- 投稿日:2020-01-15T23:47:09+09:00
Tensorflow2のMirroredStrategyを使って複数GPUで計算する
概要
非常に簡単。tf.distribute.MirroredStrategy
tf.distribute.MirroredStrategyのスコープ内でネットワークを構築するだけ。変更は数行ですむ。Keras APIを用いた実装例
ここでは簡単な例として隠れ層が1層のみからなるシンプルなネットワークを構築しています。
import tensorflow as tf from tensorflow.keras.models import Model from tensorflow.keras.layers import Dense, Input from tensorflow.keras.optimizers import Adam with tf.distribute.MirroredStrategy().scope(): # このブロックでネットワークを構築する x = Input(32, dtype=tf.int32, name='x') hidden = Dense(20, activation='relu', name='hidden')(x) y = Dense(5, activation='sigmoid', name='y')(hidden) model = Model(inputs=x, outputs=y) model.compile( optimizer=Adam(lr=0.001), loss='binary_crossentropy', ) model.fit( x_train, y_train, epochs=10, batch_size=16, )関連
公式なドキュメントは次の通り。
Keras APIをそのまま利用する場合はこの記事で紹介した通りだが、custom training loopを実装している場合などは、さらに考慮すべき点がいくつかある。その場合は上記のドキュメントを参照していただきたい。
multi_gpu_model()は2020年4月以降に廃止予定とのこと。
- 投稿日:2020-01-15T23:42:44+09:00
[Python3 入門 9日目] 5章 Pyの化粧箱:モジュール、パッケージ、プログラム(5.1〜5.4)
5.1 スタンドアローンプログラム
- テキストターミナル、またはターミナルウィンドウでPythonを実行している場合、Pythonプログラムの名前に続いてプログラムファイル名を入力する。
test1.pyprint("This stadalone program works!")結果$ python test1.py This stadalone program works!5.2 コマンドライン引数
test2.pyimport sys print("Program arguments:",sys.argv)結果$ python test2.py Program arguments: ['test2.py'] $ python test2.py tra la la Program arguments: ['test2.py', 'tra', 'la', 'la']5.3 モージュールとimport文
- モジュールはPythonコードをまとめたファイルである。
- 他のモジュールのコードはimport文で参照する。こうすると、インポートしたモージュールのコード、変数をプログラム内で使えるようになる。
5.3.1 モジュールのインポート
- import文の最も単純な使い方はimport moduleという形式。ここでmoduleの部分は他のPythonファイルのファイル名から拡張子の.pyを取り除いたもの。
- import文を通り過ぎると、メインプログラムはmodule.というプレフィックスを付ける限り、module.pyに含まれる全ての部分にアクセスできるようになる。
- インポートされるコードが複数の場所で使われる場合には、関数の外でインポートすることを考えると良い。
メインプログラム#reportモジュールをインポート import report description=report.get_description() print("Today is weather:",description)report.py#モジュール #get_description()はPython標準のrandomモジュールからchoice関数をインポートしている。 def get_description(): """プロと同じようにランダムな天気を返す""" from random import choice possibilities=["rain","snow","sleet","fog","sun","who knows"] return choice(possibilities)結果$ python weatherman.py Today is weather: fog $ python weatherman.py Today is weather: sun $ python weatherman.py Today is weather: fog書き換え可能#randomモジュールから直接choice関数をインポートしている。 def get_description(): """プロと同じようにランダムな天気を返す""" import random possibilities=["rain","snow","sleet","fog","sun","who knows"] return random.choice(possibilities)>>> import random >>> def get_description(): ... possibilities=["rain","snow","sleet","fog","sun","who knows"] ... return random.choice(possibilities) ... >>> get_description <function get_description at 0x11035b950> >>> get_description() 'who knows' >>> get_description() 'who knows' >>>5.3.2 別名によるモジュールのインポート
- 別名を使ってインポートできる。
import report as x description=x.get_description() print("Today is weather:",description)5.3.3 必要なものだけをインポートする方法
- Pythonではモジュールから一つ以上の部品だけをインポートすることができる。
元の名前でインポートfrom report import get_description description = get_description() print("Today is weather:",description)do_itでインポートfrom report import get_description as do_it description = do_it() print("Today is weather:",description)5.3.4 モジュールサーチパス
- 使われるファイルは最初にマッチしたファイルである。そのため自分でrandomというモジュールを定義し、それが標準ライブラリよりも前のサーチパスに含まれていた場合、標準ライプラリのrandomにはアクセスできない。
>>> for place in sys.path: ... print(place) ... practice/lib/python37.zip practice/lib/python3.7 practice/lib/python3.7/lib-dynload usr/local/var/pyenv/versions/3.7.5/lib/python3.7 practice/lib/python3.7/site-packages5.4 パッケージ
- モジュールはパッケージと呼ばれる階層構造に組織できる。
- sourcesディレクトリには以下の2つのファイルに加え、init.pyという名前のファイルが必要。中身は空で良いが、Pythonはこのファイルがあるディレクトリをパッケージとして扱うため。
メインプログラム#enumerate関数はインデックス番号、要素の順に値を取得できる。第二引数に1を指定することでインデックスを1に指定できる。 from sources import daily, weekly print("Daily forecast:",daily.forecast()) print("Weekly forecast:") for number, outlook in enumerate(weekly.forecast(),1): print(number, outlook)sources/daily.py#モジュール1 def forecast(): "偽の天気予報" return "like yesterday"sources/weekly.py#モジュール2 def forecast(): "偽の週間天気予報" return ["snow","more snow","sleet","freezing rain","rain","fog","hail"]結果$ python weather.py Daily forecast: like yesterday Weekly forecast: 1 snow 2 more snow 3 sleet 4 freezing rain 5 rain 6 fog 7 hail感想
今日は風が冷たい1日でした。
参考文献
「Bill Lubanovic著 『入門 Python3』(オライリージャパン発行)」
- 投稿日:2020-01-15T23:42:44+09:00
[Python3 入門 9日目] 5章 Pyの化粧箱:モジュール、パッケージ、プログラム(5.1〜)
5.1 スタンドアローンプログラム
- テキストターミナル、またはターミナルウィンドウでPythonを実行している場合、Pythonプログラムの名前に続いてプログラムファイル名を入力する。
test1.pyprint("This stadalone program works!")結果$ python test1.py This stadalone program works!5.2 コマンドライン引数
test2.pyimport sys print("Program arguments:",sys.argv)結果$ python test2.py Program arguments: ['test2.py'] $ python test2.py tra la la Program arguments: ['test2.py', 'tra', 'la', 'la']5.3 モージュールとimport文
- モジュールはPythonコードをまとめたファイルである。
- 他のモジュールのコードはimport文で参照する。こうすると、インポートしたモージュールのコード、変数をプログラム内で使えるようになる。
5.3.1 モジュールのインポート
- import文の最も単純な使い方はimport moduleという形式。ここでmoduleの部分は他のPythonファイルのファイル名から拡張子の.pyを取り除いたもの。
- import文を通り過ぎると、メインプログラムはmodule.というプレフィックスを付ける限り、module.pyに含まれる全ての部分にアクセスできるようになる。
- インポートされるコードが複数の場所で使われる場合には、関数の外でインポートすることを考えると良い。
メインプログラム#reportモジュールをインポート import report description=report.get_description() print("Today is weather:",description)report.py#モジュール #get_description()はPython標準のrandomモジュールからchoice関数をインポートしている。 def get_description(): """プロと同じようにランダムな天気を返す""" from random import choice possibilities=["rain","snow","sleet","fog","sun","who knows"] return choice(possibilities)結果$ python weatherman.py Today is weather: fog $ python weatherman.py Today is weather: sun $ python weatherman.py Today is weather: fog書き換え可能#randomモジュールから直接choice関数をインポートしている。 def get_description(): """プロと同じようにランダムな天気を返す""" import random possibilities=["rain","snow","sleet","fog","sun","who knows"] return random.choice(possibilities)>>> import random >>> def get_description(): ... possibilities=["rain","snow","sleet","fog","sun","who knows"] ... return random.choice(possibilities) ... >>> get_description <function get_description at 0x11035b950> >>> get_description() 'who knows' >>> get_description() 'who knows' >>>5.3.2 別名によるモジュールのインポート
- 別名を使ってインポートできる。
import report as x description=x.get_description() print("Today is weather:",description)5.3.3 必要なものだけをインポートする方法
- Pythonではモジュールから一つ以上の部品だけをインポートすることができる。
元の名前でインポートfrom report import get_description description = get_description() print("Today is weather:",description)do_itでインポートfrom report import get_description as do_it description = do_it() print("Today is weather:",description)5.3.4 モジュールサーチパス
- 使われるファイルは最初にマッチしたファイルである。そのため自分でrandomというモジュールを定義し、それが標準ライブラリよりも前のサーチパスに含まれていた場合、標準ライプラリのrandomにはアクセスできない。
>>> for place in sys.path: ... print(place) ... practice/lib/python37.zip practice/lib/python3.7 practice/lib/python3.7/lib-dynload usr/local/var/pyenv/versions/3.7.5/lib/python3.7 practice/lib/python3.7/site-packages5.4 パッケージ
- モジュールはパッケージと呼ばれる階層構造に組織できる。
- sourcesディレクトリには以下の2つのファイルに加え、init.pyという名前のファイルが必要。中身は空で良いが、Pythonはこのファイルがあるディレクトリをパッケージとして扱うため。
メインプログラム#enumerate関数はインデックス番号、要素の順に値を取得できる。第二引数に1を指定することでインデックスを1に指定できる。 from sources import daily, weekly print("Daily forecast:",daily.forecast()) print("Weekly forecast:") for number, outlook in enumerate(weekly.forecast(),1): print(number, outlook)sources/daily.py#モジュール1 def forecast(): "偽の天気予報" return "like yesterday"sources/weekly.py#モジュール2 def forecast(): "偽の週間天気予報" return ["snow","more snow","sleet","freezing rain","rain","fog","hail"]結果$ python weather.py Daily forecast: like yesterday Weekly forecast: 1 snow 2 more snow 3 sleet 4 freezing rain 5 rain 6 fog 7 hail感想
今日は風が冷たい1日でした。
4.9 デコレータが未だに不明なのでご教示いただければと思います。参考文献
「Bill Lubanovic著 『入門 Python3』(オライリージャパン発行)」
- 投稿日:2020-01-15T23:38:39+09:00
モンテカルロ法で琵琶湖の面積の割合を求める
Discraimer
このPostには、技術的な内容と同様かそれ以上に滋賀県民が滋賀県をひたすら愛するだけの内容が含まれています。純粋な技術記事を読みたい方は他をあたってください。技術的にすごいことは何も起きていません。
滋賀県民
こんにちは。滋賀県民です。
皆さんは、 1/6という数字を聞いて何を思い浮かべるでしょうか。実はこれは、滋賀県全体の面積にしめる琵琶湖の面積の割合です。
この数字は、県内の小学校5年生以上なら誰しも必ず知っているはずの値で、結構な割合の県民は知っています。というのも、滋賀県では、フローティングスクール という事業が展開されており、県下の小学5年生は、琵琶湖上に浮かぶ学習船(一応県立学校という位置づけです)の中で一泊の宿泊を含む研修活動を行います。この船は、うみのこ と呼ばれていて、2018年、30年以上親しまれた船が引退して、今はリニューアルされた新船となっています。
なかなかいい体験なので、滋賀県民で良かったことの一つです。
ぜひ一度ご覧ください。 : https://uminoko.jp
ちなみにですが、このうみのこに乗船する小学生が、研修前に覚える「希望の船」という歌を、「地味にまだ歌える」という人が多くて面白いです。無論、私もその一人です。
この船で、県下の小学生たちは、プランクトンの観察やロープワーク体験、カッター(小型の船)での活動などを行います。そのために事前・事後学習を死ぬほどやるのですが、その中でよく出てくる値のうちの一つがこの1/6なのです。
最近では、この 1/6の知名度にあやかって、コクヨが ロクブンノイチ野帳 なるものも出しています。琵琶湖水系沿岸のヨシから生産された紙を使用していて、なかなか良いのでぜひご購入ください。
https://www.kokuyo-shop.jp/sp/ProductDetail.aspx?sku=4560107742501
さて、本題に移りましょう。
ここまでご説明したように、1/6 なのですが、残念ながら京都民や大阪民は口を揃えてこう言います。 「滋賀とか半分くらい琵琶湖ちゃうの?」
そう思うのも当然でしょう。彼らには琵琶湖の周りに広がる豊かで広大な山林が見えていないのでしょう。
しかしながら、流石にそれを甘んじて受け入れるわけにはいきません。
というわけで、大阪、京都民にもできる。というか全世界どこにいてもできる、面積の割合の実験を提案します。
モンテカルロ法
この記事をお読みの方はご存知でしょう。
円周率を求めるのにも非常によく使われる手法です。
円周率を求めるときには、正方形の中にしめる円の面積の割合を求めます。そう、ある領域における面積の割合は、一定の精度までは確率的に求めることが可能です。
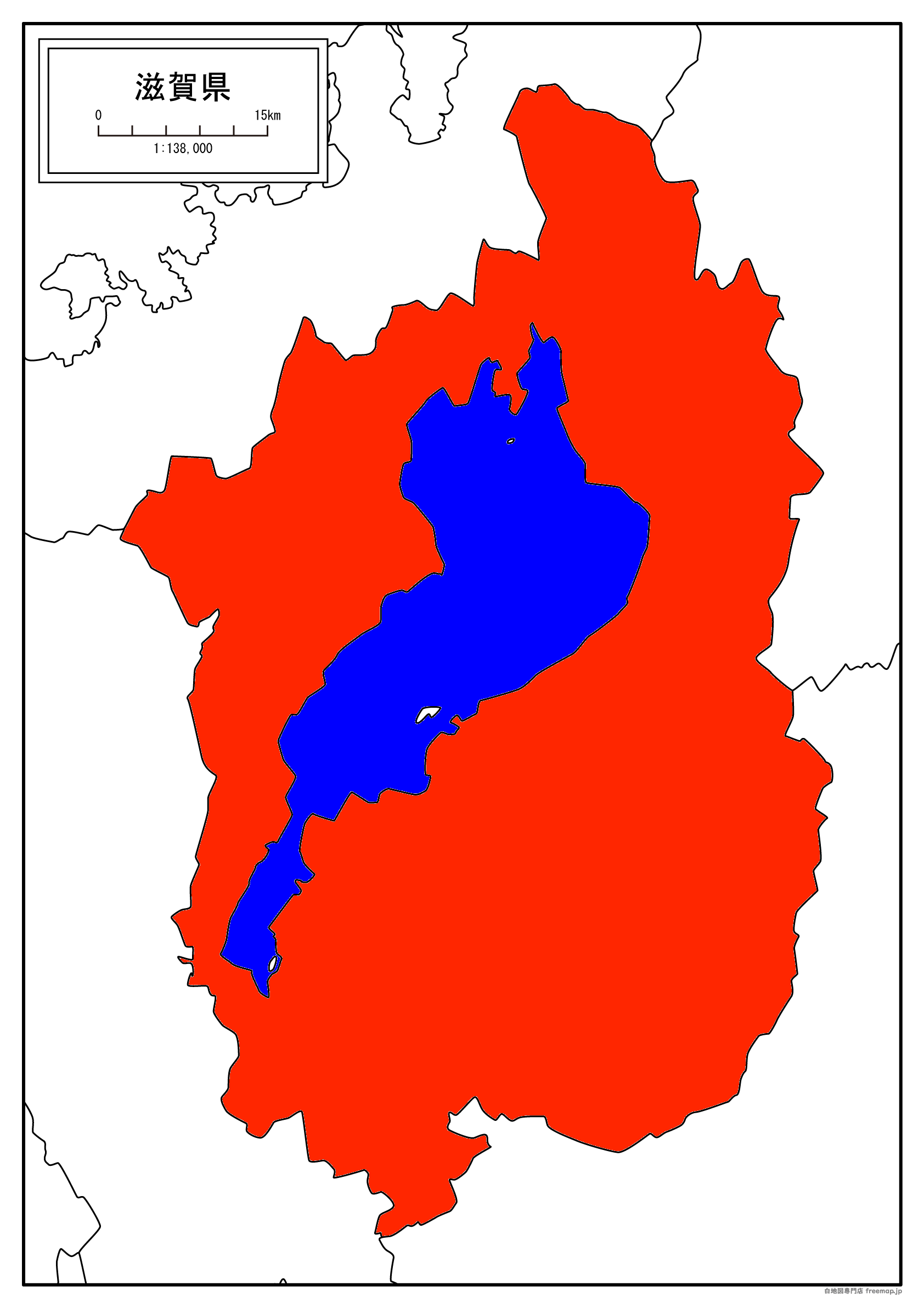
というわけで、滋賀県にしめる琵琶湖の面積をモンテカルロ法で求めます。地図の入手
まずは、琵琶湖の面積と滋賀県の面積を決定させるベースになる地図を用意します。
とりあえずこれでいいでしょう。https://www.freemap.jp/itemFreeDlPage.php?b=shiga&s=shiga
地図の処理
次に、白地図に色をつけます。
これは、地図中の 滋賀県ではないエリア 滋賀県の陸のエリア 滋賀県の琵琶湖のエリア をソフトウェアから判別できるようにするための処理です。
適当に塗りつぶしてください。
今回、私はSeashoreを使って 滋賀県の陸のエリア にrgb(255,38,0)、滋賀県の琵琶湖のエリアにrgb(0,0,255)の色をつけました。
ぷよぐらみんぐ
基本的には円周率を求めるのと同じで、領域(正方形とか滋賀県とか)中にランダムな点を設定し、それが指定の領域(円とか琵琶湖とか)に入っているかを判定する処理を繰り返します。
本当に円とやっていることは変わらないので、あまり気にすることないと思いますが、少し気にしないといけないのは、分母はepoch数ではありません。
琵琶湖に入った数を滋賀県に入った数で割ってください。
これを識別するために色をつけています。
画像中のある座標の色のデータは、皆さんご存知のようにOpenCVを用いてimreadして出てくる配列の[y,x]番地にアクセスすることで得られます。
そのほかに気にすることは特にないと思います。
一応これでは試行回数は50000回に設定しています。import cv2 import numpy as np print("Biwako Area inspector") print("©︎ Yusei ito 2020") print("=========================") print("Importing image..") img = cv2.imread('./map.png') #Processed map image file height, width, channels = img.shape[:3] print("Image Imported.") print("\tWidth:"+str(width)) print("\tHeight:"+str(height)) count_max=50000 count_shiga=0 count_biwako=0 for i in range(0,count_max): px=img[np.random.randint(height),np.random.randint(width)]#Be attention. Array is formed as [y,x] and return is formed [blue,green,red] if (px[0]==0 and px[1]==38 and px[2]==255): count_shiga+=1 if (px[0]==255 and px[1]==0 and px[2]==0): count_shiga+=1 count_biwako+=1 if (count_max%10==0): devisionBy=1 if count_shiga==0 else count_shiga print(str(i)+"\t"+str(count_biwako/devisionBy)) print("All Process succeed.\r\n\r\n") print("Attempt:"+str(count_max)) print("Shiga:"+str(count_shiga)) print("Biwako:"+str(count_biwako)) print("Overall Score:"+str(count_biwako/count_shiga))実行結果は、冗長なので一番最後だけ貼ります。
ロクブンノイチなので、期待値は1/6=0.1666666....です。Attempt:50000 Shiga:21143 Biwako:3493 Overall Score:0.16520834318687036良いですね。なかなか良いです。
というわけで、滋賀県はいいところです。一度はお越しくださいね。
この投稿に関するもの一式はGitHubにまとめています。合わせてご覧ください。
- 投稿日:2020-01-15T23:17:32+09:00
Notion API 로 Page,Todo 블록 만들기
Notion API 호출로 Page/Todo 블록 추가하는 방법을 공유합니다.
https://github.com/jamalex/notion-py 활용하였습니다.☕️ 예) 스벅남은 매일 아침 9시 아아를 마시고, 체크합니다.
준비물
- python v3.5 이상
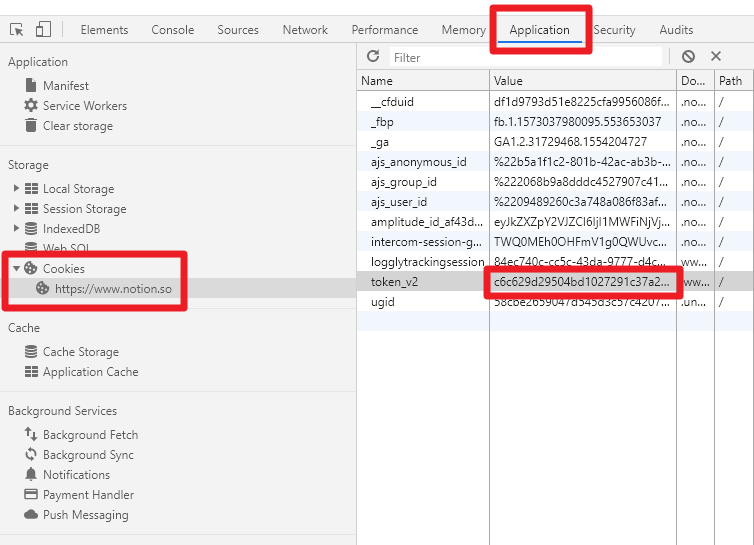
- token_v2 ✅ 노션 웹 로그인 -> F12 -> Application -> Cookies -> token_v2
시작
1. 사전설치
$ pip install notion2. 소스코드
add_childpage.py생성$ vi add_childpage.pyfrom notion.client import NotionClient from notion.block import TodoBlock from notion.block import PageBlock # login token_v2 = 'c6c629d29504bd10272...012345678901234512345' # 준비물의 token_v2 client = NotionClient(token_v2=token_v2) # 스벅남 페이지 URL url = "https://www.notion.so/openwiki/d8e3e99628eb4e21a258575367ee72c5" page = client.get_block(url) print("Page 제목은 :", page.title) ################################ # API 호출로 PageBlock 추가 ################################ print(page.children.add_new(PageBlock, title='2020.01.11')) print(page.children.add_new(PageBlock, title='2020.01.12')) print(page.children.add_new(PageBlock, title='2020.01.13')) print(page.children.add_new(PageBlock, title='2020.01.14')) print(page.children.add_new(PageBlock, title='2020.01.15')) #################################### # PageBlock에 TodoBlock 추가 #################################### for child in page.children : child_page = client.get_block(child.id) child_page.children.add_new(TodoBlock, title="09:00 아아벤티")3. 실행
$ python ./add_childpage.py4. 확인
기타


- 投稿日:2020-01-15T23:17:32+09:00
Create Page/Todo Block with Notion API
How to add a Page / Todo block with the Notion API call.
I used https://github.com/jamalex/notion-py☕️ Ex) Starbucks man drinks nine o'clock every morning and check.
Ready
- python v3.5 ↑
- token_v2 ✅ Notion web login -> F12 -> Application -> Cookies -> token_v2
Start
1. Pre installation
$ pip install notion2. Source code
add_childpage.py$ vi add_childpage.pyfrom notion.client import NotionClient from notion.block import TodoBlock from notion.block import PageBlock # login token_v2 = 'c6c629d29504bd10272...012345678901234512345' # 준비물의 token_v2 client = NotionClient(token_v2=token_v2) # 스벅남 페이지 URL url = "https://www.notion.so/openwiki/d8e3e99628eb4e21a258575367ee72c5" page = client.get_block(url) print("Page 제목은 :", page.title) ################################ # API 호출로 PageBlock 추가 ################################ print(page.children.add_new(PageBlock, title='2020.01.11')) print(page.children.add_new(PageBlock, title='2020.01.12')) print(page.children.add_new(PageBlock, title='2020.01.13')) print(page.children.add_new(PageBlock, title='2020.01.14')) print(page.children.add_new(PageBlock, title='2020.01.15')) #################################### # PageBlock에 TodoBlock 추가 #################################### for child in page.children : child_page = client.get_block(child.id) child_page.children.add_new(TodoBlock, title="09:00 아아벤티")3. Run
$ python ./add_childpage.py4. Result
Etc
- 投稿日:2020-01-15T23:10:22+09:00
Siri に Slackbot が投稿した AWS 請求額を読み上げる仕事をさせる
はじめに
iPhone を使い始めて10年弱、 Siri が全く働いていないことに気付きました。
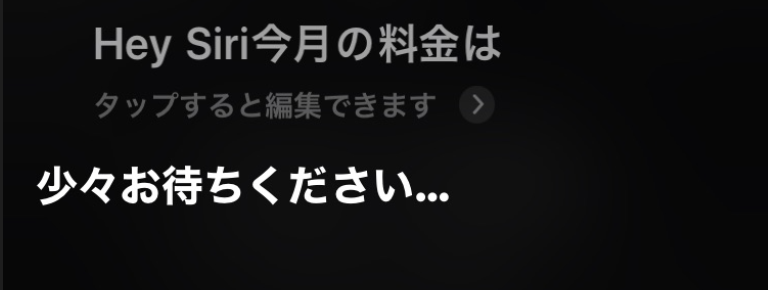
スマートスピーカーが流行っている昨今、自分の Siri にももっと活躍して欲しいので Slackbot が投稿した AWS 請求額を読み上げてもらうことにしました。結果から見せるとこんな感じです。
料金を聞くと...
Slackに投稿した内容を読み上げてくれました。
では、作り方諸々を紹介していきます。構成
構成はこんな感じになります。
それぞれの役割を紹介していきます。
- Siri
- 音声呼び出しによるショートカットアプリの実行
- Slack に投稿された AWS 請求額の読み上げ
- ショートカットアプリ
- SlackAPI を使用して投稿
- SlackAPI を使用して最新の投稿を JSON で取得
- 取得された JSON 情報から必要な内容を抽出
- Slackbot
- Lambda の呼び出し
- Lambda
- AWS 請求額の取得
処理内容
今回はショートカットアプリに重点を置いて説明していきます。
Lambda と Slackbot についてはそれぞれ以下の記事にて詳細を記載しているので参照してください。
Lambda:(Python)AWSの請求金額を取得する
Slackbot:echobotを作成し、Slackに通知するそれでは、ショートカットを作成していきます。
まず、ショートカット名を決めます。
Siri にショートカット名を呼びかけると登録しているショートカットを実行してくれます。
なので今回は『今月の料金は』というショートカット名にします。
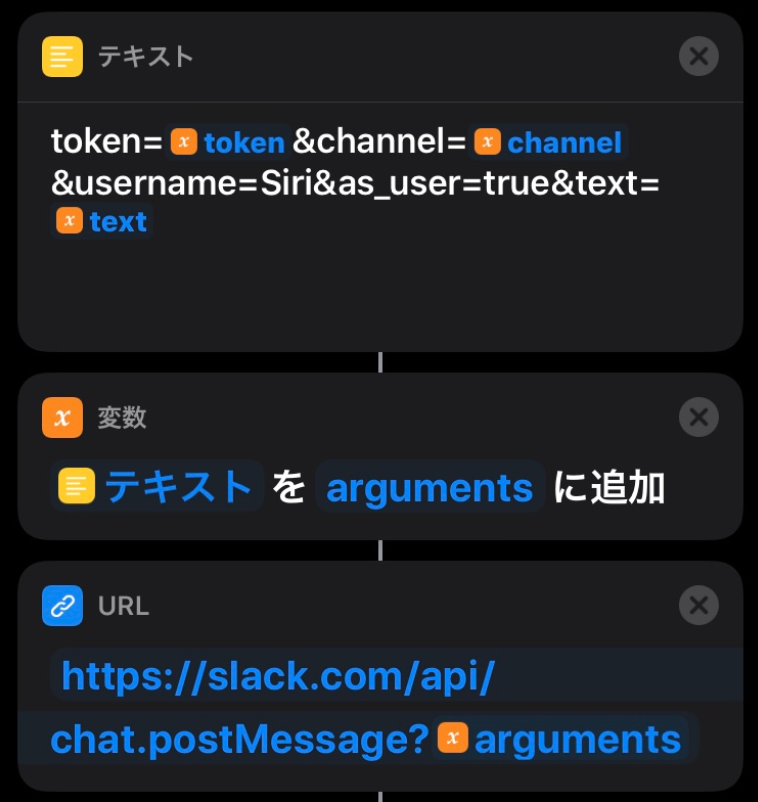
(『AWSの料金は』としたかったのですが Siri が AWS の部分を理解してくれませんでした...)続いて、各処理で使用する変数を定義していきます。
- token:SlackAPI で使用する token (今回は Legacy tokens を使用しています。)
- channel_nm:SlackAPI で投稿するチャンネル名
- channel_id:SlackAPI で最新の投稿を取得する対象のチャンネルID
- text:Slack に投稿する文章
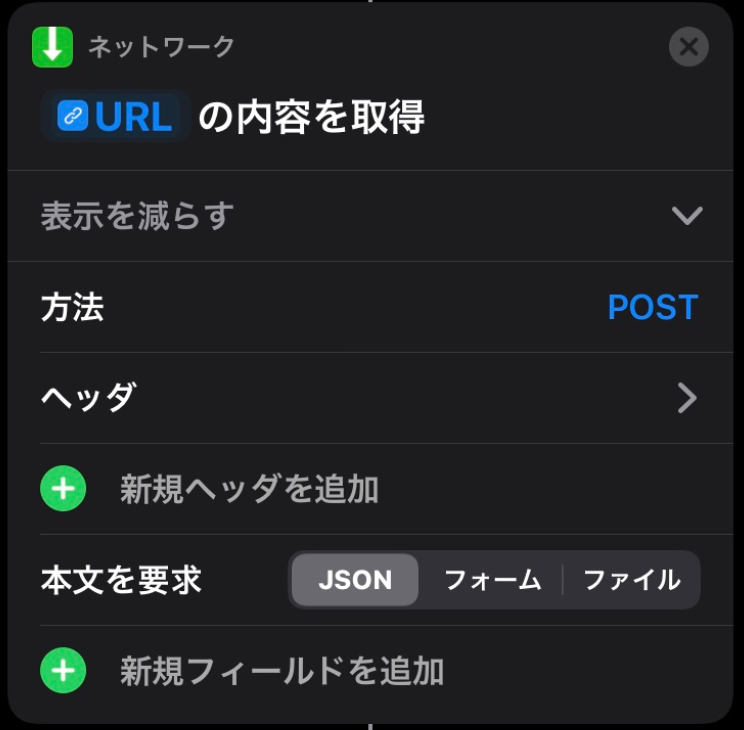
変数が設定できたら、 Slack 投稿用 API の URL を作成し、実行します。
API を実行すると、 AWS 請求額取得 Lambda が実行されます。結果がSlackに投稿されるまで時間がかかるので待機させます。
待機後、 Slack の最新投稿取得APIを実行していきます。
投稿用 API の時と同様に URL を作成し、APIを実行します。
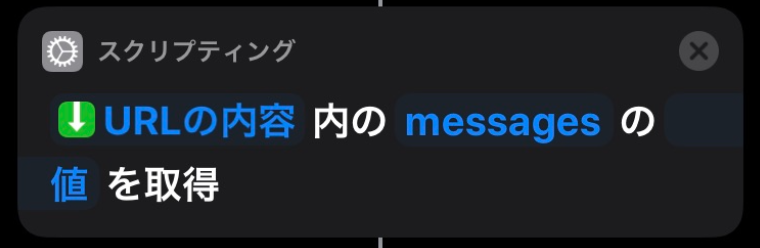
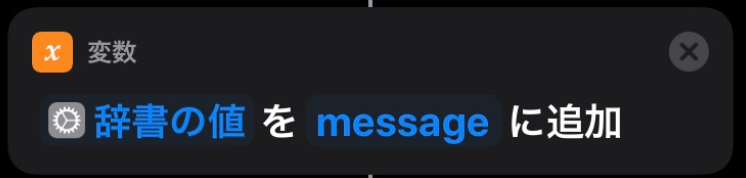
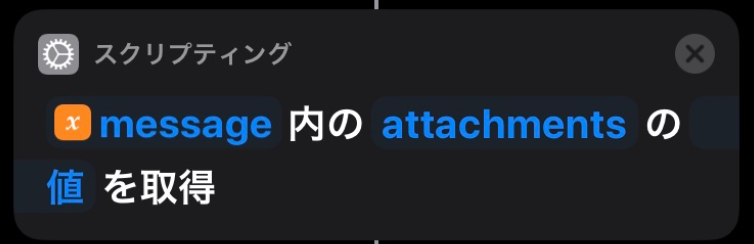
最新投稿取得 API を実行すると以下のような JSON が返却されます。{"messages": [{ "bot_id":"XXXXXXXX", "ts":"1579095866.000200", "attachments": [{ "color":"36a64f", "id":1, "fallback":" ・AWS Cost Explorer: 1.04 USD\n ・Tax: 0.10 USD", "pretext":"01月01日から01月14日の請求額は、1.14 USDです。", "text":" ・AWS Cost Explorer: 1.04 USD\n ・Tax: 0.10 USD" }], "type":"message", "subtype":"bot_message", "text":"" }], "has_more":true, "ok":true, "channel_actions_ts":null, "channel_actions_count":0}ここから pretext の値を変数に追加していきます。
これで Siri に読み上げてもらう内容が取得できました。
最後に読み上げる文章をテキストに起こし、読み上げのアクションを設定します。
完成です。
Siri に向かって『 Hey Siri! 』と話しかけましょう!おわりに
これで Siri が一つ仕事を覚えてくれました。
この構成を使えばもっといろいろな事ができると思います。
今回は Slack + Lambda をショートカットアプリから呼び出しましたが、 アプリの Pythonista3 から Python を実行しても面白い事ができると思います。








- 投稿日:2020-01-15T22:59:36+09:00
不均衡データの確率予測
はじめに
機械学習でクラス分類を行う際、クラス分類結果と同時に、それらのクラスに属する確率も得たいときがあります。
正例のデータ数が負例のデータ数に比べて極端に少ない場合(このようなデータを不均衡データと呼びます)、それらのデータをすべて用いて予測モデルを構築すると、予測結果も負例となることが多く、正例のデータを精度よく分類することが難しくなる傾向があります。そこで、負例のデータ数が正例のデータ数と等しくなるようにアンダーサンプリングしたデータを用いてモデルを構築することが多いです。これによって、正例のデータも精度よく分類できるようになりますが、正例と負例のデータ数のバランスがもとのデータと異なるため、確率の予測結果に、アンダーサンプリングによるバイアスが生じてしまいます。この問題への対処法は、すでに下記のブログなどにまとめている方もいらっしゃいますが、アンダーサンプリングしたデータで構築したモデルが出力する確率のバイアスを除去し、補正する方法について、備忘録としてまとめます。本記事では、確率予測のためのモデルとして、シンプルにロジスティック回帰モデルを利用します。
アンダーサンプリングによるバイアスの補正方法
アンダーサンプリングによるバイアスの補正方法は、論文Calibrating Probability with Undersampling for Unbalanced Classificationで提案されています。
いま、説明変数 $X$ から目的変数 $Y$($Y$は0か1のいずれかの値をとる)を予測する二値分類タスクを考えます。
もともとのデータセット $(X, Y)$ を、正例のデータ数が極端に少ない不均衡データとし、アンダーサンプリングにより負例のデータ数を正例のデータ数と等しくしたデータセットを $(X_s, Y_s)$ とします。また、$(X, Y)$ に含まれるあるデータ(サンプル)が、$(X_s, Y_s)$ にも含まれる場合に1をとり、$(X_s, Y_s)$ に含まれない場合に0をとるサンプリング変数 $s$ を導入します。もともとのデータセット $(X, Y)$ を用いて構築したモデルに説明変数を与えたとき、正例と予測する確率は $p(y=1|x)$ と表現されます。また、アンダーサンプリングしたデータセット $(X_s, Y_s)$ を用いて構築したモデルに説明変数を与えたとき、正例と予測する確率は $p(y=1|x,s=1)$ と表現されます。$p=p(y=1|x), p_s=p(y|x,s=1)$ とすると、$p$ と $p_s$ の関係は以下のようになります。
p=\frac{\beta p_s}{\beta p_s-p_s+1}ここで、$\beta=N^+/N^-$($N^+$ は正例のデータ数、$N^-$ は負例のデータ数)です。
導出
以下は詳細な式の説明なので、興味がない方は読み飛ばしてください。
ベイズの定理、および $p(s|y,x)=p(s|y)$ から、アンダーサンプリングしたデータセット $(X_s, Y_s)$ を用いて構築したモデルが予測する確率は下記のように書けます。
p(y=1|x,s=1)=\frac{p(s=1|y=1)p(y=1|x)}{p(s=1|y=1)p(y=1|x)+p(s=1|y=0)p(y=0|x)}いま、正例のデータ数が極端に少なく、$y=1$ となるデータはすべてサンプリングされるため、$p(s=1|y=1)=1$ とすると、
p(y=1|x,s=1)=\frac{p(y=1|x)}{p(y=1|x)+p(s=1|y=0)p(y=0|x)}と書けます。
さらに、$p=p(y=1|x), p_s=p(y|x,s=1), \beta=p(s=1|y=0)$ とすると、p_s=\frac{p}{p+\beta(1-p)}となります。最後に、$p$が左辺にくるように変形すると、
p=\frac{\beta p_s}{\beta p_s-p_s+1}となります。
最後の式が意味することは、アンダーサンプリングしたデータを用いて構築したモデルが予測する確率 $p_s$ を補正することでバイアスを除去し、もともとのデータを用いて構築したモデルが予測する確率 $p$ を計算できるということです。ここで、$\beta=p(s=1|y=0)$ は、負例のデータがサンプリングされる確率を表します。いま、負例のデータは正例のデータと同じ数だけサンプリングするため、$\beta=N^+/N^-$($N^+$ は正例のデータ数、$N^-$ は負例のデータ数)に近似できます。
コード例
以下では、実際のコード例を示しつつ、予測確率を補正する実験をします。(以下のコードの動作環境は、Python 3.7.3, pandas 0.24.2, scikit-learn 0.20.3 です。)
実験は以下の流れで行います。
1. 不均衡データをそのまま用いてモデルを構築し、分類精度を検証する。
2. アンダーサンプリングしたデータを用いてモデルを構築し、分類精度は改善するが、確率の予測精度は低いことを検証する。
3. アンダーサンプリングによるバイアスを除去する補正をかけることで、確率の予測精度が改善するかを検証する。ここでは、UCI Machine Learning Repository で公開されている、Adultデータセットを使います。このデータセットは、性別や年齢などのデータから、個人の年収が50,000$以上か否かを分類するためのデータセットです。
まず、利用するデータを読み込みます。ここでは、Adultデータセットの
adult.data, adult.testをCSVファイルとしてローカルに保存し、前者を学習用データ、後者を検証用データとして使います。import numpy as np import pandas as pd # データの読み込み train_data = pd.read_csv('./adult_data.csv', names=['age', 'workclass', 'fnlwgt', 'education', 'education-num', 'marital-status', 'occupation', 'relationship', 'race', 'sex', 'capital-gain', 'capital-loss', 'hours-per-week', 'native-country', 'obj']) test_data = pd.read_csv('./adult_test.csv', names=['age', 'workclass', 'fnlwgt', 'education', 'education-num', 'marital-status', 'occupation', 'relationship', 'race', 'sex', 'capital-gain', 'capital-loss', 'hours-per-week', 'native-country', 'obj'], skiprows=1) data = pd.concat([train_data, test_data]) # 説明変数X, 目的変数Yの加工 X = pd.get_dummies(data.drop('obj', axis=1)) Y = data['obj'].map(lambda x: 1 if x==' >50K' or x==' >50K.' else 0) # 目的変数は 1 or 0 # 学習用データと検証用データに分割 train_size = len(train_data) X_train, X_test = X.iloc[:train_size], X.iloc[train_size:] Y_train, Y_test = Y.iloc[:train_size], Y.iloc[train_size:]学習データにおける正例の割合を見ると、およそ24%と負例に比べて少なく、不均衡データといえます。
print('positive ratio = {:.2f}%'.format((len(Y_train[Y_train==1])/len(Y_train))*100)) #出力=> positive ratio = 24.08%この学習データをそのまま用いてモデルを構築すると、分類精度はAUC=0.57と低く、再現率(Recall)も0.26と低いことがわかります。学習データにおける負例のデータ数が多く、予測結果が負例となる場合が多くなり、再現率(正例のデータを正しく正例と分類できる割合)が低くなっていると考えられます。
from sklearn.linear_model import LogisticRegression from sklearn.metrics import roc_auc_score, recall_score # モデル構築 lr = LogisticRegression(random_state=0) lr.fit(X_train, Y_train) # 分類精度を検証 prob = lr.predict_proba(X_test)[:, 1] # 目的変数が1である確率を予測 pred = lr.predict(X_test) # 1 or 0 に分類 auc = roc_auc_score(y_true=Y_test, y_score=prob) print('AUC = {:.2f}'.format(auc)) recall = recall_score(y_true=Y_test, y_pred=pred) print('recall = {:.2f}'.format(recall)) #出力=> AUC = 0.57 #出力=> recall = 0.26次に、学習データにおける負例のデータ数が正例のデータ数と等しくなるようにアンダーサンプリングを行い、このデータを用いてモデルを構築すると、分類精度はAUC=0.90, recall=0.86 と大きく改善することがわかります。
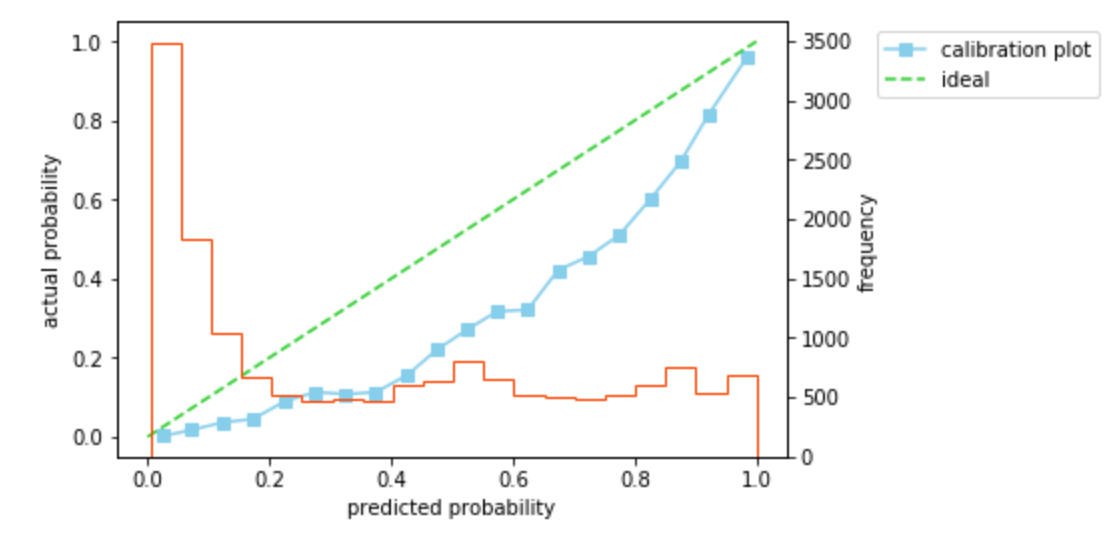
# アンダーサンプリング pos_idx = Y_train[Y_train==1].index neg_idx = Y_train[Y_train==0].sample(n=len(Y_train[Y_train==1]), replace=False, random_state=0).index idx = np.concatenate([pos_idx, neg_idx]) X_train_sampled = X_train.iloc[idx] Y_train_sampled = Y_train.iloc[idx] # モデル構築 lr = LogisticRegression(random_state=0) lr.fit(X_train_sampled, Y_train_sampled) # 分類精度を検証 prob = lr.predict_proba(X_test)[:, 1] pred = lr.predict(X_test) auc = roc_auc_score(y_true=Y_test, y_score=prob) print('AUC = {:.2f}'.format(auc)) recall = recall_score(y_true=Y_test, y_pred=pred) print('recall = {:.2f}'.format(recall)) #出力=> AUC = 0.90 #出力=> recall = 0.86このとき、確率の予測精度を見てみます。ログ損失は0.41、キャリブレーションプロットは45度線よりも下側を通ることがわかります。キャリブレーションプロットが45度線の下側を通ることは、予測した確率が実際の確率よりも大きいことを意味します。いま、負例のデータ数が正例のデータ数と等しくなるようにアンダーサンプリングしたデータを用いてモデルを構築しているため、実際よりも正例のデータ数の割合が大きい状態で学習が行われ、確率が大きめに予測されていると考えられます。
import matplotlib.pyplot as plt %matplotlib inline from sklearn.calibration import calibration_curve from sklearn.metrics import log_loss def calibration_plot(y_true, y_prob): prob_true, prob_pred = calibration_curve(y_true=y_true, y_prob=y_prob, n_bins=20) fig, ax1 = plt.subplots() ax1.plot(prob_pred, prob_true, marker='s', label='calibration plot', color='skyblue') # キャリプレーションプロットを作成 ax1.plot([0, 1], [0, 1], linestyle='--', label='ideal', color='limegreen') # 45度線をプロット ax1.legend(bbox_to_anchor=(1.12, 1), loc='upper left') plt.xlabel('predicted probability') plt.ylabel('actual probability') ax2 = ax1.twinx() # 2軸を追加 ax2.hist(prob, bins=20, histtype='step', color='orangered') # スコアのヒストグラムも併せてプロット plt.ylabel('frequency') plt.show() prob = lr.predict_proba(X_test)[:, 1] loss = log_loss(y_true=Y_test, y_pred=prob) print('log loss = {:.2f}'.format(loss)) calibration_plot(y_true=Y_test, y_prob=prob) #出力=> log loss = 0.41
では、アンダーサンプリングによるバイアスを除去し、確率を補正してみます。$\beta$を計算し、$
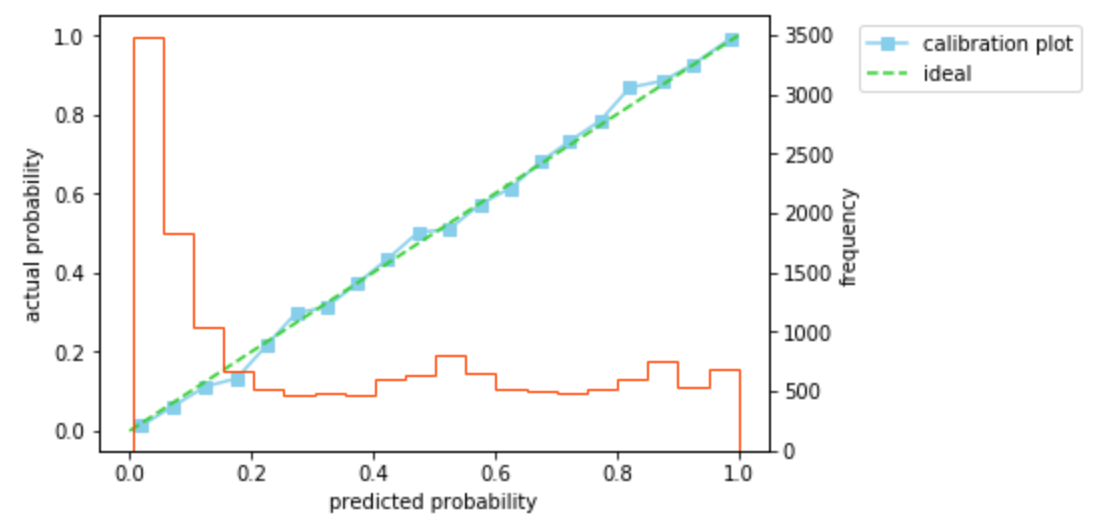
p=\beta p_s/(\beta p_s-p_s+1$)にしたがって確率を補正すると、ログ損失は0.32と改善し、キャリブレーションプロットもほぼ45度線にのっていることがわかります。ここで、$\beta$は学習用データの正例/負例のデータ数を用いている(検証用データの正例/負例のデータ数は未知としている)ことに注意してください。beta = len(Y_train[Y_train==1]) / len(Y_train[Y_train==0]) prob_corrected = beta*prob / (beta*prob - prob + 1) loss = log_loss(y_true=Y_test, y_pred=prob_corrected) print('log loss = {:.2f}'.format(loss)) calibration_plot(y_true=Y_test, y_prob=prob_corrected) #出力=> log loss = 0.32
確かにアンダーサンプリングによるバイアスを除去し、確率を補正できることを確認できました。検証は以上です。
おわりに
この記事では、アンダーサンプリングしたデータを用いて構築したモデルが予測する確率の補正方法について、簡単にまとめました。間違いなどありましたらご指摘いただけますと幸いです。
参考
- 投稿日:2020-01-15T22:56:22+09:00
poetryで作ったpythonプロジェクトをVSCodeに読み込ませるとエラーになった時の対処法
はじめに
Poetryの環境をVSCodeに読み込ませたらimportエラーになってしまいました。
その後、無事にエラーが解消されたのですが、ハマったのでメモを残します。環境
Mac mojave
なぜ起きるのか
Poetryは仮想環境を設定値に従って作成するのがデフォルトの動作です。
VSCode的にはそんなん知ったことではないので、poetryを無視して読み込もうとするもライブラリが全く見つからないという自体になり解決できないとしてエラーになります。それじゃどうするのか
設定変更してpoetry環境の作り直しをする必要があります。
Poetryはどんな設定でも一度作ってしまうとその環境を優先して読み込む仕様のようなので、手順を踏んで作り直さないと思った通りになりません。1:設定確認
まずはpoetryの設定を確認します。
ここで重要なのはvirtualenvs.in-projectです。
エラーになる人はここがfalseになっているかと思います。この設定はpoetryでインストールしたものをどこに配置するかの設定になっており、
falseの場合はvirtualenvs.pathで設定されたフォルダに格納されます。」$ poetry config --list cache-dir = "/Users/tasogarei/Library/Caches/pypoetry" virtualenvs.create = true virtualenvs.in-project = false virtualenvs.path = "{cache-dir}/virtualenvs" # /Users/tasogarei/Library/Caches/pypoetry/virtualenvs2:設定変更
virtualenvs.in-projectをtrueに変更します。
この設定はpoetryでインストールする箇所をプロジェクトのルートフォルダに配置するかの設定になっており、trueにすることでルートフォルダに配置されるようになります。$ poetry config virtualenvs.in-project true3:既存の削除
poetryの仕様で一度作ってしまうと設定変更しても特に関係なく変更前のファイルを見に行きます。
よって、virtualenvs.pathにあるフォルダを削除してあげないと変更しても意味がありません。ということで、該当フォルダ内にある読みこみたいプロジェクトのフォルダを丸っと削除してあげてください。
4:poetryによるパッケージインストール
準備が整ったので、再びパッケージのインストールを実施します。
私は念の為initからやり直しましたが、initは必要ありません。$ poetry install5:VSCodeで確認
installが完了すると.venvフォルダがルートに生成されます。
今後はここにパッケージが入ることになり、VSCodeはいい感じにこのフォルダを読んでくれるため(特に追加の設定はいりません)、起動したらエラーが消えているかと思います。これにて作業完了です。
- 投稿日:2020-01-15T22:19:52+09:00
Pythonが書きやすいんじゃなくて、numpyやscipyが書きやすいんだよ
numpyやscipy
をもっと良い言語に移植してくれ。
- 投稿日:2020-01-15T22:11:34+09:00
集合内包表記
1s = set() for i in range(10): s.add(i) print(s)1の実行結果{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}これを内包表記にすると
内包表記1s = {i for i in range(10)} print(s)内包表記1の実行結果{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}リスト内包表記の時と同様に、
3で割って余り0の数字のみ集合に入れるには内包表記2s = {i for i in range(10) if i % 3 == 0} print(s)内包表記2の実行結果{0, 3, 6, 9}
- 投稿日:2020-01-15T21:35:25+09:00
集合のメソッド add remove clear
1s = {1, 2, 3, 4, 5} s.add(6) print(s)1の実行結果{1, 2, 3, 4, 5, 6}2s = {1, 2, 3, 4, 5} s.remove(5) print(s)2の実行結果{1, 2, 3, 4}3s = {1, 2, 3, 4, 5} s.clear() print(s)3の実行結果set()空の辞書{}と区別する為に、
空集合はset()と表す。
- 投稿日:2020-01-15T20:31:47+09:00
Python で任意の関数をカリー化……もどき。
Python で任意の関数をカリー化するのは、結構面倒です (参考: Pythonでカリー化を書いてみる)。
ですが、呼び出し可能オブジェクトを利用して一見カリー化できているように見せかけることはできます。 カンタンナコト。
あぁ、そんな簡単に言うな
カリー化というとラムダ式を頑張ってこねくり回したくなりますが、この方法だと Dunder メソッドの実装を工夫するだけで同様のことができます。
import re class Curried: def __init__(self, f, regex=None, *args, **kwargs): self.__f = f self.__regex = regex if regex is not None else \ re.compile('{}\\(\\) missing \\d+ required'.format(f.__name__)) self.__args = args if args is not None else () self.__kwargs = kwargs if kwargs is not None else {} def __call__(self, *arg, **kwarg): cls = type(self) new_args = self.__args + arg new_kwargs = dict(**self.__kwargs, **kwarg) try: return self.__f(*new_args, **new_kwargs) except TypeError as e: if self.__regex.match(e.args[0]): return cls(self.__f, self.__regex, *new_args, **new_kwargs) else: raise e @property def __name__(self): return self.__f.__name__この
Curriedインスタンスは引数を一つずつ受け取りながら元の関数の引数に満ちるまでCurriedインスタンスを生成し続けます。 返るのはあくまでも関数ではありませんが、関数のように呼び出し可能なオブジェクトです。右手上げるならその手に責任が宿ると思え
このようにして使うのだ。
def add(x, y): return x + y def add3(x, y, z): return x + y + z print(Curried(add)(2)(3)) print(Curried(add3)(2)(3)(4))5 9一見カリー化した関数を呼び出しているように見えますね?
オブジェクトのメソッドに対しても使えます。
class Foo(object): def __init__(self, seed=1): self.seed = seed def add(self, x, y): return self.seed * (x + y) def multiply(self, x, y): return self.seed * x * y f = Foo(3) print(Curried(f.add)(2)(3)) print(Curried(f.multiply)(2)(3))15 18また、参考記事ではできなかったカリー化関数 (しつこいようですが、こっちのは本当は関数ではないです) の使い回しもできます。
add2 = Curried(add)(2) print(add2(3)) print(add2(4))5 6
- 投稿日:2020-01-15T20:20:10+09:00
QGISで実用性皆無なtky2jgdプラグインを作る その3
今回のお題
その2ではプラグイン上のボタンをクリックしたら旧座標の2次元のポイント、ライン、ポリゴンのレイヤが属性値を引き継ぎつつ新座標に変換されるところまで作りました。
しかし、平面直角座標系の変換時に正しく変換されないバグが発生しています。
今回はこちらのバグの原因を調べて修正していきます。最終目標地点
・順変換(日本測地系→世界測地系)できること(済)
・緯度経度、平面直角に関わらず変換できること(不具合)
・すべてのジオメトリタイプの変換ができること(済)
・属性値を引き継いだ変換後レイヤができること(済)
・パラメータファイルの補正値を補間して精度をあげること ※難易度:中
・複数のレイヤを選択して一度に変換できること
・逆変換(世界測地系→日本測地系)もできること ※難易度:高デバッグ
どのタイミングで座標がおかしくなっているのか調べるために座標変換の前後で値をダンプしてみる。
def execTrans(self): # 変換後レイヤを生成 afterLayer = self.createAfterLayer() # 編集開始 afterLayer.startEditing() fields = afterLayer.fields() inFeat = QgsFeature() feats = self.layer.getFeatures() cnt = 0 while feats.nextFeature( inFeat ): attributes = inFeat.attributes() beforeGeom = QgsGeometry( inFeat.geometry() ) beforewkt1 = beforeGeom.asWkt() #debug if not self.isLonlat: beforeGeom.transform(self.trans4301) beforewkt2 = beforeGeom.asWkt() #debug afterGeom = self.moveCorrection(beforeGeom) afterwkt1 = afterGeom.asWkt() #debug if not self.isLonlat: afterGeom.transform(self.transTo) afterwkt2 = afterGeom.asWkt() #debug ############### #debug ############### with open('d:/exchange.log', 'a') as f: print("-------------旧座標-------------", file=f) print(beforewkt1, file=f) print("-------------旧座標 → 4301-------------", file=f) print(beforewkt2, file=f) print("-------------4301 move-------------", file=f) print(afterwkt1, file=f) print("-------------4301 → 新座標-------------", file=f) print(afterwkt2, file=f)メッシュコードと移動量も吐いておこう。
def moveCorrection(self, geom): for i, v in enumerate(geom.vertices()): meshcode = self.Coordinate2MeshCode(v.y(), v.x()) correction = self.par[meshcode] ############### #debug ############### with open('d:/exchange.log', 'a') as f: print("####################\n meshcode:" + str(meshcode) + " : " + str(correction), file=f) geom.moveVertex(v.x() + correction[1], v.y() + correction[0], i) return geomまずは正常に動いていると思われる緯度経度のサンプルデータを使って検証
シンプルに数ポイントのレイヤにしておく。実行結果
#################### meshcode:52365699.0 : (0.0032275777777777776, -0.002950277777777778) -------------旧座標------------- Point (136.87317102877543107 35.16588581584142048) -------------旧座標 → 4301------------- Point (136.87317102877543107 35.16588581584142048) -------------4301 move------------- Point (136.87022075099764606 35.16911339361919886) -------------4301 → 新座標------------- Point (136.87022075099764606 35.16911339361919886) #################### meshcode:52365750.0 : (0.003231211111111111, -0.002950475) -------------旧座標------------- Point (136.87685587271937493 35.13286893949518941) -------------旧座標 → 4301------------- Point (136.87685587271937493 35.13286893949518941) -------------4301 move------------- Point (136.87390539771936915 35.13610015060630332) -------------4301 → 新座標------------- Point (136.87390539771936915 35.13610015060630332) #################### meshcode:52365782.0 : (0.0032296583333333334, -0.00295335) -------------旧座標------------- Point (136.90695057909175603 35.15078176167821056) -------------旧座標 → 4301------------- Point (136.90695057909175603 35.15078176167821056) -------------4301 move------------- Point (136.90399722909174329 35.15401142001154255) -------------4301 → 新座標------------- Point (136.90399722909174329 35.15401142001154255)「旧座標 → 4301」と「4301 → 新座標」は処理していないので無視して旧座標と移動後の値を確認する。
136.87317102877543107 - 136.87022075099764606 ≒ 0.002950277778
35.16588581584142048 - 35.16911339361919886 ≒ -0.0032275777777パラメータファイルの移動量が正しく反映されている。
Web版TKY2JGDでも確認
良い感じだと思います。
では今度はこのサンプルデータを平面直角座標系にして検証します。
#################### meshcode:52365699.0 : (0.0032275777777777776, -0.002950277777777778) -------------旧座標------------- Point (-26732.67109687992706313 -92487.54723248640948441) -------------旧座標 → 4301------------- Point (136.87317102877543107 35.16588581584142048) -------------4301 move------------- Point (136.87022075099764606 35.16911339361919886) -------------4301 → 新座標------------- Point (-27272.61809458389689098 -91780.23878862317360472) #################### meshcode:52365750.0 : (0.003231211111111111, -0.002950475) -------------旧座標------------- Point (-26407.70557931492294301 -96150.79488501154992264) -------------旧座標 → 4301------------- Point (136.87685587271937493 35.13286893949519651) -------------4301 move------------- Point (136.87390539771936915 35.13610015060631042) -------------4301 → 新座標------------- Point (-26947.79513530126496335 -95443.0704856463271426) #################### meshcode:52365782.0 : (0.0032296583333333334, -0.00295335) -------------旧座標------------- Point (-23660.26983992193709128 -94171.45945985670550726) -------------旧座標 → 4301------------- Point (136.90695057909175603 35.15078176167821766) -------------4301 move------------- Point (136.90399722909174329 35.15401142001154966) -------------4301 → 新座標------------- Point (-24200.68891517832889804 -93464.00120055227307603)先ほどの結果と比較してメッシュコードの取得、パラメータファイルの移動量も同じです。
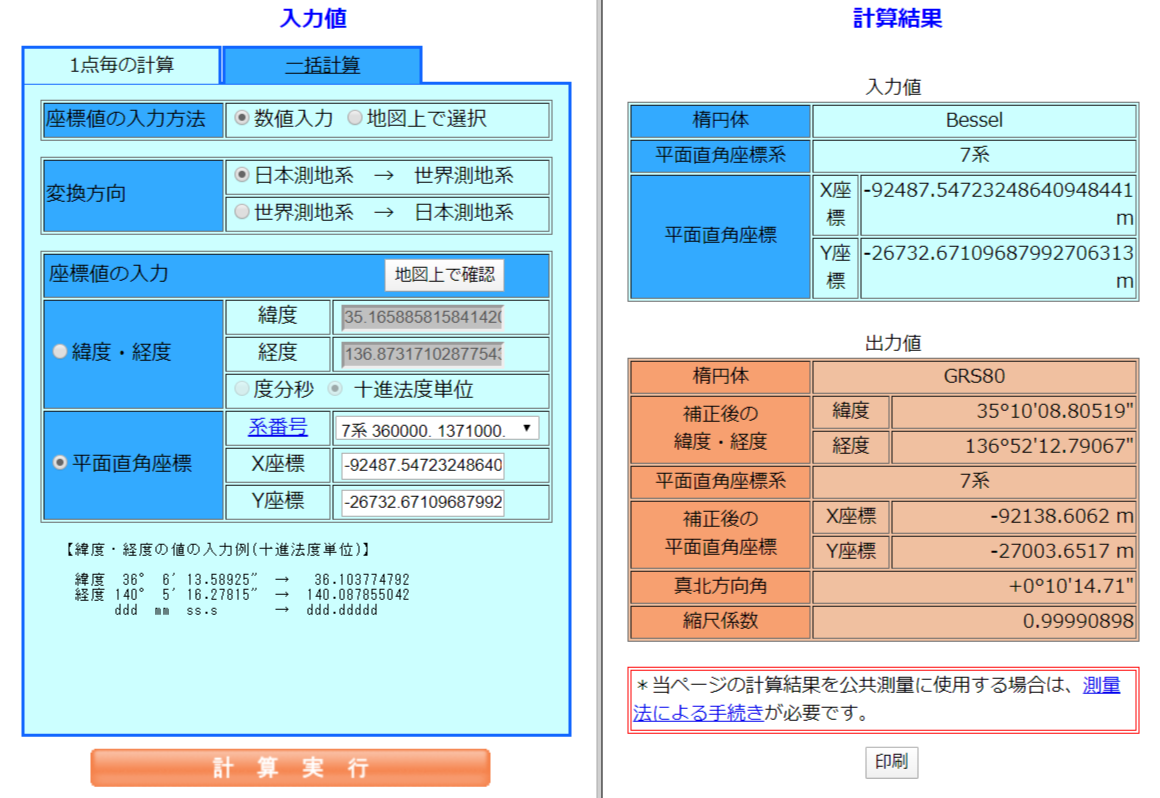
新座標の変換結果をWeb版TKY2JGDで確認
1点目ですが
処理 X Y プラグイン -27272.61809458389689098 -91780.23878862317360472 Web版TKY2JGD -27003.6517 -92138.6062 あちゃー、全然違ってしまっていますね。
緯度経度の結果と比較すると移動までは正常で新座標への変換でおかしくなっていることが判りました。何が悪いのか見直してみます。
!!!
最後の変換は4301ではなく4612から変換しないといけないことに気が付きました。
そりゃズレるわ。修正
self.transToの変換前CRSを4612に変更するようソースを修正します。
def setCrsTrans(self): crs4301 = QgsCoordinateReferenceSystem(4301, QgsCoordinateReferenceSystem.EpsgCrsId) crs4612 = QgsCoordinateReferenceSystem(4612, QgsCoordinateReferenceSystem.EpsgCrsId) if not self.isLonlat: crsFrom = QgsCoordinateReferenceSystem(self.srid, QgsCoordinateReferenceSystem.EpsgCrsId) self.trans4301 = QgsCoordinateTransform(crsFrom, crs4301, QgsProject.instance()) crsTo = QgsCoordinateReferenceSystem(self.toSrid, QgsCoordinateReferenceSystem.EpsgCrsId) self.transTo = QgsCoordinateTransform(crs4612, crsTo, QgsProject.instance())再度実行
#################### meshcode:52365699.0 : (0.0032275777777777776, -0.002950277777777778) -------------旧座標------------- Point (-26732.67109687992706313 -92487.54723248640948441) -------------旧座標 → 4301------------- Point (136.87317102877543107 35.16588581584142048) -------------4301 move------------- Point (136.87022075099764606 35.16911339361919886) -------------4612 → 新座標------------- Point (-27003.54940856946996064 -92138.51321844129415695) #################### meshcode:52365750.0 : (0.003231211111111111, -0.002950475) -------------旧座標------------- Point (-26407.70557931492294301 -96150.79488501154992264) -------------旧座標 → 4301------------- Point (136.87685587271937493 35.13286893949519651) -------------4301 move------------- Point (136.87390539771936915 35.13610015060631042) -------------4612 → 新座標------------- Point (-26678.68443605181892053 -95801.75775258826615755) #################### meshcode:52365782.0 : (0.0032296583333333334, -0.00295335) -------------旧座標------------- Point (-23660.26983992193709128 -94171.45945985670550726) -------------旧座標 → 4301------------- Point (136.90695057909175603 35.15078176167821766) -------------4301 move------------- Point (136.90399722909174329 35.15401142001154966) -------------4612 → 新座標------------- Point (-23931.23210011895207572 -93822.46488364967808593)今度の結果は
処理 X Y プラグイン -27003.54940856946996064 -92138.51321844129415695 Web版TKY2JGD -27003.6517 -92138.6062 変換後の座標が正しい位置になりました。
続デバッグ
続いてポイント3点繋いでラインにした地物を変換テストします。
#################### meshcode:52365699.0 : (0.0032275777777777776, -0.002950277777777778) #################### meshcode:52365750.0 : (0.003231211111111111, -0.002950475) #################### meshcode:52365782.0 : (0.0032296583333333334, -0.00295335) -------------旧座標------------- LineString (-26732.67109687992706313 -92487.54723248640948441, -26407.70557931492294301 -96150.79488501154992264, -23660.26983992193709128 -94171.45945985670550726) -------------旧座標 → 4301------------- LineString (136.87317102877543107 35.16588581584142048, 136.87685587271937493 35.13286893949519651, 136.90695057909175603 35.15078176167821766) -------------4301 move------------- LineString (136.87022075099764606 35.16911339361919886, 136.87390539771936915 35.13610015060631042, 136.90399722909174329 35.15401142001154966) -------------4612 → 新座標------------- LineString (-27003.54940856946996064 -92138.51321844129415695, -26678.68443605181892053 -95801.75775258826615755, -23931.23210011895207572 -93822.46488364967808593)ポイントの変換結果と比較して、問題なく変換できていることが確認できました。
今度はポイント3点繋いでポリゴンにした地物を変換テストします。
#################### meshcode:52365699.0 : (0.0032275777777777776, -0.002950277777777778) #################### meshcode:52365750.0 : (0.003231211111111111, -0.002950475) #################### meshcode:52365782.0 : (0.0032296583333333334, -0.00295335) #################### meshcode:52366609.0 : (0.003226383333333333, -0.00295045) -------------旧座標------------- Polygon ((-26732.67109687992706313 -92487.54723248640948441, -26407.70557931492294301 -96150.79488501154992264, -23660.26983992193709128 -94171.45945985670550726, -26732.67109687992706313 -92487.54723248640948441)) -------------旧座標 → 4301------------- Polygon ((136.87317102877543107 35.16588581584142048, 136.87685587271937493 35.13286893949519651, 136.90695057909175603 35.15078176167821766, 136.87317102877543107 35.16588581584142048)) -------------4301 move------------- Polygon ((136.86727030099766012 35.17233977695253344, 136.87390539771936915 35.13610015060631042, 136.90399722909174329 35.15401142001154966, 136.86727030099766012 35.17233977695253344)) -------------4612 → 新座標------------- Polygon ((-27271.2323161015738151 -91779.79549598139419686, -26678.68443605181892053 -95801.75775258826615755, -23931.23210011895207572 -93822.46488364967808593, -27271.2323161015738151 -91779.79549598139419686))1点目と最終点がおかしいです。
ポイントの結果と比較してみると移動後の段階でおかしくなっていることが判ります。
値の差を確認するとパラメータファイルの移動量分ずれているようです。うーん、リングの終点に移動をかけてはいけないのかな?
テストデータのポリゴンにリングを追加してテストしてみます。
#################### meshcode:52365699.0 : (0.0032275777777777776, -0.002950277777777778) #################### meshcode:52365782.0 : (0.0032296583333333334, -0.00295335) #################### meshcode:52365750.0 : (0.003231211111111111, -0.002950475) #################### meshcode:52366609.0 : (0.003226383333333333, -0.00295045) #################### meshcode:52365780.0 : (0.0032288083333333337, -0.0029512249999999996) #################### meshcode:52365770.0 : (0.0032296333333333336, -0.0029509749999999998) #################### meshcode:52365771.0 : (0.0032301111111111107, -0.002952058333333333) #################### meshcode:52365780.0 : (0.0032288083333333337, -0.0029512249999999996) -------------旧座標------------- MultiPolygon (((-26732.67109687992706313 -92487.54723248640948441, -23660.26983992193709128 -94171.45945985670550726, -26407.70557931492294301 -96150.79488501154992264, -26732.67109687992706313 -92487.54723248640948441),(-26087.2897302932869934 -93786.75537118859938346, -26087.2897302932869934 -94614.34977696483838372, -25276.93687463738024235 -94441.93427576145040803, -26087.2897302932869934 -93786.75537118859938346))) -------------旧座標 → 4301------------- MultiPolygon (((136.87317102877543107 35.16588581584142048, 136.90695057909175603 35.15078176167821766, 136.87685587271937493 35.13286893949519651, 136.87317102877543107 35.16588581584142048),(136.88029758847102357 35.15418997263552825, 136.8803237277067808 35.14672891674221233, 136.8892130654492405 35.14830399731092569, 136.88029758847102357 35.15418997263552825))) -------------4301 move------------- MultiPolygon (((136.86727030099766012 35.17233977695253344, 136.90399722909174329 35.15401142001154966, 136.87390539771936915 35.13610015060631042, 136.86727030099766012 35.17233977695253344),(136.8743951384710158 35.16064758930219369, 136.87737275270677628 35.14995855007554582, 136.88626100711590539 35.15153410842203385, 136.8743951384710158 35.16064758930219369))) -------------4301 → 新座標------------- MultiPolygon (((-27271.2323161015738151 -91779.79549598139419686, -23931.23210011895207572 -93822.46488364967808593, -26678.68443605181892053 -95801.75775258826615755, -27271.2323161015738151 -91779.79549598139419686),(-26626.05832836601621239 -93078.77546303598501254, -26358.24300081738692825 -94265.33339575032005087, -25547.91871392306347843 -94092.87040038264240138, -26626.05832836601621239 -93078.77546303598501254)))-------------4301 move-------------
MultiPolygon (((136.86727030099766012 35.17233977695253344, 136.90399722909174329 35.15401142001154966, 136.87390539771936915 35.13610015060631042, 136.86727030099766012 35.17233977695253344),(136.8743951384710158...リングが2つあってもリングの1点目と最終点が同じズレ方しちゃうことが判明。
ということはポリゴンの時は地物のvertexを全部移動するような処理では駄目だということですね。リングの1点目と最終点はどちらかは移動処理をしないように修正が必要。
修正
parts()でパートのイテレタ取得して、リング毎のジオメトリに対してvartexを取得しつつ
vertices_beginなんかで判定して飛ばすのかなぁとか妄想しています。
が、具体的にやり方が判らない。時間がかかりそうなので一旦ここまでで投稿しておく。
つづく

- 投稿日:2020-01-15T19:41:44+09:00
データベースのテーブルをCSVでぶっこ抜き【RとpythonからODBC接続】
皆さんCSVでデータベースのデータ抜きたい時どうしてるんですか?
よかったら教えてください!
私はこんな感じ↓↓↓データベースのテーブルをCSVにしたい
抽出依頼が来てデータベースに対してクエリ書いて出た結果をCSVにしたい。
社内データ分析者はSQL書いて分析用のファイルを作成したりします。
エクセルで組んでODBC接続してきてもいいのですが、どうせならそのまま統計ソフトにデータをぶち込みたい。
そのまま数値の計算ロジックや入れ替えロジックを分析ソフト側で処理してしまいたい。ODBCで接続
データベースとの接続の仲介をしてくれるodbcなるものがあります。
ODBCの設定やなんたるかは他のサイトに任せましょう。
データベースを自分で設定する人でなければ、誰かが使っているはずなので聞きましょう。
とりあえずデータベースサーバのIPアドレスと接続用ドライバを聞けばOKです。設定時に「データソース名」を設定します。
これをメモっておいてください。まずR言語の方から
RのインストールはCRANからダウンロードしてインストール、Rエディタに以下のスクリプトを打ち込めば実行できます。
テーブルの想定 と ぶっこ抜きスクリプト
user_logという600万レコードが詰まっているデーブルがあったとする
普通にデータベースに接続するソフトですべて抜き出そうとすると、とてつもなく時間がかかる。
他の人も接続していたらサーバーのCPU負荷が恐ろしいことになって皆様から怒られること必須。データベースに繋げるソフトでは →CSE が好き。
これもODBCのデータソース名とID,passが分かれば接続できる。基本的にはこんな構図
library(RODBC) conn_DB <- odbcConnect("データソース名", "割り振られたID", "IDと一緒に発行されるであろうpass") query <- paste0("select count(*) from user_log") tbl <- sqlQuery(conn_DB, query) odbcClose(conn_DB)これをFOR文で回す。
まず上でデータベースに接続してテーブルが何行あるか確認できる。
600万と確認できたとしよう。
一括で抜こうとするとサーバーのCPUが思考停止するので分割で小規模に抜いていく。
分析ソフト側もメモリがパンパンになってしまう可能性があるので細かく書き出して最後に結合することをオススメする。SEQ<-seq(1,6000000,5000) LIM<-length(SEQ)-1 conn_DB <- odbcConnect("データソース名", "割り振られたID", "IDと一緒に発行されるであろうpass") for(i in 1:LIM){ query <- paste0( "select * from user_log ", "limit 5000 offset ", as.numeric(SEQ[i]) ) tbl <- sqlQuery(conn_DB, query) write.csv(tbl, paste0("this_is_",i,"th.csv"), row.names=F) Sys.sleep(10) } odbcClose(conn_DB)細かい解説と注意
これで細かく5000レコードに分けてデータを抽出できた。
SQLで書いているクエリをpaste0で結合させてやればいい。
SQL中にシングルクォーテーション記号がある場合はバックスラッシュを前に着けてやる。where colum = '10'where colum = \'10\'paste0で文字を結合するとSQLの改行が消える時があるので注意しながら書くこと。
paste0("select * from user_log", "where colum = '10'")select * from user_logwhere colum = '10'くっついちゃっている。
抽出したデータを結合
setwd("csvを吐き出したファイルのpath") lf <- list.files(pattern="csv") data <- data.frame() for(i in 1:length(lf)){ add <- fread(lf[i]) data <- rbind(data,add) }これでdataに600万のデータが入る。
PCに十分なメモリ積んでないと処理がカタマルので注意。機械学習するなら各csvをミニバッチに相当させるとよろしいのでは?
python言語編
ある程度方針は説明したので以降は説明を割愛して書く。
import pyodbc import numpy as np import pandas as pd cnx = pyodbc.connect('DSN=データソース名; UID=IDを入れる; PWD=passを入れる') cursor = cnx.cursor() list_for = np.arange(1,60000,5000) list_for=list_for.tolist() for i in range(len(list_for)): made_que = "SELECT * FROM user_log " + "LIMIT 5000 OFFSET " + str(list_for[i]) cursor.execute(made_que) tbl = cursor.fetchall() array_format = np.array(tbl) dataframe_format = pd.DataFrame(array_format) dataframe_format.to_csv('csv_data/' + str(i) + '.csv')以上
抽出してからが分析本番
- 投稿日:2020-01-15T18:44:07+09:00
AtCoder Beginner Contest 066 過去問復習
所要時間
A問題
小さい二つを選べば良い。
answerA.pya,b,c=map(int,input().split()) x=[a,b,c] print(sum(x)-max(x))B問題
末尾を順に消して考えていけば良い。
answerB.pys=input() l=len(s) for i in range(1,l//2): k=(l-i*2) if s[:k//2]==s[k//2:k]: print(k) breakC問題
実際にpushしていく様子を考えれば奇数番目と偶数番目にpushしたものでそれぞれ並び方が違う(サンプルを参照)ことがわかるので、その並び方を素直に実装すると以下のようになる。(nの偶奇で場合分けが存在するのにも注意が必要。)
answerC.pyn=int(input()) a=[i for i in input().split()] b=[] c=[] if n%2==0: for i in range(n): if i%2==0: b.append(a[i]) else: c.append(a[i]) else: for i in range(n): if i%2==0: c.append(a[i]) else: b.append(a[i]) c=c[::-1] print(" ".join(c)+" "+" ".join(b))D問題
普通に方針は立てられたのですが、実装を詰めきれませんでした。(実装力も課題の一つですが、量をこなすしかなさそうですね…。)
となっていた数時間後に基本中の基本のミスに気づいてなかったことが発覚しました。負の剰余は意図しない挙動になる!!
こちらの記事を参照すればわかるのですが、剰余には複数の定義があるらしく、それぞれの言語で異なった挙動を示すようです。これを避けるにはコードにも書いた通り負の数を正の数に直せば良いです。(基本なのだろうけどC++の勉強が疎かで知りませんでした。C++についてもっとちゃんと勉強しておくべきですね…)
方針については、全体からの長さkの部分列について重複を含めてカウントすると、$ _{n+1} C _k $になるので、重複する場合があるかどうかを考えて実験をします。実験により、二つ存在する数をxとし、xがインデックスi,j(0<=i,j<=N)にある時、その二つをどちらも部分列に含めた時は重複する場合が存在せず、その二つのいずれも部分列に含めない時も同様に重複が存在しないことがわかります。
ここで、片方のxのみを部分列に含める時を考えます。i+1~j-1の部分の数が含まれている時を考えると、iにあるxについては右側にその数は位置しjにあるxについては左側にその数は位置するので違う部分列として分けられることがわかります。したがって、0~i-1、j+1~Nにある数およびどちらかのxの中から選んだ部分列は重複しており、$ _{i+(n-j)} C _{k-1}$が長さkの部分列について重複する部分列の個数になります。
したがって、$ _{n+1} C _k - _{i+(n-j)} C _{k-1} $ を求めれば良いのですが、ここで先ほど書いたように負の剰余が発生しないように負の数の場合はMODを足していくことで正の剰余に帰着させれば良いです。また、コンビネーションの計算はけんちょんさんのものをお借りしています。詳しくはこちらの記事を参照してください。
answerD.cc#include<iostream> #include<vector> #include<utility> using namespace std; const int MAX = 1000000; const int MOD = 1000000007; long long fac[MAX], finv[MAX], inv[MAX]; // テーブルを作る前処理 void COMinit() { fac[0] = fac[1] = 1; finv[0] = finv[1] = 1; inv[1] = 1; for (int i = 2; i < MAX; i++){ fac[i] = fac[i - 1] * i % MOD; inv[i] = MOD - inv[MOD%i] * (MOD / i) % MOD; finv[i] = finv[i - 1] * inv[i] % MOD; } } // 二項係数計算 long long COM(int n, int k){ if (n < k) return 0; if (n < 0 || k < 0) return 0; return fac[n] * (finv[k] * finv[n - k] % MOD) % MOD; } int main(){ // 前処理 COMinit(); int n;cin >> n; vector<int> a(n+1);for(int i=0;i<n+1;i++){cin >> a[i];a[i]-=1;} vector<bool> b(n,true); for(int i=0;i<n+1;i++){b[a[i]]=!b[a[i]];} pair<int,int> p=make_pair(-1,-1); for(int i=0;i<n+1;i++){ if(b[a[i]]){ if(p.first==-1){p.first=i;} else{p.second=i;break;} } } //以下の部分で初めはcを出力したが、c<0の可能性があるので正確にMODの余りが出ない for(int i=1;i<=n+1;i++){ int c=COM(n+1,i)-COM(p.first+(n-p.second),i-1); while(c<0){ c+=MOD; } cout << c%MOD << endl; } }

- 投稿日:2020-01-15T18:43:24+09:00
AtCoder Beginner Contest 066 過去問復習
所要時間
A問題
小さい二つを選べば良い。
answerA.pya,b,c=map(int,input().split()) x=[a,b,c] print(sum(x)-max(x))B問題
末尾を順に消して考えていけば良い。
answerB.pys=input() l=len(s) for i in range(1,l//2): k=(l-i*2) if s[:k//2]==s[k//2:k]: print(k) breakC問題
実際にpushしていく様子を考えれば奇数番目と偶数番目にpushしたものでそれぞれ並び方が違う(サンプルを参照)ことがわかるので、その並び方を素直に実装すると以下のようになる。(nの偶奇で場合分けが存在するのにも注意が必要。)
answerC.pyn=int(input()) a=[i for i in input().split()] b=[] c=[] if n%2==0: for i in range(n): if i%2==0: b.append(a[i]) else: c.append(a[i]) else: for i in range(n): if i%2==0: c.append(a[i]) else: b.append(a[i]) c=c[::-1] print(" ".join(c)+" "+" ".join(b))D問題
普通に方針は立てられたのですが、実装を詰めきれませんでした。(実装力も課題の一つですが、量をこなすしかなさそうですね…。)
となっていた数時間後に基本中の基本のミスに気づいてなかったことが発覚しました。負の剰余は意図しない挙動になる!!
こちらの記事を参照すればわかるのですが、剰余には複数の定義があるらしく、それぞれの言語で異なった挙動を示すようです。これを避けるにはコードにも書いた通り負の数を正の数に直せば良いです。(基本なのだろうけどC++の勉強が疎かで知りませんでした。C++についてもっとちゃんと勉強しておくべきですね…)
方針については、全体からの長さkの部分列について重複を含めてカウントすると、$ _{n+1} C _k $になるので、重複する場合があるかどうかを考えて実験をします。実験により、二つ存在する数をxとし、xがインデックスi,j(0<=i,j<=N)にある時、その二つをどちらも部分列に含めた時は重複する場合が存在せず、その二つのいずれも部分列に含めない時も同様に重複が存在しないことがわかります。
ここで、片方のxのみを部分列に含める時を考えます。i+1~j-1の部分の数が含まれている時を考えると、iにあるxについては右側にその数は位置しjにあるxについては左側にその数は位置するので違う部分列として分けられることがわかります。したがって、0~i-1、j+1~Nにある数およびどちらかのxの中から選んだ部分列は重複しており、$ _{i+(n-j)} C _{k-1}$が長さkの部分列について重複する部分列の個数になります。
したがって、$ _{n+1} C _k - _{i+(n-j)} C _{k-1} $ を求めれば良いのですが、ここで先ほど書いたように負の剰余が発生しないように負の数の場合はMODを足していくことで正の剰余に帰着させれば良いです。また、コンビネーションの計算はけんちょんさんのものをお借りしています。詳しくはこちらの記事を参照してください。
answerD.cc#include<iostream> #include<vector> #include<utility> using namespace std; const int MAX = 1000000; const int MOD = 1000000007; long long fac[MAX], finv[MAX], inv[MAX]; // テーブルを作る前処理 void COMinit() { fac[0] = fac[1] = 1; finv[0] = finv[1] = 1; inv[1] = 1; for (int i = 2; i < MAX; i++){ fac[i] = fac[i - 1] * i % MOD; inv[i] = MOD - inv[MOD%i] * (MOD / i) % MOD; finv[i] = finv[i - 1] * inv[i] % MOD; } } // 二項係数計算 long long COM(int n, int k){ if (n < k) return 0; if (n < 0 || k < 0) return 0; return fac[n] * (finv[k] * finv[n - k] % MOD) % MOD; } int main(){ // 前処理 COMinit(); int n;cin >> n; vector<int> a(n+1);for(int i=0;i<n+1;i++){cin >> a[i];a[i]-=1;} vector<bool> b(n,true); for(int i=0;i<n+1;i++){b[a[i]]=!b[a[i]];} pair<int,int> p=make_pair(-1,-1); for(int i=0;i<n+1;i++){ if(b[a[i]]){ if(p.first==-1){p.first=i;} else{p.second=i;break;} } } //以下の部分で初めはcを出力したが、c<0の可能性があるので正確にMODの余りが出ない for(int i=1;i<=n+1;i++){ int c=COM(n+1,i)-COM(p.first+(n-p.second),i-1); while(c<0){ c+=MOD; } cout << c%MOD << endl; } }
- 投稿日:2020-01-15T18:40:29+09:00
Elasticsearchインストールと基本操作 for ubuntu
Elasticsearchインストールと基本操作
インストール編 (on Ubuntu18.04)
ElasticSearch Install
install Java
$ sudo apt install openjdk-11-jdkinstall Elasticsearch
$ wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
$ echo "deb https://artifacts.elastic.co/packages/6.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-6.x.list
$ sudo apt update
$ sudo apt install elasticsearch$ sudo systemctl start elasticsearch
$ sudo systemctl status elasticsearch確認
$ curl http://127.0.0.1:9200Kibana Install
$ apt update
$ apt install kibana$ systemctl start kibana
確認
access http://localhost:5601kuromoji Install
$ sudo /usr/share/elasticsearch/bin/elasticsearch-plugin install analysis-kuromoji
CRUD編
bookというインデックスを作成、ドキュメントをひとつ作成。
PUT /book/_doc/1 { "title":"ビジネスPython超入門", "author":"中島省吾", "publisherName":"日経BP", "salesDate":"2019年6月7日", "itemPrice":"2592" }ドキュメントIDを指定せずに自動生成
PUT /book/_doc { "title":"ビジネスPython超入門", "author":"中島省吾", "publisherName":"日経BP", "salesDate":"2019年6月7日", "itemPrice":"2592" } ※ドキュメントIDは20桁のランダムな英数字になるドキュメントの取得
GET /book/_doc/1ドキュメントを更新
POST /book/_update/1 { "doc": { "itemPrice": 1292 } }ドキュメントを削除
DELETE /book/_doc/1インデックスを削除
GET /book/_mappingマッピング(スキーマのようなもの)を確認
GET /book/_mappingインデックスを作成
PUT /bookマッピングを指定してインデックスを作成
PUT /book { "mappings": { "properties": { "title": { "type": "keyword" }, "author": { "type": "keyword" }, "publisherName": { "type": "keyword" }, "isbn" : { "type": "keyword" }, "itemCaption" : { "type": "text" }, "itePrice" : { "type": "long"} } } }複数のドキュメントを一度に作成
POST /book/_bulk {"index": {"_id": 1}} { "title": "退屈なことはPythonにやらせよう", "author": "Al Sweigart/相川愛三","publisherName":" オライリー・ジャパン", "isbn":" 9784873117782", "itemCaption":"ファイル名の変更や表計算のデータ更新といった作業は、日々の仕事の中で頻繁に発生します。ひとつふたつ修正するだけであれば問題ないのですが、それが数十、数百となってくると手に負えません。そのような単純な繰り返し作業はコンピュータに肩代わりしてもらうとすごくラクになります。本書では、手作業だと膨大に時間がかかる処理を一瞬でこなすPython3プログラムの作り方について学びます。対象読者はノンプログラマー。本書で基本をマスターすれば、プログラミング未経験者でも面倒な単純作業を苦もなくこなす便利なプログラムを作れるようになります。さらに、章末の練習問題を解くことで、類似のタスクを自動処理するスキルをもっと高めることができます。", "itemPrice": 3996 } {"index": {"_id": 2}} { "title":" ビジネスPython超入門","author":"中島省吾","publisherName":" 日経 BP","isbn":" 9784296102136","itemCaption":" ビジネスに欠かせないプログラミングの基本スキルが学べる!人工知能で注目の言語、Pythonを初歩から解説。書き方から実行手順までステップ・バイ・ステップ。条件分岐や繰り返しなどの必須構文を着実にマスター。ネットの情報を自動取得、Webスクレイピングの基礎。手書き文字を認識する機械学習をゼロから体験。","itemPrice": 2592} {"index": {"_id": 3}} { "title":"入門Python","author":" ビル・ルバノビック/ 斎藤 康 毅","publisherName":" オライリー・ジャパン"," isbn":" 9784873117386","itemCaption":"Pythonが誕生して四半世紀。データサイエンスやウェブ開発、セキュリティなどさまざまな分野でPythonの人気が急上昇中です。プログラミング教育の現場でもCに代わってPythonの採用が増えてきています。本書は、プログラミングが初めてという人を対象に書かれた、Pythonの入門書です。前提とする知識は特にありません。プログラミングおよびPythonの基礎からウェブ、データベース、ネットワーク、並行処理といった応用まで、Pythonプログラミングをわかりやすく丁寧に説明します。","itemPrice": 3996} {"index": {"_id": 4}} { "title":" 新・明解Python入門","author":"柴田望洋","publisherName":"SBクリエイティブ","isbn":"9784815601522","itemCaption":"適切なサンプルプログラム299編と分かりやすい図表165点で、Pythonの文法とプログラミングの基礎を系統立てて着実に学習できます。","itemPrice": 2808} {"index": {"_id": 5}} { "title":"独学プログラマーPython言語の基本から仕事のやり方まで","author":" コーリー・アルソフ/ 清水川 貴之"," publisherName":" 日経BP"," isbn":"9784822292270"," itemCaption":"オブジェクト指向、シェル、正規表現、パッケージ管理、バージョン管理、データ構造、アルゴリズム、仕事の見つけ方・やり方。Python言語の基本から仕事のやり方まで、プログラマーとして働くために必要な知識・ノウハウが1冊で丸わかり。","itemPrice": 2376}ドキュメントに項目を追加
POST /book/_update/5 { "doc": { "discountRate": 0 } }検索編
すべてのドキュメントを検索
GET /book/_searh GET book/_search { "query": { "match_all": {} } }指定した単語を含むドキュメントを検索
GET book/_search { "query": { "match": { "itemCaption": "プログラミング" } } }and条件でドキュメントを検索
GET book/_search { "query": { "bool": { "must": [ { "match": { "itemCaption": "プログラミング" } }, { "match": { "itemCaption": "入門" } } ] } } }not検索(ある単語を含まない)
GET book/_search { "query": { "bool": { "must_not": [ { "match": { "itemCaption": "入門" } } ] } } }or検索
GET book/_search { "query": { "bool": { "should": [ { "match": { "itemCaption": "プログラミング" } }, { "match": { "itemCaption": "入門" } } ] } } }特定の単語を重み付けして検索
GET book/_search { "query": { "bool": { "should": [ { "match": { "itemCaption": { "query": "プログラミング" } } }, { "match": { "itemCaption": { "query": "入門", "boost": 5 } } } ] } } }ハイライト検索
GET book/_search { "query": { "match": { "itemCaption": "プログラミング" } }, "highlight": { "fields": { "itemCaption": {} } } }範囲での絞り込み検索およびソート
GET book/_search { "query": { "range": { "itemPrice": { "lte": 3000 } } }, "sort": [ { "itePrice": { "order": "asc" } } ] }アグリゲーションを利用して統計データを作成
プログラミングを含むデータを値段範囲ごとにアイテム数を集計
GET book/_search { "query": { "match": { "itemCaption": "プログラミング" } }, "aggregations": { "itemPrice_bucket": { "range": { "field": "itemPrice", "ranges": [ { "key": "0-1500", "from": 0, "to": 1500 }, { "key": "1501-3000", "from": 1501, "to": 3000 }, { "key": "3000-4500", "from": 3001, "to": 4500 } ] } } } }
- 投稿日:2020-01-15T18:25:00+09:00
辞書包括表記
1name = ['太郎', '次郎', '三郎'] job = ['勇者', '戦士', '魔法使い'] d= {} for x, y in zip(name, job): d[x] = y print(d)1の実行結果{'太郎': '勇者', '次郎': '戦士', '三郎': '魔法使い'}これを辞書包括表記で書くと
辞書包括表記name = ['太郎', '次郎', '三郎'] job = ['勇者', '戦士', '魔法使い'] d = {x: y for x, y in zip(name, job)} print(d)辞書包括表記の実行結果{'太郎': '勇者', '次郎': '戦士', '三郎': '魔法使い'}
- 投稿日:2020-01-15T17:57:23+09:00
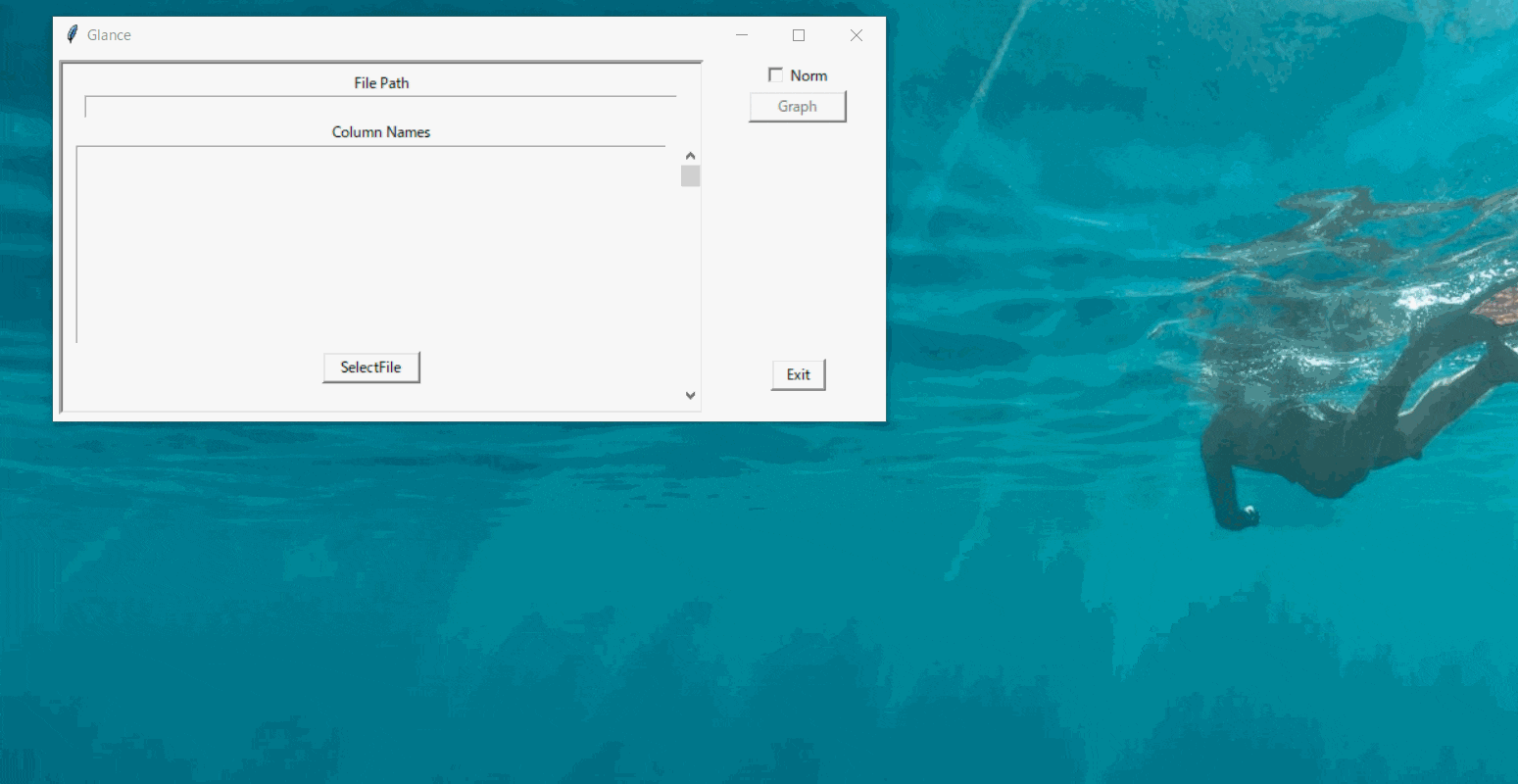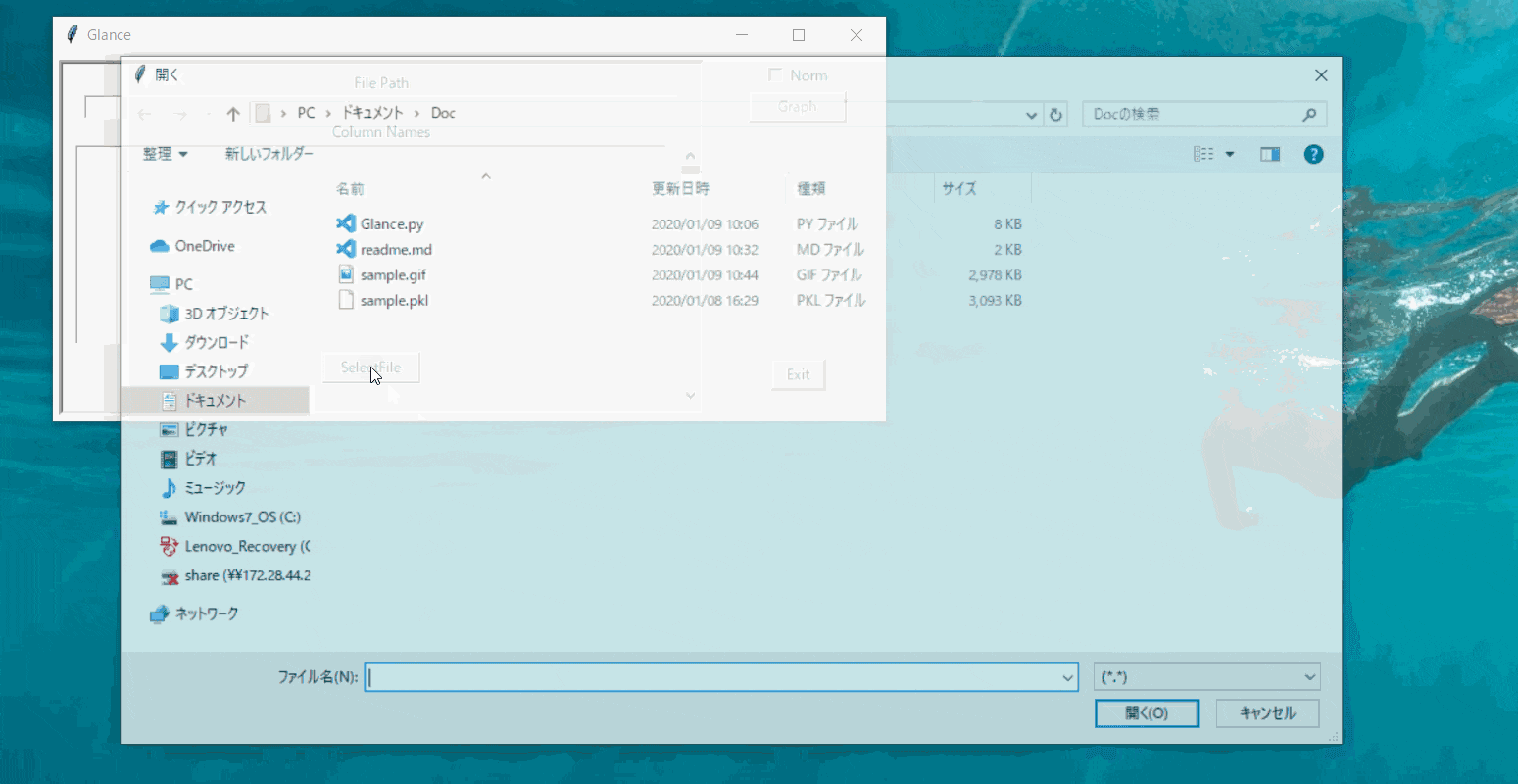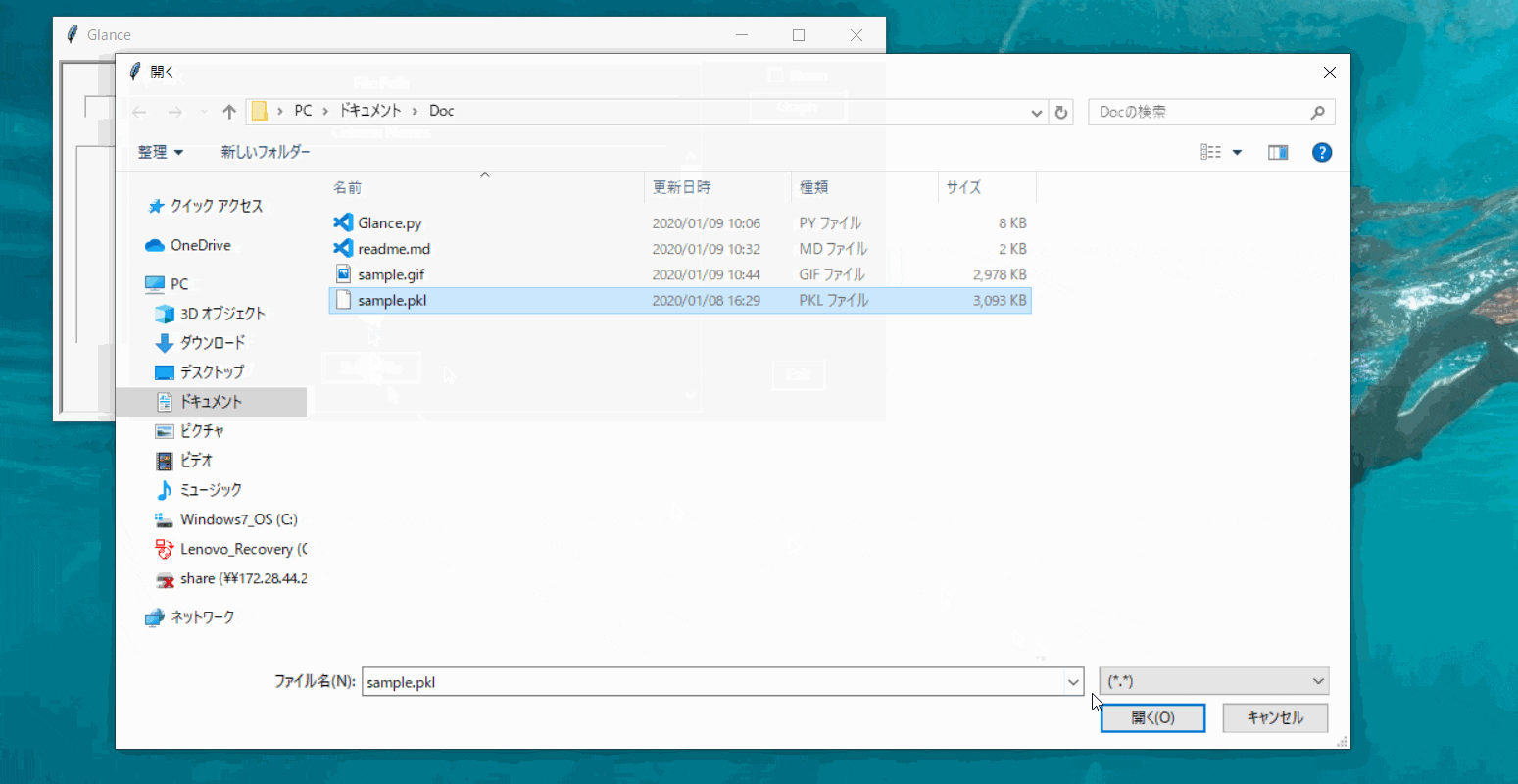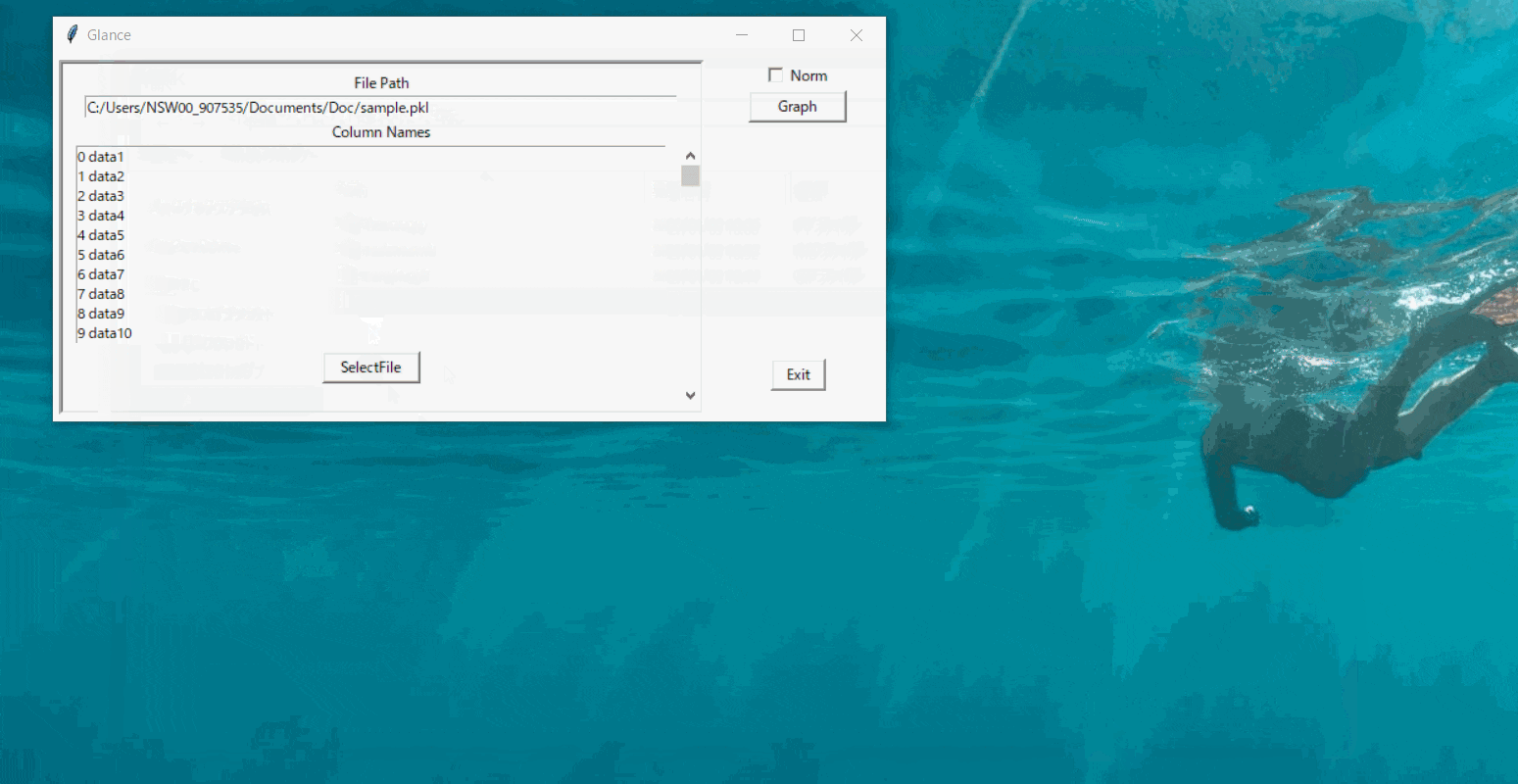
GUI操作でデータを手軽にグラフ表示するツールを作ったったった
データ分析の作業をしていると、データを数字で追うのとは別にグラフ等で視覚的にデータの特徴を確認することも多々あると思います。
そういった作業が多く、データの組みあわせを自由に変えながらグラフをすぐに表示できる「Glance」というツールを作ってみました。
GUI作成にはPythonのtkinterというライブラリを使用しました。ファイルはこちらにあります。
※Windows環境で使う用に作ったのでMac環境だと多分別途修正が必要です...概要
読み込んだデータから選択してグラフ表示するだけのシンプルなツールです。
実装した動作は大きく3つあります。
ファイル選択からデータを読み込みそのカラムを一覧で表示する
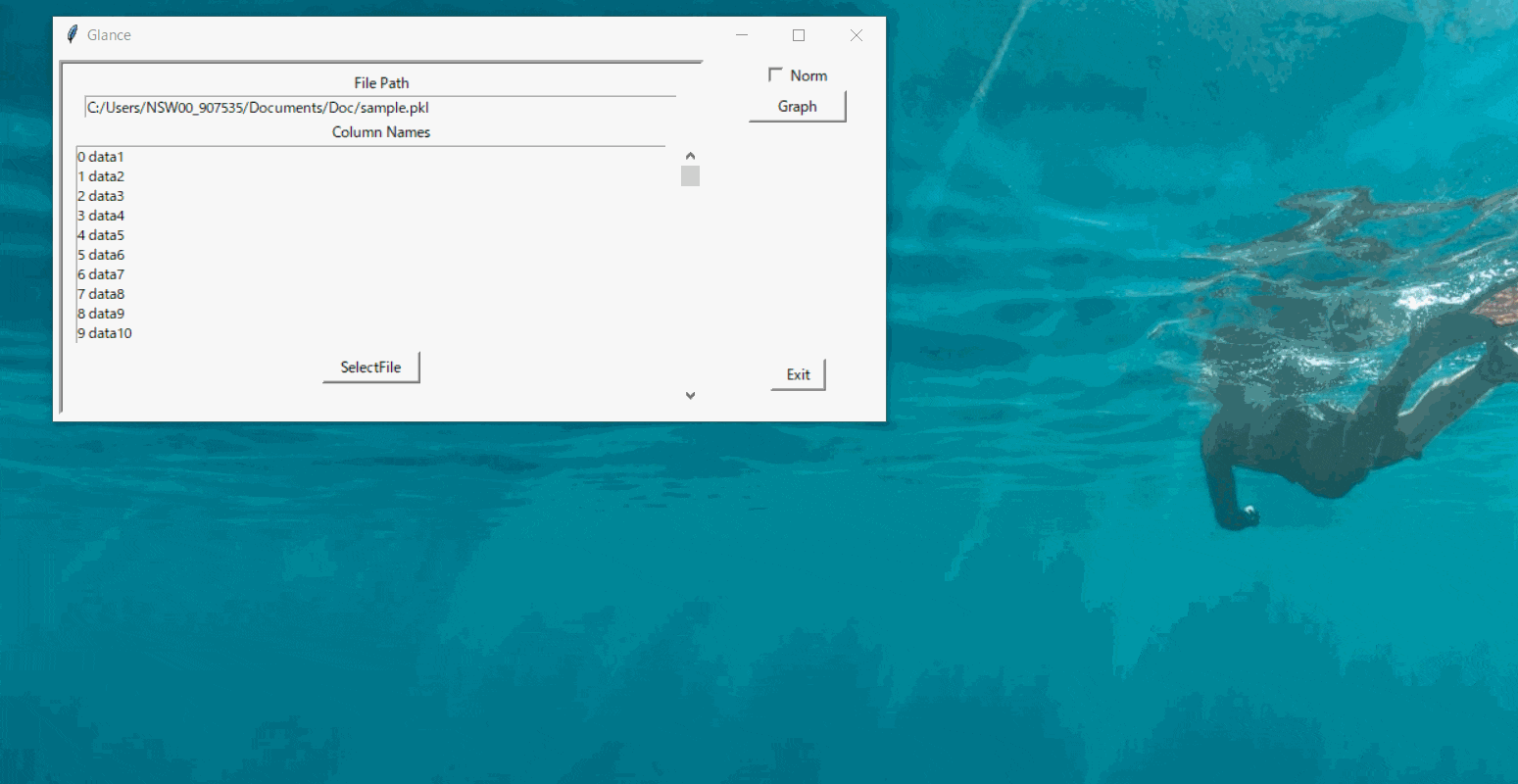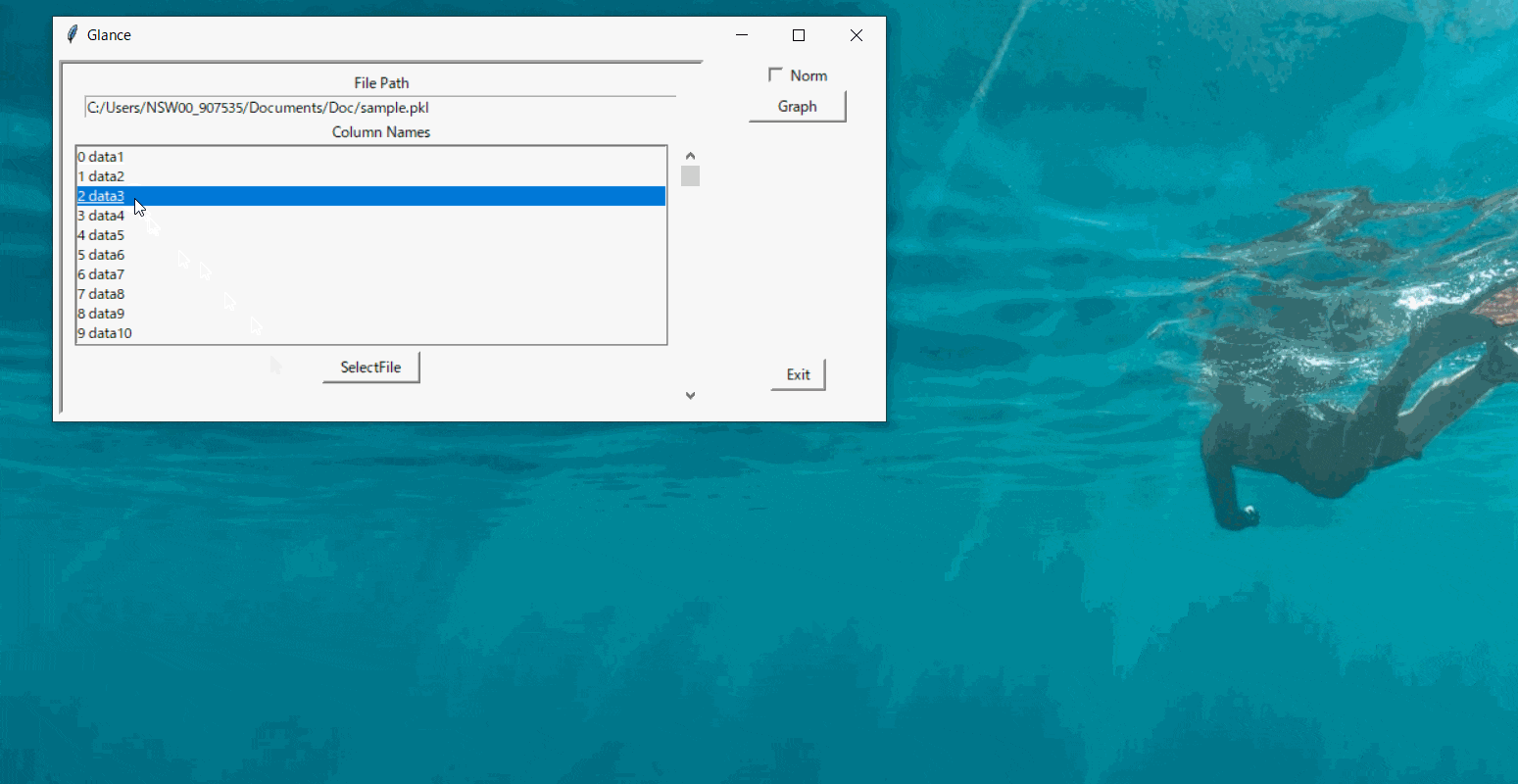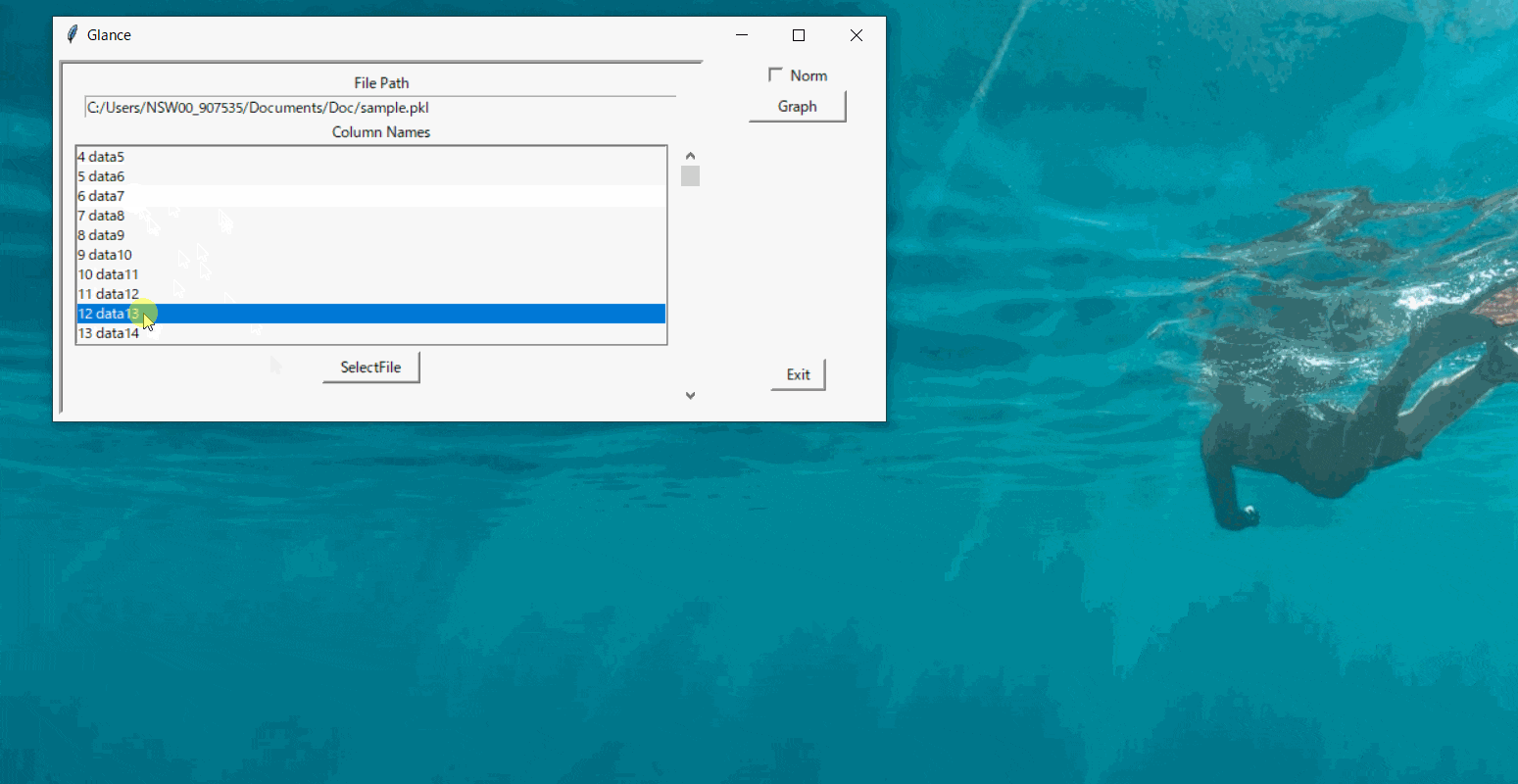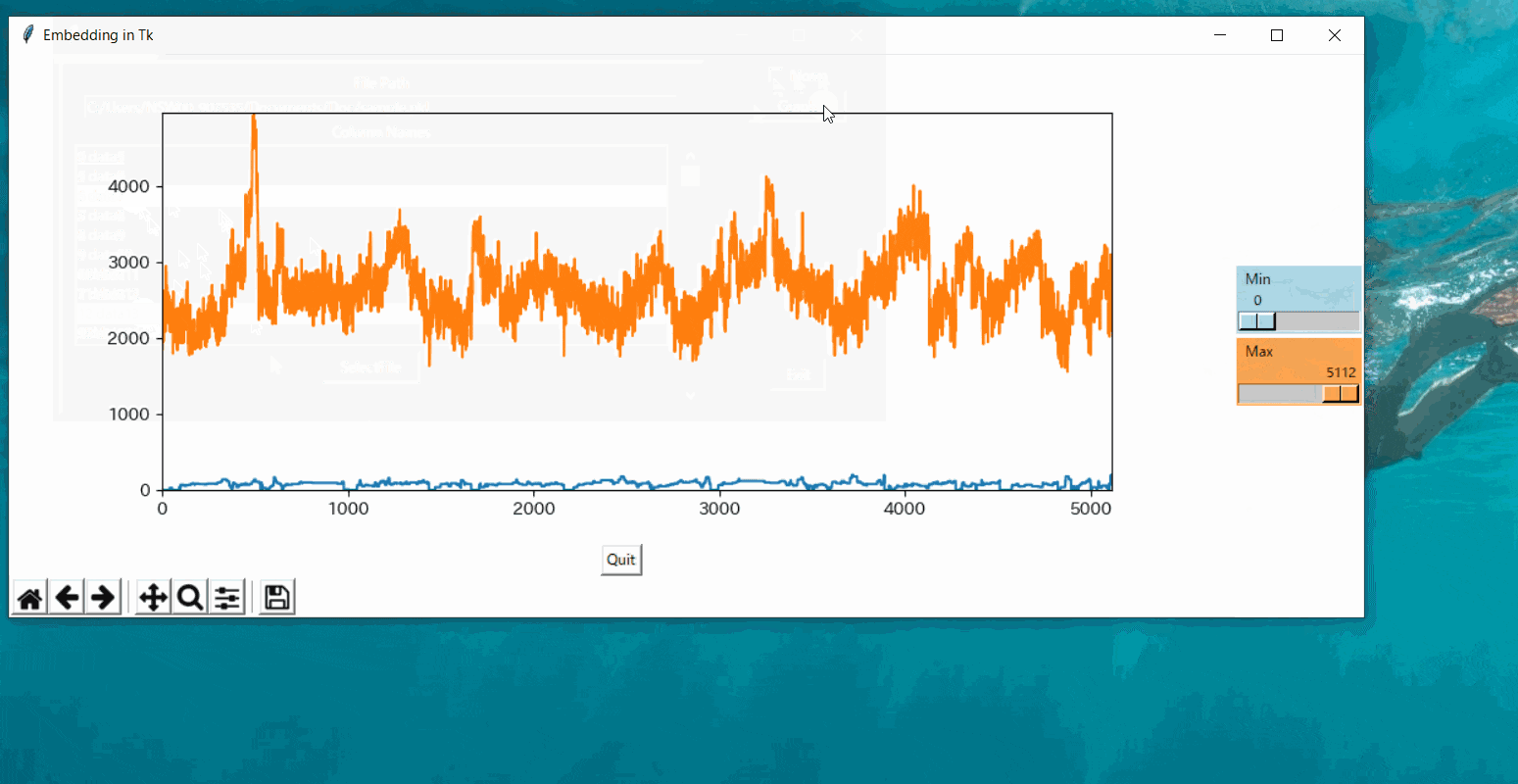
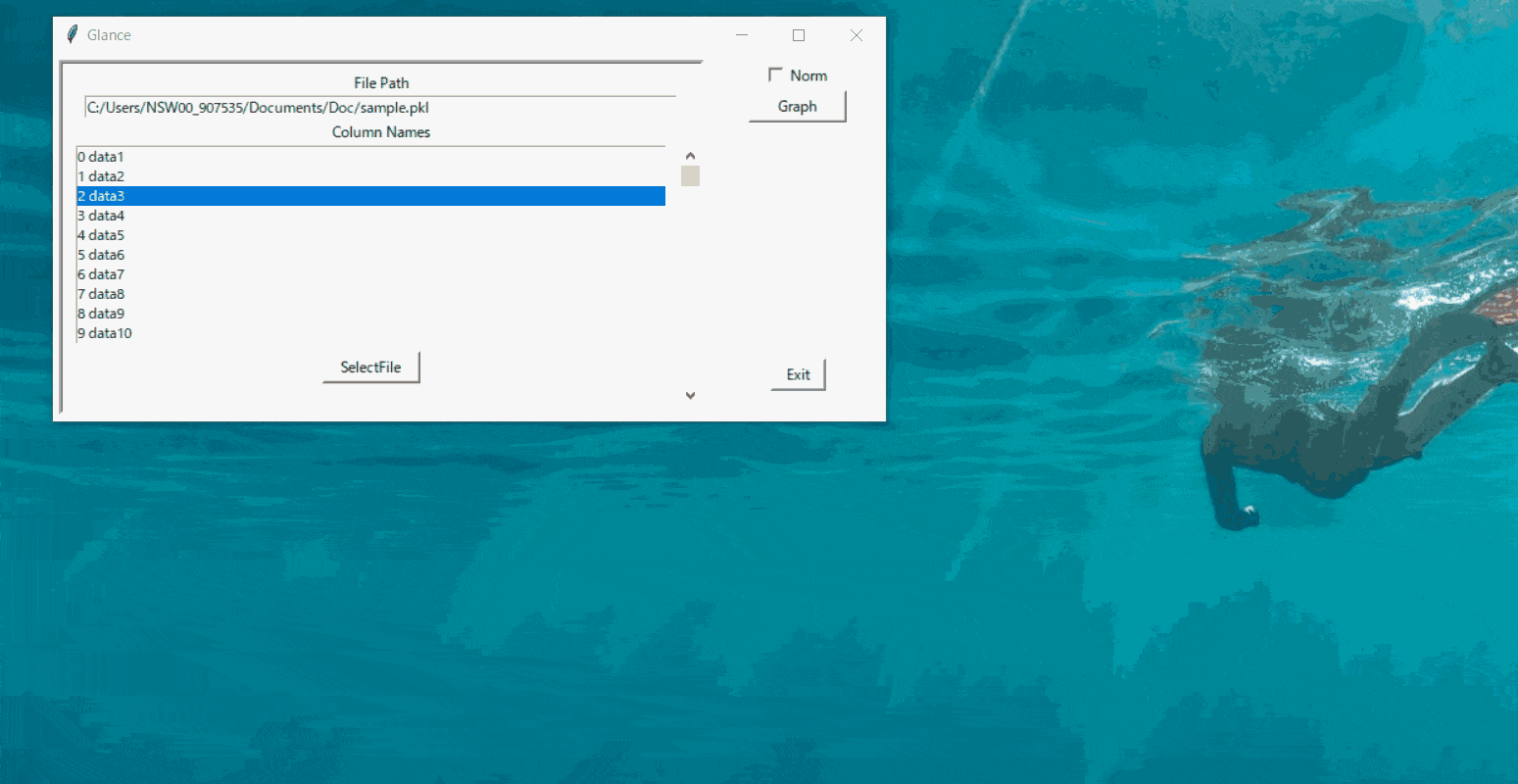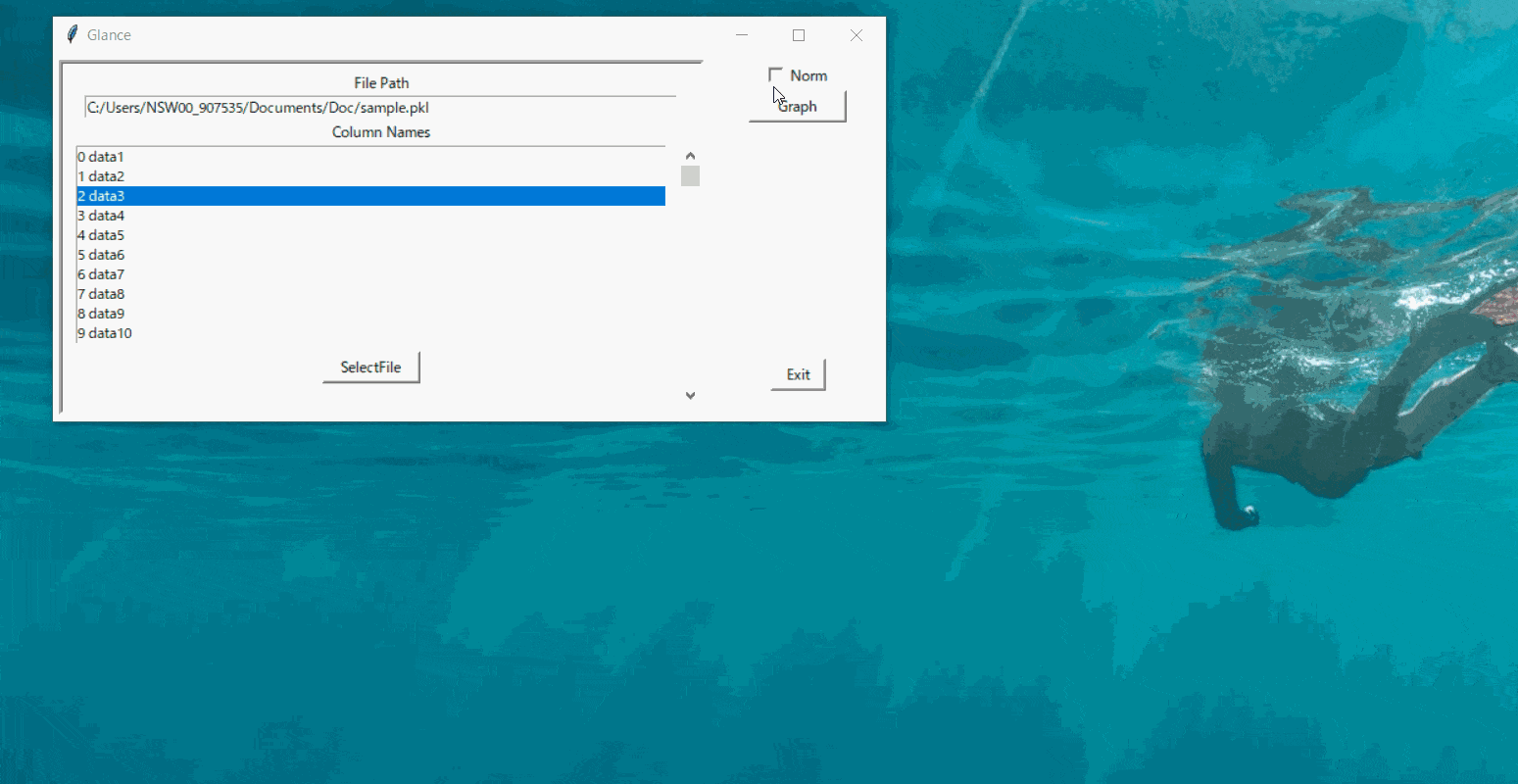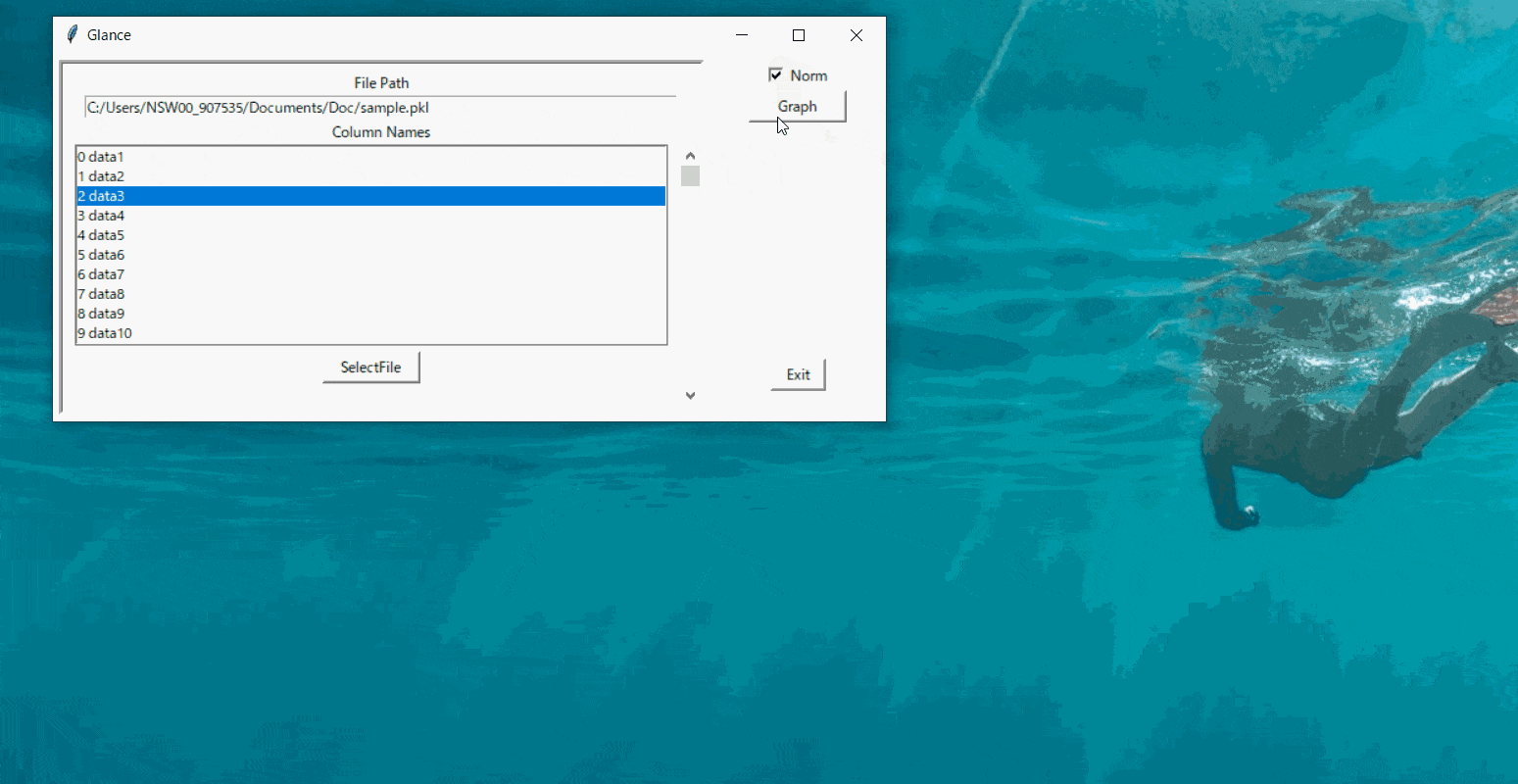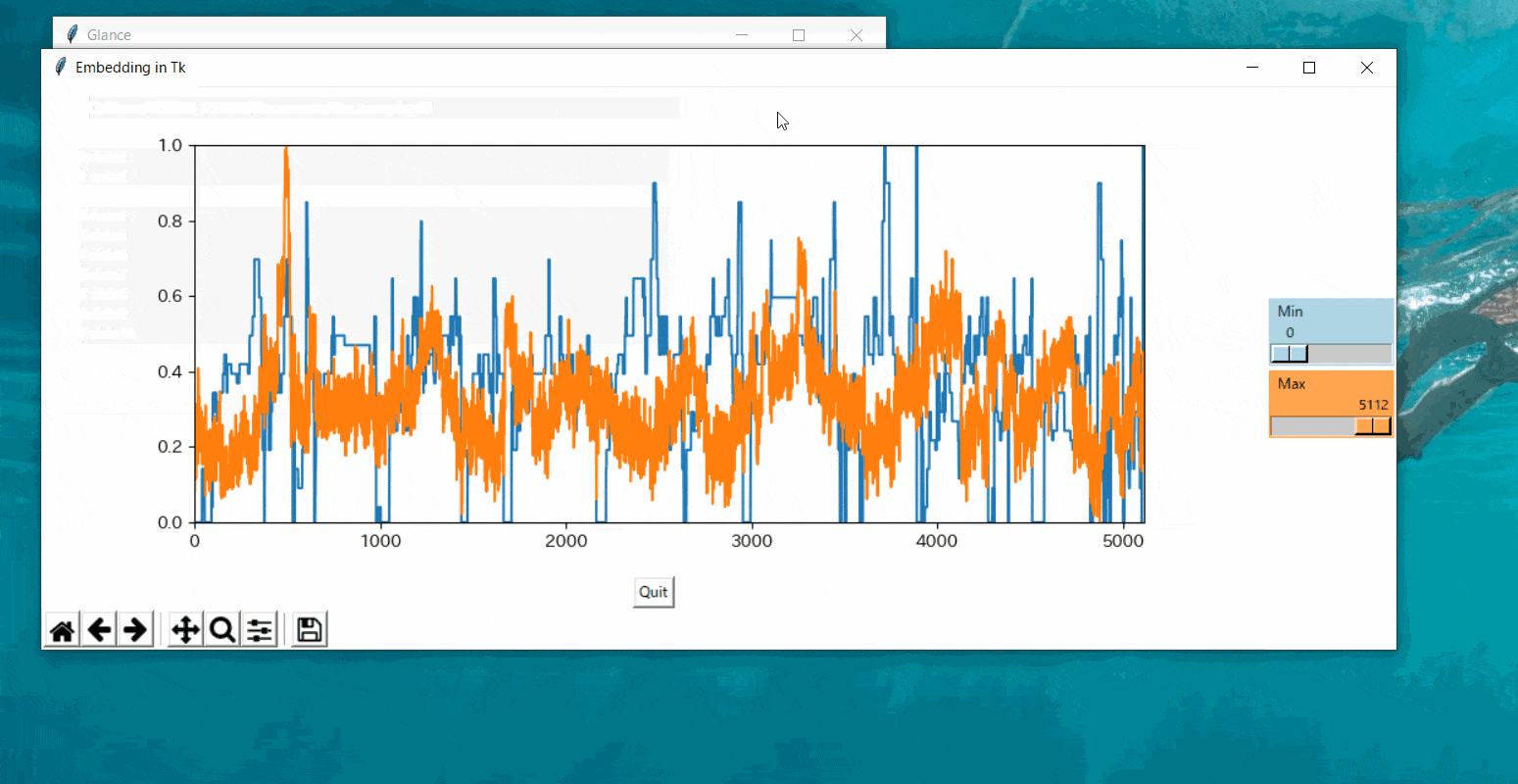
データを選択してグラフを表示する
※「norm」のチェックを入れると0~1に正規化した値でプロット
スライダーによって動的にグラフの表示範囲を変更する
ハマった部分の簡単な紹介
tkinter内での値の受け渡しについて
今回初めてtkinterを使いましたが、詰まったところのひとつとして「ウィジェットに割り当てた関数の返り値を受け取り方がわからない」というところです。
そのためにデータを持たせるためのクラスを定義して、オブジェクトに逐一データを持たせることで受け渡しする必要がありそうでした。例えば今回のツールの場合、ファイルから読み取る
fileselectという関数がありますが、読み取ったデータフレームはreturnで返すわけではなく、処理の中でオブジェクトに持たせています。def fileselect(): root = tkinter.Tk() root.withdraw() fTyp = [("", "*")] iDir = os.path.abspath(os.path.dirname(__file__)) model.path = tkinter.filedialog.askopenfilename(filetypes=fTyp, initialdir=iDir) suffix = model.path.rsplit('.', 1)[1] if suffix == 'csv' or suffix == 'pkl': model.set_data(suffix) #ここでデータを持たせている。 graph.config(state='active') Entry1.insert(tk.END, model.path) line_size = columns_list.size() columns_list.delete(0, line_size) for column in enumerate(model.data.columns): columns_list.insert(tk.END, column) else: tkinter.messagebox.showinfo(model.path, 'csvかpickleファイルを選択してください。')グラフを動的に更新する方法
tkinterのウィジェットを関数で操作する場合、
変数のスコープ上関数の中に操作用関数を定義することになります。今回はグラフを別窓で開く
new_windowも定義していますので、
グラフを更新するredraw関数の構造は以下のようになります。def main(): # 処理 def new_window(): def redraw(): # 処理 scale = tk.Scale(command=redraw) # スライドバーこうすることで、scaleを操作するたびにredraw関数が実行されるようになります。
redraw関数の中は自由でよいですが、matplotlibで表現する内容を変更した後
canvas.draw()が最後に無いとGUI上に反映されないので気をつけて下さい。コードを分けられない
これは解決していない問題なのですが、自分の書き方的にはmain()の中に
他の関数を全て定義してしまっているので関数や別ファイルとして外出しすることができませんでした。
(でもこうするしか関数でウィジェットを操作する方法がわからない...)結果的にmain()が長くなって読みづらくなってしまうのですがどうしたものか...
コード全体
import os import tkinter as tk import tkinter.filedialog import tkinter.messagebox import japanize_matplotlib from matplotlib.backends.backend_tkagg import ( FigureCanvasTkAgg, NavigationToolbar2Tk) from matplotlib.figure import Figure import numpy as np import pandas as pd def main(): class model_data: def __init__(self): self.data = pd.DataFrame() self.path = '' self.columns = [] def set_path(self, file_path): self.path = file_path def set_data(self, suffix): if suffix == 'csv': self.data = pd.read_csv(self.path) elif suffix == 'pkl': self.data = pd.read_pickle(self.path) def new_window(event): if any(model.data): def _quit_sub(): sub_win.destroy() def _redraw(event): min_lim = min_scale.get() max_lim = max_scale.get() val = [] if min_lim >= max_lim: return else: t = target.iloc[min_lim:max_lim, :] for index in selection: label = target.columns[index] val.append(t[label].max()) val.append(t[label].min()) max_val = max(val) min_val = min(val) ax.set_xlim(min_lim, max_lim) ax.set_ylim(min_val, max_val) canvas.draw() selection = columns_list.curselection() sub_win = tk.Toplevel(root) sub_win.configure(bg='white') sub_win.wm_title("Embedding in Tk") target = model.data.copy() target.reset_index(drop=True, inplace=True) fig = Figure(figsize=(10, 4), dpi=100) ax = fig.add_subplot(111) if norm_bln.get(): for index in selection: label = target.columns[index] max_num = target[label].max() min_num = target[label].min() target[label] = (target[label] - min_num) / (max_num - min_num) ax.plot(target.index, target[label], label=label) else: for index in selection: label = target.columns[index] ax.plot(target.index, target[label], label=label) canvas_frame = tk.Frame(master=sub_win, bg='white') canvas_frame.pack(side=tk.LEFT) canvas = FigureCanvasTkAgg(fig, master=canvas_frame) canvas.draw() canvas.get_tk_widget().pack(side=tk.TOP, fill=tk.BOTH, expand=1) control_frame = tk.Frame(master=sub_win) control_frame.pack(side=tk.RIGHT) toolbar = NavigationToolbar2Tk(canvas, canvas_frame) toolbar.update() canvas.get_tk_widget().pack(side=tk.TOP, fill=tk.BOTH, expand=True) min_scale = tk.Scale(control_frame, label='Min', orient='h', from_=0, bg='light blue', resolution=1, to=model.data.shape[0]-1, command=_redraw) min_scale.pack(anchor=tk.NW) max_scale = tk.Scale(control_frame, label='Max', orient='h', from_=1, bg='tan1', resolution=1, to=model.data.shape[0], command=_redraw) max_scale.set(target.shape[0]) max_scale.pack(anchor=tk.NW) button = tkinter.Button(master=canvas_frame, text="Quit", command=_quit_sub) button.pack(side=tkinter.BOTTOM) else: tkinter.messagebox.showinfo('Glance.py', '先に読み込むデータを選択してください') def fileselect(): root = tkinter.Tk() root.withdraw() fTyp = [("", "*")] iDir = os.path.abspath(os.path.dirname(__file__)) model.path = tkinter.filedialog.askopenfilename(filetypes=fTyp, initialdir=iDir) suffix = model.path.rsplit('.', 1)[1] if suffix == 'csv' or suffix == 'pkl': model.set_data(suffix) graph.config(state='active') Entry1.insert(tk.END, model.path) line_size = columns_list.size() columns_list.delete(0, line_size) for column in enumerate(model.data.columns): columns_list.insert(tk.END, column) else: tkinter.messagebox.showinfo(model.path, 'csvかpickleファイルを選択してください。') def _quit(event): root.quit() root.destroy() root = tk.Tk() model = model_data() root.title('Glance') root.geometry('680x300') frame1 = tk.Frame(bd=3, relief=tk.SUNKEN, pady=5) frame1.pack(padx=5, pady=5, ipadx=10, ipady=10, side=tk.LEFT) Static1 = tk.Label(frame1, text='File Path') Static1.pack() Entry1 = tk.Entry(frame1, width=80) Entry1.insert(tk.END, model.path) Entry1.pack() Static1 = tk.Label(frame1, text='Column Names') Static1.pack() var = tk.StringVar(value=[]) columns_list = tk.Listbox(frame1, listvariable=var, width=80, selectmode='multiple') scrollbar = tk.Scrollbar(frame1, command=columns_list.yview) columns_list.yscrollcommand = scrollbar.set scrollbar.pack(fill=tk.BOTH, side=tk.RIGHT) columns_list.pack() Button1 = tk.Button(frame1, text='SelectFile', width=10, command=fileselect) Button1.pack(pady=5) frame2 = tk.Frame() frame2.pack(padx=5, pady=5, ipadx=10, ipady=10, fill=tk.BOTH) norm_bln = tk.BooleanVar() norm_bln.set('False') norm = tkinter.Checkbutton(frame2, variable=norm_bln, text='Norm') norm.pack() graph = tk.Button(frame2, text='Graph', width=10, state='disable') graph.bind("<Button-1>", new_window) graph.pack() frame3 = tk.Frame() frame3.pack(padx=5, pady=5, ipadx=10, ipady=10, side=tk.BOTTOM) Button2 = tk.Button(frame3, text='Exit', width=5) Button2.bind("<Button-1>", _quit) Button2.pack() root.mainloop() if __name__ == "__main__": main()参考ページ

- 投稿日:2020-01-15T17:38:35+09:00
SVGファイルをAutoCADで編集してPNGにするまで。
SVG > DXF
ちょっとしたSVGファイルをAutoCADで編集して最終的にPNGにしたかったのですが、AutoCADでは直接SVGを読み込むことができませんでした。
検索すると沢山の変換サイトがありましたが、最初に試したサイトではDWGもDXFもAutoCADでは開くことができませんでした。
気を取り直して次のサイトで変換したら見事に開くことができました。
SVGをDXFに変換する オンライン フリー - SVG DXF 変換AutoCAD > PNG (ダメでした)
AutoCADで編集した後はPNGで出力したかったのですが、次のページのように
PNGOUTコマンドで書き出したPNG画像は、とても実用できるレベルではなく、サムネイルやアイコンにも使えないくらいの粗さでした。
PNGOUT[PNG 書き出し] (コマンド) | AutoCAD 2016 | Autodesk Knowledge NetworkAutoCAD > PDF
印刷のクオリティーに関しては文句なしの実力があるので、ファイルへ書き出すのではなく印刷物として出力したらバッチリでした。
プリセットされてるPDFのプロッタ環境設定は5つもありましたが、僕は迷わずに3番目の
AutoCAD PDF (High Quality Print).pc3を選びました。(他は試してません。)
- DWG to PDF.pc3
- AutoCAD 2015 以前で使用されている汎用ドライバ。
- AutoCAD PDF (General Documentation).pc3
- ほとんどの用途に適した汎用ドライバ。
- AutoCAD PDF (High Quality Print).pc3
- 用紙への印刷用に最適化された PDF ファイルを生成します。
- AutoCAD PDF (Smallest File).pc3
- 可能な限り小さいファイル サイズの PDF を生成します。
- AutoCAD PDF (Web and Mobile).pc3
- モバイル デバイスや Web ブラウザのハイパーリンクをサポートする PDF ファイルを生成します。
PDF > PNG
これも検索したら沢山のサイトが見つかったのでとりあえず一番上のサイトで試したらうまくいきました。
PDF PNG 変換 – オンラインでPDFをPNGに背景を透明にする。
PythonのPILを使って背景を透明にしました。
# インポートはこれだけ from PIL import Image # 画像をオープン im = Image.open("hoge.png") # 8bit グレイスケールモードに変換する。 L = im.convert("L") # Lチャンネルの白黒を反転して、 A = L.point(lambda x: 255 if x < 128 else 0) # アルファチャンネルAとして合体する。 im = Image.merge("LA",(L,A)) # 画像を保存する。 im.save("hoge2.png")以上、SVGファイルを編集してPNGにするまでのメモでした。
SVGファイルをPNGにするのはPythonだけでできるのですが、SVGを編集したうえでとなるとそれなりの環境が必要になると思います。
今回は、SSDの故障が原因でOSの再構築の為、会社や手元にあるものでの作業になりましたが、変換サイトのおかげでとても助かりました。
- 投稿日:2020-01-15T17:20:46+09:00
python configparser によるパラメータ設定
pythonの標準ライブラリーであるconfigparserを用いたパラメータ設定方法と、設定パラメータの使用方法に関して記載しています。
git : k-washi
Iniファイル
configparserで読み込む設定を記載するファイルです。
例としては、以下のように記載できます。
コメントは#を使用して書くことができます。config.ini[Microphone] #マイクのID ID = 0 SamplingRate = 44100 [Output] #出力デバイスのID ID = 1 #Record 1: SavePathに出力, 0:IDのデバイスに出力し続ける。 Record = 1 #recording time [sec] >= 1 RecordTime = 15設定ファイルの読み込み
config.iniファイル, 設定値を読み込む。
loggerに関しては、Pythonのloggingモジュールの使い方を参考にしてください。
- 設定ファイルがあるならconfig_ini.read()で設定ファイルを読み込む。
- config_ini["設定分類"]["設定値名"]で設定値を読み込む.
読み込んだ設定値は、stringなので、数字はint, floatなどで変換する。
また、0, 1で設定したYes/Noの値は、boolとすることで、True, Falseに変換できる。utils/config.pyimport os import sys sys.path.append(os.path.join(os.path.dirname(__file__), '..')) # ------------ from utils.logConf import logging logger = logging.getLogger(__name__) # ------------- import configparser CONFIG_FILE_PATH = './config.ini' class configInit(): def __init__(self): config_ini = configparser.ConfigParser() if not os.path.exists(CONFIG_FILE_PATH): logger.error('設定ファイルがありません') exit(-1) config_ini.read(CONFIG_FILE_PATH, encoding='utf-8') logging.info('----設定開始----') try: self.MicID = int(config_ini['Microphone']['ID']) self.SamplingRate = int(config_ini['Microphone']['SamplingRate']) self.OutpuID = int(config_ini['Output']['ID']) self.Record = bool(int(config_ini['Output']['Record'])) self.RecordTime = float(config_ini['Output']['RecordTime']) except Exception as e: logger.critical("config error {0}".format(e))設定値を使用
- 設定読み込みファイルの設定クラスconfigInitをimportする。
- Conf = configInit() でインスタンス化し、設定ファイルを読み込む。
- Conf.設定値名 で使用可能
import os import sys sys.path.append(os.path.join(os.path.dirname(__file__), '..')) # ------------ from utils.config import configInit Conf = configInit() from utils.logConf import logging logger = logging.getLogger(__name__) # ----------- logger.info(Conf.MicID) #2020-01-15 17:12:03,929 [config.py:28] INFO ----設定開始---- #2020-01-15 17:12:03,930 [confTest.py:15] INFO 0 #MicIDまとめ
以上、pythonの設定ファイルに関してでした。
システムを作るとき、後で外部設定をさせようとしたときに修正が少なくなるため、上記のように簡単にでも設定しておくことをおすすめします。
- 投稿日:2020-01-15T17:15:46+09:00
全自動植物撮影装置の稼働状況をslackに通知するプログラム
植物撮影装置の稼働状況をslack経由でnotifyしてくれるpythonプログラムを作った話
こんな感じになりました。
撮影装置がエラーで停止する。
↓
なんとかしてくれというnoticeがslackで来る。
経緯
理化学研究所CSRSが開発した植物自動育成&撮影装置。詳細は上のプレス(日本語)か、論文(英語、オープンアクセス)を参照。
Fujita et al., 2018.植物をベルトコンベアで回しながら備え付けのカメラで経時的に写真や生育データをPCに貯めていく装置なのですが、どうしてもエラーでときたま止まってしまうことがあるそうです。原因の詳細は把握していませんが、部品破損、土や溶液の付着による劣化などによるハード的な原因から、給水タンクの水涸れなど様々だと思われます。さらに担当研究員が常駐する部屋と制御PC付きの装置がある部屋は研究棟が異なるため、正常に稼働しているかどうかのモニタリングを随時行い続けるのが大変だったそう。ネットワーク経由で保存先のフォルダの最新の更新時刻を見ればいいじゃないかという話だと当初は思ったのですが、1装置にカメラの種類だけフォルダがあること、装置の数だけさらに掛け算で増えることを考慮すると、とてもとてもという状況でした。撮影装置を利用する側として共同研究の話を進めているときに、これでは自分の実験データ取得にも支障が出るということで急遽つくることにしました。
制御ソフトにエラー対処機能を実装するのは困難(一度完成しているハード制御するソフトウェアに手を出したくない)と判断したので、外部からフォルダの更新状況を監視し、slackにその状況を通知するシンプルなプログラムを作りました。以下備忘録と情報共有。
アイディア
-python
-監視すべきフォルダを指定する
-サブフォルダが生成される場合があるので、recursiveに指定フォルダ内を探索する。
-指定したインターバルを挟んでフォルダ内のファイルに差分がなければ通知する。
-1日に1回程度、プログラムが通常稼働していることを通知する。
- 通知する方法はtwitter*かslack
* twitterのapi登録のステップにどれだけの時間かかるかわからなかったのでslackにした。
- pythonからslackへの自動投稿はqiitaでincoming webhookとかで検索してよく使われているコードを利用することにした。プログラム
1. 必要ライブラリの読み込みと自動インストール
遠隔でpythonを実行してもらう場合、pip install~~~を指示すること自体が実はハードルが高いことがわかったので、その部分もスクリプトに内包した。
from pip._internal import main as _main import importlib def _import(name, module, ver=None): try: globals()[name] = importlib.import_module(module) except ImportError: try: if ver is None: _main(['install', module]) else: _main(['install', '{}=={}'.format(module, ver)]) globals()[name] = importlib.import_module(module) except: print("can't import: {}".format(module)) _import('requests','requests') _import('argparse','argparse') _import('json','json') _import('threading','threading')参考
https://vaaaaaanquish.hatenablog.com/entry/2018/12/02/210647
https://stackoverflow.com/questions/12332975/installing-python-module-within-code起動時にライブラリがなくインポートエラーを吐く場合、インストールしてから再度インポートを試みる。
requests, argparse, json, threadingは標準インストールされてないことが多かったので指定した。2. argparseでコマンドライン引数の管理
parser = argparse.ArgumentParser() parser.add_argument('-i', '--interval',default=1) parser.add_argument('-d', '--dir', nargs='+', help="pass abs directory pass as list", required = True) parser.add_argument('-n', '--name',default="RIPPS監視プログラム_第一号")interval: ファイル確認頻度(時間)
dir: 監視フォルダ(絶対パス)、複数指定可能
name:slack投稿者名下のように使う
python monitor.py --dir PATH1 PATH2 --interval 1.5 --name RIPPS_monitoring_robot_13. 他ハードコード変数
SLACK_WEBHOOK = "https://hooks.slack.com/services/XXXXXXXXXXXXX"
start = time.time()4. 初回監視フォルダスキャンとslack投稿
def initiation(path,nfiles): message = "%sの監視を開始します。 監視下のフォルダには現在%d個のファイルがあります。%s時間ごとに更新チェックします。" % (path,nfiles,args.interval) ellapsed = int(time.time() - start) payload_dic = { "icon_emoji": ':heartpulse:', "text": message, "username": args.name + "_" + str(int(ellapsed/(60*60))), "channel": "#general", # #も必要 } try: r = requests.post(SLACK_WEBHOOK, data=json.dumps(payload_dic)) except requests.ConnectionError: print(requests.ConnectionError) print("slackに接続できませんでした。") befores = [] for i, path_to_watch in enumerate(args.dir): print(path_to_watch) assert os.path.isdir(path_to_watch) == True, print("%s is not a valid directory" % path_to_watch) if path_to_watch[-1] != "/": path_to_watch += "/**" else: path_to_watch += "**" before = dict ([(f, None) for f in glob.glob(path_to_watch,recursive=True)]) initiation(path_to_watch,len(before)) args.dir[i] = path_to_watch befores.append(before)
- 複数ディレクトリを監視するオプションを入れた場合、args.dirはリストになるので、for loopで処理する。単一フォルダでも対応可能。
- ディレクトリじゃなかった場合、assertion errorではじく。
- glob.globのrecursive=Trueかつパスの末端に**がついているとサブディレクトリまでサーチする(はず)なので、入力引数の末端に**を付加しておく。フォルダをterminalやcommand promptに引っ張って落としても対応可能なようにしておくため。パスの末端に〜〜を付加してください、という指示は結構複雑だし、使用者が抜け落とすことがあるので。
- glob.globで取得したファイル一覧(正確にはフォルダの数も入ってしまっているけど)を辞書型にして、辞書のlengthをinitiation functionにわたす。
- initiation functionでslackのチャンネルに投稿する。
- 初期状態の監視フォルダのファイル名をbeforesリストに格納しておいて、後に差分比較用に使う。
以下は2つのフォルダを監視するよう設定した場合のbotの挙動
5.フォルダ監視
def errorpostslack(path): error_message = "監視対象フォルダ(%s)が%s時間以上更新されていません" % (path,args.interval) #更新なしメッセージ ellapsed = int(time.time() - start) payload_dic = { "icon_emoji": ':cry:', "text": error_message, "username": args.name + "_" + str(int(ellapsed/(60*60))), "channel": "#general", # #も必要 } try: r = requests.post(SLACK_WEBHOOK, data=json.dumps(payload_dic)) except requests.ConnectionError: print(requests.ConnectionError) print("slackに接続できませんでした。") while 1: time.sleep(float(args.interval)*60*60) for i, (before, path_to_watch) in enumerate(zip(befores,args.directory)): after = dict ([(f, None) for f in glob.glob(path_to_watch,recursive=True)]) added = [f for f in after if not f in before] removed = [f for f in before if not f in after] if added: print ("Added: ", ", ".join (added)) #goodpostslack(added) pass elif removed: print ("Removed: ", ", ".join (removed)) pass else: errorpostslack(path_to_watch) befores[i] = after
- 設定したinterval(時間)をもとにインターバル(秒)を挟んでループを実行。
- 初期スキャンで取得したbeforesリストとdirectoryをzipで同時に吐き出す。enumerateはここでは意味がないが、バグとり用の名残。
- 2回目以降は更新されたbeforesを利用する
- 各ループごとに、最新のglob.globによるファイル一覧を取得する。beforeと比べ、ファイルが増えていた場合はaddedに、消えていた場合はremovedのリストを作成する。変化がない場合はadded、removedともにemptyで、elseの処理が実行される。
- added removedともにpassはいらないけれど、printをコメントアウトしたとき用に残してある。
- ファイル更新がなかった場合、errorpostslack functionを呼んでエラーメッセージをslackに投稿する
結果
6.生存報告
きちんと撮影装置が稼働して、画像がたまり続けていた場合、通知が何もない。かといってインターバルごとに正常通知がきつづけるのも煩わしい。ということで一日一回の生存報告する機能を追加する。
def dailynotice(): message = "1日1回の定期報告です。" ellapsed = int(time.time() - start) for i, (before, path_to_watch) in enumerate(zip(befores,args.dir)): nfiles = len(glob.glob(path_to_watch,recursive=True)) message += "%sのフォルダ下には%d個のフォルダ・ファイルが存在します" % (path_to_watch,nfiles) payload_dic = { "icon_emoji": ':smile:', "text": message, "username": args.name + "_" + str(int(ellapsed/(60*60))), "channel": "#general", # #も必要 } try: r = requests.post(SLACK_WEBHOOK, data=json.dumps(payload_dic)) except requests.ConnectionError: print(requests.ConnectionError) print("slackに接続できませんでした。") while 1: dailynotice() time.sleep(24*60*60)結果
7. エラー検知と生存報告の共存
while loopが2つあるのでthreadingで同時に回す。
pseudocode def error_check(): 監視フォルダの更新チェック関数 def daily_check(): 生存報告 t1 = Thread(target = error_check) t2 = Thread(target = daily_check) t1.start() t2.start()8.最後に
- コードはgithubにアップした。https://github.com/totti0223/ripps_utility
- slackのincoming webhookのurlもコマンドライン引数にしようかと迷ったが使用者が混乱するのでハードコードにした。
- macのオートメーターとか、フリーのソフトウェアとか他の方法も多分に存在するだろうけれども、pythonで作る方が早かった。ご存知でしたらぜひ言語、osプラットフォーム問わず教えて下さい(slack経由じゃなくても)。
- 生存報告、エラー報告ごとにアイコンを変えているのに、同じ投稿者が続けてポストするとスレッドまとめられて反映されずに悲しい。。
- 苦肉の策で投稿者名(username)の最後にプログラム起動からの時間をmergeすることによって対処。美しくない。投稿者名が同じでもアイコンが1つずつ表示されるときもあって法則性がよくわからない。payload_dic = { "icon_emoji": ':heartpulse:', "text": message, "username": args.name + "_" + str(int(ellapsed/(60*60))), "channel": "#general", # #も必要 }





- 投稿日:2020-01-15T16:57:19+09:00
Pythonのloggingモジュールの使い方
pythonのlogginモジュールの設定を一元管理し、以下のように、日時、ログを書き出したファイル名、 ログレベル(debug, info, error, ...), 出力メッセージと、一貫したフォーマットで出力させる方法を記載します。
2020-01-15 16:54:52,751 [logTest.py:9] INFO メッセージです。※ とりあえず、使うことができれば良い人向けです。(ログをローカルに吐き出すなどの処理に関しては説明していません。)
Git: k-washi
python ver: 3.6.8ログの設定
logConf.pyファイルで、formatやログレベルを管理します。
utils/logConf.pyimport logging format="%(asctime)s [%(filename)s:%(lineno)d] %(levelname)-8s %(message)s" logging.basicConfig(level=logging.DEBUG, format=format)ログの処理
ログ処理を行うファイルで、
- logConf.pyまでパスを通す
- nameで使用するファイルにおけるロガーを設定
を行います。
そして、logger.nfoやlogger.errorによりロギングできます。import os import sys sys.path.append(os.path.join(os.path.dirname(__file__), '..')) from utils.logConf import logging logger = logging.getLogger(__name__) logger.info("メッセージです。") logger.error("エラーです。") """ 2020-01-15 16:54:52,751 [logTest.py:9] INFO メッセージです。 2020-01-15 16:54:52,751 [logTest.py:10] ERROR エラーです。 """まとめ
以上で、簡単なロギング処理が可能となりました。
もし、追加でログのファイル出力等を行う場合、logConf.pyファイルを変更していけば、追加機能も簡単に追加できます。
- 投稿日:2020-01-15T16:54:53+09:00
chrome80でSameSite=Noneを明記しないといけなくなった問題、djangoユーザーはみんなどうしてるんだろう。
背景
ウェブサイトの所有者は、ほかのサイトで使用可能なサードパーティCookieに明示的な属性を追加することを義務付けられるようになります。
参考:https://digiday.jp/platforms/what-is-chrome-samesite/django側の対応
django/http/response.pydef set_cookie(self, key, value='', max_age=None, expires=None, path='/', domain=None, secure=False, httponly=False, samesite=None): ... if samesite: if samesite.lower() not in ('lax', 'none', 'strict'): raise ValueError('samesite must be "lax", "none" or "strict".') self.cookies[key]['samesite'] = samesite ...けど、これ最新の3.0.2に入ってない
- 投稿日:2020-01-15T16:53:04+09:00
摂動展開とシミュレーション 摂動法編
摂動法とは
摂動法とは、物理の分野で非常に発達した方程式の近似計算法である。この解法を利用することによって、普通に計算を行ったら解くのが難しい微分方程式や偏微分方程式を近似的に解くことができる。摂動法を2種類に分類すると、『摂動問題』と『特異摂動問題』の2種類に分けられる。前者は順を追って解くことができるが、特異摂動問題は確立された解き方はほとんどない。
この記事では、摂動問題法を紹介する。簡単な微分方程式の解を導出と数値シミュレーションを行なった結果を示す。
一階の非線形常微分方程式
\dot{y} + y + \epsilon y^2 =0 \\ s.t. y(0)=1, \epsilon=o(1)一般に非線形問題の求解は非常に困難であることはよく知られている。ここでは、$\epsilon$が十分に小さいことを仮定している。
単純に考えると、$\epsilon$は十分に小さいんだったら、0として扱ってみたらいいのではないかと考える人もいるだろう。その時の解は簡単にy=exp(-x)と導出することができるだろう。この近似計算は、いい近似と言えるのだろうか?
def sim(time,y=1,e=0.01): save=[y] dt=0.01*e step=int(time/dt) for i in range(step): y=y-dt*y-e*dt*y**2 save.append(y) return save y1=sim(2) a=np.linspace(0,2,len(y1)) y=np.exp(-a) plt.plot(sim(2),a) plt.plot(y,a) plt.show()
このように、真の分布と大きく変わらないことがわかります。この近似を摂動論の言葉で0次の近似と言います。この近似をより良いものにするために、摂動展開を行いましょう。
y=y_0+\epsilon y_1+\epsilon^2 y_2+...このように$\epsilon$の漸近級数をつくります。これを微分方程式に代入して2次までとくと、
y_0=exp(-x)\\ \dot{y_1}+y_1+y_o^2=0\\ y_1=-exp(-x)+exp(-2x)\\ \dot{y_2}+y_2+2y_0y_1=0\\ y_2=exp(-x)-2exp(-2x)+exp(-3x)\\これをシミュレーションする。
y1=sim(2) a=np.linspace(0,2,len(y1)) y=np.exp(-a) y2=np.exp(-2*a) y3=np.exp(-3*a) plt.plot(sim(2),a) plt.plot(y,a) plt.plot(y1+(y2-y)*0.01,a) plt.plot(y1+(y2-y)*0.01+(y-2*y2+y3)*0.0001,a) plt.savefig("simu") plt.show()
結果を見てわかるように、非常に精度が良いことがわかる。
結論
このようにして近似計算をすると、かなり近似の精度が良くなることがわかる。
次回、この近似計算がうまくいかない永年項問題を紹介し、特異摂動法について説明する。


- 投稿日:2020-01-15T16:41:54+09:00
Pythonのloggingモジュールの使い方
pythonのlogginモジュールの設定を一元管理し、以下のように、日時、ログを書き出したファイル名、 ログレベル(debug, info, error, ...), 出力メッセージと、一貫したフォーマットで出力させる方法を記載します。
2020-01-15 15:32:36,638 __main__ INFO メッセージです。※ とりあえず、使うことができれば良い人向けです。(ログをローカルに吐き出すなどの処理に関しては説明していません。)
Git: k-washi
python ver: 3.6.8ログの設定
logConf.pyファイルで、formatやログレベルを管理します。
utils/logConf.pyimport logging format="%(asctime)s %(name)-12s %(levelname)-8s %(message)s" logging.basicConfig(level=logging.DEBUG, format=format)ログの処理
ログ処理を行うファイルで、
- logConf.pyまでパスを通す
- nameで使用するファイルにおけるロガーを設定
を行います。
そして、logger.nfoやlogger.errorによりロギングできます。import os import sys sys.path.append(os.path.join(os.path.dirname(__file__), '..')) from utils.logConf import logging logger = logging.getLogger(__name__) logger.info("メッセージです。") logger.error("エラーです。") """ 2020-01-15 16:38:53,265 __main__ INFO メッセージです。 2020-01-15 16:38:53,266 __main__ ERROR エラーです。 """まとめ
以上で、簡単なロギング処理が可能となりました。
もし、追加でログのファイル出力等を行う場合、logConf.pyファイルを変更していけば、追加機能も簡単に追加できます。
- 投稿日:2020-01-15T16:22:51+09:00
Pythonのloggingモジュールの使い方
pythonのlogginモジュールの設定を一元管理し、以下のように、日時、ログを書き出したファイル名、 ログレベル(debug, info, error, ...), 出力メッセージと、一貫したフォーマットで出力させる方法を記載します。
2020-01-15 15:32:36,638 __main__ INFO メッセージです。※ とりあえず、使うことができれば良い人向けです。(ログをローカルに吐き出すなどの処理に関しては説明していません。)
Git: k-washi
python version 3.6.8ログの設定
logConf.pyファイルで、formatやログレベルを管理します。
utils/logConf.pyimport logging format="%(asctime)s %(name)-12s %(levelname)-8s %(message)s" logging.basicConfig(level=logging.DEBUG, format=format)ログの処理
ログ処理を行うファイルで、
- logConf.pyまでパスを通す
- nameで使用するファイルにおけるロガーを設定
を行います。
そして、logger.nfoやlogger.errorによりロギングできます。import os import sys sys.path.append(os.path.join(os.path.dirname(__file__), '..')) import logging logger = logging.getLogger(__name__) logger.info("メッセージです。") logger.error("エラーです。")まとめ
以上で、簡単なロギング処理が可能となりました。
もし、追加でログのファイル出力等を行う場合、logConf.pyファイルを変更していけば、追加機能も簡単に追加できます。
- 投稿日:2020-01-15T14:42:22+09:00
【python】世界チャンピオン「ミスター・サタン」変身アプリをつくった
はじめに
みんなのあこがれ、世界チャンピオン「ミスター・サタン」。その「ミスター・サタン」に変身できるアプリを作ってみました。特徴的な眉、髭・アフロヘアーを身にまとえば、これであなたも「ミスター・サタン」!
雑(w)!
技術的には、face_recognitionというライブラリを使って顔の各種パーツの座標を取得し、それをもとに眉・髭・アフロの位置と大きさを計算し、描画しています。
face_recognitionとは
Face Recognitionは、顔を認識・操作できる世界で最も単純な顔認識ライブラリです。
Face Recognition
Recognize and manipulate faces from Python or from the command line with the world's simplest face recognition library.
使用するには、まずpipでインストールを行います。
$ pip install opencv-python $ pip install opencv-contrib-python $ pip install cmake $ pip install face_recognition試しに、下記画像を使って、顔パーツの取得を行ってみます。
import face_recognition import cv2 F = "image.jpg" image = face_recognition.load_image_file(F) face_landmarks_list = face_recognition.face_landmarks(image) print(face_landmarks_list)
各パーツの座標が取得できました。
取得できた座標を実際の画像にプロットしてみます。bgr = cv2.imread(F) for face_landmarks in face_landmarks_list: for facial_feature in face_landmarks.keys(): for i in range(len(face_landmarks[facial_feature])): cv2.drawMarker(bgr, face_landmarks[facial_feature][i], color=(255, 0, 0), markerType=cv2.MARKER_CROSS, thickness=1) cv2.imshow('', bgr) cv2.waitKey(0) cv2.destroyAllWindows()
おおよそ、正しく認識できていることが分かります。
実際のコード
1.pipでインストール
$ pip install opencv-python $ pip install opencv-contrib-python $ pip install cmake $ pip install face_recognition2.ライブラリのインポート・定数宣言
import face_recognition import cv2 from PIL import Image import numpy as np# 画像の縦幅・横幅の最大サイズ MAX_IMAGE_WIDTH = 10000 MAX_IMAGE_HEIGHT = 100003.関数の定義(オーバーレイ描画・座標を配列に格納)
class CvOverlayImage(object): """ [summary] OpenCV形式の画像に指定画像を重ねる """ def __init__(self): pass @classmethod def overlay( cls, cv_background_image, cv_overlay_image, point, ): """ [summary] OpenCV形式の画像に指定画像を重ねる Parameters ---------- cv_background_image : [OpenCV Image] cv_overlay_image : [OpenCV Image] point : [(x, y)] Returns : [OpenCV Image] """ overlay_height, overlay_width = cv_overlay_image.shape[:2] # OpenCV形式の画像をPIL形式に変換(α値含む) # 背景画像 cv_rgb_bg_image = cv2.cvtColor(cv_background_image, cv2.COLOR_BGR2RGB) pil_rgb_bg_image = Image.fromarray(cv_rgb_bg_image) pil_rgba_bg_image = pil_rgb_bg_image.convert('RGBA') # オーバーレイ画像 cv_rgb_ol_image = cv2.cvtColor(cv_overlay_image, cv2.COLOR_BGRA2RGBA) pil_rgb_ol_image = Image.fromarray(cv_rgb_ol_image) pil_rgba_ol_image = pil_rgb_ol_image.convert('RGBA') # composite()は同サイズ画像同士が必須のため、合成用画像を用意 pil_rgba_bg_temp = Image.new('RGBA', pil_rgba_bg_image.size, (255, 255, 255, 0)) # 座標を指定し重ね合わせる pil_rgba_bg_temp.paste(pil_rgba_ol_image, point, pil_rgba_ol_image) result_image = \ Image.alpha_composite(pil_rgba_bg_image, pil_rgba_bg_temp) # OpenCV形式画像へ変換 cv_bgr_result_image = cv2.cvtColor( np.asarray(result_image), cv2.COLOR_RGBA2BGRA) return cv_bgr_result_imagedef GetPosi(posi_name): """ [summary] 指定した顔パーツの座標を取得する Parameters ---------- posi_name : [str] Returns : [left_X、right_X, Top_Y, Bottom_Y] """ for face_landmarks in face_landmarks_list: minX = MAX_IMAGE_WIDTH maxX = 0 minY = MAX_IMAGE_HEIGHT maxY = 0 for i in range(len(face_landmarks[posi_name])): if face_landmarks[posi_name][i][0] < minX: minX = face_landmarks[posi_name][i][0] if face_landmarks[posi_name][i][0] > maxX: maxX = face_landmarks[posi_name][i][0] if face_landmarks[posi_name][i][1] < minY: minY = face_landmarks[posi_name][i][1] if face_landmarks[posi_name][i][1] > maxY: maxY = face_landmarks[posi_name][i][1] return [minX, maxX, minY, maxY]4.顔のランドマークを取得
# ファイル名の定義 F = "sample.jpg"# 画像から顔のランドマークを取得 image_fl = face_recognition.load_image_file(F) face_landmarks_list = face_recognition.face_landmarks(image_fl)5.眉・髭・アフロの位置を計算
# 各パーツの座標を取得 eye_r = GetPosi('right_eye') eye_l = GetPosi('left_eye') mouse = GetPosi('top_lip') nose = GetPosi('nose_tip') chin = GetPosi('chin') # 取得座標から眉幅・ひげ幅を算出 brow_h = int((eye_r[3] - eye_r[2]) * 2) face_w = chin[1] - chin[0] beard_h = int((mouse[2] - nose[2]) * 0.7) beard_w = int((face_w - (mouse[1] - mouse[0])) * 0.2) beard_h2 = int((chin[3] - mouse[2]) * 0.6) beard_h3 = int((chin[3] - mouse[2]) * 0.3) scale = int(face_w / 20) scale2 = scale * 2 # アフロ画像の場所を算出(左右対称じゃないため微調整あり) hair_w = int(face_w * 1.83) hair_h = int(hair_w * 0.64) hair_x = int(chin[0] - (hair_w / 2 - face_w / 2) + scale * 1.5) hair_y = eye_l[2] - hair_h# 眉・髭の座標計算 eyeb_r = np.array( [ [eye_r[0] - scale2, eye_r[2] - brow_h], [eye_r[1] + scale2, eye_r[2] - brow_h - scale2], [eye_r[1] + scale2, eye_r[2] - scale * 2] , [eye_r[0] - scale2, eye_r[2]] ] ) eyeb_l = np.array( [ [eye_l[0] - scale2, eye_l[2] - brow_h - scale2], [eye_l[1] + scale2, eye_l[2] - brow_h], [eye_l[1] + scale2, eye_l[2]] , [eye_l[0] - scale2, eye_l[2] - scale * 2] ] ) beard_c = np.array( [ [mouse[0] - scale, mouse[2] - beard_h], [mouse[1] + scale, mouse[2] - beard_h], [mouse[1] + scale, mouse[2] - 0] , [mouse[0] - scale, mouse[2] - 0] ] ) beard_l = np.array( [ [mouse[0] - beard_w, mouse[2] - beard_h - scale], [mouse[0] - 5, mouse[2] - beard_h], [mouse[0] - 5, mouse[2] + beard_h2], [mouse[0] - beard_w, mouse[2] + beard_h3] ] ) beard_r = np.array( [ [mouse[1] + 5, mouse[2] - beard_h], [mouse[1] + beard_w, mouse[2] - beard_h - scale], [mouse[1] + beard_w, mouse[2] + beard_h3], [mouse[1] + 5, mouse[2] + beard_h2] ] )6.眉・髭・アフロの描画
# OpenCVでファイル読み込み image = cv2.imread(F) # 眉毛・ひげ・描画処理 cv2.fillConvexPoly(image, points =eyeb_r, color=(0, 0, 0)) cv2.fillConvexPoly(image, points =eyeb_l, color=(0, 0, 0)) cv2.fillConvexPoly(image, points =beard_c, color=(0, 0, 0)) cv2.fillConvexPoly(image, points =beard_l, color=(0, 0, 0)) cv2.fillConvexPoly(image, points =beard_r, color=(0, 0, 0))# アフロ画像をオーバーレイ表示 cv_background_image = image cv_overlay_image = cv2.imread( "head.png", cv2.IMREAD_UNCHANGED) # IMREAD_UNCHANGEDを指定しα込みで読み込む cv_overlay_image = cv2.resize(cv_overlay_image, (hair_w, hair_h)) point = (hair_x, hair_y) image = CvOverlayImage.overlay(cv_background_image, cv_overlay_image, point) # 画像描画 cv2.imshow("image", image) cv2.waitKey(0) cv2.destroyAllWindows()おまけ
使用したアフロ画像です。背景は透過です。head.jpgとし、作業フォルダにおいてください。
終わりに
現時点では、正面画像のみ対応しています。Face Recognitionが、いい感じで座標を取得してくれるので、ちょっとの加工で作れました。出力したものの中には個人的に面白い出来のものもありましたが、肖像権の兼ね合いであきらめました。いろんな画像で遊んでもらえたら幸いです。
参考サイト







