- 投稿日:2020-02-17T23:57:42+09:00
JavaとGoの値渡し/参照渡しを整理する
自分はこれまでにJava, Goを勉強してきた。この二言語における値渡し/参照渡しをここで整理してしまう。
そもそも定義
値渡し(call by value): メソッドの引数に、新たに値のコピーを作って渡す方法のこと。参照渡し(call by reference): メソッドの引数に、変数そのものの参照を渡す方法のこと。Javaの場合
- メソッドへの引数は100%
値渡しで渡される。- が、Javaのオブジェクトが変数に収納されている時、そこに収納されているのは「そのオブジェクトが収納された場所を示す
参照値(reference value)」である- よって、オブジェクトを引数として渡すときにはその
参照値(reference value)のコピーが渡されている。- この結果、「引数に渡したオブジェクトが参照渡しで書き換えられている」かのように勘違いしそうになる。
Goの場合
- ポインタを引数として渡すことで
参照渡しを実現する。- Golangの構造体/Arrayは(Javaのオブジェクトとは違って)
値型。すなわちその全てのフィールド/要素を収納する場所を確保し、それを構造体を表す変数に収納しているイメージ。- よって構造体を
値渡しすると、そのフィールドの全てがコピーされる。これを書き換えても元の構造体は書き変わらない。- 一方で、map/sliceは(Javaのオブジェクトと同様)
参照型。すなわち変数に入っているのは要素のポインタが入った容器であり、各要素にアクセスするにはポインタを辿っているイメージ(参考)。- このため、これらを
値渡ししたとしても、元のmap/sliceが書き換わってしまう。よって、普通これらをポインタ渡しする意味はなく、普通そうしない(参考)。補足
参照渡し ≒ ポインタ渡しであるかのように書いたが、そこの細かいところはこちらに詳しい。値型/参照型の説明は正確ではないかもしれないのであくまでイメージとして捉えてほしい。参考
- もう参照渡しとは言わせない (だいぶ参考にさせていただきました)
- Goの値型と参照型
- 投稿日:2020-02-17T23:13:21+09:00
Spring Framework (STS)にPivotal tc server Developer Editionを作成する
開発環境
Windows10
workspace-spring-tool-suite-4-4.5.1.RELEASE (2020/2/17現在 英語版)初期状態
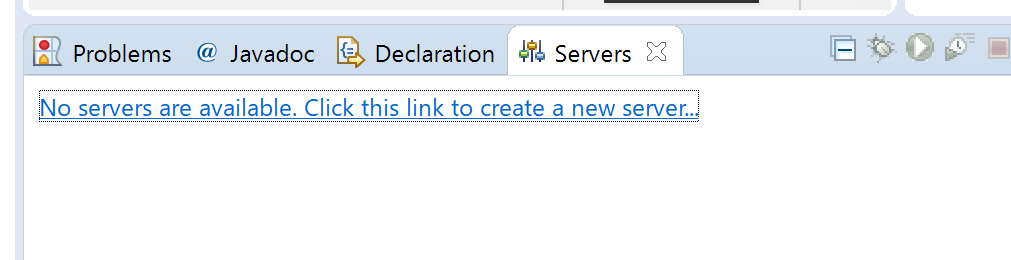
STS(Spring Tool Suite)のServersビューにPivotal tc server Developer Editionがない。
最終状態
STS上に、Pivotal tc server Developer Editionを構築し、サーバを起動する。
手順
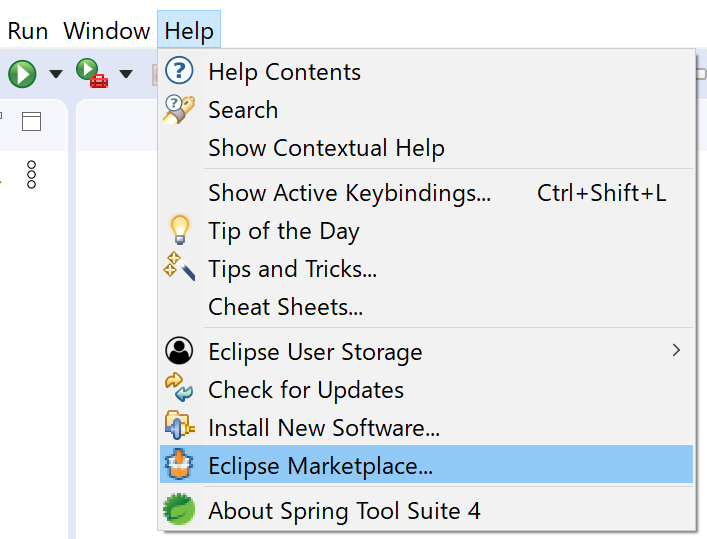
1.メニュー→Help→Eclipse Marketplace...を選択する。
2.Eclipse Marketplaceの画面になる。
SearchタブのFind:フィールドに「pivotal」と入力しEnterキーを押すと、「Pivotal tc Server Integration for Eclise 3.9.11.RELEASE」が表示される。
右下にあるInstallボタンを押す。しばらく待つ。
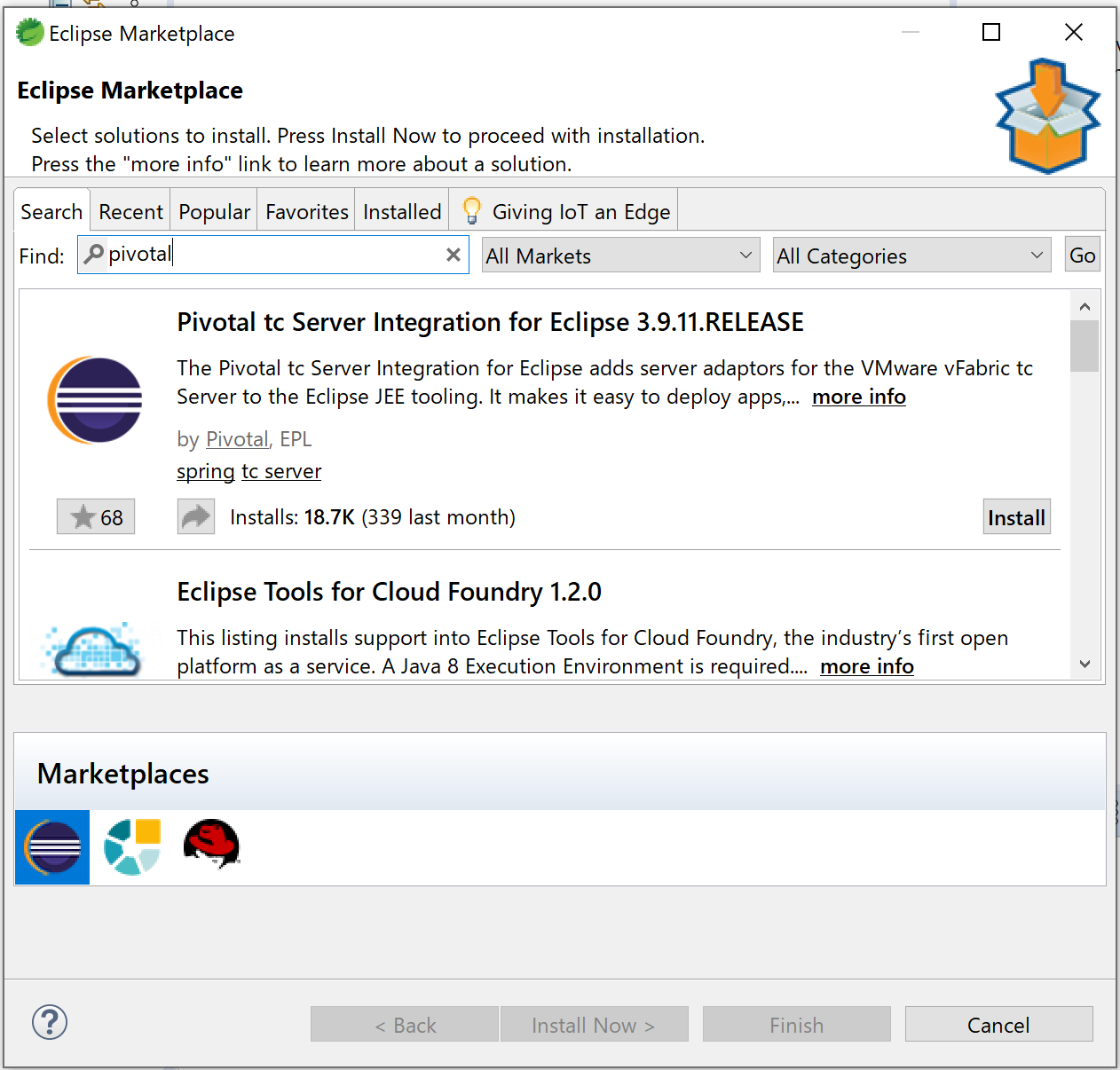
3.Confirm Selected Features の画面が表示される。
必要なソフトウェアにチェックが入っていることを確認して、Confirmボタンを押す。(今回はSpring Dashboardも同時にインストールする。)しばらく待つ。
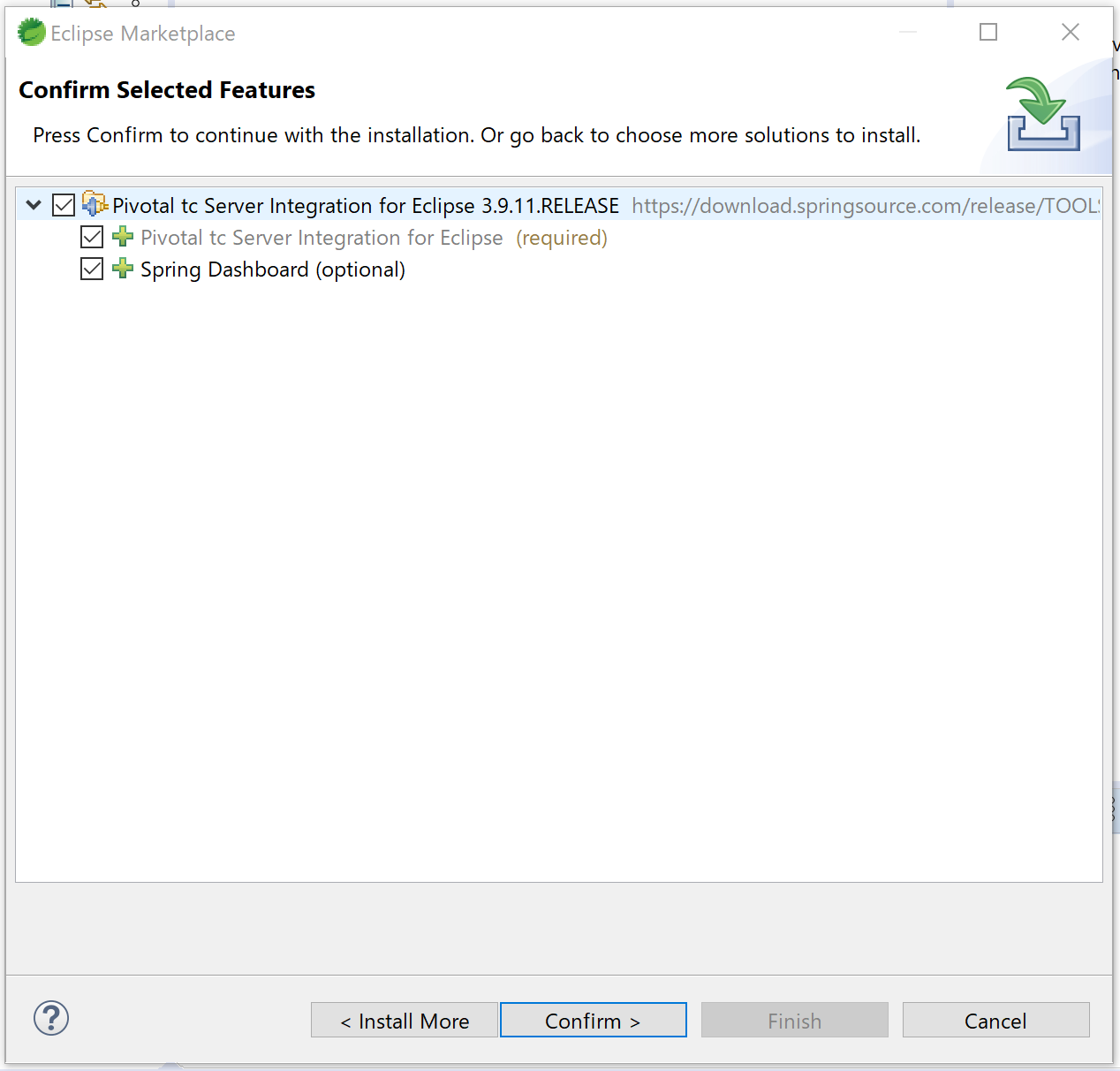
4.Review Licensesの画面になる。
使用条件に同意する。「I accept the terms of the license agreements」をONにしてFinishボタンを押す。
左下にInstalling Software(xx%)と表示されるのでしばらく待つ。
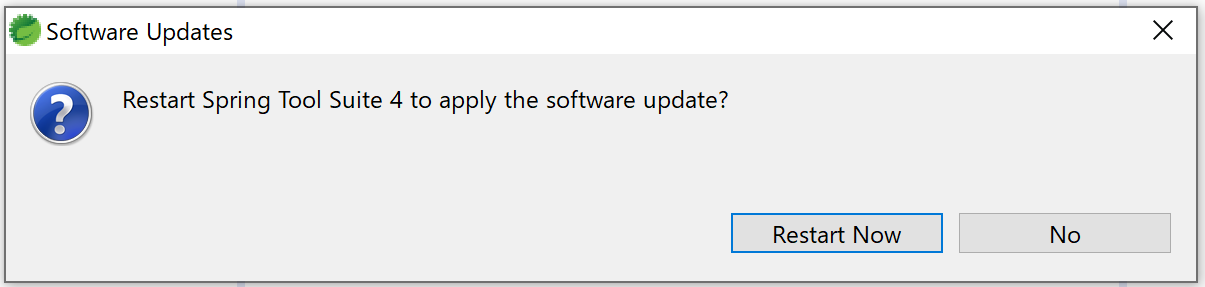
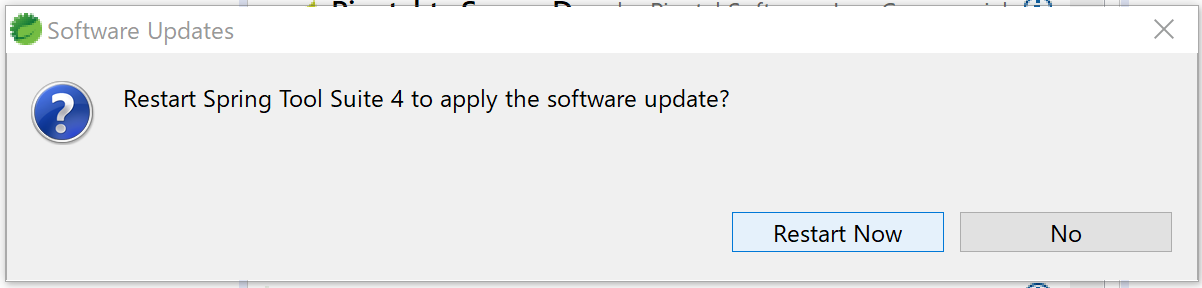
5.インストールが済んだら、STSを再起動する。
Restart Nowボタンを押す。
6.再起動すると自動的にダッシュボードの画面が表示される。
表示されない場合は、メニュー→Help→Dashboardで表示できる。
7.Dashboardを下方向にスクロールする。
Manageという囲みの中にある「IDE Extension」ボタンを押す。
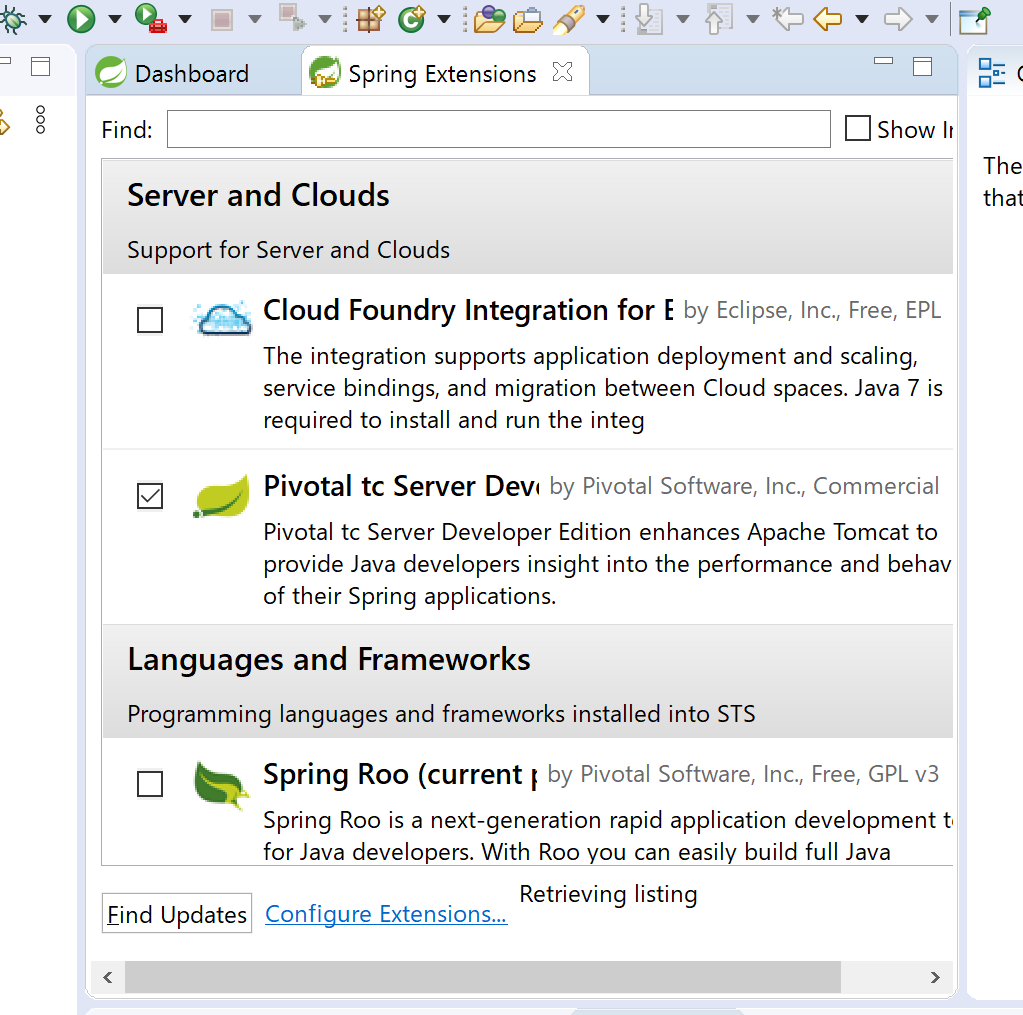
8.Spring Extensionsの画面にあるPivotal tc Server Developer Editionのチェックボックスにチェックを入れる。ウィンドウを一番下までスクロールして、右下にあるInstallボタンを押す。(分かりにくい場所にあるので注意)
9.画面の指示に従い、Nextボタンで進む。Review Licensesの画面になる。
使用条件に同意する。「I accept the terms of the license agreements」をONにしてFinishボタンを押す。左下にInstalling Software(xx%)と表示されるのでしばらく待つ。10.インストールが済んだら、STSを再起動する。Restart Nowボタンを押す。
11.Serversビューから「No servers are available.Click this link to~」のリンクをクリックする。
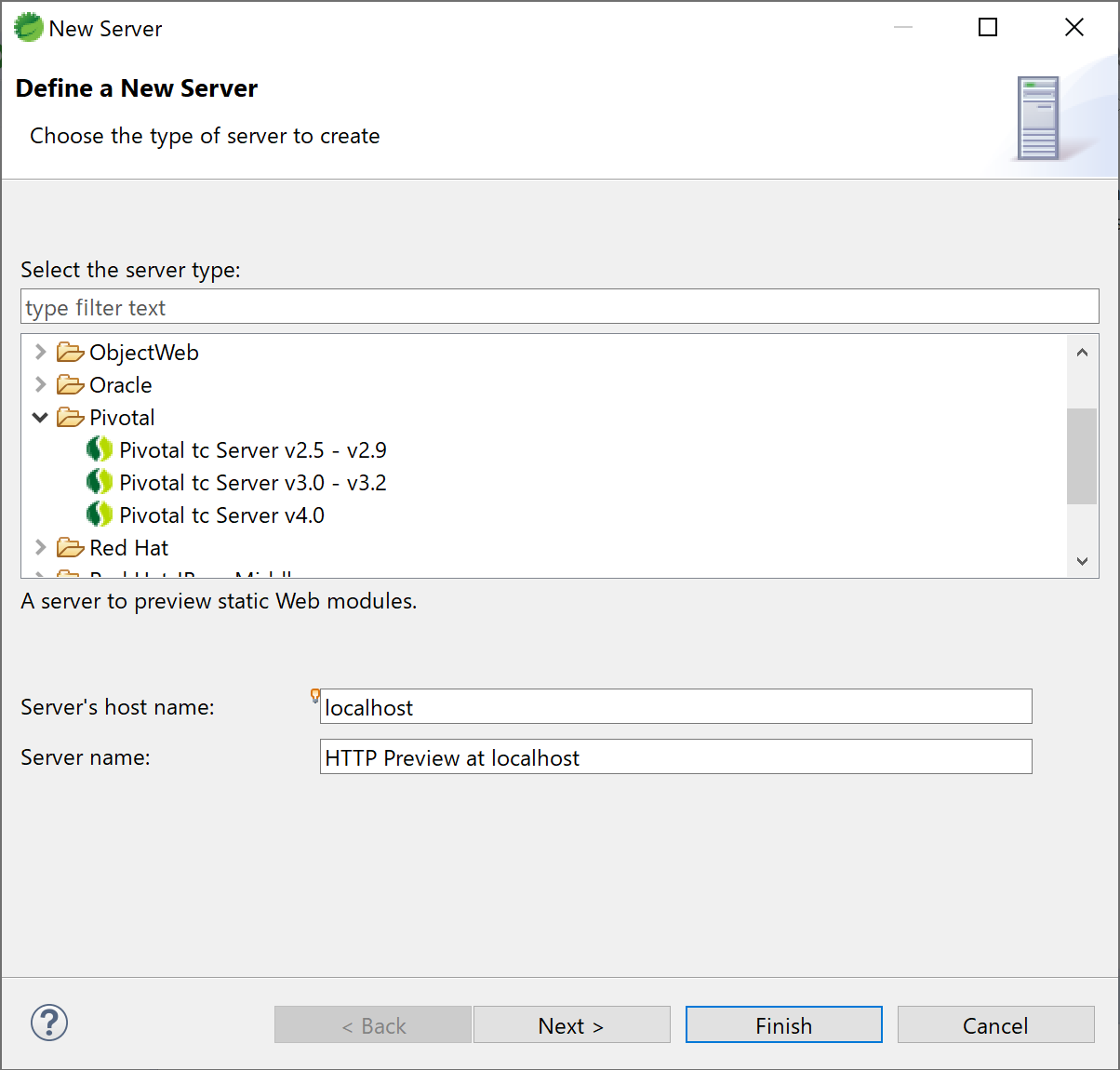
12.New Serverの画面が表示される。「Pivotal tc Server v4.0」を選択してNextボタンをクリックする。
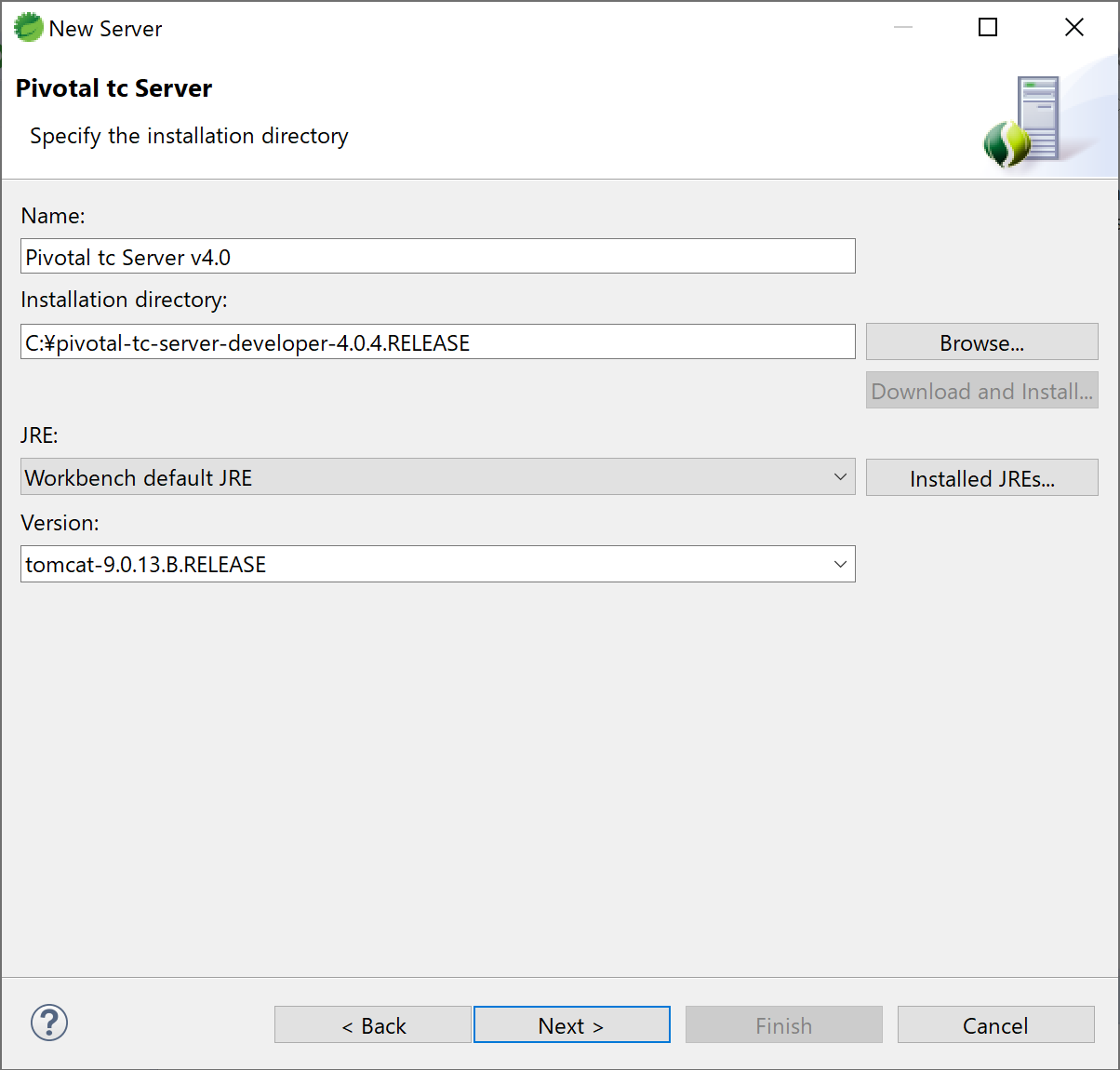
13.Pivotal tc Serverの画面になる。Installation directoryのテキストボックスに、pivotal-tc-server-developer-4.0.4.RELEASEの場所を指定する。(通常はc:ドライブの直下にある) Nextボタンを押す。
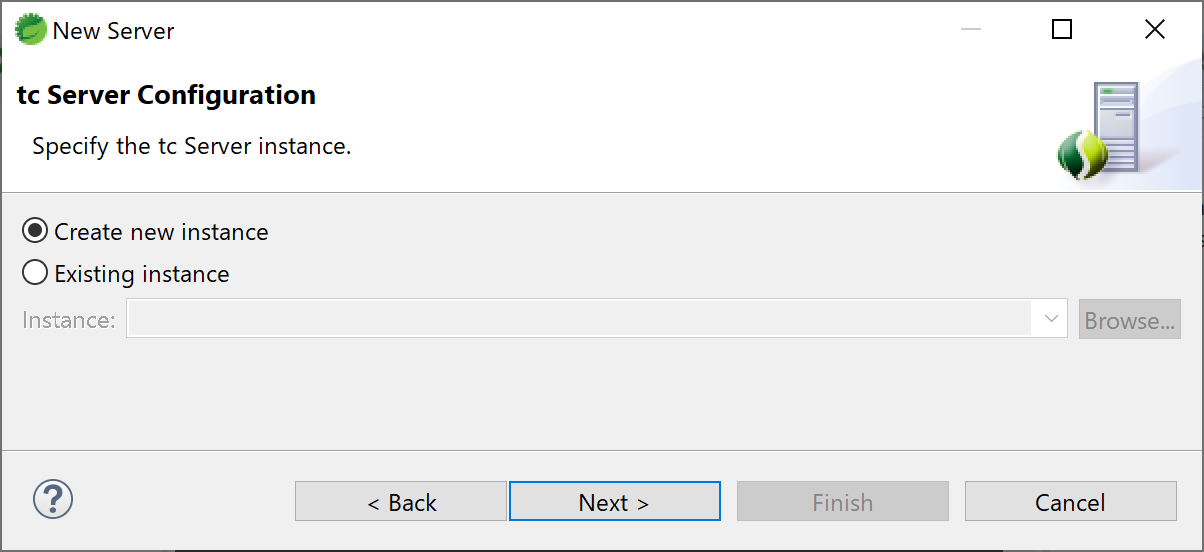
14.tc Server Configurationの画面になる。
Ceate new instanceが選択されていることを確認してNextボタンを押す。
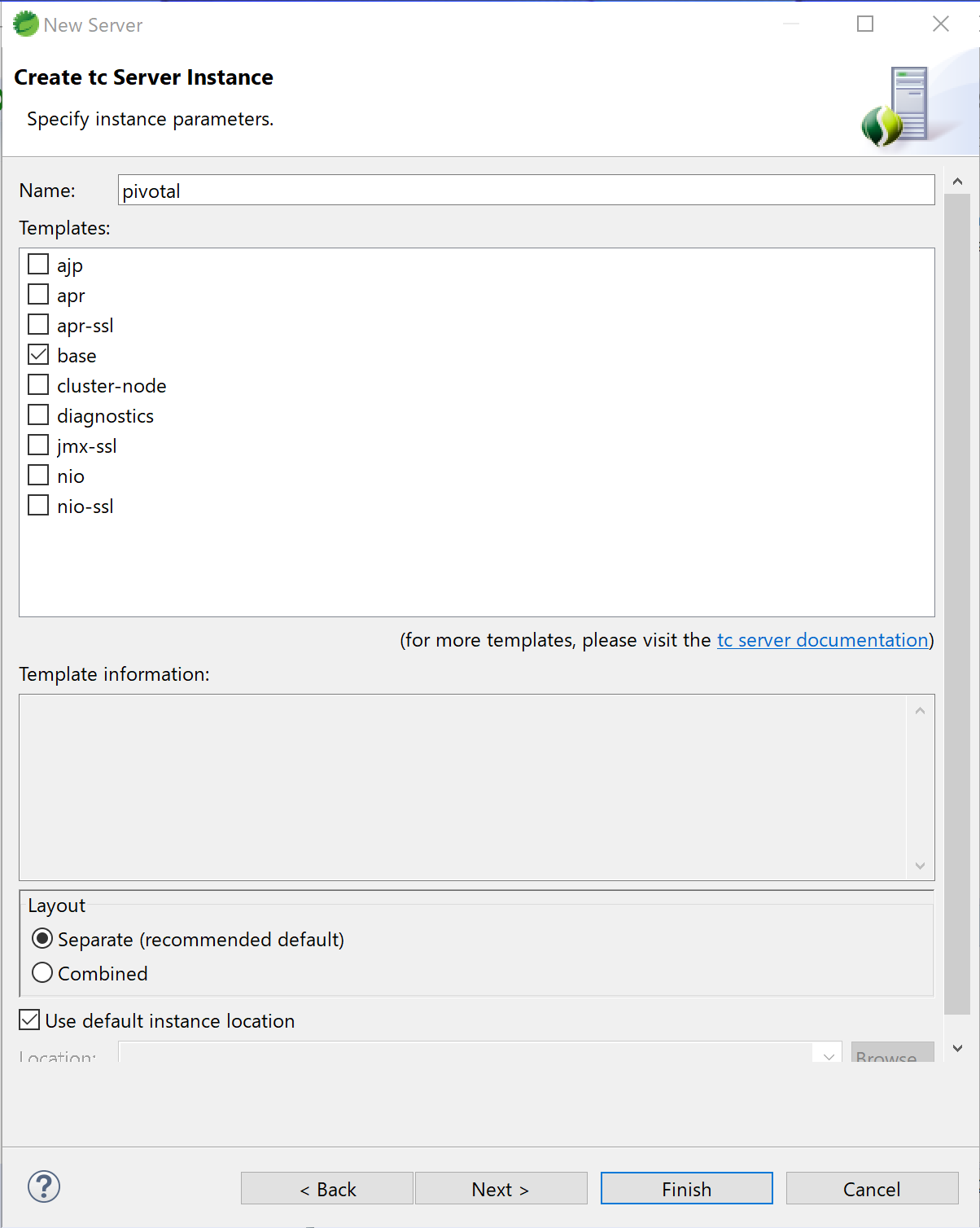
15.Create tc Server Instanceの画面になる。Nameテキストボックスには、任意の分かりやすい名前をつける。Templatesはbaseにチェックを入れてFinishボタンを押す。
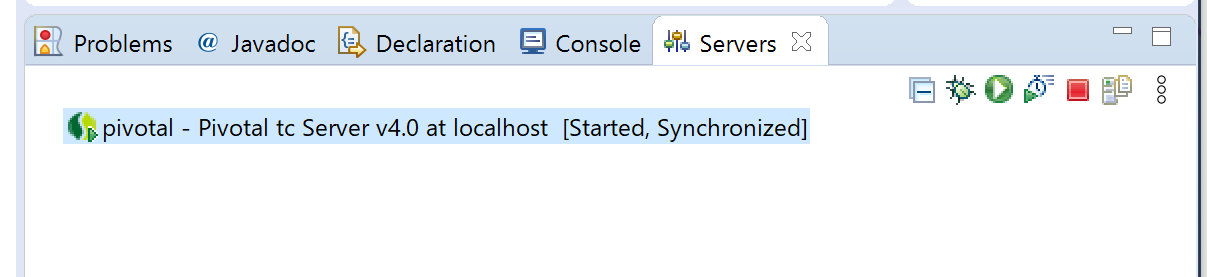
16.Serversビューにpivotalサーバができていることが確認できる。pivotalサーバを選択した状態で、実行アイコン(緑の三角ボタン)を押すとサーバが起動する。
補足
特になし
2020/2/17 Collab KM
- 投稿日:2020-02-17T22:44:41+09:00
COTOHA API の構文解析 を Java でパースする
REST APIの利用
COTOHA API のようなREST APIの利用では3つの処理が必要になります。
- HTTPリクエストの作成
- HTTPリクエストの送信(エラー発生時のハンドリング)
- HTTPレスポンスの受信
このうち前回の記事( COTOHA API の構文解析 を Java で利用してみる )では
1.(作成)と 2.(送信)に相当する処理を行っていましたが、レスポンスは単なるJSONで放置していましたので Javaのクラスにマッピングすることにします。Java クラス
私が日曜大工で作成している NLP4J にて 係り受けを実装したモデルである DefaultKeywordWithDependency クラスを用意していますので、そこにマップすることにします。
※本職では英語の解析を業務としており、日曜大工でオープンソース版のNLP用Javaライブラリ開発+日本語の解析をしています。DefaultKeywordWithDependency
https://github.com/oyahiroki/nlp4j/blob/master/nlp4j/nlp4j-core/src/main/java/nlp4j/impl/DefaultKeywordWithDependency.javaParser
構文解析結果のJSON は以下のような感じになっています。構文解析の結果はツリー状のデータになるのですが、JSON的にはツリーにはなっていないことが読み取れます。
{ "result": [ { "chunk_info": {"id": 0,"head": 2,"dep": "D","chunk_head": 0,"chunk_func": 1, "links": [] }, "tokens": [ { "id": 0,"form": "今日","kana": "キョウ","lemma": "今日","pos": "名詞", "features": ["日時"], "dependency_labels": [{"token_id": 1,"label": "case"}], "attributes": {} }, { "id": 1,"form": "は","kana": "ハ","lemma": "は","pos": "連用助詞", "features": [], "attributes": {} } ] }, {...(略)...}, {...(略)...} ] } ], "status": 0, "message": "" }以下がパースのためのクラスです。(コードはすべてMaven RepositoryとGithubで公開予定です)
package nlp4j.cotoha; import java.lang.invoke.MethodHandles; import java.util.ArrayList; import java.util.HashMap; import org.apache.logging.log4j.LogManager; import org.apache.logging.log4j.Logger; import com.google.gson.Gson; import com.google.gson.JsonArray; import com.google.gson.JsonObject; import nlp4j.Keyword; import nlp4j.impl.DefaultKeywordWithDependency; /** * COTOHA API 構文解析 V1 のレスポンスJSONをパースする * * @author Hiroki Oya * @since 1.0.0.0 * */ public class CotohaNlpV1ResponseHandler { static private final Logger logger = LogManager.getLogger(MethodHandles.lookup().lookupClass()); // 構文のルートとして抽出されたキーワード ArrayList<DefaultKeywordWithDependency> roots = new ArrayList<>(); // キーワードの並び ArrayList<Keyword> keywords = new ArrayList<>(); /** * @return 抽出された係り受けルートキーワード */ public ArrayList<DefaultKeywordWithDependency> getRoots() { return roots; } /** * @return 語の並び */ public ArrayList<Keyword> getKeywords() { return keywords; } /** * @param json COTOHA API 構文解析のレスポンスJSON */ public void parse(String json) { // Map: token_id --> Keyword HashMap<String, DefaultKeywordWithDependency> mapKwd = new HashMap<>(); // Map: id --> Keyword HashMap<String, DefaultKeywordWithDependency> idMapKwd = new HashMap<>(); // JSON Parser Gson gson = new Gson(); // COTOHA API RESPONSE JsonObject result = gson.fromJson(json, JsonObject.class); // 文の中で出てきた順 int sequence = 0; // { // "result":[ // {"chunk_info":{...},"tokens"[{...},{...},{...}]}, // {...}, // {...} // ] // } // chunk_info と tokens を合わせたオブジェクト JsonArray chunk_tokens = result.getAsJsonArray("result"); // FOR EACH(chunk_tokens) for (int idxChunkTokens = 0; idxChunkTokens < chunk_tokens.size(); idxChunkTokens++) { JsonObject chunk_token = chunk_tokens.get(idxChunkTokens).getAsJsonObject(); // 1. chunk_info JsonObject chunk_info = chunk_token.get("chunk_info").getAsJsonObject(); int chunk_head = -1; { logger.debug("chunk_info: " + chunk_info); chunk_head = chunk_info.get("head").getAsInt(); } // 2. tokens JsonArray tokens = chunk_token.get("tokens").getAsJsonArray(); // FOR EACH TOKENS for (int idxTokens = 0; idxTokens < tokens.size(); idxTokens++) { JsonObject token = tokens.get(idxTokens).getAsJsonObject(); // X-Y 形式のID String token_id = idxChunkTokens + "-" + idxTokens; logger.debug("token_id: " + token_id); logger.debug("token: " + token); // token のうちの最後かどうか。trueであれば係り受けの先は次のtoken boolean isLastOfTokens = (idxTokens == tokens.size() - 1); if (isLastOfTokens) { logger.debug("最後のトークン: chunk_head:" + chunk_head); } // 文の最後かどうか boolean isLastOfSentence = (chunk_head == -1 && idxTokens == tokens.size() - 1) // || (token.get("pos") != null && token.get("pos").getAsString().equals("句点")); // 係り受け形式のキーワード (nlp4j で定義) DefaultKeywordWithDependency kw = new DefaultKeywordWithDependency(); // 文中で出てきた順の連番 kw.setSequence(sequence); sequence++; // lemma:見出し語:原形 if (token.get("lemma") != null) { kw.setLex(token.get("lemma").getAsString()); } else { logger.warn("lemma is null"); } String id = "" + token.get("id").getAsInt(); // 次のtokenのID String next_token = null; // IF(最後のtokenでない)THEN if (isLastOfTokens == false) { next_token = idxChunkTokens + "-" + (idxTokens + 1); } // ELSE(最後のtoken) else { // IF(文の最後でない) THEN if (isLastOfSentence == false) { next_token = chunk_head + "-" + "0"; } // ELSE(文の最後) else { logger.debug("文の区切り"); next_token = null; sequence = 0; } } logger.debug("next_token: " + next_token); kw.setDependencyKey(next_token); // set facet 品詞 kw.setFacet(token.get("pos").getAsString()); // set str 表出形 kw.setStr(token.get("form").getAsString()); // set reading 読み kw.setReading(token.get("kana").getAsString()); logger.debug("keyword : " + kw); mapKwd.put(token_id, kw); idMapKwd.put(id, kw); keywords.add(kw); // dependency labels: 読んでみるが捨てる ^_^ 後日利用の予定 if (token.get("dependency_labels") != null) { JsonArray arr = token.get("dependency_labels").getAsJsonArray(); for (int n = 0; n < arr.size(); n++) { JsonObject obj = arr.get(n).getAsJsonObject(); logger.debug(obj.get("token_id").getAsInt()); logger.debug(obj.get("label").getAsString()); String parentID = "" + obj.get("token_id").getAsInt(); String label = obj.get("label").getAsString(); if (idMapKwd.get(parentID) != null) { logger.debug(idMapKwd.get(parentID).getLex() + " ... " + kw.getLex() + "(" + label + ")"); } } } // 最後のchunk で最後のtoken の場合、ルートになる } // END OF FOR EACH TOKENS logger.debug("---"); } // END OF FOR EACH (chunk_tokens) logger.debug("ツリーの組み立て"); // 係り受けの情報をもとにNodeツリーを組み立てる for (String key : mapKwd.keySet()) { DefaultKeywordWithDependency kw = mapKwd.get(key); // 係り受け先のキー String depKey = kw.getDependencyKey(); // IF(ルートでない) if (depKey != null) { if (mapKwd.containsKey(depKey)) { DefaultKeywordWithDependency parent = mapKwd.get(depKey); kw.setParent(parent); } else { // ??? throw new RuntimeException("head not found"); } } // ELSE(ルート) else { roots.add(kw); logger.debug(kw.toStringAsXml()); logger.debug(kw.toStringAsDependencyList()); logger.debug(kw.toStringAsDependencyTree()); } } // END OF(係り受けの情報をもとにNodeツリーを組み立てる) } }Parser の利用
TestCaseとして、COTOHA 構文解析APIの結果を保存しておいたJSONをパースして、文字として出力してみることにします。
(後日、Githubで公開予定)File file = new File("src/test/resources/nlp_v1_parse_002.json"); String json = FileUtils.readFileToString(file, "UTF-8"); CotohaNlpV1ResponseHandler handler = new CotohaNlpV1ResponseHandler(); handler.parse(json); List<DefaultKeywordWithDependency> roots = handler.getRoots(); // root は構文解析のルートキーワード for (DefaultKeywordWithDependency root : roots) { System.err.println(root.toStringAsDependencyTree()); } System.err.println("---"); // キーワードの並びとして扱う for (Keyword kwd : handler.getKeywords()) { System.err.println(kwd.toString()); }結果
以下のような感じになりました。
生JSONだと読みづらいですが、ツリー状に出力してみました。
係り受けの様子がわかりやすくなりました。-sequence=6,lex=。,str=。 -sequence=5,lex=です,str=です -sequence=4,lex=天気,str=天気 -sequence=1,lex=は,str=は -sequence=0,lex=今日,str=今日 -sequence=3,lex=い,str=い -sequence=2,lex=いい,str=い -sequence=7,lex=。,str=。 -sequence=6,lex=ます,str=ます -sequence=5,lex=き,str=き -sequence=4,lex=行く,str=行 -sequence=1,lex=は,str=は -sequence=0,lex=明日,str=明日 -sequence=3,lex=に,str=に -sequence=2,lex=学校,str=学校 --- 今日 [sequence=0, dependencyKey=0-1, hasChildren=false, hasParent=false, facet=名詞, lex=今日, str=今日, reading=キョウ, begin=-1, end=-1] は [sequence=1, dependencyKey=2-0, hasChildren=true, hasParent=false, facet=連用助詞, lex=は, str=は, reading=ハ, begin=-1, end=-1] いい [sequence=2, dependencyKey=1-1, hasChildren=false, hasParent=false, facet=形容詞語幹, lex=いい, str=い, reading=イ, begin=-1, end=-1] い [sequence=3, dependencyKey=2-0, hasChildren=true, hasParent=false, facet=形容詞接尾辞, lex=い, str=い, reading=イ, begin=-1, end=-1] 天気 [sequence=4, dependencyKey=2-1, hasChildren=true, hasParent=false, facet=名詞, lex=天気, str=天気, reading=テンキ, begin=-1, end=-1] です [sequence=5, dependencyKey=2-2, hasChildren=true, hasParent=false, facet=判定詞, lex=です, str=です, reading=デス, begin=-1, end=-1] 。 [sequence=6, dependencyKey=null, hasChildren=true, hasParent=true, facet=句点, lex=。, str=。, reading=, begin=-1, end=-1] 明日 [sequence=0, dependencyKey=3-1, hasChildren=false, hasParent=false, facet=名詞, lex=明日, str=明日, reading=アス, begin=-1, end=-1] は [sequence=1, dependencyKey=5-0, hasChildren=true, hasParent=false, facet=連用助詞, lex=は, str=は, reading=ハ, begin=-1, end=-1] 学校 [sequence=2, dependencyKey=4-1, hasChildren=false, hasParent=false, facet=名詞, lex=学校, str=学校, reading=ガッコウ, begin=-1, end=-1] に [sequence=3, dependencyKey=5-0, hasChildren=true, hasParent=false, facet=格助詞, lex=に, str=に, reading=ニ, begin=-1, end=-1] 行く [sequence=4, dependencyKey=5-1, hasChildren=true, hasParent=false, facet=動詞語幹, lex=行く, str=行, reading=イ, begin=-1, end=-1] き [sequence=5, dependencyKey=5-2, hasChildren=true, hasParent=false, facet=動詞活用語尾, lex=き, str=き, reading=キ, begin=-1, end=-1] ます [sequence=6, dependencyKey=5-3, hasChildren=true, hasParent=false, facet=動詞接尾辞, lex=ます, str=ます, reading=マス, begin=-1, end=-1] 。 [sequence=7, dependencyKey=null, hasChildren=true, hasParent=true, facet=句点, lex=。, str=。, reading=, begin=-1, end=-1]所感
Javaのクラスとして扱いやすいということは、業務で利用するうえでも扱いやすいということになります。
構文解析の結果をパースするのはそれなりに手間ですが、業務の世界ではここからが勝負です。(!)
ネタ系の記事には全く興味ありません。以上
- 投稿日:2020-02-17T21:30:32+09:00
Javaの戻り値を理解しよう
Javaの戻り値を理解しよう
戻り値とは?
プログラムによって出力される値のことです。
詳しくは、
「分かりそう」で「分からない」でも「分かった」気になれるIT用語辞典より
戻り値 (return value)とはを参考にしてください。
わかりやすく図示されています。ここでは、実際にプログラムを用いて説明していきます。
プログラムの概要-sample1-
main()メソッドからaverage()メソッドを呼び出し、1,2の平均を表示するプログラムです。
必ず、average()メソッドのデータ型は戻り値のデータ型と一致させましょう。サンプルコードを見てみよう
sample1.java1 public class sample1 { 2 public static void main(String[] args) { 3 double number = average(1,2); 4 System.out.print(number); 5 } 6 static double average(int a, int b) { 7 double x = (a + b) / 2; 8 return x; 9 } 10}出力
1.5
注意すべきポイント
戻り値は1.5のため、戻り値のデータ型はdouble型となります。
3行目: 戻り値がdouble型で返ってくるためnumberもdouble型で定義します
6行目:average()メソッドのデータ型はdouble型(=戻り値のデータ型)で宣言します。
ここで言う戻り値は?
このプログラムで言う戻り値は1.5です。
プログラムに入力する値(引数)は、main()メソッドに入力した1,2
プログラムが出力する値(戻り値)は、sum()メソッドから出力された1.5
となります。プログラムの概要-sample2-
main()メソッドからsum()メソッドを呼び出し、1,2の合計を表示するプログラムです。サンプルコードを見てみよう
sample2.java1 public class sample2 { 2 public static void main(String[] args) { 3 int number = sum(1,2); 4 System.out.print(number); 5 } 6 static int sum(int a, int b) { 7 int x = a + b; 8 return x; 9 } 10}出力
3
ここで言う戻り値は?
このプログラムで言う戻り値は3です。
プログラムに入力する値(引数)は、main()メソッドに入力した1,2
プログラムが出力する値(戻り値)は、sum()メソッドから出力された3
となります。
- 投稿日:2020-02-17T21:30:32+09:00
Javaの戻り値が存在するメソッドは戻り値のデータ型で宣言する
戻り値とは?
プログラムによって出力される値のことです。
詳しくは、
「分かりそう」で「分からない」でも「分かった」気になれるIT用語辞典より
戻り値 (return value)とはを参考にしてください。
わかりやすく図示されています。ここでは、実際にプログラムを用いて説明していきます。
これだけ覚えて帰って!
戻り値が存在する場合は戻り値のデータ型で宣言する! プログラムの概要-sample1-
main()メソッドからaverage()メソッドを呼び出し、1,2の平均を表示するプログラムです。
main()メソッドは戻り値がないためvoid型で宣言します。
average()メソッドは戻り値が存在するため、void型で宣言できません。
戻り値が存在する場合は戻り値のデータ型で宣言します。サンプルコードを見てみよう
sample1.java1 public class sample1 { 2 public static void main(String[] args) { 3 double number = average(1,2); 4 System.out.print(number); 5 } 6 static double average(int a, int b) { 7 double x = (a + b) / 2.0; 8 return x; 9 } 10}出力
1.5
注意すべきポイント
戻り値は1.5のため、戻り値のデータ型はdouble型となります。
3行目: 戻り値がdouble型で返ってくるためnumberもdouble型で定義します
6行目:average()メソッドのデータ型はdouble型(=戻り値のデータ型)で宣言します。引数と戻り値は?
引数(プログラムに入力する値)は、
main()メソッドに入力した1,2
戻り値(プログラムが出力する値)は、average()メソッドから出力された1.5
となります。まとめ
Javaを勉強し始めてすぐ、戻り値とメソッドの関係がわからず理解に時間がかかってしまいました。
この記事が皆さんのお役に立てれば幸いです。
- 投稿日:2020-02-17T19:08:39+09:00
プロジェクト・ファセット Java バージョン 13 はサポートされません。となった時の対応方法
- 環境
- Windows10 Pro 64bit バージョン1903
- Eclipse Version: 2019-12 (4.14.0)
- Tomcat 9.0.31
- プロジェクトのJava 13.0.2
事象 : EclipseでTomcat9を設定中にプロジェクトを選択したら怒られた
新規にTomcat9を追加した時のこと・・・
原因 : Tomcat9のJREのバージョンがプロジェクトと違うから
今回は、JRE11になっていました
対応 : Tomcat9のJREをプロジェクトに合わせる
- [ランタイム環境の構成...]リンクからダイアログを表示する
- [Tomcat9]を選択して[編集]ボタンでダイアログを表示する
- JREからJava13を選択する
- 後で間違えないように[名前]を「Tomcat9 (Java13)」に変更して[完了]ボタンでダイアログを閉じる
- [適用して閉じる]ボタンでダイアログを閉じる
- [次へ] > プロジェクトを追加 > [完了]


- 投稿日:2020-02-17T14:08:09+09:00
RedHat Jboss Developer StudioでCodeLensを実現する
背景
CodeLensというのは、Microsoft Visual Studio に搭載されているいわば参照元列挙機能のことで、Visual Studio 2017以前のバージョンでは製品版(Professional版、Enterprise版など)でしかCodeLensの使用が制限されていました。つまり、お金を出さなければ使えない、リッチな機能というわけです。(Visual Studio 2019ではCommunity版でもCodeLensが使えるようになりました?)
↓Visual Studio CodeにおけるCodeLensの例
CodeLensを使おうと思ったら、Visual Studioか、オープンソースのVisual Studio Codeを使う以外選択肢がなかったのですが、この度、RedHat Jboss Developer StudioでもCodeLensを使用する方法を見つけたため、共有する次第です。
前提条件
今回の記事の対象となる、RedHat Jboss Developer Studioのバージョンは次の通りです。
Version: 11.3.0.GA
RedHat Jboss Developer StudioでCodeLensを実現するには、前準備として以下が必要です。
- JDK のインストール
- Maven 3+ のインストール(PATHも通してあること)
インストール手順
- RedHat Jboss Developer Studioをインストールします。
https://github.com/dhq-boiler/codelens-eclipse からソースコードをZipでダウンロードするか、gitでクローンします。
※なお、dhq-boiler/codelens-eclipseプロジェクトはフォークしたプロジェクトであり、ビルドに必要な修正を加えたものです。元のプロジェクトはangelozerr/codelens-eclipseです。angelozerr/codelens-eclipseを崇めましょう。
ビルドします。ソースコードをダウンロードしたフォルダでコマンドプロンプトを開き、
mvn clean installを実行します。
初回ビルドにはしばらく時間がかかります…。
コマンドプロンプトで"BUILD SUCCESS"と表示されたら、次に進みます。
*.jarファイルをコピーします。
コピーするファイル
- codelens-eclipse\org.eclipse.codelens\target\org.eclipse.codelens-1.1.0-SNAPSHOT.jar
- codelens-eclipse\org.eclipse.codelens.editors\target\org.eclipse.codelens.editors-1.1.0-SNAPSHOT.jar
- codelens-eclipse\org.eclipse.codelens.feature\target\org.eclipse.codelens.feature-1.1.0-SNAPSHOT.jar
- codelens-eclipse\org.eclipse.codelens.jdt\target\org.eclipse.codelens.jdt-1.1.0-SNAPSHOT.jar
- codelens-eclipse\org.eclipse.codelens.jface.fragment\target\org.eclipse.codelens.jface.fragment-1.1.0-SNAPSHOT.jar
- codelens-eclipse\org.eclipse.codelens.swt.fragment\target\org.eclipse.codelens.swt.fragment-1.1.0-SNAPSHOT.jar
コピー先フォルダ
RedHat Jboss Developer Studioインストールフォルダ\studio\plugins
RedHat Jboss Developer Studioを
-cleanオプション付きで起動します。devstudio.exe -clean
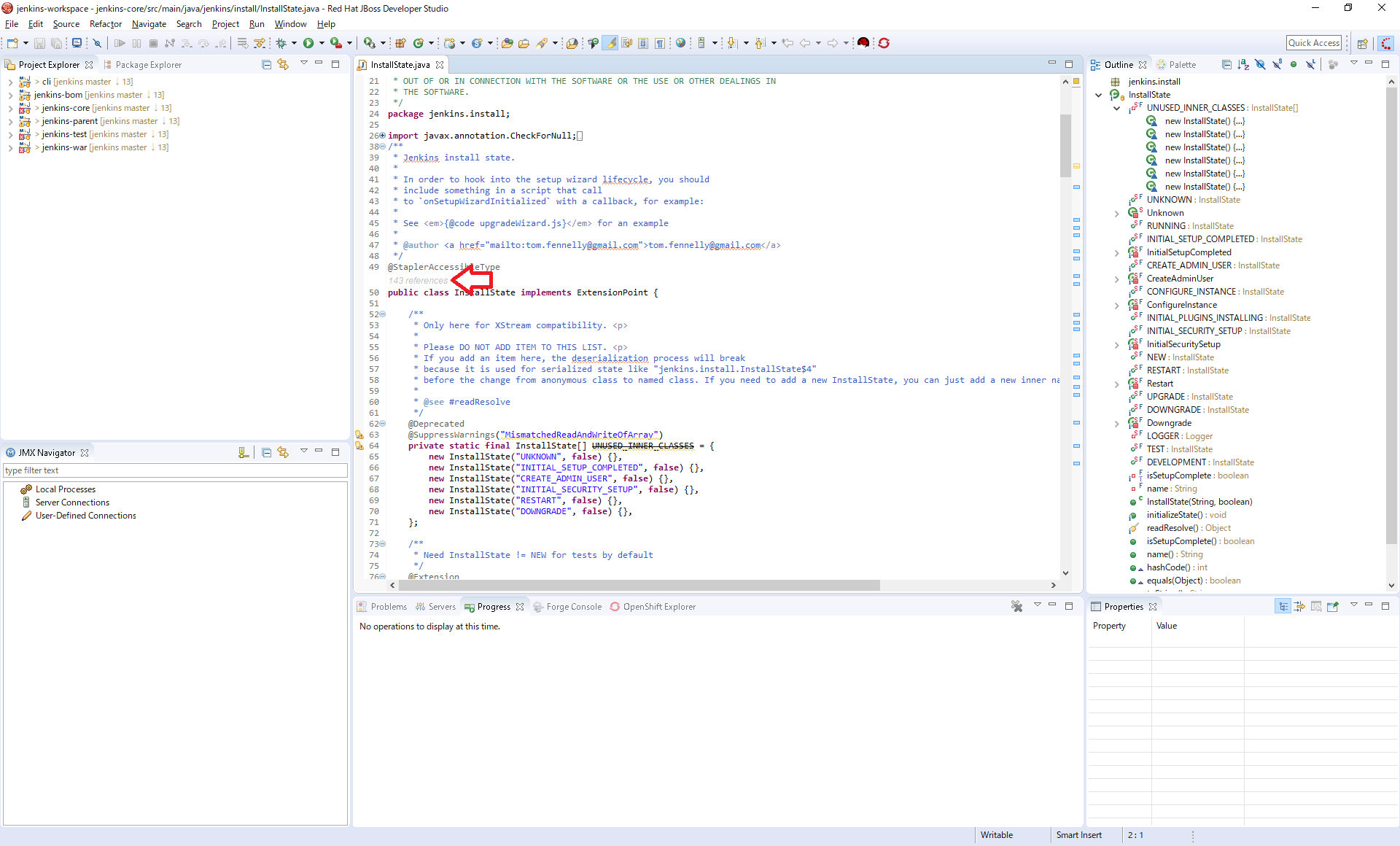
このようにクラスの上部、またはメソッドの上部に
N referencesと表示されればインストール完了です!注意
このcodelens-eclipseプラグインは未完成であり、本家のCodeLensにはあってこのプラグインにない機能はあります。(例えば、"N reference"の部分をクリックすると参照元が一覧できるウィンドウが開く)このプラグインの開発は2017年10月に止まっていますし、これ以上期待するのはやめておいたほうが良さそうです。または、Eclipseのプラグイン開発に詳しい方がこのプロジェクトをフォークして引き継ぐかですね。


- 投稿日:2020-02-17T13:46:47+09:00
Azure Search + Java Apache HttpClient で POSTリクエストによる検索
公式ドキュメント
Search Documents (Azure Cognitive Search REST API)
https://docs.microsoft.com/en-us/rest/api/searchservice/Search-Documents結論
POSTリクエストのときはURLが違うというところに少しハマりました。
コード
package hello; import org.apache.http.client.methods.CloseableHttpResponse; import org.apache.http.client.methods.HttpPost; import org.apache.http.client.utils.URIBuilder; import org.apache.http.entity.ContentType; import org.apache.http.entity.StringEntity; import org.apache.http.impl.client.CloseableHttpClient; import org.apache.http.impl.client.HttpClients; import org.apache.http.util.EntityUtils; import com.google.gson.JsonObject; public class HelloAzurePostSearch { public static void main(String[] args) throws Exception { // 公式ドキュメント // https://docs.microsoft.com/en-us/rest/api/searchservice/Search-Documents // POST https://[service name].search.windows.net/indexes/[index name]/docs/search // ?api-version=[api-version] // Content-Type: application/json // api-key: [admin or query key] String serviceName = "{your service name}"; String indexName = "{your index name}"; String apiVersion = "2019-05-06"; String adminKey = "{your admin key}"; URIBuilder builder = new URIBuilder("https://" + serviceName + ".search.windows.net" // + "/indexes/" + indexName + "/docs" // + "/search" // ←GETとPOSTでURLが異なる点に注意! ) // .addParameter("api-version", apiVersion); JsonObject requestBody = new JsonObject(); { requestBody.addProperty("search", "*"); requestBody.addProperty("count", true); } CloseableHttpClient client = HttpClients.createDefault(); HttpPost httpPost = new HttpPost(builder.build()); httpPost.addHeader("api-key", adminKey); StringEntity requestEntity // = new StringEntity(requestBody.toString(), ContentType.APPLICATION_JSON); httpPost.setEntity(requestEntity); CloseableHttpResponse response = client.execute(httpPost); System.err.println(response.getStatusLine().getStatusCode()); // response body System.err.println(EntityUtils.toString(response.getEntity())); client.close(); } }以上
- 投稿日:2020-02-17T13:03:00+09:00
IBM Javaのjavacoreを解析するには、TMDAを使おう
TL;DR
- IBM Javaは、スレッドダンプがHotSpotとは違う、独自の形式(javacore)になっている
- *inux環境であれば
kill -3でjavacoreは取得できるが、こちらを読むにはTMDAを使うのがよさそうjavacoreとTMDA
IBM Javaでスレッドダンプを取得する場合、以下のような手順で行うようです。
*inux環境であれば、
kill -3ですね。ここで取得できるのがjavacore、ですと。
ただ、ここで取得できるjavacoreはHotSpotとだいぶ形式が異なるようで、ちょっと読みづらい感じが…。
そこで、IBM Thread and Monitor Dump Analyzer for Java (TMDA)を使ってjavacoreを解析すると、より見やすくなるようです。
IBM Thread and Monitor Dump Analyzer for Java (TMDA)
javacoreを取得してみる
試しに取得してみましょう。IBM JavaのDockerイメージがあるので、こちらを使用してみます。
コンテナを起動。
$ docker container run -it --rm --name ibmjava ibmjava:8 bash # java -version java version "1.8.0_241" Java(TM) SE Runtime Environment (build 8.0.6.5 - pxa6480sr6fp5-20200111_02(SR6 FP5)) IBM J9 VM (build 2.9, JRE 1.8.0 Linux amd64-64-Bit Compressed References 20200108_436782 (JIT enabled, AOT enabled) OpenJ9 - 7d1059c OMR - d059105 IBM - c8aee39) JCL - 20200110_01 based on Oracle jdk8u241-b07javacoreを取得する対象としては、Apache Tomcatを利用しましょう。
# cd # wget http://ftp.yz.yamagata-u.ac.jp/pub/network/apache/tomcat/tomcat-9/v9.0.31/bin/apache-tomcat-9.0.31.tar.gz # tar xf apache-tomcat-9.0.31.tar.gz # cd apache-tomcat-9.0.31 root@fbb2898f4717:~/apache-tomcat-9.0.31# bin/startup.sh Using CATALINA_BASE: /root/apache-tomcat-9.0.31 Using CATALINA_HOME: /root/apache-tomcat-9.0.31 Using CATALINA_TMPDIR: /root/apache-tomcat-9.0.31/temp Using JRE_HOME: /opt/ibm/java/jre Using CLASSPATH: /root/apache-tomcat-9.0.31/bin/bootstrap.jar:/root/apache-tomcat-9.0.31/bin/tomcat-juli.jar Tomcat started.Tomcatが起動しました。
Tomcatプロセスに、
-3(SIGQUIT)シグナルを送ります。# kill -3 [PID]javacoreが出力されました。
# ls -l total 608 -rw-r----- 1 root root 18982 Feb 5 19:36 BUILDING.txt -rw-r----- 1 root root 5409 Feb 5 19:36 CONTRIBUTING.md -rw-r----- 1 root root 57092 Feb 5 19:36 LICENSE -rw-r----- 1 root root 2333 Feb 5 19:36 NOTICE -rw-r----- 1 root root 3255 Feb 5 19:36 README.md -rw-r----- 1 root root 6898 Feb 5 19:36 RELEASE-NOTES -rw-r----- 1 root root 16262 Feb 5 19:36 RUNNING.txt drwxr-x--- 2 root root 4096 Feb 17 03:40 bin drwx------ 3 root root 4096 Feb 17 03:40 conf -rw-r----- 1 root root 472769 Feb 17 03:41 javacore.20200217.034113.22.0001.txt drwxr-x--- 2 root root 4096 Feb 17 03:40 lib drwxr-x--- 2 root root 4096 Feb 17 03:40 logs drwxr-x--- 2 root root 4096 Feb 17 03:40 temp drwxr-x--- 7 root root 4096 Feb 5 19:34 webapps drwxr-x--- 3 root root 4096 Feb 17 03:40 work軽く、中を見てみます。
# cat javacore.20200217.034113.22.0001.txt 0SECTION TITLE subcomponent dump routine NULL =============================== 1TICHARSET ANSI_X3.4-1968 1TISIGINFO Dump Event "user" (00004000) received 1TIDATETIME Date: 2020/02/17 at 03:41:13:542 1TINANOTIME System nanotime: 13446928231692 1TIFILENAME Javacore filename: /root/apache-tomcat-9.0.31/javacore.20200217.034113.22.0001.txt 1TIREQFLAGS Request Flags: 0x81 (exclusive+preempt) 1TIPREPSTATE Prep State: 0x104 (exclusive_vm_access+trace_disabled) NULL ------------------------------------------------------------------------ 0SECTION GPINFO subcomponent dump routine NULL ================================ 2XHOSLEVEL OS Level : Linux 4.15.0-76-generic 2XHCPUS Processors - 3XHCPUARCH Architecture : amd64 3XHNUMCPUS How Many : 4 3XHNUMASUP NUMA is either not supported or has been disabled by user NULL 1XHERROR2 Register dump section only produced for SIGSEGV, SIGILL or SIGFPE. NULL NULL ------------------------------------------------------------------------ 0SECTION ENVINFO subcomponent dump routine NULL ================================= 1CIJAVAVERSION JRE 1.8.0 Linux amd64-64 (build 8.0.6.5 - pxa6480sr6fp5-20200111_02(SR6 FP5)) 1CIVMVERSION 20200108_436782 1CIJ9VMVERSION 7d1059c 1CIJITVERSION tr.open_20200107_095049_7d1059c 1CIOMRVERSION d059105_CMPRSS 1CIIBMVERSION c8aee39 1CIJITMODES JIT enabled, AOT enabled, FSD disabled, HCR enabled 1CIRUNNINGAS Running as a standalone JVM 1CIVMIDLESTATE VM Idle State: ACTIVE 1CICONTINFO Running in container : TRUE 1CICGRPINFO JVM support for cgroups enabled : TRUE 1CISTARTTIME JVM start time: 2020/02/17 at 03:40:38:297 1CISTARTNANO JVM start nanotime: 13411683675953 1CIPROCESSID Process ID: 22 (0x16) 1CICMDLINE /opt/ibm/java/jre/bin/java -Djava.util.logging.config.file=/root/apache-tomcat-9.0.31/conf/logging.properties -Djava.util.logging.manager=org.apache.juli.ClassLoaderLogManager -Djdk.tls.ephemeralDHKeySize=2048 -Djava.protocol.handler.pkgs=org.apache.catalina.webresources -Dorg.apache.catalina.security.SecurityListener.UMASK=0027 -Dignore.endorsed.dirs= -classpath /root/apache-tomcat-9.0.31/bin/bootstrap.jar:/root/apache-tomcat-9.0.31/bin/tomcat-juli.jar -Dcatalina.base=/root/apache-tomcat-9.0.31 -Dcatalina.home=/root/apache-tomcat-9.0.31 -Djava.io.tmpdir=/root/apache-tomcat-9.0.31/temp org.apache.catalina.startup.Bootstrap start 1CIJAVAHOMEDIR Java Home Dir: /opt/ibm/java/jre 1CIJAVADLLDIR Java DLL Dir: /opt/ibm/java/jre/bin 1CISYSCP Sys Classpath: /opt/ibm/java/jre/lib/amd64/compressedrefs/jclSC180/vm.jar;/opt/ibm/java/jre/lib/se-service.jar;/opt/ibm/java/jre/lib/math.jar;/opt/ibm/java/jre/lib/ibmorb.jar;/opt/ibm/java/jre/lib/ibmorbapi.jar;/opt/ibm/java/jre/lib/ibmcfw.jar;/opt/ibm/java/jre/lib/ibmpkcs.jar;/opt/ibm/java/jre/lib/ibmcertpathfw.jar;/opt/ibm/java/jre/lib/ibmjgssfw.jar;/opt/ibm/java/jre/lib/ibmjssefw.jar;/opt/ibm/java/jre/lib/ibmsaslfw.jar;/opt/ibm/java/jre/lib/ibmjcefw.jar;/opt/ibm/java/jre/lib/ibmjgssprovider.jar;/opt/ibm/java/jre/lib/ibmjsseprovider2.jar;/opt/ibm/java/jre/lib/ibmcertpathprovider.jar;/opt/ibm/java/jre/lib/xmldsigfw.jar;/opt/ibm/java/jre/lib/xml.jar;/opt/ibm/java/jre/lib/charsets.jar;/opt/ibm/java/jre/lib/resources.jar;/opt/ibm/java/jre/lib/rt.jar;/opt/ibm/java/jre/lib/dataaccess.jar; 1CIUSERARGS UserArgs: 2CIUSERARG -Xoptionsfile=/opt/ibm/java/jre/lib/amd64/compressedrefs/options.default 2CIUSERARG -Xlockword:mode=default,noLockword=java/lang/String,noLockword=java/util/MapEntry,noLockword=java/util/HashMap$Entry,noLockword=org/apache/harmony/luni/util/ModifiedMap$Entry,noLockword=java/util/Hashtable$Entry,noLockword=java/lang/invoke/MethodType,noLockword=java/lang/invoke/MethodHandle,noLockword=java/lang/invoke/CollectHandle,noLockword=java/lang/invoke/ConstructorHandle,noLockword=java/lang/invoke/ConvertHandle,noLockword=java/lang/invoke/ArgumentConversionHandle,noLockword=java/lang/invoke/AsTypeHandle,noLockword=java/lang/invoke/ExplicitCastHandle,noLockword=java/lang/invoke/FilterReturnHandle,noLockword=java/lang/invoke/DirectHandle,noLockword=java/lang/invoke/ReceiverBoundHandle,noLockword=java/lang/invoke/DynamicInvokerHandle,noLockword=java/lang/invoke/FieldHandle,noLockword=java/lang/invoke/FieldGetterHandle,noLockword=java/lang/invoke/FieldSetterHandle,noLockword=java/lang/invoke/StaticFieldGetterHandle,noLockword=java/lang/invoke/StaticFieldSetterHandle,noLockword=java/lang/invoke/IndirectHandle,noLockword=java/lang/invoke/InterfaceHandle,noLockword=java/lang/invoke/VirtualHandle,noLockword=java/lang/invoke/PrimitiveHandle,noLockword=java/lang/invoke/InvokeExactHandle,noLockword=java/lang/invoke/InvokeGenericHandle,noLockword=java/lang/invoke/VarargsCollectorHandle,noLockword=java/lang/invoke/ThunkTuple 2CIUSERARG -Xjcl:jclse29 2CIUSERARG -Dcom.ibm.oti.vm.bootstrap.library.path=/opt/ibm/java/jre/lib/amd64/compressedrefs:/opt/ibm/java/jre/lib/amd64 2CIUSERARG -Dsun.boot.library.path=/opt/ibm/java/jre/lib/amd64/compressedrefs:/opt/ibm/java/jre/lib/amd64 2CIUSERARG -Djava.library.path=/opt/ibm/java/jre/lib/amd64/compressedrefs:/opt/ibm/java/jre/lib/amd64:/usr/lib64:/usr/lib 2CIUSERARG -Djava.home=/opt/ibm/java/jre 2CIUSERARG -Djava.ext.dirs=/opt/ibm/java/jre/lib/ext 2CIUSERARG -Duser.dir=/root/apache-tomcat-9.0.31 2CIUSERARG -XX:+UseContainerSupport 2CIUSERARG -Djava.class.path=. 〜省略〜 3CLTEXTCLASS org/apache/tomcat/util/IntrospectionUtils$SecurePropertySource(0x00000000019DEE00) 3CLTEXTCLASS [Lorg/apache/tomcat/util/IntrospectionUtils$PropertySource;(0x00000000019DEC00) 3CLTEXTCLASS org/apache/tomcat/util/IntrospectionUtils$PropertySource(0x00000000019DEA00) 3CLTEXTCLASS org/apache/tomcat/util/digester/SetPropertiesRule(0x00000000019DE800) 3CLTEXTCLASS org/apache/tomcat/util/digester/SetNextRule(0x00000000019DDF00) 3CLTEXTCLASS org/apache/tomcat/util/digester/FactoryCreateRule(0x00000000019DDB00) 3CLTEXTCLASS org/apache/tomcat/util/digester/CallParamRule(0x00000000019DD300) 3CLTEXTCLASS org/apache/tomcat/util/digester/CallMethodRule(0x00000000019DCC00) 3CLTEXTCLASS org/apache/tomcat/util/digester/Rules(0x00000000019DC500) 3CLTEXTCLASS org/apache/tomcat/util/digester/Digester(0x00000000019DC000) 3CLTEXTCLASS org/apache/catalina/Container(0x00000000019D1800) 3CLTEXTCLASS org/apache/tomcat/util/file/ConfigFileLoader(0x00000000019D1000) 3CLTEXTCLASS org/apache/tomcat/util/file/ConfigurationSource$1(0x00000000019D0D00) 3CLTEXTCLASS org/apache/catalina/startup/CatalinaBaseConfigurationSource(0x00000000019D0700) 3CLTEXTCLASS org/apache/tomcat/util/ExceptionUtils(0x00000000019D0000) 3CLTEXTCLASS org/apache/catalina/security/SecurityConfig(0x00000000019CFE00) 3CLTEXTCLASS org/apache/tomcat/util/res/StringManager$1(0x00000000019CF700) 3CLTEXTCLASS org/apache/tomcat/util/res/StringManager(0x00000000019CF200) 3CLTEXTCLASS org/apache/tomcat/util/log/SystemLogHandler(0x00000000019CE300) 3CLTEXTCLASS org/apache/catalina/LifecycleState(0x00000000019CDF00) 3CLTEXTCLASS org/apache/catalina/startup/Catalina$CatalinaShutdownHook(0x00000000019CB600) 3CLTEXTCLASS org/apache/tomcat/util/file/ConfigurationSource(0x00000000019CB100) 3CLTEXTCLASS org/apache/catalina/LifecycleException(0x00000000019CAE00) 3CLTEXTCLASS org/apache/catalina/startup/SetParentClassLoaderRule(0x00000000019CAA00) 3CLTEXTCLASS org/apache/tomcat/util/digester/RuleSet(0x00000000019CA800) 3CLTEXTCLASS org/apache/catalina/startup/CertificateCreateRule(0x00000000019CA400) 3CLTEXTCLASS org/apache/catalina/startup/AddPortOffsetRule(0x00000000019CA000) 3CLTEXTCLASS org/apache/catalina/startup/SetAllPropertiesRule(0x00000000019C9D00) 3CLTEXTCLASS org/apache/catalina/startup/ConnectorCreateRule(0x00000000019C9500) 3CLTEXTCLASS org/apache/catalina/startup/ListenerCreateRule(0x00000000019C8D00) 3CLTEXTCLASS org/apache/tomcat/util/digester/ObjectCreateRule(0x000000000197E300) 3CLTEXTCLASS org/apache/tomcat/util/digester/Rule(0x000000000197D700) 3CLTEXTCLASS org/apache/catalina/startup/Catalina(0x00000000019C0800) 2CLTEXTCLLOAD Loader sun/reflect/DelegatingClassLoader(0x00000000E00DE640) 3CLTEXTCLASS sun/reflect/GeneratedMethodAccessor2(0x00000000019CCA00) 2CLTEXTCLLOAD Loader sun/reflect/DelegatingClassLoader(0x00000000E013B110) 3CLTEXTCLASS sun/reflect/GeneratedMethodAccessor3(0x0000000001A52100) 2CLTEXTCLLOAD Loader sun/reflect/DelegatingClassLoader(0x00000000E0261650) 3CLTEXTCLASS sun/reflect/GeneratedConstructorAccessor1(0x00000000018A8700) 2CLTEXTCLLOAD Loader sun/reflect/DelegatingClassLoader(0x00000000E0301418) 3CLTEXTCLASS sun/reflect/GeneratedConstructorAccessor2(0x00000000018A8C00) 2CLTEXTCLLOAD Loader sun/reflect/DelegatingClassLoader(0x00000000E0301460) 3CLTEXTCLASS sun/reflect/GeneratedMethodAccessor4(0x00000000018A9100) 2CLTEXTCLLOAD Loader sun/reflect/DelegatingClassLoader(0x00000000E03014A8) 3CLTEXTCLASS sun/reflect/GeneratedMethodAccessor5(0x00000000018A9600) 2CLTEXTCLLOAD Loader sun/reflect/DelegatingClassLoader(0x00000000E03014F0) 3CLTEXTCLASS sun/reflect/GeneratedMethodAccessor6(0x00000000018A9A00) 2CLTEXTCLLOAD Loader sun/reflect/DelegatingClassLoader(0x00000000E0301538) 3CLTEXTCLASS sun/reflect/GeneratedMethodAccessor7(0x00000000018A9F00) 2CLTEXTCLLOAD Loader sun/reflect/DelegatingClassLoader(0x00000000E0301580) 3CLTEXTCLASS sun/reflect/GeneratedMethodAccessor8(0x0000000001C0ED00) 2CLTEXTCLLOAD Loader sun/reflect/DelegatingClassLoader(0x00000000E03015C8) 3CLTEXTCLASS sun/reflect/GeneratedConstructorAccessor3(0x0000000001C17700) NULL ------------------------------------------------------------------------ 0SECTION Javadump End section NULL ---------------------- END OF DUMP -------------------------------------スレッドダンプも含まれているようです。
3XMTHREADINFO "main" J9VMThread:0x000000000177C700, omrthread_t:0x00007F30D8007C70, java/lang/Thread:0x00000000E0036A98, state:R, prio=5 3XMJAVALTHREAD (java/lang/Thread getId:0x1, isDaemon:false) 3XMTHREADINFO1 (native thread ID:0x17, native priority:0x5, native policy:UNKNOWN, vmstate:R, vm thread flags:0x000000a1) 3XMTHREADINFO2 (native stack address range from:0x00007F30DCC75000, to:0x00007F30DD475000, size:0x800000) 3XMCPUTIME CPU usage total: 2.041586755 secs, current category="Application" 3XMHEAPALLOC Heap bytes allocated since last GC cycle=1918344 (0x1D4588) 3XMTHREADINFO3 Java callstack: 4XESTACKTRACE at java/net/PlainSocketImpl.socketAccept(Native Method) 4XESTACKTRACE at java/net/AbstractPlainSocketImpl.accept(AbstractPlainSocketImpl.java:450) 4XESTACKTRACE at java/net/ServerSocket.implAccept(ServerSocket.java:623) 4XESTACKTRACE at java/net/ServerSocket.accept(ServerSocket.java:582) 4XESTACKTRACE at org/apache/catalina/core/StandardServer.await(StandardServer.java:609) 4XESTACKTRACE at org/apache/catalina/startup/Catalina.await(Catalina.java:721) 4XESTACKTRACE at org/apache/catalina/startup/Catalina.start(Catalina.java:667) 4XESTACKTRACE at sun/reflect/NativeMethodAccessorImpl.invoke0(Native Method) 4XESTACKTRACE at sun/reflect/NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:90) 4XESTACKTRACE at sun/reflect/DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:55(Compiled Code)) 4XESTACKTRACE at java/lang/reflect/Method.invoke(Method.java:508(Compiled Code)) 4XESTACKTRACE at org/apache/catalina/startup/Bootstrap.start(Bootstrap.java:343) 4XESTACKTRACE at org/apache/catalina/startup/Bootstrap.main(Bootstrap.java:474) 3XMTHREADINFO3 Native callstack: 4XENATIVESTACK (0x00007F30D7DD3852 [libj9prt29.so+0x50852]) 4XENATIVESTACK (0x00007F30D7DA55E3 [libj9prt29.so+0x225e3]) 4XENATIVESTACK (0x00007F30D7DD38CE [libj9prt29.so+0x508ce]) 4XENATIVESTACK (0x00007F30D7DD39C4 [libj9prt29.so+0x509c4]) 4XENATIVESTACK (0x00007F30D7DA55E3 [libj9prt29.so+0x225e3]) 4XENATIVESTACK (0x00007F30D7DD372B [libj9prt29.so+0x5072b]) 4XENATIVESTACK (0x00007F30D7DCFB0F [libj9prt29.so+0x4cb0f]) 4XENATIVESTACK (0x00007F30DE456890 [libpthread.so.0+0x12890]) 4XENATIVESTACK __poll+0x49 (0x00007F30DDD41BF9 [libc.so.6+0x114bf9]) 4XENATIVESTACK JCL_Poll+0x5b (0x00007F30D27AB20B [libjava.so+0x1620b]) 4XENATIVESTACK (0x00007F30C1653321 [libnet.so+0x14321]) 4XENATIVESTACK Java_java_net_PlainSocketImpl_socketAccept+0x137 (0x00007F30C164D557 [libnet.so+0xe557]) 4XENATIVESTACK (0x00007F30DC5DEDA4 [libj9vm29.so+0x13bda4]) 4XENATIVESTACK (0x00007F30DC5DC4C7 [libj9vm29.so+0x1394c7]) 4XENATIVESTACK (0x00007F30DC4C8AFE [libj9vm29.so+0x25afe]) 4XENATIVESTACK (0x00007F30DC4B5930 [libj9vm29.so+0x12930]) 4XENATIVESTACK (0x00007F30DC5772E2 [libj9vm29.so+0xd42e2]) NULLですが、確かにHotSpotの形式に慣れていると、だいぶ戸惑いますね。
とりあえず、このjavacoreをホスト側に取り出しておきます。
$ docker container cp ibmjava:/root/apache-tomcat-9.0.31/javacore.20200217.034113.22.0001.txt ./.TMDAを使う
では、TMDAを使って取得したjavacoreを見てみましょう。
TMDAをダウンロードします。
IBM Thread and Monitor Dump Analyzer for Java (TMDA)
$ wget https://public.dhe.ibm.com/software/websphere/appserv/support/tools/jca/jca464.jar起動。
$ java -jar jca464.jarこんな感じのツールが起動しました。
記載時点のバージョンは、こちら。メニューのHelp → About IBM Thread and Monitor Dump Analyzer for Java Technologyから確認できます。
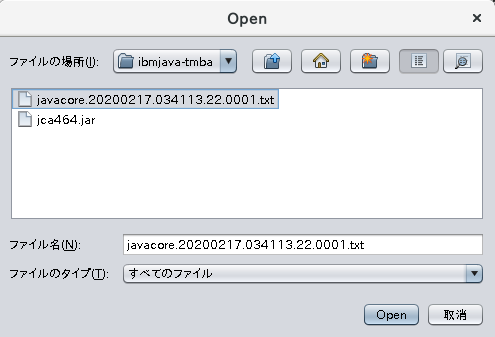
では、javacoreを開きましょう。メニューのOpen → Open Thread Dumpsを選択して、先程取得したjavacoreを開きます。
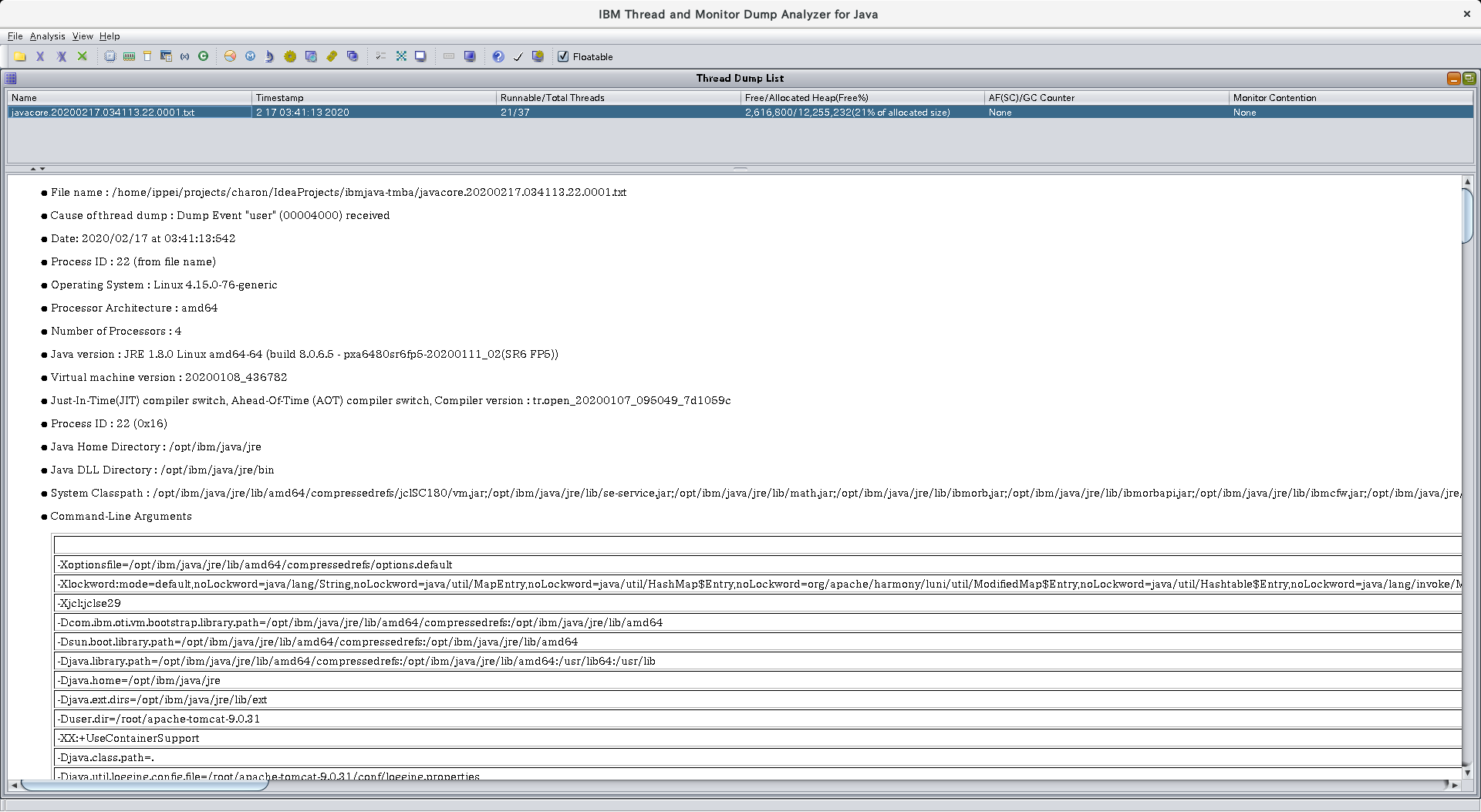
すると、こんな感じで情報が表示されます。
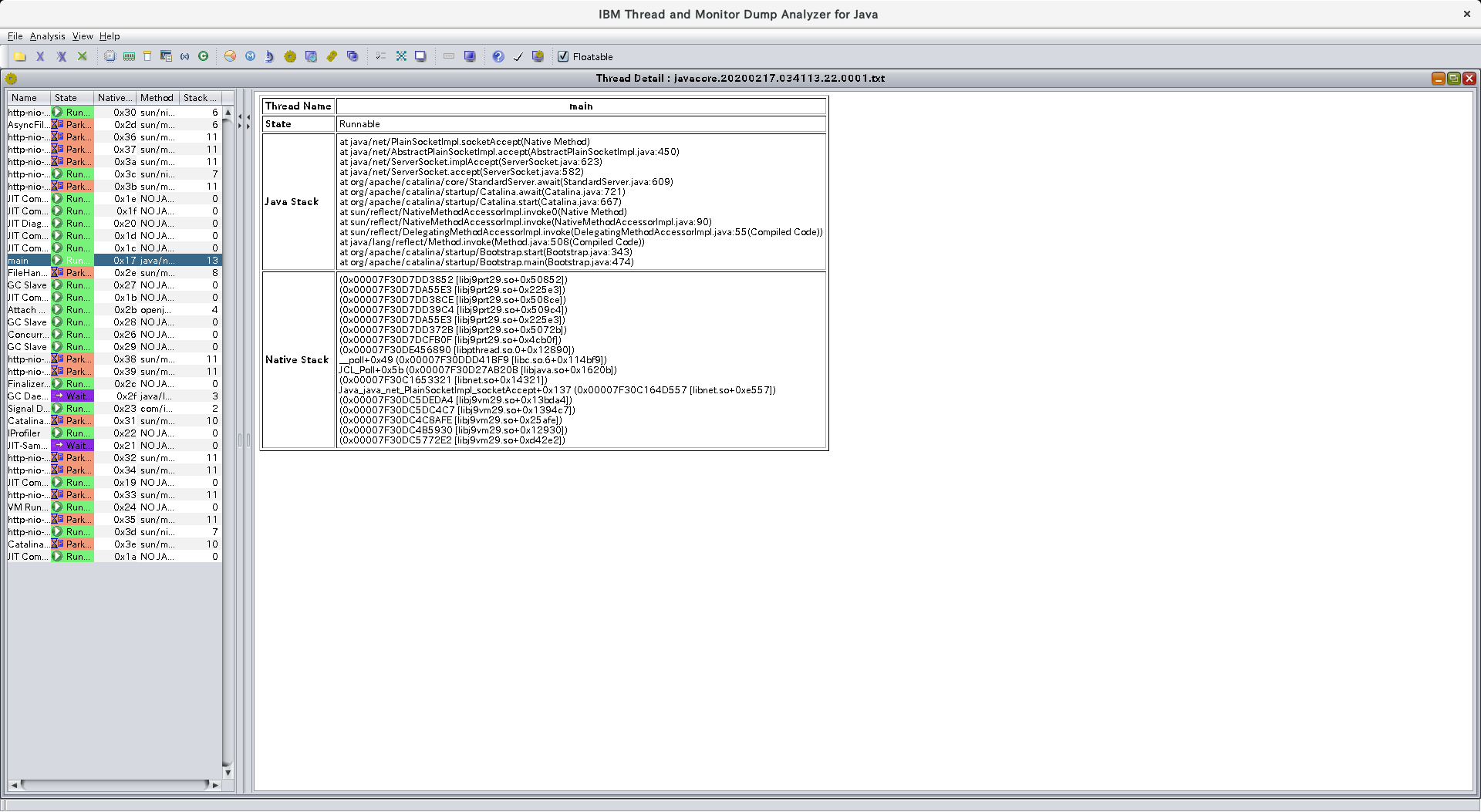
スレッドの情報を見たい場合は、Thread Status AnalyticsやThread Detailを見るとよいでしょう。
こうすると、(HotSpotで)見慣れたスレッドダンプの形式になりますね。
その他、TMDAではこういった情報も見れそうなので、スレッドダンプ以外の情報からの解析もできそうですね。
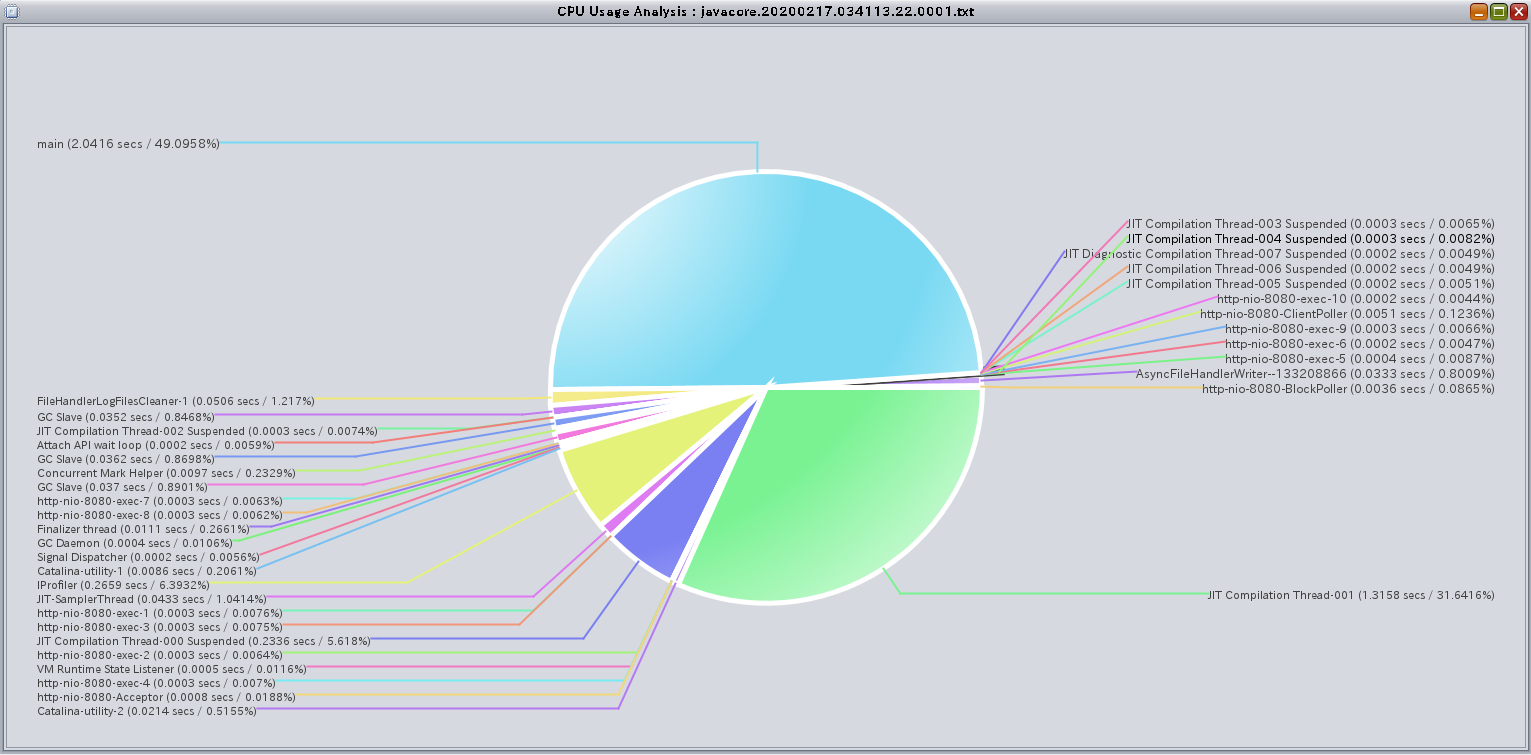
たとえば、CPU Usage Analysisだと、スレッドごとのCPU使用率が見れそうです。
IBM Javaを使うことがあれば、TMDAのことは頭に入れておいた方が良さそうかなと。



- 投稿日:2020-02-17T10:35:06+09:00
Eclipse che
Eclipseを使ったJAVAのセミナなどを開催したことがある。
Eclipseを土台とした道具類のセミナを主催し、開発元の方に講演・演習をしていただいたことが数種類ある。
あまりうまくいかなかったのは、UML-Bとか。
今だに Eclipse cheを使いこなせていない。
上記道具類の一つが、PizzaFactoryというクロスコンパイラを含む道具。
https://github.com/PizzaFactoryそのche版がこちら
https://github.com/PizzaFactory/cheGetting Started
SaaS Cloud: Self-service Eclipse Che developer workspaces hosted at che.openshift.io
https://www.eclipse.org/che/getting-started/cloud/Che quick-starts
https://www.eclipse.org/che/docs/che-7/che-quick-starts/Running Che locally on a personal workstation.
Deploying Che on Kubernetes on Amazon Elastic Compute Cloud .
Installing Che on OpenShift 3 using the Operator.
Installing Che on OpenShift 4 from OperatorHub.
Installing Che on Google Cloud Platform.
Installing Che on Microsoft Azure.
Accessing Che from OpenShift Developer Perspective.すでに利用しているCloudが一覧にあればそれを利用する。そうでなければ、on a personal workstationを利用するかどうか。
SaaS Cloudをたどると
Create a Free accountを選ぶと
Licence条項がむつかしい。
- I have read and agree to the エンタープライズ契約 .
- I have read and agree to the Red Hat OpenShift Online Services Agreement .
- I have read and agree to the Developer Program Terms & Conditions .
いろいろ触っていると価格に到達。
https://www.openshift.com/products/online/
どの道を辿るとよいか迷う。
支援(support)
ところで、PizzaFactory/cheでは有償の支援(support)を2019年11月から始めたらしい。
確かにタダで使えるものに金を払うお人好しは滅多に居ないよなぁ。ということで、リターンを設定してみた。$1000 、GitHub Sponsors にしては、強気の法人向け価格w https://t.co/KVJcVttNha pic.twitter.com/FW3aqIg7Dq
— もなか (@monamour555) November 4, 2019

- 投稿日:2020-02-17T07:40:30+09:00
使えるようになって(いて)欲しいプログラミング言語
はじめに
私はすでに全く若手ではないのだが、個人的な意見として、また新たに入ってくる技術者に言っていることを書いてみる。勿論賛否あって良い。
何気に私はいわゆる組込み系の仕事をしているのだが、ソフトウェア・オリエンテッドであまり組込みっぽくない人種です。
使えるようになって(いて)欲しいプログラミング言語
概ね以下の3種類でそれぞれ1つずつ。
システム記述系
こういう括りが正しいかは別として、C/C++、Java、C#など。
プログラムの動きとか、コンピューターの動きとか、きちんと知るにはCが最適。アセンブラとは言わない。アセンブラでもいいけど、プロセッサごとに違うしね。概念は知ってると良い。
ただ、Cを実務で使うのはどうしても必要でなければ避けたいのが本音。スキルの差がモロに品質に直結するので。
後、オブジェクト指向しづらいし。それができるというのとはまた別。C++は好きだが、仕様がカオスになりすぎて完全にマニアの世界。Javaはできると実務でも使えて、オブジェクト指向にも慣れるので良いかもしれない。
C#も簡単で分かりやすかった。Windowsでしかいまいち使わないが。
スクリプト系
Ruby、Python、今更使わないがベテランはPerlか。何でも良い。何か使えれば考え方は大概一緒で応用が効くだろう。
スクリプト言語は超絶楽に何でもできる。製品開発だって個人的な業務効率化だっていける。なので、使えるようになっておくと様々な場面で重宝される。
JavaScript
というか、TypeScriptか。
クライアント系はもうこれ一択。組込み系だって最近はWebブラウザ内蔵してるし、UIやるには必需品。
デスクトップでも node.js で何でもできるし。
ただ、node.js はひとつのザ・ワールドになっていて全くライトな感じではないのがちょっと引っ掛かるが。
まとめ
上記は網羅的な形ではないが、上記の方針で取り組んでいれば、新たに何か学ばなくてはならなくなってもどこかのスキルがベースになって応用が効く。
どちらかというと言語そのものよりもライブラリやフレームワークのスキル習得のほうが重要になるが、それを使いこなす上での前提知識の習得に時間がかかるようでは心許ない所なので、ある程度応用が効く形でスキル習得していくのが良い。
その上で、技術は知識よりも実践(熟練)なので、沢山書く機会を作ることを意識してもらえれば、嬉しい。