- 投稿日:2020-01-19T23:41:52+09:00
S3 で SPA をホスティングするとき、アクセスする URL が 404 のときに index.html を返す方法
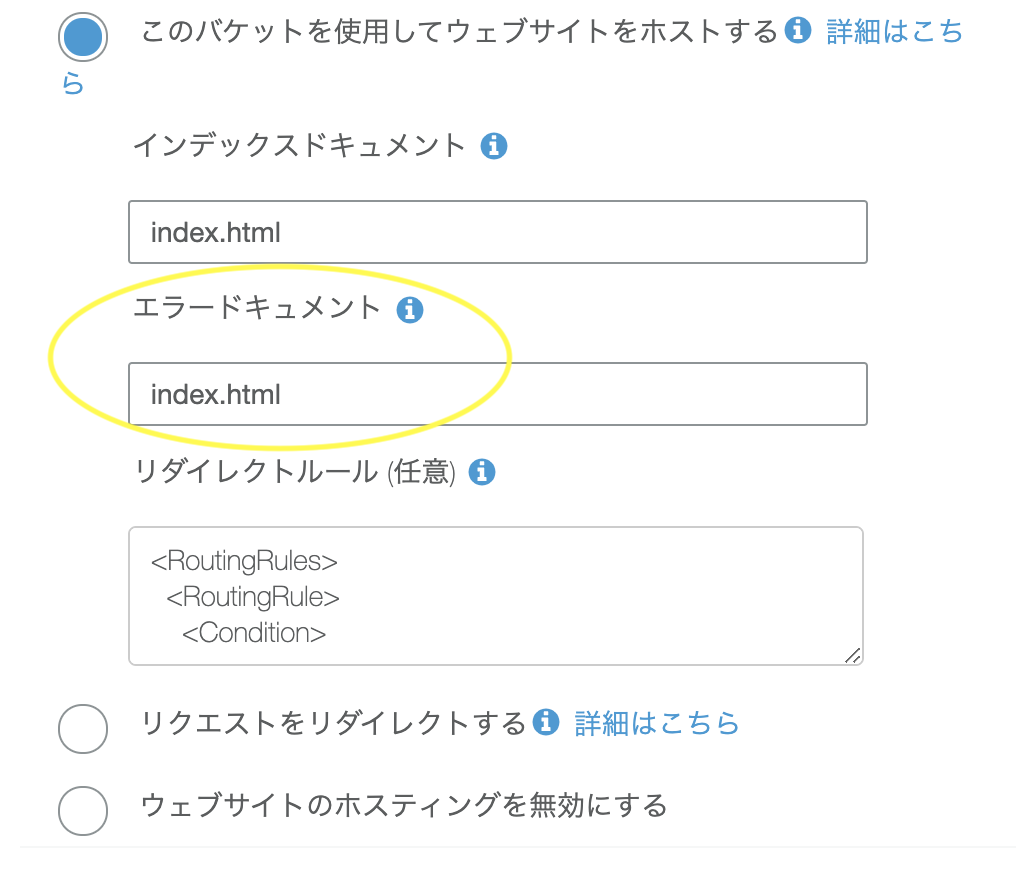
- 投稿日:2020-01-19T20:02:21+09:00
マストドン構築2日目 on AWS
経緯
前回書いた マストドン構築1日目 on AWS の続きです。
半年ほど前に AWS & Docker ド素人の状態から
なんとかインスタンスをたてて運用していました。EC2の上にDockerで本番運用していましたが、だんだん辛くなってきたのでDockerから降ろすことにしました。
その作業ログです。環境 / ツール
macOS Mojavi 10.14.6
AWS参考にしたもの
マストドンGitHub
https://github.com/tootsuite/mastodon
公式ドキュメント
https://docs.joinmastodon.org/admin/install/サーバー内での作業
まずサーバーにsshログインします。
$ ssh ubuntu@3.112.***.*** -i ~/.ssh/hoge.pem作業に入る前に、とりあえずrootユーザーになります。
sudo su -そして、mastodonユーザーに切り替えます。
# su - mastodonマストドンのセットアップ
マストドンのソースをgit cloneして来ます
$ git clone https://github.com/tootsuite/mastodon.git live && cd live最新の安定したリリースをダウンロードします。
git checkout $(git tag -l | grep -v 'rc[0-9]*$' | sort -V | tail -n 1)ちなみにバージョンを指定する場合は、以下のやり方で指定します。
例:2.9.3を指定する場合。$ git checkout v2.9.3RubyとJavaScriptの依存ファイルをインストールします。
$ bundle install -j$(getconf _NPROCESSORS_ONLN) --deployment --without development test rbenv: version `2.6.1' is not installed (set by /home/mastodon/live/.ruby-version)なんと、マストドン2.9.3はRubyの2.6.1でないと動かないっぽいです。
(以下、最新版をインストールしている方には不要の工程です)
2.6.1をインストールしなおします。$ RUBY_CONFIGURE_OPTS=--with-jemalloc rbenv install 2.6.1 $ rbenv global 2.6.1設定ファイルの編集
対話型セットアップウィザードを実行します。
RAILS_ENV=production bundle exec rake mastodon:setup対話型セットアップウィザードとは
一問一答式でmastodonリポジトリの.env.productionにある設定ファイルの中身をセットアップすることが出来ます。
もし間違えてしまっても、メールサーバーの設定などは後から.env.productionで編集する事が可能です。※新規でインスタンスを立てる場合は先にメールサーバーなどの設定が必要です。
ちなみに、わたしはAWSの勉強のために SES(Simple Email Service)を利用しましたが
よほどAWSを使いたいか大規模運営をする予定でなければ、送信制限解除の申請などやることが多くなるためお勧めしません。
無料メールサーバーではmailgunなどが良いかもしれません。以下、聞かれる内容と回答例です。
Your instance is identified by its domain name. Changing it afterward will break things. Domein name : uneune.shiosyakeyakini.info(ドメイン名を入力します) Single user mode disables registrations and redirects the landing page to your public profile. Do you want to enabled single user mode? no (お一人様で使う気はないのでno) Are you using Docker to run Mastodon? no (今回はDockerを使わずに運用するのでno) PostgreSQL host: /var/run/postgresql (デフォルト) PostgreSQL port: 5432 (デフォルト) Name of PostgreSQL database: mastodon_production (デフォルト) Name of PostgreSQL user: mastodon (さきほど設定したもの。デフォルト) Password of PostgreSQL user: (パスワード設定している場合は入力) Database configuration works! ? Redis host: localhost (デフォルト) Redis port: 6379 (デフォルト) Redis Password: (パスワード設定していないので空欄) Redis configuration works! ? Do you want to store upload file on the cloud? No (よくわからないのでno) Do you want to send e-mails from localhost? No (AWS SESのメールを使いたかったのでNo) SMTP server: email-smtp.us-west-2.amazonaws.com (SESのメールサーバー) SMTP port: 587 (SESのメールサーバーのSMTPポート) SMTP username: (メールアカウント)`SMTP_LOGIN=`の内容 SMTP password: (ひみつ) SMTP authentication: plain (デフォルト) SMTP OpenSSL verify mode: none (デフォルト) E-mail address to send e-mails from: don.suwa3.me@gmail.com Send a test e-mail with this configuration right now? Yes (試しに送る=>パスワードを間違えていて送れなかった。) Send test e-mail to: (よく使うメールアドレス) E-mail could not be sent with this configuration, try again? : no (あとで再設定します) Save configuration?: true Prepare the database now? : true The final step is compiling CSS/JS assets. This may take a while and consume a lot of RAM. Compile the assets now?: Yes (めちゃくちゃ時間かかります) Do you want to create an admin user straight away? : true (管理者用アカウントを作ります) Username: suwa3 E-mail: (ひみつ) You can login with the password: (長いパスワード)=>控えますおまけ
Compile the assets now?
で、時間がかかりすぎて途中でコケました。
最初から一問一答する気になれないときは
assets:precompileと、指定して再開することもできます?$ RAILS_ENV=production bundle exec rails assets:precompile次回予告
3日目はNginxのセットアップです。
作業が進み次第、Qiitaに作業ログを残したいと思います。
- 投稿日:2020-01-19T19:21:06+09:00
アル中カタカタ〜!大事なキーを異世界に転生!また俺何かやっちゃいました?
システムエンジニアになって10ヶ月のピッチピチのJK(Java書き)のキー太郎です!
先日最近購入しましたMacBook Proを友達の家に持って行って、酒呑みながらカタカタいじってたときの失敗談です。ゆる〜く聞き流してください。週末久しぶりに友人と食事をした私はそのまま友人宅飲み会をすることに。MacBook Proを開きながらあれこれよくわからんウンチクを語りながら例の飲み物(角ハイ金)を飲んでいました。そしてどういう流れからか私は友人に自慢をしたくなりました。
キー太郎「そういえばさ〜最近秒で俺サーバ作れるようになったんだよね〜」
友人「どうやって?」
キー太郎「EC2ていうえーだぶりゅーえす?を使うと簡単にサーバ立ち上げることができるんだぜ〜」
友人「すげーーーーーーーーーー!!!!!!!!!!!!!!!!」
キー太郎「また俺何かやっちゃいました?笑笑」macでEC2を立ち上げるには
1:AWSマネジメントコンソールからEC2を選択し、キーペアを作成する。
2:作成した秘密鍵(pem)をダウンロードする。
3:キーの権限を変更する。chmod 400 ●●●●●.pem
4:sshコマンドを実行する。
ssh ec2-user@00.00.00.00 -i ●●●●●.pem
5:サーバが稼働する。
| _| )
| ( / Amazon Linux 2 AMI
__|_|___|ざっくりと説明しましたがこんな感じです。
さてその後一通り自慢を終えた私はキーを保存しておくためのディレクトリを作成し、作成後にキーを移動しようと思い実行に移します。そのことがある悲劇を生むとは梅雨知らず、、、
キー太郎(酔)「キーをただ外にほっぽり出しておくのもなんかアレだしディレクトリでも作成してそんなかで管理しておきますかね〜」
キー太郎(酔)「まずはディレクトリを作るぞーい」
キー太郎「ディレクトリを作るには確かmkdir or touch だったけな・・・」touch SSH
キー太郎「そんで次はカレントディレクトリにあるキーを移動させると・・・」
キー太郎「mvコマンドで異世界転生させたるわ!!!!!」mv ●●●●●.pem /●●/●●/SSH/
キー太郎「実行っと・・・うん!特にエラーもなく実行できたみたいだな」
キー太郎「さて無事に作業終わったし祝酒でも開けますかね笑笑」その後達成感に浸りながらとりあえず再びssh接続をしようと試みます。まずキーが入っているSSHディレクトリ移動しようとします。
cd SSH
キー太郎「移動っと・・・あれ?」
cd: not a directory: ●●●●●.pem
キー太郎「ディレクトリじゃない・・・?どういうこと?アクセス権限の問題か?いやディレクトリじゃないよってターミナルに言われとるし・・・」
その後あらゆる手段試してもそのディレクトリには移動できませんでした。
キー太郎「はあああああああ・・・・終わったわ。完全に詰んだ。ディレクトリに入れなかったら鍵取り出せんわ・・・・」
さて感の良い方なら最初の方に気づいているかもしれません。その通りです。この悲劇は最初に実行したコマンドであるtouchコマンドが原因なのです。
touchコマンドはファイルのタイムスタンプを変更するコマンドであり、存在しないファイル名を指定することで、内容の入っていないファイルを新規作成する機能を持っています。詳しくはググってください。
最初から整理します。
カレントディレクトリには
●●●●●.pem
touch SSH コマンド実行後のカレントディレクトリは
●●●●●.pem SSH
という状態になっておりtouchコマンドをディレクトリを作るコマンドだと思っていた私はSSHをディレクトリだと認識しています。その後キーをSSHディレクトリに移動させようとmvコマンドを実行します。
mv ●●●●●.pem SSH
ここでも深刻な問題が起っています。mvコマンドは移動させることだけではなく名前を変更させることもできるコマンドなのです!つまり・・・・
mv 名前を変えたいファイル名 変更したい名前
というように上記の私が実行したコマンドは移動させるのではなく名前を変えるコマンドととらえられてしまったのです。笑笑 また名前を変えた後SSHという同じ名前をしたファイルが存在することになるので、旧SSHファイルはSSHという名前に変わったキーである新SSHファイルに上書きされます。そうなるとカレントディレクトリに残るのはSSHという文字のみ・・・あたかもSSHディレクトリにキーの移動が成功したように見えるのです。
mvコマンド実行後のカレントディレクトリは
/*SSHというディレクトリが存在するのではなくSSHという名前の●●●●●.pemが存在しているだけ/
SSH酔っ払っていてそのことに気づかなかった私はあたかもキーがnot a directoryという自分で作った謎のディレクトリにキーを異世界転生させてしまったと錯覚したのです。
また俺何かやっちゃいました?
●今回の事件からの学び
・大事なファイルを移動させるときは細心の注意を払う。
・コマンドを正確に理解した上でコマンドを実行する。
・酒を飲みながら作業してはいけない。その後・・・
キー太郎「なんだったんだこれは・・狐に包まれた気分。」
友人「ぱっと見.txtとか.html.javaとかついてないとディレクトリかと思うよな」
キー太郎「まあ擬似異世界転生体験できたし良いか笑!!!」
友人「委員会!」以上です。ここまで駄文を読んでいただき本当にありがとうございます。何か気づいた点、突っ込みどころがありましたらなんなりとコメントを送ってください。
- 投稿日:2020-01-19T19:17:23+09:00
Amazon API GatewayのHTTP API使ってみた
はじめに
lambdaをさわっててAPIGatewayのコンソールを覗いてみたら見覚えのない選択肢がありました。
このHTTP APIなるもの、新機能らしいです。
しかも出たばかり。
ホットなので使ってみました。※検証時点ではプレビュー版となります。
HTTP API
クラスメソッドさんが解説してくれてます。
いつも助かります。
https://dev.classmethod.jp/cloud/aws/amazon-api-gateway-http-or-rest/なにやら従来のREST APIよりも簡単に使えそうな雰囲気ですね。
やりたい事
curlでapi叩いてlambda動かしたい。
認証も噛ませたい。やってみた
lambda作る
- ウィザードに従い、ぽちぽち作る。
- 言語はpython3.7を指定。
- ソースはこんな感じ。
import json def lambda_handler(event, context): return { 'isBase64Encoded': False, 'statusCode': 200, 'headers': {}, 'body': '{"message": "Hello Lambda"}' }
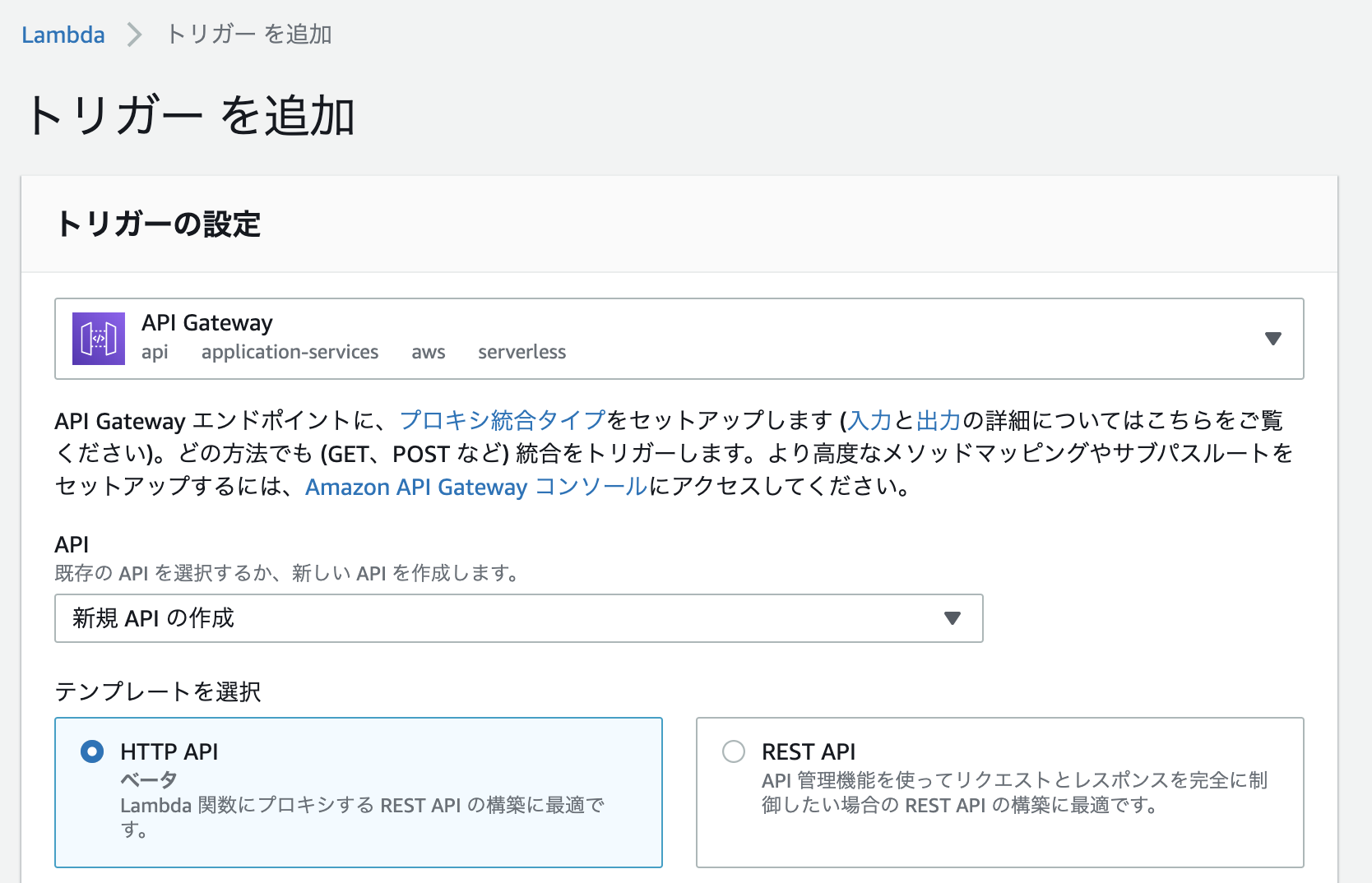
トリガーを追加からAPI Gatewayを追加する。
HTTP APIを指定する。
Cognitoの設定
非公開のlambdaを作りたかったので認証必須。
HTTP APIはCognito使うのが良さそう。
認証不要なAPIの場合は、この手順不要かと思います。ユーザープールを作る
- デフォルトでユーザープール作成する。
- ユーザーを1人作成する。
- メールが送られてくる。
- アプリクライアントを作成する。
- 次のチェックボックスだけONにする。
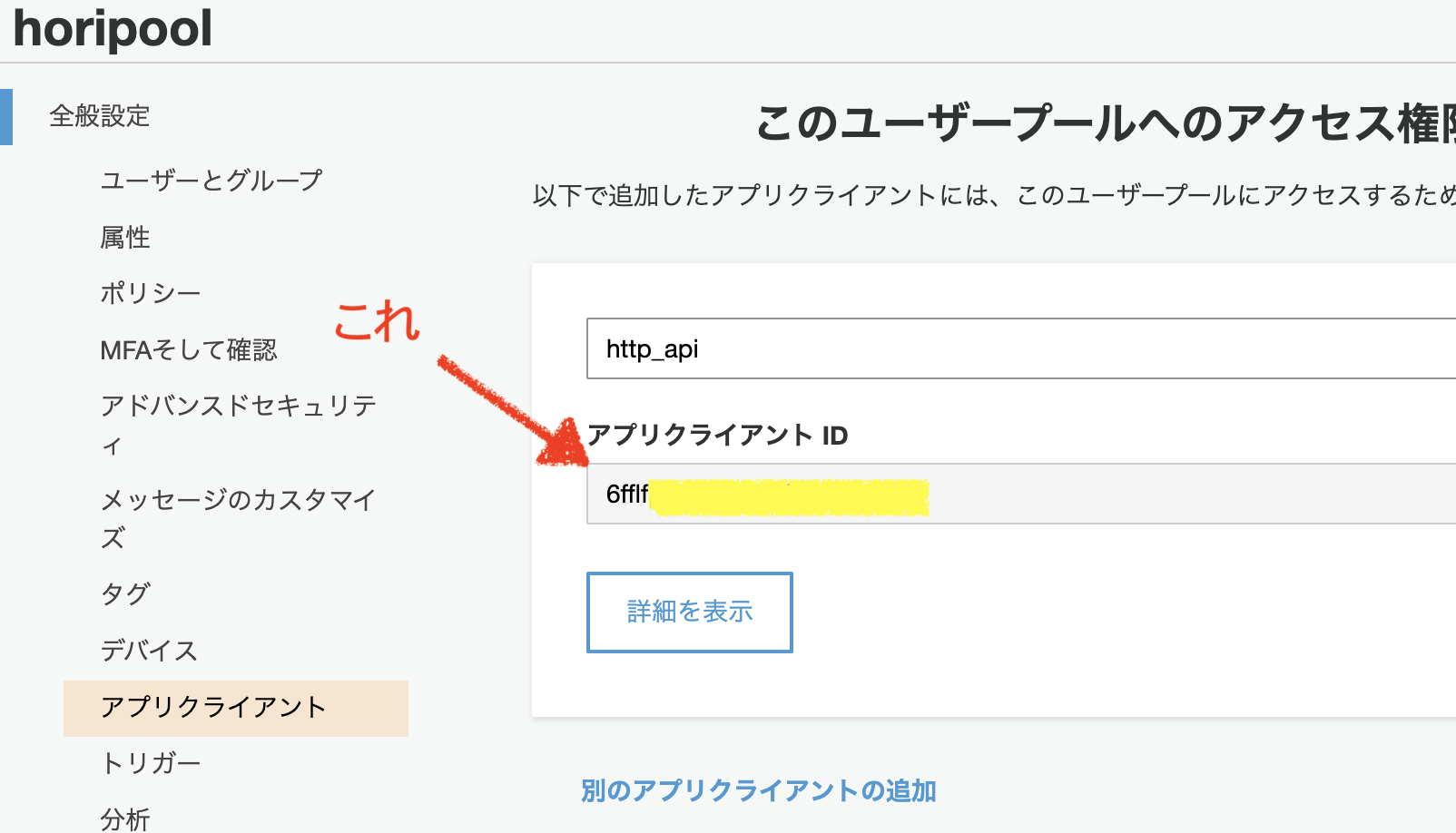
認証用の管理 API のユーザー名パスワード認証を有効にする (ALLOW_ADMIN_USER_PASSWORD_AUTH)更新トークンベースの認証を有効にする (ALLOW_REFRESH_TOKEN_AUTH)(OFFにできなかった)フェデレーティッドアイデンティティ
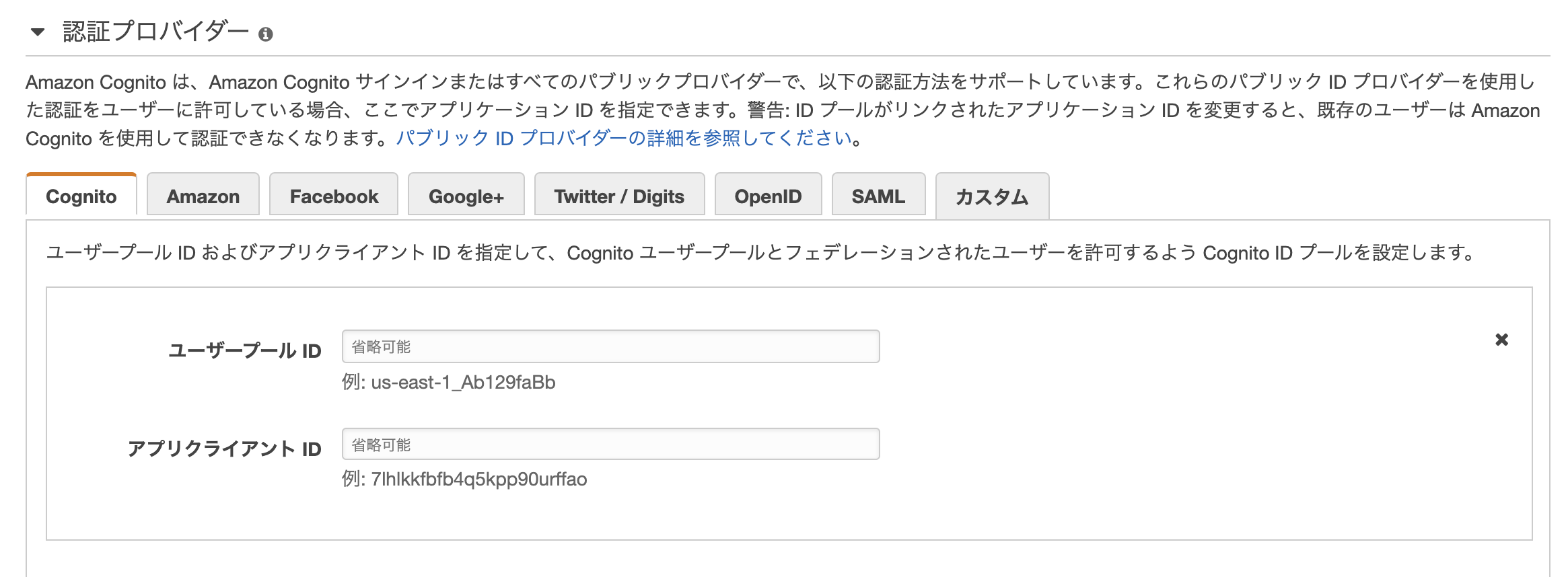
- 先ほど作ったユーザープールの画面で下記をメモります。
ユーザープールID

アプリクライアントID
- フェデレーティッドアイデンティティを開きます。
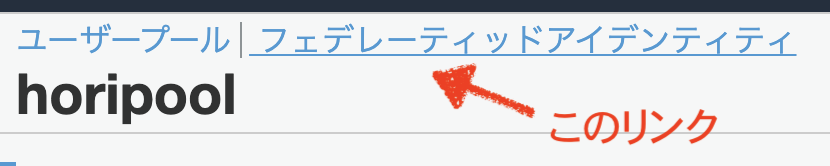
新しいIDプールの作成ボタンを押して、メモった情報を入力し、作成します。
API Gatewayの設定
公式資料はこれかな?
https://docs.aws.amazon.com/ja_jp/apigateway/latest/developerguide/http-api-examples.html認証を有効にしたいので、下記の設定を行う。
公式資料はこれ。
https://docs.aws.amazon.com/ja_jp/apigateway/latest/developerguide/http-api-jwt-authorizer.html
- API Gatewayのコンソールから、lambdaから作成したAPIを開く。
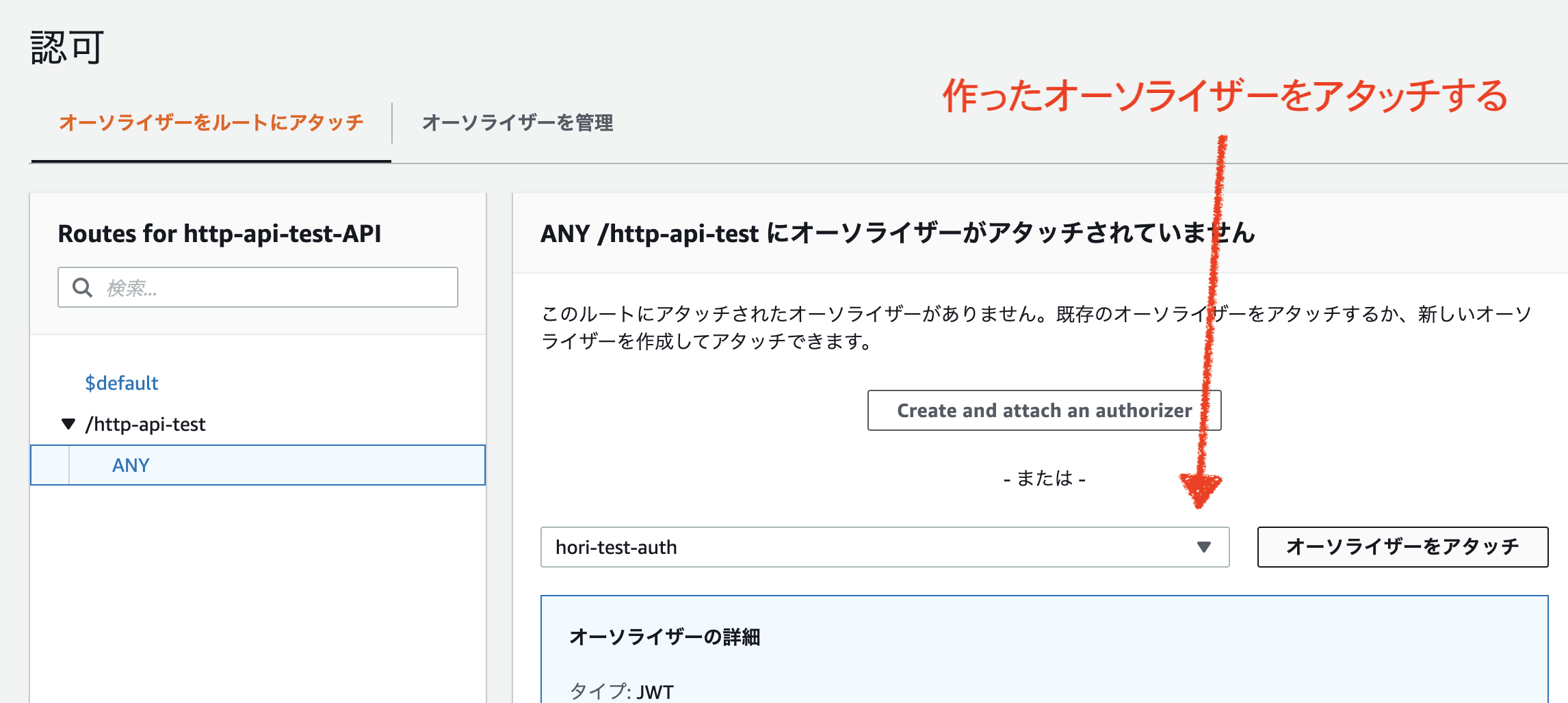
認可からオーソライザーを作成する。
- こんな感じでつくる。

- 作ったオーソライザーをルートにアタッチする。
APIを叩いてみる
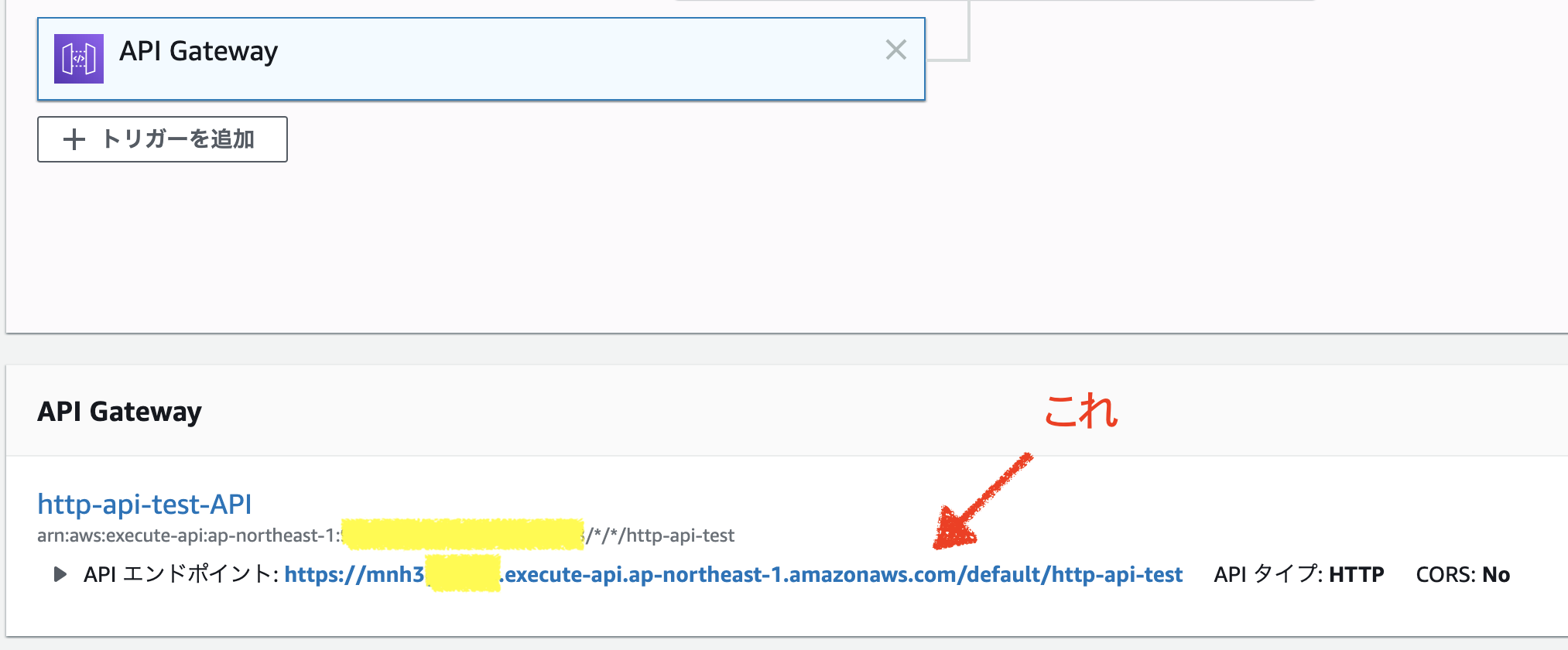
とりあえず、叩いてみる。
URLはlambdaのAPI Gatewayの箇所に書いてある。
$ curl https://mnh3XXXXXX.execute-api.ap-northeast-1.amazonaws.com/default/http-api-test {"message":"Unauthorized"}認証作ったし動かなくて正解。
認証情報の取得
JWTなる認証はJSON形式のトークンを使って認証をやりとりするそうな。
まずはトークン取得。
*--user-pool-idはユーザープールIDを指定。
*--client-idはアプリクライアントIDを指定。
*--auth-parametersはcognitoで作成したユーザーの名前とパスワードを指定。$ aws cognito-idp admin-initiate-auth --user-pool-id ap-northeast-1_ItJXXXXXX --client-id 6fflXXXXXXXXXXXXXXXXXXXXXX --auth-flow ADMIN_USER_PASSWORD_AUTH --auth-parameters "USERNAME=tsuyoshi,PASSWORD=password" { "ChallengeName": "NEW_PASSWORD_REQUIRED", "Session": "MktQ~(長いので省略)~Qoj9zrYg-lsWI", "ChallengeParameters": { "USER_ID_FOR_SRP": "tsuyoshi", "requiredAttributes": "[]", "userAttributes": "{\"email_verified\":\"true\",\"email\":\"hori@hogehoge.jp\"}" } }https://docs.aws.amazon.com/cli/latest/reference/cognito-idp/admin-initiate-auth.html
まずはパスワード変更してね。って事らしい。https://docs.aws.amazon.com/cli/latest/reference/cognito-idp/admin-respond-to-auth-challenge.html
パスワード変更する
*--user-pool-idはユーザープールIDを指定。
*--client-idはアプリクライアントIDを指定。
*--challenge-responsesでユーザーの名前と新しいパスワードを指定。
*--sessionは直前に実行したコマンドで返ってきたSessionsの値をコピペ。$ aws cognito-idp admin-respond-to-auth-challenge --user-pool-id ap-northeast-1_ItJXXXXXX --client-id 6fflXXXXXXXXXXXXXXXXXXXXXX --challenge-name NEW_PASSWORD_REQUIRED --challenge-responses NEW_PASSWORD='P@55w0rd',USERNAME=tsuyoshi --session "MktQk~(長いので省略)~Qoj9zrYg-lsWI"改めてトークンの取得。
$ aws cognito-idp admin-initiate-auth --user-pool-id ap-northeast-1_ItJXXXXXX --client-id 6fflXXXXXXXXXXXXXXXXXXXXXX --auth-flow ADMIN_USER_PASSWORD_AUTH --auth-parameters "USERNAME=tsuyoshi,PASSWORD=P@55w0rd" { "ChallengeParameters": {}, "AuthenticationResult": { "AccessToken": "eyJr~(省略)~MaT_g", "ExpiresIn": 3600, "TokenType": "Bearer", "RefreshToken": "eyJ~(省略)~KVw", "IdToken": "eyJr~(省略)~uXg" } }認証につかうのは
AuthenticationResult.IdTokenっぽい。証情報をつかってAPIを叩く
$ curl -H 'Authorization: eyJr~(省略)~uXg' https://mnh3XXXXXX.execute-api.ap-northeast-1.amazonaws.com/default/http-api-test {"message": "Hello Lambda"}うごいた!
備考
- オーソライザーをデタッチしたら、認証介さずアクセスできた。オープンなAPI。
- urlはdefaultを省略できるので
https://mnh3XXXXXX.execute-api.ap-northeast-1.amazonaws.com/http-api-testでもアクセスできる。- パスパラメータ等はまだつかえないのかな・・・?

- 投稿日:2020-01-19T17:40:14+09:00
[AWS]Webサーバーの構築方法
2020年1月19日現在の内容です。
用語説明
EC2(Elastic Compute Cloud)
AWSクラウド上の仮想サーバー
インスタンス:EC2から立てられたサーバーのこと特徴
- 数分で起動し、1時間または秒単位の従量課金
- サーバーの追加・削除、マシンスペック変更も数分で可能
- OSより上のレイヤについては自由に設定できる
作成手順
- AMIの選択
- インスタンスタイプの選択
- ストレージの追加
- セキュリティグループの設定
- SSHキーペアの設定
AMI(Amazon Machine Image)
インスタンス起動に必要な情報が入ったOSのイメージ
サーバーのテンプレートのようなもの特徴
- AWSやサードパーティがAMIを提供
- 自前のカスタムAMIも作成可能
- カスタムAMIから何台でもEC2インスタンスを起動可能
インスタンスタイプ
サーバーのスペックを定義したもの
概要
- インスタンスタイプにより、CPU、メモリ、ストレージ、ネットワーク帯域が異なる
- インスタンスタイプにより料金が異なる(スペックが高いほど料金も高い)
- アクセス数などに応じて必要なスペックのあるインスタンスタイプを選択する
ストレージ
サーバーに紐付けるデータの保存場所
EC2のストレージは2種類存在するEBS(Elastic Block Store)
- 高い可用性と耐久性を持つストレージ
- 他のインスタンスに付け替え可能
- EC2インスタンスをSTOP(一時停止)/Terminate(永久破棄)してもEBSは保持可能
- Snapshot(増分バックアップ)を取得しS3に保存可能
- EBSの費用が別途発生
- OSやDBなどの永続性と耐久性が必要なデータの格納に使用
インスタンスストア
- インスタンス専用の一時的なストレージ
- 他のインスタンスに付け替えることができない
- EC2インスタンスをSTOP/Terminateするとクリアされる
- 追加費用は発生しない(無料)
- 一時ファイルやキャッシュなど失われても問題がないデータの格納に使用
一般的にはEBSの利用が多い
SSH
サーバーと自分のパソコン(クライアント)をセキュアにつなぐサービスのこと
(通信内容が暗号化された遠隔ログインシステム)EC2にログインするときはSSHを使用する
公開鍵認証
- サーバーへのログイン時に認証を行う仕組み
- ユーザー名とパスワードを使用した認証と比べ、よりセキュリティが高い
- 公開鍵暗号(秘密鍵と公開鍵)を用いて認証を行う
- 公開鍵はサーバーが保有。秘密鍵を持っているユーザーだけログイン可能
公開鍵:南京錠のイメージ
秘密鍵:鍵のイメージEC2ではSSHログイン時に公開鍵認証を行っている
ポート番号
プログラムのアドレス
同一コンピューター内で通信を行うプログラムを識別するときに利用される
- SSHサーバー:ポート番号22
- HTTPサーバー:ポート番号80
- SMTPサーバー:ポート番号25
ポート番号を決める方法は2種類ある
標準で決められている番号
- 代表的なプログラムが使うポート番号はあらかじめ決められている(ウェルノウンポート番号)
- SSH:22
- SMTP:25
- HTTP:80
- HTTPS:443
- ウェルノウンポート番号は0〜1023のいずれかの整数値
- 接続元(クライアント)が接続先のポート番号を省略した場合、ウェルノウンポート番号が使用される
動的に決まる番号
- サーバーはポート番号が決まっている必要があるが、クライアントはポート番号が決まってなくても良い
- クライアントのポート番号はOSが他のポート番号と重複しないように、ランダムに決める
- 動的に割り当てる番号は49142〜65535のいずれかの整数値
ファイアウォール
ネットワークを不正アクセスから守るために、「通して良い通信だけを通して、それ以外は通さない」機能の総称
AWSでは、セキュリティグループがファイアウォールの役割を担っている
Elastic IPアドレス
- インターネット経由でアクセスで可能な固定グローバルIPアドレスを取得でき、インスタンスに付与できるサービス
- インスタンスを削除するまで付与したIPアドレスを使用できる
- Elastic IPアドレスはEC2インスタンスに関連付けられていて、インスタンスが起動中であれば無料で利用できる(インスタンスが使用されていなかった場合、課金される)
構築手順
- EC2インスタンスを設置する
- Apacheをインストールする
- SSHでサーバーにログイン
- Apacheをインストール
- ファイアウォールを設定する
EC2インスタンスの作成
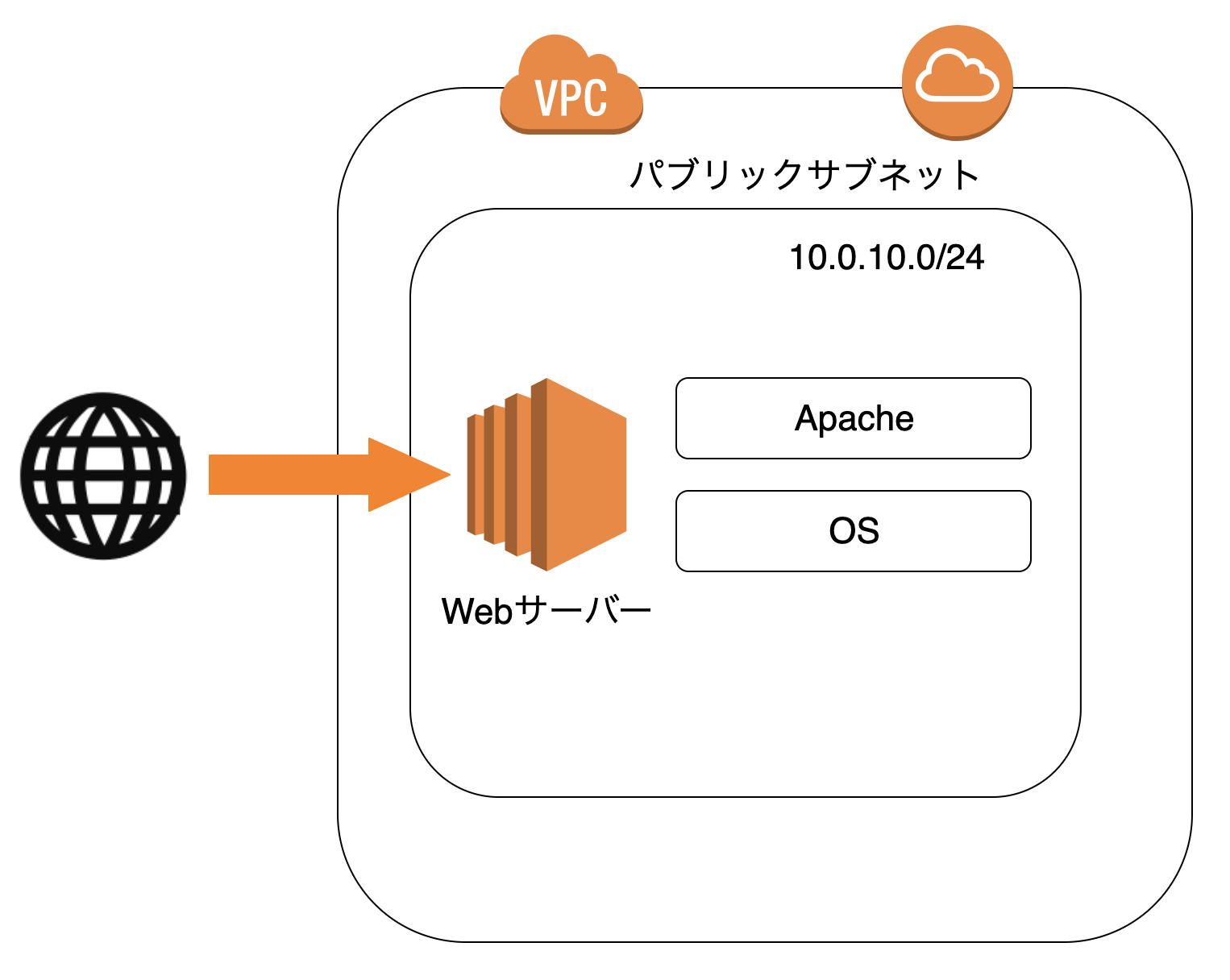
EC2インスタンスをパブリックサブネットに設置する
サービス → EC2を検索
「インスタンス」をクリック
「インスタンスの作成」をクリック
「Amazon Linux 2」を選択
(特に理由がなければAmazon Linux 2で問題ない)
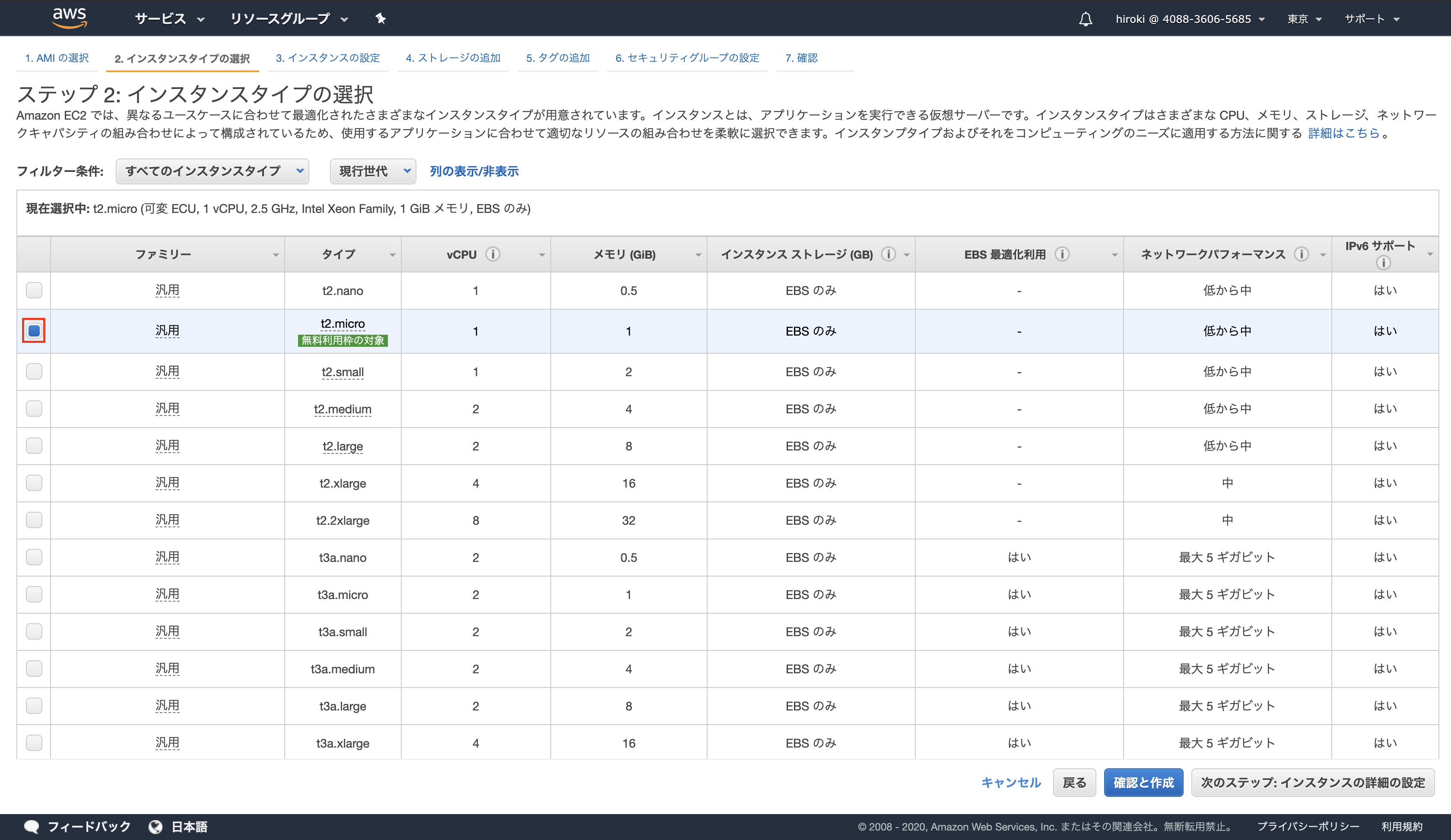
「t2.micro」を選択し、「次のステップ」をクリック
(t2.microはパフォーマンスが低いが動作検証では十分足りる)
以下の通り設定し、「次のステップ」をクリック
- 「スポットインスタンスのリクエスト」を選択すると低料金で利用できるが、インスタンスが中断する可能性がある
- 「ネットワーク」は作成したVPC
- 「サブネット」はパブリックサブネット
- インターネットに接続する場合「自動割り当てパブリック IP」を有効にする
- 「配置グループ」を選択すると複数のEC2インスタンス間の通信を高速する
- 「キャパシティーの予約」を開くにするとアベイラビリティゾーンのリソースを事前に確保してEC2インスタンスを常に起動できる状態にできる(追加料金が発生)
- 「IAMロール」はEC2インスタンスが他のAWSサービスと連携するときの権限を設定
- 一般的に本番環境では「削除保護の有効化」を設定する
- 「テナンシー」ではハードウェアを専有するか共有するかを選択する(専有すると追加料金が発生)
- 「Elastic Inference」は機械学習でGPUを使用する際にコスト効率を良くするためのもの
- 「T2/T3 無制限」はバースト(サーバーにアクセスが集中した際CPUをフル稼働させる状態)を無制限にできる(追加料金が発生)
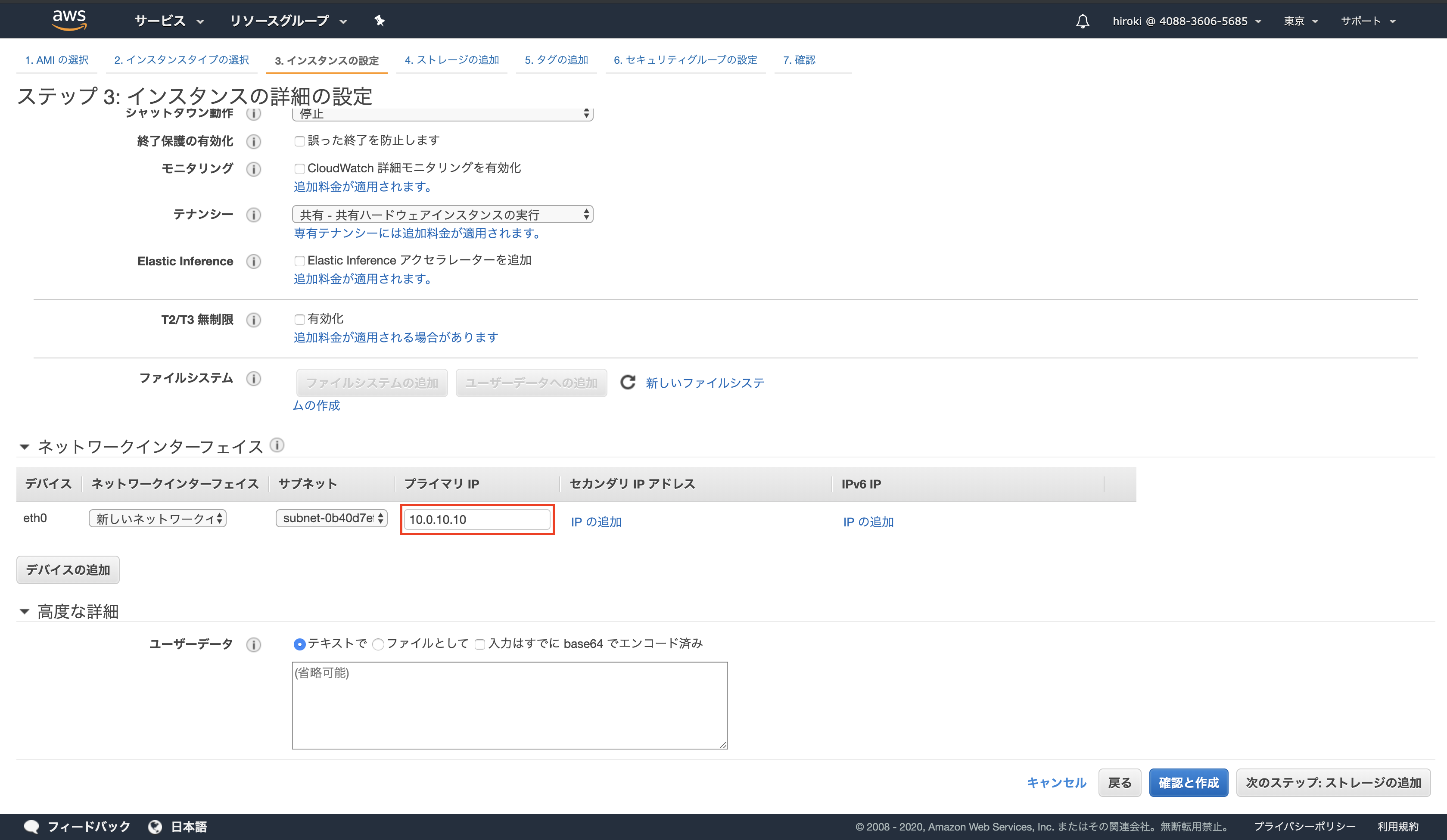
ネットワークインターフェースでプライベートIPを設定する
*パブリックサブネットの範囲内で設定する
以下の通り設定し、「次のステップ」をクリック
任意のタグを追加・設定し、「次のステップ」をクリック
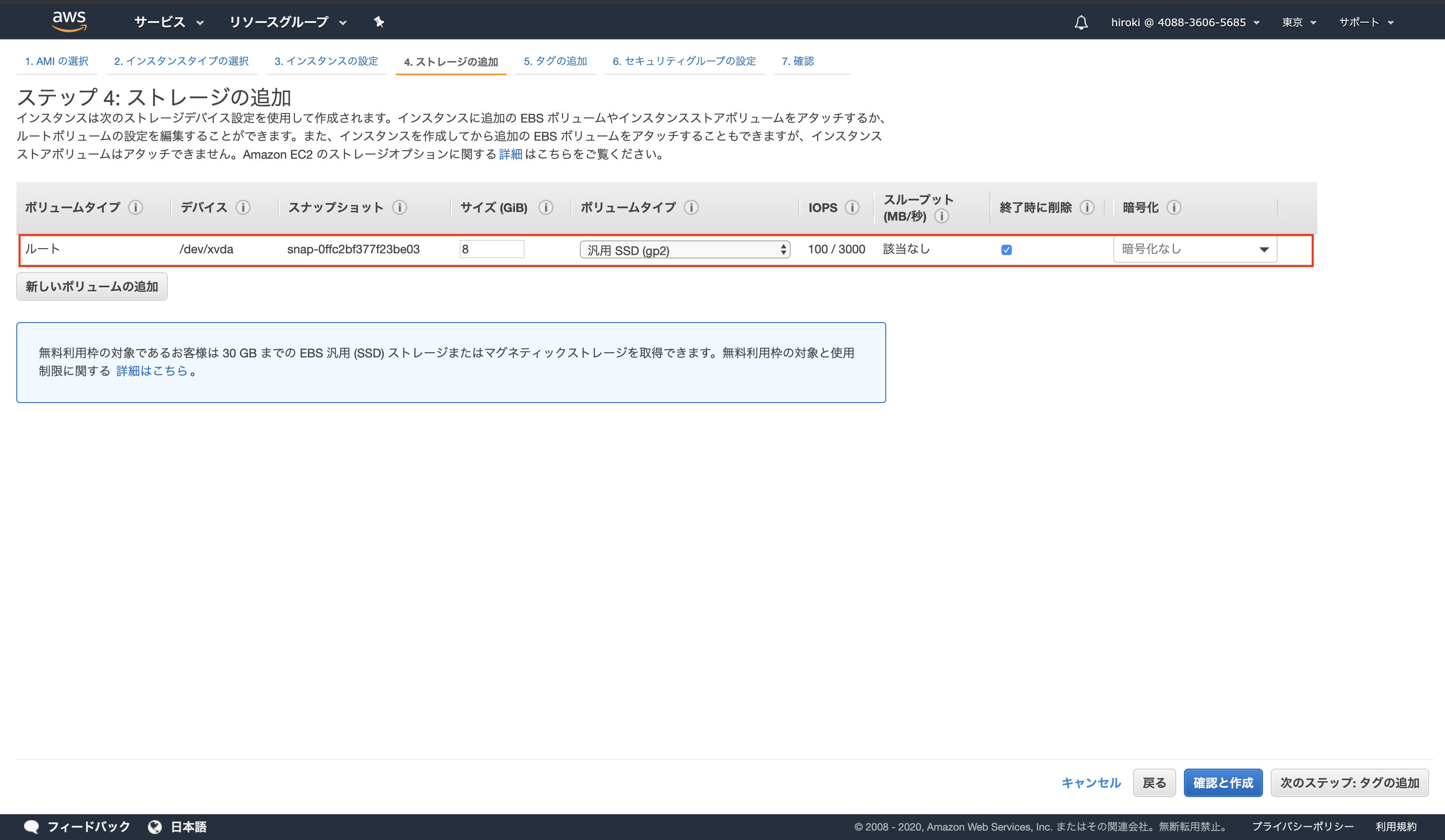
以下の通り設定し、「確認と作成」をクリック
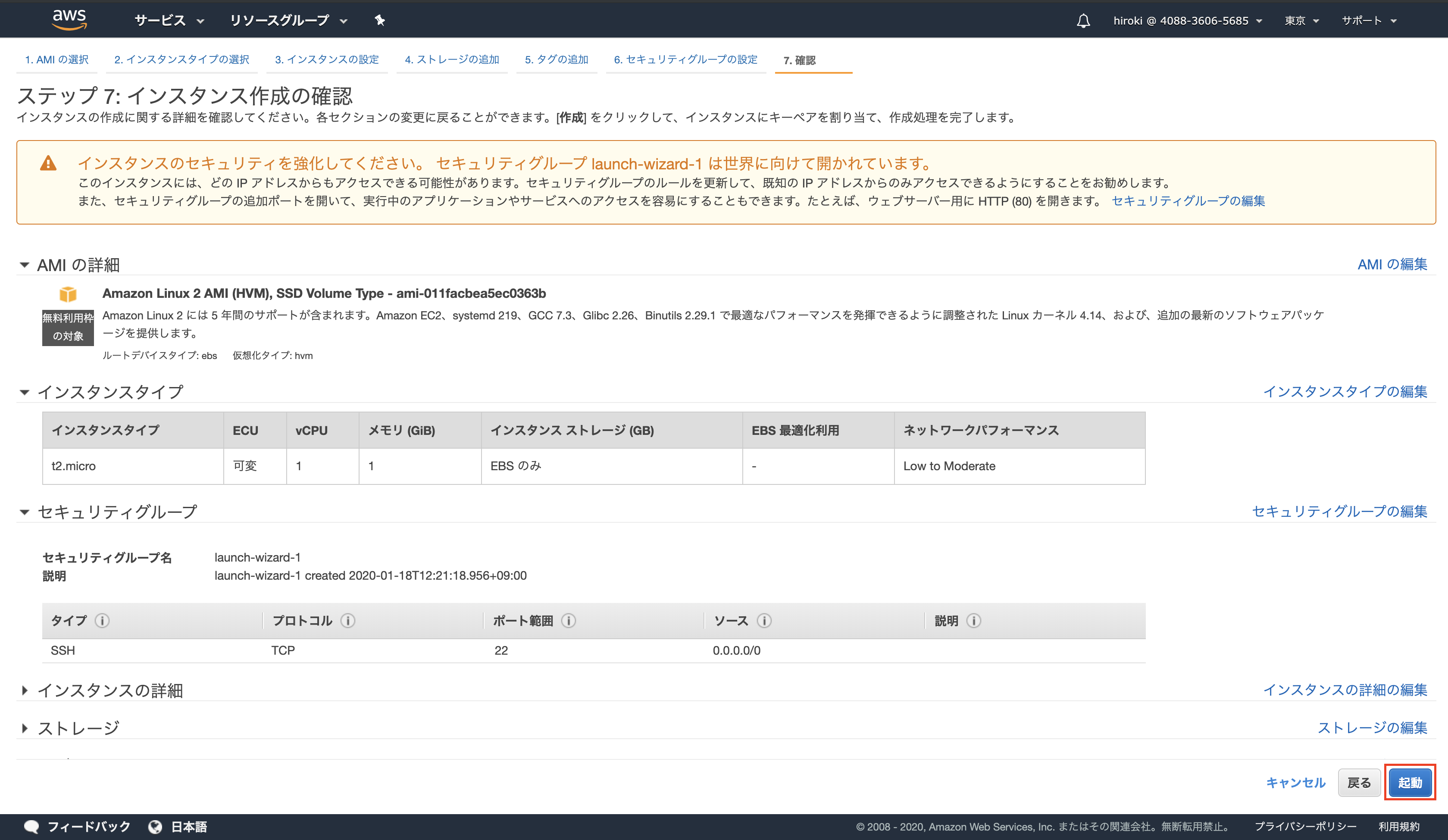
設定内容を確認し、問題なければ「起動」をクリック
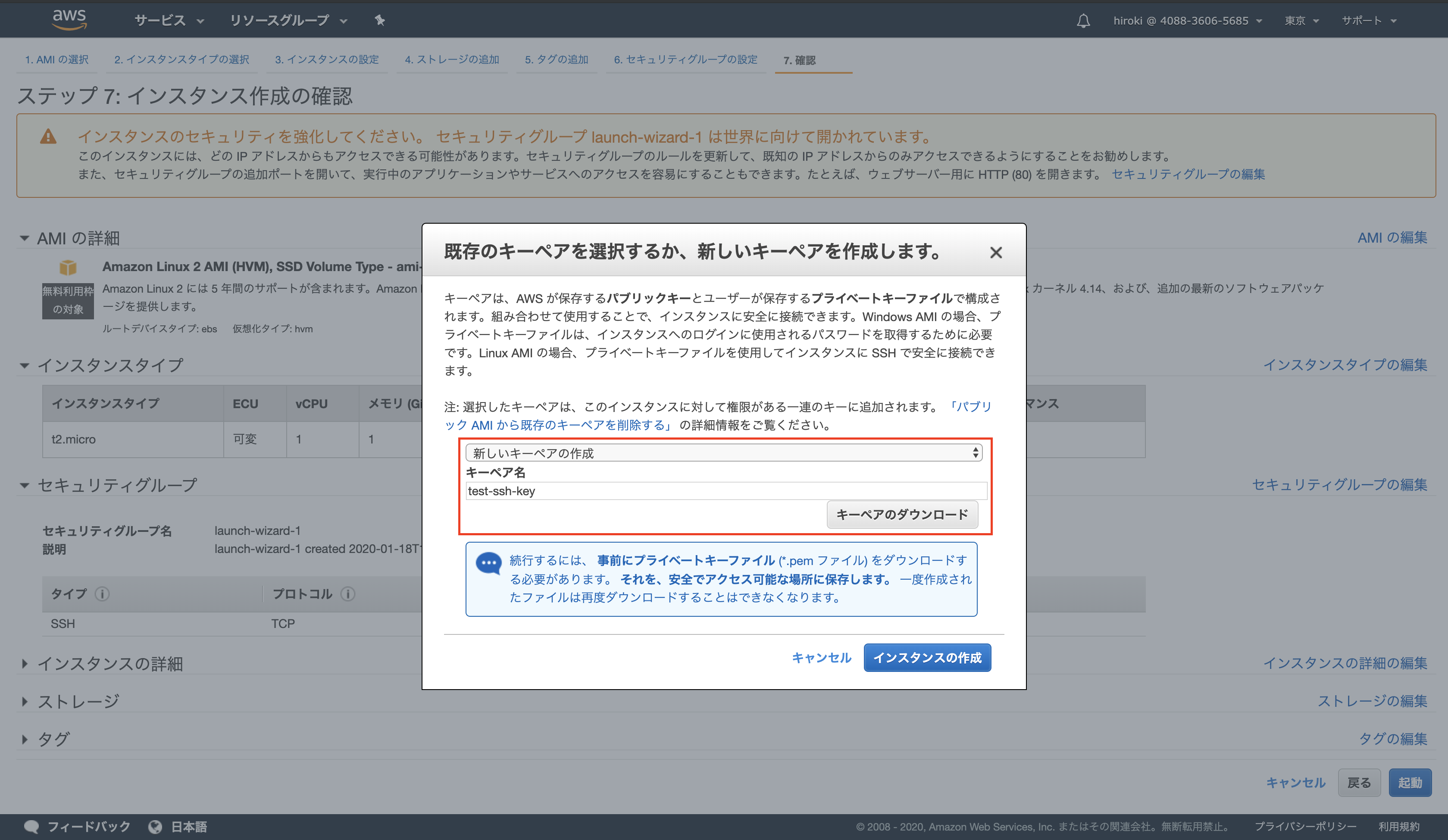
新しいキーペアを作成し、ダウンロードする
*キーペアのダウンロードはこれ以降できないので、必ずダウンロードしておく
ダウンロードが完了したら「インスタンスの作成」をクリック
「インスタンスの表示」をクリック
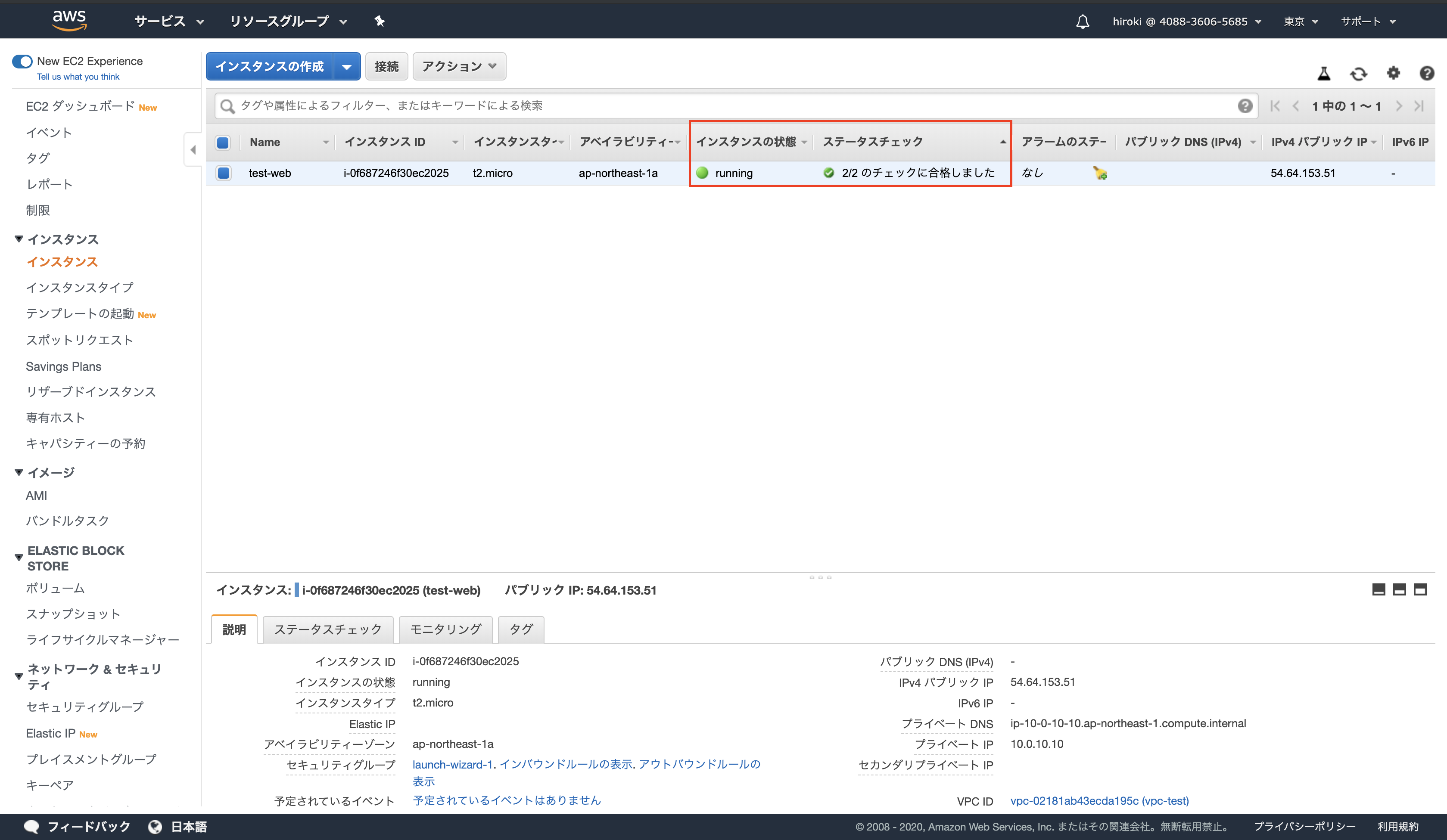
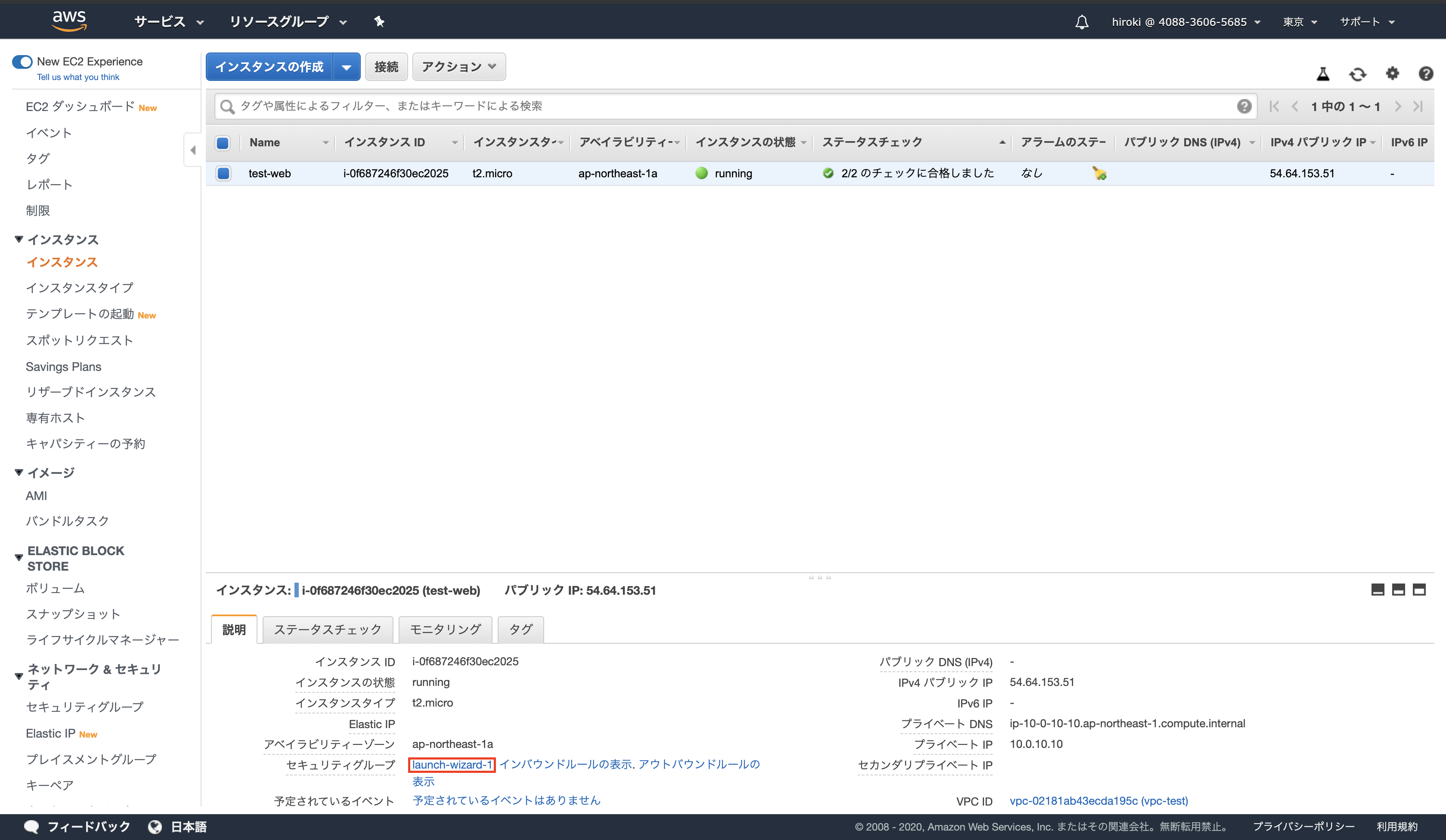
インスタンスが作成されていることを確認
(一定時間経過後「インスタンスの状態」が「runnning」,「ステータスチェック」が「2/2のチェックに合格しました」となる)
SSHでEC2インスタンスに接続
*MACの手順
ターミナルを起動し、ダウンロードした秘密鍵(pemファイル)の権限を変更する
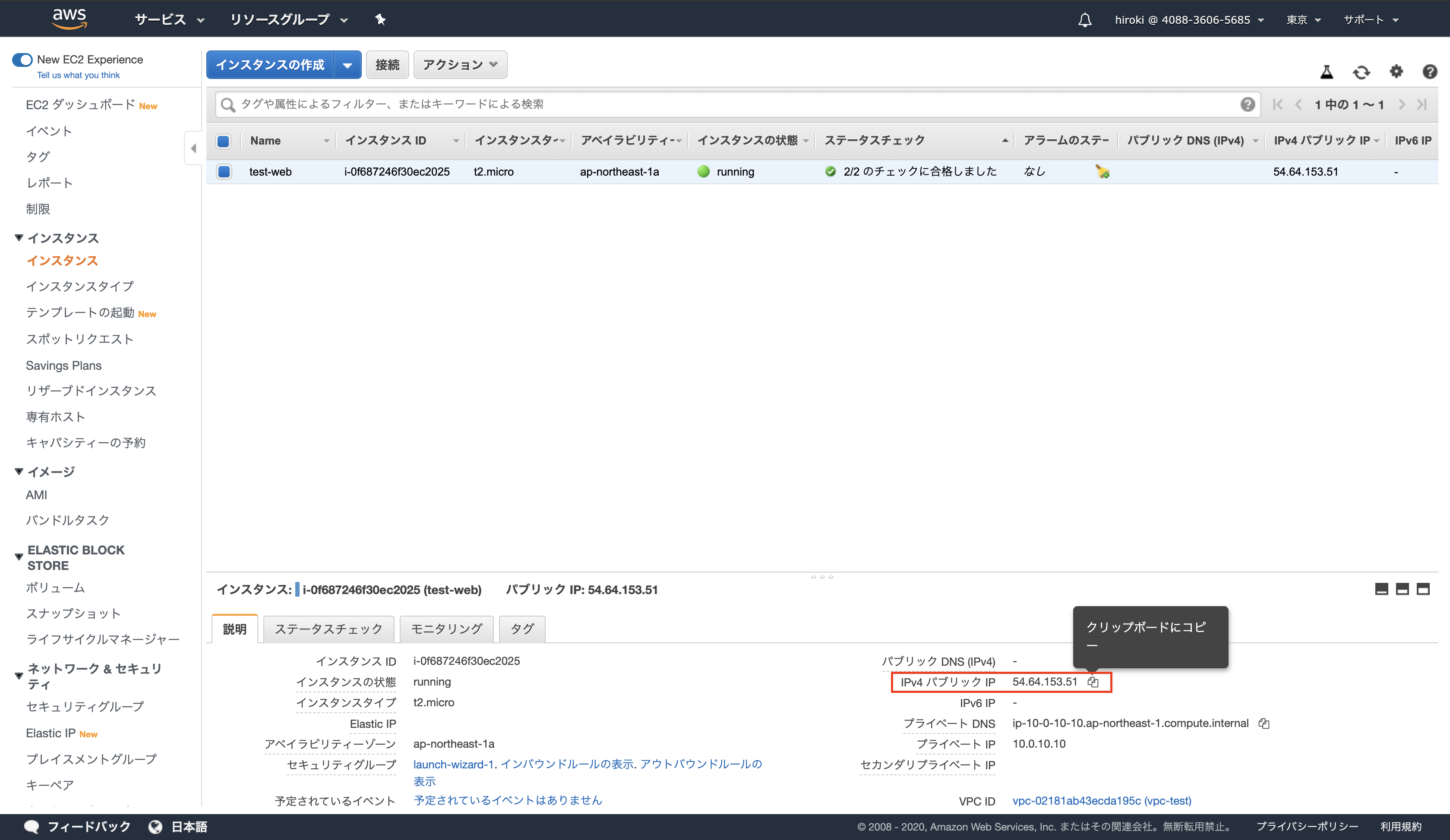
chmod 600 test-ssh-key.pem作成したEC2インスタンスのパブリックIPアドレスをコピーする
sshコマンドでログインする
ssh -i test-ssh-key.pem ec2-user@54.64.153.51
↑秘密鍵(test-ssh-key.pem)を用いてユーザー名(ec2-user)でIPアドレス(54.64.153.51)に接続する
(初回ログインの場合「Are you sure you want to continue connecting (yes/no)?」と聞かれるので「yes」を選択)
exitでログアウトできるApacheのインストール
パッケージを最新に更新する
sudo yum update -yApacheのインストール
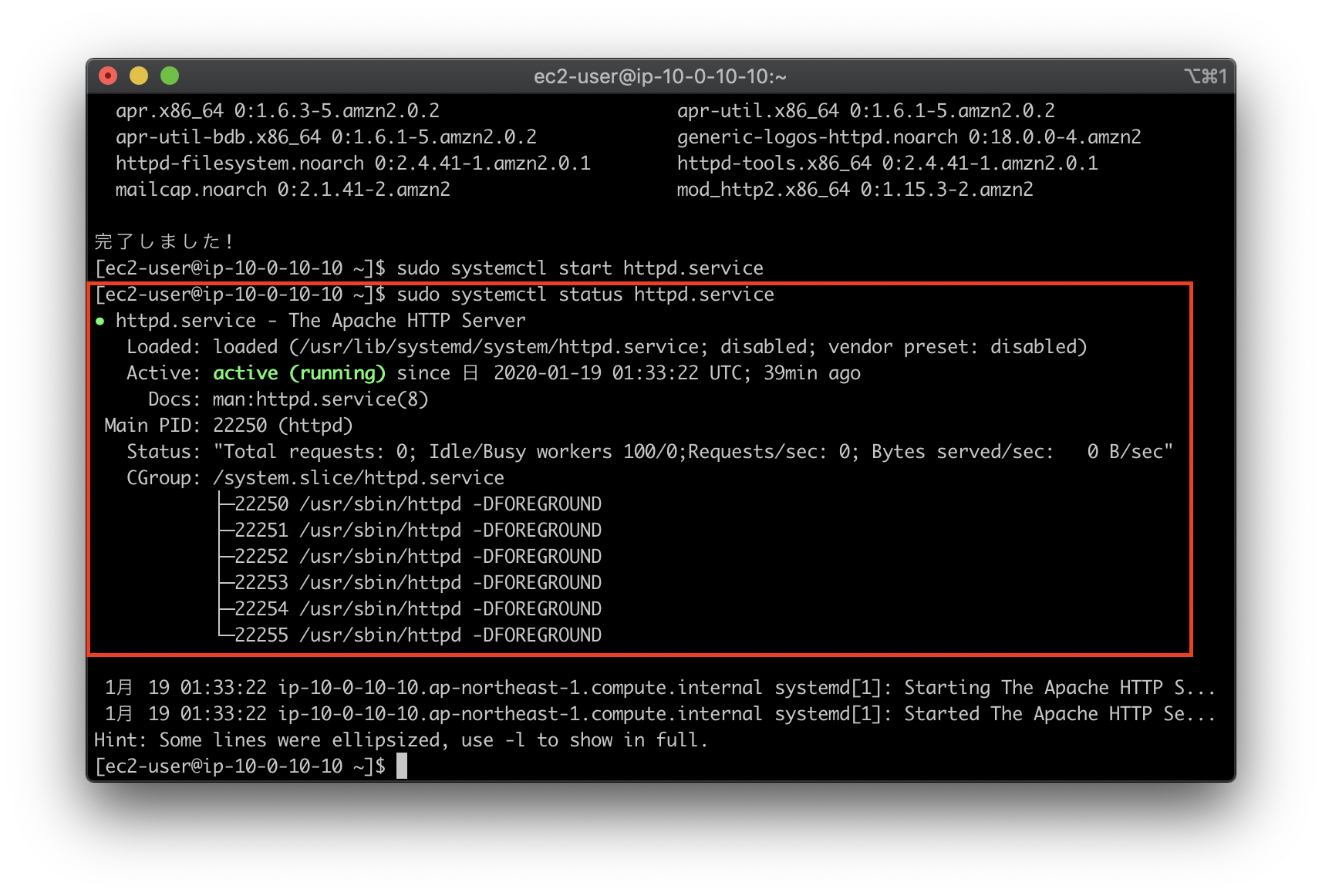
sudo yum install httpd -yApacheの起動
sudo systemctl start httpd.serviceApacheが起動されていることを確認
sudo systemctl status httpd.service
サーバーが停止・再起動したらApacheも停止するので、サーバーが起動したときにApacheも自動で起動するように設定
sudo systemctl enable httpd.serviceApacheの自動起動が反映されていることを確認
sudo systemctl is-enabled httpd.service
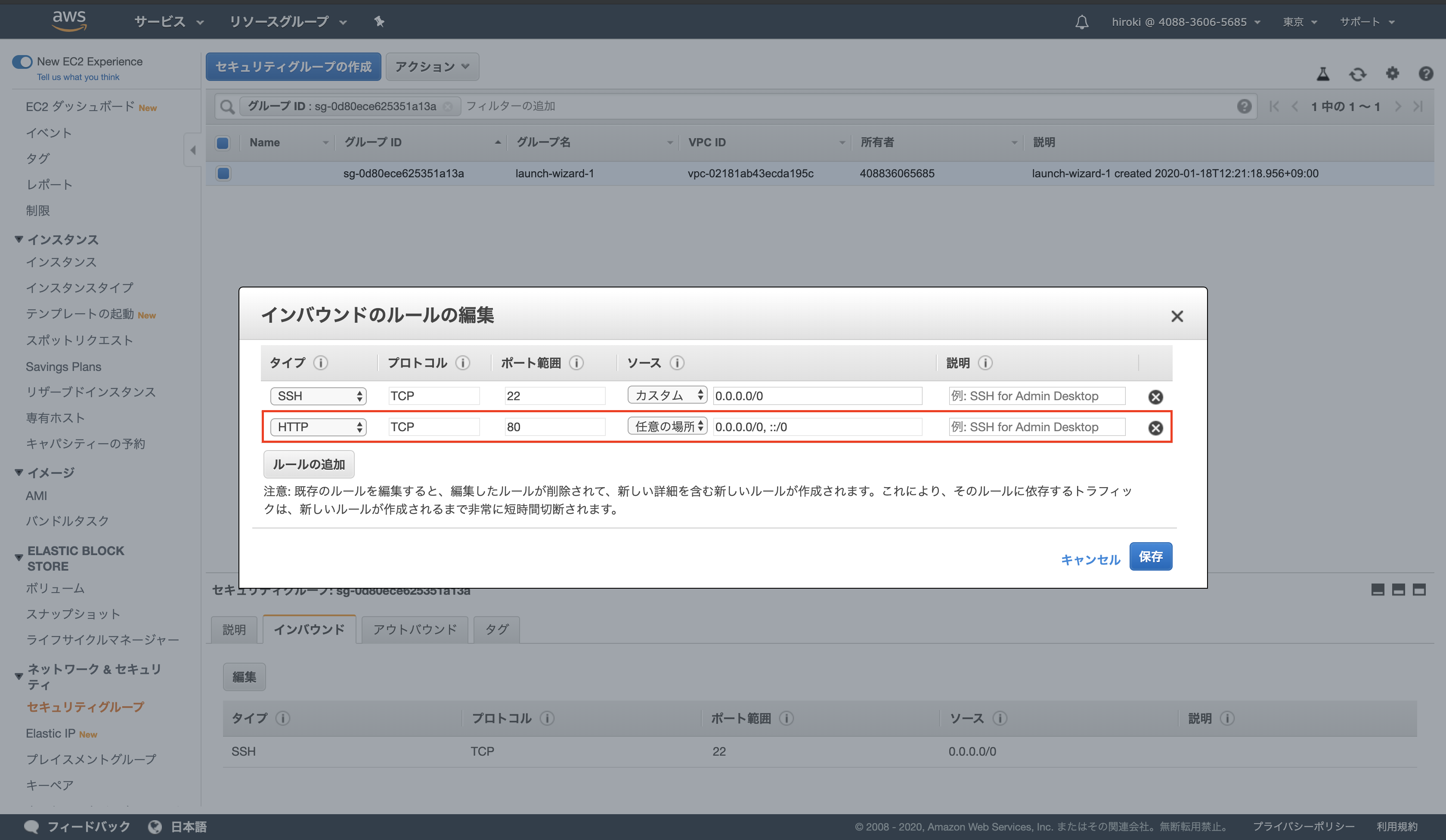
ファイアウォールの設定
セキュリティグループの80番を開ける
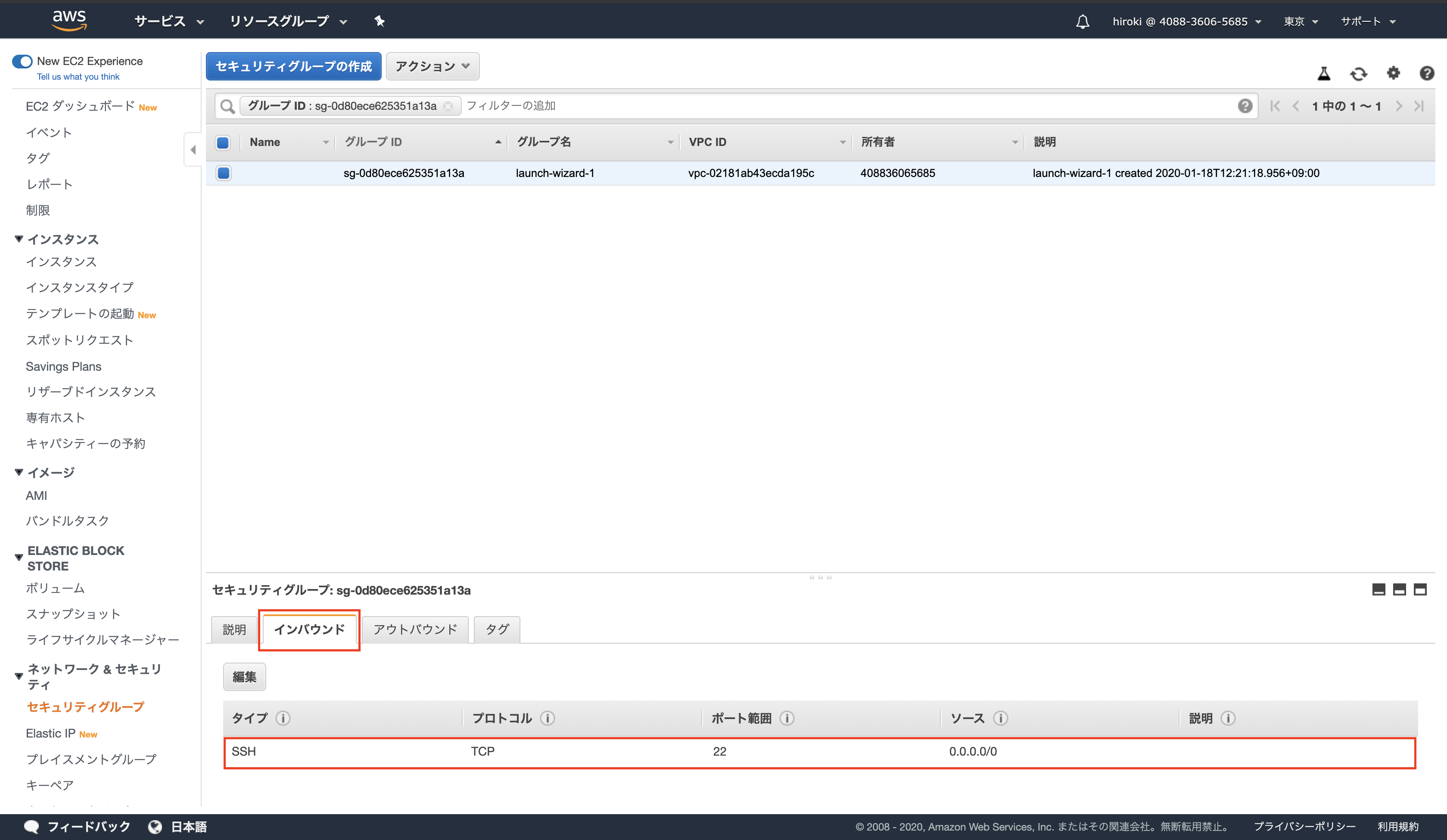
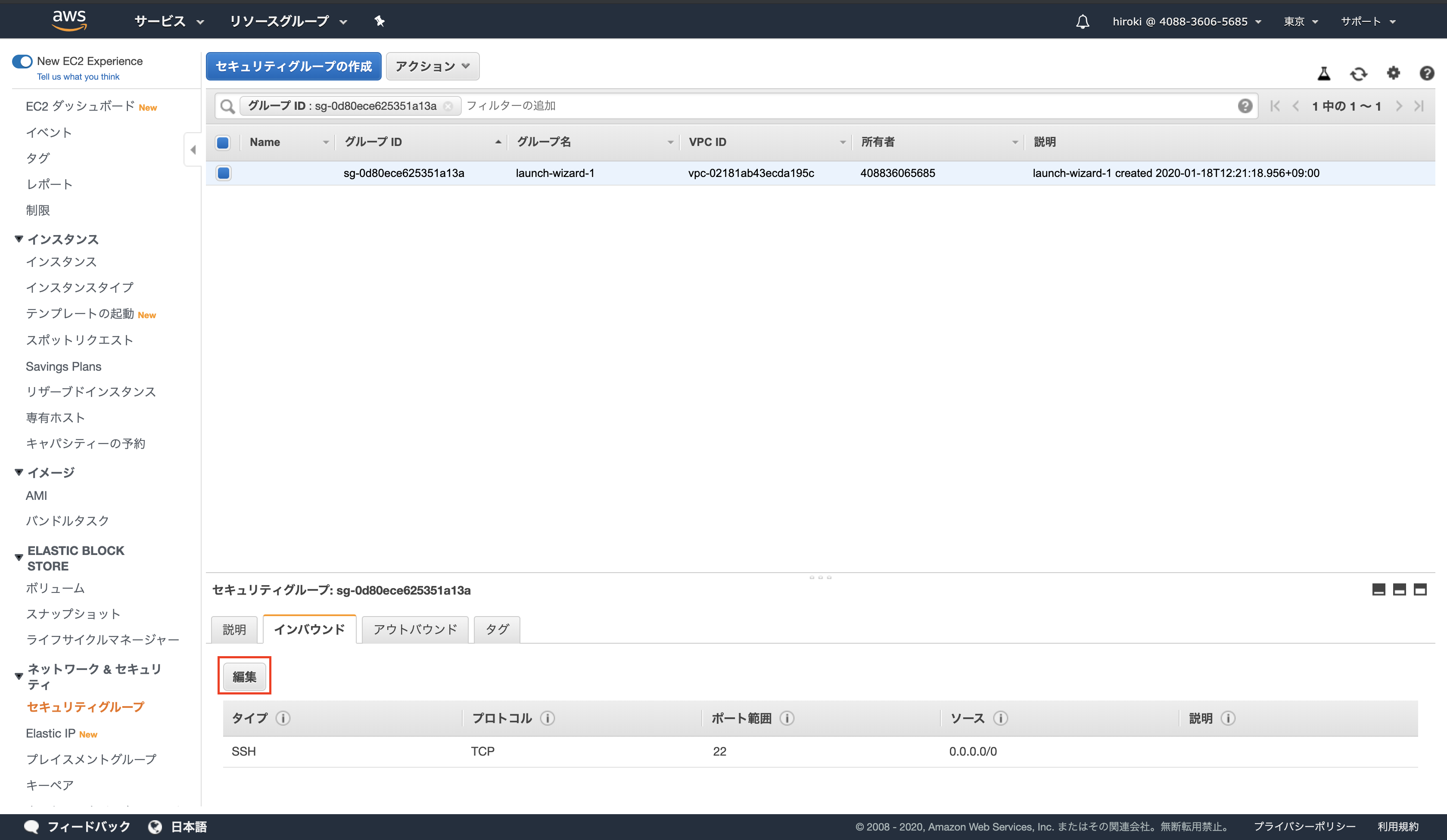
EC2インスタンスのセキュリティグループをクリック
「インバウンド」をクリックし、SSH(ポート番号22)しか表示されていないことを確認
「編集」 → 「ルールの追加」をクリック
以下の通り設定し、「保存」をクリック
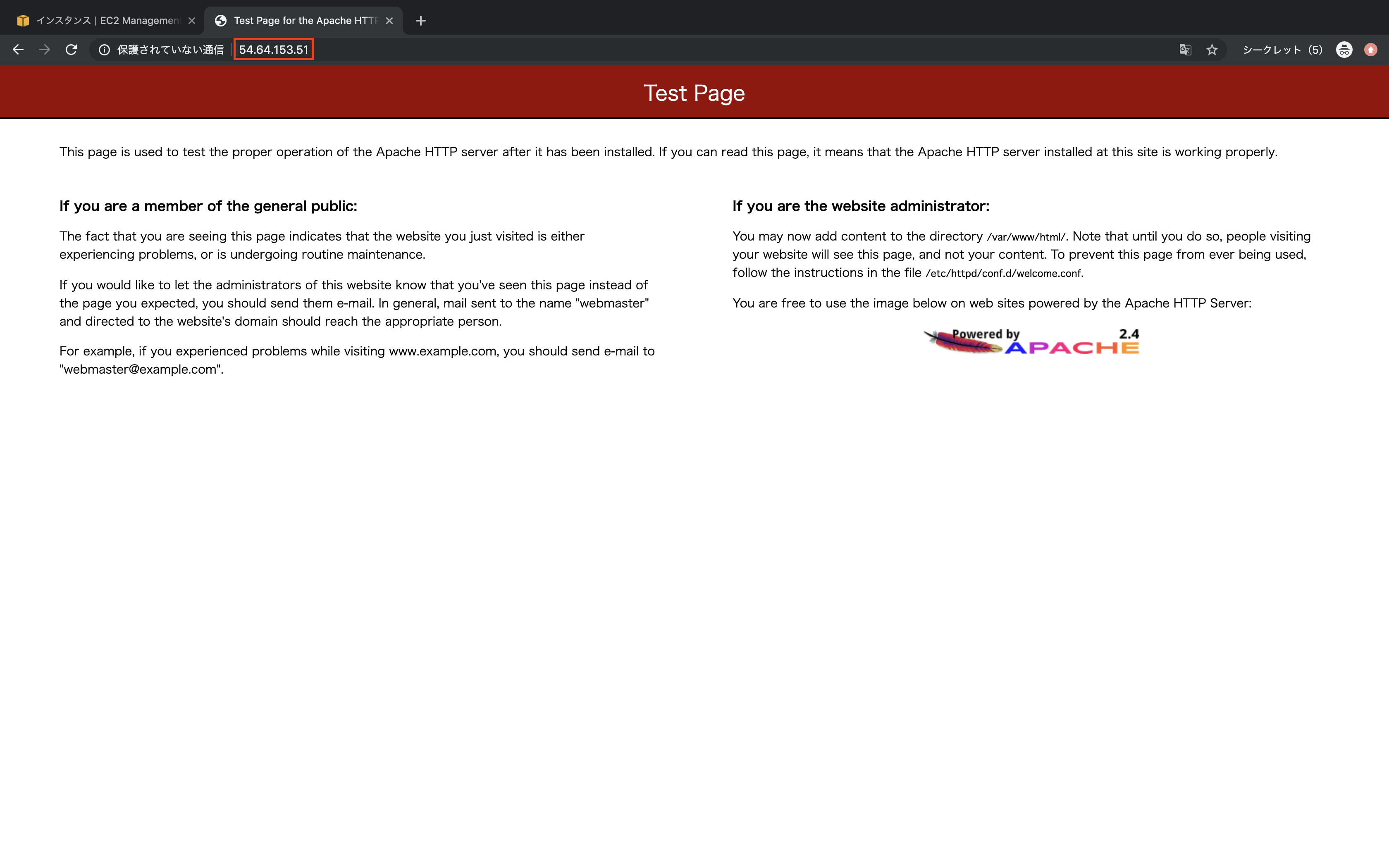
EC2インスタンスのIPアドレスをブラウザで開き、HTTP通信ができていることを確認
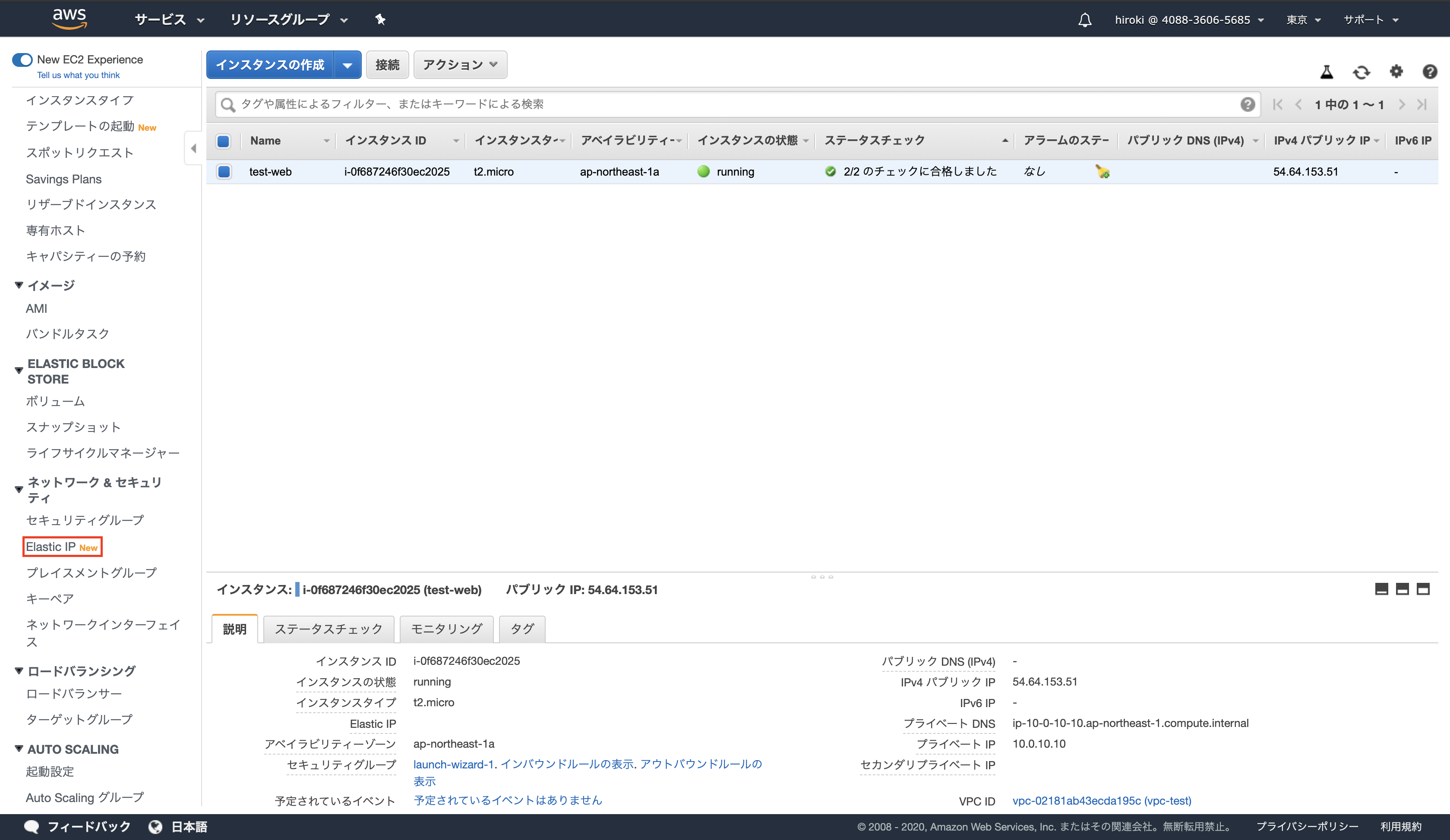
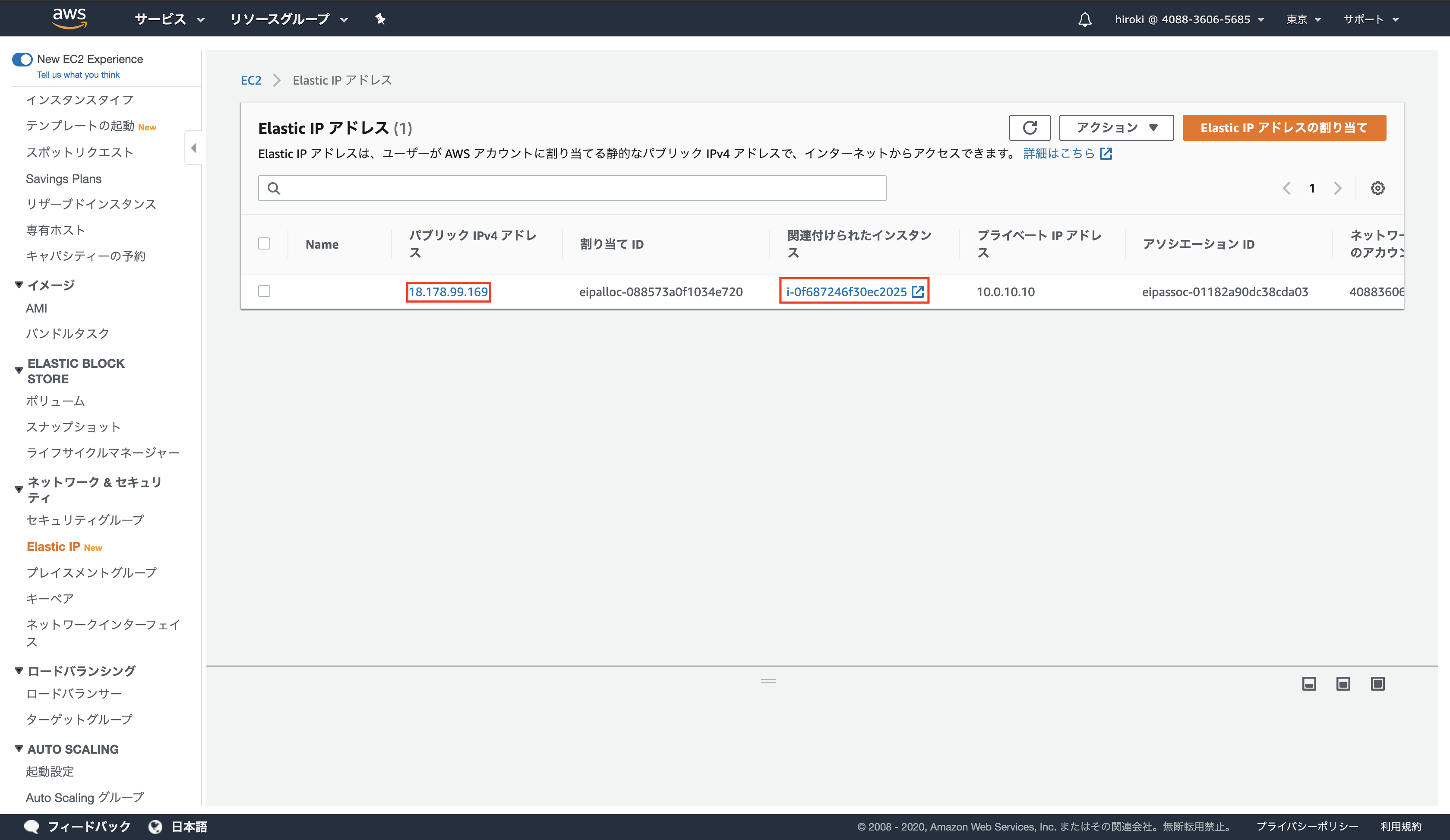
Elastic IPアドレスを紐付ける
「Elastic IP」をクリック
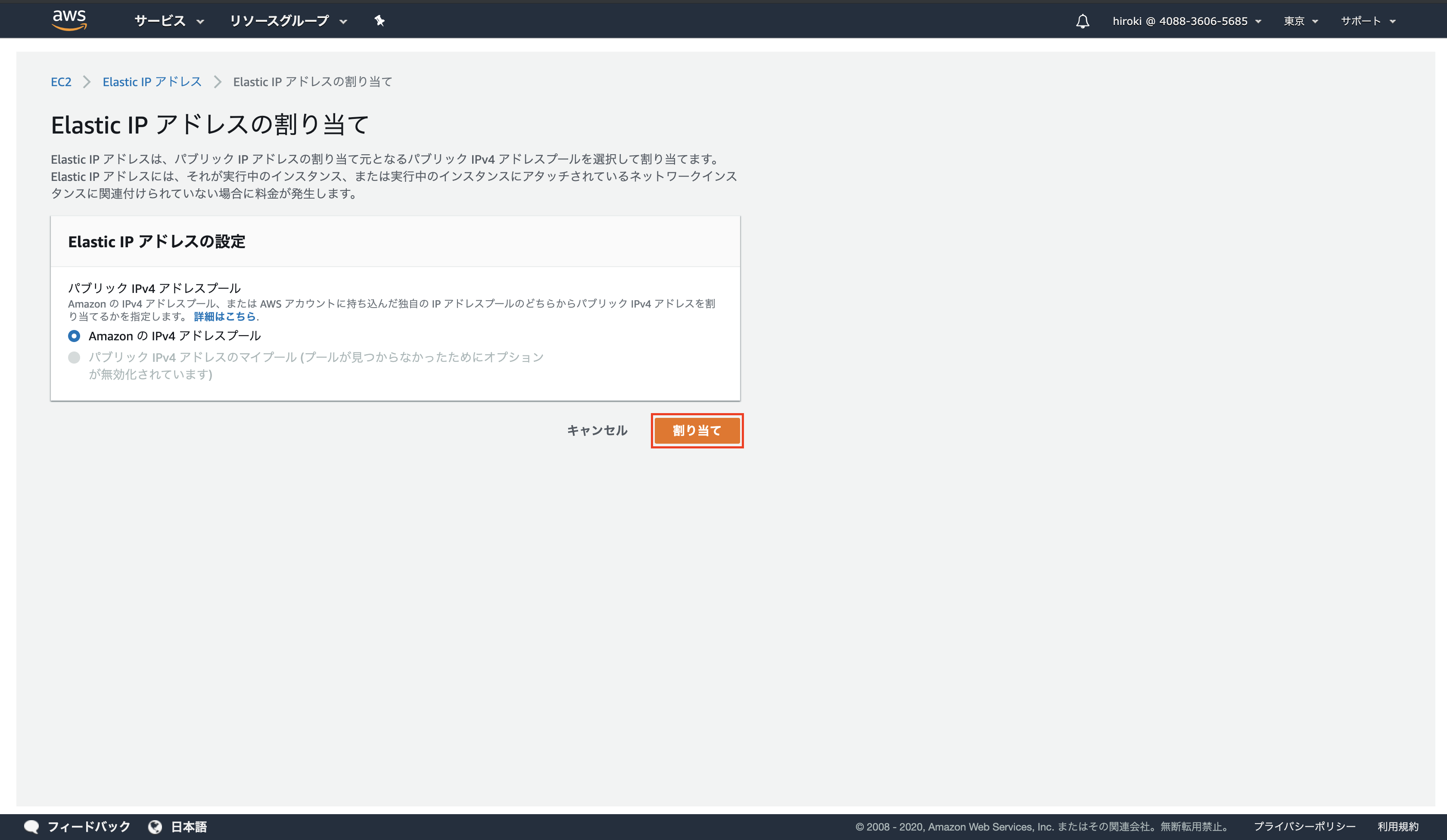
「Elastic IPアドレスの割り当て」をクリック
「割り当て」をクリック
「このElastic IPアドレスを関連付ける」をクリック
以下の通り設定し、「関連付ける」をクリック
インスタンス:作成したEC2インスタンス
プライベートIPアドレス:EC2インスタンスに設定したプライベートIPアドレス
割り当てたIPアドレスををブラウザで開き、Apacheのページが表示されていることを確認
おまけ(Webサーバーの片付け方)
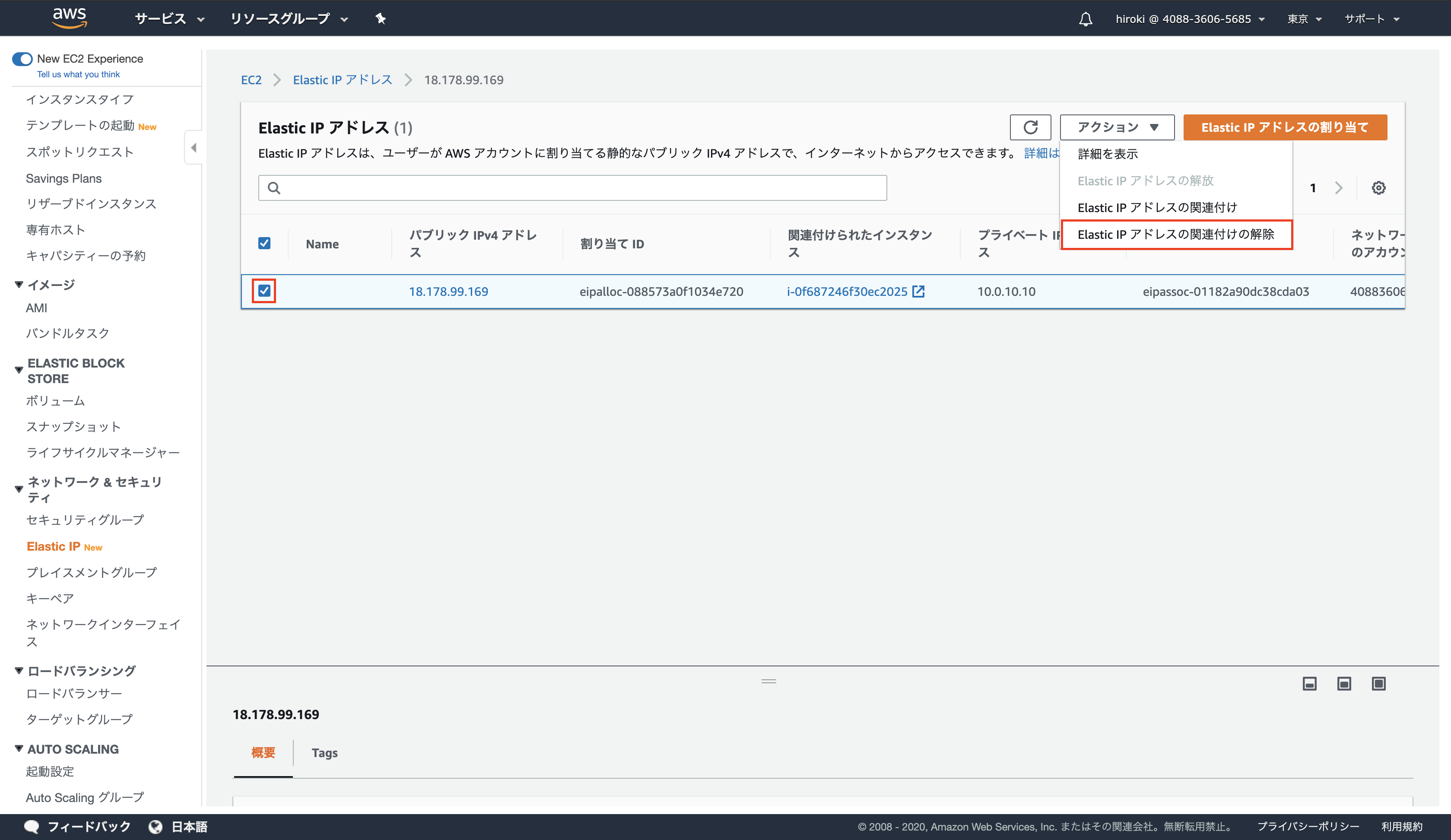
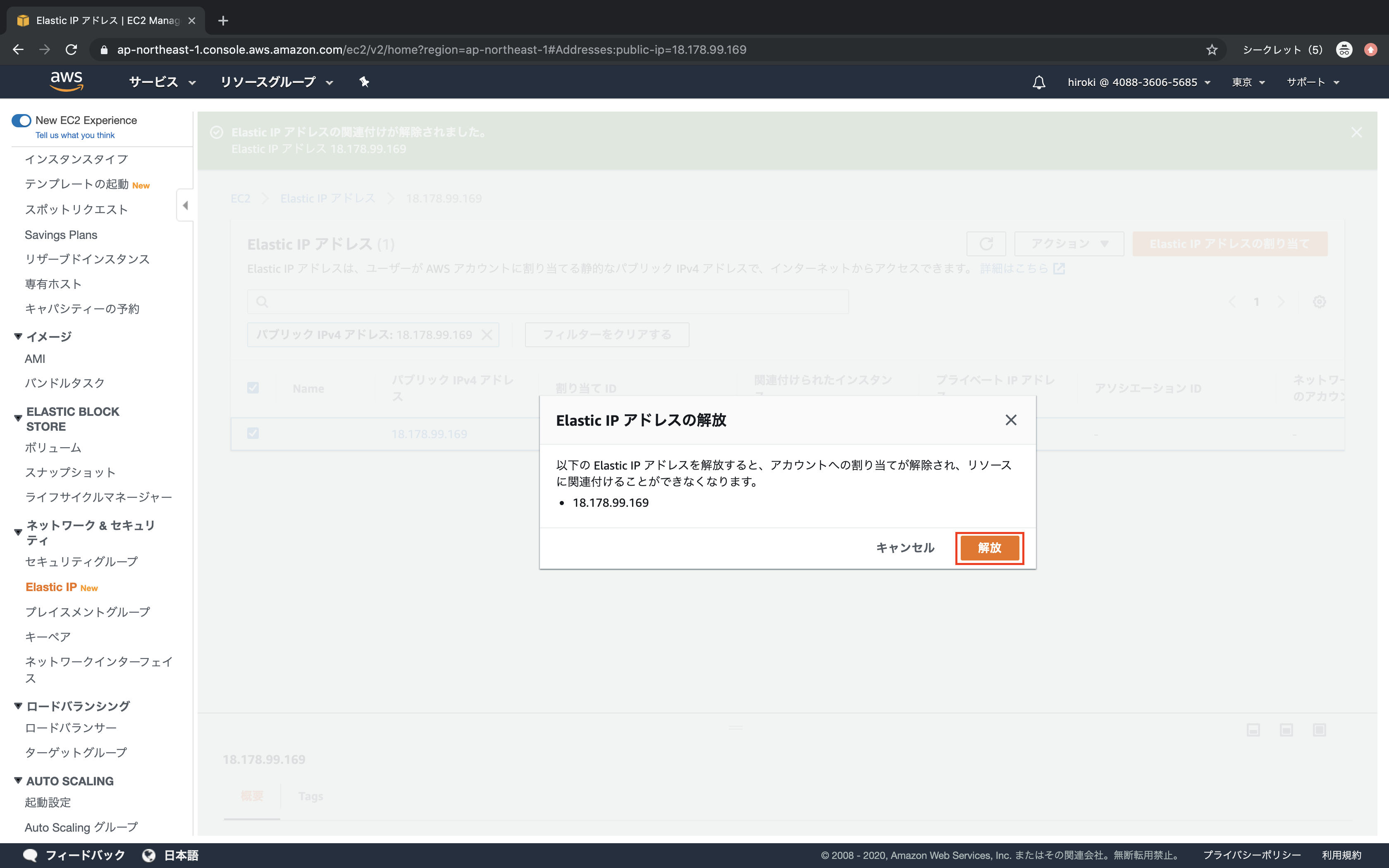
Elastic IPアドレスの開放
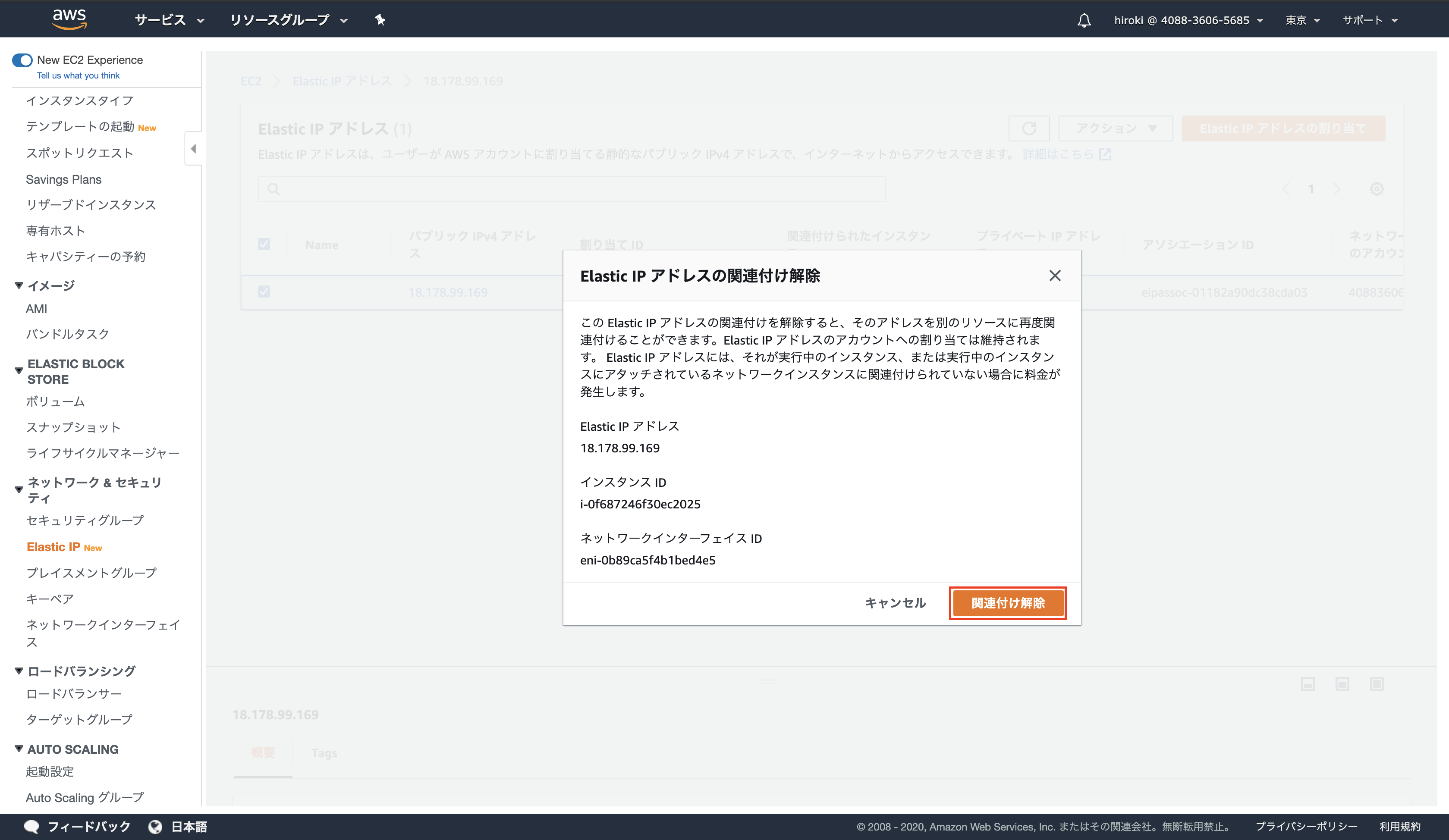
Elastic IPアドレスを選択し、「アクション」 → 「Elastic IPアドレスの関連付けの解除」をクリック
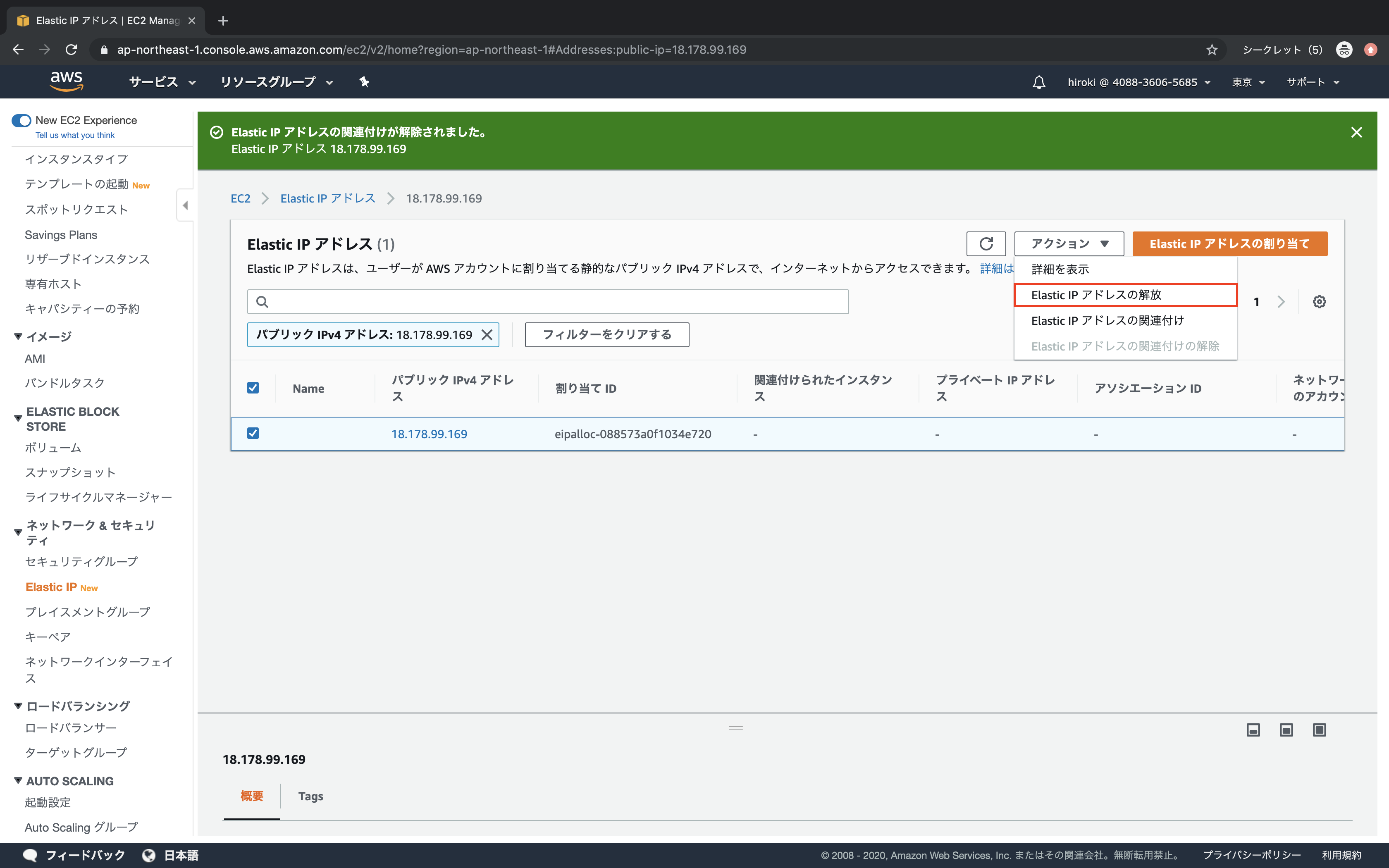
「関連付け解除」をクリック
「アクション」 → 「Elastic IPアドレスの解放」をクリック
「解放」をクリック
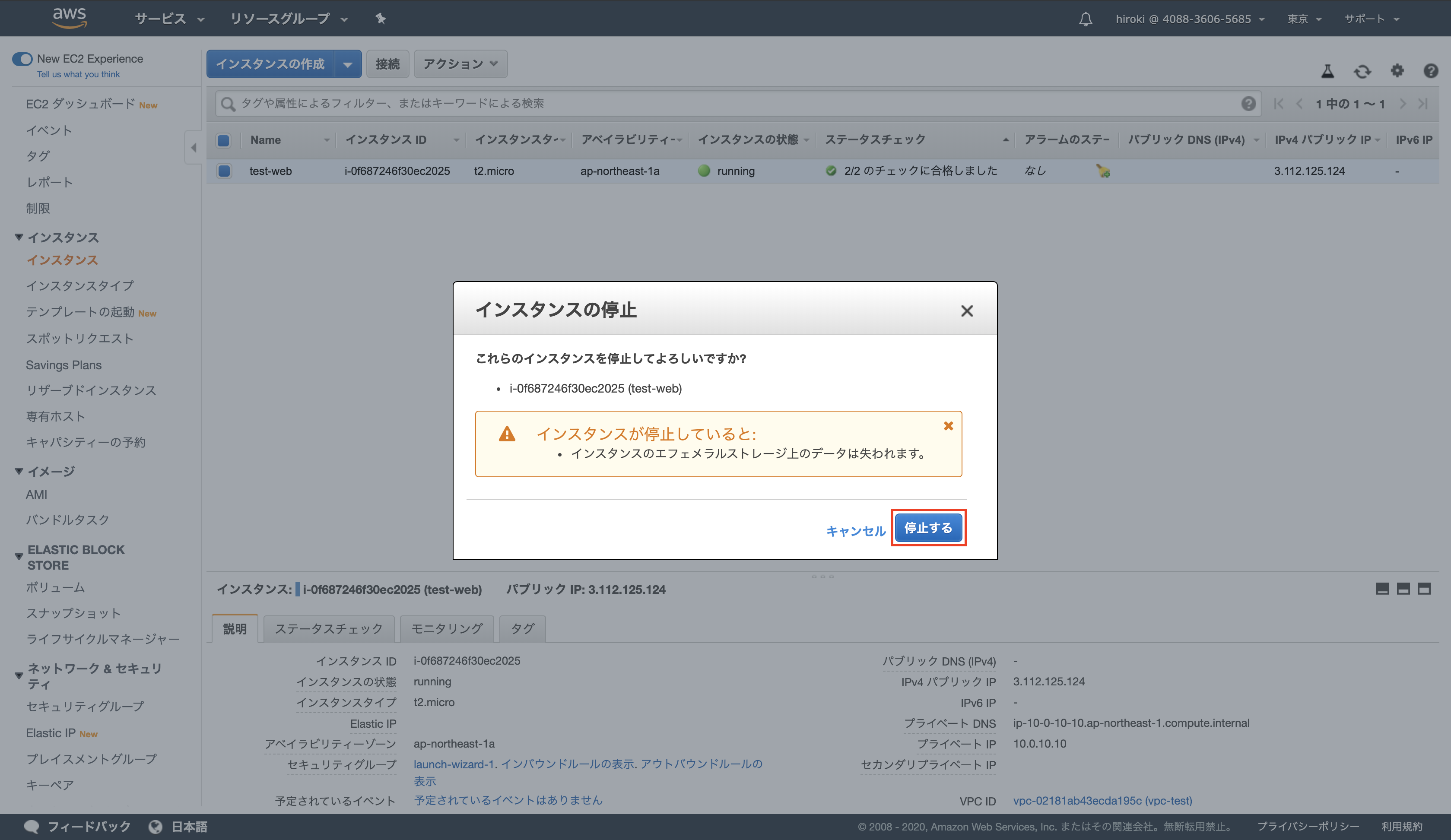
EC2インスタンスの停止
「インスタンス」をクリック
「アクション」 → 「インスタンスの状態」 → 「停止」をクリック
「停止する」をクリック
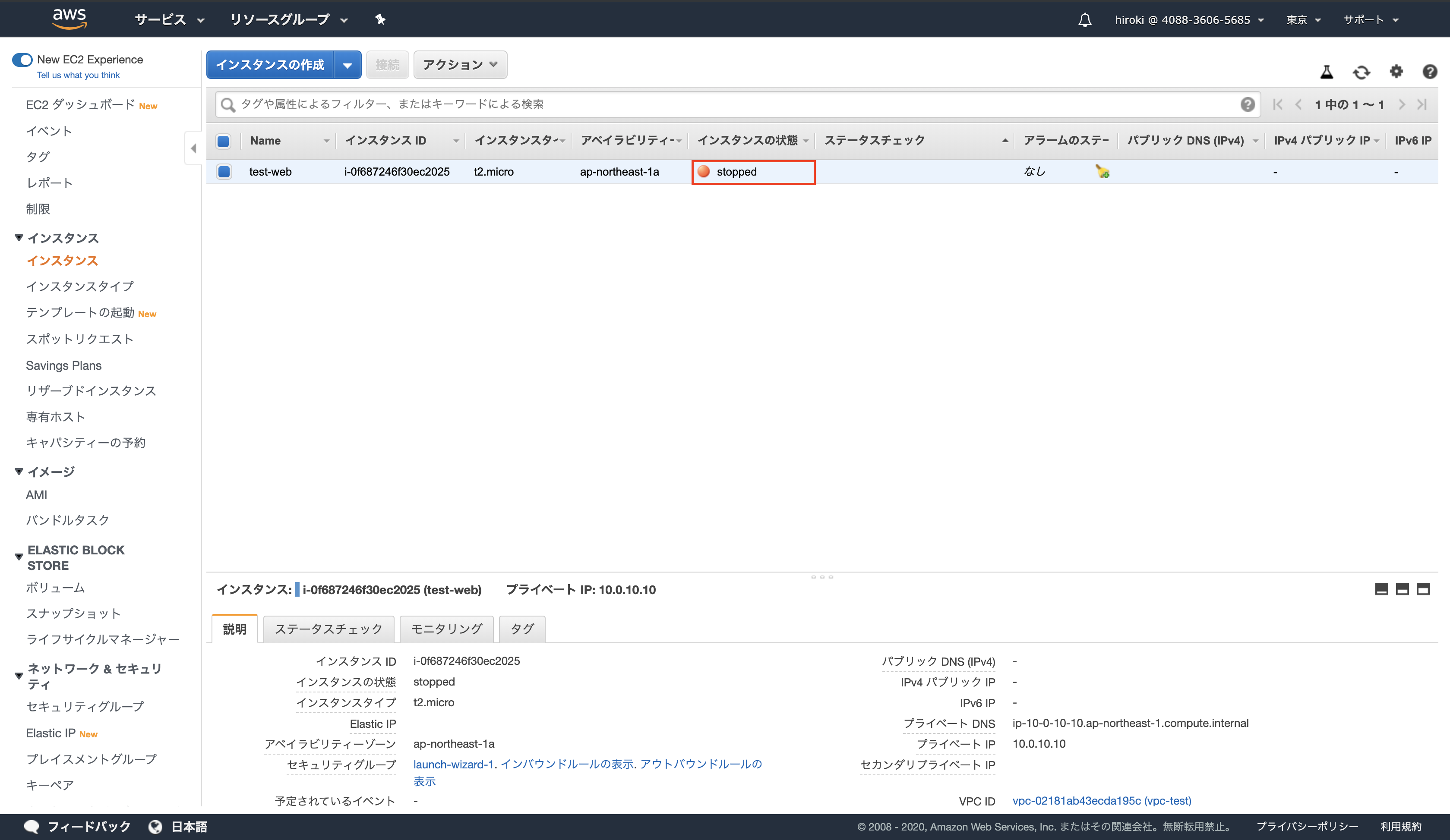
インスタンスが停止したことを確認
参考










- 投稿日:2020-01-19T17:10:45+09:00
AWS Well-Architected Frameworkから学ぶクラウド設計のベストプラクティス
AWS Well-Architected Framework
AWSやGCP, Azureといったパブリッククラウドが浸透したことでクラウドを使ってシステムを設計することは当たり前の時代となりました。
AWS Well-Architected Frameworkにはクラウドで設計する上で意識すべきことやベストプラクティスがまとめられており、クラウドを扱うエンジニアは必読の内容になっています。
自分自身、非常に勉強になったので備忘録としてまとめてみます。
原文のwhitepaperは以下のリンクにあります。
https://aws.amazon.com/jp/architecture/well-architected/5本の柱
クラウドを利用してシステムを設計する上で考えるべきことは、以下の5つです。
- 運用上の優秀性
- セキュリティー
- 信頼性
- パフォーマンス効率
- コスト最適化
これら5つの項目について、それぞれのベストプラクティスを説明していきます。予算やリソースには限りがあるので、実際のシステム設計でこれら全てを完璧に満たすことは難しいかもしれませんが、5本の柱の中で特に重視すべきものを考えてみてください。
意識すべき柱が明確になった後に、以下にまとめるベストプラクティスを参照していただけると良いかなと思います。
運用上の優秀性
ビジネス価値を提供し続けるためには、継続的にシステムを改善しつつ、安定稼働させる必要があります。日々の運用を支えるための指針が運用上の優秀性として説明されています。
運用上の優秀性のベストプラクティス分野
- 準備
- 運用
- 進化
準備
ビジネスを成功させる上ではシステムを安定稼働させるための準備が不可欠です。以下の項目を考えておきましょう。
- 障害を予想する
AWSではインフラをコードとして管理することができるため、本番環境をコード化しておくことで、テスト用に同じ環境を容易に作成することができます。
これによって、障害に備えた高負荷テストなどの実験を容易に行うことができます。
また、コード化することにより、gitでバージョン管理ができるため、変更点を明確にできます。
コード化を実現する代表的なサービスはCloudFormationですが、最近はPythonやTypescriptなどで構成管理を記述可能なAWS CDKも登場しており、アプリ開発者も簡単にインフラをコード化できます。
当たり前ですが、オンプレではまず実現できない、クラウドを使う上での大きなメリットの一つでしょう。
- システムの標準ルールを設定する
システムを構築する前に、ビジネスの要件を満たすためにシステムが準拠するべきルールを決めておくことが重要です。AWS Configを利用することで、ガイドラインを設定し、システムが準拠しているかどうかチェックできます。コンプライアンスやセキュリティーを担保するためにも、AWS Configは必ず設定しましょう。
運用
- インフラのメトリクスやアプリケーション、顧客行動をモニタリングする
運用の成功はビジネスの成果をあげることやその成果を評価することです。また、コストを最適化したり、顧客満足度を高めるためにシステムのどの箇所を改善すべきか明確にすることも運用していく上で重要です。
AWSではCloudWatchでインフラのメトリクスを監視し、CloudTrailでAWSのリソースの変更履歴をモニタリングすることができ、CloudWatch LogsでAWSリソースのログを収集することができます。
これらのサービスを利用することで、システムの問題や改善点を特定、分析することが可能になります。進化
- 定期的にロールバック可能な小さな変更を適用する
ビジネスを成功させる上では継続的かつ高速にフィードバックループを回すことが重要です。
最近では当たり前になったCI/CDもこれを実現する技術の一つと言えます。
システムの変更は小規模な変更を定期的に行うことを意識します。
変更を小さくしておくことで、問題があってもすぐにロールバックして対応できるメリットもあります。
AWSではCodeBuildでCI, CodeDeployでCD, CodePipelineやCodeStarでCI/CDフローを構築することができます。運用上の優秀性に関して使用するAWSサービスまとめ
セキュリティー
セキュリティーのベストプラクティス分野
- アイデンティティ管理とアクセス管理
- 発見的統制
- インフラストラクチャー保護
- データ保護
- インシデント対応
アイデンティティ管理とアクセス管理
AWSでの権限管理はIAMで行います。
AWSを利用する上で、最も重要なサービスがIAMといっても過言ではなく、IAMを使って、ユーザーごとに適切な最小権限を与え、役割分担を徹底することがセキュリティーを担保する上で極めて重要です。
AWSを扱う人は必ずIAMを学んでおきましょう。
IAMのベストプラクティスについては、AWSに関する書籍を多く執筆されている佐々木拓郎さんの書籍がおすすめです。https://booth.pm/ja/items/1563844発見的統制
品質の担保やコンプライアンス義務を果たすために、セキュリティーの潜在的な脅威やインシデントを特定しておくことが大切です。
AWSではCloudTrailによって、AWSアカウントのアクティビィティやリソース変更の追跡、CloudWatchによって、メトリクスの監視、AWS Configによってリソース設定履歴をモニタリングし、セキュリティー的な脅威を事前に検知することができます。また、AWS GuardDutyは不正操作をモニタリングしてくれるマネジメントサービスで、取り敢えず有効にしておくことをお勧めします。クラスメソッドさんの記事でも、全てのAWSユーザーが利用すべきサービスとして取り上げられています。インフラストラクチャ保護
堅牢性の高いインフラを構築するためには、複数レイヤーでのセキュリティー対策が重要です。VPC, サブネット、ロードバランサー、インスタンス、OS、アプリケーションの全てのレイヤーでセキュリティー対策を行うことを徹底しましょう。
データ保護
データの暗号化やバージョニングによって、データを安全に保管できるようにしましょう。
S3を使うことでデータのバージョニングが可能になります。また、S3は99.999999999%の耐久性を担保するために、保存されたデータを三箇所以上のアベイラビリティーゾーンで自動的に複製されています。
また、S3はデフォルトでは以下の暗号化オプションが提供されています。
- S3で管理されたキーによる暗号化
- KMSで管理されたキーによる暗号化 一つ目のオプションではAWSがキーの管理をし、二つ目のKMSによる暗号化を利用すると、暗号化キーに対する権限制御や証跡をCloudTrailで追跡できるようになる利点があります。 また、ELBのSSL Terminationを使用することで、クライアントとELB間の通信をSSL通信を有効化し、ELBとインスタンス間の通信をHTTP通信とすることで、インスタンス全てのSSL証明書を管理する必要がなくなり、ELBで証明書を一括で管理できます。
インシデント対応
セキュリティー的な対策や発見的統制などの予防的な実装が十分されていても、実際にアクシデントが発生したときの運用手順や復旧操作を準備しておくことは重要です。
以下の対策を行いましょう。
- メトリクスやリソースのログを収集しておき、インシデントの原因の特定とその対策を考えられるようにする。
- 自動化処理によって、インシデント発生時に自動的にアクションがトリガーされるようにする。
- CloudFormationやAWS CDKを使って、安全で隔離された環境に本番環境と同じシステムを構築して高負荷対策を行ったり、インシデントのシミュレーションを行うこと。
セキュリティーに関して使用するAWSサービスまとめ
- IAM
- AWS Organization
- AWS CloudTrail
- AWS Config
- AWS GuardDuty
- https://aws.amazon.com/jp/iam/
- VPC
- AWS CloudFront
- AWS Shield
- AWS WAF
- ELB
- S3
- EBS
- Macie
- KMS
信頼性
インフラやサービスの中断から復旧し、需要に適したリソースを動的に獲得して、安定的にサービスを稼働させたり、アクシデントの際に素早く復旧させることが重要です。
信頼性のベストプラクティス分野
- 基盤
- 変更管理
- 障害の管理
基盤
設計する段階で、信頼性を担保する基本的な要件を満たしておく必要があります。(ネットワーク性能やコンピューティング性能など)
オンプレでは事前に必要なリソースを準備しておく必要があるのに対し、クラウドでは基本的に制限を持たないように設計しておくことが重要です。
ネットワーク性能などの基本的な要件はAWSが担保してくれているので、ユーザーはAWSリソースの割り当てを適切に行い、基盤を構築することを意識しましょう。変更管理
変更がシステムに与える影響を、監視、モニタリングします。AWS CloudTrailでリソースの変更を管理したり、IAMでシステムを変更できるユーザーを制限しましょう。
障害の管理
どんなシステムでも障害が発生する確率は0%ではありません。
そのため、障害を検出して、再発を防止することが重要です。
具体的にはAWS CloudWatchでリソースのメトリクスを管理し、SNSを使用して、AWS lambdaのアクションをトリガーすることで、自動的に復旧アクションを行うこともできます。
ELBのヘルスチェックとAutoScalingを組み合わせることで、自動的にインスタンスを復旧することもできます。信頼性に関するAWSサービスまとめ
- AWS CloudWatch
- CloudWatch Logs
- CloudWatch Events
- IAM
- VPC
- AWS Trusted Advisor
- AWS Shield
- AWS AutoScaling
- CloudFormation
パフォーマンス効率
システム要件を満たしつつ、効率的にリソースを使用することや、要件の変化やテクノロジーの進化に対応しつつも、効率的にシステムを運用することはビジネスを成功させる上で重要です。
パフォーマンス効率のベストプラクティス分野
- 選択
- レビュー
- モニタリング
- トレードオフ
選択
システムの要件に対して、最適なAWSリソースを選択することが重要です。
例えば、セッション管理はRDSよりも、Elastic Cacheを使用する方が効率的ですし、EC2を使用するよりも、AWS Lambdaを使用して、イベントが発生したときのみ処理を行う方が、効率的なケースもあります。
AWSリソースを選択する上では、以下の4つの項目を意識しましょう。コンピューティング
様々な種類のEC2インスタンスが用意されており、どれが最適か検討しましょう。(SSD, GPUなど)また、ECSやAWS Fargateなどのコンテナ技術が適しているケースもあります。また画像処理やログ処理などはイベント駆動型のAWS Lambdaがコスト効率が良いです。
ストレージ
S3には以下のようにデータの種類やアクセス頻度に応じて、最適なオプションが用意されています。
- S3 標準
アクセス頻度の高いデータ向けのストレージクラスでデフォルトではこれが選択されます。- S3 Intelligent-Tiering
アクセス頻度を自動的に判別し、最もコスト効率の良いストレージクラスに自動的に移動させます。- S3 低頻度アクセス
アクセス頻度が低いデータですが、必要になった時にすぐに取り出す必要のあるデータに最適なストレージクラスです。S3標準と同じ機能を安く利用することができますが、データを取り出す際に料金が発生するのが特徴です。- S3 1 ゾーン – 低頻度アクセス (S3 1 ゾーン – IA)
S3 低頻度アクセスと同様にアクセス頻度の低いデータに向いていますが、データが一つのアベイラビリティーゾーンにのみ保存されます。そのため、可用性は低下しますが、料金はS3 低頻度アクセスよりも20%抑えることができます。- S3 Glacier
アーカイブ目的のデータに適しているストレージクラスです。取り出す際には、数分から数時間かかりますが、コストは圧倒的に安く済ませることができます。- S3 Glacier Deep Archive
一年のうち一回か二回しかアクセスされないデータを対象としています。容量あたりのコストは最も低いストレージクラスです。データベース
データの使用目的に応じて最適なデータベースを使用することがコスト最適化につながります。
- RDS
フルマネージドのリレーショナルデータベースです。
- DynamoDB
Key-ValueストアのNoSQL。データ容量に制限がなく、テーブルを自動的にスケーリングすることができます。RDSより高速にデータの格納と取得ができるため、ゲームやアドテクなど、短いレイテンシーが要求されるケースに使用されます。
- Redshift
列指向型のデータベースで巨大なデータを使用する分析に適しています。
- ElasticCache
データ容量に制限がある一方で、高速にアクセスできるため、セッション管理などに使用されます。
シンプルなデータ構造向きのMemcachedと暗号化や高可用性、複雑なデータ構造にも対応しているRedisがあります。ネットワーク
レイテンシーやI/O機能の要件を満たすために最適なサービスを使用することが重要です。
- EBS最適化インスタンス
デフォルトではEC2インスタンスとEBS間の帯域はEBSへのI/O以外に他のインスタンスへの通信にも使用されます。より優れたI/O性能を求める場合は、EC2とEBSの間に専用の帯域を設定することでより高いパフォーマンスを得ることができます。このオプションのことをEBS最適化インスタンスと呼びます。- CloudFront
ユーザーからのリクエストを最寄りのエッジサーバーに誘導し、高速にコンテンツ配信を行うことができます。- S3 Transfer Acceleration
クライアントとS3バケット間の通信を高速化することができます。内部ではCloudFrontが使用されているようです。- Route53
Route53は単純な名前解決だけでなく、動的に転送先を決定するルーティングポリシーになっています。 以下の種類があるので、要件によって使い分けるようにしましょう。シンプルルーティング
通常のDNSと同じ、単純な名前解決
フェイルオーバールーティング
ヘルスチェックの結果に基づいて、使用可能なインスタンスにのみルーティングを行う。
位置情報ルーティング
クライアントの位置情報に基づいてルーティングされる。
地理的近接性ルーティング
ユーザーとリソースの地理的情報に基づいてルーティングされる。
レイテンシーに基づくルーティング
複数リージョンにリソースが存在する時に、最もレイテンシーの少ないリージョンにルーティングする。
複数値回答ルーティング
DNSクエリに対して、複数の値を返すように設定する
加重ルーティング
単一のドメインに複数のリソースを紐付けて、重みづけに基づいてトラフィックを分散させることができるルーティング
- VPCエンドポイント
VPCにエンドポイントを付けることで、本来はインターネットからしかアクセスできないリソースにVPC内部からアクセスできるようになります。」- AWS DirectConnect
オンプレミスからAWSに専用の回線を設けることができるサービスレビュー
AWSサービスは日々新しいものが追加されていますので、常に最新の情報をキャッチアップし、有効なテクノロジーは活用しましょう。
クラスメソッドさんのサイトでは、AWSで新しいサービスが追加されるとすぐに解説記事が追加されるので、いつも参考にさせていただいてます。
もちろん公式サイトも日々チェックしましょう。モニタリング
アーキテクチャが完成した後は、そのパフォーマンスをモニタリングしておき、メトリクスが閾値を超えた時に、アラームを発生させるようにします。
AWS CloudWatchでメトリクスを監視し、SQSやAWS Lambdaで自動的にアクションをトリガーしてパフォーマンスの問題を回避できるようにしておきましょう。トレードオフ
パフォーマンスの中でも、どの項目を重要視するのか決めておきましょう。
例えば、データの整合性や耐久性を一番に考えるのか、レイテンシーや応答速度を重視するのかなど、トレードオフを考えてアーキテクチャを設計しましょう。パフォーマンス効率に関するAWSサービス
- AWS CloudWatch
- AWS Auto Scaling
- AWS EBS
- S3
- RDS
- DynamoDB
- Redshift
- ElastiCache
- Route 53
- VPCエンドポイント
- AWS DirectConnect
コスト最適化
当たり前のことですが、ビジネスを行う上で、低価格でシステムを運用することは重要です。
コスト最適化のベストプラクティス分野
- 費用認識
- 費用対効果の高いリソース
- 需要と供給を一致させる
- 長期的な最適化
費用認識
AWS CostExplorerを使用して費用の内訳を把握しておきましょう。また、AWS Budgetsを使用して予想よりも多くの費用が発生した時にアラートを通知することができます。設定ミスなどで多額の費用が発生するケースがあるので、必ず設定しておきましょう。
費用対効果の高いリソース
要件に応じて、最適なリソースを使用しましょう。
例えば、EC2インスタンスの場合は種類によって、かなり費用を削減できる場合があります。
- リザーブドインスタンス
1年間または3年間でEC2インスタンスを予約して使用することで割引が受けられます。- スポットインスタンス
AWSがEC2インスタンスの使用量を時価で提供し、ユーザーが設定した価格よりもAWSの提示した価格の方が低い場合は、インスタンスを使用できます。EMRを使用してビッグデータを処理するときなど、途中でインスタンスが停止しても支障がない場合に使用することで、大幅に安くEC2インスタンスを使用できます。- ハードウェア占有インスタンス
通常はEC2インスタンスは他のユーザーと共有したホストコンピュータを使用しますが、このオプションにすると、専用のホストコンピュータにEC2インスタンスを割り当てることができます。ただし、どのホストコンピュータは指定することができません。- Dedicated Hosts
ハードウェア占有インスタンスと同様に、専用のホストコンピュータを使用でき、インスタンスが配置されるホストコンピュータも指定することができます。 ### 需要と供給を一致させる 高負荷のアクセスに備えてプロビジョニングする時間を設定するなど、リソースを最適に配分します。 AutoScalingを使用すると、需要ベース、バッファーベース、時間ベースのアプローチで必要に応じたリソースの追加や削除が可能になります。長期的な最適化
日々AWSのサービスはアップデートされるため、最適なサービスを日々取り入れるようにしましょう。例えば、新しいマネージドサービスが発表されるとそれまで、EC2インスタンスにミドルウェアをインストールして運用する場合と比較して、コストを節約できる場合があります。
コスト最適化に関するAWSサービス
まとめ
クラウド技術を使って、安定した効率的なシステムを構築するために5本の柱を意識して設計し、それぞれのベストプラクティスを遵守しましょう。
- 投稿日:2020-01-19T16:32:53+09:00
AWS Amplify API作成
amplify push をしたらエラーが発生。
この記事を参考に問題を解決しました。しかし、amplify add apiで別のエラーに引っかかる。
MacBook-Air:ampIAM ****$ amplify add api ? Please select from one of the below mentioned services: GraphQL SyntaxError: Unexpected identifier at serviceQuestions (/Users/******/.npm-global/lib/node_modules/@aws-amplify/cli/node_modules/amplify-category-api/provider-utils/awscloudformation/index.js:13:10) at Object.addResource (/Users/******/.npm-global/lib/node_modules/@aws-amplify/cli/node_modules/amplify-category-api/provider-utils/awscloudformation/index.js:54:10) at /Users/******/.npm-global/lib/node_modules/@aws-amplify/cli/node_modules/amplify-category-api/commands/api/add.js:24:35 at processTicksAndRejections (internal/process/task_queues.js:89:5) at async Object.executeAmplifyCommand (/Users/******/.npm-global/lib/node_modules/@aws-amplify/cli/node_modules/amplify-category-api/index.js:176:3) There was an error adding the API resourceとのことなので、とりあえずNode.jsの更新を行います。
$ npm install -g n $ n --stable $ n --latest $ n latestsudoを求められた場合は、npm install -g nの実行結果にあるnのフルパスを使って下記のように書くと実行できます。
sudo フルパス latest再度apiを作成。
✔ Generated GraphQL operations successfully and saved at graphql ✔ Code generated successfully and saved in file API.swift ✔ All resources are updated in the cloudうまくいきました!
@aws-amplify/cliのアップデートを行った際は、対応のバージョンにnpm及びNode.jsのアップデートが必要になるようです。
- 投稿日:2020-01-19T16:22:50+09:00
AWSのCloud9を既存インスタンスで使用する
はじめに
既存のインスタンスを使用して、Cloud9を構築します。Visual Studio CodeのRemote Developmentを使用してEC2に接続できますが、Cloud9だとブラウザがあれば動作するので、タブレットやChromeBookなどでもコーディングをできるようにします。
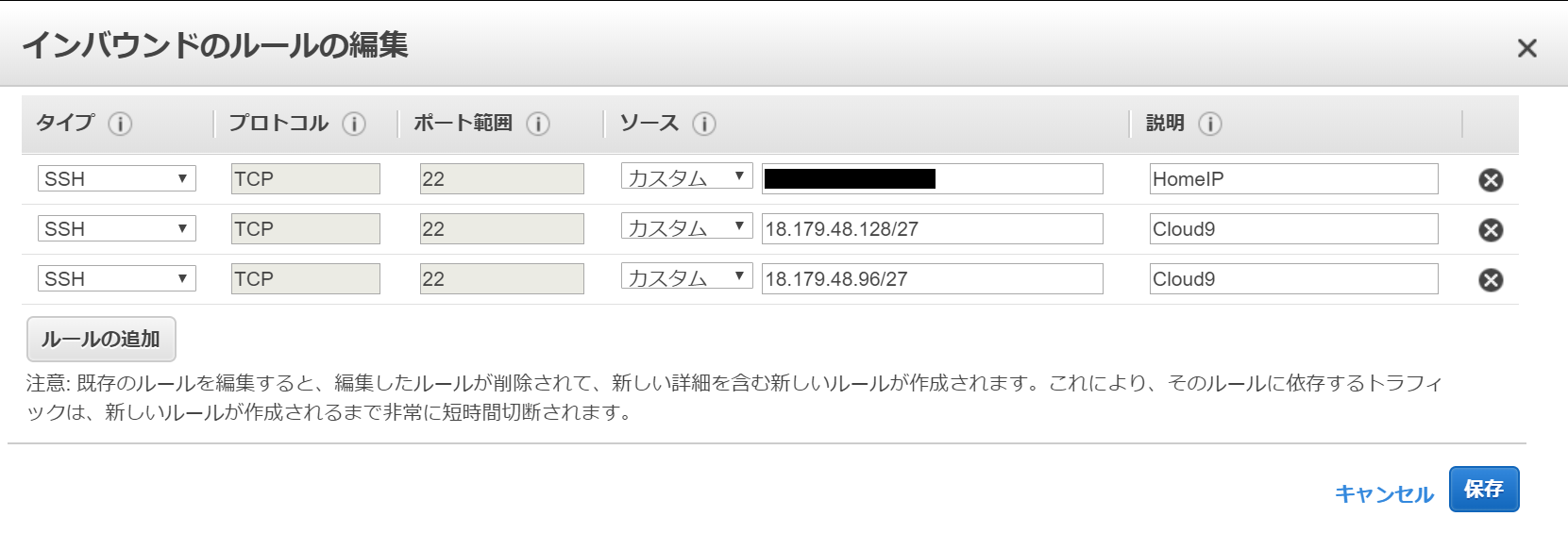
インスタンスのセキュリティーグループの変更
インバウンドルールのSSHに、Cloud9のIPアドレス
18.179.48.128/2718.179.48.96/27許可します。
IPアドレスの固定(EIPを割り当てていない場合)
EC2ダッシュボードのネットワーク&セキュリティから、Elastic IPを選択します。
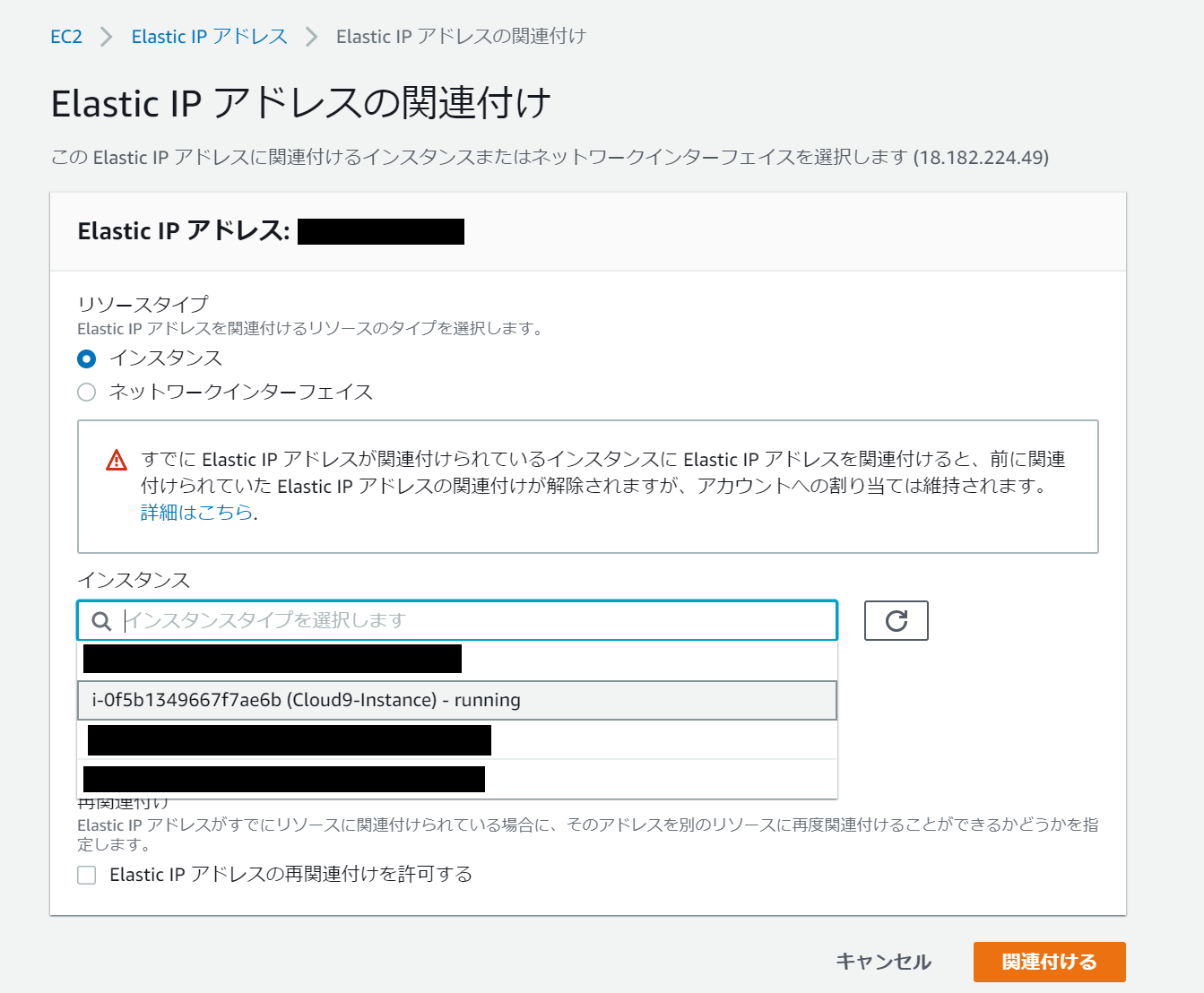
Elastic IPアドレスの割り当てを開き、割り当てをクリックします
取得したIPアドレスが選択された状態で、アクションからElastic IP アドレスの関連付けをクリックします。インスタンスが選択されていることを確認し、インスタンスの入力ボックスをクリックし、使用したいインスタンスを選択します。
Node.jsのインストール(Ubuntu向け)
最初に、アップデート&アップグレードを実行します。
sudo apt-get updatesudo apt-get -y upgradecurlのインストール
sudo apt-get -y install curlPRAの導入
sudo curl -sL https://deb.nodesource.com/setup_12.x | sudo bash -Node.jsのインストール
sudo apt-get -y install nodejsCloud9の構築
cloud9の設定
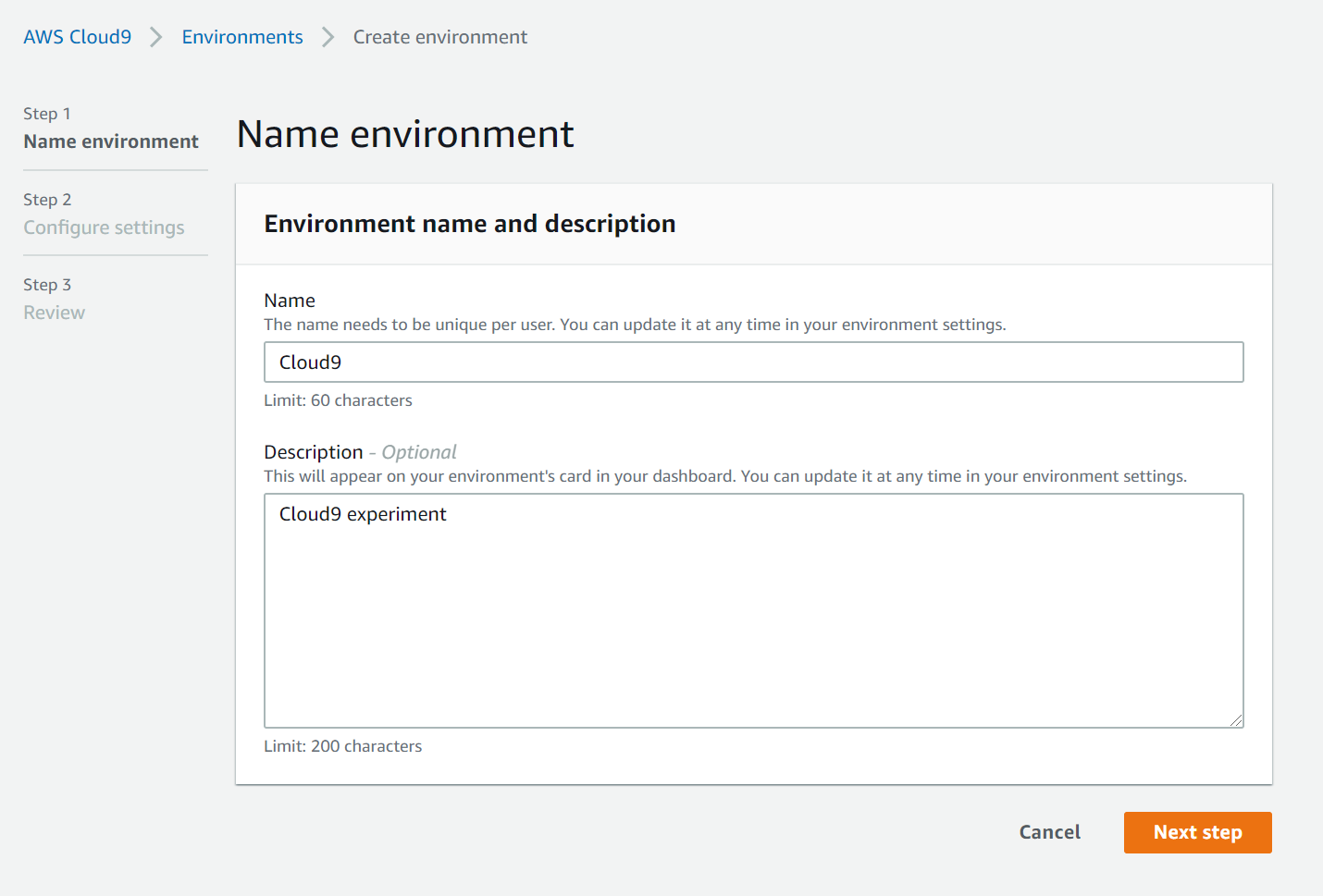
Cloud9のページのNew AWS Cloud9 environment -> Create environmentからCloud9の環境を構築します。
Nameと、Descriptionを入力します。Descriptionは省略可能です。入力が完了したら、
Next stepをクリックします。
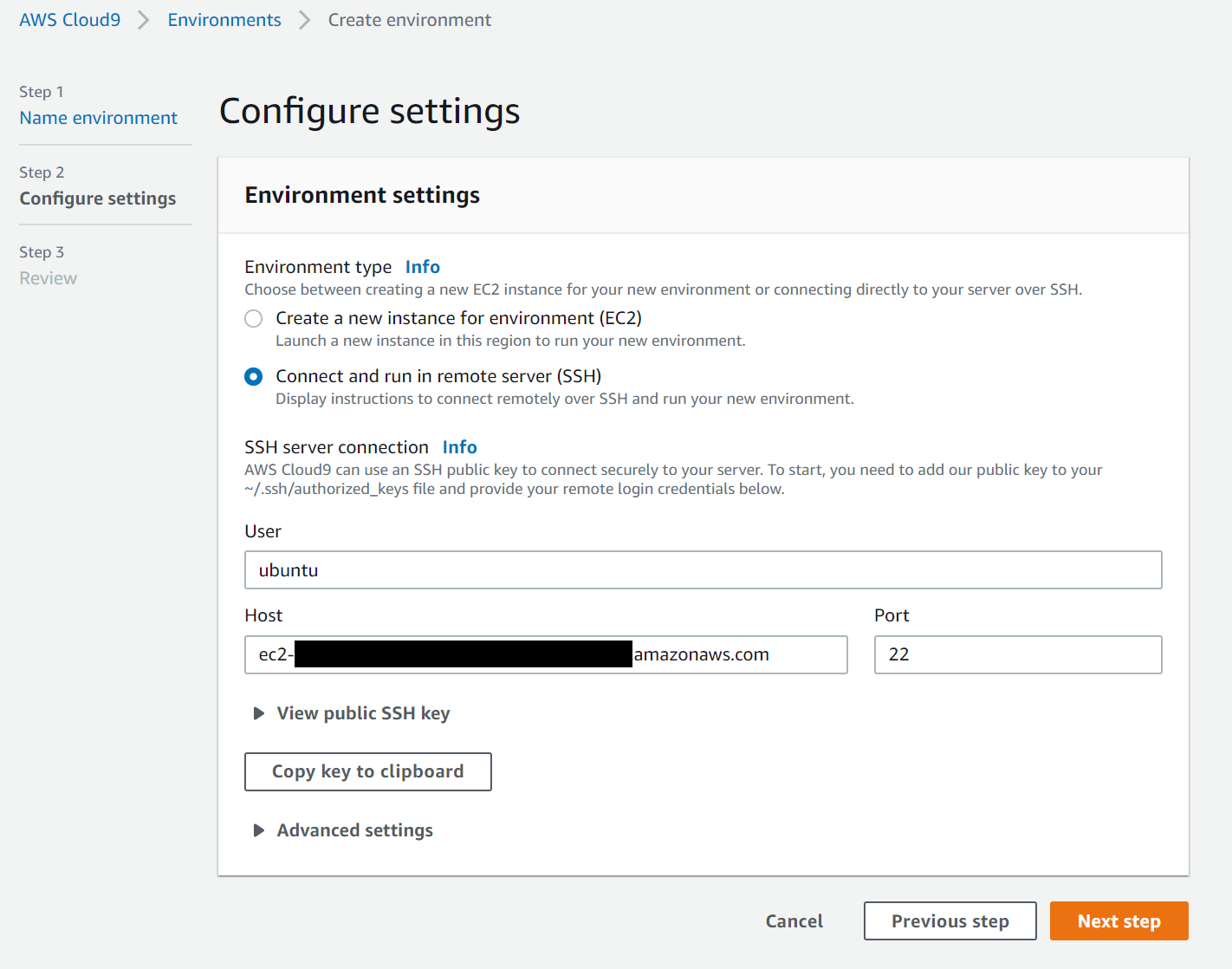
既存のインスタンスを使用するので、Environment typeから
Connect and run in remote server (SSH)を選択します。Userのところにインスタンスのユーザー名、HostにインスタンスのIPアドレス又はDNSを入力します。
View public SSH keyのところのCopy key to clipboardをクリックして、クリップボードにCloud9の公開鍵をコピーします。
インスタンスに接続し、
./.ssh/authorized_keysに上記でコピーした公開鍵を貼り付けます。
公開鍵を追加したら、Next stepをクリックします。
Reviewが表示されるので、Create environmentをクリックします。
Cloud9のインストール
Can we quickly set up AWS Cloud9 on your environment?と表示されるので、Nextをクリックします
The following components will be installed. You can untick any of the optional components.と表示されるので、すべてチェックが入っている状態で、Nextをクリックします。
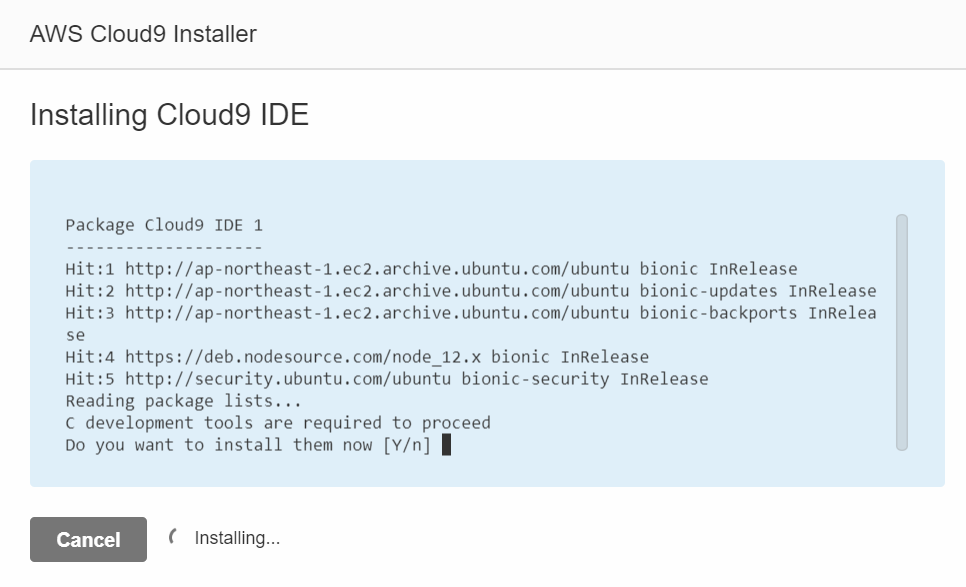
Installing Cloud9 IDEのDo you want to install them now [Y/n]が表示されたらエンターキーを押します。
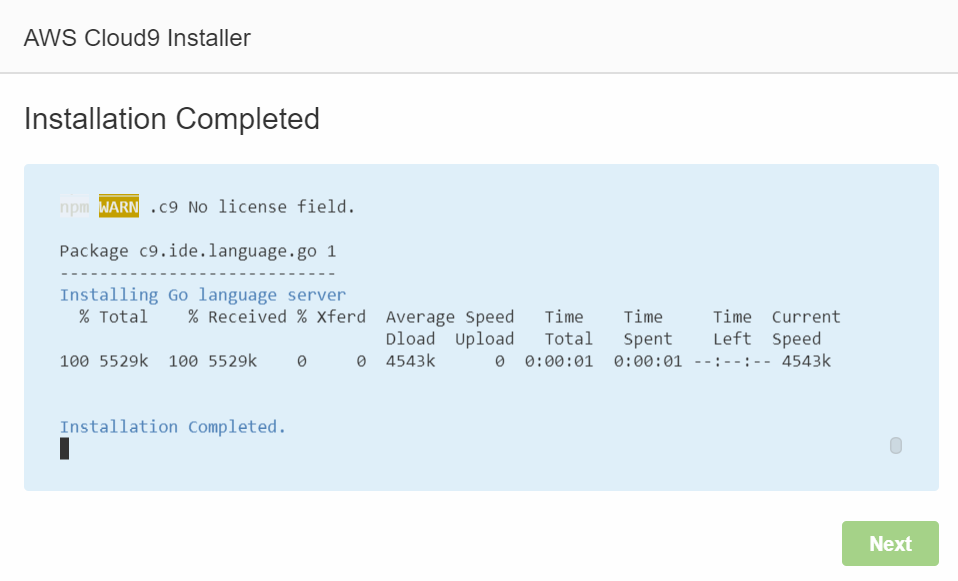
Installation Completedと表示されるとインストール成功です。Nextをクリックします。
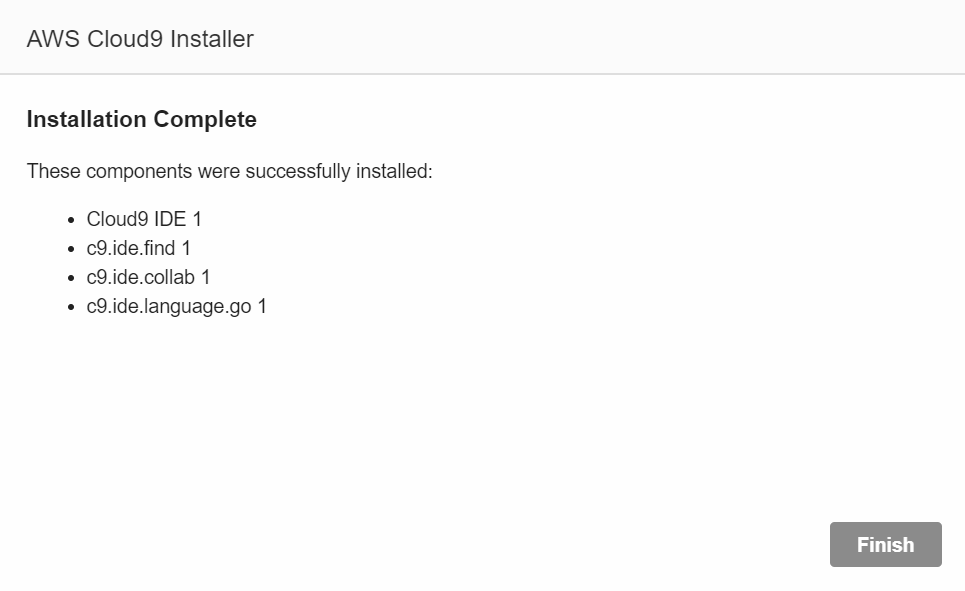
Finishをクリックして、Cloud9の使用を始めます。
Cloud9を使ってみる
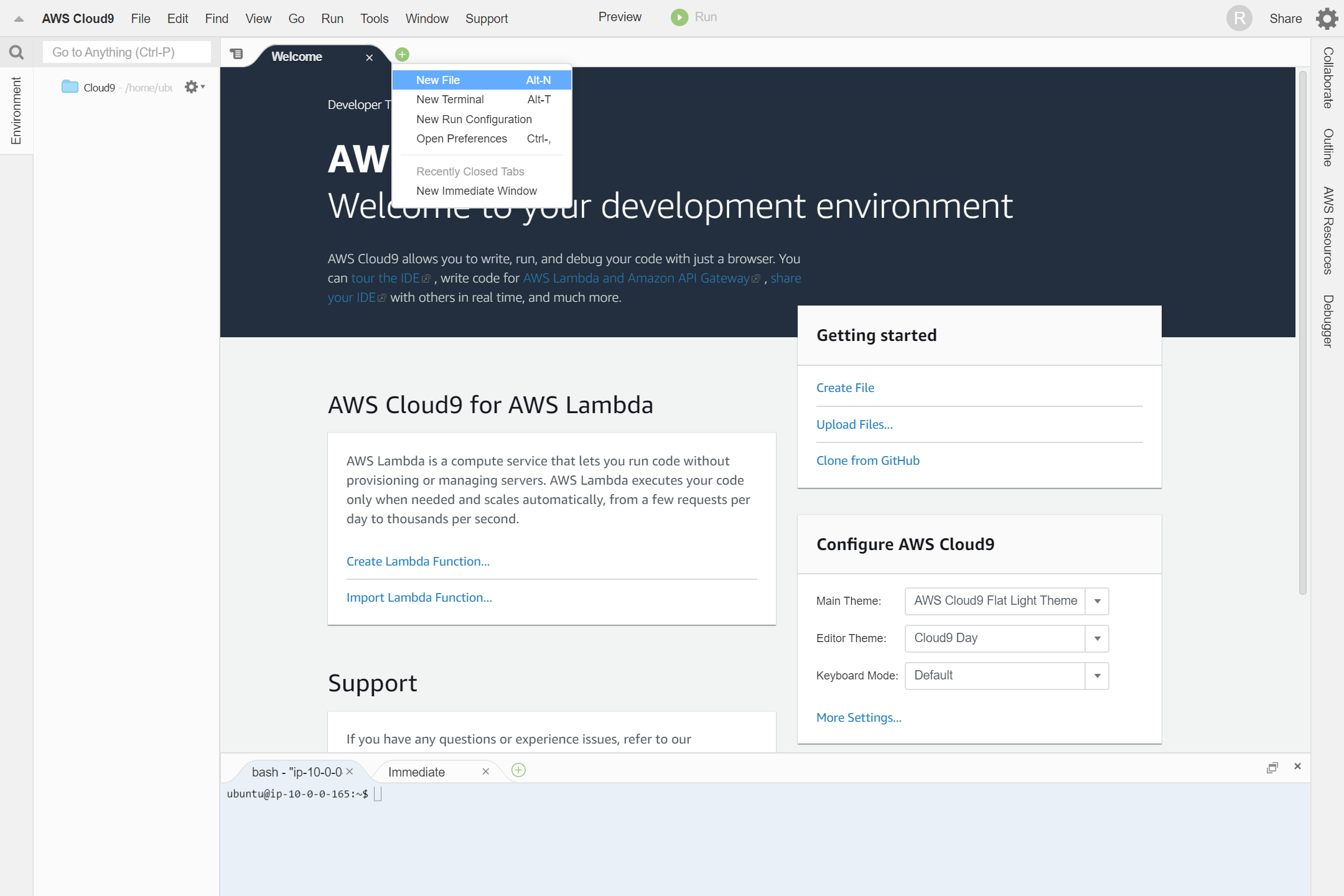
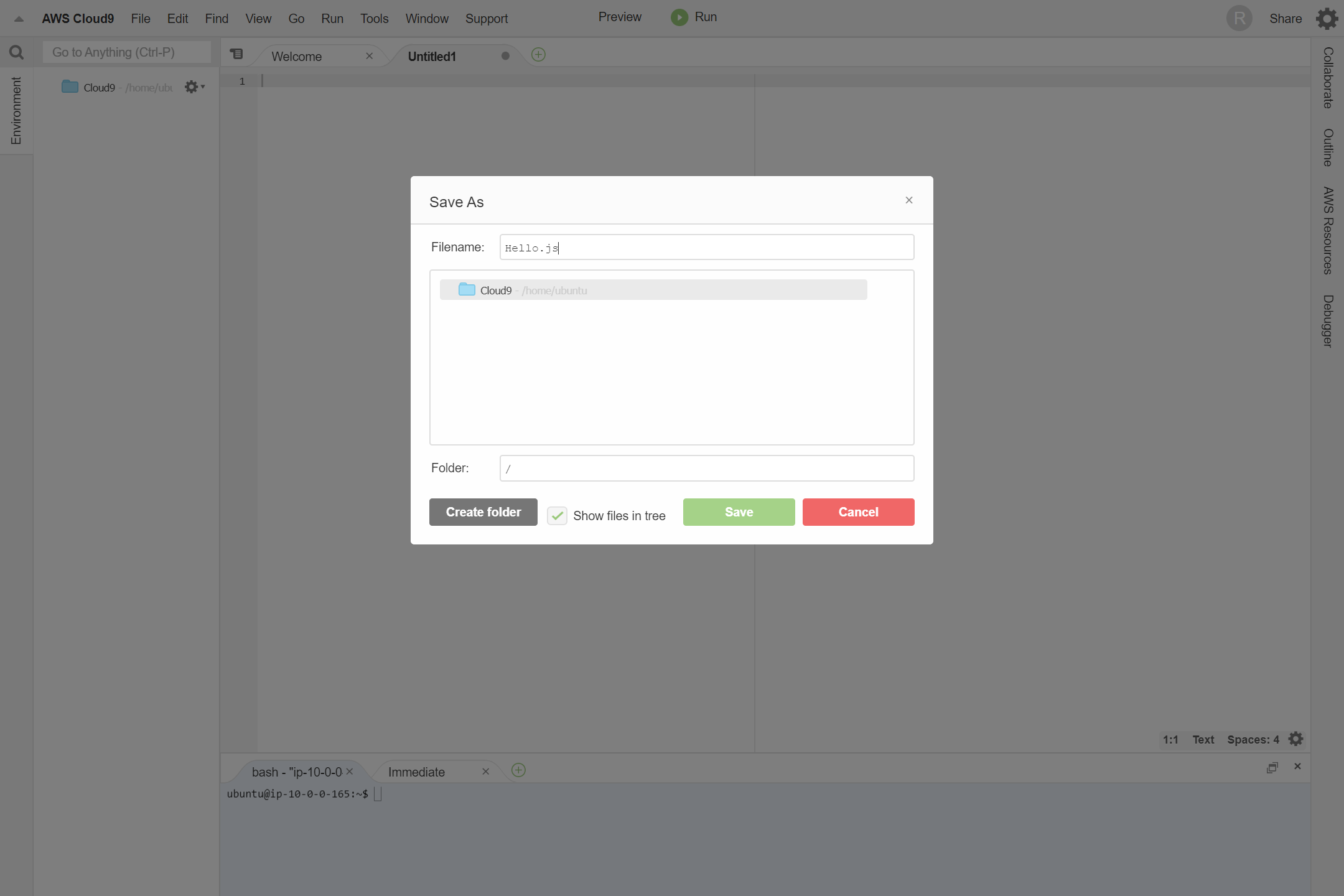
タブの+マークから、New Fileをクリックします。
Ctrl + S または、File -> Saveから、名前を付けて保存します。ここでは、Hello.jsにしました。
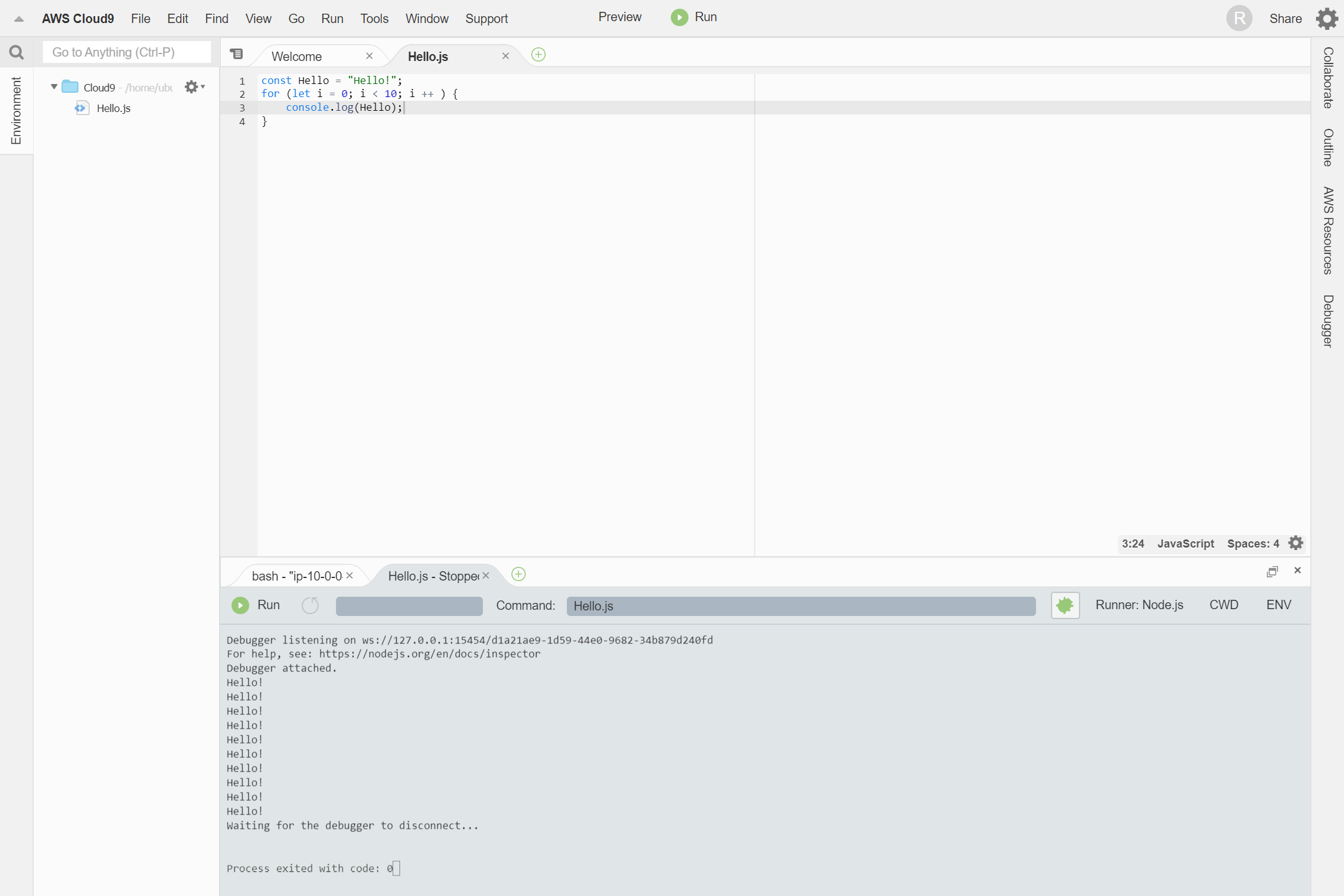
プログラムを入力します。
Hello.jsconst Hello = "Hello!"; for (let i = 0; i < 10; i ++ ) { console.log(Hello); }Alt + F5 または、Runボタンをクリックして実行します。
おわりに
ブラウザ上で動くので、デバイスに関係なくコードを書くことがき、補完機能もあるので、ちょっとしたコーディングからメインのIDEとしても使えます。複数人で編集できるので、チーム開発やペアプロにもってこいだと思います。






- 投稿日:2020-01-19T15:28:26+09:00
AWSの請求と料金
出展:AWS認定資格試験テキスト AWS認定 クラウドプラクティショナー
AWS料金モデル
使った分だけの従量課金
・AWSでは必要なときに必要なリソースを使って、使った分にだけ請求が発生する
・資本の支出を変動費にすることができる
・消費モデルをエンジニアだけでなく組織全体で受け入れることにより、コスト最適化が進む課金体系
・課金体系はサービスによって異なる(使用していた時間/使った容量 等)
・同じサービスでもリージョンによって料金が異なるものもある多彩な料金モデル
・要件に応じて最適な料金モデルを選択することでコストを最適にできる
請求ダッシュボード
請求書
・各AWSサービスの料金の内訳を見ることができる
・どのリージョンでどのサービスのどの機能を使ったかが確認できる
・請求金額は月末まで待たなくても、月の途中でも確認できるコストエクスプローラとコスト配分タグ
・コスト配分タグによってROIの請求分析ができる
・コストエクスプローラでコスト配分タグで分けた結果を可視化したり、CSV形式でダウンロードしたりできる請求アラーム
・請求金額もCloudWatchメトリクスの1つ
・請求アラームによって使いすぎを抑止するための通知ができるマルチアカウントの運用
・AWSのアカウントは個人や組織で複数作成することができる
・環境を分けたい場合や、用途によって分けたい場合にアカウントを分離するAWS Organizations
・複数アカウントを一括管理、階層管理できる
一括請求(コンソリデーティッドビリング)
・複数アカウントの請求を1つの請求にまとめることができる
AWSのサポートプラン
・適切なサポートプランを選択することで、運用の安全性を保ち、エスカレーションパス(問い合わせ先)を確保できる
ベーシックプラン
・AWSアカウントを作ったときに提供されている無料のサポートプラン
・技術サポートは、AWSサービスの稼働状況をモニタリングしているヘルスチェックについてのサポートのみ
・Trusted Advisorは最低限必要な項目のみ開発者プラン
・29USDか使用料の3%の大きいほう
・技術サポートを作成できるユーザは1ユーザ(9:00~18:00)
・構成要素についてのアーキテクチャサポート
・Trusted Advisorは最低限必要な項目のみビジネスプラン
・100USDか使用料に応じた計算式の大きいほう
・技術サポートを作成できるユーザは無制限(24時間)
・アーキテクチャはユースケースのガイダンス
・Trusted Advisorは全項目
・サポートAPIの使用可
・サードパーティソフトウェアのサポートエンタープライズプラン
・15,000USDか使用料に応じた計算式の大きいほう
・技術サポートを作成できるユーザは無制限(24時間)
・アプリケーションのアーキテクチャサポート
・Trusted Advisorは全項目
・サポートAPIの使用可
・サードパーティーソフトウェアのサポート
・テクニカルマネージャー(TAM)
・サポートコンシェルジュ
・ホワイトグローブケースルーティング
・管理ビジネス評価その他の請求サポートツール
AWS簡易見積もりツール
・請求見込額を事前に計算しておくことができる
TCO計算ツール
・AWSとオンプレミスのコストを比較するツール
- 投稿日:2020-01-19T15:20:55+09:00
AWS SAP エッセンス(未完成)
AWS SAPとは?
AWS Certified Solutions Architect - Professional のことです。
詳細はこちらの公式ページを見てみてください。自分のスペック
AWSは2019年の春ごろから業務で触り始めた。
使ったのは主にEC2,RDS,S3,lambdaで、
Code系、AmazonConnectを少し。2019年5月 AWS Certified Cloud Practitioner 取得
2019年6月 AWS Certified Solutions Architect – Associate 取得合格までのロードマップ
- 試験ガイドを確認
- Exam Readinessを見て試験のイメージをしっかり掴む
- 分野ごとに教材(ホワイトペーパーとブラックベルトがメイン)を1周する
- 組織の複雑さに対応する設計(12.5%)
- 新しいソリューションの設計 (31%)
- 移行計画(15%)
- コスト管理(12.5%)
- 既存のソリューションの継続的な改良(29%)
- 模擬試験で現状の実力確認
- 以下、繰り返し
- Udemyの問題集を解く
- 教材を再度確認
- 並行してQiitaにエッセンスをノートしていく
- 本番
公式が推奨する勉強法にUdemyでの問題演習で補強を加えたいたってシンプルなやり方です。過去に取得済みの認定はがむしゃらに詰め込んだので今回は腰を据えてじっくり取り組もうと思います。
試験ガイドをしっかり確認
何を知識として抑えるべきかをしっかり把握します。
日本語の試験ガイド
英語の試験ガイド認定準備ワークショップ(Exam Readiness)を受講
こちらを受講して以下のことを学習。
- 試験プロセスの注意事項
- 試験の構成と問題のタイプを理解
- 問題が AWS のアーキテクチャの概念とどのように関連しているかを識別
- 試験問題で問われている概念を読み取る
- 試験勉強のための時間配分を検討
勉強方法
- クラス(有料)3日間で21万円なのでパス
- ホワイトペーパーが充実
- 読解問題であり込み入った問題のキーワードを見つけ出しそれに対する適切な回答を選択する必要がある
- 試験問題は認定の価値を保つためにも外部に漏らさないでください
- 複数選択の問題はすべて正解して〇です、部分点はありません
- 170分のテスト、めちゃくちゃ長いし時間も余るわけではない
- マークを付けて飛ばしていかないと時間足りなくなるよ
- 選択肢はすべてよむこと、間違ってない解答の後により適切な解答がある場合も
- 逆に明らかな間違いとしてはじくことのできる選択肢もある
- 修飾句に着目する例えば「最もコスパがいい」とか
- 特定の機能についての記載があったら着目する、正解の選択肢はその要件を満たすものである
- 試験日前6か月に発表、リリースされたような機能は問題に反映されていない
- 消去法だけの解き方ではうまくいかないだろう=より最適なアーキテクチャを選択する必要あり
試験問題の分野と出題の比率
- 組織の複雑さに対応する設計(12.5%)
- 新しいソリューションの設計 (31%)
- 移行計画(15%)
- コスト管理(12.5%)
- 既存のソリューションの継続的な改良(29%)
分野1「組織の複雑さに対応する設計」(12.5%)
以下の3つの設計ができるようになること
- クロスアカウント認証とアクセス戦略
- ネットワーク
- マルチアカウントの AWS 環境クロスアカウント認証とアクセス戦略
- IAMオブジェクト、ユーザ、グループ、ロールの理解
- STS(Secure Token Service)を使った一時的なセキュリティ認証情報を渡す方法
- ユーザーフェデレーション
- 外部のユーザーアイデンティティに自分のアカウントのAWSリソースを使用する権限を付与的る
- 長期のセキュリティ認証情報を配布しないためにAWSアカウントのセキュリティが向上する
- SAML2.0接続とOpenIDConnect接続を理解する必要がある
- フェデレーティッドユーザー
- AWSアカウントを持たないユーザーまたはアプリケーション
- フェデレーティッドユーザーのロール
- ロールを使用することで一定の期間AWSリソースへのアクセス権を付与できる
- Microsoft AD、LDAP、Kerberosなどの外部サービスで認証できるAWS以外のユーザーが存在する売位に役立ちます
- 一時的なAWS認証情報
- 一時的なAWS認証情報とロールを組み合わせて使用すると、AWSユーザーとそれ以外との間でIDフェデレーションを提供できる
- AWS Directory Service
- Microsoft Active DirectoryをAWSの他のサービスと一緒に使用するための方法が複数ある、それぞれ理解する必要あり
- AWS Managed Microsoft AD
- AWSクラウドでマネージド型ADを使用可能にする
- AD Connector
- オンプレミスユーザーがAD経由でAWSのサービス委アクセスできるようにする
- Simple AD
- 小規模で低コストの基本的なAD機能を提供する
ネットワーク
ハイブリッド型VPN接続
- AWSマネージドVPN
- リモートネットワーク上のオンプレミスネットワーク機器からAmazonVPCにアタッチされたAWSマネージド型ネットワーク機器へのハードウェアVPN接続
- AWS VPN CloudHub
- 複数のリモートブランチオフィスをAmazonVPCに接続するハブアンドスポークモデル
- ソフトウェアVPN
- リモートネットワーク上の危機からAmazonVPC内で実行されているユーザー管理型のソフトウェアVPNアプライアンスへのVPN接続
ハイブリッド型 AWS Direct Connect(DX)
- AWSリソースとファイバー回線でつながっているDXロケーションに接続する
- Virtual Interface(仮想インターフェイス、通称VIF)をセットアップする方法
- パブリックとプライベートがある
ハイブリッド型 AWS Storage Gateway
- 4種類ありそれぞれの特徴を理解して最適なものを選べるようになること
- ファイルゲートウェイ
- テープゲートウェイ
- 保管型ボリュームゲートウェイ
- キャッシュ型ボリュームゲートウェイ
VPC エンドポイント
インターネットゲートウェイまたは仮想ゲートウェイを介さずに、インスタンスがプライベートIPを使用して、AWSサービスと接続することを可能にする仮想デバイス
- インターネットフェイスエンドポイント
- インターフェイスVPCエンドポイントはプライベートIPアドレスを持ったENIで、AWS PrivateLinkを使用するサービスあてのトラフィックのエントリポイントになります。
- ゲートウェイエンドポイント
- ルートテーブルでしていされたルートのターゲットであるゲートウェイ。このタイプのエンドポイントは、サポートされているAWSのサービス(S3やDynamoDBなど)へのトラフィックに使用される。
- デフォルトではIAMユーザーにはエンドポイントを使用するアクセス許可はない。IAMユーザーポリシーを作成して、エンドポイントを作成・変更・記述・削除するアクセス許可をユーザーに付与できます。 IAMポリシーを介してVPCエンドポイントへのアクセスを管理する
マルチアカウントのAWS環境
リソースと請求の分離
- 多くの場合、要素ごとに固有のアカウントを用意することで特定の分離を監査機関に証明することが容易になる
- 例えば開発アカウントがありそれが独立している場合、開発者は規制対象のグローバルアカウントにアクセスできないことを簡単に証明できます。
- 1つのアカウント内で分離をするには明確なポリシーの分離を証明できる必要がある
複数アカウントの請求戦略
- グループエイリアスに通知を送信
- アカウント全体でAWSタグ付け標準を使用
- AWS API およびスクリプトで会社のベースラインの設定を自動化
AWS Oraganizations
- 複数のAWSアカウントをポリシーベースで一元管理
- アカウント全体のポリシーを管理し、不要なアクセスをブロック
- APIを使用して新しいアカウントの作成お自動化
- アカウントを組織単位(OU)に編成する
- AWS一括請求(コンソリデーティッドビリング)
(執筆中)
- 投稿日:2020-01-19T15:20:55+09:00
AWS SAP エッセンス(執筆中 毎週更新)
はじめに
この記事は未完成です。
合格した上で書き終わって完成なのでよろしくお願いします。
(応援していただけたら超喜びます)
現在の進捗 約3%AWS SAPとは?
AWS Certified Solutions Architect - Professional のことです。
詳細はこちらの公式ページを見てみてください。自分のスペック
AWSは2019年の春ごろから業務で触り始めた。
使ったのは主にEC2,RDS,S3,lambdaで、
Code系、AmazonConnectを少し。2019年5月 AWS Certified Cloud Practitioner 取得
2019年6月 AWS Certified Solutions Architect – Associate 取得合格までのロードマップ
- 試験ガイドを確認
- Exam Readinessを見て試験のイメージをしっかり掴む
- 分野ごとに教材(ホワイトペーパーとブラックベルトがメイン)を1周する
- 組織の複雑さに対応する設計(12.5%)
- 新しいソリューションの設計 (31%)
- 移行計画(15%)
- コスト管理(12.5%)
- 既存のソリューションの継続的な改良(29%)
- 模擬試験で現状の実力確認
- 以下、繰り返し
- Udemyの問題集を解く
- 教材を再度確認
- 並行してQiitaにエッセンスをノートしていく
- 本番(4月末予定)
公式が推奨する勉強法にUdemyでの問題演習で補強を加えたいたってシンプルなやり方です。過去に取得済みの認定はがむしゃらに詰め込んだので今回は腰を据えてじっくり取り組もうと思います。
試験ガイドをしっかり確認
何を知識として抑えるべきかをしっかり把握します。
日本語の試験ガイド
英語の試験ガイド認定準備ワークショップ(Exam Readiness)を受講
こちらを受講して以下のことを学習。
- 試験プロセスの注意事項
- 試験の構成と問題のタイプを理解
- 問題が AWS のアーキテクチャの概念とどのように関連しているかを識別
- 試験問題で問われている概念を読み取る
- 試験勉強のための時間配分を検討
勉強方法
- クラス(有料)3日間で21万円なのでパス
- ホワイトペーパーが充実
- 読解問題であり込み入った問題のキーワードを見つけ出しそれに対する適切な回答を選択する必要がある
- 試験問題は認定の価値を保つためにも外部に漏らさないでください
- 複数選択の問題はすべて正解して〇です、部分点はありません
- 170分のテスト、めちゃくちゃ長いし時間も余るわけではない
- マークを付けて飛ばしていかないと時間足りなくなるよ
- 選択肢はすべてよむこと、間違ってない解答の後により適切な解答がある場合も
- 逆に明らかな間違いとしてはじくことのできる選択肢もある
- 修飾句に着目する例えば「最もコスパがいい」とか
- 特定の機能についての記載があったら着目する、正解の選択肢はその要件を満たすものである
- 試験日前6か月に発表、リリースされたような機能は問題に反映されていない
- 消去法だけの解き方ではうまくいかないだろう=より最適なアーキテクチャを選択する必要あり
試験問題の分野と出題の比率
- 組織の複雑さに対応する設計(12.5%)
- 新しいソリューションの設計 (31%)
- 移行計画(15%)
- コスト管理(12.5%)
- 既存のソリューションの継続的な改良(29%)
分野1「組織の複雑さに対応する設計」(12.5%)
以下の3つの設計ができるようになること
- クロスアカウント認証とアクセス戦略
- ネットワーク
- マルチアカウントの AWS 環境クロスアカウント認証とアクセス戦略
- IAMオブジェクト、ユーザ、グループ、ロールの理解
- STS(Secure Token Service)を使った一時的なセキュリティ認証情報を渡す方法
- ユーザーフェデレーション
- 外部のユーザーアイデンティティに自分のアカウントのAWSリソースを使用する権限を付与的る
- 長期のセキュリティ認証情報を配布しないためにAWSアカウントのセキュリティが向上する
- SAML2.0接続とOpenIDConnect接続を理解する必要がある
- フェデレーティッドユーザー
- AWSアカウントを持たないユーザーまたはアプリケーション
- フェデレーティッドユーザーのロール
- ロールを使用することで一定の期間AWSリソースへのアクセス権を付与できる
- Microsoft AD、LDAP、Kerberosなどの外部サービスで認証できるAWS以外のユーザーが存在する売位に役立ちます
- 一時的なAWS認証情報
- 一時的なAWS認証情報とロールを組み合わせて使用すると、AWSユーザーとそれ以外との間でIDフェデレーションを提供できる
- AWS Directory Service
- Microsoft Active DirectoryをAWSの他のサービスと一緒に使用するための方法が複数ある、それぞれ理解する必要あり
- AWS Managed Microsoft AD
- AWSクラウドでマネージド型ADを使用可能にする
- AD Connector
- オンプレミスユーザーがAD経由でAWSのサービス委アクセスできるようにする
- Simple AD
- 小規模で低コストの基本的なAD機能を提供する
ネットワーク
ハイブリッド型VPN接続
- AWSマネージドVPN
- リモートネットワーク上のオンプレミスネットワーク機器からAmazonVPCにアタッチされたAWSマネージド型ネットワーク機器へのハードウェアVPN接続
- AWS VPN CloudHub
- 複数のリモートブランチオフィスをAmazonVPCに接続するハブアンドスポークモデル
- ソフトウェアVPN
- リモートネットワーク上の危機からAmazonVPC内で実行されているユーザー管理型のソフトウェアVPNアプライアンスへのVPN接続
ハイブリッド型 AWS Direct Connect(DX)
- AWSリソースとファイバー回線でつながっているDXロケーションに接続する
- Virtual Interface(仮想インターフェイス、通称VIF)をセットアップする方法
- パブリックとプライベートがある
ハイブリッド型 AWS Storage Gateway
- 4種類ありそれぞれの特徴を理解して最適なものを選べるようになること
- ファイルゲートウェイ
- テープゲートウェイ
- 保管型ボリュームゲートウェイ
- キャッシュ型ボリュームゲートウェイ
VPC エンドポイント
インターネットゲートウェイまたは仮想ゲートウェイを介さずに、インスタンスがプライベートIPを使用して、AWSサービスと接続することを可能にする仮想デバイス
- インターネットフェイスエンドポイント
- インターフェイスVPCエンドポイントはプライベートIPアドレスを持ったENIで、AWS PrivateLinkを使用するサービスあてのトラフィックのエントリポイントになります。
- ゲートウェイエンドポイント
- ルートテーブルでしていされたルートのターゲットであるゲートウェイ。このタイプのエンドポイントは、サポートされているAWSのサービス(S3やDynamoDBなど)へのトラフィックに使用される。
- デフォルトではIAMユーザーにはエンドポイントを使用するアクセス許可はない。IAMユーザーポリシーを作成して、エンドポイントを作成・変更・記述・削除するアクセス許可をユーザーに付与できます。 IAMポリシーを介してVPCエンドポイントへのアクセスを管理する
マルチアカウントのAWS環境
リソースと請求の分離
- 多くの場合、要素ごとに固有のアカウントを用意することで特定の分離を監査機関に証明することが容易になる
- 例えば開発アカウントがありそれが独立している場合、開発者は規制対象のグローバルアカウントにアクセスできないことを簡単に証明できます。
- 1つのアカウント内で分離をするには明確なポリシーの分離を証明できる必要がある
複数アカウントの請求戦略
- グループエイリアスに通知を送信
- アカウント全体でAWSタグ付け標準を使用
- AWS API およびスクリプトで会社のベースラインの設定を自動化
AWS Oraganizations
- 複数のAWSアカウントをポリシーベースで一元管理
- アカウント全体のポリシーを管理し、不要なアクセスをブロック
- APIを使用して新しいアカウントの作成お自動化
- アカウントを組織単位(OU)に編成する
- AWS一括請求(コンソリデーティッドビリング)
(執筆中 毎週更新)
- 投稿日:2020-01-19T14:57:51+09:00
AWSでDB(MySQL)を作成した後、A5:SQL Mk-2で接続して管理する方法
AWSでは、AWSを初めて使うという方向けに様々なチュートリアルを公式サイトで展開しており、そのチュートリアルに沿って進めていけば基本的なAWSサービスの操作や使用方法について理解することができます。
https://aws.amazon.com/jp/getting-started/tutorials/DB作成もチュートリアルが展開されており、簡単にDB作成・クライアントソフトからの接続ができるのですが、如何せんチュートリアルで紹介されているクライアントソフト「MySQL Workbench」が使いずらいのなんの。
(「MySQL Workbench」を使ったことがないからかもしれませんが。)しかも私のデスクトップPCではインストールしたのにも関わらず、なぜかプロセスが立ち上がらない事象に陥ってしまったのでこれはもうアカンと。
(おそらく「Visual C++ Redistributable for Visual Studio 2013」ランタイムがインストールされていないからと思われる。)なので、よくエンジニアの間で使用されているDB操作フリーソフト「A5:SQL Mk-2」でAWSに作成したDB(MySQL)にアクセスをする方法をご紹介したいと思います。
参考サイト
今回参考にしたサイトはこちらです。
https://a1-style.net/amazon-web-service/rds-mysql-a5-sql-mk2/(AWS)DB(MySQL)を作成
まずは、AWSでDB(MySQL)を作成していきます。
下記AWS公式サイトのDB作成チュートリアルのステップ1まで進めましょう。
ステップ2からは進めなくて大丈夫です。
https://aws.amazon.com/jp/getting-started/tutorials/create-mysql-db/(AWS)セキュリティグループを変更して管理PCからのアクセスを許可する
下記のデータベース管理画面に移動します。
移動後DB識別子のリンクをクリックします。
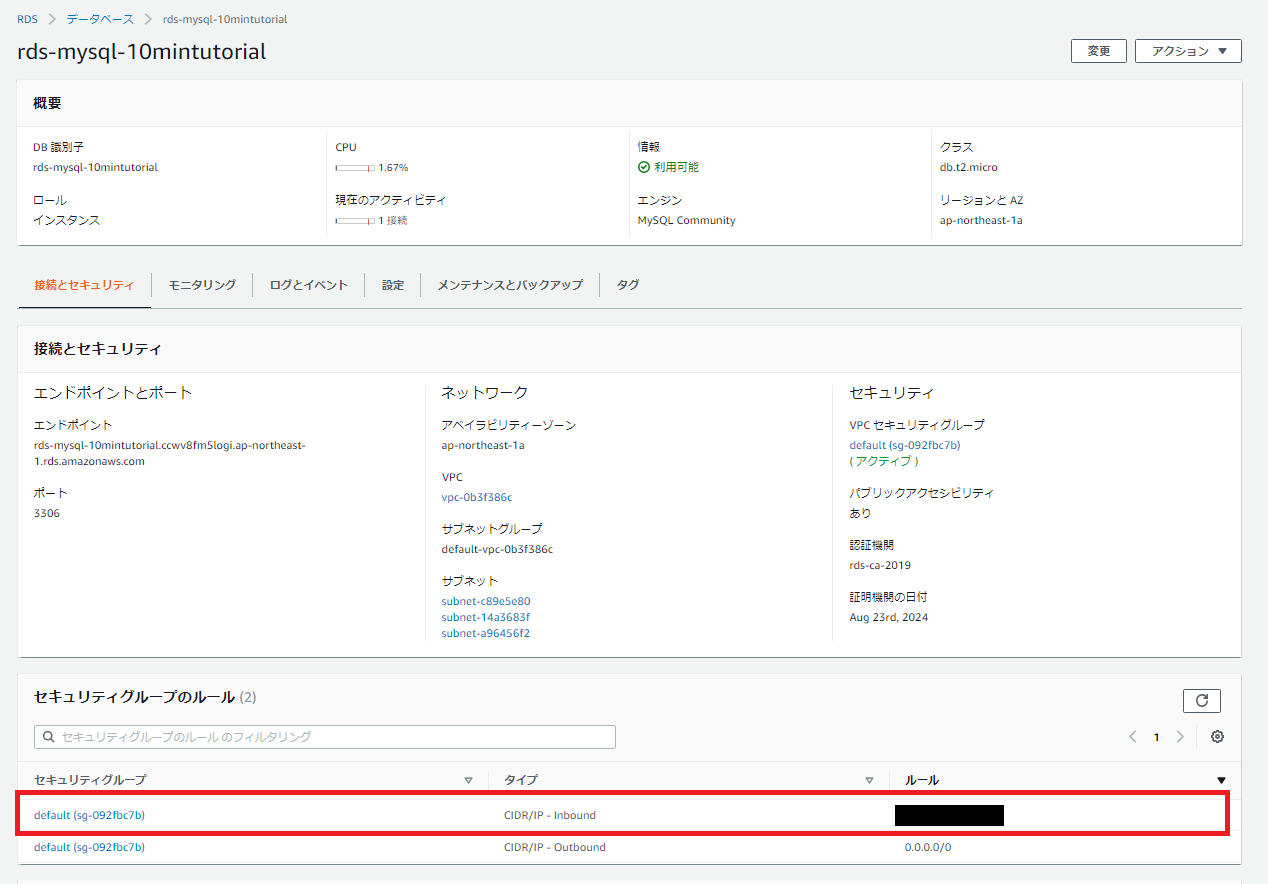
DBの概要や詳細情報が表示される画面になると思うので、画面中央のセキュリティグループのルールの欄を確認します。
恐らくセキュリティグループのルールとしてデフォルトで設定されている設定が2つ表示されていると思うので、上のセキュリティグループのリンクをクリックします。
セキュリティグループの設定画面に移動したら、画面下のインバウンドタブをクリックし編集ボタンをクリックします。
(下記画像はすでに設定をしている項目が表示されているため気にしなくて良いです。)
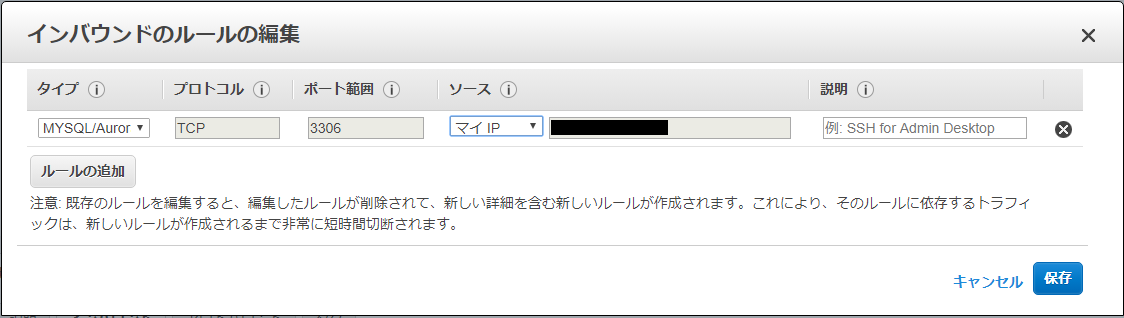
編集ボタンをクリックすると下記画面のポップアップが表示されるので、下記画像の項目通り「タイプ」「プロトコル」「ポート範囲」入力をしましょう。
ポート範囲はデフォルトでは「3306」です。変更をしている場合はこちらも変更する必要があります。また、ソースの欄はDB接続をしたいPCのIPアドレスを入力するのですが、プルダウンでマイIPを選択すると自動的にIPアドレスが入力されるため特に調べる必要はありません。
すべて入力したら右下の保存ボタンをクリックして完了です。
これでAWSに作成したDBに外部(管理PC)からアクセスすることができるようになりました。
A5:SQL Mk-2で作成したDB(MySQL)と接続をする
A5:SQL Mk-2のダウンロードについて
A5:SQL Mk-2は下記URLからダウンロードすることができます。
https://a5m2.mmatsubara.com/DB接続方法
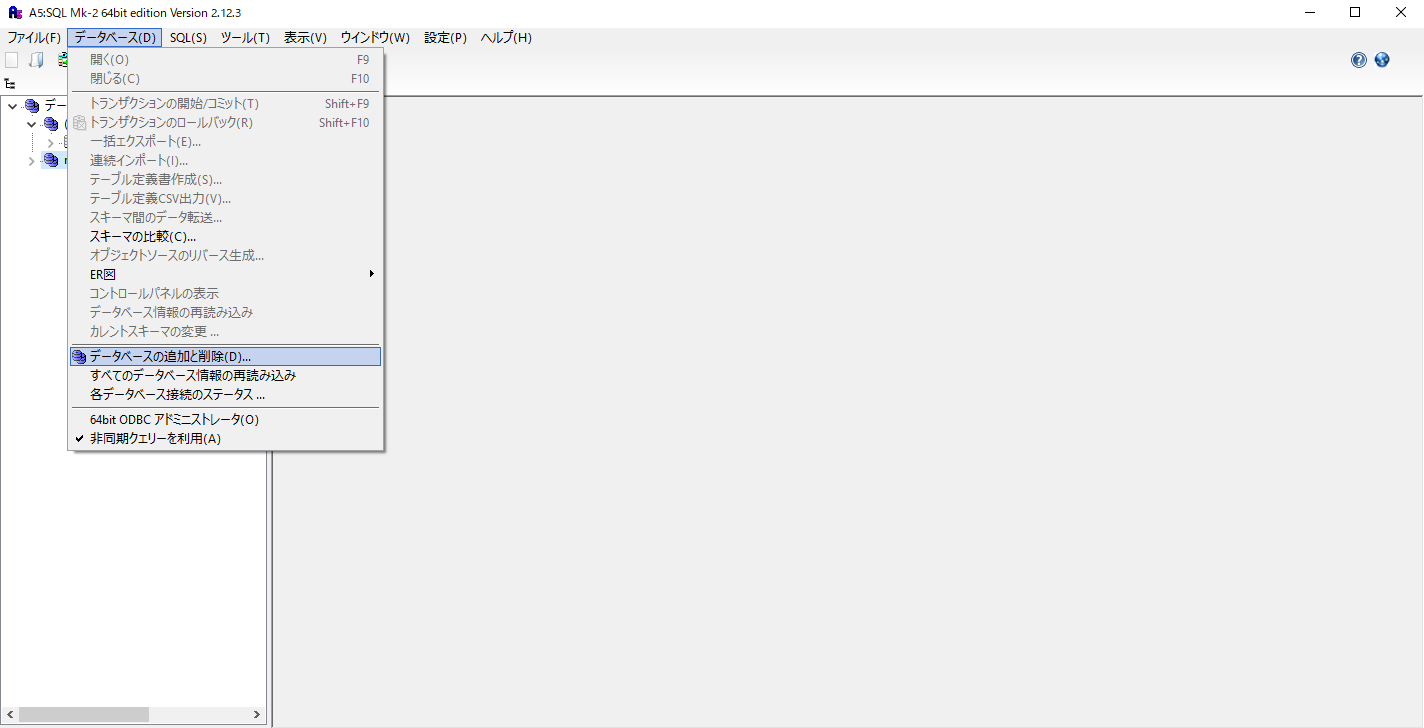
ダウンロードしたA5:SQL Mk-2を開き、上部メニューからデータベース>データベースの追加・削除を選択します。
表示したウィンドウの下部にある追加をクリックします。
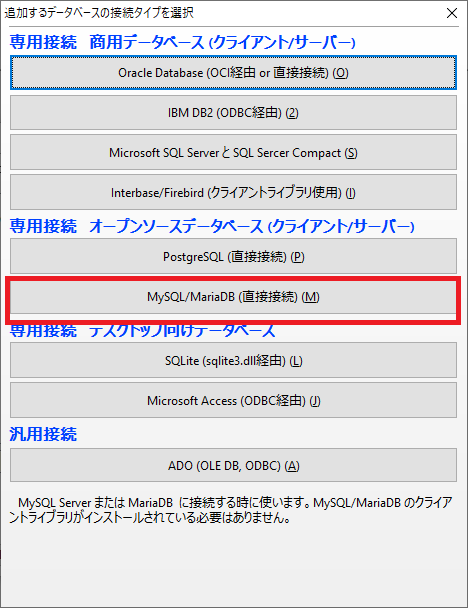
下記赤枠の部分「MySQL/MariaDB(直接接続)」を選択します。
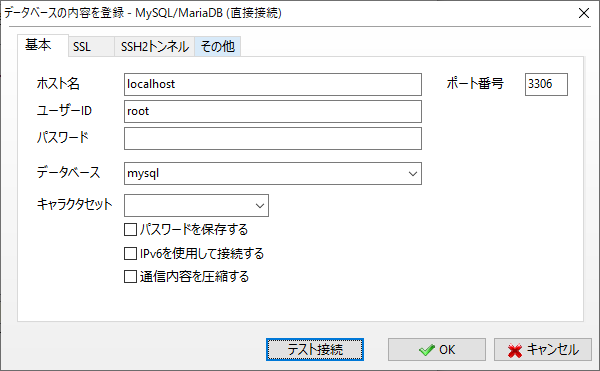
下記画面が表示されるので、データベースの情報を入力していきます。
入力後、OKをクリックします。
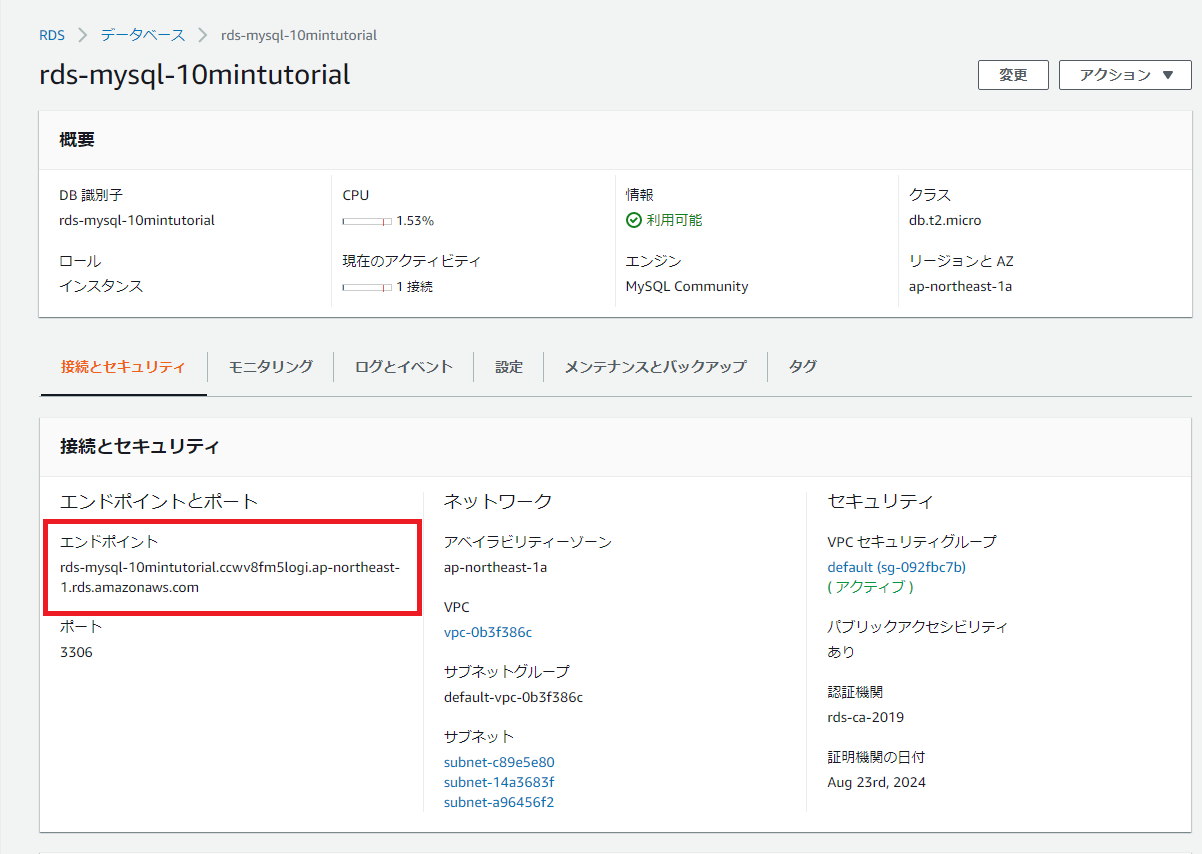
ホスト名:エンドポイント名(※)
ユーザーID:masterUsername
(AWSのチュートリアルを進めているとmasterUsernameで作られているかと思います。別のユーザーIDで作成している場合はそのユーザーIDを入力する)
パスワード:DB作成時のパスワード
※ホスト名に入力するエンドポイント名は下記画像の左側に表示されているエンドポイント名を入力します。
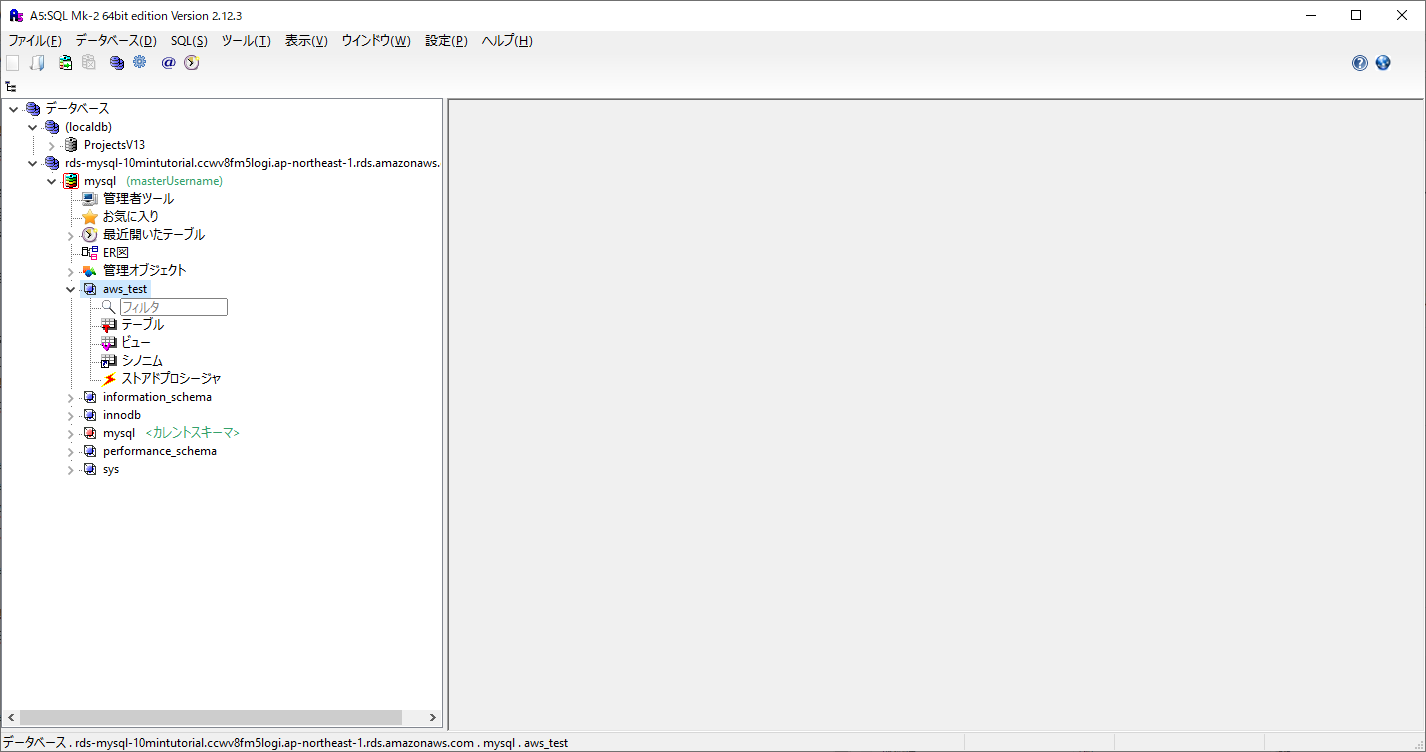
接続が問題なく完了すると、A5:SQL Mk-2の左側の枠に接続したDBの情報が表示されます。
ちなみに今回は、データベース名を「aws_test」で作成しているため、aws_testというデータベースが作成されていることがわかります。(データベースのみのため、テーブルなどの情報はもちろん追加されていません。)
これで、A5:SQL Mk-2でAWSのDB(MySQL)に接続することができました。
最後に
AWSでデータベースを作成するとこんなにも簡単なんだと思うと同時に、かなりさらにシステム開発としてできる幅が広がった気がします。
今回は、セキュリティグループのインバウンド設定で固定PCのIPアドレスを設定しましたが、このような設定は開発環境などだけにとどめておき、本番環境でのDB設定では行わないようにしましょう。当たり前ですが。


- 投稿日:2020-01-19T14:50:03+09:00
【Rails】ActionMailer + AWS SES
はじめに
Rails アプリケーションからユーザーへメールを飛ばす方法としてAWS SESというサービスがあるので、こちらの使い方を説明させていただきます。
設定方法なので知っていればすぐにできるんですが、知らなければやり方を見つけるだけでかなり時間がかかってしまうと思います。
時間短縮の一助になれば嬉しいです。関連リンク
Gmailを用いたActionMailerの使い方についても下記に載せておくので、必要であれば参考にしてください。。
- Gmailを用いた ActionMailer の使い方
アプリケーション作成
以下の項目については、上記の"Gmailを用いた ActionMailer の使い方"と同様となるため、そちらをご参照ください。
- Mailer作成コマンド(rails g mailer ~)
- Mailer
- Controller
- View
ドメイン関連
下記リンク先をご参照ください。
- AWSだけで独自ドメインを取得して自分のWebページを公開するまで[画像で解説] 2018冬
- 【AWS】Amazon SES / Messaging・Route53を用いてドメインメールを送信する
IAMユーザーの作成
下記リンク先をご参照ください。
- AWS IAMユーザー作成方法
config / yaml設定
config/development.rb# ActionMailer Setting with AWS SES config.action_mailer.delivery_method = :smtp config.action_mailer.perform_caching = true config.action_mailer.default_url_options = { host: Rails.application.secrets.host } ActionMailer::Base.smtp_settings = { :address => Rails.application.secrets.address, :port => 587, :domain => Rails.application.secrets.domain, :authentication => :login, :user_name => Rails.application.secrets.access_key_id, :password => Rails.application.secrets.secret_access_key }config/production.rb# ActionMailer Setting with AWS SES config.action_mailer.delivery_method = :smtp config.action_mailer.perform_caching = true config.action_mailer.default_url_options = { host: Rails.application.secrets.host } ActionMailer::Base.smtp_settings = { :address => Rails.application.secrets.address, :port => 587, :domain => Rails.application.secrets.domain, :authentication => :login, :user_name => Rails.application.secrets.access_key_id, :password => Rails.application.secrets.secret_access_key }secret.ymldevelopment: host: ec2-*****.ap-northeast-1.compute.amazonaws.com # EC2インスタンス の パブリック DNS (IPv4) を入力する。 access_key_id: A******************A # 上記で取得した値 secret_access_key: B******************************************B # 上記で取得した値 address: email-smtp.us-east-1.amazonaws.com # 自身が仕様しているリージョン domain: c*****.com # 上記で取得した値 production: host: <%= ENV['AWS_HOST'] %> # ElasticBeanstalk を使う場合、環境変数へ入力する。 access_key_id: <%= ENV['AWS_ACCESS_KEY_ID'] %> # ElasticBeanstalk を使う場合、環境変数へ入力する。 secret_access_key: <%= ENV['AWS_SECRET_ACCESS_KEY'] %> # ElasticBeanstalk を使う場合、環境変数へ入力する。 address: <%= ENV['AWS_ADDRESS'] %> # ElasticBeanstalk を使う場合、環境変数へ入力する。 domain: <%= ENV['AWS_DOMAIN'] %> # ElasticBeanstalk を使う場合、環境変数へ入力する。まとめ
今回、ドメインを取得するところもAWSのサービスを使って説明をさせていただきましたが、ドメイン取得については他のサービスを使ったほうがコストが低いケースもありますので、あくまで一例とさせていただきます。
個人的には色々なサービスを使うよりもAWSでまとめて管理できるほうが管理コストも含めると安いのではないかなーと思ったりします。
お好きな方法で取り組んでいただけたらなと思います。参考
- Amazon SES SMTP 認証情報を取得する
- RailsのActionMailerからAmazon SESのSMTPでメールを送信する
- 投稿日:2020-01-19T14:49:39+09:00
Railsチュートリアル 第13章 ユーザーのマイクロポスト - 本番環境での画像アップロード
本番環境での画像アップロードに必要な技術
本番環境に画像をアップロードするためには、以下のような技術が必要となります。
- AWS IAMにおけるグループおよびユーザーの設定
- AWS S3バケットの新規作成およびアクセス権設定
- 本番環境に適用するRails設定の記述
- Herokuの環境変数設定
特に未経験の人にとっては、相応に高度で総合力が試されるパートではないかと思われます。
本番環境での画像アップロードに必要な設定
現在までに実装した画像アップローダーは、ローカルのファイルシステムに画像を保存するようになっているため、本番環境での使用には適していません。「ローカルのファイルシステムに画像を保存する」という動作は、
app/uploaders/picture_uploader.rb内の以下の記述に由来します。app/uploaders/picture_uploader.rb(抜粋)# Choose what kind of storage to use for this uploader: storage :file # storage :fog「本番環境では、ローカルのファイルシステムとは別のクラウドストレージに画像を保存する」という設定にしたい場合、以下のように、「本番環境では
foggemを使用する。それ以外ではローカルのファイルシステムに画像を保存する。」という記述を行います。class PictureUploader < CarrierWave::Uploader::Base # ...略 # Choose what kind of storage to use for this uploader: - storage :file - # storage :fog + if Rails.env.production? + storage :fog + else + storage :file + end # ...略 end
Rails.env.production?は、本番環境であればtrue、それ以外の環境(開発環境・テスト環境等)ではfalseを返します1。Amazon Web Servicesの設定
- マイクロポストの画像を保存するためのAWS S3バケットを新規に作成する
- AWSのリソースに対してプログラムによるアクセスが可能なユーザーを新規に作成する
- 当該ユーザーは、AWSマネジメントコンソールにはアクセスしない
- 別途当該S3バケットへのアクセス権を持つグループを割り当てる
- 上記ユーザーに割り当てるためのグループを新規に作成する
- 当該S3バケットへのフルアクセスを許可する
- S3バケットの新規作成・削除は明示的に拒否する
以上の条件を前提として、以下の情報を参考にして設定しました。
- 初めてのAWS (Amazon Web Service)
- AWSで請求アラートを設定する - Qiita
- 特定S3バケットに対してのみアクセスを許可したい – サーバーワークスエンジニアブログ
- エラー<Message>Access Denied</Message> 〜Rails + Carrierwave + HerokuでAWS S3に画像を保存〜 - Qiita
特に、一番下に書かれた情報については見落としがちかと思います。
なお、Secretキーの内容を閲覧できるのは、Accessキーの新規作成時のみです。Accessキーに対応するSecretキーがわからない場合は、Accessキーそのものを新規作成する必要があります。
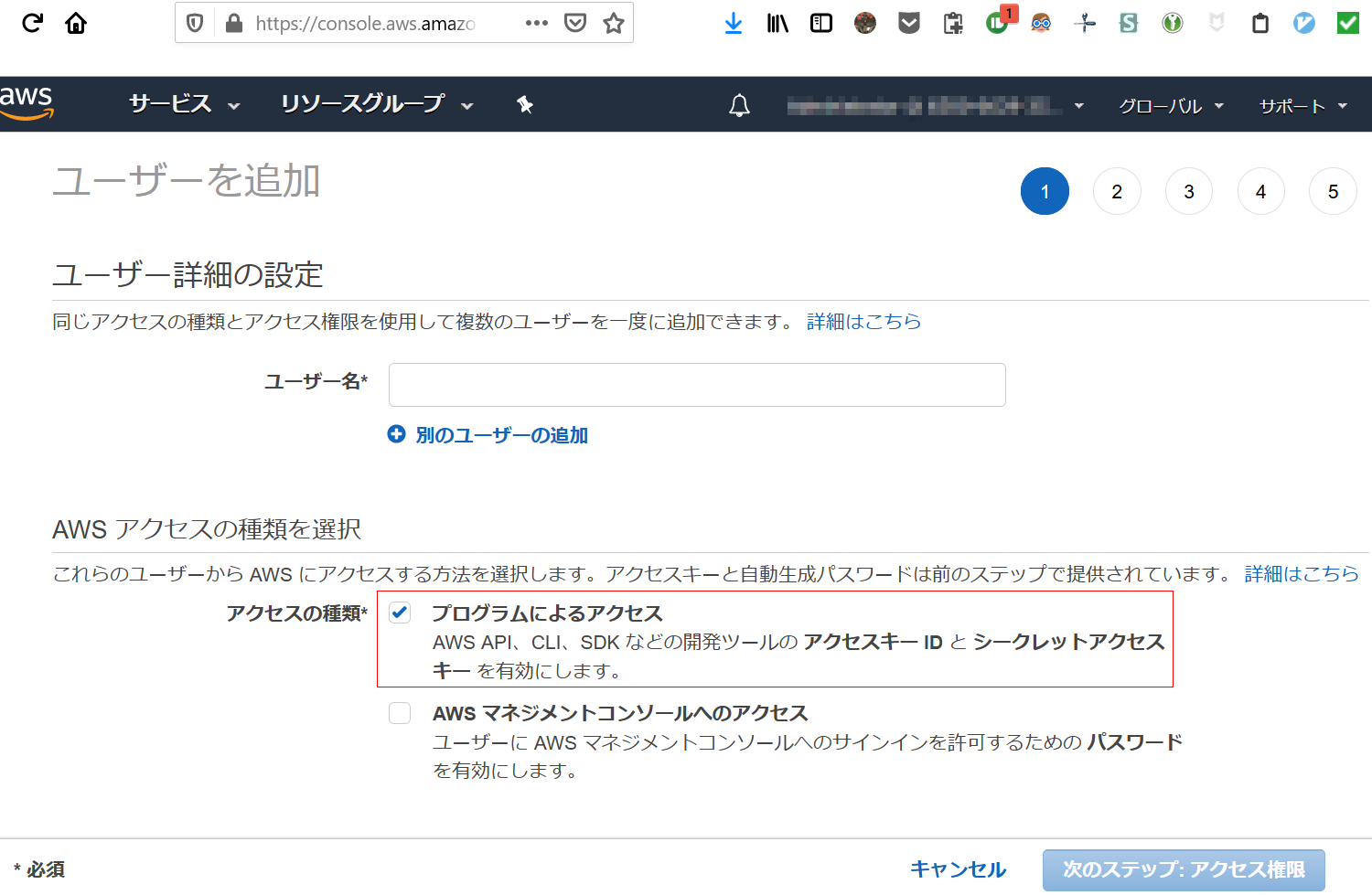
IAMにて「AWSマネジメントコンソールにはアクセスせず、プログラムによるアクセスのみを許可する」というユーザーを作成するには
GUIで行う場合、ユーザー作成の最初の画面で「プログラムによるアクセス」のみにチェックを入れます。「AWS マネジメントコンソールへのアクセス」にはチェックを入れません。
S3バケットへのパブリックアクセスを部分的に許可する
今回開発中のアプリケーションにおいて、S3バケットへの画像の保存を正常に行うには、以下2つの設定を行う必要があります。
- S3バケットの「アクセス権限 - ブロックパブリックアクセス (バケット設定)」の設定を変更する
- S3バケットの「アクセス権限 - バケットポリシー」の設定を変更する
S3バケットの「アクセス権限 - ブロックパブリックアクセス (バケット設定)」の設定を変更する
- 「新規のパブリックバケットポリシーまたはアクセスポイントポリシーを介して付与されたバケットとオブジェクトへのパブリックアクセスをブロックする」のチェックボックスは「オン」
- 上記以外のチェックボックスはオフ
S3バケットの「アクセス権限 - バケットポリシー」の設定を変更する
「アクセス権限 - バケットポリシー」のJSONエディタに、以下のJSONを入力していきます。
{ "Version": "2012-10-17", "Statement": [ { "Sid": "statement1", "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::[12桁のアカウントID]:user/[今回作成したユーザー名]" }, "Action": "*", "Resource": "arn:aws:s3:::[バケット名]/*" } ] }CarrierWaveを通してS3を使うようにする
S3アカウントの作成と設定が終わったら、CarrierWaveに与える追加の設定を記述していきます。その内容は以下のようになります。
config/initializers/carrier_wave.rbif Rails.env.production? CarrierWave.configure do |config| config.fog_credentials = { # Amazon S3用の設定 :provider => 'AWS', :region => ENV['S3_REGION'], :aws_access_key_id => ENV['S3_ACCESS_KEY'], :aws_secret_access_key => ENV['S3_SECRET_KEY'] } config.fog_directory = ENV['S3_BUCKET'] end endポイントは以下です。
- S3バケットへのアクセスに必要な情報は、Herokuの環境変数によって与えるようにしている
- 「機密情報はソースコードにベタ書きしてはいけない」というのは大原則である
- Herokuの環境変数は、手動で設定する必要がある
CarrierWave.configureの用法は、以前の演習で作成したconfig/initializers/skip_image_resizing.rbと同様である
- 対象環境はtestではなくproduction
config.fog_credentialsの設定内容は「ハッシュの配列」として与えるなお、「GitHubのパブリックリポジトリにAWSのアクセスキーをアップロードしてしまった場合に何が起こるか」については、以下のようなリソースに詳しく書かれています。本当に怖いですね。
- AWSで不正利用され80000ドルの請求が来た話 - Qiita
- 初心者がAWSでミスって不正利用されて$6,000請求、泣きそうになったお話。 - Qiita
- GitHub に AWS キーペアを上げると抜かれるってほんと???試してみよー! - Qiita
- 「GitHubのパブリックリポジトリにAWSのアクセスキーをアップロードしたら抜かれるのか」という実験。結果は「抜かれるまでの時間はわずか13分だった」というものであったそうです。
Herokuの環境変数に、S3バケットにアクセスするために必要な情報を追加する
Herokuの環境変数を設定するコマンドは、
heroku config:setとなります。以下のように使用します。heroku config:set [環境変数名]="[値]"S3バケットにアクセスするために必要な情報のうち、セキュリティ確保の観点からソースコードに記述しない項目は以下の4つです。これらをHerokuの環境変数として与える必要があります。
- S3バケットのAccessキー
- S3バケットのSecretキー
- S3バケットのID
- S3バケットが属するリージョンのコード
- 東京リージョンであればap-northeast-1となります
>>> heroku config:set S3_ACCESS_KEY="Accessキー" >>> heroku config:set S3_SECRET_KEY="Secretキー" >>> heroku config:set S3_BUCKET="バケットID" >>> heroku config:set S3_REGION="リージョン"画像を保存するディレクトリを、Gitによる管理対象から除外する
画像をはじめとするバイナリファイルは、一般に、Gitほかバージョン管理システムによるバージョン管理の対象とはなりません。そのため、バイナリファイルを保存するディレクトリは、バージョン管理の対象から除外する必要があります。
「Git管理下にあるディレクトリに格納されている特定リソースのみを、Gitによる管理対象から除外したい」という場合、一般に、「当該リソースについて、Gitリポジトリのルートディレクトリからのパスを
.gitignoreファイルに記述する」という方法により実現できます。画像を保存するディレクトリは、Gitリポジトリのルートディレクトリを
/とすると、/public/uploadsとなります。結果、
.gitignoreに追加する内容は以下のようになります。.gitignore# See https://help.github.com/articles/ignoring-files for more about ignoring files. # # If you find yourself ignoring temporary files generated by your text editor # or operating system, you probably want to add a global ignore instead: # git config --global core.excludesfile '~/.gitignore_global' # ...略 + + # Ignore updated images + /public/uploadsここまでの変更をHerokuにデプロイする
ソースコードに対する変更は、当然ながらデプロイしなければHeroku(に限らず本番環境全般)に反映されません。
masterブランチの変更内容をHerokuにプッシュする
まずは、masterブランチの内容をHerokuにpushしていきます。
>>> git push herokumasterブランチの内容をHerokuにpushすると、裏で自動的にBundlerが動きます。
pgやfog、ならびにそれらが必要とするgemが次々にインストールされる様子がコンソール出力からも見て取れます。データベースをリセットする
続いて、Heroku上のRDBの内容を一度完全にリセットします。
>>> heroku pg:reset DATABASEなお、この操作を行うにあたっては、追加の確認が求められます。「データベースのリセット」というのは、影響範囲が極めて大きい破壊的変更であるためです。
>>> heroku pg:reset DATABASE ▸ WARNING: Destructive action ▸ postgresql-cylindrical-32893 will lose all of its data ▸ ▸ To proceed, type [アプリ名] or re-run this command with --confirm [アプリ名] > [アプリ名] Resetting postgresql-cylindrical-32893... doneデータベースの構造と内容の再構築
まずはデータベースの構造の再構築からです。Herokuにおけるデータベースの構造の再構築は、
heroku run rails db:migrateコマンドで行います。>>> heroku run rails db:migrate Running rails db:migrate on ⬢ [アプリ名]... up, run.8443 (Free) ...略 == 20190928080951 CreateUsers: migrating ====================================== == 20190928080951 CreateUsers: migrated (0.0093s) ============================= == 20191010034159 AddIndexToUsersEmail: migrating ============================= == 20191010034159 AddIndexToUsersEmail: migrated (0.0070s) ==================== == 20191013040411 AddPasswordDigestToUsers: migrating ========================= == 20191013040411 AddPasswordDigestToUsers: migrated (0.0024s) ================ == 20191104221611 AddRememberDigestToUsers: migrating ========================= == 20191104221611 AddRememberDigestToUsers: migrated (0.0028s) ================ == 20191128032931 AddAdminToUsers: migrating ================================== == 20191128032931 AddAdminToUsers: migrated (0.0099s) ========================= == 20191202093532 AddActivationToUsers: migrating ============================= == 20191202093532 AddActivationToUsers: migrated (0.0089s) ==================== == 20191211225559 AddResetToUsers: migrating ================================== == 20191211225559 AddResetToUsers: migrated (0.0048s) ========================= == 20191218224953 CreateMicroposts: migrating ================================= == 20191218224953 CreateMicroposts: migrated (0.0330s) ======================== == 20200105225338 AddPictureToMicroposts: migrated (0.0019s) ================== ...略マイグレーションの進捗に、サンプルアプリケーションに積み上げてきた機能とその実装履歴が見えます。積み上げてきたものの歴史を感じられていいですよね。
続いてはデータベースの内容の再構築です。こちらは
heroku run rails db:seedコマンドで行います。AWSの設定情報が正しく与えられていれば、画像つきのマイクロポストを正常に投稿できます。その際、Herokuのログには以下のような記録が残ります。
2020-01-18T13:31:34.647241+00:00 app[web.1]: I, [2020-01-18T13:31:34.647131 #4] INFO -- : [5d55adcb-c098-456a-8352-89e9afd326a6] Started POST "/microposts" for 1.33.232.123 at 2020-01-18 13:31:34 +0000 2020-01-18T13:31:34.648257+00:00 app[web.1]: I, [2020-01-18T13:31:34.648156 #4] INFO -- : [5d55adcb-c098-456a-8352-89e9afd326a6] Processing by MicropostsController#create as HTML 2020-01-18T13:31:34.648445+00:00 app[web.1]: I, [2020-01-18T13:31:34.648361 #4] INFO -- : [5d55adcb-c098-456a-8352-89e9afd326a6] Parameters: {"utf8"=>"✓", "authenticity_token"=>"MILJ4TEbgpIItHsVQbg+f09zcrOzVHCT8rTACTQesXuw/smIusnvBoM9eP3LgfNFC8nK3X72awHdZPIwpYhM5A==", "micropost"=>{"content"=>"LGTM!", "picture"=>#<ActionDispatch::Http::UploadedFile:0x00007f94603397e8 @tempfile=#<Tempfile:/tmp/RackMultipart20200118-4-jt3qxq.png>, @original_filename="lgtm3.png", @content_type="image/png", @headers="Content-Disposition: form-data; name=\"micropost[picture]\"; filename=\"lgtm3.png\"\r\nContent-Type: image/png\r\n">}, "commit"=>"Post"} 2020-01-18T13:31:34.652670+00:00 app[web.1]: D, [2020-01-18T13:31:34.652572 #4] DEBUG -- : [5d55adcb-c098-456a-8352-89e9afd326a6] User Load (1.9ms) SELECT "users".* FROM "users" WHERE "users"."id" = $1 LIMIT $2 [["id", 1], ["LIMIT", 1]] 2020-01-18T13:31:35.092221+00:00 app[web.1]: D, [2020-01-18T13:31:35.092040 #4] DEBUG -- : [5d55adcb-c098-456a-8352-89e9afd326a6] (11.6ms) BEGIN 2020-01-18T13:31:35.095644+00:00 app[web.1]: D, [2020-01-18T13:31:35.095539 #4] DEBUG -- : [5d55adcb-c098-456a-8352-89e9afd326a6] SQL (1.2ms) INSERT INTO "microposts" ("content", "user_id", "created_at", "updated_at", "picture") VALUES ($1, $2, $3, $4, $5) RETURNING "id" [["content", "LGTM!"], ["user_id", 1], ["created_at", "2020-01-18 13:31:35.093179"], ["updated_at", "2020-01-18 13:31:35.093179"], ["picture", "lgtm3.png"]] 2020-01-18T13:31:36.478723+00:00 heroku[router]: at=info method=POST path="/microposts" host=warm-woodland-62915.herokuapp.com request_id=5d55adcb-c098-456a-8352-89e9afd326a6 fwd="1.33.232.123" dyno=web.1 connect=0ms service=3010ms status=302 bytes=1017 protocol=https 2020-01-18T13:31:36.473495+00:00 app[web.1]: D, [2020-01-18T13:31:36.473384 #4] DEBUG -- : [5d55adcb-c098-456a-8352-89e9afd326a6] (1.7ms) COMMIT 2020-01-18T13:31:36.474219+00:00 app[web.1]: I, [2020-01-18T13:31:36.473995 #4] INFO -- : [5d55adcb-c098-456a-8352-89e9afd326a6] Redirected to https://warm-woodland-62915.herokuapp.com/ 2020-01-18T13:31:36.474222+00:00 app[web.1]: I, [2020-01-18T13:31:36.474157 #4] INFO -- : [5d55adcb-c098-456a-8352-89e9afd326a6] Completed 302 Found in 1826ms (ActiveRecord: 16.4ms)AWS S3を使っているからといって、Heroku側のログには特段変わった内容のログが記録されるわけではないといえそうです。
「テスト環境では
true、それ以外の環境ではfalseを返す」という動作をするRails.env.test?は、Railsチュートリアルの第13章中、「演習 - 画像のリサイズ」で用いましたね。 ↩

- 投稿日:2020-01-19T14:16:47+09:00
SSMパラメータストアを読み書きするCLIを作ってみた
秘密鍵の管理にAWS Systems Manager(SSM)のパラメータストアを使うことが増えたため、以前から欲しいと思っていたCLIを作ってみました。(Go言語で実装)
概要
- SSM Vaultの紹介
- Dockerコンテナから秘密鍵を参照する
- aws-vaultのメタデータ経由でAWSアクセスキーを手に入れる
- Terraformでパラメータをコード管理する
SSM Vault
SSM Vaultはパラメータストアを手軽に読み書きするためのコマンドで、次のような機能があります。
# 秘密鍵に名前をつけて保存(SecureString) $ ssm-vault write /app/dev/DB_PASSWORD Enter secret: ******** # 任意のテキストを暗号化せずに保存(String) $ ssm-vault write /app/dev/DB_USERNAME -s Enter text: dbuser # 登録済みのパラメータをツリー表示する $ ssm-vault tree . └── /app/ └── dev/ ├── DB_PASSWORD? (alias/aws/ssm) └── DB_USERNAME # 保存してある秘密鍵をクリップボードに読み込み $ ssm-vault c /app/dev/DB_PASSWORD Copied to clipboard: /app/dev/DB_PASSWORD # ファイルを暗号化して保存 $ ssm-vault write /app/dev/private_key < pkey.pem # 保存してある秘密鍵をファイルに出力 $ ssm-vault read /app/dev/private_key -o pkey.pem -m 0600Dockerもよく使うので、コンテナの中から秘密鍵を参照するときに使える便利機能も追加しています。一つはテンプレートへのパラメータの埋め込み。
# テンプレートを展開してファイルに出力 $ ssm-vault render -o ~/.my.cnf <<EOT [client] user={{aws_ssm_parameter "/app/dev/DB_USERNAME"}} password={{aws_ssm_parameter "/app/dev/DB_PASSWORD"}} EOT $ cat ~/.my.cnf [client] user=dbuser password=MY-SUPER-SECRETそれから、パラメータを環境変数に読み込んで任意のコマンドを実行可能です。
# パラメータの値を環境変数にセットしてコマンド実行 $ ssm-vault exec -p /app/dev -- env | grep DB_ DB_PASSWORD=MY-SUPER-SECRET DB_USERNAME=dbuserDockerコンテナからの秘密鍵の参照
上記のコマンドを使って、Dockerコンテナからパラメータの値を参照できるようにします。もちろんアプリケーションからAWS SDKで直接パラメータを読んでもいいのですが、環境変数を参照したり、設定ファイルを読み込んだりしたいときも多いでしょう。
コンテナの起動にはdocker-composeを使うケースを考えます。まずは単純に環境変数でパラメータを受け渡します。
docker-compose.ymlの中では設定したい環境変数名を列挙しておきます。次の例では、PostgreSQLの初期ユーザーを環境変数で指定しています。version: '3' services: db: image: postgres:latest environment: - POSTGRES_USER - POSTGRES_PASSWORD - POSTGRES_DB環境変数にセットしたい値をパラメータとして登録します。環境変数の名前はパラメータ名を大文字にして自動生成されます。
$ ssm-vault write /app/dev/postgres/user -s Enter text: dbuser $ ssm-vault write /app/dev/postgres/password Enter secret: ******** $ ssm-vault write /app/dev/postgres/db -s Enter text: app # 環境変数を確認 $ ssm-vault exec -p /app/dev -- env | grep POSTGRES POSTGRES_DB=app POSTGRES_PASSWORD=MY-SUPER-SECRET POSTGRES_USER=dbuserあとは
aws-vault exec経由でコンテナを起動すればOKです。# 環境変数をセットしてDockerコンテナを起動 $ ssm-vault exec -p /app/dev -- docker-compose up dbssm-vaultをコンテナに埋め込む
毎回コマンドを打ち込むのも面倒なので、コンテナの中にssm-vaultを埋め込みます。先ほどと同じパラメータをアプリサーバーから読み込みましょう。例えば、次のような
docker-compose.ymlとDockerfileでコンテナを作成します。# docker-compose.yml app: build: . environment: - AWS_REGION=ap-northeast-1 - POSTGRES_USER - POSTGRES_PASSWORD - POSTGRES_DB - POSTGRES_HOST=db# Dockerfile FROM python:3.7 # ssm-vaultをインストール ENV SSM_VAULT_VERSION v1.0.0 ENV SSM_VAULT_CHECKSUM 1f8cc1479cb5e2688eca81de4ba1ee99e4bc08a1c753b38b648a5a3bbbf4c474 RUN wget -O /usr/local/bin/ssm-vault https://github.com/k24d/ssm-vault/releases/download/$SSM_VAULT_VERSION/ssm-vault-linux-amd64 RUN echo "$SSM_VAULT_CHECKSUM /usr/local/bin/ssm-vault" | sha256sum -c && chmod 755 /usr/local/bin/ssm-vault # ssm-vaultを経由してコマンドを実行する ENTRYPOINT ["/usr/local/bin/ssm-vault", "exec", "-p", "/app/dev", "--"] CMD ["bash"]コンテナを起動すると、最初から環境変数がセットされていることがわかります。
# コンテナをビルド $ docker-compose build # コンテナを起動 $ docker-compose run app # ssm-vaultによって環境変数がセットされている root@e76999aa0d95:/app# env | grep POSTGRES POSTGRES_HOST=db POSTGRES_PASSWORD=my-secret-password POSTGRES_USER=dbuser POSTGRES_DB=app設定ファイルへのパラメータ埋め込み
実際には、コンテナの起動はもっと複雑な手順を踏むことも多いので、筆者はよくコンテナの中で起動スクリプトを実行します。アプリケーションに設定ファイルがある場合には、スクリプトの中で
ssm-vault renderで秘密鍵を埋め込みます。# Dockerfile # 起動スクリプトをコピー COPY ./run.sh /app/run.sh # スクリプトを実行する CMD ["/app/run.sh"]#!/bin/bash # 環境ごとのパラメータのパス PARAMETER_PATH="/app/${APP_ENV:-dev}" # 設定ファイルにパラメータの値を埋め込む /usr/local/bin/ssm-vault render /app/config.template -p $PARAMETER_PATH -o /app/config.py # 秘密鍵をファイルに書き出す /usr/local/bin/ssm-vault read $PARAMETER_PATH/private_key -o /app/pkey.pem # 環境変数をセットしてアプリケーション起動 export FLASK_APP=/app/app.py exec /usr/local/bin/ssm-vault exec -p $PARAMETER_PATH -- flask runaws-vaultによるAWSアクセスキー管理
パラメータストアにアクセスするにはAWSのアクセスキーが必要です。開発中のDockerコンテナからAWSにアクセスするにはaws-vaultを使うと便利です。
aws-vaultはユーザーの
~/.aws/configを読み込んで、指定したプロファイルでSTSトークンを作成して環境変数をセットしてくれます。サーバーモードで起動すると、EC2などで使えるのと同じインスタンスメタデータが使えるようになり、Dockerコンテナの中からでも自動的にアクセスキーが入手できるようになります。# ~/.aws/config [profile dev] region=ap-northeast-1 role_arn=arn:aws:iam::<ACCOUNT-ID>:role/dev source_profile=default# メタデータサーバーを起動 $ aws-vault exec dev --server筆者はいつも開発中は、開発用のプロファイルを指定してメタデータサーバーを一つ起動しています。そうするとホスト上でもコンテナの中からでも同じように指定したロールでAWSのAPIが呼び出せるようになります。
Terraformによるパラメータのコード管理
パラメータをCLIで登録してしまうと、次第に数が増えてきたときに、どのパラメータが今も有効なのかわからなくなってきます。ソースコードに秘密鍵を書くのは避けるにしても、パラメータの存在そのものはコード管理できることが望ましいでしょう。
パラメータの値は開発環境か本番環境かによっても異なるので、アプリケーションというよりはインフラ構成管理の一部として捉えます。いわゆる「Infrastructure as Code(IaC)」の思想に基づいて、秘密鍵をどのように扱うのか一貫したツールで状態管理します。
利用するIaCツールは何でもいいのですが、筆者は今のところTerraformを利用しています。例えば、データベースのユーザー名とパスワードをパラメータに保存しつつ、RDSのインスタンスを立ち上げるなら次のようなコードになります。ここでは16文字のパスワードを自動生成しています。
# ユーザー名(dbuser)をパラメータ登録する(暗号化なし) resource "aws_ssm_parameter" "db_username" { name = "/org/repo/dev/DB_USERNAME" value = "dbuser" type = "String" } # 16文字のパスワードを自動生成 resource "random_password" "db_password" { length = 16 special = true override_special = "_%@" } # 生成したパスワードをパラメータ登録する(暗号化あり) resource "aws_ssm_parameter" "db_password" { name = "/org/repo/dev/DB_PASSWORD" value = random_password.db_password.result type = "SecureString" } # パラメータの値を用いてインスタンスを作成 resource "aws_db_instance" "db" { instance_class = "db.t3.micro" ... username = aws_ssm_parameter.db_username.value password = aws_ssm_parameter.db_password.value }保存済みのパラメータを読み込む
上記のようにランダムなパスワードを生成するのではなく、外部サービスからAPIキーなどの秘密鍵を受け取ることも多いでしょう。そのような秘密鍵は直接コードに書くのではなく、ssm-vaultで別途パラメータストアに保存してから、それをTerraformで読み出すようにします。次のようになります。
# 保存済みのパスワードをパラメータストアから読み込む data "aws_ssm_parameter" "db_password" { name = "/org/repo/dev/DB_PASSWORD" } # パラメータの値を用いてインスタンスを作成 resource "aws_db_instance" "example" { instance_class = "db.t3.micro" ... username = aws_ssm_parameter.db_username.value password = data.aws_ssm_parameter.db_password.value }利用するIaCツールによっては、秘密鍵を暗号化してリポジトリに保存できるものもありますが、そうすると暗号化の鍵をどうするといった問題が発生するため、結局はサーバー側に鍵を集約する方向に落ち着きました。Terraformでは鍵の名前だけを管理します。
AWSのアクセスキーはいれずれにせよ各エンジニアが保有するので、アクセスキーさえ適切に保護できていれば、それ以外の鍵は必要な人が必要なときに取ってこれる状態にします。
IDと秘密鍵をセットで記録する
秘密鍵は公開鍵(IDなど)とペアで作られることがよくあります。AWSであれば、アクセスキーIDとシークレットアクセスキーがペアになります。データベースならユーザー名とパスワードがペアになります。
新しく鍵を発行したときには、簡単なコメントを添えて、次のような形でTerraformに登録します。
# XXXサービスのクライアントIDと秘密鍵。次のページから作成。 # https://console.service.example/... resource "aws_ssm_parameter" "service_client_id" { name = "/org/repo/dev/service/client_id" value = "1234..." type = "String" } data "aws_ssm_parameter" "service_client_secret" { name = "/org/repo/dev/service/client_secret" }このうち公開鍵(ID)の方はssm-vaultは使わずに、Terraformのファイルに値をベタ書きしておきます。そうすると後からIDを検索しやすくなります。仮にIDが存在しない場合にでも、秘密鍵を登録したときには必ずTerraformにも記録することを習慣にしておくと、履歴を見て誰がどのような目的で鍵を作成したのか把握しやすくなるでしょう。
この方法だと秘密鍵を変更した履歴をGitで管理することは出来ませんが、パラメータストアでは過去の値はバージョン付きで保存されているため、仮に古い値が必要になっても取り出すことは可能です。
パラメータの命名規則
パラメータの名前に決まったルールはありませんが、自分は次のような形式にしています。
名前の先頭部分はGitHubのリポジトリ名に合わせます。つまり、組織の名前(またはユーザー名)で始まり、リポジトリの名前がそれに続きます。そうするとパラメータの管理に責任を持つリポジトリが明確になり、リポジトリを使ってパラメータのライフサイクルを追跡しやすくなります。パラメータの値は開発環境や本番環境によっても異なるので、環境の名前もパラメータ名に含めます。Terraformによる構成管理も環境ごとにディレクトリを分けて、環境別の設定はそこに集めています。
セキュリティ上の考察
セキュリティ上の懸念点をいくつかまとめておきます。
環境変数に秘密鍵を入れるのは危険?
Twelve-factor Appなどの影響で、アプリケーションの設定に環境変数を使うことが多くなり、パスワードなども環境変数にセットすることが増えています。それに対して「秘密鍵は環境変数に入れるべきではない」という批判をよく見かけます。(例:Environment Variables Considered Harmful for Your Secrets - Hacker News)
ポイントとしては次の二つが大きいでしょうか。
- 環境変数の内容は他のプロセスから簡単に見ることができる
- 環境変数の内容は予期せず書き出されてしまうことがある
1つ目については、例えばmacOSなら
ps ewwコマンドで環境変数が丸見えになります。Dockerであればdocker inspectするとコンテナ起動時の環境変数がわかります。環境変数を使わずに、ローカルファイルに秘密鍵を書き出して所有者以外に読めないようにしておけば、少なくともそのユーザー権限が乗っ取られない限りは読まれないので安全性が高まる、という意見です。これには反論もあり、システムに浸入された時点で環境変数だろうとローカルファイルだろうと危険なことには変わりないし、ファイルは間違ってgitに追加するといったトラブルもあるので、どちらも一長一短ありそうです。
2つ目のポイントの方が厄介で、ソフトウェアによってはエラー発生時に環境変数をすべてログに吐き出すものや、管理画面に環境変数を表示するようなものもあります。環境変数は親から子供のプロセスへと引き継がれ、どこで予期せぬ使われ方をするかもわからないので危険である、という意見です。
これは確かにその通りで、いい反論が思いつきません。環境変数はお手軽なので自分もよく使いますが、本番環境ではきちんと設定ファイルを生成した方がよさそうです。
Terraformのステートファイルには秘密鍵が保存される
Terraformではステートファイルにインフラの状態を書き込みますが、そのファイルには生パスワードがそのまま書き込まれるようになっています。
ステートファイルをS3などの外部ストレージに置くことで情報漏洩のリスクを減らせますが、いずれにせよ鍵が外部に書き出されることを念頭に置いてアクセス制限する必要があります。
実際にテストデータで検証したところ、秘密鍵のパスを
data "aws_ssm_parameter"として記述するだけで、それを使っていなくてもステートファイルには秘密鍵が書き出されることを確認しました。これでは無駄にリスクを増やすだけなので、秘密鍵のパスを書くのは最低限にするか、あるいはコメントやドキュメントとして記述するだけに留めておく方がいいかもしれません。有償版のTerraform Cloudだとステートファイルが暗号化されてアクセスコントールも出来るようなので、いずれ試してみようかと思っています。
IAMによるアクセスコントロール
パラメータストアのアクセスコントロールはIAMで設定し、CloudTrailに監査ログが残るようになっています。既にIAMやCloudTrailに慣れている人にとっては有難いですが、慣れるまでは大変かもしれません。
秘密鍵のアクセスコントロールは、パラメータのパスを指定して制限する以外にも、KMSの暗号化キーに対して制限を行う方法もあります。重要度の高い秘密鍵などは、その鍵を読み書きするためのロールを明確に分けて、専用のKMSキーで暗号化しておくといいかもしれません。

- 投稿日:2020-01-19T12:40:13+09:00
AWSの管理サービス
出展:AWS認定資格試験テキスト AWS認定 クラウドプラクティショナー
Cloud Watch
・標準メトリクスというAWSが管理している範囲の情報をユーザの追加設定なしで自動的に収集され始める
CloudWatchの特徴
標準(組み込み)メトリクスの収集、可視化
・AWSがコントロールできる範囲(たとえばEC2ではハイパーバイザーまで)の、AWSが提供している範囲で知り得る情報を標準メトリクスとして収集する
・ユーザのコントロール範囲のOS以上の情報については、AWSが勝手にモニタリングすることはない
・標準メトリクスとして収集された値は、マネージメントコンソールのメトリクス画面やダッシュボーでで可視化できるカスタムメトリクスの収集、可視化
・ユーザがコントロールしている範囲についてはCloudWatchのPutMetricDataAPIを使用してCloudatchへカスタムメトリクスとして書き込むことができる
・CloudWatchへメトリクスを書き込むプログラムはCloudWatchエージェントとして提供されているので、EC2へインストールするだけで使用できるログの収集
・CloudWatch Logsはログを収集する機能
・EC2のアプリケーションのログや、Lambdaのログ、VPS Flow Logsなどを収集することができる
・CloudWatchエージェントをインストールし設定することでCloudWatch Logsへ書き出せる
・ログの情報をEC2の外部に保管することで、EC2をよりステートレス(情報や状態を持たない構成)にできる
・CloudWatch Logsは文字列のフィルタリング結果をメトリクスとして扱えるアラーム
・CloudWatchでは、各サービスから収集したメトリクス値に対してアラームを設定することができる
・アラームに対してのアクション
・EC2回復:
・EC2のホストに障害が発生したときに自動で回復する
・Auto Scalingの実行:
・Auto Scalingポリシーでは、CloudWatchのアラームに基づいて、スケールイン/スケールアウトのアクションを実行する
・SNSへの通知:
・SNS(Amazon Simple Notification Service)へ通知することでそのメッセージをEメールで送信したり、Lamdbaへ渡すなどができる
・Eメールで送信することで、監視の仕組みを簡単に構築できる
・Lambdaにメッセージを渡して実行することで、アラームの次の処理を自動化することができる保存期間について
・メトリクス:
・60秒未満のデータポイント(高分解能力カスタムメトリクス)は3時間
・1分(詳細モニタリング)のデータポイントは15日間
・5分(標準)のデータポイントは63日間
・1時間のデータポイントは455日間
・この期間を超えたメトリクスは消去される
・これ以上の期間にわたってデータ分析などに使用する場合はS3に保存する
・CloudWatch Logs
・任意の保存期間を設定できる
・消去しないことも可能Trusted Advisor
・ユーザのAWSアカウント環境の状態を自動的にチェックして回り、ベストプラクティスに対してどうであったかを示すアドバイスをレポートする
コスト最適化
使用率の低いEC2インスタンス
・無駄なコストが発生していないかがチェックされる
・使っていないものは終了する、過剰なインスタンスは適切なサイズに変更するなどの対策でコストを最適化する
例)・使っていないのに起動中のインスタンス
・検証やテストで使って終了を忘れているインスタンス
・過剰に高いスペックのインスタンスリザーブドインスタンスの最適化
・リザーブドインスタンスを購入したほうがコスト最適化につながるかどうかをレポートする
・購入済みのリザーブドインスタンスについて、有効期限が切れる30日前からアラートの対象になるパフォーマンス
・最適なサービス、サイズが選択されているかがチェックされる
・主な項目
・使用率の高いEC2インスタンス:
・EC2に実装している処理に対してリソースが不足していないか
・対象の処理が最も早く完了するインスタンスタイプに変更することが推奨される
・セキュリティグループルールの増大:
・セキュリティグループのルールが多いとそれだけネットワークトラフィックが制御されることになる
・このアラートをきっかけに、ルールをまとめることができないか、対象のインスタンスにそれだけのポートを必要とする機能を多くインストールしていないか、インスタンスを分けることはできないかを検討する
・コンテンツ配信の最適化
・CloudFrontにキャッシュをン持つことで、S3から直接配信するよりもパフォーマンスが向上する
・キャッシュがどれだけ使われているかを示すヒット率についてもチェックされるセキュリティ
・環境にリスクのある設定がないかチェックされる
・主な項目
・S3バケットのアクセス許可:
・誰でもアクセスできるS3バケットがないかチェックする
・セキュリティグループの開かれたポート:
・リスクの高い特定のポートが、送信元無制限でアクセス許可されているセキュリティグループをピックアップする
・パブリックなスナップショット:
・EBSやRDSのスナップショットが意図せず誤って公開設定されていないか
・ルートアカウントのMFA、IAMの使用
・運用するための最低権限を設定したIAMユーザを作成して、ルートアカウントにもIAMユーザにもMFA(多要素認証)を設定するフォールトトレランス(耐障害性)
・低い耐障害性がないかチェックする
・主な項目
・EBSのスナップショット:
・EBSのスナップショットが作成されていない、または最後に作成されてから時間が経過したことがチェックされる
・EC2、ELBの最適化:
・複数のアベイラビリティゾーンでバランスよく配置されているかがチェックされる
・ELBではクロスゾーン負荷分散やConnecting Draining(セッション完了を待ってから切り離す機能)が無効になっているロードバランサーがないかもチェックされる
・RDBのマルチAZ:
・マルチAZになっていないデータベースインスタンスがチェックされるサービス制限
・意図しない操作や不正アクセスによってユーザに不利益が生じないよう、サービス制限がある(ソフトリミット)
・サービス制限では、制限に近づいたサービスにアラートが報告されるその他の管理ツール
AWS Cloud Trail
・AWSアカウント内のすべてのAPI呼び出しを記録する(AWSアカウント内におけるすべての操作を記録する)
AWS COnfig
・AWSリソースの変更を記録する
AWS CloudFormation
・AWSの各リソースを含めた環境を自動作成/更新/管理する
・同一のAWS環境を何度でも構築することができるElastic Beanstalk
・Webアプリケーションの環境をAWSに構築する
- 投稿日:2020-01-19T10:24:54+09:00
AWSのデータベースサービス
出展:AWS認定資格試験テキスト AWS認定 クラウドプラクティショナー
RDS
RDSの概要
・Amazon Relatinal Database Serviceの略
・オンプレミスで使われているデータベースエンジンをそのまま簡単に使うことができる
・使用できるデータベース
・Amazon Aurora
・MyAQL
・PostgreSQL
・MariaDB
・Oracle
・Microsoft SQL ServerRDSとEC2の違い
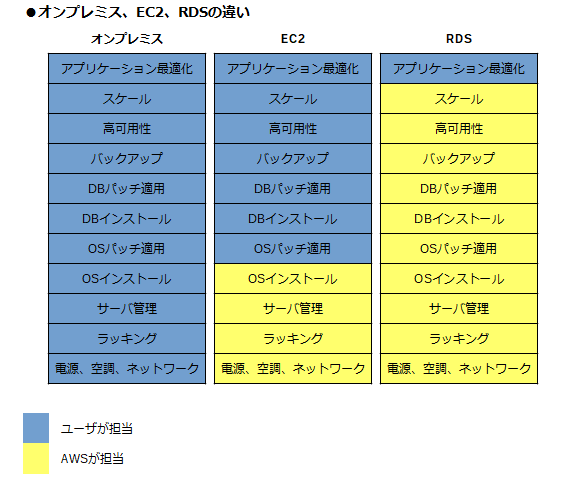
メンテナンス
・RDSではOS、データベースエンジンのメンテナンスをAWSに任せることができる
バックアップ
・RDSでは、デフォルトで7日間の自動バックアップが適用されている
・バックアップの期間は0~35日まで設定でき、指定した時間にバックアップデータが作成される
・35日を越えてバックアップデータを保持しておく必要がある場合は、手動のスナップショットを作成できる
・自動バックアップも手動スナップショットもRDSのスナップショットインターフェイスからアクセスできるが、実体はS3の機能を利用して保存される
・ポイントタイムリカバリー:
・自動バックアップを設定している期間内であれば、秒数まで指定して特定の時点のインスタンスを復元できる
・過去直近では5分前に戻すことができる
・トランザクションログが保存されていることで実現される
・RDSの起動が完了した時点で自動でトランザクションログの保存が開始される高可用性
・RDSのマルチAZ配置をオンにすると、アベイラビリティゾーンをまたいだレプリケーションが自動的に行われる
・レプリケーション、フェイルオーバーはRDSの機能によって自動的に行われるAmazon Auroraの概要
・MySQL/PostgreSQL互換の、クラウドに最適化されたリレーショナルデータベース
・バックアップが非常に強固
・スタンバイにアクセスできる(リードレプリカがマスター昇格する)
・リードレプリカは15個作成できる
・RDSMySQLに比べて5倍の性能
・ディスク容量を見込みで確保しなくても自動で増加するDMS
・Amazon Database Migration Serviceの略
・オンプレミスからAWS、AWSからAWSへデータベースの移行をする場合に使用する
・DMSによりオンプレミスからAWSへの継続的なデータ移行を行い、システムのダウンタイムを最小限にできるDynamoDB
DynamoDBの概要
・NoSQL型の高いパフォーマンスを持ったフルマネージド型のデータベースサービス
・リージョンを選択して使うことができる
・アベイラリティゾーンは意識しなくてもよい
・DynamoDBにテーブルを作って、そこにアイテムと呼ばれるデータを保存すると、自動的に複数のアベイラビリティゾーンの複数の施設で同期され保存される
・データ容量は無制限
・使用している容量のみが課金対象
・性能はユーザが決定するDynamoDBとRDSの違い
RDS
・垂直スケーリングによりスケールアップする
・基本的には1つのインスタンスで処理を行う
・厳密な処理をすることができるが、大量のアクセスには向かない
・SQL型のテーブル形式
・中規模程度のアクセス量で、整合性や複雑なクエリを必要とする場合に使用DynamoDB
・水平スケーリングが可能
・大量のアクセスがあってもパフォーマンスを保ったまま処理ができる
・トランザクションを必要とする処理や、複雑なクエリには向かない
・NoSQL型のデータ形式
・1つのデータはアイテムとして扱う
・大規模なアクセス量で、単純な自由度の高いデータモデルを扱う場合はDynamoDBを使用その他のデータベースサービス
・Amazon Redshift:
・高速でシンプルなデータウェアハウスサービス
・データ分析に使用
・Amazon ElastCashe:
・インメモリデータストアサービス
・オープンソースのRedis、Memcashedのマネージドサービスとして使用
・RDSやDynamoDBのクエリ結果のキャッシュに使用したり、アプリケーションのセッション情報を管理する用途で使われる
・Amazon Nopute
・フルマネージドなグラフデータベースサービス
・関係性や相関情報を扱う
・SNS、レコメンデーション(提案)エンジン、経路案内、物流最適化などのアプリケーション機能に使用される
- 投稿日:2020-01-19T10:06:21+09:00
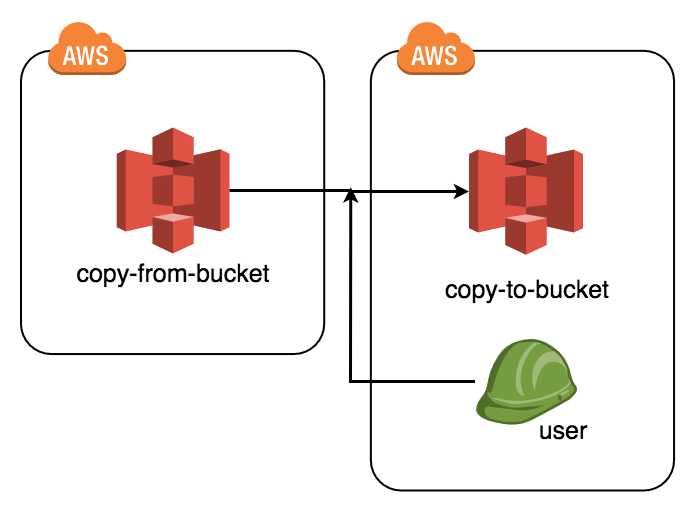
異なるAWSアカウント間のS3内データを移動する方法
はじめに
以下のように、Bucket_A(以下copy-from-bucketとする)にあるデータを異なるAWSアカウントにあるBucket_B(以下copy-to-bucketとする)にコピーするための設定方法について説明します。
こうした設定を使う状況としては、異なるアカウントのデータを移動させるのに、大容量すぎて一度ローカルに落としてから再度別アカウントバケットへ移動などという操作が困難なときなどが考えられるでしょう。
手順
1.コピー先となるアカウントに、コピー専用ユーザーを作成する
異なるアカウントのデータをいじるのは、オペミスで大事なデータを消去してしまったりする危険性もあるので、権限を最小限にしたコピー専用ユーザーを作成したほうがいいです。ここでは新規に専用ユーザーを作る前提で話を進めます。
※ここからの作業はコピー先アカウント内での操作となります。コピー専用ユーザー新規作成
コピーに必要な権限を持たせるため、以下のポリシーを記載したJSONファイルを作成してください。
※「copy-from-bucket」はコピー元バケット名に、「copy-to-bucket」はコピー先バケット名に置き換えること。copy_only_user_policy.json{ "Statement": [ { "Action": ["s3:ListBucket", "s3:GetObject"], "Effect": "Allow", "Resource": [ "arn:aws:s3:::copy-from-bucket", "arn:aws:s3:::copy-from-bucket/*" ] }, { "Action": ["s3:ListBucket", "s3:PutObject", "s3:PutObjectAcl"], "Effect": "Allow", "Resource": [ "arn:aws:s3:::copy-to-bucket", "arn:aws:s3:::copy-to-bucket/*" ] } ], "Version": "2012-10-17" }次にユーザーを新規作成します。
※AWSコンソールからやってもOKです。create_user.sh# ユーザー作成 $ aws iam create-user --user-name copy_only_user # 作成したユーザーを任意のグループに追加【必須ではない】 $ aws iam add-user-to-group \ --group-name HOGEGROUP \ --user-name copy_only_userユーザー設定
コピー専用ユーザーと、普段の作業をするユーザーは異なりますね。
AWS CLIで任意でユーザーを切り替えられるような設定をしておきましょう。
アクセスキーとシークレットアクセスキーを発行し、設定します。
(アクセスキー=ユーザーアカウントID、シークレットアクセスキー=パスワードのようなものです)create_access_key.sh# アクセスキーとシークレットアクセスキーを発行する。 $ aws iam create-access-key --user-name copy_only_user出力結果
以下のSecretAccessKey(????????????の部分)とAccessKeyId(!!!!!!!!!!!!の部分)をどこかに保存しておきましょう。
{ "AccessKey": { "UserName": "ユーザー名", "Status": "Active", "CreateDate": "2015-04-03T04:10:43.927Z", "SecretAccessKey": "????????????", "AccessKeyId": "!!!!!!!!!!!!" } }次にAWS CLIのユーザー設定をします。
一行目のコマンドを押すと以下四つの情報を聞かれるので、それぞれ入力していきます。set_copy_only_user_info.sh$ aws configure --profile copy_only_user AWS Access Key ID [None]: !!!!!!!!!!!! AWS Secret Access Key [None]: ???????????? Default region name [None]: ap-northeast-1 Default output format [None]: textコピー専用ユーザーにポリシーを付与します。
$ aws iam create-policy --policy-name \ copy_user_policy --policy-document \ file://copy_only_user_policy.json # 123456789012のところは現在作業中のAWSアカウントIDに読み替えてください。 $ aws iam attach-user-policy --user-name copy_only_user \ --policy-arn arn:aws:iam::123456789012:policy/copy_user_policyこれでいつでもprofileオプションをセットすることでこのユーザーとしてコマンドが打てます。
ls_s3_as_copy_only_user.sh$ aws s3 ls s3://copy-to-bucket/ --profile copy_only_user【補足】各ユーザーとアクセスキー/シークレットアクセスキーは以下の場所をみると確認できます。
Chk_user_credentials.sh$ cat ~/.aws/credentials次にコピー元バケットに以上のポリシーを設定します。
2.コピー元バケットのバケットポリシー設定
コピー元のバケットに、異なるアカウントからのアクセス許可の設定を付与します。まずは以下のJSONファイルを作成します。
※ここからの作業はコピー元アカウント内での操作となります。copy_from_bucket_policy.json{ "Version": "2012-10-17", "Statement": [ { "Sid": "ReadAccess", "Effect": "Allow", "Principal": { "AWS": "325045486985" }, "Action": [ "s3:ListBucket", "s3:GetObject" ], "Resource": [ "arn:aws:s3:::copy-from-bucket/*", "arn:aws:s3:::copy-from-bucket" ] } ] }このバケットポリシーを設定しましょう。
put-bucket-policy.sh$ aws s3api put-bucket-policy --bucket copy-from-bucket --policy file://copy_from_bucket_policy.json最後に以下のコマンドでデータが移動できたら成功です。
copy_data.sh$ aws s3 sync s3://copy-from-bucket/ s3://copy-to-bucket/ --profile copy_only_userおしまい
- 投稿日:2020-01-19T01:08:38+09:00
AWS ルートアカウントが使用されたことを通知する監視設定について
1. はじめに
担当サービスでは、これまで CloudWatch アラームを Slack へ飛ばすために 自作 Lambda を作成して設定していたが、最近 AWS Chatbot が登場したので、CloudWatch アラーム から Slack へ通知する部分を、自作 Lambda は止めて AWS Chatbot を使った監視設定へ切り替えて、監視設定をエンハンスした(AWS Chatbot はまだ現時点ではベータ版なので、少し不満な点もあるけど、これから新機能や改良されるはずなので積極的に使うようにしている・・)。
AWS Chatbot では、CloudWatch アラームの他に、Health イベントや Budgets アラートもサポートしているので、これらの通知も AWS Chatbot を使う設定にした(今後は、RDS や ElastiCache のイベントサブスクリプションもサポートされるといいな・・)。
(AWS Chatbot のことはまた改めて書くとして・・)そんなこんなで監視設定の見直しをしていたら、AWS ルートアカウントで AWSマネジメントコンソール にサインインしたときの監視設定もこれまでのものがあまりイケてなかったので、入れ替えることにした。
見直しの結果、AWS ルートアカウント使用チェック監視は、AWS 公式ブログに載っている方法に切り替えることにした。ただ、残念ながら、この監視は AWS Chatbot 化にはしなかった。自作 Lambda を作ればできるけど。。
2. AWS ルートアカウント利用の監視
IAMドキュメント では、AWS ルートアカウントの利用禁止を推奨している。この運用ポリシーで AWS ルートアカウント が利用された場合は、ある意味緊急事態。誰が何の目的で何を行ったのかを即座に確認する必要がある。
- CloudTrail を全リージョンで有効にする。ルートアカウント認証情報を使用してAWSマネジメントコンソールにサインインする
↓
そのアクティビティ情報が CloudTrail 用の CloudWatch ロググループに格納される(格納されるまで10分〜20分ほどかかる)。- そのロググループに次のような CloudWatch ログメトリクスフィルタを設定する。「ルートアカウント認証情報を使用したアクティビティ情報が保存されたら Amazon SNS へ送信する」
- Amazon SNS から Slack へ通知するための自作 Lambda を SNSのサブスクリプションに設定する。
これまでの監視設定は、AWS ルートアカウント利用から通知まで遅くても20分ほどかかり、少しタイムラグがあった。あと、アクティビティが発生したかどうかというだけの通知のため、アクティビティの内容は通知メッセージに入っていない。
他の方法で監視できないかなと思い、まず、AWS Config のマネージドルールに無いか探してみたけど、要望を満たすようなルールはなさそうだった。
で、ググっていたら、次のAWS公式ブログを見つけた。 AWS ルートユーザーアカウントが使用されたことを通知する CloudWatch イベントルールを作成するにはどうすればよいですか?(最終更新日が2019年4月19日だから、比較的新しい。ルートアカウントの利用禁止を推奨しているわりに、AWS Config にルールがなく、こんな感じでユーザに設定させるのはどうかと思うが・・)この AWS公式ブログ の方法では、CloudTrail からのログインイベント通知をトリガーにして CloudWatch イベントが発動して SNS へ通知するため、ほぼリアルタイムで通知を受け取ることができる。ただし、AWS Chatbot には対応してないっぽい。(試しに、サブスクリプションに AWS Chatbot を設定した SNS へ送信してみたけど、Slack へ通知が来なかった。なので、通知を Slack へ送りたい場合は、自作Lambdaを設定するか、メールからSlackへ通知するような小細工をしないといけない。)試しに、メールへ通知する設定を入れてアラームを飛ばしてみたら、次のようなメールが届いた。接続元IPアドレスや、User-Agent がある。{"version":"0","id":"20b9482a-bed9-e295-0f5f-008dcc3c0175","detail-type":"AWS Console Sign In via CloudTrail","source":"aws.signin","account":"********","time":"2020-01-18T13:22:50Z","region":"us-east-1","resources":[],"detail":{"eventVersion":"1.05","userIdentity":{"type":"Root","principalId":"*****","arn":"arn:aws:iam::*****:root","accountId":"********"},"eventTime":"2020-01-18T13:22:50Z","eventSource":"signin.amazonaws.com","eventName":"ConsoleLogin","awsRegion":"global","sourceIPAddress":"?.?.?.?","userAgent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36","requestParameters":null,"responseElements":{"ConsoleLogin":"Success"},"additionalEventData":{"LoginTo":"https://console.aws.amazon.com/console/home?state=hashArgs%23&isauthcode=true","MobileVersion":"No","MFAUsed":"Yes"},"eventID":"0b218cfc-b3a1-4524-8a15-ec7bedb1dacb","eventType":"AwsConsoleSignIn"}}3. AWS 公式ブログの ルートアカウント利用監視設定
AWS ルートユーザーアカウントが使用されたことを通知する CloudWatch イベントルールを作成するにはどうすればよいですか?
この公式ブログの監視設定は、まず CloudTrail の設定を行ってから、CloudFormation で監視用のスタックを作成するだけ。3.1 CloudTrail設定
サインインは us-east-1 リージョンのイベントなので、証跡情報を全てのリージョンに適用する。
重要事項の設定
AWS マネジメントコンソール での管理イベントのログ記録重要: 開始する前に、CloudWatch イベントの CloudTrail Management 読み取り/書き込みイベントを必ず [All] または [Write-only] に設定して、ログインイベント通知をトリガーしてください。詳細については、読み取り専用/書き込み専用イベントを参照してください。
上記2つの設定を施したCloudTrailの設定確認
3.2 公式ブログにある CloudFormation テンプレートを us-east-1 でスタック作成する
- AWSマネジメントコンソールのURLは必ず 「https://us-east-1.signin.aws.amazon.com/〜」 となる通り、サインインイベントは us-east-1 で発生する。なので、CloudWatch イベントも us-east-1 に作成する必要があるため、公式ブロブの CloudFormation テンプレートをそのまま使い、us-east-1 リージョン の CloudFormation でスタック作成する。
Root-AWS-Console-Sign-In-CloudTrail.yml
# Copyright 2019 Amazon.com, Inc. or its affiliates. All Rights Reserved. # Permission is hereby granted, free of charge, to any person obtaining a copy of this # software and associated documentation files (the "Software"), to deal in the Software # without restriction, including without limitation the rights to use, copy, modify, # merge, publish, distribute, sublicense, and/or sell copies of the Software, and to # permit persons to whom the Software is furnished to do so. # # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, # INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A # PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT # HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION # OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE # SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. AWSTemplateFormatVersion: '2010-09-09' Description: ROOT-AWS-Console-Sign-In-via-CloudTrail Metadata: AWS::CloudFormation::Interface: ParameterGroups: - Label: default: Amazon SNS parameters Parameters: - Email Address Parameters: EmailAddress: Type: String AllowedPattern: "^[\\x20-\\x45]?[\\w-\\+]+(\\.[\\w]+)*@[\\w-]+(\\.[\\w]+)*(\\.[a-z]{2,})$" ConstraintDescription: Email address required. Description: Enter an email address you want to subscribe to the Amazon SNS topic that will send notifications if your account's AWS root user logs in. Resources: RootActivitySNSTopic: Type: AWS::SNS::Topic Properties: DisplayName: ROOT-AWS-Console-Sign-In-via-CloudTrail Subscription: - Endpoint: Ref: EmailAddress Protocol: email TopicName: ROOT-AWS-Console-Sign-In-via-CloudTrail EventsRule: Type: AWS::Events::Rule Properties: Description: Events rule for monitoring root AWS Console Sign In activity EventPattern: detail-type: - AWS Console Sign In via CloudTrail detail: userIdentity: type: - Root Name: Fn::Sub: "${AWS::StackName}-RootActivityRule" State: ENABLED Targets: - Arn: Ref: RootActivitySNSTopic Id: RootActivitySNSTopic DependsOn: - RootActivitySNSTopic RootPolicyDocument: Type: AWS::SNS::TopicPolicy Properties: PolicyDocument: Id: RootPolicyDocument Version: '2012-10-17' Statement: - Sid: RootPolicyDocument Effect: Allow Principal: Service: events.amazonaws.com Action: sns:Publish Resource: - Ref: RootActivitySNSTopic Topics: - Ref: RootActivitySNSTopic Outputs: EventsRule: Value: Ref: EventsRule Export: Name: Fn::Sub: "${AWS::StackName}-RootAPIMonitorEventsRule" Description: Event Rule ID.
スタック作成前に、アラームを送信する (緊急用の)メールアドレス を入力する。
スタック作成後に、その メールアドレスに、"AWS Notification - Subscription Confirmation" メールが届くので、メールの中の "Confirm subscription" リンクを踏む。
作成されるリソース
us-east-1 リージョンの CloudWatch ルールの設定はこんな感じ
us-east-1 リージョンの Amazon SNS の設定はこんな感じ
(エンドポイントを追加したい場合は、「サブスクリプションの作成」で設定する感じかな)
設定は以上でおわり。簡単。
3.3 AWS ルートアカウントでサインインして 指定したメールアドレスに通知が来るかテスト
AWS ルートアカウントでAWSマネジメントコンソールにサインイン後、1〜2分で通知が来る。
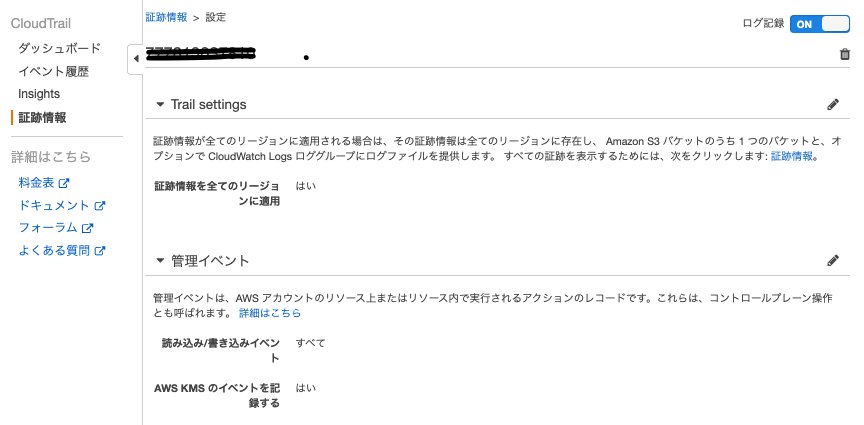
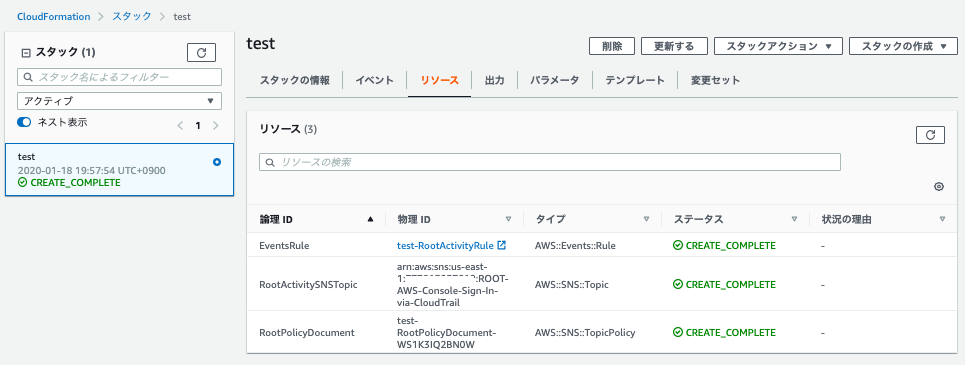
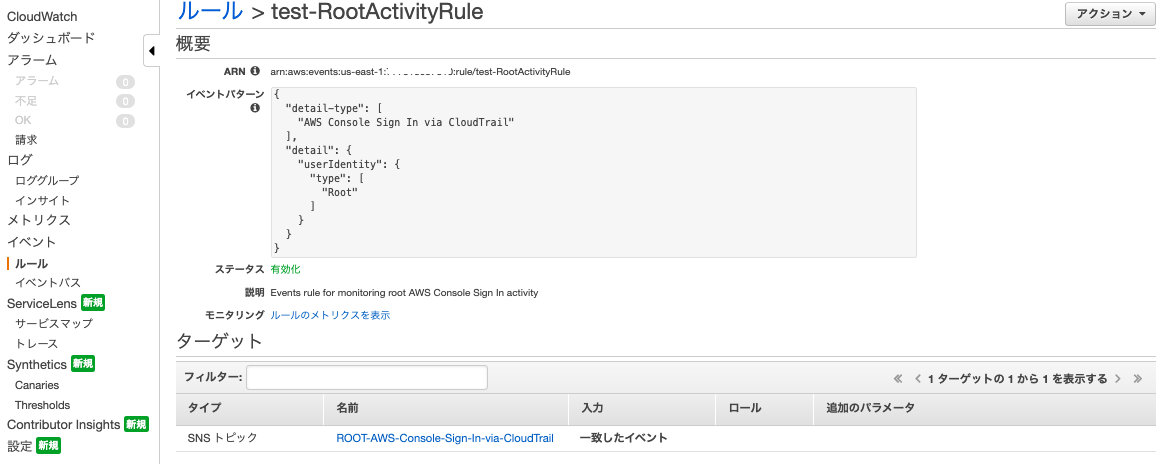

- 投稿日:2020-01-19T01:08:38+09:00
AWS ルートアカウントが使用されたことを通知する監視設定
1. はじめに
担当サービスでは、これまで CloudWatch アラームを Slack へ飛ばすために 自作 Lambda を作成して設定していたが、最近 AWS Chatbot が登場したので、CloudWatch アラーム から Slack へ通知する部分を、自作 Lambda は止めて AWS Chatbot を使った監視設定へ切り替えて、監視設定をエンハンスした(AWS Chatbot はまだ現時点ではベータ版なので、少し不満な点もあるけど、これから新機能や改良されるはずなので積極的に使うようにしている・・)。
AWS Chatbot では、CloudWatch アラームの他に、Health イベントや Budgets アラートもサポートしているので、これらの通知も AWS Chatbot を使う設定にした(今後は、RDS や ElastiCache のイベントサブスクリプションもサポートされるといいな・・)。
(AWS Chatbot のことはまた改めて書くとして・・)そんなこんなで監視設定の見直しをしていたら、AWS ルートアカウントで AWSマネジメントコンソール にサインインしたときの監視設定もこれまでのものがあまりイケてなかったので、入れ替えることにした。
見直しの結果、AWS ルートアカウント使用チェック監視は、AWS 公式ブログに載っている方法に切り替えることにした。ただ、残念ながら、この監視は AWS Chatbot 化にはしなかった。自作 Lambda を作ればできるけど。。
2. AWS ルートアカウント利用の監視
IAMドキュメント では、AWS ルートアカウントの利用禁止を推奨している。この運用ポリシーで AWS ルートアカウント が利用された場合は、ある意味緊急事態。誰が何の目的で何を行ったのかを即座に確認する必要がある。
- CloudTrail を全リージョンで有効にする。ルートアカウント認証情報を使用してAWSマネジメントコンソールにサインインする
↓
そのアクティビティ情報が CloudTrail 用の CloudWatch ロググループに格納される(格納されるまで10分〜20分ほどかかる)。- そのロググループに次のような CloudWatch ログメトリクスフィルタを設定する。「ルートアカウント認証情報を使用したアクティビティ情報が保存されたら Amazon SNS へ送信する」
- Amazon SNS から Slack へ通知するための自作 Lambda を SNSのサブスクリプションに設定する。
これまでの監視設定は、AWS ルートアカウント利用から通知まで遅くても20分ほどかかり、少しタイムラグがあった。あと、アクティビティが発生したかどうかというだけの通知のため、アクティビティの内容は通知メッセージに入っていない。
他の方法で監視できないかなと思い、まず、AWS Config のマネージドルールに無いか探してみたけど、要望を満たすようなルールはなさそうだった。
で、ググっていたら、次のAWS公式ブログを見つけた。 AWS ルートユーザーアカウントが使用されたことを通知する CloudWatch イベントルールを作成するにはどうすればよいですか?(最終更新日が2019年4月19日だから、比較的新しい。ルートアカウントの利用禁止を推奨しているわりに、AWS Config にルールがなく、こんな感じでユーザに設定させるのはどうかと思うが・・)この AWS公式ブログ の方法では、CloudTrail からのログインイベント通知をトリガーにして CloudWatch イベントが発動して SNS へ通知するため、ほぼリアルタイムで通知を受け取ることができる。ただし、AWS Chatbot には対応してないっぽい。(試しに、サブスクリプションに AWS Chatbot を設定した SNS へ送信してみたけど、Slack へ通知が来なかった。なので、通知を Slack へ送りたい場合は、自作Lambdaを設定するか、メールからSlackへ通知するような小細工をしないといけない。)試しに、メールへ通知する設定を入れてアラームを飛ばしてみたら、次のようなメールが届いた。接続元IPアドレスや、User-Agent がある。{"version":"0","id":"20b9482a-bed9-e295-0f5f-008dcc3c0175","detail-type":"AWS Console Sign In via CloudTrail","source":"aws.signin","account":"********","time":"2020-01-18T13:22:50Z","region":"us-east-1","resources":[],"detail":{"eventVersion":"1.05","userIdentity":{"type":"Root","principalId":"*****","arn":"arn:aws:iam::*****:root","accountId":"********"},"eventTime":"2020-01-18T13:22:50Z","eventSource":"signin.amazonaws.com","eventName":"ConsoleLogin","awsRegion":"global","sourceIPAddress":"?.?.?.?","userAgent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36","requestParameters":null,"responseElements":{"ConsoleLogin":"Success"},"additionalEventData":{"LoginTo":"https://console.aws.amazon.com/console/home?state=hashArgs%23&isauthcode=true","MobileVersion":"No","MFAUsed":"Yes"},"eventID":"0b218cfc-b3a1-4524-8a15-ec7bedb1dacb","eventType":"AwsConsoleSignIn"}}3. AWS 公式ブログの ルートアカウント利用監視設定
AWS ルートユーザーアカウントが使用されたことを通知する CloudWatch イベントルールを作成するにはどうすればよいですか?
この公式ブログの監視設定は、まず CloudTrail の設定を行ってから、CloudFormation で監視用のスタックを作成するだけ。3.1 CloudTrail設定
サインインは us-east-1 リージョンのイベントなので、証跡情報を全てのリージョンに適用する。
重要事項の設定
AWS マネジメントコンソール での管理イベントのログ記録重要: 開始する前に、CloudWatch イベントの CloudTrail Management 読み取り/書き込みイベントを必ず [All] または [Write-only] に設定して、ログインイベント通知をトリガーしてください。詳細については、読み取り専用/書き込み専用イベントを参照してください。
上記2つの設定を施したCloudTrailの設定確認
3.2 公式ブログにある CloudFormation テンプレートを us-east-1 でスタック作成する
- AWSマネジメントコンソールのURLは必ず 「https://us-east-1.signin.aws.amazon.com/〜」 となる通り、サインインイベントは us-east-1 で発生する。なので、CloudWatch イベントも us-east-1 に作成する必要があるため、公式ブロブの CloudFormation テンプレートをそのまま使い、us-east-1 リージョン の CloudFormation でスタック作成する。
Root-AWS-Console-Sign-In-CloudTrail.yml
# Copyright 2019 Amazon.com, Inc. or its affiliates. All Rights Reserved. # Permission is hereby granted, free of charge, to any person obtaining a copy of this # software and associated documentation files (the "Software"), to deal in the Software # without restriction, including without limitation the rights to use, copy, modify, # merge, publish, distribute, sublicense, and/or sell copies of the Software, and to # permit persons to whom the Software is furnished to do so. # # THE SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR IMPLIED, # INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY, FITNESS FOR A # PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE AUTHORS OR COPYRIGHT # HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER LIABILITY, WHETHER IN AN ACTION # OF CONTRACT, TORT OR OTHERWISE, ARISING FROM, OUT OF OR IN CONNECTION WITH THE # SOFTWARE OR THE USE OR OTHER DEALINGS IN THE SOFTWARE. AWSTemplateFormatVersion: '2010-09-09' Description: ROOT-AWS-Console-Sign-In-via-CloudTrail Metadata: AWS::CloudFormation::Interface: ParameterGroups: - Label: default: Amazon SNS parameters Parameters: - Email Address Parameters: EmailAddress: Type: String AllowedPattern: "^[\\x20-\\x45]?[\\w-\\+]+(\\.[\\w]+)*@[\\w-]+(\\.[\\w]+)*(\\.[a-z]{2,})$" ConstraintDescription: Email address required. Description: Enter an email address you want to subscribe to the Amazon SNS topic that will send notifications if your account's AWS root user logs in. Resources: RootActivitySNSTopic: Type: AWS::SNS::Topic Properties: DisplayName: ROOT-AWS-Console-Sign-In-via-CloudTrail Subscription: - Endpoint: Ref: EmailAddress Protocol: email TopicName: ROOT-AWS-Console-Sign-In-via-CloudTrail EventsRule: Type: AWS::Events::Rule Properties: Description: Events rule for monitoring root AWS Console Sign In activity EventPattern: detail-type: - AWS Console Sign In via CloudTrail detail: userIdentity: type: - Root Name: Fn::Sub: "${AWS::StackName}-RootActivityRule" State: ENABLED Targets: - Arn: Ref: RootActivitySNSTopic Id: RootActivitySNSTopic DependsOn: - RootActivitySNSTopic RootPolicyDocument: Type: AWS::SNS::TopicPolicy Properties: PolicyDocument: Id: RootPolicyDocument Version: '2012-10-17' Statement: - Sid: RootPolicyDocument Effect: Allow Principal: Service: events.amazonaws.com Action: sns:Publish Resource: - Ref: RootActivitySNSTopic Topics: - Ref: RootActivitySNSTopic Outputs: EventsRule: Value: Ref: EventsRule Export: Name: Fn::Sub: "${AWS::StackName}-RootAPIMonitorEventsRule" Description: Event Rule ID.
スタック作成前に、アラームを送信する (緊急用の)メールアドレス を入力する。
スタック作成後に、その メールアドレスに、"AWS Notification - Subscription Confirmation" メールが届くので、メールの中の "Confirm subscription" リンクを踏む。
作成されるリソース
us-east-1 リージョンの CloudWatch ルールの設定はこんな感じ
us-east-1 リージョンの Amazon SNS の設定はこんな感じ
(エンドポイントを追加したい場合は、「サブスクリプションの作成」で設定する感じかな)
設定は以上でおわり。簡単。
3.3 AWS ルートアカウントでサインインして 指定したメールアドレスに通知が来るかテスト
AWS ルートアカウントでAWSマネジメントコンソールにサインイン後、1〜2分で通知が来る。
ちなみに、通知はサインインのときの一回きり。
サインインを継続していても最初の一回の通知しか来ない。
リマインド通知したい場合、現時点ではSNSトピックなどではそのような機能がないため、独自でLambdaなりで実装する必要がある。
- 投稿日:2020-01-19T00:42:45+09:00
Blockchain Template (無料枠はないか), hyperledgerFablic
シンクラPCにブロックチェーン使えないか、ローカルでhyperledgerFablic
Bookmark
Amazon ECS(Elastic Container Service)
AWS Managed Blockchainの概要
https://dev.classmethod.jp/cloud/aws/amazon-managed-blockchain-introduce/AWS Managed Blockchainの歩き方 #1 環境構築トランザクション実行編
★https://qiita.com/ksukenobe/items/fde330ccdf6ef7031050Dockerを使って1サーバーで複数Webサービスを運用する
https://qiita.com/miyasakura_/items/5cd3b05aa9c5e4f3f4beAWSのEC2でDockerを試してみる
https://qiita.com/yumatsud/items/33bc22f7d8f640a286f4WS Lambda上のheadless chromeをPythonで動かす
https://qiita.com/nabehide/items/754eb7b7e9fff9a1047dAmazon Managed BlockchainがリリースされたのでHyperledger Fabricも合わせて情報をまとめてみた
https://qiita.com/kai_kou/items/5a968f42c5f96296f6feAWS LambdaにPythonコードをzipでアップロードして実行する方法を詳しく
https://www.suzu6.net/posts/83-lambda-zip/AWS LambdaにLayerなるものが追加されたのでPythonで簡単に使ってみる #reinvent
https://dev.classmethod.jp/server-side/python/lambda-layer-simply-use-by-python/AWS 模試
https://book.impress.co.jp/books/1118101069□ IBM資料
https://www.scsk.jp/lib/product/oss/pdf/Hyperledger_1.pdf
http://www.maff.go.jp/j/shokusan/fcp/whats_fcp/attach/pdf/up180831-2/1_IBM_blockchain_document.pdf■ AWS online seminer
https://pages.awscloud.com/event_JAPAN_GetCert-20190823_LP.htmlpythonでブロックチェーンを体感
- 投稿日:2020-01-19T00:42:45+09:00
BlockChainの実用に向けての調査
調べること
- Blockchain Template (無料枠はないか), hyperledgerFablic
- シンクラPCにブロックチェーン使えないか、ローカルでhyperledgerFablic
pythonでブロックチェーンを体感する
まず、ハッシュ、プルーフといった基礎ワードの理解と、どういう仕組みでデータ改ざんに強いのかを知る。
https://www.sejuku.net/blog/75079
https://www.slideshare.net/oracle4engineer/ochacafe-4-hyperledger-fabric
https://hyperledger-fabric.readthedocs.io/en/release-1.4/memo
Amazon ECS(Elastic Container Service)
AWS Managed Blockchainの概要
https://dev.classmethod.jp/cloud/aws/amazon-managed-blockchain-introduce/AWS Managed Blockchainの歩き方 #1 環境構築トランザクション実行編
★https://qiita.com/ksukenobe/items/fde330ccdf6ef7031050Dockerを使って1サーバーで複数Webサービスを運用する
https://qiita.com/miyasakura_/items/5cd3b05aa9c5e4f3f4beAWSのEC2でDockerを試してみる
https://qiita.com/yumatsud/items/33bc22f7d8f640a286f4WS Lambda上のheadless chromeをPythonで動かす
https://qiita.com/nabehide/items/754eb7b7e9fff9a1047dAmazon Managed BlockchainがリリースされたのでHyperledger Fabricも合わせて情報をまとめてみた
https://qiita.com/kai_kou/items/5a968f42c5f96296f6feAWS LambdaにPythonコードをzipでアップロードして実行する方法を詳しく
https://www.suzu6.net/posts/83-lambda-zip/AWS LambdaにLayerなるものが追加されたのでPythonで簡単に使ってみる #reinvent
https://dev.classmethod.jp/server-side/python/lambda-layer-simply-use-by-python/AWS 模試
https://book.impress.co.jp/books/1118101069□ IBM資料
https://www.scsk.jp/lib/product/oss/pdf/Hyperledger_1.pdf
http://www.maff.go.jp/j/shokusan/fcp/whats_fcp/attach/pdf/up180831-2/1_IBM_blockchain_document.pdf■ AWS online seminer
https://pages.awscloud.com/event_JAPAN_GetCert-20190823_LP.html
- 投稿日:2020-01-19T00:15:49+09:00
node.js製のlamdaアプリをコマンド一発でアップロードする方法
node.jsでlambdaのアプリを作っているのですが、コードやパッケージが増えてくるとインライン編集出来なくなったり、zipでアップロードする必要が出てきます。ちょっとした変更でもわざわざawsのサイトに行ってアップロードするのは面倒ですし、複数のlambdaアプリを作っていたら間違えて別の関数にアップロードしてしまった、といった事故も起きるかもしれません。そこで、コンソールからコマンドでアップロードできるようにする方法を書きます。
※動作確認環境: macOS 10.14.6
aws CLIの設定
まずawsのCLIをインストールします。バージョンが出ればOKです。
$ brew install python3 $ pip3 install aws $ aws --version次にawsのユーザー情報を設定する必要がありますが、アクセスキーが必要になります。IAMでAdministratorAccessポリシーを持ったユーザーを作成しておきます。
https://blog-asnpce.com/technology/313アクセスキー、シークレットアクセスキー、リージョンを
aws configureで設定します。$ aws configure AWS Access Key ID [None]: xxxxxxxxxxxxxxx AWS Secret Access Key [None]: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx Default region name [None]: ap-northeast-1 Default output format [None]: // 設定せずそのままEnterこれでコンソールからawsのcliを使用するときに自分のアカウントを操作することができるようになりました。
package.jsonの編集
package.jsonを編集し、lambdaアプリのディレクトリで
npm run deployを実行するとアップロード出来るようにします。
package.jsonのscripts内にdeployというプロパティ名でコマンドをセットします。セットするコマンドは以下です。このコマンドを実行することにより、package.jsonが入っているディレクトリをzipに圧縮してからCLIでアップロード出来ます。
{}内はご自身のlambdaアプリに合わせてください。zipのファイル名はなんでもいいです。zip -r {zipファイルの名前}.zip ./ -x \"*.zip\" && aws lambda update-function-code --function-name {lambda関数の名前} --zip-file fileb://{zipファイルの名前}.zippackage.json{ "name": "prodfunc", "version": "1.0.0", "engines": { "node": ">=12.0.0" }, "description": "", "main": "index.js", "scripts": { // ここに追加 "deploy": "zip -r prodfunc.zip ./ -x \"*.zip\" && aws lambda update-function-code --function-name prodfunc --zip-file fileb://prodfunc.zip" }, "author": "", "license": "ISC", "dependencies": { // 略 } }コンソールで以下を実行し、エラーが出なければ成功です。
$ npm run deploy参考
https://docs.aws.amazon.com/lambda/latest/dg/nodejs-create-deployment-pkg.html
- 投稿日:2020-01-19T00:15:49+09:00
node.js製のlambdaアプリをコマンド一発でアップロードする方法
node.jsでlambdaのアプリを作っているのですが、コードやパッケージが増えてくるとインライン編集出来なくなったり、zipでアップロードする必要が出てきます。ちょっとした変更でもわざわざawsのサイトに行ってアップロードするのは面倒ですし、複数のlambdaアプリを作っていたら間違えて別の関数にアップロードしてしまった、といった事故も起きるかもしれません。そこで、コンソールからコマンドでアップロードできるようにする方法を書きます。
※動作確認環境: macOS 10.14.6
aws CLIの設定
まずawsのCLIをインストールします。バージョンが出ればOKです。
$ brew install python3 $ pip3 install aws $ aws --version次にawsのユーザー情報を設定する必要がありますが、アクセスキーが必要になります。IAMでAdministratorAccessポリシーを持ったユーザーを作成しておきます。
https://blog-asnpce.com/technology/313アクセスキー、シークレットアクセスキー、リージョンを
aws configureで設定します。$ aws configure AWS Access Key ID [None]: xxxxxxxxxxxxxxx AWS Secret Access Key [None]: xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx Default region name [None]: ap-northeast-1 Default output format [None]: // 設定せずそのままEnterこれでコンソールからawsのcliを使用するときに自分のアカウントを操作することができるようになりました。
package.jsonの編集
package.jsonを編集し、lambdaアプリのディレクトリで
npm run deployを実行するとアップロード出来るようにします。
package.jsonのscripts内にdeployというプロパティ名でコマンドをセットします。セットするコマンドは以下です。このコマンドを実行することにより、package.jsonが入っているディレクトリをzipに圧縮してからCLIでアップロード出来ます。
{}内はご自身のlambdaアプリに合わせてください。zipのファイル名はなんでもいいです。zip -r {zipファイルの名前}.zip ./ -x \"*.zip\" && aws lambda update-function-code --function-name {lambda関数の名前} --zip-file fileb://{zipファイルの名前}.zippackage.json{ "name": "prodfunc", "version": "1.0.0", "engines": { "node": ">=12.0.0" }, "description": "", "main": "index.js", "scripts": { // ここに追加 "deploy": "zip -r prodfunc.zip ./ -x \"*.zip\" && aws lambda update-function-code --function-name prodfunc --zip-file fileb://prodfunc.zip" }, "author": "", "license": "ISC", "dependencies": { // 略 } }コンソールで以下を実行し、エラーが出なければ成功です。
$ npm run deploy参考
https://docs.aws.amazon.com/lambda/latest/dg/nodejs-create-deployment-pkg.html
- 投稿日:2020-01-19T00:12:36+09:00
Amazon EKS on AWS Fargateに触れてみた備忘録
概要
AWS re:Invent 2019にて Amazon EKS on AWS Fargate がGAになったと発表された模様なので、遅ればせながら触れてみた備忘録を残してみたいと思います。
ちなみにこの記事を参考にしながら動かしてみました。
準備
事前に必要なものとしては
eksctlなるものがあると良いとのこと。
AWS CLIをいれておくのと、AWS CLI Credentialsを作成しておけばOK。eksctl
eksctlとはAmazon EKS上にkubernates clusterを作ったり管理したりできるコマンドラインツールとのこと。
Getting Started with eksctlを参考に準備してみる。インストール
自分は
macOSなのでbrewを使ってインストールしてみます。
Weaveworks Homebrew tapのインストール$ brew tap weaveworks/tap Updating Homebrew... ==> Auto-updated Homebrew! Updated 1 tap (homebrew/cask). No changes to formulae. ==> Tapping weaveworks/tap Cloning into '/usr/local/Homebrew/Library/Taps/weaveworks/homebrew-tap'... remote: Enumerating objects: 10, done. remote: Counting objects: 100% (10/10), done. remote: Compressing objects: 100% (9/9), done. remote: Total 10 (delta 1), reused 3 (delta 0), pack-reused 0 Unpacking objects: 100% (10/10), done. Tapped 4 formulae (30 files, 10.5KB).
eksctlのインストール$ brew install weaveworks/tap/eksctl ==> Installing eksctl from weaveworks/tap ==> Installing dependencies for weaveworks/tap/eksctl: kubernetes-cli and aws-iam-authenticator ==> Installing weaveworks/tap/eksctl dependency: kubernetes-cli ・・・・・ ? /usr/local/Cellar/kubernetes-cli/1.17.1: 235 files, 49MB ==> Installing weaveworks/tap/eksctl dependency: aws-iam-authenticator ・・・・・ ? /usr/local/Cellar/aws-iam-authenticator/0.4.0: 5 files, 24.9MB ==> Installing weaveworks/tap/eksctl ・・・・・ ? /usr/local/Cellar/eksctl/0.12.0: 3 files, 87.0MB, built in 14 minutes 43 seconds $ eksctl version [ℹ] version.Info{BuiltAt:"", GitCommit:"", GitTag:"0.12.0"}クラスタの作成
インストールしたeksctlでクラスタを作成してみます。
$ eksctl create cluster --name demo-newsblog --region ap-northeast-1 --fargate [ℹ] eksctl version 0.12.0 [ℹ] using region ap-northeast-1 [ℹ] setting availability zones to [ap-northeast-1d ap-northeast-1a ap-northeast-1c] [ℹ] subnets for ap-northeast-1d - public:〜 private:〜 [ℹ] subnets for ap-northeast-1a - public:〜 private:〜 [ℹ] subnets for ap-northeast-1c - public:〜 private:〜 [ℹ] using Kubernetes version 1.14 [ℹ] creating EKS cluster "demo-newsblog" in "ap-northeast-1" region with Fargate profile [ℹ] if you encounter any issues, check CloudFormation console or try 'eksctl utils describe-stacks --region=ap-northeast-1 --cluster=demo-newsblog' [ℹ] CloudWatch logging will not be enabled for cluster "demo-newsblog" in "ap-northeast-1" [ℹ] you can enable it with 'eksctl utils update-cluster-logging --region=ap-northeast-1 --cluster=demo-newsblog' [ℹ] Kubernetes API endpoint access will use default of {publicAccess=true, privateAccess=false} for cluster "demo-newsblog" in "ap-northeast-1" [ℹ] 1 task: { create cluster control plane "demo-newsblog" } [ℹ] building cluster stack "eksctl-demo-newsblog-cluster" [ℹ] deploying stack "eksctl-demo-newsblog-cluster" [✔] all EKS cluster resources for "demo-newsblog" have been created [✔] saved kubeconfig as "/Users/yumatsud/.kube/config" [ℹ] creating Fargate profile "fp-default" on EKS cluster "demo-newsblog" [ℹ] created Fargate profile "fp-default" on EKS cluster "demo-newsblog" [ℹ] "coredns" is now schedulable onto Fargate [ℹ] "coredns" is now scheduled onto Fargate [ℹ] "coredns" pods are now scheduled onto Fargate [✖] parsing kubectl version string (upstream error: error: EOF ) / "0.0.0": Version string empty [ℹ] cluster should be functional despite missing (or misconfigured) client binaries [✔] EKS cluster "demo-newsblog" in "ap-northeast-1" region is readyちょっとだけ中身を見てみると、
- 各AZ毎にpublic subnetとprivate subnetが作られる
- SGもコントロールパネルとノードのやりとり用やノード間のやりとり用などが自動で作られる
- IAMロールやCloudWatch Logsなども作られる
とかで自動的に色々と作ってくれるのば便利ですね。上記コマンドだと、
parsing kubectl version string (upstream error: error: EOF) / "0.0.0": Version string empty
ですが、クラスタはちゃんと作られてたっぽいです。念の為下記で確認したところ、$ kubectl version Please enter Username:のように入力を求められてしまうからで、これ自体は こちらの記事 にある通り、kubectlのバージョンが低いと出てしまうとのこと。
eksctlの該当箇所はこちらでした。Fargate Profile
Fargate Profileというのが最初はなんのこっちゃ?と思いましたが、Profileの追加画面を見てみると、
とのことで、podをどこでどのように動かすかなどを定義するものらしいです。
ここからroleやsubnetを追加していくのですが、参考にしてた記事によると、
only private subnets are supported for Fargate pods
とあったので、public subnetは除いてみました。そのあとにpodを動かす
namespaceを設定し、確認後に作成する。これだけで、namespaceに一致するpodがあれば、そこでpodが動くようです。
ちなみに、jsonを定義してコマンドラインから作成することもできるとのこと。deploy
nginxのコンテナを動かしてみます。$ kubectl create deployment demo-app --image=nginx deployment.apps/demo-app created $ kubectl get pods NAME READY STATUS RESTARTS AGE demo-app-6dbfc49497-frmdq 0/1 ContainerCreating 0 45s $ kubectl get nodes NAME STATUS ROLES AGE VERSION fargate-ip-<ip>.ap-northeast-1.compute.internal Ready <none> 160m v1.14.8-eks fargate-ip-<ip>.ap-northeast-1.compute.internal Ready <none> 160m v1.14.8-eks fargate-ip-<ip>.ap-northeast-1.compute.internal Ready <none> 5s v1.14.8-eks $ kubectl get pods NAME READY STATUS RESTARTS AGE demo-app-6dbfc49497-frmdq 1/1 Running 0 3m9sここまでで Getting Started with eksctl の実行は終了。。。これだけだと物足りないので、アクセスできるところまでやってみる。
AWS ALB Ingress Controller
Kubernetes Ingress with AWS ALB Ingress Controllerを参考にインターネットからアクセスできるようにしてみようと思います。
ちなみに、実際にALBを作成してアクセスできるようにするには「Amazon EKS on Fargate で ALB Ingress Controller を使用する」が参考になりそうでした。
- クラスターの OIDC プロバイダーをセットアップ
$ eksctl utils associate-iam-oidc-provider --cluster demo-newsblog --approve [ℹ] eksctl version 0.12.0 [ℹ] using region ap-northeast-1 [ℹ] will create IAM Open ID Connect provider for cluster "demo-newsblog" in "ap-northeast-1" [✔] created IAM Open ID Connect provider for cluster "demo-newsblog" in "ap-northeast-1"
AWS ALB Ingress controllerに必要なRBACの作成$ kubectl apply -f https://raw.githubusercontent.com/kubernetes-sigs/aws-alb-ingress-controller/v1.1.4/docs/examples/rbac-role.yaml clusterrole.rbac.authorization.k8s.io/alb-ingress-controller created clusterrolebinding.rbac.authorization.k8s.io/alb-ingress-controller created serviceaccount/alb-ingress-controller created
ALB Ingress controllerがAWS APIにアクセスするためのIAMポリシーの作成$ aws iam create-policy \ --policy-name ALBIngressControllerIAMPolicy \ --policy-document https://raw.githubusercontent.com/kubernetes-sigs/aws-alb-ingress-controller/v1.1.4/docs/examples/iam-policy.json
- Kubernetes用のサービスアカウント作成し、上記で作成したIAMロールを付与
$ eksctl create iamserviceaccount \ > --cluster=demo-newsblog \ > --namespace=kube-system \ > --name=alb-ingress-controller \ > --attach-policy-arn=<上記のarn> \ > --override-existing-serviceaccounts \ > --approve [ℹ] eksctl version 0.12.0 [ℹ] using region ap-northeast-1 [ℹ] 1 iamserviceaccount (kube-system/alb-ingress-controller) was included (based on the include/exclude rules) [!] metadata of serviceaccounts that exist in Kubernetes will be updated, as --override-existing-serviceaccounts was set [ℹ] 1 task: { 2 sequential sub-tasks: { create IAM role for serviceaccount "kube-system/alb-ingress-controller", create serviceaccount "kube-system/alb-ingress-controller" } } [ℹ] building iamserviceaccount stack "eksctl-demo-newsblog-addon-iamserviceaccount-kube-system-alb-ingress-controller" [ℹ] deploying stack "eksctl-demo-newsblog-addon-iamserviceaccount-kube-system-alb-ingress-controller" [ℹ] serviceaccount "kube-system/alb-ingress-controller" already exists [ℹ] updated serviceaccount "kube-system/alb-ingress-controller"
AWS ALB Ingress controllerをdeploy$ curl -sS "https://raw.githubusercontent.com/kubernetes-sigs/aws-alb-ingress-controller/v1.1.4/docs/examples/alb-ingress-controller.yaml" \ | sed "s/# - --cluster-name=devCluster/- --cluster-name=demo-newsblog/g" | kubectl apply -f - deployment.apps/alb-ingress-controller created $ kubectl logs -n kube-system $(kubectl get po -n kube-system | grep alb-ingress | awk '{print $1}') W0118 14:31:53.198889 1 client_config.go:549] Neither --kubeconfig nor --master was specified. Using the inClusterConfig. This might not work. ------------------------------------------------------------------------------- AWS ALB Ingress controller Release: v1.1.4 Build: git-0db46039 Repository: https://github.com/kubernetes-sigs/aws-alb-ingress-controller.git -------------------------------------------------------------------------------
- サンプルアプリケーションの 2048 game をデプロイ
$ kubectl apply -f https://raw.githubusercontent.com/kubernetes-sigs/aws-alb-ingress-controller/v1.1.4/docs/examples/2048/2048-namespace.yaml namespace/2048-game created $ kubectl apply -f https://raw.githubusercontent.com/kubernetes-sigs/aws-alb-ingress-controller/v1.1.4/docs/examples/2048/2048-deployment.yaml deployment.apps/2048-deployment created $ kubectl apply -f https://raw.githubusercontent.com/kubernetes-sigs/aws-alb-ingress-controller/v1.1.4/docs/examples/2048/2048-service.yaml service/service-2048 created
- Ingressリソースのデプロイ
$ kubectl apply -f https://raw.githubusercontent.com/kubernetes-sigs/aws-alb-ingress-controller/v1.1.4/docs/examples/2048/2048-ingress.yaml ingress.extensions/2048-ingress created
- 下記の
DNS-Name-Of-Your-ALBで動作確認$ kubectl get ingress/2048-ingress -n 2048-game NAME HOSTS ADDRESS PORTS AGE 2048-ingress * <<アクセス先>> 80 3m感想
eksctlとkubectlを使い分けていく必要があるのがやや面倒ですが、
AWSのリソースとの組み合わせをこのくらいの手順でやれるのは良いかもですね。
あとはproductionに耐えうるものにするにはどうするかを検討していければ実サービスでも使えそうだなと思いました。参考
