- 投稿日:2020-01-23T21:14:18+09:00
駆け足で振り返れ SQLセミナー(チューニング基礎編)
はじめに
去る2020年1月10日、オラクル本社で開催されたMySQL 8.0入門セミナー ~チューニング基礎編、SQLチューニング編~に参加してきました。
今回は、セミナーの概要に沿って、特に強調されていたなと感じた点を掻いつまんでいこうかと思います。
なお、セミナーの資料は下記ページからダウンロードすることが可能です。
(*2020/1時点。要Oracleアカウント登録)■MySQL 8.0入門セミナー講演資料 (チューニング基礎編、SQLチューニング編)
パフォーマンスチューニングの目的
限られたリソースの中で、最大限のパフォーマンスを出すこと。
パフォーマンスの指標
パフォーマンス指標には以下のものがある。
- スループット(単位時間あたりの処理能力)
- レスポンスタイム(処理を実行してから結果が返ってくるまでの時間)
- スケーラビリティ
- 上記の組み合わせ
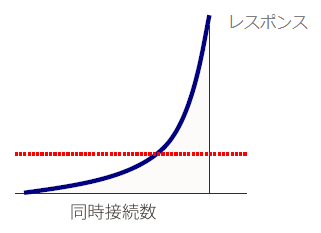
レスポンスタイムはキューイングによる遅延+実行時間で構成されるため、パフォーマンスの改善時にはキューイングによる遅延か実行時間のどちらかを改善する必要がある。
なお、システムが飽和状態に近付くとキューイングによる遅延が急激に増大する。(以下の図はセミナー資料より引用)
電話(リクエスト)に対応できるオペレーターが足りなくなり、オペレーターが空くまで待ちが発生する…ようなイメージ。パフォーマンス箇所を見極めるには、実行時間を計測し、ボトルネックを見極めることが重要。
チューニングのアプローチ
DBチューニング(全体最適)
サーバー(特にパラメータ)をチューニングする。
主にスループット向上につながる。SQLチューニング(個別最適)
個別のSQLのチューニング。
主にレスポンスタイム向上につながる。DBチューニング
DBのパラメータを調節してチューニングを行う。
主にデータベース管理者(DBA)が行う領域。ステータス変数などの情報から稼働状況を確認し、システム変数の設定値が適切か判断・調整する。
サーバー設定の確認
システム変数・ステータス変数の確認
システム変数はオプションファイルで確認・設定ができる。
UNIX: my.cnf
Windows: my.iniMySQL Serverの動作を監視するためにステータス変数を確認する。
特定のクエリについて調査する場合、mysql>FLUSH STATUS; <クエリ実行>; SHOW STATUS;コマンドラインではなく、GUIでシステム変数やステータス変数を確認したい場合は、MySQL Workbenchを使用すると確認できる。
性能分析のためのsysスキーマがMySQL5.7からデフォルトで実装されている。MySQL Serverチューニングの流れ
サーバーのコネクション&スレッド
設定ファイル my.cnf
max_connections(151) 1
許容可能なコネクション数を設定する。メモリを消費しきるので、実際のコネクション数に対して多すぎる値にはしないこと。thered_cache_size(9)*
スレッドをコネクションの切断後にもキャッシュする。
キャッシュすると、クエリが連続する際にクエリ間の同じ処理を使いまわせる。一般的にはmax_connections/3程度。コネクションスレッド毎のバッファ
- sort_buffer_size(256KB)
ソート用メモリサイズ。メモリ上で収まらなくなったらディスク(ファイル)を使用する。
SHOW STATUSのsort_merge_passesで、ファイルを利用したマージソートのパス数が確認できる。ソートがメモリ上だけでおさまらない場合には要確認。
InnoDB
Storage Enginesについては、基本的にInnoDBのことを考えていればいいらしい。
- innodb_buffer_pool_size(128MB)2
デフォルトだとサイズは小さくなっている。MySQL & InnoDBのみを利用している場合、メインメモリの80%程度を割り当てると良い。
- innodb_log_file_size(48MB)
これもデフォルトだとサイズが小さい。innodb_buffer_pool_sizeの25%~100%程度にすると良い。
- innodb_fike_per_size(ON)
テーブル欄にでOS上のファイルを分ける設定。ONを推奨(デフォルトでもON)。
スキーマのデザイン
はじめに細かい設定を考慮しておくことが大事。
- 正規化/非正規化の検討
- CharじゃなくてVarchar
- INTが使えるところはINT
- NOT NULLを宣言する
- インデックスを貼るときは頭から何文字か(プレフィックス)で貼れないか検討する
SQLチューニング
個別の処理のチューニング。
SQLチューニングによって、数十倍に性能が向上することは珍しくない。
チューニングの流れは以下の通り。
- 問題となるSQLの特定
- 実行計画やSQL実行時の稼働統計などの確認
- チューニング実施
1. 問題となるSQLの特定
スロークエリログ
指定した実行時間以上のクエリを出力する。
システム変数slow_query_logを設定すると出力される。
long_query_time
出力する実行時間のしきい値。細かすぎると出力されすぎるので、どのくらいのしきい値にするかは都度決定する。log_queryes_not_usiong_indexes
インデックスを貼っていないクエリを出力する。mysqldumpslow
スロークエリログのサマリを出せるツール。ログの出力が多いときにチューニングすべきクエリを特定するのに便利。[使用例]
mysqldumpslow -s at <スロークエリログファイル名>show full Processlist
現在実行にかかっているクエリを特定可能。実行した時点のスナップショットが表示される。
パフォーマンススキーマのThreadsテーブル
show full Processlist+αの情報が確認できる。また、show full Processlistよりもオーバーヘッドが少ない。2. 実行計画やSQL実行時の稼働統計などの確認
SQLの実行計画はオプティマイザ3が作成している。
Explainコマンドでオプティマイザが作成した計画を確認できる。Explain <実行計画を見たいSQL文>;Explainチェックポイント
Explainを実行すると、下記の項目が出力される。
項目名 説明 ID クエリのID(テーブルのIDではない) Select_type クエリの種類 table 対象のテーブル partitions 対象のパーティション(パーティションテーブルではない場合NULL) type レコードアクセスタイプ Possible_keys 利用可能なインデックス key 選択されたインデックス key_len 選択されたインデックスの長さ ref インデックスと比較される列 rows 行数の概算見積もり filtered フィルタリングされる行の割合 Extra 追加情報 見るべきポイント(ざっくり)
rows
実際に取り出される行数。これが少ないほど実行時間は短いということになる。Type
ここの値はかなり重要。以下の値の場合は優秀。
- const 結果が1行になるケース
- eq_ref JOINの場合の最適な結合型
次の値は高速ではないが、クエリによっては仕方がない場合も。
- uniq_subquery 最も遅いSELECTタイプだが、サブクエリの中では最速。
- range BETWEENや不等号、INを使うと出現。
以下の場合はチューニングを検討した方が良い。
- index フルインデックススキャン。大抵refまたはeq_refに改善できる。(ただし、ORDER BY+LIMITが入っている場合は出てきても良い、また行数が少ない場合は問題ない。)
- ALL テーブルフルスキャン。全行を処理する場合以外は避けるべき。
Select_type
[DEPENDENT UNION]および、[DEPENDENT SUBQUERY]は可能な限り避ける。
Extra
- Using index これが出力される場合は理想的。
以下は可能な限り避けた方が良い。
- Using filesort 内部で行をソート処理する。JOINの中で出てきたら非常に注意。
- Using temporary テンポラリテーブルを使用する。遅くなる傾向あり。Unionとか使ってないのに出たら要注意。
- Using where 取り出した行をさらにWhere条件で絞り込む。
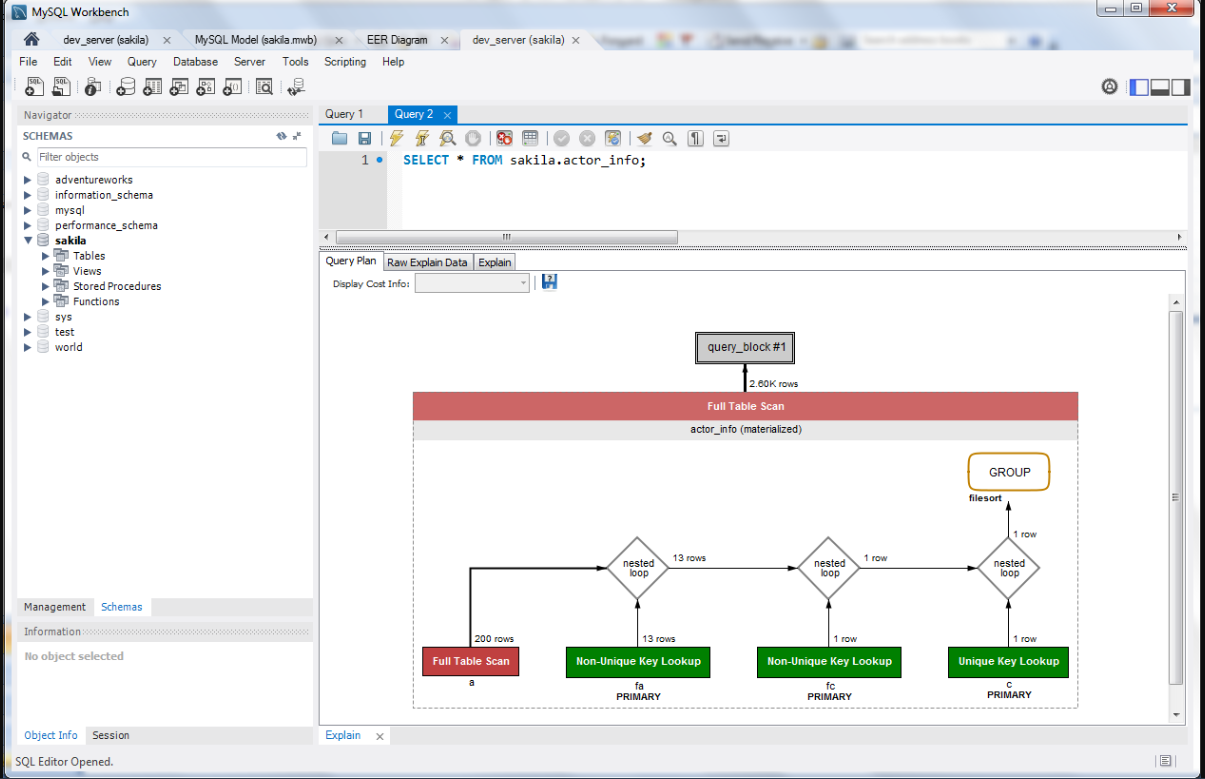
なお、MySQL Workbench にはVisual Explainという機能があり、実行計画をフローチャートで確認できる。(画像はMySQLのサイト4より。)
3.チューニングの実施
インデックスの活用
インデックスが使われていないクエリはインデックスを使って処理できないか考える。
(ただし、大量データにアクセスする場合5はインデックスを使わない方が高速になる。)インデックスは付けすぎないこと。参照時の性能はあがるが、更新時にはオーバーヘッドになる。
また、カーディナリティ6の低いデータにインデックスを付けても役立たない場合が多い。複数テーブルのJOIN
- JOINの順番と各テーブルに対するアクセスパスが重要
- 小さなテーブルからJOINする。2テーブルでもどちらからアクセスするかで効率は変わる。
- WHERE句での絞込みもどのテーブルに対して実施するのが効率的か、考えて実施する。
- インデックス列はそのまま参照しないと使えない。計算式(where a*100>=90など)は使わないこと。
サブクエリについて
サブクエリが遅かったのは昔の話。MySQL5.6から最適化が強化されている。
オプティマイザの制御
SQLが狙った計画通りにならないとき、オプティマイザの判断を制御することで、実行計画が変化することがある。
インデックスヒント
特定のインデックスを使用するようにオプティマイザに促す。強制力によって3種類ある。FOR句を使ってスコープを指定することもできる。(JOINのため、ORDER BYのため、など)
- USE INDEX 特定のインデックスを使用するように指示を出す
- FORCE INDEX
USE INDEXに加え、「テーブルスキャンを選択しない」指示を出す- IGNORE INDEX 特定のインデックスを使用しないように指示を出す(ここまですることは少ない)
[使用例]
mysql> EXPLAIN SELECT * FROM world.Country USE INDEX(Cont) WHERE Continent='Africa' OR Continent='Asia';Straght JOINヒント
JOINの順番を指定できる。指定すると、左側のテーブルが右側のテーブルより先に読み取られる。
OUTER JOINの時は使えない。mysql> EXPLAIN SELECT CountryLanguage.Language,Country.Name,COUNT(*) FROM City STRAIGHT_JOIN Country ON City.CountryCode=Country.Code STRAIGHT_JOIN CountryLanguage ON City.CountryCode=CountryLanguage.CountryCode GROUP BY CountryLanguage.Language,Country.Name ORDER BY CountryLanguage.Language;おわりに
軽く書くつもりが、メモをまとめるだけで、なかなかボリューミーになりました。
書ききれなかった部分に関しては、資料を参照いただくか、実際にセミナー参加していただくのがいいのかなと思います。(Oracleの回し者ではないですが。。。)
基礎だけでもチューニングで考慮できる点はたくさんあることを学びました。
クエリを書く機会はまだまだ多くないですが、たくさんの選択肢を知っておくことで、今後に活かしていけるのではと思いました。
カッコ()内はデフォルト値。()*は自動計算でデフォルト値が決まる。 ↩
こちらもカッコ()内はデフォルト値。 ↩
オプティマイザ(Optimizer)は、SQLの実行計画を作成している。計画はコストに基づいており、最もコストが低いと思われるものを作成する。オプティマイザの判断が必ずしも最適だとは限らない。 ↩
MySQL Workbench: パフォーマンス
https://www.mysql.com/jp/products/workbench/performance/ ↩表データの全件を取得する場合など ↩
カーディナリティ:値が取りうるバリエーションの度合い。たとえば値が「YES」か「NO」2通りしかない場合はカーディナリティは低い。「顧客番号」など様々な値を取る場合はカーディナリティが高いと言える。 ↩
- 投稿日:2020-01-23T17:53:15+09:00
【Golang】 mysql データベース処理
概要
本記事では、Golangにおけるdatabase/sqlライブラリを用いたMySQLデータベースに対する処理例を示す。
処理例では、ユーザーデータを仮定し、エラー処理についても例を示す。以下のようになテーブルを想定する。
CREATE TABLE user_db.users ( id INT NOT NULL AUTO_INCREMENT, first_name VARCHAR(45) NULL, last_name VARCHAR(45) NULL, email VARCHAR(45) NOT NULL, data_created DATETIME NULL DEFAULT CURRENT_TIMESTAMP, status TINYINT(1) NOT NULL, PRIMARY KEY (id), UNIQUE INDEX email_UNIQUE (email ASC));pkgのインストール
mysqlのドライバーpkgをインストールする。
go get github.com/go-sql-driver/mysql処理の流れ
実行する処理は、以下のプログラムの通りである。
1. ユーザ1データの挿入
2. ユーザーデータ取得ミス例(エラー処理を示すため)
3. ユーザ2データ挿入
4. Status1のユーザデータを探索、取得
5. ユーザーデータ取得(4で取得したがGETの例を示すため)
6. ユーザーデータの更新
7. ユーザーデータの削除main.gopackage main import ( "fmt" "log" "github.com/k-washi/golang-cookbook/database/user_db/method" ) func main() { //ユーザデータの挿入 user := &method.User{ID: 1, FirstName: "Trou", LastName: "Tanaka", Email: "123s456@test.com", Status: 1} if err := user.Save(); err != nil { log.Println(err) //2020/01/23 03:15:08 email already exist } log.Println(user) //2020/01/23 04:06:32 &{1 Trou Tanaka 123s456@test.com <nil>} //ユーザーデータの取得(IDミス) user = &method.User{ID: 3} if err := user.Get(); err != nil { log.Println(err) //2020/01/23 03:26:24 user not found } log.Println(user) //ユーザデータ挿入 user = &method.User{ID: 2, FirstName: "k", LastName: "washi", Email: "654321@test.com", Status: 1} if err := user.Save(); err != nil { log.Println(err) } //ユーザデータのStatus:1をFind res, err := user.FindByStatus(1) if err != nil { log.Println(err) } for i, u := range res { fmt.Println("user :", i, u) //user : 0 {37 Trou Tanaka 123s456@test.com 2020-01-23 05:07:35 +0000 UTC 1} //ユーザデータの取得(IDを使用するため、ループ内で処理) user = &method.User{ID: u.ID} if err := user.Get(); err != nil { log.Println(err) } log.Println(user) //2020/01/23 03:03:52 &{1 Trou Tanaka 123s456@test.com 2020-01-23 02:29:56 +0000 UTC} //ユーザデータ更新 user.FirstName = "Taro2" user.LastName = "Tanaka2" user.Email = "123s456@test.com" user.Status = 1 if err := user.Update(); err != nil { log.Println(err) } log.Println(user) //2020/01/23 03:54:51 &{1 Taro2 Tanaka2 123s456@test.com 2020-01-23 02:29:56 +0000 UTC} //ユーザデータの削除 user = &method.User{ID: u.ID} if err := user.Delete(); err != nil { log.Println(err) } log.Println("Success Delete") } }データベースの初期設定
sql.OpenでDBと接続を確立し、接続を確立している。
_ "github.com/go-sql-driver/mysql"をmysqlを扱うため、インポートしている。
設定は,user:password@tcp(host:port)/dbnameの形式の引数をとり、parseTime=trueは、時刻を扱うために設定している。Client, err := sql.Open()とせず、予め、Client,errを定義し、client, err = sql.Open()としている。前者では、もしClientを関数外で定義している場合、nilになるため。
また、コメントアウトしているが、実際は、環境変数を用いて、DBの設定を行うほうが良い。
user_db/user_db.gopackage user_db import ( "database/sql" "fmt" "log" _ "github.com/go-sql-driver/mysql" ) var ( //Client user_id database Client *sql.DB err error ) /* //実際は、環境変数を読み込んで、DBの設定を行う。 //export mysql_user_name="root" const ( mysql_user_naem: "mysql_user_name" ) var userName := os.Getenv(mysql_user_naem) */ func init() { //user:password@tcp(host:port)/dbname dataSourceName := fmt.Sprintf("%s:%s@tcp(%s)/%s?charset=utf8&parseTime=true", "root", "", "127.0.0.1:3306", "user_db", ) log.Println(fmt.Sprintf("about to connect to %s", dataSourceName)) //open db by mysql driver and data source name. //https://github.com/go-sql-driver/mysql/issues/150 (Issue) Client, err = sql.Open("mysql", dataSourceName) if err != nil { panic(err) } if err = Client.Ping(); err != nil { panic(err) } log.Println("database successfully configured") }データベース処理
GET, POSTなどのメソッドを定義している。
ここで定義しているUser 構造体が本記事で扱っているユーザデータである。const内には、ここで扱うSQLを定義している。エラーはparseErrorとして定義している。mysqlに関するエラーは個別に取り出せ、switcで場合できることを例で示している。1062は、Uniqueに対するエラーである。
GET, SELECTの際、*.Scanを実行する場合は、アドレスを渡す必要があることに注意する。
method/method.gopackage method import ( "fmt" "log" "strings" "time" "github.com/go-sql-driver/mysql" "github.com/k-washi/golang-cookbook/database/user_db/user_db" ) const ( queryInsertUser = "INSERT INTO users(first_name, last_name, email, status) VALUES(?, ?, ?, ?);" queryGetUser = "SELECT id, first_name, last_name, email, data_created, status FROM users WHERE id=?;" queryUpdateUser = "UPDATE users SET first_name=?, last_name=?, email=?, status=? WHERE id=?;" queryDeleteUser = "DELETE FROM users WHERE id=?;" querySelectUserByStatus = "SELECT id, first_name, last_name, email, data_created, status FROM users WHERE status=?;" errorNoRow = "no rows in result set" ) //User info type User struct { ID int64 FirstName string LastName string Email string Date *time.Time Status int } var ( //UserDB = make(map[int64]*User) ) func (user *User) Get() error { stmt, err := user_db.Client.Prepare(queryGetUser) if err != nil { return err } defer stmt.Close() result := stmt.QueryRow(user.ID) if getErr := result.Scan(&user.ID, &user.FirstName, &user.LastName, &user.Email, &user.Date, &user.Status); getErr != nil { return parseError(getErr) } return nil } func (user *User) Save() error { stmt, err := user_db.Client.Prepare(queryInsertUser) if err != nil { return err } defer stmt.Close() insertResult, saveErr := stmt.Exec(user.FirstName, user.LastName, user.Email, user.Status) if saveErr != nil { return parseError(saveErr) } userID, err := insertResult.LastInsertId() if err != nil { return err } user.ID = userID log.Println("Save user data") return nil } func (user *User) Update() error { stmt, err := user_db.Client.Prepare(queryUpdateUser) if err != nil { return err } defer stmt.Close() if _, updErr := stmt.Exec(user.FirstName, user.LastName, user.Email, user.Status, user.ID); updErr != nil { return parseError(updErr) } return nil } func (user *User) Delete() error { stmt, err := user_db.Client.Prepare(queryDeleteUser) if err != nil { return err } defer stmt.Close() if _, delErr := stmt.Exec(user.ID); delErr != nil { return parseError(delErr) } return nil } func (user *User) FindByStatus(status int) ([]User, error) { stmt, err := user_db.Client.Prepare(querySelectUserByStatus) if err != nil { return nil, err } defer stmt.Close() rows, err := stmt.Query(status) if err != nil { return nil, parseError(err) } defer rows.Close() res := make([]User, 0) for rows.Next() { var user User if err := rows.Scan(&user.ID, &user.FirstName, &user.LastName, &user.Email, &user.Date, &user.Status); err != nil { return nil, parseError(err) } res = append(res, user) } return res, nil } func parseError(err error) error { sqlErr, ok := err.(*mysql.MySQLError) if !ok { if strings.Contains(err.Error(), errorNoRow) { return fmt.Errorf("user not found") } return err } //以下,sql依存のエラー switch sqlErr.Number { case 1062: //email_UNIQUE error return fmt.Errorf("email already exist") } return err }まとめ
GolangによるMySQLデータベースに対する処理の例を示しました。
コードは、k-washi/golang-cookbook/database/user_db/を参考にしてみてください。
- 投稿日:2020-01-23T17:35:10+09:00
DBのクォーテーション整理したった
データベースのクォーテーション、使い方まちまち。
まとめた。
'シングル' "ダブル" `バック`[大カッコ] 備考 MySQL 文字列定数 文字列定数 引用識別子 (なし) 引用識別子はUNIX系では大文字小文字を区別1 MySQL
(ANSI_QUOTES モード)文字列定数 引用識別子 引用識別子 (なし) PostgreSQL 文字列定数 引用識別子 (なし) (なし) 引用識別子では大文字小文字を区別 Oracle 文字列定数 引用識別子 (なし) (なし) 引用識別子では大文字小文字を区別 SQLite 文字列定数 引用識別子 引用識別子 引用識別子 Microsoft SQL Server
(Transact-SQL)文字列定数 引用識別子 (なし) 引用識別子 QUOTED_IDENTIFIER が ON (既定値) の場合 こうみると、MySQLが異端児ってのがよくわかる。
引用識別子は識別子の1つ。識別子はテーブル名やカラム名など、データベース中のオブジェクトを表す文字列だが、決まった引用符(クォーテーションマーク)で囲むことで、空白や予約語などの特別な文字列を用いることができる(エスケープできる)のが引用識別子である。
ただ、そんな特別な文字列を使ったテーブル名やカラム名は、混乱の元なので、使わないほうがよいだろうね。
- 文字列は 'シングルクォーテーション' で囲む。
- 引用識別子を使わなくてもいいような名前づけ。
が良さげなプラクティスですね。2
クエリ作成ツールなどでは、
` `が付加された状態でSQL文が作成されたりするので、”テーブル名は小文字に統一”といったルールを決めておくとよいだろう。 ↩
- 投稿日:2020-01-23T17:35:10+09:00
DBごとのSQLのクォーテーションを整理したった
データベースのクォーテーション、使い方まちまち。
まとめた。
'シングル' "ダブル" `バック`[大カッコ] 備考 MySQL 文字列定数 文字列定数 引用識別子 (なし) 引用識別子はUNIX系では大文字小文字を区別1 MySQL
(ANSI_QUOTES モード)文字列定数 引用識別子 引用識別子 (なし) PostgreSQL 文字列定数 引用識別子 (なし) (なし) 引用識別子では大文字小文字を区別 Oracle 文字列定数 引用識別子 (なし) (なし) 引用識別子では大文字小文字を区別 SQLite 文字列定数 引用識別子 引用識別子 引用識別子 Microsoft SQL Server
(Transact-SQL)文字列定数 引用識別子 (なし) 引用識別子 QUOTED_IDENTIFIER が ON (既定値) の場合 こうみると、MySQLが異端児ってのがよくわかる。
引用識別子は識別子の1つ。識別子はテーブル名やカラム名など、データベース中のオブジェクトを表す文字列だが、決まった引用符(クォーテーションマーク)で囲むことで、空白や予約語などの特別な文字列を用いることができる(エスケープできる)のが引用識別子である。
ただ、そんな特別な文字列を使ったテーブル名やカラム名は、混乱の元なので、使わないほうがよいだろうね。
- 文字列は 'シングルクォーテーション' で囲む。
- 引用識別子を使わなくてもいいような名前づけ。
が良さげなプラクティスですね。2
クエリ作成ツールなどでは、
` `が付加された状態でSQL文が作成されたりするので、”テーブル名は小文字に統一”といったルールを決めておくとよいだろう。引用識別子で作られたテーブルは、大文字小文字を区別する名前になるからだ。 ↩
- 投稿日:2020-01-23T17:35:10+09:00
DBクォーテーション整理したった
データベースのクォーテーション、使い方まちまち。
まとめた。
'シングル' "ダブル" `バック`[大カッコ] 備考 MySQL 文字列定数 文字列定数 引用識別子 (なし) 引用識別子はUNIX系では大文字小文字を区別1 MySQL
(ANSI_QUOTES モード)文字列定数 引用識別子 引用識別子 (なし) PostgreSQL 文字列定数 引用識別子 (なし) (なし) 引用識別子では大文字小文字を区別 Oracle 文字列定数 引用識別子 (なし) (なし) 引用識別子では大文字小文字を区別 SQLite 文字列定数 引用識別子 引用識別子 引用識別子 Microsoft SQL Server
(Transact-SQL)文字列定数 引用識別子 (なし) 引用識別子 QUOTED_IDENTIFIER が ON (既定値) の場合 こうみると、MySQLが異端児ってのがよくわかる。
引用識別子は識別子の1つ。識別子はテーブル名やカラム名など、データベース中のオブジェクトを表す文字列だが、決まった引用符(クォーテーションマーク)で囲むことで、空白や予約語などの特別な文字列を用いることができる(エスケープできる)のが引用識別子である。
ただ、そんな特別な文字列を使ったテーブル名やカラム名は、混乱の元なので、使わないほうがよいだろうね。
- 文字列は 'シングルクォーテーション' で囲む。
- 引用識別子を使わなくてもいいような名前づけ。
が良さげなプラクティスですね。2
クエリ作成ツールなどでは、
` `が付加された状態でSQL文が作成されたりするので、”テーブル名は小文字に統一”といったルールを決めておくとよいだろう。 ↩
- 投稿日:2020-01-23T17:15:25+09:00
MariaDB(MySQL)での767byte問題を解決する
概要
Laravelの決済周りのテーブルを作成しようとしたときに、以下のようなエラーで失敗しました。
SQLSTATE[42000]: Syntax error or access violation: 1071 Specified key was too long; max key length is 767 bytes (SQL: alter table `users` add index `users_stripe_id_ind ex`(`stripe_id`))MySQLでは767バイト以上のカラムに対してはインデックスを貼れないようです。
対処法
1. インデックスの制限をあげる
my.confを書き換えることで、制限をあげることができます。
my.confの配置場所を探す$ mysql --help | grep my.cnf
- 設定を追記
my.conf[mysqld] innodb_large_prefix innodb_file_per_table=1 innodb_file_format=Barracuda
- 設定されているか確認
> SHOW GLOBAL VARIABLES LIKE 'innodb_file%'; +--------------------------+-----------+ | Variable_name | Value | +--------------------------+-----------+ | innodb_file_format | Barracuda | | innodb_file_format_check | ON | | innodb_file_format_max | Antelope | | innodb_file_per_table | ON | +--------------------------+-----------+ 4 rows in set (0.01 sec) > SHOW GLOBAL VARIABLES LIKE 'innodb_large%'; +---------------------+-------+ | Variable_name | Value | +---------------------+-------+ | innodb_large_prefix | ON | +---------------------+-------+ 1 row in set (0.00 sec)2. MariaDBのバージョンをあげる
MariaDBのバージョンが10.1以下の場合、
my.confの設定だけでは不十分で、10.2以上にあげる必要があります。バージョンアップに関してはこちらの記事でまとめたので、必要であれば参考にしていただけると幸いです。
参考
https://github.com/gogs/gogs/issues/4894
https://yassu.jp/pukiwiki/index.php?MySQL%20767byte%CC%E4%C2%EA
- 投稿日:2020-01-23T16:53:03+09:00
AmazonLinuxのMariaDBを10.1から10.2にバージョンアップ
概要
MariaDBを10.1から10.2にアップデートした際のメモです。
yumでやってみる
- 現在の設定を確認
$ sudo vi /etc/yum.repos.d/MariaDB.repo
- アップデートしたいバージョンにURLを変更
- 今回は
10.1の部分を10.2に書き換えました。/etc/yum.repos.d/MariaDB.repo# MariaDB 10.1 CentOS repository list - created 2016-03-13 07:22 UTC # http://mariadb.org/mariadb/repositories/ [mariadb] name = MariaDB baseurl = http://yum.mariadb.org/10.1/centos6-amd64 # ここを変える gpgkey=https://yum.mariadb.org/RPM-GPG-KEY-MariaDB gpgcheck=1
- 現在インストールされているパッケージを確認
$ rpm -qa | grep -i mariadb
- アップデート
$ sudo yum install -y MariaDB-server MariaDB-client実行結果
Loaded plugins: priorities, update-motd, upgrade-helper amzn-main | 2.1 kB 00:00:00 amzn-updates | 2.3 kB 00:00:00 mariadb | 2.9 kB 00:00:00 mariadb/primary_db | 42 kB 00:00:00 89 packages excluded due to repository priority protections Resolving Dependencies --> Running transaction check ---> Package MariaDB-client.x86_64 0:10.1.43-1.el6 will be updated ---> Package MariaDB-client.x86_64 0:10.2.30-1.el6 will be an update ---> Package MariaDB-server.x86_64 0:10.1.43-1.el6 will be updated ---> Package MariaDB-server.x86_64 0:10.2.30-1.el6 will be an update --> Finished Dependency Resolution Dependencies Resolved ========================================================================================== Package Arch Version Repository Size ========================================================================================== Updating: MariaDB-client x86_64 10.2.30-1.el6 mariadb 49 M MariaDB-server x86_64 10.2.30-1.el6 mariadb 112 M Transaction Summary ========================================================================================== Upgrade 2 Packages Total download size: 161 M Downloading packages: (1/2): MariaDB-10.2.30-centos6-x86_64-client.rpm | 49 MB 00:00:09 (2/2): MariaDB-10.2.30-centos6-x86_64-server.rpm | 112 MB 00:00:20 ------------------------------------------------------------------------------------------ Total 8.0 MB/s | 161 MB 00:00:20 Running transaction check Running transaction test Transaction test succeeded Running transaction Updating : MariaDB-client-10.2.30-1.el6.x86_64 1/4 ****************************************************************** A MySQL or MariaDB server package (MariaDB-server-10.1.43-1.el6.x86_64) is installed. Upgrading directly from MySQL 10.1 to MariaDB 10.2 may not be safe in all cases. A manual dump and restore using mysqldump is recommended. It is important to review the MariaDB manual's Upgrading section for version-specific incompatibilities. A manual upgrade is required. - Ensure that you have a complete, working backup of your data and my.cnf files - Shut down the MySQL server cleanly - Remove the existing MySQL packages. Usually this command will list the packages you should remove: rpm -qa | grep -i '^mysql-' You may choose to use 'rpm --nodeps -ev <package-name>' to remove the package which contains the mysqlclient shared library. The library will be reinstalled by the MariaDB-shared package. - Install the new MariaDB packages supplied by MariaDB Foundation - Ensure that the MariaDB server is started - Run the 'mysql_upgrade' program This is a brief description of the upgrade process. Important details can be found in the MariaDB manual, in the Upgrading section. ****************************************************************** error: %pre(MariaDB-server-10.2.30-1.el6.x86_64) scriptlet failed, exit status 1 Error in PREIN scriptlet in rpm package MariaDB-server-10.2.30-1.el6.x86_64 error: MariaDB-server-10.2.30-1.el6.x86_64: install failed error: MariaDB-server-10.1.43-1.el6.x86_64: erase skipped Cleanup : MariaDB-client-10.1.43-1.el6.x86_64 3/4 Verifying : MariaDB-client-10.2.30-1.el6.x86_64 1/4 Verifying : MariaDB-client-10.1.43-1.el6.x86_64 2/4 Verifying : MariaDB-server-10.2.30-1.el6.x86_64 3/4 MariaDB-server-10.1.43-1.el6.x86_64 was supposed to be removed but is not! Verifying : MariaDB-server-10.1.43-1.el6.x86_64 4/4 Updated: MariaDB-client.x86_64 0:10.2.30-1.el6 Failed: MariaDB-server.x86_64 0:10.1.43-1.el6 MariaDB-server.x86_64 0:10.2.30-1.el6 Complete手動でアップデートしろと言われた
手動アップデート
1. バックアップ
- 一応データベースとmy.confのバックアップをとります
$ sudo cp /etc/my.cnf /etc/my.cnf.org2. MariaDB停止
$ sudo service mysql stop Shutting down MariaDB... SUCCESS!3. 古いMariaDBを削除
- インストールされているMariaDBを確認(上でupdateを試行しているので、clientだけ10.2になっています。)
$ yum list installed | grep maria MariaDB-client.x86_64 10.2.30-1.el6 @mariadb MariaDB-common.x86_64 10.1.43-1.el6 @mariadb MariaDB-compat.x86_64 10.1.43-1.el6 @mariadb MariaDB-server.x86_64 10.1.43-1.el6 @mariadb galera.x86_64 25.3.28-1.rhel6.el6 @mariadb
- 今回は10.1から10.2にするので、
MariaDB-common.x86_64を消す$ sudo yum remove MariaDB-common.x86_64
- 消えたか確認
$ yum list installed | grep maria galera.x86_64 25.3.28-1.rhel6.el6 @mariadb依存してる物は全部消えるので、MariaDB周りが全部消えました。
結果的に、ver.10.1関連が消えました。4. 新しいMariaDBをインストール
$ sudo yum install -y MariaDB-server MariaDB-client実行結果
Loaded plugins: priorities, update-motd, upgrade-helper 89 packages excluded due to repository priority protections Resolving Dependencies --> Running transaction check ---> Package MariaDB-client.x86_64 0:10.2.30-1.el6 will be installed --> Processing Dependency: MariaDB-common for package: MariaDB-client-10.2.30-1.el6.x86_64 ---> Package MariaDB-server.x86_64 0:10.2.30-1.el6 will be installed --> Running transaction check ---> Package MariaDB-common.x86_64 0:10.2.30-1.el6 will be installed --> Processing Dependency: MariaDB-compat for package: MariaDB-common-10.2.30-1.el6.x86_64 --> Running transaction check ---> Package MariaDB-compat.x86_64 0:10.2.30-1.el6 will be installed --> Finished Dependency Resolution Dependencies Resolved ========================================================================================== Package Arch Version Repository Size ========================================================================================== Installing: MariaDB-client x86_64 10.2.30-1.el6 mariadb 49 M MariaDB-server x86_64 10.2.30-1.el6 mariadb 112 M Installing for dependencies: MariaDB-common x86_64 10.2.30-1.el6 mariadb 173 k MariaDB-compat x86_64 10.2.30-1.el6 mariadb 4.0 M Transaction Summary ========================================================================================== Install 2 Packages (+2 Dependent packages) Total download size: 166 M Installed size: 699 M Downloading packages: (1/4): MariaDB-10.2.30-centos6-x86_64-common.rpm | 173 kB 00:00:01 (2/4): MariaDB-10.2.30-centos6-x86_64-compat.rpm | 4.0 MB 00:00:01 (3/4): MariaDB-10.2.30-centos6-x86_64-client.rpm | 49 MB 00:00:10 (4/4): MariaDB-10.2.30-centos6-x86_64-server.rpm | 112 MB 00:00:13 ------------------------------------------------------------------------------------------ Total 10 MB/s | 166 MB 00:00:16 Running transaction check Running transaction test Transaction test succeeded Running transaction Installing : MariaDB-common-10.2.30-1.el6.x86_64 1/4 Installing : MariaDB-compat-10.2.30-1.el6.x86_64 2/4 Installing : MariaDB-client-10.2.30-1.el6.x86_64 3/4 Installing : MariaDB-server-10.2.30-1.el6.x86_64 4/4 /usr/sbin/semodule: SELinux policy is not managed or store cannot be accessed. Verifying : MariaDB-compat-10.2.30-1.el6.x86_64 1/4 Verifying : MariaDB-common-10.2.30-1.el6.x86_64 2/4 Verifying : MariaDB-server-10.2.30-1.el6.x86_64 3/4 Verifying : MariaDB-client-10.2.30-1.el6.x86_64 4/4 Installed: MariaDB-client.x86_64 0:10.2.30-1.el6 MariaDB-server.x86_64 0:10.2.30-1.el6 Dependency Installed: MariaDB-common.x86_64 0:10.2.30-1.el6 MariaDB-compat.x86_64 0:10.2.30-1.el6 Complete!
- インストールされたか確認
$ yum list installed | grep maria MariaDB-client.x86_64 10.2.30-1.el6 @mariadb MariaDB-common.x86_64 10.2.30-1.el6 @mariadb MariaDB-compat.x86_64 10.2.30-1.el6 @mariadb MariaDB-server.x86_64 10.2.30-1.el6 @mariadb galera.x86_64 25.3.28-1.rhel6.el6 @mariadb10.1から10.2にバージョンが変わっていることが確認できました。
5. 起動
- バックアップしておいたconfを再設定
$ sudo mv /etc/my.cnf.org /etc/my.cnf
- MariaDB起動
$ sudo service mysql startログインできなくなった場合
- アップデート後にログインはおろか、
mysql --versionもできなくなったmysql.userテーブルが初期化されたっぽい(アプリケーションのデータベースは残ってるのに、、)ERROR 1045 (28000): Access denied for user 'username'@'localhost' (using password: NO)
- セーフモードで起動
$ sudo mysqld_safe --skip-grant-tables & $ mysql -urootログイン後は以下の方法で良しなにユーザー権限を与える。
既にあるユーザのパスワードを変更
> UPDATE mysql.user SET authentication_string = PASSWORD('your_password') WHERE User = 'your_username' AND Host = 'localhost';パスワード付きでユーザーを作成
> grant all privileges on *.* to your_username@localhost identified by 'your_password' with grant option;パスワードなしでユーザーを作成
> flush privileges; > CREATE USER your_username@localhost
- MariaDB再起動
$ sudo service mysql restart参考
https://yassu.jp/pukiwiki/index.php?MySQL%20767byte%CC%E4%C2%EA
https://qiita.com/rururu_kenken/items/5ec05d50eae8796ca96a
- 投稿日:2020-01-23T15:19:08+09:00
MySQLにデータ投入時にコケたら、リトライする前に show processlist;
夜通し回していたバッチがコケた
Embulkを利用して、半年間くらいの日次のアクセスログ(全部で1億件弱くらい)をMySQLに取り込むバッチを回していたのですが、
始業時間開始とともに回したものの、2h、3h経っても終わらず、遂には定時が過ぎても終わらなかったので、
disownコマンドとかで処理を裏に回して、しょうがなく帰ることに。
翌日出勤して結果を見るとorg.embulk.exec.PartialExecutionException: java.lang.RuntimeException: com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failureうーむ、。
今回、私が回したバッチの処理自体は、S3→RDSにデータを取り込むという単純なものですが、
その中で、大体以下の処理を行っていました。
1. 1h単位でデータを分割して、それぞれ一時テーブルに突っ込む
2. それらをとあるテーブルにUNION ALL
3. 一時テーブルを削除ログを見ると、2→3でコケて、DBには削除されなかった大量の一時テーブルが…。
(おそらくUNION ALLで時間かかったから、このエラーが起きました)ソケットタイムアウトの設定時間を伸ばす
ひとまずエラー文で調べるとこちらの記事がヒットしたので、
ありがたく拝見させていただくことに。
EmbulkでMySQLに大量データを投入してみる - その2Embulk定義ファイルでoptionとして7200000ミリ秒(120分)に設定してみる。
こちらを私の手元のEmbulk定義ファイルにも追記しました。
これでいけるかな〜、ということでバッチ処理再開。しばらく経ってみると、またコケている!!
com.mysql.jdbc.exceptions.jdbc4.MySQLTransactionRollbackException: Lock wait timeout exceeded; try restarting transactionこれはやってしまいましたね。
(まだ一時テーブルがいっぱい残ってしまった…。)show processlist; で実行中のプロセス確認
最初にバッチがコケたときのプロセスが行き場を無くして止まってしまっていて、
テーブルにはロックがかかっていたようです。mysql> show processlist; +---------+-------+----------------+----+---------+-------+---------------------------------+--------------------------------------------------------------------------------------------+ | Id | User | Host | db | Command | Time | State | Info | +---------+-------+----------------+----+---------+-------+---------------------------------+--------------------------------------------------------------------------------------------+ | 3465142 | user | 192.0.2.0:50426| db | Query | 27901 | Waiting for table metadata lock | DROP TABLE IF EXISTS `useractionlog_0000016fc953540d_embulk000` | | 3477659 | user | 192.0.2.0:51904| db | Query | 22776 | Waiting for table metadata lock | DROP TABLE IF EXISTS `useractionlog_0000016fc9a0888b_embulk000` | | 3491019 | user | 192.0.2.0:53374| db | Query | 17313 | Waiting for table metadata lock | DROP TABLE IF EXISTS `useractionlog_0000016fc9eebfe2_embulk000` | | 3504640 | user | 192.0.2.0:54860| db | Query | 11819 | Waiting for table metadata lock | DROP TABLE IF EXISTS `useractionlog_0000016fca4218ca_embulk000` | | 3518290 | user | 192.0.2.0:56392| db | Query | 6310 | Waiting for table metadata lock | DROP TABLE IF EXISTS `useractionlog_0000016fca95efff_embulk000` | | 3526923 | user | 192.0.2.0:58008| db | Query | 2895 | Sending data | INSERT INTO `useractionlog` (`user_id`, `session_key`, `request_at`, `path`, `site`, `view | | 3534260 | user | 192.0.2.0:59470| db | Query | 0 | starting | show processlist | +---------+-------+----------------+----+---------+-------+---------------------------------+--------------------------------------------------------------------------------------------+ 7 rows in set (0.01 sec)これらをkillしないと再実行しても、いつまで経ってもテーブルのロックが解除されず、エラーが起こってしまうのでした。
順にkillしましょう。mysql> kill 3465142; ~~ mysql> kill 3526923;これらをkillして、バッチ処理は再開すると、
エラーを吐くことなく無事終了しました。
めでたし、めでたし。なお、killしてもプロセスがこのように消えない時があります。
mysql> show processlist; +---------+-------+----------------+----+---------+-------+---------------------------------+--------------------------------------------------------------------------------------------+ | Id | User | Host | db | Command | Time | State | Info | +---------+-------+----------------+----+---------+-------+---------------------------------+--------------------------------------------------------------------------------------------+ | 3526923 | user | 192.0.2.0:58008| db | Killed | 12502 | Sending data | INSERT INTO `useractionlog` (`user_id`, `session_key`, `request_at`, `path`, `site`, `view | | 3540724 | user | 192.0.2.0:59470| db | Query | 0 | starting | show processlist | +---------+-------+----------------+----+---------+-------+---------------------------------+--------------------------------------------------------------------------------------------+ 7 rows in set (0.01 sec)この場合は消えないままに処理を再開しても、
Lock wait timeout exceeded;がまた発生してしまうので、ちゃんと消えたのを確認してから、処理を再開しましょう。
(私はこのrowが3h弱残り続けたので、気長に待つ必要があるかもしれません)
- 投稿日:2020-01-23T15:17:56+09:00
opensslの読み込み不具合でMySQLが起動しない時の対処【Homebrew】
状況
$ sudo mysql.server start 15:08:37 dyld: Library not loaded: /usr/local/opt/openssl/lib/libssl.1.0.0.dylib Referenced from: /usr/local/Cellar/mysql/5.7.17/bin/my_print_defaults Reason: image not found Starting MySQL .dyld: Library not loaded: /usr/local/opt/openssl/lib/libssl.1.0.0.dylib Referenced from: /usr/local/Cellar/mysql/5.7.17/bin/my_print_defaults Reason: image not found dyld: Library not loaded: /usr/local/opt/openssl/lib/libssl.1.0.0.dylib Referenced from: /usr/local/Cellar/mysql/5.7.17/bin/my_print_defaults Reason: image not found /usr/local/Cellar/mysql/5.7.17/bin/mysqld_safe: line 193: 37626 Abort trap: 6 nohup /usr/local/Cellar/mysql/5.7.17/bin/mysqld --basedir=/usr/local/Cellar/mysql/5.7.17 --datadir=/usr/local/var/mysql --plugin-dir=/usr/local/Cellar/mysql/5.7.17/lib/plugin --user=mysql --log-error=/usr/local/var/mysql/xxx.local.err --pid-file=/usr/local/var/mysql/xxx.local.pid < /dev/null > /dev/null 2>&1 ERROR! The server quit without updating PID file (/usr/local/var/mysql/xxx.local.pid).解決策
brew経由でopensslを入れ直す。
brew update && brew upgrade brew uninstall --ignore-dependencies openssl; brew install https://github.com/tebelorg/Tump/releases/download/v1.0.0/openssl.rb
- 投稿日:2020-01-23T12:46:14+09:00
大阪でLaravelの勉強会を開催しました。
大阪でLaravel勉強会しました
大阪って東京に比べると本当に勉強会とカンファレンスとか少ないんですよね。。
特にフレームワークのLaravelとかになると月に1回あるかないか(最近は増えてきた)なので今回は自分で主催して勉強会を開催しよう!と思い、この会を企画した次第です。
発表者テーブル
発表者 内容 ナミザト Laravelワカンネ(゚⊿゚)から「完全に理解した()」までステップアップ カッポ LaravelとSymfony Daisuke Laravel5 と Laravel6 の違い -認証編- ムカエ LaravelでSNSログインを実装 saito_takashi_1117 Laravelをデザインパターンで考察する ~ Builder Pattern ~ ぼんばー MySQLと文字コードの話 flowphantom Laravel4に触れた感想 Yui Amazon LightsailにLaravel環境作ってみた
登壇枠(15min)
Laravelワカンネ(゚⊿゚)から「完全に理解した()」までステップアップ
登壇者 ナミザト
トップバッターは今回主催で筆者のワタクシです。
Laravel始めた時って何となくで動いちゃうので、どういうフローで処理が実行されているのか
分かってない人がほとんどだと思ったので今回の題材は
Laravelのライフサイクル(アクセスしてページが表示されるまでの実行フロー)とLaravelでよく目にする機能について簡単にお話しました!質問は一つもありませんでした!!
多分クソつまらなかった
資料
Laravelワカンネ(゚⊿゚)から「完全に理解した()」までステップアップ
LaravelとSymfony
登壇者 カッポ
緊急システム障害対応のため登壇叶わずw
最後の懇親会の串カツ屋でLTしてくれましたw
LaravelとSymfonyのコマンドやディレクトリ構造、プロジェクトを作成する時のフローの違いについて話ししてくれました!
資料
次回の登壇で発表するそうです
Laravel5 と Laravel6 の違い -認証編-
登壇者 Daisuke
Larvel5とLaravel6のAuth認証導入手順の違いを実際にLiveコーディングしながら(しゅごい)
説明してくれました!Laravel5ではターミナルで一発で済んだAuth認証導入
php artisan make:authLaravel6では少し手順が増えてます。
ライブラリをインストール
$ composer require laravel/uiUIのタイプを選択する
vue/react/bootstrapから選択が可能
$ php artisan ui vue --authnpmインストール&実行
先ほど選択したvue.jsをインストール
$ npm install $ npm run dev
資料
LT枠
LaravelでSNSログインを実装
発表者 ムカエ
SNSログインが簡単に実装できるライブラリ「Socialite」を使ってLaravel×Twitterログインを実装するというお話でした!(
半分くらいステマしてたけど)やっぱりトーク慣れしてて、聞いてて面白かったです。
TwitterAPIの申請方法はどうやってやるんですか?という質問があり、
先日たまたまその申請方法を記事にしたらしいのでそちらを参考にしてくださいとの事(サクラかな)TwitterAPI アカウント申請〜許可まで【2020年版】
資料
その他ステマ
Laravel6.0(PHP7.3)+MySQL+Laradockで簡易的なECサイトを作る①
Laravelをデザインパターンで考察する ~ Builder Pattern ~
発表者 saito_takashi_1117
デザインパターンとは
クラス設計における定石集で、全部で23パターンあり、それぞれに特徴があります。
GoF(Gang of Four)とは『オブジェクト指向における再利用のためのデザインパターン』の著者である4人の事を指す(絶対メンバー中に中二病おる)Laravelに用意されているBuilder Patternを簡単に利用するための抽象クラスを考察してみた!という説明をしてくれました!
インスタンス生成過程を隠蔽し、シンプルに再利用するために継承して使用することができる。らしい...
資料
https://qiita.com/7_asupara/items/c76af3c466b5450ef7d2
MySQLと文字コードの話
発表者 ぼんばー
Laravelはあまり触ってないが、MySQLならチョットワカルので文字コードのお話でした!
有名な寿司ビール問題を例にあげて分かりやすく説明してくれました!寿司ビール問題とは
?=?のような絵文字は同じ文字扱い
このように文字コードが原因でMySQLにて絵文字が同じ文字列扱いを受ける問題を寿司ビール問題と言うらしい(なぜ)ちなみにLaravelの標準のcharsetは
utf8mb4で、collationはutf8mb4_unicode_ciです思わず手がロボットのアームになってしまったぼんばーさん
ちなみにTwitterでLaravelのDBは何を使ってるか投票を募集するとほとんどがMySQLだったそう(会場でも9.5割くらいMySQLだった)
資料もかなり分かりやすくまとめてくれてるので必見!!
資料
Laravel4に触れた感想
発表者 flowphantom
今は亡きLaravel4について語ってくれました。Vueのくだりで会場爆笑でしたw
面白いのでぜひ資料覗いてみてください!また追加でLaravelを完全に意識してであろうPythonのフレームワーク「Masonite」も紹介してくれました!
ディレクトリ構造とか最初の画面とかほぼ同じらしい...!
資料
Amazon LightsailにLaravel環境作ってみた
発表者 Yui
AWSエンジニアでLaravelは起動した画面で満足してしまったYuiさんに無理やりLTをお願いしました(
ヤクザ)AWSのレンタルサーバーみたいに使えるVPS*「Amazon Lightsail」*でLaravel環境を構築した時にcomposerがメモリ不足でインストールできない問題にぶち当たった事を説明してくれました!
解決方法は一つ上のスペックに変えるという金の暴力で解決w
一応swap領域確保してインストールする方法もあるが、やっぱりあまりよろしくないらしい
ちなみに筆者も試しにLightsail使ってみたが、結構良かった!初めてでも30分くらいで環境作れました
資料
Amazon Lightsail に Laravel環境を作ってみた
記事に記事のURL(資料は記事の下)
最後に
当日に無断キャンセル4人いたり(一人は開始1時間後に無断キャンセルw)、唯一の共同運営者(カッポくん)がシステム障害で途中参加だったりして大変でしたが、結果有意義な時間になれたかなーと思いました。
次は3ヵ月後くらいでいいかなみなさんお疲れ様でした!








- 投稿日:2020-01-23T11:40:05+09:00
MySQLの全文検索の種類について
MySQLの全文検索について
3種類有ります
自然言語検索
検索文字列が人間の自然な言語でのフレーズとして解釈されます。
特徴
特別な演算子は無い
ストップワードリストが適用される動作
IN NATURAL LANGUAGE MODE 修飾子が指定されている場合または修飾子がまったく指定されていない場合は、全文検索が自然言語検索になる
ブール検索
特別なクエリー言語のルールを使用して検索文字列が解釈される。
特徴
文字列には、検索対象の単語が含まれる
一致する行に単語が存在しなければならない、または存在してはならないように、あるいは通常よりも単語の重みが高くまたは低くなるように、要件を指定する演算子を含めることもできます。
特定の共通単語 (ストップワード) は、検索インデックスから省略され、検索文字列に存在しない場合は一致が行われません。動作
IN BOOLEAN MODE 修飾子が有る場合、ブール検索になります。
クエリー拡張検索
自然言語検索を改善したもの
特徴
自然言語検索を実行する際は、検索文字列が使用される。
その後、検索で返されたもっとも関連性の高い行からの単語が検索文字列に追加され、再度検索が実行される。
クエリーでは、2 回目の検索からの行が返されます。動作
IN NATURAL LANGUAGE MODE WITH QUERY EXPANSION または WITH QUERY EXPANSION 修飾子が有る場合は、クエリー拡張検索を行います。
- 投稿日:2020-01-23T10:42:16+09:00
グラフ描画のためのデータベース操作
グラフ描画のためのデータベース操作
どうやってデータを間引くか
剰余系を使って間引く
データベースに記録したデータをグラフにしたい場合、あまりにもデータが多いので間引く必要がある。
そもそも、データベースはスキップという操作があまり得意ではない。
それでもテーブルのIDを単純に剰余系で間引くSQLは、こんな感じ。SELECT id,`CreateAt`,`機器ID`,`温度` FROM data_table WHERE MOD(id,100)=0これだと、複数の機器がデータベースに記録されていた時に、データの最初と最後が欠けてしまう機器が出てくる。
そこで機器ごとの連続した番号が必要と思い、データベースに記録する時に連番を振っておくseq列を追加。SELECT id,`CreateAt`,`機器ID`,`温度` FROM data_table WHERE `機器ID`='XXXX-XXXX' AND MOD(seq,100)=0一応もれなく計算出来るが、機器毎にSQLを発行して読み出すので、機種が増える毎に計算時間が遅くなって行く。
データベースの得意なのは集計
ある時、別件で1時間毎にデータを集計する機能を追加して気づいた。
スキップするのではなく、1時間毎の平均を取るSQLを書いてみた。SELECT DATE_FORMAT(`CreateAt`, '%Y-%m-%d %H:00:00') AS hour, `機種ID`,AVG(`温度`) AS tempr FROM data_table GROUP BY `機種ID`,hour HAVING tempr別の書き方で、こう書ける事も分かった。
SELECT FROM_UNIXTIME(TRUNCATE(UNIX_TIMESTAMP(`CreateAt`)/3600,0)*3600) as sec, `機器ID`,AVG(`温度`) AS tempr FROM data_table GROUP BY `機種ID`,sec HAVING temprこの書き方だと任意の秒数で集計ができるのに気づいた。
グラフの横軸は時間なので、横軸に表示する範囲の日時を描画点数で割って、あらかじめ描画点の間隔の秒数を求めておく。$start = strtotime(最初のdatetime); $end = strtotime(最後のdatetime); $diff = $end - $start; $secPerPoint = intval($diff/描画点数);SELECT FROM_UNIXTIME(TRUNCATE(UNIX_TIMESTAMP(`CreateAt`)/{$secPerPoint},0)*{$secPerPoint}) as sec, `機器ID`,AVG(`温度`) AS tempr FROM data_table GROUP BY `機種ID`,sec HAVING tempr間引くよりも平均を取る。そうすればGROUP BYが使えるので、一度のSQLで機器単位の平均を求めることができる。プログラムも単純になる。
肝心のスピードだが、多少早くなったが、グラフに送るデータの量が多いところがボトルネックになってた。例えばX軸の時間とかは、全機種共通なので1つだけ送るとかデータ転送量減らす予定。
- 投稿日:2020-01-23T09:41:17+09:00
RDSとIAMでパスワードレス認証(Python)
MySQLのパスワードベタ書きしないでよくなります
{}内は適宜置き換えてね1. ユーザ作成
CREATE USER '{MySQLユーザ名}'@'%' IDENTIFIED WITH AWSAuthenticationPlugin as 'RDS'; # ユーザ作成 GRANT ALL PRIVILEGES ON {MySQLDB名}.* TO '{MySQLユーザ名}'@'%' REQUIRE SSL; # 権限2. IAMポリシー
こんな感じでポリシーを作る
jsonで直接アタッチするならこんな感じ
{ "Effect": "Allow", "Action": "rds-db:connect", "Resource": "arn:aws:rds-db:{AWS::Region}:{AWS::AccountId}:dbuser:cluster-{リソースID}/{MySQLユーザ名}", }CloudFormationならこんな感じ
iamRole: - Effect: Allow Action: - "rds-db:connect" Resource: - 'Fn::Join': - ':' - - 'arn:aws:rds-db' - Ref: 'AWS::Region' - Ref: 'AWS::AccountId' - 'dbuser:cluster-{リソースID}/{MySQLユーザ名}'3. 一時パスワードで接続!
こんな感じでトークン(一時パスワード)を発行する
client = boto3.client("rds") # トークン取得 token = client.generate_db_auth_token( DBHostname=RDS_HOST, Port=RDS_PORT, DBUsername=RDS_USER_NAME ) db_connection = mysql.connector.connect( host=RDS_HOST, port=RDS_PORT, database=RDS_DB_NAME, user=RDS_USER_NAME, passwd=token )たったこんだけ
かんたんにゃ〜〜