- 投稿日:2020-02-04T23:40:13+09:00
【RaspberryPi】部屋の照明を消すと自動的に LCD も消灯するエコ設計 DIY
前回は液晶ディスプレイを消灯できるものに交換しました。
次はロマンを追い求めてみたいと思います。仕様
- 部屋の照明が消える
- Arduino に接続された照度センサーにより部屋の照度を検知(50 以下になる)
- Python がシリアル通信から部屋の照度を取得(50 以下を取得)
- 部屋が暗い状態に(照度 50 以下に)変化したら液晶ディスプレイの消灯コマンドを実行
- 部屋の照明を点ける
- 部屋が明るい状態に(照度 50 以上に)変化したら点灯コマンドを実行
背景
- コマンドをいちいち打つのが面倒
- かといって部屋に人がいない(照明を消した)状態で LCD 点きっぱなしはもったいない
- ロマン重視
ハードウェア設計
マイコン:Arduino Micro
照度センサー:NJL7302L-F3 1個
抵抗:10kΩ 1個回路はそれほど難しいものではないです。
入力は 5V で、出力が A3 と抵抗 10kΩ -> GND になっているだけです。
(回路図では抵抗が 220Ω になってますが、それしか絵が見つけられなかったので読み替えてください)
ソフトウェア設計
まずは Arduino で実行するプログラムのソースコードです。
A3(アナログ3番ポート)を読み取って、1秒おきにシリアル通信へ書き出すだけのシンプルなものです。mySketch.inovoid setup() { //start serial connection Serial.begin(9600); //configure pin A3 as an input and enable the internal resistor pinMode(A3, INPUT); } void loop() { //read the photocell value into a variable int sensorVal = analogRead(A3); //print out the value of the photocell Serial.println(sensorVal); //delay 1000 ms delay(1000); }インターフェース設計
UI 画面表示とバックライト制御は Python が行います。
まずは Tkinter で画面を作りますが、パディング(padx, pady)を取ったところがグレーになってます。
※数値などの表示はダミーです。ちなみにソースコードの一部はこんな感じ。
main.pyself.label1=Label(self, text="接続先", bg="white", font=("Sans", 16, "normal")) self.label1.grid(row=0, column=0, sticky="news", padx=5, pady=2) self.label2=Label(self, text="/dev/ttyACM0", bg="#E4E4FF", font=("Sans", 16, "normal")) self.label2.grid(row=0, column=1, sticky="news", padx=5, pady=2)内部パディング(ipadx, ipady)にしてはどうか。
結果はこちら。
いやいや、そうじゃないんだ。
空間というか、白背景で余白を持たせたいだけなんだ。なんとかならないものかと調べていると、
白背景のフレームを親に置き、子としてラベルを所属させたら良いとの情報。main.pyself.label1=Label(self, text="接続先", bg="white", font=("Sans", 16, "normal")) self.label1.grid(row=0, column=0, sticky="news", ipadx=5, ipady=2) self.frame2=Frame(self, bg="white") self.frame2.grid(row=0, column=1, sticky="news") self.frame2.columnconfigure(0, weight=1) self.label2=Label(self.frame2, text="", bg="#E4E4FF", font=("Sans", 16, "normal")) self.label2.grid(row=0, column=0, sticky="news", padx=5, pady=2)
今度はうまく行きました。
ネット民達は天才だらけですな。
しかし、これだけのために半日潰してますからね。報われないっす。仕上げ
センサーデバイス(Arduino)を探して、接続できれば接続して「接続先」と「通信速度」を表示します。
例外時は何もしません。1秒後に再処理して接続できたらそれで良いと判断できるからです。main.py# 表示を更新 def update(self): # センサーデバイスを探す self.ser_name=sensor_setting.dev_search() try: # 通信準備中かつ、センサーデバイスが OS に認識されている場合 if not self.ser_init and self.ser_name != "": # シリアル通信の初期化 self.ser=serial.Serial(self.ser_name, sensor_setting.bps, timeout=sensor_setting.timeout) # 通信準備完了 self.ser_init=True # 接続先を表示 self.label2.configure(text=self.ser_name) # 接続速度を表示 self.label4.configure(text="{0}bps".format(sensor_setting.bps)) # 例外時は何もしない except: pass接続できたらシリアル通信を開始して、照度を取得します。
部屋が暗くなったらバックライト消灯、明るくなったら点灯するように連動します。例外発生時は次の1秒後にリトライします。
main.pytry: # シリアル通信を開始 if self.ser.is_open == False: self.ser.open() # 1行受信(b'照度¥r¥n' の形式で受信) serval=self.ser.readline() if len(serval) >= 0: # 改行コードを削除(b'照度') serval=serval.strip() # バイナリ形式から文字列に変換(照度) serval=serval.decode("utf-8") # 照度を更新 self.label12.configure(text=serval) # バックライト点灯中に部屋が暗くなったら if int(serval) < 50 and self.backlight_state == 1: # バックライト消灯 os.system('sudo sh -c "echo 0 > /sys/class/backlight/soc\:backlight/brightness"') self.backlight_state=0 # バックライト消灯中に部屋が明るくなったら elif int(serval) >= 50 and self.backlight_state == 0: # バックライト点灯 os.system('sudo sh -c "echo 1 > /sys/class/backlight/soc\:backlight/brightness"') self.backlight_state=1 # 例外時 except: # センサー表示をクリア self.label6.configure(text="") self.label8.configure(text="") self.label10.configure(text="") self.label12.configure(text="") # 1秒後に再表示 self.master.after(1000, self.update)ウィンドウを閉じる前に、バックライトを点灯します。
バックライト制御が中断するので、点灯しておいた方が何かあったときは便利かなと思いました。main.py# 閉じるボタンイベント def on_closing(): if messagebox.askyesno("Quit", "終了しますか?"): # バックライト点灯 os.system('sudo sh -c "echo 1 > /sys/class/backlight/soc\:backlight/brightness"') # アプリケーション終了 root.destroy()まとめ
Python ソースコードは長めなので、
ご興味ありましたら GitHub をご参照ください。
https://github.com/km7902/mySensorなんとか、部屋の照明と連動してバックライト ON/OFF ができるようになりました。
消費電力は「ちりつも」ですから。地球に優しいシステムになりました。次は温度・湿度・気圧を取得してデータベースに記録し続けるという
仕組みができたらいいなと思っています。
![Screenshot_20200201[1].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F362854%2Fb065f721-0b11-ca52-a9e1-9975d4376e3a.png?ixlib=rb-1.2.2&auto=format&gif-q=60&q=75&s=1224c03db96c860bc66b079e7dd48d09)

![Screenshot_20200201[2].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F362854%2Fb1dd8d22-27a7-b2fd-19d0-c3459eb35a30.png?ixlib=rb-1.2.2&auto=format&gif-q=60&q=75&s=417fbff62f3539b006be7f8f29fff6e2)
![Screenshot_20200201[3].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F362854%2F61d21020-0c87-815e-ab51-a01503316625.png?ixlib=rb-1.2.2&auto=format&gif-q=60&q=75&s=9452fcb3ae7dd66da5b8c8e5b613514c)
![Screenshot_20200201[4].png](https://qiita-user-contents.imgix.net/https%3A%2F%2Fqiita-image-store.s3.ap-northeast-1.amazonaws.com%2F0%2F362854%2Fbe5f96fb-d4a7-0612-1d22-d02b3280a450.png?ixlib=rb-1.2.2&auto=format&gif-q=60&q=75&s=aa5592963b740584e38af3d59a79174e)
- 投稿日:2020-02-04T23:32:15+09:00
Pythonの例外処理についてまとめてみた
例外処理
今日はエラーについて解説していきます。初歩的な内容ですが、エラーなんて
try~except書いときゃいいんでしょ?という方は、参考にしてみてください。また、説明に誤りがある場合コメントをいただけると幸いです。さて、Pythonで生じるエラーは主に二つに大別されます。一つは構文エラー(syntax error)と例外(exception)です。
構文エラー
これは、プログラムを実行する前から誤っていると判断できる際に起こります。例えば、識別子(identifier)の規則を満たしていない変数名を使ったり、インデントがおかしかったり、とにかく文法がおかしい時に生じるエラーのことです。
a[0]をa[0}と書いたり、ifをofと書いたり...(これやったことありますか?僕はあります...)例を上げきれませんね。簡単に言えば、構文エラーはプログラムを書く練習をしていれば減ってくる文法ミスです。一応例を書いておきます笑#構文エラーの例 a = [1, 2, 3] print(a[3})出力
print(a[3}) ^ SyntaxError: invalid syntax例外
これはプログラムを実行中にコンピュータが(インタプリタが?)「こいつは処理できないぞ?」と判断した際に生じるエラーです。簡単な例で言えば
a = [1, 2, 3] print(a[3])出力
1 a = [1, 2, 3] ----> 2 print(a[3]) IndexError: list index out of range配列の要素はインデックス番号2までしか存在しませんから、
a[3]を出力しようとすると当然例外が発生します。ここでは例外の例としてIndexErrorを示しましたが、まだまだたくさんあります。例外を捕捉する
さて、プログラムを実行した時に、例外が発生しても処理を続けたい場合があります。その際はお馴染みの
try~exceptを使います。例外処理によってZeroDivisionErrorが出てもプログラムが止まらないようにしてみましょう。a = 1 b = 0 try: print(a/b) except ZeroDivisionError: print('0で割っちゃダメでしよ?ZeroDivisionErrorがでたでし') finally: print('割り算はむずかちぃでし')出力
0で割っちゃダメでしよ?ZeroDivisionErrorがでたでし 割り算はむずかちぃでし上の例のように、最後の後始末的に
finallyをつけてもいいです。これは例外が発生しようがしまいが最後に実行され、そこで処理が中断、終了します。複数の例外を捕捉する
exceptには、次のようにタプルで複数の例外を捕捉できるよう指定できます。try: a = int(input('a = ')) b = int(input('b = ')) print(a/b) except (ValueError, ZeroDivisionError): print('ValueErrorかZeroDivisionErrorが起こっているでし')出力1
a = 1.5 ValueErrorかZeroDivisionErrorが起こっているでし出力2
a = 1 b = 0 ValueErrorかZeroDivisionErrorが起こっているでし例外に名前を付ける
さらに、発生した例外に名前をつけることもできます。以下では、
ValueErrorかZeroDivisionErrorが発生するよう入力していますが、発生した例外を捕獲し、ERという名前をつけています。try: a = int(input('a = ')) b = int(input('b = ')) print(a/b) except (ValueError, ZeroDivisionError) as ER: print(f'{type(ER)}が起こっているでし')出力1
a = 1.5 <class 'ValueError'>が起こっているでし出力2
a = 1 b = 0 <class 'ZeroDivisionError'>が起こっているでしこの
ERという名前はexceptのスイート内でしか使えないので気をつけてください。次のようにするとNameErrorが発生してしまいます(せっかくなのでこのNameErrorも捕捉してやりましょう)。try: a = int(input('a = ')) b = int(input('b = ')) print(a/b) except (ValueError, ZeroDivisionError) as ER: pass try: print(ER) except NameError: print('ERって何のことでしか?')出力
a = 1.5 ERって何のことでしか?raiseで例外を発生させる
raiseによって意図的に例外を発生させることもできます。ただしここで使えるのはBaseExceptionクラスのサブクラスかインスタンスに限られます。(後述しますが、よく見る例外はほとんどこのBaseExceptionのサブクラスです。)def ErFunc(b: int) -> None: if b == 0: raise ZeroDivisionError b = 0 try: ErFunc(b) except BaseException as ER: print(f'{type(ER)}が発生してるでし')出力
<class 'ZeroDivisionError'>が発生してるでしここでは
BaseExceptionクラスが指定されているので、その派生クラスは何でも捕捉できるようになっています。ここではZeroDivisionErrorが捕捉されています。ユーザー定義の例外
最後に、クラスを使ってユーザー定義の例外クラスを作成することもできます。以下は一桁の二つの自然数の和を求めるプログラムですが、負の数や二桁の数が入力されたり、和が二桁になると例外を発生させるようにします。
ParameterRangeExceptionクラスもReturnRangeExceptionクラスもどちらも範囲に関するクラスなので、RangeExceptionクラスから継承しています。もちろん、標準組み込みクラスであるExceptionクラスから継承するようにしても問題ありません。class RangeException(Exception): pass class ParameterRangeException(RangeException): pass class ReturnRangeException(RangeException): pass def add(a: int, b: int) -> int: if not 0 < a < 10: raise ParameterRangeException if not 0 < b < 10: raise ParameterRangeException if a + b > 10: raise ReturnRangeException else: return a + b try: a = int(input()) b = int(input()) print(f'二数の和は{add(a, b)}でし') except ParameterRangeException as PRE: print(f'{type(PRE)}が生じてるでし。仮引数は0~10を入れるでし') except ReturnRangeException as RRE: print(f'{type(RRE)}が生じてるでし。返却値を9以下にしなきゃダメでし') finally: print('例外の説明は以上でし')出力1
1 8 二数の和は9でし 例外の説明は以上でし出力2
2 11 <class '__main__.ParameterRangeException'>が生じてるでし。仮引数は0~10を入れるでし 例外の説明は以上でし出力3
5 7 <class '__main__.ReturnRangeException'>が生じてるでし。返却値を9以下にしなきゃダメでし 例外の説明は以上でし補足
Pythonに用意されている標準組み込み例外の親クラスは
BaseExceptionクラスです。これを親として、Exceptionクラスがあり、これを継承した形でValueErrorクラスやIndexErrorクラスが存在しています。ユーザー定義の例外を作る場合、
UserExceptionClass()の引数にBaseExceptionを入れてはいけません。仕様的にBaseExceptionクラスはユーザー定義例外に継承されることを前提としていないようです。
BaseExceptionクラスの子クラスとしてArithmeticErrorクラスがありますが、このクラスの下にOverflowErrorクラスやZeroDivisionErrorクラスが存在します。もし算術エラーを扱いたいのであれば、ユーザー定義例外を作る際、引数にArithmeticErrorを入れても構いません(Exceptionクラスまたはそれよりも下部のクラスであれば何でもOK)。
- 投稿日:2020-02-04T23:24:32+09:00
Backtraderのインストール
backtraderの日本語記事が少なかったので自分が書いてみることにしました。
つまづいたことや動かしてみてわかったことを書き留めていこうと思います。
間違っている部分を見つけたらコメント等で指摘していただけると幸いです。backtrader人口が増えてもっと解説記事が増えたらいいなー、と願ってます。
私の動作環境
Windows8.1pro 64bit
Anaconda3 2019.10
(backtrader用の仮想環境をPython3.5で構築)Python3.5仮想環境にJupyternotebookインストールするときの注意
Anaconda3のインストールや仮想環境の構築に関してはわかりやすくて詳しい記事がたくさんありますのでそちらを参考にしてみてください。
私の場合、仮想環境にJupyternotebookをインストールしたら起動時にカーネルエラーが発生しました。Win32apiが見つからないという趣旨のことが書かれていて仮想環境にPIP経由でpywin32をインストールすることで解決できました。こちらの記事に詳しく書かれています。
Anacondaの仮想環境で個別のPython環境を作る方法 | エビワークス
https://ebi-works.com/anaconda-env/PypIのbactraderページではPython3.7まで対応とあるのですが、Python3.5で開発という記述があったので念の為に3.5で仮想環境を作りました。こちらにbactraderをインストールしていきます。
backtraderインストール
Anacondapromptから仮想環境を立ち上げます。私はenvbactraderという環境名にしました。インストールの際にこの [plotting]をつけるとmatplotlibも一緒にインストールされます。
install.py(envbacktrader) C:\Users\xxxx pip install backtrader[plotting]念のためconda listコマンドでパッケージを確認してみます。
condalist.py(envbacktrader) C:\Users\xxxx conda list # packages in environment at C:\Users\xxxx\Anaconda3\envs\envbacktrader: # # Name Version Build Channel backtrader 1.9.74.123 pypi_0 pypi blas 1.0 mkl bleach 3.1.0 py_0 ca-certificates 2019.11.27 0 certifi 2018.8.24 py35_1 colorama 0.4.3 py_0 cycler 0.10.0 pypi_0 pypi decorator 4.4.1 py_0 defusedxml 0.6.0 py_0 entrypoints 0.2.3 py35_2 icc_rt 2019.0.0 h0cc432a_1 #......省略無事インストールされました。
- 投稿日:2020-02-04T22:50:07+09:00
Fn Projectを使ってPythonで書いたfunctionを動かしてみる
概要
このエントリでは、OSSのFaaSサーバである「Fn Project」を使い、Pythonの関数を動かすパターンを扱います。
下図のようなPythonによる掛け算の関数をFnのサーバにデプロイして動かします。
想定読者
- Fn ProjectでのJavaScriptプログラムまだ自分で動かしていない方
- 「Fn Projectを使ってJavaScriptで書いたfunctionをNodeで動かしてみる」のPython版に興味がある方
準備
Fn Projectを動かすまでのところは、別エントリ「OCIのMicro InstanceでCentOSにFn Projectのサーバをインストールしてみる」を参照ください。
このエントリでは、筆者はOCIのMicro Instanceの上で作業しています。
Pythonでfunctionを動かす
作業の基本的な流れは、Introduction to Fn with Pythonに書いてあるものに従っています。
Fn上のアプリ
別のエントリ「Fn Projectを使ってJavaScriptで書いたfunctionをNodeで動かしてみる」で、「fn create app」で、fn上に「calc-fn-app」アプリを作ってあるものにFunctionを追加する形をとります。
登録
/multiplyという位置にPythonで関数を一つ作るため、「fn init」を実行します。
$ fn init --runtime python --trigger http multiply Creating function at: ./multiply Function boilerplate generated. func.yaml created.下記のような3つのファイルができています。
$ ls func.py func.yaml requirements.txtコードを変更
下記のような、入力値のleftとrightを足して返すような関数に書き換えます。
import io import json from decimal import * from fdk import response def handler(ctx, data: io.BytesIO=None): value = Decimal('NaN') try: body = json.loads(data.getvalue()) left = Decimal(body.get('left')) right = Decimal(body.get('right')) value = left * right except (Exception, ValueError) as ex: print(str(ex)) return response.Response( ctx, response_data=json.dumps( {"result": str(value)}), headers={"Content-Type": "application/json"} )アプリデプロイします。「-w」で作業ディレクトリを指定して、登録しています。
fn --verbose deploy --app calc-fn-app --local -w /home/opc/calc-fn-app/multiply初回実行時には、以下のような流れとなるようです。
$ fn --verbose deploy --app calc-fn-app --local -w /home/opc/calc-fn-app/multiply Deploying multiply to app: calc-fn-app Bumped to version 0.0.2 Building image fndemouser/multiply:0.0.2 FN_REGISTRY: fndemouser Current Context: default Sending build context to Docker daemon 6.144kB Step 1/12 : FROM fnproject/python:3.6-dev as build-stage 3.6-dev: Pulling from fnproject/python 80369df48736: Pull complete aaba0609d543: Pull complete a97b990f94a5: Pull complete af4a941e5376: Pull complete 709c35256bb6: Pull complete 3c3deb8445b4: Pull complete Digest: sha256:8ac8c28a68fd0442b9ddcdf6a41f30230482d72d1024cafca06c9f1ac0bd821c Status: Downloaded newer image for fnproject/python:3.6-dev ---> c5dbe9a0175b Step 2/12 : WORKDIR /function ---> Running in f7aaa0e58f7a Removing intermediate container f7aaa0e58f7a ---> 697f68e69e7c Step 3/12 : ADD requirements.txt /function/ ---> c4472f73a275 Step 4/12 : RUN pip3 install --target /python/ --no-cache --no-cache-dir -r requirements.txt && rm -fr ~/.cache/pip /tmp* requirements.txt func.yaml Dockerfile .venv ---> Running in 4f758b74080b Collecting fdk Downloading https://files.pythonhosted.org/packages/1d/b8/41b81bf76766f7e810627728647a8076626070a6e1d01a18a8ed16bd3d3f/fdk-0.1.12-py3-none-any.whl (46kB) Collecting iso8601==0.1.12 Downloading https://files.pythonhosted.org/packages/ef/57/7162609dab394d38bbc7077b7ba0a6f10fb09d8b7701ea56fa1edc0c4345/iso8601-0.1.12-py2.py3-none-any.whl Collecting httptools>=0.0.10 Downloading https://files.pythonhosted.org/packages/1b/03/215969db11abe8741e9c266a4cbe803a372bd86dd35fa0084c4df6d4bd00/httptools-0.0.13.tar.gz (104kB) Collecting pbr!=2.1.0,>=2.0.0 Downloading https://files.pythonhosted.org/packages/7a/db/a968fd7beb9fe06901c1841cb25c9ccb666ca1b9a19b114d1bbedf1126fc/pbr-5.4.4-py2.py3-none-any.whl (110kB) Collecting pytest==4.0.1 Downloading https://files.pythonhosted.org/packages/81/27/d4302e4e00497448081120f65029696070806bc8e649b83f644de006d710/pytest-4.0.1-py2.py3-none-any.whl (217kB) Collecting pytest-asyncio==0.9.0 Downloading https://files.pythonhosted.org/packages/33/7f/2ed9f460872ebcc62d30afad167673ca10df36ff56a6f6df2f1d3671adc8/pytest_asyncio-0.9.0-py3-none-any.whl Collecting py>=1.5.0 Downloading https://files.pythonhosted.org/packages/99/8d/21e1767c009211a62a8e3067280bfce76e89c9f876180308515942304d2d/py-1.8.1-py2.py3-none-any.whl (83kB) Collecting pluggy>=0.7 Downloading https://files.pythonhosted.org/packages/a0/28/85c7aa31b80d150b772fbe4a229487bc6644da9ccb7e427dd8cc60cb8a62/pluggy-0.13.1-py2.py3-none-any.whl Collecting attrs>=17.4.0 Downloading https://files.pythonhosted.org/packages/a2/db/4313ab3be961f7a763066401fb77f7748373b6094076ae2bda2806988af6/attrs-19.3.0-py2.py3-none-any.whl Collecting setuptools Downloading https://files.pythonhosted.org/packages/a7/c5/6c1acea1b4ea88b86b03280f3fde1efa04fefecd4e7d2af13e602661cde4/setuptools-45.1.0-py3-none-any.whl (583kB) Collecting more-itertools>=4.0.0 Downloading https://files.pythonhosted.org/packages/72/96/4297306cc270eef1e3461da034a3bebe7c84eff052326b130824e98fc3fb/more_itertools-8.2.0-py3-none-any.whl (43kB) Collecting six>=1.10.0 Downloading https://files.pythonhosted.org/packages/65/eb/1f97cb97bfc2390a276969c6fae16075da282f5058082d4cb10c6c5c1dba/six-1.14.0-py2.py3-none-any.whl Collecting atomicwrites>=1.0 Downloading https://files.pythonhosted.org/packages/52/90/6155aa926f43f2b2a22b01be7241be3bfd1ceaf7d0b3267213e8127d41f4/atomicwrites-1.3.0-py2.py3-none-any.whl Collecting importlib-metadata>=0.12; python_version < "3.8" Downloading https://files.pythonhosted.org/packages/8b/03/a00d504808808912751e64ccf414be53c29cad620e3de2421135fcae3025/importlib_metadata-1.5.0-py2.py3-none-any.whl Collecting zipp>=0.5 Downloading https://files.pythonhosted.org/packages/be/69/4ac28bf238f287f1677f41392e24d2c4ffafcf11648c23824f5f62ef6ccb/zipp-2.1.0-py3-none-any.whl Building wheels for collected packages: httptools Building wheel for httptools (setup.py): started Building wheel for httptools (setup.py): finished with status 'done' Created wheel for httptools: filename=httptools-0.0.13-cp36-cp36m-linux_x86_64.whl size=217310 sha256=51eb19168c0639662416a8ad83b9df7d7ceb8eb14a58ce3bec5ffe3ab3b07a7f Stored in directory: /tmp/pip-ephem-wheel-cache-pwxrmfa5/wheels/e8/3e/2e/013f99b42efc25cf3589730cf380738e46b1e5edaf2f78d525 Successfully built httptools Installing collected packages: iso8601, httptools, pbr, py, zipp, importlib-metadata, pluggy, attrs, setuptools, more-itertools, six, atomicwrites, pytest, pytest-asyncio, fdk Successfully installed atomicwrites-1.3.0 attrs-19.3.0 fdk-0.1.12 httptools-0.0.13 importlib-metadata-1.5.0 iso8601-0.1.12 more-itertools-8.2.0 pbr-5.4.4 pluggy-0.13.1 py-1.8.1 pytest-4.0.1 pytest-asyncio-0.9.0 setuptools-45.1.0 six-1.14.0 zipp-2.1.0 WARNING: You are using pip version 19.3.1; however, version 20.0.2 is available. You should consider upgrading via the 'pip install --upgrade pip' command. Removing intermediate container 4f758b74080b ---> 5246c18d4e6f Step 5/12 : ADD . /function/ ---> c6181bb33bd1 Step 6/12 : RUN rm -fr /function/.pip_cache ---> Running in 695fe059e692 Removing intermediate container 695fe059e692 ---> 5ea69eaafc3a Step 7/12 : FROM fnproject/python:3.6 3.6: Pulling from fnproject/python 80369df48736: Already exists aaba0609d543: Already exists a97b990f94a5: Already exists af4a941e5376: Already exists 709c35256bb6: Already exists 671870542c6c: Pull complete 936a6f40830a: Pull complete Digest: sha256:3b438ba11405bba0f6e1e8d8819c9b8be38249da7253491f3cf9f7e5ed6c0ec6 Status: Downloaded newer image for fnproject/python:3.6 ---> e8e10863d7cd Step 8/12 : WORKDIR /function ---> Running in ddbc794f4bd9 Removing intermediate container ddbc794f4bd9 ---> 4e3bed62a7f5 Step 9/12 : COPY --from=build-stage /python /python ---> b1c7d4fd7598 Step 10/12 : COPY --from=build-stage /function /function ---> 87446e069bd2 Step 11/12 : ENV PYTHONPATH=/function:/python ---> Running in af075fbcae2c Removing intermediate container af075fbcae2c ---> 98a9f515e7e0 Step 12/12 : ENTRYPOINT ["/python/bin/fdk", "/function/func.py", "handler"] ---> Running in 555033ab1e55 Removing intermediate container 555033ab1e55 ---> 9942a3d98858 Successfully built 9942a3d98858 Successfully tagged fndemouser/multiply:0.0.2 Updating function multiply using image fndemouser/multiply:0.0.2... Successfully created function: multiply with fndemouser/multiply:0.0.2 Successfully created trigger: multiply Trigger Endpoint: http://127.0.0.1:18080/t/calc-fn-app/multiplyfnのコマンドで確認します。(別エントリでplus,minusを作ってあります)
$ fn list fn calc-fn-app NAME IMAGE ID multiply fndemouser/multiply:0.0.2 01E086F2D6NG8G00GZJ000001E plus fndemouser/plus:0.0.2 01E0393FDCNG8G00GZJ000000E subtract fndemouser/subtract:0.0.3 01E05KAKGENG8G00GZJ0000013Dockerのコマンドで確認すると、対応するコンテナのイメージができていることがわかります。
$ docker images | grep multiply fndemouser/multiply 0.0.2 9942a3d98858 About a minute ago 175MB実行
登録時の末尾にあったURLにcurlでアクセスしてみます。
$ curl -d '{"left":"2", "right":"4"}' http://127.0.0.1:18080/t/calc-fn-app/multiply {"result": "8"}2*4の結果である8が返ってきています。
おわりに
このエントリでは、Fn projectを使ってPythonで書いたfunctionを動かしてみることを扱いました。
このエントリで使用したコードは、https://github.com/hrkt/calc-fn-app/releases/tag/0.0.3のタグに格納してあります。
補足:外部ライブラリ
このエントリでは、外部ライブラリを使いませんでしたが、requirements.txt中に記載することで、pipを利用できます。
補足:このエントリを書くにあたり
このエントリを書くにあたり、OCIのマイクロインスタンス上に下記の状況を作り、ノートPCからクラウド側にsshでリモートでつないで作業しました。
- sshの先にscreenで複数枚のウインドウ上げておいて作業して
- VS CodeをWEBで動かして「cdr/code-serverとOCIのAlways FreeのMicroインスタンスでVS Codeを動かしてみる」
- Fn projectのサーバもそこで動かして
- コードはGitHubに

- 投稿日:2020-02-04T22:15:05+09:00
SciPy 1.4 のソースビルドには pybind11 が必要
- 環境: Debian 10 (native/WSL), Python 3.8
普段 scipy を pip でインストールするときにソースビルドして Intel-MKL とリンク していたのですが, scipy 1.4 からビルドに失敗するようになりました. なんでかなと思ったら, この issue で述べられているように, scipy 1.4 から pybind11 が必要になったからでした. なのでアップグレード前にインストールします.
$ pip3 install pybind11 $ pip3 install --upgrade --no-binary :all: scipyこれでできました.
$ pip3 freeze | grep scipy scipy==1.4.1その他の要求については 公式のドキュメント を参照してください.
- 投稿日:2020-02-04T22:11:43+09:00
Tensorflow.Kerasモデルで TPU/GPU/CPU を自動的に切り替える
はじめに
この記事は、TensorFlow.kerasを使用していたとき、ハードウェア情報(主にColaboratoryのランタイム情報)を読み取って、TPUとGPU(一応CPUも)を自動的に切り替えて実行できるプログラムを書く方法をまとめています。
(手動でコメントアウトするのが面倒になってきたため)大体、公式サイト(Google Cloud, Cloud TPU Docs)掲載のKerasとTPUでMNISTを要約した内容です。tensorflow.kerasに慣れている方は、参照元を読んだほうがわかりやすいかもしれません。
補足・注意など
- 動作検証はColaboratory上で実施しています。
- たぶんtensorflow ver2にも対応しています。
- tensorflow.keras 用のコードです。(puer keras や tensoflow ではない)
- 記述(特に解説)に誤りがある可能性があります。
TPU/GPU/CPUを自動的に切り替えるコード
# ハードウェア情報取得 import tensorflow as tf try: tpu = tf.distribute.cluster_resolver.TPUClusterResolver() # TPU detection except ValueError: tpu = None gpus = tf.config.experimental.list_logical_devices("GPU") if tpu: tf.tpu.experimental.initialize_tpu_system(tpu) strategy = tf.distribute.experimental.TPUStrategy(tpu, steps_per_run=128) # Going back and forth between TPU and host is expensive. Better to run 128 batches on the TPU before reporting back. print('Running on TPU ', tpu.cluster_spec().as_dict()['worker']) elif len(gpus) > 1: strategy = tf.distribute.MirroredStrategy([gpu.name for gpu in gpus]) print('Running on multiple GPUs ', [gpu.name for gpu in gpus]) elif len(gpus) == 1: strategy = tf.distribute.get_strategy() # default strategy that works on CPU and single GPU print('Running on single GPU ', gpus[0].name) else: strategy = tf.distribute.get_strategy() # default strategy that works on CPU and single GPU print('Running on CPU') print("Number of accelerators: ", strategy.num_replicas_in_sync) # モデル作成やモデルロード、モデルコンパイル時に、with strategy.scope()で囲む from tensorflow import keras with strategy.scope(): model = make_model()特に難しいことは考えずに以下の2点を実行すれば、ハードウェアに応じて、TPU/GPU/CPUを勝手に切り替えてくれるようになります。
import tensorflow as tf〜print("Number of accelerators (略までをコピペで貼り付ける- モデル定義やモデル読み込み部分を
with strategy.scope():のスコープ内に入れる解説っぽいなにか
- 優先度
- プログラムのとおり「TPU > multi GPU > single GPU > CPU」の順で選択します。
tf.distribute.cluster_resolver.TPUClusterResolver()
- TPUのハードウェア情報を獲得します。TPUが利用できない環境ではエラーが発生します。
tf.config.experimental.list_logical_devices("GPU")
- GPUのハードウェア情報を獲得します。返り値はリストです。なお、"CPU"を与えれば、CPUの情報も取得できます。
if tpu:以降
- それぞれのデバイスの定義方法です。TPUとmultiGPUが特殊で、「こう書くものだ」と覚えてしまったほうが良いでしょう。
tf.distribute.get_strategy()
- ハードウェア情報を参照しているのではなく、インストールされているtensorflowがGPUに対応しているかを見ています。
- つまり、実行時でなく、tensorflowインストール時に決まる値です(のはずです)。
- GPUを搭載しているのに、上手く行かない場合はCUDAのインストール周りを見直しましょう(参考:GPU support)
おわりに
この記事では、tensorflow.keras で、ハードウェアの状況に応じて、TPU/GPU/CPUを自動的に切り替える方法を解説しました。
tensorflow.kerasでTPUを活用して、より良いディープラーニングライフを。
- 投稿日:2020-02-04T21:58:56+09:00
Pythonista3を使ってTwitterの検索にヒットした画像と動画をiPhoneに自動保存する
背景
前回の記事(Pythonista3を使ってTwitterのTLをiphoneに音読してもらう)と動機はほぼ同じです。今回はTwitterの検索結果から画像と動画のみを抽出してiPhoneに自動保存します。
環境
iPhone8 13.2.3
Pythonista3 3.2
Tweepy 3.8.0準備
・Pythonista3のインストール
・Twitter APIの登録申請
・StaShのインストール
・tweepy, requests, youtube-dlのインストールコード
sav_photo_video.py#!Pythonista3 #twitterから検索に一致した画像をiphoneのアルバムに納めるプログラム import os, requests, photos, youtube_dl import twitterconfig from twitterconfig import api #検索する言葉から画像と動画のurlのリストを返す関数 def twitter_to_url_out(q, max_id): gazou_suu = 0 douga_suu = 0 kensakukekka = api.search(q = q, count = 20, max_id = max_id) if max_id != None: kensakukekka = kensakukekka[1:] gazou_url_list = [] douga_url_list = [] max_id_list = [] for match_tweet in kensakukekka: max_id_list.append(match_tweet.id) try: video_url = match_tweet.extended_entities['media'][0]['video_info']['variants'][1]['url'] douga_url_list.append(video_url) except: try: for x in match_tweet.extended_entities['media']: gazou_url = x['media_url'] gazou_url_list.append(gazou_url) except: continue max_id = min(max_id_list) gazou_url_list = sorted(set(gazou_url_list), key=gazou_url_list.index) douga_url_list = sorted(set(douga_url_list), key=douga_url_list.index) return max_id, gazou_url_list, douga_url_list #url_listを引数にとって、それぞれの動画を保存する関数 def douga_hozon(urllist): douga_suu = 0 for url in urllist: try: with youtube_dl.YoutubeDL() as ydl: ydl.download([url]) douga_suu += 1 except: continue return douga_suu #url_listを引数にとって、それぞれの画像を保存する関数 def gazou_hozon(urllist): gazou_list = [] for url in urllist: response = requests.get(url) try: response.raise_for_status() except: continue filename = str(url.split('/')[-1]) newfile = open(filename,'wb') for chunk in response.iter_content(10000): newfile.write(chunk) newfile.close() gazou_list.append(filename) image_asset_list = [] for gazou in gazou_list: image_asset = photos.create_image_asset(gazou) image_asset_list.append(image_asset) try: os.remove(gazou) except: continue album_list = photos.get_albums() album_name_dict = {} number = 0 for album in album_list: album_name = str(album).split('"')[1] album_name_dict[album_name] = number number += 1 if kensakukotoba in album_name_dict.keys(): new_album = album_list[int(album_name_dict[kensakukotoba])] else: new_album = photos.create_album(kensakukotoba) new_album.add_assets(image_asset_list) gazou_suu = len(image_asset_list) return gazou_suu kensakukotoba = input('検索したい言葉は\n') hosiikazu = int(input('欲しい画像数は\n')) max_id = None s_gazou_url_list = [] s_douga_url_list = [] syu_kai = 1 while len(s_gazou_url_list) < hosiikazu: print(str(syu_kai) + '周目') max_id, gazou_url_list, douga_url_list = twitter_to_url_out(q = kensakukotoba, max_id = max_id) syu_kai += 1 for gazou_url in gazou_url_list: s_gazou_url_list.append(gazou_url) for douga_url in douga_url_list: s_douga_url_list.append(douga_url) s_gazou_url_list = sorted(set(s_gazou_url_list), key=s_gazou_url_list.index) s_douga_url_list = sorted(set(s_douga_url_list), key=s_douga_url_list.index) if syu_kai == 30: break douga_suu = douga_hozon(s_douga_url_list) gazou_suu = gazou_hozon(s_gazou_url_list) print('保存終了(画像数:' + str(gazou_suu) + ' , 動画数:' + str(douga_suu) + ')')結果
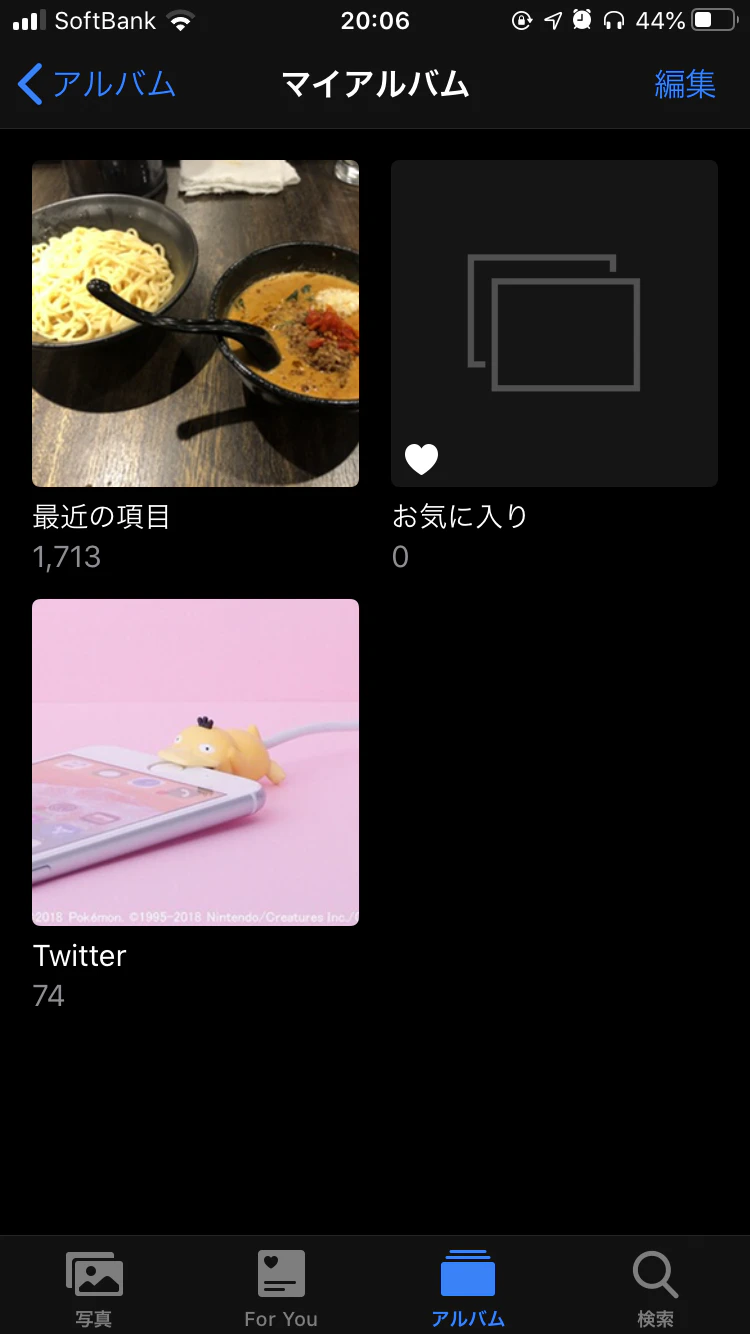
初めの状態。写真もアルバムもありません。
プログラムを開いて検索キーワードと保存したい最低枚数を指定
少し待って・・・
保存終了とでたら終了です。
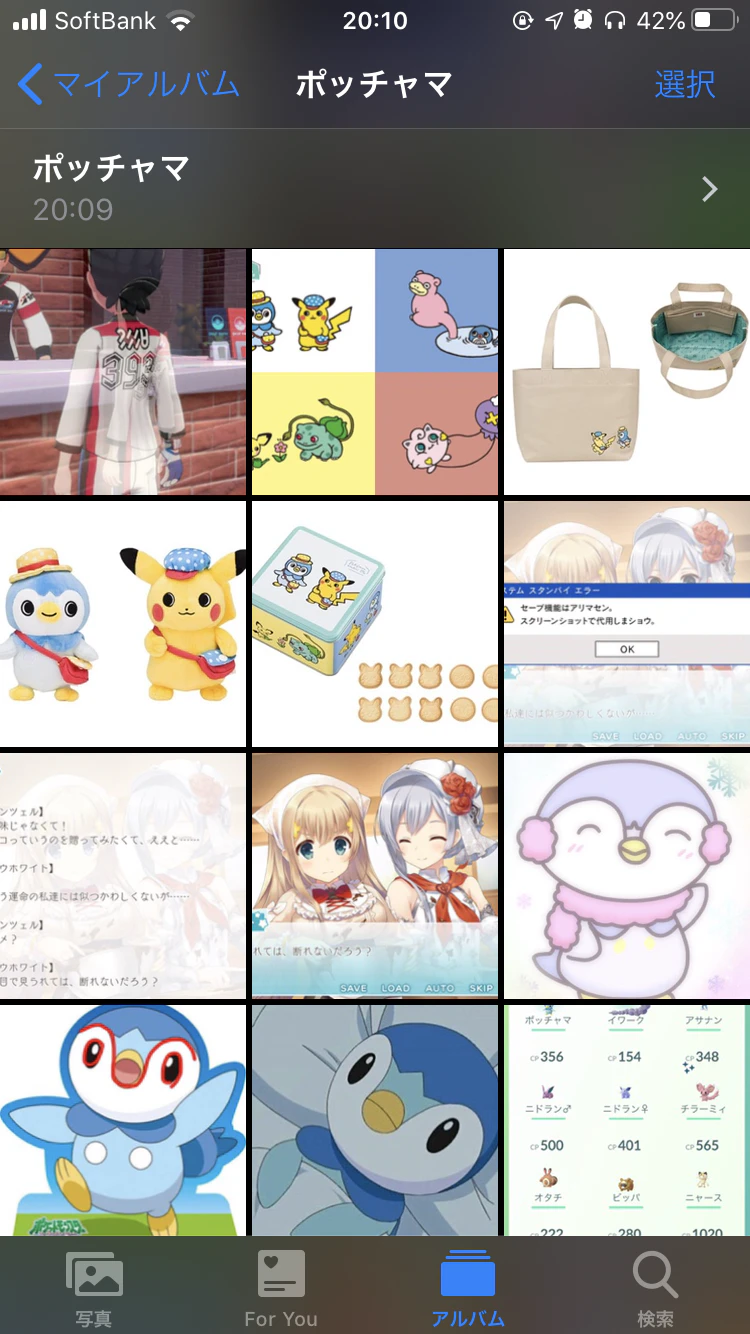
再度見てみると自動的にアルバムが作成され、今回保存された画像が格納されています。
動画はpythonista内のコードがあるディレクトリにあります。
解説
動画を写真と同じようにアルバムに収める方法が分かりませんでした。(pythonistaのphotosが動画に非対応?)分かる方がいらっしゃったらぜひ教えてください。
検索回数のリミットや検索方法は、各自使いやすいように変更してください。課題
何度か使っていて気になったこと
○動画のより良い保存方法
とりあえず時間があるときにフォルダ分けくらいはできるようにしようかなと思いました。○重複する画像の自動削除
何度か同じキーワードで検索すると、どうしても同じ画像がちらほら保存されている状態に。同じ名前のアルバムはできないようにしていますが、検索結果と既存のアルバムを比較する部分があるといいかなと思いました。結論
やりたいことは形になりました!が、使いやすくするための改善の余地はまだまだありそうです・・・



- 投稿日:2020-02-04T20:39:50+09:00
[Python]Qiitaの記事情報をmongoDBに突っ込んだ
やりたいこと
Qiitaの記事情報をQiitaAPIで取得し、どの記事、どのタグがよく見られているのか?などを確認したい。
その第一歩として、APIで取得した情報をmongoDBに登録してみるQiitaの記事情報を取得する
今回の内容はPythonで書いています。
記事情報の取得は以下の記事を参考にさせていただきました。get_qiita_info.pyimport requests import logging import json formatter = '%(asctime)s %(name)-12s %(levelname)-8s %(message)s' logging.basicConfig(level=logging.WARNING, format=formatter) logger = logging.getLogger(__name__) class GetQiitaInfo(object): def __init__(self): self.token = 'your token' def get_next_url(self, response): """次のページがある場合は'rel="next"'としてurlが含まれるので、urlを抽出して返す。 ない場合はNoneを返す。 link: <https://qiita.com/api/v2/authenticated_user/items?page=1>; rel="first", <https://qiita.com/api/v2/authenticated_user/items?page=2>; rel="next", <https://qiita.com/api/v2/authenticated_user/items?page=4>; rel="last" :param response: :return: 次のurl """ link = response.headers['link'] if link is None: return None links = link.split(',') for link in links: if 'rel="next"' in link: return link[link.find('<') + 1:link.find('>')] return None def get_items(self): """ページネーションして全ての記事を取得し、 ストック数とビュー数は一覧に含まれないので、それらの情報も追加して返す。 :param token: :return: 記事のリスト """ url = 'https://qiita.com/api/v2/authenticated_user/items' headers = {'Authorization': 'Bearer {}'.format(self.token)} items = [] while True: response = requests.get(url, headers=headers) response.raise_for_status() items.extend(json.loads(response.text)) logger.info('GET {}'.format(url)) # 次のurlがあるかを確認する url = self.get_next_url(response) if url is None: break # 各記事についてビュー数とストック数の情報を取得して追加する # page_views_countは一覧APIにもフィールドはあるがnullが返ってくる for item in items: # ビュー数 url = 'https://qiita.com/api/v2/items/{}'.format(item['id']) logger.info('GET {}'.format(url)) response = requests.get(url, headers=headers) response.raise_for_status() itemJson = json.loads(response.text) item['page_views_count'] = itemJson['page_views_count'] item['tag1'] = itemJson['tags'][0]['name'] item['tag2'] = itemJson['tags'][1]['name'] if len(itemJson['tags']) >= 2 else '' item['tag3'] = itemJson['tags'][2]['name'] if len(itemJson['tags']) >= 3 else '' item['tag4'] = itemJson['tags'][3]['name'] if len(itemJson['tags']) >= 4 else '' item['tag5'] = itemJson['tags'][4]['name'] if len(itemJson['tags']) >= 5 else '' tag_list = [] for i in range(len(itemJson['tags'])): tag_list.append(itemJson['tags'][i]['name']) item['tag_list'] = tag_list # ストック数 url = 'https://qiita.com/api/v2/items/{}/stockers'.format(item['id']) logger.info('GET {}'.format(url)) response = requests.get(url, headers=headers) response.raise_for_status() users = json.loads(response.text) for user in users: logger.info({ 'id': user['id'], 'name': user['name'] }) item['stocks_count'] = len(users) return items自身の勉強のため、参考にさせていただいた記事から2点変更を加えました。
・クラスにした
・tag1~tag5、tag_listを追加mongoDB操作用クラス
以前にmongoDB操作の記事を書きましたが、その内容のままです。
参考
Pythonでmongodbを操作する~その4:insert編~mongo_sample.pyfrom pymongo import MongoClient class MongoSample(object): def __init__(self, dbName, collectionName): self.client = MongoClient() self.db = self.client[dbName] #DB名を設定 self.collection = self.db.get_collection(collectionName) def find_one(self, projection=None,filter=None, sort=None): return self.collection.find_one(projection=projection,filter=filter,sort=sort) def find(self, projection=None,filter=None, sort=None): return self.collection.find(projection=projection,filter=filter,sort=sort) def insert_one(self, document): return self.collection.insert_one(document) def insert_many(self, documents): return self.collection.insert_many(documents)記事情報を取得しmongoDBに登録する
sample.pyfrom get_qiita_info import GetQiitaInfo from mongo_sample import MongoSample # Qiitaの記事情報を取得する qiita = GetQiitaInfo() items = qiita.get_items() # arg1:DB Name # arg2:Collection Name mongo = MongoSample("db", "qiita") # 不要なキー値を削除しないのであれば # mongo.insert_many(items) # で一括登録 for item in items: # rendered_body/body は不要なので削除 item.pop("rendered_body") item.pop("body") # 一件ずつ登録 mongo.insert_one(item) result = mongo.find_one() print(result)上記のコードを実行後のmongoDBを見てみます。
※上記のコードの実行結果として1件データを表示していますが、1行に表示されて見辛いのでmongoDBで確認。。> db.qiita.findOne() { "_id" : ObjectId("5e38ff43c92e7c532aeffb47"), "coediting" : false, "comments_count" : 0, "created_at" : "2020-02-04T13:37:44+09:00", "group" : null, "id" : "331ae2289a95f5a9b901", "likes_count" : 0, "private" : false, "reactions_count" : 0, "tags" : [ { "name" : "Python", "versions" : [ ] }, { "name" : "Python3", "versions" : [ ] } ], "title" : "[Python]No value for argument 'self' in unbound method callが出た", "updated_at" : "2020-02-04T13:37:44+09:00", "url" : "https://qiita.com/bc_yuuuuuki/items/331ae2289a95f5a9b901", "user" : { "description" : "ブロックチェーン/AI/Python/Golang/MongoDBなどを学習中です。\r\nこのサイトにおける掲載内容はあくまで私自身の見解であり、必ずしも私の所属団体・企業における立場、戦略、意見を代表するものではありません。", "facebook_id" : "", "followees_count" : 0, "followers_count" : 2, "github_login_name" : null, "id" : "bc_yuuuuuki", "items_count" : 28, "linkedin_id" : "", "location" : "", "name" : "", "organization" : "", "permanent_id" : 476876, "profile_image_url" : "https://pbs.twimg.com/profile_images/1157834557783072768/ktpc9kGV_bigger.jpg", "team_only" : false, "twitter_screen_name" : "bc_yuuuuuki", "website_url" : "" }, "page_views_count" : 54, "tag1" : "Python", "tag2" : "Python3", "tag_list" : [ "Python", "Python3" ], "stocks_count" : 0 }登録されていることが確認出来ました。
感想
今回のコードではAPIの取得結果に多少手を加えていますが、APIを叩いて取得したJSONを何も考えずに突っ込んで検索や集計が出来るようになるのは便利ですね。
- 投稿日:2020-02-04T19:56:11+09:00
プログラミング歴1ヶ月 PythonでNYダウの株価を抽出!
初めまして、Kayです。
投資をやっていまして、今年の1月からPythonにフロンティアを感じ、投資に応用出来ないかということで、ようやくYahooファイナンスの株価の抽出くらいまでたどり着きました。
というわけで、プログラミング歴は1ヶ月です(笑)使用したもの
言語:Python3
ライブラリ:urllib、BeautifulSoup
MacBook Pro
BeautifulSoupをインストールする
shell.sh$ pip3 install beautifulsoup自分の場合、MacOSだったので、pip3インストールとなりました。windowsの人は違うと思うので注意してください。
Pythonのコード
dow.pyimport urllib.request import ssl from bs4 import BeautifulSoup url = "https://finance.yahoo.co.jp/quote/%5EDJI" ssl._create_default_https_context = ssl._create_unverified_context html = urllib.request.urlopen(url) soup = BeautifulSoup(html, "html.parser") p = soup.find_all("p") dow = "" for tag in p: try: string_ = tag.get("class").pop(0) if string_ in "wlbmIy9W": dow = tag.string break except: pass print(dow)BeautifulSoupでYahooファイナンスからurlを引っ張ってきます。
↓
株価がpというところに入っているのでhtmlデータの中のpを検索します。
↓
pの中のclass="wlbmIy9W"の場所を特定するようにfor文とtry except文で構築する。ちなみに、サイトを右クリックで検証を押すと、簡単に抽出箇所を特定できます。
Python3ではSSL証明書が必要になるのが注意点
import ssl ssl._create_default_https_context = ssl._create_unverified_contextPython3ではこのコードを書き込む必要があります。
書かないと必ずエラーになります。
もしかしたらPython2では必要ないかもしれません。抽出完了
shell.sh$ python dow.py >>>28,399.81ようやく抽出完了です。5時間もかかりました(笑)
今後はもっと発展させていきたいですね。参考にさせていただいた記事
こちらの方がもっと発展したコードを書いているので必読です!

- 投稿日:2020-02-04T19:54:18+09:00
オブジェクト指向
class Person(object): def __init__(self, age=1): self.age = age def drive(self): if self.age >= 18: print('OK') else: raise Exception('No drive') class Baby(Person): def __init__(self, age=1): if age < 18: super().__init__(age) else: raise ValueError class Adult(Person): def __init__(self, age=18): if age >= 18: super().__init__(age) else: raise ValueError class Car(object): def __init__(self, model=None): self.model = model def run(self): print('run') def ride(self, person): person.drive() baby = Baby() adult = Adult() car = Car() car.ride(adult)実行結果OK最後の行を
car.ride(baby)にかえると
実行結果Exception: No drive
- 投稿日:2020-02-04T19:17:58+09:00
セグメント木を一歩一歩実装して理解しようとする(python)
はじめに
AtCoderをやっているとセグ木貼って終わりとか強い人がTwitterでつぶやいているのを度々見かけるのですが、自前で持っていなかったのでこの際実装して理解、応用につなげようと言う記事です。
今コンテスト中でたまたま検索でたどり着いて今すぐ実装がほしいひとは、実装まとめにコードがあります。
動作保証はできませんが。何番煎じだよというのはごめんなさい。
なるたけあいだの実装を省かないことで差別化しようと考えています。1点更新、区間取得の最も基本的な構造にします。
遅延評価とかは気合があったら(か、必要に迫られたら)そのうち続編で書きます。参考にしたサイトさん達
http://beet-aizu.hatenablog.com/entry/2017/09/10/132258
https://www.slideshare.net/iwiwi/ss-3578491
http://tsutaj.hatenablog.com/entry/2017/03/29/204841セグメント木とは
何ができるの?
決まった性質を満たす操作、演算に関しての区間クエリをO(logN)で求めることができる。(例えば1番目か5番目までの要素の最小値を求めるクエリ)
ただし、構築にはO(N)かかるので注意じゃあどんな演算なら使えるの?
モノイドと呼ばれるものなら埋め込める。
モノイドとは
ちょっと厳密性を欠くと思うが、
結合則が成立し、単位元が存在すれば良い。
結合則とは
例えば足し算で考えると、
$$(a+b)+c = a+(b+c)$$
となることで、3つ以上のものの間で演算するときにどこから計算しても結果が変わらなければ良い
これが成り立つから、セグメント木は値の取得で区間をどんどん分割していける。
([0,6)→([0,4)+[4,6)のように)単位元とは
元というと難しいが、応用上は、足し算で考えると、
$$a + 0 = 0+ a = a$$
となるように、それと演算すると、もとの数と同じになるような数を単位元と呼ぶ
他に、例えば掛け算を考えれば$$ a \cdot 1 = 1 \cdot a = a$$
になって1が単位元である。モノイド(にできるもの)の例
演算 単位元 足し算 0 掛け算 1 最小値 INF ※1 最大値 -INF ※2 最小公倍数 1 ※1 要は出てきうる値以上の値をとれば単位元になる。例えば問題の制約で$A_i<=10^4$とかならば、単位元を$10^4+1$にすると、常に $min(A_i,10^4+1) = min(10^4+1,A_i) = A_i$となり単位元である。
全自然数とかが対象だと単位元は存在しない。※2 最小値のときと似た議論で、出てきうる値以下のものをとると単位元になる。
他にも制約などによってはもっと特殊な演算もモノイドとして扱えることもあると思うが、そんなの思いつく人間はこんな記事読む必要もないと思うので置いておく。
[参考]
http://beet-aizu.hatenablog.com/entry/2017/09/10/132258どんな構造なの?
カバーする区間に関してのクエリの結果を持つ2分木である。配列で実装する。
こんな感じ。下に行くほど区間がどんどん半々で小さくなっていく。
配列のインデックスに注目してほしいが、親のインデックス×2,親のインデックス×2+1で子のインデックスが取得できる。BIT(Binary index tree)とか二分木系では基本だけど初めて見たとき感動した。ちなみにこれは1-indexで考えているからで、0-indexのときは×2+1,×2+2になる。どっちでもいいといえばよいが、個人的に1-indexだと子から親を見る操作が、2でわって切り捨てるだけですむので1-indexにしている。
ここで一番下の葉にクエリをかけたい配列の元データが入ることになる。(今回だとサイズ4の配列である)
配列の要素数が2^kじゃなかったら?
一番下の葉の数が、もともと区間クエリを計算したい対象とする配列が入る分用意できるように木の深さを決める。
余った部分は単位元で埋めておけば良い。さっきとすこし変えて配列サイズ=3の例を考えてみる。
余った部分に上で出てきた単位元を埋めておくと、
このように、特に影響を与えずに処理できる。
実装
初期化
末端の葉っぱの数が2^kの形で、クエリをかけたい配列のサイズ以上確保できるように、木を格納する配列サイズを決める。
$$1+2+4+8+\cdots+2^n = 2^{n+1} -1$$
であることを考えると、
$$2^k >= (データ配列サイズ)$$
となる、kについて、$2^{k+1}$のサイズの木格納用配列を用意すれば良い。
実装はこんな感じ。class segtree: def __init__(self, n,operator,identity): """ n:データ配列のサイズ operator:演算子(モノイド)。関数オブジェクト identity:演算子に対応する単位元 """ nb = bin(n)[2:] #2進数に変換して戦闘の0bを取り除く bc = sum([int(digit) for digit in nb]) #bitで1が立ってる数。これが1のときはちょうど2^nb.そうじゃないときは、2^nb<n<2^(nb+1) if bc == 1: #2^nbなら self.num_end_leaves = 2**(len(nb)-1) #最下段の葉っぱは2^nb個 else:#そうじゃないなら2^(nb+1)確保 self.num_end_leaves = 2**(len(nb)) self.array = [identity for i in range(self.num_end_leaves * 2)] #単位元で初期化 self.identity = identity self.operator =operator #後で使うので単位元と演算子を持っておく値の更新
最初にちらっと書いたが、1-indexだと自分のインデックスを2で割って切り捨てると自分の親になる。(3→1,5→2のように)
これを大元までたどって順々に演算子を適用して行くことで値を更新する。
この部分だけの実装はこんな感じ。def update(self,x,val): """ x:代入場所 val:代入する値 """ actual_x = x+self.num_leaves #1-indexの末端の葉のindexがどこから始まるか分を足す(例えばデータ配列サイズ4のとき木配列サイズは8で、後半部はindex4から始まる。 self.array[actual_x] = val #値を更新する while actual_x > 0 : actual_x = actual_x//2#親を見る self.array[actual_x] = self.operator(self.array[actual_x*2],self.array[actual_x*2+1])#あたらしい子をつかって親を更新値の取得
ある範囲に関して、できるだけ大きい範囲をカバーする葉どうしの組み合わせでその範囲を表現できれば良い。
たとえば、データ配列のサイズが4で[0,2]の範囲が欲しかったとしたら、
こんな感じで、
- クエリに対して自分の担当範囲がはみ出していたら、子を見る。
- クエリの範囲に自分の担当範囲が入っていたら、値を返す。
- クエリと関係ない位置だったら単位元を返す。
を繰り返すと今回であれば[0,1],[2],単位元が値として得られてこれらの部分領域をマージしていく感じで、
$$operator([0,1],[2],単位元) = operator([0,1],[2]) = operator([0,2])$$
区間クエリを得ることができる。実装はこんなかんじ。
def get(self,q_left,q_right,arr_ind=1,leaf_left=0,depth=0): """ q_left:クエリ区間の左 q_right:クエリ区間の右 arr_ind:木配列のインデックス。最初は親なので1 leaf_left:木配列インデックスに対して、それが表す葉がカバーする範囲の左 depth:木配列での深さ。カバー範囲の広さの計算に使用 """ width_of_floor = self.num_end_leaves//(2**depth) #今の葉のカバー幅 leaf_right = leaf_left+width_of_floor-1 #左端とカバー幅から今の葉のカバー範囲の右を求める。 if leaf_left > q_right or leaf_right < q_left: return self.identity #クエリ領域と葉が関係ないなら単位元を返す elif leaf_left >= q_left and leaf_right <= q_right: return self.array[arr_ind] #クエリ領域に葉がすっぽり入ってるなら、葉の値を返す else: #そうじゃないならば、子を見る val_l = self.get(q_left,q_right,2*arr_ind,leaf_left,depth+1)#子の左 val_r = self.get(q_left,q_right,2*arr_ind+1,leaf_left+width_of_floor//2,depth+1)#子の右 return self.operator(val_l,val_r)#子をマージする演算をする。実装まとめ
今までのをくっつけただけなので、折りたたみ
class segtree: def __init__(self, n,operator,identity): nb = bin(n)[2:] bc = sum([int(digit) for digit in nb]) if bc == 1: self.num_end_leaves = 2**(len(nb)-1) else: self.num_end_leaves = 2**(len(nb)) self.array = [identity for i in range(self.num_end_leaves * 2)] self.identity = identity self.operator =operator def update(self,x,val): actual_x = x+self.num_end_leaves self.array[actual_x] = val while actual_x > 0 : actual_x = actual_x//2 self.array[actual_x] = self.operator(self.array[actual_x*2],self.array[actual_x*2+1]) def get(self,q_left,q_right,arr_ind=1,leaf_left=0,depth=0): width_of_floor = self.num_end_leaves//(2**depth) leaf_right = leaf_left+width_of_floor-1 if leaf_left > q_right or leaf_right < q_left: return self.identity elif leaf_left >= q_left and leaf_right <= q_right: return self.array[arr_ind] else: val_l = self.get(q_left,q_right,2*arr_ind,leaf_left,depth+1) val_r = self.get(q_left,q_right,2*arr_ind+1,leaf_left+width_of_floor//2,depth+1) return self.operator(val_l,val_r)
お試し
適当なrangeの配列を作って、最小値を聞いてみる。
ついでに実行時間も適当に図る。s_tree = segtree(10**5,min,10**9) #10**5までの配列なので適当に単位元は10**9 arr = [i for i in range(10**5)] print(datetime.datetime.now()) for i,a in enumerate(arr): s_tree.update(i,a) print(datetime.datetime.now()) print(s_tree.get(0,10**4)) print(s_tree.get(3*10**4,5**10**4)) print(s_tree.get(2,7*10**4)) print(datetime.datetime.now())2020-02-04 19:15:34.934814 2020-02-04 19:15:35.646339 0 30000 2 2020-02-04 19:15:35.646587やっぱり構築が一番重い。
動作は正常そう。(もっと複雑な問題で動かしてみないとバグ埋まってそうですが。)





- 投稿日:2020-02-04T18:58:12+09:00
PythonでModuleNotFoundError: No module named 'XXX'が起きた時の対応
表題の対処メモです。
今回はWTFormsが無い想定です。まずはpip showでモジュールが存在するか確認
pip show WTForms Name: WTForms Version: 2.2.1 Summary: A flexible forms validation and rendering library for Python web development. Home-page: https://wtforms.readthedocs.io/ Author: Thomas Johansson, James Crasta Author-email: wtforms@simplecodes.com License: BSD Location: /Users/XXX/.pyenv/versions/3.7.5/lib/python3.7/site-packages Requires: Required-by: wtforms-validators, Flask-WTF※ここで存在しなければモジュールをインストール(pip install Flask-WTF)してください。
ソースにLocationのパスを通す
sample.pyimport sys sys.path.append("/Users/XXX/.pyenv/versions/3.7.5/lib/python3.7/site-packages")これで解決しました。
参考
https://web.plus-idea.net/2017/05/python-import-error-no-module-name/
- 投稿日:2020-02-04T17:51:51+09:00
MobileNetV2-SSDLiteのPascal-VOCデータセットによる学習 [Docker版リメイク]
PINTO_model_zoo
1. Introduction
1年前に記事にしたMobileNetV2-SSDLiteのトレーニング環境構築記事を超簡易仕様にリメイクしました。 GPU対応版の最新のDockerが導入されている段階から作業に着手すると、15分ほどでトレーニングを開始できると思います。 ミスり要素はほぼ無いと思います。 学習が終わったらトレーニング済みモデル(.ckpt/.pb)の
Integer Quantizationを実施して Github へコミットする予定です。 トレーニング用データセットの前処理など、全ての処理はシェルスクリプト内に記載してありますので、気になる方はconstants.shあるいはprepare_checkpoint_and_dataset.shあるいはretrain_detection_model.shの内容をご覧ください。2. Environment
- Ubuntu 18.04 x86_64, RAM 16GB, Geforce GTX1070
- Tensorflow-GPU v1.15.2
- Docker 19.03.5
- Pascal VOC 2012/2007 Dataset
- MobileNetV2-SSDLite
3. Procedure
Creating_Docker_files$ DETECT_DIR=${HOME}/edgetpu/detection && mkdir -p $DETECT_DIR $ cd $DETECT_DIR && nano DockerfileDockerfile### Ubuntu 18.04 FROM tensorflow/tensorflow:1.15.2-gpu-py3 RUN apt-get update && \ DEBIAN_FRONTEND=noninteractive apt-get install -y \ protobuf-compiler python-pil python-lxml python-tk \ autoconf automake libtool curl make g++ unzip wget git nano \ libgflags-dev libgoogle-glog-dev liblmdb-dev libleveldb-dev \ libhdf5-serial-dev libhdf5-dev python3-opencv python-opencv \ python3-dev python3-numpy python3-skimage gfortran libturbojpeg \ python-dev python-numpy python-skimage python3-pip python-pip \ libboost-all-dev libopenblas-dev libsnappy-dev software-properties-common \ protobuf-compiler python-pil python-lxml python-tk libfreetype6-dev pkg-config \ libpng-dev libhdf5-100 libhdf5-cpp-100 # Get the tensorflow models research directory, and move it into tensorflow source folder to match recommendation of installation RUN git clone https://github.com/tensorflow/models.git && \ mkdir -p /tensorflow && \ mv models /tensorflow # Install the Tensorflow Object Detection API from here # https://github.com/tensorflow/models/blob/master/research/object_detection/g3doc/installation.md # Install object detection api dependencies RUN pip3 install Cython && \ pip3 install contextlib2 && \ pip3 install pillow && \ pip3 install lxml && \ pip3 install jupyter && \ pip3 install matplotlib && \ pip2 install Cython && \ pip2 install contextlib2 && \ pip2 install pillow && \ pip2 install lxml && \ pip2 install jupyter && \ pip2 install matplotlib # Get protoc 3.0.0, rather than the old version already in the container RUN curl -OL "https://github.com/google/protobuf/releases/download/v3.0.0/protoc-3.0.0-linux-x86_64.zip" && \ unzip protoc-3.0.0-linux-x86_64.zip -d proto3 && \ mv proto3/bin/* /usr/local/bin && \ mv proto3/include/* /usr/local/include && \ rm -rf proto3 protoc-3.0.0-linux-x86_64.zip # Install pycocoapi RUN git clone --depth 1 https://github.com/cocodataset/cocoapi.git && \ cd cocoapi/PythonAPI && \ make -j8 && \ cp -r pycocotools /tensorflow/models/research && \ cd ../../ && \ rm -rf cocoapi # Run protoc on the object detection repo RUN cd /tensorflow/models/research && \ protoc object_detection/protos/*.proto --python_out=. # Set the PYTHONPATH to finish installing the API ENV PYTHONPATH $PYTHONPATH:/tensorflow/models/research:/tensorflow/models/research/slim # Install wget (to make life easier below) and editors (to allow people to edit the files inside the container) RUN apt-get update && \ apt-get install -y wget nano ARG work_dir=/tensorflow/models/research # Get object detection transfer learning scripts. ARG scripts_link="http://storage.googleapis.com/cloud-iot-edge-pretrained-models/docker/obj_det_scripts.tgz" RUN cd ${work_dir} && \ wget -O obj_det_scripts.tgz ${scripts_link} && \ tar zxvf obj_det_scripts.tgz WORKDIR ${work_dir}Ctrl + O
Ctrl + XBuild_a_Docker_image$ docker build - < Dockerfile --tag training_containerStart_Docker_container$ docker run \ --runtime=nvidia \ --name training_container \ -it \ --privileged \ -p 6006:6006 \ training_container \ /bin/bash
Download_training_shell_script### Download constants.sh $ curl -sc /tmp/cookie "https://drive.google.com/uc?export=download&id=1e74pfaoHqp6WiWwTGamzN7wNRTDoR3q3" > /dev/null $ CODE="$(awk '/_warning_/ {print $NF}' /tmp/cookie)" $ curl -Lb /tmp/cookie "https://drive.google.com/uc?export=download&confirm=${CODE}&id=1e74pfaoHqp6WiWwTGamzN7wNRTDoR3q3" -o constants.sh ### Download prepare_checkpoint_and_dataset.sh $ curl -sc /tmp/cookie "https://drive.google.com/uc?export=download&id=1Rk2VRGBwZnlcfl3DmryPMbNpICJ2R-vr" > /dev/null $ CODE="$(awk '/_warning_/ {print $NF}' /tmp/cookie)" $ curl -Lb /tmp/cookie "https://drive.google.com/uc?export=download&confirm=${CODE}&id=1Rk2VRGBwZnlcfl3DmryPMbNpICJ2R-vr" -o prepare_checkpoint_and_dataset.sh ### Download retrain_detection_model.sh $ curl -sc /tmp/cookie "https://drive.google.com/uc?export=download&id=1MbjoqxBG56aDyvGxBbJd1QCbGo4nDKnm" > /dev/null $ CODE="$(awk '/_warning_/ {print $NF}' /tmp/cookie)" $ curl -Lb /tmp/cookie "https://drive.google.com/uc?export=download&confirm=${CODE}&id=1MbjoqxBG56aDyvGxBbJd1QCbGo4nDKnm" -o retrain_detection_model.sh
constants.sh
constants.sh#!/bin/bash declare -A ckpt_link_map declare -A ckpt_name_map declare -A config_filename_map ckpt_link_map["mobilenet_v2_ssdlite"]="http://download.tensorflow.org/models/object_detection/ssdlite_mobilenet_v2_coco_2018_05_09.tar.gz" ckpt_name_map["mobilenet_v2_ssdlite"]="ssdlite_mobilenet_v2_coco_2018_05_09" config_filename_map["mobilenet_v2_ssdlite-true"]="pipeline_mobilenet_v2_ssdlite_retrain_whole_model.config" INPUT_TENSORS='normalized_input_image_tensor' OUTPUT_TENSORS='TFLite_Detection_PostProcess,TFLite_Detection_PostProcess:1,TFLite_Detection_PostProcess:2,TFLite_Detection_PostProcess:3' OBJ_DET_DIR="$PWD" #rm -rf "${OBJ_DET_DIR}/learn" mkdir -p "${OBJ_DET_DIR}/learn" LEARN_DIR="${OBJ_DET_DIR}/learn" #rm -rf "${LEARN_DIR}/data" #rm -rf "${LEARN_DIR}/ckpt" #rm -rf "${LEARN_DIR}/train" #rm -rf "${LEARN_DIR}/models" mkdir -p "${LEARN_DIR}/data" mkdir -p "${LEARN_DIR}/ckpt" mkdir -p "${LEARN_DIR}/train" mkdir -p "${LEARN_DIR}/models" DATASET_DIR="${LEARN_DIR}/data" CKPT_DIR="${LEARN_DIR}/ckpt" TRAIN_DIR="${LEARN_DIR}/train" OUTPUT_DIR="${LEARN_DIR}/models"
prepare_checkpoint_and_dataset.sh
prepare_checkpoint_and_dataset.sh#!/bin/bash # Exit script on error. set -e # Echo each command, easier for debugging. set -x usage() { cat << END_OF_USAGE Downloads checkpoint and dataset needed for the tutorial. --network_type Can be one of [mobilenet_v1_ssd, mobilenet_v2_ssd], mobilenet_v1_ssd by default. --train_whole_model Whether or not to train all layers of the model. false by default, in which only the last few layers are trained. --help Display this help. END_OF_USAGE } network_type="mobilenet_v2_ssdlite" train_whole_model="true" while [[ $# -gt 0 ]]; do case "$1" in --network_type) network_type=$2 shift 2 ;; --train_whole_model) train_whole_model=$2 shift 2;; --help) usage exit 0 ;; --*) echo "Unknown flag $1" usage exit 1 ;; esac done source "$PWD/constants.sh" echo "PREPARING checkpoint..." mkdir -p "${LEARN_DIR}" ckpt_link="${ckpt_link_map[${network_type}]}" ckpt_name="${ckpt_name_map[${network_type}]}" cd "${LEARN_DIR}" rm -rf "${CKPT_DIR}/${ckpt_name}" wget -O "${CKPT_DIR}/${ckpt_name}.tar.gz" "$ckpt_link" tar -zxvf "${CKPT_DIR}/${ckpt_name}.tar.gz" -C "${CKPT_DIR}" rm "${CKPT_DIR}/${ckpt_name}.tar.gz" rm -rf "${CKPT_DIR}/saved_model" cp -r ${CKPT_DIR}/${ckpt_name}/* "${CKPT_DIR}/" echo "CHOSING config file..." cd "${OBJ_DET_DIR}" curl -sc /tmp/cookie "https://drive.google.com/uc?export=download&id=1IoHkfxfkXSUM8nnevrb_dVct72fMJ7t2" > /dev/null CODE="$(awk '/_warning_/ {print $NF}' /tmp/cookie)" curl -Lb /tmp/cookie "https://drive.google.com/uc?export=download&confirm=${CODE}&id=1IoHkfxfkXSUM8nnevrb_dVct72fMJ7t2" -o pipeline.config mv pipeline.config "${CKPT_DIR}" echo "REPLACING variables in config file..." sed -i "s%PATH_TO_BE_CONFIGURED/model.ckpt%${CKPT_DIR}/model.ckpt%g" "${CKPT_DIR}/pipeline.config" sed -i "s%PATH_TO_BE_CONFIGURED/mscoco_label_map.pbtxt%${DATASET_DIR}/pascal_label_map.pbtxt%g" "${CKPT_DIR}/pipeline.config" sed -i "s%PATH_TO_BE_CONFIGURED/mscoco_train.record%${DATASET_DIR}/pascal_train.record%g" "${CKPT_DIR}/pipeline.config" sed -i "s%PATH_TO_BE_CONFIGURED/mscoco_val.record%${DATASET_DIR}/pascal_val.record%g" "${CKPT_DIR}/pipeline.config" echo "PREPARING dataset" rm -rf "${DATASET_DIR}" mkdir -p "${DATASET_DIR}" cd "${DATASET_DIR}" # VOCtrainval_11-May-2012.tar <--- 1.86GB curl -sc /tmp/cookie "https://drive.google.com/uc?export=download&id=1rATNHizJdVHnaJtt-hW9MOgjxoaajzdh" > /dev/null CODE="$(awk '/_warning_/ {print $NF}' /tmp/cookie)" curl -Lb /tmp/cookie "https://drive.google.com/uc?export=download&confirm=${CODE}&id=1rATNHizJdVHnaJtt-hW9MOgjxoaajzdh" -o VOCtrainval_11-May-2012.tar # VOCtrainval_06-Nov-2007.tar <--- 460MB curl -sc /tmp/cookie "https://drive.google.com/uc?export=download&id=1c8laJUn-aaWEhE5NlDwIdNv5ZdogUAcD" > /dev/null CODE="$(awk '/_warning_/ {print $NF}' /tmp/cookie)" curl -Lb /tmp/cookie "https://drive.google.com/uc?export=download&confirm=${CODE}&id=1c8laJUn-aaWEhE5NlDwIdNv5ZdogUAcD" -o VOCtrainval_06-Nov-2007.tar # Extract the data. tar -xvf VOCtrainval_11-May-2012.tar && rm VOCtrainval_11-May-2012.tar tar -xvf VOCtrainval_06-Nov-2007.tar && rm VOCtrainval_06-Nov-2007.tar echo "PREPARING label map..." cd "${OBJ_DET_DIR}" cp "object_detection/data/pascal_label_map.pbtxt" "${DATASET_DIR}" echo "CONVERTING dataset to TF Record..." protoc object_detection/protos/*.proto --python_out=. python3 object_detection/dataset_tools/create_pascal_tf_record.py \ --label_map_path="${DATASET_DIR}/pascal_label_map.pbtxt" \ --data_dir=${DATASET_DIR}/VOCdevkit \ --year=merged \ --set=train \ --output_path="${DATASET_DIR}/pascal_train.record" python3 object_detection/dataset_tools/create_pascal_tf_record.py \ --label_map_path="${DATASET_DIR}/pascal_label_map.pbtxt" \ --data_dir=${DATASET_DIR}/VOCdevkit \ --year=merged \ --set=val \ --output_path="${DATASET_DIR}/pascal_val.record"
retrain_detection_model.sh
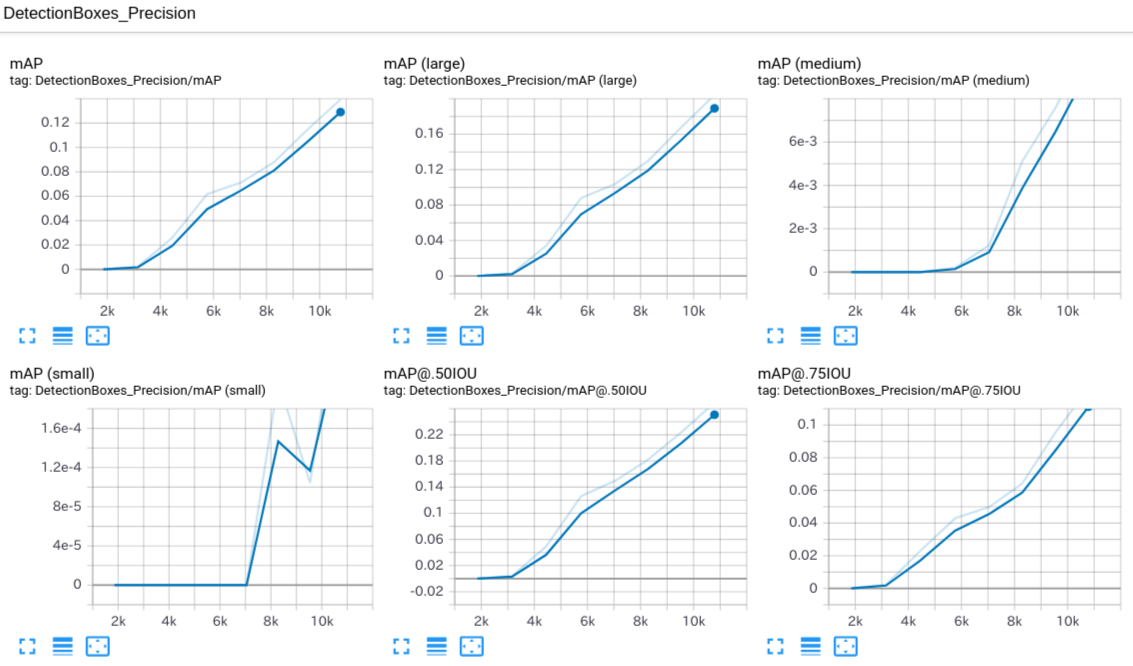
retrain_detection_model.sh#!/bin/bash # Exit script on error. set -e # Echo each command, easier for debugging. set -x usage() { cat << END_OF_USAGE Starts retraining detection model. --num_training_steps Number of training steps to run, 500 by default. --num_eval_steps Number of evaluation steps to run, 100 by default. --help Display this help. END_OF_USAGE } num_training_steps=200000 while [[ $# -gt 0 ]]; do case "$1" in --num_training_steps) num_training_steps=$2 shift 2 ;; --num_eval_steps) num_eval_steps=$2 shift 2 ;; --help) usage exit 0 ;; --*) echo "Unknown flag $1" usage exit 1 ;; esac done source "$PWD/constants.sh" python3 object_detection/model_main.py \ --pipeline_config_path="${CKPT_DIR}/pipeline.config" \ --model_dir="${TRAIN_DIR}" \ --num_train_steps="${num_training_steps}" \ --num_eval_steps="${num_eval_steps}"Granting_execution_authority_to_script_files$ chmod +x constants.sh $ chmod +x prepare_checkpoint_and_dataset.sh $ chmod +x retrain_detection_model.shData_preparation_and_Training### Data preparation $ ./prepare_checkpoint_and_dataset.sh ### Training $ NUM_TRAINING_STEPS=1000000 && \ NUM_EVAL_STEPS=100 && \ rm -rf learn/train && \ ./retrain_detection_model.sh \ --num_training_steps ${NUM_TRAINING_STEPS} \ --num_eval_steps ${NUM_EVAL_STEPS}check_the_progress_of_learning### Check learning status with Tensorboard $ docker exec -it training_container /bin/bash $ cd learn/train $ tensorboard --logdir=.<Progress of learning>
Extract_files_from_Docker_container$ docker cp 07a048c6b1b8:/tensorflow/models/research/learn/train/model.ckpt-7044.data-00000-of-00001 . $ docker cp 07a048c6b1b8:/tensorflow/models/research/learn/train/model.ckpt-7044.index . $ docker cp 07a048c6b1b8:/tensorflow/models/research/learn/train/model.ckpt-7044.meta . $ docker cp 07a048c6b1b8:/tensorflow/models/research/learn/train/graph.pbtxt . $ docker cp 07a048c6b1b8:/tensorflow/models/research/learn/train/checkpoint .

- 投稿日:2020-02-04T16:56:18+09:00
Jupyter notebookのショートカットをカスタマイズしてsublime text風にする
Jupyter Notebookでsublime textのショートカットを使用する方法を紹介します。
行の複製、複数選択、複数行同時編集といったsublime textでの便利な機能を使用できます。
また、ショートカットの割り当てを変更することもできます。Jupyter Notebookとは
Pythonのコードと実行結果をまとめて保存できるエディタです。
公式サイトのトップページで雰囲気をつかめます:Project Jupyter | HomeJupyter Notebookのショートカットには2種類ある:「エディタのショートカット」と「コマンド実行」のショートカット
Jupyter notebookでは、コードの塊(セル)を実行したり、セルを追加すると言った機能があります。
これらの機能のショートカットをカスタマイズする方法は、公式で詳しく説明されています: Customize keymaps — Jupyter Notebook 6.0.3 documentation以下のように、ショートカットカスタマイズ用のファイルを作成することでカスタマイズできます。
~/.jupyter/nbconfig/notebook.json{ "keys": { "command": { "bind": { "G,G,G":"jupyter-notebook:restart-kernel-and-run-all-cells" } } }, }また、GUIで直感的にショートカットを変更することもできます。
しかし、エディタでのコード編集に使用するショートカットについては、解説があまり充実していないように思います。
この記事では、エディタ・ショートカットのカスタマイズ方法を説明します。
以下の方法により、コード編集用のショートカットをカスタマイズでき、例えばsublime textのショートカットを使用できるようになります。
custom.jsでjupyter notebookでのJavaScriptの動作をカスタマイズ
jupyter notebookで読み込まれるJavaScriptファイルの中には、ユーザーがカスタマイズするのを想定したものがあります。
それがcustom.jsです。これは、デフォルトでは配置されていませんが、存在する場合には自動的に読み込まれます。
~/.jupyter/custom/custom.jsに、ファイルを作成してください。OSによって配置場所がことなるかもしれないので、import jupyter_core jupyter_core.paths.jupyter_config_dir() # この結果が、'~/.jupyter'になるはずです。 # その場合、'~/.jupyter/custom/custom.js'が読まれます。で確認してみてください。
このcustom.jsに以下のように書きます。
jupyter notebookのJavaScriptでは、モジュールの管理にrequirejsが使用されているので、その構文に整合するように書きます。.jupyter/custom/custom.jsdefine([ "custom/js_required/import-sublime-keybindings", "base/js/events" ], function(keybindings, events) { "use strict"; keybindings.bindSublimeKeymap(); });外部のファイルにて、以下のようにショートカット設定を書き、custom.jsで読み込みます。
.jupyter/custom/js_required/import-sublime-keybindings.jsdefine([ 'base/js/namespace', 'notebook/js/cell', 'codemirror/lib/codemirror', 'codemirror/keymap/sublime' ], function(IPython, cell, CodeMirror) { "use strict"; var bindSublimeKeymap = function() { var map = CodeMirror.keyMap.sublime; var notebook = IPython.notebook; if (!notebook) return; // 既存のショートカットを無効化する関数 var deleteIfExist = function(strCommand) { if (map[strCommand]) { delete map[strCommand]; } }; // ここでキーマップをsublime textに設定 cell.Cell.options_default.cm_config.keyMap = 'sublime'; // Cmd-Enterのショートカットを無効化する deleteIfExist("Cmd-Enter"); // sublime textでデフォルトで用意されていないショートカットを自分で用意する map["Shift-Cmd-D"] = "deleteLine"; map["Cmd-D"] = "duplicateLine"; map["Alt-W"] = "wrapLines"; map["Cmd-B"] = "selectNextOccurrence"; map["Shift-Cmd-M"] = "selectBetweenBrackets"; map["Alt-Up"] = "swapLineUp"; map["ALt-Down"] = "swapLineDown"; // 以上で新規セルにショートカットが設定される。 // 既存セルにも適用するために以下を実行 var cells = IPython.notebook.get_cells(); var numCells = cells.length; for (var c = 0; c < numCells; c++) { cells[c].code_mirror.setOption('keyMap', 'sublime'); } }; return { bindSublimeKeymap: bindSublimeKeymap }; });これでJupyter notebookを再起動すれば、ショートカットが適用されるはずです。
- 投稿日:2020-02-04T16:54:29+09:00
Google Colaboratory と IBM Watson Personality Insights を用いてクラウド環境上で性格診断ツールを作る
Google Colaboratryの設定
Chromeのインストール
[Google Chrome]で検索してChromeをインストール
GoogleDrive内にColaboratryをインストールする
空ドライブ内で右クリックをしてアプリを追加をクリック
検索欄に [Colaboratry]と入力してアプリをクリック
インストール!!
再度空ドライブにて右クリックをして[Google Colaboratry]をクリック
以下の画面が表示されれば設定完了!!(ここでコーディングをしていきます。)
IBM Watson Personality Insightsの設定
IBM Cloud の設定
IBM Cloudのページにジャンプ!!
アカウントがあればログイン、なければ新規登録をしてください。
画面上部の[カタログ]をクリック後、検索欄に[Personality Insigts]を入力し、以下の画面にし、[Personality Insigts]をクリックします。
各項目の入力
ジャンプした先のページでの設定は次の様にしてください。
- 地域の選択
- 東京(特に指定はないが後のコーディングで変化が生まれる)
- 料金プラン
- ライト
- サービス名
- 任意の文字列(わかりやすいもの)
- リソース・グループの設定
- Default
- タグ
- 任意(なくてもよい)
上記項目を設定後に画面右側にある作成をクリック
ジャンプした先で画面左のタブから[管理]クリックし、APIKeyとURLを確認してメモをします
以上でIBM Watson Personality Insightsの設定は終了です。Pythonによるプログラミング
Google Colaboratryを開いてコーディングができる環境を構築してください(下の画面にしてください)
コーディング
PersonalityInsights.ipynb!pip install ibm_watson #Colab環境に足りないモジュールをインストールします #必要なもージュールのインポート import json # json解析モジュールのインポート from ibm_watson import PersonalityInsightsV3 # PersonalityInsights from ibm_cloud_sdk_core.authenticators import IAMAuthenticator from os.path import join, dirname def analyze_personality(): #------------------------------入力---------------------------------- authenticator = IAMAuthenticator('XXXXXXXX') #APIkeyを入力 #--------------------------------------------------------------------- service = PersonalityInsightsV3( version='2018-10-30', authenticator= authenticator) #------------------------------入力---------------------------------- service.set_service_url('XXXXXXXXXX') #URLを入力 #-------------------------------------------------------------------- # 性格を分析 with open('XXXXXXX.txt', 'r') as profile_text: #解析したいtxtファイルを絶対パスで指定 profile = service.profile( profile_text.read(), 'application/json', content_language='ja', accept_language='ja').get_result() # ファイルに書き込み with open('/content/result.json', 'w') as resultFile: json.dump(profile, resultFile, ensure_ascii=False, indent=2) analyze_personality() #関数を実行先ほどメモをしたAPIkeyとURLを所定の場所にコピペしてください
※汚くてすみません(汗実行
Colaboratry 画面ない上部のタブの中にある[ランタイム]をクリックし、[全てのセルを実行をクリック]。
画面左のタブのファイルマークをクリックし、クラウド環境下の指定したディレクトリにjsonファイルが生成されていれば成功ですお疲れ様でした
何かあれば教えてください


- 投稿日:2020-02-04T16:34:26+09:00
IBMi上のDBをJayDeBeApi使ってpython+JDBCでつついてみる
IBM i上のデータをPythonで取り出せないか
ひょんなことから、IBM i (AS400とも呼ばれたOSです) のデータを取り出す必要に迫られました。
やりたいこと
IBM i上のデータを取り出して、LinuxとかWindowsで使いたい
システム内のデータを使って、機械学習だったり分析だったりをしたいと思うことがあります。
単純にPythonを使うだけなら、IBM i上で処理することもできます。が、今回はGPU使ってDLだったりMLしたいので、Linux上にデータを持ってくる必要があります。
そのために、JDBC+Pythonでデータを引っ張ってこようと思います。もちろん、Javaを使ってデータを取ってきてもよいです。
今回はPythonの方が得意という理由でPythonからJDBCを使うことにしました。
(DLやMLはPythonで書くことが多いので、その処理にも入れやすかも)JayDeBeApiを使ってみる
今回は、JDBCのAPIを叩くためのPythonライブラリとして、
JayDeBeApiを使います。
https://github.com/baztian/jaydebeapi結構いろんな種類のDBに対応しています。
DB2もありますね!Supported databases
In theory every database with a suitable JDBC driver should work. It is confirmed to work with the following databases:
SQLite
Hypersonic SQL (HSQLDB)
IBM DB2
IBM DB2 for mainframes
Oracle
Teradata DB
Netezza
Mimer DB
Microsoft SQL Server
MySQL
PostgreSQL
many more...準備
今回は、Python3.6で動かします。
各ソフトウェアのバージョンは以下の通り
- Python == 3.6
- JayDeBeApi == 1.1.1
- JPype1 == 0.6.3
インストール
pipでインストールできます。
pip install JayDeBeApiJPypeのバージョンが最新だと、実行時にエラーが発生したので、0.6.3で再インストールしました。
pip install JPype1==0.6.3 --force-reinstallJDBCドライバーの準備
今回はIBM iに標準で用意されているJarファイルを利用します。
jt400.jarが下記のディレクトリに格納されているので、IBM iから利用するLinux環境にコピーします。/QIBM/ProdData/HTTP/Public/jt400/lib/jt400.jar簡単なデータ取得
<hostname>,<user>,<password>はお使いの環境に合わせて設定してください。import jaydebeapi conn = jaydebeapi.connect("com.ibm.as400.access.AS400JDBCDriver", "jdbc:as400://<hostname>", ["<user>", "<password>"], "/home/IBMi/jt400.jar",) cur = conn.cursor() cur.execute("select * from TSLIB.WORKDAY") cur.fetchall() curs.close() conn.close()このPythonスクリプトを実行することで、IBM iからデータを取得できました。
executeのSQL文を変更することで、DBに対する操作も変えられます。
- 投稿日:2020-02-04T15:31:58+09:00
Pythonとセキュリティ - ①Pythonとは
概要
Pythonは1991年に発表されたインタプリタ形式のプログラミング言語で、オランダ出身のプログラマ「Guido van Rossum(グイド・ヴァンロッサム)」によって開発された。
2020年1月を基準として最新バージョンは、Python2「2.7.17」、Python3「3.8.1」である。2008年の末から、Pythonは「バージョン2」と「バージョン3」に分かれて使用されている。Python2とPython3はお互いに互換ができないところも多いため、プログラムを作る際に、二つのバージョンのうち、一つ選ぶ必要がある。Python2は2020年4月に「2.7.18」が公開された後は公式な技術サポートは終了される。また、Python3から新たにサポートされるライブラリや脆弱性なども修正されているため、Pythonを習い始めようとしているのであれば、Python3をお勧めする。Pythonのメリット
容易性
Pythonの一番のメリットは簡単で、だれでもすぐプログラムが作れる容易性である。下記で「Hello World」を出力する例を、CとPython言語で作ってみた。
hello_world.c#include <stdio.h> int main() { printf("Hello World"); return 0; }hello_world.pyprint("Hello World")このようにCは5行で表現するコードが、Pythonでは1行で表現できる。また、文法的に括弧({,})やセミコロン(;)などが不要で、インデント(字下げ)でシンタックスを区別するため、ソースコードがより分かりやすい。
強い連携性(glue)
Pythonはシステムプログラミングや複雑な演算が多いプログラムには合わない。だが、Pythonは連携性があるため、他の言語で作られたプログラムにPythonが含められる。例えば、複雑な演算や、早い処理速度が必要な部分はCで作り、そこにPythonを含めることも可能である。もちろんCだけではなく、C++やJAVA, JavaScriptなど多様な言語とPythonを並行で使うことができる。
様々なライブラリ
個人的には一番のメリットだと考えてるのは厖大なライブラリの数である。GUIを開発するためのTkinterまたはPyQTや、ゲーム作成のためのPygame, Pythonで作成されたプログラムを実行ファイルとして作ってくれるPyInstaller、ウェブのクローリングのためのBeautiful Soupなど、記述したライブラリ以外にも厖大なライブラリが存在しているため、効率的に開発ができる。
クロスプラットフォーム開発
前述の通り、厖大なライブラリを提供しているため、OSの環境にかかわらず開発ができる。例として、WindowsでPythonを利用してGUIを開発する場合、ライブラリとしてTkinterまたは、PyQTライブラリを使用する。このライブラリをLinuxでも同じライブラリを使い、開発と実行ができる。このようにPythonのライブラリは厖大で、各OSもサポートしている。
ツールが作りやすい
数多いライブラリとオープンソースまた、簡単な文法ですぐプログラムが作れるPythonはシステム担当者などがツールを作ることに適している。
上記のメリット以外にもPythonでの開発で得られるメリットはたくさんある。その代わりインタプリタ言語であるため、速度の問題や、モバイルプラットフォームでは合わないなどもちろんデメリットもある。
まとめ
Pythonは開発の容易性をメリットとして多角的な開発で使用している。今回はPythonの概要
また、Pythonを使うことのメリットに対して学んでみた。次回は、実際Pythonを利用してセキュリ
ティに役に立つツールを作ってみよう。
- 投稿日:2020-02-04T15:10:47+09:00
2020年Jリーグの登録選手を年齢分析してみたが、外れ値は52歳のキングカズ以外にもいた。
概要
- 2020年1月31日に、2020明治安田生命Jリーグの登録選手が公開されました。
- 公式サイトやデータサイトから選手リストを抽出し、その生年月日から年齢を算出する。
- そのデータを
matplotlibのboxplotから年齢分布を読み取る。- その
boxplotの外れ値(outlier)について調べた。データ
- 公式サイト>例:北海道コンサドーレ札幌
- データサイト>選手・監督・審判>例:北海道コンサドーレ札幌
- 今回はスクレイピングの解説は省略します。以下のようなデータ形式で進めます。
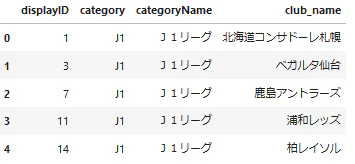
* ローカルデータは以下の項目になります。
コード
box_plot.pyimport pandas as pd import matplotlib.pyplot as plt %matplotlib inline # スクレイピングしたデータ data = pd.read_csv('./csv/all_player_mst_2020.csv', sep=',', encoding='utf-8') # ''表示順'、'カテゴリーID'、'カテゴリー名'、クラブ名'のローカルファイルを読み込む club = pd.read_csv('./csv/mst_club_2020.csv', sep=',', encoding='utf-8') # 生年月日から年齢を算出する関数 def get_age(birthday): today = int(pd.to_datetime('today').strftime('%Y%m%d')) birthday = int(pd.to_datetime(birthday).strftime('%Y%m%d')) return int((today - birthday) / 10000) data['年齢'] = data['生年月日'].apply(lambda date: get_age(date))
- 生年月日から年齢を算出し、年齢列を追加する。参考サイト
 box_plot.py# J1,J2,J3の年齢をリスト化する J1 = club[club['category'] == 'J1']['club_name'] J1_age = {} for c_name in J1: tmp_age = list(data[data['クラブ名'] == c_name]['年齢']) J1_age[c_name] = tmp_age J2 = club[club['category'] == 'J2']['club_name'] J2_age = {} for c_name in J2: tmp_age = list(data[data['クラブ名'] == c_name]['年齢']) J2_age[c_name] = tmp_age J3 = club[club['category'] == 'J3']['club_name'] J3_age = {} for c_name in J3: tmp_age = list(data[data['クラブ名'] == c_name]['年齢']) J3_age[c_name] = tmp_age
box_plot.py# J1,J2,J3の年齢をリスト化する J1 = club[club['category'] == 'J1']['club_name'] J1_age = {} for c_name in J1: tmp_age = list(data[data['クラブ名'] == c_name]['年齢']) J1_age[c_name] = tmp_age J2 = club[club['category'] == 'J2']['club_name'] J2_age = {} for c_name in J2: tmp_age = list(data[data['クラブ名'] == c_name]['年齢']) J2_age[c_name] = tmp_age J3 = club[club['category'] == 'J3']['club_name'] J3_age = {} for c_name in J3: tmp_age = list(data[data['クラブ名'] == c_name]['年齢']) J3_age[c_name] = tmp_age各カテゴリーでクラブ単位の年齢データをリスト形式に作成する。
box_plot.pyfig = plt.figure(figsize=(16,16),dpi=144) fig.suptitle('2020明治安田生命Jリーグ', x=0.5, y=0.9, fontsize=18) fig.subplots_adjust(hspace=0.1) plt.rcParams["font.family"] = "IPAexGothic" red_circle = dict(markerfacecolor='r', marker='o') # J1 ax1 = fig.add_subplot(311) ax1.boxplot(J1_age.values(), labels=J1_age.keys(), vert=False, flierprops=red_circle) ax1.invert_yaxis() ax1.set_ylabel('J1', fontsize=16) ax1.set_xlim(15,55) # J2 ax2 = fig.add_subplot(312, sharex=ax1) ax2.boxplot(J2_age.values(), labels=J2_age.keys(), vert=False, flierprops=red_circle) ax2.invert_yaxis() ax2.set_ylabel('J2', fontsize=16) # J3 ax3 = fig.add_subplot(313 ,sharex=ax1) ax3.boxplot(J3_age.values(), labels=J3_age.keys(), vert=False, flierprops=red_circle) ax3.invert_yaxis() ax3.set_ylabel('J3', fontsize=16) plt.show() #グラフの画像保存 plt.savefig('./img/2020_jleague_age_boxplot.png')箱ひげ図のポイント
* J1・J2・J3の3つのグラフのタイトルsuptitle
* それぞれの上下の間隔を少なくするsubplots_adjust
* 外れ値のマーカーをカスタマイズred_circle = dict(markerfacecolor='r', marker='o')
* クラブ名が日本語なので横向きにするboxplot(x, labels=label, vert=False,...)
グラフから読み取れる内容
- ああ、やっぱりキングカズ(三浦 知良選手)は外れているよなー!
- 北海道コンサドーレは3つも外れ値があるじゃないか!
- 川崎は中村 憲剛選手だろうね。
- J2,J3とカテゴリーが下がるほど、外れ値が多くないか?
- 外れ値は、どう計算されているの?疑問?
ここからが本題
外れ値(はずれち、英: outlier)は、統計学において、他の値から大きく外れた値のこと。測定ミス・記録ミス等に起因する異常値とは概念的には異なるが、実用上は区別できないこともある。
出典: フリー百科事典『ウィキペディア(Wikipedia)』で、計算方法は?
工学のためのデータサイエンス入門
フリーな統計環境Rを用いたデータ解析
瀬間 茂・神保 雅一・鎌倉 稔成・金藤 浩司共著
数理工学社:2004年初版2刷以前買った上記書籍から箱型図(箱ひげ図)の作成について解説があり、この投稿のために作図しました。
検証
box_ploy.py# 北海道コンサドーレ札幌を対象に検証 sapporo = pd.DataFrame(J1_age[J1[0]]) q1 = sapporo.describe().loc['25%'] q3 = sapporo.describe().loc['75%'] iqr = q3 - q1 outlier_min = q1 - (iqr) * 1.5 outlier_max = q3 + (iqr) * 1.5 outer_min = sapporo[sapporo < outlier_min[0]] outer_max = sapporo[sapporo > outlier_max[0]] print( outer_min, outer_max)結果
box_plot.py0 0 NaN 1 NaN 2 NaN 3 NaN 4 NaN 5 NaN 6 NaN 7 NaN 8 NaN 9 NaN 10 NaN 11 NaN 12 NaN 13 NaN 14 NaN 15 NaN 16 NaN 17 NaN 18 NaN 19 NaN 20 NaN 21 NaN 22 NaN 23 NaN 24 NaN 25 NaN 0 0 35.0 1 NaN 2 NaN 3 34.0 4 NaN 5 NaN 6 NaN 7 NaN 8 NaN 9 NaN 10 NaN 11 NaN 12 NaN 13 NaN 14 NaN 15 NaN 16 NaN 17 34.0 18 NaN 19 NaN 20 NaN 21 NaN 22 NaN 23 NaN 24 NaN 25 37.0J1のグラフで北海道コンサドーレ札幌は、3つの外れ値がありましたが、実際は同年齢が2名いましたので4名が外れ値です。
実際の外れ値の選手名一覧(一部)
category クラブ名 選手名 生年月日 年齢 J1 北海道コンサドーレ札幌 菅野 孝憲 1984/5/3 35 J1 北海道コンサドーレ札幌 石川 直樹 1985/9/13 34 J1 北海道コンサドーレ札幌 早坂 良太 1985/9/19 34 J1 北海道コンサドーレ札幌 ジェイ 1982/5/7 37 J1 川崎フロンターレ 中村 憲剛 1980/10/31 39 J1 横浜FC 三浦 知良 1967/2/26 52 J2 水戸ホーリーホック 木村 祐志 1987/10/5 32 ・・・ ・・・ ・・・ ・・・ ・・・ まとめ
- 外れ値はIQR(3/4四分位数-1/4四分位数)の範囲に影響される。
- 箱ひげ図は知っていたが使ったことなく、作図の深堀りができた。
- テーマ>データ取得>データ整形>可視化>検証までができた。
- [課題]発表から4日間かかったので、これくらい1日で出来ないといかんと反省!
- 引用の仕方などが適切でない場合、ご指摘ください。
参考サイト



- 投稿日:2020-02-04T13:37:44+09:00
[Python]No value for argument 'self' in unbound method callが出た
Python初心者です。
selfの考え方をイマイチ理解出来ておらず、地味に躓いたのでメモhello.pyclass HelloWorld: def __init__(self): self.message = 'Hello,World' def gree(self): print(self.message)sample.pyimport hello h = hello.HelloWorld h.gree()このコードだとh.gree()で「No value for argument 'self' in unbound method call」というエラーになる。
エラーの内容は関数greeの引数selfがないよというものselfって関数呼び出し時の引数に指定しなくていいんじゃないんだっけ?と躓いた。
sample.pyのコードを以下にすることで解決
sample.pyimport hello h = hello.HelloWorld() h.gree()参考
sample.pyh = hello.HelloWorld print(type(h)) h = hello.HelloWorld() print(type(h))<class 'type'> <class 'hello.HelloWorld'>hello.HelloWorld だとクラス定義を代入
hello.HelloWorld()だとクラスのインスタンスを代入selfはクラスのインスタンス情報を保持するものなので、hello.HelloWorld だと動かないと理解
- 投稿日:2020-02-04T12:00:52+09:00
機械学習の書籍多いけど、どれ買えば良いの?レベル別にオススメ!!<初心者向け>
はじめに
機械学習の書籍多いけど、どれ買えば良いのかをレベル別にオススメします。
レベルはレベル1~レベル5の五段階です。
今の自分にあったレベルから書籍を選んでみて下さい。
また3〜4ヶ月でここに紹介した書籍を読み進められるとベストです。
勉強方法はこのnoteでは触れませんが、Couseraのマシンラーニングコースなどオンラインでとても良い講座があるので、書籍以外のサービスも活用してみて下さい。*AIに関して勉強したい方は下記の2つご利用ください!
AI Academy無料でPythonや機械学習、ディープラーニングが学べるオンラインAIプログラミング学習サービス
*一部コンテンツは月額980円にて全て利用可能。AI Academy Bootcamp
個人向け2ヶ月10万円で受講可能な、受講後すぐに業務で使える分析力を身に着けられるAI・データ活用ブートキャンプ人工知能基礎編<レベル1>
まずは、機械学習やディープラーニングのプログラミングから入る前に、全体像の俯瞰と用語の整理をしましょう。
AIって何?何ができるの?ディープラーニングってよく聞くけど何がすごいの?
そういった方はレベル1です。
まずは以下3冊を読み進めてみて下さい。人工知能は人間を超えるか ディープラーニングの先にあるもの (角川EPUB選書)
1,540円
深層学習教科書 ディープラーニング G検定(ジェネラリスト) 公式テキスト
3,080円
文系AI人材になる: 統計・プログラム知識は不要
1,760円
機械学習編<レベル2>
上記から2,3冊読めば、AIのイメージ、AI、機械学習、ディープラーニングの関係性、できる事、できない事などイメージできたかと思います。
次に機械学習プログラミングを行います。まずは、下記の書籍を購入し、機械学習の主要なアルゴリズムを俯瞰して下さい。
2,653円
もし、Pythonの知識や、機械学習プログラミングのイメージがつかなかった方は、下記の書籍に戻って進めてみて下さい。
2,801円
機械学習図鑑を読み終えた方は、次に選ぶのは以下のオライリーから出版されている機械学習の本です。4週間〜1ヶ月を目処に一通り読み進めてみて下さい。全部理解しようとせず7、8割の理解で構いません。Pythonではじめる機械学習 ―scikit-learnで学ぶ特徴量エンジニアリングと機械学習の基礎
3,740円
機械学習のための数学編<レベル3>
さて、pythonを用いて機械学習の一連のイメージが出来たら、数学の範囲をカバーしましょう。
回帰分析やロジスティック回帰、サポートベクターマシン、ニューラルネットワークの内部を学んでいきます。
ここで選ぶのは下記3冊です。やさしく学ぶ 機械学習を理解するための数学のきほん アヤノ&ミオと一緒に学ぶ 機械学習の理論と数学、実装まで
2,696円
機械学習のエッセンス -実装しながら学ぶPython,数学,アルゴリズム- (Machine Learning)
3,080円
3,180円
大学数学までやった方は真ん中の機械学習のエッセンスだけ購入すると良いです。
数学に苦手意識がある方や、復習も兼ねて機械学習の数学を勉強したい方は①機械学習を理解するための数学のきほん→②ディープラーニングの数学→③機械学習のエッセンスの順に読んでみて下さい。ディープラーニング<フレームワークを用いた実装編/レベル4>
次にKerasやPyTorchといった深層学習フレームワークを用いてディープラーニングを進めてみましょう。
4,190円
詳解ディープラーニング 第2版 ~TensorFlow/Keras・PyTorchによる時系列データ処理~ (Compass Booksシリーズ)
3,740円
つくりながら学ぶ!PyTorchによる発展ディープラーニング
3,445円
上記3冊がオススメです。ディープラーニング編<理論と実装編/レベル5>
では、機械学習編同様に、理論と実装も行なっていきましょう。
購入する書籍は下記の2冊です。ゼロから作るDeep Learning ―Pythonで学ぶディープラーニングの理論と実装
3,672円
ゼロから作るDeep Learning ❷ ―自然言語処理編
3,960円
最後に
今回は14冊紹介しましたが、全て購入するのに5万円ほどかかります。
ですが、全て購入しなくても必要な書籍だけ購入し進めてみて下さい。
この書籍を3〜6ヶ月かけて読み進めるだけでも基本的な基礎知識は身につきます。(これ全て読んだから転職等できる訳ではないのでご注意を。)
少しでも参考になったら、いいね!(スキ)とシェアして頂けると嬉しいです!*AIに関して勉強したい方は下記の2つご利用ください!
AI Academy
無料でPythonや機械学習、ディープラーニングが学べるオンラインAIプログラミング学習サービス
*一部コンテンツは月額980円にて全て利用可能。AI Academy Bootcamp
個人向け2ヶ月10万円で受講可能な、受講後すぐに業務で使える分析力を身に着けられるAI・データ活用ブートキャンプ















- 投稿日:2020-02-04T11:54:19+09:00
aiohttpを無理やりmockする
無理やり行きます。
test_aiohttp_mock.py::
import asyncio from unittest import mock import aiohttp import pytest async def send_request(): async with aiohttp.ClientSession() as session: resp = await session.get('http://127.0.0.1:8234') resp.raise_for_status() # mock class DummyResponse(mock.MagicMock): def __await__(self): tmp = yield return self class DummyClientSession: def __init__(self, resp: DummyResponse): self.resp = resp def __await__(self): tmp = yield return self def __aenter__(self): return self async def __aexit__(self, *args, **kwargs): await self.close() async def close(self, *args, **kwargs): pass async def get(self, *args, **kwargs): return self.resp # testing @pytest.mark.asyncio async def test_simple(): dummy_resp = DummyResponse() async with DummyClientSession(dummy_resp) as client: resp = await client.get() resp.raise_for_status() assert dummy_resp.raise_for_status.called @pytest.mark.asyncio async def test_aiohttp(): with mock.patch("aiohttp.ClientSession") as ClientSession: dummy_resp = DummyResponse() ClientSession.return_value = DummyClientSession(dummy_resp) await send_request() assert dummy_resp.raise_for_status.called実行
pytest test_aiohttp_mock.py出力::
============================= test session starts ============================== platform darwin -- Python 3.8.0, pytest-5.3.5, py-1.8.1, pluggy-0.13.1 rootdir: /srv/JeYA9JoHojZtZYG/blogs/python-async plugins: asyncio-0.10.0 collected 2 items test_aiohttp_mock.py .. [100%] =============================== warnings summary =============================== /Users/JeYA9JoHojZtZYG/.virtualenvs/py38/lib/python3.8/site-packages/aiohttp/helpers.py:107 /Users/JeYA9JoHojZtZYG/.virtualenvs/py38/lib/python3.8/site-packages/aiohttp/helpers.py:107: DeprecationWarning: "@coroutine" decorator is deprecated since Python 3.8, use "async def" instead def noop(*args, **kwargs): # type: ignore -- Docs: https://docs.pytest.org/en/latest/warnings.html ========================= 2 passed, 1 warning in 0.20s =========================
- 投稿日:2020-02-04T10:20:01+09:00
Python2から3に変更されなかった
python2から3に変更されない...
$ python --version Python 2.7.15 $ brew install python3 $ python3 --version -bash: python3: command not foundあれ、python3がインストールされてない...
解決?
# python3をインストール $ brew install python3 Ignoring bindex-0.5.0 because its extensions are not built. Try: gem pristine bindex --version 0.5.0 Ignoring bootsnap-1.3.1 because its extensions are not built. Try: gem pristine bootsnap --version 1.3.1 Ignoring byebug-10.0.2 because its extensions are not built. Try: gem pristine byebug --version 10.0.2 Ignoring byebug-9.0.6 because its extensions are not built. Try: gem pristine byebug --version 9.0.6 Ignoring bindex-0.5.0 because its extensions are not built. Try: gem pristine bindex --version 0.5.0 Ignoring bootsnap-1.3.1 because its extensions are not built. Try: gem pristine bootsnap --version 1.3.1 Ignoring byebug-10.0.2 because its extensions are not built. Try: gem pristine byebug --version 10.0.2 Ignoring byebug-9.0.6 because its extensions are not built. Try: gem pristine byebug --version 9.0.6 Warning: python 3.7.6_1 is already installed, its just not linked You can use `brew link python` to link this version. $ brew link python Linking /usr/local/Cellar/python/3.7.6_1... Error: Could not symlink Frameworks/Python.framework/Headers Target /usr/local/Frameworks/Python.framework/Headers is a symlink belonging to python@2. You can unlink it: brew unlink python@2 To force the link and overwrite all conflicting files: brew link --overwrite python To list all files that would be deleted: brew link --overwrite --dry-run python # unlinkしてみる $ brew unlink python@2 Unlinking /usr/local/Cellar/python@2/2.7.15_1... 39 symlinks removed $ brew link python Linking /usr/local/Cellar/python/3.7.6_1... 28 symlinks created # 確認 $ python3 --version Python 3.7.6python3がきちんとインストールされたっぽい?
- 投稿日:2020-02-04T09:45:48+09:00
OpenCVで勉強中にスマホをいじったら警告するアプリをつくった
はじめに
PythonとOpenCVの勉強を始めました.
その際,Qiitaの情報にはとてもお世話になったので勉強したことの整理も兼ねて投稿します.
投稿するのも初めてなので拙いところがあると思いますが,これを読んだ方の参考になれば幸いです.できたもの
机の上に置いてあるスマホをテンプレートマッチングにより認識して,中央付近の明度から電源が入っているかを判定し,一定時間電源がついていたら警告するアプリです.
使ったもの
- WEBカメラ UCAM-C520FEBK
- Python 3.7.5
- pip 20.0.1
- numpy 1.18.1
- opencv-python 4.1.2.30
- PyInstaller 3.6
各モジュールはpipを用いて簡単にインストールできます.
やり方は以下のサイトを参考にしました.
https://qiita.com/fiftystorm36/items/1a285b5fbf99f8ac82eb (opencv-python, numpy)
https://techacademy.jp/magazine/18963 (PyInstaller)開発の流れ
- 警告に使用する画像とテンプレートマッチングに使う画像を用意する
- WEBカメラにより取得した画像と用意した画像でテンプレートマッチングを行い,スマホの位置を取得できるようにする
- スマホの中央付近の明度がある閾値以上のとき電源が入っていると判断し,カウントを行い一定回数カウントした場合警告する画像を表示するようにする
- できたファイルのexe化
画像の準備
まず,警告用の画像はオンライン上のものを適当にダウンロードしました.
また,テンプレート画像は以下のプログラムを用いて取得しました.
temp.pyimport numpy as np import cv2 cap = cv2.VideoCapture(0) while(True): # webカメラの画像を読み込み回転 ret, frame = cap.read() img1 = cv2.flip(frame, -1) cv2.imshow("img", img1) # Escキーを押したら保存して終了 k = cv2.waitKey(0) if k == 27: cv2.imwrite('model.png',img1) break cap.release() cv2.destroyAllWindows()これにより model.png が得られるはずです.
これからスマホの部分のみをトリミングすれば以下のようなものが得られます.
これで画像の準備は終了です.
スマホの位置の取得
スマホの位置は以下のようなプログラムで取得しました.
caution.pyimport numpy as np import cv2 cap = cv2.VideoCapture(0) while(True): # webカメラの画像を読み込み,回転 ret, frame = cap.read() img = cv2.flip(frame, -1) # あらかじめ撮影したスマホの画像を読み込み temp = cv2.imread('model.png') # マッチングテンプレートを実行 # 比較方法はcv2.TM_CCOEFF_NORMEDを選択 result = cv2.matchTemplate(img, temp, cv2.TM_CCOEFF_NORMED) # 検出結果から検出領域の位置と値を取得 # 類似度が高い領域の左上の位置がmax_loc min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(result) # 類似度が高い領域の右下と中央の位置を取得 # マッチングがうまくいかなかったときは前のループの位置を使用 if max_loc[0] < img.shape[1] - temp.shape[1] and \ max_loc[1] < img.shape[0] - temp.shape[0]: topleft_x, topleft_y = max_loc h, w = temp.shape[:2] bottom_right = (topleft_x + w, topleft_y + h) center = (topleft_x + w / 2, topleft_y + h / 2) print(center) # 検出領域を青い長方形で囲んで表示 result = img cv2.rectangle(result,(topleft_x, topleft_y), bottom_right, (255, 0, 0), 2) cv2.imshow("img", result) # 1秒待機してEscキーの入力があると終了 k = cv2.waitKey(1000) if k == 27: cv2.imwrite("temp.png", result) break cap.release() cv2.destroyAllWindows()最初にテンプレートマッチングができないとcenterをprintできずエラーが出るため,最初は電源を切って置いておく必要があります.
うまくテンプレートマッチングができていれば以下のようになるはずです.
明度から電源が入っているか判定
以下のプログラムで電源が入っているか判定し,長時間電源が入っていると警告する画像を表示します.
caution.pyimport numpy as np import cv2 cap = cv2.VideoCapture(0) count = 0 while(True): # webカメラの画像を読み込み,回転 ret, frame = cap.read() img = cv2.flip(frame, -1) # あらかじめ撮影したスマホの画像を読み込み temp = cv2.imread('model.png') # マッチングテンプレートを実行 # 比較方法はcv2.TM_CCOEFF_NORMEDを選択 result = cv2.matchTemplate(img, temp, cv2.TM_CCOEFF_NORMED) # 検出結果から検出領域の位置と値を取得 # 類似度が高い領域の左上の位置がmax_loc min_val, max_val, min_loc, max_loc = cv2.minMaxLoc(result) # 類似度が高い領域の右下と中央の位置を取得 # マッチングがうまくいかなかったときは前のループの位置を使用 if max_loc[0] < img.shape[1] - temp.shape[1] and \ max_loc[1] < img.shape[0] - temp.shape[0]: topleft_x, topleft_y = max_loc h, w = temp.shape[:2] bottom_right = (topleft_x + w, topleft_y + h) center = (topleft_x + w / 2, topleft_y + h / 2) print(center) # HSV変換 hsv_image = cv2.cvtColor(img, cv2.COLOR_BGR2HSV) # 取得した点の中央の明度によりスマホを使っているか判定し,使っているときカウント # 誤検出防止のため周囲の明度も使用 value = 0 for i in range(-15, 16): for j in range(-15, 16): value = value + hsv_image[int(center[0]) + i][int(center[1]) + j][2] v_ave = value / 961 if v_ave > 200: print("ON, 明度:", v_ave) count = count + 5 else: print("OFF, 明度:", v_ave) # 検出領域を青い長方形で囲んで表示 # 中央の位置は赤い円で表示 result = img cv2.rectangle(result,(topleft_x, topleft_y), bottom_right, (255, 0, 0), 2) cv2.circle(result, (int(center[0]), int(center[1])), 5, (0, 0, 255)) cv2.imshow("img", result) # カウントが一定以上されると画像を表示 if count > 50: img4 = cv2.imread('studyordie.jpg') cv2.imshow('studyordie', img4) cv2.moveWindow('studyordie', 555, 0) cv2.waitKey(0) count = 0 break print("count = ", count) count = count - 1 if count < 0: count = 0 # 1秒待機してEscキーの入力があると終了 k = cv2.waitKey(1000) if k == 27: break cap.release() cv2.destroyAllWindows()これを実行すればマッチングの画像と同時に以下のようなコンソールが見られるはずです.
このcountの値が50を超えるときに警告の画像が表示されます.(157.0, 193.0) OFF, 明度: 159.49739854318418 count = 0(225.0, 260.0) ON, 明度: 203.90426638917793 count = 15ここで明度を求めるときにマッチングの中心を中心とした31×31の正方形での平均としていますが,これは一点のみだと蛍光灯の反射?で大きな値が返されてしまったからです.
使用する環境によってここと,閾値の値は変わると思います.exe化
デスクトップのショートカットをダブルクリックするだけで使えるようにしたかったのでexe化をしました.
Pyinstallerが入った状態でpyinstaller caution.py --onefileのコマンドでexe化できます.
exe化した後は用意した画像をdistフォルダ内に入れる必要があるので注意してください.
ショートカットを作成してデスクトップに貼れば終わりです.




- 投稿日:2020-02-04T08:24:44+09:00
気象データをもとに「天気図っぽい前線」を機械学習で描いてみる(3)
気象データをもとに「天気図っぽい前線」を機械学習で描いてみる(3)
前回、気象データをもとに「天気図っぽい前線」を機械学習で描いてみる(2)として、GPV形式の数値データを可視化するまでの話をまとめました。
今回は、教師データとして前線データを抽出するまでの話を纏めます。学習戦略
前線の位置に前線画像を生成させる
前回可視化した、複数種類の気象データ画像を認識して、速報天気図の前線と同じ場所に、前線画像を生成することを目指します。
具体的には、ある時刻の気象データ画像(6種類 各256x256サイズ)を入力とし、出力として256x256サイズの画像を生成させるニューラルネットワークを作ります。
この出力画像は、速報天気図から作った前線画像を教師画像とします。
教師画像は、速報天気図から、寒冷前線要素を「青」、温暖前線と閉塞前線を「赤」、それ以外は「白」という3値に変換したものを作ります。出力画像の各ピクセルごとに、トリコロールのどれに相当するのかをクロスエントロピーで計算させて、最も確率の高い結果でそのピクセルに色を付けます。
前線だけ対象とするのはなぜ?
天気図そのものを生成させずに、前線だけとしているのはなぜか?
実際のところ、私も最初は天気図そのものを生成させようとしましたが、結果としては等圧線の生成に引っ張られてしまうようで、なかなか思うようになりませんでした。
前線要素の抽出
速報天気図の前線要素
速報天気図の前線要素は、寒冷前線(青色)、温暖前線(赤色)、閉塞前線(ピンク)、停滞前線(青と赤)となっています。
(2019年6月23日12時UTC)
わりと賑やかな天気図で、華南地方から東シナ海を通り日本の南に停滞前線が延びています。
また三陸沖の低気圧(30km/hで移動しているもの)は閉塞しており、閉塞前線、温暖前線と寒冷前線が延びています。切り取った画像
ここから前線要素だけを色を基準に切り取ります。
地形図、緯度経度線、等圧線は不要ですので、黒や緑は除外します。
閉塞前線も微妙にピンクを残すのをやめて、赤色にしました。
ただ、「低」とか「高」といった記号だけは残りますが、まあ目をつむります。結果的はこの記号の位置も学習してしまいました
つまるところ、速報天気図から、寒冷前線要素を「青」、温暖前線と閉塞前線を「赤」、それ以外は「白」という3値に変換した画像を作り、教師画像とします。
画像の切り取り方
天気図から色をもとに前線要素を切り取るには、PILを用いました。
下記あたりを参考にさせて頂きました。cripping.pyt_img = load_img(t_imgfile) # 天気図画像を読み込む t_data = img_to_array(t_img)/255 # 数値配列に変換する #- Mask Fornt Line m_data = 255*t_data # 同じサイズの画像を一枚作る m_img = array_to_img(m_data) # 数値配列に変換する img_size = m_img.size mask1 = Image.new('RGB', img_size) # RGBによる画像データを生成 for x in range(img_size[0]): for y in range(img_size[1]): r,g,b = m_img.getpixel((x,y)) # ピクセルのRGB値を読み取る if(r>g+25): if(r>b-40): # 赤と決まれば(255,0,0) r=255 b=0 g=0 else: r,g,b=255,255,255 # 赤でなければ「白」 elif(b>r): if(b>g+25): # 青と決まれば(0,0,255) b=255 g,r=0,0 else: r,g,b=255,255,255 # 青でなければ「白」 else: r,g,b=255,255,255 # その他は「白」とする mask1.putpixel((x,y),(r,g,b)) # 画像のピクセル値に代入する色のRGBの判別は、25とか40とかの遊びを設けています。
速報天気図の前線画像は拡大すると、例えば赤にしても周囲の海の色や経度線の緑などとの境界部分で、色同士が混じっています。このあたりも教師画像化する際には拾っておかないと、細いギザギザした線になってしまうため、判定範囲に遊びを設けています。
MacOSに標準搭載されている「Digital Color Meter」を使ってRGB値を読み取りながら、トライアンドエラーで遊び範囲を決めました。
まとめ
今回は、前線を自動描画する機械学習を作成するにあたっての教師データとなる前線要素を、どのようにして天気図から抽出したかを纏めました。
実はカラーの天気図は手持ちが少なく、白黒の天気図ならば過去に遡って沢山あったので、この白黒版からも教師データを作成する必要が生じてきました。
そこで、下のように白黒天気図(右)を左のカラー天気図に変換するCNNを作成してから、今回説明した画像切り出しプログラムを使って前線要素を切り出すということをやりました。
次回は、教師データを増やすために行った、白黒天気図をカラー化するという話を投稿する予定です。


- 投稿日:2020-02-04T06:48:11+09:00
np.newaxisで次元を上げてブロードキャスト演算
3次元のnp.arrayのイメージがつかん、np.newaxisとは何ぞや、という疑問から自分なりの理解を書き留めた記事です。np.arrayのイメージやnp.newaxisの基本的なところを書いた前半の記事はこちら。
この記事では、np.newaxisの使いどころについて。具体的には、前半の記事で最初に述べた、2次元ベクトルを複数並べた2次元配列が2つあったときに両者に含まれるベクトル間の距離の二乗を総当たりで求める計算をやってみます。STEP 3. ブロードキャスト
本題に入る前に、ブロードキャストについておさらい。形が違う配列同士の演算を忖度してやってくれるやつです。
>>> x = np.array([1, 2]) # よこ2たて1のベクトル >>> A = np.array([[1, 2], [3, 4], [5, 6]]) # よこ2たて3の行列 >>> B = np.array([[1], [2]]) # よこ1たて2の行列 >>> C = np.array([[[1], [2]], [[3], [4]]]) # よこ1たて2奥行き2の3次元配列 >>> x + A # よこ2たて3の行列になる array([[2, 4], [4, 6], [6, 8]]) >>> x + B # よこ2たて2の行列になる array([[2, 3], [3, 4]]) >>> x + C # よこ2たて2奥行き2の3次元配列になる array([[[2, 3], [3, 4]], [[4, 5], [5, 6]]])
STEP 4. 次元を上げてブロードキャスト演算
本題に戻って、np.newaxisって何がうれしいの?っていう話です。
一次元配列の場合
手始めに一次元配列で考えると、「2つの配列の各要素同士の総当たり演算結果を新しい軸に格納する」ためにnp.newaxisが使えるっていうところでしょうか。
例えば$x=[1, 3, 5, 7]$と$y=[2, 4, 6]$があって$4\times3=12$通りの総当たり計算をしたいとき、np.newaxisで$y$をたて3よこ1の行列に変換してから$x$と演算すれば、たて3よこ4の行列がブロードキャストによって得られる訳です。
>>> x = np.array([1, 3, 5, 7]) >>> y = np.array([2, 4, 6]) >>> x[np.newaxis, :] + y[:, np.newaxis] # xの要素とyの要素の総当たりで足し算する array([[ 3, 5, 7, 9], [ 5, 7, 9, 11], [ 7, 9, 11, 13]]) # x + y[:, np.newaxis] でも同じ
二次元配列の場合
では二次元の場合どうなるでしょうか?
以下のように同じ次元の横ベクトル(ここでは2次元)が縦に並んだ配列が2つあるとします。>>> A = np.array([[1, 2], [3, 4], [5, 6]]) >>> B = np.array([[1, 1], [2, 2]])このとき、うまい具合にnp.newaxisを導入してやれば、ベクトルの各成分それぞれについて、総当たり演算ができます。一次元配列の総当たり演算を同時に複数回やるイメージ(上だと$x$成分と$y$成分)。
>>> A[np.newaxis, :, :] - B[:, np.newaxis, :] # x成分とy成分の総当たり引き算 array([[[ 0, 1], [ 2, 3], [ 4, 5]], [[[-1, 0], [ 1, 2], [ 3, 4]]]) # A - B[:, np.newaxis, :] でも同じ
きちんとブロードキャストしてくれるように揃えれば、newaxisの取り方を変えても同じ値を得ることができます。
>>> A.T[np.newaxis, :, :] - B[:, :, np.newaxis] # x成分とy成分の総当たり引き算 array([[[ 0, 2, 4], [ 1, 3, 5]], [[[-1, 1, 3], [ 0, 2, 4]]]) # A.T - B[:, :, np.newaxis] でも同じ
本題
上の2次元ベクトルの組$A$と$B$があったとき、(ベクトル間距離)$^2$を総当たりで求めましょう。
$(a_x, a_y)$と$(b_x, b_y)$の距離の二乗は $(a_x-b_x)^2+(a_y-b_y)^2$ なので、まず$x$成分同士、$y$成分同士の引き算の二乗を総当たりにやればよく、それはまさしく上でやった計算を二乗するだけです。そのあと、$x$成分の差の二乗と$y$成分の差の二乗を足す= 新しい軸として$A$にも$B$にも追加していない3つ目の軸でsumしてやれば良いです(絵でイメージした方がわかりやすい)。>>> ((A.T[np.newaxis, :, :] - B[:, :, np.newaxis])**2).sum(axis=1) array([[ 1, 13, 41], [ 1, 5, 25]]) # ((A.T - B[:, :, np.newaxis])**2).sum(axis=1) でもよい
これは前回の一番最初に『機械学習のエッセンス』から抜粋してきた式と等価です。
また上で見たように、$A$や$B$に追加するnewaxisの場所は一意ではなく、以下のようにしても同じ結果が得られます。>>> ((A[np.newaxis, :, :] - B[:, np.newaxis, :])**2).sum(axis=2) array([[ 1, 13, 41], [ 1, 5, 25]]) # ((A - B[:, np.newaxis, :])**2).sum(axis=2) でもOK >>> ((A.T[:, np.newaxis, :] - B.T[:, :, np.newaxis])**2).sum(axis=0) array([[ 1, 13, 41], [ 1, 5, 25]])ベクトル間距離を求めるには、これの平方根を取ればいいです。

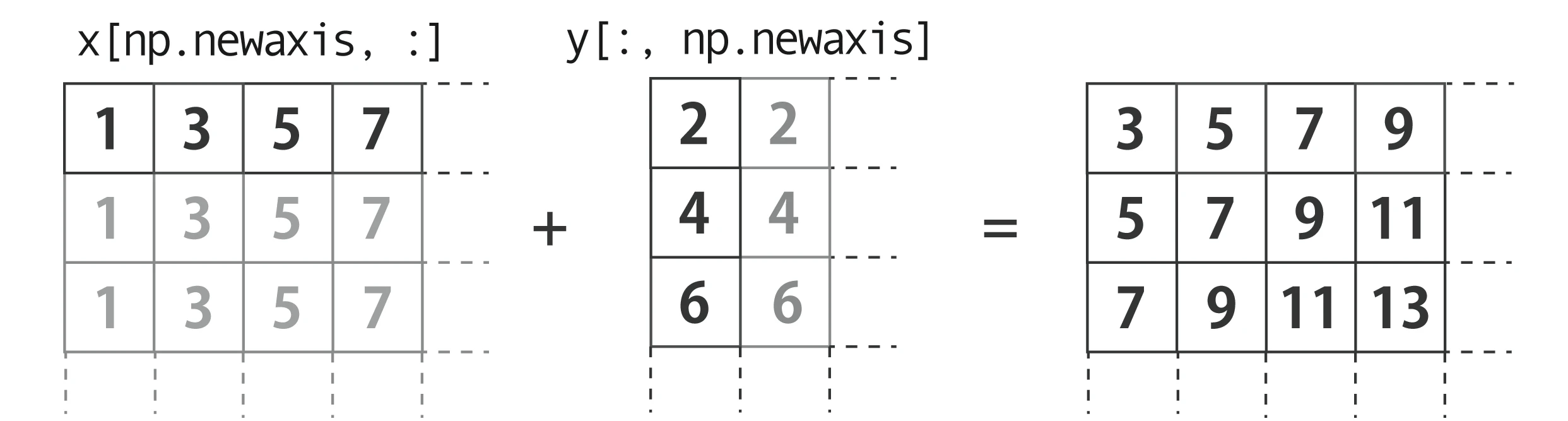



- 投稿日:2020-02-04T06:19:59+09:00
言語処理100本ノック-20(pandas使用):JSONデータの読み込み
言語処理100本ノック 2015「第3章: 正規表現」の20本目「JSONデータの読み込み」記録です。
1年以上前にやった内容の復習なのですが、ほとんど覚えていなかったです。正規表現は、必要な時に毎回ググりながらやっていたのですが、少なくても記事などにアウトプットしないと私には意味が小さいと痛感しました。
20本目は正規表現課題の準備としてJSONファイル読込で、非常に簡単です。pandasを使って読み込んでいますが、改めてpandasの便利さを実感します。参考リンク
リンク 備考 020.JSONデータの読み込み.ipynb 回答プログラムのGitHubリンク 素人の言語処理100本ノック:20 多くのソース部分のコピペ元 ゼロから覚えるPython正規表現の基本とTips 当ノックで学習した内容を整理しました 正規表現 HOWTO Python公式の正規表現How To re --- 正規表現操作 Python公式のreパッケージ説明 環境
種類 バージョン 内容 OS Ubuntu18.04.01 LTS 仮想で動かしています pyenv 1.2.15 複数Python環境を使うことがあるのでpyenv使っています Python 3.6.9 pyenv上でpython3.6.9を使っています
3.7や3.8系を使っていないことに深い理由はありません
パッケージはvenvを使って管理しています上記環境で、以下のPython追加パッケージを使っています。通常のpipでインストールするだけです。
種類 バージョン pandas 0.25.3 第3章: 正規表現
学習内容
Wikipediaのページのマークアップ記述に正規表現を適用することで,様々な情報・知識を取り出します.
正規表現, JSON, Wikipedia, InfoBox, ウェブサービス
ノック内容
Wikipediaの記事を以下のフォーマットで書き出したファイルjawiki-country.json.gzがある.
- 1行に1記事の情報がJSON形式で格納される
- 各行には記事名が"title"キーに,記事本文が"text"キーの辞書オブジェクトに格納され,そのオブジェクトがJSON形式で書き出される
- ファイル全体はgzipで圧縮される
以下の処理を行うプログラムを作成せよ.
20. JSONデータの読み込み
Wikipedia記事のJSONファイルを読み込み,「イギリス」に関する記事本文を表示せよ.問題21-29では,ここで抽出した記事本文に対して実行せよ.
回答
回答プログラム 020.JSONデータの読み込み.ipynb
from pprint import pprint import pandas as pd df_wiki = pd.read_json('./jawiki-country.json', lines=True) pprint(df_wiki[(df_wiki['title'] == 'イギリス')]['text'].values.item())回答解説
read_json関数でJSONファイルを読み込んでいます。linesパラメータにTrueを渡すことでJSON Linesというフォーマットを読み込めます。df_wiki = pd.read_json('./jawiki-country.json', lines=True)読み込んだ
DataFrameはこんな感じ。titleに国名が入っています。
結果を最後に出力します。改行したかったので
pprint関数使っています。pprint(df_wiki[(df_wiki['title'] == 'イギリス')]['text'].values.item())出力結果('{{redirect|UK}}\n' '{{基礎情報 国\n' '|略名 = イギリス\n' 中略 '[[Category:君主国]]\n' '[[Category:島国|くれいとふりてん]]\n' '[[Category:1801年に設立された州・地域]]')

- 投稿日:2020-02-04T05:34:46+09:00
いらすとやの画像をドット絵にしたった。(part2)
Background
直接的なドット絵の改善についてではないですが、いらすとやの画像をドット絵にしたった。(part1)で周辺の画像がドットに変換しきれなかったので解決方法について説明します。
Method
方法としては、元画像の幅高さサイズの2倍ある画像を用意します。イメージとしてはラップの上にサンドイッチを置くイメージです
def wrapMat(height, width): dst = np.zeros((height, width, 4), np.uint8) dst[:] = tuple((0,255,0,128)) return dst if __name__ == "__main__": #元画像 mat = cv2.imread(path,cv2.IMREAD_UNCHANGED) #幅高さを二つ折りにする top = int(mat.shape[0] * 0.5) left = int(mat.shape[1] * 0.5) wrap = wrapMat(top*4,left*4) cv2.imwrite("mono_wrap.png", wrap)
見た目でわかりやすく、
G=255、α(透過度)=128にしています。次にドット絵にしたい画像を真ん中に配置します。
wrap[top:top + mat.shape[0], left:left + mat.shape[1]] = mat cv2.imwrite("wrap.png", wrap)
で、ドット絵に変換します。
周辺に灰色のラインが生成されていますが、ちょうど境界線上でラップ画像の配色と透明色の平均値が算出されたためだと思います。あとはこの画像を元画像のサイズにトリミングします。
cv2.imwrite("trim.png",wrap[top:top + mat.shape[0], left:left + mat.shape[1]])
縁の方に灰色のラインが残るかと思ったのですが期待通りに出力できました。もし表示される場合はラップ画像の配色を
(R,G,B,A)=(0,0,0,0)にすれば問題ないです。Development
全体のコードです。
import cv2 import numpy as np import sys def wrapMat(height, width): dst = np.zeros((height, width, 4), np.uint8) dst[:] = tuple((0,255,0,128)) return dst def convertReduceColor(src): thresholds = [42,127,212] range_color = [0, 85, 170, 255] count = 0 for th in thresholds: if src <= th: break count += 1 return range_color[count] if __name__ == "__main__": __CELL_SIZE__ = 16 path = sys.argv[1] mat = cv2.imread(path,cv2.IMREAD_UNCHANGED) top = int(mat.shape[0] * 0.5) left = int(mat.shape[1] * 0.5) # ラップ画像作成 wrap = wrapMat(top*4,left*4) # 元画像を配置 wrap[top:top + mat.shape[0], left:left + mat.shape[1]] = mat #ドット絵作成 height, width = wrap.shape[:-1] for w in range(width//__CELL_SIZE__-1): for h in range(height//__CELL_SIZE__-1): c = np.mean( np.mean( wrap[h*__CELL_SIZE__:(h+1)*__CELL_SIZE__, w*__CELL_SIZE__:(w+1)*__CELL_SIZE__], axis=0 ), axis=0 ) wrap[ h*__CELL_SIZE__:(h+1)*__CELL_SIZE__, w*__CELL_SIZE__:(w+1)*__CELL_SIZE__ ] = tuple([convertReduceColor(c[0]), convertReduceColor(c[1]), convertReduceColor(c[2]), c[3]]) #トリミング trim = wrap[top:top + mat.shape[0], left:left + mat.shape[1]] cv2.imwrite("trim.png",trim)Future
次回はモノクロ画像を4つの配色にする方法を考えてみるとです。
Reference





- 投稿日:2020-02-04T02:44:20+09:00
PythonのPipelineパッケージ比較:Airflow, Luigi, Gokart, Metaflow, Kedro, PipelineX
この記事では、Open-sourceのPipeline/Workflow開発用PythonパッケージのAirflow, Luigi, Gokart, Metaflow, Kedro, PipelineXを比較します。
この記事では、"Pipeline"、"Workflow"、"DAG"の単語はほぼ同じ意味で使用しています。
要約
- ?: 良い
- ??: より良い
Airflow
https://github.com/apache/airflow
2015年にAirbnb社からリリースされました。
Airflowは、Pythonコード(独立したPythonモジュール)でDAGを定義します。
(オプションとして、非公式の dag-factory 等を使用して、YAMLでDAGを定義できます。)良い点:
- DAGの可視化、実行進捗監視、スケジューリング、トリガリング機能をGUI上で使えます。
- Celeryを使用した分散コンピューティングを使えます。
- DAGの定義はモジュラーで、処理関数とは独立してます。
- Workflowは
SubDagOperatorを使用してネストできます。- Slackに通知できます。
良いとは言えない点:
- 依存タスク間でデータベースを介さずにデータを渡せるように設計されていません。 Airflow内の依存タスク間で非構造化データ(画像、動画、pickle等)を渡す良い方法がありません。
- ファイルアクセス(読み書き)のためのコードが別途必要になります。
- 中間生成データファイルやデータベースを使用して、自動的にPipelineの途中から実行できません。
Luigi
https://github.com/spotify/luigi
2012年にSpotify社からリリースされました。
Luigiは、Pythonコードで、3つのクラスメソッド(
requires,output,run)を持つTaskの子クラス達によりPipelineを定義します。良い点:
Targetクラスを使用したTask.outputメソッドで定義されたとおり、ローカルかクラウド(AWS, GCP, Azure)上の中間データファイルやデータベースを使用して、 自動的にPipelineの途中から実行できます。- 依存タスク間で任意のデータを渡すようにコーディングできます。
- DAGの可視化、実行進捗監視機能をGUI上で使えます。
良いとは言えない点:
- ファイルやデータベースアクセス(読み書き)するためのコードを書く必要があります。
- Pipeline定義、タスク処理(ETLのうちのTransform)、データアクセス(ETLのうちのExtract&Load)が密に結合していて、モジュラーではありません。 将来のプロジェクトで再利用するためにタスククラスを修正しないといけません。
Gokart
https://github.com/m3dev/gokart
2018年12月にエムスリー社からリリースされました。
Gokartは内部でLuigiを使用します。
良い点:
Luigiの良い点に追加として:
- pickle, npz, gz, txt, csv, tsv, json, xml 形式のファイルアクセス(読み書き)ラッパーがFileProcessorクラスとして提供されます。
- 各実験パラメータを保存する仕組みが備わっています。thunderboltというビューワーが提供されます。
- 中間ファイル名に含まれた、パラメータセットに固有のハッシュ文字列を参照して、パラメータが変更された際にはタスクを再実行します。
様々なパラメータセットで実験するのに有用です。
- クラスデコレータを使用してLuigiのrequiresクラスメソッドを簡潔に書くためのシンタクティックシュガーが提供されます。
- Slackに通知できます。良いとは言えない点:
- サポートされているデータファイル形式が限られています。サポートされていない形式を使用するためには、ファイルやデータベースアクセス(読み書き)するためのコードを書く必要があります。
- Pipeline定義とタスク処理(ETLのうちのTransform)が密に結合していて、モジュラーではありません。将来のプロジェクトで再利用するためにタスククラスを修正しないといけません。
Metaflow
https://github.com/Netflix/metaflow
2019年12月にNetflix社からリリースされました。
Metaflowは、Pythonコードで、
stepデコレータ付きのクラスメソッドを含むFlowSpecの子クラスによりPipelineを定義します。良い点:
- AWSサービス(特にAWS Batch)とのインテグレーション。
良いとは言えない点:
- ファイルやデータベースアクセス(読み書き)するためのコードを書く必要があります。
- Pipeline定義、タスク処理(ETLのうちのTransform)、データアクセス(ETLのうちのExtract&Load)が密に結合していて、モジュラーではありません。 将来のプロジェクトで再利用するためにタスククラスを修正しないといけません。
- GUIはありません。
- GCP、Azureにあまり対応していません。
- 中間生成データファイルやデータベースを使用して、自動的にPipelineの途中から実行できません。
Kedro
https://github.com/quantumblacklabs/kedro
2019年5月にMcKinseyの子会社のQuantumBlack社からリリースされました。
Kedroは、Pythonコード(独立したPythonモジュール)で、3つの引数
(func: タスク処理関数,inputs: 入力データ名(複数の場合はlist or dict),outputs: 出力データ名(複数の場合はlist or dict))
を持つnode関数のリストによりPipelineを定義します。良い点:
- ローカル又はクラウド(AWSのS3 GCPのGCS)上のCSV, Pickle, YAML, JSON, Parquet, Excel, textファイル、SQL、Spark等のリソースへのアクセス(読み書き)用の ラッパーを
DataSetクラスとして備えています。- 対応していないデータ形式へのサポートは、ユーザーにより追加できます。
- Pipeline定義、タスク処理(ETLのうちのTransform)、データアクセス(ETLのうちのExtract&Load)は独立していて、モジュラーです。 将来のプロジェクトで簡単に再利用できます。
- Pipelineはネストできます。(Pipelineは他のPipelineの一部として使用できます。)
- GUI (kedro-viz)でDAGを可視化できます。
良いとは言えない点:
- 中間生成データファイルやデータベースを使用して、自動的にPipelineの途中から実行できません。
- GUI (kedro-viz)で実行進捗監視する機能はありません。
- 大抵の場合は使用しないパッケージ(pyarrow 等)が
requirements.txtに含まれています。PipelineX:
https://github.com/Minyus/pipelinex
2019年11月にKedroユーザー(私)によりリリースされました。
PipelineXはKedroとMLflowを内部で使用します。
PiplineXは、YAML(独立したYAMLファイル)で、KedroよりもPipelineを定義します。良い点:
Kedroの長所に追加として:
- 中間データファイルやデータベースを使用して、自動的にPipelineの途中から実行できます。
- Kedro Pipelineを簡潔に書くためのシンタクティックシュガーを使用できます。
(例:PyTorch (torch.nn.Sequential) や Keras (tf.keras.Sequential) に似たSequential API)
- KedroDataSetcatalog を簡潔に書くためのシンタクティックシュガーを使用できます。
(例:ファイルパス内のファイル名をデータセットインスタンス名として使用)
- Kedroと後方互換性があります。
- 各実験パラメータ、メトリック、モデルその他の生成データファイルを保存するするためのMLflowとのインテグレーションを使用できます。
- PyTorch, Ignite, pandas, OpenCVといったデータサイエンスで一般的なパッケージとのインテグレーションを使用できます。
- コンピュータビジョンアプリケーションで有用な画像セット(画像を含むフォルダ)を扱うためのDataSetクラスを使用できます。
- 元のKedroで提供されているものよりもリーンなプロジェクトテンプレートが提供されます。良いとは言えない点:
- GUI (kedro-viz)で実行進捗監視する機能はありません。
- 大抵の場合は使用しないパッケージ(pyarrow 等)がKedroの
requirements.txtに含まれています。- PipelineXは、現時点では一個人(私)により開発、メンテナンスされています。
プラットフォームに特化したパッケージ
Argo
https://github.com/argoproj/argo
ArgoはKubernetesを使用してPipelineを実行します。
Kubeflow Pipelines
https://github.com/kubeflow/pipelines
Kubeflow Pipelinesは内部でArgoを使用します。
Oozie
https://github.com/apache/oozie
Hadoopジョブを管理できます。
Azkaban
https://github.com/azkaban/azkaban
Hadoopジョブを管理できます。
リファレンス
Airflow
- https://github.com/apache/airflow
- https://airflow.apache.org/docs/stable/howto/initialize-database.html
- https://medium.com/datareply/integrating-slack-alerts-in-airflow-c9dcd155105Luigi
- https://github.com/spotify/luigi
- https://luigi.readthedocs.io/en/stable/api/luigi.contrib.html
- https://www.m3tech.blog/entry/2018/11/12/110000Gokart
- https://github.com/m3dev/gokart
- https://www.m3tech.blog/entry/2019/09/30/120229
- https://qiita.com/Hase8388/items/8cf0e5c77f00b555748fMetaflow
- https://github.com/Netflix/metaflow
- https://docs.metaflow.org/metaflow/basics
- https://docs.metaflow.org/metaflow/scaling
- https://medium.com/bigdatarepublic/a-review-of-netflixs-metaflow-65c6956e168dKedro
- https://github.com/quantumblacklabs/kedro
- https://kedro.readthedocs.io/en/latest/03_tutorial/04_create_pipelines.html
- https://kedro.readthedocs.io/en/latest/kedro.io.html#data-sets
- https://medium.com/mhiro2/building-pipeline-with-kedro-for-ml-competition-63e1db42d179PipelineX
- https://github.com/Minyus/pipelinexAirflow vs Luigi
- https://towardsdatascience.com/data-pipelines-luigi-airflow-everything-you-need-to-know-18dc741449b7
- https://medium.com/better-programming/airbnbs-airflow-versus-spotify-s-luigi-bd4c7c2c0791
- https://www.quora.com/Which-is-a-better-data-pipeline-scheduling-platform-Airflow-or-Luigi不正確な点
不正確な点がありましたら、お知らせください。
https://github.com/Minyus/Python_Packages_for_Pipeline_Workflow/blob/master/ja/README.md へのプルリクエストを歓迎します。
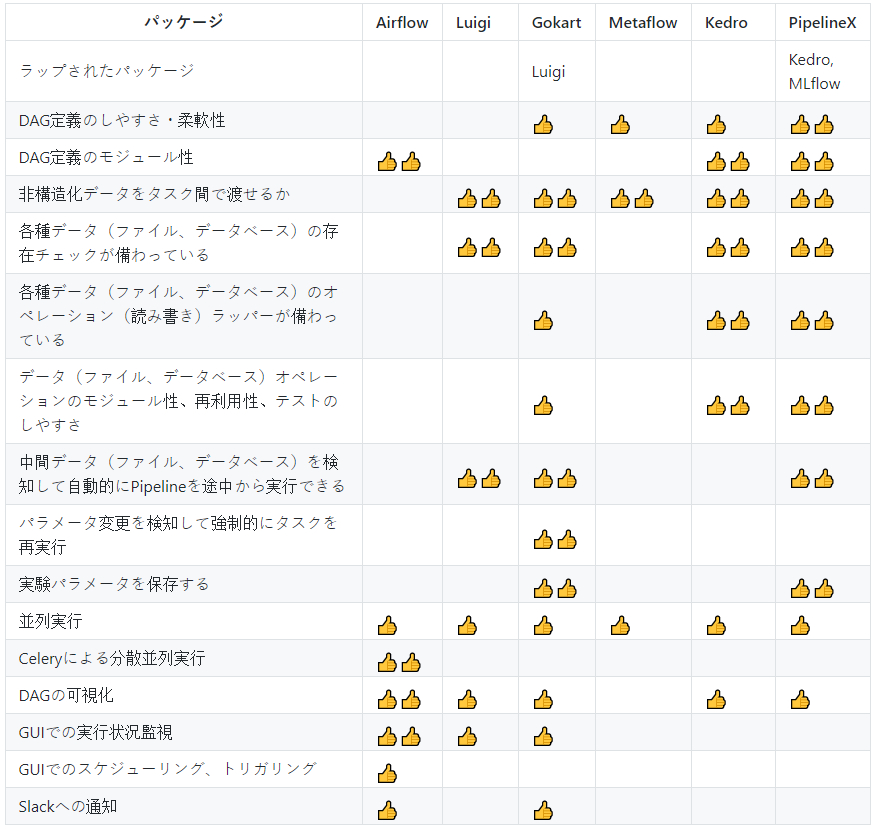
- 投稿日:2020-02-04T02:07:33+09:00
「世界で闘うプログラミング力を鍛える本」Pythonコード解答例 - 2.8 ループの検出
「世界で闘うプログラミング力を鍛える本」Pythonコード解答例 - 2.8 ループの検出
CHAP2. 連結リスト
Pythonコード解答例
from chap2_function import* def FindBeginning(head_node): slow = head_node fast = head_node while fast and fast.next: slow = slow.next fast = fast.next.next if slow == fast: break if fast == None or fast.next == None: return None slow = head_node while slow != fast: slow = slow.next fast = fast.next return fast sll = SinglyLinkedList() sll.append(1) sll.append(2) sll.append(3) sll.append(4) sll.append(5) sll.printList(sll.head) sll.insertNode(sll.head.next.next.next.next,sll.head.next.next) print("sll[0]: ", sll.head.data) print("sll[1]: ",sll.head.next.data) print("sll[2]: ",sll.head.next.next.data) print("sll[3]: ",sll.head.next.next.next.data) print("sll[4]: ",sll.head.next.next.next.next.data) print("sll[5]: ",sll.head.next.next.next.next.next.data) print("sll[6]: ",sll.head.next.next.next.next.next.next.data) print("出力: ",FindBeginning(sll.head).data)Python関数(ノードクラス, 双方向リストクラス)
chap2_function.py# ノードクラス class Node: # コンストラクタ def __init__(self, data): self.data = data self.next = None self.prev = None # 単方向リストクラス class SinglyLinkedList: # コンストラクタ def __init__(self): self.head = None def insertNode(self, prev_node, new_node): if prev_node is None: print("the given previous node cannot be NULL") return if new_node is None: print("the given new node cannot be NULL") return # prev_nodeで指定したノードの次ノードを新ノードにする prev_node.next = new_node # 最終ノードからのノード挿入 def append(self, new_data): # ノード生成 new_node = Node(new_data) # 新ノードの次ノードをNone定義 new_node.next = None # もしヘッドノードが設定されていない(空のリスト)場合、新ノードをヘッドノードに設定する if self.head is None: new_node.prev = None self.head = new_node return # 最終ノードを設定する(順方向走査) last = self.head while(last.next is not None): last = last.next # 新ノードを最終ノードに指定する last.next = new_node return # This function prints contents of linked list # starting from the given node def printList(self, node): last = None print("単方向リスト: \n") print("順方向走査") while(node is not None): print(node.data,end="") last = node node = node.next if node: print(" -> ",end="") else: print("\n") # 双方向リストクラス class DoublyLinkedList: # コンストラクタ def __init__(self): self.head = None # 第一ノードからのノード挿入 def push(self, new_data): # ノード生成 new_node = Node(new_data) # 新ノードの次ノードをそもそもヘッドノードだったものにする new_node.next = self.head # そもそもヘッドノードだったものの前ノードを新ノードにする if self.head is not None: self.head.prev = new_node # 新ノードをヘッドノードにする self.head = new_node # 中間地点でのノード挿入 def insert(self, prev_node, new_data): # prev_nodeで指定したノードの後にノード挿入するか指定 # もしNoneの場合は、関数を出る if prev_node is None: print("the given previous node cannot be NULL") return # ノード生成 new_node = Node(new_data) # 新ノードの次ノードをprev_nodeで指定したノードの次ノードにする new_node.next = prev_node.next # prev_nodeで指定したノードの次ノードを新ノードにする prev_node.next = new_node # 新ノードの前ノードをprev_nodeで指定したノードにする new_node.prev = prev_node # 新ノードの次ノードをprev_nodeで指定したノードの次ノードにしたが、そのノードの前ノードも新ノードにする if new_node.next is not None: new_node.next.prev = new_node def insertNode(self, prev_node, new_node): # prev_nodeで指定したノードの後にノード挿入するか指定 # もしNoneの場合は、関数を出る if prev_node is None: print("the given previous node cannot be NULL") return if new_node is None: print("the given new node cannot be NULL") return # prev_nodeで指定したノードの次ノードを新ノードにする prev_node.next = new_node # 新ノードの前ノードをprev_nodeで指定したノードにする new_node.prev = prev_node # 最終ノードからのノード挿入 def append(self, new_data): # ノード生成 new_node = Node(new_data) # 新ノードの次ノードをNone定義 new_node.next = None # もしヘッドノードが設定されていない(空のリスト)場合、新ノードをヘッドノードに設定する if self.head is None: new_node.prev = None self.head = new_node return # 最終ノードを設定する(順方向走査) last = self.head while(last.next is not None): last = last.next # 新ノードを最終ノードに指定する last.next = new_node # 7. 新ノードの前ノードをそもそも最終ノードだったものにする new_node.prev = last return def delete(self,del_node): if self.head == None or del_node == None: return if self.head == del_node: self.head = del_node.next if del_node.next != None: del_node.next.prev = del_node.prev if del_node.prev != None: del_node.prev.next = del_node.next # This function prints contents of linked list # starting from the given node def printList(self, node): last = None print("双方向リスト: \n") print("順方向走査") while(node is not None): print(node.data,end="") last = node node = node.next if node: print(" -> ",end="") else: print("\n") print("逆方向走査") while(last is not None): print(last.data,end="") last = last.prev if last: print(" -> ",end="") else: print("\n") if __name__ == '__main__': # 空の双方向リストの生成 # DLL: None dll = DoublyLinkedList() # DLL: None -> 6(ヘッド/ラスト) -> None dll.append(6) # DLL: None -> 7(ヘッド) -> 6(ラスト) -> None dll.push(7) # DLL: None -> 1(ヘッド) -> 7 -> 6(ラスト) -> None dll.push(1) # DLL: None -> 1(ヘッド) -> 7 -> 6 -> 4(ラスト) -> None dll.append(4) # DLL: None -> 1(ヘッド) -> 7 -> 8 -> 6 -> 4(ラスト) -> None dll.insert(dll.head.next, 8) # DLL: None -> 1(ヘッド) -> 8 -> 6 -> 4(ラスト) -> None dll.delete(dll.head.next) dll.printList(dll.head) sll = SinglyLinkedList() sll.append(1) sll.append(8) sll.append(6) sll.append(4) sll.printList(sll.head)参考文献
[1] GeeksforGeeks: Doubly Linked List | Set 1 (Introduction and Insertion)
[2] GeeksforGeeks: Delete a node in a Doubly Linked List
- 投稿日:2020-02-04T02:05:05+09:00
【特許分析】Pythonでお金を掛けずにパテントマップを作ってみた
はじめに
いっちょ特許分析でもやってみっかと思ったので、やってみることにしました。
具体的に特許分析というと、例えば下のようなプロットがあります。
(図はJ-STOREマニュアルより引用)
縦軸が特許出願者を、横軸が特許が出た年を、円の大きさが特許の数を示しており、バブルチャートと呼ばれています。
世の中には有料でこのようなプロットを作ってくれるなにかが存在します。今回は、無料で使える特許データベースのJ-PlatPatを使って特許文献を検索し、その結果をPythonで処理することでこんな感じのプロットを作っていきたいと思います。
J-PlatPatとは
wikipediaさん曰く、
特許情報プラットフォーム(とっきょじょうほうプラットフォーム、英: Japan Platform for Patent Information)は、独立行政法人工業所有権情報・研修館(INPIT)が運営する特許、実用新案、意匠及び商標等の産業財産権関連の工業所有権公報等を無料で検索・照会可能なデータベースである。
とのことです。
ここで重要なのは使用にお金がかからないということですが、無料なりに多くの制限があり、安易に手を出すと憤死する危険があります。今回は、このプラットフォームの攻略法が半分、得られたデータの処理の解説が半分といった構成になっています。
データ収集
自分が興味があるのは電池、特に充放電可能ないわゆる二次電池なので、これを検索したいですね。
しかし、例えば普通に"電池"と検索した場合、太陽電池や燃料電池も検索に引っかかります。
ここまでは普通の検索でも起きることです。Solar cellやFuel cellを"電池"と訳した人類への憎悪を募らせつつ、J-PlatPatの特許・実用新案検索=>論理式入力で以下のように入力します。
この/TIはタイトルを示していて、この場合は特許タイトルに'二次電池'あるいは'蓄電池'が含まれる特許が検索されます。
論理式を使えば、その他いろいろな指定ができるので世界が広がります。詳細はJ-PlatPatのヘルプを参照しましょう。この指定では60459件の特許が引っ掛かります。
しかしながら、J-PlatPatの検索結果の表示数は最大3000件なので死にます。
なので発行日を指定して検索します。
発行日の指定は論理式ではなく検索オプションから行います。
この場合は2019年1月1日から2020年1月1日までの1年間の間に出た特許が表示されます。これで、以下のように1408件の特許が表示されます(2020/2/4現在)。
ここで1件ごとに特許内容をスクレイピングしたいのですが、それは禁じられています(注意事項参照)。決してやってはいけません。
一覧の"CSV出力"で勘弁してやるか……と思いますよね。では押しましょう。CSV出力を行うには、100件以下に絞り込んでください。
はい死にました。この記事はこれで終わりです。
嘘です。焦らずに"一覧印刷"を押しましょう。
すると、上のように"一覧印刷|J-PlatPat[JPP]"というウィンドウがポップアップします。この画面には、1408件すべての特許が含まれています。
印刷ではなく、右クリックをしてHTMLファイルを保存します。
これで2019年の特許データ取得は完了です。あとは適当に発行年度をずらしつつ、2018, 2017年...と特許一覧のHTMLを手動で取得していきます。
今回は2005~2019年の15年分のデータを取得しました。虚無感を感じる作業ですが実際そんなに手間でもなく、10分ぐらいで終わります。
HTMLからCSVへの変換
PythonのBeautifulSoupを使えば、HTMLのテーブルの中身をCSVに変換するのは簡単です。
下のようにちょちょいっと。
HTMLファイルは./htmlから読み込み、CSVファイルを./csvに書き込みます。from bs4 import BeautifulSoup import re import glob import pandas as pd path = glob.glob('./html/*.html') for p in path: name = p.replace('.html','').replace('./html\\','') html = open(p,'r',encoding="utf-8_sig") soup = BeautifulSoup(html,"html.parser") tr = soup.find_all('tr') columns = [i.text.replace('\n','') for i in tr[0].find_all('th')] df = pd.DataFrame(index=[],columns=columns[1:]) for l in tr[1:]: lines = [i.text for i in l.find_all('td')] lines = [i.replace('\n','') if n != 6 else re.sub(r'[\n]+', ",", i) for n,i in enumerate(lines)] lines = pd.Series(lines, index=df.columns) df = df.append(lines,ignore_index=True) df.to_csv('./csv/'+name+'.csv', encoding='utf_8_sig', index=False)手動でローカルに保存したHTMLファイルの処理をしているだけなので、J-PlatPatには一切アクセスしません。セーフです。
得られたデータフレームの一部を以下に示します(patent2005.csv)
こんな感じのCSVが2005~2019年の15個保存されます。
J-PlatPatがCSVの全件出力に対応してくれれば必要ない作業です
文献番号 出願番号 出願日 公知日 発明の名称 出願人/権利者 FI 再表2005/124920 特願2006-514740 2005/06/14 2005/12/29 鉛蓄電池 パナソニック株式会社 ,C22C11/00,C22C11/02,C22C11/06,他, 再表2005/124899 特願2006-514659 2005/03/09 2005/12/29 二次電池およびその製造方法 パナソニック株式会社 ,H01M2/16@M,H01M4/02@B,H01M4/02@Z,他, 再表2005/124898 特願2006-514732 2005/06/13 2005/12/29 リチウム二次電池用正極活物質粉末 AGCセイミケミカル株式会社 ,H01M4/02@C,H01M4/36@E,H01M4/36,他, 再表2005/122318 特願2006-514434 2005/05/18 2005/12/22 非水電解液およびそれを用いたリチウム二次電池 宇部興産株式会社 ,H01M4/02@C,H01M4/02@D,H01M4/36,他, 特開2005-353584 特願2005-140521 2005/05/13 2005/12/22 リチウムイオン二次電池とその製造法 パナソニック株式会社 他 ,H01M2/16@P,H01M4/02,101,H01M4/02,108,他, バブルチャートの作成
バブルチャートを作るうえで、対象の出願者(企業)をどのように選ぶかという問題があります。
今回は、それぞれの年度での特許出願数トップ10の企業を引っ張ってくると、ちょうど30社になったので、そのようにします。以下のようにデータを整理します。
import matplotlib.pyplot as plt import matplotlib.cm as cm import glob import pandas as pd import collections import numpy as np import seaborn as sns path = glob.glob('./csv/*.csv') app_top10_dic = {} #それぞれの年度のTOP10企業と出願数 app_total_dic = {} #それぞれの年度の全ての企業と出願数 app_all = [] #バブルチャートの対象となる企業のリスト for p in path: name = p.replace('.csv',' ').replace('./csv\\patent','').replace(' ','') df = pd.read_csv(p) app_list = df['出願人/権利者'] app_list = [i.rstrip('他').replace(' ','').replace('\u3000',' ') for i in app_list] app_set = collections.Counter(app_list) app_top10 = app_set.most_common()[:10] app_all.extend([i[0] for i in app_top10]) app_top10_dic[name] = app_top10 app_total = app_set.most_common() app_total_dic[name] = app_total app_all = list(set(app_all))列に出願者(企業)、行に出願年度を取った行列を作ります。
まずは以下のように空の行列(df)を作ってから、years = list(app_top10_dic.keys()) df = pd.DataFrame(index=app_all,columns=years).fillna(0)これに出願数を以下のように加えていきます。
for i in app_total_dic: dic = app_total_dic[i] for d in dic: if(d[0] in app_all): df[i][d[0]] += d[1]最終的に、以下のような行列が得られます。
2005 2006 2007 2008 2009 2010 2011 2012 2013 2014 2015 2016 2017 2018 2019 住友金属鉱山株式会社 6 14 7 13 2 7 15 18 16 25 35 54 56 60 61 古河電池株式会社 46 40 34 41 33 31 23 9 12 13 11 7 11 11 13 大日本印刷株式会社 4 14 12 0 5 9 29 59 5 9 2 1 5 0 0 三洋電機株式会社 181 137 155 120 96 102 120 110 104 180 73 65 26 59 45 三星エスディアイ株式会社 83 138 24 32 38 52 108 57 41 49 69 40 16 14 22 : : : : : : : : : : : : : : : : 株式会社半導体エネルギー研究所 0 0 0 0 0 0 9 7 15 16 22 54 24 12 12 株式会社ジーエス・ユアサコーポレーション 57 20 11 17 0 0 0 0 0 0 0 0 0 0 0 株式会社GSユアサ 43 16 38 40 39 44 56 76 79 75 99 72 83 41 31 日立マクセル株式会社 29 20 8 28 26 17 39 49 48 46 63 35 39 14 0 日本ゼオン株式会社 2 5 5 5 6 16 28 29 43 67 62 45 55 22 2 これはpandasのデータフレームとして得られているので、seabornを使えば簡単にヒートマップを作ることができます。
fig = plt.figure(figsize=(6,10),dpi=150) sns.heatmap(df,square=True,cmap='Reds')
これで十分な気もしますが、バブルチャートも作ります。
これは一発では作れない(はず)なので、自分で頑張ります。
色気づいて凡例も入れます。fig = plt.figure(figsize=(6,10),dpi=150) for n,y in enumerate(years): for m,x in enumerate(app_all[::-1]): plt.scatter(y,x,s=int(df[y][x])) size = [100,200,300] for s in size: plt.scatter(-100,-100,s=s,facecolor='white',edgecolor='black',label=str(s)) plt.legend(title='Patents', bbox_to_anchor=(1.03, 1), loc='upper left',labelspacing=1,borderpad=1) plt.xlim(-1,15) plt.ylim(-1,30) plt.xticks(rotation=45) plt.show()
できました。
確かにヒートマップよりこっちの方が分かりやすい。全体をざっと見てみると、2013年以降トヨタが強いという発見があります。
色々あった2017年以降も東芝がコンスタントに特許を出してるのは意外。すごいですね。
パナソニックの特許が減っていますが、パナソニックIPマネジメントや三洋電機(子会社)の出願を考慮すればそうでもない?
他にも日立の関連会社が多すぎとか、GSユアサとジーエス・ユアサコーポレーションは何が違うんだとかあるので、グループ企業は統合する必要がありそうですね。まとめ
そんなわけで、Pythonを使って特許分析にちょっと触れてみました。
J-PlatPatの仕様に振り回されたりPandasの使い方を忘れていたりいろいろありましたが、とりあえずバブルチャートは作れたので目標達成です。ただ、検索項目の指定が不十分なため、取りこぼした特許がある可能性があります。
この部分はいろいろと試行錯誤が必要そうな感じです。特許本文まで手に入れば、自然言語解析でいろいろと面白いことができそうな感じですが……。
本文まで参照することを考えればGoogle Patent Public Datasetsを使った方がいいのかも?とりあえず満足したのでここで終わり!
注意事項
J-PlatPat利用上のご案内の「大量アクセス・ロボットアクセス等に対する制限」には以下のように書かれています。
J-PlatPatは産業財産権情報に関して公共的に利用されるものです。したがって、一般の利用を妨げる可能性がある、データの単純な収集を目的とした大量データのダウンロードや、ロボットアクセス(プログラムによる定期的な自動データ収集)のような行為は禁止させていただいております。
そんなわけで、プログラムによる自動収集はNGです。
やってはいけません。気を付けましょう。今回のデータ収集が"データの単純な収集を目的とした大量データのダウンロード"に値するかどうかは議論があると思いますが、実際のところ15個のファイルをダウンロードしただけなのでたぶん大丈夫だと思います。