- 投稿日:2020-01-23T22:05:04+09:00
DjangoアプリをDocker上に構築しAWS Fargateにデプロイする
はじめに
AI、機械学習やビッグデータ解析などでPythonが注目されています。
Pythonを用いたウェブアプリケーションが今後増加することが予測される中、PythonのフレームワークであるDjangoを用いてアプリを作成し、AWS Fargateにコンテナでデプロイをするまでの一連の流れを毎日投稿していきます。所属しているFintechスタートアップでの開発経験からDjango+Docker+AWS Fargateの構成は
1)学習コストが低い
2)共同開発しやすい
3)スケールしやすい
という特徴があり、個人やスタートアップによるwebアプリケーション開発のベストプラクティスであると考えています。項目毎に細切れに投稿していくので詳細については各投稿を参照してください。
日々記事を投稿しそのリンクを本ページに追加していくので、本ページは目次として使ってください。目次
1.なぜ今、Pythonなのか
2.Djangoについて
3.Dockerについて
(1)DockerでHello,World
4.Docker上でDjangoアプリケーションを動かす
5.PostgresSQL
6.アプリケーションの作成
(1)Custom User
(2)URLs
(3)Views
(4)認証機能
(5)環境変数
7.Emailの設定
8.ファイルのアップロード
9.権限
10.検索
11.Perfomance
12.セキュリティ
13.デプロイ
- 投稿日:2020-01-23T21:48:50+09:00
AWS関連
- EIPとEC2はアカウントが異なっても利用できるのかどうか
- ALBを使って301リダイレクトができる。SSL証明書設定がAWSだけで完結する件
- AWS図,クラウドサービス利用図
- AWS_Direct_Connectの使用状況確認
- Amazon_Connect_SalesForce
- Radius_監視+AWS_DLM
- AWS_サポートチャットシステム_appsync
EIPとEC2はアカウントが異なっても利用できるのかどうか
EIPとEC2は分けれるのか?
EIPを管理するアカウントと、EC2が動作しているアカウントを分ける必要ができたので調べました。
なぜ必要か
外部APIとの連携でEIPだけ別のアカウントで管理したい。
具体的にできるかどうか
結論
無理そう。。。
EIPの関連付けインスタンスに同じアカウント内のものしか出てこない。。。
Peeringしたらいいのか?ALBを使って301リダイレクトができる。SSL証明書設定がAWSだけで完結する件
https://dev.classmethod.jp/cloud/aws/alb-redirects/
AWS図,クラウドサービス利用図
AWS_Direct_Connectの使用状況確認
Amazon_Connect_SalesForce
Radius_監視+AWS_DLM
AWS_サポートチャットシステム_appsync
- 投稿日:2020-01-23T19:12:41+09:00
【AWS】S3へのデータアップロード
aws s3 cp uploadFileName s3://bucketName/▼403になったらアクセス権限を確認
https://aws.amazon.com/jp/premiumsupport/knowledge-center/s3-troubleshoot-403/・private
・public-read
・public-read-write
・authenticated-read
・bucket-owner-read
・bucket-owner-full-control
・log-delivery-writeaws s3 cp uploadFileName s3://bucketName/ --acl public-readただし、public-readにすると全世界からアクセス可能になるので注意
- 投稿日:2020-01-23T18:59:00+09:00
flaws.cloudに挑戦してみた
はじめに
先日、大和セキュリティ勉強会に参加してきまして、とても勉強になったので備忘録程度に記事を書こうと思います。今回やったのは、flaws.cloudというサイトです。ctf形式でAWSにおけるハッキングトピックを学べるサイトになっています。level1からlevel6までの計6問で構成されています。詳しいwrite upはもっと偉大な方々が書かれているので適度な感じに書いていこうと思います。解き方もそこで教えてもらった解き方で書かせてもらいます。
事前準備
今回はawsに関する問題なのでawscliを使用します。そのためこちらでawscliのインストールと初期設定をしてください。
※regionはすべてのクレデンシャルで'us-west-2'で設定してください。level1
flaws.cloudにアクセスすると説明が書かれていて、一番下に次の問題のページのサブドメインを見つけてねっていう問題文が書かれています。
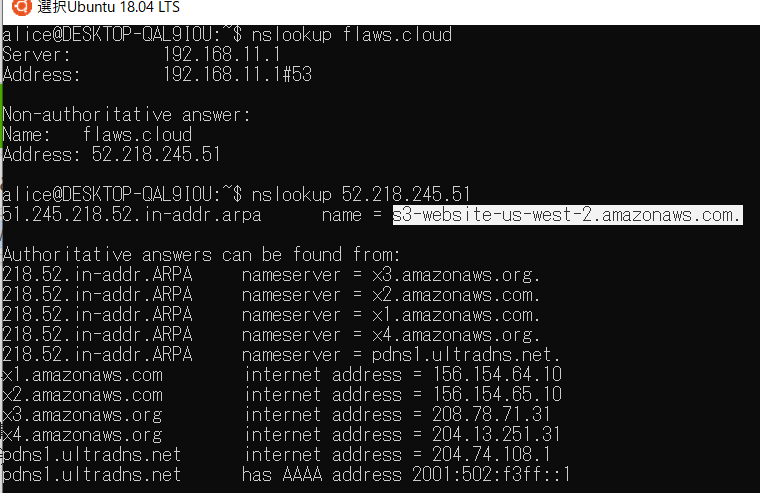
1 現状わかっているのはflaws.cloudというドメインだけです。
なのでまず
nslookupでドメインの調査してみます。
そうするとipアドレスが出てきます。これをまたnslookupで逆引きします。
するとs3-website-us-west-2.amazonaws.comと出てくるのでawsのs3というサービスで動いていることがわかります。次に"aws s3 サブドメイン"で検索するとドメインの命名規則が見つかります。そこから上記のURLのwebsiteの部分を消せばバケット内のファイル一覧が見られます。
見るからに怪しいhtmlファイルが存在するのでアクセスするとlevel2のURLが張られています。
解説
これはpermissionの設定不備のため誰でもバケットの中身見れてしまうことから生まれます。みなさんは間違ってもpermisssionをEveryoneにはしないように。level3まで似たような問題が続きます。
level2
次はURLが載ってますがアクセスできません。なのでawscliでアクセスしてみます。
また怪しいhtmlファイルがあったのでアクセスするとlevel3のURLの書かれたページでした.
解説
これはpermissionの設定を"Any Authenticated AWS User"にしてあるためです。これはawsのアカウントからなら誰でもアクセスできるという設定です。
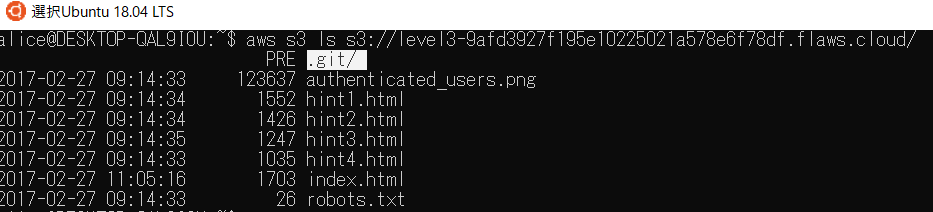
level3
先ほど同じようにバケットの中身を見てます。
.git/があるのでaws s3 cp s3://level3-9afd3927f195e10225021a578e6f78df.flaws.cloud . --recursiveでダウンロードします。これを解析していきます。
間違えてあげてしまったaccess_key.txtが復元できたので、このアクセスキーで
aws configure --profile profile_nameで設定します。その上でバケット内を見てみるとここからはlevel2と一緒です。
解説
よくあるgitに誤ってpushしてしまったverです。pushを取り消さなければこのように復元できてしまいます。ほかにもソースコードの中にパスワードなどをハードコーディングしているのを誤ってpushしてしまうと同じことが起きます。
level4
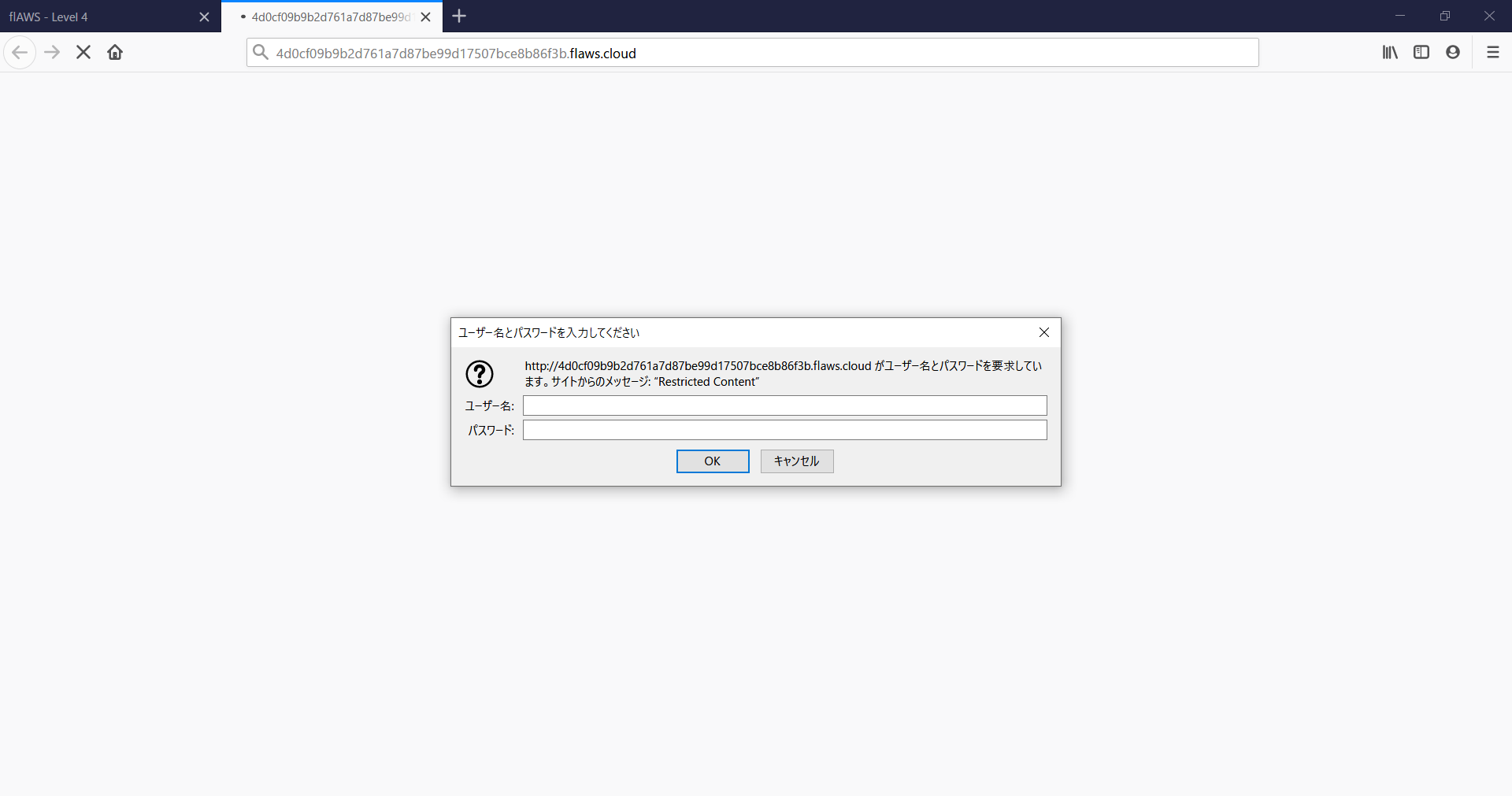
ここからレベルが跳ね上がります。
次はBASIC認証を求められます。いつもならSQLiやwebアプリケーションの脆弱性を探って攻撃してみますが、今回は違います。そして問題文にも書いてありますが、今回はs3は関係なくEC2が題材です。そして問題文にsnapshotが関係しているのがわかるのでsnapshotを取得するところから始まります。
aws ec2 describe-snapshot --profile profile_nameでスナップショットに関する情報を取得できますが、そのままでは不必要な情報まで取得できてしまうのでフィルタをかける必要があります。aws sts get-caller-identity -–profile level3でクレデンシャルに関する情報を取得します。
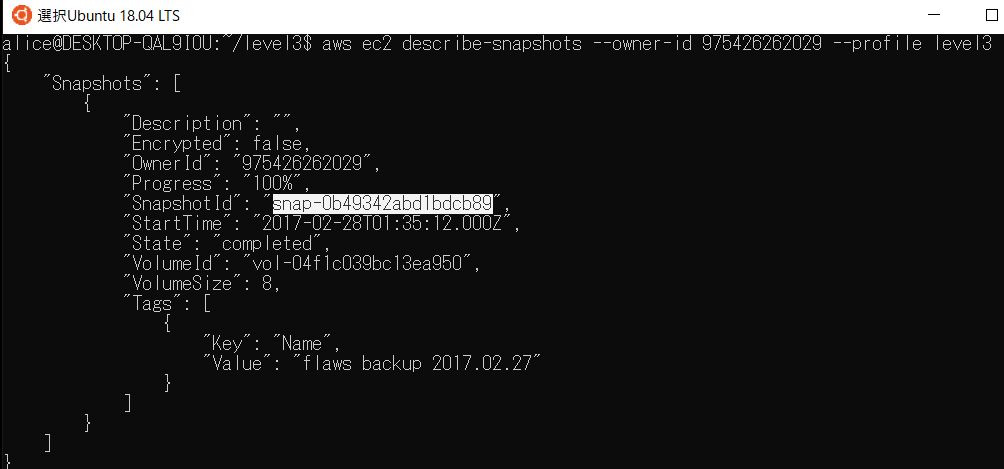
そうするとawsのアカウントidが取得できるので、それを使ってフィルタします。
aws ec2 describe-snapshots --owner-id 975426262029 --profile level3によって欲しいsnapshotに関する情報だけを取得できます。
このsnapshotが欲しいので
aws ec2 describe-snapshot-attribute --snapshot-id snap-0b49342abd1bdcb89 --attribute createVolumePermission --profile level3でpermissionを確認します。
allなので誰でも作成することが可能なことがわかります。なので自分のアカウントにコピーします。
aws ec2 create-volume --availability-zone us-west-2b --region us-west2 --snapshot-id snap-0b49342abd1bdcb89ここでリージョンとアヴェラビリティゾーンを指定する必要があります。
次は、自分でEC2のUbuntuを作成して、先ほど作成したボリュームをアタッチします。その後EC2にSSHでアクセスします。EC2の/snap/に先ほどアタッチしたボリュームがあるのでマウントします。ここから2種類BASIC認証の認証情報を取得する方法があります。
1つはマウントしたボリュームのホームディレクトリに.passwdを生成するシェルスクリプトを見る方法です。
もう1つは~/.bash_historyをさかのぼると最初に設定したときのログが見ることができます。
これでBASIC認証を突破することができ、level5に進むことができます。解説
これはスナップショットの作成のpermissionがallになっているのが元凶です。デフォルトでは権限は与えられてないので誤って設定しなければ問題はないです。
level5, level6
誠に遺憾ですが自分の技術力ではlevel5以上は理解が追い付かず歯が立ちませんでした。なんとなく空気としてはわかるのでまとめときます。
・level5 SSRFを用いたクレデンシャルの奪取
・level6 aws特有の機能を複合された問題で、lambda関数がキーだそうまとめ
今回はlevel5以外は脆弱性などを突いた攻撃は行っておらず、すべて設定のミスを突いた問題です。やはり基本ですが"permissionは必要最低限"がとても重要ですね。そしてawsにおいてクレデンシャル情報はとても大事なことがよくわかります。
今回は大和セキュリティさんに初めて参加させていただいて、とても勉強になったので記事に書かせていただきました。使用されたスライドは上がっているので是非そちらを見てください。ありがとうございました。






- 投稿日:2020-01-23T18:44:50+09:00
terraformで単一アカウントのECRを複数アカウントでアクセスさせる
overview
複数アカウントが前提なAWSで、個人的にはECRは一つのアカウントに集約したほうが管理しやすいです。
その集約したECRに対して、各アカウントに権限を与えるような設定を施します。
コード
tree
$ tree ecr/ ecr/ ├── main.tf └── variables.tfvariables.tf
variable "ecr_repositories" { type = list(string) default = [ "hoge", // https://github.com/xxxxx/hoge "fuga", // https://github.com/xxxxx/fuga ] }main.tf
/* ECRは1箇所に集約したほうが管理しやすいので、operationアカウントのみに作成します */ resource "aws_ecr_repository" "this" { # countでやると、listの中間削除すると全部作り直しになる # ので0.12から入ったfor_eachを入れると、問題なくなる # https://github.com/hashicorp/terraform/issues/10850 for_each = toset(var.ecr_repositories) name = each.value image_scanning_configuration { scan_on_push = true } } resource "aws_ecr_repository_policy" "this" { for_each = toset(var.ecr_repositories) repository = aws_ecr_repository.this[each.value].name # もしアカウントが追加されたら、arn:aws:iamを追加してね policy = data.aws_iam_policy_document.this.json } /* クロスアカウントにECRの操作権限を与えるポリシー */ data "aws_iam_policy_document" "this" { statement { effect = "Allow" principals { type = "AWS" identifiers = [ "arn:aws:iam::${var.AWS_ACCOUNT_自分自身のアカウントID}:root", "arn:aws:iam::${var.AWS_ACCOUNT_権限を与えたいアカウントID}:root", "arn:aws:iam::${var.AWS_ACCOUNT_権限を与えたいアカウントID}:root", ] } # Delete以外を与える actions = [ "ecr:GetAuthorizationToken", "ecr:BatchGetImage", "ecr:BatchCheckLayerAvailability", "ecr:GetDownloadUrlForLayer", "ecr:InitiateLayerUpload", "ecr:CompleteLayerUpload", "ecr:UploadLayerPart", "ecr:DescribeImages", "ecr:PutImage", "ecr:DescribeRepositories", "ecr:GetRepositoryPolicy", "ecr:ListImages", "ecr:BatchDeleteImage", ] } } # untagged な イメージについては 1日で削除する resource "aws_ecr_lifecycle_policy" "this" { for_each = toset(var.ecr_repositories) repository = aws_ecr_repository.this[each.value].name policy = <<EOF { "rules": [ { "rulePriority": 1, "description": "Expire images older than 1 days", "selection": { "tagStatus": "untagged", "countType": "sinceImagePushed", "countUnit": "days", "countNumber": 1 }, "action": { "type": "expire" } } ] } EOF }ポイント
for_each = toset(var.ecr_repositories)コメントにも書いてますが、countでやると、listの中間削除すると全部作り直しになる
のでterraform v0.12 から入ったfor_eachを入れると、問題なくなります。
ref: https://github.com/hashicorp/terraform/issues/10850untaggedなイメージは削除して良いとして、それ以外のライフサイクルはruleで定義するのは難しそうだったので、Goなどでlifecycleツールを作ってcronで毎日動かす想定をしてます。
なのでまた、アカウントに対してdelete権限は与えてません。
- 投稿日:2020-01-23T17:43:16+09:00
ArgoでCIパイプラインを構築する
実現したいこと
argo workflowを使ってCIパイプラインを構築する
今回はリポジトリのクローンまで
対象はGithubプライベートリポジトリ(内容は前回と同じ)環境
- Golang 1.13.5
- Docker 18
- AWS 東京リージョン
argoはAWS EKSクラスターに配置
やったこと
Argoの導入
基本的には Argo公式ドキュメントに沿って進める
前提としてEKSにCI用クラスタ
ci-clusterを作成しておく# namespaceの作成 kubectl create ns argo # install.yamlをダウンロードしてargo namespaceにapply kubectl apply -n argo -f https://raw.githubusercontent.com/argoproj/argo/v2.2.1/manifests/install.yaml # default namespaceのサービスアカウントにadmin権限を付与 kubectl create rolebinding default-admin --clusterrole=admin --serviceaccount=default:default
とりあえずexampleを動かす
Argoはyamlでパイプラインを記述する
例として公式exampleのconflip.yamlを実行するcoinflip.yaml
# The coinflip example combines the use of a script result, # along with conditionals, to take a dynamic path in the # workflow. In this example, depending on the result of the # first step, 'flip-coin', the template will either run the # 'heads' step or the 'tails' step. apiVersion: argoproj.io/v1alpha1 kind: Workflow metadata: generateName: coinflip- spec: # entorypointで指定されたtemplates.nameが起動時に実行される entrypoint: cinflip templates: # ここからパイプラインの構成 - name: coinflip steps: # name: タスクの名前 - - name: flip-coin # 実際のタスクの処理への参照 template: flip-coin # - - name: stage-name で直列のタスクになる - - name: heads template: heads when: "{{steps.flip-coin.outputs.result}} == heads" # - name: stage-name で直前のタスクと並列のタスクになる - name: tails template: tails when: "{{steps.flip-coin.outputs.result}} == tails" # パイプラインの構成ここまで # タスクの中身の定義 - name: flip-coin # タスク毎にPodが立ち上がるのでそれぞれのタスクで起動するイメージを指定する script: image: python:alpine3.6 # タスク内で実行するコマンドの言語指定 今回はpython command: [python] # 実際に実行させる処理 source: | import random result = "heads" if random.randint(0,1) == 0 else "tails" print(result) - name: heads container: image: alpine:3.6 # タスク内で実行するコマンドの言語指定 今回はshell command: [sh, -c] args: ["echo \"it was heads\""] - name: tails container: image: alpine:3.6 command: [sh, -c] args: ["echo \"it was tails\""]パイプラインの実行は
argo submitで行うargo submit coinflip.yaml Name: coinflip-pwk7p Namespace: argo ServiceAccount: default Status: Pending Created: Thu Jan 23 09:52:11 +0900 (1 second from now)これで argo namespace上にタスク毎のPodが立ち上がりそれぞれ順に実行される
今回であれば作成されるPodは3つ
作成されるPod名は以下の通り
${metadata.generateName}{パイプライン毎のプレフィクス}-{タスク毎のプレフィクス}
今回であれば例えばcoinflip-pwk7p-4162510633
UIツールでパイプラインを監視する
argoにはUIツールが備わっているので,パイプラインの構成が複雑になる場合などに有用である.
前段でinstall.yamlを使ってargoの起動をした場合は,既にargo-ui-{プレフィクス}という名前のPodが立てられているはず.
以下のコマンドでUIツールをlocalhost:8001にポートフォワードするkubectl -n argo port-forward deployment/argo-ui 8001:8001これでブラウザでパイプラインの実行を確認できるようになった.
UIツールをインターネットから確認する
localhostから確認しているUIツールをインターネット経由で確認できるようにする
これで,確認のために毎回ポートフォワードする必要がなくなるargo-ui serviceのTypeを ClusterIPからLoadBalancerに変更する
argoを導入した際のinstall.yamlを編集する
. . . apiVersion: v1 kind: Service metadata: name: argo-ui namespace: argo # TypeをLoadBalancerに変更 spec: type: LoadBalancer # アクセス元IPアドレスを制限したい場合は記述 loadBalancerSourceRanges: - "ALLOWED ACCESS IP" ports: - port: 80 targetPort: 8001 selector: app: argo-ui . . .これを再度 applyすればLoadBalancerのエンドポイントからargo-uiにアクセスできる
Githubから
大筋は公式exampleのinput-artifact-git.yaml
apiVersion: argoproj.io/v1alpha1 kind: Workflow metadata: generateName: input-artifact-git- spec: entrypoint: git-clone templates: - name: git-clone inputs: artifacts: - name: argo-source path: /src git: repo: https://github.com/argoproj/argo.git revision: "v2.1.1" container: image: golang:1.10 command: [sh, -c] args: ["git status && ls && cat VERSION"] workingDir: /srcこのパイプラインは
git-cloneタスク1つのみの単純なもので
git-cloneも実行しているコマンドはgit status && ls && cat VERSION"のみ
ただ,このタスクの実行前にgitリポジトリのリソースを入力Artifactとして/src配下に配置している今回は
myOrg/myRepoリポジトリのmasterブランチをクローンしたいので以下のようになるapiVersion: argoproj.io/v1alpha1 kind: Workflow metadata: generateName: input-artifact-git- spec: entrypoint: git-clone templates: - name: git-clone inputs: artifacts: - name: argo-source # リポジトリの中身を配置するディレクトリ path: /src # gitリポジトリ指定 git: repo: https://github.com/myOrg/myRepo.git revision: "master" container: image: golang:1.10 command: [sh, -c] args: ["git status && ls && cat VERSION"] workingDir: /src
プライベートリポジトリからクローンする
前段の方法ではパブリックリポジトリしかクローンできない
プライベートリポジトリからクローンする場合にはgitの認証情報を登録する必要がある再びinput-artifact-git.yamlを参考にすると下記のようになる
apiVersion: argoproj.io/v1alpha1 kind: Workflow metadata: generateName: input-artifact-git- spec: entrypoint: git-clone templates: - name: git-clone inputs: artifacts: - name: argo-source # リポジトリの中身を配置するディレクトリ path: /src # gitリポジトリ指定 git: repo: https://github.com/myOrg/myRepo.git revision: "master" # gitの認証情報を指定 # kubernetes Secretから github-creds.usernameを取得する usernameSecret: name: github-creds key: username # kubernetes Secretから github-creds.passwordを取得する passwordSecret: name: github-creds key: password container: image: golang:1.10 command: [sh, -c] args: ["git status && ls && cat REDOME.md"] workingDir: /srcパイプラインの定義ファイルに直接認証情報を書くのではなくKubernetesのSecretsに格納された認証情報を呼び出す
今回は github-credsに usernameとpasswordという名前で登録しておく
動かす
argo submit input-artifact-git.yamlちゃんとクローンできた
完成
とりあえずgitプライベートリポジトリからクローンができるところまで完成
この後testだったりbuildだったりを記述していく
ここから先は他のciツールと大差ない(と思っている)つまづいたところは,
- Secret内の認証情報をタスク内で参照するところ
- admin権限を付与するサービスアカウントを間違えていたこと
- タスク内でechoやprintした内容が各podのログに出力されていたこと
各タスクのログはタスクを実行するPodに出力されるのでエラーが起きた際には,
どのタスク内でパイプラインが止まったのかを見て,そのPodの中に入るといった手順が必要
stern などのPod横断で監視できるツールを導入するのが良さそうそのあと
gitクローンだけではCIとはとても呼べないので,このあとはクローンしたリソースを使ってtest/build/imageプッシュをしていく
また,手動でパイプラインを動かしているのでgithubのwebhookを使って,masterブランチのpushをトリガーにパイプラインの実行ができるように
argo eventsを導入する
- 投稿日:2020-01-23T17:43:16+09:00
[WIP]ArgoでCIパイプラインを構築する
実現したいこと
argo workflowを使ってCIパイプラインを構築する
対象はGithubプライベートリポジトリ(内容は前回と同じ)環境
- Golang 1.13.5
- Docker 18
- AWS 東京リージョン
argoはAWS EKSクラスターに配置
イメージのプッシュ先は同アカウント内ECRやったこと
Argoの導入
基本的には Argo公式ドキュメントに沿って進める
前提としてEKSにCI用クラスタ
ci-clusterを作成しておく# namespaceの作成 kubectl create ns argo # install.yamlをダウンロードしてargo namespaceにapply kubectl apply -n argo -f https://raw.githubusercontent.com/argoproj/argo/v2.2.1/manifests/install.yaml # default namespaceのサービスアカウントにadmin権限を付与 kubectl create rolebinding default-admin --clusterrole=admin --serviceaccount=default:defaultArgoでパイプラインを構築する
とりあえずexampleを動かす
Argoはyamlでパイプラインを記述する
例として公式exampleのconflip.yamlを実行するcoinflip.yaml
# The coinflip example combines the use of a script result, # along with conditionals, to take a dynamic path in the # workflow. In this example, depending on the result of the # first step, 'flip-coin', the template will either run the # 'heads' step or the 'tails' step. apiVersion: argoproj.io/v1alpha1 kind: Workflow metadata: generateName: coinflip- spec: # entorypointで指定されたtemplates.nameが起動時に実行される entrypoint: cinflip templates: # ここからパイプラインの構成 - name: coinflip steps: # name: タスクの名前 - - name: flip-coin # 実際のタスクの処理への参照 template: flip-coin # - - name: stage-name で直列のタスクになる - - name: heads template: heads when: "{{steps.flip-coin.outputs.result}} == heads" # - name: stage-name で直前のタスクと並列のタスクになる - name: tails template: tails when: "{{steps.flip-coin.outputs.result}} == tails" # パイプラインの構成ここまで # タスクの中身の定義 - name: flip-coin # タスク毎にPodが立ち上がるのでそれぞれのタスクで起動するイメージを指定する script: image: python:alpine3.6 # タスク内で実行するコマンドの言語指定 今回はpython command: [python] # 実際に実行させる処理 source: | import random result = "heads" if random.randint(0,1) == 0 else "tails" print(result) - name: heads container: image: alpine:3.6 # タスク内で実行するコマンドの言語指定 今回はshell command: [sh, -c] args: ["echo \"it was heads\""] - name: tails container: image: alpine:3.6 command: [sh, -c] args: ["echo \"it was tails\""]パイプラインの実行は
argo submitで行うargo submit coinflip.yaml Name: coinflip-pwk7p Namespace: argo ServiceAccount: default Status: Pending Created: Thu Jan 23 09:52:11 +0900 (1 second from now)これで argo namespace上にタスク毎のPodが立ち上がりそれぞれ順に実行される
今回であれば作成されるPodは3つ
作成されるPod名は以下の通り
${metadata.generateName}{パイプライン毎のプレフィクス}-{タスク毎のプレフィクス}
今回であれば例えばcoinflip-pwk7p-4162510633UIツールでパイプラインを監視する
argoにはUIツールが備わっているので,パイプラインの構成が複雑になる場合などに有用である.
前段でinstall.yamlを使ってargoの起動をした場合は,既にargo-ui-{プレフィクス}という名前のPodが立てられているはず.
以下のコマンドでUIツールをlocalhost:8001にポートフォワードするkubectl -n argo port-forward deployment/argo-ui 8001:8001これでブラウザでパイプラインの実行を確認できるようになった.
- 投稿日:2020-01-23T16:59:17+09:00
MediaLiveで出力したアーカイブファイルをMP4に自動変換する
はじめに
MediaLiveでライブ配信を行う際、アーカイブを残しておくことがあるかと思います。
2020年1月現在では、MediaLiveのアーカイブ出力はtsファイル形式のみ対応しています。tsファイルはVLCなどの動画プレイヤーを使わないと再生することができないため、
利用しやすいmp4ファイルに変換する必要があるという機会に何度か遭遇しました。そのときに構築した自動でmp4に変換する仕組みを簡単に記載しておきます。
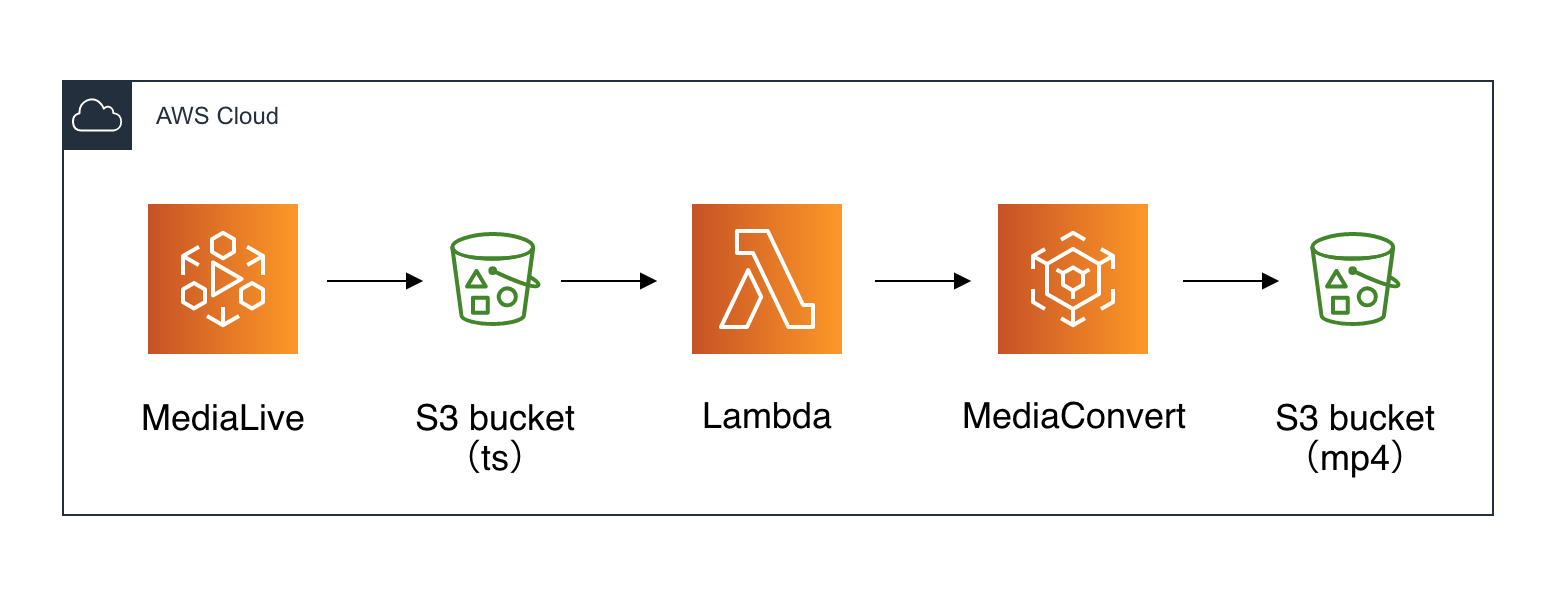
ざっくり構成図
MediaLive -> S3 -> Lambda -> MediaConvert -> S3
MediaLive
Output Groupで「Archive」を選択します。
S3
tsファイルを置くフォルダと
mp4ファイルを置くフォルダを用意します。IAM
IAMロールを2つ作成します。
MediaConvert用 IAMロール
Policyはロール作成時に自動でアタッチされます。
- AmazonS3FullAccess
- AmazonAPIGatewayInvokeFullAccess
Lambda用 IAMロール
AWSデフォルトのPolicyを使用する場合はこのPolicyがあれば動作します。
(本番環境で構築する際は権限を絞りましょう)
- AWSElementalMediaConvertFullAccess
MediaConvert
mp4に変換させるジョブテンプレートを作成します。
(参考までに、JSONを貼っておきます){ "Queue": "arn:aws:mediaconvert:ap-northeast-1:<account-id>:queues/<キューの名前>", "Name": "<ジョブテンプレートの名前>", "Settings": { "OutputGroups": [ { "Name": "File Group", "Outputs": [ { "ContainerSettings": { "Container": "MP4", "Mp4Settings": { "CslgAtom": "INCLUDE", "CttsVersion": 0, "FreeSpaceBox": "EXCLUDE", "MoovPlacement": "PROGRESSIVE_DOWNLOAD" } }, "VideoDescription": { "Width": 1280, "ScalingBehavior": "DEFAULT", "Height": 720, "TimecodeInsertion": "DISABLED", "AntiAlias": "ENABLED", "Sharpness": 50, "CodecSettings": { "Codec": "H_264", "H264Settings": { "InterlaceMode": "PROGRESSIVE", "NumberReferenceFrames": 3, "Syntax": "DEFAULT", "Softness": 0, "GopClosedCadence": 1, "GopSize": 90, "Slices": 1, "GopBReference": "DISABLED", "SlowPal": "DISABLED", "SpatialAdaptiveQuantization": "ENABLED", "TemporalAdaptiveQuantization": "ENABLED", "FlickerAdaptiveQuantization": "DISABLED", "EntropyEncoding": "CABAC", "Bitrate": 1000000, "FramerateControl": "INITIALIZE_FROM_SOURCE", "RateControlMode": "CBR", "CodecProfile": "MAIN", "Telecine": "NONE", "MinIInterval": 0, "AdaptiveQuantization": "HIGH", "CodecLevel": "AUTO", "FieldEncoding": "PAFF", "SceneChangeDetect": "ENABLED", "QualityTuningLevel": "SINGLE_PASS", "FramerateConversionAlgorithm": "DUPLICATE_DROP", "UnregisteredSeiTimecode": "DISABLED", "GopSizeUnits": "FRAMES", "ParControl": "INITIALIZE_FROM_SOURCE", "NumberBFramesBetweenReferenceFrames": 2, "RepeatPps": "DISABLED", "DynamicSubGop": "STATIC" } }, "AfdSignaling": "NONE", "DropFrameTimecode": "ENABLED", "RespondToAfd": "NONE", "ColorMetadata": "INSERT" }, "AudioDescriptions": [ { "AudioTypeControl": "FOLLOW_INPUT", "AudioSourceName": "Audio Selector 1", "CodecSettings": { "Codec": "AAC", "AacSettings": { "AudioDescriptionBroadcasterMix": "NORMAL", "Bitrate": 96000, "RateControlMode": "CBR", "CodecProfile": "LC", "CodingMode": "CODING_MODE_2_0", "RawFormat": "NONE", "SampleRate": 48000, "Specification": "MPEG4" } }, "LanguageCodeControl": "FOLLOW_INPUT" } ], "Extension": ".mp4" } ], "OutputGroupSettings": { "Type": "FILE_GROUP_SETTINGS", "FileGroupSettings": { "Destination": "s3://<任意のS3バケット>/" } } } ], "AdAvailOffset": 0, "Inputs": [ { "AudioSelectors": { "Audio Selector 1": { "Offset": 0, "DefaultSelection": "DEFAULT", "ProgramSelection": 1 } }, "VideoSelector": { "ColorSpace": "FOLLOW", "Rotate": "DEGREE_0", "AlphaBehavior": "DISCARD" }, "FilterEnable": "AUTO", "PsiControl": "USE_PSI", "FilterStrength": 0, "DeblockFilter": "DISABLED", "DenoiseFilter": "DISABLED", "TimecodeSource": "EMBEDDED" } ] }, "AccelerationSettings": { "Mode": "DISABLED" }, "StatusUpdateInterval": "SECONDS_60", "Priority": 0 }Lambda
S3にtsファイルが作成されたら発火するLambda関数を作成します。
S3トリガー
- イベントタイプ:ObjectCreated
- サフィックス:.ts
- プレフィックス:<任意のS3バケット>
関数
- ランタイム:Python 3.8
lambda_function.pyfrom __future__ import print_function import json import urllib.parse import boto3 import os print('Loading function') mediaconvert = boto3.client('mediaconvert', region_name='ap-northeast-1', endpoint_url='https://xxxxxxxx.mediaconvert.ap-northeast-1.amazonaws.com') s3 = boto3.client('s3') def lambda_handler(event, context): # Get the object from the event and show its content type bucket = event['Records'][0]['s3']['bucket']['name'] key = urllib.parse.unquote_plus(event['Records'][0]['s3']['object']['key'], encoding='utf-8') inputFile = "s3://" + bucket + "/" + key outputKey = "s3://<任意のS3バケット>/" try: # Load job.json from disk and store as Python object: job_object with open("job.json", "r") as jsonfile: job_object = json.load(jsonfile) # Input/Output Setting job_object["Inputs"][0]["FileInput"] = inputFile job_object["OutputGroups"][0]["OutputGroupSettings"]["FileGroupSettings"]["Destination"] = outputKey # Exec MediaConvert's job response = mediaconvert.create_job( JobTemplate='arn:aws:mediaconvert:ap-northeast-1:<account-id>:jobTemplates/<ジョブテンプレートの名前>', Queue='arn:aws:mediaconvert:ap-northeast-1:<account-id>:queues/<キューの名前>', Role='arn:aws:iam::<account-id>:role/<ロールの名前>', Settings=job_object ) except Exception as e: print(e) raise ejob.json{ "OutputGroups": [ { "Name": "File Group", "OutputGroupSettings": { "Type": "FILE_GROUP_SETTINGS", "FileGroupSettings": { "Destination": "" } } } ], "Inputs": [ { "FileInput": "" } ] }
- 投稿日:2020-01-23T16:00:35+09:00
RedshiftでGRANTする時に地味なハマり方したときのメモ
前提
Redshiftで、あるスキーマテーブルを特定のユーザにSELECT権限を付与したかったが、なかなか上手く進まずハマったのでメモ。
TL;DR
RedshiftでGRANTするときには、SELECT権限だけじゃなく、スキーマに対して
GRANT USAGEも必要です。実行すべきコマンド
adminでRedshiftに入り、下記のクエリを実行する。
GRANT USAGE ON SCHEMA <権限付与したいスキーマ名> TO <権限付与したいユーザ名>; GRANT SELECT ON ALL TABLES IN SCHEMA <権限付与したいスキーマ名> TO <権限付与したいユーザ名>;
- 投稿日:2020-01-23T15:11:50+09:00
実践Terraformを読んで学びになったことと読了前に早めに知っておきたかったこと
実践Terraform AWSにおけるシステム設計とベストプラクティスのコードを写経して学びになったことをざっくりまとめてみました。
あと読了する前に知っておきたかったなということがあったのでそれも書いてみました。
参考になれば幸いです。※TerraformもAWSもGet Startedやチュートリアルに載っていそうな基本も学べたのですがそれらは省いています。
Terraformについて学びになったこと
Terraformのインストール方法と各方法に対する所感
方法は3つありました。
- Terraformをそのままインストール→簡単
- tfenvを使ってインストール→複数人で開発するときに適している
- .terraformversionファイルをリポジトリに含めるとチームメンバーが「tfenvinstall」コマンドを実行するだけで、バージョンを統一できる。
- DockernizedTerraform(terraformがインストールされたコンテナ)を使う→個人で使う分には十分。バージョン切り替えもイメージを変えればいいだけなので。ただ環境変数の設定などでハマりどころはある。(別記事でまとめる予定)
コマンド実施の基本的な流れ
- initで初期化
- planで変更内容を確認
- applyでコードの内容を適用(この時点でEC2インスタンスの起動やネットワーク設定の反映がされる)
- (不要になったら)destoryでリソースを削除
注意点
- applyによって既存のリソースを更新できるが、コードの変更内容によってはリソースが一度削除されて再生成されるのでplan実施時に削除されるか確認が必要。
- planで変更内容はでるが、実行してからはじめてわかるエラーもある。
- たとえばplanでは存在しないamiidを指定しているコードがあってもエラーにならない。apply実施ではじめてエラーとなり、誤っているとわかる。
Terraformでの設計や実装時の注意
基本的な考え方は他のプログラミング言語とは変わらないと感じました。
コードの可読性や再利用性、モジュールの凝集度や結合度を考えて設計して実装するのは共通して大事!ディレクトリ構成は標準があるので、基本的にはこれに倣って作るほうが良いようです。ただこれをそのまま使うと開発やステージング、本番環境を一部パラメータを変更して構築したいときにどうするか悩むところがありました。このあたりは検索すると色んな人が考えて実践しているようなので参考にさせていただこうと思います。
AWSについて学びになったこと
git-secretsとawslabsのリポジトリの存在
便利なツールとしてgit-secretsが紹介されていました。
git-secretsはアクセスキーやパスワードのような秘匿情報をGitでコミットしようとすると、警告してくれます。
野村 友規. 実践Terraform AWSにおけるシステム設計とベストプラクティス (Japanese Edition) (Kindle の位置No.249-250). Kindle 版.
各種ログはJSON形式で出力させるようにするとCloudWatchLogsInsightsで簡単にログが検索できる
CloudWatchLogsInsightsはCloudWatchLogsで残っているログがJSON形式であれば専用の検索クエリで検索できるようになります。そのため、ECS FargateとかでコンテナのアプリケーションログをJSON形式で出力するようにしておくと、わざわざログ検索の仕組みを作らなくてよくなります。
ただし、CloudWatch Logsはストレージとしては割高なので古いログはS3へ入れるようにした方が良いとのこと。GCPやAzureなどの他のクラウドサービスも、ログを特定の形式にしていたら検索しやすいようにしているかもしれません。他のクラウドサービス使うときも調べておいたほうが良い項目だなと思いました。
実践する前に知っておいたほうが楽だと思ったこと
以下のことは本を読む前に知っておいたらちょっと楽になったかなと思いました。
Terraformのファイル名の付け方
- tfファイル名はAWSサービス名か役割のどちらかで統一したほうがいい
- ファイル名はAWSサービス名と役割のどちらを書くにしても短縮形はあまり使わないほうがいい(自分でもわからなくなるため)
気づいたら以下のようにファイルができていて、ファイルを開かないと詳細がわからないという残念な感じになりました。
├── imds.tf <-- imdsは"in memory data store"の略で中身はElastic Cacheの定義。サービス名でも役割でもない。辛い。 ├── kms.tf <-- AWS Key Management Service (KMS)の定義。サービス名がそのままファイル名に。 ├── lb.tf <-- Elastic Load BalancingのApplication Load Balancerを使って構築するLoad Balancer。役割がファイル名に。 ├── main.tf ├── network.tf <-- Amazon VPCのみを使って定義したネットワーク設定。役割がファイル名に。 ...とくにはじめて触るサービスの場合は略さない方がよかったですね。AWSやAmazon Elasticは省略されていても問題なさそうなので、
サービス名で統一するなら以下のようにしたらよかったかなと。
- AWS Key Management Service(KMS) -> KeyMangagementService.tf
- Amazon Elastic Container Registry (ECR) -> ContainerRegistry.tf
- Amazon Elastic Container Service (Amazon ECS) -> ContainerService.tf
まずリソースを指定して削除できるようにするオプションは中盤辺りから知っておけば楽だっただろうなと思いました。↓です。
terraform destroy -target=hogehogeちょっと試したいことがあってサンプルコードを一部変えてapplyを実行したらなんかよくわからない状態になることがありました。このとき、一度作り直したいためサブコマンドdestroyで全部ぶっ壊して都度applyしていたのですが、そうすると別に壊さなくていいネットワーク設定や独立しているEC2インスタンスまで壊してまた作っていました。これはけっこう時間がかかります。そのため試したい部分だけ変更して作り治せるようにこのオプションを使っていればよかったなと思いました。
あとは、デバッグログの設定方法。
TF_LOGにはログレベルとして、TRACE・DEBUG・INFO・WARN・ERRORを指定できます。DEBUGレベルのログを出力する場合、次のように実行します。
$ TF_LOG=debug terraform apply
また、環境変数「TF_LOG_PATH」を使うと、ログをファイル出力できます。
$ TF_LOG=debug TF_LOG_PATH=/tmp/terraform.log terraform apply野村 友規. 実践Terraform AWSにおけるシステム設計とベストプラクティス (Japanese Edition) (Kindle の位置No.3843-3848). Kindle 版.
これは本の終わりの方の28章「落ち穂拾い」で書かれています。ただ、こちらもよくわからないエラーで失敗したときに原因を辿れるように先に知っておければなと思いました。
さいごに
上記意外にもやってみたらハマって、そこで学びになった点はあるのですが、それも書き出すとめっちゃ長くなるのでそれは別で書こうかなと思います。
得られたことが多い分、まとめようとするとボリュームも多い・・。
次に本を読むときは章単位でまとめていこうと思いました。時間が経つと忘れてしまうこともあるし、内容をまとめにくくなるので。
- 投稿日:2020-01-23T12:07:46+09:00
【Rails】 Heroku, Aws で詰まったときに見る記事まとめ
Heroku
db
heroku pg:reset DATABASE_URL heroku run rake db:migrate or heroku run rake db:seed【Rails】Heroku上でApplication Error(H10 App crashed)【PostgreSQL】
group :production do gem 'pg', '0.20.0' endメモ
heroku run rails cでheroku上のdbの中身を確認できる。
heroku run rails db:migrate:statusでdbの状態を見れる。
heroku logs -tで詳しいエラー内容を見れる。assets
Rails4 asset pipeline関連設定まとめ(Heroku対応込)
RAILS_ENV=production bundle exec rake assets:precompile assets:clean git add . git commit -m "hoge" git push origin hoge git push heroku【rails】【heroku】【bootstrap】herokuでCSS、font、JavaScriptが反映されない。
credentials.yml.enc, master.key
【Rails5.2】credentials.yml.encとmaster.keyでのデプロイによる今までとの変更点
EDITOR=vim bin/rails credentials:editrailsのエラー「Errno::EACCES: Permission denied」の解決
production環境でsecret_tokenをセットする(rails)
AWS
- 投稿日:2020-01-23T11:34:48+09:00
【AWS】EC2でphpMyAdminを利用し、RDSへアクセス
phpMyAdminをインストールする
①必要な依存ファイルをインストール
sudo yum update sudo yum install httpd sudo yum install php70-mbstring.x86_64 php70-zip.x86_64 -yphpの最新バージョン(7.2)をインストール
最新のphpやPythonは下記のコマンドでインストールする必要が有る
インストールできるモジュール一覧とインストールするphp7.2についての情報を確認する。amazon-linux-extras amazon-linux-extras info php7.2php7.2をインストールする
sudo amazon-linux-extras install php7.2インストールされたバージョンを確認する。
sudo yum list installed | grep httpd sudo yum list installed | grep php②apacheの再起動
sudo service httpd restart③
/var/www/htmlに移動cd /var/www/html④このドキュメントルートにphpMyAdminのパッケージをダウンロードします
sudo wget https://www.phpmyadmin.net/downloads/phpMyAdmin-latest-all-languages.tar.gz⑤phpMyAdminファイルを作ってそこにパッケージを展開します
sudo mkdir phpMyAdmin sudo tar -xvzf phpMyAdmin-latest-all-languages.tar.gz -C phpMyAdmin --strip-components 1⑥
phpMyAdmin-latest-all-languages.tar.gzを削除しますsudo rm phpMyAdmin-latest-all-languages.tar.gz⑦ブラウザで
phpMyAdminが開くか確認する
インスタンスのIPアドレス/phpMyAdminにアクセス
EC2へのアクセスを行う為、インバウンドの設定を行い、アクセス可能な状態にしておく
これでphpMyAdminを入れられました
RDSへのアクセス設定
現状のままだとLocalHostのデータベースにアクセスするように設定されているので、データベースのアクセスを変更していく。
設定ファイルの更新
サンプルの設定ファイルをコピーする
cd /var/www/html/phpMyAdmin/ sudo cp config.sample.inc.php config.inc.phpパーミッションを変更し、設定ファイルの情報を更新する。
sudo chmod 660 config.inc.php ★これを実行すると起動できなくなるので不要 sudo vim config.inc.php下記の箇所を編集し、
ESCを押してから:wqで保存して終了してください。設定ファイル.php/* Server parameters */ $cfg['Servers'][$i]['host'] = '自分のRDSのエンドポイント' $cfg['Servers'][$i]['compress'] = false; $cfg['Servers'][$i]['AllowNoPassword'] = false;自分のエンドポイントが分からない場合は、RDSの画面から確認する事が可能です。
各種追加設定
Cookie用のパスフレーズの設定
config.inc.phpファイル内のCookie用のパスフレーズを設定します。sudo vim config.inc.php設定ファイル.php/** * This is needed for cookie based authentication to encrypt password in * cookie. Needs to be 32 chars long. */ $cfg['blowfish_secret'] = 'Cookie用の32文字以上の文字列を定義する'; /* YOU MUST FILL IN THIS FOR COOKIE AUTH! */ (例) $cfg['blowfish_secret'] = 'kcBuC08452nW0qTCVFXEQV0HO7KhrCYAAACCCCV';mbstringのインストール
下記のコマンドでインストール可能なphpの拡張機能を検索します。
sudo yum list php-* | grep amzn2extra-php7.2実行結果[ec2-user@ip-10-0-10-165 phpMyAdmin]$ sudo yum list php-* | grep amzn2extra-php7.2 php-cli.x86_64 7.2.24-1.amzn2.0.1 @amzn2extra-php7.2 php-common.x86_64 7.2.24-1.amzn2.0.1 @amzn2extra-php7.2 php-fpm.x86_64 7.2.24-1.amzn2.0.1 @amzn2extra-php7.2 php-json.x86_64 7.2.24-1.amzn2.0.1 @amzn2extra-php7.2 php-mysqlnd.x86_64 7.2.24-1.amzn2.0.1 @amzn2extra-php7.2 php-pdo.x86_64 7.2.24-1.amzn2.0.1 @amzn2extra-php7.2 php.x86_64 7.2.24-1.amzn2.0.1 amzn2extra-php7.2 php-bcmath.x86_64 7.2.24-1.amzn2.0.1 amzn2extra-php7.2 php-dba.x86_64 7.2.24-1.amzn2.0.1 amzn2extra-php7.2 php-dbg.x86_64 7.2.24-1.amzn2.0.1 amzn2extra-php7.2 php-devel.x86_64 7.2.24-1.amzn2.0.1 amzn2extra-php7.2 php-embedded.x86_64 7.2.24-1.amzn2.0.1 amzn2extra-php7.2 php-enchant.x86_64 7.2.24-1.amzn2.0.1 amzn2extra-php7.2 php-gd.x86_64 7.2.24-1.amzn2.0.1 amzn2extra-php7.2 php-gmp.x86_64 7.2.24-1.amzn2.0.1 amzn2extra-php7.2 php-intl.x86_64 7.2.24-1.amzn2.0.1 amzn2extra-php7.2 php-ldap.x86_64 7.2.24-1.amzn2.0.1 amzn2extra-php7.2 php-mbstring.x86_64 7.2.24-1.amzn2.0.1 amzn2extra-php7.2 php-odbc.x86_64 7.2.24-1.amzn2.0.1 amzn2extra-php7.2 php-opcache.x86_64 7.2.24-1.amzn2.0.1 amzn2extra-php7.2 php-pecl-apcu.x86_64 5.1.12-3.amzn2.0.1 amzn2extra-php7.2 php-pecl-apcu-devel.noarch 5.1.12-3.amzn2.0.1 amzn2extra-php7.2 php-pecl-igbinary.x86_64 2.0.7-3.amzn2.0.1 amzn2extra-php7.2 php-pecl-igbinary-devel.noarch 2.0.7-3.amzn2.0.1 amzn2extra-php7.2 php-pecl-imagick.x86_64 3.4.4-1.amzn2.0.1 amzn2extra-php7.2 php-pecl-imagick-devel.noarch 3.4.4-1.amzn2.0.1 amzn2extra-php7.2 php-pecl-libsodium.x86_64 2.0.21-1.amzn2.0.1 amzn2extra-php7.2 php-pecl-mcrypt.x86_64 1.0.1-3.amzn2.0.1 amzn2extra-php7.2 php-pecl-memcached.x86_64 3.0.4-3.amzn2.0.1 amzn2extra-php7.2 php-pecl-msgpack.x86_64 2.0.2-3.amzn2.0.1 amzn2extra-php7.2 php-pecl-msgpack-devel.noarch 2.0.2-3.amzn2.0.1 amzn2extra-php7.2 php-pecl-oauth.x86_64 2.0.2-3.amzn2.0.1 amzn2extra-php7.2 php-pecl-redis.x86_64 4.3.0-1.amzn2 amzn2extra-php7.2 php-pecl-ssh2.x86_64 1.1.2-3.amzn2.0.1 amzn2extra-php7.2 php-pecl-uuid.x86_64 1.0.4-3.amzn2.0.1 amzn2extra-php7.2 php-pecl-zip.x86_64 1.15.2-3.amzn2.0.1 amzn2extra-php7.2 php-pgsql.x86_64 7.2.24-1.amzn2.0.1 amzn2extra-php7.2@amzn2extra-php7.2と表示されている物がインストールされているパッケージです。
今回は、必要なパッケージを導入します。
sudo yum install php-mbstring
php.iniの設定失敗した時のためにバックアップを取っておく
sudo cp /etc/php.ini /etc/php.ini.defaultviでファイルを開いて編集(保存は同じく:wq)
sudo vi /etc/php.iniphp.ini# HTTPヘッダにPHPのバージョンを記載しない - expose_php = On + expose_php = Off # メモリ上限を引き上げる - memory_limit = 128M + memory_limit = 512M # エラーログのパスを変更 - error_log = php_errors.log + error_log = /var/log/php_errors.log # POST送信の許容サイズを引き上げる - post_max_size = 8M + post_max_size = 16M # アップロードファイルの許容サイズを引き上げる - upload_max_filesize = 2M + upload_max_filesize = 8M # timezoneの設定 - date.timezone = + date.timezone = Asia/Tokyo # デフォルト言語を日本語に設定 - mbstring.language = Japanese + mbstring.language = Japanese # 文字コード検出のデフォルト値を定義 - mbstring.detect_order = auto + mbstring.detect_order = auto設定を反映
記述ミスが無いかを確認
sudo service httpd configtest設定を反映
sudo service httpd restart※設定が反映されない場合は、サーバーを再起動すると直ることが有ります。
Tempフォルダの作成
$cfg['TempDir'] (/var/www/html/phpMyAdmin/tmp/) にアクセスできません。phpMyAdmin はテンプレートをキャッシュすることができないため、低速になります。というエラーの対処を行います。
「phpMyAdmin」フォルダに移動し、下記のコマンドでフォルダを作成し、パーミッションを更新します。
sudo mkdir tmp
sudo chmod 777 tmp
参考サイト
- 投稿日:2020-01-23T11:11:57+09:00
serverlessとLambda
serverlessとLambda
話すこと
- lambdaでできること
- serverless frameworkでできること
Lambdaのusecase
- web application
- 定期的なtask処理
- Event処理
Faas
- Function as a serviceの略
- AWS Lambdaが一番有名なFaasだが他にもいっぱいある
- cloud functions(GCP)
- Azure Functions(microsoft)
Lambdaで使用可能な言語
- aws公式でサポートしている言語
- node
- Python
- Ruby
- Java
- golang
- 基本何でも動く
- custom runtimeを使えば何でも
- https://docs.aws.amazon.com/ja_jp/lambda/latest/dg/runtimes-custom.html
- lambdaでRustを動かしている事例もあり
Lambdaの主な制限
- package size
- 250MB(Layer含む)
- 50MB(Layer含まない)
- functionのtimeout
- 900秒(15分)
- accountごとの同時実行数
- 1000
アーキテクチャ設計における優先順位(推奨)
- LambdaでできることはLambda(faas)でやる
- Lambdaでできない(もしくは難しい)なら、ECSやsagemakerなどmanagedなコンテナ技術を使う
- それでも難しい場合はec2を選択
Common problems
- package sizeが大きくなってしまい50MBに収まらない
- numpyやpandasのようなpackageを使う際によく起きる
- 後述のlayerである程度解決
- 一つのfunctionで同時実行数を専有してしまい、他のfunctionが動かない
- cross compile問題
- macでinstallしたpackageをそのままdeployしても動かない
- lambdaが動作しているamazon linux用のbuildが必要
LambdaのCost
- request
- 1000000件/0.20 USD で、無料利用枠は 1 か月に1000000
- compute
- 1GB-秒につき 0.00001667 USD で、無料利用枠は 400000GB-秒
- 1GBのmemoryなら400000/86400=4.62962963なので4-5日間は絶えず処理していても無料
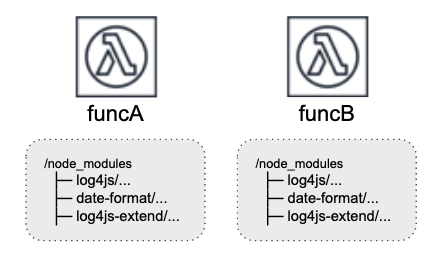
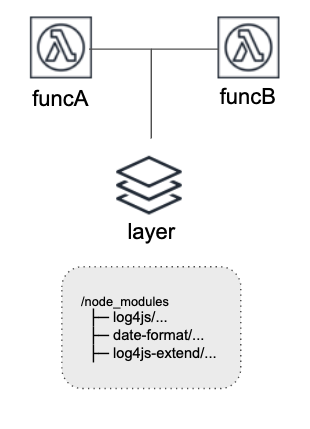
Lambda layer
- 2018年のre:inventで発表された機能
- lambda functionを機能単位でlayerに切り出せる
- これまであったfat moduleの容量問題はこれで解決
- 1 functionにつけられるlayerは5まで
Layer前
Layer後
Frameworkがやってくれること
- faasのorchestration
- faasといっても、functionだけでsystemが成立することはほぼありえない
- web applicationでもendpointだったりstorageだったりが必要になる
各種Framework
- AWS SAM
- zappa
- Apex
- serverless framework
AWS SAM
- AWSが公式で提供しているFramework
- Serverless Application Model
- iaasにおけるterraformとcloudformationの関係性に近い
zappa
- aws で serverless python web serviceを実現するflaskベースのOSSフレームワーク
- apigateway + LambdaのよくあるパターンをFlaskで書く
- GCPは対応していない
- 事例があんま多くなさそう
Apex
- Lambdaのorchestration tool
- 面白い機能として、terraform integrationがある
- apex infra applyでterraformを実行できる
- 事例があんま多くなさそう
- No longer maintainedと書いてありもう長くなさそう、、
serverless framework
serverless frameworkのいいところ
- コミュニティが強力
- ググれば情報がたくさん出てくる
- pluginが多数あり、大抵のことはpluginを使えば実現できる
- いざというときは自分でpluginを作ればいい
- serverlessはnode製なのでnodeで実装
- eventから処理までがseamlessに書ける
- lambda+api gatewayというよくある組み合わせを爆速で作れる
get start
$ npm install -g serverless $ sls create -t aws-python3
serverless frameworkのyamlに書けること
- provider
- 環境変数
- iam role
- cloudformationのstack
- custom
- layer
- function
provider
provider: name: aws runtime: python3.7 stage: ${opt:stage, self:custom.defaultStage} environment: ${file(config/environments/${self:provider.stage}.yml)} region: ${self:provider.environment.REGION} timeout: ${self:provider.environment.TIMEOUT, "120"} memorySize: ${self:provider.environment.MEMORY_SIZE, "256"} # bucketの設定だが、serverSideEncryptionはserverless-deployment-bucketが必要 deploymentBucket: name: ${self:provider.stage}-${self:service}-deployment serverSideEncryption: AES256 iamRoleStatements: - Effect: "Allow" Action: - "iam:ListAccountAliases" Resource: "*"
function
- 呼び出す関数とその発火するeventを定義
- eventから処理までseamlessに書ける
function
# spotのeventを処理する ec2_spot: handler: handlers/main.spot_notify events: - cloudwatchEvent: event: source: - "aws.ec2" detail-type: - "EC2 Spot Instance Interruption Warning" # 定期的に処理する cost_service: handler: handlers/main.cost_notify events: - schedule: "cron(0 0 2 * ? *)"
function
def spot_notify(event, context): instance_id = event.get("detail").get("instance-id") ... return def cost_notify(event, context): ... return
- eventの中にserviceから送信される情報が入っている
ここまで書くとlocalで関数をdebug実行可能
$ sls invoke local --function ${関数名} -d '${callbackされるjson}'
- 静的言語だとできない模様(javaとか)
custom
- yaml内で使う変数の定義
- ${self:custom.XXXXX}でyaml内で参照できる
- pluginの設定
custom
custom: defaultStage: dev pythonRequirements: ... localstack: ... rust: ...
Layer
layers: lib: name: ${self:service}-lib-lambda-layer-${self:provider.stage} path: layers/lib package: exclude: - 'python/lib/__pycache__/**' func_a: handler: handlers/hoge.func_a layers: # ↑で独自で作ったlayer - {Ref: LibLambdaLayer} # serverless-python-requirementsが自動で作ってくれるlayer - {Ref: PythonRequirementsLambdaLayer} ...
鉄板のplugin
- serverless-python-requirements
- pipの管理をうまくやってくれる
- requirements.txtからzipを生成してくれたり
- pipenvにも対応している
- layer化すると便利(packageを共通化できる)
- serverless-offline
- apigateway+lambdaに類似したセットをlocalで実行できる
- serverless-iam-roles-per-function
- lambda関数ごとに権限を分離できる
その他の使ってるplugin
- serverless-deployment-bucket
- deployに必要なbucketの暗号化
- serverless-rust
- serverlessでrustのcodeをbuild, deployしてくれる
- serverless-localstack
- localstack(仮想aws)を使ったtestを実行
web apiを作る際の組み合わせ例
awsgiとflaskでweb api(yaml)
functions: flask: handler: handlers/flask.handler events: - http: path: /{any+} method: ANY
awsgiとflaskでweb api(コード)
import awsgi from flask import ( Flask, jsonify, ) app = Flask(__name__) @app.route('/index') def index(): return jsonify(status=200, message='OK') @app.route('/submit', methods=['POST']) def submit(): return request.get_data() def handler(event, context): return awsgi.response(app, event, context)
awsgiとflaskでweb api
- ANYにすることで、許可するpathやmethodをApplication側でハンドリングできる
- Lambda関数を量産する必要がない
- local開発ではserverless-offlineを使えばapi gatewayのendpointをlocalで起動できる
- RestのAPIを作る場合はこれが一番ラクだと思う
- もちろんgraphqlも使える
plugins: - serverless-python-requirements - serverless-offline ...
時間があったらdemoします
- 投稿日:2020-01-23T10:49:45+09:00
AWS初心者によるAWS初心者のためのAWS環境自動化入門
はじめに
AWS上の環境構築の自動化サービスについて、勉強していたのですが
どれがどういう役割なの?違いをわかりやすくまとめた記事があると便利だよな!と思い、記事にしてみました。
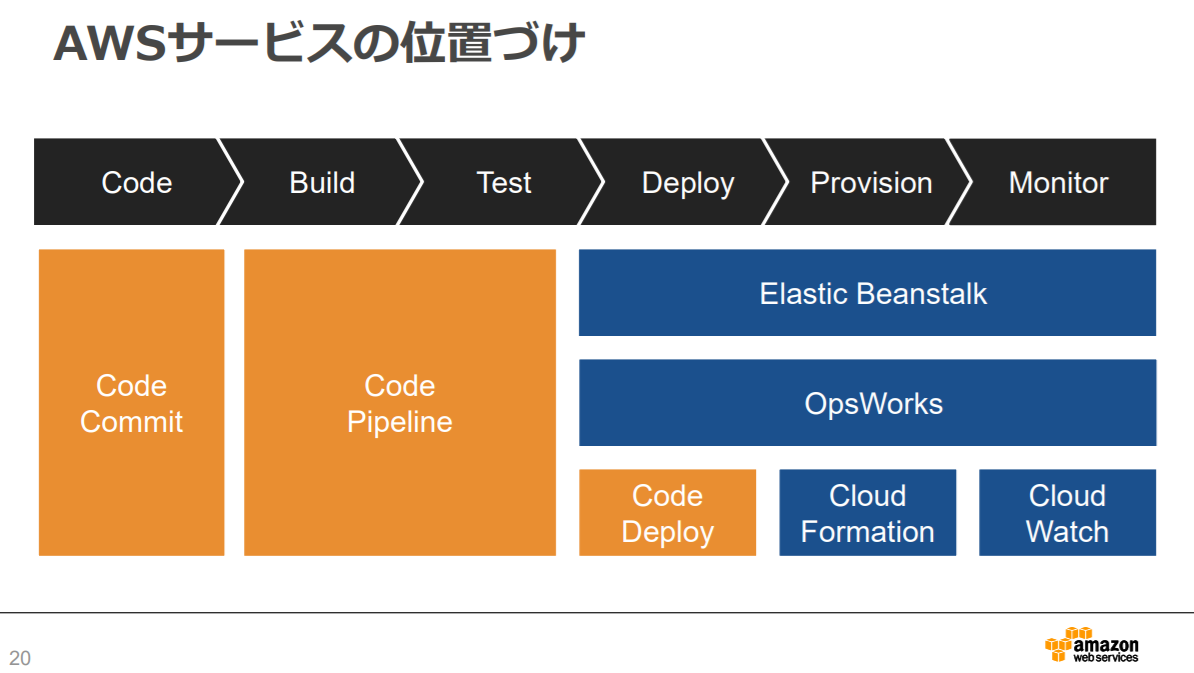
AWS 公式slideshareより抜粋Elastic Beanstalk
サーバーからネットワークの設定まで、アプリケーションの開発に必要な環境をあらかじめ整えてくれています。
運用やコストの面でもサポートしてくれて、面倒な環境の構築は Elastic Beanstalk に任せて、コードを書くだけでアプリケーションを作成することができます。
- 開発言語は、Java / PHP / Python / Python(with Docker) / Node.js / Go / NET / Ruby
- アプリケーションをアップロードするだけで展開できる
- サーバーやストレージなどアプリケーションの状態をモニタリングしたり、OSとデーターベースの管理ができる
- モニタリングやセキュリティーに必要なパッケージのみ使用してくれるので、不要なコストを削減
- 複数のユーザーや企業が同じアプリケーションを共有し、各々でカスタマイズすることが可能
AWS CloudFormation
ほとんどすべてのAWSのリソースの構築や設定を行えるので、最も自由度が高いサービスです。
クラウド環境内のすべてのインフラストラクチャリソースを記述して、事前準備するための共通言語を提供します。
- JSON フォーマットを使用して構成を記述
- CloudFormer を使用すると、現在の構成をJSONフォーマットに変換でき、構成のコピーや雛形の作成が楽に
- CloudFormation で作成したAWSリソースは、CloudFormation 以外の方法で変更してはいけない
AWS OpsWorks
サーバーのパッチ適用、アップデート、バックアップが自動的に実行され
Chef や Puppet (あらかじめ用意しておいた設定ファイルに基づいて、サーバーのさまざまな設定を自動的に行うソフトウェア、設定管理ツール)のマネージド型インスタンスを利用できるようになる、構成管理サービスです。
- 独自の設定管理システムを運用したり、そのインフラストラクチャを管理しなくて良い
- サーバーのパッチ適用、アップデート、バックアップの自動化
- ソフトウェアの設定、パッケージのインストール、データベースのセットアップ、サーバーのスケーリング、コードのデプロイといった運用が自動化
- サポート範囲は、Amazon EC2 インスタンス、Amazon EBS ボリューム、Elastic IP、Amazon CloudWatch メトリクスなど、アプリケーション志向の AWS リソースに限られている
Chef
ファイルに記述した設定内容に応じて自動的にユーザーの作成やパッケージのインストール、設定ファイルの編集などを行うツールです。
Chefでは「Cookbook(クックブック)」や「Recipe(レシピ)」と呼ばれる設定ファイルの再利用がしやすい構造になっている点が特徴。
Ruby と Erlang で記述。Chef はフランス語で言う「料理人」が由来になっており、その構成要素も料理をモチーフにして命名されたそうです。Puppet
サーバーの環境設定やインストールなどを自動化する設定管理ツール。
Puppet は Ruby で実装されており、各種操作の実行を行うためのフロントエンドであるpuppetコマンドと、各種機能を実装した Ruby ライブラリから構成されています。それぞれのサービスの適正
OpsWorks CloudFormation Elastic Beanstalk 用途 アプリケーションのモデル化、デプロイ、設定、管理、および関連アクティビティ アプリケーションのモデル化、デプロイ、設定、管理、および関連アクティビティ インスタンス上のWEBアプリケーションの展開と管理を自動化 管理レベル より詳細で高レベル。柔軟性があり、単純な構成も複雑な構成も対応 環境の土台を作る インフラ環境そのものを自動で展開したり管理するには不向き 自由度 ユーザー独自のChefのクックブックを使用できる。EC2がほぼ自由に設定可能 OSより下のレイヤーでは自由度が高い。JSON or YAMLで記述してコード化 プログラミング言語、Docker コンテナのプラットフォーム 構成 スタックやレイヤーといったコンセプトに基づく 5 種類のテンプレート要素で自由にスタックを構成。 主なサーバはApache / Nginx / Tomcat / IIS 需要者 知識があり、運用に効率性・柔軟性がほしい 自分で好きなように管理モデルをカスタムしたい 専門知識がない、とりあえずな環境が欲しい 所感
繰り返し高頻度で行われる環境構築や、デプロイの作業は自動化できたほうが確実に効率が良いですよね。
手作業によるミスや、長時間の作業の無駄を省くためにも、重宝するべきサービスだと思います。
どこまで詳細に設定する必要があるのかで、どれを使うか選べるのも良い点ですね。公式サイトリンク
- 投稿日:2020-01-23T10:19:20+09:00
Node.jsとDynamoDBで日時データの処理
DynamoDBに日時データを持たせる2つの方法
- データ型を
Stringにして2016-02-15や2015-12-21T17:42:34Zのように文字列で持たせる。- データ型を
Numberにして1579740176030のように数値で持たせる。2.項のNumber型の実用例としては、エポック時間 (1970 年 1 月 1 日の 00:00:00 UTC 以降の秒数) を利用することができる。(UNIXTIMEの詳細)
Node.jsでエポック時間を扱う
現在の日時をDateオブジェクトで取得する
const date = new Date(); console.log(date); // 2020-01-23T01:09:41.444Z console.log(typeof date); // 'object'現在の日時をエポック時間で取得する
const date = Date.now(); console.log(date); // 1579740176030 console.log(typeof date); // 'number'DynamoDBから取得したエポック時間をDateオブジェクトへ変換する
const unixtime = 1579740176030; // DynamoDBから取得したエポック時間と想定 const date = new Date(unixtime); console.log(date); // 2020-01-23T01:09:41.444Z console.log(typeof date); // 'object'
- 投稿日:2020-01-23T09:41:17+09:00
RDSとIAMでパスワードレス認証(Python)
MySQLのパスワードベタ書きしないでよくなります
{}内は適宜置き換えてね1. ユーザ作成
CREATE USER '{MySQLユーザ名}'@'%' IDENTIFIED WITH AWSAuthenticationPlugin as 'RDS'; # ユーザ作成 GRANT ALL PRIVILEGES ON {MySQLDB名}.* TO '{MySQLユーザ名}'@'%' REQUIRE SSL; # 権限2. IAMポリシー
こんな感じでポリシーを作る
jsonで直接アタッチするならこんな感じ
{ "Effect": "Allow", "Action": "rds-db:connect", "Resource": "arn:aws:rds-db:{AWS::Region}:{AWS::AccountId}:dbuser:cluster-{リソースID}/{MySQLユーザ名}", }CloudFormationならこんな感じ
iamRole: - Effect: Allow Action: - "rds-db:connect" Resource: - 'Fn::Join': - ':' - - 'arn:aws:rds-db' - Ref: 'AWS::Region' - Ref: 'AWS::AccountId' - 'dbuser:cluster-{リソースID}/{MySQLユーザ名}'3. 一時パスワードで接続!
こんな感じでトークン(一時パスワード)を発行する
client = boto3.client("rds") # トークン取得 token = client.generate_db_auth_token( DBHostname=RDS_HOST, Port=RDS_PORT, DBUsername=RDS_USER_NAME ) db_connection = mysql.connector.connect( host=RDS_HOST, port=RDS_PORT, database=RDS_DB_NAME, user=RDS_USER_NAME, passwd=token )たったこんだけ
かんたんにゃ〜〜
- 投稿日:2020-01-23T01:32:55+09:00
AWS Sysopsアドミニストレーターアソシエイト資格に合格しました。
はじめに
先週(1/17)ですが、AWS Certified SysOps Administrator - Associate (SOA)の試験に受かりましたので、勉強方法や試験での手応えについて記載しようと思います。
勉強期間
資格取得に動き始めたのが2019年12月中旬頃(クリスマスの少し前ぐらい)でした。
勉強期間としては1ヶ月程になりますが、途中Azureの資格に浮気したり年末帰省して胃腸炎にかかってダウンしたりしたので、真面目に詰め込んだらもう少し早く取れたと思います。
自分は上記の通りSAAを取得済みだったので、その時の内容を思い出す+アルファの知識を仕入れるだけで良かったですが、AWSを全く知らない人はクラウド固有の考え方含めて覚えることが多いのである程度の期間を取った方が良いです。
(色々な記事でも触れられていますが、SOAから入るとハードルが高いのでSAAから取ることをお勧めします)獲得スコア
受験日 スコア/合格点/満点 結果 2020/1/17 731/720/1000 合格 正直手応えはあったのですが、思ったよりぎりぎりでした……。
学習で使った教材
AWS公式
AWSはアップデートが早く、書籍の内容が既に陳腐化している場合も多々あるので、基本的にはAWSが提供しているドキュメントやトレーニングが本命となります。
言わずもがなですが、試験ガイドにあるサンプル問題と模擬試験は必ずやりましょう。
あとはSOAのデジタルトレーニング(無料のeラーニング)も観ました。
(字幕なしの英語なのでハードルは高いですが、試験範囲のサービスを知るだけでもかなり有用だと思います)今回一番お世話になったのは、やはりBlackbeltセミナーの資料(と動画)ですね。
SOAの場合、Cloudwatch、IAM、セキュリティ系(NACLとセキュリティグループなど)あたりが特に重要になります。
最低限、どのサービスがどんなことをやるためのものかはわかっていた方が良いです。これはSOAに限らずAWSの資格全般に言えることですが。
(例えば、GuardDutyとShieldとInspectorはそれぞれどんなサービスなのか、などなど)https://aws.amazon.com/jp/aws-jp-introduction/
書籍
「AWS認定アソシエイト3資格対策~ソリューションアーキテクト、デベロッパー、SysOpsアドミニストレーター~」
Developerの資格取得も視野に入れていたので購入。
ただ、試験範囲にあるサービスについて概要程度のことしか書いていなかったのであまり役には立ちませんでした。(これからAWSを学ぶ人には有用だと思います)問題集
「AWS WEB問題集で学習しよう」
SAAの時もお世話になったWEB問題集。
今回は試験までの日数が少なかったので、有料プランではなく無料分のみ活用しました。
(もし落ちていたら購入していたと思います)「WHIZLABS」
試験問題を販売している海外のサイト。
WEB問題集に比べて割安ですが、同じ理由で無料の問題(15問)だけ活用しました。
紹介していた記事では「Google翻訳で対応できる!」とあったものの、実際にやってみたらコピペ不可(そもそも右クリック不可)でやり方がわからなかったので、気合で英語のまま解きました。試験を受けての所感
・試験時間は130分でしたが、文章をちゃんと読んで理解してから解くと意外とあっという間でした。(SAAの時は眠くてしょうがなかったですが、今回はそんなこともなく)
・サービスの目的(○○は何のためのサービスか、など)を問う問題はなく、「知っている前提」で設計や運用のベストプラクティスについて問う問題が出る
・セキュリティの問題は多かった気がする(その辺りのサービスの理解が不十分だったのでだいぶ減点されたと思います)
・S3バケットポリシーの定義内容を読み解いたり、ルートテーブルのstateを見て「どんな状態か」を問うような、そこそこピンポイントな問題もあったので、もっと実際に手を動かした方が良かった(なのでハンズオンやサービスのチュートリアルは一通りやるべきだった)今後の予定
次はDeveloper(DVA)とクラウドプラクティショナーを取る予定です。(できれば今月中)
資格に限らず、今年は色々身に付けていきたいです(具体的にはコンテナやterraformなど)。
- 投稿日:2020-01-23T01:04:40+09:00
起動中のインスタンスからEBSボリュームのDeleteOnTermination設定を変更する。
起動中のEC2インスタンスのEBSボリュームのDeleteOnTermination設定を変更する手順。
通常、コンソールからだと、起動時のボリュームアタッチ時にしか設定できない。
そのため、あとから変更したい場合や、起動後にボリュームをアタッチした場合にはベットCLIから設定する必要があり、aws ec2 modify-instance-attributeコマンドで設定可能である。# EBS作成 $ aws ec2 create-volume --availability-zone ap-northeast-1a --size 8 --volume-type gp2 $ aws ec2 create-volume --availability-zone ap-northeast-1a --size 8 --volume-type gp2 # EBSアタッチ $ aws ec2 attach-volume --instance-id i-0cd13d242c52faxxx --volume-id vol-0c715576745bdbf9c --device /dev/sdb $ aws ec2 attach-volume --instance-id i-0cd13d242c52faxxx --volume-id vol-0c589364244gmdl2a --device /dev/sdc # 設定ファイルを作成 $ touch mapping.json $ nano mapping.json $ cat mapping.json [ { "DeviceName": "/dev/sdb", "Ebs": { "DeleteOnTermination": true } } # インスタンス終了時の挙動を反映 $ aws ec2 modify-instance-attribute --instance-id i-0cd13d242c52faxxx --block-device-mappings file://mapping.json # マウントされていることを確認 $ df /dev/sdb $ df /dev/sdcEC2コンソールのナビゲーションペインからボリュームを選択し、3つ(インスタンス生成時のデフォルトのebs+今作成したebs2つ)が
in-useであることを確認。EC2コンソールからインスタンスを終了。
再度EBSを確認すると1つのボリューム(削除設定をしなかった方のvol-id)のみが
availableで残っていることが確認できる。なお、
mapping.jsonファイルとしないでコマンドのいオプションにずらずら書くことも可能。
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/terminating-instances.html#preserving-volumes-on-termination
- 投稿日:2020-01-23T00:53:21+09:00
Warning: Identity file ChatSpace.pem not accessible: No such file or directory. ec2-user@13.112.68.204: Permission denied (publickey).のエラーの解決例
1.エラーの内容
一度シャットダウンして日を置いて下記のコマンドをしようとしたらできませんでした。
エラー文は下記の通りNeverland:~ kontatomoya$ ssh -i ChatSpace.pem ec2-user@13.112.68.204 #ログインのコマンドを打ちました Warning: Identity file ChatSpace.pem not accessible: No such file or directory. ec2-user@13.112.68.204: Permission denied (publickey). #ログインできないとのこと2.原因と解決方法
原因はディレクトリを.ssh(pemファイルのある場所)でコマンドしていなかったからでした。
なので下記のコマンドでログインできますNeverland:~ kontatomoya$ cd .ssh #ディレクトリを移動 Neverland:.ssh kontatomoya$ ssh -i ChatSpace.pem ec2-user@13.112.68.204 #コマンドを打ち込む3.このエラーで手が止まる理由
エラーを理解できなかった理由はpemファイルが何者でどういうコマンドか理解していなかったからでした。
まずpemとは「ただのファイル書式が決まった入れ物のことで、証明書、鍵をいくつでも含めることができるものです。つまり、鍵または証明書またはその両方」です。
この説明で理解された方も多いと思いますが'ssh -i ChatSpace.pem ec2-user@13.112.68.204'はec2-user@13.112.68.204のアプリケーションのpemファイルに情報をinsert(挿入)しますよという意味になります。
なのでpemファイルがない場所ではそもそも情報を追加などできませんのでタイトルのようなエラーが出てきます。
コマンドの内容を理解していれば現在のディレクトリが間違っているのだなと気づくことができます。