- 投稿日:2019-12-09T23:27:48+09:00
bash , zsh等の確認・変更
- 投稿日:2019-12-09T23:11:39+09:00
Dashにおける@app.callbackの繰り返しInput,Stateをきれいに書く方法
DashのInput,Stateの変数による書き方
- DashのInputやStateの第1引数には、id名を入れる必要がある。
- id名を連番にしたり、特定の名称+Noみたいな書き方をするとすっきりかけます。
- 繰り返しのInput,Stateがある場合は、下記の方法が良いと思います。
# nは適当ですが、下記のように適当にFOOSを作り、 # STATESとして、リストを作ってあげることで、@app.callback内のStateに置き換えることができます。 # この方法でInputも作ることができます。 n = 5 FOOS = ['foo' + str(i) for i in range(n)] STATES = [State(foo, 'value') for foo in FOOS] @app.callback( Output('plot', 'children'), [Input('button', 'n_clicks')], STATES) def update_contents(clicks, *args): print("click_num:{}".format(clicks)) foo_args = args[0:len(FOOS) - 1] return foo_args[0]知らなかったときの、Input,Stateの書き方
- このやり方を知らなかったときは、下記のように書いていました。
- 冗長性だったものをきれいに書くことができました。
@app.callback( Output('plot', 'children'), [Input('button', 'n_clicks')], [State('foo1','value'),State('foo2','value'),State('foo3','value'),State('foo4','value'),State('foo5','value')] def update_contents(clicks, *args): print("click_num:{}".format(clicks)) foo_args = args[0:len(FOOS) - 1] return foo_args[0]
- 投稿日:2019-12-09T22:24:00+09:00
【Python】クラス変数と__init__ってどっちが最初に実行されるの?
pythonを書いていてふと思いました。
「クラス変数と__init__はどっちが先に実行されるんだ???」
深掘りはしません。小ネタです。
最後まで読むにはもったいないくらいの小ネタなので最初に結果書いちゃいます。結果
最初にクラス変数の処理が行われ、その後に__init__が実行されます。
検証
クラス変数と__init__にそれぞれprint()を書きます。その実行結果からどちらが先に表示されたかを確認します。
test.pyclass main: s = 'クラス変数が定義されました。' print(s) def __init__(self): s = '__init__が実行されました。' print(s) if __name__ == '__main__': main()結果$ python test.py クラス変数が定義されました。 __init__が実行されました。先にクラス変数が実行され、その後に__init__が実行されています。
では、次は__init__の下にクラス変数を定義してみましょう。コードは汚くなりますが検証なので...test.pyclass main: def __init__(self): s = '__init__が実行されました。' print(s) s = 'クラス変数が定義されました。' print(s) if __name__ == '__main__': main()結果$ python test.py クラス変数が定義されました。 __init__が実行されました。結果は変わっていません。どちらを上に書いても必ずクラス変数から実行されることがわかりました。
それだけです。追記
コメントで
main()を呼ばずに実行してみてください。
面白い結果になりますよ。と頂き、やってみたところクラス変数の部分のみ実行されました。この挙動を理解出来次第、この記事は修正致します。
一生初心者から抜け出せません。でも楽しいです。
- 投稿日:2019-12-09T22:12:51+09:00
python初心者があれこれ調べてみた
あれこれ調べてみた
python初心者が使うコードについてあれこれ調べてみた
Pillowについて
ブログに画像をアップする上でpillowをinstallする必要があるので調べた。
今も開発が進められているpythonのライブラリ(より高度なことをするならopenCV)
画像の色の変換やトリミングなど加工が色々できるpip
パッケージをinstallするときに使う。
pip install ## みたいな感じstatic_URL
project名/setting.pyの一番下にあるコード。以下のURLがわかりやすい
https://qiita.com/saira/items/a1c565c4a2eace268a07os.path()
osに依存する様々な機能を利用するためのモジュール
ファイルやディレクトリ操作が可能
os.path.joinはパスとファイル名を結合できる
MEDIA_ROOT = os.path.join(BASE_DIR, 'media')はBASE_DIRとmediaを結合している
os.path.dirname()は指定したパスからファイル名を除いたものを返す
https://codor.co.jp/django/about-basedirフォルダ名の中にproject名があり、app名が並列になっている
projectフォルダ名
┗project名
┗app名ImageFields
modelの中にある画像ファイルを扱うための変数
- 投稿日:2019-12-09T22:00:14+09:00
データを分析できない学生Kaggler(低迷期)が自分を分析する
はじめに
自己紹介
チズチズと申します。今は14歳で中2です。
多趣味型ですが、特にタイピングをしていました。(過去形)今は技量低めのイキリKagglerになってます。
”一応”IEEEで銅メダルを取りました。なぜ”一応”なのかは後ほどわかります。
AtCoderに飽きてからKaggleに入門しました。絶対に自分の力でMasterになってやる。
書こうと思ったきっかけ
アドベントカレンダー書いてみたかったので。
何か記事を書こうとは思ったんですけど、今はスキルでは技術を紹介するレベルではないので今のKaggle低迷期の現状をリアルに伝えようと思います。所詮Kaggleも競プロみたいなもんだろとか思ってましたが、完全に舐めてました。やることちゃんとやらないと生きてけない……
要約するとデータ分析できないKagglerが自分を分析するという記事です(自己啓発系サイエンティスト)
文字ばかりで読みづらいかもしれませんが読んでもらえると嬉しいです。あと、アドバイスはうるさいくらいでもいいのでください。お願いします。
教訓は下にまとめます。
Kaggle低迷期の現状
これまでとこれからを書くよりもまず自分の現状を書いたほうが良いと思いました。
今はいろいろコンペに参加しているんですけど、低迷期なのでわからないことだらけです。言語の壁
I speak Japanese.I'm not good at English. I'm learning English. I should keep learning a lot:)
母国語は日本語なので英語は苦手です。(オンライン英会話をやって少し学ぼうとはしているけど)Kaggleはすべて英語です。Discussionも。もちろん、日本語で書いても良いんですけど日本人同士の議論になってしまうのでGoogle翻訳を使ってでも英語を使うべきっぽいです。
もちろん、外国語なので難しいんですけどちゃんと読めばわかります。(特にnotebookはグラフやコード付きなので尚更)
言語を理由にしてできないはただの言い訳なのかなと思いました。変に語らなければ中学英語でも大抵の質問の受け答えもできます。(GitHubのissueやDiscussionでも普通に)
Google翻訳使えば読めないわけではないですが、まだ少し抵抗があります。日常から英語に触れようと、スマホの設定はすべて英語にしています……(でもまだ全然慣れない)
本質を理解していない
言語の壁に付随してくる問題だと思うんですけど、そもそもデータの特性がわからないので何を分析すればよいのかもわからずただひたすらEDAを読んでわからずに1日を終える日を繰り返してしまっています。「何がしたいのか」を理解せずにイキってEDAカーネルを読むのはお前には100万年早いんだよってことでしょうか。反省します。
今まで何回やるやる詐欺をしていたことだろうか。
わからない日々が繰り返されるとだんだん憂鬱になってくるのでやる気も失せてきます。マイナビコンペのときは日本語だったおかげか何をするのかが大体わかっていたのでやる気に満ちあふれていました。
やる気はあるんですけど五里霧中の中ビーチフラッグをしているようで諦めたくなる
Kaggle本を読んで少しでも前が見えるように模索していきたい……
キラキラプログラミング初心者にはなれない
どちらかというと存在ダークネスただのコントリビューターになってます。
ビルド失敗して環境全部ぶち壊してOS初期化させたり、メモリのスワップ溢れさせて1TBのSSDを満杯にさせてしまって起動不可能にさせてしまったり……とダークネスな事件ばかり起きてます。
Kaggleのdiscussion見てると面白い特徴を見つけてる人が多々いて、すげぇなと感心してしまうんですけどそれまでに何時間データと見つめ合ってたのだろうか考えてしまいます。
本質が理解できればもうこっちのもんだと思っています。何をするべきかわかるのでどんどん仮説立てて実験して立証させてスコア上げて喜んで人生単調増加しそうです。
本質理解できればキラキラプログラマーになれるんでしょうか。カッコつけプログラマーになろうとして墜落した話
- classを用いてコメントもドキュメントレベルに記載して
- 必要のないところまでのログの管理(そもそもログの管理すら怪しいが)
- Gitをちゃんと使ってピカピカコーディング
理想像を追い求めていった結果墜落しました。理由はシンプルで、本質じゃないところに時間を書けて本質(データサイエンス)を見失ってしまったことにあります。
Gitも使おうと思いましたが、気まぐれでコード書いてるのでcommitするの忘れてしまいます。
class使うと中の変数の確認が面倒なのでできるだけnotebookのように書こうと思います。IEEEコンペで何があったか
あのコンペは自分が初めてkaggleでメダルを取ったコンペでした。しかし、何もわからないまま終えてしまったのでそこまで誇れません……というのもほとんどデータを理解しておらずわからないまま進んでいたのでパラメータいじったりよくわからない特徴量作って遊んでたら偶然スコアが上がっただけです。一部は実力かもしれませんが、ほとんど何もしてないし何もわからなかったので メダル=やったぜ ではないなと実感しました。
以上の理由から”一応”メダル取ったぜ と記しました。今度のコンペでは堂々たるメダルを取ってやりたい……
まとめると
教科書が読めない子どもたち 状態になってます。(1年前くらいに本買いました)
読解力が無い人間はAIに変わっていくとか書いてありますが、AIを作っていく人間が読解力がなかったら本末転倒……
データの読解力というかコンペの読解力を上げていく必要があると考えました。
反省と教訓
目的を理解する
これが多分いちばん大事だと思いました。今まで”目的”がわからないまま何となくデータを見て何となくコーディングしていましたが、やっぱり何となくなので全然うまくいきません。しかも、議論がよくわかりません(目的がわからないので)
とりあえず、序盤は目的を理解することから始めて自分は何をすればよいのかを明確にしてからコンペを進めるべきだとわかりました。早とちりして怠惰に謎のEDAしたりよくわからない分析したりするくらいならoverviewをちゃんと読もうと思います。(starter kernelとか参考になるらしい)
アウトプットする(?)
これは自分が初心者だからであって全員に当てはまるものではないと思いますが、自分は多分アウトプットしたほうがいい人間だと思います。
先程の目的を理解するところでもあったとおりに目的がわからないと進めませんが、もし万が一自分がトンチンカンな理解をしていたらどうでしょう。アンタ!何やってるの!違う!(極端ですが)とでも刺されない限りは平常運行できないでしょう。
場合によってはそのアウトプットが評価されることもあると思うので常識的な範囲内で可能な限りするべきなのかなぁと思いました。
過去には黒歴史混じりのJapanese Kernel(周りは英語で書いてるのに自分だけ日本語でKernelを作成)もありましたが、書いて損はなかったなとは思っています。
くじけない
これはマイナビコンペから得た教訓です。
実際マイナビコンペは最初ソロでちょちょっとやってたんですけど全然精度が上がらず諦めていたんですけど、チームマージしてからチームのためにやるぞ!!!!って気持ちでいろいろ調べたり分析したりしたら新しい発見が見つかってきました。メモをする癖をつける
Jupyter NotebookでもSlack1人チャンネルでも自分が今日何をしたのか(実験とその結果)はすべてメモするべきだと感じました。3日経つと人間忘れてしまいますし、2ヶ月あるコンペで1日1日何をしたかなんて覚えてられません。自分が何をするべきなのかを理解するためにも無駄な実験回さないためにもメモを取るべきだと思いました。(長々と書く必要はないと思いますが)
マイナビコンペのときも、Slackの過去ログは参考になりました。個人参加ではあまり意識していませんでしたが、チームで取り組んだときに気付きました。
おわりに
読んでくれてありがとうございました。
自分はこの記事を書いたことによって低迷期を脱出できそうな感じがしています。
これが全てじゃないと思いますし、所詮Kaggle Expert未満なので最適解とはかけ離れてるかもしれません。
Kaggle Grand Master達は意識せずに呼吸するようにデータサイエンスできるんでしょうかね……(他人のことなのでわからないですけど)しかしこの記事が誰かの役に立ってくれたら嬉しい限りです。
何かあれば何でもコメントください!
まだデータサイエンスのデの字も読めていない初心者ですが、少しずつスキルを磨き上げていこうと思います。低迷期ですが、まだまだKaggleは諦めてません。
”真”データサイエンティストになってまたQiita記事書けるようになりたいです。
- 投稿日:2019-12-09T21:57:42+09:00
最高のランダムドットステレオグラム(RDS)を求めて。
前回の記事でPythonを使ってオリジナルのランダムドットステレオグラムの作成に挑戦した。
無事に立体視をすることはできたのだが、単に丸印やテキストを立体視しただけで満足してしまった。今回はもう少しかっこいいものを作る。
色を変更する
前回はランダムドットステレオグラムをグレースケールで表示させていた。これがなんか昔のテレビの砂嵐みたいで怖い。
Matplotlibにはグレースケール以外にもいろいろなカラーマップがあるので変更してみた。plt.imshow(stereogram, cmap='spring')
貞子感がなくなってだいぶPOPになった。イイネ。深み
前回は立体パターンの深度マップを2値で作成していた。これではいろんな意味で深みがない。
深度マップを連続的な数値にすることで立体の浮かび上がらせる程度を調整することができる。ためしに下のようなパターンを準備した。
def make_depthmap(shape=(400, 600)): depthmap = np.zeros(shape, dtype=np.float) cv2.circle(depthmap, (200, 100), 50, (255 ,255, 255), -1) cv2.circle(depthmap, (400, 100), 50, (200 ,200, 200), -1) cv2.circle(depthmap, (300, 200), 50, (155 ,155, 155), -1) cv2.circle(depthmap, (200, 300), 50, (100 ,100, 100), -1) cv2.circle(depthmap, (400, 300), 50, (55 ,55, 55), -1) return depthmap
左上からZ順に暗くなっていくパターン。これでRDSを作成してみる。
すごいぞ。深度マップの暗さに応じて、飛び出し具合が変わっている。
こんなパターンでもやってみた。def make_rectangle_depthmap(shape=(400, 600)): depthmap = np.zeros(shape, dtype=np.float) for i in range(16): c = 255 - i * 16 cv2.rectangle(depthmap, (100+i*25, 100), (125+i*25, 300), (c, c, c), -1) return depthmap
結果がこちら
階段みたいに見える。イイネ。
おわり
次回は写真(2次元画像)から深度マップを作成して、普通の写真を立体視できるようにしたい。
ランダムドットステレオグラマーになりたい。





- 投稿日:2019-12-09T21:23:56+09:00
__version__の罠とベストプラクティス
Pythonモジュールを配布する場合、そのバージョン番号を記述する必要がありますが、
pip installした後にpip listで参照出来るように、setup.pyのsetup(verison='')に記述import mylibraryした後にmylibrary.__version__で参照出来るように、mylibrary/__init__.pyに記述の2つの記述が必要になります。
当然、同じバージョン番号を2箇所に書くのは手間、かつ間違いの元なので、1箇所で済ませたい所です。
__version__.pyにバージョン番号を記述し、mylibrary/__version__.py__version_info__ = (1, 0, 0) __version__ = '.'.join(map(str, __version_info__))
setup.pyと__init__.pyからimport __version__するという構成は、よくあるパターンだと思います。__version__の罠
この構成には問題があります。
__init__.py(もしくは__init__.pyでimportしているコアモジュール)に、
非標準モジュールのimportを記述した場合です。mylibrary/__init__.pyfrom __version__ import __version__ from core import MyClass # mylibrary.MyClassで使えるようにするためのショートカットmylibrary/core.pyimport numpy as np # MyClassで必要な外部モジュールのimport class MyClass(object): pasこの状態で
setup.pyを実行すると、、、突然のImportError> py setup.py install Traceback (most recent call last): File "C:\Users\hoge\git\example\setup.py", line 4, in <module> from mylibrary import __version__ File "C:\Users\hoge\git\example\mylibrary\__init__.py", line 2, in <module> from .core import MyClass File "C:\Users\hoge\git\example\mylibrary\core.py", line 1, in <module> import numpy as np ImportError: No module named numpyImportErrorとなり、mylibraryモジュールのインストールが出来なくなります。
numpyをインストールするためのinstall_requiresが
setup.pyに記述してあるにも関わらず、
そのsetup.pyが実行出来ずにインストール出来ないという、「金庫の中の鍵」状態です。ベストだったプラクティス1
原因は
__version__.pyをimportすると、同じディレクトリの__init__.pyも一緒にimportされてしまう為です。
従って、解決策は「importせずに__version__.pyを読み込む」です。setup.py#!/usr/bin/python from setuptools import setup, find_packages # from __version__ import __version__ # 削除、ImportErrorの原因 import os packages = find_packages() ns = dict() for package in packages: version_file = os.path.join(package, '__version__.py') if os.path.exists(version_file): with open(version_file, mode='rt') as f: eval(compile(f.read(), version_file, 'exec'), dict(), ns) break __version__ = ns['__version__'] del ns setup( version=__version__, )詳しく解説はしませんが、
__version__.pyを探し、evaluateして、変数__version__を直接取り出しています。
この方法で、ImportErrorを引き起こす__init__.pyのimportを回避することが出来ます。とは言え、
setup.pyにメタデータ以外のコードを書きすぎるのは抵抗があるし、
__init__.pyで非標準モジュールをimportしたらダメというのも現実的ではありません。「バージョン番号の記述を1箇所にまとめようとしたらエラーになった」みたいな事がが容易に起こり得るようでは、
「__version__はアンチパターン」という意見が出るのも頷けます。ベストプラクティス
setup.pyをこう記述してください。setup.pyfrom setuptools import setup setup()見ての通り、
setup()を呼び出すだけで、設定は空っぽです。
setup()は中身が空かどうかに関わらず、setup.cfgファイルがあれば、そこから不足している設定を取得します。
そして、setup.cfgにはファイルと変数を指定して参照する記述方法があります。setup.cfg[metadata] version = attr: mylibrary.__version__.__version__これで
setup()のversionに、ファイルmylibrary/__version__.pyの変数__version__を適用したのと同じ効果があります。ところで、この方法でも、
__version__.pyをimportするのと同じ様に、
__init__.pyもimportされるのではないか?- そしてImportErrorになるのではないか?
という気がしますが、
setup.cfgに記述した変数の参照は「ベストではないプラクティス」のsetup.pyと同じように、
importの仕組みを通さずにファイルを直接eval()するようで、ImportErrorにはなりません。まとめ
version以外にも
setup.pyに記述していた大抵の事は、setup.cfgにスマートに記述できます。
また、setup()のメタデータだけでなくflake8やpy.test、nosetestなどの設定も一緒に記述することが出来、
ディレクトリを綺麗に保つことにも役立ちます。せっかく
setup.cfgを置くのだから、最大限活用して行きたいですね。
本当はこれを「ベストプラクティス」として今年のAdventCalendarを書くつもりでしたが、直前になって圧倒的に簡単な方法が見つかったので、まるっとボツになりました。悔しいのでそのまま置いておきます。
setup.cfgが使えないような超絶古い環境を使っている人は参考にしてください。 ↩
- 投稿日:2019-12-09T21:23:22+09:00
QiitaでアウトプットしたものをWord cloudでまとめてみた
プロトアウトスタジオアドベントカレンダー10発目の記事です!
概要
プロトアウトスタジオに入ってから、Qiitaでアウトプットするようになりました。
(まだまだ全然数少ないですが)そこで今回は、これまでどんなもの書いたんだっけという振り返りも兼ねて、
自分がアウトプットしたものをPythonのWord Cloudで可視化していこうと思います。Word Cloudについて
WordCloudとは、文章の中から出現頻度が高い単語を選んで、単語の出現頻度に応じた大きさで図示していくものです。
Python用のライブラリがあるので、コードもこちらを参考にしていきます。
http://amueller.github.io/word_cloud/index.htmlスクレイピングで文章集める
Word Cloudで可視化するために、自分のQiitaをスクレイピングして、文章(材料)を集めていきます。
自分の過去記事使いながらまずは記事のタグ情報を集めて可視化します。
scraping.pyimport urllib.request from bs4 import BeautifulSoup url = "https://qiita.com/sksk_go" res = urllib.request.urlopen(url) soup = BeautifulSoup(res, 'html.parser') #タグ取得用に書き換え name = soup.find_all("a",class_="u-link-unstyled TagList__label") ret = [] for t in name: ret.append(t.text) print(ret)集めたテキストをWord Cloudで表現してみます。
Word Cloudで処理
こちらの記事参考にします。
[Python]銀河鉄道の夜をWordCloudで可視化してみた!wordcloud.pyimport MeCab from wordcloud import WordCloud data = open("data.txt","rb").read() text = data.decode('utf-8') mecab = MeCab.Tagger("-ochasen") node = mecab.parseToNode(text) data_text = [] while node: word = node.surface hinnsi = node.feature.split(",")[0] if hinnsi in ["動詞","副詞","形容詞","名詞"]: data_text.append(word) else: print("|{0}|の品詞は{1}だから追加しない".format(node.surface,node.feature.split(",")[0])) print("-"*35) node = node.next text = ' '.join(data_text) #除外ワード stop_words = [ u'てる', u'いる', u'なる', u'れる', u'する', u'ある', u'こと', u'これ', u'さん', u'して', \ u'くれる', u'やる', u'くださる', u'そう', u'せる', u'した', u'思う', \ u'それ', u'ここ', u'ちゃん', u'くん', u'', u'て',u'に',u'を',u'は',u'の', u'が', u'と', u'た', u'し', u'で', \ u'ない', u'も', u'な', u'い', u'か', u'ので', u'よう', u''] wordcloud = WordCloud(font_path='/System/Library/Fonts/ヒラギノ明朝 ProN.ttc',width=480, height=300,background_color='white',stopwords=set(stop_words)) # テキストからワードクラウドを生成する。 wordcloud.generate(text) # ファイルに保存する。 wordcloud.to_file('wordcloud.png')できたものがこちら
記事の量少ないのでスカスカですね……
Python成分多めな感じ。厚めに教わったIoTなども入ってますね。おまけ
先ほどはタグだけだったので、自分のQiita記事の文章をとってきて、Word Cloudで可視化してみます。
所々変な単語入ってますが、なんとなく言いたいことわかります。
やっぱPythonとか機械学習とかそっちの成分多めですね。
自分の興味もどちらかというと強いですし。傾向がわかるのではないでしょうか。終わりに
Qiitaを題材にWord Cloud使ってみましたが、Twitterとか、ブログとかそういう普通の文章から取ってみた方がより個性出てて面白そうですね。歌詞とか小説とかそういう文章でやってみるのも面白そう。
aki_sugaさんです!お楽しみに!


- 投稿日:2019-12-09T21:10:51+09:00
65日目 Jupyter notebookでグラフを描くためにmatplotlibをインストールしました。
Jupyter notebookでmatplotlibを使ってみます。
importしてみると・・・
あら、はいっていません。
matplotlibで調べると、いろんなグラフのサンプルがありました。おもしろそうなのでダウンロード。後でみてみます。
matplotlibをインストール
$ conda install matplotlib Collecting package metadata (current_repodata.json): done Solving environment: / The environment is inconsistent, please check the package plan carefully The following packages are causing the inconsistency: (以下略、7分後) Preparing transaction: done Verifying transaction: done Executing transaction: done $ $ pip list | grep matplotlib matplotlib 3.1.1いい感じです。
Jupyter notebookを起動して、matplotlibを呼び出します。
font cache を作るからちょっと待ってねってメッセージがでます。ちょっとってどのくらいでしょう。とりあえず5分待ってみました。
とくに変化はないので、とりあえず次へ。
グラフを書いてみます。
グラフができました!
(1時間)



- 投稿日:2019-12-09T20:42:35+09:00
Pythonの標準ライブラリ:前半(Python学習メモ⑧)
OSインターフェース
オペレーティングシステムとやりとりする関数
import os os.getcwd() # カレントディレクトリ取得 os.system('mkdir today') # システム側のシェルでコマンド実行ファイルやディレクトリの管理には
shutilモジュールが便利import shutil shutil.copyfile('data.db', 'archive.db') shuti.move('/build/executables', 'installdir')ファイルのワイルドカード
globモジュールはディレクトリ内をワイルドカード検索してファイルのリストを返す
import glob glob.glob('*.py') #.pyが末尾につくファイルのリストが返却されるコマンドライン引数
pythonをコマンド実行した際に渡した引数は
sys.argvに格納されるimport sys print(sys.argv) # 引数リストを取得 # 0番目の要素はファイル名になる他にも引数を扱うモジュールとして以下がある
- getopt
- argparse
エラー出力のリダイレクトとプログラムの終了
sysモジュールのstdin, stdout, stderrを使用する
stderrはstdoutがリダイレクトされている際もメッセージを表示するのに便利文字列パターンマッチング
正規表現などは
reモジュールを使用して実装できるimport re print(re.findall(r'\bf[a-z]*', 'whitch foot or hand fell fastest')) # ['foot', 'fell', 'fastest'] print(re.sub(r'(\b[a-z]+) \1', r'\1', 'cat in the the hat')) # cat in the hat数学
mathモジュール
import math math.cos(math.pi / 4) # 0.7071067811865476 math.log(1024, 2) # 10.0randomモジュール
import random random.choice(['apple', 'pear', 'banana']) # リストからランダムにチョイス # 'apple' random.sample(range(100), 10) # range(100)から10個抽出(重複無し) # [48, 5, 42, 15, 23, 78, 55, 72, 39, 1] random.random() # ランダムな浮動小数点数 # 0.2785335302723758 random.randrange(6) # range(6)からランダムに選んだ整数 # 0statisticsモジュール - 統計量を求める
import statistics data = [2.75, 1.75, 1.25, 0.25, 0.5, 1.25, 3.5] statistics.mean(data) # 平均 # 1.6071428571428572 statistics.median(data) # 中央値 # 1.25 statistics.variance(data) # 分散 # 1.3720238095238095他の数値計算用モジュールはSciPyプロジェクトを参照
インターネットへのアクセス
- urllib.request - URLにあるリソースを取得する
from urllib.request import urlopen with urlopen('http://tycho.usno.navy.mil/cgi-bin/timer.pl') as response: for line in response: line = line.decode('utf-8') # バイナリデータをテキストにデコード if 'EST' in line or 'EDT' in line: # 東部標準時を探す print(line)
- smtplib - メールを送る
import smtplib server = smtplib.SMTP('localhost') server.sendmail('soothsayer@example.org', 'jcaesar@example.org', """To: jcaesar@example.org From: soothsayer@example.org Beware the Ideas of March. """ ) server.quit()日付と時間
from datetime import date now = date.today() print(now) # 2019-12-09 print(now.strftime("%m-%d-%y. %d %b %Y is a %A on the %d day of %B.")) # 12-09-19. 09 Dec 2019 is a Monday on the 09 day of December. birthday = date(1964, 7, 31) age = now - birthday print(age.days) # 20219パフォーマンス計測
変数の交換でのパフォーマンス差を測ってみる
from timeit import Timer time1 = Timer('t=a; a=b; b=t', 'a=1; b=2').timeit() time2 = Timer('a,b = b,a', 'a=1; b=2').timeit() print(time1) # 0.020502762 print(time2) # 0.018866841999999995他にも
profileやpstatsモジュールは大きめのコードブロックに対して計測するのに適している品質管理
関数を書くときにテストも一緒に書いておき、開発中にテストを実行する
doctestモジュールは、モジュールをスキャンし、docstringに埋め込まれたテストを検証するテストは一般的なコールとその結果を
docstringに記載するdef average(values): """数値のリストから算術平均を計算 >>> print(average([20, 30, 70])) 40.0 """ return sum(values) / len(values) import doctest doctest.testmod() # 埋め込まれたテストを自動で検証する
unittestモジュールはより包括的な一連のテストを別ファイルに持つことができるimport unittest from doctest_sample import average class TestStatisticalFunctions(unittest.TestCase): def test_average(self): self.assertEqual(average([20, 30, 70]), 40.0) self.assertEqual(round(average([1, 5, 7]), 1), 4.3) with self.assertRaises(ZeroDivisionError): average([]) with self.assertRaises(TypeError): average(20, 30, 70) unittest.main()
- 投稿日:2019-12-09T20:41:11+09:00
Python の全て異常クラス
BaseException +-- SystemExit +-- KeyboardInterrupt +-- GeneratorExit +-- Exception +-- StopIteration +-- StopAsyncIteration +-- ArithmeticError | +-- FloatingPointError | +-- OverflowError | +-- ZeroDivisionError +-- AssertionError +-- AttributeError +-- BufferError +-- EOFError +-- ImportError | +-- ModuleNotFoundError +-- LookupError | +-- IndexError | +-- KeyError +-- MemoryError +-- NameError | +-- UnboundLocalError +-- OSError | +-- BlockingIOError | +-- ChildProcessError | +-- ConnectionError | | +-- BrokenPipeError | | +-- ConnectionAbortedError | | +-- ConnectionRefusedError | | +-- ConnectionResetError | +-- FileExistsError | +-- FileNotFoundError | +-- InterruptedError | +-- IsADirectoryError | +-- NotADirectoryError | +-- PermissionError | +-- ProcessLookupError | +-- TimeoutError +-- ReferenceError +-- RuntimeError | +-- NotImplementedError | +-- RecursionError +-- SyntaxError | +-- IndentationError | +-- TabError +-- SystemError +-- TypeError +-- ValueError | +-- UnicodeError | +-- UnicodeDecodeError | +-- UnicodeEncodeError | +-- UnicodeTranslateError +-- Warning +-- DeprecationWarning +-- PendingDeprecationWarning +-- RuntimeWarning +-- SyntaxWarning +-- UserWarning +-- FutureWarning +-- ImportWarning +-- UnicodeWarning +-- BytesWarning +-- ResourceWarning
- 投稿日:2019-12-09T20:41:11+09:00
Python 例外クラス一覧
BaseException +-- SystemExit +-- KeyboardInterrupt +-- GeneratorExit +-- Exception +-- StopIteration +-- StopAsyncIteration +-- ArithmeticError | +-- FloatingPointError | +-- OverflowError | +-- ZeroDivisionError +-- AssertionError +-- AttributeError +-- BufferError +-- EOFError +-- ImportError | +-- ModuleNotFoundError +-- LookupError | +-- IndexError | +-- KeyError +-- MemoryError +-- NameError | +-- UnboundLocalError +-- OSError | +-- BlockingIOError | +-- ChildProcessError | +-- ConnectionError | | +-- BrokenPipeError | | +-- ConnectionAbortedError | | +-- ConnectionRefusedError | | +-- ConnectionResetError | +-- FileExistsError | +-- FileNotFoundError | +-- InterruptedError | +-- IsADirectoryError | +-- NotADirectoryError | +-- PermissionError | +-- ProcessLookupError | +-- TimeoutError +-- ReferenceError +-- RuntimeError | +-- NotImplementedError | +-- RecursionError +-- SyntaxError | +-- IndentationError | +-- TabError +-- SystemError +-- TypeError +-- ValueError | +-- UnicodeError | +-- UnicodeDecodeError | +-- UnicodeEncodeError | +-- UnicodeTranslateError +-- Warning +-- DeprecationWarning +-- PendingDeprecationWarning +-- RuntimeWarning +-- SyntaxWarning +-- UserWarning +-- FutureWarning +-- ImportWarning +-- UnicodeWarning +-- BytesWarning +-- ResourceWarning
- 投稿日:2019-12-09T20:28:31+09:00
Microsoft Cognitive Toolkit : eXplainable AI - Activation Maximization
目標
Microsoft Cognitive Toolkit (CNTK) を用いて畳み込みニューラルネットワークの入力画像の最大化をやってみました。
人工知能に関する断創録 - 畳み込みニューラルネットワークの可視化 を参考にしました。
導入
入力画像の最大化とは
画像分類を行うデファクトスタンダードである畳み込みニューラルネットワーク (CNN) がどのように画像から特徴量を獲得して分類するかは非常に興味深い話題であり、日々研究が進められています。その一環として、入力画像の最大化というものがあります。
一般的に画像中の物体を分類する CNN は画像を入力として受け取り、どのカテゴリーに分類されるかを出力しますが、入力画像の最大化ではこれを逆に考えます。[1]
つまり、出力が最大になるような入力画像はどんな画像かを求める問題となります。そしてあるカテゴリーへの出力が最大になるような入力画像は、例えばカテゴリーが猫である入力画像であれば、それは CNN が捉える最も猫らしい画像であり、その画像には猫が写っていると期待できます。
事前学習済みの VGGNet
今回は事前学習済みの VGG19 [2] を用いました。VGGNet はオックスフォード大学の Visual Geometry Group が開発した畳み込みニューラルネットワークで、3x3-s1 の畳み込み層と ReLU 活性関数、2x2-s2 の最大値プーリングそして全結合層のみで構成されています。
Batch Normalization [3] や Residual Connection [4] がまだなかった時期に層の深さと性能向上の関係を調べるために訓練された非常にシンプルなモデルですが、様々な研究・開発で事前学習済みモデルとして採用されるモデルであり、VGG Mystery という議論のタネにもなる興味深いモデルです。
CNTK の形式で保存された事前学習済みの VGG19 は以下の URL からダウンロードできます。
https://www.cntk.ai/Models/Caffe_Converted/VGG19_ImageNet_Caffe.model入力画像の最大化アルゴリズム
入力画像の最大化の定式化は、以下のような最適解問題になります。
x' = x + \eta \frac{\partial a_i(x)}{\partial x}$x$ は入力画像、$a_i$ は出力層の $i$ 番目のノードを表し、$\eta$ は学習率を表します。入力画像の初期値は乱数とします。
また、画像の見栄えを良くするために隣接画素間の差分を考慮する Total Validation による正則化を導入します。
TV = \sum_{i, j} \sqrt{(I_{i+1, j} - I_{i, j})^2 + (I_{i, j+1} - I_{i, j})^2}実装
実行環境
ハードウェア
・CPU Intel(R) Core(TM) i7-6700K 4.00GHz
・GPU NVIDIA GeForce GTX 1060 6GBソフトウェア
・Windows 10 Pro 1903
・CUDA 10.0
・cuDNN 7.6
・Python 3.6.6
・cntk-gpu 2.7
・matplotlib 3.1.1
・numpy 1.17.3実行するプログラム
actmax.pyimport cntk as C import matplotlib.pyplot as plt import numpy as np img_channel = 3 img_height = 224 img_width = 224 alpha = 1.0 beta = 1.0 epsilon = 1e-5 def vgg19(h): model = C.load_model("./VGG19_ImageNet_Caffe.model") params = model.parameters for i in range(16): h = C.convolution(params[-(2 * i + 2)].value, h, strides=1, auto_padding=[False, True, True]) + params[-(2 * i + 1)].value h = C.relu(h) if i in [1, 3, 7, 11, 15]: h = C.pooling(h, C.MAX_POOLING, pooling_window_shape=(2, 2), strides=(2, 2), auto_padding=[False, True, True]) h = C.reshape(h, -1) h = C.times(h, params[4].value.reshape(-1, 4096)) + params[5].value h = C.times(h, params[2].value) + params[3].value h = C.times(h, params[0].value) + params[1].value return h if __name__ == "__main__": input = C.input_variable(shape=(3, 224, 224), dtype="float32", needs_gradient=True) model = vgg19(input / 255) img = np.ascontiguousarray((np.random.rand(3, 224, 224) - 0.5) * 20 + 127, dtype="float32") node = 65 # sea snake # # activation maximization # activation = C.element_times(alpha, model[node]) total_variation = C.reduce_sum( # total variation regularization C.sqrt(C.square(input[:, 1:, :-1] - input[:, :-1, :-1]) + C.square(input[:, :-1, 1:] - input[:, :-1, :-1]))) activation -= C.element_times(beta, (total_variation / np.prod(input.shape))) for i in range(500): grads = activation.grad({input: img})[0] grads /= (np.sqrt(np.mean(np.square(grads))) + epsilon) img += grads prob = C.softmax(model).eval({input: img}) plt.figure() plt.imshow(np.transpose(np.clip((img - img.mean() / img.std()) / 255, 0, 1) * 255, (1, 2, 0)).astype("uint8")) plt.axis("off") plt.title("{:s} {:.2f}%".format(label[prob.argmax()][:-1], prob.max() * 100)) plt.show()
結果
65番目 sea snake, 718番目 pier, 99番目 goose の結果を可視化したものが下図です。ウミヘビや桟橋、ガチョウの特徴らしきものが写っている画像になり、再入力した際のカテゴリーは 100% に近くなっています。
上の例は成功していますが、最適化問題であるため失敗することもあります。その場合はパラメータなどを調整することによって改善できる場合もあるようです。
参考
Neural Style Transfer with Adversarially Robust Classifiers
人工知能に関する断創録 - 畳み込みニューラルネットワークの可視化
- Dumitru Erhan, Yoshua Bengio, Aaron Courville, and Pascal Vincent "Visualizing Higher-Layer Features of a Deep Network", University of Montreal. 2009, 1341(3), 1.
- Karen Simonyan and Andrew Zisserman. "Very Deep Convolutional Networks for Large-Scale Image Recognition", arXiv preprint arXiv:1409.1556 (2014).
- Ioffe Sergey and Christian Szegedy. "Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift", arXiv preprint arXiv:1502.03167 (2015).
- Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. "Deep Residual Learning for Image Recognition", The IEEE Conference on Computer Vision and Pattern Recognition. 2016, pp 770-778.

- 投稿日:2019-12-09T20:28:14+09:00
Natural Language API(感情分析)がネットスラングに対応しているか自分なりに検証してみた
概要
- はじめに
- 評価方法
- 手順
- twitterAPIでテキストデータを集める
- 前処理
- Google Cloud Natural Language API
- ヒストグラム
- 検定
- 標本数は足りているか
- 改善点
- おわりに
- 参考
はじめに
僕は自然言語処理でテキストデータの感情分析をすることにハマっています。それをやっている中で、ネットスラングに対応することは難しいことだと感じました。それで、今回、Google Cloud Natural Language APIにある感情分析サービス(以下 Natural Language API)がネットスラングに対応しているか自分なりに検証してみることにしました。
(注意)自分なりに検証してみただけで、必ずしもNatural Language APIがネットスラングに対応しているかを決定づけるものではないです。評価方法
文によっては、「笑う」は「草」と置き換えることができると考えたので、それを使って評価を行います。例えば、以下の文は同じ意味になります。
・3分で3rt4いいねは笑う
・3分で3rt4いいねは草文を複数用意して、Natural Language APIで評価を行った時に、「笑う」と「草」でスコアの平均に差があるか検定します。
手順
手順は以下の通りです。
- twitterAPIでテキストデータを集める
- テキストデータに対して前処理
- Natural Language APIでスコアを出す
- 求めたスコアに対して検定を行う
twitterAPIでテキストデータを集める
twitterAPIを使用するには申請が必要なので、[1]を見ながら申請しました。1日で申請が通りました。
申請が通ったので、テキストデータを取得します。[2]のコードをベースにしています。前処理があるので、取得したテキストデータはテキストファイルに書き込むようにしました。検索キーワードを「笑う」にして検索しています。
import json from requests_oauthlib import OAuth1Session # OAuth認証部分 CK = "" CS = "" AT = "" ATS = "" twitter = OAuth1Session(CK, CS, AT, ATS) url = 'https://api.twitter.com/1.1/search/tweets.json' keyword = '笑う' params ={ 'count' : 100, # 取得するtweet数 'q' : keyword, # 検索キーワード } f = open('./data/1/backup1.txt','w') req = twitter.get(url, params = params) print(req.status_code) if req.status_code == 200: res = json.loads(req.text) for line in res['statuses']: print(line['text']) f.write(line['text'] + '\n') print('*******************************************') else: print("Failed: %d" % req.status_code)検索結果は以下のようになります。
・確かに場外に出すけども相撲は笑う
・笑うとこだから!笑うとこ!!
・なんだそれwwww笑うわwwww前処理
取得したテキストデータを整えます。
ここでやる作業は以下の4つです。
- 「RT 」「@XXXX」といったいらない文字列の除去
- テキストデータから笑いがある行のみを抽出
- 「草」に置き換えられる「笑う」かの判定
- 「笑う」を「草」に変更した文を作成し、csvにまとめる
1と2は以下のように実装しました。
2はツイートの中に改行がある場合があって、3を行う際に大変に感じたので除去しました。import re readF = open('./data/1/backup1.txt','r') writeF = open('./data/1/preprocessing1.txt','w') lines = readF.readlines() for line in lines: if '笑う' in line: #「RT 」の除去 line = re.sub('RT ', "", line) #「@XXXX 」または「@XXXX」の除去 line = re.sub('(@\w*\W* )|(@\w*\W*)', "", line) writeF.write(line) readF.close() writeF.close()3が一番大変でした。
・「笑う」が文末に来ている
・「笑う」の後が句点
・「笑う」の後が「w」
といった場合は高確率で「草」と置き換えることができるとデータを見ていて思ったのですが、データが偏ってしまうと考えました。結局は人力で判定しました。置き換えることができないと判断したテキストデータは除去しました。標本数は200になりました。
4は以下のように実装しました。
import csv import pandas as pd count = 6 lines = [] for i in range(count): print(i) readF = open('./data/'+ str(i+1) + '/preprocessing' + str(i+1) + '.txt') lines += readF.readlines() df = pd.DataFrame([],columns=['warau', 'kusa']) replaceLines = [] for line in lines: replaceLines.append(line.replace('笑う', '草')) df["warau"] = lines df["kusa"] = replaceLines df.to_csv("./data/preprocessing.csv",index=False)ここまでの処理の結果は以下の画像のようになります。
Google Cloud Natural Language API
Google Cloud Natural Language APIにある感情分析サービスはテキストが持っている感情スコアを返してくれます。感情スコアは1に近いほどポジティブで−1に近いほどネガティブです[3]。Google Cloud Natural Language APIには感情分析サービス以外にもコンテンツ分類などもあります。
プログラムは[4]を基に実装しました。
「笑う」・「草」の文をそれぞれNatural Language APIに渡し、それぞれ結果をListに格納します。そしてそれを"warauResult"・"kusaResult"をカラム名として、pandasに追加します。最後に、csvファイルを出力します。from google.cloud import language from google.cloud.language import enums from google.cloud.language import types import os import pandas as pd credential_path = "/pass/xxx.json" os.environ['GOOGLE_APPLICATION_CREDENTIALS'] = credential_path client = language.LanguageServiceClient() warauResultList = [] kusaResultList = [] df = pd.read_csv('./data/preprocessing.csv') count = 9 for index,text in df.iterrows(): #\nの除去 text["warau"] = text["warau"].replace('\n', '') text["kusa"] = text["kusa"].replace('\n', '') #warauの解析 document = types.Document( content=text["warau"], type=enums.Document.Type.PLAIN_TEXT) sentiment = client.analyze_sentiment(document=document).document_sentiment warauResultList.append(sentiment.score) #kusaの解析 document = types.Document( content=text["kusa"], type=enums.Document.Type.PLAIN_TEXT) sentiment = client.analyze_sentiment(document=document).document_sentiment kusaResultList.append(sentiment.score) df["warauResult"] = warauResultList df["kusaResult"] = kusaResultList df.to_csv("./data/result.csv",index=False)ここまでの処理の結果は以下の画像のようになります。
ヒストグラム
warauResultのヒストグラムは以下の通りです。
kusaResultのヒストグラムは以下の通りです。
それぞれ正規分布に従っていると仮定します。
検定
warauResultに格納されている値とkusaResultに格納されている値を比較します。
今回は標本間で対応がある場合の平均差の検定を行います。[5]と[6]を参考にしました。・帰無仮説・・・「笑う」を「草」に変えてもスコアは変わらなかった
・対立仮説・・・「笑う」を「草」に変えたことによってスコアは変わったプログラムは以下のようになります。
from scipy import stats import pandas as pd #標本間で対応がある場合の平均差の検定 df = pd.read_csv('./data/result.csv') stats.ttest_rel(df["warauResult"], df["kusaResult"])結果は以下の通りです。
Ttest_relResult(statistic=3.0558408995373356, pvalue=0.0025520814940409413)stats.ttest_relのリファレンスは[7]です。
引用:「 If the p-value is smaller than the threshold, e.g. 1%, 5% or 10%, then we reject the null hypothesis of equal averages.」
つまり、今回は, pvalueが約2.5%と小さいので、帰無仮説は棄却されます。よって「笑う」を「草」に変えたことによってスコアは変わったとなります。標本には「草」に置き換えられる「笑う」が入った文しかありません(主観的)。なのに、スコアが変わるということはNatural Language APIがネットスラングに対応できてないと結論づけられます。
標本数は足りているか
warauResult、kusaResultそれぞれ、平均の区間推定を行います。[8]を参考にしました。
\begin{aligned} \bar{X}-z_{\frac{\alpha}{2}}\sqrt{\frac{s^2}{n}} < \mu < \bar{X}+z_{\frac{\alpha}{2}}\sqrt{\frac{s^2}{n}} \end{aligned}プログラムは以下のようになります。
from scipy import stats import math print("warauResultの標本平均",df['warauResult'].mean()) print("kusaResultの標本平均",df['kusaResult'].mean()) #.var()は不偏分散を求める print("warauResultの区間推定",stats.norm.interval(alpha=0.95, loc=df['warauResult'].mean(), scale=math.sqrt(df['warauResult'].var() / len(df)))) print("kusaResultの区間推定",stats.norm.interval(alpha=0.95, loc=df['kusaResult'].mean(), scale=math.sqrt(df['kusaResult'].var() / len(df))))結果は以下の通りです。
warauResultの標本平均 0.0014999993890523911
kusaResultの標本平均 -0.061000001728534696
warauResultの区間推定 (-0.0630797610044764, 0.06607975978258118)
kusaResultの区間推定 (-0.11646731178466276, -0.005532691672406637)誤差範囲
・warauResult:約±0.06458
・kusaResult: 約±0.05546Natural Language APIが返す感情スコアの範囲は1から-1です。この範囲における誤差±0.06は小さいと考えました。
ちなみに[9]のように誤差範囲を基に必要なサンプル数を出すことができます。
・warauResultについて
・信頼係数95%
・誤差範囲±0.06458
この時、標本数は200となります。import numpy as np #母集団の標準偏差はわからないので、不偏分散の平方根で代用 rutoN = (1.96 * np.sqrt(df['warauResult'].var()))/ 0.06458 N = rutoN * rutoN print(N)結果は以下の通りです。
200.0058661538003改善点
・「草」に置き換えられる「笑う」かの判定を一人で行っており、客観的でない
→複数人で評価をする・今のデータの集め方は多くの標本数を集めることができない
→必要な標本の数が多い場合、パターンを見つけ自動化を検討する・誤差範囲をどうやって決めるか
→誤差範囲がどれぐらいであればいいかの理由が欲しいおわりに
来年もAdvent Calendarに参加したいですね。
参考
[1]https://qiita.com/kngsym2018/items/2524d21455aac111cdee
[2]https://qiita.com/tomozo6/items/d7fac0f942f3c4c66daf
[3]https://cloud.google.com/natural-language/docs/basics#interpreting_sentiment_analysis_values
[4]https://cloud.google.com/natural-language/docs/quickstart-client-libraries#client-libraries-install-python
[5]https://bellcurve.jp/statistics/course/9453.html
[6]https://ohke.hateblo.jp/entry/2018/05/19/230000
[7]https://docs.scipy.org/doc/scipy-0.14.0/reference/generated/scipy.stats.ttest_rel.html
[8]https://ohke.hateblo.jp/entry/2018/05/12/230000
[9]https://toukeigaku-jouhou.info/2018/01/23/how-to-calculate-samplesize/




- 投稿日:2019-12-09T20:17:37+09:00
WTFormsでAnyOfバリデーションがSelectMultipleFieldのとき常にエラーを返す
TL; DR
AnyOfバリデーションがSelectMultipleFieldに対応していないため。
カスタムバリデーションを用いる必要がある。詳細
AnyOfバリデーションの実装をみると、SelectMultipleFieldに対応していません。
SelectMultipleFieldの場合、field.dataがlist型で渡ってくるので562行目が常にTrueを返してしまいます。解決策
こんな感じでSelectMultipleField用のバリデーションを作成してあげれば良いです。
def anyof_for_multiple_field(values): message = 'Invalid value, must be one of: {0}.'.format( ','.join(values) ) def _validate(form, field): error = False for value in field.data: if value not in values: error = True if error: raise ValidationError(message) return _validate
- 投稿日:2019-12-09T19:33:00+09:00
openpyxl 色 早見表
背景
opnepyxlの棒グラフのcolorが実際どんな色かわからない。確認しようと思う。
(ちょっとずつ追記していきます。)prstClr
https://openpyxl.readthedocs.io/en/stable/api/openpyxl.drawing.colors.html
prstClr Value must be one of {‘yellowGreen’, ‘darkSeaGreen’, ‘mediumBlue’, ‘maroon’, ‘lightCoral’, ‘pink’, ‘orangeRed’, ‘ltCyan’, ‘ltGrey’, ‘navajoWhite’, ‘saddleBrown’, ‘sienna’, ‘medSeaGreen’, ‘firebrick’, ‘lightGrey’, ‘blue’, ‘dkGoldenrod’, ‘darkGreen’, ‘lightGreen’, ‘indigo’, ‘wheat’, ‘mediumSlateBlue’, ‘linen’, ‘skyBlue’, ‘midnightBlue’, ‘darkOrchid’, ‘dkGray’, ‘brown’, ‘lightBlue’, ‘medSlateBlue’, ‘ivory’, ‘purple’, ‘dkOliveGreen’, ‘chocolate’, ‘darkSlateGrey’, ‘darkGrey’, ‘cornflowerBlue’, ‘dkGrey’, ‘dkRed’, ‘chartreuse’, ‘indianRed’, ‘deepPink’, ‘aqua’, ‘darkSalmon’, ‘whiteSmoke’, ‘lightGoldenrodYellow’, ‘turquoise’, ‘paleGreen’, ‘slateGray’, ‘lightGray’, ‘mediumSpringGreen’, ‘ghostWhite’, ‘seaShell’, ‘gray’, ‘darkKhaki’, ‘deepSkyBlue’, ‘lightSlateGrey’, ‘snow’, ‘darkSlateBlue’, ‘slateBlue’, ‘black’, ‘peru’, ‘plum’, ‘ltCoral’, ‘forestGreen’, ‘darkMagenta’, ‘dimGray’, ‘cornsilk’, ‘burlyWood’, ‘cadetBlue’, ‘lavenderBlush’, ‘orange’, ‘violet’, ‘mediumOrchid’, ‘fuchsia’, ‘ltYellow’, ‘silver’, ‘ltSalmon’, ‘tan’, ‘lightSkyBlue’, ‘dimGrey’, ‘lightPink’, ‘moccasin’, ‘darkGray’, ‘cyan’, ‘paleTurquoise’, ‘aliceBlue’, ‘dkBlue’, ‘ltPink’, ‘royalBlue’, ‘seaGreen’, ‘steelBlue’, ‘medOrchid’, ‘antiqueWhite’, ‘darkGoldenrod’, ‘khaki’, ‘paleGoldenrod’, ‘ltSeaGreen’, ‘dkCyan’, ‘red’, ‘crimson’, ‘dkSeaGreen’, ‘limeGreen’, ‘paleVioletRed’, ‘thistle’, ‘dkMagenta’, ‘salmon’, ‘ltGoldenrodYellow’, ‘powderBlue’, ‘blanchedAlmond’, ‘grey’, ‘springGreen’, ‘ltBlue’, ‘ltGreen’, ‘mediumAquamarine’, ‘papayaWhip’, ‘darkTurquoise’, ‘mediumVioletRed’, ‘dkOrange’, ‘green’, ‘oldLace’, ‘white’, ‘dkTurquoise’, ‘coral’, ‘medVioletRed’, ‘lightSteelBlue’, ‘blueViolet’, ‘greenYellow’, ‘hotPink’, ‘medTurquoise’, ‘dkViolet’, ‘orchid’, ‘dkOrchid’, ‘mediumTurquoise’, ‘darkRed’, ‘medSpringGreen’, ‘ltSteelBlue’, ‘sandyBrown’, ‘dodgerBlue’, ‘tomato’, ‘ltSlateGray’, ‘lightYellow’, ‘medAquamarine’, ‘magenta’, ‘rosyBrown’, ‘gainsboro’, ‘darkOrange’, ‘dkSlateGrey’, ‘darkViolet’, ‘medBlue’, ‘beige’, ‘dkSlateBlue’, ‘lightSlateGray’, ‘lightSalmon’, ‘lavender’, ‘floralWhite’, ‘slateGrey’, ‘dkKhaki’, ‘mistyRose’, ‘bisque’, ‘darkOliveGreen’, ‘dkGreen’, ‘peachPuff’, ‘lightSeaGreen’, ‘gold’, ‘navy’, ‘medPurple’, ‘yellow’, ‘mediumSeaGreen’, ‘lemonChiffon’, ‘ltSlateGrey’, ‘azure’, ‘lightCyan’, ‘goldenrod’, ‘darkCyan’, ‘ltGray’, ‘aquamarine’, ‘lime’, ‘honeydew’, ‘darkBlue’, ‘mediumPurple’, ‘darkSlateGray’, ‘teal’, ‘olive’, ‘lawnGreen’, ‘dkSlateGray’, ‘ltSkyBlue’, ‘oliveDrab’, ‘mintCream’, ‘dkSalmon’}yellowGreen

- 投稿日:2019-12-09T19:02:09+09:00
pathlib.Pathのリストを自然順ソートする
概要
pathlib.Path形式の要素を持つリストは,natsorted()関数が適用できない.
そこで,自然順ソートするための関数を自作した.sorted()関数とnatsorted()関数
sorted()関数は,リストの要素を辞書順ソートする関数.
例えばこのようなリストがあるとき,strs = ["dir/10", "dir/1", "dir/3" , "dir/24"]このように書けば,
for s in sorted(strs): print(s)こうなる.
dir/1 dir/10 dir/24 dir/3辞書順なのでまあそうなるのが妥当だが,人間の感覚ではいささか気持ち悪い.
対してnatsorted()関数は,リストの要素を自然順ソートする関数(モジュールが必要).
同じリストに対して,このように書けば,from natsort import natsorted for s in natsorted(strs): print(s)こうなる.
dir/1 dir/3 dir/10 dir/24こっちの方がしっくりくる.
natsorted()関数最高!Pathが要素だとどうなるか
例えば下のようなディレクトリ構造のとき,
dir ├ 1 ├ 3 ├ 10 └ 24このようにpathlib.Path形式のリストが作成できる.
pathlibモジュールに関しては調べれば解説がたくさん見つかるので割愛.import pathlib paths = [p for p in pathlib.Path("./dir/").iterdir() if p.is_dir()]じゃあこれを自然順ソートしてみると,
from natsort import natsorted for p in natsorted(paths): print(p)こうなる.
dir\1 dir\10 dir\24 dir\3辞書順じゃん!
まあきっとPath形式には対応していないんでしょうな.
だから辞書順で読み込んで,そのまんまになっていると.
要素はstrとかintじゃないといかんということか(この辺よくわかってない.情報求む).解決策
こんな関数を自作した.
sorted()関数はkeyを引数に指定できることを利用している.def paths_sorted(paths): return sorted(paths, key = lambda x: int(x.name))これをこうやって使えば,
for p in paths_sorted(paths): print(p)こうなる.
dir\1 dir\3 dir\10 dir\24望み通りの結果が得られた.
その他
自分の場合はディレクトリ名が数値だったのでディレクトリ名をintに変換してkeyとした.
no1, no2...みたいに文字列を含む場合はstrにしてnatsorted()を使えばいいと思う(モジュールは必要だけど).
ディレクトリじゃなくてファイルでも同様の方法が適用できるはず.
- 投稿日:2019-12-09T18:44:17+09:00
プログラミング入門(Python)のTAで作ったipynbの採点システム
本記事は,DSL Advent Calendar 2019の9日目の記事です.
8日目の記事に引き続き弊学での講義「プログラミング入門」についてのお話です.私はその講義でTAをやっているのですが,受講者は毎週課題を与えられて次の週の講義までに終わらせてくるといった,要するに宿題があります.TAにはその課題を毎週採点するといった業務が課せられます.初めの方は簡単なプログラムばかりで課題の内容も簡単なのですが,回を重ねる毎に内容も出力との照らし合せもより複雑になってくるのでPythonで動く採点システムを作りました.
「退屈なことはPythonにやらせよう」ってやつです.
課題
課題はjupyter notebookで解答できる.ipynb形式で配布され,中に問題と解答用のセルが用意されているのでそこにコードを記述し出力があっているか確かめる形式になっています.基本的にはコードセルの中身だけ編集して結果を確かめるように伝えてあるので,常に特定のセルの出力をチェックするだけで点数は付けられるようになっています.
以下にイメージを持っていただくために,簡単に課題を再現した画像を載せておきます.
問題はとても簡単なものにしましたが,おおよそこんな感じです.
採点について
採点基準
まずは採点基準についてです.毎回の課題や問題でそれぞれ変わってきますが,大まかな基準としては下の3つです.
- プログラムがエラーを起こさない
- 出力結果が正しい
- 指定された文法や構文が使われている
1,2番目基準はそのままですが,3つ目の「指定された文法や構文」というのはその週に習った
forやifの事です.
(毎回プログラムの構造に指定があるわけではないです)採点方法
予めTAには課題の答えと採点基準が配布されます.各TAはおおよそ20人ぐらいの解答済みのipynbが配布され,それをjupyter notebook上で開いて一つ一つのソースコードや出力結果や再実行を確かめて採点結果を評価欄に書き込みます.現在は満点が4点で一つにつきおおよそ4つ確かめれば良いものの,私はこの作業がやってられなかったのでスクリプト化してみました.(某IIのシステムがlabじゃなくてnotebookなおかげで大量にタブ開いて通信待ってさらにセルを評価し直すというのは辛かった)
採点システム
やることは以下の通り
- 全員分のipynbをリスト化
- ipynbをparse
- 解答用セルを特定
- 正規表現
reや 評価exec()でソースコードや出力を正答と比較- 満点の場合 ipynb に点数を書き込み
それぞれについてソースコードを載せながら解説していきます.
全員分のipynbをリスト化
Python標準モジュールの pathlib を使います.
import pathlib # path to notebook(.ipynb) p_nb = pathlib.Path("../path/to/notebook/")ipynb を parse
ipynbの中身はjsonなので
json.load()でparseできます.
また,ipynbの全てでループを回すときに,pathlibを使いやすくする glob モジュールを使っています.import glob import json # notebooks(.ipynb) for _nb in p_nb.glob("*.ipynb"): # load json (*.ipynb) with open(_nb, "r")as f: nb = json.load(f) cells = nb["cells"]ipynbの詳しい構造の解説は省略しますが,セルの情報は
{"cell": [cell1, cell2, cell3], ...}のようになっているので,nb["cells"]でそのリストが取得可能です.これ以降のソースコードは一段インデント下がっている状態ですが省略しますのでご注意ください.
解答用セルを特定
cellの中身は大まかには以下の通りです.
- cell_type: 'markdown' や 'code' など
- source: マークダウンテキストやソースコードなど (1行ずつのリスト)
- outputs: ソースコードの出力結果 (エラーなども含まれる)
その他にも情報は含まれますが,今回のシステムで使うのは上記の3つです.
では,解答用のセルを特定します.
今回は上で例として挙げたipynbに対等するようにソースコードを書いています.
一回の採点で最高でも4回は使うので関数化しています.def identify_cell(sentence, cells, cell_type='markdown'): """全てのセルから条件に一致するセルの番号をreturn""" for i,_cell in enumerate(cells): if _cell['cell_type'] == cell_type \ and _cell['source'][0] == sentence: _cell_num = i break return _cell_num # identify cell _cn = identify_cell(sentence="## 問1\n", cells=cells) ans_cell = cells[_cn + 1]
identify_cell()でチェックしているのは,
cell_typeがmarkdownであること,またsourceの1行目が"## 問1\n"であることです.
上記の条件に一致したセルの番号をreturnで返しています.ここからは
pprint()などを使いながらセルの中身をチェックしていくと良いです.注意しなければいけないのは,答えを確認したいのはソースコードやその出力結果なので,次のセルである
_cn + 1番目のセルを解答用セルとして変数に格納しておきます.ソースコードや出力を正答と比較
1問目の「Hello World!」を出力せよ.という問題の正否をチェックしてみます.
今回は出力結果があっているかどうかだけ確かめれば良いので以下の通り.try: result = ans_cell['outputs'][0]["text"][0] if result == "Hello World!": score += 1 except: passちなみに,try-exceptを用いているのは課題が無回答だった場合に対応しているためです.(outputsの中身が無かったりする)
ifで対応しても良かったのですが,多くの解答を見ていると本当に様々な場所でエラー吐かれるのでこれで妥協しました.現在の実際に運用しているソースコードでは,毎週pathとこの部分を変えるだけで動くようになっています.
解答のパターンや注意事項は別途記事下部に載せておきます.満点の場合 ipynb に点数を書き込み
本来なら満点以外でも書き込んでも良いのですが,念のための解答ipynbのチェックと間違っている問題があった人には別途コメントをしているので現在のような仕様にしております.
if score == 2: # 満点=2点の場合 # identify cell _cn = identify_cell(sentence="## 評価\n", cells=cells) # score cellの上書き cells[_cn + 1] = {'cell_type': 'code', 'execution_count': None, 'metadata': {}, 'outputs': [], 'source': [str(2)]} # 解答用のipynbにdump (上書き) json.dump(nb, _nb.open("w"))こちらは弊研究室の同じくTAをやっている方(@y_k)に提供してもらいました.
プログラムの中身としては,scoreが満点の場合のみ評価結果を入力するセルに満点の数字を記入したものを上書きし,ipynbを保存しています.ただ誤ったものを上書きしてしまうと面倒くさいことになってしまうので,本番環境ではこちらとは別に元のipynbのバックアップは取るスクリプトも用意しています.
注意事項
解答のチェックをする際に気をつけなければいけない部分を多少並べておきます.
挙げたもの以外にもプログラミング初心者だと本当に様々な変化球を投げてくるので割と大変です.
print()での出力とipythonで使える変数のみでの出力は出力のパターンが異なる
これだけでも"outputs"の中身が違うためプログラムが大きく変わったりするので結構大変.
プログラムを評価しなければいけない時,簡単は
exec(script)としても出力結果が得られない.これも結構大変で,評価基準に評価し直さなければいけないものがあるとき,
exec(script)(scriptはstrのソースコード)を用いて結果を確かめるのですが,scriptにあるprint()はjupyter notebook上でも表示されないどころか出力を得るのがかなり大変です.私は,標準出力を上書きするプログラムを書いて対応しましたがあまりオススメできないかもしれません(通常時のprint()も表示されなくなるため).一応ソースコード載せておきます.import sys import io import contextlib @contextlib.contextmanager def stdoutIO(stdout=None): old = sys.stdout if stdout is None: stdout = io.StringIO() sys.stdout = stdout yield stdout sys.stdout = old # 実行 try: with stdoutIO() as s: exec(script) # 以下でprint()の出力を取得 output = s.getvalue().split() except: # script Errorの場合except pass全角半角問題
答えに記号や数字で全角になるものがあると,正答と一致しなくなるので間違っている扱いになってしまいます.ですので出力結果を予め半角に変換しておくと多少楽になります.
def trans_hankaku(sentence: str) -> str: """全角文字を半角文字に変換する関数""" return sentence.translate( str.maketrans( {chr(0xFF01 + i): chr(0x21 + i) for i in range(94)} ))上記のように半角に変換する関数を定義しておくと楽かもしれません.
まとめ
今回は「退屈なことはPythonにやらせよう」を実践することができました!(読んだことない)
本日分の記事も昨日のDSLアドベントカレンダー8日目の記事 同様,誰かの助けになればと思います.ソースコードや今回用いたipynbはこちらにおいておきます.
https://github.com/liseos-x140/scoring_ipynbあとがき
jupyterのバージョンや種類によって生成されるipynbの構造が違う可能性があるので,あくまで参考程度にしてもらえると嬉しいです.
またソースコードについては,まだまだ開発段階なのである程度まとまり次第また更新できればと思っています.参考


- 投稿日:2019-12-09T18:37:27+09:00
かけ算的に条件分岐が増えるコードをすっきり記述する
はじめに
コードを書いているとときどき、かけ算的(組み合わせ的)に条件分岐が発生することがあります。
例えば、
- 新規ユーザーか既存ユーザーかなどのユーザー種別によって送るメールの文面を変えたり、送らなかったりする。文面の種類も複数ある。
- 外部サービスAPIの取得結果によって処理が分岐する。さらに内部のデータベースの状態によっても対応が変わる。
などなど。
こういったときに見通しを悪くすることなく、変更に強くするにはどうしていったらいいか、というのがこの記事のテーマです。
コード例はPythonで示しますが、考え方はプログラミング言語によらず、実装もオブジェクト指向の言語であればだいたい同じ実装ができると思います。例) 映画の料金設定
ここでは映画の料金設定を例として見ていきたいと思います。
例えば、購入者には一般の大人、学生、シニアがおり、それぞれ時間帯(日中、レイトショー)に応じて料金が変わる、というようなケースです。
日中 レイトショー 一般 1800円 1300円 学生 1500円 1500円 シニア 1100円 1100円 仮に基準料金(1800円)に対する割引料金ルールが存在し、そのルール適用をコードで表現することを考えてみます。
基準の金額からの割引料金ルール
平日 平日(レイトショー) 一般 +-0円 -500円 学生 -300円 -500円 シニア -700円 -700円 手続き的に書いた場合
こうしたとき、単純に手続き的な条件分岐で書いていくと次のようにつらい感じになります。
from datetime import datetime import enum # 鑑賞者の区分 class ViewerType(enum.Enum): ADULT = "adult" STUDENT = "student" SENIOR = "senior" # 鑑賞者区分、映画の開始時間、基準料金を元に鑑賞料金を返す def charge(viewer_type: ViewerType, movie_start_at: datetime base_charge: int) -> int: # 20時以降はレイトショー if movie_start_at.hour < 20: if viewer_type == ViewerType.ADULT: return base_charge elif viewer_type == ViewerType.STUDENT: return base_charge - 300 else: return base_charge - 700 if viewer_type == ViewerType.ADULT or viewer_type == ViewerType.STUDENT: return base_charge - 500 else: return base_charge - 700パッと見ても全体の見通しが悪く、ちゃんと漏れなく実装されているかが伝わりにくいと思います。
また、会員登録者といった購入者の種別が増えたり、シニア料金のルールが変わったとき、どこに処理を追加してよいのかも分かりにくいです。条件分岐を文脈(コンテキスト)として捉える
こういったとき、やりたい処理に対して影響を与える出来事(条件分岐の元となるデータ)を文脈(コンテキスト)として捉えると見通しをよくできます。
今回の場合はレイトショーかどうかの基準となる上映開始時間を、最終的な料金を決定するための文脈(コンテキスト)としてコードで表現します。
from datetime import datetime import dataclasses @dataclasses.dataclass class MovieStartAtContext: movie_start_at: datetime def is_late_show(self) -> bool: return self.movie_start_at.hour >= 20ひとまずこれで上映開始時間時間がレイトショーかどうかという文脈(コンテキスト)は表現できましたが、これを先ほどの手続き的なコードに展開してしまうと意味がありません。
重要なのは、この判断の上でコードが実行できるようにしてあげることです。
from datetime import datetime import dataclasses @dataclasses.dataclass class MovieStartAtContext: movie_start_at: datetime def is_late_show(self) -> bool: return self.movie_start_at.hour >= 20 # 鑑賞者別の料金計算 # # レイトショーかどうかによって、鑑賞者(Viewer)の呼び出されるメソッドが変わる # # - レイトショーの場合: late_show_charge() # - 日中の場合: normal_charge() def charge_for(self, viewer: Viewer, base_charge: int) -> int: if self.is_late_show(): return viewer.late_show_charge(base_charge) return viewer.normal_charge(base_charge)このようにすることで、 鑑賞者の種別ごとにレイトショー用、通常料金用それぞれの計算メソッドを定義してあげればよくなります(適切なメソッドを呼び出すのは上映時間コンテキスト側の責務)。
鑑賞者別の料金計算ロジックの実装
鑑賞者別の料金計算の実装は次のようになります。
class Viewer: def normal_charge(self, base_charge: int) -> int: pass def late_show_charge(self, base_charge: int) -> int: pass class AdultViewer(Viewer): def normal_charge(self, base_charge: int) -> int: return base_charge def late_show_charge(self, base_charge: int) -> int: return base_charge - 500 class StudentViewer(Viewer): def normal_charge(self, base_charge: int) -> int: return base_charge - 300 def late_show_charge(self, base_charge: int) -> int: return base_charge - 500 class SeniorViewer(Viewer): def normal_charge(self, base_charge: int) -> int: return base_charge - 700 def late_show_charge(self, base_charge: int) -> int: return base_charge - 700割引料金ルールの表がほぼそのままコードに表現されているのがわかると思います。
基準の金額からの割引料金ルール
平日 平日(レイトショー) 一般 +-0円 -500円 学生 -300円 -500円 シニア -700円 -700円 コードの統合
最終的に、これまで定義したコードを統合すると、もともとの
charge()関数は次のようになります。class ViewerFactory: viewer_mapping = { ViewerType.ADULT: AdultViewer(), ViewerType.STUDENT: StudentViewer(), ViewerType.SENIOR: SeniorViewer() } @classmethod def create(cls, viewer_type: ViewerType) -> Viewer: return cls.viewer_mapping[viewer_type] def charge(viewer_type: ViewerType, movie_start_at: datetime, base_charge: int) -> int: context = MovieStartAtContext(movie_start_at) viewer = ViewerFactory.create(viewer_type) return context.charge_for(viewer, base_charge)このようにしてあげることで、例にあげた会員登録者という種別が増えたときは新たな鑑賞者クラスを定義してあげればよいですし、休日料金といった新たな料金区分が増えた場合でも、実装箇所に迷うことなく実装してあげることができると思います。
まとめ
条件分岐が、かけ算的(組み合わせ的)に発生するとき
- 分岐の原因となっている出来事(データ)をコンテキストとして捉えてみる
- そのコンテキストをオブジェクトとして表現し、条件判断をそこに集約する
- さらに、集約した条件判断の上で処理を実行できるようにする
うまくいけば、コードをすっきり拡張しやすくすることができます。
実装の参考になればうれしいです。
- 投稿日:2019-12-09T18:27:10+09:00
自分が直したmypyのエラーをgitと連動して抽出する
19新卒のものです。
今年からサーバーサイドに触れていろいろやらせて頂いております。今回はgitと連動してmypyのエラー出力の増減をわかりやすく表示するようにした話をします。
前置き: mypyとは
pythonにおける型アノテーションに対して静的解析を行ってくれるツールです。
先人の記事があるので読むことをお勧めします。
mypyやっていくぞ
mypyやっていったぞはじめに
事のはじまりは担当案件でのmypyのバージョンが長いこと更新されていなかったこと(0.540)でした。
リリースノートを見るとFriday, 20 October 2017などと書いてあります。軽い気持ちでローカルで最新版を導入してみたところ、アップデートで追加されたチェック項目に関連して沢山のエラーが生えてきます。
とりあえず抑制するオプションつければ通るけど…これは…直そう
そして手元でエラー直せないかなと手を付けてみたのですが、普通に辛くなりました。
結構な規模になっている案件コード全体にエラーが偏在しているため、ちょっと直しただけでは改善が見えないのが精神的につらい…もぅマヂ無理。可視化しょ…
作った
可視化というのは言いすぎなのですが(そもそも元から見えてる情報なので)、
自分が潰したエラーのリストが分かりやすく表示されてくれたら、気分的にも良いものになるんじゃないか?と考えました。
方針はシンプルで、変更前と変更後でmypyを2回走らせてdiffを取ります。
gitと連動してワークツリーとHEADの差分呼び出してなんやかんやすればできるはずという方針が立ちます。
実行時間が2倍になりますが、一方でmypyの対象を差分ファイルだけに絞ることができるので大丈夫という希望的観測で行きます。というわけで作りました。
https://github.com/fujita-ma/mymypyrustで書いていることに重大な理由はないのですが、
行単位のテキスト処理が多かったので、イテレータの処理をストレスなく書けるのが楽だったと思います。
ぶっちゃけpythonでもいいんですが、せっかくだから仕事で使ってない言語でやりたかったというのが正直なところです。使ってみる
mypyのサンプルにあるコードで試してみます。
http://www.mypy-lang.org/examples.htmlmain.pyclass BankAccount: def __init__(self, initial_balance=0): self.balance = initial_balance def deposit(self, amount): self.balance += amount def withdraw(self, amount): self.balance -= amount def overdrawn(self): return self.balance < 0 my_account = BankAccount(15) my_account.withdraw(5) print(my_account.balance)mypyを走らせましょう。
❯ mypy --strict ./ main.py:2: error: Function is missing a type annotation main.py:4: error: Function is missing a type annotation main.py:6: error: Function is missing a type annotation main.py:8: error: Function is missing a return type annotation main.py:11: error: Call to untyped function "BankAccount" in typed contextエラーが出ています。
これを一旦コミットしたのち、一部アノテーションを修正してmypyとmymypyをそれぞれ走らせてみます。main.pyclass BankAccount: def __init__(self, initial_balance: int = 0) -> None: # Annotated self.balance = initial_balance def deposit(self, amount): self.balance += amount def withdraw(self, amount): self.balance -= amount def overdrawn(self): return self.balance < 0 my_account = BankAccount(15) my_account.withdraw(5) print(my_account.balance)❯ mypy --strict ./ main.py:4: error: Function is missing a type annotation main.py:6: error: Function is missing a type annotation main.py:8: error: Function is missing a return type annotation main.py:12: error: Call to untyped function "withdraw" in typed context❯ mymypy main.py -main.py:2:_: error: Function is missing a type annotation main.py:4:4: error: Function is missing a type annotation main.py:6:6: error: Function is missing a type annotation main.py:8:8: error: Function is missing a return type annotation -main.py:11:11: error: Call to untyped function "BankAccount" in typed context +main.py:12:12: error: Call to untyped function "withdraw" in typed context潰したエラーが赤くハイライトされています!
また副産物として、逆に追加されたエラーが緑色でハイライトされています。
エラーを修正したことで、隠れていた別のエラーが出てくるというのは良くあることです。ちゃんと全部潰しておきます。全部のアノテーションを適切につけると↓のようになります。
main.pyclass BankAccount: def __init__(self, initial_balance: int = 0) -> None: self.balance = initial_balance def deposit(self, amount: int) -> None: self.balance += amount def withdraw(self, amount: int) -> None: self.balance -= amount def overdrawn(self) -> bool: return self.balance < 0 my_account = BankAccount(15) my_account.withdraw(5) print(my_account.balance)❯ mypy --strict ./❯ mymypy main.py -main.py:2:_: error: Function is missing a type annotation -main.py:4:_: error: Function is missing a type annotation -main.py:6:_: error: Function is missing a type annotation -main.py:8:_: error: Function is missing a return type annotation -main.py:11:11: error: Call to untyped function "BankAccount" in typed context自分の働きで5個のエラーが潰せました。うれしい。
適当なリポジトリで試してみる
ちょっと遊んでみます。
リビジョンの扱いはgit diffに準じているつもりなので、適当なコミットを指定すればその間の差分も取れます。
mypyのリポジトリを覗いてコミットを漁ってみましょう。a5005f4aa977e4911bce5c828fd707ca8680d592
The `inner_types` attribute seems to have no effect.
リファクタリングしたらしいコミットを見つけました。クローンしてmymypyにかけてみましょう。
❯ mymypy a5005f4~ a5005f4 mypy/checker.py mypy/checker.py:64:64: error: Module 'mypy.semanal' has no attribute 'set_callable_name' -mypy/checker.py:2813:_: error: Too many arguments for "PartialType" -mypy/checker.py:2823:_: error: Too many arguments for "PartialType" mypy/checker.py:2959:2959: error: unused 'type: ignore' comment -mypy/checker.py:3022:_: error: "PartialType" has no attribute "inner_types" -mypy/checker.py:3024:_: error: "PartialType" has no attribute "inner_types" mypy/checker.py:4137:4133: error: unused 'type: ignore' comment -mypy/checker.py:4311:_: error: "PartialType" has no attribute "inner_types" mypy/checkexpr.py mypy/checkexpr.py:203:203: error: unused 'type: ignore' comment -mypy/checkexpr.py:592:_: error: "PartialType" has no attribute "inner_types" -mypy/checkexpr.py:606:_: error: "PartialType" has no attribute "inner_types" mypy/checkexpr.py:2368:2361: error: Returning Any from function declared to return "Optional[str]" mypy/checkexpr.py:3003:2996: error: unused 'type: ignore' comment mypy/type_visitor.py mypy/type_visitor.py:167:167: error: unused 'type: ignore' comment mypy/type_visitor.py:207:207: error: unused 'type: ignore' comment mypy/type_visitor.py:229:229: error: unused 'type: ignore' comment -mypy/type_visitor.py:293:_: error: "PartialType" has no attribute "inner_types" mypy/types.py mypy/types.py:190:190: error: unused 'type: ignore' comment mypy/types.py:497:497: error: Returning Any from function declared to return "T" mypy/types.py:520:520: error: Returning Any from function declared to return "T" mypy/types.py:808:808: error: Returning Any from function declared to return "Union[Dict[str, Any], str]" mypy/types.py:1557:1557: error: Returning Any from function declared to return "T" mypy/types.py:1669:1669: error: Returning Any from function declared to return "T" mypy/types.py:1789:1786: error: Returning Any from function declared to return "T" mypy/types.py:1844:1841: error: unused 'type: ignore' comment mypy/types.py:1889:1886: error: Returning Any from function declared to return "T"リファクタリングの効果が見えていますね。
楽しい✌('ω' ✌)三 ✌('ω')✌ 三( ✌'ω') ✌(死語)おわりに
気分転換がてら適当な方針で作ったのですが、そこそこ良い感じに表示できたので満足しています。
せっかくだから業務に活用していこうと思います。実際に使ってみたらバグも沢山見つかるだろうし
- 投稿日:2019-12-09T18:01:51+09:00
Airflowを使ってみてつまづいたこと
はじめに
弊社でデータ基盤を構築する際、データパイプラインとしてAirflowを採用しました。
その際、つまづいた箇所がいくつかあったので書き記しておきます。弊社でのAirflow
弊社では機械学習を使用したシステムを複数、開発運用しています。
プロジェクトが増え、運用が進んでいく上で共通して以下のような要望を満たすものが必要になってきました。
- 必要な複数のデータソースに一つのエンドポイントでアクセスできる
- 同じクエリであればどんな時でも同じ結果が返ってくる
- クエリが詰まらない
そこで、我々はデータ基盤が必要なフェーズだと判断し、構築するに至りました。
データ基盤を構築する際に元のデータをデータウェアハウスやデータマート用に加工する必要があります。その際にデータパイプラインとして以下のような要件を満たす必要がありました。
- 同じロジックであればエラー等で中断再開する、データが作成された状態で最初から叩き直すといった状況でも最終的に作成されているデータは同じになる
- 一日分ごとにデータ処理が行われる
- 処理が失敗したことにすぐに気づくことができ、どこの処理から再開すればいいか明確になっている
これらを満たせそうなツールとしてAirflowを採用しました。
概念図でいうと下の部分です。
Aiflowでは上記の要件を満たすように実装を行いました。
- 前回分までのTaskInstanceが完了するまで今回分のTaskInstanceを動かさない
- 仮に作成したいデータがすでに作られていた場合はタスクをskipする
- 過去分を処理後、日時で実行する
- 今回分のTaskInstanceが成功した、失敗した場合は通知を出す
前提
Airflowのバージョンは
1.10.5です。つまづき1. execution_dateと実行日
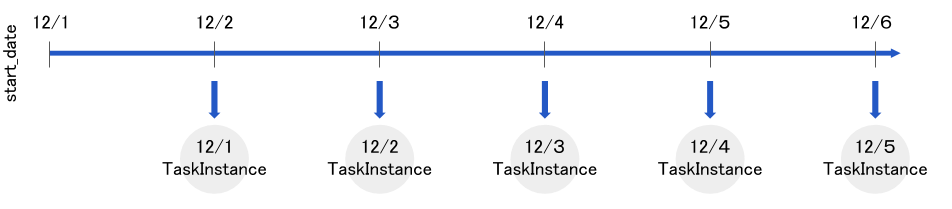
default_args = { 'owner': 'Airflow', 'start_date': datetime(2019, 12, 1), } dag = DAG('tutorial1', default_args=default_args, schedule_interval=timedelta(days=1))このコードは
execution_dateが2019-12-01T00:00:00+00:00から
12/1, 12/2, 12/3 ...といったように実行され、過去分の実行が終了すると一日ごとの実行になります。
この時、今日が2019-12-06T01:00:00+00:00(UTC)だったと仮定するとexecution_dateがいつになるまで実行されるでしょうか。答えは
2019-12-05T00:00:00+00:00(UTC)までのTaskInstanceが実行されます。
私は今日の日付が12/6になったらexecution_dateが12/6のところまで実行されると勘違いしていました。
以下イメージ図です。
これに加えてタスク内でタイムゾーン:
Asia/Tokyoで時間を扱いたい等の要件が重なると
混乱する可能性も高くなるので気をつけてください。つまづき2. 前日分のTask Instanceを待つ
前日のTaskInstanceの実行結果を使用して本日分の処理を行う必要があったため、
本日分のTaskInstanceは前日分までのTaskInstanceの成功を待つ必要がありました。
そのため、前回のTaskInstanceの特定のタスク結果を待つwait_for_downstreamを使用しました。t1 = BashOperator( task_id='print1', bash_command='echo 1', wait_for_downstream=True, dag=dag)しかし、
wait_for_downstreamは前回のTaskInstance全体の結果を待つわけではありません。t1 = BashOperator( task_id='print1', bash_command='echo 1', wait_for_downstream=True, dag=dag) t2 = BashOperator( task_id='print2', bash_command='echo 2', wait_for_downstream=True, dag=dag) t1 >> t2と記述した場合、前回分のt1タスクが完了した時点で(t2の完了を待つことなく)、今回分のt1タスクが実行されます。しかし、今回分のt1タスクは前回分t1,t2タスクどちらも待つ必要があります。
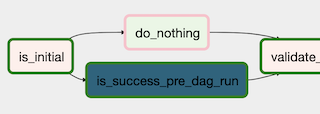
そこでExternalTaskSensorを使用し、前回分の最後のタスクを待つように設定しました。t_check_previous_dag_run = ExternalTaskSensor( task_id='is_success_pre_dag_run', external_dag_id=dag.dag_id, allowed_states=['success', 'skipped'], external_task_id='your_last_task_id', execution_delta=timedelta(days=1) ) # t1は最初に実行したいtask t_check_previous_dag_run >> t1しかし、この記述だけだと最初に動くTaskInstance(execution_date=start_date)
が存在しないタスクの完了を待ちつづけ、先に進まなくなります。そのため、さらに
# is_initialは最初の実行か判定するための関数をuser_defined_macrosで設定して使用している t_check_is_initial = BranchPythonOperator( task_id='is_initial', python_callable=lambda is_initial_str: 'do_nothing' if is_initial_str == 'True' else 'is_success_pre_dag_run', # NOQA op_args=['{{ is_initial(execution_date) }}'] ) t_do_nothing = DummyOperator( task_id='do_nothing' ) # skipされないようにtrigger_rule='none_failed'を設定 t1 = BashOperator( task_id='print1', bash_command='echo 1', trigger_rule='none_failed', dag=dag) t_check_is_initial >> t_check_previous_dag_run >> t1 t_check_is_initial >> t_do_nothing >> t1といったコードを書き、最初の実行では
ExternalTaskSensorをSkipすることで回避しました。冗長になりましたが前日のTaskInstanceを待つことが明確になりました。
とはいえはやはり冗長なので必ず前日の実行結果を待つ別の方法を知っている方はご教授ください。
つまづき3. ShortCircuitOperator,Skipステータスのルール
ShortCircuitOperatorはpython_callableで宣言された関数がfalseを返した時、後続のタスクを全てに対してskipステータスを付与します。
そのため、直後のタスクはskipするががさらに先のタスクは実行させたいといったことができません。
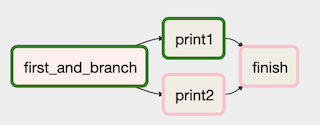
上記の例ではshortcircuitタスク(ShortCircuitOperator)を使用してprint2_2はskipさせてfinishタスクを実行させるといったことはできません。
また
BranchPythonOperatorにおいても後続のタスクのtrigger_ruleをデフォルトのall_successにしていると似たようなことが起こります。t0 = BranchPythonOperator( task_id='first_and_branch', python_callable=lambda: 'print1', dag=dag) t1 = BashOperator( task_id='print1', bash_command='echo 1', dag=dag) t2 = BashOperator( task_id='print2', bash_command='echo 2', dag=dag) t3 = BashOperator( task_id='finish', bash_command='echo finish', dag=dag ) t0 >> t1 t0 >> t2 t1 >> t3 t2 >> t3
finishタスクのtrigger_ruleが
all_sucessだと親タスクのどれか一つでもskipステータスになるとskipステータスになります.親のタスクに一つもfailステータスがついていない場合にはfinishタスクを実行させたい場合は
下記のようにtrigger_ruleを'none_failed'に設定すると想定通りの動きになります。t3 = BashOperator( task_id='finish', bash_command='echo finish', trigger_rule='none_failed', dag=dag )なお、first_and_branchタスクの部分が
ShortCircuitOperatorでpython_callableの結果がfalseであった場合、後続タスクはtrigger_ruleに関わらず全てskipステータスになります。つまづき4. 失敗時の通知
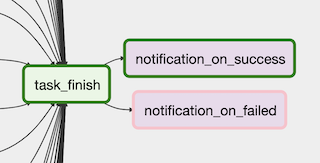
なにかのタスクが失敗した場合はslack通知を送れるようにdefault_argsを使用して
下記のように記述しました。def send_slack(): # slack通知を出す処理 default_args = { 'start_date': datetime(2019, 12, 1), 'on_failure_callback': send_slack }しかし、この書き方の場合、なんらかの理由でslack通知がされなかった時にairflowの管理画面にその旨が表示されません。そのため、slack通知タスク自体がこけていることに気づくことができないことがありました。
そのため、以下のようにタスクの最後にslack通知を送ることを明示することでslack通知自体が失敗していても管理画面を見ればそれに気づくことができるようになりました。t_finish = DummyOperator( task_id='task_finish', trigger_rule='none_failed', ) # 独自に作成したSlack通知を送るOperatorを使用 # trigger_ruleでtaskを振り分けることで成功失敗に関わらず通知がとぶ t_notification_on_success = CustomSlackOperator( task_id='notification_on_success', trigger_rule='none_failed' ) t_notification_on_failed = CustomSlackOperator( task_id='notification_on_failed', is_success=False, trigger_rule='one_failed' ) t_finish >> t_notification_on_success t_finish >> t_notification_on_failed
slack側の設定がいつの間にか変更されていることが原因で通知自体が失敗するといったことも考えられるので
通知タスクも明示しておいたほうが安心できると思います。まとめ
他にも細かい部分でつまづきましたが、
ドキュメントをしっかり読めば解決するパターンがほとんどでした(時にはソースコードも読みましたが)。Airflowは
- Dagをpythonコードで柔軟に定義できる
- 過去分はバッチのように動作し、それ以降は定期実行のように動作する(表現が難しい。。)といったことができる数少ないツールです。
そのため、複数の複雑なタスクを定常的に動かす際は有力な候補になりうるツールだと思います。


- 投稿日:2019-12-09T17:25:50+09:00
Python初心者がDjango+celeryでハマったこと3選 - その1
はじめに
「Djangoだったら社内に有識者がたくさんいる」って言ってたじゃないですかっー!!!!フューチャー Advent Calendar 2019 10日目の記事です。
今年のアドベントカレンダーはガチネタ多すぎて怖いわ...今回は、golangとかrailsとか書いてた私が、
初Pythonで突貫でシステム構築することになり、ハマったこと3選を公開していきます。
1記事でまとめようとしたら長くなったので、3記事でまとめます。※なお、本記事で出てくるsqlは一部formatしてます
3行1行で
- Djangoのmodelはdefault等の設定をDBに反映してくれない(この記事!)
- DMLの管理方法(comming soon...)
- celery+sqsの使い方(comming soon...)
前提環境
環境は、Python Django入門 (1)を(6)の記事まで順にこなした前提とします。
公式リファレンスじゃないけど良記事でした。
出来上がったものがhttps://github.com/kakky/mybook20 においてあるのも嬉しいですね。
(以下検証はこのコミットで実施してます。https://github.com/kakky/mybook20/commit/82e741652bfd7f82f5c0bc601e04b7585632d266)上記をcloneしてきた場合は、事前準備として、以下を実行しておきましょう。
$ python manage.py migrate $ python manage.py createsuperuser $ python manage.py runserverここで躓いた場合は、前提となっている記事をご参照ください。
上記コマンドが書いてあるのはこの記事です。
Python Django入門 (3)本題
Djangoのmodelはdefault等の設定をDBに反映してくれない
準備
cms/models.pyのclass Bookを以下のように変更しましょう。cms/models.pyclass Book(models.Model): """書籍""" name = models.CharField('書籍名', max_length=255, unique=True) publisher = models.CharField('出版社', max_length=255) page = models.IntegerField('ページ数', blank=True, default=0) on_sale = models.BooleanField('販売中', default=True) created_at = models.DateTimeField(auto_now_add=True) updated_at = models.DateTimeField(auto_now=True) def __str__(self): return self.name
created_atとupdated_atを追加し、insert, update時にそれぞれ現在時刻を埋め、on_saleを追加しデフォルト値をTrueにしておきます。さらに、
nameにunique=Trueを付け足しています。
なお、全てのカラムはデフォルトで、null=Falseとなっており、not null制約の挙動となります。modelを変更したので、以下のようにmigrationファイルを作成します。
初期値を埋めろと怒られるので、適当にtimezone.nowとしておきます。$ python manage.py makemigrations You are trying to add the field 'created_at' with 'auto_now_add=True' to book without a default; the database needs something to populate existing rows. 1) Provide a one-off default now (will be set on all existing rows) 2) Quit, and let me add a default in models.py Select an option: 1 Please enter the default value now, as valid Python You can accept the default 'timezone.now' by pressing 'Enter' or you can provide another value. The datetime and django.utils.timezone modules are available, so you can do e.g. timezone.now Type 'exit' to exit this prompt [default: timezone.now] >>> timezone.nowmigrationをかけます。
python manage.py migrate動作確認
http://127.0.0.1:8000/admin/ に移動し、Bookを追加します。(詳細省略)
DBの中身も見てみましょう。
$ sqlite> select * from cms_book; id|name|page|created_at|on_sale|updated_at|publisher 1|悪魔の寵児|100|2019-12-09 13:03:29.102973|1|2019-12-09 13:03:29.132151|角川文庫
created_atupdated_at入っており、良さそうです。※on_saleは1でTrueを表します。
ではここで、DBに直接insertしてみましょう。sqlite> insert into cms_book(name, publisher, page) values('悪魔の手毬唄', '集英社', 200); Error: NOT NULL constraint failed: cms_book.created_atなぜか、現在時刻が自動的に入るはずの
created_atがnot null制約に違反していると怒られます。
そこで、created_at,updated_atをCURRENT_TIMESTAMPで埋めてみます。sqlite> insert into cms_book( name, publisher, page, created_at, updated_at ) values( '悪魔の手毬唄', '集英社', 200, CURRENT_TIMESTAMP, CURRENT_TIMESTAMP ) ; Error: NOT NULL constraint failed: cms_book.on_sale今度は、default値を指定したはずのon_saleがnullだと怒られます。
仕方ないので、on_saleも値を明示的に指定してやります。sqlite> insert into cms_book( name, publisher, page, on_sale, created_at, updated_at ) values( '悪魔の手毬唄', '集英社', 200, 0, CURRENT_TIMESTAMP, CURRENT_TIMESTAMP ) ; sqlite> select * from cms_book; id|name|page|created_at|on_sale|updated_at|publisher 1|悪魔の寵児|100|2019-12-09 13:03:29.102973|1|2019-12-09 13:03:29.132151|角川文庫 2|悪魔の手毬唄|200|2019-12-09 13:12:17|0|2019-12-09 13:12:17|集英社今度はうまくinsert出来ました。
なぜ、defaultや、auto_now_add,auto_nowを設定したカラムでNOT NULL constraintが発生したのでしょうか?
順に見ていきます。sqlite> .schema cms_book CREATE TABLE IF NOT EXISTS "cms_book"( "id" integer NOT NULL PRIMARY KEY AUTOINCREMENT, "name" varchar(255) NOT NULL UNIQUE, "page" integer NOT NULL, "created_at" datetime NOT NULL, "on_sale" bool NOT NULL, "updated_at" datetime NOT NULL, "publisher" varchar(255) NOT NULL ) ;テーブル定義の時点では、既に、
defaultとauto_now系は落ちてしまっています。
migrationファイルと生成されたsqlを確認します。cms/migrations/0002_auto_20191209_2202.pyoperations = [ migrations.AddField( model_name='book', name='created_at', field=models.DateTimeField(auto_now_add=True, default=django.utils.timezone.now), preserve_default=False, ), migrations.AddField( model_name='book', name='on_sale', field=models.BooleanField(default=True, verbose_name='販売中'), ), migrations.AddField( model_name='book', name='updated_at', field=models.DateTimeField(auto_now=True), ), migrations.AlterField( model_name='book', name='name', field=models.CharField(max_length=255, unique=True, verbose_name='書籍名'), ), migrations.AlterField( model_name='book', name='publisher', field=models.CharField(max_length=255, verbose_name='出版社'), ), ]$ python manage.py showmigrations admin [X] 0001_initial (省略) cms [X] 0001_initial [X] 0002_auto_20191209_2202 (省略) $ python manage.py sqlmigrate cms 0002_auto_20191209_2202 BEGIN; (省略) -- -- Alter field publisher on book -- CREATE TABLE "new__cms_book"( "id" integer NOT NULL PRIMARY KEY AUTOINCREMENT, "name" varchar(255) NOT NULL UNIQUE, "page" integer NOT NULL, "created_at" datetime NOT NULL, "on_sale" bool NOT NULL, "updated_at" datetime NOT NULL, "publisher" varchar(255) NOT NULL ) ; INSERT INTO "new__cms_book"( "id", "name", "page", "created_at", "on_sale", "updated_at", "publisher" ) SELECT "id", "name", "page", "created_at", "on_sale", "updated_at", "publisher" FROM "cms_book" ; DROP TABLE "cms_book" ; ALTER TABLE "new__cms_book" RENAME TO "cms_book" ; COMMIT ;migrationファイルの方では、
default=Trueのように表記が残っているのが確認出来ます.
生成されるsqlの方は長いので省略しましたが、(あとなんでわざわざcreate, drop, alterしてるのかは知らんが)
注目いただきたいのは以下の部分です。CREATE TABLE "new__cms_book"( "id" integer NOT NULL PRIMARY KEY AUTOINCREMENT, "name" varchar(255) NOT NULL UNIQUE, "page" integer NOT NULL, "created_at" datetime NOT NULL, "on_sale" bool NOT NULL, "updated_at" datetime NOT NULL, "publisher" varchar(255) NOT NULL )見事に、
default値やauto_nowが落ちてしまっています。
ちなみに、この挙動はsqliteだけでなくpostgresql等でも同様の挙動でした。解決策
当初、ググってもなかなか見つからなかったのですが、この現象についてはこちらのstackoverflowで言及されていました。
https://stackoverflow.com/questions/53706125/django-default-at-database意訳すると、「modelとDBスキーマは別モン。not nullとuniqueは適用してやるけどdefaultは無理やわ!」...ってことらしいです。
1つのDBを複数のアプリケーションから参照・更新したり、手パッチ当てたりする場合は少なくないと思うのですが、Djangoユーザは困らないんでしょうかね...
回避策としては、modelから生成されたDDLではなく、地道にERDからDDL(生SQL)を起こすのが良さそうです。最後に
これだけ普及しているFWでこんなに実用性に問題のある挙動が許されているのか...と驚愕しました。
トラブル解決には、生のSQLが読めるなど、低レイヤーな部分も抑えておくことがより大事だと再認しました。

- 投稿日:2019-12-09T16:29:38+09:00
TemplateViewを使ってみよう!IndexView編
DB(データベース)の中身を一覧表示しよう!
目標はListViewというテンプレートビューを用いて、データベース上のデータをリスト表示することです。
開発現場ではそんなの1時間でできるよ!?と怒られたことも(-_-;)しかし、今回もdjango使いたての方向けにやさし目に書き上げております。
ListViewの使い方としては例えば掲示板アプリ、お店の一覧などで用いられます。
Amazonの商品一覧ページのようなものだって作れるようになりますよ!IndexViewのおさえるべき特徴について
面倒なビューの記述がなくなります。
かなり簡単に表示が可能なため、練習にうってつけであることも言えます。
また、仮のページ作成ができるので、素早くwebサイトの開発が可能です。
覚えて損はありません!今回のファイル構成
mysite │ db.sqlite3 │ manage.py ├─mysite │ │ settings.py │ │ urls.py └─test_app │ admin.py(ここをadmin画面設定のために編集) │ apps.py │ models.py(ここをモデル定義のために編集) │ tests.py │ urls.py(ここもルーティング設定のために編集) │ views.py(ここもIndexView設定のために編集) ├─migrations ├─templates └─test_app └─list.html(ここもページ上にリスト表示させるため編集)新規モデルの作成
モデル定義ファイル、models.pyを編集して行きます。
モデルとは、DBのテーブルを定義するファイルです。
まずはmodels.pyの編集に移ってからなれるのがおすすめです。
後でモデルとは何なのかわかってきます。このモデルを作成することを、テーブルを切る、とも開発現場では表現されます。
models.pyの編集は以下の通りとなります。
models.pyfrom django.db import models # Create your models here. class Shop(models.Model): #各フィールドの定義 name = models.CharField('shopname',max_length=30) tell_num = models.CharField('tell_number',max_length=13) address = models.CharField('address',max_length=30) created_at = models.DateTimeField(auto_now_add=True) #admin画面の表示内容 def __str__(self): return self.namemodelsをインポートしているところについてですが、modelsとはなんなのかいまだに私もわかりません。あまり意識すべきところではないため慣れて覚えておく必要があります。
ただし、ここから言えることはShopというクラス定義を行い、models.Modelを継承していることがわかります。
継承することにより、モデルとして各フィールドの定義を行うことができます。文字列を入れたい場合は
models.CharField、日付を入れたい場合はmodels.DateTimeFieldを用います。数字を入れたい場合はmodels.IntegerFieldを用いるため、忘れたら思い出す感覚で結構です!モデル定義ができたら、このコマンドを入力してみましょう!
$python manage.py makemigrations Migrations for 'test_app': test_app\migrations\0001_initial.py - Create model Shopずらずらっと何か出てきましたね。
- Create model Shopが表示されていたら成功です!続いて、マイグレートを行います。
DBはモデル定義の変更履歴を差分で取っています。
models.pyの変更のたびにこのコマンドを2つセットで入力することをお忘れないようにお願いします。それでは、マイグレート(移行)!
$python manage.py migrate Operations to perform: Apply all migrations: admin, auth, contenttypes, sessions, test_app Running migrations: Applying contenttypes.0001_initial... OK Applying auth.0001_initial... OK Applying admin.0001_initial... OK Applying admin.0002_logentry_remove_auto_add... OK Applying admin.0003_logentry_add_action_flag_choices... OK Applying contenttypes.0002_remove_content_type_name... OK Applying auth.0002_alter_permission_name_max_length... OK Applying auth.0003_alter_user_email_max_length... OK Applying auth.0004_alter_user_username_opts... OK Applying auth.0005_alter_user_last_login_null... OK Applying auth.0006_require_contenttypes_0002... OK Applying auth.0007_alter_validators_add_error_messages... OK Applying auth.0008_alter_user_username_max_length... OK Applying auth.0009_alter_user_last_name_max_length... OK Applying auth.0010_alter_group_name_max_length... OK Applying auth.0011_update_proxy_permissions... OK Applying sessions.0001_initial... OK Applying test_app.0001_initial... OKこの
... OKがすべて表示されていたら、成功です!続いては作成モデルの確認をadmin管理画面で行っていきます。
adminスーパーユーザーの作成
初めてadmin管理画面にログインする際、ここでadmin管理画面にログインするためのユーザーアカウントが必要となります。
createsuperuserで最高権限のユーザーを作成してみましょう!最初のadmin管理画面にログインするために必要です。$python manage.py createsuperuserユーザー名とパスワード、emailadressを入力します。
$python manage.py createsuperuser Username (leave blank to use 'user'):ユーザー名はブランクでEnterをたたくとデフォルトであるuserが設定されます。
お好きな名前を入力しましょう。$python manage.py createsuperuser Username (leave blank to use 'user'): Email address: Password: Password (again): Superuser created successfully.次々とメアド、パスワードの入力が要求されます。
パスワードのみ二回確認、空欄不可なので注意しましょう。すべて打ち終えたら、現在作成したユーザーとパスワードを用いて、ログインしてみましょう!
admin管理画面で作成モデルの確認
今回使用されているDBはsqlite3です。
これはDjangoに標準インストールされているDBなので、このままで作業を進めましょう。
ここでは先ほどのモデルの作成状況を見てみることが目標です。
あれれ、作成したDBテーブルが表示されていません。?
これは、作成テーブルをadmin.pyに登録していないことが原因です。
admin.pyに登録してみましょう。admin.pyfrom django.contrib import admin from .models import Shop # ここにモデル名を含め書き足す admin.site.register(Shop)admin管理画面にログインすると、
(補足)ログインURLはhttp://localhost:8000/admin
モデルの追加がされています。
仮にデータを挿入してみましょう!
追加方法はこのように行います。
ADD SHOPを押す
店の名前、電話番号、住所を入れる
SAVEで保存OK!
それでは。ルーティング設定に参ります!
ルーティングをurls.pyで設定
URLに/indexと打つと、リスト画面が表示されるようにすることが目標。
urls.pyfrom django.urls import path from . import views urlpatterns = [ path('index/',views.IndexView.as_view(),name='index'), ]views.pyではテンプレートビューである
ListViewを継承したビュークラスを定義します。
as_view()を付けることにより、ビューとしてdjangoに認識されます。テンプレートビューを用いる場合は必要であるといった程度で覚えてください。それでは、viewの設定です。
リスト表示用のIndexViewをviews.pyで設定
TemplateViewを用いたviews.pyでの設定はかなりシンプルです。
それはモデルを指定することとテンプレートを指定することです。
ListViewを継承することで、めっちゃ簡単に設定することができます。以下のテンプレートの指定について、2通りの設定が考えられます。
templateを指定する場合は、templates/test_app/list.htmlとなっているファイルに対し、以下のようにtemplate_nameで指定します。テンプレートを指定しているviews.pyfrom django.views import generic from .models import Shop # Create your views here. class IndexView(generic.ListView): model = Shop template_name = 'test_app/list.html' #IndexViewの中に指定templateファイル名を指定しない場合はモデル名_list.htmlと書き方が決まっているため、この後に注意しましょう。
具体的に、test_app_list.htmlといった指定になります。テンプレートを指定しないviews.pyfrom django.views import generic from .models import Shop # Create your views here. class IndexView(generic.ListView): model = Shopちなみに、
template_nameを指定してもモデル名_list.htmlのhtmlファイルがあるか探してくれます。djangoは優秀、て思ってみましょうかね?ページ表示のためのhtmlファイルの設定
list.html<!DOCTYPE html> <html> <head> <meta charset="utf-8"> </head> <body> <p>一覧の表示</p> <table> <tr> <th>店名</th> <th>電話番号</th> <th>住所</th> <th>ページ作成日</th> </tr> {% for shop in shop_list %}#ここに注目! <tr> <td>{{ shop.name }}</td> <td>{{ shop.tell_num }}</td> <td>{{ shop.address }}</td> <td>{{ shop.created_at }}</td> </tr> {% endfor %} </table> </body> </html>モデル名_listと変数を書くと、モデルデータの一覧が取得できます。ここはルールなので覚えるところです。
for文で一つ一つ取得し、.nameなどとモデルのカラム名を指定し、表形式で表示を行っております。
カラム名は忘れますので、models.pyで確認を行ってください!
それでは、サーバーを起動し、$python manage.py runserverhttp://localhost:8000/indexで表示を確認してみましょう!
表示が確認できない場合は、エラーをググったり、怪しい設定部分を確認してみましょう。
すべて正しく設定できれば表示されます。自分を信じてあきらめないでください!!最後に
今回はTemplateViewを用いたリスト表示の書き方についてのまとめでした。
この手順を覚えられればかなり応用がきいたり、バックエンドの設定が大まかにわかってきます。中級者へ突破するための第一ステップとなるところになりそうなので、取り上げてみました!それでは、一緒に頑張ってゆきましょう!






- 投稿日:2019-12-09T16:27:47+09:00
Python のCoroutine(コルーチン)理解
def consumer(): r = '' while True: n = yield r if not n: return print('[CONSUMER] Consuming %s...' % n) r = '200 OK' def produce(c): c.send(None) n = 0 while n < 5: n = n + 1 print('[PRODUCER] Producing %s...' % n) r = c.send(n) print('[PRODUCER] Consumer return: %s' % r) c.close() c = consumer() produce(c)[PRODUCER] Producing 1...
[CONSUMER] Consuming 1...
[PRODUCER] Consumer return: 200 OK
[PRODUCER] Producing 2...
[CONSUMER] Consuming 2...
[PRODUCER] Consumer return: 200 OK
[PRODUCER] Producing 3...
[CONSUMER] Consuming 3...
[PRODUCER] Consumer return: 200 OK
[PRODUCER] Producing 4...
[CONSUMER] Consuming 4...
[PRODUCER] Consumer return: 200 OK
[PRODUCER] Producing 5...
[CONSUMER] Consuming 5...
[PRODUCER] Consumer return: 200 OK
- 投稿日:2019-12-09T15:59:29+09:00
pip install でSSL証明書関連?のエラー
pip installしようとすると、下記のエラー。pip is configured with locations that require TLS/SSL, however the ssl module in Python is not available. Retrying (Retry(total=4, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError("Can't connect to HTTPS URL because the SSL module is not available.")': /simple/pip/ Retrying (Retry(total=3, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError("Can't connect to HTTPS URL because the SSL module is not available.")': /simple/pip/ Retrying (Retry(total=2, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError("Can't connect to HTTPS URL because the SSL module is not available.")': /simple/pip/ Retrying (Retry(total=1, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError("Can't connect to HTTPS URL because the SSL module is not available.")': /simple/pip/ Retrying (Retry(total=0, connect=None, read=None, redirect=None, status=None)) after connection broken by 'SSLError("Can't connect to HTTPS URL because the SSL module is not available.")': /simple/pip/ Could not fetch URL https://pypi.org/simple/pip/: There was a problem confirming the ssl certificate: HTTPSConnectionPool(host='pypi.org', port=443): Max retries exceeded with url: /simple/pip/ (Caused by SSLError("Can't connect to HTTPS URL because the SSL module is not available.")) - skipping Requirement already up-to-date: pip in ./.anyenv/envs/pyenv/versions/3.7.3/lib/python3.7/site-packages (19.0.3)SSL関連のエラーっぽいので、とりあえずOpenSSLを入れ直したりしてみる。
brew install opensslが、ダメ。~/.pip/conf.pipにtrustedの設定を追加してもダメ。
解決
Pythonとpipを再インストールすると解決した。pyenvを使っていたので、
pyenv install 3.8.0 python global 3.8.0 curl -kL https://bootstrap.pypa.io/get-pip.py | pythonを実行後、再度
pip installを実行すると問題なく動いた。もやもやするけど、動いたから一旦よしとしておこう。。。
- 投稿日:2019-12-09T15:58:00+09:00
Matplotlibを使って高校数学+大学数学に出てくる関数をビジュアル化
この記事は呉高専 Advent Calendar 2019 12日目の記事です。
はじめに
数学の勉強をしていると、さまざまな「関数」に出会います。我々はそれらの関数をしばしば微分したり積分したり、あるいはその関数の極値を求めたり変曲点を求めたりします。しかし、これらの操作は機械的な処理で計算できるため、もとの関数がどのようなどのような性質をもつか、どのような形であるかはあまり意識する必要がありません。それはそれで数学の偉大なところですが、今回は高校数学や大学数学で扱うような関数のグラフをきちんとイメージできるように、Pythonを使って様々な形で記述されるグラフを描画していきます。
本記事は「コードをコピペしてあとはちょろっと書き換えるだけ」を心がけて作成しています。そのため記事中にはコメントアウト多めのコードをたくさん記載しています。記事が長くなっているため、適宜ジャンプ機能を活用してお読みください。
環境
Python3系
- 各自環境を用意してくださいnumpy
-pip3 install numpyによりインストールできますmatplotlib
-pip3 install matplotlibによりインストールできますjapanize-matplotlib
-pip3 install japanize-matplotlibによりインストールできます
- matplotlibで日本語を扱えるようにします2Dグラフ
y = f(x)
以下は $y = x^2$ のグラフを描画する例です。
import numpy as np import matplotlib.pyplot as plt import japanize_matplotlib PI = np.pi # 円周率をPIで使えるようにする # 定義域を指定 x = np.linspace(-10, 10, 1000000) # ここに関数を記述 y = x**2 plt.plot(x, y) plt.grid(which='major', color='gray', linestyle='--') plt.grid(which='minor', color='gray', linestyle='--') # 自動で軸をとりたい場合 plt.axes().set_aspect('equal', 'datalim') # 手動で軸を取りたい場合 # plt.axes().set_aspect('equal') # plt.xlim([-10, 10]) # plt.ylim([-100, 100]) plt.show()定義域(xの範囲)の指定
x = np.linspace(xの最小値, xの最大値, 分割数 = 1000000)により指定します。分割数は基本
1000000固定で良いですが、処理が重い場合は値を小さくしてください。関数の記述
y = x**2の部分を適宜自分の描画したい関数に書き換えます。初等関数を利用する際はnpにある関数を利用します。mathモジュールは使わないようにしましょう。例えば
$y = \sin{x}$ の場合は
y = np.sin(x)$y = e^x$ の場合は
y = np.exp(x)とします。
軸の設定
自動で軸を取る場合はそのままで良いですが、自分で軸の最大値最小値を設定したくなる場合もあります。
その場合は、
# 自動で軸をとりたい場合 # plt.axes().set_aspect('equal', 'datalim') # 手動で軸を取りたい場合 plt.axes().set_aspect('equal') plt.xlim([xの最小値, xの最大値]) plt.ylim([yの最小値, yの最大値])としましょう。
2つ以上のグラフを同時に描画
$y = \sin{x}$ と $y = \cos{x}$ を同時に描画する例です。
import numpy as np import matplotlib.pyplot as plt import japanize_matplotlib PI = np.pi # 円周率をPIで使えるようにする # 定義域を指定 x = np.linspace(0, 2*PI, 1000000) # ここに関数を記述 y1 = np.sin(x) y2 = np.cos(x) plt.plot(x, y1, label='sin') plt.plot(x, y2, label='cos') plt.grid(which='major', color='gray', linestyle='--') plt.grid(which='minor', color='gray', linestyle='--') # ラベルの描画 plt.legend() # 自動で軸をとりたい場合 plt.axes().set_aspect('equal', 'datalim') # 手動で軸を取りたい場合 # plt.axes().set_aspect('equal') # plt.xlim([-10, 10]) # plt.ylim([0, 100]) plt.show()2つ以上の関数を同時に描画する場合は、
label='ラベル名'をつけるようにしましょう。3つ以上の場合でも同様に関数を増やしていけば良いです。グラフの色も自動で設定してくれます。
対数軸で描画
以下は $y = e^{-x} = \exp{(-x)}$ のグラフを対数軸で描画する例です。
電気の学生なら対数軸を扱うことも多くあると思います。
import math import numpy as np import matplotlib.pyplot as plt import japanize_matplotlib PI = np.pi # 円周率をPIで使えるようにする # 定義域の設定 x = np.linspace(-5, 5, 1000000) # ここに関数を記述 y = np.exp(-x) plt.plot(x, y, label='exp(-x)') plt.grid(which='major', color='gray', linestyle='--') plt.grid(which='minor', color='gray', linestyle='--') # ラベルの描画 plt.legend() # 対数軸に設定 plt.yscale('log') # x軸も対数にする場合はplt.xscale('log')を追加 # 自動で軸をとりたい場合 # plt.axes().set_aspect('equal', 'datalim') # 手動で軸を取りたい場合 # plt.axes().set_aspect('equal') # plt.xlim([-10, 10]) # plt.ylim([0, 100]) plt.show()今回は対数軸なので「自動で軸をとる」設定は外しています。
陰関数の描画
陰関数とは $F(x, y) = 0$ の形で記述される関数です。
例えば、$x^2 + y^2 - 1 = 0$は陰関数と言えます。 $y = f(x)$のように $y$ を陽に記述できない場合によく使われますね。
以下は、$F(x, y) = x^2 - 2xy - y^2 + 7 = 0$ を描画する例です。どんなグラフになるか想像できるでしょうか?
import math import numpy as np import matplotlib.pyplot as plt import japanize_matplotlib PI = np.pi # 円周率をPIで使えるようにする # x の範囲 x_range = np.linspace(-10, 10, 1000) # y の範囲 y_range = np.linspace(-10, 10, 1000) x, y = np.meshgrid(x_range, y_range) # 陰関数 F = 0 F = x**2 - 2*x*y - y**2 + 7 # 軸を自動で設定する場合 plt.gca().set_aspect('equal', adjustable='box') # 軸を手動で設定する場合 # plt.axis([-10, 10, -10, 10]) plt.grid(which='major', color='gray', linestyle='--') plt.grid(which='minor', color='gray', linestyle='--') plt.contour(x, y, F, [0], colors="blue") plt.show()細かい説明はしませんが、2変数関数 $z = F(x, y)$ の高さ $z = 0$ の地点の等高線を記述するという方法で陰関数を描画しています。
実際書き換えるのは関数 $F(x, y)$ の部分と $x$ と $y$ の範囲くらいでしょう。
曲線の媒介変数表示
媒介変数表示とは、関数を $y=f(x)$の形で表現せず、媒介変数と呼ばれる変数 $t$ によって表現する方法です。式で書くと以下のようになります。
\left\{ \begin{array}{ll} x = \varphi(t) \\ y = \psi(t) \end{array} \right.以下は
\left\{ \begin{array}{ll} x = \left(1 + \cos{t} \right) \cos{t} \\ y = \left(1 + \cos{t} \right) \sin{t} \end{array} \right.のグラフを描画する例です。
import math import numpy as np import matplotlib.pyplot as plt import japanize_matplotlib PI = np.pi # 円周率をPIで使えるようにする # t の範囲 t = np.linspace(0, 2*PI, 1000000) # 関数を記述 x = (1 + np.cos(t))*np.cos(t) y = (1 + np.cos(t))*np.sin(t) # 軸を自動で設定する場合 plt.gca().set_aspect('equal', adjustable='box') # 軸を手動で設定する場合 # plt.axis([-10, 10, -10, 10]) plt.grid(which='major', color='gray', linestyle='--') plt.grid(which='minor', color='gray', linestyle='--') plt.plot(x, y) plt.show()例はいわゆるカージオイドです。
媒介変数表示を使えば興味深いグラフが簡単に得られますね。
参考 : 媒介変数表示された有名な曲線7つ - 高校数学の美しい物語2次元のベクトル関数
高校数学までで扱うベクトルは向きと大きさが常に一定な「定ベクトル」でした。
一方、大学数学からは時間などの変数によってベクトルの大きさや向きが変わる「ベクトル関数」を扱います。ベクトル関数は $\vec{r}(t) = (x(t),\ y(t))$ という形で書かれます。
以下は $\vec{r}(t) = (\cos^3{t},\ \sin^3{t})$ のグラフ(軌跡)を描画する例です。
import math import numpy as np import matplotlib.pyplot as plt import japanize_matplotlib PI = np.pi # 円周率をPIで使えるようにする # t の範囲 t = np.linspace(0, 2*PI, 1000000) # x(t) を記述 x = (np.cos(t))**3 # y(t) を記述 y = (np.sin(t))**3 # 軸を自動で設定する場合 plt.gca().set_aspect('equal', adjustable='box') # 軸を手動で設定する場合 # plt.axes().set_aspect('equal') # plt.axis([-10, 10, -10, 10]) plt.grid(which='major', color='gray', linestyle='--') plt.grid(which='minor', color='gray', linestyle='--') plt.plot(x, y) plt.show()プログラムは「曲線の媒介変数表示」とほぼ同じ、というか全く同じになりますね。
ベクトル軌跡(ナイキスト線図)
複素数 $z(t) = x(t) + y(t)\cdot i$ について、$t$を動かしたときの複素数の軌跡をプロットしたものを「ベクトル線図・ナイキスト線図」などといいます。
電気回路理論を例を出せば、インピーダンス $\dot{Z} = R + j \omega L$について、抵抗 $R$ が変化したらインピーダンス $\dot{Z}$ はどうなるかなーとか角周波数 $\omega$ を変化させたらどなるかなーとかっていうのを見るのに使います。
特に制御工学ではナイキスト線図という言い方が好まれます。伝達関数の周波数応答を見るために使います。(これ以上解説を詳しくすると長くなるのでやめておきます。)
以下は
z(\omega) = \dfrac{1}{1-\omega^2 + \omega i}について、 $\omega$ を変化させる場合のベクトル軌跡を描画する例です。プログラム中では $\omega$ を
tで表現しています。
import numpy as np import matplotlib.pyplot as plt import japanize_matplotlib import japanise_matplotlib PI = np.pi # 円周率をPIで使えるようにする # 計算式 t = np.arange(0, 10, 0.001) # np.arange(tの最小値(普通 0 ), tの最大値, 刻み) # 関数を記述 ## 複素数は 4i などと `j` をつければ良い ## `変数*i` などという場合は `変数 * 1j` とする z = 1 / (1 - t**2 + t*1j); # 実部と虚部を取得 Re = z.real Im = z.imag # 横軸の変数。縦軸の変数。 plt.plot(Re, Im) # グリッド補助線 plt.grid(which='major', color='gray', linestyle='--') plt.grid(which='minor', color='gray', linestyle='--') # 軸を自動で設定する場合 plt.gca().set_aspect('equal', adjustable='box') # 軸を手動で設定する場合 # plt.axes().set_aspect('equal') # plt.axis([-10, 10, -10, 10]) # 描画実行 plt.show()Pythonでは虚数単位は $i$ ではなく $j$ を用います(電気を勉強している人ならおなじみですね)。
例えば、
$4i$を表現したいときは、
4j$2ti$を表現したいときは
2*x * 1jとします。
有理化などをせず、そのまま記述すればプロットされるので嬉しいです。
二次元ベクトル
matplotlibにはベクトルを描画する関数
plt.quiver()がありますが、定ベクトルを書くには少し構文が厄介です。そこでplot_vector2D()という関数を自作し描画を簡単にしました。以下は
\begin{align} \vec{v_1} &= ( 5,\ 1) \\ \vec{v_2} &= ( 2,\ 4) \\ \vec{v_3} &= \vec{v_2} - \vec{v_1} \end{align}の3つのベクトルを描画する例です。
import math import numpy as np import matplotlib.pyplot as plt import japanize_matplotlib PI = np.pi # 円周率をPIで使えるようにする def plot_vector2D(pos, vec, color='blue', scale=1.0): plt.quiver(pos[0], pos[1], vec[0], vec[1], color=color, angles='xy', scale_units='xy', scale=scale) # ベクトルを記述 v1 = np.array([5, 1]) v2 = np.array([2, 4]) v3 = v2 - v1 plot_vector2D([0, 0], v1, color='red') plot_vector2D([0, 0], v2, color='green') plot_vector2D(v1, v3) plt.grid(which='major', color='gray', linestyle='--') plt.grid(which='minor', color='gray', linestyle='--') # 軸の設定 ## x の最大値最小値 plt.xlim([-6, 6]) ## y の最大値最小値 plt.ylim([-6, 6]) plt.axes().set_aspect('equal') plt.show()plot_vector2D関数
定ベクトルをプロットするための関数
plot_vector2D()に以下のように引数を渡せばベクトルがプロットされます。plot_vector2D(始点, 方向, color='色(省略可)', scale=単位ベクトルのスケール(省略可))例えば原点からベクトルを伸ばす場合は
plot_vector2D([0, 0], v)とします。
colorとscaleは、それぞれデフォルト値のblue、1.0になります。
scaleで指定した大きさですべてのベクトルが割られて描画されます。
例えばscale=5.0と指定すると、すべてのベクトルの大きさが5分の1になります。scale を変更しても始点の位置は調整されないことに注意してください。
基本的にはデフォルト値の
scale=1.0で良いかと思いますが、後述のベクトル場では適宜値を変更したほうが良いかもしれません。軸の設定
plt.axes().set_aspect('equal', 'datalim')を使ってもうまく自動で調整されないことが多いので、手動で設定する必要があります。plt.xlim([x軸の最小値, x軸の最大値]) plt.ylim([y軸の最小値, y軸の最大値])のように設定してください。
二次元のベクトル場
水の流れのように、各場所・各点 $P(x,\ y)$ でベクトル $\boldsymbol{v}(P) = \boldsymbol{v}(x,\ y)$ が分布しているとき、それをベクトル場といいます。
以下は ベクトル場
\boldsymbol{v}(x,\ y) = \left(2y,\ 3x \right)を描画する例です。
import math import numpy as np import matplotlib.pyplot as plt PI = np.pi # 円周率をPIで使えるようにする # x の範囲 x_range = np.arange(-3, 3, 0.5) # y の範囲 y_range = np.arange(-3, 3, 0.5) x, y = np.meshgrid(x_range, y_range) # ベクトル場 v(x, y) = (u(x, y), v(x, y)) u = 2*y v = 3*x plt.quiver(x, y, u, v, color='blue', angles='xy', scale_units='xy', scale=5.0) plt.grid(which='major', color='gray', linestyle='--') plt.grid(which='minor', color='gray', linestyle='--') # 自動で軸をとりたい場合 plt.axes().set_aspect('equal', 'datalim') # 手動で軸を取りたい場合 # plt.axes().set_aspect('equal') # plt.xlim([-10, 10]) # plt.ylim([0, 100]) plt.show()x, y の範囲
いままで $x,\ y$ の範囲を指定する関数として
np.linspace(最小値, 最大値, 分割数)を使っていましたが、ここではnp.arange(最小値, 最大値, 間隔)を使っています。 分割数でデータの細かさを表現するより、矢印をどのくらいの間隔で置くかで表現したほうがわかりやすいからです。関数の記述
ベクトル場を $\boldsymbol{v}(x, y) = \left(u(x,\ y),\ v(x,\ y) \right)$ と表したときの $u(x,\ y),\ v(x,\ y)$ を書けばよいです。
変数
x、yはベクトルの始点 $(x,\ y)$を表しています。plt.quiver関数
plt.quiver関数でベクトルをプロットしていますが、
plt.quiver(x, y, u, v, color='blue', angles='xy', scale_units='xy', scale=5.0)の引数のうち、
scale=5.0には注意してください。
本来のスケールで描画するならscale=1.0を指定すればよいです。
しかし、スケールが1だと矢印が長すぎて見えづらくなることもよくあります。そこでscaleで数値を指定すれば、その大きさでベクトルが割られ、見やすくなります。3Dグラフ
z = f(x, y)
二変数関数のグラフは三次元空間に描画されます。
以下は $z = y^2 - x^2$ のグラフを描画する例です。
import numpy as np import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D import japanize_matplotlib PI = np.pi # 円周率をPIで使えるようにする fig = plt.figure() ax = fig.add_subplot(111, projection="3d") # x と y の範囲の設定 x_range = np.linspace(-20, 20, 1000) y_range = np.linspace(-20, 20, 1000) x, y = np.meshgrid(x_range, y_range) # 関数を記述 z = y**2 - x**2 ax.plot_surface(x, y, z, cmap = "summer") ax.contour(x, y, z, colors = "gray", offset = -1) # 底面に等高線を描画 # 自動で軸を設定する場合は記述なし # 手動で軸を設定する場合 # ax.set_xlim(-20, 20) # ax.set_ylim(-20, 20) # ax.set_zlim(-1500, 1500) ax.set_xlabel("x") ax.set_ylabel("y") ax.set_zlabel("z") plt.show()コードの雰囲気が少し変わりましたが、いじるところは2Dの場合と大差ありません。書き換えるとすれば $z = f(x, y)$ の記述と、軸の設定くらいでしょう。
軸の設定(スケール)には十分注意しましょう。今回は見栄え重視のため軸を自動で設定しました。そのため、x,y軸とz軸のスケールが異なっています(2変数関数はxとyのスケールに比べてzのスケールは大きくなりがちなので、手動でスケールを合わせたところで微妙な感じにはなりますが…)
とにかくグラフを眺めるときは軸のスケールの確認を忘れないようにしましょう。
三次元のベクトル関数
以下は $\vec{r}(t) = (\sin{t},\ \cos{t},\ t)$ のグラフを描画する例です。
import numpy as np import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D import japanize_matplotlib PI = np.pi # 円周率をPIで使えるようにする fig = plt.figure() ax = fig.add_subplot(111, projection="3d") # パラメータ t の範囲を設定 t = np.linspace(-6*PI, 6*PI, 1000) # x(t) を記述 x = np.cos(t) # y(t) を記述 y = np.sin(t) # z(t) を記述 z = t ax.plot(x, y, z) # 自動で軸を設定する場合は記述なし # 手動で軸を設定する場合 # ax.set_xlim(-20, 20) # ax.set_ylim(-20, 20) # ax.set_zlim(-1500, 1500) ax.set_xlabel("x") ax.set_ylabel("y") ax.set_zlabel("z") plt.show()物理の話をすれば、速度 $\vec{v}(t)$ や 位置 $\vec{x}(t)$ などが三次元ベクトル関数の例にあげられます。
三次元ベクトル
ベクトルを描画する関数
plt.quiver()を使いますが、二次元同様、定ベクトルを書くには少し構文が厄介です。
そこでplot_vector3D()という関数を自作し描画を簡単にしました。以下は
\vec{v_1} = (1,\ 2,\ 3) \\ \vec{v_2} = (-4,\ 5,\ 1) \\ \vec{v_3} = \vec{v_2} - \vec{v_1}の3つのベクトルを描画する例です。
import math import numpy as np import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D import japanize_matplotlib PI = np.pi # 円周率をPIで使えるようにする fig = plt.figure() ax = fig.add_subplot(111, projection="3d") def plot_vector3D(ax, pos, vec, color='blue', scale=1.0): ax.quiver(pos[0], pos[1], pos[2], vec[0], vec[1], vec[2], color=color, length=1/scale) # ベクトルを記述 v1 = np.array([1, 2, 3]) v2 = np.array([-4, 4, 1]) v3 = v2 - v1 plot_vector3D(ax, [0, 0, 0], v1, color='red') plot_vector3D(ax, [0, 0, 0], v2, color='green') plot_vector3D(ax, v1, v3) # 軸の設定 ax.set_xlim([-5, 5]) ax.set_ylim([-5, 5]) ax.set_zlim([-5, 5]) ax.set_xlabel("x") ax.set_ylabel("y") ax.set_zlabel("z") plt.show()
plot_vector3D()関数に以下のように引数を渡せばベクトルがプロットされます。plot_vector3D(ax, 始点, 方向, color='色(省略可)', scale=単位ベクトルのスケール)scale を変更しても始点の位置は調整されないことに注意してください。
2次元の場合とほぼ同じですね。
三次元のベクトル場
三次元のベクトル場も二次元と同様に定義されます。
以下は ベクトル場
\boldsymbol{v}(t) = \left( x(x+y+z),\ y(x+y+z),\ z(x+y+z) \right)を描画する例です。
import math import numpy as np import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D import japanize_matplotlib PI = np.pi # 円周率をPIで使えるようにする fig = plt.figure() ax = fig.add_subplot(111, projection="3d") # x の範囲 x_range = np.arange(-2, 2, 1) # y の範囲 y_range = np.arange(-2, 2, 1) # z の範囲 z_range = np.arange(-2, 2, 1) x, y, z = np.meshgrid(x_range, y_range, z_range) # ベクトル場 v(x, y, z) = (u(x, y, z), v(x, y, z), w(x, y, z)) u = x*(x + y + z) v = y*(x + y + z) w = z*(x + y + z) ax.quiver(x, y, z, u, v, w, color='blue', length=1/5.0, normalize=False) ax.set_xlim([-5, 5]) ax.set_ylim([-5, 5]) ax.set_zlim([-5, 5]) ax.set_xlabel("x") ax.set_ylabel("y") ax.set_zlabel("z") plt.show()二次元の場合とほぼ同じですね。
単位ベクトルのスケールの指定が
scaleではなくlengthになっていることに注意してください。
単位ベクトルがlength倍のスケールで描画されます。uv曲面
3次元空間内の曲面は、位置ベクトル $\boldsymbol{r}$ が2変数 $u,\ v$の関数で、$\boldsymbol{r} = \boldsymbol{r}(u,\ v)$ で表すことができます。これを$uv$曲面と呼びます。
ベクトル解析の分野でよく使われますね。
以下は $\boldsymbol{r}(u,v) = (2u,\ 3v,\ u^2 + v^2)$ のグラフ(曲面)を描画する例です。
import numpy as np import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D import japanize_matplotlib PI = np.pi # 円周率をPIで使えるようにする fig = plt.figure() ax = fig.add_subplot(111, projection="3d") # u の範囲を指定 urange = np.linspace(-20, 20, 1000) # v の範囲を指定 vrange = np.linspace(-20, 20, 1000) u, v = np.meshgrid(urange, vrange) # 曲面 r(u, v) を記述 x = 2*u y = 3*v z = u**2 + v**2 ax.plot_surface(x, y, z, cmap = "summer") ax.contour(x, y, z, colors = "gray", offset = -1) # 底面に等高線を描画 ax.set_xlabel("x") ax.set_ylabel("y") ax.set_zlabel("z") plt.show()応用
グラフを装飾する
グラフを装飾する方法はたくさんありますが、ここではその一部を紹介します。
以下は オームの法則 $V = RI$ を描画した例です。
import math import numpy as np import matplotlib.pyplot as plt import japanize_matplotlib PI = np.pi # 円周率をPIで使えるようにする # 定義域を指定 I = np.linspace(-5, 5, 1000000) # ここに関数を記述 R = 1.0 V = R*I plt.plot(I, V) plt.grid(which='major', color='gray', linestyle='--') plt.grid(which='minor', color='gray', linestyle='--') # タイトルをつける plt.title(r'オームの法則(抵抗 $R = 1$ [${\rm \Omega}$])') plt.xlabel('電流 $I$ [A]') plt.ylabel('電圧 $V$ [V]') # 自動で軸をとりたい場合 plt.axes().set_aspect('equal', 'datalim') # 手動で軸を取りたい場合 # plt.axes().set_aspect('equal') # plt.xlim([-10, 10]) # plt.ylim([-100, 100]) # 目盛りを 1 ごとつける plt.xticks(np.arange(-5, 5+1, 1)) plt.yticks(np.arange(-5, 5+1, 1)) # x軸とy軸を実線にする plt.hlines([0], -5, 5, color='gray') plt.vlines([0], -5*R, 5*R, color='gray') plt.show()タイトルやラベルをつける
plt.title()やplt.xlabel()、plt.ylabel()を用いることでグラフにタイトルやラベルをつけることができます。
$で囲うことで、$\TeX$記法を使うこともできますが、バックスラッシュ\を使う場合は文字列を囲うクォーテーションの前にrをつける必要があります。目盛りの細かさを変更する
plt.xticks(np.arange(-5, 5+1, 1))とplt.yticks(np.arange(-5, 5+1, 1))を使ってxとyの目盛りの細かさをそれぞれ変更できます。
np.arange(最小値, 最大値, 間隔(公差))ですが、範囲が[最小値, 最大値)であることには注意しましょう。(最大値は含まないということです。)x軸とy軸を実線にする
水平線を引く関数
plt.hlines()と 垂直線を引く関数plt.vlines()を使ってx軸とy軸を引いてみました。補助線を描画する
オームの法則を使った例ではx軸とy軸を引くために
plt.hlines()とplt.vlines()を使いましたが、これらの関数は補助線を描画するのに便利です。$y = \sin{x}$ について
\begin{align} x &= \pi,\ 2\pi \\ y &= -1,\ -\frac{\sqrt{2}}{2},\ \frac{\sqrt{2}}{2},\ 1 \end{align}の部分に補助線を描画する例です。
import math import numpy as np import matplotlib.pyplot as plt import japanize_matplotlib PI = np.pi # 円周率をPIで使えるようにする x = np.linspace(0, 2*PI + PI/2, 1000000) y = np.sin(x) plt.plot(x, y) plt.grid(which='major', color='gray', linestyle='--') plt.grid(which='minor', color='gray', linestyle='--') plt.title(r'$y = \sin{x}$') plt.axes().set_aspect('equal') plt.xlim([0, 2*PI + PI/2]) plt.ylim([-2, 2]) # 水平な補助線を引く plt.hlines([-1, -np.sqrt(2)/2, np.sqrt(2)/2, 1], 0, 2*PI + PI/2, color='red', linestyle='--') # 垂直な補助線を引く plt.vlines([PI, 2*PI], -2, 2, color='red', linestyle='--') plt.hlines([0], 0, 2*PI + PI/2, color='gray') plt.vlines([0], -2, 2, color='gray') plt.show()関数の引数の意味は以下の通りです。
plt.hlines([補助線を引き始めるyの値のリスト], xの最小値, xの最大値, color='色', linestyle='-や--や:') plt.vlines([補助線を引き始めるxの値のリスト], yの最小値, yの最大値, color='色', linestyle='-や--や:')2つ以上のグラフを並べて描画
2つ以上のグラフを並べて描画するには、
fig.add_subplot()関数を使います。以下は 曲面 $z = x^2 + y^2 - 1$ と 曲線 $F(x, y) = x^2 + y^2 - 1 = 0$ を同時に描画する例です。
import math import numpy as np import matplotlib.pyplot as plt from mpl_toolkits.mplot3d import Axes3D import japanize_matplotlib PI = np.pi # 円周率をPIで使えるようにする x_range = np.linspace(-2, 2, 1000) y_range = np.linspace(-2, 2, 1000) x, y = np.meshgrid(x_range, y_range) # 陰関数 z = x**2 + y**2 - 1 # ウィンドウの大きさを指定(グラフ1枚あたり 8 を想定) fig = plt.figure(figsize=(16, 8)) # 描画の設定 ax1 = fig.add_subplot(1, 2, 1, projection="3d") ax1.set_title('曲面z = f(x, y)') ax1.set_xlabel("x", size = 16) ax1.set_ylabel("y", size = 16) ax1.set_zlabel("z", size = 16) ax1.plot_surface(x, y, z, cmap = "summer") ax1.contour(x, y, z, colors = "black", offset = -1) # 底面に等高線を描画 ax1.set_aspect('equal', adjustable='datalim') ax2 = fig.add_subplot(1, 2, 2) ax2.set_title('曲線 f(x, y) = 0') ax2.axis([-2, 2, -2, 2]) ax2.set_aspect('equal', adjustable='datalim') ax2.grid(which='major', color='gray', linestyle='--') ax2.grid(which='minor', color='gray', linestyle='--') ax2.contour(x, y, z, [0], colors="blue") plt.show()2枚以上のグラフを扱う場合は、
axという変数を使ってそれぞれのグラフの設定・プロットを行うと考えてください。まず、
fig.add_subplot()関数を使って、ひとつのaxを作成します。
「何行何列あるグラフのうち、何番目にそのグラフを置くか」というように引数を指定します。# 2Dの場合 ax = fig.add_subplot(行, 列, 何番目) # 3Dの場合 ax = fig.add_subplot(行, 列数 何番目, projection="3d")次に
axを使って設定、プロットを行います。axにある関数はpltにある関数とかなり似ていますが、関数名が全く同じというわけでもないので各自調べて下さい。そして、この
axを表示したいグラフの枚数だけ作成します。特別な関数
周期関数や条件分岐がある関数の描画を考えます。
結局はnp.ndarray型をいかに扱うかなのでわからないことがあればnp.ndarrayをキーワードに検索をすれば良いでしょう。いくつか例をあげます。
ReLU関数(ランプ関数)
ReLU関数(ランプ関数)は以下のように定義されます。
f(x) = \left\{ \begin{array}{ll} x & (x \geq 0) \\ 0 & (x \lt 0) \end{array} \right.
numpyのnp.maximum(a, b)を使うことでうまく関数を記述することができます。
import math import numpy as np import matplotlib.pyplot as plt import japanize_matplotlib PI = np.pi # 円周率をPIで使えるようにする x = np.linspace(-5, 5, 1000000) # ReLU関数 y = np.maximum(x, 0) plt.plot(x, y) plt.grid(which='major', color='gray', linestyle='--') plt.grid(which='minor', color='gray', linestyle='--') plt.title('ReLU関数') plt.axes().set_aspect('equal', 'datalim') plt.xticks(np.arange(-5, 5+1, 1)) plt.yticks(np.arange(-5, 5+1, 1)) plt.hlines([0], -5, 5, color='gray') plt.vlines([0], -5, 5, color='gray') plt.show()条件分岐がある関数
f(x) = \left\{ \begin{array}{ll} \dfrac{3}{2}x & (0 \leq x < 2) \\ 3 & (2 \leq x < 4) \\ -\dfrac{3}{2}x + 9 & (otherwise) \end{array} \right.のグラフを描画することを考えましょう。
np.ndarrayのなかで条件に合う要素を抜き出すのがnp.where()関数です。np.where(条件式, Trueの場合の値, Falseの場合の値)という使い方をします。複数の条件式を組み合わせる場合は
andやorの代わりに&、|を使います。以下に実装例を示します。
import math import numpy as np import matplotlib.pyplot as plt import japanize_matplotlib PI = np.pi # 円周率をPIで使えるようにする x = np.linspace(0, 6, 1000000) # 関数の定義 y = np.where((0 <= x) & (x < 2), 1.5*x, np.where((2 <= x) & (x < 4), 3, -1.5*x + 9)) plt.plot(x, y) plt.grid(which='major', color='gray', linestyle='--') plt.grid(which='minor', color='gray', linestyle='--') plt.axes().set_aspect('equal', 'datalim') plt.xticks(np.arange(0, 6+1, 1)) plt.yticks(np.arange(0, 6+1, 1)) plt.hlines([0], 0, 6, color='gray') plt.vlines([0], min(y)-1, max(y)+1, color='gray') plt.show()関数の実装部分がかなり読みにくいですが、これで実現できます。
こんな関数も面白いかもしれませんね~
# 関数の定義 y = np.sin(x) y = np.where(np.abs(y) > np.sqrt(3) / 2, np.sign(y)*np.sqrt(3) / 2, y)周期関数
周期の剰余(MOD)を計算するというアイデアで周期関数を記述することができます。
以下は $f(x) = x^2,\ \ f(x+2) = f(x)$ のグラフを描画する例です。
import math import numpy as np import matplotlib.pyplot as plt import japanize_matplotlib PI = np.pi # 円周率をPIで使えるようにする x = np.linspace(-6, 6, 1000000) # 周期 T の関数 T = 2 y = (x % T)**2 plt.plot(x, y) plt.grid(which='major', color='gray', linestyle='--') plt.grid(which='minor', color='gray', linestyle='--') plt.axes().set_aspect('equal', 'datalim') plt.xticks(np.arange(-6, 6+1, 1)) plt.yticks(np.arange(-1, 5+1, 1)) plt.hlines([0], -6, 6, color='gray') plt.vlines([0], -1, 5, color='gray') plt.show()接線の方程式を描画する
ある点 $x = a$ における関数 $f(x)$ の接線の方程式を描画しましょう。
まず、接線の傾き $f'(a)$ を求めます。定義式から $f'(a)$ は
f'(a) = \lim_{h \to 0} \frac{f(a+h) - f(a)}{h}で求めることができます。
さて、人間が計算するのであればこの定義式からゴチャゴチャ式を変形して……としますが、コンピュータ的には $h = 10^{-10}$ というように $h$ に微小な値を代入することで近似的に微分係数を計算することができます。ただし、もとの定義式のままだと、「 $a$ 点から $a+h$ 点までの差 / $h$」なので、正確に $a$ 点で微分することができません。そこで、
f'(a) = \lim_{h \to 0} \frac{f(a+h) - f(a-h)}{2h}とすることで、正確に $a$ 点での微分を求めます。
次に、接線の方程式を求めます。通る点と直線の公式からずばり、
y = f'(a) (x - a) + f(a)です。さあ、あとは実装するだけですね。
以下は $y = x^2 + 2x + 1$ のグラフと、 $x = 1$ における接線のグラフを描画する例です。
import numpy as np import matplotlib.pyplot as plt import japanize_matplotlib PI = np.pi # 円周率をPIで使えるようにする # 対象の関数 def f(x): return 0.5*x**2 + x + 0.5 # 微分係数を求める def diff(fun, a): h = 10**(-10) return (fun(a + h) - fun(a - h)) / (2*h) # 関数の定義 ## 対象の関数 x1 = np.linspace(-6, 4, 1000000) y1 = f(x1) ## 接線 x2 = np.linspace(-1, 5, 1000000) a = 1 k = diff(f, a) y2 = k*(x2 - a) + f(a) plt.plot(x1, y1, label='$y=x^2 + 2x + 1$') plt.plot(x2, y2, label='接線') plt.grid(which='major', color='gray', linestyle='--') plt.grid(which='minor', color='gray', linestyle='--') plt.legend() plt.axes().set_aspect('equal', 'datalim') plt.show()最後に
Matplotlibの関数はここで紹介した以外にもたくさんあります。ぜひいろいろ試してみてください。
気分によってはもうすこしサンプルを追加するかも。





















- 投稿日:2019-12-09T15:55:52+09:00
欠損値 python
今回は欠損値について、記事を書いていきます。
内容
・欠損値とは
・欠損値の確認方法
・欠損値の対処法欠損値とは
欠損値とはデータの値がはいっていないことをいいます。
例えば、表データに空欄やNULLといった具体的な数値が入っていない状態のことです。
欠損値があるとうまくデータがとれないため、グラフに可視化しても偏りがでてしまいます。欠損値の確認方法
では、欠損値を見つけるためにはどういう方法があるのでしょうか。
それはpythonを使えば容易にみつけることができます。ここではcsvデータをつかっていることとします。isnull関数
pythonではデータが入っていないところを簡単に見つけてくれる関数があります。それは「isnull()」です。これはデータのないところを一つ一つの欄にFalse,Trueを表示してくれる関数です。値がない場合はTrue、ある場合はFalseを表示してくれます。
any関数
では、データ一つ一つチェックしてくれなていいよ、欠損値があるかないかをしりたい場合は「any()」という関数をisnull()の後に付け足すことで各列(カラム)に欠損値があるかを確認してくれます。出力結果は、各カラムに対してTrue,Falseで表示されます。欠損値がある場合はTrue、ない場合はFalseを表示してくれます。
sum関数
欠損値の個数をしりたい場合に使います。これもany関数と同様にisnull関数の後に付け加えることでnullの個数を出力することができます。
value_counts関数
指定した列の数値の個数を調べてくれる関数です。例えば、0という数が10個ありますよというような出力結果を得ることができます。
欠損値の対処法
欠損値を確認しただけでは何も意味がありません。それを具体的な数値を代入しないといけません。これを補間といいます。
fillna関数
では、表のnullのところに数値を補間していきましょう。この時に使うのが「fllna」という関数です。この関数は表のnullが表示されているところをすべて数値に変えてくれます。引数に数値を指定することで好きな値を指定して保管することができます。fillna(0)とすれば、nullをすべて0に補間してくれます。
dropna関数
具体的な数値に入れ替えるのではなく、nullがある行を削除したい場合は「dropna」という関数を使います。厳密には、ある列にnullがあった場合、それに対応した行を削除します。特定の列をしてする場合には引数に「subset=["列名"]」と指定します。
- 投稿日:2019-12-09T15:51:58+09:00
フラクタル図形をもっと細かく → numba
課題で出されたフラクタル図形のマンデルブロ集合で遊びまくったお話です。
課題ではマンデルブロ集合を $-2.5 < x < 1.0\space, \space-1.0 < y < 1.0$ の範囲を $400×400$ のドット絵でを作りました。
しかし、 $400×400$ のドット絵だと輪郭がガタガタでせっかくできたのに感動が足りない…
もっとドット数を増やしたい!そこで使ったのがnumbaです。
Let's pip install numbanumbaとは
numbaは、Pythonで実装された関数を実行中にコンパイルするJITコンパイラを提供するパッケージです。(実行中→Just-In-Time)
冬休みに暇があったら説明追加します(しないパターン)
そのため、
for文を高速で回すことができます。
フラクタル図形を描画 == for文ぶんぶん回す -> Trueなので今回の目的にぴったり。単純なコードで実行速度を比較してみる
1〜n までの総和 $\left(\sum_{k=1}^nk\right)$ を
- Pythonのみで実装した関数
- 1の関数に
@jitデコレータをつけた関数の両方で求めて、その実行速度を比較してみました。
実行時間にばらつきがあったので、下のコードは平均の時間が計算しやすいjupyterを使いました。コード
from numba import jit import matplotlib.pyplot as plt %matplotlib inline def sum_py(n): s = 0 for i in range(n): s += i return s @jit def sum_jit(n): s = 0 for i in range(n): s += i return s sum_jit(0) # 初回の実行はコンパイルの時間を含むので、先に実行しておく ns = [10 ** i for i in range(2, 7)] time_py =[] time_jit = [] for n in ns: a = %timeit -r 3 -n 100 -o sum_py(n) b = %timeit -r 3 -n 100 -o sum_jit(n) time_py.append(a.average) time_jit.append(b.average) plt.figure() plt.plot(ns, time_py, label="python") plt.plot(ns, time_jit, label="jit") plt.xscale("log") plt.yscale("log") plt.legend()実行結果
縦軸:時間(秒)、横軸:ループ回数
JITでコンパイルした関数は、ループ回数を増やしても全く遅くならない!フラクタル図形の計算を高速化する
元々のコード
下がnumbaで高速化する前の(1番上の図を描画した)コードです。
import matplotlib.pyplot as plt from numba import jit import numpy as np # 領域の大きさ (x_min, x_max) = (-2.5, 1.0) (y_min, y_max) = (-1.0, 1.0) # 小領域の数 = M x N (M, N) = (400,) * 2 # 各座標 xs = np.linspace(x_min, x_max, M) ys = np.linspace(y_min, y_max, N) # 発散の評価 K = 1000 def is_to_infty(z0): z = z0 for k in range(K): if abs(z) > 2: return np.sqrt(k/K) z = (z ** 2) + z0 return 1. def mandelbrot(xs, ys): P = np.zeros((N, M)) for j, y in enumerate(ys): for i, x in enumerate(xs): P[j, i] = is_to_infty(complex(x, y)) return P img = mandelbrot(xs ,ys) plt.figure(figsize=((x_max - x_min) * 3.5, (y_max - y_min) * 3.5)) plt.imshow(img, origin='lower', extent=(x_min, x_max, y_min, y_max), cmap=cm.jet, interpolation='nearest') plt.show() # plt.savefig("mandelbrot.png", dpi=N//8)この記事のテーマはnumbaなので、フラクタル図形のマンデルブロ集合についての詳しい解説は省略します。
このコードはmandelbrot関数内で $400^2$ 回for文が繰り返されているので、そこに時間がかかってしまいます。matplotlibのオプションについて
- そもそも
for文どうこうよりもplt.imshow(img)がめちゃくちゃ時間かかります。- せっかく
N, Mを大きくしても、dpiを指定しないとそのままの画質で保存できません。- だいたい
img=N//8にすると、imgの要素数がそのまま画像に画素数になります。(10:16画面の場合)numbaをつかう
とは言っても、変更点は関数に
@jitをつけるだけ@jit def is_to_infty(z0): ... @jit def mandelbrot(xs, ys): ...実行結果の比較
コードの1部分を下のようにして実行結果を比較してみると、
from time import time start = time() img = mandelbrot(xs ,ys) end = time() print(end - start)結果
python: 6.6 秒 numba : 0.8 秒約8倍。しかしこの差は、先ほどの総和の実行速度のグラフのように
for文の繰り返し回数が多くなるほど大きくなります。つまり、$400^2$ 回から$10000^2$ 回にすると…もっと細かく!(本題)
さてやっと本題です。numbaはただの手段であって今回の目的はきれいなマンデルブロ集合を見たいということです!
(M, N) = (10000,) * 2えーっと、1万回ループのネストは1億回ループかな笑
どんな画像ができるんだろう
わくわくどきどき
注意:約6MBです。クリックして画像を別タブで開いたりする時は気をつけてください。
画像サイズが大きすぎるとTwitterには怒られましたが、Qiitaは画像サイズ10MBまで耐えるみたいですね。笑
シャレにならない重さだったので、画像が欲しかったら上のコードに@jitをつけて1億回ループに変更したコードを各自ぶん回してください。(2分もしないはずです。)下の画像(809KB)は、一部を拡大して最初のと比較したものです。
後記
YouTubeによくある、1点をずっと拡大し続けるアニメーションとかできたら面白そう。前から3Blue1Brownという数学チャンネルのアニメーションがかっこいいなーと思っていたけど、それが最近Pythonで書かれていてgithubで公開されていたことを知ったのでのぞいてみたい。
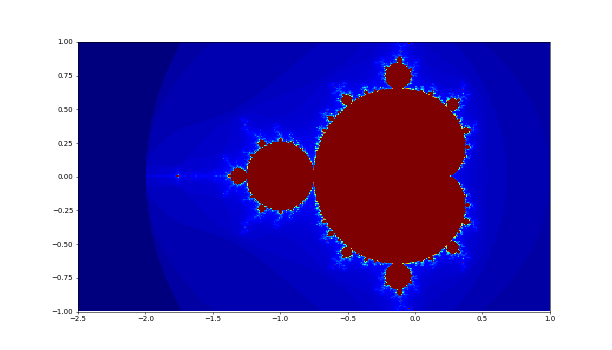
- 投稿日:2019-12-09T15:29:10+09:00
Pythonで複素数扱うときに役立ちそうなことをまとめてみる
普段は量子コンピュータのシミュレータをPythonで書いています。
その都合上、複素数は大変よく使います。Python, numpyは複素数もサポートされており、あんまり困ることはないのですが、いくつか罠もあるので、そこらへんをまとめておきます。
Pythonでの複素数の基本
このへんは、普通にリファレンスに載ってるやつです。軽くおさらい。
虚数単位は
1j、型はcomplex数学では多くの場合、虚数単位にはiが使われますが、Pythonでは
1jが使われます。
(電気などの分野で、iは電流に使っているので虚数単位をjと置く、というのを見たことがありますが、それ以外の分野では他に知りません)
2jとか、1.23jのような書き方もできます。(普通に1jの2倍、1.23倍、という意味)
1と1.で型に違いがあるのに対し、1jと1.jはどちらも同じです。a, bをfloatとして、
a + b * 1.jはcomplex(a, b)と書くこともできます。
.real,.imagで実部、虚部を取り出すconjugate()で複素共役をとる
(1 + 2j).realは1,(1 + 2j).imagは2です。メソッドではないので()を付けないことに注意してください。
複素共役は(1 + 2j).conjugate()のように、.conjugate()を使います。こちらはメソッドなので()が必要です。
ちなみに.real,.imag,conjugate()は、実はfloatやintに対しても使えます。numpyも普通に使える
numpyでも
np.array([1 + 2j, 3, 4j, 5+6.7j])のように、普通に複素数が使えます。このときdtypeは、デフォルトでは'complex128'になります。
.real,.imag,.conjugate()もnumpyのarrayに対して使うことができます。
また、numpyでは、.conjugate()のかわりに.conj()でも構いません。なお、行列のエルミート共役取るのが
.conj().Tとする必要があり、やや面倒です。
np.matrixだと.Hでできたんですが。np.arrayにはないようです。
mathのかわりにcmath
import mathのかわりにimport cmathを使います。
mathの関数が定義域や値域を実数にとっているのに対し、cmathは定義域や値域に複素数も含まれます。
詳細は公式ドキュメント参照。複素数の偏角を求める
phase()や、半径と偏角のタプルを返すpolar()や、半径と偏角から複素数を作るrect()といった便利な関数も用意されてます。Pythonで複素数を扱うときの注意
いくつか罠やその対処を書いていきます。
複素数になりうるなら、numpyのarrayは予め複素数で作る
Pythonは自分で型を書かなくても暗黙のうちに型変換してくれますが、numpyでは、arrayは型を持っていて、勝手にarrayの型が変わることはありません。(intのarrayがfloatにならないのも同様です)
a = np.array([1., 2.]) # dtypeがfloat64 a *= 1j # UFuncTypeError: Cannot cast ufunc 'multiply' output from dtype('complex128') to dtype('float64') with casting rule 'same_kind'こうならないために
np.array([1., 2.], dtype=np.complex128)のように最初から型を指定するか、
np.array([1+0j, 2.], dtype=np.complex128)のように最初から複素数を含めるかが必要です。複素ベクトルの内積は
np.dotではなくnp.vdotこれは本当に罠です。
複素ベクトルの内積は$u\cdot v = \sum_{i=1}^n u_i^* v_i$のように、$u$の複素共役と$v$との各成分の積の和を取るのが普通ですが、
np.dotでは、複素共役をとらず、そのまま各成分の積の和を取ります。どうしてもnp.dotを使う必要がある場合は、自分で複素共役を取ってつかいましょう。
一方、np.vdotを使うと、複素ベクトルであっても適切に内積を取れます。当たり前だけど、複素数同士は大小の比較ができない
他の言語で複素数を扱っている人には当たり前ですが。複素数同士は比較ができません。
より正確には、「複素数型」の大小比較ができないので、プログラマが計算結果が実数になっていると知っていても、コンピュータにとって複素数型だったら、大小比較はできません。
.realなどで実数にする必要があります。複素数配列の「絶対値の2乗」は効率がいい方法がないらしい
np.absは、内部的にはsqrt(real**2 + imag**2)のような計算をしているので、これを2乗するのは無駄が多いです。
一方、arr.real ** 2 + arr.imag **2のような計算をPython側で書くと、インプレースで計算されず、無駄なメモリ確保が生じます。
以前調べたことがあるんですが、StackOverflowには、numba使え、と書いてありました。Python, numpyだけでインプレースに無駄な開平計算をせずにやる方法は意外とないみたいです。
- 投稿日:2019-12-09T15:14:39+09:00
Trio + httpxでPythonで気軽に非同期のhttpクライアントを実装する
PythonではTrioという非同期処理用のライブラリが使い勝手が良いのですが、低レイヤーなAPIしか用意されていないので単体で利用するとけっこうつらいものがあります。幸いhttpxというhttpクライアントライブラリにTrioモードが用意されているので、そちらを利用してみました。
利用ライブラリ
https://github.com/encode/httpx
requestsに似た使い勝手で、非同期処理のhttpクライアントライブラリです。Trio用のモードも用意されています。この記事で利用した当時のバージョンは0.7.8です。
https://github.com/python-trio/trio
ユーザーフレンドリーな非同期処理のライブラリです。当時のバージョンは0.13.0です。
コード
このようなコードになります。詳しくはhttpxの公式ドキュメントを読んでください。
基本的にはこのようなコードになります。
import httpx from httpx.concurrency.trio import TrioBackend import trio async def main(): # timeoutの値はよしなに変えてください async with httpx.AsyncClient(backend=TrioBackend(), timeout=None) as client: response = await client.get('https://www.example.com/') print(response) trio.run(main)並列でリストの内容をリクエストを送るときは、次のようなコードになると思います。
asyncio.gatherのようなリストを返すAPIは存在しないので、クロージャを使って工夫する必要あります。詳しくはこちらのStackOverflowを読んでください。async def main(): # 並列でリクエストを送りたいurl urls = ['https://www.example.com/', 'https://www.example2.com/'] results = [] async def _inner(client, url): response = await client.get(url) results.append(response) async with httpx.AsyncClient(backend=TrioBackend(), timeout=None) as client: async with trio.open_nursery() as nursery: for url in urls: nursery.start_soon(_inner, client, url) print(results)参考記事
Trioに関して日本語で読みたい方はこちらでどうぞ。