- 投稿日:2020-02-08T23:56:56+09:00
書籍「15Stepで踏破 自然言語処理アプリケーション開発入門」をやってみる - 3章Step12メモ
内容
15stepで踏破 自然言語処理アプリケーション入門 を読み進めていくにあたっての自分用のメモです。
今回は3章Step12で、自分なりのポイントをメモります。
CNN自体は大体勉強したことがあるので、内容はざっくりと。準備
- 個人用MacPC:MacOS Mojave バージョン10.14.6
- docker version:Client, Server共にバージョン19.03.2
章の概要
前章ではword embeddingsを導入することにより、単語の分散表現を特徴量として扱えるようになれた。
ただ、文レベルの特徴量に仕立てるには分散表現の合計や平均を取る必要があり、それだけだと予測がBoW系に劣ってしまう。
この章では単語の分散表現を文に対応する形で並べた列を入力とした畳み込みニューラルネットワーク(CNN)を構築する。12.1 ~ 12.4
CNNの層 内容 Convolutional layer ・入力
・word embeddingsによって得られた単語の分散表現列
・CNN層を重ねる場合、前層のPooling layerの出力列
・文を構成する各単語の分散表現列の長さを揃える
・超えた長さは無視する
・足りない分はゼロベクトルで埋める
・文構成の方向に対してkernel_sizeごとに、重みと掛け合わせてバイアスを加えて出力の一つとする
・文構成の方向に対してstrideごとに同操作を繰り返すが、重みは前層と同じ重みを用いる:weight sharingPooling layer ・入力
・Convolutional layerの出力列
・Max poolingやAverage poolingがあるが、非線形処理であるMax poolingの方が高性能
・文構成の方向に対してstrideごとに同操作を繰り返すことができるが、strideを設定せずに一括で処理する方法もある;global max pooling, global average poolingfully-connected layer
(densely-connected layer;全結合層)・多クラス分類するために多層パーセプトロンに入力したい
・pooling layerの出力は2次元配列なので、多層パーセプトロンに入力できる1次元配列に変換する12.5 KerasによるCNNの実装
word embeddingの分散表現の平均を特徴量とする(識別器:SVC)
前章では分散表現を合計していたので、平均して実行してみた。
import numpy as np from gensim.models import Word2Vec from sklearn.svm import SVC from tokenizer import tokenize from sklearn.pipeline import Pipeline class DialogueAgent: def __init__(self): self.model = Word2Vec.load( './latest-ja-word2vec-gensim-model/word2vec.gensim.model') # <1> def train(self, texts, labels): pipeline = Pipeline([ ('classifier', SVC()), ]) pipeline.fit(texts, labels) self.pipeline = pipeline def predict(self, texts): return self.pipeline.predict(texts) # 内容はStep11のものとほぼ同じ def calc_text_feature(self, text): ~~ # return np.sum(word_vectors, axis=0) return np.average(word_vectors, axis=0)evaluate_dialogue_agent.pyfrom os.path import dirname, join, normpath import pandas as pd import numpy as np from sklearn.metrics import accuracy_score from <実装したモジュール名> import DialogueAgent if __name__ == '__main__': BASE_DIR = normpath(dirname(__file__)) # Training training_data = pd.read_csv(join(BASE_DIR, './training_data.csv')) dialogue_agent = DialogueAgent() X_train = np.array([dialogue_agent.calc_text_feature(text) for text in training_data['text']]) y_train = np.array(training_data['label']) dialogue_agent.train(X_train, y_train) # Evaluation test_data = pd.read_csv(join(BASE_DIR, './test_data.csv')) X_test = np.array([dialogue_agent.calc_text_feature(text) for text in test_data['text']]) y_test = np.array(test_data['label']) y_pred = dialogue_agent.predict(X_test) print(accuracy_score(y_test, y_pred))word embeddingの分散表現の合計/平均を特徴量とする(識別器:NN)
上記では識別器がSVCだったので、これをNNに変更してみる。
各単語の分散表現を平均しているので、分散表現の次元texts.shape[1]がKerasClassifierのinput_dimとして設定する。~~ def _build_mlp(self, input_dim, hidden_units, output_dim): mlp = Sequential() mlp.add(Dense(units=hidden_units, input_dim=input_dim, activation='relu')) mlp.add(Dense(units=output_dim, activation='softmax')) mlp.compile(loss='categorical_crossentropy', optimizer='adam') return mlp def train(self, texts, labels, hidden_units = 32, classifier__epochs = 100): feature_dim = texts.shape[1] print(feature_dim) n_labels = max(labels) + 1 classifier = KerasClassifier(build_fn=self._build_mlp, input_dim=feature_dim, hidden_units=hidden_units, output_dim=n_labels) pipeline = Pipeline([ ('classifier', classifier), ]) pipeline.fit(texts, labels, classifier__epochs=classifier__epochs) self.pipeline = pipeline def predict(self, texts): return self.pipeline.predict(texts) ~~word embeddingの分散表現をそのまま特徴量とする(入力層:Embedding -> Flatten -> Dense)
word embeddingの分散表現は二次元配列なので、Flatten層を入れた後に、Dense層に入力する。
# モデル構築 model = Sequential() model.add(get_keras_embedding(we_model.wv, input_shape=(MAX_SEQUENCE_LENGTH, ), trainable=False)) model.add(Flatten()) model.add(Dense(units=256, activation='relu')) model.add(Dense(units=128, activation='relu')) model.add(Dense(units=n_classes, activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer='rmsprop', metrics=['accuracy'])word embeddingの分散表現をそのまま特徴量とする(入力層:Embedding -> CNN(Dense))
word embeddingの分散表現をCNNのConvolutional layerに入力するが、kernel_sizeを分散表現の次元
x_train.shape[1]にして実質Dense層と同じ構成にする。# モデル構築 model = Sequential() model.add(get_keras_embedding(we_model.wv, input_shape=(MAX_SEQUENCE_LENGTH, ), trainable=False)) # <6> # 1D Convolution model.add(Conv1D(filters=256, kernel_size=x_train.shape[1], strides=1, activation='relu')) # Global max pooling model.add(MaxPooling1D(pool_size=int(model.output.shape[1]))) model.add(Flatten()) model.add(Dense(units=128, activation='relu')) model.add(Dense(units=n_classes, activation='softmax')) model.compile(loss='categorical_crossentropy', optimizer='rmsprop', metrics=['accuracy'])word embeddingの分散表現をそのまま特徴量とする(入力層:Embedding -> CNN)
word embeddingの分散表現をCNNのConvolutional layerに入力する。
書籍通りなので詳細は省略。Embedding層Embedding(input_dim=word_num + 1, output_dim=embedding_dim, weights=[weights_with_zero], *args, **kwargs) ↓ # *args, **kwargsは実際はこんな感じ Embedding(input_dim=word_num + 1, output_dim=embedding_dim, weights=[weights_with_zero], input_shape=(MAX_SEQUENCE_LENGTH, ), trainable=False)
- trainable:学習時に重みを更新しない(すでに学習済みの重みを用いてEmbeddingするので学習による重み更新は不要)
- input_shape:Kerasで層をaddで追加する際、一番はじめの入力層に指定
- input_dim/output_dim:Embedding層の重みのin/outのdim。Embedding層の出力次元はoutput_dimと等しくなる
実行結果
word embeddingsの分散表現 識別器 実行結果 合計 SVC 0.40425531914893614 平均 SVC 0.425531914893617 合計/平均 NN 0.5638297872340425 /
0.5531914893617021行列のまま Embedding -> Flatten -> Dense 0.5319148936170213 行列のまま Embedding -> CNN(Dense) 0.5 行列のまま Embedding -> CNN 0.6808510638297872
- 通常実装(Step01):37.2%
- 前処理追加(Step02):43.6%
- 前処理+特徴抽出変更(Step04):58.5%
- 前処理+特徴抽出変更+識別器変更RandomForest(Step06):61.7%
- 前処理+特徴抽出変更+識別器変更NN(Step09):66.0%
- 前処理+特徴抽出変更(Step11):40.4%
- 前処理+特徴抽出変更+識別器変更CNN(Step12):68.1%
- 投稿日:2020-02-08T22:56:13+09:00
データサイエンティストになれるかな
自己紹介も兼ねた駄文から始めてみようと思う。
世の中AI(人工知能)ブームである。一昔前、AIといえばAction Itemを指していたが今や「AIって書くと紛らわしいからアクションアイテムって書けよ」と言われる(実話)時代になった。
現在は第3次人工知能ブームということで、いろんな人が「我が社もAIに取り組まないとけない」と鼻息が荒くなってきた。自分はといえば、データ分析の重要性についてはなんとなく認識しつつ、目立つWebページなんかはつまみ食いしていて、なんとなく概要はわかっていたものの、体系的に勉強したり技術をつけるということは年齢的なものや仕事を理由にこれまで避けてきた。
ところが、いろんなWebや書籍などの情報を見れば見るほどデータがいかに大事かということに気づく。その昔パソコンが使えるとヲタクだと言われたが、自分がその時に感じた、これ(コンピュータ)は将来くるぞという感覚に似たものを感じた。これは乗るしかない、この大波に!というわけで、何周遅れかわからないほど遅れているが、データサイエンティストの勉強の経過を記していこうと思う。
筆者のスペックや経験など
- 小学生の時にMSX BASICに触れる
- 中学生でマイコンBASICマガジン(通称ベーマガ)の写経を覚える
- 執念で親にFM-TOWNSを買ってもらう
- カーネルのバージョンがまだ0.9とかの時代にLinuxに出会う
- 首都圏の某大学で情報工学を専攻、コンピュータサイエンスはそれなりに学んだが、なぜか半導体工学の研究室に進み、大学院はなんとか卒業
- 理系の道を歩んだので、数学や物理の知識はまー人並みの大学レベル
- 某メーカーに就職したものの、技術どっぷりというよりは企画屋みたいなことをしている
- 仕事とは無関係に、RubyやPythonやJavascriptなどは趣味として嗜む程度
- 業務上それなりに大量のデータに触れることはあるが、AccessやExcelのピボットがわかればなんとかなる程度ではある
- 楽器演奏や写真を趣味にしてる
- などなど
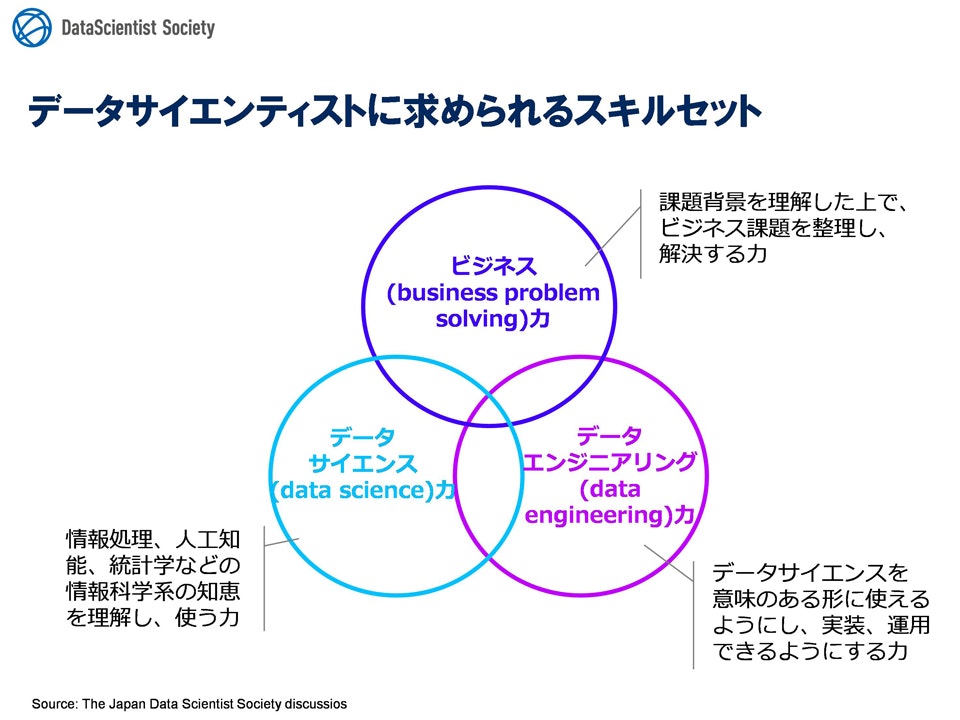
データサイエンティストの定義
人それぞれ思うところはあるだろうが、データサイエンティスト協会は、2014年12月10日のプレスリリースにおいて、以下のようにデータサイエンティストを定義していた。
「データサイエンティストとは、データサイエンス力、データエンジニアリング力をベースにデータから価値を創出し、ビジネス課題に答えを出すプロフェッショナル」
つまり、データを分析する高度なスキルを持っているだけではダメで、クライアントの課題をビジネスの観点から的確に捉え、課題に見合ったデータを定義し、高度な分析をもとに問題を解決するアプローチを取れることが必要になるという理解をした。
今後書いていくこと
自らをデータサイエンティストと言えるところまで持ち上げるにあたって学習したことを自分なりにアウトプットすることを目標にする。
機械学習
いわゆるG検定レベルの知識を網羅したい
- 教師あり学習や教師なし学習の具体的な内容とか理論とか手法とか
- ニューラルネットワークやディープラーニングについて
- できれば研究や応用分野について
コーディング
Pythonを使って、kaggleなんかに取り組みながらライブラリの使い方なんかをまとめていこうかなーと
正直日経XTECHさんにこんな記事を出されてしまうとあと書くことなくなってしまうのが本音だが、自分の学習用として割り切って書いていこうと思っています。よろしくどうぞ。
- 投稿日:2020-02-08T22:10:43+09:00
2020年Jリーグの移籍状況を可視化したいんだけど、どうする?
動機
- サッカーは、毎シーズン多くの選手が移籍します。
- 今シーズンの公式サイトには、1650名(2020/1/31時点)の選手が登録されています。
- また、移籍情報を公開しているサイトJ'S GOAL’Sサイトに移籍情報が上がっています。
- 以前から、この選手の流動状態を可視化出来ないものかと考えていました。
- Google先生に「流入流出 グラフ」と検索しても使えそうなものはヒットしませんでした。
- それを「流入流出 可視化」とすると「サンキーダイアグラム」を発見!これは使えるかも!
サンキーダイアグラムについて
サンキー・ダイアグラム(英Sankey diagram)は工程間の流量を表現する図表である。矢印の太さで流れの量を表している。特にエネルギーや物資、経費等の変位を表す為に使われる。
出典: フリー百科事典『ウィキペディア(Wikipedia)』
- pythonでsankeyダイアグラム
- やってみよう分析!第7章: Google Charts Sankey Diagramを使ってデータ可視化
- github:ipysankeywidget
- demo:Exporting Images.ipynb
- plotly: Sankey Diagram in Python
- matplotlib: sankey
本家
matplotlibはさっぱりわからない、plotlyはとても美しいがさっぱりわからない。で一番簡単な demo:Exporting Images.ipynbでトライ!写経
sankey.pyfrom ipysankeywidget import SankeyWidget from ipywidgets import Layout
- 事前に
pip install ipysankeywidgetでライブラリをインストールします。- また
jupyter labで使用する場合は、$ jupyter labextension install jupyter-sankey-widget @jupyter-widgets/jupyterlab-managerと拡張機能を登録します。
sankey.pylinks = [ {'source': 'start', 'target': 'A', 'value': 2}, {'source': 'A', 'target': 'B', 'value': 2}, {'source': 'C', 'target': 'A', 'value': 2}, {'source': 'A', 'target': 'C', 'value': 2}, ]これがデータ部分なので、移籍のダミーデータに置き換えます。
sankey.pylinks = [ {'source': '北海道_in', 'target': '海外_out', 'value': 1}, {'source': '北海道_in', 'target': 'J2_out', 'value': 1}, {'source': '北海道_in', 'target': '大学_out', 'value': 3}, {'source': '湘南_in', 'target': '北海道_out', 'value': 1}, {'source': 'J3_in', 'target': '北海道_out', 'value': 1}, ]sankey.pylayout = Layout(width="600", height="400") sankey = SankeyWidget(links=links, layout=layout) sankey.auto_save_png('./img/test.png')出力の画像のサイズは幅:600ピクセル,高さ:400ピクセルで、PNG形式で保存します。
説明するまでもないですが、加入した選手が5名で移籍した選手が2名の流れが表現できました。
(見てくれはショボいですが、一応流れは表現できそうですね)まとめ
- 「pythonでsankeyダイアグラム」@deaikeiさんやdemo:Exporting Images.ipynbの二番煎じでまだ勉強が足りない。
- J'S GOAL’Sサイトでは、著作権について文書・画像・映像等の複製禁止と明示しています。なのででスクレイピング手法や可視化の結果の共有は行いません。
- サンキーダイアグラムの可視化に関して知見が得られた。

- 投稿日:2020-02-08T21:58:12+09:00
pythonでツイートにいいねしてみた。。
python学習アウトプット #3
1. インタラクティブシェル
ターミナルでpythonと打って実行すると(>>>)こんなやつが出てきたらインタラクティブシェルに入ってるって感じすかねぇ
・ インタラクティブシェルとは...
インタラクティブシェルとは、オプション -c を付加されずに起動されるシェルで、標準入出力が(仮想)端末に接続されているもの、、、らしい笑
よくわかんないす。2.whichコマンド
・ whichコマンドとは
コマンドが実際に実行されているパスを探してくれるらしい。
パスとは、プログラム名だけで実行できるようにするために、PATH という環境変数(設定の一種)に「このプログラムも名前だけで実行できるようにしてください」という値を追加すること、、、らしいです。3. twitter APIを使って、あるキーワードに引っかかったツイートに[いいね]を押してくれるプログラムを試してみました!
結果...
ちゃんとキーワードに引っかかった方のツイートにいいねを押してくれてましたっ
まぁコードは教えてもらっている先生が書いたコードに、APIキーとキーワードを入れただけなんですけどね笑
自分でも書けるようになるために、書いてもらったコードを見たり、自分でもいじってみたりしてどれがどういう動きをしているのかしっかり勉強しますっ
- 投稿日:2020-02-08T21:18:52+09:00
Python ブール演算の戻り値はbool型とは限らない
Pythonでブール演算を行えるのはbool型だけではなく、戻り値もbool型とは限らない。
オブジェクトの真理値を確認するには
bool():>>> bool(123) True >>> bool([1,2,3]) True >>> bool('abc') True >>> bool({'a':1, 'b':2, 'c':3}) True >>> bool((1,2,3)) True >>> bool(0) False >>> bool([]) False >>> bool('') False >>> bool({}) False >>> bool(()) False >>> bool(None) Falseand
左オブジェクトの真理値が真なら右オブジェクトを返す:
>>> True and True True >>> [1,2,3] and 'abc' 'abc' >>> 'abc' and [1,2,3] [1, 2, 3] >>> True and False False >>> [1,2,3] and '' '' >>> 'abc' and [] []左オブジェクトの真理値が偽なら左オブジェクトを返す:
>>> False and True False >>> [] and 'abc' [] >>> '' and [1,2,3] '' >>> False and False False >>> [] and '' [] >>> '' and [] ''or
左オブジェクトの真理値が真なら左オブジェクトを返す:
>>> True or True True >>> [1,2,3] or 'abc' [1, 2, 3] >>> 'abc' or [1,2,3] 'abc' >>> True or False True >>> [1,2,3] or '' [1, 2, 3] >>> 'abc' or [] 'abc'左オブジェクトの真理値が偽なら右オブジェクトを返す:
>>> False or True True >>> [] or 'abc' 'abc' >>> '' or [1,2,3] [1, 2, 3] >>> False or False False >>> [] or '' '' >>> '' or [] []not
bool型しか返さない。
オブジェクトの真理値が真ならFalse:>>> not True False >>> not [1,2,3] False >>> not 'abc' Falseオブジェクトの真理値が偽ならTrue:
>>> not False True >>> not [] True >>> not '' True
- 投稿日:2020-02-08T21:02:36+09:00
CHEMBLIDから構造データを取得する
はじめに
CHEMBLIDからChEMBLに問い合わせてSDFやSMILES等の構造データを取り出す方法について調べてみた。
単一化合物のSDF(MOL)の取得
まず、単一のChEMBLIDを指定してMOLデータを取得するには以下の通りURLをたたけばよい。
CHEMBLIDは所定のものを指定する。ここでのポイントは末尾にformat=sdfをつけるという点である。https://www.ebi.ac.uk/chembl/api/data/molecule/CHEMBL1607289?format=sdf複数化合物のSDFの取得
次に複数のChEMBLIDを指定して一気にSDFを取得するには、以下のURLをたたけばよい。
ここでのポイントは複数のChEMBLEIDを指定する際にセミコロンで区切るという点である。https://www.ebi.ac.uk/chembl/api/data/molecule/set/CHEMBL1607289;CHEMBL1607290?format=sdf化合物データの取得
SDFではなく、分子量やSMILESなど様々なデータを取得するには、以下のようにformat=sdfを指定しなければよい。
https://www.ebi.ac.uk/chembl/api/data/molecule/set/CHEMBL1607289すると以下のようなXML形式で化合物データを得ることができる。
<?xml version="1.0" encoding="utf-8"?> <response> <molecules> <molecule> <atc_classifications/> <availability_type>-1</availability_type> <biotherapeutic/> <black_box_warning>0</black_box_warning> <chebi_par_id/> <chirality>-1</chirality> <cross_references> <molecule> <xref_id>26754105</xref_id> <xref_name>SID: 26754105</xref_name> <xref_src>PubChem</xref_src> </molecule> </cross_references> <dosed_ingredient/> <first_approval/> <first_in_class>-1</first_in_class> <helm_notation/> <indication_class/> <inorganic_flag>-1</inorganic_flag> <max_phase/> <molecule_chembl_id>CHEMBL1607289</molecule_chembl_id> <molecule_hierarchy> <molecule_chembl_id>CHEMBL1607289</molecule_chembl_id> <parent_chembl_id>CHEMBL1607289</parent_chembl_id> </molecule_hierarchy> <molecule_properties> <acd_logd>-2.11</acd_logd> <acd_logp>-2.11</acd_logp> <acd_most_apka>13.22</acd_most_apka> <acd_most_bpka>5</acd_most_bpka> <alogp>-1.58</alogp> <aromatic_rings>1</aromatic_rings> <full_molformula>C16H22N2O6</full_molformula> <full_mwt>338.36</full_mwt> <hba>8</hba> <hba_lipinski>8</hba_lipinski> <hbd>4</hbd> <hbd_lipinski>4</hbd_lipinski> <heavy_atoms>24</heavy_atoms> <molecular_species>NEUTRAL</molecular_species> <mw_freebase>338.36</mw_freebase> <mw_monoisotopic>338.1478</mw_monoisotopic> <num_lipinski_ro5_violations/> <num_ro5_violations/> <psa>123.35</psa> <qed_weighted>0.49</qed_weighted> <ro3_pass>N</ro3_pass> <rtb>3</rtb> </molecule_properties> <molecule_structures> <canonical_smiles>COC(=O)[C@@H]1C[C@@]2(O)[C@H](O)[C@H](O)[C@H](O)C[C@H]2N1Cc3cccnc3</canonical_smiles> <standard_inchi>InChI=1S/C16H22N2O6/c1-24-15(22)10-6-16(23)12(5-11(19)13(20)14(16)21)18(10)8-9-3-2-4-17-7-9/h2-4,7,10-14,19-21,23H,5-6,8H2,1H3/t10-,11+,12+,13+,14+,16-/m0/s1</standard_inchi> <standard_inchi_key>JKLLFWDPMLWZFY-SFEJEDPTSA-N</standard_inchi_key> </molecule_structures> <molecule_synonyms/> <molecule_type>Small molecule</molecule_type> <natural_product>-1</natural_product> <oral/> <parenteral/> <polymer_flag/> <pref_name/> <prodrug>-1</prodrug> <structure_type>MOL</structure_type> <therapeutic_flag/> <topical/> <usan_stem/> <usan_stem_definition/> <usan_substem/> <usan_year/> <withdrawn_class/> <withdrawn_country/> <withdrawn_flag/> <withdrawn_reason/> <withdrawn_year/> </molecule> </molecules> </response>Pythonから取得
最後に今回調べた方法を用いて、テキストファイルに記載したCHEMBLEIDのリストからSDFやSMILESをまとめて取得するPythonのプログラムを書いてみた。
GetStructureFromChEMBLE.pyimport argparse import requests import xml.etree.ElementTree as ET def main(): parser = argparse.ArgumentParser() parser.add_argument("-input", type=str, required=True) parser.add_argument("-type", type=str, default="sdf", choices=["sdf", "smiles"]), parser.add_argument("-output", type=str, required=True) args = parser.parse_args() ids_str = "" ids = [] with open(args.input) as f: lines = f.readlines(); for line in lines: line = line.rstrip() if len(ids_str) > 0: ids_str += ";" ids_str += line ids.append(line) url = "https://www.ebi.ac.uk/chembl/api/data/molecule/set/" + ids_str if args.type == "sdf": url += "?format=sdf" result = requests.get(url) if args.type == "sdf": with open(args.output, "w") as f: f.write(result.text) else: root = ET.fromstring(result.text) with open(args.output, "w") as f: for i in range(len(root[0])): structures = root[0][i].find("molecule_structures") f.write("{0}\t{1}\t{2}\n".format( ids[i], structures.find("canonical_smiles").text, structures.find("standard_inchi").text)) if __name__ == "__main__": main()使い方は-inputオプションでCHEMBLEIDのリストを1行1つで記載したファイルを指定し、-typeオプションでsdfまたはsmilesを指定する。そして-outputオプションで出力するファイルを指定すればよい。
入力ファイル例
input.txtCHEMBL6329 CHEMBL6328 CHEMBL265667 CHEMBL6362 CHEMBL267864出力ファイル例
-type=smilesを指定した場合は、以下のようにCHEMLEIDとSMILES, Inchiをタブ区切り形式で出力するoutput.tsvCHEMBL6329 Cc1cc(ccc1C(=O)c2ccccc2Cl)N3N=CC(=O)NC3=O InChI=1S/C17H12ClN3O3/c1-10-8-11(21-17(24)20-15(22)9-19-21)6-7-12(10)16(23)13-4-2-3-5-14(13)18/h2-9H,1H3,(H,20,22,24) CHEMBL6328 Cc1cc(ccc1C(=O)c2ccc(cc2)C#N)N3N=CC(=O)NC3=O InChI=1S/C18H12N4O3/c1-11-8-14(22-18(25)21-16(23)10-20-22)6-7-15(11)17(24)13-4-2-12(9-19)3-5-13/h2-8,10H,1H3,(H,21,23,25) CHEMBL265667 Cc1cc(cc(C)c1C(O)c2ccc(Cl)cc2)N3N=CC(=O)NC3=O InChI=1S/C18H16ClN3O3/c1-10-7-14(22-18(25)21-15(23)9-20-22)8-11(2)16(10)17(24)12-3-5-13(19)6-4-12/h3-9,17,24H,1-2H3,(H,21,23,25) CHEMBL6362 Cc1ccc(cc1)C(=O)c2ccc(cc2)N3N=CC(=O)NC3=O InChI=1S/C17H13N3O3/c1-11-2-4-12(5-3-11)16(22)13-6-8-14(9-7-13)20-17(23)19-15(21)10-18-20/h2-10H,1H3,(H,19,21,23) CHEMBL267864 Cc1cc(ccc1C(=O)c2ccc(Cl)cc2)N3N=CC(=O)NC3=O InChI=1S/C17H12ClN3O3/c1-10-8-13(21-17(24)20-15(22)9-19-21)6-7-14(10)16(23)11-2-4-12(18)5-3-11/h2-9H,1H3,(H,20,22,24)おわりに
参考のURLにAPIの説明があるが、あまりにも情報が足りないため、以前インストールしたChEMBL webresource clientのソースをハックしながら思考錯誤が必要だった。ローカルにもChEMBLのV25をインストールしたので、これからガンガンハックしてみたい。
参考
- 投稿日:2020-02-08T20:55:32+09:00
ALMAデータリダクション
気がむいたら更新していく予定
目次
casaを用いた解析
データ処理
- download
- concat
- split
clean
番外編
- large surveyのダウンロード&処理用pkgはこちら
データの加工
- cubeを積分強度 or 速度分散 or 速度場 or T peakにする
- 速度軸をbiningする
- 空間グリッドを揃える
- 速度グリッドを揃える
- 空間をsmoothingする
- 連続波を差し引く
- rms以下をzeroにする
便利ツール集
- image -> fitsに変換
- fits -> imageに変換
- headerを確認する
- 観測の境界線のfitsを作成
- listobsからspwを自動選択
pythonを用いた解析
- Jy/beamからKに単位変換
- headerを編集する
- Missing Fluxを求める
- 空間分解能を揃える(convolution)
- 質量を求める
- continuumから求める
- 12COから求める
- 13COから求める
- filamentを同定する
- GMCを同定する
図の作成
更新日
- 20200208 工事開始
- 投稿日:2020-02-08T20:28:53+09:00
Pythonローカル開発環境構築テンプレート【Flask/Django/Jupyter with Docker + VSCode】
概要
ローカル環境を構築することには、それなりのコストを伴います。もちろんここで多少苦労したほうがよいという意見はすごく分かります。が、それで気持ちが削がれてしまうのももったいないと思う次第です。
そこで、Flask/Django/JupyterNotebook向けの Python開発環境構築を3コマンドで完了 させられるようなテンプレートを作成しました。(cdを除く)前提条件
- MacOSであること
gitおよびmakeコマンドが有効であること(デフォルトで有効なはず)※
condaがインストールされている場合は、pipとのバッティングが発生し中途で失敗する可能性があります。ローカル構築イメージ
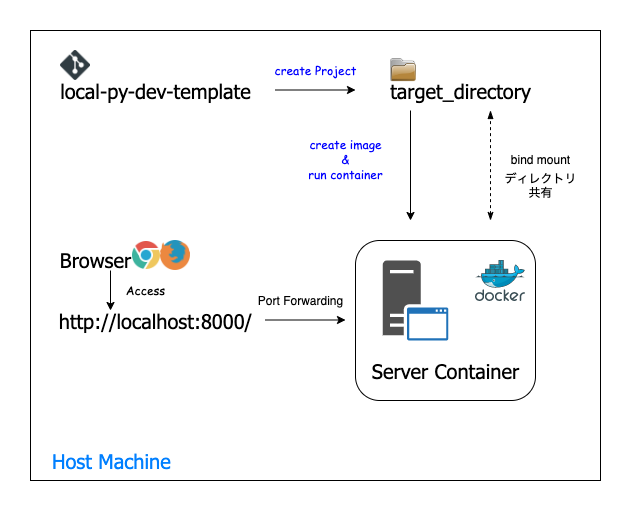
Dockerコンテナ上でアプリを動かすことになります。よく分かっていなくても、Dockerコンテナを使って開発していると言うことができます。
- bind mountによってホストPCからコンテナへのディレクトリ提供を行っています。これにより、ホストPC側で編集したファイルの内容をコンテナ側で読み込むことを実現しています。
- ホストPCからのアクセスについては、ポートフォワーディングを採用しています。プロジェクトによってコンテナ側の接続ポートは変更していますが、フォワードするホスト側のポートはすべて8000番に統一しました。
構築手順
1. テンプレートをダウンロード
git cloneによるダウンロード方法を記載します。Terminalgit clone git@github.com:mintak21/local-py-dev-template.git2. テンプレートを開発用ディレクトリへ展開
展開先ディレクトリを指定して、プロジェクトの展開を行います。
作成したプロジェクトに応じて、makeコマンドを使い分けます。Terminalcd local-py-dev-template # jupyterプロジェクトを作成する場合 make create_jupyter_pj # flaskプロジェクトを作成する場合 make create_flask_pj # djangoプロジェクトを作成する場合 make create_django_pj
- 指定可能な引数
引数名 概要 省略時値 TARGET_DIR 展開先ディレクトリ(存在しない場合は作成) ~/workspace/project DJANGO_PJ_NAME djangoの場合に指定可能。Djangoテンプレートのプロジェクト名 mysite 引数を指定したコマンド例
Terminal# 1つ上の階層のflask_dirディレクトリにflaskプロジェクトを展開 make create_flask_pj TARGET_DIR=../flask_dir # ~/workspaceディレクトリにdjangoプロジェクトを展開、djangoプロジェクト名はblogとする make create_django_pj TARGET_DIR=~/workspace DJANGO_PJ_NAME=blog3. コンテナ起動
2にて展開したディレクトリへ移動し、Dockerイメージ、コンテナを作成、起動を行います。
Terminalcd ${TARGET_DIR} make run4. 接続
いずれのコンテナもホストPCの8000番ポートでのポートフォワーディングを行なっているので、以下にアクセスすることができれば接続ができ、記載している内容が表示されていれば設定完了です。
アクセス先: http://localhost:8000/
プロジェクト 期待結果 Jupyter Jupyterホーム画面で、 HelloPython.ipynbファイルが見えているFlask Hello Flask!と表示されているDjango ロケットが出ている 5. コンテナ停止(Shutdown)
Foregroundで実行しているため、ターミナル上のプロセスを停止することでコンテナが停止します。
ターミナルで
Ctrl + Cおまけ. Visual-Studio-Codeセットアップ
ここまでで、起動と接続が出来たので、これ以降は開発を進めていくことになります。
開発エディタにはVimやpytorchなどもありますが、ここではVisual-Studio-Codeを用いて開発を進められるようにしています。
導入は1コマンドで完了します。Terminalmake setup_vscode # local-py-dev-templateディレクトリで実行設定概略
単に
Visual-Studio-Codeをインストールするだけではなく、静的解析やpytestなどの設定、必要&有用な拡張機能の導入も同時に行うようにしています。
brew caskによるVisual-Studio-Codeのインストール- パッケージ導入(
pip)
- 静的解析:flake8
- import整列:isort
- フォーマッタ:autopep8
- typeチェック:mypy
- テスト:pytest
- 拡張機能導入(
code --install-extension)
- Microsoft-Python : Python拡張ツール(必須)
- Bracket Pair Colorizer : 対応するかぎかっこが色で見やすくなる
- Whitespace+ : タブと空白を可視化
- Docker : vscodeでDockerが扱える
- vscode-icons : アイコンを見やすくする
- autoDocString : DocString作成補助
Others
ローカル側も
pipenvなどの仮想環境を利用すべきかもしれませんが、自分の知るpythonicな諸先輩方はピュアPythonを使っていることが多かったため、これに倣い仮想環境は導入していません。Reference
- 投稿日:2020-02-08T19:41:51+09:00
クラスメソッド スタティックメソッド
class Person(object): kind = 'human' def __init__(self): self.x = 100 @classmethod def what_is_your_kind(cls): return cls.kind @staticmethod def about(year): print('human about {}'.format(year)) print(Person.what_is_your_kind()) Person.about(1999)実行結果human human about 1999
Person.what_is_your_kind()で
Person()となっておらずオブジェクトができていないので、
本来はエラーとなる。しかし、
what_is_your_kindをクラスメソッドにする事で、
what_is_your_kindオブジェクトのメソッドではなく、
クラスのメソッドとなりアクセスできる様になる。
- 投稿日:2020-02-08T19:21:55+09:00
【DarkNet】YOLOを使ってドアラ検出 Part1
はじめに
手軽に物体検出を試したいなあと思って手を出した次第であります。
そこで今回は某名古屋球団のマスコットである愛らしいドアラの検出をします。DarkNet
今回の主役「DarkNet」
これがDarkNetのサイト。
「なんか厨二くさいサイトは・・・」と思うかもしれませんが、こいつが今回の主役です。DarkNetでは画像検出に用いるアルゴリズムを楽に動かして画像検出の為のプロセスを最小限に抑えてくれてます。
画像検出アルゴリズム「YOLO」
YOLO(You Only Look Once)とは、深層学習を基礎とした一般検出技術です。一般検出技術にはR-CNNやFast R-CNNなどいくつかあるそうですが、YOLOの強みはやはり速度です。動画からリアルタイムでの物体検出ができます。
YOLOの特徴
YOLOは与えた入力画像から、
- オブジェクトに近い候補領域を切り出し
- それぞれの候補領域でのクラス確率を算出
高いクラス確率を出力した候補領域を元に、検出対象を以下のように矩形で囲います。
R-CNNでは上記の二点を順番に実行しますが、YOLOでは同時に実行できることが高速な物体検出の秘訣です。画像検出までの道のり
主な作業は7段階です。
一番面倒な作業は「教師データの作成(アノテーション)」です。ここは本当に作業ゲー。
Part1では太字のところまで説明していきます。
- DarkNetをInstall
- アノテーションソフトをInstall
- 教師データの作成(アノテーション)
- 設定ファイルの編集
- darknet19_448.conv.23を取得
- 学習
- テスト
DarkNetをInstall
githubを通じて取得できます。
[Darknet]フォルダが生成されるのを確認してください。Terminal$ git clone https://github.com/preddle/darknet.gitアノテーションソフトをInstall
アノテーションソフトとは・・・
教師データを作成する際に、入力画像に付随するメタデータの作成を手助けしてくれます。
ここでのメタデータは画像に対して、対象クラス名(ex. dog, cat etc...)と画像中の選択領域の座標(=検出したいオブジェクトらしい対象領域)のことを指します。今回はYOLOを用いた画像検出ですので、YOLOに合った教師データを作る必要があります。
以下のように画像の領域を①分類クラス②領域座標に変換してくれます。今回はアノテーションソフトにLabelImgを使用します。
LabelImgの使い方:http://takesan.hatenablog.com/entry/2018/08/16/013452Terminal$ git clone https://github.com/tzutalin/labelImg.git $ sudo apt install pyqt5-dev-tools $ sudo apt install python3-pip $ sudo pip3 install lxml $ cd labelImg $ make qt5py3Anaconda環境で作業されてる方は、condaコマンドでpyqt5をインストールできないかもしれません。その場合、pyqt5のインストール:https://githubja.com/tzutalin/labelimgのサイトを参考にされてはいかがでしょうか。
LabelImg/dataの中にあるpredefined_class.txtを修正します。こちらはデフォルトで20のクラスが登録されているのですが、自分で新たにクラスを作成する場合には厄介となるので、自分が学習したいクラス名だけ登録しておきます。
predefined_class.txtdogここで一瞬PythonコマンドでlabelImgディレクトリ下にあるlabelImg.pyを実行してやらないといけません(コードは書いていない)。
Terminal#current -> ~/labelImg $ python labelImg.pyLabelImgでアノテーション画面が開けます。
参考サイト
LabelImg導入①
LabelImg導入②
AnacondaでのLabelImg導入教師データの作成
教師データ
一般的には教師データはGithubからダウンロードしたDarknet/dataに格納します。
今回はドアラの画像をDarknet/data/doara(適宜変更)に格納しました。アノテーション
アノテーションについては前回にて参照。
アノテーションはLabelImgを用いて作業していきます。その前に・・・
オリジナルのクラスに検出させたい時、labelImg/data/predefined_class.txtを全て削除し、オリジナルクラス名(日本語不可)に書き換えます。今回はドアラを検出したいので、クラス名はdoaraとします。labelImg/data/predefined_class.txt(デフォルトで入力されているクラス名を削除) doara(適宜変更)アノテーションの流れ
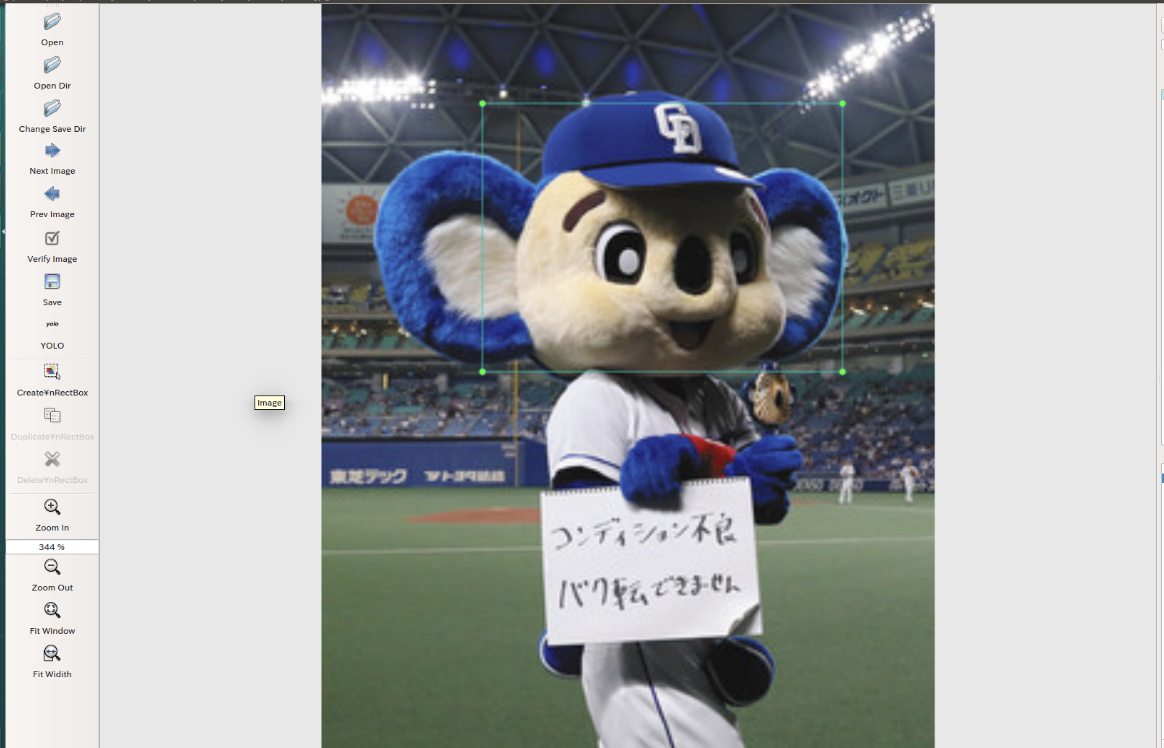
- 左上の[OpenDir]より、Darknet/data/doaraを選択すると、アノテーションを開始できます。
- YOLOを用いる場合、「Pascal VOC」→「YOLO」へ設定してください。
- [Create¥nRectBox]より検出したい領域を矩形で囲む事ができます。
- AutoSaveモードにすると保存が楽([View]→[Autosave]にチェック)
- [Save]
- [Next Image]
こんな感じ
アノテーションで、検出オブジェクトらしい領域の座標をtextファイルに出力しました。
ここまでくれば、DarkNetにてアノテーション作業で作成したメタデータ(座標text+クラス名)を読み込ませ、DarkNetでのハイパーパラメータを調節して学習させるだけです。メタデータには数字の羅列が書き込まれています。
Darknet/data/doara/image01.txtクラス番号(ex.0,1,2・・・) 矩形の四隅の座標これを教師データの画像分だけ繰り返します。
アノテーションは面倒ですが、丁寧に数多くやると精度は向上します。全画像のパスをファイルに書き込む
教師画像(.jpg)と座標データ(.txt)がDarknet/data/doaraには存在しています。
今から教師画像のパスを新たに作成するPATHファイル(.txt)に書き込みます。そしてDarknetはこのPATHファイル(.txt)を通じて教師画像の場所を見つける事になります。以下のDarknet/data/doara/make_PATH.pyで簡単にPATHファイルを生成できます。
今回は拡張子がjpgの状態の画像を対象としています。
他の拡張子で試される方は、以下のスクリプトの"jpg"の部分を書き換えるといいでしょう。Darknet/data/doara/make_PATH.pyimport glob, os #現在のディレクトリを取得 current_dir = os.path.dirname(os.path.abspath(__file__))+'/' #全画像に対してテストデータ(:訓練データ)の比率[%]を設定 percentage_test = 10; #PATHファイルのファイル名設定 file_train = open('train2020.txt', 'a') file_test = open('test2020.txt', 'a') #教師画像のパスをPATHファイルに書き込み #画像の拡張子に注意(今回はjpg version) counter = 1 index_test = round(100 / percentage_test) for pathAndFilename in glob.iglob(os.path.join(current_dir, "*.jpg")): #ファイル名からtitleと拡張子を分割 title, ext = os.path.splitext(os.path.basename(pathAndFilename)) if counter == index_test: counter = 1 file_test.write(current_dir + title + '.jpg' + "\n") else: file_train.write(current_dir + title + '.jpg' + "\n") counter = counter + 1Terminal#current -> ~/Darknet/data/doara $ python make_PATH.pyすると教師画像のパスを列挙したPATHファイル(この場合、train2020.txtとtest2020.txt)が生成されます。
上記のmake_PATH.pyをそのまま実行した場合、Darknet/data/doara/train2020.txtとDarknet/data/doara/test2020.txtがきちんと存在しているはずです。Part1はここでひとまず終わりです。
次回はPart2で最後までやろうと思います。

- 投稿日:2020-02-08T18:48:16+09:00
B2902 SMU + 82357Bによる自動測定
Keysight B2902 SMU + Keysight 82357B USB-GPIBを使って自動測定するためのメモです。
USB-GPIBインターフェースの接続
ここではKeysight純正のUSB-GPIBインターフェースをVISA (Virtual Instrument Software Architecture)でつなぐ。VISAは測定器制御のためのソフトウェア共通規格。
- KeySight USB-GPIBインターフェース 82357B接続し,PCのUSB端子につなぐ。「不明なデバイス」として認識される。[ドライバーの更新]で探しても出てこない。
- 82357B, ドライバで検索すると,2007年版のドライバ(XP, 2000用)が出てくる。これは使わない。(ことが後でわかった)
- Agilent IO Libraries Suite 14.2が必要なので,これを検索してダウンロード。実際にはIO Library Suite 2018というもの。ファイル名 IOLibSuite_18_1_24715.exe。
- IO Libraries Suiteを実行してインストール。Visual C++ 2012, 2015, を入れられてしまう。これを入れると,82357Bが不明なデバイスでなくなりWindowsに認識される。
- pip install pyvisa [Enter] でPythonのVISAコントロールをインストールする。
- B2902の設定を行なう。System>>Info>>Date/Time, System>>PLC
- I/O>>GPIBでAddressが23であることを確認。”GPIB0::23::INSTR”
- pythonで下記を実行する。
Python 3.6.2 (v3.6.2:5fd33b5, Jul 8 2017, 04:14:34) [MSC v.1900 32 bit (Intel)] on win32 Type "help", "copyright", "credits" or "license" for more information. >>> import visa >>> rm = visa.ResourceManager() >>> rm.list_resources() ('GPIB0::23::INSTR',) >>> inst = rm.open_resource('GPIB0::23::INSTR') >>> print(inst.query("*IDN?")) Keysight Technologies,B2902A,MY51143336,3.1.1645.5820 >>>コマンドの要点
- 60Hz電源設定 “:SYST:LFR 60”
- CH1, 2の出力をON/OFFする “:OUTP1 ON”, “:OUTP2 ON”
- SOUR, SENS, OUTPはその後にチャネル番号を続ける。
- MEAS?はMEAS? (@1,2) とチャンネルリストを続ける。
スポット測定
inst.write("*RST") inst.write("*CLS") inst.write(":sour1:func:mode volt") inst.write(":sour2:func:mode curr") inst.write(":sens1:curr:rang:auto on") inst.write(":sens2.volt:rang:auto on") inst.write("outp1 on") inst.write("outp2 on") inst.write(":sour1:volt 20") inst.query("meas:curr? (@1)").strip() inst.query("meas:volt? (@2)").strip()階段測定
npoint = 20 inst.write("*RST") inst.write(":sour:func:mode volt") inst.write(":sour:volt:mode swe") inst.write(":sour:volt:start 0") inst.write(":sour:volt:stop 1") inst.write(":sour:volt:poin {}".format(npoint) inst.write(":sens:func \"curr\"") inst.write(":sens:curr:nplc 1") inst.write(":sens:curr:prot 0.1") inst.write(":trig:sour aint") inst.write(":trig:coun {}".format(npoint) inst.write(":outp on") ans = inst.query(":fetc:arr:curr? (@1)").strip().split(,)終了判定
while (True): if int(inst.query(":STAT:OPER:COND?")) & 18 == 18: breakCh2で行っていたら,18のところが1152になる。
- 投稿日:2020-02-08T17:57:20+09:00
Python3の標準モジュールで完結するRPC
目次
- 今のPythonのRPCは種類が多すぎる
- 標準ライブラリで実行できる価値
- コードの説明
- 実際に動かしてみて
今のPythonのRPCは種類が多すぎる
2020年現在、数多くのRPCがOSSとして公開されていますが、種類が多すぎる点と、それに伴う選択コストの増加と、評価コストの増加、学習コストの増加が個人的な課題
であると感じています。社会人をやっているととにかく時間が貴重なので、次々現れるライブラリを検討していたり、使い方を学んだりしているのは、PoCを素早く行う場合やAPIなど閉じた小さ
いプロダクトを作る際には適切ではありません。Pythonでは
multiprocessingの中にmanagerクラスが存在して、multiprocessing時のプロセス間通信をネットワーク越しに動作させることで、高性能なRemote Procudure Callを実装することができます。Remote Procudure Call(以下, RPC)とは、ネットワーク上の別のコンピュータで、何らかの処理を呼び出したり、処理させたりすることで、大規模な分散処理を行う際に
便利です。標準ライブラリで実行できる価値
数多くのライブラリを使ってきたのですが、そのライブラリのメンテナがいなくなったりpull requestを受け入れられる体制を持っていなかったり、時間がなかったりな
どで多くの、"良さそう"と思われるライブラリが過去の時代に取り残されていきました。できれば、ライブラリ依存せず、かつ簡単に実装できれば、それはPythonが存在する限り(もしくはPythonの中でdeprecatedにならない限り)使用できることになります。
コードの説明
serverとclientに分けて考えることができる要素で、serverは命令を待ち受け、clientは命令を発行します。server
from multiprocessing.managers import BaseManager as Manager import os # インメモリのKVSを想定 obj = {} def get(k): print('get', k) return obj.get(k) def put(k, v): obj[k] = v print('put', k,v) # serverのunameを取得(LinuxとかMacOSとかわかる関数) def get_uname(): print('get_uname') return str(os.uname()) if __name__ == "__main__": port_num = 4343 Manager.register("get", get) # 待受に使う関数を登録 Manager.register("put", put) Manager.register("get_uname", get_uname) manager = Manager(("", port_num), authkey=b"password") # ホスト名を空白にすることで任意の箇所から命令を受け入れられる。パスワードが設定できる manager.start() input("Press any key to kill server".center(50, "-")) # なにか入力したら終了 manager.shutdown()client
from multiprocessing.managers import BaseManager as Manager Manager.register("get") # 関数を登録 Manager.register("put") Manager.register("get_uname") if __name__ == "__main__": port_num = 4343 manager = Manager(address=('25.48.219.74', port_num), authkey=b"password") manager.connect() print('get', manager.get('a')) # Noneが帰ってくるはず print('put', manager.put('a', 10)) # a -> 10をセット print('get', manager.get('a').conjugate()) # 10が帰ってくるはず, (primitive型などは、conjugate関数で値を取り出す) print('get_uname', manager.get_uname()) # MacOSでクライアントを実行しているが、ServerのLinuxが帰ってくるはず実際に動かしてみて
serverをLinux(Ubuntu), clientをMacOS(darwin)から、コンビニカフェからお家のPCに上記のプログラムを実行してみまました。
結果は想定通りで、任意の動作をさせることができました。

これで例えば、YouTubeの視聴数や、Twitterのトレンドキーワードなどは処理できそうですし、いちいち高頻度でBigQueryやRedShiftなどを稼働させなくても効率的にデー
タをアグリゲートできます。新しいすごいツールを学習することも重要ですが、既存のもので小さく収めることも重要で、全体的なやりたいことに対する達成コストが非常に安く済むので、ぜひこの方
法も検討していただけると幸いです。おまけ:YouTubeの視聴数カウントコード
clientをフォークして複数から大量のアクセスが有ったという想定で、やってみました。
cleint
from concurrent.futures import ProcessPoolExecutor import random from multiprocessing.managers import BaseManager as Manager Manager.register("get") # 関数を登録 Manager.register("inc") def extract(x): if hasattr(x, 'conjugate'): return x.conjugate() else: return x def hikakin_watch(num): port_num = 4343 manager = Manager(address=('127.0.0.1', port_num), authkey=b"password") manager.connect() for i in range(1000): try: now = extract(manager.get('hikakin')) print(now) manager.inc('hikakin') except Exception as exc: print(exc) if __name__ == "__main__": with ProcessPoolExecutor(max_workers=5) as exe: exe.map(hikakin_watch, list(range(5))) port_num = 4343 manager = Manager(address=('127.0.0.1', port_num), authkey=b"password") manager.connect() now = extract(manager.get('hikakin')) print(now)server
from multiprocessing.managers import BaseManager as Manager import os # インメモリのKVSを想定 obj = {} def get(k): if k not in obj: obj[k] = 0 return obj.get(k) def inc(k): obj[k] += 1 if __name__ == "__main__": port_num = 4343 Manager.register("get", get) # 待受に使う関数を登録 Manager.register("inc", inc) manager = Manager(("", port_num), authkey=b"password") # ホスト名を空白にすることで任意の箇所から命令を受け入れられる。パスワードが設定できる manager.start() input("Press any key to kill server".center(50, "-")) # なにか入力したら終了 manager.shutdown()期待する出力として5000が得られ、並列アクセスに対しても、きちんと排他制御ができることがわかりました。
YouTubeの視聴数のカウントなどに使えそうです。
- 投稿日:2020-02-08T17:32:48+09:00
テーブルのデータをCSV形式で高速に出力する小ネタ
記事の内容
以前、同僚からテーブルのデータをCSV出力するのに時間が掛かるという話をされたので、ちょっとした内容ですがアドバイスしました。
時間の計測まではしていなかったので、どのくらい早くなるのか簡単な検証も踏まえてメモを残します。
前提
・テーブルの内容は全データそのまま出力する
・PostgreSQL 12.1用意データ
準備したデータは以下のidだけ違うデータを1000万件用意しました。
-[ RECORD 1 ]-------- id | 1 data1 | aiueo data2 | kakikukeko data3 | sasshisuseso data4 | tachitsuteto data5 | naninuneno data6 | hahihuheho data7 | mamimumemo data8 | yayuyo data9 | rarirurero data10 | wawon出力方法1
出力方法1は全データ取得して、プログラムの中でCSV形式に変換するという内容です。
SQL
select * from demo出力コード
csv_out.pyimport psycopg2 import time def get_connection(): return psycopg2.connect("host=localhost port=5432 dbname=sampledb user=postgres password=postgres") path = "csv1.csv" with get_connection() as conn: with conn.cursor() as cur: start = time.time() cur.execute("select * from demo") exec_time = time.time() - start print(exec_time) start = time.time() with open(path, "w") as f: i = 1 for row in cur: csv = '' for data in row: csv = csv + str(data) + ',' f.write(csv[:-1] + '\n') if i % 1000 == 0: f.flush() i += 1 exec_time = time.time() - start print(exec_time)出力方法2
SQLでSQL形式に変換しておく方法です。
SQL
select id | ',' | data1 | ',' | data2 | ',' | data3 | ',' | data4 | ',' | data5 | ',' | data6 | ',' | data7 | ',' | data8 | ',' | data9 | ',' | data10 as data from demo出力コード
csv_out2.pyimport psycopg2 import time def get_connection(): return psycopg2.connect("host=localhost port=5432 dbname=sampledb user=postgres password=postgres") path = "csv2.csv" with get_connection() as conn: with conn.cursor() as cur: start = time.time() cur.execute("select id || ',' || data1 || ',' || data2 || ',' || data3 || ',' || data4 || ',' || data5 || ',' || data6 || ',' || data7 || ',' || data8 || ',' || data9 || ',' || data10 as data from demo") exec_time = time.time() - start print(exec_time) start = time.time() with open(path, "w") as f: i = 1 for row in cur: for data in row: f.write(data + '\n') if i % 1000 == 0: f.flush() i += 1 exec_time = time.time() - start print(exec_time)出力結果
結果は以下の通りです。
処理 出力方法1 出力方法2 SQL 11.68s 13.35s ファイル出力 56.95s 15.05s 出力方法2の方が早く出力できました。
感想
個人的にはもう少し早くなるかなと思ってましたが、出力カラム数が少ないのでこんなものかもしれません。
出力するカラム数が増えるほど効果が出てくるやり方です。DBサーバに接続してCSV出力をするのであれば、ExportコマンドやCOPY TOコマンドなどの方が早く出力が出来ると思います。
ただ、業務システムの保守開発ではテーブルのデータをそのまま出力するという処理は割とあるので、そういった場合にこのやり方を使っています。
- 投稿日:2020-02-08T17:30:41+09:00
Python初心者です。どこがエラーか教えていただけないでしょうか?
user_reply=input("ロボットは好きですか?(yes,no,maybe,laserで答えてください)")
if user_reply=="yes":
print("ピー ブー!")
elif user_reply=="maybe":
print("はっきりしろよ人間!")
elif user_reply=="laser":
print("ビーーーーム!")
elif user_reply=="no":
print("いいもん。ロボットも君が好きじゃないから。")
elif:
print("君たち人間のくだらなさにはあきれるよ。")
- 投稿日:2020-02-08T17:19:08+09:00
GoogleCloudFunctionsのデプロイでハマった('ascii' codec can't encode character u'\u281b' in position 58 が出る)
概要
- GCPのCloudFunctionsをローカルからデプロイしようとしたらうまくいかなかった
- 試行錯誤の末にうまくいくようになったので、検証経緯と解決策をメモる
- 似たようなエラーにハマった方への助けになれば幸いです
エラー内容
[usr_id@PC_NAME] ~/Documents/project/function_name % gcloud functions deploy function-name --region asia-northeast1 --runtime python37 --trigger-topic topic-name # デプロイコマンド Deploying function (may take a while - up to 2 minutes)...failed. ERROR: gcloud crashed (UnicodeEncodeError): 'ascii' codec can't encode character u'\u281b' in position 58: ordinal not in range(128) If you would like to report this issue, please run the following command: gcloud feedback To check gcloud for common problems, please run the following command: gcloud info --run-diagnostics [usr_id@PC_NAME] ~/Documents/project/function_name % gcloud info --run-diagnostics # エラー詳細 Network diagnostic detects and fixes local network connection issues. Exception in thread Thread-1: Traceback (most recent call last): File "/Users/usr_id/.pyenv/versions/2.7.0/lib/python2.7/threading.py", line 530, in __bootstrap_inner self.run() File "/Users/usr_id/.pyenv/versions/2.7.0/lib/python2.7/threading.py", line 483, in run self.__target(*self.__args, **self.__kwargs) File "/Users/usr_id/google-cloud-sdk/lib/googlecloudsdk/core/console/progress_tracker.py", line 164, in Ticker if self.Tick(): File "/Users/usr_id/google-cloud-sdk/lib/googlecloudsdk/core/console/progress_tracker.py", line 235, in Tick self._Print(self._GetSuffix()) File "/Users/usr_id/google-cloud-sdk/lib/googlecloudsdk/core/console/progress_tracker.py", line 261, in _Print self._console_output.UpdateConsole() File "/Users/usr_id/google-cloud-sdk/lib/googlecloudsdk/core/console/multiline.py", line 154, in UpdateConsole self._UpdateConsole() File "/Users/usr_id/google-cloud-sdk/lib/googlecloudsdk/core/console/multiline.py", line 168, in _UpdateConsole self._messages[self._last_print_index].Print() File "/Users/usr_id/google-cloud-sdk/lib/googlecloudsdk/core/console/multiline.py", line 281, in Print self._WriteLine(line) File "/Users/usr_id/google-cloud-sdk/lib/googlecloudsdk/core/console/multiline.py", line 331, in _WriteLine self._stream.write(self._level * INDENTATION_WIDTH * ' ' + line) UnicodeEncodeError: 'ascii' codec can't encode character u'\u281b' in position 30: ordinal not in range(128) Checking network connection...done. Reachability Check passed. Network diagnostic passed (1/1 checks passed). Property diagnostic detects issues that may be caused by properties. Checking hidden properties...done. Hidden Property Check passed. Property diagnostic passed (1/1 checks passed).
- デプロイしたらよくわからないエラーが出る
gcloud crashed (UnicodeEncodeError): 'ascii' codec can't encode character u'\u281b' in position 58: ordinal not in range(128)
- ログを見るとデプロイまではうまくいって、ターミナルに結果を返すところで失敗しているように見える
- コンソールを見ると、デプロイは成功している
- おそらくターミナルに結果を返そうとしているところでエラーが出ている
設定内容
- SDKで利用しているPython
- pyenvで入れたpython2.7
[usr_id@PC_NAME] ~/Documents/project/function-name % echo $CLOUDSDK_PYTHON /Users/usr_id/.pyenv/versions/2.7.0/bin/python対応その1
- デフォルトエンコードを変更してみる
- 参考:
デフォルトエンコード変更前
% $CLOUDSDK_PYTHON Python 2.7 (r27:82500, Nov 1 2019, 14:21:44) [GCC 4.2.1 Compatible Apple LLVM 10.0.1 (clang-1001.0.46.4)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>> import sys >>> sys.getdefaultencoding() 'shift-jis' >>>デフォルトエンコードを変更してみる
[usr_id@PC_NAME] ~/.pyenv/versions/2.7.0/lib/python2.7/site-packages % pwd /Users/usr_id/.pyenv/versions/2.7.0/lib/python2.7/site-packages [usr_id@PC_NAME] ~/.pyenv/versions/2.7.0/lib/python2.7/site-packages % cat sitecustomize.py import sys sys.setdefaultencoding('utf-8') [usr_id@PC_NAME] ~/.pyenv/versions/2.7.0/lib/python2.7/site-packages % $CLOUDSDK_PYTHON Python 2.7 (r27:82500, Nov 1 2019, 14:21:44) [GCC 4.2.1 Compatible Apple LLVM 10.0.1 (clang-1001.0.46.4)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>> import sys >>> sys.getdefaultencoding() 'utf-8' >>>
- ダメだった
- そもそもデフォルトエンコードが
shift-jisになっていて、エラー内容の'ascii' codec can't encodeに合わない- もしかして
$CLOUDSDK_PYTHONでpyenvで入れたpythonを指定しているけど、デプロイで実際に使われているpythonは違うものが使われている・・・?対応その2
- MacデフォルトのPythonでデフォルトエンコードを変更してみる → これで解決!
変更してみる
[usr_id@PC_NAME] /Library/Python/2.7/site-packages % echo $CLOUDSDK_PYTHON /usr/bin/python2.7 [usr_id@PC_NAME] /Library/Python/2.7/site-packages % pwd /Library/Python/2.7/site-packages [usr_id@PC_NAME] /Library/Python/2.7/site-packages % $CLOUDSDK_PYTHON Python 2.7.16 (default, Oct 16 2019, 00:34:56) [GCC 4.2.1 Compatible Apple LLVM 10.0.1 (clang-1001.0.37.14)] on darwin Type "help", "copyright", "credits" or "license" for more information. >>> import sys >>> sys.getdefaultencoding() 'utf-8' >>>
- これで解決した!
[usr_id@PC_NAME] ~/Documents/project/function-name % gcloud functions deploy function-name --region asia-northeast1 --runtime python37 --trigger-topic topicname Deploying function (may take a while - up to 2 minutes)...done. availableMemoryMb: 256 entryPoint: function-name eventTrigger: eventType: google.pubsub.topic.publish failurePolicy: {} resource: projects/project-name/topics/topicname service: pubsub.googleapis.com ingressSettings: ALLOW_ALL labels: deployment-tool: cli-gcloud name: projects/project-name/locations/asia-northeast1/functions/function-name runtime: python37 serviceAccountEmail: project-name@appspot.gserviceaccount.com sourceUploadUrl: hogehoge status: ACTIVE timeout: 60s updateTime: '2020-02-06T02:15:16Z' versionId: '19'原因(想像)
- cli実行後のインジケーターのところで出力している記号がasciiだと表示できないっぽい
u'\u281b'→ ⠛ この記号だった- ↓のくるくるしてるとこ
- なのでデプロイだけ成功して、コマンド実行したターミナル表示のところだけ失敗したっぽい
$CLOUDSDK_PYTHONで指定してるからそっちのpythonが利用されるかと思いきや、Macデフォルトのほうが使用されてたりする。PATHも通してたはずなんだが・・・・
- pyenvに頼りすぎるのは良くないのかもしれない
備考
- gcloudコマンドのバージョンとかメモるの忘れた(Qiita記事書いてる環境とハマった環境が別なため)ので、あとで覚えてたら追記します

- 投稿日:2020-02-08T16:56:51+09:00
機械学習(AI)初学者のファーストステップ
機械学習(AI)初学者のファーストステップ
MicroSoft Azure Machine Learning を使ったGUIベースのAI作成します。
1.とりあえず環境を用意しよう!
2.とりあえず言われるままAIをつくってみよう!Azureの無料アカウントを作成
https://azure.microsoft.com/ja-jp/
Azureにワークスペースを作成
※作成したワークスペースが気に入らなかったりして削除した場合はワークスペースだけ削除されるのでプランは前回と同じものを設定してください(無料プランは1個しか設定できない)(もしくはプランも消してください)
⇒(「リソースグループ」や「すべてのリソース」)で探すとよいです。Microsoft Azure Mechine Learningを起動する
Sign Inする(ワークスペース作成時にサインインしてるはずなので押せばログインできます。)試してみる
https://kinpatucom.tech/azure-ml-mnist/
ここが一番わかりやすかったので提示しておきます。
- 投稿日:2020-02-08T16:43:35+09:00
辞書型の参照には絶対getを使いましょう
Pythonで辞書(Dict)型を参照する2つの方法
Pythonで辞書型のオブジェクトの値を参照するのには2つの方法があります。
- そのまま参照する
- getメソッドを使う
前者は使わない方がよいのですが、その理由をご紹介します。
1. そのまま参照する場合
解説のために簡単なクラスを作成します。
sample_class.pyclass SampleDict1: def __init__(self, params: dict): self.name = params['name'] self.age = params['age'] self.sex = params['sex']これはインスタンスを作成する際に、作成するための情報を辞書型の引数で渡す方法です。APIのリクエストボディにJSONで作成データを格納し、それをサーバ側で辞書型に変換してモデル層に渡すときなどにこのようなやり方をすることがあると思います。
ここで、このクラスのインスタンスを作成してみます。
from sample_class import SampleDict1 params = {'name':'test', 'age':38, 'sex':'male'} sample_dict1 = SampleDict1(params) print(sample_dict1.__dict__) # {'name': 'test', 'age': 38, 'sex': 'male'}無事に作成することができました。インスタンスを作成する際に渡す辞書型オブジェクトに、パラメータの不足がない場合は何の問題もありません。
では、辞書型オブジェクトにsexが含まれていない場合を見てみましょう。from sample_class import SampleDict1 params = {'name':'test', 'age':38} sample_dict1 = SampleDict1(params) # KeyError: 'sex'辞書型オブジェクトを直接参照している場合で、指定したkeyがオブジェクトに存在しないときは、KeyErrorという例外が発生してしまいます。
そのため、例えば、sexパラメータを必須としないなどの場合に、直接参照するやり方だと以下のように実装するはずです。sample_class.pyclass SampleDict1: def __init__(self, params: dict): self.name = params['name'] self.age = params['age'] if 'sex' in params.keys(): self.sex = params['sex']あるいは
sample_class.pyclass SampleDict1: def __init__(self, params: dict): try: self.name = params['name'] self.age = params['age'] self.sex = params['sex'] except KeyError: pass…後者のやり方は完全に馬鹿げていますが、スキルがない人が書いたコード量の多いソースで見かけることがあります。このように、辞書型オブジェクトを直接参照する方法は、無駄なバリデーションや例外処理を必要とする場合が出てきてしまいます。
2. getメソッドを使う
それではgetメソッドを使って辞書型オブジェクトの値を参照するとどのようになるのでしょうか。
sample_class.pyclass SampleDict2: def __init__(self, params): self.name = params.get('name') self.age = params.get('age') self.sex = params.get('sex')インスタンスを作成してみます。
from sample_class import SampleDict2 params = {'name':'test', 'age':38, 'sex':'male'} sample_dict2 = SampleDict2(params) print(sample_dict2.__dict__) # {'name': 'test', 'age': 38, 'sex': 'male'}パラメータに不足ない場合は1の場合と同様に正常に作成できました。それではパラメータが足りない場合はどうなるのでしょうか。
from sample_class import SampleDict1 params = {'name':'test', 'age':38} sample_dict1 = SampleDict1(params) print(sample_dict2.__dict__) # {'name': 'test', 'age': 38, 'sex': None}このように、KeyErrorにはならずにNoneが格納されました。これであれば、sexパラメータを必須としないなどの場合に、追加的な処理を必要としません。また、無駄なバリデーションや例外処理がないことによって可読性を損いません。
さらに、sexパラメータに何も値がないときは'unknown'としたい場合でも、1の場合よりもすっきりと書くことができます。
まず、1の直接参照する場合は以下のように実装するでしょう。sample_class.pyclass SampleDict1: def __init__(self, params: dict): self.name = params['name'] self.age = params['age'] if 'sex' in params.keys(): self.sex = params['sex'] else: self.sex = 'unknown'一方、2のgetメソッドを使う場合は以下のように実装できます。
sample_class.pyclass SampleDict2: def __init__(self, params): self.name = params.get('name') self.age = params.get('age') self.sex = params.get('sex', 'unknown') # dict.get(key[, default]) # Return the value for key if key is in the dictionary, else default.このように、デフォルトの値を設定する際に、1の直接参照する方法だと4行使用するのに対して、2のgetメソッドを使う場合だと1行で書くことができます。
おわりに
以上で見てきたように、辞書型のオブジェクトの値を参照する際に、1の直接参照する方法よりも、2のgetメソッドを使う方が便利です。なので、直接参照しているコード書いていた方は今すぐにそのコードをすべてgetメソッドに変えてください(切実に)。
補足
最後の例について、一応1の場合でも以下のように書くことはできますがおすすめはしません。
1行が長くなり、PEP8で定められてる80行未満ルールに違反しやすくなるのと、それを回避するのに\を挟んで改行すると恐ろしく可読性と保守性が悪くなるからです。これをするくらいならまだ4行に分けた方がましだと思います。sample_class.pyclass SampleDict1: def __init__(self, params: dict): self.name = params['name'] self.age = params['age'] self.sex = params['sex'] if 'sex' in params.keys() else 'unknown'
- 投稿日:2020-02-08T16:43:35+09:00
辞書型の参照にはなるべくgetを使いましょう
Pythonで辞書(Dict)型を参照する2つの方法
Pythonで辞書型のオブジェクトの値を参照するのには2つの方法があります。
- そのまま参照する
- getメソッドを使う
前者は使わない方がよいのですが、修正しました。コメント欄を参照
前者はあまり使わない方が良いのですが、その理由をご紹介します。1. そのまま参照する場合
解説のために簡単なクラスを作成します。
sample_class.pyclass SampleDict1: def __init__(self, params: dict): self.name = params['name'] self.age = params['age'] self.sex = params['sex']これはインスタンスを作成する際に、作成するための情報を辞書型の引数で渡す方法です。APIのリクエストボディにJSONで作成データを格納し、それをサーバ側で辞書型に変換してモデル層に渡すときなどにこのようなやり方をすることがあると思います。
ここで、このクラスのインスタンスを作成してみます。
from sample_class import SampleDict1 params = {'name':'test', 'age':38, 'sex':'male'} sample_dict1 = SampleDict1(params) print(sample_dict1.__dict__) # {'name': 'test', 'age': 38, 'sex': 'male'}無事に作成することができました。インスタンスを作成する際に渡す辞書型オブジェクトに、パラメータの不足がない場合は何の問題もありません。
では、辞書型オブジェクトにsexが含まれていない場合を見てみましょう。from sample_class import SampleDict1 params = {'name':'test', 'age':38} sample_dict1 = SampleDict1(params) # KeyError: 'sex'辞書型オブジェクトを直接参照している場合で、指定したkeyがオブジェクトに存在しないときは、KeyErrorという例外が発生してしまいます。
そのため、例えば、sexパラメータを必須としないなどの場合に、直接参照するやり方だと以下のように実装するはずです。sample_class.pyclass SampleDict1: def __init__(self, params: dict): self.name = params['name'] self.age = params['age'] if 'sex' in params.keys(): self.sex = params['sex']あるいは
sample_class.pyclass SampleDict1: def __init__(self, params: dict): try: self.name = params['name'] self.age = params['age'] self.sex = params['sex'] except KeyError: pass…後者のやり方は完全に馬鹿げていますが、スキルがない人が書いたコード量の多いソースで見かけることがあります。このように、辞書型オブジェクトを直接参照する方法は、無駄なバリデーションや例外処理を必要とする場合が出てきてしまいます。
2. getメソッドを使う
それではgetメソッドを使って辞書型オブジェクトの値を参照するとどのようになるのでしょうか。
sample_class.pyclass SampleDict2: def __init__(self, params): self.name = params.get('name') self.age = params.get('age') self.sex = params.get('sex')インスタンスを作成してみます。
from sample_class import SampleDict2 params = {'name':'test', 'age':38, 'sex':'male'} sample_dict2 = SampleDict2(params) print(sample_dict2.__dict__) # {'name': 'test', 'age': 38, 'sex': 'male'}パラメータに不足ない場合は1の場合と同様に正常に作成できました。それではパラメータが足りない場合はどうなるのでしょうか。
from sample_class import SampleDict1 params = {'name':'test', 'age':38} sample_dict1 = SampleDict1(params) print(sample_dict2.__dict__) # {'name': 'test', 'age': 38, 'sex': None}このように、KeyErrorにはならずにNoneが格納されました。これであれば、sexパラメータを必須としないなどの場合に、追加的な処理を必要としません。また、無駄なバリデーションや例外処理がないことによって可読性を損いません。
さらに、sexパラメータに何も値がないときは'unknown'としたい場合でも、1の場合よりもすっきりと書くことができます。
まず、1の直接参照する場合は以下のように実装するでしょう。sample_class.pyclass SampleDict1: def __init__(self, params: dict): self.name = params['name'] self.age = params['age'] if 'sex' in params.keys(): self.sex = params['sex'] else: self.sex = 'unknown'一方、2のgetメソッドを使う場合は以下のように実装できます。
sample_class.pyclass SampleDict2: def __init__(self, params): self.name = params.get('name') self.age = params.get('age') self.sex = params.get('sex', 'unknown') # dict.get(key[, default]) # Return the value for key if key is in the dictionary, else default.このように、デフォルトの値を設定する際に、1の直接参照する方法だと4行使用するのに対して、2のgetメソッドを使う場合だと1行で書くことができます。
おわりに
以上で見てきたように、辞書型のオブジェクトの値を参照する際に、1の直接参照する方法よりも、2のgetメソッドを使う方が便利です。なので、直接参照しているコード書いていた方は今すぐにそのコードをすべてgetメソッドに変えてください(切実に)。
補足
最後の例について、一応1の場合でも以下のように書くことはできますがおすすめはしません。
1行が長くなり、PEP8で定められてる80行未満ルールに違反しやすくなるのと、それを回避するのに\を挟んで改行すると恐ろしく可読性と保守性が悪くなるからです。これをするくらいならまだ4行に分けた方がましだと思います。sample_class.pyclass SampleDict1: def __init__(self, params: dict): self.name = params['name'] self.age = params['age'] self.sex = params['sex'] if 'sex' in params.keys() else 'unknown'
- 投稿日:2020-02-08T16:39:10+09:00
【Python】AtCoderで必要になるかもしれない知識
AtCoder初心者が問題を解いていくうえで、
役立つかもしれない知識をメモとして残していく。入力
いろんな入力の受け取り。
文字の受け取り
S = input()数値の受け取り
N = int(input())空白数値受け取り
A,B = map(int,input().split())入力回数を受け取り、その回数分入力を受け取る
角かっこを使った書き方を内包表記というN = int(input()) #入力回数 l = [int(input()) for i in range(N)] #N回の数値入力をリストとして取得入力回数を受け取り、その回数分空白数値を受け取る
Q = int(input()) L = [0]*Q R = [0]*Q for i in range(Q): L[i], R[i] = map(int, input().split())あとで文字列を変更したい場合、文字のリストとして受け取っておく
入力PythonT = [s for s in input()] T[0] = "p" print("".join(T))python出力
リストを空白ありで出力
l = [1,2,3] print(*l)1 2 3リストを空白なしで出力
l = [1,2,3] l = map(str,l) #joinは文字列に対してなので、文字列に変換 print("".join(l))123format
リスト
ソート
降順にソート
スライス操作
逆順に出力enumerate
素数判定
最大公約数、最小公倍数
順列、組み合わせ
アスキーコード ord、chr
【ord】
アスキーコードに変換
【chr】
アスキーコードから文字に変換151 A - Next Alphabet
c = input() print(chr(ord(c) + 1))
- 投稿日:2020-02-08T16:11:11+09:00
【Python】家虎に逆位相の音を合成して無音を作る
はじめに
こちらの記事を参考にさせていただきました。
音声分析ド素人が逆位相ミュージックを聞いたら、そこに訪れたのは混乱とそして静寂だったやること
家虎と逆の波形(逆位相)の音を作成し、2つを合成することで家虎を無力化(無音)させます。
手順としては以下の通りです。・家虎(音源)の読み込み
・逆位相の作成
・家虎と逆位相を合成(無音化)家虎とは
アイドルや声優のライブで使われる『イェッタイガー』というコール(掛け声)のことです。主にサビの前で叫ばれることから曲の雰囲気を壊すとしてネット上で議論の対象になることがよくあります。
先日もブシロード取締役の木谷高明氏が次のようなツイートをしたことで話題になりました。
お知らせ。家虎根絶する方向で動きます。今後、明らかにライブの妨害に当たるものは退出に留まらず、ブラックリスト化。場合によっては損害賠償請求など法的手段の検討もさせて頂きます。ご理解よろしくお願いします。
— 木谷高明 (@kidanit) February 1, 2020準備
使用するライブラリ
2つのライブラリを使います。
Pydub:音源の編集
matplotlib:波形のプロット環境によってはffmpegのインストールが必要なことがあります。
詳しくはこちらの記事をどうぞ音源
今回使うのはi☆Risの幻想曲WONDERLANDのサビ前で入る家虎です。
所持している家虎のサンプルがこれしかありませんでした。
現場でやると楽しいから消したくなかった。実践
ファイルの読み込みと波形の表示
まず音源の読み込みと再生をします。
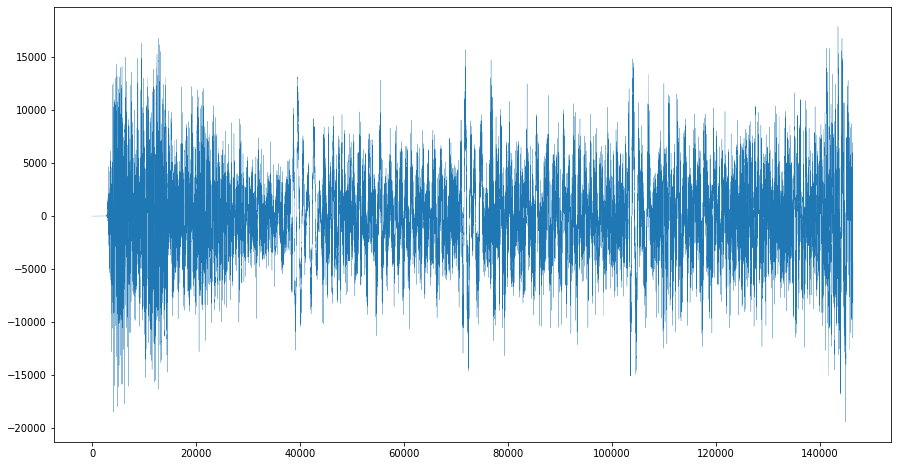
from pydub import AudioSegment from pydub.playback import play import matplotlib.pyplot as plt # ファイル読み込み audio = AudioSegment.from_mp3('tiger.mp3') # 再生 play(audio)はっきりと家虎が聞こえます。
波形を表示させてみましょう。
# 波形の表示 a_graph = audio.get_array_of_samples() plt.figure(figsize=(15, 8)) plt.plot(a_graph,lw=0.25) plt.show()
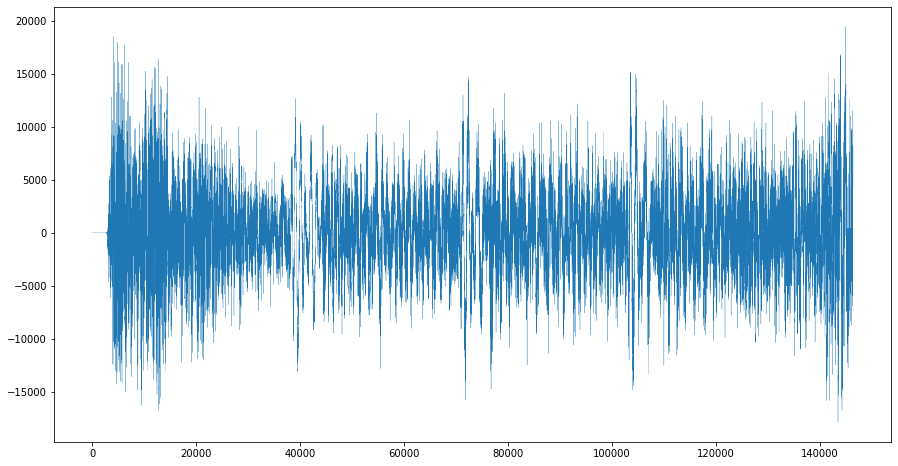
逆位相の作成
さきほどの波形を反転して表示させます。
できたものが家虎の逆位相になります。# 波形を反転(逆位相) invert = audio.invert_phase() # 波形の表示 i_graph = invert.get_array_of_samples() plt.figure(figsize=(15, 8)) plt.plot(i_graph,lw=0.25) plt.show()
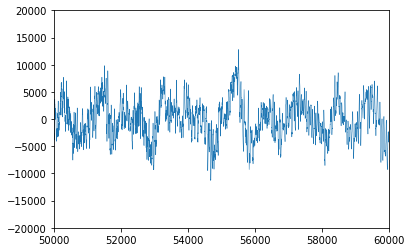
反転しているか分かりづらいので一部を切り取ったうえで比較してみます。
反転してますね。ちなみに反転させた音を聴いてみましたが、元の音源との違いが判りませんでした。
波形が逆になっても聴こえ方には影響しないのでしょうか。合成
通常の波形と反転させた波形を合成していきます。
# 合成 synthesize = audio.overlay(invert) #波形の表示 s_graph = synthesize.get_array_of_samples() plt.figure(figsize=(15, 8)) plt.plot(s_graph,lw=2) plt.show()
見事に音が無くなっています。
2つの音波が打ち消しあうことで無音が作り出されるわけですね。
これで家虎を気にすることなく曲を楽しめるようになりました。課題
家虎をキャンセリングするといいつつ、実は家虎以外の音も消してしまっています。
white forcesのようにサビ前が完全な無音になる曲なら問題ありませんが、大抵はなにかしら楽器の音が入っているため、それも含めて消してしまうのは曲の雰囲気の点から改善する必要があります。
ただ、曲以外の音を抽出する方法が思いつかないので今回はここまでとさせていただきます。終わりに
ここまで読んでくださりありがとうございました。修正やアドバイス等あればコメント欄にお願いします。
余談ですが、私は家虎推奨派でも否定派でもございません。誤解のないように。

- 投稿日:2020-02-08T16:10:49+09:00
【python】英語勉強用アプリに使用する、各単語の音声ファイルを自動ダウンロードするアプリを作成してみた
あらすじ
下記記事にて作成した英語勉強用アプリでは、英単語の音声ファイルが必要になる。
https://qiita.com/Fuminori_Souma/private/0706716fdebf08572c6cその音声ファイルを手動でダウンロードするのは時間と手間がかかって大変なので、
webスクレイピングで自動的にダウンロードすることにした。音声ファイルはweblio様のもの有難くをダウンロードいただきます。
※ weblio様にご迷惑をかけないよう、速度は遅め(恐らく手動以下)に設定しています。
ソースファイル
get_sound_file.pyimport sys import tkinter import time import re import urllib.request from tkinter import messagebox from selenium import webdriver from selenium.webdriver.common.by import By from selenium.webdriver.common.keys import Keys from selenium.webdriver.common.action_chains import ActionChains class Frame(tkinter.Frame): def __init__(self, master=None): tkinter.Frame.__init__(self, master) self.master.title('音声ファイルをgetくん') self.master.geometry("400x300") # ラベルの設定 text_1 = tkinter.Label(self, text=u'音声ファイルを取得したい単語を、下のテキストボックスに入力して下さい。') text_1.pack(pady='7') text_2 = tkinter.Label(self, text=u'※ 複数の単語を入力する場合は「,」で区切って下さい。') text_2.pack() # テキスト(エントリーの複数ver.)の設定 self.ent_words = tkinter.Text(self, height=15) self.ent_words.pack(padx='30') # プッシュボタンの設定 bttn_start = tkinter.Button(self, text = u'開始', command=self.start_get_file) bttn_start.bind("<Button-1>") #(Button-2でホイールクリック、3で右クリック) bttn_start.pack(pady='7') def checkAlnum(self, word): # 入力された単語に不要な記号等が含まれていないかチェック alnum = re.compile(r'^[a-zA-Z]+$') # 正規表現をコンパイル result = alnum.match(word) is not None # matchで条件に合えばSRE_Match objectを、そうでなければNone(False)を返す return result def delete_symbols(self, word): # 文字列に含まれた記号等を削除 # return word.replace(',', '').replace('.', '').replace('-', '').replace(' ', '') return word.replace(',', '').replace(' ', '') def get_mp3(self, word, driver): # weblioのページを開いてmp3ファイルを取得 dir = 'C:/Users/fumin/OneDrive' # 音声ファイルのダウンロード先 # 単語検索用のテキストボックスに単語を入力して検索ボタンを押下 driver.find_element_by_xpath("//*[@id=\"searchWord\"]").clear() # テキストボックスを初期化 driver.find_element_by_xpath("//*[@id=\"searchWord\"]").send_keys(word) driver.find_element_by_xpath("//*[@id=\"headFixBxTR\"]/input").click() time.sleep(5) # 音声ファイルが存在する(=「プレーヤー再生」が存在する)場合 if not driver.find_elements_by_xpath("//*[@id=\"audioDownloadPlayUrl\"]/i") == []: # 「プレーヤー再生」を押してmp3ファイルを新しいウィンドウで開く driver.find_element_by_xpath("//*[@id=\"audioDownloadPlayUrl\"]/i").click() time.sleep(5) # 操作対象のウィンドウを、新しく開いたmp3ファイルに変更する handles = driver.window_handles driver.switch_to.window(handles[1]) # mp3ファイルをダウンロードする urllib.request.urlretrieve(driver.current_url, (dir + '/' + word + '.mp3')) driver.close() # 操作対象のウィンドウを元のウィンドウに戻す driver.switch_to.window(handles[0]) return 'OK' else: # 音声ファイルが存在しない(=「プレーヤー再生」が存在しない)場合 return 'NG' def start_get_file(self): reslist = {} # 単語の音声ファイルが存在したか否か (空の辞書型で初期化) words = self.ent_words.get('1.0', 'end') # テキストボックスに入力した単語リストを取得 if self.checkAlnum(self.delete_symbols(words)): # 正しく入力されている(英字及び「,」以外が入力されていない)場合 ww = [x.strip() for x in words.split(',')] # 入力の単語リストをカンマで区切ってlist型として格納 # ブラウザを開く drv = webdriver.Chrome("C:/Users/fumin/pybraries/chromedriver_ver79/chromedriver") time.sleep(10) # 操作するページ(weblio)を開く drv.get("https://ejje.weblio.jp/") time.sleep(10) j = 0 # NG単語(mp3ファイルが存在しない単語)の数 for i in range(len(ww)): # mp3ファイルを取得 reslist[ww[i]] = self.get_mp3(ww[i], drv) if reslist[ww[i]] == 'NG': # mp3ファイルが存在しない単語をNGリストに追加 j += 1 # NG単語数を加算 if j <= 1: # 1つ目のNG単語は文字列型として格納 nglist = ww[i] elif j == 2: # 2つ目のNG単語は1つ目とカンマ区切りで繋げてlist型に変換 nglist = (nglist + ',' + ww[i]).split(',') else: # 3つ目以降はlist型に順次追加 nglist.append(ww[i]) drv.close() # 単語取得処理が終了したらブラウザを閉じる if 'nglist' in locals(): # 音声ファイルが存在しなかった単語がある場合 if j == 1: # NG単語が1つだけの場合 messagebox.showinfo('', '下記を除いた、全単語の音声ファイルをダウンロードしました。\n\n' + nglist) else: # NG単語が2つ以上の場合 messagebox.showinfo('', '下記を除いた、全単語の音声ファイルをダウンロードしました。\n\n' + ', '.join(nglist)) else: messagebox.showinfo('', '入力された全単語の音声ファイルをダウンロードしました。') else: # 正しく入力されていない(英字及び「,」以外が入力されている)場合 messagebox.showinfo('', '英字及び「,」以外が入力されています。削除した後に再度実行して下さい。') if __name__ == '__main__': # フレームの設定 root = Frame() root.pack() root.mainloop()備考
weblioのサイト負担をかけるのはまずいためかなり速度を遅めにした。。そのため、
ダウンロードする速度は、手動と大して変わりません。
(速度ではなく、あくまで自動化したことに意義があると考えています)課題
mp3ファイルを開いた際に、いちいち音声ファイルが再生されてしまう。。そのため、
再生される時だけmp3ファイルの音声を調節して音声が再生されないようにした。。が、mp3ファイルの
音量バーを調節できなかった。PC自体の音量自体を一瞬0にすることも考えたが、音楽を聴きながら
ダウンロードしていた場合、その音楽も途切れてしまう!と考え、止む無く断念した。mp3ファイルのダウンロード方法について、最初は右クリック->名前を付けてオーディオを保存 を
選択しようと思っていたが、右クリックによって出てきたコンテキストメニューは、Seleniumでは
アクセス不可らしい。。そのため、urllibを使用してmp3ファイルをダウンロードした。
結果的にmp3ファイルをダウンロードできたのはいいが、今後右クリックは必要になったときは
困るなあ。。その他の参考にさせていただいた情報
大変お世話になりました。誠にありがとうございます。
最後に
ここ間違ってるぞ!ここだめだぞ!ここはこうした方がいいぞ!等ございましたら、
是非ご指摘いただけますと涙を流して喜びます。
- 投稿日:2020-02-08T16:08:37+09:00
【python】英単語の微妙な音声の聞き分けを練習するためのアプリを作ってみた
あらすじ
以前、海外旅行中、子猫を抱えた現地の人に英語で話しかけられた時の話。
外国の人「How to say "kitchen" in Japanese ?」
自分「(?? なんでいきなりそんなこと聞くんだろう…)DAIDOKORO」
外国の人「?? … ? What?」
自分「DAIDOKORO !」
外国の人「…Oh, DAIDOKORO! OK! DAIDOKORO!」後日
自分「こうゆうことがあってさ。なんであんなこと聞いてきたんだろうな」
友達「それ、kitchenじゃなくてkittenって言ったんじゃない?
子猫抱えてたんでしょ?」
自分「ああそっか、kittenか!子猫のことね!
kitchenと発音が似てるから間違えてしまったよ!hahaha」自分・友達「…」
自分「英語、勉強しよう…」
作りたいもの
発音が似ている2つの単語を画面上に表示し、
どちらかの音声ファイルをランダムで再生する。
発音されたとユーザーが判断した方の単語を選択し、
正解もしくは不正解を画面上に表示する。また、発音記号が似ている様々な単語のペアは
発音記号ごとにまとめ、どの発音記号の聞き分けに
挑むか、ユーザーが選択できるようにする。例えば、私も含め多くの人が悩む'r'と'l'の違いを
学習するとする。ゲームを開始すると、例えばlightかrightのどちらの音声が
ランダムで再生がされ、再生されたと思う方を選択する。すると、正解 or 不正解が表示されるようにする。
因みに下記のように、lightとrightという単語は、最初の
発音記号がlとrという以外、全く同じである。
単語 発音記号 light lάɪt right rάɪt 開発環境
- PC:windows10
- 言語 :python 3.7.3
- IDE :pycharm
- GUI :Tkinter
- 英単語情報の格納:json
また、本ツールで使用する英語単語の音声ファイルはweblio様からダウンロードさせて
いただくが、多くの英単語のファイルを1つずつダウンロードするのは非常に手間が
かかる。そこで、webスクレイピングで英単語を自動でダウンロードするツールを作った。↓
https://qiita.com/Fuminori_Souma/private/60ce627e66209763d4f2このツールを使用すれば、欲しい音声ファイルが簡単にダウンロードできる。
ただし本ツールのjsonファイルに記載している単語の音声ファイルはGoogle driveにて公開(後述)実際に作ったもの
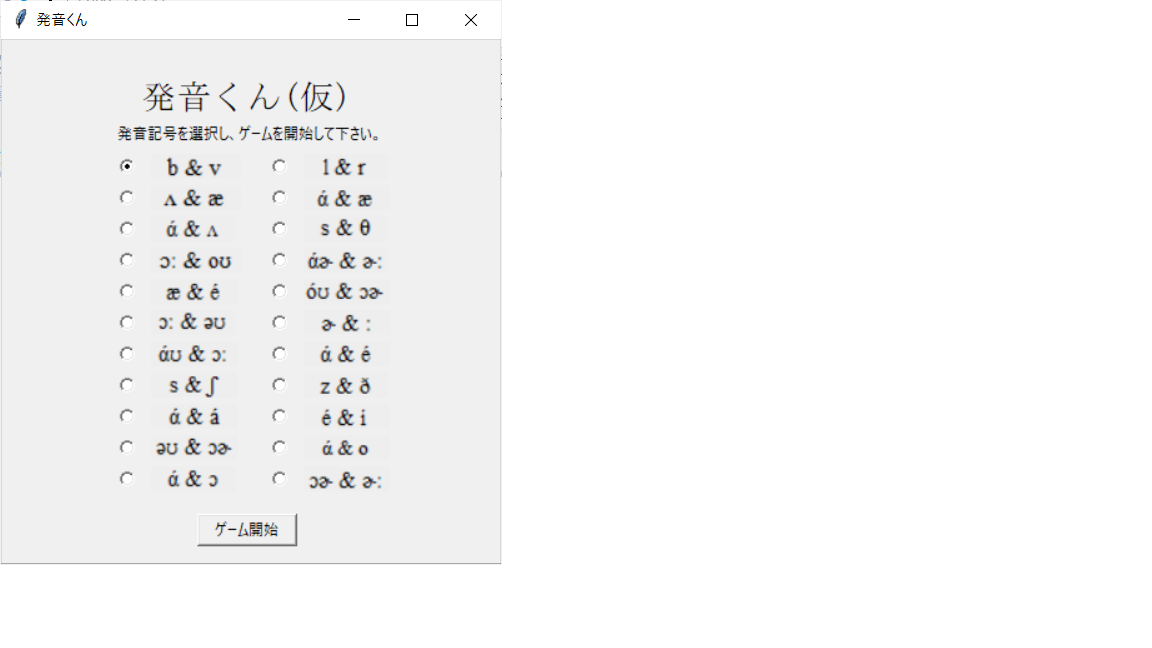
実行直後の画面はこんな感じ。
今日はこれまた日本人が苦手とする、's'と'th'の聞き分けに挑戦するぞ。
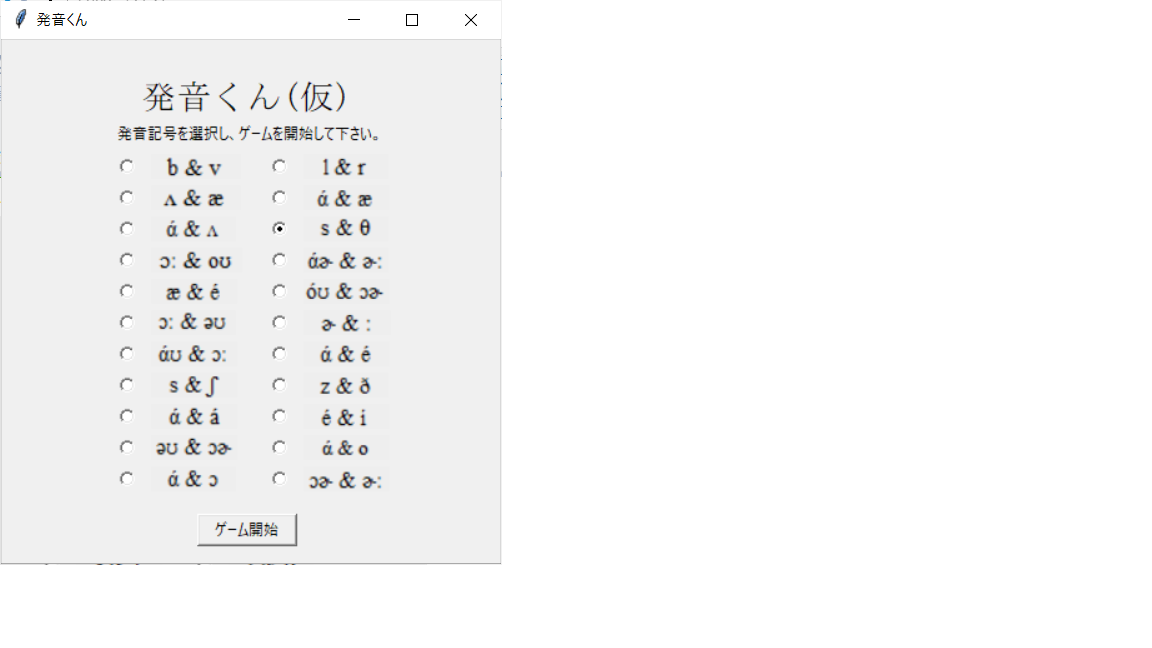
「ゲーム開始」ボタンを押すと、ゲーム画面に変化。問題は全部で14問か。
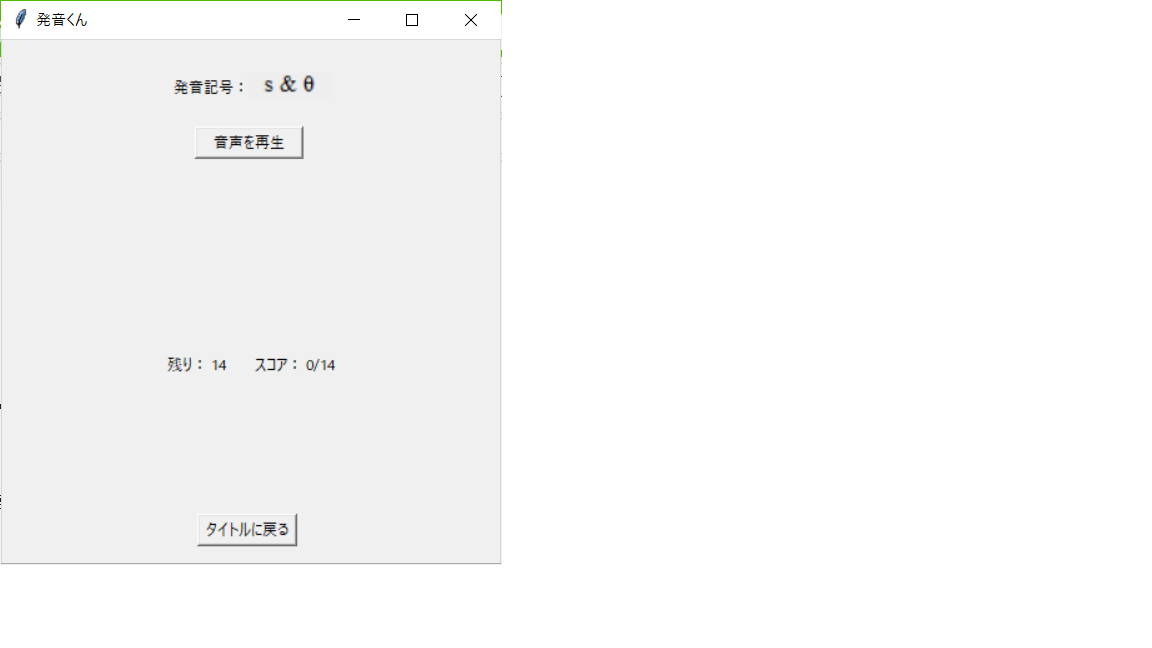
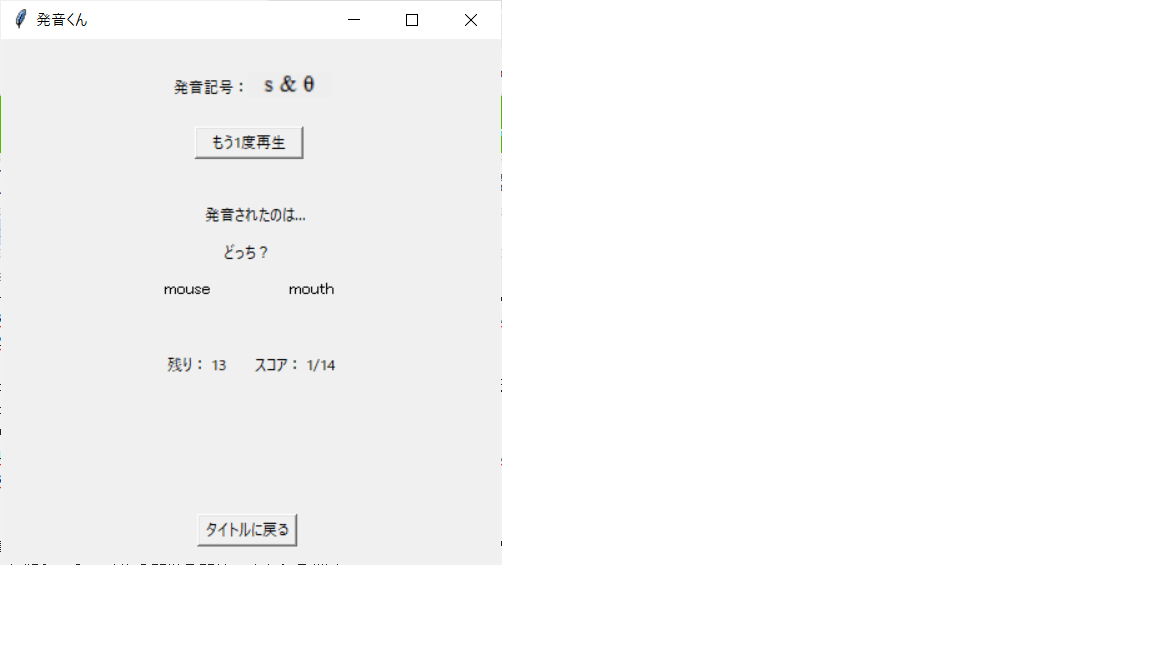
さっそく「音声を再生」ボタンを押すと、音声ファイルが再生され、選択肢が2つ出てきた。
むっ、どっちが発音されたのかな。。「もう一度再生」ボタンを押して、もう一回聞いてみよう。
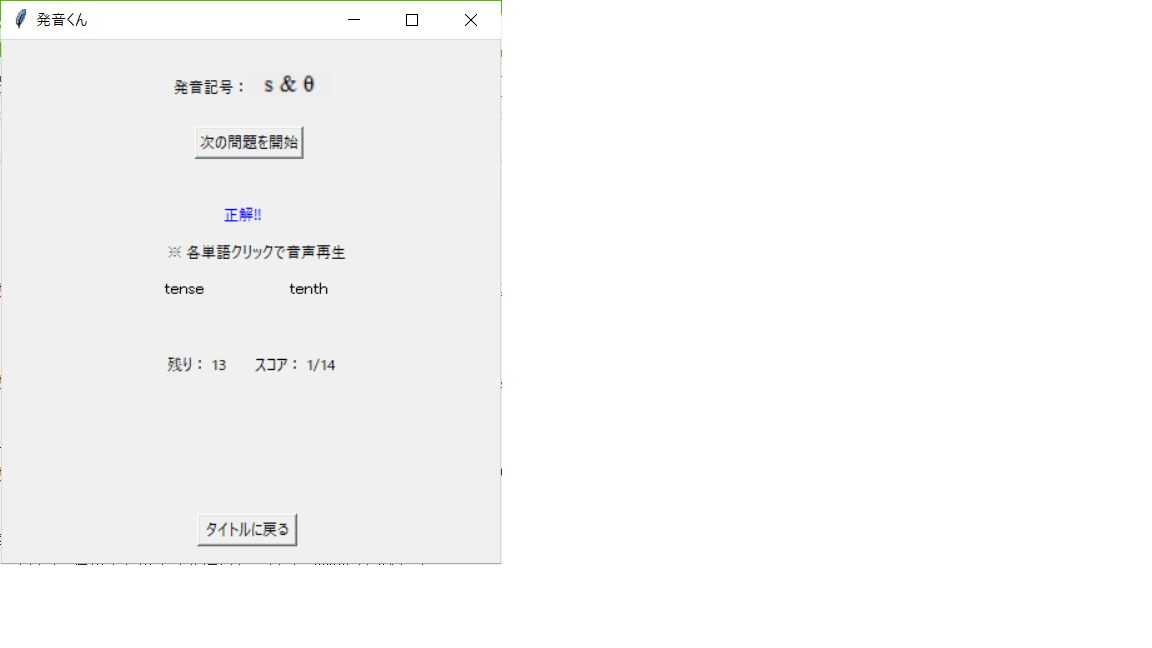
分かった、左のtenseだ!「tense」テキストをクリックして回答しよう。
見事正解!やったね。「tense」と「tenth」をクリックして再生し、それぞれの
音声の違いを確認しておこう。
それが終わったら「次の問題を開始」ボタンを押そう。
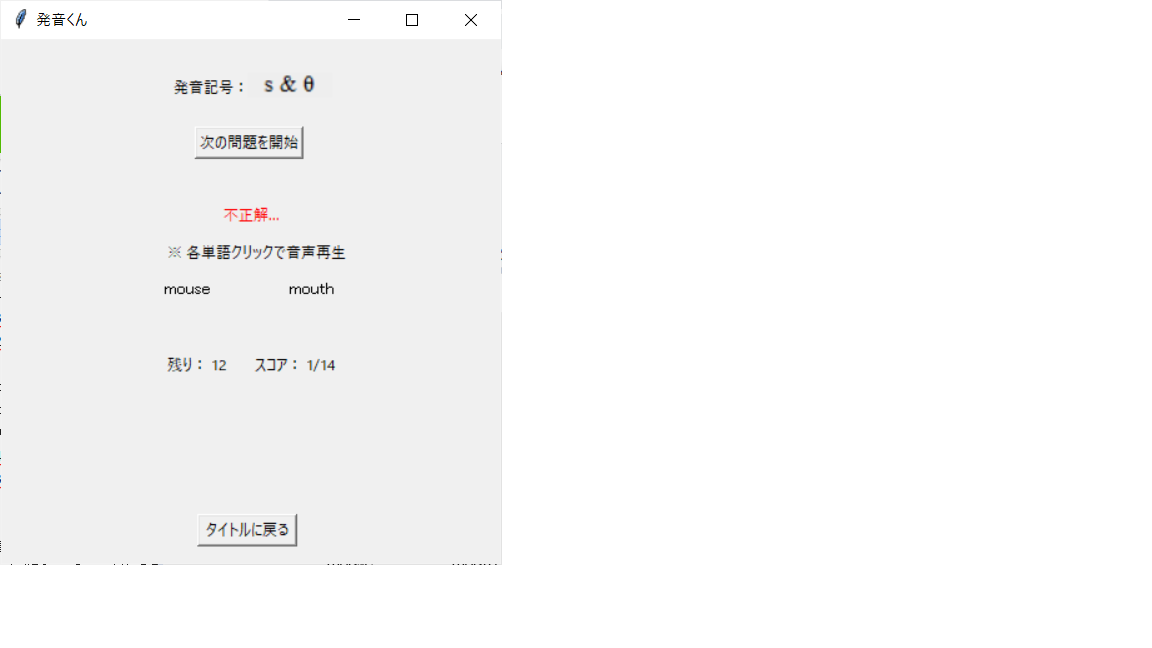
今度は「mouse」と「mouth」か。分かった、mouthだ!
…違うじゃないか。畜生!
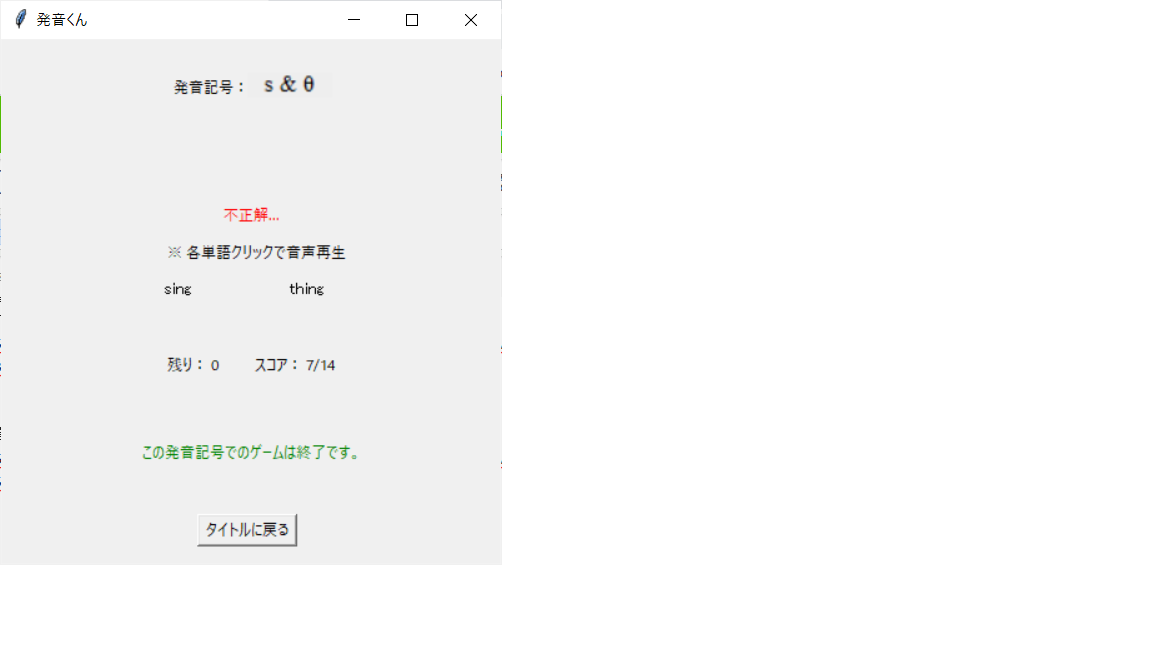
…全部終わったぞ。14問中7問正解か。ま、まあまあだな(汗)
「タイトルに戻る」ボタンを押そう。
じゃあ次は'b'と'v'の聞き分けに挑戦してみようか。
こんな感じで使用します。
ソースファイル
English_study.pyimport sys import tkinter from tkinter import messagebox from mutagen.mp3 import MP3 as mp3 from tkinter import * import pygame import time import json import random from PIL import Image, ImageTk def ques_start_next(event): # 問題を開始/もう一度音声を再生/次の問題を開始 if bttn_repnxt['text'] == '音声を再生': global word1 global word2 global rep_word # 実際に発音された単語 global id text_res["text"] = '' # 前回の問題への答えをリセット group = ps words = random.choice(list(wordlist['Wordlist'][group])) id = 'id' + str(quorder[qunum - renum]) word1 = (wordlist['Wordlist'][group][id]['word1']) word2 = (wordlist['Wordlist'][group][id]['word2']) rep_word = wordlist['Wordlist'][group][id][random.choice(list(wordlist['Wordlist'][group][words]))] rep_mp3(rep_word) # 音声ファイルを再生 # オブジェクト状態の変更 text_w1["text"] = word1 text_w2["text"] = word2 text_ques1["text"] = '発音されたのは…' text_ques2["text"] = 'どっち?' bttn_repnxt['text'] = 'もう1度再生' text_adc.place_forget() elif bttn_repnxt['text'] == 'もう1度再生': rep_mp3(rep_word) # 音声ファイルを再生 else: # '次の問題を開始' # オブジェクト状態を変更 bttn_repnxt['text'] = '音声を再生' text_res.place_forget() # 次の問題を開始 (音声ファイルを再生) ques_start_next(event) def rep_mp3(tgt_word): # 音声を再生 filename = 'C:/Users/fumin/OneDrive/デスクトップ/English_words/' + tgt_word + '.mp3' # 再生したいmp3ファイル pygame.mixer.init() pygame.mixer.music.load(filename) # 音源を読み込み mp3_length = mp3(filename).info.length # 音源の長さ取得 pygame.mixer.music.play(1) # 再生開始。1の部分を変えるとn回再生(その場合は次の行の秒数も×nすること) time.sleep(mp3_length + 0.25) # 再生開始後、音源の長さだけ待つ(0.25待つのは誤差解消) pygame.mixer.music.stop() # 音源の長さ待ったら再生停止 def enlarge_word(event): # マウスポインタを置いたwordを大きく表示 if str(event.widget["text"]) == word1: text_w1["font"] = ("", 12) # 文字を大きく表示 text_w1["cursor"] = "hand2" # マウスポインタを人差し指型に変更 else: text_w2["font"] = ("", 12) # 文字を大きく表示 text_w2["cursor"] = "hand2" # マウスポインタを人差し指型に変更 def undo_word(event): # マウスポインタから外れたwordを元のサイズに戻す if str(event.widget["text"]) == word1: text_w1["font"] = ("", 10) # 文字を最初のサイズで表示 else: text_w2["font"] = ("", 10) # 文字を最初のサイズで表示 def choose_word(event): # ユーザが選択したwordが正解かどうか判定 global oknum global renum if bttn_repnxt['text'] == 'もう1度再生': # 正解と注意書きを表示 text_res.place(x=175, y=130) text_adc.place(x=130, y=160) if str(event.widget["text"]) == word1: # 左側の単語を選択した場合 if rep_word == word1: text_res["text"] = '正解!!' else: text_res["text"] = '不正解…' else: # 右側の単語を選択した場合 if rep_word == word2: text_res["text"] = '正解!!' else: text_res["text"] = '不正解…' if text_res["text"] == '正解!!': oknum = oknum + 1 # 正解数を加算 text_res["foreground"] = 'blue' else: text_res["foreground"] = 'red' renum -= 1 # 残りの問題数を減算 # オブジェクト状態を変更 text_scr['text'] = 'スコア: ' + str(oknum) + '/' + str(qunum) text_rest['text'] = '残り: ' + str(renum) text_ques1["text"] = '' text_ques2["text"] = '' bttn_repnxt["text"] = '次の問題を開始' if renum == 0: # 全問題が終わった場合 bttn_repnxt.place_forget() text_end.place(x=110, y=320) elif bttn_repnxt['text'] == '次の問題を開始': # 次の問題の音声を再生 if str(event.widget["text"]) == word1: rep_mp3(wordlist['Wordlist'][ps][id]['word1']) else: rep_mp3(wordlist['Wordlist'][ps][id]['word2']) def create_radioboutton(row, column, pdx, num, value): # タイトル画面のラジオボタンを生成 rdbtn[num] = tkinter.Radiobutton(frame, value=value, command=rb_clicked, variable=var, text=u'') rdbtn[num].grid(row=row, column=column, padx=0, ipadx=pdx, pady=yinvl) def create_picture(row='df', column='df', pdx='df', num='df'): # タイトル画面の発音記号(画像)を生成 if row == 'df' and column == 'df'and pdx == 'df'and num == 'df': # タイトル画面の場合 cv[rbnum] = Canvas(width=70, height=20) cv[rbnum].create_image(1, 1, image=pngfile[rbnum], anchor=NW) cv[rbnum].place(x=195, y=25) else: # ゲーム開始画面の場合 cv[num] = Canvas(frame, width=70, height=20) cv[num].create_image(1, 1, image=pngfile[num], anchor=NW) cv[num].grid(row=row, column=column, ipadx=pdx, pady=yinvl) def rb_clicked(): # 勉強する発音記号を選択 global rbnum global ps rbnum = int(var.get()) # 選択したラジオボタン(=発音記号)の番号を格納 ps = list(wordlist['Wordlist'])[rbnum] # 選択した発音記号を選択 def switch_mode(event): # ゲームを開始 / タイトル画面に戻る global qunum # 全問題の数 global oknum # 正解した問題の数 global renum # 残りの問題の数 global quorder # 問題出題の順番 if bttn_swmode['text'] == 'ゲーム開始': # 最初の画面にあったオブジェクトを非表示 frame.place_forget() text_title.place_forget() text_ques3.place_forget() # ゲーム用のオブジェクトを表示 bttn_repnxt.place(x=155, y=70) text_scr.place(x=200, y=250) text_rest.place(x=130, y=250) text_w1.place(x=128, y=190) text_w2.place(x=228, y=190) text_ps.place(x=135, y=28) text_ques1.place(x=160, y=130) text_ques2.place(x=175, y=160) create_picture() # 各種設定 oknum = 0 qunum = len(wordlist['Wordlist'][ps]) renum = qunum text_scr['text'] = 'スコア: ' + str(oknum) + '/' + str(qunum) text_rest['text'] = '残り: ' + str(renum) quorder = random.sample(range(1, qunum + 1), k=qunum) bttn_swmode['text'] = 'タイトルに戻る' text_w1["text"] = '' text_w2["text"] = '' text_ques1["text"] = '' text_ques2["text"] = '' bttn_repnxt['text'] = '音声を再生' else: # タイトル画面に戻る if renum == 0 or (renum != 0 and messagebox.askyesno('確認', 'まだ問題が残っています。タイトル画面に戻りますか?')): # if messagebox.askyesno('確認', 'まだ問題が残っています。タイトル画面に戻りますか?'): # ゲーム画面にあったオブジェクトを非表示 bttn_repnxt.place_forget() text_scr.place_forget() text_rest.place_forget() text_w1.place_forget() text_w2.place_forget() text_ps.place_forget() text_ques1.place_forget() text_ques2.place_forget() text_end.place_forget() text_res.place_forget() text_adc.place_forget() cv[rbnum].place_forget() # タイトル画面用のオブジェクトを表示 frame.place(x=90, y=90) text_title.place(x=110, y=30) text_ques3.place(x=90, y=65) bttn_swmode['text'] = 'ゲーム開始' # 画面の表示 root = tkinter.Tk() root.title(u"発音くん") root.geometry("400x420") root.columnconfigure(0, weight=1) root.rowconfigure(0, weight=1) # Frame frame = tkinter.Frame(root) frame.place(x=90, y=90) frame.columnconfigure(0, weight=1) frame.rowconfigure(0, weight=1) # ラベルの設定 text_w1 = tkinter.Label(text=u'', font=("", 10)) text_w1.bind("<Enter>", enlarge_word) text_w1.bind("<Leave>", undo_word) text_w1.bind("<Button-1>", choose_word) text_w2 = tkinter.Label(text=u'', font=("", 10)) text_w2.bind("<Enter>", enlarge_word) text_w2.bind("<Leave>", undo_word) text_w2.bind("<Button-1>", choose_word) text_ques1 = tkinter.Label(text=u'') text_ques2 = tkinter.Label(text=u'') text_ques3 = tkinter.Label(text=u'発音記号を選択し、ゲームを開始して下さい。') text_ques3.place(x=90, y=65) text_ps = tkinter.Label(text=u'発音記号:') text_adc = tkinter.Label(text=u'※ 各単語クリックで音声再生') text_res = tkinter.Label(text=u'') text_scr = tkinter.Label(text=u'') text_rest = tkinter.Label(text=u'') text_title = tkinter.Label(text=u'発音くん(仮)', font=(u'MS 明朝', 20)) text_title.place(x=110, y=30) text_end = tkinter.Label(text=u'この発音記号でのゲームは終了です。') text_end["foreground"] = 'green' # プッシュボタンの設定 bttn_repnxt = tkinter.Button(text=u'音声を再生', width=11) bttn_repnxt.bind("<Button-1>", ques_start_next) # (Button-2でホイールクリック、3で右クリック) bttn_swmode = tkinter.Button(text=u'ゲーム開始', width=10) bttn_swmode.bind("<Button-1>", switch_mode) # (Button-2でホイールクリック、3で右クリック) bttn_swmode.place(x=157, y=380) # ラジオボタンの配置に使用するパラメータの設定 xinvl = 30 yinvl = 0 var = StringVar() var.set('0') # ラジオボタンを「チェックしていない状態」に設定 f = open("C:/Users/fumin/OneDrive/デスクトップ/Wordlist.json", 'r') wordlist = json.load(f) oknum = 0 rb_clicked() # 初期状態で選択しているラジオボタン # 画像情報及びラジオボタン情報を格納する変数の初期化 pngfile = [''] * len(wordlist['Wordlist']) cv = [''] * len(wordlist['Wordlist']) rdbtn = [''] * len(wordlist['Wordlist']) # ラジオボタン/発音記号の設定 for i in range(int(len(wordlist['Wordlist'])/2)): ipadx = 10 pngfile[i*2] = PhotoImage(file="C:/Users/fumin/OneDrive/画像/" + list(wordlist['Wordlist'])[i * 2] + ".PNG") pngfile[i*2+1] = PhotoImage(file="C:/Users/fumin/OneDrive/画像/" + list(wordlist['Wordlist'])[i * 2 + 1] + ".PNG") create_radioboutton(i+1, 1, 0, i*2, i*2) create_picture(i+1, 2, ipadx, i*2) create_radioboutton(i+1, 3, 0, i*2+1, i*2+1) create_picture(i+1, 4, ipadx, i*2+1) root.mainloop()英単語情報格納ファイル
Wordlist.json{ "Wordlist": { "b_v" : { "id1" : { "word1": "boat", "word2": "vote" }, "id2" : { "word1": "bury", "word2": "vary" }, "id3" : { "word1": "base", "word2": "vase" }, "id4" : { "word1": "bent", "word2": "vent" }, "id5" : { "word1": "ban", "word2": "van" }, "id6" : { "word1": "best", "word2": "vest" }, "id7" : { "word1": "bat", "word2": "vat" } }, "l_r" : { "id1" : { "word1": "light", "word2": "right" }, "id2" : { "word1": "lice", "word2": "rice" }, "id3" : { "word1": "long", "word2": "wrong" }, "id4" : { "word1": "lock", "word2": "rock" }, "id5" : { "word1": "lane", "word2": "rain" }, "id6" : { "word1": "lend", "word2": "rend" }, "id7" : { "word1": "lead", "word2": "read" }, "id8" : { "word1": "loom", "word2": "room" }, "id9" : { "word1": "lace", "word2": "race" }, "id10" : { "word1": "lack", "word2": "rack" }, "id11" : { "word1": "lake", "word2": "rake" }, "id12" : { "word1": "lamp", "word2": "ramp" }, "id13" : { "word1": "lank", "word2": "rank" }, "id14" : { "word1": "late", "word2": "rate" }, "id15" : { "word1": "law", "word2": "raw" }, "id16" : { "word1": "clown", "word2": "crown" }, "id17" : { "word1": "folk", "word2": "fork" }, "id18" : { "word1": "glamour", "word2": "grammar" }, "id19" : { "word1": "flee", "word2": "free" }, "id20" : { "word1": "allow", "word2": "arrow" }, "id21" : { "word1": "belly", "word2": "berry" }, "id22" : { "word1": "blanch", "word2": "branch" }, "id23" : { "word1": "bland", "word2": "brand" }, "id24" : { "word1": "bravely", "word2": "bravery" }, "id25" : { "word1": "bleach", "word2": "breach" }, "id26" : { "word1": "bleed", "word2": "breed" }, "id27" : { "word1": "blink", "word2": "brink" }, "id28" : { "word1": "bully", "word2": "burly" }, "id29" : { "word1": "collect", "word2": "correct" }, "id30" : { "word1": "flesh", "word2": "fresh" } }, "crt_ash" : { "id1" : { "word1": "bug", "word2": "bag" }, "id2" : { "word1": "fun", "word2": "fam" }, "id3" : { "word1": "tusk", "word2": "task" }, "id4" : { "word1": "much", "word2": "match" }, "id5" : { "word1": "buck", "word2": "back" }, "id6" : { "word1": "crush", "word2": "crash" }, "id7" : { "word1": "suck", "word2": "sack" }, "id8" : { "word1": "stuff", "word2": "staff" }, "id9" : { "word1": "mud", "word2": "mad" }, "id10" : { "word1": "musk", "word2": "mask" }, "id11" : { "word1": "lump", "word2": "lamp" }, "id12" : { "word1": "bung", "word2": "bang" }, "id13" : { "word1": "hut", "word2": "hat" }, "id14" : { "word1": "rump", "word2": "ramp" }, "id15" : { "word1": "uncle", "word2": "ankle" }, "id16" : { "word1": "muster", "word2": "master" }, "id17" : { "word1": "bund", "word2": "band" }, "id18" : { "word1": "puppy", "word2": "pappy" }, "id19" : { "word1": "double", "word2": "dabble" }, "id20" : { "word1": "hunk", "word2": "hank" }, "id21" : { "word1": "stunned", "word2": "stand" } }, "ash_alfa" : { "id1" : { "word1": "pappy", "word2": "poppy" }, "id2" : { "word1": "adapt", "word2": "adopt" }, "id3" : { "word1": "bag", "word2": "bog" }, "id4" : { "word1": "back", "word2": "bock" }, "id5" : { "word1": "sack", "word2": "sock" }, "id6" : { "word1": "mask", "word2": "mosque" }, "id7" : { "word1": "hat", "word2": "hot" }, "id8" : { "word1": "ramp", "word2": "romp" }, "id9" : { "word1": "band", "word2": "bond" }, "id10" : { "word1": "possible", "word2": "passable" }, "id11" : { "word1": "sad", "word2": "sod" }, "id12" : { "word1": "tap", "word2": "top" }, "id13" : { "word1": "nat", "word2": "not" }, "id14" : { "word1": "hank", "word2": "honk" }, "id15" : { "word1": "bax", "word2": "box" }, "id16" : { "word1": "valley", "word2": "volley" }, "id17" : { "word1": "sax", "word2": "sox" } }, "alfa_crt" : { "id1" : { "word1": "body", "word2": "buddy" }, "id2" : { "word1": "wander", "word2": "wonder" }, "id3" : { "word1": "soccer", "word2": "sucker" }, "id4" : { "word1": "poppy", "word2": "puppy" }, "id5" : { "word1": "bond", "word2": "bund" }, "id6" : { "word1": "romp", "word2": "rump" }, "id7" : { "word1": "hot", "word2": "hut" }, "id8" : { "word1": "mosque", "word2": "musk" }, "id9" : { "word1": "sock", "word2": "suck" }, "id10" : { "word1": "bock", "word2": "buck" }, "id11" : { "word1": "bog", "word2": "bug" }, "id12" : { "word1": "collar", "word2": "color" }, "id13" : { "word1": "rob", "word2": "rub" }, "id14" : { "word1": "honk", "word2": "hunk" }, "id15" : { "word1": "calm", "word2": "come" }, "id16" : { "word1": "coddle", "word2": "cuddle" } }, "s_th" : { "id1" : { "word1": "sink", "word2": "think" }, "id2" : { "word1": "sick", "word2": "thick" }, "id3" : { "word1": "sing", "word2": "thing" }, "id4" : { "word1": "sought", "word2": "thought" }, "id5" : { "word1": "sank", "word2": "thank" }, "id6" : { "word1": "seam", "word2": "theme" }, "id7" : { "word1": "sin", "word2": "thin" }, "id8" : { "word1": "mouse", "word2": "mouth" }, "id9" : { "word1": "tense", "word2": "tenth" }, "id10" : { "word1": "force", "word2": "forth" }, "id11" : { "word1": "worse", "word2": "worth" }, "id12" : { "word1": "face", "word2": "faith" }, "id13" : { "word1": "boss", "word2": "both" }, "id14" : { "word1": "mass", "word2": "math" } }, "oo-lvc_ou" : { "id1" : { "word1": "called", "word2": "cold" }, "id2" : { "word1": "raw", "word2": "row" }, "id3" : { "word1": "law", "word2": "low" }, "id4" : { "word1": "call", "word2": "coal" }, "id5" : { "word1": "hall", "word2": "hole" }, "id6" : { "word1": "tall", "word2": "toll" }, "id7" : { "word1": "bawl", "word2": "bowl" }, "id8" : { "word1": "tall", "word2": "tole" }, "id9" : { "word1": "lawn", "word2": "loan" }, "id10" : { "word1": "pawl", "word2": "pole" }, "id11" : { "word1": "ball", "word2": "bole" }, "id12" : { "word1": "caught", "word2": "coat" } }, "alfa-hschwa_hschwa-lvc" : { "id1" : { "word1": "heart", "word2": "hurt" }, "id2" : { "word1": "hard", "word2": "heard" }, "id3" : { "word1": "carve", "word2": "curve" }, "id4" : { "word1": "lark", "word2": "lurk" }, "id5" : { "word1": "bard", "word2": "bird" }, "id6" : { "word1": "far", "word2": "fur" }, "id7" : { "word1": "park", "word2": "perk" } }, "ash_e" : { "id1" : { "word1": "adapt", "word2": "adept" }, "id2" : { "word1": "parish", "word2": "perish" }, "id3" : { "word1": "marry", "word2": "merry" }, "id4" : { "word1": "back", "word2": "beck" }, "id5" : { "word1": "band", "word2": "bend" }, "id6" : { "word1": "nat", "word2": "net" }, "id7" : { "word1": "bag", "word2": "beg" }, "id8" : { "word1": "hat", "word2": "het" } }, "ou_oo-hschwa" : { "id1" : { "word1": "motor", "word2": "mortar" }, "id2" : { "word1": "load", "word2": "lord" }, "id3" : { "word1": "bode", "word2": "board" }, "id4" : { "word1": "coat", "word2": "court" }, "id5" : { "word1": "boa", "word2": "bore" }, "id6" : { "word1": "hose", "word2": "hoarse" }, "id7" : { "word1": "woe", "word2": "war" } }, "oo-lvc_schwa-u" : { "id1" : { "word1": "walk", "word2": "woke" }, "id2" : { "word1": "bought", "word2": "boat" }, "id3" : { "word1": "cost", "word2": "coast" }, "id4" : { "word1": "flaw", "word2": "flow" }, "id5" : { "word1": "hall", "word2": "whole" }, "id6" : { "word1": "nought", "word2": "note" } }, "hschwa_lvc" : { "id1" : { "word1": "fort", "word2": "fought" }, "id2" : { "word1": "sort", "word2": "sought" }, "id3" : { "word1": "source", "word2": "sauce" }, "id4" : { "word1": "lorn", "word2": "lawn" }, "id5" : { "word1": "there", "word2": "their" }, "id6" : { "word1": "court", "word2": "caught" } }, "alfau_oo" : { "id1" : { "word1": "brown", "word2": "brawn" }, "id2" : { "word1": "drown", "word2": "drawn" }, "id3" : { "word1": "down", "word2": "dawn" }, "id4" : { "word1": "sow", "word2": "saw" }, "id5" : { "word1": "sough", "word2": "saw" }, "id6" : { "word1": "tout", "word2": "taught" } }, "alfa_e" : { "id1" : { "word1": "not", "word2": "net" }, "id2" : { "word1": "adopt", "word2": "adept" }, "id3" : { "word1": "bog", "word2": "beg" }, "id4" : { "word1": "hot", "word2": "het" }, "id5" : { "word1": "bock", "word2": "beck" }, "id6" : { "word1": "bond", "word2": "bend" } }, "s_esh" : { "id1" : { "word1": "seat", "word2": "sheet" }, "id2" : { "word1": "see", "word2": "she" }, "id3" : { "word1": "seep", "word2": "sheep" }, "id4" : { "word1": "seer", "word2": "sheer" }, "id5" : { "word1": "sip", "word2": "ship" } }, "z_eth" : { "id1" : { "word1": "wiz", "word2": "with" }, "id2" : { "word1": "zen", "word2": "then" }, "id3" : { "word1": "breeze", "word2": "breathe" }, "id4" : { "word1": "tease", "word2": "teethe" }, "id5" : { "word1": "closing", "word2": "clothing" } }, "alfa_a" : { "id1" : { "word1": "drier", "word2": "dryer" }, "id2" : { "word1": "find", "word2": "fined" }, "id3" : { "word1": "guise", "word2": "guys" }, "id4" : { "word1": "lime", "word2": "lyme" } }, "e_i" : { "id1" : { "word1": "wary", "word2": "weary" }, "id2" : { "word1": "emigrant", "word2": "immigrant" }, "id3" : { "word1": "desert", "word2": "dessert" }, "id4" : { "word1": "tear", "word2": "tier" } }, "schwa-u_oo-hschwa" : { "id1" : { "word1": "woe", "word2": "war" }, "id2" : { "word1": "foam", "word2": "form" }, "id3" : { "word1": "foe", "word2": "four" } }, "alfa_o" : { "id1" : { "word1": "dow", "word2": "dough" }, "id2" : { "word1": "wow", "word2": "woe" }, "id3" : { "word1": "allow", "word2": "alow" } }, "alfa_oo" : { "id1" : { "word1": "noun", "word2": "known" }, "id2" : { "word1": "farm", "word2": "form" }, "id3" : { "word1": "what", "word2": "wat" } }, "oo-hschwa_hschwa-lvc" : { "id1" : { "word1": "warm", "word2": "worm" }, "id2" : { "word1": "ward", "word2": "word" }, "id3" : { "word1": "torn", "word2": "turn" } }, "other" : { "id1" : { "word1": "with", "word2": "width" }, "id2" : { "word1": "breathe", "word2": "breadth" }, "id3" : { "word1": "father", "word2": "further" }, "id4" : { "word1": "borrow", "word2": "borough" }, "id5" : { "word1": "hole", "word2": "whole" }, "id6" : { "word1": "toe", "word2": "tow" }, "id7" : { "word1": "bill", "word2": "beer" }, "id8" : { "word1": "all", "word2": "oar" }, "id9" : { "word1": "shock", "word2": "shook" }, "id10" : { "word1": "crock", "word2": "crook" }, "id11" : { "word1": "aren't", "word2": "ant" }, "id12" : { "word1": "parse", "word2": "pass" }, "id13" : { "word1": "some", "word2": "sum" }, "id14" : { "word1": "discus", "word2": "discuss" }, "id15" : { "word1": "gall", "word2": "girl" }, "id16" : { "word1": "walk", "word2": "work" } } } }アプリの使用に必要なファイルについて()
以下に格納しました。
https://drive.google.com/open?id=1u4l5wo-6SC00Ys0xBZO_am1v2yPjb_NU本当はこんなことせずにGithubで管理が効率的と思いますが。。勉強中なので暫定的にGoogle driveに格納しました。
上記ドライブに格納したファイルをローカルにダウンロードし、ローカルでの置き場所に合わせて下記のように.pyに記載されているディレクトリを変更します。(面倒ですが)
置き場所 ソースの変更箇所 音声ファイル(mp3) 変数「filename」右辺のディレクトリ jsonファイル 変数「f」右辺のディレクトリ 画像ファイル(png) 変数「pngfile」右辺のディレクトリ 英単語情報格納ファイル(json)について
上記の通り、jsonファイルは発音記号の違いごとに単語のペアをまとめてある。発音記号はそのまま書いても扱えないため、下記のように英語で書いて対応した。
発音記号 名称 上記のjsonでの書き方 æ アッシュ ash ʃ エッシュ esh ə シュワー schwa ɚ 鉤付き(hooked)シュワー hschwa ɔ 開いた(open)o oo α アルファ alfa ː 長母音コロン(long vowel colon) lvc ʌ キャレット、ウェッジ、ハット crt ð エズ eth θ シータ th 例えば「ɚ」と「ː」のペアの場合は「hschwa_lvc」と記載した。
因みにaやrやvなどは、そのまま記載した。
備考
実は以前、pythonではなく、下記書籍を参考にしながら、C++を.NET用に拡張したC++/CLIで同様のアプリを作成したことがあります。
しかしC++/CLRという仕様が複雑かつ情報がないという難儀な言語の前に悪戦苦闘し、何とか本投稿と似たようなものは作ったものの、メンテ性に欠ける扱いづらい代物と化してしまったため、pythonで作り直して本記事にて投稿しました。
参考にさせていただいた情報
特に下記にお世話になりました。いつも有益な情報を下さり、大変感謝しております。
最後に
GUIやソースに対して改善案など、フィードバックいただけると大変嬉しいです!!

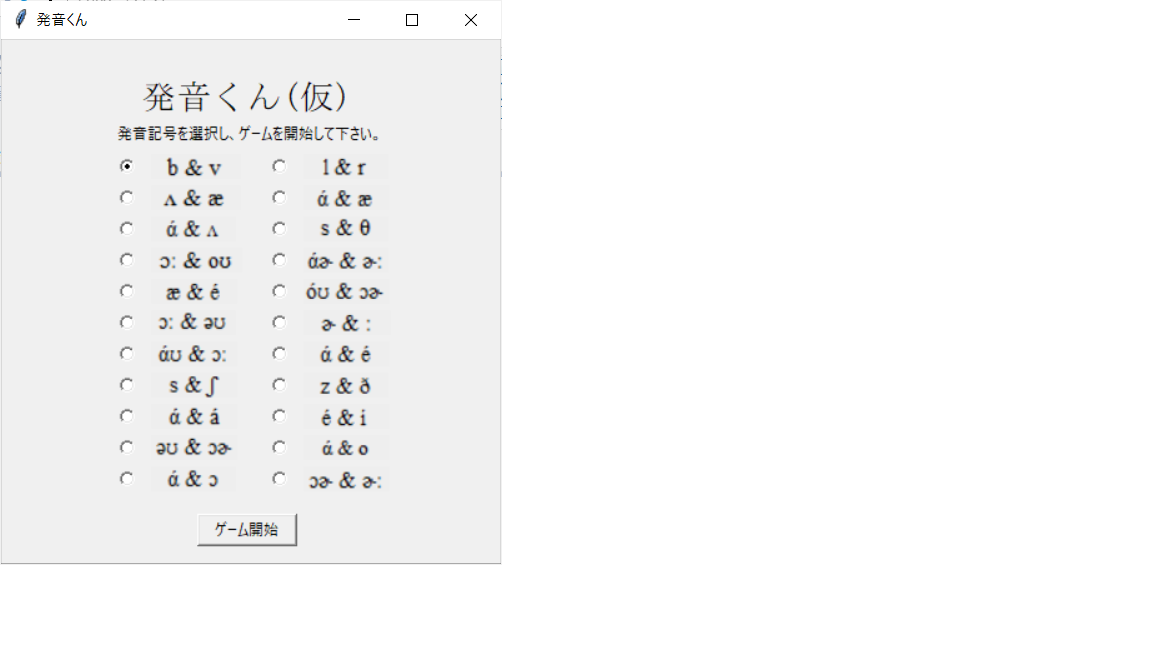
- 投稿日:2020-02-08T15:50:52+09:00
vscode + pytest 環境で tensorflow 使ってるとテストディスカバリが失敗する
この記事は何
Python 開発環境を VSCode に移し中、pytest を VSCode 環境で動かそうと色々試すも何故かディスカバリに失敗してしまい、しばらく詰まったのでメモ。
背景
Remote Development で繋いでいる VSCode 環境で、新たに Python プロジェクトを作成しています。
Python 環境は poetry で作成し、テストのため pytest を導入しました。
CUI から pytest がpoetry run pytest問題なく実行できることを確認し、VSCode 上からテストを実行させようとしたところ、テストディスカバリに失敗しました。原因
VSCode から pytest でテストディスカバリを行う際に、何故か標準出力があると失敗扱いになっていました。
下記の issue などから何かしら標準出力があると失敗することが指摘されています。
https://github.com/microsoft/vscode-python/issues/6594
https://github.com/microsoft/vscode-python/issues/7574TensorFlow を使っている場合、
import tensorflow as tfするだけで色々 Warning だったりが出てしまいますが、それが原因だったようです。解決策
上記 issue の通りです。TensorFlow の出力を制御するため、次のようなファイルを
.envという名前でプロジェクトに置きます。.envTF_CPP_MIN_LOG_LEVEL='2'TF のログ出力を制御するための環境変数です。2を設定することで、WARNINGまでは出なくなります。3にするとエラーも出なくなります。
他の種類の標準出力もなんらかの方法で出ないようにできれば、対策できそうです。
以上です。原因が標準出力だということに気づくのに時間かかったので、参考になれば...
- 投稿日:2020-02-08T15:27:11+09:00
DockerでPythonのWebアプリケーションをnginx + gunicorn で起動する
構成
- Webサーバー
- nginx
- WSGIサーバー(APサーバー)
- Gunicorn
- Webアプリケーションフレームワーク
- Django
- ここではWSGIを使用するので、WSGIに準拠していれば他のフレームワークでも良い
- この記事ではDjango固有の設定は発生しない
- WebサーバーとWSGIサーバーはDockerコンテナで稼働させる
- WebサーバーとWSGIサーバーの通信にはUNIXドメインソケットを使用する
用語の整理
WSGIサーバーとは
- WSGIとはWeb Server Gateway Interfaceのことで、WebサーバーとPythonのAPサーバー間通信のプロトコルのこと
- DjangoやFlask、Bottleなどのフレームワークもこのプロトコルに準拠している
- 上記のWSGIに則ったAPサーバーをWSGIサーバーと呼び、Gunicornはその一種
- gunicorn以外のWSGIサーバーにはuWSGIがある
UNIXドメインソケットとは
- ファイルシステムのパスを通して通信相手を探す通信方法
- そのパスにファイルが作成され、それぞれのプロセスがそのファイルにアクセスする
- 単にファイルを共有しているだけに思えるが、作成されるファイルはソケットファイルと呼ばれる特殊なファイルであり実態はない
- あくまで通信のインターフェース
構築
Gunicorn
- まずはWSGIサーバーを単体で稼働させてみる
プロジェクト作成
- Djangoをインストールする
$ pip install Django==3.0.2
- 作業環境でプロジェクトを作成する
$ django-admin.py startproject django_project .
- ここではdjango_projectという名前でプロジェクトを作成
- treeコマンドで確認すると以下のようになる
$ tree . ├── django_project │ ├── __init__.py │ ├── asgi.py │ ├── settings.py │ ├── urls.py │ └── wsgi.py ├── manage.pyGunicornコンテナ起動
- Dockerfileを作成
FROM python:3.8.0-alpine WORKDIR /usr/src/app ENV PYTHONDONTWRITEBYTECODE 1 ENV PYTHONUNBUFFERED 1 RUN pip install --upgrade pip COPY ./requirements.txt /usr/src/app/requirements.txt RUN pip install -r requirements.txt
- requirements.txt は以下の通り
requirements.txtDjango==3.0.2 gunicorn==20.0.4
- ビルドする
$ docker build -t gunicorn:tmp .
- docker-compose.yamlの記載は以下の通り
- 後でnginxの情報も追記する
version: '3.7' services: gunicorn: image: gunicorn:tmp container_name: gunicorn command: python manage.py runserver 0.0.0.0:8000 volumes: - .:/usr/src/app/ ports: - 8000:8000
python manage.py runserver 0.0.0.0:8000コマンドでテスト用簡易サーバーが起動される- ここでは稼働確認のため8000番のポートをフォワーディングしている
$ docker-compose up -dで起動してlocalhost:8000にアクセスしてDjangoの画面が表示されればOK
NginxでUNIXドメインソケット使用する設定
- 公式のDockerイメージを使用するが、UNIXドメインソケットの設定を記載したconfファイルを作成し起動時にマウントさせる
- gunicorn.confという名前で以下の内容を記載
gunicorn.confupstream gunicorn-django { server unix:///var/run/gunicorn/gunicorn.sock; } server { listen 80; server_name localhost; location / { try_files $uri @gunicorn; } location @gunicorn { proxy_pass http://gunicorn-django; } }
upstream gunicorn-django{…}の内容がUNIXドメインソケットの設定- 記載したパスのソケットファイルを介することでgunicornと通信を行う
- つまりgunicorn側からもこのソケットファイルを呼び出す設定が必要になる
- あとはlocationのproxy_passでupstreamで指定したgunicorn-djangoを指定すればよい
- Nginxのdocker-compose.yamlの記載は以下の通り
version: '3.7' services: nginx: image: nginx:1.17.7 container_name: nginx ports: - "80:80" volumes: - ./gunicorn.conf:/etc/nginx/conf.d/default.conf
- Nginx内に
/etc/nginx/conf.d/default.confという名前でマウントする- Nginxは/etc/nginx/nginx.confを起動時に読み取り、そのファイル内で
include /etc/nginx/conf.d/*.conf;という記載がされているため、/etc/nginx/conf.d配下に自分で作成したconfファイルをマウントしておけば起動時に一緒に読み込んでくれるGunicornでUNIXドメインソケット使用する設定
- 先ほどローカルで起動させた状態から多少変更を加える
コンテナの起動コマンド
WSGIの設定
- GunicornがNginxと通信を行えるよう、以下のようなgunicornコマンドを叩く必要がある
gunicorn django_project.wsgi
- これは今回django_projectというプロジェクトを作成したときに構築されるdjango_project配下にあるwsgi.pyを読み込む
- ローカルで起動させるときはmanage.pyを起動させたが、WSGIで通信させるときはこのコマンドが必要になる
UNIXドメインソケットの設定
- UNIXドメインソケットで通信させるため、
--bindで起動時ソケットファイルのパスを指定するgunicorn django_project.wsgi --bind=unix:/var/run/gunicorn/gunicorn.sock
- これによりgunicornへのUNIXドメインソケット通信が可能になる
Doickerfile修正
- 上記の内容を基に、DockerfileのCMDを変更
DockerfileFROM python:3.8.0-alpine WORKDIR /usr/src/app ENV PYTHONDONTWRITEBYTECODE 1 ENV PYTHONUNBUFFERED 1 RUN pip install --upgrade pip COPY ./requirements.txt /usr/src/app/requirements.txt RUN pip install -r requirements.txt RUN mkdir -p /var/run/gunicorn CMD ["gunicorn", "django_project.wsgi", "--bind=unix:/var/run/gunicorn/gunicorn.sock"]
- 再度ビルドしておく
$ docker build -t gunicorn:latest .Djangoプロジェクトへアクセスできるホストを指定
- django_project配下に作成されるsetting.py内の
ALLOWED_HOSTS=[]に指定する- 本来なら制限するべきだが、ここでは全てのホストからのアクセスを許可するため
ALLOWED_HOSTS=[*]にしておく- このファイルはwsgi.pyから呼び出されている
UNIXドメインソケット通信でマウントするボリュームを作成
- Nginx、Gunicornでソケットファイルのパスを指定したので、ソケットファイルのボリュームを作成する必要がある
- 今回はDockerで起動させるので、DockerのVolumeを起動時に作成し、2つのコンテナからそのVolumeにマウントを行う
- 最終的なdocker-compose.yamlは以下の通り
docker-compose.yamlversion: '3.7' services: gunicorn: image: gunicorn:latest container_name: gunicorn volumes: - .:/usr/src/app/ - gunicorn:/var/run/gunicorn nginx: image: nginx:1.17.7 container_name: nginx depends_on: - gunicorn ports: - "80:80" volumes: - ./gunicorn.conf:/etc/nginx/conf.d/default.conf - gunicorn:/var/run/gunicorn volumes: gunicorn: driver: local
- gunicornというVolumeを作成し、それぞれのコンテナにマウントする(今回はどちらのコンテナでも
/var/run/gunicornを指定している)稼働
- 以下のコマンドで起動
$ docker-compose up -d Starting gunicorn ... done Starting nginx ... done
- 起動後に
localhostにアクセスしてみる
- 画面が表示されればOK
- 最初にGunicornを単体で稼働させたときと表示されている画面は同じだが、今回はnginxを経由して表示されている
ソースコード
- 今回作成したファイル一式はこちら
参考
- 投稿日:2020-02-08T15:05:16+09:00
[Microservices] FreezeTime Middleware
概要
世の中には様々なシステムがあるが、それぞれ皆E2Eテストを一生懸命書いていると思う。
そういうテストには「月末」や「年末」に動きが変わる事を確認したい、というテストもあるだろう。
しかもmicroservice architectureだと複数のシステムが連携して動作するので、それら全ての時刻について考える必要がある。これをどうテストするのか?。
「こんな風にしてみた」という紹介記事。構成
PythonにFreezeGunという時刻をモックするライブラリがあるが、これを使って分散システム全体の時刻をモックしてしまおう!というのがこの文章で書きたい事。
手順
全てのmicroserviceのヘッダに、
x-freeze-time : {epoch time}というヘッダを追加する。テストを実行するときは、それぞれのリクエストにモックしたい時刻を付与して実行する。もちろんヘッダがないときは現実の時刻を使うよ!
内部リクエスト(microservice -> 別のmicroservice呼び出し)時は、このヘッダをパススルーする。
FreezeTimeMiddlewareを準備する
というのがおおまかな手順。さて、FreezeTimeMiddlewareとは?
FreezeGun
FreezeGunは、unittestのために時刻をモックする、pythonのライブラリ。
https://github.com/spulec/freezegun通常は、こんな感じでunitttestで使用する。
@freeze_time("2000-01-11 00:00:00") def test_hoge(self): """hogeのテスト""" # ここでdatetime.Nowするとモックされた時刻が帰るよ!これを使って、E2Eテストのための時刻モック機構を準備する。
我々はDjango Rest Frameworkを使ったので、Django Middlewareとして実装している。FreezeTime Middleware
import logging from freezegun import freeze_time from datetime import datetime, timezone log = logging.getLogger(__name__) # set libraries you want to ignore mock by freezegun. freeze_time_ignore = ['boto3', 'botocore'] class FreezeTimeMiddleware: """Mock python datetime by header 'x-freeze-time'""" def __init__(self, get_response): """Override""" self.get_response = get_response log.warning("FreezeTimeMiddleware initialized. (don't use in production!)") def __call__(self, request): """Override""" epoch = int(request.META.get("HTTP_X_FREEZE_TIME", 0)) if epoch: mock_datetime = datetime.fromtimestamp(epoch, tz=timezone.utc) log.warning("mock python datetime as %s", mock_datetime) with freeze_time(mock_datetime, ignore=freeze_time_ignore): return self.get_response(request) else: return self.get_response(request)やっていることは単純なので見ればわかると思う。
注意点
boto3やbotocore(AWSライブラリ)までモックしてしまうと、クラウドサービスへのリクエストを認証するためのSign時刻が狂って認証に失敗する。こういう「ロジックと関係のないライブラリ」はモックしないようignoreしておく必要がある。おそらくどのクラウドでも事情は似たようなものだろう。
X-系ヘッダは、内部リクエスト(microservice-microservice連携)時は全てパススルーするように、標準のrequestsをラップするような内部リクエスト用ライブラリを準備しておくと、ヘッダ連携に関しては心配する事がなくなると思う。パススルーとは?
要するに、自分がリクエストを受けたとき、リクエストに付与されていたヘッダを、自分から他のサービスにリクエストするときにそのまま同じものを送信するという事。結論
これはPython Djangoだが、他の言語でもやることは同じのはず。時刻が関わるE2Eテストの実行はとても難しいので、こういう方法を準備してやれば時刻に関わるE2Eテストが怖くなくなるのではないだろうかと思う。
- 投稿日:2020-02-08T15:01:12+09:00
Python3の標準入力(競プロ)
はじめに
競プロやコーディングテストで使う標準入力のメモです。
それぞれ上が入力、下がソースコードです。
※Python3.4.3では動作確認済み。基本
Python3の組み込み関数
input()はキーボードからの入力を文字列として取得する関数です。
以下のように入力が複数行になるときはinput()1回毎に1行ずつ取得されます。99 hiN = input() M = input() # N = '99' # M = hi'1つの整数
NN = int(input())2つ以上の整数
N MN, M = map(int, input().split())2つ以上の整数(スペース区切りで横並びをリスト化)
A_1 A_2 ... A_NA = list(map(int, input().split()))2つ以上の整数(N行の改行区切りをリスト化)
N A_1 A_2 ... A_NN = int(input()) A = [int(input()) for _ in range(N)]N行 M列の整数
N P_(1,1) P_(1,2) ... P_(1,M) ... P_(N,1) P_(N,2) ... P_(N,M)N = int(input()) P = [list(map(int, input().split())) for _ in range(N)]おまけ
先頭の整数とそれ以降に分ける
K S_1 S_2 ... S_NK, *S = list(map(int, input().split())) # K = K # S = [S_1, S_2, ... S_N]
*Sついては(リストの)アンパックというそうです。
Pythonにおけるアスタリスク*については以下の記事に詳しく書かれていました。
- 投稿日:2020-02-08T14:41:53+09:00
PandasのDataFrameの要素を列名指定で更新する
目的
DataFrameの要素を列名指定で更新したい
環境
OS: ubuntu18.04
pythonバージョン: 3.6.9ソースコード
main.py#!/usr/bin/env python3 import pandas as pd if __name__ == '__main__': dic = {'key1':[1,2,3],'key2':[4,5,6],'key3':[7,8,9]} df = pd.DataFrame.from_dict(dic) print(df) df.iloc[-1, df.columns.get_loc('key2')] = 10 #末尾行のKey2の値を更新 print(df)結果
key1 key2 key3 0 1 4 7 1 2 5 8 2 3 6 9 key1 key2 key3 0 1 4 7 1 2 5 8 2 3 10 9
- 投稿日:2020-02-08T14:35:30+09:00
クラス変数
1class Person(object): kind = 'human' def __init__(self, name): self.name = name def who_are_you(self): print(self.name, self.kind) p1 = Person('A') p2 = Person('B') p1.who_are_you() p2.who_are_you()1の実行結果A human B humanクラス変数(この場合はkind)は、
つくった全てのオブジェクトで共用される。2class T(object): words = [] def add_word(self, word): self.words.append(word) c = T() c.add_word('apple') c.add_word('banana') print(c.words) d = T() d.add_word('orange') d.add_word('cake') print(d.words)2の実行結果['apple', 'banana'] ['apple', 'banana', 'orange', 'cake']cというオブジェクトとdというオブジェクト2つのオブジェクトをつくったが、
wordsがクラス変数なので、
cとdで共用されてしまっている。これがバグにつながる事がある。
これを防ぐためには、
都度__init__で初期化(インスタンス変数に代入)する。3class T(object): def __init__(self): self.words = [] def add_word(self, word): self.words.append(word) c = T() c.add_word('apple') c.add_word('banana') print(c.words) d = T() d.add_word('orange') d.add_word('cake') print(d.words)3の実行結果['apple', 'banana'] ['orange', 'cake']
- 投稿日:2020-02-08T13:57:54+09:00
numpy備忘録2/transposeは行と列を入れ替えるだけじゃない
1.はじめに
transeposeの詳しい使い方が良く分からなかったので、調べた結果を備忘録として残します。2.2次元配列
import numpy as np img = np.array([[ 0, 1], [ 2, 3]]) img = img.transpose(1,0) print(img) # [[0 2] # [1 3]]変換無しが
transpose(0, 1)で、軸ナンバーは、x軸(0), y軸(1)です。
transpose(1, 0)で、x軸(0)とy軸(1)が入れ替わり、いわゆる転置行列になります。3.3次元配列
img = np.array([[[ 0, 1, 2], [ 3, 4, 5], [ 6, 7, 8]], [[ 9,10,11], [12,13,14], [15,16,17]]]) img = img.transpose(0, 2, 1) print(img) # [[[ 0 3 6] # [ 1 4 7] # [ 2 5 8]] # [[ 9 12 15] # [10 13 16] # [11 14 17]]]変換無しが
transpose(0, 1, 2)で、軸ナンバーは、チャンネル軸(0), x軸(1), y軸(2)です(チャンネル軸は適当に付けた名前です)。x軸, y軸の軸ナンバーは次元数に応じて変化することに注意して下さい。
transpose(0, 2, 1)で、x軸(1)とy軸(2)が入れ替わります。img = np.array([[[ 0, 1, 2], [ 3, 4, 5], [ 6, 7, 8]], [[ 9,10,11], [12,13,14], [15,16,17]]]) img = img.transpose(1, 0, 2) print(img) # [[[ 0 1 2] # [ 9 10 11]] # [[ 3 4 5] # [12 13 14]] # [[ 6 7 8] # [15 16 17]]]
transpose(1, 0, 2)とx軸(1)をチャネル軸(0)の前に持って来ると、今までは各行列内の処理だったのが、行列間の処理になります。2つの行列の、0行目で1つの行列、1行目で1つの行列、2行目で1つの行列を作ります。img = np.array([[[ 0, 1, 2], [ 3, 4, 5], [ 6, 7, 8]], [[ 9,10,11], [12,13,14], [15,16,17]]]) img = img.transpose(2, 0, 1) print(img) # [[[ 0 3 6] # [ 9 12 15]] # [[ 1 4 7] # [10 13 16]] # [[ 2 5 8] # [11 14 17]]]
transpose(2, 0, 1)とy軸(2)をチャネル軸(0)の前に持って来ると、先程同様、行列間の処理になります。今度は、2つの行列の0列目で1つの行列、1列目で1つの行列、2列目で1つの行列を作ります。img = np.array([[[ 0, 1, 2], [ 3, 4, 5], [ 6, 7, 8]], [[ 9,10,11], [12,13,14], [15,16,17]]]) img = img.transpose(1, 2, 0) print(img) # [[[ 0 9] # [ 1 10] # [ 2 11]] # [[ 3 12] # [ 4 13] # [ 5 14]] # [[ 6 15] # [ 7 16] # [ 8 17]]]さて、
transpose(1, 2, 0)とx軸(1), y軸(2)の両方をチャネル軸(0)の前に持って来るとどうなるか。各行列の同じ座標の値を串刺しにしてまとめます。今回は、x軸(0)が先頭(優先)なので、0行目を串刺しにして1つ行列を作り、1行目を串刺しにして1つの行列を作り、2行目を串刺しにして1つの行列を作ります。
img = np.array([[[ 0, 1, 2], [ 3, 4, 5], [ 6, 7, 8]], [[ 9,10,11], [12,13,14], [15,16,17]]]) img = img.transpose(2, 1, 0) print(img) # [[[ 0 9] # [ 3 12] # [ 6 15]] # [[ 1 10] # [ 4 13] # [ 7 16]] # [[ 2 11] # [ 5 14] # [ 8 17]]]今度は、
transpose(2, 1, 0)とy軸(2)を先頭に持って来ると、y軸(2)が優先になり、0列目を串刺しにして1つ行列を作り、1列目を串刺しにして1つの行列を作り、2列目を串刺しにして1つの行列を作ります。
4次元配列
いよいよ、4次元です。特筆すべき例を一つだけ、説明します。
img = np.array([ [[[ 0, 1, 2], [ 3, 4, 5], [ 6, 7, 8]], [[ 9,10,11], [12,13,14], [15,16,17]]], [[[18,19,20], [21,22,23], [24,25,26]], [[27,28,29], [30,31,32], [33,34,35]]] ]) img = img.transpose(2, 3, 0, 1) print(img) # [[[[ 0 9] # [18 27]] # [[ 1 10] # [19 28]] # [[ 2 11] # [20 29]]] # [[[ 3 12] # [21 30]] # [[ 4 13] # [22 31]] # [[ 5 14] # [23 32]]] # [[[ 6 15] # [24 33]] # [[ 7 16] # [25 34]] # [[ 8 17] # [26 35]]]]変換無しが
transpose(0, 1, 2, 3)で、軸ナンバーは、バッチ軸(0), チャンネル軸(1), x軸(2), y軸(3)です(バッチ軸, チャンネル軸は適当に名前を付けてます)。4次元配列で、
transpose(2, 3, 0, 1)とやると、各行列の同じ座標を串刺しにするのは3次元配列と同じですが、集計の単位が行ではなく、座標単位となります。そして、座標は、0行0列, 0行1列, 0行2列, 1行0列, ... という順番で行列をまとめます。
transpose(3, 2, 0, 1)の場合は、座標の進む順番が、0行0列, 1行0列, 2行0列, 0行1列, ... に変わるだけで後は同じです。4.実際の使用例
im2colという畳み込み演算を高速に行うアルゴリズムで、transposeが使われている例を、簡単なサンプルで説明します。
左の4つの行列から右の行列に変換するにはどうしたら良いでしょうか?img = np.array([ [[[ 0, 1, 2], [ 4, 5, 6], [ 8, 9, 0]], [[ 1, 2, 3], [ 5, 6, 7], [ 9, 0, 1]]], [[[ 4, 5, 6], [ 8, 9, 0], [ 2, 3, 4]], [[ 5, 6, 7], [ 9, 0, 1], [ 3, 4, 5]]] ]) print('img.shape = ',img.shape) img = img.transpose(2, 3, 0, 1) print(img) # img.shape = (2, 2, 3, 3) # [[[[0 1] # [4 5]] # [[1 2] # [5 6]] # [[2 3] # [6 7]]] # [[[4 5] # [8 9]] # [[5 6] # [9 0]] # [[6 7] # [0 1]]] # [[[8 9] # [2 3]] # [[9 0] # [3 4]] # [[0 1] # [4 5]]]]そうなんです。先程の
transpose(2, 3, 0, 1)を使うと、各座標を串刺しにして座標単位でまとめることが出来ます。後は、リシェイプを掛ければ、img = img.reshape(9, -1) print(img) # [[ 0 9 18 27] # [ 3 12 21 30] # [ 6 15 24 33] # [ 1 10 19 28] # [ 4 13 22 31] # [ 7 16 25 34] # [ 2 11 20 29] # [ 5 14 23 32] # [ 8 17 26 35]]出来てしまいました!
reshape(9, -1)は、9行だけ決めて後は自動的にリシェイプする形式の書き方(配列がとても大きい時に便利)で、もちろんreshape(9, 4)でもOKです。結局、先程の処理は、
transpose(2, 3, 0, 1).reshape(9, -1)とたった1行で表せるわけです。さすが、numpy。
- 投稿日:2020-02-08T13:22:21+09:00
ChEMBL webresource clientのインストール
はじめに
そろそろChEMBLについて勉強しようと思う。手始めにChEMBL webresource clientというPythonのインターフェースを見つけたのでこれをインストールしてみた。
ChEMBL webresource clientとは
ChEMBLグループによって開発およびサポートされている唯一の公式Pythonクライアントライブラリ。PythonからChEMBLデータや化学情報学ツールにアクセスするのに役立つ。SQLやRESTを知らなくても使える。
インストール
python3.6のAnaconda仮想環境上で、以下の通りcondaでいけた。
conda install -c conda-forge chembl_webresource_client Collecting package metadata (current_repodata.json): done Solving environment: done ==> WARNING: A newer version of conda exists. <== current version: 4.7.12 latest version: 4.8.2 Please update conda by running $ conda update -n base -c defaults conda ## Package Plan ## environment location: /home/kimisyo/anaconda3/envs/chemlearn added / updated specs: - chembl_webresource_client The following packages will be downloaded: package | build ---------------------------|----------------- chembl_webresource_client-0.10.0| py36_1 89 KB conda-forge easydict-1.9 | py_0 9 KB conda-forge gevent-1.4.0 | py36h516909a_0 2.5 MB conda-forge greenlet-0.4.15 | py36h516909a_0 22 KB conda-forge grequests-0.4.0 | py_0 6 KB conda-forge requests_cache-0.4.13 | py_0 16 KB conda-forge ------------------------------------------------------------ Total: 2.7 MB The following NEW packages will be INSTALLED: chembl_webresourc~ conda-forge/linux-64::chembl_webresource_client-0.10.0-py36_1 easydict conda-forge/noarch::easydict-1.9-py_0 gevent conda-forge/linux-64::gevent-1.4.0-py36h516909a_0 greenlet conda-forge/linux-64::greenlet-0.4.15-py36h516909a_0 grequests conda-forge/noarch::grequests-0.4.0-py_0 requests_cache conda-forge/noarch::requests_cache-0.4.13-py_0 Proceed ([y]/n)? y Downloading and Extracting Packages easydict-1.9 | 9 KB | ##################################################### | 100% greenlet-0.4.15 | 22 KB | ##################################################### | 100% gevent-1.4.0 | 2.5 MB | ##################################################### | 100% chembl_webresource_c | 89 KB | ##################################################### | 100% grequests-0.4.0 | 6 KB | ##################################################### | 100% requests_cache-0.4.1 | 16 KB | ##################################################### | 100% Preparing transaction: done Verifying transaction: done Executing transaction: done使ってみた感想はまた別途。
参考