- 投稿日:2020-01-18T23:58:49+09:00
独学ではじめてAWS(EC2)にデプロイする方法⑩(macでNginxのインストールと設定)
Nginx
Webサーバの一種であるNginxの導入と設定を行います。
nginxは静的コンテンツ(つまりサーバ上のファイル)を高速に配信するように設計されている。
ユーザーのリクエストに対して静的コンテンツの取り出し処理を行い、そして動的コンテンツの生成をアプリケーションサーバに依頼することが可能Nginxをインストール
下記のコマンドでインストール
[ec2-user@ip-172-31-25-189 ~]$ sudo yum -y install nginxNginxの設定ファイルを編集
[ec2-user@ip-172-31-25-189 ~]$ sudo vim /etc/nginx/conf.d/rails.conf下記を貼り付ける
(ディレクトリの場所などは、自分にあった場所を指定してください)rails.confupstream app_server { # Unicornと連携させるための設定。 # アプリケーション名を自身のアプリ名に書き換えることに注意。今回であればおそらく server unix:/var/〇〇〇(アプリをまとめているディレクトリ)/〇〇〇〇〇〇<アプリケーション名>/tmp/sockets/unicorn.sock; } # {}で囲った部分をブロックと呼ぶ。サーバの設定ができる server { # このプログラムが接続を受け付けるポート番号 listen 80; # 接続を受け付けるリクエストURL ここに書いていないURLではアクセスできない server_name 18.〇〇〇.〇〇〇.〇〇(Elastic IP); # クライアントからアップロードされてくるファイルの容量の上限を2ギガに設定。デフォルトは1メガなので大きめにしておく client_max_body_size 2g; # 接続が来た際のrootディレクトリ root /var/www/〇〇〇〇〇<アプリケーション名>/public; # assetsファイル(CSSやJavaScriptのファイルなど)にアクセスが来た際に適用される設定 location ^~ /assets/ { gzip_static on; expires max; add_header Cache-Control public; } try_files $uri/index.html $uri @unicorn; location @unicorn { proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; proxy_pass http://app_server; } error_page 500 502 503 504 /500.html; }
- 3行目の<アプリケーション名> となっている箇所は、ご自身のものに変更してください。
- 11行目の<Elastic IP>となっている箇所も同様に、ご自身のものに変更してください。
- 14行目の<アプリケーション名> となっている箇所は、ご自身のものに変更してください。
Nginxの権限を変更
POSTメソッドでもエラーが出ないようにするために、下記のコマンドも実行してください。
[ec2-user@ip-172-31-25-189 ~]$ cd /var/lib [ec2-user@ip-172-31-25-189 lib]$ sudo chmod -R 775 nginxNginxを再起動して設定ファイルを再読み込み
[ec2-user@ip-172-31-25-189 lib]$ cd ~ [ec2-user@ip-172-31-25-189 ~]$ sudo service nginx restartローカルでunicorn.rb修正
listen 3000 ↓以下のように修正 listen "#{app_path}/tmp/sockets/unicorn.sock"Githubで変更点をpushしたら、本番環境でも反映させます。
ターミナル(EC2)[ec2-user@ip-172-31-25-189 ~]$ cd /var/www/アプリ名 [ec2-user@ip-172-31-23-189 <アプリ名>]$ git pull origin masterUnicornを再起動
[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ ps aux | grep unicorn ec2-user 17877 0.4 18.1 588472 182840 ? Sl 01:55 0:02 unicorn_rails master -c config/unicorn.rb -E production -D ec2-user 17881 0.0 17.3 589088 175164 ? Sl 01:55 0:00 unicorn_rails worker[0] -c config/unicorn.rb -E production -D ec2-user 17911 0.0 0.2 110532 2180 pts/0 S+ 02:05 0:00 grep --color=auto unicorn続いて、unicorn_rails master(一番上)のプロセスをkillします。
[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ kill <確認したunicorn rails masterのPID(上のコードでは17877)>unicornを起動します
[ec2-user@ip-172-31-23-189 <アプリ名>]$ RAILS_SERVE_STATIC_FILES=1 unicorn_rails -c config/unicorn.rb -E production -DブラウザからElastic IPでアクセス
https:// (Elastic IP)
これでサイトが表示されず、下記が表示されたら、、、、、、、、、
もう一度、下記をやり直してください。
Nginxの設定ファイルを編集
[ec2-user@ip-172-31-25-189 ~]$ sudo vim /etc/nginx/conf.d/rails.conf下記を貼り付ける
(ディレクトリの場所などは、自分にあった場所を指定してください)rails.confupstream app_server { # Unicornと連携させるための設定。 # アプリケーション名を自身のアプリ名に書き換えることに注意。今回であればおそらく server unix:/var/〇〇〇(アプリをまとめているディレクトリ)/〇〇〇〇〇〇<アプリケーション名>/tmp/sockets/unicorn.sock; } # {}で囲った部分をブロックと呼ぶ。サーバの設定ができる server { # このプログラムが接続を受け付けるポート番号 listen 80; # 接続を受け付けるリクエストURL ここに書いていないURLではアクセスできない server_name 18.〇〇〇.〇〇〇.〇〇(Elastic IP); # クライアントからアップロードされてくるファイルの容量の上限を2ギガに設定。デフォルトは1メガなので大きめにしておく client_max_body_size 2g; # 接続が来た際のrootディレクトリ root /var/www/〇〇〇〇〇<アプリケーション名>/public; # assetsファイル(CSSやJavaScriptのファイルなど)にアクセスが来た際に適用される設定 location ^~ /assets/ { gzip_static on; expires max; add_header Cache-Control public; } try_files $uri/index.html $uri @unicorn; location @unicorn { proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; proxy_pass http://app_server; } error_page 500 502 503 504 /500.html; }これで無事にサイトが表示されたら、完了です!
- 投稿日:2020-01-18T23:47:08+09:00
Capistranoでの自動デプロイでエラーが起きた際の対処方法
この記事について
この記事では、自身がRailsで開発しているアプリをCapistranoでデプロイをしようとした時にエラーが発生し、解決するまでに試した作業を書いています。
同様のエラーが起きた際に自分が読み返すために書いていますが、他の方の参考にもなれば嬉しいです。
前回の記事と同じような状況ながら違う原因でエラーが出ていたので、別の記事として書くことにしました。エラーが起こった時の状況
Capistranoで自動デプロイを実行したがエラーのため完了でしませんでした。
エラーの内容を確認してみると、以下のように書かれていました。00:15 deploy:migrating 01 $HOME/.rbenv/bin/rbenv exec bundle exec rake db:migrate 01 rake aborted! 01 StandardError: An error has occurred, all later migrations canceled: 01 01 Mysql2::Error: Table 'users' already exists: CREATE TABLE `users` (`id` bigint NOT NULL AUTO_INCREMENT PRIMARY KEY, `name` var…まだまだエラー表示は続きますが、要は「migrationでuserテーブルを作成しようとしたが、userテーブルが既に存在するので実行できません」ってことですね。
チーム開発をしている状況で、migrationファイルが変わってしまって上手くマイグレーションできなかったものと思われます。今後も開発中にチームメンバーの更新によって変更が発生する可能性も無くはないでしょうか。解決までの作業
今回のエラーはmigrationファイルと現状のデータベースで齟齬が発生してしまったため起こったものと考えられます。
そこでデータベースを一度削除し、1からマイグレーションを行うことで解決できると考えました。サーバー環境のMySQLに接続し、既存のデータベースを削除する
ターミナルからawsにアクセスし、データベースを操作するためにMySQLに接続します。
mysql -u root -pパスワードを入力すればMySQLへの接続が完了します。接続できたら既存のデータベースを削除します。まずは削除するデータベースを確認します。
show databases; # 実行結果 +--------------------+ | Database | +--------------------+ | information_schema | | sample_production | | mysql | | performance_schema | +--------------------+ 4 rows in set (0.00 sec)データベースの名前が確認できたら、そのデータベースを削除します。
mysql> drop database`sample_production`; # 実行結果 Query OK, 9 rows affected (0.07 sec)これで既存のデータベースは削除されました。
データベースを再作成する
データベースがないままだと自動デプロイができませんので、削除した後は再びデータベースを作成します。
MySQLからの操作でも作成できそうですが、今回はawsからの操作で作成します。mysql> quit [ec2-user@ip-111-111-111-111 sample]$ rails db:create RAILS_ENV=productionマイグレーションを実行する(自動デプロイを実行)
bundle exec cap production deploy以上です。今回はこの作業で自動デプロイができるように復旧できました。
- 投稿日:2020-01-18T23:31:36+09:00
AWS(EC2)でNginxのrails.confを設定する方法
AWSのNginxを設定する際に、rails.confファイルの設定をします。
この方法の説明が意外とないので、説明していきます
Nginxの設定ファイルを編集
[ec2-user@ip-172-31-25-189 ~]$ sudo vim /etc/nginx/conf.d/rails.confrails.confファイルが開かれたら、下記の記述をします。
rails.confupstream app_server { # Unicornと連携させるための設定。 # アプリケーション名を自身のアプリ名に書き換えることに注意。 server unix:/var/〇〇〇(アプリをまとめているディレクトリ)/〇〇〇〇〇〇<アプリケーション名>/tmp/sockets/unicorn.sock; } # {}で囲った部分をブロックと呼ぶ。サーバの設定ができる server { # このプログラムが接続を受け付けるポート番号 listen 80; # 接続を受け付けるリクエストURL ここに書いていないURLではアクセスできない server_name 18.〇〇〇.〇〇〇.〇〇(Elastic IP); # クライアントからアップロードされてくるファイルの容量の上限を2ギガに設定。デフォルトは1メガなので大きめにしておく client_max_body_size 2g; # 接続が来た際のrootディレクトリ root /var/www/〇〇〇〇〇<アプリケーション名>/public; # assetsファイル(CSSやJavaScriptのファイルなど)にアクセスが来た際に適用される設定 location ^~ /assets/ { gzip_static on; expires max; add_header Cache-Control public; } try_files $uri/index.html $uri @unicorn; location @unicorn { proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header Host $http_host; proxy_redirect off; proxy_pass http://app_server; } error_page 500 502 503 504 /500.html; }3行目の<アプリケーション名> となっている箇所は、ご自身のものに変更してください。
11行目の<Elastic IP>となっている箇所も同様に、ご自身のものに変更してください。
14行目の<アプリケーション名> となっている箇所は、ご自身のものに変更してください。これで設定ができます。
- 投稿日:2020-01-18T23:22:48+09:00
AWSのネットワークサービス
出展:AWS認定資格試験テキスト AWS認定 クラウドプラクティショナー
VPC
VPCの概要
・Amazon Virtual Private Cloudの略
・隔離されたプライベートなネットワーク構成をユーザがコントロールできるサービス
・主な機能要素
・VPC/サブネット/インターネットゲートウェイ/ルートテーブル/セキュリティグループ/ネットワークACL/NATゲートウェイVPCの作成
・リージョンを選択して複数のアベイラビリティゾーンをまたがって作成する
・CIDR(Classless Inter-Domain Routing)でVPCのプライベートIPアドレスを定義するサブネット
・アベイラビリティゾーンを選択して作成する
・CIDRでサブネットのプライベートIPアドレス範囲を定義する
・最初のIPアドレスと最後の1つのIPアドレスがAWSによって予約されている
例)・10.0.1.0:ネットワークアドレス
・10.0.1.1:VPCルータ用
・10.0.1.2:AWSで予約
・10.0.1.3:将来の利用のためにAWSで予約
・10.0.1.255:ネットワークブロードキャストアドレスインターネットゲートウェイ
・VPCとパブリックインターネットを接続するためのゲートウェイ
・水平スケーリングによる冗長性と高い可用性を持っているため、単一障害点(SPOF)にはならない
・帯域幅の制限なし
・作成してVPCにアタッチすることで使用できるルートテーブル
・サブネット内のリソースがどこに接続できるかを定義する
・VPCを選択して作成、エントリを設定しサブネットに関連付けることで、サブネットの通信経路を決定するパブリックサブネットとプライベートサブネット
・パブリックサブネット:
・インターネットゲートウェイに対してのルートを持つルートテーブルに関連付けられる
・パブリックサブネット内のインスタンスなどのリソースは、外部との直接通信ができる
・プライベートサブネット:
・インターネットゲートウェイに対してのルートを持たないルートテーブルに関連付けられる
・プライベートサブネット内のインスタンスは外部アクセスから保護できる
・プライベートサブネット内のリソースはパブリックサブネット内のリソースと通信できるセキュリティグループ
・インスタンスに対してのトラフィックを制御する仮想ファイアウォール
・許可するインバウンドのポートと送信元を設定するホワイトリスト
・送信元には、CIDRか他のセキュリティグループIDを指定できるネットワークACL
・サブネットに対して設定する仮想ファイアウォール機能
・デフォルトですべてのインバウンド(受信)とアウトバウンド(送信)が許可されている
・拒否するものだけを設定するブラックリストとして使用できる
・特に必要な要件がなければ、デフォルトのままでかまわない(追加のセキュリティレイヤー)外部からEC2インスタンスにアクセスするための重要ポイント
・インターネットゲートウェイをVPCにアタッチする
・インターネットゲートウェイへの経路を持つルートテーブルをサブネットに関連付ける
・EC2インスタンスをそのサブネット内で起動する
・EC2インスタンスにパブリックIPアドレスを有効にする
(またはEC2のパブリックIPアドレスを固定するElastic IPをアタッチする)ハイブリッド環境構成
・VPCに既存のオンプレミス環境からVPNまたは専用線で接続する
・既存のオンプレミス環境の拡張先としてAWSを使用するハードウェアVPN接続
・AWSに作成した仮想プライベートゲートウェイと、オンプレミス側のカスタマーゲートウェイを指定してVPN接続を作成する
例)社内のプライベートネットワークのみで稼働する業務アプリケーションをAWSで実現する
・仮想プライベートゲートウェイはVPCに1つアタッチできる
・インターネットゲートウェイ同様に可用性、冗長性に優れるダイレクトコネクト(AWS Direct Connect)
・AWSとデータセンターの間でプライベートなネットワーク接続を確立する
・帯域を確保する
・セキュリティとコンプライアンス要件を満たすCloudFront(Amazon CloudFront)
・世界中に150ヵ所以上あるエッジロケーションを使い、最も低いレイテンシー(遅延度)でコンテンツを配信できるコンテンツ配信ネットワーク(Contents Delivery Network、CDN)
CloudFrontの特徴
・キャッシュによる低レイテンシー配信
・エッジロケーションにキャッシュを持つことで低レイテンシー配信を実現する
・ユーザの近くからの低レイテンシー配信
・世界中のエッジロケーションが利用できるので、ユーザへは最もレイテンシーの低いエッジロケーションから配信される
・安全性の高いセキュリティ
・CloudFrontにユーザが所有しているドメインの証明書を設定することで、ユーザからHTTPSのアクセスを受けることができ、通信データを保護できる
・証明書はAmazon Certificate Managerを使用すると、追加費用なしで作成、管理できる
・AWS Shield、AWS WAFなどのセキュリティサービスと組み合わせることで、外部からの攻撃や脅威からオリジナルコンテンツを保護できるRoute 53(Amazon Route 53)
・DNSサービス
・ドメインに対してのIPアドレスをマッピングしてユーザからの問い合わせに回答する
・Route53はエッジロケーションで使用されるRoute 53の主な特徴
様々なルーティング機能
・シンプルルーティング:
問い合わせに対して、単一のIPアドレス情報を回答するシンプルなルーティング
・レイテンシーベースのルーティング/Geo DNS
1つのドメインに対して複数のDNSレコードを用意しておき、地理的な場所を近くしてレイテンシー(遅延度)が低くなるようにルーティングを行う
・加重ラウンドロビン:
1つのドメインに対して複数のレコードを用意しておき割合を決め、その割合に応じて回答を返す
・複数値回答:
複数のレコードからランダムに回答する高可用性を実現するヘルスチェックとフェイルオーバー
・ルーティングにヘルスチェックを組み合わせることで、システム全体の可用性を高める
ルートドメイン(Zone Apex)のエイリアスコード
・Zone Apexと呼ばれる、サブドメインのないトップレベルのルートドメインにエイリアス(別名)を設定することで、ルートドメインにも複数のリソースを設定でき、可用性の高いシステム機械を作ることができる
- 投稿日:2020-01-18T22:02:44+09:00
Github Actionsを使ってAWS Lambda関数を更新する
モチベーション
AWSコンソールを開いたり、AWS CLIを使わずに、gitの操作だけでAWS Lambda関数のデプロイを完了します。
近年、Github AcitonsというGithub純正のCI/CDツールがリリースされました。
これを使って、Githubで管理しているAWS Lambda関数の変更を、AWSに反映します。先駆者
検索すると、AWS Lambda関数をデプロイするGithub Acitonsがいくつか公開されているのが見つかります。1
例えば Deploy AWS Lambda function のソースコードを見てみましょう。
aws-sdkを使っているのがわかります。2
その中でもupdate_function_codeメソッドを使っています。3同様に
aws-sdkを使えば上手くいきそうです。
今回はRuby用のaws-sdk-lambda gemを使います。準備
IAMユーザー
万が一、AWSのIDとパスワードが漏れたときに、該アカウントだけを停止できるように、AWS上にdeploy専用のIAMユーザーを作成します。
必要なIAMポリシーは次のとおりです。{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": "lambda:UpdateFunctionCode", "Resource": "arn:aws:lambda:ap-northeast-1:XXXXXXXX:function:tange" } ] }
Actionには今回使いたいupdate_function_codeメソッドを表すlambda:UpdateFunctionCodeを指定します。
Resourceには、更新対象のLambda関数のARNの値を指定します。ここでは
arn:aws:lambda:ap-northeast-1:XXXXXXX:function:tangeを指定しました。Github Secrets
Github Actionsには、リポジトリに設定されたパスワードのような秘密情報を参照する機能があります。
IAMのaccess_key_idとsecret_access_keyをGithub Actionsから参照するのに使います。手順は暗号化されたシークレットの作成と利用 - GitHub ヘルプを参照してください。
Github Actions
完成形
最初に完成形を示します。これをLambda関数を管理しているリポジトリに追加すると、Github Acitonsは動作します。
.github/workflows/deploy_lambda.ymlname: Ruby on: [push] jobs: build: runs-on: ubuntu-latest steps: - uses: actions/checkout@v1 - name: Set up Ruby 2.5 uses: actions/setup-ruby@v1 with: ruby-version: 2.5.x - name: bundle install run: | gem install bundler bundle install --deployment - name: Zip run: | zip deploy_package lambda_function.rb -r vendor - name: Deploy env: access_key_id: ${{ secrets.access_key_id }} secret_access_key: ${{ secrets.secret_access_key }} run: | gem install aws-sdk-lambda bin/deploy各ジョブの解説
リポジトリへのpushに応じてGithub Actionsを起動する
on: [push]onには色々なトリガーが指定できます。
詳しくはワークフローをトリガーするイベント - GitHub ヘルプを見てください。ソースコードをチェックアウトする
- uses: actions/checkout@v1Ruby 2.5の環境を作る
AWS Lambdaはruby 2.5をサポートしています。4
- name: Set up Ruby 2.5 uses: actions/setup-ruby@v1 with: ruby-version: 2.5.x依存ライブラリをダウンロードする
- name: bundle install run: | gem install bundler bundle install --deployment
--deploymentをつけると、依存ライブラリはvendorディレクトリ配下に格納されます。zip圧縮
zipコマンドで必要なファイルを1つのzipファイルに纏めます。
- name: Zip run: | zip deploy_package lambda_function.rb -r vendor
deploy_packageは作成するzipファイル名です。
lambda_function.rbはzipファイルに含めるファイル名です。
AWS LambdaでRubyランタイムを使うときのデフォルトファイル名がlambda_function.rbです。
他に必要なファイルがあれば、空白で区切って続けて書いてください。
-r vendorはbundle installコマンドで保存した依存ライブラリをzipファイルに入れるためにつけています。
他に必要なディレクトリがあれば追加してください。AWSにアップロード
- name: Deploy env: access_key_id: ${{ secrets.access_key_id }} secret_access_key: ${{ secrets.secret_access_key }} run: | gem install aws-sdk-lambda bin/deployGithub Secretsに設定した秘密情報を読み込みます。
env: access_key_id: ${{ secrets.access_key_id }} secret_access_key: ${{ secrets.secret_access_key }}
${{ secrets.access_key_id }}がGithub Secretsを参照している箇所です。デプロイに必要な
aws-sdk-lambdagemをインストールして、デプロイを実行します。run: | gem install aws-sdk-lambda bin/deploy
bin/deployはRubyスクリプトです。bin/deploy#!/usr/bin/env ruby require "aws-sdk-lambda" client = Aws::Lambda::Client.new region: "ap-northeast-1", access_key_id: ENV["access_key_id"], secret_access_key: ENV["secret_access_key"] zip_file = File.open "deploy_package.zip", "r" client.update_function_code function_name: "tange", zip_file: zip_fileAws::Lambda::Client#update_function_codeを使って、AWS Lambda関数を更新します。
https://github.com/marketplace?utf8=%E2%9C%93&type=actions&query=lambda ↩
https://github.com/yvesgurcan/deploy-lambda-function/blob/master/index.js#L4 ↩
https://github.com/yvesgurcan/deploy-lambda-function/blob/master/index.js#L34 ↩
https://docs.aws.amazon.com/lambda/latest/dg/lambda-runtimes.html ↩
- 投稿日:2020-01-18T22:02:44+09:00
Github Actionsを使ってRuby製のAWS Lambda関数を更新する
モチベーション
AWSコンソールを開いたり、AWS CLIを使わずに、gitの操作だけでAWS Lambda関数のデプロイを完了します。
近年、Github AcitonsというGithub純正のCI/CDツールがリリースされました。
これを使って、Githubで管理しているAWS Lambda関数の変更を、AWSに反映します。前提条件
今回はRubyで作成されたAWS Lambda関数を更新します。
Lambda関数とデプロイスクリプトが同じ言語だとメンテナンスが楽なので、デプロイにもRubyを使います。先駆者
検索すると、AWS Lambda関数をデプロイするGithub Acitonsがいくつか公開されているのが見つかります。1
例えば Deploy AWS Lambda function のソースコードを見てみましょう。
aws-sdkを使っているのがわかります。2
その中でもupdate_function_codeメソッドを使っています。3引数にはZipファイルを指定しています。
AWSコンソールでAWS Lambda関数を更新するときと同様に、zipファイルを作って更新すれば良さそうです。Ruby用のaws-sdk-lambda gemを使います。
準備
IAMユーザー
万が一、AWSのIDとパスワードが漏れたときに、該アカウントだけを停止できるように、AWS上にdeploy専用のIAMユーザーを作成します。
必要なIAMポリシーは次のとおりです。{ "Version": "2012-10-17", "Statement": [ { "Sid": "VisualEditor0", "Effect": "Allow", "Action": "lambda:UpdateFunctionCode", "Resource": "arn:aws:lambda:ap-northeast-1:XXXXXXXX:function:tange" } ] }
Actionには今回使いたいupdate_function_codeメソッドを表すlambda:UpdateFunctionCodeを指定します。
Resourceには、更新対象のLambda関数のARNの値を指定します。ここでは
arn:aws:lambda:ap-northeast-1:XXXXXXX:function:tangeを指定しました。Github Secrets
Github Actionsには、リポジトリに設定されたパスワードのような秘密情報を参照する機能があります。
IAMのaccess_key_idとsecret_access_keyをGithub Actionsから参照するのに使います。手順は暗号化されたシークレットの作成と利用 - GitHub ヘルプを参照してください。
Github Actions
完成形
最初に完成形を示します。これをLambda関数を管理しているリポジトリに追加すると、Github Acitonsは動作します。
.github/workflows/deploy_lambda.ymlname: Ruby on: [push] jobs: build: runs-on: ubuntu-latest steps: - uses: actions/checkout@v1 - name: Ruby 2.5の環境を作る uses: actions/setup-ruby@v1 with: ruby-version: 2.5.x - name: 依存gemをダウンロード run: | gem install bundler bundle config set deployment 'true' bundle install - name: zip圧縮 run: | zip deploy_package lambda_function.rb -r vendor - name: AWSにアップロード env: access_key_id: ${{ secrets.access_key_id }} secret_access_key: ${{ secrets.secret_access_key }} run: | gem install aws-sdk-lambda bin/deploy各ジョブの解説
リポジトリへのpushに応じてGithub Actionsを起動する
on: [push]onには色々なトリガーが指定できます。
詳しくはワークフローをトリガーするイベント - GitHub ヘルプを見てください。ソースコードをチェックアウトする
- uses: actions/checkout@v1Ruby 2.5の環境を作る
AWS Lambdaはruby 2.5をサポートしています。4
- name: Ruby 2.5の環境を作る uses: actions/setup-ruby@v1 with: ruby-version: 2.5.x依存gemをダウンロード
- name: bundle install run: | gem install bundler bundle config set deployment 'true' bundle installAWS Lambdaでは、関数は実行可能は状態でアップロードする必要があります。
つまりアップロードzipファイルには依存ライブラリも入れる必要があります。
zipファイルに入れやすくするため、依存gemをローカルディレクトリにインストールします。
bundle config set deployment 'true'を設定すると、依存ライブラリはvendorディレクトリ配下に格納されます。zip圧縮
zipコマンドで必要なファイルを1つのzipファイルに纏めます。
- name: Zip run: | zip deploy_package lambda_function.rb -r vendor
deploy_packageは作成するzipファイル名です。
lambda_function.rbはzipファイルに含めるファイル名です。
AWS LambdaでRubyランタイムを使うときのデフォルトファイル名がlambda_function.rbです。
他に必要なファイルがあれば、空白で区切って続けて書いてください。
-r vendorはbundle installコマンドで保存した依存ライブラリをzipファイルに入れるためにつけています。
他に必要なディレクトリがあれば追加してください。AWSにアップロード
- name: Deploy env: access_key_id: ${{ secrets.access_key_id }} secret_access_key: ${{ secrets.secret_access_key }} run: | gem install aws-sdk-lambda bin/deployGithub Secretsに設定した秘密情報を読み込みます。
env: access_key_id: ${{ secrets.access_key_id }} secret_access_key: ${{ secrets.secret_access_key }}
${{ secrets.access_key_id }}がGithub Secretsを参照している箇所です。デプロイに必要な
aws-sdk-lambdagemをインストールして、デプロイを実行します。run: | gem install aws-sdk-lambda bin/deploy
bin/deployはRubyスクリプトです。bin/deploy#!/usr/bin/env ruby require "aws-sdk-lambda" client = Aws::Lambda::Client.new region: "ap-northeast-1", access_key_id: ENV["access_key_id"], secret_access_key: ENV["secret_access_key"] zip_file = File.open "deploy_package.zip", "r" client.update_function_code function_name: "tange", zip_file: zip_fileAws::Lambda::Client#update_function_codeを使って、AWS Lambda関数を更新します。
https://github.com/marketplace?utf8=%E2%9C%93&type=actions&query=lambda ↩
https://github.com/yvesgurcan/deploy-lambda-function/blob/master/index.js#L4 ↩
https://github.com/yvesgurcan/deploy-lambda-function/blob/master/index.js#L34 ↩
https://docs.aws.amazon.com/lambda/latest/dg/lambda-runtimes.html ↩
- 投稿日:2020-01-18T21:58:20+09:00
ActiveRecord::AdapterNotSpecified: 'production' database is not configured. が表示された場合
アセットコンパイル時に下記を実行するが
ターミナル(EC2)[ec2-user@ip-172-31-23-189 <アプリ名>]$ rails assets:precompile RAILS_ENV=productionこの際にエラーが表示される場合がある。
エラーが出る場合
ActiveRecord::AdapterNotSpecified: 'production' database is not configured. Available: ["default", "development", "test", "database", "username", "password", "socket"]下記を修正してください
database.yamlに『 <<: *default 』を追記する
(もともとあるが、いらないだろうと思い消してしまうとエラーが表示される)config/database.ymlproduction: <<: *default # ここが抜けているはず database: <%= Rails.application.credentials.db[:database] %> username: <%= Rails.application.credentials.db[:username] %> password: <%= Rails.application.credentials.db[:password] %> socket: <%= Rails.application.credentials.db[:socket] %>追記したらpullして更新しましょう
ターミナル(EC2)[ec2-user@ip-172-31-23-189 <アプリ名>] git pull origin master再度
ターミナル(EC2)[ec2-user@ip-172-31-23-189 <アプリ名>]$ rails assets:precompile RAILS_ENV=production今度は成功するはずです
- 投稿日:2020-01-18T20:43:35+09:00
AWS DeepLens Tips
AWS DeepLens Tips
TL;DR
AWS DeepLensがやっと届いたので動かしてました。
挙動を掴むまで結構ハマったので、注意点とか確認方法などのTipsを纏めてみました。トラブルシューティング
DeepLensのセットアップ中にインターネットに接続できない
手順にも記載されていますが仕様です。DeepLensのセットアップ時には
Registration用のUSBポートでセットアップで使用するPCに接続しますが、この際有線LANとして認識されます。
無線LANの設定よりも有線されるため、セットアップで使用しているPCが一時的に通常利用しているネットワークから切り離されます。注意書きを読み飛ばしているとびっくりするのでご注意を。
SSHでログインできない
初期設定ではSSHでログインできません。SSHサーバは別途設定を行って有効化する必要があります。
SSHの有効化をしても保存ができない
ネットで調べると、以下の
reset pinholeでセットアップ用のアクセスポイントを有効化して設定する方法がでてくる事がありますが、なぜかこの方法だとSSHの設定を変更しても保存ができません(なぜか保存ボタンが存在しない)。
Registration用のUSBポートでUSB接続した上で、AWSコンソールからデバイスの設定を変更する手順であればSSHを有効化して保存が可能です。ビデオストリームを表示するための4000ポートで待ち受けているサービスがない
色々いじっているとこの状態になることがあります。
ビデオストリームはvideoserverというプログラムが4000ポートでサービスしています。
videoserverは以下が本体です。/opt/awscam/awsmedia/video_server.py
videoserverが稼働しているかどうかは以下で確認ができます。sudo service videoserver status動いていないようであれば、以下の様に実行してみるとSSLエラーと表示されることがあります。
sudo /opt/awscam/awsmedia/video_server.pyなんらかの原因で証明書がおかしくなるらしく、この状態であれば以下のコマンドでawscamを再インストールすると直ります。
sudo apt-get install awscam --reinstall sudo apt-get install awscam-webserver --reinstall証明書をインストールしたのにChromeでビデオストリームが表示できない
Macの場合の話ですが、証明書をキーチェーンに登録した後にChromeは一度完全に終了させる必要があります。
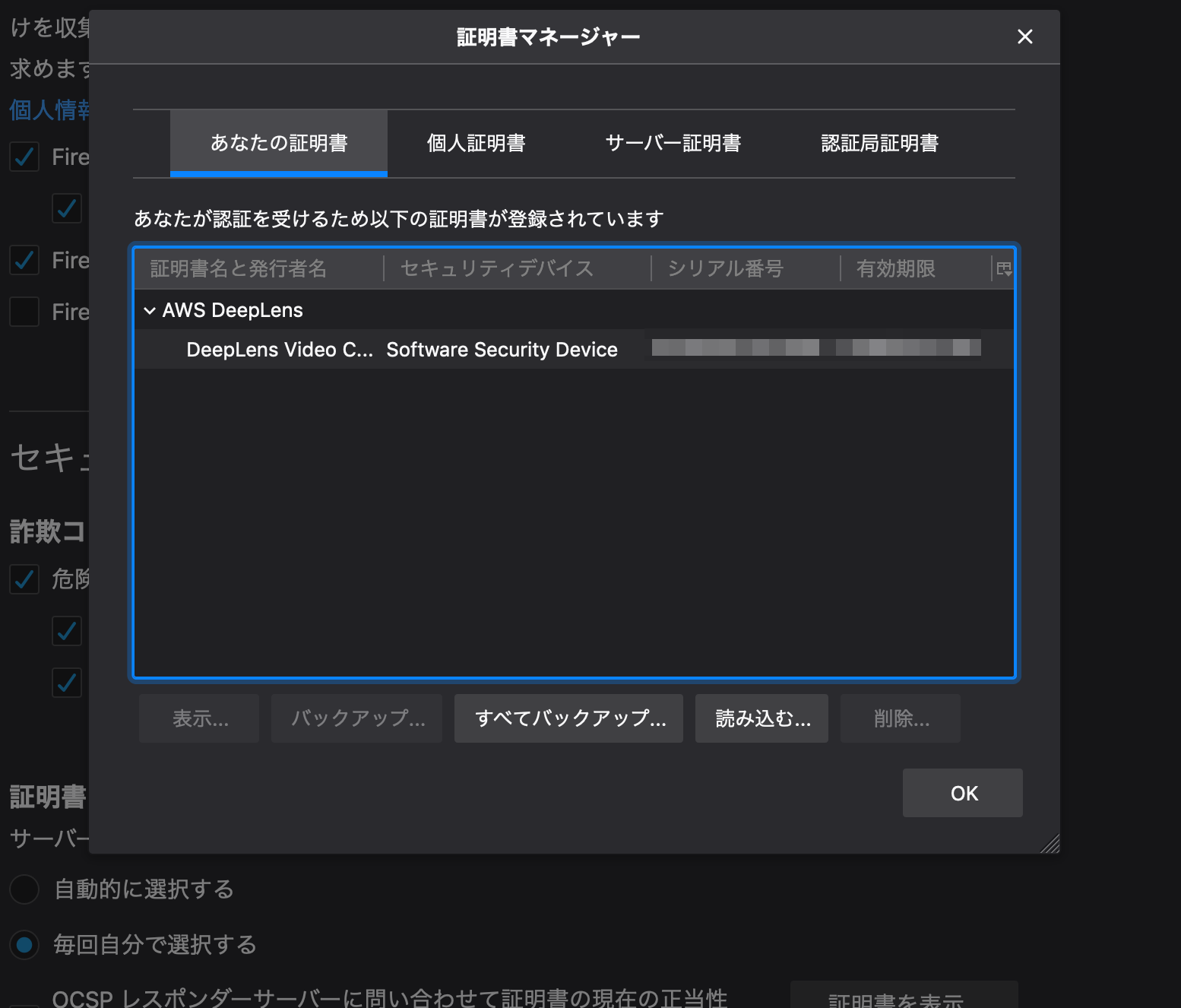
Firefoxでビデオストリームを表示できない
手順にもありますがFirefoxはキーチェーンではなく、Firefox固有の設定画面で設定する必要があります。
以下の画面です。
一番上のLEDが点灯しない
プロジェクトをデプロイしていない、あるいはデプロイしたプロジェクトが正しく起動していません。
デプロイしたプロジェクトはDeepLens上でLambdaとして起動します。DeepLens上のLambdaはpython2のプロセスとして表示されます。ps aux | grep python2これで表示されないようであれば、以下の様に
awscam関連のサービスを再インストールしてみると直るかもしれません。sudo apt-get install awscam --reinstall sudo apt-get install awscam-webserver --reinstallステルスSSIDの無線LANに接続したい
AWSコンソールからは設定できません。SSHで接続して設定する必要があります。
nmcli dev wifi connect "your-ssid" password "your-password" hidden yesとりあえずgreengrassdを再起動してみる
プロジェクトのデプロイが進まない場合や、デプロイしたプロジェクトが起動しない場合(AWSコンソール上でオンラインにならない場合)は、
greengrassdを再起動してみると改善するかもしれません。sudo service greengrassd restartdeeplens用のsource.listが無効になっている
原因が不明ですが、私の場合は
apt用のsourcelistが不完全な形で保存されていました。
aptが参照するリポジトリは/etc/apt/sources.listに設定されています。DeepLens固有のリポジトリは
aws_deeplens.listというファイル名で存在するはずですが、私の場合はなぜかaws_deeplens.list.saveだけ存在するという状態でした。この状態の場合、以下のコマンドでファイル名を変更してから
aptを実行する必要があるかも知れません。cd /etc/apt/sources.list sudo mv aws_deeplens.list.save aws_deeplens.list sudo apt-get update一番下のLEDが点滅している
awscam-intel-dldtというパッケージを再インストールすると治るかも知れません。sudo apt-get install awscam-intel-dldt --reinstallなぜか
videoserver.serviceのパーミッションが変
/var/log/syslogを見ていたらvideoserver.serviceのパーミッションが変だと警告が出ていました。
ほっといてもいいような気がしますが、以下のコマンドで修正できます。sudo chmod 644 /etc/systemd/system/videoserver.service工場出荷状態に戻したい
工場出荷状態に戻すためにはブート用のUSBメモリ(16GB以上)を用意し、ブートイメージと初期設定用のファイルをダウンロードして設定する必要があります。
以下の手順を参照してください。USBメモリのパーティション分割に指定があり、さらに一部のファイルシステムにNTFSを要求します。
MacでもWindowsでも簡単に必要な準備ができないので、(手元にあれば)Ubuntuマシンで行うかDeepLensにモニタとキーボード、マウスを接続して準備する必要があります。情報の確認
待ち受けているポート一覧を表示する
ss -antp | grep -i LISTENデーモンのステータスを確認する
service [デーモン名] statusservice greengrassd statusデーモンの一覧を確認する
service --status-allファイアウォールを無効化する
普通に使っている限りは必要ありません。
sudo ufw disable有効化する場合は以下を実行してください。
sudo ufw enableDeepLensの温度を確認する
DeepLensは推論まで行うためかなり機体の温度が高くなります。
熱のせいか不意に再起動するため、温度を確認したくなるかもしれません。grep temperature /var/log/syslog参考文献
- 投稿日:2020-01-18T20:23:04+09:00
Can't connect to local MySQL server through socket '/tmp/mysql.sock'が表示された場合
AWSのEC2にデプロイしようとした際に、下記エラーが表示された場合の対処方法をまとめたいと思います。
『Can't connect to local MySQL server through socket '/tmp/mysql.sock'』原因
問題点としては、下記のsocketに接続できないのが問題
credentials.ymldb: database: アプリ名 username: root password: 設定したPW socket: /var/lib/mysql/mysql.sock #ここに接続ができないmysqlを再起動すると、/var/lib/mysql/mysql.sockが自動的に作成されるので、起動
Can't connect to local MySQL server through socket '/tmp/mysql.sock' (2)
1) MySQLの起動確認
Mysql2::Error: Can't connect to local MySQL server through socket '/var/lib/mysql/mysql.sock'というエラーが起こった場合、mysqlが起動していない可能性があります。ターミナル(EC2)sudo service mysqld start #再起動をさせたい場合は、 sudo service mysqld restart改善があるか?確認
Can't connect to local MySQL server through socket '/tmp/mysql.sock' (13)
database.ymlとcredentials.ymlの中身に漏れがないか確認をしてください
database.ymlにsocketの記述漏れがあれば、エラーがおきますcredentials.ymldb: database: アプリ名 username: root password: 設定したPW socket: /var/lib/mysql/mysql.sockconfig/database.ymlproduction: database: <%= Rails.application.credentials.db[:database] %> username: <%= Rails.application.credentials.db[:username] %> password: <%= Rails.application.credentials.db[:password] %> socket: <%= Rails.application.credentials.db[:socket] %> #ここのsocketが抜けていないか???
- 投稿日:2020-01-18T20:23:04+09:00
Can't connect to local MySQL server through socket '/tmp/mysql.sock'が表示された場合(本番環境)
AWSのEC2にデプロイしようとした際に、下記エラーが表示された場合の対処方法をまとめたいと思います。
『Can't connect to local MySQL server through socket '/tmp/mysql.sock'』原因
問題点としては、下記のsocketに接続できないのが問題
credentials.ymldb: database: アプリ名 username: root password: 設定したPW socket: /var/lib/mysql/mysql.sock #ここに接続ができないmysqlを再起動すると、/var/lib/mysql/mysql.sockが自動的に作成されるので、起動
Can't connect to local MySQL server through socket '/tmp/mysql.sock' (2)
1) MySQLの起動確認
Mysql2::Error: Can't connect to local MySQL server through socket '/var/lib/mysql/mysql.sock'というエラーが起こった場合、mysqlが起動していない可能性があります。ターミナル(EC2)sudo service mysqld start #再起動をさせたい場合は、 sudo service mysqld restart改善があるか?確認
Can't connect to local MySQL server through socket '/tmp/mysql.sock' (13)
database.ymlとcredentials.ymlの中身に漏れがないか確認をしてください
database.ymlにsocketの記述漏れがあれば、エラーがおきますcredentials.ymldb: database: アプリ名 username: root password: 設定したPW socket: /var/lib/mysql/mysql.sockconfig/database.ymlproduction: database: <%= Rails.application.credentials.db[:database] %> username: <%= Rails.application.credentials.db[:username] %> password: <%= Rails.application.credentials.db[:password] %> socket: <%= Rails.application.credentials.db[:socket] %> #ここのsocketが抜けていないか???
- 投稿日:2020-01-18T19:19:12+09:00
AWS初心者が AWS 公式ドキュメントを読む前に
はじめに
エンジニアをしている方は、何か調べ物をする場合は基本的に公式ドキュメントを参照される方が多いと思います。しかし分かりやすいドキュメントの場合はよいのですが、AWS ユーザガイドは英語から機械翻訳をしているのか日本語が非常に読みづらいため、AWS初心者や初めて使うサービスの場合、AWS ドキュメントを参考に進めるとなかなか苦戦します。例:EC2 ユーザガイド
実際に自分も初めて AWS を使った時は、このAWS ドキュメントの理解にとても苦しめられました。そこで本記事では、AWS初心者の方が AWS のとあるサービスを初めて触る時にスムーズに理解できるようになるにはどうすればいいか について書こうと思います。
流れ
「AWS is 何」を3行でまとめてみるよ
まずは超概要を理解する。とりあえず、一言でどんなサービスなのかを理解する。超概要なので別にとばしてもよいです。
AWS Black Belt Online Seminar
次は AWS Black Belt Online Seminar (動画) をみる。一般的な知識から解説してくれるため、概要理解にはぴったり。1サービスだいたい1時間ぐらいで、話すスピードが全体的にゆっくりめなので、再生速度をあげて聞くのがおすすめです。動画で説明している PDF の資料は AWS サービス別資料 を参照しましょう。
Google 検索
サービス名+やりたいことここら辺でだいたいサービスの概要は理解できたため、じゃあ具体的にどう構築・実装するかについて考え始めるところだと思います。ここで Google検索で
サービス名+やりたいことで検索をします。例えば、ec2 サーバ構築というワードで検索します。何種類か検索するとわかると思いますが、Classmethod社の DeveloppersIO が上位に出てくると思います。やってみた系の記事中心に、画像豊富に説明をしてくれるのでとてもわかりやすいためとりあえずこれを見て、余裕があれば実際にサービスを触ってみるのがよいと思います。記事の作成日が古い場合、現状のサービスの機能と異なっていることがあるので注意しましょう。AWS 公式ドキュメント
おそらく細かい部分で情報が足りないことがあったり、ブログ記事だと正確ではないことがあります。よって最後には必ず AWS ユーザガイドを参照しましょう。おそらく、最初に AWS ユーザガイドを読むときと比較して、理解度が全然異なると思います。
その他
AWS 用語集
AWS における公式の用語集。用語がわからない時に参照する。
AWS関連本
AWS関連本は正直おすすめではないです。理由は、AWSに限らずクラウドサービスは進化がとても早いため、数ヶ月もすれば情報が陳腐化します。AWSの情報は公式を中心に収集するようにしましょう。
- 投稿日:2020-01-18T19:19:12+09:00
AWS初心者が公式ドキュメントを読む前に
はじめに
エンジニアをしている方は、何か調べ物をする場合は基本的に公式ドキュメントを参照される方が多いと思います。しかし分かりやすいドキュメントの場合はよいのですが、AWS ユーザガイドは英語から機械翻訳をしているのか日本語が非常に読みづらいため、AWS初心者や初めて使うサービスの場合、AWS ドキュメントを参考に進めるとなかなか苦戦します。例:EC2 ユーザガイド
実際に自分も初めて AWS を使った時は、このAWS ドキュメントの理解にとても苦しめられました。そこで本記事では、AWS初心者の方が AWS のとあるサービスを初めて触る時にスムーズに理解できるようになるにはどうすればいいか について書こうと思います。
流れ
1. 「AWS is 何」を3行でまとめてみるよ
まずは超概要を理解する。とりあえず、一言でどんなサービスなのかを理解する。超概要なので別にとばしてもよいです。
2. AWS Black Belt Online Seminar
次は AWS Black Belt Online Seminar (動画) をみる。一般的な知識から解説してくれるため、概要理解にはぴったり。1サービスだいたい1時間ぐらいで、話すスピードが全体的にゆっくりめなので、再生速度をあげて聞くのがおすすめです。動画で説明している PDF の資料は AWS サービス別資料 を参照しましょう。
3. Google 検索
サービス名+やりたいことここら辺でだいたいサービスの概要は理解できたため、じゃあ具体的にどう構築・実装するかについて考え始めるところだと思います。ここで Google検索で
サービス名+やりたいことで検索をします。例えば、ec2 サーバ構築というワードで検索します。何種類か検索するとわかると思いますが、Classmethod社の DeveloppersIO が上位に出てくると思います。やってみた系の記事中心に、画像豊富に説明をしてくれるのでとてもわかりやすいためとりあえずこれを見て、余裕があれば実際にサービスを触ってみるのがよいと思います。記事の作成日が古い場合、現状のサービスの機能と異なっていることがあるので注意しましょう。4. AWS 公式ドキュメント
おそらく細かい部分で情報が足りないことがあったり、ブログ記事だと正確ではないことがあるため最後は必ず AWS ユーザガイドを参照しましょう。おそらく最初に AWS ユーザガイドを読むときと比較して、理解度が全然異なると思います。
その他
AWS 用語集
AWS における公式の用語集です。用語がわからない時に参照しましょう。
AWS関連本
AWS関連本は正直おすすめではないです。理由は、AWSに限らずクラウドサービスは進化がとても早いため、数ヶ月もすれば情報が陳腐化します。AWSの情報は公式を中心に収集するようにしましょう。
- 投稿日:2020-01-18T19:19:12+09:00
AWS 公式ドキュメントを読む前に
はじめに
エンジニアをしている方は、何か調べ物をする場合は基本的に公式ドキュメントを参照される方が多いと思います。しかし分かりやすいドキュメントの場合はよいのですが、AWS ユーザガイドは英語から機械翻訳をしているのか日本語が非常に読みづらいため、AWS初心者や初めて使うサービスの場合、AWS ドキュメントを参考に進めるとなかなか苦戦します。例:EC2 ユーザガイド
実際に自分も初めて AWS を使った時は、このAWS ドキュメントの理解にとても苦しめられました。そこで本記事では、AWS初心者の方が AWS のとあるサービスを初めて触る時にスムーズに理解できるようになるにはどうすればいいか について書こうと思います。
流れ
1. 「AWS is 何」を3行でまとめてみるよ
まずは超概要を理解する。とりあえず、一言でどんなサービスなのかを理解する。超概要なので別にとばしてもよいです。
2. AWS Black Belt Online Seminar
次は AWS Black Belt Online Seminar (動画) をみる。一般的な知識から解説してくれるため、概要理解にはぴったり。1サービスだいたい1時間ぐらいで、話すスピードが全体的にゆっくりめなので、再生速度をあげて聞くのがおすすめです。動画で説明している PDF の資料は AWS サービス別資料 を参照しましょう。
3. Google 検索
サービス名+やりたいことここら辺でだいたいサービスの概要は理解できたため、じゃあ具体的にどう構築・実装するかについて考え始めるところだと思います。ここで Google検索で
サービス名+やりたいことで検索をします。例えば、ec2 サーバ構築というワードで検索します。何種類か検索するとわかると思いますが、Classmethod社の DeveloppersIO が上位に出てくると思います。やってみた系の記事中心に、画像豊富に説明をしてくれるのでとてもわかりやすいためとりあえずこれを見て、余裕があれば実際にサービスを触ってみるのがよいと思います。記事の作成日が古い場合、現状のサービスの機能と異なっていることがあるので注意しましょう。4. AWS 公式ドキュメント
おそらく細かい部分で情報が足りないことがあったり、ブログ記事だと正確ではないことがあるため最後は必ず AWS ユーザガイドを参照しましょう。おそらく最初に AWS ユーザガイドを読むときと比較して、理解度が全然異なると思います。
その他
AWS 用語集
AWS における公式の用語集です。用語がわからない時に参照しましょう。
AWS関連本
AWS関連本は正直おすすめではないです。理由は、AWSに限らずクラウドサービスは進化がとても早いため、数ヶ月もすれば情報が陳腐化します。AWSの情報は公式を中心に収集するようにしましょう。
- 投稿日:2020-01-18T19:18:22+09:00
rails5.2のmaster.keyを本番環境(AWS EC2)に設定する方法
master.keyを作成していないとどうなるのか?
master.keyを本番環境で設定しておかなければ、rails db:create RAILS_ENV=productionなどを実行した際にエラーが表示される。
rails db:create RAILS_ENV=productionを実行
$ rails db:create RAILS_ENV=productionするとエラーが表示される
rails aborted! NoMethodError: Cannot load database configuration: undefined method `[]' for nil:NilClassこの'[]'はdatabase.ymlの下記が読み込めないために発生する。
database.ymlproduction: <<: *default database: <%= Rails.application.credentials.db[:database] %> username: <%= Rails.application.credentials.db[:username] %> password: <%= Rails.application.credentials.db[:password] %> socket: <%= Rails.application.credentials.db[:socket] %>'[]'は、[:database]、[:username]、[:password]、[:socket]が読み込めないことを意味している。
なぜ読み込めないのか?
credential.ymlの中身は他の人が閲覧できないように暗号化されている。
この暗号化を解除するのがmaster.key。
master.keyは扉を開ける鍵の役割をしており、鍵を使って解除しなければ、その先のデータを読み込むことができない。これは、本番環境でも同じです。
master.keyがなければ、暗号化を解除できないので、環境変数を読み込めずエラーとなる。本番環境のshared/configにmaster.keyを作成
ローカル環境にある,master.keyの中身を確認する
rails newで作成された、ローカルのmaster.keyを確認する。
$ vi config/master.keyすると下記のようにmaster.keyの中身が表示されます。
fadfdfdgaf44623535y....この表示された、master.keyの値をコピーしましょう
表示されたmaster.keyをコピーします。
これを本番環境で貼り付けていきます。本番環境でmaster.keyを作成
EC2のアプリのconfigを開きましょう
#本番環境 [ec2-user@ip-172-31-23-189 ~]$ cd /var/ここはそれぞれ違います/[アプリ名] [ec2-user@ip-172-31-23-189 <アプリ名>]$ cd configそうしたら、本番環境上でmaster.keyを作成します
[ec2-user@ip-172-31-23-189 config]$ vi master.key # ローカル環境のmaster.keyの値を入力 fsdgagaf08deg424~~~~~画像だと下記のような画面になります。
『 i 』を押すと----INSERT-----と表示がされて、文字入力ができます。
ここにコピーしたローカルのmaster.keyの値を貼り付けします。『 esc 』ボタンを押した後、:wq入力して保存します
これで本番環境でもmaster.keyが設定されています。

- 投稿日:2020-01-18T19:18:22+09:00
【rails5.2】master.keyを本番環境(AWS EC2)に設定する方法
master.keyを作成していないとどうなるのか?
master.keyを本番環境で設定しておかなければ、rails db:create RAILS_ENV=productionなどを実行した際にエラーが表示される。
rails db:create RAILS_ENV=productionを実行
$ rails db:create RAILS_ENV=productionするとエラーが表示される
rails aborted! NoMethodError: Cannot load database configuration: undefined method `[]' for nil:NilClassこの'[]'はdatabase.ymlの下記が読み込めないために発生する。
database.ymlproduction: <<: *default database: <%= Rails.application.credentials.db[:database] %> username: <%= Rails.application.credentials.db[:username] %> password: <%= Rails.application.credentials.db[:password] %> socket: <%= Rails.application.credentials.db[:socket] %>'[]'は、[:database]、[:username]、[:password]、[:socket]などの環境変数が読み込めないことを意味している。
なぜ読み込めないのか?
credential.ymlの中身は他の人が閲覧できないように暗号化されている。
この暗号化を解除するのがmaster.key。
master.keyは扉を開ける鍵の役割をしており、鍵を使って解除しなければ、その先のデータを読み込むことができない。これは、本番環境でも同じです。
master.keyがなければ、暗号化を解除できないので、環境変数を読み込めずエラーとなる。本番環境のshared/configにmaster.keyを作成
ローカル環境にある,master.keyの中身を確認する
rails newで作成された、ローカルのmaster.keyを確認する。
$ vi config/master.keyすると下記のようにmaster.keyの中身が表示されます。
fadfdfdgaf44623535y....この表示された、master.keyの値をコピーしましょう
表示されたmaster.keyをコピーします。
これを本番環境で貼り付けていきます。本番環境でmaster.keyを作成
EC2のアプリのconfigを開きましょう
#本番環境 [ec2-user@ip-172-31-23-189 ~]$ cd /var/ここはそれぞれ違います/[アプリ名] [ec2-user@ip-172-31-23-189 <アプリ名>]$ cd configそうしたら、本番環境上でmaster.keyを作成します
[ec2-user@ip-172-31-23-189 config]$ vi master.key # ローカル環境のmaster.keyの値を入力 fsdgagaf08deg424~~~~~画像だと下記のような画面になります。
『 i 』を押すと----INSERT-----と表示がされて、文字入力ができます。
ここにコピーしたローカルのmaster.keyの値を貼り付けします。『 esc 』ボタンを押した後、:wq入力して保存します
これで本番環境でもmaster.keyが設定されています。
- 投稿日:2020-01-18T19:18:22+09:00
【rails5.2】master.keyを本番環境(AWS EC2)に設定(追加作成)する方法
master.keyを作成していないとどうなるのか?
master.keyを本番環境で設定しておかなければ、rails db:create RAILS_ENV=productionなどを実行した際にエラーが表示される。
rails db:create RAILS_ENV=productionを実行
$ rails db:create RAILS_ENV=productionするとエラーが表示される
rails aborted! NoMethodError: Cannot load database configuration: undefined method `[]' for nil:NilClassこの'[]'はdatabase.ymlの下記が読み込めないために発生する。
database.ymlproduction: <<: *default database: <%= Rails.application.credentials.db[:database] %> username: <%= Rails.application.credentials.db[:username] %> password: <%= Rails.application.credentials.db[:password] %> socket: <%= Rails.application.credentials.db[:socket] %>'[]'は、[:database]、[:username]、[:password]、[:socket]などの環境変数が読み込めないことを意味している。
なぜ読み込めないのか?
credential.ymlの中身は他の人が閲覧できないように暗号化されている。
この暗号化を解除するのがmaster.key。
master.keyは扉を開ける鍵の役割をしており、鍵を使って解除しなければ、その先のデータを読み込むことができない。これは、本番環境でも同じです。
master.keyがなければ、暗号化を解除できないので、環境変数を読み込めずエラーとなる。本番環境のshared/configにmaster.keyを作成
ローカル環境にある,master.keyの中身を確認する
rails newで作成された、ローカルのmaster.keyを確認する。
$ vi config/master.keyすると下記のようにmaster.keyの中身が表示されます。
fadfdfdgaf44623535y....この表示された、master.keyの値をコピーしましょう
表示されたmaster.keyをコピーします。
これを本番環境で貼り付けていきます。本番環境でmaster.keyを作成
EC2のアプリのconfigを開きましょう
#本番環境 [ec2-user@ip-172-31-23-189 ~]$ cd /var/ここはそれぞれ違います/[アプリ名] [ec2-user@ip-172-31-23-189 <アプリ名>]$ cd configそうしたら、本番環境上でmaster.keyを作成します
[ec2-user@ip-172-31-23-189 config]$ vi master.key # ローカル環境のmaster.keyの値を入力 fsdgagaf08deg424~~~~~画像だと下記のような画面になります。
『 i 』を押すと----INSERT-----と表示がされて、文字入力ができます。
ここにコピーしたローカルのmaster.keyの値を貼り付けします。『 esc 』ボタンを押した後、:wq入力して保存します
これで本番環境でもmaster.keyが設定されています。
- 投稿日:2020-01-18T18:47:34+09:00
独学ではじめてAWSのEC2にデプロイする方法⑨(Railsの起動)
ポートの解放
config/unicorn.rb に listen 3000 と記述しましたが、これはRailsのサーバを3000番ポートで起動するということを意味するのでした。
HTTPがつながるように「ポート」を開放する必要があります。手順
1.EC2を開く
2. 『実行中のインスタンス』を開く
3. インスタンスを選択
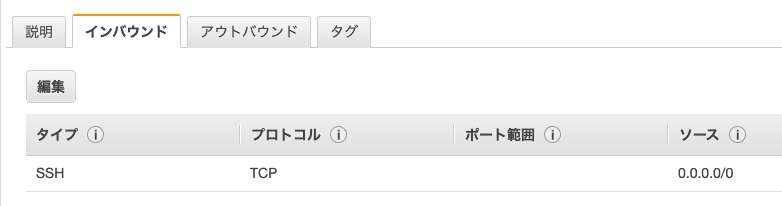
4. セキュリティグループの『launch-wizard-3』をクリック
5. 下記の画面が表示される
6.『 インバウンド 』を選択
7. 『 編集 』をクリック
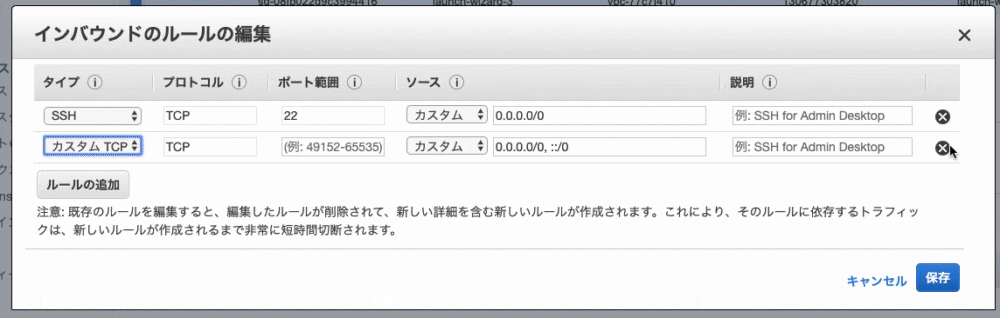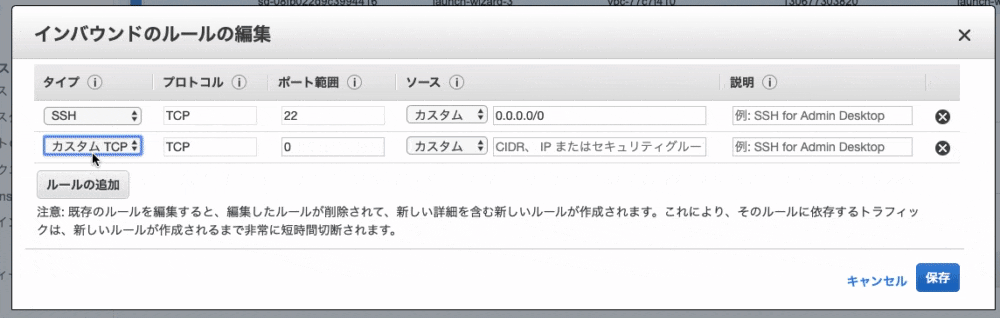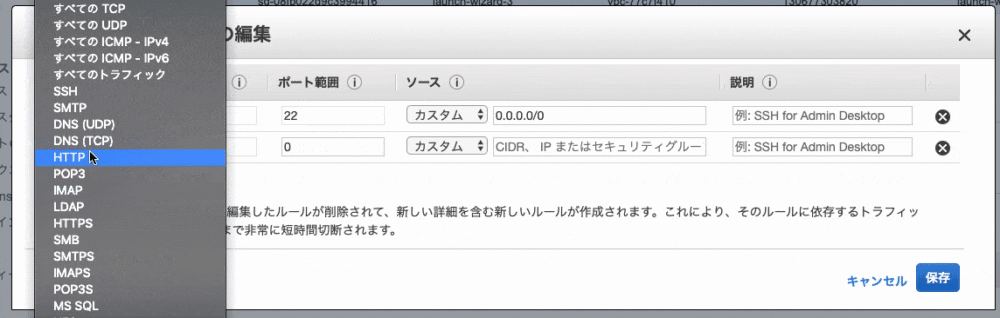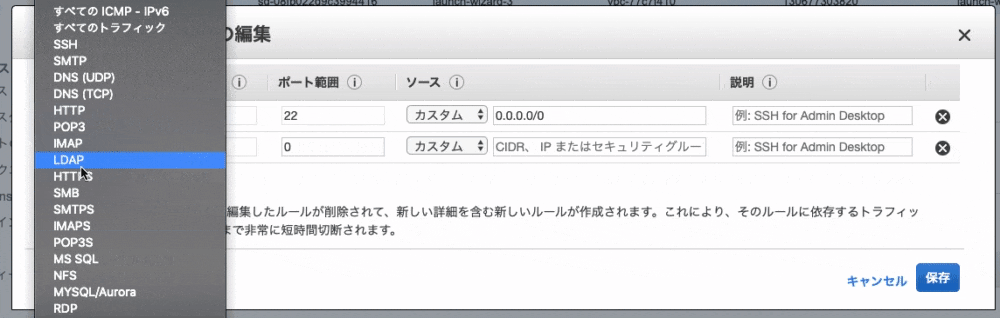
8. 左下の『ルールの追加』をクリック
9. タイプ:「カスタムTCPルール」、プロトコルを「TCP」、ポート範囲を「3000」、送信元を「カスタム」「0.0.0.0/0」に設定
10. 画面左下の『 保存 』をクリックRailsの起動
Rails 5.1以前の場合
database.ymlに下記を追加します
config/database.yml(ローカル)production: <<: *default database: アプリ名 username: root password: <%= ENV['DATABASE_PASSWORD'] %> socket: /var/lib/mysql/mysql.sock追記が完了したら、EC2でも反映させます。
EC2とGithubは接続できているため、git pullコマンドを利用します。ターミナル(EC2)[ec2-user@ip-172-31-23-189 <アプリ名>] git pull origin masterデータベースの作成をする
ターミナル(EC2)[ec2-user@ip-172-31-23-189 <アプリ名>]$ rails db:create RAILS_ENV=production Created database '<データベース名>'この際に下記の表示が出た場合、、、うまくいっていません。
アプリのディレクトリを開いてからコマンドを実行しましょう
#うまくいかない = アプリ名を指定していない [ec2-user@ip-172-31-23-189 ~( ここが指定されていない )]$ rails db:create RAILS_ENV=production Created database '<データベース名>' #アプリ名(リポジトリ)を指定しているのでちゃんと処理がされる [ec2-user@ip-172-31-23-189 <アプリ名>]$ rails db:create RAILS_ENV=production Created database '<データベース名>'rails db:migrateを実行して、migrationを完了させる。
ターミナル(EC2)[ec2-user@ip-172-31-23-189 <アプリ名>]$ rails db:migrate RAILS_ENV=productionエラーが出る場合
Mysql2::Error: Can't connect to local MySQL server through socket '/var/lib/mysql/mysql.sock'というエラーが起こった場合、mysqlが起動していない可能性があります。
ターミナル(EC2)sudo service mysqld start #再起動をさせたい場合は、 sudo service mysqld restartというコマンドをターミナルから打ち込み、mysqlの起動を試してみましょう。
参考記事
Can't connect to local MySQL server through socket '/tmp/mysql.sock' (2)ユニコーンを起動
[ec2-user@ip-172-31-23-189 ~]$ cd /var/www/[リポジトリ] [ec2-user@ip-172-31-23-189 <app名>]$ bundle exec unicorn_rails -c config/unicorn.rb -E production -DRails5.2以降の場合
credentials.ymlの設定
ターミナル(ローカル)アプリ名 $ EDITOR=vim bin/rails credentials:editすると編集画面が表示されます。
しかし文字入力ができないので、
『 i 』を押して、----INSERT----モードに変更します下記を入力します。
credentials.ymldb: database: アプリ名 username: root password: 設定したPW socket: /var/lib/mysql/mysql.sockpasswordははじめてAWSでデプロイする方法⑤(EC2の環境構築、Ruby, MySQL)の『MySQLのrootパスワードの設定』で設定しています。
次に、database.ymlにcredential.ymlで設定した環境変数を記述します
config/database.ymlproduction: <<: *default database: <%= Rails.application.credentials.db[:database] %> username: <%= Rails.application.credentials.db[:username] %> password: <%= Rails.application.credentials.db[:password] %> socket: <%= Rails.application.credentials.db[:socket] %>本番環境のshared/configにmaster.keyを作成
ローカル環境にある,master.keyの中身を確認する
rails newで作成された、ローカルのmaster.keyを確認する。
$ vi config/master.keyすると下記のようにmaster.keyの中身が表示されます。
fadfdfdgaf44623535y....この表示された、master.keyの値をコピーしましょう
表示されたmaster.keyをコピーします。
これを本番環境で貼り付けていきます。本番環境でmaster.keyを作成
EC2のアプリのconfigを開きましょう
#本番環境 [ec2-user@ip-172-31-23-189 ~]$ cd /var/ここはそれぞれ違います/[アプリ名] [ec2-user@ip-172-31-23-189 <アプリ名>]$ cd shared/configそうしたら、本番環境上でmaster.keyを作成します
[ec2-user@ip-172-31-23-189 config]$ vi master.key # ローカル環境のmaster.keyの値を入力 fsdgagaf08deg424~~~~~画像だと下記のような画面になります。
『 i 』を押すと----INSERT-----と表示がされて、文字入力ができます。
ここにコピーしたローカルのmaster.keyの値を貼り付けします。『 esc 』ボタンを押した入力モードを終了
『 :wq 』入力して保存しますこれで本番環境でもmaster.keyが設定されています。
ユニコーンを起動
[ec2-user@ip-172-31-23-189 ~]$ cd /var/www/[リポジトリ] [ec2-user@ip-172-31-23-189 <app名>]$ bundle exec unicorn_rails -c config/unicorn.rb -E production -Dエラーが発生した場合
Can't connect to local MySQL server through socket '/tmp/mysql.sock' (2)
Mysql2::Error: Can't connect to local MySQL server through socket '/var/lib/mysql/mysql.sock'というエラーが起こった場合、mysqlが起動していない可能性があります。
ターミナル(EC2)sudo service mysqld start #再起動をさせたい場合は、 sudo service mysqld restartCan't connect to local MySQL server through socket '/tmp/mysql.sock' (13)
database.ymlとcredentials.ymlの中身に漏れがないか確認をしてください
credentials.ymldb: database: アプリ名 username: root password: 設定したPW socket: /var/lib/mysql/mysql.sockconfig/database.ymlproduction: <<: *default database: <%= Rails.application.credentials.db[:database] %> username: <%= Rails.application.credentials.db[:username] %> password: <%= Rails.application.credentials.db[:password] %> socket: <%= Rails.application.credentials.db[:socket] %> #ここのsocketが抜けていないか???サイトにアクセスしてみる
ブラウザで http://<サーバに紐付けたElastic IP>:3000/ にアクセスしてみましょう
ブラウザにCSSの反映されていない(ビューが崩れている)画面が表示されていれば成功です。アセットコンパイルする
レイアウトが崩れてしまっているでしょう。
開発中には正常に表示されていたのに、本番ではうまく表示されないのはなぜでしょうか?
これは、開発中はアクセス毎にアセットファイル(画像・CSS・JSファイルの総称)を自動的にコンパイル(圧縮)する仕組みが備わっていますが、本番モードのときにはパフォーマンスのためアクセス毎には実行されないようになっているためです。
ターミナル(EC2)[ec2-user@ip-172-31-23-189 <アプリ名>]$ rails assets:precompile RAILS_ENV=production成功した場合Yarn executable was not detected in the system. Download Yarn at https://yarnpkg.com/en/docs/install I, [2020-01-18T12:51:01.4345644 #1265] INFO -- : Writing /var/app/web-share/public/assets/member_photo_noimage_thumb-224a733c50d48aba6d9fdaded809788bbeb5ea5f6d6b8368adaebb95e58bcf53.png I, [2020-01-18T12:51:02.2615123#1265] INFO -- : Writing /var/app/appname/public/assets/application-bc071e28a78e2b63c9313afed5ad3476e00e3f0e5b12445c37214d1f1317be48.js I, [2020-01-18T12:51:02.2626434 #1265] INFO -- : Writing /var/app/appname/public/assets/application-bc071e28a78e2b63c9313afed5ad3476e00e3f0e5b12445c37214d1f1317be48.js.gz I, [2020-01-18T12:51:08.484546 #1265] INFO -- : Writing /var/app/appname/public/assets/application-8549fb9a804686e593d5c0f90a2412a39de85908e5fb58fdf6681d4b0073d891.css I, [2020-01-18T12:51:08.485454 #1265] INFO -- : Writing /var/app/appname/public/assets/application-8549fb9a804686e593d5c0f90a2412a39de85908e5fb58fdf6681d4b0073d891.css.gzエラーが出る場合
ActiveRecord::AdapterNotSpecified: 'production' database is not configured. Available: ["default", "development", "test", "database", "username", "password", "socket"]下記を修正してください
config/database.ymlproduction: <<: *default # ここが抜けているはず database: <%= Rails.application.credentials.db[:database] %> username: <%= Rails.application.credentials.db[:username] %> password: <%= Rails.application.credentials.db[:password] %> socket: <%= Rails.application.credentials.db[:socket] %>追記したら
ターミナル(EC2)[ec2-user@ip-172-31-23-189 <アプリ名>] git pull origin master再度
ターミナル(EC2)[ec2-user@ip-172-31-23-189 <アプリ名>]$ rails assets:precompile RAILS_ENV=production今度は成功するはずです
成功した場合Yarn executable was not detected in the system. Download Yarn at https://yarnpkg.com/en/docs/install I, [2020-01-18T12:51:01.4345644 #1265] INFO -- : Writing /var/app/web-share/public/assets/member_photo_noimage_thumb-224a733c50d48aba6d9fdaded809788bbeb5ea5f6d6b8368adaebb95e58bcf53.png I, [2020-01-18T12:51:02.2615123#1265] INFO -- : Writing /var/app/appname/public/assets/application-bc071e28a78e2b63c9313afed5ad3476e00e3f0e5b12445c37214d1f1317be48.js I, [2020-01-18T12:51:02.2626434 #1265] INFO -- : Writing /var/app/appname/public/assets/application-bc071e28a78e2b63c9313afed5ad3476e00e3f0e5b12445c37214d1f1317be48.js.gz I, [2020-01-18T12:51:08.484546 #1265] INFO -- : Writing /var/app/appname/public/assets/application-8549fb9a804686e593d5c0f90a2412a39de85908e5fb58fdf6681d4b0073d891.css I, [2020-01-18T12:51:08.485454 #1265] INFO -- : Writing /var/app/appname/public/assets/application-8549fb9a804686e593d5c0f90a2412a39de85908e5fb58fdf6681d4b0073d891.css.gzRailsの再起動
コンパイルが成功したら反映を確認するため、Railsを再起動します。しかし、まずは今動いているUnicornをストップします。
EC2のターミナルから以下のように入力します。「aux」と打っているのは、psコマンドのオプションです。表示結果を見やすくしてくれます。また、| grep unicornとしているのはpsコマンドの結果からunicorn関連のプロセスのみを抽出するためです。
[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ ps aux | grep unicorn ec2-user 17877 0.4 18.1 588472 182840 ? Sl 01:55 0:02 unicorn_rails master -c config/unicorn.rb -E production -D ec2-user 17881 0.0 17.3 589088 175164 ? Sl 01:55 0:00 unicorn_rails worker[0] -c config/unicorn.rb -E production -D ec2-user 17911 0.0 0.2 110532 2180 pts/0 S+ 02:05 0:00 grep --color=auto unicorn大事なのは左から2番目の列です。ここに表示されるのがプロセスのid、つまりPIDになります。
「unicorn_rails master」と表示されているプロセスがUnicornのプロセス本体です。この時のPIDは、17877となっています。[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ kill <確認したunicorn rails masterのPID>killコマンド:現在動いているプロセスを停止させるためのコマンドです
再度、プロセスを表示させ終了できていることを確認しましょう。
[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ ps aux | grep unicorn ... ec2-user 17911 0.0 0.2 110532 2180 pts/0 S+ 02:05 0:00 grep --color=auto unicorn3つあった項目が一つになっています
では、Railsを起動させましょう!
[ec2-user@ip-172-31-23-189 <リポジトリ名>]$ RAILS_SERVE_STATIC_FILES=1 unicorn_rails -c config/unicorn.rb -E production -Dもう一度、ブラウザで http://<Elastic IP>:3000/ にアクセスしてみましょう。今度はレイアウト崩れも無くサイトが正常に表示されていることでしょう。
参考
【Rails5.2】credentials.yml.encとmaster.keyでのデプロイによる今までとの変更点
【備忘録】credentials.yml.encにdatabase設定を保存する





- 投稿日:2020-01-18T16:27:00+09:00
Railsチュートリアル第1章で勉強をブロックしたやつ
はじめに
この記事では私がRailsチュートリアルの第1章でつまづいた所を共有します。
個人的な備忘録ですが、プログラミング学習入門で人気のRailsなのでお役に立てればうれしいです!実行環境
AWS Cloud9を使用しました。チュートリアルの手順通りに環境設定しました。
問題
rails serverを実行し、アプリケーションをブラウザで開こうとしたところ、
まったく開きませんでした...解決策
色々調べた結果、ブラウザに導入していた広告ブロックが邪魔をしていました。広告ブロックを停止するとブラウザでRailsのウェルカム画面が無事表示されました。
また、下図のような表示がずっとでていましたが、EC2を再起動すれば解決しました。
こちらの記事が参考になります。
まとめ
広告ブロックはプログラミング学習以外では非常に便利ですが、プログラミング学習するときは常時切っておくほうがよいかもしれません。

- 投稿日:2020-01-18T16:20:37+09:00
AWS CDKでのFargateデプロイ
前回の記事「Cloudformationを使ったFargateサービスのデプロイプロセスについて考えてみた」のCDK版です。
CDKを実際に使ってみたかったので、比較も兼ねて前回のCloudformationファイルをCDKに置き換えてみました。
(一部設定を変えている部分がありますので全て完全に一致しているわけではないです)前回記事の「4.Fargateへのデプロイ」の部分の代替手段となる方法ですので前回記事とあわせてご確認ください。
コードはこちら。
https://github.com/nyasba/fargate-spring-web/tree/qiita-cdk/cdkdeployFargateへのデプロイ(CDK版)
プロジェクト構成
typescript+yarnで開発しました。
├── README.md ├── bin コマンド実行時のエンドポイントとなるtsファイル ├── cdk.context.json cdkのcontextで参照したデータの保存ファイル(VPC内のネットワーク構成など次回のStack作成時に変更すべきでないリソースの情報を保存する) ├── cdk.json cdk実行時のapp引数のデフォルト設定ファイル ├── cdk.out cdkの出力ファイル ├── jest.config.js テスト用の設定ファイル ├── lib cdkのコード ├── node_modules ├── package.json ├── test テストコード ├── tsconfig.json └── yarn.lock yarnのlockファイル※cdk.context.jsonはデプロイした環境が保存されるので本来はGit管理下においておくべきものです
https://docs.aws.amazon.com/cdk/latest/guide/context.htmlCDKのコード説明
CDKのentrypointとなるコードです。ここの中で既存で存在するVPCをCDKのインスタンスとして取得する(Lookup)はできないようでした。
bin/cdkdeploy.ts#!/usr/bin/env node import 'source-map-support/register'; import * as cdk from '@aws-cdk/core'; import { AlbFargateStack } from '../lib/alb-fargate-stack'; import devProps from '../env/example.json' const app = new cdk.App(); const stack = new AlbFargateStack(app, devProps.projectName, devProps); app.synth();Stackクラスです。 Props/ExportはCDKのコードの作法に合わせました。基本HighLevelなクラスを利用して作成することにしています。前回の記事から変更したところはPrivateSubnetにSubnetを配置し、PublicIPを割り当てないようにした点です。そのため、事前にPrivateLinkの設定が必要となっています。
lib/alb-fargate-stack.tsimport * as cdk from '@aws-cdk/core'; import ec2 = require("@aws-cdk/aws-ec2"); import ecs = require("@aws-cdk/aws-ecs"); import ecr = require("@aws-cdk/aws-ecr"); import elbv2 = require('@aws-cdk/aws-elasticloadbalancingv2'); import applicationautoscaling = require('@aws-cdk/aws-applicationautoscaling') import iam = require('@aws-cdk/aws-iam') import logs = require("@aws-cdk/aws-logs"); import { Duration, Tag } from '@aws-cdk/core'; import { StackPropsBase, StackExportsBase } from './stack-base'; import { SubnetSelection } from '@aws-cdk/aws-ec2'; interface AlbFargateStackProps extends StackPropsBase { ecrRepositoryName: string, vpcId: string, albSubnetSelection?: SubnetSelection, ecsSubnetSelection?: SubnetSelection, logGroupName: string, taskExecutionRoleName: string, containerRoleName: string, autoscalingRoleName: string } interface AlbFargateStackExports extends StackExportsBase { endpointUrl: string } export class AlbFargateStack extends cdk.Stack { readonly props: AlbFargateStackProps readonly exports: AlbFargateStackExports constructor(scope: cdk.Construct, id: string, props: AlbFargateStackProps) { super(scope, id, props) this.props = props // vpc (既存リソースを参照する) const appVpc = ec2.Vpc.fromLookup(this, 'VPC', { vpcId: this.props.vpcId }) // role (既存リソースを参照する) const appTaskExecutionRole = iam.Role.fromRoleArn(this, 'task-exec-role', `arn:aws:iam::${this.account}:role/${this.props.taskExecutionRoleName}`) const appContainerRole = iam.Role.fromRoleArn(this, 'task-role', `arn:aws:iam::${this.account}:role/${this.props.containerRoleName}`) const appAutoscalingRole = iam.Role.fromRoleArn(this, 'autoscaling-role', `arn:aws:iam::${this.account}:role/${this.props.autoscalingRoleName}`) // tagの設定 全般に適用される Tag.add(this, 'project', this.props.projectName) // sg for alb const albSecurityGroup = new ec2.SecurityGroup(this, this.createResourceName('alb-sg'), { securityGroupName: this.createResourceName('alb-sg'), vpc: appVpc }) albSecurityGroup.addIngressRule(ec2.Peer.anyIpv4(), ec2.Port.tcp(80)) albSecurityGroup.addIngressRule(ec2.Peer.anyIpv4(), ec2.Port.tcp(443)) // sg for ecs serivce const ecsSecurityGroup = new ec2.SecurityGroup(this, this.createResourceName('ecs-sg'), { securityGroupName: this.createResourceName('ecs-sg'), vpc: appVpc }) ecsSecurityGroup.addIngressRule(albSecurityGroup, ec2.Port.tcp(80)) // alb target group const albTargetGroup = new elbv2.ApplicationTargetGroup(this, this.createResourceName('tg'), { vpc: appVpc, targetGroupName: this.createResourceName('tg'), protocol: elbv2.ApplicationProtocol.HTTP, port: 80, healthCheck: { path: "/healthcheck" } }) // alb const appAlb = new elbv2.ApplicationLoadBalancer(this, this.createResourceName('alb'), { vpc: appVpc, vpcSubnets: appVpc.selectSubnets(this.props.albSubnetSelection || { subnetType: ec2.SubnetType.PUBLIC }), loadBalancerName: this.createResourceName('alb'), internetFacing: true, securityGroup: albSecurityGroup }) appAlb.addListener(this.createResourceName('alb-listener'), { protocol: elbv2.ApplicationProtocol.HTTP, port: 80, defaultTargetGroups: [albTargetGroup] }) // ecs cluster const appCluster = new ecs.Cluster(this, this.createResourceName('cluster'), { vpc: appVpc, clusterName: this.createResourceName('cluster') }) // log group for ecs (import) const appLogGroup = logs.LogGroup.fromLogGroupName(this, this.createResourceName('log-group'), this.props.logGroupName) // ecr repository (import) const appEcrRepository = ecr.Repository.fromRepositoryName(this, this.createResourceName('repository'), this.props.ecrRepositoryName) // task definition const appTaskDefinition = new ecs.TaskDefinition(this, this.createResourceName('task'), { family: this.createResourceName('task'), executionRole: appTaskExecutionRole, taskRole: appContainerRole, networkMode: ecs.NetworkMode.AWS_VPC, compatibility: ecs.Compatibility.FARGATE, cpu: '512', memoryMiB: '1024' }) // container definition const appContainerDefinition = new ecs.ContainerDefinition(this, this.createResourceName('container'), { image: ecs.ContainerImage.fromEcrRepository(appEcrRepository, 'latest'), environment: { "Key": "Test" }, logging: ecs.LogDriver.awsLogs({ streamPrefix: this.createResourceName(''), logGroup: appLogGroup }), taskDefinition: appTaskDefinition }) appContainerDefinition.addPortMappings({ containerPort: 80, hostPort: 80, protocol: ecs.Protocol.TCP }) // service const appService = new ecs.FargateService(this, this.createResourceName('service'), { cluster: appCluster, assignPublicIp: false, desiredCount: 1, serviceName: this.createResourceName('service'), taskDefinition: appTaskDefinition, vpcSubnets: appVpc.selectSubnets(this.props.ecsSubnetSelection || { subnetType: ec2.SubnetType.PRIVATE }), securityGroup: ecsSecurityGroup, healthCheckGracePeriod: Duration.minutes(2), deploymentController: { type: ecs.DeploymentControllerType.ECS } }) albTargetGroup.addTarget(appService.loadBalancerTarget({ containerName: appContainerDefinition.containerName, containerPort: appContainerDefinition.containerPort })) // auto scaling const appAutoScaling = new applicationautoscaling.ScalableTarget(this, this.createResourceName('scalabletarget'), { minCapacity: 1, maxCapacity: 2, resourceId: `service/${appCluster.clusterName}/${appService.serviceName}`, role: appAutoscalingRole, scalableDimension: "ecs:service:DesiredCount", serviceNamespace: applicationautoscaling.ServiceNamespace.ECS }) new applicationautoscaling.TargetTrackingScalingPolicy(this, this.createResourceName('policy'), { policyName: this.createResourceName('policy'), scalingTarget: appAutoScaling, targetValue: 80, predefinedMetric: applicationautoscaling.PredefinedMetric.ECS_SERVICE_AVERAGE_CPU_UTILIZATION, disableScaleIn: false, scaleInCooldown: Duration.minutes(5), scaleOutCooldown: Duration.minutes(5), }) // output設定 new cdk.CfnOutput(this, 'output', { exportName: 'endpointUrl', value: `http://${appAlb.loadBalancerDnsName}/` }) } private createResourceName(suffix: string): string { return `${this.props.projectName}-${this.props.profile}-${suffix}` } }テスト
3種類のテストがあるが、いずれもあまりテストを書くほどの効果が見込めないのでテストは書かない
- snapshotテスト:cdkのバージョンアップに伴うテンプレートの出力内容の差分チェックができるのはよいが、そこまではしなくてもよいと判断
- full-grainedテスト:固定値を設定するところばかりのため、ユニットテストが有効な部分が見当たらなかった
- validationテスト:カスタムでバリデーション実装していないため意味がなさそう
デプロイ
事前準備
- プロファイルおよびインプットパラメータの設定を行っておくこと
- VPCにはPublic/Privateサブネットを用意しておくこと
- PrivateサブネットにはS3、ECR、CloudWatchLogsへのエンドポイント(PrivateLink)を設定しておくこと
- LogGroupを作成しておくこと
- 設定ファイルに指定したIAMロールを事前に作っておくこと
- 設定ファイルに指定したECRリポジトリを事前に作り、アプリケーションをpushしておくこと
環境構築
コードをCloneしてきて、ライブラリをインストール
yarn install設定(プロファイル)
https://docs.aws.amazon.com/ja_jp/cli/latest/userguide/cli-configure-profiles.html
設定
env/xxx.jsonという形式で管理し、cdkdeploy.tsの中で直接importする。env/example.jsonを書き換えても構わないcloudformationのテンプレート出力
cdk synth --profile xxxtsファイルのコンパイル(できてないと違うものがデプロイされるので要注意)
yarn build実行
cdk deploy --profile xxx This deployment will make potentially sensitive changes according to your current security approval level (--require-approval broadening). Please confirm you intend to make the following modifications: IAM Statement Changes ┌───┬────────────────────────────────────────────────────────────────────────┬────────┬─────────────────────────────────────────────────────────────────────────┬──────────────────────────┬───────────┐ │ │ Resource │ Effect │ Action │ Principal │ Condition │ ├───┼────────────────────────────────────────────────────────────────────────┼────────┼─────────────────────────────────────────────────────────────────────────┼──────────────────────────┼───────────┤ │ + │ * │ Allow │ ecr:GetAuthorizationToken │ AWS:ecsTaskExecutionRole │ │ ├───┼────────────────────────────────────────────────────────────────────────┼────────┼─────────────────────────────────────────────────────────────────────────┼──────────────────────────┼───────────┤ │ + │ arn:${AWS::Partition}:ecr:ap-northeast-1:xxxxxxxxxxxx:repository/webap │ Allow │ ecr:BatchCheckLayerAvailability │ AWS:ecsTaskExecutionRole │ │ │ │ p │ │ ecr:BatchGetImage │ │ │ │ │ │ │ ecr:GetDownloadUrlForLayer │ │ │ ├───┼────────────────────────────────────────────────────────────────────────┼────────┼─────────────────────────────────────────────────────────────────────────┼──────────────────────────┼───────────┤ │ + │ arn:${AWS::Partition}:logs:ap-northeast-1:xxxxxxxxxxxx:log-group:farga │ Allow │ logs:CreateLogStream │ AWS:ecsTaskExecutionRole │ │ │ │ te-webapp-dev-log-group │ │ logs:PutLogEvents │ │ │ └───┴────────────────────────────────────────────────────────────────────────┴────────┴─────────────────────────────────────────────────────────────────────────┴──────────────────────────┴───────────┘ Security Group Changes ┌───┬──────────────────────────────────────┬─────┬────────────┬──────────────────────────────────────┐ │ │ Group │ Dir │ Protocol │ Peer │ ├───┼──────────────────────────────────────┼─────┼────────────┼──────────────────────────────────────┤ │ + │ ${fargate-webapp-dev-alb-sg.GroupId} │ In │ TCP 80 │ Everyone (IPv4) │ │ + │ ${fargate-webapp-dev-alb-sg.GroupId} │ In │ TCP 443 │ Everyone (IPv4) │ │ + │ ${fargate-webapp-dev-alb-sg.GroupId} │ Out │ Everything │ Everyone (IPv4) │ ├───┼──────────────────────────────────────┼─────┼────────────┼──────────────────────────────────────┤ │ + │ ${fargate-webapp-dev-ecs-sg.GroupId} │ In │ TCP 80 │ ${fargate-webapp-dev-alb-sg.GroupId} │ │ + │ ${fargate-webapp-dev-ecs-sg.GroupId} │ Out │ Everything │ Everyone (IPv4) │ └───┴──────────────────────────────────────┴─────┴────────────┴──────────────────────────────────────┘ (NOTE: There may be security-related changes not in this list. See https://github.com/aws/aws-cdk/issues/1299) Do you wish to deploy these changes (y/n)? y fargate-webapp-dev: deploying... fargate-webapp-dev: creating CloudFormation changeset... 0/14 | 16:08:31 | CREATE_IN_PROGRESS | AWS::EC2::SecurityGroup | fargate-webapp-dev-alb-sg (fargatewebappdevalbsg) 0/14 | 16:08:31 | CREATE_IN_PROGRESS | AWS::IAM::Policy | task-exec-role/Policy (taskexecrolePolicy) 0/14 | 16:08:32 | CREATE_IN_PROGRESS | AWS::ElasticLoadBalancingV2::TargetGroup | fargate-webapp-dev-tg (fargatewebappdevtg) 0/14 | 16:08:32 | CREATE_IN_PROGRESS | AWS::CDK::Metadata | CDKMetadata 0/14 | 16:08:32 | CREATE_IN_PROGRESS | AWS::ECS::TaskDefinition | fargate-webapp-dev-task (fargatewebappdevtask) 0/14 | 16:08:32 | CREATE_IN_PROGRESS | AWS::ECS::Cluster | fargate-webapp-dev-cluster (fargatewebappdevcluster) 0/14 | 16:08:32 | CREATE_IN_PROGRESS | AWS::EC2::SecurityGroup | fargate-webapp-dev-ecs-sg (fargatewebappdevecssg) 0/14 | 16:08:32 | CREATE_IN_PROGRESS | AWS::ECS::TaskDefinition | fargate-webapp-dev-task (fargatewebappdevtask) Resource creation Initiated 0/14 | 16:08:32 | CREATE_IN_PROGRESS | AWS::ECS::Cluster | fargate-webapp-dev-cluster (fargatewebappdevcluster) Resource creation Initiated 1/14 | 16:08:32 | CREATE_COMPLETE | AWS::ECS::TaskDefinition | fargate-webapp-dev-task (fargatewebappdevtask) 1/14 | 16:08:33 | CREATE_IN_PROGRESS | AWS::ElasticLoadBalancingV2::TargetGroup | fargate-webapp-dev-tg (fargatewebappdevtg) Resource creation Initiated 2/14 | 16:08:33 | CREATE_COMPLETE | AWS::ElasticLoadBalancingV2::TargetGroup | fargate-webapp-dev-tg (fargatewebappdevtg) 3/14 | 16:08:33 | CREATE_COMPLETE | AWS::ECS::Cluster | fargate-webapp-dev-cluster (fargatewebappdevcluster) 3/14 | 16:08:33 | CREATE_IN_PROGRESS | AWS::IAM::Policy | task-exec-role/Policy (taskexecrolePolicy) Resource creation Initiated 3/14 | 16:08:34 | CREATE_IN_PROGRESS | AWS::CDK::Metadata | CDKMetadata Resource creation Initiated 4/14 | 16:08:34 | CREATE_COMPLETE | AWS::CDK::Metadata | CDKMetadata 4/14 | 16:08:37 | CREATE_IN_PROGRESS | AWS::EC2::SecurityGroup | fargate-webapp-dev-alb-sg (fargatewebappdevalbsg) Resource creation Initiated 4/14 | 16:08:37 | CREATE_IN_PROGRESS | AWS::EC2::SecurityGroup | fargate-webapp-dev-ecs-sg (fargatewebappdevecssg) Resource creation Initiated 5/14 | 16:08:39 | CREATE_COMPLETE | AWS::EC2::SecurityGroup | fargate-webapp-dev-alb-sg (fargatewebappdevalbsg) 6/14 | 16:08:39 | CREATE_COMPLETE | AWS::EC2::SecurityGroup | fargate-webapp-dev-ecs-sg (fargatewebappdevecssg) 6/14 | 16:08:41 | CREATE_IN_PROGRESS | AWS::EC2::SecurityGroupIngress | fargate-webapp-dev-ecs-sg/from fargatewebappdevfargatewebappdevalbsg:80 (fargatewebappdevecssgfromfargatewebappdevfargatewebappdevalbsg) 6/14 | 16:08:41 | CREATE_IN_PROGRESS | AWS::ElasticLoadBalancingV2::LoadBalancer | fargate-webapp-dev-alb (fargatewebappdevalb) 6/14 | 16:08:41 | CREATE_IN_PROGRESS | AWS::EC2::SecurityGroupIngress | fargate-webapp-dev-ecs-sg/from fargatewebappdevfargatewebappdevalbsg:80 (fargatewebappdevecssgfromfargatewebappdevfargatewebappdevalbsg) Resource creation Initiated 7/14 | 16:08:42 | CREATE_COMPLETE | AWS::EC2::SecurityGroupIngress | fargate-webapp-dev-ecs-sg/from fargatewebappdevfargatewebappdevalbsg:80 (fargatewebappdevecssgfromfargatewebappdevfargatewebappdevalbsg) 7/14 | 16:08:42 | CREATE_IN_PROGRESS | AWS::ElasticLoadBalancingV2::LoadBalancer | fargate-webapp-dev-alb (fargatewebappdevalb) Resource creation Initiated 8/14 | 16:08:50 | CREATE_COMPLETE | AWS::IAM::Policy | task-exec-role/Policy (taskexecrolePolicy) 8/14 Currently in progress: fargatewebappdevalb 9/14 | 16:10:44 | CREATE_COMPLETE | AWS::ElasticLoadBalancingV2::LoadBalancer | fargate-webapp-dev-alb (fargatewebappdevalb) 9/14 | 16:10:46 | CREATE_IN_PROGRESS | AWS::ElasticLoadBalancingV2::Listener | fargate-webapp-dev-alb/fargate-webapp-dev-alb-listener (fargatewebappdevalbfargatewebappdevalblistene) 9/14 | 16:10:47 | CREATE_IN_PROGRESS | AWS::ElasticLoadBalancingV2::Listener | fargate-webapp-dev-alb/fargate-webapp-dev-alb-listener (fargatewebappdevalbfargatewebappdevalblistene) Resource creation Initiated 10/14 | 16:10:47 | CREATE_COMPLETE | AWS::ElasticLoadBalancingV2::Listener | fargate-webapp-dev-alb/fargate-webapp-dev-alb-listener (fargatewebappdevalbfargatewebappdevalblistene) 10/14 | 16:11:01 | CREATE_IN_PROGRESS | AWS::ECS::Service | fargate-webapp-dev-service/Service (fargatewebappdevserviceService) 10/14 | 16:11:02 | CREATE_IN_PROGRESS | AWS::ECS::Service | fargate-webapp-dev-service/Service (fargatewebappdevserviceService) Resource creation Initiated 10/14 Currently in progress: fargatewebappdevserviceService 11/14 | 16:12:03 | CREATE_COMPLETE | AWS::ECS::Service | fargate-webapp-dev-service/Service (fargatewebappdevserviceService) 11/14 | 16:12:05 | CREATE_IN_PROGRESS | AWS::ApplicationAutoScaling::ScalableTarget | fargate-webapp-dev-scalabletarget (fargatewebappdevscalabletarget) 11/14 | 16:12:06 | CREATE_IN_PROGRESS | AWS::ApplicationAutoScaling::ScalableTarget | fargate-webapp-dev-scalabletarget (fargatewebappdevscalabletarget) Resource creation Initiated 12/14 | 16:12:06 | CREATE_COMPLETE | AWS::ApplicationAutoScaling::ScalableTarget | fargate-webapp-dev-scalabletarget (fargatewebappdevscalabletarget) ✅ fargate-webapp-dev Outputs: fargate-webapp-dev.output = http://fargate-webapp-dev-alb-xxxxxxx.ap-northeast-1.elb.amazonaws.com/ Stack ARN: arn:aws:cloudformation:ap-northeast-1:xxxxxxxxxxxx:stack/fargate-webapp-dev/xxxxx環境削除
cdk destroy --profile xxx感想
- 環境依存をどう外出しにするか、StackのParameter部分をどう表現するかを悩みましたが、いい感じに表現できたと思います。
- CDKはリソース間の関連がコードで表現されるので
Refを書くよりかなり楽でした。リソースの命名も楽になりました。- Typescriptの型定義ファイルを見ることでできることがわかるのでCloudformationよりは苦労しなかったです
- 残念ながら現時点(2020/01/18)ではCloudformationでFargateのBlueGreenデプロイメントが対応していないようなので、別途記事にまとめるつもりです。https://github.com/aws/containers-roadmap/issues/130
CDKいいですね。
- 投稿日:2020-01-18T15:55:10+09:00
AWS認定クラウドプラクティショナー 受験記録(2020/1)
はじめに
先日(2020/1)、AWS認定クラウドプラクティショナーを受験し、何とか合格することができましたので、具体的な勉強方法などについて記録したいと思います。
AWSにかかるスキル
AWSを使うプロジェクトはこれまでに2つほど経験しているのですが、いずれも開発したシステムのホスト先がAWSというだけであり、AWSを直接触ることはありませんでしたので、実質的な実務経験は無しに等しいです。
使用した教材
以下の教材を使用しました。
1.AWS認定資格試験テキスト AWS認定 クラウドプラクティショナー
全般的に非常にわかりやすく説明されていて、各章の最後にある問題も、実際の試験と同程度のレベルのものとなっており、説明・問題ともに非常に有用でした。
通勤の電車内で、説明・問題合わせて2周しました。
2.AWS認定 クラウドプラクティショナー 模擬問題集 Kindle版
実際の試験と同数の65問×2セットの問題集となっており、こちらも実際の試験と同程度のレベルのものとなり、非常に有用でした。
受験日の前日・当日の午前中に、一通りの問題を解きました。
3.AWS:ゼロから実践するAmazon Web Services。手を動かしながらインフラの基礎を習得
こちらはUdemyの動画講義ですが、EC2・VPC・RDS・S3など、AWSの基本的なサービスを使ったプロトタイプ開発に沿った内容となっており、講師の説明も丁寧でわかりやすく、実際に手を動かしてAWSの基本を覚えるのに非常に有用でした。
週末、自宅で受講しました。
以上の教材による学習を1か月程度の期間で行いました。
試験結果
スコア846で合格でした。
所感
今後についてはわかりませんが、癖のあるような問題は基本的には出ないようで、上述の教材などを使って一通りの試験範囲の学習と問題をこなせば、十分合格できる試験だと思いました。
Qiitaへの投稿は初めてなので、読みづらいところなどあるかもしれませんが、今後受験予定の皆様のご参考になればと思います。
- 投稿日:2020-01-18T13:51:55+09:00
[AWS][CFn]IAMの設定2
はじめに
お久しぶりです。なじむです。年末年始とバタバタしていて更新が遅くなりました(サボっていただけ)
前回、IAMの設定について記載しました。
今回はネストスタックを使用して、IAMの設定をしていこうという記事なります。前提
前回と同じです。
- コンソールにログインした後、スイッチロールを行い任意のロールにスイッチする
- 上述のスイッチロールは特定のIPからしか実行できないよう制限する
- スイッチロールした後はIPアドレスの制限を設けず、任意の操作を実行可能とする
今回、ネストスタックを用いて記載したいのは、各グループで共通のポリシーを使用する場合があり、それを都度記載するのが面倒(管理も煩雑)になるので、ネストスタックを用いて共通部分は1回しか書かないようにしようと思います。
サンプルコード
ネストスタックはその名の通り、ネストしたスタックです。親スタックがあり、その親スタックから子スタックを作成します。
今回の場合は以下のようにします。
- 親スタック:iam.yaml
- 子スタック:common.yaml、Administrator.yaml
では、サンプルコードです。
iam.yaml
--- AWSTemplateFormatVersion: 2010-09-09 Description: IAM - Parents #------------------------------ # Parameters: Set your argv. #------------------------------ Parameters: IAMCommonTemplateURL: Type: String Description: Template URL of IAM Common. IAMAdministratorTemplateURL: Type: String Description: Template URL of IAM Administrator. #------------------------------ # Resources: Your resource list #------------------------------ Resources: # IAM Resource ## Common IAMCommon: Type: AWS::CloudFormation::Stack Properties: TemplateURL: !Ref IAMCommonTemplateURL ## Administrator IAMAdministrator: Type: AWS::CloudFormation::Stack Properties: TemplateURL: !Ref IAMAdministratorTemplateURL Parameters: OnlyMyIPAccess: !GetAtt IAMCommon.Outputs.OnlyMyIPAccess「!GetAtt IAMCommon.Outputs.OnlyMyIPAccess」の記載、「!GetAtt IAMCommon.Resources.OnlyMyIPAccess」じゃダメなのかと思い試してみたら以下のエラーが出力されて怒られました。ちゃんとOutputsしないとダメみたいですね。
Template error: resource IAMCommon does not support attribute type Resources.OnlyMyIPAccess in Fn::GetAtt
common.yaml
--- AWSTemplateFormatVersion: 2010-09-09 Description: IAM - Policy for common #------------------------------ # Resources: Your resource list #------------------------------ Resources: # IAM(Policy) Resource ## Group's Policy -- MyIPAccess OnlyMyIPAccess: Type: AWS::IAM::ManagedPolicy Properties: PolicyDocument: Version: 2012-10-17 Statement: - Effect: Deny Action: "*" Resource: "*" Condition: NotIpAddress: aws:SourceIp: - xxx.xxx.xxx.xxx/xx # ここは任意のIPアドレスに修正してください。 #------------------------------ # Output: Use values by Other stack #------------------------------ Outputs: # RoleViewBillingUsers OnlyMyIPAccess: Value: !Ref OnlyMyIPAccessAdministrator.yaml
--- AWSTemplateFormatVersion: 2010-09-09 Description: IAM - Group, Role, Policy for Administrator #------------------------------ # Parameters: Set your argv. #------------------------------ Parameters: OnlyMyIPAccess: Type: String Description: IAM Policy ARN of OnlyMyIPAccess. #------------------------------ # Resources: Your resource list #------------------------------ Resources: # IAM(Group) Resource ## Administrator GroupAdministrator: Type: AWS::IAM::Group Properties: GroupName: Administrator ManagedPolicyArns: - !Ref AssumeAdministrator - !Ref OnlyMyIPAccess # IAM(Role) Resource ## Administrator RoleAdministrator: Type: AWS::IAM::Role Properties: RoleName: Administrator AssumeRolePolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Action: sts:AssumeRole Principal: AWS: !Sub ${AWS::AccountId} ManagedPolicyArns: - arn:aws:iam::aws:policy/AdministratorAccess Path: "/" # IAM(Policy) Resource ## Group's Policy -- Administrator AssumeAdministrator: Type: AWS::IAM::ManagedPolicy Properties: PolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Action: sts:AssumeRole Resource: !GetAtt RoleAdministrator.Arn作成方法
ネストスタックの作成方法を簡単に記載します。ネストスタックの作成方法は通常のスタックの作成方法と少し異なるので注意が必要ですね。
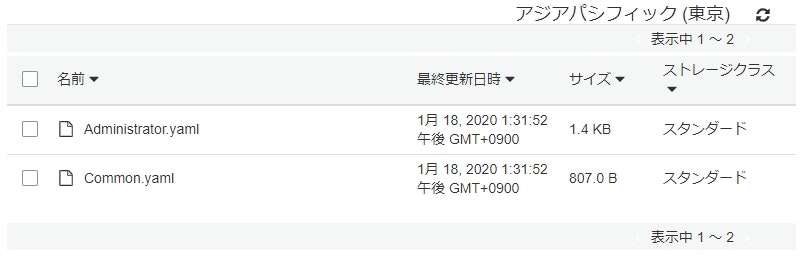
S3に子スタック用のyamlファイルをアップロード
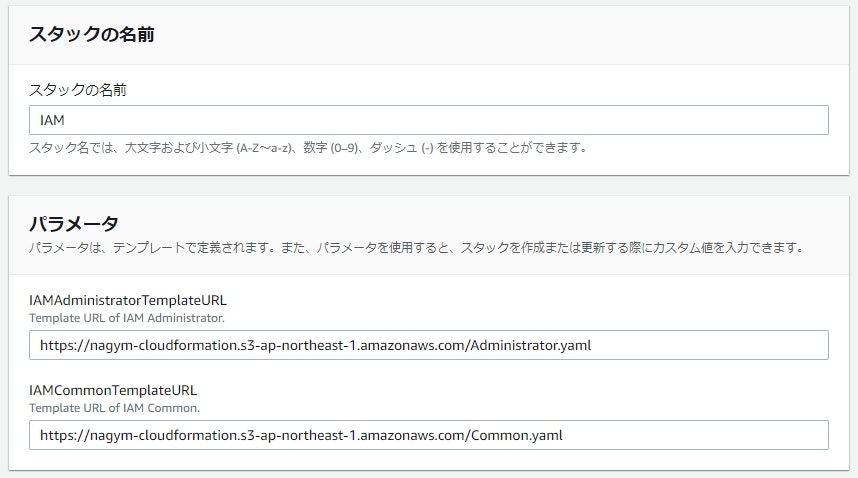
親スタック作成時のパラメータに子スタックのyamlのURLを指定
実行結果
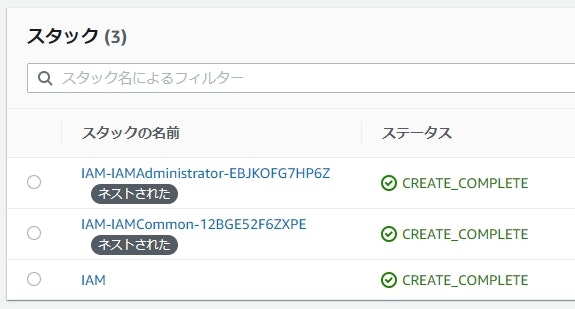
こちらは前回と同じため、実際に作成されるリソースは省略します。ネストスタックがどのように表示されるかだけ記載します。
まとめ
今回はネストスタックを使用してIAMポリシーを設定してみました。ネストスタックはうまく使えば構成が簡単に分かるようになるので、うまい使い方を考えてみるが良いと思います。
一方で、スタックを更新するときには全ての子スタックが見た目上変更される(Modifyになる)ので、その点は今後AWSに改善してほしい点です。追伸
普段、エディターはSublime Textを使用しているのですが、Markdown Previewのプラグインを入れたら捗りました。
- 投稿日:2020-01-18T12:26:21+09:00
EBS拡張にかかる時間
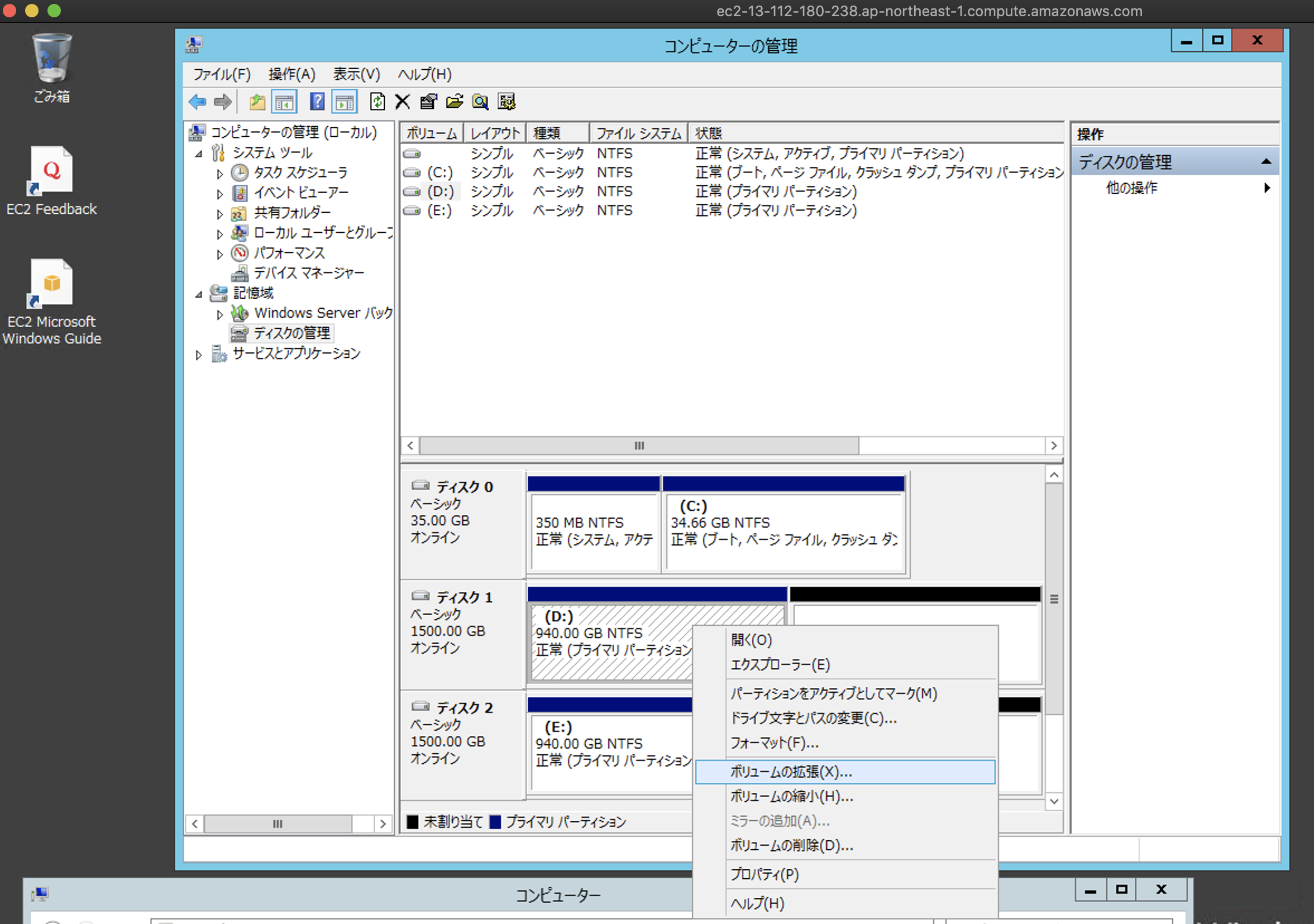
940GBのEBSボリュームを1.5TBに拡張した
EC2環境
OSとディスクサイズが無料枠の範囲外なので時間との戦いです
キー バリュー OS Windows2012(not R2) インスタンスタイプ t2.micro ディスク C(35GB),D(940GB),E(940GB)の計3個 手順
①EC2作成。DとEドライブを各々940GBで割当しておきます。
②DとEドライブに適当なファイルを作成しておきます。(正常にファイルシステムが拡張されたかの確認用)
③AWSマネージメントコンソールからDとEドライブを各々1.5TBに拡張。状態が「in-use」になるまで約7分(早い
)
④OSから「ディスクの管理」画面にてディスクをスキャンするとEBS拡張した分のディスクが見えます。
⑥ファイルシステムを拡張。この手順実施後はすぐに拡張したサイズが認識されます。
⑦最後に③で作成したファイルが正常に見えたら成功です。
ここまでかかった時間は20分でした
後は、EC2とEBSを削除して終了です。
コストが幾らかかったか少し心配さいごに
今回のファイルシステム拡張は短時間で終わりましたが、ドキュメントを見る限りでは時間がかかる可能性を想定しておいた方が良さそうです。オンプレの場合とは違うという意識・感覚は必須ですね。
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/monitoring-volume-modifications.html





- 投稿日:2020-01-18T12:26:21+09:00
EBS(Elastic Block Storage)拡張にかかる時間
オンラインで940GBのEBSボリュームを1.5TBに拡張した
EC2環境
OSとディスクサイズが無料枠の範囲外なので時間との戦いです
キー バリュー OS Windows2012(not R2) インスタンスタイプ t2.micro ディスク D(940GB),E(940GB) 手順
①EC2作成。DとEドライブを各々940GBで割当しておきます。
②DとEドライブに適当なファイルを作成しておきます。(正常にファイルシステムが拡張されたかの確認用)
③AWSマネージメントコンソールからDとEドライブを各々1.5TBに拡張。状態が「optimizing」から「in-use」になるまで約7分(早い
④OSから「ディスクの管理」画面にてディスクをスキャンするとEBS拡張した分のディスクが見えます。
⑥ファイルシステムを拡張。この手順実施後はすぐに拡張したサイズが認識されます。
⑦最後に③で作成したファイルが正常に見えたら成功です。
ここまでかかった時間は約10分でした
後は、EC2とEBSを削除して終了です。
コストが幾らかかったか少し心配さいごに
今回のファイルシステム拡張は短時間で終わりましたが、ドキュメントを見る限りでは時間がかかる可能性を想定しておいた方が良さそうです。オンプレの場合とは違うという意識・感覚は必須ですね。
https://docs.aws.amazon.com/ja_jp/AWSEC2/latest/UserGuide/monitoring-volume-modifications.html
- 投稿日:2020-01-18T12:26:21+09:00
EBS(Elastic Block Storage)拡張の所要時間
オンラインで940GBのEBSボリュームを1.5TBに拡張した
EC2環境
OS(Windows2012)とディスク(3TB)が無料枠の範囲外なので、時間との戦いです
キー バリュー OS Windows2012(not R2) インスタンスタイプ t2.micro ディスク D(940GB),E(940GB) 手順
①まずはEC2作成。DとEドライブは各々940GBを予め割当しておきます。
②DとEドライブに適当なファイルを作成しておきます。(正常にファイルシステムが拡張されたかの確認用)
③AWSマネージメントコンソールからDとEドライブを各々1.5TBに拡張。状態が「optimizing」から「in-use」になるまで約7分(早い
④OSから「ディスクの管理」画面にてディスクをスキャンするとEBS拡張した分のディスクが見えます。
⑥ファイルシステムを拡張。この手順実施後はすぐに拡張したサイズが認識されます。
⑦最後に②で作成したファイルが正常に見えたら成功です。
ここまでかかった時間は約10分でした
後は、EC2とEBSを削除して終了です。
コストが幾らかかったか少し心配さいごに
- 今回のファイルシステム拡張は短時間で終わりましたが、ドキュメントを見る限りでは時間がかかる可能性を想定しておいた方が良さそうです。オンプレの場合とは違うという意識・感覚は必須ですね。
- まさにバネのような「Elastic(弾力性のある)」な実験くんでした。
- 投稿日:2020-01-18T11:11:38+09:00
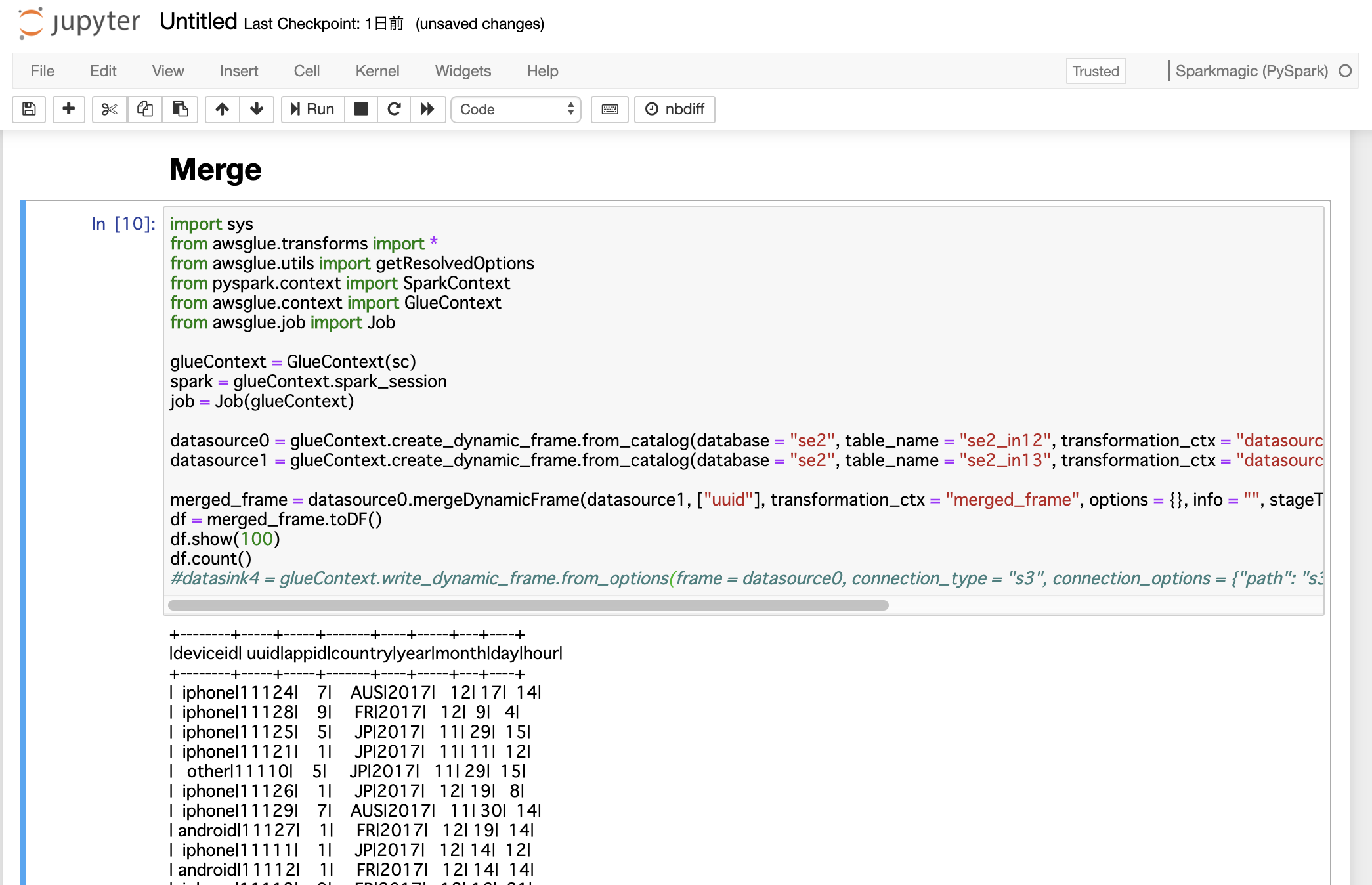
Glueの使い方的な㊸(DynamicFrameのMerge)
DynamicFrameのmergeDynamicFrameを使ってデータのマージ
2つのDynamicFrameをマージするというだけです。同じ意味を持つデータで、別ファイルとして行われた更新をマージしたい場合によいかもしれません。
ジョブの内容
JupyterNotebookで、2つのDynamicFrameをマージします。
全体の流れ
- 前準備
- ジョブ実行
- 確認
前準備
ソースデータ
(uuidをキーとしてこの後のジョブを実施します)
cvlog1.csv
19件のデータ
cvlog1.csvdeviceid,uuid,appid,country,year,month,day,hour iphone,11111,001,JP,2017,12,14,12 android,11112,001,FR,2017,12,14,14 iphone,11113,009,FR,2017,12,16,21 iphone,11114,007,AUS,2017,12,17,18 other,11115,005,JP,2017,12,29,15 iphone,11116,001,JP,2017,12,15,11 pc,11118,001,FR,2017,12,01,01 pc,11117,009,FR,2017,12,02,18 iphone,11119,007,AUS,2017,11,21,14 other,11110,005,JP,2017,11,29,15 iphone,11121,001,JP,2017,11,11,12 android,11122,001,FR,2017,11,30,20 iphone,11123,009,FR,2017,11,14,14 iphone,11124,007,AUS,2017,12,17,14 iphone,11125,005,JP,2017,11,29,15 iphone,11126,001,JP,2017,12,19,08 android,11127,001,FR,2017,12,19,14 iphone,11128,009,FR,2017,12,09,04 iphone,11129,007,AUS,2017,11,30,14cvlog2.csv
csvlog1.csvを元にした17件のデータ
csvlog1.csvとの変更点は以下3つcvlog1.csvにはないデータ(cvlog2.csvからuuidが11110,11121の2件削除)
other,11110,005,JP,2017,11,29,15
iphone,11121,001,JP,2017,11,11,12cvlog1.csvとcvlog2.csv両方に同じuuidで他の値が異なるデータ(cvlog2.csvからuuidが11122,11123の2件のdeviceidをn/aに修正)
n/a,11122,001,FR,2017,11,30,20
n/a,11123,009,FR,2017,11,14,14cvlog1.csvにないデータ(cvlog2.csvからuuidが11124-11129の6件を21124-21129に修正)
n/a,21124,007,AUS,2017,12,17,14
n/a,21125,005,JP,2017,11,29,15
n/a,21126,001,JP,2017,12,19,08
n/a,21127,001,FR,2017,12,19,14
n/a,21128,009,FR,2017,12,09,04
n/a,21129,007,AUS,2017,11,30,14cvlog2.csvdeviceid,uuid,appid,country,year,month,day,hour iphone,11111,001,JP,2017,12,14,12 android,11112,001,FR,2017,12,14,14 iphone,11113,009,FR,2017,12,16,21 iphone,11114,007,AUS,2017,12,17,18 other,11115,005,JP,2017,12,29,15 iphone,11116,001,JP,2017,12,15,11 pc,11118,001,FR,2017,12,01,01 pc,11117,009,FR,2017,12,02,18 iphone,11119,007,AUS,2017,11,21,14 n/a,11122,001,FR,2017,11,30,20 n/a,11123,009,FR,2017,11,14,14 n/a,21124,007,AUS,2017,12,17,14 n/a,21125,005,JP,2017,11,29,15 n/a,21126,001,JP,2017,12,19,08 n/a,21127,001,FR,2017,12,19,14 n/a,21128,009,FR,2017,12,09,04 n/a,21129,007,AUS,2017,11,30,14S3にアップロード
両ファイルをS3にアップロード
Glueクローラーなどでテーブル作成手順はこの辺を参考にしてもらえたらと
https://qiita.com/pioho07/items/c9ce1d0677777f974ffeジョブ実行
【参考】公式ページから引用↓
mergeDynamicFrame(stage_dynamic_frame, primary_keys, transformation_ctx = "", options = {}, info = "", stageThreshold = 0, totalThreshold = 0)JupyterNotebookの起動します。
手順はこの辺を参考にしてもらえたらと
https://qiita.com/pioho07/items/29bd779f84b4add9cf2cmergejobimport sys from awsglue.transforms import * from awsglue.utils import getResolvedOptions from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.job import Job glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) datasource0 = glueContext.create_dynamic_frame.from_catalog(database = "se2", table_name = "se2_in12", transformation_ctx = "datasource0") datasource1 = glueContext.create_dynamic_frame.from_catalog(database = "se2", table_name = "se2_in13", transformation_ctx = "datasource1") merged_frame = datasource0.mergeDynamicFrame(datasource1, ["uuid"], transformation_ctx = "merged_frame", options = {}, info = "", stageThreshold = 0, totalThreshold = 0) df = merged_frame.toDF() df.show(100) df.count()+--------+-----+-----+-------+----+-----+---+----+ |deviceid| uuid|appid|country|year|month|day|hour| +--------+-----+-----+-------+----+-----+---+----+ | iphone|11124| 7| AUS|2017| 12| 17| 14| | iphone|11128| 9| FR|2017| 12| 9| 4| | iphone|11125| 5| JP|2017| 11| 29| 15| | iphone|11121| 1| JP|2017| 11| 11| 12| | other|11110| 5| JP|2017| 11| 29| 15| | iphone|11126| 1| JP|2017| 12| 19| 8| | iphone|11129| 7| AUS|2017| 11| 30| 14| | android|11127| 1| FR|2017| 12| 19| 14| | iphone|11111| 1| JP|2017| 12| 14| 12| | android|11112| 1| FR|2017| 12| 14| 14| | iphone|11113| 9| FR|2017| 12| 16| 21| | iphone|11114| 7| AUS|2017| 12| 17| 18| | other|11115| 5| JP|2017| 12| 29| 15| | iphone|11116| 1| JP|2017| 12| 15| 11| | pc|11118| 1| FR|2017| 12| 1| 1| | pc|11117| 9| FR|2017| 12| 2| 18| | iphone|11119| 7| AUS|2017| 11| 21| 14| | n/a|11122| 1| FR|2017| 11| 30| 20| | n/a|11123| 9| FR|2017| 11| 14| 14| | n/a|21124| 7| AUS|2017| 12| 17| 14| | n/a|21125| 5| JP|2017| 11| 29| 15| | n/a|21126| 1| JP|2017| 12| 19| 8| | n/a|21127| 1| FR|2017| 12| 19| 14| | n/a|21128| 9| FR|2017| 12| 9| 4| | n/a|21129| 7| AUS|2017| 11| 30| 14| +--------+-----+-----+-------+----+-----+---+----+ 25
ジョブの確認
動きとしては2つ目のデータ(cvlog2.csv)の値で上書かれるようになります。
cvlog1.csvにしかないデータ(cvlog2.csvからuuidが11110,11121の2件削除)
1つ目のcvlog1.csvにしかないデータは保持されます
cvlog1.csvとcvlog2.csv両方に同じuuidで他の値が異なるデータ(cvlog2.csvからuuidが11122,11123の2件のdeviceidをn/aに修正)
1つ目のcvlog1.csvと2つ目cvlog2.csvに同一キーがあり他のカラムの値が異なっている場合、2つ目の値で上書きされます
cvlog1.csvにないデータ(cvlog2.csvからuuidが11124-11129の6件を21124-21129に修正)
2つ目のcvlog2.csvにしかないデータはそのままマージされます
こちらも是非
Glueの使い方まとめ
https://qiita.com/pioho07/items/32f76a16cbf49f9f712f
- 投稿日:2020-01-18T02:51:09+09:00
www付きをwwwなしへリダイレクトをALBで(terraform)
resource "aws_lb_listener_rule" "redirect" { listener_arn = aws_lb_listener.https.arn priority = 90 action { type = "redirect" redirect { host = "example.com" path = "/#{path}" port = "443" protocol = "HTTPS" query = "#{query}" status_code = "HTTP_301" } } condition { field = "host-header" values = ["www.example.com"] } }
- 投稿日:2020-01-18T00:38:46+09:00
RDS for PostgreSQLで監査ログをCloudWatchLogsに出力する
pgauditの有効化
1. RDSに接続する
下記コマンドを実行する
psql -U [ユーザ名] -h [RDSのエンドポイント] -d [DB名]2. pgauditが利用するDBロールを作成する
下記コマンドを実行する
=> CREATE ROLE rds_pgaudit;3. RDSのパラメータグループを変更する
AWS管理コンソールから RDS > パラメータグループ > 設定するインスタンスのパラメータグループ で変更する
下記は 必須
パラメータ名 値 pgaudit.role rds_pgaudit shared_preload_libraries pgaudit 下記は 任意
パラメータ名 許可される値 説明 pgaudit.log_level debug5, debug4, debug3, debug2, debug1, info, notice, warning, log(デフォルト) ログレベル pgaudit.log ddl, function, misc, read, role, write, none(デフォルト), all, -ddl, -function, -misc, -read, -role, -write 監査ログの種類 4. RDSを再起動して、変更したパラメータを反映する
5. RDSに再接続する
下記コマンドを実行する
psql -U [ユーザ名] -h [RDSのエンドポイント] -d [DB名]6. 再起動後、pgauditがロードされていることを確認する
下記の内容であればOK
=> SHOW shared_preload_libraries; shared_preload_libraries -------------------------- rdsutils,pgaudit (1 row)7. pgauditの拡張機能を有効化する。
下記コマンドを実行する
=> CREATE EXTENSION pgaudit;8. pgauditに作成したロールがアタッチされているか確認する。
下記の内容であればOK
=> SHOW pgaudit.role; pgaudit.role -------------- rds_pgauditCloudWatchLogsへのログ出力
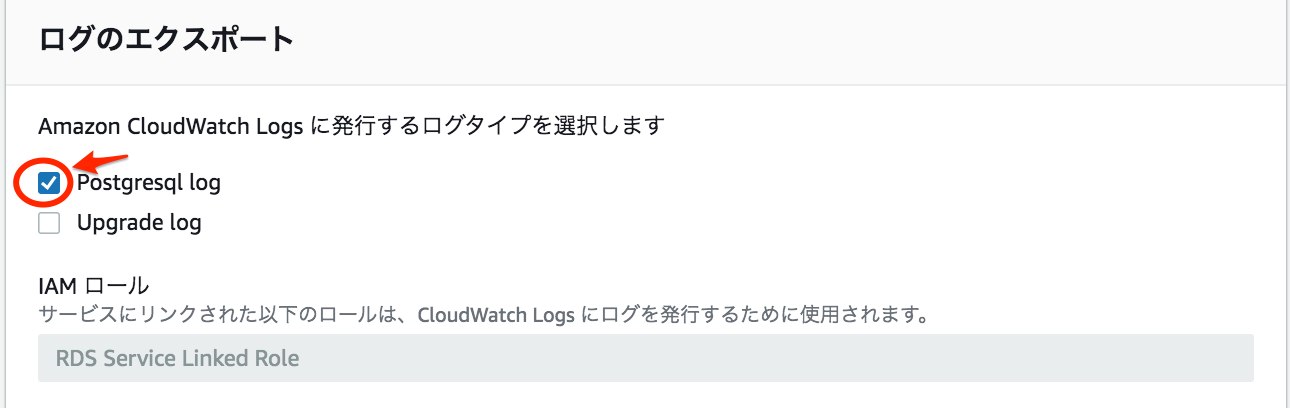
1. ログのエクスポートで Postgresql log にチェックを入れる
AWS管理コンソールから DBインスタンスの[ログのエクスポート]の設定を変更する
2. ログが CloudWatchLogs に出力されていることを確認する
AWS管理コンソールから CloudWatch > ロググループ で確認する
出力先ロググループ名 /aws/Instance/{DBインスタンス名}/postgresql
参考

- 投稿日:2020-01-18T00:23:23+09:00
CloudWatchアラームでN個中M個がしきい値を超えたらアラームにする設定、CloudFormationでどう書くっけ?
いきなりまとめ
いまの開発チームでは、AWSリソースをCloudFormationを使って管理しているんですが、
CloudWatchアラームを作成する時、「データポイントN個中M個が閾値を超えたらアラームっていう設定ってCloudFormationでどう書くっけ?」
「EvaluationPeriodsの単位って秒だっけ?回数だっけ?」
「PeriodとEvaluationPeriodsってどっちがどっちだっけ?」を迷って、
毎回、AWSドキュメントを見たり、ググったりしていて、
そんな自分にもいい加減嫌気がさしてきたので、記事にまとめました。結論として、
[Period]秒間隔にメトリクスを出したとして、直近[EvaluationPeriods]個中、[DatapointsToAlarm]個が閾値を上回ればアラームになる
です。具体例
実際に作って見ますね。
こんなテンプレートをCloudFormationに流してみます。AWSTemplateFormatVersion: '2010-09-09' Resources: SampleAlarm: Type: AWS::CloudWatch::Alarm Properties: ActionsEnabled: false AlarmDescription: 'This is a sample alarm.' AlarmName: 'sample alarm' MetricName: 'ApproximateNumberOfMessagesVisible' Namespace: AWS/SQS Dimensions: - Name: QueueName Value: !Sub 'sample-queue' Period: 180 Statistic: 'Maximum' ComparisonOperator: 'GreaterThanThreshold' Threshold: 5 EvaluationPeriods: 3 DatapointsToAlarm: 2すると、CloudWatchアラームの画面に作ったアラームが出てくるんですが、
しきい値のところが「9分内の2データポイントに対するApproximateNumberOfMessagesVisible > 5」になってますよね?
つまりそういうことなんです。
わっからへんわぁ
AWSドキュメントにも書いてあるんですが、ドキュメントにはEvaluationPeriodsについてこう書いてあるんです。
EvaluationPeriods
指定した [Threshold] の値とデータを比較する時間。必須: はい
タイプ: 整数
最小: 1
Update requires: No interruption「データを比較する時間」?じゃあ秒とかで指定するのねって思わないですか?
いえ、EvaluationPeriodsはデータポイントの「個数」です。
ここが毎回迷ってたポイントでした。ここでコーヒーブレイク
先ほどのアラームですが、古いデザインのコンソールでアラームの詳細を開くと、こんな感じです。
赤枠のとこを読むと、あなたがCloudFormationで設定した3分間隔っていう値は、AWSとしては微妙な値なので、「変更の保存」を押すときに1分間隔に上書き保存してあげるよ!!!みたいなことを言っています。
今さら変更すると、テンプレートの内容と乖離して困るー・・・。
でも、新しいデザインのコンソールで開くと、こんな感じ。
データポイントが3分間隔で表示されているし、先ほどの変な警告メッセージも出ていない。わーい。
新しいデザインって、そんな改善も入っているんですね!というお話でした。


