- 投稿日:2019-12-09T22:44:22+09:00
dokojavaで「大石泉すき」を出力する
はじめに
この記事は「大石泉すき」 Advent Calendar 2019への参加記事です。
今回はプログラミング経験が未経験のP(プロデューサー)でも、プログラミングが気軽に体験できるdokojavaを使用して「大石泉すき」を出力する方法をご紹介します。
筆者自身、開発経験が少ないので、間違った記述がございましたら、ご指摘お願い致します。dokojavaとは
「dokojava」は、Java言語で記述したコードをブラウザ上で実行できる開発環境です。
使い方
コード
コードを記述したら、画面右下端の「≫」ボタンをクリックします。
コンパイル
コンパイル結果で、エラー・警告が出ていなければ、画面右下端の「▶」ボタンをクリックします。
実行
実行結果画面にて、コードに記述した内容が表示されます。
「大石泉すき」を出力する
コード画面にて、以下のコードを記述します。
Main.javapublic class Main { public static void main(String[] args) { System.out.println("大石泉すき"); } }記述したコードをコンパイルし、実行すると、「大石泉すき」が出力されます。
勘の良いPなら、気付いているかもしれませんが、「hello,world!」を「大石泉すき」に書き換えると、「大石泉すき」を出力できます。
おわりに
以上、簡単に「大石泉すき」を出力する方法をご紹介しました。
12月8日に参加登録したのに、1日遅れになり、申し訳ございませんでした。
本記事を読んで、気軽に「大石泉すき」を出力して頂ければ幸いです。




- 投稿日:2019-12-09T20:59:28+09:00
C#でJavaのenumを再現する
この記事は StudioZ Tech Advent Calendar 2019 の11日目の記事です。
はじめに
5年ぐらい前からUnityを使うようになり、JavaからC#に転向しました。
似たところの多い言語なのでほとんど違和感なく使うことができたのですが、唯一困ったのがenumの仕様。
そこでJavaのenumをC#で再現できないか考えてみました。Javaのenumの特性と実装方法
- 列挙子は列挙型のインスタンスを持つ
- 普通にクラスを使えば満たせます
- 外部からインスタンスの生成ができない
- コンストラクタをprivateにすることで対応可能です
- 列挙型.列挙子でアクセスできる
- 列挙子のインスタンスをstaticフィールドで管理すればアクセス可能になります
- 同名の列挙子は定義できない
- 同名のフィールドは定義できないので、staticフィールドで管理する時点で満たされます
ここまでの条件をコードにするとこんな感じになります
public class EnumSample { public static EnumSample Enum1 = new EnumSample(); public static EnumSample Enum2 = new EnumSample(); public static EnumSample Enum3 = new EnumSample(); public static EnumSample Enum4 = new EnumSample(); // 外部からのインスタンス生成不可 private EnumSample() {} }
- 列挙子は固有の値を持つことができる
- コンストラクタで値を受け取ってフィールドに持つようにします
- ただし静的に重複のチェックをすることはできません(実行時のチェックは可能)
public class EnumSample2 { public static EnumSample2 Enum1 = new EnumSample2( 1 ); public static EnumSample2 Enum2 = new EnumSample2( 2 ); public static EnumSample2 Enum3 = new EnumSample2( 3 ); public static EnumSample2 Enum4 = new EnumSample2( 4 ); public int Num; // 外部からのインスタンス生成不可 private EnumSample2( int num ) { Num = num; // 重複チェックを入れるとしたらこの辺でやる // Dictionaryに詰めていってContainsKeyでチェックするのが楽そう } }
- インスタンスごとにメソッドを実装できる
- 列挙体クラスを抽象クラスにし、列挙子ごとにクラスを継承してメソッドを実装します
- 列挙子ごとに実装必須にしたい場合はabstract、デフォルト動作を定義したい場合はvirtualにします
- 列挙子間で共通化したい処理は親クラス側、差別化したい処理は子クラス側に実装することで重複処理をなくすことができます
- 列挙体はインタフェースを実装できる
- 列挙型にインタフェースを実装する宣言をするだけです
// ドロップアイテムのインタフェース public interface IDropItem { string Name { get; } int Price { get; } string Description { get; } } // ドロップアイテムとして扱える武器の列挙型 public abstract class Weapon : IDropItem { public static Weapon Sword = new WeaponSword(); private class WeaponSword : Weapon { // コンストラクタがpublicでもクラス自体はprivateなので外部からはインスタンス生成不可 public WeaponSword() {} public override string Name { get { return "剣"; } } public override int Price { get { return 100; } } public override string Description { get { return "いい感じの説明"; } } public override void Attack() { base.Slash(); } } public static Weapon Spear = new WeaponSpear(); private class WeaponSpear : Weapon { public WeaponSpear() {} public override string Name { get { return "槍"; } } public override int Price { get { return 50; } } public override string Description { get { return "そんな感じの説明"; } } public override void Attack() { base.Pierce(); } } public static Weapon Club = new WeaponClub(); private class WeaponClub : Weapon { public WeaponClub() {} public override string Name { get { return "棍棒"; } } public override int Price { get { return 10; } } public override string Description { get { return "とてもアレな説明"; } } // Attack()の実装は省略可能 } protected Weapon() {} // 名前、価格、説明は必ず列挙子で定義する public abstract string Name { get; } public abstract int Price { get; } public abstract string Description { get; } // 攻撃処理の実装は省略可能 public virtual void Attack() { // オーバーライドしない場合はデフォルトとして殴る処理 Strike(); } // protectedで宣言したプロパティやメソッドは列挙子側からアクセスできる protected void Slash() { // 切る武器の処理 } protected void Pierce() { // 刺す武器の処理 } protected void Strike() { // 殴る武器の処理 } }C#ではできないこと
- 列挙子をswitchの条件に使う
- caseには定数しか使えないので、実態がクラスである列挙子を使うことはできません
- とはいえ列挙子側に処理を実装できるので、switchは基本的に使う必要はないと思います
おわりに
ぱっと見面倒そうに見えますが、Java式enumを使うことによって、ポリモーフィズムを実現しやすくなります
機会があったらぜひ試してみてください参考
- 投稿日:2019-12-09T20:27:27+09:00
The JacocoReportBase.setClassDirectories(FileCollection) method has been deprecated.
現象
次のようにJaCoCoのレポート対象から特定のクラスを除外している場合に、
jacocoTestReport { reports { html.enabled = true xml.enabled = true } afterEvaluate { // 自動生成されるクラスをカバレッジ集計対象から除外 classDirectories = files(classDirectories.files.collect { fileTree(dir: it, exclude: [ '**/_*.class', '**/*DaoImpl.class' ]) }) }Gradle 6.0で
JacocoReportBase#setClassDirectoriesは廃止されるよと警告されます。The JacocoReportBase.setClassDirectories(FileCollection) method has been deprecated. This is scheduled to be removed in Gradle 6.0. Use getClassDirectories().from(...) at build_e2otrmuro5f5yvbdc9709fstk$_run_closure1$_closure10$_closure16.doCall(/path/to/build.gradle:46) (Run with --stacktrace to get the full stack trace of this deprecation warning.)確認環境
- macOS 10.13.6
- Gradle 5.1
- JaCoCo 0.8.4
修正方法
警告メッセージの示す通り、
JacocoReportBase#getClassDirectoriesを使って書き換えます。Gradle力が低くて、警告メッセージの通り修正するだけでも毎回ググっている気がする…diff --git a/build.gradle b/build.gradle index 54b418e84..be6bd6966 100644 --- a/build.gradle +++ b/build.gradle @@ -43,7 +43,7 @@ allprojects { subproj -> } afterEvaluate { // 自動生成されるクラスをカバレッジ集計対象から除外 - classDirectories = files(classDirectories.files.collect { + classDirectories.from = files(classDirectories.files.collect { fileTree(dir: it, exclude: [ '**/_*.class', '**/*DaoImpl.class' ])
- 投稿日:2019-12-09T18:52:41+09:00
OpenAMにおけるInjectorHolderの使われ方
はじめに
本稿では、Google GuiceのInjectorおよびそれから構成されるInjectorHolderがOpenAMでどのように使われているかについて説明します。関連するコードはForgeRock社のGuice Coreというパッケージにあります。ソースコードはここから参照可能です。まずは、Guice Injectorの基本的な説明から始めます。
Guice Injector の基本
もうすぐクリスマス/年末なので
SeasonsGreetingインターフェイスを実装するChristmasGreetingとNewYearGreetingという2つのクラスを使って説明します。注目していただきたいのは、
Guice#createInjector(Module...)メソッドでInjectorのインスタンスを取得している部分です。import com.google.inject.AbstractModule; import com.google.inject.Guice; import com.google.inject.Injector; public class Example01 { public interface SeasonsGreeting { void greeting(); } public static class ChristmasGreeting implements SeasonsGreeting { @Override public void greeting() { System.out.println("Merry Christmas!"); } } public static class NewYearGreeting implements SeasonsGreeting { @Override public void greeting() { System.out.println("Happy New Year!"); } } public static void main(String[] args) { Injector injector = Guice.createInjector(new AbstractModule() { @Override protected void configure() { bind(SeasonsGreeting.class).to(ChristmasGreeting.class); } }); SeasonsGreeting sg = injector.getInstance(SeasonsGreeting.class); sg.greeting(); } }
configure()メソッドでSeasonsGreetingインターフェイスとその実装であるChristmasGreetingを結びつけています。それに従って生成されたinjectorはChristmasGreetingのインスタンスを返すようになります。実行結果Merry Christmas!上記の例では、
Guice#createInjector(Module...)の引数はひとつだけでしたが、以下のように複数指定することも可能です。public static Injector createInjector(java.lang.Iterable<? extends Module> modules)これを使えば
Moduleを拡張したクラスで指定された複数の設定を一気に読み込むことが可能です。こうして生成されたInjectorのインスタンスを繰り返し使うために一定の「置き場所」を提供するのが、次に説明するInjectorHolderになります。InjectorHolderについて
InjectorHolderの「ホールダー」という名前からは、生成した
Injectorのインスタンスを保存しておき、必要に応じて取り出して使うという感じがします。しかし、実際にはInjectorはInjectorHolderの内部で生成され、内部で使用されます。外に出されることは無いため、ラッパーと呼んだ方が実態に近いかもしれません。以下のコードでは、冒頭から列挙型が出てきます。ただひとつの要素(
INSTANCE)を持つ列挙型を使ってシングルトンを実装する方法は
Effective Java 第3版の項目3でも紹介されています。ここではそれを使ってInjectorHolderをシングルトンとして定義しています。private コンストラクタ内で
InjectorFactoryを使ってInjectorを生成している部分に注目してください。public enum InjectorHolder { /** * The Singleton instance of the InjectorHolder. */ INSTANCE; private Injector injector; /** * Constructs an instance of the InjectorHolder and initialises the Guice Injector. */ private InjectorHolder() { InjectorFactory injectorFactory = new InjectorFactory(new GuiceModuleCreator(), new GuiceInjectorCreator(), InjectorConfiguration.getGuiceModuleLoader()); try { injector = injectorFactory.createInjector(InjectorConfiguration.getModuleAnnotation()); } catch (Exception e) { e.printStackTrace(); throw new IllegalStateException(e); } } /** * @param clazz The class to get an instance of. * @param <T> The type of class to get. * @return A non-null instance of the class. */ public static <T> T getInstance(Class<T> clazz) { return INSTANCE.injector.getInstance(clazz); }最後の
getInstance(Class<T> clazz)メソッドはこのシングルトン自身やシングルトンに登録されたInjectorインスタンスを返すのではなく、それを使って生成されたclazzのインスタンスを返すようになっています。それでは、
InjectorFactoryがどのようにしてInjectorのインスタンスを生成しているか見てみることにしましょう。InjectorFactory について
既に説明したように
Injectorの生成時には、Moduleを拡張したクラスのインスタンスを複数指定することができます。それぞれの拡張クラスは異なる設定でConfigure()メソッドをオーバーライドしています。それらのうちどの拡張クラスをロードの対象とするかの判定には@GuiceModuleというアノテーションを使います。具体的には、InjectorFactoryは
@GuiceModuleというアノテーションの付いたModuleの拡張クラスをクラスパス上で検索して- それらをインスタンス化し
Guice#createInjector()に引数として渡してInjectorを生成するという処理を行っています。以下のコードはその導入部分です。その他の部分は長くなるので省略しています。詳しくは公開されているコードを見てください。
final class InjectorFactory { /** * Creates a new Guice injector which is configured by all modules found by the {@link GuiceModuleLoader} * implementation. * * @param moduleAnnotation The module annotation. * @return A non-null Guice injector. */ Injector createInjector(Class<? extends Annotation> moduleAnnotation) { /* This does not need to by synchronized as it is only ever called from the constructor of the InjectorHolder enum, which is thread-safe so no two threads can create an injector at the same time. This does mean that this method MUST not be called/used by another other class! */ return injectorCreator.createInjector(createModules(moduleAnnotation)); }InjectorHolderの仕組みについて見てきました。以下では、OpenAMでどのように使われているかについて見ていくことにします。
OpenAMでの使われ方
OpenAMをGoogle Guice対応にするという作業はかなり前に終わっています。一般的に言って、OpenAMのような大規模なソフトウェアをGoogle Guiceに対応させることは容易ではありません。まずは、依存関係ツリーの枝葉に近い単純なサブツリーから開始して、より複雑なオブジェクトの方向に向かってツリーを辿っていくことになります。複雑なツリーでは、一気に書き換えられない場合もあるかもしれません。そうした場合には、書き換えが完了したクラスと未完了のクラスの「境目」にInjectorHolderを配置します。未完了のクラスのなかでInjectorHolderを使い書き換えが完了したクラスのオブジェクトを生成します。その先の依存関係の解決は、Google Guiceに任せるという方法です。書き換えが進むに従ってInjectorHolderも動かしていきます。こうすることにより複雑なソフトウェアでも漸進的に書き換えていくことが可能になります。
そもそもGoogle Guiceに対応させることができない、もしくは対応させるメリットがないということもあります。OpenAMの場合は、認証サービスがそれにあたります。OpenAMは多要素認証を行うために、様々な認証モジュールのインスタンスを独自に管理する仕組みを持っています。これをGoogle Guiceに対応させることは難しいため、InjectorHolderは個々の認証モジュールのレベルで使っています。
おわりに
OpenAMでは"non-Guice World"と"Guice World"の「境目」にInjectorHolderを配置していることを見てきました。興味があれば、OpenAMコンソーシアムで公開しているソースコードを見て下さい。
- 投稿日:2019-12-09T17:53:32+09:00
JavaにおけるHashMapの仕組みを深堀り
HashMapの基本
- Map(key,valueの格納データ形式)の実装クラスで多分一番使われているやつ。
- Hash関数を使って高速にデータの検索が可能(配列・リストの線形検索より計算量が少ないとされる)
HashMap<String, Integer> map = new HashMap<>(); map.put("Sato", 22); map.put("Takahashi", 24); map.put("Nomura", 32);HashMapの仕組み
(1) HashMapの格納できる数が5の例で考える。
(2)key:Sato value:22を格納しようとする。
a. Satoのハッシュ値144を算出する(例なので適当な数字です)
b. 144を要素数の5で割ってあまりを取得 144/5 = 28 ...4
c. 4にkey:Sato value:22を格納する。[0] [1] [Nomura, 32] [2] [3] [Takahashi, 24] [4] [Sato,22](3) データを取り出すときは同様の計算をしてkeyからどこに目的のデータが格納されているか計算する。
(4) Hash値の余剰が衝突することもあり、同じ場所に複数のデータが格納されることもあり得る(以下の例)[0] [1] [Nomura, 32] [2] [3] [Takahashi, 24] [4] [Sato,22] [Ito, 98]容量の拡張に関して
- 要素数が増えてくるとrehashを行い格納数を増やす。Javaの場合は負荷係数を元に算出される。
- 要素数が
容量 × 負荷係数を超えた時点でrehashが行われる。- JavaのHashMapは、デフォルトの容量は16、負荷係数は0.75である。
参考文献
- 投稿日:2019-12-09T16:44:53+09:00
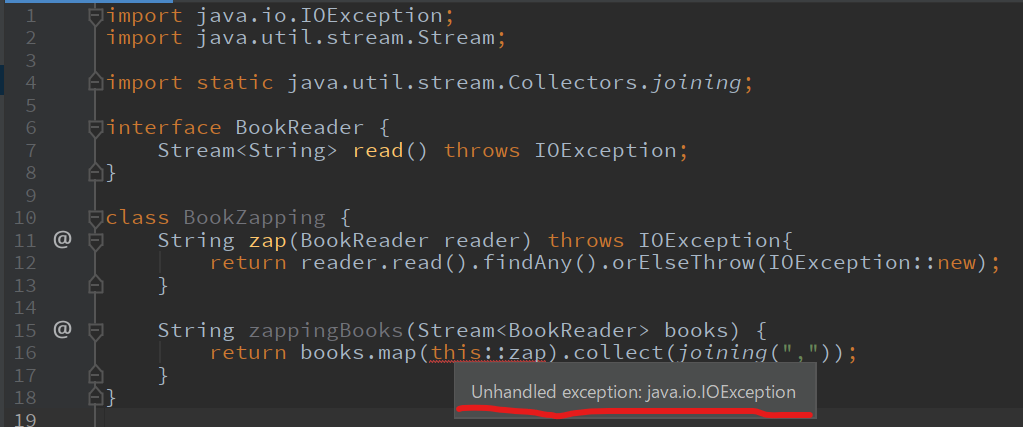
Streamの中からIOExceptionを外に投げたい?それなら
こういうことありませんか?
Streamで値を処理していて、途中のラムダ式内で検査例外を処理しないといけないようなケース
注:
BookReaderは外部にあるなどで、変えるのが大変だと思ってくださいよくあるであろう対処
実行時エラーRuntimeErrorに変えてしまうケース。
メソッド内やprivateな範囲できちんとエラーをハンドリングしているならまだしも、publicな世界に例外をぶっ飛ばしていたりしたらもう大変ですね。
また、今はそんなことをしていなくても、カジュアルにそういうことができてしまう作りになっている点が不安です。無理にStreamつかわなきゃいいじゃん
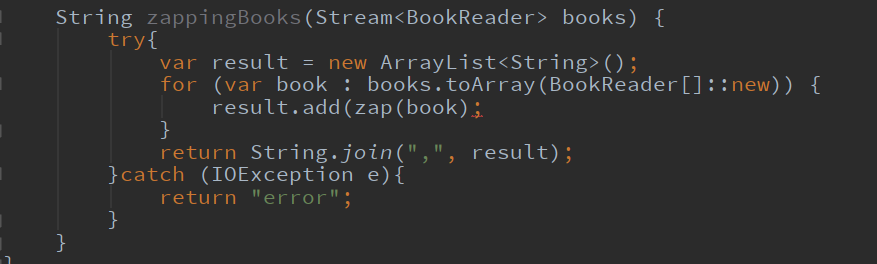
ごもっとも。RuntimeError投げるよりかはよっぽどマシだとは思います。
ローカル変数をが0個から2個に増えたり、2倍以上のコーディング量になったり、ネストが2レベル深くなってますが、チーム全員がこれで満足しているなら別に良いんではないでしょうか。本題
たとえばGolangではタプル(複数のインスタンスの組)を使って異常系の結果を呼び出し元へ伝搬させますが、Javaではタプルを言語仕様レベルではサポートしていません。
クラスを作れば代替できますが、関数型プログラミングに関してはScalaやHaskellを参考にすると、よりよいアイデアがあります。Vavrは、Javaで関数型プログラミングをやりやすくするためのライブラリです。
Either
RightかLeftいずれかの値をとるクラスです。正常系はRight、異常系はLeftにするのが通例です。(ダジャレ)
Optionalの強化版なイメージを持ってもらえればいいかと思います。
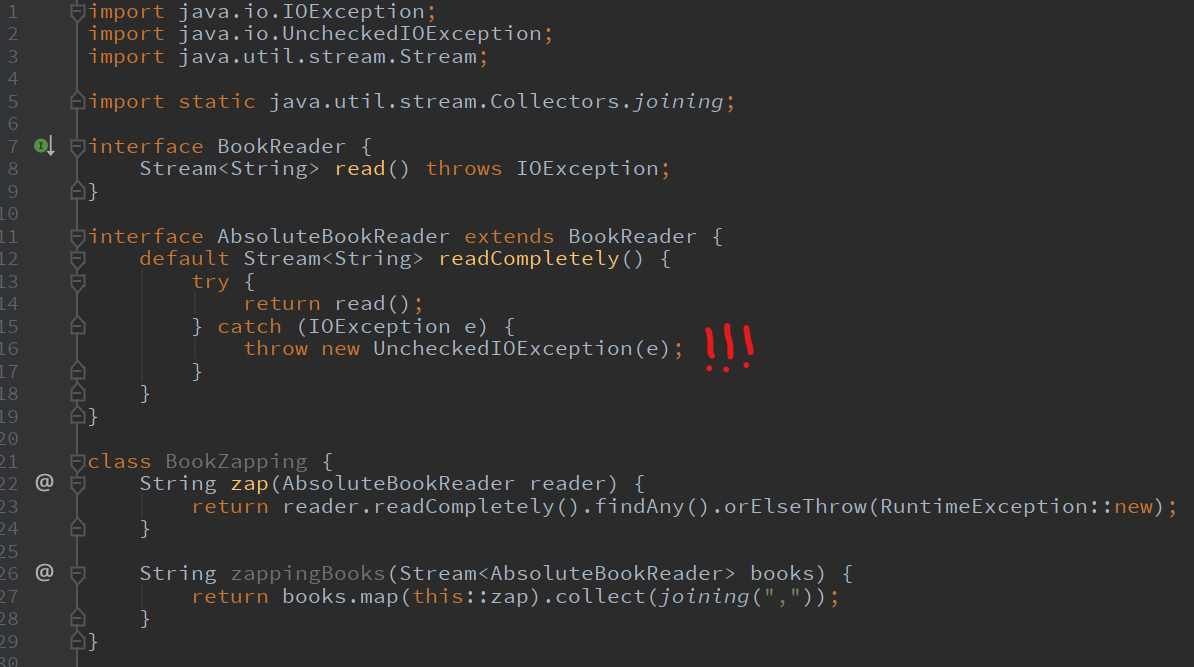
Optionalではnullか否かという情報しかStreamの下流へ流せませんが、Eitherは例外などの値を流すことができます。Try
名前そのまま、try-catchを関数型に書くためのクラスです。
検査例外を投げうるラムダ式を受け取り、例外が発生したときの処理をラムダの形で表現できます。こちらも
Either同様に正常値・異常値のいずれかを内包しているOptional強化版と思ってください。雰囲気だけ見るとTry一択に感じますが、Tryでは異常系処理の入力が
Throwableになってしまいダウンキャストが発生しがちなので、Eitherで書いたほうがもやもやしないケースもあります。書いてみる
例えばこんな感じになるかと思います。
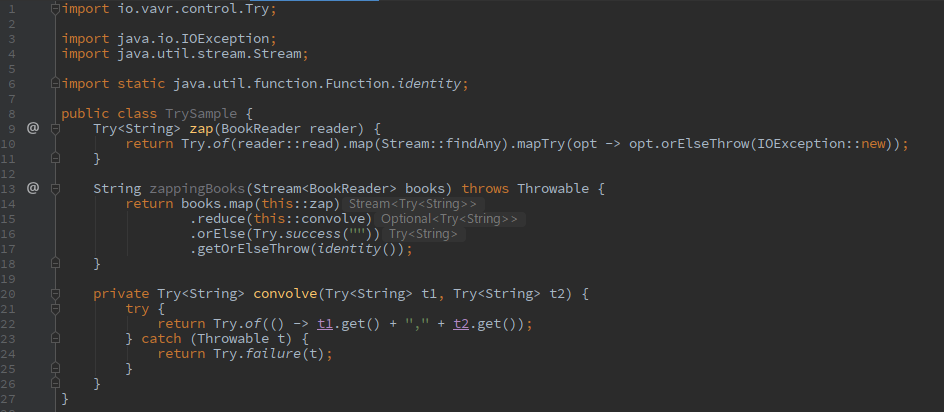
Either:
Try:
Tryは
throws Throwableな点に注意。正しくハンドリングするならダウンキャストが必要になってくる。ちなみに
Vavrはがっつり使いはじめると、もはやJavaに見えなくなって保守しにくくなり、なぜScalaやHaskellを使わないのだろうと自問し始めてしまうので、つまみ食い程度に使うことをおすすめします。
ほかの解決案
無理にJavaを使いつづけなくてもいいのでは?とボスに進言してもいいかもしれません。
雑感
これ、OSSの話かなぁ…


- 投稿日:2019-12-09T15:11:55+09:00
indexOfメソッド、substringメソッド、replaceAllメソッド、replaceメソッド、charAtメソッド、trimメソッド
初学者ですが、個人的な勉強のためまとめました
indexOfメソッド
・引数で指定された文字(列)が文字列の、どの位置に存在するかを調べるためのメソッド
・下記の例ではindexOfメソッドの引数の中に「c」という文字を入れると、2が戻される
・もし、文字が存在しなければ-1が戻される(例)引数が文字の場合
Sample.javaString str="abcde"; System.out.println(str.indexOf('c'));・文字列を引数に入れた場合、その文字列が始まる最初の文字列を戻す
・下記の例ではindexOfメソッドの引数の中に「cd」という文字を入れると、2が戻される
・もし、文字列が存在しなければ-1が戻されるSample.javaString str="abcde"; System.out.println(str.indexOf("cd"));substringメソッド
・文字列から任意の文字列を抽出するメソッド
・抽出する文字列の指定は、第一引数に開始位置の番号、第二引数に終了位置に1足した番号
・引数を一つだけ取るとその位置以降のすべての文字列を抽出する
・下記の例だと、範囲が2~3なので㏅を戻すSample.javapublic class Sample { public static void main(String[] args) { String str = "abcde"; System.out.println(str.substring(2, 4)); } }replaceAllメソッド
・第1引数で指定した正規表現のパターンで文字列を検索し、マッチした文字列を第2引数で指定した文字列で置換
・対象の文字列.replaceAll(正規表現, 置換する文字列)
・以下の例は正規表現を指定し、0111022203330を戻している
・“[a-z]+”は対象の文字列にaからzまでの文字が含まれているか判断し、含まれていた場合は指定した置換文字列で一括置換Sample.javapublic class Sample { public static void main(String[] args) { String str = "abc111def222ghi333a"; str = str.replaceAll("[a-z]+", "0"); System.out.println(str); } }replaceメソッド
・文字列を置き換えるためのメソッド
・対象の文字列.replace(置換される文字列, 置換する文字列)
・char型の引数を二つ受け取るものと、Charsequence型の引数を二つ受け取るものの2種類があり、どちらかか片方しか使えない
・StringクラスはCharSequence型のサブクラスcharAtメソッド
・文字列のうち、引数の位置にある文字を戻す
・下記の例は、String型がimmutableなのでstrを取得すると元のstrが出力されてしまう。char型に変更する、新しくインスタンスを作るなどしなくてはいけないSample.javapublic class Sample { public static void main(String[] args) { String str = "abcde"; char ch=str.charAt(0); System.out.println(str);//実行結果:abcde System.out.println(str.charAt(0));//実行結果:a System.out.println(ch);//実行結果:a } }trimメソッド
・文字列の前後にある空白を除去するためのメソッド
・範囲は文字コードで「¥u0000~¥u0020」であり、空文字、改行、ヘッダ開始、水平タブ、ベル、伝送終了などの制御コードも除去対処の「空白」に含む
- 投稿日:2019-12-09T15:06:21+09:00
Firebase MLKit
Introduction
ML Kit for Firebase is a machine learning toolkit made by Google for Android and iOS. (Well still in Beta version)
With this kit you can use on-device pre-trained APIs :You can also use cloud APIs for more accurate answer :
- Text recognition
- Face detection
- Barcode scanning
- Image labeling
- Object detection & tracking
- Language identification
- Translation
- Smart reply generator (only in english)
You can use your custom pre-trained models and you can train your own classification model. (for images labeling only)
- Text recognition
- Image labeling
- Landmark recognition
Android dependency
In app/build.gradle you should add :android { //... aaptOptions { noCompress "tflite" } } dependencies { //... // ml-vision general implementation 'com.google.firebase:firebase-ml-vision:24.0.1' // Face Detection (contours) implementation 'com.google.firebase:firebase-ml-vision-face-model:19.0.0' // Barcode Scanning implementation 'com.google.firebase:firebase-ml-vision-barcode-model:16.0.1' // Image labeling implementation 'com.google.firebase:firebase-ml-vision-image-label-model:19.0.0' // Object detection implementation 'com.google.firebase:firebase-ml-vision-object-detection-model:19.0.3' // ml-natural general implementation 'com.google.firebase:firebase-ml-natural-language:22.0.0' // Langauge identification implementation 'com.google.firebase:firebase-ml-natural-language-language-id-model:20.0.7' // Translation implementation 'com.google.firebase:firebase-ml-natural-language-translate-model:20.0.7' // Smart Replies implementation 'com.google.firebase:firebase-ml-natural-language-smart-reply-model:20.0.7' } apply plugin: 'com.google.gms.google-services'If you want to use a custom pre-trained model(AutoML-trined model) to load your own model you will need to add :
implementation 'com.google.firebase:firebase-ml-vision-automl:18.0.3'
Text recognition
 // Create FirebaseVisionImage Object (here from an url) FirebaseVisionImage image = FirebaseVisionImage.fromFilePath(context, uri); // Create an instance of FirebaseVisionTextRecognizer with on-device model FirebaseVisionTextRecognizer detector = FirebaseVision.getInstance().getOnDeviceTextRecognizer(); // Or with cloud model // FirebaseVisionTextRecognizer detector = FirebaseVision.getInstance().getCloudTextRecognizer(); // Process the image Task<FirebaseVisionText> result = detector.processImage(image) .addOnSuccessListener(new OnSuccessListener<FirebaseVisionText>() { @Override public void onSuccess(FirebaseVisionText firebaseVisionText) { // Task completed successfully // ... } }) .addOnFailureListener( new OnFailureListener() { @Override public void onFailure(@NonNull Exception e) { // Task failed with an exception // ... } });
// Create FirebaseVisionImage Object (here from an url) FirebaseVisionImage image = FirebaseVisionImage.fromFilePath(context, uri); // Create an instance of FirebaseVisionTextRecognizer with on-device model FirebaseVisionTextRecognizer detector = FirebaseVision.getInstance().getOnDeviceTextRecognizer(); // Or with cloud model // FirebaseVisionTextRecognizer detector = FirebaseVision.getInstance().getCloudTextRecognizer(); // Process the image Task<FirebaseVisionText> result = detector.processImage(image) .addOnSuccessListener(new OnSuccessListener<FirebaseVisionText>() { @Override public void onSuccess(FirebaseVisionText firebaseVisionText) { // Task completed successfully // ... } }) .addOnFailureListener( new OnFailureListener() { @Override public void onFailure(@NonNull Exception e) { // Task failed with an exception // ... } });FirebaseVisionText will contain bounding box, text, language recognized, paragraph, confidence score.
Face detection

Face detection is done on device only and you can get facial contours too (optional).// Create FirebaseVisionImage Object (here from an url) FirebaseVisionImage image = FirebaseVisionImage.fromFilePath(context, uri); // Set Options FirebaseVisionFaceDetectorOptions options = new FirebaseVisionFaceDetectorOptions.Builder() .setPerformanceMode(FirebaseVisionFaceDetectorOptions.ACCURATE) .setClassificationMode(FirebaseVisionFaceDetectorOptions.ALL_CLASSIFICATIONS) .setLandmarkMode(FirebaseVisionFaceDetectorOptions.ALL_LANDMARKS) .setContourMode(FirebaseVisionFaceDetectorOptions.ALL_CONTOURS) .build(); // Create an instance of FirebaseVisionFaceDetector FirebaseVisionFaceDetector detector = FirebaseVision.getInstance().getVisionFaceDetector(options); // Process the image Task<List<FirebaseVisionFace>> result = detector.detectInImage(image) .addOnSuccessListener( new OnSuccessListener<List<FirebaseVisionFace>>() { @Override public void onSuccess(List<FirebaseVisionFace> faces) { // Task completed successfully // ... } }) .addOnFailureListener( new OnFailureListener() { @Override public void onFailure(@NonNull Exception e) { // Task failed with an exception // ... } });As a result FirebaseVisionFace contains : Face bounds, head rotation, eyes ears, mouth nose coordinate, classification probability (smiling, eyes opened, happy ...)
You can also get a tracking Id in case of video streaming.Barcode scanning
Many different formats are supported :
Code 128, Code 39, Code 93, Codabar, EAN-13, EAN-8, ITF, UPC-A, UPC-E, QR Code, PDF417, Aztec, Data Matrix.// Create FirebaseVisionImage Object (here from an url) FirebaseVisionImage image = FirebaseVisionImage.fromFilePath(context, uri); // Set Options FirebaseVisionBarcodeDetectorOptions options = new FirebaseVisionBarcodeDetectorOptions.Builder() .setBarcodeFormats( FirebaseVisionBarcode.FORMAT_QR_CODE, FirebaseVisionBarcode.FORMAT_AZTEC) .build(); // Create an instance of FirebaseVisionBarcodeDetector FirebaseVisionBarcodeDetector detector = FirebaseVision.getInstance().getVisionBarcodeDetector(); // Process the image Task<List<FirebaseVisionBarcode>> result = detector.detectInImage(image) .addOnSuccessListener(new OnSuccessListener<List<FirebaseVisionBarcode>>() { @Override public void onSuccess(List<FirebaseVisionBarcode> barcodes) { // Task completed successfully // ... } }) .addOnFailureListener(new OnFailureListener() { @Override public void onFailure(@NonNull Exception e) { // Task failed with an exception // ... } });The results will depend on the barcode type
Image labeling
Image labeling can be used on-device with ~400 labels or on-cloud with ~10000 labels// Create FirebaseVisionImage Object (here from an url) FirebaseVisionImage image = FirebaseVisionImage.fromFilePath(context, uri); // Create an instance of FirebaseVisionImageLabeler with on-device model FirebaseVisionImageLabeler labeler = FirebaseVision.getInstance().getOnDeviceImageLabeler(); // Or with cloud model // FirebaseVisionCloudImageLabelerOptions options = new FirebaseVisionCloudImageLabelerOptions.Builder().setConfidenceThreshold(0.7f).build(); // FirebaseVisionImageLabeler labeler = FirebaseVision.getInstance().getOnDeviceImageLabeler(options); // Process the image labeler.processImage(image) .addOnSuccessListener(new OnSuccessListener<List<FirebaseVisionImageLabel>>() { @Override public void onSuccess(List<FirebaseVisionImageLabel> labels) { // Task completed successfully // ... } }) .addOnFailureListener(new OnFailureListener() { @Override public void onFailure(@NonNull Exception e) { // Task failed with an exception // ... } });Return is just a list of FirebaseVisionImageLabel who contains : label and confidence score.
You can use AutoML Vision Edge to use your own model of classification.
Object detection & tracking
With this you can identify main object and track it (when streaming)// Create FirebaseVisionImage Object (here from an url) FirebaseVisionImage image = FirebaseVisionImage.fromFilePath(context, uri); // Multiple object detection in static images FirebaseVisionObjectDetectorOptions options = new FirebaseVisionObjectDetectorOptions.Builder() .setDetectorMode(FirebaseVisionObjectDetectorOptions.SINGLE_IMAGE_MODE) .enableMultipleObjects() .enableClassification() // Optional .build(); // Create an instance of FirebaseVisionObjectDetector FirebaseVisionObjectDetector objectDetector = FirebaseVision.getInstance().getOnDeviceObjectDetector(options); // Process the image objectDetector.processImage(image) .addOnSuccessListener( new OnSuccessListener<List<FirebaseVisionObject>>() { @Override public void onSuccess(List<FirebaseVisionObject> detectedObjects) { // Task completed successfully // ... } }) .addOnFailureListener( new OnFailureListener() { @Override public void onFailure(@NonNull Exception e) { // Task failed with an exception // ... } });Result is a list of FirebaseVisionObject who contains: tracking Id, bounds, category, confidence score.
Landmark recognition
You can recognize well-known landmarks in an image. This api can only be use on-cloud.// Create FirebaseVisionImage Object (here from an url) FirebaseVisionImage image = FirebaseVisionImage.fromFilePath(context, uri); // Set the options FirebaseVisionCloudDetectorOptions options = new FirebaseVisionCloudDetectorOptions.Builder() .setModelType(FirebaseVisionCloudDetectorOptions.LATEST_MODEL) .setMaxResults(15) .build(); // Create an instance of FirebaseVisionCloudLandmarkDetector FirebaseVisionCloudLandmarkDetector detector = FirebaseVision.getInstance().getVisionCloudLandmarkDetector(options); // Process the image Task<List<FirebaseVisionCloudLandmark>> result = detector.detectInImage(image) .addOnSuccessListener(new OnSuccessListener<List<FirebaseVisionCloudLandmark>>() { @Override public void onSuccess(List<FirebaseVisionCloudLandmark> firebaseVisionCloudLandmarks) { // Task completed successfully // ... } }) .addOnFailureListener(new OnFailureListener() { @Override public void onFailure(@NonNull Exception e) { // Task failed with an exception // ... } });Result is a list of FirebaseVisionCloudLandmark who contains: Name, bounds, latitude, longitude, confidence score.
Language identification
This api doesn't use image but String.FirebaseLanguageIdentification languageIdentifier = FirebaseNaturalLanguage.getInstance().getLanguageIdentification(); languageIdentifier.identifyAllLanguages(text) .addOnSuccessListener( new OnSuccessListener<String>() { @Override public void onSuccess(List<IdentifiedLanguage> identifiedLanguages) { for (IdentifiedLanguage identifiedLanguage : identifiedLanguages) { String language = identifiedLanguage.getLanguageCode(); float confidence = identifiedLanguage.getConfidence(); Log.i(TAG, language + " (" + confidence + ")"); } } }) .addOnFailureListener( new OnFailureListener() { @Override public void onFailure(@NonNull Exception e) { // Model couldn’t be loaded or other internal error. // ... } });Result is a list of IdentifiedLanguage who contains: Language Code and confidence score.
Translation
Translation can be done with a on-device api but it can be use only for casual and simple translation over 59 languages (Japanese is supported).
Model is trained to translate to and from English; so if you choose to translate between non-English languages, English will be used as an intermediate translation, which can affect quality.// Create an English-Japanese translator: FirebaseTranslatorOptions options = new FirebaseTranslatorOptions.Builder() .setSourceLanguage(FirebaseTranslateLanguage.EN) .setTargetLanguage(FirebaseTranslateLanguage.JP) .build(); final FirebaseTranslator englishJapaneseTranslator = FirebaseNaturalLanguage.getInstance().getTranslator(options); final String text = "Merry Christmas"; // We need to download the model first // Each model is around 30MB and are stored locally to be reused FirebaseModelDownloadConditions conditions = new FirebaseModelDownloadConditions.Builder() .requireWifi() .build(); englishJapaneseTranslator.downloadModelIfNeeded(conditions) .addOnSuccessListener( new OnSuccessListener<Void>() { @Override public void onSuccess(Void v) { // Model downloaded successfully. We can start translation englishJapaneseTranslator.translate(text) .addOnSuccessListener( new OnSuccessListener<String>() { @Override public void onSuccess(@NonNull String translatedText) { // Translation successful. // translatedText <- "メリークリスマス" } }) .addOnFailureListener( new OnFailureListener() { @Override public void onFailure(@NonNull Exception e) { // Error during the translation. } }); } }) .addOnFailureListener( new OnFailureListener() { @Override public void onFailure(@NonNull Exception e) { // Model couldn’t be downloaded or other internal error. } });Smart reply generator (only in english)
The model work with the 10 most recent messages and provides a maximum of 3 suggested responses.
// Define a conversation history // Local User speaks to Remote User // Smart reply is about what Local User may answer. List<FirebaseTextMessage> conversation = new ArrayList<>(); conversation.add(FirebaseTextMessage.createForRemoteUser("It's Christmas time", System.currentTimeMillis(),"userId1")); conversation.add(FirebaseTextMessage.createForLocalUser("Kids are happy", System.currentTimeMillis())); conversation.add(FirebaseTextMessage.createForRemoteUser("Will Santa Claus come tonight ?", System.currentTimeMillis(),"userId1")); FirebaseSmartReply smartReply = FirebaseNaturalLanguage.getInstance().getSmartReply(); smartReply.suggestReplies(conversation) .addOnSuccessListener(new OnSuccessListener<SmartReplySuggestionResult>() { @Override public void onSuccess(SmartReplySuggestionResult result) { if (result.getStatus() == SmartReplySuggestionResult.STATUS_NOT_SUPPORTED_LANGUAGE) { // The conversation's language isn't supported, so the // the result doesn't contain any suggestions. } else if (result.getStatus() == SmartReplySuggestionResult.STATUS_SUCCESS) { // Task completed successfully for (SmartReplySuggestion suggestion : result.getSuggestions()) { String replyText = suggestion.getText(); } } } }) .addOnFailureListener(new OnFailureListener() { @Override public void onFailure(@NonNull Exception e) { // Task failed with an exception } });As result a list of SmartReplySuggestion Object. Each one will contain only a text.






- 投稿日:2019-12-09T14:37:33+09:00
java競技プログラミングmemo
はじめに
javaで競技プログラミングをするときによく使うコードをまとめた。
C++に比べ、javaで競技プログラミングをしている人は少なく、情報が少ないため、この記事の執筆に至った。
標準ライブラリのみ使用することを想定している。基本コード
コンテスト開始前に、以下のようにコードを用意している。
import java.util.*; public class Main { public static void main(String[] args) { Scanner sc = new Scanner(System.in); int N = sc.nextInt(); System.out.println(); } }また、以下のように定義している。
static int MOD = 1000000007;入力
配列の入力
Arrays.setAllを用いることで、for文を使うよりもすっきりとした記述ができる。
int[] a = new int[N]; Arrays.setAll(a, i -> sc.nextInt());木の入力
どのノードからどのノードに枝があるか、HashMapに保存している。
Map<Integer, HashSet<Integer>> edge = new HashMap<>(); for(int i = 1; i <= N; i++) edge.put(i, new HashSet<>()); for (int i = 1; i < N-1; i++) { int a = sc.nextInt(); int b = sc.nextInt(); edge.get(a).add(b); edge.get(b).add(a); }枝に順序がある木の入力
出力が必要な場合など、枝の順番が情報として必要な場合は、枝を自作クラスとし、HashMapに保存する。
想定問題:ABC146D Coloring Edges on Treestatic int N; static Map<Integer, HashSet<edge>> m = new HashMap<>(); static class edge{ int to, id; edge(int to, int id){ this.to = to; this.id = id; } } public static void main(String[] args) { for(int i = 0; i < N-1; i++) { int a = sc.nextInt(); int b = sc.nextInt(); if(!m.containsKey(a)) m.put(a, new HashSet<>()); m.get(a).add(new edge(b, i)); } }各種手法
bit全探索
Nが小さい(N < 20程度)ときに、2^N通りを全探索する。
boolean[] x = new boolean[N]; for(int i = 0; i < 1<<N; i++) { for(int j = 0; j < N; j++) { if ((1 & i >> j) == 1) x[j] = true; else x[j] = false; } }各種メソッド
最小公倍数
ユークリッドの互除法を再帰関数で表現する。
public static int gcd(int a, int b) { return b == 0 ? a: gcd(b, a % b); }最大公約数
最小公倍数を用いる。
public static int lcm(int a, int b) { return a / gcd(a, b) * b; }階乗 n!
再帰関数の基本である。
public static long factorial(long n){ return n <= 0 ? 1 : n * factorial(n-1); }組み合わせ nCr
組み合わせを求める際、10^9+7で割った余りを出力する場合を考える。
Nが小さい場合(< 2000程度)は、パスカルの三角形を考え、動的計画法によって求めることができる。int MAX = 2000; long[][] com = new long[MAX][MAX]; for(int i = 0; i < MAX; i++) com[i][0] = 1; for(int i = 1; i < MAX; i++) { for(int j = 1; j <= i; j++) { com[i][j] = com[i-1][j-1] + com[i-1][j]; com[i][j] %= MOD; } }Nが大きい場合は、逆元を求める必要がある。
メインメソッドでCOMinit()を呼び出すことにより計算を行い、combination(n, r)によりnCrを求められるようにしている。public static int MOD = 1_000_000_007; public static int MAX = 100000; public static long[] fac = new long[MAX]; public static long[] finv = new long[MAX]; public static long[] inv = new long[MAX]; public static void COMinit() { fac[0] = fac[1] = 1; finv[0] = finv[1] = 1; inv[1] = 1; for(int i = 2; i < MAX; i++) { fac[i] = fac[i-1] * i % MOD; inv[i] = MOD - inv[MOD%i] * (MOD/i) % MOD; finv[i] = finv[i-1] * inv[i] % MOD; } } public static long combination(int n, int k){ if(n < k || n < 0 || k < 0) return 0; return fac[n] * (finv[k] * finv[n-k] % MOD) % MOD; } public static void main(String[] args) { COMinit(); System.out.println(combination(2000, 3)); }全順列の出力
N!通り全ての順列を出力する。
static List<String> z; public static void permutation(String q, String ans){ if(q.length() <= 1) { z.add(ans + q); } else { for (int i = 0; i < q.length(); i++) { permutation(q.substring(0, i) + q.substring(i + 1), ans + q.charAt(i)); } } } public static void main(String[] args) { z = new ArrayList<>(); permutation("12345",""); for(int i = 0; i < z.size(); i++) System.out.println(z.get(i)); }二分探索
javaではArrays.binarySearchによって二分探索が可能。
Arrays.binarySearchは配列がキーを含むならその位置を、含まないならばそのキーを挿入するべき位置を返す。
C++のlower_bound、upper_boundのようなメソッドが存在しないため、二分探索によって個数をカウントすることができない。
そこで、自ら実装した。public static int lowerbound(int[] a, int key) { if(a[a.length-1] < key) return a.length; int lb = 0, ub = a.length-1, mid; do { mid = (ub+lb)/2; if(a[mid] < key) lb = mid + 1; else ub = mid; }while(lb < ub); return ub; }public static int upperbound(int[] a, int key) { if(a[a.length-1] <= key) return a.length; int lb = 0, ub = a.length-1, mid; do { mid = (ub+lb)/2; if(a[mid] <= key) lb = mid + 1; else ub = mid; }while(lb < ub); return ub; }public static int count(int[] a, int key) { return upperbound(a, key) - lowerbound(a, key); }因数分解
因数分解し、HashMapに保存するメソッド。
static Map<Integer, Integer> fact = new HashMap<>(); public static void factorization(int N){ for(int i = 2; i <= Math.sqrt(N); i ++) { if(N % i == 0) { int n = 0; while(N % i == 0) { N /= i; n++; } fact.put(i, n); } } if(N > 1) fact.put(N, 1); }追記
この記事は編集途中である。
随時更新していこうと思う。
- 投稿日:2019-12-09T11:41:55+09:00
Java Mapをループさせる方法(Stream API / 拡張for文)
JavaでMapをループさせる方法をメモ
Map<String, String> map = new HashMap<>(); // mapのkey,valueのset処理は省略 // Streamのパターン map.forEach((k, v) -> { System.out.println(k); System.out.println(v); }); // 拡張for文のパターン for(Map.Entry<String, String> entry : map.entrySet()){ System.out.println(entry.getKey()); System.out.println(entry.getValue()); }Stream APIの方がすっきりして見やすいかも。
- 投稿日:2019-12-09T11:41:55+09:00
Java Mapをループさせる方法(forEach / 拡張for文)
JavaでMapをループさせる方法をメモ
Map<String, String> map = new HashMap<>(); // mapのkey,valueのset処理は省略 // forEachのパターン map.forEach((k, v) -> { System.out.println(k); System.out.println(v); }); // 拡張for文のパターン for(Map.Entry<String, String> entry : map.entrySet()){ System.out.println(entry.getKey()); System.out.println(entry.getValue()); }forEachの方がすっきりして見やすいかも。
- 投稿日:2019-12-09T10:02:37+09:00
リフレクションなるものを知った
なんか不思議でおもしろいぞこれ
Reflection.javapackage reflection; import java.lang.reflect.Method; public class Reflection { private static <T> void test(Class<T> t) { try { // インスタンスを取得 Object instance = t.newInstance(); // メソッドを取得 Method method = t.getMethod("test", String.class); // メソッド実行 method.invoke(instance, "わっほい"); } catch (ReflectiveOperationException e) { e.printStackTrace(); } } public static void main(String[] args) { test(ReflectionTest.class); } } class ReflectionTest { public void test(String str) { System.out.println(str); } }結果
わっほいとまぁ、なんだろう
リモートでPCにアクセスする感じでクラスにアクセスして、メソッドをアクセスして みたいな
これを使えばprivateメソッドとかも実行できちゃうらしいです
やってみよう
privateにしてみた.javaclass ReflectionTest { private void test(String str) { System.out.println(str); } }結果
java.lang.NoSuchMethodException: reflection.ReflectionTest.test(java.lang.String) at java.lang.Class.getMethod(Unknown Source) at reflection.Reflection.test(Reflection.java:14) at reflection.Reflection.main(Reflection.java:25)だめじゃん!!!うそつき!!!
これが必要らしい.javapackage reflection; import java.lang.reflect.Method; public class Reflection { private static <T> void test(Class<T> t) { try { // インスタンスを取得 Object instance = t.newInstance(); // メソッドを取得 Method method = t.getDeclaredMethod("test", String.class); // privateの場合, アクセスしますよ宣言が必要 method.setAccessible(true); // メソッド実行 method.invoke(instance, "わっほい"); } catch (ReflectiveOperationException e) { e.printStackTrace(); } } public static void main(String[] args) { test(ReflectionTest.class); } } class ReflectionTest { @SuppressWarnings("unused") private void test(String str) { System.out.println(str); } }
MethodクラスのsetAccessibleメソッドでtrueを設定しなきゃだめらしいですねまぁこいつはtestクラスとかでもprivateにアクセスしたりとか
なんかこう強引になんでもできるみたいな
ただよくわからん
ReflectiveOperationExceptionとかいうようわからん例外もある上に少し間違えるとすぐいろんな例外とぶんで
んまぁもうほんと力業ですねぇ
- 投稿日:2019-12-09T08:54:51+09:00
Processingでクリスマス
普段データ操作とかユーザーインターフェースのプログラムばかり書いていると、たまには仕事とまったく関係ないプログラムを書きたくなりますよね。
そんな訳で今回はProcessingでちょっとクリスマスっぽい絵でも描いてみましょう。Processingとは
Processingは電子アートとビジュアルデザインのためのプログラミング言語であり、統合開発環境です。
こう書くと少し難しいものに思えるかもしれませんが、プログラムを書くことで絵を描けるくらいに考えてもらっても大丈夫だと思います。
記述したプログラムによる変化が視覚的にすぐにわかるので、データ操作をするようなプログラムよりも実行結果の違いがわかりやすいという特徴があります。ProcessingはJavaで作られており、プログラムも基本はJavaで記述しますが、モードを追加することでPythonやJavaScriptなどでも記述できます。
自分の興味のあるプログラミング言語でProcessingにトライしてみましょう。インストールしてみよう
Processingのインストールは下記のページからZIPファイルをダウンロードし、解凍してからWindowsであればProcessing.exeを、MacであればProcessing.appをダブルクリックして実行するだけです。
https://processing.org/download/
Processingを起動すると、下記のようなIDEが表示されます。
さっそく何か描いてみましょう。
下記のプログラムをコピーしてIDEに貼り付けて実行してみてください。
実行は左上の三角が書かれているボタンです。size(300,250); background(255); stroke(0); fill(255); ellipse(150,160,100,100); // body line(110,130,70,100); // left arm line(190,130,230,100); // right arm ellipse(150,100,60,60); // head arc(150, 106, 30, 25, -TWO_PI, -PI); // mouth fill(0); rectMode(CENTER); rect(150,65,34,20); // hat line(125,75,175,75); // brim ellipse(142,92,5,5); // left eye ellipse(158,92,5,5); // right eye noStroke(); fill(255,100,0); ellipse(150,102,7,7); // nose
こんなのが出てくれば成功です。
プログラムは単純に各パーツの丸を描いて塗り潰したり線を引いたりしているだけです。
各パーツの数値を変えることで絵が変化するので、色々ためしてみましょう。サンプルプログラム
今回はProcessingのプログラムの書き方については言及しません。
Processingの書き方やサンプルプログラムはWebで検索するとたくさん出てきます。
サンプルプログラムを写経したり、書き換えて動かしてみることで、プログラムの書き方はすぐに解ると思いますので、サンプルプログラムをたくさん動かしてみることをお勧めします。
ここではいくつかのサンプルプログラムをご紹介します。イルミネーション
クリスマスなのに部屋が殺風景だと感じたら、PCのディスプレイをクリスマスイルミネーションにしてしまいましょう。
サンプルプログラムの描画領域や円のサイズを調整してディスプレイを華やかにしてみてください。
やっていることは乱数で座標、丸の大きさ、色、透過度を変化させて描画しているだけです。
setup()は最初に1回だけ実行され、draw()は定期的に繰り返し実行されます。void setup() { size(700,400); background(0); smooth(); } void draw() { float r = random(255); float g = random(255); float b = random(255); float a = random(255); float x = random(width); float y = random(height); float diameter = random(20); noStroke(); fill(r,g,b,a); ellipse(x,y,diameter,diameter); }
フラクタル図形で木を書く
フラクタル図形とは、「図形の部分と全体が自己相似(再帰)になっているもの」です。
フラクタル図形にはいろいろな種類がありますが、ここではクリスマスツリーにちなんで木のようなものを描いてみましょう。int angle = 110; void setup() { background(255); size(600, 600, P2D); tree(300, 600, 0.0, radians(0), radians(angle), 200, 10); tree(300, 600, 0.0, radians(angle), radians(0), 200, 10); } void tree(float posX, float posY, float angle, float forkRight, float forkLeft, float length, int counter) { if (counter == 0) { return; } float nextX = posX + length * sin(angle); float nextY = posY - length * cos(angle); line(posX, posY, nextX, nextY); tree(nextX, nextY, angle + forkRight, forkRight, forkLeft, length*0.6, counter - 1); tree(nextX, nextY, angle - forkLeft, forkRight, forkLeft, length*0.6, counter - 1); }
再帰処理に慣れていないと読みにくいかもしれませんが、同じ形のものを縮小して一定回数繰り返し描画しています。
angleの値を変化させると、木の形が変化するので試してみましょう。
下記は size=80 にした時の描画結果になります。
フラクタル図形で雪の結晶を書く
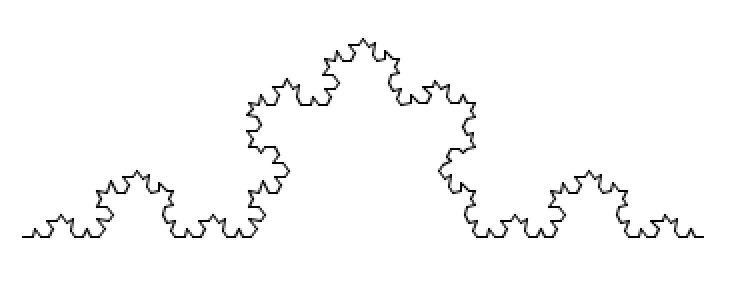
フラクタル図形の一種にコッホ曲線というのがあります。
線分を3等分し、分割した2点を頂点とする正三角形の作図を無限に繰り返すことによって下記の様な図形が作成できます。
このコッホ曲線を正三角形に配置すると、雪の結晶のような図形が出現します。
この図形はコッホ雪片と呼ばれます。
以下のサンプルは、コッホ雪片を段階的に作成するプログラムです。
実際に動かしてみてコッホ雪片がどのように作られるのかを見てみましょう。int depth = -1; void setup(){ background(255); size(400, 400); frameRate(1); } void draw() { background(255); depth++; if (depth > 5) { depth = 0; } int border = (int) (width * 0.8); int triangleHeight = (int) (border * Math.sin(Math.toRadians(60.0))); Point p1 = new Point(width / 2, 10); Point p2 = new Point(width / 2 - border / 2, 10 + triangleHeight); Point p3 = new Point(width / 2 + border / 2, 10 + triangleHeight); drawKochCurve(depth, p1, p2); drawKochCurve(depth, p2, p3); drawKochCurve(depth, p3, p1); } void drawKochCurve(int count, Point p1, Point p2) { stroke(0); if (count == 0) { line(p1.x, p1.y, p2.x, p2.y); } else { int deltaX = p2.x - p1.x; int deltaY = p2.y - p1.y; double cosConst = Math.cos(Math.toRadians(30.0)); int zx = (int)((p1.x + p2.x)/2 + cosConst * (p1.y - p2.y)/3.0); int zy = (int)((p1.y + p2.y)/2 + cosConst * (p2.x - p1.x)/3.0); Point x = new Point(p1.x + deltaX / 3, p1.y + deltaY / 3); Point y = new Point(p1.x + deltaX * 2 / 3, p1.y + deltaY * 2 / 3); Point z = new Point(zx, zy); drawKochCurve(count - 1, p1, x); drawKochCurve(count - 1, x, z); drawKochCurve(count - 1, z, y); drawKochCurve(count - 1, y, p2); } } class Point { int x; int y; Point(int x, int y){ this.x = x; this.y = y; } }The Nature of Code
ここまでいかがでしたでしょうか。
Processingというものに少しでも興味を持ってもらえたら幸いです。
最後に「The Nature of Code」について紹介させてください。
「The Nature of Code」は物理や数学の法則・公式といった自然界のルールをProcessingを使って記述する方法について書かれた書籍です。
今回紹介したフラクタル図形についても詳しく書かれているので、興味のあるかたはご一読ください。https://www.amazon.co.jp/Nature-Code-Processingではじめる自然現象のシミュレーション-ダニエル・シフマン/dp/4862462456
英語版であれば、下記のサイトから無料で閲覧することができます。
それでは皆様、良いクリスマスをお迎えください。





- 投稿日:2019-12-09T05:17:37+09:00
Java High Level REST Client Tips
Elastic Stack (Elasticsearch) Advent Calendar 2019の11日目の記事です
はじめに
「Java High Level REST Client」を使用することで、Javaアプリからhttpを介してElasticsearchへアクセスできる
以前は「TransportClient」が使用されていたが8.0で廃止されているため、
「Java High Level REST Client Tips」 もしくは「Java Low Level REST Client」の使用が推奨されている今回は、検索(Search API)に絞った使用例を紹介します
注意点
- Java High Level REST ClientはJava 1.8が必要
- Elasticsearchとの接続は、マイナーバージョンの通信保証する
例)
Elasticsearch(7.0) Java High Level REST(7.0) → OK
Elasticsearch(7.0) Java High Level REST(6.8) → NG※通信を保証するだけで、バージョンアップ時の新機能は対応してないことが多い
準備
Elasticsearchの環境 → ElasticCloud
Java8(JDK1.8.0)インデックス「qiita」を作成
PUT /qiita { "mappings": { "properties": { "user": { "type": "keyword" }, "post_date": { "type": "date" }, "active": { "type": "boolean" }, "message": { "type": "text" } } } } POST qiita/_doc { "user" : "qiita", "post_date" : "2019-12-11T00:10:30Z", "active":"false", "message" : "trying out High Level REST Client" } GET qiita/_search ... { "_index" : "qiita", "_type" : "_doc", "_id" : "yjDo5m4Bj4TzcUq3pmoX", "_score" : 1.0, "_source" : { "user" : "qiita", "post_date" : "2019-12-11T00:10:30Z", "active" : "false", "message" : "trying out High Level REST Client" } } ...pon.xml
<dependencies> ... <dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-high-level-client</artifactId> <version>7.5.0</version> </dependency> <dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-client</artifactId> <version>7.5.0</version> </dependency> ... </dependencies>接続用Clinent作成
基本的には、Initializationの例で問題ない
RestHighLevelClient client = new RestHighLevelClient( RestClient.builder( new HttpHost("localhost", 9200, "http"), new HttpHost("localhost", 9201, "http"))); client.close();ElasticCloudの場合
ElasticCloudなど認証機能を導入している場合は、下記の設定が必要がある
String username = "elastic"; String password = "pass"; String host = "host"; int port = 9243; int nextPort = 9244; String protocol = "https"; final CredentialsProvider credentialsProvider = new BasicCredentialsProvider(); credentialsProvider.setCredentials( AuthScope.ANY, new UsernamePasswordCredentials(username, password)); RestClientBuilder client = RestClient.builder( new HttpHost(host, port, protocol), new HttpHost(host, nextPort, protocol)) .setHttpClientConfigCallback((h) -> h.setDefaultCredentialsProvider(credentialsProvider)); RestHighLevelClient client = new RestHighLevelClient(client); client.close();データ取得
先ほど作成したclientを使用することで「GET qiita/_search」と似た取得ができます
try (RestHighLevelClient client = new RestHighLevelClient(client)) { SearchSourceBuilder searchBuilder = SearchSourceBuilder.searchSource(); // quite*のようにワイルドカード指定できる SearchRequest request = new SearchRequest("qiita").source(searchBuilder); // データ取得 SearchHits hits = client.search(request, RequestOptions.DEFAULT).getHits(); for(SearchHit hit : hits) { Map<String, Object> sourceAsMap = hit.getSourceAsMap(); // 1レコードごとの値を設定 String user = (String) sourceAsMap.get("user"); String post_date = (String) sourceAsMap.get("post_date"); String message = (String) sourceAsMap.get("message"); System.out.println(String.format("user:%s data:%s message:%s",user , post_date, message)); } }catch (IOException io) {}参考: Search API
サイズの設定
「SearchSourceBuilder」に設定する
サイズはデフォルトは10件しか取得しない// default 10 SearchSourceBuilder searchBuilder = SearchSourceBuilder.searchSource(); searchBuilder.size(100);ソート
「SearchSourceBuilder」に設定する
SortOrderでASCとDESCを切り替えるSearchSourceBuilder searchBuilder = SearchSourceBuilder.searchSource(); searchBuilder.sort(new FieldSortBuilder("_id").order(SortOrder.DESC));検索クエリ(フィルタ)
Building Queriesに書かれているのは一通り使える(全部試したわけではない)が簡単なものを紹介する
基本、「SearchSourceBuilder」に設定するRange Query(期間指定)
日本時刻の「2019-12-12T00:10:30」から「2019-12-13T00:10:31」まで取得している
SearchSourceBuilder searchBuilder = SearchSourceBuilder.searchSource(); QueryBuilder query = QueryBuilders .rangeQuery("post_date") .from("2019-12-12T00:10:30") .to("2019-12-13T00:10:31") .timeZone("+09:00"); searchBuilder.query(query);注意が必要なのは、下記のように指定すると
「2019-12-09T00:00:00.000」〜「2019-12-13T23:59:59.999」まで取得するQueryBuilder query = QueryBuilders .rangeQuery("post_date") .from("2019-12-12") .to("2019-12-13") .timeZone("+09:00"); searchBuilder.query(query);12日のみのデータを取得するには下記のようになる
fromを含める場合は「includeLower」:true
toを含める場合は「includeUpper」 :trueQueryBuilder query = QueryBuilders .rangeQuery("post_date") .from("2019-12-12") .to("2019-12-13") .includeLower(true) .includeUpper(false) .timeZone("+09:00"); searchBuilder.query(query);Match Query
全文検索のクエリは下記
SearchSourceBuilder searchBuilder = SearchSourceBuilder.searchSource(); QueryBuilder query = QueryBuilders.matchQuery("message", "REST Level "); QueryBuilder query = QueryBuilders.matchQuery("message", "Level REST"); QueryBuilder query = QueryBuilders.matchPhraseQuery("message", "REST Level"); // フレーズ検索なので取得0件 QueryBuilder query = QueryBuilders.matchPhraseQuery("message", "Level REST"); searchBuilder.query(query);Term Query
完全一致で検索される、Termクエリは下記
QueryBuilder query = QueryBuilders.termQuery("user", "qiita");Bool Query(AND OR NOT)
Elastic Elastic SQL 説明 must AND filter AND スコアを無視する should OR mustnot NOT ※スコアを使用しない検索の場合はなるべくfilterを使う
Elasticsearchのbool queryを利用してAND OR NOTを書いてみるがとても分かりやすいAND
「must」「filter」どちらでも良い
「filter」の例はこんな感じ
SearchSourceBuilder searchBuilder = SearchSourceBuilder.searchSource(); BoolQueryBuilder boolQuery = QueryBuilders.boolQuery(); QueryBuilder query1 = QueryBuilders.matchQuery("message", "JAVA"); QueryBuilder query2 = QueryBuilders.matchQuery("message", "REST"); boolQuery.filter(query1); boolQuery.filter(query2); searchBuilder.query(boolQuery);OR
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery(); QueryBuilder query1 = QueryBuilders.matchQuery("message", "JAVA"); QueryBuilder query2 = QueryBuilders.matchQuery("message", "REST"); boolQuery.should(query1); boolQuery.should(query2);NOT
BoolQueryBuilder boolQuery = QueryBuilders.boolQuery(); QueryBuilder query = QueryBuilders.termQuery("user", "qiita"); boolQuery.mustNot(query);JSON形式で検索するには?
下記のようにJSON形式でも取得することができる
Search Template APISearchTemplateRequest request = new SearchTemplateRequest(); request.setRequest(new SearchRequest("qiita")); request.setScriptType(ScriptType.INLINE); request.setScript( "{" + " \"query\": { \"match\" : { \"{{field}}\" : \"{{value}}\" } }," + " \"size\" : \"{{size}}\"" + "}"); Map<String, Object> scriptParams = new HashMap<>(); scriptParams.put("field", "message"); scriptParams.put("value", "REST"); scriptParams.put("size", 5); request.setScriptParams(scriptParams); SearchTemplateResponse response = client.searchTemplate(request, RequestOptions.DEFAULT); SearchResponse searchResponse = response.getResponse(); SearchHit[] results = searchResponse.getHits().getHits();Frozen indices
6.8.1の「Java High Level REST Client」より使用することができる
Elasticsaerchに「Frozen indices」の実装された時には反映されていないため注意が必要How to Search Freeze Index using Java High Level REST Client
SearchRequest request = new SearchRequest("qiita").source(searchBuilder); request.indicesOptions(IndicesOptions.fromOptions( true, true, true, false, request.indicesOptions().allowAliasesToMultipleIndices(), request.indicesOptions().forbidClosedIndices(), request.indicesOptions().ignoreAliases(), true // ←ここでfrozen indexを検索できるか設定 true:検索可能 ));参考資料
終わりに
「Java High Level REST Client」の日本語記事が少なく、英語・中国記事を読むことが多いです。
ドキュメントに大体書いてあるのですが、新機能追加後は「Java High Level REST Client」では対応していないみたいなことがありソースやリリースノートを読まないといけないこともあります。明日は@NAO_MK2さんです。
- 投稿日:2019-12-09T01:19:12+09:00
[Java11] Stream API まとめ -Streamによるメリット-
Stream とは
コレクションに対するマップ-リデュース変換など、要素のストリームに対する関数型の操作をサポートするクラスです。
引用元: 公式ドキュメントまずは実際に見てみる
公式リファレンスより抜き出したものを一部改変
stream.javafinal int sum = widgets.stream() .filter(w -> w.getColor() == RED) .mapToInt(w -> w.getWeight()) .sum();上の例では、
widgetsからcolorがREDのものを抽出してweightの値の合計を計算しています。
for文で書くと以下のようになります。for文.javaint sum = 0; for (Widget w: widgets) { if (w.getColor() == RED) { sum += w.getWeight(); } }何ができるの?
冒頭で書いた通りStreamとは「コレクションに対するマップ-リデュース変換など、要素のストリームに対する関数型の操作をサポートするクラスです。」
- コレクションに対するマップ-リデュース変換
ざっくり言うと今までfor文でやっていたこと、です。
上の合計値の計算然り、最大値の取得や新しいリストの作成などができます。
- 関数型の操作をサポートする
Streamクラスのメソッドの多くが関数型インターフェースを引数に取ります。例えばfilter関数にはどのようにフィルターをかけるか、mapToInt関数にはどのように整数型に変換するかを引数に渡します。
Streamには新しいStreamを返すメソッドがたくさん用意されており、そこに処理を渡すことで柔軟な処理が可能になっています。何が良いの?
メリットとしては以下の 2 つが大きいと思います
- 可読性の向上
- 並列処理によるパフォーマンスの改善
可読性の向上
Streanを使った書き方が通常のコードと比べて「宣言的」だからです。
上の例の特に合計(sum)を求める部分に着目してください。
Streamの場合
sum()を呼び出しているだけ。
データの集合に対して、「合計値を求めてくれ」と言っているだけです。for文の場合
sumの初期値を0とし各要素の値を加算している。最終的な値が合計値となる。
「合計値の求める方法」を実装しています。for文の方はStreamの方と比べて「命令的」と呼びます。
「宣言的」な書き方では、細かい実装の隠蔽とコードの量の短縮ができます。やることを宣言しているだけなのでコードから何をしたいかが理解しやすいです。
逆に「命令的」な書き方は、やる内容を細かく記述するため処理が複雑になる程、理解が難しくなりバグの原因にもなります。経験上、Streamを使う使わないによらず、1つのメソッドにおける命令的なコードは少ない方が、読みやすく安全なコードが書けます。
並列処理によるパフォーマンスの改善
こちらの恩恵は得られないケースの方が多いです。(経験上)
なぜなら、余程大量のデータを扱わないかぎりは直列で実行する方が速いためです。幸いStreanの実行を並列処理に変えるには
parallel()呼び出すだけで済みます。
闇雲に並列処理にするのではなく、データ量、順番が保持されないことによる問題を考えて利用することで、並列処理の恩恵を最大限受けることができます。以下の記事が参考になります。
参考: ラムダ式で本領を発揮する関数型インターフェースとStream APIの基礎知識 (3/3)どうやって書くの?
Stream を使って処理を書くには3 ステップあります。
- Stream を作成する
- 中間操作
- 終端操作
例で示すと以下の通りです。
stream.javafinal int sum = widgets.stream() // Streamの作成 .filter(w -> w.getColor() == RED) // 中間操作 .mapToInt(w -> w.getWeight()) // 中間操作 .sum(); // 終端操作stream を作成する
ListやSetなどのCollectionから作成することが多いと思います。
widgets.stream()がまさにそれです。その他、いくつかの値からStreamを作る方法、Stream.Builderを使う方法、などがあります。中間操作
filtermapToIntが中間操作にあたります。各要素の値の変換や条件に基づいた要素の抽出などを行います。
Stream<T>やIntStreamなどのStreamを返します。Streamを返すためメソッドチェーンが可能です。
中間操作の処理はfileterなどを呼び出したタイミングではなく。終端操作実行時に初めて実行されます。これは中間操作を
実際に中間操作の実行タイミングがわかる例
public class Main { public static void main(String[] args) throws Exception { List<Widget> widgets = List.of(new Widget(RED, 10), new Widget(BLUE, 20)); Stream<Widget> stream1 = widgets.stream(); Stream<Widget> stream2 = stream1.filter(w -> w.getColor() == RED); System.out.println("complete filtering"); IntStream stream3 = stream2.mapToInt(w -> w.getWeight()); System.out.println("complete mappint to integer"); final int sum = stream3.sum(); } } class Widget { private Color color; private int weight; public Widget(Color color, int weight) { this.color = color; this.weight = weight; } public Color getColor() { System.out.println(color); return color; } public int getWeight() { System.out.println(weight); return weight; } }complete filtering complete mappint to integer java.awt.Color[r=255,g=0,b=0] 10 java.awt.Color[r=0,g=0,b=255]中間操作の直後には各処理が実行されていないことが見て取れます。
終端操作
sumが終端操作にあたります。これ以外にはcollectfindFirstなどがあります。合計値や新しいコレクションを返したりします。
中間操作と違い返す値は様々です。できることは多種多様に及びます。「合計値を求める」「新しいCollectionの生成」「各要素への処理(forEach)」などがあります。中間操作と終端操作のできることは実例を示した方が良いと思うので次回以降に詳しくまとめたいと思います。
関数型インターフェース
今まで無視してきましたが、
w -> w.getColor() == REDw -> w.getWeight()の存在に触れたいと思います。
この文法をラムダ式と呼びますが、必ずしもラムダ式を書く必要はありません。
ラムダ式は関数型インターフェースを実装するための1つの手段にすぎません。Streamのほとんどのメソッドが関数型インターフェースを引数にとるため、ここの理解はStreamの理解において避けては通れません。
正直、最初は雰囲気で書いてしまっても問題ないのでここから先は最悪理解できなくてもStreamを書くには問題ないかもしれないです。
関数型インターフェースとは
インターフェースの一種です。このインターフェースはたった1つのメソッドを持ちます
Javaに標準で用意されているもののほか、自分で作成することもできます。それぞれの型がわかりやすいように、最初の例をなるべく分割すると以下のようになります。
Stream<Widget> stream1 = widgets.stream(); Predicate<Widget> predicate = w -> w.getColor() == RED; Stream<Widget> stream2 = stream1.filter(predicate); ToIntFunction<Widget> toIntFunction = w -> w.getWeight(); IntStream stream3 = stream2.mapToInt(toIntFunction); final int sum = stream3.sum();ラムダ式の代入先になっている
PredicateToIntFunctionが関数型インターフェースです。ToIntFunctionの定義は以下のようになっています。java.util.function.ToIntFunction.java@FunctionalInterface public interface ToIntFunction<T> { int applyAsInt(T value); }関数型インターフェースには
@FunctionalInterfaceを付与しますが、付けなくとも機能的には問題ありません。実装の方法
Streamのメソッドに渡すために関数型インターフェースを実装したインスタンスを生成する必要がありますが、実装の方法は主に3通りあります。
- 匿名クラス
- ラムダ式
- メソッド参照
です。
では、それぞれの実装方法を比較してみましょう。
前提として、このようなWidgetクラスがあるものとします。Widget.javaclass Widget { private Color color; private int weight; public Widget(Color color, int weight) { this.color = color; this.weight = weight; } public Color getColor() { return color; } public boolean isColorRed() { return color == RED; } public int getWeight() { return weight; } }匿名クラス
とても読みやすいとは言えないです。
匿名クラス.javafinal int sum = widgets.stream() .filter(new Predicate<Widget>() { public boolean test(Widget w) { return w.isColorRed(); } }) .mapToInt(new ToIntFunction<Widget>() { public int applyAsInt(Widget w) { return w.getWeight(); } }) .sum();
一応これでもできます...
当然これでも動きます。
static class WidgetTestColorIsRed implements Predicate<Widget> { public boolean test(Widget w) { return w.isColorRed(); } } static class WidgetToWeightFunction implements ToIntFunction<Widget> { public int applyAsInt(Widget w) { return w.getWeight(); } }final int sum = widgets.stream() .filter(new WidgetTestColorIsRed()) .mapToInt(new WidgetToWeightFunction()) .sum();まぁ、書けるだけで書くケースは全くと言っていいほどないと思います。
ラムダ式
圧倒的に読みやすくなりました。
ラムダ式.javafinal int sum = widgets.stream() .filter(w -> w.isColorRed()) .mapToInt(w -> w.getWeight()) .sum();ラムダ式の書き方にも何通りかあります。
// 引数なし () -> "定数"; // 引数1個 n -> n + 1; // 括弧の省略が可能 (n) -> 2 * n; // 引数2個以上 (a, b) -> Math.sqrt(a * a + b * b); (x, y, z) -> x * y * z; // 複数行 (a, b, c) -> { double s = (a + b + c) / 2; return Math.sqrt(s * (s - a) * (s - b) * (s - c)); }メソッド参照
ここまで使ってきませんでしたが、メソッド参照で書ける場合は積極的に使った方がコードが見やすくなります。
wのような変数を置かないで済むのと、その時点でStreamの要素の型が何なのかが分かるので読みやすいです。
クラス::メソッドのように書きます。メソッド参照.javafinal int sum = widgets.stream() .filter(Widget::isColorRed) .mapToInt(Widget::getWeight) .sum();匿名クラスもラムダ式もメソッド参照も関数型インターフェースのインスタンスを生成するための方法です。自分で定義した関数型インターフェースであっても同様の方法でインスタンスの作成が可能です。
関数型インターフェースでは、たった1つのメソッドを実装すればいいことがわかっているため、ラムダ式のような型の情報が全くない書き方でも推論でどうにかなるわけです。おわりに
次回、Streamの具体的な使い方を紹介したいと思います。
参考
- 投稿日:2019-12-09T00:49:51+09:00
楽しい楽しいプログラミングの勉強会に参加しよう!
自己紹介
初めまして!
私は独学でプログラミングをしている高校生です。
一番好きな言語はJavaですプログラミングの成果や出来事をメインに書いていこうと思います
概要
私は11月27日に初めてCoderDojoにニンジャとして参加して12月8日にCo-KonPILE #0に参加しました。
そこで私が学んだことや楽しかったこと、よいところを説明します勉強会やイベントに行きたいと思ったきっかけ
私が独学でプログラミング始めたのは、中学1~2年生の頃です。
お年玉でRaspberry Pi 2を購入して、プログラミングを勉強しました
しかし、当時私の周りにはプログラミングを一緒にやる仲間がいなくて、ただ一人で独学していました。
友人と少し一緒にJavaをやったことはあります高校2年生になって、さすがに一人でやるのも疲れてきたので、ノートパソコンを持っている今、
無料で参加できるプログラミング会を探すことにしました。CoderDojoとの出会い
初めての参加で作成したプログラムは、Jsoupを使ったGoogleのロゴ画像のURLを取得する簡単なプログラムです
そこでいろいろな話をして、貴重な経験ができました!
Co-KonPILE #0
CoderDojoから帰ったあと、JSoupの使い方をアドバイスしていただいた方にお礼の連絡をしました。
そして、12月9日にCo-KonPILEを開催するのでもし良かったらどうぞ、みたいな感じで返信が来たので参加しました。
都会に住んでいない私にとっては参加がしやすいのです。Co-KoNPILe (ここんぱいる)
東京都の小平市や国分寺市や小金井市で地道に積み重ねる IT 勉強会的なものです
参加費 : 大人500円(会場費やおやつ代に充当),学生無料当日、ゆるーく雑談をしながらパソコンを使って楽しかったです!
今後も私はITのイベントに参加していきます
イベントに参加する良いところ
・貴重な経験や情報交換ができること
・楽しくプログラミングができること
まとめ ~プログラミングの勉強会に参加しよう~
独学で一人でプログラミングは、やっぱり寂しいです。
なのでたくさん交流会や、勉強会に参加することが大事だと思います!