- 投稿日:2020-01-20T22:27:13+09:00
S3を使わずにEC2のストレージを利用して、ファイルを保存する
某expertスクールを卒業後、同じようなやり方で簡易的にpythonでapiをアップロードしようとしたら、権限周りで失敗したので備忘録として
EC2の種類
簡易的にpythonのapiを作成するため、S3を使わずストレージ中にapiで出てきたファイルを保存します。
- tタイプ
- ubuntu 18.04
EC2ログイン後
スクールのカリキュラムでは、/var/www/を作成して、その中にアプリを入れていましたが、それでは権限周りでエラーが出てしまうので、ログイン後のhome/ubuntu/直下にgit cloneしましょう。
$ ssh -i /path/my-key-pair.pem ubuntu@x.xxx.xxx.xxx(IPv4アドレス) # ユーザー名部分はubuntuなので注意(ec2-userではない) (ログイン後) $ git clone https://github.com/yyuu/pyenv.git ~/.pyenv $ echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bash_profile $ echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bash_profile $ echo 'eval "$(pyenv init -)"' >> ~/.bash_profile $ source ~/.bash_profile $ pyenv install 3.6.2(ここでpythonのバージョンを選ぶ) $ pyenv global 3.6.2 $ pyenv rehash $ apt-get -y update $ apt-get install -y --fix-missing $ apt-get build-essential $ apt-get software-properties-common $ git clone クローン元のURLapiをバックグラウンドで起動
通常通りにpython run.appすると、PCを閉じたり、EC2をログアウトした際にアプリもとまってしまうため、下記コマンドでバックグラウンドで起動します。
$ nohup python main.py &
- 投稿日:2020-01-20T21:12:57+09:00
お名前.comからRoute53へドメイン移管
- 投稿日:2020-01-20T21:03:35+09:00
codecommitのPullRequestをredmineのチケットに連携する
概要
これのシリーズもの
codecommitでpullrequestしたときに、関連するredmineのチケットのコメントに通知を出したくてごにょごにょした記録。
手順にはなってませんが、ヒントにはなるかな、と。
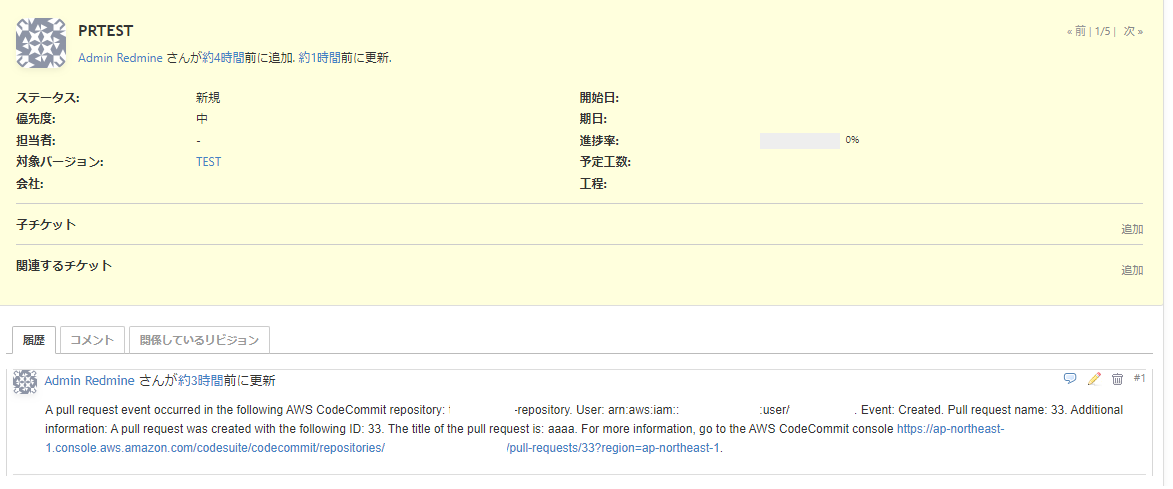
こんな感じで。
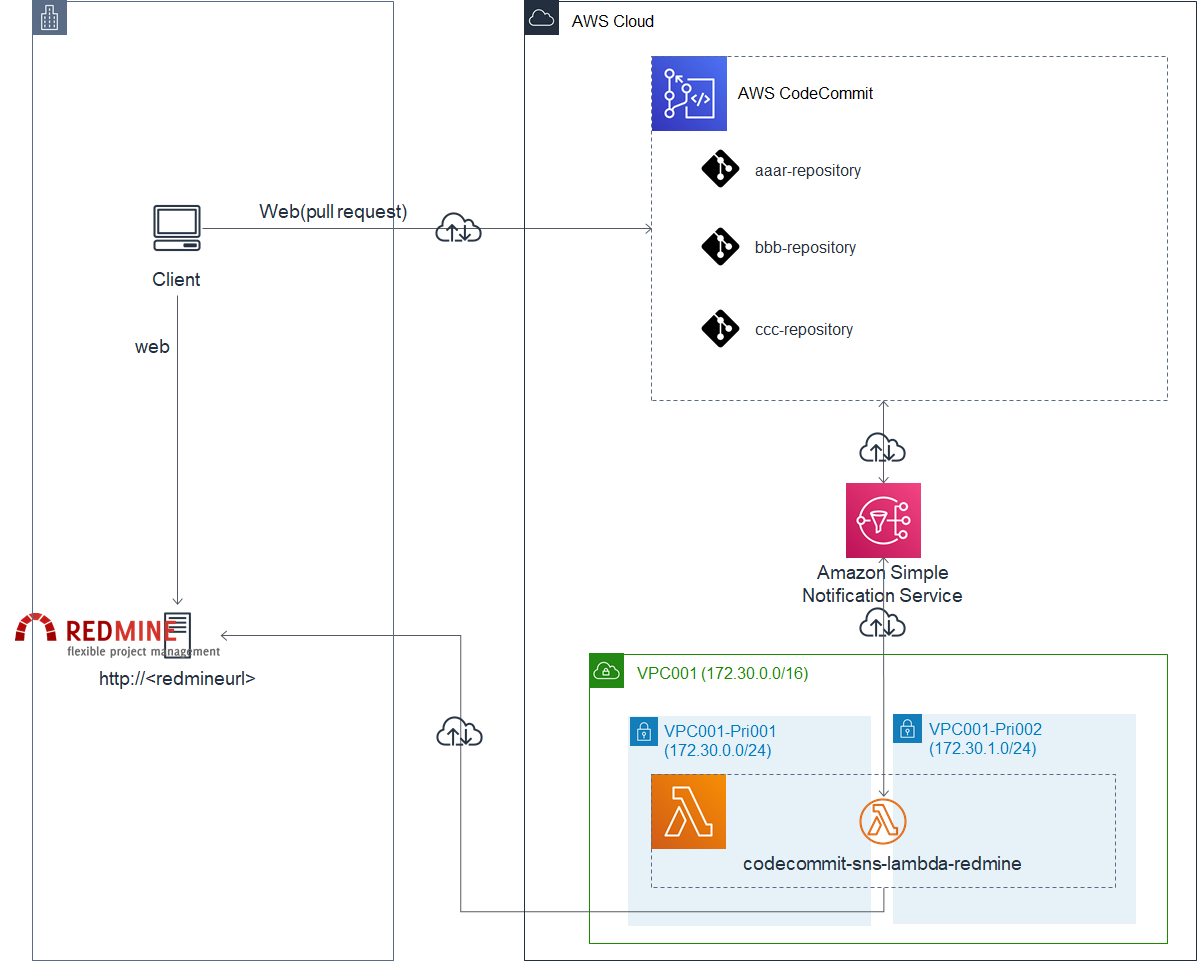
やりたい構成図
ざっくりこんなかんじ
やったこと概要
前提
codecommitでブランチを切るときに必ずredmineのチケット番号を記載する運用ルールにしていたので、更新対象のチケット番号はブランチ名からとってくることにした
redmine側の設定
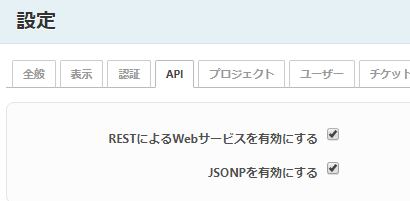
APIを有効にする
- adminで入って「管理」→「設定」から
AWS側の設定
Lambdaの設定をする
- snsから通知されたメッセージを拾ってredmineのrestAPIをたたくpythonを書く
- python_redmineを使えるようにLambdaLayerを設定した
- 参考にさせて頂いたサイトはこちら
- 宛先がオンプレサーバのためVPC経由で通信できるようにする必要があり、LambdaがVPC起動できるようにする
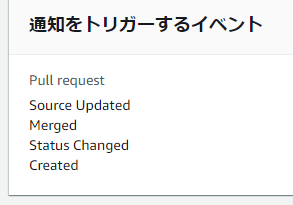
codecommitに通知ルールを設定し、codecommit上で何かイベントがあったときにSNSにメッセージが飛ぶようにする
- 今回は以下の設定とした
苦労した点
- snsから受け取ったデータ(jsonフォーマット)の中の"Message"はcodecommitが発したjsonだと思われ、ここから必要なものをredmineに投げたかったのだが、これを取得するのに難儀した。
- 以下のようにしたらいけた ※ここについていい方法やメカニズムがわかればぜひ教えてください
# このような取り出しをしたら「TypeError: string indices must be integers」になった # eventName = event['Records'][0]['Sns']['Message']['detail']['event'] # どうも"Message"は単なるstringみたいなので、 # 仕方ないので一度json形式に変換して必要なキーを取り出した Message_str = event['Records'][0]['Sns']['Message'] Message = json.loads(Message_str) eventName = Message['detail']['event']Lambdaのコード
import json from redminelib import Redmine import re def lambda_handler(event, context): # SNSのメッセージからcodecommitのメッセージを抜き出す # ただしstringになってしまうので、最後にjson.loadsをする Message_str = event['Records'][0]['Sns']['Message'] Message = json.loads(Message_str) # print("Message " +str(Message)) # redmineに投げるリクエストに必要な要素を取り出す branchName = Message['detail']['sourceReference'].split('/')[2] eventName = Message['detail']['event'] notificationBody = Message['detail']['notificationBody'] #print("branchName " +str(branchName)) #print("eventName " +str(eventName)) #print("notificationBody "+str(notificationBody)) # redmineを更新する # 対象チケット番号をブランチ名から取得する m = re.search(r'#\d+', branchName) issueNo_str = str(m.group()) # もしも対象チケット番号がなかったら処理しない、あったら処理する if issueNo_str: issueNo = int(issueNo_str[1:]) redmine = Redmine('http://<redmineurl>/', username='admin', password='xxxxxx') issue = redmine.issue.get(issueNo) issue.notes = notificationBody issue.save() #print(issue) #print(issue.notes)
- 投稿日:2020-01-20T21:01:50+09:00
AWS・GCP・AzureのIoTプラットフォームを調べている
IoT プラットフォーム?
各社のIoTソリューションはどこも基本的こんな感じ
- 大量センサからデータをクラウドへ集約
- 集めたデータをデータベース化しリアルタイム(ストリーム技術)に可視化
- Machine LearningやAI技術を使ってデータを分析(エッジでもML)
- イベントベースでのアクション・制御(Lamdaなど)
これにより、センサからのデータ集約→可視化・分析→センサへの制御(フィードバック)つまりセンサ運用の完全自動化を狙うことができそうな感じです。クラウドにはそもそもここに書いたストリームやイベント制御やMLなどのサービスがそろってるのでそのツールチェーンをそのまま使えばいいという発想
アーキテクチャ
当然ながら、コア(クラウド内)とエッジ(オンサイト)が分かれており、コア側は既存のクラウドのサービスを活用する形。
GCP
Azure
スペックをまとめてみる
プレイヤ AWS Azure GCP コンポーネント AWS IoT Core IoT Hub Cloud IoT Core エッジコンポーネント AWS IoT Greengrass1 IoT Edge Cloud IoT Edge プロトコル MQTT
HTTP1.1
WebsocketsMQTT v3.1.1
HTTP1.1
AMQP1.0MQTT
HTTPセキュリティ TSL1.2
x.509
SigV4
カスタムトークンx.509
セキュリティトークン公開鍵認証 RSA, ES256
JWTハードウェア パートナーデバイス + FreeRTOS2 パートナーデバイス3 Android Things4 その他 デバイスシャドウ ? Edge TPU プロトコルはMQTTかHTTP、各社デバイスパートナを持っており、そのデバイス上で使えるSDKを提供している感じ。エッジでは機械学習
各サービスの資料
軽くググったら出てきた資料たち
SORACOM
SORACOMはこの分野でかなり頑張ってる感じ。GAFAのIoTプラッフォトームの劣化版を作らず、彼らに乗っかって早くPoCを回してやりたいことをやってしまおうというアイデア。以下の資料は、技術だけじゃなくて、IoTプロジェクトの進め方、ベストプラクティスに言及していて面白い。GCP, Azure, AWSともにアーキテクチャの図が横通しで見られる。
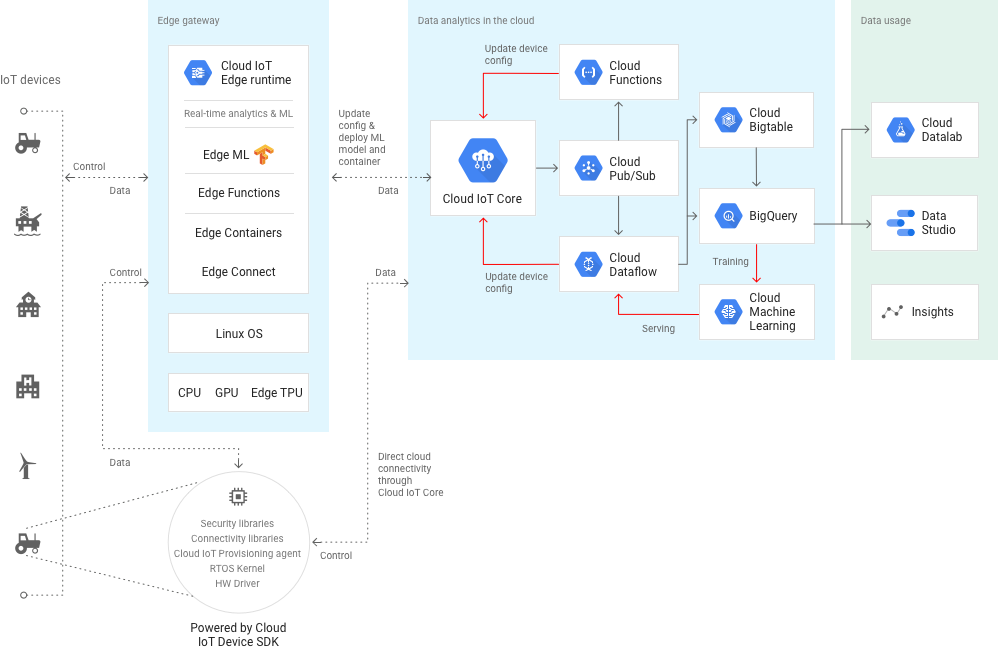
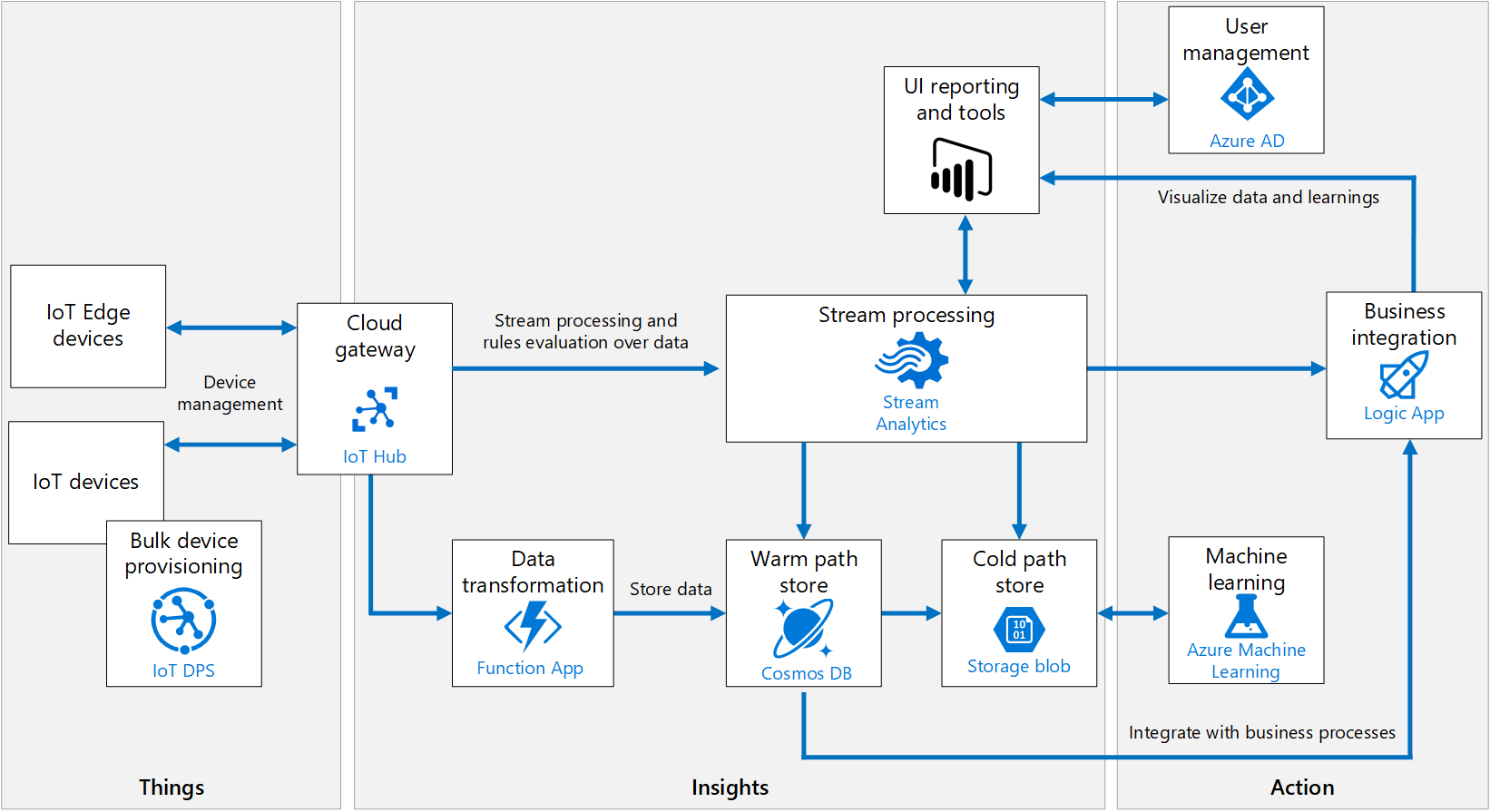
- 投稿日:2020-01-20T20:56:45+09:00
機械学習でひさ子のギターを自分のギターに持ち替えてもらう -準備編-
CycleGANを使って何かをする
CycleGANの仕組みや詳細はよくわかっていないし、他のいいものを読んでください
馬をしまうまに変えたり、風景画をモネっぽくしたりできるものである。形が同じで色や模様だけ違うものにするのに向いている。そんなにセンスを感じない題材かもしれないけど、個人的に結構嬉しくなりそうなのをやってみよう
→サンバーストのジャズマスターをブラックのジャズマスターに塗り替える ことにする。
最近復活して大騒ぎ、ライブもとっても素敵だった田渕ひさ子さんの使うギターはfenderのジャズマスター、色はサンバースト。私の使ってるギターはCrewsのジャズマスターで色はブラックです。ブランドとかギターの形とかは今回どうでもいいけど、たまたま似ている。
準備編
私の環境
- macOS High Sierra 10.13.6
- Anaconda3
- Python3.7.2
- Chrome バージョン: 79.0.3945.130(Official Build) (64 ビット)
画像を用意する
google_images_downloadというもので画像を一括ダウンロードできるのでそうしました。
参照:機械学習用の画像集めに便利な「google-images-download」の使い方pip install google_images_downloadインストールして、
googleimagesdownload --keywords "サンバースト ジャズマスター"などやりました。
デフォで100枚しか持ってこれないけど、100枚あたりが精度的にもちょうどよかった。今回人が一緒に写っているものも欲しかったので、検索ワードを変えながら増やしました。
100枚以上欲しい場合はchromeDriverが必要で、ダウンロードしたらgoogleimagesdownload -ri -cd "chromedriver.exe" -l 300 -k "sunburst jazzmaster"で使えました。-lのあとが枚数。私なんかしばらくうまくいかなくて、結局カレントディレクトリに入れてないあたりで失敗してたみたい?
目的のものじゃないやつも含まれてしまうので、めんどいけど手作業で消しました・・・サンバーストはめっちゃ使用者いるけど黒は全然いなくて泣いてる
あとで自分のギターを撮りまくるかもしれない画像のサイズを合わせる
今回のコードは画像サイズを256x256に合わせると良さそう
参考にしたのは以下2サイト参考にというかパクろうとしたけど、アホでそれすらできずに5億時間かかってしまった…
構造としては、2つ目のサイトをベースに、リサイズの具体的な操作は1つ目のコードを引用した という感じ。
今回は様々なサイズ、比率の画像を256x256の形にしたかったので、長い方に合わせてリサイズしてから余白を追加する方法をとりました。GitHubにあげている私のコード最終形↓
resize.py引っかかったとこ
- ① ディレクトリの相対パスをなんて書けばいいかわからない
Downloads ├── black └── img.jpgがたくさん ├── sun ├── sun_resize └── resize.py
- 元のコードに
bundle_resize('dir')とあり、dirを書き換える必要があった- Downloads/blackって書いたりblackだけ書いたり迷走した
- 結局
bundle_resize('black/')って書いたらできた② リサイズしたものを別のフォルダに入れたい
- os.makedirs(ファイル名, exist_ok=True)でファイル作成
- out_pathを少し書き換えるだけでよかった
階層構造を作る
cycleGANの方のデータセットを確認すると、
maps ├── trainA ├── trainB ├── testA └── testBみたいな感じになっているので、そうする。もうわからないので手作業で適当にやります
フォルダの名前は、色々変えるの難しそうだから同じ名前で作って差し替える実行編
おまけ
黒いジャズマスターを使ってやっているバンド
【 PV公開〜!】
— ぺんぎんの憂鬱 (@mofmofpenguin) June 7, 2019
ぺんぎんの憂鬱の初PVを公開しました。下北沢を中心に活動する、女性ボーカルの3〜4ピース宅録バンド。
諦めの漂う歌詞と気怠くて透明感のある歌声、でかくて歪んだギター、シンプルで凝ったリズム隊が特徴のオルタナティブロック。聞いてね いぇー
フル→ https://t.co/0xAd08hXZE pic.twitter.com/feIuTibvzA


- 投稿日:2020-01-20T19:11:20+09:00
Elastic Beanstalkのインスタンスやボリュームのタグをデプロイ時に更新
なぜ
- .ebextensionsで環境プロパティからインスタンスやボリュームにカスタムタグを追加している。管理ルールが変わりタグ更新が必要になったため、何気なく更新したらデプロイが失敗した。目的の環境プロパティをタグ以外の処で参照していた。
- シンプルに.ebextensionsを修正する何のことでもないことだが、保守担当に説明すると承認が必要のこと。これは時間がかかりそうだ。
遠回り
サーバ構成もプログラムも遠回りしてはいけない。根本原因をつぶすのがベストだ。しかし、
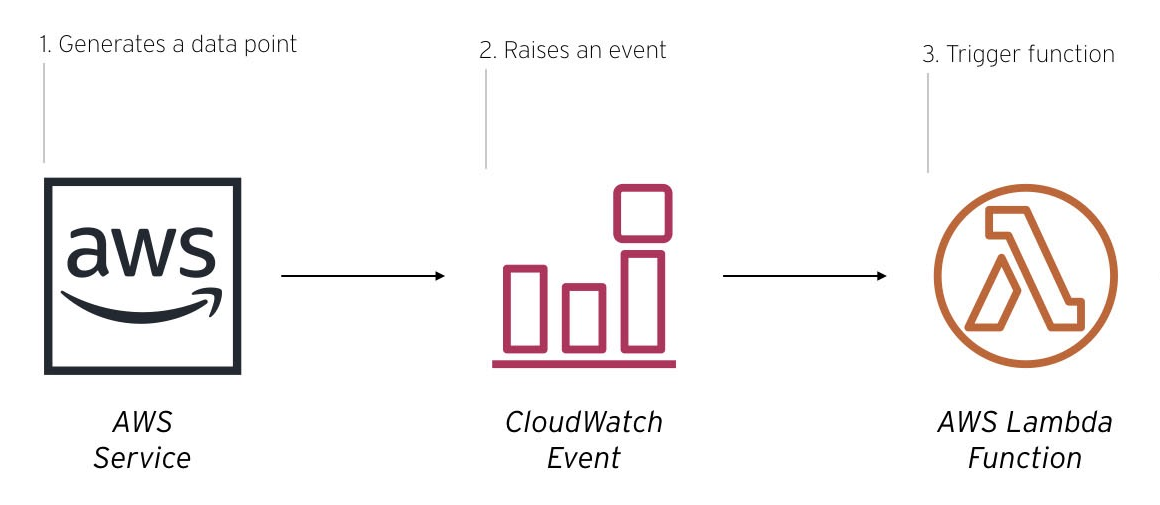
承認とリリースまで1~2ヵ月はかかりそうなことと、以前からLambdaのイベントトリガーを試してみたかったことがあり今回は遠回りをする。
Lambda
- LambdaのRoleは事前登録しておく
Python3.8import json import boto3 def lambda_handler(event, context): evt = str(event) #json parseできない文字列が飛んでくるため # eb-app, new-tag, old-tag //環境変数の利用をお勧め apps = [ ["app1", "newapp1", "oldapp1"], ["app2", "newapp2", "oldapp2"], ["app3", "newapp3", "oldapp3"], ... ... ] newTag = '' oldTag = '' for app in apps: if evt.find(app[0]) > -1: newTag = app[1] oldTag = app[2] break if len(newTag) > 1: print(str(newTag)) newTags = [{ 'Key': "Project", 'Value': newTag }] ec2 = boto3.resource('ec2', region_name="ap-northeast-1") instances = ec2.instances.filter( Filters = [{'Name': 'tag:Project', 'Values': [oldTag]}] ) for instance in instances: hasTag = 0 for tag in instance.tags: if tag['Key'] == 'Project': #調整対象タグ hasTag += 1 elif tag['Key'] == 'elasticbeanstalk:environment-id': #Elastic Beanstalkのインスタンのみにしたい hasTag += 1 if hasTag == 2: # 1.ec2のタグ更新 ec2.create_tags( Resources=[instance.instance_id], Tags=newTags ) #print(instance.instance_id) # 2.volumeのタグ更新 update_voltag(instance, newTags) return { 'statusCode': 200, 'body': json.dumps('OK') } def update_voltag(instance, ptags): instId = instance.instance_id print(instId) for vol in instance.volumes.all(): print('Updating tags for {}'.format(vol.id)) vol.create_tags(Tags=ptags)CloudWatch Events Rule
- 名前: EbUpdateEnvironment -> Lambdaのトリガーに追加
- イベントパターン
{ "source": [ "aws.elasticbeanstalk" ], "detail-type": [ "AWS API Call via CloudTrail" ], "detail": { "eventSource": [ "elasticbeanstalk.amazonaws.com" ], "eventName": [ "UpdateEnvironment" ] } }おまけ
イベントトリガーをSQSにすると
def lambda_handler(event, context): for record in event['Records']: pval = record["body"] #ここにElastic Beanstalkのアプリ名 print(str(pval))イベント発行
例え、zabbixで環境更新を検知したとしてアクションで設定
Elastic Beanstalkのデプロイ -> zabbixでアイテムで更新検知&アクション(SQSキュー生成) -> Lambda実行
zabbixアイテム例:https://qiita.com/mkawanee/items/66fb507ab9bd53638f58/usr/bin/aws sqs send-message --queue-url https://sqs.ap-northeast-1.amazonaws.com/12345678/infra-modify-tag \ --region ap-northeast-1 --profile awsX --message-body {EVENT.NAME}参照
- 投稿日:2020-01-20T16:22:21+09:00
IT初心者がAWSのセキュリティ対策を学ぶ【SAA試験対策】
はじめに
AWSの5つの設計原則の一つである【セキュリティ】。
ソリューションアーキテクトの試験を受けるにあたり、セキュリティに関することは必ず出てくる問題なので、理解を深めるために
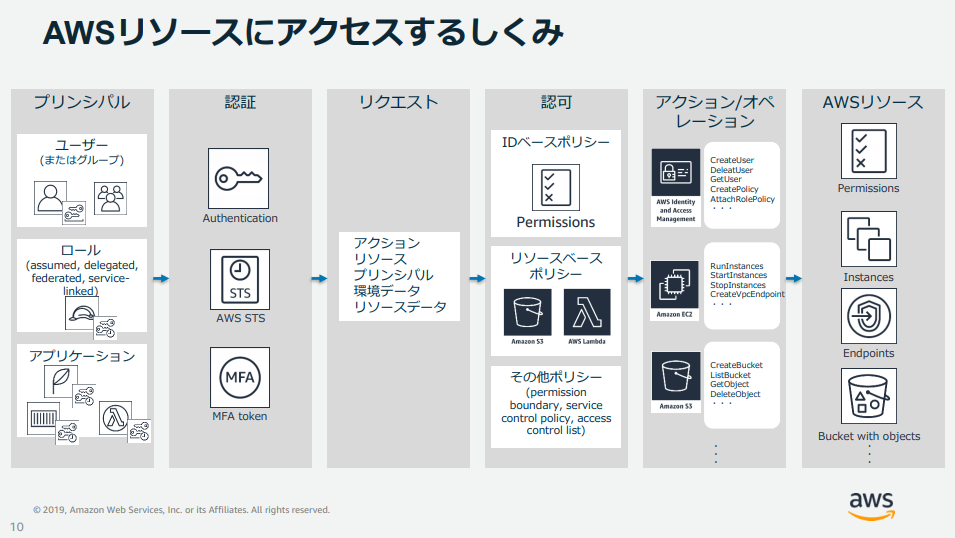
主なサービスについて、公式の BlackBelt やよくある質問などから抜粋して、要点だけでまとめてみました。AWS Identity and Access Management (IAM)
AWS リソースを安全に操作するために、認証・認可の仕組みを提供するサービス。
最小限の認証情報の生成、強固なパスワードポリシー、特権ユーザーでの MFA 有効化が ID の保護に有効です。主な活用
- 各 AWS リソースに対して、別々のアクセス権限をユーザーごとに付与できる
- 多要素認証(Multi-Factor Authentication : MFA)によるセキュリティの強化
- 一時的な認証権限を用いた権限の委任
- 他の ID プロバイダーで認証されたユーザーに、AWS リソースへの一時的なアクセス
- 世界中の AWS リージョンで、同じ ID と権限を利用可能
AWS Cognito
「認証」「許可」「ユーザー管理」などの機能を提供するサービス。
モバイルやウェブアプリケーションに、ユーザーのサインアップと認証機能を簡単に追加。
AWS 内のアプリケーションのバックエンドリソース、または Amazon API Gateway で保護されているサービスにアクセスするための、一時的なセキュリティ認証情報を付与できます。
ユーザーがどのデバイスからサービスにアクセスしても、ストレスなく使えるようになるものです。主な活用
- モバイル・Web アプリでユーザ認証が楽に
- Facebook や Twitter、Amazon、Google、Apple などのサードパーティーを通じてサインイン
- 認証ユーザや管理者ユーザ限定のコンテンツを配信
- アクセスキー等の認証情報をアプリに直接コーディングしなくて良い
- 一人で複数デバイスの利用をサポートしてUXを向上
- データをローカルに保存。オフラインの場合でもアプリケーションを使用でき、オンラインになった時にデータを自動的に同期
AWS Inspector
Amazon EC2 にエージェント(ソフトウェア)を派遣し、プラットフォーム(土台となる環境)の脆弱性診断を行う有料サービスです。
自動化されたセキュリティ評価サービスで、Amazon EC2 インスタンスのネットワークアクセスと、そのインスタンスで実行しているアプリケーションのセキュリティ状態をテストできます。
開発環境全体で、または静的な本番システムに対して、セキュリティ上の脆弱性の評価ができます。
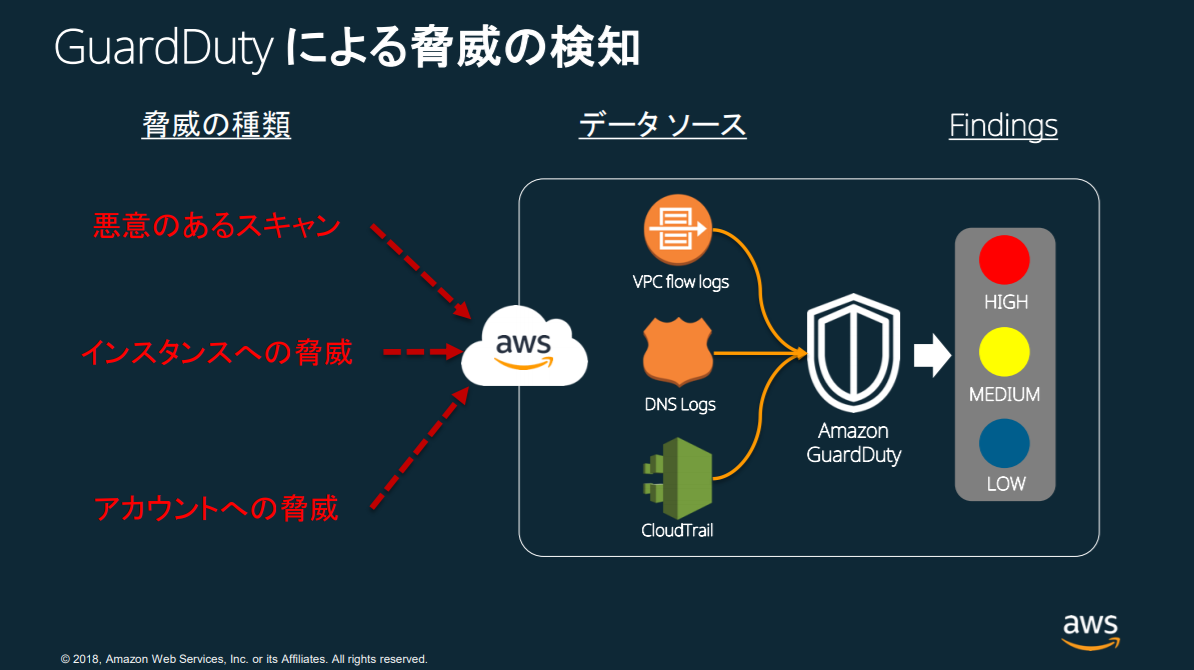
AWS GuardDuty
悪意のある操作や不正な動作を、継続的にモニタリングする脅威検出サービス。
AWS 環境のセキュリティを継続的にチェックしてくれ、各種ログを自動的に取得して、機械学習で分析して異常を通知してくれます。
分析の対象となるログは、AWS CloudTrail、Amazon VPCフローログ、DNSログなど、複数のAWSにおける数千億にもわたるイベントです。
AWS のアカウントとワークロードの継続的なモニタリングが楽になり
詳細なアラートを提供し、既存のイベント管理、ワークフローシステムと簡単に統合可能です。
AWS Directory Service
ユーザー、グループ、コンピューター、およびその他のリソースといった組織についての情報を含むディレクトリ機能を提供する権限管理サービスです。
AWS クラウド内にディレクトリをセットアップして運用することや、AWS リソースを既存のオンプレミス Microsoft Active Directory に接続することが簡単に行えます。主な活用
- ユーザーとグループの管理
- アプリケーションとサービスへのシングルサインオン(1回の本人認証で、複数の異なるアプリケーションやシステムを利用できる認証の仕組み)を提供
- グループポリシーの作成と適用
- Amazon EC2 インスタンスのドメインへの参加
- クラウドベースの Linux と Microsoft Windows ワークロードのデプロイと管理の簡素化
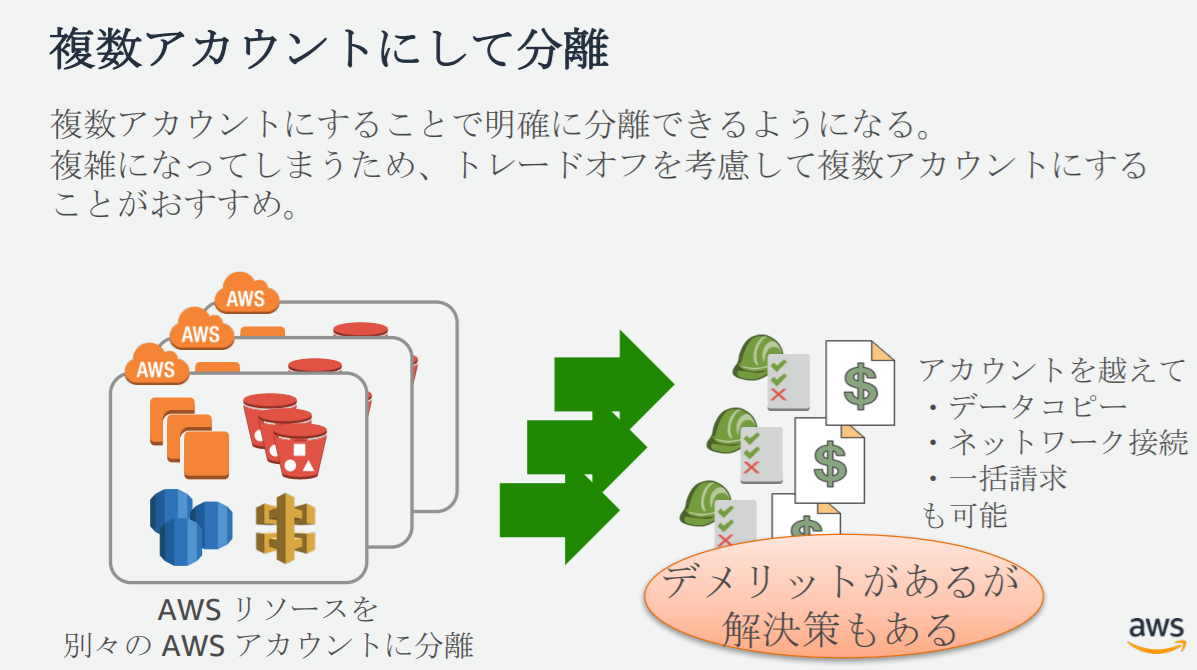
AWS Organizations
複数 AWS アカウントを一元管理できるサービス。
アカウントをグループ化して、ポリシーを適⽤し利⽤サービスを制限します。
アカウント新規作成の自動化や請求の簡素化、複数アカウントの請求を⼀括にできます。主な活用
- 複数の AWS アカウントへの一括請求
- AWS アカウントの作成と管理の自動化
- AWS のサービス、リソース、リージョンへのアクセスを管理
- 複数の AWS アカウントに適用するポリシーを集中管理
- 複数アカウント間で AWS のサービスを設定
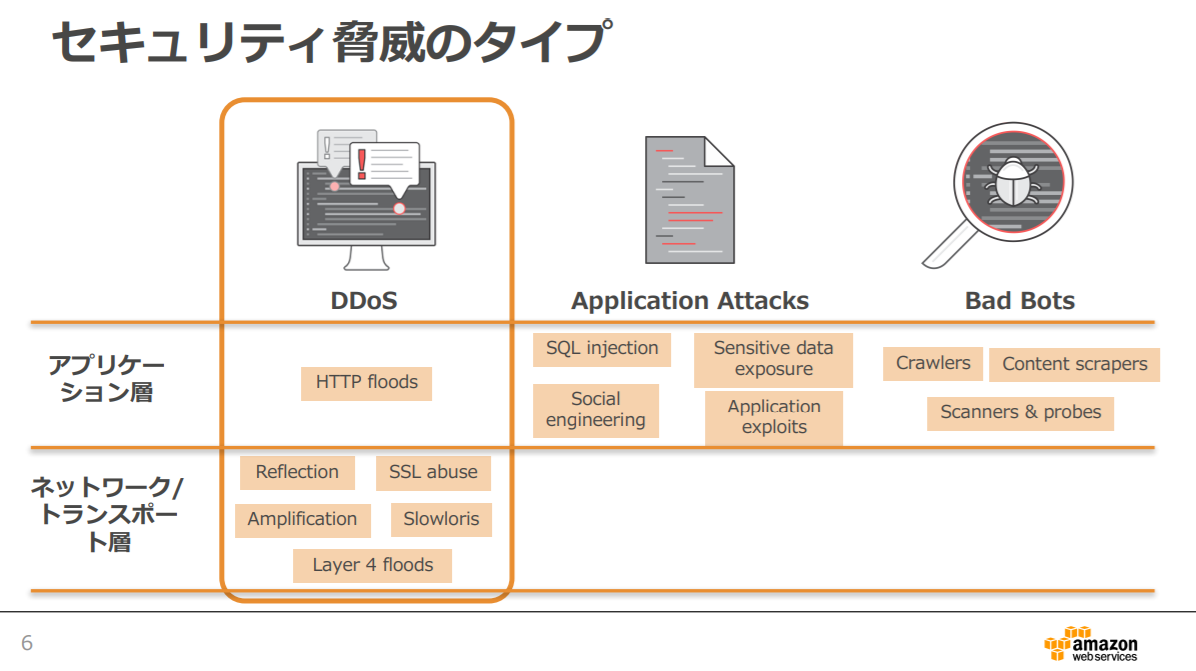
AWS Shield
AWS で実行されるアプリケーションを Distributed Denial of Service (DDoS) 攻撃から保護するサービスです。
Standard は、追加料金なしで自動的に有効化されます。Advanced は任意で利用できる有料サービスです。
有料サービスは、Amazon EC2、Elastic Load Balancing (ELB)、Amazon CloudFront、AWS Global Accelerator、Route 53 で実行中のアプリケーションを標的とする、高度化された大規模な攻撃からの保護が強化されます。
CloudHSM
安全なキーストレージと暗号通信を提供するサービス。
ユーザー自身にしかアクセスできない方法で、データ暗号化に使用される暗号キーを安全に生成、保存、管理することができます。
クラウド内の専用ハードウェアセキュリティモジュール (HSM) を使用して、データセキュリティに対する企業コンプライアンス要件、契約上のコンプライアンス要件、法令遵守の要件を満たすことができます。
CloudHSM は既存のデータ保護を補完する役割を果たし、HSM 内での暗号キー保護を可能にします。
安全なキー管理に対する、米国政府標準規格に適合するように設計、検証されています。主な活用
- KMS のカスタムキーストアとして使用
- SSL/TLS 暗号化、復号処理のオフロード(システムの負荷を他の機器などが肩代わりして軽減する仕組み)
- NGINX, Apache, Windows Server IIS との連携
- CA局の秘密鍵管理
- Oracle DBのTransparent Data Encryption(透過型暗号。表や表領域のデータを自動で暗号化して保存)
- PKCS #11ライブラリ経由で連携
- ファイルやデータへのデジタル署名
- デジタル権限管理
- CloudHSM をサポートするサードパーティソリューションとの統合

AWS Key Management Service
データを保護するための暗号化キーの一元管理が出来るサービス。
AWS サービスとの統合により、容易にデータの暗号化を行うことができ、アプリケーション上のデータの暗号化にも利用することができます。
暗号鍵の保管、鍵のアクセス制御等、鍵自身のセキュリティを管理するインフラストラクチャ Key Management Infrastructure を採用。主な活用
- 暗号鍵の作成、管理、運用
- 鍵利用の権限管理、監査
- 暗号鍵を保存、暗号鍵を使用するための安全なロケーションを提供
- マスターキーは FIPS 140-2検定済暗号化モジュールによって保護
- AWS サービスとの統合 (S3, EBS, Redshift, RDS, Snowball等)
- SDK との連携で独自アプリケーションデータも暗号化
- CloudTrail との統合による組み込み型の監査対応機能
備考
【Perfect Forward Secrecy】通称PFS
暗号鍵とその暗号鍵を複合するための秘密鍵が、両方漏洩しても暗号鍵を複合できない、というカギ交換に関する概念。
長期間にわたってデータを解読されないよう、暗号鍵(共通鍵)の元になる情報を使い捨てる方式を採用しています。終わりに
セキュリティの強度やコスト効率、通信制御やデータ暗号化など、状況や用途で組み合わせが多様になっていくことがわかりました。
ホワイトリスト型(許可した通信のみを通す)、最小限の権限設定が重要であること
安全性において安心できるよう、AWS の推奨するベストプラクティスに沿ってサービスを覚えていくことが、試験にも実務にも生かされていきそうです。公式サイトリンク



- 投稿日:2020-01-20T14:52:12+09:00
実践Terraformを写経してみたらよかったって話
実践Terraform AWSにおけるシステム設計とベストプラクティスのコードを写経してみたらよかったので感想をば。
実践Terraformを読んだ動機
本書は、Terraformを使ってAWS上にシステムを構築するノウハウを、200以上のサンプルコードとともに紹介する、Terraform初級者から中級者向け解説書です。
引用元:実践Terraform AWSにおけるシステム設計とベストプラクティス, https://nextpublishing.jp/book/10983.html, (検索年月日:2020年1月20日)
この本は上記紹介文にあるようにAWSとTerraformについて学べる本です。
AWSは自社で利用されているので理解を深めたかったというのと、Terraformは前から興味があったのでやってみました。以下のものを構築するので、個人でサービスを作るときにTerraformでコード化しておけば、さっとインフラを作れそうだというのもやる動機となりました。
- MultiAZ環境
- LoadBalancer
- アプリやバッチをコンテナで実行できるECS
- RDSやインメモリデータストア
- GitHubと連携しているCI/CD環境
感想
自分はTerraformもAWSもちょっと触ったことがある程度の経験しかありませんでした。
- Terraform:Get Startedをちょっとやった。
- AWS:業務で使っているけど、構築はインフラチームの人がやってもらっているのもあってしっかり理解しているかは怪しい。
という感じです。まあほとんど初心者ですね。
写経してみた結果とても学べることが多い良書でした。
- TerraformもAWSも丁寧に説明があり、ひとつひとつの章、節は短くまとめてくれている。
- 説明に対して細かくサンプルコードがあり、どれもちゃんと実行できる。
- 説明を読んではコードを書いて実行できるため、読んだ内容理解できているか細かい頻度で確認しながら進められる。
- AWSを使ったwebサービスの基本的なアーキテクチャを設計から学べられる。
という点がよかったです。
わがままをいうと
良い本だったとはっきり言えるのですが、わがままを言うと以下の点が改善されたらさらによいなと思いました。
サンプルコードでリソース名やデータ名など名前をつけるところがほぼexampleとなっているため、コードのどことどこが一致していなければいけないのかということは、本の文章を注意深く読まないとすぐにわからなかった。
よく作られそうなアーキテクチャで環境構築をできるようになっているのはとてもよい。LoadBalancerを立てて、ECSでコンテナを実行して、RDSやインメモリデータストアをたてる。ただ、LoadBalancerでリクエストを受けて、アプリが実行されてRDSを更新とかそういう連動するところまでは実施しない。実施されていたらより実用的だなと思いました。(GitHubと連携したCI・CD環境も構築するけど、実行するところの詳細までは書いていなかった。)
読んでどうなった?
TerraformについてはAWSプロバイダーで書かれたコードならある程度読めるようにはなったかなと。あとはひたすら書いていけば身につきそうです。
ただ、わがまま2の点で書いたとおり写経してできたコードは欲しかったインフラを構築できるではありませんでした。しかし、そういうものを作ろうとしたらあとどうすればよいのか?とイメージはできるぐらいになりました。AWSについてはVPCやEC2、Route53、S3、ELB、ECSなど各サービスの理解は深まったと思います。たとえばVPCであれば、サブネットやインターネットゲートウェイなど、どういう構成要素があって、どう関連しているかわかったかなと。
ただ、改めてAWSコンソールでVPCを作ると戸惑うところはあるので、AWSコンソールで作るのは別で練習したほうがよいなと思いました。TerraformもAWSもある程度知識を得られて、あとは手を動かしていけば使いこなせるようになれそうでした。一冊で2つの技術についてこの段階までいけるのはとても価値ある本でした。
これからどんどんどちらも使っていこうと思います!!
著者の野村 友規さん @tmknom に感謝!!
- 投稿日:2020-01-20T13:25:37+09:00
Amplifyとは何者なのか
AWS Amplify とは
セキュアでスケーラブルなモバイルアプリケーションとウェブアプリケーションを構築するための開発プラットフォーム
https://aws.amazon.com/jp/amplify/?nc2=h_ql_prod_mo_awsaAWS Amplifyを使うことで、モバイル/Webアプリが利用する、AWS上のサーバーレスなバックエンドリソースを簡単に構築できます。
例えば以下のような機能を持つサーバーレスアプリケーションを簡単に構築することができます。
- データストア
- 認証
- 分析
- API
- ストレージ
などなど ( 詳細 )
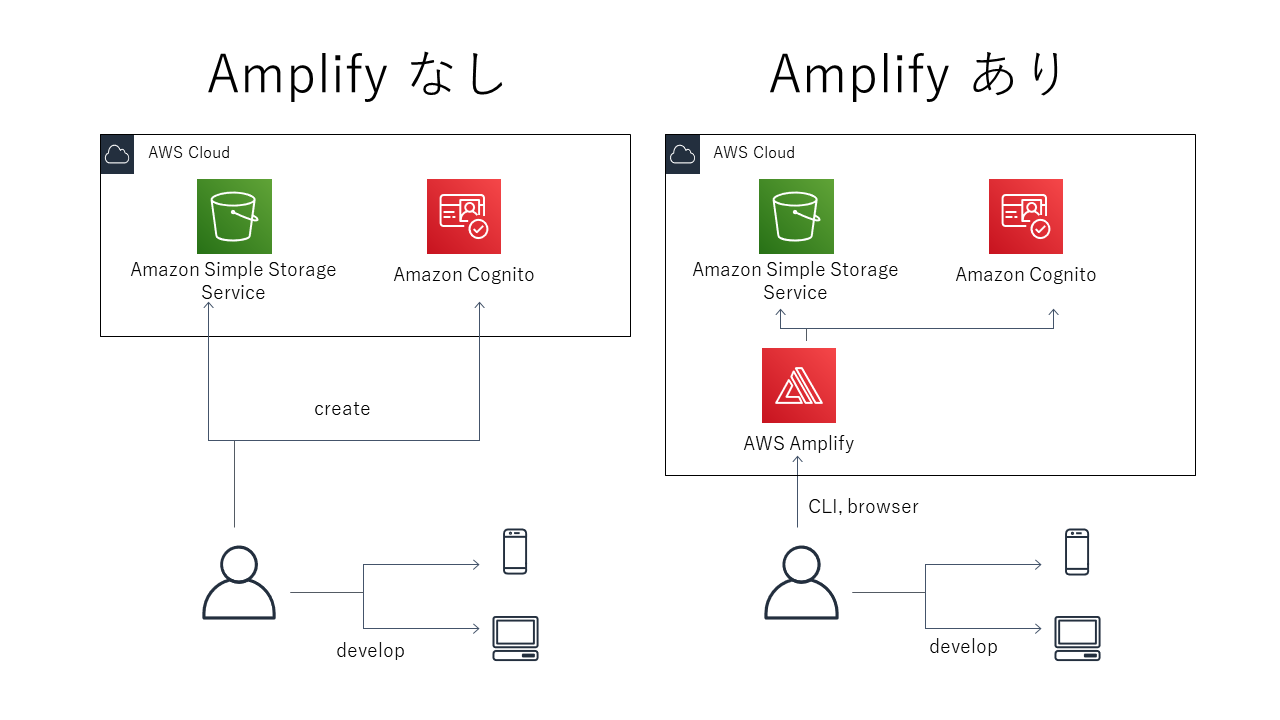
イメージ図としてはこうなると思います。
AWS Amplify を構成するサービス
AWS Amplifyには、ライブラリ、CLI、コンソール、などといったさまざまなサービスが含まれています。
- Amplify Framework
- ライブラリ
- ライブラリを使用して、AWSの機能を活用するモバイル、Webアプリを構築できる
- CLI
- コマンドラインから、アプリが使用するAWS上のサーバーレスなバックエンドを構築することができる
$ amplify add apiなどのコマンドを利用してやりたいこと(apiの追加)を対話的に構築できる- Amplify Console
- Webアプリケーションのホスティングを行える
- 静的サイトのホスティングだけであればGithubを連携するだけ
- サーバーレスなバックエンドもデプロイできる
参考
- 投稿日:2020-01-20T13:17:05+09:00
特定のS3 バケットだけにアクセスするポリシーを30秒で書く
色々調べたのだけど、とにかくパターンが多すぎて怖い
ので、一番簡素で強力と思えたパターンだけ書きます。
(違ってたらぜひご指摘ください!)hogehoge.comを置き換えてご利用下さい。
(ここではcloudfrontでスタティックページを配信してるユースケースを想定しています)s3-singlebucket-policy.json# テンプレ { "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": "s3:*", "Resource": [ "arn:aws:s3:::hogehoge.com", "arn:aws:s3:::hogehoge.com/*" ] }, { "Effect": "Deny", "NotAction": "s3:*", "NotResource": [ "arn:aws:s3:::hogehoge.com", "arn:aws:s3:::hogehoge.com/*" ] } ] }使うのは「iamユーザー」
いろんな設定の仕方があるかと思いますが、僕は上記ポリシーを作成後、
そのポリシーを適用したユーザーをバケットごとに作成しています。
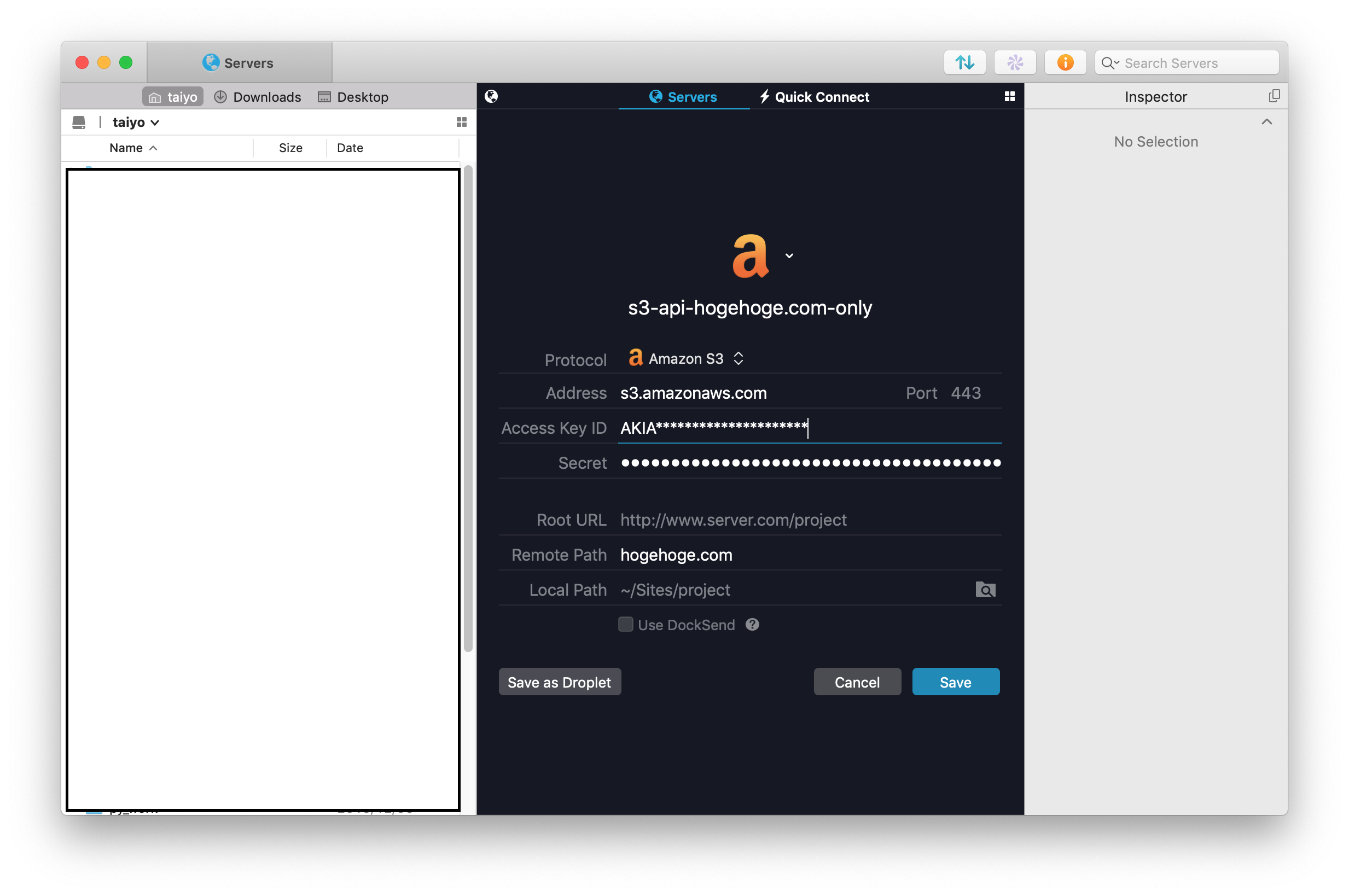
(プラグマティックアクセスを有効に・ManagementコンソールはOFF)Cyderduck や Transmit で使う時
「指定バケットをデフォルトパス」に指定しないとエラーになります。(デフォルトはバケット全体をListしようとするため)
CyberDuckだと「QuickConnect」にそのオプションが無いのだけ軽くハマりました。
普通に「新規作成」から詳細設定を指定してあげればOK!Transmit:
CyberDuck:
より詳しくは
セキュリティ的なベストプラクティスなのか?
これで僕が求めていた事は実現(作業者ごとに個別のバケットアクセスを管理 - 管理者のみ複数バケットにアクセス可)出来ているのですが、
AWS勉強中の身ですのでこれで完全かはわかりません。
具体的には「ポリシー・Deny」を上回る権限設定が出来るか、これから調べたいと思います。「S3全員見えちゃう運用」からのステップアップとしては上記でも充分有効、程度にお読み頂ければ。

- 投稿日:2020-01-20T12:16:47+09:00
二段階認証�のGitアカウントでのAWS SageMakerとのリポジトリ連携
これはなに?
- セキュリティ観点でGitアカウントに二段階認証を入れている
- SageMakerで更新するJupyter Notebook、他ファイルをGit管理したい
以上のような状態を達成するために少しハマったので備忘録。
作業環境
AWS SageMakerのJupyter notebook上
二段階認証を行ったGitアカウントどうやる
AWSのドキュメント通り。
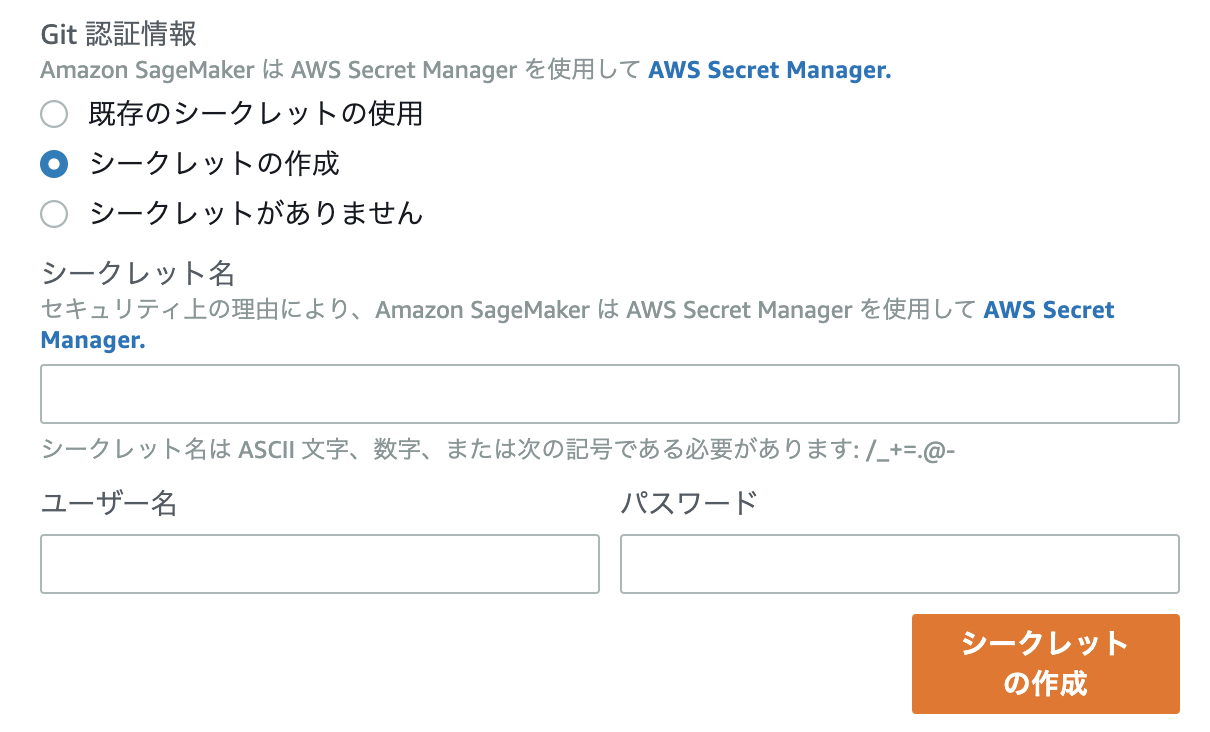
このページのAmazon SageMaker アカウントに Git リポジトリを追加する (コンソール)という項目内の、
この部分に従う。
(SageMaker上でGithubのユーザー名・パスワードでSageMaker-リポジトリ間の連携を行うと、JupyterNotebookインスタンスをGitリポジトリと連携した状態で立ち上げると認証エラーが発生し、起動失敗してしまう)二段階認証を行っている場合はSageMakerとGitリポジトリを連携する際にパスワード部分に上画像にある個人用アクセストークンを利用する。
こちらで手順通りに設定すると最後にアクセストークンが発行される。
ここで発行されるアクセストークンがSageMakerとリポジトリを紐付ける時にパスワードの部分に入力する文字列になる。AWSコンソール内のSageMaker > Githubリポジトリ > リポジトリの追加で下画像の項目を入力する。
ユーザー名:Githubアカウント名
パスワード:アクセストークン
入力した後はシークレットを作成し、Jupyter Notebookにこのリポジトリを紐付ける。
紐付けが終わった後はJupyter Notebook内でのヘッダー部分に「Git」という項目があるので選択する。
Git > Git Command in Terminalで通常通りGitコマンドを入力。git add hogehoge.ipynb git commit "first commit" git push origin masterJupyter Notebook上の管理したいファイルに対して、いつものように
git pushしてやれば連携したリポジトリ側にJupyterNotebookの管理ファイルが追加されています!!DONE!!

- 投稿日:2020-01-20T12:08:39+09:00
DynamoDB CLI
実際にコンソールの画面を確認しながら、実施してみるのがよい。
create-table
aws dynamodb create-table \ --table-name Music \ --attribute-definitions \ AttributeName=Artist,AttributeType=S \ AttributeName=SongTitle,AttributeType=S \ --key-schema \ AttributeName=Artist,KeyType=HASH \ AttributeName=SongTitle,KeyType=RANGE \ --provisioned-throughput \ ReadCapacityUnits=10,WriteCapacityUnits=5put-item
aws dynamodb put-item \ --table-name Music \ --item \ '{"Artist": {"S": "Namie Amuro"}, "SongTitle": {"S": "cotrail"}, "AlbumTitle": {"S": "fell"}, "Awards": {"N": "1"}}' aws dynamodb put-item \ --table-name Music \ --item \ '{"Artist": {"S": "one ok rock"}, "SongTitle": {"S": "kannzenkankakudremer"}, "AlbumTitle": {"S": "Niche Syndrome"}, "Awards": {"N": "10"} }'get-item
aws dynamodb get-item --consistent-read \ --table-name Music \ --key '{ "Artist": {"S": "Namie Amuro"}, "SongTitle": {"S": "cotrail"}}'update-item
aws dynamodb update-item \ --table-name Music \ --key '{ "Artist": {"S": "one ok rock"}, "SongTitle": {"S": "kannzenkankakudremer"}}' \ --update-expression "SET AlbumTitle = :newval" \ --expression-attribute-values '{":newval":{"S":"Updated Album Title"}}' \ --return-values ALL_NEWquery
aws dynamodb query \ --table-name Music \ --key-condition-expression "Artist = :name" \ --expression-attribute-values '{":name":{"S":"one ok rock"}}'GSI
aws dynamodb update-table \ --table-name Music \ --attribute-definitions AttributeName=AlbumTitle,AttributeType=S \ --global-secondary-index-updates \ "[{\"Create\":{\"IndexName\": \"AlbumTitle-index\",\"KeySchema\":[{\"AttributeName\":\"AlbumTitle\",\"KeyType\":\"HASH\"}], \ \"ProvisionedThroughput\": {\"ReadCapacityUnits\": 10, \"WriteCapacityUnits\": 5 },\"Projection\":{\"ProjectionType\":\"ALL\"}}}]" aws dynamodb query \ --table-name Music \ --index-name AlbumTitle-index \ --key-condition-expression "AlbumTitle = :name" \ --expression-attribute-values '{":name":{"S":"Niche Syndrome"}}'delete-table
aws dynamodb delete-table --table-name MusicLSI
aws dynamodb create-table --table-name Music \ --attribute-definitions AttributeName=Artist,AttributeType=S AttributeName=SongTitle,AttributeType=S \ AttributeName=AlbumTitle,AttributeType=S \ --key-schema AttributeName=Artist,KeyType=HASH AttributeName=SongTitle,KeyType=RANGE \ --provisioned-throughput \ ReadCapacityUnits=10,WriteCapacityUnits=5 \ --local-secondary-indexes \ "[{\"IndexName\": \"AlbumTitleIndex\", \"KeySchema\":[{\"AttributeName\":\"Artist\",\"KeyType\":\"HASH\"}, {\"AttributeName\":\"AlbumTitle\",\"KeyType\":\"RANGE\"}], \"Projection\":{\"ProjectionType\":\"INCLUDE\", \"NonKeyAttributes\":[\"Genre\", \"Year\"]}}]"
セカンダリインデックス 説明 GSI テーブルに対し、パーティションキー+レンジキーだと効率の悪くなるクエリ(キー以外を条件にした検索等)を効率良くするために作成する明示的インデックス。全く別の属性をパーティションキー+レンジキーとして指定できる。 LSI グローバル同様明示的に追加するインデックスだが、パーティションキーは変更できない。
- 投稿日:2020-01-20T10:18:57+09:00
codecommitとredmineを連携させる
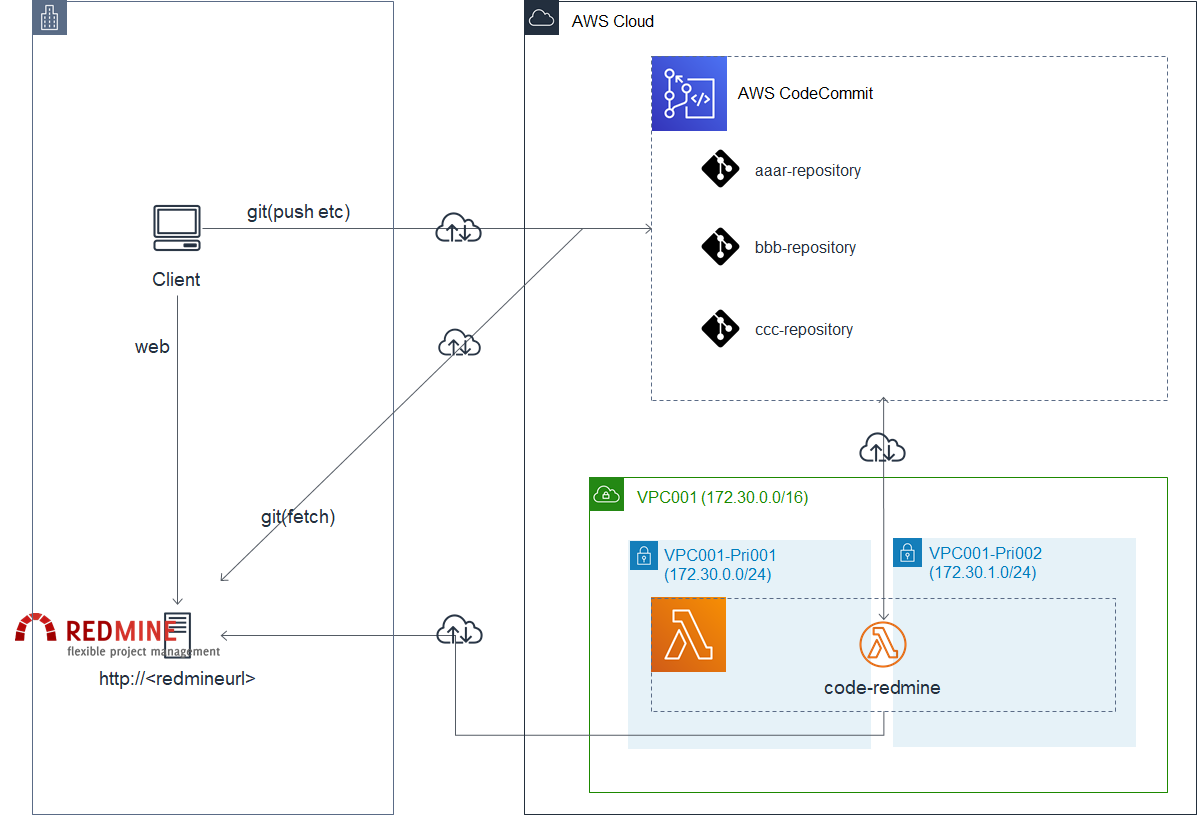
概要
世の中的にgit→redmineはやり方整ってるけど、codecommit→redmineは無いのでごにょごにょした記録。
手順にはなってませんが、ヒントにはなるかな、と。やりたい構成図
ざっくりこんなかんじ
やったこと概要
redmine側の設定
- redmineにgit連携のプラグインgithub_hookを入れる
- redmineのサーバにcodecommit上のリポジトリのbareリポジトリを作る
参考にしたサイトはこちら
AWS側の設定
- codecommitにトリガーを設定し、codecommit上で何かイベントがあったときにLambdaが起動するようにする
- Lambdaの設定をする
- イベント拾ってpostするpythonを書く
- 宛先がオンプレサーバのためVPC経由で通信できるようにする必要があり、LambdaがVPC起動できるようにする
苦労した点
- bareリポジトリをID/Pass入力無しでfetchできるようにする
- ここを参考に
- redmineがコンテナなので、コンテナの中からできるようにするために exec -itで入ってやって終わってcommitがめんどい
- github_hookに何をPOSTすればいいのかわからん
- 自前のgitlabからテスト送信してみて、何送ってるかログから確認した
- VPCでLambdaを起動させる
- IAMポリシー不足でエラー出てるのに気づかなかった(上のほうにデカデカとでてた)
Lambdaのコード
import json import boto3 import urllib import urllib.request codecommit = boto3.client('codecommit') def lambda_handler(event, context): references = { reference['ref'] for reference in event['Records'][0]['codecommit']['references'] } #print("-------------------") #print("event: " +str(event)) #print("context: " +str(context)) # event(Lambdaに渡される情報)からrepository名とcommitNoを拾ってくる repository = event['Records'][0]['eventSourceARN'].split(':')[5] commitNo = event['Records'][0]['codecommit']['references'][0]['commit'] try: # codecommitからcomittした情報をもろもろ取ってくる response = codecommit.get_commit(repositoryName=repository,commitId=commitNo) # redmine連携に必要な情報をセット id = response['commit']['commitId'] message = response['commit']['message'] timestamp = response['commit']['author']['date'] authorname= response['commit']['author']['name'] authoremail= response['commit']['author']['email'] # codecommitからcodecommitのURL情報を取ってくる(いらないかも) response = codecommit.get_repository(repositoryName=repository) codecommiturl=response['repositoryMetadata']['cloneUrlHttp'] +"/" +id # redmineにPOSTする # <redmine-url><projectname><repositryname>は環境に合わせて redmine = 'http://<redmine-url>/github_hook?project_id=<projectname>&repository_id=<repositryname>' str_data = { 'id': id, 'message': message, 'timestamp': timestamp, 'url': codecommiturl, 'author': { 'name': authorname, 'email': authoremail } } headers = { 'Content-Type': 'application/json' } json_data = json.dumps(str_data).encode("utf-8") # requestを作成 req = urllib.request.Request(url=redmine,data=json_data,headers=headers) # requestを投げる with urllib.request.urlopen(req) as res: body = res.read().decode('utf-8') print(body) try: with urllib.request.urlopen(req) as res: body = res.read() print(res) print(body) except urllib.error.HTTPError as err: print(err.code) except urllib.error.URLError as err: print(err.reason) return response['repositoryMetadata']['cloneUrlHttp'] except Exception as e: print(e) print('Error getting repository {}. Make sure it exists and that your repository is in the same region as this function.'.format(repository)) raise e
- 投稿日:2020-01-20T04:14:28+09:00
AWS CLIのアカウントを変更するためのコマンドを作成する
はじめに
AWSのアカウントを個人用と会社用で切り替えて使うのが思いのほか面倒だったので変更用のコマンドを作成しました。
環境
macOS Catalina 10.15.2
AWSのアカウント情報の確認
AWSのアカウント情報は
~/.aws/configにあります。
以下のような情報が入っています。$ cat ~/.aws/config [default] output = json region = ap-northeast-1 [profile s3deploy-user] output = json region = ap-northeast-1 [profile home-user] output = json region = ap-northeast-1 [profile lambada-user] output = json region = ap-northeast-1認証情報は
~/.aws/credentialsで確認できます。アカウントの切り替えには以下のコマンドを実行する必要があります。
# shellを閉じるまで有効 export AWS_DEFAULT_PROFILE=test-user # 実行時のみ aws deploy create-application --application-name HelloWorld --profile test-userコマンドの作成
chmod風にchawsというコマンドで作成することにします。
# chaws TARGET_FILE=~/.aws/config PROFILES=() while read LINE do if [[ $LINE =~ ^.*\[profile(.*)\].*$ ]] then PROFILES+=(`echo ${BASH_REMATCH[1]} | tr -d " "`) fi done < $TARGET_FILE select res in "${PROFILES[@]}" do sed -i -e '/AWS_DEFAULT_PROFILE/d' ~/.zshrc echo export AWS_DEFAULT_PROFILE=$res >> ~/.zshrc break doneこれを適当につくったフォルダにいれてパスを通します。
今回は~/binフォルダに入れます。cd ~/bin/ # 実行権限を付与 $ sudo chmod 755 chaws # 環境変数を追加 $ echo export PATH='~/bin:$PATH' >> ~/.zshrc # 読み込み $ source ~/.bash_profile $ source ~/.zshrcさっそく実行してみます。
$ chaws 1) s3deploy-user 2) home-user 3) lambada-user # Enter 2 # 確認 $ source ~/.zshrc $ echo $AWS_DEFAULT_PROFILE home-userちゃんと切り替わりました。
参考記事
https://qiita.com/ryuzee/items/e3ce493f132f1981f57a
https://qiita.com/JJJJJJJJ/items/cc4357f5ba2a9eed809d
- 投稿日:2020-01-20T04:14:28+09:00
AWS CLIのアカウントを切り替えるためのコマンドを作成する
はじめに
AWSのアカウントを個人用と会社用で切り替えて使うのが思いのほか面倒だったので変更用のコマンドを作成しました。
環境
macOS Catalina 10.15.2
AWSのアカウント情報の確認
AWSのアカウント情報は
~/.aws/configにあります。
以下のような情報が入っています。$ cat ~/.aws/config [default] output = json region = ap-northeast-1 [profile s3deploy-user] output = json region = ap-northeast-1 [profile home-user] output = json region = ap-northeast-1 [profile lambada-user] output = json region = ap-northeast-1認証情報は
~/.aws/credentialsで確認できます。アカウントの切り替えには以下のコマンドを実行する必要があります。
# shellを閉じるまで有効 export AWS_DEFAULT_PROFILE=test-user # 実行時のみ aws deploy create-application --application-name HelloWorld --profile test-userコマンドの作成
chmod風にchawsというコマンドで作成することにします。
# chaws TARGET_FILE=~/.aws/config PROFILES=() while read LINE do if [[ $LINE =~ ^.*\[profile(.*)\].*$ ]] then PROFILES+=(`echo ${BASH_REMATCH[1]} | tr -d " "`) fi done < $TARGET_FILE select res in "${PROFILES[@]}" do sed -i -e '/AWS_DEFAULT_PROFILE/d' ~/.zshrc echo export AWS_DEFAULT_PROFILE=$res >> ~/.zshrc break doneこれを適当につくったフォルダにいれてパスを通します。
今回は~/binフォルダに入れます。cd ~/bin/ # 実行権限を付与 $ sudo chmod 755 chaws # 環境変数を追加 $ echo export PATH='~/bin:$PATH' >> ~/.zshrc # 読み込み $ source ~/.zshrcさっそく実行してみます。
$ chaws 1) s3deploy-user 2) home-user 3) lambada-user # Enter 2 # 確認 $ source ~/.zshrc $ echo $AWS_DEFAULT_PROFILE home-userちゃんと切り替わりました。
bashを利用している人は、.zshrcのところを.bash_profileで動作すると思います。参考記事
https://qiita.com/ryuzee/items/e3ce493f132f1981f57a
https://qiita.com/JJJJJJJJ/items/cc4357f5ba2a9eed809d
- 投稿日:2020-01-20T01:32:38+09:00
【これからプログラミング&クラウドを始める人向け】AWS Cloud9 を利用して Ruby の開発環境を作ってみる③ - Ruby のバージョン管理
はじめに
この記事は無料で AWS Cloud9 を利用してプログラム学習を開始する方法いついて入門者向けに記載した内容になっています。
AWS アカウントの作り方は → こちら
AWS Cloud9 の開始方法は → こちら今回行うこと
複数の案件や学習教材を利用した場合、それぞれ Ruby のバージョンが異なる場合があります。
今回は複数の Ruby のバージョンをインストールして状況に応じてバージョン変更する方法を Cloud9 上で実践してみます。Ruby のバージョン確認
- 右下の□ボタンを押すとコマンドコンソールが全画面表示になります。
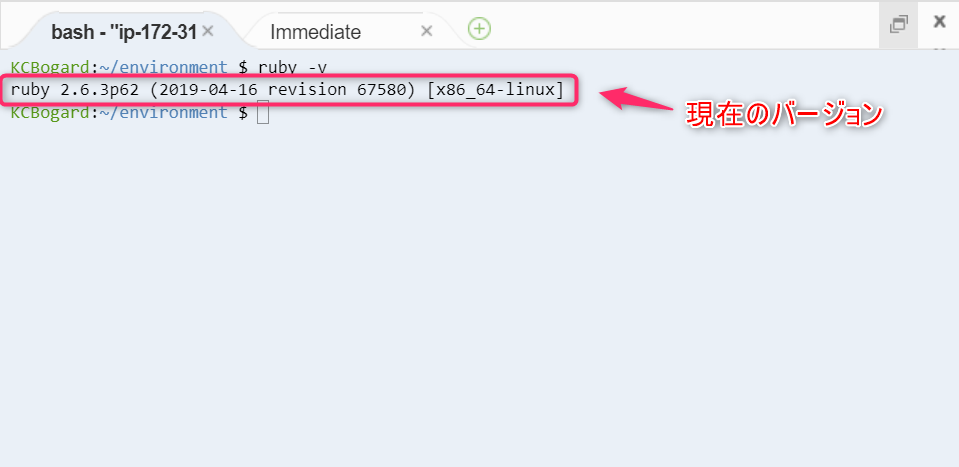
- AWS Cloud9 上で現在インストールされている Ruby のバージョンを確認してみます。
ruby -v
バージョン管理ソフトウェアの導入
- 今回は「 rvm (Ruby Version Manager) 」を利用する手順になります。
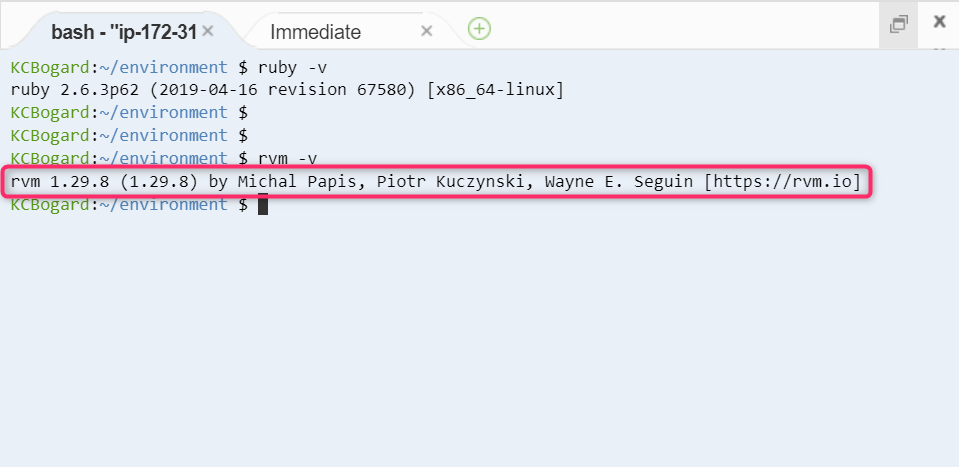
- 先程と同様にまずは Cloud 9 上の rvm のバージョンを確認します。
rvm -v
- 上記のコマンドを入力すると rvm のバージョンが表示されます。
- 次に rvm のヘルプ表示を行います。
rvm help※ rvm とだけ入力してもヘルプは表示されます。
- 入力するとコマンドとその説明が表示されます。
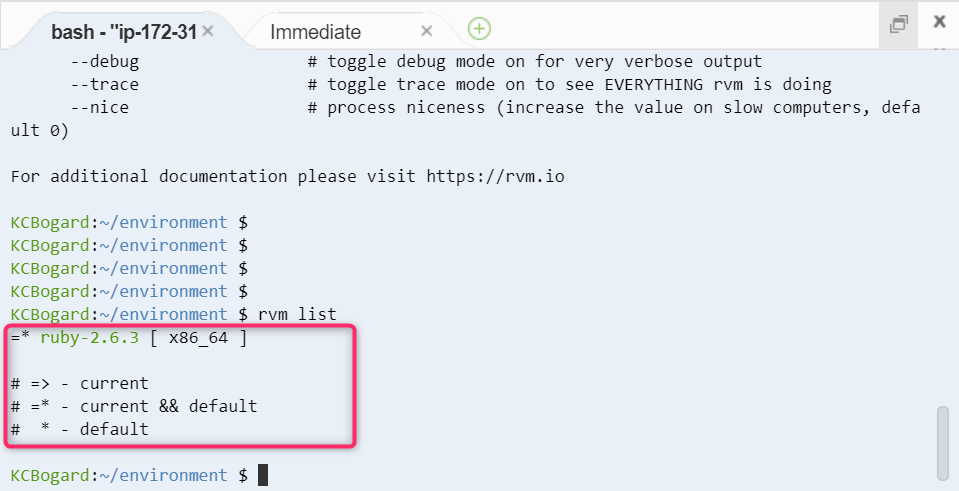
- 次にこの環境に表示されている ruby のバージョンを表示してみます。
rvm list
- 現在この環境で利用されているバージョンは 2.6.3 であると表示されています。
- 次にインストール可能なバージョンを確認します。
rvm list known
- 実行可能な Ruby のバージョンがずらっと出てきます
このように実際に環境を構築する際にはヘルプを開き、バージョンを確認しながら進めることになります。
Cloud9上に Ruby 別バージョンのインストール
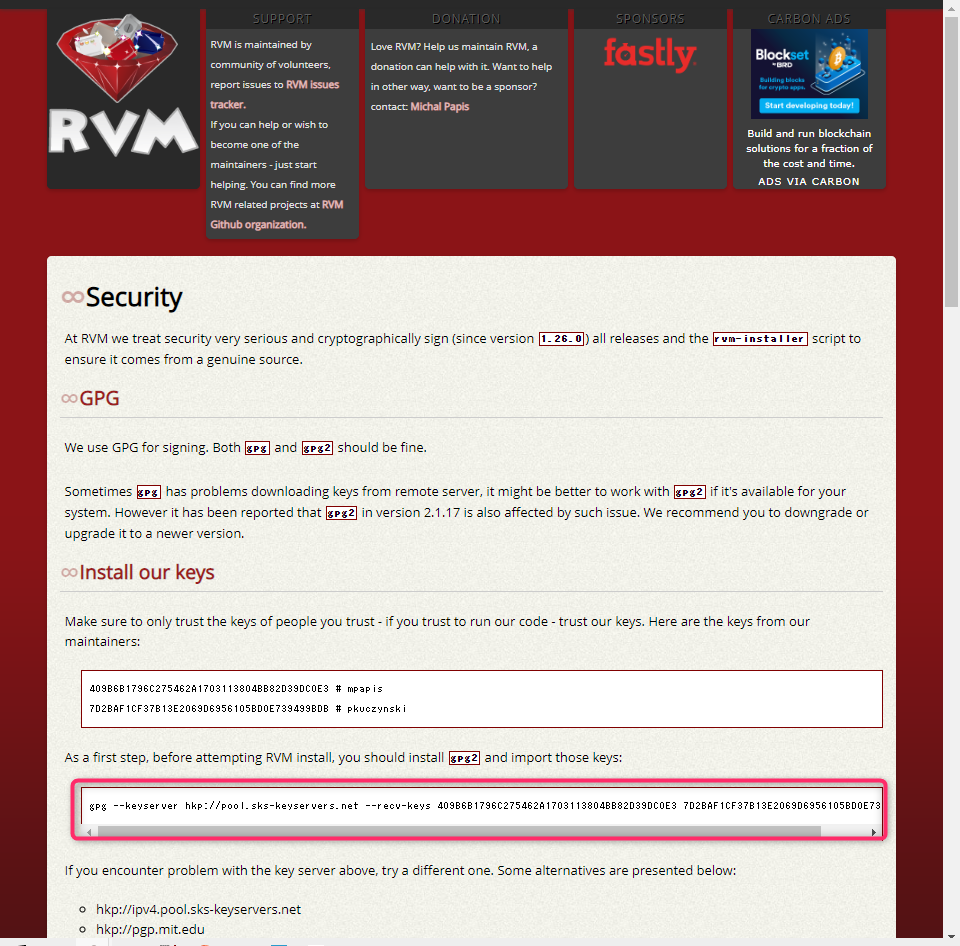
鍵のインストール
- RVMの公式サイトから以下画像の枠部分のコマンドをコピーします。
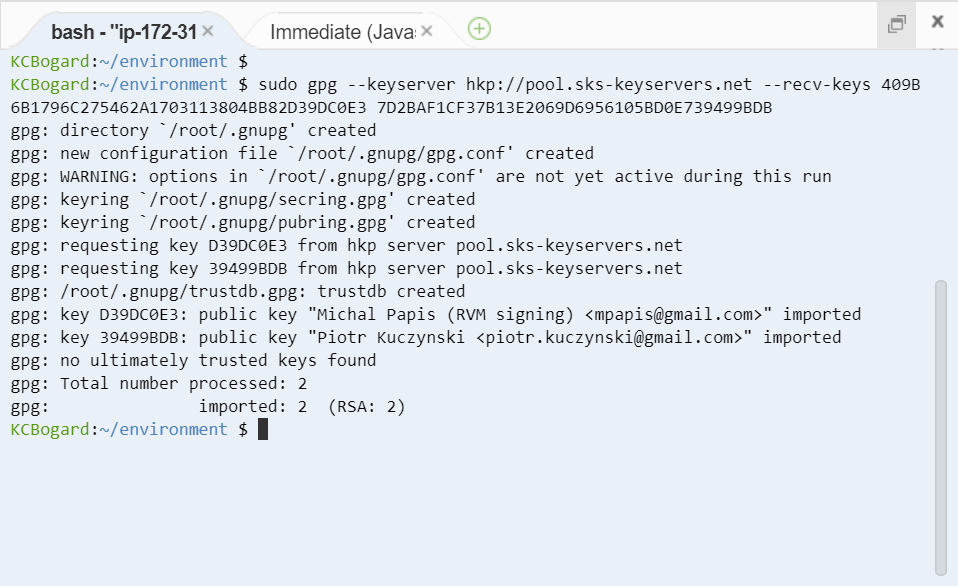
- コマンドをターミナル上で実行します。root 権限での実行が必要なため sudo 権限で実行します。
sudo gpg --keyserver hkp://pool.sks-keyservers.net --recv-keys 409B6B1796C275462A1703113804BB82D39DC0E3 7D2BAF1CF37B13E2069D6956105BD0E739499BDB
- 実行後の画面はこのようになっています。
バージョンを指定してインストールする
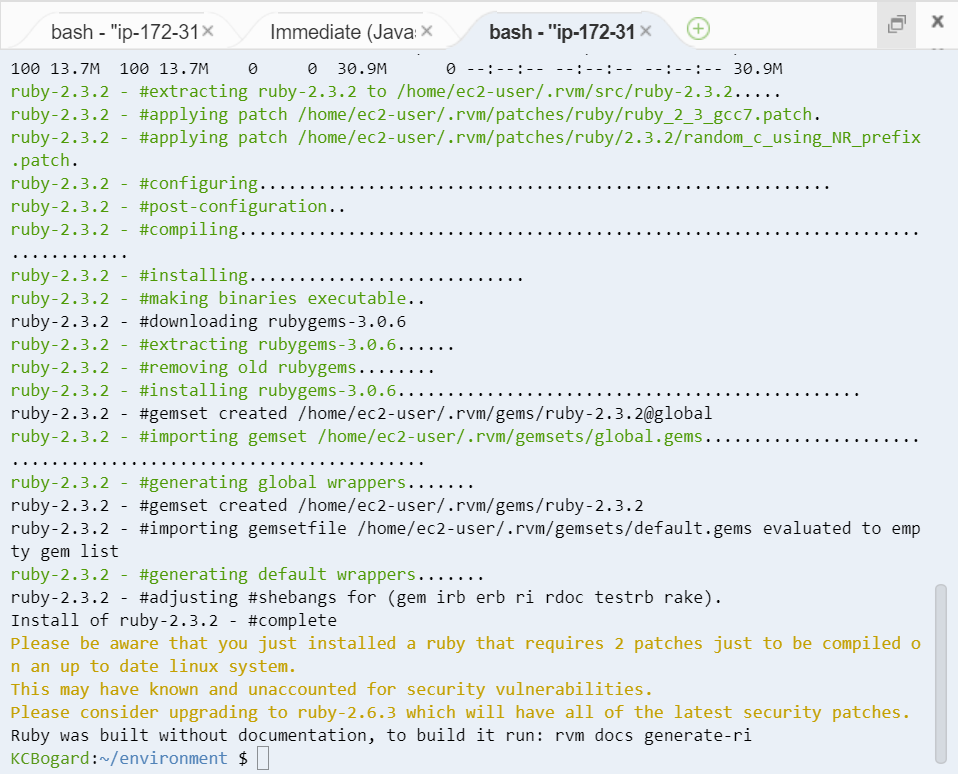
- 今回は敢えて 2.3.2 をインストールしてみます。
- 数分ほど完了までに時間がかかります。
rvm install 2.3.2
- 完了後の画面はこんな感じです。
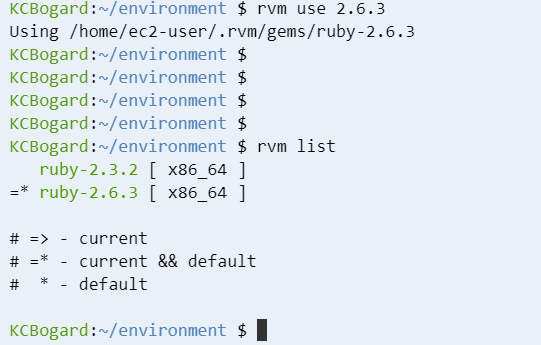
- ここで改めてインストールされているバージョンを確認します。
rvm list
- 以下のキャプチャのように言語の使用状況は言語表示の手前の記号で判断ができます。
- => 現在使用中のバージョン
- =* 現在使用中かつデフォルト設定バージョン
- * デフォルト設定されているバージョン
- 現在はインストールした 2.3.2 が使用中の設定になっています。
使用するバージョンの変更
- 以下のコマンドで使用するバージョンを変更することができます。
rvm use 2.6.2(対象バージョン)
- 実行結果と確認結果は以下のようになっています。
- ## デフォルト設定のバージョンの変更
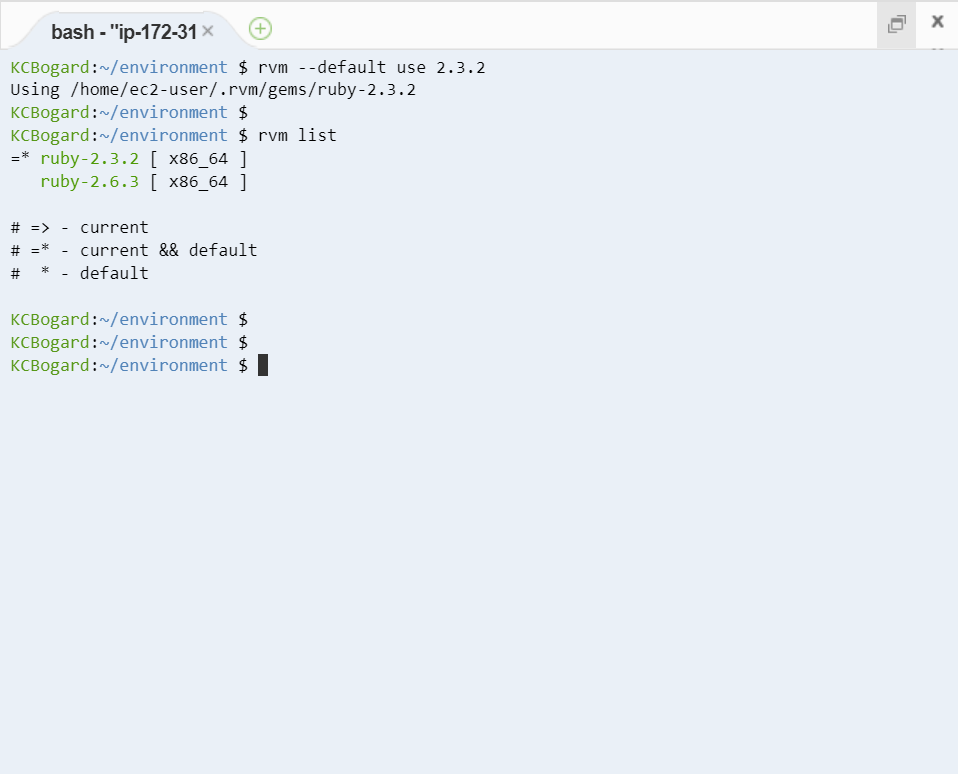
- デフォルトのバージョンは --default を追加したコマンドで変更ができます。
rvm --default use 2.3.2(対象バージョン)
インストールした特定バージョンの削除
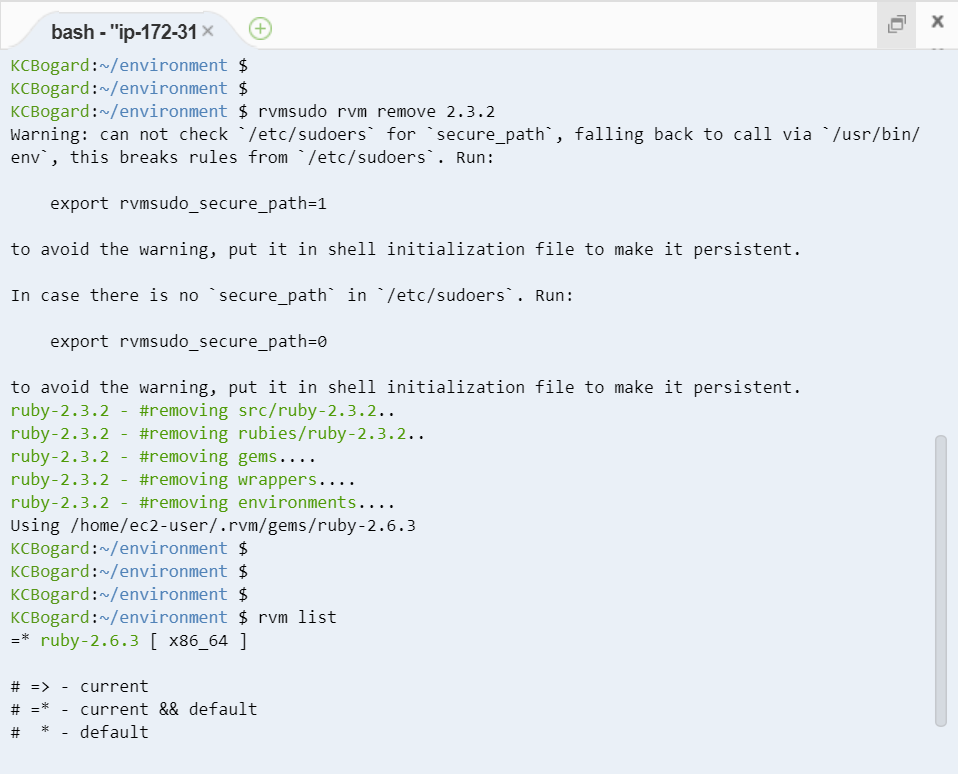
- 以下のコマンドで削除することができます。
rvmsudo rvm remove 2.3.2
- 実行結果
まとめ
上記のようにバージョン管理のソフトウェアを活用して、複数バージョンの管理を行うことが可能です。行う内容自体は他の言語でも同様のことを進めていくことになります。次回は Git 環境を AWS のサービスを利用して用意していく記事を書こうと思います。お楽しみに!
関連記事



- 投稿日:2020-01-20T01:08:47+09:00
AWS Amplify フレームワークの使い方Part6〜GraphQL Transform @auth編〜
はじめに
Amplifyでの肝の部分であるAPI(AppSync = GraphQL)のスキーマ設計の第二弾として、権限設定の
@authの解説を行っていきます。定義
公式ドキュメントに掲載されている定義には、どんな設定ができるのかが詰まっているので、要チェックです。(そして気づいたら更新されていたりするので注意!!)
この定義を使いこなすことで、より細かい権限設定が可能となります。@authについてこの記事で初めて知る方は、この定義を読むとわかりにくいので、ここはとばして次の解説から読んでもらった後にこの定義を読むことをお勧めします。directive @auth(rules: [AuthRule!]!) on OBJECT, FIELD_DEFINITION input AuthRule { allow: AuthStrategy! provider: AuthProvider ownerField: String # defaults to "owner" when using owner auth identityClaim: String # defaults to "username" when using owner auth groupClaim: String # defaults to "cognito:groups" when using Group auth groups: [String] # Required when using Static Group auth groupsField: String # defaults to "groups" when using Dynamic Group auth operations: [ModelOperation] # Required for finer control # The following arguments are deprecated. It is encouraged to use the 'operations' argument. queries: [ModelQuery] mutations: [ModelMutation] } enum AuthStrategy { owner groups private public } enum AuthProvider { apiKey iam oidc userPools } enum ModelOperation { create update delete read } # The following objects are deprecated. It is encouraged to use ModelOperations. enum ModelQuery { get list } enum ModelMutation { create update delete }allow:権限設定の対象
現状の製作中のアプリでは、ownerとgroupsを多用しています。最近(2019年中頃?)、privateとpublicが追加され、まだ利用はしていませんが、活用の幅が広がっています。
- owner
データの所有者(Cognitoの認証ユーザー)に対しての権限設定- groups
データのgroup(Cognito内のグループ)に属するユーザーとそれ以外に対しての権限設定- private
Cognitoの認証ユーザーに対しての権限設定(調査していないので、おそらく)- public
Cognitoの未認証ユーザー調に対しての権限設定。(調査していないので、おそらく)provider:認証の方法
以下の4パターンがあるようですが、現在作成中のアプリではとくに設定したことがないです。APIの初期設定時に、userPoolsでの認証をデフォルトにしているので、おそらく各@authごとに設定しなくても自動的にuserPoolsになっているものと思われます。
- apiKey:APIキー
- iam:iamユーザー
- oidc:Open ID Connect
- userPools:Cognito User Pools
ownerFiled:owner情報を入れるカラム指定
権限設定の対象をownerにした場合に宣言し、対象のレコードの所有者のid情報が入るカラムを指定します。指定しない場合は、ownerが自動で入ります。
groups:ユーザープールのグループの指定
権限設定の対象をgroupsにした場合に宣言し、ユーザープールに作成されているグループを指定します。デフォルト値はないので必ず指定が必要です。
groupsFiled:groups情報を入れるカラム指定
権限設定の対象をgroupsに設定し、かつ動的なグループ設定をしたい場合に宣言します。指定したカラムに、ユーザープールのグループを配列で書き込むことで、動的にグループに権限を付与することができます。
identityClaim:owner認証のための属性情報を指定(cognito)
ownerFiledに書き込まれたidをどのユーザープールの情報を使って認証するかを指定します。デフォルト値はusernameです。例えば、cognitoに登録したuserameが
tanakaの場合、ownerFiledに指定したカラムにtanakaの文字列が入っている時のみ、指定された権限を有することができます。groupClaim:groups認証のための情報を指定(cognito)
デフォルトは
cognito:groupsになっており、cognitoのグループを見に行くようになっています。詳しく調べていませんが、指定ができるということは、cognitoのグループ機能以外もつかうことができる、ということだと思うので、色々使える用途はありそうです。operations:対象者のCRUDの制限を指定
CRUDの権限指定である肝の部分です。若干癖があるので、ここでは簡単に概要を説明し、後ほど細かくご説明します。指定しない場合は、デフォルトでcreate、update、delete、readのすべてが指定されます。
- read:対象者のみ読み取り可能にする
- create:ownerFiledの値にログインユーザーの情報を自動入力してくれる。(groupsの場合は、対象のgroupに属する場合のみcreateが可能)
- update:対象者のみが更新可能にする
- dalate:対象者のみが削除可能にする
解説
公式ドキュメントの内容をもとに、記事情報(Post)を参考事例として、各動作を解説していきます。
所有者のみがCRUDできる
// ①シンプルバージョン type Post @model @auth(rules: [{allow: owner}]) { id: ID! title: String! } // ②詳細バージョン type Post @model @auth(rules: [{allow: owner, ownerField: "owner", operations: [read, create, update, delete]}]) { id: ID! title: String! owner: String }①と②は基本的には同じ動作になります。これだけで、所有者のみがCRUDできる権限を付与できます。create時に自動で、ownerカラムに作成者のcognitoのusernameが書き込みされ、そのuserしかread、update、deleteができません。
所有者を指定①
type Post @model @auth(rules: [{allow: owner, ownerField: "userId", operations: [read, create, update, delete]}]) { id: ID! title: String! userId: String }ownerFieldを指定することで、ownerカラムではなく、別のカラム(userId)に自動書き込みをすることができます。また、create時に、userIdに値を渡してcreateすると、自動書込ではなく、その値が書き込まれます。(用途あまりないですが、第三者に所有権をはじめから与えることができます。)
複数の所有者を指定
type Post @model @auth(rules: [{allow: owner, ownerField: "editors", operations: [read, create, update, delete]}]) { id: ID! title: String! editors: [String] }ownerFieldにlist型を指定することで、そのlistに含まれるすべてのユーザーに権限を付与することができます。
所有者のみread可能
type Post @model @auth(rules: [{allow: owner}, operations: [read] }]) { id: ID! title: String! owner: String }上記の記載方法だと、readはもちろ所有者のみですが、updateやdeleteを制限していないため、だれでもupdateとdeleteができてしまう、という歪な状況になります。
所有者のみupdateとdeleteが可能、readは誰でもOK
type Post @model @auth(rules: [{allow: owner}, operations: [create, update, delete] }]) { id: ID! title: String! owner: String }これが一番良く使うパターンの権限設定の1つです。
所有者ごとに権限を分ける
type Post @model @auth(rules: [ {allow: owner}, operations: [read, create, update, delete] }, {allow: owner, ownerField: "editors", operations: [read, update]} ]) { id: ID! title: String! owner: Stirng editors: [String] }上記の例では、owner(作成者)は自由にCRUDができますが、editors権限のユーザーはreadとupdateしかできません。
Cognitoのグループを使った権限設定
type Post @model @auth(rules: [ {allow: groups, groups: ["Admin"], operations: [read, create, update, delete]}, {allow: groups, groups: ["Viewer"], operations: [read]} ]) { id: ID! title: String! }CognitoのユーザープールでAdminグループに所属しているユーザーは、すべてのCRUD処理が行なえますが、Viewerに所属しているユーザーは、readしかできません。また、どちらにも含まれていないユーザーは、この情報には一切触れることができません。
動的なグループ設定
type Post @model @auth(rules: [ {allow: groups, groupsField: "groups", operations: [read, create, update, delete]} ]) { id: ID! title: String! groups:[String] }groupsFieldを設定することで、groupsに書き込みしたグループに所属するユーザーにCRUDの権限が付与されます。
public認証
type Post @model @auth(rules: [{allow: public}]) { id: ID! title: String! }これで未認証ユーザーでも認証なくAPIでCRUDが可能になる?らしい。APIを認証モードで設定している場合、この記述だけだと利用できないようなので、なにか追加で設定がいるものと思われます。
private認証
type Post @model @auth(rules: [{allow: private}]) { id: ID! title: String! }これで、認証ユーザー(ログイン済み)しかCRUDができないようになる?らしい。APIを認証モードで設定している場合は、おそらくこれがデフォルトになっているため、
@authを何も宣言しなくても、認証ユーザーしかCRUDができない仕様になっていると勝手に思っています。フィールドレベルの認証
type Post @model { id: ID! title: String! owner: String description: String @auth(rules: [{allow: owner}, operations: [read] }]) }こんな感じでフィールドレベルでの制限も可能です。上記の例では、descriptionのみownerしかreadすることができません。それ以外は、全ユーザーがread可能です。
レコードレベル認証✕フィールドレベル認証
type Post @model @auth(rules: [{allow: groups, groups: ["Admin"], operations: [read, create, update, delete]}]) { id: ID! title: String! owner: String description: String @auth(rules: [{allow: owner, ownerField: "owner", operations: [read}]) }これまでのレコードレベル認証とフィールドレベル認証を掛け合わすことも可能です。
上記の例では、レコードレベルではAdminグループに所属するユーザーがreadができますが、descriptionについては、ownerのみread権限に設定しているため、AdminグループのユーザーがgetPostでdescriptionを取得しようとするとエラーになります。
逆にownerが、Adminグループに所属していない場合もエラーになります。ポイント
スキーマ設計において、重要なポイントについてお伝えします。
レコードレベル認証とフィールドレベル認証
上記でも解説しましたが、レコードレベル認証とフィールドレベル認証は同時に設定することができ、かつそれぞれ複数設定することができます。
1つのテーブルでレコードレベル認証だけ、フィールドレベル認証だけを複数設定した場合は、そのどれかに当てはまればOKですが、レコードレベル認証とフィールドレベル認証が同時に存在する場合は、レコードレベル認証に当てはまるかつフィールドレベル認証にも当てはまる必要があります。// レコードレベル認証3つ R1,R2,R3 // フィールドレベル認証3つ F1,F2,F3 // 権限の適用はこんな感じ (R1 || R2 || R3) && (F1 || F2 || F3)色々と試しましたが、レコードに対しての
@authには全カラムに共通する権限を記載し、フィールドレベルの@authでより厳しく権限を制限していく形に落ち着いています。ownerのcreateとgroupsのcreate制限の違い
ownerのcreateは権限制限ではなく、指定のカラムへのidの自動書込だが、groupによるcreateはそのグループに属するものだけがcreateできる権限を持つことができる。
エラーを見る
$ amplify push後に、スキーマ設定で何かしらのミスがあればエラーが大量に出てきますが、基本的にはその1つ目のエラーが原因のテーブルの可能性が高いので、1つ目のエラー内容を確認してください。おわりに
ややボリューミーな内容になりましたが、amplifyで権限設定をしようと思うと最低でもこの記事の内容の理解は必須です。まだ深堀りできていない部分も多いので、ご存知な情報があれば是非コメントお願いします。
参考
関連記事
AWS amplify フレームワークの使い方Part1〜Auth設定編〜
AWS Amplify フレームワークの使い方Part2〜Auth実践編〜
AWS Amplify フレームワークの使い方Part3〜API設定編〜
AWS Amplify フレームワークの使い方Part4〜API実践編〜
AWS Amplify フレームワークの使い方Part5〜GraphQL Transform @model編〜