- 投稿日:2020-01-19T23:56:31+09:00
APIGateway+Lambda+ServerlessFramework(言語:Python&Golang)の色々。offlineモードとかバイナリアップロードとか
はじめに
APIGateway+Lambdaを使って、RESTfullなAPIによるPDF生成APIをデプロイメントする時に色々とハマったので、その時の備忘録を記事にしました。
基本はServerlessFrameworkを使ったデプロイメントの自動化を目指して作業をしていった内容をまとめています。
APIGatewayでメディアタイプの追加
まず、APIGatewayのバイナリレスポンス対応がどういうフローになるかを説明しておきます。
【リクエスト】
ブラウザ → (jsonリクエスト) → APIGateway → Lambda【レスポンス】
Lambda → (ファイルを文字列:Base64変換) → APIGateway → (文字列をデコード:Base64変換) → ブラウザ上記のようにLambdaからはBase64変換されたバイナリデータの文字列が返却される事が期待されています。Lambdaで返却する時の処理として、ここがまずポイントになります。
APIGatewayのバイナリサポート周辺
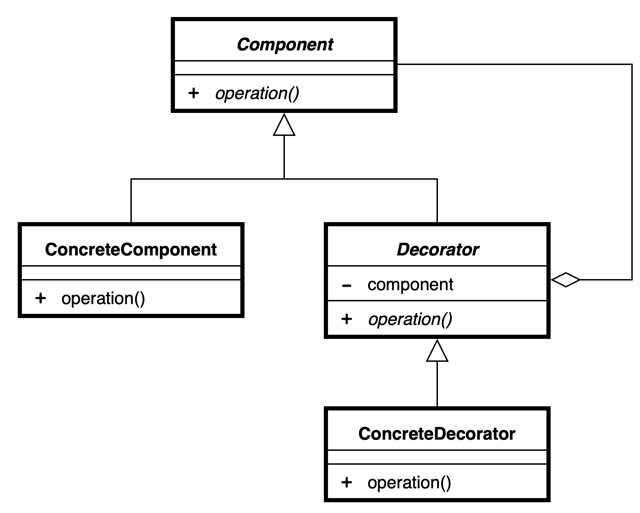
APIGatewayでPDFファイルを直接返す場合、APIGatewayでバイナリサポートを有効にする必要がある。
バイナリサポートは、GUIのAWS Consoleで言うと
まず、ここにメディアタイプを追加する必要がある。
これをServerlessFrameworkのPluginで対応させる場合は以下のPluginを使って対応可能。ちなみに、すごく紛らわしいがserverless-apigwy-binaryというPluginもある。これは後ほど説明するが、この↑バイナリメディアタイプを設定するものではないので、要注意。
統合リクエストの設定(英語名:Integration)
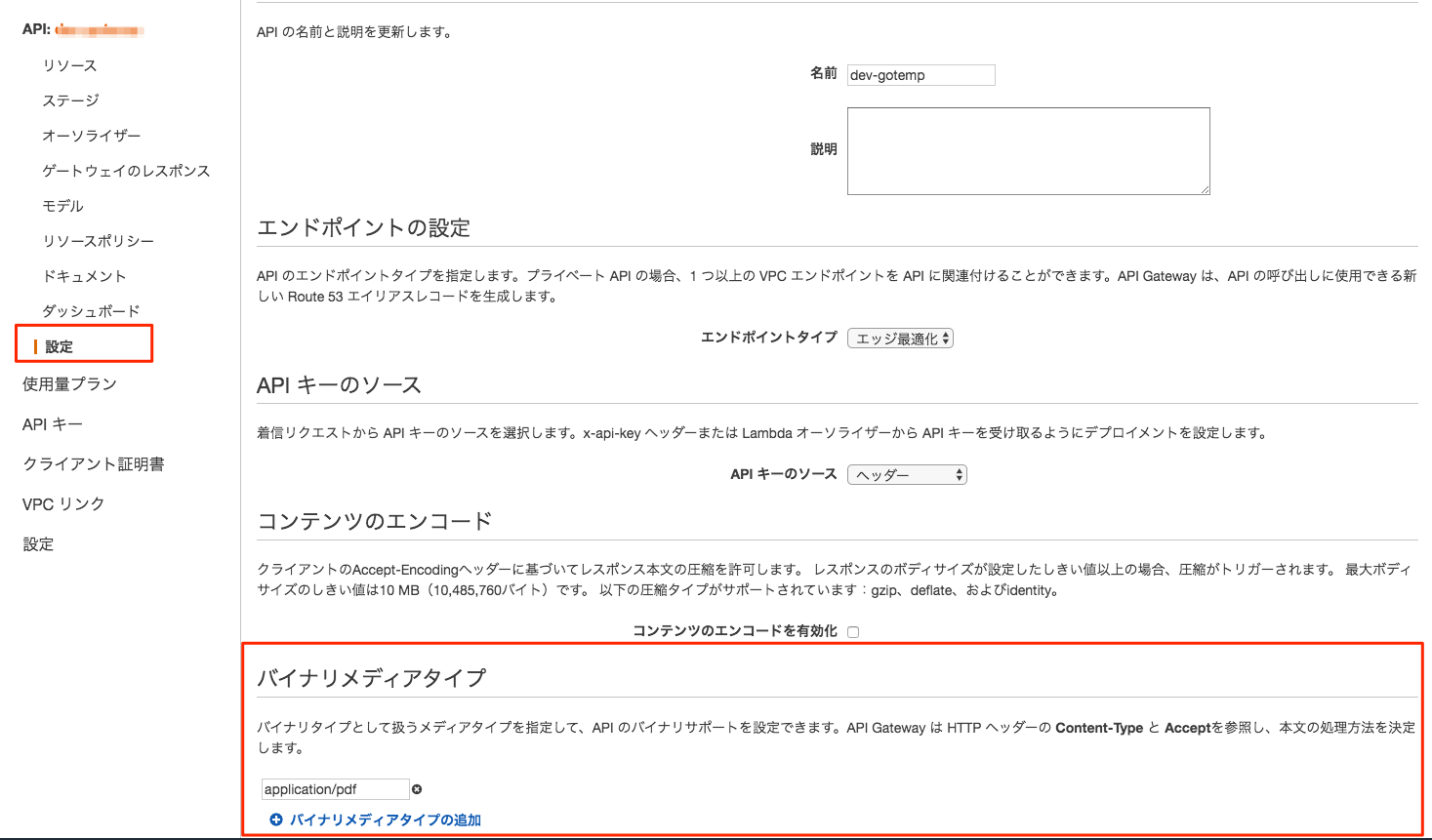
結構ハマった所。通常のServerlessFrameworkで生成されるテンプレートを使ってデプロイすると、統合リクエストは「Lambdaプロキシ統合の使用」にチェックが入った状態でデプロイされます。
ここを外すと、「統合レスポンス(英語名:IntegrationResponse)」が変更できるようになります。この時、統合リクエストのマッピングテンプレートは、マッピングテンプレートをどう使えば良いか習熟している場合は普通にそこを設定すれば良いのだろうけど、良くわからない場合は「テンプレートが定義されていない場合(推奨)」を選択しておきつつ、設定されてるマッピングテンプレートを全て削除しておくのが良いと思います。
参考リンク
- 投稿日:2020-01-19T23:25:52+09:00
約束された勝利(『趣味 × 機械学習』)
はじめに
初投稿です。
社内のLT用に拵えたネタを書き記します。
(今後も継続してアウトプットしていけるよう精進します、、)目次
- 前置き・目的
- システム全体の流れ
- 詳細
- 実践結果発表
- 結論
- TODO
1.前置き・目的
タイトル:『趣味 × 機械学習』
という大々的なタイトルなんですが、
私の趣味はパチスロです。パチスロとは
パチンコ店に設置されているスロットマシンのことで、法律では『回胴式遊技機』という名前を付けられている。
パチンコ店にあるスロットマシンだから、パチスロと呼ばれている。
パチスロには6段階(※)の設定と呼ばれるものがあり、閉店後にパチンコ店員が手作業で変えている。
※すべての機種が6段階というわけではありません。具体的な例を挙げて説明していきます。
『ゴーゴージャグラーKK(北電子様)』
(こちらの顔ならご存じの方も多いかと思います。)この台の基本スペックは以下のようになっています。
先ほど説明したように、スロットの台には設定というものがあり、
おおよそ6段階に設定されています。
そして、設定が上がっていくにつれて機械割という台のスペックも上がっていきます。この設定というものは、毎晩パチンコ屋の店員さんが手作業で変更しているものになります。
※据え置きということもあります。そこで私は考えました。
手作業で設定を入れているなら、
無意識に法則性が生まれているのでは...?
ということで、目的
パチスロのデータを収集し、機械学習を用いて法則を導いて、必ず勝利する。
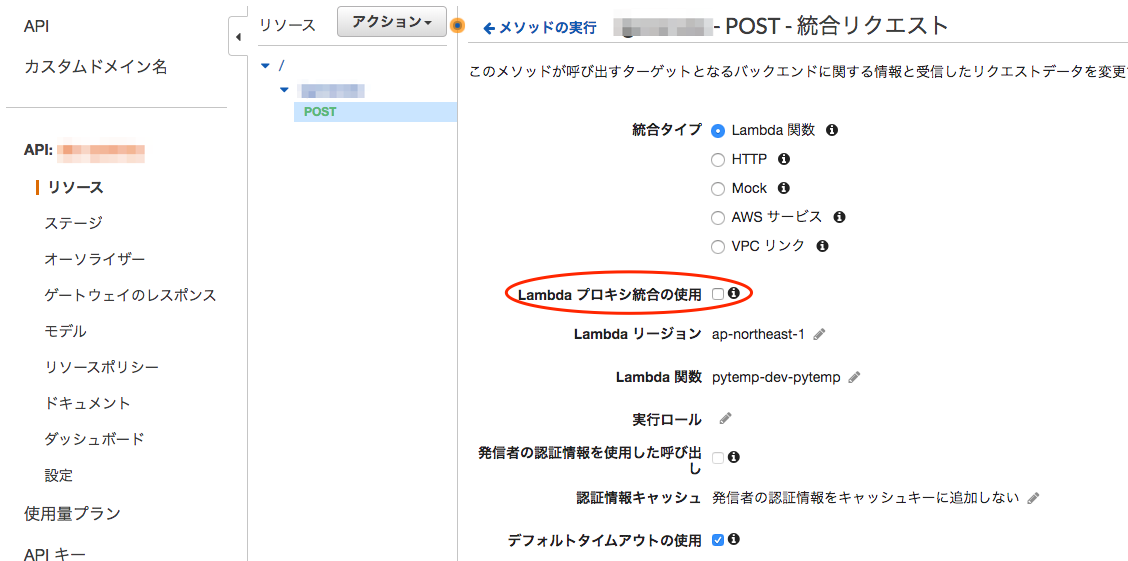
2.システム全体の流れ
今回のシステムをめちゃくちゃアバウトに説明すると以下の構図です。
それぞれ順を追って説明していきます。
3.詳細
① データ収集
本システムはPythonを用いて実装しています。
環境
Windows10 + Anaconda3使用したライブラリ
収集期間
2019/7/15 - 2019/9/14
※毎日23:20に収集実際に収集してきたデータ
年 月 日 曜日 台 台番号 BIG REG 合成確率 累計ゲーム 2019 7 16 火 ハナハナホウオウEX-30-2 1353 12 7 1/199.2 3784 2019 7 16 火 ハナハナホウオウEX-30-2 1355 12 8 1/121.9 2438 2019 7 16 火 ハナハナホウオウEX-30-2 1356 4 1 1/338.4 1692 2019 7 16 火 ハナハナホウオウEX-30-2 1357 9 9 1/176.7 3179 2019 7 16 火 ハナハナホウオウEX-30-2 1358 2 1 1/148.4 445
■ つまずきポイント
パチンコの出玉情報を見れるサイトがスマホからのアクセスのみ対応だった。
chromedriverのオプションでデバイスを指定して解決
mobile_emulation = { "deviceName": "Nexus 5" } chrome_options = webdriver.ChromeOptions() chrome_options.add_experimental_option("mobileEmulation", mobile_emulation) driver = webdriver.Chrome("C:/chromedriver.exe", desired_capabilities = chrome_options.to_capabilities()) driver.get("パチ屋のURL")② 機械学習
scikitlearnの『ランダムフォレスト』を利用。
今回はジャグラーの拡大でデータを止めて学習、
学習させたモデルから、その台がその日、設定いくつなのかを予測!!
- 目的変数:設定
- 説明変数:年月日、曜日
全然スマートじゃない前処理
# ごちゃごちゃdataframeをいじくった後に、、 # 確率から設定を推測(目的変数なのに推測値という...) tmp = line[1][8].split("/") hoge = float(tmp[0]) / float(tmp[1]) if hoge >= my_pro[5]: hoge_np = np.append(hoge_np, 5) elif hoge >= my_pro[4]: hoge_np = np.append(hoge_np, 4) elif hoge >= my_pro[3]: hoge_np = np.append(hoge_np, 3) elif hoge >= my_pro[2]: hoge_np = np.append(hoge_np, 2) elif hoge >= my_pro[1]: hoge_np = np.append(hoge_np, 1) else: hoge_np = np.append(hoge_np, 0) # ほかにもいろいろとごちゃごちゃ...いじったら学習モデルにポイ投げ
# 訓練用と評価用に分ける x_train, x_test, y_train, y_test = model_selection.train_test_split(x, y, test_size=0.2) # 学習 model = RandomForestClassifier() model.fit(x_train, y_train)③ 実践
■ 実践日
2019/10/5(土)■ ロケーション
某パチンコ屋
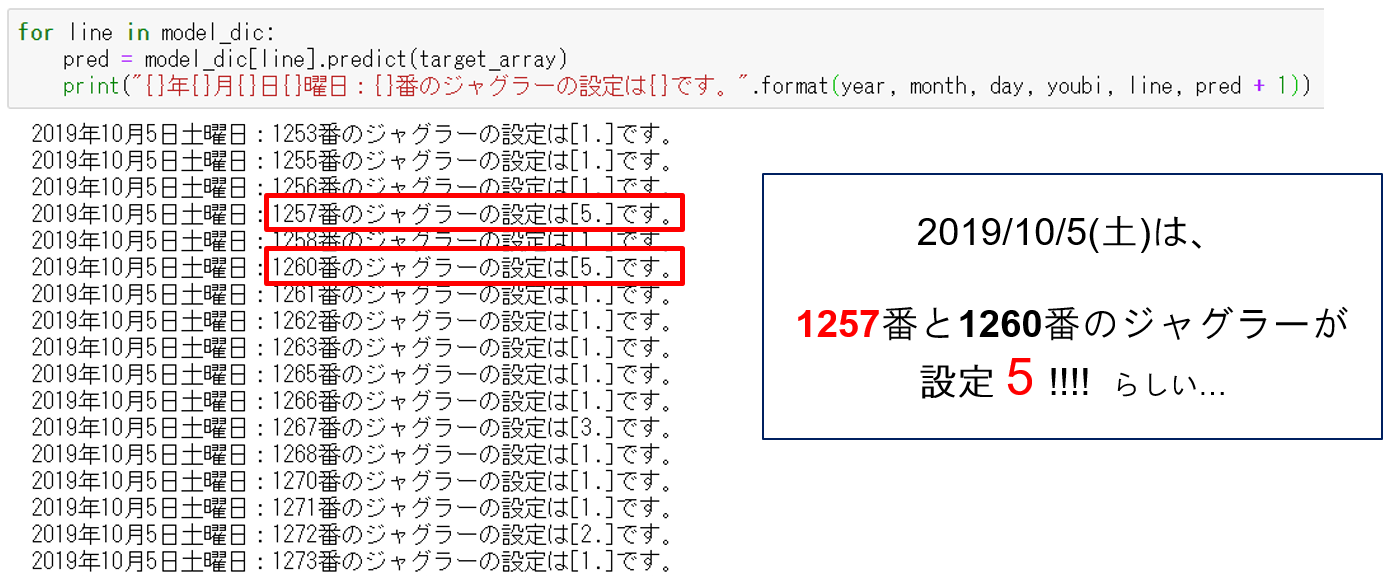
運命の予測結果は、、、こちら!!!
これは1257番のジャグラー(設定は5!!)を打てば絶対勝てる!!
ということで、
4.実践結果発表
普段打ちに行くときは諭吉を三人ほど連れて行くのですが、
今回は勝てるので、諭吉二人で実践に臨みました!!果たして結果は、、!!!
↓
はい、見事に諭吉二人を持っていかれました。
5.結論
そんなに甘くない。
6.TODO
以下反省点を踏まえ、絶対に勝てるようブラッシュアップしていきます。
目指せ億万長者!!
※次負けたら引退します。
最後までお付き合いいただきありがとうございました。
反省点
- 説明変数が尤もらしくない。
- 前日の設定や左右の台の設定は考慮すべき。
- 店の傾向を観察すべき。
- そもそもデータ数が多くない。
- というか傾向とかあるかわからない。
- 設定推測できたとしても勝てるとは限らない。(パチスロの闇)





- 投稿日:2020-01-19T23:12:40+09:00
Jupyterhubで教室を作る
Jupyterhubのことがようやく少しわかってきました。
皆様はJupyterhubという最強のPython実行環境を使っているでしょうか?
Kaggleなどもありますが自分が持っているサーバーインスタンス上でJupyterhubを動かすことができれば結構便利です。
将来的にはトレーニングなどで使えないかなと思いJupyterhubでの運用方法を模索していました。
その中で特にユーザーの作り方とユーザーがログインしたときのホームディレクトリを設定する方法がわからなかったので共有します。
まずはJupyterhubのインストール
$ pip install jupyterhubJupyterhubのデーモン化(起動しっぱなしにする)
#外部からアクセスできるようにホストも設定 $ nohup jupyterhub --ip=0.0.0.0 >> jupyterhub.log 2>&1 &CONFIGをつくる
jupyterhub_config.pyというファイルが作られます。
$ jupyterhub --generate-configユーザーのホワイトリストの設定
ホワイトリストのユーザー名しかうけつけないようにします。
jupyterhub_config.pyc.Authenticator.whitelist = {'【ユーザー名】'}ユーザーごとのホームディレクトリの設定
{username}でログインしたユーザーネームで可変になるように設定します。ユーザーごとの最上位のディレクトリを設定します。Jupyterhubではユーザーのディレクトリを作ってくれないので自分で作っておくことをお忘れなく。
jupyterhub_config.pyc.Spawner.notebook_dir = '/home/【ユーザー名】/jupyterhub/{username}'更新履歴
- 2020/01/19 新規作成
- 投稿日:2020-01-19T23:07:14+09:00
Python 3 エンジニア認定基礎試験を受験した感想
はじめに
Python 3 エンジニア認定基礎試験を受験してきましたので、簡単に感想を記録しておきます。
個人的に受験前に知りたかった情報などが書ければと思います。Python 3 エンジニア認定基礎試験とは
項目 制限時間 60分 問題数 40問 合格ライン 70%(700/1000点) 筆者について
都内にある中規模の会社に入社して2年目のSEです。
今までにシェルスクリプト、C、C#の開発を経験しました。
Pythonについては半年前までは一度も触ったことがありませんでしたが、流行の言語である(?)との情報を聞き受験に至りました。
あと、弊社では、この類いの試験に合格するとなんと会社からお小遣いがもらえます(あるあるだと思いますが)。業務では、社内で使用するツールをPythonで1ヶ月弱かけて作成したほどの経験しかありません。
学習方法
- 「Progate」で2ヶ月課金して学習。
https://prog-8.com/languages/python- 「DIVE INTO EXAM」の模擬試験を3週間ほどみっちり行う。 最終的には95%くらいの得点率まで到達しました。
https://exam.diveintocode.jp/exam- 書籍は購入しましたが、ほぼ読みませんでした。
受験当日
予約方法などは他の方が丁寧に書いてくださっているので割愛します。
以下に記載するのは私の場合であり、受験会場によって異なる場合はありますのでご了承ください。持ち物
受験票メールに記載されています。
- 受験票
印刷して持参しろとありますが、氏名を伝えれば良いのでなくても問題ありません。- 顔写真付きの身分証明書
学生の場合は学生証が必要なようです。- Odyssey ID・パスワードを控えたメモ用紙
パスワードを紙に記載するのには抵抗があったので持参しませんでした。 受験時に必要になりますが、失念した場合確認する術がないようです。 私は直前に確認して完全に記憶しました。受付
自分の場合は受付時刻が14:15~14:25でした。
遅刻をすると受験できないようですが、自分は30分前に到着したため完全に時間をもてあましました。
14:15頃に受付に行き氏名を伝えて受付完了です。携帯電話、腕時計、筆記用具は持ち込み不可です。
ロッカーに荷物をしまいますが、自分はPCとカメラを持参していたので詰め込むのに苦労しました。荷物は軽くしておきましょう。受験時
一人ずつPCが置いてある席に通されます。席に座るとOdyssey ID・パスワードを入力してログインします。
合図があると各々のタイミングで試験を開始します。
受験した方の記録を見ると15分や20分で回答が完了したとのことでしたが、私は30分ほどで見直しまで完了しました。
他の試験の受験者も含め一番最初の退出者でした。受験後
回答完了後にアンケート(8問)に回答すると結果が表示されます。
点数と合否のみでどの問題を間違えたかなどは見えないようでした。
私は800/1000点で合格でした。受験した感想
受験した経験のある先輩や、こちらの記事などを見ると「模擬試験で勉強するだけで十分だ」、「試験問題は簡単だ」とありますが、Pythonを業務で使用したことがなくコーディング時も文法をGoogle先生にいちいち聞いているような人間としては言うほど簡単ではなかった印象です。
確かに模擬試験が100%であれば合格はすると思いますが、いくらか初見の問題がありますので実際にコーディングしておくとより安心して受験できると思います。さいごに
取得した資格は「基本情報技術者試験」「応用情報技術者試験」に次ぐ3つめの資格です。多い方ではないと思います。
よく「勉強をする目的が資格取得になってしまっては意味がない」と言われることがありますが、私は「勉強をするきっかけが資格取得であっても良い」と考えています。
今回はPythonを学習するするきっかけになって良かったと思っています。基本情報や応用情報と比べたらよっぽど楽に取れました。もっと早く受験していればなと若干後悔しているほどです。
今年は「資格取得Year」にしようと思います。稚拙な文章で申し訳ありません。ご覧いただきありがとうございました。
- 投稿日:2020-01-19T23:04:00+09:00
Windows10 HomeでDockerを使うときのメモ
はじめに
普段の業務での開発環境はUbuntuなのですが、わけあって私物のwin10 Homeで開発をする機会ができたので、そのときの環境構築手順のメモです。
普段業務で散々お世話になっているので、いい機会だと思い初投稿。やりたいこと
- Pythonの開発環境を作りたいが、Anacondaは結構な頻度でハマるポイントに出会うので使いたくない
- 普段使う開発環境(Ubuntu 18.04 LTS)になるべく近付けたい
ということで、Docker入れてubuntuのコンテナをpythonのバージョン毎に個別に建てるのが何も考えずに出来てきっと楽。
pythonのライブラリはrequirement.txt作って使いまわし、python自体のバージョンはDockerfileの時点で書き換えるつもり。0. 実行時の環境
作業開始時点で環境構築に影響がありそうなのは以下くらい。
- Windows10 Home
- Git for Windows(2.18.0.windows.1)
基本的にGit bash使って作業しています。
1. Dockerのインストール
Docker for WindowsはHomeだと使えないので、Docker Toolboxをインストールする。
https://github.com/docker/toolbox/releasesから最新版のインストーラをダウンロードし実行。記事作成時は19.03.1でした。
終了後、以下の3つのアイコンがデスクトップに作成されているはずなので、一番右のDocker Quickstart Terminalを実行。
ターミナルが立ち上がって初期設定が始まるので、しばらく待つ。DockerのクジラのAAが無事出れば多分無事成功2. Docker周りの準備
無事Dockerのインストールが終了したので、ubuntuのイメージを持ってくる
$ docker pull ubuntu:18.04無事pull出来ていれば、以下のコマンドで確認できる。
$ docker images REPOSITORY TAG IMAGE ID CREATED SIZE ubuntu 18.04 ccc6e87d482b 3 days ago 64.2MB3. Python環境の準備
上記imageをベースにpythonの開発環境が整ったimageを作成するため、適当なディレクトリを作り、Dockerfileを用意。
よく使うDockerfileの中身はこんな感じ。RUNたくさん使うとレイヤーが増えて良くないとか見た気もするけど、自分で使うだけなので気にしない方針。
python3.8とかにしたい場合は、Dockerfileの中身のpythonの部分だけ書き換えれば多分問題ないです。FROM ubuntu:18.04 RUN apt update && apt upgrade -y RUN apt install vim python3.7 python3.7-distutils curl -y RUN ln -s /usr/bin/python3.7 /usr/bin/python RUN curl "https://bootstrap.pypa.io/get-pip.py" -o "get-pip.py" && python get-pip.py RUN apt autoremove上記を元にimageを作成。
# imageの作成 $ docker build -t <image name> . # 作成したimageの確認(今回はu18_py37という名前で作成) $ docker images REPOSITORY TAG IMAGE ID CREATED SIZE u18_py37 latest 86bc6cf8e1a9 7 hours ago 214MB ubuntu 18.04 ccc6e87d482b 3 days ago 64.2MB4. 実行
上記imageを使ってコンテナをたてる。
$ docker run --net host --name test -v //c/Users/<User Name>/docker:/wrk -it u18_py37 bashおわりに
とりあえず環境構築自体はこんな感じでしょうか。
ここのやり方良くない等、ご指摘あればよろしくお願いします。
作った環境で初めてwebAPI叩くコード書いたりするのですが、それはまたそのうち別記事で。

- 投稿日:2020-01-19T23:04:00+09:00
Windows10 HomeでのDockerを使ったpython環境構築手順メモ
はじめに
普段の業務での開発環境はUbuntuなのですが、わけあって私物のwin10 Homeで開発をする機会ができたので、そのときの環境構築手順のメモです。
普段業務で散々お世話になっているので、いい機会だと思い初投稿。やりたいこと
- Pythonの開発環境を作りたいが、Anacondaは結構な頻度でハマるポイントに出会うので使いたくない
- 普段使う開発環境(Ubuntu 18.04 LTS)になるべく近付けたい
ということで、Docker入れてubuntuのコンテナをpythonのバージョン毎に個別に建てるのが何も考えずに出来てきっと楽。
pythonのライブラリはrequirement.txt作って使いまわし、python自体のバージョンはDockerfileの時点で書き換えるつもり。0. 実行時の環境
作業開始時点で環境構築に影響がありそうなのは以下くらい。
- Windows10 Home
- Git for Windows(2.18.0.windows.1)
基本的にGit bash使って作業しています。
1. Dockerのインストール
Docker for WindowsはHomeだと使えないので、Docker Toolboxをインストールする。
https://github.com/docker/toolbox/releasesから最新版のインストーラをダウンロードし実行。記事作成時は19.03.1でした。
終了後、以下の3つのアイコンがデスクトップに作成されているはずなので、一番右のDocker Quickstart Terminalを実行。
ターミナルが立ち上がって初期設定が始まるので、しばらく待つ。DockerのクジラのAAが無事出れば多分無事成功2. Docker周りの準備
無事Dockerのインストールが終了したので、ubuntuのイメージを持ってくる
$ docker pull ubuntu:18.04無事pull出来ていれば、以下のコマンドで確認できる。
$ docker images REPOSITORY TAG IMAGE ID CREATED SIZE ubuntu 18.04 ccc6e87d482b 3 days ago 64.2MB3. Python環境の準備
上記imageをベースにpythonの開発環境が整ったimageを作成するため、適当なディレクトリを作り、Dockerfileを用意。
よく使うDockerfileの中身はこんな感じ。RUNたくさん使うとレイヤーが増えて良くないとか見た気もするけど、自分で使うだけなので気にしない方針。
python3.8とかにしたい場合は、Dockerfileの中身のpythonの部分だけ書き換えれば多分問題ないです。FROM ubuntu:18.04 RUN apt update && apt upgrade -y RUN apt install vim python3.7 python3.7-distutils curl -y RUN ln -s /usr/bin/python3.7 /usr/bin/python RUN curl "https://bootstrap.pypa.io/get-pip.py" -o "get-pip.py" && python get-pip.py RUN apt autoremove上記を元にimageを作成。
# imageの作成 $ docker build -t <image name> . # 作成したimageの確認(今回はu18_py37という名前で作成) $ docker images REPOSITORY TAG IMAGE ID CREATED SIZE u18_py37 latest 86bc6cf8e1a9 7 hours ago 214MB ubuntu 18.04 ccc6e87d482b 3 days ago 64.2MB4. 実行
上記imageを使ってコンテナをたてる。
$ docker run --net host --name test -v //c/Users/<User Name>/docker:/wrk -it u18_py37 bashおわりに
とりあえず環境構築自体はこんな感じでしょうか。
ここのやり方良くない等、ご指摘あればよろしくお願いします。
作った環境で初めてwebAPI叩くコード書いたりするのですが、それはまたそのうち別記事で。
- 投稿日:2020-01-19T22:43:29+09:00
Django の Twitter 認証で悩んだところ
前置き
social-auth-app-django を使う
Django で Web アプリを作っていて、ログインに Twitter 認証を使うことにしました。
social-auth-app-django を使うと簡単にできると聞いて、使うことにしました。social-auth-app-django の使い方については、Python Social Auth’s documentation という公式のドキュメントがあります。
他にも、ネットで検索すれば簡単に使い始める方法がいくつかヒットします (これとか)。この記事で扱う内容
social-auth-app-django はとても簡単に導入できるようになっているのですが、それでも導入する上で悩んだ箇所があったので、この記事では私が悩んだ部分について書きます。
※ social-auth-app-jango は Twitter 以外にも対応していますが、この記事では Twitter 認証のみ扱います。
その前に全体の手順を確認する
唐突に悩んだ箇所の話をするのも分かりにくいと思うので、ざっと導入の手順を確認しておきます。
細かい説明はしません。分かっている方は飛ばしてください。1. Twitter に API アクセス用のアプリを作る
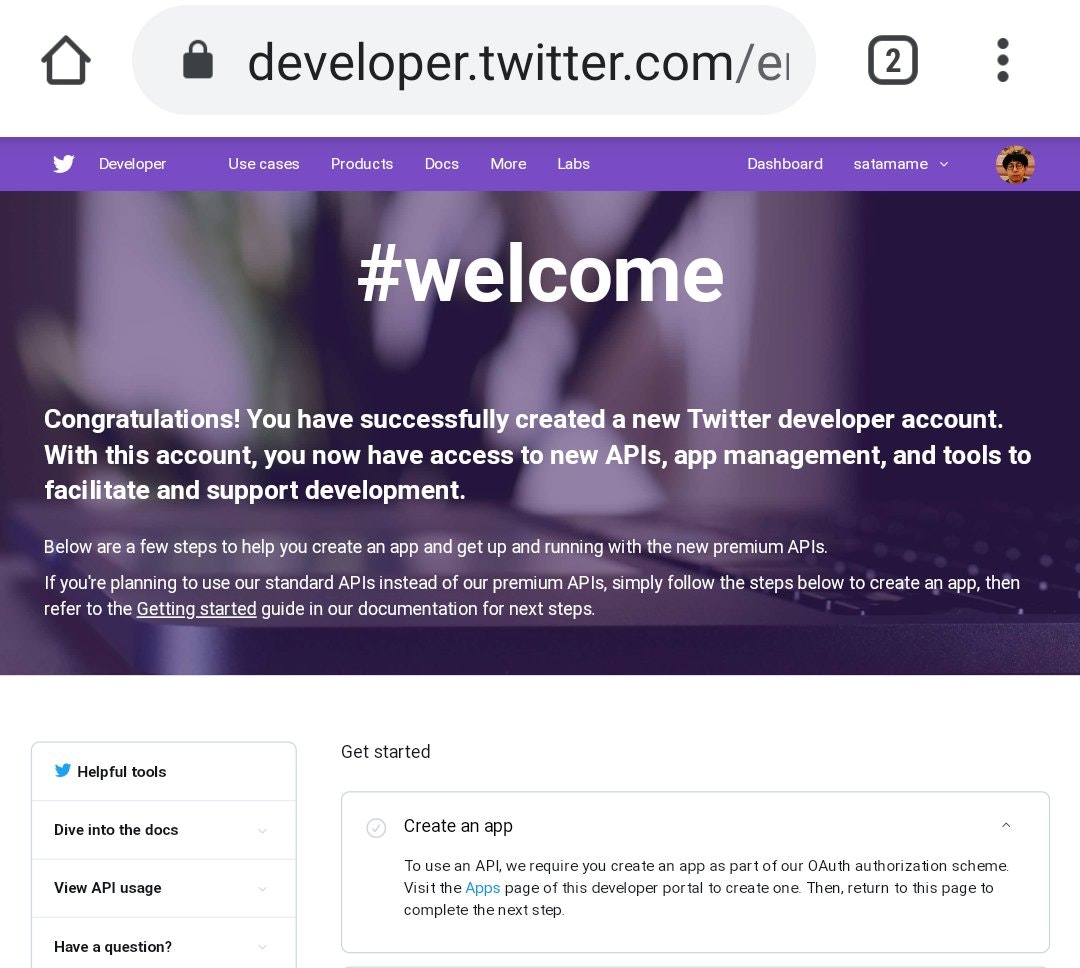
Twitter にデベロッパ登録していることが前提です。
アプリを作るのは、ダッシュボード から "Create an app" を押して、必要事項を記入するだけです。私の場合ここで、Twitter アプリが作れないという問題が発生しました。
また、Callback URLs は required (必須) ではありませんが、アプリを認証に使うには正しく設定する必要があります。
詳しくは下の方の "悩んだところ" で説明します。Twitter アプリが出来て、Callback URLs も正しく設定されたものとして、次へ進みます。
2. モジュールのインストール
pip なり pipenv で、PyPI からインストールできます。
$ pip install social-auth-app-django3. API key と API secret key
Twitter API にアクセスするのに、API key と API secret key が必要になります。
確認するには ダッシュボード から作ったアプリの Details へ進み、Keys and tokens というタブを選択します。
表示された Consumer API keys の2つのキーをコピーして使います。これらのキーは公開してはいけませんが、開発用であれば settings.py に直接書いても良いでしょう。
settings.pySOCIAL_AUTH_TWITTER_KEY = 'XXXXXXXXXXXXXXX' SOCIAL_AUTH_TWITTER_SECRET = 'YYYYYYYYYYYYYY'プロジェクトを公開している場合はリポジトリに含まない形で、ローカルとそれ以外でそれぞれ読み込めるようにします。
SECRET_KEY変数で同じことをしているはずなので問題ないでしょう。4. settings.py の編集
INSTALLED_APPSに 'social_django' を追加します。settings.pyINSTALLED_APPS = [ ... 'social_django', # 追加 ]
TEMPLATESに context_processors を追加します。settings.pyTEMPLATES = [ { ... 'OPTIONS': { 'context_processors': [ 'social_django.context_processors.backends', # 追加 'social_django.context_processors.login_redirect', # 追加 ], }, }, ]Name space と Backends を追加します。
settings.py# For social-auth-app-django SOCIAL_AUTH_URL_NAMESPACE = 'social' # 追加 AUTHENTICATION_BACKENDS = [ 'social_core.backends.twitter.TwitterOAuth', # 追加 'django.contrib.auth.backends.ModelBackend', # 追加 ]5. urls.py の編集
urlspatternsに 'social_django.urls' をインクルードします。urls.pyurlpatterns = [ ... path('', include('social_django.urls')), # 追加 path('admin/', admin.site.urls), ... ]これにより
/login/twitter/,/complete/twitter/,/disconnect/twitter/というリクエストに反応できるようになります。ちなみにドキュメントでは以下のような (古い) 書き方になっています。
url('', include('social_django.urls', namespace='social')),6. migrate
ここまで設定できたら、migrate して DB を更新します。
Twitter アカウントと Django のアカウントを関連付けるテーブルが追加されます。$ python manage.py makemigrations social_django $ python manage.py migrate7. ログインページを作る
ネットで social-auth-app-jango の使い方を紹介している記事をみると、ログインページを1から作っているページと、ログインボタンの書き方だけを説明しているページがありました。
どうするのが良いのか、ちょっとだけ悩んだので以下で説明します。
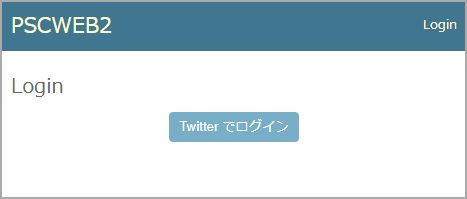
ちなみにボタンの書き方はこうです。
<button type="button" class="button" onclick="location.href='{% url 'social:begin' 'twitter' %}'"> Twitter でログイン </button>これを設置すれば、Twitter 認証ができるようになります。
悩んだところ
上記の手順の中で、私が悩んだところについて説明します。
Twitter アプリが作れない
もしかしたら、最近 Twitter のデベロッパ登録をした人は、この問題は起きないかも知れません。
私は以前からデベロッパ登録をしていて、Django のためにアプリを作ろうとしたところ、再度デベロッパ申請をするように言われました。指示どおり申請をすると、以下のページが表示されました。
これでアプリを作れるはず、と思ったのですが、必要事項を記入して注意事項も読んで、これで終わりかと思ったところでこんな画面になりました。
原因
このページ を参考に解決することができました。
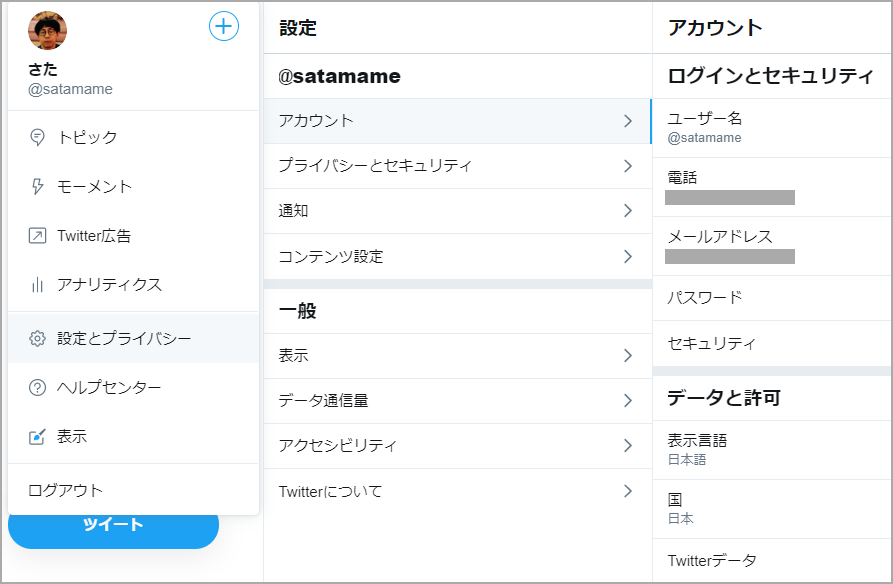
結論としては私の場合、Twitter アカウントに電話番号を設定したらアプリを作れるようになりました。
電話番号をどこから設定するのかも最初わからなかったので書いておきますと、デベロッパのダッシュボードではなく、普通に Twitter のホームから、「設定とプライバシー」>「アカウント」で設定できました。
Callback URLs
「Twitter でログイン」ボタンを設置して最初に動作確認した時、403エラーになりました。
原因は Twitter アプリ側の Callback URLs の設定でした。前置きのところで参照した こちらのページ にはちゃんと書いてあったのですが、最初は他のページを見ていたせいで、Callback URLs が間違っていました。
設定によっても変わりますので、自分の環境で urls.py を確認するのが良いでしょう。この記事の上記の手順で設定した場合は、以下の URL を設定するのが正しいようです。
- ローカルで runserver する場合
- http://127.0.0.1:8000/complete/twitter/
- Web にデプロイする場合
- サービスのルート/complete/twitter/
ログインページをどうするか
最初に参照したページではログイン/ログアウトページを1から作り、そのためのアプリ (Django プロジェクト内の app) も作っていました。
そうする必要があるのかと思いましたが、そうではありませんでした。
上の "7. ログインページを作る" で書いたボタンを、すでにあるログインページに貼るだけです。もちろん、Twitter 認証でログインするための特別なページを作りたい場合はそうすれば良いです。
私のプロジェクトではサインアップ機能もつけていないので、ログインは Twitter 認証だけにして、元々あったフォームはログインページのテンプレートから削除 (コメントアウト) してしまいました。テンプレートの書き換え
ログイン/ログアウトページのテンプレートは、たいてい 'templates/registration/' フォルダに入っていると思います。
実際にはプロジェクトによって異なりますので、そのプロジェクトで使っているテンプレートを見つけて編集します。こんな感じで、元々あったフォームを単品のボタンに置き換えてしまいました。
login.html... <div align="center"> <button type="button" class="button" onclick="location.href='{% url 'social:begin' 'twitter' %}'"> Twitter でログイン</button> </div> <!-- <div align="center"> <form method="post" action="{% url 'login' %}"> {% csrf_token %} <table> {{ form.as_table }} </table> <div> </div> <input type="submit" class="button" value="Login"/> <input type="hidden" name="next" value="{{ next }}"/> </form> </div> --> ...表示されたログインページ
元々あったフォームをコメントアウトしなければ、「Twitter でログイン」ボタンと共存させることもできます。
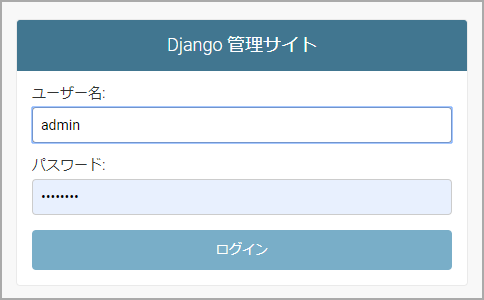
ログアウトページは変更の必要はありません。admin でログインするには
上の例ではパスワードでのログインは出来ないようにしましたが、admin でログインしたい場合は 'サービスのルート/admin/' にアクセスすれば、admin 用のログインページが開きます。
ただしログアウトページについては、たいてい共通のものを使っているので、admin でログアウトして「もう一度ログインする」というリンクを押しても「Twitter でログイン」の方へ行ってしまうと思います。
管理用のページにはアクセスし難い方が良いので、私はそのままにしています。

- 投稿日:2020-01-19T22:43:25+09:00
Python素人が走る
はじめまして。
はじめて投稿します。プログラミングは「0」からのスタートに近いです。みなさまに御指導いただきたく、恥ずかしながら記事を書いています。
Javaからスタートしたのですが、Oracleが有償になったという話をウェブにて知り、昨日からPythonに切り替えました。本を参考に型とメソッドの項から自作のプログラムを書いてみたのですが、このプログラムはありでしょうか。
number_1 = 41 number_2 = 37 buried = 'アドレスの語呂はよいみんな{}{}です。'.format(number_1,number_2) print(buried)とても不格好なプログラムであると思います。もし不備やアドバイスなどがあれば、ご連絡いただけると嬉しいです。どうぞ宜しくお願いします。
- 投稿日:2020-01-19T22:42:40+09:00
AtCoder Beginner Contest 152 参戦記
AtCoder Beginner Contest 152 参戦記
ABC152A - AC or WA
1分半で突破. 書くだけ.
N, M = map(int, input().split()) if N == M: print('Yes') else: print('No')ABC152B - Comparing Strings
2分で突破. 書くだけ.
a, b = map(int, input().split()) if a < b: print(str(a) * b) else: print(str(b) * a)ABC152C - Low Elements
5分で突破. 流石に二重ループは TLE なので、現時点の最小値を持ち回す必要あり. 題意を理解するのに少し時間を使った.
N = int(input()) P = list(map(int, input().split())) result = 0 m = P[0] for i in range(N): if P[i] <= m: result += 1 m = P[i] print(result)ABC152D - Handstand 2
26分で突破. N回ループ回しても大丈夫だと見切れればさして難しくはない. 先頭と末尾の組み合わせで個数を集計すれば一発.
N = int(input()) t = [[0] * 10 for _ in range(10)] for i in range(1, N + 1): s = str(i) t[int(s[0])][int(s[-1])] += 1 result = 0 for i in range(1, 10): for j in range(1, 10): result += t[i][j] * t[j][i] print(result)ABC152E - Flatten
敗退. 最小公倍数を求めて集計するナイーブな実装では TLE だった.
- 投稿日:2020-01-19T22:39:28+09:00
書籍「15Stepで踏破 自然言語処理アプリケーション開発入門」をやってみる - 2章Step01メモ
内容
15stepで踏破 自然言語処理アプリケーション入門 を読み進めていくにあたっての自分用のメモです。
今回は2章Step01で、自分なりのポイントをメモります。準備
- 個人用MacPC:MacOS Mojave バージョン10.14.6
- docker version:Client, Server共にバージョン19.03.2
章の概要
簡単な対話エージェントを題材にして、自然言語処理プログラミングの要素の一部を体験する。
- わかち書き
- 特徴ベクトル化
- 識別
- 評価
docker環境でのスクリプト実行方法
# 実行したいスクリプトdialogue_agent.pyが存在するディレクトリで実行 # ただし、実行に必要なcsvも同じディレクトリにあるとする # docker run -it -v $(pwd):/usr/src/app/ <dockerイメージ>:<タグ> python <実行スクリプト> $ docker run -it -v $(pwd):/usr/src/app/ 15step:latest python dialogue_agent.py01.1 対話エージェントシステム
作るべきは「文を入力すると、その文が属するクラスを予測し、クラスIDを出力するシステム」である。テキスト分類という問題設定である。
# 対話エージェントシステムの実行イメージ ~~ dialogue_agent = DialogueAgent() dialogue_agent.train(training_data) predicted_class = dialogue_agent.predict('入力文') ~~01.2 わかち書き
文を単語に分解することをわかち書きという。英語のように単語の間にスペースがある言語は不要である。
日本語におけるわかち書きを行うソフトウェアとして広く利用されているのがMeCab(めかぶ)である。
品詞情報の付与まで含んだわかち書きを形態素解析と呼ぶ。表層形のみを取得したい場合はparseToNodeを用いる。(mecab-python3は0.996.2より古いバージョンで正しく動作しないバグがあるらしい)
import MeCab tagger = MeCab.Tagger() node = tagger.parseToNode('<入力文>') # 最初と最後のnode.surfaceは空文字列となる while node: print(node.surface) node = node.next-Owakati引数を与えてMeCab.Tagger()を実行すると、コマンドラインで
$ mecab -Owakatiと実行した時のようにスペース(' ')で分割したわかち書きの結果のみを出力できる。
ただし、半角スペースを含む単語が登場した時に、区切り文字と単語の一部の半角スペースが区別できず正しくわかち書きできないのでこの実装は避けた方が良い。(辞書によっては半角スペースを含んだ単語を扱うので)01.3 特徴ベクトル化
1つの文章を(決まった長さの)1つのベクトルで表すことにより、コンピュータで計算可能な形式となる。
Bag of Words
- 単語にインデックスを割り当てる
- 文ごとに単語の登場回数を数える
- 文ごとに各単語の登場回数を並べる
下記の通り、文章を決まった長さ(ここでは長さ10)のベクトルで表す。
BagofWordsの例# 私は私のことが好きなあなたが好きです bow0 = [2, 1, 0, 2, 1, 2, 1, 1, 1, 1] # 私はラーメンが好きです bow1 = [1, 0, 1, 1, 0, 1, 1, 0, 0, 1]Bag of Wordsの実装
コード詳細は省略。
内包表記の結果を確認しておく。test_bag_of_words.pyfrom tokenizer import tokenize import pprint texts = [ '私は私が好きなあなたが好きです', '私はラーメンが好きです', '富士山は日本一高い山です' ] tokenized_texts = [tokenize(text) for text in texts] pprint.pprint(tokenized_texts) bow = [[0] * 14 for i in range(len(tokenized_texts))] pprint.pprint(bow)実行結果$ docker run -it -v $(pwd):/usr/src/app/ 15step:latest python test_bag_of_words.py [['私', 'は', '私', 'が', '好き', 'な', 'あなた', 'が', '好き', 'です'], ['私', 'は', 'ラーメン', 'が', '好き', 'です'], ['富士山', 'は', '日本一', '高い', '山', 'です']] [[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0]]Column collections.Counterの利用
Pythonの標準ライブラリであるcollectionsモジュールのCounterクラスを使うと、よりシンプルにBag of Wordsを実装できる。
途中経過を確認しておく。ベクトル化の結果は上記の「Bag of Wordsの実装」結果と同じである。
test_bag_of_words_counter_ver.pyfrom collections import Counter from tokenizer import tokenize import pprint texts = [ '私は私のことが好きなあなたが好きです', '私はラーメンが好きです', '富士山は日本一高い山です' ] tokenized_texts = [tokenize(text) for text in texts] print('# Counter(..)') print(Counter(tokenized_texts[0])) counts = [Counter(tokenized_text) for tokenized_text in tokenized_texts] print('# [Counter(..) for .. in ..]') pprint.pprint(counts) sum_counts = sum(counts, Counter()) print('# sum(.., Counter())') pprint.pprint(sum_counts) vocabulary = sum_counts.keys() print('# sum_counts.keys') print(vocabulary) print('# [[count[..] for .. in .. ] for .. in ..]') pprint.pprint([[count[word] for word in vocabulary] for count in counts])実行結果$ docker run -it -v $(pwd):/usr/src/app/ 15step:latest python test_bag_of_words_counter_ver.py # Counter(..) Counter({'私': 2, 'が': 2, '好き': 2, 'は': 1, 'の': 1, 'こと': 1, 'な': 1, 'あなた': 1, 'です': 1}) # [Counter(..) for .. in ..] [Counter({'私': 2, 'が': 2, '好き': 2, 'は': 1, 'の': 1, 'こと': 1, 'な': 1, 'あなた': 1, 'です': 1}), Counter({'私': 1, 'は': 1, 'ラーメン': 1, 'が': 1, '好き': 1, 'です': 1}), Counter({'富士山': 1, 'は': 1, '日本一': 1, '高い': 1, '山': 1, 'です': 1})] # sum(.., Counter()) Counter({'私': 3, 'は': 3, 'が': 3, '好き': 3, 'です': 3, 'の': 1, 'こと': 1, 'な': 1, 'あなた': 1, 'ラーメン': 1, '富士山': 1, '日本一': 1, '高い': 1, '山': 1}) # sum_counts.keys dict_keys(['私', 'は', 'の', 'こと', 'が', '好き', 'な', 'あなた', 'です', 'ラーメン', '富士山', '日本一', '高い', '山']) # [[count[..] for .. in .. ] for .. in ..] [[2, 1, 1, 1, 2, 2, 1, 1, 1, 0, 0, 0, 0, 0], [1, 1, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 0, 0], [0, 1, 0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 1, 1]]scikit-learnによるBoWの計算
上述のように手動で実装することもできるが、scikit-learnではBoWを計算する機能を持ったクラスとしてsklearn.feature_extraction.text.CountVectorizerが提供されているので、実装はこれを使う。
vectorizer = CountVectorizer(tokenizer = tokenize) # tokenizerにcollable(関数、メソッド)を指定して、文の分割方法を指定する vectorizer.fit(texts) # 辞書作成 bow = vectorizer.transform(texts) # BoWを計算01.4 識別器
機械学習の文脈で、特徴ベクトルを入力し、そのクラスIDを出力することを識別と呼び、それを行うオブジェクトや手法を識別器と呼ぶ。
Scikit-learnの要素をpipelineで束ねる
scikit-learnが提供する各コンポーネント(CountVectorizerやSVCなど)は、fit(),predict(),transform()など統一されたAPIを持つように設計されており、sklearn.pipeline.Pipelineでまとめることができる。
pipeline例from sklearn.pipeline import Pipeline pipeline = Pipeline([ ('vectorizer', CountVectorizer(tokenizer = tokenizer), ('classifier', SVC()), ]) # vectorizer.fit() + # vectorizer.transform() + # classifier.fit() pipeline.fit(texts, labels) # vectorizer.transform() + # classifier.predict() pipeline.predict(texts) #01.5 評価
定量的な指標で機械学習システムの性能を評価する。
対話エージェントを評価してみる
様々な指標があるが、ここではaccuracy(正解率)を見てみる。
下記の例の通り、accuracyはテストデータに対するモデルの識別結果とテストデータのラベルが合っている割合を計算する。from dialogue_agent import DialogueAgent dialogue_agent = DialogueAgent() dialogue_agent.train(<train_text>, <train_label>) predictions = dialogue_agent.predict(<test_text>) print(accuracy_score(<test_label>, predictions)) # 0.37234042...
- 投稿日:2020-01-19T22:18:44+09:00
numpyでも型ヒントチェックしたいと思った
概要
Python3.5以降のPEP484で追加された型ヒント。
numpyのndarrayにも適用できないかと思い、型ヒント静的チェックツールであるmypyや、サードパーティモジュールへの対処などwp調べた結果についてまとめる。結論
結論からいうと、mypyを用いたnumpy.ndarrayの型ヒントチェックはnumpy-stubsを用いれば可能。
ただし、現(2020年1月)時点ではndarrayのdtype, shapeを指定してのmypyチェックはできない。
一方、dtype, shapeを含めた型ヒントを可読性のためのアノテーションとしてつけたいというのであれば、nptypingを用いるという選択肢がよさそう。準備
最低限以下を
pipでインストールしておく。(カッコ内は筆者の検証時の環境)
- numpy (1.18.1)
- mypy (0.761)
mypyによる型チェック
まず型チェックとは何ぞやという状態だったので実験してみた。
# ex1.py from typing import List, Tuple def calc_center(points: List[Tuple[int, int]]) -> Tuple[float, float]: '''点のリストから重心を求める''' n = len(points) x, y = 0, 0 for p in points: x += p[0] y += p[1] return x/n, y/n points_invalid = [[1, 1], [4, 2], [3, 6], [-1, 3]] print(calc_center(points_invalid)) # TypeHint Error上記のコード、もちろん正常終了するが、mypyで型ヒントチェックしてみる。
pip等でmypyをインストールしていれば、ターミナルでmypyを実行できるはずだ。>mypy ex1.py ex1.py:16: error: Argument 1 to "calc_center" has incompatible type "List[List[int]]"; expected "List[Tuple[int, int]]" Found 1 error in 1 file (checked 1 source file) >python ex1.py (1.75, 3.0)このように、型ヒントが違反している箇所を指摘してくれる。以下のように修正するとmypyによるチェックは通る。
# ex2.py from typing import List, Tuple def calc_center(points: List[Tuple[int, int]]) -> Tuple[float, float]: '''点のリストから重心を求める''' n = len(points) x, y = 0, 0 for p in points: x += p[0] y += p[1] return x/n, y/n points = [(1, 1), (4, 2), (3, 6), (-1, 3)] print(calc_center(points)) # Success>mypy ex2.py Success: no issues found in 1 source fileサードパーティモジュールに対する型チェック
座標点の計算などはnumpyのndarrayが便利であるのでそのように変更したい。
しかし、先ほどのコードにimport numpyを追加してmypyを走らすと以下エラーが出てしまう。# ex3.py from typing import List, Tuple import numpy as np def calc_center(points: List[Tuple[int, int]]) -> Tuple[float, float]: '''点のリストから重心を求める''' n = len(points) x, y = 0, 0 for p in points: x += p[0] y += p[1] return x/n, y/n points = [(1, 1), (4, 2), (3, 6), (-1, 3)] print(calc_center(points)) # Success>mypy ex3.py ex3.py:4: error: No library stub file for module 'numpy' ex3.py:4: note: (Stub files are from https://github.com/python/typeshed) Found 1 error in 1 file (checked 1 source file)エラーの原因はnumpyパッケージ自体が型ヒントに対応してないからである。
じゃあどうすんのということで以下3つのケースで対策を分けてみる。方法1. サードパーティ製の型ヒントは無視
これが一番楽な方法で一般的なようだ。
やり方は、mypy.iniという名前でファイルを作成し、以下のように記述した後カレントディレクトリに置く。[mypy] [mypy-numpy] ignore_missing_imports = True3,4行目がnumpyに対して、型ヒントチェックのエラーを無視するような設定になる。
他のサードパーティモジュールにも適用したい場合は3,4行目をコピペし、numpyの部分を変えればよい。
その他、mypy.iniに関する仕様は公式のこちらのページを参照してほしい。これでmypyチェックを正常に走らすことができる。しかし、ndarray自体の型ヒントチェックも無視されるので注意(最後の行)。
# ex4.py (ignore_missing_imports) from typing import List, Tuple import numpy as np def calc_center(points: List[Tuple[int, int]]) -> Tuple[float, float]: '''点のリストから重心を求める''' n = len(points) x, y = 0, 0 for p in points: x += p[0] y += p[1] return x/n, y/n def calc_center_np(points: np.ndarray) -> np.ndarray: '''点のリストから重心を求める(ndarray版)''' return np.average(points, axis=0) points = [(1, 1), (4, 2), (3, 6), (-1, 3)] print(calc_center(points)) # Success np_points = np.array(points, dtype=np.int) print(calc_center_np(np_points)) # Success print(calc_center_np(points)) # Success ?>mypy ex4.py Success: no issues found in 1 source file方法2. 型ヒント用スタブを作成
使いたいモジュールの型ヒント用の空っぽの関数(スタブ)を作成することで、mypyが代わりにそれらを見てくれる。スタブファイルは.pyiという拡張子で管理されている。
githubにnumpy用のスタブnumpy-stubsが公開されていて利用できる。
まず
git clone https://github.com/numpy/numpy-stubs.git等で"numpy-stubs"フォルダを持ってくる。
"numpy-stubs"フォルダを"numpy"に変更する。フォルダ構成としては以下のようになる。
numpy-stubs/ └── numpy ├── __init__.pyi └── core ├── numeric.pyi ├── numerictypes.pyi ├── _internal.pyi └── __init__.pyiさらに、
MYPYPATHという環境変数にスタブが置かれているルートフォルダパスを追加して実行する。# ex5.py (numpy-stubs) from typing import List, Tuple import numpy as np def calc_center(points: List[Tuple[int, int]]) -> Tuple[float, float]: '''点のリストから重心を求める''' n = len(points) x, y = 0, 0 for p in points: x += p[0] y += p[1] return x/n, y/n def calc_center_np(points: np.ndarray) -> np.ndarray: '''点のリストから重心を求める(ndarray版)''' return np.average(points, axis=0) points = [(1, 1), (4, 2), (3, 6), (-1, 3)] print(calc_center(points)) # Success np_points = np.array(points, dtype=np.int) np_points_float = np.array(points, dtype=np.float) print(calc_center_np(np_points)) # Success print(calc_center_np(np_points_float)) # Success print(calc_center_np(points)) # TypeHint Error>set "MYPYPATH=numpy-stubs" >mypy ex5.py ex5.py:28: error: Argument 1 to "calc_center_np" has incompatible type "List[Tuple[int, int]]"; expected "ndarray" Found 1 error in 1 file (checked 1 source file)これで、ndarray自体の型ヒントチェックが機能する。しかし、dtype, shapeの指定した上でのチェックはできない、また、いちいち環境変数を設定しなくてはいけないのが若干ネックである。
stubgen
mypyにはstubgenというスクリプトがついており、自動的に型ヒント用のファイル(.pyi拡張子)を生成してくれる。
>stubgen -p numpy
-pはパッケージ用に再帰的にスタブを生成するオプションである。
実行するとカレントディレクトリにoutフォルダが生成されておりその中にnumpyのスタブファイルが詰まっている。しかし、stubgenがうまくnumpyの構造を抽出できてないせいか、mypyチェックを実行すると別のエラーが出てしまう。numpy-stubsのようにスタブが有志で公開されてるケースもあるので、できればそちらを使う方が無難である。
方法3. nptypingも使う
方法1., 方法2.のどちらかを取ったうえで、ndarrayのdtype, shapeを含めた型ヒントを組みたいというのであれば、nptypingを用いるとよい。
PyPiから
pip install nptypingでインストールできる。nptypingはmypyによる静的な型ヒントチェックには対応していないものの、ndarrayのdtype, shapeを指定した型ヒントを
Arrayというエイリアスを用いて指定できる。以下は公式のサンプル。pandasのDataFrameのような型が入り混じった配列もOK。
from nptyping import Array Array[str, 3, 2] # 3 rows and 2 columns Array[str, 3] # 3 rows and an undefined number of columns Array[str, 3, ...] # 3 rows and an undefined number of columns Array[str, ..., 2] # an undefined number of rows and 2 columns Array[int, float, str] # int, float and str on columns 1, 2 and 3 resp. Array[int, float, str, ...] # int, float and str on columns 1, 2 and 3 resp. Array[int, float, str, 3] # int, float and str on columns 1, 2 and 3 resp. and with 3 rows
isinstanceを用いたインスタンスチェックも可能である。# ex6.py (nptyping) from typing import List, Tuple import numpy as np from nptyping import Array def calc_center(points: List[Tuple[int, int]]) -> Tuple[float, float]: '''点のリストから重心を求める''' n = len(points) x, y = 0, 0 for p in points: x += p[0] y += p[1] return x/n, y/n def calc_center_np(points: Array[int, ..., 2]) -> Array[float, 2]: '''点のリストから重心を求める(ndarray版)''' print(isinstance(points, Array[int, ..., 2])) return np.average(points, axis=0) points = [(1, 1), (4, 2), (3, 6), (-1, 3)] np_points = np.array(points, dtype=np.int) np_points_float = np.array(points, dtype=np.float) print(isinstance(calc_center_np(np_points), Array[float, 2])) # 引数: True, 戻り値: True print(isinstance(calc_center_np(np_points_float), Array[float, 2])) # 引数: False, 戻り値: True print(isinstance(calc_center_np(points), Array[float, 2])) # 引数: False, 戻り値: Truemypy.iniでnptypingを
ignore_missing_imports = Trueに設定するのを忘れずに。
実行結果は以下。>mypy ex6.py Success: no issues found in 1 source file >python ex6.py True True False True False Trueまとめ
numpyまわりの型ヒントについてざっくりまとめた。
座標・表データなどの情報をndarrayとして扱い、幾何的・統計的な演算を実装することはよくあると思う。
その際に「何次元のndarrayをこねくり回してるのか?」などと自分が書いたコードでもよく悩んだりする。
可読性や保守性も踏まえてnptypingのような型ヒントは有用だと思った。
将来的にmypyによる型チェックにも対応できるとより有用性が高まるのではないかと思う。参考記事
https://stackoverflow.com/questions/52839427/
https://www.sambaiz.net/article/188/
https://masahito.hatenablog.com/entry/2017/01/08/113343
- 投稿日:2020-01-19T22:13:19+09:00
67日目 【Kaggle入門】ランダムフォレストを使ってみたが?
KaggleのTitanic予想。前回は
全員生存モデルとGender Based Model(男性死亡・女性生存)を作りました。66日目 【Kaggle入門】一番カンタンなTitanic予想今回は機械学習ということで、ランダムフォレストを使ってみました。
元ネタはこちら。KaggleのNotebookで一番人気のレシピです。Titanic Data Science Solutions書いてあるのが英語なので、とりあえず上から下までざーっと眺めます。
結論、ランダムフォレストが一番使いやすかったようです。さっそく前回の
Gender Based Modelを元に実行してみました。
train.csvとtest.csvからデータを切り出します。この辺は前回といっしょ。
11.pyimport pandas as pd # pandasでCSVを読み込む train_df = pd.read_csv('train.csv') test_df = pd.read_csv('test.csv') #性別を男0女1に変換 train_df.replace({'Sex': {'male': 0, 'female': 1}}, inplace=True) test_df.replace({'Sex': {'male': 0, 'female': 1}}, inplace=True) #Dataframeを作る train_df = train_df.loc[:,['PassengerId','Survived','Sex']] test_df = test_df.loc[:,['PassengerId','Sex']]訓練用データから予測モデルを作ります。
・訓練用データ
train.csvを説明変数(x)と目的変数(y)に縦割りします。
・さらに擬似訓練データ(X_train, y_train)と擬似テストデータ((X_valid, y_valid)に横割りします。12.py#ベースラインモデルの構築 #データ分割のモジュールをインポート from sklearn.model_selection import train_test_split #訓練用データを元データから切り出して、.valuesでnumpy.ndarray型に変換する X = train_df.iloc[:, 2:].values #原因となる要素群 y = train_df.iloc[:, 1].values #結果 #テストデータ X_test = test_df.iloc[:, 1:].values #原因となる要素群 #訓練用データを分割して予測モデルを作る #データの分割には、scikit-learnのtrain_test_split関数を使用 #分割をランダムにするシード値を42にする(銀河ヒッチハイクガイドによる) X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.3, random_state=42)擬似訓練データで学習させ、予測モデルをつくります。
予測モデルで擬似テストデータを予測します。
結果のスコアが近いほどいい予測モデルとされています。
訓練データのスコアが良すぎる過学習や、低すぎる学習不足の場合は予測モデルを見直します。13.py#ランダムフォレストで予測モデルを作成する from sklearn.ensemble import RandomForestClassifier #擬似訓練データを学習し予測モデルを作成する。 rfc = RandomForestClassifier(n_estimators=100) rfc.fit(X_train, y_train) #擬似訓練データX_train, y_train)のスコアを見る print('Train Score: {}'.format(round(rfc.score(X_train, y_train), 3))) #擬似テストデータ(X_valid, y_valid)のスコアを見る print(' Test Score: {}'.format(round(rfc.score(X_valid, y_valid), 3)))擬似訓練スコアと擬似テストスコアを確認します。
Train Score: 0.785
Test Score: 0.791今回の結果は・・・いいんでしょうか、どうなんでしょうか。人間が学習不足ですね。
まあともかくモデルができたし予測してみましょう。作成した予測モデルでテストデータを予測します。
14.py#作成した予測モデル( rfc.predict)でテストデータ(X_test)を予測する y_pred = rfc.predict(X_test) #結果をPandasデータフレームに変換する。 submission = pd.DataFrame({ "PassengerId": test_df["PassengerId"], "Survived": y_pred }) #CSVに出力する。 submission.to_csv('titanic1-2.csv', index=False)完成!
さっそくKaggleにアップします。
Public Score:0.76555???
これは前回の男性死亡女性生存モデルと同じ結果です。
CSVファイルを確認すると確かにまったく同一でした。
元データのtrain.csvを見ると、女性の生存率は75%、男性は18%なので、ある程度は異なる予測がでると思っていたので以外でした。予測モデルは890件のtrain.csvを7:3分けにした600件余りのデータを元にしました。予測に十分な数に足りていないのかもしれません。あるいは、ランダムフォレストはあいまいな予測が苦手なのかもしれませんし、もしかしたらどこかでコーディングを間違っているのかもしれません。
この辺、ちょっとよくわからないので保留にします。
- 投稿日:2020-01-19T22:07:10+09:00
例外の復習
1l = [1, 2, 3] i = 5 print('start') try: l[0] except IndexError as ex: print('そのインデックスはありません。{}'.format(ex)) except NameError as ex: print('定義されていません。{}'.format(ex)) except Exception as ex: print('other: {}'.format(ex)) else: print("正常に処理されました。") finally: print("end")1の実行結果start 正常に処理されました。 endどのエラーも発生しないので、
elseブロックとfinallyブロックが実行された。2l = [1, 2, 3] i = 5 print('start') try: l[i] except IndexError as ex: print('そのインデックスはありません。{}'.format(ex)) except NameError as ex: print('定義されていません。{}'.format(ex)) except Exception as ex: print('other: {}'.format(ex)) else: print("正常に処理されました。") finally: print("end")2の実行結果start そのインデックスはありません。list index out of range endインデックスが2までしかないのに、
インデックス5を指定し、
IndexErrorが発生する。
なので、
except IndexError as exのブロックとfinallyブロックが実行された。3l = [1, 2, 3] i = 5 del l print('start') try: l[0] except IndexError as ex: print('そのインデックスはありません。{}'.format(ex)) except NameError as ex: print('定義されていません。{}'.format(ex)) except Exception as ex: print('other: {}'.format(ex)) else: print("正常に処理されました。") finally: print("end")3の実行結果start 定義されていません。name 'l' is not defined enddel lでlがなくなったので、
NameErrorが発生する。
なので、
except NameError as exのブロックとfinallyブロックが実行された。4l = [1, 2, 3] i = 5 print('start') try: l + () except IndexError as ex: print('そのインデックスはありません。{}'.format(ex)) except NameError as ex: print('定義されていません。{}'.format(ex)) except Exception as ex: print('other: {}'.format(ex)) else: print("正常に処理されました。") finally: print("end")4の実行結果start other: can only concatenate list (not "tuple") to list endリストとタプルを足し算するので、
IndexErrorでもNameErrorでもないエラーが発生する。
なので、
except Exception as exのブロックとfinallyブロックが実行された。
- 投稿日:2020-01-19T22:02:33+09:00
deeplearningで柴犬の写真からうちの子かどうか判定(4) Grad-CAMとGuided Grad-CAMによる可視化
はじめに
- こちらは私自身の機械学習やディープラーニングの勉強記録のアウトプットです。
- これまでdeeplearningで柴犬の写真からうちの子かどうか判定(1)とdeeplearningで柴犬の写真からうちの子かどうか判定(2)データ増量・転移学習・ファインチューニングとdeeplearningで柴犬の写真からうちの子かどうか判定(3)Grad-CAMによる可視化に引き続き、Google Colaboratoryで deep learningの分析結果の重みを、別のアプローチでも可視化します。
- 様々なエラーでつまずいた箇所などもなるべく記述し、なるべく誰でも再現がしやすいように記載します。
この記事の対象者・参考にした記事
- 対象者:以前と同じです。詳細はこちら。
- 参考にした記事
○日本一詳しくGrad-CAMとGuided Grad-CAMのソースコードを解説してみる(Keras実装)私について
- 現職は事務職。2019年9月にJDLA Deep Learning for Engeneer 2019#2を取得。
- 2020年4月からデータサイエンスの仕事にジョブチェンジをしたいと考え、転職活動を開始しました。 詳細はこちら。
前回(3)の分析の概要
- Grad-CAMを実装し、柴犬の写真の分類の根拠となっている特徴についてヒートマップを作成しました。
今回(4)の手順概要
手順1 前準備
手順2 Grad-CAMとGuided Grad-CAMの実装に必要な関数の登録
手順3 Grad-CAMのメイン処理の実装
手順4 Guided Grad-CAMのメイン処理の実装
※今回使用するGrad-CAMのコードは前回(3)で実装したものとは異なるものです。
- @kinziroさんのこちらの記事(日本一詳しくGrad-CAMとGuided Grad-CAMのソースコードを解説してみる (Keras実装)))でGuided Grad-CAMの実装が紹介されていました。こちらがgithub.comです。
- この記事で紹介されていたコードを、とにかくまず動かすことを目的に実装します。引き続き柴犬の写真データを使用して、Grad-CAMによる可視化、そしてGuided Grad-CAMによる可視化を行いたいと思います。両者の表示結果を比較して、特徴の表現の仕方についてさらに観察を深めます。
- 以下の実装は、基本的に参考にした記事のコードをそのまま書いていきます。また、以前の分析(2)でセットアップしたGoogle Driveのデータをそのまま使用します。
手順1 前準備
(1) Google Driveのマウント
柴犬の画像が入っているフォルダからColabにデータが読み込めるよう、マウントします。
# Google Driveマウント from google.colab import drive drive.mount('/content/drive')(2) 必要なライブラリをインポートします
次のコードでインポート。
# ライブラリのインポート from __future__ import print_function import keras from keras.applications import VGG16 from keras.models import Sequential, load_model, model_from_json from keras import models, optimizers, layers from keras.optimizers import SGD from keras.layers import Dense, Dropout, Activation, Flatten from sklearn.model_selection import train_test_split from PIL import Image from keras.preprocessing import image as images from keras.preprocessing.image import array_to_img, img_to_array, load_img from keras import backend as K import os import numpy as np import glob import pandas as pd import cv2(3) kerasのバージョンチェック
インポートしたkerasのバージョンを確認してみます(この記事を書いている2020/1/19現在では)このバージョンになっています)
print(keras.__version__) 2.2.5ここで注意すべき点があります。元記事についたコメントに気になる内容が書き込まれていましたが、kerasのバージョンが2.2.4以下でないと、ソースコートを実行した際にエラーが発生するらしいのです。試しにやってみると、一連のソースコード実行した一番最後の一行で次のようなエラー表示が出ました。やはりkerasのバージョンを下げてから実行しないといけないようです。
AttributeError: module 'keras.backend' has no attribute 'image_dim_ordering'(4) kerasのバージョンを下げます
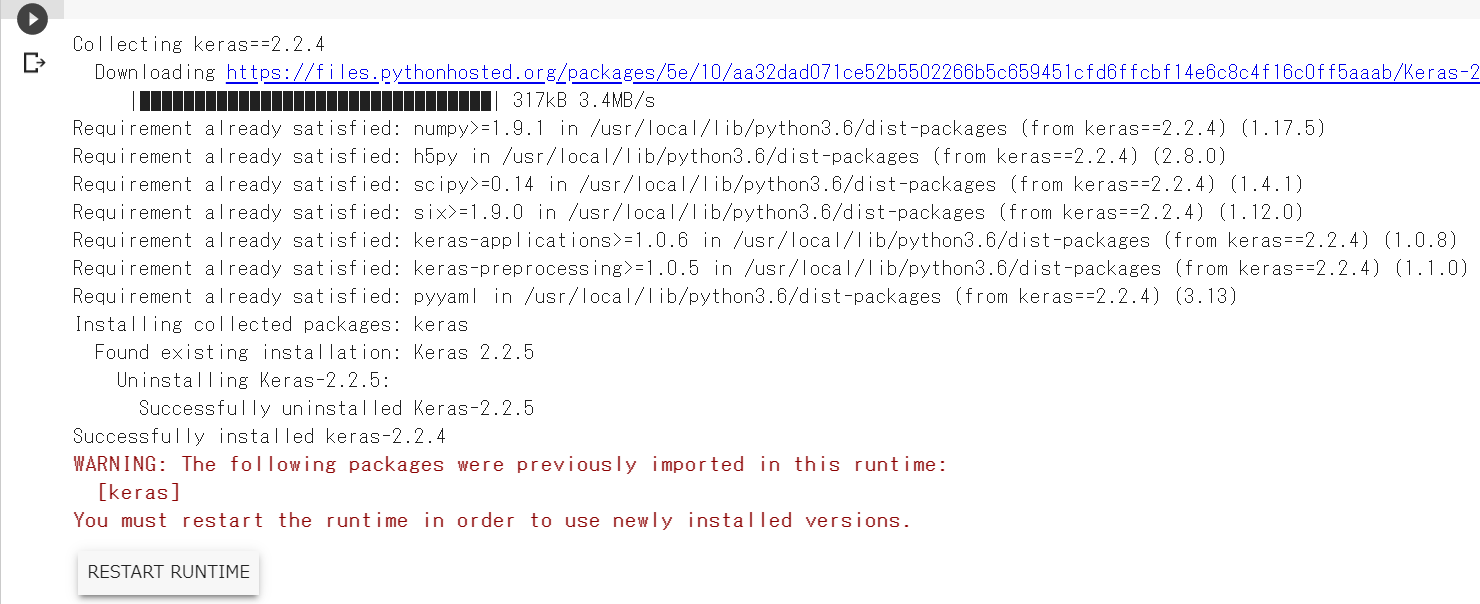
次のコードを実行します。
# kerasを特定のバージョン(2.2.4)へ変更する # 実行後にランタイムの再起動が必要 !pip install keras==2.2.4実行すると、次のような画面が出てライブラリが指定したバージョンに変更されます。が、茶色のテキストで警告表示が出ているとおり、この変更を有効にするにはランタイムの再起動が必要です。
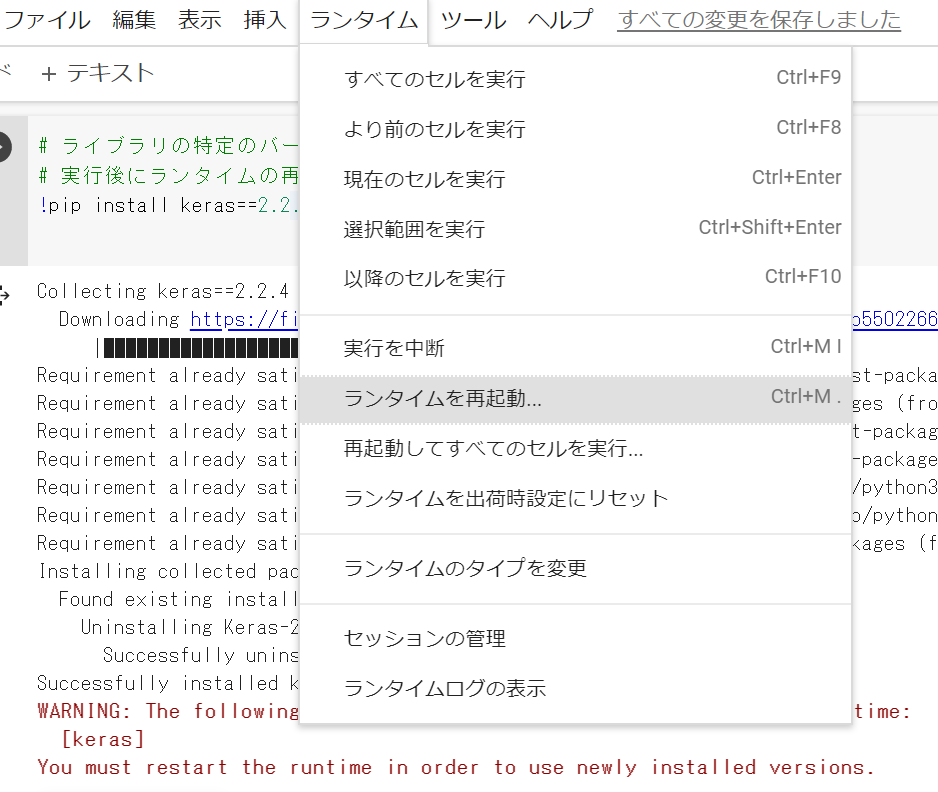
ランタイムの再起動はメニューバーの「ランタイム」から「ランタイムを再起動」をクリックします。
(5) 手順1の(1)~(3)までを再試行
ランタイムの再起動後に、手順1のこれまでのステップを再度すべて実行して、kerasのバージョンが2.2.4になっていることを確認します。
print(keras.__version__) 2.2.4手順2 Grad-CAMとGuided Grad-CAMの実装に必要な関数の登録
(1) 元記事に掲載されていた関数の定義コードを実行
以下のコードをすべて実行します。
def target_category_loss(x, category_index, nb_classes): return tf.multiply(x, K.one_hot([category_index], nb_classes)) def target_category_loss_output_shape(input_shape): return input_shape def normalize(x): # utility function to normalize a tensor by its L2 norm return x / (K.sqrt(K.mean(K.square(x))) + 1e-5) def load_image(path): #img_path = sys.argv[1] img_path = path # 引数で指定した画像ファイルを読み込む # サイズはVGG16のデフォルトである224x224にリサイズされる img = image.load_img(img_path, target_size=(224, 224)) # 読み込んだPIL形式の画像をarrayに変換 x = image.img_to_array(img) # 3次元テンソル(rows, cols, channels) を # 4次元テンソル (samples, rows, cols, channels) に変換 # 入力画像は1枚なのでsamples=1でよい x = np.expand_dims(x, axis=0) x = preprocess_input(x) return x def register_gradient(): # GuidedBackPropが登録されていなければ登録 if "GuidedBackProp" not in ops._gradient_registry._registry: # 自作勾配を登録するデコレーター # 今回は_GuidedBackProp関数を"GuidedBackProp"として登録 @ops.RegisterGradient("GuidedBackProp") def _GuidedBackProp(op, grad): '''逆伝搬してきた勾配のうち、順伝搬/逆伝搬の値がマイナスのセルのみ0にして逆伝搬する''' dtype = op.inputs[0].dtype # grad : 逆伝搬してきた勾配 # tf.cast(grad > 0., dtype) : gradが0以上のセルは1, 0以下のセルは0の行列 # tf.cast(op.inputs[0] > 0., dtype) : 入力のが0以上のセルは1, 0以下のセルは0の行列 return grad * tf.cast(grad > 0., dtype) * \ tf.cast(op.inputs[0] > 0., dtype) def compile_saliency_function(model, activation_layer='block5_conv3'): '''指定レイヤーのチャンネル方向最大値に対する入力の勾配を計算する関数の作成''' # モデルのインプット input_img = model.input # 入力層の次の層以降をレイヤー名とインスタンスの辞書として保持 layer_dict = dict([(layer.name, layer) for layer in model.layers[1:]]) # 引数で指定したレイヤー名のインスタンスの出力を取得 shape=(?, 14, 14, 512) layer_output = layer_dict[activation_layer].output # チャンネル方向に最大値を取る shape=(?, 14, 14) max_output = K.max(layer_output, axis=3) # 指定レイヤーのチャンネル方向最大値に対する入力の勾配を計算する関数 saliency = K.gradients(K.sum(max_output), input_img)[0] return K.function([input_img, K.learning_phase()], [saliency]) def modify_backprop(model, name): ''' ReLU関数の勾配を"name"勾配に置き換える''' # with内のReLUは"name"に置き換えられる g = tf.get_default_graph() with g.gradient_override_map({'Relu': name}): # ▽▽▽▽▽ 疑問4 : 新規モデルをreturnしているのに、引数のモデルのreluの置き換えが必要なのか? ▽▽▽▽▽ # activationを持っているレイヤーのみ抜き出して配列化 # get layers that have an activation layer_dict = [layer for layer in model.layers[1:] if hasattr(layer, 'activation')] # kerasのRelUをtensorflowのReLUに置き換え # replace relu activation for layer in layer_dict: if layer.activation == keras.activations.relu: layer.activation = tf.nn.relu # △△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△△ # 新しくモデルをインスタンス化 # 自作モデルを使用する場合はこちらを修正 # re-instanciate a new model new_model = VGG16(weights='imagenet') return new_model def deprocess_image(x): ''' Same normalization as in: https://github.com/fchollet/keras/blob/master/examples/conv_filter_visualization.py ''' if np.ndim(x) > 3: x = np.squeeze(x) # normalize tensor: center on 0., ensure std is 0.1 x -= x.mean() x /= (x.std() + 1e-5) x *= 0.1 # clip to [0, 1] x += 0.5 x = np.clip(x, 0, 1) # convert to RGB array x *= 255 if K.image_dim_ordering() == 'th': x = x.transpose((1, 2, 0)) x = np.clip(x, 0, 255).astype('uint8') return x def grad_cam(input_model, image, category_index, layer_name): ''' Parameters ---------- input_model : model 評価するKerasモデル image : tuple等 入力画像(枚数, 縦, 横, チャンネル) category_index : int 入力画像の分類クラス layer_name : str 最後のconv層の後のactivation層のレイヤー名. 最後のconv層でactivationを指定していればconv層のレイヤー名. batch_normalizationを使う際などのようなconv層でactivationを指定していない場合は、 そのあとのactivation層のレイヤー名. Returns ---------- cam : tuple Grad-Camの画像 heatmap : tuple ヒートマップ画像 ''' # 分類クラス数 nb_classes = 1000 # ----- 1. 入力画像の予測クラスを計算 ----- # 入力のcategory_indexが予想クラス # ----- 2. 予測クラスのLossを計算 ----- # 入力データxのcategory_indexで指定したインデックス以外を0にする処理の定義 target_layer = lambda x: target_category_loss(x, category_index, nb_classes) # 引数のinput_modelの出力層の後にtarget_layerレイヤーを追加 # modelのpredictをすると予測クラス以外の値は0になる x = input_model.layers[-1].output x = Lambda(target_layer, output_shape=target_category_loss_output_shape)(x) model = keras.models.Model(input_model.layers[0].input, x) # 予測クラス以外の値は0なのでsumをとって予測クラスの値のみ抽出 loss = K.sum(model.layers[-1].output) # 引数のlayer_nameのレイヤー(最後のconv層)のoutputを取得する conv_output = [l for l in model.layers if l.name is layer_name][0].output # ----- 3. 予測クラスのLossから最後のconv層への逆伝搬(勾配)を計算 ----- # 予想クラスの値から最後のconv層までの勾配を計算する関数を定義 # 定義した関数の # 入力 : [判定したい画像.shape=(1, 224, 224, 3)]、 # 出力 : [最後のconv層の出力値.shape=(1, 14, 14, 512), 予想クラスの値から最後のconv層までの勾配.shape=(1, 14, 14, 512)] grads = normalize(K.gradients(loss, conv_output)[0]) gradient_function = K.function([model.layers[0].input], [conv_output, grads]) # 定義した勾配計算用の関数で計算し、データの次元を整形 # 整形後 # output.shape=(14, 14, 512), grad_val.shape=(14, 14, 512) output, grads_val = gradient_function([image]) output, grads_val = output[0, :], grads_val[0, :, :, :] # ----- 4. 最後のconv層のチャンネル毎に勾配を平均を計算して、各チャンネルの重要度(重み)とする ----- # weights.shape=(512, ) # cam.shape=(14, 14) # ※疑問点1:camの初期化はzerosでなくて良いのか? weights = np.mean(grads_val, axis = (0, 1)) cam = np.ones(output.shape[0 : 2], dtype = np.float32) #cam = np.zeros(output.shape[0 : 2], dtype = np.float32) # 私の自作モデルではこちらを使用 # ----- 5. 最後のconv層の順伝搬の出力にチャンネル毎の重みをかけて、足し合わせて、ReLUを通す ----- # 最後のconv層の順伝搬の出力にチャンネル毎の重みをかけて、足し合わせ for i, w in enumerate(weights): cam += w * output[:, :, i] # 入力画像のサイズにリサイズ(14, 14) → (224, 224) cam = cv2.resize(cam, (224, 224)) # 負の値を0に置換。処理としてはReLUと同じ。 cam = np.maximum(cam, 0) # 値を0~1に正規化。 # ※疑問2 : (cam - np.min(cam))/(np.max(cam) - np.min(cam))でなくて良いのか? heatmap = cam / np.max(cam) #heatmap = (cam - np.min(cam))/(np.max(cam) - np.min(cam)) # 私の自作モデルではこちらを使用 # ----- 6. 入力画像とheatmapをかける ----- # 入力画像imageの値を0~255に正規化. image.shape=(1, 224, 224, 3) → (224, 224, 3) #Return to BGR [0..255] from the preprocessed image image = image[0, :] image -= np.min(image) # ※疑問3 : np.uint8(image / np.max(image))でなくても良いのか? image = np.minimum(image, 255) # heatmapの値を0~255にしてカラーマップ化(3チャンネル化) cam = cv2.applyColorMap(np.uint8(255*heatmap), cv2.COLORMAP_JET) # 入力画像とheatmapの足し合わせ cam = np.float32(cam) + np.float32(image) # 値を0~255に正規化 cam = 255 * cam / np.max(cam) return np.uint8(cam), heatmap手順3 Grad-CAMのメイン処理の実装
(1) 入力画像の指定
以下のコードを入力します。画像は任意の画像を指定します。(この例ではmydog7.jpgを指定)
# cd '/content/drive/'My Drive/'Colab Notebooks'内の作業フォルダへ移動 %cd '/content/drive/'My Drive/Colab Notebooks/Self_Study/02_mydog_or_otherdogs/ # ① 入力画像の読み込み # 入力画像を変換する場合はこちらを変更 # preprocessed_input = load_image(sys.argv[1]) preprocessed_input = load_image("./use_data/train/mydog/mydog07.jpg")今回の例ではこの画像を指定しました。
(2) VGG16モデルの読み込み
- VGG16モデルを読み込みます。今回はImageNetでトレーニングされたモデルをそのまま使用します。(うちの子と他の子の違いを判定している重みについては、別の機会に実装したいと思います)
# ② モデルの読み込み # 自作モデルを使用する場合はこちらを変更 model = VGG16(weights='imagenet') model.summary()モデルは次のように表示されます。
Model: "vgg16" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= input_1 (InputLayer) (None, 224, 224, 3) 0 _________________________________________________________________ block1_conv1 (Conv2D) (None, 224, 224, 64) 1792 _________________________________________________________________ block1_conv2 (Conv2D) (None, 224, 224, 64) 36928 _________________________________________________________________ block1_pool (MaxPooling2D) (None, 112, 112, 64) 0 _________________________________________________________________ block2_conv1 (Conv2D) (None, 112, 112, 128) 73856 _________________________________________________________________ block2_conv2 (Conv2D) (None, 112, 112, 128) 147584 _________________________________________________________________ block2_pool (MaxPooling2D) (None, 56, 56, 128) 0 _________________________________________________________________ block3_conv1 (Conv2D) (None, 56, 56, 256) 295168 _________________________________________________________________ block3_conv2 (Conv2D) (None, 56, 56, 256) 590080 _________________________________________________________________ block3_conv3 (Conv2D) (None, 56, 56, 256) 590080 _________________________________________________________________ block3_pool (MaxPooling2D) (None, 28, 28, 256) 0 _________________________________________________________________ block4_conv1 (Conv2D) (None, 28, 28, 512) 1180160 _________________________________________________________________ block4_conv2 (Conv2D) (None, 28, 28, 512) 2359808 _________________________________________________________________ block4_conv3 (Conv2D) (None, 28, 28, 512) 2359808 _________________________________________________________________ block4_pool (MaxPooling2D) (None, 14, 14, 512) 0 _________________________________________________________________ block5_conv1 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ block5_conv2 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ block5_conv3 (Conv2D) (None, 14, 14, 512) 2359808 _________________________________________________________________ block5_pool (MaxPooling2D) (None, 7, 7, 512) 0 _________________________________________________________________ flatten (Flatten) (None, 25088) 0 _________________________________________________________________ fc1 (Dense) (None, 4096) 102764544 _________________________________________________________________ fc2 (Dense) (None, 4096) 16781312 _________________________________________________________________ predictions (Dense) (None, 1000) 4097000 ================================================================= Total params: 138,357,544 Trainable params: 138,357,544 Non-trainable params: 0 _________________________________________________________________(3) 残りのステップを入力します。
次のコードを実行します。
# ③ 入力画像の予測確率(predictions)と予測クラス(predicted_class)の計算 # VGG16以外のモデルを使用する際はtop_1=~から3行はコメントアウト predictions = model.predict(preprocessed_input) top_1 = decode_predictions(predictions)[0][0] print('Predicted class:') print('%s (%s) with probability %.2f' % (top_1[1], top_1[0], top_1[2])) predicted_class = np.argmax(predictions) # ④ Grad-Camの計算 # 自作モデルの場合、引数の"block5_conv3"を自作モデルの最終conv層のレイヤー名に変更. cam, heatmap = grad_cam(model, preprocessed_input, predicted_class, "block5_conv3") # ⑤ 画像の保存 cv2.imwrite("gradcam.jpg", cam)Grad-CAMのヒートマップ画像が02_mydog_or_otherdogsフォルダ内に生成されます。
手順4 Guided Grad-CAMのメイン処理の実装
(1) 入力画像の指定
次のコードをすべて実行します。
# ① GuidedBackPropagation用勾配の実装 register_gradient() # ② ReLUの勾配計算をGuidedBackPropagationの勾配計算に変更 guided_model = modify_backprop(model, 'GuidedBackProp') # ③ GaidedBackPropagation計算用の関数の定義 # 自作クラスを使う場合は、こちらの引数に最後のconv層のレイヤー名を追加で指定 saliency_fn = compile_saliency_function(guided_model) # ④ GaidedBackPropagationの計算 saliency = saliency_fn([preprocessed_input, 0]) # ⑤ Guided Grad-CAMの計算 gradcam = saliency[0] * heatmap[..., np.newaxis] # ⑥ 画像の保存 cv2.imwrite("guided_gradcam.jpg", deprocess_image(gradcam))Guided Grad-CAMのヒートマップ画像が02_mydog_or_otherdogsフォルダ内に生成されます。
こういう感じで出てくるんですね。確かにヒートマップで見るよりも輪郭というか、人間が理解しやすい形での特徴をとらえているという気がします。
以下、何枚かmydog及びotherdogsで処理したものを掲載してみます。
mydog
otherdogs
今回は Grad-CAMとGuided Grad-CAMによる特徴をとらえた画像の作成を実施しました。画像に表れるそれぞれの手法での特徴量の表現は大きく異なるため、deeplearningがとらえた特徴を説明する際には、なるべく様々な切り口を併用し、総合的に理解を求めたほうが、納得感が得られそうではあります。
引き続き、様々な手法についてのアウトプットを続けていきたいと思います。



















- 投稿日:2020-01-19T21:37:00+09:00
内包表記でのif...else
リストの内包表記にif...else文がある場合、初心者はコードの読む順番に戸惑うことがあると思います。
>>> x = [8,1,7,2,6,3,5,4]内包表記のif
>>> l1 = [i for i in x if i > 5] >>> l1 [8, 7, 6]ここでの
if i > 5は内包表記の一部となります。
次のコードと等価です:>>> l1 = [] >>> for i in x: ... if i > 5: ... l1.append(i) ... >>> l1 [8, 7, 6]内包表記でのif...else
>>> l2 = [i if i > 5 else 0 for i in x] >>> l2 [8, 0, 7, 0, 6, 0, 0, 0]ここでの
i if i > 5 else 0は内包表記のシンタックスではありません。
次のコードと等価です:>>> l2 = [] >>> for i in x: ... l2.append(i if i > 5 else 0) ... >>> l2 [8, 0, 7, 0, 6, 0, 0, 0]条件式
上記の
i if i > 5 else 0は条件式という演算です。>>> i = 6 >>> i if i > 5 else 0 6 >>> i = 4 >>> i if i > 5 else 0 0ちなみに
条件式ではelseがないと怒られます。
>>> i = 6 >>> i if i > 5 File "<stdin>", line 1 i if i > 5 ^ SyntaxError: invalid syntaxなので
下記のように書いても同じく怒られます。>>> l3 = [i if i > 5 for i in x] File "<stdin>", line 1 l3 = [i if i > 5 for i in x] ^ SyntaxError: invalid syntax参考
- 投稿日:2020-01-19T21:16:43+09:00
グローバル変数とローカル変数2
1player = '太郎' def f(): player = '次郎' print('local:', locals()) f() print(player)1の実行結果local: {'player': '次郎'} 太郎ローカル変数を宣言しないで、
locals()を実行すると、2player = '太郎' def f(): print('local:', locals()) f() print(player)2の実行結果local: {} 太郎空の辞書がかえってくる。
globals()も実行してみると、
3player = '太郎' def f(): print('local:', locals()) f() print('global:', globals())3の実行結果local: {} global: {'__name__': '__main__', '__doc__': None, '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x7efff584a2b0>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': 'Main.py', '__cached__': None, 'player': '太郎', 'f': <function f at 0xxxxxxxxxxxxx>}たくさん出てくるが、
'player': '太郎'と出ている。他に
__name__は__main__であるとか、
__doc__は何も入っていなくてNoneであるとか
事前に宣言されているものがでてくる。ここでこのファンクションにドキュメントを書いてみると、
4""" test ################## """ player = '太郎' def f(): print('local:', locals()) f() print('global:', globals())4の実行結果local: {} global: {'__name__': '__main__', '__doc__': '\ntest ##################\n', '__package__': None, '__loader__': <_frozen_importlib_external.SourceFileLoader object at 0x7f73121652b0>, '__spec__': None, '__annotations__': {}, '__builtins__': <module 'builtins' (built-in)>, '__file__': 'Main.py', '__cached__': None, 'player': '太郎', 'f': <function f at 0x7f7312236e18>}
__doc__が'\ntest ##################\nとなった。関数内の
__name__や__doc__も見てみると、5player = '太郎' def f(): """Test func doc""" print(f.__name__) print(f.__doc__) f() print('global:', __name__)5の実行結果f Test func doc global: __main__まず、
print(f.__name__)
で関数fの名前が出力され、
次に、
print(f.__doc__)で関数fのドキュメントが出力される。
最後に、
print('global:', __name__)で
文字列'global:'に続いて全体ファンクションの名前が出力される。
- 投稿日:2020-01-19T20:59:04+09:00
Pythonによる行列の転置速度の比較
1. 背景
Python標準のリスト型による2次元配列から,行と列を入れ替えた2次元配列(転置行列)を得たいと思い,自作したコードがめちゃくちゃ遅かったため,どの転置行列方法が最も速いのか気になったので比較してみました.
筆者はプログラミング歴半年以下の初心者のため,間違いや改善方法などがありましたら,ご指摘いただけると幸いです.
速度の比較結果へ2. 環境
name version Python 3.7.4 Jupyter Notebook 6.0.1 NumPy 1.16.5 Pandas 0.25.1 3. 条件
- 入力はPython標準のリスト型による2次元配列
- 出力はPython標準のリスト型,numpy.arrayまたはpandas.DataFrame
3-1. 転置する行列
転置する行列名は
in_matrixとし,今回は100×100の行列を生成します.転置する行列#転置する行列in_matrixの作成 n = 100 m = 100 in_matrix = [[i for i in range(n)] for j in range(m)]3-2. 処理時間の測定
Jupyter Notebook (IPython) の
%timeitを用いて行います.
Built-in magic commands — %timeit
ループ回数は-n 10000,繰り返しは-r 10としました.処理時間の測定#処理時間の測定 %timeit -n 10000 -r 10 turn_matrix(in_matrix)4. 検討した転置方法
- 二重ループによる転置 [
turn_matrix1(),turn_matrix2()]- 組み込み関数zip()による転置 [
turn_matrix3(),turn_matrix4()]- NumPyによる転置 [
turn_matrix5()]- Pandasによる転置 [
turn_matrix6()]上記の内,組み込み関数zip(),NumPy,Pandasを用いた転置は以下を参考にさせていただきました.
Pythonリスト型の二次元配列の行と列を入れ替える(転置) | note.nkmk.me5. 速度の比較結果
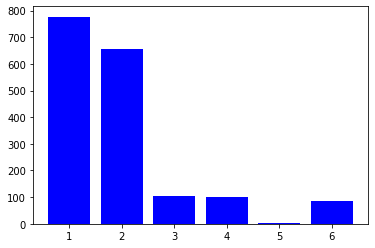
転置速度の比較では,NumPyによる転置が圧倒的に速く(1.67 µs),次いでPandasによる転置(86.3 µs),関数zip()+リスト内包表記(99.4 µs)となりました.
No. def description 転置速度 1 turn_matrix1()二重ループ1 777 µs ± 43.6 µs 2 turn_matrix2()二重ループ2 654 µs ± 83 µs 3 turn_matrix3()関数zip() 105 µs ± 4.22 µs 4 turn_matrix4()関数zip()+リスト内包表記 99.4 µs ± 1.36 µs 5 turn_matrix5()NumPy 1.67 µs ± 38.9 ns 6 turn_matrix6()Pandas 86.3 µs ± 4.54 µs
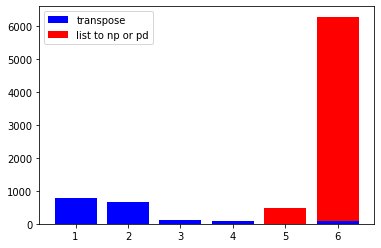
しかしながら,NumPyによる転置とPandasによる転置では,リスト型からnumpy.arrayへの変換は486 µs,pandas.DataFrameへの変換は6.19 ms掛かるため,
リスト型からの変換を含めた時間は,NumPyによる転置(487.67 µs),Pandasによる転置(6.2763 ms)となりました.
そのため,与えられる行列がリスト型である場合,リスト型の行列から転置行列を得るためのトータルの処理時間は,関数zip()+リスト内包表記(99.4 µs)が最も速いと考えられました.
No. def description 転置速度 np.arrayまたはpd.DataFrameへの変換 1 turn_matrix1()二重ループ1 777 µs ± 43.6 µs ― 2 turn_matrix2()二重ループ2 654 µs ± 83 µs ― 3 turn_matrix3()関数zip() 105 µs ± 4.22 µs ― 4 turn_matrix4()関数zip()+リスト内包表記 99.4 µs ± 1.36 µs ― 5 turn_matrix5()NumPy 1.67 µs ± 38.9 ns 486 µs ± 10.1 µs 6 turn_matrix6()Pandas 86.3 µs ± 4.54 µs 6.19 ms ± 43.1 µs
6. 転置関数
6-1. 二重ループによる転置1
関数名:
turn_matrix1()
何も参考にせず作成した二重ループによる転置.
引数matrixの行数xと列数yをforループに渡し,行数を列数,列数を行数として引数matrixから取り出す.二重ループによる転置1#転置する行列in_matrixの作成 n = 100 m = 100 in_matrix = [[i for i in range(n)] for j in range(m)] #転置関数turn_matrix1() def turn_matrix1(matrix): x = len(matrix) y = len(matrix[0]) turned = [] for i in range(y): tmp = [] for j in range(x): tmp.append(matrix[j][i]) turned.append(tmp) return turned #処理時間の測定 %timeit -r 10 -n 10000 turn_matrix1(in_matrix)実行結果
777 µs ± 43.6 µs per loop (mean ± std. dev. of 10 runs, 10000 loops each)
6-2. 二重ループによる転置2
関数名:
turn_matrix2()
6-1. 二重ループによる転置1では引数matrixの行数xと列数yを取得していましたが,引数matrixからforループで1行ずつ取り出し,同じ列番号の値をtmp行を作成し,それをturnedに追加していく.二重ループによる転置2#転置する行列in_matrixの作成 n = 100 m = 100 in_matrix = [[i for i in range(n)] for j in range(m)] #転置関数turn_matrix2() def turn_matrix2(matrix): y = len(matrix[0]) turned = [] for i in range(y): tmp = [] for j in matrix: tmp.append(j[i]) turned.append(tmp) return turned #処理時間の測定 %timeit -r 10 -n 10000 turn_matrix2(in_matrix)実行結果
654 µs ± 83 µs per loop (mean ± std. dev. of 10 runs, 10000 loops each)
6-3. 組み込み関数zip()による転置
関数名:
turn_matrix3()組み込み関数zip()による転置#転置する行列in_matrixの作成 n = 100 m = 100 in_matrix = [[i for i in range(n)] for j in range(m)] #転置関数turn_matrix3(matrix) def turn_matrix3(matrix): turned = [] for i in zip(*matrix): turned.append(list(i)) return turned #処理時間の測定 %timeit -r 10 -n 10000 turn_matrix3(in_matrix)実行結果
105 µs ± 4.22 µs per loop (mean ± std. dev. of 10 runs, 10000 loops each)
6-4. 組み込み関数zip()+リスト内包表記による転置
関数名:
turn_matrix4()組み込み関数zip()+リスト内包表記による転置#転置する行列in_matrixの作成 n = 100 m = 100 in_matrix = [[i for i in range(n)] for j in range(m)] #転置関数turn_matrix4() def turn_matrix4(matrix): return [list(x) for x in zip(*matrix)] #処理時間の測定 %timeit -r 10 -n 10000 turn_matrix3(in_matrix)実行結果
99.4 µs ± 1.36 µs per loop (mean ± std. dev. of 10 runs, 10000 loops each)※関数化しない場合
リスト内包表記turned_matrix = [list(x) for x in zip(*in_matrix)]Pythonリスト型の二次元配列の行と列を入れ替える(転置) | note.nkmk.me
6-5. NumPyによる転置
関数名:
turn_matrix5()NumPyによる転置import numpy as np #転置する行列in_matrixの作成 n = 100 m = 100 in_matrix = [[i for i in range(n)] for j in range(m)] #in_matrixからnumpy.arrayのnumpy_in_matrixの作成 %timeit numpy_in_matrix = np.array(in_matrix) #転置関数turn_matrix5() def turn_matrix5(matrix): return matrix.T #処理時間の測定 %timeit -r 10 -n 10000 turn_matrix5(numpy_in_matrix)実行結果
in_matrixからnumpy.arrayへの変換
486 µs ± 10.1 µs per loop (mean ± std. dev. of 7 runs, 1000 loops each)転置
1.67 µs ± 38.9 ns per loop (mean ± std. dev. of 10 runs, 10000 loops each)※関数化しない場合
NumPyによる転置import numpy as np turned_matrix = np.array(in_matrix).TPythonリスト型の二次元配列の行と列を入れ替える(転置) | note.nkmk.me
6-6. Pandasによる転置
関数名:
turn_matrix6()Pandasによる転置import pandas as pd #転置する行列in_matrixの作成 n = 100 m = 100 in_matrix = [[i for i in range(n)] for j in range(m)] #in_matrixからpandas.DataFrameのpandas_in_matrixの作成 %timeit pandas_in_matrix = pd.DataFrame(in_matrix) #転置関数turn_matrix6() def turn_matrix5(matrix): return matrix.T #処理時間の測定 %timeit -r 10 -n 10000 turn_matrix5(pandas_in_matrix)実行結果
・in_matrixからpandas.DataFrameへの変換
6.19 ms ± 43.1 µs per loop (mean ± std. dev. of 7 runs, 100 loops each)・転置
86.3 µs ± 4.54 µs per loop (mean ± std. dev. of 10 runs, 10000 loops each)※関数化しない場合
Pandasによる転置import pandas as pd turned_matrix = pd.DataFrame(in_matrix).T
- 投稿日:2020-01-19T20:28:08+09:00
学習記録 その24(28日目)
学習記録(28日目)
勉強開始:12/7(土)〜
教材等:
・大重美幸『詳細! Python3 入門ノート』(ソーテック社、2017年):12/7(土)〜12/19(木)読了
・Progate Python講座(全5コース):12/19(木)〜12/21(土)終了
・Andreas C. Müller、Sarah Guido『(邦題)Pythonではじめる機械学習』(オライリージャパン、2017年):12/21(土)〜12月23日(土)読了
・Kaggle : Real or Not? NLP with Disaster Tweets :12月28日(土)投稿〜1月3日(金)まで調整
・Wes Mckinney『(邦題)Pythonによるデータ分析入門』(オライリージャパン、2018年):1/4(水)〜1/13(月)読了
・斎藤康毅『ゼロから作るDeep Learning』(オライリージャパン、2016年):1/15(水)〜『ゼロから作るDeep Learning』
p.239 第7章 畳み込みニューラルネットワーク まで読み終わり。
6章 学習に関するテクニック
・最適化(Optimization):損失関数の値をできるだけ小さくできる最適なパラメータを見つけること。
パラメータ空間は複雑であり、非常に難しい問題。
いくつか手法(optimizer)が存在する。・確率的勾配降下法(stochastic gradient descent):5章までで学んだ手法。
パラメータの勾配を使い、勾配方向に向けて何度も更新、徐々に近づけていく。W ← W - η\frac{\partial L}{\partial W}ηは学習率(learning rate)。右辺の値で左辺を更新していく。
SGDの欠点は関数が伸びた形であったりする場合、つまり等方的な形状でない場合は、探索経路が非効率になりがちな点。・モーメンタム(Momentum):運動量のような概念を用いる。
新たにvという変数を導入、摩擦力や空気抵抗のような役目を果たすことで、何も力を受けない時に減速する仕組み。v ← αv - η\frac{\partial L}{\partial L}W ← W + v・AdaGrad:学習率(learning rate)の値を、学習の度合いに応じて変化させる手法。
最初は大きくし、次第に小さくさせる。h ← h + \frac{\partial L}{\partial W} ⊙ \frac{\partial L}{\partial W}W ← W - η\frac{1}{\sqrt{h}}\frac{\partial L}{\partial W}⊙はアダマール演算子。行列の要素毎の掛け算を意味する。
hが大きいほど(よく動くほど)、学習係数が小さくなる。
つまりパラメータ更新の際に、学習のスケールを調整している。・Adam:モーメンタムとAdaGradを融合させた手法。
・optimizerは上記のとおり様々な手法が存在するが、それぞれ得手不得手があるので、一概にどれが優れているかということは言えない。
(ただ、多くの研究ではSGDが好んで使われているとのこと。)・荷重減衰(Weight decay):重みパラメータが小さくなるように学習を行うことを目的とした手法
重みを小さくすることで過学習が起きづらくなり、汎化性能を高めることに近く。
(ただし、「0」は重みの対照的な構造を崩し、全てが同じような値を持ってしまう。)・Xavierの初期値:n個のノードに対し、(1 / √n)の標準偏差を持つガウス分布を初期値として用いる。
ディープラーニングのフレームワークで標準的に用いられている。
sigmoidやtanhに適している。・Heの初期値:n個のノードに対し、(2 / √n)の標準偏差を持つガウス分布を初期値として用いる。
ReLUに適している。ReLUの場合は負の領域が0になるため、より広い広がりを持たせるために倍の係数をかけているとも解釈できる。・Batch Normalization:2015年に考案された手法、コンペ等でも多く用いられている。
学習を早く進行させることができる、初期値にそれほど依存しない、過学習を抑制する、といった利点がある。
Batch Normレイヤと呼ばれるものをAffineやReLUの間に挿入することで、データ分布の正規化を行う。
学習を行う際のミニバッチを単位として、ミニバッチ毎に正規化を行う。・Dropout:Weight decayと同様に、過学習を抑制する手法として用いられる。
訓練時に隠れ層のニューロンをランダムに選び出し、選び出したニューロンを消去する。
テスト時にはすべてのニューロン信号を伝達するが、訓練時に消去した割合を乗算して出力する。
学習時にニューロンを毎回ランダム消去する、つまり、毎回異なるモデルを学習させていると解釈することもできるため、一種のアンサンブル手法に近いものがある。・ハイパーパラメータ:各層のニューロンの数やバッチサイズ、学習率やWeight decayが該当する。
テストデータを使ってハイパーパラメータを調整することは過学習に繋がるため、検証データ(validation data)と呼ばれる専用のデータを用いる。
これは自分で作る。(npのshuffleやsclearnのtrain_data_splitなど。Kaggleで使った。)・最適化は、最初はおおまかに設定、認識精度の結果を観察し、良い値が存在する範囲に向けて徐々に絞り込んでいく。
ニューラルネットワークの場合は、グリッドサーチといった規則的な探索よりも、ランダムにサンプリングして探索するほうがよい結果が出るとの報告がある。
おおまかに、とは、10のべき乗スケール、10^(-3) ~ 10^(3)、くらいが目安。
筋が悪そうなものは早い段階で見切りをつける必要があるため、学習のためのエポックは小さくするのが有効。
エポックとは、データを全て使いきった時の単位。10000データを100個のミニバッチで学習するなら、100回 = 1エポック、学習記録その22のとおり。・ベイズ最適化(Bayesian optimization)も有効。Kaggleで見る機会が多かった。
7章 畳み込みニューラルネットワーク
・畳み込みニューラルネットワーク(convoluntional neural network: CNN)
通常のニューラルネットワークに加え、「Convoluntionレイヤ(畳み込み層)」と「Poolingレイヤ(プーリング層)」という概念を加える。
代表例としてはLeNetとAlexNetという2つが挙げられる。・「Affine - ReLU(sigmoid)」というレイヤの繋がりを、「Convoluntion - ReLU(sigmoid) - (Pooling)」という繋がりに置き換える。
(ただし出力層に近い部分は通常通り。)・Affineレイヤは全てのニューロンを結合する全結合層を用いていた。
これの問題点は、全ての入力データを同等のニューロン(同次元)として扱うことにより、形状に関する情報を活かせないこと。
一方でConvoluntionレイヤは、入力データを同じ次元で次の層に出力するため、よりデータを正しく理解できる(可能性がある)。・畳み込み演算:入力データに対し、フィルターのウィンドウを一定間隔でスライドさせながら適用する。
フィルターの適応間隔を調整する変数をストライドという。(どれだけずらしながら適応していくかという話)・パディング:入力データの周囲を固定データ(0など)で埋める。
・プーリング:縦・横の空間を小さくする演算。4×4の行列を2×2の領域ずつ見ていき、たとえばMaxプーリングであれば、領域ごとの最大値を抽出して出力するなどの演算を実施する。
・これら畳み込み演算を適応する関数としてim2colというものが存在する。
im2colは、フィルターにとって都合の良いように入力データを展開する関数であり、フィルターの適応領域を先頭から順番に1列ずつ展開していく。
展開後は元のブロックの要素数より大きくなり、多くのメモリを消費するという欠点があるものの、行列計算自体が高度に最適化されているため、この行列の形に帰着させることで非常に多くの恩恵が得られる。・畳み込み層のフィルターは、ブロブ(blob: 局所的に塊にある領域)や、エッジ(edge: 色が変化する境目)といったプリミティブな情報を抽出し、次の領域に出力していくことができる。
- 投稿日:2020-01-19T20:23:26+09:00
仮想通貨自動売買スクリプトの運用
困っていること
現在運用している自動売買スクリプトはwhile文で安定して永続実行できるほど安定稼働しない。
明日から出張なのだが、せっかくなので出張中もスクリプトを実行させ続けたい。
しかしPCは持ち歩きたくない。iphone上での操作で完結させたい。while True:安定稼働しない理由
1. REST APIのエラー
2. Realtime APIのエラー
3. なぜか成行き注文の結果、0.01BTC以下の量の建玉が残り、その約定を待ち続ける。
→これに関しては、とりあえず100秒以上成行注文の約定を待っているなら、例外を投げて異常終了させるようにした。暫定対応
根本対処はいずれするとして、所謂「運用でカバー」することを考える。(よくない)
1. try文で例外を検知した場合LINE通知を行う。
pythonでのLINE通知の実装は以下を参考にした。
PythonでLINEに通知を送る
https://qiita.com/analytics-hiro/items/e42f857bd6b40bc178a3
2. 以下のようなLINE通知が来る。[自動売買完了通知] 2020-01-19 17:20:20.630975開始の処理が異常終了しました。 取引回数は3回でした。 エラー内容は以下のとおりです。 {'parent_order_acceptance_id': 'JRF20200119-082028-389427'}None3. 取引所にログインして、建玉の決済と注文のキャンセルを行う。
4. Termiusでスクリプトを実行しているサーバへSSH。
(恥ずかしながら当方はiphoneからSSHできることを本件で初めて知った。)
Termiusに関しては以下を参考にした。
iPhoneからターミナルアプリで公開鍵を使ってssh接続する方法
https://itneko.com/iphone-ssh/
5. SSHしたサーバでスクリプト実行用のシェルを実行する。rerun.sh#!/bin/sh cd ~/bf/code_bf/ source ~/bf/bin/activate nohup python IFDOCOBOTv3.1.py &6. 取引所にログインして自動売買が再開したことを確認する。
今後の課題
- そもそも落ちないスクリプトにする。(これ)
- せっかくLINE通知しているので、通知内容にURLを載せておいてワンクリックで再実行できるようにする。(API Gatewayとかでできる?)
- スクリプトが実行されているサーバがダウンした場合、上記のフローでは対処できないので対応策を考える。(最初Lambdaでの運用を思いついたが、Lambdaは長時間実行できないのでNG。AWSBatchで実装できるのだろうか。勉強不足である。)
- 自動売買スクリプト(上のサンプルだとIFDOCOBOTv3.1.py)の名前を頻繁に変えるのでそのたびに、再実行スクリプトの改修が発生する。(CodeDeploy、CodeBuildあたりで解決しようと思っている。そもそもURLから再実行できるようになればよいのだが)
- EC2インスタンスを使用しているのだが、PublicIPが再起動のために変わるのでうっかり再起動するとiphoneから接続するときにAWSマネジメントコンソールに接続しないといけなくて面倒(ElasticIPを使えば解決できるが、使っていないときはサーバを落とすことを習慣づけたいのでNG※ElasticIPはOS停止している時間が課金対象のため)
- 色々書いたが、落ちないスクリプトなどない。落ちることを前提として自動で再実行される仕組みを作るべきだ。初期化(建玉の決済と注文のキャンセル)当然自動で行う。
- 投稿日:2020-01-19T20:22:57+09:00
Python学習メモ
はじめに
pythonの勉強の為、学習内容をメモしたものです。
誤記などあればご指摘ください。組み込み関数
# 型変換 # intに変換 int("100") # 10進数 int("100", 2) # 2進数 int("100", 16) # 16進数 # float値に変換 float() # 文字列に変換 str() # 文字の出力 print("文字列") print("文字列"+"文字列2") # 文字列を連結する print("文字列"+ str(100)) # 数値を文字に変えて連結 print("文字列",100) # 文字と数字連結(間にスペースが入る) # 文字の入力 test = input() # 合計 list = [1,2,3] sum(list) # 結果 : 6 # 最大値 max(list) # 結果 : 3 # 最小値 min(list) # 結果 : 1 # 長さ len(list) # 結果 : 3for文
loop = [0,1,2,3] # 配列数分ループする for i in loop: # ループ内容 # 指定回数分ループ for i in range(5): # ループ内容 # 特定の範囲でループさせる for i in range(2,4): # ループ内容while文
cnt = 1 while cnt <= 10: print(cnt) cnt = cnt + 1 # カウント加算ループ制御
制御分 説明 break ループを抜ける(終了) continue ループの最初に戻る else ループの最後に実行する else文の使い方
elseはループが終わった後に実行されます。
ただし、break文でループを抜けた場合、elseは実行されません。Class=["田中","鈴木","佐藤"] check ="田中" # クラスの名前に「山田」がいるか確認 for name in Class: if check == name: print(name+"はクラスメイトです") break else: print(check +"はクラスメイトではありません")if文
testA = 1 if 1 == test: # True時の処理 else: # false時の処理 testB = "TEST" if "T" in testB: # True時の処理 elif "B" in testB: # true時の処理演算子
比較演算子
演算子 説明 A == B AとBが等しい A != B AとBが異なる A > B AはBより大きい A < B AはBより小さい A >= B AはB以上 A <= B AはB以下 A in B Aの要素がBに存在する 論理演算子
演算子 説明 A and B AかつB A or B AまたはB A < B and B < C
こような場合は、以下のような書き方も可能
A < B < Cビット演算子
演算子 説明 A | B 論理和(OR) A & B 論理積(AND) A ^ B 排他的論理和(XOR) A << B, A >> B シフト演算 関数
def Name1(): # 関数処理 return 0 # デフォルト引数を定義 def Name1(): # 関数処理 return 0 # デフォルト引数を定義 def Name2(name="名無し"): print( "あなたの名前は" + name + "です" ) # デフォルト引数を定義 def NameAndAge(name="名無し", age=25): print( "あなたの名前は" + name + "です" ) print( "あなたの年齢は" , age,"才です" ) # キーワードを指定する NameAndAge(age=12, name="太郎")モジュール
import random # モジュールを読み込む import random as rm # モジュールに名前を指定する from statistics import median # モジュール内の関数を読み込む from statistics import * # モジュール内の全ての関数を読み込む組み込みデータ型
数値型
型名 説明 int 整数型 float 浮動小数点型 complex 複素数型 XX進数表記
XX進数 表記 10進数から変換 XX進数から10進数に変換 16進数 0xffff hex(65535) int("0xffff",16) 2進数 0b1111 bin(15) int("0b1111",2) 8進数 0o777 oct(511) int("0c777",8) 文字列型
型名 説明 str 文字列型 bytes ファイルなどから読み込んだ文字列を扱う 置換 / 削除
test = "ABCDE" test2 = test.replace("B","O") # BをOに置換 test3 = test.replace("B","") # Bを削除 # ただし、元の変数は変化しない test # "ABCDE" test2 # "AOCDE" test3 # "ACDE"分割 / 連結
test = "1 2 3 4 5" # スペースで分割する test_split = test.split(" ") #[.]でtest_splitのデータを連結する test_join = ".".join(test_split ) test # "1 2 3 4 5" test_split # ["1","2","3","4","5"] test_join # "1.2.3.4.5"その他のメソッド
メソッド 説明 str.find( 検索文字 [ ,開始 ,終了 ] ) 文字列を先頭から検索 , ヒットしないときは-1を返す str.rfind( 検索文字 [ ,開始 ,終了 ] ) 文字列を末尾から検索 , ヒットしないときは-1を返す str.index( 検索文字 [ ,開始 ,終了 ]) 文字列を先頭から検索 , ヒットしないときはValueErrorを返す str.rindex( 検索文字 [ ,開始 ,終了 ]) 文字列を末尾から検索 , ヒットしないときはValueErrorを返す str.startwith(検索文字 [ ,開始, 終了 ]) 検索文字で開始しているときにTrueを返す str.endwith( 検索文字 [ ,開始 ,終了 ]) 検索文字で終了しているときにTrueを返す フォーマット
formatを使用して文字列を差し込む
test= "私の名前は{}です" test.format("太郎") # 私の名前は太郎です #順番を指定する test ="彼の名前は{0}です。{0}の年齢は{1}才です。" test.format("次郎","25") # 彼の名前は次郎です。次郎の年齢は25才です。 # キーワードを指定する test ="彼の名前は{Name}です。{Name}の年齢は{Age}才です。" test.format(Name="次郎",Age="25") # 彼の名前は次郎です。次郎の年齢は25才です。 # ディクショナリで指定する test = "{0[name]} は {0[age]}才です" dictionary = {'name':'太郎' , 'age':'14'} test.format(dictionary) # 太郎 は 14才です # 表記を指定する test = "私の名前は{:>10}です" # 右詰め test.format("太郎") # 私の名前は 太郎です test = "{:.1%}" test.format(0.25) # 25.0% # f文字列で表示(python3.6以降) name="太郎" f"私の名前は{name}です"エスケープ文字
文字 説明 \n 改行 \r 改行(CR) \t 水平タブ \f 改ページ \' シングルクオーテーション \" ダブルクォーテーション \\ バックスラッシュ \0 null raw文字列
rをつけると、文字をそのまま表示する
raw = r"c:\Users\XX\Document"bool型
TrueかFalseの値を取得
シーケンス
複数の要素を順番に並べた方をさす。
※ 文字列型(str型, bytes型)もシーケンスの仲間
ディクショナリ型とset型は順番という概念がない為、シーケンスには含まれない。リスト
# リストの宣言 list = [1,2,3] list2= [2,3,4] # リストの連結 list3 = list + list2 list3 # 結果 : [1,2,3,2,3,4] # 先頭を指定 list[0] = 0 list # 結果 : [0,2,3] # 末尾を指定 list[-1] = 1 list # 結果 : [0,2,1] # スライスの指定 slice = [0,1,2,3,4,5] slice[1:3] # [1,2] slice[:4] # [0, 1, 2, 3] slice[3:] # [3, 4, 5] # 偶数を指定 slice[::2] # [0,2,4] # スライスで置き換え slice[1:2] = [10,11] slice # [0, 'a', 'b', 2, 3, 4, 5] # スライスで削除 slice = [0,1,2,3,4,5] del slice[4:] slice # [0, 1, 2, 3] # 要素の削除 list = [0,1,2] del list[2] list # 結果 : [0,1] # 要素の並び替え(昇順) list = [3,5,2,1,0] list.sort() list # [0, 1, 2, 3, 5] # 要素の並び替え(降順) list = [3,5,2,1,0] list.sort(reverse=True) list # [5, 3, 2, 1, 0] # 並び替えをカスタマイズ # 配列の数字の合計が大きい順にソートする def sumAll(num): # 配列の数字を合計して返す return num[0] + num[1] + num[2] list = [[10, 50, 30],[20, 50, 40],[80, 60, 70]] list.sort(key=sumAll, reverse=True) list # [[80, 60, 70], [20, 50, 40], [10, 50, 30]]
メソッド名 説明 reverse() 逆順にする remove() 取り除く append() 末尾に要素を追加 expend() 末尾にシーケンスを追加 pop() 末尾を削除して、削除した値を返す index() 検索したい要素を探し、インデックスを返す。見つからない場合はValueErrorを返す タプル
タプルはリストによく似ているが、要素を変更出来ない。
# タプルの宣言 Months =("Jan","Feb","Mar","Apr","May","Jun","Jul") # または Months ="Jan","Feb","Mar","Apr","May","Jun","Jul" # 1要素の時は最後にカンマを入れる Day= ("Mon",) # 連結はOK Months = Months + ("Aug","Sep","Oct","Nov","Dec") # アンパック代入 a = 1 b = 2 a , b = b , a a # 2 b # 1キーとして使用する
タプルは変更できないシーケンスの為、ディクショナリのキーや、
setの要素にすることが出来る# 誕生日をディクショナリに登録 birthdays = {("4月","1日"):"山田太郎", ("6月","6日"):"山田花子", ("11月","11日"):"山田次郎"} # 日付を指定 birthday =("6月","6日") # for文で一致するキーを探す for day in birthdays: if birthday == day: print(birthdays[day]) # 山田花子 breakset
重複しない要素を管理する為に使うデータ
test1 = {1,2,3} test2 = {3,4,5} # 和集合 test1 | test2 # {1, 2, 3, 4, 5} test1.union(test2) # {1, 2, 3, 4, 5} # 差集合 test1 - test2 # {1, 2} test1.difference(test2) # {1, 2} # 論理積 test1 & test2 # {3} test1.intersection(test2) # {3} # 排他的論理和 test1 ^ test2 # {1, 2, 4, 5} test1.symmetric_difference(test2) # {1, 2, 4, 5} # リストからsetに変換 list = [1,2,3,4,5] set(list) # {1, 2, 3, 4, 5} # 比較 testA = {1,2,3,4,5,6} testB = {3,4,5} Check = testA & testB if 4 in Check: print("4はTestAとTestBに含まれる") if {3,4} <= Check: print("3,4はTestAとTestBに含まれる")辞書(ディクショナリ)
KeyとValue(値)を紐づけて配列を管理する
# ディクショナリ型を定義 test = { "名前": "太郎", "年齢": "25" "出身": "東京"} # dict()を使用して定義 dict([['key1','value1'],['key2','value2']]) # {'key1': 'value1', 'key2': 'value2'} dict(key1='value1', key2='value2') # {'key1': 'value1', 'key2': 'value2'} # 追加する test ={'名前':'太郎'} # {'名前': '太郎'} test["性別"] ="男" test # {'名前': '太郎', '性別': '男'} # updateメソッドで組み合わせる test = {'名前': '太郎', '性別': '男'} test.update({'性別':'女','年齢':'12歳'}) test # {'名前': '太郎', '性別': '女', '年齢': '12歳'} # 削除する test = {'名前': '太郎', '性別': '男'} del test["性別"] test # {'名前': '太郎'} # 要素の有無を確認し要素を追加 test = {'名前':'五郎','年齢':'12'} word = "年齢" if word in test: # 存在する test[word] = test[word]+'才' else: # 存在しない test[word] = '未記入' test # getを使って要素を追加 test = {'名前':'五郎'} word = "年齢" test[word] = test.get(word, '未記入') test # {'名前': '五郎', '年齢': '未記入'}変更 可 / 不可 データ
データ型 タイプ リスト 変更可能(mutable) ディクショナリ 変更可能(mutable) set 変更可能(mutable) bytearray 変更可能(mutable) タプル 変更不可(immutable) str/bytes 変更不可(immutable) コメント
# コメントの先頭に#をつけるdocstring
docstring(ドックストリング)を使用して関数の解説を追加する
def docstring(): ''' docstringテスト テスト1 テスト2 テスト3 ''' Test = "docstringを実行しました" print(Test) print(docstring.__doc__) # docstringの解説を文字列で取得 help(docstring) # helpから関数の解説を確認
- 投稿日:2020-01-19T20:03:33+09:00
[Python pandas] 既存のDataFrameから空のDataFrame作成
以前から、面倒なことをやって来ましたが、これが決定打!です。
df = pd.DataFrame([{field: None for field in df.columns.values}])
- 投稿日:2020-01-19T20:01:26+09:00
深層学習とかでのPythonエラー「AttributeError: module 'scipy.misc' has no attribute 'imresize'」への対処
目的
misc.imresize()で、
AttributeError: module 'scipy.misc' has no attribute 'imresize'というエラーが出る場合がある。
これは、シンプルで、
ぐぐると対策がわかるハズですが、
ちょっと、そういう活動が嫌ですね。
余裕があるときは、少し、調べたりします。
今回、わかったことを記事にします。関係する環境情報
Name: scipy
Version: 1.4.1
Summary: SciPy: Scientific Library for Python
Home-page: https://www.scipy.orgエラーと対策
原因
これは、よくあるscipyのバージョンアップの関連で、
「古いバージョンのsicpyで動作していたものが、scipy version 1.3.0以降でエラーになる」シリーズ?です。対策1 (対策2のほうがいいと思います。)
scipyを1.2.0にする
「1.3.0ではremoveします」と警告は出ますが、動作はします。block_1_hobo_org.py:23: DeprecationWarning: `imresize` is deprecated! `imresize` is deprecated in SciPy 1.0.0, and will be removed in 1.3.0. Use Pillow instead: ``numpy.array(Image.fromarray(arr).resize())``. obs = (misc.imresize(obs, (110, 84))) #===対策2
上記の警告と同時に示される
numpy.array(Image.fromarray(arr).resize())
を使う。対策2を使うときの注意事項
(まず、単に、imresizeという関数なくなりました。別のとこの、
resizeを使いなさいというシンプルでとっても簡単な話なので、
簡単なこととして、心を落ち着けて。。。。)注意1:resizeでのサイズの指定は、tupleです。
注意2:imresizeとresizeは、hightとwidthの順序が逆な気がします。具体的には、
imresize(xxx, (110, 42))だったら、
resize((42,110))
と、逆に書けばいいと思います。
ネットの説明で間違えているサイトがあるような気がします、ご注意。補足(imresizeとresieのhelpを記載)
widthとheightの順序に注目
imresizeのhelp
(余談ですが、コマンドは、例えば、「python -m pydoc PIL.Image.Image.resize」です。 Image.Imageとなります。。。。わかる方は、わかると思いますが。。。。)
C:XXXX>python -m pydoc PIL.Image.Image.resize Help on function resize in PIL.Image.Image: PIL.Image.Image.resize = resize(self, size, resample=0, box=None) Returns a resized copy of this image. :param size: The requested size in pixels, as a 2-tuple: (width, height). :param resample: An optional resampling filter. This can be one of :py:attr:`PIL.Image.NEAREST`, :py:attr:`PIL.Image.BOX`, :py:attr:`PIL.Image.BILINEAR`, :py:attr:`PIL.Image.HAMMING`, :py:attr:`PIL.Image.BICUBIC` or :py:attr:`PIL.Image.LANCZOS`. If omitted, or if the image has mode "1" or "P", it is set :py:attr:`PIL.Image.NEAREST`. See: :ref:`concept-filters`. :param box: An optional 4-tuple of floats giving the region of the source image which should be scaled. The values should be within (0, 0, width, height) rectangle. If omitted or None, the entire source is used. :returns: An :py:class:`~PIL.Image.Image` object.resieのhelp
(余談ですが、、、コマンドは、例えば、「python -m pydoc scipy.misc.imresize」です。)
C:XXXXX>python -m pydoc scipy.misc.imresize Help on function imresize in scipy.misc: scipy.misc.imresize = imresize(*args, **kwds) `imresize` is deprecated! `imresize` is deprecated in SciPy 1.0.0, and will be removed in 1.3.0. Use Pillow instead: ``numpy.array(Image.fromarray(arr).resize())``. Resize an image. This function is only available if Python Imaging Library (PIL) is installed. .. warning:: This function uses `bytescale` under the hood to rescale images to use the full (0, 255) range if ``mode`` is one of ``None, 'L', 'P', 'l'``. It will also cast data for 2-D images to ``uint32`` for ``mode=None`` (which is the default). Parameters ---------- arr : ndarray The array of image to be resized. size : int, float or tuple * int - Percentage of current size. * float - Fraction of current size. * tuple - Size of the output image (height, width). interp : str, optionalまとめ
エラーが出て、
ぐぐって、、、
そうするしかないですが、、、ちょっと、嫌です。
調べて記事にしました。。。。(ぐぐられて役立つつもりで記事にしてるので、矛盾しているのですが、将来の布石。。。。)関連(本人)
深層学習とかでのPythonエラー「ImportError: cannot import name 'imread' from 'scipy.misc' 」への対処
英語と日本語、両方使ってPythonを丁寧に学ぶ。今後
コメントなどあれば、お願いします。
勉強します、、、、
- 投稿日:2020-01-19T19:38:14+09:00
ハイブリッド暗号化が使われる理由(暗号化・復号化速度比較)
公開鍵方式(RSA)による暗号化・復号化は時間がかかることが知られており、ハイブリッドな暗号化が利用される。プログラム(Python)で暗号化復号化する方法のメモを兼ねて、実際に暗号化、復号化の速度を測ってみた。
暗号化の種類
暗号化の種類の簡単なまとめ。
対称暗号(共通鍵)方式
暗号化、復号化に同じ鍵を利用する方式。
AES (ブロック暗号)
ブロック長は128ビット固定、鍵長は128ビット・192ビット・256ビットの3つを利用可。
暗号利用モード
ブロック暗号でブロック長よりも長い情報を暗号化するための方法。
ECB (Electronic CodeBook) モード
単純にブロック分割して暗号化。同じ平文は同じ暗号文になってしまう。非推奨とされる。CBC (Cipher Block Chaining) モード
前のブロックの暗号文とXORして暗号化。最もよく利用される。順次暗号化するので暗号化時に並列処理できない。CTR (CounTeR) モード
ブロック毎にカウンターをインクリメントして暗号化、平文とXORしてブロック暗号を作る。非対称暗号(公開鍵)方式
公開鍵で暗号化、プライベート鍵で複合化する方式。
RSA暗号
大きな数の離散対数や素因数分解が困難なことを利用した暗号。
暗号文=(平文**E) % N
の{E, N}の組が暗号化時の公開鍵となる。
平文=(暗号文**D) % N
の{D, N}の組が復号化時のプライベート鍵となる。
Nとして2048ビット以上の数を用いる。2031年以降新規利用する場合は4096bit以上(ref. NIST SP800-57)。
公開鍵暗号方式でも通信の送受信者の間に悪意のある者が入ると通信を妨害できてしまう(MITM (man-in-the-middle)攻撃)。これを防ぐために公開鍵の証明書が利用される。
RSA-OAEPでは乱数を用いて、同じ平文でも毎回暗号文として異なるものが生成される。楕円曲線暗号
RSAに比べて短い鍵でも強い(224~225ビットの鍵の楕円曲線暗号は2048bitのRSAと同じ強さに相当)。
公開鍵方式と共通鍵方式の併用
数MB以上の大きなファイルを暗号化する場合、公開鍵方式では非常に暗号化、復号化に時間がかかることから共通鍵方式が用いられる。この際に利用する共通鍵を通信するために、公開鍵方式が利用される。両者の暗号強度は同程度が好ましいとされており、NIST Special Publication 800-57 Part 1
Revision 4、「鍵管理における推奨事項」の表2に参考となるセキュリティ強度が記載されている。
セキュリティ強度 秘密鍵(共通鍵)アルゴリズム IFC(例.RSA) 128 AES-128 k = 3072 192 AES-192 k = 7680 256 AES-256 k = 15360 処理時間の比較
AES-256, RSA-4096の処理時間を比較した。
動作環境
- MacBook Pro, Intel Core i5 3.1 GHz, macOS 10.13.6
- Python 3.7.4
- 必要なパッケージをインストール
pip install pycrypto pyOpenSSLAES-256での暗号化、復号化
こちらのサイトを参考に以下のAES256.pyのように実装(実際にファイルの暗号化・復号化に利用するときはパディングを削除する必要がある)。
実行すると、
$ python3 AES256.py File size = 10.0 [MB] Encode: AES_encrypt_time:0.12138915061950684[sec] Decode: AES_decrypt_time:0.12209415435791016[sec]のような結果が得られる。
10MBのファイルを暗号化、復号化するのに約0.12秒かかることがわかる。AES256.pyimport sys,struct,random from Crypto.Cipher import AES from hashlib import sha256 import time import os def generate_salt(digit_num): DIGITS_AND_ALPHABETS = "0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ" return "".join(random.sample(DIGITS_AND_ALPHABETS, digit_num)) # AES-256 def derive_key_and_iv(password, salt, bs): salted = ''.encode() dx = ''.encode() # パスワードからAES-256用のkeyとCBC用の初期ベクトル(iv)を生成 while len(salted) < 48: # 48 = AES256キー長(32byte)+IVの長さ(16byte) hash = dx + password.encode() + salt.encode() dx = sha256(hash).digest() salted = salted + dx key = salted[0:32] # 32byte -> AES-256のキーの長さ iv = salted[32:48] # 16byte (AES.block_sizeと同じサイズ, AESでは128bit(=16byte)固定) return key, iv # 暗号化 def encrypt(in_file, out_file, password): bs = AES.block_size #salt = generate_salt() #Random.new().read(bs - len('Salted__')) salt = generate_salt(AES.block_size) key, iv = derive_key_and_iv(password, salt, bs) cipher = AES.new(key, AES.MODE_CBC, iv) # CBCモードを設定。AESCipherクラスを取得。 out_file.write(('Salted__' + salt).encode()) # saltは暗号化ファイルに書き込む finished = False while not finished: chunk = in_file.read(1024 * bs) orgChunkLen = len(chunk) if len(chunk) == 0 or len(chunk) % bs != 0: padding_length = (bs - len(chunk) % bs) or bs padding = padding_length * chr(padding_length) chunk += padding.encode() finished = True if len(chunk) > 0: out_file.write(cipher.encrypt(chunk)) # 復号化 def decrypt(in_file, out_file, password): bs = AES.block_size in_file.seek(len('Salted__')) salt = in_file.read(16).decode() # saltとパスワードからkey, ivを得る。 key, iv = derive_key_and_iv(password, salt, bs) cipher = AES.new(key, AES.MODE_CBC, iv) # CBCモードを設定。AESCipherクラスを取得。 finished = False while not finished: chunk = in_file.read(1024 * bs) orgChunkLen = len(chunk) if orgChunkLen == 0 or orgChunkLen % bs != 0: padding_length = (bs - orgChunkLen % bs) or bs padding = padding_length * chr(padding_length) chunk += padding.encode() finished = True if orgChunkLen > 0: out_file.write(cipher.decrypt(chunk)[0:orgChunkLen]) def main(filename): infile = open(filename, "rb") outfile = open(filename+"_AES.bin", "wb") print("File size = ", os.path.getsize(filename) /1024/1024, "[MB]") print("Encode:") start = time.time() encrypt(infile,outfile,"password") # openssl enc -e -aes-256-cbc -salt -k "password" -in practice.bin -out practice_aes.bin elapsed_time = time.time() - start print ("AES_encrypt_time:{0}".format(elapsed_time) + "[sec]") infile.close() outfile.close() print("Decode:") outinfile = open(filename+"_AES.bin", "rb") outfile2 = open(filename+"_dec_AES.bin", "wb") start = time.time() decrypt(outinfile,outfile2,"password") elapsed_time = time.time() - start print ("AES_decrypt_time:{0}".format(elapsed_time) + "[sec]") outinfile.close() outfile2.close() if __name__== "__main__": filename = "practice.bin" main(filename)RSAでの暗号化、復号化
基本的にRSAは大きなサイズのデータを暗号化するために利用されることを想定していない。速度測定のためにチャンクに分けて実装したが、一般に推奨されるものではない。大きなサイズのデータはAESなど対称暗号を利用して暗号化する。
こちらのサイトを参考にコード改変し、196byteのチャンク単位で暗号化するようにした。
実行すると、
$ python3 RSA2048.py max_data_len= 196 Generate Key: privatePem len = 1674 publicPem len = 450 Load Key: File size = 10.0 [MB] Encode: RSA_encrypt_time:46.78378772735596[sec] Decode: RSA_decrypt_time:123.22586274147034[sec]のような結果が得られる。
10MBのファイルを暗号化するのに約47秒、復号化するのに約123秒かかることがわかる。
AESではそれぞれ約0.12秒だったため、RSAは暗号化で約400倍遅く、復号化では約1000倍遅いことがわかる。RSA2048.pyfrom Crypto.PublicKey import RSA from Crypto.Cipher import PKCS1_OAEP import base64 import time import os modulus_length = 2048 # bit max_data_len = int((int(modulus_length/8.0) - 11 )*0.8) # RSAで暗号化できる最大サイズはキーサイズより小さい。パディングに何を使うかに依存。 print("max_data_len=",max_data_len) def generate_keys(): key = RSA.generate(modulus_length) pub_key = key.publickey() return key, pub_key def encrypt_private_key(a_message, private_key): encryptor = PKCS1_OAEP.new(private_key) encrypted_msg = encryptor.encrypt(a_message) encoded_encrypted_msg = base64.b64encode(encrypted_msg) return encoded_encrypted_msg def decrypt_public_key(encoded_encrypted_msg, public_key): encryptor = PKCS1_OAEP.new(public_key) decoded_encrypted_msg = base64.b64decode(encoded_encrypted_msg) decoded_decrypted_msg = encryptor.decrypt(decoded_encrypted_msg) return decoded_decrypted_msg def encrypt_file(in_file, out_file, key): finished =False while not finished: chunk = in_file.read(max_data_len) if len(chunk) == 0 or len(chunk)%max_data_len: finished = True encdata = encrypt_private_key(chunk, key) a_number = len(encdata) out_file.write(a_number.to_bytes(4, byteorder='little')) out_file.write(encdata) out_file.close() def decrypt_file(in_file, out_file, key): finished =False while not finished: bnum = in_file.read(4) inum = int.from_bytes(bnum, byteorder='little') chunk = in_file.read(inum) if len(chunk) == 0 or len(chunk)%inum: finished = True if len(chunk) != 0: decdata = decrypt_public_key(chunk, key) out_file.write(decdata[0:len(chunk)]) out_file.close() def main(filename): print("Generate Key:") private, public = generate_keys() privateFile = open("private.pem","wb") privatePem = private.exportKey(format='PEM') print("privatePem len = ", len(privatePem)) privateFile.write(privatePem) privateFile.close() publicFile = open("public.pem","wb") publicPem = public.exportKey(format='PEM') print("publicPem len = ", len(publicPem)) publicFile.write(publicPem) publicFile.close() #print (private) #message = b'AES password or key' #print(message) #encoded = encrypt_private_key(message, public) #decrypt_public_key(encoded, private) print("Load Key:") privateFile = open("private.pem","rb") private_pem = privateFile.read() privateFile.close() private_key = RSA.importKey(private_pem) publicFile = open("public.pem","rb") public_pem = publicFile.read() publicFile.close() public_key = RSA.importKey(public_pem) print("File size = ", os.path.getsize(filename) /1024/1024, "[MB]") print("Encode:") infile = open(filename, "rb") outfile = open(filename+"_RSA.bin", "wb") start = time.time() encrypt_file(infile,outfile,public_key) elapsed_time = time.time() - start print ("RSA_encrypt_time:{0}".format(elapsed_time) + "[sec]") infile.close() outfile.close() print("Decode:") infile = open(filename+"_RSA.bin", "rb") outfile = open(filename+"_dec_RSA.bin", "wb") start = time.time() decrypt_file(infile,outfile,private_key) elapsed_time = time.time() - start print ("RSA_decrypt_time:{0}".format(elapsed_time) + "[sec]") infile.close() outfile.close() if __name__== "__main__": filename = "practice.bin" main(filename)まとめ
PythonでAESおよびRSAのテストコードを作成し、対称暗号方式(AES)と公開鍵方式(RSA)による暗号化・復号化にかかる時間を実測、RSAがどの程度高コストなのかを確認した。
10MBのファイルを暗号化復号化するのに、AESでは約0.12秒だったのに対して、RSAは暗号化で約400倍遅く、復号化では約1000倍遅いことがわかる。
実際のTSLやPGP(GnuPG)では公開鍵方式で対称暗号方式の鍵(に相当するデータ)をやりとりし、実際のデータは対称暗号が使われるが、これは今回の結果のように処理速度に大きな違いがあるためである。
- 参考図書:暗号技術入門 第3版、結城浩、SBクリエイティブ, 2015
- 投稿日:2020-01-19T19:00:54+09:00
言語処理100本ノックでPythonに入門
この記事は、C言語は少しわかるけどPythonはほぼ知らない状態で、自然言語処理を始めたい人向けです。自然言語処理の入門として名高い言語処理100本ノック2015の問題を解けるようになる最短ルートを目指しています。
Pythonは公式のドキュメントがかなり親切で、チュートリアルを読めば自力で勉強できるとは思うので、本記事では100本ノックを解くのに必要な事項だけ触っていきたいと思います。インストール
頑張りましょう。MacOSなら
$ brew install python3、Ubuntuなら$ sudo apt install python3.7 python3.7-dev素のWindowsではPythonインストール(Win10)編などを参考にするのが簡単と思われます。
対話モードでコードを実行する
コマンドラインで
$ python3とか$ python3.7などというコマンドを打ってPython3が起動できればOKです。これでPythonが対話モードで実行できる状態になります。このモードでは何か式を入力してEnterを押すと式の評価結果が返ってきます>>> 1+23Pythonの特徴の一つに「動的型付け」というものがあります。Cとは異なり、変数の型を宣言する必要は無いですし、整数(int)型が浮動小数点数(float)型になったりします。
>>> a = 1 >>> a = 5/2 >>> a2.5組み込み型
まずはPythonの標準で使える型(組み込み型)にはどういうものがあるのか見ていきましょう。上の例で出てきたintやfloatといった数値型もその一つです。100本ノック第一章では次に挙げる型だけ知っていれば解けます。
- 文字列
- リスト
- 集合
- 辞書(マッピング)文字列(str)型
言語処理をするのでまず文字列型からやっていきます。Pythonで文字列を記述するには
'か"で囲うだけです!日本語もばっちりです。文字列同士は簡単に結合させることがきます。>>> "ようこそ"'ようこそ'>>> 'hoge' + 'fuga''hogefuga'
- Cの配列のように、添え字でアクセスできます
- 負の添え字を使うと文字列の後ろからアクセスできます
>>> word = 'Python' >>> word[0]'P'>>> word[-1]'n'
- 「スライス」を使うと部分文字列を簡単に取得できます!
word[i:j]でi番目以上j番目未満の要素を取得iまたはjを省略すると「端」という意味になる>>> word[1:4]'yth'>>> word[2:-1]'tho'>>> word[:2]'thon'>>> word[2:]'thon'
word[i:j:k]でi番目以上j番目未満の要素をk個毎に取得できます>>> word[1:5:2]'yh'>>> word[::2]'Pto'>>> word[::-2]'nhy'100本ノック00番, 01番をやってみよう
文字列"stressed"の文字を逆に(末尾から先頭に向かって)並べた文字列を得よ.
nlp00.pyword = 'stressed' word[::-1]'desserts'「パタトクカシーー」という文字列の1,3,5,7文字目を取り出して連結した文字列を得よ.
nlp01.pyword = 'パタトクカシー' word[::2]'パトカー'リスト(list)型
リスト型はCで習った配列のパワーアップ版だと思えば大丈夫です。次のように記述します。
squares = [1, 4, 9, 16, 25]空のリストは次のように書きます。
empty = []リスト型は文字列型と同じように添え字アクセスやスライスができます。このような組み込み型をまとめてシーケンス型と呼んだりします。
>>> squares[:3][1, 4, 9]メソッド
Pythonでは、各々のデータ型専用の関数というものがあり、それらをメソッドと呼びます。
例えば、リスト型がもつappendメソッドはリストに要素を追加します。呼び出すには次のようにリスト.append()と書きます。>>> squares.append(36) >>> squares[1, 4, 9, 16, 25, 36]文字列型のメソッドもいくつか紹介します。
-x.split(sep):文字列xをsepで区切ることでリストを作ります
-sep.join(list):listの要素をsepで結合した文字列を作ります
-x.strip(chars):文字列の両端からcharsを削った文字列を返します
-x.rstrip(chars):文字列の右端からcharsを削った文字列を返します>>> 'I have a pen.'.split(' ')['I', 'have', 'a', 'pen.']>>> ' '.join(['I', 'have', 'a', 'pen.'])'I have a pen.'
join()がリスト型ではなく文字列型のメソッドなのは若干覚えにくいかもしれません。stack overflowを要約すると、リストの各要素が文字列になっていないと適用不可能だから、とのことです。>>> 'ehoge'.strip('e')'hog'>>> 'ehoge'.rstrip('e')'ehog'>>> 'ehoge'.rstrip('eg') # 右端からeまたはgをできるだけ削る、という意味'eho'for文
リストを理解したところで、何かの処理を繰り返すために使うfor文を扱います。
例えばCで配列の要素の総和を求めるときは次のように書いていました。int i; int squares[6] = {1, 4, 6, 16, 25, 36}; int total = 0; for(i = 0; i < 6; i++) { total = total + squares[i]; }Pythonのfor文はこうなります。
total = 0 for square in squares: total = total + square各ループで
squaresの要素が1個ずつ取り出されてsquareに代入されます。つまり、square=1,square=4,,,という具合です。
まとめるとこんな感じになります。for 要素を表す変数 in リストとか:
TAB 処理内容
inの直後を「リストとか」というように誤魔化していますが、文字列型でもOKです(各文字が文字列の要素とみなせるからです)。for文のinの直後に置けるものはイテラブル(オブジェクト)(iterable)といいますが、pythonではfor文で回せそうなものは大抵回せるのであまり気にしなくてOKです。なお、インデントはCでは任意でしたがPythonでは強制です!
組み込み関数
print()
実際にforループ中の変数の値を見てみましょう。対話モードではforブロック中の変数などを評価して値を表示してくれたりしないので、
print()関数を使います。引数は文字列型でなくなても標準出力してくれます。Cでいうところの# includeみたいなことをせずに使うことができます。このような関数は組み込み関数といいます。for square in squares: print(square)1 4 9 16 25 36このように、Pythonの
print()関数は(デフォルトでは)自動で改行してくれます。
改行を防ぐときは次のようにオプション引数endを指定します。for square in squares: print(square, end=' ')1 4 9 16 25 36len()
便利な組み込み関数を紹介していきます。
len()はリストや文字列などの長さを返します。>>> len(squares)6>>> len('あいうえお')5range()
range()は一般にfor文をn回まわしたいときに使います。for i in range(3): print(i)0 1 2※
range()の戻り値はrange型と呼ばれるもので、シーケンス型の一種です。しかし使い道はfor文かリスト型などに変換して使うくらいです。>>> range(3)range(0, 3)list(range(4))[0, 1, 2, 3]100本ノック02
このあたりでソースコードをファイルに保存して実行する方法もやってみましょう。
例えばprint('Hello World')とだけ書いたファイルをhello.pyという名前で保存し、コマンドラインで$ python3 hello.pyと打つと'Hello World'と出力されるはずです。
といったところで100本ノックの続きをやってみましょう。「パトカー」+「タクシー」の文字を先頭から交互に連結して文字列「パタトクカシーー」を得よ
これまで学んだ範囲でやってみましょう。
nlp02.pystr_a = 'パトカー' str_b = 'タクシー' for i in range(len(str_a)): print(str_a[i]+str_b[i], end='')パタトクカシーーこんなとき、組み込み関数
zip()を使えばもっと簡単に書けます。この関数は引数のイテラブルオブジェクトからi番目の要素を組にしてくれます。>>> list(zip(str_a, str_b))[('パ', 'タ'), ('ト', 'ク'), ('カ', 'シ'), ('ー', 'ー')]よって上のコードは次のように書き換えられます。とてもよく使う関数です。
for a, b in zip(str_a, str_b): print(a+b, end='')パタトクカシーータプル(tuple)型
上の説明を見て「このカンマはなんだ?」と思わなかった人はこの節を飛ばして問03を解きましょう。
この
zip()が各ループで取り出しているオブジェクトはstr_a[i]とstr_b[i]を要素とするリストみたいなものです。正しくは、タプルというもので、リストの変更不能版です。>>> list(zip(str_a, str_b))[('パ', 'タ'), ('ト', 'ク'), ('カ', 'シ'), ('ー', 'ー')]タプルはシーケンスの1種なので添え字アクセスはできますが
append()などで要素を追加することはできません。Pythonでは変更可能なものをミュータブル、変更不能なものをイミュータブルといいます。これまでスルーしてきましたが、リストはミュータブルで、文字列やタプルはイミュータブルです。>>> a = 'abc' >>> a[1] = 'a'--------------------------------------------------------------------------- TypeError Traceback (most recent call last) <ipython-input-56-ae17b2fd35d6> in <module> 1 a = 'abc' ----> 2 a[1] = 'a' TypeError: 'str' object does not support item assignment>>> a = [0, 9, 2] >>> a[1] = 1 >>> a[0, 1, 2]タプルは
()で囲んで記述しますが、通常は外側の()は不要です(関数の引数を書く()の内側などでは省略不可です)。>>> 1, 2, 3(1, 2, 3)タプルのパックとシーケンスのアンパックという代入方法
タプルの
()を省略して記述できる仕様を利用して、,区切りの複数の値をまとめて1つの変数に代入することをタプルのパックといいます。対照的に、1つのシーケンスを複数の変数にまとめて代入することをシーケンスのアンパックといいます。>>> a = 'a' >>> b = 'b' >>> t = a, b >>> t('a', 'b')>>> x, y = t >>> print(x) >>> print(y)a b横道が長くなってしまいましたが、これで
for a, b in zip(str_a, str_b):の正体がわかりました。各ループでzip関数が返すタプルをa,bという変数にアンパックしているというわけです。100本ノック03
"Now I need a drink, alcoholic of course, after the heavy lectures involving quantum mechanics."という文を単語に分解し,各単語の(アルファベットの)文字数を先頭から出現順に並べたリストを作成せよ.
この問題、ピリオドとカンマはアルファベットではないので除去しないと円周率になりません。
nlp03.pysent = "Now I need a drink, alcoholic of course, after the heavy lectures involving quantum mechanics." words = sent.split() ans = [] for word in words: ans.append(len(word.rstrip('.,'))) print(ans)[3, 1, 4, 1, 5, 9, 2, 6, 5, 3, 5, 8, 9, 7, 9]もっと良い書き方が実はあるのですが(リスト内包表記)、現段階では見なかったことにして大丈夫です。
ans = [len(word.rstrip('.,')) for word in words]辞書(dict)型
文字列やリストなどでは、要素にアクセスするのに添え字、すなわちある範囲の整数を使っていましたが、辞書型は自分が定義した「キー」でアクセスすることができます。例えば、ある単語の出現回数を記憶させたいので、キーを単語、値を出現回数とした辞書を作る、という用途があります。辞書オブジェクトは次のように定義して値を取り出します。また作った辞書にキーと値のペアを簡単に追加できます。
>>> dic = {'I':141, 'you':112} >>> dic{'I': 141, 'you': 112}>>> dic['I']141>>> dic['have'] = 256 >>> dic{'I': 141, 'you': 112, 'have': 256}※ キーにできるのは「ハッシュ可能」な型と言われますが、純粋なイミュータブルオブジェクト(文字列とかタプルとか)であればなんでも大丈夫です。
ブール(bool)型
等式や不等式などが評価されるとTrueかFalseが返ってきます。
>>> 1 == 1True>>> 1 == 2False>>> 1 < 2 <= 3Truein演算
forを伴わない
inは所属関係を判定します。>>> 1 in [1, 2, 3]True
in演算が定義されているものはコンテナ型と呼ばれますが、文字列もリストもタプルも辞書も全て大丈夫なので気にしなくて大丈夫です。if文
Pythonのif文はCとそっくりですが、
else ifではなくelifであることに注意しましょう。if 1==2: print('hoge') elif 1==3: print('fuga') else: print('bar')bar100本ノック04
"Hi He Lied Because Boron Could Not Oxidize Fluorine. New Nations Might Also Sign Peace Security Clause. Arthur King Can."という文を単語に分解し,1, 5, 6, 7, 8, 9, 15, 16, 19番目の単語は先頭の1文字,それ以外の単語は先頭に2文字を取り出し,取り出した文字列から単語の位置(先頭から何番目の単語か)への連想配列(辞書型もしくはマップ型)を作成せよ.
nlp04.pysent = "Hi He Lied Because Boron Could Not Oxidize Fluorine. New Nations Might Also Sign Peace Security Clause. Arthur King Can." positions = [1, 5, 6, 7, 8, 9, 15, 16, 19] words = sent.split() i = 1 ans = {} for word in words: if i in positions: key = word[0] else: key = word[:2] ans[key] = i i += 1print(ans){'H': 1, 'He': 2, 'Li': 3, 'Be': 4, 'B': 5, 'C': 6, 'N': 7, 'O': 8, 'F': 9, 'Ne': 10, 'Na': 11, 'Mi': 12, 'Al': 13, 'Si': 14, 'P': 15, 'S': 16, 'Cl': 17, 'Ar': 18, 'K': 19, 'Ca': 20}組み込み関数の
enumerate()を使うとループ回数をくっつけてくれるので、もっと簡単に書けます。とてもよく使います。普通にやると0から始まるのでオプション引数start=1を指定しています。ans = {} for i, word in enumerate(words, start=1): if i in where: key = word[0] else: key = word[:2] ans[key] = i関数定義、100本ノック05
次は100本ノック05をやってみましょう。
与えられたシーケンス(文字列やリストなど)からn-gramを作る関数を作成せよ.この関数を用い,"I am an NLPer"という文から単語bi-gram,文字bi-gramを得よ.
pythonで自作の関数を定義したいときは次のように書けばOKです。
def function_name(argument):
TAB 処理出力形式は指定されていないですが、例えば次のような出力をするコードを書いてみましょう。
[['I', 'am'], ['am', 'an], ['an', 'NLPer']]
シーケンスとnを引数とする関数を作れば大丈夫そうです。def ngram(seq, n): lis = [] for i in range(len(seq) - n + 1): lis.append(seq[i:i+n]) return lisここまでできた人は、
nlp05.pyという名前のファイルに次のようなこと書いて保存し、コマンドラインで$ python3 nlp05.pyと実行しましょう。nlp05.pydef ngram(seq, n): lis = [] for i in range(len(seq) - n + 1): lis.append(seq[i:i+n]) return lis if __name__ == '__main__': sent = 'I am an NLPer' words = sent.split(' ') lis = ngram(words, 2) print(lis) lis = ngram(sent, 2) print(lis)
if __name__ == '__main__':の部分は次の問題でインポートをするので必要です。疑問に思う人はいったんこの行を書かないでおくと良いと思います。また、ngram関数は次のような別解があるのですが、説明が少々長くなるので省略します。
def ngram(seq, n): return list(zip(*(seq[i:] for i in range(n))))集合(set)型、100本ノック06
次は100本ノック06です。
"paraparaparadise"と"paragraph"に含まれる文字bi-gramの集合を,それぞれ, XとYとして求め,XとYの和集合,積集合,差集合を求めよ.さらに,'se'というbi-gramがXおよびYに含まれるかどうかを調べよ.
とりあえず次のようなコードを動かしてみましょう。
from nlp05 import ngram x = set(ngram('paraparaparadise', 2)) print(x){'is', 'se', 'di', 'ap', 'ad', 'ar', 'pa', 'ra'}
from nlp05 import ngramの部分で先ほど作ったngram関数を「インポート」しています。set型は手で
x = {'pa', 'ar'}と定義することもできますが、他のコンテナ型からset()を使ってつくることもあります。和集合は
|、積集合は&、差集合は-で求めることができます。nlp06.pyfrom nlp05 import ngram x = set(ngram('paraparaparadise', 2)) y = set(ngram('paragraph', 2)) print(x | y) print(x & y) print(x - y) print(y - x) print('se' in x) print('se' in y){'is', 'se', 'di', 'ph', 'ap', 'ag', 'ad', 'ar', 'pa', 'gr', 'ra'} {'ra', 'ap', 'pa', 'ar'} {'is', 'se', 'ad', 'di'} {'ag', 'gr', 'ph'} True Falseこのin演算、問題04のようにリストに適用するとO(n)かかるので、できれば集合型に使いましょう。
文字列書式設定、100本ノック07
100本ノック07を解きます。
引数x, y, zを受け取り「x時のyはz」という文字列を返す関数を実装せよ.さらに,x=12, y="気温", z=22.4として,実行結果を確認せよ.
これを文字列同士を
+で結合しまくる方法でやるのは大変です。Pythonでは3つの方法があります。printf 形式
>>> x = 12 >>> y = '気温' >>> '%d時の%s' % (x, y)'12時の気温'str.format() (Python2.6以降)
>>> '{}時の{}'.format(x, y)'12時の気温'f-string (Python3.6以降)
>>> f'{x}時の{y}''12時の気温'どれを使えばええんねん
基本的にはf-stringが一番楽。ただし桁数を指定する場合はprintf形式が高速らしいです(参考)
これで07番は特に迷うことなくできるでしょう。100本ノック08, 09
08のコードポイントと文字の変換をやってくれる組み込み関数
ord()とchr()を使えばできます。09はrandomモジュールの
shuffle()かsample()を使えばできます。インポートを忘れずに。2章の前に
最後に、ファイル読み込みの方法だけやっておきます。
Pythonではファイルポインタがイテラブルオブジェクトになっています。ですのでテキストファイルを1行ずつ読みたいときは次のように書きます。with open('hightemp.txt') as f: for line in f: print(line, end='')with構文は、
f = open('hightemp.txt')の実行と、ブロックを抜けるときのf.close()を勝手にやってくれる優れものです。ファイルを読み書きするときにぜひ使いましょう。for文の各ループでは
lineに各行の内容が代入されています。ファイルに書き込みたいときは
open()の第2引数に'w'を渡し、f.write(line)などを使えばよいです。標準入力を一行ずつ読みたいときは
sys.stdinを使います。import sys for line in sys.stdin: print(line, end='')おわりに
これでPythonの基本を押さえることができたはずです。本当は内包表記、イテレータ、ジェネレータ、引数リストのアンパックあたりの内容も扱いたかったのですが、断腸の思いで割愛しました。興味のある人は調べてみて下さい。
- 投稿日:2020-01-19T17:46:50+09:00
Flaskアプリをherokuにデプロイ(苦苦々)
Flaskアプリをherokuにデプロイ(苦苦々)
なかなか苦労させられる。
$ heroku logs --tailで遭遇したエラー
error code=H10 desc="App crashed"
error code=h14 desc="no web processes running"
など。
それぞれをStackoverflowなどで対処療法しても解決しない。
しかし下記の方法でうまく行った。Python仮想環境を作る
$ virtualenv flaskapp $ cd flaskapp仮想環境をアクティベイトする
$ source bin/activateこんな感じになる。
$ (flaskapp) $ここでマシン環境に影響を及ぼさずにpipでいろいろインストールできる。
たとえば、
$ (flaskapp) $ pip install requests $ (flaskapp) $ pip install Flaskとかとか。
ここではgunicornとFlaskをインストールする。
$ (flaskapp) $ pip3 install Flask gunicorn【gunicorn参考】: GunicornはpythonのWSGI(Web Server Gateway Interface) HTTP ServerでRubyのUnicornの派生。Gunicornは様々なフレームワークと比べると、とってもシンプルな実装で、軽量なサーバー。
参照:https://qiita.com/arata-honda/items/09e1c350b1bd8a186e9c
【使い方】
pip install gunicornでgunicornをインストールして、
gunicorn hello:appで起動する。Herokuの準備
Herokuのサインインは済んでいる前提
Heroku CLIインストール
$ (flaskapp) $ wget -qO- https://cli-assets.heroku.com/install-ubuntu.sh | shHerokuにログイン
$ (flaskapp) $ heroku login準備ファイル
- Procfile
$ echo "web: gunicorn app:app --log-file -" > Procfile
- requirements.txt
$ (flaskapp) $ pip3 freeze > requirements.txt Click==7.0 Flask==1.1.1 gunicorn==20.0.4 itsdangerous==1.1.0 Jinja2==2.10.3 MarkupSafe==1.1.1 Werkzeug==0.16.0
- runtime.txt(任意)
$ (flaskapp) $ python -V | sed -n "s/Python /python-/p" > runtime.txt
- app.py
from flask import Flask import os app = Flask(__name__) @app.route('/') def hello_world(): return 'Hello World!' if __name__ == "__main__": app.run(host="0.0.0.0", port=int(os.environ.get("PORT", 5000)))ここでただ単にapp.run()としないところが味噌。
この時点でローカルでちゃんと動くか確認。
$ (flaskapp) $ python app.py * Serving Flask app "app" (lazy loading) * Environment: production WARNING: This is a development server. Do not use it in a production deployment. Use a production WSGI server instead. * Debug mode: off * Running on http://0.0.0.0:5000/ (Press CTRL+C to quit) $ curl http://127.0.0.1:5000 Hello World!herokuへデプロイ
$ (flaskapp) $ git init $ (flaskapp) $ echo "*.DS_Store" > .gitignore $ (flaskapp) $ git add . $ (flaskapp) $ git commit -m 'first commit' $ (flaskapp) $ heroku create $ (flaskapp) $ git push heroku master動作確認
HerokuコンソールのResources画面でProcfileのフレーズが表示されているか確認
画面右上のOpen appボタンをクリック
別画面が開いて無事にHello Worldと表示された。

- 投稿日:2020-01-19T17:22:01+09:00
66日目 【Kaggle入門】一番カンタンなTitanic予想
Kaggleの「Titanic: Machine Learning from Disaster」にチャレンジしてみました。
Kaggleは機械学習の練度を競う武闘会・・・のようです。
エントリーすると初心者向けのコンテンツがありましたので、さっそくガイダンスの動画を見ます。
超早口な英語!!!
中身はタイタニックの事故の概要と、データセットの解説、チュートリアル、Kaggleの使い方などなどでした。早口すぎて聞き取れないので、日本語Wikiのタイタニック号沈没事故に目を通しておきます。
ざっくりまとめると、
・深夜眠っている間の事故だったので、初動が遅れに遅れた。
・救命道具が十分になかった。(安全だと思われていた)
・貴族と平民、男性と女性、年齢で生存率が大きく違う。図を見た印象ですが、氷山にぶつかって穴があいたエリアの死亡率が高いのではと思います。
船の全景がわかるトレーラー。映画ですが船の大きさ、人数、当時の雰囲気がつかめると思います。(この人たちがこれから・・・)
予測に使うデータ
訓練用が891、テストデータが418ありました。
データの定義は次のとおりです。
変数 定義 備考 Survived 生存したかどうか 0 = No, 1 = Yes Pclass チケットのクラス 1 = 1st, 2 = 2nd, 3 = 3rd Name 名前 Sex 性別 Age 年齢 SibSp 乗船していた兄弟姉妹・配偶者の数 Parch 乗船していた親・子供の数 Ticket チケット番号 Fare チケット料金 Cabin キャビン番号 embarked 乗船した港 C = Cherbourg, Q = Queenstown, S = Southampton さてプログラミング!
プログラムの例は「Notebook」にどっさり投稿されてるので人気のものをいくつかチェック。
日本語のチュートリアルもありました。
Kaggleタイタニック はじめの一歩 (1st Step for Kaggle Titanic)ざっくり読んで頭がごちゃごちゃになったので、まずは話をカンタンにするため全員生存モデルを作りました。"Survived"がぜんぶ1の列を作ってKaggleにアップするだけです。
Titanic全員生存モデル["Survived"] = 1
00.pyimport pandas as pd # CSVを読み込む test = pd.read_csv('test.csv') # Survived列を追加。 test["Survived"] = 1 #確認 print(test["Survived"]) #提出用にPassengerIdとSurvivedだけにする。 test = test.loc[:,['PassengerId','Survived']] #CSVに出力(インデックスは不要) test.to_csv('titanic1-1.csv',index=False)できたCSVを確認し、Kaggleにコミットします。
Public Score 0.37320
lederbord 15800位
Public Scoreが実際の生存率(31.9%)に近い値となりました。
lederbordはその人の最高だったスコアで順位がつくらしく、正確な順位はわからなかったのですが0.37320は15800位のあたりでした。同じスコアの集団、つまり世界には同じ事を考えている人がこんなにいる・・・これはちょっと・・・感動してしまいました。
最下位は0、下から数えて70位でした。スコア0ということは全問正解の裏返しということで、これはこれで気になるスコアです。
全員死亡モデル
["Survived"] = 0としたCSVをKaggleにアップします。
1 - 0.37320 = 0.6268なので同じくらいの値を期待した所、Public Score:0.62679でした。だいたい合っています。男性死亡、女性生存モデル
今度は男性なら死亡、女性なら生存と単純に割り振ってみます。
タイタニックでは男性の死亡率が高く、女性の生存率が高かったので、これでも予測が上がるはずです。01.py#pandasを使います import pandas as pd # CSVを読み込む test = pd.read_csv('test.csv') # Survived列を追加 test["Survived"] = 0 #女性だったら1(生存)に置き換え test.loc[test["Sex"] == 'female', "Survived"] = 1 #提出用にPassengerIdとSurvivedだけにする。 test = test.loc[:,['PassengerId','Survived']] #CSVに出力(インデックスは不要) test.to_csv('titanic1.csv',index=False)Public Score:0.76555
lederbord:12457位/15000人くらい?
Gender Based ModelのCSVと中身が一緒のようです。
ごくシンプルなモデルでも
0.76555ですから、ここからどうやって予測の精度をあげるかが腕の見せ所なのでしょう。まずはルールの確認というあたりです。


- 投稿日:2020-01-19T17:21:55+09:00
【Kaggle】Baseline modelの構築、Pipeline処理
0. はじめに
Kaggleなどで機械学習を用いて回帰・分類をする際のおおまかな流れは、
データの読み込み→欠損値処理→ラベルエンコーディング→
→EDA→ワンホットエンコーディング→
→ベースラインモデルの作成→複雑なモデルの構築→
→パラメーターチューニング
みたいな感じです。その中でも、ベースラインモデルでの回帰・分類は割とパターンとして解けます。
さらに、そこにPipeline処理を用いることでより素早く解けます。
そこで、今回はベースラインモデルの構築、パイプライン処理についてまとめてみました。1. 準備
今回用いたデータセットは、Kaggleに落ちているtitanicのデータセットです。
ワンホットエンコーディングまではこんな感じ。
ここまでの詳細は前回の記事にまとめています。In[1]%matplotlib inline import matplotlib as plt import pandas as pd import numpy as np import seaborn as sns import collections df = pd.read_csv('./train.csv') df = df.set_index('PassengerId') #一意性がある列をindexに設定する df = df.drop(['Name', 'Ticket'], axis=1) #分析に不要な列をdropする df = df.drop(['Cabin'], axis=1) #分析には使いにくそうなので削除 df = df.dropna(subset = ['Embarked']) #Cabinは欠損が少ないのでdropnaで行で削除 df = df.fillna(method = 'ffill') #他の列は前のデータから補完 from sklearn.preprocessing import LabelEncoder for column in ['Sex','Embarked']: le = LabelEncoder() le.fit(df[column]) df[column] = le.transform(df[column]) df_continuous = df[['Age','SibSp','Parch','Fare']] df = pd.get_dummies(df, columns = ['Pclass','Embarked']) df.head()次に、これをtrain_test_splitでtrainデータとtestデータに分割します。
In[2]from sklearn.model_selection import train_test_split X = df.drop(['Survived'], axis=1) y = df['Survived'] validation_size = 0.20 seed = 42 X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=validation_size,random_state=seed)2. Baseline Modelの作成
Thanks: https://www.kaggle.com/mdiqbalbajmi/titanic-survival-prediction-beginner
必要なライブラリはこんな感じ。
In[3]from sklearn.model_selection import KFold from sklearn.model_selection import cross_val_score from sklearn.neighbors import KNeighborsClassifier from sklearn.discriminant_analysis import LinearDiscriminantAnalysis from sklearn.naive_bayes import GaussianNB from sklearn.svm import SVC from sklearn.linear_model import LogisticRegression from sklearn.tree import DecisionTreeClassifier今回は、この6つのアルゴリズムをベースモデルとして用います。
- Logistic回帰
- 線形判別
- KNN(k近傍法)
- CART(決定木)
- ガウシアンナイーブベイズ
- サポートベクターマシーン
また、KFoldによる交叉検証を用いて、各モデルのスコアの分散も確認します。
In[4]# Spot-check Algorithms models = [] # In LogisticRegression set: solver='lbfgs',multi_class ='auto', max_iter=10000 to overcome warning models.append(('LR',LogisticRegression(solver='lbfgs',multi_class='auto',max_iter=10000))) models.append(('LDA',LinearDiscriminantAnalysis())) models.append(('KNN',KNeighborsClassifier())) models.append(('CART',DecisionTreeClassifier())) models.append(('NB',GaussianNB())) models.append(('SVM',SVC(gamma='scale'))) # evaluate each model in turn results = [] names = [] for name, model in models: # initializing kfold by n_splits=10(no.of K) kfold = KFold(n_splits = 10, random_state=seed, shuffle=True) #crossvalidation # cross validation score of given model using cross-validation=kfold cv_results = cross_val_score(model,X_train,y_train,cv=kfold, scoring="accuracy") # appending cross validation result to results list results.append(cv_results) # appending name of algorithm to names list names.append(name) # printing cross_validation_result's mean and standard_deviation print(name, cv_results.mean()*100.0, "(",cv_results.std()*100.0,")")出力はこんな感じ。
out[4]LR 80.15845070422536 ( 5.042746503951439 ) LDA 79.31533646322379 ( 5.259067356458109 ) KNN 71.1658841940532 ( 3.9044128926316235 ) CART 76.50821596244131 ( 4.1506876372712815 ) NB 77.91471048513301 ( 4.426999157571688 ) SVM 66.9424882629108 ( 6.042153317290744 )これを箱ひげ図で可視化します。
In[5]figure = plt.figure() figure.suptitle('Algorithm Comparison') ax = figure.add_subplot(111) plt.boxplot(results) ax.set_xticklabels(names);出力されたグラフがこちらです。
3. Pipeline処理
複数の処理がある時、それらの処理をパイプライン化しておくことでいくつか嬉しいことがあります。
コードが簡潔にできたり、GridSearchと組み合わせることでハイパーパラメーターの探索が簡単になったりなど。今回は、Standard Scaling(標準化)とモデルによる分類をパイプライン化してみます。
In[6]# import pipeline to make machine learning pipeline to overcome data leakage problem from sklearn.pipeline import Pipeline # import StandardScaler to Column Standardize the data # many algorithm assumes data to be Standardized from sklearn.preprocessing import StandardScaler # test options and evaluation matrix num_folds=10 seed=42 scoring='accuracy' # import warnings filter from warnings import simplefilter # ignore all future warnings simplefilter(action='ignore', category=FutureWarning)warningが出てくるので、そのまわりも対処しています。
ベースモデルごとにpipelineを構築し、それらをpipelinesに格納します。
In[7]# source of code: machinelearningmastery.com # Standardize the dataset pipelines = [] pipelines.append(('ScaledLR', Pipeline([('Scaler', StandardScaler()),('LR',LogisticRegression(solver='lbfgs',multi_class='auto',max_iter=10000))]))) pipelines.append(('ScaledLDA', Pipeline([('Scaler', StandardScaler()),('LDA',LinearDiscriminantAnalysis())]))) pipelines.append(('ScaledKNN', Pipeline([('Scaler', StandardScaler()),('KNN',KNeighborsClassifier())]))) pipelines.append(('ScaledCART', Pipeline([('Scaler', StandardScaler()),('CART',DecisionTreeClassifier())]))) pipelines.append(('ScaledNB', Pipeline([('Scaler', StandardScaler()),('NB',GaussianNB())]))) pipelines.append(('ScaledSVM', Pipeline([('Scaler', StandardScaler()),('SVM', SVC(gamma='scale'))]))) results = [] names = [] for name, model in pipelines: kfold = KFold(n_splits=num_folds, random_state=seed) cv_results = cross_val_score(model, X_train, y_train, cv=kfold, scoring=scoring) results.append(cv_results) names.append(name) msg = "%s: %f (%f)" % (name, cv_results.mean()*100, cv_results.std()) print(msg)出力がこちらです。
out[7]ScaledLR: 79.743740 (0.029184) ScaledLDA: 79.045383 (0.042826) ScaledKNN: 82.838419 (0.031490) ScaledCART: 78.761737 (0.028512) ScaledNB: 77.779734 (0.037019) ScaledSVM: 82.703443 (0.029366)これを箱ひげ図にプロットします。
In[8]# Compare Algorithms fig = plt.figure() fig.suptitle('Algorithm Comparison') ax = fig.add_subplot(111) plt.boxplot(results) ax.set_xticklabels(names) plt.show()出力されたグラフはこの通り。
4. まとめ
ベースラインモデルの構築、パイプライン処理についてまとめてみました。
パイプライン処理は中々奥が深そうですね。記事ネタ、コメントなど随時募集中です。
- 投稿日:2020-01-19T17:02:04+09:00
ケモインフォマティクスで学ぶPandas
はじめに
ケモインフォマティクスで学ぶNumPyに続き、リピドミクス(脂質の網羅解析)を題材として、Pythonの代表的なライブラリの一つである「Pandas」について解説していきます。
ケモインフォマティクスの実践例を中心に説明していきますので、基本を確認したいという人は以下の記事を読んでからこの記事を読んでみてください。SeriesとDataFrameの作成
Pandasを使うことで、表計算を簡単に行えるようになります。
ライブラリを利用するには、まず
importでライブラリを読み込みます。
慣習的に、pdと略すことが多いです。Pandasでは、「Series」と「DataFrame」の2種類のデータ構造を扱います。
Seriesは1次元のデータで、リストや辞書に似たデータ構造になります。
import pandas as pd index_fatty_acids = ['FA 16:0', 'FA 16:1', 'FA 18:0', 'FA 18:1', 'FA 18:2', 'FA 18:3', 'FA 18:4', 'FA 20:0', 'FA 20:3', 'FA 20:4', 'FA 20:5'] numbers_carbon = pd.Series([16, 16, 18, 18, 18, 18, 18, 20, 20, 20, 20], index=index_fatty_acids) numbers_unsaturation = pd.Series([0, 1, 0, 1, 2, 3, 4, 0, 3, 4, 5], index=index_fatty_acids) print(numbers_carbon) print(numbers_unsaturation)上の例で、
index_fatty_acidsは、データの名称のようなものだと思ってもらえればいいと思います。
下のように、辞書をもとにSeriesを作ることもできます。index_fatty_acidsを辞書のキーとします。
ただ、コードが長くなってしまうので、index=でリストを指定する方が良いでしょう。import pandas as pd numbers_carbon = pd.Series({ 'FA 16:0': 16, 'FA 16:1': 16, 'FA 18:0': 18, 'FA 18:1': 18, 'FA 18:2': 18, 'FA 18:3': 18, 'FA 18:4': 18, 'FA 20:0': 20, 'FA 20:3': 20, 'FA 20:4': 20, 'FA 20:5': 20 }) print(numbers_carbon)一方、DataFrameは、Seriesを結合して作られる2次元のデータになります。
import pandas as pd index_fatty_acids = ['FA 16:0', 'FA 16:1', 'FA 18:0', 'FA 18:1', 'FA 18:2', 'FA 18:3', 'FA 18:4', 'FA 20:0', 'FA 20:3', 'FA 20:4', 'FA 20:5'] numbers_carbon = pd.Series([16, 16, 18, 18, 18, 18, 18, 20, 20, 20, 20], index=index_fatty_acids) numbers_unsaturation = pd.Series([0, 1, 0, 1, 2, 3, 4, 0, 3, 4, 5], index=index_fatty_acids) df_fatty_acids = pd.DataFrame({'Cn': numbers_carbon, 'Un': numbers_unsaturation}) print(df_fatty_acids)上の例で、
pd.DataFrameの中にある辞書のキーは、表の列名にあたります。
一方、先ほどSeriesを作成した時に指定したindexは、行名になります。
ちなみに、df_fatty_acidsのdfは、 「dataframe」の略です。データの参照
DataFrameの行名と列名を参照するには、それぞれ
indexとcolumnsを用います。import pandas as pd index_fatty_acids = ['FA 16:0', 'FA 16:1', 'FA 18:0', 'FA 18:1', 'FA 18:2', 'FA 18:3', 'FA 18:4', 'FA 20:0', 'FA 20:3', 'FA 20:4', 'FA 20:5'] numbers_carbon = pd.Series([16, 16, 18, 18, 18, 18, 18, 20, 20, 20, 20], index=index_fatty_acids) numbers_unsaturation = pd.Series([0, 1, 0, 1, 2, 3, 4, 0, 3, 4, 5], index=index_fatty_acids) df_fatty_acids = pd.DataFrame({'Cn': numbers_carbon, 'Un': numbers_unsaturation}) print(df_fatty_acids.index) # 行名 print(df_fatty_acids.columns) # 列名DataFrameの特定の要素にアクセスするには、以下のように書きます。
import pandas as pd index_fatty_acids = ['FA 16:0', 'FA 16:1', 'FA 18:0', 'FA 18:1', 'FA 18:2', 'FA 18:3', 'FA 18:4', 'FA 20:0', 'FA 20:3', 'FA 20:4', 'FA 20:5'] numbers_carbon = pd.Series([16, 16, 18, 18, 18, 18, 18, 20, 20, 20, 20], index=index_fatty_acids) numbers_unsaturation = pd.Series([0, 1, 0, 1, 2, 3, 4, 0, 3, 4, 5], index=index_fatty_acids) df_fatty_acids = pd.DataFrame({'Cn': numbers_carbon, 'Un': numbers_unsaturation}) print(df_fatty_acids['Cn']) # 列名を指定 print(df_fatty_acids.Cn) # 列名を指定 print(df_fatty_acids['Cn'][0]) # 列名を指定し、行番号を指定 print(df_fatty_acids[2:5]) # 行番号(インデックス番号)をスライスで指定 print(df_fatty_acids[5:]) # 指定した行番号以降のデータを抽出 print(df_fatty_acids[:5]) # 指定した行番号までのデータを抽出 print(df_fatty_acids[-5:]) # 後ろから数えた行番号 print(df_fatty_acids[2:5]['Cn']) # 行番号と列名を指定 print(df_fatty_acids.loc['FA 16:0', 'Cn']) # 行名と列名を指定 print(df_fatty_acids.loc['FA 16:0']) # 行名を指定 print(df_fatty_acids.loc[:, 'Cn']) # 列名を指定 print(df_fatty_acids.iloc[0, 0]) # 行番号と列番号を指定 print(df_fatty_acids.iloc[0]) # 行番号を指定 print(df_fatty_acids.iloc[:, 0]) # 列番号を指定 print(df_fatty_acids.iloc[-1, -1]) # 最後の行の最後の列の要素行名や列名を指定するのが良いのか、行番号や列番号を指定するのか良いのかは、ケースバイケースなので、その都度やりやすい方を選ぶのが良いでしょう。
また、指定した条件を満たすデータを抽出することもできます。
import pandas as pd index_fatty_acids = ['FA 16:0', 'FA 16:1', 'FA 18:0', 'FA 18:1', 'FA 18:2', 'FA 18:3', 'FA 18:4', 'FA 20:0', 'FA 20:3', 'FA 20:4', 'FA 20:5'] numbers_carbon = pd.Series([16, 16, 18, 18, 18, 18, 18, 20, 20, 20, 20], index=index_fatty_acids) numbers_unsaturation = pd.Series([0, 1, 0, 1, 2, 3, 4, 0, 3, 4, 5], index=index_fatty_acids) df_fatty_acids = pd.DataFrame({'Cn': numbers_carbon, 'Un': numbers_unsaturation}) print(df_fatty_acids[df_fatty_acids['Cn'] >= 18]) # 条件を満たす行を抽出したDataFrame print(df_fatty_acids[df_fatty_acids['Cn'] >= 18]['Cn']) # 条件を満たす行を抽出したDataFrameで列名を指定して抽出 print(df_fatty_acids[df_fatty_acids['Cn'] >= 18].iloc[:, 0]) # 条件を満たす行を抽出したDataFrameで列番号を指定して抽出 print(df_fatty_acids[(df_fatty_acids['Cn'] >= 18) & (df_fatty_acids['Un'] >= 2)]) # 複数の条件を指定(and) print(df_fatty_acids[(df_fatty_acids['Cn'] >= 18) | (df_fatty_acids['Un'] >= 1)]) # 複数の条件を指定(or)複数の条件を指定する時は、条件ごとにかっこ
()が必要です。忘れないようにしましょう。データの追加
DataFrame名['列名']で、特定の列を指定できますが、DataFrameにない列名を指定した場合、新たに列が作成されます。
また、別の列のデータをもとに、計算することも簡単にできます。import pandas as pd index_fatty_acids = ['FA 16:0', 'FA 16:1', 'FA 18:0', 'FA 18:1', 'FA 18:2', 'FA 18:3', 'FA 18:4', 'FA 20:0', 'FA 20:3', 'FA 20:4', 'FA 20:5'] numbers_carbon = pd.Series([16, 16, 18, 18, 18, 18, 18, 20, 20, 20, 20], index=index_fatty_acids) numbers_unsaturation = pd.Series([0, 1, 0, 1, 2, 3, 4, 0, 3, 4, 5], index=index_fatty_acids) df_fatty_acids = pd.DataFrame({'Cn': numbers_carbon, 'Un': numbers_unsaturation}) df_fatty_acids['C'] = df_fatty_acids['Cn'] df_fatty_acids['H'] = df_fatty_acids['Cn'] * 2 - df_fatty_acids['Un'] * 2 df_fatty_acids['O'] = 2 print(df_fatty_acids)上の例では、
CnとUnの列の値をもとに、各脂肪酸分子種の炭素原子数Cと水素原子数Hを計算しています。
df_fatty_acidsを出力すると、新たにCとHとOの列が追加されていることが分かります。算術計算
次に、各脂肪酸分子種の精密質量を求めることを考えてみます。
import pandas as pd index_fatty_acids = ['FA 16:0', 'FA 16:1', 'FA 18:0', 'FA 18:1', 'FA 18:2', 'FA 18:3', 'FA 18:4', 'FA 20:0', 'FA 20:3', 'FA 20:4', 'FA 20:5'] numbers_carbon = pd.Series([16, 16, 18, 18, 18, 18, 18, 20, 20, 20, 20], index=index_fatty_acids) numbers_unsaturation = pd.Series([0, 1, 0, 1, 2, 3, 4, 0, 3, 4, 5], index=index_fatty_acids) df_fatty_acids = pd.DataFrame({'Cn': numbers_carbon, 'Un': numbers_unsaturation}) df_fatty_acids['C'] = df_fatty_acids['Cn'] df_fatty_acids['H'] = df_fatty_acids['Cn'] * 2 - df_fatty_acids['Un'] * 2 df_fatty_acids['O'] = 2 df_fatty_acids['Exact mass'] = pd.Series([0] * len(index_fatty_acids), index=index_fatty_acids) # とりあえず全ての行に0を入れておく exact_masses = pd.Series({'C': 12, 'H': 1.00783, 'O': 15.99491}) for atom in exact_masses.index: df_fatty_acids['Exact mass'] += exact_masses[atom] * df_fatty_acids[atom] # 精密質量を計算 print(df_fatty_acids)上の例では、各原子の精密質量に原子数をかけたものを足し合わせることで脂肪酸分子の精密質量を求めています。
文字列の結合
次に、組成式を求めてみます。
import pandas as pd index_fatty_acids = ['FA 16:0', 'FA 16:1', 'FA 18:0', 'FA 18:1', 'FA 18:2', 'FA 18:3', 'FA 18:4', 'FA 20:0', 'FA 20:3', 'FA 20:4', 'FA 20:5'] numbers_carbon = pd.Series([16, 16, 18, 18, 18, 18, 18, 20, 20, 20, 20], index=index_fatty_acids) numbers_unsaturation = pd.Series([0, 1, 0, 1, 2, 3, 4, 0, 3, 4, 5], index=index_fatty_acids) df_fatty_acids = pd.DataFrame({'Cn': numbers_carbon, 'Un': numbers_unsaturation}) df_fatty_acids['C'] = df_fatty_acids['Cn'] df_fatty_acids['H'] = df_fatty_acids['Cn'] * 2 - df_fatty_acids['Un'] * 2 df_fatty_acids['O'] = 2 df_fatty_acids['Molecular formula'] = pd.Series([''] * len(index_fatty_acids), index=index_fatty_acids) # とりあえず全ての行に空文字を入れておく exact_masses = pd.Series({'C': 12, 'H': 1.00783, 'O': 15.99491}) for atom in exact_masses.index: df_fatty_acids['Molecular formula'] += atom + df_fatty_acids[atom].astype(str) # 組成式をかく print(df_fatty_acids)元素記号と原子数を文字列として結合させれば良いわけですが、
C、H、Oに入っているデータは数値のため、結合する前に文字列に変換する必要があります。
そこで、上の例ではastype(str)として、数値を文字列に変換した上で結合しているわけです。外部ファイルへの出力
次は出来上がったデータを外部ファイルとして出力することを考えます。
import pandas as pd index_fatty_acids = ['FA 16:0', 'FA 16:1', 'FA 18:0', 'FA 18:1', 'FA 18:2', 'FA 18:3', 'FA 18:4', 'FA 20:0', 'FA 20:3', 'FA 20:4', 'FA 20:5'] numbers_carbon = pd.Series([16, 16, 18, 18, 18, 18, 18, 20, 20, 20, 20], index=index_fatty_acids) numbers_unsaturation = pd.Series([0, 1, 0, 1, 2, 3, 4, 0, 3, 4, 5], index=index_fatty_acids) df_fatty_acids = pd.DataFrame({'Cn': numbers_carbon, 'Un': numbers_unsaturation}) df_fatty_acids['C'] = df_fatty_acids['Cn'] df_fatty_acids['H'] = df_fatty_acids['Cn'] * 2 - df_fatty_acids['Un'] * 2 df_fatty_acids['O'] = 2 df_fatty_acids['Exact mass'] = pd.Series([0] * len(index_fatty_acids), index=index_fatty_acids) df_fatty_acids['Exact mass'] = pd.Series([0] * len(index_fatty_acids), index=index_fatty_acids) exact_masses = pd.Series({'C': 12, 'H': 1.00783, 'O': 15.99491}) for atom in exact_masses.index: df_fatty_acids['Exact mass'] += exact_masses[atom] * df_fatty_acids[atom] # 精密質量 for atom in exact_masses.index: df_fatty_acids['Molecular formula'] += atom + df_fatty_acids[atom].astype(str) # 組成式 df_fatty_acids.to_csv('fatty_acids.csv') # CSVファイルとして出力 df_fatty_acids.to_csv('fatty_acids.txt', sep='\t') # タブ区切りテキストファイルとして出力 df_fatty_acids.to_excel('fatty_acids.xlsx', sheet_name='fatty_acids') # エクセルファイルとして出力外部ファイルの読み込み
逆に、外部ファイルを読み込むには、以下のようにします。
import pandas as pd df_csv = pd.read_csv('fatty_acids.csv', index_col=0) #CSVファイルを読み込み df_text = pd.read_csv('fatty_acids.txt', sep='\t', index_col=0) # タブ区切りテキストファイルを読み込み df_excel = pd.read_excel('fatty_acids.xlsx', index_col=0) # エクセルファイルを読み込み print(df_csv) print(df_text) print(df_excel)DataFrameの最初あるいは最後の数行のみを読み込むには以下のようにします。
import pandas as pd df_csv = pd.read_csv('fatty_acids.csv', index_col=0) #CSVファイルを読み込み df_text = pd.read_csv('fatty_acids.txt', sep='\t', index_col=0) # タブ区切りテキストファイルを読み込み df_excel = pd.read_excel('fatty_acids.xlsx', index_col=0) # エクセルファイルを読み込み print(df_csv.head()) # 最初の5行を表示 print(df_csv.head(3)) # 最初の3行を表示 print(df_csv.tail()) # 最後の5行を表示
headは、最初の指定した行数のデータを、tailは最後の指定した行数のデータを抽出します。
行数を指定しなかった場合は、デフォルトで5行分が表示されます。
df_textやdf_excelについても同様です。以上のように、外部ファイルをDataFrameとして読み込んで、どのような形でデータが格納されているか分かれば、特定の行や列を抽出したり、新しい列を追加して計算したりして、出来上がった表を出力する、というのがデータ分析の基本的な流れになります。
まとめ
ここでは、Pandasについて、ケモインフォマティクスで使える実践的な知識を中心に解説しました。
もう一度要点をおさらいしておきましょう。
- Pandasでは、SeriesとDataFrameの2種類のデータ構造を扱えます。
- 特定の行や列を抽出したり、条件を満たすデータのみを取り出したりなど、データベース操作のような処理ができます。
- 外部ファイルを読み込んだり、出力したりすることもできます。
次回は、Matplotlibについて解説する予定です。
参考資料・リンク
- 投稿日:2020-01-19T16:59:21+09:00
Djangoでテスト駆動開発 その1
Djangoでテスト駆動開発 1
なぜやるのか
Django Girls Tutorialをはじめ、先人たちのありがたいリソースを使って独学でDjangoの勉強をしてきましたが、Djangoでのテスト駆動開発を身に着けられる日本語リソースは見当たりませんでした。私のように独学でプログラミングを進めている方々の少しでも参考になればと思い、投稿させて頂きます。
これはDjangoでテスト駆動開発(Test Driven Development, 以下:TDD)を理解していくための記録です。
まだまだ勉強不足のため、間違っている点があれば御指摘頂けると幸いです。。今回はTest-Driven Development with Python: Obey the Testing Goat: Using Django, Selenium, and JavaScript (English Edition) 2nd Editionを元に学習を進めていきます。
こちらの参考文献ではDjango1.1系とFireFoxを使って機能テスト等を実施していますが、今回はDjagno3系とGoogle Chromeで機能テストを実施していきます。また一部、個人的な改造を行っていますが(Project名をConfigに変えるなど、、)、大きな変更はありません。
それではやっていきましょう。
仮想環境の構築
# projectディレクトリの作成 $ mkdir django-TDD $ cd djagno-TDD # 仮想環境の作成 $ python -m venv venv-tdd # 仮想環境の有効化 $ venv-tdd/Script/activate # pipとsetuptoolsのアップグレード $ python -m pip install --upgrade pip setuptools # DjangoとSeleniumのインストール $ pip install django selenium installing collected packages: sqlparse, pytz, asgiref, django, urllib3, selenium Successfully installed asgiref-3.2.3 django-3.0.2 pytz-2019.3 selenium-3.141.0 sqlparse-0.3.0 urllib3-1.25.7Google Chromeを使って機能テストを実施するので、Google ChromeのWebドライバーをダウンロードする。
現在の環境がGoogle Chromeバージョン: 79.0.3945.130(Official Build) (64 ビット)なので、
Google Chrome DriverはChromeDriver 79.0.3945.16をダウンロードした。Part1. The Basics of TDD and Django
Chapter1. Getting Django Set Up Using a Functional Test
Websiteを作成することを決めたとき、通常の最初のステップはweb-frameworkをインストールして設定を書き換えて、、と進めていくが、TDDでは必ずテストを最初に書く。
TDDの開発サイクルは、下記を徹底することである。
- テストを書く
- テストを実行して失敗することを確認する。
- テストが成功するようにコードを書く。
最初に我々が確認したいことは、、、
確認事項
- Djangoがインストールされていて、問題なく働くこと。
確認方法
- ローカルでDjangoの開発用サーバーが確認できること。
これを実施するためにSeleniumを使ってブラウザを自動で操作させる。
機能テストを書く
functional_tests.pyを作成する。
# django-tdd/functional_tests.py from selenium import webdriver browser = webdriver.Chrome() browser.get('http://localhost:8000') assert 'Django' in browser.titleこれが最初の機能テストとなる。これを実行する。
$ python functional_tests.py Traceback (most recent call last): File "functional_tests.py", line 8, in <module> assert 'Django' in browser.title AssertionErrorブラウザがseleniumによって自動で起動されるが、エラーページが表示されるのがわかる。シェル上でもAssertionErrorが表示されていることがわかる。これを解決したい。
Djagnoを起動する
この機能テストをクリアさせるためにDjagnoプロジェクトを開始して、開発用サーバーを起動する。
$ django-admin startproject config . $ python manage.py runserver Watching for file changes with StatReloader Performing system checks... System check identified no issues (0 silenced). You have 17 unapplied migration(s). Your project may not work properly until you apply the migrations for app(s): admin, auth, contenttypes, sessions. Run 'python manage.py migrate' to apply them. January 19, 2020 - 15:36:31 Django version 3.0.2, using settings 'config.settings' Starting development server at http://127.0.0.1:8000/ Quit the server with CTRL-BREAK.Django(3.0.2)はconfig.settingsを使って開発用サーバ
http://127.0.0.1:8000/を起動したことがわかる。ここで別のシェルを起動して仮想環境を有効にした後、機能テストを実行する。
$ python manage.py functional_tests.py DevTools listening on ws://127.0.0.1:54716/devtools/browser/6ddf9ee8-7b35-41f5-8700-d740ef24c8dcこの結果、AssertionErrorは表示されず、ブラウザでもエラーは表示されなかった。
機能テストを実行して、Djagnoが確かに機能していることが確認された!!!!
Gitレポジトリに登録
TDDはVersion Control Systemとともに進められる。
$ git init . $ type nul > .gitignoregitで管理したくないものを.gitignoreで管理する。
#.gitignore db.sqlite3 debug.log /venv-tdd.gitignoreを作成したので、これで変更を追加する。
$ git add . $ git status On branch master No commits yet Changes to be committed: (use "git rm --cached <file>..." to unstage) new file: .gitignore new file: .vscode/settings.json new file: README.md new file: README_Part1.md new file: chromedriver.exe new file: config/__init__.py new file: config/__pycache__/__init__.cpython-37.pyc new file: config/__pycache__/settings.cpython-37.pyc new file: config/__pycache__/urls.cpython-37.pyc new file: config/__pycache__/wsgi.cpython-37.pyc new file: config/asgi.py new file: config/settings.py new file: config/urls.py new file: config/wsgi.py new file: functional_tests.py new file: manage.pyここで変更に加えたくないhoge.pycや、pycacheフォルダなどが変更に追加されてしまった。これを除外させたい。
$ git rm -r --chashed config/__pycache__ .vscode.gitignoreを編集する
# .gitignore db.sqlite3 debug.log /venv-tdd .vscode __pycache__ *.pyc$ git status On branch master No commits yet Changes to be committed: (use "git rm --cached <file>..." to unstage) new file: .gitignore new file: README.md new file: README_Part1.md new file: chromedriver.exe new file: config/__init__.py new file: config/asgi.py new file: config/settings.py new file: config/urls.py new file: config/wsgi.py new file: functional_tests.py new file: manage.py Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git checkout -- <file>..." to discard changes in working directory) modified: .gitignore modified: README_Part1.md狙い通りにgit statusが修正された。
これでコミットする。$ git add .ここで、commitする前に、Djagnoのconfig/settings.pyでのSECRET_KRYなどもコミットさせたくない。
$ git rm -r --cached config/settings.py $ git status On branch master No commits yet Changes to be committed: (use "git rm --cached <file>..." to unstage) new file: .gitignore new file: README.md new file: README_Part1.md new file: chromedriver.exe new file: config/__init__.py new file: config/asgi.py new file: config/urls.py new file: config/wsgi.py new file: functional_tests.py new file: manage.py Changes not staged for commit: (use "git add <file>..." to update what will be committed) (use "git checkout -- <file>..." to discard changes in working directory) modified: README_Part1.md Untracked files: (use "git add <file>..." to include in what will be committed) config/settings.pypython-dotenvをつかってシステム変数を.envファイルにまとめてコミットしないようにする。
$ pip install python-dotenvconfig/settings.pyを変更
# config/settings.py """ Django settings for config project. Generated by 'django-admin startproject' using Django 3.0.2. For more information on this file, see https://docs.djangoproject.com/en/3.0/topics/settings/ For the full list of settings and their values, see https://docs.djangoproject.com/en/3.0/ref/settings/ """ import os from dotenv import load_dotenv # 追加 # Build paths inside the project like this: os.path.join(BASE_DIR, ...) BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) PROJECT_NAME = os.path.basename(BASE_DIR) # 追加 # Quick-start development settings - unsuitable for production # See https://docs.djangoproject.com/en/3.0/howto/deployment/checklist/ # .envの読み込み load_dotenv(os.path.join(BASE_DIR, '.env')) # 追加 # SECURITY WARNING: keep the secret key used in production secret! SECRET_KEY = os.getenv('SECRET_KEY') # 変更 # SECURITY WARNING: don't run with debug turned on in production! DEBUG = True ALLOWED_HOSTS = ['*'] # 変更 # Application definition INSTALLED_APPS = [ 'django.contrib.admin', 'django.contrib.auth', 'django.contrib.contenttypes', 'django.contrib.sessions', 'django.contrib.messages', 'django.contrib.staticfiles', ] MIDDLEWARE = [ 'django.middleware.security.SecurityMiddleware', 'django.contrib.sessions.middleware.SessionMiddleware', 'django.middleware.common.CommonMiddleware', 'django.middleware.csrf.CsrfViewMiddleware', 'django.contrib.auth.middleware.AuthenticationMiddleware', 'django.contrib.messages.middleware.MessageMiddleware', 'django.middleware.clickjacking.XFrameOptionsMiddleware', ] ROOT_URLCONF = 'config.urls' TEMPLATES = [ { 'BACKEND': 'django.template.backends.django.DjangoTemplates', 'DIRS': [os.path.join(BASE_DIR, 'templates')], # 変更 'APP_DIRS': True, 'OPTIONS': { 'context_processors': [ 'django.template.context_processors.debug', 'django.template.context_processors.request', 'django.contrib.auth.context_processors.auth', 'django.contrib.messages.context_processors.messages', ], }, }, ] WSGI_APPLICATION = 'config.wsgi.application' # Database # https://docs.djangoproject.com/en/3.0/ref/settings/#databases DATABASES = { 'default': { 'ENGINE': 'django.db.backends.sqlite3', 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'), } } # Password validation # https://docs.djangoproject.com/en/3.0/ref/settings/#auth-password-validators AUTH_PASSWORD_VALIDATORS = [ { 'NAME': 'django.contrib.auth.password_validation.UserAttributeSimilarityValidator', }, { 'NAME': 'django.contrib.auth.password_validation.MinimumLengthValidator', }, { 'NAME': 'django.contrib.auth.password_validation.CommonPasswordValidator', }, { 'NAME': 'django.contrib.auth.password_validation.NumericPasswordValidator', }, ] # Internationalization # https://docs.djangoproject.com/en/3.0/topics/i18n/ LANGUAGE_CODE = 'ja' # 変更 TIME_ZONE = 'Asia/Tokyo' # 変更 USE_I18N = True USE_L10N = True USE_TZ = True # Static files (CSS, JavaScript, Images) # https://docs.djangoproject.com/en/3.0/howto/static-files/ STATIC_URL = '/static/'この状態で変更を追加して、コミットする。
$ type nul > .env.envにSECRET_KEYを追加。
# .env SECRET_KEY = 'your_secret_key'.gitignoreに.envを追加する。
db.sqlite3 debug.log /venv-tdd .vscode __pycache__ *.pyc .env # 追加変更を記録する。
$ git add . $ git status $ git commit -m "first commit!"Chapter1 まとめ
機能テストを記述するところからDjangoプロジェクトをスタートしました。
この調子で読み進めていきます。
- 投稿日:2020-01-19T16:54:02+09:00
Pythonで、デザインパターン「Decorator」を学ぶ
GoFのデザインパターンを学習する素材として、書籍「増補改訂版Java言語で学ぶデザインパターン入門」が参考になるみたいですね。
ただ、取り上げられている実例は、JAVAベースのため、自分の理解を深めるためにも、Pythonで同等のプラクティスに挑んでみました。
■ Decorator(デコレータ・パターン)
Decoratorパターン(デコレータ・パターン)とは、GoF(Gang of Four; 4人のギャングたち)によって定義されたデザインパターンの1つである。 このパターンは、既存のオブジェクトに新しい機能や振る舞いを動的に追加することを可能にする。
□ 備忘録
オブジェクトにどんどんデコレーション(飾り付け)を施していくようなデザインパターンとのことです。
スポンジケーキに、クリームを塗り、イチゴを載せればストロベリーショートケーキになるような感じです。
Pythonプログラミングに携わっていると、よくお目にかかるやつですね。■ "Decorator"のサンプルプログラム
実際に、Decoratorパターンを活用したサンプルプログラムを動かしてみて、次のような動作の様子を確認したいと思います。
- 文字列
Hello, world.をそのまま表示する- 文字列
Hello, world.の前後に、#文字を差し込んで表示する- 文字列
Hello, world.の前後に、#文字を差し込んで、さらに、 枠線で囲んで表示する- 文字列
HELLOを 枠線で囲んで、前後に、*文字を差し込んで、さらに、 枠線で2回囲んで、、、(以下、略)$ python Main.py Hello, world. #Hello, world.# +---------------+ |#Hello, world.#| +---------------+ /+-----------+/ /|+---------+|/ /||*+-----+*||/ /||*|HELLO|*||/ /||*+-----+*||/ /|+---------+|/ /+-----------+/見た目、ハノイの塔みたいな表示になりました。
■ サンプルプログラムの詳細
Gitリポジトリにも、同様のコードをアップしています。
https://github.com/ttsubo/study_of_design_pattern/tree/master/Decorator/step1
- ディレクトリ構成
. ├── Main.py └── decorator ├── __init__.py ├── border.py └── display.py(1) Componentの役
機能を追加するときの核に役です。
Component役は。スポンジケーキのインタフェースだけを定めます。
サンプルプログラムでは、Displayクラスが、この役を努めます。decorator/display.pyfrom abc import ABCMeta, abstractmethod class Display(metaclass=ABCMeta): @abstractmethod def getColumns(self): pass @abstractmethod def getRows(self): pass @abstractmethod def getRowText(self, row): pass def show(self): for i in range(self.getRows()): print(self.getRowText(i)) ... (snip)(2) ConcreteComponentの役
Component役のインタフェースを実装している具体的なスポンジケーキです。
サンプルプログラムでは、StringDisplayクラスが、この役を努めます。decorator/display.pyclass StringDisplay(Display): def __init__(self, string): self.string = string def getColumns(self): return len(self.string) def getRows(self): return 1 def getRowText(self, row): if row == 0: return self.string else: return None(3) Decorator(装飾者)の役
Component役と同じインタフェースを持ちます。そして、さらに、このDecorator役が飾る対象となるComponent役を持っています。この役は、自分が飾っている対象を「知っている」わけです。
サンプルプログラムでは、Borderクラスが、この役を努めます。decorator/border.pyfrom decorator.display import Display class Border(Display): def __init__(self, display): self.display = display(4) ConcreteDecorator(具体的な装飾者)の役
具体的な
Decoratorの役です。
サンプルプログラムでは、SideBorderクラスと、FullBorderクラスが、この役を努めます。decorator/border.pyclass SideBorder(Border): def __init__(self, display, ch): super(SideBorder, self).__init__(display) self.__borderChar = ch def getColumns(self): return 1 + self.display.getColumns() + 1 def getRows(self): return self.display.getRows() def getRowText(self, row): return self.__borderChar + self.display.getRowText(row) + self.__borderChar class FullBorder(Border): def __init__(self, display): super(FullBorder, self).__init__(display) def getColumns(self): return 1 + self.display.getColumns() + 1 def getRows(self): return 1 + self.display.getRows() + 1 def getRowText(self, row): if row == 0: return '+' + self.__make_line('-', self.display.getColumns()) + '+' elif row == self.display.getRows() + 1: return '+' + self.__make_line('-', self.display.getColumns()) + '+' else: return '|' + self.display.getRowText(row - 1) + '|' def __make_line(self, char, count): buf = '' for _ in range(count): buf += char return buf(5) Client(依頼人)の役
サンプルプログラムでは、
startMainメソッドが、この役を努めます。Main.pyfrom decorator.display import StringDisplay from decorator.border import SideBorder, FullBorder def startMain(): b1 = StringDisplay('Hello, world.') b2 = SideBorder(b1, '#') b3 = FullBorder(b2) b1.show() b2.show() b3.show() print("") b4 = SideBorder( FullBorder( FullBorder( SideBorder( FullBorder( StringDisplay('HELLO') ), '*' ) ) ), '/' ) b4.show() if __name__ == '__main__': startMain()□ 備忘録 (Pythonデコレータを活用してみる!) -その1-
Pythonプログラミングで、よく、デコレータを見かける機会が多いので、
startMainメソッドの部分をPythonデコレータで書き換えてみたいと思います。こちらのブログ記事「Python: 色々なデコレータの作り方と使い方、そして本質」を参考になりました。
Gitリポジトリにも、同様のコードをアップしています。
https://github.com/ttsubo/study_of_design_pattern/tree/master/Decorator/step2decorator/display.pyfrom abc import ABCMeta, abstractmethod className = [] class Display(metaclass=ABCMeta): @abstractmethod def getColumns(self): pass @abstractmethod def getRows(self): pass @abstractmethod def getRowText(self, row): pass def show(self): for i in range(self.getRows()): print(self.getRowText(i)) class StringDisplay(Display): def __init__(self, func): self.string = "Hello, world." self.func = func super(StringDisplay, self).__init__() def getColumns(self): return len(self.string) def getRows(self): return 1 def getRowText(self, row): if row == 0: return self.string else: return None def __call__(self): global className className.append(self) return self.func()decorator/border.pyfrom decorator.display import Display, className class Border(Display): def __init__(self, display): self.display = display super(Border, self).__init__() class SideBorder(Border): def __init__(self, func): self.func = func self.__borderChar = '#' super(SideBorder, self).__init__(func) def getColumns(self): return 1 + self.display.getColumns() + 1 def getRows(self): return self.display.getRows() def getRowText(self, row): return self.__borderChar + self.display.getRowText(row) + self.__borderChar def __call__(self): global className className.append(self) return self.func() class FullBorder(Border): def __init__(self, func): self.func = func super(FullBorder, self).__init__(func) def getColumns(self): return 1 + self.display.getColumns() + 1 def getRows(self): return 1 + self.display.getRows() + 1 def getRowText(self, row): if row == 0: return '+' + self.__make_line('-', self.display.getColumns()) + '+' elif row == self.display.getRows() + 1: return '+' + self.__make_line('-', self.display.getColumns()) + '+' else: return '|' + self.display.getRowText(row - 1) + '|' def __make_line(self, char, count): buf = '' for _ in range(count): buf += char return buf def __call__(self): global className className.append(self) return self.func()Main.pyfrom decorator.display import StringDisplay, className from decorator.border import FullBorder, SideBorder def startMain(): @FullBorder @SideBorder @StringDisplay def dummy1(): className[2].show() className[1].show() className[0].show() dummy1() print("") className.clear() @SideBorder @FullBorder @FullBorder @SideBorder @FullBorder @StringDisplay def dummy2(): className[0].show() dummy2() if __name__ == '__main__': startMain()動かしてみます。
$ python Main.py Hello, world. #Hello, world.# +---------------+ |#Hello, world.#| +---------------+ #+-------------------+# #|+-----------------+|# #||#+-------------+#||# #||#|Hello, world.|#||# #||#+-------------+#||# #|+-----------------+|# #+-------------------+#ここでのやり方では、枠線の文字を
#と、文字列Hello, world.を埋め込みにしてしまったので、プログラミングの柔軟性が損なってしまった結果になってしまいました。□ 備忘録 (Pythonデコレータを活用してみる!) -その2-
枠線の文字や、文字列を適時、指定できるように、Pythonデコレータのやり方を、さらに改善してみます。
こちらのQiita記事「OpenStackを活用して、WSGI アプリケーションの仕組みを理解するを参考にしています。Gitリポジトリにも、同様のコードをアップしています。
https://github.com/ttsubo/study_of_design_pattern/tree/master/Decorator/step3decorator/display.pyfrom abc import ABCMeta, abstractmethod className = [] class Display(metaclass=ABCMeta): @abstractmethod def getColumns(self): pass @abstractmethod def getRows(self): pass @abstractmethod def getRowText(self, row): pass def show(self): for i in range(self.getRows()): print(self.getRowText(i)) class StringDisplay(Display): def __init__(self, func, string): self.string = string self.func = func super(StringDisplay, self).__init__() def getColumns(self): return len(self.string) def getRows(self): return 1 def getRowText(self, row): if row == 0: return self.string else: return None def __call__(self): global className className.append(self) return self.func() def StringDisplay_filter(string): def filter(func): return StringDisplay(func, string) return filterdecorator/border.pyfrom decorator.display import Display, className class Border(Display): def __init__(self, display): self.display = display super(Border, self).__init__() class SideBorder(Border): def __init__(self, func, ch): self.func = func self.__borderChar = ch super(SideBorder, self).__init__(func) def getColumns(self): return 1 + self.display.getColumns() + 1 def getRows(self): return self.display.getRows() def getRowText(self, row): return self.__borderChar + self.display.getRowText(row) + self.__borderChar def __call__(self): global className className.append(self) return self.func() def SideBorder_filter(ch): def filter(func): return SideBorder(func, ch) return filter class FullBorder(Border): def __init__(self, func): self.func = func super(FullBorder, self).__init__(func) def getColumns(self): return 1 + self.display.getColumns() + 1 def getRows(self): return 1 + self.display.getRows() + 1 def getRowText(self, row): if row == 0: return '+' + self.__make_line('-', self.display.getColumns()) + '+' elif row == self.display.getRows() + 1: return '+' + self.__make_line('-', self.display.getColumns()) + '+' else: return '|' + self.display.getRowText(row - 1) + '|' def __make_line(self, char, count): buf = '' for _ in range(count): buf += char return buf def __call__(self): global className className.append(self) return self.func()Main.pyfrom decorator.display import StringDisplay_filter, className from decorator.border import SideBorder_filter, FullBorder def startMain(): @FullBorder @SideBorder_filter('#') @StringDisplay_filter("Hello, world.") def dummy1(): className[2].show() className[1].show() className[0].show() dummy1() print("") className.clear() @SideBorder_filter('/') @FullBorder @FullBorder @SideBorder_filter('*') @FullBorder @StringDisplay_filter("HELLO") def dummy2(): className[0].show() dummy2() if __name__ == '__main__': startMain()動かしてみます。
$ python Main.py Hello, world. #Hello, world.# +---------------+ |#Hello, world.#| +---------------+ /+-----------+/ /|+---------+|/ /||*+-----+*||/ /||*|HELLO|*||/ /||*+-----+*||/ /|+---------+|/ /+-----------+/最初の動作結果と同じになりましたので、これで、ひとまず、完成とします。
■ 参考URL