- 投稿日:2020-01-23T23:58:13+09:00
Node.jsからFBX SDK Pythonを呼べるDockerイメージ作った
Node.jsからFBX SDK Pythonを呼べるDockerイメージ作った
とある事情により、Node.jsからFBX SDK Pythonを呼ぶ必要があったので、Dockerイメージを作りました。
作ったDockerイメージは以下に公開しました。
https://hub.docker.com/r/seguropus/fbx-sdk-python-nodejsサンプルコード
サンプルコードを以下に置きます。
https://github.com/segurvita/docker-fbx-sdk-python-nodejsサンプルコードの使い方
# Dockerイメージをビルド docker-compose build # Dockerコンテナを起動 docker-compose upこれで、以下のような表示が出れば成功です。
fbx-sdk-python-nodejs | # FBX SDK can read the following formats. fbx-sdk-python-nodejs | 00 FBX (*.fbx) fbx-sdk-python-nodejs | 01 AutoCAD DXF (*.dxf) fbx-sdk-python-nodejs | 02 Alias OBJ (*.obj) fbx-sdk-python-nodejs | 03 3D Studio 3DS (*.3ds) fbx-sdk-python-nodejs | 04 Collada DAE (*.dae) fbx-sdk-python-nodejs | 05 Alembic ABC (*.abc) fbx-sdk-python-nodejs | 06 Biovision BVH (*.bvh) fbx-sdk-python-nodejs | 07 Motion Analysis HTR (*.htr) fbx-sdk-python-nodejs | 08 Motion Analysis TRC (*.trc) fbx-sdk-python-nodejs | 09 Acclaim ASF (*.asf) fbx-sdk-python-nodejs | 10 Acclaim AMC (*.amc) fbx-sdk-python-nodejs | 11 Vicon C3D (*.c3d) fbx-sdk-python-nodejs | 12 Adaptive Optics AOA (*.aoa) fbx-sdk-python-nodejs | 13 Superfluo MCD (*.mcd) fbx-sdk-python-nodejs | 14 (*.zip) fbx-sdk-python-nodejs exited with code 0表示されているのは、FBX SDKが読み込み可能なファイル形式の一覧です。
これが表示されたということは、無事にFBX SDK Pythonにアクセスできているということになります。
何が起きてるのか?
まず、
docker-compose upでDockerコンテナーが起動します。Dockerコンテナーは、起動したらNode.jsのコード
index.jsを実行します。
index.jsはPythonのコードmain.pyを呼びます。
main.pyはFBX SDK Pythonから対応フォーマット一覧を取得して、表示します。Dockerfile
PythonとNode.jsが同居したDockerイメージを公開している方がいたので、そちらをもとに
Dockerfileを作成してみました。Dockerfile# Python 2.7とNode.js 12が入ったAlpine FROM nikolaik/python-nodejs:python2.7-nodejs12-alpine # apkでライブラリ更新 RUN apk update && \ apk add \ curl \ libxml2 \ libstdc++ # FBX SDKをダウンロード RUN curl -L \ https://damassets.autodesk.net/content/dam/autodesk/www/adn/fbx/20195/fbx20195_fbxpythonsdk_linux.tar.gz \ -o /tmp/fbx20195_fbxpythonsdk_linux.tar.gz # インストール先フォルダ作成 RUN mkdir -p /python-fbx/install # FBX SDKを解凍 RUN tar -zxvf \ /tmp/fbx20195_fbxpythonsdk_linux.tar.gz \ -C /python-fbx && \ printf "yes\nn" | \ /python-fbx/fbx20195_fbxpythonsdk_linux \ /python-fbx/install # FBX SDKをインストール RUN cp /python-fbx/install/lib/Python27_ucs4_x64/* \ /usr/local/lib/python2.7/site-packages/ # python-shellをインストール RUN npm install -g python-shell # 一時ファイルを削除 RUN rm -r /python-fbx RUN rm /tmp/fbx20195_fbxpythonsdk_linux.tar.gz # 環境変数NODE_PATHを設定 ENV NODE_PATH /usr/local/lib/node_modules
python-shellというのは、Node.jsからPythonを呼ぶためのライブラリです。グローバル領域にインストールしたので、index.jsが
requireで取得できるように、環境変数NODE_PATHを設定しています。docker-compose.yml
docker-compose.ymlはこんな感じです。docker-compose.ymlversion: '3' services: fbx-sdk-python-nodejs: image: 'seguropus/fbx-sdk-python-nodejs' container_name: 'fbx-sdk-python-nodejs' build: context: ./ dockerfile: ./Dockerfile volumes: - .:/src working_dir: /src command: node index.jsDockerコンテナー起動時に
index.jsが実行されます。index.js
index.jsはこんな感じです。
index.jsconst pythonShell = require('python-shell'); // python-shellのオプション const pyOption = { mode: 'text', pythonPath: '/usr/local/bin/python', pythonOptions: ['-u'], scriptPath: '/src', } // main.pyを実行 const pyShell = new pythonShell.PythonShell('main.py', pyOption); // Pythonの標準出力を表示 pyShell.on('message', (message) => { console.log(message); }); // 終了処理 pyShell.end(function (err, code, signal) { if (err) { console.error(err); } console.log('The exit code was: ' + code); });
python-shellでmain.pyを呼んでいます。main.py
main.pyはこんな感じです。main.pyfrom fbx import * def list_reader_format(manager): print('# FBX SDK can read the following formats.') for formatIndex in range(manager.GetIOPluginRegistry().GetReaderFormatCount()): description = manager.GetIOPluginRegistry().GetReaderFormatDescription(formatIndex) print(formatIndex, description) def main(): # Create manager = FbxManager.Create() scene = FbxScene.Create(manager, "fbxScene") # List list_reader_format(manager) # Destroy scene.Destroy() manager.Destroy() if __name__ == '__main__': main()
from fbx import *でFBX SDK Pythonを読み込んでいます。
list_reader_format()という関数で、FBX SDK Pythonが読み込み可能なファイル形式の一覧を標準出力に表示しています。無事にNode.jsからFBX SDK Pythonを呼べるDockerイメージを作ることができました!
Docker Hubに公開してみる
せっかくなので、Docker Hubに公開してみます。
# ログインする docker login # Dockerイメージをプッシュする docker push seguropus/fbx-sdk-python-nodejs以下に公開されました。
https://hub.docker.com/r/seguropus/fbx-sdk-python-nodejsさいごに
本記事作成にあたり、以下のページを参考にしました。ありがとうございました。
- 投稿日:2020-01-23T23:36:02+09:00
Pythonでsorted関数やgroupby関数へdefを渡すときの注意点??
Pythonを勉強しているのですが、ハマってしまって、1時間ぐらい立ち往生しました。
一応解決したのですが、どうしても腑に落ちなくて、もしこのメカニズムがわかる方がいらっしゃったらご教示いただけると嬉しいと思い、書きます。以下は、選手名とブロックの組み合わせで、ロサンゼルスとニューヨークの選手を混ぜて、AブロックとBブロックにそれぞれ分けるプログラムです。
groupLeague.pyimport itertools LA = [('Jake', 'B'), ('Elwood', 'A')] NY = [('James', 'A'), ('Carry', 'B'), ('Steven', 'B')] data = itertools.chain(LA, NY) def getSortKey(item): return item[1] grp = itertools.groupby(sorted(data, key=getSortKey(data), getSortKey(data))しかし、これを実行すると、
TypeError: 'itertools.chain' object is not subscriptable
とエラーで弾かれてしまいます。さっぱりわからず大ハマリしたんですが、別のサンプルプログラムを見て直した所、動作しました。
最後の行の、grp = itertools.groupby(sorted(data, key=getSortKey(data)), getSortKey(data))を、
grp = itertools.groupby(sorted(data, key=getSortKey), getSortKey)と、getSortKeyの引数を除いたところ、正常に動作しました。
とりあえずプログラムは動いたんですが、このメカニズムがさっぱりわかりません。
groupbyの2つ目の引数「key部」としてkey値の他に「keyを取得できる関数」を指定できるというのはわかるのですが、関数を指定する場合、なぜ引数を書かなくて良い(というか引数を書いたらエラー)になるのでしょうか??動作を確認する限りでは、第一引数の「iterable部」(sorted~)が自動的に引数として扱われていると思うのですが、ドキュメントにはそれらしい記述は何もありませんでした。【参考】
Pythonドキュメント itertools --- 効率的なループ実行のためのイテレータ生成関数sorted関数も同様です。key=getSortkeyの部分で、引数は自動的に第一引数のdataを取っているように見えるのですが、そのメカニズムがわかりません(ドキュメントにもやっぱり記載はありませんでした)。
【参考】
Pythonドキュメント 組み込み関数 sortedこれ、引数を取らないで良いのってどういうメカニズムなんでしょうか…??
調べてみたけどどうしてもわかりませんでした。
多分初歩的な質問だと思うので大変恐縮ですが、ご存じの方はご教示いただけますと大変助かります。この手のトリッキーな仕様って、どうやって対処したら良いんだろう…。
- 投稿日:2020-01-23T23:28:45+09:00
【StyleGAN入門】自前マシンで独自学習♬
今回はStyleGANを使ってアニメ顔の学習に挑戦してみました。
学習に関する参考はほとんどなく以下のものがありました。結構学習に時間もかかるし、情報も不十分でしたが、一応自前マシンで学習でき、かつ学習途中からの再学習もできたので、記事にまとめておきます。
【参考】
①How To Use Custom Datasets With StyleGAN - TensorFlow Implementation
②styleganで独自モデルの学習方法
③StyleGAN log
④Making Anime Faces With StyleGANやったこと
・アニメ顔データの準備
・とにかく学習する
・潜在空間でのミキシングをやってみる
・再学習するには・アニメ顔データの準備
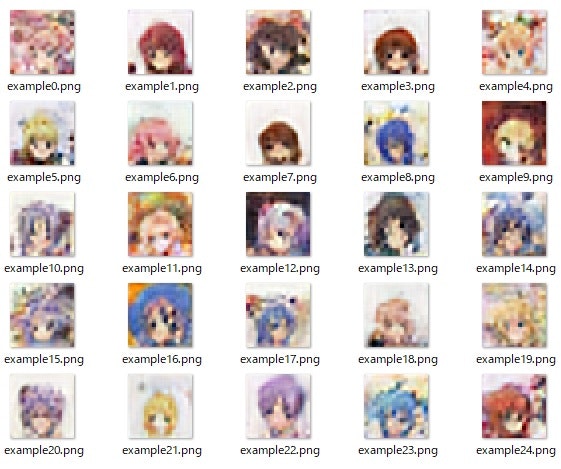
アニメ顔は以前DCGANで利用したサイトから、ダウンロードして準備しました。
今回の利用のポイントは少なくとも画像サイズを合わせて、かつファイル名を変更して読み取りやすく、1.pngのように変更すること。
StyleGANの学習という意味では目鼻顔などのアラインメントを合わせたいが、次回にパスした。
ということで、上記のデータ整理は以下のコードで実施した。
ちなみにサイズ(128,128)を1000個用意した。from PIL import Image import glob import random files = glob.glob("./anime/**/*.png", recursive=True) files = random.sample(files, 1000) res = [] sk=0 for path in files: img = Image.open(path) img = img.resize((128, 128)) img.save( "img/{}.png".format(sk)) sk += 1・とにかく学習する
学習コードは、参考①のビデオと参考②を眺めつつ、以下のようにした。
kimgは学習image数であり、単位が千imgを意味している。
総学習イメージ数が3400kimgを意味する
次の行は学習開始解像度=4
そして、custom_datasetがtf_reccordsに変換した画像のDir(=datasets/custom_dataset)である。さらに、とりあえずの学習ということで、解像度=64で学習してみたが問題なく学習できた。
また、StyleGANはgganであり、サイズ毎学習であるが、サイズ毎のminibatchサイズも以下のとおり、小さめに設定した。train.total_kimg = 3400、 sched.lod_initial_resolution = 4 desc += '-custom_dataset'; dataset = EasyDict(tfrecord_dir='custom_dataset', resolution=64); train.mirror_augment = False desc += '-1gpu'; submit_config.num_gpus = 1; sched.minibatch_base = 4; sched.minibatch_dict = {4: 128, 8: 64, 16: 32, 32: 16, 64: 8, 128: 8, 256: 4, 512: 2}つまり、以下の必要最小限で動く。
train.py# Copyright (c) 2019, NVIDIA CORPORATION. All rights reserved. # # This work is licensed under the Creative Commons Attribution-NonCommercial # 4.0 International License. To view a copy of this license, visit # http://creativecommons.org/licenses/by-nc/4.0/ or send a letter to # Creative Commons, PO Box 1866, Mountain View, CA 94042, USA. """Main entry point for training StyleGAN and ProGAN networks.""" import copy import dnnlib from dnnlib import EasyDict import config from metrics import metric_base #---------------------------------------------------------------------------- # Official training configs for StyleGAN, targeted mainly for FFHQ. if 1: desc = 'sgan' # Description string included in result subdir name. train = EasyDict(run_func_name='training.training_loop.training_loop') # Options for training loop. G = EasyDict(func_name='training.networks_stylegan.G_style') # Options for generator network. D = EasyDict(func_name='training.networks_stylegan.D_basic') # Options for discriminator network. G_opt = EasyDict(beta1=0.0, beta2=0.99, epsilon=1e-8) # Options for generator optimizer. D_opt = EasyDict(beta1=0.0, beta2=0.99, epsilon=1e-8) # Options for discriminator optimizer. G_loss = EasyDict(func_name='training.loss.G_logistic_nonsaturating') # Options for generator loss. D_loss = EasyDict(func_name='training.loss.D_logistic_simplegp', r1_gamma=10.0) # Options for discriminator loss. dataset = EasyDict() # Options for load_dataset(). sched = EasyDict() # Options for TrainingSchedule. grid = EasyDict(size='4k', layout='random') #4k # Options for setup_snapshot_image_grid(). metrics = [metric_base.fid50k] # Options for MetricGroup. submit_config = dnnlib.SubmitConfig() # Options for dnnlib.submit_run(). tf_config = {'rnd.np_random_seed': 1000} # Options for tflib.init_tf(). # Dataset. desc += '-custom_dataset'; dataset = EasyDict(tfrecord_dir='custom_dataset', resolution=64); train.mirror_augment = False # Number of GPUs. desc += '-1gpu'; submit_config.num_gpus = 1; sched.minibatch_base = 4; sched.minibatch_dict = {4: 128, 8: 64, 16: 32, 32: 16, 64: 8, 128: 8, 256: 4, 512: 2} # Default options. train.total_kimg = 3400 sched.lod_initial_resolution = 4 sched.G_lrate_dict = {128: 0.0015, 256: 0.002, 512: 0.003, 1024: 0.003} sched.D_lrate_dict = EasyDict(sched.G_lrate_dict) #---------------------------------------------------------------------------- # Main entry point for training. # Calls the function indicated by 'train' using the selected options. def main(): kwargs = EasyDict(train) kwargs.update(G_args=G, D_args=D, G_opt_args=G_opt, D_opt_args=D_opt, G_loss_args=G_loss, D_loss_args=D_loss) kwargs.update(dataset_args=dataset, sched_args=sched, grid_args=grid, metric_arg_list=metrics, tf_config=tf_config) kwargs.submit_config = copy.deepcopy(submit_config) kwargs.submit_config.run_dir_root = dnnlib.submission.submit.get_template_from_path(config.result_dir) kwargs.submit_config.run_dir_ignore += config.run_dir_ignore kwargs.submit_config.run_desc = desc dnnlib.submit_run(**kwargs) #---------------------------------------------------------------------------- if __name__ == "__main__": main() #----------------------------------------------------------------------------なお、データのtfreccordsへの変換は参考①から以下のように実施した。
※ここで元画像は./animeに入れておく、そして画像サイズ毎の変換ファイルはcustom_datasetに6個のサイズの異なるファイルが格納された。python dataset_tool.py create_from_images datasets/custom_dataset ./anime上記でとりあえず、学習できると思う。
・潜在空間でのミキシングをやってみる
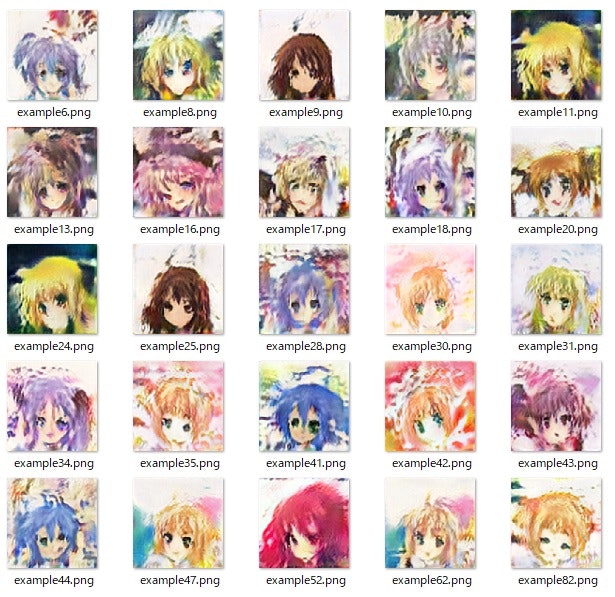
1060マシンで上記のコードを10h程度で以下の絵が得られる。
決して綺麗とは言えないが、とにかく最弱マシンでも学習できた。
さらに、潜在空間での17,18のミキシングをやってみると以下の絵が得られた。
1080マシンで解像度128x128サイズで1d8h程度回して、kimg=4705の場合以下のように画像がしっかりしてきた。
※これでもpid50K=168程度で精度はまだまだだが、。。。以前のDCGANの画像と比べてこちらの方が綺麗に見える
さらに、潜在空間での11,82のミキシングをやってみると以下の絵が得られた。
・再学習するには
最後に禁断(誰も公開していないようなので)の途中中断した場合の継続学習の仕方が出来たので、まとめておく。
※この方法はちょっとだけ参考②と参考④に記載がある
以下のコードで実施する。
すなわち、training_loop.pyの以下の部分を修正する。resume_run_id = "latest", #None, # Run ID or network pkl to resume training from, None = start from scratch. resume_snapshot = './results/00001-sgan-custom_dataset-1gpu/network-snapshot-.pkl', #None, # Snapshot index to resume training from, None = autodetect.また、network_snapshot_ticks = 1, # How often to export network snapshots? として、毎回出力にしている。
training_loop.pydef training_loop( submit_config, G_args = {}, # Options for generator network. D_args = {}, # Options for discriminator network. G_opt_args = {}, # Options for generator optimizer. D_opt_args = {}, # Options for discriminator optimizer. G_loss_args = {}, # Options for generator loss. D_loss_args = {}, # Options for discriminator loss. dataset_args = {}, # Options for dataset.load_dataset(). sched_args = {}, # Options for train.TrainingSchedule. grid_args = {}, # Options for train.setup_snapshot_image_grid(). metric_arg_list = [], # Options for MetricGroup. tf_config = {}, # Options for tflib.init_tf(). G_smoothing_kimg = 10.0, # Half-life of the running average of generator weights. D_repeats = 1, # How many times the discriminator is trained per G iteration. minibatch_repeats = 4, # Number of minibatches to run before adjusting training parameters. reset_opt_for_new_lod = True, # Reset optimizer internal state (e.g. Adam moments) when new layers are introduced? total_kimg = 15000, # Total length of the training, measured in thousands of real images. mirror_augment = False, # Enable mirror augment? drange_net = [-1,1], # Dynamic range used when feeding image data to the networks. image_snapshot_ticks = 1, # How often to export image snapshots? network_snapshot_ticks = 1, # How often to export network snapshots? default=10 save_tf_graph = False, # Include full TensorFlow computation graph in the tfevents file? save_weight_histograms = False, # Include weight histograms in the tfevents file? resume_run_id = "latest", #None, # Run ID or network pkl to resume training from, None = start from scratch. resume_snapshot = './results/00001-sgan-custom_dataset-1gpu/network-snapshot-.pkl', #None, # Snapshot index to resume training from, None = autodetect. resume_kimg = 1040.9, # Assumed training progress at the beginning. Affects reporting and training schedule. resume_time = 5599.0): # Assumed wallclock time at the beginning. Affects reporting.resume_time = 5599.0
は秒単位で入力する。
このままだとメモリーがたまらないので、さらに上書き保存するためにもう一か所、下のコードのように変更した。train_loops.pyif cur_tick % network_snapshot_ticks == 0 or done or cur_tick == 1: #pkl = os.path.join(submit_config.run_dir, 'network-snapshot-%06d.pkl' % (cur_nimg // 1000)) pkl = os.path.join(submit_config.run_dir, 'network-snapshot-.pkl') misc.save_pkl((G, D, Gs), pkl) metrics.run(pkl, run_dir=submit_config.run_dir, num_gpus=submit_config.num_gpus, tf_config=tf_config)計算が1080マシンでもかなりかかるので、これを利用した結果については後日公開したいと思う。
まとめ
・自前マシンでStyleGANの学習ができるようになった
・学習データで今まで報告したようなミキシングが出来た
・途中で中断した場合の再開の仕方が分かった・今回は1000データだが、100以下の少数データの結果も見ようと思う
・さらに精度を追求してスタイルなどもやってみようと思うおまけ
dnnlib: Running training.training_loop.training_loop() on localhost... Streaming data using training.dataset.TFRecordDataset... Dataset shape = [3, 64, 64] Dynamic range = [0, 255] Label size = 0 Constructing networks... G Params OutputShape WeightShape --- --- --- --- latents_in - (?, 512) - labels_in - (?, 0) - lod - () - dlatent_avg - (512,) - G_mapping/latents_in - (?, 512) - G_mapping/labels_in - (?, 0) - G_mapping/PixelNorm - (?, 512) - G_mapping/Dense0 262656 (?, 512) (512, 512) G_mapping/Dense1 262656 (?, 512) (512, 512) G_mapping/Dense2 262656 (?, 512) (512, 512) G_mapping/Dense3 262656 (?, 512) (512, 512) G_mapping/Dense4 262656 (?, 512) (512, 512) G_mapping/Dense5 262656 (?, 512) (512, 512) G_mapping/Dense6 262656 (?, 512) (512, 512) G_mapping/Dense7 262656 (?, 512) (512, 512) G_mapping/Broadcast - (?, 10, 512) - G_mapping/dlatents_out - (?, 10, 512) - Truncation - (?, 10, 512) - G_synthesis/dlatents_in - (?, 10, 512) - G_synthesis/4x4/Const 534528 (?, 512, 4, 4) (512,) G_synthesis/4x4/Conv 2885632 (?, 512, 4, 4) (3, 3, 512, 512) G_synthesis/ToRGB_lod4 1539 (?, 3, 4, 4) (1, 1, 512, 3) G_synthesis/8x8/Conv0_up 2885632 (?, 512, 8, 8) (3, 3, 512, 512) G_synthesis/8x8/Conv1 2885632 (?, 512, 8, 8) (3, 3, 512, 512) G_synthesis/ToRGB_lod3 1539 (?, 3, 8, 8) (1, 1, 512, 3) G_synthesis/Upscale2D - (?, 3, 8, 8) - G_synthesis/Grow_lod3 - (?, 3, 8, 8) - G_synthesis/16x16/Conv0_up 2885632 (?, 512, 16, 16) (3, 3, 512, 512) G_synthesis/16x16/Conv1 2885632 (?, 512, 16, 16) (3, 3, 512, 512) G_synthesis/ToRGB_lod2 1539 (?, 3, 16, 16) (1, 1, 512, 3) G_synthesis/Upscale2D_1 - (?, 3, 16, 16) - G_synthesis/Grow_lod2 - (?, 3, 16, 16) - G_synthesis/32x32/Conv0_up 2885632 (?, 512, 32, 32) (3, 3, 512, 512) G_synthesis/32x32/Conv1 2885632 (?, 512, 32, 32) (3, 3, 512, 512) G_synthesis/ToRGB_lod1 1539 (?, 3, 32, 32) (1, 1, 512, 3) G_synthesis/Upscale2D_2 - (?, 3, 32, 32) - G_synthesis/Grow_lod1 - (?, 3, 32, 32) - G_synthesis/64x64/Conv0_up 1442816 (?, 256, 64, 64) (3, 3, 512, 256) G_synthesis/64x64/Conv1 852992 (?, 256, 64, 64) (3, 3, 256, 256) G_synthesis/ToRGB_lod0 771 (?, 3, 64, 64) (1, 1, 256, 3) G_synthesis/Upscale2D_3 - (?, 3, 64, 64) - G_synthesis/Grow_lod0 - (?, 3, 64, 64) - G_synthesis/images_out - (?, 3, 64, 64) - G_synthesis/lod - () - G_synthesis/noise0 - (1, 1, 4, 4) - G_synthesis/noise1 - (1, 1, 4, 4) - G_synthesis/noise2 - (1, 1, 8, 8) - G_synthesis/noise3 - (1, 1, 8, 8) - G_synthesis/noise4 - (1, 1, 16, 16) - G_synthesis/noise5 - (1, 1, 16, 16) - G_synthesis/noise6 - (1, 1, 32, 32) - G_synthesis/noise7 - (1, 1, 32, 32) - G_synthesis/noise8 - (1, 1, 64, 64) - G_synthesis/noise9 - (1, 1, 64, 64) - images_out - (?, 3, 64, 64) - --- --- --- --- Total 25137935 D Params OutputShape WeightShape --- --- --- --- images_in - (?, 3, 64, 64) - labels_in - (?, 0) - lod - () - FromRGB_lod0 1024 (?, 256, 64, 64) (1, 1, 3, 256) 64x64/Conv0 590080 (?, 256, 64, 64) (3, 3, 256, 256) 64x64/Conv1_down 1180160 (?, 512, 32, 32) (3, 3, 256, 512) Downscale2D - (?, 3, 32, 32) - FromRGB_lod1 2048 (?, 512, 32, 32) (1, 1, 3, 512) Grow_lod0 - (?, 512, 32, 32) - 32x32/Conv0 2359808 (?, 512, 32, 32) (3, 3, 512, 512) 32x32/Conv1_down 2359808 (?, 512, 16, 16) (3, 3, 512, 512) Downscale2D_1 - (?, 3, 16, 16) - FromRGB_lod2 2048 (?, 512, 16, 16) (1, 1, 3, 512) Grow_lod1 - (?, 512, 16, 16) - 16x16/Conv0 2359808 (?, 512, 16, 16) (3, 3, 512, 512) 16x16/Conv1_down 2359808 (?, 512, 8, 8) (3, 3, 512, 512) Downscale2D_2 - (?, 3, 8, 8) - FromRGB_lod3 2048 (?, 512, 8, 8) (1, 1, 3, 512) Grow_lod2 - (?, 512, 8, 8) - 8x8/Conv0 2359808 (?, 512, 8, 8) (3, 3, 512, 512) 8x8/Conv1_down 2359808 (?, 512, 4, 4) (3, 3, 512, 512) Downscale2D_3 - (?, 3, 4, 4) - FromRGB_lod4 2048 (?, 512, 4, 4) (1, 1, 3, 512) Grow_lod3 - (?, 512, 4, 4) - 4x4/MinibatchStddev - (?, 513, 4, 4) - 4x4/Conv 2364416 (?, 512, 4, 4) (3, 3, 513, 512) 4x4/Dense0 4194816 (?, 512) (8192, 512) 4x4/Dense1 513 (?, 1) (512, 1) scores_out - (?, 1) - --- --- --- --- Total 22498049 Building TensorFlow graph... WARNING: The TensorFlow contrib module will not be included in TensorFlow 2.0. For more information, please see: * https://github.com/tensorflow/community/blob/master/rfcs/20180907-contrib-sunset.md * https://github.com/tensorflow/addons If you depend on functionality not listed there, please file an issue. Setting up snapshot image grid... Setting up run dir... Training... tick 1 kimg 160.3 lod 4.00 minibatch 128 time 5m 35s sec/tick 297.2 sec/kimg 1.85 maintenance 38.0 gpumem 1.7 network-snapshot-000160 time 16m 22s fid50k 454.0154 C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:541: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_qint8 = np.dtype([("qint8", np.int8, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:542: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_quint8 = np.dtype([("quint8", np.uint8, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:543: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_qint16 = np.dtype([("qint16", np.int16, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:544: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_quint16 = np.dtype([("quint16", np.uint16, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:545: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_qint32 = np.dtype([("qint32", np.int32, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:550: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. np_resource = np.dtype([("resource", np.ubyte, 1)]) tick 2 kimg 320.5 lod 4.00 minibatch 128 time 26m 00s sec/tick 222.0 sec/kimg 1.39 maintenance 1002.8 gpumem 2.0 tick 3 kimg 480.8 lod 4.00 minibatch 128 time 29m 43s sec/tick 222.0 sec/kimg 1.38 maintenance 1.4 gpumem 2.0 tick 4 kimg 620.8 lod 3.97 minibatch 64 time 33m 41s sec/tick 236.2 sec/kimg 1.69 maintenance 1.2 gpumem 2.0 tick 5 kimg 760.8 lod 3.73 minibatch 64 time 41m 24s sec/tick 462.3 sec/kimg 3.30 maintenance 1.3 gpumem 2.0 tick 6 kimg 900.9 lod 3.50 minibatch 64 time 49m 07s sec/tick 461.2 sec/kimg 3.29 maintenance 1.3 gpumem 2.0 tick 7 kimg 1040.9 lod 3.27 minibatch 64 time 56m 49s sec/tick 461.2 sec/kimg 3.29 maintenance 1.3 gpumem 2.0 tick 8 kimg 1180.9 lod 3.03 minibatch 64 time 1h 04m 31s sec/tick 460.2 sec/kimg 3.29 maintenance 1.3 gpumem 2.0 tick 9 kimg 1321.0 lod 3.00 minibatch 64 time 1h 12m 06s sec/tick 453.5 sec/kimg 3.24 maintenance 1.3 gpumem 2.0 tick 10 kimg 1461.0 lod 3.00 minibatch 64 time 1h 19m 40s sec/tick 452.6 sec/kimg 3.23 maintenance 1.3 gpumem 2.0 network-snapshot-001460 time 8m 33s fid50k 378.7820 tick 11 kimg 1601.0 lod 3.00 minibatch 64 time 1h 35m 49s sec/tick 453.8 sec/kimg 3.24 maintenance 515.6 gpumem 2.0 tick 12 kimg 1741.1 lod 3.00 minibatch 64 time 1h 43m 24s sec/tick 453.8 sec/kimg 3.24 maintenance 1.3 gpumem 2.0 tick 13 kimg 1861.1 lod 2.90 minibatch 32 time 1h 57m 38s sec/tick 852.2 sec/kimg 7.10 maintenance 1.3 gpumem 2.0 tick 14 kimg 1981.2 lod 2.70 minibatch 32 time 2h 18m 55s sec/tick 1275.3 sec/kimg 10.62 maintenance 2.0 gpumem 2.0 tick 15 kimg 2101.2 lod 2.50 minibatch 32 time 2h 40m 10s sec/tick 1273.1 sec/kimg 10.60 maintenance 1.9 gpumem 2.0 tick 16 kimg 2221.3 lod 2.30 minibatch 32 time 3h 01m 25s sec/tick 1273.0 sec/kimg 10.60 maintenance 1.9 gpumem 2.0 tick 17 kimg 2341.4 lod 2.10 minibatch 32 time 3h 22m 42s sec/tick 1275.0 sec/kimg 10.62 maintenance 1.9 gpumem 2.0 tick 18 kimg 2461.4 lod 2.00 minibatch 32 time 3h 43m 49s sec/tick 1265.4 sec/kimg 10.54 maintenance 1.9 gpumem 2.0 tick 19 kimg 2581.5 lod 2.00 minibatch 32 time 4h 04m 45s sec/tick 1253.8 sec/kimg 10.44 maintenance 1.9 gpumem 2.0 tick 20 kimg 2701.6 lod 2.00 minibatch 32 time 4h 25m 41s sec/tick 1254.5 sec/kimg 10.45 maintenance 1.9 gpumem 2.0 network-snapshot-002701 time 9m 08s fid50k 338.4830 tick 21 kimg 2821.6 lod 2.00 minibatch 32 time 4h 55m 47s sec/tick 1255.4 sec/kimg 10.46 maintenance 551.1 gpumem 2.0 tick 22 kimg 2941.7 lod 2.00 minibatch 32 time 5h 16m 44s sec/tick 1254.7 sec/kimg 10.45 maintenance 1.8 gpumem 2.0 tick 23 kimg 3041.7 lod 1.93 minibatch 16 time 5h 52m 23s sec/tick 2136.8 sec/kimg 21.36 maintenance 1.8 gpumem 2.0 tick 24 kimg 3141.8 lod 1.76 minibatch 16 time 6h 52m 21s sec/tick 3593.7 sec/kimg 35.93 maintenance 4.5 gpumem 2.0 tick 25 kimg 3241.8 lod 1.60 minibatch 16 time 7h 52m 23s sec/tick 3597.7 sec/kimg 35.97 maintenance 4.5 gpumem 2.0 tick 26 kimg 3341.8 lod 1.43 minibatch 16 time 8h 52m 34s sec/tick 3606.5 sec/kimg 36.05 maintenance 4.6 gpumem 2.0 tick 27 kimg 3400.0 lod 1.33 minibatch 16 time 9h 27m 29s sec/tick 2090.0 sec/kimg 35.92 maintenance 4.6 gpumem 2.0 network-snapshot-003400 time 11m 15s fid50k 327.9088 dnnlib: Finished training.training_loop.training_loop() in 9h 38m 52s.(keras-gpu) C:\Users\user\stylegan-master>python train.py C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorflow\python\framework\dtypes.py:526: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_qint8 = np.dtype([("qint8", np.int8, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorflow\python\framework\dtypes.py:527: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_quint8 = np.dtype([("quint8", np.uint8, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorflow\python\framework\dtypes.py:528: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_qint16 = np.dtype([("qint16", np.int16, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorflow\python\framework\dtypes.py:529: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_quint16 = np.dtype([("quint16", np.uint16, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorflow\python\framework\dtypes.py:530: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_qint32 = np.dtype([("qint32", np.int32, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorflow\python\framework\dtypes.py:535: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. np_resource = np.dtype([("resource", np.ubyte, 1)]) Creating the run dir: results\00004-sgan-custom_dataset-1gpu Copying files to the run dir dnnlib: Running training.training_loop.training_loop() on localhost... Streaming data using training.dataset.TFRecordDataset... WARNING:tensorflow:From C:\Users\user\stylegan-master\training\dataset.py:76: tf_record_iterator (from tensorflow.python.lib.io.tf_record) is deprecated and will be removed in a future version. Instructions for updating: Use eager execution and: `tf.data.TFRecordDataset(path)` WARNING:tensorflow:From C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorflow\python\framework\op_def_library.py:263: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version. Instructions for updating: Colocations handled automatically by placer. Dataset shape = [3, 128, 128] Dynamic range = [0, 255] Label size = 0 Constructing networks... G Params OutputShape WeightShape --- --- --- --- latents_in - (?, 512) - labels_in - (?, 0) - lod - () - dlatent_avg - (512,) - G_mapping/latents_in - (?, 512) - G_mapping/labels_in - (?, 0) - G_mapping/PixelNorm - (?, 512) - G_mapping/Dense0 262656 (?, 512) (512, 512) G_mapping/Dense1 262656 (?, 512) (512, 512) G_mapping/Dense2 262656 (?, 512) (512, 512) G_mapping/Dense3 262656 (?, 512) (512, 512) G_mapping/Dense4 262656 (?, 512) (512, 512) G_mapping/Dense5 262656 (?, 512) (512, 512) G_mapping/Dense6 262656 (?, 512) (512, 512) G_mapping/Dense7 262656 (?, 512) (512, 512) G_mapping/Broadcast - (?, 12, 512) - G_mapping/dlatents_out - (?, 12, 512) - Truncation - (?, 12, 512) - G_synthesis/dlatents_in - (?, 12, 512) - G_synthesis/4x4/Const 534528 (?, 512, 4, 4) (512,) G_synthesis/4x4/Conv 2885632 (?, 512, 4, 4) (3, 3, 512, 512) G_synthesis/ToRGB_lod5 1539 (?, 3, 4, 4) (1, 1, 512, 3) G_synthesis/8x8/Conv0_up 2885632 (?, 512, 8, 8) (3, 3, 512, 512) G_synthesis/8x8/Conv1 2885632 (?, 512, 8, 8) (3, 3, 512, 512) G_synthesis/ToRGB_lod4 1539 (?, 3, 8, 8) (1, 1, 512, 3) G_synthesis/Upscale2D - (?, 3, 8, 8) - G_synthesis/Grow_lod4 - (?, 3, 8, 8) - G_synthesis/16x16/Conv0_up 2885632 (?, 512, 16, 16) (3, 3, 512, 512) G_synthesis/16x16/Conv1 2885632 (?, 512, 16, 16) (3, 3, 512, 512) G_synthesis/ToRGB_lod3 1539 (?, 3, 16, 16) (1, 1, 512, 3) G_synthesis/Upscale2D_1 - (?, 3, 16, 16) - G_synthesis/Grow_lod3 - (?, 3, 16, 16) - G_synthesis/32x32/Conv0_up 2885632 (?, 512, 32, 32) (3, 3, 512, 512) G_synthesis/32x32/Conv1 2885632 (?, 512, 32, 32) (3, 3, 512, 512) G_synthesis/ToRGB_lod2 1539 (?, 3, 32, 32) (1, 1, 512, 3) G_synthesis/Upscale2D_2 - (?, 3, 32, 32) - G_synthesis/Grow_lod2 - (?, 3, 32, 32) - G_synthesis/64x64/Conv0_up 1442816 (?, 256, 64, 64) (3, 3, 512, 256) G_synthesis/64x64/Conv1 852992 (?, 256, 64, 64) (3, 3, 256, 256) G_synthesis/ToRGB_lod1 771 (?, 3, 64, 64) (1, 1, 256, 3) G_synthesis/Upscale2D_3 - (?, 3, 64, 64) - G_synthesis/Grow_lod1 - (?, 3, 64, 64) - G_synthesis/128x128/Conv0_up 426496 (?, 128, 128, 128) (3, 3, 256, 128) G_synthesis/128x128/Conv1 279040 (?, 128, 128, 128) (3, 3, 128, 128) G_synthesis/ToRGB_lod0 387 (?, 3, 128, 128) (1, 1, 128, 3) G_synthesis/Upscale2D_4 - (?, 3, 128, 128) - G_synthesis/Grow_lod0 - (?, 3, 128, 128) - G_synthesis/images_out - (?, 3, 128, 128) - G_synthesis/lod - () - G_synthesis/noise0 - (1, 1, 4, 4) - G_synthesis/noise1 - (1, 1, 4, 4) - G_synthesis/noise2 - (1, 1, 8, 8) - G_synthesis/noise3 - (1, 1, 8, 8) - G_synthesis/noise4 - (1, 1, 16, 16) - G_synthesis/noise5 - (1, 1, 16, 16) - G_synthesis/noise6 - (1, 1, 32, 32) - G_synthesis/noise7 - (1, 1, 32, 32) - G_synthesis/noise8 - (1, 1, 64, 64) - G_synthesis/noise9 - (1, 1, 64, 64) - G_synthesis/noise10 - (1, 1, 128, 128) - G_synthesis/noise11 - (1, 1, 128, 128) - images_out - (?, 3, 128, 128) - --- --- --- --- Total 25843858 D Params OutputShape WeightShape --- --- --- --- images_in - (?, 3, 128, 128) - labels_in - (?, 0) - lod - () - FromRGB_lod0 512 (?, 128, 128, 128) (1, 1, 3, 128) 128x128/Conv0 147584 (?, 128, 128, 128) (3, 3, 128, 128) 128x128/Conv1_down 295168 (?, 256, 64, 64) (3, 3, 128, 256) Downscale2D - (?, 3, 64, 64) - FromRGB_lod1 1024 (?, 256, 64, 64) (1, 1, 3, 256) Grow_lod0 - (?, 256, 64, 64) - 64x64/Conv0 590080 (?, 256, 64, 64) (3, 3, 256, 256) 64x64/Conv1_down 1180160 (?, 512, 32, 32) (3, 3, 256, 512) Downscale2D_1 - (?, 3, 32, 32) - FromRGB_lod2 2048 (?, 512, 32, 32) (1, 1, 3, 512) Grow_lod1 - (?, 512, 32, 32) - 32x32/Conv0 2359808 (?, 512, 32, 32) (3, 3, 512, 512) 32x32/Conv1_down 2359808 (?, 512, 16, 16) (3, 3, 512, 512) Downscale2D_2 - (?, 3, 16, 16) - FromRGB_lod3 2048 (?, 512, 16, 16) (1, 1, 3, 512) Grow_lod2 - (?, 512, 16, 16) - 16x16/Conv0 2359808 (?, 512, 16, 16) (3, 3, 512, 512) 16x16/Conv1_down 2359808 (?, 512, 8, 8) (3, 3, 512, 512) Downscale2D_3 - (?, 3, 8, 8) - FromRGB_lod4 2048 (?, 512, 8, 8) (1, 1, 3, 512) Grow_lod3 - (?, 512, 8, 8) - 8x8/Conv0 2359808 (?, 512, 8, 8) (3, 3, 512, 512) 8x8/Conv1_down 2359808 (?, 512, 4, 4) (3, 3, 512, 512) Downscale2D_4 - (?, 3, 4, 4) - FromRGB_lod5 2048 (?, 512, 4, 4) (1, 1, 3, 512) Grow_lod4 - (?, 512, 4, 4) - 4x4/MinibatchStddev - (?, 513, 4, 4) - 4x4/Conv 2364416 (?, 512, 4, 4) (3, 3, 513, 512) 4x4/Dense0 4194816 (?, 512) (8192, 512) 4x4/Dense1 513 (?, 1) (512, 1) scores_out - (?, 1) - --- --- --- --- Total 22941313 Building TensorFlow graph... WARNING:tensorflow:From C:\Users\user\stylegan-master\training\training_loop.py:167: div (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version. Instructions for updating: Deprecated in favor of operator or tf.math.divide. WARNING:tensorflow:From C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorflow\python\ops\math_ops.py:3066: to_int32 (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version. Instructions for updating: Use tf.cast instead. WARNING: The TensorFlow contrib module will not be included in TensorFlow 2.0. For more information, please see: * https://github.com/tensorflow/community/blob/master/rfcs/20180907-contrib-sunset.md * https://github.com/tensorflow/addons If you depend on functionality not listed there, please file an issue. Setting up snapshot image grid... 2020-01-20 07:05:17.296825: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.08GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available. 2020-01-20 07:05:17.320746: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.08GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available. 2020-01-20 07:05:17.342289: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 2.15GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available. 2020-01-20 07:05:17.350675: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.08GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available. 2020-01-20 07:05:17.399302: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.10GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available. Setting up run dir... Training... 2020-01-20 07:05:35.259782: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.33GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available. 2020-01-20 07:05:35.316821: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.33GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available. 2020-01-20 07:05:35.386177: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.33GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available. 2020-01-20 07:05:35.430917: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.33GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available. 2020-01-20 07:05:35.476293: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.33GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available. tick 1 kimg 140.0 lod 4.00 minibatch 64 time 8m 55s sec/tick 483.6 sec/kimg 3.45 maintenance 51.7 gpumem 1.6 network-snapshot-000140 time 8m 46s fid50k 360.7307 C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:541: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_qint8 = np.dtype([("qint8", np.int8, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:542: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_quint8 = np.dtype([("quint8", np.uint8, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:543: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_qint16 = np.dtype([("qint16", np.int16, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:544: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_quint16 = np.dtype([("quint16", np.uint16, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:545: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_qint32 = np.dtype([("qint32", np.int32, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:550: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. np_resource = np.dtype([("resource", np.ubyte, 1)]) tick 2 kimg 280.1 lod 4.00 minibatch 64 time 25m 58s sec/tick 479.1 sec/kimg 3.42 maintenance 543.3 gpumem 2.0 tick 3 kimg 420.1 lod 4.00 minibatch 64 time 33m 59s sec/tick 479.0 sec/kimg 3.42 maintenance 2.3 gpumem 2.0 tick 4 kimg 560.1 lod 4.00 minibatch 64 time 42m 01s sec/tick 479.8 sec/kimg 3.43 maintenance 2.2 gpumem 2.0 tick 5 kimg 680.2 lod 3.87 minibatch 32 time 59m 14s sec/tick 1030.6 sec/kimg 8.58 maintenance 2.2 gpumem 2.0 tick 6 kimg 800.3 lod 3.67 minibatch 32 time 1h 21m 24s sec/tick 1327.7 sec/kimg 11.06 maintenance 2.2 gpumem 2.0 tick 7 kimg 920.3 lod 3.47 minibatch 32 time 1h 43m 29s sec/tick 1323.3 sec/kimg 11.02 maintenance 2.2 gpumem 2.0 tick 8 kimg 1040.4 lod 3.27 minibatch 32 time 2h 05m 23s sec/tick 1311.2 sec/kimg 10.92 maintenance 2.2 gpumem 2.0 tick 9 kimg 1160.4 lod 3.07 minibatch 32 time 2h 27m 16s sec/tick 1311.7 sec/kimg 10.92 maintenance 2.2 gpumem 2.0 tick 10 kimg 1280.5 lod 3.00 minibatch 32 time 2h 48m 55s sec/tick 1296.9 sec/kimg 10.80 maintenance 2.2 gpumem 2.0 network-snapshot-001280 time 9m 16s fid50k 292.2210 tick 11 kimg 1400.6 lod 3.00 minibatch 32 time 3h 19m 47s sec/tick 1291.2 sec/kimg 10.75 maintenance 560.0 gpumem 2.0 tick 12 kimg 1520.6 lod 3.00 minibatch 32 time 3h 41m 20s sec/tick 1291.5 sec/kimg 10.76 maintenance 2.2 gpumem 2.0 tick 13 kimg 1640.7 lod 3.00 minibatch 32 time 4h 02m 53s sec/tick 1290.3 sec/kimg 10.75 maintenance 2.3 gpumem 2.0 tick 14 kimg 1760.8 lod 3.00 minibatch 32 time 4h 24m 26s sec/tick 1290.8 sec/kimg 10.75 maintenance 2.2 gpumem 2.0 tick 15 kimg 1860.8 lod 2.90 minibatch 16 time 5h 08m 55s sec/tick 2667.1 sec/kimg 26.66 maintenance 2.2 gpumem 2.0 tick 16 kimg 1960.8 lod 2.73 minibatch 16 time 6h 10m 02s sec/tick 3663.8 sec/kimg 36.63 maintenance 3.3 gpumem 2.0 tick 17 kimg 2060.9 lod 2.57 minibatch 16 time 7h 11m 09s sec/tick 3663.3 sec/kimg 36.62 maintenance 3.3 gpumem 2.0 tick 18 kimg 2160.9 lod 2.40 minibatch 16 time 8h 12m 15s sec/tick 3663.3 sec/kimg 36.62 maintenance 3.3 gpumem 2.0 tick 19 kimg 2260.9 lod 2.23 minibatch 16 time 9h 13m 22s sec/tick 3663.0 sec/kimg 36.62 maintenance 3.3 gpumem 2.0 tick 20 kimg 2361.0 lod 2.07 minibatch 16 time 10h 14m 28s sec/tick 3662.6 sec/kimg 36.61 maintenance 3.3 gpumem 2.0 network-snapshot-002360 time 11m 20s fid50k 329.8881 tick 21 kimg 2461.0 lod 2.00 minibatch 16 time 11h 26m 28s sec/tick 3635.4 sec/kimg 36.34 maintenance 685.2 gpumem 2.0 tick 22 kimg 2561.0 lod 2.00 minibatch 16 time 12h 27m 40s sec/tick 3668.3 sec/kimg 36.67 maintenance 3.3 gpumem 2.0 tick 23 kimg 2661.1 lod 2.00 minibatch 16 time 13h 28m 13s sec/tick 3630.0 sec/kimg 36.29 maintenance 3.4 gpumem 2.0 tick 24 kimg 2761.1 lod 2.00 minibatch 16 time 14h 29m 10s sec/tick 3652.9 sec/kimg 36.52 maintenance 3.4 gpumem 2.0 tick 25 kimg 2861.1 lod 2.00 minibatch 16 time 15h 29m 52s sec/tick 3639.3 sec/kimg 36.38 maintenance 3.3 gpumem 2.0 tick 26 kimg 2961.2 lod 2.00 minibatch 16 time 16h 30m 13s sec/tick 3617.6 sec/kimg 36.16 maintenance 3.3 gpumem 2.0 tick 27 kimg 3041.2 lod 1.93 minibatch 8 time 18h 07m 10s sec/tick 5814.1 sec/kimg 72.68 maintenance 3.3 gpumem 2.0 tick 28 kimg 3121.2 lod 1.80 minibatch 8 time 20h 29m 23s sec/tick 8525.3 sec/kimg 106.57 maintenance 7.0 gpumem 2.0 tick 29 kimg 3201.2 lod 1.66 minibatch 8 time 22h 51m 39s sec/tick 8528.9 sec/kimg 106.61 maintenance 7.2 gpumem 2.0 tick 30 kimg 3281.2 lod 1.53 minibatch 8 time 1d 01h 14m sec/tick 8536.7 sec/kimg 106.71 maintenance 7.3 gpumem 2.0 network-snapshot-003281 time 14m 53s fid50k 321.2979 tick 31 kimg 3361.2 lod 1.40 minibatch 8 time 1d 03h 51m sec/tick 8535.0 sec/kimg 106.69 maintenance 902.6 gpumem 2.0 tick 32 kimg 3441.2 lod 1.26 minibatch 8 time 1d 06h 13m sec/tick 8542.2 sec/kimg 106.78 maintenance 7.4 gpumem 2.0 tick 33 kimg 3521.2 lod 1.13 minibatch 8 time 1d 08h 36m sec/tick 8540.9 sec/kimg 106.76 maintenance 7.6 gpumem 2.0 tick 34 kimg 3601.2 lod 1.00 minibatch 8 time 1d 10h 58m sec/tick 8538.5 sec/kimg 106.73 maintenance 7.5 gpumem 2.0 tick 35 kimg 3681.2 lod 1.00 minibatch 8 time 1d 13h 19m sec/tick 8427.5 sec/kimg 105.34 maintenance 7.5 gpumem 2.0 ...


- 投稿日:2020-01-23T23:28:45+09:00
【StyleGAN入門】自前マシンでアニメ顔の独自学習♬
今回はStyleGANを使ってアニメ顔の学習に挑戦してみました。
学習に関する参考はほとんどなく以下のものがありました。結構学習に時間もかかるし、情報も不十分でしたが、一応自前マシンで学習でき、かつ学習途中からの再学習もできたので、記事にまとめておきます。
【参考】
①How To Use Custom Datasets With StyleGAN - TensorFlow Implementation
②styleganで独自モデルの学習方法
③StyleGAN log
④Making Anime Faces With StyleGANやったこと
・アニメ顔データの準備
・とにかく学習する
・潜在空間でのミキシングをやってみる
・再学習するには・アニメ顔データの準備
アニメ顔は以前DCGANで利用したサイトから、ダウンロードして準備しました。
今回の利用のポイントは少なくとも画像サイズを合わせて、かつファイル名を変更して読み取りやすく、1.pngのように変更すること。
StyleGANの学習という意味では目鼻顔などのアラインメントを合わせたいが、次回にパスした。
ということで、上記のデータ整理は以下のコードで実施した。
ちなみにサイズ(128,128)を1000個用意した。from PIL import Image import glob import random files = glob.glob("./anime/**/*.png", recursive=True) files = random.sample(files, 1000) res = [] sk=0 for path in files: img = Image.open(path) img = img.resize((128, 128)) img.save( "img/{}.png".format(sk)) sk += 1・とにかく学習する
学習コードは、参考①のビデオと参考②を眺めつつ、以下のようにした。
kimgは学習image数であり、単位が千imgを意味している。
総学習イメージ数が3400kimgを意味する
次の行は学習開始解像度=4
そして、custom_datasetがtf_reccordsに変換した画像のDir(=datasets/custom_dataset)である。さらに、とりあえずの学習ということで、解像度=64で学習してみたが問題なく学習できた。
また、StyleGANはpganであり、サイズ毎学習であるが、サイズ毎のminibatchサイズも以下のとおり、小さめに設定した。train.total_kimg = 3400、 sched.lod_initial_resolution = 4 desc += '-custom_dataset'; dataset = EasyDict(tfrecord_dir='custom_dataset', resolution=64); train.mirror_augment = False desc += '-1gpu'; submit_config.num_gpus = 1; sched.minibatch_base = 4; sched.minibatch_dict = {4: 128, 8: 64, 16: 32, 32: 16, 64: 8, 128: 8, 256: 4, 512: 2}つまり、以下の必要最小限で動く。
train.py# Copyright (c) 2019, NVIDIA CORPORATION. All rights reserved. # # This work is licensed under the Creative Commons Attribution-NonCommercial # 4.0 International License. To view a copy of this license, visit # http://creativecommons.org/licenses/by-nc/4.0/ or send a letter to # Creative Commons, PO Box 1866, Mountain View, CA 94042, USA. """Main entry point for training StyleGAN and ProGAN networks.""" import copy import dnnlib from dnnlib import EasyDict import config from metrics import metric_base #---------------------------------------------------------------------------- # Official training configs for StyleGAN, targeted mainly for FFHQ. if 1: desc = 'sgan' # Description string included in result subdir name. train = EasyDict(run_func_name='training.training_loop.training_loop') # Options for training loop. G = EasyDict(func_name='training.networks_stylegan.G_style') # Options for generator network. D = EasyDict(func_name='training.networks_stylegan.D_basic') # Options for discriminator network. G_opt = EasyDict(beta1=0.0, beta2=0.99, epsilon=1e-8) # Options for generator optimizer. D_opt = EasyDict(beta1=0.0, beta2=0.99, epsilon=1e-8) # Options for discriminator optimizer. G_loss = EasyDict(func_name='training.loss.G_logistic_nonsaturating') # Options for generator loss. D_loss = EasyDict(func_name='training.loss.D_logistic_simplegp', r1_gamma=10.0) # Options for discriminator loss. dataset = EasyDict() # Options for load_dataset(). sched = EasyDict() # Options for TrainingSchedule. grid = EasyDict(size='4k', layout='random') #4k # Options for setup_snapshot_image_grid(). metrics = [metric_base.fid50k] # Options for MetricGroup. submit_config = dnnlib.SubmitConfig() # Options for dnnlib.submit_run(). tf_config = {'rnd.np_random_seed': 1000} # Options for tflib.init_tf(). # Dataset. desc += '-custom_dataset'; dataset = EasyDict(tfrecord_dir='custom_dataset', resolution=64); train.mirror_augment = False # Number of GPUs. desc += '-1gpu'; submit_config.num_gpus = 1; sched.minibatch_base = 4; sched.minibatch_dict = {4: 128, 8: 64, 16: 32, 32: 16, 64: 8, 128: 8, 256: 4, 512: 2} # Default options. train.total_kimg = 3400 sched.lod_initial_resolution = 4 sched.G_lrate_dict = {128: 0.0015, 256: 0.002, 512: 0.003, 1024: 0.003} sched.D_lrate_dict = EasyDict(sched.G_lrate_dict) #---------------------------------------------------------------------------- # Main entry point for training. # Calls the function indicated by 'train' using the selected options. def main(): kwargs = EasyDict(train) kwargs.update(G_args=G, D_args=D, G_opt_args=G_opt, D_opt_args=D_opt, G_loss_args=G_loss, D_loss_args=D_loss) kwargs.update(dataset_args=dataset, sched_args=sched, grid_args=grid, metric_arg_list=metrics, tf_config=tf_config) kwargs.submit_config = copy.deepcopy(submit_config) kwargs.submit_config.run_dir_root = dnnlib.submission.submit.get_template_from_path(config.result_dir) kwargs.submit_config.run_dir_ignore += config.run_dir_ignore kwargs.submit_config.run_desc = desc dnnlib.submit_run(**kwargs) #---------------------------------------------------------------------------- if __name__ == "__main__": main() #----------------------------------------------------------------------------なお、データのtfreccordsへの変換は参考①から以下のように実施した。
※ここで元画像は./animeに入れておく、そして画像サイズ毎の変換ファイルはcustom_datasetに6個のサイズの異なるファイルが格納された。python dataset_tool.py create_from_images datasets/custom_dataset ./anime上記でとりあえず、学習できると思う。
・潜在空間でのミキシングをやってみる
1060マシンで上記のコードを10h程度で以下の絵が得られる。
決して綺麗とは言えないが、とにかく最弱マシンでも学習できた。
さらに、潜在空間での17,18のミキシングをやってみると以下の絵が得られた。
1080マシンで解像度128x128サイズで1d8h程度回して、kimg=4705の場合以下のように画像がしっかりしてきた。
※これでもpid50K=168程度で精度はまだまだだが、。。。以前のDCGANの画像と比べてこちらの方が綺麗に見える
さらに、潜在空間での11,82のミキシングをやってみると以下の絵が得られた。
・再学習するには
最後に禁断(誰も公開していないようなので)の途中中断した場合の継続学習の仕方が出来たので、まとめておく。
※この方法はちょっとだけ参考②と参考④に記載がある
以下のコードで実施する。
すなわち、training_loop.pyの以下の部分を修正する。resume_run_id = "latest", #None, # Run ID or network pkl to resume training from, None = start from scratch. resume_snapshot = './results/00001-sgan-custom_dataset-1gpu/network-snapshot-.pkl', #None, # Snapshot index to resume training from, None = autodetect.また、network_snapshot_ticks = 1, # How often to export network snapshots? として、毎回出力にしている。
training_loop.pydef training_loop( submit_config, G_args = {}, # Options for generator network. D_args = {}, # Options for discriminator network. G_opt_args = {}, # Options for generator optimizer. D_opt_args = {}, # Options for discriminator optimizer. G_loss_args = {}, # Options for generator loss. D_loss_args = {}, # Options for discriminator loss. dataset_args = {}, # Options for dataset.load_dataset(). sched_args = {}, # Options for train.TrainingSchedule. grid_args = {}, # Options for train.setup_snapshot_image_grid(). metric_arg_list = [], # Options for MetricGroup. tf_config = {}, # Options for tflib.init_tf(). G_smoothing_kimg = 10.0, # Half-life of the running average of generator weights. D_repeats = 1, # How many times the discriminator is trained per G iteration. minibatch_repeats = 4, # Number of minibatches to run before adjusting training parameters. reset_opt_for_new_lod = True, # Reset optimizer internal state (e.g. Adam moments) when new layers are introduced? total_kimg = 15000, # Total length of the training, measured in thousands of real images. mirror_augment = False, # Enable mirror augment? drange_net = [-1,1], # Dynamic range used when feeding image data to the networks. image_snapshot_ticks = 1, # How often to export image snapshots? network_snapshot_ticks = 1, # How often to export network snapshots? default=10 save_tf_graph = False, # Include full TensorFlow computation graph in the tfevents file? save_weight_histograms = False, # Include weight histograms in the tfevents file? resume_run_id = "latest", #None, # Run ID or network pkl to resume training from, None = start from scratch. resume_snapshot = './results/00001-sgan-custom_dataset-1gpu/network-snapshot-.pkl', #None, # Snapshot index to resume training from, None = autodetect. resume_kimg = 1040.9, # Assumed training progress at the beginning. Affects reporting and training schedule. resume_time = 5599.0): # Assumed wallclock time at the beginning. Affects reporting.resume_time = 5599.0
は秒単位で入力する。
このままだとメモリーがたまらないので、さらに上書き保存するためにもう一か所、下のコードのように変更した。train_loops.pyif cur_tick % network_snapshot_ticks == 0 or done or cur_tick == 1: #pkl = os.path.join(submit_config.run_dir, 'network-snapshot-%06d.pkl' % (cur_nimg // 1000)) pkl = os.path.join(submit_config.run_dir, 'network-snapshot-.pkl') misc.save_pkl((G, D, Gs), pkl) metrics.run(pkl, run_dir=submit_config.run_dir, num_gpus=submit_config.num_gpus, tf_config=tf_config)計算が1080マシンでもかなりかかるので、これを利用した結果については後日公開したいと思う。
まとめ
・自前マシンでStyleGANの学習ができるようになった
・学習データで今まで報告したようなミキシングが出来た
・途中で中断した場合の再開の仕方が分かった・今回は1000データだが、100以下の少数データの結果も見ようと思う
・さらに精度を追求してスタイルなどもやってみようと思うおまけ
dnnlib: Running training.training_loop.training_loop() on localhost... Streaming data using training.dataset.TFRecordDataset... Dataset shape = [3, 64, 64] Dynamic range = [0, 255] Label size = 0 Constructing networks... G Params OutputShape WeightShape --- --- --- --- latents_in - (?, 512) - labels_in - (?, 0) - lod - () - dlatent_avg - (512,) - G_mapping/latents_in - (?, 512) - G_mapping/labels_in - (?, 0) - G_mapping/PixelNorm - (?, 512) - G_mapping/Dense0 262656 (?, 512) (512, 512) G_mapping/Dense1 262656 (?, 512) (512, 512) G_mapping/Dense2 262656 (?, 512) (512, 512) G_mapping/Dense3 262656 (?, 512) (512, 512) G_mapping/Dense4 262656 (?, 512) (512, 512) G_mapping/Dense5 262656 (?, 512) (512, 512) G_mapping/Dense6 262656 (?, 512) (512, 512) G_mapping/Dense7 262656 (?, 512) (512, 512) G_mapping/Broadcast - (?, 10, 512) - G_mapping/dlatents_out - (?, 10, 512) - Truncation - (?, 10, 512) - G_synthesis/dlatents_in - (?, 10, 512) - G_synthesis/4x4/Const 534528 (?, 512, 4, 4) (512,) G_synthesis/4x4/Conv 2885632 (?, 512, 4, 4) (3, 3, 512, 512) G_synthesis/ToRGB_lod4 1539 (?, 3, 4, 4) (1, 1, 512, 3) G_synthesis/8x8/Conv0_up 2885632 (?, 512, 8, 8) (3, 3, 512, 512) G_synthesis/8x8/Conv1 2885632 (?, 512, 8, 8) (3, 3, 512, 512) G_synthesis/ToRGB_lod3 1539 (?, 3, 8, 8) (1, 1, 512, 3) G_synthesis/Upscale2D - (?, 3, 8, 8) - G_synthesis/Grow_lod3 - (?, 3, 8, 8) - G_synthesis/16x16/Conv0_up 2885632 (?, 512, 16, 16) (3, 3, 512, 512) G_synthesis/16x16/Conv1 2885632 (?, 512, 16, 16) (3, 3, 512, 512) G_synthesis/ToRGB_lod2 1539 (?, 3, 16, 16) (1, 1, 512, 3) G_synthesis/Upscale2D_1 - (?, 3, 16, 16) - G_synthesis/Grow_lod2 - (?, 3, 16, 16) - G_synthesis/32x32/Conv0_up 2885632 (?, 512, 32, 32) (3, 3, 512, 512) G_synthesis/32x32/Conv1 2885632 (?, 512, 32, 32) (3, 3, 512, 512) G_synthesis/ToRGB_lod1 1539 (?, 3, 32, 32) (1, 1, 512, 3) G_synthesis/Upscale2D_2 - (?, 3, 32, 32) - G_synthesis/Grow_lod1 - (?, 3, 32, 32) - G_synthesis/64x64/Conv0_up 1442816 (?, 256, 64, 64) (3, 3, 512, 256) G_synthesis/64x64/Conv1 852992 (?, 256, 64, 64) (3, 3, 256, 256) G_synthesis/ToRGB_lod0 771 (?, 3, 64, 64) (1, 1, 256, 3) G_synthesis/Upscale2D_3 - (?, 3, 64, 64) - G_synthesis/Grow_lod0 - (?, 3, 64, 64) - G_synthesis/images_out - (?, 3, 64, 64) - G_synthesis/lod - () - G_synthesis/noise0 - (1, 1, 4, 4) - G_synthesis/noise1 - (1, 1, 4, 4) - G_synthesis/noise2 - (1, 1, 8, 8) - G_synthesis/noise3 - (1, 1, 8, 8) - G_synthesis/noise4 - (1, 1, 16, 16) - G_synthesis/noise5 - (1, 1, 16, 16) - G_synthesis/noise6 - (1, 1, 32, 32) - G_synthesis/noise7 - (1, 1, 32, 32) - G_synthesis/noise8 - (1, 1, 64, 64) - G_synthesis/noise9 - (1, 1, 64, 64) - images_out - (?, 3, 64, 64) - --- --- --- --- Total 25137935 D Params OutputShape WeightShape --- --- --- --- images_in - (?, 3, 64, 64) - labels_in - (?, 0) - lod - () - FromRGB_lod0 1024 (?, 256, 64, 64) (1, 1, 3, 256) 64x64/Conv0 590080 (?, 256, 64, 64) (3, 3, 256, 256) 64x64/Conv1_down 1180160 (?, 512, 32, 32) (3, 3, 256, 512) Downscale2D - (?, 3, 32, 32) - FromRGB_lod1 2048 (?, 512, 32, 32) (1, 1, 3, 512) Grow_lod0 - (?, 512, 32, 32) - 32x32/Conv0 2359808 (?, 512, 32, 32) (3, 3, 512, 512) 32x32/Conv1_down 2359808 (?, 512, 16, 16) (3, 3, 512, 512) Downscale2D_1 - (?, 3, 16, 16) - FromRGB_lod2 2048 (?, 512, 16, 16) (1, 1, 3, 512) Grow_lod1 - (?, 512, 16, 16) - 16x16/Conv0 2359808 (?, 512, 16, 16) (3, 3, 512, 512) 16x16/Conv1_down 2359808 (?, 512, 8, 8) (3, 3, 512, 512) Downscale2D_2 - (?, 3, 8, 8) - FromRGB_lod3 2048 (?, 512, 8, 8) (1, 1, 3, 512) Grow_lod2 - (?, 512, 8, 8) - 8x8/Conv0 2359808 (?, 512, 8, 8) (3, 3, 512, 512) 8x8/Conv1_down 2359808 (?, 512, 4, 4) (3, 3, 512, 512) Downscale2D_3 - (?, 3, 4, 4) - FromRGB_lod4 2048 (?, 512, 4, 4) (1, 1, 3, 512) Grow_lod3 - (?, 512, 4, 4) - 4x4/MinibatchStddev - (?, 513, 4, 4) - 4x4/Conv 2364416 (?, 512, 4, 4) (3, 3, 513, 512) 4x4/Dense0 4194816 (?, 512) (8192, 512) 4x4/Dense1 513 (?, 1) (512, 1) scores_out - (?, 1) - --- --- --- --- Total 22498049 Building TensorFlow graph... WARNING: The TensorFlow contrib module will not be included in TensorFlow 2.0. For more information, please see: * https://github.com/tensorflow/community/blob/master/rfcs/20180907-contrib-sunset.md * https://github.com/tensorflow/addons If you depend on functionality not listed there, please file an issue. Setting up snapshot image grid... Setting up run dir... Training... tick 1 kimg 160.3 lod 4.00 minibatch 128 time 5m 35s sec/tick 297.2 sec/kimg 1.85 maintenance 38.0 gpumem 1.7 network-snapshot-000160 time 16m 22s fid50k 454.0154 C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:541: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_qint8 = np.dtype([("qint8", np.int8, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:542: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_quint8 = np.dtype([("quint8", np.uint8, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:543: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_qint16 = np.dtype([("qint16", np.int16, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:544: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_quint16 = np.dtype([("quint16", np.uint16, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:545: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_qint32 = np.dtype([("qint32", np.int32, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:550: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. np_resource = np.dtype([("resource", np.ubyte, 1)]) tick 2 kimg 320.5 lod 4.00 minibatch 128 time 26m 00s sec/tick 222.0 sec/kimg 1.39 maintenance 1002.8 gpumem 2.0 tick 3 kimg 480.8 lod 4.00 minibatch 128 time 29m 43s sec/tick 222.0 sec/kimg 1.38 maintenance 1.4 gpumem 2.0 tick 4 kimg 620.8 lod 3.97 minibatch 64 time 33m 41s sec/tick 236.2 sec/kimg 1.69 maintenance 1.2 gpumem 2.0 tick 5 kimg 760.8 lod 3.73 minibatch 64 time 41m 24s sec/tick 462.3 sec/kimg 3.30 maintenance 1.3 gpumem 2.0 tick 6 kimg 900.9 lod 3.50 minibatch 64 time 49m 07s sec/tick 461.2 sec/kimg 3.29 maintenance 1.3 gpumem 2.0 tick 7 kimg 1040.9 lod 3.27 minibatch 64 time 56m 49s sec/tick 461.2 sec/kimg 3.29 maintenance 1.3 gpumem 2.0 tick 8 kimg 1180.9 lod 3.03 minibatch 64 time 1h 04m 31s sec/tick 460.2 sec/kimg 3.29 maintenance 1.3 gpumem 2.0 tick 9 kimg 1321.0 lod 3.00 minibatch 64 time 1h 12m 06s sec/tick 453.5 sec/kimg 3.24 maintenance 1.3 gpumem 2.0 tick 10 kimg 1461.0 lod 3.00 minibatch 64 time 1h 19m 40s sec/tick 452.6 sec/kimg 3.23 maintenance 1.3 gpumem 2.0 network-snapshot-001460 time 8m 33s fid50k 378.7820 tick 11 kimg 1601.0 lod 3.00 minibatch 64 time 1h 35m 49s sec/tick 453.8 sec/kimg 3.24 maintenance 515.6 gpumem 2.0 tick 12 kimg 1741.1 lod 3.00 minibatch 64 time 1h 43m 24s sec/tick 453.8 sec/kimg 3.24 maintenance 1.3 gpumem 2.0 tick 13 kimg 1861.1 lod 2.90 minibatch 32 time 1h 57m 38s sec/tick 852.2 sec/kimg 7.10 maintenance 1.3 gpumem 2.0 tick 14 kimg 1981.2 lod 2.70 minibatch 32 time 2h 18m 55s sec/tick 1275.3 sec/kimg 10.62 maintenance 2.0 gpumem 2.0 tick 15 kimg 2101.2 lod 2.50 minibatch 32 time 2h 40m 10s sec/tick 1273.1 sec/kimg 10.60 maintenance 1.9 gpumem 2.0 tick 16 kimg 2221.3 lod 2.30 minibatch 32 time 3h 01m 25s sec/tick 1273.0 sec/kimg 10.60 maintenance 1.9 gpumem 2.0 tick 17 kimg 2341.4 lod 2.10 minibatch 32 time 3h 22m 42s sec/tick 1275.0 sec/kimg 10.62 maintenance 1.9 gpumem 2.0 tick 18 kimg 2461.4 lod 2.00 minibatch 32 time 3h 43m 49s sec/tick 1265.4 sec/kimg 10.54 maintenance 1.9 gpumem 2.0 tick 19 kimg 2581.5 lod 2.00 minibatch 32 time 4h 04m 45s sec/tick 1253.8 sec/kimg 10.44 maintenance 1.9 gpumem 2.0 tick 20 kimg 2701.6 lod 2.00 minibatch 32 time 4h 25m 41s sec/tick 1254.5 sec/kimg 10.45 maintenance 1.9 gpumem 2.0 network-snapshot-002701 time 9m 08s fid50k 338.4830 tick 21 kimg 2821.6 lod 2.00 minibatch 32 time 4h 55m 47s sec/tick 1255.4 sec/kimg 10.46 maintenance 551.1 gpumem 2.0 tick 22 kimg 2941.7 lod 2.00 minibatch 32 time 5h 16m 44s sec/tick 1254.7 sec/kimg 10.45 maintenance 1.8 gpumem 2.0 tick 23 kimg 3041.7 lod 1.93 minibatch 16 time 5h 52m 23s sec/tick 2136.8 sec/kimg 21.36 maintenance 1.8 gpumem 2.0 tick 24 kimg 3141.8 lod 1.76 minibatch 16 time 6h 52m 21s sec/tick 3593.7 sec/kimg 35.93 maintenance 4.5 gpumem 2.0 tick 25 kimg 3241.8 lod 1.60 minibatch 16 time 7h 52m 23s sec/tick 3597.7 sec/kimg 35.97 maintenance 4.5 gpumem 2.0 tick 26 kimg 3341.8 lod 1.43 minibatch 16 time 8h 52m 34s sec/tick 3606.5 sec/kimg 36.05 maintenance 4.6 gpumem 2.0 tick 27 kimg 3400.0 lod 1.33 minibatch 16 time 9h 27m 29s sec/tick 2090.0 sec/kimg 35.92 maintenance 4.6 gpumem 2.0 network-snapshot-003400 time 11m 15s fid50k 327.9088 dnnlib: Finished training.training_loop.training_loop() in 9h 38m 52s.(keras-gpu) C:\Users\user\stylegan-master>python train.py C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorflow\python\framework\dtypes.py:526: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_qint8 = np.dtype([("qint8", np.int8, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorflow\python\framework\dtypes.py:527: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_quint8 = np.dtype([("quint8", np.uint8, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorflow\python\framework\dtypes.py:528: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_qint16 = np.dtype([("qint16", np.int16, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorflow\python\framework\dtypes.py:529: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_quint16 = np.dtype([("quint16", np.uint16, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorflow\python\framework\dtypes.py:530: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_qint32 = np.dtype([("qint32", np.int32, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorflow\python\framework\dtypes.py:535: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. np_resource = np.dtype([("resource", np.ubyte, 1)]) Creating the run dir: results\00004-sgan-custom_dataset-1gpu Copying files to the run dir dnnlib: Running training.training_loop.training_loop() on localhost... Streaming data using training.dataset.TFRecordDataset... WARNING:tensorflow:From C:\Users\user\stylegan-master\training\dataset.py:76: tf_record_iterator (from tensorflow.python.lib.io.tf_record) is deprecated and will be removed in a future version. Instructions for updating: Use eager execution and: `tf.data.TFRecordDataset(path)` WARNING:tensorflow:From C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorflow\python\framework\op_def_library.py:263: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version. Instructions for updating: Colocations handled automatically by placer. Dataset shape = [3, 128, 128] Dynamic range = [0, 255] Label size = 0 Constructing networks... G Params OutputShape WeightShape --- --- --- --- latents_in - (?, 512) - labels_in - (?, 0) - lod - () - dlatent_avg - (512,) - G_mapping/latents_in - (?, 512) - G_mapping/labels_in - (?, 0) - G_mapping/PixelNorm - (?, 512) - G_mapping/Dense0 262656 (?, 512) (512, 512) G_mapping/Dense1 262656 (?, 512) (512, 512) G_mapping/Dense2 262656 (?, 512) (512, 512) G_mapping/Dense3 262656 (?, 512) (512, 512) G_mapping/Dense4 262656 (?, 512) (512, 512) G_mapping/Dense5 262656 (?, 512) (512, 512) G_mapping/Dense6 262656 (?, 512) (512, 512) G_mapping/Dense7 262656 (?, 512) (512, 512) G_mapping/Broadcast - (?, 12, 512) - G_mapping/dlatents_out - (?, 12, 512) - Truncation - (?, 12, 512) - G_synthesis/dlatents_in - (?, 12, 512) - G_synthesis/4x4/Const 534528 (?, 512, 4, 4) (512,) G_synthesis/4x4/Conv 2885632 (?, 512, 4, 4) (3, 3, 512, 512) G_synthesis/ToRGB_lod5 1539 (?, 3, 4, 4) (1, 1, 512, 3) G_synthesis/8x8/Conv0_up 2885632 (?, 512, 8, 8) (3, 3, 512, 512) G_synthesis/8x8/Conv1 2885632 (?, 512, 8, 8) (3, 3, 512, 512) G_synthesis/ToRGB_lod4 1539 (?, 3, 8, 8) (1, 1, 512, 3) G_synthesis/Upscale2D - (?, 3, 8, 8) - G_synthesis/Grow_lod4 - (?, 3, 8, 8) - G_synthesis/16x16/Conv0_up 2885632 (?, 512, 16, 16) (3, 3, 512, 512) G_synthesis/16x16/Conv1 2885632 (?, 512, 16, 16) (3, 3, 512, 512) G_synthesis/ToRGB_lod3 1539 (?, 3, 16, 16) (1, 1, 512, 3) G_synthesis/Upscale2D_1 - (?, 3, 16, 16) - G_synthesis/Grow_lod3 - (?, 3, 16, 16) - G_synthesis/32x32/Conv0_up 2885632 (?, 512, 32, 32) (3, 3, 512, 512) G_synthesis/32x32/Conv1 2885632 (?, 512, 32, 32) (3, 3, 512, 512) G_synthesis/ToRGB_lod2 1539 (?, 3, 32, 32) (1, 1, 512, 3) G_synthesis/Upscale2D_2 - (?, 3, 32, 32) - G_synthesis/Grow_lod2 - (?, 3, 32, 32) - G_synthesis/64x64/Conv0_up 1442816 (?, 256, 64, 64) (3, 3, 512, 256) G_synthesis/64x64/Conv1 852992 (?, 256, 64, 64) (3, 3, 256, 256) G_synthesis/ToRGB_lod1 771 (?, 3, 64, 64) (1, 1, 256, 3) G_synthesis/Upscale2D_3 - (?, 3, 64, 64) - G_synthesis/Grow_lod1 - (?, 3, 64, 64) - G_synthesis/128x128/Conv0_up 426496 (?, 128, 128, 128) (3, 3, 256, 128) G_synthesis/128x128/Conv1 279040 (?, 128, 128, 128) (3, 3, 128, 128) G_synthesis/ToRGB_lod0 387 (?, 3, 128, 128) (1, 1, 128, 3) G_synthesis/Upscale2D_4 - (?, 3, 128, 128) - G_synthesis/Grow_lod0 - (?, 3, 128, 128) - G_synthesis/images_out - (?, 3, 128, 128) - G_synthesis/lod - () - G_synthesis/noise0 - (1, 1, 4, 4) - G_synthesis/noise1 - (1, 1, 4, 4) - G_synthesis/noise2 - (1, 1, 8, 8) - G_synthesis/noise3 - (1, 1, 8, 8) - G_synthesis/noise4 - (1, 1, 16, 16) - G_synthesis/noise5 - (1, 1, 16, 16) - G_synthesis/noise6 - (1, 1, 32, 32) - G_synthesis/noise7 - (1, 1, 32, 32) - G_synthesis/noise8 - (1, 1, 64, 64) - G_synthesis/noise9 - (1, 1, 64, 64) - G_synthesis/noise10 - (1, 1, 128, 128) - G_synthesis/noise11 - (1, 1, 128, 128) - images_out - (?, 3, 128, 128) - --- --- --- --- Total 25843858 D Params OutputShape WeightShape --- --- --- --- images_in - (?, 3, 128, 128) - labels_in - (?, 0) - lod - () - FromRGB_lod0 512 (?, 128, 128, 128) (1, 1, 3, 128) 128x128/Conv0 147584 (?, 128, 128, 128) (3, 3, 128, 128) 128x128/Conv1_down 295168 (?, 256, 64, 64) (3, 3, 128, 256) Downscale2D - (?, 3, 64, 64) - FromRGB_lod1 1024 (?, 256, 64, 64) (1, 1, 3, 256) Grow_lod0 - (?, 256, 64, 64) - 64x64/Conv0 590080 (?, 256, 64, 64) (3, 3, 256, 256) 64x64/Conv1_down 1180160 (?, 512, 32, 32) (3, 3, 256, 512) Downscale2D_1 - (?, 3, 32, 32) - FromRGB_lod2 2048 (?, 512, 32, 32) (1, 1, 3, 512) Grow_lod1 - (?, 512, 32, 32) - 32x32/Conv0 2359808 (?, 512, 32, 32) (3, 3, 512, 512) 32x32/Conv1_down 2359808 (?, 512, 16, 16) (3, 3, 512, 512) Downscale2D_2 - (?, 3, 16, 16) - FromRGB_lod3 2048 (?, 512, 16, 16) (1, 1, 3, 512) Grow_lod2 - (?, 512, 16, 16) - 16x16/Conv0 2359808 (?, 512, 16, 16) (3, 3, 512, 512) 16x16/Conv1_down 2359808 (?, 512, 8, 8) (3, 3, 512, 512) Downscale2D_3 - (?, 3, 8, 8) - FromRGB_lod4 2048 (?, 512, 8, 8) (1, 1, 3, 512) Grow_lod3 - (?, 512, 8, 8) - 8x8/Conv0 2359808 (?, 512, 8, 8) (3, 3, 512, 512) 8x8/Conv1_down 2359808 (?, 512, 4, 4) (3, 3, 512, 512) Downscale2D_4 - (?, 3, 4, 4) - FromRGB_lod5 2048 (?, 512, 4, 4) (1, 1, 3, 512) Grow_lod4 - (?, 512, 4, 4) - 4x4/MinibatchStddev - (?, 513, 4, 4) - 4x4/Conv 2364416 (?, 512, 4, 4) (3, 3, 513, 512) 4x4/Dense0 4194816 (?, 512) (8192, 512) 4x4/Dense1 513 (?, 1) (512, 1) scores_out - (?, 1) - --- --- --- --- Total 22941313 Building TensorFlow graph... WARNING:tensorflow:From C:\Users\user\stylegan-master\training\training_loop.py:167: div (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version. Instructions for updating: Deprecated in favor of operator or tf.math.divide. WARNING:tensorflow:From C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorflow\python\ops\math_ops.py:3066: to_int32 (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version. Instructions for updating: Use tf.cast instead. WARNING: The TensorFlow contrib module will not be included in TensorFlow 2.0. For more information, please see: * https://github.com/tensorflow/community/blob/master/rfcs/20180907-contrib-sunset.md * https://github.com/tensorflow/addons If you depend on functionality not listed there, please file an issue. Setting up snapshot image grid... 2020-01-20 07:05:17.296825: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.08GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available. 2020-01-20 07:05:17.320746: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.08GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available. 2020-01-20 07:05:17.342289: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 2.15GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available. 2020-01-20 07:05:17.350675: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.08GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available. 2020-01-20 07:05:17.399302: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.10GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available. Setting up run dir... Training... 2020-01-20 07:05:35.259782: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.33GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available. 2020-01-20 07:05:35.316821: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.33GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available. 2020-01-20 07:05:35.386177: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.33GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available. 2020-01-20 07:05:35.430917: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.33GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available. 2020-01-20 07:05:35.476293: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.33GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available. tick 1 kimg 140.0 lod 4.00 minibatch 64 time 8m 55s sec/tick 483.6 sec/kimg 3.45 maintenance 51.7 gpumem 1.6 network-snapshot-000140 time 8m 46s fid50k 360.7307 C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:541: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_qint8 = np.dtype([("qint8", np.int8, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:542: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_quint8 = np.dtype([("quint8", np.uint8, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:543: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_qint16 = np.dtype([("qint16", np.int16, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:544: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_quint16 = np.dtype([("quint16", np.uint16, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:545: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_qint32 = np.dtype([("qint32", np.int32, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:550: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. np_resource = np.dtype([("resource", np.ubyte, 1)]) tick 2 kimg 280.1 lod 4.00 minibatch 64 time 25m 58s sec/tick 479.1 sec/kimg 3.42 maintenance 543.3 gpumem 2.0 tick 3 kimg 420.1 lod 4.00 minibatch 64 time 33m 59s sec/tick 479.0 sec/kimg 3.42 maintenance 2.3 gpumem 2.0 tick 4 kimg 560.1 lod 4.00 minibatch 64 time 42m 01s sec/tick 479.8 sec/kimg 3.43 maintenance 2.2 gpumem 2.0 tick 5 kimg 680.2 lod 3.87 minibatch 32 time 59m 14s sec/tick 1030.6 sec/kimg 8.58 maintenance 2.2 gpumem 2.0 tick 6 kimg 800.3 lod 3.67 minibatch 32 time 1h 21m 24s sec/tick 1327.7 sec/kimg 11.06 maintenance 2.2 gpumem 2.0 tick 7 kimg 920.3 lod 3.47 minibatch 32 time 1h 43m 29s sec/tick 1323.3 sec/kimg 11.02 maintenance 2.2 gpumem 2.0 tick 8 kimg 1040.4 lod 3.27 minibatch 32 time 2h 05m 23s sec/tick 1311.2 sec/kimg 10.92 maintenance 2.2 gpumem 2.0 tick 9 kimg 1160.4 lod 3.07 minibatch 32 time 2h 27m 16s sec/tick 1311.7 sec/kimg 10.92 maintenance 2.2 gpumem 2.0 tick 10 kimg 1280.5 lod 3.00 minibatch 32 time 2h 48m 55s sec/tick 1296.9 sec/kimg 10.80 maintenance 2.2 gpumem 2.0 network-snapshot-001280 time 9m 16s fid50k 292.2210 tick 11 kimg 1400.6 lod 3.00 minibatch 32 time 3h 19m 47s sec/tick 1291.2 sec/kimg 10.75 maintenance 560.0 gpumem 2.0 tick 12 kimg 1520.6 lod 3.00 minibatch 32 time 3h 41m 20s sec/tick 1291.5 sec/kimg 10.76 maintenance 2.2 gpumem 2.0 tick 13 kimg 1640.7 lod 3.00 minibatch 32 time 4h 02m 53s sec/tick 1290.3 sec/kimg 10.75 maintenance 2.3 gpumem 2.0 tick 14 kimg 1760.8 lod 3.00 minibatch 32 time 4h 24m 26s sec/tick 1290.8 sec/kimg 10.75 maintenance 2.2 gpumem 2.0 tick 15 kimg 1860.8 lod 2.90 minibatch 16 time 5h 08m 55s sec/tick 2667.1 sec/kimg 26.66 maintenance 2.2 gpumem 2.0 tick 16 kimg 1960.8 lod 2.73 minibatch 16 time 6h 10m 02s sec/tick 3663.8 sec/kimg 36.63 maintenance 3.3 gpumem 2.0 tick 17 kimg 2060.9 lod 2.57 minibatch 16 time 7h 11m 09s sec/tick 3663.3 sec/kimg 36.62 maintenance 3.3 gpumem 2.0 tick 18 kimg 2160.9 lod 2.40 minibatch 16 time 8h 12m 15s sec/tick 3663.3 sec/kimg 36.62 maintenance 3.3 gpumem 2.0 tick 19 kimg 2260.9 lod 2.23 minibatch 16 time 9h 13m 22s sec/tick 3663.0 sec/kimg 36.62 maintenance 3.3 gpumem 2.0 tick 20 kimg 2361.0 lod 2.07 minibatch 16 time 10h 14m 28s sec/tick 3662.6 sec/kimg 36.61 maintenance 3.3 gpumem 2.0 network-snapshot-002360 time 11m 20s fid50k 329.8881 tick 21 kimg 2461.0 lod 2.00 minibatch 16 time 11h 26m 28s sec/tick 3635.4 sec/kimg 36.34 maintenance 685.2 gpumem 2.0 tick 22 kimg 2561.0 lod 2.00 minibatch 16 time 12h 27m 40s sec/tick 3668.3 sec/kimg 36.67 maintenance 3.3 gpumem 2.0 tick 23 kimg 2661.1 lod 2.00 minibatch 16 time 13h 28m 13s sec/tick 3630.0 sec/kimg 36.29 maintenance 3.4 gpumem 2.0 tick 24 kimg 2761.1 lod 2.00 minibatch 16 time 14h 29m 10s sec/tick 3652.9 sec/kimg 36.52 maintenance 3.4 gpumem 2.0 tick 25 kimg 2861.1 lod 2.00 minibatch 16 time 15h 29m 52s sec/tick 3639.3 sec/kimg 36.38 maintenance 3.3 gpumem 2.0 tick 26 kimg 2961.2 lod 2.00 minibatch 16 time 16h 30m 13s sec/tick 3617.6 sec/kimg 36.16 maintenance 3.3 gpumem 2.0 tick 27 kimg 3041.2 lod 1.93 minibatch 8 time 18h 07m 10s sec/tick 5814.1 sec/kimg 72.68 maintenance 3.3 gpumem 2.0 tick 28 kimg 3121.2 lod 1.80 minibatch 8 time 20h 29m 23s sec/tick 8525.3 sec/kimg 106.57 maintenance 7.0 gpumem 2.0 tick 29 kimg 3201.2 lod 1.66 minibatch 8 time 22h 51m 39s sec/tick 8528.9 sec/kimg 106.61 maintenance 7.2 gpumem 2.0 tick 30 kimg 3281.2 lod 1.53 minibatch 8 time 1d 01h 14m sec/tick 8536.7 sec/kimg 106.71 maintenance 7.3 gpumem 2.0 network-snapshot-003281 time 14m 53s fid50k 321.2979 tick 31 kimg 3361.2 lod 1.40 minibatch 8 time 1d 03h 51m sec/tick 8535.0 sec/kimg 106.69 maintenance 902.6 gpumem 2.0 tick 32 kimg 3441.2 lod 1.26 minibatch 8 time 1d 06h 13m sec/tick 8542.2 sec/kimg 106.78 maintenance 7.4 gpumem 2.0 tick 33 kimg 3521.2 lod 1.13 minibatch 8 time 1d 08h 36m sec/tick 8540.9 sec/kimg 106.76 maintenance 7.6 gpumem 2.0 tick 34 kimg 3601.2 lod 1.00 minibatch 8 time 1d 10h 58m sec/tick 8538.5 sec/kimg 106.73 maintenance 7.5 gpumem 2.0 tick 35 kimg 3681.2 lod 1.00 minibatch 8 time 1d 13h 19m sec/tick 8427.5 sec/kimg 105.34 maintenance 7.5 gpumem 2.0 ...
- 投稿日:2020-01-23T23:28:45+09:00
【StyleGAN入門】自前マシンでアニメの独自学習♬
今回はStyleGANを使ってアニメ顔の学習に挑戦してみました。
学習に関する参考はほとんどなく以下のものがありました。結構学習に時間もかかるし、情報も不十分でしたが、一応自前マシンで学習でき、かつ学習途中からの再学習もできたので、記事にまとめておきます。
【参考】
①How To Use Custom Datasets With StyleGAN - TensorFlow Implementation
②styleganで独自モデルの学習方法
③StyleGAN log
④Making Anime Faces With StyleGANやったこと
・アニメ顔データの準備
・とにかく学習する
・潜在空間でのミキシングをやってみる
・再学習するには・アニメ顔データの準備
アニメ顔は以前DCGANで利用したサイトから、ダウンロードして準備しました。
今回の利用のポイントは少なくとも画像サイズを合わせて、かつファイル名を変更して読み取りやすく、1.pngのように変更すること。
StyleGANの学習という意味では目鼻顔などのアラインメントを合わせたいが、次回にパスした。
ということで、上記のデータ整理は以下のコードで実施した。
ちなみにサイズ(128,128)を1000個用意した。from PIL import Image import glob import random files = glob.glob("./anime/**/*.png", recursive=True) files = random.sample(files, 1000) res = [] sk=0 for path in files: img = Image.open(path) img = img.resize((128, 128)) img.save( "img/{}.png".format(sk)) sk += 1・とにかく学習する
学習コードは、参考①のビデオと参考②を眺めつつ、以下のようにした。
kimgは学習image数であり、単位が千imgを意味している。
総学習イメージ数が3400kimgを意味する
次の行は学習開始解像度=4
そして、custom_datasetがtf_recordsに変換した画像のDir(=datasets/custom_dataset)である。さらに、とりあえずの学習ということで、解像度=64で学習してみたが問題なく学習できた。
また、StyleGANはpganであり、サイズ毎学習であるが、サイズ毎のminibatchサイズも以下のとおり、小さめに設定した。train.total_kimg = 3400、 sched.lod_initial_resolution = 4 desc += '-custom_dataset'; dataset = EasyDict(tfrecord_dir='custom_dataset', resolution=64); train.mirror_augment = False desc += '-1gpu'; submit_config.num_gpus = 1; sched.minibatch_base = 4; sched.minibatch_dict = {4: 128, 8: 64, 16: 32, 32: 16, 64: 8, 128: 8, 256: 4, 512: 2}つまり、以下の必要最小限で動く。
train.py# Copyright (c) 2019, NVIDIA CORPORATION. All rights reserved. # # This work is licensed under the Creative Commons Attribution-NonCommercial # 4.0 International License. To view a copy of this license, visit # http://creativecommons.org/licenses/by-nc/4.0/ or send a letter to # Creative Commons, PO Box 1866, Mountain View, CA 94042, USA. """Main entry point for training StyleGAN and ProGAN networks.""" import copy import dnnlib from dnnlib import EasyDict import config from metrics import metric_base #---------------------------------------------------------------------------- # Official training configs for StyleGAN, targeted mainly for FFHQ. if 1: desc = 'sgan' # Description string included in result subdir name. train = EasyDict(run_func_name='training.training_loop.training_loop') # Options for training loop. G = EasyDict(func_name='training.networks_stylegan.G_style') # Options for generator network. D = EasyDict(func_name='training.networks_stylegan.D_basic') # Options for discriminator network. G_opt = EasyDict(beta1=0.0, beta2=0.99, epsilon=1e-8) # Options for generator optimizer. D_opt = EasyDict(beta1=0.0, beta2=0.99, epsilon=1e-8) # Options for discriminator optimizer. G_loss = EasyDict(func_name='training.loss.G_logistic_nonsaturating') # Options for generator loss. D_loss = EasyDict(func_name='training.loss.D_logistic_simplegp', r1_gamma=10.0) # Options for discriminator loss. dataset = EasyDict() # Options for load_dataset(). sched = EasyDict() # Options for TrainingSchedule. grid = EasyDict(size='4k', layout='random') #4k # Options for setup_snapshot_image_grid(). metrics = [metric_base.fid50k] # Options for MetricGroup. submit_config = dnnlib.SubmitConfig() # Options for dnnlib.submit_run(). tf_config = {'rnd.np_random_seed': 1000} # Options for tflib.init_tf(). # Dataset. desc += '-custom_dataset'; dataset = EasyDict(tfrecord_dir='custom_dataset', resolution=64); train.mirror_augment = False # Number of GPUs. desc += '-1gpu'; submit_config.num_gpus = 1; sched.minibatch_base = 4; sched.minibatch_dict = {4: 128, 8: 64, 16: 32, 32: 16, 64: 8, 128: 8, 256: 4, 512: 2} # Default options. train.total_kimg = 3400 sched.lod_initial_resolution = 4 sched.G_lrate_dict = {128: 0.0015, 256: 0.002, 512: 0.003, 1024: 0.003} sched.D_lrate_dict = EasyDict(sched.G_lrate_dict) #---------------------------------------------------------------------------- # Main entry point for training. # Calls the function indicated by 'train' using the selected options. def main(): kwargs = EasyDict(train) kwargs.update(G_args=G, D_args=D, G_opt_args=G_opt, D_opt_args=D_opt, G_loss_args=G_loss, D_loss_args=D_loss) kwargs.update(dataset_args=dataset, sched_args=sched, grid_args=grid, metric_arg_list=metrics, tf_config=tf_config) kwargs.submit_config = copy.deepcopy(submit_config) kwargs.submit_config.run_dir_root = dnnlib.submission.submit.get_template_from_path(config.result_dir) kwargs.submit_config.run_dir_ignore += config.run_dir_ignore kwargs.submit_config.run_desc = desc dnnlib.submit_run(**kwargs) #---------------------------------------------------------------------------- if __name__ == "__main__": main() #----------------------------------------------------------------------------なお、データのtfrecordsへの変換は参考①から以下のように実施した。
※ここで元画像は./animeに入れておく、そして画像サイズ毎の変換ファイルはcustom_datasetに6個のサイズの異なるファイルが格納された。python dataset_tool.py create_from_images datasets/custom_dataset ./anime上記でとりあえず、学習できると思う。
・潜在空間でのミキシングをやってみる
1060マシンで上記のコードを10h程度で以下の絵が得られる。
決して綺麗とは言えないが、とにかく最弱マシンでも学習できた。
さらに、潜在空間での17,18のミキシングをやってみると以下の絵が得られた。
1080マシンで解像度128x128サイズで1d8h程度回して、kimg=4705の場合以下のように画像がしっかりしてきた。
※これでもpid50K=168程度で精度はまだまだだが、。。。以前のDCGANの画像と比べてこちらの方が綺麗に見える
さらに、潜在空間での11,82のミキシングをやってみると以下の絵が得られた。
・再学習するには
最後に禁断(誰も公開していないようなので)の途中中断した場合の継続学習の仕方が出来たので、まとめておく。
※この方法はちょっとだけ参考②と参考④に記載がある
以下のコードで実施する。
すなわち、training_loop.pyの以下の部分を修正する。resume_run_id = "latest", #None, # Run ID or network pkl to resume training from, None = start from scratch. resume_snapshot = './results/00001-sgan-custom_dataset-1gpu/network-snapshot-.pkl', #None, # Snapshot index to resume training from, None = autodetect.また、network_snapshot_ticks = 1, # How often to export network snapshots? として、毎回出力にしている。
training_loop.pydef training_loop( submit_config, G_args = {}, # Options for generator network. D_args = {}, # Options for discriminator network. G_opt_args = {}, # Options for generator optimizer. D_opt_args = {}, # Options for discriminator optimizer. G_loss_args = {}, # Options for generator loss. D_loss_args = {}, # Options for discriminator loss. dataset_args = {}, # Options for dataset.load_dataset(). sched_args = {}, # Options for train.TrainingSchedule. grid_args = {}, # Options for train.setup_snapshot_image_grid(). metric_arg_list = [], # Options for MetricGroup. tf_config = {}, # Options for tflib.init_tf(). G_smoothing_kimg = 10.0, # Half-life of the running average of generator weights. D_repeats = 1, # How many times the discriminator is trained per G iteration. minibatch_repeats = 4, # Number of minibatches to run before adjusting training parameters. reset_opt_for_new_lod = True, # Reset optimizer internal state (e.g. Adam moments) when new layers are introduced? total_kimg = 15000, # Total length of the training, measured in thousands of real images. mirror_augment = False, # Enable mirror augment? drange_net = [-1,1], # Dynamic range used when feeding image data to the networks. image_snapshot_ticks = 1, # How often to export image snapshots? network_snapshot_ticks = 1, # How often to export network snapshots? default=10 save_tf_graph = False, # Include full TensorFlow computation graph in the tfevents file? save_weight_histograms = False, # Include weight histograms in the tfevents file? resume_run_id = "latest", #None, # Run ID or network pkl to resume training from, None = start from scratch. resume_snapshot = './results/00001-sgan-custom_dataset-1gpu/network-snapshot-.pkl', #None, # Snapshot index to resume training from, None = autodetect. resume_kimg = 1040.9, # Assumed training progress at the beginning. Affects reporting and training schedule. resume_time = 5599.0): # Assumed wallclock time at the beginning. Affects reporting.resume_time = 5599.0
は秒単位で入力する。
このままだとメモリーがたまらないので、さらに上書き保存するためにもう一か所、下のコードのように変更した。train_loops.pyif cur_tick % network_snapshot_ticks == 0 or done or cur_tick == 1: #pkl = os.path.join(submit_config.run_dir, 'network-snapshot-%06d.pkl' % (cur_nimg // 1000)) pkl = os.path.join(submit_config.run_dir, 'network-snapshot-.pkl') misc.save_pkl((G, D, Gs), pkl) metrics.run(pkl, run_dir=submit_config.run_dir, num_gpus=submit_config.num_gpus, tf_config=tf_config)計算が1080マシンでもかなりかかるので、これを利用した結果については後日公開したいと思う。
まとめ
・自前マシンでStyleGANの学習ができるようになった
・学習データで今まで報告したようなミキシングが出来た
・途中で中断した場合の再開の仕方が分かった・今回は1000データだが、100以下の少数データの結果も見ようと思う
・さらに精度を追求してスタイルなどもやってみようと思うおまけ
dnnlib: Running training.training_loop.training_loop() on localhost... Streaming data using training.dataset.TFRecordDataset... Dataset shape = [3, 64, 64] Dynamic range = [0, 255] Label size = 0 Constructing networks... G Params OutputShape WeightShape --- --- --- --- latents_in - (?, 512) - labels_in - (?, 0) - lod - () - dlatent_avg - (512,) - G_mapping/latents_in - (?, 512) - G_mapping/labels_in - (?, 0) - G_mapping/PixelNorm - (?, 512) - G_mapping/Dense0 262656 (?, 512) (512, 512) G_mapping/Dense1 262656 (?, 512) (512, 512) G_mapping/Dense2 262656 (?, 512) (512, 512) G_mapping/Dense3 262656 (?, 512) (512, 512) G_mapping/Dense4 262656 (?, 512) (512, 512) G_mapping/Dense5 262656 (?, 512) (512, 512) G_mapping/Dense6 262656 (?, 512) (512, 512) G_mapping/Dense7 262656 (?, 512) (512, 512) G_mapping/Broadcast - (?, 10, 512) - G_mapping/dlatents_out - (?, 10, 512) - Truncation - (?, 10, 512) - G_synthesis/dlatents_in - (?, 10, 512) - G_synthesis/4x4/Const 534528 (?, 512, 4, 4) (512,) G_synthesis/4x4/Conv 2885632 (?, 512, 4, 4) (3, 3, 512, 512) G_synthesis/ToRGB_lod4 1539 (?, 3, 4, 4) (1, 1, 512, 3) G_synthesis/8x8/Conv0_up 2885632 (?, 512, 8, 8) (3, 3, 512, 512) G_synthesis/8x8/Conv1 2885632 (?, 512, 8, 8) (3, 3, 512, 512) G_synthesis/ToRGB_lod3 1539 (?, 3, 8, 8) (1, 1, 512, 3) G_synthesis/Upscale2D - (?, 3, 8, 8) - G_synthesis/Grow_lod3 - (?, 3, 8, 8) - G_synthesis/16x16/Conv0_up 2885632 (?, 512, 16, 16) (3, 3, 512, 512) G_synthesis/16x16/Conv1 2885632 (?, 512, 16, 16) (3, 3, 512, 512) G_synthesis/ToRGB_lod2 1539 (?, 3, 16, 16) (1, 1, 512, 3) G_synthesis/Upscale2D_1 - (?, 3, 16, 16) - G_synthesis/Grow_lod2 - (?, 3, 16, 16) - G_synthesis/32x32/Conv0_up 2885632 (?, 512, 32, 32) (3, 3, 512, 512) G_synthesis/32x32/Conv1 2885632 (?, 512, 32, 32) (3, 3, 512, 512) G_synthesis/ToRGB_lod1 1539 (?, 3, 32, 32) (1, 1, 512, 3) G_synthesis/Upscale2D_2 - (?, 3, 32, 32) - G_synthesis/Grow_lod1 - (?, 3, 32, 32) - G_synthesis/64x64/Conv0_up 1442816 (?, 256, 64, 64) (3, 3, 512, 256) G_synthesis/64x64/Conv1 852992 (?, 256, 64, 64) (3, 3, 256, 256) G_synthesis/ToRGB_lod0 771 (?, 3, 64, 64) (1, 1, 256, 3) G_synthesis/Upscale2D_3 - (?, 3, 64, 64) - G_synthesis/Grow_lod0 - (?, 3, 64, 64) - G_synthesis/images_out - (?, 3, 64, 64) - G_synthesis/lod - () - G_synthesis/noise0 - (1, 1, 4, 4) - G_synthesis/noise1 - (1, 1, 4, 4) - G_synthesis/noise2 - (1, 1, 8, 8) - G_synthesis/noise3 - (1, 1, 8, 8) - G_synthesis/noise4 - (1, 1, 16, 16) - G_synthesis/noise5 - (1, 1, 16, 16) - G_synthesis/noise6 - (1, 1, 32, 32) - G_synthesis/noise7 - (1, 1, 32, 32) - G_synthesis/noise8 - (1, 1, 64, 64) - G_synthesis/noise9 - (1, 1, 64, 64) - images_out - (?, 3, 64, 64) - --- --- --- --- Total 25137935 D Params OutputShape WeightShape --- --- --- --- images_in - (?, 3, 64, 64) - labels_in - (?, 0) - lod - () - FromRGB_lod0 1024 (?, 256, 64, 64) (1, 1, 3, 256) 64x64/Conv0 590080 (?, 256, 64, 64) (3, 3, 256, 256) 64x64/Conv1_down 1180160 (?, 512, 32, 32) (3, 3, 256, 512) Downscale2D - (?, 3, 32, 32) - FromRGB_lod1 2048 (?, 512, 32, 32) (1, 1, 3, 512) Grow_lod0 - (?, 512, 32, 32) - 32x32/Conv0 2359808 (?, 512, 32, 32) (3, 3, 512, 512) 32x32/Conv1_down 2359808 (?, 512, 16, 16) (3, 3, 512, 512) Downscale2D_1 - (?, 3, 16, 16) - FromRGB_lod2 2048 (?, 512, 16, 16) (1, 1, 3, 512) Grow_lod1 - (?, 512, 16, 16) - 16x16/Conv0 2359808 (?, 512, 16, 16) (3, 3, 512, 512) 16x16/Conv1_down 2359808 (?, 512, 8, 8) (3, 3, 512, 512) Downscale2D_2 - (?, 3, 8, 8) - FromRGB_lod3 2048 (?, 512, 8, 8) (1, 1, 3, 512) Grow_lod2 - (?, 512, 8, 8) - 8x8/Conv0 2359808 (?, 512, 8, 8) (3, 3, 512, 512) 8x8/Conv1_down 2359808 (?, 512, 4, 4) (3, 3, 512, 512) Downscale2D_3 - (?, 3, 4, 4) - FromRGB_lod4 2048 (?, 512, 4, 4) (1, 1, 3, 512) Grow_lod3 - (?, 512, 4, 4) - 4x4/MinibatchStddev - (?, 513, 4, 4) - 4x4/Conv 2364416 (?, 512, 4, 4) (3, 3, 513, 512) 4x4/Dense0 4194816 (?, 512) (8192, 512) 4x4/Dense1 513 (?, 1) (512, 1) scores_out - (?, 1) - --- --- --- --- Total 22498049 Building TensorFlow graph... WARNING: The TensorFlow contrib module will not be included in TensorFlow 2.0. For more information, please see: * https://github.com/tensorflow/community/blob/master/rfcs/20180907-contrib-sunset.md * https://github.com/tensorflow/addons If you depend on functionality not listed there, please file an issue. Setting up snapshot image grid... Setting up run dir... Training... tick 1 kimg 160.3 lod 4.00 minibatch 128 time 5m 35s sec/tick 297.2 sec/kimg 1.85 maintenance 38.0 gpumem 1.7 network-snapshot-000160 time 16m 22s fid50k 454.0154 C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:541: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_qint8 = np.dtype([("qint8", np.int8, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:542: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_quint8 = np.dtype([("quint8", np.uint8, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:543: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_qint16 = np.dtype([("qint16", np.int16, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:544: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_quint16 = np.dtype([("quint16", np.uint16, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:545: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_qint32 = np.dtype([("qint32", np.int32, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:550: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. np_resource = np.dtype([("resource", np.ubyte, 1)]) tick 2 kimg 320.5 lod 4.00 minibatch 128 time 26m 00s sec/tick 222.0 sec/kimg 1.39 maintenance 1002.8 gpumem 2.0 tick 3 kimg 480.8 lod 4.00 minibatch 128 time 29m 43s sec/tick 222.0 sec/kimg 1.38 maintenance 1.4 gpumem 2.0 tick 4 kimg 620.8 lod 3.97 minibatch 64 time 33m 41s sec/tick 236.2 sec/kimg 1.69 maintenance 1.2 gpumem 2.0 tick 5 kimg 760.8 lod 3.73 minibatch 64 time 41m 24s sec/tick 462.3 sec/kimg 3.30 maintenance 1.3 gpumem 2.0 tick 6 kimg 900.9 lod 3.50 minibatch 64 time 49m 07s sec/tick 461.2 sec/kimg 3.29 maintenance 1.3 gpumem 2.0 tick 7 kimg 1040.9 lod 3.27 minibatch 64 time 56m 49s sec/tick 461.2 sec/kimg 3.29 maintenance 1.3 gpumem 2.0 tick 8 kimg 1180.9 lod 3.03 minibatch 64 time 1h 04m 31s sec/tick 460.2 sec/kimg 3.29 maintenance 1.3 gpumem 2.0 tick 9 kimg 1321.0 lod 3.00 minibatch 64 time 1h 12m 06s sec/tick 453.5 sec/kimg 3.24 maintenance 1.3 gpumem 2.0 tick 10 kimg 1461.0 lod 3.00 minibatch 64 time 1h 19m 40s sec/tick 452.6 sec/kimg 3.23 maintenance 1.3 gpumem 2.0 network-snapshot-001460 time 8m 33s fid50k 378.7820 tick 11 kimg 1601.0 lod 3.00 minibatch 64 time 1h 35m 49s sec/tick 453.8 sec/kimg 3.24 maintenance 515.6 gpumem 2.0 tick 12 kimg 1741.1 lod 3.00 minibatch 64 time 1h 43m 24s sec/tick 453.8 sec/kimg 3.24 maintenance 1.3 gpumem 2.0 tick 13 kimg 1861.1 lod 2.90 minibatch 32 time 1h 57m 38s sec/tick 852.2 sec/kimg 7.10 maintenance 1.3 gpumem 2.0 tick 14 kimg 1981.2 lod 2.70 minibatch 32 time 2h 18m 55s sec/tick 1275.3 sec/kimg 10.62 maintenance 2.0 gpumem 2.0 tick 15 kimg 2101.2 lod 2.50 minibatch 32 time 2h 40m 10s sec/tick 1273.1 sec/kimg 10.60 maintenance 1.9 gpumem 2.0 tick 16 kimg 2221.3 lod 2.30 minibatch 32 time 3h 01m 25s sec/tick 1273.0 sec/kimg 10.60 maintenance 1.9 gpumem 2.0 tick 17 kimg 2341.4 lod 2.10 minibatch 32 time 3h 22m 42s sec/tick 1275.0 sec/kimg 10.62 maintenance 1.9 gpumem 2.0 tick 18 kimg 2461.4 lod 2.00 minibatch 32 time 3h 43m 49s sec/tick 1265.4 sec/kimg 10.54 maintenance 1.9 gpumem 2.0 tick 19 kimg 2581.5 lod 2.00 minibatch 32 time 4h 04m 45s sec/tick 1253.8 sec/kimg 10.44 maintenance 1.9 gpumem 2.0 tick 20 kimg 2701.6 lod 2.00 minibatch 32 time 4h 25m 41s sec/tick 1254.5 sec/kimg 10.45 maintenance 1.9 gpumem 2.0 network-snapshot-002701 time 9m 08s fid50k 338.4830 tick 21 kimg 2821.6 lod 2.00 minibatch 32 time 4h 55m 47s sec/tick 1255.4 sec/kimg 10.46 maintenance 551.1 gpumem 2.0 tick 22 kimg 2941.7 lod 2.00 minibatch 32 time 5h 16m 44s sec/tick 1254.7 sec/kimg 10.45 maintenance 1.8 gpumem 2.0 tick 23 kimg 3041.7 lod 1.93 minibatch 16 time 5h 52m 23s sec/tick 2136.8 sec/kimg 21.36 maintenance 1.8 gpumem 2.0 tick 24 kimg 3141.8 lod 1.76 minibatch 16 time 6h 52m 21s sec/tick 3593.7 sec/kimg 35.93 maintenance 4.5 gpumem 2.0 tick 25 kimg 3241.8 lod 1.60 minibatch 16 time 7h 52m 23s sec/tick 3597.7 sec/kimg 35.97 maintenance 4.5 gpumem 2.0 tick 26 kimg 3341.8 lod 1.43 minibatch 16 time 8h 52m 34s sec/tick 3606.5 sec/kimg 36.05 maintenance 4.6 gpumem 2.0 tick 27 kimg 3400.0 lod 1.33 minibatch 16 time 9h 27m 29s sec/tick 2090.0 sec/kimg 35.92 maintenance 4.6 gpumem 2.0 network-snapshot-003400 time 11m 15s fid50k 327.9088 dnnlib: Finished training.training_loop.training_loop() in 9h 38m 52s.(keras-gpu) C:\Users\user\stylegan-master>python train.py C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorflow\python\framework\dtypes.py:526: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_qint8 = np.dtype([("qint8", np.int8, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorflow\python\framework\dtypes.py:527: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_quint8 = np.dtype([("quint8", np.uint8, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorflow\python\framework\dtypes.py:528: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_qint16 = np.dtype([("qint16", np.int16, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorflow\python\framework\dtypes.py:529: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_quint16 = np.dtype([("quint16", np.uint16, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorflow\python\framework\dtypes.py:530: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_qint32 = np.dtype([("qint32", np.int32, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorflow\python\framework\dtypes.py:535: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. np_resource = np.dtype([("resource", np.ubyte, 1)]) Creating the run dir: results\00004-sgan-custom_dataset-1gpu Copying files to the run dir dnnlib: Running training.training_loop.training_loop() on localhost... Streaming data using training.dataset.TFRecordDataset... WARNING:tensorflow:From C:\Users\user\stylegan-master\training\dataset.py:76: tf_record_iterator (from tensorflow.python.lib.io.tf_record) is deprecated and will be removed in a future version. Instructions for updating: Use eager execution and: `tf.data.TFRecordDataset(path)` WARNING:tensorflow:From C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorflow\python\framework\op_def_library.py:263: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version. Instructions for updating: Colocations handled automatically by placer. Dataset shape = [3, 128, 128] Dynamic range = [0, 255] Label size = 0 Constructing networks... G Params OutputShape WeightShape --- --- --- --- latents_in - (?, 512) - labels_in - (?, 0) - lod - () - dlatent_avg - (512,) - G_mapping/latents_in - (?, 512) - G_mapping/labels_in - (?, 0) - G_mapping/PixelNorm - (?, 512) - G_mapping/Dense0 262656 (?, 512) (512, 512) G_mapping/Dense1 262656 (?, 512) (512, 512) G_mapping/Dense2 262656 (?, 512) (512, 512) G_mapping/Dense3 262656 (?, 512) (512, 512) G_mapping/Dense4 262656 (?, 512) (512, 512) G_mapping/Dense5 262656 (?, 512) (512, 512) G_mapping/Dense6 262656 (?, 512) (512, 512) G_mapping/Dense7 262656 (?, 512) (512, 512) G_mapping/Broadcast - (?, 12, 512) - G_mapping/dlatents_out - (?, 12, 512) - Truncation - (?, 12, 512) - G_synthesis/dlatents_in - (?, 12, 512) - G_synthesis/4x4/Const 534528 (?, 512, 4, 4) (512,) G_synthesis/4x4/Conv 2885632 (?, 512, 4, 4) (3, 3, 512, 512) G_synthesis/ToRGB_lod5 1539 (?, 3, 4, 4) (1, 1, 512, 3) G_synthesis/8x8/Conv0_up 2885632 (?, 512, 8, 8) (3, 3, 512, 512) G_synthesis/8x8/Conv1 2885632 (?, 512, 8, 8) (3, 3, 512, 512) G_synthesis/ToRGB_lod4 1539 (?, 3, 8, 8) (1, 1, 512, 3) G_synthesis/Upscale2D - (?, 3, 8, 8) - G_synthesis/Grow_lod4 - (?, 3, 8, 8) - G_synthesis/16x16/Conv0_up 2885632 (?, 512, 16, 16) (3, 3, 512, 512) G_synthesis/16x16/Conv1 2885632 (?, 512, 16, 16) (3, 3, 512, 512) G_synthesis/ToRGB_lod3 1539 (?, 3, 16, 16) (1, 1, 512, 3) G_synthesis/Upscale2D_1 - (?, 3, 16, 16) - G_synthesis/Grow_lod3 - (?, 3, 16, 16) - G_synthesis/32x32/Conv0_up 2885632 (?, 512, 32, 32) (3, 3, 512, 512) G_synthesis/32x32/Conv1 2885632 (?, 512, 32, 32) (3, 3, 512, 512) G_synthesis/ToRGB_lod2 1539 (?, 3, 32, 32) (1, 1, 512, 3) G_synthesis/Upscale2D_2 - (?, 3, 32, 32) - G_synthesis/Grow_lod2 - (?, 3, 32, 32) - G_synthesis/64x64/Conv0_up 1442816 (?, 256, 64, 64) (3, 3, 512, 256) G_synthesis/64x64/Conv1 852992 (?, 256, 64, 64) (3, 3, 256, 256) G_synthesis/ToRGB_lod1 771 (?, 3, 64, 64) (1, 1, 256, 3) G_synthesis/Upscale2D_3 - (?, 3, 64, 64) - G_synthesis/Grow_lod1 - (?, 3, 64, 64) - G_synthesis/128x128/Conv0_up 426496 (?, 128, 128, 128) (3, 3, 256, 128) G_synthesis/128x128/Conv1 279040 (?, 128, 128, 128) (3, 3, 128, 128) G_synthesis/ToRGB_lod0 387 (?, 3, 128, 128) (1, 1, 128, 3) G_synthesis/Upscale2D_4 - (?, 3, 128, 128) - G_synthesis/Grow_lod0 - (?, 3, 128, 128) - G_synthesis/images_out - (?, 3, 128, 128) - G_synthesis/lod - () - G_synthesis/noise0 - (1, 1, 4, 4) - G_synthesis/noise1 - (1, 1, 4, 4) - G_synthesis/noise2 - (1, 1, 8, 8) - G_synthesis/noise3 - (1, 1, 8, 8) - G_synthesis/noise4 - (1, 1, 16, 16) - G_synthesis/noise5 - (1, 1, 16, 16) - G_synthesis/noise6 - (1, 1, 32, 32) - G_synthesis/noise7 - (1, 1, 32, 32) - G_synthesis/noise8 - (1, 1, 64, 64) - G_synthesis/noise9 - (1, 1, 64, 64) - G_synthesis/noise10 - (1, 1, 128, 128) - G_synthesis/noise11 - (1, 1, 128, 128) - images_out - (?, 3, 128, 128) - --- --- --- --- Total 25843858 D Params OutputShape WeightShape --- --- --- --- images_in - (?, 3, 128, 128) - labels_in - (?, 0) - lod - () - FromRGB_lod0 512 (?, 128, 128, 128) (1, 1, 3, 128) 128x128/Conv0 147584 (?, 128, 128, 128) (3, 3, 128, 128) 128x128/Conv1_down 295168 (?, 256, 64, 64) (3, 3, 128, 256) Downscale2D - (?, 3, 64, 64) - FromRGB_lod1 1024 (?, 256, 64, 64) (1, 1, 3, 256) Grow_lod0 - (?, 256, 64, 64) - 64x64/Conv0 590080 (?, 256, 64, 64) (3, 3, 256, 256) 64x64/Conv1_down 1180160 (?, 512, 32, 32) (3, 3, 256, 512) Downscale2D_1 - (?, 3, 32, 32) - FromRGB_lod2 2048 (?, 512, 32, 32) (1, 1, 3, 512) Grow_lod1 - (?, 512, 32, 32) - 32x32/Conv0 2359808 (?, 512, 32, 32) (3, 3, 512, 512) 32x32/Conv1_down 2359808 (?, 512, 16, 16) (3, 3, 512, 512) Downscale2D_2 - (?, 3, 16, 16) - FromRGB_lod3 2048 (?, 512, 16, 16) (1, 1, 3, 512) Grow_lod2 - (?, 512, 16, 16) - 16x16/Conv0 2359808 (?, 512, 16, 16) (3, 3, 512, 512) 16x16/Conv1_down 2359808 (?, 512, 8, 8) (3, 3, 512, 512) Downscale2D_3 - (?, 3, 8, 8) - FromRGB_lod4 2048 (?, 512, 8, 8) (1, 1, 3, 512) Grow_lod3 - (?, 512, 8, 8) - 8x8/Conv0 2359808 (?, 512, 8, 8) (3, 3, 512, 512) 8x8/Conv1_down 2359808 (?, 512, 4, 4) (3, 3, 512, 512) Downscale2D_4 - (?, 3, 4, 4) - FromRGB_lod5 2048 (?, 512, 4, 4) (1, 1, 3, 512) Grow_lod4 - (?, 512, 4, 4) - 4x4/MinibatchStddev - (?, 513, 4, 4) - 4x4/Conv 2364416 (?, 512, 4, 4) (3, 3, 513, 512) 4x4/Dense0 4194816 (?, 512) (8192, 512) 4x4/Dense1 513 (?, 1) (512, 1) scores_out - (?, 1) - --- --- --- --- Total 22941313 Building TensorFlow graph... WARNING:tensorflow:From C:\Users\user\stylegan-master\training\training_loop.py:167: div (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version. Instructions for updating: Deprecated in favor of operator or tf.math.divide. WARNING:tensorflow:From C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorflow\python\ops\math_ops.py:3066: to_int32 (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version. Instructions for updating: Use tf.cast instead. WARNING: The TensorFlow contrib module will not be included in TensorFlow 2.0. For more information, please see: * https://github.com/tensorflow/community/blob/master/rfcs/20180907-contrib-sunset.md * https://github.com/tensorflow/addons If you depend on functionality not listed there, please file an issue. Setting up snapshot image grid... 2020-01-20 07:05:17.296825: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.08GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available. 2020-01-20 07:05:17.320746: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.08GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available. 2020-01-20 07:05:17.342289: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 2.15GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available. 2020-01-20 07:05:17.350675: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.08GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available. 2020-01-20 07:05:17.399302: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.10GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available. Setting up run dir... Training... 2020-01-20 07:05:35.259782: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.33GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available. 2020-01-20 07:05:35.316821: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.33GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available. 2020-01-20 07:05:35.386177: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.33GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available. 2020-01-20 07:05:35.430917: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.33GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available. 2020-01-20 07:05:35.476293: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 1.33GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available. tick 1 kimg 140.0 lod 4.00 minibatch 64 time 8m 55s sec/tick 483.6 sec/kimg 3.45 maintenance 51.7 gpumem 1.6 network-snapshot-000140 time 8m 46s fid50k 360.7307 C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:541: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_qint8 = np.dtype([("qint8", np.int8, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:542: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_quint8 = np.dtype([("quint8", np.uint8, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:543: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_qint16 = np.dtype([("qint16", np.int16, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:544: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_quint16 = np.dtype([("quint16", np.uint16, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:545: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. _np_qint32 = np.dtype([("qint32", np.int32, 1)]) C:\Users\user\Anaconda3\envs\keras-gpu\lib\site-packages\tensorboard\compat\tensorflow_stub\dtypes.py:550: FutureWarning: Passing (type, 1) or '1type' as a synonym of type is deprecated; in a future version of numpy, it will be understood as (type, (1,)) / '(1,)type'. np_resource = np.dtype([("resource", np.ubyte, 1)]) tick 2 kimg 280.1 lod 4.00 minibatch 64 time 25m 58s sec/tick 479.1 sec/kimg 3.42 maintenance 543.3 gpumem 2.0 tick 3 kimg 420.1 lod 4.00 minibatch 64 time 33m 59s sec/tick 479.0 sec/kimg 3.42 maintenance 2.3 gpumem 2.0 tick 4 kimg 560.1 lod 4.00 minibatch 64 time 42m 01s sec/tick 479.8 sec/kimg 3.43 maintenance 2.2 gpumem 2.0 tick 5 kimg 680.2 lod 3.87 minibatch 32 time 59m 14s sec/tick 1030.6 sec/kimg 8.58 maintenance 2.2 gpumem 2.0 tick 6 kimg 800.3 lod 3.67 minibatch 32 time 1h 21m 24s sec/tick 1327.7 sec/kimg 11.06 maintenance 2.2 gpumem 2.0 tick 7 kimg 920.3 lod 3.47 minibatch 32 time 1h 43m 29s sec/tick 1323.3 sec/kimg 11.02 maintenance 2.2 gpumem 2.0 tick 8 kimg 1040.4 lod 3.27 minibatch 32 time 2h 05m 23s sec/tick 1311.2 sec/kimg 10.92 maintenance 2.2 gpumem 2.0 tick 9 kimg 1160.4 lod 3.07 minibatch 32 time 2h 27m 16s sec/tick 1311.7 sec/kimg 10.92 maintenance 2.2 gpumem 2.0 tick 10 kimg 1280.5 lod 3.00 minibatch 32 time 2h 48m 55s sec/tick 1296.9 sec/kimg 10.80 maintenance 2.2 gpumem 2.0 network-snapshot-001280 time 9m 16s fid50k 292.2210 tick 11 kimg 1400.6 lod 3.00 minibatch 32 time 3h 19m 47s sec/tick 1291.2 sec/kimg 10.75 maintenance 560.0 gpumem 2.0 tick 12 kimg 1520.6 lod 3.00 minibatch 32 time 3h 41m 20s sec/tick 1291.5 sec/kimg 10.76 maintenance 2.2 gpumem 2.0 tick 13 kimg 1640.7 lod 3.00 minibatch 32 time 4h 02m 53s sec/tick 1290.3 sec/kimg 10.75 maintenance 2.3 gpumem 2.0 tick 14 kimg 1760.8 lod 3.00 minibatch 32 time 4h 24m 26s sec/tick 1290.8 sec/kimg 10.75 maintenance 2.2 gpumem 2.0 tick 15 kimg 1860.8 lod 2.90 minibatch 16 time 5h 08m 55s sec/tick 2667.1 sec/kimg 26.66 maintenance 2.2 gpumem 2.0 tick 16 kimg 1960.8 lod 2.73 minibatch 16 time 6h 10m 02s sec/tick 3663.8 sec/kimg 36.63 maintenance 3.3 gpumem 2.0 tick 17 kimg 2060.9 lod 2.57 minibatch 16 time 7h 11m 09s sec/tick 3663.3 sec/kimg 36.62 maintenance 3.3 gpumem 2.0 tick 18 kimg 2160.9 lod 2.40 minibatch 16 time 8h 12m 15s sec/tick 3663.3 sec/kimg 36.62 maintenance 3.3 gpumem 2.0 tick 19 kimg 2260.9 lod 2.23 minibatch 16 time 9h 13m 22s sec/tick 3663.0 sec/kimg 36.62 maintenance 3.3 gpumem 2.0 tick 20 kimg 2361.0 lod 2.07 minibatch 16 time 10h 14m 28s sec/tick 3662.6 sec/kimg 36.61 maintenance 3.3 gpumem 2.0 network-snapshot-002360 time 11m 20s fid50k 329.8881 tick 21 kimg 2461.0 lod 2.00 minibatch 16 time 11h 26m 28s sec/tick 3635.4 sec/kimg 36.34 maintenance 685.2 gpumem 2.0 tick 22 kimg 2561.0 lod 2.00 minibatch 16 time 12h 27m 40s sec/tick 3668.3 sec/kimg 36.67 maintenance 3.3 gpumem 2.0 tick 23 kimg 2661.1 lod 2.00 minibatch 16 time 13h 28m 13s sec/tick 3630.0 sec/kimg 36.29 maintenance 3.4 gpumem 2.0 tick 24 kimg 2761.1 lod 2.00 minibatch 16 time 14h 29m 10s sec/tick 3652.9 sec/kimg 36.52 maintenance 3.4 gpumem 2.0 tick 25 kimg 2861.1 lod 2.00 minibatch 16 time 15h 29m 52s sec/tick 3639.3 sec/kimg 36.38 maintenance 3.3 gpumem 2.0 tick 26 kimg 2961.2 lod 2.00 minibatch 16 time 16h 30m 13s sec/tick 3617.6 sec/kimg 36.16 maintenance 3.3 gpumem 2.0 tick 27 kimg 3041.2 lod 1.93 minibatch 8 time 18h 07m 10s sec/tick 5814.1 sec/kimg 72.68 maintenance 3.3 gpumem 2.0 tick 28 kimg 3121.2 lod 1.80 minibatch 8 time 20h 29m 23s sec/tick 8525.3 sec/kimg 106.57 maintenance 7.0 gpumem 2.0 tick 29 kimg 3201.2 lod 1.66 minibatch 8 time 22h 51m 39s sec/tick 8528.9 sec/kimg 106.61 maintenance 7.2 gpumem 2.0 tick 30 kimg 3281.2 lod 1.53 minibatch 8 time 1d 01h 14m sec/tick 8536.7 sec/kimg 106.71 maintenance 7.3 gpumem 2.0 network-snapshot-003281 time 14m 53s fid50k 321.2979 tick 31 kimg 3361.2 lod 1.40 minibatch 8 time 1d 03h 51m sec/tick 8535.0 sec/kimg 106.69 maintenance 902.6 gpumem 2.0 tick 32 kimg 3441.2 lod 1.26 minibatch 8 time 1d 06h 13m sec/tick 8542.2 sec/kimg 106.78 maintenance 7.4 gpumem 2.0 tick 33 kimg 3521.2 lod 1.13 minibatch 8 time 1d 08h 36m sec/tick 8540.9 sec/kimg 106.76 maintenance 7.6 gpumem 2.0 tick 34 kimg 3601.2 lod 1.00 minibatch 8 time 1d 10h 58m sec/tick 8538.5 sec/kimg 106.73 maintenance 7.5 gpumem 2.0 tick 35 kimg 3681.2 lod 1.00 minibatch 8 time 1d 13h 19m sec/tick 8427.5 sec/kimg 105.34 maintenance 7.5 gpumem 2.0 ...
- 投稿日:2020-01-23T22:52:58+09:00
Qiskit: WeightedPauliOperator, MatrixOperator, InitialStateなどなど
はじめに
Qiskitで量子プログラミングをするのに際して重要なclassの使い方を記します。
特に、Qiskit AquaなどでQAOAだったりを使うときに必要かなと思います。
まだまだ未熟なところもあると思いますが、参考にしてくれると嬉しいです。WeightedPailiOperator
QAOAだったり、VQEだったりにハミルトニアンを読み込ませるときに使うclass methodです。
qiskit.aqua.optimization.ising ではmax cutやtspなどのWeigthedPauliOperatorを返してくれるclass methodが提供されていますが、実際に自分で作ろうとすると少し大変です。
WeightedPauliOperatorに入れるclass methodはPauli classと呼ばれるものです。この説明を行いたいと思い餡巣。Pauli
まずは、sample code
とりあえず、使う物すべてimportimport numpy as np from qiskit.aqua.operators import WeightedPauliOperator, MatrixOperator from qiskit.aqua.operators.op_converter import to_weighted_pauli_operator from qiskit.aqua.components.initial_states import Custom, InitialState from qiskit.quantum_info import Pauli from qiskit import QuantumRegister, ClassicalRegister, QuantumCircuit次に一番簡単な例
pauli_list = [] num_qubit = 3 z_p = np.zeros(num_qubit, dtype=bool) x_p = np.zeros(num_qubit, dtype=bool) pauli_list.append([1, Pauli(z_p, x_p)])この場合はIIIをハミルトニアンに追加します。
次に、ZIZを追加したいときz_p[0] = True z_p[2] = True pauli_list.append([1, Pauli(z_p, x_p)])ちなみに、appendしているlistの一つ目の要素(今は1)のところにはcomplex numberを入れることができます。次に、XXXを追加したいとき。
for i in range(num_qubit): x_p[i] = True z_p = np.zeros(num_qubit, dtype=bool) pauli_list.append([1, Pauli(z_p, x_p)])Yを入れたいときはxもzもTrueにすればいいですね。
これを直接QAOAなどには入力できないのでqubitOp = WeightedPauliOperator(paulis=pauli_list)で、完了です。
ちなみに、中身を見たい場合はprint(qubitOp.print_details())でok
出力はIII (1+0j) ZIZ (1+0j) XXX (1+0j)MatrixOperator
このclassはもっと直感的に記述したい人におすすめです。
例えばZ operatorを入れたいときはz = np.array([[1, 0], [0, -1]]) z = MatrixOperator(z) # 中身を見てみる print(z.print_details())出力は
(0, 0) 1 (1, 1) -1この形はなんだろう??と思うかもしれませんが、
|0><0|-|1><1|のことですね。
しかし、このままではQAOAなどに入力することができません。そこでconvertします。z = to_weighted_pauli_operator(z) # 中身を見てみる print(z.print_details())出力は
Z (1+0j)しっかり変形されましたね。しかしながら、複数のqubitを使っていきたい場合はtensorを計算しないといけないので、少し大変です。
InitialState
QAOAの関数の四つ目の引数のinitial_state
使い方がいまいちわからずInitialStateを使えばよいことは分かるが、いまいち、、、
調べてみてもなかなか出なかったのでここに記します。Custom
circuitをInitialStateに変換するmethodがCustomです。
例えば\frac{|00>+|01>+|10>+|11>}{2}をinitial stateとして使いたいとき
qr = QuantumRegister(2) qc = QuantumCircuit(qr) qc.h(qr) Custom(2, circuit=qc)とすれば、QuantumCircuit classをInitialState classに変換することができます。
まとめ
自分で作ったHamiltonianでQAOAを実行してみたかったので勉強しました。
Qiskitの資料がネットに少ないので少しでも助けになればと思っています。
- 投稿日:2020-01-23T22:41:10+09:00
Python初心者がProgeteでPythonを始める方法
Python初心者がProgeteでPythonを始めてみた。
まずはProgateへアクセス
https://prog-8.com/無料の会員登録でアカウントを作成する
レッスン一覧からPythonを選択
全部で5レッスン+2記事を選択する

- 投稿日:2020-01-23T22:36:41+09:00
3次元の回転をクラスタリングする
背景
車の3次元姿勢を予測するKaggleのコンペをやる過程で、3次元の回転をクラスタリングすることで離散化し、回転を求める問題をクラス分類として解くアプローチを検討しました。結局は、車は自由に回転できるわけではなく、ほぼ道路に平行な回転しか自由度がないため、その回転角度をsin(θ), cos(θ)で回帰するモデルのほうが筋が良いためお蔵入りになりました。回転角のクラスタリングとかニーズ全くなさそうですが、やっていて面白かったのでメモ書きとして残しておきます。
ちなみに、クラス分類として解くのは、例えば回転に制限のない人工衛星の姿勢推定とかでは意味があったかもしれません。
クラスタリングアルゴリズム
回転を扱う場合、scipy.spatial.transform.Rotationを利用すると、オイラー角、クォータニオン、回転行列が全て簡単に扱えるので、これを使うのが良いと思います。
クラスタリングアルゴリズムとしては、明確にクラスタがあるわけではなく、回転空間を分割したいだけなので単純にkmeansを使います。
2つの回転の距離は、片方の回転からもう片方の回転に変化させる最小の角度で定義するのが自然ですが、この角度は、片方の逆変換でもう片方を回転させ、クォータニオンに変換してその角度として取得できます。
# code from https://www.kaggle.com/its7171/metrics-evaluation-script def rot_dist(rot1, rot2): diff = Rotation.inv(rot2) * rot1 w = np.clip(diff.as_quat()[-1], -1., 1.) w = (math.acos(w) * 360) / math.pi if w > 180: w = 360 - w return w複数の回転角の平均は、文献1で提案されています。内容はなるほど分からんなのですが、なんとこちらの記事に解説がありました!使うだけであれば、Matlab実装をPythonに移植した実装があるのでそれを使います。
# code from https://github.com/christophhagen/averaging-quaternions # https://github.com/christophhagen/averaging-quaternions/blob/master/LICENSE def average_rotations(rots): # Number of quaternions to average M = len(rots) Q = np.array([q.as_quat() for q in rots]) A = np.zeros(shape=(4, 4)) for i in range(M): q = Q[i,:] # multiply q with its transposed version q' and add A A = np.outer(q,q) + A # scale A = (1.0/M)*A # compute eigenvalues and -vectors eigenValues, eigenVectors = np.linalg.eig(A) # Sort by largest eigenvalue eigenVectors = eigenVectors[:,eigenValues.argsort()[::-1]] # return the real part of the largest eigenvector (has only real part) return Rotation.from_quat(np.real(eigenVectors[:,0]))これらの距離と平均を利用してkmeanを行います。
def kmeans(samples, k, reduce, distance, max_iter=300): sample_num = len(samples) centroids = [samples[i] for i in np.random.choice(sample_num, k)] for i in range(max_iter): dist = 0.0 centroid_id_to_samples = defaultdict(list) for sample in samples: distances = [distance(sample, c) for c in centroids] nearest_id = np.argmin(np.array(distances)) dist += distances[nearest_id] centroid_id_to_samples[nearest_id].append(sample) print(i, dist / sample_num) for k, v in centroid_id_to_samples.items(): centroids[k] = reduce(v) return centroids実際にこれを利用して、車の姿勢をクラスタリングしてみた結果が、KaggleのNotebookにありますので、参照してみて下さい。
下記のような形で同じ姿勢の車がクラスタリングされます(オクルージョンとか見切れがあって分かりにくいですが)。
F. Markley, Y. Cheng, J. Crassidis, and Y. Oshman, "Averaging Quaternions," in Journal of Guidance, Control, and Dynamics, vol. 30, no. 4, pp. 1193-1197, 2007. ↩


- 投稿日:2020-01-23T22:33:47+09:00
opensslで暗号化したファイルをpythonからopensslで復号
以前、pythonのライブラリを使って暗号化・復号化する記事を書いたりもしましたが、そんな事をしなくても大抵の場合、opensslをコマンドから実行すれば十分ということに気が付きました。
動作確認環境
arch linux
openssl 1.1.1
python3.8.1$ openssl enc -e -aes-256-cbc -k 'password' -in original_file -out encrypted_fileopenssl 1.1.1だと"Using -iter or -pbkdf2 would be better."という警告がでますが、このオプションをつけると古いバージョンで復号化できなくなるので注意。
decrypt.pyfrom subprocess import run, PIPE password = 'password' file_path = 'encrypted_file' completed = run(args=[ 'openssl', 'enc', '-d', '-aes-256-cbc', '-k', password, '-in', file_path], check=True, stdout=PIPE) print(completed.stdout.decode())
- 投稿日:2020-01-23T22:24:12+09:00
networkxメモ
TL;DR
networkxを使って解析することが多かったので簡単にメモ
そのうち記事にするかもspring layoutの固定
spring layoutで書くと毎回違うネットワークが生成させるので、固定したい。
numpyのrandomseedを固定すれば生成されるネットワークを固定できる。import numpy as np import networkx as nx import matplotlib.pyplot as plt np.random.seed(10) G = nx.read_gml("/path/to/gmlfile") pos = nx.spring_layout(G) fig, ax = plt.subplots() nx.draw_networkx_nodes(G, pos, ax=ax) nx.draw_networkx_edges(G, pos, ax=ax) plt.show()
- 投稿日:2020-01-23T22:12:41+09:00
今更ベイズ更新
はじめに
雰囲気でベイズ更新について語っていたので、きちんと勉強し直したいと思ってまとめました。n番煎じ記事です。
参考
- 5分でわかる(範囲の)ベイズ統計学(https://www.slideshare.net/matsukenbook/15-59154892)
- 確率分布のベイズ推定(http://arduinopid.web.fc2.com/P19.html)
- ココイチのスプーンの当選確率をベイズ推定する(https://rmizutaa.hatenablog.com/entry/2019/02/15/200700)
手順
ベイズ更新
ベイズ推定をざっくりまとめると、尤度(=モデル)のパラメータをMLEで点推定するのではなく、ベイズの定理を用いてパラメータの分布を推定するというものです。ベイズの定理は次の式で表されます。
p(w|x) = \frac{p(x|w)p(w)}{p(x)}$p(x|w)$が尤度(=モデル)、$p(w)$が事前分布、$p(x)$がデータの発生確率です。$p(w|x)$を事後分布と言います。
この式は、モデルのパラメータ$w$の事前分布に尤度をかけることで、データ$x$が与えられたときのパラメータ$w$の分布(事後分布)が得られるという式になっています。ベイズ更新はベイズの定理を使用して、逐次的に事後分布を更新する仕組みです。以下の展開はこちらを参考にしました。
まず、ベイズの定理の式変形を行います。\begin{align} &p(A, B, C) = p(A|B, C)p(B, C) = p(B, C|A)p(A) \\ \Rightarrow& p(A|B, C) = \frac{p(B, C|A)p(A)}{p(B, C)} \end{align}ここまでは一般に成り立ちます。
次に、BとCは独立かつAを与えたもとで条件付き独立であるとします。すると次の式が得られます。
\begin{align} p(A|B, C) &= \frac{p(B, C|A)p(A)}{p(B, C)} \\ &= \frac{p(B|A)p(C|A)p(A)}{p(B)p(C)} \\ &= \frac{p(C|A)}{p(C)}\frac{p(B|A)p(A)}{p(B)} \\ &= \frac{p(C|A)}{p(C)}p(A|B) \end{align}さて、Aに$w$を、Bに最初に観測されたデータ$x_1$を、Cに二つ目に観測されたデータ$x_2$を入れてみます。
「$x_1$と$x_2$は独立かつ$w$を与えたもとで条件付き独立」とは、観測されたデータたちは独立に分布から生成されており、かつ尤度(=モデル)も$x_1$と$x_2$が独立になるようにモデリングするということを意味します。この特性は時系列に相関があるようなデータでは成り立たないことに注意してください。
このとき、次の式が成り立ちます。\begin{align} p(w|x_1, x_2) = \frac{p(x_2|w)}{p(x_2)}p(w|x_1) \end{align}データ$x_1$と$x_2$が与えられたもとでの$w$の事後分布は、$p(w|x_1)$を事前分布にもつ、$x_2$と$w$のベイズの定理になっています!
この関係を利用して、適当な事前分布を与える→データが与えられたら事後分布を求める→事後分布を事前分布に読み替える→データが与えられたら事後分布を求める→...と逐次的に事後分布を更新することができます。これがベイズ更新の仕組みです。ベイズ更新の例
こちらを参考にしてベイズ更新を計算してみます。
歪んだコインを考えます。このコインで表が出る確率をベイズ推定してみましょう。コインの出目はそれぞれの試行で独立に得られるとします。
まず、コインの出目について尤度、すなわちモデルを考えます。コインの表裏は二値変数なのでベルヌーイ分布に従います。したがって尤度はベルヌーイ分布になります。表を$x=1$、裏を$x=0$に対応させます。$w$は0から1の間の実数で、表が出る確率そのものに対応します。したがって、ベイズ更新で求められる$w$の分布そのものが、表が出る確率の分布になります。ベルヌーイ分布は次のように書けます。
\begin{align} p(x|w) = w^x(1-w)^{1-x} \end{align}事前分布は無情報事前分布として$p(w)=1$としましょう。$p(x)$は未知ですが、$w$に注目した場合は規格化定数なので、$p(w|x)$の積分が1になる条件から自動的に求めることができます。
では、コインを振っていきます。
1回目:表
\begin{align} p(w|x_1=1) \propto p(x_1=1|w)p(w) = w \end{align}0から1まで積分すると1になるので、すでに規格化されています。
\begin{align} p(w|x_1=1) = w \end{align}これが2回目の事前分布$p(w) = p(w|x_1=1) = w$になります。
2回目:表
\begin{align} p(w|x_1=1, x_2=1) \propto p(x_2=1|w)p(w) = w^2 \end{align}積分すると、1/3になるので、規格化すると次のようになります。
\begin{align} p(w|x_1=1, x_2=1) = 3w^2 \end{align}これが3回目の事前分布$p(w) = p(w|x_1=1, x_2=1) = 3w^2$になります。
3回目:裏
\begin{align} p(w|x_1=1, x_2=1, x_3=0) \propto p(x_3=0|w)p(w) = 3(1-w)w^2 \end{align}積分すると、1/4になるので、規格化すると次のようになります。
\begin{align} p(w|x_1=1, x_2=1, x_3=0) = 12(1-w)w^2 \end{align}このようにして、コインが表になる確率$w$の分布を求めることができます。
ベイズ更新の例の実装
上で見た例をPythonで実装してみましょう。実装はこちらを参考にしました。
import sympy import numpy as np import matplotlib.pyplot as plt np.random.rand() # コインの表裏の系列 xs = [1, 1, 0] # 表、表、裏 # 事前分布は無情報事前分布とします prior_prob = 1 # 積分するシンボル w = sympy.Symbol('w') # 初期化しておきます # jupyter notebookで繰りし実行する場合に必要です posterior_prob = None # 事後分布の逐次計算 for x in xs: # 事後分布(未規格化)を計算 if x==1: posterior_prob = w*prior_prob else: posterior_prob = (1-w)*prior_prob # 規格化 Z = sympy.integrate(posterior_prob, (w, 0, 1)) posterior_prob = posterior_prob/Z # 事前分布の置き換え prior_prob = posterior_prob plt.figure(figsize=(5, 4)) X = np.linspace(0, 1, 100) plt.plot(X, [posterior_prob.subs(w, i) for i in X]) plt.xlabel("w") plt.show()
おまけ
もう少しデータがある場合の推定をやってみます。
表が出る確率が0.35のコインで、試行回数を30回に増やして推定してみます。
データが増えるほど推定が正確になっていくので、分布がシャープになっていきます。import sympy import numpy as np import matplotlib.pyplot as plt np.random.rand(0) def bernoulli_sampler(w, n): """wは1が出る確率で、nは生成するデータの数""" xs = np.random.rand(n) xs = xs<w return xs.astype("int") # コインの表裏の系列 xs = bernoulli_sampler(0.35, 30) # 事前分布は無情報事前分布とします prior_prob = 1 # 積分するシンボル w = sympy.Symbol('w') # 初期化しておきます # jupyter notebookで繰りし実行する場合に必要です posterior_prob = None # 事後分布の逐次計算 for x in xs: # 事後分布(未規格化)を計算 if x==1: posterior_prob = w*prior_prob else: posterior_prob = (1-w)*prior_prob # 規格化 Z = sympy.integrate(posterior_prob, (w, 0, 1)) posterior_prob = posterior_prob/Z # 事前分布の置き換え prior_prob = posterior_prob plt.figure(figsize=(5, 4)) X = np.linspace(0, 1, 100) plt.plot(X, [posterior_prob.subs(w, i) for i in X]) plt.xlabel("w") plt.show()
おわりに
BとCは独立かつAを与えたもとで条件付き独立であるとする部分がポイントです。
- 投稿日:2020-01-23T22:12:41+09:00
ベイズ更新
はじめに
雰囲気でベイズ更新について語っていたので、きちんと勉強し直したいと思ってまとめました。n番煎じ記事です。
参考
- 5分でわかる(範囲の)ベイズ統計学(https://www.slideshare.net/matsukenbook/15-59154892)
- 確率分布のベイズ推定(http://arduinopid.web.fc2.com/P19.html)
- ココイチのスプーンの当選確率をベイズ推定する(https://rmizutaa.hatenablog.com/entry/2019/02/15/200700)
手順
ベイズ更新
ベイズ推定をざっくりまとめると、尤度(=モデル)のパラメータをMLEで点推定するのではなく、ベイズの定理を用いてパラメータの分布を推定するというものです。ベイズの定理は次の式で表されます。
p(w|x) = \frac{p(x|w)p(w)}{p(x)}$p(x|w)$が尤度(=モデル)、$p(w)$が事前分布、$p(x)$がデータの発生確率です。$p(w|x)$を事後分布と言います。
この式は、モデルのパラメータ$w$の事前分布に尤度をかけることで、データ$x$が与えられたときのパラメータ$w$の分布(事後分布)が得られるという式になっています。ベイズ更新はベイズの定理を使用して、逐次的に事後分布を更新する仕組みです。以下の展開はこちらを参考にしました。
まず、ベイズの定理の式変形を行います。\begin{align} &p(A, B, C) = p(A|B, C)p(B, C) = p(B, C|A)p(A) \\ \Rightarrow& p(A|B, C) = \frac{p(B, C|A)p(A)}{p(B, C)} \end{align}ここまでは一般に成り立ちます。
次に、BとCは独立かつAを与えたもとで条件付き独立であるとします。すると次の式が得られます。
\begin{align} p(A|B, C) &= \frac{p(B, C|A)p(A)}{p(B, C)} \\ &= \frac{p(B|A)p(C|A)p(A)}{p(B)p(C)} \\ &= \frac{p(C|A)}{p(C)}\frac{p(B|A)p(A)}{p(B)} \\ &= \frac{p(C|A)}{p(C)}p(A|B) \end{align}さて、Aに$w$を、Bに最初に観測されたデータ$x_1$を、Cに二つ目に観測されたデータ$x_2$を入れてみます。
「$x_1$と$x_2$は独立かつ$w$を与えたもとで条件付き独立」とは、観測されたデータたちは独立に分布から生成されており、かつ尤度(=モデル)も$x_1$と$x_2$が独立になるようにモデリングするということを意味します。この特性は時系列に相関があるようなデータでは成り立たないことに注意してください。
このとき、次の式が成り立ちます。\begin{align} p(w|x_1, x_2) = \frac{p(x_2|w)}{p(x_2)}p(w|x_1) \end{align}データ$x_1$と$x_2$が与えられたもとでの$w$の事後分布は、$p(w|x_1)$を事前分布にもつ、$x_2$と$w$のベイズの定理になっています!
この関係を利用して、適当な事前分布を与える→データが与えられたら事後分布を求める→事後分布を事前分布に読み替える→データが与えられたら事後分布を求める→...と逐次的に事後分布を更新することができます。これがベイズ更新の仕組みです。ベイズ更新の例
こちらを参考にしてベイズ更新を計算してみます。
歪んだコインを考えます。このコインで表が出る確率をベイズ推定してみましょう。コインの出目はそれぞれの試行で独立に得られるとします。
まず、コインの出目について尤度、すなわちモデルを考えます。コインの表裏は二値変数なのでベルヌーイ分布に従います。したがって尤度はベルヌーイ分布になります。表を$x=1$、裏を$x=0$に対応させます。$w$は0から1の間の実数で、表が出る確率そのものに対応します。したがって、ベイズ更新で求められる$w$の分布そのものが、表が出る確率の分布になります。ベルヌーイ分布は次のように書けます。
\begin{align} p(x|w) = w^x(1-w)^{1-x} \end{align}事前分布は無情報事前分布として$p(w)=1$としましょう。$p(x)$は未知ですが、$w$に注目した場合は規格化定数なので、$p(w|x)$の積分が1になる条件から自動的に求めることができます。
では、コインを振っていきます。
1回目:表
\begin{align} p(w|x_1=1) \propto p(x_1=1|w)p(w) = w \end{align}0から1まで積分すると1になるので、すでに規格化されています。
\begin{align} p(w|x_1=1) = w \end{align}これが2回目の事前分布$p(w) = p(w|x_1=1) = w$になります。
2回目:表
\begin{align} p(w|x_1=1, x_2=1) \propto p(x_2=1|w)p(w) = w^2 \end{align}積分すると、1/3になるので、規格化すると次のようになります。
\begin{align} p(w|x_1=1, x_2=1) = 3w^2 \end{align}これが3回目の事前分布$p(w) = p(w|x_1=1, x_2=1) = 3w^2$になります。
3回目:裏
\begin{align} p(w|x_1=1, x_2=1, x_3=0) \propto p(x_3=0|w)p(w) = 3(1-w)w^2 \end{align}積分すると、1/4になるので、規格化すると次のようになります。
\begin{align} p(w|x_1=1, x_2=1, x_3=0) = 12(1-w)w^2 \end{align}このようにして、コインが表になる確率$w$の分布を求めることができます。
ベイズ更新の例の実装
上で見た例をPythonで実装してみましょう。実装はこちらを参考にしました。
import sympy import numpy as np import matplotlib.pyplot as plt np.random.rand() # コインの表裏の系列 xs = [1, 1, 0] # 表、表、裏 # 事前分布は無情報事前分布とします prior_prob = 1 # 積分するシンボル w = sympy.Symbol('w') # 初期化しておきます # jupyter notebookで繰りし実行する場合に必要です posterior_prob = None # 事後分布の逐次計算 for x in xs: # 事後分布(未規格化)を計算 if x==1: posterior_prob = w*prior_prob else: posterior_prob = (1-w)*prior_prob # 規格化 Z = sympy.integrate(posterior_prob, (w, 0, 1)) posterior_prob = posterior_prob/Z # 事前分布の置き換え prior_prob = posterior_prob plt.figure(figsize=(5, 4)) X = np.linspace(0, 1, 100) plt.plot(X, [posterior_prob.subs(w, i) for i in X]) plt.xlabel("w") plt.show()
おまけ
もう少しデータがある場合の推定をやってみます。
表が出る確率が0.35のコインで、試行回数を30回に増やして推定してみます。
データが増えるほど推定が正確になっていくので、分布がシャープになっていきます。import sympy import numpy as np import matplotlib.pyplot as plt np.random.rand(0) def bernoulli_sampler(w, n): """wは1が出る確率で、nは生成するデータの数""" xs = np.random.rand(n) xs = xs<w return xs.astype("int") # コインの表裏の系列 xs = bernoulli_sampler(0.35, 30) # 事前分布は無情報事前分布とします prior_prob = 1 # 積分するシンボル w = sympy.Symbol('w') # 初期化しておきます # jupyter notebookで繰りし実行する場合に必要です posterior_prob = None # 事後分布の逐次計算 for x in xs: # 事後分布(未規格化)を計算 if x==1: posterior_prob = w*prior_prob else: posterior_prob = (1-w)*prior_prob # 規格化 Z = sympy.integrate(posterior_prob, (w, 0, 1)) posterior_prob = posterior_prob/Z # 事前分布の置き換え prior_prob = posterior_prob plt.figure(figsize=(5, 4)) X = np.linspace(0, 1, 100) plt.plot(X, [posterior_prob.subs(w, i) for i in X]) plt.xlabel("w") plt.show()
おわりに
BとCは独立かつAを与えたもとで条件付き独立であるとする部分がポイントです。
- 投稿日:2020-01-23T22:05:04+09:00
DjangoアプリをDocker上に構築しAWS Fargateにデプロイする
はじめに
AI、機械学習やビッグデータ解析などでPythonが注目されています。
Pythonを用いたウェブアプリケーションが今後増加することが予測される中、PythonのフレームワークであるDjangoを用いてアプリを作成し、AWS Fargateにコンテナでデプロイをするまでの一連の流れを今後投稿していきます。所属しているFintechスタートアップでの開発経験からDjango+Docker+AWS Fargateの構成は
1)学習コストが低い
2)共同開発しやすい
3)スケールしやすい
という特徴があり、個人やスタートアップによるwebアプリケーション開発のベストプラクティスであると考えています。項目毎に細切れに投稿していくので詳細については各投稿を参照してください。
日々記事を投稿しそのリンクを本ページに追加していくので、本ページは目次として使ってください。目次
1.なぜ今、Pythonなのか
2.Djangoについて
3.Dockerについて
(1)DockerでHello,World
4.Docker上でDjangoアプリケーションを動かす
5.PostgresSQL
6.アプリケーションの作成
(1)Custom User
(2)URLs
(3)Views
(4)認証機能
(5)環境変数
7.Emailの設定
8.ファイルのアップロード
9.権限
10.検索
11.Perfomance
12.セキュリティ
13.デプロイ
- 投稿日:2020-01-23T20:50:57+09:00
DockerでHello,World
はじめに
DockerをインストールしてHello,Worldを表示させます。
OSはMacを使用します。Docker for Macのインストール
DockerをインストールするためにDocker Hubで無料のアカウントを作成します。アカウントを作成後した後、下記リンクからDocker for Macをダウンロード、その後インストールします。
・Docker for Mac
インストール後 --versionでバーションが表示されればインストール成功。
$ docker --versionDockerでHello,World
“Hello, World” image を使用します。Dockerのテストrunに便利なイメージです。ターミナルでdocker run hello-wordを実行すると公式のDocker imageがコンテナにダウンロードされ、イメージが実行されます。
$ docker run hello-world Unable to find image 'hello-world:latest' locally latest: Pulling from library/hello-world 1b930d010525: Pull complete Digest: sha256:9572f7cdcc2963463447a53466950bc15a2d1917ca215a2f Status: Downloaded newer image for hello-world:latest Hello from Docker! This message shows that your installation appears to be working correctly. To generate this message, Docker took the following steps: 1. The Docker client contacted the Docker daemon. 2. The Docker daemon pulled the "hello-world" image from the Docker Hub. (amd64) 3. The Docker daemon created a new container from that image which runs the executable that produces the output you are currently reading. 4. The Docker daemon streamed that output to the Docker client, which sent it to your terminal. To try something more ambitious, you can run an Ubuntu container with: $ docker run -it ubuntu bash Share images, automate workflows, and more with a free Docker ID: https://hub.docker.com/ For more examples and ideas, visit: https://docs.docker.com/get-started/コンテナの情報を確認する
docker infoコマンドでDockerの情報が確認できます。
$ docker info ... Server: Containers: 1 Running: 0 Paused: 0 Stopped: 1 Images: 1 ...これでDockerがインストールされ無事に起動したことが確認できました。
- 投稿日:2020-01-23T19:24:26+09:00
pykakasiを使用したPythonコードについて、PyInstallerで生成したバイナリの実行時エラー「KeyError: '_max_key_len_'」を回避する
記事の内容
pykakasiを使用したPythonコードについて、PyInstallerで生成した実行ファイルを実行したら、エラー「KeyError: 'max_key_len'」が発生しました。
それを回避する方法を記録しておきます。
Linux(Ubuntu 18.04)、python 3.7.5で実行し、pipenvを使用しています。サンプルコード
この記事のコードを改変して使用しました。以下の3ファイルを使用し、foo.pyをバイナリにしたものを起動することにします。
foo.pyfrom mymod1 import bar from mymod2 import hoge bar("Hello!") hoge("ほげ!")mymod1.pydef bar(s): print(f"bar: {s}")mymod2.pyimport pykakasi def hoge(s): kakasi = pykakasi.kakasi() kakasi.setMode('H', 'a') kakasi.setMode('K', 'a') kakasi.setMode('J', 'a') conv = kakasi.getConverter() print(conv.do(s))実行時エラーが起きるまでの手順
端末で以下を実行して、モジュールをインストールします。
pipenv install setuptools pykakasi現段階で存在するファイルは以下の通りです。
$ ls Pipfile foo.py mymod1.py mymod2.py生成されたPipfileは以下の通り。
[[source]] name = "pypi" url = "https://pypi.org/simple" verify_ssl = true [dev-packages] [packages] setuptools = "*" pykakasi = "*" [requires] python_version = "3.7"端末で以下を実行して、実行ファイルを作成します。
pipenv run pyinstaller foo.pylsでファイルを確認すると、buildディレクトリとdistディレクトリが生成されています。
$ ls Pipfile build dist foo.py foo.spec mymod1.py mymod2.py「dist/foo/foo」が実行ファイルですので、動かしてみると、以下のように「KeyError: 'max_key_len'」が発生しました。
$ dist/foo/foo bar: Hello! Traceback (most recent call last): File "foo.py", line 5, in <module> hoge("ほげ!") File "mymod2.py", line 10, in hoge conv = kakasi.getConverter() File "pykakasi/kakasi.py", line 91, in getConverter File "pykakasi/kanji.py", line 30, in __init__ File "pykakasi/kanji.py", line 126, in __init__ KeyError: '_max_key_len_' [6202] Failed to execute script foo実行時エラーの回避
dist配下のpykakashiの辞書が不足しているのが原因でした。
dist配下には、以下のように辞書が1つ存在します。$ ls dist/foo/pykakasi/data/ itaijidict3.db一方で、pipenvによるインストール先には8つの辞書がありました。
$ ls `pipenv --venv`/lib/python3.7/site-packages/pykakasi/data/ hepburndict3.db itaijidict3.db kunreidict3.db passportdict3.db hepburnhira3.db kanwadict4.db kunreihira3.db passporthira3.dbこれをdist配下にコピーします。
$ cp `pipenv --venv`/lib/python3.7/site-packages/pykakasi/data/* dist/foo/pykakasi/data/ $ ls dist/foo/pykakasi/data/ hepburndict3.db itaijidict3.db kunreidict3.db passportdict3.db hepburnhira3.db kanwadict4.db kunreihira3.db passporthira3.db再度バイナリを実行すると、以下のように正常に動きました。
$ dist/foo/foo bar: Hello! hoge!
- 投稿日:2020-01-23T19:01:42+09:00
運用/保守の手間を減らした話
前提
作業端末はWindows。運用/保守対象はUnix系サーバが数十台。
このUnix系サーバで必要なデータをCSV形式で生成し、Windows上でゴニョゴニョするのが目的。
以下言語はksh93とPython当時の状況
各サーバにログインしてコマンド叩いてテキストでデータ取ってた。
こんな非効率的なことはありえない。
改良してやる!改良
第一手
各Unix系サーバ上に、必要なデータをCSV化するスクリプト(以下moge.sh)をばらまく。
これで1台あたり数分まで短縮。
数十台でスクリプト実行してからFilezilla等で取ってくる。それからWindowsでゴニョゴニョする。
まだ面倒。第2手
どこか1台のサーバで全サーバのスクリプト起動できるようにして、ついでにコピーもしよう。
こんな感じkicker.kshcat servers.list | while read HOST ; do ssh ${HOST} -n /hoge/moge.sh scp ${HOST}:/hoge/moge.csv ./data/${HOST}.csv done終わったら1台から全CSVをFilezilla等で取ってくる。
でも直列だからスクリプトが終わるまで1時間位かかる。第3手
sshが遅いんだからこいつをバックグラウンドにしたらいいじゃん。
つーわけでこんな感じkicker2.kshcat servers.list | while read HOST ; do ssh ${HOST} /hoge/moge.sh & PID[${HOST}]=$! done while [[ ${#PID[*]} -ne 0 ]] ; do for HOST in ${!PID[*]} ; do if ! ps -ef | grep -w ${PID[${HOST}]} ; then scp ${HOST}:/hoge/moge.csv ./data/${HOST}.csv unset PID[${LPAR}] fi done sleep 1 done数分で終わるようになったけど、結局WindowsからFilezilla的なものが面倒。
第4手
CSVをゴニョゴニョするのにexcel作れるPythonが都合がいいってことで言語決定。
※自分がお勉強したかったからという理由も当然ある。
こんな感じkicker3.pywith open("server.lst", "r", encoding='shift-jis') as fd: for host in fd: proc = subprocess.Popen(["ssh", host, "/hoge/moge.sh"], stdout=DEVNULL, stderr=DEVNULL) proclist[proc.pid] = proc while proclist: for pid in list(proclist): if proclist[pid].poll() is not None: del proc[pid] subprocess.Popen(["scp", host + ":/hoge/moge.csv", "./" + host + ".csv"], stdout=DEVNULL, stderr=DEVNULL) sleep(1)WSLだと動く、でもコマンドプロンプト向けにすると途中で止まる。server.listの中身を少なくする(5~6個まで)なら動く。
なんで?第4手延長戦
全くわからなかったので、取り敢えずPythonのasyncioで非同期実行させたほうが
いいかもしれない。ということで研究開始。
紆余曲折を経てこんな感じ。kicker4.pyasync def _run(host): ssh = "ssh %s /hoge/moge.sh" % host p = await asyncio.create_subprocess_exec(ssh, stdout=DEVNULL, stderr=DEVNULL) await p.wait() scp = ["scp", host + ":/hoge/moge.csv", "./" + host + "%s.csv"] p = subprocess.run(scp, stdoutDEVNULL, stderr=DEVNULL) loop = asyncio.ProactorEventLoop() asyncio.set_event_loop(loop) with open("server.lst", "r", encoding='shift-jis') as fd: funcs = asyncio.gather(*[_run(host) for host in fd]) loop.run_until_complete(funcs)これまた動かない。全く事象は変わらない。
ここで気づいたこと。止まったときにEnterを叩くと動く。
なんで?
標準入力がなにか問題?解決
最初のkshのスクリプトに正解が書いてあります。
sshの"-n"オプションが原因です。
kshではreadとsshが標準入力を食い合うから"-n"が必要だと思っていたので、
最初からつけていました。ところがPythonはssh以外に標準入力を食うやつが
いないので、何もしないでもいいだろうという先入観が問題だったようです。
バックグラウンドで複数のsshを起動するにあたり、標準入力は制御が必要なようです。
(stdin=subprocess.DEVNULLは駄目でした)
WSLで動いたのはまだ謎のままですが、もう使わないので調査しません。なぜWSLを使わなくしたのか
Pythonスクリプトの中で、Windowsでゴニョゴニョのためにopenpyxlも使っています。
これがWSL上だと時々BSODを食らわしてくれるので、コマンドプロンプトから動く
ように改修しました。素朴な疑問
なんでsubprocessってコマンドの与え方が複数あるんだろう?統一したらいいのに。
- 投稿日:2020-01-23T18:30:04+09:00
Auth0を使ってPython/Flaskで手軽に多機能なログイン/ログアウトを実現する 修正
参考サイト
Auth0を使ってPython/Flaskで手軽に多機能なログイン/ログアウトを実現する
https://blanktar.jp/blog/2017/11/python-flask-auth0.html上記サイトに一部、動かない部分があったので修正した。
修正箇所
from jwt.algorithms import RSAAlgorithm @app.route('/callback') def auth_callback(): # Auth0がくれた情報を取得する。 resp = auth0.authorized_response() if resp is None: return 'nothing data', 403 # 署名をチェックするための情報を取得してくる。 jwks = json.loads(urllib.request.urlopen("https://"+AUTH0_DOMAIN+"/.well-known/jwks.json").read()) # JWT形式のデータを復号して、ユーザーについての情報を得る。 # ついでに、署名が正しいかどうか検証している。 try: payload = jwt.decode(resp['id_token'], RSAAlgorithm.from_jwk( json.dumps(jwks['keys'][0])), audience=AUTH0_CLIENT_ID, algorithms='RS256') except Exception as e: print(e) return 'something wrong', 403 # 署名がおかしい。 # flaskのSessionを使ってcookieにユーザーデータを保存。 flask.session['profile'] = { 'id': payload['sub'], 'name': payload['name'], 'picture': payload['picture'], } # マイページに飛ばす。 return flask.redirect(flask.url_for('mypage'))
- 投稿日:2020-01-23T18:24:26+09:00
PyKNPでJUMAN++を使ったらValueErrorが出た
エラー内容
PyKNPからJuman++を使って日本語文を形態素分解しようとしたらこんなエラーが...!
ValueError: invalid literal for int() with base 10: 'input'
(PythonからJuman, Juman++を使う方法は省略)File "/$HOME/.pyenv/versions/anaconda3-2019.03/lib/python3.6/site-packages/pyknp/ juman/morpheme.py", line 143, in _parse_spec self.hinsi_id = int(parts[4]) ValueError: invalid literal for int() with base 10: 'input'エラーの原因候補
とりあえずエラーメッセージを元に調べてみると
半角スペースとか、半角文字が悪さをしてしまう模様。
入力テキストの修正
ということで半角文字を全部全角文字に置き換えます。
しかし
半角文字を全部全角文字、修正しても同じエラーが出続けた。
どうやら上記記事の状況とは原因が違うらしい。原因判明
関係ないけどpdbって便利よね
そこでpdbで実行し、エラー時の変数
partsの中身をチェックしてみた最初からそうしろ。(Pdb) parts ['InvalidParameter:', 'byte', 'size', 'of', 'input', 'string', '(4302)', 'is', 'greater', 'than│(base) ', 'maximum', 'allowed', '(4096)'](エラー発生時に本来は解析結果が入るリストにエラー内容が入る仕様だったとは...)
どうも入力文字列のサイズ(バイト数)が大きすぎたそうです。
入力文字列の限界は合計4096バイトみたいなのでそれ以下の容量に制限した方が良さそう。とりあえず解決法
BERTに流すデータセットを作る過程だったんですが、長すぎる文はパス!
UTF-8は文字種によってバイト数が違うっぽいのでカットするのめんどくさい4096バイトより大きい文は次のような条件で検出して何らかの回避策をしましょう。
(分割するなりパスするなり)
これは文字列textのバイト数を調べて比較しています。if len(text.encode('utf-8')) > 4096:文字列の文字数長ではなくバイト数を調べる方法はこちら
まとめ
PyKNPからJuman++を使う時にエラーが発生する原因は、以上で紹介した記事と合わせると
でした。
- 投稿日:2020-01-23T18:02:16+09:00
【備忘録】ExcelからPythonのコードを実行する(xlwings)
他者のPC上で行う業務(Excelのデータ加工)の自動化のため、openpyxl + PyInstallerで自動化ツールを作成するものの起動が遅くてイライラ。かといって、Excel VBAを覚えるのもめんどくさい。もっと楽な方法ないかな~と思っていたら以下の記事を発見。
ExcelからPythonコードを呼び出して使えるとのこと。しかし、どうもうまくいかない。そんなときに以下の記事を発見。
これが上手くいった。
Excelが入っているWindows PCにAnacondaインストール&ちょっと設定して貰えれば、ExcelファイルとPythonファイルを渡すだけで良くなりそう。
なので備忘録にまとめた。環境
- Windows 10 Home Edition
- PyCharm Community Edition 2019.1.3
- Anaconda 3(xlwings==0.15.8 pywin32==223)
- Excel(Office 365)
ExcelからPythonコードを実行する(やり方)
前述の環境は整っている前提。xlwingsとpywin32はAnacondaとセットでインストールされる。
①Excel マクロ有効ブック(*.xlsm)を作成する
後で作成するPythonコードとExcel マクロ有効ブックは、
1)同じディレクトリにあること
2)ファイル名(拡張子より前)が同一であること
が動作の必要条件。それを考慮したファイル名にすること。
今回はファイル名を「excel_test.xlsm」とした。②Excel VBEにxlwings.basをインポート
1)Excelを起動し、開発タブの「Visual Basic」をクリックしてVBEを起動
2)VBEのファイル>ファイルのインポートをクリックし、下記パスのファイル(xlwings.bas)を選択、インポート
パス:C:\Users{ユーザー名}\Anaconda3\pkgs\xlwings-{xlwingsのバージョン}-py{Pythonのバージョン}\Lib\site-packages\xlwings\xlwings.bas
インポートが成功していれば、下図のとおり、標準モジュールフォルダに「xlwings」ができる。
③Pythonファイルを作成
前述のとおり、Excel マクロ有効ブックと同じファイル名(拡張子より前)で、同じディレクトリに作成すること。
今回はファイル名を「excel_test.py」とし、コードは下記内容とした。excel_test.py# coding: utf-8 import xlwings as xw def copy_add_text(): txt = xw.Range('A1').value txt += ', I am the Doctor.' xw.Range('B3').value = txt④VBEで標準モジュールを追加し、Pythonファイルのメソッドを呼び出すコードを記述
コードの内容は以下のとおり。
1 Option Explicit 2 3 Public Sub copyText() 4 Call RunPython("import excel_test; excel_test.copy_add_text()") 5 End Sub【補足】
4行目の引数は、"import モジュール名; モジュール名.メソッド名"とする。
※モジュール名=Pythonファイル名(拡張子不要)⑤Excelの開発タブ>マクロにメソッドが追加されているので呼び出す
今回のコードは「●●, I am the Doctor.」の●●にA1セルの文字列が代入されたものをB3セルに貼り付けるというもの。
実行結果は下図のとおり。
その他
pywin32==227でwin32apiのインポートエラーが発生。
pywin32==224にしたら解決。
詳細は不明。

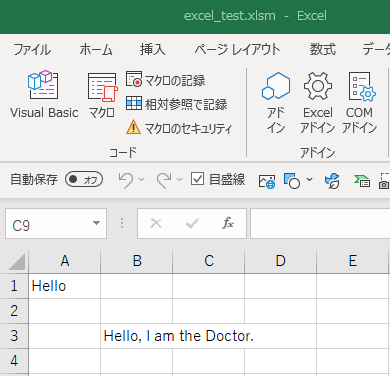
- 投稿日:2020-01-23T17:54:06+09:00
VagrantでLinux(CentOS)構築時に正しくソフトウェアをバージョンアップする方法 〜Python2.7からPython3.6へのバージョンアップの例を用いて〜
PATHとは?
Linuxに限らず、コマンドを実行する際にフルパスを書く必要がないのはPATHにそのパスの情報が保存されているからです。例えば、Linuxをシャットダウンする際に
/usr/sbin/shutdown -h nowではなくshutdown -h nowと書いて実行できるのは、/usr/sbin/がPATHに登録されているからです。PATHの確認方法
以下を実行。
echo $PATH実行結果:
自分の場合、いじったのでこうなっています。PATHは何個でも登録してもよく、
:で各パスに区切られています。バージョンが違う同じソフトウェアを入れた時の対処
例えばCentOS7だとディフォルトで
python 2.7が入っています。python --versionを実行すると、そのバージョン情報が出てきます。
ここで、新たに以下のコマンドを叩きRed Hut Enterprise Linuxを使用してpython 3.6を落としてくるとします。sudo yum -y install centos-release-scl; sudo yum -y install rh-python36; sudo scl enable rh-python36 bash;この後に
python --versionを実行すると、python 3.6を見ていますが、Vagrantの操作等でパスを再度読み込んだ際に元に戻ってしまいます。これはRed Hut Enterprise Linuxで落としたpython 3.6が/usr/binには行かずに/opt/rh/rh-python36/root/bin/へ落ちるためです。この/opt/rh/rh-python36/root/bin/をPATHへ登録し、/usr/binにあるpython2.7を取り除かない限りは綺麗にpythonのバージョンアップができません。ちなみにLinuxが参照しているpythonのパスは以下のコマンドでわかります。which python
pythonに限らず、なんでもこのwhichでLinuxが参照しているコマンドの実際のパスがわかります。
python2.7など、古いバージョンのプログラムを取りのぞくときは、rmコマンドで削除するより、mvコマンドで名前を変えて取り置いといた方がいいです。以下Pythonの例をとった時のコマンドです。sudo mv /usr/bin/python2.7 /usr/bin/python2.7_oldこれでLinuxがPython2.7を退避することができます。
PATHの変更方法
いくつかあると思いますが、自分が好きなのは
sourceコマンドで~/.bash_profileというファイルを取り込む方法です。~/.bash_profileにはPATHの情報があり、source ~/.bash_profileを実行することでPATH登録が行われます。シェルスクリプトでこれを実行する人に注意して欲しいんですが、この~がどこなのかスクリプト内に明記しておくべきです。というのもルートユーザーと一般ユーザーでは~の部分が違います(動画参照)。
Vagrantfileにシェルを仕込ませて実行した場合、~がどちらを向いてるか自分はわからなかった(vagrant provisionを行うと実行ユーザーはvagrantなのに~は/root/側を見ているようだった)ので、明記しました。結果、以下のコマンドでPATHを読み込ませました。
#/home/vagrant/.bash_profileにPATH情報を設定 echo "export PATH="/opt/rh/rh-python36/root/bin:/usr/bin:/usr/sbin"" >> /home/vagrant/.bash_profile; #PATH情報を登録 source /home/vagrant/.bash_profile;最後に
上記のステップを押さえておけば、どんなソフトウェアでも問題なくバージョンアップが可能です。
自分はsqlite 3.2をsqlite 3.29へ同じアプローチでバージョンアップできました。

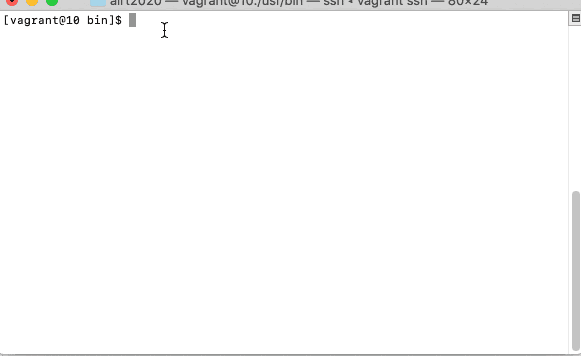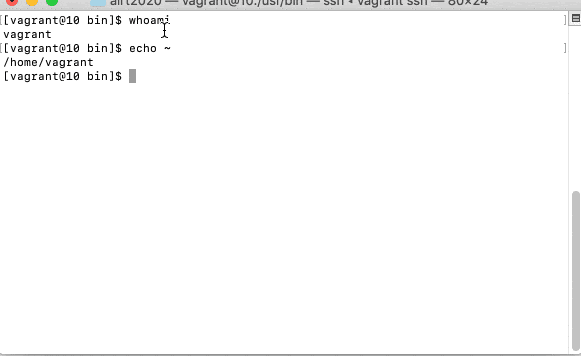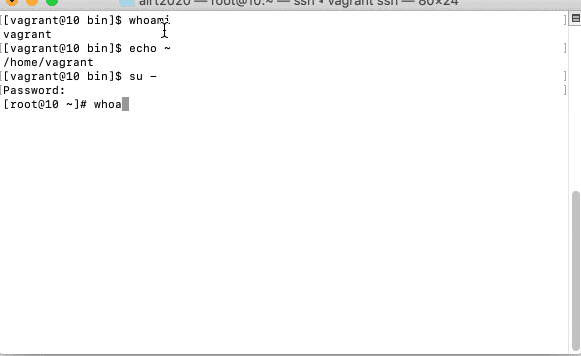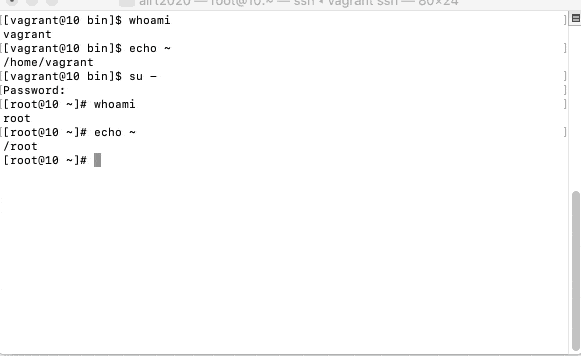
- 投稿日:2020-01-23T16:53:11+09:00
冬だけどサマーウォーズのケンジ君の脳内を考えてみた(継続は力なり?
記事をご覧くださりありがとうございます。
どうも、びりどらです。
メンタルが壊れて昨年10月に会社を退職して、
ほうれん草を植えたり、カメを買い始めたり
謎のチャレンジをしている変人です。
びりどら(ひとり)はみんなのために...(謎の宣言
※専門家ではないので、内容に不備があるかもしれません、ご了承ください。取り扱う内容
この記事は某アニメのキャラクターケンジ君が、夏樹先輩の誕生日(年月日)から曜日を脳内算出していて
すごいと思いつつ、pythonで自分なりにツェラーの公式(モジュロ演算)した記事です。(1)ヒートショック危険お知らせ装置/(ラジオ体操)圧電ブザー演奏装置の開発
(2)OpenCvを用いてホウレンソウの成長把握/OpenCVを用いてマクロ(陸ガメ)の生態把握
(3)GPSの猛勉強・GPS便利ツールなどを作る
(4)アルゴリズムのお勉強
(5)PHPフレームワークのお勉強
(-) メンタルの療養←ココソースコード
Zeller.py# -*- coding: utf-8 -*- import math import sys args = sys.argv YYYYMMDD = args[1] def main(): #びりメモ:切り捨てで整数化:math.floor() """ 0 :土 1 :日 2 :月 3 :火 4 :水 5 :木 6 :金 """ yearU =int(YYYYMMDD[-8])*10+int(YYYYMMDD[-7]) yearD =int(YYYYMMDD[-6])*10+int(YYYYMMDD[-5]) month =int(YYYYMMDD[-4])*10+int(YYYYMMDD[-3]) day =int(YYYYMMDD[-2])*10+int(YYYYMMDD[-1]) if month == 1: yearD = yearD-1 month = 13 elif month == 2: yearD = yearD-1 month = 14 #曜日を求める計算(ツェラーの公式) week=(day+math.floor(((month+1)*26)/10)+(yearD)+math.floor(yearD/4)+math.floor(yearU/4)-(2*yearU))%7 if week == 0: print("土") elif week == 1: print("日") elif week == 2: print("月") elif week == 3: print("火") elif week == 4: print("水") elif week == 5: print("木") elif week == 6: print("金") else: print("err") if __name__ == '__main__': main()コマンドラインに下記通り、YYYYMMDD形式で入力すると曜日が出てきます。
(base) C:\Users\BiriDora\Desktop>python Zeller.py 20200125 土エンジニアスキルについて
(保留)
最後に
自分も四則演算がぱぱっと脳内でできるといいんですけどね。
(お仕事)よろしくお願いしまーす!(苦笑)この記事をご覧になった方。
pythonはSwith文がありません。ですので、if文で書きました。数値演算は面白いので、よかったら、実行させてみてください。
それでは✋
- 投稿日:2020-01-23T15:12:54+09:00
ExcelファイルをJSONに一括変換【Python】
注意:Python初心者のメモです。
Pythonの
excel2jsonというプラグインを使用してxlsxをJSONに変換した。
excel2jsonの機能は限られていて、ただ Excel データを JSON に変換するだけ。ドキュメントには変換する方法しか書いてないので、設定も特になさそう。参考サイト先にもあるとおり
Pandasを使う方法もあったが、今回は変換方法をよしなにして欲しかったためexcel2jsonを使ってみた。あと整数は浮動小数点数に変換されるらしい。ぜひ以下のサイトもご覧ください。参考:
- Python Excel to JSON Conversion - JournalDev
- excel2json-3 · PyPI(Excel to JSON Converter)import excel2json xlsx_path = 'C:/Users/username/Documents/xlsx_files/hoge.xlsx' excel2json.convert_from_file(xlsx_path) # --> C:/Users/username/Documents/xlsx_files/Sheet1.json が出力されるExcel のシート名がそのまま出力ファイル名になる。出力ファイル名指定は正直欲しかった。この仕様は限られた用途にしか使えないかも……
ファイル群を一括変換!!
Tobiiっていう視線解析ソフトからExcelファイルを書き出せて、視線データを自分のプログラムで解析したかった。なのでソフトから出力した複数の Excel ファイル群を一斉に JSON に変換したかった。一応、一斉変換のコードも置いておく。
ループさせて複数のファイルを変換するとき、作成された JSON ファイルを常に上書きしようとするので(名前が同じ)、毎回 Rename する必要がある。シートが複数ある場合は
Sheet2.jsonとかが出てくるので対策が必要。
私の場合、Dataという名前のシートが1つだけだったので仕様としては十分。import excel2json import pathlib import os from halo import Halo from shutil import move spinner = Halo(spinner='dots') # loading画面のぐるぐる path = 'C:/Users/username/Documents/xlsx_files' # xlsxファイル群が入ってるpath xlsx_files = list(pathlib.Path(path).glob('*.xlsx')) # xlsxファイル群のリストを作る for i in xlsx_files: xlsx_path = '%s/%s' % (path, i.name) # xlsxファイルのpathと名前 if os.path.exists(json_path): # 既にjsonファイルがあればスキップ print('Skip to %s' % i.name) else: try: spinner.start('Converting: %s' % i.name) excel2json.convert_from_file(xlsx_path) # jsonに変換 except Exception as inst: # 変換失敗 spinner.fail(inst) else: # 変換成功 json_path = '%s/output/%s.json' % (path, i.name[:-5]) # jsonファイルの出力先path move('%s/Data.json' % path, json_path) #Data.jsonをRenameして移動 spinner.succeed('Success: %s.json' % i.name[:-5])※ 出力先のフォルダ(outputフォルダ)は先に作っておかないと怒られる(それはそう)。
※ TobiiのソフトからExcelを出力すると、シート名はData固定になる。参考:
- pythonでフォルダ内のファイル名のみ取得する方法
- Pythonメモ : haloでターミナルにスピナー(処理中)を表示
- 投稿日:2020-01-23T14:53:16+09:00
Tello Eduを子機にしてwifiアクセスポイントに接続する【python】
1 Telloを起動し、PCをTelloに接続する
この段階では、Tello(親機)、PC(子機)となっている
2 プログラムを実行しTelloをwifiに接続する
tello_wifi_access.pyimport socket tello_ip = '192.168.10.1' tello_port = 8889 socket = socket.socket(socket.AF_INET, socket.SOCK_DGRAM) tello_address = (tello_ip , tello_port) socket.sendto('command'.encode('utf-8'),tello_address) socket.sendto('ap SSID PASSWORD'.encode('utf-8'),tello_address)SSIDとPASSWORDは接続するwifiのものに変更してください。
そうするとTelloは子機モードになり、SSIDのwifiに接続します。
一度設定すると設定は保存され、次回Telloが起動したときも自動的にwifiに接続します。
- 投稿日:2020-01-23T14:48:10+09:00
Tensorflowの用語集
tensorflowの関数は説明してもわかりにくいので、使用例のみで解説します。
tf.Variable()
import tensorflow as tf x = tf.Variable(10 , name="x") y = x * 5 print(y)出力
Tensor("mul_1:0", shape=(), dtype=int32)上記のコードを見ると、出力が50のように思えますが、テンソルが出力されます。
では、次に、50が出力されるにはどのようにすればよいでしょうか。x = tf.Variable(10 , name="x") y = x * 5 sess = tf.InteractiveSession() sess.run(tf.global_variables_initializer()) sess.run(y)出力50
tensorflowでは、tf.sessionを通じて計算グラフを構築して実行しなければいけません。tf.global_variables_initializer()は、計算グラフ内の変数の初期化の役割を果たしますtf.placeholder()
tf.placeholder(dtype, shape=None, name=None)
dtype: 変数に代入される型を代入します。
shape: 割り当てる変数のshape
name: 変数の名前返り値
直接評価されない、feedされる変数のTensorプログラム例
x = tf.placeholder(tf.int32) y = tf.constant(1) z = x + y with tf.Session() as sess: print(sess.run(z, feed_dict={x: 2}))出力
3
x=2を実行時に定義
次に、、tf.placeholderに配列を渡します。x = tf.placeholder(tf.int32, shape=[2]) y = tf.placeholder(tf.int32, shape=[2]) z = x*y with tf.Session() as sess: print(sess.run(z, feed_dict={x: [2, 1], y: [1, 2]}))出力
[2 2]tf.placeholder_with_default
tf.placeholder_with_defaultを使うことで、初期値を決められる、かつ、実行時に変更もできます。
x = tf.placeholder_with_default(1, shape=[]) y = tf.constant(1) with tf.Session() as sess: print(sess.run(x + y))出力
0x = tf.placeholder_with_default(1, shape=[]) y = tf.constant(1) with tf.Session() as sess: print(sess.run(x + y, feed_dict={x: -1}))出力
2tf.shape
tf.shapeは動的に変更されうるshapeに使用します。
x = tf.placeholder(tf.int32, shape=[None, 3]) size = tf.shape(x)[0] sess = tf.Session() sess.run(size, feed_dict={x: [[1, 2, 3], [1, 2, 3]]})出力
2.get_shape
.get_shapeは変更されないshapeに使用します。
x = tf.constant(1, shape=[2, 3, 4]) x.get_shape()[1]出力
Dimension(3)参考文献
Tensorflowで学ぶディープラーニング入門
- 投稿日:2020-01-23T14:46:57+09:00
Pythonで前月を計算する
意外とめんどくさかったのでメモしておきます。
サードパーティのpython-dateutilというモジュールを使います。datetime.timedeltaで計算できるかと思いましたが、月の計算には対応していないようでした。pip install python-dateutilfrom datetime import datetime, date, timedelta from dateutil.relativedelta import relativedelta today = datetime.today() previous_month = today - relativedelta(months=1) print(previous_month.month)12
- 投稿日:2020-01-23T14:17:05+09:00
Pytorchによる1D-CNN,2D-CNNスクラッチ実装まとめ
はじめに
TensorFlowからPytorchに移行して半年ほど経ったので基礎的なところをまとめておきます。
今回は以下の3つに焦点を当てたいと思います。
- 事前学習モデルの利用
- 1DCNNの実装
- 2DCNNの実装
*1DCNNは簡単に説明して、2DCNNに焦点を当てたいと思います。
*理論的なことについては書いておりません。実装中心の記事です。1.事前学習モデルの利用
現在使える事前学習済モデルは以下のモデルです。
- AlexNet
- VGG
- ResNet
- SqueezeNet
- DenseNet
- Inception v3
- GoogLeNet
- ShuffleNet v2
- MobileNet v2
- ResNeXt
- Wide ResNet
- MNasNet
ImageNetでの学習済モデルを使用する際は以下のように使います。
import torchvision model = torchvision.models.alexnet(pretrained=True)
pretrained=TrueにしないとImageNetでの学習済の重みはロードされません。デフォが
pretrained=Falseになっているので注意してください。モデルの構造を確認したければ
print(model)で確認出来ます。以下が実行結果です。AlexNet( (features): Sequential( (0): Conv2d(3, 64, kernel_size=(11, 11), stride=(4, 4), padding=(2, 2)) (1): ReLU(inplace=True) (2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False) (3): Conv2d(64, 192, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2)) (4): ReLU(inplace=True) (5): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False) (6): Conv2d(192, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (7): ReLU(inplace=True) (8): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (9): ReLU(inplace=True) (10): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (11): ReLU(inplace=True) (12): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False) ) (avgpool): AdaptiveAvgPool2d(output_size=(6, 6)) (classifier): Sequential( (0): Dropout(p=0.5, inplace=False) (1): Linear(in_features=9216, out_features=4096, bias=True) (2): ReLU(inplace=True) (3): Dropout(p=0.5, inplace=False) (4): Linear(in_features=4096, out_features=4096, bias=True) (5): ReLU(inplace=True) (6): Linear(in_features=4096, out_features=1000, bias=True) ) )もし自分のデータでクラス分類したいときは、以下のように変更します。
2クラス分類を例にします。model.classifier[6].out_features = 2もう一度
print(model)を実行すると変わっているのが確認出来ます。AlexNet( (features): Sequential( (0): Conv2d(3, 64, kernel_size=(11, 11), stride=(4, 4), padding=(2, 2)) (1): ReLU(inplace=True) (2): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False) (3): Conv2d(64, 192, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2)) (4): ReLU(inplace=True) (5): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False) (6): Conv2d(192, 384, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (7): ReLU(inplace=True) (8): Conv2d(384, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (9): ReLU(inplace=True) (10): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)) (11): ReLU(inplace=True) (12): MaxPool2d(kernel_size=3, stride=2, padding=0, dilation=1, ceil_mode=False) ) (avgpool): AdaptiveAvgPool2d(output_size=(6, 6)) (classifier): Sequential( (0): Dropout(p=0.5, inplace=False) (1): Linear(in_features=9216, out_features=4096, bias=True) (2): ReLU(inplace=True) (3): Dropout(p=0.5, inplace=False) (4): Linear(in_features=4096, out_features=4096, bias=True) (5): ReLU(inplace=True) (6): Linear(in_features=4096, out_features=2, bias=True) ) )2. 1DCNNの実装
それでは本題に入ります。
今回は1DのCNNをスクラッチで実装します。
簡単な例です。import torch import torch.nn as nn class Net1D(nn.Module): def __init__(self): super(SimpleNet,self).__init__() self.conv1 = nn.Conv1d(1, 8,kernel_size=3, stride=1) self.bn1 = nn.BatchNorm1d(8) self.relu = nn.ReLU() self.maxpool = nn.MaxPool1d(kernel_size=3, stride=2) self.conv2 = nn.Conv1d(8, 16,kernel_size=3, stride=1) self.bn2 = nn.BatchNorm1d(16) self.conv3 = nn.Conv1d(16,64,kernel_size=3, stride=1) self.gap = nn.AdaptiveAvgPool1d(1) self.fc = nn.Linear(64,2) def forward(self,x): x = self.conv1(x) x = self.bn1(x) x = self.relu(x) x = self.maxpool(x) x = self.conv2(x) x = self.bn2(x) x = self.relu(x) x = self.maxpool(x) x = self.conv3(x) x = self.gap(x) x = x.view(x.size(0),-1) x = self.fc(x) return xもし、このモデルがうまく出来ているか確認するなら以下のように試してください。
model = SimpleNet() in_data = torch.randn(8,1,50) out_data = model(data) print(out_size.size()) #torch.Size([8, 2])
torch.randn()で適当な入力データを用意します。←このやり方便利です!2Dでも応用出来ます!- 入力は
torch.randn(バッチサイズ、チャネル数、1次元配列の大きさ)です。 出力のサイズがtorch.Size([8, 2])となっているのは、torch.Size(バッチサイズ、最後の出力)と言うことです。分類タスクをやりたければこの後に、softmaxを通してあげれば良いです。
また、
torchsummaryと言う特徴マップの大きさを確認できる便利なライブラリがあるのでそちらも使ってみてください。以前に記事を書いたのでリンクを貼っておきます。===============================================================
Pytorchでモデル構築するとき、torchsummaryがマジ使える件について
===============================================================
【nn.Conv1d】
nn.Conv1d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros')
parameters 概要 in_channels 入力のチャネル数。 out_channels 畳み込みをした後のチャネル数。フィルター数。 kernel_size カーネルの大きさ。 stride カーネルをどのくらい移動させるか。 padding パディングの大きさ。1を指定すると両端に挿入するので2だけ大きくなる。デフォは0。 dilation フィルターの間の空間を変更。atrous convなどで利用。 groups デフォは1。数を大きくすると計算コスト削減。 bias biasを含むかどうか。デフォはTrue padding_mode パディングのモード。デフォは0。 【nn.BatchNorm1d】
nn.BatchNorm1d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
num_featuresはひつつ前のレイヤーのout_channelsの値と同じ数を入れれば大丈夫です。3. 2DのCNN
簡単なCNNのサンプルを書きました。
今回フィルター数やカーネルサイズは適当に決めています。
自作でネットワークを作成する場合は、考慮しながら値を決めてください。import torch import torch.nn as nn class Net2D(nn.Module): def __init__(self): super(Net,self).__init__() self.conv1 = nn.Conv2d(3,16,kernel_size=3,stride=2) self.bn1 = nn.BatchNorm2d(16) self.relu = nn.ReLU() self.maxpool = nn.MaxPool2d(2) self.conv2 = nn.Conv2d(16,32,kernel_size=3,stride=2) self.bn2 = nn.BatchNorm2d(32) self.conv3 = nn.Conv2d(32,64,kernel_size=3,stride=2) self.gap = nn.AdaptiveAvgPool2d(1) self.fc1 = nn.Linear(64,32) self.fc2 = nn.Linear(32,2) def forward(self,x): x = self.conv1(x) x = self.bn1(x) x = self.relu(x) x = self.maxpool(x) x = self.conv2(x) x = self.bn2(x) x = self.relu(x) x = self.maxpool(x) x = self.conv3(x) x = self.gap(x) x = x.view(x.size(0),-1) x = self.fc1(x) x = self.fc2(x) return x
- 自作モデルを作る際は、
nn.Moduleを継承する必要があります。基本的には、
initで使用する層を定義します。
パラメタがあるものをinitに、パラメタがないものはforwardに定義するような記事をよく見ますが、print(model)の際にreluなどが表示されないので、私はパラメタがないreluのようなものでも今回のようにinitに定義します。
forwardのほうで、モデルの構造を決めます。【nn.Conv2d】
nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True, padding_mode='zeros')
parameters 概要 in_channels 入力のチャネル数。RGBの画像では3になる。 out_channels 畳み込みをした後のチャネル数。フィルター数。 kernel_size カーネルの大きさ。 stride カーネルをどのくらい移動させるか。 padding パディングの大きさ。1を指定すると両端に挿入するので2だけ大きくなる。デフォは0。 dilation フィルターの間の空間を変更。atrous convなどで利用。 groups デフォは1。数を大きくすると計算コスト削減。 bias biasを含むかどうか。デフォはTrue padding_mode パディングのモード。デフォは0。 【nn.BatchNorm2d】
nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
バッチ正規化は、バッチ内の要素ごとに平均と標準偏差を求めます。
畳み込みのときは、バッチ内のチャネルの対して正規化します。全結合層のときはユニットになります。他にも、
Layer Norm、Instance Norm、Group Normなどがあるので気になるのがある方は検索してみてください。【nn.ReLU】
nn.ReLU(inplace=False)
- (x) = max(0,x)
- ReLUは活性化関数です。他には、
ReLU6、RReLU、SELU、CELU、Sigmoidなどあります。【nn.MaxPool2d】
nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)特徴を強調されるためにプーリング層を使います。
- 大きく分けて2パターンの方法があるので以下で確認します。
①poolのサイズが正方形のとき
m = nn.MaxPool2d(3, stride=2) #(pool of square window of size=3, stride=2)②poolの大きさをカスタマイズしたいとき
m = nn.MaxPool2d((3, 2), stride=(2, 1)) #(pool of non-square window)【nn.AdaptiveMaxPool2d】
nn.AdaptiveMaxPool2d(output_size, return_indices=False)よく、
Global Max Poolingと呼ばれるものです。
各チャネルを値一つにしてくれるので、全結合層につなぐ前によく使われます。
output_sizeに1チャネルのアウトプットサイズを入れます。
output_size=1が使うことが多いと思います。【nn.Linear】
nn.Linear(in_features, out_features, bias=True)in_features, out_featuresを指定して使います。
全結合層を実装したときは、こちらを使います。終わりに
Pytorchに移行して半年ぐらい経ちますが、非常に使いやすいです。
今回の記事が少しでも参考になればと思います。参考文献
- 投稿日:2020-01-23T13:55:01+09:00
python-aptについて
Ubuntuユーザーならわけもわからず使っているであろう
atpコマンド。実はタイトルのpython-atpが深く関わっている。以下、アップデートマネージャーの説明から引用しました。python-aptとは
apt_pkg Python インターフェースは、Python プログラムから以下に示す様々な機 能の実行を簡単に行うことを可能とするために、内部の
libapt-pkg 機構への完全 なアクセスを提供します。
.
- Access to the APT configuration system
- Access to the APT package information database
- Parsing of Debian package control files, and other files with a
similar structure
.
同梱される 'aptsources' Python インターフェースは、sources.list ファイルの
設定を、リポジトリやディストリビューションのレベルで抽象化する機能を提供します。まとめ
pyenvいれたしシステム(/usr/bin/)のpythonは使わないから削除しちゃえ!と軽い気持ちで
apt remove --force-depends pythonとかやらないように。大変な事態になります。
- 投稿日:2020-01-23T13:40:55+09:00
sorted
点数の低い順ranking = { 'A':100, 'B':80, 'C':95 } print(sorted(ranking, key=ranking.get))実行結果['B', 'C', 'A']点数の高い順ranking = { 'A':100, 'B':80, 'C':95 } print(sorted(ranking, key=ranking.get, reverse=True))実行結果['A', 'C', 'B']
- 投稿日:2020-01-23T13:40:00+09:00
畳み込みニューラルネットワーク (CNN)に対する画像の回転・拡大・色などの影響
畳み込みニューラルネットワーク (CNN)と、他の機械学習手法(勾配ブースティング・多層パーセプトロン)の特徴を理解することを目的に、画像に回転・拡大・色の変更などの処理を行った時に分類性能がどう変わるかを試してみました。
画像は コアラとクマの画像を自動生成する の方法で生成しました。コアラさんとクマさんをシルエットで区別できるでしょうか?
コード
画像データ読み込み
from PIL import Image koalas = [] for i in range(num_data): koala = Image.open("koala_or_bear/koala_{}.jpg".format(i)) koalas.append(koala) bears = [] for i in range(num_data): bear = Image.open("koala_or_bear/bear_{}.jpg".format(i)) bears.append(bear)先頭データ表示
%matplotlib inline import matplotlib.pyplot as plt fig = plt.figure(figsize=(10,10)) for i in range(16): ax = fig.add_subplot(4, 4, i+1) ax.axis('off') if i < 8: ax.set_title('koala_{}'.format(i)) ax.imshow(koalas[i],cmap=plt.cm.gray, interpolation='none') else: ax.set_title('bear_{}'.format(i - 8)) ax.imshow(bears[i - 8],cmap=plt.cm.gray, interpolation='none') plt.show()説明変数・目的変数
import numpy as np X = [] # 説明変数 Y = [] # 目的変数 index = 0 for koala in koalas: resize_img = koala.resize((128, 128)) r, g, b = resize_img.split() r_resize_img = np.asarray(np.float32(r)/255.0) g_resize_img = np.asarray(np.float32(g)/255.0) b_resize_img = np.asarray(np.float32(b)/255.0) rgb_resize_img = np.asarray([r_resize_img, g_resize_img, b_resize_img]) X.append(rgb_resize_img) Y.append(0) index += 1 if index >= num_data: break index = 0 for bear in bears: resize_img = bear.resize((128, 128)) r, g, b = resize_img.split() r_resize_img = np.asarray(np.float32(r)/255.0) g_resize_img = np.asarray(np.float32(g)/255.0) b_resize_img = np.asarray(np.float32(b)/255.0) rgb_resize_img = np.asarray([r_resize_img, g_resize_img, b_resize_img]) X.append(rgb_resize_img) Y.append(1) index += 1 if index >= num_data: break X = np.array(X, dtype='float32') Y = np.array(Y, dtype='int64')教師セット・テストセットに分離
from sklearn import model_selection X_train, X_test, Y_train, Y_test = model_selection.train_test_split( X, Y, test_size=0.1 )scikit-learn用にデータ型変換
d1, d2, d3, d4 = X_train.shape X_train_a = X_train.reshape((d1, d2 * d3 * d4)) Y_train_onehot = np.identity(2)[Y_train] d1, d2, d3, d4 = X_test.shape X_test_a = X_test.reshape((d1, d2 * d3 * d4)) Y_test_onehot = np.identity(2)[Y_test]PyTorch用にデータ型変換
import torch from torch.utils.data import TensorDataset from torch.utils.data import DataLoader X_train_t = torch.from_numpy(X_train).float() Y_train_t = torch.from_numpy(Y_train).long() X_train_v = torch.autograd.Variable(X_train_t) Y_train_v = torch.autograd.Variable(Y_train_t) X_test_t = torch.from_numpy(X_test).float() Y_test_t = torch.from_numpy(Y_test).long() X_test_v = torch.autograd.Variable(X_test_t) Y_test_v = torch.autograd.Variable(Y_test_t) train = TensorDataset(X_train_t, Y_train_t) train_loader = DataLoader(train, batch_size=32, shuffle=True)勾配ブースティング
%%time from sklearn.ensemble import GradientBoostingClassifier classifier = GradientBoostingClassifier() classifier.fit(X_train_a, Y_train) print("Accuracy score (train): ", classifier.score(X_train_a, Y_train)) print("Accuracy score (test): ", classifier.score(X_test_a, Y_test))多層パーセプトロン(中間1層)
%%time from sklearn.neural_network import MLPClassifier classifier = MLPClassifier(max_iter=10000, early_stopping=True) classifier.fit(X_train_a, Y_train) print("Accuracy score (train): ", classifier.score(X_train_a, Y_train)) print("Accuracy score (test): ", classifier.score(X_test_a, Y_test))多層パーセプトロン(中間2層)
%%time from sklearn.neural_network import MLPClassifier classifier = MLPClassifier(max_iter=10000, early_stopping=True, hidden_layer_sizes=(100, 100)) classifier.fit(X_train_a, Y_train) print("Accuracy score (train): ", classifier.score(X_train_a, Y_train)) print("Accuracy score (test): ", classifier.score(X_test_a, Y_test))畳み込みニューラルネットワーク (CNN)
ネットワークの定義
class CNN(torch.nn.Module): def __init__(self): super(CNN, self).__init__() self.conv1 = torch.nn.Conv2d(3, 10, 5) self.conv2 = torch.nn.Conv2d(10, 20, 5) self.fc1 = torch.nn.Linear(20 * 29 * 29, 50) self.fc2 = torch.nn.Linear(50, 2) def forward(self, x): x = torch.nn.functional.relu(self.conv1(x)) x = torch.nn.functional.max_pool2d(x, 2) x = torch.nn.functional.relu(self.conv2(x)) x = torch.nn.functional.max_pool2d(x, 2) x = x.view(-1, 20 * 29 * 29) x = torch.nn.functional.relu(self.fc1(x)) x = torch.nn.functional.log_softmax(self.fc2(x), 1) return xネットワーク構造の確認
from torchsummary import summary model = CNN() summary(model, X[0].shape)---------------------------------------------------------------- Layer (type) Output Shape Param # ================================================================ Conv2d-1 [-1, 10, 124, 124] 760 Conv2d-2 [-1, 20, 58, 58] 5,020 Linear-3 [-1, 50] 841,050 Linear-4 [-1, 2] 102 ================================================================ Total params: 846,932 Trainable params: 846,932 Non-trainable params: 0 ---------------------------------------------------------------- Input size (MB): 0.19 Forward/backward pass size (MB): 1.69 Params size (MB): 3.23 Estimated Total Size (MB): 5.11 ----------------------------------------------------------------実行のための関数
def learn(model, criterion, optimizer, n_iteration): for epoch in range(n_iteration): total_loss = np.array(0, dtype='float64') for x, y in train_loader: x = torch.autograd.Variable(x) y = torch.autograd.Variable(y) optimizer.zero_grad() y_pred = model(x) loss = criterion(y_pred, y) loss.backward() optimizer.step() total_loss += loss.data.numpy() if (epoch + 1) % 10 == 0: print(epoch + 1, total_loss) if total_loss == np.array(0, dtype='float64'): break loss_history.append(total_loss) return model実行用コード
#%%time model = CNN() criterion = torch.nn.CrossEntropyLoss() optimizer = torch.optim.Adam(model.parameters(), lr=0.01) loss_history = [] model = learn(model, criterion, optimizer, 300)損失履歴表示
ax = plt.subplot(2, 1, 1) ax.plot(loss_history) ax.grid() ax = plt.subplot(2, 1, 2) ax.plot(loss_history) ax.set_yscale('log') ax.grid()正答率
正答率(教師セット)
Y_pred = torch.max(model(X_train_v).data, 1)[1] accuracy = sum(Y_train == Y_pred.numpy()) / len(Y_train) print(accuracy)正答率(テストセット)
Y_pred = torch.max(model(X_test_v).data, 1)[1] accuracy = sum(Y_test == Y_pred.numpy()) / len(Y_test) print(accuracy)結果
まずは、コアラさんとクマさんを区別する一番簡単な問題です。
手法 学習時間 正答率(教師セット) 正答率(テストセット) 勾配ブースティング 1min 2s 1.0 1.0 多層パーセプトロン(中間1層) 50.9 s 1.0 1.0 多層パーセプトロン(中間2層) 35.1 s 1.0 1.0 畳み込みニューラルネットワーク (CNN) - 1.0 1.0 どの予測法も完璧に答えることができました。
拡大
コアラさんとクマさんをランダムな倍率で拡大してみましょう。このときついでに、少しだけ縦横にずらしてみます。
手法 学習時間 正答率(教師セット) 正答率(テストセット) 勾配ブースティング 5min 11s 1.0 0.975 多層パーセプトロン(中間1層) 1min 4s 1.0 1.0 多層パーセプトロン(中間2層) 1min 4s 0.977 1.0 畳み込みニューラルネットワーク (CNN) - 1.0 1.0 勾配ブースティングの正答率が、ほんの少しだけ落ちましたね。畳み込みニューラルネットワーク (CNN)は完璧な正答率です。
邪魔物あり
背景に、邪魔になりそうなものを描き込みましょう。
手法 学習時間 正答率(教師セット) 正答率(テストセット) 勾配ブースティング 1min 23s 1.0 1.0 多層パーセプトロン(中間1層) 38.3 s 1.0 1.0 多層パーセプトロン(中間2層) 1min 3s 0.983 1.0 畳み込みニューラルネットワーク (CNN) - 1.0 1.0 ほとんど影響ないようです。
背景だけ彩色
背景をカラフルにしてみます。
手法 学習時間 正答率(教師セット) 正答率(テストセット) 勾配ブースティング 1min 30s 1.0 1.0 多層パーセプトロン(中間1層) 43.9 s 0.9916 1.0 多層パーセプトロン(中間2層) 41.6 s 1.0 1.0 畳み込みニューラルネットワーク (CNN) - 1.0 1.0 これもほとんど影響ないようです。
動物だけ彩色
コアラさんとクマさんをカラフルにしてみましょう。
手法 学習時間 正答率(教師セット) 正答率(テストセット) 勾配ブースティング 4min 26s 1.0 0.975 多層パーセプトロン(中間1層) 27.8 s 0.494 0.55 多層パーセプトロン(中間2層) 1min 9s 0.816 0.775 畳み込みニューラルネットワーク (CNN) - 0.505 0.45 予測精度がかなり落ちました。畳み込みニューラルネットワーク (CNN)の性能がガタ落ち。あれ?意外にも多層パーセプトロン(中間2層)が健闘してる。そして、勾配ブースティングは、ほとんど性能が落ちてない。すごいぞ。
拡大・彩色・邪魔物あり
手法 学習時間 正答率(教師セット) 正答率(テストセット) 勾配ブースティング 7min 24s 1.0 0.9 多層パーセプトロン(中間1層) 42.4 s 0.6861 0.6 多層パーセプトロン(中間2層) 1min 50s 0.925 0.75 畳み込みニューラルネットワーク (CNN) - 0.5 0.5 難易度が上がったけど、勾配ブースティングはかなり健闘してる。畳み込みニューラルネットワーク (CNN)は全く使い物になってない。
拡大・彩色・動物だけ黒・邪魔物あり
手法 学習時間 正答率(教師セット) 正答率(テストセット) 勾配ブースティング 6min 12s 1.0 0.975 多層パーセプトロン(中間1層) 1min 1s 0.9916 0.975 多層パーセプトロン(中間2層) 1min 12s 1.0 1.0 畳み込みニューラルネットワーク (CNN) - 1.0 1.0 コアラさん・クマさんの色を黒に統一するだけで、全ての予測性能が回復した。やっぱりそこが判断基準なわけね。
回転
まわるまわるよ コアラは回る クマも回る
手法 学習時間 正答率(教師セット) 正答率(テストセット) 勾配ブースティング 3min 10s 1.0 0.925 多層パーセプトロン(中間1層) 27.4 s 0.5 0.5 多層パーセプトロン(中間2層) 1min 20s 0.994 1.0 畳み込みニューラルネットワーク (CNN) - 1.0 1.0 多層パーセプトロン(中間1層)はダメでしたが他の皆さんは回転についてこれたようです。勾配ブースティングは回転が少し苦手っぽい。
回転・拡大
回転しながら拡大もしてみましょう。
手法 学習時間 正答率(教師セット) 正答率(テストセット) 勾配ブースティング 5min 28s 1.0 0.775 多層パーセプトロン(中間1層) 1min 33s 0.825 0.7 多層パーセプトロン(中間2層) 30.9 s 0.65 0.675 畳み込みニューラルネットワーク (CNN) - 0.505 0.45 回転だけなら平気、拡大だけなら平気。だけど、回転しながら拡大だと、みなさん混乱してしまうようですね。それでも、勾配ブースティング、よく頑張ってる。
回転・拡大・彩色・動物だけ黒・邪魔物あり
手法 学習時間 正答率(教師セット) 正答率(テストセット) 勾配ブースティング 7min 6s 1.0 0.6 多層パーセプトロン(中間1層) 29.5 s 0.5194 0.325 多層パーセプトロン(中間2層) 33 s 0.572 0.65 畳み込みニューラルネットワーク (CNN) - 0.5194 0.325 いろんな要因(回転・拡大・邪魔物・色)が個別で攻めてくると、大した問題ではなくても、それらの要因が混ざって攻めてくると難しくなるようですね。
いろんな要因全部のせ
手法 学習時間 正答率(教師セット) 正答率(テストセット) 勾配ブースティング 7min 55s 1.0 0.45 多層パーセプトロン(中間1層) 31.8 s 0.505 0.45 多層パーセプトロン(中間2層) 55.7 s 0.6027 0.45 畳み込みニューラルネットワーク (CNN) - 0.505 0.45 いろんな要因を全部乗っけました。これはどの方法でもお手上げのようです。
まとめ
畳み込みニューラルネットワーク (CNN)について、感覚を掴みたかったので、「CNNの一人勝ち!!!」な結果を出したかったのですが、結論は「勾配ブースティングすげええええ!」になってしまいました。(ヽ´ω`)










