- 投稿日:2020-01-18T23:51:02+09:00
【Python】OpenJTalkとTalk APIを使って会話する(音声出力まで)
はじめに
以前自作のslackbotを作った際にリクルートのTalk APIを用いて自動返信機能を作ったことがありました。それと最近環境構築したOpenJTalkを使えば実際に話してくれるじゃん!と思ってやってみました。友達がいないわけではないです
※OpenJTalkをインストールしていなくてもTalk APIを用いて会話はできます環境
Windows 10
Python 3.7
OpenJTalk
pya3rt (talk apiを使う用)準備
OpenJTalk
Python からも使える音声合成ソフトです。こちらの記事に環境構築からPythonで話すまでまとめてあります。
会話機能
Talk API
文字列を送ったら返答を返してくれるAPIです。
BOTで使える会話API・ライブラリ・サービスまとめを参考にさせていただきました。Talk API
リクルートテクノロジーがオープンイノベーションの一環で社内で用いられていた機械学習・ディープラーニング技術ををAPIとして一般公開したものの一つ。他にもA/Bテストのための画像の好ましさを判定するモデルを作成できるImage InfluenceAPIや文章の自動生成及び入力補助をしてくれるText Suggest APIなど面白いものが公開されている。ここからメアド登録してAPI発行できます。
Talk APIpya3rt
Pythonから簡単に使えるpya3rtというライブラリが提供されています。以下のコマンドでインストールしてください。
pip install pya3rtコード
会話機能
会話機能の部分を関数にしました。messageはAPIに送る文字列で返り値は会話の返答です。
import pya3rt def send_message(message): apikey = "api key" client = pya3rt.TalkClient(apikey) reply_message = client.talk(message) return reply_message['results'][0]['reply']reply_messageの中身はこのようになっています。
{'status': 0, 'message': 'ok', 'results': [{'perplexity': 0.06766985185966182, 'reply': 'こんにちは'}]}返答部分だけ抜きたかったので
reply_message['results'][0]['reply']
としました。音声出力
次は音声出力の部分ですが、この記事で作った
jtalk.pyを呼び出します。import jtalk jtalk.jtalk('喋らせたい文字')結果
これらを合わせると以下のようになります。
コンソールから文字列を受け取る⇒APIに投げる⇒音声出力するという流れです。import pya3rt import jtalk def send_message(message): apikey = "api key" client = pya3rt.TalkClient(apikey) reply_message = client.talk(message) return reply_message['results'][0]['reply'] if __name__ == "__main__": while True: message = input("message : ") reply = send_message(message) print(reply) jtalk.jtalk(result)出力結果。OpenJTalkが使えていると返答(message : がない方)が音声出力されます。
message : こんにちは こんにちは message : 雪が降ったね 風邪ですか? message : さむいですね 私もそう思います message : だよねー そうですよね message : あなたは誰ですか? 私はまだ名前がないんですおわりに
とても簡単に実装できました。PythonとAPIはすごいですね。
あとは音声認識ができればもう人とコンピューターが会話できますね。参考にさせていただいたサイト
BOTで使える会話API・ライブラリ・サービスまとめ
リクルートのTalk APIを用いてslack bot(python製)に会話機能を追加する
- 投稿日:2020-01-18T23:42:24+09:00
Python学習にCheckioのすすめ
話すこと
この間、仕事先の先輩から聞いたCheckioというものを試してみて、ハマった
(卒論締め切り間近に面白くて時間が溶けた)ので紹介したいと思う。Checkioとは
pythonとJavaScriptについて、問題を解きながら学習を進めていくというもの。
問題に正解すると次の問題が解けるようになっていくので、完全にゲーム感覚で進めていける。(これが時間を溶かす原因)Checkioの良いところ
pythonの学習についてはProgateなんかが有名だと思うけれど、これはレッスンが進むとお金がかかってしまう...
もちろんお金をかけた分だけ良いレッスンが受けれるので、お金をかけるのも当然ありだと思う。ただ、タダより良いものはないというのが人の性だと思います!
そして、こう書いているのでCheckioは無料でできるんです!
また、Checkioはweb上で問題を解いていくのでハマりがちなPythonの環境構築をしなくて良いのも魅力の1つだと思います。
さらに、Checkioは書いたコードを投稿できて、見た人からコメントをもらえる上に、自分が正解した問題については、他人の投稿したコードを見ることができます!
これを見るだけでも相当良い勉強になるんじゃないかなと思います!難しい問題にはヒントもついているものもあり、そのヒントをもとに解いていくこともできるので、初めてPythonやる人にもおすすめできます。
Checkioの今一歩の点
これに関しては完全に個人的な意見なのですが、問題文等々が英語なので、そこだけ少し苦労します...
(英語勉強すれば良い話)
これ読んだ人が始めてくれて、日本人でやってる人の人口増えたら、日本語版リリースされないかなという淡い期待を持ちつつこの記事書いてます...Checkioの始め方
Checkioここから、ページに飛んで、Githubアカウント、Facebookアカウント、Googleアカウントのどれかでログインできます。
例題
ログインする前にどんな問題があるのか知りたいという人もいると思うので、例題として、実際にCheckioに出されている問題を載せます。
あんまり例題載せると楽しみなくなるので、1問だけにします。問題
長さが10文字以上で、大文字、小文字、数字を全て含むパスワードであるかどうかを判別してください。def checkio(data): # この部分に回答となる巻数書いていきます。 if len(data) < 10: # 長さが10未満のものを排除 return False elif data.isalpha(): # 全てアルファベットのものを排除 return False elif data.islower(): # 全て小文字のものを排除 return False elif data.isupper(): # 全て大文字のものを排除 return False elif data.isdigit(): # 全て数字のものを排除 return False else: # 残ったものが良いパスワード return True #Some hints #Just check all conditions if __name__ == '__main__': #These "asserts" using only for self-checking and not necessary for auto-testing assert checkio('A1213pokl') == False, "1st example" assert checkio('bAse730onE4') == True, "2nd example" assert checkio('asasasasasasasaas') == False, "3rd example" assert checkio('QWERTYqwerty') == False, "4th example" assert checkio('123456123456') == False, "5th example" assert checkio('QwErTy911poqqqq') == True, "6th example" print("Coding complete? Click 'Check' to review your tests and earn cool rewards!")上記のは私の回答です。
ちなみに投稿された中で1番ランキングが高かったコードは以下の感じimport re DIGIT_RE = re.compile('\d') UPPER_CASE_RE = re.compile('[A-Z]') LOWER_CASE_RE = re.compile('[a-z]') def checkio(data): """ Return True if password strong and False if not A password is strong if it contains at least 10 symbols, and one digit, one upper case and one lower case letter. """ if len(data) < 10: return False if not DIGIT_RE.search(data): return False if not UPPER_CASE_RE.search(data): return False if not LOWER_CASE_RE.search(data): return False return True if __name__ == '__main__': assert checkio('A1213pokl')==False, 'First' assert checkio('bAse730onE4')==True, 'Second' assert checkio('asasasasasasasaas')==False, 'Third' assert checkio('QWERTYqwerty')==False, 'Fourth' assert checkio('123456123456')==False, 'Fifth' assert checkio('QwErTy911poqqqq')==True, 'Sixth' print('All ok')正規表現使ってますね。
確かにこっちの方がパッと見で何してるかわかりやすいかもしれないです。と、まぁ、こんな風に他の人の書いたコード見れるのはやっぱり勉強になるかなと思います。
まとめ
ここまで、Checkioについて紹介してきました。
少しでも興味持ってくれた人とかいたら是非やってみてください!(無料なので笑)
やってみて良いと感じたら、他の人にも是非おすすめしてみたください!
最後にもう一度だけ、リンク貼っておきます。
Checkio
- 投稿日:2020-01-18T23:34:39+09:00
機械学習がわかるようになるステップを記録していく
動画3本と本1冊で大体わかるようになる。
みたいなコンセプトで書いてみる
オススメの動画
- まずは動かしてみる:「【機械学習超入門】初心者はまず動くモデルを作る」
- ディープラーニングのさわりがわかる:「内職が要らないくらい分かりやすいディープラーニング入門」
- pythonのライブラリを学ぶ入り口:「【機械学習超入門】scikit-learnについて【知っておきたいライブラリ】」
オススメのPythonの本
とにかく触ってみる
https://www.amazon.co.jp/Python実践データ分析100本ノック-下山-輝昌/dp/4798058750結局何がわかるようになれば良いのか
上記をやると、以下のようなものが身につく。
- Pythonを書いてみてモデルを作って予測したという経験
- Kaggleのサイトに行けば色々なデータを入手・Tryできることを知っておくこと
- アルゴリズムってどういうイメージなのかという感覚
- アルゴリズムは、最適化問題を解くもの。という感覚
- 回帰とか勾配ブースティングなどのなんとなくの仕組みとユースケース
- データの前処理
- One Hot Encodingとか、正規化とか
番外編
書き溜めていくゴミ箱てきなもの
次にわかるようになるべきもの
- XGBoostの例
- ハイパーパラメータのチューニング項目、カーネルとかも
- 投稿日:2020-01-18T23:14:38+09:00
AtCoder キーエンス プログラミング コンテスト 2020 参戦記
AtCoder キーエンス プログラミング コンテスト 2020 参戦記
A - Painting
9分半で突破. 縦、横長い方で何回塗ったら超えるか、それだけ. 最初勘違いして交互に塗っていくと思ったせいで時間がかかってしまって順位どん底に…….
H = int(input()) W = int(input()) N = int(input()) t = max(H, W) print((N + t - 1) // t)C - Subarray Sum
13分?で突破. S を K 個、どう足しても S にならないものを N - K 個並べればいいだけ. 回答の数列の各値は 1~109 であることには注意.
N, K, S = map(int, input().split()) result = [S % 10 ** 9 + 1] * N for i in range(K): result[i] = S print(*result)B - Robot Arms
敗退.
追記: 解説を Python のコードに落として AC. 自分が書いた WA 食らったコードと違う部分は x でソートするか、x + l でソートするか、それだけだった…….
N = int(input()) XL = [list(map(int, input().split())) for _ in range(N)] t = [(x + l, x - l) for x, l in XL] t.sort() max_r = -float('inf') result = 0 for i in range(N): r, l = t[i] if max_r <= l: result += 1 max_r = r print(result)
- 投稿日:2020-01-18T23:09:41+09:00
OpenFOAMの時系列データとsetsデータの読み込み
概要
OpenFOAMの時系列データとsetsデータ(sampleコマンドで出力する空間分布のデータ)をPythonで読み込むための関数をつくって,matplotlibでのプロットを簡略化しました。
前提として,OpenFOAMの時系列データはリスタートの度に新しいディレクトリに保存されますが,それをcatコマンドでくっつけてひとつづきのファイルになってるとします。
Pythonのコード
時系列データの読み込み関数用関数
- caseはケースファイル名
- positionsには時系列データの場所の情報をリストでいれます。
- variablesが時系列データの物理量(p, Uとか)のリスト
- 各位置の時系列データを一括で読み込みます。
- 「物理量_場所」の文字列をkey,実際のデータをndarrayとしてvalueにもつディクショナリデータを返します。
def readHistory(case, positions, variables): import numpy as np """ case: case name (string data) positions: position name (list data) variables: physical quantities (list data) """ data ={} for position in positions: for variable in variables: key = variable+"_"+position value = np.genfromtxt(case+"/"+position+"/"+variable, unpack=True) data[key] = value return datasetsデータの読み込み用関数
引数の説明
- caseはケースファイル名
- fileはsetsデータのファイル名
- variablesが出力したい物理量(p, Uとか)のリスト
- setsデータは複数の物理量のデータが1つのファイルに出力されるので,各物理量を個別に読み込みます。
- 「物理量_場所」の文字列をkey,実際のデータをdataframeとしてvalueにもつディクショナリデータを返します。
def readSets(case, file, variables): import numpy as np import pandas as pd import glob import os """ case: case name (string data) file: sets data file name (string data) variables: physical quantities (list data) """ # list of timing list1 = glob.glob(case + "/sets/*") variable_names = file.split("_") # remove ".xy" variable_names[-1] = variable_names[-1].split(".")[0] position, variable_names[0] = variable_names[0], "x" #print(variable_names) data = {} for variable in variables: key = variable+"_"+position data[key] = pd.DataFrame() for i in list1: path = i+"/" + file df = pd.read_table(path, header = None, names = variable_names) data[key] = pd.concat([data[key], df[variable]], axis=1,) list_index=[] for i in list1: list_index.append(str(float(os.path.basename(i)))) data[key].columns = list_index data[key] = pd.concat([df[variable_names[0]], data[key].sort_index(axis=1)], axis=1) # return dictionary of dataframe return datamatplotlibでプロット
matplotlibでデータをプロットします。
データの配置は以下のようになってるとします。
test01がケース名。test01/position-A/p
test01/position-A/U
test01/position-B/p
test01/position-B/U
test01/sets/0/center_p_k.xy
test01/sets/10/center_p_k.xyp, Uはposition-A, Bの時系列データ
center_p_k.xyは時刻0,10の分布データ
です。ケースが複数あって,ケース名だけ変えたプロットを簡単に作ることを想定した作りになってます。
import matplotlib.pyplot as plt %matplotlib inline case = "test01" history_position = ["position-A", "position-B"] history_variables = ["p", "U"] sets_variables = ["p", "k"] sets_position = "center" dataSet_test01= [readHistory(case, history_position, history_variables), readSets(case, "center_p_k.xy", sets_variables)] # 時系列データ一式のプロット for i in history_position: for j in history_variables: fig = plt.figure(figsize=(8,8)) ax = fig.add_subplot(111) ax.plot(dataSet_test01[0][j+"_"+i][0], dataSet_test01[0][j+"_"+i][1], label=j) ax.legend(bbox_to_anchor=(1.01, 1., 0., 0), loc='upper left', borderaxespad=0.,) # 空間分布のプロット for sets in sets_variables: for column in dataSet_test01[1][sets+"_"+sets_position]: fig = plt.figure(figsize=(8,8)) ax = fig.add_subplot(111) ax.plot(dataSet_test01[1][sets+"_"+sets_position]["x"], dataSet_test01[1][sets+"_"+sets_position][column], label=sets+"_"+column) ax.legend(bbox_to_anchor=(1.01, 1., 0., 0), loc='upper left', borderaxespad=0.,)
- 投稿日:2020-01-18T22:49:45+09:00
言語処理100本ノック-91:アナロジーデータの準備
言語処理100本ノック 2015の91本目「アナロジーデータの準備」の記録です。
今回は後のノックのための前処理系ということで技術的には超簡単です。参考リンク
リンク 備考 091.アナロジーデータの準備.ipynb 回答プログラムのGitHubリンク 素人の言語処理100本ノック:91 言語処理100本ノックで常にお世話になっています 環境
種類 バージョン 内容 OS Ubuntu18.04.01 LTS 仮想で動かしています pyenv 1.2.15 複数Python環境を使うことがあるのでpyenv使っています Python 3.6.9 pyenv上でpython3.6.9を使っています
3.7や3.8系を使っていないことに深い理由はありません
パッケージはvenvを使って管理しています課題
第10章: ベクトル空間法 (II)
第10章では,前章に引き続き単語ベクトルの学習に取り組む.
91. アナロジーデータの準備
単語アナロジーの評価データをダウンロードせよ.このデータ中で": "で始まる行はセクション名を表す.例えば,": capital-common-countries"という行は,"capital-common-countries"というセクションの開始を表している.ダウンロードした評価データの中で,"family"というセクションに含まれる評価事例を抜き出してファイルに保存せよ.
※単語アナロジーの評価データのオリジナルのリンクは、リンク切れなのでここでは変えています。
課題補足
「アナロジーデータ」とは類推のためのデータのようです。
下記に先頭10行を出しています。: capital-common-countriesのように先頭にコロンがあるとブロックを意味していて、その後にAthens Greece Baghdad Iraqと首都と国の関係が2セット1行に並びます。
このようにブロックとその後に数十行何らかの関係性が2セット1行で並ぶデータです。今回は、このデータからfamilyブロックのコンテンツを抜き出します。questions-words.txt: capital-common-countries Athens Greece Baghdad Iraq Athens Greece Bangkok Thailand Athens Greece Beijing China Athens Greece Berlin Germany Athens Greece Bern Switzerland Athens Greece Cairo Egypt Athens Greece Canberra Australia Athens Greece Hanoi Vietnam Athens Greece Havana Cuba回答
回答プログラム 091.アナロジーデータの準備.ipynb
with open('./questions-words.txt') as file_in, \ open('./091.analogy_family.txt', 'w') as file_out: target = False # 対象のデータ for line in file_in: if target: # 対象データの場合は別のセクションになるまで出力 if line.startswith(': '): break print(line.strip(), file=file_out) elif line.startswith(': family'): # 対象データ発見 target = True回答解説
正直、技術的に特別なことをしていないので解説する点がないです。強いて言うならば9割以上が素人の言語処理100本ノック:91のコピペということぐらいです。
結果のテキストの先頭10行は以下の通りです。091.analogy_family.txtboy girl brother sister boy girl brothers sisters boy girl dad mom boy girl father mother boy girl grandfather grandmother boy girl grandpa grandma boy girl grandson granddaughter boy girl groom bride boy girl he she boy girl his her 以後略
- 投稿日:2020-01-18T22:31:23+09:00
Python3.9の新機能 (まとめ)
はじめに
Python 3.5から What's Newの内容をまとめる記事を投稿してきました。
これからはリリースサイクルが早くなるので投稿の頻度が増えそうですが、Pythonを1.xの頃から追っかけていた古株のエンジニアとして出来るだけ続けていきたいなと思っています。
そして、こちらの記事で書いたようにPython2は今年の1月1日でEnd-of-lifeを迎えました。Python3がメンテナンスされている唯一のPythonという中で初めてリリースされる 3.9にどのような新機能が追加されていくのか楽しみです。
なお、前回から「小変更はこの記事で、大きめの変更は別記事で書いてここにリンクを張る」という風に前回からまとめ方を変えましたが、今回もそれを踏襲したいと思います。そして全部の変更を網羅するのではなく個人的に気になったものを中心に載せていきます。
まずは今回から1年周期になった開発ロードマップ(PEP-596)。
- 3.9 開発開始: 2019-06-04 (完了)
- 3.9.0 alpha 1: 2019-11-19 (完了)
- 3.9.0 alpha 2: 2019-12-16 -> 2019-12-18 (完了)
- 3.9.0 alpha 3: 2020-01-13
- 3.9.0 alpha 4: 2020-02-17
- 3.9.0 alpha 5: 2020-03-16
- 3.9.0 alpha 6: 2020-04-13
- 3.9.0 beta 1: 2020-05-18 (これ以降は新機能の追加なし)
- 3.9.0 beta 2: 2020-06-08
- 3.9.0 beta 3: 2020-06-29
- 3.9.0 beta 4: 2020-07-20
- 3.9.0 candidate 1: 2020-08-10
- 3.9.0 candidate 2: 2020-09-14
- 3.9.0 final: 2020-10-05
更新履歴
2020.01.18
最初のバージョン。a2が 2019-12-18にリリースされましたが、そのwhat's new をベースに書いています。a3が2020-01-13予定だったのでそれを待ってからと思っていましたが、遅れているみたいなのでとりあえずこれで出しちゃいます。
新しい機能
(まだ入っていないようです)
その他の言語の変更
インポート時のエラーが
ValueErrorではなくImportErrorをあげるようになる階層構造になっているパッケージ内では、上の階層のモジュールを
import ..module_1というようにインポートできますが、これを例えばパッケージのトップレベルでやってしまうとエラーになります。その場合、これまでは
ValueError: attempted relative import beyond top-level packageという
ValueErrorがでてましたが、3.9からはImportError: attempted relative import beyond top-level packageという
ImportErrorになります。同様に、importlib.util.resove_name()のエラーもValueErrorからImportErrorになります。非互換の変更なので、この例外を捕まえて処理しているコードは変更の必要がありますが、まあ真っ当な変更ですね。ローカルファイルを実行した時の実行時のパスが絶対パスになる
python script.pyとした時に__file__属性にその実行したスクリプトのファイル名が入りますが、これまではコマンドラインで書かれたままの相対パスでしたが、3.9からは絶対パスになります。なお、What's new にはsys.path[0]の値も絶対パスになるって書かれているのですが、これは今のバージョンでもそうなのでドキュメント上のミスなんじゃないかなと思っています。それから、過去の議論を追うと、
sys.argv[0]も絶対パスに変えちゃおうとしていたみたいです。が、そこは影響範囲が大きすぎるといういうツッコミが入り、そちらは取りやめになったみたいです。確かにそれはちょっとやり過ぎだと思うので良かったです。ふー。空文字列("")に対する
replaceの挙動の変更空文字列("")に対して
replaceメソッドを適用した時の挙動が変わります。これまでは、オプションのcount引数(最大何回変更を適用するかを指定する)が付いているとおかしな結果が出ていました。"".replace("", "p") = "p" "".replace("", "p", 1) = "" "".replace("", "p", 2) = ""これが、3.9になると、より一貫性を保った形でこうなります。
"".replace("", "p") = "p" "".replace("", "p", 1) = "p" "".replace("", "p", 2) = "p"まあ、はっきり言ってバグ修正のレベルだと思いますが、「(たぶん無いと思うけど)万が一、この挙動に依存した実装をしている人が困るので以前のバージョンにはバックポートしない」とのこと。
モジュールの改善
asyncio
asyncioには幾つか変更が加わっています。一番面白そうだなと思ったのは
PidfdChildWatcherの追加です。asyncioには子プロセスを複数作ってその結果を非同期に待ち受けるということができるのですが、「子プロセスの終了を検知する」というのが意外と難しい。これまで4つほどのやり方が実装されていて、子プロセスを作る毎に監視の為のスレッドを作成する方法、シグナル(SIGCHLD)を使う方法が2つ、そしてos.waitpid()を使う方法がありました。それぞれ一長一短があり、ユーザが必要に応じて変更することができます(デフォルトはスレッド作成のもの)。今回、ここにpidfsを使ったものが追加されます。
pidfsは私も今回はじめて知ったのですが、Linuxに新たに導入された仕掛けで、プロセスをファイルディスクリプタで指し示すことが出来るようになります。Unixでは通常、プロセスをPID (Process ID)で指し示しますが、システム全体で共有されていて32ビットの signed integer (符号付き整数)なので、システムが稼働し続けプロセスの生成と消去を繰り返すといずれ枯渇してしまいます。そのため、以前使っていた(既に消滅したプロセスの)PIDを再利用することになりますが、これがセキュリティ的な穴になり得ることがわかっています。その対策として、プロセスごとに個別の番号を割り振るファイルディスクリプタの考え方をプロセスにも適用し、子プロセスへのアクセスをそれを用いて出来るようになっています。3.9で追加された
PidfdChildWatcherはスレッドやシグナルを必要とはせず、他のプロセスを邪魔することもないので、「ちょうどよい」子プロセス監視の実装となっています。課題はLinuxの比較的新しいバージョン(5.3以上)でしか使えないことですが、徐々に広がっていけばこれを使える機会も増えてくるのではないかと思います。pathlib
シンボリックリンクの先をたどる
pathlib.Path.readlink()が追加されています。例えば、b -> aというリンクがあった場合、これまでもos.readlink()を使えばimport os os.readlink('b')で
'a'を得られましたが、ファイルパスを文字列で与えなければなりませんでした。3.9からはPathオブジェクトにメソッドとしてreadlink()が追加されたので、import pathlib p = Path('b') b.readlink()こんな風にできます。この例だと
os.readlink()よりもステップ数が多くなっちゃていますが、Pathオブジェクトを使って例えば/usr/local/binの下のシンボリックリンクを表示するツールはこんな風に書けます。from pathlib import Path p = Path('/usr/local/bin/') for child in p.iterdir(): if child.is_symlink(): print(f'{child} -> {child.readlink()}')最適化
廃止予定
math.factorial()が浮動小数点を入れると小数点以下0でも廃止予定の警告がでるようになりおます。将来的にはTypeErrorになるようです。randomモジュールで、今はハッシュ可能であればシードとしてどんな型のデータでも良かったのですが、結果が一意に決まることを保証するためにNone、int、float、str、bytesとbytearrayのみがシードして使えることになります。機能削除
array.arrayのtostring()とfromstring()メソッドが消去されました。3.2の頃から廃止予定になっていてtobytes()とfrombytes()のエイリアスになっていました。まとめ
Python 3.9の変更点についてまとめてみました。まだ大きな機能追加はありませんが、ベータの開始まで4ヶ月ほどあるのでその間に色々と追加されていくのだと思います。この記事も適宜アップデートしていきたいと思います。
- 投稿日:2020-01-18T22:21:35+09:00
言語処理100本ノック-90(Gensim使用):word2vecによる学習
言語処理100本ノック 2015の90本目「word2vecによる学習」の記録です。
今まで第9章でやってきた内容をパッケージ使って簡単にやってしまおう、という設問です。メモリ不足などを気にしながら必死にやってきた内容が3行程度のコードでできてしまうのは、拍子抜けな反面素晴らしさを痛感します。
今回は設問で指定されているGoogle社のword2vecを使わずにオープンソースのGeinsimを使っています。パッケージの更新頻度も多く、よく使われていると聞いたことがあるからです(にわか知識で、しっかりと調べていません)。参考リンク
リンク 備考 090.word2vecによる学習.ipynb 回答プログラムのGitHubリンク 素人の言語処理100本ノック:90 言語処理100本ノックで常にお世話になっています 環境
種類 バージョン 内容 OS Ubuntu18.04.01 LTS 仮想で動かしています pyenv 1.2.15 複数Python環境を使うことがあるのでpyenv使っています Python 3.6.9 pyenv上でpython3.6.9を使っています
3.7や3.8系を使っていないことに深い理由はありません
パッケージはvenvを使って管理しています上記環境で、以下のPython追加パッケージを使っています。通常のpipでインストールするだけです。
種類 バージョン gensim 3.8.1 numpy 1.17.4 課題
第10章: ベクトル空間法 (II)
第10章では,前章に引き続き単語ベクトルの学習に取り組む.
90. word2vecによる学習
81で作成したコーパスに対してword2vecを適用し,単語ベクトルを学習せよ.さらに,学習した単語ベクトルの形式を変換し,86-89のプログラムを動かせ.
回答
回答プログラム 090.word2vecによる学習.ipynb
from pprint import pprint from gensim.models import word2vec corpus = word2vec.Text8Corpus('./../09.ベクトル空間法 (I)/081.corpus.txt') model = word2vec.Word2Vec(corpus, size=300) model.save('090.word2vec.model') # 86. 単語ベクトルの表示 pprint(model.wv['United_States']) # 87. 単語の類似度 print(np.dot(model.wv['United_States'], model.wv['U.S']) / (np.linalg.norm(model.wv['United_States']) * np.linalg.norm(model.wv['U.S']))) # 88. 類似度の高い単語10件 pprint(model.wv.most_similar('England')) # 89. 加法構成性によるアナロジー # vec("Spain") - vec("Madrid") + vec("Athens") pprint(model.wv.most_similar(positive=['Spain', 'Athens'], negative=['Madrid']))回答解説
単語ベクトル生成
まずはファイル読込です。
Text8Corpus関数を使っている例が多いなと思い、そもそもText8Corpusとは何と思って調べました。
記事「日本語版text8コーパスを作って分散表現を学習する」によるとtext8とは以下の処理をしたWikipediaのデータらしい。
- テキストと画像キャプションは保持
- テーブルや外国語バージョンへのリンクを除去
- 引用、脚注、マークアップを除去
- ハイパーテキストはアンカーテキストだけ保持。それ以外は除去
- 数字はつづりを変換。たとえば、"20"は"two zero"に変換
- 大文字を小文字に変換
- a-zの範囲に入らない文字はスペースに変換
大文字はあった気もするが、だいたい条件に合致している気がしたので
Text8Corpusを使いました。corpus = word2vec.Text8Corpus('./../09.ベクトル空間法 (I)/081.corpus.txt')あとは
Word2Vec関数を使うだけで300次元の単語ベクトル完成です。4分弱で生成できました。すごい・・・
オプションは使わなかったですが、gemsimのword2vecのオプション一覧がわかりやすかったです。model = word2vec.Word2Vec(corpus, size=300)そして、後続のノックのためにファイル保存しておきます。
model.save('090.word2vec.model')そうすると以下の3ファイルができるようです。1つでないのが気持ち悪いです。
ファイル サイズ 090.word2vec.model 5MB 090.word2vec.model.trainables.syn1neg.npy 103MB 090.word2vec.model.wv.vectors.npy 103MB 86. 単語ベクトルの表示
85で得た単語の意味ベクトルを読み込み,"United States"のベクトルを表示せよ.ただし,"United States"は内部的には"United_States"と表現されていることに注意せよ.
model.wvにベクトルが入っているので指定してあげるだけです。pprint(model.wv['United_States'])array([ 2.3478289 , -0.61461514, 0.0478639 , 0.6709404 , 1.1090833 , -1.0814637 , -0.78162867, -1.2584596 , -0.04286158, 1.2928476 , 結果略87. 単語の類似度
85で得た単語の意味ベクトルを読み込み,"United States"と"U.S."のコサイン類似度を計算せよ.ただし,"U.S."は内部的に"U.S"と表現されていることに注意せよ.
modelを使って第9章と同じベクトル同士のコサイン類似度計算をします。
第9章では0.837516976284694だったので、より類似度が高い数値が出ています。print(np.dot(model.wv['United_States'], model.wv['U.S']) / (np.linalg.norm(model.wv['United_States']) * np.linalg.norm(model.wv['U.S'])))0.860159688. 類似度の高い単語10件
85で得た単語の意味ベクトルを読み込み,"England"とコサイン類似度が高い10語と,その類似度を出力せよ.
modst_similar関数を使うだけで出力できます。pprint(model.wv.most_similar('England'))[('Scotland', 0.7884809970855713), ('Wales', 0.7721374034881592), ('Ireland', 0.6838206052780151), ('Britain', 0.6335258483886719), ('Hampshire', 0.6147407293319702), ('London', 0.6021863222122192), ('Cork', 0.5809425115585327), ('Manchester', 0.5767091512680054), ('Liverpool', 0.5765234231948853), ('Orleans', 0.5624016523361206)]ちなみに第9章での結果は以下の通りでしたが、今回はイギリスに関連する単語がより上位に出てきていて、より正しいデータが出力されていることがわかります。
Scotland 0.6364961613062289 Italy 0.6033905306935802 Wales 0.5961887337227456 Australia 0.5953277272306978 Spain 0.5752511915429617 Japan 0.5611603300967408 France 0.5547284075334182 Germany 0.5539239745925412 United_Kingdom 0.5225684232409136 Cheshire 0.512528614477968889. 加法構成性によるアナロジー
85で得た単語の意味ベクトルを読み込み,vec("Spain") - vec("Madrid") + vec("Athens")を計算し,そのベクトルと類似度の高い10語とその類似度を出力せよ.
modst_similar関数にpositiveとnegativeを渡すと計算して、類似度の高い10語を出力してくれます。pprint(model.wv.most_similar(positive=['Spain', 'Athens'], negative=['Madrid']))[('Denmark', 0.7606724500656128), ('Italy', 0.7585107088088989), ('Austria', 0.7528095841407776), ('Greece', 0.7401891350746155), ('Egypt', 0.7314825057983398), ('Russia', 0.7225484848022461), ('Great_Britain', 0.7184625864028931), ('Norway', 0.7148114442825317), ('Rome', 0.7076312303543091), ('kingdom', 0.6994863748550415)]ちなみに第9章での結果は以下の通りでしたが、今回はギリシャも4位に出てきていてより正しいデータが出力されていることがわかります。
Spain 0.8178213952646727 Sweden 0.8071582503798717 Austria 0.7795030693787409 Italy 0.7466099164394225 Germany 0.7429125848677439 Belgium 0.729240312232219 Netherlands 0.7193045612969573 Télévisions 0.7067876635156688 Denmark 0.7062857691945504 France 0.7014078181006329
- 投稿日:2020-01-18T22:08:36+09:00
Angular スターターキットを作った
目的
Angularの開発経験がない人向けのサンプルコードを作る必要があったため作成した。
公式のチュートリアルもあるのだが、根本からちゃんと理解させるために書かれているので、結構回りくどくて必要最低限のところにたどり着くまで時間が掛かってしまう。
今回は細かいことは良いから、基本的な画面が動けば良し、という人向けのコードを作った。
このコードを真似しながら初心者でも自分で機能を追加できるようになるのが理想。構成
Frontend
- Angular
- Angular Material
Backend
- Django
- Django Restframework
コード
Angular Sample
Django Restframework Sample
注意
- これから少しずつ改善させていくが、まだ簡単なデータ検索画面が1つあるだけ。
今後の予定
- コードのコメントやReadmeを充実させて、初心者が機能追加・改修をし易くする
- データ登録画面を開発する
- データ検索画面を Angular Material のコンポーネントを使いリッチにする
- etc...
- 投稿日:2020-01-18T20:47:09+09:00
AtCoder Beginner Contest 075 過去問復習
所要時間
感想
今回もバチャコン中に他の用事をしてしまい、D問題を解ききることができませんでした…。
今日はコンテストがあるので頑張ります!A問題
bとc同じならa、cとa同じならb、aとb同じならcを出力(今回は三項演算子を二つ組み合わせてみました。)。
answerA.pya,b,c=map(int,input().split()) print(a if b==c else b if c==a else c)B問題
8近傍の判定を行えば良い。判定部分が異常に長くなるのはどうすれば直るんでしょうか…。
コメントを頂き短く書くことができました。以下のような工夫をしました。
boolは整数型のサブクラスなので足し算ができること、盤面内にあるかどうかの判定は周りに"."を加えることで簡単に出来ること(この簡略化は前のAtCoderの問題でもやった気がする。)を利用しました。answerB.pyh,w=map(int,input().split()) s=[list(input()) for i in range(h)] def count_8(i,j): global h,w,s cnt=0 if i-1>=0 and j-1>=0: if s[i-1][j-1]=="#": cnt+=1 if i-1>=0 and j+1<=w-1: if s[i-1][j+1]=="#": cnt+=1 if i+1<=h-1 and j-1>=0: if s[i+1][j-1]=="#": cnt+=1 if i+1<=h-1 and j+1<=w-1: if s[i+1][j+1]=="#": cnt+=1 if i-1>=0: if s[i-1][j]=="#": cnt+=1 if j-1>=0: if s[i][j-1]=="#": cnt+=1 if i+1<=h-1: if s[i+1][j]=="#": cnt+=1 if j+1<=w-1: if s[i][j+1]=="#": cnt+=1 return str(cnt) for i in range(h): for j in range(w): if s[i][j]=="#": print("#",end="") else: print(count_8(i,j),end="") print()answerC_better.pyh,w=map(int,input().split()) s=[input()+"." if i!=h else "."*(w+1) for i in range(h+1)] def count_8(i,j): global h,w,s cnt=(s[i-1][j-1]=="#")+(s[i-1][j+1]=="#")+(s[i+1][j-1]=="#")+(s[i+1][j+1]=="#") \ +(s[i-1][j]=="#")+(s[i][j-1]=="#")+(s[i+1][j]=="#")+(s[i][j+1]=="#") return cnt for i in range(h): s_sub="" for j in range(w): if s[i][j]=="#": s_sub+="#" else: s_sub+=str(count_8(i,j)) print(s_sub)C問題
Writer解とは違う解き方でやりました。
まず、一辺しかつながっていない頂点を考えると、その辺を除くとその頂点は非連結になってしまいます。したがって、そのような辺については連結であるために必要な辺なので橋になります。
次に二辺以上つながっている頂点(a)について考えます。その二辺のうちの片方が橋(a-b)であったと仮定すると、その片方の橋はbが非連結でないための橋になります。したがって、その頂点aのための橋はもう片方の橋になります。つまり、n(>=3)辺の場合でも橋がn-1本あればもう一つの辺も橋になることがわかります。
したがって、辺が一辺しかない頂点をチェックしてその辺を取り除いていくという作業を繰り返し、辺が一辺しかない頂点がなくなるまで繰り返すことで橋である辺を全て求めることができます。answerC.pyn,m=map(int,input().split()) x=[[] for i in range(n)] for i in range(m): a,b=map(int,input().split()) x[a-1].append(b-1) x[b-1].append(a-1) def size0find(): global x,n next=[] for i in range(n): if len(x[i])==1: next.append(i) k=x[i][0] x[i].remove(k) x[k].remove(i) return next cnt=0 while True: y=size0find() l=len(y) if l==0: break cnt+=l print(cnt)D問題
方針を立てることが難しく、解答を見ながら実装しました。
問題を解く際の着眼点をまとめながら復習していきたいと思います。
まずはじめは全てのありうる場合を書き出したのですが、計算量が$10^{15}$以上なので間に合わないのは明らかです(解いてる時に気づけませんでした…)。方針を間違えたのは別に良かったのですが、そこからの切り替えがやはりできていないと感じました。以下はTLE解になります。answerD_TLE.pyimport itertools n,k=map(int,input().split()) xy=[list(map(int,input().split())) for i in range(n)] t=[i for i in range(n)] s=list(itertools.permutations(t,k)) #print(s) l=len(s) inf=10000000000 x_min=inf y_min=inf x_max=-inf y_max=-inf for i in range(n): x,y=xy[i] if x<x_min:x_min=x if y<y_min:y_min=y if x>x_max:x_max=x if y>y_max:y_max=y area=(x_max-x_min)*(y_max-y_min) for i in range(l): x_min=inf y_min=inf x_max=-inf y_max=-inf for j in range(k): x,y=xy[s[i][j]] if x<x_min:x_min=x if y<y_min:y_min=y if x>x_max:x_max=x if y>y_max:y_max=y #print(area) area=min((x_max-x_min)*(y_max-y_min),area) print(area)ここから正答について書きます。
まず、長方形の面積は四つの辺が決まると求まります。さらに、その辺上に点がある時最小の長方形となることも明らかです。したがって、四つの辺がそれぞれ点を通るように狭めていき、K個以上を含む長方形の中で最小の長方形を求めれば良いです。
ここで、四つの辺の選び方は、それぞれ$ _n C _2 $であり(O($n^4$))、その長方形がどの頂点をそれぞれ含んでいるのかを考える(O($n$))ことで合わせてO($n^5$)でありギリギリ間に合います(Pythonでは間に合いので二次元累積和によりO(n^4)に計算量を落とす必要があります。今回はPyPyで通しました。)。
また、四つの辺を選ぶ際に、長方形の中に含まれる点がkより小さい場合を数えるのは無駄なのでそのような場合が含まれないよう、kを下回ったらbreakするようにしました。answerD.pyn,k=map(int,input().split()) xy=[list(map(int,input().split())) for i in range(n)] x,y=[[xy[i][0],i] for i in range(n)],[[xy[i][1],i] for i in range(n)] x.sort() y.sort() ans=10**18*4 for i1 in range(n): i1_sub=n-i1 x_sub1=x[i1][0] for l1 in range(i1_sub,1,-1): x_sub2=x[i1+l1-1][0] for i2 in range(n): i2_sub=n-i2 y_sub1=y[i2][0] for l2 in range(i2_sub,1,-1): y_sub2=y[i2+l2-1][0] z=[0]*n for i in range(n): if x_sub1<=xy[i][0]<=x_sub2 and y_sub1<=xy[i][1]<=y_sub2: z[i]=1 if sum(z)>=k: ans=min((x_sub2-x_sub1)*(y_sub2-y_sub1),ans) else: break print(ans)追記(1/19)
定数倍高速化が趣味なので今日の午前中も定数倍高速化をしていました。
PyPyによる速度比較で1357ms→619msまでの高速化をしましたが、Pythonではまだ通りません(おそらくさらに3倍早くしないと通りません。)。
また、O($n^5$)→O($n^4 \times log(n)$)に直したコードも下に貼ってありますが、nの値が小さいため、十分な高速化ができませんでした(関数呼び出しとwhileが遅い?もう少しうまくやればいい感じにできそうだけど。)。answerD.pyn,k=map(int,input().split()) xy=[list(map(int,input().split())) for i in range(n)] x,y=[[xy[i][0],i] for i in range(n)],[[xy[i][1],i] for i in range(n)] x.sort() y.sort() ans=10**18*4 for i1 in range(n): i1_sub=n-i1 x_sub1=x[i1][0] for l1 in range(i1_sub,1,-1): x_sub2=x[i1+l1-1][0] for i2 in range(n): i2_sub=n-i2 y_sub1=y[i2][0] x_subsub=x_sub2-x_sub1 for l2 in range(i2_sub,1,-1): y_sub2=y[i2+l2-1][0] z=0 for i in range(n): if x_sub1<=xy[i][0]<=x_sub2 and y_sub1<=xy[i][1]<=y_sub2: z+=1 if z>=k: ans=min(x_subsub*(y_sub2-y_sub1),ans) break else: break print(ans)answerD.pyn,k=map(int,input().split()) xy=[list(map(int,input().split())) for i in range(n)] x,y=[[xy[i][0],i] for i in range(n)],[[xy[i][1],i] for i in range(n)] x.sort() y.sort() inf=10**18*4 ans=inf def upper_k(x_sub1,x_sub2,y_sub1,y_sub2): global n,k,xy z=0 for i in range(n): if x_sub1<=xy[i][0]<=x_sub2 and y_sub1<=xy[i][1]<=y_sub2: z+=1 if z>=k:return True return False for i1 in range(n): i1_sub=n-i1 x_sub1=x[i1][0] for l1 in range(i1_sub,1,-1): x_sub2=x[i1+l1-1][0] x_subsub=x_sub2-x_sub1 for i2 in range(n): ans_sub=inf i2_sub=n-i2 y_sub1=y[i2][0] l,r=2,i2_sub if r<l:break while l+1<r: t=(l+r)//2 y_sub2=y[i2+t-1][0] if upper_k(x_sub1,x_sub2,y_sub1,y_sub2): r=t else: l=t y_sub2=y[i2+r-1][0] if upper_k(x_sub1,x_sub2,y_sub1,y_sub2): ans=min(x_subsub*(y_sub2-y_sub1),ans) if l!=r: y_sub2=y[i2+l-1][0] if upper_k(x_sub1,x_sub2,y_sub1,y_sub2): ans=min(x_subsub*(y_sub2-y_sub1),ans) print(ans)

- 投稿日:2020-01-18T20:41:32+09:00
ケモインフォマティクスで学ぶNumPy
はじめに
ケモインフォマティクスで学ぶPythonのクラスに続き、リピドミクス(脂質の網羅解析)を題材として、Pythonの代表的なライブラリの一つである「NumPy」について解説していきます。
ケモインフォマティクスの実践例を中心に説明していきますので、基本を確認したいという人は以下の記事を読んでからこの記事を読んでみてください。NumPyを用いた基本的な演算
NumPyを使うことで、ベクトルや行列演算を高速で行うことができます。
まず、
import ライブラリ名でライブラリを読み込むことができます。
さらに、as 略号をつけることで、以降はここで書いた略号でライブラリを呼び出す(指し示す)ことができます。
NumPyの場合は、慣習的にnpとすることが多いです。import numpy as np masses = np.array([12, 1.00783, 15.99491]) # 炭素、水素、酸素原子の精密質量を格納したndarray numbers = np.array([16, 32, 2]) # パルミチン酸の炭素、水素、酸素原子の数 print(masses * numbers) # 元素ごとに精密質量を計算 print(sum((masses * numbers))) # パルミチン酸の精密質量上のように、
np.array(リスト)とすることで、複数の要素を持つベクトルを作成することができます。
四則演算をすると、要素ごとに演算が行われます。
また、sumを使うことで、全ての要素の合計値を求めることができます。リストとの違い
np.array(リスト)で作成されるベクトルは、リストによく似ていますが、データ型はlistではなく、numpy.ndarrayになります。
numpy.ndarrayどうしを掛け算すると、各要素を掛けたnumpy.ndarrayが返されますが、listどうしを掛け算すると、TypeErrorとなり演算ができません。masses_ndarray = np.array([12, 1.00783, 15.99491]) print(type(masses_ndarray)) # numpy.ndarray masses_list = [12, 1.00783, 15.99491] print(type(masses_list)) # list print(list(masses_ndarray)) # [12, 1.00783, 15.99491] numbers_list = [16, 32, 2] # print(masses_list * numbers_list) # TypeError応用:原子量の計算
次に、原子およびその同位体の精密質量と天然同位体存在比をもとに、原子量を求めることを考えます。
exact_mass_H = np.array([1.00783, 2.01410]) # 同位体の精密質量 isotope_ratio_H = np.array([0.99989, 0.00011]) # 同位体の天然存在比 molecular_weight_H = sum(exact_mass_H * isotope_ratio_H) # 原子量を計算 print(molecular_weight_H) # 水素の原子量応用:複数の化合物の精密質量の計算
最後に、複数の脂肪酸分子種の精密質量を求めてみます。
numbers = np.array([[16, 32, 2], [18, 36, 2], [18, 34, 2]]) # パルミチン酸、ステアリン酸、オレイン酸の元素組成 print(masses * numbers) # 各分子種の各元素の精密質量を計算 print(np.sum(masses * numbers, axis=1)) # 各分子種の精密質量を計算まとめ
ここでは、NumPyについて、ケモインフォマティクスで使える実践的な知識を中心に解説しました。
もう一度要点をおさらいしておきましょう。
- NumPyを使うことで、ベクトルの要素どうしの演算が簡単に行えます。
- 原子量や分子量、精密質量の計算に使えます。
次回は、Pandasについて解説する予定です。
参考資料・リンク
- 投稿日:2020-01-18T20:37:10+09:00
【Python】図の目盛りラベルを取得・編集
本記事では
import matplotlib.pyplot as pltやfig = plt.figure()を前提にしています.まとめ
Pythonで出力された図の目盛りラベルを取得するためには,
- plt.draw() で一旦図を確定
- locs, labs = plt.xticks() で目盛りを取得
- _labs = [ lab.get_text() for lab in labs ] で目盛りラベルの文字列を取得
- ~ラベル文字列の変更~
- plt.xticks( locs, _labs ) で図の目盛りを変更
という手順が必要です.
もしくは直接labsの要素を書き換えることでも編集できます(例:labs[0].set_va( 'top' ))
後者の方法の方が,文字列以外の編集も可能なため便利な場合もあります.~以下解説~
目盛りの取得
目盛りの文字列が取得できないとき
Pythonがデフォルトで出力する目盛りを取得しても,ラベルの情報が含まれていない場合があります.
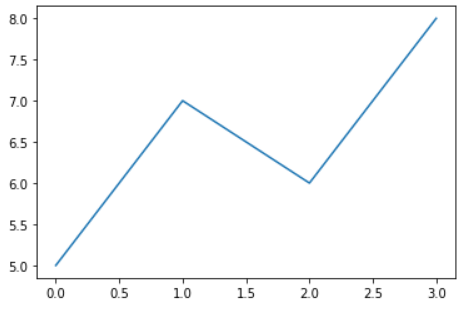
例えばplt.plot( [ 5, 7, 6 ] )を実行すると下の図が表示されますが,
この目盛りを取得しても,ラベルの情報は
''になっています.なお,plt.xticks()の2つ目の返り値は文字列ではなく,matplotlib.text.Textオブジェクトのリストなので,.get_text()というメソッドで文字列を取得しています:xlocs, xlabs = plt.xticks() print( xlocs ) # [-0.5 0. 0.5 1. 1.5 2. 2.5 3. 3.5] print( [ xlab.get_text() for xlab in xlabs ] ) # ['', '', '', '', '', '', '', '', ''] ylocs, ylabs = plt.xticks() print( ylocs ) # [4.5 5. 5.5 6. 6.5 7. 7.5 8. 8.5] print( [ ylab.get_text() for ylab in ylabs ] ) # ['', '', '', '', '', '', '', '', '']更に言うと,今出力されている図の目盛りよりも上下左右に余分な目盛り(横軸の-0.5など)が含まれています.
これは,Python側が「目盛りは現在未確定で,以降も追加編集に応じて適宜調整します」という状態だからです.
stackoverflow: Getting empty tick labels before showing a plot in Matplotlib図の確定→目盛り文字列の取得が可能に
従って図を一旦確定させるために,
plt.draw()もしくはfig.canvas.draw()を行います.
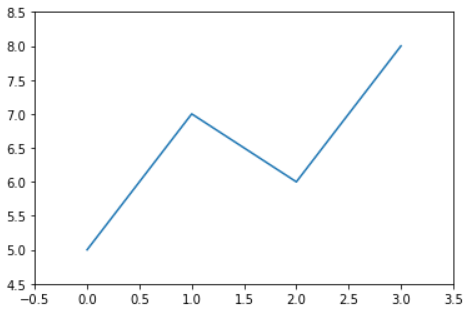
すると,目盛りの文字列も確定するので,(表示される図は変わりませんが)図に表示されている文字列が取得できるようになります.plt.plot( [ 5, 7, 6, 8 ] ) plt.draw() xlocs, xlabs = plt.xticks() print( xlocs ) # [-0.5 0. 0.5 1. 1.5 2. 2.5 3. 3.5] print( [ xlab.get_text() for xlab in xlabs ] ) # ['−0.5', '0.0', '0.5', '1.0', '1.5', '2.0', '2.5', '3.0', '3.5'] ylocs, ylabs = plt.yticks() print( ylocs ) # [4.5 5. 5.5 6. 6.5 7. 7.5 8. 8.5] print( [ ylab.get_text() for ylab in ylabs ] ) # ['4.5', '5.0', '5.5', '6.0', '6.5', '7.0', '7.5', '8.0', '8.5']目盛りラベルの更新
この段階でも上下左右の余分な目盛りが含まれているので,無編集でも再び
plt.xticks( xlocs, xlabs )を行うと,余分な目盛りが表示されてしまうために図の余白が大きくなります:plt.xticks( xlocs, xlabs ) plt.yticks( ylocs, ylabs )
従って図の範囲を変えたくない場合には,
xlim(),ylim()で図の範囲を指定するか,目盛りのリストを適宜トリミング(例:xlocs[1:-1])する必要があります.xmin, xmax = plt.xlim() ymin, ymax = plt.ylim() plt.xticks( xlocs, xlabs ) plt.yticks( ylocs, ylabs ) plt.xlim( xmin, xmax ) plt.ylim( ymin, ymax ) # === OR === plt.xticks( xlocs[1:-1], xlabs[1:-1] ) plt.yticks( ylocs[1:-1], ylabs[1:-1] )matplotlib.text.Textクラスに直接アクセスする
上では目盛りラベルの文字列を一旦取得しましたが,
plt.xticks()で得られるmatplotlib.text.Textクラスに直接アクセスすることで,目盛りの体裁を1個ずつ編集することができます.
その編集には,下ページのメソッド一覧(set_*)を使います.例えば,
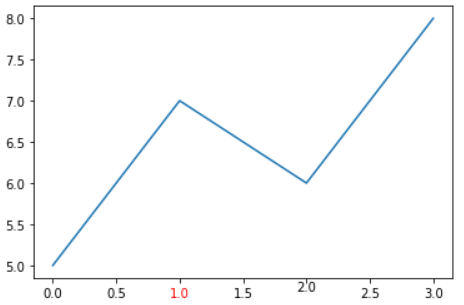
matplotlib公式: matplotlib.text.Textxlocs, xlabs = plt.xticks() xlabs[3].set_color( 'red' ) xlabs[5].set_va( 'center' )では,横軸の一部の色,高さを変えています.
これを活用すると,目盛りラベルが長くなってしまうときに,ラベルを互い違いに表示することもできます:
stackoverflow: Aligning rotated xticklabels with their respective xticks
- 投稿日:2020-01-18T20:34:56+09:00
LINEのグループトークを学習して、グループメンバーのように会話するLINEbotを作る
普段使っているグループトークにいきなり謎のAIが乱入してきたら面白いと思い、機械学習やLINEbotの使い方を学ぶ意味も込めて、LINEのグループトークを学習してあたかもグループメンバーのように会話するLINEbotを作ったので、手順をまとめます。
TensorFlowで会話AIを作ってみた。
作成にはこちらのページと、tensorflowの公式リファレンスを参考にさせていただきました。
また機械学習についてはなんとなくでしか理解していないため、これをきっかけにモデルの作り方など学んでいこうと思いました...必要なもの
- LINE atのアカウント
- ある程度のグループトークの会話データ(1〜2MB)
- pythonの実行環境
- 学習に使うライブラリ各種(tensorflow, mecab)
実装の流れ
ここからは、以下の手順で進めていきます。
Tensorflowサイド
- グループトークの会話データをダウンロードする
- 会話データの前処理を行う
- 作成したデータセットを使ってモデルを学習させる
LINEbotサイド
- Line atのアカウントを用意する
- オウム返しするするとこまで確認
- 誰かが話したらその言葉をモデルに投げ込み、得られた出力を発言する
実装
1. グループトークの会話データをダウンロードする
スマホのグループトーク画面→右上のメニュー→右上の歯車マーク→「トーク履歴を送信」で、
python実行環境のあるPCに会話データを送信します。2. 会話データの前処理を行う
会話データファイルから、モデルを学習させるためデータセットを作成します。
たとえば「今どこ?」→「バイト」→「まじか」という会話があれば、入力"今どこ?"-出力"バイト"という会話ペアと、入力"バイト"-出力"まじか"という会話ペアを作成します。
preprocess.pyimport MeCab talkFile = open('会話データファイルの名前', 'r') input = open('input.txt', 'w') output = open('output.txt', 'w') line = talkFile.readline() wakati = MeCab.Tagger("-Owakati") hiragana = "ぁあぃいぅうぇえぉおかがきぎくぐけげこごさざしじすずせぜそぞただちぢっつづてでとどなにぬねのはばぱひびぴふぶぷへべぺほぼぽまみむめもゃやゅゆょよらりるれろゎわゐゑをん" katakana = "ァアィイゥウェエォオカガキギクグケゲコゴサザシジスズセゼソゾタダチヂッツヅテデトドナニヌネノハバパヒビピフブプヘベペホボポマミムメモャヤュユョヨラリルレロヮワヰヱヲンヴ" def filterStr(str): if str == "": return False word = str.split("\t")[-1] if '/' in word or '[' in word or len(word) > 12: return False for ch in word: if ch in hiragana or ch in katakana: return word return False def processedStr(str): str = wakati.parse(str.strip()) str = "<start> " + str.replace('\n','') + "<end>\n" return str wordList = [] while line: word = filterStr(line) if word: wordList.append(processedStr(word)) line = talkFile.readline() talkFile.close() for index in range(len(wordList)): if index == 0: input.write(wordList[index]) elif index == len(wordList)-1: output.write(wordList[index]) else: input.write(wordList[index]) output.write(wordList[index]) print(wordList[index]) input.close() output.close()これで、
<start> いい な それ <end>
のように、各会話データから日時・発言した人などの余分な情報をのぞき、なおかつ形態素解析を施してタグを付加したデータセットinput.txtとoutput.txtが生成されました。3. 作成したデータセットを使ってモデルを学習させる
機械翻訳-Tensorflow 2.xのリファレンスにお世話になります。
TensorFlow 2.0 : 上級 Tutorials : テキスト :- ニューラル機械翻訳 with Attention 11/12/2019
一番最近の記事を参考にさせていただきました。
まず、記事をそのまま実装しうまく動くことを確かめます。GPUを使わない場合はものすごく時間がかかってしまいますが、一応終わります。
その後、関数load_datasetの前で先程作成したデータセットを読み込み、load_datasetを書き換えます。また、そのすぐ下のデータセットの数量を表す変数も、読み込んだ会話データの数より小さくセットしておきます。"..."は、その間に何行かコードがあることを示しています。training_model.py... inputf = open('input.txt', 'r') outputf = open('output.txt', 'r') ilist = inputf.readlines() olist = outputf.readlines() for i in range(len(ilist)): ilist[i] = ilist[i].replace('\n','') for i in range(len(olist)): olist[i] = olist[i].replace('\n','') inputf.close() outputf.close() def load_dataset(path, num_examples=None): targ_lang = olist inp_lang = ilist input_tensor, inp_lang_tokenizer = tokenize(inp_lang) target_tensor, targ_lang_tokenizer = tokenize(targ_lang) return input_tensor, target_tensor, inp_lang_tokenizer, targ_lang_tokenizer num_examples = #データセットの数量より小さくセット ...会話データを一段ずつずらして入出力ペアを生成するので、データセットの数量を会話データの数と同じにしてしまうとエラーが発生します。
また、翻訳では前処理は必要ないためコメントアウトし、translate関数を書き換えたら完成です。training_model.py... def evaluate(sentence): attention_plot = np.zeros(max_length_targ, max_length_inp) #sentence = preprocess_sentence(sentence) ... ... def translate(sentence): result, sentence, attention_plot = evaluate(sentence) print('{}'.format(result.replace(' <end>', '').replace(' ',''))) attention_plot = attention_plot[:len(result.split(' ')), :len(sentence.split(' '))] plot_attention(attention_plot, sentence.split(' '), result.split(' ')) checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir)) translate('今 どこ ?')ここでtraining_model.pyを実行し、それっぽい出力が帰ってきたら成功です(この時点では自分で単語ごとに区切ってやる必要があります)。
ここからは学習済みモデルをチェックポイントを使って読み込んでいくので、学習部分のコードをコメントアウトして、最後に対話モードを付け足します。
training_model.py... import MeCab ... ''' for epoch in range(EPOCHS): start = time.time() enc_hidden = encoder.initialize_hidden_state() total_loss = 0 for (batch, (inp, targ)) in enumerate(dataset.take(steps_per_epoch)): batch_loss = train_step(inp, targ, enc_hidden) total_loss += batch_loss if batch % 100 == 0: print('Epoch {} Batch {} Loss {:.4f}'.format(epoch + 1, batch, batch_loss.numpy())) # saving (checkpoint) the model every 2 epochs if (epoch + 1) % 2 == 0: checkpoint.save(file_prefix = checkpoint_prefix) print('Epoch {} Loss {:.4f}'.format(epoch + 1, total_loss / steps_per_epoch)) print('Time taken for 1 epoch {} sec\n'.format(time.time() - start)) ''' def evaluate(sentence): attention_plot = np.zeros((max_length_targ, max_length_inp)) #sentence = preprocess_sentence(sentence) inputs = [] for i in sentence.split(' '): if i != '': if i in inp_lang.word_index: inputs.append(inp_lang.word_index[i]) else: return False, False, False inputs = tf.keras.preprocessing.sequence.pad_sequences([inputs], maxlen=max_length_inp, padding='post') inputs = tf.convert_to_tensor(inputs) ... ... def translate(sentence): wakati = MeCab.Tagger("-Owakati") inputList = wakati.parse(sentence.replace('\n','').strip()).replace('\n','') result, inputList, attention_plot = evaluate(inputList) if result: print('{}'.format(result.replace('<end>', '').replace(' ',''))) checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir)) while True: print(">", end="") inputStr = input() translate(inputStr)ここでtraining_model.pyを実行すると、最初の読み込みの後にこのようにAIとリアルタイムで対話することができるようになります。短いワードなら割とそれっぽく返してくるので、開発中にツボることが増えてきます。機械学習すげぇ...
4. Line atのアカウントを用意する 5. オウム返しするするとこまで確認
ここはPythonを利用したLINE Botの作り方を現役エンジニアが解説【初心者向け】でとてもわかりやすく解説されていたため省略します。
重要なのはこのサイトでも出てくる、LINEbotの動作を定義するapp.pyファイルです。最後にこの中身を書き換えていきます。6. 誰かが話したらその言葉をモデルに投げ込み、得られた出力を発言する
まず、training_model.pyのtranslate関数を書き換えて対話モードを無効にします。
training_model.py... def translate(sentence): wakati = MeCab.Tagger("-Owakati") inputList = wakati.parse(sentence.replace('\n','').strip()).replace('\n','') result, inputList, attention_plot = evaluate(inputList) if result: return result.replace('<end>', '').replace(' ','') else: return False checkpoint.restore(tf.train.latest_checkpoint(checkpoint_dir)) ''' while True: print(">", end="") inputStr = input() translate(inputStr) '''そして、app.pyでtraining_modelを読み込んで、イベント発生時にtranslate関数が走るようにすれば完成です。
app.py... import training_model ... def callback(): ... for event in events: if not isinstance(event, MessageEvent): continue if not isinstance(event.message, TextMessage): continue reply = training_model.translate(event.message.text) if reply: line_bot_api.reply_message( event.reply_token, TextSendMessage(text=reply) ) return 'OK' ...実際にトークに乱入させてみた様子がこんな感じです。
大学生の内輪トークということでかなりスレスレの単語が飛びかっていたので、ネットに上げられるのはこのくらいでした...グループトークを学習させたAIをそのグループトークに乱入させてみた pic.twitter.com/rLq5WnzqUG
— nunor (@nunorlabo) January 18, 2020最初は自宅のワンボードPC(トーク監視用)と研究室のサーバ(モデル学習用)を連携させた実装だったのですが、一度全トークを学習させた後は大きな計算リソースはいらないことに気づいたため、今では全てワンボードPCで動かせています。つまり、最初だけPCに頑張ってもらえば、あとは新しいトークを少しずつ学習させていくだけなので潤沢な計算リソースがなくても無問題というわけです。
うまくいったら、早速トークに乱入させてみてください!

- 投稿日:2020-01-18T19:56:40+09:00
FGOのスター集中の確率・期待値の計算
注意
この記事はFGOことFate/Grand Orderというソーシャルゲームのあるアルゴリズムについての記事です。
はじめに
FGOではクリティカルが戦術の大きな部分を占めますが、クリティカルスターの集中の計算はちょっと面倒です。
仕様は
- サーヴァント毎に集中度(SW)が設定されている。(10~200)
- 集中度アップ・ダウンの効果によって増減する。
- サーヴァント3騎から5枚のカードをランダムに配布する。
- それぞれのカードについて、ランダムに集中度にボーナス(+0x2, +20x2, +50x1)が加算される。
- ボーナス加算後の集中度に応じて保有しているクリティカルスターを振り分ける。
- 10個振り分けられたカードにはそれ以上振り分けられない。
計算例
以下のようなサーヴァントで考えます。
- SW
- サーヴァント1:200
- サーヴァント2:50
- サーヴァント3:10
サーヴァント1から2枚、2から2枚、3から1枚配布され、ボーナスを+0, +0, +50, +20, +20で考えると…
- いずれのカードもスター10個未満の時
配布カード サーヴァント1
カードAサーヴァント1
カードBサーヴァント
カードCサーヴァント2
カードDサーヴァント3
カードE集中度 200 200 50 50 10 ボーナス +0 +0 +50 +20 +20 合計 200 200 100 70 30 比率(%) 33.3 33.3 16.7 11.7 5
- カードAがスター10個になった時
配布カード サーヴァント1
カードAサーヴァント1
カードBサーヴァント
カードCサーヴァント2
カードDサーヴァント3
カードE集中度 - 200 50 50 10 ボーナス - +0 +50 +20 +20 合計 - 200 100 70 30 比率(%) - 50 25 17.5 7.5
- カードAとBがスター10個になった時
配布カード サーヴァント1
カードAサーヴァント1
カードBサーヴァント
カードCサーヴァント2
カードDサーヴァント3
カードE集中度 - - 50 50 10 ボーナス - - +50 +20 +20 合計 - - 100 70 30 比率(%) - - 50 35 15 ………と、このように確率が変化していきます。
計算
ボーナスは振り分けの過程で変化しないので無視して、一般化して考えます。
カード$n$に$y$個のスターが振り分けられる確率は、
- カード$n$に$y-1$個スターがあって、カード$n$に1個スターが振り分けられる確率
- カード$n$に$y$個スターがあって、カード$n$以外に1個スターが振り分けられる確率
の合計です。
これをPythonプログラムで実装します。実装
fgostarcalc.pyimport math #各カードのSW(ボーナス込み):カード1~カード5 SW = [200, 200, 100, 70, 30] #各カードのスター0~10個の状態の確率を保持 Probabilities = [None for _ in range(11**6)] Probabilities[0] = 1 #任意の桁の数字の取得(各カードのスターの個数) def digitnum(decim, base, ind): return(math.floor((decim % (base**ind))/(base**(ind-1)))) #各桁の数字の合計(スターの合計) def sumdigit(decim, base): if decim == 0: return 0 else: return(sum([digitnum(decim, base, i) for i in range(1, 2+math.ceil(math.log(decim, base)))])) #有効性の検証 def is_valid(decim, base, totalstar, card, holdstar): if digitnum(decim, base, card) == holdstar: if sumdigit(decim, base) == totalstar: return True return False #各状態の確率計算の再帰関数 def calc_starprob(decim, base, totalstar, card, holdstar): #print(decim, base, totalstar, card, holdstar) starweights = [0 if digitnum(decim, base, x+1) == base-1 else SW[x] for x in range(5)] starprob = [SW[x]/(sum(starweights)-starweights[x]+SW[x]) for x in range(5)] starweights[card] = SW[card] if decim < 0 or totalstar < 0 or holdstar < 0: print("Error: ", decim, base, totalstar, card, holdstar) raise if Probabilities[decim] != None: return(Probabilities[decim]) else: tmp = [0] for x in range(5): if digitnum(decim, base, x+1) == 0: continue else: if x+1 == card and holdstar > 0: tmp += [calc_starprob(decim-base**x, base, totalstar-1, card, holdstar-1)*starprob[x]] elif x+1 != card: tmp += [calc_starprob(decim-base**x, base, totalstar-1, card, holdstar)*starprob[x]] Probabilities[decim] = sum(tmp) return(Probabilities[decim]) #totalstar個スターがある時のcardにholdstar個のスターが集まる確率 def calc_probability(totalstar,card,holdstar): return(sum([calc_starprob(x, 11, totalstar, card, holdstar) for x in range(11**5) if is_valid(x, 11, totalstar, card, holdstar)])) #totalstar個スターがある時のcardにholdstar個以上のスターが集まる確率 def calc_moreprobability(totalstar,card,holdstar): tmp=0 for star in range(holdstar, 11): tmp+=sum([calc_starprob(x, 11, totalstar, card, star) for x in range(11**5) if is_valid(x, 11, totalstar, card, star)]) return(tmp) #totalstar個スターがある時のcardにholdstar個以下のスターが集まる確率 def calc_lessprobability(totalstar,card,holdstar): tmp=0 for star in range(0,holdstar+1): tmp+=sum([calc_starprob(x, 11, totalstar, card, star) for x in range(11**5) if is_valid(x, 11, totalstar, card, star)]) return(tmp) #totalstar個スターがある時のcardに集まるスターの個数の期待値 def calc_expectation(totalstar,card): tmp=0 for star in range(0, 11): tmp+=calc_probability(totalstar, card, star)*star return(tmp) #cardに集まるスターの個数の期待値がstar個となるのに必要なスターの個数(整数値) def calc_totalstar_expectation(card,star): if star>10: star=10 for totalstar in range(50): if calc_expectation(totalstar,card)>star: return(totalstar)テスト
#サンプル(25個スターがある時に8個がカード1に集まる確率) print(calc_probability(25, 1, 8)) #0.1693947010897705 #サンプル(20個スターがある時にカード1に集まるスターの個数の期待値) print(calc_expectation(20, 1)) #6.862519232471602 #サンプル(カード1に期待値4個以上集めるのに必要なスターの個数) print(calc_totalstar_expectation(1,4)) #12おわりに
あまり早い実装とは言えませんが、一応計算できました。
確率、期待値、必要な個数なども計算できます。
ランダムなボーナスも$\frac{5!}{2!2!}=30$通りなのでこれを応用すればすべてのパターンを計算することが出来ると思います。
- 投稿日:2020-01-18T19:39:41+09:00
jupyterlabの拡張機能の設定が反映されない時の対処法
- 投稿日:2020-01-18T19:19:54+09:00
Pytestでローカルに一時的なhttpサーバを起動する
ユニットテスト実行時にローカルサーバを立てることで外部に依存しないテストを行うことができる。
APIやクローラ開発で便利。
流れはこんな感じ
conftest.pyにフィクスチャとしてhttpサーバの起動/終了処理を記述- テスト関数の中でフィクスチャを呼び出す
実装
- conftest.py
conftest.pyimport pytest from http.server import ( HTTPServer as SuperHTTPServer, SimpleHTTPRequestHandler ) import threading class HTTPServer(SuperHTTPServer): """ ThreadでSimpleHTTPServerを動かすためのラッパー用Class. Ctrl + Cで終了されるとThreadだけが死んで残る. KeyboardInterruptはpassする. """ def run(self): try: self.serve_forever() except KeyboardInterrupt: pass finally: self.server_close() @pytest.fixture() def http_server(): host, port = '127.0.0.1', 8888 url = f'http://{host}:{port}/index.html' # serve_forever をスレッド下で実行 server = HTTPServer((host, port), SimpleHTTPRequestHandler) thread = threading.Thread(None, server.run) thread.start() yield url # ここでテストに遷移 # スレッドを終了 server.shutdown() thread.join()
yield文でテスト関数に制御を移す。
unittestにおけるsetUpとtearDownがそれぞれにyield文の前後あたる。実行ディレクトリにコンテンツを配置しておく。
index.html<html>Hello pytest!</html>テスト関数でフィクスチャ(
http_server)を利用する
- test_httpserver.py
test_httpserver.pyimport requests def test_index(http_server): url = http_server response = requests.get(url) assert response.text == '<html>Hello pytest!</html>'実行結果
$ pytest --setup-show test_httpserver.py ========================================= test session starts =========================================platform linux -- Python 3.8.1, pytest-5.3.3, py-1.8.1, pluggy-0.13.1 rootdir: /home/skokado/workspace/sandbox collected 1 item test_httpserver.py SETUP F http_server test_httpserver.py::test_index (fixtures used: http_server). TEARDOWN F http_server ========================================== 1 passed in 0.60s ==========================================
--setup-showオプションをつけることでフィクスチャの生成をトレースできる。
test_index関数でフィクスチャhttp_serverが使用されているのがわかる。その他
ばんくし(@vaaaaanquish)さん、参考にさせて頂きました
- 投稿日:2020-01-18T19:16:34+09:00
とりあえずPythonでFireBase Cloud Firestoreを使ってみる
はじめに
「とりあえず、PythonでFireBaseのCloud Firestoreを使ってみたい!」ということで、
FireBaseの公式ドキュメントに従いながら、基本的なところの「データの出入力」をやってみたときの手順を書きます。まずは...「プロジェクト」を作成しよう
「プロジェクト」は、Firestoreをはじめ,Cloud Functions, Authentication, Hosting などのサービスを使うための"まとめるもの"です。
FireBaseで作成したプロジェクトは、GCPでも共通です。それでは、プロジェクトを作っていきましょう。
まずは、FireBase Consoleに移動します。
真ん中の方の「プロジェクトの作成」をクリックします。
プロジェクトの名前を入力し、「続行」をクリックします。手順2/3で「Google アナリティクス(Firebase プロジェクト向け)」の説明が出てくるので、有効にするかどうかはお好みで。(今回はオフにします。)
最後に「プロジェクトの作成」をクリックすると、自動的に作成作業が始まります。
少しすると、以下のように「新しいプロジェクトの準備ができました」と表示されるので、「続行」をクリックします。
そうすると、コンソールに画面が遷移します。
これで、プロジェクトの作成が完了しました。
Cloud Firestoreのデータベースを作成しよう
Cloud Firestore では、"データ"を書き込んでいく"ドキュメント"、
ドキュメントをまとめておくための"コレクション"(フォルダーのようなもの)があります。
「データベース」は、コレクションを入れておくための"箱"です。...。難しいですね。
よくわからない方は、ほかの方のとってもわかりやすい記事を見てみてくださいね!それでは、まずデータベースを作成していきましょう。
左側のメニューから「Database」をクリックします。
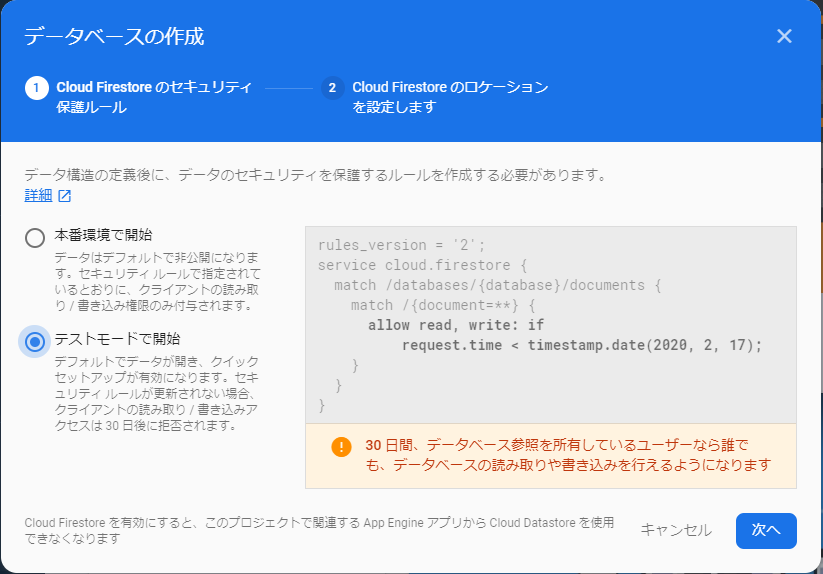
続いて「データベースの作成」をクリックします。なんかダイアログが出てくるので、「テストモードで開始」を選択してから「次へ」
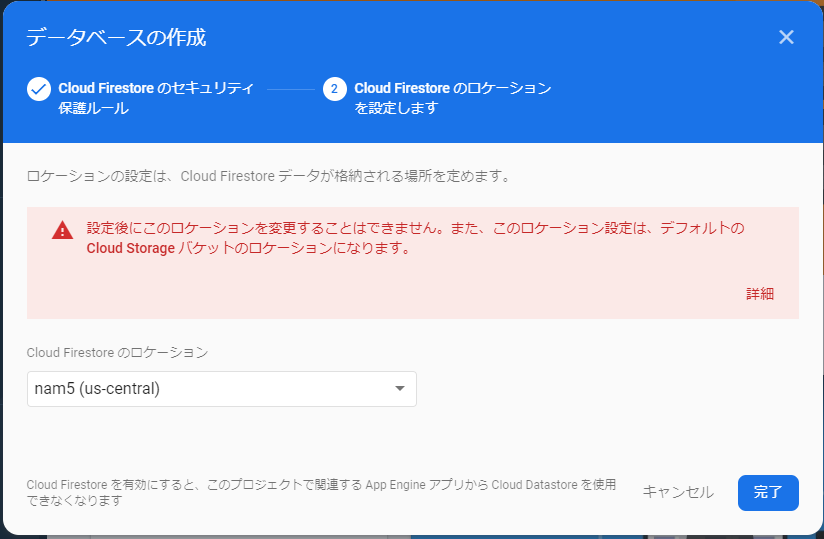
ロケーションの選択はそのままで、「完了」をクリックします。
プロビジョニングとセキュリティの設定が終わると、自動的に以下の画面に遷移します。
これでデータベースの作成が完了しました。
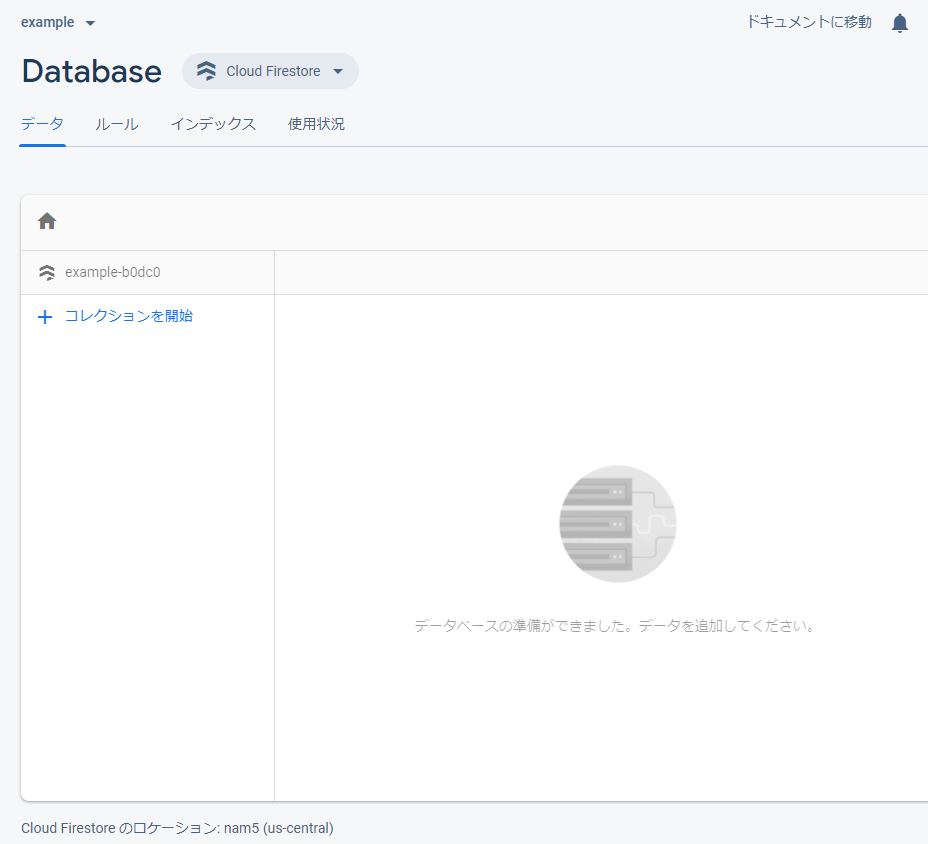
コレクションとドキュメントを作成しよう
それでは、データを流し込む準備をしましょう。
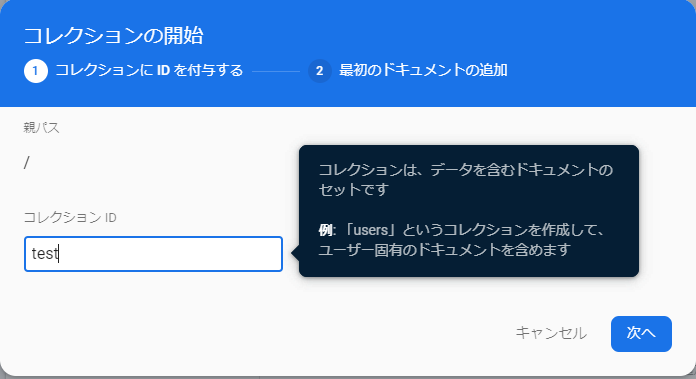
真ん中の方の「コレクションを開始」をクリックします。
なんかダイアログが出てくるので、「コレクションID」に任意の文字列(コレクションの名前)を入力します。
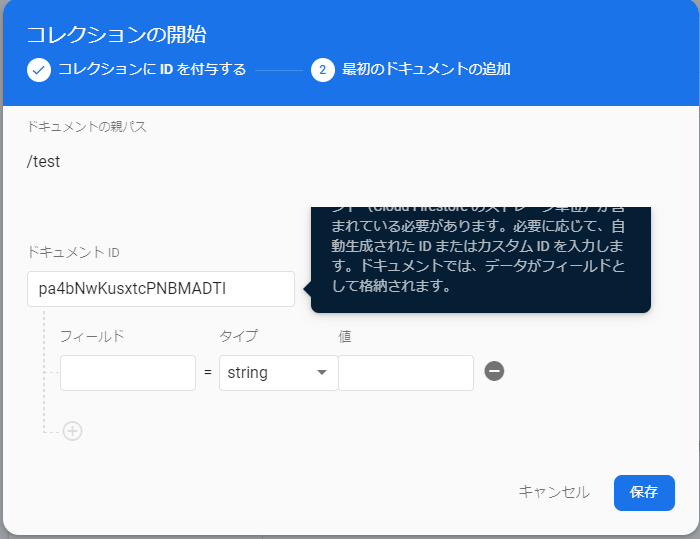
「ドキュメントID」は任意の文字列でもいいですし、「自動ID」をクリックすると、適当に割り当ててくれます。
「フィールド」は設定してもいいですが、データを入れていくと、勝手に生成してくれます。
そうすると、コレクションとドキュメントを一気に作ってくれるので、これでデータを流し込む準備はおわりです。
APIキーをもってこよう
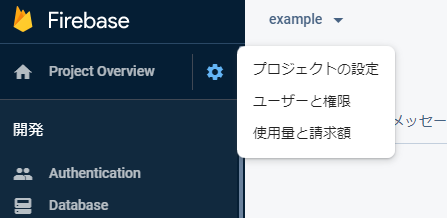
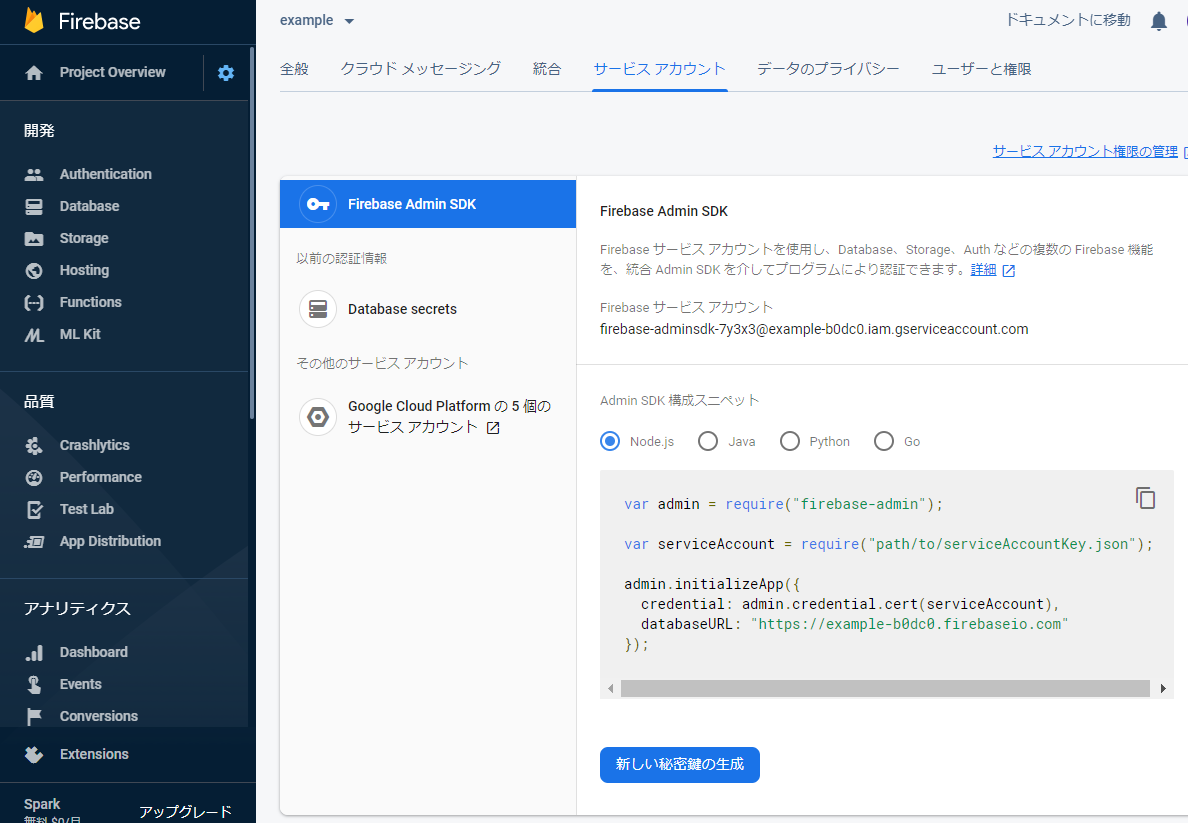
最後に、PythonからFireBaseをいじるためのAPIキーを生成し,ダウンロードします。
左上の歯車マーク→「プロジェクトの設定」をクリックします。
続いて、「サービスアカウント」を選択します。
そのまま、「新しい秘密鍵の生成」をクリックし、「キーを生成」をクリックします。
Jsonファイルがダウンロードされるので、適当なところに保管してください。ではPythonだ!
ここからは一旦FireBaseを離れ、Python側の作業に入ります。
ここに書いているコードは、公式ドキュメントから引用し、一部を改変しています。ライブラリを入れよう
PythonからFireBaseをいじるためのライブラリがすでにできています。
pip install firebase-adminを実行し、FireBaseのライブラリをインストールします。
まずは初期化しよう
Cloud Firestore SDK インスタンスを初期化します。
import firebase_admin from firebase_admin import credentials from firebase_admin import firestore cred = credentials.Certificate('秘密鍵のパスを書いてね.json') firebase_admin.initialize_app(cred) db = firestore.client()これだけでSDKは初期化され、データの出入力が可能となります。
じゃ、データを追加してみよう
それでは、前の手順で作成したデータベースにデータを追加してみましょう。
公式ドキュメントのサンプルをそのまま使います。
下のコードは、先ほどの初期化のコードの下に追記してくださいね!doc_ref = db.collection(u'users').document(u'alovelace') doc_ref.set({ u'first': u'Ada', u'last': u'Lovelace', u'born': 1815 })ちょっとした解説
db.collection(u'users')...データベース内のどのコレクションを指定するか
.document(u'alovelace')...前で指定したコレクション内の どのドキュメントを指定するか
u'first': u'Ada',..."first"フィールドに"Ada"という値を追加するそれでは実行してみましょう!
正しく実行されると、FireBase Console側ではこのような表示になっていると思います。
今度はデータを読み取ってみよう
では、追加したデータを読み取ってみましょう。
ここでは、Pythonの出力ウィンドウにそのまま文字列を出力します。初期化のコードの下に
users_ref = db.collection(u'users') docs = users_ref.stream() for doc in docs: print(u'{} => {}'.format(doc.id, doc.to_dict()))うまくいくと、次のように出力されるかと思います。
では、追加したデータを削除してみよう
最後に、データを削除してみましょう。
削除する前の構造は下のようになっていると思います
追加したフィールドだけを削除するには
city_ref = db.collection(u'users').document(u'alovelace') city_ref.update({ u'born': firestore.DELETE_FIELD })このコードでは、"born"フィールドを削除しています。
ドキュメントごと削除するには
db.collection(u'users').document(u'alovelace').delete()コレクションも削除するには
def delete_collection(coll_ref, batch_size): docs = coll_ref.limit(batch_size).get() deleted = 0 for doc in docs: print(u'Deleting doc {} => {}'.format(doc.id, doc.to_dict())) doc.reference.delete() deleted = deleted + 1 if deleted >= batch_size: return delete_collection(coll_ref, batch_size)(コレクションを削除するときは、すべてのドキュメントを取得し,削除する必要があります。)
以上で、基本的な操作は終わりになります。
おわりに
読みにくい記事だったと思いますが,ここまで読んでくださりありがとうございました。
よいFireBaseライフを!





- 投稿日:2020-01-18T18:40:24+09:00
Splashメモリ使いすぎ問題の回答(案)
弊研究室のアドベントカレンダーまさか無事に終わるとは思っていませんでした。
今回ははSplashのメモリ問題について書きます。結論
メモリ食いすぎたら勝手に落ちるから再起動
これは何か
以前にScrapyはいいぞぉって記事を書きました。しかしScrapyには一点問題があります。それは、当然のようにJavaScriptが動作しないことです。JavaScriptを使うページをScrapyでスクレイピングするときによく使うのがSplashというツールです。
Splashは、JavaScriptをレンダリングしてくれるサーバで、WebAPIを使ってアクセスすることで指定したサイトのJavaScript実行後のソースを取得することができます。中身はPythonで書かれていて、TwistedとQT3を使っているみたいです。
問題
そんな便利なSplashですが、1つ大きな問題があります。それは、メモリをめちゃくちゃ消費することです。
下の図は、Splashのメモリ消費量のグラフです。
リクエストをすればするほど消費するメモリが増えていきます。この調子ではいくらメモリを積んでもあっという間になくなってしまいます。
Githubにも同様のIssueは立っていますが、Pythonの仕様でメモリを解放することができないみたいです。
https://github.com/scrapinghub/splash/issues/674解決策
Pythonの問題は流石に手が打てません。もし知っている人がいたら教えてください。
上記のIssueにも書いてあるように、メモリを解放するには一回Splashを落とす以外に方法がありません。ただ、Splashを手動で落とすわけにはいかないので自動で落とす必要があります。cronとかで1分ごとに再起動みたいなスクリプトを書くのもアリですがめんどくさい。そんなときにどうすればいいか。メモリ不足で落ちるまで待ちましょう。そして自動で再起動させましょう
あまり頭がいい解決策ではないですがこれが一番楽です。
どうするか
以下のような状況を対象にします。
- SplashはDockerで動かしてる
- docker-composeを使っている
まず、SplashのDockerコンテナが使えるメモリの上限を設定します。docker-composeはversion3から
mem_limitがなくなってしまったので2を使います。
また、落ちた時に自動で再起動するようにrestart:alwaysをつけてあげます。version: "2" services: splash: image: "scrapinghub/splash:3.3" ports: - "8050:8050" mem_limit: 2g restart: always command: --disable-browser-caches --maxrss 4000これでメモリを必要以上に食うことがなくなりました。
終わりに
途中でも言ったようにあまり頭のいい解決策ではないです。もっと賢く楽にできる方法があったら教えてください。
参考にしたサイト

- 投稿日:2020-01-18T18:03:12+09:00
【PyTorch】BERTを日本語で動かす
はじめに
自然言語処理の様々なタスクでSOTAを更新しているBERTですが、Google本家がGithubで公開しているものはTensorflowをベースに実装されています。
PyTorch使いの人はPyTorch版を使いたいところですが、PyTorch版は作っていないのでHuggingFaceが作ったやつを使ってね、ただし我々は開発に関与していないので詳しいことは彼らに訊いてね!とQAに書かれています。HuggingFace製のBERTですが、2019年12月までは日本語のpre-trained modelsがありませんでした。
そのため、英語では気軽に試せたのですが、日本語ではpre-trained modelsを自分で用意する必要がありました。
しかし、2019年12月についに日本語のpre-trained modelsが追加されました。
https://huggingface.co/transformers/pretrained_models.html
- bert-base-japanese
- bert-base-japanese-whole-word-masking
- bert-base-japanese-char
- bert-base-japanese-char-whole-word-masking
東北大学の乾研究室が作成したもので、4つのモデルが使えます。
特別な事情がなければ2番目のbert-base-japanese-whole-word-maskingを使うのがよいでしょう。
通常版とWhole Word Masking版では、Whole Word Masking版の方がfine-tuningしたタスクの精度が少し高い傾向にあるようです1。これにより、PyTorch版BERTを日本語でも手軽に試すことができるようになりました。
BERTとは?
BERTの仕組みは既に様々なブログや書籍で紹介されているので、詳細な説明は割愛します。
簡単に説明すると、
- 大量の教師なしコーパスからpre-trained modelsを作成
- Masked Language ModelとNext Sentence Predicitionの2種類の言語タスクを解くことで事前学習する
- pre-trained modelsをfine-tuningしてタスクを解く
という処理の流れになります。
Pre-trained modelsの作成には大量のコンピュータ資源と時間を要しますが、これによりタスクの精度向上が図れるというのがBERTのポイントの一つです。Pre-trained models
まずは、事前学習したpre-trained modelsの精度を確認します。
今回はMasked Language Modelの精度を確認します。
Masked Language Modelを簡単に説明すると、文の中のある単語をマスクしておき、そのマスクされた単語を予測するというものです。BertJapaneseTokenizerとBertForMaskedLMを使い、次のように書くことができます。
「テレビでサッカーの試合を見る。」という文の「サッカー」をマスクして、その単語を予測するというものです。import torch from transformers import BertJapaneseTokenizer, BertForMaskedLM # Load pre-trained tokenizer tokenizer = BertJapaneseTokenizer.from_pretrained('bert-base-japanese-whole-word-masking') # Tokenize input text = 'テレビでサッカーの試合を見る。' tokenized_text = tokenizer.tokenize(text) # ['テレビ', 'で', 'サッカー', 'の', '試合', 'を', '見る', '。'] # Mask a token that we will try to predict back with `BertForMaskedLM` masked_index = 2 tokenized_text[masked_index] = '[MASK]' # ['テレビ', 'で', '[MASK]', 'の', '試合', 'を', '見る', '。'] # Convert token to vocabulary indices indexed_tokens = tokenizer.convert_tokens_to_ids(tokenized_text) # [571, 12, 4, 5, 608, 11, 2867, 8] # Convert inputs to PyTorch tensors tokens_tensor = torch.tensor([indexed_tokens]) # tensor([[ 571, 12, 4, 5, 608, 11, 2867, 8]]) # Load pre-trained model model = BertForMaskedLM.from_pretrained('bert-base-japanese-whole-word-masking') model.eval() # Predict with torch.no_grad(): outputs = model(tokens_tensor) predictions = outputs[0][0, masked_index].topk(5) # 予測結果の上位5件を抽出 # Show results for i, index_t in enumerate(predictions.indices): index = index_t.item() token = tokenizer.convert_ids_to_tokens([index])[0] print(i, token)上記のプログラムの実行結果は次のようになります。
「サッカー」が3位に登場しており、他の単語も日本語として正しそうな結果になっています。
日本ではあまり馴染みのない「クリケット」や大リーグのチーム名が出てくるのは、Wikipediaのデータから事前学習したためだと考えられます。0 クリケット 1 タイガース 2 サッカー 3 メッツ 4 カブス以上より、pre-trained modelsが正しく事前学習されていることが確認できました。
次は、このpre-trained modelsをもとにfine-tuningしてタスクを解きます。Fine-tuning with BERT
日本語のオリジナルデータで動くようにソースコードを修正
HuggingFaceのGitHubには、fine-tuningしてタスクを解く例が幾つか載っています。
しかし、これらは英語のデータセットを対象にしたもので、日本語のデータセットを対象にしたものはありません2。そこで、既存のソースコードを修正して、日本語のオリジナルデータでも動くようにします。
自然言語処理で基本的なタスクであるテキスト分類を想定し、GLUEのテキスト分類に使われているソースコードを対象とします。
そして、
- examples/run_glue.py
- src/transformers/data/processors/glue.py
- src/transformers/data/metrics/__init__.py
の3つのプログラムを修正します。
1. examples/run_glue.py
次のように
BertTokenizerをBertJapaneseTokenizerに変更します。変更するのは2箇所だけです。from transformers import ( WEIGHTS_NAME, AdamW, AlbertConfig, AlbertForSequenceClassification, AlbertTokenizer, BertConfig, BertForSequenceClassification, # BertTokenizer, BertJapaneseTokenizer, # 追加 DistilBertConfig, DistilBertForSequenceClassification, DistilBertTokenizer, RobertaConfig, RobertaForSequenceClassification, RobertaTokenizer, XLMConfig, XLMForSequenceClassification, XLMRobertaConfig, XLMRobertaForSequenceClassification, XLMRobertaTokenizer, XLMTokenizer, XLNetConfig, XLNetForSequenceClassification, XLNetTokenizer, get_linear_schedule_with_warmup, )MODEL_CLASSES = { # "bert": (BertConfig, BertForSequenceClassification, BertTokenizer), "bert": (BertConfig, BertForSequenceClassification, BertJapaneseTokenizer), # 追加 "xlnet": (XLNetConfig, XLNetForSequenceClassification, XLNetTokenizer), "xlm": (XLMConfig, XLMForSequenceClassification, XLMTokenizer), "roberta": (RobertaConfig, RobertaForSequenceClassification, RobertaTokenizer), "distilbert": (DistilBertConfig, DistilBertForSequenceClassification, DistilBertTokenizer), "albert": (AlbertConfig, AlbertForSequenceClassification, AlbertTokenizer), "xlmroberta": (XLMRobertaConfig, XLMRobertaForSequenceClassification, XLMRobertaTokenizer), }2. src/transformers/data/processors/glue.py
学習データ(train.tsv)と検証データ(dev.tsv)を読み込む部分です。
次のようにglue_tasks_num_labels、glue_processors、glue_output_modesにoriginalというタスクを追加した上で、OriginalProcessorというクラスを追加します。glue_tasks_num_labels = { "cola": 2, "mnli": 3, "mrpc": 2, "sst-2": 2, "sts-b": 1, "qqp": 2, "qnli": 2, "rte": 2, "wnli": 2, "original": 2, # 追加 } glue_processors = { "cola": ColaProcessor, "mnli": MnliProcessor, "mnli-mm": MnliMismatchedProcessor, "mrpc": MrpcProcessor, "sst-2": Sst2Processor, "sts-b": StsbProcessor, "qqp": QqpProcessor, "qnli": QnliProcessor, "rte": RteProcessor, "wnli": WnliProcessor, "original": OriginalProcessor, # 追加 } glue_output_modes = { "cola": "classification", "mnli": "classification", "mnli-mm": "classification", "mrpc": "classification", "sst-2": "classification", "sts-b": "regression", "qqp": "classification", "qnli": "classification", "rte": "classification", "wnli": "classification", "original": "classification", # 追加 }class OriginalProcessor(DataProcessor): """Processor for the original data set.""" def get_example_from_tensor_dict(self, tensor_dict): """See base class.""" return InputExample( tensor_dict["idx"].numpy(), tensor_dict["sentence"].numpy().decode("utf-8"), None, str(tensor_dict["label"].numpy()), ) def get_train_examples(self, data_dir): """See base class.""" return self._create_examples(self._read_tsv(os.path.join(data_dir, "train.tsv")), "train") def get_dev_examples(self, data_dir): """See base class.""" return self._create_examples(self._read_tsv(os.path.join(data_dir, "dev.tsv")), "dev") def get_labels(self): """See base class.""" return ["0", "1"] def _create_examples(self, lines, set_type): """Creates examples for the training and dev sets.""" examples = [] for (i, line) in enumerate(lines): # TSVファイルにヘッダー行がある場合はコメントアウトを外す # if i == 0: # continue guid = "%s-%s" % (set_type, i) text_a = line[0] label = line[1] examples.append(InputExample(guid=guid, text_a=text_a, text_b=None, label=label)) return examples学習データと検証データは、
- テキスト
- ラベル
の2列から成るTSVファイルを想定しています。
train.tsv面白かった 0 楽しかった 0 退屈だった 1 悲しかった 1dev.tsv満喫した 0 辛かった 1上記のプログラムは2値分類を想定していますが、多値分類のときはラベルの数と値を適宜修正して下さい。
3. src/transformers/data/metrics/__init__.py
検証データを使って精度を算出する部分です。
次のように条件式でtask_name == "original"の場合を追加するだけです。def glue_compute_metrics(task_name, preds, labels): assert len(preds) == len(labels) if task_name == "cola": return {"mcc": matthews_corrcoef(labels, preds)} elif task_name == "sst-2": return {"acc": simple_accuracy(preds, labels)} elif task_name == "mrpc": return acc_and_f1(preds, labels) elif task_name == "sts-b": return pearson_and_spearman(preds, labels) elif task_name == "qqp": return acc_and_f1(preds, labels) elif task_name == "mnli": return {"acc": simple_accuracy(preds, labels)} elif task_name == "mnli-mm": return {"acc": simple_accuracy(preds, labels)} elif task_name == "qnli": return {"acc": simple_accuracy(preds, labels)} elif task_name == "rte": return {"acc": simple_accuracy(preds, labels)} elif task_name == "wnli": return {"acc": simple_accuracy(preds, labels)} # 追加 elif task_name == "original": return {"acc": simple_accuracy(preds, labels)} else: raise KeyError(task_name)Fine-tuningしてタスクを解く
日本語のオリジナルデータでも動くようになったので、あとはfine-tuningしてタスクを解くだけです。
これは次のコマンドを実行するのみです。学習データと検証データのファイルはdata/original/配下に入れておきます。$ python examples/run_glue.py \ --data_dir=data/original/ \ --model_type=bert \ --model_name_or_path=bert-base-japanese-whole-word-masking \ --task_name=original \ --do_train \ --do_eval \ --output_dir=output/original上記のコマンドを実行して問題なく終了すれば、次のようなログが出力されます。
accの値が1.0となっており、検証データの2件が正しく分類できていることが分かります。01/18/2020 17:08:39 - INFO - __main__ - Saving features into cached file data/original/cached_dev_bert-base-japanese-whole-word-masking_128_original 01/18/2020 17:08:39 - INFO - __main__ - ***** Running evaluation ***** 01/18/2020 17:08:39 - INFO - __main__ - Num examples = 2 01/18/2020 17:08:39 - INFO - __main__ - Batch size = 8 Evaluating: 100%|███████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 2.59it/s] 01/18/2020 17:08:40 - INFO - __main__ - ***** Eval results ***** 01/18/2020 17:08:40 - INFO - __main__ - acc = 1.0そして、
output/original/配下にモデルファイルが作成されていることが確認できます。$ find output/original output/original output/original/added_tokens.json output/original/tokenizer_config.json output/original/special_tokens_map.json output/original/config.json output/original/training_args.bin output/original/vocab.txt output/original/pytorch_model.bin output/original/eval_results.txtおわりに
PyTorch版のBERTを使って日本語のテキスト分類をする方法を紹介しました。
他のソースコードも修正すれば、テキスト分類だけでなくテキスト生成や質問応答などのタスクも行うことができます。これまでPyTorchを使ってBERTを日本語で動かすのはハードルが高かったですが、日本語のpre-trained modelsが公開されたことでそのハードルが非常に低くなったように思います。
是非、皆さんもPyTorch版のBERTを日本語のタスクで試して下さい。参考記事
https://techlife.cookpad.com/entry/2018/12/04/093000
http://kento1109.hatenablog.com/entry/2019/08/23/092944
- 投稿日:2020-01-18T16:44:13+09:00
TF2.0 のカスタムループで gradient accumulation (tf.gather 等のケース含む)
この記事は何
TensorFlow が 2.0 にアップデートされ、学習コードのカスタムループ ( Keras での
.fit()などではなく、自前で iteration を回す書き方 )が非常に書きやすくなりました。
その中で Gradient Accumulation を実装しようとしたときに少し詰まったため、メモとして公開します。ここ間違ってるよ!とかもっと良いやり方があるよ!という場合はぜひ教えてほしいです?
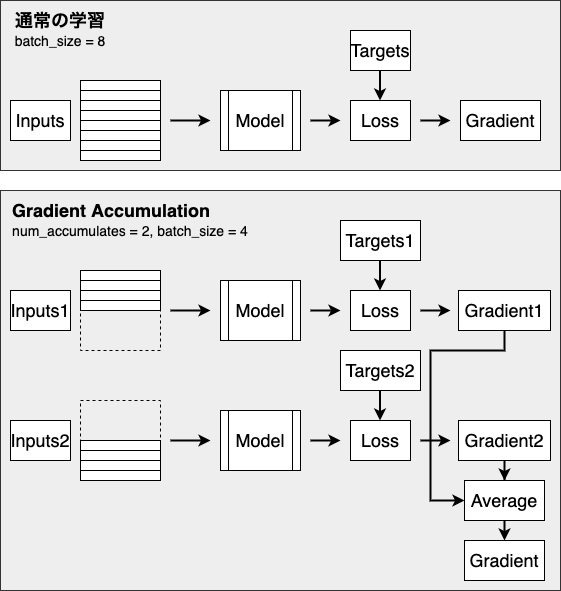
Gradient Accumulation とは
ざっくりです。詳しい説明は他を当たってください?♂️
Deep Learning モデルの学習のためには、一般的に多くの GPU メモリが必要となります。
より大きなモデルを学習する際には数十 GB というメモリが必要となるため、多くの場合は単純に入力の batch size を小さくすることで対応します。
この方法を選択した場合、batch size が小さくなるので次のようなデメリットがあります。
- 学習に時間がかかる
- 精度が劣化する
特に後者は深刻な問題で、batch size を小さくすることで精度が劣化するという報告や、学習時に learning rate を調整するのではなく batch size を大きくするほうが性能改善につながるなどの報告がされています(特に自然言語処理の分野)123。
そこで、batch size を大きくしたまま、メモリ効率をよく計算する方法の1つとして、gradient accumulation が挙げられます。
やることは単純で、小さい(メモリに乗る量の) batch size で計算した gradient を保存しておき、複数回分ためてから平均を取り、それを用いてモデルのパラメータを更新する、というものです。
複数回分の batch の計算で 1 step となるため、時間はかかってしまいますが、大きな batch size でモデルを学習させるのと同等になるため、精度は維持することができます。
TensorFlow 2.0 カスタムループでの実装
雑に簡略化した学習用コードを書いてみました。
説明用の notebook はこちらにおいてるので詳細見たい方はご覧ください〜?通常の学習 (gradient accumulation を使用しない) の場合
train_step内のtape.gradient(loss, model.trainable_variables)で loss から gradient を計算し、optimizer に渡して更新しています。no_accumulationdef train(config: Config, dataset: tf.data.Dataset, model: Model): global_step = 0 for e in range(config.num_epochs): global_step = train_epoch(config, dataset, model, global_step) print(f'{e+1} epoch finished. step: {global_step}') save(config.ckptdir, model) def train_epoch(config: Config, dataset: tf.data.Dataset, model: Model, start_step: int = 0) -> tf.Tensor: '''Train 1 epoch ''' gradients = None global_step = start_step for i, batch in enumerate(dataset): global_step = i + start_step x_train, y_train = batch gradients = train_step(x_train, y_train, loss_fn, optimizer) gradient_zip = zip(gradients, model.trainable_variables) optimizer.apply_gradients(gradient_zip) return global_step @tf.function def train_step(x_train: tf.Tensor, y_train: tf.Tensor, loss_fn: tf.keras.losses.Loss, optimizer: tf.keras.optimizers.Optimizer): '''Train 1 step and return gradients ''' with tf.GradientTape() as tape: outputs = model(x_train) loss = tf.reduce_mean(loss_fn(y_train, logits)) gradients = tape.gradient(loss, model.trainable_variables) return gradientsgradient accumulation の場合
複数ステップの gradients の平均を計算するためのメソッドを追加します。
tape.gradient(loss, model.trainable_variables)では各パラメータごとの tf.Tensor 型の gradientが List で返るため、それぞれの要素について平均を取るようにします。def accumulated_gradients(gradients: Optional[List[tf.Tensor]], step_gradients: List[tf.Tensor], num_grad_accumulates: int) -> tf.Tensor: '''Compute accumulated gradients by ones of this step and ones of accumulated Args: gradients: computed accumulated gradients so far step_gradients: gradients for this step num_grad_accumulates: the amount of accumulation ''' if gradients is None: gradients = [g / num_grad_accumulates for g in step_gradients] else: for i, g in enumerate(step_gradients): gradients[i] += g / num_grad_accumulates return gradients
train_stepで得られた step_gradients に上記のaccumulated_gradientsを適用して平均の gradients を得ます。
加えて、指定回数分計算されたときだけ optimizer でパラメータ更新を行うようにします。def train_epoch(config: Config, dataset: tf.data.Dataset, model: Model, start_step: int = 0) -> tf.Tensor: '''Train 1 epoch ''' gradients = None global_step = start_step for i, batch in enumerate(dataset): dummy_step = i + start_step * config.num_grad_accumulates x_train, y_train = batch step_gradients = train_step(x_train, y_train, loss_fn, optimizer) gradients = accumulated_gradients(gradients, step_gradients, config.num_grad_accumulates) if (dummy_step + 1) % config.num_grad_accumulates == 0: gradient_zip = zip(gradients, model.trainable_variables) optimizer.apply_gradients(gradient_zip) gradients = None if (global_step + 1) % config.step_summary_output == 0: write_train_summary(train_summary_writer, metrics, step=global_step + 1) global_step += 1 return global_step @tf.function def train_step(x_train: tf.Tensor, y_train: tf.Tensor, loss_fn: tf.keras.losses.Loss, optimizer: tf.keras.optimizers.Optimizer): with tf.GradientTape() as tape: outputs = model(x_train) loss = tf.reduce_mean(loss_fn(y_train, logits)) gradients = tape.gradient(loss, model.trainable_variables) return gradientstf.gather などの IndexSlices が得られる演算を使用している場合
先に結論
次のような
flat_gradientをかませばOKだと思います。メモリ効率は若干悪くなるので、もっと良いやり方が分かる方は教えていただけると幸いです def accumulated_gradients(gradients: Optional[List[tf.Tensor]], step_gradients: List[Union[tf.Tensor, tf.IndexedSlices]], num_grad_accumulates: int) -> tf.Tensor: '''Compute accumulated gradients by ones of this step and ones of accumulated Args: gradients: computed accumulated gradients so far step_gradients: gradients for this step num_grad_accumulates: the amount of accumulation ''' if gradients is None: gradients = [flat_gradients(g) / num_grad_accumulates for g in step_gradients] else: for i, g in enumerate(step_gradients): gradients[i] += flat_gradients(g) / num_grad_accumulates return gradients def flat_gradients(grads_or_idx_slices: tf.Tensor) -> tf.Tensor: '''Convert gradients to original size tf.Tensor if it's tf.IndexedSlices. When computing gradients for operation concerning `tf.gather`, the type of gradients is tf.IndexedSlices. ''' if type(grads_or_idx_slices) == tf.IndexedSlices: return tf.scatter_nd( tf.expand_dims(grads_or_idx_slices.indices, 1), grads_or_idx_slices.values, grads_or_idx_slices.dense_shape ) return grads_or_idx_slices
def accumulated_gradients(gradients: Optional[List[tf.Tensor]], step_gradients: List[Union[tf.Tensor, tf.IndexedSlices]], num_grad_accumulates: int) -> tf.Tensor: '''Compute accumulated gradients by ones of this step and ones of accumulated Args: gradients: computed accumulated gradients so far step_gradients: gradients for this step num_grad_accumulates: the amount of accumulation ''' if gradients is None: gradients = [flat_gradients(g) / num_grad_accumulates for g in step_gradients] else: for i, g in enumerate(step_gradients): gradients[i] += flat_gradients(g) / num_grad_accumulates return gradients def flat_gradients(grads_or_idx_slices: tf.Tensor) -> tf.Tensor: '''Convert gradients to original size tf.Tensor if it's tf.IndexedSlices. When computing gradients for operation concerning `tf.gather`, the type of gradients is tf.IndexedSlices. ''' if type(grads_or_idx_slices) == tf.IndexedSlices: return tf.scatter_nd( tf.expand_dims(grads_or_idx_slices.indices, 1), grads_or_idx_slices.values, grads_or_idx_slices.dense_shape ) return grads_or_idx_slices説明
自然言語処理の分野で embedding layer を使用しているなどのケースでは、モデルで
tf.gatherを利用していることが多いと思います。tf.gather を使っていると、tape.gradient(loss, model.trainable_variables)の返り値の List の中身の型が変わります。
具体的に BERT のモデルで gradients を計算したものを見てみたのが下記です。[ <tensorflow.python.framework.indexed_slices.IndexedSlices object at 0x7ff8a45c6358>, <tensorflow.python.framework.indexed_slices.IndexedSlices object at 0x7ff8a45c6400>, <tensorflow.python.framework.indexed_slices.IndexedSlices object at 0x7ff8a45c6438>, <tf.Tensor: shape=(1024,), dtype=float32, numpy=array([ 0.00075448, 0.00063159, 0.00468317, ..., 0.00663265, 0.00084392, -0.00198008], dtype=float32)>, .... ]4行目からは通常の
tf.Tensor型の gradients が続きますが、3行目までがtf.IndexedSlices型になってます。
tf.gatherは Embedding Matrix のような大きな行列から、特定の index の部分を取ってくるのに使われます。
TensorFlow > API > TensorFlow Core r2.1 > Python > tf.gather
自然言語処理の例で言うなら、元の embedding matrix は[vocab_size, embedding_size]の shape の行列で、vocab_sizeは数万オーダーになることが多いので、めちゃでかいです。
メモリ効率を上げるために、元の embedding matrix をまるまる保持するのではなく、必要な部分の Slice のみを保持するようにしたのがtf.IndexSlices型になります。
TensorFlow > API > TensorFlow Core r2.1 > Python > tf.IndexedSlicesこのまま gradients の平均を取ろうとすると、
tf.Tensor型ではないので四則演算などがそのまま適用できずエラーになります。今回は次のように元の matrix を復元して対応しています4。tf.scatter_nd(tf.expand_dims(idx_slices.indices, 1), idx_slices.values, idx_slices.dense_shape)以上です。
Pytorch は gradient accumulation めっちゃ簡単に出来るので羨ましいです

- 投稿日:2020-01-18T16:29:34+09:00
bitflyer API ですべての親注文(特殊注文)もキャンセルするにはcancelallchildordersが使えるようだ
cancelallchildordersという名前だが、親注文(特殊注文)もキャンセルされる
pybitflyerだとこう
def cancelallchildorders(self, **params): """Cancel All Orders API Type -------- HTTP Private API Parameters ---------- product_code: The product for the corresponding order. Designate "BTC_JPY", "FX_BTC_JPY" or "ETH_BTC". Response -------- If the parameters are correct, the status code will show 200 OK. Docs ---- https://lightning.bitflyer.jp/docs?lang=en#cancel-all-orders """ if not all([self.api_key, self.api_secret]): raise AuthException() endpoint = "/v1/me/cancelallchildorders" return self.request(endpoint, "POST", params=params)サンプル(親注文がある状態で)
cancel = bfapi.cancelallchildorders(product_code=SYMBOL) print(cancel)→何も表示はされない。
bfapi.getchildorders(product_code=SYMBOL)実行結果[{'id': 263032602, 'parent_order_id': 'JCP20200118-065956-905830', 'product_code': 'FX_BTC_JPY', 'side': 'BUYSELL', 'parent_order_type': 'IFDOCO', 'price': 1006594.0, 'average_price': 0.0, 'size': 0.03, 'parent_order_state': 'CANCELED', 'expire_date': '2020-01-18T08:39:56.61', 'parent_order_date': '2020-01-18T06:59:56.61', 'parent_order_acceptance_id': 'JRF20200118-065956-127674', 'outstanding_size': 0.0, 'cancel_size': 0.03, 'executed_size': 0.0, 'total_commission': 0.0}, . . .parent_order_stateが'CANCELED'であることを確認
所感
IFDOCO注文をfor文で実行させています。
forループの最初に全ポジションの解消と全オーダのキャンセルをすることで初期化するべきと思い、今回の結果に至りました。
- 投稿日:2020-01-18T16:29:34+09:00
bitflyer API ですべての親注文(特殊注文)をキャンセルするにはcancelallchildordersが使えるようだ
cancelallchildordersという名前だが、親注文(特殊注文)もキャンセルされる
pybitflyerだとこう
def cancelallchildorders(self, **params): """Cancel All Orders API Type -------- HTTP Private API Parameters ---------- product_code: The product for the corresponding order. Designate "BTC_JPY", "FX_BTC_JPY" or "ETH_BTC". Response -------- If the parameters are correct, the status code will show 200 OK. Docs ---- https://lightning.bitflyer.jp/docs?lang=en#cancel-all-orders """ if not all([self.api_key, self.api_secret]): raise AuthException() endpoint = "/v1/me/cancelallchildorders" return self.request(endpoint, "POST", params=params)※注意事項
以下、2020/01/18に当方の環境で実行した場合の結果です。
別の環境で実行した場合、またはAPI側の仕様変更により異なる動作になる可能性は十分にあります。
以下の結果を利用してBOT等を作成される際は、十分に検証した上で、作成願います。サンプル(親注文がある状態で)
cancel = bfapi.cancelallchildorders(product_code=SYMBOL) print(cancel)→何も表示はされない。
bfapi.getparentorders(product_code=SYMBOL)実行結果[{'id': 263032602, 'parent_order_id': 'JCP20200118-065956-905830', 'product_code': 'FX_BTC_JPY', 'side': 'BUYSELL', 'parent_order_type': 'IFDOCO', 'price': 1006594.0, 'average_price': 0.0, 'size': 0.03, 'parent_order_state': 'CANCELED', 'expire_date': '2020-01-18T08:39:56.61', 'parent_order_date': '2020-01-18T06:59:56.61', 'parent_order_acceptance_id': 'JRF20200118-065956-127674', 'outstanding_size': 0.0, 'cancel_size': 0.03, 'executed_size': 0.0, 'total_commission': 0.0}, . . .parent_order_stateが'CANCELED'であることを確認
所感
IFDOCO注文をfor文で実行させています。
forループの最初に全ポジションの解消と全オーダのキャンセルをすることで初期化するべきと思い、今回の結果に至りました。
同じようなことを実現したい方の役に立てればと思います。
- 投稿日:2020-01-18T16:28:42+09:00
Pandas 基礎用法
OverView
Pandas で各集計結果を取得する際の指定について、基本的な用法をまとめる。
以下、dataをDataFrameオブジェクトとする。指定インデックスの行を取得
data[<index>] # インデックス1の行を取得する # インデックスは0始まりなので、2行目 data[1]指定カラム名の列を取得
data[<column_name>]: 指定カラム名の列を取得 # カラム名'name'の列を取得する data['name']条件を満たす行のみを取得
data[<インデックス単位のboolean>]: Trueになってる行のみを取得インデックス単位のbooleanイメージは以下。
こちらの例だと、インデックス0,2の行のみを抽出する。0 True 1 False 2 True 3 False
- 投稿日:2020-01-18T16:28:42+09:00
Pandas 抽出基礎文法
OverView
Pandas で各集計結果を取得する際の指定について、基本的な用法をまとめる。
以下、dataをDataFrameオブジェクトとする。指定インデックスの行を取得
data[<index>] # インデックス1の行を取得する # (インデックスは0始まりなので、2行目となる) data[1]指定カラム名の列を取得
data[<column_name>] # カラム名'name'の列を取得する data['name']条件を満たす行のみを取得
data[<インデックス単位のboolean>]インデックス単位のbooleanイメージは以下。
こちらの例だと、インデックス0,2の行のみを抽出する。0 True 1 False 2 True 3 Falseインデックス単位boolean生成例は以下。Pythonの判定式もそのまま使える。
# ageカラムの値が20以上 data['age'] >= 20 # nameカラムが'郎’の文字を含む data['name'].str.contains('郎') # nameカラムが重複していない data[~data['name'].duplicated()]
- 投稿日:2020-01-18T16:16:48+09:00
3状態量子ウォークの量子コンピュータ実装
3状態量子ウォークの量子コンピュータ実装
3状態量子ウォークの実装をまとめる.
ここまで,量子ウォークの量子コンピュータ実装3によって、任意のサイクルサイズの量子ウォークを実装してきた.しかし,そのどれもが状態として0または1のふたつしかない,2状態量子ウォークであった.そこで,状態数3の量子ウォークを考えたい.
前回同様,サイクル上量子ウォークのシフト作用素についてはEfficient quantum circuit implementation of quantum walksを参考.3状態の量子ウォークについて
3状態量子ウォークとは内部状態が3つある量子ウォークのことをいう.特に$3\times 3$のGrover行列をコイン作用素に選んだものを,3状態Grover Walkという.詳細は,量子ウォークを参考.
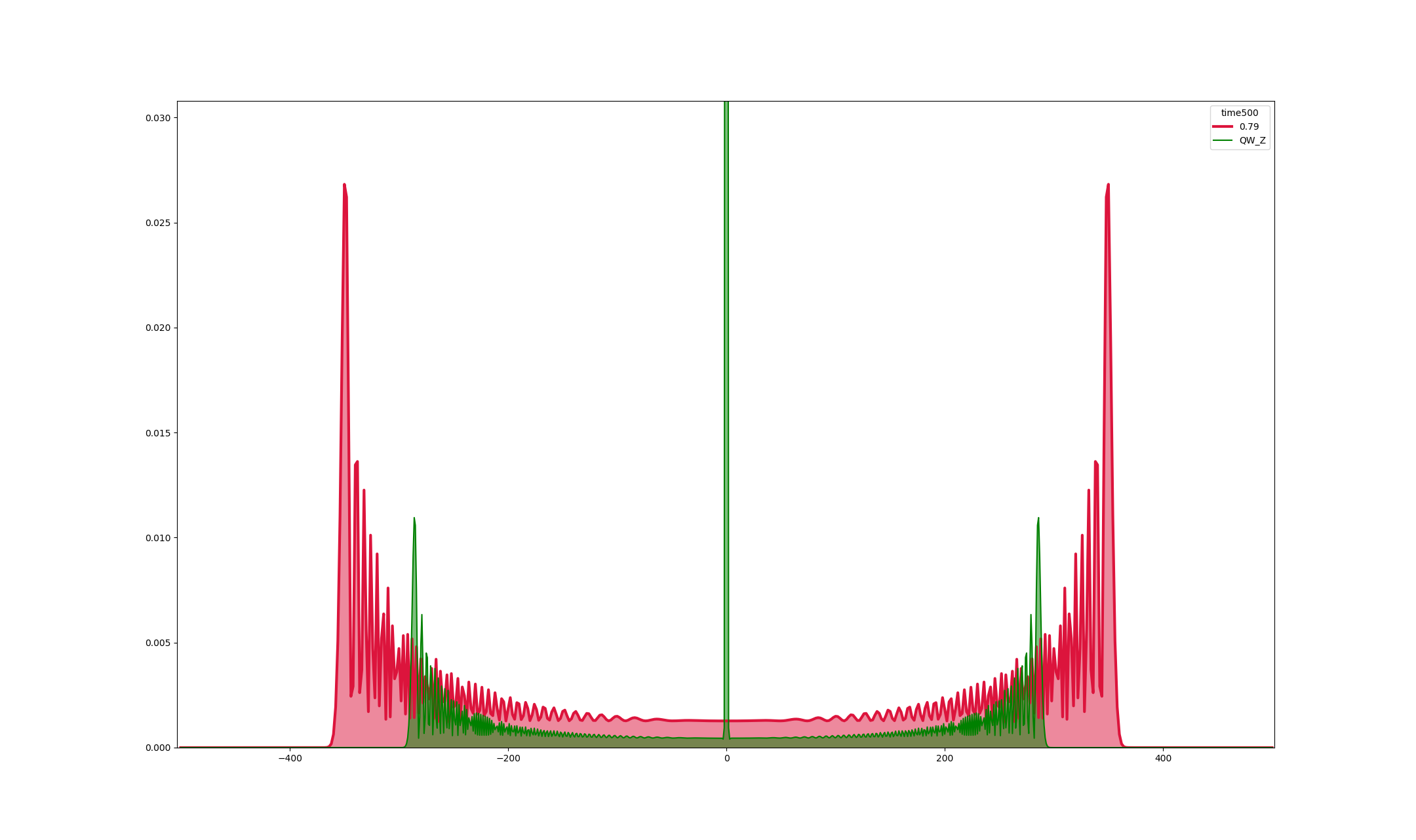
具体的なダイナミクスは後で説明するとして,1次元上3状態GroverWalkの特徴は,空間的に一様なコインを配置しても原点付近の局在化と線形的な広がりが,同時に起こることである.
1次元2状態アダマールウォークと1次元3状態GroverWalkの原点出発で時刻500の数値シミュレーションのグラフである.原点付近局在化がよくわかる.さて、量子コンピュータで実装するには、1次元などの無限系ではなく,有限系でないといけないのでサイクル上の3状態GroverWalkを実装していく.全体の時間発展を
W=\hat{S}\hat{C}とする.
3状態GroverWalkを考えているので,シフト作用素$\hat{C}$に,$3\times3$Grover行列\hat{C}=I\otimes C\\ \mbox{ただし}C=\frac{2}{3}\begin{bmatrix}1&1&1\\1&1&1\\1&1&1\end{bmatrix}-I=\frac{1}{3}\begin{bmatrix}-1&2&2\\2&-1&2\\2&2&-1\end{bmatrix}を採用する.
シフト作用素は,サイクル上の3状態(00,01,10)を考えているの,\hat{S}=\sum_{x}(|x-1\rangle\langle x|\otimes|00\rangle \langle 00|+|x\rangle\langle x|\otimes|01\rangle \langle 01|+|x+1\rangle\langle x|\otimes|10\rangle \langle 10|)とする.
- 状態が00だと場所-1,
- 状態が01だとその場に留まる
- 状態が10だと場所+1
をしている.回路を考える
状態3を実装するために,2量子ビット使うと状態は00,01,10,11の4つになってしまう。したかがって、コイン作用素とシフト作用素を4状態表記に変換する。
コイン作用素
\hat{C}=I\otimes C\\ \mbox{ただし}C=\begin{bmatrix}\frac{-1}{3}&\frac{2}{3}&\frac{2}{3}&0\\\frac{2}{3}&\frac{-1}{3}&\frac{2}{3}&0\\\frac{2}{3}&\frac{2}{3}&\frac{-1}{3}&0\\0&0&0&1\end{bmatrix}シフト作用素
\hat{S}=\sum_{x}(|x-1\rangle\langle x|\otimes|00\rangle \langle 00|+|x\rangle\langle x|\otimes|01\rangle \langle 01|+|x+1\rangle\langle x|\otimes|10\rangle \langle 10|+|x\rangle\langle x|\otimes |11\rangle\langle 11|)このようにとると、状態11については他の状態と混じることのない、独立したものが作れる。したがって、初期状態に状態11を与えなければ、3状態の量子ウォークの実装になっている。
回路作成
Grover行列
$4\times 4$行列の中に$3\times 3$のGrover行列を作る。ここは計算によってパラメータを調べた結果だけ紹介する。
import numpy as np from qiskit import QuantumCircuit, ClassicalRegister, QuantumRegister from qiskit import execute import math th1=3*math.pi/2 th2=(math.pi+math.acos(1/3))*2 th3=math.pi/2 q = QuantumRegister(2, 'q') grqc = QuantumCircuit(q) grqc.x(q[0]) grqc.x(q[1]) grqc.cu3(th3,0,0,q[0],q[1]) grqc.cu3(th2,0,0,q[1],q[0]) grqc.cu3(th1,0,0,q[0],q[1]) grqc.x(q[0]) grqc.x(q[1])このようにゲートを作ると$4\times 4$のなかに$3\times 3$のGroverコインができる.以下で確認をしておく.
from qiskit import BasicAer # unitary simulator backend で実行 backend = BasicAer.get_backend('unitary_simulator') job = execute(grqc, backend) result = job.result() # Show the results print(result.get_unitary(grqc, decimals=3))[[-0.333+0.j 0.667+0.j 0.667+0.j 0. +0.j]
[ 0.667+0.j -0.333+0.j 0.667+0.j 0. +0.j]
[ 0.667+0.j 0.667+0.j -0.333+0.j 0. +0.j]
[ 0. +0.j 0. +0.j 0. +0.j 1. +0.j]]回路実装
量子レジスター、古典レジスター、そしてそれらから量子回路を考える.
* 場所qbits $\Rightarrow q[0]q[1]$
* 状態qbits $\Rightarrow qc[0]qc[1]$
* 予備qbits $\Rightarrow qaf[0]$
として回路を考える.場所の$\pm 1$操作の基本的な考え方は,量子ウォークの量子コンピュータ実装2による.def cccx(circ,c1,c2,c3,tg,re): circ.ccx(c1,c2,re) circ.ccx(c3,re,tg) circ.ccx(c1,c2,re)cccnotゲートを使いたいので準備したら,回路を作る.
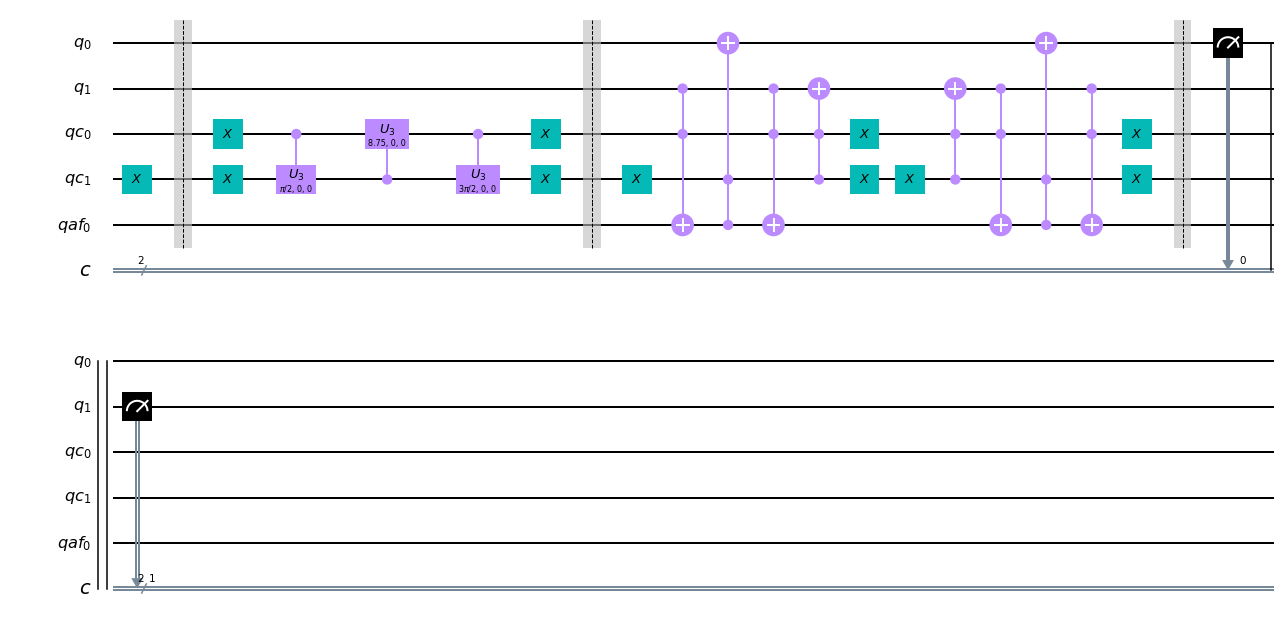
from qiskit import QuantumCircuit, ClassicalRegister, QuantumRegister from qiskit import execute from qiskit.tools.visualization import plot_histogram import math q = QuantumRegister(2, 'q') qc = QuantumRegister(2, 'qc') qaf = QuantumRegister(1,'qaf') c = ClassicalRegister(2, 'c') gqc = QuantumCircuit(q,qc,qaf,c) th1=3*math.pi/2 th2=(math.pi+math.acos(1/3))*2 th3=math.pi/2 #時間 t=1 #初期状態をセット gqc.x(qc[1]) gqc.barrier() #時間発展 for i in range(t): #coin-ope gqc.x(qc[0]) gqc.x(qc[1]) gqc.cu3(th3,0,0,qc[0],qc[1]) gqc.cu3(th2,0,0,qc[1],qc[0]) gqc.cu3(th1,0,0,qc[0],qc[1]) gqc.x(qc[0]) gqc.x(qc[1]) gqc.barrier() #shift-ope cycle gqc.x(qc[1]) cccx(gqc,q[1],qc[0],qc[1],q[0],qaf[0]) gqc.ccx(qc[0],qc[1],q[1]) gqc.x(qc[1]) gqc.x(qc[0]) gqc.x(qc[1]) gqc.ccx(qc[0],qc[1],q[1]) cccx(gqc,q[1],qc[0],qc[1],q[0],qaf[0]) gqc.x(qc[0]) gqc.x(qc[1]) gqc.barrier() #観測 gqc.measure(q,c) gqc.draw()
最初の部分で,初期状態をつくる.今回は
\Psi=|00\rangle\otimes|01\rangleを作る。
2つ目の部分が,状態の部分がコイン作用素.
3つ目の部分が,「状態10なら場所+1,状態00なら場所-1,状態01,11なら場所は変わらない」というシフト作用素を表現している.以上をシミュレータで実行する.
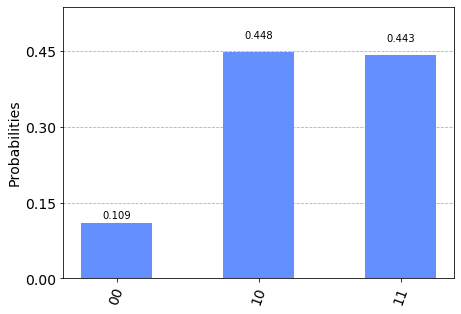
provider=IBMQ.get_provider(group='open') backend_cs=provider.get_backend('ibmq_qasm_simulator') job_cs = execute(gqc, backend_cs,shots=4096) result_cs = job_cs.result() counts_cs = result_cs.get_counts(gqc) print(counts_cs) plot_histogram(counts_cs)
このシミュレーション結果は,
\hat{S}\hat{C}|00\rangle\otimes|01\rangle\\ =\hat{S}\left\{|00\rangle\otimes\frac{2}{3}|00\rangle+|00\rangle\otimes\frac{-1}{3}|01\rangle+|00\rangle\otimes\frac{2}{3}|10\rangle\right\}\\ =\frac{2}{3}|11\rangle\otimes|00\rangle+\frac{-1}{3}|00\rangle\otimes|01\rangle+\frac{2}{3}|01\rangle\otimes|10\rangleより,場所$11$,$00$,$01$の観測確率は,それぞれ$\frac{4}{9}$,$\frac{1}{9}$,$\frac{4}{9}$となるはずなので,正しくシミュレーションできたとわかる.
補足
状態を多くして,それに対応したコイン作用素とシフト作用素を作りあげることで,任意のグラフ上での量子ウォークを実装することができる.トーラス上4状態量子ウォークが,サイクル上2状態量子ウォークの簡単な応用で作れる.
冒頭に紹介した,1次元上Groverの原点付近での停留項は,サイクル16で時刻7くらいまで発展させると,量子コンピュータのサイクル上での実験でも確認できる.
- 投稿日:2020-01-18T14:55:57+09:00
Python scikit-learn 現場でよく使う予測モデルTIPS集
サポートベクトル編
ここではscikit-learn 予測モデルを汎化して現場でコピペTIPS集として掲載します。
条件
1.データ、特徴量
・某エンターテインメント系銘柄の2019年一年分の株価データを使用
・同期間の日経平均インバース・インデックスを使用
・特徴量の最適な組合せか否かバリデーション手法については言及しない2.モデル
・実装方法を趣旨とし学習不足や過学習、予測値の精度といった評価指標についてパラメータチューニングまで追求しない
サポートベクトル回帰
1.線形回帰
出来高と株価の相関をみる
・回帰線とSVR境界線の傾きを確認する
・マージン内の分布を確認する
・線形回帰とSVR回帰の平均二乗誤差を確認するimport matplotlib.pyplot as plt import numpy as np from sklearn.linear_model import LinearRegression from sklearn.svm import SVR from sklearn.preprocessing import StandardScaler from sklearn.model_selection import train_test_split from sklearn.metrics import mean_squared_error npArray = np.loadtxt("stock.csv", delimiter = ",", dtype = "float",skiprows=1) # 特徴量(出来高) x = npArray[:,2:3] # 予測データ(株価) y = npArray[:, 3:4].ravel() # 訓練データと評価データに分割 x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)#, random_state=0) # 特徴量の標準化 sc = StandardScaler() # 訓練データを変換器で標準化 x_train_std = sc.fit_transform(x_train) # 訓練データで訓練した変換器でテストデータを標準化 x_test_std = sc.transform(x_test) # 線形回帰モデルを作成 mod = LinearRegression() # SVRモデルを作成 mod2 = SVR(kernel='linear', C=10000.0, epsilon=250.0) # 線形回帰モデル学習 mod.fit(x_train_std, y_train) # SVR mod2.fit(x_train_std, y_train) # 訓練データ(出来高)のプロット plt.figure(figsize=(8,5)) # 出来高のソート(最小値、最大値間まで0.1刻ndarray作成) x_ndar = np.arange(x_train_std.min(), x_train_std.max(), 0.1)[:, np.newaxis] # 出来高の線形回帰予測 y_ndar_prd = mod.predict(x_ndar) # 出来高のSVR予測 y_ndar_svr = mod2.predict(x_ndar) ## MSE(平均二乗誤差) mse_train_lin=mod.predict(x_train_std) mse_test_lin=mod.predict(x_test_std) mse_train_svr= mod2.predict(x_train_std) mse_test_svr = mod2.predict(x_test_std) # 線形回帰のMSE print('線形回帰MSE 訓練 = %.1f,テスト = %.1f' % (mean_squared_error(y_train,mse_train_lin),mean_squared_error(y_test, mse_test_lin))) # SVRのMSE print('SVRMSE 訓練 = %.1f,テスト = %.1f' % (mean_squared_error(y_train,mse_train_svr),mean_squared_error(y_test, mse_test_svr)))random_stateを指定せず数回トライするといずれも当然の事ながらSVRのMSEが少ない
1回目
線形回帰のMSE 訓練 = 38153.4 ,テスト = 33161.9
SVRのMSE 訓練 = 52439.9 ,テスト = 56707.7
2回目
線形回帰のMSE 訓練 = 37836.4 ,テスト = 33841.3
SVRのMSE 訓練 = 54044.5 ,テスト = 51083.7
3回目
線形回帰のMSE 訓練 = 37381.3 ,テスト = 35616.6
SVRのMSE 訓練 = 53499.2 ,テスト = 53619.4以下でこれを散布図にプロットしてみよう
# 出来高と株価の散布図 plt.scatter(x_train_std, y_train, color='blue', label='data') # 回帰直線 plt.plot(x_ndar, y_ndar_prd, color='green', linestyle='-', label='LinearRegression') # 境界線 plt.plot(x_ndar, y_ndar_svr ,color='red', linestyle='-', label='SVR') # マージン線 plt.plot(x_ndar, y_ndar_svr + mod2.epsilon, color='orange', linestyle='-.', label='margin') plt.plot(x_ndar, y_ndar_svr - mod2.epsilon, color='orange', linestyle='-.') # ラベル plt.ylabel('Closing price') plt.xlabel('Volume') plt.title('SVR Regression') # 凡例 plt.legend(loc='lower right') plt.show()
回帰線の傾きよりSVRの境界線のほうがなだらかとなる
マージンをepsilonを250円でとってみたが出来高に合わせ株価も目立った投げもなく概ね順調に上昇基調で推移しているといって良さそうだ。

- 投稿日:2020-01-18T14:40:54+09:00
WSL(Ubuntu) + Docker Desktop for Windows + docker-lambda + Python で AWS Lambda のローカル開発環境を構築
概要
AWS Lambda のローカル開発環境を Windows 上で構築しなければならなくなったため、
自分なりの構築手順を備忘録として記述していきます。
その通りやるだけで簡単に構築できる素晴らしい記事 を参考に進めていきたいと思います。
- WSL(Windows Subsystem for Linux)の環境を構築します。
- ローカルに Docker Desktop for Windows の環境を構築します。
- WSL からローカルの Docker Desktop for Windows を操作できるようにします。
- ローカル環境に AWS Lambda(Python) の開発環境を構築します。
環境情報
- Windows10 Pro(1909)
- WSL(Ubuntu 18.* LTS)
- bash
- Docker
- Python3.6
※ちなみに記事の内容は bash を想定して書いていますが
私の環境は fish ですので表示が間違っている可能性があります。
万が一、間違っている箇所がありましたら、
お手数ですがコメントで教えていただけると助かります。前提知識
- 基本的なLinux(Ubuntu, bash)の操作を理解している
- 仮想OS, WSL, Dockerに関する基本的な知識がある
- AWS Lambda の基本的な知識がある
WSLの構築
下記の素晴らしい記事を参考に「おまけ」「アンインストール」以外を実施
※下記の 初めにやっておく設定 の中で Hyper-V にチェックが無い場合は
一緒にチェックを入れて有効にしてください。Docker Desktop on Windows をインストール
下記の素晴らしい記事を参考に「おまけ」「アンインストール」以外を実施
docker desktop for windows + WSL で docker 環境ソースを準備
GitHub にこの記事で使用するソースのテンプレートを用意しました。
下記のリンクから MIT License で公開しています。
ご自由にお使いください。エイリアスを登録
新規のLambda関数はテンプレートのソースを基に作成していくため、
Dockerを実行する際のコマンドは常に一定になる想定です。
毎回入力するのは大変ですので、あらかじめ WSL にエイリアスを登録しておきます。.bash_aliases を vim で開く(無ければ新規作成)
~$ sudo vim ~/.bash_aliases && source ~/.bash_aliases.bash_aliases に下記コマンドを追加
.bash_aliasesalias docrun='docker run -v $(wslpath -m $PWD):/var/task --env-file .env lambci/lambda:python3.6 lambda_function.lambda_handler $(printf "%s" $(cat event.json))'簡単にですが
docrunの内容を説明します。
docker run
Dockerイメージからコンテナを生成・実行
-v $(wslpath -m $PWD):/var/task:
ホストOSのディレクトリ:コンテナのディレクトリ でボリュームを割り当てています。
※コンテナ上の/var/taskの中で、左に指定したホストOSのディレクトリの中が見えるということです。
ただし、WSL 上でローカル環境のディレクトリにいる時/mnt/d/Program/Python/AWS/docker-lambda $ echo $PWD /mnt/d/Program/Python/AWS/docker-lambdaとなっていますので、これをローカル環境のパスに変換するために
/mnt/d/Program/Python/AWS/docker-lambda $ echo $(wslpath -m $PWD) D:/Program/Python/AWS/docker-lambdaとしています。
--env-file .env
環境変数ファイルを読み込みます。
lambci/lambda:python3.6
Dockerイメージを指定しています。
lambda_function.lambda_handler
lambda_function.py の lambda_handler を実行するようにしています。
$(printf "%s" $(cat event.json))
event.json の内容を lambda_handler の引数 event に渡しています。Lambda関数を実行してみる
Windows
テンプレートのソースファイルを作業ディレクトリにコピーします。(ここでは
D:\Program\Python\AWS\docker-lambdaにします。)WSL
作業ディレクトリに移動
~$ cd /mnt/d/Program/Python/AWS/docker-lambda/Lambda関数を実行
/mnt/d/Program/Python/AWS/docker-lambda $ docrun START RequestId: c02ba91d-7783-1719-3b5e-269dfb11c807 Version: $LATEST event:{'Hello': 'World'} ENV:LOCAL END RequestId: c02ba91d-7783-1719-3b5e-269dfb11c807 REPORT RequestId: c02ba91d-7783-1719-3b5e-269dfb11c807 Init Duration: 439.63 ms Duration: 4.32 ms Billed Duration: 100 ms Memory Size: 1536 MB Max Memory Used: 39 MB "{\"message\": \"success\"}"初めて実行する時はDockerイメージのPullから始まります。
Pull完了後に関数が実行され、上記のような表示がされれば環境構築は完了です。参考
WSLのインストール・アンインストール方法
docker desktop for windows + WSL で docker 環境
docker-lambdaでAWS Lambda環境をお手軽に動かす
いまさらだけどDockerに入門したので分かりやすくまとめてみた最後に
なるべく初学者の方にもわかるように説明しているつもりですが、
分かりづらい点があったり、間違っている点がありましたら
コメントをいただけると助かります。
- 投稿日:2020-01-18T14:40:54+09:00
WSL + Docker Desktop for Windows + docker-lambda + Python でローカル開発環境を構築
概要
AWS Lambda のローカル開発環境を Windows 上で構築しなければならなくなったため、
自分なりの構築手順を備忘録として記述していきます。
その通りやるだけで簡単に構築できる素晴らしい記事 を参考に進めていきたいと思います。
- WSL(Windows Subsystem for Linux)の環境を構築します。
- ローカルに Docker Desktop for Windows の環境を構築します。
- WSL からローカルの Docker Desktop for Windows を操作できるようにします。
- ローカル環境に AWS Lambda(Python) の開発環境を構築します。
環境情報
- Windows10 Pro(1909)
- WSL(Ubuntu 18.* LTS)
- bash
- Docker
- Python3.6
※ちなみに記事の内容は bash を想定して書いていますが
私の環境は fish ですので表示が間違っている可能性があります。
万が一、間違っている箇所がありましたら、
お手数ですがコメントで教えていただけると助かります。前提知識
- 基本的なLinux(Ubuntu, bash)の操作を理解している
- 仮想OS, WSL, Dockerに関する基本的な知識がある
- AWS Lambda の基本的な知識がある
WSLの構築
下記の素晴らしい記事を参考に「おまけ」「アンインストール」以外を実施
※下記の 初めにやっておく設定 の中で Hyper-V にチェックが無い場合は
一緒にチェックを入れて有効にしてください。Docker Desktop on Windows をインストール
下記の素晴らしい記事を参考に「おまけ」「アンインストール」以外を実施
docker desktop for windows + WSL で docker 環境ソースを準備
GitHub にこの記事で使用するソースのテンプレートを用意しました。
下記のリンクから MIT License で公開しています。
ご自由にお使いください。エイリアスを登録
新規のLambda関数はテンプレートのソースを基に作成していくため、
Dockerを実行する際のコマンドは常に一定になる想定です。
毎回入力するのは大変ですので、あらかじめ WSL にエイリアスを登録しておきます。.bash_aliases を vim で開く(無ければ新規作成)
~$ sudo vim ~/.bash_aliases && source ~/.bash_aliases.bash_aliases に下記コマンドを追加
.bash_aliasesalias docrun='docker run -v $(wslpath -m $PWD):/var/task --env-file .env lambci/lambda:python3.6 lambda_function.lambda_handler $(printf "%s" $(cat event.json))'簡単にですが
docrunの内容を説明します。
docker run
Dockerイメージからコンテナを生成・実行
-v $(wslpath -m $PWD):/var/task:
ホストOSのディレクトリ:コンテナのディレクトリ でボリュームを割り当てています。
※コンテナ上の/var/taskの中で、左に指定したホストOSのディレクトリの中が見えるということです。
ただし、WSL 上でローカル環境のディレクトリにいる時/mnt/d/Program/Python/AWS/docker-lambda $ echo $PWD /mnt/d/Program/Python/AWS/docker-lambdaとなっていますので、これをローカル環境のパスに変換するために
/mnt/d/Program/Python/AWS/docker-lambda $ echo $(wslpath -m $PWD) D:/Program/Python/AWS/docker-lambdaとしています。
--env-file .env
環境変数ファイルを読み込みます。
lambci/lambda:python3.6
Dockerイメージを指定しています。
lambda_function.lambda_handler
lambda_function.py の lambda_handler を実行するようにしています。
$(printf "%s" $(cat event.json))
event.json の内容を lambda_handler の引数 event に渡しています。Lambda関数を実行してみる
Windows
テンプレートのソースファイルを作業ディレクトリにコピーします。(ここでは
D:\Program\Python\AWS\docker-lambdaにします。)WSL
作業ディレクトリに移動
~$ cd /mnt/d/Program/Python/AWS/docker-lambda/Lambda関数を実行
/mnt/d/Program/Python/AWS/docker-lambda $ docrun START RequestId: c02ba91d-7783-1719-3b5e-269dfb11c807 Version: $LATEST event:{'Hello': 'World'} ENV:LOCAL END RequestId: c02ba91d-7783-1719-3b5e-269dfb11c807 REPORT RequestId: c02ba91d-7783-1719-3b5e-269dfb11c807 Init Duration: 439.63 ms Duration: 4.32 ms Billed Duration: 100 ms Memory Size: 1536 MB Max Memory Used: 39 MB "{\"message\": \"success\"}"初めて実行する時はDockerイメージのPullから始まります。
Pull完了後に関数が実行され、上記のような表示がされれば環境構築は完了です。参考
WSLのインストール・アンインストール方法
docker desktop for windows + WSL で docker 環境
docker-lambdaでAWS Lambda環境をお手軽に動かす
いまさらだけどDockerに入門したので分かりやすくまとめてみた最後に
なるべく初学者の方にもわかるように説明しているつもりですが、
分かりづらい点があったり、間違っている点がありましたら
コメントをいただけると助かります。
- 投稿日:2020-01-18T14:20:57+09:00
【ハッカソン】RaspberryPi にCDできるツールを作った件について【便利ツール】
はじめに
最近のwebアプリケーション開発ではCI(Continuous Integration)やCD(Continuous Delivery)が充実していて、リモートリポジトリにpushすれば自動的に本番環境が更新されるので便利ですよね
でも、本番環境がローカル端末だった場合は、CIツールにCDしてもらうわけにもいかず、リモートの変更を毎回pullしなきゃいけないので面倒くさい
ましてやハッカソンみたいな時間がない中で 本番環境がRaspberryPiの場合、RaspberryPiでの開発はどころかコマンドを打つ手間も減らしたい
ということで、RaspberryPiに仕込んでおけばリモートリポジトリが更新されるたびにpullしてくれるCDツール、CanDyPi を作りました!
これで来年は最優秀賞間違いなしCanDyPi
CanDyPi is a Continuous Delivery tool for raspberry Pi.
作りは簡単。GitHubのwebhook機能を使って、RaspberryPiからforwardingしたngrokのエンドポイントにwebhookをひっかけます。CanDyPiがリポジトリ更新のメッセージを受け取ったら、pullコマンドを実行して最新のソースに更新します。
CanDyPiはpythonで書かれていて、サーバに
flask・git操作にgitpythonを使っています。使い方
事前準備
- python 3系
- ngrok
- git
- GitHubのリポジトリ
手順
4ステップで使えます
1. ラズパイで、gitのSSH接続
SSH設定にしないと、pullの度にパスワードを入力しなきゃいけないので、ラズパイ操作から解放されません・・・
この辺りの記事が参考になります。
GitHubでssh接続する手順~公開鍵・秘密鍵の生成から~2. ラズパイで、CanDyPiのインストール&実行
pipでインストールできます。
㊟python3系でインストール&実行してください
$ pip install candypi実行も簡単!
CDしたいリポジトリのパスを引数に与えてください。
(デフォルトでは、50000ポートで立ち上がります)
$ candypi /Users/tiwasa/sample_project3. ラズパイで、ngrokの起動
candypiを起動したポートを指定して、ngrokを起動してください。
$ ngrok http 50000ngrok by (Ctrl+C to quit) Session Status online Account XXXXXXXX (Plan: Free) Version 2.2.8 Region United States (us) Web Interface http://127.0.0.1:4040 Forwarding http://XXXXXXXX.ngrok.io -> localhost:50000 Forwarding https://XXXXXXXX.ngrok.io -> localhost:500004. GitHubで、webHooks設定
CDしたいリポジトリにwebhookを登録します。
GitHubのSettings -> Webhooksで、add webhookのPayload URLに、ngrokのForwarding https://XXXXXXXX.ngrok.io -> localhost:50000表示されたhttpsのアドレスを入れてadd webhook してください。(その他の項目はdefaultのままで大丈夫です。)
5. 完成
CDしたいリポジトリのmasterブランチに更新が発生すると、ラズパイ内のローカルリポジトリでpullコマンドが走って、最新になります。
さいごに
年末年始に作ったので、私自身もまだ実践投入していません。なんか手ごろなハッカソンないかな~?
もし使っていて気が付いたことがあったら、GitHubのissueか、このページのコメント欄に書いていただけると回答します。
ちなみに、ラズパイと同じローカルネットワーク上に開発用PCを配置できるんだったら、vscodeのリモートデベロップのほうが便利だと思います。ま、会場次第で別のLANに配置される可能性もあるから、CanDyPiの存在価値もある
・・・と
・・・思いたい
- 投稿日:2020-01-18T14:09:36+09:00
東京大学大学院情報理工学系研究科 創造情報学専攻 2012年度冬 プログラミング試験
2012年度冬の院試の解答例です
※記載の内容は筆者が個人的に解いたものであり、正答を保証するものではなく、また東京大学及び本試験内容の提供に関わる組織とは無関係です。出題テーマ
- 数値解析
問題文
※ 東京大学側から指摘があった場合は問題文を削除いたします。
配布ファイルを作るための関数
実際の配布ファイルは無いので結果の検証用
import random def make_data(file_path, data_num): with open(file_path, 'w', encoding='ascii') as f: for i in range(data_num): x = random.randrange(30) y = random.randrange(30) if i < data_num-1: f.write('({0}, {1})\n'.format(x, y)) else: f.write('({0}, {1})'.format(x, y)) def make_data2(file_path, data_num): with open(file_path, 'w', encoding='ascii') as f: for i in range(data_num): x = i y = None if i < 15: y = int(x * 0.5 + 2) else: y = int(4 * x - 50) if i < data_num-1: f.write('({0}, {1})\n'.format(x, y)) else: f.write('({0}, {1})'.format(x, y)) make_data('test001.txt', 30) make_data2('test002.txt', 30)関数, クラス
from PrintArray import PrintArray class Point(object): def __init__(self, x, y): self.x = x self.y = y def __repr__(self): return '({0}, {1})'.format(self.x, self.y) def __lt__(self, point): if self.y == point.y: return self.x < point.x else: return self.y < point.y def inputdata(file_path): with open(file_path, 'r', encoding='ascii') as f: lines = f.readlines() ret = [] for line in lines: line_list = line.strip().split(', ') p = Point(int(line_list[0][1:]), int(line_list[1][:-1])) ret.append(p) return ret class DataGraph(object): def __init__(self): self.canvas = [[' ' for _ in range(64)] for _ in range(32)] for i in range(4): self.canvas[30-i*10][0] = str(i) if i > 0: self.canvas[30-i*10][1] = str(0) for i in range(30): self.canvas[29-i][2] = '|' self.canvas[30][2] = '+' self.canvas[31][2] = str(0) for i in range(1, 4): self.canvas[31][2+i*20] = str(i) self.canvas[31][2+i*20+1] = str(0) for i in range(3, 64): self.canvas[30][i] = '-' def show(self): PrintArray(self.canvas) def add(self, point, marker='*'): self.canvas[30-point.y][1+point.x*2+2] = marker def add_line_point(self, point, marker='o'): x = format_point5(point.x) i_x, s_x = divide(x) y = int(point.y) if x > 0: if s_x > 0: self.canvas[30-y][1+i_x*2+2] = marker else: self.canvas[30-y][1+i_x*2+1] = marker # 0.5刻みにformatする def format_point5(x): l = int(x // 1) r = l + 1 m = l + 0.5 abs_l = abs(x-l) abs_r = abs(x-r) abs_m = abs(x-m) tmp = [[abs_l, l], [abs_r, r], [abs_m, m]] tmp.sort() return tmp[0][1] # intと小数に分ける def divide(x): i = int(x // 1) return i, x - i def make_linear_data(a, b): ret = [] s = set() esp = 1e-5 for x in range(30): x1 = x y1 = int(a*x1+b - esp) x2 = x+0.5 y2 = int(a*x2+b - esp) if not(y1 in s): s.add(y1) ret.append(Point(x1, y1)) if not(y2 in s): s.add(y2) ret.append(Point(x2, y2)) return ret def calc_a_b(points): N = len(points) a1 = 0 a2 = 0 a3 = 0 a4 = 0 for k in range(N): p = points[k] a1 += (p.x*p.y) a2 += p.x a3 += p.y a4 += p.x**2 a1 *= N a4 *= N a = None if (a4 - a2**2) == 0: a = 1e9+7 else: a = (a1 - (a2 * a3)) / (a4 - a2**2) b1 = 0 b2 = 0 b3 = 0 b4 = 0 for k in range(N): p = points[k] b1 += p.x**2 b2 += p.y b3 += p.x*p.y b4 += p.x if (N*b1 - b4**2) == 0: b = 1e9+7 else: b = (b1*b2 - b3*b4)/(N*b1 - b4**2) return a, b def calc_E(a1, b1, a2, b2, xm, points): ret = 0 for p in points: if p.x < xm: ret += (abs(p.y - (a1*p.x+b1)))**2 else: ret += (abs(p.y - (a2*p.x+b2)))**2 return ret def divide_points_by_xm(points, xm): ret1 = [] ret2 = [] for p in points: if p.x < xm: ret1.append(p) else: ret2.append(p) return ret1, ret2(1)
def solve1(): points = inputdata('test001.txt') points.sort() print(points[-1]) return(2)
def solve2(): points = inputdata('test001.txt') DG = DataGraph() for p in points: DG.add(p) DG.show() return(3)
def solve3(): points = make_linear_data(0.8, 2.0) DG = DataGraph() for p in points: DG.add_line_point(p) DG.show() return(4)
def solve4(): points = inputdata('test001.txt') DG = DataGraph() a, b = calc_a_b(points) l_points = make_linear_data(a, b) for p in points: DG.add(p) for p in l_points: DG.add_line_point(p) DG.show() return(5) 接続する折れ線近似は分かりませんでした...
以下は接続しない時です...
def solve5(): points = inputdata('test002.txt') DG = DataGraph() ans_a1 = None ans_b1 = None ans_a2 = None ans_b2 = None ans_xm = None e = 1e9+7 for i in range(60): xm = 0.5 * i ps1, ps2 = divide_points_by_xm(points, xm) if len(ps1) == 0: a2, b2 = calc_a_b(ps2) em = calc_E(a2, b2, a2, b2, xm, points) if em < e: e = em ans_a1 = a2 ans_b1 = b2 ans_a2 = a2 ans_b2 = b2 ans_xm = xm elif len(ps2) == 0: a1, b1 = calc_a_b(ps1) em = calc_E(a1, b1, a1, b1, xm, points) if em < e: e = em ans_a1 = a1 ans_b1 = b1 ans_a2 = a1 ans_b2 = b1 ans_xm = xm else: a1, b1 = calc_a_b(ps1) a2, b2 = calc_a_b(ps2) em = calc_E(a1, b1, a2, b2, xm, points) if em < e: e = em ans_a1 = a1 ans_b1 = b1 ans_a2 = a2 ans_b2 = b2 ans_xm = xm print(ans_a1, ans_b1, ans_a2, ans_b2, ans_xm) return感想
- 創造情報の問題を今までかなり解いてきましたがその中で最もひどい問題でした。
- 理由としては問題があまりにも不親切で作るグラフの条件が把握できません。その上に図2に至ってはグラフが間違っている始末です。図2の右上の点を見てもらうとわかるのですがx=28か29の範囲にあります。x=28としてy=28*0.8+2.0=24.4, x=27として見ても23.6、小数以下切り捨てでもy=23これが図ではy=22、図2を参考にして作成せよって何ですか?
- ascii文字でグラフを書かせるにしてはx軸方向の区分があまりにも分かりづらいです。図1をまず参考にすると、こちらは入力が必ず整数であることも考慮すると多分x=nは(n*'--')+'-'の位置に配置させます。しかしこれは問題文をよく拡大して見ないと分からないですし、直線の方に至っては描画ではx=0.5単位で描画するわけでもなく、図2が間違っているせいで基準がわからないです。流石に問題としてひどいと思われます。僕は独自に解釈してy方向が初めて一個分離れるときのみをプロットする形にしました。
- 作者としてはそこらへんは解答者に委ねているだけなのかもしれませんが、あまりにも不親切です。
- (5)の折れ線近似ですがこれは接続しない時を求めた後にym=(a1*xm+b1 + a2*xm+b2)にしてbの方は変えずにa1, a2を調整するやり方くらいしか思いつかなかったです...


