- 投稿日:2020-01-19T19:21:06+09:00
アル中カタカタ〜!大事なキーを異世界に転生!また俺何かやっちゃいました?
システムエンジニアになって10ヶ月のピッチピチのJK(Java書き)のキー太郎です!
先日最近購入しましたMacBook Proを友達の家に持って行って、酒呑みながらカタカタいじってたときの失敗談です。ゆる〜く聞き流してください。週末久しぶりに友人と食事をした私はそのまま友人宅飲み会をすることに。MacBook Proを開きながらあれこれよくわからんウンチクを語りながら例の飲み物(角ハイ金)を飲んでいました。そしてどういう流れからか私は友人に自慢をしたくなりました。
キー太郎「そういえばさ〜最近秒で俺サーバ作れるようになったんだよね〜」
友人「どうやって?」
キー太郎「EC2ていうえーだぶりゅーえす?を使うと簡単にサーバ立ち上げることができるんだぜ〜」
友人「すげーーーーーーーーーー!!!!!!!!!!!!!!!!」
キー太郎「また俺何かやっちゃいました?笑笑」macでEC2を立ち上げるには
1:AWSマネジメントコンソールからEC2を選択し、キーペアを作成する。
2:作成した秘密鍵(pem)をダウンロードする。
3:キーの権限を変更する。chmod 400 ●●●●●.pem
4:sshコマンドを実行する。
ssh ec2-user@00.00.00.00 -i ●●●●●.pem
5:サーバが稼働する。
| _| )
| ( / Amazon Linux 2 AMI
__|_|___|ざっくりと説明しましたがこんな感じです。
さてその後一通り自慢を終えた私はキーを保存しておくためのディレクトリを作成し、作成後にキーを移動しようと思い実行に移します。そのことがある悲劇を生むとは梅雨知らず、、、
キー太郎(酔)「キーをただ外にほっぽり出しておくのもなんかアレだしディレクトリでも作成してそんなかで管理しておきますかね〜」
キー太郎(酔)「まずはディレクトリを作るぞーい」
キー太郎「ディレクトリを作るには確かmkdir or touch だったけな・・・」touch SSH
キー太郎「そんで次はカレントディレクトリにあるキーを移動させると・・・」
キー太郎「mvコマンドで異世界転生させたるわ!!!!!」mv ●●●●●.pem /●●/●●/SSH/
キー太郎「実行っと・・・うん!特にエラーもなく実行できたみたいだな」
キー太郎「さて無事に作業終わったし祝酒でも開けますかね笑笑」その後達成感に浸りながらとりあえず再びssh接続をしようと試みます。まずキーが入っているSSHディレクトリ移動しようとします。
cd SSH
キー太郎「移動っと・・・あれ?」
cd: not a directory: ●●●●●.pem
キー太郎「ディレクトリじゃない・・・?どういうこと?アクセス権限の問題か?いやディレクトリじゃないよってターミナルに言われとるし・・・」
その後あらゆる手段試してもそのディレクトリには移動できませんでした。
キー太郎「はあああああああ・・・・終わったわ。完全に詰んだ。ディレクトリに入れなかったら鍵取り出せんわ・・・・」
さて感の良い方なら最初の方に気づいているかもしれません。その通りです。この悲劇は最初に実行したコマンドであるtouchコマンドが原因なのです。
touchコマンドはファイルのタイムスタンプを変更するコマンドであり、存在しないファイル名を指定することで、内容の入っていないファイルを新規作成する機能を持っています。詳しくはググってください。
最初から整理します。
カレントディレクトリには
●●●●●.pem
touch SSH コマンド実行後のカレントディレクトリは
●●●●●.pem SSH
という状態になっておりtouchコマンドをディレクトリを作るコマンドだと思っていた私はSSHをディレクトリだと認識しています。その後キーをSSHディレクトリに移動させようとmvコマンドを実行します。
mv ●●●●●.pem SSH
ここでも深刻な問題が起っています。mvコマンドは移動させることだけではなく名前を変更させることもできるコマンドなのです!つまり・・・・
mv 名前を変えたいファイル名 変更したい名前
というように上記の私が実行したコマンドは移動させるのではなく名前を変えるコマンドととらえられてしまったのです。笑笑 また名前を変えた後SSHという同じ名前をしたファイルが存在することになるので、旧SSHファイルはSSHという名前に変わったキーである新SSHファイルに上書きされます。そうなるとカレントディレクトリに残るのはSSHという文字のみ・・・あたかもSSHディレクトリにキーの移動が成功したように見えるのです。
mvコマンド実行後のカレントディレクトリは
/*SSHというディレクトリが存在するのではなくSSHという名前の●●●●●.pemが存在しているだけ/
SSH酔っ払っていてそのことに気づかなかった私はあたかもキーがnot a directoryという自分で作った謎のディレクトリにキーを異世界転生させてしまったと錯覚したのです。
また俺何かやっちゃいました?
●今回の事件からの学び
・大事なファイルを移動させるときは細心の注意を払う。
・コマンドを正確に理解した上でコマンドを実行する。
・酒を飲みながら作業してはいけない。その後・・・
キー太郎「なんだったんだこれは・・狐に包まれた気分。」
友人「ぱっと見.txtとか.html.javaとかついてないとディレクトリかと思うよな」
キー太郎「まあ擬似異世界転生体験できたし良いか笑!!!」
友人「委員会!」以上です。ここまで駄文を読んでいただき本当にありがとうございます。何か気づいた点、突っ込みどころがありましたらなんなりとコメントを送ってください。
- 投稿日:2020-01-19T15:10:06+09:00
グラフィカルなVIMエディター Neovim-Qt を導入する
素晴らしきエディターであるVIMの正統進化版、その名はNeovim-Qt。モダンな次世代なグラフィカルなVimらしく、聞くところによるとNo1エディタの呼び声高いらしい。
とにかく使わない訳はなく何がどう違うか分からないまま乗り換えることにした。Vimer遍歴
Vim △
Gvim ☓
Neovim ○
Neovim-qt ◎ いまここインストール
sudo apt install neovim-qt設定
init.vim
neovimは設定ファイルが
.vimrcではないらしく。~/.config/nvim/init.vimから読み込むらしく、.vimrcのシンボリックリンクを作成した。シンボリックリンクを作成ln -s ~/.vimrc ~/.config/nvim/init.vimフォント変更
~/.config/nvim/ginit.vimGuifont DejaVu Sans Mono:h15詳しく知りたい方はこちら
https://github.com/equalsraf/neovim-qt/wikiプラグインを使えるようにする
自分は
Vim Plugを使わせてもらっているので、Neovim版のVim Plugをcurlで頂いてくる。curl -fLo ~/.local/share/nvim/site/autoload/plug.vim --create-dirs \ https://raw.githubusercontent.com/junegunn/vim-plug/master/plug.vimまとめ
NERDTreeをファイルマネージャー感覚で扱えるのはGvim全般の魅力ですね。
こちらの記事の比較がよくわかりやすい。
https://vim.blue/what-is-neovim/
- 投稿日:2020-01-19T13:53:40+09:00
Ubuntu 19.10 Eoan Ermine に Apache Tomcat 9 をインストールして Hello World
Apache Tomcat 9 をインストール
tomcat9 パッケージをインストールする。
$ sudo apt install tomcat9依存関係で tomcat9-common や libtomcat9-java パッケージ等もインストールされる。
$ dpkg -l | grep tomcat ii libtomcat9-java 9.0.24-1 all Apache Tomcat 9 - Servlet and JSP engine -- core libraries ii tomcat9 9.0.24-1 all Apache Tomcat 9 - Servlet and JSP engine ii tomcat9-common 9.0.24-1 all Apache Tomcat 9 - Servlet and JSP engine -- common filesApache Tomcat 9 が起動しているか curl 等で確認できる。
$ curl http://localhost:8080/ <?xml version="1.0" encoding="ISO-8859-1"?> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd"> <html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en"> <head> <title>Apache Tomcat</title> </head> <body> <h1>It works !</h1> (以下略)トップページは /var/lib/tomcat9/webapps/ROOT ディレクトリにある。
$ tree /var/lib/tomcat9/webapps/ /var/lib/tomcat9/webapps/ └── ROOT ├── META-INF │ └── context.xml └── index.html$ ls -lR /var/lib/tomcat9/webapps/ /var/lib/tomcat9/webapps/: 合計 4 drwxr-xr-x 3 root root 4096 1月 19 12:56 ROOT /var/lib/tomcat9/webapps/ROOT: 合計 8 drwxr-xr-x 2 root root 4096 1月 19 12:25 META-INF -rw-r--r-- 1 root root 1899 1月 19 12:56 index.html /var/lib/tomcat9/webapps/ROOT/META-INF: 合計 4 -rw-r--r-- 1 root root 49 1月 19 12:25 context.xmlHello World な Web アプリケーションをデプロイ
webapps 以下に hello ディレクトリを作成して一般ユーザーアカウント用の権限を設定。
$ sudo mkdir /var/lib/tomcat9/webapps/hello $ sudo chown hoge:hoge /var/lib/tomcat9/webapps/helloHello World な JSP ファイルを /var/lib/tomcat9/webapps/hello/index.jsp に設置。
<%@ page contentType="text/html; charset=utf-8" %><html><body> Hello JSP World!<br> java.version: <%= System.getProperty("java.version") %><br> java.vm.name: <%= System.getProperty("java.vm.name") %><br> </body></html>curl 等で動作確認。
$ curl http://localhost:8080/hello/ <html><body> Hello JSP World!<br> java.version: 11.0.5<br> java.vm.name: OpenJDK 64-Bit Server VM<br> </body></html>Apache Tomcat 9 の起動と停止
systemd に登録されている tomcat を確認するとユニット名は tomcat9 になっている。
$ systemctl list-unit-files --type=service | grep tomcat tomcat9.service enabledsystemctl start tomcat9 で Tomcat 9 を起動できる。
$ sudo systemctl start tomcat9systemctl stop tomcat9 で Tomcat 9 を停止できる。
$ sudo systemctl stop tomcat9tomcat9 パッケージのファイル一覧
dpkg -L コマンドで確認できる。
設定ファイル等の場所もこれでわかる。$ dpkg -L tomcat9 /. /etc /etc/cron.daily /etc/cron.daily/tomcat9 /etc/logrotate.d /etc/rsyslog.d /etc/rsyslog.d/tomcat9.conf /etc/tomcat9 /etc/tomcat9/Catalina /etc/tomcat9/policy.d /etc/tomcat9/policy.d/01system.policy /etc/tomcat9/policy.d/02debian.policy /etc/tomcat9/policy.d/03catalina.policy /etc/tomcat9/policy.d/04webapps.policy /etc/tomcat9/policy.d/50local.policy /lib /lib/systemd /lib/systemd/system /lib/systemd/system/tomcat9.service /usr /usr/lib /usr/lib/sysusers.d /usr/lib/sysusers.d/tomcat9.conf /usr/lib/tmpfiles.d /usr/lib/tmpfiles.d/tomcat9.conf /usr/libexec /usr/libexec/tomcat9 /usr/libexec/tomcat9/tomcat-start.sh /usr/libexec/tomcat9/tomcat-update-policy.sh /usr/share /usr/share/doc /usr/share/doc/tomcat9 /usr/share/doc/tomcat9/copyright /usr/share/tomcat9 /usr/share/tomcat9/default.template /usr/share/tomcat9/etc /usr/share/tomcat9/etc/catalina.properties /usr/share/tomcat9/etc/context.xml /usr/share/tomcat9/etc/jaspic-providers.xml /usr/share/tomcat9/etc/logging.properties /usr/share/tomcat9/etc/server.xml /usr/share/tomcat9/etc/tomcat-users.xml /usr/share/tomcat9/etc/web.xml /usr/share/tomcat9/logrotate.template /usr/share/tomcat9-root /usr/share/tomcat9-root/default_root /usr/share/tomcat9-root/default_root/META-INF /usr/share/tomcat9-root/default_root/META-INF/context.xml /usr/share/tomcat9-root/default_root/index.html /var /var/cache /var/cache/tomcat9 /var/lib /var/lib/tomcat9 /var/lib/tomcat9/lib /var/lib/tomcat9/webapps /var/log /var/log/tomcat9 /usr/share/doc/tomcat9/README.Debian /usr/share/doc/tomcat9/changelog.Debian.gz /var/lib/tomcat9/conf /var/lib/tomcat9/logs /var/lib/tomcat9/work参考資料
- 投稿日:2020-01-19T13:38:54+09:00
Xubuntuサーバを作ってみた。
はじめまして
今回Qiita初投稿となります!
(昨年6月に登録しましたが、記事のストックオンリーで、投稿せずじまいでした)
この度、社宅?内にLinuxサーバを導入することとなりましたが、
(今現在)目的は次の通りです。1.PHP、Ruby等の学習環境を構築
2.宅内NASの構築
3.将来的に外部に公開も視野にサーバにするマシンは、以下の通りです。
機種:自作機
CPU:AMD E-350(1.622GHz)
RAM:8GB
BIOS:E7698AMS V1.5(2011/4/22)
HDD:640GB+1TB
USB:2.0*10、3.0*2BIOSをチェックしてみると…
いざ、電源をON→BIOSをチェック。
重要な部分を
- ONBOARDLAN:ON
- SATA:AHCIモード
- HPET:ON
- IGD(CPU統合グラフィック):AUTO
- USB3.0 LEGACYMODE:ON
- WAKE UP EVENT BY BIOS
に設定したあと、ブートの順番を
- USB Floppy
- USB CD/DVD
- USB HardDisk
- USB KEY
- CD/DVD
- 内臓HDD
に設定します。
インストールOSで大いに迷う
インストールするOSですが…
サーバとしての運用がメインですが、
不測の事態に備えて(?)GUI環境も導入!メモリが8GBと比較的リッチですが、
CPUは64bit対応とはいえ、クロック数が1.6GHzとプアですので、Xubuntu 18.04LTS 64bitをセレクト。
インストールDVDを作成、ドライブにセット。
インストールの際、
- アップデートをダウンロード
- サードパーティー製をインストール
にチェックを入れます。
HDDパーティション設定
インストールの種類:それ以外
に設定後、1台目のHDD(640GB):/dev/sda
2台目のHDD(1TB):/dev/sdb
となっているのを確認。/dev/sdaのパーティションは
- swap:16.4GB(基本パーティション・swap)
- /boot:256MB(基本パーティション・ext4)
- /usr:40960MB(論理パーティション・ext4)
- /var:20480MB(論理パーティション・ext4)
- /var/log:51200MB(論理パーティション・ext4)←ログ用
- /:20480MB(論理パーティション・ext4)
- /tmp:1024MB(論理パーティション・ext4)
- /opt:40960MB(論理パーティション・ext4)
- /rsv:40960MB(論理パーティション・ext4)←予備用
- /home:407430MB(基本パーティション・ext4)
/dev/sdbのパーティションは
NAS用の予定です(XFSフォーマットを検討)
- 投稿日:2020-01-19T13:11:01+09:00
linux削除コマンド
前提
削除コマンドは現在いるカレントディレクトリの中身を消すpwd
/var/www/html
ls
index.php wp-blog-header.php wp-includes wp-settings.php
license.txt wp-comments-post.php wp-links-opml.php wp-signup.php
readme.html wp-config-sample.php wp-load.php wp-trackback.php
wp-activate.php wp-content wp-login.php xmlrpc.php
wp-admin wp-cron.php wp-mail.phprm -rf ディレクトリ名で中身が入っているディレクトリ丸ごと削除
例:# rm -rf wp-admin
※ オプション意味
-rオプションは中身ごと消す
-fオプションは「削除してもいいですか?」などの都度アナウンスをが迷惑な場合に使う全部削除
rm -rf *
- 投稿日:2020-01-19T09:30:12+09:00
駆け出しエンジニアの頃に知ってたら超捗ってたlinux系コマンド・テクニックまとめ
はじめに
僕が初めて現場に入ったときは、ターミナルの真っ黒い画面に面食らっていましたが、今では最も眺めている時間の長いものになりました。
プログラミングを始めてから1年半がたった今でも、ほぼ毎日のように使っているLinux系のコマンド・テクニックをまとめました!
これさえ抑えておけば、駆け出しエンジニアの方はとりあえず現場に放り込まれてもサバイブできるはずです!
コマンドまとめ
ls
listの略。
コマンドを打ったディレクトリ以下のファイル・フォルダを表示してくれます。lsの使用例
> lspwd
print work directoryの略。
現在のディレクトリの位置を表示してくれます。pwdの使用例
> pwd → /Users/hoge/pathcd
change directoryの略。
ディレクトリ移動ができます。何もつけずcdだけ打つとホームディレクトリに、cd -と打つと、直前にいたディレクトリに移動できます。cdの使用例
> cd path/to/hoge → hogeディレクトリに移動mv
moveの略。
ファイル・ディレクトリの移動ができます。ファイルのリネームをしたいときもコイツを使います。mvの使用例
ファイルの移動。hoge.txtをsome_directoryに移動させる > mv hoge.txt some_directory ファイルのリネーム。hoge.txtをfuga.txtにリネームする > mv hoge.txt fuga.txtcp
copyの略。
cp 第1引数 第2引数で、第1引数のファイルを第2引数にコピーします。cpの使用例
hoge.txtをsome_directoryの中にfuga.txtという名前でコピー > cp hoge.txt some_directory/fuga.txtfind
名前の通り、ファイルやディレクトリを探しだすコマンドです。ちょっと複雑で難しいのですが、なれるとむっちゃ便利です。
findの使用例
拡張子が`md`のファイルを現在いるディレクトリ以下から探し出します (ルートディレクトリで実行すると全ディレクトリに対して検索するので検索結果がエグいことになります) > find . -name "*.md"grep
Global regular expression printの略。
コマンドを打ったディレクトリ以下からファイルを読み込み、テキストを検索してくれるコマンドです。grepの使用例
> grep hoge → hoge.md 17:hogehoge/fugafuga fuga.md 25:→ /Users/hoge/path 33:> cd path/to/hoge 34:→ hogeディレクトリに移動 hogefuga.md 27:/Users/hogeちなみに、ripgrepというgrepの進化版(亜種?)がありまして、ripgrepのほうが圧倒的に早いので、こちらをおすすめしておきます。
cat
concatenate(鎖状につなぐ)の略。猫ちゃんではありません。
指定したファイルの中身が閲覧できます。catの使用例
> cat hoge.txt → hogehogehogeho hogehogehogeho hogehogehogehomore
指定したファイルの中身が閲覧できます。
catとは違い、ファイルの中身がちょっとずつ表示されるので、ファイルの行数が多いときに使うと便利です。moreを打った後は、qを押すと、もとの画面に戻ります。moreの使用例
> more hoge.txtless
moreの進化版みたいなコマンドです。今回はmoreとlessの両方を紹介しましたが、基本的にはどちらか一つだけ使えるようになっておけばOKです!moreと同じくコマンドを叩くと、閲覧モードに移行し、
qを押すともとの画面に戻ります。↓の記事も参考になるのでぜひ。
エンジニアなら知っておきたい lessコマンドtips 11選
lessの使用例
> less hoge.txthead
指定したファイルを上から○行だけ表示してくれます。
head -10と数字を指定すると、ファイルの上から10行だけ、みたいなことが可能になります。headの使用例
head -10 hoge.txt → (hoge.txtの上から10行分が表示される)tail
headとは逆で、指定したファイルを下から○行だけ表示します。headと同じく、tail -10と数字を指定すると、ファイルの下から10行だけ表示、みたいなことが可能になります。tailの使用例
tail -10 fuga.txt → (fuga.txtの下から10行分が表示される)echo
引数をあてると、その引数の内容を出力します。環境構築などでよく見るコマンドですね。
echoの使用例
> echo $PATH → /Users/sukebeeeeei/.tfenv/bin:/Users/sukebeeeeei/node_modules:/Users/sukebeeeeei/.nodenv/bin:/Users/sukebeeeeei/.nodenv/shims:/usr/local/opt/mysql@5.7/bin:/Users/sukebeeeeei/go/bin:/Users/sukebeeeeei/.goenv/shims:/Users/sukebeeeeei/.goenv/bin:/Users/sukebeeeeei/.pyenv/shims:/Users/sukebeeeeei/.pyenv/bin:/Users/sukebeeeeei/.rbenv/shims:/Users/sukebeeeeei/.rbenv/bin:/usr/local/bin:/usr/bin:/bin:/usr/local/sbin:/usr/sbin:/sbin:/Library/TeX/texbin:/usr/local/go/bin:/opt/X11/bin:/usr/local/texlive/2018/bin/x86_64-darwin/:/Users/sukebeeeeei/dotfiles (PATHが表示されてます)touch
ファイルを作成します。なんで
touchという名前なのでしょうか。誰か教えてください。touchの使用例
> touch hoge.txt → (中身が空のhoge.txtが作成されます)vi・vim
vi・vimが開けます。わざわざvscodeやatomなどのエディターを開くのが面倒なときなどに使いますね。後は、
vim hoge.txtとすると、hoge.txtが存在しなかった場合に、ファイルを生成してくれるので、
- あるファイルを作成し
- そのファイルにちょろっと書き込みをする
というときには頻出のコマンドです。vi・vimに関しては、基本的なコマンドはすべてのエンジニアが習得しておくべきなので、使ったことがないよーという方は、この際にぜひ練習してみてください。
vi・vimの使用例
> vim hoge.txtmkdir
make directoryの略です。その名の通り、ディレクトリを作成するコマンドです。
mkdirの使用例
> mkdir hoge → (hogeディレクトリが作成されます)rm
removeの略。ファイルを削除するときに使うコマンドです。
使い方をミスると破滅するので、ご利用は計画的にどうぞrmの使用例
> rm hoge.txt → hoge.txtが削除されますrmdir
remove directoryの略。ディレクトリを削除するときに使うコマンドです。中身が空っぽのディレクトリしか消せません。ですので、ほぼほぼ使うことはないですw(この記事で紹介しておきながら)ファイルが中にあるディレクトリを消したい場合は、
> rm -rf hoge_directoryとすることがほとんどです。rmdirの使用例
> rmdir hoge_empty_directory → (hoge_empty_directoryを削除)ln
linkの略です。シンボリックリンクを作ることができます。シンボリックリンクとはなんぞや?、という方は下記記事をご参照ください。lnの使用例
> ln -s ~/dotfiles/vimrc/_vimrc ~/.vimrcman
manualの略。
コマンドの説明を表示するコマンド(ややこしい)です。「あーーーこのコマンドどうやって使うんだっけ?」とか、「このコマンドのオプションって何があるんだっけ?」というときに使います。manの使用例
> man ls → (lsコマンドの説明書がでてくる)sudo
superuser doの略です。すぅーどぅーとか、須藤さんと読むことが多いです。管理者権限でコマンドを実行したいときに使います。
sudoをつけると、コマンドを叩いた後にパスワードを聞かれるので、それを入力してコマンドを実行します。sudoの使用例
> sudo vim hoge.txt →Password: (パスワードを入力してEnterを押すとコマンドが実行できる)history
その名の通り、今までに打ってきたコマンドの履歴が表示されます。
historyの使用例
> history → ... 11879 less must_cover_linux_commands.md 11880 tail must_cover_linux_commands.md 11881 more must_cover_linux_commands.md 11882 head must_cover_linux_commands.md 11883 more must_cover_linux_commands.md -n 100 11884 more must_cover_linux_commands.md -n 3 ...便利テクニック集
コマンドラインを扱う上で、知っているととても捗るテクニックを紹介します。知っている人からしたら当たり前のことなんですが、それを誰もが知っているとは限りませんからね。僕も初めて現場に入って数ヶ月ぐらいして初めて知りましたし、知った当時はいたく感動したものです。
“< > >>”
解説するより実例を出したほうが理解は早いと思うので、参考例をば。
> ruby calculate.rb < input_data.txt (calculate.rbを実行し、そのデータとしてinput_data.txtを指定します) > ruby calculate.rb > output_data.txt (calculate.rbを実行し、その出力結果をoutput_data.txtに出力します。output_data.txtが存在していなかった場合はファイルの作成も勝手に行われます。output_data.txtが存在していた場合は、ファイルの中身が出力結果で上書きされます) > ruby calculate.rb >> output_data.txt (cdalculate.rbを実行し、その出力結果をoutput_data.txtの末尾に追加します。> output_data.txtとは違い、ファイルの中身が上書きされないのがポイント) > ruby calculate.rb < input_data.txt > output_data.txt (<と>、および>>は組み合わせることができます。↑では、calculate.rbを実行し、実行に用いるデータはinput_data.txtの中身を、そして実行結果をoutput_data.txtに出力します)pipe (|)
コマンドとコマンドをつなげることができます。むっっっっちゃ使います。
> cat hoge.txt | grep fuga (hoge.txtのなかでfugaという文字列が含まれている場所を探す)$(), ``
$()のカッコの内部でコマンドを実行し、その結果を返してくれます。といっても、これだけでは全然意味がわからないと思うので、実例を出します。> cat $(ls) (先に$(ls)が実行され、その結果がcatの引数となります。その結果、↑のコマンドを実行したディレクトリ配下のファイルの中身がすべて表示されます。)正規表現
例えば
grepコマンドでは、*や+、.などの正規表現を使うことができます。というより、grepはもともとGlobal regular expression printの略なので、正規表現が使えるのは当たり前なんですけどねw
*と+は同じ文字の繰り返し(*は空文字を含むのに対し+は1文字以上)。.は任意の1文字ですね。> grep .*hoge (hogeを含む文章を検索)コマンドとテクニックを組み合わせてみる
では、今までに紹介したコマンドとテクニックを組み合わせてみます!
うわーあのコマンドなんだっけーってとき
ctrl + rで過去のコマンドが検索できますが、↓のコマンドでも同じことができます。
> history | grep command_name(macの場合) Downloadに入っているファイルのうち最新○件の名前を知りたい
> ls -lat ~/Downloads | head -10 total 3408200 drwxr-xr-x+ 112 keisuke staff 3584 1 18 21:49 .. drwx------@ 569 keisuke staff 18208 1 18 18:54 . -rw-r--r--@ 1 keisuke staff 65540 1 18 18:54 .DS_Store -rw-r--r--@ 1 keisuke staff 254894 1 18 18:54 finished.zip -rw-r--r--@ 1 keisuke staff 1692 1 17 22:53 dupSSHkey.pem -rw-r--r--@ 1 keisuke staff 128909 1 13 10:19 assignment-2-problem.zip -rw-r--r--@ 1 keisuke staff 129247 1 12 11:43 01-start.zip -rw-r--r--@ 1 keisuke staff 26651 1 12 11:43 learning-card.pdf -rw-r--r--@ 1 keisuke staff 236506 1 12 11:25 forms-03-finished.zip.zshrc(もしくは.bashrc)に文字列を挿入したい
環境構築するときによく見るコマンドですね。''の中身をechoで出力し、その出力結果を~/.zshrcに挿入する、というコマンドです。
echo 'export PATH=">HOME/.nodenv/bin:>PATH"' >> ~/.zshrc特定のプロセスIDを調べたい
grepというプロセスが動いているか調べるコマンドです。
> ps aux | grep grep sukebeeeeei 80328 0.0 0.0 4268280 656 s012 S+ 9:52PM 0:00.00 grep --color=auto --exclude-dir=.bzr --exclude-dir=CVS --exclude-dir=.git --exclude-dir=.hg --exclude-dir=.svn grep2個下のディレクトリにあるファイルを一覧でみたいとき
↓のような構造のディレクトリがあるとします(僕のQiitaに上げる記事を保存してあるディレクトリですw) > qiita-outputs git:(master) ✗ tree . ├── README.md ├── alfred_techniques.md ├── articles │ └── nukistagram_release.md ├── english_acronym.md ├── env_and_env_fetch │ └── sample.rb ├── favorite_english_site.md ├── must_cover_linux_commands.md ├── must_gem_list.md ├── path_understanding.md ├── peco_intro.md ├── really_good_software.md └── software_engineer_general_knowlegde.md 2 directories, 12 files (正規表現を用いてやってみる。ディレクトリの構造が複数層見られる) > qiita-outputs git:(master) ✗ ls * README.md must_gem_list.md alfred_techniques.md path_understanding.md english_acronym.md peco_intro.md favorite_english_site.md really_good_software.md must_cover_linux_commands.md software_engineer_general_knowlegde.md articles: nukistagram_release.md env_and_env_fetch: sample.rb (2個下のディレクトリのファイルを調べる) > qiita-outputs git:(master) ✗ ls */* articles/nukistagram_release.md env_and_env_fetch/sample.rb出力結果のうち、先頭10行だけを見たい
> ls */* | head -10出力結果が長くなるので、一部をちょい出しにしてチェックしていきたい
> ls */* | lessdockerのイメージをまとめて消したいとき
> docker rmi $(docker images -q) もしくは > docker rmi `docker images -q`
docker imagesでdockerのイメージ一覧が見られます。オプションで-qをつけることによって、イメージIDだけが表示されるように。それを先に
$(docker images -q)で処理して、その返り値に対してdocker rmiを実行します。(rmi: remove image)参考までに。
docker imagesのうち、先頭5つだけを見たい場合。> ~ docker images | head -5 REPOSITORY TAG IMAGE ID CREATED SIZE <none> <none> 8769696a985d 4 days ago 910MB <none> <none> 694f9395f0e7 4 days ago 1.04GB <none> <none> 8ff2255c3c50 4 days ago 995MB <none> <none> a1457d2c753d 2 weeks ago 995MB <none> <none> 788141cacfc5 2 weeks ago 998MB
docker imagesのうち、先頭5つのイメージIDだけをみたいとき> ~ docker images -q | head -5 8769696a985d 694f9395f0e7 8ff2255c3c50 a1457d2c753d 788141cacfc5grepの検索結果をファイルに出力する
> grep hoge > hoge_search_result.txt出力したテキストを置換して表示したい
sed(stream editorの略)というコマンドを使うと、テキストの置換ができたり、色々テクニカルで面白いことができるようになります。> echo abcabc | sed s/ca/12/g → ab12bcgrepで一致したうち、その前後の行の内容も知りたいとき
grep -C nで一致したところの前後n行も表示できる > grep -C 3 "search_word" search_fileあるコマンドのオプションの内容をパッと知りたいとき
例えば、findコマンドで、正規表現はどのように扱うのか、オプションをつければいいのか、とかを知りたいとする。そういうときはこれ。
findコマンドについてマニュアルを表示し、そのマニュアルのなかで"regular expression"に一致する箇所を、その前後3行も含めて表示する > man find | grep -C 3 "regular expression" The options are as follows: -E Interpret regular expressions followed by -regex and -iregex pri- maries as extended (modern) regular expressions rather than basic regular expressions (BRE's). The re_format(7) manual page fully describes both formats. -H Cause the file information and file type (see stat(2)) returned -- -- -regex pattern True if the whole path of the file matches pattern using regular expression. To match a file named ``./foo/xyzzy'', you can use the regular expression ``.*/[xyz]*'' or ``.*/foo/.*'', but not ``xyzzy'' or ``/foo/''. -samefile name最後に
上記で紹介したコマンドやテクニックも、シェルスクリプトとかエイリアスと組み合わせるともっともっと強力になるのですが、本記事から逸脱した内容となるためなくなく断念しました。この記事がバズったら、そのあたりを解説した記事も執筆したいなぁと考えていたり。
「ワイはこんなコマンド使ってるで!」、みたいな便利tipsがあったらぜひコメントを!
間違いや誤字脱字の報告もぜひぜひお願いします!参考文献
Linuxコマンドは単語の意味を理解するとグッと身近なものになる
- 投稿日:2020-01-19T06:01:58+09:00
シンボリックリンクについて
- 投稿日:2020-01-19T03:40:20+09:00
Linux - copy_mm()あたりを眺めてみる
概要
マルチプロセス/スレッドあたりの違いの雰囲気を掴むために読んでみたのでまとめ。
見るバージョンは5.4を読んでみる
torvalds/linuxLinuxにおけるスレッドとプロセス
グリーンスレッド/ネイティブスレッド
- グリーンスレッド
OSではなく仮想マシンなどよってスケジュールされるスレッド。
OSの機能によらずにマルチスレッド環境をエミュレートする。
- ネイティブスレッド(軽量プロセス,LWP)
スレッドの実行スケジュールはOSのスケジューラが行う
(psコマンドでは-Lを付けて表示可能)カーネルソースを眺めてみた
基本的にはfork(2)でもpthred_create()でも内部的にはdo_fork()を呼び出している。
cloneは呼び出された後はdo_forkを呼び出す。
プロセスとスレッドの生成の違いはこのdo_fork()を呼び出す際のフラグに差異があって区別されている模様。long sys_clone(unsigned long clone_flags, unsigned long newsp, void __user *parent_tid, void __user *child_tid) { long ret; if (!newsp) newsp = UPT_SP(¤t->thread.regs.regs); current->thread.forking = 1; ret = do_fork(clone_flags, newsp, ¤t->thread.regs, 0, parent_tid, child_tid); current->thread.forking = 0; return ret; }処理の流れの概要
① do_fork()
② _do_fork()
③ copy_process()
④ copy_mm()
⑤ dup_mmap() (LWPではない場合は以下でcowの処理をする)
⑥ copy_page_range()
⑦ copy_one_pte() vmエリアを1つのタスクから別のタスクにコピーstatic int copy_mm(unsigned long clone_flags, struct task_struct *tsk) { struct mm_struct *mm, *oldmm; int retval; tsk->min_flt = tsk->maj_flt = 0; tsk->nvcsw = tsk->nivcsw = 0; #ifdef CONFIG_DETECT_HUNG_TASK tsk->last_switch_count = tsk->nvcsw + tsk->nivcsw; tsk->last_switch_time = 0; #endif tsk->mm = NULL; tsk->active_mm = NULL; oldmm = current->mm; if (!oldmm) return 0; // vmacacheエントリの初期化 vmacache_flush(tsk); // CLONE_VM が設定された場合、呼び出し元のプロセスと子プロセスは // 同じメモリー空間で 実行される。 if (clone_flags & CLONE_VM) { mmget(oldmm); // 親プロセスのmmを子にセットしgood_mmへ mm = oldmm; goto good_mm; } retval = -ENOMEM; // CLONE_VMがセットされていない場合は既存のmm構造体を複製する mm = dup_mm(tsk, current->mm); if (!mm) goto fail_nomem; good_mm: tsk->mm = mm; tsk->active_mm = mm; return 0; fail_nomem: return retval; }clone(2)の先で呼ばれるcopy_mmの処理。
CLONE_VMが設定されている(スレッド生成時のフラグ)場合は親プロセスとアドレスを共有していることがわかった。
https://linuxjm.osdn.jp/html/LDP_man-pages/man2/clone.2.htmlstatic struct mm_struct *dup_mm(struct task_struct *tsk, struct mm_struct *oldmm) { struct mm_struct *mm; int err; mm = allocate_mm(); if (!mm) goto fail_nomem; // 親プロセス のメモリを生成されるプロセスへコピー memcpy(mm, oldmm, sizeof(*mm)); if (!mm_init(mm, tsk, mm->user_ns)) goto fail_nomem; err = dup_mmap(mm, oldmm); if (err) goto free_pt; mm->hiwater_rss = get_mm_rss(mm); mm->hiwater_vm = mm->total_vm; if (mm->binfmt && !try_module_get(mm->binfmt->module)) goto free_pt; return mm; free_pt: /* don't put binfmt in mmput, we haven't got module yet */ mm->binfmt = NULL; mm_init_owner(mm, NULL); mmput(mm); fail_nomem: return NULL; }copy_mmのメインの処理。
前段の処理の時点でCLONE_VM(スレッド)が設定されている場合はここの処理は行われない。
スレッドはスレッド作成元のデータにアクセスが可能。プロセスの場合は親プロセスのメモリをコピーしていく処理を行なっていく。(後述予定。。)補足
mm_struct - アドレス空間の情報を管理する構造体
項目 概要 mmap vm_area_struct の先頭を保持する mm_rb メモリエリアを高速に探すための red-black tree を保持する mmap_cache メモリ参照の局所生(locality)を生かして高速化するためのもの mm_count この構造体の参照カウンタ。0ならどのオブジェクトがも指されていない mm_list mm_struct 構造体のリストを作るためのフィールド start_code, end_code テキストセグメントの開始番地と終了番地 start_brk, brk ヒープの開始番地と終了番地 start_stack スタックの開始番地 参考

- 投稿日:2020-01-19T02:23:05+09:00
BESSの開発メモその01:BESSのインストールと基本的な使用方法
はじめに
これはBESS(Berkeley Extensible Software Switch)の開発に関するガイドブックである。公式Wikiには英語版にしかない上、内容も少ない、だからこのメモを書く。このメモには、公式Wikiにある重要な内容も含めて、自分が開発、ソースコードを読むときの理解や発見などが含めている。
もし誰かの助けになれば、それは幸いなことになる。公式ページ -> BESS
公式WikiとRepo -> BESS Wiki開発環境
Ubuntu 18.04 LTS 推奨
VMwareでUbuntuをインストールのはおすすめする。スナップショット機能を活用し、システムに回復不可能なダメージが出れば、簡単に正常状態に戻れる。
決してVMに十分なメモリを設置すること、2~4GBのは目安。依存関係のインストール
BESSには次のソフトパッケージが必要:
sudo apt install make apt-transport-https ca-certificates g++ make pkg-config libunwind8-dev liblzma-dev zlib1g-dev libpcap-dev libssl-dev libnuma-dev git python python-pip python-scapy libgflags-dev libgoogle-glog-dev libgraph-easy-perl libgtest-dev libgrpc++-dev libprotobuf-dev libc-ares-dev libbenchmark-dev libgtest-dev protobuf-compiler-grpc pip install --user protobuf grpcio scapyビルド
Repoからクローンとスクリプトを実行:
git clone https://github.com/NetSys/bess.git cd bess/ sudo ./build.py次の出力ならビルド成功:
> sudo ./build.py Configuring DPDK... - "Mellanox OFED" is not available. Disabling MLX4 and MLX5 PMDs... Building DPDK... Generating protobuf codes for pybess... Building BESS daemon... Building BESS kernel module (4.15.0-74-generic - running kernel) ... Done.注意事項
- もしビルドの途中でDPDKのダウンロードをできなくなれば、出力を従って、マニュアルでダウンロードし、フォルダ
depsで解凍、そしてもう一度ビルドする。- もし
coreのソースコードをかきかえたら、再ビルドの前に関係する*.oファイルを消去するのはおすすめする。- フォルダ
core/pbにあるソースコードはprotobufで生成する、だからビルドの前に何もない。- すべてのwarningはerrorとして扱っている。errorがあればビルドは絶対に失敗する。
- hugepageの設置は決してビルドのあとにすること。もし順番が間違ったら、次のエーラが発生するかも:
Log: make: Entering directory '/home/****/bess/core' [CXX] opts.o [CXX] worker.o [CXX] packet_pool.o [CXX] task.o [CXX] resume_hook.o [CXX] memory.o [CXX] dpdk.o [CXX] event.o [CXX] gate.o [CXX] port.o [CXX] main.o [CXX] debug.o [CXX] module_graph.o [CXX] bessctl.o g++: internal compiler error: Killed (program cc1plus) Please submit a full bug report, with preprocessed source if appropriate. See <file:///usr/share/doc/gcc-7/README.Bugs> for instructions. Error: bessctl.o g++ -o bessctl.o -c bessctl.cc -std=c++17 -g3 -ggdb3 -march=native -isystem /home/****/bess/deps/dpdk-17.11/build/include -isystem /home/****/bess/core -isystem ./.. -isystem /home/****/bess/core/modules -D_GNU_SOURCE -Werror -Wall -Wextra -Wcast-align -Wno-error=deprecated-declarations -pthread -I/usr/include/x86_64-linux-gnu -fno-gnu-unique -O3 -DNDEBUG -MT bessctl.o -MMD -MP -MF .deps/bessctl.d Makefile:439: recipe for target 'bessctl.o' failed make: *** [bessctl.o] Error 1 make: Leaving directory '/home/****/bess/core' Error has occured running command: make -j1 -C corehugepageの設置
毎回のリブートにはこの設置が必要。
次のコマンドを実行する(システムによってコマンドが異なる):
# For single-node systems sudo sysctl vm.nr_hugepages=1024 # For multi-node (NUMA) systems echo 1024 | sudo tee /sys/devices/system/node/node0/hugepages/hugepages-2048kB/nr_hugepages echo 1024 | sudo tee /sys/devices/system/node/node1/hugepages/hugepages-2048kB/nr_hugepagesBESSを起動し、テストスクリプトを実行する
次のコマンドを実行する
> sudo bessctl/bessctl Type "help" for more information. Connection to localhost:10514 failed Perhaps bessd daemon is not running locally? Try "daemon start". <disconnected> $その後
daemon startを実行:Done. localhost:10514 $このときBESSはすでに起動された。
あるテストスクリプトを実行してみよう:
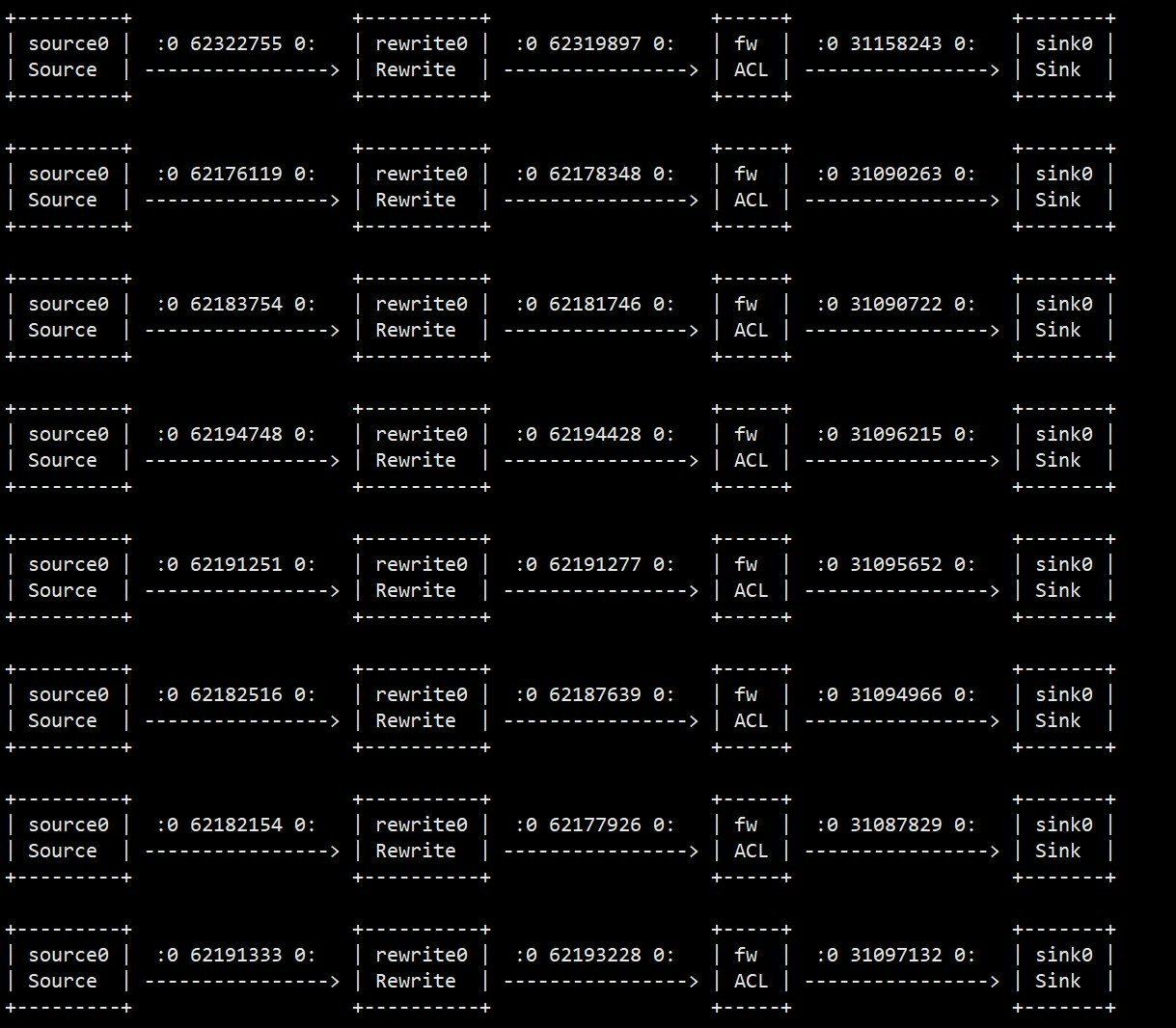
$ run samples/aclその結果:
Done. localhost:10514 $なんの出力もない。それは、このスクリプトにはなんの出力コマンドも含めていない。
コマンドmonitor pipelineを入力し、次の出力が出る:
これはテストスクリプトを成功に実行する証である。
続き
次には、BESSのスクリプトを書き方を紹介する。BESSが持っているモジュールを使う方法も理解できるはず。
- 投稿日:2020-01-19T00:20:05+09:00
Linux#コマンドメモ1
pwd
show your directory
clear
clear the terminal
drwxr?
- d:directory
- r:read
- w:write
- x:execute
- r:read
ls
list all the things in the directory
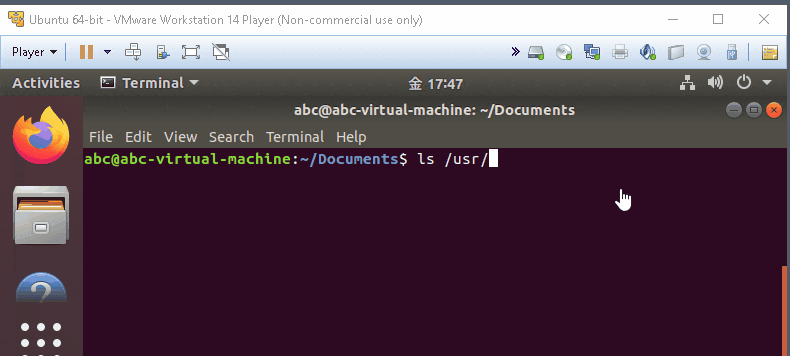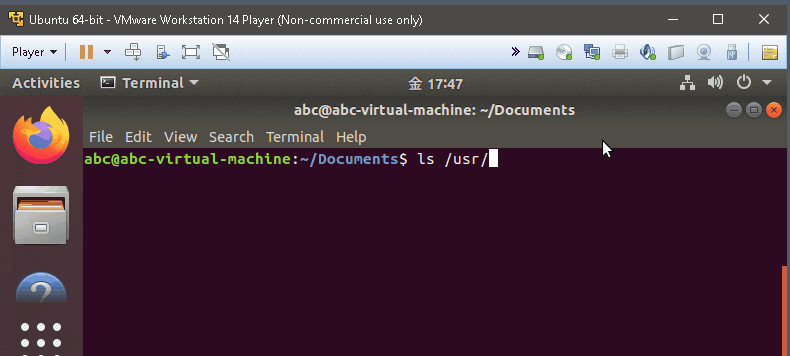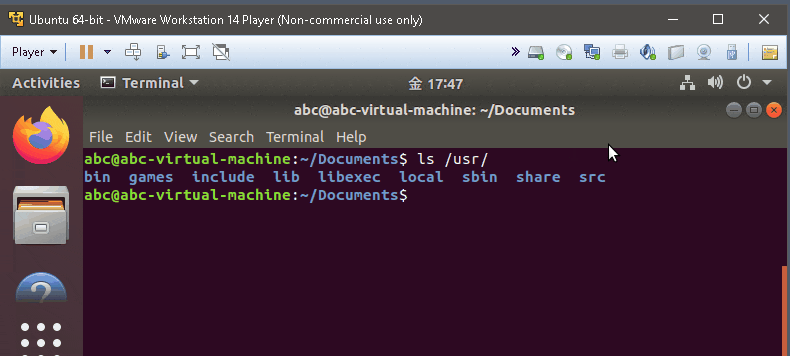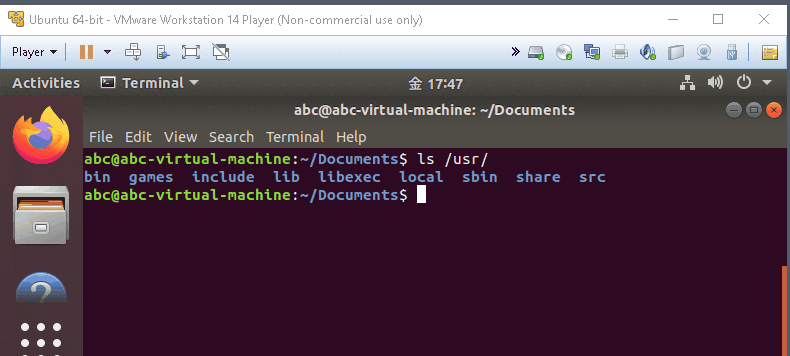
ls /usr/
- list the things inside usr directory
ls ..
- list out a back directory
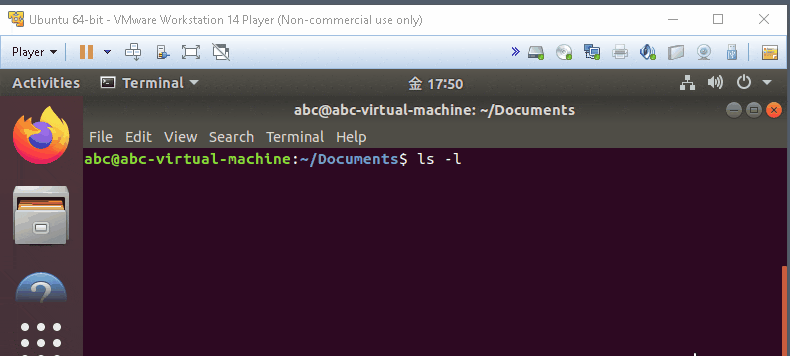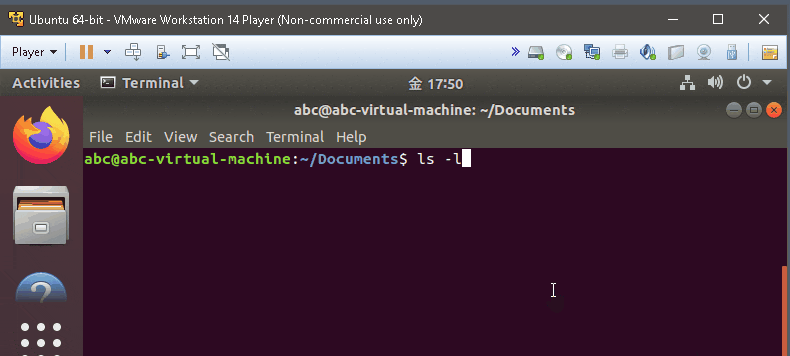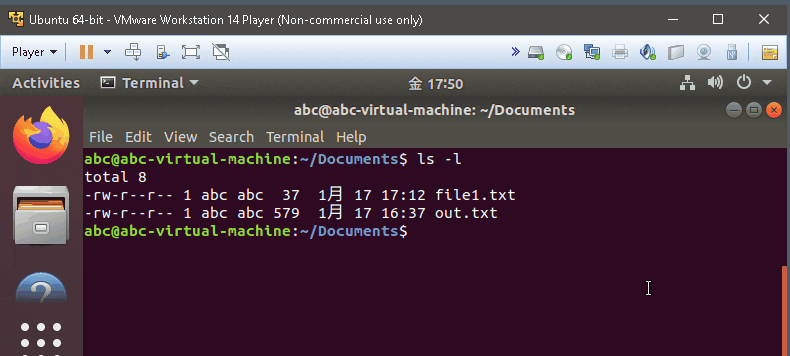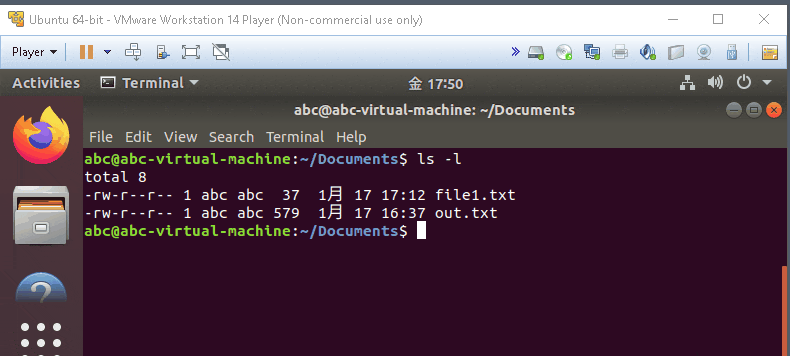
ls -l
- display in long format
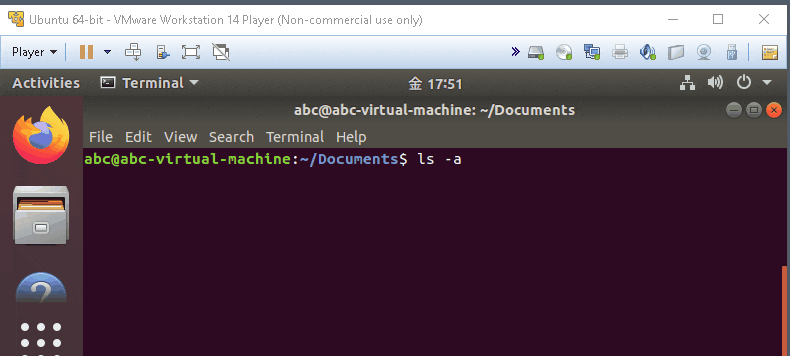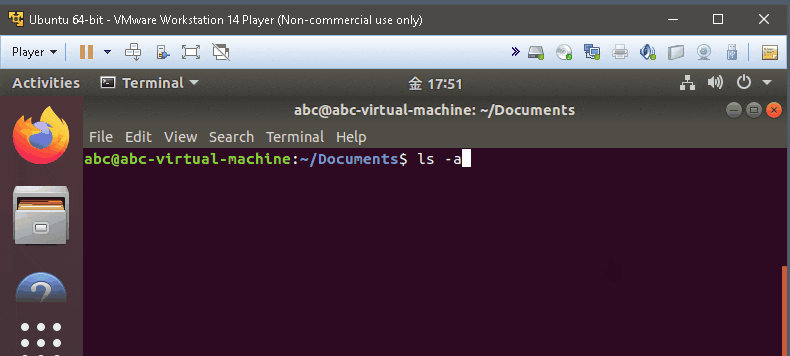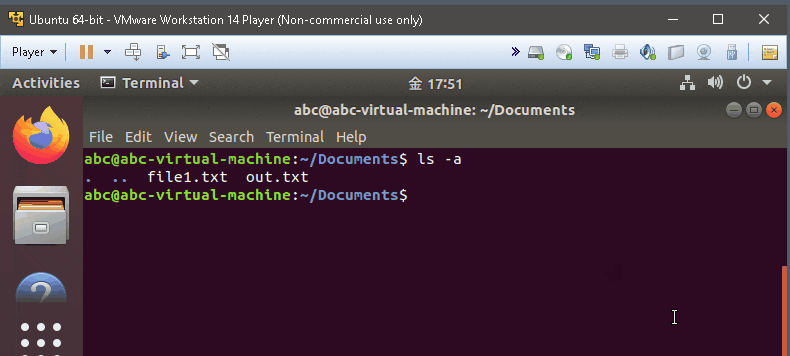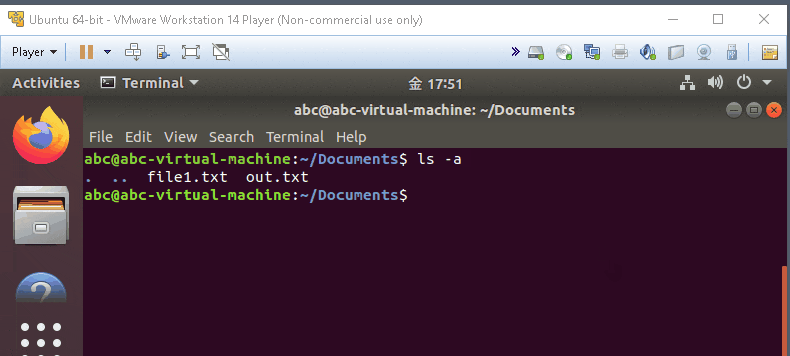
ls -a
- show the hidden things also
ls -la
- list in long format and show the hidden things also
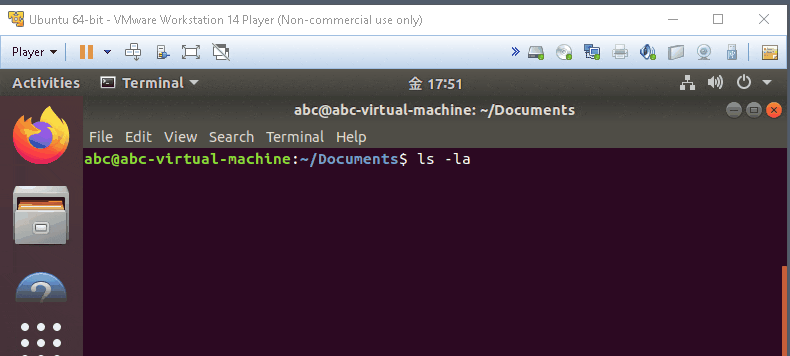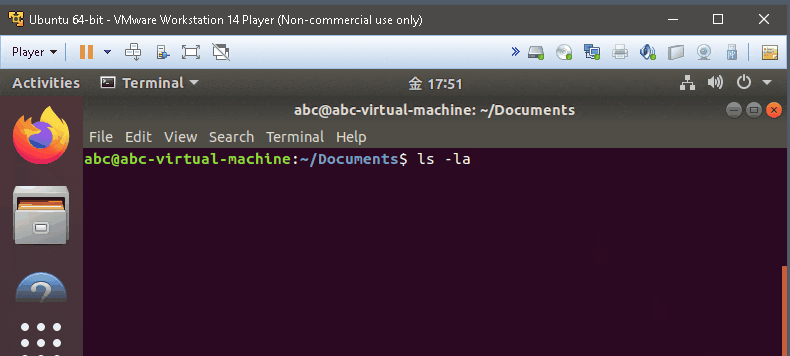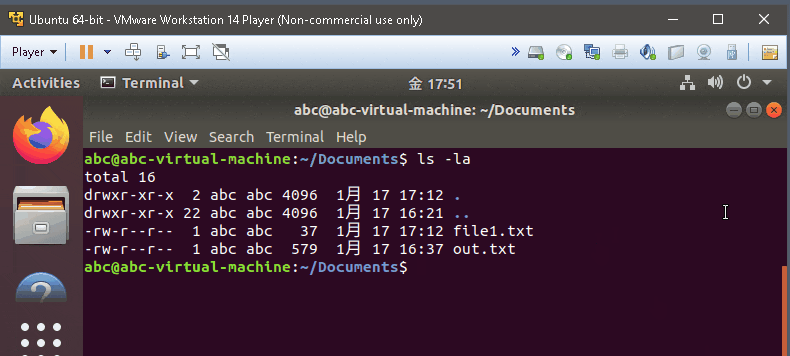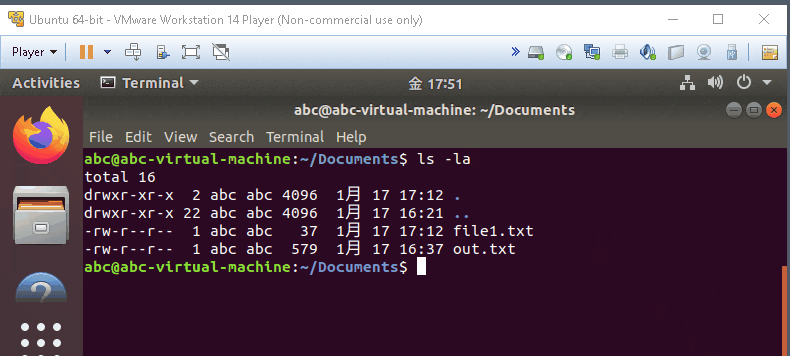
ls -lS
- list the item and sort by Size
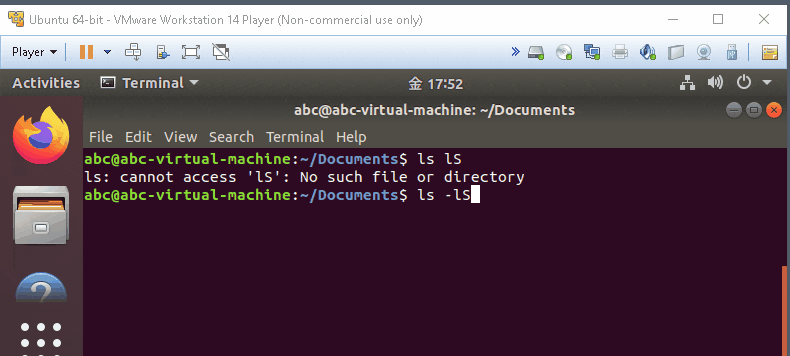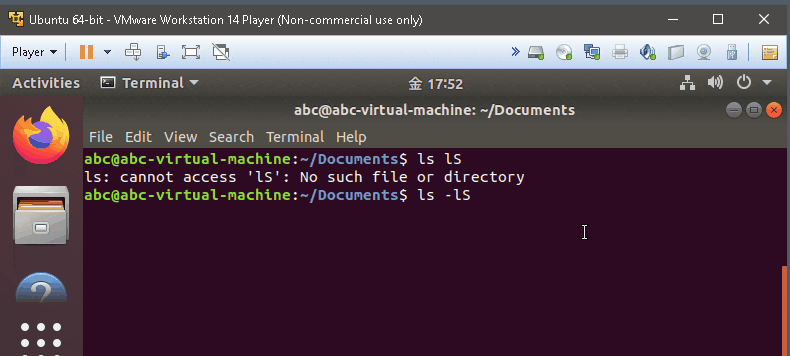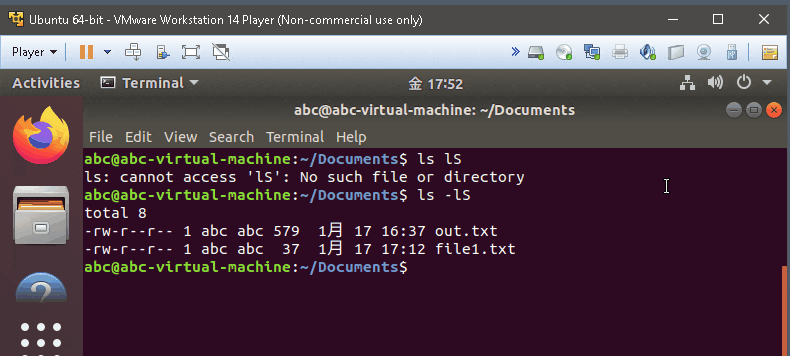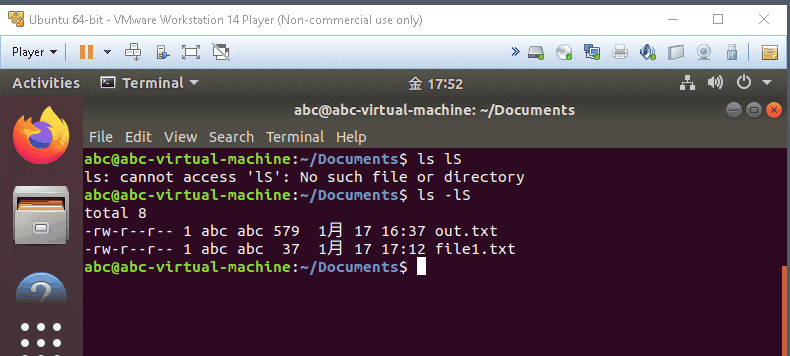
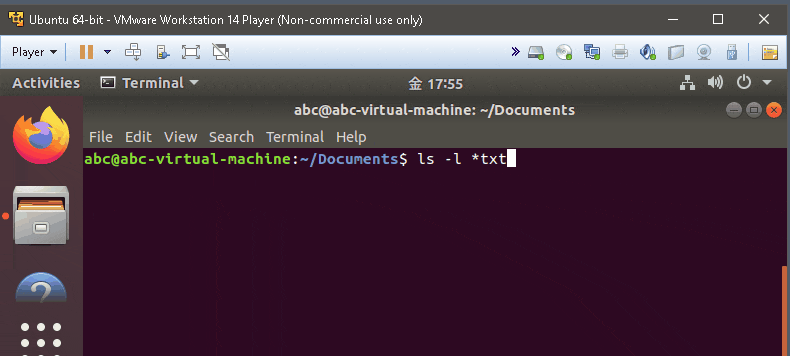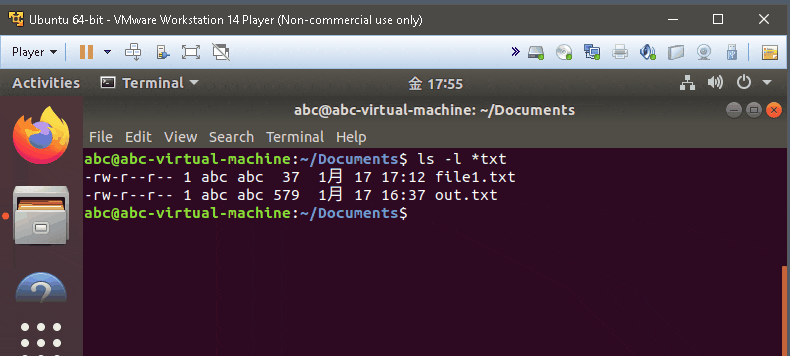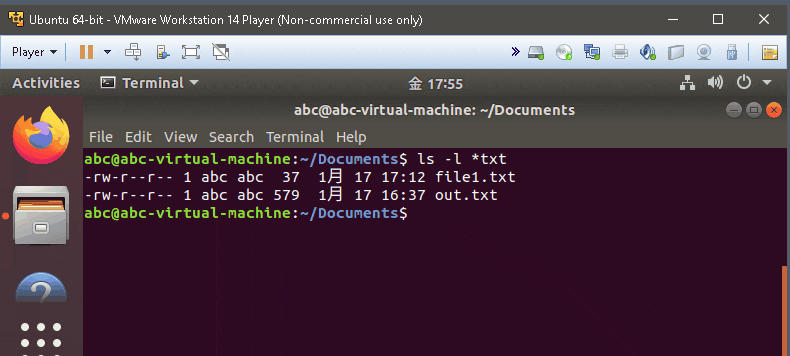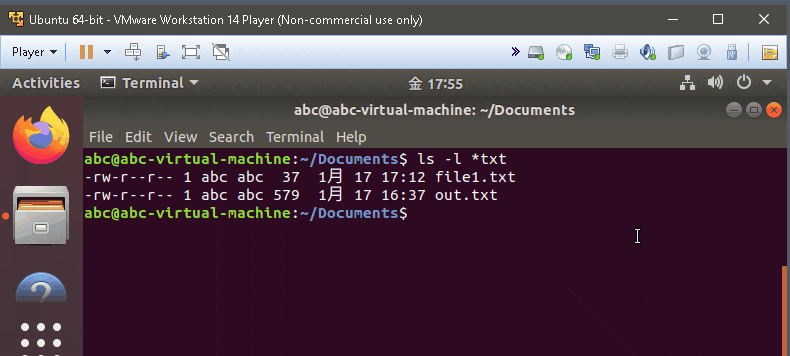
ls -l *txt
- list the item with .txt only
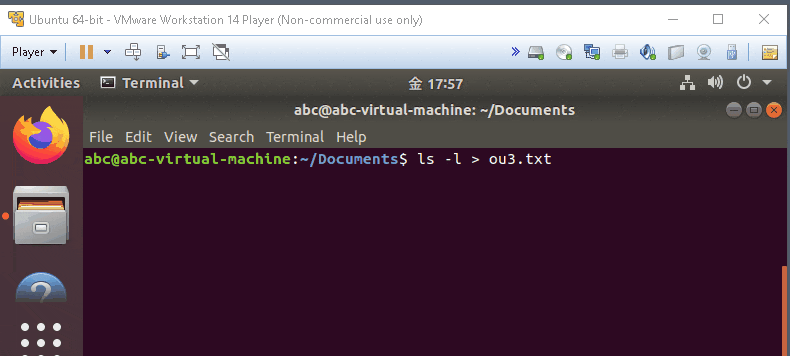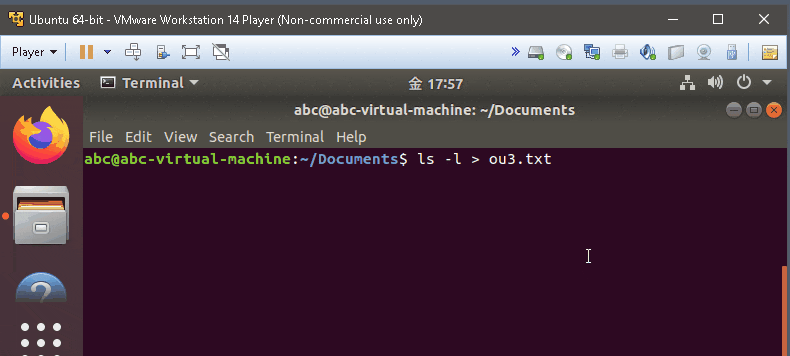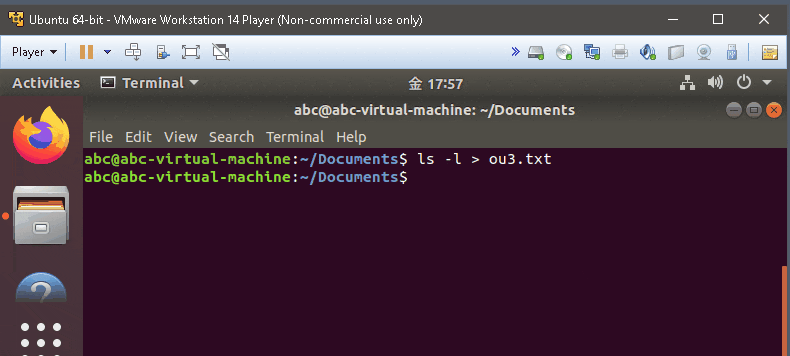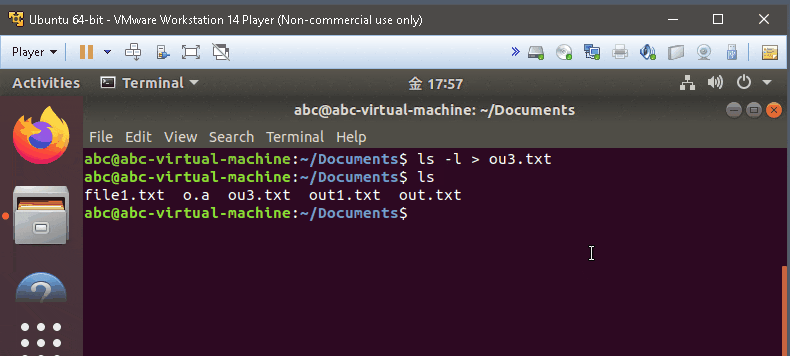
ls -lS >path
- list the item and sort by Size and output the result to file as path.
ls -d */
- list all directory
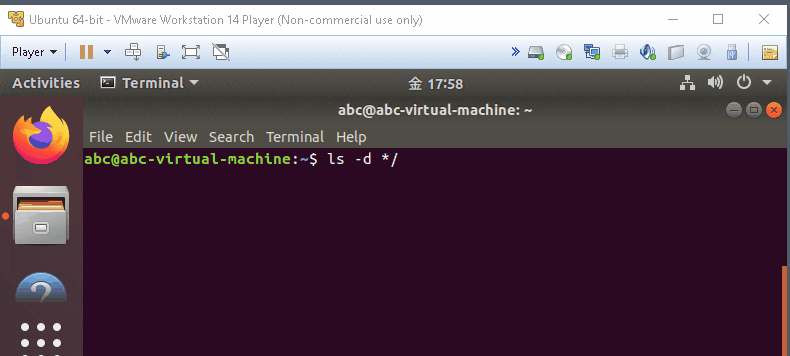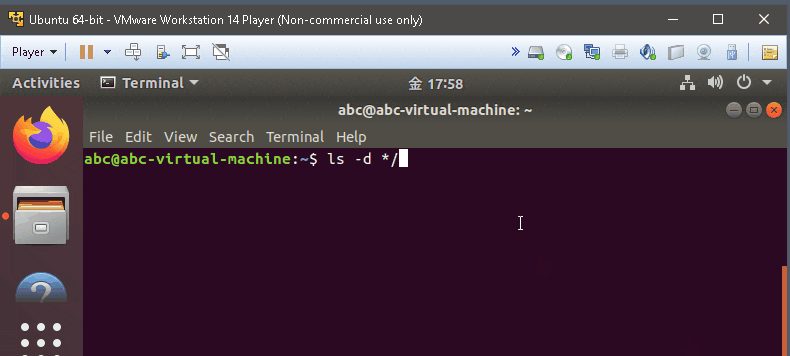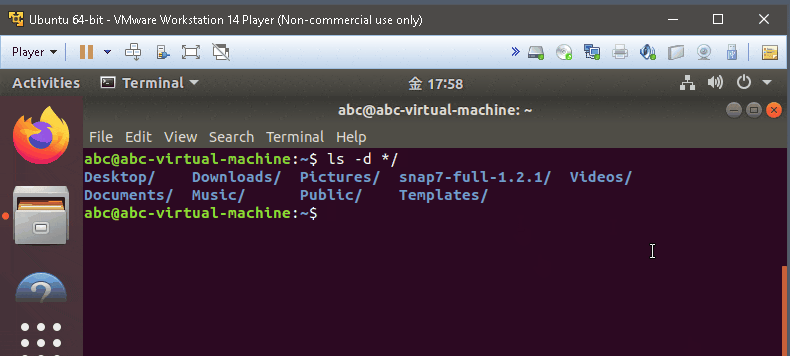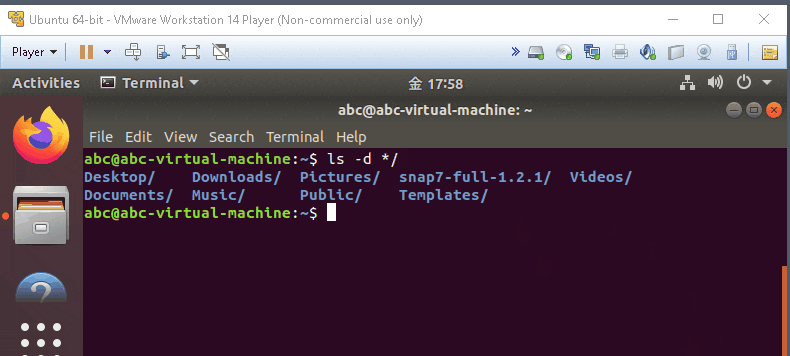
man ls
- got the manual of ls
cd
Change directory
- cd ~
- go back to home directory
- cd ..
- go back one directory
- cd /your path
- go to directory that you want to
cat
- cat
- enter somethings and it will echo back
Ctrl+D to End
- cat yourpath.files
- show the file
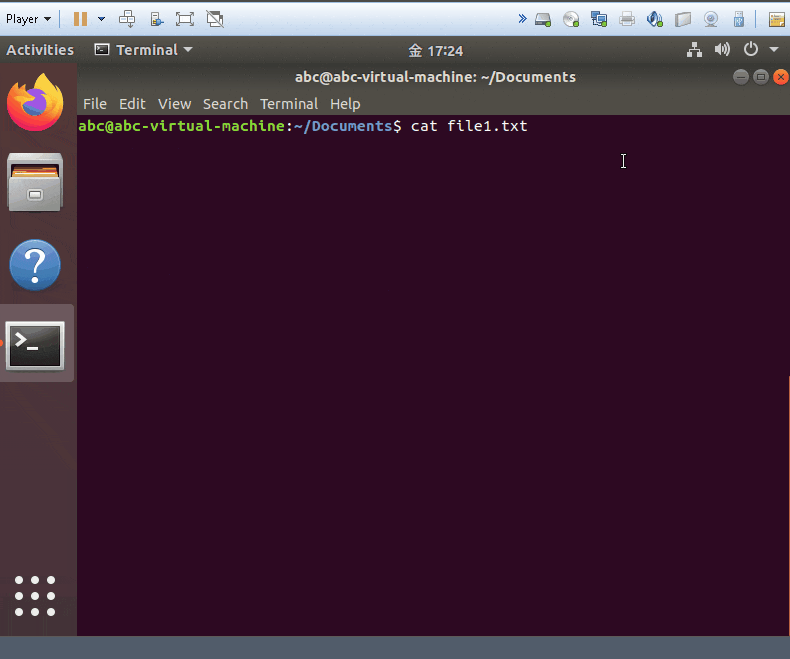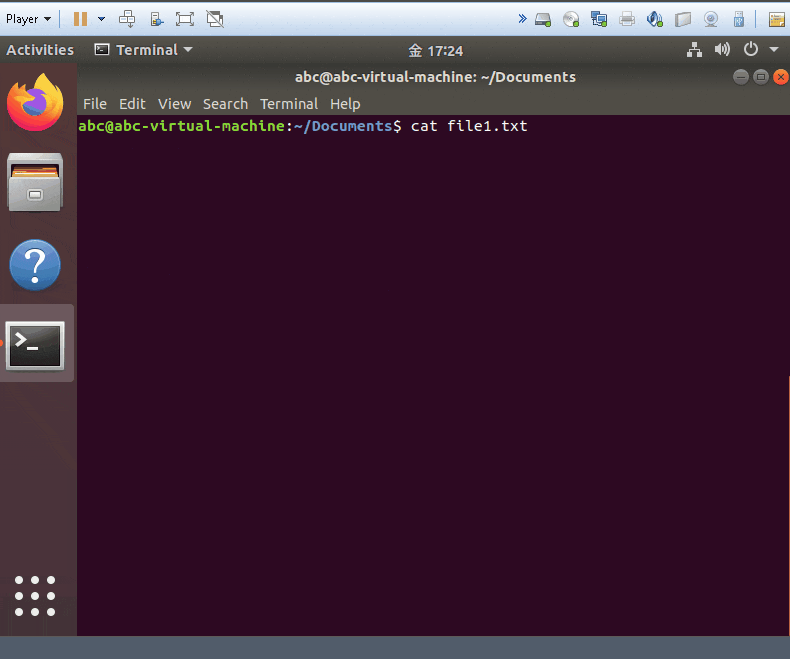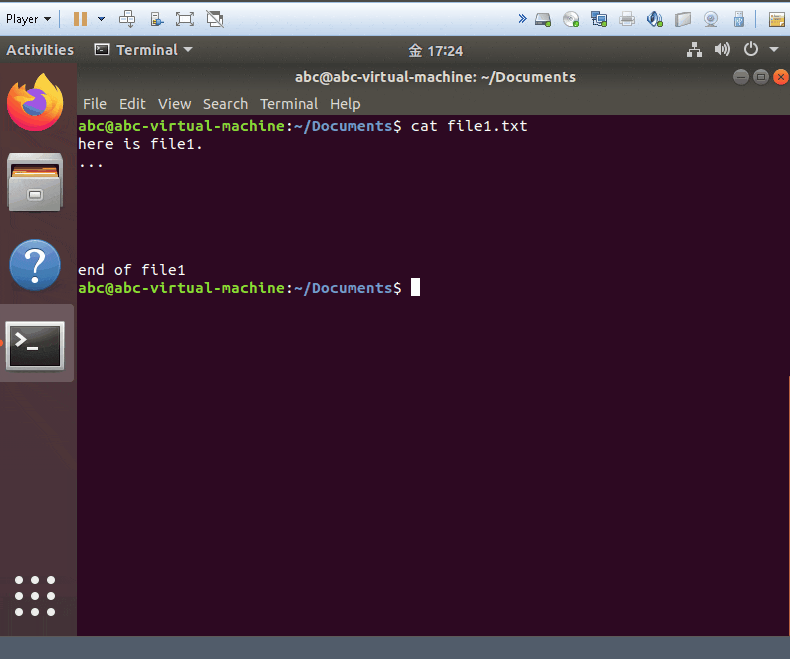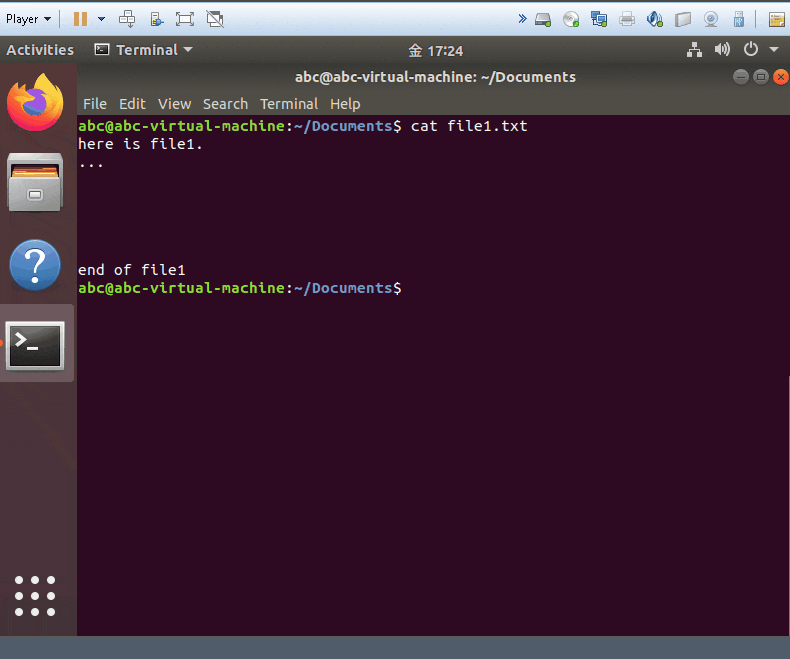
cat yourfile1 yourfile
- show the files
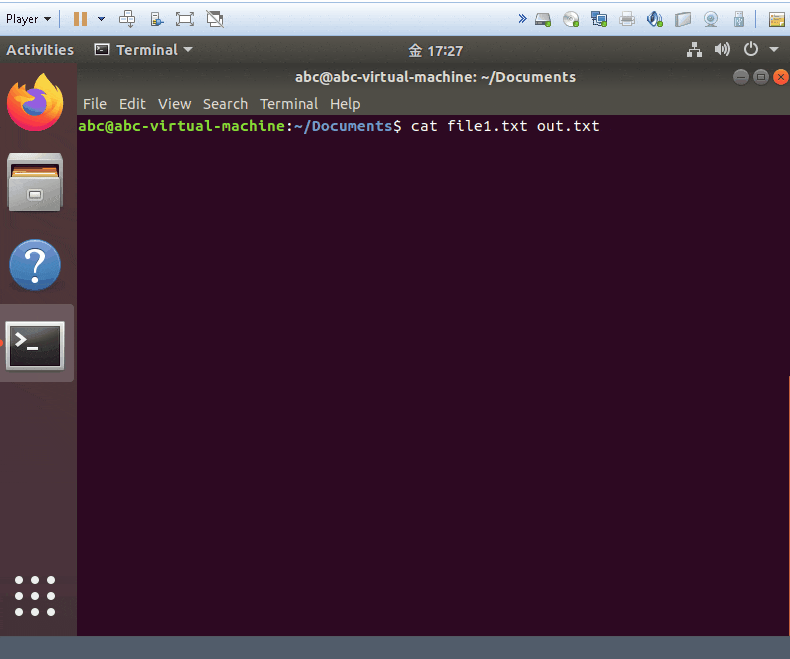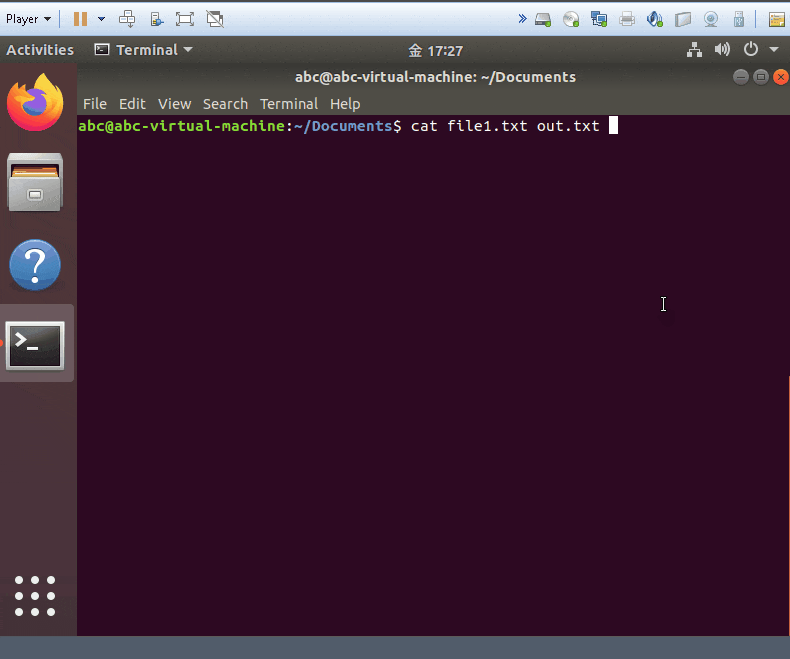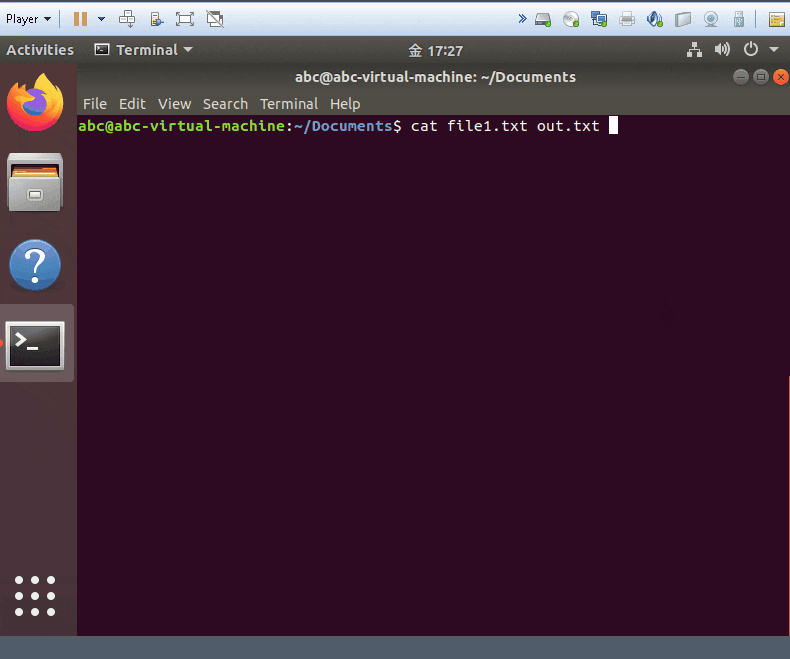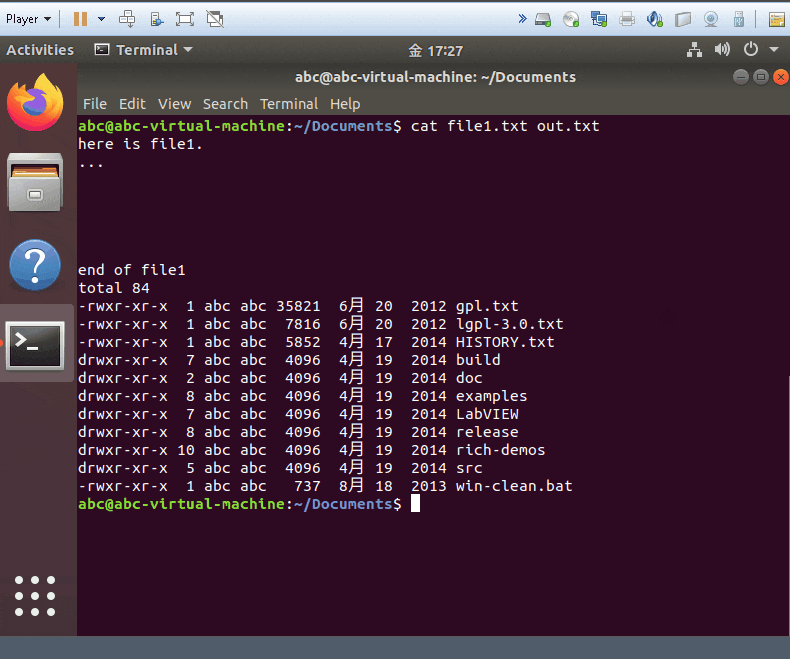
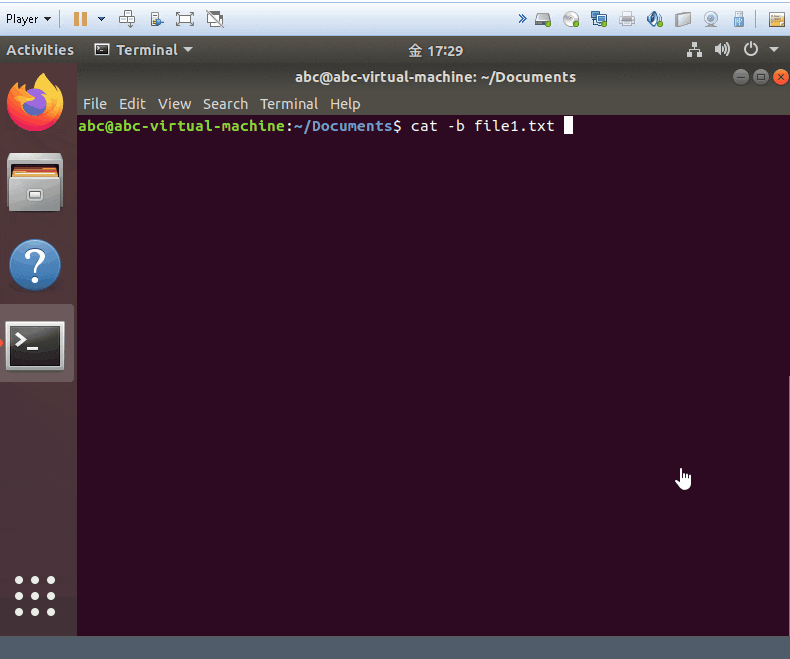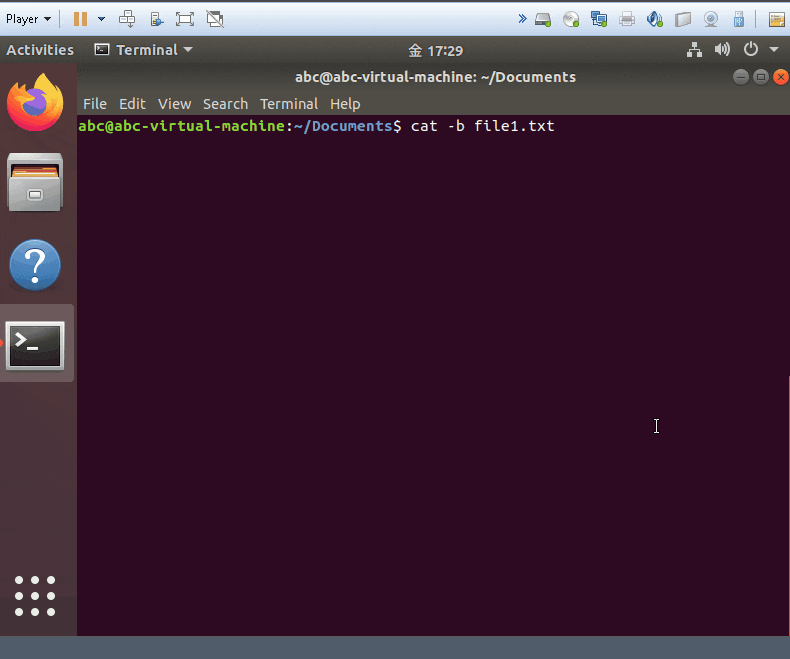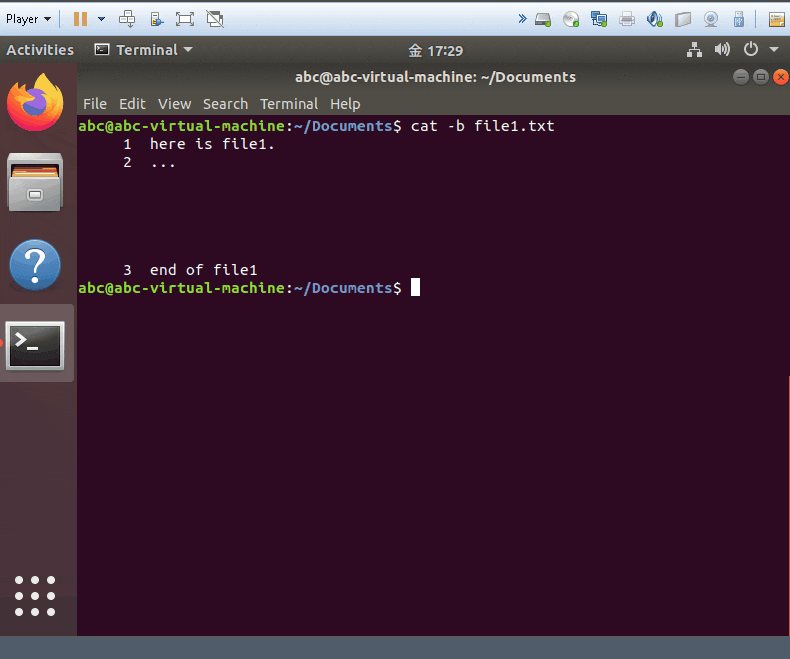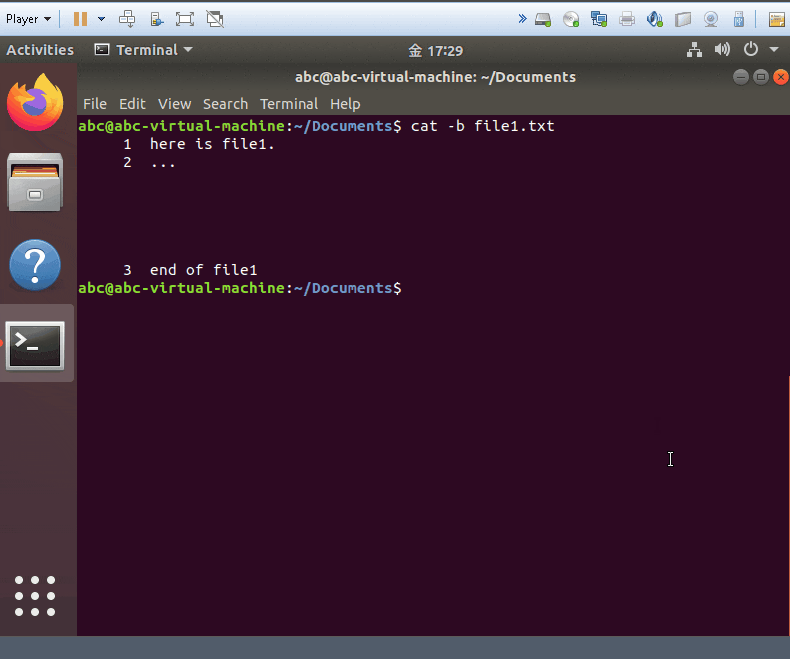
cat -b yourfile
- show and add the line numbers on the non-blank line
cat -n yourfile
- show and add the line numbers on all the lines.
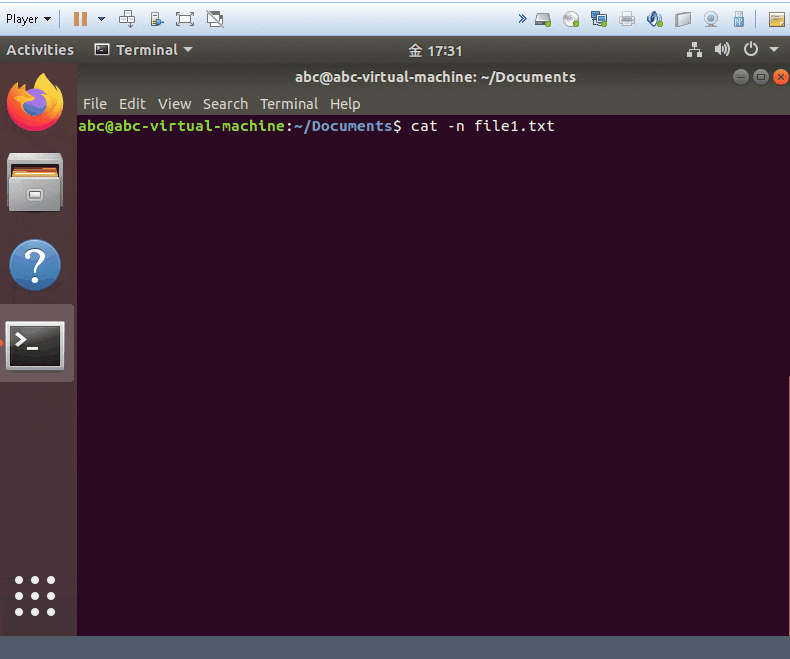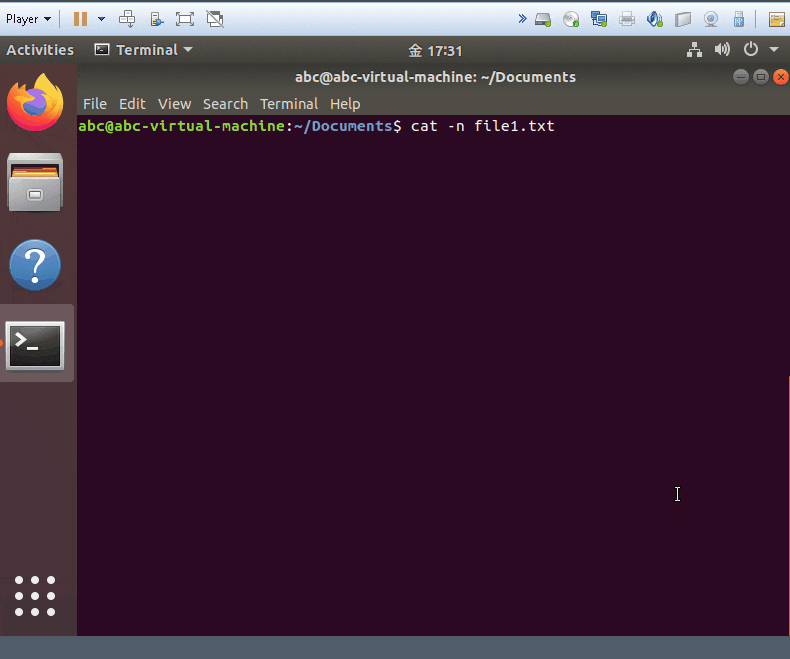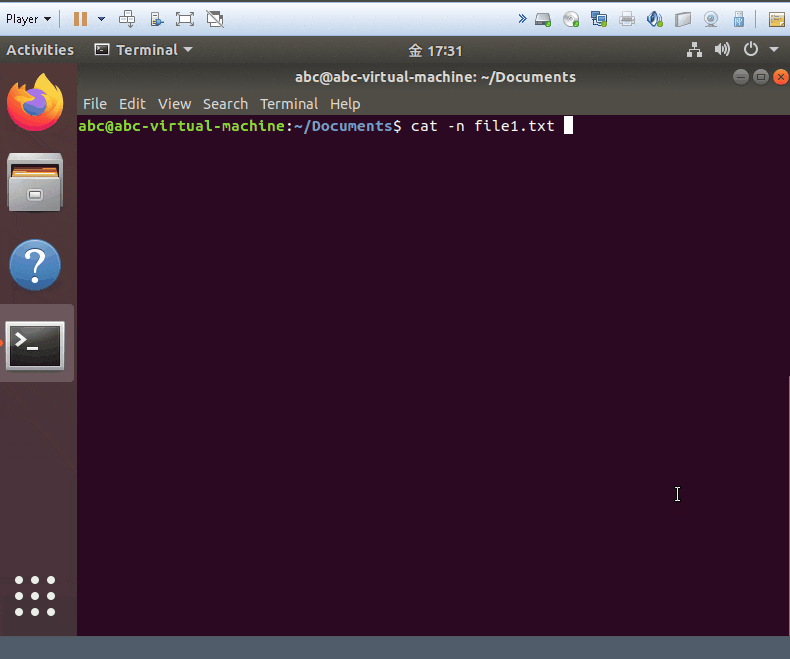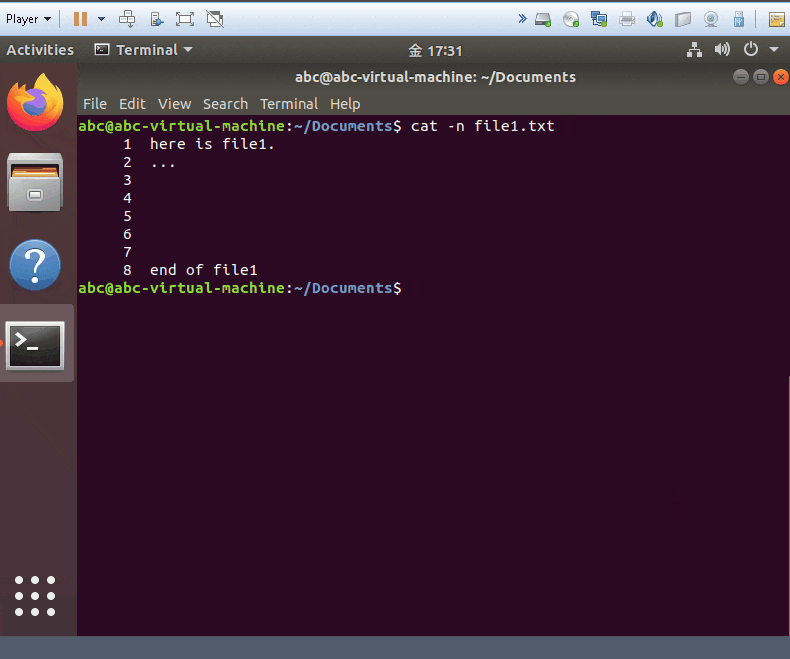
cat -s yourfile
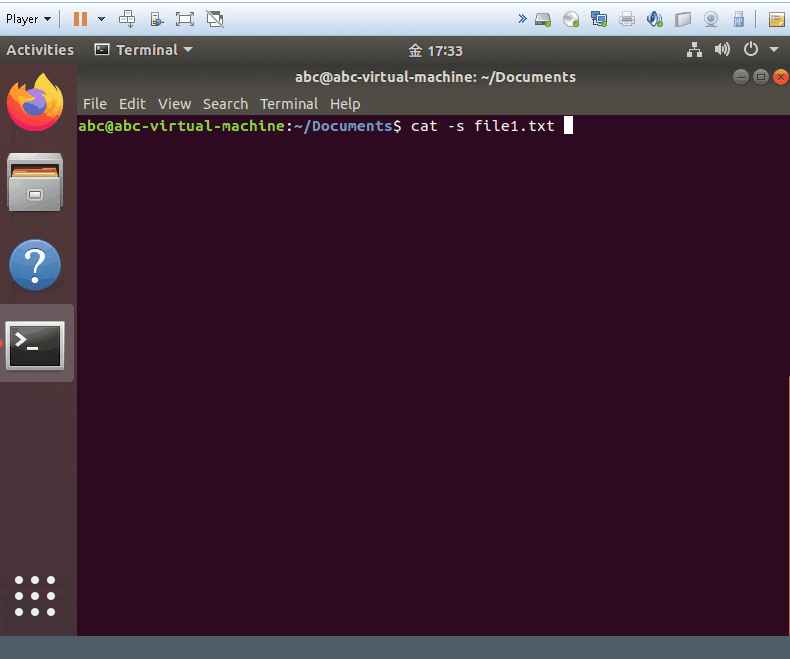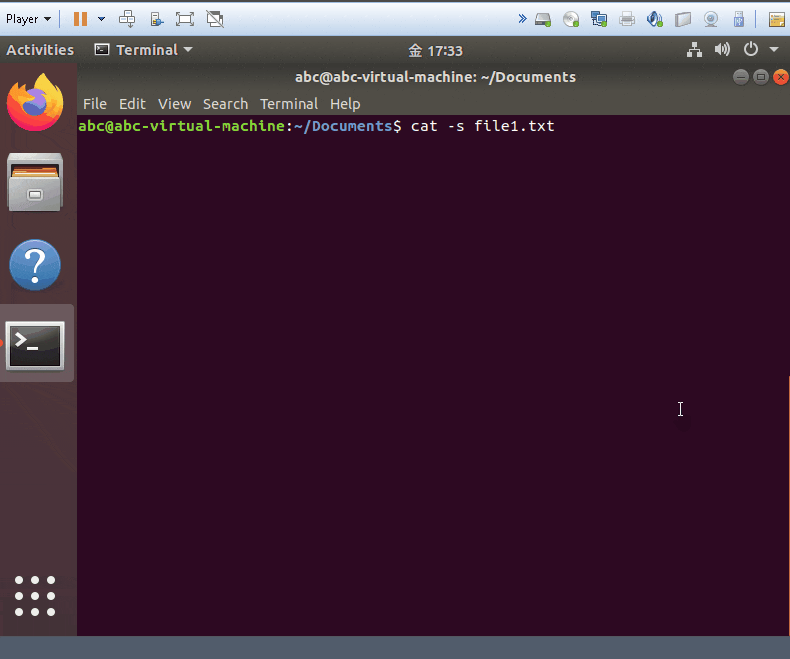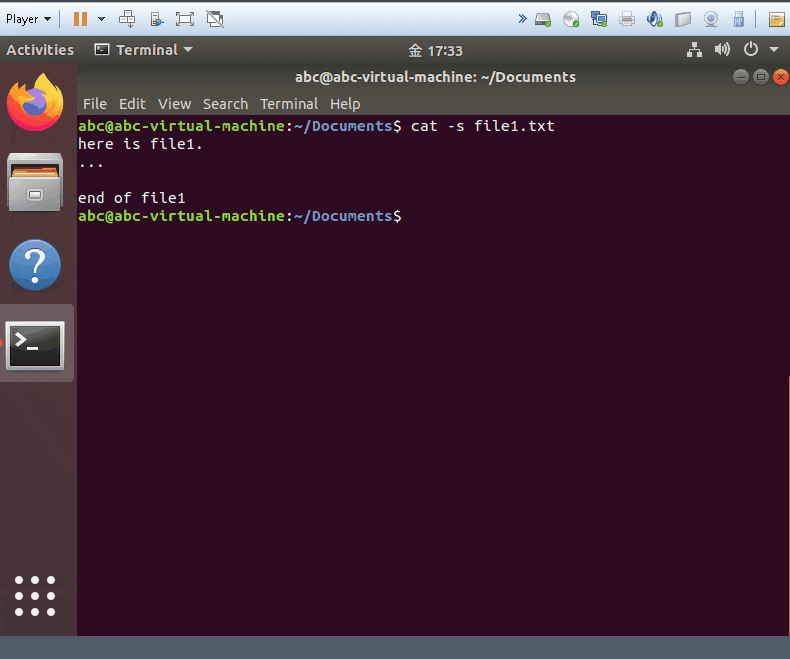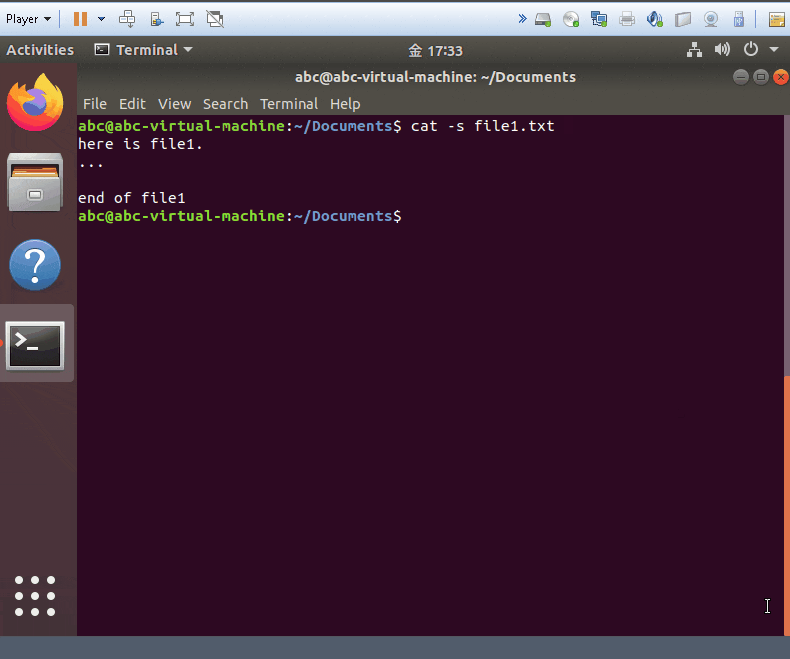
- show your files and decrease all the blank line to one line
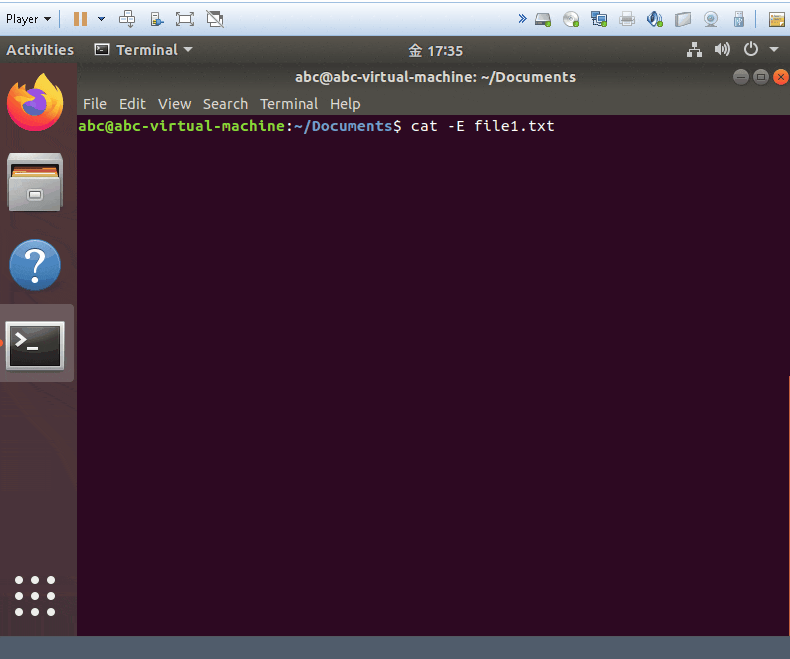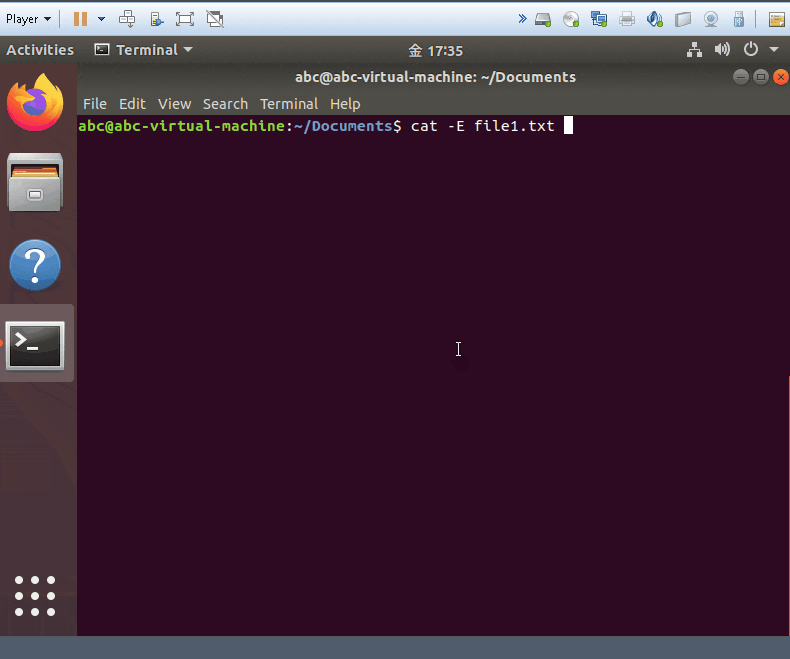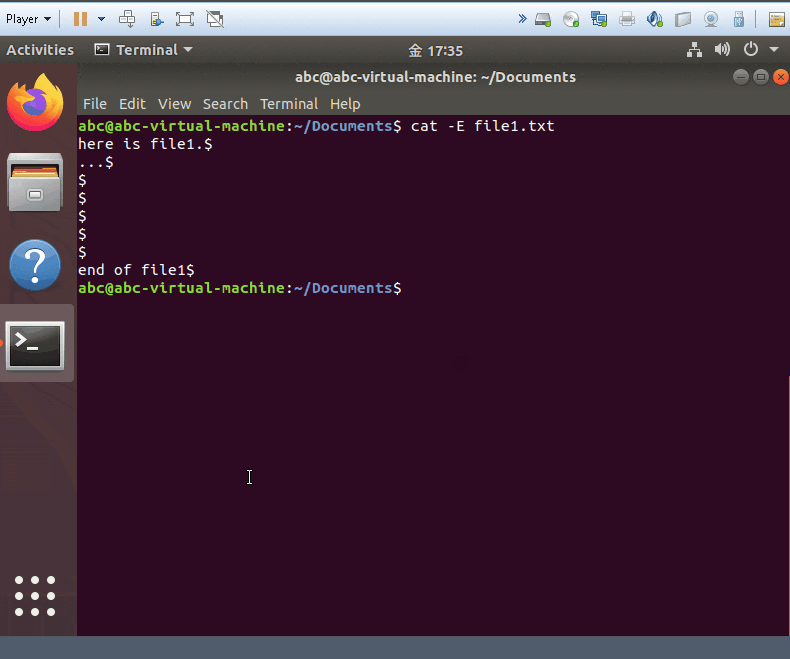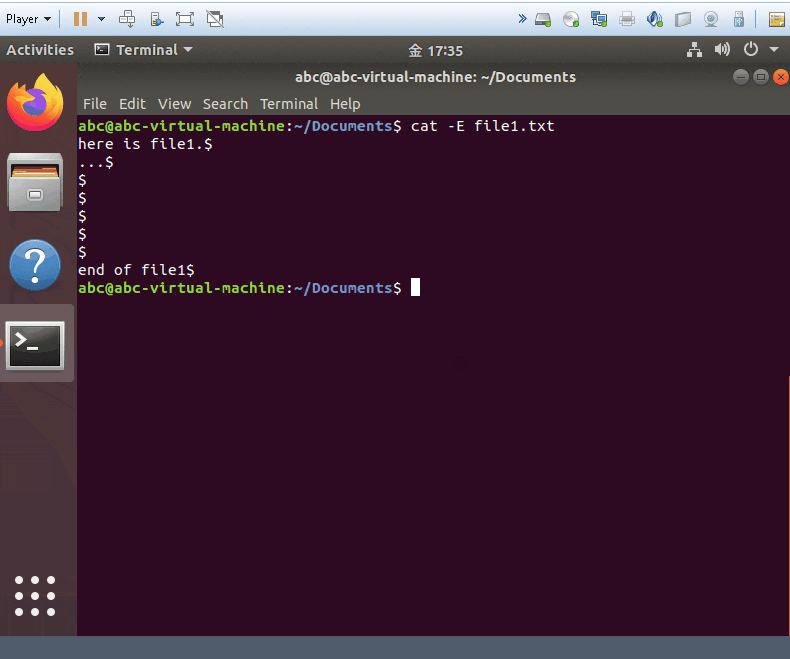
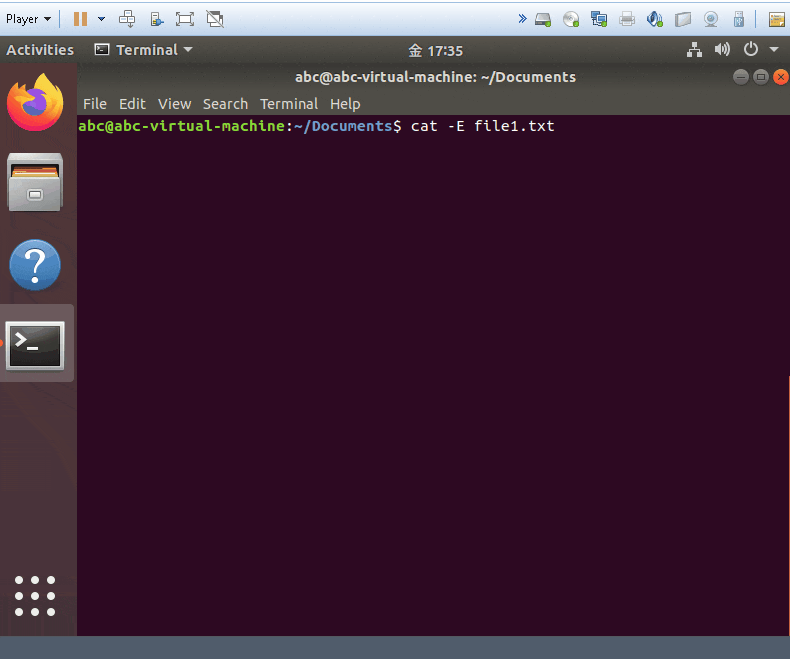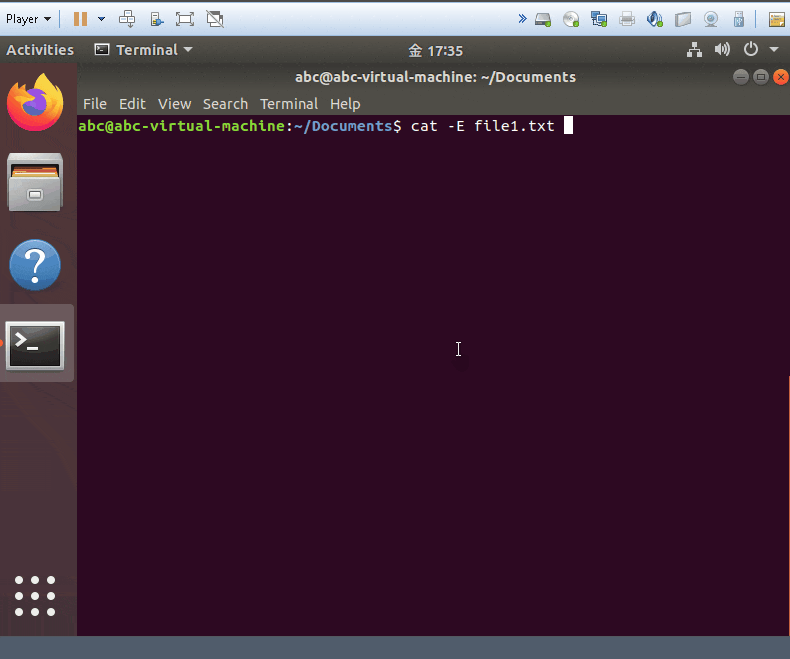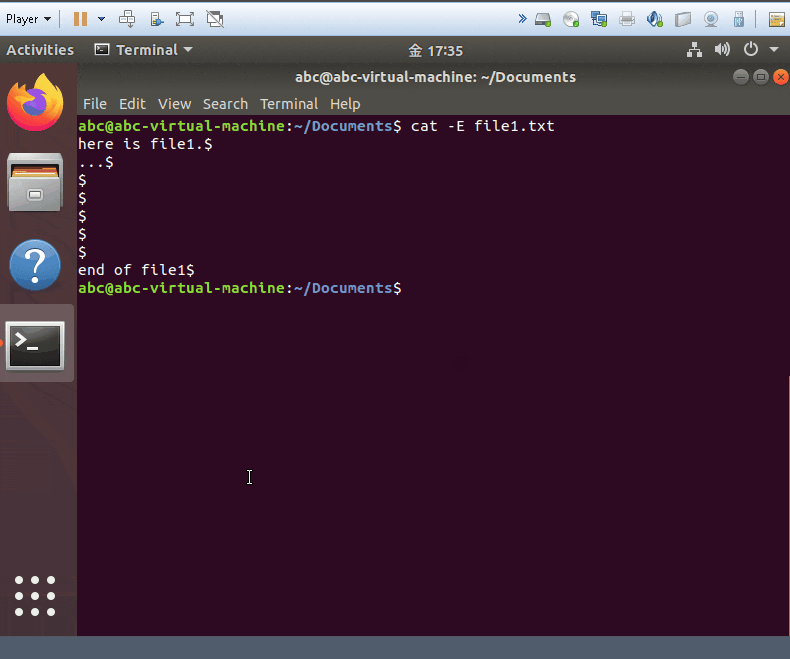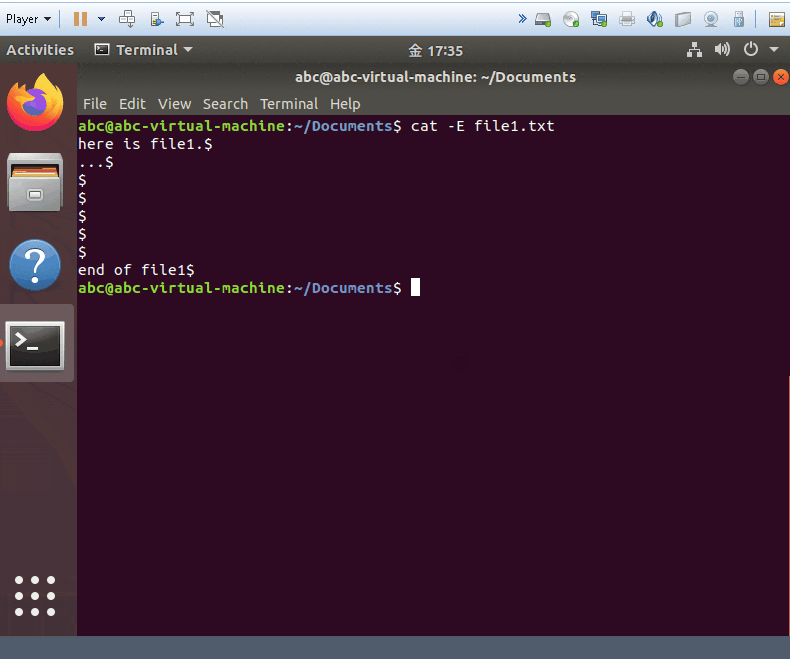
cat -E yourfile
- show your files and add $ symobl on each of end line.!