- 投稿日:2020-01-18T20:34:56+09:00
LINEのグループトークを学習して、グループメンバーのように会話するLINEbotを作る
普段使っているグループトークにいきなり謎のAIが乱入してきたら面白いと思い、機械学習やLINEbotの使い方を学ぶ意味も込めて、LINEのグループトークを学習してあたかもグループメンバーのように会話するLINEbotを作ったので、手順をまとめます。
TensorFlowで会話AIを作ってみた。
作成にはこちらのページと、tensorflowの公式リファレンスを参考にさせていただきました。
また機械学習についてはなんとなくでしか理解していないため、これをきっかけにモデルの作り方など学んでいこうと思いました...必要なもの
- LINE atのアカウント
- ある程度のグループトークの会話データ(1〜2MB)
- pythonの実行環境
- 学習に使うライブラリ各種(tensorflow, mecab)
実装の流れ
ここからは、以下の手順で進めていきます。
Tensorflowサイド
- グループトークの会話データをダウンロードする
- 会話データの前処理を行う
- 作成したデータセットを使ってモデルを学習させる
LINEbotサイド
- Line atのアカウントを用意する
- オウム返しするするとこまで確認
- 誰かが話したらその言葉をモデルに投げ込み、得られた出力を発言する
実装
1. グループトークの会話データをダウンロードする
スマホのグループトーク画面→右上のメニュー→右上の歯車マーク→「トーク履歴を送信」で、
python実行環境のあるPCに会話データを送信します。2. 会話データの前処理を行う
会話データファイルから、モデルを学習させるためデータセットを作成します。
たとえば「今どこ?」→「バイト」→「まじか」という会話があれば、入力"今どこ?"-出力"バイト"という会話ペアと、入力"バイト"-出力"まじか"という会話ペアを作成します。
preprocess.pyimport MeCab talkFile = open('会話データファイルの名前', 'r') input = open('input.txt', 'w') output = open('output.txt', 'w') line = talkFile.readline() wakati = MeCab.Tagger("-Owakati") hiragana = "ぁあぃいぅうぇえぉおかがきぎくぐけげこごさざしじすずせぜそぞただちぢっつづてでとどなにぬねのはばぱひびぴふぶぷへべぺほぼぽまみむめもゃやゅゆょよらりるれろゎわゐゑをん" katakana = "ァアィイゥウェエォオカガキギクグケゲコゴサザシジスズセゼソゾタダチヂッツヅテデトドナニヌネノハバパヒビピフブプヘベペホボポマミムメモャヤュユョヨラリルレロヮワヰヱヲンヴ" def filterStr(str): if str == "": return False word = str.split("\t")[-1] if '/' in word or '[' in word or len(word) > 12: return False for ch in word: if ch in hiragana or ch in katakana: return word return False def processedStr(str): str = wakati.parse(str.strip()) str = "<start> " + str.replace('\n','') + "<end>\n" return str wordList = [] while line: word = filterStr(line) if word: wordList.append(processedStr(word)) line = talkFile.readline() talkFile.close() for index in range(len(wordList)): if index == 0: input.write(wordList[index]) elif index == len(wordList)-1: output.write(wordList[index]) else: input.write(wordList[index]) output.write(wordList[index]) print(wordList[index]) input.close() output.close()これで、
<start> いい な それ <end>
のように、各会話データから日時・発言した人などの余分な情報をのぞき、なおかつ形態素解析を施してタグを付加したデータセットinput.txtとoutput.txtが生成されました。3. 作成したデータセットを使ってモデルを学習させる
機械翻訳-Tensorflow 2.xのリファレンスにお世話になります。
TensorFlow 2.0 : 上級 Tutorials : テキスト :- ニューラル機械翻訳 with Attention 11/12/2019
一番最近の記事を参考にさせていただきました。
まず、記事をそのまま実装しうまく動くことを確かめます。GPUを使わない場合はものすごく時間がかかってしまいますが、一応終わります。
その後、関数load_datasetの前で先程作成したデータセットを読み込み、load_datasetを書き換えます。また、そのすぐ下のデータセットの数量を表す変数も、読み込んだ会話データの数より小さくセットしておきます。"..."は、その間に何行かコードがあることを示しています。training_model.py... inputf = open('input.txt', 'r') outputf = open('output.txt', 'r') ilist = inputf.readlines() olist = outputf.readlines() for i in range(len(ilist)): ilist[i] = ilist[i].replace('\n','') for i in range(len(olist)): olist[i] = olist[i].replace('\n','') inputf.close() outputf.close() def load_dataset(path, num_examples=None): targ_lang = olist inp_lang = ilist input_tensor, inp_lang_tokenizer = tokenize(inp_lang) target_tensor, targ_lang_tokenizer = tokenize(targ_lang) return input_tensor, target_tensor, inp_lang_tokenizer, targ_lang_tokenizer num_examples = #データセットの数量より小さくセット ...会話データを一段ずつずらして入出力ペアを生成するので、データセットの数量を会話データの数と同じにしてしまうとエラーが発生します。
また、翻訳では前処理は必要ないためコメントアウトし、translate関数を書き換えたら完成です。training_model.py... def evaluate(sentence): attention_plot = np.zeros(max_length_targ, max_length_inp) #sentence = preprocess_sentence(sentence) ... ... def translate(sentence): result, sentence, attention_plot = evaluate(sentence) print('{}'.format(result.replace(' <end>', '').replace(' ',''))) attention_plot = attention_plot[:len(result.split(' ')), :len(sentence.split(' '))] plot_attention(attention_plot, sentence.split(' '), result.split(' ')) checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir)) translate('今 どこ ?')ここでtraining_model.pyを実行し、それっぽい出力が帰ってきたら成功です(この時点では自分で単語ごとに区切ってやる必要があります)。
ここからは学習済みモデルをチェックポイントを使って読み込んでいくので、学習部分のコードをコメントアウトして、最後に対話モードを付け足します。
training_model.py... import MeCab ... ''' for epoch in range(EPOCHS): start = time.time() enc_hidden = encoder.initialize_hidden_state() total_loss = 0 for (batch, (inp, targ)) in enumerate(dataset.take(steps_per_epoch)): batch_loss = train_step(inp, targ, enc_hidden) total_loss += batch_loss if batch % 100 == 0: print('Epoch {} Batch {} Loss {:.4f}'.format(epoch + 1, batch, batch_loss.numpy())) # saving (checkpoint) the model every 2 epochs if (epoch + 1) % 2 == 0: checkpoint.save(file_prefix = checkpoint_prefix) print('Epoch {} Loss {:.4f}'.format(epoch + 1, total_loss / steps_per_epoch)) print('Time taken for 1 epoch {} sec\n'.format(time.time() - start)) ''' def evaluate(sentence): attention_plot = np.zeros((max_length_targ, max_length_inp)) #sentence = preprocess_sentence(sentence) inputs = [] for i in sentence.split(' '): if i != '': if i in inp_lang.word_index: inputs.append(inp_lang.word_index[i]) else: return False, False, False inputs = tf.keras.preprocessing.sequence.pad_sequences([inputs], maxlen=max_length_inp, padding='post') inputs = tf.convert_to_tensor(inputs) ... ... def translate(sentence): wakati = MeCab.Tagger("-Owakati") inputList = wakati.parse(sentence.replace('\n','').strip()).replace('\n','') result, inputList, attention_plot = evaluate(inputList) if result: print('{}'.format(result.replace('<end>', '').replace(' ',''))) checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir)) while True: print(">", end="") inputStr = input() translate(inputStr)ここでtraining_model.pyを実行すると、最初の読み込みの後にこのようにAIとリアルタイムで対話することができるようになります。短いワードなら割とそれっぽく返してくるので、開発中にツボることが増えてきます。機械学習すげぇ...
4. Line atのアカウントを用意する 5. オウム返しするするとこまで確認
ここはPythonを利用したLINE Botの作り方を現役エンジニアが解説【初心者向け】でとてもわかりやすく解説されていたため省略します。
重要なのはこのサイトでも出てくる、LINEbotの動作を定義するapp.pyファイルです。最後にこの中身を書き換えていきます。6. 誰かが話したらその言葉をモデルに投げ込み、得られた出力を発言する
まず、training_model.pyのtranslate関数を書き換えて対話モードを無効にします。
training_model.py... def translate(sentence): wakati = MeCab.Tagger("-Owakati") inputList = wakati.parse(sentence.replace('\n','').strip()).replace('\n','') result, inputList, attention_plot = evaluate(inputList) if result: return result.replace('<end>', '').replace(' ','') else: return False checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir)) ''' while True: print(">", end="") inputStr = input() translate(inputStr) '''そして、app.pyでtraining_modelを読み込んで、イベント発生時にtranslate関数が走るようにすれば完成です。
app.py... import training_model ... def callback(): ... for event in events: if not isinstance(event, MessageEvent): continue if not isinstance(event.message, TextMessage): continue reply = training_model.translate(event.message.text) if reply: line_bot_api.reply_message( event.reply_token, TextSendMessage(text=reply) ) return 'OK' ...実際にトークに乱入させてみた様子がこんな感じです。
大学生の内輪トークということでかなりスレスレの単語が飛びかっていたので、ネットに上げられるのはこのくらいでした...グループトークを学習させたAIをそのグループトークに乱入させてみた pic.twitter.com/rLq5WnzqUG
— nunor (@nunorlabo) January 18, 2020最初は自宅のワンボードPC(トーク監視用)と研究室のサーバ(モデル学習用)を連携させた実装だったのですが、一度全トークを学習させた後は大きな計算リソースはいらないことに気づいたため、今では全てワンボードPCで動かせています。つまり、最初だけPCに頑張ってもらえば、あとは新しいトークを少しずつ学習させていくだけなので潤沢な計算リソースがなくても無問題というわけです。
うまくいったら、早速トークに乱入させてみてください!

- 投稿日:2020-01-18T16:44:13+09:00
TF2.0 のカスタムループで gradient accumulation (tf.gather 等のケース含む)
この記事は何
TensorFlow が 2.0 にアップデートされ、学習コードのカスタムループ ( Keras での
.fit()などではなく、自前で iteration を回す書き方 )が非常に書きやすくなりました。
その中で Gradient Accumulation を実装しようとしたときに少し詰まったため、メモとして公開します。ここ間違ってるよ!とかもっと良いやり方があるよ!という場合はぜひ教えてほしいです?
Gradient Accumulation とは
ざっくりです。詳しい説明は他を当たってください?♂️
Deep Learning モデルの学習のためには、一般的に多くの GPU メモリが必要となります。
より大きなモデルを学習する際には数十 GB というメモリが必要となるため、多くの場合は単純に入力の batch size を小さくすることで対応します。
この方法を選択した場合、batch size が小さくなるので次のようなデメリットがあります。
- 学習に時間がかかる
- 精度が劣化する
特に後者は深刻な問題で、batch size を小さくすることで精度が劣化するという報告や、学習時に learning rate を調整するのではなく batch size を大きくするほうが性能改善につながるなどの報告がされています(特に自然言語処理の分野)123。
そこで、batch size を大きくしたまま、メモリ効率をよく計算する方法の1つとして、gradient accumulation が挙げられます。
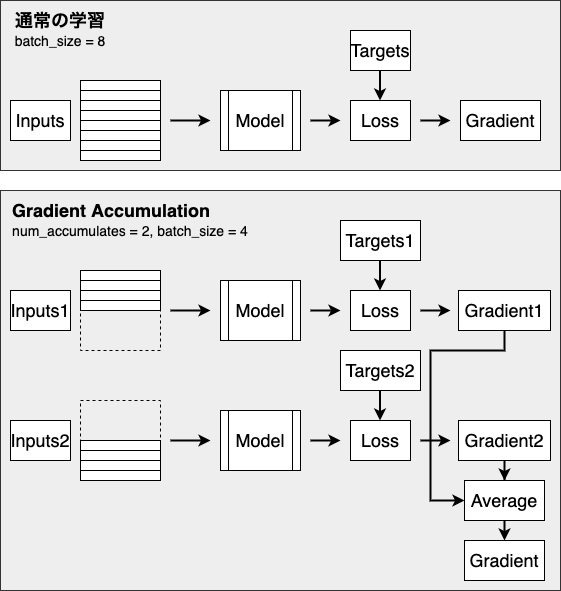
やることは単純で、小さい(メモリに乗る量の) batch size で計算した gradient を保存しておき、複数回分ためてから平均を取り、それを用いてモデルのパラメータを更新する、というものです。
複数回分の batch の計算で 1 step となるため、時間はかかってしまいますが、大きな batch size でモデルを学習させるのと同等になるため、精度は維持することができます。
TensorFlow 2.0 カスタムループでの実装
雑に簡略化した学習用コードを書いてみました。
説明用の notebook はこちらにおいてるので詳細見たい方はご覧ください〜?通常の学習 (gradient accumulation を使用しない) の場合
train_step内のtape.gradient(loss, model.trainable_variables)で loss から gradient を計算し、optimizer に渡して更新しています。no_accumulationdef train(config: Config, dataset: tf.data.Dataset, model: Model): global_step = 0 for e in range(config.num_epochs): global_step = train_epoch(config, dataset, model, global_step) print(f'{e+1} epoch finished. step: {global_step}') save(config.ckptdir, model) def train_epoch(config: Config, dataset: tf.data.Dataset, model: Model, start_step: int = 0) -> tf.Tensor: '''Train 1 epoch ''' gradients = None global_step = start_step for i, batch in enumerate(dataset): global_step = i + start_step x_train, y_train = batch gradients = train_step(x_train, y_train, loss_fn, optimizer) gradient_zip = zip(gradients, model.trainable_variables) optimizer.apply_gradients(gradient_zip) return global_step @tf.function def train_step(x_train: tf.Tensor, y_train: tf.Tensor, loss_fn: tf.keras.losses.Loss, optimizer: tf.keras.optimizers.Optimizer): '''Train 1 step and return gradients ''' with tf.GradientTape() as tape: outputs = model(x_train) loss = tf.reduce_mean(loss_fn(y_train, logits)) gradients = tape.gradient(loss, model.trainable_variables) return gradientsgradient accumulation の場合
複数ステップの gradients の平均を計算するためのメソッドを追加します。
tape.gradient(loss, model.trainable_variables)では各パラメータごとの tf.Tensor 型の gradientが List で返るため、それぞれの要素について平均を取るようにします。def accumulated_gradients(gradients: Optional[List[tf.Tensor]], step_gradients: List[tf.Tensor], num_grad_accumulates: int) -> tf.Tensor: '''Compute accumulated gradients by ones of this step and ones of accumulated Args: gradients: computed accumulated gradients so far step_gradients: gradients for this step num_grad_accumulates: the amount of accumulation ''' if gradients is None: gradients = [g / num_grad_accumulates for g in step_gradients] else: for i, g in enumerate(step_gradients): gradients[i] += g / num_grad_accumulates return gradients
train_stepで得られた step_gradients に上記のaccumulated_gradientsを適用して平均の gradients を得ます。
加えて、指定回数分計算されたときだけ optimizer でパラメータ更新を行うようにします。def train_epoch(config: Config, dataset: tf.data.Dataset, model: Model, start_step: int = 0) -> tf.Tensor: '''Train 1 epoch ''' gradients = None global_step = start_step for i, batch in enumerate(dataset): dummy_step = i + start_step * config.num_grad_accumulates x_train, y_train = batch step_gradients = train_step(x_train, y_train, loss_fn, optimizer) gradients = accumulated_gradients(gradients, step_gradients, config.num_grad_accumulates) if (dummy_step + 1) % config.num_grad_accumulates == 0: gradient_zip = zip(gradients, model.trainable_variables) optimizer.apply_gradients(gradient_zip) gradients = None if (global_step + 1) % config.step_summary_output == 0: write_train_summary(train_summary_writer, metrics, step=global_step + 1) global_step += 1 return global_step @tf.function def train_step(x_train: tf.Tensor, y_train: tf.Tensor, loss_fn: tf.keras.losses.Loss, optimizer: tf.keras.optimizers.Optimizer): with tf.GradientTape() as tape: outputs = model(x_train) loss = tf.reduce_mean(loss_fn(y_train, logits)) gradients = tape.gradient(loss, model.trainable_variables) return gradientstf.gather などの IndexSlices が得られる演算を使用している場合
先に結論
次のような
flat_gradientをかませばOKだと思います。メモリ効率は若干悪くなるので、もっと良いやり方が分かる方は教えていただけると幸いです def accumulated_gradients(gradients: Optional[List[tf.Tensor]], step_gradients: List[Union[tf.Tensor, tf.IndexedSlices]], num_grad_accumulates: int) -> tf.Tensor: '''Compute accumulated gradients by ones of this step and ones of accumulated Args: gradients: computed accumulated gradients so far step_gradients: gradients for this step num_grad_accumulates: the amount of accumulation ''' if gradients is None: gradients = [flat_gradients(g) / num_grad_accumulates for g in step_gradients] else: for i, g in enumerate(step_gradients): gradients[i] += flat_gradients(g) / num_grad_accumulates return gradients def flat_gradients(grads_or_idx_slices: tf.Tensor) -> tf.Tensor: '''Convert gradients to original size tf.Tensor if it's tf.IndexedSlices. When computing gradients for operation concerning `tf.gather`, the type of gradients is tf.IndexedSlices. ''' if type(grads_or_idx_slices) == tf.IndexedSlices: return tf.scatter_nd( tf.expand_dims(grads_or_idx_slices.indices, 1), grads_or_idx_slices.values, grads_or_idx_slices.dense_shape ) return grads_or_idx_slices
def accumulated_gradients(gradients: Optional[List[tf.Tensor]], step_gradients: List[Union[tf.Tensor, tf.IndexedSlices]], num_grad_accumulates: int) -> tf.Tensor: '''Compute accumulated gradients by ones of this step and ones of accumulated Args: gradients: computed accumulated gradients so far step_gradients: gradients for this step num_grad_accumulates: the amount of accumulation ''' if gradients is None: gradients = [flat_gradients(g) / num_grad_accumulates for g in step_gradients] else: for i, g in enumerate(step_gradients): gradients[i] += flat_gradients(g) / num_grad_accumulates return gradients def flat_gradients(grads_or_idx_slices: tf.Tensor) -> tf.Tensor: '''Convert gradients to original size tf.Tensor if it's tf.IndexedSlices. When computing gradients for operation concerning `tf.gather`, the type of gradients is tf.IndexedSlices. ''' if type(grads_or_idx_slices) == tf.IndexedSlices: return tf.scatter_nd( tf.expand_dims(grads_or_idx_slices.indices, 1), grads_or_idx_slices.values, grads_or_idx_slices.dense_shape ) return grads_or_idx_slices説明
自然言語処理の分野で embedding layer を使用しているなどのケースでは、モデルで
tf.gatherを利用していることが多いと思います。tf.gather を使っていると、tape.gradient(loss, model.trainable_variables)の返り値の List の中身の型が変わります。
具体的に BERT のモデルで gradients を計算したものを見てみたのが下記です。[ <tensorflow.python.framework.indexed_slices.IndexedSlices object at 0x7ff8a45c6358>, <tensorflow.python.framework.indexed_slices.IndexedSlices object at 0x7ff8a45c6400>, <tensorflow.python.framework.indexed_slices.IndexedSlices object at 0x7ff8a45c6438>, <tf.Tensor: shape=(1024,), dtype=float32, numpy=array([ 0.00075448, 0.00063159, 0.00468317, ..., 0.00663265, 0.00084392, -0.00198008], dtype=float32)>, .... ]4行目からは通常の
tf.Tensor型の gradients が続きますが、3行目までがtf.IndexedSlices型になってます。
tf.gatherは Embedding Matrix のような大きな行列から、特定の index の部分を取ってくるのに使われます。
TensorFlow > API > TensorFlow Core r2.1 > Python > tf.gather
自然言語処理の例で言うなら、元の embedding matrix は[vocab_size, embedding_size]の shape の行列で、vocab_sizeは数万オーダーになることが多いので、めちゃでかいです。
メモリ効率を上げるために、元の embedding matrix をまるまる保持するのではなく、必要な部分の Slice のみを保持するようにしたのがtf.IndexSlices型になります。
TensorFlow > API > TensorFlow Core r2.1 > Python > tf.IndexedSlicesこのまま gradients の平均を取ろうとすると、
tf.Tensor型ではないので四則演算などがそのまま適用できずエラーになります。今回は次のように元の matrix を復元して対応しています4。tf.scatter_nd(tf.expand_dims(idx_slices.indices, 1), idx_slices.values, idx_slices.dense_shape)以上です。
Pytorch は gradient accumulation めっちゃ簡単に出来るので羨ましいです

- 投稿日:2020-01-18T03:43:04+09:00
illustration2vecをkerasモデルに変換するコードを作ってみた
概要
https://github.com/rezoo/illustration2vec
illustration2vecはイラストの特徴やタグを検出できるモデルです。モデルの構造はほぼVGGモデルです。オリジナルのVGGとは変更されている箇所もあるので、詳細は上記リンクに解説論文があるのでそちらを。caffeとchainerのモデルです。面白いモデルですがchainerが開発終了するようなので、ぜひ再利用したいと思いkerasへの変換コードを書きました。torchは使ったことがないのでスルーで。実行はgoogle colaboratoryで行ったので以下にリンクを。
https://colab.research.google.com/drive/1UZN7pn4UzU5s501dwSIA2IHGmjnAmouYリンク先が開けない場合は以下をcolabにコピペすれば動くと思います。
全コード
!git clone https://github.com/rezoo/illustration2vec.git !sh illustration2vec/get_models.sh !pip install -r /content/illustration2vec/requirements.txt !mv /content/illustration2vec/i2v /content/ import i2v illust2vec_tag = i2v.make_i2v_with_chainer('/content/illustration2vec/illust2vec_tag_ver200.caffemodel', '/content/illustration2vec/tag_list.json') %tensorflow_version 2.x import tensorflow as tf import numpy as np #tag estimater model model_tag = tf.keras.Sequential(name='illustration2vec_tag') model_tag.add(tf.keras.layers.Input(shape=(224, 224, 3))) pool_idx = [0, 1, 3, 5, 7] for i, chainer_layer in enumerate(illust2vec_tag.net.children()): kernel, bias = tuple(chainer_layer.params()) k_kernel = np.transpose(kernel.data, axes=[3, 2, 1, 0]) bias = bias.data if i == 0: k_kernel = k_kernel[:,:,::-1,:] channel = bias.shape[0] keras_layer = tf.keras.layers.Conv2D(channel, 3, padding='SAME', activation='relu', kernel_initializer=tf.keras.initializers.constant(k_kernel), bias_initializer=tf.keras.initializers.constant(bias), name='Conv_%d'%i) model_tag.add(keras_layer) if i in pool_idx: model_tag.add(tf.keras.layers.MaxPooling2D()) del kernel, bias model_tag.add(tf.keras.layers.AveragePooling2D(pool_size=(7, 7))) model_tag.add(tf.keras.layers.Lambda(lambda x : tf.nn.sigmoid(tf.squeeze(x, axis=[1, 2])), name='sigmoid')) model_tag.save('illust2vec_tag_ver200.h5') del model_tag, illust2vec_tag #feature vector model illust2vec = i2v.make_i2v_with_chainer('/content/illustration2vec/illust2vec_ver200.caffemodel') model = tf.keras.Sequential(name='illustration2vec') model.add(tf.keras.layers.Input(shape=(224, 224, 3))) pool_idx = [0, 1, 3, 5, 7] for i, chainer_layer in enumerate(illust2vec.net.children()): if i == 12: break kernel, bias = tuple(chainer_layer.params()) if len(kernel.data.shape) == 4: k_kernel = np.transpose(kernel.data, axes=[3, 2, 1, 0]) bias = bias.data if i == 0: k_kernel = k_kernel[:,:,::-1,:] channel = bias.shape[0] keras_layer = tf.keras.layers.Conv2D(channel, 3, padding='SAME', activation='relu', kernel_initializer=tf.keras.initializers.constant(k_kernel), bias_initializer=tf.keras.initializers.constant(bias), name='Conv_%d'%i) model.add(keras_layer) if i in pool_idx: model.add(tf.keras.layers.MaxPooling2D()) elif i == 10: model.add(tf.keras.layers.Flatten()) elif len(kernel.data.shape) == 2: model.add(tf.keras.layers.Dense(4096, kernel_initializer=tf.keras.initializers.constant(kernel.data), bias_initializer=tf.keras.initializers.constant(bias.data), name='encode1')) del kernel, bias model.save('illust2vec_ver200.h5') del model, illust2vec def resize(imgs): mean = tf.constant(np.array([181.13838569, 167.47864617, 164.76139251]).reshape((1, 1, 3)), dtype=tf.float32) resized = [] for img in imgs: img = tf.cast(img, tf.float32) im_max = tf.reduce_max(img, keepdims=True) im_min = tf.reduce_min(img, keepdims=True) im_std = (img - im_min) / (im_max - im_min + 1e-10) resized_std = tf.image.resize(im_std, (224, 224)) resized_im = resized_std*(im_max - im_min) + im_min resized_im = resized_im - mean resized.append(tf.expand_dims(resized_im, 0)) return tf.concat(resized, 0)解説
やっていることはシンプルでkerasで同じ構造のモデルを定義してchainerモデルのweightで初期化しているだけです。
変更点は以下の3つ。
・weightのtranspose
このchainerモデルのconvolutionのカーネルは(out_channel, in_channel, k_size, k_size)になっていますが、kerasモデル用に(k_size, k_size, in_channel, out_channel)に転置しています。
・入力画像をBGRからRGBに変更
元のモデルは入力画像はBGRになっていますが、RGBでの入力に変更しました。そのため第1層の畳み込みのカーネルをin_channelの軸で逆順にしています。
・入力画像をchannel_lastに変更
chainerのconvolutionは入力は(N, C, H, W)になっていますが、kerasのデフォルトの(N, H, W, C)になっています。変換後のモデルの入力は(batch, 224, 224, 3)のサイズです。上記のcolabリンク先か全コードの中のresize関数に画像のnumpy.arrayのリストを渡せばリサイズ+正規化を行ってくれます。illust2vec_tag_ver200.h5とillust2vec_ver200.h5の2つのモデルがありますが、1つ目の出力はhttps://github.com/rezoo/illustration2vecにあるtag_list.jsonの1539個のタグそれぞれの確率になります。2つ目のモデルの出力は画像のfeature vectorになっています。
何か不備があれば指摘していただければと。
- 投稿日:2020-01-18T01:35:22+09:00
tf-pose-estimationを動かすためにインストールが必要な物まとめ
概要
tf-pose-estimationを動かす時に事前にインストールすべき物が結構あってそれが原因で詰まったりしたのでメモ
ちなみにtf-pose-estimationの導入は以下の記事を参考に行った。
https://qiita.com/ikekou/items/9a632b10588b423db172インストールが必要な物
Git
以下のコマンドを実行する際に必要になる事前作業です。
git clone https://www.github.com/ildoonet/tf-pose-estimation何はともあれGitをいれる。Git入れないとプロジェクトのクローンも実行できない。
MacでGit導入(Homebrew利用)
https://qiita.com/kimurayut/items/6f50cf1060e44e664c3bpython、pip、numpy
以下のコマンドを実行する際に必要になる事前作業です。
pip3 install -r requirements.txt
tf-pose-estimationはpythonを用いて利用することが多いので入れておく。
また、インストールはpip。numpyはプロジェクトのモジュールの中でインポートされているので入れておく。大丈夫かと思いますが、慣れていない方は以下の手順でインストールしてください。
$ brew install pyenv $ pyenv install 3.6.5 $ pyenv global 3.6.5 $ eval "$(pyenv init -)" $ pip3 install numpypcre,swig
以下のコマンドを実行する際に必要になる事前作業です。
$ swig -python -c++ pafprocess.i && python3 setup.py build_ext --inplaceインストールは以下の記事の手順を参考にしてください。
https://qiita.com/Rotten_Fruits/items/bb4764c765d7e1cdf96fwget
以下のコマンドを実行する際に必要になる事前作業です。
bash download.sh【インストール方法】
$ brew install wgetopencv,tensorflow
以下のコマンドを実行する際に必要になる事前作業です。
python -c 'import tf_pose; tf_pose.infer(image="./images/p1.jpg")'【インストール方法】
$ pip install opencv-python $ pip install -U tensorflow==1.15) ※tensorflowのバージョンは1.15にしてください以上
これでスムーズに導入できるはず!
