- 投稿日:2019-12-09T23:57:52+09:00
Amazon SageMaker 物体検出モデルの構築 ~Honey Bees~
Amazon AI by ナレコム Advent Calendar 2019の8日目の記事です。
AWS公式機械学習トレーニングの Amazon SageMaker: Build an Object Detection Model Using Images Labeled with Ground Truth (Japanese) (Ground Truth のラベルが付いたイメージを使用して、オブジェクト検出モデルを構築) を参考に、物体検出のモデル構築についてまとめてみました。
物体検出とは
今回は画像からミツバチの検出を行います。
クラスタリング(分類)・・・1枚の画像がどのタグに分類できるか
物体検出・・・1枚の画像の中から特定の物体の境界ボックス(BoundingBox)を検出
セグメンテーション・・・ピクセル単位での分類データのダウンロード
iNaturalist.org から CC0 ライセンスに基づくミツバチの画像500枚を使用します。
ここからダウンロードしてください。学習画像500枚、テスト画像10枚、アノテーションデータ(.manifest)で構成されています。
ラベリングの実施
output.manifest は GroundTruth を使ってラベリングされた結果です。
各行が各学習画像のアノテーション結果になっています。{"source-ref":"s3://sagemaker-remars/datasets/na-bees/500/10006450.jpg","bees-500":{"annotations":[{"class_id":0,"width":95.39999999999998,"top":256.2,"height":86.80000000000001,"left":177}],"image_size":[{"width":500,"depth":3,"height":500}]},"bees-500-metadata":{"job-name":"labeling-job/bees-500","class-map":{"0":"bee"},"human-annotated":"yes","objects":[{"confidence":0.75}],"creation-date":"2019-05-16T00:15:58.914553","type":"groundtruth/object-detection"}} {"source-ref":"s3://sagemaker-remars/datasets/na-bees/500/10022723.jpg","bees-500":{"annotations":[{"class_id":0,"width":93.8,"top":228.8,"height":135,"left":126.8}],"image_size":[{"width":375,"depth":3,"height":500}]},"bees-500-metadata":{"job-name":"labeling-job/bees-500","class-map":{"0":"bee"},"human-annotated":"yes","objects":[{"confidence":0.82}],"creation-date":"2019-05-16T00:41:33.384412","type":"groundtruth/object-detection"}} {"source-ref":"s3://sagemaker-remars/datasets/na-bees/500/10059108.jpg","bees-500":{"annotations":[{"class_id":0,"width":157.39999999999998,"top":188.60000000000002,"height":131.2,"left":110.8}],"image_size":[{"width":375,"depth":3,"height":500}]},"bees-500-metadata":{"job-name":"labeling-job/bees-500","class-map":{"0":"bee"},"human-annotated":"yes","objects":[{"confidence":0.8}],"creation-date":"2019-05-16T00:57:28.636681","type":"groundtruth/object-detection"}} ・・・output.manifestを編集するか、ラベリングツールは好きなもの(VoTTなど)を使用し、下記のようなをフォーマットでアノテーションデータを作成します。
{"source-ref": "s3://{bucketname}/{foldername}/train/{root}.{exts}", "train/validation": {"annotations": [{"class_id": {class_id}, "width": {width}, "top": {top}, "height": {height}, "left": {left}}], "image_size": [{"width": {width}, "depth": {depth}, "height": {height}}]}}
- "source-ref":画像のS3パス
- "train/validation":学習(Train)もしくは検証(Validation)
- "annotations":アノテーションデータ
- "class_id":検出するタグ(タグごとに0から順につける番号)
- "width", "top", "height", "left":タグの境界ボックスの左上の点(top, left)とボックスのサイズ(width, height)
- "image_size":画像幅(width)、チャンネル数(depth)、画像高さ(height)
今回は学習画像(Train)を400枚、残りの100枚を検証画像(Validation)とし、train.manifest、validation.manifest の2つを作成します。対応する画像のファイル形式はJPGとPNGになります。
train.manifest
{"source-ref": "s3://sagemaker-mlbees/20191208/train/10006450.jpg", "train": {"annotations": [{"class_id": 0, "width": 95, "top": 256, "height": 86, "left": 177}], "image_size": [{"width": 500, "depth": 3, "height": 500}]}} {"source-ref": "s3://sagemaker-mlbees/20191208/train/10022723.jpg", "train": {"annotations": [{"class_id": 0, "width": 93, "top": 228, "height": 135, "left": 126}], "image_size": [{"width": 375, "depth": 3, "height": 500}]}} {"source-ref": "s3://sagemaker-mlbees/20191208/train/10059108.jpg", "train": {"annotations": [{"class_id": 0, "width": 157, "top": 188, "height": 131, "left": 110}], "image_size": [{"width": 375, "depth": 3, "height": 500}]}} ・・・ {"source-ref": "s3://sagemaker-mlbees/20191208/train/10437385.jpg", "train": {"annotations": [{"class_id": 0, "width": 38, "top": 306, "height": 31, "left": 73}, {"class_id": 0, "width": 40, "top": 281, "height": 24, "left": 214}, {"class_id": 0, "width": 37, "top": 283, "height": 24, "left": 281}, {"class_id": 0, "width": 40, "top": 236, "height": 26, "left": 360}, {"class_id": 0, "width": 25, "top": 192, "height": 24, "left": 300}, {"class_id": 0, "width": 36, "top": 193, "height": 29, "left": 144}, {"class_id": 0, "width": 19, "top": 146, "height": 23, "left": 224}, {"class_id": 0, "width": 20, "top": 105, "height": 23, "left": 418}, {"class_id": 0, "width": 30, "top": 340, "height": 29, "left": 20}, {"class_id": 0, "width": 27, "top": 162, "height": 18, "left": 211}, {"class_id": 0, "width": 20, "top": 104, "height": 23, "left": 226}, {"class_id": 0, "width": 34, "top": 208, "height": 38, "left": 451}, {"class_id": 0, "width": 35, "top": 331, "height": 24, "left": 52}, {"class_id": 0, "width": 37, "top": 278, "height": 25, "left": 312}, {"class_id": 0, "width": 31, "top": 171, "height": 17, "left": 175}, {"class_id": 0, "width": 26, "top": 152, "height": 16, "left": 177}, {"class_id": 0, "width": 15, "top": 166, "height": 24, "left": 375}, {"class_id": 0, "width": 25, "top": 177, "height": 17, "left": 408}, {"class_id": 0, "width": 22, "top": 160, "height": 18, "left": 395}, {"class_id": 0, "width": 20, "top": 126, "height": 16, "left": 375}, {"class_id": 0, "width": 17, "top": 141, "height": 17, "left": 319}, {"class_id": 0, "width": 16, "top": 135, "height": 17, "left": 349}, {"class_id": 0, "width": 17, "top": 137, "height": 17, "left": 302}, {"class_id": 0, "width": 18, "top": 135, "height": 19, "left": 279}, {"class_id": 0, "width": 26, "top": 101, "height": 22, "left": 470}, {"class_id": 0, "width": 19, "top": 78, "height": 13, "left": 397}, {"class_id": 0, "width": 15, "top": 96, "height": 18, "left": 366}, {"class_id": 0, "width": 21, "top": 101, "height": 19, "left": 171}, {"class_id": 0, "width": 21, "top": 47, "height": 17, "left": 173}, {"class_id": 0, "width": 11, "top": 54, "height": 15, "left": 232}, {"class_id": 0, "width": 16, "top": 66, "height": 13, "left": 241}, {"class_id": 0, "width": 23, "top": 89, "height": 17, "left": 244}, {"class_id": 0, "width": 13, "top": 80, "height": 18, "left": 275}, {"class_id": 0, "width": 19, "top": 74, "height": 14, "left": 329}, {"class_id": 0, "width": 17, "top": 76, "height": 14, "left": 365}, {"class_id": 0, "width": 18, "top": 80, "height": 17, "left": 312}, {"class_id": 0, "width": 15, "top": 22, "height": 25, "left": 401}, {"class_id": 0, "width": 19, "top": 39, "height": 17, "left": 347}, {"class_id": 0, "width": 16, "top": 42, "height": 15, "left": 309}, {"class_id": 0, "width": 16, "top": 53, "height": 12, "left": 281}, {"class_id": 0, "width": 15, "top": 59, "height": 14, "left": 284}, {"class_id": 0, "width": 12, "top": 20, "height": 15, "left": 181},validation.manifest
validation.manifest は "train" の部分を "validation" に置換してください。{"source-ref": "s3://sagemaker-mlbees/20191208/train/6381998.jpg", "validation": {"annotations": [{"class_id": 0, "width": 215, "top": 70, "height": 196, "left": 104}], "image_size": [{"width": 416, "depth": 3, "height": 369}]}} {"source-ref": "s3://sagemaker-mlbees/20191208/train/6415127.jpg", "validation": {"annotations": [{"class_id": 0, "width": 121, "top": 94, "height": 100, "left": 73}], "image_size": [{"width": 484, "depth": 3, "height": 500}]}} {"source-ref": "s3://sagemaker-mlbees/20191208/train/6415462.jpg", "validation": {"annotations": [{"class_id": 0, "width": 52, "top": 187, "height": 56, "left": 71}, {"class_id": 0, "width": 50, "top": 173, "height": 59, "left": 197}, {"class_id": 0, "width": 65, "top": 316, "height": 48, "left": 363}, {"class_id": 0, "width": 66, "top": 112, "height": 45, "left": 244}], "image_size": [{"width": 500, "depth": 3, "height": 452}]}}アノテーションデータに指定したS3のパス(この例では s3://sagemaker-mlbees/20191208/train/ )へ500枚の学習および検証画像をアップロードします。
s3://sagemaker-mlbees/20191208/ へアノテーションデータ( train.manifest, validation.manifest )をアップロードします。
次のトレーニングジョブ作成時にこれらのパスを使うのでメモっておいてください。
モデルをトレーニングしてデプロイする
トレーニングジョブの作成
SageMaker を開き、トレーニングジョブを作成します。
ジョブ設定
ジョブ名 mlbees-20191208 IAMロール 新しいロールの作成(AmazonSageMaker-ExecutionRole-20191208Txxxxxx) アルゴリズムのソース AmazonSageMaker組み込みアルゴリズム アルゴリズムの選択 ObjectDetection コンテナ 825641698319.dkr.ecr.us-east-2.amazonaws.com/object-detection:1 入力モード Pipe インスタンスタイプ ml.p2.xlarge インスタンス数 1 インスタンスあたりの追加のストレージボリューム(GB) 50 最大ランタイム 360000 seconds ネットワーク
ネットワーク分離の有効化 false ハイパーパラメータ
base_network resnet-50 use_pretrained_model 1 num_classes 1 epochs 30 larning_rate 0.001 lr_scheduler_factor 0.1 optimizer sgd momentum 0.9 weight_decay 0.0005 mini_batch_size 8 image_shape 300 label_width 350 num_training_samples 400 nms_threshold 0.45 overlap_threshold 0.5 freeze_layer_pattern false early_stopping false early_stopping_min_epochs 10 early_stopping_patience 5 early_stopping_tolerance 0.0 入力データ設定
train
チャンネル名 train 入力モードオプション Pipe コンテンツタイプ application/x-recordio 圧縮タイプ None レコードラッパー RecordIO Data source S3 S3データタイプ AugmentedManifestFile S3データディストリビューションタイプ FullyReplicated AugmentedManifestFile 属性名 (パイプ入力モード必須) source-ref, train S3の場所 s3://sagemaker-mlbees/20191208/train.manifest validation
チャンネル名 validation 入力モードオプション Pipe コンテンツタイプ application/x-recordio 圧縮タイプ None レコードラッパー RecordIO Data source S3 S3データタイプ AugmentedManifestFile S3データディストリビューションタイプ FullyReplicated AugmentedManifestFile 属性名 (パイプ入力モード必須) source-ref, validation S3の場所 s3://sagemaker-mlbees/20191208/validation.manifest 出力データ設定
S3出力パス s3://sagemaker-mlbees/20191208/ マネージド型スポットのトレーニング
マネージド型スポットトレーニングの有効化 True ジョブが終了するまでの最大待機時間 オプション停止条件 360000 seconds トレーニングジョブがInProgressからCompletedになったら学習が完了です。
モデルの作成
モデルを作成します。
モデル設定
モデル名 mlbees-20191208 IAMロール トレーニングジョブと同じもの コンテナの定義1
コンテナ入力オプション モデルアーティファクトと推論イメージの場所を指定します。 モデルアーティファクトと推論イメージの場所を指定します。 単一のモデルを使用する 推論コードイメージの場所 825641698319.dkr.ecr.us-east-2.amazonaws.com/object-detection:1 アーティファクトの場所 s3://sagemaker-mlbees/20191208/mlbees-20191208/output/model.tar.gz ネットワーク
ネットワーク分離の有効化 False エンドポイントの作成と設定
エンドポイント設定を作成します。
Endpoint
エンドポイント名 mlbees-20191208 エンドポイント設定のアタッチ
新しいエンドポイント設定の作成 新しいエンドポイント設定
エンドポイント設定名 mlbees-20191208 エンドポイント設定の作成が完了したら、エンドポイントを作成します。
Creating からInService になったら使えます。推論
作成したエンドポイントを用いてテスト画像を推論します。
AWS CLIを設定して、下記のPythonコードを実行しましょう!import boto3 import json with open("dataset/test/22971237.jpg", "rb") as f: image = f.read() response = boto3.client('sagemaker-runtime').invoke_endpoint( EndpointName="mlbees-20191208", Body=image, ContentType='image/jpeg' ) predictions = json.loads(response['Body'].read()) print(predictions)推論結果は、(class_id, score, xmin, ymin, xmax, ymax)の順で格納されており、それぞれ
class_id:タグID
score:推論スコア
xmin:境界ボックスの左上のx値(※画像サイズで正規化してあるので注意)
ymin:境界ボックスの左上のy値(※画像サイズで正規化してあるので注意)
xmax:境界ボックスの右下のx値(※画像サイズで正規化してあるので注意)
ymax:境界ボックスの右下のy値 (※画像サイズで正規化してあるので注意)
になっています{'prediction': [[0.0, 0.4678894877433777, 0.30429762601852417, 0.24999865889549255, 0.6138879060745239, 0.6268823146820068], [0.0, 0.42358464002609253, 0.06584984064102173, 0.06060954928398132, 0.9343515038490295, 0.9401313066482544], [0.0, 0.41352295875549316, 0.30878573656082153, 0.10083526372909546, 0.6731508374214172, 0.5129770636558533], [0.0, 0.39709046483039856, 0.33817505836486816, 0.4873414635658264, 0.6675703525543213, 0.9277041554450989], [0.0, 0.378907710313797, 0.0, 0.0, 0.3687918484210968, 0.5197888016700745], [0.0, 0.37673383951187134, 0.07746218144893646, 0.0, 0.5161272287368774, 0.3293883800506592], [0.0, 0.3741675913333893, 0.0, 0.460550993680954, 0.36986619234085083, 1.0], [0.0, 0.37143221497535706, 0.5950260162353516, 0.0, 1.0, 0.21253566443920135], [0.0, 0.3708018660545349, 0.3493179380893707, 0.0, 1.0, 0.6512178182601929], [0.0, 0.3700588643550873, 0.27566099166870117, 0.0, 0.713475227355957, 0.3211899995803833], [0.0, 0.3692185580730438, 0.39444130659103394, 0.3983367681503296, 1.0, 1.0], [0.0, 0.36762967705726624, 0.2224271595478058, 0.21391180157661438, 0.7647933959960938, 0.7966573238372803], [0.0, 0.3665901720523834, 0.0, 0.31598204374313354, 0.5442211627960205, 0.7052187323570251], [0.0, 0.36615416407585144, 0.0, 0.7466477751731873, 0.3294963836669922, 1.0], [0.0, 0.3645714223384857, 0.78152996301651, 0.0, 1.0, 0.38953807950019836], [0.0, 0.3632708489894867, 0.6367571353912354, 0.14908206462860107, 1.0, 0.8790770769119263], [0.0, 0.3581337630748749, 0.0, 0.7736784815788269, 0.11148740351200104, 1.0], [0.0, 0.35730576515197754, 0.18405702710151672, 0.5357580184936523, 0.8030450344085693, 1.0], [0.0, 0.35632744431495667, 0.4812198281288147, 0.0, 0.9089540839195251, 0.32849448919296265], [0.0, 0.35606932640075684, 0.4814307987689972, 0.3763745427131653, 0.6160391569137573, 0.5194752216339111], [0.0, 0.35529276728630066, 0.0, 0.0, 0.08277034014463425, 0.051912762224674225], [0.0, 0.35219448804855347, 0.5505965352058411, 0.33695971965789795, 0.7397928833961487, 0.5715459585189819], [0.0, 0.3487113118171692, 0.42075949907302856, 0.844500720500946, 0.47111785411834717, 0.8974922299385071], [0.0, 0.3482074737548828, 0.0, 0.0, 0.3503129482269287, 0.24298378825187683], [0.0, 0.3474455773830414, 0.5203220844268799, 0.2931615710258484, 0.8834731578826904, 0.7036521434783936], [0.0, 0.3472687304019928, 0.0, 0.0, 0.10882196575403214, 0.22120940685272217], [0.0, 0.3466414511203766, 0.4666988253593445, 0.6249315142631531, 0.5282527804374695, 0.6908530592918396], [0.0, 0.3453116714954376, 0.31746411323547363, 0.8423987627029419, 0.3688467741012573, 0.8994448184967041], [0.0, 0.3440929353237152, 0.7796421647071838, 0.6209114789962769, 1.0, 1.0], [0.0, 0.34316927194595337, 0.6643545031547546, 0.0558457225561142, 1.0, 0.535685122013092], [0.0, 0.3427833914756775, 0.544445812702179, 0.08242097496986389, 0.8637402653694153, 0.5203053951263428], [0.0, 0.3418370485305786, 0.0, 0.6646335124969482, 0.6075617074966431, 0.987572431564331], [0.0, 0.341707706451416, 0.07544617354869843, 0.1437387317419052, 0.5128083229064941, 0.4533810019493103], [0.0, 0.3399723768234253, 0.5327222943305969, 0.4944736957550049, 0.8722519278526306, 0.9193394184112549], [0.0, 0.3384418189525604, 0.35905712842941284, 0.4564792513847351, 0.5525619983673096, 0.6246435046195984], [0.0, 0.33811572194099426, 0.0, 0.8843855261802673, 0.20716631412506104, 1.0], [0.0, 0.3380047082901001, 0.6239446997642517, 6.010197103023529e-05, 0.7040519118309021, 0.05022969841957092], [0.0, 0.33621808886528015, 0.526395320892334, 0.35611313581466675, 0.5769199132919312, 0.4400783181190491], [0.0, 0.33464792370796204, 0.7893296480178833, 0.1616135984659195, 0.8427752256393433, 0.2122565656900406], [0.0, 0.3313765525817871, 0.0, 0.21833011507987976, 0.23080405592918396, 0.7796567678451538], [0.0, 0.3295021951198578, 0.6871658563613892, 0.16251946985721588, 0.7505543231964111, 0.20261342823505402], [0.0, 0.32939413189888, 0.8877862691879272, 0.0, 1.0, 0.21754144132137299], [0.0, 0.3280572295188904, 0.683427095413208, 0.05675225332379341, 0.7324377298355103, 0.1061081737279892], [0.0, 0.3280175030231476, 0.7337505221366882, 0.21456307172775269, 0.7870777249336243, 0.26403456926345825], [0.0, 0.32741934061050415, 0.7871232628822327, 0.0, 1.0, 0.11095887422561646], [0.0, 0.32711800932884216, 0.6125258207321167, 0.7707194089889526, 1.0, 1.0], [0.0, 0.3256891369819641, 0.0, 0.9203382730484009, 0.0562296137213707, 1.0], [0.0, 0.32530954480171204, 0.35250425338745117, 0.0, 0.5488604307174683, 0.1449427455663681], [0.0, 0.324715256690979, 0.45405250787734985, 0.0, 0.6479468941688538, 0.14573422074317932], [0.0, 0.3244691491127014, 0.5747636556625366, 0.6804345846176147, 0.6344759464263916, 0.7449156045913696], [0.0, 0.3242606818675995, 0.0, 0.7802523374557495, 0.060774143785238266, 0.8526475429534912], [0.0, 0.3231322765350342, 0.4211777150630951, 0.7901055216789246, 0.4736692011356354, 0.8448881506919861], [0.0, 0.3225260376930237, 0.6855562329292297, 0.2695790231227875, 0.7485852837562561, 0.3097873032093048], [0.0, 0.3223261833190918, 0.5165964961051941, 0.30369797348976135, 0.5838491320610046, 0.37661054730415344], [0.0, 0.3190132975578308, 0.6840611696243286, 0.11031299084424973, 0.7345172166824341, 0.15836459398269653], [0.0, 0.31880688667297363, 0.5868977308273315, 0.7858849167823792, 0.6264750957489014, 0.8554143309593201], [0.0, 0.318799763917923, 0.10135529190301895, 0.6273577213287354, 0.16216304898262024, 0.6878644227981567], [0.0, 0.3178630471229553, 0.2491334080696106, 0.0, 0.4503113031387329, 0.1459662914276123], [0.0, 0.31764253973960876, 0.0, 0.729369044303894, 0.06217200309038162, 0.8002824783325195], [0.0, 0.316314160823822, 0.13572518527507782, 0.4907791018486023, 0.4709596633911133, 0.918556272983551], [0.0, 0.31614798307418823, 0.7361401319503784, 0.161359503865242, 0.7889970541000366, 0.21088607609272003], [0.0, 0.3158923387527466, 0.36976388096809387, 0.7920727729797363, 0.42588844895362854, 0.8462352752685547], [0.0, 0.3157651722431183, 0.36776894330978394, 0.8443600535392761, 0.4184507131576538, 0.8987955451011658], [0.0, 0.3152107894420624, 0.9517414569854736, 0.5720713138580322, 0.9960393905639648, 0.6536024808883667], [0.0, 0.31452468037605286, 0.6303567886352539, 0.056085046380758286, 0.6810942888259888, 0.10801681876182556], [0.0, 0.31429141759872437, 0.3200715184211731, 0.09504622220993042, 0.3662959933280945, 0.1773381233215332], [0.0, 0.314095675945282, 0.5308109521865845, 0.6801299452781677, 0.5753098726272583, 0.7513325810432434], [0.0, 0.3140608072280884, 0.6809313297271729, 0.2178284078836441, 0.7347820997238159, 0.26759111881256104], [0.0, 0.31373119354248047, 0.5221344232559204, 0.7350226640701294, 0.5814639329910278, 0.7973107099533081], [0.0, 0.3117356598377228, 0.4218320846557617, 0.20239503681659698, 0.4763789772987366, 0.28319358825683594], [0.0, 0.31127995252609253, 0.42516055703163147, 0.3630872070789337, 0.47294357419013977, 0.429222971200943], [0.0, 0.31101304292678833, 0.8473232388496399, 0.8993422389030457, 0.8852854371070862, 0.9573569893836975], [0.0, 0.30946406722068787, 0.5220901370048523, 0.7896288633346558, 0.575954258441925, 0.8456448316574097], [0.0, 0.3092215061187744, 0.5670506954193115, 0.9440076947212219, 0.639283299446106, 1.0], [0.0, 0.30905911326408386, 0.9063401818275452, 0.9130138158798218, 1.0, 1.0], [0.0, 0.3090510964393616, 0.5135889053344727, 0.5722286701202393, 0.578898549079895, 0.6422014236450195], [0.0, 0.30885469913482666, 0.5250933170318604, 0.8471934795379639, 0.5761620998382568, 0.9015847444534302], [0.0, 0.30866655707359314, 0.951046884059906, 0.35804468393325806, 0.997364342212677, 0.4444500803947449], [0.0, 0.3081985414028168, 0.16665951907634735, 0.052841365337371826, 0.44393396377563477, 0.5633533000946045], [0.0, 0.30809155106544495, 0.8756505250930786, 0.8173004388809204, 1.0, 1.0], [0.0, 0.30627647042274475, 0.4542831778526306, 0.4180346727371216, 0.6407758593559265, 0.6615869998931885], [0.0, 0.30577099323272705, 0.36145180463790894, 0.21161268651485443, 0.43976718187332153, 0.26231950521469116], [0.0, 0.3056153357028961, 0.950568675994873, 0.6223926544189453, 0.9963271617889404, 0.7067312002182007], [0.0, 0.3048050105571747, 0.7901118397712708, 0.3691854476928711, 0.8498157858848572, 0.4268338680267334], [0.0, 0.3046548366546631, 0.4767646789550781, 0.6647834181785583, 0.9210307598114014, 1.0], [0.0, 0.3040694296360016, 0.9493268132209778, 0.7254079580307007, 0.9974527955055237, 0.8113071918487549], [0.0, 0.3036992847919464, 0.7842162847518921, 0.522617757320404, 0.8383376598358154, 0.5814014077186584], [0.0, 0.3035878539085388, 0.0, 0.5602916479110718, 0.15254323184490204, 0.7438892126083374], [0.0, 0.3035617172718048, 0.9525880217552185, 0.41422122716903687, 0.9983840584754944, 0.49657273292541504], [0.0, 0.3034290373325348, 0.09489327669143677, 0.9379873275756836, 0.168815016746521, 1.0], [0.0, 0.30334362387657166, 0.3615919351577759, 0.9473257064819336, 0.42423540353775024, 1.0], [0.0, 0.302979052066803, 0.4229004383087158, 0.1517314910888672, 0.4750792980194092, 0.2332150936126709], [0.0, 0.30288878083229065, 0.5509763360023499, 0.16333407163619995, 0.7436758875846863, 0.3406045436859131], [0.0, 0.302875816822052, 0.5253306031227112, 0.41257160902023315, 0.5755682587623596, 0.4916040897369385], [0.0, 0.3023538291454315, 0.7781322598457336, 0.9446988105773926, 0.8505274653434753, 1.0], [0.0, 0.3018416464328766, 0.04201468452811241, 0.0, 0.12768010795116425, 0.05132518336176872], [0.0, 0.3018025755882263, 0.638735294342041, 0.11266299337148666, 0.700247049331665, 0.15081219375133514], [0.0, 0.3017869293689728, 0.8701384663581848, 0.22678041458129883, 1.0, 0.47191929817199707], [0.0, 0.30173516273498535, 0.46991971135139465, 0.5788829326629639, 0.5528373718261719, 0.6279313564300537], [0.0, 0.3015425503253937, 0.702499508857727, 0.4966621398925781, 1.0, 0.8961905241012573], [0.0, 0.30097973346710205, 0.0, 0.6766150593757629, 0.062443431466817856, 0.7492969632148743], [0.0, 0.2999502122402191, 0.46926426887512207, 0.7879582643508911, 0.5222427248954773, 0.8441793918609619], [0.0, 0.2998069226741791, 0.8383838534355164, 0.7387928366661072, 0.9041901230812073, 0.7820411324501038], [0.0, 0.2997302711009979, 0.6266809701919556, 0.6829532384872437, 0.687191367149353, 0.7437620162963867], [0.0, 0.29922932386398315, 0.2766895890235901, 0.7345049381256104, 0.7165694832801819, 1.0], [0.0, 0.29915371537208557, 0.6280661225318909, 0.37325695157051086, 0.701719343662262, 0.41669437289237976], [0.0, 0.2988787591457367, 0.9512851238250732, 0.521103024482727, 0.9948536157608032, 0.6019420623779297], [0.0, 0.2982707619667053, 0.0020293742418289185, 0.5068413615226746, 0.05407947301864624, 0.5978963971138], [0.0, 0.2981034517288208, 0.8889434337615967, 0.6884158253669739, 0.9598939418792725, 0.731789767742157], [0.0, 0.29724669456481934, 0.7976745367050171, 0.5782050490379333, 0.8368011713027954, 0.6447365880012512], [0.0, 0.29685869812965393, 0.9411171078681946, 0.785904049873352, 1.0, 0.8544464111328125], [0.0, 0.29628944396972656, 0.25656986236572266, 0.0014236383140087128, 0.3422602415084839, 0.05571365728974342], [0.0, 0.29552161693573, 0.11159392446279526, 0.10173332691192627, 0.1531572937965393, 0.17168718576431274], [0.0, 0.2954811751842499, 0.0, 0.21423587203025818, 0.0765061229467392, 0.2614700198173523], [0.0, 0.2952989935874939, 0.15916989743709564, 0.32192519307136536, 0.3372461199760437, 0.5637787580490112], [0.0, 0.2952832579612732, 0.5180695056915283, 0.6282444000244141, 0.5831331014633179, 0.6977766752243042], [0.0, 0.2950413227081299, 0.8828567266464233, 0.939605712890625, 0.9554505348205566, 1.0], [0.0, 0.2945857346057892, 0.32042452692985535, 0.37924274802207947, 0.3600386679172516, 0.43792232871055603], [0.0, 0.2944544851779938, 0.373241662979126, 0.37452229857444763, 0.41563618183135986, 0.4352876842021942], [0.0, 0.2942132353782654, 0.8290576934814453, 0.9420439600944519, 0.902672529220581, 1.0], [0.0, 0.2941124439239502, 0.5380184054374695, 0.37435197830200195, 0.6709570288658142, 0.5188630819320679], [0.0, 0.2940295338630676, 0.7430799603462219, 0.11170899868011475, 0.8037078976631165, 0.15102824568748474], [0.0, 0.293331116437912, 0.35394763946533203, 0.34981769323349, 0.5498237609863281, 0.5380789637565613], [0.0, 0.29332756996154785, 0.4114592671394348, 0.9471758604049683, 0.4766947627067566, 1.0], [0.0, 0.29272541403770447, 0.5713214874267578, 0.0004309359937906265, 0.6492958068847656, 0.05033056437969208], [0.0, 0.2925208806991577, 0.7396335005760193, 0.05556988716125488, 0.7874881625175476, 0.10414917767047882], [0.0, 0.29249969124794006, 0.47896528244018555, 0.7397496700286865, 0.5195545554161072, 0.8028196096420288], [0.0, 0.2924167215824127, 0.933567464351654, 0.0, 1.0, 0.05580366402864456], [0.0, 0.29215577244758606, 0.4724491238594055, 0.84593665599823, 0.5229489803314209, 0.8991013765335083], [0.0, 0.2921390235424042, 0.4273237884044647, 0.6821130514144897, 0.47838541865348816, 0.7363201379776001], [0.0, 0.2918897867202759, 0.9429163932800293, 0.8406599760055542, 1.0, 0.9075591564178467], [0.0, 0.2918473780155182, 0.5128514170646667, 0.9449970126152039, 0.5849166512489319, 1.0], [0.0, 0.2911980152130127, 0.3602719008922577, 0.0, 0.4299685060977936, 0.06602838635444641], [0.0, 0.29032817482948303, 0.4254702925682068, 0.3083078861236572, 0.47212082147598267, 0.3808460235595703], [0.0, 0.2898170053958893, 0.7874332666397095, 0.2158052623271942, 0.8402680158615112, 0.26326441764831543], [0.0, 0.28945106267929077, 0.0, 0.0, 0.20739901065826416, 0.11667156964540482], [0.0, 0.2893337309360504, 0.4705773890018463, 0.4750300943851471, 0.5540667772293091, 0.5243601202964783], [0.0, 0.289265900850296, 0.6800929307937622, 0.0, 0.7377841472625732, 0.06092862784862518], [0.0, 0.2889595627784729, 0.8434596657752991, 0.31377309560775757, 0.8996695876121521, 0.370649516582489], [0.0, 0.2888559401035309, 0.37120816111564636, 0.04520254209637642, 0.4176694452762604, 0.1255854219198227], [0.0, 0.28823786973953247, 0.4785866141319275, 0.9381502866744995, 0.5244562029838562, 1.0], [0.0, 0.2881348431110382, 0.20553499460220337, 0.8335792422294617, 0.26337143778800964, 0.8998133540153503], [0.0, 0.28776055574417114, 0.848702073097229, 0.7896995544433594, 0.8853460550308228, 0.8488997220993042], [0.0, 0.28757259249687195, 0.8688817024230957, 0.12569433450698853, 1.0, 0.37085333466529846], [0.0, 0.2872491776943207, 0.5691465735435486, 0.25578054785728455, 0.6365798115730286, 0.32962414622306824], [0.0, 0.28710606694221497, 0.20785976946353912, 0.3741651475429535, 0.2643526792526245, 0.42936912178993225], [0.0, 0.287015825510025, 0.6081342697143555, 0.3686332702636719, 1.0, 0.6216212511062622], [0.0, 0.28659290075302124, 0.3108674883842468, 0.2117319256067276, 0.3869855999946594, 0.2622150182723999], [0.0, 0.28577154874801636, 0.3714808523654938, 0.09464675933122635, 0.41979309916496277, 0.17836514115333557], [0.0, 0.28570878505706787, 0.8963097929954529, 0.05641122907400131, 0.9497058987617493, 0.11036554723978043], [0.0, 0.28569257259368896, 0.9403613209724426, 0.2626246213912964, 1.0, 0.3157275915145874], [0.0, 0.2856108546257019, 0.5140482783317566, 0.26451432704925537, 0.5973600745201111, 0.3160684108734131], [0.0, 0.2852841019630432, 0.6335992217063904, 0.0, 0.679035484790802, 0.07775532454252243], [0.0, 0.28523746132850647, 0.57380610704422, 0.7360888123512268, 0.6322826743125916, 0.7948341965675354], [0.0, 0.2850608825683594, 0.2614211142063141, 0.4769710600376129, 0.3177346885204315, 0.5308374166488647], [0.0, 0.2847842574119568, 0.7914046049118042, 0.05570163577795029, 0.8404449224472046, 0.10548176616430283], [0.0, 0.2846382260322571, 0.25523650646209717, 0.9453313946723938, 0.318317174911499, 1.0], [0.0, 0.2845005393028259, 0.8596287369728088, 0.35657915472984314, 1.0, 0.5540792346000671], [0.0, 0.2843627333641052, 0.41853857040405273, 0.5140296220779419, 0.4780052900314331, 0.5822768211364746], [0.0, 0.28411853313446045, 0.7431882619857788, 0.5747441649436951, 0.7822370529174805, 0.6451032757759094], [0.0, 0.2838780879974365, 0.48433569073677063, 0.7505739331245422, 0.6222746968269348, 0.8824090361595154], [0.0, 0.28370994329452515, 0.5477281808853149, 0.4361770451068878, 0.740065336227417, 0.6665181517601013], [0.0, 0.28352266550064087, 0.0, 0.6035395860671997, 0.19002968072891235, 0.9050962924957275], [0.0, 0.28339964151382446, 0.5550472736358643, 0.06040928512811661, 0.7510890960693359, 0.2383417785167694], [0.0, 0.28322362899780273, 0.8587049245834351, 0.4579421281814575, 1.0, 0.655707836151123], [0.0, 0.2831907868385315, 0.6806806325912476, 0.3685862123966217, 0.7362295389175415, 0.4201270043849945], [0.0, 0.28298673033714294, 0.4577640891075134, 0.9509414434432983, 0.5475930571556091, 0.9990087747573853], [0.0, 0.2825695276260376, 0.6534325480461121, 0.0, 0.8546033501625061, 0.1414952278137207], [0.0, 0.2825687825679779, 0.32393306493759155, 0.0, 0.46664130687713623, 0.0958959311246872], [0.0, 0.28248947858810425, 0.7344797849655151, 0.0, 0.792578935623169, 0.059951916337013245], [0.0, 0.2822904884815216, 0.25265052914619446, 0.25429606437683105, 0.4493076503276825, 0.44751179218292236], [0.0, 0.2821846306324005, 0.3152012228965759, 0.7858959436416626, 0.37233418226242065, 0.8456672430038452]]}ベストスコアの境界ボックスを可視化します。
まとめ
トレーニングビデオを参考に、ミツバチの物体検出モデルを作成しました。画像をアノテーションしてファイルをアップロードし、GUI上でちょちょいと設定を書いて学習するだけで、物体検出ができます。今後は、ハイパーパラメータの設定やチューニング方法、再学習して運用する方法などについて学んでいきましょう。



- 投稿日:2019-12-09T23:19:07+09:00
家の環境(温度・湿度・大気圧)をAWSに蓄積して分析してみるの巻 その2
前回まで
今回の内容
今回は、AWS IoT向けにデバイスからpublishするところまで作業します。
先にデバイス側のコードを紹介
aws-iot-publish.ino#include <time.h> #include <ESP8266WiFi.h> #include <WiFiClientSecure.h> #include <PubSubClient.h> #include "BME280SPI.h" #define JST 3600*9 const String wifiSSID = "<yourSSID>"; // お使いのWiFiのSSIDを入力してください const String wifiPass = "<yourPass>"; // お使いのWiFiのパスワードを入力してください const uint8_t pinLED = 14; // 緑LEDピン番号 const uint8_t pinSW = 0; // タクトスイッチSW1ピン番号 const uint8_t pinBME280CS = 15; // BME280センサーCSピン番号 const uint8_t pinSDCS = 2; // SDカードCSピン番号 const char* server = "<AWS IoTのエンドポイント>"; const int port = 8883; const char* pubTopic = "<トピック名>"; const char* Root_CA = \ "-----BEGIN CERTIFICATE----\n" \ "~\n" \ "~\n" \ "中略\n" \ "-----END CERTIFICATE-----\n"; const char* Client_cert = \ "-----BEGIN CERTIFICATE-----\n" \ "~\n" \ "~\n" \ "中略\n" \ "-----END CERTIFICATE-----\n"; const char* Client_private = \ "-----BEGIN RSA PRIVATE KEY-----\n" \ "~\n" \ "~\n" \ "中略\n" \ "-----END RSA PRIVATE KEY-----\n"; WiFiClientSecure espClient; PubSubClient mqttClient(espClient); //--------------------------------- // 変数 BME280SPI bme280(pinBME280CS); // BME280センサーを制御するクラス bool statWiFiConnected = true; // WiFiに接続されているかを記憶しておく uint32_t lastStat = 0; // 最後にstat()を実行した時間を記憶しておく char currentTimeStr[19]; //--------------------------------- // 関数 void connectAWSIoT() { while (!mqttClient.connected()) { if (mqttClient.connect("ESP8266")) { Serial.println("AWSIoT Connected."); } else { Serial.print("Failed. Error state="); Serial.print(mqttClient.state()); // Wait 5 seconds before retrying delay(5000); } } } void mqttCallback (char* topic, byte* payload, unsigned int length) { Serial.print("Received. topic="); Serial.println(topic); for (int i = 0; i < length; i++) { Serial.print((char)payload[i]); } Serial.print("\n"); } void mqttLoop() { if (!mqttClient.connected()) { connectAWSIoT(); } mqttClient.loop(); } void getCurrentDateTimeStr() { time_t t; struct tm *tm; t = time(NULL); tm = localtime(&t); sprintf(currentTimeStr,"%04d/%02d/%02d %02d:%02d:%02d", tm->tm_year+1900, tm->tm_mon+1, tm->tm_mday, tm->tm_hour, tm->tm_min, tm->tm_sec); } void setup() { Serial.begin(115200); delay(1); Serial.printf("\n\n-----------------------\n"); Serial.printf("Program Start\n"); pinMode(pinLED, OUTPUT); // LED pinMode(pinSW, INPUT); // SW1 // SPI CSピンをHighにする pinMode(pinBME280CS, OUTPUT); pinMode(pinSDCS, OUTPUT); digitalWrite(pinBME280CS, HIGH); digitalWrite(pinSDCS, HIGH); // BME280 Measure until success while(BME280SPI::statSuccess!=bme280.meas()){ Serial.print("BME280 is not available\n"); delay(5000); } // WiFi Serial.printf("\nWiFi"); WiFi.mode(WIFI_STA); WiFi.begin(wifiSSID.c_str(), wifiPass.c_str()); // 接続完了まで待つ while(WiFi.status()!=WL_CONNECTED){ delay(1000); } Serial.printf(" Connected IP : "); Serial.println(WiFi.localIP()); //時刻合わせ configTime( JST, 0, "ntp.nict.jp", "ntp.jst.mfeed.ad.jp"); delay(5000); getCurrentDateTimeStr(); Serial.printf("Current date-time is "); Serial.println(currentTimeStr); //AWSへの接続処理 //証明書、秘密鍵のオブジェクト作成 BearSSL::X509List cert(Root_CA); BearSSL::X509List client_crt(Client_cert); BearSSL::PrivateKey key(Client_private); //証明書、秘密鍵の設定 espClient.setTrustAnchors(&cert); espClient.setClientRSACert(&client_crt, &key); //接続処理 mqttClient.setServer(server, port); mqttClient.setCallback(mqttCallback); connectAWSIoT(); } // 5秒おきに動作状況を確認する処理 void stat(){ pinMode(pinLED, OUTPUT); if(WiFi.status()==WL_CONNECTED){ // WiFi切断 -> 接続に変わった場合ログを残す if(!statWiFiConnected){ statWiFiConnected = true; Serial.println(" WiFi Connected"); Serial.println(WiFi.localIP()); } // 正常状態 LEDを1回点滅 digitalWrite(pinLED, 1); delay(100); digitalWrite(pinLED, 0); }else{ // WiFi接続 -> 切断に変わった場合ログを残す if(statWiFiConnected){ statWiFiConnected = false; Serial.printf(" WiFi Disconnected\n"); } // WiFi切断状態 LEDを2回点滅 digitalWrite(pinLED, 1); delay(50); digitalWrite(pinLED, 0); delay(450); digitalWrite(pinLED, 1); delay(50); digitalWrite(pinLED, 0); } } // センサーの気温、気圧、湿度をAWSにpublishする void publishToAWS() { Serial.printf("Start publishing data to AWS\n"); // 測定処理おこなう bme280.meas(); // センサーからデータ取得に失敗 if(!bme280.getResult()){ Serial.printf(" BME280 Not Available\n"); return; } getCurrentDateTimeStr(); String json = "{"; json += "\"time\":\""; json += currentTimeStr, json += "\","; json += "\"temperature\":\""; json += bme280.getMeasStr(BME280SPI::selectTemp).c_str(); json += "\","; json += "\"humidity\":\""; json += bme280.getMeasStr(BME280SPI::selectHumidity).c_str(); json += "\","; json += "\"temperature\":\""; json += bme280.getMeasStr(BME280SPI::selectPressure).c_str(); json += "\"}"; Serial.println(json); if(!mqttClient.publish(pubTopic, json.c_str())){ Serial.println("Failed to publish\n"); }else{ Serial.println("Succeed to publish\n"); } } void loop() { if(millis() > lastStat+5000){ // 5秒おきに実行 lastStat = millis(); stat(); publishToAWS(); } delay(1); // 消費電力低減 mqttClient.loop(); }ポイント
全体的に
- ループとかwifi接続とかの実装はこちらの公式サンプルを参考に実装。
- とりあえずpublishすることを優先したので、実装的に変なとこありますがご容赦ください。
証明書・秘密鍵について
- とりあえず今回はベタ書きしました。
- 最初、ここのやり方を参考に実装したけどうまくいかず。
- こんなエラーが出た
error: no matching function for call to BearSSL::WiFiClientSecure::setCACert(const char*&)- 参考にしてた人のライブラリがESP32用で、
WifiSecureClientの実装が同名ながら違っていた(今回使ったのはESP8266)- 最終的にここを見て解決
- この参考記事には時刻合わせも必要という記載があったのでここを参考に実装しました。
センサー情報の取得について
- 公式のサンプルを元に実装しました。
掲載コード以外でやったこと
- 最初のほう、
fork/exec /Users/yourusername/Library/Arduino15/packages/esp8266/tools/python3/3.7.2-post1/python3: no such file or directoryというエラーが出ました。
- この記事を参考に対処して解決。
PubSubClient.hのパラメーターをいじりました。
MQTT_MAX_PACKET_SIZEを256に。
- publishに失敗する原因を切り分けてるうちに、publishするデータ長によって成否が分かれたので気づいた。
MQTT_KEEPALIVEを30に。
- ここに書いてたのでとりあえず。
- とりあえず動作確認する際は、AWS IoTのテスト機能でpublishしたデータをsubscribeできるか確認しました。デバイスがpublishするトピックをテスト機能のほうでsubscribeして、うまくいけばpublishされたデータが見れるようになります。

次回やる予定
publishしたデータをDynamoDBにぶち込んで何しか可視化したいと思います。
他、参考記事
https://blog.maripo.org/2017/07/esp32-aws-iot/
https://blog.maripo.org/2017/07/esp32-aws-iot-troubleshooting/
- 投稿日:2019-12-09T22:58:27+09:00
AWSの多要素認証に1passwordが使えたけど使っちゃダメだと思った話
1passwordのアイテム編集画面で、フィールドタイプを眺めててふと思った。「ワンタイムパスワードってあるけど、これ、AWSで多要素認証するときの『仮想MFAデバイス』に使えるのでは」と。結論から言えば、使えた。快適。でもこれは多分「人をダメにするナントカ」的な快適さだ。やっちゃいけないやつだ。
AWSの多要素認証
AWSでは、AWSアカウントの管理者であるrootユーザー(メールアドレスでログインする人)と、利用者であるIAMユーザー(ユーザーIDでログインする人)のどちらでも、多要素認証(MFA:Multi-Factor Authentication)を設定して認証を強化できる。
- 認証方法はパスワード認証+ワンタイムパスワード(当人が知っていること+当人が持っているもの)
- ワンタイムパスワードの生成には、専用のデバイスであるU2FセキュリティキーやハードウェアMFAデバイス、スマホアプリである仮想MFAデバイスのどちらかが使える
- SMSによる認証もプレビュー提供されていたものの「間もなく(略)サポートを終了します。新規のお客様が、この機能をプレビューすることはできません」。
利用できるスマホアプリは「IAM - Multi-factor Authentication」の「Virtual MFA Applications」にまとめられていて、現時点ではAuthy、Duo Mobile、LastPass Authenticator、Microsoft Authenticator、Google Authenticatorがリストアップされていた。
僕は当初、自分のiPhoneにGoogle Authenticatorをインストールし、IAM ユーザーの仮想 MFA デバイスの有効化を行って、2段階認証でAWSにログインできることを確認した。
1passwordによるMFA
1passwordに記録していたIAMユーザー情報を修正していて、ふとフィールドタイプに「ワンタイムパスワード」があるのが気になった。AWS側では、仮想MFAデバイスの要件として次のように書いている。
電話や他のデバイスを仮想多要素認証 (MFA) デバイスとして使用できます。これを行うには、標準ベースの TOTP (時刻ベースのワンタイムパスワード) アルゴリズムである RFC 6238 に準拠するモバイルアプリをインストールします。これらのアプリは、6 桁の認証コードを生成します。
(仮想 Multi-Factor Authentication (MFA) デバイスの有効化 (コンソール) - AWS Identity and Access Management)1passwordのワンタイムパスワード機能は、リリース時のブログエントリーを見るとTOTPであるらしい。
1Password 5.2 for iOS and 1Password 4.1.0.538 for Windows are out, and they provide support for using Time-based One Time Passwords (TOTP) in your Logins
(TOTP for 1Password users | 1Password)これ、もしかして1passwordも使えるのでは、と思って試してみた。1password登録されたIAMユーザー情報にワンタイムパスワードフィールドを追加するとして、手順は「仮想 Multi-Factor Authentication (MFA) デバイスの有効化 (コンソール)」を1password用に編集すると、こうなる。
- AWS マネジメントコンソール にサインインし、IAM コンソールを開きます。
- ナビゲーションペインで [ユーザー] を選択します。
- [ユーザー名] リストから対象の MFA ユーザーの名前を選択します。
- [Security credentials] タブを選択します。[Assigned MFA device (割り当て済み MFA デバイス)] の横で、[管理] を選択します。
- [MFA デバイスの管理] ウィザードで、[仮想 MFA デバイス]、[Continue (続行)] の順に選択します。
- 1passwordを開きます。IAMユーザー情報を登録したアイテムを開き、編集状態にします。ユーザーIDやパスワードのフィールドの下に、新しいフィールドを追加し、「ワンタイムパスワード」タイプを選びます。
- AWSの[MFA デバイスの管理] ウィザードで [手動設定のシークレットキーを表示] を選択し、1passwordに追加した「ワンタイムパスワード」フィールドに入力し、保存します。
- [MFA デバイスの管理] ウィザードの [MFA code 1 (MFA コード 1)] ボックスに、1passwordに表示されているワンタイムパスワード(6桁の数字)を入力します。デバイスが新しいワンタイムパススワードを生成するまで待ちます (最長 30 秒)。生成されたら [MFA code 2 (MFA コード 2)] ボックスに 2 つ目のワンタイムパススワードを入力します。[Assign MFA (MFA の割り当て)] を選択します。
これで1passwordでワンタイムパスワードを生成できるようになり、AWS側も多要素認証でログインできるようになった。実際にログインしてみると、通常時のIDとパスワードと同様に、ワンタイムパスワードも自動(または半自動)入力されるようになる。ログインがとても簡単、快適になる。
でもMFAで1password使っちゃダメかもと思う
Windows上の1passwordでワンタイムパスワードのフィールドを追加して、その後iPhone上の1passwordを見てみると、当然だけどデータは同期されワンタイムパスワードのフィールドが出てきた。iPhone上でAWSのコンソールにログインしたところ、こちらでも多要素認証でうまく認証された。すごく便利。でもこれはよくないことかもしれない。僕は「仮想 MFA デバイスの交換または更新」を参照して、1passwordを無効化し、Google Authenticatorを登録しなおした。
Windows(具体的には社有のSurface Pro)上の1passwordとiPhone上の1passwordの両方でMFAの二段階目をクリアできたということは、もうこの2段階目は特定のデバイスを持っていることに依存しないということだ。僕のIDで他のデバイスに1passwordをインストールすることができれば、さらにそのデバイスでも2段階目をクリアできる。「AWSのパスワード」と「特定のスマホ(デバイス)」ではなく、「AWSのパスワード」と「1passwordのマスターパスワード」でAWSにログインできてしまう。
MFA(多要素認証)で求められるのは「多段階」ということではない。知識、所有物、生体情報のうち2種類以上の要素を組合わせて使うことだ。「AWSのパスワード」と「1passwordのマスターパスワード」では、どちらも「知識」だから1種類の要素しか使っていない。これは多段階認証ではあっても多要素認証ではない。僕が複数のデバイスで使えるワンタイムパスワード生成アプリを選んでしまったから、そうなっちゃったのだ。求められているのがワンタイムパスワードだけなら1passwordを活用すべきだけど、MFAなら1passwordを組み合わせちゃいけなかった。
古い話だけど「タスポ(taspo)」の運用が開始された頃に自販機にタスポを添付した店主がいて、「財務省の福岡の出先や日本たばこ産業から『なるべくやめてほしい』と電話などで注意を受けたというが、店主は『法律違反ではないはず』と、撤去の意向はない」と報じられた。同じようにAWSの多要素認証化も、導入時には「設定しました」「これからはMFA必須です」だけでは、僕のように快適だけどMFAを台無しにする組み合わせを選択しちゃうかもしれない。なんでMFAを導入するのかとかMFAってなんのことなのかとか、認識と思いを共有しないとコケそうだ。
参照
- 投稿日:2019-12-09T22:02:54+09:00
クラウドはdhcpが当たり前
さて、つい最近とあるプロジェクトにて。
「Azureの設定的には、インタフェースには静的なIPを振りますが、OSの設定としてはdhcpを設定します」
と説明したところ
「そんなのあり得ない!」
という反応を受けました。
どうやら「クラウドに中途半端に詳しい人が勘違いしてることあるある」っぽいネタのようですので、解説していきたいと思います。Azure(やらAWSやら)では基本的にOS設定はDHCP
さて、皆さんはAzure、或いはAWSで新規に仮想マシンを建てる時、OSの中身はほぼデフォルト設定になっているという事は理解されているかと思います。
OSのデフォルト設定は、DHCP設定なのです。
つまり、事実として、OSはDHCP設定のままでいると、AzureなりAWSなりが設定している「ネットワークの設定」が設定される仕組みになっているのです。その際、サブネットマスクだの、デフォルトゲートウェイだの、DNSだのが自動で設定されるのです。DHCP設定しないとどうなるの?
こまる事だらけです。
特に[VMのクローンを作る]という時に大変困った事になります。
例えばOSの設定として、192.168.0.10というアドレスを設定してしまったとしましょう。すると、そのクローンとして192.168.0.11というIPアドレスを持つクローンを作っても、そのクローンはパケットを受信して来れません。そのクローンの仮想マシンは、自分のIPを192.168.0.10だと思っているからです。
バカハブという言葉を聞いた事がありますか?とにかくネットワークに流れるパケットを、つながっている全てのノードに送信してしまうハブの事です。最近はめったに見なくなりました。ネットワークのキャプチャなどで大変に役に立つものです。
そして、そのバカハブにつないでも、大抵のPCは混乱なく通信をする事が可能です。それは、自分のIPアドレスを知っていて、そのIP以外の通信を受け取らない、という仕組みが出来ているからです。クラウドの設定と、OSの設定は違うんだよ
「何を当たり前の事を言ってるんだ」と思われるかもですが、これが理解出来ていない人、ホントに多いんですよ。
上記を読めば、まさかの勘違いも解消するかもと思っているのですが、ウチの職場で延々と「わからない」を繰り返している方がいらっしゃったので、改めて執筆してみました。
- 投稿日:2019-12-09T22:02:54+09:00
クラウドはhdcpが当たり前
さて、つい最近とあるプロジェクトにて。
「Azureの設定的には、インタフェースには静的なIPを振りますが、OSの設定としてはdhcpを設定します」
と説明したところ
「そんなのあり得ない!」
という反応を受けました。
どうやら「クラウドに中途半端に詳しい人が勘違いしてることあるある」っぽいネタのようですので、解説していきたいと思います。Azure(やらAWSやら)では基本的にOS設定はDHCP
さて、皆さんはAzure、或いはAWSで新規に仮想マシンを建てる時、OSの中身はほぼデフォルト設定になっているという事は理解されているかと思います。
OSのデフォルト設定は、DHCP設定なのです。
つまり、事実として、OSはDHCP設定のままでいると、AzureなりAWSなりが設定している「ネットワークの設定」が設定される仕組みになっているのです。その際、サブネットマスクだの、デフォルトゲートウェイだの、DNSだのが自動で設定されるのです。DHCP設定しないとどうなるの?
こまる事だらけです。
特に[VMのクローンを作る]という時に大変困った事になります。
例えばOSの設定として、192.168.0.10というアドレスを設定してしまったとしましょう。すると、そのクローンとして192.168.0.11というIPアドレスを持つクローンを作っても、そのクローンはパケットを受信して来れません。そのクローンの仮想マシンは、自分のIPを192.168.0.10だと思っているからです。
バカハブという言葉を聞いた事がありますか?とにかくネットワークに流れるパケットを、つながっている全てのノードに送信してしまうハブの事です。最近はめったに見なくなりました。ネットワークのキャプチャなどで大変に役に立つものです。
そして、そのバカハブにつないでも、大抵のPCは混乱なく通信をする事が可能です。それは、自分のIPアドレスを知っていて、そのIP以外の通信を受け取らない、という仕組みが出来ているからです。クラウドの設定と、OSの設定は違うんだよ
「何を当たり前の事を言ってるんだ」と思われるかもですが、これが理解出来ていない人、ホントに多いんですよ。
上記を読めば、まさかの勘違いも解消するかもと思っているのですが、ウチの職場で延々と「わからない」を繰り返している方がいらっしゃったので、改めて執筆してみました。
- 投稿日:2019-12-09T20:45:54+09:00
AWS re:Inventを有意義に過ごすための10個のTips
これはMedia Doアドベントカレンダーの何日目かわからない記事です。
先日、ラスベガスで開催されたAWS re:Invent2019に参加してきました。
そのときに「次行くときはこうしよう」と思ったことをTipsとしてまとめます。①セッション予約は登録解禁後すぐやろう
re:Inventのセッション予約は、開催約2ヶ月前の日本時間深夜2時に開始されます。
そのとき、「明日の昼ぐらいに予約すればいいや」とか思っていると人気のセッションはすぐ埋まってしまっていました。re:Invent全体の参加者約7万人に対して、セッションの会場は数百人程度なのですごい競争率です。なのでセッションの予約は開始直後にやってしまいましょう。
予約開始時にすぐ目当てのセッションを予約するには、当然それより前に公開されているセッション一覧に目を通しておく必要があります。re:Inventでのセッションの総数はおよそ3000個もあって、この一覧に目を通すことすら難しいので、サーバーレスとか機械学習、ブロックチェーンなど、自分が興味のあるトピックをあらかじめ絞っておくと良いと思います。(というか、そうしないと厳しいです)
②通常SessionよりWorkshop、Chalk Talkなどを優先しよう
re:Inventのセッションには色々種類があります。主なものは以下のとおりです。
- Keynote: 基調講演
- Session: スピーカーが喋っているのを約1時間聞くだけ
- Chalk Talk: 15分講演、残り45分は質疑応答という少人数セッション
- Workshop: 2時間程度の時間で実際手を動かして何かを作ったりするハンズオン形式
- Builder Session: Workshopをさらに少人数(6人とか)で行う
re:InventのセッションにはYoutubeで動画公開されるものとされないものがあります。KeynoteやSessionに関しては動画公開され、内容としても基本的にはスピーカーが喋っているのを聞くだけです。主要なKeynoteについては演出も凝っていて会場の興奮度も高いのでぜひ生で参加して会場の雰囲気含めて楽しみたいところですが、それ以外の通常SessionよりはなるべくWorkshopやChalk Talkを優先して受講すると良いと思います。
③セッションのキャンセル待ちは難しいのでなるべく避けよう
予約できなかったセッションにどうしても参加したい場合、キャンセル待ちすることになります。
re:Invent開催前までは、キャンセル待ちリストに登録されて運が良ければ繰り上がるという形ですが、re:Invent開催期間中のキャンセル待ちは、実際にセッション開始前に行列に並び、正規の登録者が遅刻などして欠員が出た場合にのみセッション参加が認められる運用になります。
その場合、原則としてセッション開始1時間前から待ち行列が作られます。しかしDeepComposerのハンズオンなどはあまりの人気ぶりから、スタッフが早めに待ち行列の案内を始め、規定通りのセッション開始1時間前に行ったらすでにキャンセル待ち50人とかになっておりキャンセル待ちが絶望的な状況が発生していました。なので行列が作られると想定される場所の近くに待機して、行列が始まったらすぐ並ぶようにしましょう。とういうかそもそも、セッションの予約を計画的に行い、キャンセル待ちに並ばずに受講できるようにしましょう。。
ちなみに各セッションは開始10分前までに入場手続きをしないと問答無用で予約が取り消され、キャンセル待ちの人を優先して入場させていました。(おそらくセッション開始時間を厳守するため)
?DeepComposerハンズオンのキャンセル待ち行列④なるべくVenetianの近くに泊まろう
Venetianというホテルがre:Inventのメイン会場となっており、Keynote(基調講演)などの主要なプログラムはそこで行われます。なので、移動を楽にするためにできるだけVenetian、またはVenetianの近くのホテルに泊まるのがおすすめです。
セッション間の時間はけっこうみんな廊下の地べたに座って休憩していましたが、できればゆっくり休みたいので部屋に戻りやすい環境を作りたいところです。Certificate LoungeというAWS認定資格を持った人だけ入れる休憩所も用意されていますが、今年はその休憩所がVenetianにしかない、かつそんなに広くなく(50席ぐらい)常に満員だったので、セッション間の空き時間をCertificate Loungeで潰すという方針はそんなにおすすめできないかな、という印象でした。
ちなみに今回、Certificate Loungeを使うために渡米前にソリューションアーキテクトアソシエイトを取得したのですが、そんなわけで別に取らなくても良かったです。(ただ、それをモチベーションにして計画的に勉強できたのは良かったです)
?Certificate Loungeの様子⑤新サービス発表後、セッション受講スケジュールを再確認しよう
re:InventではおもにKeynoteで新サービスの発表がおこなわれます。そしてそれと同時にその新サービスに関連するハンズオンなどが開講されます。
なので発表されたばかりの新サービスをいち早くキャッチアップしたい!となったら新サービス発表後にその関連セッションを探して予約しましょう。
このとき、「NEW LAUNCH」というキーワードでスケジュール検索すると、新サービスのセッションをかんたんに絞り込みできるのでおすすめです。
ちなみに、その年の新サービスが発表される主なタイミングは以下の2つです。
- 0日目のMidnight Madness(前夜祭)の最後
- 例年、DeepLens, DeepRacer, DeepComposerなど機械学習がらみのガジェットが発表され、そのハンズオンに参加すると現物をもらうことができます。かなり競争率高いです
- 2日目の朝のKeynote
- AWS CEOによるre:Inventで一番重要なKeynoteです。ここでかなりの数の新サービスが発表されます
⑥ラスベガスのホテル施設には期待しないでおこう
僕が泊まったのは某4つ星ホテルでしたが、
- ウォシュレットなし
- ガウンなし
- スリッパなし
- 冷蔵庫なし(備え付けの冷蔵庫の中身を動かすと使用したとみなされて使用料50ドル+飲み物代がかかり、実質使えない)
と、値段の割には...という内容でした。他のホテルも設備的にはだいたい同じようなものでした。
なので、ラスベガスの高級ホテルといっても設備には期待しないほうがいいかもしれません。⑦レンタルWi-Fi、プリペイドSIMはなくても何とかなるぞ
今回、レンタルWi-Fiを持っていきましたが、基本的にre:Inventの会場となる各ホテルにはそのホテルの無料Wi-FiとAWSの無料Wi-Fiが飛んでいるので、会場間の移動時ぐらいにしか持っていったWi-Fiを使うことはありませんでした。その会場間の移動時もシャトルバスが出ているのでUberを使う機会もありませんでした。
⑧無料の食べ物・飲み物で食いつなごう
re:Inventの会場では、昼食やおやつが支給されます。
昼食はビュッフェとGrab&Go(要は弁当)の2種類があって、会場で食べるか持ち帰って部屋などで食べるかを選択できますが、弁当は個人的にかなり量が多かったので、次の日の朝ごはんにしたりなどしていました。
水やコーヒーはホテルの色んな所に設置されていて、だいたいいつでも飲むことができますし、昼食やおやつの時間にはコーラやスプライト、紅茶などのソフトドリンクも支給されます。
なのでre:Invent開催中の食事代は夕食分ぐらいしかかからないと思います。
?ビュッフェはこんな感じ
?弁当はこんな感じ⑨SWAG(ノベルティ)を効率よく手に入れよう
re:Inventでは、会場の各地でSWAG(ノベルティ)が配布されています。
パターンとしては、
- re:Inventに参加したら必ずもらえるもの(今回はパーカーと水筒)
- 特定の場所に行き、条件を満たせばもらえるもの
- 「基調講演で最初に入場した1000名限定」でもらえるTシャツ
- Expo(常設展示)の各ブースでもらえるステッカー、Tシャツなど
- Certificate Loungeに入場するともらえるロンT、靴下、バッジ
- etc
があります。
心がけておくこととしては、以下の3つで十分かと思います。
- Expoには早いタイミング(1or2日目)で行って、目当てのブースのノベルティをもらう
- 各日のKeynoteなどre:Inventの主要イベントはなるべく早めに会場に行く
- それ以外はもらえたらラッキーぐらいに考える(いちいち調べる暇がない)
Tシャツ、ステッカーなどエンジニアにとって嬉しいお土産が無料で手に入るので、効率よくお土産を手に入れていきましょう。
?ノベルティは引換券だけもらい、あとで引換所で現物をもらう形式のものも多いです⑩遊びの予定は到着日と金曜日に入れよう
せっかくラスベガスに来ているので、空いた時間にラスベガスならではのアクティビティを体験しておくと良いと思います。(例. カジノ、シルクドゥソレイユ鑑賞、グランドキャニオン観光など)
ただ、なんだかんだでre:Invent開催中は夜もエンジニア同士の交流イベントがあったりするので、24時とかに部屋に戻ってきて、次の日は朝8時半開始のKeynoteに行くために6時起き、というようになかなかハードスケジュールになりがちでした。
なので、個人的な予定は到着日の夕方〜夜か、re:Invent最終日の金曜日(この日はセッションは午前中までしかない)に入れると良いと思います。
まとめ
僕は今回がre:Invent初参加だったので、まだまだ最適化できる余地があるかも知れません。この記事が来年参加する方の参考になれば幸いです。





- 投稿日:2019-12-09T19:42:14+09:00
AWS Toolkit for Visual Studio CodeでVSCodeからAWS SAMアプリをデプロイする
はじめに
AWSでサーバーレスアプリをサクッと作る場合は、AWS SAM CLI等を使ってコマンドラインから構築することもできますが、AWS Toolkit for Visual Studio Codeを使って普段のエディタからも同じことができます。
Node.js、Java、Python、Goに対応しています。
さらにAWS Toolkitを使うとローカルでのデバッグ、テストも容易になります。
多少SAMコマンドも紹介しますが、AWS Toolkitを使って簡単なアプリ(API Gateway + Lambda)をデプロイするところまでやってみます。AWS SAMとは
https://aws.amazon.com/jp/serverless/sam/faqs/
AWS サーバーレスアプリケーションモデル (AWS SAM) は、サーバーレスアプリケーション構築用のオープンソースフレームワークです。迅速に記述可能な構文で関数、API、データベース、イベントソースマッピングを表現できます。リソースごとにわずか数行で、任意のアプリケーションを定義して YAML を使用してモデリングできます。
SAMテンプレートとはCloudFormationの拡張版です。
JSON、YAMLフォーマットで、AWSのサーバーレスリソースを記載します。
専用のコマンドラインツールが用意されていますが、デプロイする時はCloudFormationに対してデプロイされます。SAMに対応しているAWSリソースはこちら
https://docs.aws.amazon.com/ja_jp/serverlessrepo/latest/devguide/using-aws-sam.html#supported-resources-for-serverlessrepoAWS Toolkit for Visual Studio Codeとは
https://aws.amazon.com/jp/visualstudiocode/
AWS Toolkit for Visual Studio Code は、Visual Studio Code 用のオープンソースプラグインで、アマゾン ウェブ サービス上でのアプリケーションの作成、デバッグ、デプロイを容易にします。AWS Toolkit for Visual Studio Code を使用すると、AWS 上での Visual Studio Code を使用したアプリケーションの構築をより迅速に開始でき、生産性が向上します。このツールキットは、使用開始のサポート、ステップ実行によるデバッグ、および IDE からのデプロイを含む、サーバーレスアプリケーションの統合開発環境を提供します。
準備(環境構築)
・Mac、Windows、Linuxのいずれかを用意します。
・公式ドキュメントに従ってAWS CLI、AWS SAM、Dockerもインストールします。
・Visual Studio Codeをインストールします。
・VS CodeのExtensions (拡張機能)で使用する言語のランタイムSDK(Node.js、Java、Python、Go)とAWS Toolkit for Visual Studio Codeをインストールします。
・AWSアカウントと認証情報(IAMユーザーのアクセスキーシークレットキー)を取得して、AWS CLIにセットアップしておきます。
・SAMテンプレートやLambdaソースコードをアップロードするためのS3バケットを作成しておきます。手順
・VS CodeにAWS認証情報を設定
・アプリケーションの雛形作成
・実装
・ローカルデバッグ
・ローカル実行
・ローカルテスト
・テンプレート検証
・デプロイVS CodeにAWS認証情報を設定
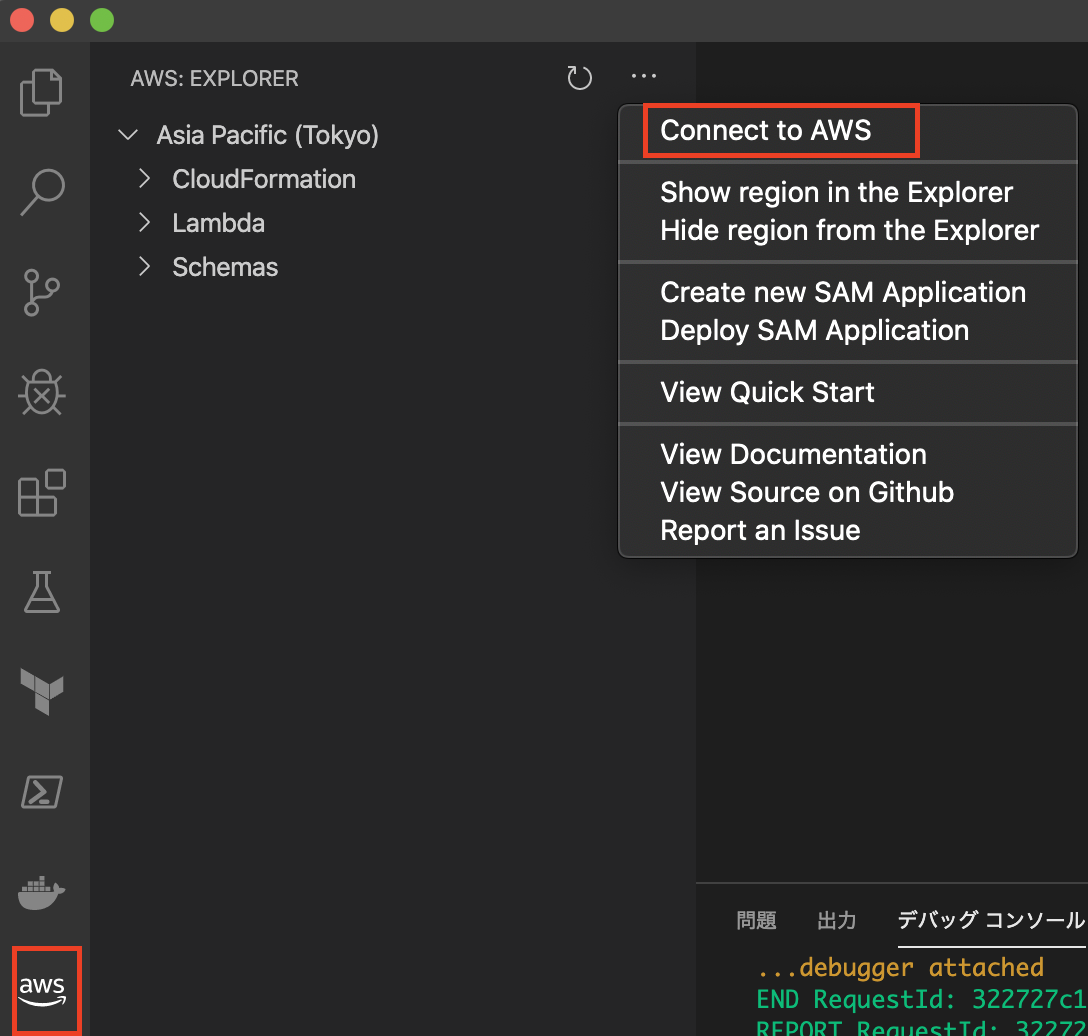
VS Codeを開き、左ペインにAWS Toolkitアイコンが追加されていることを確認します。
メニューから「Connect to AWS」を選択し、使用する認証情報のプロファイルを指定します。
アプリケーションの雛形作成
メニューから「Create new SAM Application」を選択し、ランタイム、ワークフォルダ、アプリ名を入力します。
Lambda Functionのソースコード、テストコード、SAMテンプレート(template.yaml)、READMEが自動生成されます。
ここからカスタマイズしていきます。
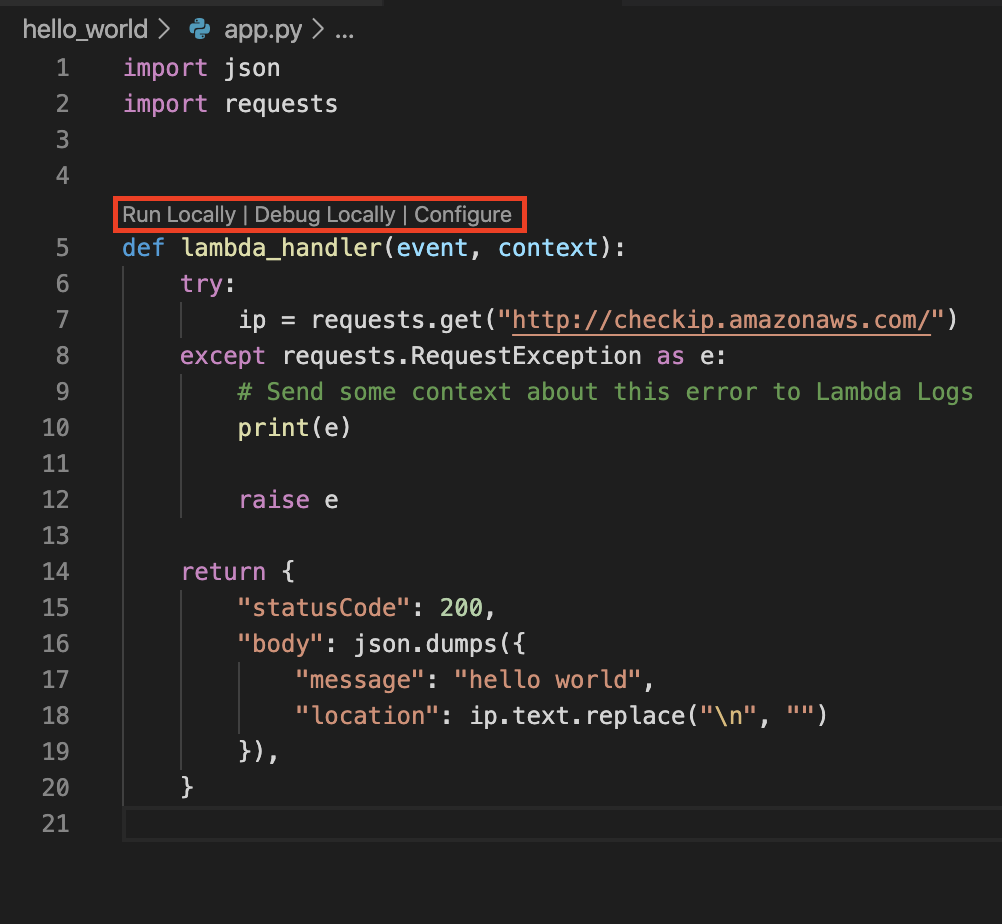
実装
app.pyを開くと「Run Locally」「Debug Locally」「Configure」が表示されます。
デフォルトのコメントアウトを外します。(実行環境のIPアドレスを取得するロジックを追加します)
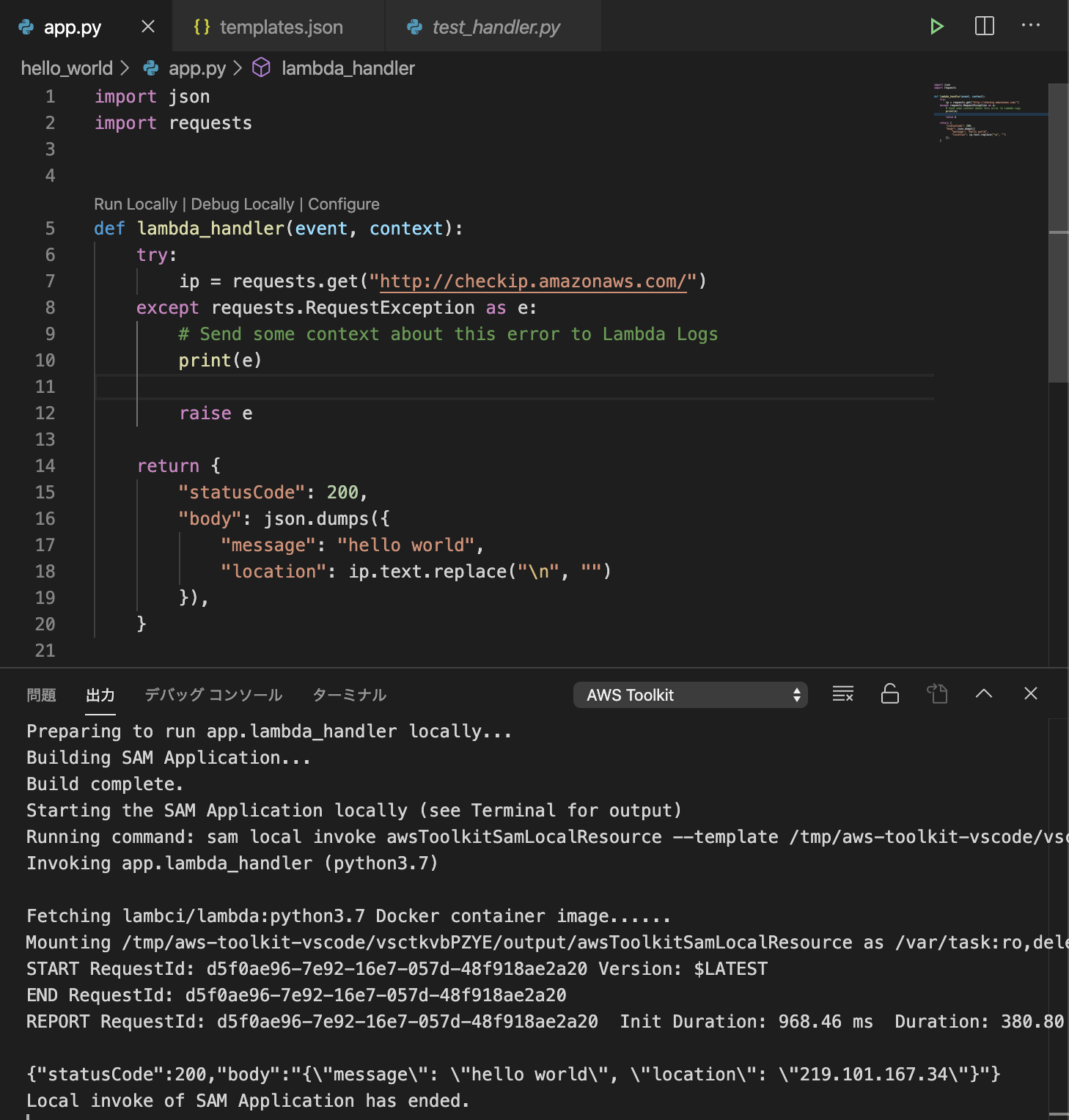
ローカル実行
ここでDockerを起動しておく必要があります。
app.pyを開き、ブレークポイントを指定して「Run Locally」を選択します。
コンテナが起動し、しばらくすると結果が返ります。
実装したLambdaのコード(app.py)をDocker上で実行できました。
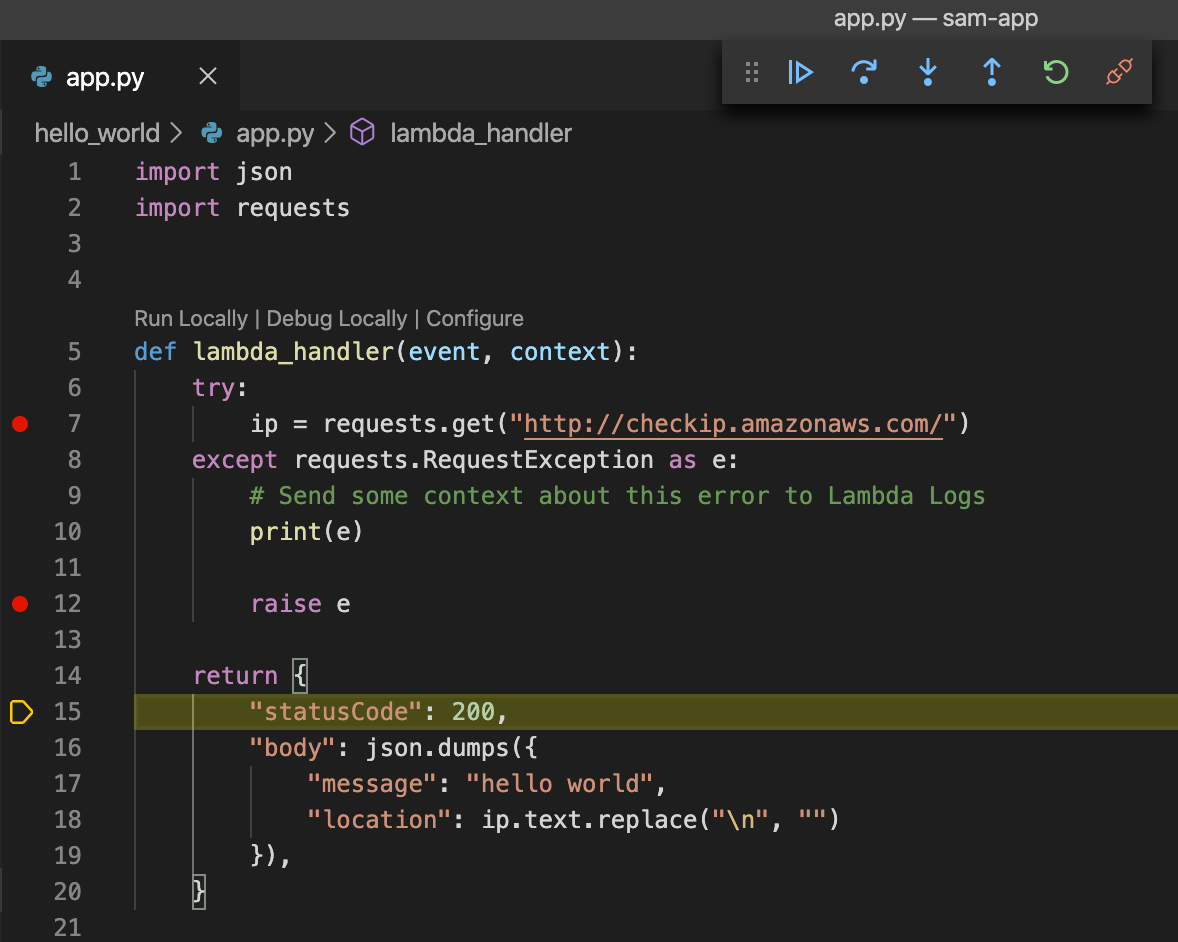
ローカルデバッグ
次にデバッグしてみます。
app.pyを開き、ブレークポイントを指定して「Debug Locally」を選択します。
このように簡単にLambdaをデバックできます。
「Configure」を選択して、パラメータのeventを編集することもできます。
ローカルテスト
今回はPythonを選択したのでpipでpytestをインストールしておきます。
pip install pytest
以下コマンドをプロジェクト直下のターミナルから実行します。
python -m pytest tests/ -v
テンプレート検証
テストが終わったら、SAMテンプレート(template.yaml)の構文をコマンドで検証します。
ターミナルから下記コマンドを実行します。
sam validate
構文に誤りがあると怒られます。デプロイ
最後にデプロイします。
メニューから「Deploy SAM Application」を選択し、SAMテンプレートファイル名(template.yaml)、リージョン(ap-northeast-1)、準備したS3バケット名、CloudFormationスタック名を指定します。
するとデプロイが始まります。Starting SAM Application deployment... Building SAM Application... Packaging SAM Application to S3 Bucket: ${S3バケット名} with profile: saml Deploying SAM Application to CloudFormation Stack: sam-app with profile: saml Successfully deployed SAM Application to CloudFormation Stack: sam-app with profile: samlおめでとうございます。デプロイ成功です。
念の為、出力されたリソースもCloudFormationから取得してみます。
aws cloudformation describe-stacks --stack-name sam-app --output text
成功していれば、IAM Role、Lambda Function、API Gatewayのリソースが取得できます。最後にデプロイされたLambdaを実行してみましょう。
メニューからCloudFormaionの下にデプロイされたLambdaが表示されますので右クリックして「Invoke on AWS」を選択。
下のようにパラメータを設定して「Invoke」で実行して結果を確認します。
まとめ
いかがでしたでしょうか。
個人の開発環境としては十分ですね。AWS Toolkitを使うとコマンドラインに抵抗がある方でも簡単にSAMを使ってデプロイできます。
SAMのメリットはCloudFormationと同様にインフラをコード化することです。
SAMを使えばサーバーレスのアプリを簡単にコード化できるので、チーム開発でも捗りますね。
テストとデプロイのステップをパイプラインに組み込めば、簡単にCI/CD化も可能です。
AWS CDKもサポートしているようなので機会があればそちらもやってみたいと思います。


- 投稿日:2019-12-09T19:06:37+09:00
Now Available on Amazon SageMaker: The Deep Graph Library 和訳してみた
はじめに
今回は、Julien Simon 氏が2019年12月3日に投稿した「Now Available on Amazon SageMaker: The Deep Graph Library」の内容を翻訳し、まとめてみました。本記事と Deep Graph については下記リンク参照。
■リンク
Now Available on Amazon SageMaker: The Deep Graph Library
The Deep Graph LibraryNow Available on Amazon SageMaker: The Deep Graph Library
Deep Graph Library
Amazon SageMaker で、Deep Graph Library が利用できるようになったことを、発表します。
Deep Graph Library は、オープンソースライブラリです。特徴としては、グラフニューラルネットワーク(GNN)の実装を簡単に行うことができます。
ディープラーニングは、テキストやイメージ、あるいはビデオなどの複雑なデータから精巧なパターンを切り抜くことができます。しかし、全てのデータセットにディープラーニングが当てはまるとは限りません。グラフ表示で十分な場合もあります。その様なデータセットに対しては、畳込ニューラルネットワークや、回帰型ニューラルネットワークといった伝統的なニューラルネットワークアーキテクチャに替わる別のアプローチが必要となります。A Primer On Graph Neural Networks
グラフニューラルネットワーク(GNN)は、今日のマシンラーニングにおいて最もエキサイティングな開発の1つです。
GNN は、以下の様なデータセットの予測モデルのトレーニングに利用されます。
- グラフで関係性のある人間同士の繋がりを示しているソーシャルネットワーク
- グラフで顧客と商品の相互作用を示す推薦システム
- グラフで原子と結合でモデル化されチエル合成物質を示している化学解析
- グラフでIPアドレスとソースの疎通を示しているサイバーセキュリティ
等々、上記以外にも対象となるデータセットは沢山あります。
殆どの場合、これらのデータセットは膨大であるにも関わらず、十分にラベル化されていません。Introducing The Deep Graph Library
Deep Graph Library(DGL) は、2018年12月に、初めてリリースされました。DGL は Python オープンソースライブラリで、データセットに GNN の構築やトレーニング、そして評価を簡単に行うことができます。
DGL は、PyTorch や Apache MXNet といった有名なディープラーニングのフレームワーク上に構築されております。また、DGL 内に実装されているカッティングエッジモデルの数々を試すことも可能です。例えば、下記のコマンドを入力することで、グラフ畳み込みネットワーク(GCN)と、CORA データセットを使用したドキュメント分類モデルを簡単にトレーニングできます。$ python3 train.py --dataset cora --gpu 0 --self-loopDGL には、簡単にダウンロードし、実験できるデータセットが用意されております。DGL をインストールし、ローカルで利用することも可能ですが、AWS ではより簡単に利用できるよう、PyTorch および Apache MXNet の Deep Learning Containers に追加しました。これにより、どんな規模のモデルのトレーニングもデプロイもできます。
Using DGL On Amazon SageMaker
SageMaker の例のために Github リポジトリに例題を追加しております。そのうちの1つ、Tox 21 データセットを使用した分子毒性予測のシンプルな GNN トレーニングを簡単に紹介したいと思います。
- 取り組む内容
- 12 の異なるターゲット(生体細胞内の受容体など)に対して、新しい化合物の潜在的な毒性を把握すること
- データセットについて
- 8,000 ちょっとの化合物がデータセットにある
- 各化合物はグラフ(原子は頂点、原子結合はエッジ)としてモデル化されている
- 12回ラベル付けされている(1つのターゲットに1つのラベル)
GNNを使用し、マルチラベルバイナリ分類モデルを構築することで、候補分子の潜在的な毒性を予測できるようにします。
トレーニングスクリプトでは、下記のコマンドで DGL のコレクションから簡単にデータセットをダウンロードできます。from dgl.data.chem import Tox21 dataset = Tox21()同じ様に、DGL モデル zoo を使用することで、GNN 分類器を簡単に構築することができます。
from dgl import model_zoo model = model_zoo.chem.GCNClassifier( in_feats=args['n_input'], gcn_hidden_feats=[args['n_hidden'] for _ in range(args['n_layers'])], n_tasks=dataset.n_tasks, classifier_hidden_feats=args['n_hidden']).to(args['device'])残りのコードの大部分はバニラ PyTorch で、このライブラリに精通していれば、ベアリングを見つけることができるはずです。
Amazon SageMaker でこのコードを実行する場合は、SageMaker を 使用して、EstimatorDGL コンテナのフルネームとトレーニングスクリプトの名前をハイパーパラメーターとして渡すだけです。estimator = sagemaker.estimator.Estimator(container, role, train_instance_count=1, train_instance_type='ml.p3.2xlarge', hyperparameters={'entrypoint': 'main.py'}, sagemaker_session=sess) code_location = sess.upload_data(CODE_PATH, bucket=bucket, key_prefix=custom_code_upload_location) estimator.fit({'training-code': code_location}) <output removed> epoch 23/100, batch 48/49, loss 0.4684 epoch 23/100, batch 49/49, loss 0.5389 epoch 23/100, training roc-auc 0.9451 EarlyStopping counter: 10 out of 10 epoch 23/100, validation roc-auc 0.8375, best validation roc-auc 0.8495 Best validation score 0.8495 Test score 0.8273 2019-11-21 14:11:03 Uploading - Uploading generated training model 2019-11-21 14:11:03 Completed - Training job completed Training seconds: 209 Billable seconds: 209これで、S3 でトレーニング済みのモデルを取得し、それを使用して、実際の実験を実行することなく、多数の化合物の毒性を予測できました。
おわりに
Now Available on Amazon SageMaker: The Deep Graph Library の和訳は以上となります。
- 投稿日:2019-12-09T18:58:01+09:00
kinesisを利用した際のアンチパターン
パーソンリンクアドベントカレンダー11日目の投稿です。
こんにちは桑原です。kinesisを案件で使った際にサクッとうまく行かない構成で開発を行ったのでアンチパターンとしてメモしておきます。
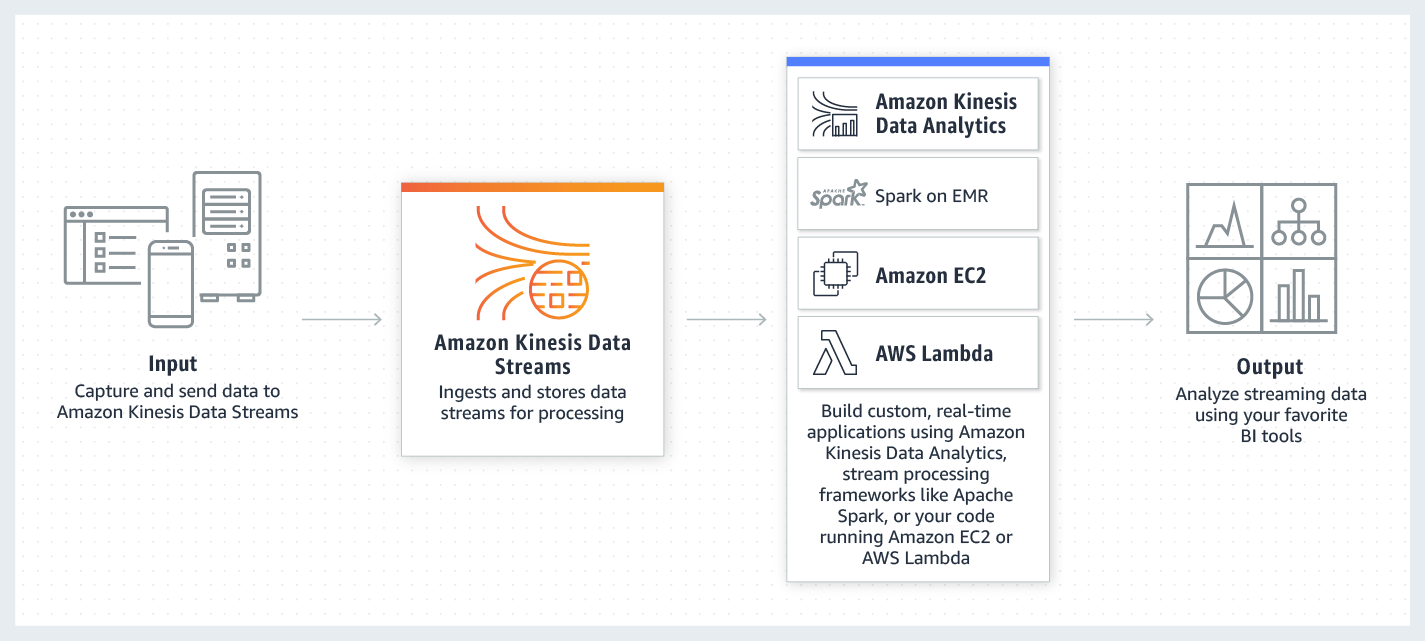
kinesisとは
まず初めにkinesisについて解説します。
ざっくりいうと膨大なデータをシャードという単位でまとめて別のシステム送信するサービスとなります。
送信先にはS3、Lambda、Firehoseなど様々なAWSのサービスへ連携が可能です。以下、AWS公式の解説です。
Amazon Kinesis でストリーミングデータをリアルタイムで収集、処理、分析することが簡単になるため、インサイトを適時に取得して新しい情報に迅速に対応できます。Amazon Kinesis は、アプリケーションの要件に最適なツールを柔軟に選択できるだけでなく、あらゆる規模のストリーミングデータをコスト効率良く処理するための主要機能を提供します。Amazon Kinesis をお使いになると、機械学習、分析、その他のアプリケーションに用いる動画、音声、アプリケーションログ、ウェブサイトのクリックストリーム、IoT テレメトリーデータをリアルタイムで取り込めます。Amazon Kinesis はデータを受信するとすぐに処理および分析を行うため、すべてのデータを収集するのを待たずに処理を開始して直ちに応答することが可能です。※https://aws.amazon.com/jp/kinesis/
仕組み
kinesisに連携可能なサービス
今回は案件で利用しようとした2つを紹介します。
Amazon Kinesis Data Firehose
Firehoseはkiensisからのデータを別のサービスへロードすることができます。
kinesis → Firehose → s3のような連携であればコンソールからの設定のみで実行可能です。
※https://aws.amazon.com/jp/kinesis/data-firehose/Amazon Kinesis Data Analytics
Analyticsはkinesisから受け取ったデータをリアルタイムで分析を行うことが可能です。
※https://aws.amazon.com/jp/kinesis/data-analytics/今回陥った事象
上記のkinesisに連携可能なサービス一覧に連携できない状態に陥りました。
kinsisに合わない仕様(AWSサポートお墨付き)
kinesisはデータを送信する際にレコード単位で処理できる想定ですが、今回の用件ではデータが圧縮されて送信される状態でした。
圧縮することでシャード数を削減し、料金を大幅に下げることが可能なためこの仕様を選択したとのことでした。(一理あります)
詳しい数字は出せないのですが計算上シャード数は10分の1程度まで下がり料金的にも大幅な削減となっていました。
しかし圧縮することで連携できないサービスがあることが判明しました。連携できないサービス
kinesisに連携可能なサービス一覧で記載した下記サービスに非対応の圧縮ファイルを用いることで意図した挙動で処理が実行されない状態でした。
マネージドサービスが使えずにとても悲しかったことを覚えています。
・Firehose
・Analytics(zipは対応しているようです)対応方法
Firehoseが利用できないことがわかったため、lambdaとfluentdを使ってkinesisからデータ取得を行っています。
それぞれの処理途中で解凍処理を実行しています。
現状では膨大なデータでの連携テストを実施できていないですが、秒間数千程度であれば処理途中での解凍は問題なく実行できています。
処理速度の問題でPythonからGoへ言語を変更するなどを行いました。今後起きる可能性がある未解決事項
kinesisの後続処理で解凍とリアルタイムでのデータ送信を行っているため、秒間数十万件というデータが流れてきた場合にkinesisと同じ速度でデータを流すことが可能なのかの検証が必要です。
スケールアウト可能な設計になっているのでkinesisで節約した分がここに乗る気がしています。まとめ
サービスにあった仕様で構築できれば公式のベストプラクティスに当てはまった開発もでき期間の短縮が可能だったと思います。
サービスには想定された使い方がありそこから外れると大変な目に合ったという体験談でした。


- 投稿日:2019-12-09T18:57:04+09:00
[AWS] re:Invent2019 の自分まとめ
概要
- re:Invent2019で発表された全てではありません
- 自社サービスで活用可能性がありそうなものを独自で抽出しています
- 全てを知る場合は
Whats' Newの確認をおすすめします新サービスにあるBeta/Previewについて
Amazon S3アクセスポイント
概要
- S3への新しいアクセス方法
- バケットポリシーの管理がアクセスポイント単位で可能になる
ユースケース
- S3アクセスポイントのうれしい点を自分なりの理解で解説してみる
- 複数のアクセス設定をバケットポリシー1つで管理していたものをポリシー別にアクセスポイントを作成して煩雑さを取り除く
- バケットポリシーの設定ミスの影響を最小限に留めることができる
- VPC内アクセスに限定するアクセスポイントを発行できセキュリティ向上
コスト
- なし
AWS Compute Optimizer
概要
- 機械学習ベースの最適なEC2インスタンスをオススメしてくれるサービス
- M、C、R、T、Xインスタンスに対して有効
ユースケース
- EC2インスタンスの最適化を行いたいときの判断材料として利用する
コスト
- Computeリソース(おそらくEC2??)
- CloudWatchのモニタリング料金
どれぐらいのコストがかかるか未知数(そんなかかんない?)
API Gateway HTTP API (Beta)
概要
- REST APIよりも安く利用可能です(最大71%OFF)
- APIプロキシ機能のみ提供します
- LambdaやHTTPバックエンドにプロキシするAPIを構築するために最適化されサーバレスに最適
- OIDC、OAuth2をサポート
- CORSもOK
ユースケース
- Lambdaのみで構築するシンプルなAPI
- HTTPのプロキシAPI
コスト
- REST APIと比較して最大71%OFF
Amazon CodeGuru(Preview)
概要
- 自動化コードレビュー
- 負荷の高い、コストのかかるコードを見つけ修正・改善の提案を行ってくれる
- アプリケーションパフォーマンス向上に役立つ
- CodeCommitにリポジトリがり関連付けることで使用可能
- 東京リージョンはまだ(2019年12月5日現在)
ユースケース
- コード改善に利用する
コスト
- 1か月にスキャンされる
コード100行あたり0.75ドル- 200行のコードを100プルリクエストした場合
- 200/100 * 0.75 * 100 = $150
- 結構高い!
Fargate Spot
概要
- EC2スポットインスタンスのFargate版
- 最大で70%オフ
ユースケース
- フォールトトレラントな箇所
- 一部が落ちても問題なく可動するシステム
コスト
- 1時間あたりのvCPU単位
- $0.015168(通常:$0.05056)
- 1時間あたりのGB単位
- $0.001659(通常:$0.00553)
Amazon Elasticsearch Service UltraWarm(Preview)
概要
- ESの最大懸念点であるコスト改善
- 格納データを高頻度、低頻度に分けることでコスト削減される
- 高頻度:EBS
- 低頻度:S3
- 最大900TBものHot-Warm層を設けることで90%ものコスト削減を実現する
- バージョン6.8から利用可能
- 新規ドメインに適用可能
- 東京リージョンはまだ(2019年12月5日現在)
ユースケース
- アクセス頻度に偏りがあるES
- UltraWarmからのデータ取得性能が許容可能
- コストに悩んでいる
コスト
- GBあたりのコストを最大90%削減する
AWS Step Functions Expressワークフロー
概要
- StepFunctionsの新しいワークフロー
- 従来のワークフローよりも高スループットと低コストを実現する
- 100,000/秒を超える呼び出しをサポート
- 従来:2,000/秒
- 従来のワークフローとかなり仕様が異なる
ユースケース
- IoTなどの高スループットが必要な時
- 従来ワークフローの性能が不要でコスト削減したい時
- 実行時間制限が5分なので超短期間処理に使用する
コスト
- 実行回数、実行時間、メモリ消費量に基づく料金が設定されている
- 従来は状態遷移毎に対して設定
AWS Identity and Access Management(IAM)Access Analyzer
概要
- IAM管理サービス
- IAMからワンクリックぽちっ!で使える
- ポリシーが意図したサービスへのアクセスのみ提供することを監視
- ポリシーの追加、更新を検知できる
- AWS Security Hubはこのサービスと統合される
ユースケース
- セキュリティ向上
コスト
- なし
Access Analyzer for Amazon S3
概要
- S3のアクセスポリシー監視サービス
- 不要な公開バケットを生み出さないようにする
ユースケース
- セキュリティ向上
コスト
- なし
Amazon CloudWatch Contributor Insights(Preview)
概要
- DynamoDBテーブルのキーとトラフィックの傾向をひと目で確認できる診断サービス
- 頻繁にアクセスされるキーの特定に役立つ
ユースケース
- DynamoDBの最適化
コスト
- 1ルールあたり$0.50
- ルールに一致する100万イベントごとに$0.30
AWSコンソールからリージョンにすばやくアクセス
概要
- AWSコンソール右上のリージョン選択にリージョンコード(ap-northeast-1とか)が表示されるようになった
ユースケース
- なし
コスト
- なし
Amazon Athena ユーザー定義関数(UDF)のサポート(Prevew)
概要
- ユーザー定義関数が利用可能になった
- クエリを発行するとJavaで記述したLambdaが起動してレコードに対する処理を実行可能
- データ圧縮、データ加工などなど
- 1クエリで取得できる複数レコードに対して1Lambdaが起動する
- 東京リージョンはまだ(2019年12月5日現在)
- バージニア北部のみ
ユースケース
- クエリ結果取得と同時に処理が必要な場合
コスト
- Lambda起動分のコスト
AWS for Fluent BitがAmazon Kinesis Data Streamsをサポート
概要
- FluentBitからKinesisDateStreamsへログ送信できるようになった
- FluentBit:ログ転送ツール
- ログをまとめて別の場所にポンッとできたり
ユースケース
- Kinesisへログを投げてログ解析基盤を構築する
- CloudWatchLogsはコスト高いので別ログ基盤を構築する
コスト
- なし
AWS タグポリシー
概要
- タグ付け管理の支援を行う
- 指定できるタグを指定したりタグに指定できる値を制限したり出来る
- AWS Organizationで一元管理できる
ユースケース
- コスト管理用タグのつけ間違えやつけ忘れを監視する
コスト
- なし
AWS Lambda非同期呼び出しの宛先をサポート
概要
- Lambda非同期呼び出し時に結果を受け取る宛先を指定できるようになった
- 別のLambda
- SNS
- SQS
- EventBridge(CloudWatchEvents)
ユースケース
- 非同期呼び出ししたLambdaの結果を別処理で利用したい場合
コスト
- なし
AWS Lambda Provisioned Concurrency
概要
- Lambdaでコールドスタート対策が公式にサポートされた
- AutoScalingを利用してProvisionedする値を動的変更することも可能
ユースケース
- 初期起動時からシビアなレスポンスを必要とする処理
コスト
AWS Lambda Supports Amazon SQS FIFO as Event Source
概要
- LambdaのイベントトリガーにSQSのFIFOを指定することが出来るようになった
- 順序保証されたキューの取得が可能
ユースケース
- メッセージ取得に順序保証が必要な処理
コスト
- なし
Amazon CloudWatch ServiceLens
概要
- アプリケーションの健全性、パフォーマンス、可用性を1か所で視覚化および分析できる新しい機能
- CloudWatchメトリクス、ログ、X-Rayからのトレースを結びつけてアプリケーションの依存関係をビューする
- AWS X-Rayを有効にすることで利用可能
ユースケース
- よりワークロードに寄せたモニタリングの実施
- マイクロサービスなどの分散された処理の一元モニタリング
コスト
- ServerLens自体はコストなし

- 投稿日:2019-12-09T18:47:26+09:00
Serverless framework x CircleCI でAWS lambdaのローカル開発環境構築
Linc’well Advent Calendar10日目の記事です。
当社が展開するクリニックグループの CLINIC FORの予約システム で、認証機能の一部にAWS Cognitoへの移行を進めております。
予約システム全体としてはモノリシックなRailsアプリケーションで開発をしてきたのですが、AWS CognitoをRailsアプリケーションの上に被すように実装する必要がり、連携をするためにAWS CognitoのTriggerをlambdaで実装する必要がでてきました。
この記事では、ローカル環境でのlambda開発、テストをどう構築したかをまとめます。
lambda 開発環境構築
今回は、Serverless Frameworkを使って開発を進めます。Frameworkのinstallとprojectを作成します。
npm install -g serverless serverless create --template aws-nodejs --name cognito-triggers --path cognito-triggers cd cognito-triggerslambda の依存パッケージをインストール
RailsアプリケーションにAWS Cognitoを連携させるために、http clientとして
axiosを使います。npm init npm install axios --savelambda のコードを書く
このは、AWS Cognitoのサインアップ前 Lambda triggerです。AWS Cognitoは、自前のバックエンド等と連携するため、沢山のTriggerを提供しています。
ご興味あるかたは、こちらをご覧ください。
サインアップ前に、入力されたemailが、登録済 or 未登録 か判定して、登録済であればCognitoへ登録、未登録であればCognitoへ登録しない仕様の実装です。
pre-sign-up.js'use strict'; const axios = require('axios'); async function exists(server, data, callback) { let url = 'https://' + server + '/api/endpoint/exists'; const config = { headers: { "Content-Type": "application/json" }, responseType: 'json' }; await axios.get(url, {params: data}, config) .then(response => { console.log('response:', response.data); callback(null, response.data); }) .catch(function (error) { callback(error); }); } module.exports.exec = async (event, context, callback) => { console.log('start pre authentication user:', event.userName); console.log(event) let userAttributes = event['request']['userAttributes'] let email = userAttributes["email"]; let rails_server_url = process.env.API_HOST_NAME; await exists(rails_server_url, { email: email }, (err, response) => { if (err) { return context.fail("Connection error"); } // ユーザーの 登録済 or 未登録判定 if (response.user_exists == false) { // 未登録 console.log('user not exists:', email); context.succeed(event); } else { // 登録済 console.log('user exists:', email); context.fail("user exists"); } }); };lambda をテストする
Lambdaをテストするために、下記2つをmockする必要あります。
- AWS Cognitoのcontext
- axios
これらをmockしてテストします。
テストに必要なパッケージをインストール
テストフレームワークとして
jest、AWS Cognitoのmockとしてaws-lambda-mock-context serverless-prune-pluginもインストールします。npm install jest aws-lambda-mock-context serverless-prune-plugin --save-devevent data の準備
加えて、AWS CognitoがTriggerで送信してくるeventも準備する必要あります。
pre-sign-up-event-data.jsmodule.exports = { testEvent: { "userName": "test@example.com", "request": { "userAttributes": { "email": "test@example.com" } } } };テストコード
pre-sign-up.test.js'use strict' const { exec } = require('./pre-sign-up'); const event = require('./pre-sign-up-event-data'); // mock const context = require('aws-lambda-mock-context'); const axios = require('axios'); jest.mock('axios'); describe('user-migration.js.exec()', () => { describe('user_status: CONFIRM', () => { describe('user not exists', () => { it('return event', async () => { // axios mock axios.get.mockResolvedValue({ data: {user_exists: false} }); const ctx = context(); await exec(event.testEvent, ctx, function () { }); // AWS Cognito の context判定 await ctx.Promise .then(result => { expect(result).toBe(event.testEvent); }); }); }); describe('user exists', () => { it('through error', async () => { // axios mock axios.get.mockResolvedValue({ data: {user_exists: true} }); const ctx = context(); await exec(event.testEvent, ctx, function () { }); // AWS Cognito の context判定 await ctx.Promise .catch(err => { expect(err).not.toBeNull(); }); }); }); }); });テスト実行
ローカル環境でテスト実行できるはずです。
npx jestlambda の deploy
dev, stg, prd と deploy をしたいと考えると、
sls deploy -v --stage devこんな感じでdeployできると嬉しい。
stage別の設定ファイルを作成する
- environments/dev.yml
- environments/stg.yml
- environments/prd.yml
のように配置する。内容は下記の通り。
environments/dev.ymlprofile: your_aws_profile_name region: aws_region_name functionNamePrefix: function-prefix- apiHostName: your-host-name.co.jpserverless.yml の編集
sls deploy -v --stage devから環境依存部分を解決できるように変数を展開する。
serverless.ymlservice: cognito-triggers provider: name: aws runtime: nodejs12.x stage: ${opt:stage} profile: ${self:custom.environments.${opt:stage}.profile} region: ${self:custom.environments.${opt:stage}.region} environment: API_HOST_NAME: ${self:custom.environments.${opt:stage}.apiHostName} plugins: - serverless-prune-plugin custom: prune: automatic: true number: 5 environments: dev: ${file(./environments/dev.yml)} stg: ${file(./environments/stg.yml)} prd: ${file(./environments/prd.yml)} functions: pre-sign-up: name: ${self:custom.environments.${opt:stage}.functionNamePrefix}cognito-trigger-pre-sign-up handler: pre-sign-up.exec user-migration: name: ${self:custom.environments.${opt:stage}.functionNamePrefix}cognito-trigger--user-migration handler: user-migration.exec post-authentication: name: ${self:custom.environments.${opt:stage}.functionNamePrefix}cognito-trigger--post-authentication handler: post-authentication.exec post-confirmation: name: ${self:custom.environments.${opt:stage}.functionNamePrefix}cognito-trigger--post-confirmation handler: post-confirmation.execCIrcleCI で継続的にtest実行するための設定
詳細は割愛しますが、↓のように、install, test 実行を追加。
.circleci/config.yml: steps: - run: name: install dependencies for lambda/cognito-triggers command: npm install working_directory: lambda/cognito-triggers : - run: name: run tests for lambda/cognito-triggers command: npm test working_directory: lambda/cognito-triggers :まとめ
こんな感じで、ローカル環境での開発、テスト、テスト後のDeployまで一気通貫できました。さらに良いプラクティスがあればフィードバック頂けたら幸いです!
- 投稿日:2019-12-09T18:30:56+09:00
Amazon RDS Proxy with AWS Lambda を試してみる
先日の re:Invent で RDS Proxy がプレビュー版ですが発表されました。
AWS Lambda は水平スケールするため RDS と相性が良くないと常々言われてきましたが、この機能でそれが解消されるのでしょうか?というわけで実際機能を試してみようと思います。
リソース作成
テスト用のVPC、RDS、Lambda Function、RDS Proxy を作成します
VPC, RDS 作成
今回 VPC、RDS はさくっと CloudFormation で作成
https://github.com/kobarasukimaro/rds-proxy-test/blob/master/cfn/rds-proxy-sample.ymlRDS の設定
パラメータグループで
max_connectionを 20 に設定しています。RDS Proxy 作成
RDS Proxy は画面から作成します。 awscli でも
1.16.300以上でしたら作成できます。以下のような感じで作成しました。サブネットが空になってますがちゃんと設定しています。関連付けるデータベースのサブネットが自動的にサジェストされるのであまり迷うことはないかと思います。
シークレットはこの画面から作成しても候補に出てこないで予め作っておいたほうが良いかも。
Lambda 作成
Lambda は Serverless Framework で作成します。
sls deploy --stage xxxテスト用コード
Python で簡単に作成
lambdaimport mysql.connector DB_USER = os.environ["DB_USER"] DB_PASSWORD = os.environ["DB_PASSWORD"] DB_HOST = os.environ["DB_HOST"] DB_NAME = os.environ["DB_NAME"] def execute_query(event): config = { 'user': DB_USER, 'password': DB_PASSWORD, 'host': DB_HOST, 'database' : DB_NAME, } cnx = mysql.connector.connect(**config) cursor = cnx.cursor() query = ("SELECT SLEEP(10)") cursor.execute(query) def lambda_handler(event, context): execute_query(event)Lambda Function に RDS Proxy を登録
しなくても Proxy に接続できました。
↓に Proxy を登録すると IAM ロールが作られるので、 IAM 認証必須の場合に必要なのかもしれません。
試してみる
最大コネクションが7個ある RDS で、 10秒スリープする Lambda Function を同時に 10並列で実行してみます
実行の前に
RDS に設定した
max_connectionは 20 ですが、
RDS 自体がコネクション 4個と RDS Proxy が 8個確保していて、さらにテスト中はコネクションの様子を見るためにコンソールから1個コネクションを使っているため実質的に Lambda が使えるコネクションは 7個となります。processlistMySQL [test]> show processlist; +-----+---------------+---------------------+------+---------+------+-------------+------------------+ | Id | User | Host | db | Command | Time | State | Info | +-----+---------------+---------------------+------+---------+------+-------------+------------------+ | 2 | rdsproxyadmin | xxx.xxx.xxx.xxx:xxxx | NULL | Sleep | 0 | cleaning up | NULL | | 3 | rdsproxyadmin | xxx.xxx.xxx.xxx:xxxx | NULL | Sleep | 0 | cleaning up | NULL | | 4 | rdsproxyadmin | xxx.xxx.xxx.xxx:xxxx | NULL | Sleep | 0 | cleaning up | NULL | | 5 | rdsproxyadmin | xxx.xxx.xxx.xxx:xxxx | NULL | Sleep | 0 | cleaning up | NULL | | 6 | rdsproxyadmin | xxx.xxx.xxx.xxx:xxxx | NULL | Sleep | 0 | cleaning up | NULL | | 9 | rdsadmin | localhost | NULL | Sleep | 1 | cleaning up | NULL | | 11 | rdsadmin | localhost | NULL | Sleep | 0 | cleaning up | NULL | | 55 | rdsadmin | localhost | NULL | Sleep | 14 | cleaning up | NULL | | 56 | rdsproxyadmin | xxx.xxx.xxx.xxx:xxxx | NULL | Sleep | 0 | cleaning up | NULL | | 57 | rdsproxyadmin | xxx.xxx.xxx.xxx:xxxx | NULL | Sleep | 0 | cleaning up | NULL | | 67 | rdsadmin | localhost | NULL | Sleep | 34 | cleaning up | NULL | | 122 | rdsproxyadmin | xxx.xxx.xxx.xxx:xxxx | NULL | Sleep | 0 | cleaning up | NULL | | 124 | admin | xxx.xxx.xxx.xxx:xxxx | test | Query | 0 | starting | show processlist | +-----+---------------+---------------------+------+---------+------+-------------+------------------+ 13 rows in set (0.01 sec)Proxy なし
まずは今まで通り、普通に RDS に接続した動作を試してみます
実行
Serverless Framework でローカルから10回実行
lambdainvoke$ for ((i=0; i<10; i++)); do serverless invoke --function proxy-test --stage xxx -r ap-northeast-1 &; done結果
CloudWatch で結果を見てみると、10回中 3回失敗しているのを確認できます
CloudWatch Logs を見ると
Too many connectionsが発生していたので想定通りの挙動となりますerror$ aws logs get-log-events --log-group-name /aws/lambda/xxxxxxxxx --log-stream-name "2019/12/10/[\$LATEST]xxxxxxxxxxxx" <中略> [ERROR] OperationalError: 1040 (08004): Too many connections <中略>Proxy あり
DB の接続先を RDS Proxy に変更して試してみます
実行
先ほどと同じように Serverless Framework でローカルから10回実行
lambdainvoke$ for ((i=0; i<10; i++)); do serverless invoke --function proxy-test --stage xxx -r ap-northeast-1 &; done結果
CloudWatch で結果を見てみると、10回中 全て成功しているのを確認できます
Duration を見てみると Max が約 20秒、 Min が約 10秒となってるので、max connection からあぶれたコネクションは空きが出るまで待っているものと思われます
ログも見てみましたが、 20秒かかっている実行はコネクションで待っているのが確認できます(赤枠がコネクション待ち)
RDS Proxy が想定通りの役割を果たしてくれています。 Lambda + RDS 使う場合の大きな心配事が一つ解消されるので GA になるのが楽しみですね。
ハマりどころ
CloudFormation から作成したシークレットだとエラー
最初 CloudFormation から RDS 用のシークレットを作成して RDS Proxy で読み込んでみたのですが、
Client authentication failed for user "{DBユーザー名}" with auth-plugin "mysql_native_password" and TLS on. Reason: Invalid credentials.というエラーが出てコネクションが張れませんでした。
画面からシークレットを作成した場合は上手くいったので、 CloudFormation 側で何か足りないものがあったとは思いますが原因は今の所不明です。Lambda でコネクションするときに Too many connections が出てしまう
これはテスト用にコネクション数の設定をいじっていたのが原因だったのですが
max_connectionを 1 や 10 に設定したところ、 RDS と RDS Proxy がコネクションを確保するのに気づかなかったので、そっちの確保が優先されて Lambda からコネクションが張れませんでした。 RDS のデフォルトのコネクション数で使う場合には全く問題はないかと思います。設定は正しいのに Lost connection が出てコネクションが張れない
リソースは全て構築したしコネクション数の設定も問題ないし、さあ試そうと思ったところ、 Lambda で
[ERROR] InterfaceError: 2055: Lost connection to MySQL server at '{RDS Proxy のDNS}:3306', system error: 8 EOF occurred in violation of protocol (_ssl.c:1076)というエラーが出てコネクションできませんでした。
どうやらmysql-connector-pythonのバージョンが原因で、8.0.17だとこのエラーが発生するようです。
また、Python 3.7 でこの事象を確認してます。 3.8 では未確認です。やり残し
- フェイルオーバーの速度比較
- RDS 直と Proxy のレイテンシー比較
- Python3.8 と mysql-connector-python >= 8.0.17 が動作するかどうか
- Lost connection の原因
コード
今回試したコード一式はこちら
https://github.com/kobarasukimaro/rds-proxy-test











- 投稿日:2019-12-09T18:01:15+09:00
AWS基礎
AWSに関わることになったので、基本的なキーワード等について簡単にメモる。
最低限のキーワードをピックアップしているため、その他の気になるキーワードや詳細解説についてはAWS公式サイトを参照ください。
AWSのアカウント
AWSにはAWSアカウントとIAMユーザーと呼ばれる2種類のアカウントがあります。
AWSアカウントとは、AWSサインアップするときに作成されるアカウントのことです。このアカウントでは、AWSアカウントの全てのサービスをネットワーク上のどこからでも操作できる権限を持っているため、ルートアカウントとも呼ばれています。
非常に危険なアカウントであるため、取り扱いには十分注意する必要があります。従って、日常的なタスクには、それが管理者タスクであっても、ルートユーザーを使用しないことが推奨されており、ルートユーザーは最初のIAMユーザーを作成するためだけに使用し、それ以外の操作はIAMユーザーを利用するというのがベストプラクティスとされています。
IAMユーザーについては、別途後述します。
リソース
リソースとは、S3のバケット、オブジェクト、EC2インスタンス等AWS上のリソースのことを指します。ARNによってリソースを特定できます。
ARN(Amazon Resource Name)
Amazon リソースネーム (ARN) は、AWS リソースを一意に識別します。IAM ポリシー、Amazon Relational Database Service (Amazon RDS) タグ、API コールなど、明らかに全 AWS に渡るリソースを指定する必要がある場合、ARN が必要です。
AWS Organizations
AWS Organizations は、作成し一元管理する組織に、複数の AWS アカウントを統合するためのアカウント管理サービスです。AWS Organizations には、利用者の予算、セキュリティ、コンプライアンスのニーズをより適切に満たすアカウント管理および一括請求機能が備わっています。組織の管理者は、組織内にアカウントを作成したり、既存のアカウントを組織に招待して参加させることができます。
IAM(Identity and Access Management)
IAMでは、AWS のサービスやリソースへのアクセスを安全に管理できます。IAM を使用すると、AWS のユーザーとグループを作成および管理し、アクセス権を使用して AWS リソースへのアクセスを許可および拒否できます。
つまり、「誰が」「どのAWSサービスの」「どのリソースに対して」「どんな操作を」「許可する(許可しない)」という情報を定義することが可能となります。
IAMポリシー
IAMではポリシーによって「Action(どのサービスの)」「Resource(どういう機能や範囲を)」「Effect(許可 or 拒否)」という3つの大きなルールに基づいてAWSの各サービスを利用するうえでのさまざまな権限をせっていします。
AWSが最初から設定しているポリシーをAWS管理ポリシーといい、各ユーザーが独自に作成したポリシーをカスタマー管理ポリシーといいます。作成されたポリシーは、ユーザー、グループ、ロールに付与することができます。
使い分けとしては、AWS管理ポリシーで基本的な権限を付与し、カスタマー管理ポリシーでIPアドレス制限などの成約をかけるといった方法があります。
※対象ごとに作成・付与するインラインポリシーと呼ばれるポリシーも存在するが、管理が煩雑になるので基本的には利用しない方向がよいが、一時的に個別のユーザーに権限を付与する時に利用するといった方法がある。
IAMユーザー
IAMユーザーは、AWSの各利用者に1つずつ与えられる、AWSを利用するための認証情報(ID)です。利用者がAWSマネジメントコンソールにログインして操作するときや、CLI(後述)を利用してAWSを操作するときに使用します。
各IAMユーザーに対して、操作を許可する(しない)サービスを定義することができ、各IAMユーザーの権限を正しく制限することで、AWSをより安全に使用することができます。
IAMグループ
一方、グループは同じ権限を持ったユーザーの集まりです。グループは、AWSへのアクセス認証情報は保持しません。認証はあくまでユーザーで行い、グループは認証されたユーザーがどういった権限(サービスの利用可否)を持つかを管理します。
グループの目的は権限を容易に、かつ、正確に管理することです。複数のユーザーに同一の権限を個別に与えると、権限付与の過不足等、ミスが発生する確率が高くなります。
ユーザーとグループは多対多の関係を持つことができるので、1つのグループに複数のユーザーが属することはもちろん、1つのユーザーが複数のグループに属することもできます。
ただし、グループを階層化することはできないので、グループで一定の権限をまとめておいて、ユーザーに対して必要なグループを割り当てる運用が望ましいです。
IAMロール
ロールは永続的な権限(アクセスキー、シークレットアクセスキー)を保持するユーザーとは異なり、一時的にAWSリソースへアクセス権限を付与する場合に使用します。
ロールを定義することで実現できることのひとつに、クロスアカウントアクセスがあります。複数のAWSアカウント間のリソースを1つのIAMアカウント(IAMユーザー)で操作したい場合、ロールを定義して必要なAWSリソースに対するアクセス権限を一時的に与えることで実現できます。
AWS CLI(Command Line Interface)
AWS コマンドラインインターフェース (CLI) は、AWS サービスをコマンドラインで操作することができる統合ツールです。基本的にはAWSマネジメントコンソールとほぼ同等の操作が可能。そのため、コンソール画面から行っていた操作をプログラムに組み込んだり、バッチ化することでAWSサービスをよりプログラマブルに利用することが可能になります。
MFA(Multi-Factor Authentication:多要素認証・2段階認証)
AWSアカウントもIAMユーザーもAWSマネジメントコンソールにログインする時は、IDとパスワードを必要とします。しかし、AWSアカウントや重要な権限を持つIAMユーザーは、これだけの認証では不十分です。
AWSではIDとパスワードに加えて、ワンタイムパスワードを使った多要素認証(MFA)に対応しています。
Amazon EC2(Amazon Elastic Compute Cloud)
Amazon EC2は、AWS クラウドでサイズが変更できるコンピューティングキャパシティーを提供します。Amazon EC2 の使用により、ハードウェアに事前投資する必要がなくなり、アプリケーションをより速く開発およびデプロイできます。Amazon EC2 を使用して必要な数 (またはそれ以下) の仮想サーバーを起動して、セキュリティおよびネットワーキングの設定と、ストレージの管理を行います。Amazon EC2 では、要件変更や需要増に対応して迅速に拡張または縮小できるため、サーバートラフィック予測が不要になります。
Amazon S3(Amazon Simple Storage Service)
Amazon S3 はインターネット用のストレージサービスです。また、ウェブスケールのコンピューティングを開発者が簡単に利用できるよう設計されています。
Amazon S3 のウェブサービスインターフェイスはシンプルで、いつでも、ウェブのどこからでも容量に関係なくデータを格納および取得できます。これにより、すべての開発者が、スケーラブルで信頼性が高く、かつ高速で安価なデータストレージインフラストラクチャを利用できるようになります。このインフラストラクチャは、Amazon が使用しているウェブサイトのグローバルネットワークと同じものです。このサービスの目的は、規模の拡大や縮小のメリットを最大限に活かし、開発者に提供することです。
AWS Cloud Trail
AWS CloudTrail は、AWS アカウントのガバナンス、コンプライアンス、および運用とリスクの監査を行えるように支援する AWS のサービスです。ユーザー、ロール、または AWS のサービスによって実行されたアクションは、CloudTrail にイベントとして記録されます。イベントには、AWS マネジメントコンソール、AWS Command Line Interface、および AWS SDK と API で実行されたアクションが含まれます。
CloudTrail は、作成時に AWS アカウントで有効になります。AWS アカウントでアクティビティが発生した場合、そのアクティビティは CloudTrail イベントに記録されます。
AWS アカウントアクティビティの可視性は、セキュリティと運用のベストプラクティスにおける重要な側面です。CloudTrail を使用して、AWS インフラストラクチャ全体のアカウントアクティビティを表示、検索、ダウンロード、アーカイブ、分析、応答できます。アクションを実行したユーザーやアプリケーション、対象のリソース、イベントの発生日時、およびその他の詳細情報を識別して、AWS アカウントのアクティビティの分析と対応に役立てることができます。
Route53
Amazon Route 53 は、可用性と拡張性に優れたドメインネームシステム(DNS)ウェブサービスです。Route 53 を使用すると、ドメイン登録、DNS ルーティング、ヘルスチェックの 3 つの主要な機能を任意の組み合わせで実行できます。
Terraform
HashiCorpが作っているツールで、インフラをコード化(Infrastructure as Code)するために利用する。
こちらは別途解説(予定)
- 投稿日:2019-12-09T17:59:20+09:00
AWS re:Invent 2019で発表【Amazon SageMaker Studio】
AWS re:Invent 2019で新たなサービスがドドン!と発表されました!
特に機械学習のサービスは豊富なリリースが発表され、大注目されています。今回は初心者の方向けに分かりやすく「Amazon SageMaker Studio」というAWSの機械学習における幅広いサービスを一つの画面で実行できる環境について、ご紹介させて頂きたいと思います。
AWS re:Inventって?
AWSイベント 公式ページより
AWS re:Invent は、AWSやパートナーによって多くの新サービスや新機能が発表と、 1,800 を超えるセッションや最新のテクノロジーの展示やデモンストレーションが行われます。
またテクノロジーを満喫できるパーティ re:Playなどの様々なプログラムがラスベガスのエリアで開催される、AWS最大にして世界規模のカンファレンスです。Amazon SageMaker Studio
画像は公式サイトより。
Machine learning開発に必要なすべてのツールを統合したWebベースの統合開発環境(IDE)。
AWSが機械学習に特化した統合開発環境としては初のサービス。ぜーんぶまるっと統合した状態で視覚的にわかりやすく、機械学習に必要になるすべての環境が自動的に用意されています。
これにより迅速に変更を加え、結果を観察し、より速く反復することができるので反映する時間を短縮できます。開発の生産性を大幅に向上できそうです!
Webベースで動作するので、Webブラウザから利用することができ、プロジェクトを作成する段階で自動的にインスタンスの作成やサーバのセットアップも完了しインフラの管理も必要がない仕様になっています。
統合されているツール
- Notebooks
- notebookをささっと使い始められる
- Experiments
- 機械学習の実験を構成・記録・比較できる
- Debugger
- リアルタイムに自動アラートでモデルのバグを排除する
- Model Monitor
- 稼働中のモデルの監視、検出ができる
- Autopilot
- どのような判断によってモデルを構築したかを、詳細に視覚化する。ユーザーのデータから最適なモデルを自動的に作成できます。
なぜ統合開発環境が必要か
自前で機械学習を行うすべての実行環境を行おうとすると、本来は複雑な作業をする上、ツールの行き来を手動で行うのでいちいち時間がかかるといった面倒があります。
機械学習を行う手順とそれらを実行するツール間が全て別々になっているからです。
- データの収集と前処理
- モデリング
- 学習
- 評価と最適化
- アプリケーションへの組み込み
たとえば、新しいアルゴリズム(問題を解くための計算方法や手順)を試したりハイパーパラメーター(推論や予測の枠組みの中で決定されないパラメータのこと)を設定する際、数百や数千の実験を行いますが、この実験結果をすべて手動で管理することになります。
これに時間がかかりすぎると、最善のモデルを見つけ出すことや実験の中で得た知見を活用することが非常に難しくなります。その課題を解決するためにAmazon SageMaker Studioを使用するべきということです。
活用法
- 作業工程、学習、訓練、データの展開や実行するプログラムを作るコードの記述。
- 実験を追跡、データの視覚化、バグを修正する作業と監視
- ノートブック、データセット、コード設定、 トレーニングの分析、アラートを管理
- モデルのチューニング、モニタリング
- データセットの前処理やパラメータを調節したり、 複製、再生したりできる
- 手順のすべては環境内で追跡
- 同じプロジェクトに対して作業している他のユーザーと、プロジェクトやフォルダを共有する機能もありそこでノートブックや成果について議論することができます。
12月12日(木)現時点ではオハイオUS Eastリージョンで使用可能です。
早く活用できるようになりたーい!公式サイトリンク

- 投稿日:2019-12-09T17:41:37+09:00
SREやクラウドエンジニアが読むと良さげな本まとめ
一年半ぐらい前にアプリケーションエンジニアからSREにコンバートした筆者が、いま役に立ってるなぁっていう本を紹介します。アプリケーションコードを書いてるときは下のレイヤの技術に興味なかったんですが、改めて勉強してみると楽しいです。
コンピュータシステム
クラウド全盛とはいえ、コンピュータの仕組みはおさえておくと役立ちます。コレ系の本はわりと小難しいものが多いですが、個人的に楽しく読めた本を紹介します。
Raspberry Piで学ぶコンピュータアーキテクチャ
Raspberry Piと銘打たれてますが、コンピュータアーキテクチャの歴史的な背景も踏まえて解説されています。プロセッサ・メモリ・ストレージ・ネットワーク・OS・プログラミングなど、コンピュータ単体の基本的な知識を学べます。 歴史をあわせて知ることができるため、知的好奇心がおおいに刺激され、楽しく読むことができます。この本が難しく感じられる場合は、プログラムはなぜ動くのかもオススメです。
Linux
コマンドの使い方は入門書片手に実践すると早いですが、仕組みを知るにはやはり本がてっとり早いです。
[試して理解]Linuxのしくみ
Linuxカーネルの全体像を知るのに最適な本です。プロセススケジューラ・メモリ管理・記憶階層・ファイルシステムなど、Linuxがどのように動いているか解説しています。図解が豊富で非常に分かりやすいです。Linuxに限らずOS周りは小難しい本や分厚い本が多いですが、この本は浅すぎず深すぎずという絶妙な塩梅になっています。もっと早く出会いたかった!
詳解 Linuxカーネル
少し古いですが、日本語でLinuxカーネルについて詳述した貴重な書籍です。いきなり通読するのはちょっとキツいので、最初は興味のあるところだけつまみ食いでもよいでしょう。筆者の場合はプロセスやシグナルについて詳しく知りたかったので、その部分だけ読みました。そのうち通読チャレンジしたいところです。なお本棚に飾ってあるとカッコいい書籍のひとつだと、勝手に思っています。
ネットワーク
ネットワークは分かりやすい入門書がいくつも出版されています。
マスタリングTCP/IP―入門編―
TCP/IPについて入門するならこの本、という定番書です。それほど詳細に深入りしているわけではありませんが、とっかかりとしては十分な情報が提供されています。ネットワーク周りのプロトコルは最終的にRFCを読むことになりますが、いきなりRFCを読むのはキツいので、まずはこの本で概要をつかむのがオススメです。つい最近、第6版が出版されました。
DNSがよくわかる教科書
なんとなくとっつきずらいDNSについて学び直そうと手にとった本です。非常にわかりやすく書かれており、スラスラと読みすすめることができます。DNSの動作原理を知れるのもよいのですが、個人的にはサイバー攻撃とその対策がとても面白かったです。DNSってキーワードは知ってるけど、実はよくわかってないんだよな〜という人にオススメです。
インフラ基礎
一言でインフラと言っても幅広いですが、特にクラウドメインのエンジニアに役立ちそうな本を集めました。
インフラエンジニアの教科書2
インフラの基本が幅広く網羅されており、OS・ネットワーク・データベース・セキュリティ・障害対応の基本を学べます。この本では運用時に起こりやすい問題もまとめられており、実践的なノウハウが満載です。インフラの本としては珍しく薄いので、挫折しづらいのもポイントが高いです。アプリケーションエンジニアにも読んでほしいオススメの一冊です。クラウドではなく自身でハードウェアの選定を行う人はインフラエンジニアの教科書もあわせてどうぞ。
絵で見てわかるITインフラの仕組み
システム設計で必要になる知識が平易な言葉で解説されています。同期/非同期・キュー・排他制御・キャッシュ・レプリケーションなど、説明なしで使われることの多い用語を丁寧に説明しています。また3層アーキテクチャのWebシステムやシステムの冗長化、パフォーマンスチューニングの基礎などを図解もふんだんに交えて解説します。システム設計においては基本的なことばかりですが、意外とこのレベルのことを分かりやすく解説した本は少ないので貴重です。書籍ではないですがGitHubで公開されているシステム設計入門もあわせてどうぞ。
Infrastructure as Code
いまや基礎教養といえるInfrastructure as Codeについてガッツリ学べます。ツールの使い方ではなく、思想や設計について体系化されています。便利なツールは世の中にいろいろありますが、それらがどのような課題を解決しているのか、全体像を知るのにピッタリです。Infrastructure as Codeのアンチパターンやベストプラクティスが一気に学べる、密度の濃い書籍です。
AWS
パブリッククラウドの代表格といえばAWSです。ユーザーが多いだけあって、本もたくさん出版されています。GCPやAzureは触っていないので、本記事では紹介しませんw
Amazon Web Services パターン別構築・運用ガイド
AWS入門者向けの本で、AWSを網羅的に学べます。AWS初学者にオススメの本はありますかと聞かれたら、この本を推すことにしています。AWSアカウントを作成したけど、なにしたらいいか分からん!という人はこの本からはじめてみましょう。セキュリティに不安な人は、筆者が昔書いたAWSアカウントを取得したら速攻でやっておくべき初期設定まとめもあわせてご覧ください。
Amazon Web Services 業務システム設計・移行ガイド
AWS本としてはめずらしく中級者向けです。AWSのマルチアカウント管理やネットワーク設計、AWSにおけるシステム設計パターンなどがまとめられています。初学者には向きませんが、会社でAWSを本番運用しているようなエンジニアであれば、手元においておく価値があります。
システム運用
ソフトウェア開発の本は山ほどありますが、意外とデプロイ・運用・監視まわりの本は希少です。形式知化がされづらい領域ですが、その中でも良い本をピックアップしてみました。
継続的デリバリー
今でこそCI/CDは当たり前になりましたが、この本ではCI/CDの基本原則を網羅しています。バージョン管理や継続的インテグレーションからはじまり、デプロイメントパイプラインの設計・データベースや依存ライブラリの管理、はてはコンプライアンスと監査まで非常に幅広い内容を扱っています。さすがに少し古さを感じますが、なぜCI/CDが重要なのかをじっくり学べる書籍です。
入門 監視
システムの運用において重要な要素にもかかわらず、あまり形式知化されてない領域が監視です。監視の基本原則にはじまり、フロントエンド監視やアプリケーション監視・サーバ監視など技術レイヤごとに監視戦略が説明されます。これを読むだけでいきなり正しい監視設計ができるわけではないですが、スタートを切るには必要十分な情報がコンパクトに提供されます。
SRE サイトリライアビリティエンジニアリング
すっかり有名となったSite Reliability Engineeringについて書かれた本です。障害対応や手作業による運用を50%以下に抑え、ソフトウェアエンジニアリングの活動に注力するべし説かれているのが特徴です。特に9章までの原則では、SLO・エラーバジェット・リリースエンジニアリング・トイル・モニタリングなどの実践的な考え方が目白押しです。
システムアーキテクチャ
アーキテクチャ設計はある程度経験がないとよく分からんってなりますが、自分で試行錯誤したあと読むと一気に腹落ちします。
クラウドネイティブアーキテクチャ
クラウドを前提にシステムを設計する際に、どういう観点を大事にすればいいかを教えてくれます。スケーラビリティやセキュリティ、コスト最適化などはオンプレでも重要ですが、クラウドを前提にした場合の指針を与えてくれます。すでにクラウドで本番運用している人には当たり前のことばかりですが、その当たり前を言語化していることはまさに値千金といえます。
マイクロサービスアーキテクチャ
マイクロサービスを設計するために必要な観点が網羅されている本です。いきなりドメイン駆動設計の境界づけられたコンテキストの話が登場し、デプロイ・テスト・監視・セキュリティなどの技術的なトピックスを説明しています。またアーキテクトの役割やコンウェイの法則といった組織に与える影響まで議論されており、コンパクトながら濃密な情報が提供されています。
ソフトウェアシステムアーキテクチャ構築の原理
システムアーキテクチャを設計するうえで、どのような観点を網羅すればよいかを体系化した野心的な書籍です。コンテキスト・機能・開発・デプロイメント・運用など、各観点の設計プロセスが詳細に記述されています。あわせてパフォーマンス・スケーラビリティ・可用性・セキュリティなどの品質特性についても解説されます。決して初級者向けではありませんが、アーキテクチャ設計の能力を高めたいのであれば、ぜひとも読破したい一冊です。
ソフトウェア設計
Infrastructure as Codeに代表されるように、インフラメインの人がコードを書くのは当たり前になりました。そんなコードを書く人たちにオススメの二冊を紹介します。
A Philosophy of Software Design
本記事では数少ない洋書です。この本ではソフトウェアの複雑さについて説明し、その複雑さを最小限に抑えるテクニックを提示してくれます。個人的に感動したのは複雑性の症状として、変更の増幅・認知的負荷・未知の未知という3つに整理している点です。平易な英語で書かれていて読みやすいので、英語に苦手意識がある人もぜひチャレンジしてほしい一冊です。
Clean Architecture
プログラミングパラダイムからはじまり、モジュール設計・コンポーネント設計について整理したあとに、ソフトウェアシステムのアーキテクチャ設計について解説されます。ビジネスルールを中核に、いかに境界線を引くか、という技芸はアプリケーションレベルではもちろん、システムレベルの設計でも示唆を与えてくれます。
教養
すべてのソフトウェアエンジニアにオススメしたい、そんな名著を集めてみました。普遍的な考え方が学べるので、未読ならぜひ読んでみてほしい本ばかりです。
達人プログラマー
20年もの歳月を生き抜いた名著です。ソフトウェアエンジニアとしてキャリアを積むにあたって知るべき考え方がたくさん散りばめられています。難しいことは書かれていませんが、ある程度の期間、ソフトウェア開発の経験があるほうが心にしみるかもしれません。筆者が技術書の中でもっとも好きなのはこの本で、今でもたまに読み返しています。
ライト、ついてますか
ソフトウェアエンジニアの人は問題解決が得意な人も多いでしょう。しかし、この本のテーマは問題発見です。どれだけ問題解決の能力が高くても、正しい問題を定義できなければ価値を生みません。ウィットに富んでおり、問題の捉え方を見つめなおすキッカケをくれるワインバーグの名著です。
UNIXという考え方
UNIX哲学という言葉を聞いたことがあるかもしれません。UNIX哲学では「ひとつのことを、うまくやれ」など、現在のソフトウェア開発にも大きな影響を与えている考え方が散りばめられています。技術書というよりは読み物に近く専門知識が不要なので、気分転換に読むのもよいでしょう。
チーム開発
仕事のジャンルに関わらずチームで活動している人は多いでしょう。ここでは楽しく成果が出せるチームづくりに役立つ本を紹介します。
Team Geek
この本では最初に有名な、謙虚(Humility)・尊敬(Respect)・信頼(Trust)の三本柱HRTを説明します。そして、あらゆる人間関係はHRTの欠如によるものだ、という立場でチーム・コミュニティ・社内組織での立ち回り方を解説していきます。ただの精神論ではなく、実践的なプラクティスが散りばめられており、チームで活動しているなら読んでおきたい一冊です。
エクストリームプログラミング
達人プログラマー同様に20年前に初版が発売された書籍です。昔は先進的だったTDDやリファクタリング、継続的インテグレーションなどのプラクティスはすでに当たり前になってしまいました。しかしこの本の真価は4章と5章の価値と原則にあります。普遍的な考え方は長く通用するので、ぜひとも血肉にしておきたいものです。
ピープルウエア
「実際のところ、ソフトウェア開発上の問題の多くは、技術的というより社会学的なものである。」という一節からはじまる、エンジニアリングマネジメントの名著です。名言のオンパレードであんまり書くとネタバレになるので書きませんが、チームリーダーやマネージャーなら一度は読んでほしい一冊です。ここに書いてあることを頭に入れておくだけでも、かなりよいチームにできるでしょう。
あわせて読みたい
本当はもっともっと紹介したいんですが、あとはタイトルだけ並べておきます。絶版の本も混じってますが、ご愛嬌ということで。
- コンピュータシステム
- Linux/Unix
- ネットワーク
- セキュリティ
- クラウドネイティブ
- システム運用
- システムアーキテクチャ
- ソフトウェア設計
- 教養
- チーム開発
- 組織
おわりに
おそらくこのリストにあの本がねーじゃねーか!とご立腹の方もいるでしょう。ぜひ、あなたのオススメも教えてください。
ちなみに本記事ではWebシステムアーキテクチャの地図を描く構想を参考に体系化を試みたんですが、ムリ!ってなったため、カテゴリは結構適当です。もう少し体系的に学べるといいんですが、体系化は今後の宿題ということで筆を置きます。
- 投稿日:2019-12-09T15:56:58+09:00
AWS Transit Gateway Network Manager さっそく触ってみた
こんにちは、あやたこです。
ちょうどTrangit Gatewayを触る機会があったので、今回のre:Inventで発表されたNetwork Managerもついでに触ってみました
0.前提
既にTrangit GatewayでVPC又はVPNが接続されている必要があります
また、Network Manager が参照する Transit Gateway は同じAWSアカウント内にあるものとします1.Global Networkを作成する
VPCサービスから Network Manager を開き、 Create a Global Network を選択します
Global Networkを識別するための名前を適宜入力する
2.Transit GatewayをGlobal Networkに登録する
作成したGlobal Networkを選択した後、左メニューからTransit gatewaysを選択、Transit Gatewayを登録
Network Managerで管理する既存のTransit Gatewayを選択し、登録
3.ネットワークトポロジを確認してみる
左メニューのダッシュボードを選択し、さらにトポロジタブを選択します
すると、上記のようなネットワークトポロジが自動的に生成されます
上記例は、1つのTransit Gatewayに3つのVPCと3つのVPNが接続されている状態ですが、関連付けがうまくされていないため少し歪な構成になっています
4以降でオンプレミスデータセンターやルーター情報を設定し、CGWと関連付けます4.オンプレミスデータセンターの情報を定義する
左メニューのSitesを選択し、サイトを作成します
データセンター等の名前を定義し、アドレスに住所を入力し作成を押下します
緯度と経度はAWSが住所から自動で検索してくれます(例では、札幌駅の住所を仮で設定しています)
5.デバイス情報を定義し、関連付けをする
左メニューのDevicesを選択し、デバイスを作成します
ルーターの名前やその他パラメーターを適宜入力します
作成した後、デバイスを選択し概要からサイトを関連付けをします
先ほど作成したサイトをプルダウンから選択します
次に、デバイスの オンプレミスの関連付け タブから 関連付け を選択します
作成したルーターに相当するカスタマーゲートウェイをプルダウンから選択し関連付けを作成します
6.ダッシュボードの地域、トポロジにきちんと関連付けが反映されていることを確認する
うまくオンプレミスルーターとCGWが関連付けられたことで下記のようなトポロジに更新されます
また、地域タブを選択すると、住所から座標を割り当てて下記のようなmapが表示されるかと思います
また、モニタリングタブでトラフィック等も確認できると思いますまとめ
無料でこれだけ簡単にグローバルネットワークの可視化ができるとはさすがAWSといったかんじですね
簡単が故に現時点ではあまり作り込めないのが玉にきずですが、今後に期待ですね
他にもいろいろアップデートが来てるので、どんどん触ってみたいと思います














- 投稿日:2019-12-09T15:46:48+09:00
Kinesisストリームのサーバーサイド暗号を試してみる
サーバーサイドでは、Kinesisストリームのストレージ I/O のタイミングで暗号・復号処理を行います。
とりあえずやってみたのでメモ。
1.Kinesis ストリームを作成し、暗号化する
2.CLI で暗号化されたストリームを確認
$ aws kinesis describe-stream --stream-name test { "StreamDescription": { "KeyId": "arn:aws:kms:ap-northeast-1:123456789012:key/c22d289b-669b-4e64-830b-30713982cccc", ※ "EncryptionType": "KMS", ※3.Kinesis ストリームにデータを投入
$ aws kinesis put-record --stream-name test --data aaa --partition-key 111 { "ShardId": "shardId-000000000000", "EncryptionType": "KMS", ※ "SequenceNumber": "49602066998617934605647566514234616470937753180109275138" }4.Kinesis ストリームからデータを取得し、暗号化されていることを確認
$ aws kinesis get-shard-iterator --stream-name test --shard-id shardId-000000000000 --shard-iterator-type TRIM_HORIZON { "ShardIterator": "AAAAAAAAAA" }※シャードイテレーターの有効期間は 300 秒です。
$ aws kinesis get-records --shard-iterator "AAAAAAAAAA" { "Records": [ { "Data": "Yg==", "PartitionKey": "b", "ApproximateArrivalTimestamp": 1499878938.69, "EncryptionType": "KMS", ※ "SequenceNumber": "49575030693030991390093810531763277195232933088973553666" } ], "NextShardIterator": "DUMMY-NEXT", "MillisBehindLatest": 0 }

- 投稿日:2019-12-09T15:19:43+09:00
ぼくの友達、Redshift君を紹介します
結構前
上司「humum君、うちの分析環境(オンプレ)の課題もろもろ解決しといて~。予算はまあまあとっといたから!」
ぼく「!?!?」
なんだかんだなんとかした
冒頭の無茶ぶりの結果、もろもろの検討や折衝、
めんどうな社内稟議を経て
ビジネスサイドの社員が売上などのデータ分析をするためにAWS Redshift × BIツールの環境を提供しています。その過程でRedshift君とだいぶ仲良くなれました。
結構いいやつなのでみんなにも知ってほしいのですが、彼は自分でしゃべれないので代わってこの記事で紹介させてもらいますね。対象読者
・業務でRedshiftを触るけれどまだあまり仲良くない人
・分析基盤の調査や検討をしている人
・カジュアルにRedshiftを知れればいいやの人
それではレッツゴー
Redshift君のプロフィール
・フルマネージドのDWH(データウェアハウス)サービス
・postgreSQLを元にした列指向型DB
・「ノードスライス」「分散キー」による分散処理だいたいこんなやつです
もうちょっと詳しく紹介しますねフルマネージドのDWHサービス
インスタンス管理が楽。S3を介してデータロードで使います
updateやdeleteは滅多に使いません。COPYが爆速なので差分更新より洗い替えが推奨です
もちろんスケーラビリティが高いです。格納データ量にもよりますが、お願いすると数分~1日程度でスケールアウトしてくれます
(残念ながらサービス停止時間はゼロではない。。。がリサイズ中ずっとでもない)postgreSQLを元にした列指向型DB
DWHといえば列指向ですよね
列のベクトルにデータを圧縮して保持するので、・比較的データ圧縮が効く
・集計系のSQLが早いという特徴を持っています。ちなみにトランザクションは張れます
集計の速さとは反対に一件のデータを取り出すようなクエリプランは遅いので、間違っても業務用RDBと一緒にしてはいけません圧縮率はどんぶりで60%~80%くらい
RedshiftはpostgreSQLを元に開発されており、ほとんどのSQLは流用できます
が、関数で一部違うところもあるので気を付けて問い合わせてあげてくださいまた、postgreSQL同様にデッドタプルの考慮が必要です
データ量に比例してVACUUMコストが増大するので、なるべくVACUUMしなくて済む設計がベターです
サイズの大きいテーブルではディープコピーしてあげてください「ノードスライス」「分散キー」による分散処理
やっと本題、これが一番の特徴です
DWHといっても色々ありますが、それぞれ分散処理や高速化のアプローチの仕組みが違います
Redshiftのスペックを引き出すには、「ノードスライス」「分散キー」を理解する必要があります
まず、ノードスライス = ノード数×CPU数
各スライスにデータを分散して格納。各CPUにそれぞれ並列で分散処理をさせることで、高速化しています
また1テーブルに一つだけ、分散キーを指定できます
テーブルにデータをロードする際、この分散キーのカラム値のハッシュ値ごとにスライスに格納します
なお、他テーブルとJOINするクエリプランでは結合キーが別スライスに存在する場合のクエリプランはとても高コストです
え?
他テーブルとJOINするクエリプランでは結合キーが別スライスに存在する場合のクエリプランはとても高コストです
どういうこと?
次の場合のSQLで説明しますねSELECT --salesテーブルにidsから名前をJOIN SUM(売上) , 名前 FROM sales INNER JOIN ids ON sales.id = ids.id GROUP BY 名前
この時、左のスライスのsales.idの「id0003」は、別スライスである右側スライスのids.id「id0003」とそのままでは結合できません
上記の状態でクエリを実行すると、闇の魔術「DS_BCAST_INNER」が発動します
DS_BCAST_INNERとは、スライス内のデータを別スライスに再分散する実行計画です
発動するとSQLを実行してからスライス間でデータの再分散が始まります
当然、高コストです
分散処理とか言ってる場合じゃありません何も考えないで設計すると、たいていDS_BCAST_INNERの洗礼を頂きます
Redshift君気難しい。。。
回避策として、分散キーを指定せずデータ格納時に全てのスライスにテーブル全量のコピーを持たせる方法があります
当然的確な分散キーを指定した場合と比較して、スライス数分ディスク容量を使用するのでメタ情報などのテーブルでこの分散方法を選択します今回の場合だと、データロード時にデータ容量が少なくなりそうなテーブル:idsのテーブルコピーを各スライスに全量格納するように分散方法を指定するのがベターです
テーブル設計時に、分散方式を「ALL」に指定しますCREATE TABLE public.ids ( ids CHARACTER(6) encode lzo , 名前 CHARACTER VARYING(256) encode lzo ) DISTSTYLE ALL;というわけで、仲良くなる前にちゃんと手順を踏んで徐々に距離を詰めてあげてください
Redshift君「嫌なやつみたいになっとるやん!ちゃんと、良いところももっと書いてーなっ!!!」
しゃべった!?!?
次回、『ぼくの友達、Redshift君を持ち上げます』




- 投稿日:2019-12-09T14:02:57+09:00
CodeCommit内のREADME.mdに埋め込む画像をS3から参照しようとしてもダメだった件について...
タイトル通りです。GitHubなら自身のリポジトリ内に置いた画像を配置してそこを参照することができるんですが、CodeCommitではできません。代替案としてS3に画像を配置してオブジェクトのURLを参照しようと3時間ほど格闘したんですが、どうやら無理みたいです。(参考)
今後の機能修正に期待ですね!あと、今まで曖昧だったAWSのJSONポリシーの書き方について勉強になりました!それは今度描きます!(笑)
- 投稿日:2019-12-09T13:09:37+09:00
【AWS・Tello】声でドローンを操作してみたPart1
はじめに
この記事は
ドローンを活用した避難勧告システム
の第二章です.
製作背景などはそれを参照してください.また,本章の内容は以下の内容が前提なので,まだ読まれていない方はまずそちらをご覧ください.
第一章【AWS・Tello】ドローンをクラウド上で操作するシステムの構築概要
TelloドローンをAlexaを使って声で操作してみましょう.インフラはAWSを使用します.
まず動画で完成形を見てみましょう.
システム構成図
やること
前回まででIoTCoreとTelloの通信を確認したので今回は
lambdaでAlexaスキルのエンドポイントをホスティングし,IoTCoreにpublishするところまでやりましょう.
Part1. スキル開発・lambdaとの連携
Part2. lambdaからIoTCoreへの通信スキル開発
スキル作成
alexa developer console (以下ADC)にログインし,カスタムスキルを作成します.
スキルのバックエンドに「ユーザー定義のプロビジョニング」を選択すると自前でlambda関数を用意する必要があります.「Alexa-Hosted」を選択するとADC上のコードエディタを使えて初学者に易しく取っ付き易い気がします.IoTCoreとの通信するので今後の拡張性も考え,ここでは自前でlambda関数を用意する前者のやり方で行います.
というわけでlambdaを新しく用意しときます.lambdaのARNは控えといてスキルのエンドポイントでデフォルトの地域の箇所に設定します.
スキル用語集
優しいのでスキルの基本用語を再確認してあげます.後ほど詳しく触れます.
呼び出し名: 対話(セッション)を始める合言葉
インテント: 対話の意図(開発者が自由に設定することができます)
ビルトインインテント: デフォルトで組み込まれているインテント(キャンセル・ストップ・ヘルプなど)
サンプル発話: セッション内で特定のインテントを呼ぶための合言葉
スロット: サンプル発話で保持させられる変数のようなもの
ビルトインスロット: 既に用意されているスロット(数字や施設名,女優名もある...すごい)
カスタムスロット: 開発者が自由に設定できるスロットちなみにスロットは同義語やID指定など柔軟に設定できるから素晴らしい.
スキル詳しく
今回のドローン制御システムで設定したスキルの詳細です.(参考までに)
呼び出し名: 「コントローラー」
インテント: Controller/Land
ドローンを動かしたい時にControllerインテント, 着陸したい時にLandインテント
(Flipインテントなんか面白そう)
サンプル発話:
Contorollerインテントの場合
ビルトインスロット: num(数字)
カスタムスロット: direction(方向)
つまりControllerインテントでは,進む方向と距離の二つの情報が必要になります.好みになりますが,実際のスキルで方向しか声で入力されなかった場合に距離を聞き返す工夫をするべきです.
ここらへんの対話モデルはjsonで定義できるっぽいので付録で載せときます.バックエンド
先程作ったlambdaをいじります.ここで「Alexa Skills Kit SDK」を使った方が絶対良いです.使わなくてもできますが,リクエストパラメータのjsonのネストが深くて処理がめんどくさそうです.
言語はPythonにします.Nodejsを使う人が多くてPython使う人が少ないのでここではあえてPythonにしました.Alexa Skills Kit SDK for Python
まずlambdaでask_sdk_coreをimportしてください.
$ import ask_sdk_coreただそのままだと外部ライブラリは読み込めないのでask_sdk_coreをlayerとして追加しましょう.
ローカルでプロジェクトにpip installして,プロジェクト全体をzip化してlambdaにアップロードする方法もあります.以下のリンクではその方法およびlambdaのローカル開発のエコシステムをまとめましたので気になる方はご覧ください.
【AWS・Lambda】Python外部ライブラリ読み込み方法ask_sdk_coreはPurePythonなライブラリなのでlayer用のzipファイルを作る環境はどれでも大丈夫なはずです.MacOSで行いました.(python3.7の例)
$ mkdir -p build/python/lib/python3.7/site-packages $ pip3 install ask_sdk_core -t build/python/lib/python3.7/site-packages/ $ cd build $ zip -r ask_sdk.zip .生成されたask_sdk.zipをlayerに追加し,lambda内でlayerを適応させればライブラリが読み込まれます.
lambdaトリガーの設定
今回のlambdaトリガーはもちろんAlexa Skill KitでスキルIDは先程作ったスキルのIDを貼り付けます.
まとめ
Alexaのスキルの対話モデルとlambdaとの連携ができました.
次はlambdaのコード開発とIoTCoreの連携を行います.長くなりましたのでPart2に移ります.
第三章【AWS・Tello】声でドローンを操作してみたPart2付録
対話モデルをjsonで載せときます.インテントなど新しく作られた場合は,GitHubにPRお願いします
https://github.com/shoda888/tello_ask_model{ "interactionModel": { "languageModel": { "invocationName": "コントローラー", "intents": [ { "name": "AMAZON.CancelIntent", "samples": [] }, { "name": "AMAZON.HelpIntent", "samples": [] }, { "name": "AMAZON.StopIntent", "samples": [] }, { "name": "Controller", "slots": [ { "name": "num", "type": "AMAZON.NUMBER" }, { "name": "direction", "type": "direction" } ], "samples": [ "{direction} {num}", " {num} センチ {direction} に移動して", "{direction} に {num} センチ", "{direction} に {num} センチ移動して" ] }, { "name": "AMAZON.NavigateHomeIntent", "samples": [] }, { "name": "Land", "slots": [], "samples": [ "着陸", "着陸して", "ランド" ] } ], "types": [ { "name": "direction", "values": [ { "id": "back", "name": { "value": "うしろ", "synonyms": [ "後ろ", "後方" ] } }, { "id": "forward", "name": { "value": "まえ", "synonyms": [ "前", "前方" ] } }, { "id": "down", "name": { "value": "した", "synonyms": [ "下", "下降", "下方" ] } }, { "id": "up", "name": { "value": "うえ", "synonyms": [ "上", "上方", "上昇" ] } }, { "id": "left", "name": { "value": "ひだり", "synonyms": [ "左" ] } }, { "id": "right", "name": { "value": "みぎ", "synonyms": [ "右" ] } } ] } ] } } }










- 投稿日:2019-12-09T13:08:04+09:00
AWS Chatbotを使ってSlackからALBのログを検索する
この記事はiRidge Advent Calendar 2019 10日目の記事です。
先日AWS Chatbotを利用してSlackからAWSコマンドを発行する機能のβ版が発表されました。
- AWS Chatbot now supports running commands from Slack (beta)
- Running AWS commands from Slack using AWS Chatbot
もともとAWS Chatbotを利用してCost ExplorerのBudgets AlertをSlackに流すくらいのことはやっていたのですが、コマンドが実行できることでやれることがより増えそうだなと思い、今回はよく業務で行っていたALBのログ検索を行い結果を取得するのをSlackで完結できるかを試してみました。
今回やること
- AWS Chatbotを設定する
- Lambdaを作る
- SlackからAWS Chatbot経由でLambdaを呼び出す
- Lambdaでテーブルに対してクエリを実行
- S3に出力された結果ファイルのオブジェクトを取得するためのPresigned URLを生成
- 生成されたPresigned URLを返却
- Lambdaをデプロイする
- SlackからLambdaを呼び出す
- まとめ
前提
Athenaのテーブル作成、Partitionの作成は完了している前提で書いてます。テーブルの作成等はAWSの下記のドキュメントが参考になると思います。
AWS Chatbotを設定する
まずはChatbotの設定をしていきます。
workspaceの設定をします。Chat clientをSlackにしてConfigure clientを押すとworkspaceにアクセスするための権限を求めてくるので、問題なければ許可します。
Chatbotを利用するchannelを選びます。
Chatbotが利用するIAM Roleを定義します。ある程度まとまったPolicyがテンプレートとして準備されているようです。作成したタイミングでは下記のテンプレートが準備されていました。
- Notification Permission: CloudWatchからメトリックグラフを取得するのを許可する権限
- Read-only command permissions: Readのコマンドを許可する権限
- Lambda-invoke command permissions: サポートされているクライアントでLambdaの呼び出しを許可する権限
- AWS Support command permissions: support APIを呼び出しを許可する権限
今回は、Lambdaの呼び出しだけで良かったので、Lambda-invoke command permissionsのテンプレートを利用しました。Defaultだと、すべてのLambdaに対するinvokeが許可されているようなので、適宜呼び出せる関数は制御したほうが良さそうです。下記がテンプレートで付与されたLambdaの呼び出し用のIAM Policyです。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "lambda:invokeAsync", "lambda:invokeFunction" ], "Resource": [ "*" ] } ] }あとSNSの設定項目がありますが、今回は不要なので割愛します。CloudWatchのAlarmや、CostExplorerのBudgetsに関する通知を送るときは設定が必要になってきます。
Lambdaを作る
Slack から呼び出すLambdaを作成します。Lambdaの中では下記の処理を実装しました。
- Athenaのクエリを実行、結果をS3に出力させる
- 配置された結果ファイルに対するpresigned-urlを取得する
下記コードです。テーブル等は適当なものに変更してるのでそのままじゃ動かないです。
サンプルコード
main.pyimport boto3 import time from urllib.parse import urlparse athena_client = boto3.client('athena') s3_client = boto3.client('s3') query_format = ''' select * from <table> limit 10 ''' def execute(): response = athena_client.start_query_execution( QueryString=query_format, ResultConfiguration={ 'OutputLocation': 's3://<S3 bucket name to output result>', } ) return response['QueryExecutionId'] def get_output_location(query_execution_id): while True: response = athena_client.get_query_execution( QueryExecutionId=query_execution_id ) print(response['QueryExecution']['Status']['State']) if response['QueryExecution']['Status']['State'] in ['QUEUED', 'RUNNING']: time.sleep(5) continue if response['QueryExecution']['Status']['State'] == 'SUCCEEDED': return response['QueryExecution']['ResultConfiguration']['OutputLocation'] print(response) return None def get_presigned_url(location): parsed_s3path = urlparse(location) print(parsed_s3path) response = s3_client.generate_presigned_url( 'get_object', Params={ 'Bucket': parsed_s3path.netloc, 'Key': parsed_s3path.path.replace('/','') }, ExpiresIn=3600) return response def lambda_handler(context, event): query_execution_id = execute() output_location = get_output_location(query_execution_id) if output_location is None: print("Query Failed!!") return "Query Failed!!" presigned_url = get_presigned_url(output_location) print(presigned_url) return presigned_url if __name__ == "__main__": context = {} event = {} lambda_handler(context, event)
Athenaに対してクエリを投げるときは
start_query_executionでクエリを実行したあと、get_query_executionを実行して結果の状態を把握する必要があるみたいでした。とりあえずLoopの中で5秒おきに実行するようにしていますが、実行時間が長いクエリだとLambdaのコストが増えるため微妙だなと思っています。SNSとかSQSを間に挟んで待ち時間を関数の外に出せば節約できそうですが、今回は一旦Lambda関数内でsleepさせることにしました。Lambdaをデプロイする
Apexを使ってLambdaをデプロイしました。(よく使っているので)
ディレクトリ構成は下記のような感じです。treeaws-chatbot/ ├── functions │ └── athena-query-executor │ └── main.py └── project.jsonproject.json{ "name": "aws-chatbot", "description": "", "runtime": "python3.7", "memory": 128, "timeout": 300, "handler": "main.lambda_handler", "role": "arn:aws:iam::<Your AWS Account ID>:role/<Your role name>", "nameTemplate": "{{.Function.Name}}", "environment": {} }デプロイは下記コマンドで行います。
deployapex deploy -r ap-northeast-1 -p <your profile>Lambdaに割り当てるIAM RoleにはAmazonAthenaFullAccess、AmazonS3ReadOnlyAccessを割り当てました。本当は権限を絞っていきたいんですが、Athenaの権限が思ったより複雑だったので検証の段階では動かすことを優先しました。ちゃんと運用するときはしっかり理解した上での設定が必要だなと感じています。
SlackからLambdaを呼び出す
Lambdaがデプロイできたら、いよいよSlackからLambdaを呼び出してみます。
Chatbotの設定画面で設定したchannelに
/invite @awsでchatbotのユーザーを招待します。
ユーザーが招待できたら次の内容をchannelに投下してLambdaを実行します。
@aws lambda invoke --function-name <Your function name> --region ap-northeast-1
実行すると本当に実行してよいかを聞かれます。(スクリーンショットの Would you like~ あたり。) YES とするとLambdaの実行が始まります。
Lambdaの実行が完了すると戻り値として、Payload,ExecutedVersion,StatusCodeが返却されます。
どうやらPayloadはbase64エンコードされた状態で返却されるようです。。。(マスクしているので見えませんがbase64エンコードされた状態となっています。)想定ではここでpresined-urlをクリックしてAthena実行結果のcsvをゲットする算段だったのですが、ローカルでbase64デコードする一手間が挟まってしまいました。。
しかし、デコードした結果のURLからは正しくcsvを取得することができました。まとめ
今回Chatbotを使ってみた所感です。
ChatOps環境を作りやすくなった
AWS Chatbotを使うとAWS連携がより手軽にできるようになったと感じました。以前AWS Chatbotが出る前にもSlackでスラッシュコマンド等を作ったことがあり、そのときはAPI Gateway + Lambdaを作成してバックエンドを作成したのですが、API Gatewayの設定が地味にめんどくさかった記憶があります。今回Chatbotで直接AWSコマンドを実行可能になり、API Gateway等を作る手間は削減されたのかなと感じます。個人的にオペレーション用に作るものはなるべく単純にしておきたいという思いがあるので、その点は少しスッキリしてよかったかなと思います。
権限管理は慎重に
SlackからAWSへの操作をできるようになるため、Chatbotに付与する権限は用途ごとにきっちり絞ったほうがよいなと感じました。DefaultのIAMポリシーテンプレートをそのまま使うのではなく、実行できる関数を絞っておくなどして、不用意な事故を防ぐ必要があるなと感じます。Chatbotに限った話ではないですが、ここで使うIAMにも必要最小限の権限を付与するというのを意識しておけば良さそうです。
個人の環境に左右されにくくなる
特定の操作をSlack上でできるので、よく行う運用作業をいくつかまとめられれば誰でもすぐログ調査等ができるようになる点はいいなと思いました。各個人に払い出されている権限、ツールのバージョン等を統一せずに調査等、必要な操作環境を提供できる点は良さそうです。
戻り値のPayloadをbase64デコードした状態で表示してほしい
今回試してみた結果Payloadがbase64エンコードされて返ってくることがわかりました。。base64デコードした状態で表示してくれれば戻ってきたpresigned-urlから直接ファイルがダウンロードできるのに、、、。ちなみに、AWS CLIで
lambda invokeを実行するとoutfileに指定したファイルに戻ってきた結果が書き込まれるのですが、それはbase64デコードされた状態となっていました。呼び出せるコマンドはまだ少ない?
当初Athenaのクエリ実行コマンドを、直接Slackから呼び出そうとしたのですが下記のエラーが出ました。まだ対応しているコマンドが限られているのかもしれません。今後呼び出せるコマンドが増えるといいなと思っています。
I can't run the command athena start-query-execution because it isn't enabled.




- 投稿日:2019-12-09T12:50:35+09:00
Amazon ElastiCache ノードのタイプ変更
ElastiCache Redisのスケールダウン
品質の高いアプリケーションを提供するには、必要不可欠なElastiCacheですが、適切なノードの数とタイプを選ばないとコストが高くついてしまうので、利用状態をみつつノードのスケールダウンを実施した時のメモ
リソースの利用状態の確認
下記のメトリックスを確認する
- CPU使用率
- スワップの使用率
- メモリの使用率
- ネットワーク帯域
- ノードのタイプによっては帯域で詰まることがある(意外と盲点)
利用状態
CPUメモリ共に10%くらいしか使っていない、ネットワーク帯域もそこまで多くないということでサイズダウンを決定
手順
- 手動でバックアップ
- アクションからバックアップを選択

バックアップ名の入力しバックアップを作成する
バックアップの所で少し待つと、ステータスがavailableになる
- バックアップから復元
- チェックボックスをチェックし、リストアボタンをクリックする
- フォームが表示されるので適切に記載
- Redis一覧に復元したクラスターが現れる

- 復元したクラスターの確認
- 新しいエンドポイントが作成される
注意点
- 復元したクラスターはエンドポイントが変わるので、アプリの変更が必要
- バックアップからアプリのエンドポイント変更までの間に新旧のクラスターでデータの差分が発生するので考慮が必要な場合がある
参考
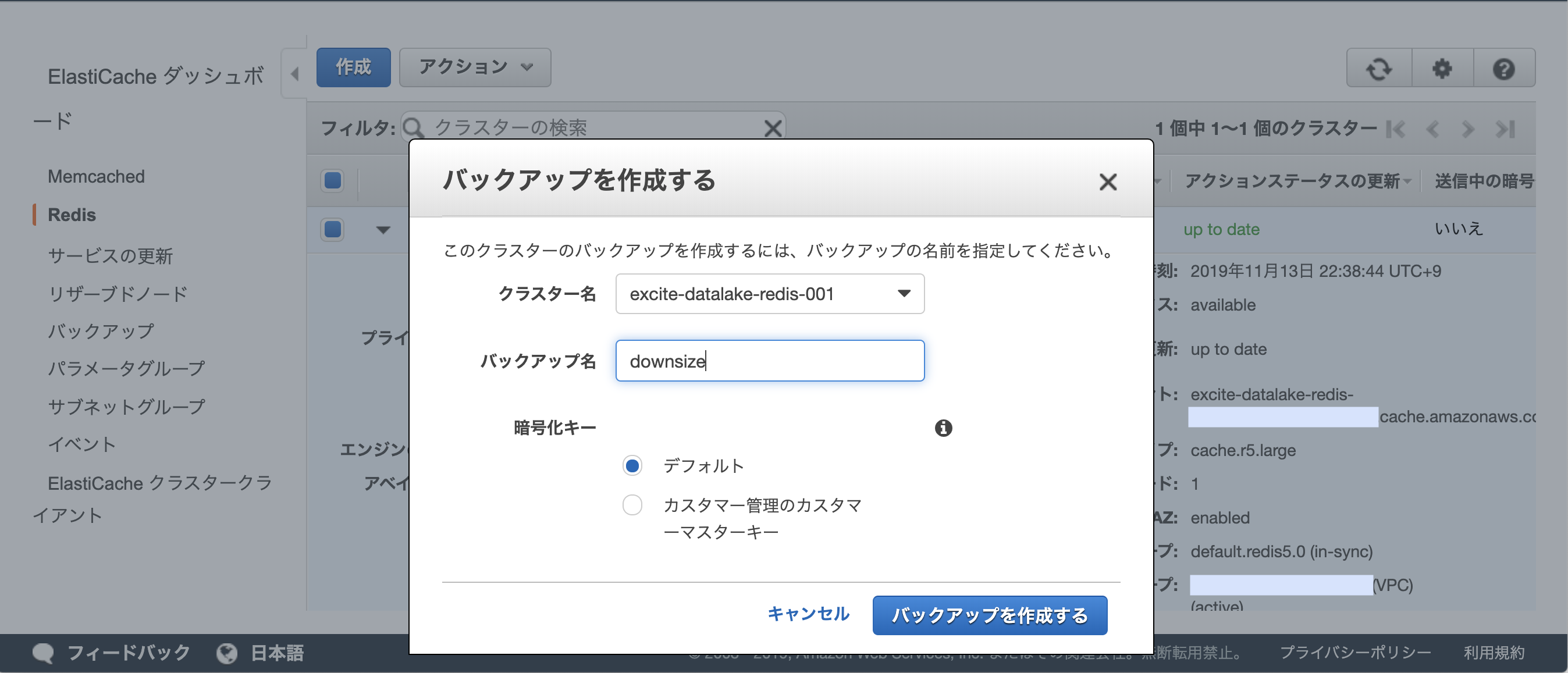
- 投稿日:2019-12-09T12:11:37+09:00
バケット一覧を見せずにS3を使わせる方法
はじめに
S3をIAMユーザに使わせるときに、バケット一覧を見せたくない。という要望は多いと思います。
CyberDuckとかサードパーティのソフトを使うことなく、
ブラウザのみでマネジメントコンソールからアクセスさせたい。このような場合、いろいろググってもListAllMyBucketsの権限は必須であり、
バケット一覧が見えてしまうのは仕方がないという情報が割と多くヒットするのですが、
この権限を与えずともマネジメントコンソールから利用できるということに気が付きました。手順
一言で言うと、 IAMユーザにはバケット以下に直結するURLを通知する だけです。
早速作ってみましょう。バケットを作る
適当な名前でバケットを作ります。
IAMユーザにはこのバケットにのみアクセスさせることとします。ポリシーを作る
適当な名前でポリシーを作ります。
{ "Version": "2012-10-17", "Statement": [ { "Effect": "Allow", "Action": [ "s3:Get*", "s3:List*" ], "Resource": [ "arn:aws:s3:::バケット名/", "arn:aws:s3:::バケット名/*" ] } ] }このような感じで先ほど作成したバケットにのみ権限を与えます。
"s3:List*"を与えているのでListAllMyBucketsも含まれているようにも思えますが、
Resourceでバケット名を制限しているので実質的に無効であり、
ListAllMyBucketsは与えていない ことに注目です。
ここではReadOnly的な感じで権限を与えていますが、
要望に応じて適宜変更してください。IAMユーザを作る
適当なIAMユーザを作り、ID/パスワードを発行します。
このIAMユーザには先ほど作ったポリシーを与えます。連絡する
ここが重要なのですが、
利用者にURLを伝えるときにはS3のバケットのURLを伝えます。
https://s3.console.aws.amazon.com/s3/buckets/バケット名/このURLにアクセスするとIAMのログイン画面が表示され、
ログインに成功するとバケットの中身が表示されます。
もちろん、ディレクトリを上にさかのぼってバケットの一覧を表示させようとすると
Access Deny となってはじかれます。参考
- 投稿日:2019-12-09T11:18:52+09:00
AWS re:Invent 2019 ノート
AWS re:Invent 2019 に参加したまとめ。
感想
設計について blast radius というキーワードが目についたので個人的に頭に入れる必要がある。
キーとして train your builders というものがあり、学習型カンファレンスである re:invent 自体もそうだし、 builders' library によるベストプラクティスの提供、DeepRacer のような機械学習に対する開発者の学習サービスの提供など、aws がその機会を提供しているのも各所で感じられた。
動向としては新サービスとしては ai/ml 系、on-prem との障壁を無くすために高性能な処理と低遅延のネットワーク系の追加が主であるように見えた。
イベントについてメモ
las vegas のホテル&カジノ群で行われる大規模なイベントという感じで、隣の会場まで歩いて 20 min くらい掛かるので歩き疲れた(Bally's という交通の便が最適ではないホテルに滞在したので顕著だった)。 可能なら会場となるホテルのどれかに滞在した方がシャトルでの移動で楽になりそう。
食事は朝昼で buffet か grab & go、食べるところは大抵広かったので初日の昼だけ grab & go にしたけど後は buffet で食べた。料理はアジア料理、メキシコ料理、etc. と日によって変わっていたようで、特に食事に支障はなかった。
セッション
動画リスト
- https://www.youtube.com/user/AmazonWebServices
- https://www.youtube.com/channel/UCdoadna9HFHsxXWhafhNvKw/playlists
Keynotes 気になったスライド
https://youtu.be/7-31KgImGgU?list=PLhr1KZpdzukcAXSVwQ3L9cWD4QgKPCQ5S&t=1745
- compute
- 高性能な instances への対応 1
- fargate for eks、eks インフラの managed
- networking、言及なし
https://youtu.be/7-31KgImGgU?list=PLhr1KZpdzukcAXSVwQ3L9cWD4QgKPCQ5S&t=4676
- cassandra (mcs) の追加、 wide column database
https://youtu.be/7-31KgImGgU?list=PLhr1KZpdzukcAXSVwQ3L9cWD4QgKPCQ5S&t=8142
- ai/ml シリーズ
https://youtu.be/7-31KgImGgU?list=PLhr1KZpdzukcAXSVwQ3L9cWD4QgKPCQ5S&t=9371
- breaking through barriers 1
- outposts (on-prem workload)
- local zones (low latency to local end-users)
- wavelength (5G)
Keynotes 気になったサービス
- Amazon CodeGuru
- Java のみっぽいので色々な言語の対応が待ち遠しい
- Amazon Kendra
- 企業内ドキュメントの検索は皆困っていて需要があるんだろう
- Amazon Builders' Library
- 読む必要がある
以下、雑多な参加したセッションの個人メモ
Midnight Madness
Queue up at 8 pm とあったが、開始まで二時間待つのも待機列で一時間ほど掛かるのもどちらも辛い。
ラスベガスにたどり着くまでに体力を消耗しすぎて最後まで参加できず。ARC411-R - [REPEAT] Reducing blast radius with cell-based architectures
- state machine
- serverless (aws takes care av zone)
- zone based
- regional control plane -> zone (zone control plane, data plane)
- well architectured framework
- tenets
- minimize blast radius (spike, etc.)
- serverless (lambda, kinesis - no zone based)
- infra as code
- analytics cell router -> analytics cells -> KINESIS -> s3 for datastore -> (engineer, asap, ml, etc.)
- s3 -> asap -> detections cell router -> detection cells -> findings repos
- router
- s3 event log -> sns -> (analytics cell router)[sqs -> (lambda -> dynamodb rules)] -> analytics cells
- rules
- load balancing, data segregation (source recognized source a to cell a)
- data replication (prod cells copy to test cells), blue/green deployment
- never look s3? spof (よくわからんかった)
- cell
- apache flink checkpoint and save
- key takeways
- small vs. large
- design for failure
- thinnest possible layer
CON421-R - [REPEAT] Amazon EKS under the hood
- under the hood
- eks managed vpc | customer managed vpc
- zone 間はどうふりわけるのか? -> 53 っぽい
- eks celluar arch (1 cell = 1 aws account = frontend, cluster events, control plane management, etc.)
- pipeline -> prow cluster
- enhancement
- managed node groups (single command, up to date, ha)
- simplify worker node management, self managed, k8s ecosystem tooling (autoscaler)
- vision (globally available, easy to use, production ready, cost-effective, high performance)
- snap service mesh on eks
- eks, envoy, switchboard, spinnaker
ARC335-R - [REPEAT] Designing for failure: Architecting resilient systems on AWS
https://www.youtube.com/watch?v=BJVzwaTiOdk
- RPO, RTO -> mission
- tier 1, 2, ...
- well architected framework: shared responsibility model
- resilient aws infra
- fault isolation zones: cell-based, multi-az
- microservice
- distributed best practices: throttling, retry, circuit breaker
- strategy: backup & restore (multi-region) high level rto, rpo
- strategy: pilot light
- strategy: warm standby
- strategy: active-active
- (one ex. read locally, write globally)
- s3 - cross-region replication
- replication time control (new! two weeks ago)
- ebs - snapshot copy
- dynamodb - multi-master, multi-region (no complexity write globally)
- rds:- cross-region read replicas
- inter-region vpc peering -> white paper
- snapchat
- 99.99% (tier0), 99.95% (tier1), 99% (tier2), 95% (tier3)
- legacy
- monolithic, single region -> multi-region active-active
- repl: dynamodb streams -> stream service -> other regions, etc.
- continuous resilience
- disaster recovery -> chaos engineering -> continuous resilience
KYN201 - Monday Night Live
https://www.youtube.com/watch?v=GPUWATKe15E
目新しい情報はなかったらしい?
席を立つ人が目立った。KYN202 - Keynote by Andy Jassy
https://www.youtube.com/watch?v=7-31KgImGgU
65000+ attendees
3000+ sessions! transformation
- senior leadership team conviction and alignment
- top down aggressive goals
- train your builders
- don't let paralysis stop you before you start
97% on premises
- user: goldman saches
- comupute (nitro, chip)
- m6g, r6g, c6g instances (gravition chip)
- inf1 (infrantia chip)
- containers
- fargate for eks https://aws.amazon.com/jp/blogs/aws/amazon-eks-on-aws-fargate-now-generally-available/
- serverless
- data silos -> data lake
- s3 access point https://aws.amazon.com/jp/blogs/aws/easily-manage-shared-data-sets-with-amazon-s3-access-points/
- redshift ra3 instances with managed storage https://aws.amazon.com/jp/blogs/aws/amazon-redshift-update-next-generation-compute-instances-and-managed-analytics-optimized-storage/
- elasticsearch service (ultrawarm) https://aws.amazon.com/jp/blogs/aws/announcing-ultrawarm-preview-for-amazon-elasticsearch-service/
- database
- managed cassandra service (wide column) https://aws.amazon.com/jp/blogs/aws/new-amazon-managed-apache-cassandra-service-mcs/
- ml
- usecase: health care
- sage maker studio, notebooks, experiments, debugger, model monitor, autopilot
- fraud detector
- codeguru (一番盛り上がった)
- contact lens for amazon connect
- kendra
- break on-prem barriers
- outposts GA
- native aws or vmware cloud on aws
- local zones
- 5G
- 8 capabilities
- wavelength
SVS310-R1 - [REPEAT 1] Securing enterprise-grade serverless apps
https://www.youtube.com/watch?v=D2JyI7QV8c4
- speed + security
- security: where to start?
- identity
- diy identity store - vulunerable
- hashed - attask, salt hashed - ...
- (ok) ssecure remote password protocol (SRP)
- Amazon Cognito (SRP, etc.)
- x multiple identities o centralize identity management and privilege management
- delegation: OIDC + OAUTH, federation: SAML, no long-term credentials, rbac
- delegation
- aws security token service -> temporary iam creds
- jwt: identity token, access token, refresh token
- least privilege, iam condition
- access control to api gateway
- with cognito
- allowed -> jwt + context.identity
- with lambda authorizer -> policy
- others
- basic request vailidations on api gateway: parameters, payload with JSON schema
- CORS
- access control to dynamodb (iam, cognito condition), s3 (iam, bucket policies)
- s3 access point (multi access control)
- lambda
- shared responsibility model
- iam invoke, actions, assume
- common vulnerabilities: ddos
- aws shield
- common: OWASP top risks to web apps - XSS
- aws waf filtering rules
- common: SQL injection
- use prepared
- apply security at all layers
- secure coding practices
- accessing db creds: x hard coded, ! env or config file, o aws secrets manager, o iam authentication for amazon rds
- data api for amazon aurora serverless https://docs.aws.amazon.com/ja_jp/AmazonRDS/latest/AuroraUserGuide/data-api.html
- monolitic functions -> microservies + event-driven architectures (small functions)
- owasp secure coding practices
STP203 - The modern startup: A look at today’s most successful architectures
https://www.youtube.com/watch?v=pHxuFKGALK0
- find and eliminate blockers and wait states
- remove human interaction, self service tools, abstraction layers allow for modular evolution
- enable your developers
- preparing hackathon
- everything continuous, all the time
- how long x takes?
- keep your systems simple
- gall's law
- democratize your data
develop a culture of openness
legacy: ecs containers
- goal: 100x clients, faster, more data
shift
- docker -> serverless, tdd, devops, devs, and QA are all one
CON323-R1 - [REPEAT 1] AWS App Mesh under the hood
https://www.youtube.com/watch?v=h3syq1vbplE
- working backward
- customer want: routing, observability, security, transparency
- arch
- proxy
- virtual node, virtual service, virtual router
- design
- frontend service, envoy management service, transformer
- frontend service
- authentication
- authorization
- validation
- persistence
- picking
- customer configuration/metadata, relationships between resources, serializable cross-key/table -> JournalDB
- transformer
- mesh id -> buckets (split brain -> allow extra)
- event-driven processing
- reactive, efficient, creates backlog, requires reconciliation
- level-driven processing: bounded workload (bimodal behavior), self-healing, less efficient
- envoy
- envoy data store
- synthesized envoy configuration, relationships node to manifest, eventually consistency, single key -> dynamodb
- discovery - listeners - routes - secrets - clusters - endpoints
- management
- actor system(connection manager, manifest manager, aws cloud map, aws certificate manager)
- operations (canary)
- deployment: first (container images and cloudformation templates), second, remaining
- monitoring: rate, errors, duration (+ cloudwatch log insight)
AIM207-R5 - [REPEAT 5] Get started with AWS DeepRacer
https://github.com/aws-samples/aws-deepracer-workshops
CON325-R - [NEW LAUNCH!] [REPEAT] Enabling application-first thinking with Amazon ECS capacity providers
- orchestraction ecs/eks, compute ec2/fargate
- containers: 150%+ growth, 80% share (cloud)
- ecs internal customers (sagemaker, etc) - dogfooding
- infrastructure first
- terminology: ecs cluster (namespace), ecs task (like pods), service (many tasks)
- start ec2 instances first, and then run ecs tasks (infra first)
- task placement: available instances -> resources (like resource limit) -> placement constraints (like affinity) -> strategy
- infra first: available instances not found, spread placement strategies, scaling (cloudwatch metrics -> alarm auto scaling groups: metrics are based only on existing tasks and resources)
- application first
- tenets: applications own their requirements, infrastructure responds to application requirements
- ECS Capacity Providers
- ecs cluster ( ecs cp ( ec2 asg (ec2 instances)))
- ecs cp
- abstracts capacity
- 0-10 /cluster
- used by tasks/services
- run tasks under cp without instances -> instances start -> tasks placed
- ec2 spot / fargate spot
- price up to 90%/80%
- reclaimed by ec2/ reclaimed
- instances pools/automatic
ARC349-R1 - [REPEAT 1] Beyond five 9s: Lessons from our highest available data planes
https://www.youtube.com/watch?v=2L1S0zfnIzo
- api caller -> | (api) control plane - config -> data plane (server) | <- client
- 10 patterns
- insist on the highest standards
- raise the bar for testing
- 1000s unit tests, 100s integration tests, pre-prod env, roll-forward/back testing
- be technically fearless
- mitigate fear with professionalism, testing, and open-@minded scrutiny
- aws lindbergh award
- modeling
- focus on blast radius
- modular separation
- double down on simplicity
- saying no to many features,
- unreasonable redundancy
- striping, shuffle sharding
- teeny cache
- static stability
- degrade gracefully
KYN204 - Keynote by Dr. Werner Vogels
https://www.youtube.com/watch?v=OdzaTbaQwTg
DOP210-L - Leadership Session: Developer Tools on AWS
- external/internal, builder.tools
- dev/test
- delivery: dev/test -> review -> pre-production -> production
- dev/test
- use cloud desktops at amazon
- use cloud9 internally
- support aws toolkit for third party IDE
- debugging timeline 30min -> 10 min
- demo
- review
- codecommit supports approval rules
- codeguru review/profiler
- ci/cd
- 2001: monolith -> 2002: 2-pizza teams (devops, full ownership, full accountability, focused innovation)
- delivery pipelines (dev tool team)
- delivery: source -> build -> alpha (pre-production, automated tests) -> beta (pre-production, automated integration tests, load/perf tests, browser tests) -> gamma (pre-production, automated integration tests, synthetics tests, api smoke tests) -> one az/fractional (production, synthetic monitoring) ... -> one region...
- delivery is pessimistic
- pipeline blockers: time windows, pipeline policies, ocverage, review, security scans, dependency updates, etc.
- modern applications
- monolithic -> n-tier -> micoservices & serverless
- aws cdk
- a look ahead
- security
SEC209-R1 - [REPEAT 1] Getting started with AWS identity
- before the cloud (firewall, etc.) -> in the cloud (iam)
- iam roles: recommendation - have at least admin and readonly
- authentication and authorization
- iam role -> resource
- short-term creds for iam role
- if any policy denies -> access denied
- if some policy allows -> allow
- otherwise denied
- cross account: recommendation - keep it simple
- resource based policy
- role trust policy
on-prem が 97% 残ってるのでそれを取っていく感じの進化? ↩
- 投稿日:2019-12-09T11:15:14+09:00
AWS マルチアカウントの管理を Toil にしないために
この記事は GLOBIS Advent Calendar 2019 - Qiita の9日目です。
7月に GLOBIS へ SRE として参画してから、集中的に取り組んできたことの1つである「AWSマルチアカウントの構成や運用効率化」に関して書いていきます。
AWS マルチアカウント構成について
GLOBIS では AWS アカウントを環境ごとに分ける構成を取っています。各サービスにつき開発、ステージング、本番環境という形で 3 アカウントを設けており、現在その総数は 20 に届こうかというところです。私が参画し始めた後にもアカウントは増えています。
マルチアカウント構成はポピュラーな AWS アカウントの使い方だとは思いますが、 GLOBIS の場合以下のメリットを感じています。
- GLOBIS はサービスごとに開発チームが分かれており、各チームへ的確に分割された AWS IAM 権限を付与しやすい。
- AWS リソースを操作する際に、誤ったサービス / 環境を操作してしまう可能性が低い。
- 1アカウント内のリソースはすべて1つのサービスを構成する要素となっているため、インフラ構成が見通しやすい。
しかし一方で、サービスの増加に比例して管理対象のアカウントが増えてしまうのが SRE には辛いところです。いわゆる SRE book にも、 Toil の定義として「サービスの成長に対して $O(n)$ であること」が書かれており、アカウントの増加に比例して管理作業が増えるような事態は避けていく必要があります。そこで7月からの活動の中では、以下のような効率化作業を実施しました。
- Switch role の導入
- ChatOps の促進
- Infrastructure as Code の促進
順に見ていきます。
Switch role の導入
様々な AWS アカウントを日々行き来しながら作業する SRE については、すべて Switch Role (sts:AssumeRole) を使った IAM に移行しました。
通常ですと、 AWS マネジメントコンソールからは同時に1つの AWS アカウントにしかログインできませんので、複数のアカウントで並行作業を行いたいときは、複数のブラウザを使うなどして、セッションを分ける必要があります。 Switch Role を活用すると、 1つの IAM User から、別の AWS アカウントの IAM Role へコンソール上で Switch ができるようになり、アカウントごとにログインや認証操作を行わずとも、スムーズにアカウント間を行き来できるようになります。
Terraform による設定作業自動化
Switch Role を「使う」こと自体は非常に便利なのですが、そのための設定作業については、 Switch 元のアカウントに IAM User を作成し、さらに Switch 先の各アカウントに IAM Role を設ける必要があり、煩雑になりがちです。そこで Switch Role の作成や削除は Terraform で管理しています。
Terraform の実行は CodePipeline + CodeBuild を用いて自動化しました。 GitHub で Pull Request を出すと
terraform planが実行されて、 mercari/tfnotify により結果が Pull Request に貼り付けられます。 Pull Request を master ブランチへ merge されるとterraform applyが実行される仕組みです。
ポイントとしては、この Terraform の実行にもマルチアカウントな権限を必要とする点です。そこで CodeBuild の IAM Role には以下のような権限を与えています。
data "aws_iam_policy_document" "codebuild_iam_terraform_policy" { statement { actions = [ "sts:AssumeRole" ] resources = [ "arn:aws:iam::*:role/codebuild_iam_terraform", ] } }この権限の意味するところは、任意の AWS アカウントの
codebuild_iam_terraformという role へassumeRoleが可能となる、ということです。そのため新しい AWS アカウントが追加された際には、そのアカウントに IAM Rolecodebuild_iam_terraformを作成するという最小限の操作だけで、 Terraform の動作対象に含めることができます。開発 / ステージングと本番は混在させない
Switch Role を設定する際の原則として、開発 / ステージングから本番へ、本番から開発 / ステージングへは Switch をさせないようにしています。これはひとえに誤操作の防止という観点です。
サードパーティ OSS の活用
また Switch Role の利用にあたっては、以下のようなサードパーティツールを活用することで、さらに利便性を高めることができています。
- AWS Extended Switch Roles
- マネジメントコンソール右上に表示される Switch 先アカウントの履歴をカスタマイズ可能になる Chrome 機能拡張
- 通常は直近5アカウントの履歴しか表示されませんが、好きなアカウントを自由に表示させることができるようになります
- aws-vault
- AWS CLI の API キーを Keychain で管理できるなど、認証操作を強化してくれる CLI ツール
- AWS CLI で switch role を行う場合、一時的な switch 用のクレデンシャルキーを発行して、そのキーを環境変数に設定して、、、と面倒だけど、 aws-vault だと1コマンドで switch できます
- 詳細な背景は割愛しますが、現時点で Terraform で Switch Role + MFA を使う場合、このツールを使うのがほぼ必須になります
ChatOps の促進
AWS アカウントの切り替えが簡単になったとは言え、簡単かつ頻発する作業であればログインすら行わずに済ませたいところです。そこで ChatOps を活用しています。
例えば弊社ではデプロイに CodePipeline を用いているのですが、本番環境のみ事故を避けるために手動でパイプラインを起動する必要があり、またさらに承認フェーズを挟むようにしています。これを Slack 上だけで完結できるようにしました。
具体的にはこのような構成です。 slash command でパイプラインを起動し、承認フェーズに至ると SNS と Lambda を経由して、以下のように Interactive Message Button が Slack に表示されます。
ボタンをクリックすると、誰がクリックしたのかが明示的に Slack へ残されます。
図中にも書いてある通り、この構成は Serverless Framework で記述しており、新しい AWS アカウントが追加されたときにも、すぐに展開が可能になっています。
この他にも、各メンバーが必要に応じて Lambda を書くなどして、 GuardDuty の検知やセキュリティ上重要な操作の実行など、様々な Notification を Slack へ送っています。
Infrastructure as Code の促進
GLOBIS では積極的なインフラのコード化を是としており、従来から Ansible や Codenize.tools を利用しているほか、独自の Python スクリプトなども用いています。最近ではこれに加えて Terraform や Serverless Framework も活用が進んでいます。
Ansible は別として、 Terraform 、 Serverless Framework 、 Codenize.tools はいずれも AWS のコード化に使うツールで担当範囲が重なるようにも思えますが、主に以下のように適材適所で使い分けています。
- Codenize.tools : Route53 (roadworker)
- Serverless Framework : AWS Lambda 関連
- Terraform : それ以外
Codenize.tools
Route53 についてはレコード数が増えてくると
terraform planがかなり遅くなります。--parallelismによる並列数の増加なども試みましたが、今のところ改善策が見つからないため、 Terraform ではなく roadworker を使う形としています。記述も Terraform に比べてかなりシンプルに書くことができるのが魅力です。Serverless Framework
GLOBIS では先の slack 通知に使う Lambda のように、全アカウント横断で用いることができる汎用的な Lambda が少なくありません。そのため Lambda のコードを更新すると、全アカウントに対してデプロイ作業を行わなくてはなりません。
さすがにいちいち zip で固めてアップロードして、、、とはやっていられず、デプロイをワンコマンドで済ませるために Serverless Framework (sls) の導入を進めました。実行に必要となる IAM Role なども含めて YAML で簡潔に定義できる点、 zip にまとめてデプロイする処理がワンコマンドで済む点などを鑑みると、 Lambda については Terraform より sls でコード化したほうが取り回しがしやすいと感じています。
ただ、すでにデプロイ済みの Lambda を後から sls でコード化する、 import 操作を行うのは困難です。これは sls が裏側では Cloud Formation (CFn) に紐ついているため、単にコード化するだけではなく、 CFn の stack も作らなくてはならないあたりが関係しています(まぁ一旦 Lambda を削除して、 sls から改めてアップロードすればいい話だったりもしますが)。
そのため sls 導入以前よりデプロイ済みの Lambda については、代替として Makefile によるデプロイコマンドの統一を進めつつあります。
FUNCTION_NAME := dummy PROFILE := dummy lambda_function.zip: zip lambda_function.zip lambda_function.py .PHONY: update-code update-code: lambda_function.zip aws lambda update-function-code --function-name $(FUNCTION_NAME) --zip-file fileb://lambda_function.zip --publish --profile $(PROFILE) .PHONY: clean clean: rm -f lambda_function.zip .PHONY: deploy deploy: update-code cleanなお、最終的には sls や Makefile のコマンド実行自体を CodePipeline などで自動化するつもりです。
Terraform
Terraform は部分的に導入していますが、まだ活用方法を模索中という段階です。すべてをコード化することは時間的にも難しいことがあり、再利用性の高い構成を module 化することで、効果的に導入していければと考えています。
例えば SPA などは、 CloudFront + S3 + Lambda@Edge というほぼ決め打ちの構成が存在しているので、 module 化を進めやすい部分です。また各 AWS アカウントで統一的な構成を取っている箇所もコード化を進めるべき部分です。 GLOBIS の場合、サブネット構成が DMZ は第3オクテットが1、 Trust は2、という具合に統一したルールを設けているほか、 S3 バケットもログ用のバスケット、 CodeBuild の artifact を置くためのバケットなど、標準的に必要となるものがいくつか定まっています。このように標準化されている部分をコード化することから進めるのが妥当と考えています。
今後取り組みたいこと
最後に、今後取り組んでいきたいことをいくつかまとめて、この記事の〆とします。
Slack からの AWS CLI 実行
先日発表されたばかりの新機能です。 AWS Chatbot を使って、 Slack 上から AWS CLI の実行ができます。
Running AWS commands from Slack using AWS Chatbot | AWS DevOps Blog
さすがにリソース変更を伴う操作を Slack Channel のメンバー全員に許可してしまうのは怖いですが、稼働中 instance の ID や IP を調べるなど、 read 系の操作を可能にするだけでも利便性はかなり高まるのではないかと思います。
Organizations の活用
これは個人的な感想なのですが、正直 AWS Organizations はローンチ当初そこまで出来ることが多いわけでもなく、それほど魅力は感じていませんでした。
しかし、最近は Control Tower や Saving Plans など、 Organizations が有効化されていることを前提として、マルチアカウントにガバナンスをもたらしてくれるサービスが増えてきています(Saving Plansで「推奨事項」を表示するのに、 Organizations が必要です)。おそらく今後もこの流れが続き、マルチアカウントを統制する上で Organizations が必須になりそうな気がしています。そのためそろそろ Organizations 導入も考えるべきではないかという声は、チーム内で何度か挙がっています。
構成自体の見直し
GLOBIS のエンジニア組織が出来て3年近くが経ち、インフラ構成自体も大きく見直して良い時期になりつつあります。
例えば EC2 へ ssh 接続するためのいわゆる「踏み台サーバー」を現在は AWS アカウントごとに設けていますが、これを統合したり、 SSM Session Manager に代替することで、踏み台の管理コストが抑制が図れるのではないかと考えています。またコンテナの導入も検討を始めていますが、仮に EKS を導入するとなると、 k8s の RBAC と IAM をどのように絡めて権限制御を行うかを考えなくてはならなくなったり、コンテナエコシステムを前提とした AWS 構成が求められるようになります。今後どのようにサービスが拡充されていくのか長期的に考えつつ、スケールしやすいインフラを改めて考えていきたいところです。
このような Toil を抑える仕組みを常に考えていくことによって、 GLOBIS のサービス拡大を今後も SRE の立場から下支えできればと考えています。




- 投稿日:2019-12-09T10:21:08+09:00
AWS認定セキュリティ専門知識(SCS)を、1年の空白期間を経て取得したやったことまとめ
はじめに
AWS認定セキュリティ専門知識(SCS)について、受験者数の絶対数が少ないのか試験対策に関する参考記事の投稿が少なく情報収集に苦労しました。
今回、2ヶ月ほどの準備をして取得できた試験準備のコツなどについてまとめてみました。セキュリティ専門知識に関わるAWS関連サービスのイメージを掴んでいただければ幸いです。
本記事の主な対象者
- AWS認定の他の試験区分は取得済みで、セキュリティ専門知識の受験を検討している方
- 取得に向けて有効な学習方法などの情報収集したい方
筆者のAWS認定履歴
AWS認定 取得日 ソリューションアーキテクト - アソシエイト 2018-05-13 デベロッパー - アソシエイト 2018-06-03 SysOpsアドミニストレーター - アソシエイト 2018-06-10 ソリューションアーキテクト - プロフェッショナル 2018-07-29 DevOpsエンジニア - プロフェッショナル 2018-08-26 ビッグデータ専門知識 2019-08-25 セキュリティ専門知識 2019-12-08 実は、昨年のDevOpsエンジニアプロフェッショナルを取得直後に、模擬試験無料バウチャーを使用して模擬試験を受けていました。その時は半分程度のスコアだったのを今でも覚えています。それから、計画止まりとなっていましたが、ビッグデータ専門知識を取得したことをきっかけに再度取得を目指すこととしました。
今回のスコア(2019-12-08受験)
総合スコア: 831/1000 (ボーダー750) スコアと評価 分野 1: インシデント対応 -> 再学習の必要あり 分野 2: ログと監視 -> 十分な知識を有する 分野 3: インフラストラクチャのセキュリティ -> 十分な知識を有する 分野 4: ID およびアクセス管理 -> 十分な知識を有する 分野 5: データ保護 -> 十分な知識を有するAWS認定セキュリティ専門知識(SCS)について
ここからが本題となります。
まずは、以下の公式ページから試験概要の把握を行いました。具体的な試験準備で効果があったと思えること
実際に受験をしてみて、試験対策として効果があったと思う内容について、主観的な効果度合いで順に記載します。
AWS サービス別資料 (旧ブラックベルト)
分野毎に、理解したと思えるレベルまで繰り返し読みこみました。あとはセキュリティ関連すると思われたホワイトペーバーをざっと目を通し、横串の全体感を把握しました。
- インシデント対応
- EC2, IAM, CloudWatch, Lambda, KMS, SES
- ログと監視
- CloudTrail, Config, CloudWatch, Athena, SNS
- インフラストラクチャのセキュリティ
- VPC, CloudFront, WAF, Shield, Inspector, Trusted Advisor, GuardDuty, Macie
- IDおよびアクセス管理
- IAM, Directory Service, Organizations, Cognito, S3/Glacier, KMS
- データ保護
- KMS, CloudHSM, Certificate Manager, Systems Manager, Secrets Manager
- ホワイトペーバー
- セキュリティのベストプラクティス
- KMSのベストプラクティス
- DDoSに対するベストプラクティス
ユーザーズガイド
プロフェッショナルやスペシャリティの試験区分になるとワンライナーの知識問題が出ることは稀で、ほぼほぼシナリオベースの与えられた条件の中からもっともらしいものを選択する能力が問われます。
これは、いくつかの試験区分を受けてみての経験則なのですが、正答を選択する基本的な考え方は、ユーザーズガイドに網羅されています。逆に、ユーザーズガイドに記載されていない技術的な手法は正答になり得ない可能性が高いと考えます。理解が不足している内容に遭遇した場合、ユーザーズガイドから該当部分を探してみる、記載されているチュートリアル通りに手を動かしてみるといったことをお勧めします。
- ユーザーズガイド: チュートリアル:AWS アカウント間の IAM ロールを使用したアクセスの委任
動画学習サイトの活用
英語力は必要となりますが、網羅的な試験対策コースがあります。動画を視聴する時間はそれなりに取られます。何れかのサイトを利用しておくと試験前の安心感が得られると思います(サイトのみの紹介、コースはお好みで)その他試験TIPS
以下、私見を多分に含むメモです。キーワードの参考に。
AWSサービス
IAM
- ポリシードキュメントJSONレベルの認証認可トラブルシューティング
- STSに関わる、IAMロール の 信頼ポリシー3つの区分
- Permissions Boundary によるアクセス制御
- リソースベースのポリシーと、IDベースのポリシーは何が違うか
Organization
- Service control policies による組織内アカウントrootユーザーのアクセス制御
CloudTrail
- ヒトに着目したログ収集
- マルチリージョン、マルチアカウント
- S3に集まるログをどう活用するか
Config
- モノに着目したログ収集
- ルールに基づく適合評価、修復アクション
- AWS Maneged: ベーシックなルール
- Customer Maneged: Lambdaでカスタマイズする独自管理ルール
CloudWatch
- ログ集積基盤、各サービスから集めたログから何ができるかは結局同じ
- フィルタ > メトリクス > アラート
KMS
- ホワイトペーバー記載事項の理解(必ず目を通して下さい)
- 3つの鍵の区分とローテーション、削除の運用
- キーポリシーと、IAMポリシーの併用が必要となるアクセス制御
EC2
- EC2 SSHキーペア、トラブルシューティング
- メタデータ内の公開鍵のありか
- KMSと絡めたEBS、AMI、スナップショットの暗号化できることできないこと
VPC
- ルートテーブル、NAT、NACL、SG、ネットワーク疎通トラブルシューティング
CloudFront
- 地域制限。国単位でブラックリスト、ホワイトリスト指定可能
- OAIによるS3保護
- CloudFront用のSSL証明書は、バージニア北部リージョン(us-east-1)にて設定
- デフォルト証明書
- カスタム証明書(ACM、IAM)
- WAF連携による詳細なアクセス制限
WAF、Shield
- WAFのルールで設定可能なアクセス制限
- クロスサイトスクリプティング
- GEO制限
- IPアドレス
- サイズ
- SQLインジェクション
- 文字列パターンマッチ(ヘッダ、メソッド、クエリ、ボディ)
- Shieldアドバンスドは課金必要
Inspector
- EC2にエージェントをインストールするEC2ホスト診断
- ルールパッケージ4つの違い
- CVE(Common Vulnerabilities and Exposures)共通脆弱性識別子
- 主要なベンダーのソフトウェア製品の脆弱性をチェック
- CIS
- 業界標準のOSレベルのセキュリティベンチマーク
- セキュリティのベストプラクティス
- 主にSSH、パスワードに関するセキュリティチェック
- ネットワーク到達可能性(旧:実行時の振る舞い分析)
- ネットワーク設定を分析して セキュリティ上の脆弱性、ポートをチェック
Trusted Advisor
- SGのポート無制限チェック、IAMのベストプラクティス適合チェック
Lambda
- ファンクションポリシー、実行ロール
SSM
- Patch Manager
- パラメータストア
- Run コマンド
ユースケース
認証情報漏洩、紛失、剥奪
- AWS アクセスキー
- SSH キーペア
- root ユーザーアカウント管理
オンプレミス連携(ADFS)
- データセンターとのセキュアな回線接続
- IAMロール、STS、SAMLをベースとしたADFS仕組みの深い理解
DDoS対策
- ホワイトペーバーのDDos基本対策の理解
- エッジセキュリティとしてのCloudFrontの機能
- L3/L4、はShieldでデフォルト保護
- L7は、WAFで自前保護
- 混同しがちな2つのWAF
- AWS WAF
- 3rdPartyWAF on EC2 (要サンドイッチ)
SSL証明書の運用
- ACMおよびIAMで管理
- CloudFrontは、バージニア北部リージョン(us-east-1)にて設定
- ALBはサービスを展開する任意のリージョンにて設定
- TLSターミネーションはどこでするか
おわりに
今回は、CloudFrontやWAFを設定してみて、curlを投げで遊ぶなど、手を動かしながら楽しく学ぶことでできました。
その他日頃触らないようなAWSサービスに触れてみる良い機会にもなりました。今後受験を検討される方の一助になれば幸いです。
著者関連リンク
- 投稿日:2019-12-09T09:44:27+09:00
AWS SDK for PHPv3でAWS SNSからSMSを送信するよ
おはようございます。パグと申します。
今日は、AWSのSimpleNotificationServiceで「日本国内の携帯電話に」
SMS送信をしてみます。ちょくちょく書き方を忘れてしまうので、備忘録です。
めっちゃ簡単です。use Aws\Sns\SnsClient;←これは読み込んで。 use Aws\Exception\AwsException;←これは別になくてもいいけどまずPHPのComposer.pharでphpSDKのV3を落としておきましょう。
Classの上部でClientを読み込みします。あとIAMで、
SNS操作権限のあるユーザーを作っておきます。$aws = ['credentials' => ['key' => 'IAMで作ったユーザーのキー', 'secret' => 'IAMで作ったシークレットキー'], 'region' => 'ap-northeast-1(環境のあるregion)', 'version' => '2010-03-31'←ここは落としたSDKのVersionにより異なる ];versionの日付を間違えると、あんた!その日付間違ってるわ!って
エラーが出ます。credentialsがうまくいかない人が多そうなので、
配列はこんな感じにするよって参考で書いてみました。普通のIAMユーザーを使ってます。$message = 'AWSから送信しています!'; $replace = substr( $tel , 1 , strlen($tel)-1 ); $phone = "+81".$replace; try { $snsClient = (new SnsClient($aws)); $result = $snsClient->publish([ 'Message' => $message." ".(New Datetime())->format("H:m:i"), 'PhoneNumber' => $phone, ]); } catch (AwsException $e) { // output error message if fails error_log($e->getMessage()); }上から順に説明していくと、
$messageで、送りたいMSGを指定します。
その次の$replaceなんですけど、例えば日本国内に送る場合は、
「09012345678」
という電話番号に送る場合は、前方の前0をとって、
国番号の「+81」をつけます。なので、前ゼロ取ってます。
なので、'phoneNumber'で指定したのは、「+819012345678」という番号になっています。あとはpublishメソッドに渡すだけ〜簡単。
来ましたよ。
ちなみにいろんな電話番号でくるよ
埋め尽くされた!!!!AWSの電話番号なんだけど、一応隠してみたw
最初のキャプチャみたいに他の国からくることもあるし、070番号からくることもある。
100通くらい送ったけど、070の確率が高かったです。簡易SMS認証などに利用できるのではないでしょうか〜。
きになるお値段
Amazon SNS の料金
ここに書いてあるけど、結構良心的。
ではでは、パグでしたー。またねー。



- 投稿日:2019-12-09T09:16:54+09:00
イベントレポート(AWS / インフラエンジニアのスキルアップとキャリア戦略
AWS関連のイベント、セミナーに参加してきましたので、自分に対する備忘も兼ねて要点を纏めておきたいと思います。
・参加イベント
AWS / インフラエンジニアのスキルアップとキャリア戦略
https://engineer_career.splashthat.com/3人の方の豊富な経験から若手に向けたキャリアについてのメッセージを桑原 宜昭 氏がディスカッション形式で進行するイベントでした。
パネルディスカッションは6つのテーマで構成されていました。(自分は遅刻で参加したので、最初の方は聞けませんでした)
技術についてというよりは考え方についての話がメインだったと思います。イベントの概要と主催三者の取り組みについて
遅刻で聞けず。。
塩谷 啓 氏 クラスメソッド株式会社
Gavin Zhou 氏 フリーランス
塚田 朗弘 氏 アマゾン ウェブ サービス ジャパン株式会社
桑原 宜昭 氏 モデレーターパネルディスカッション
技術のこと
議題:AWS登場前と後のインフラの変化について、インフラ技術の今後について
Gavin Zhou 氏・・AWS無ければフリーランスできなかった。(個人ではデータセンター入るなどのセキュリティ条件がクリアできない)
塩谷 啓 氏・・IaC流行るのでアプリとインフラの棲み分けなくなる、DevOpsなどのような運用と開発の線引きはしてほしくない。
塚田 朗弘 氏・・今までは一つのことに集中していたが、AWSに入って仕事の幅が広がった。お金のこと
議題:インフラエンジニアの給与について、フリーランスの単価について
Gavin Zhou 氏・・正社員(大規模会社)年収:700万⇒フリーランス:月次100万
AWS フリーランス中央値単価は80万
組織・チームのこと
塚田 朗弘 氏・・・AWSのベストプラクティスを満たすように動く。
キャリアのこと
Gavin Zhou 氏 ・・・技術あまり関係ない。3~5年やれば大体一緒になる。メンタル重要。好奇心、過去の技術は捨てる。勉強力。
塩谷 啓 氏・・・ スキルのポータビリティ意識する。どこでも通用するスキルとその現場のルールを分けて意識して身につける。
塚田 朗弘 氏・・・ キャリアの今後は分からないので、目の前のことに集中する。常にチャレンジする。
若手エンジニアに伝えたいこと
Gavin Zhou 氏 ・・・英語重要。qiita(日本語)ではなくgithub(英語)を見る。ストレス発散重要。
塩谷 啓 氏・・・ 変化を楽しもう。 健康は命より大事(笑)。
塚田 朗弘 氏・・・やはり英語。あと応用力。お金についての知識。スタートアップするとき。ストックオプション or 株質問
・インフラ提案を通しやすくするアプローチについて
Gavin Zhou 氏・・とりあえずやってみること。アジャイル開発
塚田 朗弘 氏・・相手の目線に立つ
・GPU導入事例を聞きたい
塚田 朗弘 氏・・・Sagemaker事例は増えている。メルカリ:画像検索や自動運転。
- 投稿日:2019-12-09T07:13:13+09:00
AWS Amplify の ServiceWorker で Web Push 対応を実装してみる - クライアント編
Web Push、送りたいことありますよね。
この記事は Web Push 通知を使うアプリを AWS Amplify で作ってみる話です。
特にクライアント側を AWS Amplify でどう実装するかを見てみます。
当初サーバー側もあわせて書こうとしたのですが、分量が多くなりそうだったので今回は一旦クライアント編として、サーバー編はまた Amplify の API カテゴリを絡めたものを後日書きます(たぶん)。Web Push やりたいときにやらなきゃいけないこと
Web Push を運用しようとすると、けっこう色々やることがあります。
- Push を受け取るクライアント側
- Service Worker の実装
- 購読状態管理、Service Worker 登録等を行うフロントアプリケーションの実装
- 購読処理時に払い出されるエンドポイントをサーバーサイドに送信
- Push を送るサーバー側
- 秘密鍵・公開鍵の生成、管理
- クライアントから送られてきたエンドポイント情報をサービスのユーザーと紐付けて保存、管理
- Web Push 送信用ライブラリ を使って適切なタイミングで送信
等々です。Amplify の ServiceWorker クラスはこの中で、特に 1-2. 購読状態管理、Service Worker 登録等を行うフロントアプリケーションの実装 を助けてくれます。
また、その Amplify プロジェクトで Analytics カテゴリを有効にしている場合、ServiceWorker のライフサイクルイベントを自動で収集、可視化してくれる機能も Amplify が提供してくれます。前提条件
仕様
今回は、
- ブロック済でなければページを開いたときにプッシュ通知購読の許可を求める
- 購読の停止、停止後の再購読を行う UI、機能は提供しない ※
- 現在の購読状況(未購読、購読済み、ブロック済み)を表示する
- Push 通知がサポートされていない環境(Safari 等)ではそう表示する
- 購読済みの場合は、プッシュ通知に必要なサブスクリプション情報を表示する
というモノを実装することにします。
※ 実際のサービス運用時には、購読停止の際に Unsubscribe() の実行、サーバーサイドのデータベース更新等が必要になるでしょう
参考にした資料
この記事は以下2つのドキュメント・チュートリアルを参考にしています。
この記事内では AWS Amplify が関わる Web Push の登録・受信部分のみに触れますが、実際のアプリケーションではユーザーの体験を考える上でどんなときにどう購読 ON/OFF の UI を表示すべきかなど、もう少し考えることがあります。
上の 2. のチュートリアルはそういう面にも触れられているのでぜひご覧ください。作業環境
今回は Vue project をベースにします。
$ node -v v12.13.1 $ npm -v 6.9.0 $ npm install -g @vue/cli ... $ vue --version @vue/cli 4.1.1 $ npm install -g @aws-amplify/cli ... $ amplify --version 4.5.0使った環境、ブラウザは↓です。なお、Safari は現在 Push 通知に対応していません。
* macOS High Sierra 10.13.6
* Google Chrome ver.78
* Firefox ver.68.3実装していき
Vue プロジェクト、Amplify プロジェクトの作成
$ vue create amplifywebpush ? Please pick a preset: (Use arrow keys) ❯ default (babel, eslint) ... $ cd amplifywebpush $ npm install aws-amplify aws-amplify-vue $ amplify init ? Enter a name for the project amplifywebpush ? Enter a name for the environment dev ? Choose your default editor: Vim (via Terminal, Mac OS only) ? Choose the type of app that you're building javascript Please tell us about your project ? What javascript framework are you using vue ? Source Directory Path: src ? Distribution Directory Path: dist ? Build Command: npm run-script build ? Start Command: npm run-script serve ? Do you want to use an AWS profile? Yes ? Please choose the profile you want to use yourprofilename ... $ tree -L 1 . ├── README.md ├── amplify ├── babel.config.js ├── node_modules ├── package-lock.json ├── package.json ├── public ├── src └── yarn.lock 4 directories, 5 filesはい
必要な Amplify のモジュール、カテゴリの追加
まず、ServiceWorker クラスは
@aws-amplify/coreパッケージに、Analytics はaws-amplify/analyticsに入っているのでインストールします。$ npm install @aws-amplify/core $ npm install @aws-amplify/analytics次に、Service Worker のライフタイムイベントを集計するため、アプリケーションに Analytics カテゴリを追加します。途中の選択肢は全てデフォルトで Enter を押しています。
$ amplify add analytics $ amplify push ✔ Successfully pulled backend environment dev from the cloud. Current Environment: dev | Category | Resource name | Operation | Provider plugin | | --------- | --------------- | --------- | ----------------- | | Auth | cognito57ed5053 | Create | awscloudformation | | Analytics | amplifywebpush | Create | awscloudformation | ? Are you sure you want to continue? (Y/n) Yes ... $ amplify status
src/main.jsで Amplify を初期化します。import Vue from 'vue'; import App from './App.vue'; import awsconfig from './aws-exports'; import Amplify, * as AmplifyModules from 'aws-amplify'; import { AmplifyPlugin } from 'aws-amplify-vue'; Amplify.configure(awsconfig); Vue.use(AmplifyPlugin, AmplifyModules); Vue.config.productionTip = false; new Vue({ render: h => h(App) }).$mount('#app');この時点では何も UI をいじっていないので、デフォルトの Vue プロジェクトの画面が表示されます。
$ amplify run ... App running at: - Local: http://localhost:8080/ - Network: http://192.168.0.1:8080/ Note that the development build is not optimized. To create a production build, run yarn build.
はい
ServiceWorker の実装
まず、
public/service-worker.jsを次のように実装してみます。/** * Push 通知の受信時に発火するイベント */ addEventListener('push', (event) => { console.log('[Service Worker] Push Received.'); console.log(`[Service Worker] Push had this data: "${event.data.text()}"`); if (!(self.Notification && self.Notification.permission === 'granted')) return; let data = event.data ? event.data.json() : {}; let title = data.title || "Web Push Notification"; let message = data.message || "New Push Notification Received"; let icon = "path/to/image"; let badge = "path/to/image"; let options = { body: message, icon: icon, badge: badge }; event.waitUntil(self.registration.showNotification(title, options)); }); /** * 通知がクリックされたときに発火するイベント * 通知ごとに適切なクリック時の処理を記述。 * 今回は Amplify JavaScript のドキュメントを開くという処理にする。 */ addEventListener('notificationclick', (event) => { console.log('[Service Worker] Notification click: ', event); event.notification.close(); event.waitUntil( clients.openWindow('https://aws-amplify.github.io/amplify-js') ); });これはかなり最小限の実装ですが、色々な API やキャッシュ機能を使った例としては Example Service Worker - Amplify JavaScript や ウェブアプリへのプッシュ通知の追加 - developers.google.com を参照するといいと思います。
ServiceWorker の登録
で、
src/App.vueを次のように実装します。<template> <div> <h2>Amplifyで作るWebPushアプリ</h2> <p>{{ state }}</p> <p>{{ endpointInfo }}</p> </div> </template> <script> import { ServiceWorker } from 'aws-amplify'; const serviceWorker = new ServiceWorker(); const yourPublicKey = 'Paste your public key here'; export default { name: 'app', data(){ return { registeredServiceWorker: null, state: '', endpointInfo: '', } }, methods :{ isPushSupported() { return ('serviceWorker' in navigator && 'PushManager' in window) }, async updateUI() { if (!this.isPushSupported()) { this.state = 'Push 通知がサポートされていない環境'; this.endpointInfo = ''; return; } // 購読状況によって UI を変える if (Notification.permission == 'denied') { // すでに拒否されている this.state = 'ブロック済'; this.endpointInfo = ''; } else { var subscription = await this.registeredServiceWorker.pushManager.getSubscription(); if (subscription) { // 購読済み this.state = '購読済'; this.endpointInfo = JSON.stringify(subscription); } else { // 未購読 this.state = '未購読'; this.endpointInfo = ''; } } }, }, async mounted(){ this.registeredServiceWorker = await serviceWorker.register('/service-worker.js', '/'); if ('permissions' in navigator) { let notificationPermission = await navigator.permissions.query({name:'notifications'}); notificationPermission.onchange = () => { this.updateUI(); }; } if (Notification.permission !== 'denied') { await serviceWorker.enablePush(yourPublicKey); } this.updateUI(); }, } </script>
serviceWorker.enablePush(yourPublicKey)は Push 通知の購読をユーザーに確認し、許可されたら購読処理をすすめるメソッドです。サーバー側で生成する公開鍵を引数に渡しています。この値はあとで置き換えます。これらの行は、割と Amplify が処理を隠蔽してくれているところで、例えば公開鍵は URL エンコードされた Base64 文字列を
UInt8Arrayに変換してから使う必要がありますが、それはenablePush()メソッドが内包しています。
参考: 該当部分の実装 - github.com/aws-amplify/amplify-jsこの状態で、
amplify runしてから Chrome や Firefox でページを開くと、おなじみ?の通知許可が求められます。serviceWorker.enablePush(yourPublicKey)による動作です。
公開鍵の取得と模擬的なサーバーサイドの用意
冒頭で書いたとおり、今回はフロント側について書きたいので、バックエンドは手軽に鍵生成や Push 送信のテストができるコンパニオンサイト、Push Companionを使います。
Push Companionを開くと、Public KeyとPrivate Keyが表示されています。
Public Key をコピーして、
src/App.vueに反映します。[-] const yourPublicKey = 'Paste your public key here'; [+] const yourPublicKey = 'BDirXoCByCLittjLnybgMtlmAl1Oc52zE--QIgU378Z7ljkoiWDjy2F*****************************';アプリケーションを起動して購読してみる
$ amplify run ... App running at: - Local: http://localhost:8080/ - Network: http://192.168.10.13:8080/ブラウザで
http://localhost:8080/を開き、通知許可のダイアログを表示します。
ここで許可(Allow)すると、画面上に JSON 文字列が表示されます。
この JSON 文字列は Subscription 情報などと呼ばれ、サーバーサイドから Push を送信するときの宛先情報にあたるものです。
実際のサービスでは、この後 subscriptionInfo をサーバーサイドに送り、ユーザー情報と紐付けてデータベースに保存しておくなどして、必要なときに必要なユーザーに Push を送信することができるよう管理する必要があるでしょう。
Push を送信、受信してみる
では、いよいよ Push 通知を受信してみます。またコンパニオンサイトに頼ります。
"Subscription to Send To" に、先程の SubscriptionInfo 文字列をコピーして、"Text to Send" に好きなメッセージを書いて "SEND PUSH MESSAGE" をクリックします。単なる文字列を送ってもいいのですが、通常 JSON で送ることが一般的で、今回の Service Worker 側でもそれを期待しているので、次の内容を送ってみます。
{"title": "Hello Amplify!!!", "message": "Amplifyかわいい"}

うまく実装されていれば、次のような通知が表示されます。
Vue アプリケーションのタブを閉じていたり、別 Window を表示したりしていても通知が表示されるでしょうか?通知をクリックしたとき、ちゃんと
service-worker.jsで記述した処理が実行されているでしょうか?確認してみてください。期待通りに動いていれば、これで Amplify を使ったクライアントサイドの Web Push 通知対応ができました。
Analytics の集計情報を見てみる
最初に、Service worker のイベントを集計するために Analytics カテゴリを追加してありました。ちゃんと動いているか見てみましょう。
$ amplify console analyticsAmazon Pinpoint のマネジメントコンソールが開いたら、 Analytics > Events を見てみます。
Filters を有効にすると、次のようなイベントが収集されています。
Amplify が自動的に Service worker のライフサイクルや状態変化、メッセージングなどのイベントを集計してくれています。
補足
開発中に購読状態を変更したいとき
開発中は、一度購読を許可した後にもう一度もとに戻したい、拒否を取り消したいときがたくさんあると思います。
Chrome のアドレスバーのアイコンをクリックすると、そのサイトに対する購読状態を変更することができます。
サーバーサイドの Push 送信実装について
今回はコンパニオンサイトに頼りましたが、実際にサーバーサイドからの Push 送信を自分で実装するときは Web Push 用のライブラリを使って実装することが一般的かと思います。
https://github.com/web-push-libs/
言語別のライブラリがあるので、必要のある方は見てみてください。
その辺の実装は、後日書くサーバー編で触れたいと思います。
その他考慮すること
前提条件にも書きましたが、今回の記事はクライアント側の Amplify に関わる部分にフォーカスしています。
サービスを運用する際は、これら以外に購読済みのユーザーが購読を停止するための UI や処理、ユーザーの Subscription 情報や状況を保存するバックエンドのデータベース等が必要になると思われます。
その辺も後日書くサーバー編に(ryまた、Appiterate による調べでは、不適切で不快な通知はユーザー離反の最も大きな要因になり得ます。ユーザー体験を十分に設計する必要があります。
[AWS Start-up ゼミ] よくある課題を一気に解説! 御社の技術レベルがアップする 2019 春期講習まとめ
- Amplify の
ServiceWorkerクラスは Web Push 購読処理を隠蔽して、ちょっと手軽にしてくれる- Amplify で
Analyticsカテゴリを有効にしていると、自動的に Service worker の挙動をトラッキングしてくれるみんなも Amplify で Web Push 処理しましょう。








- 投稿日:2019-12-09T05:31:57+09:00
AWS Athena で CREATE TABLE する
はじめに
AWS AthenaでCREATE TABLEを実行するやり方を紹介したいと思います。
CTAS(CREATE TABLE AS)は少し毛色が違うので、本記事では紹介しておりません。AWS GlueのCrawlerを実行してメタデータカタログを作成、編集するのが一般的ですが、Crawlerの推論だとなかなかうまくいかないこともあり、カラム数やプロパティが単純な場合はAthenaでデータカタログを作る方が楽なケースが多いように感じます。
S3に配置されたデータに対してテーブルを作成する
CREATE EXTERNAL TABLE構文を用いてテーブルを作成いたします。例として、今回は日本の人口推移データをs3://inu-is-dog/athena/c01.csvに配置しました。
(都合上、csvのヘッダーを英語表記に変更いたしました。)
出典:政府統計の総合窓口(e-Stat)(https://www.e-stat.go.jp/)配置されるデータは構造体が同じならば同じ階層に複数存在しても問題ありません。例えば、同じ構造体のc02.csvがs3://inu-is-dog/athena/c02.csvのように配置されていても大丈夫です。
csvの中身をエクセルで開くとこんな感じになります。
では、テーブルの作成を行なっていきます。今回はデフォルトで配置されている"default"のデータベースに"population_table"というテーブルを作成するためには以下のクエリを実行します。
CREATE EXTERNAL TABLE IF NOT EXISTS default.population_table ( code string, prefecture string, era_name string, japanese_calender int, year int, comment string, all_population bigint, man_population bigint, woman_population bigint ) ROW FORMAT SerDe 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' WITH SerDeProperties ("field.delim" = ",", "escapeChar"="\\", "quoteChar"="\"") STORE AS TEXTFILE LOCATION 's3://inu-is-dog/athena/' TBLPROPERTIES ('has_encrypted_data'='false', 'skip.header.line.count'='1', 'serialization.encoding'='SJIS')このクエリを例に1つずつ構文の解説をしていきます。(わかりやすいものから紹介していきます)
STORE AS
データ形式を指定します。省略した場合はTEXTFILEが適用されます。
主要なオプションは以下の通りです。
- SEQUENCEFILE
- TEXTFILE
- RCFILE
- ORC
- PARQUET
- AVRO
- INPUTFORMAT input_format_classname OUTPUTFORMAT output_format_classname
LOCATION
データの配置場所を意味します。フォルダ名またはバケット名を指定します。
ファイル名を指定しないように注意しましょう。
今回は 's3://inu-is-dog/athena/' を指定しております。TBLPROPERTIES
テーブルのプロパティを設定します。今回の場合は以下のように設定されております。
- 'has_encrypted_data'='false'
=> S3の暗号化がされていない
- 'skip.header.line.count'='1'
=> csvファイルの1行目はヘッダーなのでスキップする
- 'serialization.encoding'='SJIS'
=> 文字コードはSJIS
余談ですが、TBLPROPERTIESはCREATE TABLE後、ALTER TABLEで変更できます。
ALTER TABLE table_name SET TBLPROPERTIES ('property_name' = 'property_value' [ , ... ])ROW FORMAT
SerDe(シリアライザー/デシリアライザー)を設定です。
設定方法は2通りで
- ROW FORMATを省略するか、ROW FORMAT DELIMITEDを指定しネイティブSerDeを使用する
- SerDe句を使用する
今回は後者のSerDe句を使用しております。
SerDe句を設定する場合、推奨設定は以下になります。
データ形式がCSV(or TSV)の場合
データに引用符(シングルクォーテーションやダブルクォーテーション)が含まれないならば、LazySimpleSerDeを使用します。(TSVの場合、区切り文字を
FIELDS TERMINATED BY '\t'として指定)データに引用符(シングルクォーテーションやダブルクォーテーション)が含まれるならば、OpenCSVSerDeを使用します。OpenCSVSerDeでは、区切り文字、引用符、およびエスケープ文字をROW FORMAT SERDEの後に記述するWITH 部分で指定できます。
今回はOpenCSVSerDeのorg.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe ライブラリを使用し、
区切り文字を
,エスケープ文字を\\に、引用符を\"に設定しております。WITH SERDEPROPERTIES ("field.delim" = ",", "escapeChar"="\\", "quoteChar"="\"")他にもSerDeのプロパティを設定することができます。
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' WITH SERDEPROPERTIES ( 'serialization.format' = ',', 'field.delim' = ',', 'collection.delim' = '|', 'mapkey.delim' = ':', 'escape.delim' = '\\' )データ形式がJSONの場合
Hive JSON SerDe (ライブラリ名:org.apache.hive.hcatalog.data.JsonSerDe) または OpenX JSON SerDe (ライブラリ名:org.openx.data.jsonserde.JsonSerDe) を使用します。
Hive JSON SerDeに対して、OpenX JSON SerDeは以下のオプションを使用できるのが特徴です。
ignore.malformed.json
不正なJSONフォーマットを無視できるdots.in.keys
キーに含まれるドットをアンダーバーに置換する(Athenaではカラム名にドットがあるとエラーになる)case.insensitive
キーの文字列内の大文字、小文字を区別するColumnToJsonKeyMappings
カラム名をJSONキーにマップするデータ形式がApache Avroの場合
Avro SerDe の org.apache.hadoop.hive.serde2.avro.AvroSerDe ライブラリを使用する
データ形式がORC(Optimized Row Columnar)の場合
ORC SerDe の org.apache.hadoop.hive.ql.io.orc.OrcSerde ライブラリを使用する
または、 ZLIB圧縮を使用する。
STORED AS ORC LOCATION 's3://inu-is-dog/athena/' tblproperties ("orc.compress"="ZLIB");データ形式がParquetの場合
Parquet SerDe の org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe ライブラリを使用する
または、SNAPPY圧縮を使用する。
STORED AS PARQUET LOCATION 's3://inu-is-dog/athena/' tblproperties ("parquet.compress"="SNAPPY");Apache WebServerの場合
RegexSerDe の org.apache.hadoop.hive.serde2.RegexSerDe ライブラリを使用する
CloudTrailログの場合
CloudTrail SerDe の com.amazon.emr.hive.serde.CloudTrailSerde ライブラリを使用する
ALTER TABLE table_name SET TBLPROPERTIES ('property_name' = 'property_value' [ , ... ])PARTITION BYでパーティションテーブルを作成する
パーティション分割されたテーブルを作成するにはPATITION BY句を使用する必要があります。
例えば、csvを s3://inu-is-dog/athena/c01.csv 、s3://inu-is-dog/athena/c02.csvではなく、
s3://inu-is-dog/athena/vol1/c01.csv 、s3://inu-is-dog/athena/vol2/c02.csvと配置したとしましょう。
vol1とvol2がパーティションであることを認識させるためには、先ほどのCREATE TABLE文に
PARTITIONED BY (vol string)を以下のように追記する必要があります。CREATE EXTERNAL TABLE IF NOT EXISTS default.population_table ( code string, prefecture string, era_name string, japanese_calender int, year int, comment string, all_population bigint, man_population bigint, woman_population bigint ) PARTITIONED BY (vol string) ROW FORMAT SerDe 'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe' WITH SerDeProperties ("field.delim" = ",", "escapeChar"="\\", "quoteChar"="\"") STORE AS TEXTFILE LOCATION 's3://inu-is-dog/athena/' TBLPROPERTIES ('has_encrypted_data'='false', 'skip.header.line.count'='1', 'serialization.encoding'='SJIS')これでパーティション分割されたテーブルが出来上がります。
Athenaは読み込まれたデータの分だけ課金されるのでWHERE句でパーティション指定することは料金の節約にもつながるので重要です。
例えば、↓の場合、vol2のパーティションは読み込まれません、
SELECT * FROM default.population_table WHERE vol = 'vol1'また、パーティションテーブルはS3のプレフィックス2パターンあります。
- パーティションの値そのまま s3://inu-is-dog/athena/vol1/, s3://inu-is-dog/athena/vol2/ など
- パーティション名と値を=で指定する s3://inu-is-dog/athena/vol=1/, s3://inu-is-dog/athena/vol=2/ など
これでどのように変わるのかというと、新しいパーティションテーブルを認識させる方法が変わります。
例えば、CREATE TABLEで新しくテーブルを作成した後、新しくvol3のプレフィックスを追加したくなったとしましょう。
プレフィックスをs3://inu-is-dog/athena/vol3/とした場合、このパーティションテーブルを認識させるには、以下のクエリを実行必要があります。
ALTER TABLE default.population_table ADD PARTITION (vol='vol3') location 's3://inu-is-dog/athena/vol3/'それに対して、プレフィックスをs3://inu-is-dog/athena/vol=3/とした場合、
ALTER TABLE default.population_table ADD PARTITION (vol='3') location 's3://inu-is-dog/athena/vol=3/'だけでなく、
MSCK REPAIR TABLE default.population_tableでも新しいパーティションテーブルを認識させることができます。
新しいパーティションテーブルが複数ある場合、前者だとADD PARTITONをひたすら実行しなければいけないのに対して後者は1つのクエリで完結するのでスマートですね。
おわりに
今回はAthenaのCREATE TABLEについて紹介させていただきました。
経験上、SerDeがうまくいかないことが多かったのでその一助になればと思います。
