- 投稿日:2020-02-08T23:41:15+09:00
AWS Amplify のサインイン時の項目を変更してみた
はじめに
このページでは Amplify のサインイン画面の初期項目を変更するための方法を Document を見ながら実装しました。
日本語化対応からの修正内容はこちら
開発環境
- Windows 10
- nodist(nodeのバージョン管理)
- node 12.13.0
- VSCode
Amptify のサインイン画面を変更したい!
前提として
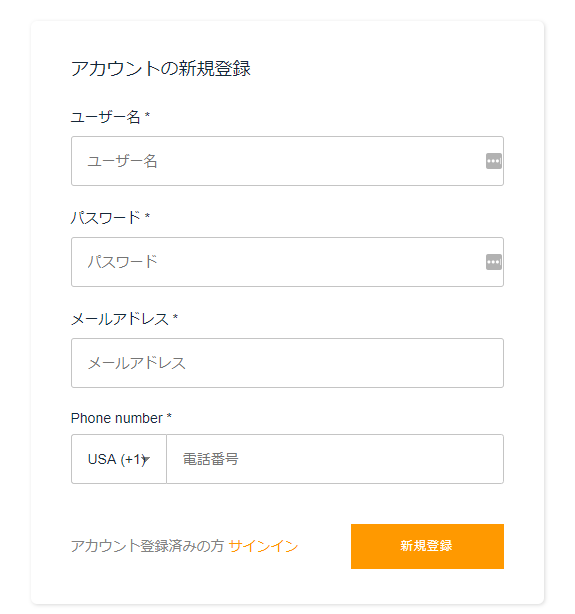
デフォルトで認証機能を作成すると、上記画像の項目が用意されます。
個人的には Cognito で電話番号は管理させたくないと思ったので…この電話番号の項目を設定出来なくすることは可能か?と思ったのが事の発端でした。カスタマイズする方法がないか調べているとリファレンスが見つかりました。
https://aws-amplify.github.io/docs/js/vue
内容を読む限り、任意の場所に用意した画面を描画できるタグがあるらしく、オプションを設定すると色々修正できるらしいです
ということで、今まで日本語化まで地道に行ってきたプロジェクトに手を入れていきます。
認証画面のカスタマイズ用のページを作成する
src/views/SampleAuth.vue<template> <amplify-authenticator v-bind:authConfig="authConfig"></amplify-authenticator> </template> <script> export default { name: "sampleAuth", data() { return { authConfig: { signUpConfig: { hiddenDefaults: ["phone_number"] } } }; } }; </script>今回項目の変更を行いたいのでカスタマイズページを用意します。
リファレンスによると amplify-authenticator タグを書くだけで、認証機能一通りの機能を用意してくれるらしいです。
こちらを用いると、authConfig 内で各ページに対してのプロパティを設定することが出来るようです。
今回は、サインアップするときの設定値を修正したいので、signUpConfig に非表示にする設定を追加しました。ルートを変更する
(before)src/router/index.js{ path: "/auth", name: "Authenticator", component: components.Authenticator }元々のソースコードは component に 「components.Authenticator」と書くことで、デフォルトの認証画面を描画指定ました。
今回はカスタムページを用意したので、こちらを呼び出すように修正します。(after)src/router/index.jsimport SampleAuth from "../views/SampleAuth"; // ・・・(中略)・・・ { path: "/auth", name: "sampleAuth", component: SampleAuth }画面を描画してみる
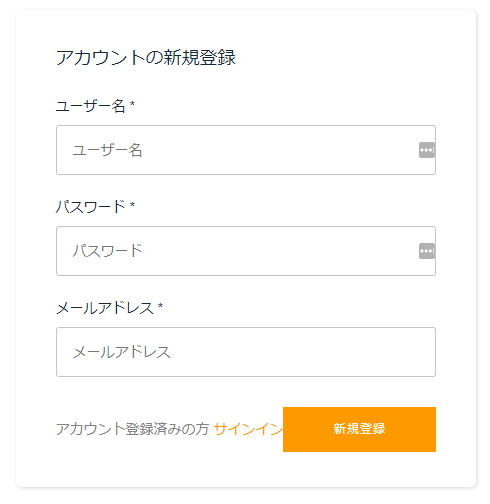
サーバを立ち上げて確認してみると、電話番号の項目が消えていました。
ユーザ登録も出来ることが確認できたので hiddenDefaults で非表示にするだけで問題なさそうです。
簡単に項目が出来たので驚きました。番外編(ログインしたならログアウトしたい)
src/components/HelloWorld.vue<amplify-sign-out></amplify-sign-out>試しに上記タグをページに追加してみました。
サインアウトボタンも表示され、機能自体も使えるようになっていました。(超簡単!)
終わりに
今までのソースを見返すだけでは、修正可能かどうかわからなかったけれど、調べてみるとリファレンスがすごくしっかりしていて、難なく調整が出来ました。
英語が本当に苦手なんですが、まずはリファレンスを見ることを実践していきたいと思いました。

- 投稿日:2020-02-08T23:02:10+09:00
Amazon Linux EOLのLambdaへの影響
はじめに
Amazon Linuxのサポート終了が発表されている。基本的に2020年12月31日まで
Developers.IO: Amazon Linux のサポート期間延長のアナウンスについて
AWS News Blog: Update on Amazon Linux AMI end-of-lifAWS LambdaってAmazon Linuxで動いてるんだけど
AWS Lambdaは、Amazon Linux / Amazon Linux 2で動いている。
ドキュメントこれ、Amazon Linuxで動いてる Python 3.7とかどうなるの?
影響は未定です
ググっても出てこなかったので、AWSサポートに聞いてみたところ
「現時点1では、影響は未定です」とのこと。2なるべくAmazon Linux 2ベースにするのが無難かな
例えば、Python 3.8は結構最近出たばっかだし
まだPython 3.7でいっかと思ってると、後で面倒な事になるかも。
- 投稿日:2020-02-08T22:18:27+09:00
Redshiftをはじめて触ってみた!
Redshiftってよくわからないし、使う必要ある?RDSでよくない?!
自分の周りではそんな声がちらほら聞こえてきます。自分もそのうちの1人で、よくわからないし、検証するにはお金がかかるから後回しにしておこう・・・という感じでした。そんなときに「Redshiftで秒単位の請求のサポートを開始」されたことを耳にしました!
https://aws.amazon.com/jp/about-aws/whats-new/2020/02/amazon-redshift-supports-per-second-billing/これならお試しに自宅で作っても費用を抑えられるし、わざわざ作るのが面倒だという方と自分の復習用にドキュメントも残そうと思います。
1. クラスターの作成
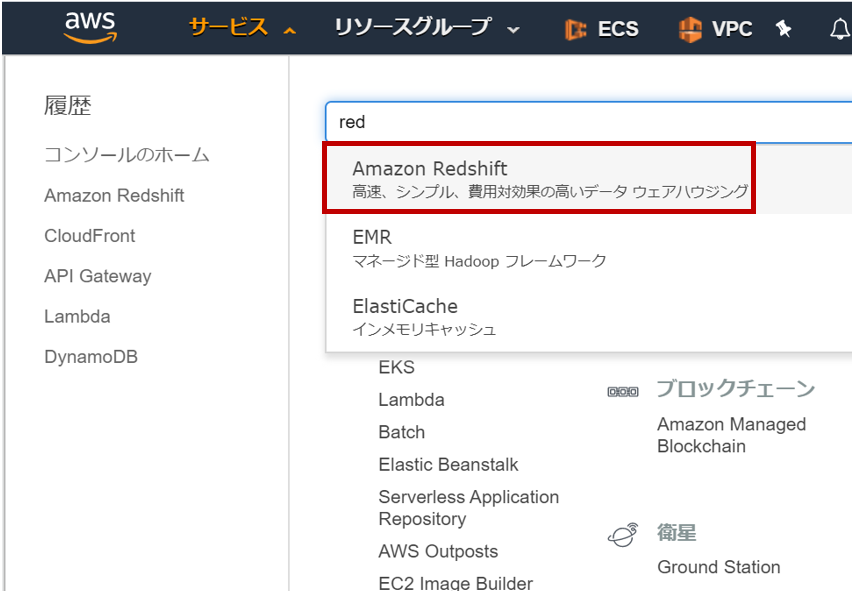
「マネージメントコンソール」にログインし、サービスメニューから「Amazon Redshift」をクリックします。
続いて、「クラスターを作成」をクリックします。
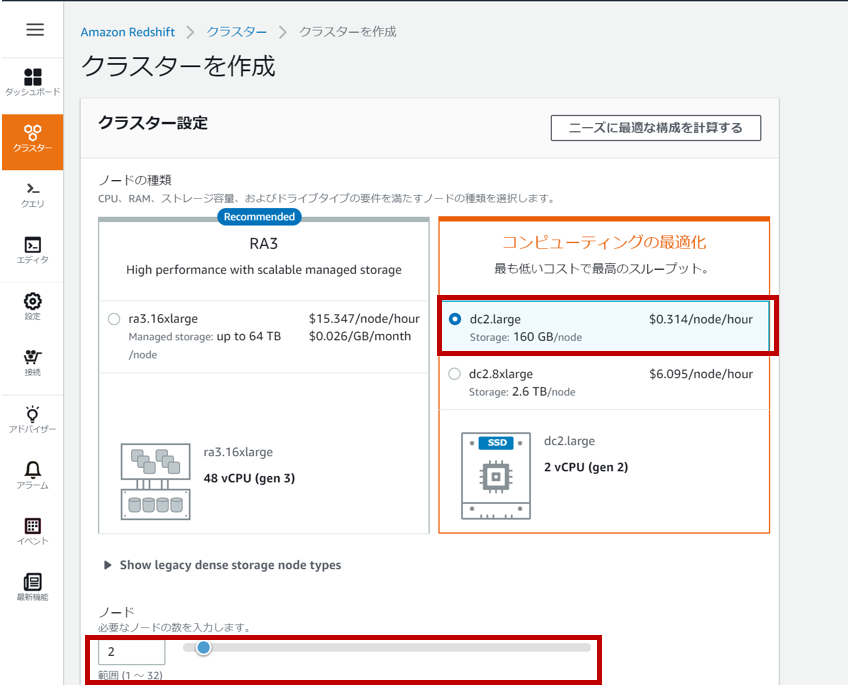
ステップ1: クラスターノードの選択
今回はお試しということなので、「dc2.large」を選択します。ノード数はデフォルトの2にしておきます。
因みに、コンソールでは時間単位の支払いに見えますが、実際は秒単位に変更されているようです。
https://dev.classmethod.jp/cloud/aws/redshift-billing-per-seconds/ステップ2. クラスターの詳細
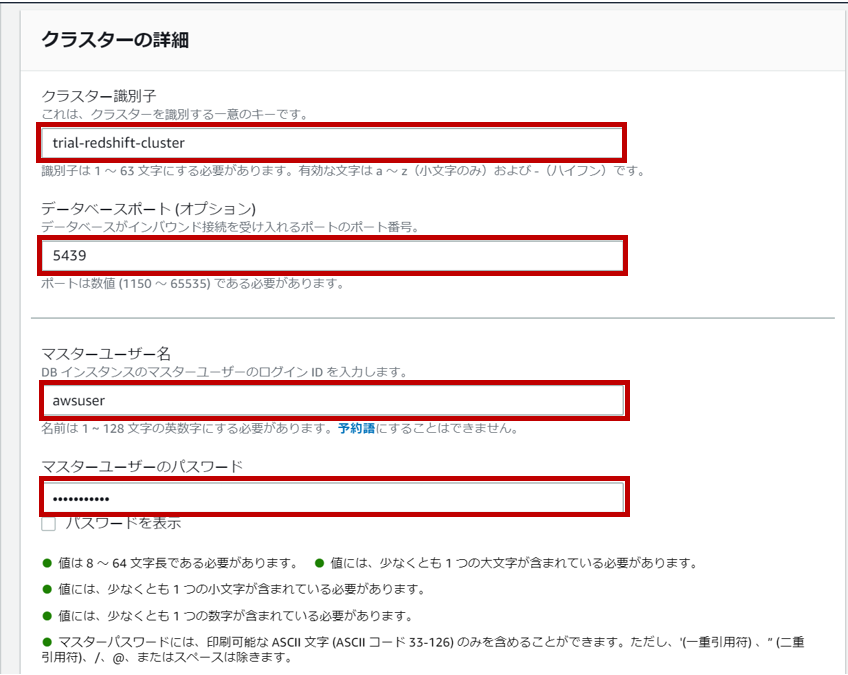
クラスター識別子、ポート、マスターユーザー名、マスターユーザーのパスワードを設定します。パスワードはRedshiftに接続するために必要なのでメモしておきましょう。
ポートはデフォルト値が5439みたいです。
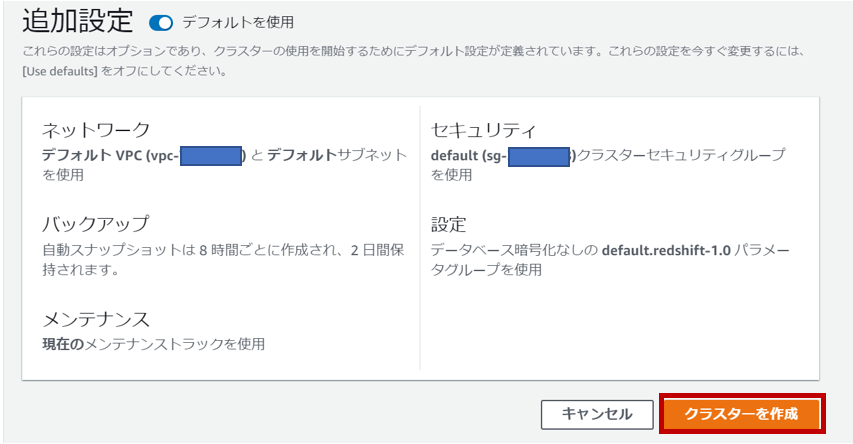
追加設定として、Redshiftの配置するVPC・サブネット、バックアップ、メンテナンス、セキュリティグループ、パラメータグループなどがカスタマイズできるみたいですが、今回はデフォルトを使用します。そして「クラスターを作成」をクリックします。
ステップ3. クラスターの作成が終わるのをのんびり待つ
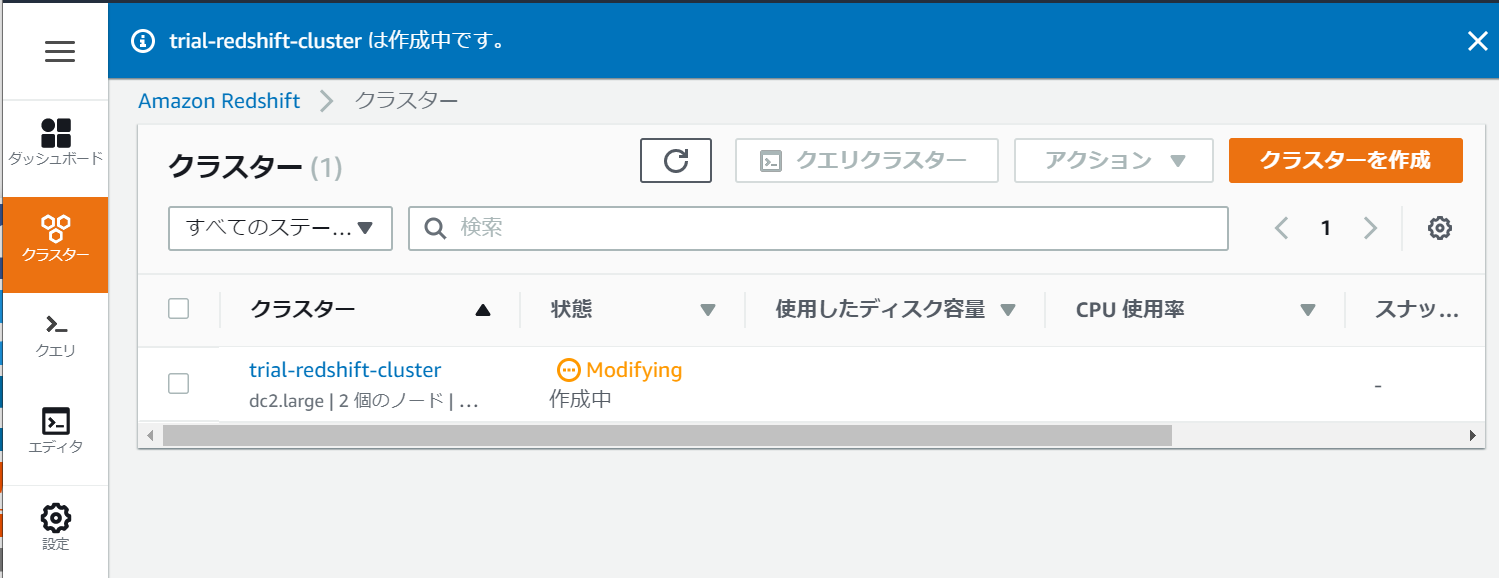
クラスターの作成中は「Modifying」となります。
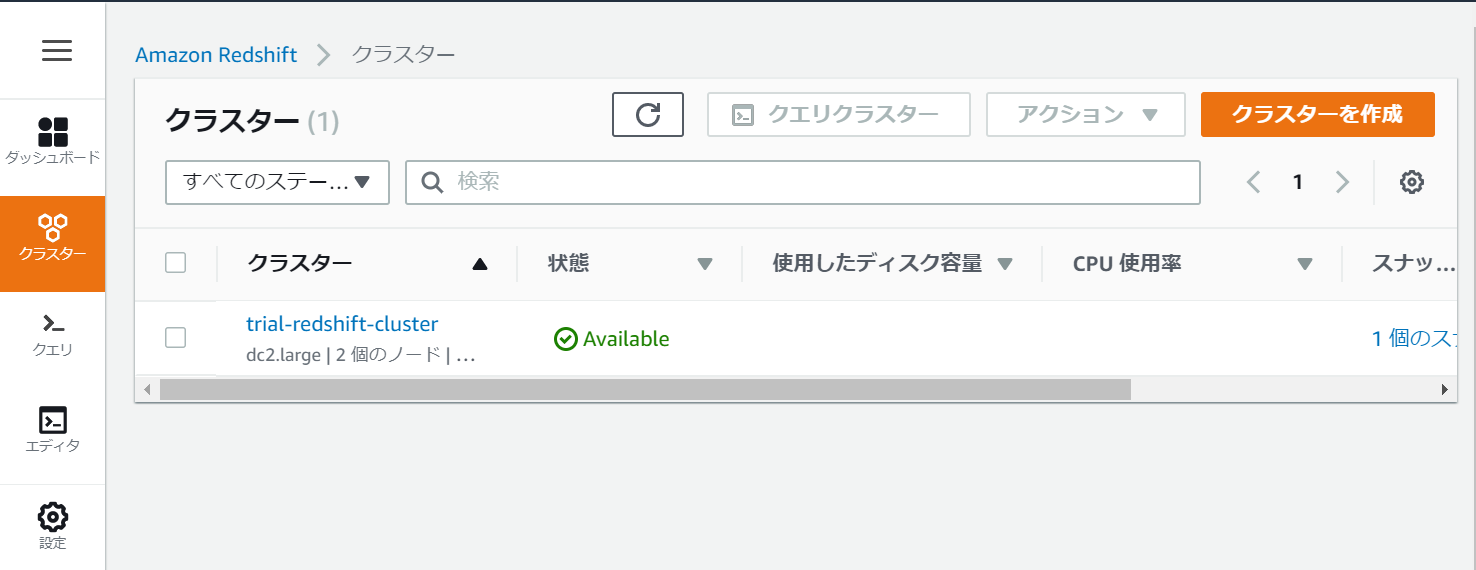
クラスターの作成が終わると「Available」となります。体感的にはカップ麺より待ちました。
2. Redshiftへの接続
マネジメントコンソールから接続する機能がありますので、今回はこちらを使いましょう。
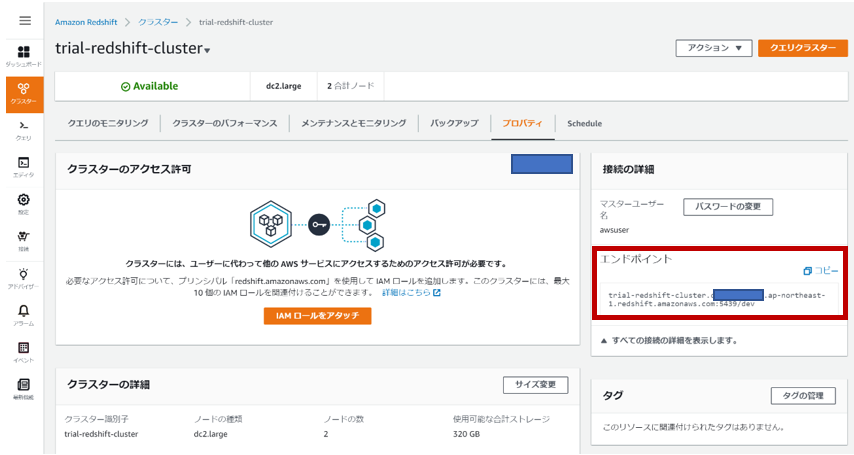
エンドポイントの情報を取得する
クラスターのプロパティからクラスターのエンドポイントとデータベース名(/以降)を取得する。
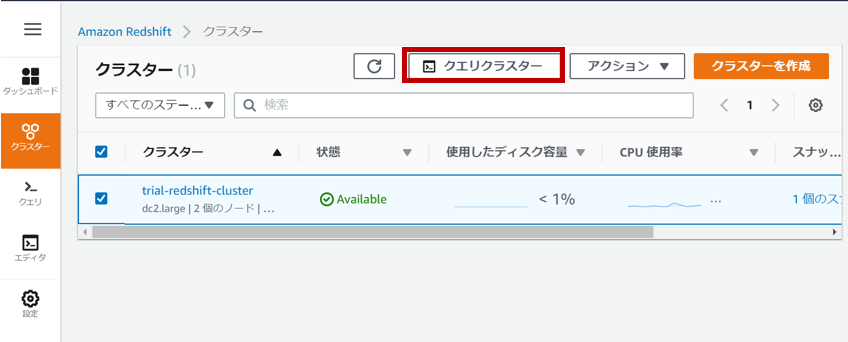
Redshiftに接続する
接続したいクラスターを選択し、「クエリクラスター」をクリックします。
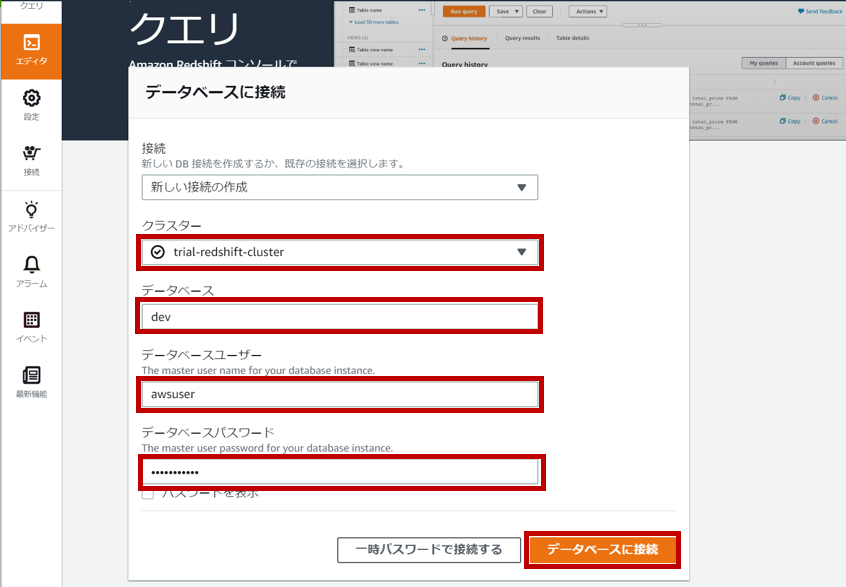
Redshiftへの接続情報を入力して、「データベースに接続」をクリックする。
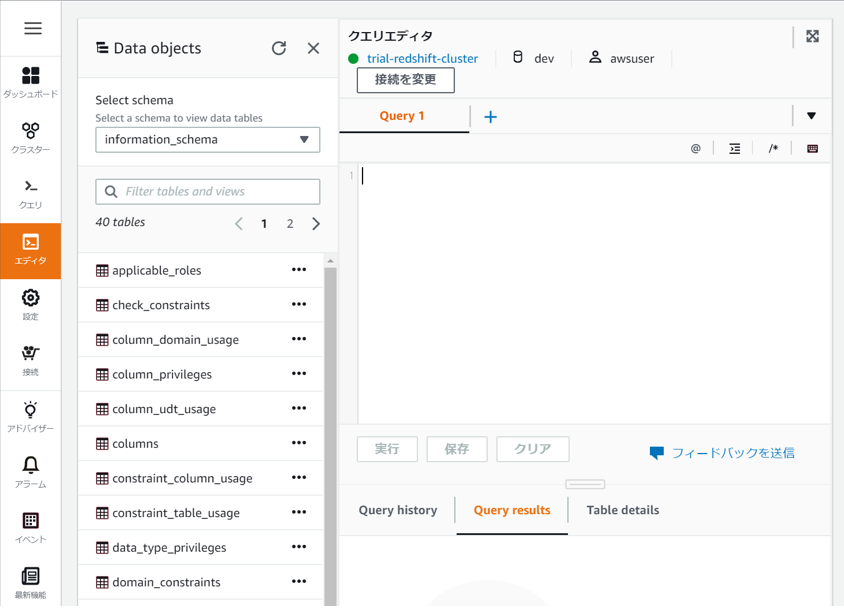
無事にRedshiftへ接続できました。
勿論、マネジメントコンソールからではなく、psqlコマンドを用いて外部から接続することもできます。その場合、セキュリティグループの許可のIAMロールを忘れないように気をつけてくださいね。3. Redshiftの削除
Redshiftの請求が秒単位になったからと言って気を抜いてはいけません。あっという間に大量の請求が舞い込んできます。検証が終わったらすぐに削除しましょう。
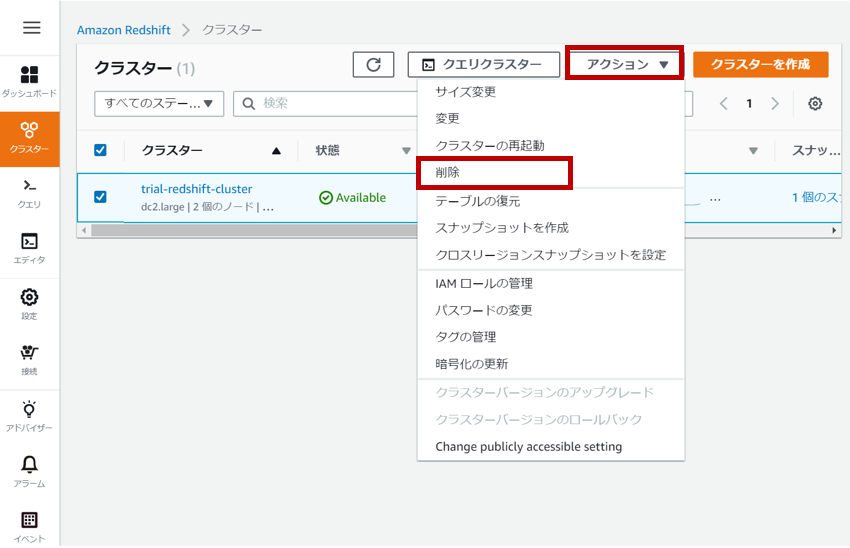
先ほど作成したクラスターを選択し、「アクション」から「削除」をクリックします。
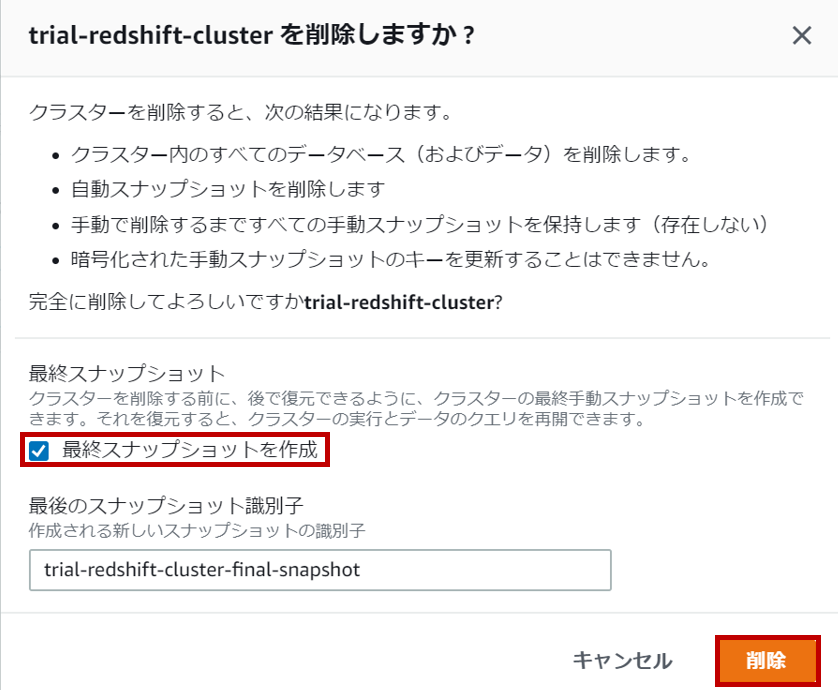
クラスターを削除すると自動スナップショットも消えますので、必要があれば最終スナップショットを作成してください。必要なければ、チェックを外してから「削除」をクリックしてください。
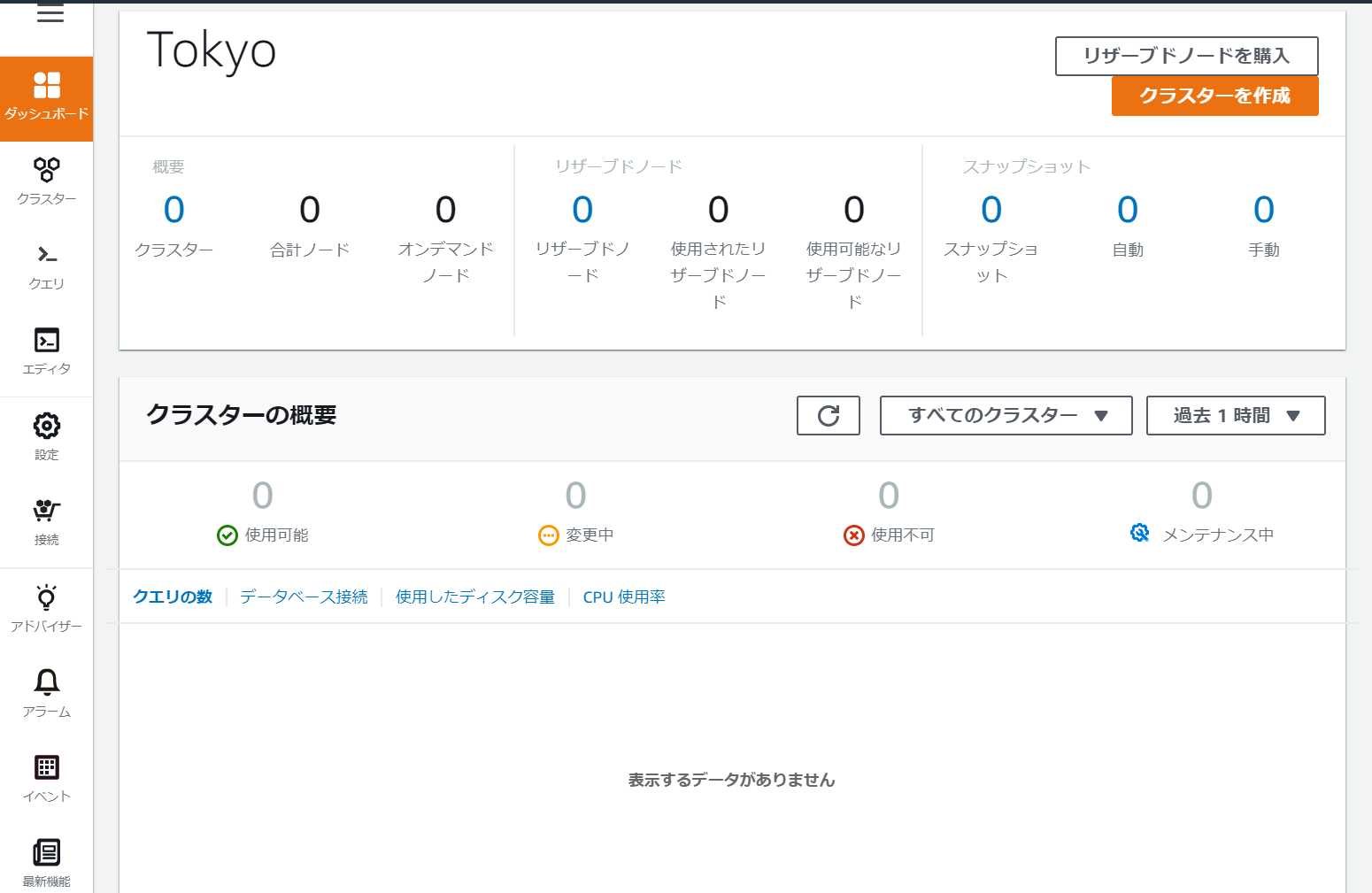
クラスター削除後にダッシュボードを見てみると綺麗さっぱりなくなっていました。これで完了です!
おわりに
Redshiftが秒単位の請求がサポートされたことで、ちょっとした検証がしやすくなったのは勿論、テスト環境で何度も立ち上げたり、データ分析用に大きいインスタンスを一時的に立ち上げることで費用を抑えられるので、個人的にはより目が離せないサービスとなりました。ということで、「Redshiftをはじめて触ってみた!」第2弾でもう少し踏み込んでみようかなと思います。

- 投稿日:2020-02-08T22:14:37+09:00
AWS DVAを取得するまで(開発経験なし)
AWS SAAとAWS SOAを取得したので
さらに知識を深めるためにAWS DVAをAWS 認定デベロッパーアソシエイトを受験し取得しました。
これでアソシエイトは制覇できました。勉強期間
AWS DVA合格が1月11日で翌年の2月8日に受験したので4週間ぐらい
勉強した内容
SOAと一緒で対策の書籍はない
ので開発者向けのサービスのBlackBelt資料をひたすら読む。https://aws.amazon.com/jp/certification/certified-developer-associate/
推奨される知識と経験
最低でも 1 つのハイレベルプログラム言語についての深い知識
AWS の主要なサービス、使用方法および AWS の基本アーキテクチャのベストプラクティスについての理解
AWS を使用するクラウドベースのアプリケーションの開発、デプロイ、デバッグの実力
AWS のサービスの API、AWS CLI、SDK を使用してアプリケーションを記述する能力
AWS のサービスの主要な機能を説明する能力
AWS の責任共有モデルについての理解
アプリケーションのライフサイクル管理についての理解
CI/CD パイプラインを使用して AWS にアプリケーションをデプロイする能力
AWS のサービスを使用または操作する能力
クラウドネイティブアプリケーションの基本的な知識を活用してコードに記述する能力
AWS セキュリティのベストプラクティスに従ったコードを記述する能力 (例: シークレットキーやアクセスキーをコードに記述せず、代わりに IAM ロールを使用することなど)
AWS 上でコードモジュールを作成し、管理およびデバッグする能力
サーバーレスアプリケーションのコードを記述する実力
開発プロセスにおけるコンテナの使用方法についての理解例えばサーバレスアーキテクチャ(API Gateway+Lambda)、それに付随するセキュリティの実装、ECSなどのコンテナサービス、Codeシリーズ系のマネージドサービス
あとは、定番ですが以下の模擬試験を購入し、繰り返し勉強しました、
https://www.whizlabs.com/aws-developer-associate/試験を振り返って
SOAよりは簡単でした。
プログラマーの方でAWSで開発をした方であれば、特に苦戦することなく合格できると思います。
わからない問題が試験中ありましたが、AWS Well-Architected Frameworkに即していると思われる答えを選ぶことが大事だと思いました。
まとめ
プログラミング経験がなくとも合格はできましたが、
正直プログラミング経験がないとあまり取得する意味がない試験なのかもしてません。
ただし、アプリ側の言ってることを理解しやすくなったり、AWSの設計方針については詳しくなれたと思います。
- 投稿日:2020-02-08T22:12:24+09:00
【体験記】AWS SAA取得しました
はじめに
AWSソリューションアーキテクトアソシエイトに無事合格しました。
合格にあたり他の受験を考えている方達の参考までにもろもろ残しておこうと思います。
※本記事は2020年3月22日までの試験バージョンの受験記となるため悪しからず。勉強時間
多分100時間ちょっとくらいだと思います。
かなり長い期間だらだらと続けてしまってましたが、ぎゅっと凝縮したらこれくらいかと。教材・勉強方法
使用した教材は以下の通りです。
書籍
徹底攻略 AWS認定 ソリューションアーキテクト – アソシエイト教科書
書籍としては一番使ったかもしれないです。
大事なサービスを満遍なく説明しており、模擬試験もついてます。
ただ、少し古いのとこれだけでは合格が難しい(ここに書いてないことも普通に試験にでる)ので、この本だけでは合格は厳しそうです。基礎をつけるには良いと思います。一夜漬け AWS認定ソリューションアーキテクト アソシエイト 直前対策テキスト
その名の通り試験直前にざっと全体を振り返るのに向いてます。
2020年3月以降の試験にも対応しているみたいなので新バージョンでの受験を考えられている方にもよいと思います。
また、この本でポイントとして解説しているところが試験に実際に出題されたようにも感じました。
ただこの本はそもそも各サービスの概要をさらっとしかやらないので、一番はじめにこの本から入ると理解が難しいかもしれません。
良くも悪くもAWSを理解するというよりはAWS認定に合格するための書籍といったところ。講座
手を動かしながら2週間で学ぶAWS基礎から応用まで
udemyの講座です。
ハンズオン形式で実際にAWSに触りながら学べる講座となります。
やはり本を読むだけでは実際にイメージしにくいので実際に触ってみるのは大事に感じました。
課金サービスにも触っていくので放置すると痛い目にみるので要注意。問題演習
AWS公式模擬試験
AWSが出している公式の模擬試験です。
自宅ですぐに受験可能ですが、3000円ほどかかります。
内容としては本試験と比べてかなり簡単です。。。
ここで7割とれたから受験するってのは結構リスクありそうです。
どんな感じの試験なのかイメージを掴む分には良さそうです。
私は書籍1冊だけ読んだあと、一回だけ受験しました。(その時は7割くらいでした)AWS 認定ソリューションアーキテクト アソシエイト模擬試験問題集(5回分325問)
模擬試験5回分のudemyの講座です。
作成者も書いている通り、癖のある、やや難易度の高い問題集となります。
ある程度勉強して、細かい部分を覚えるのには良さそうです。
実際にこの模擬試験ででた問題に似たようなものも本試験で出題されました。
公式の模擬試験よりもこっちのほうが本試験の難易度に近かったです。
参考までにこの模擬試験6割くらいで私は本試験合格しました。AWS WEB問題集で学習しよう
一部の人たちで有名(?)なサイトです。
月額3000円くらいでかなりの数の問題集を利用できます。
1セクション7問で、問題1問解くごと回答と解説が出るので、通勤中など隙間時間でサクッと勉強できるのでかなりおすすめです。
参考までにこのサイトで7〜8割取れるようになってから本試験合格できました。
そういう意味だと一番本試験の難易度に近いかも。本試験でよく問われたところ
DynamoDBの特徴とユースケース(私が受けた時たまたまかもしれませんが、DynamoDBめちゃくちゃ出ました)
EC2の購入オプションとインスタンスタイプ
CLBとALBの違い
ELBのスケーリングプラン
S3のストレージクラス
問題は受ける日とかによってランダム(なんですかね?)なので、あくまで私が受けた時はこうでしたといった感じです。
共通して言えるのは、
- どうすれば可用性が上がるか
- どれが一番低コストか
- どれが一番アプリケーションに変更を加えずに済むか
- どれが一番セキュアか
ここらへんが聞かれることは間違い無いので、学習する際にはここら辺に着目していくことが大事だと思います。


- 投稿日:2020-02-08T21:39:29+09:00
terraformによるamazonVPCセキュリティグループのicmpルール作成
はじめに
terraformを使ったセキュリティグループの管理はちょこっと癖がありますよね。
(terraformというよりAWSAPIの癖って気もしますが。。)
指定方法が特殊なICMPのルールについて自分自身の備忘も兼ねて纏めておこうと思います。terraform公式ドキュメントの記載内容
基本的な書式
resource "aws_security_group_rule" "allow_all" { type = "ingress" from_port = 0 to_port = 65535 protocol = "tcp" # Opening to 0.0.0.0/0 can lead to security vulnerabilities. cidr_blocks = # add a CIDR block here prefix_list_ids = [ "pl-12c4e678" ] security_group_id = "sg-123456" }icmpルールの場合、ポイントになるのは以下の部分です。
protocol (必須)プロトコル。 icmp、icmpv6、tcp、udp、またはすべてがプロトコル番号を使用しない場合
from_port (必須)開始ポート(またはプロトコルが「icmp」または「icmpv6」の場合はICMPタイプ番号)
to_port (必須)エンドポート(またはプロトコルが「icmp」の場合はICMPコード)要約するとICMPルールの時は以下を指定しろって事のようですね。
- protocolに「icmpまたはicmpv6」
- from_portに「icmpタイプ番号」
- to_portに「icmpコード」
ICMPタイプ番号
from_portに「ICMPタイプ番号」というのは少し違和感がありますが、
ICMPにはポート番号という概念が無いので、TYPEを代わりに指定するイメージですか。
ICMPには以下のTYPEがあります。
※v6の場合は番号が異なるので注意
Type 内容 意味 0 Echo Reply エコー応答 3 Destination Unreachable 宛先到達不能 4 Source Quench 始点抑制 5 Redirect 最適経路への変更指示 8 Echo Request エコー要求 9 Router Advertisement ルータ通知 10 Router Solicitation ルータ要求 11 Time Exceeded TTL超過によるパケット破棄の報告 12 Parameter Problem パケットパラメータにおけるエラー 13 Timestamp タイムスタンプ 14 Timestamp Reply タイムスタンプ応答 15 Information Request インフォメーション要求 16 Information Reply インフォメーション応答 17 Address Mask Request アドレスマスク要求 18 Address Mask Reply アドレスマスク応答 よく使うのはPING=エコー要求の「8」でしょうか。
ICMPコード
to_portに「icmpコード」
個人的に少し悩みどころだったのですが、ICMPコードはICMPタイプによってあるものとないものがあります。
調べた感じ、ICMPコードがあるのは「ICMP Type3」「ICMP Type5」「ICMP Type9」「ICMP Type11」「ICMP Type12」みたいですね。
※それぞれのcodeは後で時間があれば纏めるかも。ちなみに後述しますが全てのCODEを対象にする場合は「-1」です。ICMPコードがあるものはその番号を指定すれば良いでしょうが、ここでの問題はICMPコードがないものは何を指定すりゃええねん!って部分ですよね。(自分はすごく悩みました)
よく利用されるであろうエコー要求もICMPコードがない部類ですね。コンソールだと「該当なし」になりますが、CLIでそれをどう表現するんだ。。で、一生懸命探したところ、terraformではicmpコードなし=「0」を指定せよってことみたいです。
※AWSCLIのリファレンスでは「0」or「-1」がicmpコードなしとして有効な値らしいですが、terraformから実行する場合「-1」は無効な値と判定されるっぽい(実際には試してませんが)ただ、AWSAPI側では「0」を指定しても「-1」に値が変換されて設定されている可能性があるとのこと。う、うん?って感じ。そこは足並みを揃えて欲しいですね。まあ纏めると以下になるかと。
- ICMPコードがあるものは、指定したいコードまたは「-1」 ※「-1」は「すべて」の意
- ICMPコードがないものは、「0」を指定
すべてのICMP
ここまでの内容だけでは、まだ足りないものがあります。
そう、「すべてのICMP」を許可するルールはどう作るねんって話ですね。まあ、これに関してはAWSCLIのリファレンスを信じて問題なさそうです。
https://docs.aws.amazon.com/cli/latest/reference/ec2/authorize-security-group-ingress.htmlAWSCLIのリファレンスから重要な部分を抜粋すると以下です。
ICMP/ICMPv6 の場合は、ICMP/ICMPv6 タイプおよびコードも指定する必要があります。-1 を使用すると、すべての種類またはすべてのコードを意味できます。要約すると以下ですかね。
- 全てのicmpタイプ = 「-1」を指定する
- 全てのicmpコード = 「-1」を指定する
なので、「すべてのICMP」を表すのは以下になります。
protocol = "icmp" from_port = -1 to_port = -1まとめ
terraformからPINGを許可するセキュリティルールはどう指定するん?
resource "aws_security_group_rule" "allow_ping" { type = "ingress" from_port = 8 to_port = 0 protocol = "icmp" cidr_blocks = "0.0.0.0/0" security_group_id = "sg-123456" }terraformからすべてのICMPを許可するセキュリティルールはどう指定するん?
resource "aws_security_group_rule" "allow_icmp_all" { type = "ingress" from_port = -1 to_port = -1 protocol = "icmp" cidr_blocks = "0.0.0.0/0" security_group_id = "sg-123456" }簡単な調べ方
今回は正確な裏付け情報を得るためにリファレンスとかを漁りましたが、簡単に調べる方法もあります。
コンソールから手でルールを作成して、それがどんな値で設定されているか調べるという方法ですね。(こっちのが確実かも)
CLIで確認するなら
aws ec2 describe-security-groupsですかね。
※ただ、ICMPコードの時みたいに「cliでは有効だけどterraformでは無効な値」とかあるかもしれないのが困りものですが。terraformなら
terraform importですね。terraform import aws_security_group.<セキュリティグループ>
上記方法は実際には試してないのですが、
terraform importなら正確な設定値が返ってきそうな気がしますね。(時間がある時にエコー要求のルールでどんな値が返ってくるか検証してみようかなー。。)
- 投稿日:2020-02-08T21:07:27+09:00
AWS Lambdaでslackに新着論文通知
TL;DR
AWS Lambdaを用いてMicrosoft Academicで新着論文を検索してSlackに通知するツールを作った。
はじめに
研究室等のSlackに新着論文通知出せたら便利ですよね。
以前はjournalのRSSを使ってましたが、あまり関係ない論文が飛んできてイマイチ機能していなかったので自分でフェッチツールを作ることにしました。
(実際、皆さんどうしてるんでしょうか)
通知を出すだけなので、AWS LambdaやAzure Functionsといったサーバーレスアーキテクチャを用いれば非常に安価で簡単に構築できます。
今回はAWS Lambdaを用い、また論文検索にはMicrosoft AcademicのAPI、Academic Knowledge APIを用いました。
■参考
Microsoft Academic のすゝめ
- 周りで論文検索に使ってる人をあまり見ないのですが、Microsoft Academicはとても便利です。方法
このようなものを作りました。
WebHookの設定
まず、Slack側で情報を受け取るために、WebHookの設定をします。
Slackの[アプリを追加する]で、Incoming Webhookを追加します。
WebHook URLが発行されているので、インテグレーションの設定から確認します。
投稿したいチャンネル先の設定などもこちらで行うことができます。
次は、LambdaからこのWebHook URLにjsonペイロードを送信することで、Slack上に通知を出してみます。
■参考
AWS Lambdaで作るSlack bot (Incoming Webhook)AWS LambdaからWebHookに送信
まず、AWS Lambdaで関数を作成します。今回はPythonで書いていきます。
作成すると、すでに次のようなコードがあると思います。
import json def lambda_handler(event, context): # TODO implement return { 'statusCode': 200, 'body': json.dumps('Hello from Lambda!') }トリガーが起こると、lambda_handlerが実行されるという仕組みです。(トリガーの指定は後で行います)
まずは、TODO implementのところにSlackへjsonペイロードを送ってみます。import json import urllib.request def lambda_handler(event, context): # TODO implement post_slack() return { 'statusCode': 200, 'body': json.dumps('Hello from Lambda!') } def post_slack(): send_data = { "text" : "Test", } send_text = "payload=" + json.dumps(send_data) request = urllib.request.Request( "**上で確認したWebHook URL**", data=send_text.encode('utf-8'), method="POST" ) with urllib.request.urlopen(request) as response: response_body = response.read().decode('utf-8')ここまで出来たら、AWS Lambdaの右上にある[保存]を押した後、その左の[テスト]を実行してみます。
無事、指定したチャンネルに"Test"という投稿があればOKです。
ちなみにjsonペイロードで投稿するチャンネルや、投稿者の名前、アイコン、テキストレイアウトなども自由に指定することができます。
■参考
AWS Lambdaで作るSlack bot (Incoming Webhook)
SlackのIncoming Webhooksを使い倒すMicrosoft Academicの検索
Microsoft Academicを検索できるAPI、Academic Knowledge APIを用います。
ここからSubscribeして、APIキーを取得します。月10,000トランザクションなどの制約がありますが、無料で使えます。
DocumentationはWhat is Academic Knowledge APIとAcademic Search APIを見ると良いと思います。
Academic Knowledge APIには様々な機能がありますが、今回はクエリを渡して検索するEvaluateというメソッドを主に用います。
https://api.labs.cognitive.microsoft.com/academic/v1.0/evaluate?expr={expr}[&model][&count][&offset][&orderby][&attributes]上のリクエストurlのパラメータを指定し、GETリクエストを送ると論文情報が返ってきます。
クエリの書き方はQuery expression Syntaxに書かれています。
まずはシンプルに、タイトルにdeep,learningが両方含まれている2020年の論文3本の情報をSlackに通知してみます。
クエリは
expr=And(W='deep',W='learning',Y=2020)、返ってきてほしい属性にタイトル・ソース・ジャーナル名を指定&attributes=Ti,S,VFN、件数は&count=3と指定してGETをたたきます。import json import urllib.request def lambda_handler(event, context): # TODO implement search_paper() return { 'statusCode': 200, 'body': json.dumps('Hello from Lambda!') } def post_slack(message): send_data = { "text" : message, } send_text = "payload=" + json.dumps(send_data) request = urllib.request.Request( "**WebHook URL**", data=send_text.encode('utf-8'), method="POST" ) with urllib.request.urlopen(request) as response: response_body = response.read().decode('utf-8') def search_paper(): api_key = "**API KEY**" query = "And(W='deep',W='learning',Y=2020)" url = "https://api.labs.cognitive.microsoft.com/academic/v1.0/evaluate?"+"expr="+query+"&attributes=Ti,S,VFN&count=3" request = urllib.request.Request( url, method="GET", headers={"Ocp-Apim-Subscription-Key" : api_key}, ) with urllib.request.urlopen(request) as response: response_body = json.loads(response.read().decode('utf-8')) for e in response_body['entities']: message = "*Title* : {}\n*Journal* : {}\n*URL* : {}".format(e['Ti'],e['VFN'],e['S'][0]['U']) post_slack(message)
ここまででMicrosoft Academic上で検索して、その情報をSlackに通知することができました。
リクエストURLのパラメータを調整すれば、お好みのフェッチツールができるかと思います。
最後にLambdaのトリガーの設定をします。
■参考
Microsoft Academic Search APIで自分専用の論文検索エンジンを作る
- もっと複雑なクエリでの検索もあり、参考になりましたAWS Lambdaのトリガーの設定
まず、今回は新着通知ツールなので、先ほどのクエリでその日の日付で指定するようにしておきます。
import json import urllib.request import datetime #略# def search_paper(): api_key = "**API KEY**" dt_now = str(datetime.date.today()) query = "And(W='deep',W='learning',D='{}')".format(dt_now) #略#次に、Lambdaの[Designer]から[トリガーを追加]を選びます。
[トリガーの設定]で[CloudWatch Events]を選択し、[新規ルールの作成]をします。
[スケジュール式]の部分で、作成した関数を実行したいタイミングを指定します。
スケジュール式の書き方はこちらにあります。
以下は、毎日11時15分に実行する例です。
トリガーを作成したら、[追加]すれば設定完了です。
以上で、毎日Microsoft Academicで論文を検索し、Slackに通知するフェッチツールが作成できました。
(おまけ)AWS SQSを利用
以上で新着論文通知ツールはできましたが、いくつか不便な点があります。
- 条件に当てはまる論文が一度にたくさん追加されると、大量に通知が来る
- かといって
&countで検索件数を減らすと、条件に当てはまるのにフェッチしない論文が出てきてしまう- 個人的にはいっぺんに大量来るよりは、毎日1,2本ずつ通知してくれた方が嬉しい
検索条件を厳しくするという手もありますが、今回はAWS SQSというサーバレスキューイングサービスを利用してこの問題を改善します。
今回は先ほど作ったツールを「毎日検索結果をAWS SQSに全件送り、SQSに結果が残っていれば1件だけSlackに通知する」ツールに拡張してみます。
AWSからSimple Queuing Serviceで、[新しいキューの作成]をします。
今回はFIFOキューを使います。
[キューの設定]から、[コンテンツに基づく重複排除]を有効にしておきます。
これでSQSの設定は完了です。
次に、AWS LambdaがAWS SQSにアクセスできるように権限を変更します。
AWS Lambda上で先ほど設定した関数に戻り、[実行ロール]の項目から[IAMコンソールで~~~~ロールを表示します]でIAMコンソールに移動します。
[ポリシーをアタッチします]からAmazonSQSFullAccessにチェックを入れて[ポリシーのアタッチ]で完了です。
AWS LambdaからSQSにアクセスするには、boto3を用います。Documentationはこちら。
以下が実際に動かしてみたコード例です。
import json import urllib.request import datetime import boto3 def lambda_handler(event, context): # TODO implement # SQSのキューにアクセス name = '**SQSの名前.fifo**' sqs = boto3.resource('sqs') try: queue = sqs.get_queue_by_name(QueueName=name) except: return { 'statusCode': 500, 'body': json.dumps('SQS_No_Exist') } # Microsoft Academicから論文情報をフェッチ response_body = search_paper() # フェッチしたすべての情報をメッセージとして整形してキューにプッシュ for e in response_body['entities']: message = "*Title* : {}\n*Journal* : {}\n*URL* : {}".format(e['Ti'],e['VFN'],e['S'][0]['U']) queue.send_message(MessageBody = message, MessageGroupId = 'group') # キューからメッセージを取り出し、一つでもあれば最初の一つをslackに送信してキューから削除 messages = queue.receive_messages() if len(messages) != 0: message = messages[0] post_slack(message.body) message.delete() return { 'statusCode': 200, 'body': json.dumps('Hello from Lambda!') } # WebHookにmessageを送信してSlackに通知させる def post_slack(message): send_data = { "text" : message, } send_text = "payload=" + json.dumps(send_data) request = urllib.request.Request( "**WebHook URL**", data=send_text.encode('utf-8'), method="POST" ) with urllib.request.urlopen(request) as response: response_body = response.read().decode('utf-8') # Microsoft Academicでクエリに基づいて論文を検索してその結果を返す def search_paper(): api_key = "**API KEY**" dt_now = str(datetime.date.today()) query = "And(W='deep',W='learning',D='{}')".format(dt_now) url = "https://api.labs.cognitive.microsoft.com/academic/v1.0/evaluate?"+"expr="+query+"&attributes=Ti,S,VFN&count=20" request = urllib.request.Request( url, method="GET", headers={"Ocp-Apim-Subscription-Key" : api_key}, ) with urllib.request.urlopen(request) as response: response_body = json.loads(response.read().decode('utf-8')) return response_bodyこれでだいぶフレキシブルな通知ツールになったと思います。
検索クエリや通知の方法などを自由に調整できるので結構便利です。■参考
【 AWS 】S3 → Lambda → SQS にメッセージを投げるまでの構築手順!
Standard Queue から FIFO Queue へ移行した話おわりに
この程度なら無料で動かせるので、サーバーレスアーキテクチャって便利ですね。
今回はAWSでやりましたが、もしAPIの制限以上のことをやる必要がある場合はAzureでやることができるそうです。
ちなみにQiita初投稿でした。参考になればうれしいです。
AWS普段から使っているわけではないので何か間違いがあればご指摘いただけると幸いです。
(ついでにもっと便利な論文通知方法があったら知りたいです)








- 投稿日:2020-02-08T19:38:12+09:00
【AWS】IAM-APIGetway-Lambda-DynamoDB-S3でシンプルなアプリケーション制作
はじめに
サーバーレス勉強する際に、いろいろ試したメモ、
つまずいた点や、解決法など、主に自分用のメモになります。
他の方の参考にもなれば嬉しいです。やること
- DynamoDBでテーブル作成
- IAMでDynamoDB用のロール作成
- Lambda上でDynamoDBに値を挿入
- Lambda上でDynamoDBから値を取得
- API Gatewayの設定
- S3にウェブアプリケーションをアップし、公開する
- 公開されたアプリケーションでDynamoDBを操作する
DynamoDBでテーブル作成
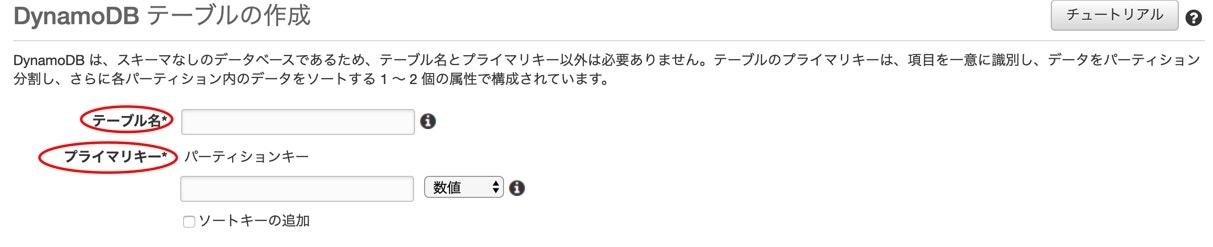
テーブルの作成をクリックしてください。
テーブル名とプライマリキーを入力します、プライマリキーのタイプは数値を選んでください。
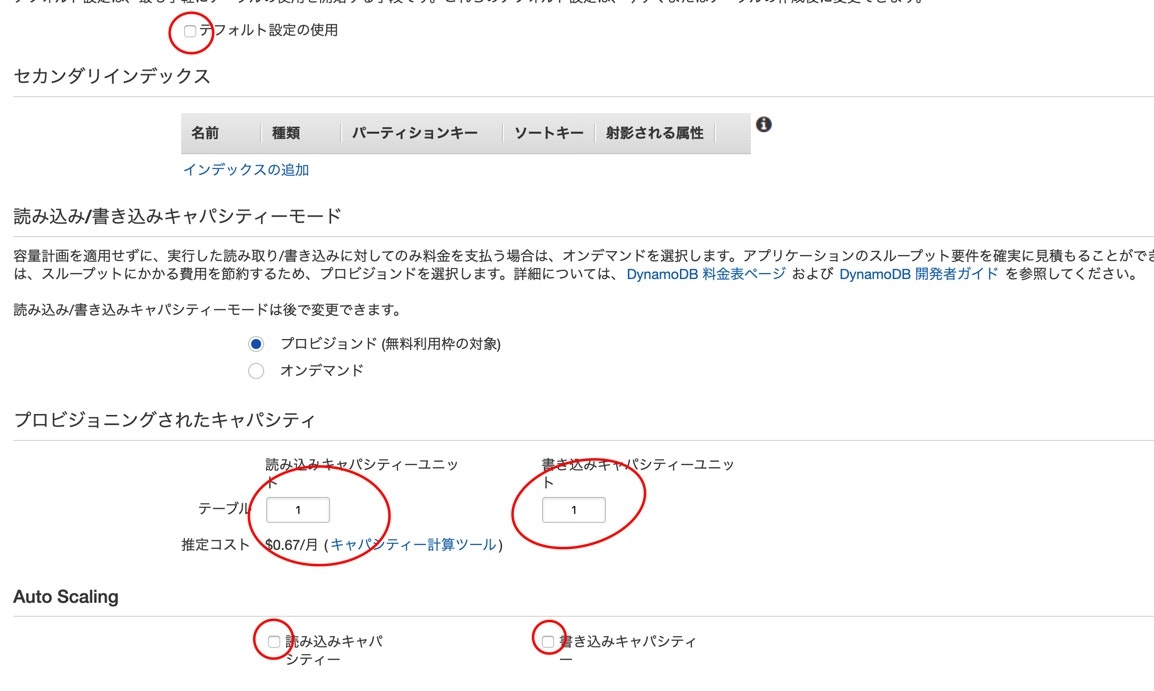
デフォルト設定の使用のチェックを外します、今回はテストのため、性能は最低限のもので良いです。
設定が終わったら
作成をクリックします、しばらくしたらテーブルが作成されるはずです。
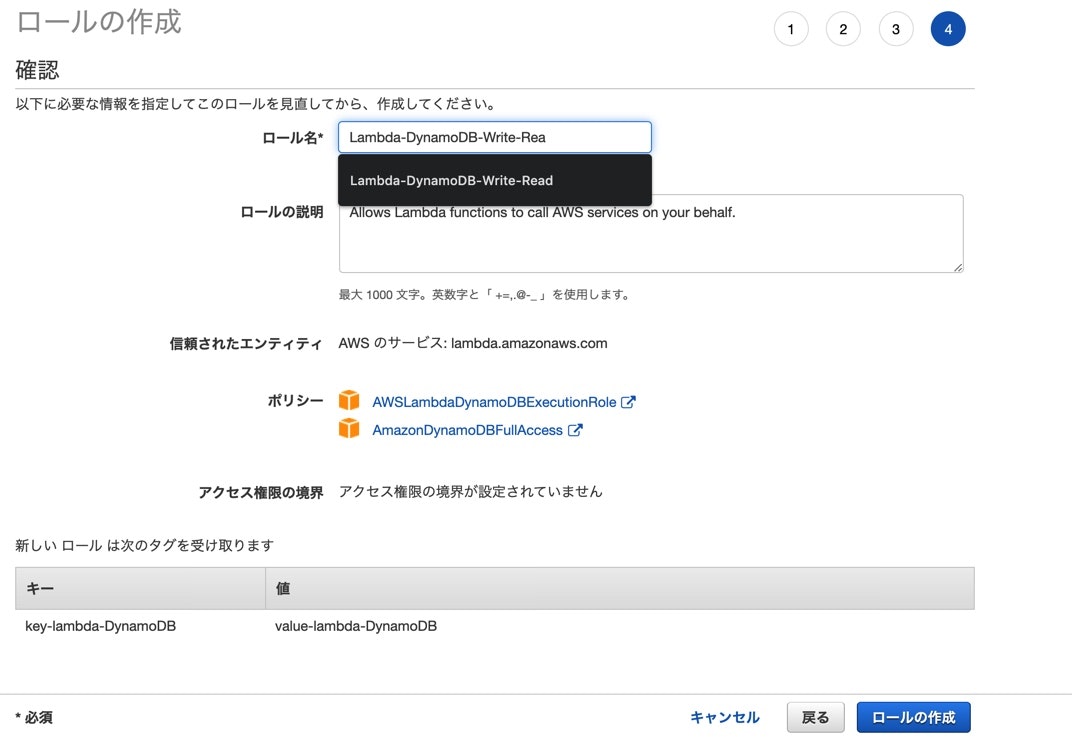
IAMでDynamoDB用のロール作成
権限なしではLambdaがDynamoDB操作できません、Lambda作成する前にまずロールを作ります。
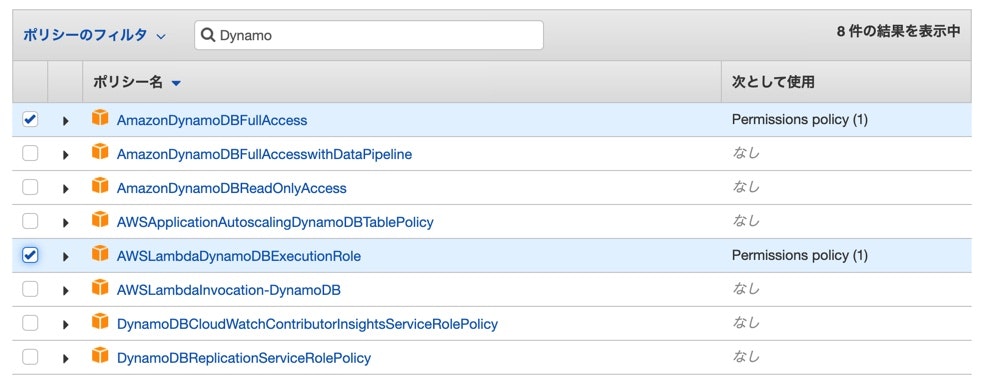
AWSサービスのLambdaを選び、次のステップを押してください。
Dynamoを検索して、AmazonDynamoDBFullAccessとAWSLambdaDynamoDBExecutionRoleにチェック入れてください。
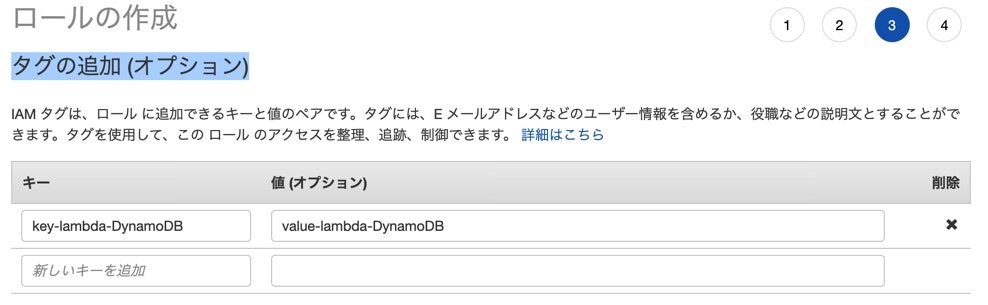
タグの追加に関しては、わかりやすいkeyとvalueでいいと思います。
ロール名も用途が分かりやすいもので良いです、作成完了したら、Lambdaの方に入ります。
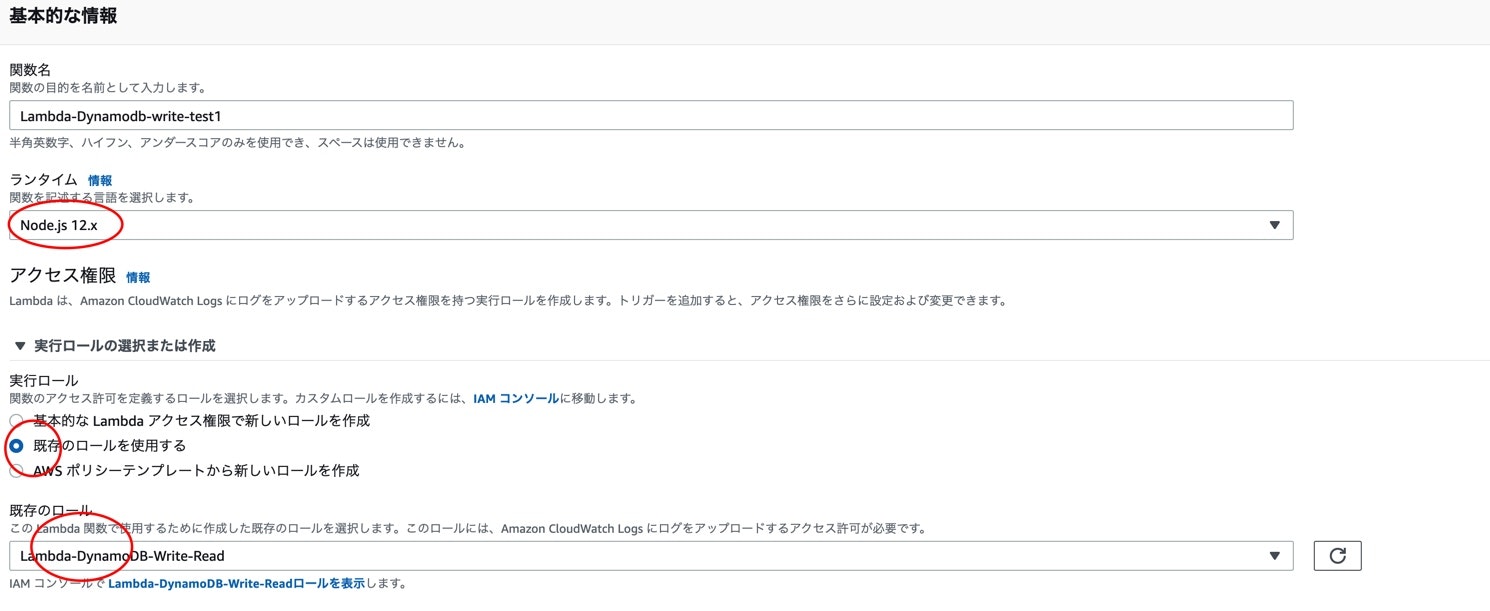
Lambda上でDynamoDBに値を挿入
関数を作ります。
関数の作成をクリック。
一から作成を選択、関数名は用途が分かりやすいものにします。
言語は今回Node.jsにします。
アクセス権限は先ほど作って置いたロールを使用します。
設定が終わったら、関数を作成します。
関数の内容はリクエストから
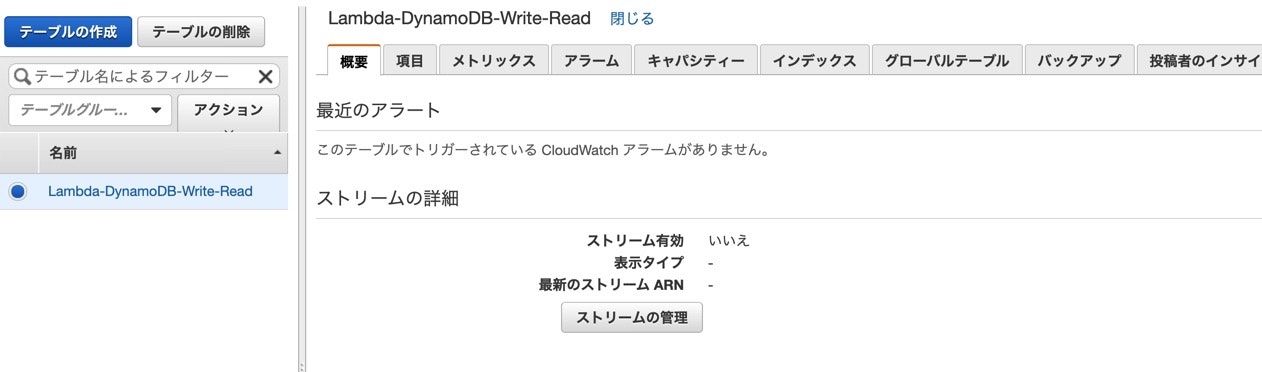
messageを受け取って、DynamonDBに保存するというシンプルな内容でした。index.js"use strict" console.log("loading function"); var AWS = require("aws-sdk"); AWS.config.region = "ap-northeast-1"; var docClient = new AWS.DynamoDB.DocumentClient(); exports.handler = function(event, context, callback) { var params = { Item:{ data: Date.now(), message: event.message }, TableName: "Lambda-DynamoDB-Write-Read", }; docClient.scan(params, function(err, data){ if(err){ console.log("Fail to write into DynamoDB"); callback(err, null); }else{ console.log("Successfully write into AWS DynamoDB"); callback(null, data); } }); };Lambda上でDynamoDBから値を取得
設定は値挿入時と同じです。
今回はデータの読み取りなので、関数名はLambda-DynamoDB-read-testにします。index.js"use strict" console.log("loading function"); const AWS = require("aws-sdk"); AWS.config.region = "ap-northeast-1" var docClient = new AWS.DynamoDB.DocumentClient(); exports.handler = function(event, context, callback){ var params = { TableName: "Lambda-DynamoDB-Write-Read", Limit: 100 }; docClient.scan(params, function(err, data){ if(err){ console.log("Fail to read from AWS DynamoDB"); callback(err, null); }else{ console.log("Successfully Read from AWS DynamoDB table"); Reflect.set(data, "headers", { "Access-Control-Allow-Origin" : "*", "Access-Control-Allow-Credentials": "true"} ); Reflect.set(data, "responseCode", 200); context.succeed(data); } }); }API Gatewayの設定
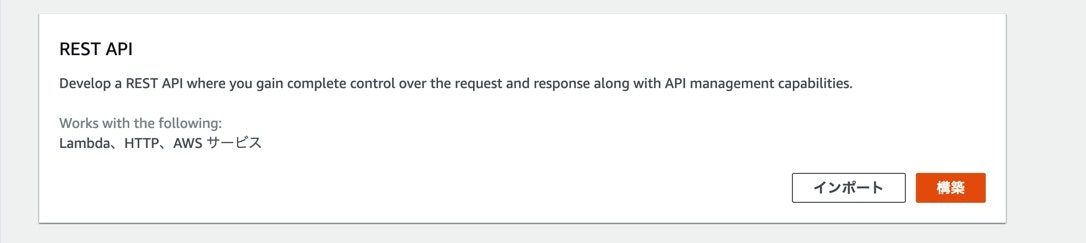
APIを作成します。
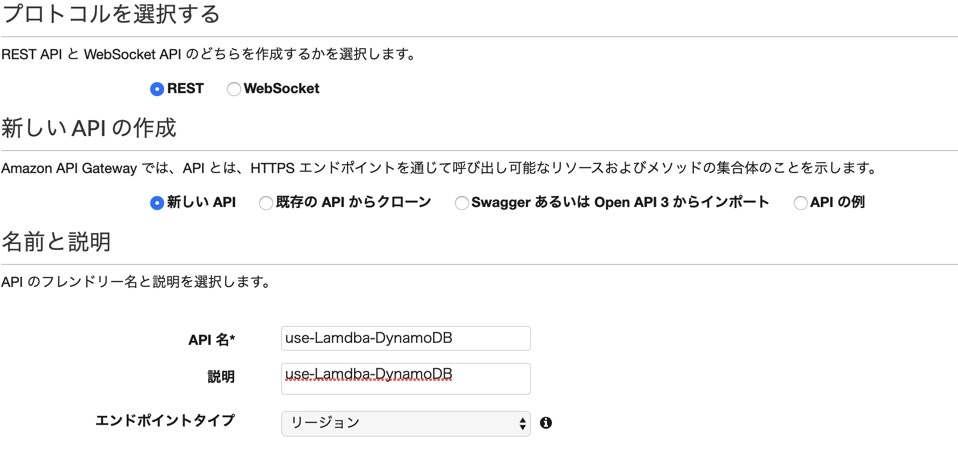
REST APIを選択します。
API名と説明を入力して、作成します。
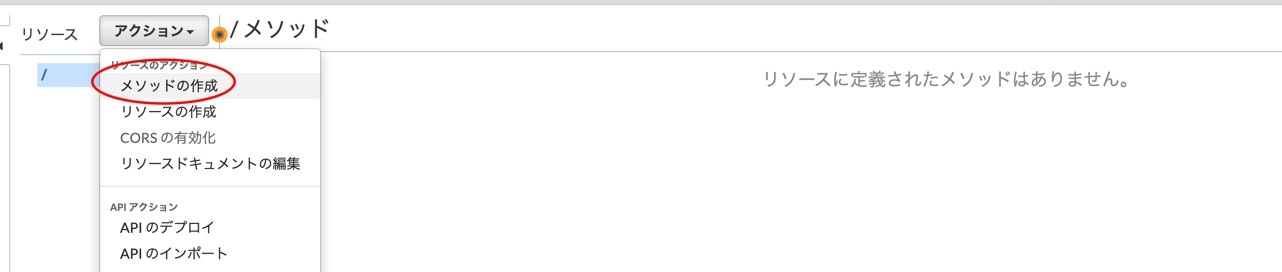
作成完了後、メニューのアクションから、メソッドの作成を選択して、GETとPOSTを作ります。
GET
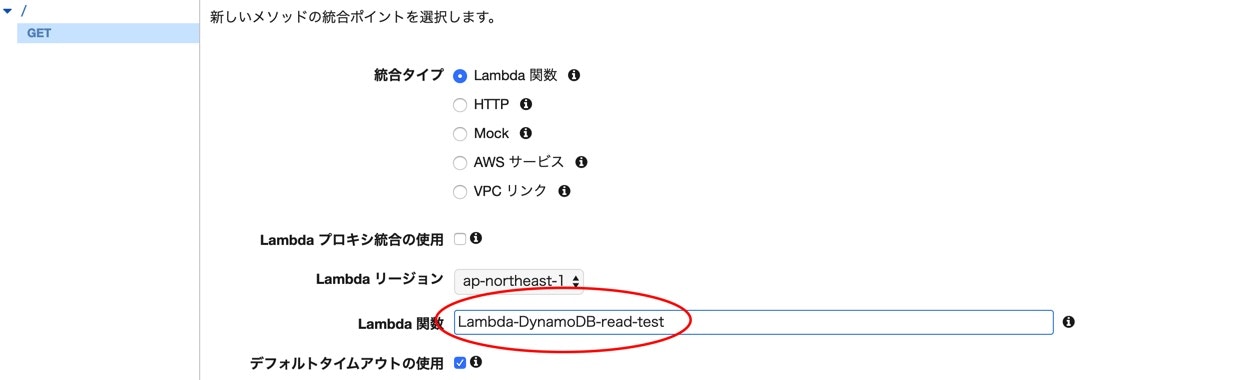
Lambda関数にチェックを入れて、
Lambda関数の所に先程作った、DynamoDBから値を取得用のLambda関数名を入れます。
Lambda 関数に権限を追加するのダイアログが出てきますが、okを選択します。
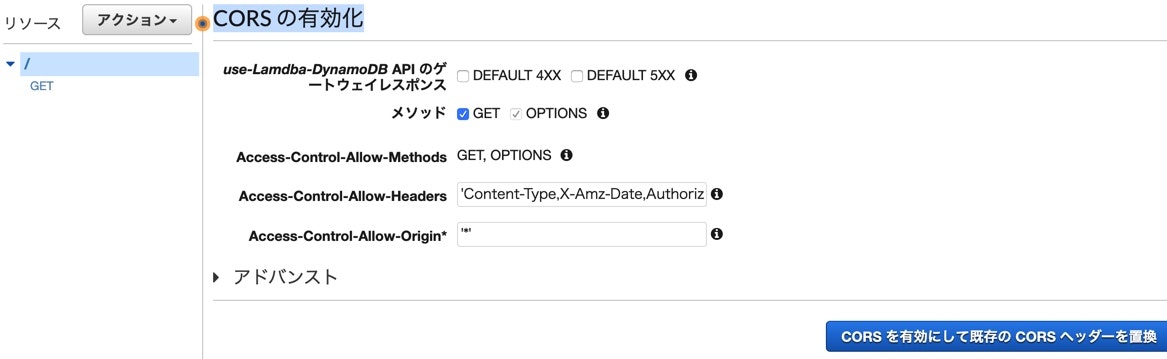
CORSを有効化します、アクションからCORS の有効化にしてください。
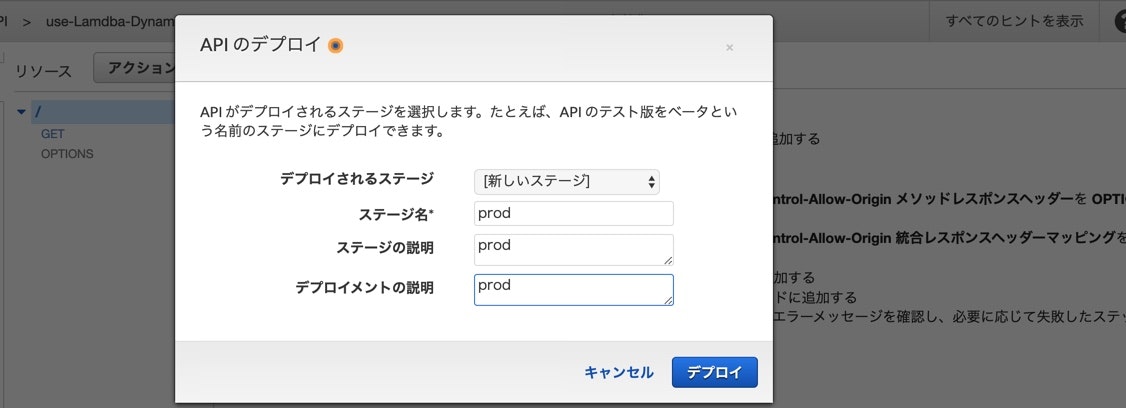
アクションから、APIのデプロイを行ないます。
新しいステージを選択して、
ステージ名*、ステージの説明、デプロイメントの説明を入力します。
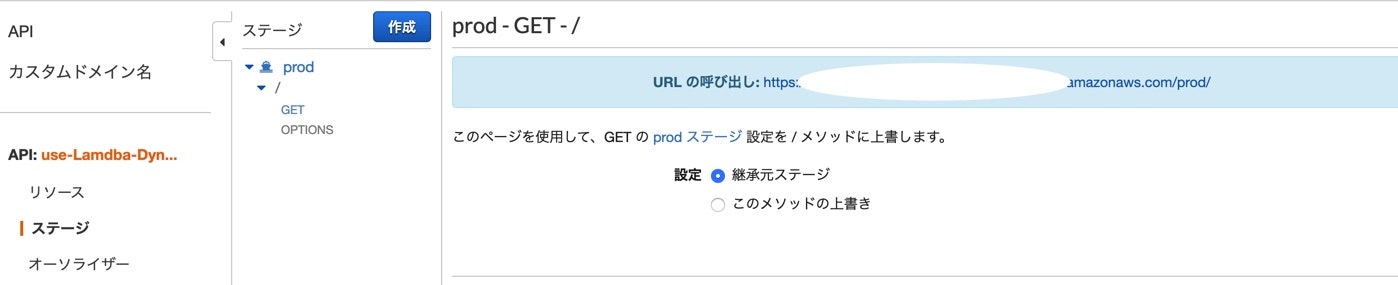
デプロイ完成したら、スタージでメソッド確認できます。
POST
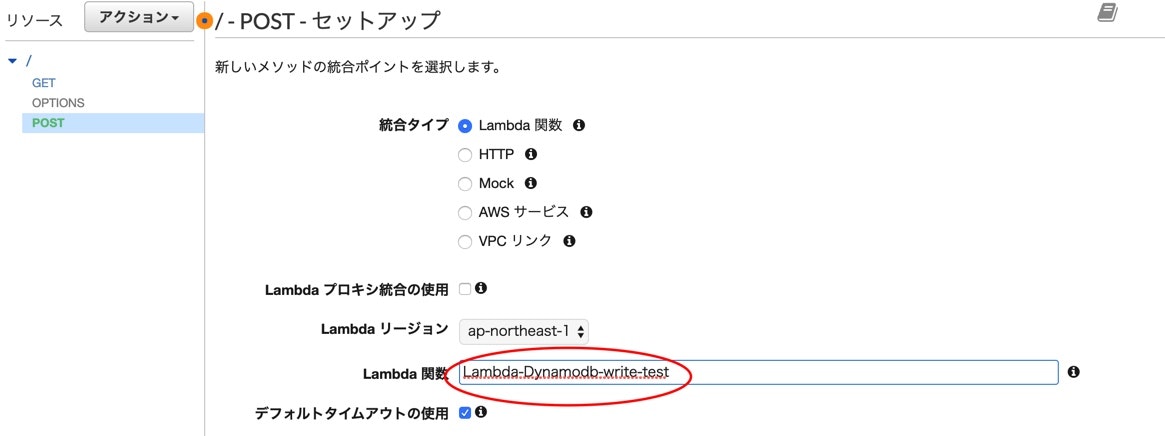
手順はGET時と基本同じです。
先程作った値を挿入用のLambda関数を使用します。
作った後、統合リクエストを選択します。
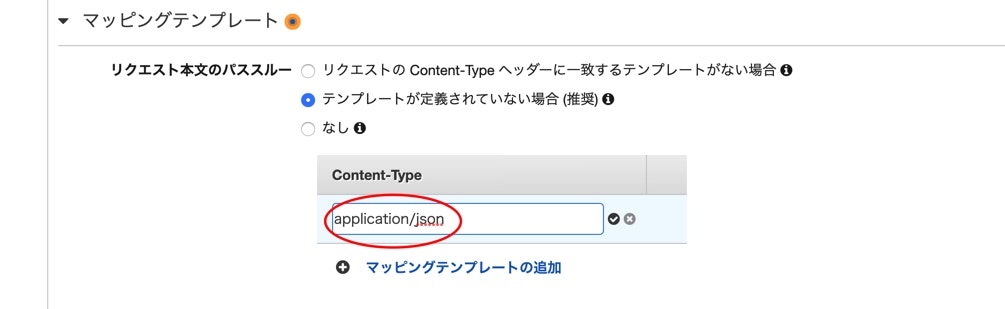
マッピングテンプレートにapplication/jsonをContent-Typeに追加します。
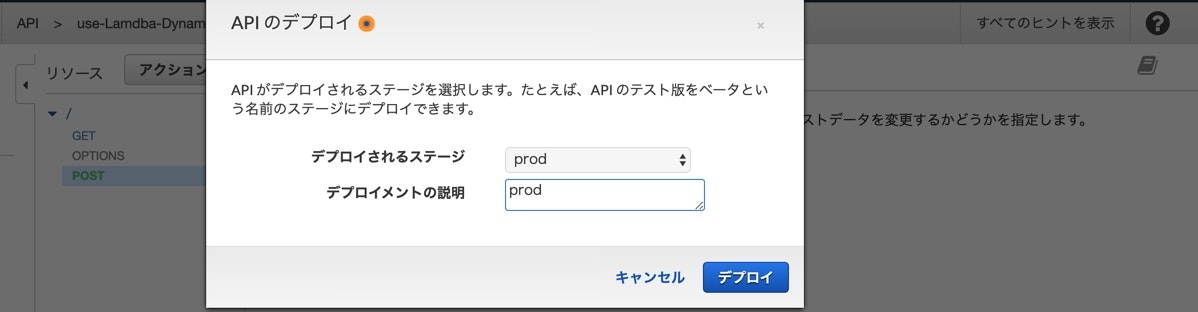
デプロイする際に、先程作ったステージを選択します。
完了後のステージはこんな感じになります。
S3にウェブアプリケーションをアップし、公開する
使用するウェブアプリのソースは以下になります。
Jqueryのmin.jsを同じディレクトリに置いてあります。
機能はajax使用して、ApiGatewayにGETとPOSTのリクエストを送り、
DynamoDBにデータ挿入、また取得します。LamdbaAPIGetwanyDynamoDB.html<html lang="en"> <head> <meta charset="UTF-8"> <title>Title1</title> <script type="text/javascript" src="./jquery-2.1.4.min.js"></script> </head> <body> <div id="entries"> </div> <h1>Write new comment</h1> <form> <label for="message">Message</label> <textarea id="message"></textarea> <button id="submitbutton">submit</button> </form> <script type="text/javascript"> var API_Gateway_URL = "APIのURL"; $(document).ready(()=>{ $.ajax({ type: "GET", url: API_Gateway_URL, success: (data)=>{ $("#entries").html(""); data.Items.forEach((getcomments)=>{ $("#entries").append("<p>" + getcomments.message+ "</p>"); }) } }); }); $(function () { $("#submitbutton").click(() => { console.log($("#message").val()); $.ajax({ url: API_Gateway_URL, type: "POST", data: JSON.stringify({"message": $("#message").val()}), contentType:'application/json', success: function (data) { location.reload(); } }); return false; }) }) </script> </body> </html>S3のパケット作ります
パケット名を入力し、リージョンは東京を使用します。
作成でパケットを作ります。
フォルダを作ります。
ウェブアプリのファイルとjqueryのmin.jsを同じフォルダーにアップロードします。
アップロードされたファイル(HtmlをJqueryのmin.js)にチェック入れて、
アクションから公開します。
公開されたアプリケーションでDynamoDBを操作する
公開されたHtmlファイルのurlを開いて、実際操作します。
以上で終わりです。









- 投稿日:2020-02-08T19:27:23+09:00
Vue.js + amplifyでプロジェクト管理サービスを作った話
プロジェクトが炎上するのには
対応が後手に回るケースもあるのでは?プロジェクトを俯瞰できたらいいんじゃないか?
プロジェクト譜という手法があります。プロジェクト譜のサービスはまだない
自分で作るろう
Webで作れば共有もしやすい開発環境は
cloud9構成
vue2
bootstrap vue UIフレームワーク
amplify
appsync データ管理
cognito ユーザー管理
全体構成ホスティングサービスもamplifyを利用
awsのcodecommitにプッシュするとビルドとデプロイが走る
デプロイフローデータアクセス
appsyncのgraphqlを利用
データストアはdynamoDBです。
スキーマを定義するとクエリの定義が作られる
amplify push api@authや@keyなどのディレクティブで認証や検索時のindexを制御できます。
ドキュメントが一番参考になる。
サンプルユーザー管理
ログイン、サインアップはamplifyvueのコンポーネントを利用
画面のカスタマイズができず、amplify authのイベントをキャッチしてダイアログを表示
サンプルプロジェクト譜エディタ
svgで実装
各要素をコンポーネントで実装
コンポーネント管理できるvuejsのメリットを活かせます。svgのイベントの管理
要素の移動
親でイベントをキャッチ
親コンポーネントが複雑化するので
処理を要素に移譲テスト環境
ユニット jest
e2eテスト jest + pupetterユニットテスト
jest
amplifyやstoreの挙動のモックを作成
テストのしやすい実装が重要e2e
jest+pupetter
nightwatchやcypressを試したが
cloud9上でインストールしたchrome driver動かさず、最終的にchrome driverを別途インストールし、pupetterで構築しました。pupetterで画面キャプチャを取れるので、cloud9上でもテスト時の画面結果を確認できます。
- 投稿日:2020-02-08T17:13:13+09:00
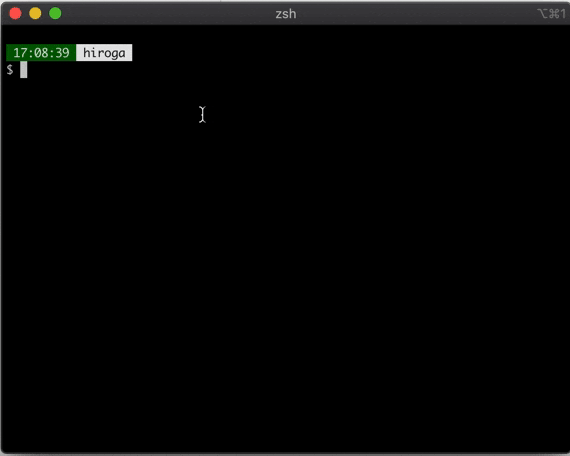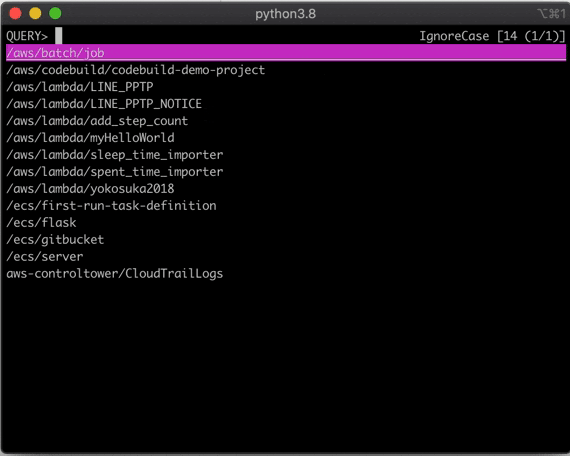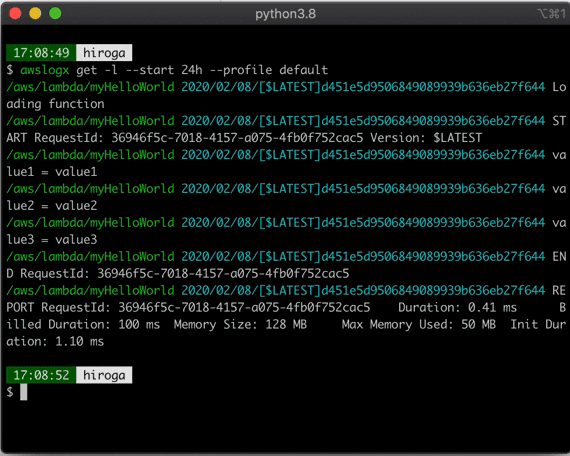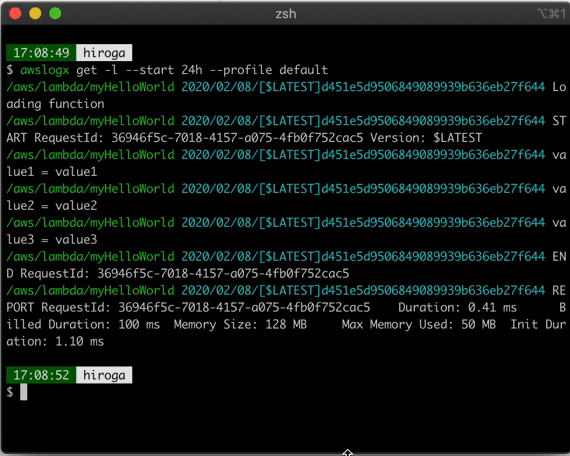
CloudWatchのLogGroupをpecoで選択してcliで見る、awslogsの拡張シェル書いた
TL;DR
AWSのCloudWatchのログをPECOで絞り込んで参照できます。
どうなっているか?
awslogsのラッパーになっています。
# 抜粋 awslogs get $(awslogs groups $AWS_PROFILE_OPTION | peco) $AWSLOGS_PURE_OPTIONS業務で使うことを想定しているので、
--profileオプションにも対応しています。
(もともとawslogsが対応している、というだけの話ですが)ソースはこちら。スターください!
https://github.com/hiroga-cc/cli/blob/master/awslogx/awslogx
- 投稿日:2020-02-08T17:09:17+09:00
An Introduction of a Microservices with ASP.net core 3x(Part-1)
This is an introduction about the Microservices architecture and we will discuss monolithic application/architecture and problems.
The goal is very clear & simple, to understand the Microservices Architecture and how to use it with the AWS component.
This is very important to understand that when it is good to use the microservices architecture or when it is not. Sometime it may be a backfire when it placed the wrong place. Microservices is not always a solution. So you have to think & identify, which architecture best fits your solution/application.
I am covering the below points in this article. I hope it will be helpful to you while developing a microservices application.
1・What is Monolithic applications?
2・Problems of Monolithic applications?
3・What is Microservices?
4・Benefits of Microservices over the Monolithic applications?
5・Architecture of Microservices with AWS(based on an application).
6・Team structure to develop the Microservices?
7・Evolution of a asp.net?
8・How you can implement it with asp.net core3x?Let's start.
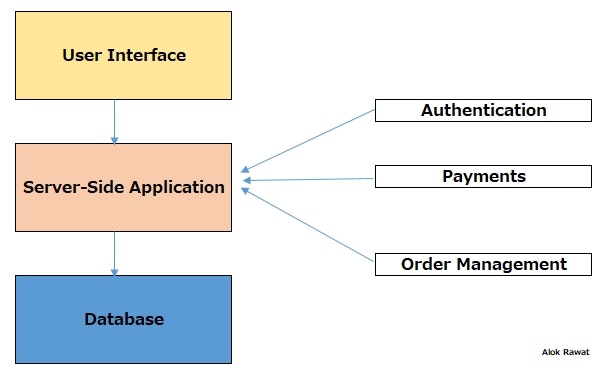
1・What is Monolithic applications?
In software engineering, a monolithic application is designed without modularity.
Without modularity means, software/application is made of component or module that they can be easily replaced or that can be reused, but in a monolithic application, there is no modularity.
One application performs many tasks and includes multiple services.
A console application is a perfect example. All the logic/database and user interface within an application.
2・Problems of Monolithic applications?
1. Can turn to a big ball of mud quickly. No single developer knows the entire code.
2. Limited reuse.
3. Scaling can be a challenge and /or costly.
4. Continuous integration and development can become complex and time-consuming.
5. They are built with one framework or programming language.
6. It's hard for multiple teams to work on one code base(e.g. code conflicts).
7. Change in one part of the application requires full build, deployment, and test.3・What is Microservices?
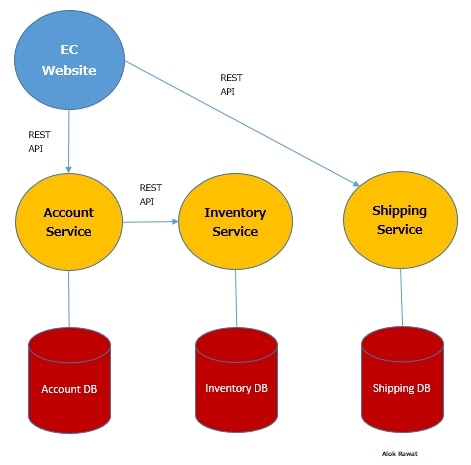
Microservices are an architectural style that develops a single application as a set of small services. Each service runs in its own process. The services communicate with clients, and often each other, using lightweight protocols, often over messaging or HTTP.Let's take an example of an e-shop.
4・Benefits of Microservices over the Monolithic applications?
There are many benefits to using microservices. Some of them are related to how they allow developers to write code.・Microservices are small applications that the development teams create independently. Since they communicate via messaging if at all, they’re not dependent on the same coding language. Developers can use the programming language that they’re most familiar with. This helps them come to work faster, with lower costs and fewer bugs.
・Since the teams are working on smaller applications and more focused problem domains, their projects tend to be more agile, too. They can iterate faster, address new features on a shorter schedule, and turn around bug fixes almost immediately. They often find more opportunities to reuse code, also.
・Microservices improve your architecture’s scalability, too.
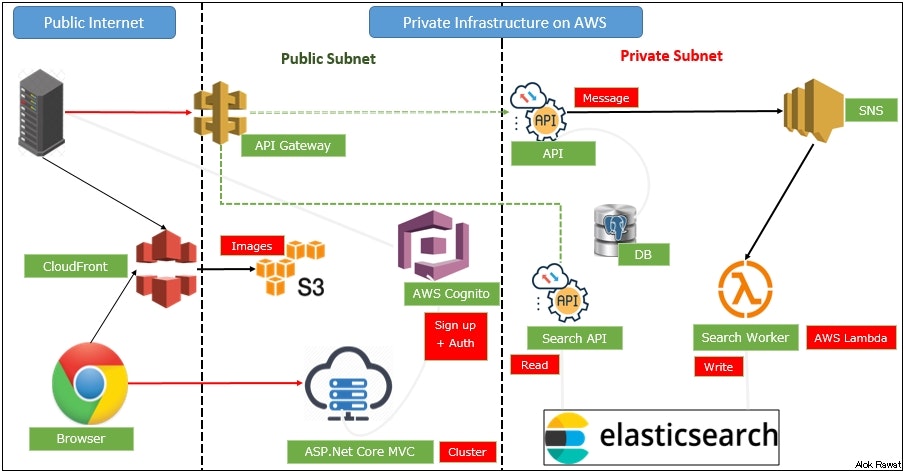
With monolithic systems, you usually end up “throwing more hardware” at the problem or purchasing expense and difficult-to-maintain enterprise software. With microservices, you can scale horizontally with standard solutions like load balancers and messaging.5・Architecture of Microservices with AWS.
Based on the attached architecture, we will develop an application in the next part.
The architecture divided into two parts.
1. Public Internet
2. Private Infrastructure on AWS(VPC)
this part also divided into two parts.
1. public subnet
2. private subnet
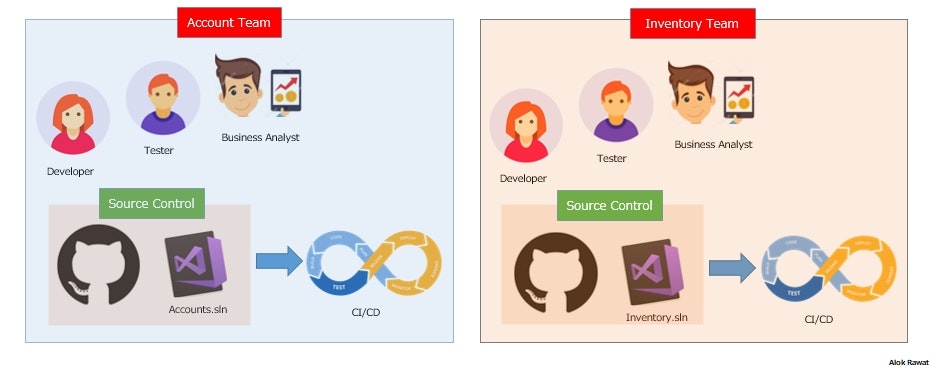
6・Team structure to develop the Microservices?
For Microservices development, it is better to create a vertical team.
Let say, Accounts Team developer completed his task then Inventory Team can assign some task to accounts team developer too. We can share the resources between the teams.And for the source control system,
should have own repo for a particular service. Do not add all services into one repo.
If the account team developer wants to help the inventory team, then he needs to take an own fork(a copy of the source code) from the git and need to submit the request to the inventory team and then someone from the inventory team will manage the request.
So that's how someone from the other team may help someone inside the other team and vice versa.
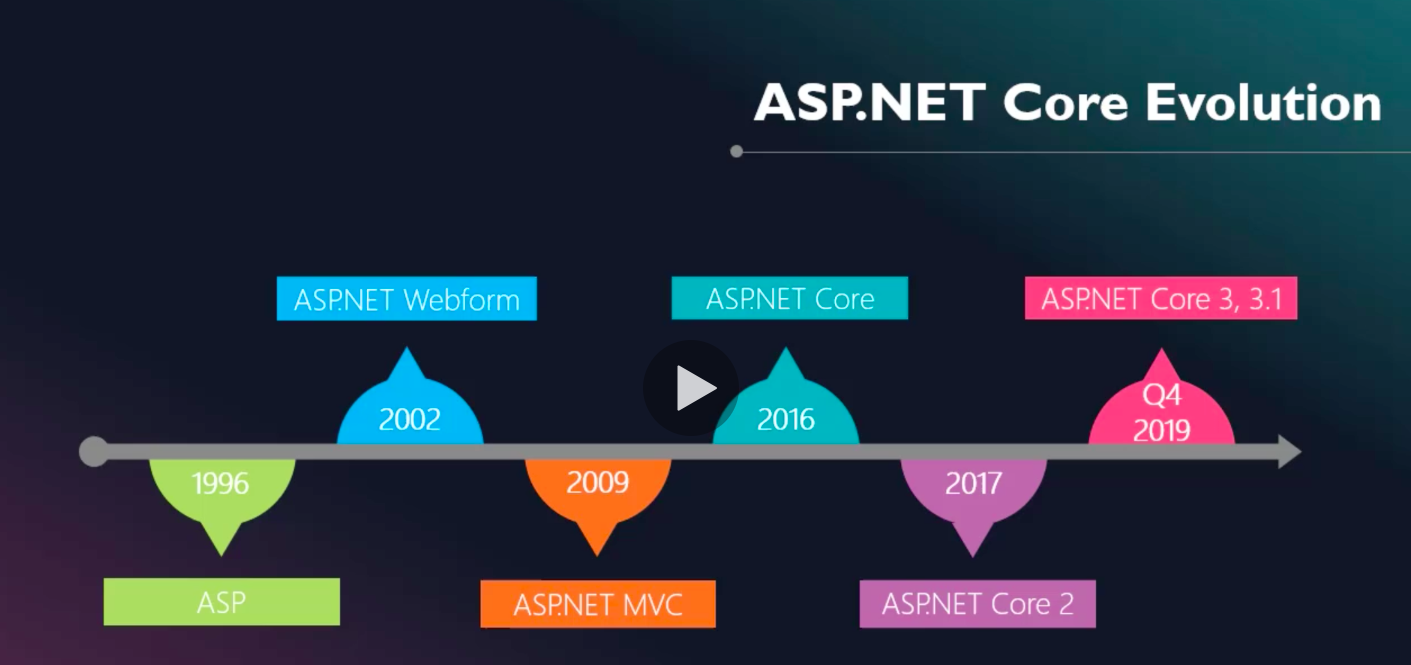
7・Evolution of a asp.net to asp.net core?
8・How you can implement it with asp.net core3x?
In the next part, we will go into the deep-diving(coding part).
till then stay tuned.If you find anything wrong then please let me correct.
Enjoy coding...
ref: https://stackify.com/what-are-microservices/
Thanks,
Alok Rawat
- 投稿日:2020-02-08T16:00:33+09:00
AWS APIGatewayに、保有しているドメインを割り当てる方法
APIGatewayをデプロイしただけだと、めっちゃ長い文字の羅列になっているので、
ドメインを割り当てることにしてみました。手順
①ACM証明書(SSL証明書)の発行リクエスト《Certificate Manager》
▼私の設定メモ
パブリック証明書のリクエスト
ドメイン:XXX
DNS検証 ※メール検証だと有効期限があり更新忘れの可能性あり。②ACM証明書のリクエストの承認(DNS)《Route 53》
DNSレコードを作成し、検証
③APIgatewayカスタムドメインの設定《APIGateway》
▼私の設定メモ
REST
ドメイン:XXX
リージョン
TLS1.0
ベースパスマッピング(API名:ステージ)④DNSレコードに"③"のレコードを追加《Route 53》
参考
https://dev.classmethod.jp/cloud/api-gateway-custom-domain-ssl/
以上です。
- 投稿日:2020-02-08T15:51:38+09:00
CloudFormationでS3バケットを作成しようとしたら「Error Code: 400 Bad Request」となる
事象
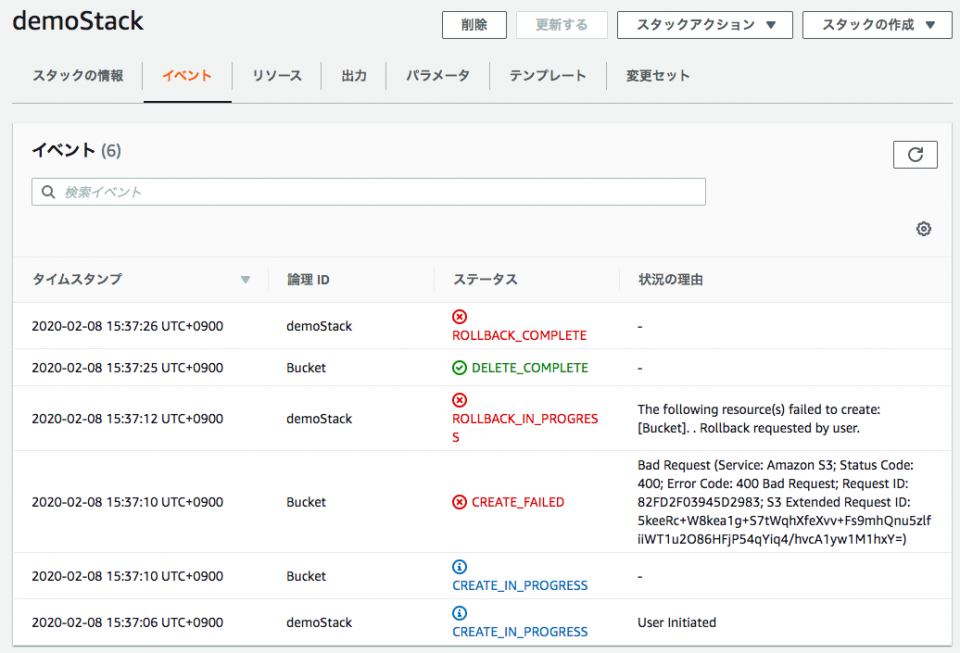
demo.ymlParameters: bucketName: Type: String Resources: Bucket: Type: AWS::S3::Bucket Properties: BucketName: !Sub $bucketNameAWS CLIで
create-stackコマンドにより上記テンプレートdemo.ymlをもとにS3バケットを作成しようとした。$ aws cloudformation create-stack \ --stack-name demoStack \ --template-body file://demo.yml \ --parameters ParameterKey=bucketName,ParameterValue=$bucket_nameしかし下記のように
Error Code: 400 Bad Requestによりバケットの作成でCREATE_FAILEDとなりスタック作成がロールバックしてしまう。
Bad Request (Service: Amazon S3; Status Code: 400; Error Code: 400 Bad Request; Request ID: 82FD2F03945D2983; S3 Extended Request ID: 5keeRc+W8kea1g+S7tWqhXfeXvv+Fs9mhQnu5zlfiiWT1u2O86HFjP54qYiq4/hvcA1yw1M1hxY=)解決
BucketNameでのParametersの指定の仕方が誤っていることが原因だった。
- 誤:
!Sub $bucketName- 正:
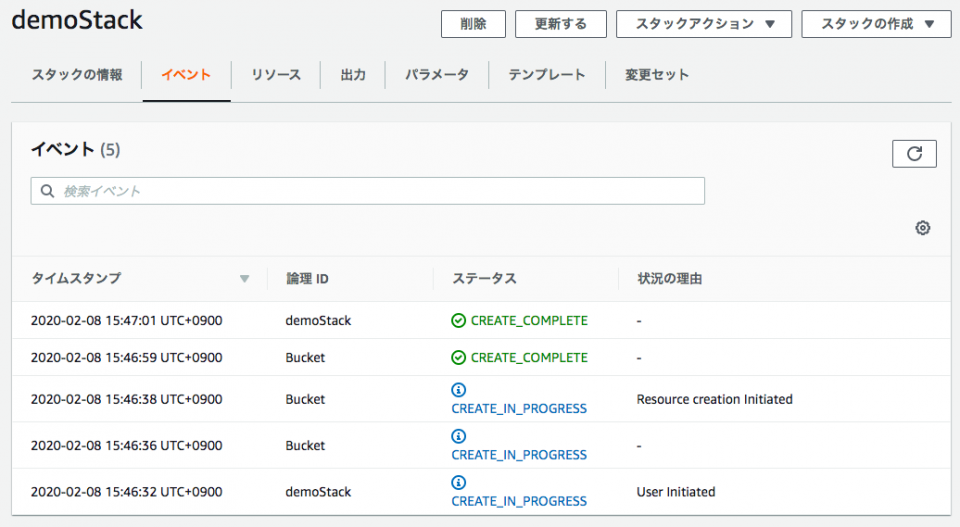
!Sub ${bucketName}または!Ref bucketNamemodified-demo.ymlParameters: bucketName: Type: String Resources: Bucket: Type: AWS::S3::Bucket Properties: BucketName: !Ref bucketName上記の修正後のテンプレート
modified-demo.ymlであればS3バケットを正常に作成することができた。
以上
- 投稿日:2020-02-08T15:08:38+09:00
AWS Lambdaと仲良くなれるかもしれないまとめ
- AWS Lambdaに関してざっとまとめてます
- 具体的な使い方ではなく、サービスの位置付けや概念に関してまとめています
概要
AWS Lambda とはによると
AWS Lambda はサーバーをプロビジョニングしたり管理する必要なくコードを実行できるコンピューティングサービスです。
AWS Lambda は必要時にのみてコードを実行し、1 日あたり数個のリクエストから 1 秒あたり数千のリクエストまで自動的にスケーリングします。使用したコンピューティング時間に対してのみお支払いいただきます- コードが実行中でなければ料金はかかりません。
AWS Lambda では、管理を全く必要とせずに、任意のアプリケーションやバックエンドサービスで仮想的にコードを実行できます。AWS Lambda は、高度な可用性のコンピューティングインフラストラクチャでコードを実行し、サーバーとオペレーティングシステム、システムのメンテナンス、容量のプロビショニングと自動スケーリング、コードのモニタリングやログ記録など、コンピューティングリソースのすべての管理を実行します。必要な操作は、AWS Lambda がサポートするいずれかの言語でコードを指定するだけです。
とのこと。
要は、
- サーバーレスなので、開発者はプログラム(「Lambda関数」と言う)を書くだけで、あとは任意のトリガーに応じて勝手にプログラムを実行してくれる
- スケーリングとか勝手にしてくれる
- EC2みたいなサーバーの管理は一切不要
- ただし、サーバーレスというのは
AWSが実行環境をよしなに提供してくれるので開発者はサーバーの構成とかを気にしなくていいということであり、決してサーバーが存在しないということではない- 実行した時間(ミリ秒単位)とその間に使ったリソースに対して課金される仕組み
- EC2だと起動している間はインスタンスに対してアクセスが発生しなくてもお金がかかるが、Lambdaは使った分だけ支払えばおK
ということ。
スゲー便利。対応言語
AWS Lambda よくある質問によると、
Q: AWS Lambda がサポートする言語は何ですか?
AWS Lambda は、ネイティブでは、Java、Go、PowerShell、Node.js、C#、Python、Ruby のコードをサポートしています。また、関数の作成にその他のプログラミング言語を使用できるようにするための Runtime API を提供しています。
とのことで、結構な言語に対応してる。
どの言語を使っても基本的に同じことができるはずだが、落ちてる情報量で言うとNode.jsやPythonが圧倒的に多い気がする。詳しくはAWS Lambda ランタイムに記載がある。
別のAWSサービスとの連携
Lambdaは、別のサービス内でのアクションをトリガーとしてLambdaを起動することができる。
AWS Lambda とはによると、
AWS Lambda を使用して、Amazon S3 バケットまたは Amazon DynamoDB テーブル内のデータの変更などのイベントに応答してコードを実行できます。Amazon API Gateway を使用して HTTP リクエストに応答してコードを実行します。または AWS SDK を使用して作成された API コールを使用してコードを呼び出します。これらの機能により、Lambda を使って Amazon S3 や Amazon DynamoDB などの AWS サービス用のデータ処理トリガーを簡単に構築し、Kinesis に保存されたストリーミングデータを処理し、AWS のスケール、パフォーマンス、およびセキュリティで運用される独自のバックエンドを作成できます。
とまぁ、一般的に開発者が必要そうなケースの大半にはトリガーが使えるようになってる。
別サービスとの連携もすごく簡単で、画像のように
トリガーを追加からAPI GatewayやS3などを選択して作成済みのサービスを選ぶことでトリガーにしたサービスとの連携が取れるようになる
AWS Lambda 実行コンテキスト
AWS Lambda 実行コンテキストによると、
実行コンテキストとは、データベース接続あるいは HTTP エンドポイントなど、Lambda 関数コードのすべての外部依存関係を初期化する一時的なランタイム環境です。
これにより、次に説明するように、「コールドスタート」やこれらの外部依存関係を初期化する必要がなくなるため、後続の呼び出しパフォーマンスが向上します。Lambdaとしても2回目起動する際に高速化したいので、状態を一定期間保存してるんですね。
とのことで、不変の処理はこの実行コンテキストに置いておくと良さそう。
逆に言うと実行の度に毎回計算などしたいものをここに置くとバグの原因になる。
例えば、Lambda実行時のUTC時間を毎回生成したい場合で実行コンテキストにその処理を書いてしまうと、2回目呼ばれた際にも1回目で計算された値が使われる。実行コンテキストの設定には時間がかかります。また、「ブートストラップ」が必要なため、Lambda 関数を呼び出すたびに若干のレイテンシーが発生します。通常、この遅延は Lambda 関数を初めて呼び出したとき、または更新されたときに発生します。
Lambda 関数が実行されると、AWS Lambda は別の Lambda 関数呼び出しに備えて、実行コンテキストを一定期間維持します。実際には、サービスは Lambda 関数の完了後実行コンテキストをフリーズさせ、再び Lambda 関数が呼び出された際に AWS Lambda がコンテキストを再利用する場合は、コンテキストを解凍して再利用します。実行コンテキストを再利用するこのアプローチには、次のような影響があります。
・ 関数のハンドラーメソッドの外部で宣言されたオブジェクトは、初期化されたままとなり、関数が再度呼び出されると追加の最適化を提供します。たとえば、Lambda 関数がデータベース接続を確立する場合、連続した呼び出しでは接続を再確立する代わりに元の接続が使用されます。接続を作成する前に接続が存在するかどうかを確認するロジックをコードに追加することをお勧めします。
・各実行コンテキストには、/tmp ディレクトリに 512 MB の追加ディスク領域があります。ディレクトリのコンテンツは、実行コンテキストが停止された際に維持され、複数の呼び出しに使用できる一時的なキャッシュを提供します。キャッシュに保存したデータが存在するかどうかを確認するための追加コードを追加できます。デプロイ制限の詳細については、「AWS Lambda の制限」を参照してください。
・Lambda 関数で開始され、関数の終了時に完了しなかったバックグラウンド処理やコールバックは、AWS Lambda が実行コンテキストを再利用する場合に再開されます。コードのバックグラウンド処理またはコールバックは、コード終了までに完了させてください。
ベストプラクティス
AWS Lambda 関数を使用する際のベストプラクティスから拝借
Lambda ハンドラーをコアロジックから分離する
- デバッグしやすくなる
実行コンテキストを活用する
- 変化しない値や処理は関数ハンドラー外で定義することで、キャッシュすることができる
- このキャッシュは同じインスタンスで処理された後続の呼び出しに対して再利用されるので、実行時間とコストが節約できる
環境変数を使用する
- Lambdaが環境変数を提供しているので、固定値はそれを用いるのが良さげ
CloudWatch Logsを活用
- Lambda関数の実行結果は自動でCloudWatch Logsに記録されるので、使用されたメモリなどを調べることでパフォーマンス改善につなげられる
Max Memory Usedというログが出るKinesisと連携する場合にはシャードを追加してスループットを向上できる場合がある
Kinesis ストリームは 1 つ以上のシャードで構成されます。 Lambda は、最大で 1 つの同時呼び出しを使用して各シャードをポーリングします。たとえば、ストリームに 100 個のアクティブなシャードがある場合は、最大で 100 個の Lambda 関数呼び出しが同時に実行されます。シャードの数を増やすと、直接的な結果として、Lambda 関数の同時呼び出しの最大数が増えます。また、Kinesis ストリーム処理のスループットが増える場合があります。Kinesis ストリームのシャード数を増やす場合は、データの適切なパーティションキー (パーティションキーを参照) を選択していることを確認し、関連レコードが同じシャードに割り当てられ、データが適切に配分されるようにします。
個人的に大事だと思うこと
Lambdaはデータに対するパイプライン処理として使う
- 既述の通りスゲー便利なんだけど、あくまでもシンプルな
関数を実行するためのサービスである(webフレームワークを提供しているわけではない)ので、個々のLambda関数は小さく保つのが良さげ
- unixの哲学で出てくる
各プログラムが一つのことをうまくやるようにせよのように、あるデータに対するパイプライン処理として使うくらいの規模に止めるのが良さげ- 参考:UNIX哲学 wikipedia
Lambdaをコードで管理する
- Lambdaは基本的にAWSマネージメントコンソール上で直接コードを書くので、バージョン管理ができない
- ちょっとデバッグしたりするためにコードを変えているうちに、元の動くコードの状態がわからなくなったりすることが割とある...
- その問題に対して、serverless frameworkというのが便利そう
- Lambda(それ以外のサービスにも対応してるっぽい)のコードをコードとして管理 & AWSへデプロイできるので、バージョン管理などの辛さから解放される
- ハンズオンはこちらを見るとわかりやすいと思います

- 投稿日:2020-02-08T14:46:25+09:00
[AWS]画像の配信方法
2020年2月8日現在の内容です。
構成イメージ
画像の保存場所をWebサーバーではなくS3にする理由
- Webサーバーのストレージが画像で一杯になることを防ぐ
- HTMLへのアクセスと画像へのアクセスを分けることで負荷分散する
- サーバーの台数を拡張しやすい
- Webサーバー上に画像が保存されていると、Webサーバーの台数を増やした際に、画像を同期する必要があり、スケールアウトが難しい
- 画像の保存場所は分離されていたほうがWebサーバーの台数を簡単に増やすことができる
- コンテンツ配信サービスから配信することで、画像配信を高速化できる
用語説明
S3(Simple Storage Service)
安価で耐久性の高いAWSのクラウドストレージサービス
特徴
- 0.023USD/GB・月と安価(1GB約3円/月)
- 99.999999999%の高い耐久性
- 容量無制限(1ファイル最大5TBまで)
- バケットやオブジェクトに対してアクセス制限を設定できる
重要概念
- バケット
- オブジェクトの保存場所(名前はグローバルでユニークな必要がある)
- オブジェクト
- S3に格納されるファイルで、URLが付与される(データ本体)
- バケット内オブジェクト数は無制限
- キー
- オブジェクトの格納URLパス
利用シーン
- 静的コンテンツの配信
- img画像はS3から配信する
- バッチ連携用のファイル置き場
- S3にファイルを置いて、バッチでそのファイルを参照して処理を行う
- ログなどの出力先
- 定期的にS3にログを送る
- 静的ウェブホスティング
- 静的なWebサイト(ランディングページ等)をS3から公開する
CloudFront
高速にコンテンツを配信するサービス
CDN(Content Delivery Network)のサービスオリジンサーバー(元となる画像を配信するサーバー)上にあるコンテンツを世界中100箇所以上にあるエッジロケーション(データセンター)にコピーし、そこから配信する
特徴
- 高速
- ユーザーから最も近いエッジロケーションから画像を配信する
- 効率的
- エッジサーバーでコンテンツのキャッシングを行うので、オリジンサーバーに負荷をかけずに配信できる
ディストリビューション
CloudFrontの設定(ルール)
SSLサーバー証明書
Webサイトの運営者が存在することを保証し、ブラウザとWebサーバーで暗号化通信を行う際の電子証明書
Certificate Manager
SSLサーバー証明書の管理を行うAWSサービス
CNAME
すでに定義されているドメイン名に対し別名を定義すること
S3のバケット作成
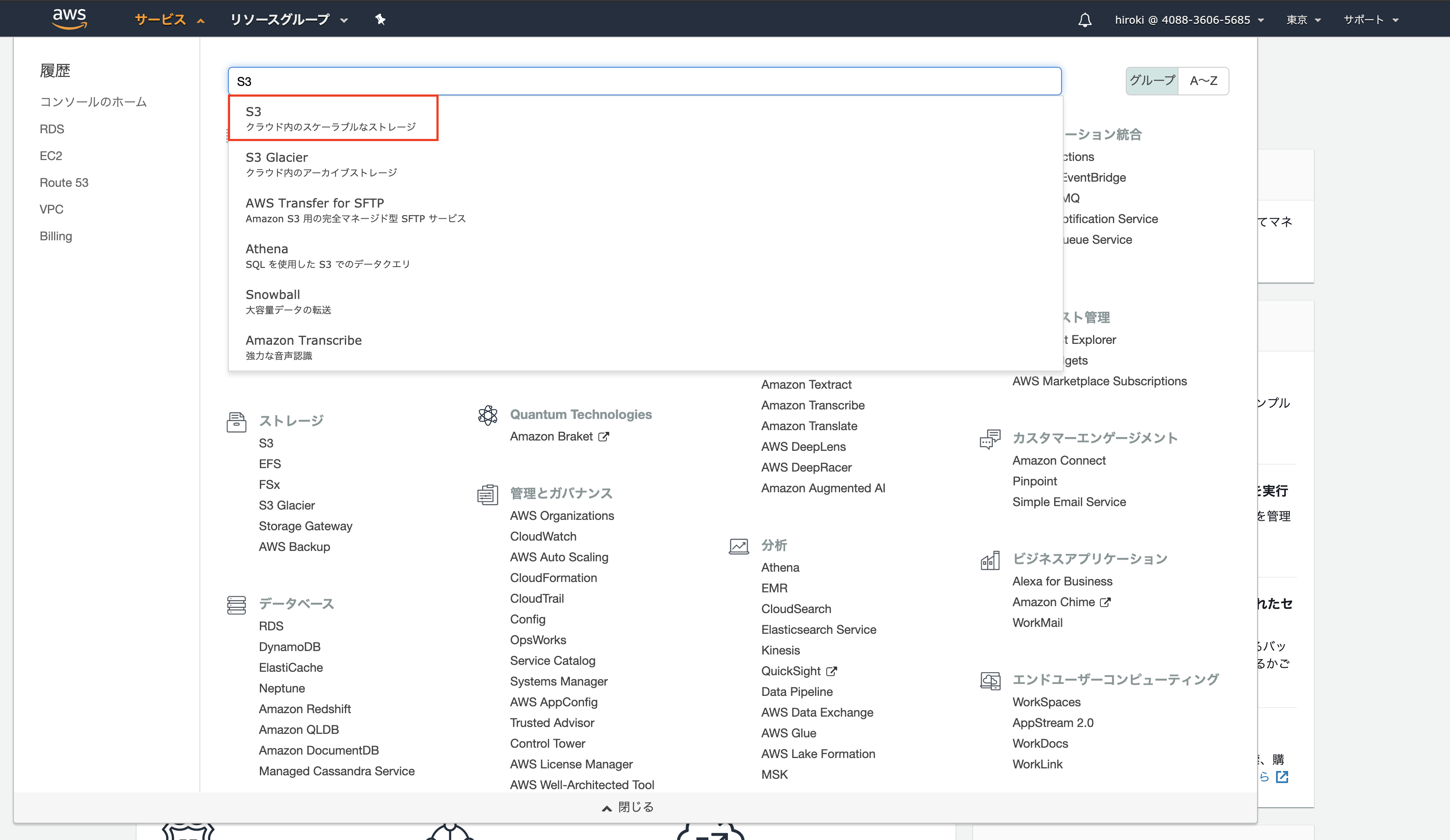
AWSコンソールからS3を検索し、クリック
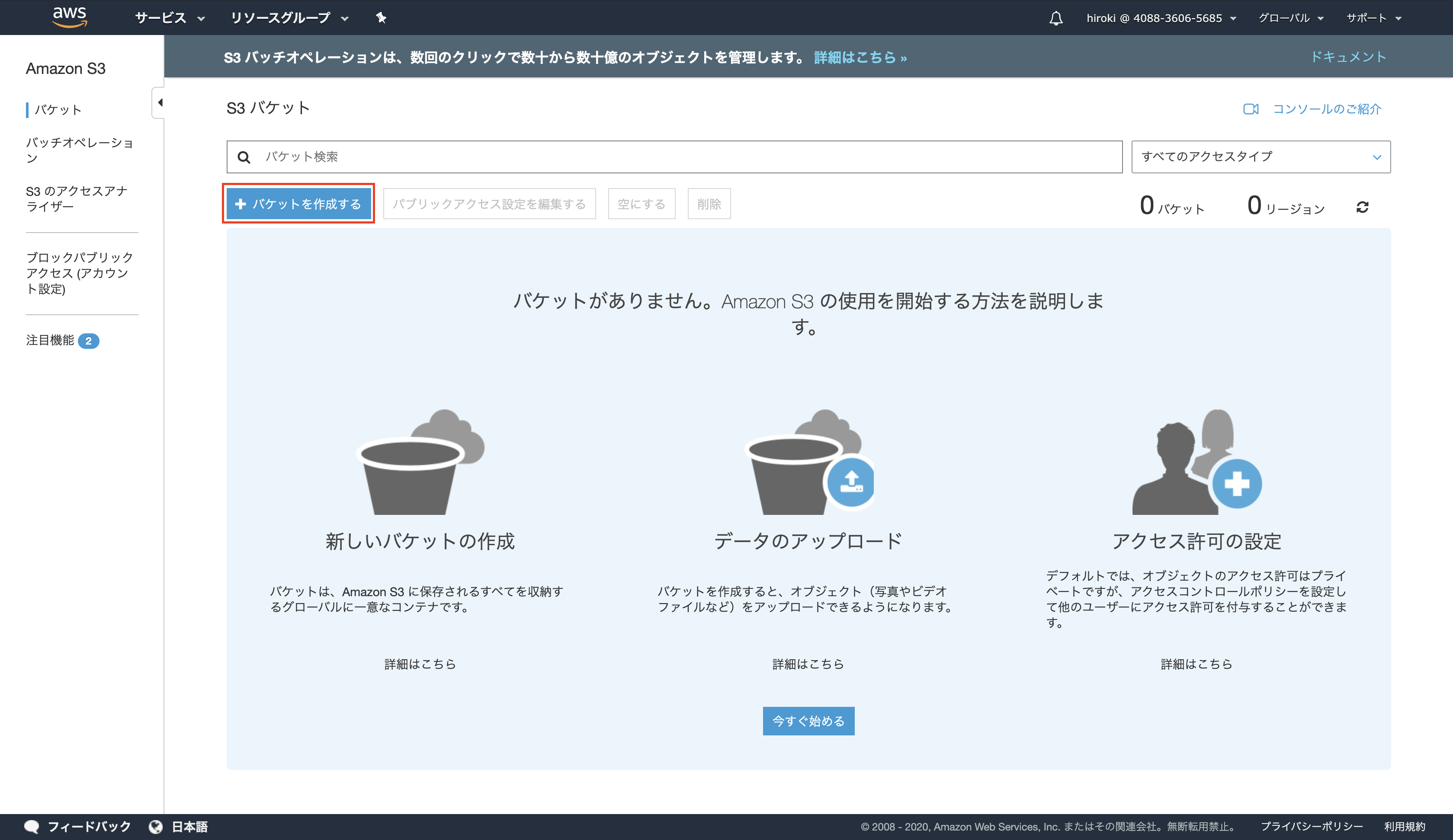
「バケットを作成する」をクリック
以下の通り設定し、「次へ」をクリック
バケット名:一意の名前
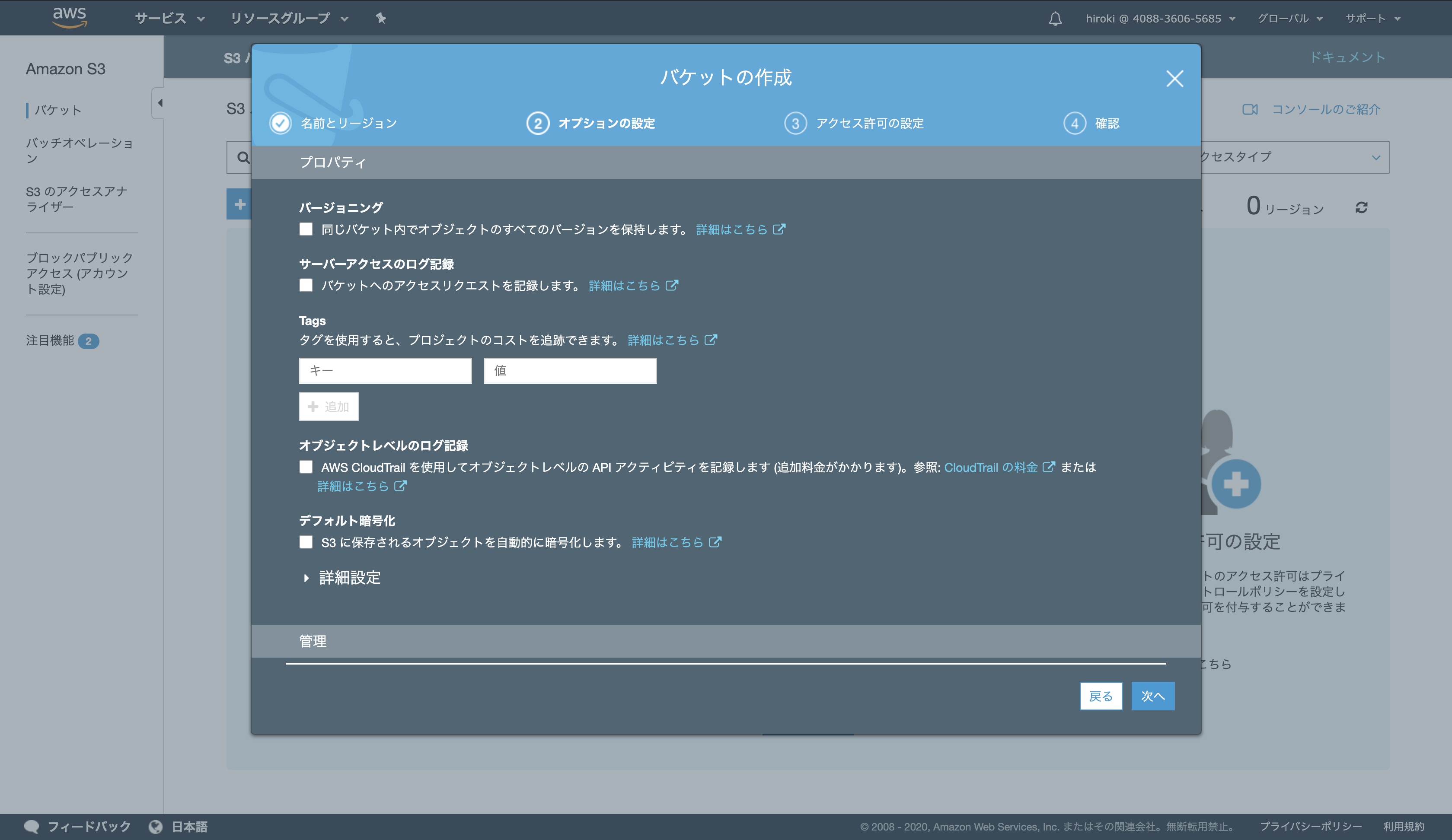
以下の通り設定し、「次へ」をクリック
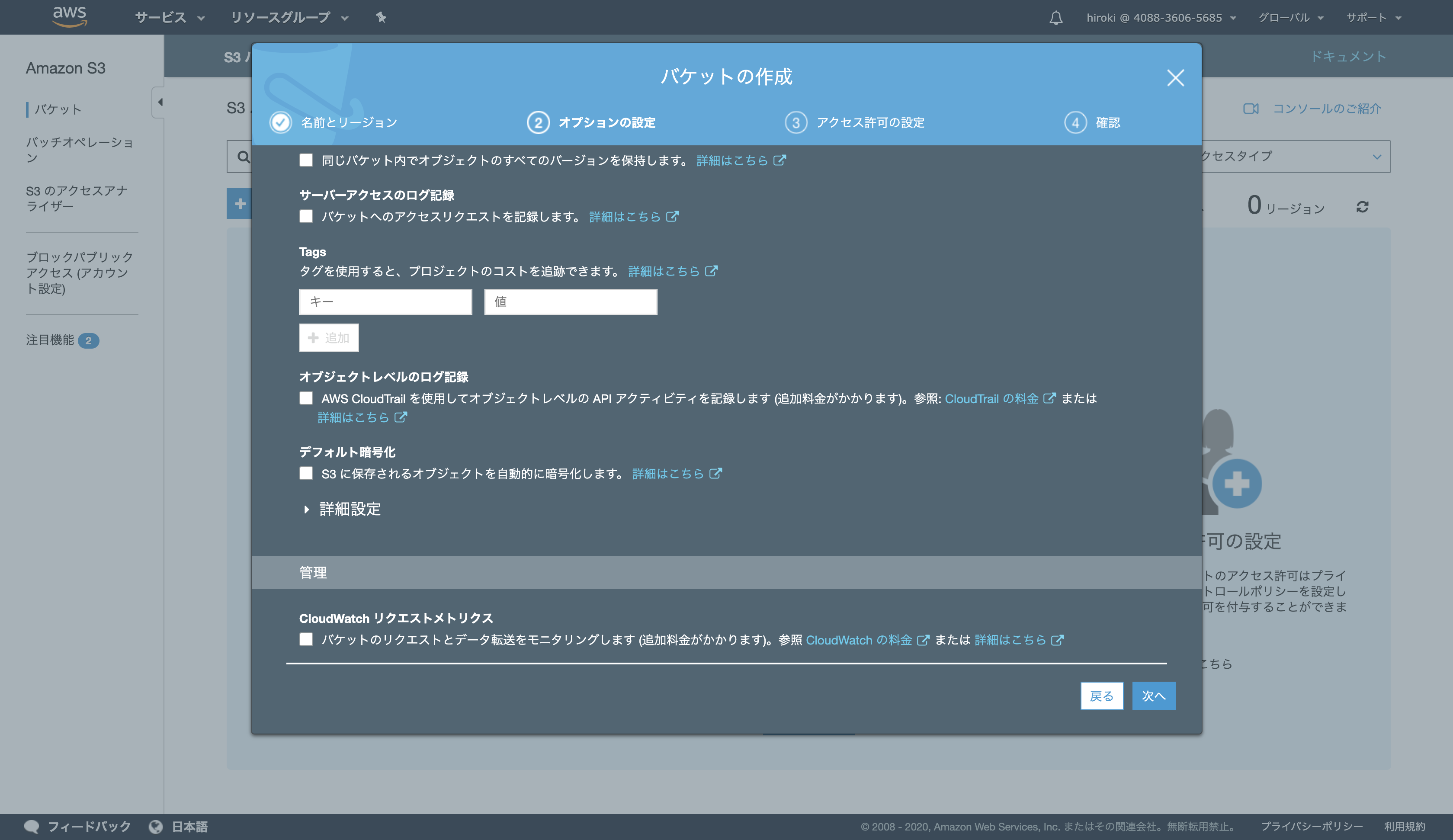
サーバーアクセスのログ記録:本番環境ではチェックしたほうが良い
以下の通り設定し、「次へ」をクリック
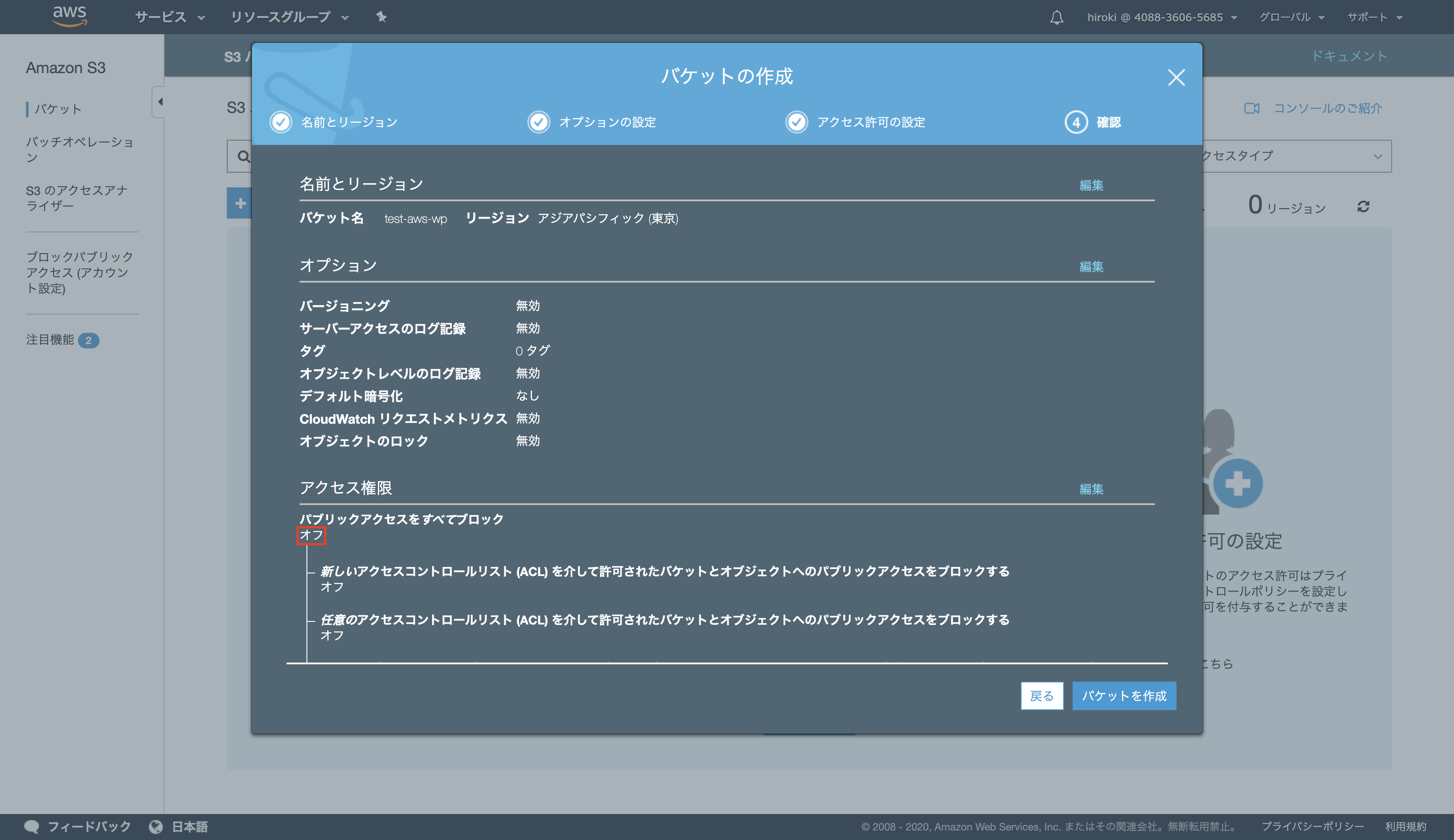
設定内容を確認し、「バケットを作成」をクリック
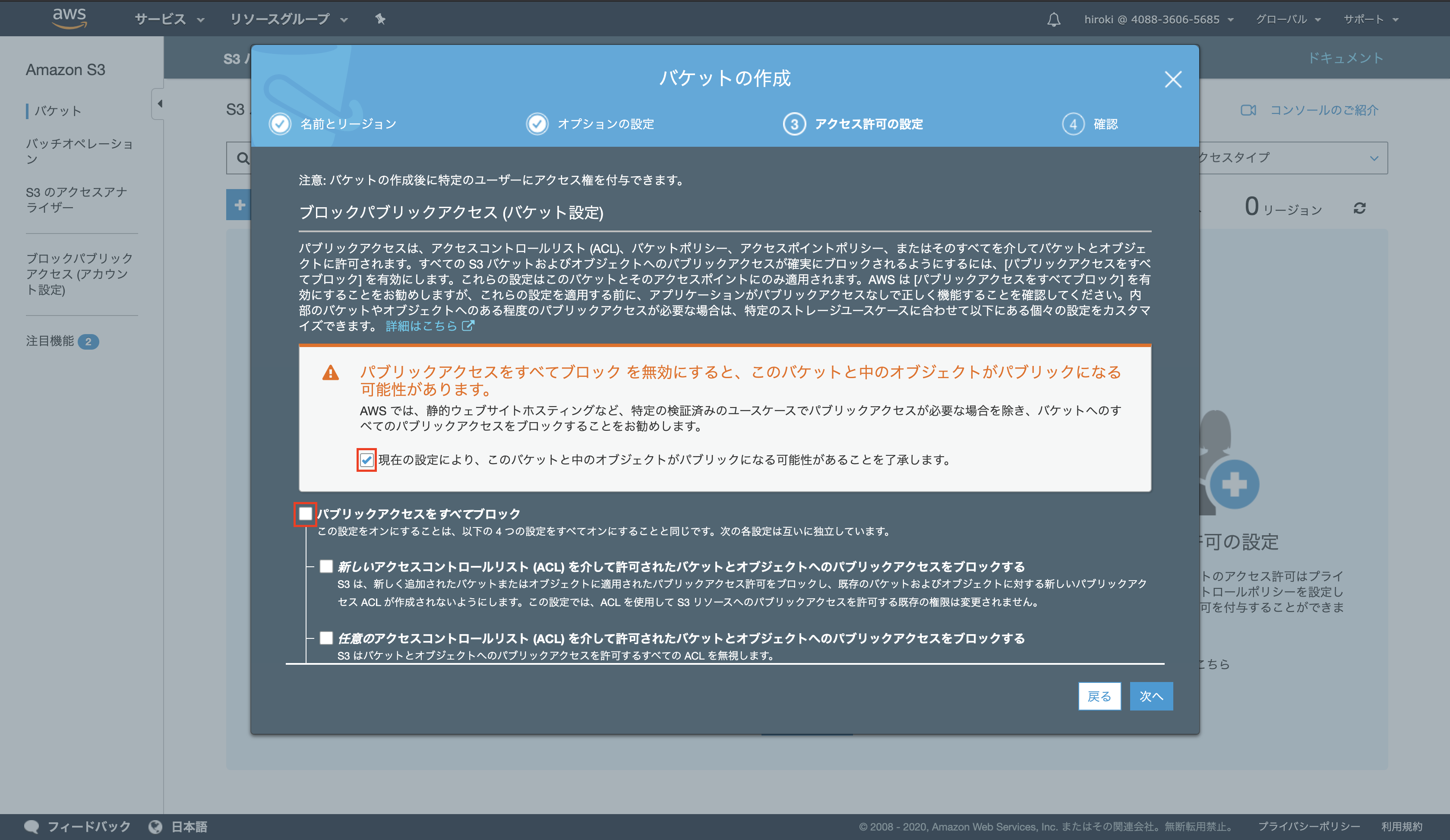
「パブリックアクセスをすべてブロック」がオフになっていること
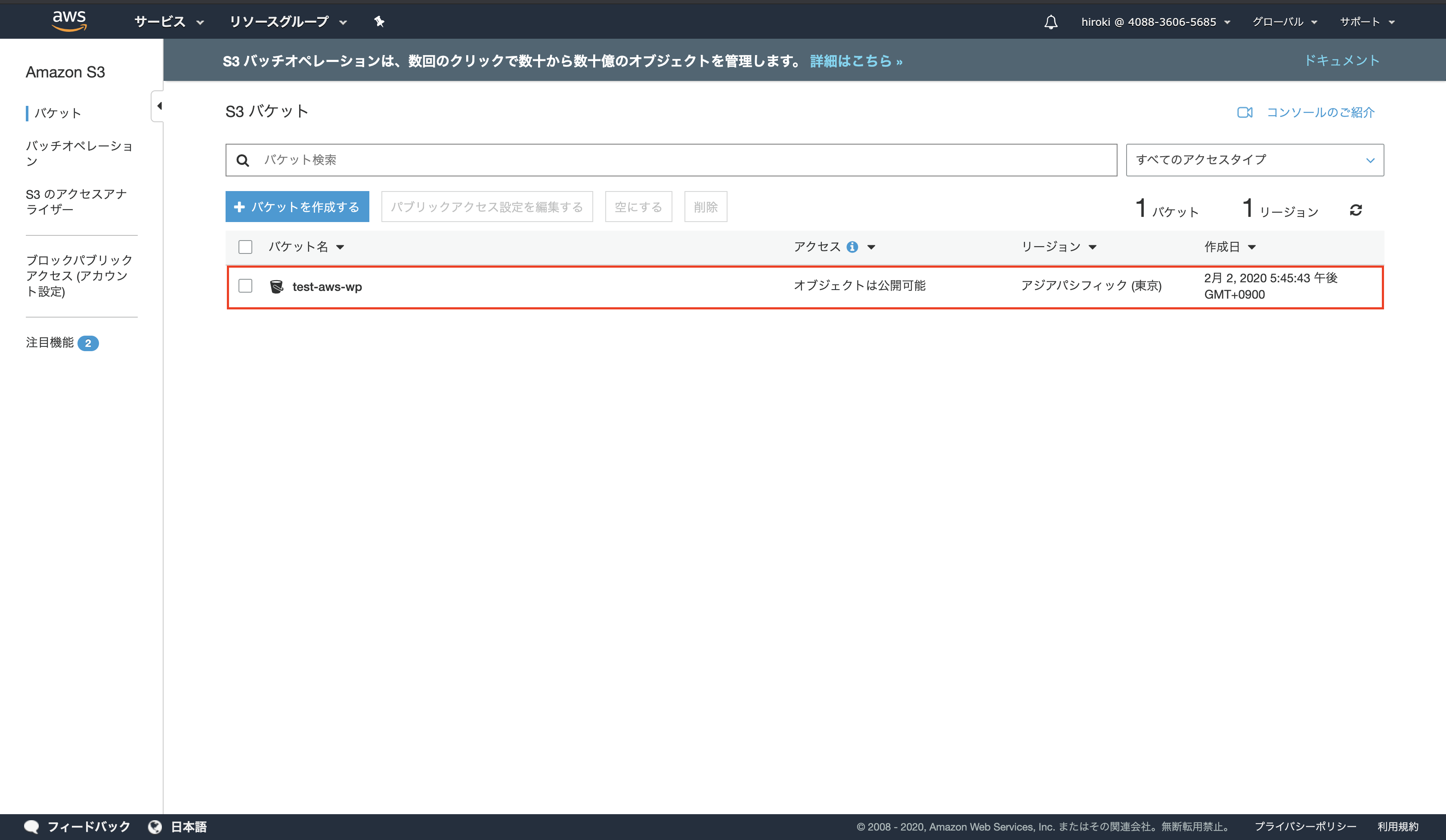
バケットが作成されていることを確認
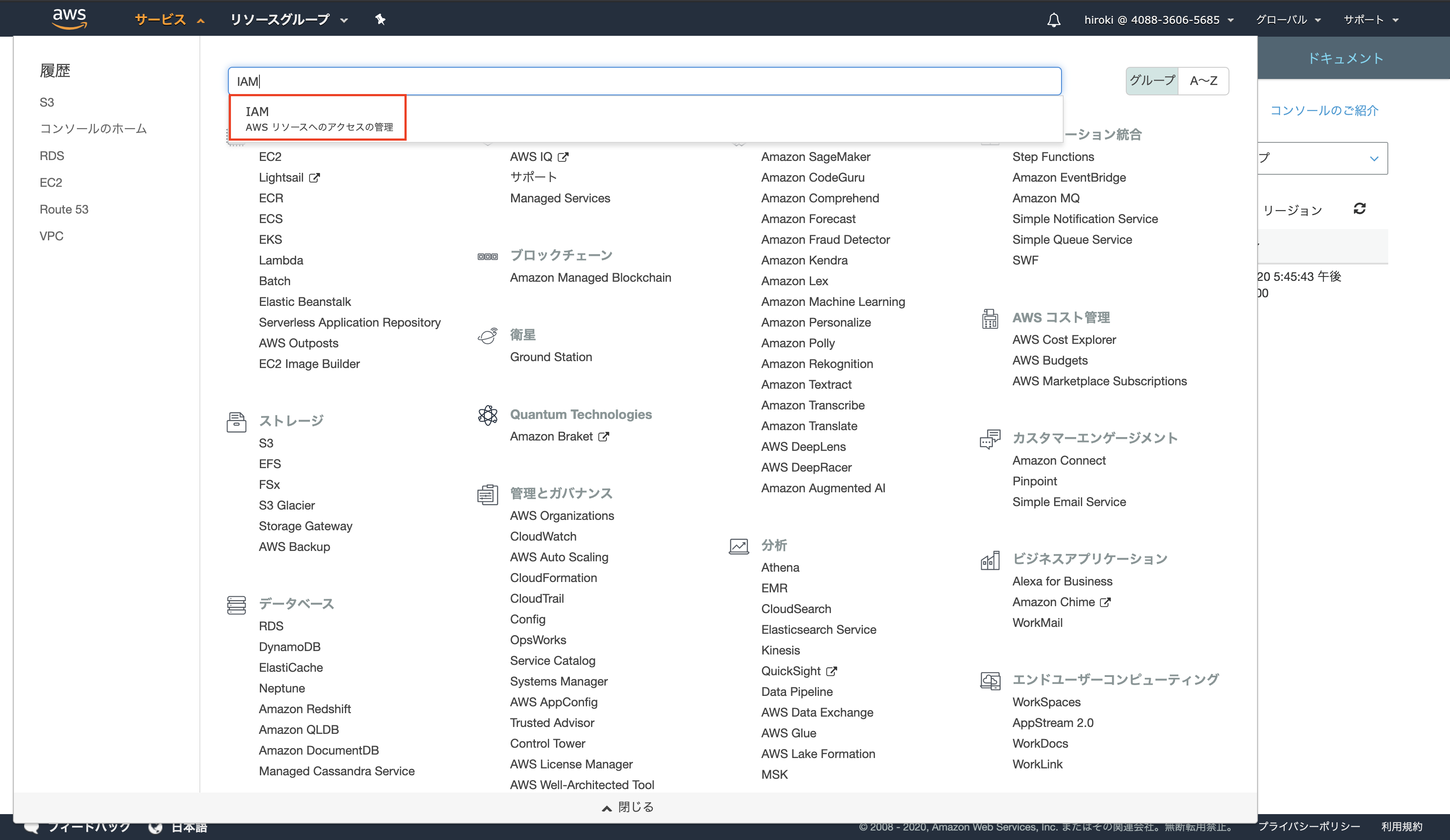
S3操作用のIAMユーザー作成
AWSコンソールからIAMを検索し、クリック
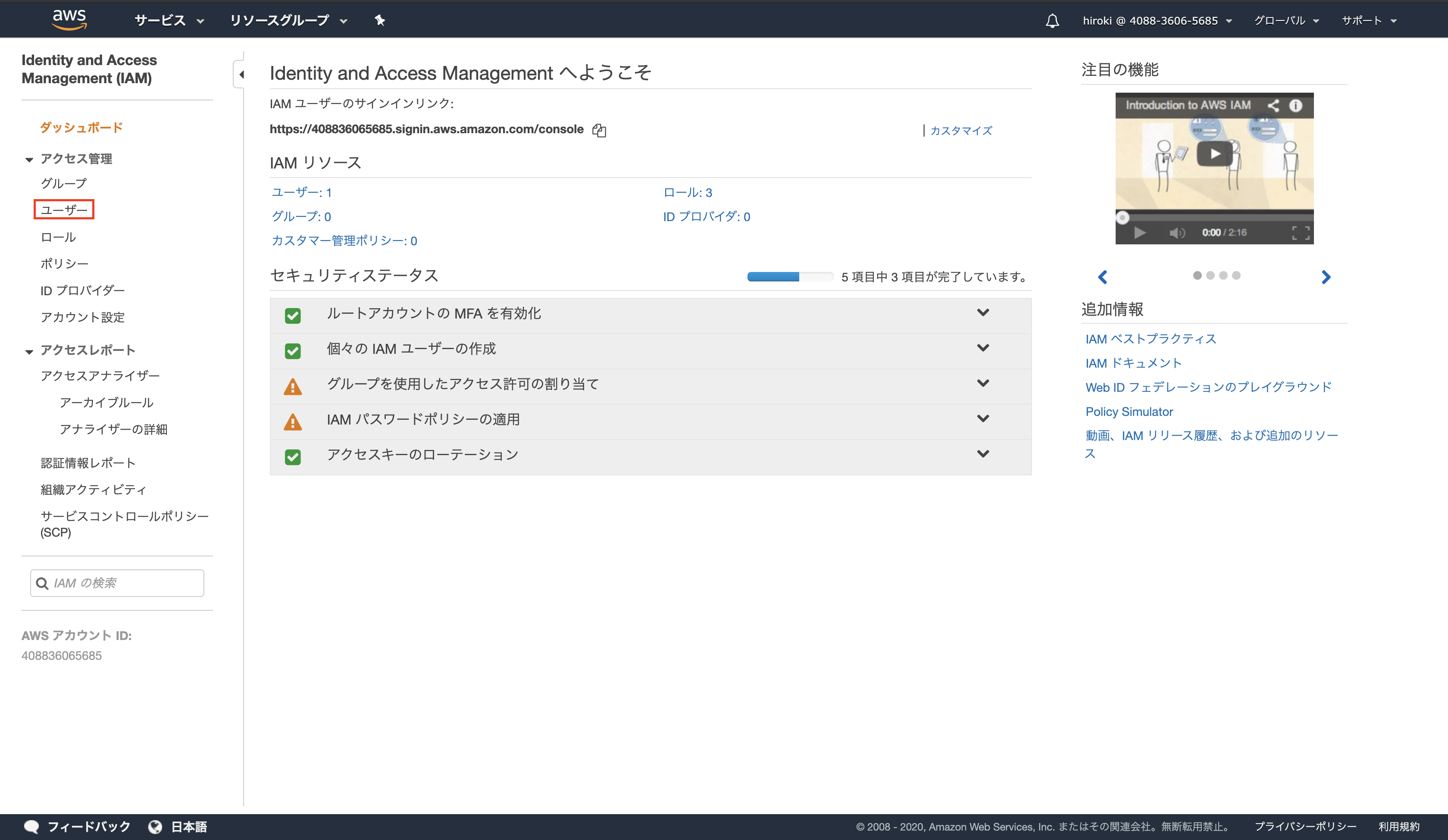
サイドバーから「ユーザー」をクリック
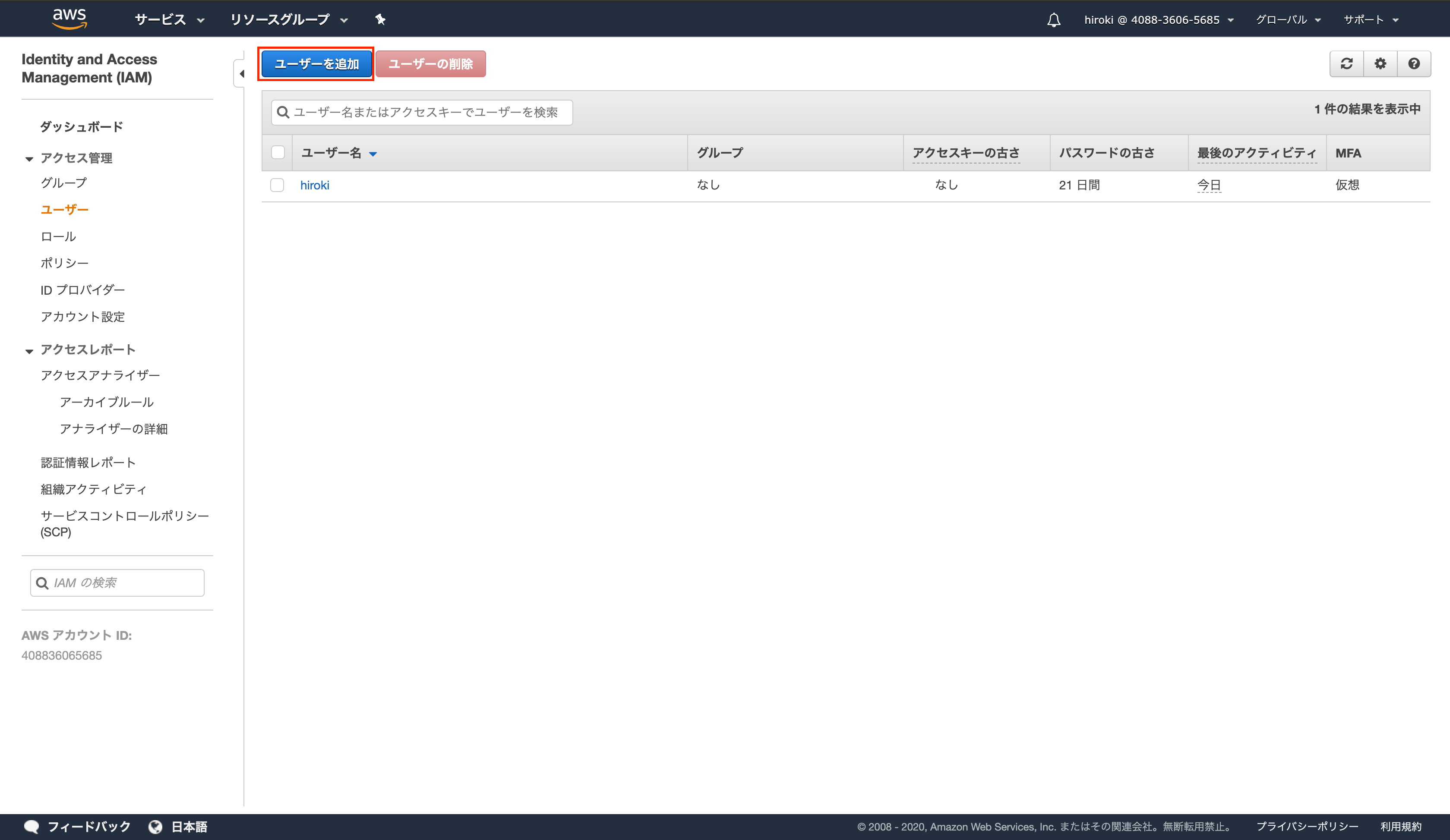
「ユーザーを追加」をクリック
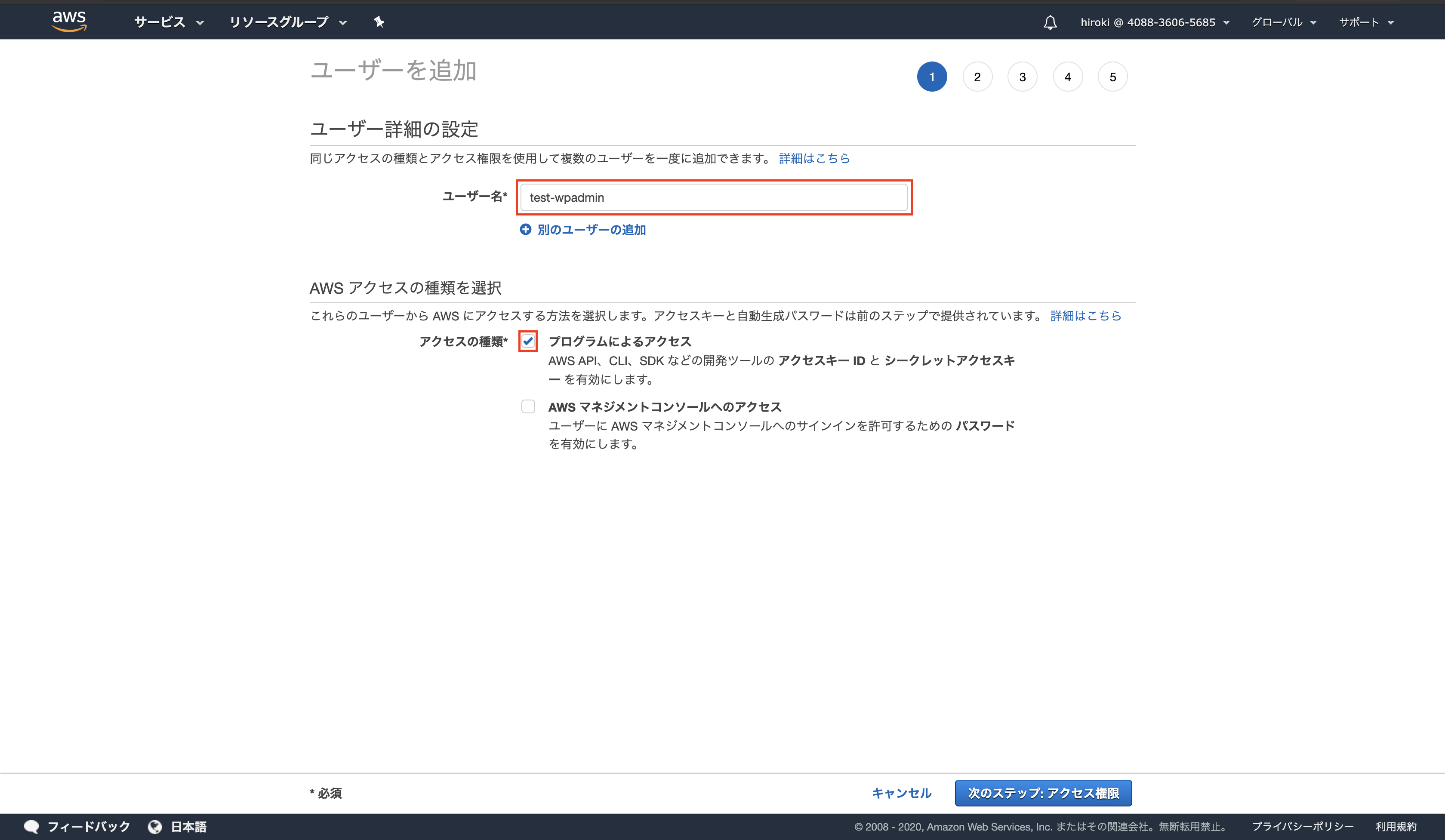
以下の通り設定し、「次のステップ」をクリック
以下の通り設定し、「次のステップ」をクリック
タグは設定せず、「次のステップ」をクリック
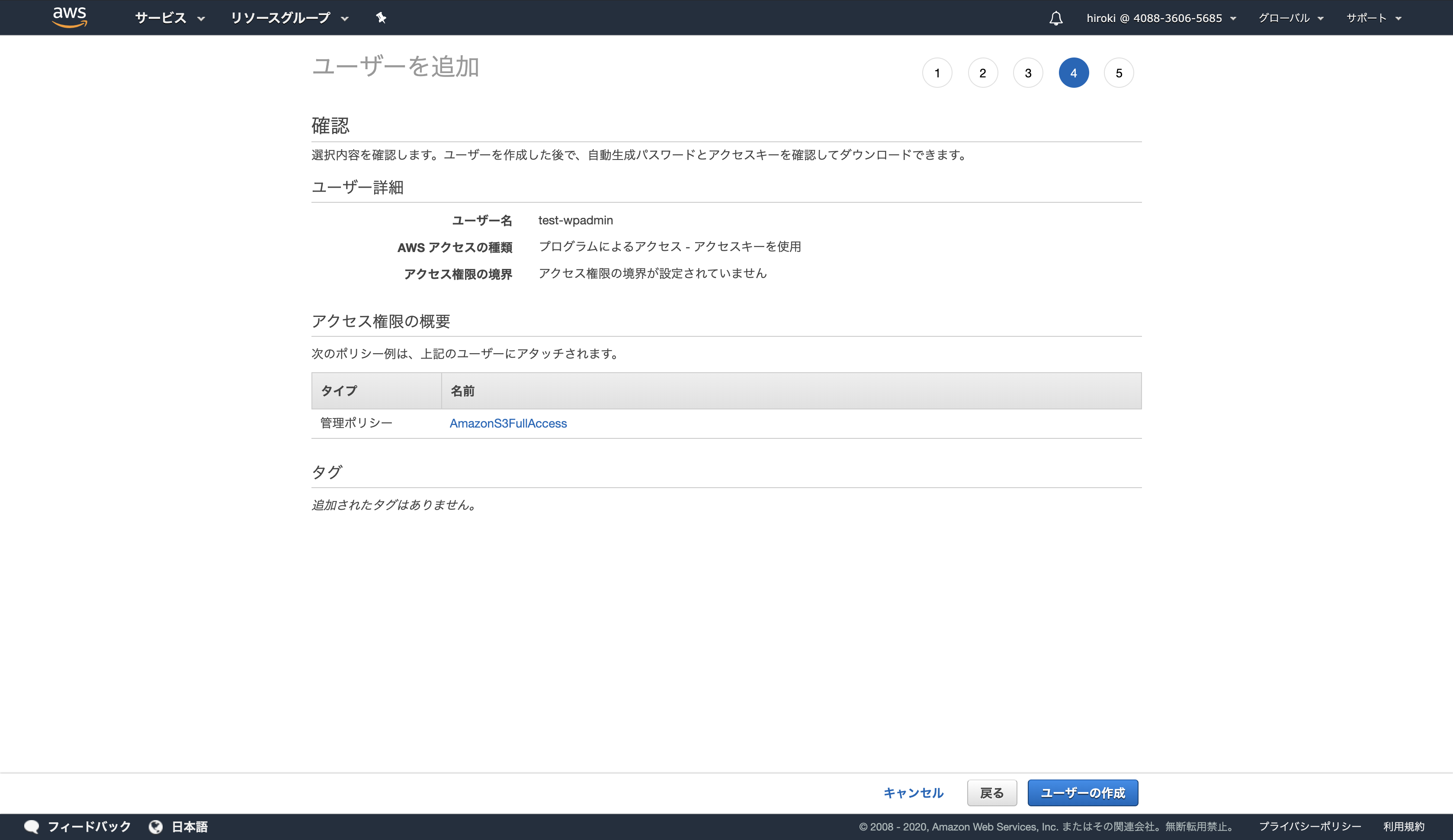
設定内容を確認し、「ユーザーの作成」をクリック
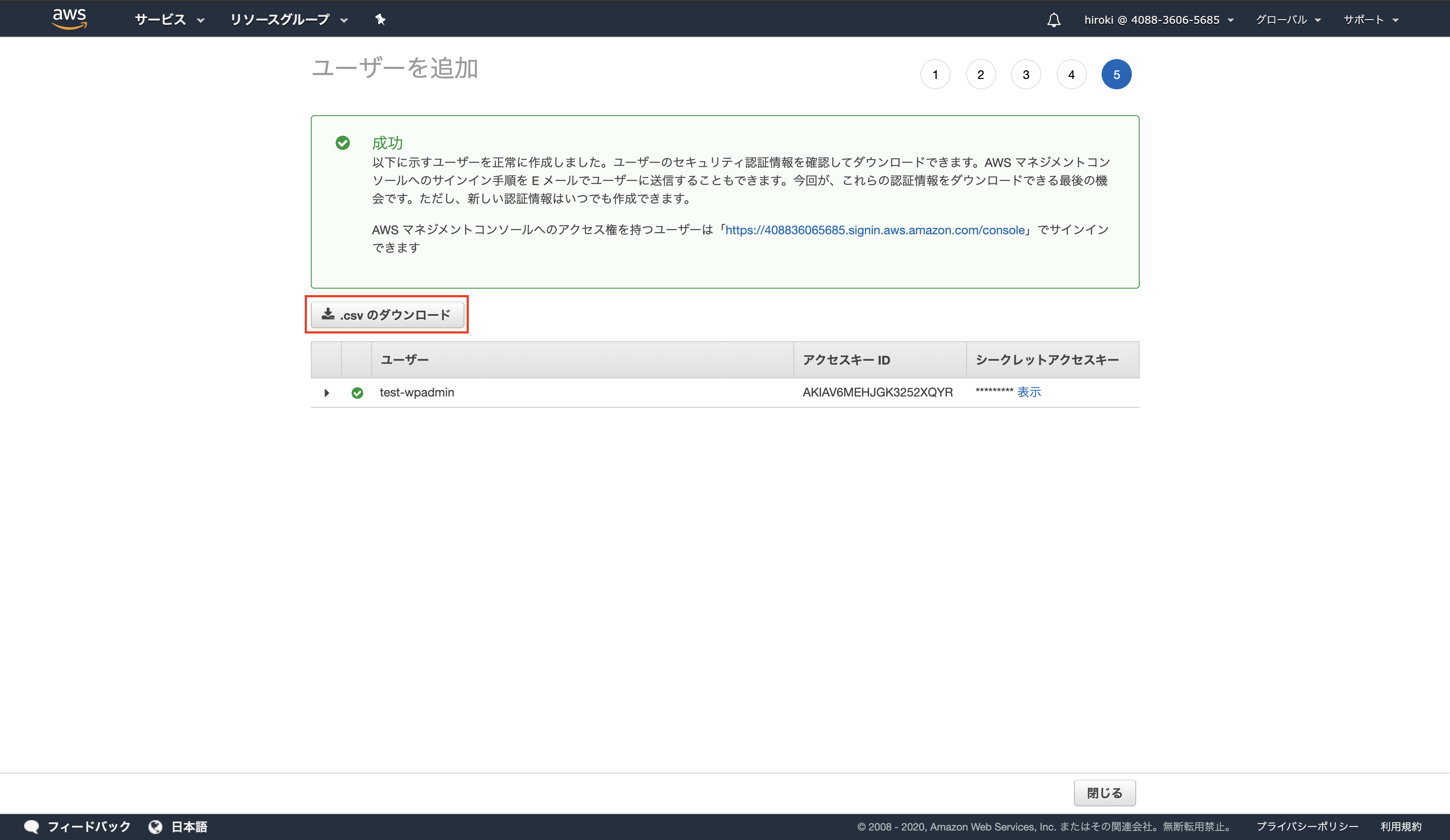
CSVのダウンロードを行うこと
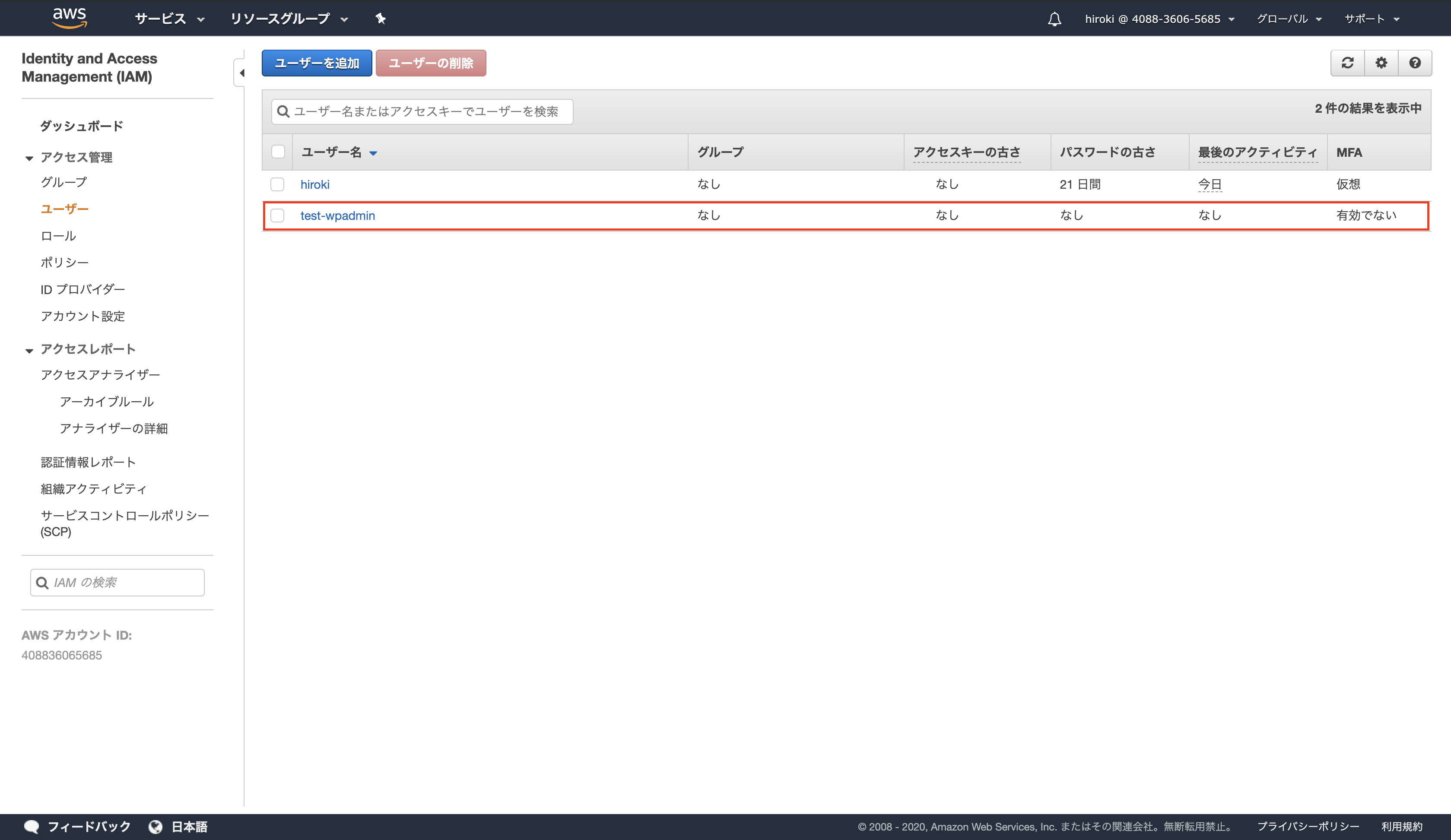
ユーザーが作成されていることを確認
WordPressの設定
プラグインをインストール
WordPressの管理画面を開く
ログイン
サイドバーのプラグイン → 新規追加をクリック
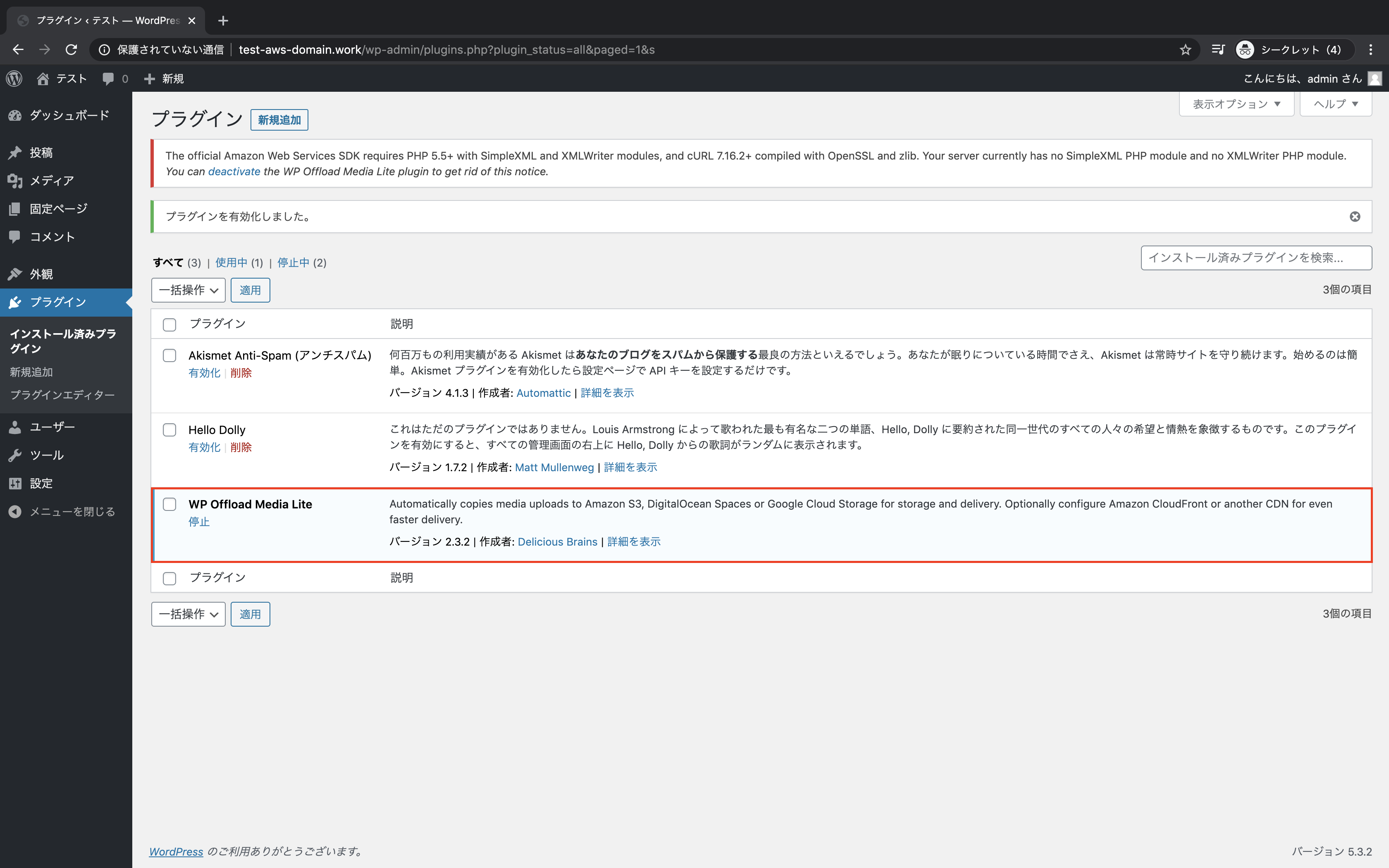
WP offload mediaを検索し、「今すぐインストール」をクリック
「有効化」をクリック
WP offload mediaが有効化になっていることを確認
ライブラリをインストール
ターミナルからEC2へSSHログイン
ssh -i test-ssh-key.pem ec2-user@18.179.167.73ライブラリをインストール
sudo yum install -y php-xml
sudo yum install -y php-gdライブラリを反映
[ec2-user@ip-10-0-10-10 ~]$ sudo systemctl restart httpd.serviceプラグインの設定
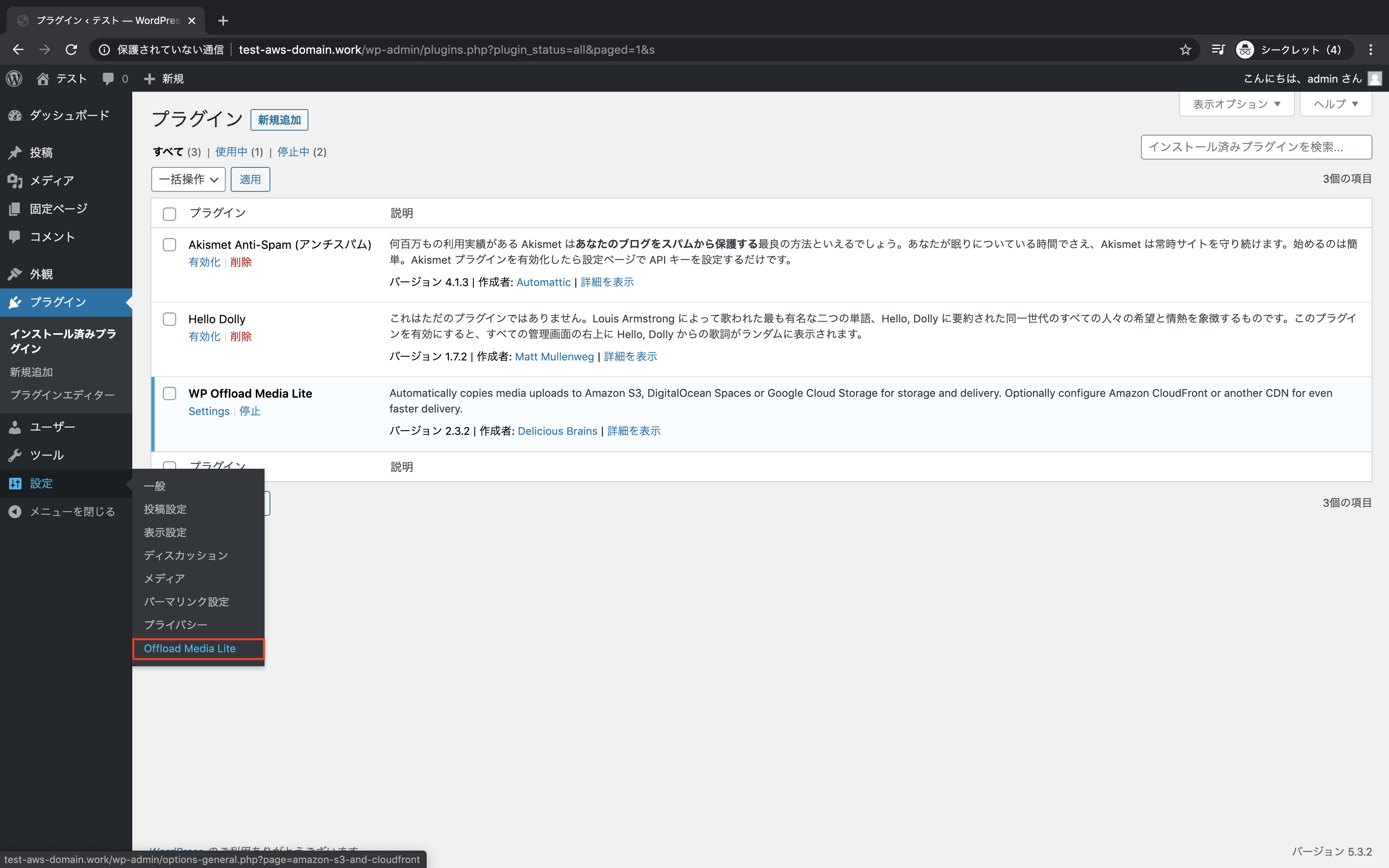
WordPressの管理画面をリロード
設定 → Offload Media Liteをクリック
offload mediaの定義情報をコピーしておく
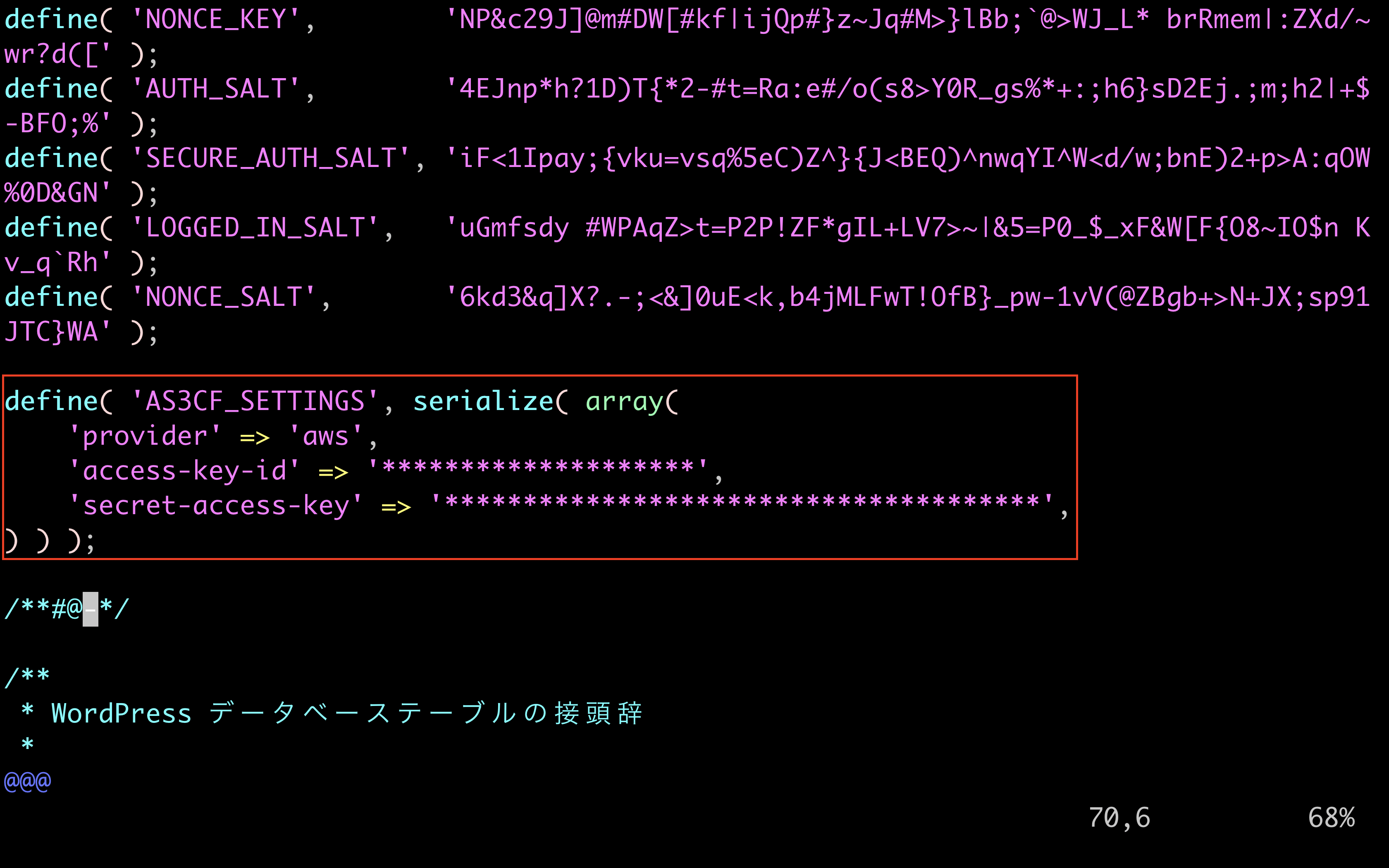
wp-config.phpを開く
[ec2-user@ip-10-0-10-10 ~]$ cd /var/www/html/ [ec2-user@ip-10-0-10-10 html]$ ls index.php wp-blog-header.php wp-cron.php wp-mail.php license.txt wp-comments-post.php wp-includes wp-settings.php readme.html wp-config-sample.php wp-links-opml.php wp-signup.php wp-activate.php wp-config.php wp-load.php wp-trackback.php wp-admin wp-content wp-login.php xmlrpc.php [ec2-user@ip-10-0-10-10 html]$ vi wp-config.phpwp-config.phpに定義情報を貼り付ける
IAMユーザー作成時にダウンロードしたCSVをもとにaccess-key-id,secret-access-keyを入力
offload mediaのページをリロード
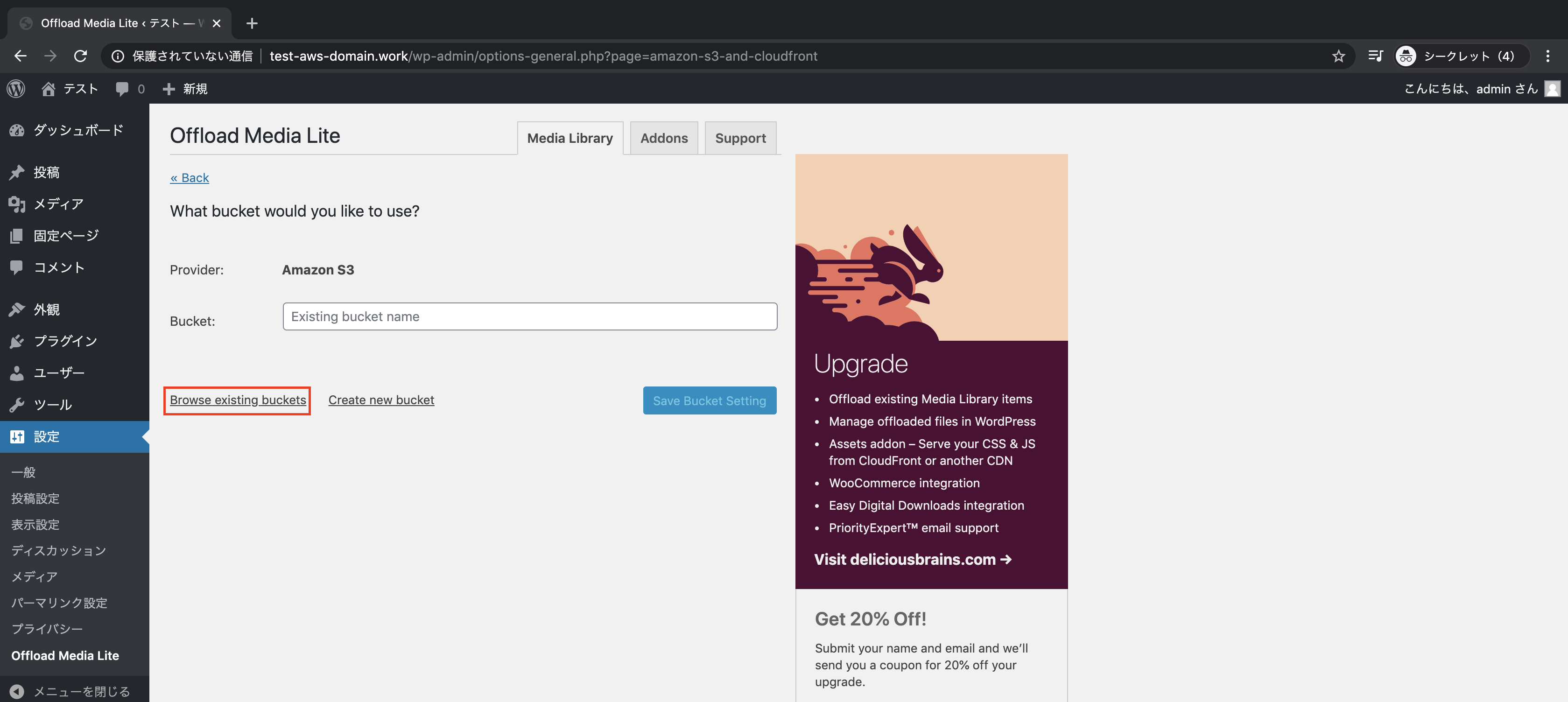
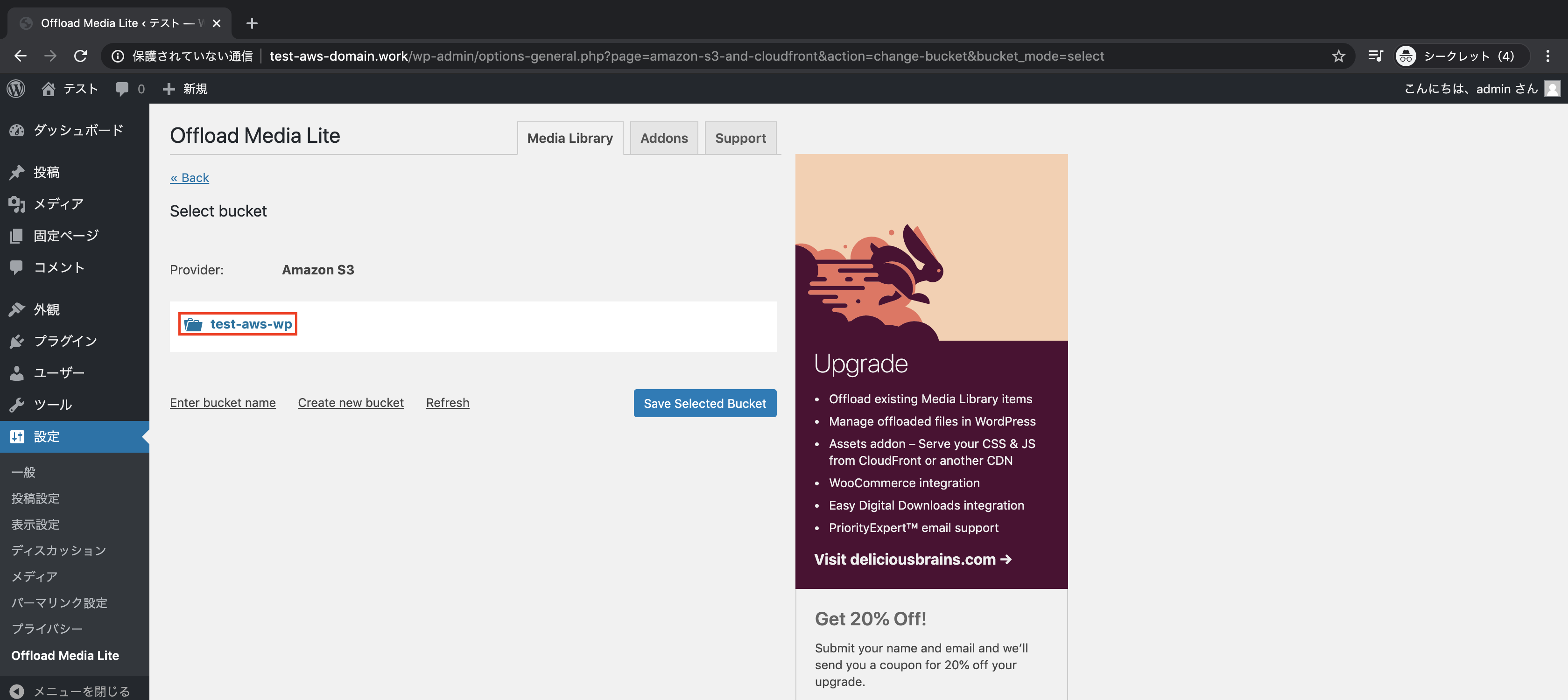
「Browse existing buckets」をクリックし
作成したバケットを選択し、「Save Selected Bucket」をクリック
設定が保存されていることを確認
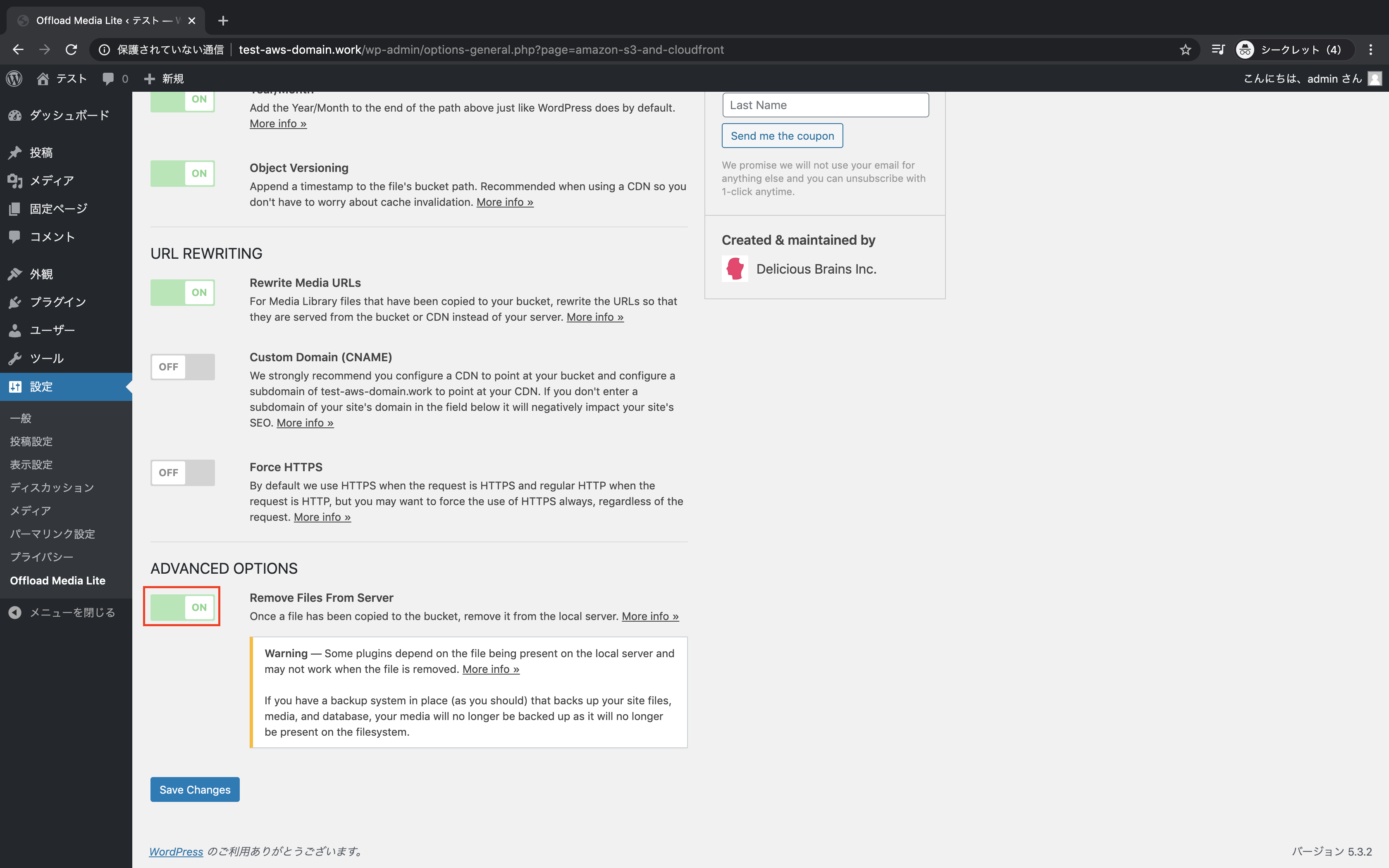
「Remove Files From Server」をONに変更し、「Save Changes」をクリック
画像のアップロード
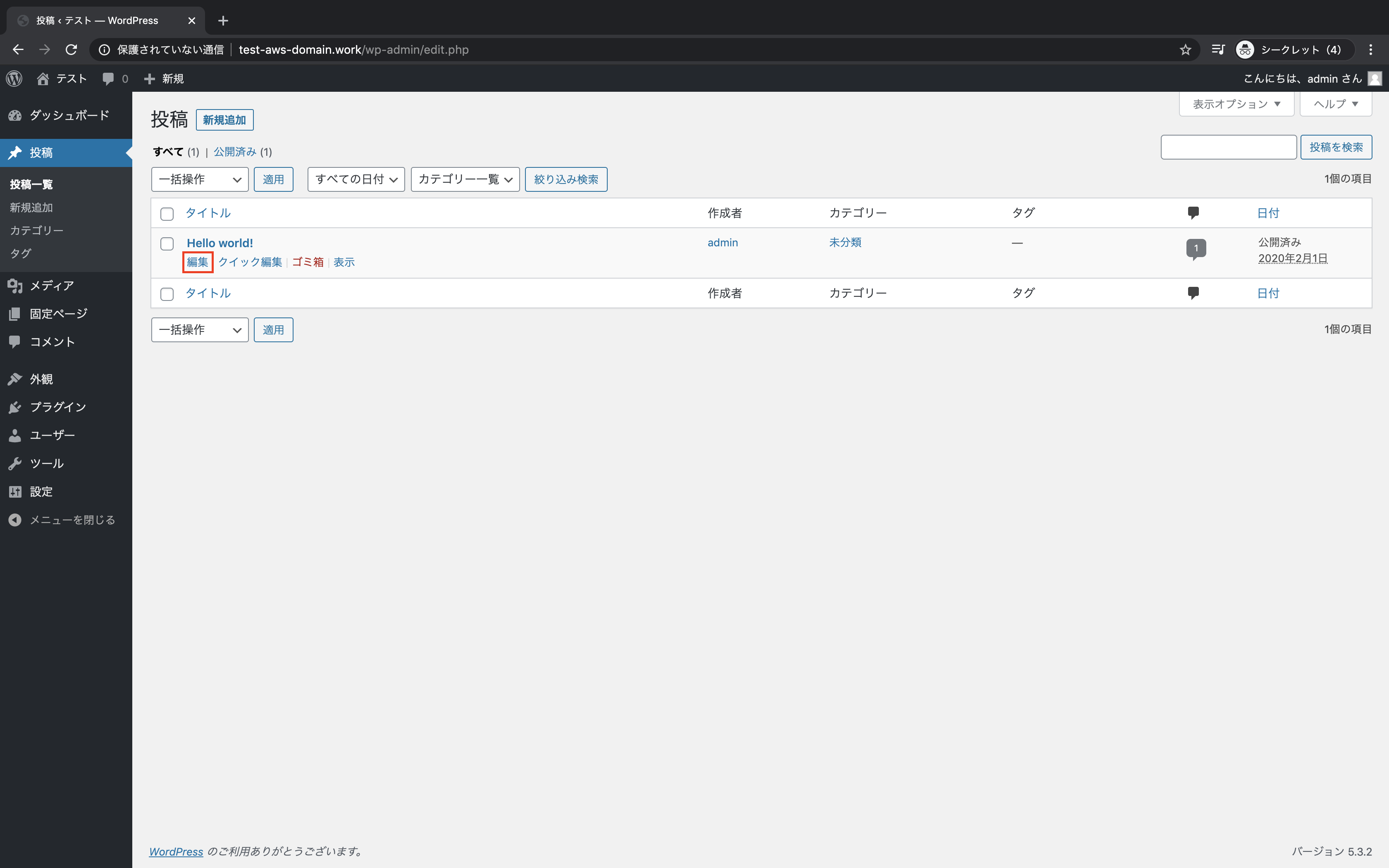
投稿 → 投稿一覧をクリック
「編集」をクリック
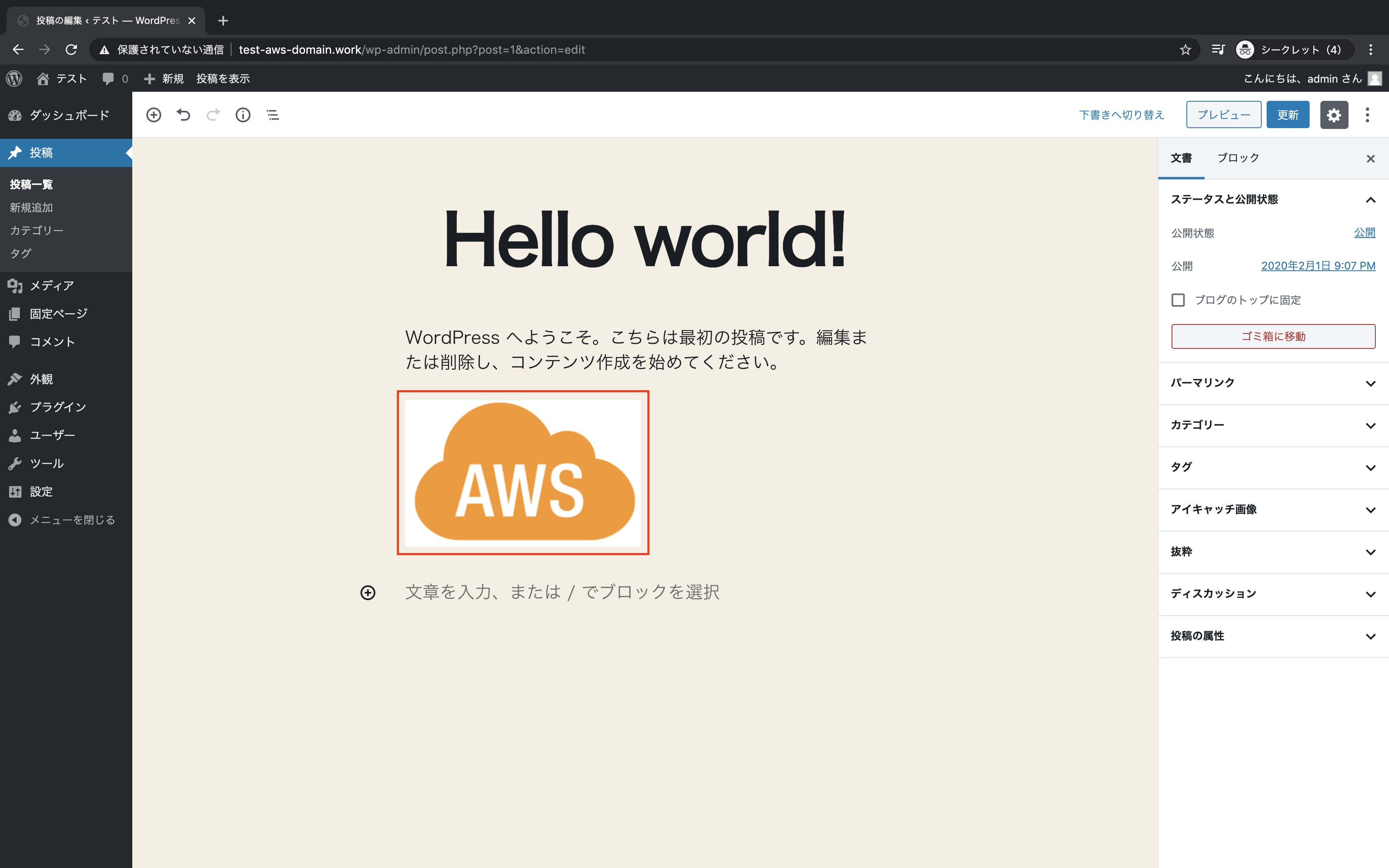
「画像の追加」をクリック
画像がアップロードされていることを確認
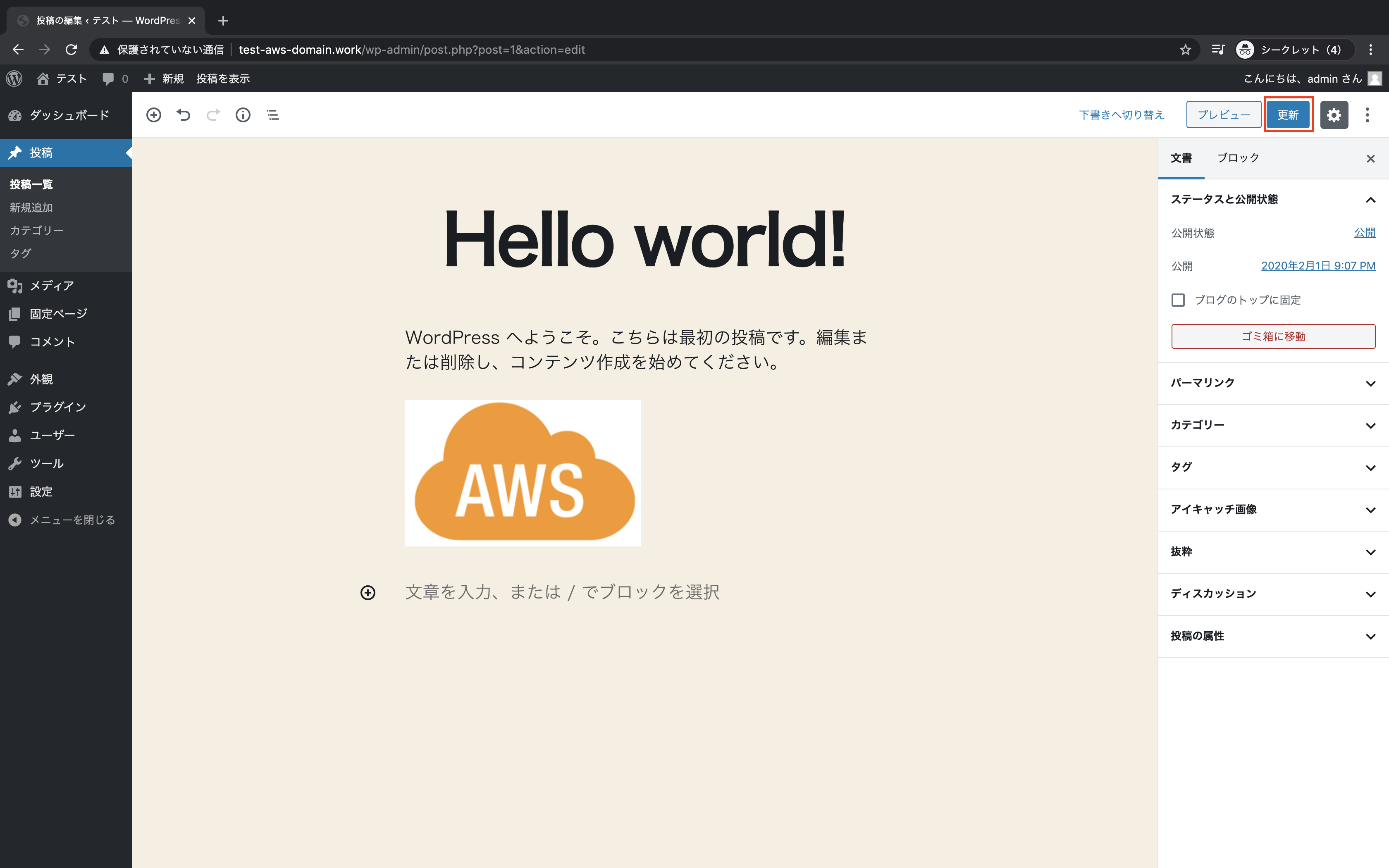
「更新」をクリック
WordPressのページに画像が表示されていることを確認
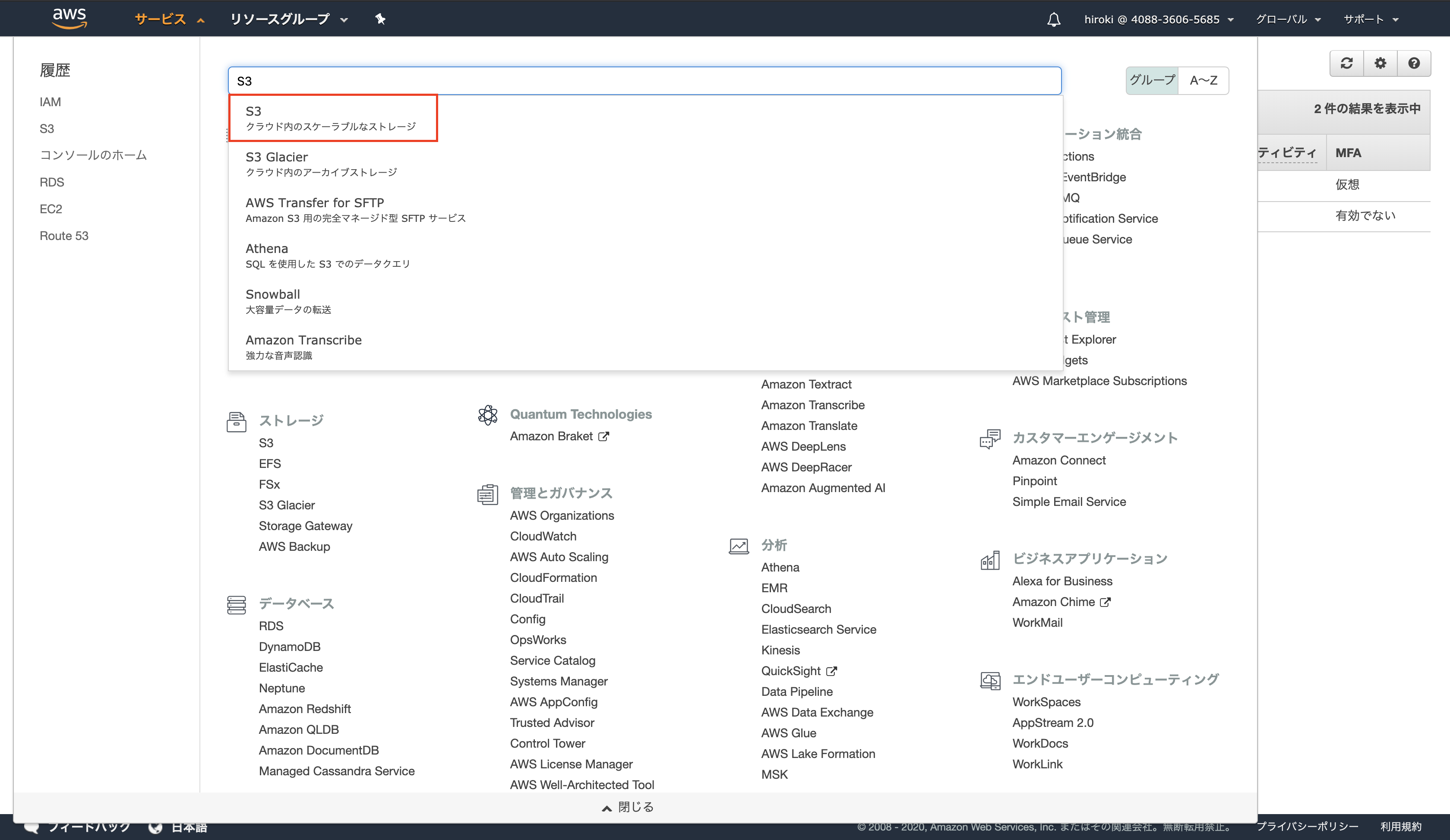
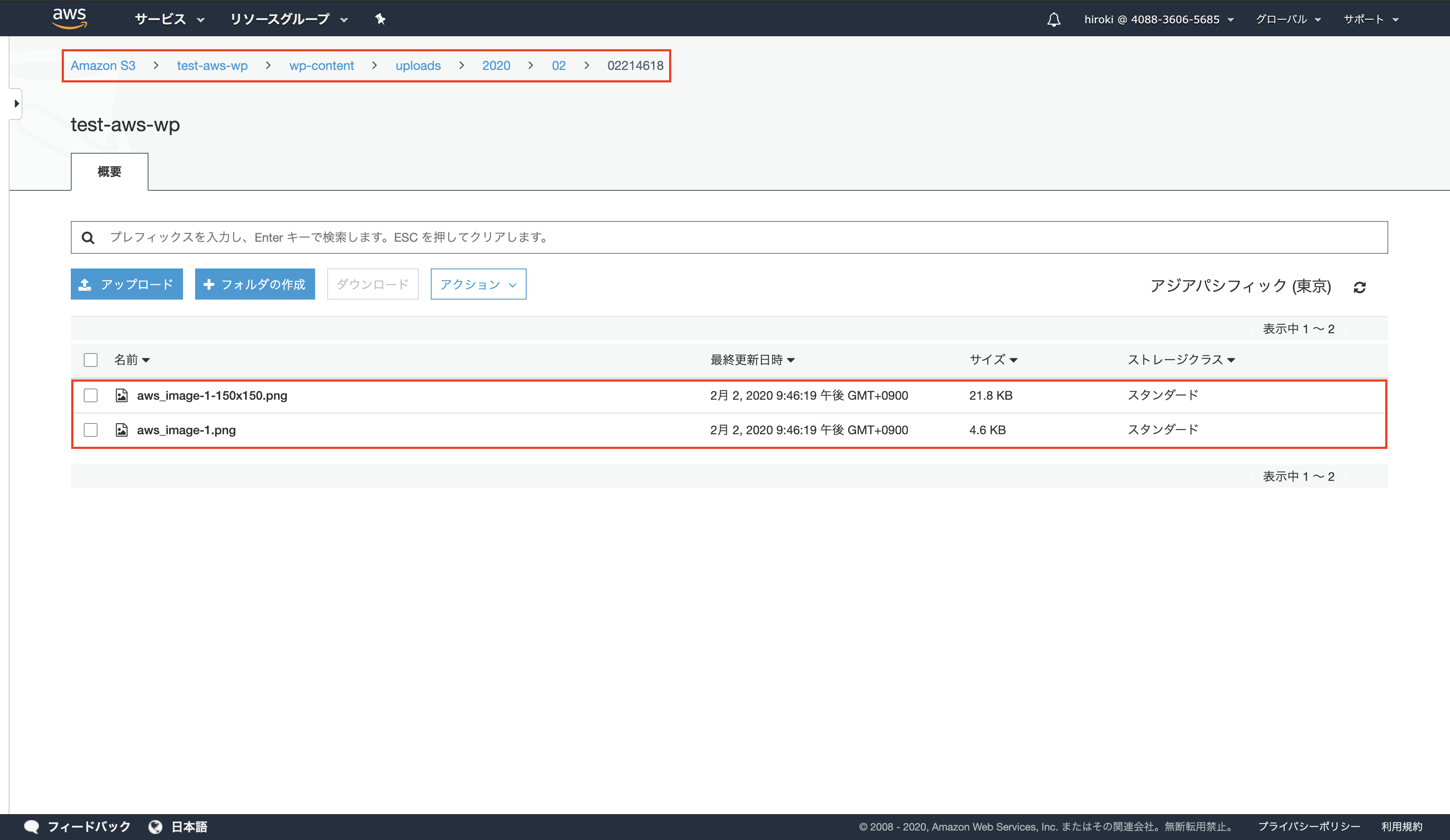
AWSコンソールからS3を検索し、クリック
対象のバケットをクリック
S3に画像が保存されていることを確認
CloudFrontから配信
ディストリビューションの作成
AWSコンソールからCloudFrontを検索し、クリック
「Create Distribution」をクリック
WEBの「Get Started」をクリック
Origin Domain Nameを指定し、「Create Distribution」をクリック
Origin Domain Name:作成したS3
Restrict Bucket Access:CloudFrontのみアクセスする(S3にはアクセスしない)
ディストリビューションが作成されていることを確認
独自ドメインから配信
SSLサーバー証明書の発行
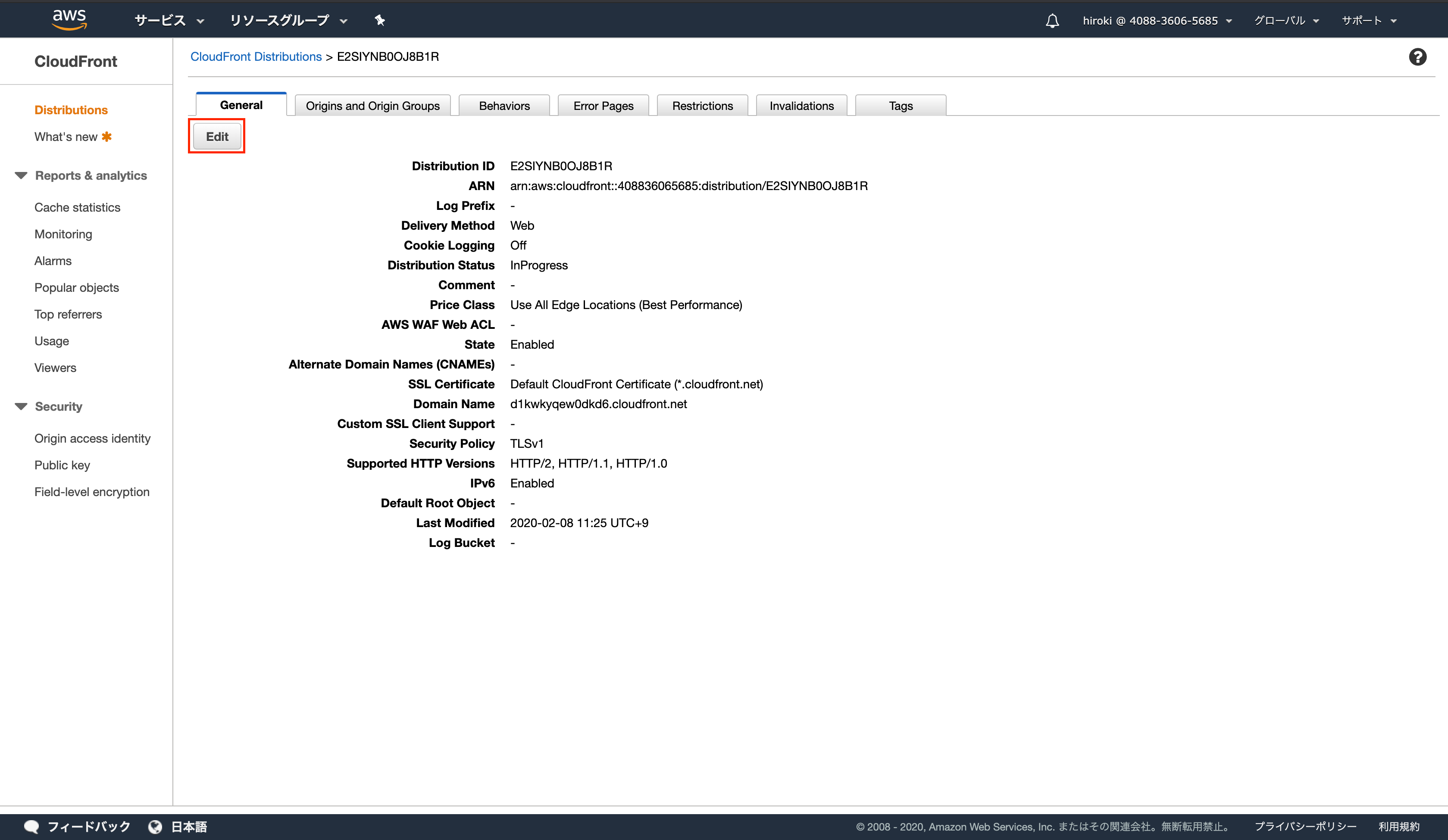
ディストリビューションのIDをクリック
「Edit」をクリック
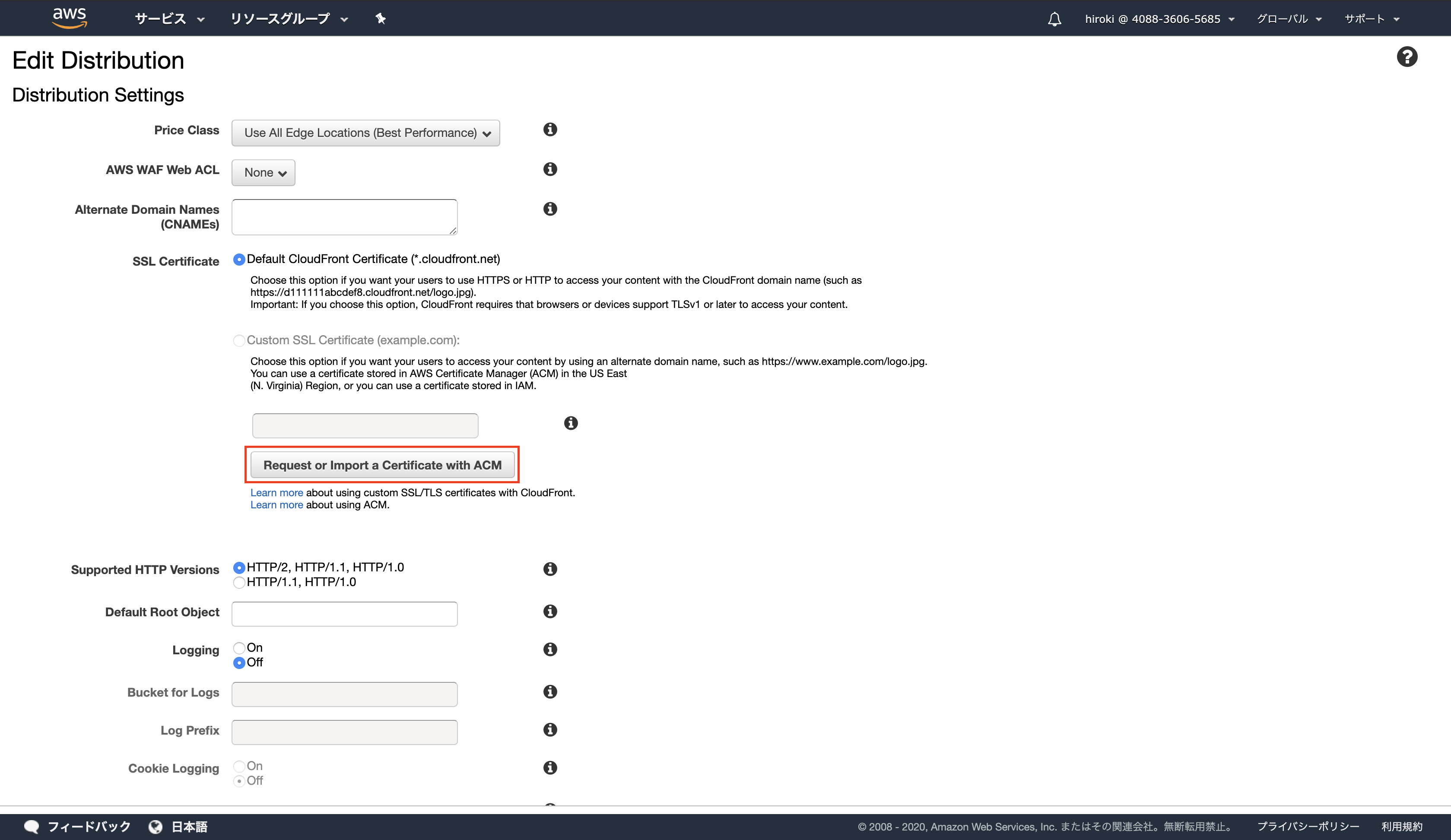
「Request or Import a Certificate with ACM」をクリック
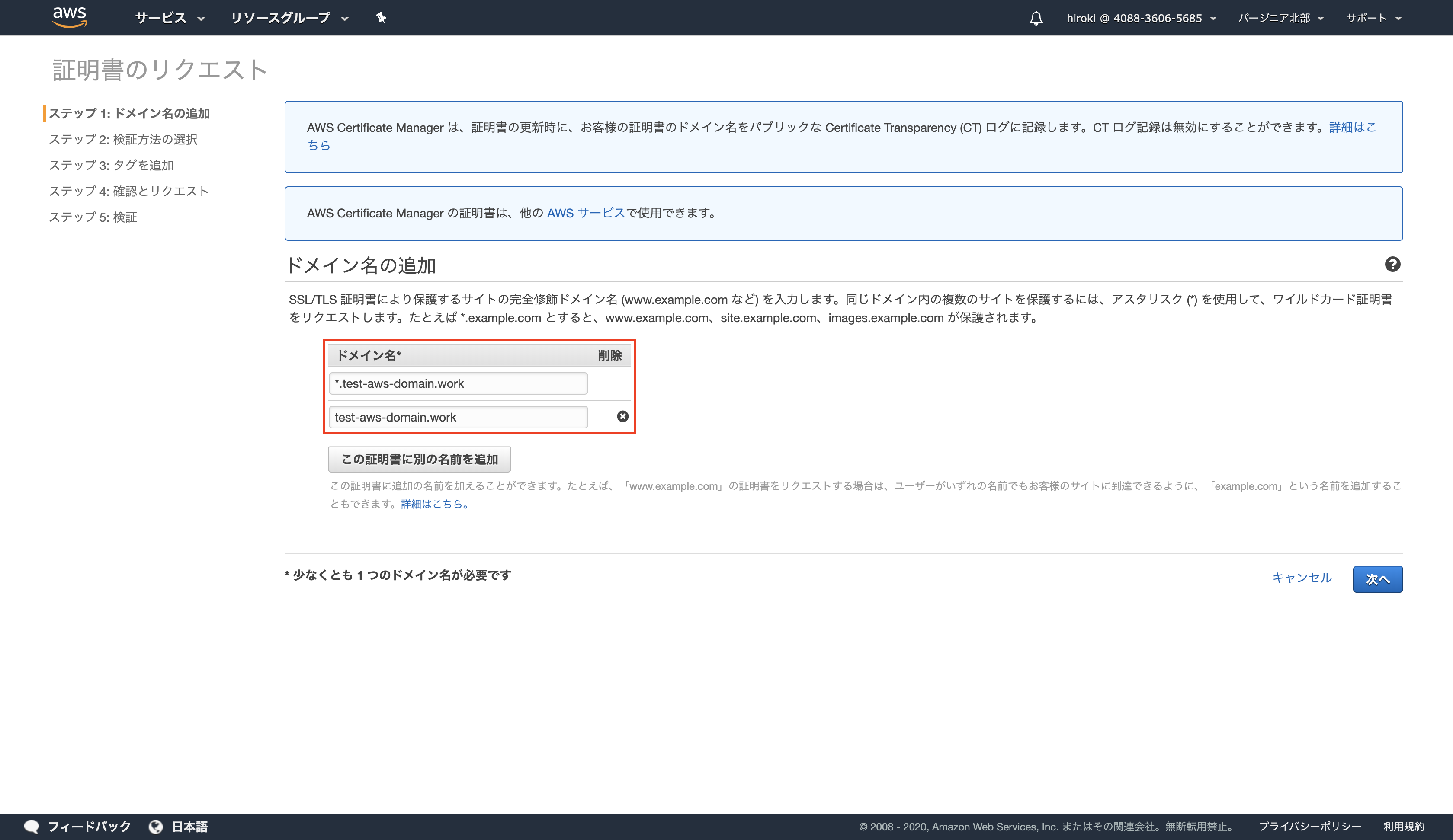
作成したドメイン名を追加し、「次へ」をクリック
(ドメイン名の前に「*.」を付与することでサブドメインに対応できる)
「DNSの検証」にチェックを入れ、「次へ」をクリック
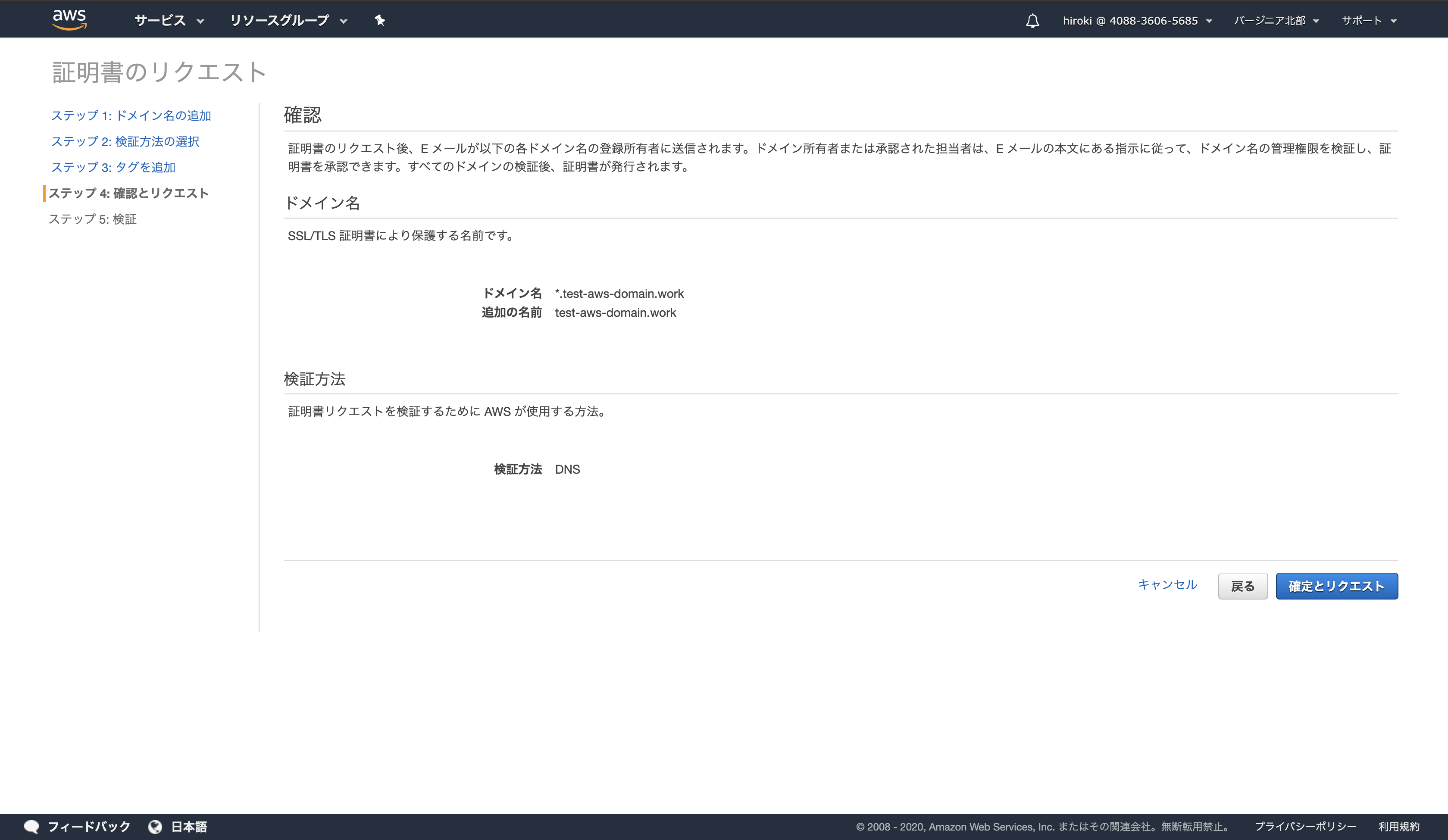
タグを任意追加し、「確認」をクリック
設定内容を確認し、「確定とリクエスト」をクリック
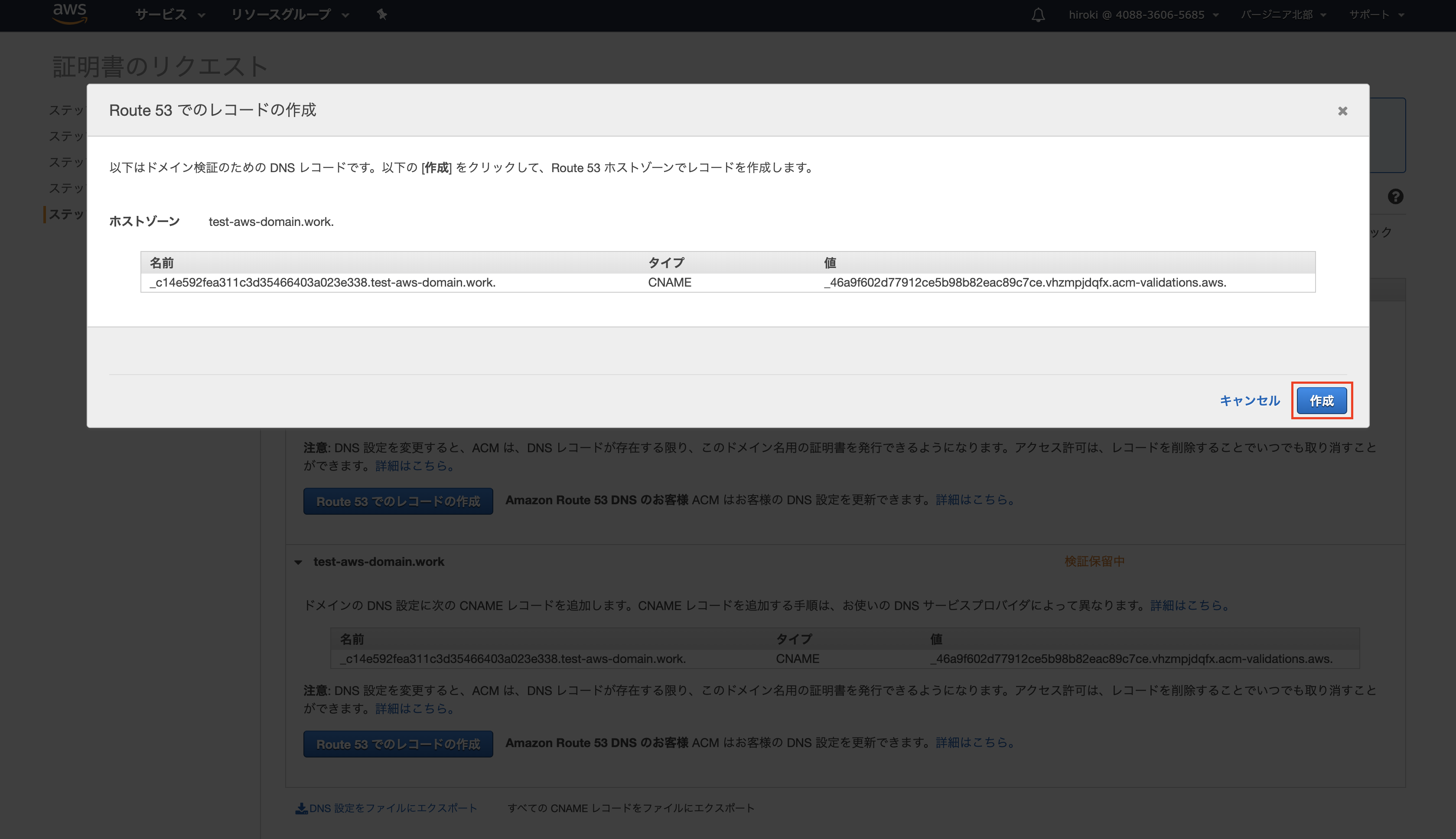
「Route 53でのレコードの作成」をクリック
「作成」をクリック
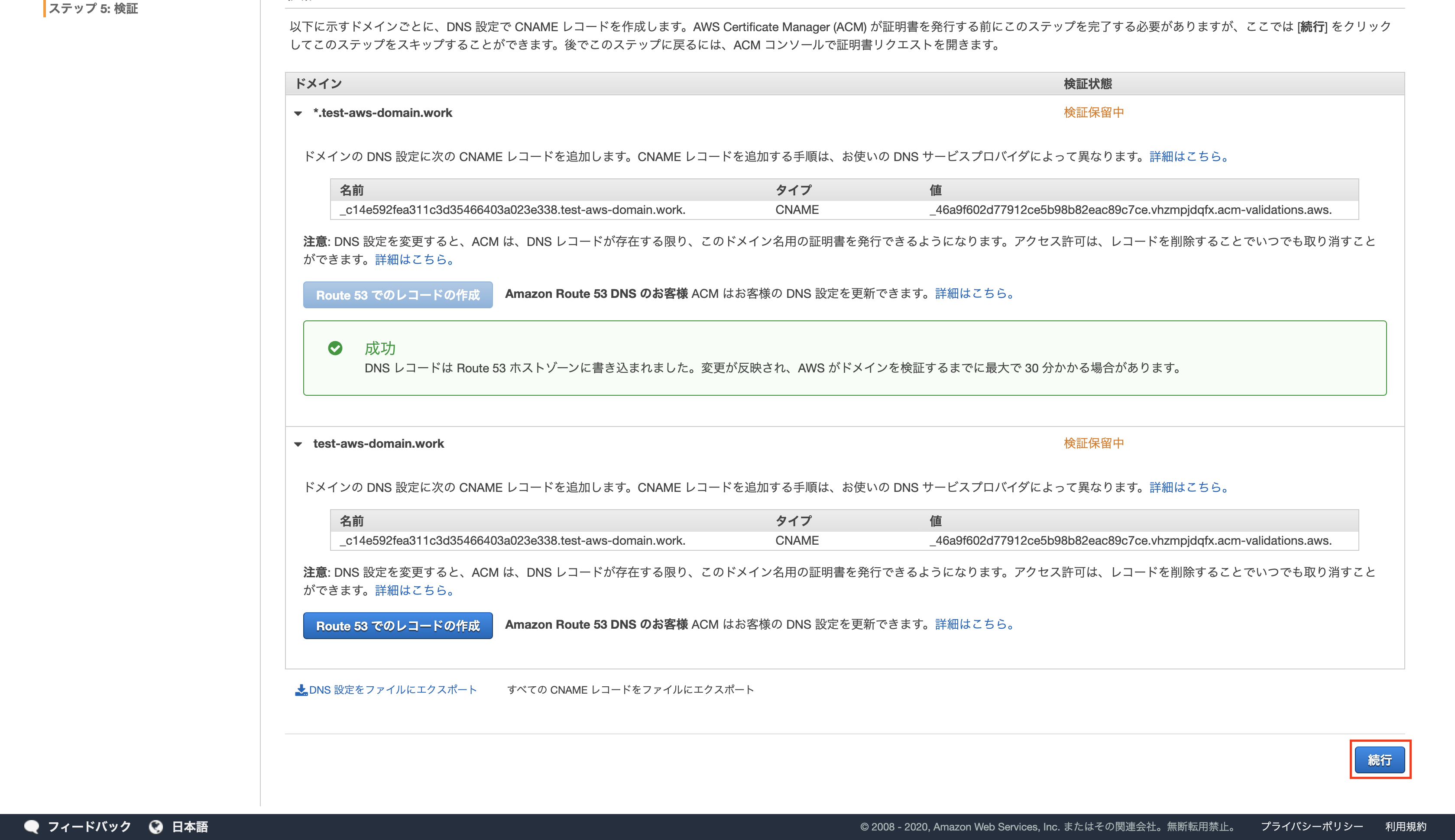
適用したドメイン全てのレコードを作成したら、「続行」をクリック
(レコードの名前が同じ場合、レコードの作成は1つで良い)
SSLサーバー証明書が発行されたことを確認
独自ドメインを登録
AWSコンソールからCloudFrontを検索し、クリック
ディストリビューションのIDをクリック
「Edit」をクリック
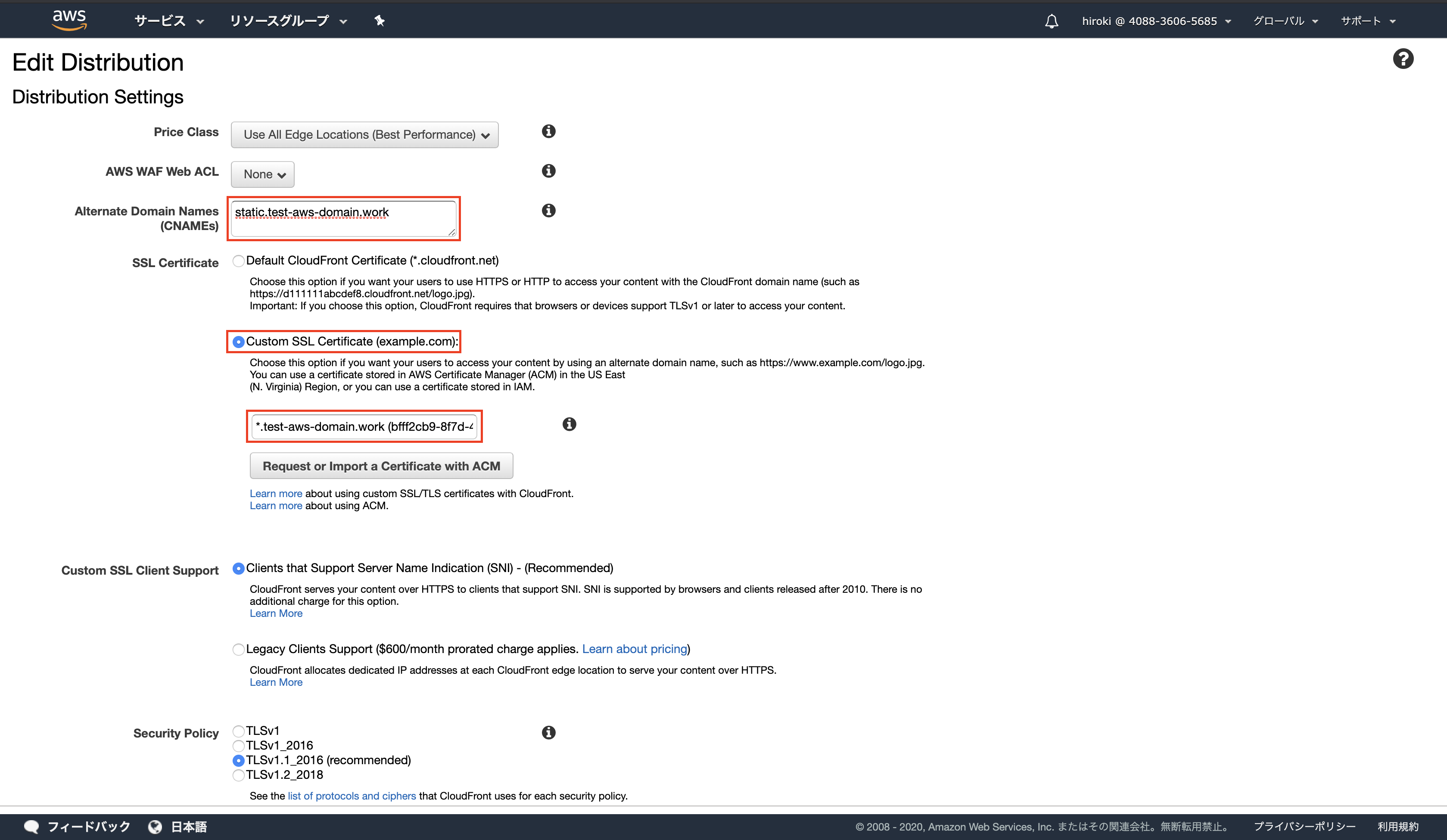
以下の通り入力し、「Yes,Edit」をクリック
Alternate Domain Names:適用したいドメイン名(今回はサブドメイン「static」を付与)
SSL Certificate:「Custom SSL Certificate」にチェックし、発行したSSLサーバー証明書を選択
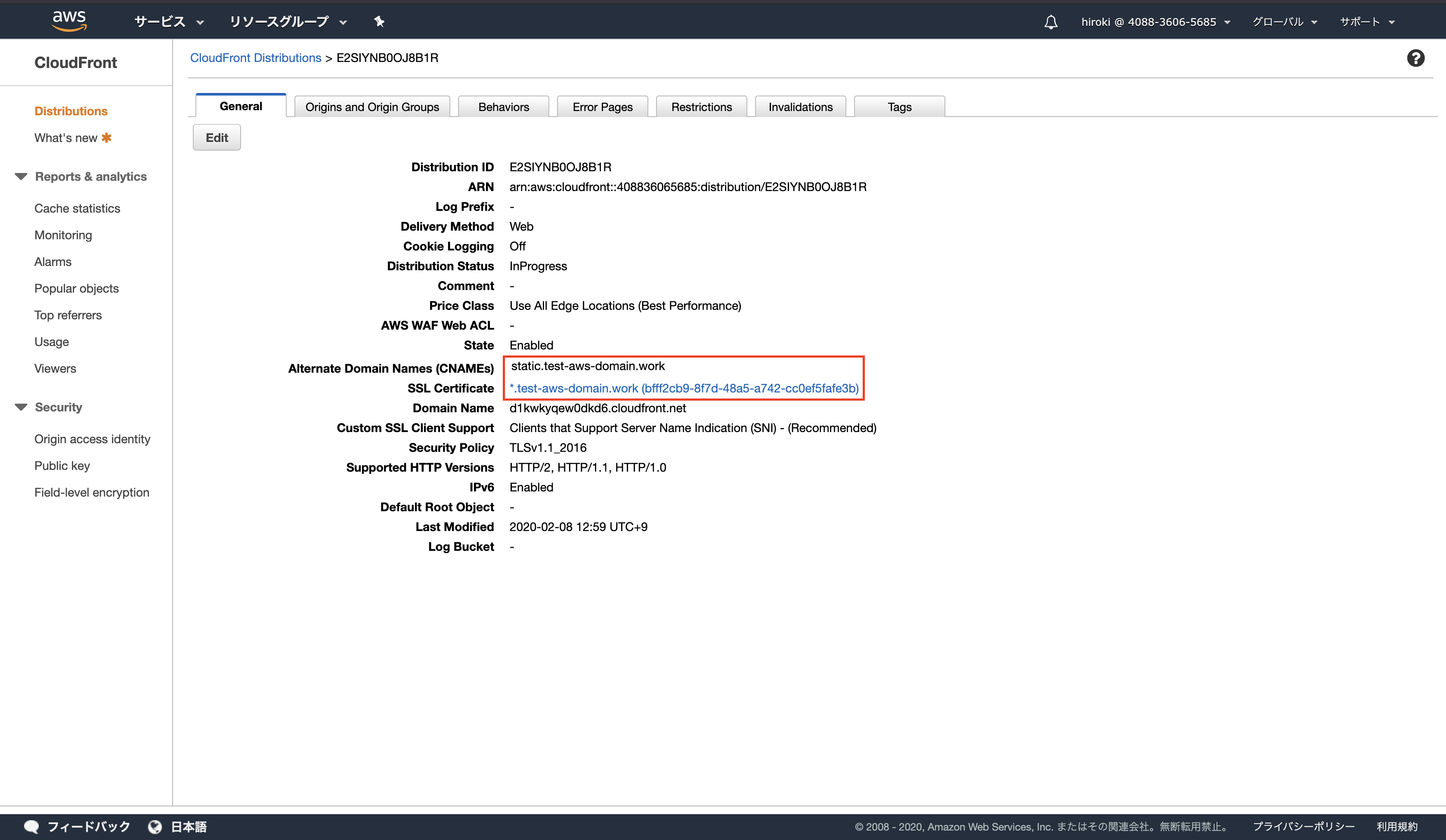
設定内容が反映されていることを確認
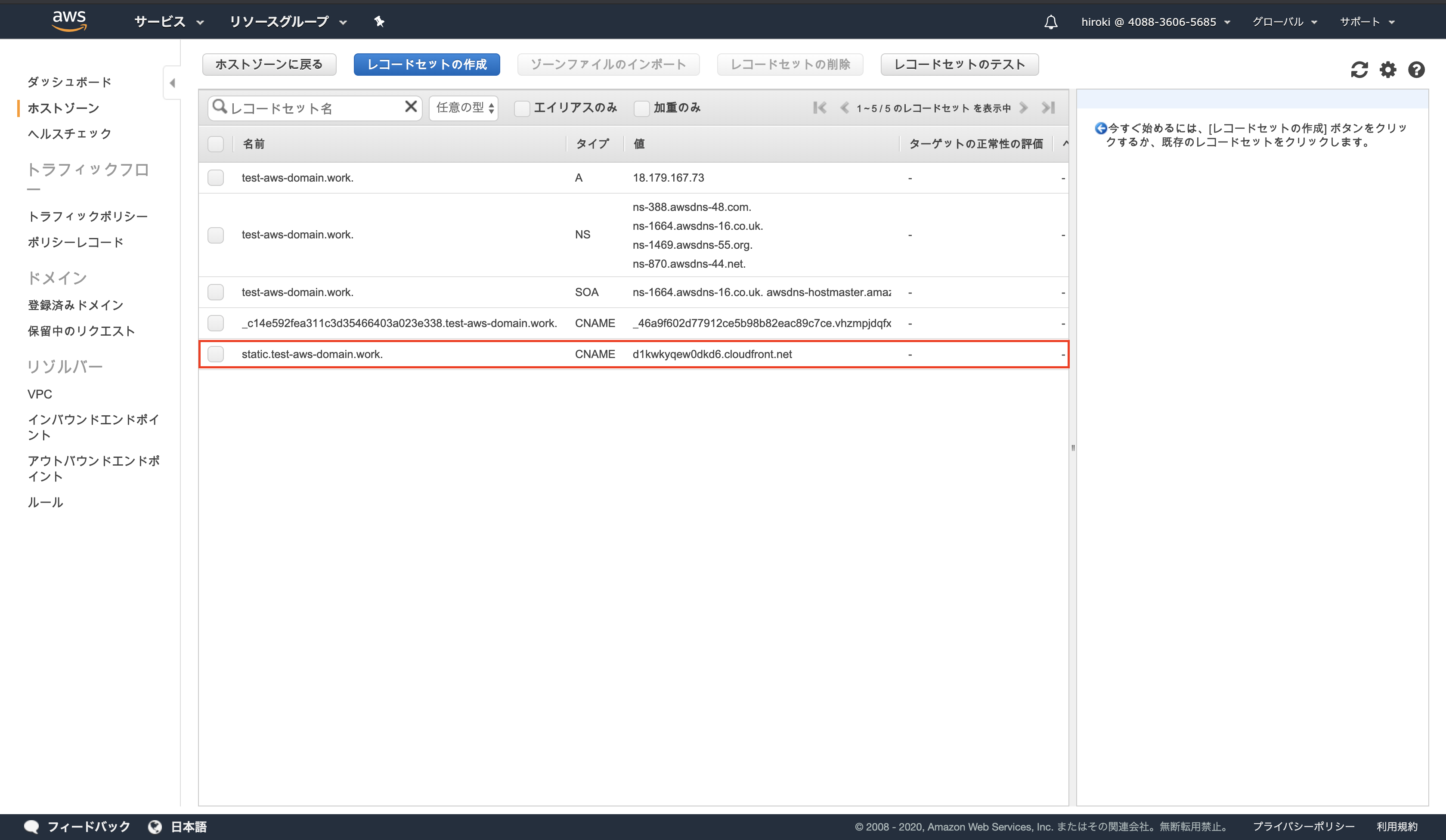
CNAMEレコードの作成
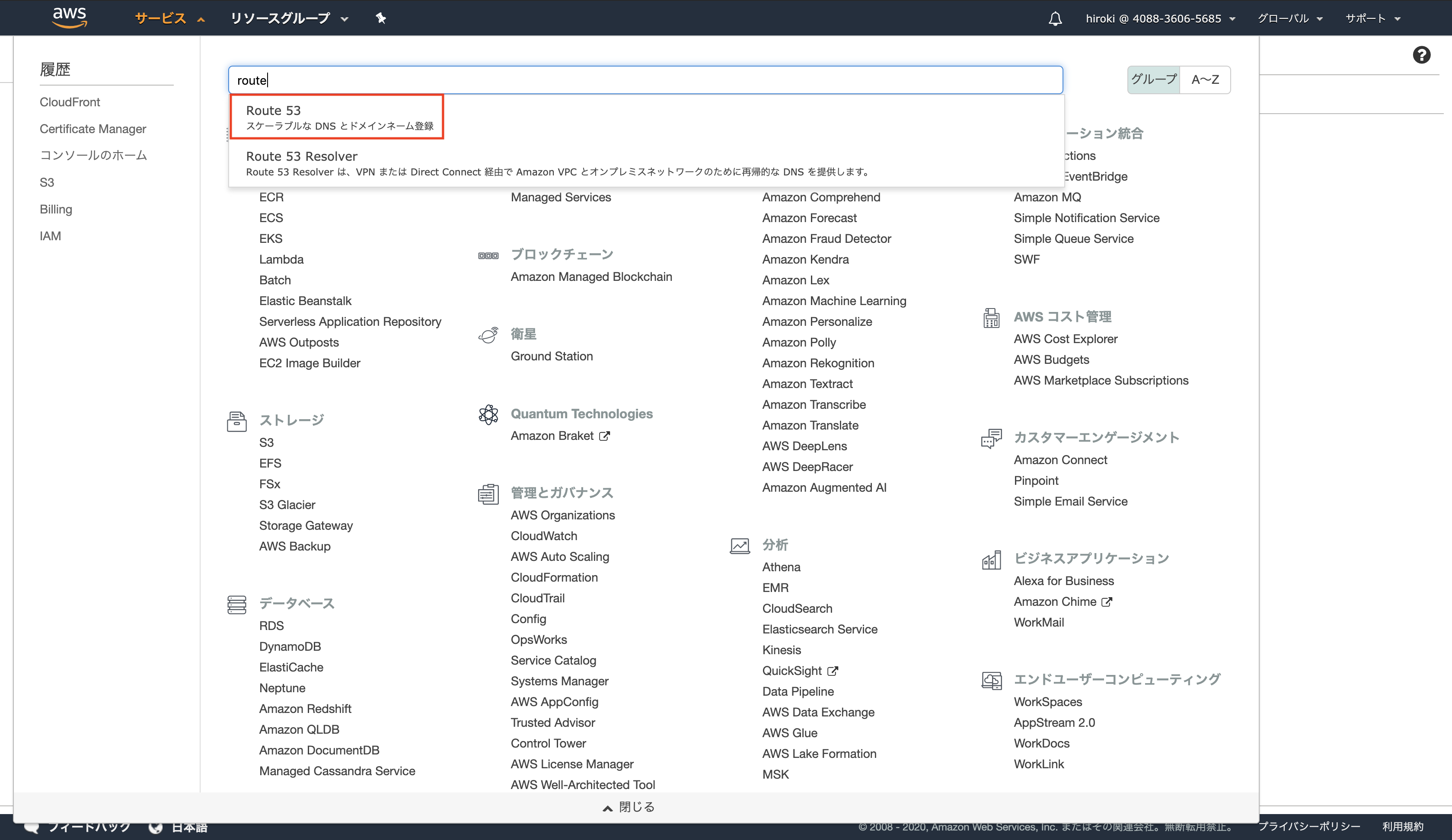
AWSコンソールからRoute 53を検索し、クリック
ホストゾーンをクリック
対象のドメイン名をクリック
「レコードセットの作成」をクリック
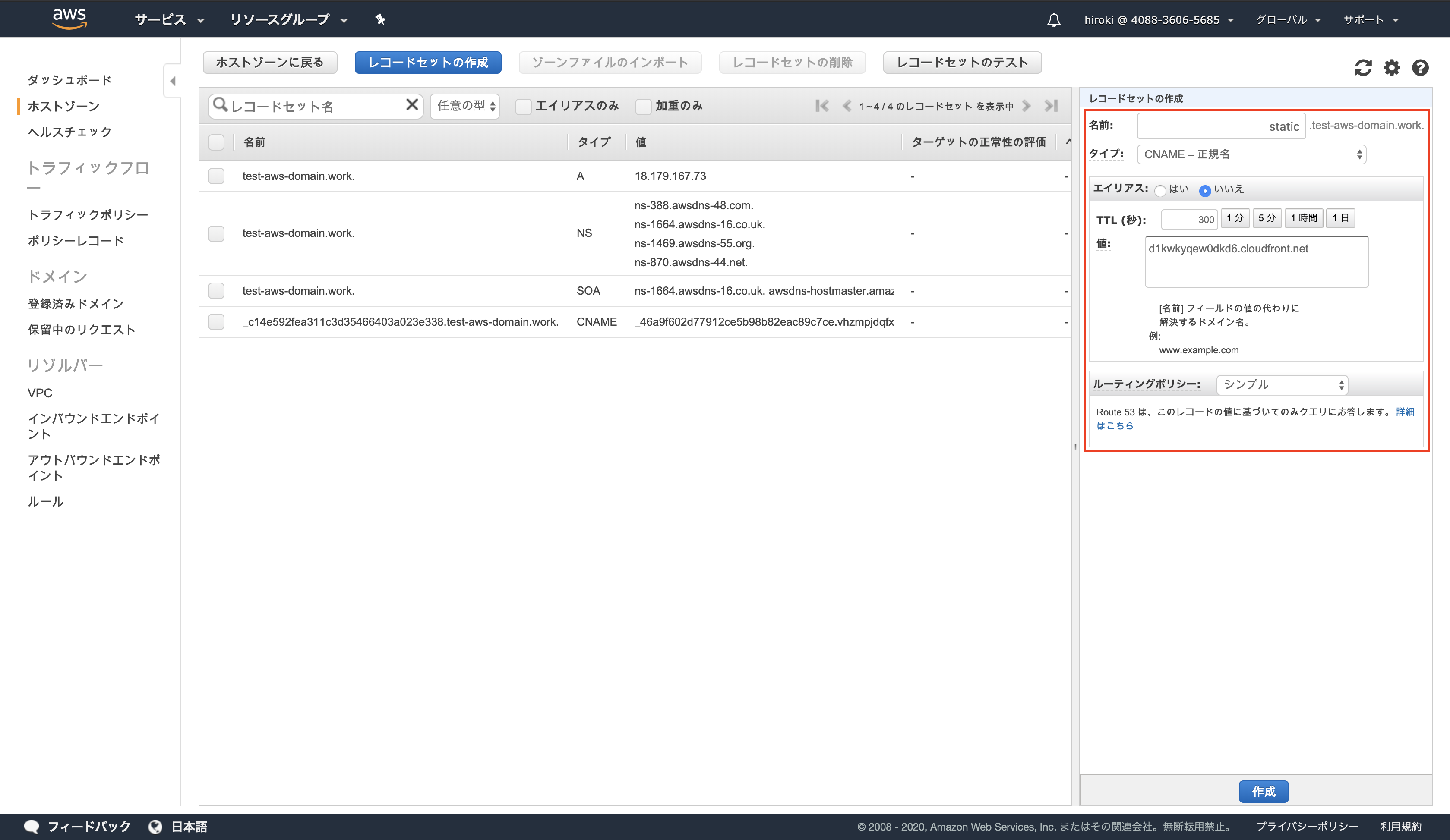
以下の通り設定し、「作成」をクリック
名前:CloudFrontで定義したサブドメイン
タイプ:CNAME
値:CloudFront DistributionのDomain Name
レコードセットが作成されていることを確認
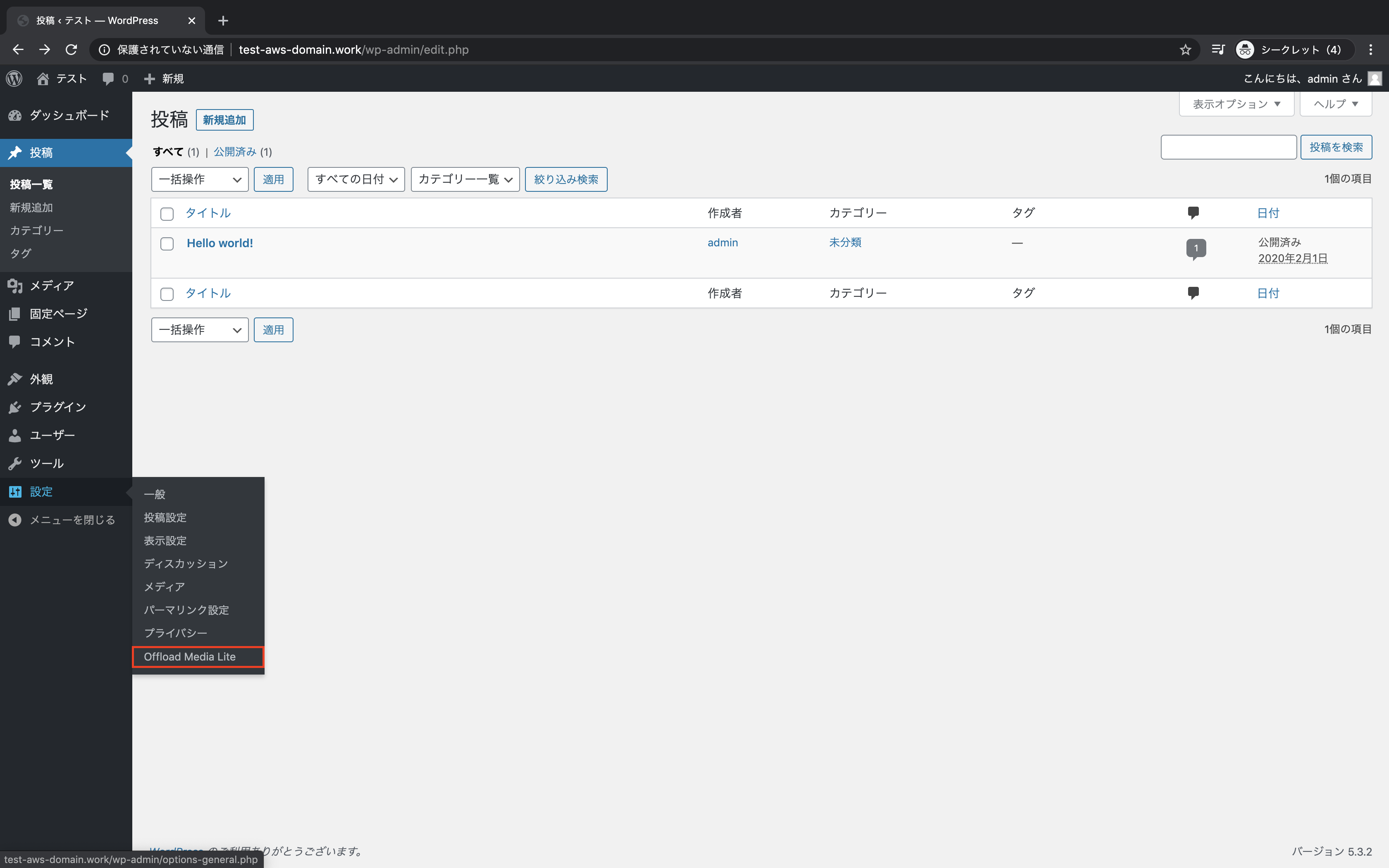
Offload Mediaの設定
WordPressの管理画面から設定 → Offload Media Liteをクリック
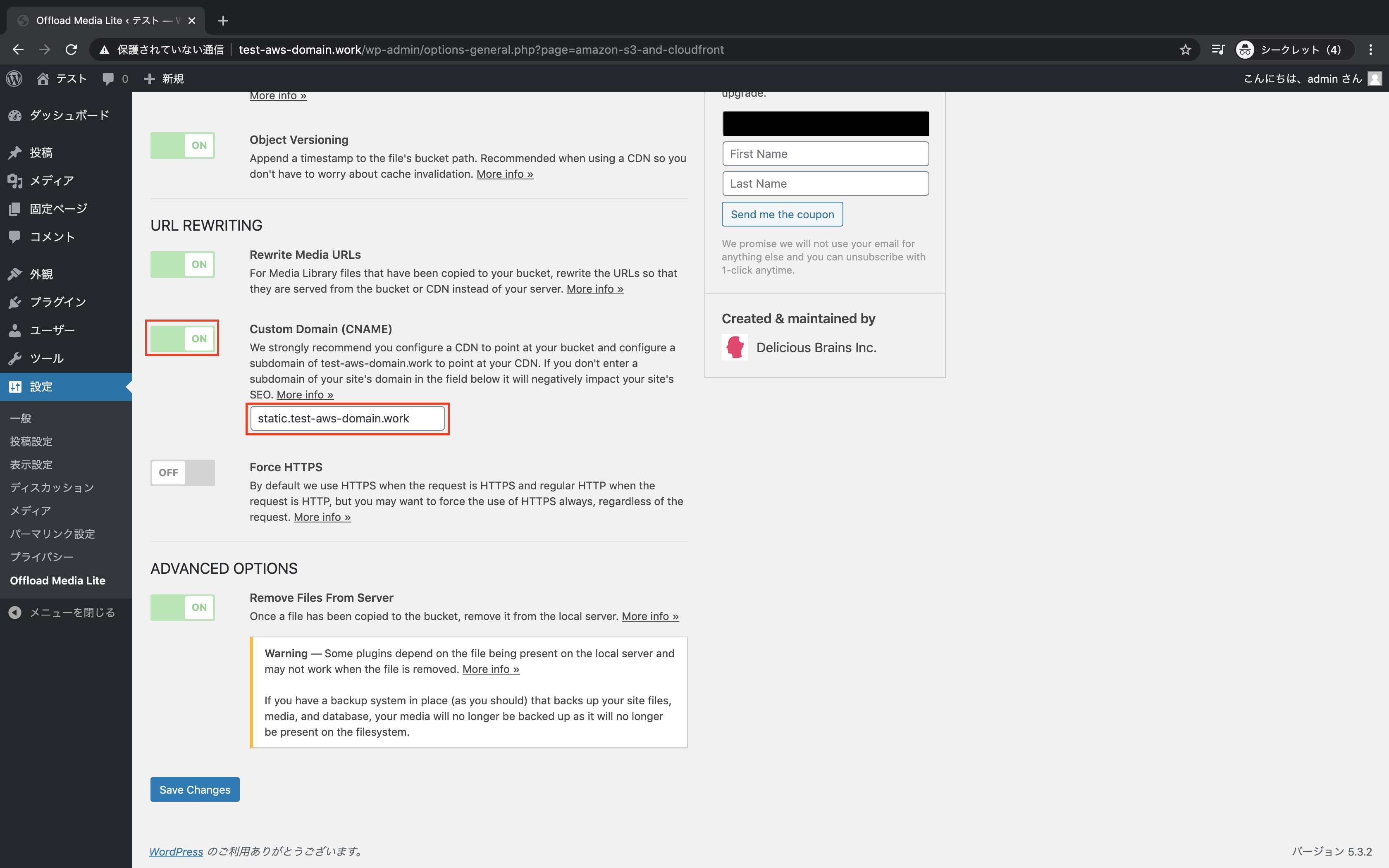
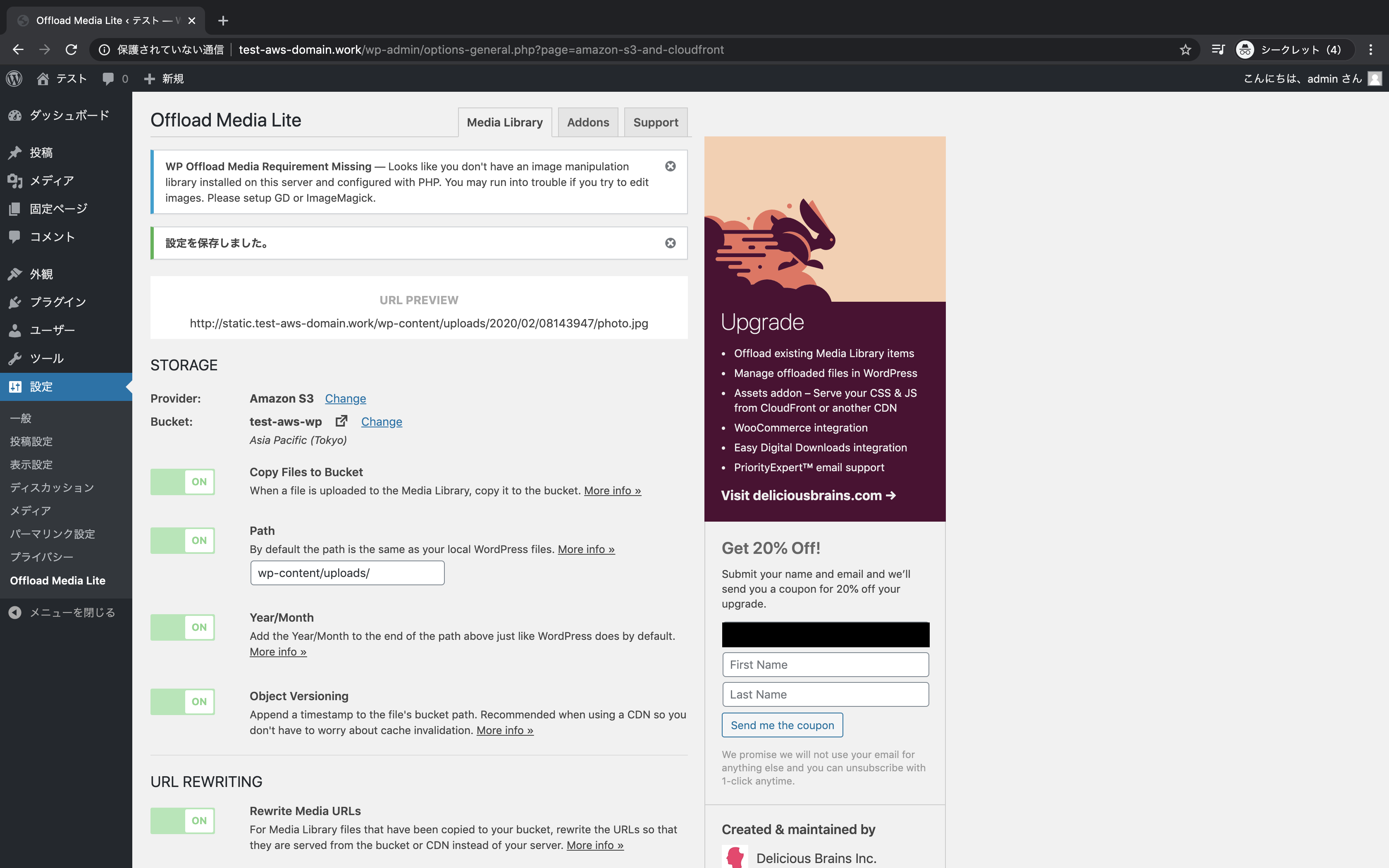
「Custom Domain」をON、CloudFrontで定義したドメイン名を入力し、「Save Changes」をクリック
設定が保存されたことを確認
参考















- 投稿日:2020-02-08T13:43:48+09:00
AWS Kinesisと仲良くなれるかもしれないまとめ
概要
- AWS Kinesisについてまとめています
- これからKinesis使う人の参考になれば幸いです
Kinesisとは
Amazon Kinesisによると、
Amazon Kinesis でストリーミングデータをリアルタイムで収集、処理、分析することが簡単になるため、インサイトを適時に取得して新しい情報に迅速に対応できます。
Amazon Kinesis は、アプリケーションの要件に最適なツールを柔軟に選択できるだけでなく、あらゆる規模のストリーミングデータをコスト効率良く処理するための主要機能を提供します。とのことで、ストリーミングデータをリアルタイムに処理するやーつです。
ちなみに、ストリーミングデータとは、AWSさんによると、ストリーミングデータは、数千ものデータソースによって継続的に生成されるデータです。
とのことです。
要は大量かつ継続的に飛んでくるデータのことなんですね。メリット
リアルタイム
Amazon Kinesis はストリーミングデータをリアルタイムで取得、バッファ、処理するため、通常は数時間から数日かかるインサイトの生成を数秒から数分で完了できます。
完全マネージド型
Amazon Kinesis は完全マネージド型ですので、インフラストラクチャを管理する必要なく、ストリーミングアプリケーションを実行できます。
スケーラブル
Amazon Kinesis はサイズの上限なくストリーミングデータに対応し、数千ものソースからのデータをとても低いレイテンシーで処理できます。
いろいろあるっぽい
Kinesisはストリーミングデータをリアルタイムで扱うサービスの総称であり、具体的にはいくつかあるっぽいです
この記事ではぼくがよく使っていたKinesis Data StreamsとKinesis Data Firehoseについて多少掘り下げてまとめています。
- Kinesis Video Streams
- ストリーミングデータが動画の場合に使う
- Kinesis Data Streams
- ストリーミングデータが動画以外(?)の場合に使う
- Kinesis Data Firehose
- ストリーミングデータをS3とかのデータストアに突っ込む場合に使う
- Kinesis Data Analytics
- SQLやJava でストリーミングデータ分析する場合に使う
Kinesis Data Streamsとは
- 大量のデータを高速かつ継続的に取り込みと集約を行うことができる
- データの取り込みと処理の応答時間はリアルタイムであるため、処理は一般的に軽量
- データがストリームに取り込まれてから処理されるまでは1秒未満くらいだそう
- 処理の流れは以下の感じ

用語
Amazon Kinesis Data Streams の用語と概念から拝借
データレコード
データレコードは、Kinesis data stream に保存されたデータの単位です。データレコードは、シーケンス番号、パーティションキー、データ BLOB (イミュータブルなバイトシーケンス) で構成されます。Kinesis Data Streams で BLOB 内のデータが検査、解釈、変更されることは一切ありません。データ BLOB は 最大 1 MB にすることができます。
シャード
シャードは、ストリーム内の一意に識別されたデータレコードのシーケンスです。ストリームは複数のシャードで構成され、各シャードが容量の 1 単位になります。各シャードは 読み取りは最大 1 秒あたり 5 件のトランザクション、データ読み取りの最大合計レートは 1 秒あたり 2 MB と 書き込みについては最大 1 秒あたり 1,000 レコード、データの最大書き込み合計レートは 1 秒あたり 1 MB (パーティションキーを含む) をサポートできます。ストリームのデータ容量は、ストリームに指定したシャードの数によって決まります。ストリームの総容量はシャードの容量の合計です。
データ転送速度が増加した場合、ストリームに割り当てられたシャード数を増やしたり、減らしたりできます。
雑にいうと、スケールアップしたい場合にはこのシャードの数を増やすとイケるっぽい
メリット
- 複数の処理を同時に独立して実行できる
- アプリケーションAでリアルタイム処理を実行しつつ、アプリケーションBでデータをS3にアーカイブするとか
- 他のAWSサービスとの連携が簡単
- S3やlambdaなどとの連携が超ラク
- 管理不要
- マネージドサービスなので自前でEC2建ててそこでストリーム処理を動かすよりもはるかに運用がラク
ユースケース
- ログとデータフィードの取り込みと処理の高速化
- リアルタイムのメトリクスとレポート作成
- リアルタイムデータ分析
- 複雑なストリーム処理
デバッグ方法
- AWS LambdaからKinesisにデータを簡単に送信できるので、それを使って任意のデータ構造のデータを送信するのがおすすめ
- IoT系などで準備が面倒い場合にはこのようにLambdaを使って擬似データを突っ込んでデバッグするのが個人的にはおすすめ
debug_kinesis.pyimport logging import boto3 import json import time logger = logging.getLogger() logger.setLevel(logging.DEBUG) kinesis_client = boto3.client('kinesis') # kinesis data streamsの名前 stream_name = 'sample_kinesis' # 連続送信する回数 exec_count = 10 # 送信間隔 sleep_time = 1 # 送信するサンプルデータ(とりあえずunix msecを送ると仮定) test_unix_msec = 1580000000000 # 指定の回数分だけKinesis Data Streamsにデータを突っ込む def bulk_put_to_kinesis(): for num in range(exec_count): # Kinesisに投入するデータの形成 put_data = { "payload": [ { } ], # なんかデータが入っていると仮定 "timestamp": test_unix_msec + num } json_data = json.dumps(put_data) put_to_kinesis(json_data) time.sleep(sleep_time) # Kinesisにデータを投入する def put_to_kinesis(put_data): try: result = kinesis_client.put_record( StreamName = stream_name, Data = put_data, PartitionKey = 'test' ) logger.info(result) except Exception as e: print('Kinesis put record excption') logger.error(e) return False # エントリポイント def lambda_handler(event, context): bulk_put_to_kinesis()Kinesis Data Firehorseとは
- リアルタイムのデータストリームをS3やRedshiftなどに配信するためのマネージドサービス
- 連携すると自動でデータを送信してくれる
- ある程度Firehorse側でデータを貯めてから配信するので、配信先に反映されるのに10秒くらいかかる
- リアルタイム処理はKinesis Data Streamで処理し、リアルタイム性を求めない処理はFirehorseで処理するのが良さそう
処理の流れは以下の感じ
送信元はいろいろ選べる
- Kinesis Data Streamsも使える(以下はFirehorseの作成画面で見られる)
- リアルタイム処理は Kinesis Data Streamsから直接Lambdaなどを経由して処理し、日次のバッチ処理は
Kinesis Data Firehorse経由である程度のデータの塊をS3に保存する(その後別サービスでS3からデータを取得してバッチデータを作る)のが良さそう
ユースケース
- ストリーミングデータをS3とかのデータストアに突っ込む場合に使う
- リアルタイム性を求めないバッチ処理やアーカイブなど
- ユーザー行動への計測系処理をRedshiftに突っ込むとか
- 計測結果は日次で見れればいいので、リアルタイムに反映される必要ない
参考

- 投稿日:2020-02-08T13:10:54+09:00
Workspaces DNS設定 (各hosts設定は面倒なので)
Workspaces DNS設定 (各hosts設定は面倒なので)
http://blog.serverworks.co.jp/tech/2019/02/27/authentication-relation-around-workspaces/
- 投稿日:2020-02-08T10:38:59+09:00
AWS DynamoDBと仲良くなれるかもしれないまとめ
概要
- DynamoDBの簡単な説明と、ハイパフォーマンスな状態で使い倒すための情報をまとめてます
- NoSQLに関する詳しい説明は省いていますので、気になる方は調べてみてください
DynamoDBの簡単なサマリー
- AWSが提供しているマネージドなNoSQL
- AWS Black Belt Techシリーズ Amazon DynamoDBが非常に参考になるので、是非ご覧ください
メリット
高い可用性と耐久性
- 大規模データを高速に出し入れできる
スループットに応じてスケーリング
- 読み込み/書き込み性能(キャパシティユニット)の変更が可能
- Auto Scalingにも対応
データ容量が実質的には無制限
テーブルのサイズ
テーブルのサイズには実用的な制限はありません。テーブルは項目数やバイト数について制限がありません。とのことで、安心して大量データを突っ込めそう
サーバーレスで管理不要
- RDSみたいにバージョンがあってというものではないので利用者側によるメンテ不要
デメリット
RDBのよくやる処理がきつい
- そもそもNoSQLなので複数テーブルを使ったjoinやトランザクション処理をしようとするのに向いてない
- 指定の形でデータを投入し、ほぼそのままの形でデータを取得するようなケースで使うのが良さそう
出てくるキーワード
Table
- RDBでいうDBテーブル
- プライマリーキーの貼り方は2種類
- Hash Key(いわゆるPrimary Key)
- Hash KeyとRange Key(いわゆる複合インデックス)
Hash Key
- パーティションキーとも呼ばれる(どれが正式かは謎..)
- 同一Hash Keyを持つデータの中での順序は保証しない
- テーブル作成時に設定する
- 後から変更できるかは不明(多分できない?)
Range Key
- ソートキーとも呼ばれる(どれが正式かは謎..)
- 同一Hash Keyを持つデータに対して、Range Keyにより順序を保証する
- 例えば、Hash KeyがuserIdでRange KeyがaccessedDateがあり、「userId=1のユーザーのaccessedDate=2020-01-01のデータを降順で取得したい」場合などに使える
- テーブル作成時に設定する
- 後から変更できるかは不明(多分できない?)
Item
- RDBでいうレコード
- 1つい上のAttributeを持つ
Attribute
- RDBでいうカラム
- Hash Key(と、指定している場合にはRange Key)以外は好きなデータを突っ込める
- あるレコードに入っているデータは
Aカラムに値を持っていて、別レコードに入っているデータはAカラムに値を持っていない、というのもできるLocal Secondary Index
- Range Key意外に絞り込み検索に使うためのキー
- Hash Keyが同一アイテム群から検索するために使う
- Range Keyは1つだけしか指定できないけど、更にRange Keyのように絞り込みをしたい場合に使う
- 一つのテーブルに最大5つまで貼れる
Global Secondary Index
- Hash Keyをまたいで検索を行うインデックス
- 例えば、userIdというHash Keyがあり、複数のuserIdに対して検索したい場合に使う
検索方法
- 以下、RDBでいうところのSQL実行方法的なやつを記載しています
- 代表的な検索情報(以下以外にもいろいろある)
1.Scan
- テーブルを総ナメするので超遅い
2.Query
- Hash KeyとRange Keyの複合条件にマッチするアイテム群を取得する
- 一般的に複数データを検索する場合にはQueryを使って検索を実行するのが望ましいと思われる
3.GetItem
- Hash Keyを条件として指定し、一軒のアイテムを取得
4.PutItem
- 1件のアイテムを書き込む
5.Update
- 1件のアイテムを更新
6. Delete
- 1件のアイテムを削除
ハイパフォーマンスな状態にするためのTips
1. テーブル設計は汎用化ではなくユースケースに応じて行う
AWSが出しているDynamoDB に合わせた NoSQL 設計が非常に参考になります
- NoSQLはRDBのように柔軟にクエリを実行するためのものではなく、特定の限られたクエリをできるだけ速く実行することを目的としている
- そのためデータ構造はRDBのように正規化して汎用的なテーブル構成をするのではなく、ビジネスユースケースの特定の要件に合わせて具体的にスキーマを設計するのがよい
- そのため、ビジネス要件が明確になっているケースでの使用が望ましい
2.特定のHash Keyにアクセスが集中しないようにする
- DynamoDBはHash Keyへのアクセスが分散される場合に高いパフォーマンスを発揮できるように設計されています
- そのため、大容量のクエリが一つのHash Keyに集中するとパフォーマンスが低下します
Hash Keyの値 均一性 ユーザーID(アプリケーションに多くのユーザーが存在する場合) 良 HTTPステータスコード(検索される可能性のあるステータスコードが少しだけある場合) 不良 3.インデックスは必要なものだけ貼る
- RDBと同じくDynamo DBでインデックスを貼ると書き込み時の性能が低下するので、必要なものに対してのみ貼る
参考
Dynamo DBの基本
- DynamoDBでのポイントまとめ
- DynamoDBによるソーシャルゲーム実装 How To
- DynamoDBのテーブル設計をするとき、自分に問いかけていること
- DynamoDBのドキュメントを結構読み込んだので、必要だと思ったことの要点まとめ
- DynamoDBを使いこなして精神的安定を手に入れた
- (AWS公式)Amazon DynamoDB とは
- (AWS公式)DynamoDB でのクエリの操作
Dynamo DBのチューニング
- 投稿日:2020-02-08T10:09:21+09:00
apacheからS3に静的ページを移行してパス補完で詰まった話
何を書いた記事か
AWS S3を用いて静的ページをホスティングする際のTipsです。
特に、apacheなどで配信されていた静的ページをS3に移行する際に使えると思います。apacheなどのMWがよしなに解析してくれていたURI PathをS3を用いたホスティングでどのように実現するかについて記載します。
ストーリー
とあるWebサイトのクラウド移行案件を進めることになりました。
そのWebサイトには、静的コンテンツ(HTML/CSS/JavaScript)のみで構成されたLP(静的ページ)が存在することがわかり、せっかくクラウドに移行するので、信頼性の高いS3から配信するようにしようと考えました。
また、対象のLPは接続できるIPに制限をかける必要があり、その実現についても考える必要がありました。As-Is
- apacheで静的ページを配信
- LoadBalancerでSSLを終端し、FirewallでIP制限を実施
- アクセスログはapache→fluentdで取得
To-Be
- 静的コンテンツはS3上に配置
- SSL通信を実現するため、CloudFrontにACM管理の証明書を持たせ、オリジンにS3を指定
- IP制限を実現するため、CloudFrontの手前にAWS WAFを設定し、IP Restrictionルールを設定
- アクセスログはCloudFrontとS3側で取得設定
S3静的コンテンツのSSL化参考
https://dev.classmethod.jp/cloud/aws/tls-for-s3-web-hosting-with-cloudfront/AWS WAFを用いたIP制限参考
https://blog.mmmcorp.co.jp/blog/2018/12/14/s3-cloudfront-awswaf/発生した問題
コンテンツをS3に配置し、CloudFrontとAWS WAFを構築して、さぁこれで完璧と思ってテストをすると、いくつかのリンクが切れていることが判明しました。
原因は、apacheがよしなに解析・補完してくれていたパスが今回の構成では補完できなくなったことにあります。例えば、下記のような補完です。
https://hoge.com/hoge/ -> https://hoge.com/hoge/index.html https://hoge.com/hoge -> https://hoge.com/hoge/index.html補完が必要なのは、2パターンでした。
- URIが
/で終わっていて、インデックスドキュメントが省略されているパターン- URIがディレクトリ名で終わっていて、ディレクトリを指定する
/とインデックスドキュメントが省略されているパターン逆に、下記のようなパターンは補完せずにそのままレスポンスを返す必要があります。
- URIにディレクトリ・ドキュメントパスまで明確に指定されているパターン。
https://hoge.com/hoge/hoge.htmlなど今回の構成でこのようなパス補完についてどのように対応すべきか考えました。
対処
結果として、Lambda@Edgeで補完処理を実行してあげると、想定通りの動きになることがわかりました。
Lambda@Edgeはエッジロケーション、つまりCloudFrontと同じロケーションで実行されます。
CloudFrontが受け取ったリクエストをインターセプトして、所定の処理を実施し、CloudFrontに流すことが可能です。今回上で補完対応が必要だとわかったパターンについて、requestエンティティを補完してあげるLambdaを作成し、@Edgeにデプロイしました。
lambda_function'use strict'; exports.handler = (event, context, callback) => { // // CloudFrontが受け取ったリクエストを取得 var request = event.Records[0].cf.request; // // URIを補完前後で変数に格納 // 変換が不要なパターンもあるので、初期化の段階でnewuriにはolduriの値を代入 var olduri = request.uri; var newuri = olduri; // // URIが / で終わってる場合(パターン1) if (olduri.slice(-1) === '/') { // 末尾にindex.htmlを詰める newuri = olduri.replace(/\/$/, '\/index.html'); } else { // URIを / でsplitし、最後の要素を取得。 // そこにピリオドが含まれていなければパターン2としてインデックスドキュメントを詰める var last_string = olduri.split('/').pop() if (!last_string.includes('.')) { newuri = olduri + '/index.html'; } } console.log(newuri) // // requestオブジェクトのuriプロパティを、置換後の値に変更 request.uri = newuri; // // CloudFrontに返す return callback(null, request); // };これで、必要な補完は実行してくれつつ、他が不要なURI構成についてはそのままCloudFrontz→オリジンS3にアクセスが行くこととなります。
注意点
今回の対応を実施したLPを運用していて気づいた注意点があります。
- Lambda@Edgeは同時実行数制限をかけることができない(コンソール上は指定できるが、効かない)
- Lambda@Edgeはエッジロケーションで実行されるので、どこのリージョンのログに現れるかがわからない(国内サービスであればほぼap-noetheast-1ですが)
他サービスで多重にlambdaを起動する必要がある場合などはedgeで同時実行数が消費されて他サービスに影響が出る可能性があるので、上限を引き上げるかAWSアカウントを分離するか検討した方がいいと思います。
まとめ
なんだかんだ言ってapacheは便利で賢いな、と思いました。
まだまだ要件次第では静的Webサイトホスティングをサーバレスで実現するのは難しいケースがありそうです。また今回の問題はそもそもHTMLのリンクパスの記法が統一されていないことが原因で発生しました。
HTML書く時はlink属性に詰めるパスパラメータの書き方は統一し、なるべく補完に頼らずにフルの相対パスを記載するのがいいと思います。