- 投稿日:2020-02-04T23:03:38+09:00
ブラウザごとの URL 解決の挙動の違い
初投稿です。
最近 Chrome にしか対応していないウェブサイトを改修する機会があった。適当に Babe って polyfi ったが、IE11 に完全対応するのは厳しそうで、それは諦めたが、 Edge44 は初期状態でちょいバグるくらいの感じだったので対応を試みた。URL の解決関係でハマったのでメモしておく。趣味人なので間違っていたらご教授ください。
URL コンストラクタの挙動が違う
JavaScript では
new URL(url, [base])の構文でベース URL を指定して URL オブジェクトを作ることができるが、url に空文字列を入れた場合の href の値が Chrome と Edge44 で微妙に違う。main.jsconst myURL = new URL("", "https://example.com/index.html") // Chrome だと myURL.href === "https://example.com/index.html" // Edge だと myURL.href === "https://example.com/" const myURL = new URL("", "https://example.com/css") // Chrome だと myURL.href === "https://example.com/css" // Edge だと myURL.href === "https://example.com/" const myURL = new URL("", "https://example.com/") // base がスラッシュで終わる場合は(偶然)返り値が一致する // ともに myURL.href === "https://example.com/" const myURL = new URL("..", "https://example.com/index.html") // url に空でない文字を入れると挙動は一致する // ともに myURL.href === "https://example.com/" const myURL = new URL("https://example.com/index.html") // ともに myURL.href === "https://example.com/index.html" const myURL = new URL("https://example.com/") // ともに myURL.href === "https://example.com/"「ベースURL」の意味からして、最初の例では Edge のように
https://example.com/を返してほしいところだが、Chrome ではそうはならない1。まるで空文字列を無視して(つまり base のつもりで入れたものを url として解釈して)いるようなふるまいを見せる。new URL("", "https://example.com/index.html") new URL("https://example.com/index.html") // Chrome では同じ内容の URL オブジェクトができるChrome と空文字列の省略
そういえば経験的に、Chrome は空文字列を勝手に無いものと扱うような雰囲気がある。たとえば以下のように適当な DOM オブジェクトを作るとする。
const input = document.createElement("input"); input.setAttribute("type", "text"); input.setAttribute("value", data[i] || ""); input.required = flag===1 ? true : false;データが存在しなければ
valueの属性値に空文字列が入るわけだが、これを HTML に起こすとブラウザ間でけっこう差が出る。Chrome では=""ごと削除され、属性名だけがタグ内に残るが、Edge44 (EdgeHTML) では空文字列の存在がきちんと残される。ちなみに Firefox は属性値省略絶対殺すマンになる。最近出た Edge79 (Chromium) では Chrome と同じように表示されるので、レンダリングエンジンの問題だろう。<!-- Chrome, and Edge79 (Chromium) --> <input type="text" value required> <!-- IE11, Edge44 (EdgeHTML), and Firefox --> <input type="text" value="" required="">HTML の属性名・属性値を省略できるか問題はややこしい、これ以上の追及はやめておくが、ともかくこのような具合で Chrome では URL コンストラクタの第一変数が抹消されてしまい、挙動がバグったのだと思われる。本来 URL() コンストラクタの第一引数に空文字列が入ることは想定されていない? TypeError が出ても仕方がない場面だが、url も base もそれっぽい USVString なので一応動いてしまう。
ほかのオブジェクト型
気になったので開発者ツールのコンソールでいろいろ試してみたが、コンストラクタに空文字列を与えても無視されない。たとえば以下のペアは異なる結果が返ってくる。
new Date("", "2") // Thu Mar 01 1900 00:00:00 GMT+0900 (日本標準時) new Date("2") // Thu Feb 01 2001 00:00:00 GMT+0900 (日本標準時) new RegExp("", "g") // /(?:)/g new RegExp("g") // /g/なお Edge44 はまた違うふるまいをする。Chromium のお気持ち察し能力が高い。
new Date("2") // [date] Invalid Date:うーん、結局ほんとうの原因が何かはよくわからないままだ。WHATWG の仕様書とか読めば解決するのかもしれないけど、読み方わからないのでいったんここまで。
2020-02-05: Edge44 (EdgeHTML) をちょっと訂正。
つまりもともとの実装は、Chrome の不適切な挙動をもとに実装されていたということになる。 ↩
- 投稿日:2020-02-04T22:42:18+09:00
CSSでグリッチっぽい表現をやる
PIXIV TECH FES. ← このサイトかなりカッコいいですよね(私は行けませんが…)(担当したのは@yui540です1)
CSSで文字を分割します、面倒くさいので構成はParcelで行きます、JavaScriptは使いませんが現実的なところを考えると要ります(アニメーションの発火を制御するのにとか…)
yarn add parcel-bundler -D npx parcel src/index.htmlこの記事は自分でも空でかける自信が無いので備忘録として書き残しておきます(アニメーションまでは面倒くさくなって書かないことになりました、書くのは文字分割までです)
HTML
まずHTMLから
1
<body> <div class="wrapper"> <div class="text-wrapper"><p>そのツイート、切らせてもらう</p></div> </div> </body>まずグリッチしたい要素(今回は
p)を.text-wrapperで囲む
.text-wrapperを更に大きな.wrapperで囲む2
<body> <div class="wrapper"> <div class="text-wrapper"><p>そのツイート、切らせてもらう</p></div> <div class="text-wrapper"><p>そのツイート、切らせてもらう</p></div> <div class="text-wrapper"><p>そのツイート、切らせてもらう</p></div> <div class="text-wrapper"><p>そのツイート、切らせてもらう</p></div> <div class="text-wrapper"><p>そのツイート、切らせてもらう</p></div> <div class="text-wrapper"><p>そのツイート、切らせてもらう</p></div> <div class="text-wrapper"><p>そのツイート、切らせてもらう</p></div> <div class="text-wrapper"><p>そのツイート、切らせてもらう</p></div> <div class="text-wrapper"><p>そのツイート、切らせてもらう</p></div> <div class="text-wrapper"><p>そのツイート、切らせてもらう</p></div> <div class="text-wrapper placeholder"><p>そのツイート、切らせてもらう</p></div> </div> </body>
.text-wrapperをn + 1個に増やす(nは分割する数です)、今回は10分割するので11個に増やします最後の要素に
.placeholderクラスを付与しておく(次からのCSSでの見通しが良くなるからです(使わない場合は:nth-of-last-typeなどでどうにか気合でやる))SCSS
forループとかを使うと一般化ができるのでかなり嬉しいのでSCSSで書く、リセットCSSなどでmargin等が消えている前提でCSSを書いていきます
1
.wrapper { position: absolute; top: 25px; left: 25px; }概略図
2
.wrapper { position: absolute; top: 25px; left: 25px; } .text-wrapper { font-size: 3rem; } .text-wrapper.placeholder { visibility: hidden; } .text-wrapper:not(.placeholder) { position: absolute; top: 0; left: 0; }
すべての
.text-wrapper要素に必要なスタイルを当てる(文字をデカくする)
.placeholder要素は場所を取るだけの要素なので見えないようにしておきます
.placeholder以外の要素はすべて重ね合わせてある状態になっています概略図
3
.wrapper { position: absolute; } .text-wrapper { font-size: 3rem; } .text-wrapper.placeholder { visibility: hidden; } .text-wrapper:not(.placeholder) { position: absolute; top: 0; left: 0; width: 10%; height: 100%; overflow: hidden; & > p { position: absolute; top: 0; white-space: nowrap; } @for $i from 1 through 10 { &:nth-of-type(#{$i}) { left: ($i - 1) * 10%; & > p { left: -(($i - 1) * 100%); } } } }
気合で理解してほしいです
文字のような要素では
white-space: nowrapを指定しないと改行されて壊れます概略図
4
.text-wrapper:not(.placeholder) { position: absolute; top: 0; left: 0; width: 10%; height: 100%; overflow: hidden; & > p { position: absolute; top: 0; white-space: nowrap; } @for $i from 1 through 10 { &:nth-of-type(#{$i}) { top: ($i * 25%); // ← ここで文字を斬る left: ($i - 1) * 10%; & > p { left: -(($i - 1) * 100%); } } } }
おー斬れました よかったですね
後はmathsassなどを使って乱数っぽく座標をずらしたりすると良いと思います(
29% * sin(1.7922rad * cos(1.9877777777deg * $i) + $i * .7rad)など)、transform, translateなどを駆使して頑張って下さい一般化
.text-wrapper:not(.placeholder) { $n: 30; position: absolute; top: 0; left: 0; width: (100% / $n); height: 100%; overflow: hidden; & > p { position: absolute; top: 0; white-space: nowrap; } @for $i from 1 through $n { &:nth-of-type(#{$i}) { left: ($i - 1) * (100% / $n); & > p { left: -(($i - 1) * 100%); } } } }作例
画像でも応用できる
transform: skew()などをやるとかなり意味がわからない動きになってメチャクチャ面白い
以上です










- 投稿日:2020-02-04T21:12:43+09:00
Google OAuth 2.0 認証を使ったGoogle Sign-Inの実装(JS編)
概要
最近はどのサイトでもSNSからのログインだったり、登録するサイトが当たり前になっています。
よく見かけるこんな感じのボタンですね。。
今回はjsだけを使って簡単にGoogle Sign-Inを実装してみます。
Googleアカウントの作成
まずはじめにGoogleアカウントを作成しましょう。
可能ならそのアプリ専用に作った方がいいと思います。Google Cloud Platformでの設定
https://console.cloud.google.com/getting-started
まずは先ほど作ったGoogleアカウントでログインしましょう。
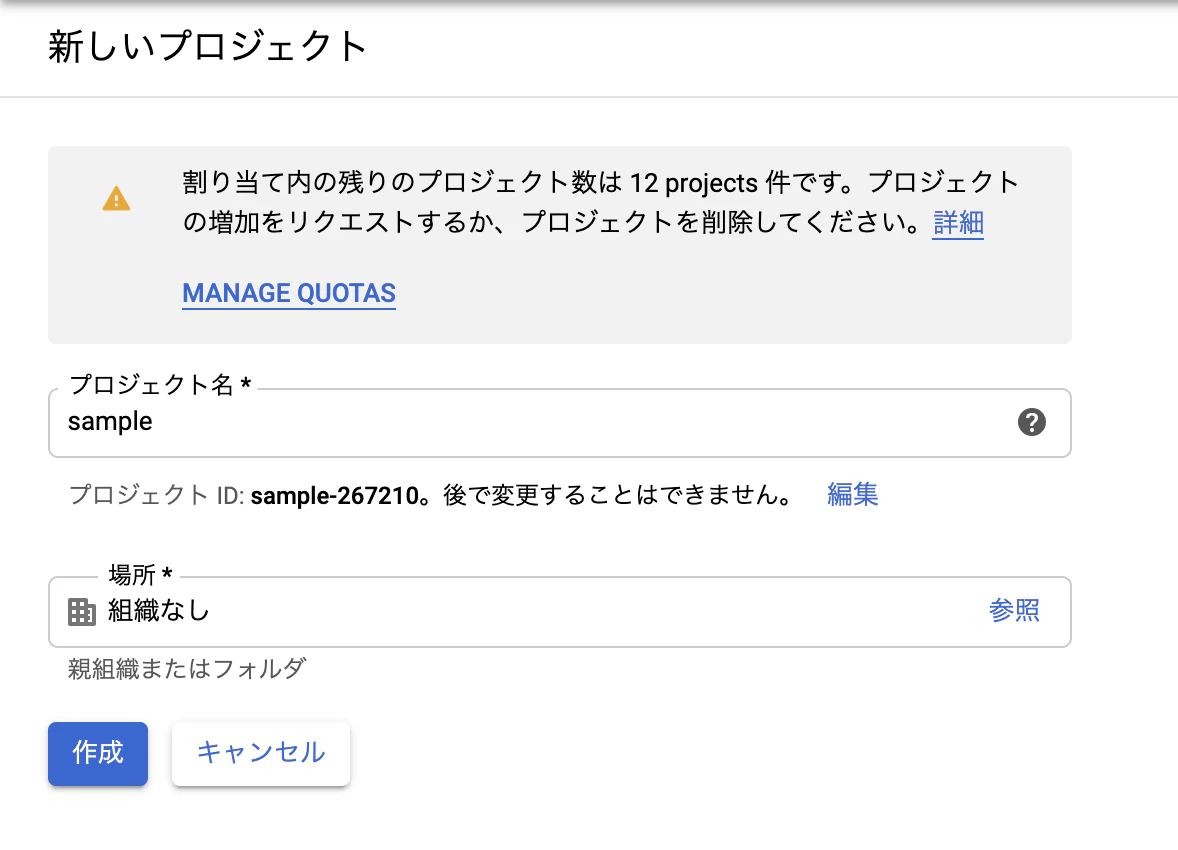
左上の[Project]からプロジェクトを作成を選択します。
プロジェクト名はわかりやすい任意の名前をつけて、場所はとりあえずこのままで作成します。
先ほど作成したプロジェクトを選択して左のメニューから
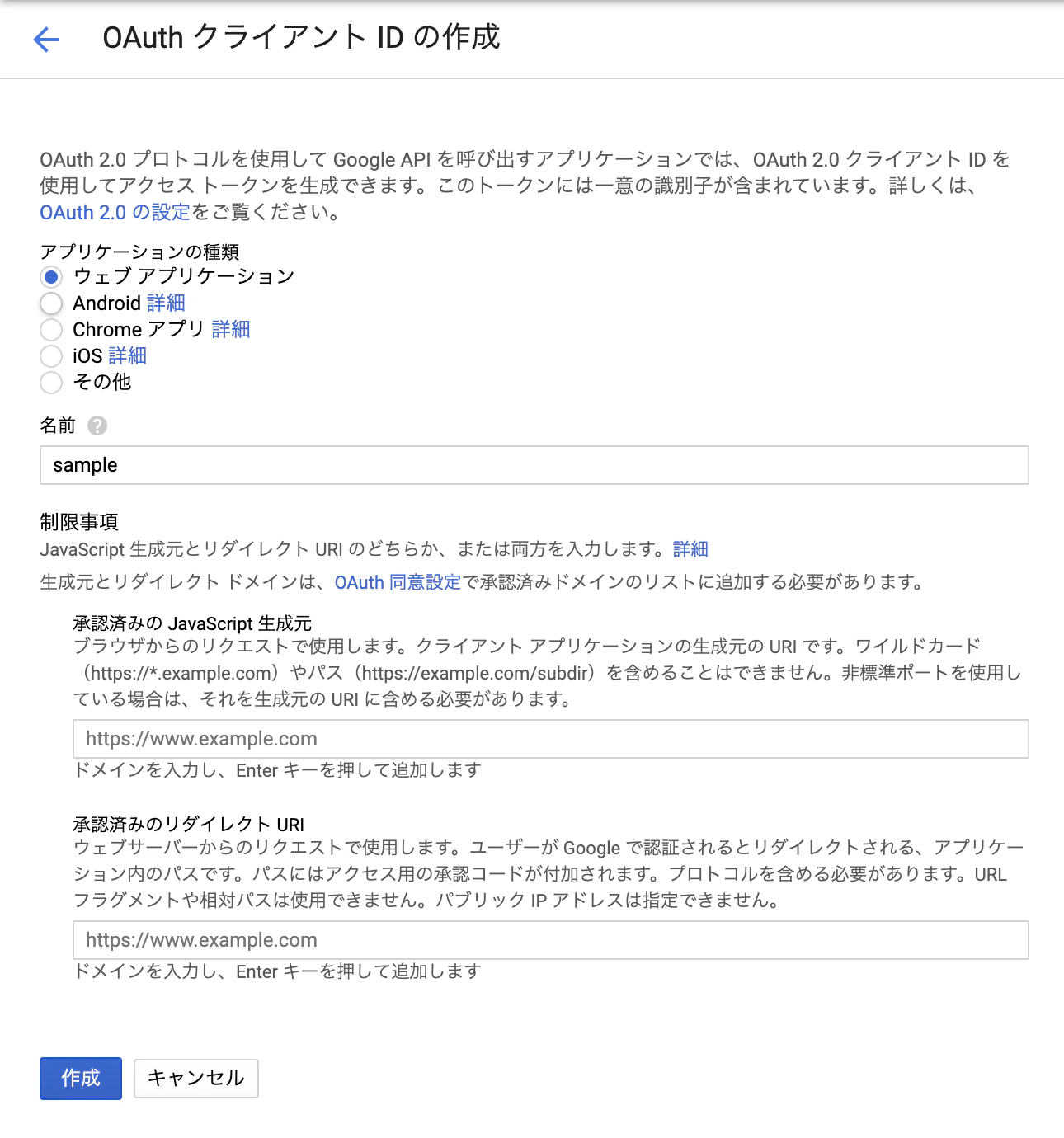
[APIとサービス]→[認証情報]を選択[認証情報を作成]→[OAuth クライアント ID]から今回使うOAuth認証情報を作成します。
今回は[ウェブアプリケーション]を選択して[名前]を入力します。
[承認済みのJavaScript生成元]には作ったアプリのDomainを入力します。(複数選択可能)
例:http://localhost:8080[承認済みのリダイレクトURI]にはユーザーが認証された後にリダイレクトされるURLを設定します。
例:http://localhost:8080/login/callback[作成]するとクライアントIDが発行されるのでメモしといてください。
実装
では実装してみましょう。
HTML<!DOCTYPE html> <html lang="ja"> <head> <meta charset="UTF-8"> <meta name="google-signin-client_id"content="YOUR_CLIENT_ID.apps.googleusercontent.com"> <script src="https://apis.google.com/js/platform.js" async defer></script> </head> <body> <div class="g-signin2" data-onsuccess="onSignIn" data-theme="dark"></div> </body> </html>正直HTMLにこの記述するだけでGoogle Sign-Inの実装はできちゃいます。
[YOUR_CLIENT_ID]は先ほどメモしたクライアントIDを入力しましょう。
簡単ですよね。更にログインしたユーザーのプロフィール情報を取得するにはgetBasicProfile()メソッドを使用します。
JavaScriptfunction onSignIn(googleUser) { var profile = googleUser.getBasicProfile(); console.log('ID: ' + profile.getId()); // GoogleのID console.log('Name: ' + profile.getName()); // アカウント名 console.log('Image URL: ' + profile.getImageUrl()); // プロフィール画像 console.log('Email: ' + profile.getEmail()); // ユーザーのメールアドレス }ちなみにログアウトを追加したい場合は、こんな感じで書けます。
HTML<a href="#" onclick="signOut();">ログアウト</a> <script> function signOut() { var auth2 = gapi.auth2.getAuthInstance(); auth2.signOut().then(function () { // ログアウトした後の処理 }); } </script>まとめ
今回はJSを使ってGoogle OAuth 2.0 認証を使ったGoogle Sign-Inの実装をしました。
ほんとこれだけでログイン機能の実装はできてしまうので皆さんも今時のおしゃれサイトにする際は使ってみてください。
ただ、実際の運用に使う際はこれだけだとセキュリティーガバガバなのでサーバーサイドでIDトークン検証したりなど、工夫が必要ですね。
また別でサーバーサイドでの処理などの実装もあげるのでよかったらみてください。参考

- 投稿日:2020-02-04T21:04:01+09:00
初心者によるプログラミング学習ログ 229日目
100日チャレンジの229日目
twitterの100日チャレンジ#タグ、#100DaysOfCode実施中です。
すでに100日超えましたが、継続。100日チャレンジは、ぱぺまぺの中ではプログラミングに限らず継続学習のために使っています。
229日目は
おはようございます
— ぱぺまぺ@webエンジニアを目指したい社畜 (@yudapinokio) February 3, 2020
229日目
・udemyで、css+javascript講座
・webサイト部分的模写#早起きチャレンジ#駆け出しエンジニアと繋がりたい#100DaysOfCode
- 投稿日:2020-02-04T13:01:13+09:00
HTML Tidyをlintとして使う
HTML Tidyは HTML/XML を整形するツールですが、副次的に HTML/XML の文法チェックも行います。そのままでは少々使い勝手が悪かったので、出力をカスタマイズして lint として使えるようにしてみました。
使用した HTML Tidy のバージョンは 5.7.28 です。
$ tidy5 --version HTML Tidy for FreeBSD version 5.7.28テストデータ
OK用とNG用で二つの HTML ファイルを用意しました。
test_ok.html<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>テストOK</title> </head> <body> 本文 </body> </html>test_ng.html<!DOCTYPE html> <html> <head> <meta charset=utf-8> <title>テストNG </head> <body> 本文 </body> </html>まず使ってみる
HTML Tidy で文法チェックのみを行うには
-eオプションを指定します。$ tidy5 -e test_ok.html test_ng.html Info: Document content looks like HTML5 No warnings or errors were found. line 4 column 1 - Info: value for attribute "charset" missing quote marks line 5 column 1 - Warning: missing </title> before </head> Info: Document content looks like HTML5 Tidy found 1 warning and 0 errors! About HTML Tidy: https://github.com/htacg/tidy-html5 Bug reports and comments: https://github.com/htacg/tidy-html5/issues Official mailing list: https://lists.w3.org/Archives/Public/public-htacg/ Latest HTML specification: http://dev.w3.org/html5/spec-author-view/ Validate your HTML documents: http://validator.w3.org/nu/ Lobby your company to join the W3C: http://www.w3.org/Consortium Do you speak a language other than English, or a different variant of English? Consider helping us to localize HTML Tidy. For details please see https://github.com/htacg/tidy-html5/blob/master/README/LOCALIZE.md
test_ok.htmlに対してはNo warnings or errors were found.、test_ng.htmlに対してはTidy found 1 warning and 0 errors!という結果が返ってきました。ただ、この出力結果では少々使い勝手が悪いですので、以後はラッパスクリプトを作って出力結果をいじっていきます。
mytidy.sh#!/bin/sh for arg; do tidy5 -e $arg done$ ./mytidy.sh test_ok.html test_ng.html Info: Document content looks like HTML5 No warnings or errors were found. (以下省略)出力のカスタマイズ
ラッパスクリプトで以下の点で出力をカスタマイズしました。
About HTML Tidy: ~以降のメッセージは冗長なので、空行以降をカット。-qオプションでも抑制できるが、info レベルの出力もカットされてしまう。- 警告がある際にのみメッセージを出力する。
$?は info レベルの出力のみの時は 0 になってしまうので、^lineを含むかどうかで判定。- メッセージ出力時、対象のファイル名を先に出力。
mytidy.sh#!/bin/sh for arg; do result=`tidy5 -e $arg 2>&1 | awk '/^$/ {nooutput=1} { if(!nooutput) print $0 }'` status=`echo "$result" | grep '^line'` if [ "${status}" != "" ] ; then echo "${arg}:" echo "${result}" echo fi donemytidy.sh> ./mytidy.sh test_ok.html test_ng.html test_ng.html: line 4 column 1 - Info: value for attribute "charset" missing quote marks line 5 column 1 - Warning: missing </title> before </head> Info: Document content looks like HTML5 Tidy found 1 warning and 0 errors!最終的には、以下のように全 HTML ファイルに対して lint をかけています。
$ find . -name "*.html" | xargs mytidy.sh経緯
冒頭に HTML の文法チェックをしようと思った経緯を書こうとしたのですが、少々長くなってしまったので末尾にもってきました。
私はあおやぎのさいとという個人サイトを20年以上やっているのですが、令和の今になっても HTML 手打ちで作ってます。CMS を使っていた時期もあるのですが、これだけサイト運営が長くなってくると、CMS の寿命の方が先に尽きてしまい、都度 CMS の移行となってしまいます。ならば HTML 手打ちで作ってった方が楽かなというのが今のところの結論です。
とはいえ全てを HTML 手打ちだけで作っていると大変ですので、補助的にツールを使ったりスクリプト書いたりして対応しています。その一環で lint として HTML Tidy を使ってみたわけです。
手打ちに限りませんが、HTML を書いているときには文法チェックが必要です。閉じタグ忘れてたり、タグの対応が違ってたりとかですね。多少の文法エラーはブラウザが勝手に推測して補正してくれるのですが、すべてのブラウザが同じように補正してくれるとは限りませんし、何よりも文法エラーは無い状態に保ちたいものです。
HTML 文法チェックを行うウェブサービスはいくつもあるのですが、これらはフォーム上に HTML を張り付けるか URL を指定して単独の HTML ファイルを検証するタイプです。既に数百ページのストックのある歴史あるサイト全体を文法チェックしたいという用途には向きません。ということでローカル環境でコマンドラインで使えるようなツールを探すことになります。
これまでは文法チェックには、Another HTML-lintというツールを使ってきました。しかしこちらは HTML 4.01 までしか対応していません。独自に拡張して HTML5 に対応しているAnother HTML-lint 5というのもあるのですが、ウェブサービスとしてのみの提供ですので私の要望には合いませんでした。なんとか HTML5 に対応したツールがないものかと探したところ、今回見つけたのが HTML Tidy だったというわけです。
- 投稿日:2020-02-04T12:08:11+09:00
:hoverを使ったら無茶チラついたので気になって悩んでしまった
とっても細かいどうでもいいところをなんとか直したくなり無茶時間かけて
試行錯誤した。解決?はしたっぽいがどういう原理なのかよく分からない・・・・やっぱりフロントは嫌いだ。
やりたかったこと。
隣接した要素で、一方にマウスオーバーすると、
display: none;
にしておいたもう一方の要素を出現させて、
出現させた要素のリンクをクリックできるようにしたい。どこのサイトも簡単そうに書いてあり、TECHのカリキュラムでもおかしなことは起こらなかったのだが・・・
chromeで開くとなんかムッチャチラつく。何これ?
色々調べたけど同じことになってる記事を見つけられなかったので、
このhoverの部分だけをhtml,cssに切り出した上でプロパティをどんどん削っていってテストした。最終的にここまでにしたけど、やっぱり改善せず。ちなみに他のブラウザの動きとして、safariはちょっとチラつく。firefoxはチラつき無し。うん、わかんね。
test.html<!DOCTYPE html> <html lang="ja"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <meta http-equiv="X-UA-Compatible" content="ie=edge"> <title>Document</title> <link rel='stylesheet' href='./test.css'> </head> <body> <div class="nickname">名前</div> <div class="box"><a href="#">ログアウト</a></div> </body> </html>※ scssは、vseditorにLive Sass Compilerっていうのを入れて、css変換して検証してた。
test.scss.nickname { height: 60px; background-color: #f0f0f0; &:hover + .box { display: block; } } .box { background-color: skyblue; display: none; position: absolute; top: 2em; height: 50px; }最終的に思い至ったのが(元々、そういう風に書いておくものなのかもしれないが・・・)
nickname要素にのみhoverを適用させた状態だと、nickname要素の範囲からマウスが外れてしまった時にbox要素が消えちゃうじゃん、と思いbox:hover{ display: block; }
を追加したらなんとかなった。test.scss.box { background-color: skyblue; display: none; position: absolute; top: 69px; height: 50px; &:hover { display: block; } }ちなみに、topを変えて試してみてたが、
双方の境界部分は、接するか、重ねるかしないとダメ、と思っていたが、
1 pixcel離れるのは許容される(1 pixcelの隙間にマウスオーバーしてもboxが消えずに済む)ということが分かった!!
どうでもいいけど。ブラウザ別に動作が変わるだろうから、きっと接するか、重ねるかしとくのが無難なんだろう。

- 投稿日:2020-02-04T11:04:56+09:00
WebとHTML, URI, HTTPの関係について基本的なこと(初学者向け)
Webとは何か
Webエンジニアへ転職する人が多くなっていますが、「そもそもWebってなんですか?」っていう方のために簡単に説明します。(私も初学者ですので誤りがあればご指摘いただけると嬉しいです。)
Web(World Wide Web)とは
Webとはインターネットで使用されるドキュメントシステムのことです。
特徴はWorld Wide Web =「世界に広がる蜘蛛の巣」という名前にある通り、インターネット上に存在する情報同士がリンクで繋がっている(ハイパーテキストシステム)点にあります。ちなみに「リンク」とは、文書の中に別の文書のURI(URL)を埋め込むことで、ユーザーがクリックして閲覧できる機能のことです。
その様が蜘蛛の巣みたいだったのでWorld Wide Webと名付けられました。私たちユーザーはWebブラウザ(ChromeやSafariやInternet Explorerなど)を使って、Webサーバから文書の情報を得ることができます。
この便利なシステムを支えているのが
URI, HTML, HTTPという3つの技術です。URI(Uniform Resource Identifier)
まずWeb上に存在する情報(リソース)を特定できるようにするためには、何らかの名前をつけて他の情報と区別しなければなりません。そこでURI(URL)というものでWeb上にあるリソースに名前をつけます。
一般的なURIは
プロトコル名://ホスト名(ドメイン名orIPアドレス)/パス
で示されます。
例えばこういうやつです。
https://qiita.com/jununこのURI(URL)は「Qiita.comというネットワークの、/junun というディレクトリに対してHTTPS通信でやり取りする」という意味になります。
ちなみにHTTPSとは、通信を暗号化することでHTTPよりも安全なプロトコルです。このURIを一意でシンプルかつ寿命が長くなる(変更されない)ように設計することで、文書間のリンクを基盤としたWebが成り立っています。
HTML(Hypertext Markup Language)
HTMLはマークアップ言語です。マークアップ言語とは、タグ(
<body>や<h1>など)で文書の構造を表現する言語です。HTMLを用いることで文書内に埋め込まれた画像や動画などへのリンクを表現することが可能になります。HTTP(Hypertext Transfer Protocol)
ブラウザとサーバのやり取りに使用される通信がHTTPです。HTMLと同様にHypertextとあるようにハイパーテキストを転送するためのプロトコル(通信規約)です。
HTTP通信で行われることを大雑把に説明すると、
1ブラウザからサーバに何らかのリクエストを送ります。
2サーバがそのリクエストに対応するアプリケーションで処理して、ブラウザにレスポンスを返します。基本的にサーバはリクエストを処理してレスポンスを返すだけという設計になっていることで、サーバのプログラムをシンプルに保つことができています。
「ステートレス」やHTTPメソッド、HTTPメッセージなどの重要な概念についてはまた別の記事にアップしようと思います。
まとめ
URI, HTML, HTTPという3つの技術が基本となってWebを実現しています。シンプルに設計されているからこそ、拡張性が高く、大規模なシステムが成り立っている点は非常にかっこいいと思います。(感想)
参照
- 投稿日:2020-02-04T00:30:27+09:00
AtomicDesignでAtomsの設計を失敗した話
概要
今回は、AtomicDesignでのコンポーネント設計をした行った時にやらかしたミスを記事にしてみました。
AtomicDesignって
最初にAtomicDesignとはなんなのかを軽く振り返ってみましょう。
Qiita内外でも多くの説明がなされているので、ざっくりと。AtomicDesignとは、コンポーネントを以下の5つの階層に分け、
コンポーネントの役割や責任を明確しそれらをルールを決めて分割していこう、という概念です。
- Atoms(原子)
- Molecules(分子)
- Organisms(有機体)
- Templates
- Pages
上が最小のコンポーネントで、下が一番大きいコンポーネントとなります。
また、AtomicDesignのルールとして、
- Atoms
- これ以上機能として分割できない機能達
- Molecules
- Atomsの集合体
- Organisms
- AtomsやMoleculesの集合体で、複雑な構成
- Templates
- MoleculesやOrganismsを配置する設計図
- Pages
- Templatesに対してデータを反映した物
といった感じですね。
それぞれの役割が明確化されていて、コンポーネントをどう作っていけばいいかの方針がわかりやすくなってますね。
それでもやらかした自分とは一体Atomsをつくってみた
まずは、設計がマズい形のAtomsを見てみましょう
今回はButton要素のコンポーネントを例に使います。button<template> <button @click="onClick"> <slot></slot> </button> </template> <script> export default { methods: { onClick() { return this.$emit("click"); } } }; </script> <style lang="scss" scoped> .Base__Button { &--green { //省略 } &--red { //省略 } &--yellow { //省略 } } </style>HTML要素とScript要素は至ってシンプルな構成です。
CSS要素に関しては、1つのファイルの中に複数のClass属性が記述する形で作ってみました。
このComponentではclass属性の指定をせずに、Componentを配置した親側でClass属性を指定するという方法をとりました。
呼び出す側の例も書いておきます。Parent<base-button class="Base__Button--green">HOGE</base-button>
親でClass属性を指定してる時点でとっても嫌な予感がするぞが、だめ!
最初はこの設計でも問題なく使えてましたが、使用するClass属性が増えて、記述が多くなってくると、
当然ながら使いづらくなってきました。というのも、新しいスタイルが必要となった場合も同じファイルに追加していくために、
アイコンに使用する目的の無色透明で小さめのスタイルを…。
次はタブ用のスタイルを…
次はgreenだけ、ボタンのサイズを色々作りたい
次は…となり、気づいたらClass属性の記述だけでファットになって、しかも複雑に絡み合い濃厚な味に…。
▂▅▇█▓▒░(‘ω’)░▒▓█▇▅▂ うわあああああああああ
Badな設計
どのような点がBadであったかを確認してみましょう。
- 親と密結合
- 親でクラス名を指定しないと見た目を固定できない
- 下手したら親にスタイルのコードを書いている
- ComponentのCSSがファット
- 1つのComponentに色んなスタイルを詰め込みすぎ
- CSSが上書きなどでスパゲッティコード化
- Atomsの外でClass属性/CSS属性を記述
- コンポーネントの状態を閉じ込めれてない
基礎的な注意点ばかりではありますね…。
なぜ、このような設計のComponentを作ってしまったかも反省しておきましょう。
- 同じようなComponentを作るのはNG
- 1つのComponentで管理やったら楽じゃん!
- Atomsのルール通り処理の機能は分割しつつスタイルはまとめたい
- 色んな箇所で使うなら同じComponentのほうがいいのでは
- でも色んなデザインにしたいけど細かく制御できないから親にCSS属性を書くしか無い
というのを考えて作りやらかしてしまいました。
特に最後のは、もはやAtomsを親からスタイルを上書きしていたので、
これ普通のButtonタグでもよくない?のとこれ疎結合になっていないよね?という、色々なルール違反な状態となっていました。そうだ、いっぱいつくればいいんだ
では、どうすればいいんだ!と悩み、色々ググって情報を漁っていたところ気づきました。
色んな人のLT資料や、記事を見ていっそのこと振り切って考えていいのかもと思ってすえたどり着いた答えが、
そうだ、必要な分のAtomsをいっぱいつくればいいんだHTML要素やJavascriptと同じように、CSSも見た目毎に最小単位まで絞り込んだComponentを作ってしまえばいいのだと。
方針としては、「Importしたら見た目も完成していたそのまま使える」ぐらいの疎結合と独立感で。
早速、先程のButtonを作り直してみました。
ImportしてるComponentが多くてパス修正が大変だったBaseButtonGreen.vue BaseButtonRed.vue BaseButtonYellow.vue BaseButtonRadius.vue BaseButtonSemiRadius.vue分解し、それぞれ作ってみました。
中身の方は、試しにBaseButtonGreen.vueを見てみましょう。BaseButtonGreen.vue<template> <button @click="onClick" class="Base__Button--green"> <slot></slot> </button> </template> <script> export default { methods: { onClick() { return this.$emit("click"); } } }; </script> <style lang="scss" scoped> .Base__Button--green { //省略 } </style>以前のComponentと違うのは、class属性をここで指定しCSSでは他のclass属性を記述していない、というところです。
BaseButtonGreen.vueは名前で表すように緑色のボタンに関係するCSS属性だけを記述し、
BaseButtonRed.vueは、赤色のボタンを。
BaseButtonRadius.vueでは、円形に関係するCSS属性だけを。
こうすることで、親とは疎結合になり独立性が高いComponentとなり、Importしそのまま使える事ができます。差分がある場合には?
BaseButtonGreen.vueの縦横幅を大きい/小さいのを使いたいとなった場合ですが、
この場合はBaseButtonGreen.vueの中に差分を書くのではなく、いっそのこと別Componentにしましょう。BaseButtonGreen.vue BaseButtonGreenLarge.vue BaseButtonGreenSmall.vueファイル名に修飾子で「Large」か「Small」などを付け加えて、違いを明確化。
このように、同じ構成や見た目だけど細部が微妙に違うAtomsを作る場合には、ファイル名に修飾子をつけました。
サイズだけではなく、hoverなどの擬似クラスでちょっとリッチなエフェクトを付けたいけど、
エフェクトがないのも必要という場合には、Componentを2つに分割する事で変更内容を1ファイルに閉じ込める事ができます。おわり
今回はAtomicDesignで私がやらかした勘違いと失敗を、どのようにルールを見直した修正したかを記事にしてみました。
割とAtomicDesignの解説記事では、Moleculesからの作り方が多く書かれていますが、
Atomsでどうやって作るの?て記事はなかなか見ないので今回ネタにしてみました。
(ついでに自分犯した失敗の反省も込めて)実際の現場ではAtomsは作らず、VuetifyなどのComponentFrameworkを使う事も多いと思われますが、
いざ自分でつくろうとすると案外どうやるんだったかな?とか、これでよかったよね?となりやすい部分であるので、
しっかりルール作りや方針確認をしたほうがいいですね!また、アプリやサイトのデザインにがっつり影響する部分でもあるので
やっぱり自分で作ってると楽しいし、これからもたくさんAtomsを作っていこうかなと確信しました。
でも作りすぎるとImportがめんどくさいので、まとめて読み込む処理を組み入れなくちゃ…(確信)