Pythonの開発環境もできました!簡単ですね!もしPythonでガリガリ書いて行きたいとお考えでしたら、ターミナルから
installmojulesudo apt install python3-pip pip3 install jupyter pip3 install ipython pip3 install numpy scipy matplotlib pandas scikit-learn flaskで必要なモジュールをインストールできます。
6. さらに別の言語を試す
もちろんC、Pythonだけでなく他のプログラミング言語も簡単に作成できます。
Google検索からUbuntu (使用したいプログラミング言語)
で検索して出てきた記事に記載されているコマンドをターミナルで入力し、VSCodeにそのプログラミング言語の拡張機能を入れるだけです。
Golang: https://github.com/golang/go/wiki/Ubuntu
Rust : https://www.rust-lang.org/tools/installLet's enjoy programming!



- 投稿日:2020-02-17T20:17:34+09:00
30分でPython入門!開発環境構築&基礎文法を学ぶ【有益な記事総まとめ】
Pythonを始めたきっかけ
TypescriptとGASでChatBotを作ったり、
競技プログラミング(AtCoder)にC#で挑戦してみたりする中で、
「これPython使えたらめっちゃ楽なのでは??」
と感じる場面が非常に多かったので、勢いで軽率に入門をキメました(σ・ω・)σやりたいこと
本記事では、macOSでVSCodeを使って
Pythonをゴリゴリ記述していくための開発環境を構築していきます。ただ、Python入門に必要となる以下の作業などについては、
世の中の強い方々が既に言語化して下さっています。✔︎ Pythonのインストール方法
✔︎ 自動整形/コーディング規約の設定
✔︎ PyPyの基礎知識
✔︎ Python3の基礎文法
✔︎ 競プロ用チートシートですので、本記事では「2020年2月現在、この順番でこの記事を読んで適切にセッティングしていけば確実にPython入門決められるよ!」という点に価値を見出し、Python入門者にとってのハブとして機能するよう、必要最小限の内容を簡単にまとめました。(・ω・。)
Python入門に有益なドキュメント
以下にジャンル別で参考になった記事を紹介していきます。
まずは公式ドキュメント
公式ドキュメントは形式張っていて読みにくいことが多いですが、日本語版があるだけマシだと思って津留を通しましょう。下記の用語集、標準ライブラリなどについては仕様が分かりやすくオススメです。
【公式】Python チュートリアル
【公式】Python 用語集
【公式】Python 標準ライブラリPythonのインストール
インストールにpyenvを使う場合と使わない場合と、数種類の記事が散見されますが、Pythonはバージョン間の互換性が薄い場合があることなどを考慮すると、pyenvを使った方がバージョン管理の都合が良さそうです。
pyenvを使ってMacにPythonの環境を構築する自動整形、コーディング規約の調整
記法に制約が比較的多いPythonの場合、自動整形の設定をしないのは死活問題になりそうです。特に入門者の場合は無用な記法エラーで時間を取られそうなので、何よりもまず導入すべきだと思います。
VSCodeのPython開発環境でpylintの代わりにflake8を導入し自動整形を設定する上記記事の補足として下記記事の内容も参照すると良い感じになります。
VS Code コーディング規約を快適に守るPythonの基礎文法
他の言語をやったことある方なら、下記の記事を一通りこなすだけでそこそこPythonを扱いこなせるようになると思います。
Python3基礎文法PyPyとは何か
PyPyを用いると、場面にもよりますが普通のPythonよりも処理が格段に早くなることが多いようです。
PyPyの基礎知識まとめ その1競プロ関連のTips
基礎文法を学び終わったら、早速AtCoderでゴリゴリにアルゴリズムを実装してPython経験値を高めていきましょう。下記の記事3つを参考にすれば、入門者でもABCのD問題くらいまでは手出せるようになるかと!
Pythonで使う競技プログラミング用チートシート
Pythonで競プロやるときによく書くコードをまとめてみた
PythonでAtCoder青になるまで -Pythonで競プロやるときに気をつけること-まとめ
とりあえずここら辺までPythonについての情報収集、開発環境の構築ができたなら、ここから先Pythonユーザとして実践に踏み出ていくことは容易だと思います。
末筆にはなりますが、Python熟練者の皆さま、入門者にはぜひこの記事を!といった参考情報ございましたら、お気軽にコメントお願いします!| ε:)ついったフォローしてね。(・ω・。)
@NadjaHarold
- 投稿日:2020-02-17T20:17:34+09:00
30分でPython入門!開発環境構築&基礎文法を学ぶ【2020年2月現在有益な記事総まとめ】
Pythonを始めたきっかけ
TypescriptとGASでChatBotを作ったり、
競技プログラミング(AtCoder)にC#で挑戦してみたりする中で、
「これPython使えたらめっちゃ楽なのでは??」
と感じる場面が非常に多かったので、勢いで軽率に入門をキメました(σ・ω・)σやりたいこと
本記事では、macOSでVSCodeを使って
Pythonをゴリゴリ記述していくための開発環境を構築していきます。ただ、Python入門に必要となる以下の作業などについては、
世の中の強い方々が既に言語化して下さっています。✔︎ Pythonのインストール方法
✔︎ 自動整形/コーディング規約の設定
✔︎ PyPyの基礎知識
✔︎ Python3の基礎文法
✔︎ 競プロ用チートシートですので、本記事では「2020年2月現在、この順番でこの記事を読んで適切にセッティングしていけば確実にPython入門決められるよ!」という点に価値を見出し、Python入門者にとってのハブとして機能するよう、必要最小限の内容を簡単にまとめました。(・ω・。)
Python入門に有益なドキュメント
以下にジャンル別で参考になった記事を紹介していきます。
まずは公式ドキュメント
公式ドキュメントは形式張っていて読みにくいことが多いですが、日本語版があるだけマシだと思って津留を通しましょう。下記の用語集、標準ライブラリなどについては仕様が分かりやすくオススメです。
【公式】Python チュートリアル
【公式】Python 用語集
【公式】Python 標準ライブラリPythonのインストール
インストールにpyenvを使う場合と使わない場合と、数種類の記事が散見されますが、Pythonはバージョン間の互換性が薄い場合があることなどを考慮すると、pyenvを使った方がバージョン管理の都合が良さそうです。
pyenvを使ってMacにPythonの環境を構築する自動整形、コーディング規約の調整
記法に制約が比較的多いPythonの場合、自動整形の設定をしないのは死活問題になりそうです。特に入門者の場合は無用な記法エラーで時間を取られそうなので、何よりもまず導入すべきだと思います。
VSCodeのPython開発環境でpylintの代わりにflake8を導入し自動整形を設定する上記記事の補足として下記記事の内容も参照すると良い感じになります。
VS Code コーディング規約を快適に守るPythonの基礎文法
他の言語をやったことある方なら、下記の記事を一通りこなすだけでそこそこPythonを扱いこなせるようになると思います。
Python3基礎文法PyPyとは何か
PyPyを用いると、場面にもよりますが普通のPythonよりも処理が格段に早くなることが多いようです。
PyPyの基礎知識まとめ その1競プロ関連のTips
基礎文法を学び終わったら、早速AtCoderでゴリゴリにアルゴリズムを実装してPython経験値を高めていきましょう。下記の記事3つを参考にすれば、入門者でもABCのD問題くらいまでは手出せるようになるかと!
Pythonで使う競技プログラミング用チートシート
Pythonで競プロやるときによく書くコードをまとめてみた
PythonでAtCoder青になるまで -Pythonで競プロやるときに気をつけること-まとめ
とりあえずここら辺までPythonについての情報収集、開発環境の構築ができたなら、ここから先Pythonユーザとして実践に踏み出ていくことは容易だと思います。
末筆にはなりますが、Python熟練者の皆さま、入門者にはぜひこの記事を!といった参考情報ございましたら、お気軽にコメントお願いします!| ε:)ついったフォローしてね。(・ω・。)
@NadjaHarold
- 投稿日:2020-02-17T19:34:57+09:00
n次ベジェ曲線を任意の地点で分割したい ~ 再帰と行列 ~
はじめに
とある事情から,ベジェ曲線の分割について調べていたのですが,
$n$次ベジェ曲線の分割方法について解説しているサイトがあまり見当たりませんでした.まぁ,ベジェ曲線なんて高々4次ぐらいまでしか使わないので$n$次なんて分からなくても問題ないのですが,
どうしても綺麗に実装したくて調べたので知識として残しておこうと思います.
一応記事内にも実装例を載せましたが,GitHubにも上げています( line_module.py 参照).再帰を利用した手法
De Casteljau のアルゴリズム(De Casteljau's algorithm)と呼ばれる手法です.
この方法では再帰を利用して,分割後の新しいベジェ曲線の制御点を求めます.
この手法は考え方が単純で実装も容易ですが,スタックサイズが小さい組み込み系などでは使いにくいという欠点があります.まぁ,ベジェ曲線なんて高々4次ぐらいまでしか(略アルゴリズム
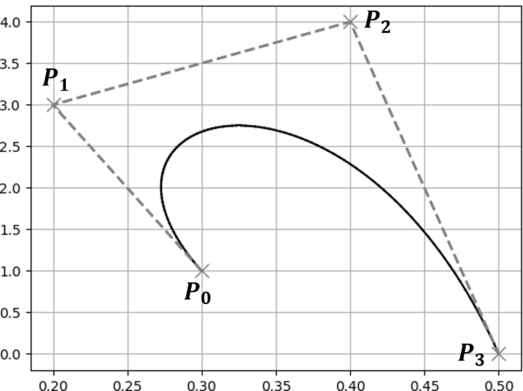
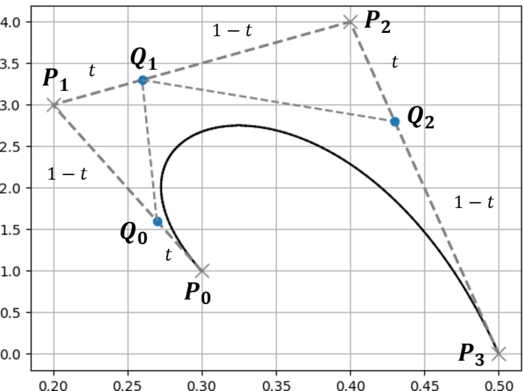
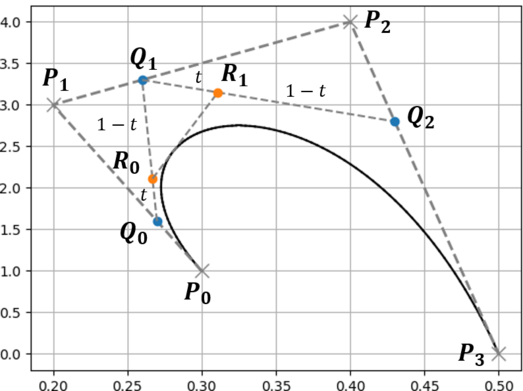
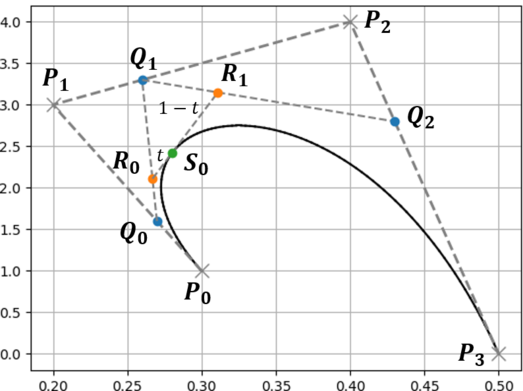
例として下に示すベジェ曲線を分割するものとします.
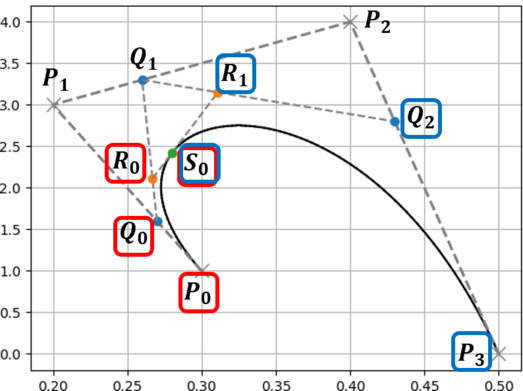
分割地点におけるベジェ曲線の媒介変数を $t$ とし,ベジェ曲線の初期の制御点を $P_i$ とします.
1. ベジェ曲線の制御点を結んだ線において $t:1-t$ となる点を求める(点$Q$).
2. 求めた点を結んだ線に対して,同様に $t:1-t$ となる点を求める(点$R$).
3. 点が1つになるまで繰り返す(点$S$).
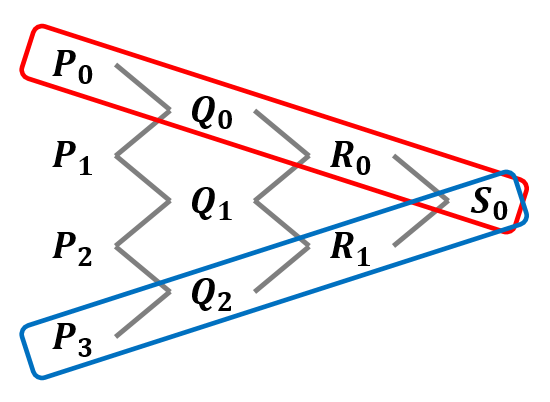
4. 初期の制御点を含めた全ての点で,添字が最小の点の集合と最大の点の集合が分割後の制御点となる.
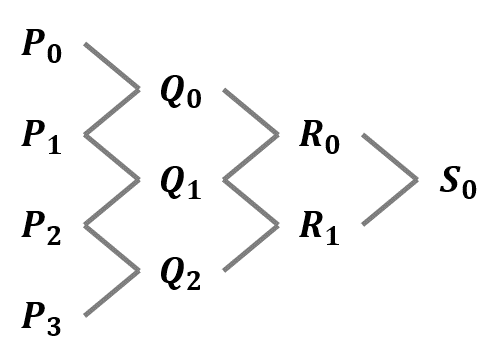
最後の部分(添字が最小の~)については,下のような木構造を書いてみると理解しやすいと思います.
下に示す木構造は,どの線分(どの2点)から新しい点が生成されたかを表したものになっています.
この木構造のうち一番外側の点,すなわち点 $\{ P_0, Q_0, R_0, S_0 \}$ と点 $\{ S_0, R_1, Q_2, P_3 \}$ が新しいベジェ曲線となります.元のベジェ曲線の始点と終点が共通であることや,媒介変数 $t$ における点(分割地点 $S_0$)が新しいベジェ曲線の始点(終点)になっていることがわかると思います.
プログラム
再帰を利用した分割プログラムの実装例を以下に示します.
import numpy as np from scipy.special import comb import matplotlib.pyplot as plt class Bezier: def __init__(self, points): points = [np.array(e).flatten() for e in points] self._n = len(points) self._points = points @property def dims(self): return self._n - 1 @property def points(self): return self._points @property def points4matplot(self): xs, ys = zip(*self.points) return xs, ys def _bernstein(self, n, i, t): return comb(n, i) * t**i * (1 - t)**(n-i) def bezier_point(self, t): p = np.zeros(2) for i, f in enumerate(self.points): p += self._bernstein(self.dims, i, t) * f return np.array(p).flatten() def _de_casteljau_algorithm(self, points, t): prev_p = None q = [] for p in points: if not prev_p is None: ## Split line into t:(1-t) q.append(np.array((1-t) * prev_p + t * p).flatten()) prev_p = p if len(q) == 1: return [q] return [q] + self._de_casteljau_algorithm(q, t) def split_with_recursion(self, t): ret = [self.points] + self._de_casteljau_algorithm(self.points, t) lp = [] rp = [] for lst in ret: ## Fetch min and max point lp.append(lst[0]) rp.append(lst[-1]) return Bezier(lp), Bezier(rp) def plot(self, ax=None, with_ctrl_pt=True, bcolor="black", ccolor="gray", resolution=100): if ax is None: _, ax = plt.subplots() prev_point = None for t in np.linspace(0, 1, resolution): bp = self.bezier_point(t) if prev_point is None: prev_point = (bp[0], bp[1]) xs, ys = zip(*(prev_point, (bp[0], bp[1]))) ax.plot(xs, ys, '-', color=bcolor) prev_point = (bp[0], bp[1]) if with_ctrl_pt: xs, ys = self.points4matplot ax.plot(xs, ys, 'x--', lw=2, color=ccolor, ms=10) return ax def main(): bezier = Bezier([(0.3, 1), (0.2, 3), (0.4, 4), (0.5, 0)]) ax = bezier.plot() left_bezier, right_bezier = bezier.split_with_recursion(0.3) left_bezier.plot(ax, bcolor = "red") right_bezier.plot(ax, bcolor = "blue") plt.grid() plt.show() if __name__ == "__main__": main()行列を利用した手法
行列を使って新しい制御点を求める手法です.
この方法ではスタックサイズが小さくても問題ない反面,計算が少々複雑になります.
まぁ,ベジェ曲線なんて高々4次(略ベジェ曲線を行列の形で表す
アルゴリズムを説明する前段階として,ベジェ曲線の行列表現について説明します.
ベジェ曲線は次のような式で表すことができます.\begin{align} F(t) &= \sum_{i=0}^{n} P_i~B_{i}^{n}(t) \end{align}$P_i$ は制御点,$B_{i}^{n}(t)$ はバーンスタイン基底関数を表します.
$n$ はベジェ曲線の次数に$1$を足した数($=$ 制御点の数)を表します.
これを行列の積の形で表すと次のようになります.\begin{align} F(t) &= \sum_{i=0}^{n} P_i~B_{i}^{n}(t) \\ &= \left( \begin{array}{ccc} B_{0}^{n} & B_{1}^{n} & \dots & B_{n}^{n} \end{array} \right) \left( \begin{array}{ccc} P_0 \\ P_1 \\ \vdots \\ P_n \end{array} \right) \end{align}また,ベジェ曲線の式を $t$ について整理すると次のように表すことができます.
ここでの $a_n$ は適当な係数を表しています.\begin{align} F(t) &= \sum_{i=0}^{n} P_i~B_{i}^{n}(t) \\ &= \left( \begin{array}{ccc} 1 & t & t^2 & \dots & t^n \end{array} \right) \left( \begin{array}{ccc} a_0 \\ a_1 \\ \vdots \\ a_n \end{array} \right) \end{align}以上のことから次のような式を導くことができます.
\begin{align} F(t) &= \left( \begin{array}{ccc} B_{0}^{n} & B_{1}^{n} & \dots & B_{n}^{n} \end{array} \right) \left( \begin{array}{ccc} P_0 \\ P_1 \\ \vdots \\ P_n \end{array} \right) = \left( \begin{array}{ccc} 1 & t & t^2 & \dots & t^n \end{array} \right) \left( \begin{array}{ccc} a_0 \\ a_1 \\ \vdots \\ a_n \end{array} \right) \\ \\ F(t) &= BP = XA \end{align}だいぶ綺麗になりました.
ここで,$A$ はある下三角行列 $U_t$ と 制御点 $P$ によって次のように表せることが分かっています.\begin{align} A &= U_tP \\ \\ &= \left( \begin{array}{ccc} {n \choose 0} {n \choose 0} (-1)^0 & 0 & \cdots & 0 \\ {n \choose 0} {n \choose 1} (-1)^1 & {n \choose 1} {n-1 \choose 0} (-1)^0 & \cdots & 0 \\ \vdots & \vdots & \cdots & \vdots \\ {n \choose 0} {n \choose n} (-1)^n & {n \choose 1} {n-1 \choose n-1} (-1)^{n-1} & \cdots & {n \choose n} {n-n \choose n-n} (-1)^{n-n} \\ \end{array} \right) \left( \begin{array}{ccc} P_0 \\ P_1 \\ \vdots \\ P_n \end{array} \right) \end{align}したがって,最終的にベジェ曲線の式は,行列を用いて次のように表すことができます.
F(t) = BP = XU_tPアルゴリズム
行列を使ったベジェ曲線分割のアルゴリズムは次のようになります.
1. ベジェ曲線を $t$ について整理して行列の形で表す.
\begin{align} F(t) &= XU_tP \\ &= \left( \begin{array}{ccc} 1 & t & t^2 & \dots & t^n \end{array} \right)U_tP \\ \end{align}2. 分割地点 $z ~(z \in t)$ を分離する.
\begin{align} F(t) &= \left( \begin{array}{ccc} 1 & t & t^2 & \dots & t^n \end{array} \right)U_tP \\ \\ &= \left( \begin{array}{ccc} 1 & (z\cdot t) & (z\cdot t)^2 & \dots & (z\cdot t)^n \end{array} \right)U_tP \\ \\ &= \left( \begin{array}{ccc} 1 & t & t^2 & \dots & t^n \end{array} \right) \left( \begin{array}{ccc} 1 & & & & 0 \\ & z & & & \\ & & z^2 & & \\ & & & \ddots & \\ 0 & & & & z^n \end{array} \right)U_tP \end{align}3. 次のように式変形を行い,$Q$ を求める.
\begin{align} F(t) &= \left( \begin{array}{ccc} 1 & t & t^2 & \dots & t^n \end{array} \right) \left( \begin{array}{ccc} 1 & & & & 0 \\ & z & & & \\ & & z^2 & & \\ & & & \ddots & \\ 0 & & & & z^n \end{array} \right)U_tP \\ &= X ~ Z U_t ~ P \\ \\ &= X ~ U_t U_t^{-1} Z U_t ~ P \\ \\ &= X ~ U_t Q ~P \end{align}上の計算では $U_t$ の位置を移動させています.
$U_t U_t^{-1}$ は単位行列になるので計算結果自体は変化しません.
$Q = U_t^{-1}ZU_t$ となります.4. $QP$ を計算し新しいベジェ曲線の制御点を算出する.
\begin{align} F(t) &= X ~ U_t Q ~P \\ &= X ~ U_t ~ P^{~\prime} \end{align}$P^{~\prime} = QP$ とするとベジェ曲線を表す式の形になります.
したがって$P^{~\prime}$ が分割後のベジェ曲線の制御点となります.
以上の手順によって分割した左側のベジェ曲線を求めることができました.
右側のベジェ曲線を求めるときは手順2において $z$ を次のようにしてから分離させ,
右側用の行列 $Q^{~\prime}$ を求めます.\begin{align} F(t) &= \left( \begin{array}{ccc} 1 & t & t^2 & \dots & t^n \end{array} \right)U_tP \\ \\ &= \left( \begin{array}{ccc} 1 & (z + (1-z)\cdot t) & (z + (1-z)\cdot t)^2 & \dots & (z + (1-z)\cdot t)^n \end{array} \right)U_tP \end{align}しかし,実際には直接計算せずとも計算済みの $Q$ を用いて $Q^{~\prime}$ を求めることができます.
具体的には,
- $Q$ の要素を $0$ の分右側に詰める.
- 右に詰めた行列の要素を上下反転する.
という操作をするだけです.
数式を用いた説明が難しいので,次の計算例の節を参照してください.計算例
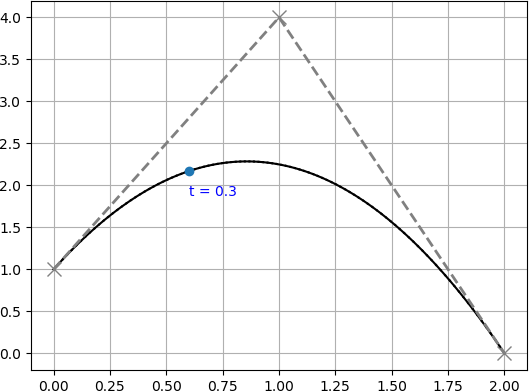
「$n$次の話ばっかりじゃよく分からん!」という人のために,行列計算による分割の計算例を載せておきます.
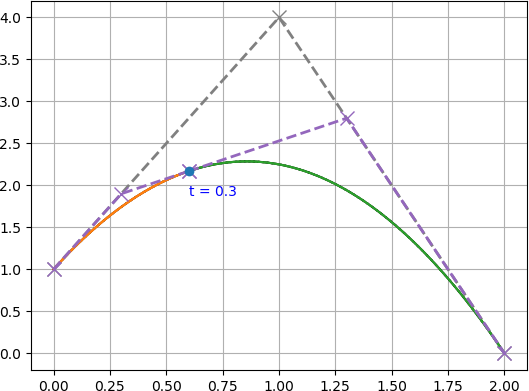
今回は例として,
$P_0=(0, 1),~ P_1=(1, 4),~ P_2=(2, 0)$
を制御点に持つ2次ベジェ曲線を $t=0.3$ の位置で分割するとします.
図で表すと下図のような曲線です.
まず,このベジェ曲線を行列の形で表し,分割地点 $z=0.3$ を分離します.
\begin{align} F(t) &= XZU_tP \\ &= \left( \begin{array}{ccc} 1 & t & t^2 \end{array} \right) \left( \begin{array}{ccc} 1 & 0 & 0 \\ 0 & z & 0 \\ 0 & 0 & z^2 \end{array} \right) \left( \begin{array}{ccc} {2 \choose 0}{2 \choose 0}(-1)^0 & 0 & 0 \\ {2 \choose 0}{2 \choose 1}(-1)^1 & {2 \choose 1}{1 \choose 0}(-1)^0 & 0 \\ {2 \choose 0}{2 \choose 2}(-1)^2 & {2 \choose 1}{1 \choose 1}(-1)^1 & {2 \choose 2}{0 \choose 0}(-1)^0 \end{array} \right) \left( \begin{array}{ccc} P_0 \\ P_1 \\ P_2 \end{array} \right) \\ \\ &= \left( \begin{array}{ccc} 1 & t & t^2 \end{array} \right) \left( \begin{array}{ccc} 1 & 0 & 0 \\ 0 & 0.3 & 0 \\ 0 & 0 & 0.09 \end{array} \right) \left( \begin{array}{ccc} 1 & 0 & 0 \\ -2 & 2 & 0 \\ 1 & -2 & 1 \end{array} \right) \left( \begin{array}{ccc} P_0 \\ P_1 \\ P_2 \end{array} \right) \end{align}ここで $Q=U_t^{-1}ZU_t$ を計算します.
\begin{align} Q &= U_t^{-1}ZU_t \\ \\ &= \left( \begin{array}{ccc} 1 & 0 & 0 \\ 1 & \frac{1}{2} & 0 \\ 1 & 1 & 1 \end{array} \right) \left( \begin{array}{ccc} 1 & 0 & 0 \\ 0 & 0.3 & 0 \\ 0 & 0 & 0.09 \end{array} \right) \left( \begin{array}{ccc} 1 & 0 & 0 \\ -2 & 2 & 0 \\ 1 & -2 & 1 \end{array} \right) \\ \\ &= \left( \begin{array}{ccc} 1 & 0 & 0 \\ 0.7 & 0.3 & 0 \\ 0.49 & 0.42 & 0.09 \end{array} \right) \end{align}式変形を行い,$Q$ を利用した式にします.
\begin{align} F(t) &= XZU_tP \\ &= XU_tU_t^{-1}ZU_tP \\ &= XU_tQP \\ &= \left( \begin{array}{ccc} 1 & t & t^2 \end{array} \right) \left( \begin{array}{ccc} 1 & 0 & 0 \\ -2 & 2 & 0 \\ 1 & -2 & 1 \end{array} \right) \left( \begin{array}{ccc} 1 & 0 & 0 \\ 0.7 & 0.3 & 0 \\ 0.49 & 0.42 & 0.09 \end{array} \right) \left( \begin{array}{ccc} P_0 \\ P_1 \\ P_2 \end{array} \right) \end{align}ここで $QP$ について計算すると,
\begin{align} QP &= \left( \begin{array}{ccc} 1 & 0 & 0 \\ 0.7 & 0.3 & 0 \\ 0.49 & 0.42 & 0.09 \end{array} \right) \left( \begin{array}{ccc} P_0 \\ P_1 \\ P_2 \end{array} \right) \\ \\ &= \left( \begin{array}{ccc} P_0 \\ 0.7P_0 + 0.3P_1 \\ 0.49P_0 + 0.42P_1 + 0.09P_2 \end{array} \right) \\ \\ &= P^{~\prime} \\ \\ \end{align}\begin{align} P^{~\prime}_x &= \left( \begin{array}{ccc} 0 \\ 0.7\cdot 0 + 0.3 \cdot 1 \\ 0.49\cdot 0 + 0.42\cdot 1 + 0.09\cdot 2 \end{array} \right) = \left( \begin{array}{ccc} 0 \\ 0.3 \\ 0.6 \end{array} \right) \end{align}\begin{align} P^{~\prime}_y &= \left( \begin{array}{ccc} 1 \\ 0.7\cdot 1 + 0.3 \cdot 4 \\ 0.49\cdot 1 + 0.42\cdot 4 + 0.09\cdot 0 \end{array} \right) = \left( \begin{array}{ccc} 1 \\ 1.9 \\ 2.17 \end{array} \right) \\ \end{align}
となり,分割した左側のベジェ曲線の制御点が
$P_0^{~\prime}=(0, 1),~ P_1^{~\prime}=(0.3, 1.9),~ P_2^{~\prime}=(0.6, 2.17)$
であることが分かりました.次は右側のベジェ曲線を求めていきます.
右側用の $U_t^{-1}Z^{~\prime}U_t = Q^{~\prime}$ は計算した $Q$ を利用して次のように求めることができます.1. $Q$ の要素を $0$ の分右側に詰める.
\begin{align} Q &= \left( \begin{array}{ccc} 1 & 0 & 0 \\ 0.7 & 0.3 & 0 \\ 0.49 & 0.42 & 0.09 \end{array} \right) \Rightarrow \left( \begin{array}{ccc} 0 & 0 & 1 \\ 0 & 0.7 & 0.3 \\ 0.49 & 0.42 & 0.09 \end{array} \right) \end{align}2. 右に詰めた行列の要素を上下反転する.
\begin{align} \left( \begin{array}{ccc} 0 & 0 & 1 \\ 0 & 0.7 & 0.3 \\ 0.49 & 0.42 & 0.09 \end{array} \right) \Rightarrow \left( \begin{array}{ccc} 0.49 & 0.42 & 0.09 \\ 0 & 0.7 & 0.3 \\ 0 & 0 & 1 \end{array} \right) = Q^{~\prime} \end{align}簡単ですね.
求めた $Q^{~\prime}$ を使うと分割した右側のベジェ曲線を求めることができます.\begin{align} Q^{~\prime}P &= \left( \begin{array}{ccc} 0.49 & 0.42 & 0.09 \\ 0 & 0.7 & 0.3 \\ 0 & 0 & 1 \end{array} \right) \left( \begin{array}{ccc} P_0 \\ P_1 \\ P_2 \end{array} \right) \\ \\ &= \left( \begin{array}{ccc} 0.49P_0 + 0.42P_1 + 0.09P_2 \\ 0.7P_1 + 0.3P_2 \\ P_2 \end{array} \right) \\ \\ &= P^{~\prime\prime} \\ \\ \end{align}\begin{align} P^{~\prime\prime}_x &= \left( \begin{array}{ccc} 0.49\cdot 0 + 0.42\cdot 1 + 0.09\cdot 2 \\ 0.7\cdot 1 + 0.3 \cdot 2 \\ 2 \end{array} \right) = \left( \begin{array}{ccc} 0.6 \\ 1.3 \\ 2 \end{array} \right) \end{align}\begin{align} P^{~\prime\prime}_y &= \left( \begin{array}{ccc} 0.49\cdot 1 + 0.42\cdot 4 + 0.09\cdot 0 \\ 0.7\cdot 4 + 0.3 \cdot 0 \\ 0 \end{array} \right) = \left( \begin{array}{ccc} 2.17 \\ 2.8 \\ 0 \end{array} \right) \end{align}
これで右側のベジェ曲線の制御点が
$P_0^{~\prime\prime}=(0.6, 2.17),~ P_1^{~\prime\prime}=(1.3, 2.8),~ P_2^{~\prime\prime}=(2, 0)$
であることが分かりました.$P_0 = P_0^{~\prime}$,$P_2^{~\prime} = P_0^{~\prime\prime}$,$P_2 = P_2^{~\prime\prime}$ であることから,うまく分割できていそうですね.
求めた左側のベジェ曲線と右側のベジェ曲線を描画すると下図の様になります.
うまいこと分割できていますね.
プログラム
行列を利用した分割プログラムの実装例を以下に示します.
import numpy as np from scipy.special import comb import matplotlib.pyplot as plt class Bezier: def __init__(self, points): points = [np.array(e).flatten() for e in points] self._n = len(points) self._points = points @property def dims(self): return self._n - 1 @property def points(self): return self._points @property def points4matplot(self): xs, ys = zip(*self.points) return xs, ys def _bernstein(self, n, i, t): return comb(n, i) * t**i * (1 - t)**(n-i) def bezier_point(self, t): p = np.zeros(2) for i, f in enumerate(self.points): p += self._bernstein(self.dims, i, t) * f return np.array(p).flatten() def split_with_matrix(self, t): M = self.create_Ut() iM = np.linalg.inv(M) Z = np.eye(self.dims + 1) for i in range(self.dims + 1): Z[i] = Z[i] * t ** i ## Caluclate Q Q = iM @ Z @ M xs, ys = self.points4matplot X = np.array(xs) Y = np.array(ys) left_bezier = Bezier(list(zip(Q @ X, Q @ Y))) ## Make Q' _Q = np.zeros((self.dims + 1, self.dims + 1)) lst = [] for i in reversed(range(self.dims + 1)): l = [-1] * i + list(range(self.dims + 1 - i)) lst.append(l) for i, l in enumerate(lst): mtx = [Q[i][e] if not e == -1 else 0 for e in l] _Q[i] = np.array(mtx) _Q = np.flipud(_Q) right_bezier = Bezier(list(zip(_Q @ X, _Q @ Y))) return left_bezier, right_bezier def create_Ut(self, dims=None): if dims is None: dims = self.dims U = np.zeros([dims + 1, dims + 1]) lmbd = lambda n, i, j: comb(n, j) * comb(n-j, i-j) * (-1)**(i - j) for i in range(dims + 1): lst = list(range(i+1)) + [-1]*(dims-i) elems = [lmbd(dims, i, j) if j >= 0 else 0.0 for j in lst] mtx = np.array(elems) U[i] = mtx return U def plot(self, ax=None, with_ctrl_pt=True, bcolor="black", ccolor="gray", resolution=100): if ax is None: _, ax = plt.subplots() prev_point = None for t in np.linspace(0, 1, resolution): bp = self.bezier_point(t) if prev_point is None: prev_point = (bp[0], bp[1]) xs, ys = zip(*(prev_point, (bp[0], bp[1]))) ax.plot(xs, ys, '-', color=bcolor) prev_point = (bp[0], bp[1]) if with_ctrl_pt: xs, ys = self.points4matplot ax.plot(xs, ys, 'x--', lw=2, color=ccolor, ms=10) return ax def main(): bezier = Bezier([(0, 1), (1, 4), (2, 0)]) ax = bezier.plot() left_bezier, right_bezier = bezier.split_with_matrix(0.3) left_bezier.plot(ax, bcolor = "red") right_bezier.plot(ax, bcolor = "blue") plt.grid() plt.show() if __name__ == "__main__": main()おわりに
本記事では$n$次ベジェ曲線の分割について紹介しました.
あまりまとまっていなかったかもしれませんが,ご容赦ください.
本記事の内容が誰かのお役に立てれば幸いです.参考文献
- 投稿日:2020-02-17T18:54:46+09:00
abc155参戦レポ
A
地味に実装が面倒臭かった。解説を聞いて反例を取り除けば実装が簡単そう。私はCounterを使った。
from collections import Counter a = Counter(map(int,input().split())) if 2 in a.values(): print("Yes") else: print("No")B
入力数の上限的に実装はそこまで難しくない。if文を一つにまとめられるようになりたい。
N = int(input()) A = list(map(int,input().split())) for a in A: if a % 2 == 1: continue if a % 3 != 0 and a % 5 != 0: print("DENIED") exit() print("APPROVED")C
もっとも出現回数が多い回数を変数に保存。その後ソートした文字列のうち、maxの回数と一致するもののみを表示。
from collections import Counter N = int(input()) S = Counter(input() for _ in range(N)) S = S.most_common() most_count = S[0][1] S.sort() for i in range(len(S)): if S[i][1] == most_count: print(S[i][0])D
問題文を見て嫌な予感がしたので、順位表へ。ほとんどの人がDよりもEを優先して解いていたのでスキップ
E
Dを飛ばしたは良いが実装できず。これは良くない。
- 投稿日:2020-02-17T18:35:59+09:00
Pythonを使ったRandom Forestで疾患分類
目的
自分のメモ用。
Random Forestを使って疾患Aと疾患Bを分ける。
入力したバイオマーカの内どれが重要かを調べる。
UCLの先行研究では、Accuracy74.0%だったのでそれを超えることが目標。作業環境
$ cat /etc/os-release NAME="Ubuntu" VERSION="18.04.3 LTS (Bionic Beaver)" ID=ubuntu ID_LIKE=debian PRETTY_NAME="Ubuntu 18.04.3 LTS" VERSION_ID="18.04" HOME_URL="https://www.ubuntu.com/" SUPPORT_URL="https://help.ubuntu.com/" BUG_REPORT_URL="https://bugs.launchpad.net/ubuntu/" PRIVACY_POLICY_URL="https://www.ubuntu.com/legal/terms-and-policies/privacy-policy" VERSION_CODENAME=bionic UBUNTU_CODENAME=bionic実行
主要なmoduleのimport
import modules import matplotlib.pyplot as plt import seaborn as sns from matplotlib import pyplot as plt import os import numpy as npFuture warningがうざいのでここで無視するよう指示。
# ignore warning import warnings warnings.simplefilter('ignore')resultをRF_resultに保存するため、RF_resultフォルダを作成。
# make directory if not os.path.isdir('RF_result'): os.mkdir('RF_result')データセットの読み込み。sys.argvを使うことで引数を指定してあげることができる。
ここでの引数はデータセットであるCSVファイルを指定してやればいい。
このデータセットにはコントロール群と疾患A, Bのデータがある。print('Start Random Forest...') # import csv file import sys args = sys.argv import pandas as pd df = pd.read_csv(args[1]).str.contains()で利用したいバイオマーカを絞る。
そしてデータだけ取り出し。# select biomarker #variable = df.iloc[:,0:672] # variable is from 1st to 672nd column. ## select map variable = df.loc[:,df.columns.str.contains('ICVF|OD|ISO|MVF')]欠損値medianでfillする。
# processing for defect values. variable = variable.fillna(variable.median()) #カテゴリ変数の変換 #df['Sex'] = df['Sex'].apply(lambda x: 1 if x == 'male' else 0) #df['Embarked'] = df['Embarked'].map( {'S': 0, 'C': 1, 'Q': 2} ).astype(int) #df = df.drop(['Cabin','Name','PassengerId','Ticket'],axis=1)コントロール群であってもAge,Sex,Intracranial Volume(ICV)によって個人差がある。
これらの影響を除くための処理。
線形近似し、y=ax+bの傾きaをゼロにするようにデータを補正。# adjust biomarkers for covariates from sklearn import linear_model def nu_freq(X_reg, y_reg): lr = linear_model.LinearRegression() lr.fit(X_reg, y_reg) return lr.coef_, lr.intercept_ def control_residuals(X, y, covar): control_covar = covar[y == 1].astype(float) control_X = X[y == 1].astype(float) n_biomarkers = control_X.shape[1] regr_params = dict((x, None) for x in range(n_biomarkers)) for i in range(n_biomarkers): mask = ~np.isnan(control_X[:, i]) & ~np.isnan(control_covar).any(axis=1) X_reg, y_reg = control_covar[mask, :], control_X[mask, i] regr_params[i] = nu_freq(X_reg, y_reg) residuals = X.copy() for key, value in regr_params.items(): residuals[:, key] -= regr_params[key][1] residuals[:, key] -= np.matmul(covar, regr_params[key][0]) return residuals ## read in covariates covars = df[['Age', 'Gender', 'ICV']].astype(float).values ## adjust biomarkers for covariates adjusted_variable = control_residuals(variable.values[:,0:672], df.Groups.values, covars) ## save data variable.to_csv("./RF_result/pre_adjusted_variable.csv", index=False) adjusted_variable_save = pd.concat([pd.DataFrame(variable.columns).T, pd.DataFrame(adjusted_variable)], axis=0) adjusted_variable_save.to_csv("./RF_result/post_adjusted_variable.csv", index=False)実際にやりたいのは、コントロール群、疾患A, Bの3分類ではなく、疾患A, Bの2分類なので
疾患A, Bのみをpick up。## select subject adjusted_variable = adjusted_variable_save[(df['Groups'] == 2)| (df['Groups'] == 3)] #print(adjusted_variable) Groups = df.Groups[(df['Groups'] == 2)| (df['Groups'] == 3)]ついにRandom Forest(ランダムフォレスト)を実行。
ハイパーパラメータの最適化もしたいのでGrid search(グリッドサーチ)を実行。
(都合上最適化されたものを記載。)# random forest #from sklearn.ensemble import RandomForestClassifier #from sklearn.metrics import (roc_curve, auc, accuracy_score) #clf = RandomForestClassifier(n_estimators=100, random_state=0) #clf = clf.fit(train_X, train_y) # training #pred_y = clf.predict(test_X) # validation #fpr, tpr, thresholds = roc_curve(test_y, pred_y, pos_label=1) #print('AUC:', auc(fpr, tpr)) #print('Accuracy:', accuracy_score(pred_y, test_y)) # Grid Search # Create the parameter grid based on the results of random search ## Create a based model from sklearn.ensemble import RandomForestClassifier from sklearn.model_selection import GridSearchCV param_grid = { 'bootstrap': [True], 'max_depth': [120], # [110,115,120,125,130] 'max_features': [200], # [200,212,225,273,250] 'min_samples_leaf': [4], # [4, 5] 'min_samples_split': [8], # [8, 10, 12] 'n_estimators': [130] # [100,110,120,130] } clf = RandomForestClassifier(random_state=5) # random_state=5, 10, Accuracy:0.754 # Instantiate the grid search model grid_search = GridSearchCV(estimator = clf, param_grid = param_grid, cv = 5, n_jobs = -1, verbose = 1) ## Fit the grid search to the data grid_search = grid_search.fit(adjusted_variable, Groups) # training print("\nBest Parameter is below.") print(grid_search.best_params_) print("\n")Grid searchで最適化されたパラメータでone leave out(one-leave-out)を実行。
1件1件の正誤と平均のAccuracyが算出される。
今回の場合だと、75.4%。# validation from sklearn.model_selection import cross_val_score from sklearn.metrics import recall_score best_grid = grid_search.best_estimator_ ## k-fold cross validation #scores = cross_val_score(best_grid, adjusted_variable, Groups, cv=5) ## leave-one-out from sklearn.model_selection import LeaveOneOut scores = cross_val_score(best_grid, adjusted_variable, Groups, cv = LeaveOneOut()) #分類器としてLeaveOneOut()を指定 print('Cross-Validation scores: {}'.format(scores)) print('Average score: {}'.format(np.mean(scores)))重要度(importance)の算出と図示。
さらに保存。# importance ## visualyze features = variable.columns importances = best_grid.feature_importances_ indices = np.argsort(importances) plt.figure(figsize=(10,10)) plt.barh(range(len(indices)), importances[indices], color='b', align='center') plt.yticks(range(len(indices)), features[indices]) plt.savefig('RF_result/importance.png') ## save importance values importance = pd.DataFrame({ 'Valiable' :features[indices], 'Importance' :importances[indices]}) importance.to_csv("./RF_result/importance.csv", index=False)使用した決定木の保存。
# save the trees(forest) import pydotplus from IPython.display import Image from graphviz import Digraph from sklearn.externals.six import StringIO from sklearn import tree print('\nSaving result to "RF_result" folder...') for i in range(1, 101): dot_data = StringIO() tree.export_graphviz(best_grid.estimators_[i-1], out_file=dot_data,feature_names=variable.columns) graph = pydotplus.graph_from_dot_data(dot_data.getvalue()) graph.write_png('./RF_result/tree' + str(i) + '.png') print('Done')まとめ
今回は、Random forestを使って疾患分類をしてみた。
我々の実験だと75.4%で先行研究の74.0%より1.4%高かった。
先行研究ではGray matter volumeのみであったが、我々はdiffusion MRIから得られるmapを入力。
とりあえず、SensitivityとSpecificityを調べたい。
- 投稿日:2020-02-17T18:07:16+09:00
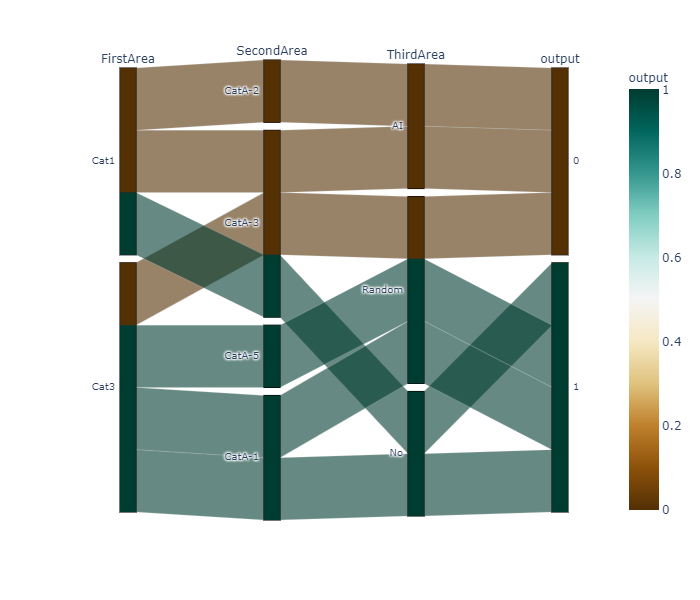
初心者でもできる‼PlotlyでSankeyDiagramを簡単に書く方法
SankyDiagramとは
サンキー・ダイアグラム(英Sankey diagram)は工程間の流量を表現する図表である。
矢印の太さで流れの量を表している。特にエネルギーや物資、経費等の変位を表す為に使われる。
出典:Wikipediaplotly(PlotlyExpress)で実装するメリット
- データフレームを読み込める。
- コードが簡単に書ける。
- インタラクティブなグラフなので、ユーザーが動かすことができる
PlotlyでのSankeyDiagramの実装
import pandas as pd import plotly.express as px # DF生成 # 1行のデータが推移を表すようにデータフレームを作成する df =pd.DataFrame([['Cat1', 'CatA-2', 'AI', 'Normal'], ['Cat1', 'CatA-3', 'AI', 'Normal'], ['Cat1', 'CatA-3', 'No', 'NG'], ['Cat3', 'CatA-3', 'Random', 'Normal'], ['Cat3', 'CatA-5', 'Random', 'NG'], ['Cat3', 'CatA-1', 'Random', 'NG'], ['Cat3', 'CatA-1', 'No', 'NG']], columns=['one','two','three',"output"]) # カテゴリー変数をダミー変数に # データフレーム最終列が文字列だとエラー? df["output"] = pd.get_dummies(df["output"]) fig = px.parallel_categories(df, dimensions=['one','two','three','output'], color="output", color_continuous_scale=px.colors.diverging.BrBG, labels={'one':'FirstArea', 'two':'SecondArea', 'three':'ThirdArea','output':'output'} ) fig.show()
- 投稿日:2020-02-17T17:56:53+09:00
大規模日本語ビジネスニュースコーパスを学習したALBERT(MeCab+Sentencepiece利用)モデルの紹介
はじめに
以前、日本語のBERT事前学習済モデルやXLNet事前学習済モデル等の紹介記事を投稿しましたストックマークの森長です。
モデル公開の記事を多くの皆様に読んでいただき、ありがとうございます。今回は、ALBERTの日本語事前学習済モデルを公開します。
さて、様々な事前学習済モデルが多数提案されている中、なぜALBERT日本語モデルを公開するかといいますと、ALBERTが、A Lite BERTと記載されるように、ただSOTAを突き詰めたものではなく、精度を維持・向上させつつもBERTを軽量化しているモデルのためです。事前学習済モデルのサイズを大きくすると性能が向上する傾向にありますが、学習時間が長くなったりメモリにのらなくなったり、作成の上での制約が(費用面の制約も)増えてきます。そのため、比較的短時間でモデルを作成でき、モデルサイズが小さいALBERTは、とても使いやすいです。
ALBERTとは
ALBERTとは、BERTを以下の手法を用いて、軽量かつ高速に学習できるよう提案されたモデルです。
- 因数分解とパラメータ共有を利用したパラメータ削減
- モデルサイズの縮小、学習時間の低減に寄与
- BertのNext Sentence PredictionタスクをSentence Order Predictionタスクに変更
- モデルの精度向上に寄与
ここでは作成したモデルのパラメータ/実験設定を述べるに留め、ALBERTというモデルの詳細説明については割愛させていただきます。
弊社のALBERT事前学習済モデルの特徴
学習元データ
以前公開しましたBERTの事前学習済モデルと同様に学習用データを日本語ビジネスニュース記事としています。そのため、本モデルは、主にビジネスに関するドメインで効果を発揮します。
tokenizer
弊社では、tokenizerにMeCab + NEologd及びSentencepieceを利用して、文章をトークン化しています。
まず、MeCabを利用することで形態素として正しく分割し、その上でSentencepieceを行うことで、語彙のカバー範囲を広げています。事前学習済モデルの詳細
事前学習用データ トークナイザー 語彙数 正規化 シーケンス長 日本語ビジネスニュース記事(300万記事) MeCab + NEologd 及び Sentencepiece 32,000語 NFKD 128 ダウンロード
公式(TensorFlow)とPyTorch版で利用可能なモデルを公開します。
ダウンロードリンク
モデルの内訳は以下の通りです。
- TensorFLow版
- model.ckpt.meta、 model.ckpt.index、 model.ckpt.data-00000-of-00001、 checkpoint
- config.json
- spiece.model (Sentencepieceのモデル)
- PyTorch版
- pytorch_model.bin
- config.json
- spiece.model (Sentencepieceのモデル)
利用方法
事前学習済モデルの使用にあたっては、TensorFlow版及びPyTorch版で公開されているサンプルスクリプトで動作しますが、入力データ(入力文章)をMeCab+NEologdでわかち書きしてください。
ALBERTの日本語事前学習済モデルを利用した所感
BERTとの比較
弊社の検証用タスク(記事の分類)においては、ALBERT-baseがBERT-baseを1%程度下回る性能となっていましたが、ALBERTはパラメータ数がBERTに比べ大幅に削減されている中で、この精度は十分実用的です。
論文でも同様にbaseモデルの比較ではALBERTの性能が少しだけ低く報告されていますが、ALBERTの凄いところは、BERT-baseモデルよりも少ないパラメータ数(モデルサイズ)のALBERT-largeで、BERT-baseの性能を越えています。
(具体的な数値は論文のTable 2をご参照ください。)今後はALBERT-large、xlarge、xxlargeと同等のパラメータサイズのALBERTモデルを作成して利用していきます。
モデルサイズについて
リソースが限られている中で、モデルサイズが50〜500MB程度に抑えられることは以下の点でとても使いやすかったです。(モデルサイズが大きいと何かと待ち時間が増えてしまいます…)
- 事前学習・検証・推論時のHDD,SSDの容量削減
- デプロイ(モデルのダウンロード速度等)の高速化
まとめ
最後までお読みいただき、ありがとうございました。
BERT、XLNet等と同様に公開したALBERT事前学習済モデルが、自然言語処理の盛り上がりに少しでも貢献ができると大変嬉しいです。
- 投稿日:2020-02-17T17:56:39+09:00
【Python】ウェブサイトの最終更新日を取得
大雑把でもいい。サイトの更新日を知りたい。
クロールしたサイトをサイト更新の日付順に並び替えたいのですが、サイトの更新日を取得する方法がわからなかったので調べました。
参照
pythonでWEB上に置いてあるファイルのタイムスタンプの取得を行いたい。投稿 2017/10/13 14:41
Last-ModifiedHTTP の Last-Modified レスポンスヘッダーは、リソースが最後に変更されたとオリジンのサーバーが判断している日時を含みます。これは受信または保存されたリソースが、同じものであるかを判断する検証材料として使用されます。 ETag ヘッダーよりも精度は低く、その代替手段になります。
実装
get_lastmodified.pyimport requests res = requests.head('https://www.kantei.go.jp') print(res.headers['Last-Modified']) import datetime html_timestamp = datetime.datetime.strptime(res.headers['Last-Modified'], "%a, %d %b %Y %H:%M:%S GMT") print(html_timestamp)% python get_lastmodified.py Mon, 17 Feb 2020 08:27:02 GMT 2020-02-17 08:27:02datetimeの標準フォーマットへの変換も行っています。
- 投稿日:2020-02-17T17:35:00+09:00
How to "web scrape" with BeautifulSoup
# uname -sr; tail -1 /etc/lsb-release Linux 4.15.0-55-generic DISTRIB_DESCRIPTION="Ubuntu 18.04.2 LTS" # apt install python3-pip # pip3 install BeautifulSoup4 # pip3 install lxml#!/usr/bin/env python3 import re import sys import requests from bs4 import BeautifulSoup as bs4 url = sys.argv[1] key = sys.argv[2] html = requests.get(url) soup = bs4(html.content,'lxml',from_encoding='utf-8') for script in soup(["script", "style"]): script.decompose() text = soup.get_text() regex = re.compile(key) for line in text.splitlines(): if line: match = regex.search(line) if match: print("%s, %s" % (url, line))# python3 bs4.py http://www.sakura.ad.jp VPS http://www.sakura.ad.jp, さくらのVPS
- 投稿日:2020-02-17T17:33:03+09:00
yahooルートラボからStravaへの自動データ移行
yahooルートラボからStravaへの自動データ移行
Yahooのルートラボは、2020年3月をもって終了してしまいます。
サービスが終了するまでにルートラボからgpxファイルをダウンロード、Stravaにアップロードし、今まで自分が走ったルートをstravaに保存しましょう!1. 自分の使用しているGoogle Chromeのバージョンを調べる
画像はhttps://www.iijmio.jp/thissite/version より2. Google Chromeに合った、"chromedriver"というソフトウェアをダウンロードする
- ここからダウンロードしてください。
- ダウンロードしたものは、.zip形式になっているので、展開したものの実行形式のものを自分のディレクトリに入れてください。
3. ターミナルを開いて、以下をターミナルで実行
pip install beautifulsoup4 pip install requests pip install selenium4. 以下のソースコードを自分の環境に合わせて書き換える
gpx.pyimport os import re import time from bs4 import BeautifulSoup import requests from selenium import webdriver from selenium.webdriver.chrome.options import Options options = Options() options.binary_location = '/Applications/Google Chrome.app/Contents/MacOS/Google Chrome' driver = webdriver.Chrome("/Users/ホームディレクトリ名/Downloads/chromedriver") def read_urls(): with open("./urls.txt", "r") as f: for row in f: yield row.replace("\n", "") def download_gpx(urls): for url in urls: response = requests.get(url) html = response.text soup = BeautifulSoup(html, "html.parser") gpx_tag = soup.find_all("a", href=re.compile("gpx")) route_name = soup.find(id="subtitle").string download_url = gpx_tag[0].get('href') res = requests.get("https://latlonglab.yahoo.co.jp/route/" + download_url.lstrip(".")) save_name = route_name + ".gpx" with open(save_name, "wb") as f: f.write(res.content) yield save_name def upload_gpx_to_strava(gpx_names): for i, gpx_name in enumerate(gpx_names): driver.get('https://labs.strava.com/gpx-to-route/#12/-122.44503/37.73651') driver.find_element_by_id("gpxFile").send_keys(os.path.join("/Users/ホームディレクトリ名/Documents/gpx/", gpx_name)) time.sleep(15) if i == 0: driver.find_element_by_id("oauthButton").click() driver.switch_to.window(driver.window_handles[-1]) driver.find_element_by_id("email").send_keys("stravaのユーザ名") driver.find_element_by_id("password").send_keys("パスワード") login_button = driver.find_element_by_id("login-button") driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") login_button.click() time.sleep(5) driver.switch_to.window(driver.window_handles[-1]) driver.find_element_by_id("saveButton").click() time.sleep(5) driver.find_element_by_class_name("save-route").click() driver.find_element_by_id("name").send_keys("\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b\b"+os.path.splitext(os.path.basename(gpx_name))[0]) driver.find_element_by_class_name("reverse").click() time.sleep(5) if __name__ == "__main__": urls = list(read_urls()) gpx_names = download_gpx(urls) upload_gpx_to_strava(gpx_names)5. gpx.pyと同じディレクトリに以下のようなルートラボへのリンクがのったurls.txtを配置
urls.txthttps://latlonglab.yahoo.co.jp/route/hoge1 https://latlonglab.yahoo.co.jp/route/hoge2 https://latlonglab.yahoo.co.jp/route/hoge3 ...6. 以下を実行
python gpx.py


- 投稿日:2020-02-17T17:18:15+09:00
AWS Lambda Layersを用いてLambda関数から外部ライブラリを読み込む。Amazon Linux 2のPython環境も整います。(Python3.6、Anaconda)
AWS Consoleにログインし、EC2からAmazon Linux 2を立てます。
インスタンスタイプはt2.microで、確認と作成ボタンをクリックします。※後述しますが、t2.mediumにしてください。
セキュリティーグループは各自で設定してください。SSH接続用に22番ポートを開けておきます。
既存のキーペアを選択、なければ新規作成してください。SSH接続する際に必要です。
インスタンスの作成中です。インスタンスの表示をクリックします。
インスタンスの状態がrunning、ステータスチェックが2/2のチェックになったら完了です。
インスタンスの作成が完了したら、IPv4パブリックIPをコピーして、PuTTYからSSH接続します。
PuTTYを開いて、Host NameのところにIPアドレスを入力してください。
Connection->SSH->Authからキーペアを選択します。PuTTYgenを用いて、.pemから.ppkに変換したものを使用します。
はいをクリックします。
ec2-userでログインできます。
ログインしたら、Pythonのバージョンを確認します。いまだにPython2系がデフォルトになっているようです。
$ python Python 2.7.16 (default, Dec 12 2019, 23:58:22) [GCC 7.3.1 20180712 (Red Hat 7.3.1-6)] on linux2 Type "help", "copyright", "credits" or "license" for more information. >>> exit()Anacondaをインストールします。AnacondaのサイトからダウンロードURLをコピーします。
ダウンロードURLに対してwgetし、bashでインストールします。
$ wget https://repo.anaconda.com/archive/Anaconda3-2019.10-Linux-x86_64.sh $ bash Anaconda3-2019.10-Linux-x86_64.shEnterで規約を読み、yesを入力。Enterでインストール開始。
Please answer 'yes' or 'no':' >>> yes Anaconda3 will now be installed into this location: /home/ec2-user/anaconda3 - Press ENTER to confirm the location - Press CTRL-C to abort the installation - Or specify a different location belowUnpacking payload ... 0%| | 0/291 [00:00<?, ?it/s]で止まったままになってしまった。
t2.mediumでできるらしいので、インスタンスの停止、インスタンスタイプの変更を行います。
current latest miniconda sh installer for linux hangs on Unpacking payload step #9345Anacondaのインストールができたら、Python3.6環境を作成します。
$ /home/ec2-user/anaconda3/bin/conda create -n py36 python=3.6 $ /home/ec2-user/anaconda3/bin/conda initインスタンスを再起動し、py36環境でpythonフォルダにライブラリをインストールします。
$ conda activate py36 $ mkdir python $ pip install -t ./python requests $ pip install -t ./python ulid-py $ pip install -t ./python pillow $ pip install -t ./python numpy $ pip install -t ./python opencv-python $ pip install -t ./python opencv-contrib-python $ pip install -t ./python pandas $ pip install -t ./python matplotlib $ pip install -t ./python foliumpythonフォルダをzip化します。
$ zip -r GachiLayers.zip pythonzipファイルをS3へアップロードするために、awscliの設定とboto3をインストールします。
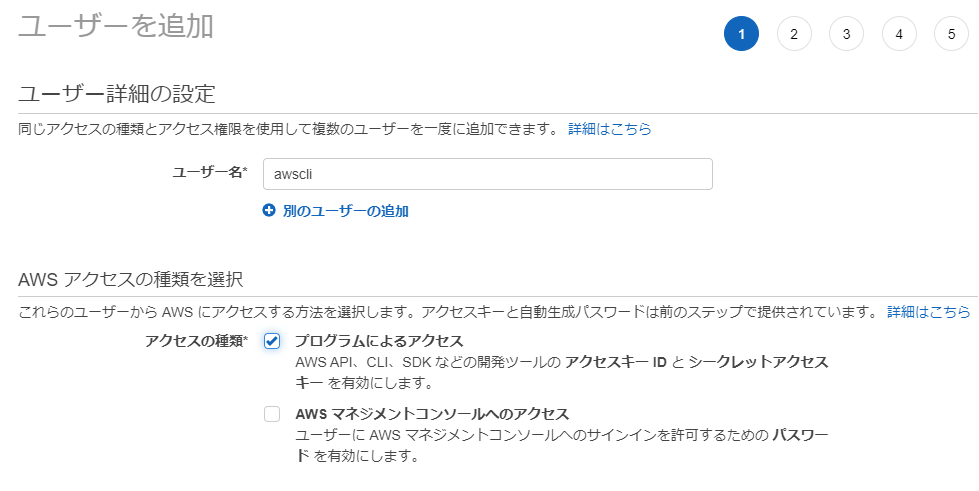
$ pip install awscli $ pip install boto3AWS Console の IAM からユーザーを作成し、AWS Access Key と Secret Access Key を取得します。
AmazonS3FullAccessのアクセス権限を与えておきます。
タグは特になし。
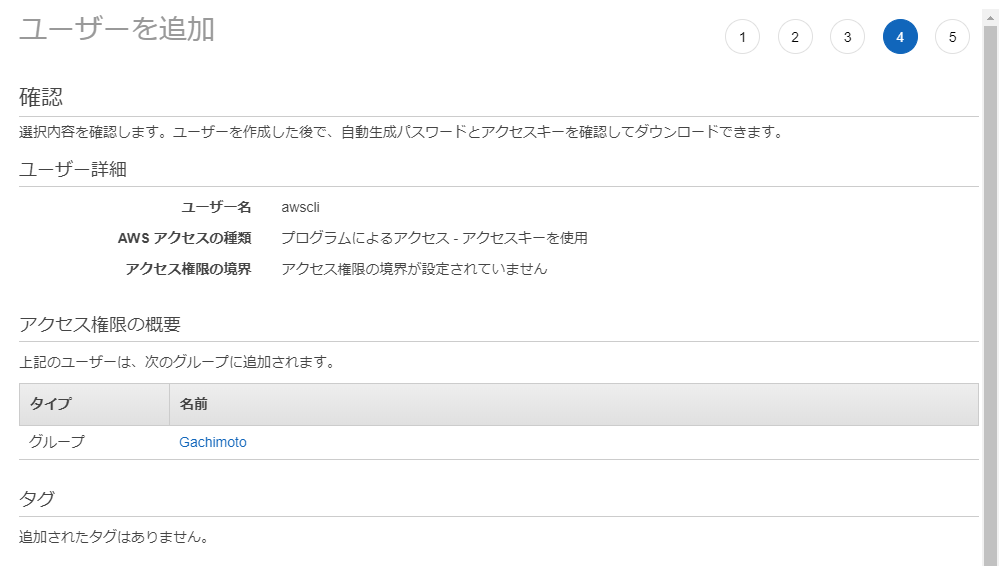
確認します。
作成に成功したら、aws configure に必要なAWS Access Key と Secret Access Key を取得できるので、大事に保管しておきます。
AWS Configureの設定、AWS Access Key と Secret Access Key を入力します。
$ aws configure AWS Access Key ID [None]: xxxxxxxxxxxxxxxxxxxx AWS Secret Access Key [None]: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx Default region name [None]: ap-northeast-1 Default output format [None]: jsonZipファイルをS3へアップロードするためのPythonプログラムを作成します。S3バケットを新規作成しておくこと。
$ vi upload.pyimport boto3 filename = 'GachiLayers.zip' s3 = boto3.resource('s3') obj = s3.Object(<INSERT YOUR BUCKET NAME>, filename) response = obj.put(Body = open(filename, 'rb'))実行します。
$ python upload.pyS3にアップロードされていることを確認します。
AWS Console から Lambda を開き、Layersからレイヤーを作成します。
作成できました。
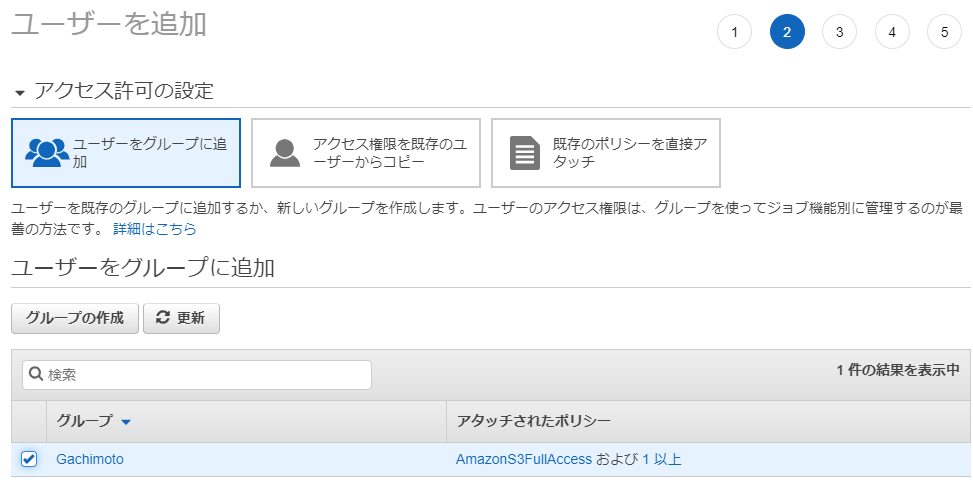
Lambda関数を作成(ランタイムはPython3.6)し、Layerを追加します。
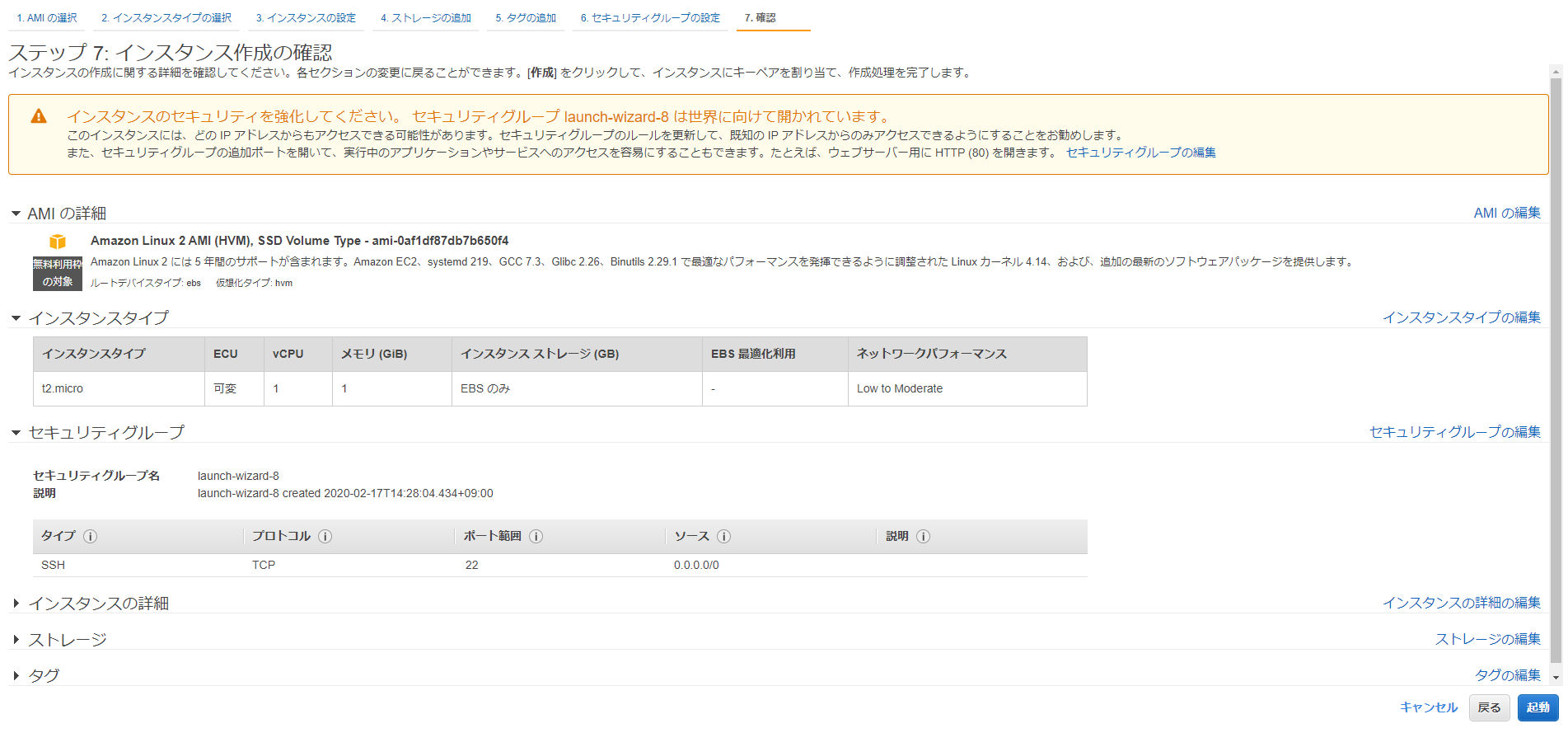
作成したレイヤーを選択。
Lamda関数を編集して、ライブラリが読み込まれていることを確認しましょう。
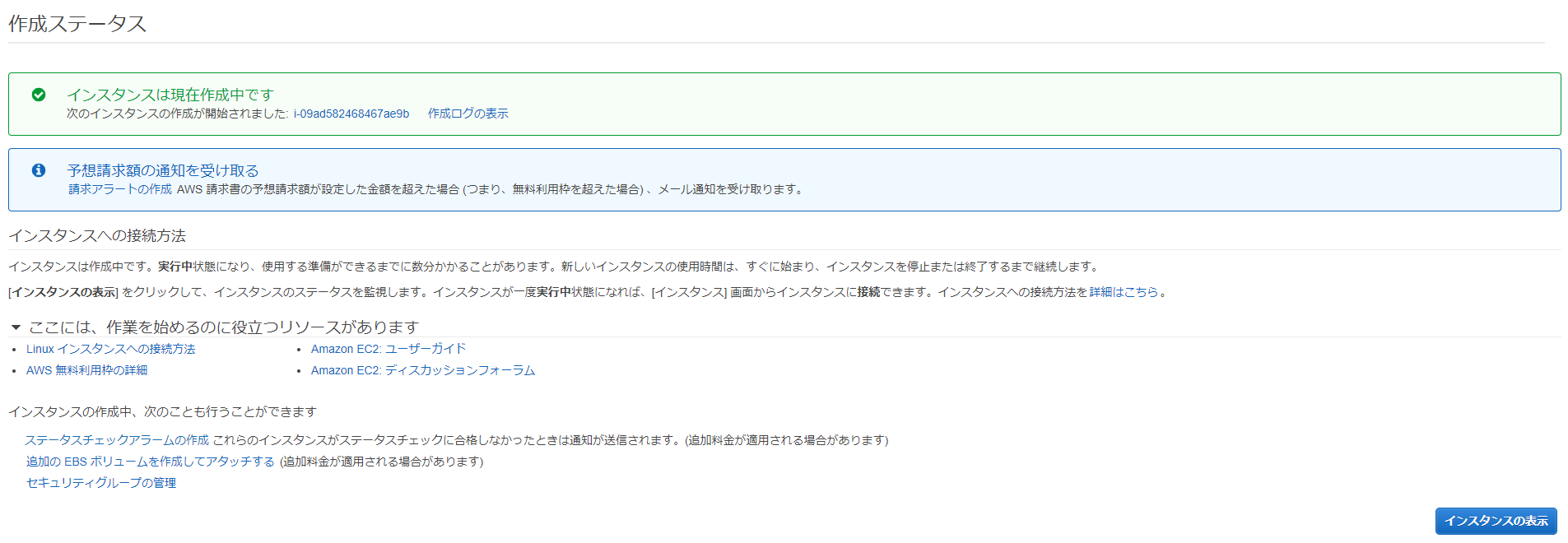
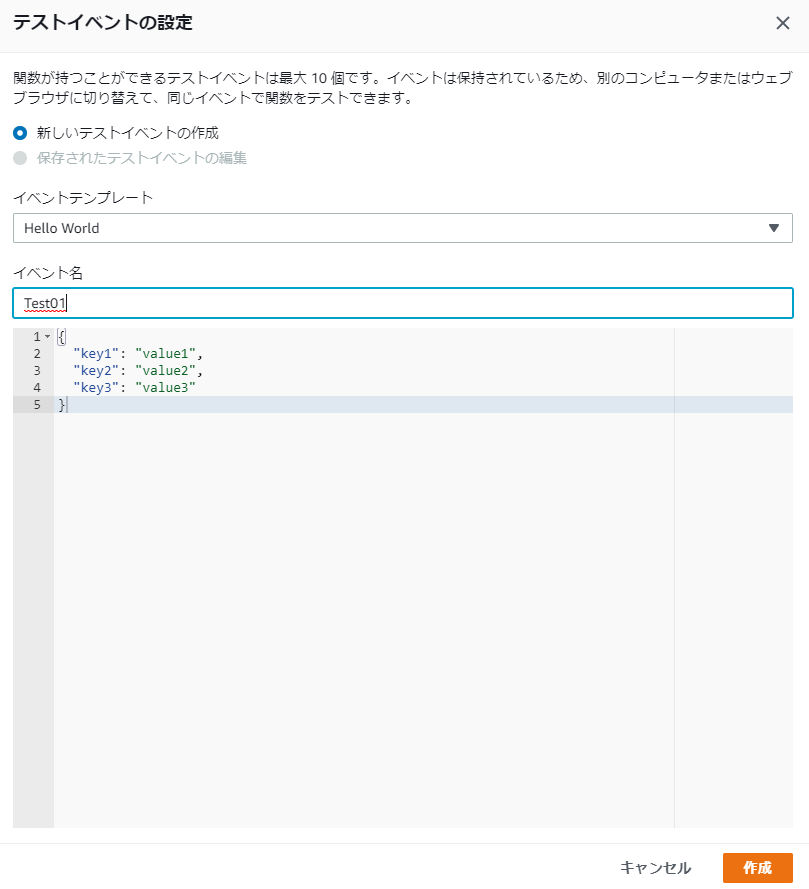
import json import requests import ulid from PIL import Image import numpy as np import cv2 import pandas as pd import matplotlib.pyplot as plt import folium from folium import plugins def lambda_handler(event, context): # TODO implement return { 'statusCode': 200, 'body': json.dumps('Hello from Lambda!') }テストイベントを作成します。
実行できれば、ライブラリが読み込まれているはずです。
Response: { "statusCode": 200, "body": "\"Hello from Lambda!\"" }お疲れ様でした。終わったらインスタンス消してもいいです。








- 投稿日:2020-02-17T17:17:32+09:00
紙まみれの会社でもRPAで自動化ができる! - Automation Anywhere の IQ Bot -
こんにちは。
世界的には最大手ながら、日本では後発のRPAベンダー・Automation Anywhere の、
IQ Bot という製品をご存じですか?製品の公式サイト↓には何かいろいろすごいこと書いていますが……
https://www.automationanywhere.com/jp/products/iq-bot要するに、これを使って何ができるかというと、
「今、紙を使ってやっている業務をRPAによる自動化の対象にできる!」
ってことなんです。
それの何がすごいの・・・? と思ったあなたも、
うおー! すげー!! 革命的!!! と思ったあなたも、ぜひぜひこの記事を読んでみてください。紙をインプットに自動化ができるメリット
ここ数年、日本にもRPA化の波が来ていますが、どうです?
あなたの会社のRPA、ちゃんと効果出てますか?この質問に胸を張って「イエス!」って答えられる人って、はぐれメタルなみのレア度だと思います。
(2020.2.17現在)これにはいくつか原因があると思うんですが、
(その原因のひとつは日本でまだ Automation Anywhere が流行りきっていないからです! とけっこう本気で思ってます)結局、日本ってなんだかんだ言って「紙は偉大なり」の文化じゃないですか。
これがネックなんですよ・・・
紙が自動化(RPA化)のネックになる理由
今ある業務をRPAを使って自動化するには、いくつか前提があるんですが、
そのひとつが、「自動化対象業務のインプットとなるデータが構造化されている」ということ。
ちょっと難しい言葉を使いましたが、要するに、
ExcelとかCSVとかデータベースに入っているような形でデータが整備されている状態じゃないと、
そもそもRPAによる業務自動化の対象にならないってことです。
つまり、業務に紙がからんでいる限り、RPAによる自動化はできない というのが、従来の常識でした。
そして、せっかくRPAを使って業務を自動化しよう! と思った会社の担当者たちが、
あの業務も紙を使ってる、この業務も紙を使ってる……
ってことで、「結局自動化できる業務ってほとんどなくね?」ってなって、挫折をしていくわけであります。
で! IQ Botはまさに、その部分を解決するツールなのであります。
IQ Botで、紙を使った業務を自動化
IQ Botが何をやっているツールかといいますと、
要するに、「異なるフォーマットの紙(画像)データから、構造化データを取り出す!」ということです。
↑出典:
https://enterprisezine.jp/article/detail/12732?p=2これができると、従来は自動化の対象から漏れてしまっていた、たとえば以下のような業務が自動化の対象になります。
- 紙を見て、書いてある内容をデータ入力する業務
- 何かのシステムのデータと紙を照合・突合する業務
- 紙と紙とを照合・突合する業務
わかりやすく「紙」と言っていますが、メールに添付されてくる注文書や請求書のPDFなども対象になります。
どうです? こういう↑業務、「RPA化したいけど諦めたわー」って経験ないですか?
そんなあなたはぜひ、Automation AnywhereのIQ Botを試してみてください!
IQ Botを試すには
昨年末あたりにコミュニティ・エディション(クラウド)が出たので、
メールアドレスを登録するだけで、無料で試せます!
https://www.automationanywhere.com/lp/rpa-editions-comparison使い方は、Automation Anywhere Universityという無料のe-Learningで学べます。
https://university.automationanywhere.com/上記もメールアドレス等の登録が必要で、サイトが英語でびびりますが、
「インテリジェントな文書処理: IQ Bot のご紹介(V6.5)」という日本語のコンテンツがあります。そのうちQiitaでも使い方のTips的なところを書いていこうと思いますが、
IQ Botに今すぐ触りたくてたまらない方は、上記からぜひ試してみてください・・・!!※この記事は、日本でまだあまり知られていないIQ Botに関する知識・情報のシェアを目的としたものであり、商用・宣伝を目的としたものではありません。

- 投稿日:2020-02-17T17:08:30+09:00
モジュール間結合度についてPythonのコード付きでまとめてみる
目的
基本情報で勉強して以来あまり触れて無くて、当時はコードを書いてみたりはしていなかったので改めて勉強として。
モジュール間結合度とは?
モジュールとモジュールの関連がどれぐらい強いかを示しています。
モジュール間結合度が低くなるようにすることで、モジュールの独立性を高めることができるとされています。
モジュールの独立性が高まると、以下のようなメリットがあります。
- モジュールが再利用しやすくなる
- テストがしやすくなる
- 仕様変更時の影響範囲を狭めることができる
例えば、以下のコードを見てみましょう。
この関数は現在の西暦をもとに、うるう年かどうか判断をしています。モジュール独立性の低いコードは再利用性も低い
from datetime import datetime from calendar import isleap #今年がうるう年かどうか判断し、結果を出力する関数 def A(): this_year = datetime.now().year if isleap(this_year): print('今年はうるう年です') else: print('今年はうるう年ではありません')では、このモジュールに「10年前がうるう年だったか判断する仕組み」を取り入れたくなったとします。
from datetime import datetime from calendar import isleap #今年がうるう年かどうか判断し、結果を出力する関数 def A(): this_year = datetime.now().year if isleap(this_year): print('今年はうるう年です') else: print('今年はうるう年ではありません') #10年前がうるう年かどうか判断し、結果を出力する関数 def B(): this_year = datetime.now().year - 10 if isleap(this_year): print('10年前はうるう年です') else: print('10年前はうるう年ではありません')モジュール独立性が低いコードはテストしにくい
ほぼ同じようなコードが書かれており、そもそも直感的にあまり良い気がしないでしょう。
さらに、テストをするときにも問題があります。
仮に関数Aに以下のようなテストデータを投入し、うるう年が正しく判定されるかテストしたくなったとします。
テストデータ 期待値 2000 今年はうるう年です 2020 今年はうるう年です 2100 今年はうるう年ではありません さて、どのようにテストしますか?
そうなんです。これではテストができません。
なぜなら、関数A・Bともに「現在の西暦を求める処理」と「うるう年を判断する仕組み」が紛れ込んでしまっており、それぞれの機能として独立していないからです。したがって、このようにするのが良いでしょう。
def A(year): if isleap(year): print('今年はうるう年です') else: print('今年はうるう年ではありません')このように、西暦情報は外から投入するようにします。
これで10年前であろうが100年前であろうが200年後であろうが、テストデータが複数あろうが関数は一つで済みます。モジュール結合度には評価基準がある
モジュール間結合度には種類があります。
評価基準 モジュール間結合度 モジュール独立性 内部結合 高い 低い 共通結合 外部結合 制御結合 スタンプ結合 データ結合 低い 高い では、ここからはコード付きでまとめていきます。
今回はPythonで再現してみます。内部結合
これに関しては今どきほぼありえなくて、なかなか再現が難しいのですが...
強いて言うならこんな感じでしょうか。こんなモジュールがあります。
username, level, attack, defence等がグローバル変数として定義されています。moduleA.pyusername = 'hogehogekun' level = 25 attack = 20 defence = 5 def show_user_status(): print('ユーザ名:' + username) print('レベル:' + str(level)) print('攻撃力:' + str(attack)) print('防御力:' + str(defence))これを利用するコードがあったとします。
main.pyimport moduleA #レベルを1上げる moduleA.level += 1 #moduleAの関数を利用してステータスを表示 moduleA.show_user_status()結果ユーザ名:hogehogekun レベル:26 攻撃力:20 防御力:5レベルは初期値が25でしたが、1増えています。
挙動としては問題ありませんが、moduleAの挙動はmainモジュールの挙動に深く依存してしまっています。共通結合
では、ユーザの情報を一つのクラスにまとめ、それらを一つのリストで管理していたとしましょう。
moduleA.pyclass User: def __init__(self, username, level, attack, defence): self.username = username self.level = level self.attack = attack self.defence = defence def show_user_status(self): print('ユーザ名:' + self.username) print('レベル:' + str(self.level)) print('攻撃力:' + str(self.attack)) print('防御力:' + str(self.defence)) #ユーザの一覧をリストで管理 user_list = [User('hogehogekun', 75, 90, 80), User('fugafugakun', 10, 5, 7)]そして、このモジュールを利用するmainA内に2つの関数があったとします。
mainA.pyimport moduleA def funcA(): del(moduleA.user_list[0]) def funcB(): print(moduleA.user_list[0].username) #funcA、funcBの順で実行 funcA() funcB()結果fugafugakun今回、あろうことかfuncAはグローバルなリストの先頭要素を削除してしまいました。
funcBが覗いたときには、hogehoge君はとっくに消えてしまい、fugafugaのみが残っていました。
ちなみにfuncBがmoduleA.user_list[1]を参照していた場合はIndexErrorが発生してしまいます。
このように、共通結合では共通のデータ構造の一部を変更したり削除したりした場合には、その共通部品を参照している全モジュールを見直す必要が出てきます。外部結合
共通結合と非常に良く似ていますが、共有されている情報がリストやオブジェクトなどのデータ構造というよりは単体のデータの集まりという認識です。
今回は、仮に累積ユーザ数とサービスステータスという情報があったとします。
moduleA.pyclass User: def __init__(self, username, level, attack, defence): self.username = username self.level = level self.attack = attack self.defence = defence def show_user_status(self): print('ユーザ名:' + self.username) print('レベル:' + str(self.level)) print('攻撃力:' + str(self.attack)) print('防御力:' + str(self.defence)) user_count = 123091 #累計ユーザ数 service_status = 200 #サービスの状況main.pyimport moduleA def funcA(): print(moduleA.user_count) def funcB(): print(moduleA.service_status) funcA() funcB()結果123091 200このコードは挙動上の問題はありません。ユーザ数もサービスステータスもfuncA、funcB内で正しく取得できています。しかし、moduleA.pyのservice_statusが数値型ではなく、文字型になるなどの仕様変更があった場合には、該当する情報を参照しているfuncBの修正が必要になります。
制御結合
制御結合は、呼び出し先の関数の処理分けを引数を使って操作します。
今回のコードでは、some_commandに1を渡すか2を渡すかで異なる処理が行われます。moduleA.pyclass User: def __init__(self, username, level, attack, defence): self.username = username self.level = level self.attack = attack self.defence = defence def some_command(self, command_id): if command_id == 1: #ステータス表示コマンド print('ユーザ名:' + self.username) print('レベル:' + str(self.level)) print('攻撃力:' + str(self.attack)) print('防御力:' + str(self.defence)) elif command_id == 2: #レベルアップコマンド print(self.username + 'のレベルが1上がった!') self.level += 1main.pyfrom moduleA import User user1 = User('hogehogekun', 40, 20, 20) user1.some_command(1) user1.some_command(2)結果ユーザ名:hogehogekun レベル:40 攻撃力:20 防御力:20 hogehogekunのレベルが1上がった!スタンプ結合
いつもどおりのUserクラスです。
今回はmain.pyのfuncAとfuncBのやり取りに着目します。
funcA内でfuncBを呼び出し、引数としてリストを渡すというなんだかそれっぽいコードに見えます。moduleA.pyclass User: def __init__(self, username, level, attack, defence): self.username = username self.level = level self.attack = attack self.defence = defence def show_user_status(self): print('ユーザ名:' + self.username) print('レベル:' + str(self.level)) print('攻撃力:' + str(self.attack)) print('防御力:' + str(self.defence))別モジュールではこのような動きをしていたとします。
main.pyfrom moduleA import User def funcA(): user_list = [User('hogehogekun', 20, 10, 10), User('fugafugakun', 99, 99, 99), User('piyopiyokun', 99, 99, 99)] funcB(user_list) def funcB(user_list): print(user_list[2].username) funcA()結果piyopiyokunこの時点では何も問題ありませんが、例えばfuncAの要素数が変わってしまった場合、funcBは影響を受けます。
main.pydef funcA(): user_list = [User('hogehogekun', 20, 10, 10), User('fugafugakun', 99, 99, 99)] funcB(user_list) def funcB(user_list): print(user_list[2].username) funcA()結果IndexError: list index out of rangeスタンプ結合ではリストごと受け渡しを行ってはいるものの、呼び出し側モジュールでは一部の情報しか利用していません。今回だとfuncBは3つの要素を持つリストを渡されているにも関わらず、3つめの要素しか利用していません。このとき、スタンプ結合ではfuncB側で利用していない要素(今回はその個数)に変更が入ったとしても、funcBは影響を受けてしまう可能性があります。
データ結合
複数のモジュール間で受け渡す情報が最小限になります。
スタンプ結合の例を踏襲すると、このような感じです。moduleA.pyclass User: def __init__(self, username, level, attack, defence): self.username = username self.level = level self.attack = attack self.defence = defence def show_user_status(self): print('ユーザ名:' + self.username) print('レベル:' + str(self.level)) print('攻撃力:' + str(self.attack)) print('防御力:' + str(self.defence))main.pydef funcA(): user_list = [User('hogehogekun', 20, 10, 10), User('fugafugakun', 99, 99, 99), User('piyopiyokun', 99, 99, 99)] funcB(user_list[2]) def funcB(target_user): print(target_user.username) funcA()結果piyopiyokunfuncBではpiyopiyokunのみを処理の対象としているので、そもそも受け渡すデータはuser_list[2]のみとします。これでuser_listの個数が減った場合、funcAに影響はありますがfuncBに影響は無いはずです。
そもそもuser_listの個数が減るということはfuncAを修正しているということですから、影響範囲はかなり小さくなっているのではないでしょうか。このように、必要な情報のみをやりとりすることによってモジュールの結合度を弱くすることができます。
追記:手元にあった本を読んでいたら、「呼び出される側のモジュールは受け取った引数によって呼び出した側のデータを直接操作できるようにする」と書いてありました。つまり参照渡しをせよということになるようです。この辺りは開発者や開発手法によって考え方にばらつきがあるようでした。
まとめ
モジュールの強度は高く、モジュール間の結合度は低く設定することで色々なメリットがあります。
- テストがしやすい
- 再利用性が高まる
- 仕様変更時の影響範囲が狭くなる
等ですね!
- 投稿日:2020-02-17T16:29:57+09:00
jupyter notebookの.ipynbファイルをpythonで実行可能な.pyファイルに変換する
XXX.ipynbは対象のnotebookファイル名。
以下のコマンドを実行すると、XXX.pyファイルが作成されます。jupyter nbconvert --to python XXX.ipynb
- 投稿日:2020-02-17T15:53:30+09:00
スポーツくじでスコア合計の新しいくじが始まるみたいだけど、
背景
- スポーツくじは、日本スポーツ振興センター(JAPAN SPORT COUNCIL)が運営する業務の一つで、「スポーツ振興」のための資金を得るために販売しています。日本スポーツ振興センター:スポーツ振興投票等業務
- スポーツくじで最高当選金6億円の「BIG」を超える「MEGA BIG」が今月から発売されます。
- 「BIG」は勝ち・分け・負けで14試合が対象で「MEGA BIG」はスコア合計で1点以下・2点・3点・4点以上で12試合が対象となります。
種別 対象試合 投票種類 確率 % BIG 14 1,0,2 1/4,782,969 0.00000020907 MEGA BIG 12 1,2,3,4 1/16,777,216 0.0000000596
- 絶望的な「BIG」を超えて、形容する言葉すらない「MEGA BIG」です。
本題
- Jリーグの試合では、スコア合計はどんな分布になっているだろうか?
- J3リーグが始まった2014年から2019年までの6年間で6,130試合を対象にした。
- 内訳は、J1:1,836試合、J2:2,772試合、J3:1,522試合です。
処理の流れ
1) 2014年から2019年までJleague Data Siteの日程・結果ページからデータを取得する
2) 1)で取得したCSVファイルを読み込みDataFrameを作成する。
3) さらにJ1・J2・J3のみのDataFrameを別途作成する。
4)matplotlibで4つのグラフを作成する。
5) 「スコア合計」を「MEGA BIG」の1点以下・2点・3点・4点以上に集計する。
6) その集計結果をグラフにする。コード
①2014年から2019年までJleague Data Siteの日程・結果ページからデータを取得する
年度 大会 節 試合日 K/O時刻 ホーム スコア アウェイ スタジアム 入場者 TV放送 0 2014 J1 第1節第1日 03/01(土) 14:04 C大阪 0-1 広島 ヤンマー 37079 スカパー!/スカパー!プレミアムサービス/NHK総合 1 2014 J1 第1節第1日 03/01(土) 14:04 名古屋 2-3 清水 豊田ス 21657 スカパー!/スカパー!プレミアムサービス/NHK名古屋/NHK静岡 2 2014 J1 第1節第1日 03/01(土) 14:05 鳥栖 5-0 徳島 ベアスタ 14296 スカパー!/スカパー!プレミアムサービス/NHK徳島/NHK佐賀 3 2014 J1 第1節第1日 03/01(土) 14:05 甲府 0-4 鹿島 国立 13809 スカパー!/スカパー!プレミアムサービス/NHK甲府/NHK水戸 4 2014 J1 第1節第1日 03/01(土) 14:05 仙台 1-2 新潟 ユアスタ 15852 スカパー!/スカパー!プレミアムサービス/NHK仙台/NHK新潟 ② ①で取得したCSVファイルを読み込み
DataFrameを作成する。col_name = ['年度','大会','節','試合日','K/O時刻','ホーム','スコア','アウェイ','スタジアム','入場者','TV放送'] results = pd.DataFrame(index=[], columns=col_name) for f in files: tmp_data = pd.read_csv(f, sep=',', encoding='utf-8') results = results.append(tmp_data, ignore_index=True, sort=False)③さらにJ1・J2・J3のみ
DataFrameを別途作成する。# J1・J2・J3のみデータのスコア合計 score_J1 = score_data[score_data['大会'] == 'J1'] idx_J1 = sorted(score_J1['スコア合計'].unique()) scoreJ1 = pd.DataFrame({'スコア合計':idx_J1, 'cnt':score_J1['スコア合計'].value_counts()}, index=idx_J1) scoreJ1 = scoreJ1.reset_index().drop('index', axis=1) score_J2 = score_data[score_data['大会'] == 'J2'] idx_J2 = sorted(score_J2['スコア合計'].unique()) scoreJ2 = pd.DataFrame({'スコア合計':idx_J2, 'cnt':score_J2['スコア合計'].value_counts()}, index=idx_J2) scoreJ2 = scoreJ2.reset_index().drop('index', axis=1) score_J3 = score_data[score_data['大会'] == 'J3'] idx_J3 = sorted(score_J3['スコア合計'].unique()) scoreJ3 = pd.DataFrame({'スコア合計':idx_J3, 'cnt':score_J3['スコア合計'].value_counts()}, index=idx_J3) scoreJ3 = scoreJ3.reset_index().drop('index', axis=1)④
matplotlibで4つのグラフを作成する。# J1・J2・J3・全体をグラフ化 fig = plt.figure(figsize=(16,9),dpi=144) fig.subplots_adjust(hspace=0.4) # オリジナルのグラフスタイル設定 plt.style.use("mystyle") plt.rcParams["font.family"] = "IPAexGothic" # グラフオブジェクトの格納用 axes = [] score_list = [scoreJ1['スコア合計'], scoreJ2['スコア合計'], scoreJ3['スコア合計'], score_all['スコア合計']] cnt_list = [scoreJ1['cnt'], scoreJ2['cnt'], scoreJ3['cnt'], score_all['cnt']] cat_list = ['J1', 'J2', 'J3', 'ALL'] # J1・J2・J3・ALLの4つのグラフをループで for i in range(4): axes.append(fig.add_subplot(4,1,i+1)) axes[i].bar(score_list[i], cnt_list[i]) [axes[i].text(score_list[i][s], cnt_list[i][s]+25, str(score), size=12, color='r', ha='center') for s, score in enumerate(cnt_list[i])] axes[i].set_xticks(np.arange(0,16,1)) axes[i].set_ylabel(cat_list[i]) axes[i].set_ylim(0,1500) axes[i].text(15-1, 1500-200, 'n:'+str(sum(cnt_list[i]))) plt.xlabel('スコア合計') txt1 = 'Jリーグで試合のスコア合計を可視化してみた。' fig.text(.05, .9, txt1, fontsize=32, horizontalalignment="left") txt2 = "引用元:JLeague Data Site" fig.text(.9, .05, txt2, fontsize=14, horizontalalignment="right") plt.savefig('./img/score.png') plt.show()
⑤「スコア合計」を「MEGA BIG」の1点以下・2点・3点・4点以上で「Mega」列を追加
# MEGAのスコア分類にする def mega(df): if df in (2, 3): return df elif df <= 1: return 1 elif df >=4: return 4 score_data['Mega'] = score_data['スコア合計'].apply(mega)⑥その集計結果をグラフにする。
まとめ
- どのリーグでも0点・1点・2点・3点の累積で全体の約75%となる。
- 0点・1点・2点・3点・4点以上の5種類とするより、出現率を平均化して、0点と1点を1として4種類としたのではないかと思われる?(推測)
- 技術的な共有は少なく、事実の共有が中心となりました。
- グラフで複数の描画を
forにループや内包表記でコード量が少なくできた。- スポーツくじは、残念ながらさらに「見返りのない寄付」色が強くなったという話。
- 投稿日:2020-02-17T15:47:35+09:00
pyenv+poetry環境下のnumpy,scipyでmklを使いたい
what's this?
表題通り, pyenv+poetry環境のnumpy, scipyでmklを使おうとする話.
解決策がわかれば簡単なのだけど, そこにたどり着くまでが意外と長かった...
環境はmac OS 10.14.6 Mojave
pyenvのバージョンは1.2.16-5-g7097f820
poetryのバージョンは1.0.3
です.結論(解決策)
多分, この記事を見てる人は同じような問題に当たっていち早く解決したいという人が多いでしょうから, 結論(解決策)を先に書きます.
プロジェクト名は
my-project, 使用するpythonのバージョンは3.7.4として進めます.
mklが標準通り/opt/intel/にインストールされていることとします.
プロジェクトのディレクトリに .venv を作るように設定されていることとします(poetry config virtualenvs.in-project true).プロジェクトディレクトリ作成 & pythonバージョン指定(ここは普通)
プロジェクトディレクトリを作成して, pythonのバージョンを指定.
ここまでは普通.$ mkdir my-project && cd $_ $ pyenv local 3.7.4仮想環境の設定(普通じゃない)
普通はpoetryが勝手に
.venvを作ってくれるから自分で.venvを作る必要はないのだが, 今回は
.venv/bin/activateを編集して, mklのための環境変数を設定する.venv/pip.confを編集して, numpy,scipyをbuildするようにしたりするので, 自分で
.venvを作る.$ python -m venv .venvmklのための環境変数を設定
$ echo -e "source /opt/intel/bin/compilervars.sh intel64\nsource /opt/intel/mkl/bin/mklvars.sh\nsource /opt/intel/tbb/bin/tbbvars.sh" >> .venv/bin/activate
.venv/pip.confを作成し,no-binary=numpy,scipy,no-use-pep517を設定.$ touch .venv/pip.conf && echo -e "[install]\nuse-pep517=false\nno-binary=numpy,scipy" >> .venv/pip.confnumpyビルド用のコンフィグファイル
$HOME/.numpy-site.cfgを次の内容で作成.[mkl] library_dirs = $MKLROOT/lib include_dirs = $MKLROOT/include mkl_libs = mkl_rt lapack_libs =pyproject.tomlの用意(ここは普通)
準備が整ったので
poetry init$ poetry init This command will guide you through creating your pyproject.toml config. Package name [my-project]: Version [0.1.0]: Description []: Author [hogehoge, n to skip]: License []: Compatible Python versions [^3.7]: Would you like to define your main dependencies interactively? (yes/no) [yes] no Would you like to define your dev dependencies (require-dev) interactively (yes/no) [yes] no Generated file [tool.poetry] name = "my-project" version = "0.1.0" description = "" authors = ["hogehoge"] [tool.poetry.dependencies] python = "^3.7" [tool.poetry.dev-dependencies] [build-system] requires = ["poetry>=0.12"] build-backend = "poetry.masonry.api" Do you confirm generation? (yes/no) [yes]cythonのインストール
まずは
cythonを入れる.$ poetry add cythonnumpyのインストール
次に
numpy.$ poetry add numpyここで,
poetry run python -c "import numpy; numpy.show_config()"とすると,Traceback (most recent call last): (中略) Original error was: dlopen(/path/to/my-project/.venv/lib/python3.7/site-packages/numpy/core/_multiarray_umath.cpython-37m-darwin.so, 2): Library not loaded: @rpath/libmkl_rt.dylib Referenced from: /path/to/my-project/.venv/lib/python3.7/site-packages/numpy/core/_multiarray_umath.cpython-37m-darwin.so Reason: image not foundと出ることがある.1
こうなった場合,$ install_name_tool -add_rpath $MKLROOT/lib .venv/lib/python3.7/site-packages/numpy/core/_multiarray_umath.cpython-37m-darwin.soを実行する.
すると,$ poetry run python -c "import numpy; numpy.show_config()" blas_mkl_info: libraries = ['mkl_rt', 'pthread'] library_dirs = ['/opt/intel/compilers_and_libraries_2020.0.166/mac/mkl/lib'] define_macros = [('SCIPY_MKL_H', None), ('HAVE_CBLAS', None)] include_dirs = ['/opt/intel/compilers_and_libraries_2020.0.166/mac/mkl', '/opt/intel/compilers_and_libraries_2020.0.166/mac/mkl/include', '/opt/intel/compilers_and_libraries_2020.0.166/mac/mkl/lib'] blas_opt_info: libraries = ['mkl_rt', 'pthread'] library_dirs = ['/opt/intel/compilers_and_libraries_2020.0.166/mac/mkl/lib'] define_macros = [('SCIPY_MKL_H', None), ('HAVE_CBLAS', None)] include_dirs = ['/opt/intel/compilers_and_libraries_2020.0.166/mac/mkl', '/opt/intel/compilers_and_libraries_2020.0.166/mac/mkl/include', '/opt/intel/compilers_and_libraries_2020.0.166/mac/mkl/lib'] lapack_mkl_info: libraries = ['mkl_rt', 'pthread'] library_dirs = ['/opt/intel/compilers_and_libraries_2020.0.166/mac/mkl/lib'] define_macros = [('SCIPY_MKL_H', None), ('HAVE_CBLAS', None)] include_dirs = ['/opt/intel/compilers_and_libraries_2020.0.166/mac/mkl', '/opt/intel/compilers_and_libraries_2020.0.166/mac/mkl/include', '/opt/intel/compilers_and_libraries_2020.0.166/mac/mkl/lib'] lapack_opt_info: libraries = ['mkl_rt', 'pthread'] library_dirs = ['/opt/intel/compilers_and_libraries_2020.0.166/mac/mkl/lib'] define_macros = [('SCIPY_MKL_H', None), ('HAVE_CBLAS', None)] include_dirs = ['/opt/intel/compilers_and_libraries_2020.0.166/mac/mkl', '/opt/intel/compilers_and_libraries_2020.0.166/mac/mkl/include', '/opt/intel/compilers_and_libraries_2020.0.166/mac/mkl/lib']となって幸せの予感...
scipyのインストール
最後にscipyを入れる.
ここまでうまくいっていればあとはすんなり行くはず.
(scipyのbuildは時間がかかります.気長に待ってください)$ poetry add scipy確認
poetry run python -c "import scipy; scipy.show_config()" lapack_mkl_info: libraries = ['mkl_rt', 'pthread'] library_dirs = ['/opt/intel/compilers_and_libraries_2020.0.166/mac/mkl/lib'] define_macros = [('SCIPY_MKL_H', None), ('HAVE_CBLAS', None)] include_dirs = ['/opt/intel/compilers_and_libraries_2020.0.166/mac/mkl', '/opt/intel/compilers_and_libraries_2020.0.166/mac/mkl/include', '/opt/intel/compilers_and_libraries_2020.0.166/mac/mkl/lib'] lapack_opt_info: libraries = ['mkl_rt', 'pthread'] library_dirs = ['/opt/intel/compilers_and_libraries_2020.0.166/mac/mkl/lib'] define_macros = [('SCIPY_MKL_H', None), ('HAVE_CBLAS', None)] include_dirs = ['/opt/intel/compilers_and_libraries_2020.0.166/mac/mkl', '/opt/intel/compilers_and_libraries_2020.0.166/mac/mkl/include', '/opt/intel/compilers_and_libraries_2020.0.166/mac/mkl/lib'] blas_mkl_info: libraries = ['mkl_rt', 'pthread'] library_dirs = ['/opt/intel/compilers_and_libraries_2020.0.166/mac/mkl/lib'] define_macros = [('SCIPY_MKL_H', None), ('HAVE_CBLAS', None)] include_dirs = ['/opt/intel/compilers_and_libraries_2020.0.166/mac/mkl', '/opt/intel/compilers_and_libraries_2020.0.166/mac/mkl/include', '/opt/intel/compilers_and_libraries_2020.0.166/mac/mkl/lib'] blas_opt_info: libraries = ['mkl_rt', 'pthread'] library_dirs = ['/opt/intel/compilers_and_libraries_2020.0.166/mac/mkl/lib'] define_macros = [('SCIPY_MKL_H', None), ('HAVE_CBLAS', None)] include_dirs = ['/opt/intel/compilers_and_libraries_2020.0.166/mac/mkl', '/opt/intel/compilers_and_libraries_2020.0.166/mac/mkl/include', '/opt/intel/compilers_and_libraries_2020.0.166/mac/mkl/lib']お疲れ様でした.
解決策に至るまで...
上の解決策に至るまでの道のりはそれなりに長かったのです.
その道のりをダイジェストでお送りします(ほぼ自分用のメモ).
読み飛ばして全く問題ないです.普通にやってみた
$ mkdir my-project $ pyenv local 3.7.4 $ python -m venv .venv $ poetry init
.venv/pip.confを[install] no-binary = numpy,scipyで作成して, それ以外の
~/.numpy-site.cfg,.venv/bin/activateは上の解決策と同じように編集.
poetry add numpyは成功する(rpath追加せなあかんけど)が,poetry add scipyを実行すると...[EnvCommandError] Command ['/path/to/my-project/.venv/bin/pip', 'install', '--no-deps', 'scipy==1.4.1'] errored with the following return code 1, and output: Collecting scipy==1.4.1 Using cached https://files.pythonhosted.org/packages/04/ab/e2eb3e3f90b9363040a3d885ccc5c79fe20c5b8a3caa8fe3bf47ff653260/scipy-1.4.1.tar.gz Installing build dependencies: started Installing build dependencies: still running... Installing build dependencies: finished with status 'done' Getting requirements to build wheel: started Getting requirements to build wheel: finished with status 'done' Preparing wheel metadata: started Preparing wheel metadata: finished with status 'error' ...(中略)... Original error was: dlopen(/private/var/folders/9x/94rd8dwd1vg49h9bt7_0kd0w0000gn/T/pip-build-env-mb4t9me7/overlay/lib/python3.7/site-packages/numpy/core/multiarray.cpython-37m-darwin.so, 2): Library not loaded: @rpath/libmkl_rt.dylib Referenced from: /private/var/folders/9x/94rd8dwd1vg49h9bt7_0kd0w0000gn/T/pip-build-env-mb4t9me7/overlay/lib/python3.7/site-packages/numpy/core/multiarray.cpython-37m-darwin.so Reason: image not foundターミナルが真っ赤になる.
numpyをbuildした後でnumpyを
no-binaryから外せばいいのでは?
.venv/pip.confを[install] no-binary = numpyとして
poetry add numpyでnumpyをインストール(ここでもrpathを追加しないとダメだが)した後,.venv/pip.confを[install] no-binary = scipyと書き直して
poetry add scipyとすると...うまく行く.けどなんか面倒なので...
もうちょっと探ってみる.pyenvだけで原因調査
端折りますが, pyenvだけでも同じ症状が出る...
/private/var/...でbuildしてるからダメなのでは?
pyenvだけの環境で--no-build-isolationをつけてpipでscipyをインストールしてみるとうまく行く.poetry環境で
no-build-isolationをつけてみる.poetryでも
build-isolationを無効にすればええんやろうと思って,.venv/pip.confを[install] build-isolation = false no-binary = numpy,scipyとしてやってみると...
無理でした.
ターミナルが真っ赤です.
泣きそうです.
no-use-pep517ならいけるのでは?色々調べてたら,
Use PEP 517 for building source distributions (use --no-use-pep517 to force legacy behaviour).
をpip reference guideで見つける.
...これ--no-use-pep517ならいけるのでは?
.venv/pip.confを[install] use-pep517=false no-binary=numpy,scipyとしてやってみる.
うまくいった.
こうして上の解決策にたどり着く.まとめ
面倒なのでよほどでない限りやらんほうがええと思う.
参考
poetry shellして仮想環境に入ってからpython起動してimport numpyするとこのエラーは出ない...けど, この状態だとpoetry add scipyが失敗するのでrpathを追加する他ない. ↩