- 投稿日:2019-11-29T23:14:15+09:00
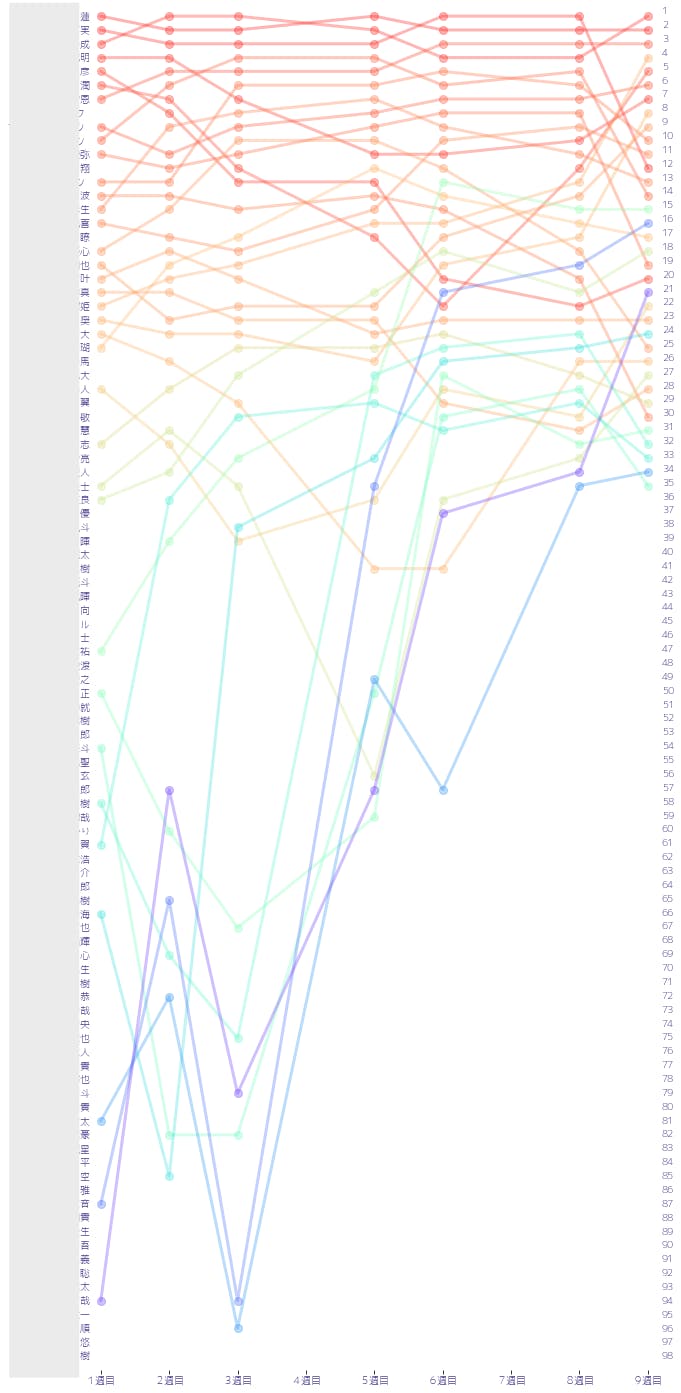
スクレイピングによるProduce 101 Japan練習生順位の可視化
Produce 101 Japanとは
PRODUCE 101 JAPAN OFFICIAL SITE
韓国から輸入されたオーディション番組の日本版で、歌手デビューしてほしい練習生への投票結果が週ごとに発表される番組です。
週が進むと、60位、35位と足切りが進んで脱落者が出てしまいます。今回は公式サイトからランキング結果をスクレイピングによって抽出し、
最新順位(2019/11/29時点で9週目)までに生き残っている練習生の順位変動を可視化してみました。出来上がりの完成図
練習生の名前は一部伏せております。
主な流れ
- スクレイピング
- データ整形
- ランキングを可視化
1. スクレイピングによりランキングを取得する
週ごとの順位を個別に収集できるように関数化。
BeautifulSoupを用いてHTMLの要素を取得しテキスト化。
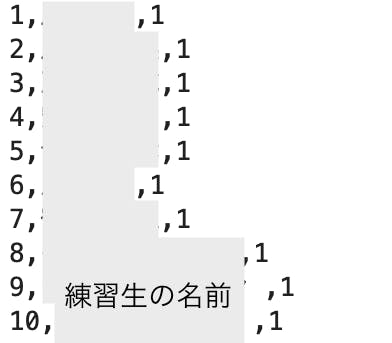
「順位,名前,週」の形で取得します(一部のみ表示しています)。
def getWeeklyRank(week): import requests from bs4 import BeautifulSoup import re # 数字でフォーマットしてランキングページのURLを取得 url = 'https://produce101.jp/rank/?week={}' html = requests.get(url.format(week)) # URLをBeautifulSoupで扱う soup = BeautifulSoup(html.text, 'lxml') # 特定のクラスのspan要素とdiv要素を取得する span_rank = soup.find_all("span", class_="icon-rank") div_name = soup.find_all("div", class_="name") # rankとnameが入っているタグのテキスト成分をリストに抽出する rank = [] for i in range(len(span_rank)): rank.append(int(span_rank[i].text)) name = [] for i in range(len(div_name)): name.append(div_name[i].text) # weeklyRankingをcsvに保存 # 1週目のみ新規作成で次週からは追加モードで書き込む if week == 1: f = open('./weeklyRank.txt', 'w') for i in range(len(rank)): f.write(str(rank[i])+','+str(name[i])+','+str(week)+'\n') f.close() elif week > 1: f = open('./weeklyRank.txt', 'a') for i in range(len(rank)): f.write(str(rank[i])+','+str(name[i])+','+str(week)+'\n') f.close()週ごとに関数を実行し、ランキングを取得。
(自動的にすべてを取得した方がかっこいいですが、今回は地道に取得していきます。)getWeeklyRank(1) getWeeklyRank(2) getWeeklyRank(3) # 4週目は順位発表なし getWeeklyRank(5) getWeeklyRank(6) # 7週目は順位発表なし getWeeklyRank(8) getWeeklyRank(9)2. データ整形によってグラフ化しやすい形式にする
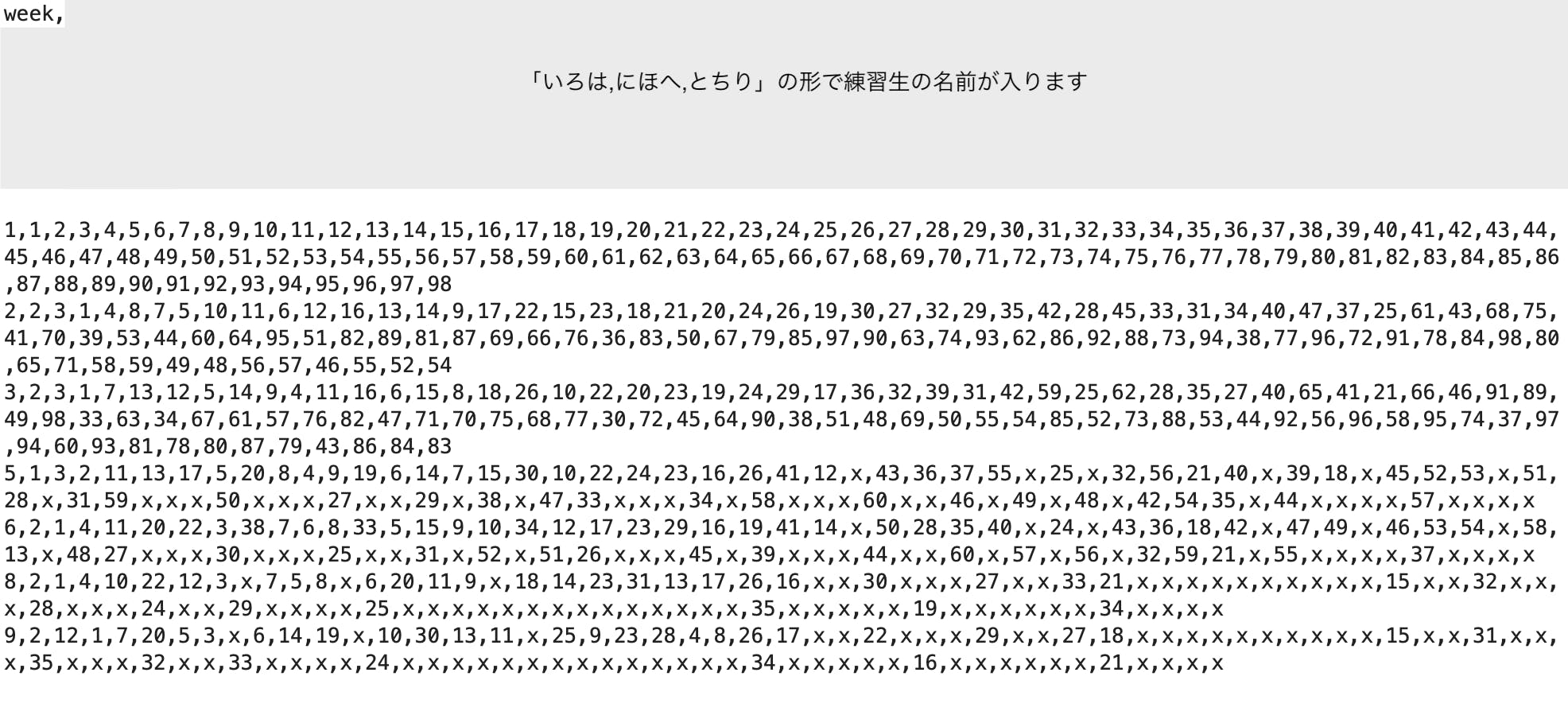
「*辞退」などの名前以外の要素を消し、列見出しを週と名前にしてランキングを入力していく形に整形します。
途中で脱落した練習生の順位は「x」で置き換えておきます。
# 辞退の表記を消す f = open('weeklyRank.txt', 'r') data_lines = f.read() data_lines = data_lines.replace(' ※辞退', '') f.close() f = open('weeklyRank.txt', 'w') f.write(data_lines) f.close()HTMLから取得したランキングデータを整形します。
5週目で60位までの足切り、8週目で35位までの足切りがあり、人数が変化するので個別に対応していきます。def getWeeklyRank_format(data_path): import pandas as pd df_rank = pd.read_csv(data_path,header=None, names=('rank', 'name', 'week')) df = df_rank[['name','week','rank']] df_week1 = df_rank[df_rank['week'] == 1] df_week5 = df_rank[df_rank['week'] == 5] df_week8 = df_rank[df_rank['week'] == 8] f = open('./weeklyRank_format.txt', 'w') f.write('week') # week1のメンバーを取得 name_week1 = [] for e in range(len(df_week1)): dfe = df[(df['week'] == 1) & (df['rank'] == e+1)] nameArray = dfe['name'].values[0] f.write(str(','+nameArray)) name_week1.append(str(nameArray)) # week5のメンバーを取得 name_week5 = [] for e in range(len(df_week5)): dfe = df[(df['week'] == 5) & (df['rank'] == e+1)] nameArray = dfe['name'].values[0] name_week5.append(str(nameArray)) f.write('\n') # week8のメンバーを取得 name_week8 = [] for e in range(len(df_week8)): dfe = df[(df['week'] == 8) & (df['rank'] == e+1)] nameArray = dfe['name'].values[0] name_week8.append(str(nameArray)) f.write('\n') # 1週目の練習生順位を列見出しとし、それ以降の順位を変数として記入していく for i in range(1,10): if i==1 or i==2 or i==3: # 0列目にweekを書く f.write(str(i)) # 次に1週目の並びで練習生の順位を取得する for j in range(0, len(name_week1)): dfi = df[(df['week'] == i) & (df['name'] == name_week1[j])] f.write(str(','+str(dfi['rank'].values[0]))) elif i==4: continue elif i==5 or i==6: # 0列目にweekを書く f.write(str(i)) # 次に1週目の並びで練習生の順位を取得する for j in range(0, len(name_week1)): if name_week1[j] in name_week5: dfk = df[(df['week'] == i) & (df['name'] == name_week1[j])] f.write(str(','+str(dfk['rank'].values[0]))) elif name_week1[j] not in name_week5: f.write(',x') elif i==7: continue elif i==8 or i==9: # 0列目にweekを書く f.write(str(i)) # 次に1週目の並びで練習生の順位を取得する for j in range(0, len(name_week1)): if name_week1[j] in name_week8: dfk = df[(df['week'] == i) & (df['name'] == name_week1[j])] f.write(str(','+str(dfk['rank'].values[0]))) elif name_week1[j] not in name_week8: f.write(',x') f.write('\n') f.close()関数を実行する。
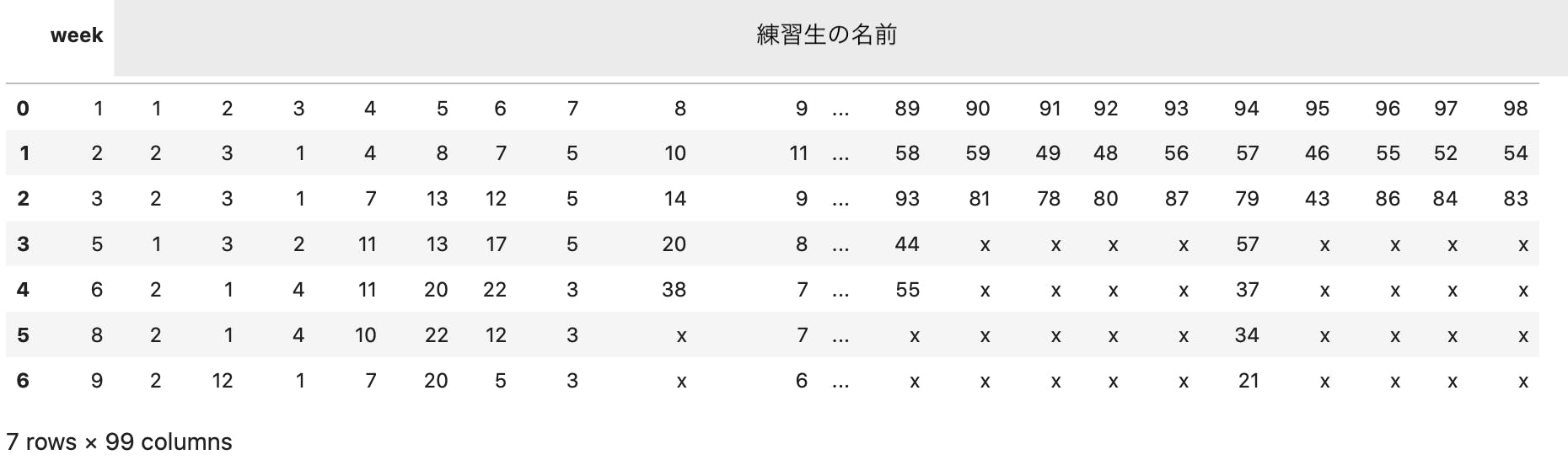
getWeeklyRank_format('./weeklyRank.txt')うまくいったか確認してみましょう。
import pandas as pd df_rank = pd.read_csv('./weeklyRank_format.txt',header=0) df_rank
3. ランキングを可視化する
今回は見栄えを意識して、ダウンロードしたフォント: JKゴシックLを使って日本語表記をしていきます。
# 1週目から9週目までの練習生ランキング # フォントをカスタマイズする import matplotlib.pyplot as plt %matplotlib inline import numpy as np # ttfファイルを直接指定してフォントを適用する import matplotlib.font_manager fp = matplotlib.font_manager.FontProperties(fname='/Users/[USER NAME]/.matplotlib/fonts/ttf/JKG-L_3.ttf') # フィールドを設定 fig, axs = plt.subplots(figsize=(10,25)) x = df_rank['week'] axs.set_xlim(0.94,9.1) axs.set_xticks([1, 2, 3, 4, 5, 6, 7, 8, 9]) axs.set_ylim(99, 0.6) axs2 = axs.twinx() labels = list(df_rank.columns[1:])[0:] axs.set_yticks(list(np.arange(1,99))) axs.set_yticklabels(labels, fontproperties=fp, color='darkslateblue') axs.set_xticklabels(['1週目', '2週目', '3週目','4週目', '5週目', '6週目', '7週目', '8週目', '9週目'], rotation=0, fontsize=14, fontproperties=fp, color='darkslateblue') axs.spines['top'].set_visible(False) axs.spines['bottom'].set_visible(False) axs.spines['right'].set_visible(False) axs.spines['left'].set_visible(False) axs.tick_params(left=False) labels2 = list((np.arange(0,99))) axs2.set_yticks(list(np.arange(1,99))) axs2.set_yticklabels(labels2[99:0:-1], fontproperties=fp, color='darkslateblue') axs2.set_ylim(0,98) axs2.spines['top'].set_visible(False) axs2.spines['bottom'].set_visible(False) axs2.spines['right'].set_visible(False) axs2.spines['left'].set_visible(False) axs2.tick_params(right=False) # 折れ線の色を虹色に cmap = plt.get_cmap('rainbow') for i in range(1, 99,1): y = df_rank[df_rank.columns[i]] if 'x' in list(y): continue else: axs.plot(x,y,color=cmap(1-i/100),marker='o',markersize=8,linewidth = 3, alpha=0.3)これでグラフが完成するはずです。
条件を設定すれば、順位を大幅にアップさせた練習生などが可視化できます。
- 投稿日:2019-11-29T22:36:38+09:00
共分散の逐次更新〜式の導出と実装まで
きっかけ
同じ研究室のメンバーの方から、分散共分散行列の逐次更新がしたいけど何かいい方法はないか、という相談を受けました。そこで見つけたのがこの記事。ここでは平均と分散の逐次更新に関する式の導出を行っています。そこの部分に関する詳しい内容は当該サイトを参照してください。
ここでは、このサイトでは詳細に触れられなかった共分散に関する式の導出を行い、分散共分散行列をPython3で計算します。共分散の導出
文字と重要な式の確認
導出する前に使用する文字や関係式を書いておきます。結構な量の変形をしますので、式を追う途中で分からなくなったらここに戻って考えてみてください。
データ
$x=(x_1,x_2,\ ...\ ,x_n),\ y=(y_1,y_2,\ ...\ ,y_n)$データの平均
$\overline{x_n}=\frac{1}{n}\sum_{i=1}^nx_i\ ,\ \overline{y_n}=\frac{1}{n}\sum_{i=1}^ny_i$共分散
$s_{xy}^{n}=\frac{1}{n}\sum_{i=1}^n{\left(x_i\ -\ \overline{x_n}\ \right)\left(y_i\ -\ \overline{y_n}\ \right)}$平均値に関する漸化式
$\overline{x_{n+1}}\ -\ \overline{x_{n}}\ =\ \frac{1}{n+1}\left(x_{n+1}\ -\ \overline{x_n}\right)\cdots\star$共分散の漸化式を導出
さあ本題です!ここから式をいじっていきますが、粘り強くついてきてくださいね!
$M_n=ns_{xy}^n$ として、$M_{n+1}-M_n$ の計算を行います。これが求まれば共分散の漸化式は簡単に求められますから。\begin{align} M_{n+1}-M_n &= \sum_{i=1}^{n+1}\left(x_i\ -\ \overline{x_{n+1}}\ \right)\left(y_i\ -\ \overline{y_{n+1}}\ \right) -\sum_{i=1}^n\left(x_i\ -\ \overline{x_n}\ \right)\left(y_i\ -\ \overline{y_n}\ \right)\\ &= \sum_{i=1}^{n+1}\left(x_iy_i\ -\ x_i\overline{y_{n+1}}\ -\ \overline{x_{n+1}}y_i\ +\ \overline{x_{n+1}}\ \overline{y_{n+1}}\right)\\ &\ -\sum_{i=1}^n\left(x_iy_i\ -\ x_i\overline{y_{n}}\ -\ \overline{x_{n}}y_i\ +\ \overline{x_{n}}\ \overline{y_{n}}\right)\\ &=x_{n+1}y_{n+1}\ +\ (n+1)\overline{x_{n+1}}\ \overline{y_{n+1}}\ -\ n\overline{x_n}\ \overline{y_n}\\ &\ -\underline{\left(\overline{y_{n+1}}\sum_{i=1}^{n+1}x_i\ +\ \overline{x_{n+1}}\sum_{i=1}^{n+1}y_i\ -\ \overline{y_{n}}\sum_{i=1}^nx_i\ -\ \overline{x_{n}}\sum_{i=1}^ny_i\right)}\cdots\ast \end{align}さて、ここまで大丈夫ですか?ここで一旦下線を引いた部分を(1)としてここの計算をしていきましょう。
簡単のために次の2つの文字を導入します。
$A_n=\sum_{i=1}^nx_i\ ,\ B_n=\sum_{i=1}^ny_i$
さあ、(1)を片付けて行きましょう!\begin{align} (1) &=\overline{y_{n+1}}\ A_{n+1}\ +\ \overline{x_{n+1}}\ B_{n+1}\ -\ \overline{y_n}\ A_n\ -\ \overline{x_n}\ B_n\\ &=2\left(\frac{1}{n+1}A_{n+1}B_{n+1}\ -\ \frac{1}{n}A_nB_n\right)\\ &=2\left\{(n+1)\ \overline{x_{n+1}}\ \overline{y_{n+1}}\ -\ n\ \overline{x_n}\ \overline{y_n}\right\} \end{align}はい、きれいになりました!これを先ほどの下線部に代入して行きましょう。
\begin{align} \ast&=x_{n+1}y_{n+1}\ +\ (n+1)\ \overline{x_{n+1}}\ \overline{y_{n+1}}\ -\ n\ \overline{x_n}\ \overline{y_n}-2\left\{(n+1)\ \overline{x_{n+1}}\ \overline{y_{n+1}}\ -\ n\ \overline{x_n}\ \overline{y_n}\right\}\\ &=x_{n+1}y_{n+1}\ -(n+1)\ \overline{x_{n+1}}\ \overline{y_{n+1}}\ +\ n\ \overline{x_n}\ \overline{y_n}\\ &=x_{n+1}y_{n+1}\ -(n+1)\underline{\left(\overline{x_{n+1}}\ \overline{y_{n+1}}\ -\ \overline{x_n}\ \overline{y_n}\right)}\ -\ \overline{x_n}\ \overline{y_n}\cdots\ast\ast \end{align}2つ目の下線です。ここを(2)として計算していきます。
\begin{align} (2)&=\left(\overline{x_{n+1}}\ -\ \overline{x_n}\right)\left(\overline{y_{n+1}}\ -\ \overline{y_n}\right)+\overline{x_{n+1}}\ \overline{y_n}+\overline{x_{n}}\ \overline{y_{n+1}}\ -2\ \overline{x_{n}}\ \overline{y_n}\\ &=\left(\overline{x_{n+1}}\ -\ \overline{x_n}\right)\left(\overline{y_{n+1}}\ -\ \overline{y_n}\right)+\overline{y_n}\left(\overline{x_{n+1}}\ -\overline{x_n}\right)+\overline{x_n}\left(\overline{y_{n+1}}\ -\overline{y_n}\right)\\ &=\frac{x_{n+1}-\overline{x_n}}{n+1}\cdot \frac{y_{n+1}-\overline{y_n}}{n+1}+ \overline{y_n}\ \frac{x_{n+1}-\overline{x_n}}{n+1}+\overline{x_n}\ \frac{y_{n+1}-\overline{y_n}}{n+1}\ (\because\ \star)\\ &=\frac{1}{n+1}\left\{ \frac{1}{n+1}\left(x_{n+1}-\overline{x_n}\right)\left(y_{n+1}-\overline{y_n}\right)+\overline{y_n}\ \left(x_{n+1}-\overline{x_n}\right)+\overline{x_n}\ \left(y_{n+1}-\overline{y_n}\right)\right\} \end{align}さあ、あともう少しでゴールです!
\begin{align} \ast\ast&=x_{n+1}y_{n+1}\ -\frac{1}{n+1}\left(x_{n+1}-\overline{x_n}\right)\left(y_{n+1}-\overline{y_n}\right)-\overline{y_n}\ \left(x_{n+1}-\overline{x_n}\right)-\overline{x_n}\ \left(y_{n+1}-\overline{y_n}\right)-\overline{x_n}\ \overline{y_n}\\ &=\frac{n}{n+1}\ x_{n+1}y_{n+1}\ -\ \frac{n}{n+1}\ x_{n+1}\overline{y_n}\ -\ \frac{n}{n+1}\ \overline{x_n}\ y_{n+1}\ +\frac{n}{n+1}\ \overline{x_n}\ \overline{y_n}\\ &=\frac{n}{n+1}\ \left(x_{n+1}\ -\ \overline{x_n}\right)\ \left(y_{n+1}\ -\ \overline{y_n}\right) \end{align}これでメインの変形は終了です。最後の仕上げをしていきます。
M_{n+1}-M_n=\frac{n}{n+1}\left(x_{n+1}\ -\ \overline{x_n}\right)\left(y_{n+1}\ -\ \overline{y_n}\right)\\ \therefore\ M_{n+1} = \frac{n}{n+1}\left(x_{n+1}\ -\ \overline{x_n}\right)\left(y_{n+1}\ -\ \overline{y_n}\right)\ +\ M_n\\ \therefore\ s_{xy}^{n+1}\ =\ \frac{n}{(n+1)^2}\left(x_{n+1}\ -\ \overline{x_n}\right)\left(y_{n+1}\ -\ \overline{y_n}\right)\ +\ \frac{n}{n+1}s_{xy}^nこれで漸化式の完成です。
Pythonで実装
漸化式ができたので実際にPythonで実装しましょう。今回は「ベクトルが逐次的に与えられ、そのベクトル集合の分散共分散行列を求めたい」というモチベーションの下、実装を行います。
import numpy as np def calc(next_val,times,var_cov_mat=None): ''' 計算を行う ''' if times > 1: # 分散共分散行列の更新 var_cov_mat = np.outer(next_val,n_mean)*(times/(times+1)**2) + var_cov_mat*times/(times+1) else: # 初期状態を定義、分散共分散行列=単位行列 var_cov_mat = np.identity(len(next_val)) return next_mean, var_cov_matこれで完成。あとはデータをどんどん入れていけば分散共分散行列を逐次的に得ることができます。
検証
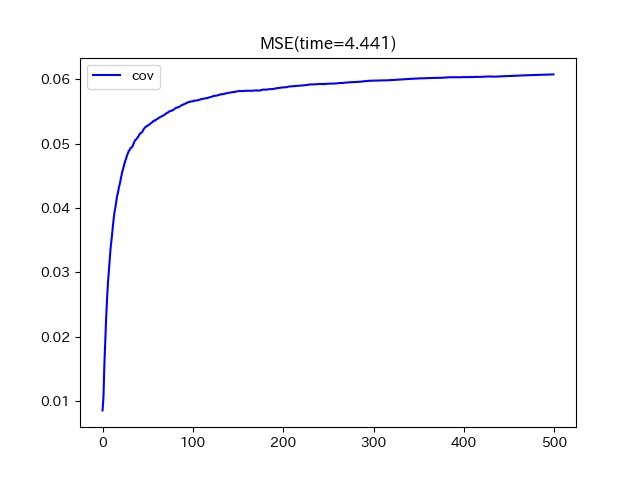
今回は512次元のベクトルを使います。ベクトルの各成分は0以上1未満の数値をランダムに与えました。
比較方法は上記の手法で求めた行列と、1回ずつnumpyで計算した行列の成分毎にみた平均二乗誤差の推移をみます。
結果はこちら。
500回の計算を4秒ちょっとで行い、おおよそ0.06くらいまでに収まるように推移しています。
まとめ
今回は共分散の逐次更新を可能にする共分散の漸化式を導出し、Pythonによる実装を行いました。計算結果はきれいに書けていると思いますが、「もっときれいに書けた!」という方がいらっしゃいましたらぜひ教えてください。
実装に関しては、初めの導入で書いた通り、相談を受けたところからスタートしており、受けた相談の内容を反映させる形で実装していますので、他の形で実装したいというときは前半の式の部分を使って実装していただければ良いと思います。ここからは本筋とは関係ありませんが、この式変形は結構大変でした。もし、式変形に興味がありましたら、上述の部分で空いている穴を埋めてみるのも良いかもしれません。結構丁寧に埋めたつもりなので、埋める場所がないと思ったら初めから自力で計算してみても面白いかもしれません。
参考にしたサイト
- 投稿日:2019-11-29T22:27:02+09:00
Pytest現在時刻テスト(日時固定)
Pytestで時刻を固定してテストする
Pythonで現在時刻を返すメソッドをテストしたいって場面に出くわしたのでメモ
日付を固定できる freezegun が便利!環境
- Python 3.7.5
- pytest-5.2.4
pytestの場合、pytestのプラグインとして
pytest-freezegunがあります。
pytestのmarkerとして@pytest.mark.freeze_timeが追加されます。test_sample.pyfrom datetime import datetime import pytest @pytest.mark.freeze_time('2019-11-27 11:23:23') def test_time(): assert datetime.today() == datetime(2019, 11, 27, 11, 23, 23)importしても大丈夫
get_today.pydef dateget(): return datetime.datetime.today()test_sample.pyfrom datetime import datetime import pytest import get_today @pytest.mark.freeze_time('2019-11-27 11:23:23') def test_time(): assert get_today.dateget() == datetime(2019, 11, 27, 11, 23, 23)$ python -m pytest test_sample.py plugins: freezegun-0.3.0.post1 collected 1 item test_sample.py . ==== 1 passed in 0.07 seconds ====補足:〇分前でテストしたい
現在時刻から〇分前(minutes=update_span)のところをいじれば〇時間前や〇日前も可能
test_sample.py@pytest.mark.freeze_time('2019-11-27 11:23:23') def test_time(): correct_value = datetime(2019, 11, 27, 11, 20, 23) subtracted_time = datetime.now() - timedelta(minutes=3) assert subtracted_time == datetime(2019, 11, 27, 11, 20, 23)
- 投稿日:2019-11-29T22:20:47+09:00
条件にあわせてsqlalchemyのfilterを動的に生成する
概要
sqlalchemyを利用した以下のような実装を見た。
渡されたユーザーリストから絞るか、テーブル全体から絞るかの差だけのメソッドであり、
(他の条件が完全に一致している)
修正を考えると共通化したほうがいいと思って解決方法を調べた。def get_specified_age_users_from_user_list(user_name_list={}, age): """ 指定されたユーザーの中で特定年齢のユーザーをUserテーブルから取得する """ users = session.query(User).\ filter(users.age==age).\ filter(users.name.in_(user_name_list)).\ all() return users def get_specified_age_users(age): """ 特定年齢のユーザーをUserテーブルから取得する """ users = session.query(User).\ filter(users.age==age).\ all() return users解決策
tuple形式にした条件をand_メソッドに渡す。from sqlalchemy import and_ def get_specified_age_users(user_name_list={}, age): filters = [] # 引数が渡された場合のみ条件を追加する if user_name_list: filters.append(User.name.in_(user_name_list)) # and_の引数はtupleである必要があるのでtuple化している users = session.query(User).\ filter(and_(*filters)).\ all() return users # 実行されるSQL ## 指定ありの場合 SELECT 省略 FROM users WHERE users.name IN (%s) ## 指定なしの場合 SELECT 省略 FROM users
- 投稿日:2019-11-29T22:11:32+09:00
M5Stack+GoogleCloudPlatformで天気予報を表示する
IoTLT Advent Calendar 2019の4日目を担当します、ニアムギです。
「M5Stackに天気予報を表示」となんともベタな内容ですが、いい感じに汎用性のある仕組みが出来たので紹介したいと思います。
家族にも好評で、日ごろ使ってくれているのも嬉しいところです。見た目
直近3日の天気予報を表示します。天気マークは長男に書いてもらいました。
このような感じで表示されます。
※実際は30秒ほどかかります…仕組み
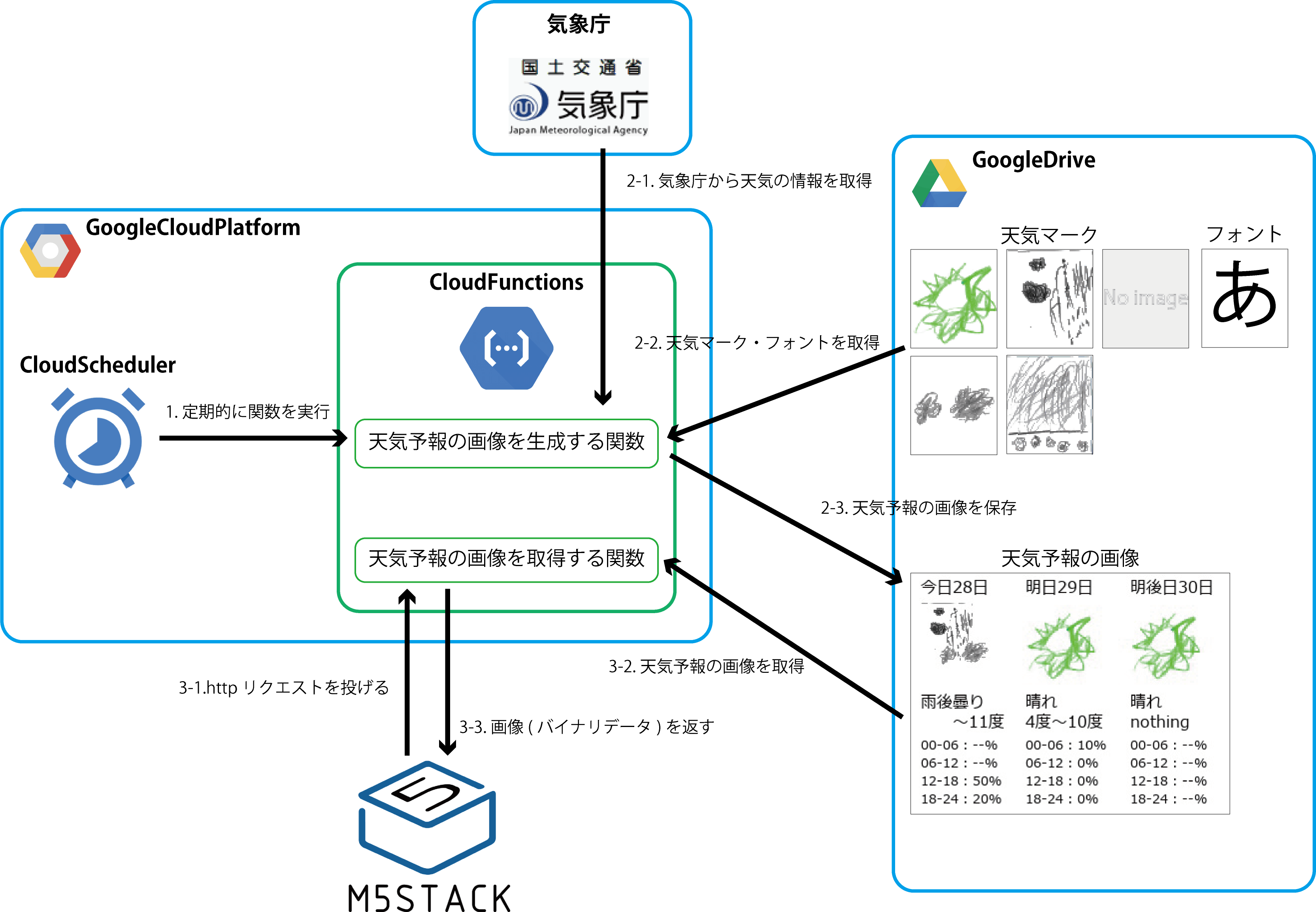
天気予報の画像を「生成する」と「取得する」の2つに分かれます。
- GoogleCloudPlatform(GCP)のCloudSchedulerで定期的に「天気予報の画像を生成する関数」を実行します。
- GCPのCloudFunctionsで天気予報の画像を作成、GoogleDriveに保存します。
- M5Stackからhttpリクエストで「天気予報の画像を取得する関数」を実行し、画像を取得します。
(詳細)画像生成について
ポイントとなるところを列挙していきます。
天気予報を取得する
気象庁の天気予報にアクセスしてデータを取得しています。
CloudFunctionsでファイルを扱う
クラウド上で動くCloudFunctionsでファイルを扱いたい場合、/tmpフォルダに保存できます。
つまり、GoogleDriveで取得したファイルを/tmpフォルダに保存することで、ローカル環境と同じようにファイルを扱えます。GoogleDriveにアクセスするための準備
あらかじめアクセスに必要なクライアントID・クライアントシークレット・リフレッシュトークンを取得しておきます。
こちらについては以前dotstudioさんのブログに書かせていただきました。NefryBTからGoogleDriveにデータをアップロードする方法をご参照ください。GoogleDriveを操作する
※ここはかなり細かい内容です。
GoogleDriveにアクセスするためにいくつか機能を用意します。GoogleDriveにアクセスするサービスを取得する関数
先ほどのクライアントID・クライアントシークレット・リフレッシュトークンを使ってGoogleDriveにアクセスするサービスを取得します。
「python リフレッシュトークン Google API: oauth2client.client を使用して更新トークンから資格情報を取得する」を参考にしました。def getDriveService(): CLIENT_ID = os.getenv("drive_client_id") CLIENT_SECRET = os.getenv("drive_client_secret") REFRESH_TOKEN = os.getenv("drive_refresh_token") creds = client.OAuth2Credentials( access_token=None, client_id=CLIENT_ID, client_secret=CLIENT_SECRET, refresh_token=REFRESH_TOKEN, token_expiry=None, token_uri=GOOGLE_TOKEN_URI, user_agent=None, revoke_uri=None, ) http = creds.authorize(httplib2.Http()) creds.refresh(http) service = build("drive", "v3", credentials=creds, cache_discovery=False) return serviceファイル名で検索してIDを取得する関数
GoogleDrive内のデータはそれぞれIDが割り振られています。
IDでデータの取得や更新を行うため、IDの検索が必要となります。def searchID(service, mimetype, nm): """Driveから一致するIDを探す """ query = "" if mimetype: query = "mimeType='" + mimetype + "'" page_token = None while True: response = ( service.files() .list( q=query, spaces="drive", fields="nextPageToken, files(id, name)", pageToken=page_token, ) .execute() ) for file in response.get("files", []): if file.get("name") == nm: return True, file.get("id") page_token = response.get("nextPageToken", None) if page_token is None: breakフォントデータを取得する関数
CloudFunctionsはクラウド上で動くため、日本語のフォントはおそらく使えないと思います。(試してないです)
そのためフォントをGoogleDriveから取得します。
mimetypeは"application/octet-stream"です。def getFontFromDrive(service, fontName): """フォントをDriveから取得、tmpフォルダに保存する """ ret, id = searchID(service, "application/octet-stream", fontName) if not ret: return None request = service.files().get_media(fileId=id) fh = io.FileIO("/tmp/" + fontName, "wb") # ファイル downloader = MediaIoBaseDownload(fh, request) done = False while done is False: status, done = downloader.next_chunk() return "/tmp/" + fontName画像データを取得する関数
天気マークを取得します。
mimetypeは"image/png"です。def getImageFromDrive(service, imageName): """画像をDriveから取得、tmpフォルダに保存する """ ret, id = searchID(service, "image/png", imageName) if not ret: return False request = service.files().get_media(fileId=id) fh = io.FileIO("/tmp/" + imageName, "wb") # ファイル downloader = MediaIoBaseDownload(fh, request) done = False while done is False: status, done = downloader.next_chunk() return True画像データをアップロードする関数
生成した天気予報の画像をGoogleDriveにアップロードします。
def uploadData(service, mimetype, fromData, toData, parentsID="root"): """ Driveにアップロードする """ try: media = MediaFileUpload(fromData, mimetype=mimetype, resumable=True) except FileNotFoundError: return False # IDを検索、該当するデータがある場合は上書きする。 ret, id = searchID(service, mimetype, toData) if ret: file_metadata = {"name": toData} file = ( service.files() .update(fileId=id, body=file_metadata, media_body=media, fields="id") .execute() ) else: file_metadata = {"name": toData, "parents": [parentsID]} file = ( service.files() .create(body=file_metadata, media_body=media, fields="id") .execute() ) return True一連の流れ
上記で用意した関数を使って、天気予報の画像をGoogleDriveにアップロードします。
def CreateImgWeather(event, context): """ get weatherImage and upload to drive for M5stack """ # 1. GoogleDriveにアクセスするサービスを取得 driveService = getDriveService() # 2. フォントを取得 fontPath = getFontFromDrive(driveService, "meiryo.ttc") if not fontPath: return False # 3. 天気マークを取得 if not getImageFromDrive(driveService, "noImage.png"): return False if not getImageFromDrive(driveService, "fine.png"): return False if not getImageFromDrive(driveService, "cloud.png"): return False if not getImageFromDrive(driveService, "rain.png"): return False if not getImageFromDrive(driveService, "snow.png"): return False # 4. 天気予報の画像を生成 weatherList = getWeekWeather() ret = createImg(fontPath, "/tmp/imgWeather.jpeg", weatherList) if not ret: return False # 5. GoogleDriveにアップロード ret = uploadData( driveService, "image/jpeg", "/tmp/imgWeather.jpeg", "imgWeather.jpeg" ) if not ret: return False return True(詳細)画像取得について
M5Stack側
詳細はソースを参照ください。
httpのPOSTリクエストでCloudFunctionsの関数にアクセスします。
こちらもまた、dotstudioさんの「HTTP通信でリクエストを投げる」を参考にしました。[ホスト名] = "[プロジェクト名].cloudfunctions.net" [関数名] = "getDriveImage_M5stack"; [ポート番号] = 443; POST /[関数名] HTTP/1.1 Host: [ホスト名]:[ポート番号] Connection: close Content-Type: application/json;charset=utf-8 Content-Length: + [ポストするjsonデータのサイズ] [ポストするjsonデータ]jsonデータ形式で以下のようなリクエストを投げます。
{ "drive" : { "img" : "[ファイル名]", "trim" : "[分割の番号]" } }一度に取得できるデータ量の都合で8分割にしています。そのため8回POSTリクエストを投げます。
CloudFunctions側
M5StackからのPOSTリクエストに合わせて、天気予報の画像を取得します。
そして8分割にしたバイナリーデータを返します。ソースを載せておきます。
import sys import os import io from io import BytesIO import numpy as np from PIL import Image import httplib2 from googleapiclient.discovery import build from oauth2client import client, GOOGLE_TOKEN_URI from apiclient.http import MediaIoBaseDownload def getDriveService(): ~画像生成と同じ~ def searchID(service, mimetype, nm): ~画像生成と同じ~ def downloadData(mimetype, data): # GoogleDriveにアクセスするサービスを取得 drive_service = getDriveService() # IDを検索 ret, id = searchID(drive_service, mimetype, data) if not ret: return False, None # 天気予報の画像を検索 request = drive_service.files().get_media(fileId=id) fh = io.BytesIO() downloader = MediaIoBaseDownload(fh, request) done = False while done is False: status, done = downloader.next_chunk() return True, fh.getvalue() def devideImage_M5stack(imgBinary, _trim): """M5Stack用に画像を分割する。返値はイメージデータ """ imgNumpy = 0x00 # 入力データの確認 if _trim.isnumeric(): trimPos = int(_trim) if trimPos <= 0 or trimPos > 8: return False else: return False # 画像の分割 # 1 2 3 4 # 5 6 7 8 Trim = [ (0, 0, 80, 120), (80, 0, 160, 120), (160, 0, 240, 120), (240, 0, 320, 120), (0, 120, 80, 240), (80, 120, 160, 240), (160, 120, 240, 240), (240, 120, 320, 240), ] # PILイメージ <- バイナリーデータ img_pil = Image.open(BytesIO(imgBinary)) # トリミング im_crop = img_pil.crop(Trim[trimPos - 1]) # numpy配列(RGBA) <- PILイメージ imgNumpy = np.asarray(im_crop) return True, imgNumpy def getBinary(img): """画像をバイナリデータへ変換 """ ret = "" pilImg = Image.fromarray(np.uint8(img)) output = io.BytesIO() pilImg.save(output, format="JPEG") ret = output.getvalue() return ret def getDriveImg_Binary(imgName, trim): """googleDriveに保存してある画像を取得する。返値はバイナリーデータ。 """ img = 0x00 # Driveから画像(バイナリーデータ)を取得 ret, imgBinary = downloadData("image/jpeg", imgName) if not ret: print("...error") return "" print(ret, len(imgBinary)) # 画像を分割する # ※M5Stack専用 if trim is not None: isGet, img = devideImage_M5stack(imgBinary, trim) if not isGet: return "" # バイナリデータに変換する imgBinary = getBinary(img) return imgBinary def getDriveImage_M5stack(request): imgName = "" trim = "0" # リクエストデータ(JSON)を変換 request_json = request.get_json() # GoogleDriveへのアクセス情報を取得 if request_json and "drive" in request_json: imgName = request_json["drive"]["img"] trim = request_json["drive"]["trim"] else: return "" # トリムした天気予報の画像を取得する ret = getDriveImg_Binary(imgName, trim) return ret応用
この仕組みの良いところは、「画像さえ用意すればM5Stackに表示できる」ことです。
つまり天気予報に限らず、スケジュールやタスクなど何にでも対応できます。M5Stack側は取得する画像名を設定するだけです。
また画像をM5Stackの外で生成しているので、画像を修正したいときにM5Stackのプログラムを触る必要はありません。以下はGoogleカレンダーを表示させたパターンです。(予定はモザイクかけています)
まとめ
今回M5Stackに合わせた画像表示システムを作れたことで、応用パターンをいくつか考えるようになりました。M5Stackのディスプレイは食卓にちょうど良い大きさなので色々と活用したいと思います。
何かの参考になれば幸いです。ではでは。
参考
NefryBTからGoogleDriveにデータをアップロードする方法
python リフレッシュトークン Google API: oauth2client.client を使用して更新トークンから資格情報を取得する
HTTP通信でリクエストを投げる


- 投稿日:2019-11-29T19:23:36+09:00
【ImageJ Fiji, Python】砂嵐画像を任意のピクセル数で簡単に生成する方法
砂嵐画像
こういうやつです。
Shaderで任意のピクセル数の砂嵐画像がほしいな~となったので作成する方法を調べました。
もっと楽な方法あったら教えて下さい。
ImageJ Fijiとは?
ImageJとは、Java というプログラミング言語で書かれた画像解析のためのソフトウェアです。
Fiji はその ImageJ の種類の内の一つで、元々の ImageJ に様々な機能が追加されているパッケージです。オープンソースである ImageJ は、研究者・開発者により機能の追加が容易にできます。Fiji is just ImageJ (Fiji こそがまさに ImageJ だ)と表現されるように、Fiji はオープンソースである ImageJ の利点を最大限に活かして多くの機能が追加され、まとめられています。
Fiji をインストールすれば多くの機能を利用することができます。例えば、超解像顕微鏡の一つであるSTOMのデータ解析のためのプラグインが含まれています。また、Java 以外のプログラミング言語で ImageJ を操作したり機能の追加をする機能も付属しています。
【引用元】:ImageJ について
手順
まずはImageJ Fijiをダウンロードします。
ダウンロードリンクダウンロード完了したら
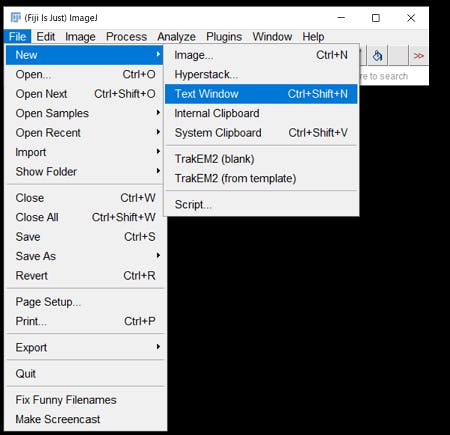
ImageJ-win64.exeを起動します。画像の通りに
Text Windowを開きます
Editorの言語設定をPythonにします。
コード
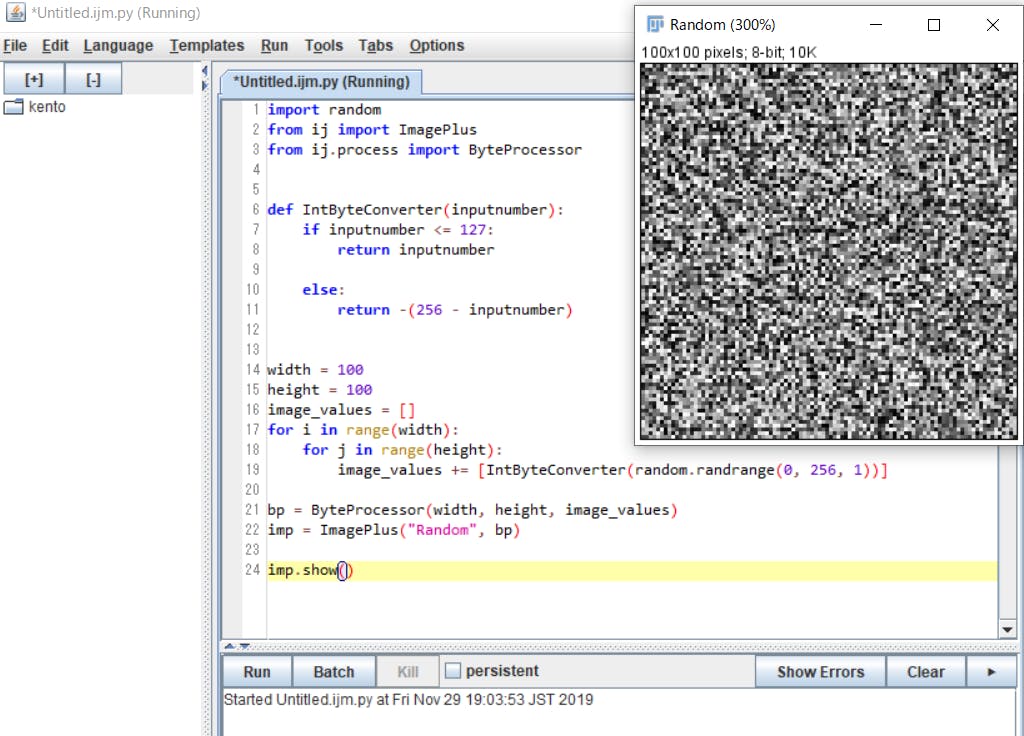
バイオ系だけどプログラミング始めました より拝借import random from ij import ImagePlus from ij.process import ByteProcessor def IntByteConverter(inputnumber): if inputnumber <= 127: return inputnumber else: return -(256 - inputnumber) width = 100 height = 100 image_values = [] for i in range(width): for j in range(height): image_values += [IntByteConverter(random.randrange(0, 256, 1))] bp = ByteProcessor(width, height, image_values) imp = ImagePlus("Random", bp) imp.show()Runを押すと画像が生成されます。
あとはCtrl+Sで画像を保存すればOKです。
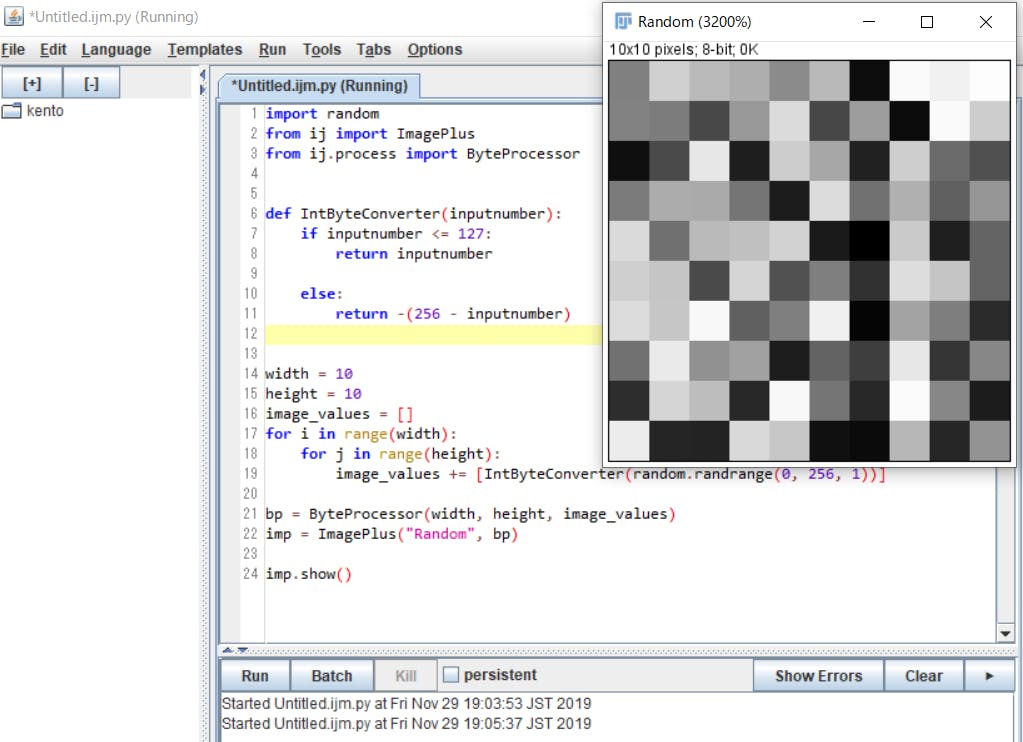
砂嵐のピクセル数を変更したい場合は下記の箇所の数値を変えれば可能です。
width = 10 height = 10
参考リンク

- 投稿日:2019-11-29T19:23:36+09:00
【ImageJ Fiji,Python】砂嵐画像を任意のピクセル数で簡単に生成する方法
砂嵐画像
こういうやつです。
Shaderで任意のピクセル数の砂嵐画像がほしいな~となったので作成する方法を調べました。
もっと楽な方法あったら教えて下さい。
ImageJ Fijiとは?
ImageJとは、Java というプログラミング言語で書かれた画像解析のためのソフトウェアです。
Fiji はその ImageJ の種類の内の一つで、元々の ImageJ に様々な機能が追加されているパッケージです。オープンソースである ImageJ は、研究者・開発者により機能の追加が容易にできます。Fiji is just ImageJ (Fiji こそがまさに ImageJ だ)と表現されるように、Fiji はオープンソースである ImageJ の利点を最大限に活かして多くの機能が追加され、まとめられています。
Fiji をインストールすれば多くの機能を利用することができます。例えば、超解像顕微鏡の一つであるSTOMのデータ解析のためのプラグインが含まれています。また、Java 以外のプログラミング言語で ImageJ を操作したり機能の追加をする機能も付属しています。
【引用元】:ImageJ について
手順
まずはImageJ Fijiをダウンロードします。
ダウンロードリンクダウンロード完了したら
ImageJ-win64.exeを起動します。画像の通りに
Text Windowを開きます
Editorの言語設定をPythonにします。
コード
バイオ系だけどプログラミング始めました より拝借import random from ij import ImagePlus from ij.process import ByteProcessor def IntByteConverter(inputnumber): if inputnumber <= 127: return inputnumber else: return -(256 - inputnumber) width = 100 height = 100 image_values = [] for i in range(width): for j in range(height): image_values += [IntByteConverter(random.randrange(0, 256, 1))] bp = ByteProcessor(width, height, image_values) imp = ImagePlus("Random", bp) imp.show()Runを押すと画像が生成されます。
あとはCtrl+Sで画像を保存すればOKです。
砂嵐のピクセル数を変更したい場合は下記の箇所の数値を変えれば可能です。
width = 10 height = 10
2019/11/30 追記
かなり短く書ける方法を教えて頂きました。
ニッチなAPIを使った場合
— Kota Miura (@kotapub) November 29, 2019
from ij.gui import NewImage
imp = NewImage.createByteImage("noise", 100, 100, 1, NewImage.GRAY8 + NewImage.FILL_BLACK)
imp.getProcessor().noise(100)https://t.co/L64UBLB8BJ()from ij.gui import NewImage imp = NewImage.createByteImage("noise", 10, 10, 1, NewImage.GRAY8 + NewImage.FILL_BLACK) imp.getProcessor().noise(100) imp.show()java.lang.IllegalArgumentException
保存したPythonファイルを指定して実行する際にこのエラーが出ました。
保存先のディレクトリ名にマルチバイト文字が含まれているとダメっぽいです。参考リンク
- 投稿日:2019-11-29T18:44:51+09:00
LINEで対話型botを作るときのコツ
こんにちは、株式会社LIFULLの二宮です。私は今年、LINE botのプロトタイプ実装に関わっていました。
LINEの開発では、Pythonなどの言語でSDKも用意されていて、簡単なbotであれば簡単に作り始められます。ただ、ある程度以上複雑なアプリケーションを作ろうとすると、実装はシナリオの管理や、FlexMessageのjsonの生成など、少し実装に苦戦すると思います。
次に実装する方のために、私が主にLINE botの実装で工夫した点を共有します。
シナリオを設定ファイルで管理できるようにした
設定ファイルで対話のシナリオをある程度一望できるようにしました。
senarioの中のtrigger_messageで正規表現を設定し、それにマッチした場合にendpointで設定されているコントローラーが呼び出されるような実装しています。config.json// jsonの仕様上、コメントは入れられませんが、便宜上入れています { "scenario": { "initial": { "trigger_message": "botを起動する", "endpoint": "controllers.initial", "possible_replies": [ "initial" ] }, // 商品を検索する応答。postback eventで "method: first_search, target: 本" のような値が動的に送られる想定 "search_products": { "trigger_message": "method: search_products, target: (?P<target>[\\s\\S]+)", "endpoint": "controllers.search_products", "possible_replies": [ "selection" ] }, // デフォルトの選択肢 "default": { "endpoint": "controllers.default", "possible_replies": [ "default" ] } }, "replies": { "initial": { "view": "views.initial", "template": [ { "mode": "text", "text": "呼び出したい機能を選んでね" }, { "mode": "flex", "template": "flex_messages/buttons.tpl.json", "alt_text": "選択肢" } ] }, "products": { "view": "views.search_result", "template": [ { "mode": "text", "text": "商品を探してみたよ" }, { "mode": "flex", "template": "flex_messages/products.tpl.json", "alt_text": "おすすめの商品" } ] } } }botとの対話の有限オートマトンを考えて、botのメッセージが状態を、ユーザーの次の遷移をボタンで選ぶようなイメージで作ってます。ただ、postback eventの内容を設定ファイルではなくメッセージの中で作ってしまっているので、ユーザーがどんな遷移を行うのかまでは管理していません。
私はPythonで実装したので、コントローラーの呼び出しはimportlibを駆使して行いました。また、私はjsonで実装してしまったのですが、コメントができないのがきついので、yamlにするか、例えばDjangoのディスパッチャのように、入力となるメッセージと実行したいクラスを紐付けるようなスクリプトを書けるようにするほうが良いかもしれません。
trigger_messageは正規表現でパースして、コントローラーでは以下のように引数として呼び出すようになっています。今回はpostback eventとして「ユーザーがこちらの用意したボタンを押す」ようなものなので正規表現をトリガーにしました(post)が、もし自由文応答するならDialogflowなどのツールで、Context(起動するコントローラー)とEntity(その引数)を設定できるようにします。script/controllers/search_products/__init__.pyfrom script.controllers._utils import AbstractController, Response, render, UserContext from script.models import search_model class Controller(AbstractController): """最初の選択肢を出すコントローラー""" def call(self, user_context: UserContext, target: str) -> Response: """コントローラーの呼び出し処理 Args: user_context: idなどをラップしたクラス target: 正規表現の名前付きキャプチャでパースした内容 Returns: ユーザーへの返信 """ products = search_model.search(target) return render("initial", proc=lambda view: view.render(products=products))FlexMessageの組み立てをテンプレートエンジン(jinja2)で行った
LINEではFlexMessageと呼ばれる自由度の高いレイアウトのメッセージを使うことができます。
そのためにはFlexMessageの複雑なjsonを組み立て、LINEのReply APIを送信する必要があります。私は最初Pythonの辞書でFlexMessageを作っていたのですがなかなかキツく、こちらの記事を参考にテンプレートエンジン(jinja2)のテンプレートを用意し、viewでそれに当てはめる実装をしました。
ただし Simulator を使ってデザインした場合、これをSDKのモデルに書き直すのは面倒です。ソースも長くなります。
このような場合にはテンプレートエンジンを使ってJSONに値を埋め込み、結果をSDKのモデルに変換したほうが良さそうです。
JSONからモデルを構築するにはnew_from_json_dict()というメソッドが用意されています。私はjinja2で実装しましたが、他の言語やライブラリでもやることはさほど変わらないと思います。
https://palletsprojects.com/p/jinja/
{ "type": "carousel", "contents": [ {% for product in products %} { "type": "bubble", "body": { "type": "box", "layout": "vertical", "contents": [ { "type": "box", "layout": "horizontal", "contents": [ { "type": "image", "url": {{ product.image | json_escape }}, "size": "full", "aspectMode": "cover", "action": { "type": "uri", "uri": {{ product.url | json_escape }} } } ] }, // 以下略こちらの
json_escapeの実態はjson.dumpsで、「文字列をエスケープして"をつけ、正しいjsonが組み立てられるようにする」という処理を行っています。class JsonTemplete(object): ENV = Environment(loader=FileSystemLoader( str(Path(__file__).resolve().parent / "../templetes"), encoding='utf8')) ENV.filters["json_escape"] = json.dumps # 以下略これを
new_from_json_dictというメソッドでSDKで読み込んで利用します。def __build_contents(self, content): """FlexSendMssage内のコンテナの型を振り分ける。 Args: content (dict): コンテナの情報 Returns: BubbleContainer/CarouselContainer: FlexSendMessage内のコンテナ """ t = content["type"] if t == "bubble": return BubbleContainer.new_from_json_dict(content) elif t == "carousel": return CarouselContainer.new_from_json_dict(content) else: raise RuntimeError(f"未対応のcontainerです: {t}")ただ「jsonとしては文法が正しいが、LINEのメッセージの仕様は満たしていない」ケースに、デバッグが少し厄介だという問題は残っています。これは良い解決方法を思いつかないので教えてください。
その他LINEのプロジェクトで苦戦した点
ユーザーのスマホ機種や設定で、FlexMessageの見た目が変わってしまい(例えば想定より文字が大きくて改行が入ってしまい)、思っていた見た目にならないことがありました。文字サイズも細かく指定できないので、あまり凝ったデザインは目指さないほうが良いです。
また、他の記事でもよく言われていますが、FlexMssageSimulatorで見た目を調整し、テンプレートでボタンの内容を埋め込んで実装するとスムーズです。
さいごに
この記事が、これからチャットボットの実装にとりかかる方の参考になると嬉しいです。
この記事はLIFULL Advent Calendarの1日目の記事です。こちらも引き続きよろしくお願いします。
- 投稿日:2019-11-29T18:24:20+09:00
Git Hookにより自動でBlenderのレンダリング・FBXエクスポートを行う
はじめに
本記事は三重大学 計算研 Advent Calendar 2019 二日目です。
サークルでゲーム開発をする際に、Blenderで制作した3DモデルデータもGitでバージョン管理しました。
ゲーム開発でBlenderのファイルを使うためにはFBXにエクスポートしたものを使うほうが都合が良いです。そこで今回Git Hookという機能を用いることで、
Git Pushを実行した際に自動でサムネイル用画像レンダリング ・ FBXエクスポートが行われるようにしました。これにより、作業が自動化できただけでなく、FBXエクスポートの設定ミスが無くなる、Blendファイルを編集した際のFBXファイルの更新忘れが無くなるというメリットもありました。
今回はGit Hookについての紹介と実際にBlenderにて自動エクスポートを行うための作業について紹介します。
Git Hookとは
Gitの標準の機能であり、特定のGitの作業を行った際にスクリプトを実行できるものです。
種類としては
- クライアント
- pre-commit : コミットメッセージ入力直前にスクリプト実行
- prepare-commit-msg : コミットメッセージ入力用エディタ起動直前にスクリプト実行。デフォルトメッセージを編集したりできる
- commit-msg : コミットメッセージ編集後にスクリプト実行
- pre-push : Push実行直前にスクリプト実行 ← 今回はこれを用いる
- pre-rebase : rebase実行直前にスクリプト実行。ゼロ以外を返せば処理を中断できる。
などがあります。
これらを使えば、
- コミットする前に自動でテスト等を行ったり(pre-commit)
- デフォルトのコミットメッセージを変更したり(prepare-commit-msg)
- 入力されたコミットメッセージが規定にそっているかを調べたり(commit-msg)
が出来ます。
他にもサーバーサイドのもありますが、今回はクライアントサイドのpre-pushを用いて、
Git Pushを行った際に自動でレンダリング、エクスポートを行えるようにします。今回実現すること
developブランチにて、Blendファイルを配置し
Git Pushすると自動で
- 画像レンダリング
- FBX生成
- masterブランチに生成したFBXファイルを配置しコミット
が行われるようになります。
想定されるディレクトリ構成は以下のようなものです。
<Push前のDevelopブランチ> ├─Scripts : 自動レンダリング、FBXエクスポート用のスクリプトを置く。具体的な内容は後述する。 └─ProjectName │ ├─blend : blendファイルを置くディレクトリ │ │ aaa.blend │ │ bbb.blend │ │ ccc.blend │ └─Textures : テクスチャを置くディレクトリ <Push後のDevelopブランチ> ├─Scripts └─ProjectName │ aaa.fbx : [自動生成]blend/aaa.blendをFBXエクスポートしたもの │ bbb.fbx : [自動生成]blend/bbb.blendをFBXエクスポートしたもの │ ccc.fbx : [自動生成]blend/ccc.blendをFBXエクスポートしたもの │ ├─blend │ │ aaa.blend │ │ bbb.blend │ │ ccc.blend │ ├─image : [自動生成]レンダリング画像が置かれるディレクトリ └─Textures : テクスチャを置くディレクトリ <Push後のmasterブランチ> └─ProjectName │ aaa.fbx │ bbb.fbx │ ccc.fbx │ └─TexturesdevelopブランチにてBlendファイルとテクスチャファイルを配置し、Pushすると、
自動でレンダリング、FBX生成がされ、
FBXファイルとテクスチャファイルをmasterにCheckoutします。開発環境
今回はWindows 10にて、
- Blender 2.8
- Git version 2.23.0.windows.1
で行いました。
作業手順
1. BlenderにPathを通す
まずは、Blender.exeにPathを通します。
環境変数のPathにBlenderのインストールディレクトリを追加します。
Blender公式サイトからインストーラーをダウンロードしてきてインストールした場合は、
"C:\Program Files\Blender Foundation\Blender"
がインストールディレクトリになると思います。環境変数の編集方法は
https://qiita.com/sta/items/6d29da0dc7069ffaae60
が参考になると思います。2. レンダリングを行うためのスクリプト
次に、レンダリングを行うためのスクリプトとして、
Scripts/render.pyに以下の内容で保存します。import bpy bpy.context.scene.render.resolution_x = 1920 bpy.context.scene.render.resolution_y = 1080 bpy.context.scene.render.resolution_percentage = 25 path = bpy.context.blend_data.filepath.rstrip(bpy.path.basename(bpy.context.blend_data.filepath)) + "../image/" + bpy.path.basename(bpy.context.blend_data.filepath).split(".")[0] +".png" bpy.data.scenes["Scene"].render.filepath = path bpy.ops.render.render( write_still=True )これにより、blend/aaa.blendであれば、image/aaa.pngにレンダリング結果が保存されます。
今回はサムネイル画像用のレンダリングなので解像度を1920x1080の25%に指定しています。
3. FBXエクスポートを行うためのスクリプト
次に、FBXエクスポートを行うためのスクリプトとして、
Scripts/ExportFBX.pyに以下の内容で保存します。import bpy,sys def fbx_export_geometry(arg_filepath='./export.fbx'): bpy.ops.export_scene.fbx( filepath=arg_filepath, object_types={'ARMATURE', 'MESH'}, bake_anim=False, ) # 出力対象の種別 # 'EMPTY':エンプティ # 'CAMERA':カメラ # 'LAMP':ランプ # 'ARMATURE':アーマチュア # 'MESH':メッシュ # 'OTHER':その他 return # 関数の実行 path = bpy.context.blend_data.filepath.rstrip(bpy.path.basename(bpy.context.blend_data.filepath)) + "../" + bpy.path.basename(bpy.context.blend_data.filepath).split(".")[0] +".fbx" fbx_export_geometry(path)これにより、blend/aaa.blendであれば、aaa.fbxにFBXエクスポートされます。
また、ここでカメラやランプを除いて、アーマチュアとメッシュのみをFBXエクスポートしています。
4. 2つのPythonスクリプトを呼び出すためのスクリプト
それでは、この2つのPythonスクリプトを呼び出すためのスクリプトを用意します。
Scripts/convert.shに以下の内容で保存します。#!/bin/bash log=$(pwd)/gitPush.sh.log echo "[$(date)] start" >> $log echo "[Messeage by convert.sh]cd git top level dir(" `git rev-parse --show-toplevel` ")" cd `git rev-parse --show-toplevel` for raw in $(git log origin/develop..develop --stat | grep ".blend") ; do if [ ${raw##*.} = "blend" ]; then echo "[Messeage by convert.sh] blend file is ${raw}" echo "[Messeage by convert.sh] Start Render.py" blender --background ${raw} --python Scripts/Render.py echo "[Messeage by convert.sh] Start ExportFBX.py" blender --background ${raw} --python Scripts/ExportFBX.py fi done echo '[Messeage by convert.sh] git commit -m "Auto Generate FBX/render image"' git add *.fbx git add *.png git commit -am "Auto convert FBX and render image"ログ用のechoの行が挟まっていますが、内容としては、
- Gitのトップレベルディレクトリに移動
- gitのlogから、変更が加わったblendファイルの名前を取得
- 変更が加わったblendファイルに対して、画像レンダリング(Render.py)、FBXエクスポート(ExportFBX.py)を実行する
- FBXファイルとレンダリングpng画像を
git addするgit commitするとなっています。
Git Hook pre-pushの設定
最後に、これまで作成してきたスクリプトをGit Hook pre-pushにて実行されるようにします。
Gitリポジトリには
.gitディレクトリが存在しますが、.git/hooks/に"pre-push"というファイル名でシェルスクリプトを保存します。
すると、Git Push実行直前にこのスクリプトが実行されるようになります。直接ここにファイルを置いてもいいですが、
.git/hooks/はGit監視下では無いので、シンボリックリンクを置いて作業しました。ちなみに、WindowsのPowerShellでのシンボリックリンクの貼り方は、下のコマンドになります。
New-Item -Type SymbolicLink .git/hooks/pre-push -Value Scripts/hooks/pre-pushpre-pushファイルには以下の内容で保存します。
#!/bin/sh remote="$1" url="$2" z40=0000000000000000000000000000000000000000 while read local_ref local_sha remote_ref remote_sha do if [[ "${remote_ref##refs/heads/}" = "develop" ]]; then `git rev-parse --show-toplevel`/Scripts/convert.sh git checkout master git checkout develop `git rev-parse --show-toplevel`'/ProjectName/*.fbx' git checkout develop `git rev-parse --show-toplevel`'/ProjectName/Textures/*' git commit -m "[Auto commit] Add FBX from develop" git checkout develop git push origin master fi done
- 作業しているブランチがdevelopかを調べる
<Gitのトップレベルディレクトリ>/Scripts/convert.shを実行。(ここで自動レンダリング、FBXエクスポートを行う)- テクスチャファイルと、自動生成したFBXファイルをMasterブランチにcheckout
- masterを
git commit- masterを
git push- といった内容です。
以上により、developブランチにBlendファイルとテクスチャをpushするだけで、自動で
- レンダリング
- FBXエクスポート
- developブランチにレンダリング画像とFBXをcommit
- masterブランチにFBXとテクスチャをCheckout
- masterブランチの
git commit&pushが行われるようになります。
さいごに
今回、blendファイルが更新されたら自動でFBXも更新するシステムを作ろうとして、Git Hookを使ってみました。
最初はCI/CDが必要なのかな...と思ってGitHub Actionsを試していたのですが、Blenderでレンダリングを行う際にサーバーサイドにGPUが必要なので悩んでいたところ、サークルの先輩にGit Hookを紹介してもらいました。
結果としてやりたかったことが実現でき、さらにクライアント側で完結するコンパクトなシステムになったと思います。
また、Git Hookで呼び出すためにBlender Pythonスクリプトも初めて使ってみましたが、これによりレンダリング・FBXエクスポートの設定ミスが無くなり、特にFBXエクスポートで誤ってランプやカメラを含んでしまいUnityで読み込んだ際におかしくなる問題が無くなりました。
これまでは自動化のモチベーションはあまりなかったのですが、自動化によるメリットをいくつも得れた良い機会でした。
Git Hookには他にもいろいろな発火タイミングがあるので、便利に使っていきたいと思います。
参考文献
- 投稿日:2019-11-29T18:24:20+09:00
Git Hookをつかって、Pushしたら自動でBlenderのレンダリング、エクスポートを行う
はじめに
本記事は三重大学 計算研 Advent Calendar 2019 二日目です。
サークルでゲーム開発をする際に、Blenderで制作した3DモデルデータもGitでバージョン管理しました。
ゲーム開発でBlenderのファイルを使うためにはFBXにエクスポートしたものを使うほうが都合が良いです。そこで今回、Git Hookという機能を用いることで、
Git Pushを実行した際に自動でレンダリング 、 FBXエクスポートが行われるようにしました。これにより、作業が自動化できただけでなく、FBXエクスポートの設定ミスが無くなる、Blendファイルを編集した際のFBXファイルの更新忘れが無くなるというメリットもありました。
今回はGit Hookについての紹介と実際にBlenderにて自動エクスポートを行うための作業について紹介します。
Git Hookとは
Gitの標準の機能であり、特定のGitの作業を行った際に、スクリプトを実行できるものです。
種類としては、
- クライアント
- pre-commit : コミットメッセージ入力直前にスクリプト実行
- prepare-commit-msg : コミットメッセージ入力用エディタ起動直前にスクリプト実行。デフォルトメッセージを編集したりできる
- commit-msg : コミットメッセージ編集後にスクリプト実行
- pre-push : Push実行直前にスクリプト実行 ← 今回はこれを用いる
- pre-rebase : rebase実行直前にスクリプト実行。ゼロ以外を返せば処理を中断できる。
といったものがあります。
これらを使えば、コミットする前に自動でテスト等を行ったり(pre-commit)、デフォルトのコミットメッセージを変更したり(prepare-commit-msg)、入力されたコミットメッセージが規定にそっているかを調べたり(commit-msg)といったことができるようになります。
他にもサーバーサイドのもの(pre-receive,update,post-receive)などがありますが、今回はクライアントサイドのpre-pushを用いて、Git Pushを行った際に自動でレンダリング、エクスポートを行えるようにします。
今回実現すること
developブランチにて、Blendファイルを配置しGit Pushすると、自動で
- 画像レンダリング
- FBX生成
- masterブランチに生成したFBXファイルを配置しコミット
が行われるようになります。
想定されるディレクトリ構成は以下のようになります。
<Developブランチ - Push前> ├─Scripts : 自動レンダリング、FBXエクスポート用のスクリプトを置く。具体的な内容は後述する。 └─ProjectName │ ├─blend : blendファイルを置くディレクトリ │ │ aaa.blend │ │ bbb.blend │ │ ccc.blend │ └─Textures : テクスチャを置くディレクトリ <developブランチ、Push後> ├─Scripts └─ProjectName │ aaa.fbx : [自動生成]blend/aaa.blendをFBXエクスポートしたもの │ bbb.fbx : [自動生成]blend/bbb.blendをFBXエクスポートしたもの │ ccc.fbx : [自動生成]blend/ccc.blendをFBXエクスポートしたもの │ ├─blend │ │ aaa.blend │ │ bbb.blend │ │ ccc.blend │ ├─image : [自動生成]レンダリング画像が置かれるディレクトリ └─Textures : テクスチャを置くディレクトリ <Push後のmasterブランチ> └─ProjectName │ aaa.fbx │ bbb.fbx │ ccc.fbx │ └─TexturesdevelopブランチにてBlendファイルとテクスチャファイルを配置し、Pushすると、自動でレンダリング、FBX生成がされ、FBXファイルとテクスチャファイルのみmasterにCheckoutします。
開発環境
今回はWindows 10にて、
- Blender 2.8
- Git version 2.23.0.windows.1
で行いました。
Blender自動レンダリング、FBXエクスポート用スクリプト
BlenderにてレンダリングとFBXエクスポートをPythonスクリプトで行えるようにします。
1. BlenderにPathを通す
まずは、Blender.exeにPathを通します。
やり方はhttps://qiita.com/sta/items/6d29da0dc7069ffaae60
が参考になると思います。2. レンダリングを行うためのスクリプト
次に、レンダリングを行うためのスクリプトとして、
Scripts/render.pyに以下の内容で保存します。import bpy bpy.context.scene.render.resolution_x = 1920 bpy.context.scene.render.resolution_y = 1080 bpy.context.scene.render.resolution_percentage = 25 path = bpy.context.blend_data.filepath.rstrip(bpy.path.basename(bpy.context.blend_data.filepath)) + "../image/" + bpy.path.basename(bpy.context.blend_data.filepath).split(".")[0] +".png" bpy.data.scenes["Scene"].render.filepath = path bpy.ops.render.render( write_still=True )これにより、blend/aaa.blendであれば、image/aaa.pngという形式でレンダリングされます。
今回はゲームで使うモデルのサムネイル画像の生成のためのレンダリングなので解像度を1920x1080の25%に指定しています。
3. FBXエクスポートを行うためのスクリプト
次に、FBXエクスポートを行うためのスクリプトとして、
Scripts/ExportFBX.pyに以下の内容で保存します。import bpy,sys def fbx_export_geometry(arg_filepath='./export.fbx'): bpy.ops.export_scene.fbx( filepath=arg_filepath, object_types={'ARMATURE', 'MESH'}, bake_anim=False, ) # 出力対象の種別 # 'EMPTY':エンプティ # 'CAMERA':カメラ # 'LAMP':ランプ # 'ARMATURE':アーマチュア # 'MESH':メッシュ # 'OTHER':その他 return # 関数の実行 path = bpy.context.blend_data.filepath.rstrip(bpy.path.basename(bpy.context.blend_data.filepath)) + "../" + bpy.path.basename(bpy.context.blend_data.filepath).split(".")[0] +".fbx" fbx_export_geometry(path)これにより、blend/aaa.blendであれば、aaa.fbxにFBXエクスポートされます。
また、ここでカメラやランプを除いて、アーマチュアとメッシュのみをFBXエクスポートしています。
4. 2つのPythonスクリプトを呼び出すためのスクリプト
それでは、この2つのPythonスクリプトを呼び出すためのスクリプトを用意します。
Scripts/convert.shに以下の内容で保存します。#!/bin/bash log=$(pwd)/gitPush.sh.log echo "[$(date)] start" >> $log echo "[Messeage by convert.sh]cd git top level dir(" `git rev-parse --show-toplevel` ")" cd `git rev-parse --show-toplevel` for raw in $(git log origin/develop..develop --stat | grep ".blend") ; do if [ ${raw##*.} = "blend" ]; then echo "[Messeage by convert.sh] blend file is ${raw}" echo "[Messeage by convert.sh] Start Render.py" blender --background ${raw} --python Scripts/Render.py echo "[Messeage by convert.sh] Start ExportFBX.py" blender --background ${raw} --python Scripts/ExportFBX.py fi done echo '[Messeage by convert.sh] git commit -m "Auto Generate FBX/render image"' git add *.fbx git add *.png git commit -am "Auto convert FBX and render image"ログ用のechoの行が挟まっていますが、内容としては、
- Gitのトップレベルディレクトリに移動
- gitのlogから、変更が加わったblendファイルの名前を取得
- 変更が加わったblendファイルに対して、画像レンダリング(Render.py)、FBXエクスポート(ExportFBX.py)を実行する
- FBXファイルとレンダリングpng画像をgit addする
- コミットする
となっています。
Git Hook pre-pushの設定
最後に、これまで作成してきたスクリプトをGit Hook pre-pushにて実行されるようにします。
Gitリポジトリには
.gitディレクトリが存在しますが、.git/hooks/に"pre-push"というファイル名でシェルスクリプトを保存します。
すると、Git Push実行直前にこのスクリプトが実行されるようになります。直接ここにファイルを置いてもいいですが、
.git/hooks/はGit監視下では無いので、シンボリックリンクを置いて作業しました。ちなみに、WindowsのPowerShellでのシンボリックリンクの貼り方は、下のコマンドになります。
New-Item -Type SymbolicLink .git/hooks/pre-push -Value Scripts/hooks/pre-pushpre-pushファイルには以下の内容で保存します。
#!/bin/sh remote="$1" url="$2" z40=0000000000000000000000000000000000000000 while read local_ref local_sha remote_ref remote_sha do if [[ "${remote_ref##refs/heads/}" = "develop" ]]; then `git rev-parse --show-toplevel`/Scripts/convert.sh git checkout master git checkout develop `git rev-parse --show-toplevel`'/ProjectName/*.fbx' git checkout develop `git rev-parse --show-toplevel`'/ProjectName/Textures/*' git commit -m "[Auto commit] Add FBX from develop" git checkout develop git push origin master fi done
- 作業しているブランチがdevelopかを調べる
<Gitのトップレベルディレクトリ>/Scripts/convert.shを実行。(ここで自動レンダリング、FBXエクスポートを行う)- テクスチャファイルと、自動生成したFBXファイルをMasterブランチにcheckout
- コミット
- masterをPush
これにより、Git Pushがされた際に自動で行われるようになります。
さいごに
今回、blendファイルが更新されたら自動でFBXも更新するシステムを作ろうとして、Git Hookを使ってみました。
最初はCI/CDが必要なのかな...と思ってGitHub Actionsを試していたのですが、Blenderでレンダリングを行う際にサーバーサイドにGPUが必要なので悩んでいたところ、サークルの先輩にGit Hookを紹介してもらいました。
結果としてやりたかったことが実現でき、さらにクライアント側で完結する無駄の少ないシステムになったと思います。
また、Git Hookで呼び出すためにBlender Pythonスクリプトも初めて使ってみましたが、これによりレンダリング・FBXエクスポートの設定ミスが無くなり、特にFBXエクスポートで誤ってランプやカメラを含んでしまいUnityで読み込んだ際におかしくなる問題が無くなりました。
これまでは自動化のモチベーションはあまりなかったのですが、今回のは自動化によるメリットをいくつも得れた良い機会でした。
Git Hookには他にもいろいろな発火タイミングがあるので、便利に使っていきたいと思います。
参考文献
- 投稿日:2019-11-29T18:24:15+09:00
主要なGAN研究の歴史(2019年11月現在)
こんな人に

2014年に発表されたGAN(Generative Adversarial Network)ですが、画期的な研究故に最近では派生研究が多くてなにがなんやら。。私自身Google先生をフル活用して色々調べてみたものの、主要な関連研究をわかりやすくまとめた日本語文献はなかなか見つけることができませんでした、残念!ということで、本記事はGAN関連の研究の流れのアウトラインを掴みたい人や、それぞれの研究
を一々調べるのがめんどくさいから論文とコードにサクッとワンクリックでとびたい人向けとなっております。ちなみに本記事は、主にGenerative Adversarial Networks - The Story So Farを参考に書かせて頂いています。そもそもGANってなんぞや?という方へ
- @triwave33さんの今さら聞けないGAN(1)
- SONYのNeural Network Console公式YouTubeチャンネル(全体の概要)
- @typecprintさんの今さら聞けないGANの目的関数(学習過程と目的関数の説明)
などを参考にしてみてください。
GANファミリーご紹介

- GAN (Generative Adversarial Network)
- CGAN (Conditional Generative Adversarial Network)
- DCGAN (Deep Convolutional Generative Adversarial Network)
- CoGAN (Coupled Generative Adversarial Networks)
- Pix2pix!
- WGAN (Wasserstein Generative Adversarial Network)
- CycleGAN
- StackGAN (Stack Generative Adversarial Network)
- ProGAN (Progressive Growing of Generative Adversarial Network)
- SAGAN (Self-Attention Generative Adversarial Network)
- BigGAN (Big Generative Adversarial Network)
- StyleGAN (Style-based Generative Adversarial Network)
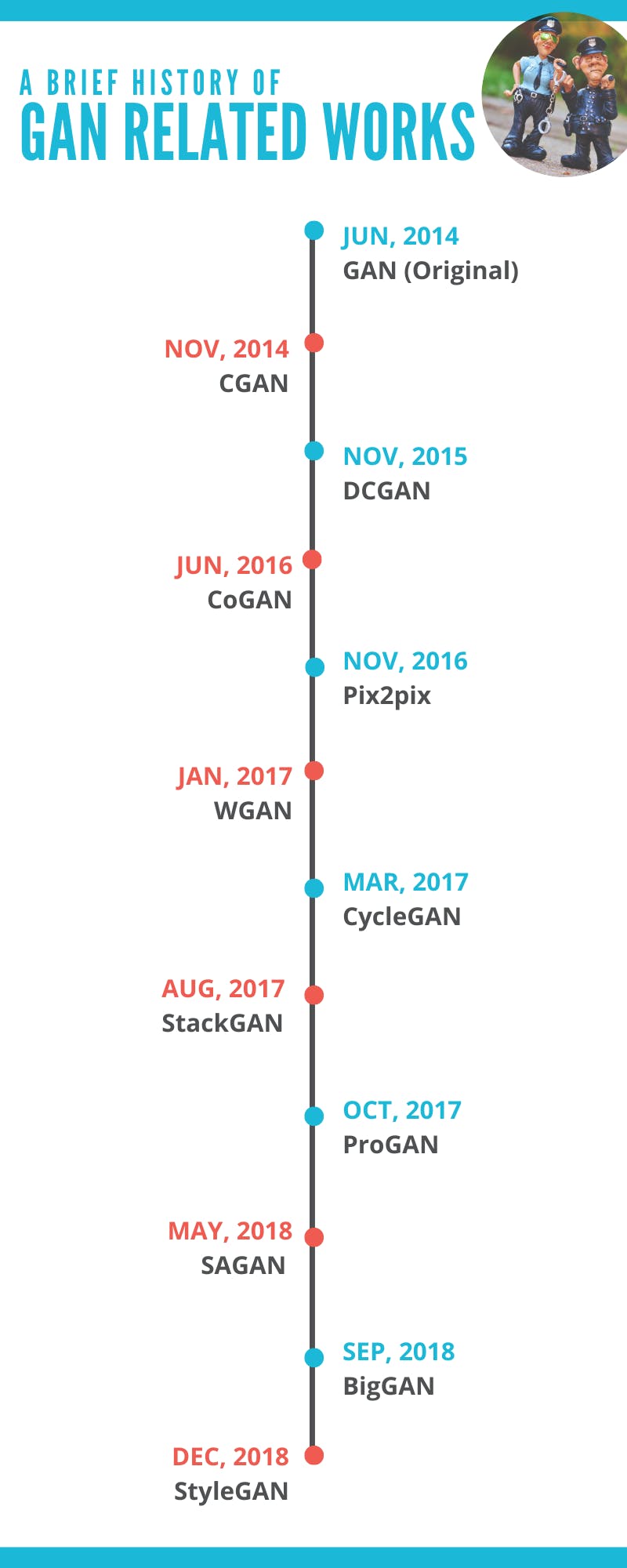
大家族ですね。(本当はもっともっと大家族です。)ここからそれぞれの研究の
- 研究論文
- コード
- ポイント
- オススメ参考文献(世界には親切で頭の良い人が沢山います)
を紹介していきます。
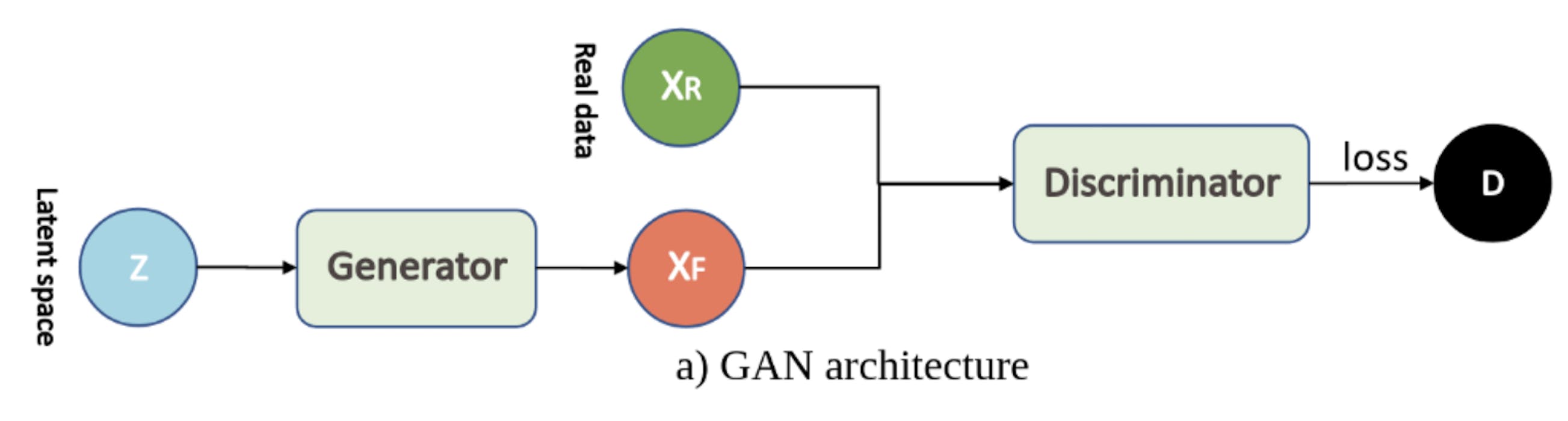
1. GAN (Generative Adversarial Network)
- Generative Adversarial Networks
- コード
- ポイント:
- 2つのニューラルネットワーク(GeneratorとDiscriminator)を用いている
- Generatorは「本物らしい」画像を作成する(最初の画像はランダムノイズから作成)
- Discriminatorは、Generatorによって生成された偽物の画像と、インプットされる本物の画像を識別する
- GeneratorとDiscriminatorは以下の目的関数を共有しており、Generatorはこの値を最小化、Discriminatorはこの値を最大化、することを目標に学習を進める
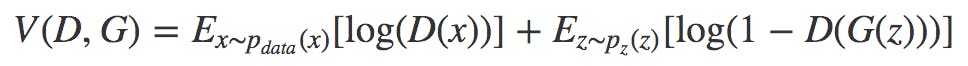
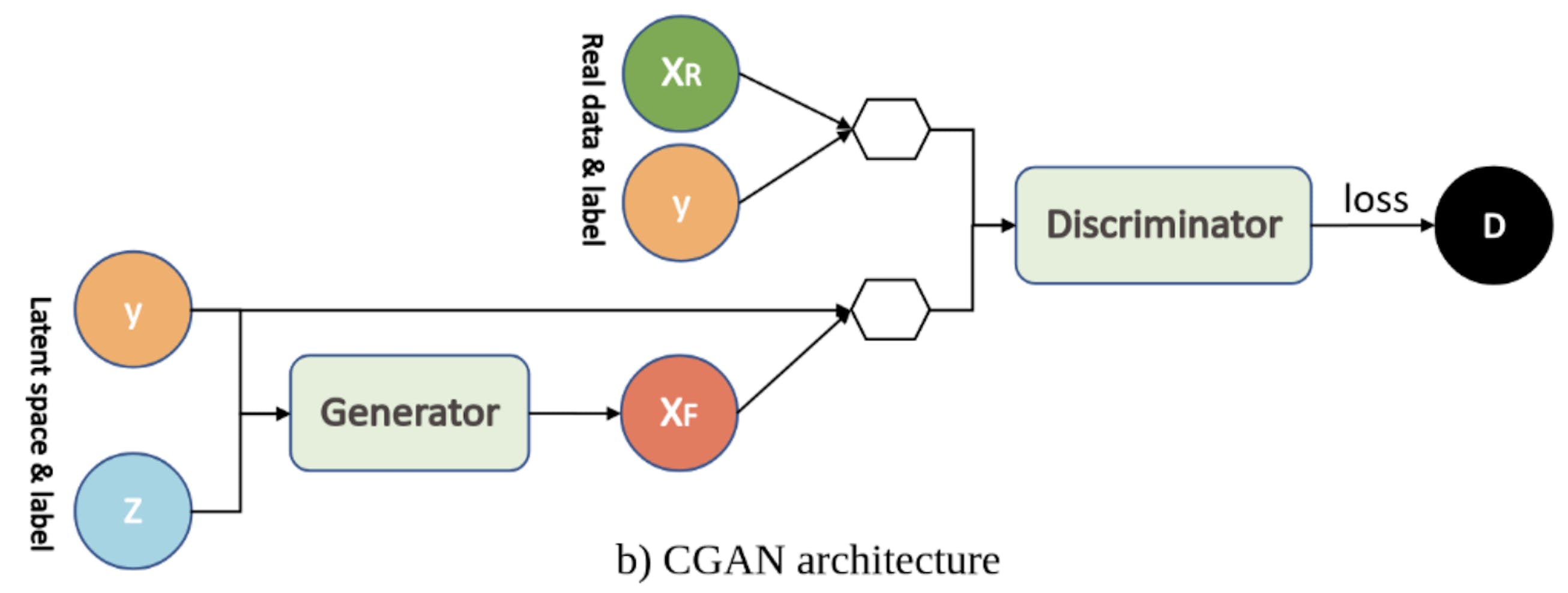
2. CGAN (Conditional Generative Adversarial Network)
- Conditional Generative Adversarial Nets
- コード
- ポイント:クラス条件ベクトル(下図のy)をGeneratorとDiscriminatorに加えることで、クラスごとに生成する画像を書き分けることができるようになった!
- オススメ参考文献:今さら聞けないGAN(6)
3. DCGAN (Deep Convolutional Generative Adversarial Network)
- Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks
- コード
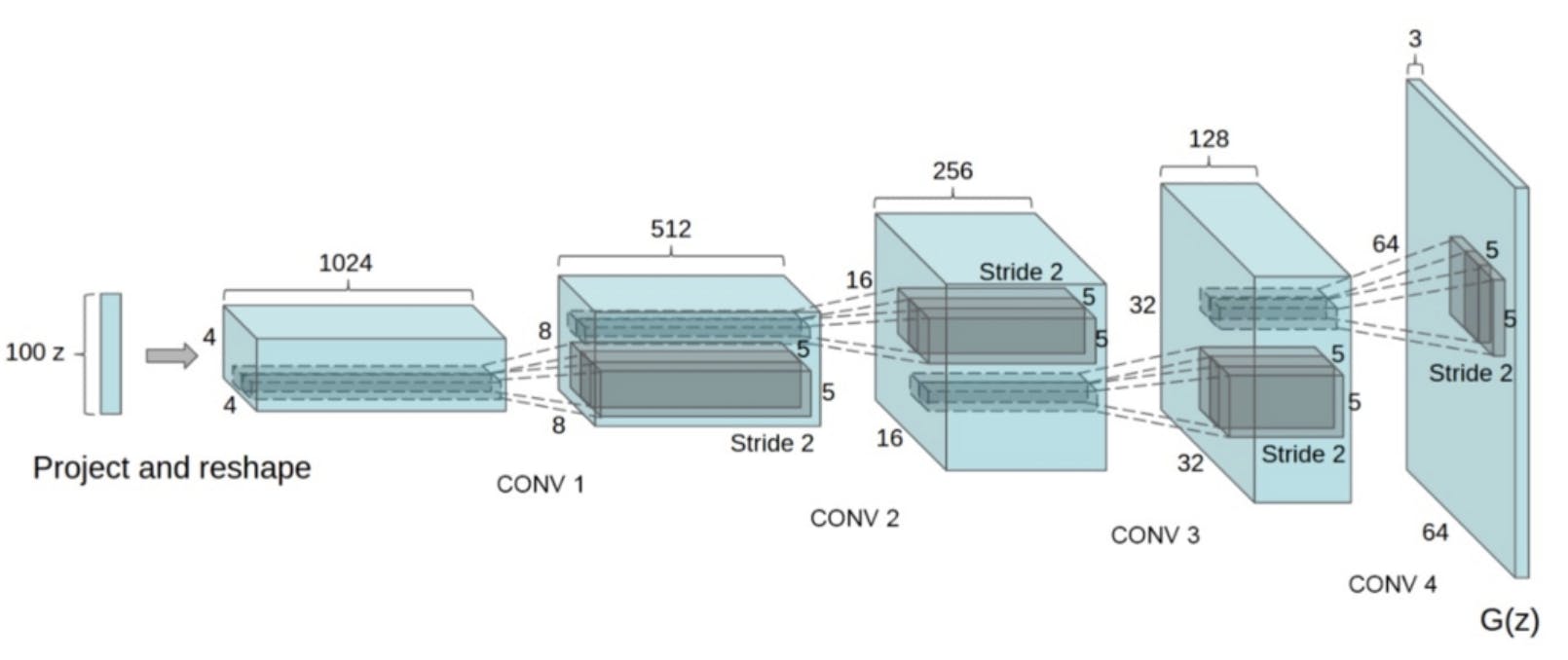
- ポイント:以下の手法を用いて画像のクオリティを向上した
- プーリング層を、ストライドありのConvolution層に入れ替える(下図)
- アンサンプリングでは逆畳み込み層を用いる
- 全結合をなくす
- 全ての層に対してバッチ正規化を行う(Generatorの出力層と、Discriminatorの入力層以外)
- Generatorにおいて、出力層以外ではReluを用いる(出力層にはtanhを用いる)
- DiscriminatorではLeakyReLUを用いる
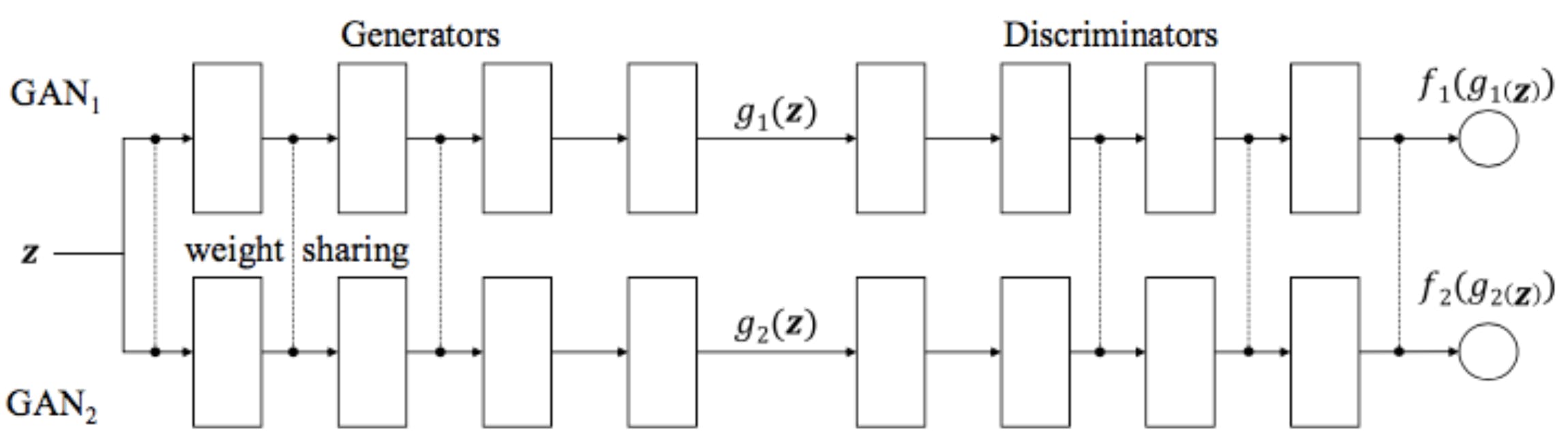
4. CoGAN (Coupled Generative Adversarial Networks)
- Coupled Generative Adversarial Networks
- コード
- ポイント:2つのGANを並列して使用した(最近はそんなにホットではないらしいです)
- オススメ参考文献:Agustinus Kristiadi's Blog
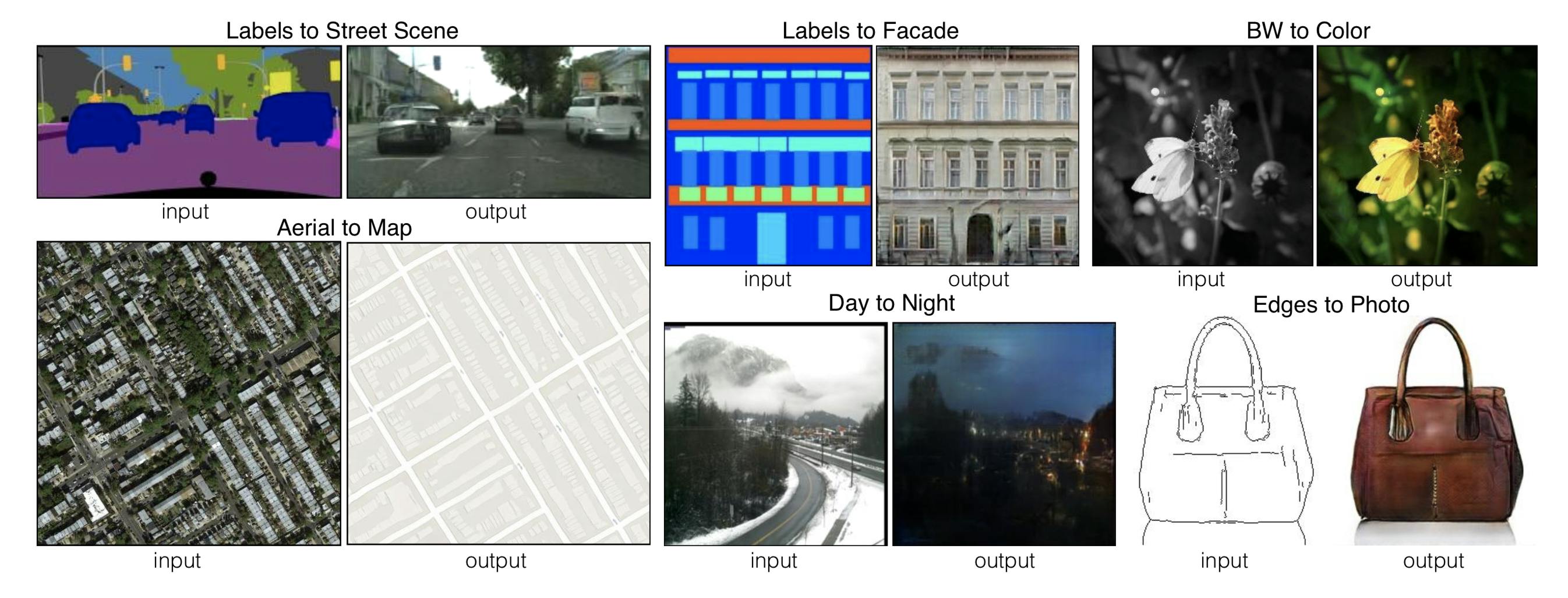
5. Pix2pix
- Image-to-Image Translation with Conditional Adversarial Networks
- コード
- ポイント:画像から画像への変換を高精度で行えるようになった
- 変換元の画像と変換先の画像が対になっている必要がある(Googleマップの同じ場所の地図と航空写真など)
- オススメ参考文献:pix2pixを理解したい
6. WGAN (Wasserstein Generative Adversarial Networks)
- Wasserstein GAN
- コード
- ポイント:以下の手法により学習が安定し、モード崩壊も回避
- 通常のGANに用いられている Jensen-Shannonダイバージェンス(勾配消失問題を引き起こす)の代わりに、Wasserstein距離を用いて損失関数を設計
- オススメ参考文献:Wasserstein GAN と Kantorovich-Rubinstein 双対性(Wasserstein距離について詳しく解説してくれています)
7. CycleGAN (Cycle Generative Adversarial Network)
- Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks
- コード
- ポイント:対となっていない2つの画像が訓練データとして与えられた際に、一方の画像からもう一方への変換が行えるようになった
- 敵対性損失」(普通のGANで使われている損失関数)にプラスして「サイクル一貫性損失」を用いることで可能となった
- 5. Pix2pixと「画像→画像変換」という点では似ているが、CycleGANではPix2pixと違って訓練データの画像群が対になっている必要がない!
- テクスチャや色の変換には強いが、構造的な変換(ex.犬→猫)は難しい
- オススメ参考文献:"GAN"の補足(鍵となるサイクル一貫性損失について解説してくれています)

できることのイメージはこんな感じです。(画像は論文を参照)
8. StackGAN (Stack Generative Adversarial Networks)
- StackGAN: Text to Photo-realistic Image Synthesis with Stacked Generative Adversarial Networks
- ポイント:テキスト表現のみを用いて高解像度の画像を生成できるようになった
- オススメ参考文献:【論文メモ:StackGAN】
論文参照。「この鳥は黒い翼をもち腹部は白いです」というテキストからこの画像が生成されます。
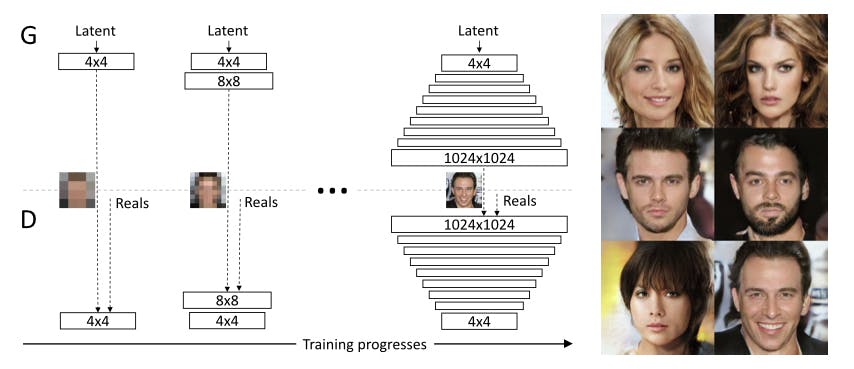
9. ProGAN (Progressive growing of Generative Adversarial Networks)
- Progressive Growing of GANs for Improved Quality, Stability, and Variation
- コード
- ポイント:低解像度の画像から徐々に学習させていき、段階的に高解像度にすることに成功した
- オススメ参考文献:【Progressive Growing of GANs for Improved Quality, Stability, and Variation】を読んだのでまとめる
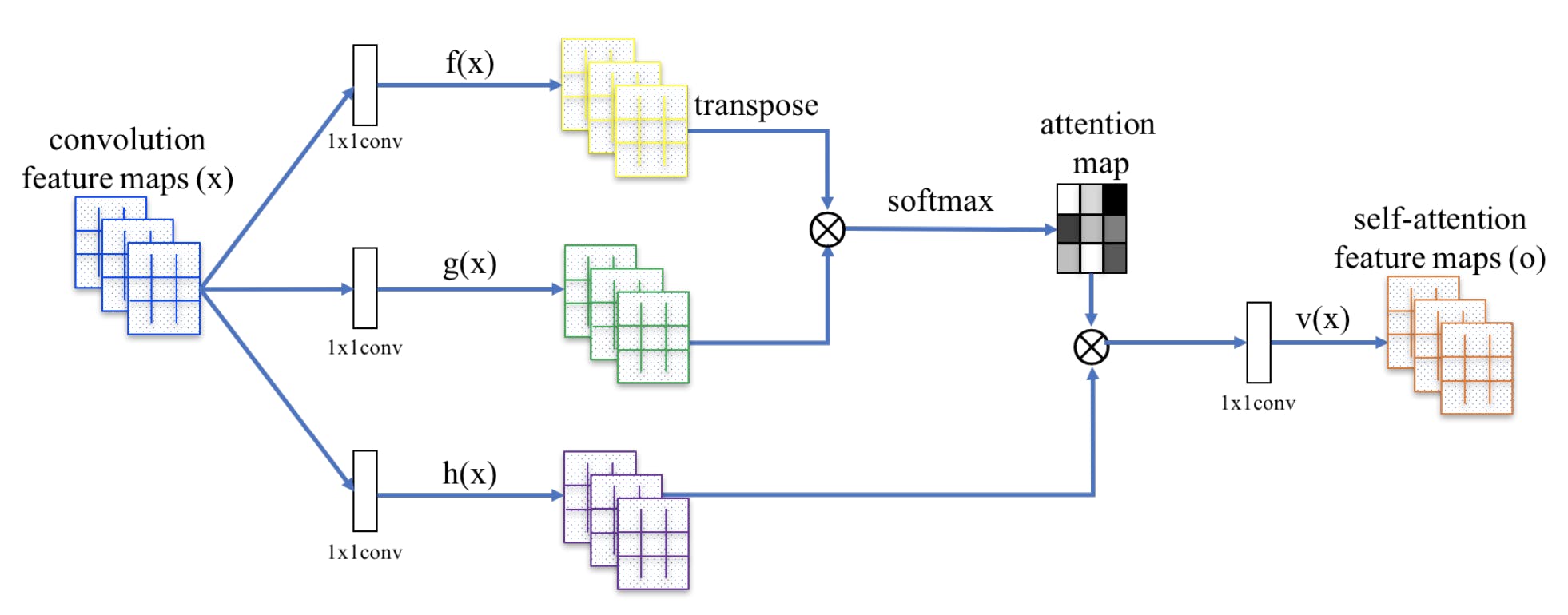
10. SAGAN (Self-Attention Generative Adversarial Networks)
- Self-Attention Generative Adversarial Networks
- コード
- ポイント:以下の手法を用いて生成画像の精度を向上させた
- Self Attentionを導入することで、画像全体の処理状態を考慮
- Spectral Normalizationを、DiscriminatorとGeneratorの双方に適用
- オススメ参考文献:SAGAN(Self Attention Generative Adversarial Network)のSelf Attention機構をざっくり理解した(その名の通り、全体像がつかみやすいです)
論文参照。Self Attention機構の構造はこんな感じです。
11. BigGAN (Big Generative Adversarial Networks)
- Large Scale GAN Training for High Fidelity Natural Image Synthesis
- コード
- ポイント:SAGANの改善版。Generatorに直行正則化を用いることで過学習を防ぎ、最大512×512ピクセルの高解像度画像を生成できるようになった
- オススメ参考文献:“Large Scale GAN Training for High Fidelity Natural Image Synthesis” -About BigGAN (日本語です)
論文中にあるBigGANで生成した画像です。ハイクオリティなのがわかりますね!
12. StyleGAN (Style-based Generative Adversarial Networks)
- A Style-Based Generator Architecture for Generative Adversarial Networks
- コード
- ポイント:スタイル変換を取り入れ新しいGeneratorを考案することで、1024×1024のサイズで高解像度の画像生成に成功した
- オススメ参考文献: StyleGAN「写真が証拠になる時代は終わった。」
終わりに

最後まで読んでいただきありがとうございます。もっとGANについて細かいとこまで知りたい&英語でもokという方は、是非こちらのNIPS 2016 Tutorial: Generative Adversarial Networksを読んでみてください。
皆さんがGANについての全体像をイメージするのに役立てていれば幸いです。(訂正などあれば是非教えてください!)


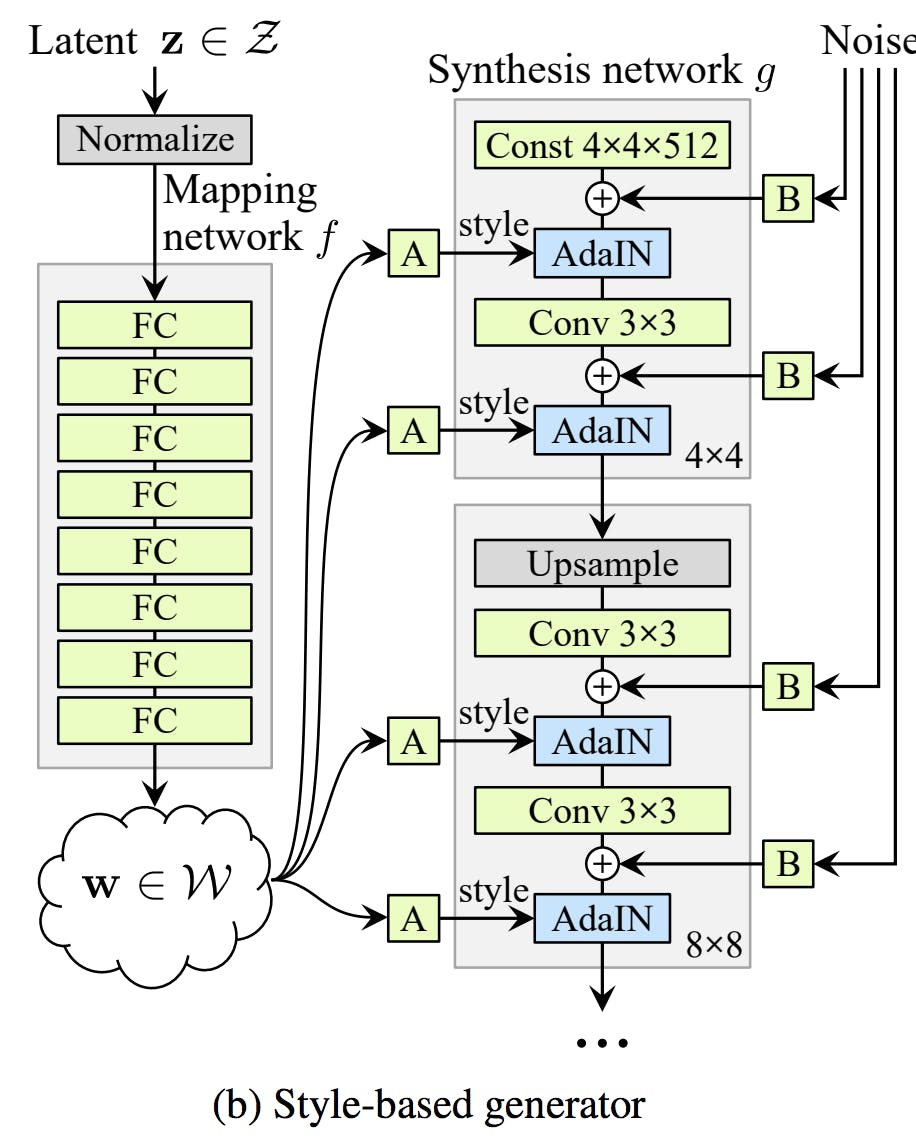
- 投稿日:2019-11-29T17:07:30+09:00
HDAにヘルプを付ける方法(Pythonスクリプトのおまけ付き)
この記事はHoudini Advent Calender 2019の8日目の記事です。
昨今、Houdiniは色んな業界でも使われるようになり、様々なHDAが各社で開発されてると思います。
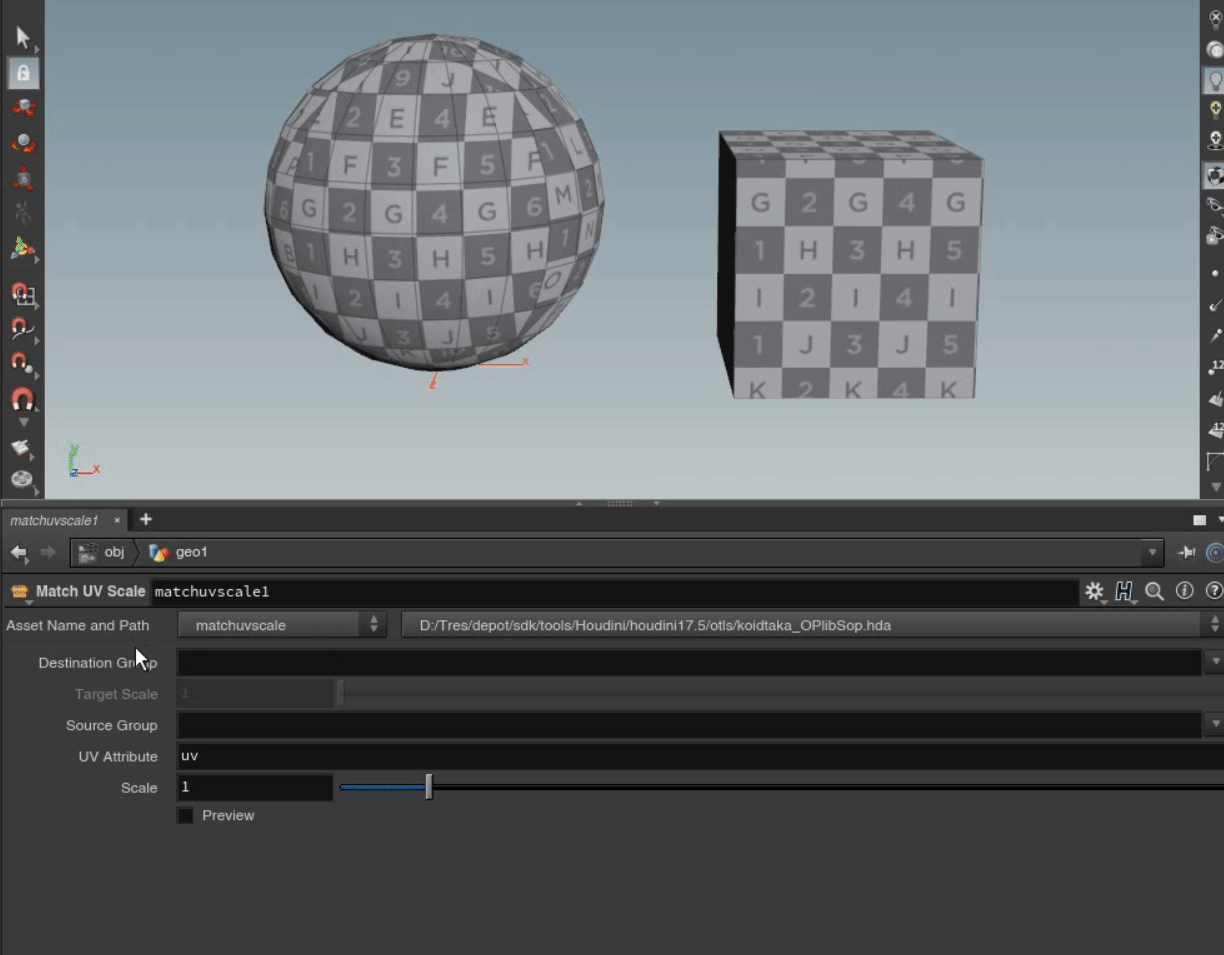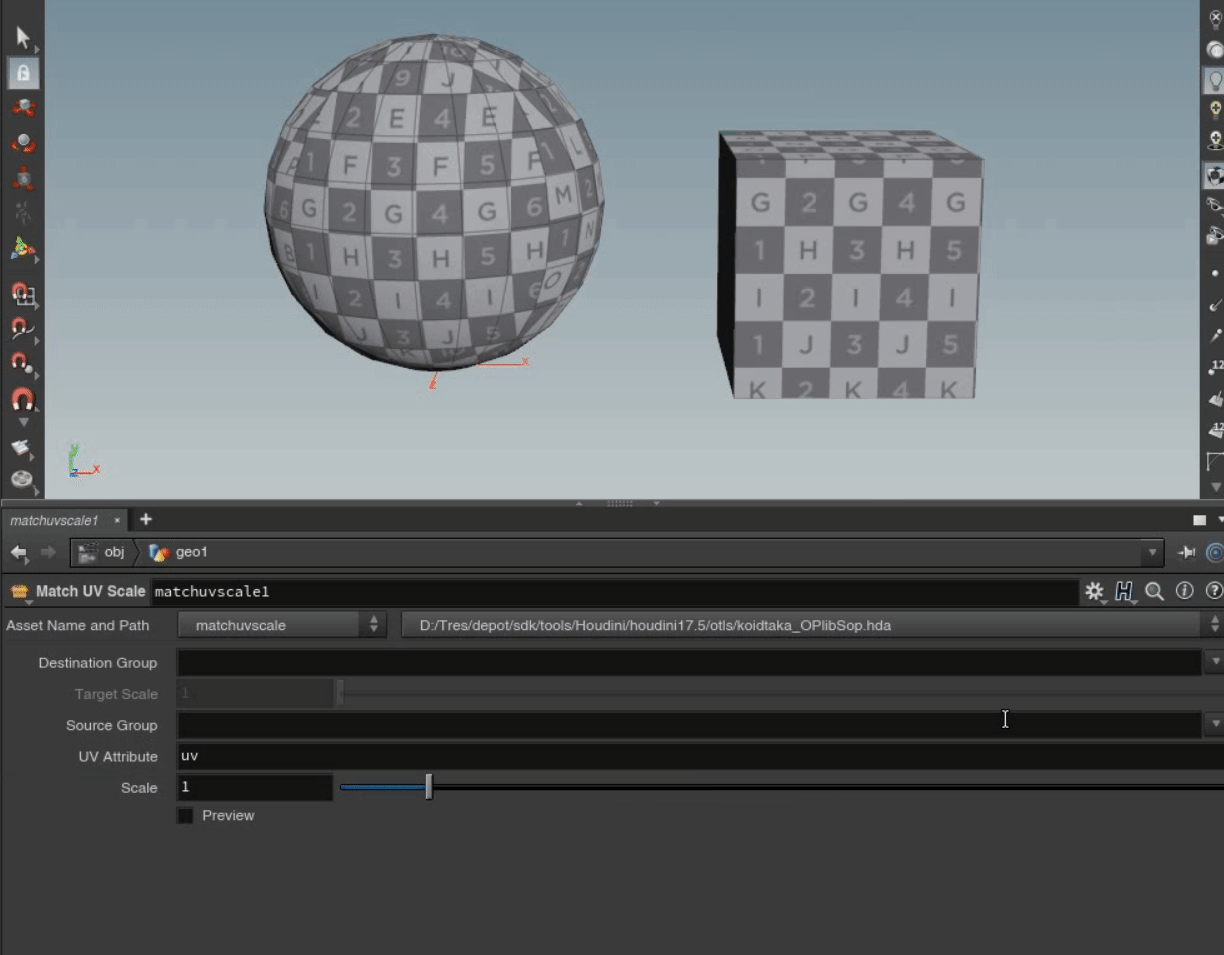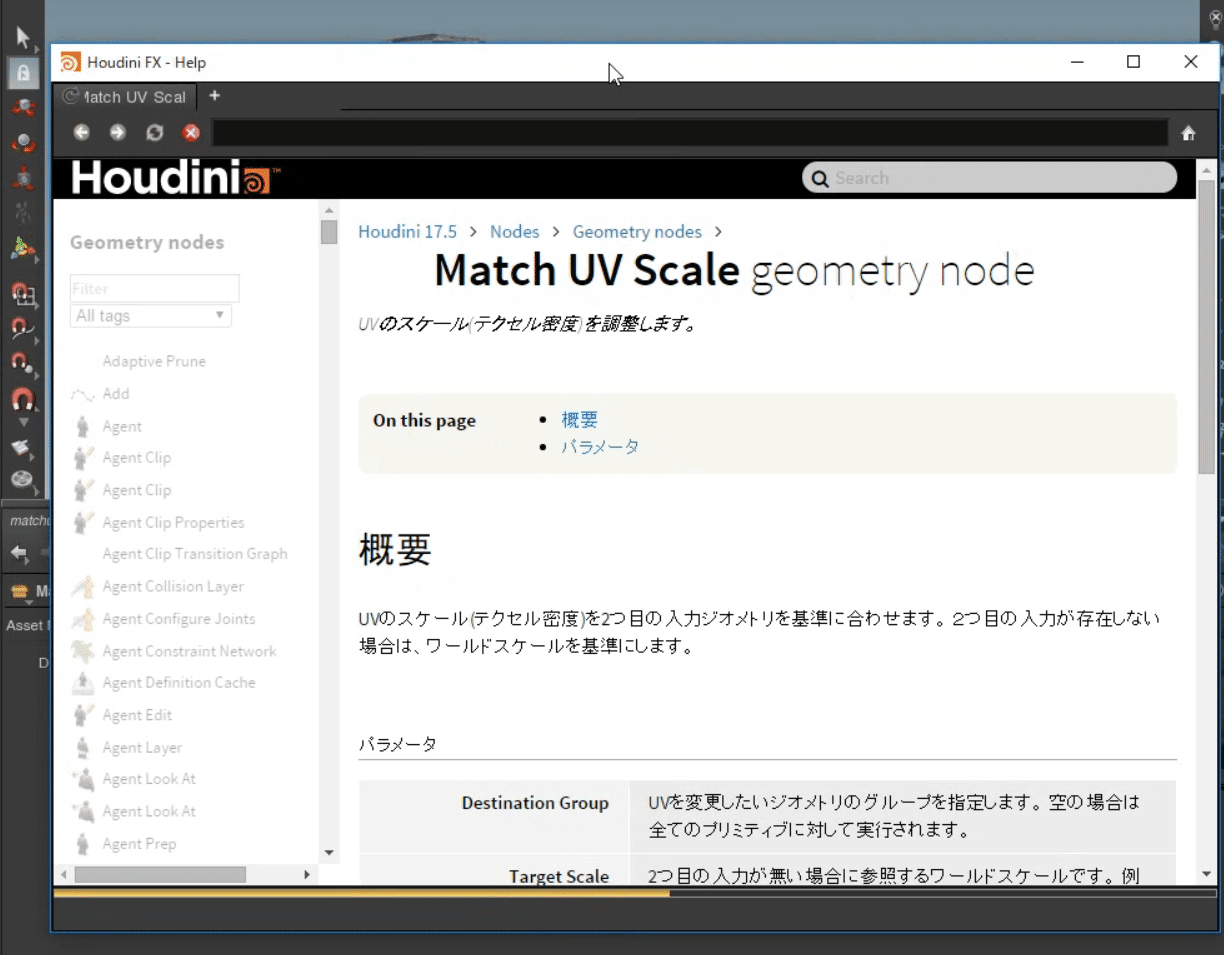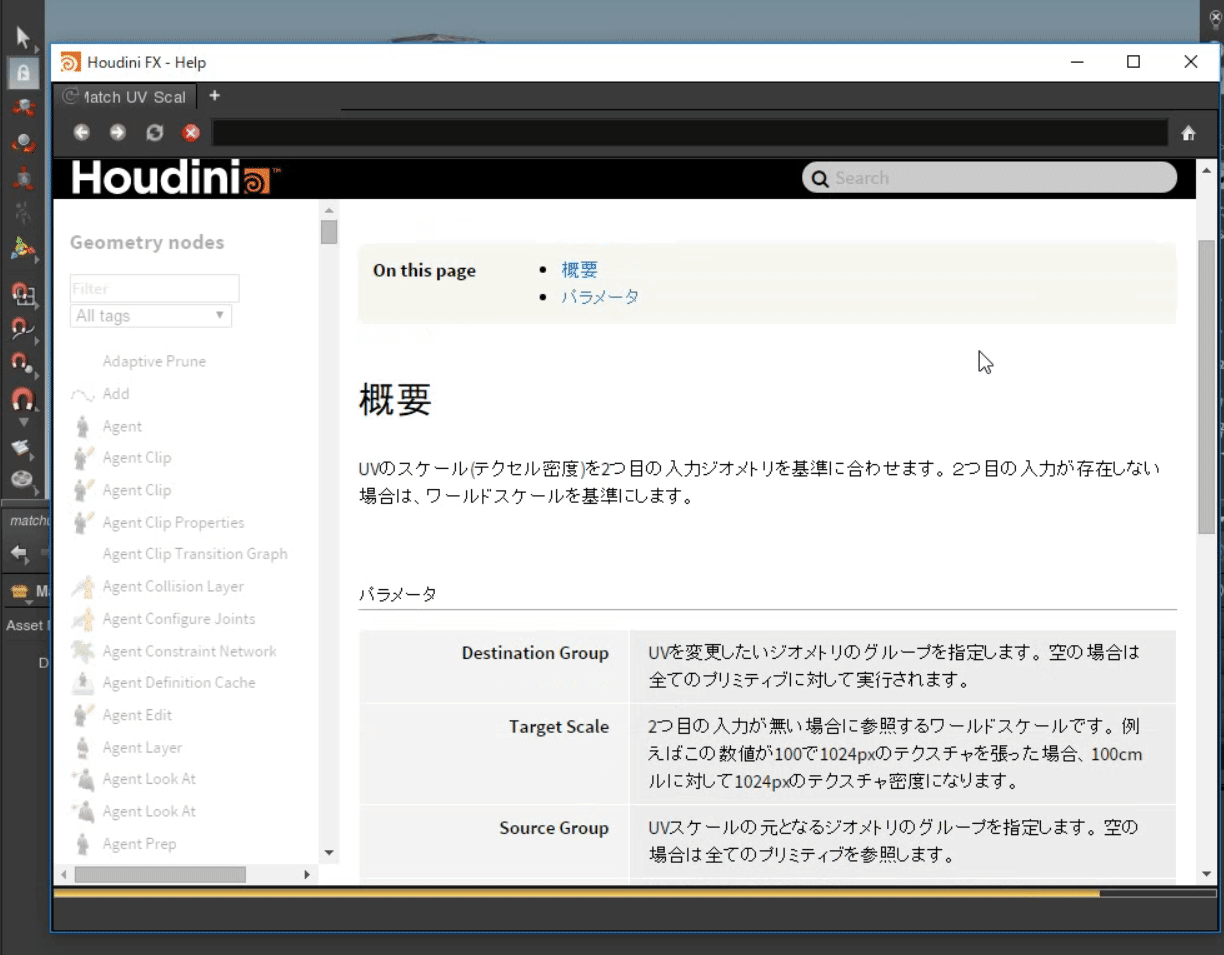
半面、管理やドキュメントの整備がされていないと他人が作ったHDAの使い方が分からない、どういったHDAが存在するか把握できないといった事態に陥ります。この記事では下図のようなパラメータに対してのツールチップと独自のドキュメントを作成する方法を紹介します。
※なお私はWindows環境しか確認環境がないため、別のプラットフォームだとディレクトリなど若干違う箇所があるかもしれませんが、ご了承下さい。
ヘルプを書く場所
ヘルプは下記の2箇所のどちらかに書く事が出来ます。
- Type PropertiesウィンドウのHelpタブ
- $HOUDINI_PATH/help/nodes/カテゴリ/オペレータタイプ名.txt
Helpタブ テキストファイル どちらに書くかはスタジオのやり方や好みによりますが、私はヘルプとHDAを別で管理したいため、テキストファイルを書いています。
ちなみに標準ノードやGame Development Toolsetも同じ方法で管理されてます。Helpの書式はWikiマークアップを使用し、書くことが出来ます。詳しくは下記ドキュメントをご覧下さい。
ドキュメントをご覧いただくと分かりますが、このWikiマークアップによる書式はかなり高機能です。
しかしその分、慣れている方はともかく、そうでない方には若干敷居が高く感じます。
そういった方はHoudini標準ノードのヘルプソースを見ることが出来るので、そこから改変する方が良いと思います。標準ノードのマークアップを見る
標準ノードのマークアップを見るには2通りのやり方があります。
パラメータエディタのヘルプボタンを押し、URL欄の最後に.txtを付ける。
ソースを見たいノードを出し、パラメータエディタのヘルプボタンをクリックし、表示されるURL(しばらく待たないと適切に表示されません)の後ろに.txtを追加することでそのノードのマークアップを見ることが出来ます。
ローカルにあるテキストファイルを見る。
ローカルのテキストファイルは$HH/help/nodes.zip/カテゴリ/オペレータタイプ名.txtに存在します。
※$HHはHoudiniインストールディレクトリ/houdiniです(例:C:/Program Files/Side Effects Software/Houdini 17.5.391/houdini)
アセットのヘルプでよく使う書式
ソースの見方が分かったところで、Align Sopのソースを例にアセットの書式についてまとめておきます。
タイトルです。=で囲みます基本的にオペレータラベルが書かれています。
iconはノードのアイコンの設定で、それ以外の箇所はフィルタリングなどに使うための情報を記述で、ヘルプの見た目には影響しません。
要約。"""で囲みます。基本2行内で収まるような簡易な説明が書かれています。
ノードの目的とオペレーションの説明です。==で囲んで、タイトルを書き、改行して説明を書きます。
イメージの挿入。../は$HOUDINI_PATH/help/を表します。アニメーションgifを読み込む場合は[Anim:ファイルパス.gif]にします。
入力による説明です。@inputsで入力について説明したセクションを始めます。
各入力に対して入力のラベルの後にコロン(:)を書きます。
その下に入力に対するノードの挙動などをインデントを付けて記述します。@paramtersでパラメータについて説明したセクションを始めます。
パラメータをフォルダで分けてる場合は== フォルダラベル ==にすることで分けることが出来ます。
パラメータにツールチップを設定していない場合、このパラメータの説明の第一段落を自動的に抽出して、それをパラメータのツールチップとして使用します。
#id:プロパティとパラメータ名を追加しなかった場合、そのパラメータのラベルを使ってパラメータのマッチングを試みます。
とはいえ、#id:プロパティをすべてのパラメータに追加する方が良いです。
そうすることで、いくつかのパラメータのラベルが重複していても、それらのパラメータは適切にリンクされます。@relatedで関連ページへのリンクのセクションを作成することができます。
さらに詳しい説明は下記ドキュメントをご覧下さい。
カスタムサンプルの作成
ヘルプにカスタムサンプルを付けることも出来ます。サンプルを作成するには下記の2つのファイルを所定の場所に置く必要があります。
- オブジェクトネットワークで作成した.hdaファイル
- サンプルの説明を書いたテキストファイル
※.hdaファイルがオブジェクトネットワーク以外の場合、例えばDopならDop Networkを作成してオブジェクトネットワークに内包する必要があります。
上記2つのファイルは同じファイル名にして、下記ディレクトリに置きます。
- $HOUDINI_PATH/help/examples/nodes/カテゴリ/オペレータタイプ名/
例えばmynodeというSopのHDAにMyNodeExampleという名前のカスタムサンプルを表示する場合は下記にサンプルファイルを置きます。
- $HOUDINI_PATH/help/examples/nodes/sop/mynode/MyNodeExample.hda
- $HOUDINI_PATH/help/examples/nodes/sop/mynode/MyNodeExample.txt
ファイルが用意出来たら下記記述をヘルプに書き足すことでカスタムサンプルを表示させる事が可能です。
:load_example: My Node Example #examplefile: /examples/nodes/sop/mynode/MyNodeExample.hda #path: /examples/nodes/sop/mynode/MyNodeExample #include: yesカスタムサンプル例
スクリプトによる半自動化
ここまでドキュメントの作成方法を説明してきましたが、毎回これを設定するのはかなり面倒です。特にパラメータが多いHDAになるとかなりの労力が必要になってきます。
そこで下図のパラメータのリストアップ、編集を行えるPythonスクリプトを使用し、ヘルプを書きやすいようにします。
スクリプトは下記GitHubのリポジトリからダウンロードして使用することが出来ます。
まとめ
以上、HDAのヘルプの書き方とスクリプトの紹介でした。
もし記事内で間違いや不明点等あれば書き込んでいただけると幸いです。
最後までお読みいただき、ありがとうございました。参考
SideFX公式ドキュメント(日本語版)


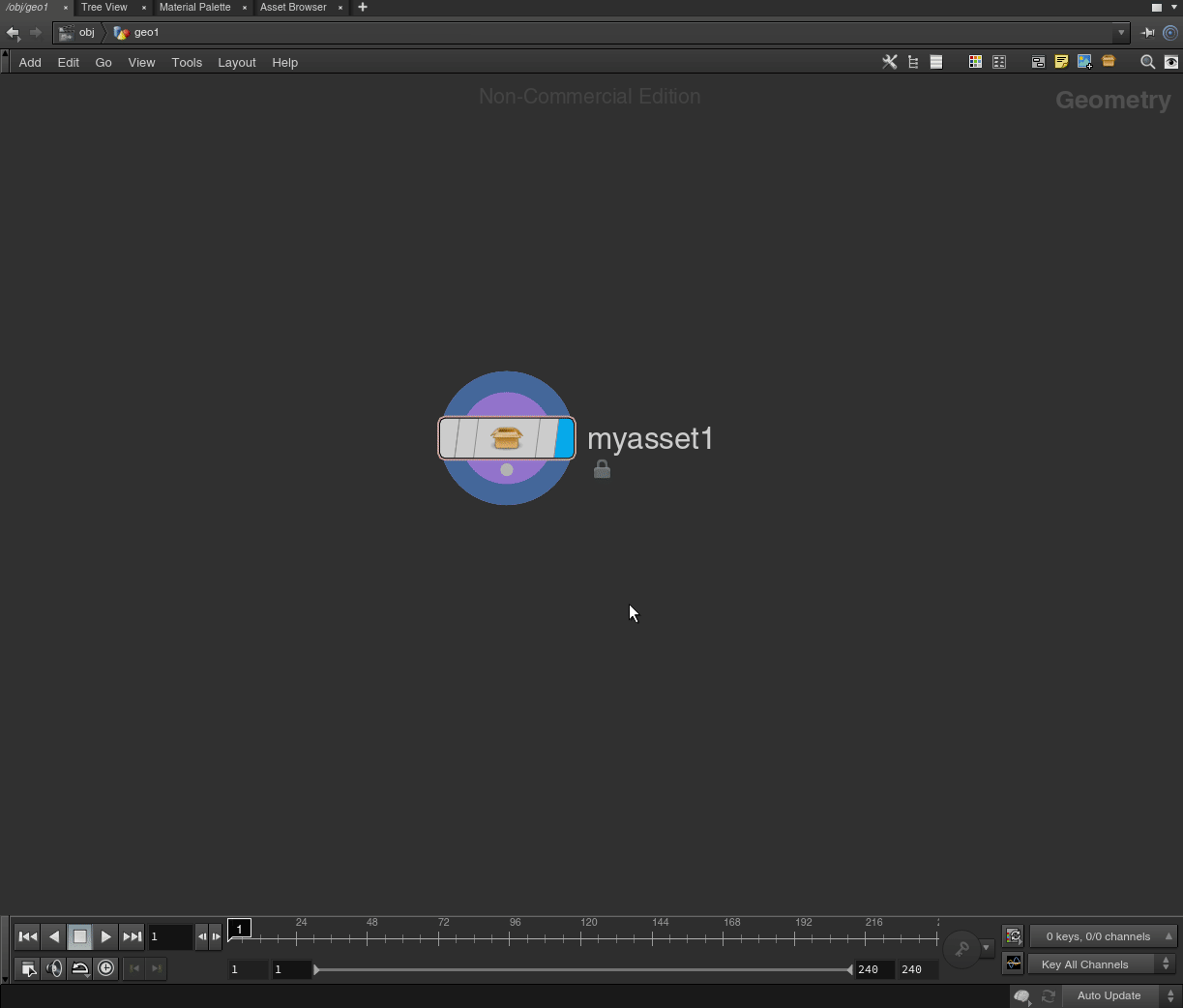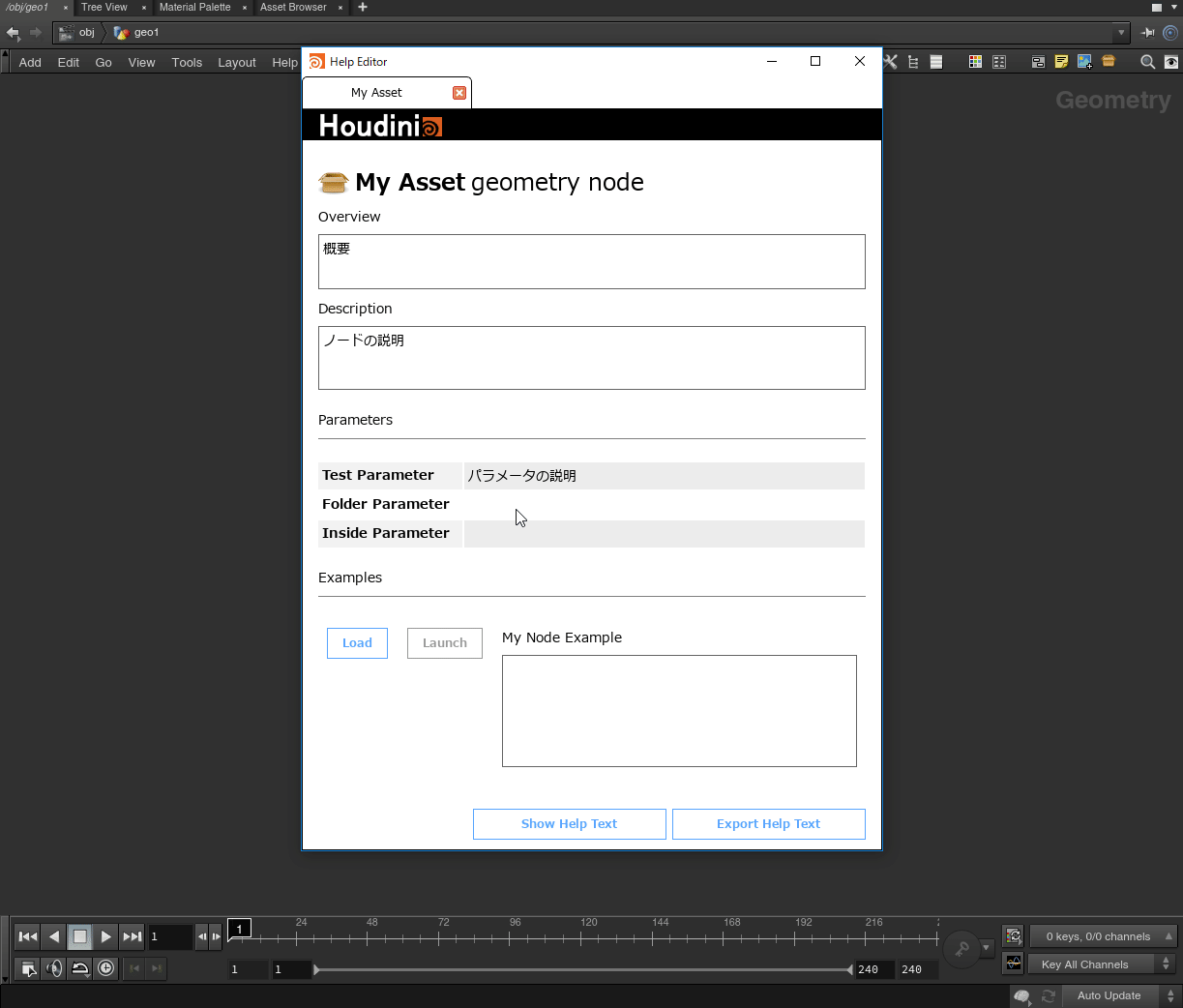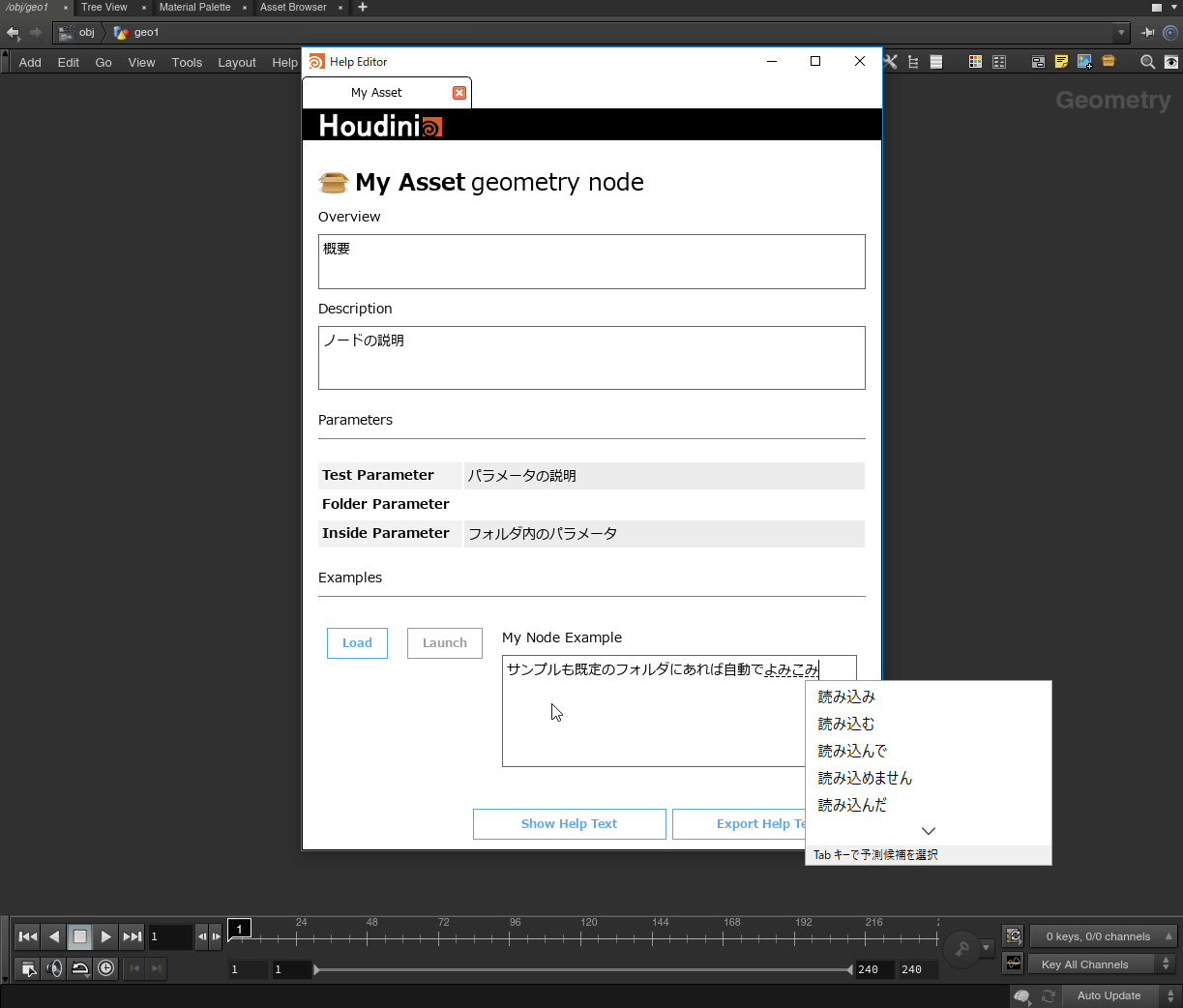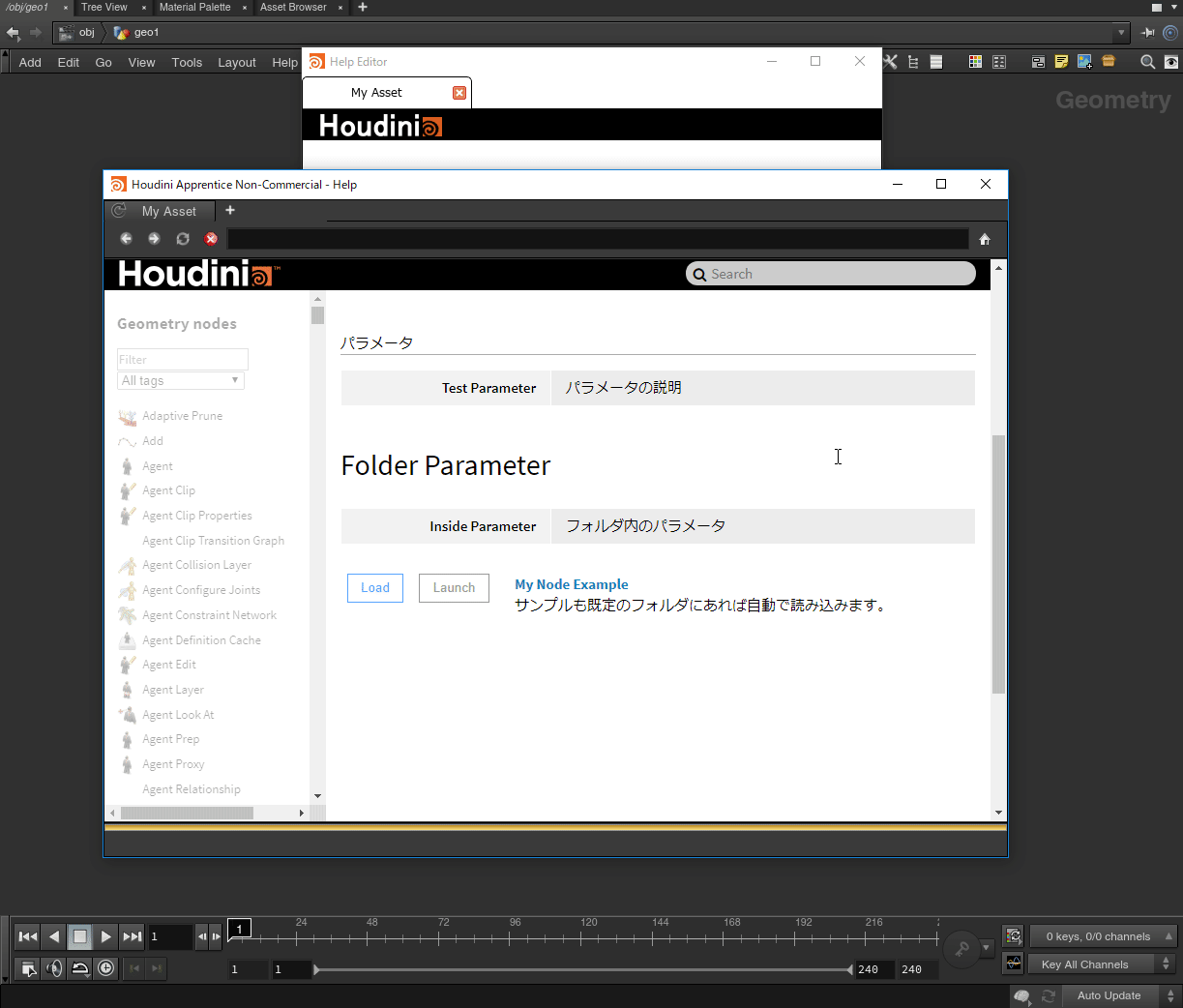
- 投稿日:2019-11-29T17:06:39+09:00
SNSテキストから顔文字・絵文字・URLを抽出する
この記事は,NTTドコモアドベントカレンダー第11日目の記事になります。
こんな人に読んでほしい
- 口コミやツイートの分析をしている人
- 顔文字・絵文字・URLを抽出するツールを探している人
- 自然言語処理に興味がある人
※ 最後の付録で実装したソースコードを公開してます!
1. はじめに
自然言語処理にとって前処理は非常に重要です。
特に、商品の口コミやツイートは顔文字やURLなどのノイズが多く、前処理しないままでは思い通りの分析ができません?
そこで本記事では、SNSテキストから顔文字・絵文字・URLを抽出して削除/置換するための前処理方法について紹介したいと思います。前処理例
2. 必要なもの
ツール
- nagisa
- 顔文字・URLの検出に使います。日本語テキスト用の形態素解析ツールです。
- 参考記事: nagisa: RNNによる日本語単語分割・品詞タグ付けツール
- emoji
- 絵文字の検出に使います。
- 参考記事: pythonで絵文字を駆逐する
インストール方法
$ pip install nagisa emojiデータ
抽出対象のSNSテキストデータです。ご自身で収集した口コミやツイートをご用意下さい。
もし手元に無い場合は、MTNTデータなどを使って試しましょう。
- MTNT: Machine Translation of Noisy Text
- MTNTデータセットは、Redditという投稿型のソーシャルサイトの書き込みを収集したものです(日本の2ちゃんねるのような掲示板サイトに近いです)。
- スラングや文法誤り、顔文字・絵文字などのノイズを多く含むSNSテキストの機械翻訳の研究用に無償公開されています。
3. 実践: SNSテキストを前処理してみよう
それでは、実際にSNSテキストから顔文字・絵文字・URLを抽出してみましょう。
3.1 方針
顔文字・URLの抽出はnagisa、絵文字の抽出はemojiを使います。
3.2 顔文字の抽出方法
nagisaは日本語テキスト用の形態素解析ツールですが、
うまく使いこなせば顔文字やURLを抽出することができます。こちらの記事でも言及されている通り、nagisaでは顔文字やURLを1つの単語として単語分割することができます。
しかし、
\(^o^)/などの手を含む顔文字は1つの単語として分割することは難しいようです。
\/補助記号 (^o^)/補助記号 //補助記号のように、3つの単語に分かれてしまいます。nagisaの解析結果
ですが、うまく処理すれば、このような顔文字も抽出することができます。
仕組みは単純で、顔文字の手を事前に定義して、顔文字の周辺から手を一緒に抽出します。import nagisa import unicodedata def extract_kaomoji(text): """ 与えられたテキストから抽出した顔文字リストを返却する。 → \(^o^)/, m(_ _)m などの 手を含む顔文字があれば、それも抽出する """ results = nagisa.extract(text, extract_postags=['補助記号']) words = results.words kaomoji_words = [] kaomoji_idx = [i for i, w in enumerate(words) if len(w) >= KAOMOJI_LEN] kaomoji_hands = ['ノ', 'ヽ', '∑', 'm', 'O', 'o', '┐', '/', '\\', '┌'] # 顔文字と手を検索 for i in kaomoji_idx: kaomoji = words[i] # 顔文字列 try: # 顔文字の左手 if words[i-1] in kaomoji_hands and 0 < i: kaomoji = words[i-1] + kaomoji # 顔文字の右手 if words[i+1] in kaomoji_hands: kaomoji = kaomoji + words[i+1] except IndexError: pass finally: kaomoji_words.append(kaomoji) return kaomoji_words text = "今日は渋谷スクランブルスクエアに行ってきた\(^o^)/ 夜景?サイコー❗️ https://hogehogehogehoge.jpg" text = unicodedata.normalize('NFKC', text) # NFKC正規化 print(extract_kaomoji(text)) # => ['\\(^o^)/'] text = "ごめんなさいm(-_-)m" text = unicodedata.normalize('NFKC', text) # NFKC正規化 print(extract_kaomoji(text)) # => ['m(-_-)m']これで、テキストから顔文字を抽出することができました。
抽出結果
今日は渋谷スクランブルスクエアに行ってきた\(^o^)/ 夜景?サイコー❗️ https://hogehogehogehoge.jpg 顔文字: \(^o^)/ ごめんなさいm(-_-)m 顔文字: m(-_-)m3.3 URLの抽出
URLの抽出はシンプルです。
必要な品詞の単語だけを抽出する関数nagisa.extractで必要な品詞タグにURLを条件付けるだけで、URLを抽出することができます。import nagisa import unicodedata def extract_url(words): results = nagisa.extract(text, extract_postags=['URL']) return results.words text = "今日は渋谷スクランブルスクエアに行ってきた\(^o^)/ 夜景?サイコー❗️ https://hogehogehogehoge.jpg" text = unicodedata.normalize('NFKC', text) # NFKC正規化 print(extract_url(text)) # => ['https://hogehogehogehoge.jpg']抽出結果
今日は渋谷スクランブルスクエアに行ってきた\(^o^)/ 夜景?サイコー❗️ https://hogehogehogehoge.jpg URL: https://hogehogehogehoge.jpg3.4 絵文字の抽出
絵文字の抽出も簡単です。
絵文字はUnicodeで定義されているため、文字のUnicodeを確認してその文字が絵文字かどうかを判定します。
emojiで絵文字のUnicodeリストを使うことができます。import emoji import nagisa import unicodedata def extract_emoji(words): return [w for w in words if w in emoji.UNICODE_EMOJI] text = "今日は渋谷スクランブルスクエアに行ってきた\(^o^)/ 夜景?サイコー❗️ https://hogehogehogehoge.jpg" text = unicodedata.normalize('NFKC', text) # NFKC正規化 print(extract_emoji(text)) # => ['?', '❗'] text = "日本語のテキストから絵文字?を抽出するよ❗" text = unicodedata.normalize('NFKC', text) # NFKC正規化 print(extract_emoji(text)) # => ['?', '❗']抽出結果
今日は渋谷スクランブルスクエアに行ってきた\(^o^)/ 夜景?サイコー❗️ https://hogehogehogehoge.jpg 絵文字: ?, ❗ 日本語のテキストから絵文字?を抽出するよ❗ 絵文字: ?, ❗4. おわりに
テキストから顔文字・絵文字・URLを抽出する前処理方法を紹介しました。
本記事で紹介した前処理(一部)は、今年ドコモとNTTが参加したWMT19のRobustness taskに投稿したシステムでも使っています。
論文でも前処理について書いていますので、ツイートや口コミの分析に取り組んでいる方のお役に立てれば幸いです。最後に、本記事を書く際に参考にさせていただいた記事を紹介します。
テキスト前処理についてとても良くまとめられているので、ぜひ参考にしてみて下さい。テキスト前処理に関する記事のまとめ
- 自然言語処理における前処理の種類とその威力
- Python3×日本語:自然言語処理の前処理まとめ
- 自然言語(前)処理
- 自然言語のpythonでの前処理のかんたん早見表(テキストクリーニング、分割、ストップワード、辞書の作成、数値化)
- Pythonを使って自然言語処理の前処理を行う
- 形態素解析前の日本語文書の前処理 (Python)
付録
本記事で実装したコード(全文)です。
ソースコード
import emoji import nagisa import unicodedata KAOMOJI_PH = "<Kaomoji>" URL_PH = "<URL>" EMOJI_PH = "<Emoji>" KAOMOJI_LEN = 5 def extract_kaomoji(text): """ 与えられたテキストから抽出した顔文字リストを返却する。 → \(^o^)/, m(_ _)m などの 手を含む顔文字があれば、それも抽出する """ results = nagisa.extract(text, extract_postags=['補助記号']) words = results.words kaomoji_words = [] kaomoji_idx = [i for i, w in enumerate(words) if len(w) >= KAOMOJI_LEN] kaomoji_hands = ['ノ', 'ヽ', '∑', 'm', 'O', 'o', '┐', '/', '\\', '┌'] # 顔文字と手を検索 for i in kaomoji_idx: kaomoji = words[i] # 顔文字列 try: # 顔文字の左手 if words[i-1] in kaomoji_hands and 0 < i: kaomoji = words[i-1] + kaomoji # 顔文字の右手 if words[i+1] in kaomoji_hands: kaomoji = kaomoji + words[i+1] except IndexError: pass finally: kaomoji_words.append(kaomoji) return kaomoji_words def extract_url(words): results = nagisa.extract(text, extract_postags=['URL']) return results.words def extract_emoji(text): results = nagisa.tagging(text) # 形態素解析 words = results.words return [w for w in words if w in emoji.UNICODE_EMOJI] def replace(text, target_list, PH): for trg in target_list: text = text.replace(trg, PH) return text def delete(text, target_list): for trg in target_list: text = text.replace(trg, "") return text text = "今日は渋谷スクランブルスクエアに行ってきた\(^o^)/ 夜景?サイコー❗️ https://hogehogehogehoge.jpg" text = unicodedata.normalize('NFKC', text) # NFKC正規化 # 入力 print("対象テキスト: {}\n".format(text)) # 抽出 kaomoji_list = extract_kaomoji(text) url_list = extract_url(text) emoji_list = extract_emoji(text) # 抽出結果 print("顔文字: {}".format(kaomoji_list)) print("URL: {}".format(url_list)) print("絵文字: {}\n".format(emoji_list)) # 削除 deleted_text = delete(text, kaomoji_list + url_list + emoji_list) print("削除: {} \n".format(deleted_text)) # 置換 replaced_text = replace(text, kaomoji_list, KAOMOJI_PH) replaced_text = replace(replaced_text, url_list, URL_PH) replaced_text = replace(replaced_text, emoji_list, EMOJI_PH) print("置換: {} \n".format(replaced_text))出力例
対象テキスト: 今日は渋谷スクランブルスクエアに行ってきた\(^o^)/ 夜景?サイコー❗️ https://hogehogehogehoge.jpg 顔文字: ['\\(^o^)/'] URL: ['https://hogehogehogehoge.jpg'] 絵文字: ['?', '❗'] 削除: 今日は渋谷スクランブルスクエアに行ってきた 夜景サイコー️ 置換: 今日は渋谷スクランブルスクエアに行ってきた<Kaomoji> 夜景<Emoji>サイコー<Emoji>️ <URL>


- 投稿日:2019-11-29T17:00:42+09:00
LightFMをMovielensに適用してみた
Factoriazation Machines関連のライブラリを調査している過程で、LightFMというライブラリに出会ったので使ってみました。
最終的には自作のデータセットに適用してみたいのですが、今回はLightFMの使い方に慣れるのをかねてMovielens(映画レコメンデーションデータセット)に適用してみます。
LightFMリポジトリ
GitHub - lyst/lightfm: A Python implementation of LightFM, a hybrid recommendation algorithm.LightFMとFMの違い
LightFMは、FMとついているのですがFactorization Machinesのライブラリではありません。
LightFMの論文を読んでみると、著者らは「LightFMはFMの特別な場合」と述べています。
FMのpython実装を探していたので、多少がっかりしたものの、読んでみるとこれでも自分の試したいタスクを解けそうなモデルをしていたのでこちらを試してみようと思いました。(あとチュートリアルやドキュメントが充実している)
通常のFMはuser id, item idの他にcontext featureとしていろんな特徴を入力に用いることができ、それぞれembeddingをとり全ての内積とって和を出力とします。
f(x)=w_0 + \sum_{i=1}^d w_ix_i + \sum_{i,j}\langle \boldsymbol v_i, \boldsymbol v_j \rangle x_ix_juser embeddingとitem embeddingの内積、context featureどうしの内積など、すべてとります。
LightFMは、FMのようにcontext featureを入れることは部分的に可能ですが、なんでもかんでも入れることができるわけではありません。
追加する特徴は、userの特徴かitemの特徴かのどちらか、という縛りがあります。
内積も、userの特徴はitemの特徴としか内積をとりません。userの特徴どうしの内積をとりません。
f(i, u)= \langle \boldsymbol p_i, \boldsymbol q_u \rangle + b_i +b_uただし
\boldsymbol p_i = \sum_{j \in f_i}\boldsymbol e_{j}^I\boldsymbol q_u = \sum_{j \in f_u}\boldsymbol e_{j}^Ub_i = \sum_{j \in f_i}b_{j}^Ub_u = \sum_{j \in f_u} b_{j}^Uです。
userやitemの特徴を与えない場合、Matrix Factorizationの形に一致します。
LightDMがサポートしているlossは、BPRとWARP、warp-kos, logistic lossです。前者3つはランキングに対するlossで、implicit feedbackでランキング学習をするのに適しています。
BPRについてはこちらに記事を書いたのでよろしければどうぞ!
【論文紹介】BPR: Bayesian Personalized Ranking from Implicit Feedback (UAI 2009)
動かしてみよう
Movielensデータセット取得
Movielensは映画レコメンデーションのデータセットで、この分野ではよく実験で用いられています。
今回は比較的小さいサイズに絞って動かしています。LightFMは親切にもMovielensをロードするクラスを提供しているので、これを使ってみます。
(LightFMのinstallはpipでもcondaでも入ります。省略)
from lightfm.datasets import fetch_movielens data = fetch_movielens() data.keys()とすると
dict_keys(["train", "test", "item_features", "item_feature_labels", "item_labels"])がかえってきました。
trainとtestは、(n_user,n_item)の行列でratingが入っています。ratingが付いてないのは0が入っています。
item_featuresは、(n_item, n_features)の行列で各itemがどの特徴を持っているかを01で表したもの...と思ったのですが、中身を見てみると正方行列でしかも単位行列っぽいです。
また、item_feature_labelは各featureの名前、item_labelsはitemの名前が入っている、とドキュメントにはあり、それぞれ(n_feature,) , (n_item,)のarrayであると書いてあるのですが、中身を見てみるとどちらも
array(['Toy Story (1995)', 'GoldenEye (1995)', 'Four Rooms (1995)', ..., 'Sliding Doors (1998)', 'You So Crazy (1994)', 'Scream of Stone (Schrei aus Stein) (1991)'], dtype=object)でした。すべてitemの名前です。
おそらくこのチュートリアルではitem featureは使わないで(つまりMatrix Factorizationで)動かしてみよう、ということですかね。
学習部分
実際にモデルを学習させる部分はこちら。
train = data["train"] test = data["test"] model = LightFM(no_components=10,learning_rate=0.05, loss='bpr') model.fit(train, epochs=10) train_precision = precision_at_k(model, train, k=10).mean() test_precision = precision_at_k(model, test, k=10).mean() train_auc = auc_score(model, train).mean() test_auc = auc_score(model, test).mean() print('Precision: train %.2f, test %.2f.' % (train_precision, test_precision)) print('AUC: train %.2f, test %.2f.' % (train_auc, test_auc))
no_componentsでembeddingの次元を指定できます。今回は10。modelのfitやaucのところで、
model.fit(train, item_features=data["item_features"], epochs=10) auc_score(model, train, item_features=data["item_features"]).mean()などとするとitem_featuresを入れることができます。
ただ、今回は入れても入れなくてもitem_featuresはitem idしか入っていないので結果は変わらないはず。
item_featureなし Precision: train 0.59, test 0.10. AUC: train 0.90, test 0.86. item_featureあり Precision: train 0.59, test 0.10. AUC: train 0.89, test 0.86.と思ったのですが、微妙に違いますね...
誤差でしょうか。LightFMのソースを見に行くと、item_featuresが指定されていないと、(n_item,n_item)の単位行列でitem featuresを作っていたので、上記の両方で同じ挙動になるはずですが。
embedding取得
学習後のembeddingは、以下のようにして取得できます。
user_embedding=model.user_embeddings item_embedding=model.item_embeddingsuser_embeddingは(n_user_features, no_components)
item_embeddingは(n_item_features, no_components)のarrayです。
先ほどソースを見に行ってわかった通り、featuresを指定しない場合はuser/item id分のembeddingが得られていました。
predict
最後、predictのところが少しつまづきポイントがあったのでメモしておきます。
user_idとitem_idを与えると、その組についてスコアを計算してくれます。
idの与え方は、まずuser一人あたりにitem idを複数与える場合があります。model.predict(user_ids=0,item_ids=[1,3,4])とすると、user0さんのitem1,3,4に対するスコアが計算されます。
userごとにrankingを作る場面が多いと思うので、この書き方は便利ですね。複数のuser idと複数のitem idの組について少し注意すべきポイントがあって、
model.predict(user_ids=[4,3,1],item_ids=[1,3,4])とやるとAssertion Errorが出ます。
正しくは
import numpy as np model.predict(user_ids=np.array([4,3,1]),item_ids=[1,3,4])ソースを読んでみると、最初にuser idがnumpy arrayでない場合はitem idと個数を揃えるためにitem idの個数分repeatする処理が入ります。
user idがintの場合(先ほど書いたuser一人当たりに複数itemに対してスコアを計算する場合)にはこれで長さが揃うのですが、user_idsをlistで与えた時もrepeatされて長さが揃わなくなります。これは罠...「user_idsがlenを計算できるか」とかでrepeatするかを決めればいいのに。リスト与えちゃう人いるでしょ...
lossについて
BPRやWARPは、ratingが正のものをpositive feedbackと捉えるような実装になってました。こちらで1に直して与える、とかはしなくてもよいみたいです。
logistic lossは、+1と-1のfeedbackがあるときに使えます、と書いてありましたが、
そのままratingの行列を与えても動きました。(内部で何をしているのかはソースを眺めただけではちょっとよくわかりませんでした)logisticPrecision: train 0.43, test 0.08. AUC: train 0.87, test 0.84.bpr(再掲)Precision: train 0.59, test 0.10. AUC: train 0.90, test 0.86.ただランキングの指標には適していないことがわかります。
おわりに
以上、これで基本的な処理は行えるようになったかと思います。
チュートリアルやドキュメントがわかりやすいこと、サポートされているlossが複数あるのは嬉しいです。
さらっと書いてしまいましたが、AUCやPrecision@kなどの評価指標も提供されているのも便利ですね。
次はいよいよ自作のデータセットに対してLightFMを適用してみようと思います!
最後まで読んでいただきありがとうございました。
- 投稿日:2019-11-29T16:55:46+09:00
【Django】SQLを指定してデータを取得する方法。
Djangoで生のクエリを実行したい場合はraw()を使えば簡単に実現できるみたい。
参考:Performing raw SQL queriesサンプルModel
models/users.pyimport django.db from models class Users(models.Model): name = models.CharField() age = models.IntegerField() sex = models.CharField()SQLを指定してデータ取得
usersテーブルの年齢が40以上のユーザーを取得する場合
sql = "SELECT * FROM users WHERE age >= 40" users = Users.objects.raw(sql)下記と同じ結果となります。
users = Users.objects.filter(age__gte=40)パラメーターを指定
パラメーターを指定して実行することもできます。
sql = "SELECT * FROM users WHERE age >= %s" users = Users.objects.raw(sql, [40])辞書型で指定する場合。上記だと、複数のパラメーターがあったときに何個目がどの値だっけ?とわかりにくくなるので、下記がおすすめ。
sql = "SELECT * FROM users WHERE age >= %(age)s AND sex = %(sex)s" params = {"age": 40, "sex": "male"} users = Users.objects.raw(sql, params)
- 投稿日:2019-11-29T16:43:12+09:00
RaspberryPi 4でPoseNetを動かしてエッジデバイスのパフォーマンスを比較する
【お詫び】
電源を変えて再計測したものに内容を更新しました。
当初公開した記録はRaspberryPi4の電源に不備があり、十分な電力を供給できておらずパフォーマンスが低下していたようです。
クロック周波数は最大周波数で回っているのを確認はしたのですが…【内容】
本記事は結果のみです。
過去の記事ででPoseNetのパフォーマンスを測定したように、ラズパイ4でもパフォーマンス測定してみました。
【結果】
【実行結果 (カメラ映像)】
解像度 Platform 推論時間 (ms) FrameIO (ms) FPS 備考 1280x720 RaspberryPi3 + EdgeTPU 279.4 75.82 2.47 RaspberryPi4 + EdgeTPU 44.9 54.14 6.95 - DevBoard 44.9 42.89 7.46 - JetsonNano + EdgeTPU 49.2 23.82 7.44 640x480 RaspberryPi3 + EdgeTPU 94.4 27.48 7.16 RaspberryPi4 + EdgeTPU 15.0 18.96 19.54 - DevBoard 13.5 15.26 24.36 - JetsonNano + EdgeTPU 15.0 8.53 29.89 カメラの性能限界 480x360 RaspberryPi3 + EdgeTPU 53.5 12.34 12.57 - RaspberryPi4 + EdgeTPU 8.0 4.24 29.98 カメラの性能限界 - DevBoard 8.2 10.92 30.18 カメラの性能限界 - JetsonNano + EdgeTPU 9.7 4.21 30.06 カメラの性能限界 【結果 (ビデオファイル)】
解像度 Platform 推論時間 (ms) FrameIO (ms) FPS 備考 640x480 RaspberryPi3 + EdgeTPU 65.3 19.59 8.68 - RaspberryPi4 + EdgeTPU 14.8 9.53 23.03 - DevBoard 13.6 14.97 20.94 - JetsonNano + EdgeTPU 15.0 6.87 30.08 480x360 RaspberryPi3 + EdgeTPU 33.9 10.27 14.64 - RaspberryPi4 + EdgeTPU 8.1 4.17 38.44 - DevBoard 7.5 8.18 31.68 - JetsonNano + EdgeTPU 8.9 4.00 45.57 当初は電源容量不足のため思ったよりパフォーマンスが出ず残念な結果でしたが、しっかり3A供給できる電源に変更したところ、DevBoardに匹敵するスコアが出るようになりました。
処理によってはDevBoardを超えているものもあります。
これだけのパフォーマンスが出せて、メモリも4GBも載っているラズパイ4とDevBoardを比べると、コスパ的にラズパイ4が優位な気がします。DevBoardはロマンで終わってしまうのでしょうか…
DevBoardは先日カーネルが更新されて色々機能アップしているようなので、後日最新版で再計測してい見ます。

- 投稿日:2019-11-29T16:10:21+09:00
minicondaでpython環境を作ったときのメモ
1. miniconda
- minicondaはanacondaの最小構成版.環境を仮想化するので大本の環境が汚くならない.バージョン管理がしやすい.まだ大して使ってないので細かいことはまだわかりません.
2. minicondaをインストールする(Mac OSX : Homebrew)
2.1 環境
- macOS Catalina 10.15.1
- Homebrew 2.2.0
- Homebrew/homebrew-core (git revision a6e8; last commit 2019-11-28)
- Homebrew/homebrew-cask (git revision 273f; last commit 2019-11-29)
2.2 Install
- homebrew-cask を入れる.すでに入ってる人はminicondaインストールへ.
terminal$ brew cask
- minicondaをインストール
terminal$ brew cask install miniconda3. 仮想環境を作り,実行
3.1 仮想環境を作る
terminal$ conda create python=3.6 -name test_environment Collecting package metadata (current_repodata.json): done Solving environment: done ## Package Plan ## environment location: /usr/local/Caskroom/miniconda/base/envs/test_environment added / updated specs: - python=3.6 The following NEW packages will be INSTALLED: ca-certificates pkgs/main/osx-64::ca-certificates-2019.10.16-0 certifi pkgs/main/osx-64::certifi-2019.9.11-py36_0 libcxx pkgs/main/osx-64::libcxx-4.0.1-hcfea43d_1 libcxxabi pkgs/main/osx-64::libcxxabi-4.0.1-hcfea43d_1 libedit pkgs/main/osx-64::libedit-3.1.20181209-hb402a30_0 libffi pkgs/main/osx-64::libffi-3.2.1-h475c297_4 ncurses pkgs/main/osx-64::ncurses-6.1-h0a44026_1 openssl pkgs/main/osx-64::openssl-1.1.1d-h1de35cc_3 pip pkgs/main/osx-64::pip-19.3.1-py36_0 python pkgs/main/osx-64::python-3.6.9-h359304d_0 readline pkgs/main/osx-64::readline-7.0-h1de35cc_5 setuptools pkgs/main/osx-64::setuptools-42.0.1-py36_0 sqlite pkgs/main/osx-64::sqlite-3.30.1-ha441bb4_0 tk pkgs/main/osx-64::tk-8.6.8-ha441bb4_0 wheel pkgs/main/osx-64::wheel-0.33.6-py36_0 xz pkgs/main/osx-64::xz-5.2.4-h1de35cc_4 zlib pkgs/main/osx-64::zlib-1.2.11-h1de35cc_3 Proceed ([y]/n)? y Preparing transaction: done Verifying transaction: done Executing transaction: done # # To activate this environment, use # # $ conda activate test_environment # # To deactivate an active environment, use # # $ conda deactivate3.2 作った環境に移動する
terminal$ conda activate test_environmenteバージョンによっては,
source activate hogehogeとする場合があるみたいですが,conda version : 4.7.12ではconda activate hogehogeとするみたいです.バージョンによる違いは未調査です.
このアクティベートは初回は成功しません.「使用しているshellでの初期化が必要」と言われるので,terminal$ conda init zshzsh のところには各々の使用してるshellを入れてください. 実行すると,以下のが.zshrcなどに記載される.
~/.zshrc# >>> conda initialize >>> # !! Contents within this block are managed by 'conda init' !! __conda_setup="$('/usr/local/Caskroom/miniconda/base/bin/conda' 'shell.zsh' 'hook' 2> /dev/null)" if [ $? -eq 0 ]; then eval "$__conda_setup" else if [ -f "/usr/local/Caskroom/miniconda/base/etc/profile.d/conda.sh" ]; then . "/usr/local/Caskroom/miniconda/base/etc/profile.d/conda.sh" else export PATH="/usr/local/Caskroom/miniconda/base/bin:$PATH" fi fi unset __conda_setup # <<< conda initialize <<<これを実行したら,あとは使えるようになっているはずなので,terminalを開き直すか,.zshrcを読み込み直す.
termianl$ source .zshrc3.3 実行し直す
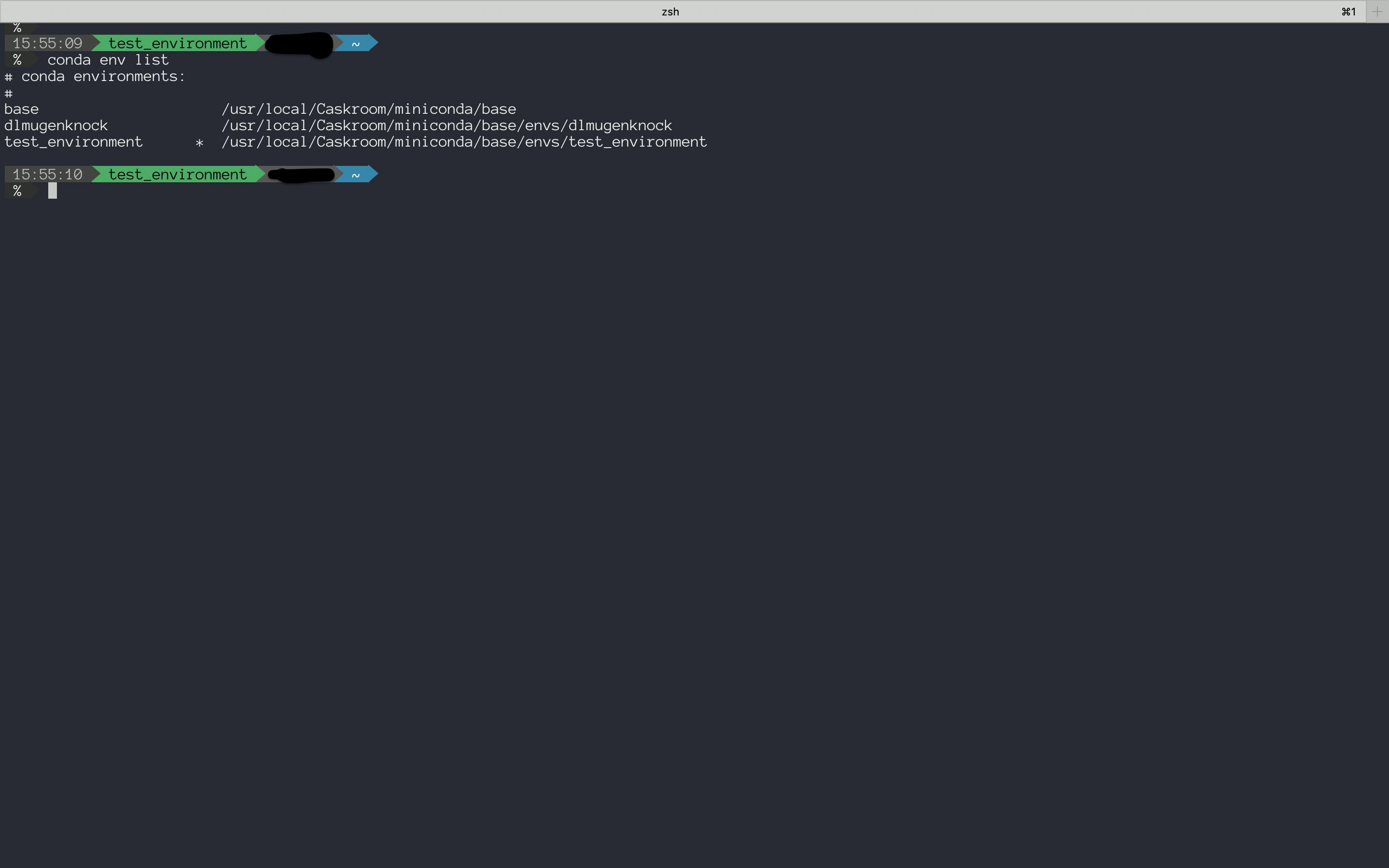
- 今いる環境,その他の環境を確認するには
terminal$ conda env list # conda environments: # base * /usr/local/Caskroom/miniconda/base dlmugenknock /usr/local/Caskroom/miniconda/base/envs/dlmugenknock test_environment /usr/local/Caskroom/miniconda/base/envs/test_environment
- 移動して,移動を確認する
terminal$ conda activate test_environment $ conda env list # conda environments: # base /usr/local/Caskroom/miniconda/base dlmugenknock /usr/local/Caskroom/miniconda/base/envs/dlmugenknock test_environment * /usr/local/Caskroom/miniconda/base/envs/test_environment
- 環境を抜けるには
terminal$ conda deactivate5. 補足
- あとはそれぞれの環境で必要なmoduleを
pip install hogehogeすればOK.- 環境を変更すると写真のように環境名が横にでるみたいです.
参考記事
- 投稿日:2019-11-29T15:51:07+09:00
SphinxでPythonコードのdocする自分用メモ
この記事は
Sphinxを使って、Pythonコードをdocumentationする自分用ノート。
下記にとても素晴らしい記事があります。
- Sphinxの使い方.docstringを読み込んで仕様書を生成仮想環境
createする
# 仮想環境名 sphinx_test ですすめていく conda create -n sphinx_test python=3.6activateする
conda activate sphinx_testsphinxパッケージのインストール
pip install sphinxdocumentプロジェクトの初期化
# docsフォルダを作業スペースにする sphinx-quickstart docs
- いくつか設定に関する質問が出てくるが、デフォルト値のままでよければ Enterキー を押していけばよい
- 下記の設定は任意
- "project name:"
- "Author name(s):"
- "Project release []"
document作成ののconfiguration
docs/conf.pyを開く- 下記の箇所のコメントアウト解除
import os import sys sys.path.insert(0, os.path.abspath('../')) # 上のディレクトリに置いたpyファイルを参照したいのでこうする # os.path.abspath('./') => os.path.abspath('../')extensionの設定
extensions = [ 'sphinx.ext.autodoc', 'sphinx.ext.napoleon' ]ここでいちどドキュメントをmakeしてみる
.\docs\make singlehtmlpyファイルからrstファイルを生成する
# "."を見落とさないように。ディレクトリ内のすべてのファイルの意味。 sphinx-apidoc -f -o .\docs .index.rstの変更
.. toctree:: :maxdepth: 2 :caption: Contents: TestClass # <- 追加したいpythonファイルPythonファイルを置く
- sphinx_test - docs - TestClass.py <-- ここに置く
- docstring形式でドキュメントしたいコメントを書く
class TestClass: """Summary line. """ def testfunc(self, x, y): """sum Args: x (int): 1st argument y (int): 2nd argument Returns: int: sum result Examples: >>> print(testfunc(2,5)) 7 """ return x + yドキュメントのmake
- さっきと同じ
.\docs\make singlehtml
- 投稿日:2019-11-29T15:46:27+09:00
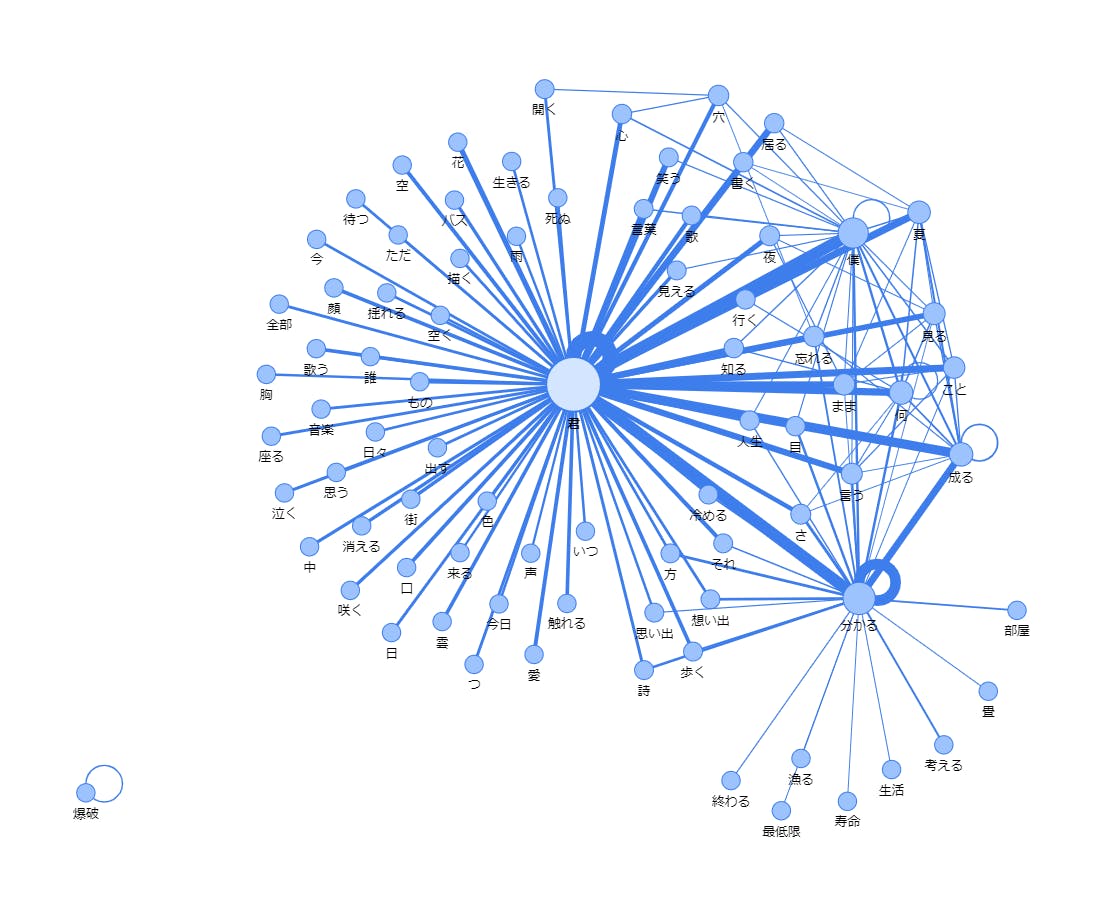
【共起解析】Pythonで簡単に共起解析する!【Python】
共起解析
前回の記事【https://qiita.com/osakasho/items/0a0b50fc17c38d96c45e 】
では、形態素解析までしかやらなかったので、今度は共起解析もしてグラフ化してみます。必要なものをインストールする
pip install pyvisコード
import spacy nlp = spacy.load('ja_ginza_nopn') import re import itertools import collections from pyvis.network import Network import pandas as pd import time """--------- 分解モジュール --------""" def sentence_separator(path, colname): black_list = ["test"] df = pd.read_csv(path, encoding="utf_8_sig") data = df[colname] sentence = [] for d in data: try: total_ls, noun_ls, verm_ls = ginza(d) sentence.append(total_ls) except: pass return sentence def ginza(word): doc = nlp(word) # 調査結果 total_ls = [] Noun_ls = [chunk.text for chunk in doc.noun_chunks] Verm_ls = [token.lemma_ for token in doc if token.pos_ == "VERB"] for n in Noun_ls: total_ls.append(n) for v in Verm_ls: total_ls.append(v) return total_ls, Noun_ls, Verm_ls """-------------------------------------""" #テキストデータの取得を行う。 filename = "list.csv" file_path = filename colname = "歌詞" #文章 sentences = sentence_separator(file_path, colname) sentence_combinations = [list(itertools.combinations(sentence, 2)) for sentence in sentences] sentence_combinations = [[tuple(sorted(words)) for words in sentence] for sentence in sentence_combinations] target_combinations = [] for sentence in sentence_combinations: target_combinations.extend(sentence) #ネットワーク描画のメイン処理 def kyoki_word_network(): # got_net = Network(height="500px", width="100%", bgcolor="#222222", font_color="white", notebook=True) got_net = Network(height="1000px", width="95%", bgcolor="#FFFFFF", font_color="black", notebook=True) # set the physics layout of the network # got_net.barnes_hut() got_net.force_atlas_2based() got_data = pd.read_csv("kyoki.csv")[:150] sources = got_data['first'] # count targets = got_data['second'] # first weights = got_data['count'] # second edge_data = zip(sources, targets, weights) for e in edge_data: src = e[0] dst = e[1] w = e[2] got_net.add_node(src, src, title=src) got_net.add_node(dst, dst, title=dst) got_net.add_edge(src, dst, value=w) neighbor_map = got_net.get_adj_list() # add neighbor data to node hover data for node in got_net.nodes: node["title"] += " Neighbors:<br>" + "<br>".join(neighbor_map[node["id"]]) node["value"] = len(neighbor_map[node["id"]]) got_net.show_buttons(filter_=['physics']) return got_net #まとめルンバ ct = collections.Counter(target_combinations) print(ct.most_common()) print(ct.most_common()[:10]) #データを一時保存 pd.DataFrame([{'first' : i[0][0], 'second' : i[0][1], 'count' : i[1]} for i in ct.most_common()]).to_csv('kyoki.csv', index=False, encoding="utf_8_sig") time.sleep(1) # 処理の実行 got_net = kyoki_word_network() got_net.show("kyoki.html")結果
kyoki.htmlが出力されていると思うので、ブラウザで起動してください。
終わり。
- 投稿日:2019-11-29T15:14:25+09:00
Python3 M2Cryptoライブラリを使用してSSL証明書の更新期限チェックをする
背景
Let's Encryptで証明書の自動更新をしているドメインで、マニュアルどおりにやっていれば、デフォルト設定で30日を切ったタイミングでSSL証明書の更新が行われるはずですが、更新が実施されているかチェックする必要性があったためスクリプトで実装しました。
実際には下記をチェック対象ドメインリストのコンフィグファイルを食わせるなどして運用しますが、実装に利用したM2Cryptoライブラリの説明があまりなかったので、実際に操作した記録を含めて書き起こしておきます。
本当は使い慣れてるurllibとかで実装できればよかったんですが、SSL証明書の検証ができる方法がよくわからなかったのでM2Cryptoライブラリを利用しました。環境
- Amazon Linux
- Python3
利用するライブラリ
- datetime
- ssl
- M2Crypto
Python実行環境
こんな感じでPyenvを利用してpython3環境を作成済み。
# pwd /root/python3 # pyenv versions system * 3.5.6 (set by /root/python3/.python-version) # python -V Python 3.5.6SSL証明書の期限確認
対話型のインタラクティブモードを利用してデータ状態などを確認しながら必要なものを揃えていきます。
import ssl import M2Crypto import datetime port = 443 hostname = 'www.qiita.com' # ドメインは適当にご自身のものを。 cert = ssl.get_server_certificate((hostname, port)) x509 = M2Crypto.X509.load_cert_string(cert) x509.get_subject().as_text() # 'CN=qiita.com'この辺から、あんまりドキュメントが見当たらなくてよくわからないので、使えるメソッドを掘り出しながら進めます。
dir(x509) # ['__class__', '__del__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', # '__gt__', '__hash__', '__init__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', # '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_ptr', '_pyfree', 'add_ext', 'as_der', 'as_pem', # 'as_text', 'check_ca', 'check_purpose', 'get_ext', 'get_ext_at', 'get_ext_count', 'get_fingerprint', 'get_issuer', 'get_not_after', # 'get_not_before', 'get_pubkey', 'get_serial_number', 'get_subject', 'get_version', 'm2_x509_free', 'save', 'save_pem', 'set_issuer', # 'set_issuer_name', 'set_not_after', 'set_not_before', 'set_pubkey', 'set_serial_number', 'set_subject', 'set_subject_name', # 'set_version', 'sign', 'verify', 'x509']使えそうなget_not_afterを発見。
type(x509.get_not_after()) # <M2Crypto.ASN1.ASN1_TIME object at 0x7f26999f1940> dir(x509.get_not_after()) # ['__class__', '__del__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', # '__gt__', '__hash__', '__init__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', # '__setattr__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_ptr', '_pyfree', '_ssl_months', 'asn1_time', # 'get_datetime', 'm2_asn1_time_free', 'set_datetime', 'set_string', 'set_time']datetimeで出力できそうな get_datetime なるものを発見。
type(x509.get_not_after().get_datetime()) # <class 'datetime.datetime'> x509.get_not_after().get_datetime() # datetime.datetime(2020, 4, 30, 12, 0, tzinfo=<Timezone: UTC>)datetimeでデータが取得できたので、後はdatetimeライブラリを利用してtimedeltaを求めてあげればOK
exp_date = x509.get_not_after().get_datetime() now = datetime.datetime.now() # datetime.datetime(2019, 11, 29, 10, 52, 24, 89337) exp_date - now Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: can't subtract offset-naive and offset-aware datetimesdatetime同士の引き算はタイムゾーンがくっついてるとできないそうです。
参考 : Pythonのタイムゾーンの扱い
ということで、タイムゾーン情報を削って比較。remaining_time = exp_date.replace(tzinfo=None) - now # datetime.timedelta(53, 15629, 910663) remaining_time.days 152無事SSL証明書の残り日数の取得ができました。
最終的なコードは以下。
割とコンパクト。import ssl import M2Crypto from cryptography import x509 from cryptography.hazmat.backends import default_backend import datetime port = 443 hostname = 'www.qiita.com' # 適宜書き換えるか引数を読み込んで下さい cert = ssl.get_server_certificate((hostname, port)) x509 = M2Crypto.X509.load_cert_string(cert) exp_date = x509.get_not_after().get_datetime() now = datetime.datetime.now() remaining_time = exp_date.replace(tzinfo=None) - now print(remaining_time.days) 152参考情報
- 投稿日:2019-11-29T15:09:01+09:00
デバッグをしてみた。
こんにちは!
今回はデバッグの練習をしていこうかなと思います。
PythonデバッグTips
最短で試すPythonテストコード
をコピペして試しているだけなので、詳細はこちらをご覧ください!!pdbでデバッグ
まずpdbでデバッグします。
以下がデバッグで使用するコードです。import pdb; for ii in range(1, 21): if ii % 15 == 0: print('Takeuchi Tsuyoshi') elif ii % 3 == 0: print('Takeuchi') elif ii % 5 == 0: print('Tsuyoshi') else: print(ii)まず起動させます。
python -m pdb ファイル名コマンド「n」を打つと一行ずつ実行されます。
(Pdb) n > /home/takeuchi/test.py(4)<module>() -> for ii in range(1, 21): (Pdb) n > /home/takeuchi/test.py(5)<module>() -> if ii % 15 == 0: (Pdb) n > /home/takeuchi/test.py(7)<module>() - > elif ii % 3 == 0: (Pdb)そしてコマンド「c」を打つと一行ずつではなく一気に処理を進めます。
> /home/takeuchi/test.py(4)<module>() -> for ii in range(1, 21): (Pdb) c Takeuchi 4 Tsuyoshi Takeuchi 7 8 Takeuchi Tsuyoshi 11 Takeuchi 13 14 Takeuchi Tsuyoshi 16 17 Takeuchi 19 Tsuyoshi The program finished and will be restarted > /home/takeuchi/test.py(1)<module>() -> import pdb; (Pdb)bでブレークポイントを指定し、そこまでの処理を確認することができます。
ためしに、if文の最初の分岐までの処理を実行してみましょう。
ちゃんと出力されました。(Pdb) b 5 Breakpoint 1 at /home/takeuchi/test.py:5 (Pdb) c > /home/takeuchi/test.py(5)<module>() -> if ii % 15 == 0: (Pdb) c 1 > /home/takeuchi/test.py(5)<module>() -> if ii % 15 == 0: (Pdb) c 2 > /home/takeuchi/test.py(5)<module>() -> if ii % 15 == 0: (Pdb) c Takeuchi > /home/takeuchi/test.py(5)<module>() -> if ii % 15 == 0: (Pdb) c 4 > /home/takeuchi/test.py(5)<module>() -> if ii % 15 == 0: (Pdb) c Tsuyoshi > /home/takeuchi/test.py(5)<module>() -> if ii % 15 == 0: (Pdb) Takeuchi > /home/takeuchi/test.py(5)<module>() -> if ii % 15 == 0: c(Pdb) c 7 > /home/takeuchi/test.py(5)<module>() -> if ii % 15 == 0: (Pdb) c 8 > /home/takeuchi/test.py(5)<module>() -> if ii % 15 == 0: (Pdb) c Takeuchi > /home/takeuchi/test.py(5)<module>() -> if ii % 15 == 0: (Pdb) c Tsuyoshi > /home/takeuchi/test.py(5)<module>() -> if ii % 15 == 0: (Pdb) c 11 > /home/takeuchi/test.py(5)<module>() -> if ii % 15 == 0: (Pdb) c Takeuchi > /home/takeuchi/test.py(5)<module>() -> if ii % 15 == 0: (Pdb) c 13 > /home/takeuchi/test.py(5)<module>() -> if ii % 15 == 0: (Pdb) c 14 > /home/takeuchi/test.py(5)<module>() -> if ii % 15 == 0: (Pdb) c Takeuchi Tsuyoshi > /home/takeuchi/test.py(5)<module>() -> if ii % 15 == 0: (Pdb)(Pdb) b 5, ii == 15とすることでiiが15のときのみ処理が止まるようになります。
つぎにテストも同じように実行していきたいと思います。
こちらもコピペになるので詳細を知りたい方は参照元をご覧ください。test2.pyimport unittest import test as tt class FizzBuzzTest(unittest.TestCase): def setUp(self): pass def tearDown(self): pass def test_normal(self): self.assertEqual(1, tt.fizzbuzz(1)) def test_fizz(self): self.assertEqual("Tsuyoshi", tt.fizzbuzz(3)) def test_buzz(self): self.assertEqual("Takeuchi", tt.fizzbuzz(5)) def test_fizzbuzz(self): self.assertEqual("Takeuchi Tsuyoshi", tt.fizzbuzz(15)) if __name__ == "__main__": unittest.main()
def setUp(self)とdef tearDown(self)は初期化・終了のタイミングで走る関数らしいです。
assertEqual()は第一引数と第二引数が同じ値かどうかを調べてくれています。
そして以下がimportしているtest.pyになります。test.pydef fizzbuzz(number): if number % 15 == 0: return "Takeuchi Tsuyoshi" if number % 5 == 0: return "Takeuchi" if number % 3 == 0: return "Tsuyoshi" return number if __name__ == "__main__": for i in range(1, 101): print(fizzbuzz(i))実行結果は以下の通りです!!
❯ python test2.py .... ---------------------------------------------------------------------- Ran 4 tests in 0.001s OK参考文献
- 投稿日:2019-11-29T14:52:45+09:00
Qiskitソースコードリーディング 〜 Terra: 回路作成からゲートや測定の追加までを読む
何をするの?
量子コンピューティングライブラリのBlueqatを作っている私が、量子コンピューティングライブラリのQiskitのソースコードを読んでみる、という企画です。
普段気になっていながらも読めていなかった部分を、せっかくなので読んでみました。タイトルの通り、今回は回路を作成して、ゲートや測定を回路に付け加えるまでの処理を読んでいきます。
なので、今回は量子計算のやり方のようなものは一切出てこない、ごくごくフロントエンドの部分だけを読みます。Qiskit概要
QiskitはIBMが開発しているオープンソースの量子コンピューティングライブラリです。
Qiskitは以下のようにパッケージが分かれていますが、インストールする際はバラバラにやるよりも
pip install qiskitでまとめてインストールした方がトラブルが少ないです。
パッケージ 役割 Qiskit Terra メインとなるパッケージです。回路を作るクラスや、回路を実機向けにトランスパイルする機能、APIを叩いて実機に投げる機能などが含まれています Qiskit Aer 量子回路のシミュレータが含まれており、通常はQiskit Terraから呼び出します Qiskit Ignis 量子回路を実機で動かした際のノイズと戦いたい人のためのライブラリです。私は使ったことがありません Qiskit Aqua 量子アルゴリズムを簡単に使えるようにしたライブラリです 今回読むのはQiskit Terraの一部です。
https://github.com/Qiskit/qiskit-terra
具体的には、README.mdに書いてあるコード
from qiskit import * qc = QuantumCircuit(2, 2) qc.h(0) qc.cx(0, 1) qc.measure([0,1], [0,1]) backend_sim = BasicAer.get_backend('qasm_simulator') result = execute(qc, backend_sim).result() print(result.get_counts(qc))のうち、
qc.measure([0,1], [0,1])までの流れを読んでいきます。GitHub上のmasterブランチを読んでいきます。
現時点のコミットIDはe7be587ですが、結構頻繁に更新されているので、記事が書き終わる頃には変わる可能性もあります。ご了承ください。QuantumCircuitクラスと動的なメソッド追加
qiskit/circuit/quantumcircuit.pyをざっと眺めましょう。
皆さん、あるはずのものがないことに、お気づきになられましたでしょうか?
先ほどのコードに注目ください。qc = QuantumCircuit(2, 2) qc.h(0) qc.cx(0, 1) qc.measure([0,1], [0,1])
QuantumCircuit.h,QuantumCircuit.cx,QuantumCircuit.measureがあるはずなのに、どこにも見つかりません。これらの量子ゲートは数が多いので別で定義したい、という気持ちはすごくよく分かります。
では、一体どこで定義されているのでしょうか。
import時に、qiskit.extensions.*が読み込まれて、ゲートはそこで追加されています。
メジャーなゲートはqiskit/extensions/standardにあります。
また、測定はqiskit/circuit/measure.pyでQuantumCircuitに追加されます。
(こういうのは、1箇所にまとめといて欲しいなぁ、と思いました)QuantumCircuitを作る
さて、ゲートや測定のメソッドの謎を解いたところで、本題に戻りましょう。
qc = QuantumCircuit(2, 2)を読んでみます。
qiskit/circuit/quantumcircuit.pyにある
QuantumCircuit.__init__を読みます。def __init__(self, *regs, name=None): if name is None: name = self.cls_prefix() + str(self.cls_instances()) # pylint: disable=not-callable # (known pylint bug: https://github.com/PyCQA/pylint/issues/1699) if sys.platform != "win32" and isinstance(mp.current_process(), mp.context.ForkProcess): name += '-{}'.format(mp.current_process().pid) self._increment_instances() if not isinstance(name, str): raise CircuitError("The circuit name should be a string " "(or None to auto-generate a name).") self.name = name # Data contains a list of instructions and their contexts, # in the order they were applied. self._data = [] # This is a map of registers bound to this circuit, by name. self.qregs = [] self.cregs = [] self.add_register(*regs) # Parameter table tracks instructions with variable parameters. self._parameter_table = ParameterTable() self._layout = Noneへー、回路に名前が必要なんですね。指定しなかったら勝手に付けてくれるみたいです。
あと、すげーくだらないんですが、プログラミングで日々消耗する者として気になったのが。
raise CircuitError("The circuit name should be a string " "(or None to auto-generate a name).")1行の文字数が多いとpylintとかに怒られるんですが、恐らくは、それを避けるために2行に分けています。
こういうの、いつも「それ怒られてもなぁ。本来は1行で表示されるものを2行に分けることで可読性上がるの? メッセージをgrepで検索とか想定してる?」って思っちゃうんですが。大人の対応ですね。あとは、中味の初期化とかですね。
add_registerも読んでみましょう。def add_register(self, *regs): """Add registers.""" if not regs: return if any([isinstance(reg, int) for reg in regs]): # QuantumCircuit defined without registers if len(regs) == 1 and isinstance(regs[0], int): # QuantumCircuit with anonymous quantum wires e.g. QuantumCircuit(2) regs = (QuantumRegister(regs[0], 'q'),) elif len(regs) == 2 and all([isinstance(reg, int) for reg in regs]): # QuantumCircuit with anonymous wires e.g. QuantumCircuit(2, 3) regs = (QuantumRegister(regs[0], 'q'), ClassicalRegister(regs[1], 'c')) else: raise CircuitError("QuantumCircuit parameters can be Registers or Integers." " If Integers, up to 2 arguments. QuantumCircuit was called" " with %s." % (regs,)) for register in regs: if register.name in [reg.name for reg in self.qregs + self.cregs]: raise CircuitError("register name \"%s\" already exists" % register.name) if isinstance(register, QuantumRegister): self.qregs.append(register) elif isinstance(register, ClassicalRegister): self.cregs.append(register) else: raise CircuitError("expected a register")元々は、Qiskitでは、
QuantumRegisterとClassicalRegisterを作らなければならなかったんですが、Qiskitがバージョンアップしていくうちに、単なる数字だけでもよくなりました。Blueqatのパクリかな?
Qiskit-TerraのREADME.mdで一番最初に出るコードも、わざわざレジスタを作らずに数字でやる、という例が示されています。Blueqatのパクリかな?
ですが、内部構造としては、レジスタがあることを前提としているようで、指定しなければ'q'という名前の量子レジスタと'c'という名前の古典レジスタが作られるようです。ちょっとした文句
その後付け部分についてですが。コメントを見たら分かるように、これ、とても微妙な感じになっています。
_add_registerのようなアンダースコア付きではなく、add_registerと、アンダースコアなしなので、これは内部だけではなく外部からも呼び出せることを想定した関数のはずです。けれど、レジスタではなく数字を渡す部分のコメントや例外メッセージを見ると、外部からの呼び出しを想定してなさそうな雰囲気になっています。「整数だったらレジスタ'q'と'c'を作る」の部分については、
__init__の中でやった方がよかったんじゃないかなぁ、と思いました。
……まぁ、今の実装で実際にすごく困るかというと、大して困らないので、いいんですが。おまけ: 数字で指定したらq, cが作られる、ということを確認する
from qiskit import * q = QuantumRegister(3, 'q') c = QuantumRegister(3, 'c') qc = QuantumCircuit(4, 4) qc.add_register(q) # => QiskitError: 'register name "q" already exists' qc.add_register(c) # => QiskitError: 'register name "c" already exists' qc = QuantumCircuit(q) qc.add_register(4) # => QiskitError: 'register name "q" already exists'うへへへへ。
Hゲートの実装
続いて、これらを見ていきます。
qc.h(0) qc.cx(0, 1) qc.measure([0,1], [0,1])
QuantumCircuit.hが実装されているqiskit/extensions/standard/h.pyを見るとdef h(self, q): # pylint: disable=invalid-name """Apply H to q.""" return self.append(HGate(), [q], []) QuantumCircuit.h = hややこしいのですが、ここでの
selfはQuantumCircuitになります。
QuantumCircuit.appendを見ていきましょう。
QuantumCircuit.appenddef append(self, instruction, qargs=None, cargs=None): """Append one or more instructions to the end of the circuit, modifying the circuit in place. Expands qargs and cargs. Args: instruction (Instruction or Operation): Instruction instance to append qargs (list(argument)): qubits to attach instruction to cargs (list(argument)): clbits to attach instruction to Returns: Instruction: a handle to the instruction that was just added """ # Convert input to instruction if not isinstance(instruction, Instruction) and hasattr(instruction, 'to_instruction'): instruction = instruction.to_instruction() expanded_qargs = [self.qbit_argument_conversion(qarg) for qarg in qargs or []] expanded_cargs = [self.cbit_argument_conversion(carg) for carg in cargs or []] instructions = InstructionSet() for (qarg, carg) in instruction.broadcast_arguments(expanded_qargs, expanded_cargs): instructions.add(self._append(instruction, qarg, carg), qarg, carg) return instructions
to_instruction()とは初めから見ていきましょう。
if not isinstance(instruction, Instruction) and hasattr(instruction, 'to_instruction'): instruction = instruction.to_instruction()ゲートや測定は
Instructionなのでスルーされるのですが。
(具体的には、HGateクラスがGateクラスを継承していて、GateクラスがInstructionクラスを継承しているので、HGateはInstructionです。他のゲートや測定も、親クラスを追っていくとInstructionに辿り着きます)そうじゃない場合、もし
to_instructionメソッドを持っていれば、それが呼び出されるようです。
ある種の「ゲートを拡張したようなもの」を追加できるようにする、という考えに見えます。grepで
to_instructionメソッドを漁ってみたところ、ハードウェア制御用のパルスに関するもの、パウリ行列やクラウス表現などのゲートではないものを回路にするためのもの、が見つかりました。ところで、「もし
Instructionじゃなく、to_instructionメソッドも持ってなければ、ここで例外投げてほしいなー」と思ったのは、私だけでしょうか。(ここで投げなくても、後段で出るからいい、という話もありそうですが)argument_conversionたち
次にいきましょう。
expanded_qargs = [self.qbit_argument_conversion(qarg) for qarg in qargs or []] expanded_cargs = [self.cbit_argument_conversion(carg) for carg in cargs or []]これらの中味を見ます。(docstringは削除して引用します)
def qbit_argument_conversion(self, qubit_representation): return QuantumCircuit._bit_argument_conversion(qubit_representation, self.qubits) def cbit_argument_conversion(self, clbit_representation): return QuantumCircuit._bit_argument_conversion(clbit_representation, self.clbits)どっちも
_bit_argument_conversionを呼び出しているだけですが、その前にself.qubits,self.clbitsってなんだろ。見てみます。@property def qubits(self): """ Returns a list of quantum bits in the order that the registers were added. """ return [qbit for qreg in self.qregs for qbit in qreg] @property def clbits(self): """ Returns a list of classical bits in the order that the registers were added. """ return [cbit for creg in self.cregs for cbit in creg]レジスタの中味を全部、ひとつのリストに並べたものですね。
例えば[QuantumRegister(3, 'q1'), QuantumRegister(2, 'q2')]の2つのレジスタがあれば、[q1[0], q1[1], q1[2], q2[0], q2[1]]が返ってきます。続いて
_bit_argument_conversionを読みます。@staticmethod def _bit_argument_conversion(bit_representation, in_array): ret = None try: if isinstance(bit_representation, Bit): # circuit.h(qr[0]) -> circuit.h([qr[0]]) ret = [bit_representation] elif isinstance(bit_representation, Register): # circuit.h(qr) -> circuit.h([qr[0], qr[1]]) ret = bit_representation[:] elif isinstance(QuantumCircuit.cast(bit_representation, int), int): # circuit.h(0) -> circuit.h([qr[0]]) ret = [in_array[bit_representation]] elif isinstance(bit_representation, slice): # circuit.h(slice(0,2)) -> circuit.h([qr[0], qr[1]]) ret = in_array[bit_representation] elif _is_bit(bit_representation): # circuit.h((qr, 0)) -> circuit.h([qr[0]]) ret = [bit_representation[0][bit_representation[1]]] elif isinstance(bit_representation, list) and \ all(_is_bit(bit) for bit in bit_representation): ret = [bit[0][bit[1]] for bit in bit_representation] elif isinstance(bit_representation, list) and \ all(isinstance(bit, Bit) for bit in bit_representation): # circuit.h([qr[0], qr[1]]) -> circuit.h([qr[0], qr[1]]) ret = bit_representation elif isinstance(QuantumCircuit.cast(bit_representation, list), (range, list)): # circuit.h([0, 1]) -> circuit.h([qr[0], qr[1]]) # circuit.h(range(0,2)) -> circuit.h([qr[0], qr[1]]) # circuit.h([qr[0],1]) -> circuit.h([qr[0], qr[1]]) ret = [index if isinstance(index, Bit) else in_array[ index] for index in bit_representation] else: raise CircuitError('Not able to expand a %s (%s)' % (bit_representation, type(bit_representation))) except IndexError: raise CircuitError('Index out of range.') except TypeError: raise CircuitError('Type error handling %s (%s)' % (bit_representation, type(bit_representation))) return ret長いですが、何をやってるかはコメントに書いてあるとおりです。
いろんな呼び出し方をサポートしてるんだな、程度に捉えておけば大丈夫です。
InstructionSetを見る
QuantumCircuit.appendも終わりが見えてきました。instructions = InstructionSet() for (qarg, carg) in instruction.broadcast_arguments(expanded_qargs, expanded_cargs): instructions.add(self._append(instruction, qarg, carg), qarg, carg) return instructionsさて。qiskit/circuit/instructionset.pyの、
InstructionSet.__init__を読んでいきましょう。class InstructionSet: """Instruction collection, and their contexts.""" def __init__(self): """New collection of instructions. The context (qargs and cargs that each instruction is attached to), is also stored separately for each instruction. """ self.instructions = [] self.qargs = [] self.cargs = []大したことをしてない感じですね。
InstructionSet.addもついでに見るとdef add(self, gate, qargs, cargs): """Add an instruction and its context (where it's attached).""" if not isinstance(gate, Instruction): raise CircuitError("attempt to add non-Instruction" + " to InstructionSet") self.instructions.append(gate) self.qargs.append(qargs) self.cargs.append(cargs)だいぶ想定通りですね。
Instruction.broadcast_argumentsを見る残り少し!
for (qarg, carg) in instruction.broadcast_arguments(expanded_qargs, expanded_cargs): instructions.add(self._append(instruction, qarg, carg), qarg, carg) return instructions
broadcast_argumentsを読んでいきます。
これはqiskit/circuit/instruction.pyで実装されていますが、qiskit/circuit/gate.pyでオーバーライドされているため、今回呼び出されるのはGate.broadcast_argumentsになります。def broadcast_arguments(self, qargs, cargs): """Validation and handling of the arguments and its relationship. For example: `cx([q[0],q[1]], q[2])` means `cx(q[0], q[2]); cx(q[1], q[2])`. This method yields the arguments in the right grouping. In the given example:: in: [[q[0],q[1]], q[2]],[] outs: [q[0], q[2]], [] [q[1], q[2]], [] The general broadcasting rules are: * If len(qargs) == 1:: [q[0], q[1]] -> [q[0]],[q[1]] * If len(qargs) == 2:: [[q[0], q[1]], [r[0], r[1]]] -> [q[0], r[0]], [q[1], r[1]] [[q[0]], [r[0], r[1]]] -> [q[0], r[0]], [q[0], r[1]] [[q[0], q[1]], [r[0]]] -> [q[0], r[0]], [q[1], r[0]] * If len(qargs) >= 3:: [q[0], q[1]], [r[0], r[1]], ...] -> [q[0], r[0], ...], [q[1], r[1], ...] Args: qargs (List): List of quantum bit arguments. cargs (List): List of classical bit arguments. Returns: Tuple(List, List): A tuple with single arguments. Raises: CircuitError: If the input is not valid. For example, the number of arguments does not match the gate expectation. """ if len(qargs) != self.num_qubits or cargs: raise CircuitError( 'The amount of qubit/clbit arguments does not match the gate expectation.') if any([not qarg for qarg in qargs]): raise CircuitError('One or more of the arguments are empty') if len(qargs) == 1: return Gate._broadcast_single_argument(qargs[0]) elif len(qargs) == 2: return Gate._broadcast_2_arguments(qargs[0], qargs[1]) elif len(qargs) >= 3: return Gate._broadcast_3_or_more_args(qargs) else: raise CircuitError('This gate cannot handle %i arguments' % len(qargs))やってること自体は、コメントにあるとおりです。
ゲートに指定する量子ビット数に応じて処理が変わっています。Hゲートの場合1個ですが、ついでなので全部見ていきましょう。@staticmethod def _broadcast_single_argument(qarg): """Expands a single argument. For example: [q[0], q[1]] -> [q[0]], [q[1]] """ # [q[0], q[1]] -> [q[0]] # -> [q[1]] for arg0 in qarg: yield [arg0], [] @staticmethod def _broadcast_2_arguments(qarg0, qarg1): if len(qarg0) == len(qarg1): # [[q[0], q[1]], [r[0], r[1]]] -> [q[0], r[0]] # -> [q[1], r[1]] for arg0, arg1 in zip(qarg0, qarg1): yield [arg0, arg1], [] elif len(qarg0) == 1: # [[q[0]], [r[0], r[1]]] -> [q[0], r[0]] # -> [q[0], r[1]] for arg1 in qarg1: yield [qarg0[0], arg1], [] elif len(qarg1) == 1: # [[q[0], q[1]], [r[0]]] -> [q[0], r[0]] # -> [q[1], r[0]] for arg0 in qarg0: yield [arg0, qarg1[0]], [] else: raise CircuitError('Not sure how to combine these two qubit arguments:\n %s\n %s' % (qarg0, qarg1)) @staticmethod def _broadcast_3_or_more_args(qargs): if all(len(qarg) == len(qargs[0]) for qarg in qargs): for arg in zip(*qargs): yield list(arg), [] else: raise CircuitError( 'Not sure how to combine these qubit arguments:\n %s\n' % qargs)1個の場合は、単にひとつずつリストに詰めて出すだけですね。
3個の場合も、[[q[0], r[0]], [q[1], r[1]], [q[2], r[2]]]を[q[0], q[1], q[2]]と[r[0], r[1], r[2]]に分けるだけ、とシンプルです。
2個の場合、コメントにあるように、省略記法を許しているようです。qc = QuantumCircuit(3, 3) qc.cx([0, 1], 2) print(qc.draw()) ''' 結果(いらないところは略): q_0: |0>──■─────── │ q_1: |0>──┼────■── ┌─┴─┐┌─┴─┐ q_2: |0>┤ X ├┤ X ├ └───┘└───┘ ''' qc = QuantumCircuit(3, 3) qc.cx(0, [1, 2]) print(qc.draw()) '''結果(いらないところは略): q_0: |0>──■────■── ┌─┴─┐ │ q_1: |0>┤ X ├──┼── └───┘┌─┴─┐ q_2: |0>─────┤ X ├ └───┘ '''このように
for (qarg, carg) in instruction.broadcast_arguments(expanded_qargs, expanded_cargs):で、ゲートを適用する量子ビットを順次取り出していることが分かります。
QuantumCircuit._appendを見る最初に言っとくと
for (qarg, carg) in instruction.broadcast_arguments(expanded_qargs, expanded_cargs): instructions.add(self._append(instruction, qarg, carg), qarg, carg)の処理ですが、コードをこれから見ると分かるように
for (qarg, carg) in instruction.broadcast_arguments(expanded_qargs, expanded_cargs): self._append(instruction, qarg, carg) instructions.add(instruction, qarg, carg)とやった方が行儀がいいですね。1行削りたくなる気持ちはプログラマなので分かりますが。
では、終わったと思ったら意外と長かった_appendを見ていきます。def _append(self, instruction, qargs, cargs): """Append an instruction to the end of the circuit, modifying the circuit in place. Args: instruction (Instruction or Operator): Instruction instance to append qargs (list(tuple)): qubits to attach instruction to cargs (list(tuple)): clbits to attach instruction to Returns: Instruction: a handle to the instruction that was just added Raises: CircuitError: if the gate is of a different shape than the wires it is being attached to. """ if not isinstance(instruction, Instruction): raise CircuitError('object is not an Instruction.') # do some compatibility checks self._check_dups(qargs) self._check_qargs(qargs) self._check_cargs(cargs) # add the instruction onto the given wires instruction_context = instruction, qargs, cargs self._data.append(instruction_context) self._update_parameter_table(instruction) return instructionまず
_check_dupsdef _check_dups(self, qubits): """Raise exception if list of qubits contains duplicates.""" squbits = set(qubits) if len(squbits) != len(qubits): raise CircuitError("duplicate qubit arguments")これは、
qargに重複がないか確認しています。
Hのような単一量子ビットゲートでは、重複は起こりえませんが、qc.cx(0, 0)のようなものを弾いてくれます。続いて、
_check_qargsと_check_cargsdef _check_qargs(self, qargs): """Raise exception if a qarg is not in this circuit or bad format.""" if not all(isinstance(i, Qubit) for i in qargs): raise CircuitError("qarg is not a Qubit") if not all(self.has_register(i.register) for i in qargs): raise CircuitError("register not in this circuit") def _check_cargs(self, cargs): """Raise exception if clbit is not in this circuit or bad format.""" if not all(isinstance(i, Clbit) for i in cargs): raise CircuitError("carg is not a Clbit") if not all(self.has_register(i.register) for i in cargs): raise CircuitError("register not in this circuit")
Qubit,Clbitについては、レジスタのインデックスを取ってq[0]のようにすると返ってくるオブジェクトです。
ちゃんと回路に含まれている量子レジスタであることを確認しています。以上でHゲートの追加は終わりです。
CXゲートの実装
qc.h(0) qc.cx(0, 1) qc.measure([0,1], [0,1])の、cxについて見てみます。
cxメソッドはqiskit/extensions/standard/cx.pyで実装されていますが、Hゲートとほぼ同じです。def cx(self, ctl, tgt): # pylint: disable=invalid-name """Apply CX from ctl to tgt.""" return self.append(CnotGate(), [ctl, tgt], []) QuantumCircuit.cx = cx QuantumCircuit.cnot = cx呼び出されると
appendが呼ばれる流れもHゲートと同じですね。測定の実装
measureについても見ていきましょう。qiskit/circuit/measure.pyを読みます。def measure(self, qubit, cbit): """Measure quantum bit into classical bit (tuples). Args: qubit (QuantumRegister|list|tuple): quantum register cbit (ClassicalRegister|list|tuple): classical register Returns: qiskit.Instruction: the attached measure instruction. Raises: CircuitError: if qubit is not in this circuit or bad format; if cbit is not in this circuit or not creg. """ return self.append(Measure(), [qubit], [cbit]) QuantumCircuit.measure = measureはい、
appendしてるだけですね。ですが、broadcast_argumentsにGateクラスのものではなくMeasureクラスのものが使われることに注意してください。def broadcast_arguments(self, qargs, cargs): qarg = qargs[0] carg = cargs[0] if len(carg) == len(qarg): for qarg, carg in zip(qarg, carg): yield [qarg], [carg] elif len(qarg) == 1 and carg: for each_carg in carg: yield qarg, [each_carg] else: raise CircuitError('register size error')
qc.measure([0,1], [0,1])の場合だと、if文の上のやつが呼び出されます。
elifの部分はqc.measure(q, c)のように、レジスタ渡しした場合に相当します。これで、本日の目標の、
qc = QuantumCircuit(2, 2)からqc.measure([0,1], [0,1])を読むことができました。まとめ
今回、量子回路の作成からゲート、測定の追加までを読みました。
量子コンピューティングライブラリでは、ゲート追加などをメソッドの形で実装するために、動的なメソッド追加を行うことが多いです。Qiskitではどのように追加されているのか見ていきました。
また、Qiskitの量子回路の実装には、量子レジスタが重要になってきます。そのあたりのハンドリングでコードが煩雑になっている印象を受けました。Qiskitの実装はやはり気になるので、続きに関してもまた読んでいきたいと思います。
- 投稿日:2019-11-29T14:29:44+09:00
強化学習24 Colaboratory+CartPole+ChainerRL+ACER
強化学習22まで終了していることが前提です。
chainerRLのexamplesからACERです。
actor-critic with experience replayの略みたいです。
細かい理論的なことは置いときます。
名著ドラゴン桜の中でも書かれていますが、楽をするためには、まず「すでにあるものに慣れる。」が大切です。なので、やってみました。
Google drive mount
import google.colab.drive google.colab.drive.mount('gdrive') !ln -s gdrive/My\ Drive mydriveprogram install
!apt-get install -y xvfb python-opengl ffmpeg > /dev/null 2>&1 !pip install pyvirtualdisplay > /dev/null 2>&1 !pip -q install JSAnimation !pip -q install chainerrlMain program
modules import
from __future__ import division from __future__ import print_function from __future__ import unicode_literals from __future__ import absolute_import from builtins import * # NOQA from future import standard_library standard_library.install_aliases() # NOQA import argparse import os import sys # This prevents numpy from using multiple threads os.environ['OMP_NUM_THREADS'] = '1' # NOQA import chainer from chainer import functions as F from chainer.initializers import LeCunNormal from chainer import links as L import gym from gym import spaces import numpy as np import chainerrl from chainerrl.action_value import DiscreteActionValue from chainerrl.agents import acer from chainerrl.distribution import SoftmaxDistribution from chainerrl import experiments from chainerrl import links from chainerrl import misc from chainerrl.optimizers import rmsprop_async from chainerrl import policies from chainerrl import q_functions from chainerrl.replay_buffer import EpisodicReplayBuffer from chainerrl import v_functionsMain
args
import logging parser = argparse.ArgumentParser() parser.add_argument('--processes', type=int,default=8) parser.add_argument('--env', type=str, default='CartPole-v0') parser.add_argument('--seed', type=int, default=0) parser.add_argument('--outdir', type=str, default='mydrive/OpenAI/CartPole/result-acer') parser.add_argument('--t-max', type=int, default=50) parser.add_argument('--n-times-replay', type=int, default=4) parser.add_argument('--n-hidden-channels', type=int, default=100) parser.add_argument('--n-hidden-layers', type=int, default=2) parser.add_argument('--replay-capacity', type=int, default=5000) parser.add_argument('--replay-start-size', type=int, default=10 ** 3) parser.add_argument('--disable-online-update', action='store_true') parser.add_argument('--beta', type=float, default=1e-2) parser.add_argument('--profile', action='store_true') parser.add_argument('--steps', type=int, default=8 * 10 ** 7) parser.add_argument('--eval-interval', type=int, default=10 ** 5) parser.add_argument('--eval-n-runs', type=int, default=10) parser.add_argument('--reward-scale-factor', type=float, default=1e-2) parser.add_argument('--rmsprop-epsilon', type=float, default=1e-2) parser.add_argument('--render', action='store_true', default=False) parser.add_argument('--lr', type=float, default=7e-4) parser.add_argument('--demo', action='store_true', default=False) parser.add_argument('--load', type=str, default='') parser.add_argument('--logger-level', type=int, default=logging.INFO) parser.add_argument('--monitor', action='store_true') parser.add_argument('--truncation-threshold', type=float, default=5) parser.add_argument('--trust-region-delta', type=float, default=0.1)変更したいところは、
args =parser.parse_args([--env].[CartPole-v0'])
のようにする。
args = parser.parse_args(['--steps','300000','--eval-interval','10000']) logging.basicConfig(level=args.logger_level, stream=sys.stdout, format='')Set a random seed used in ChainerRL.
If you use more than one processes, the results will be no longer
deterministic even with the same random seed.
misc.set_random_seed(args.seed)Set different random seeds for different subprocesses.
If seed=0 and processes=4, subprocess seeds are [0, 1, 2, 3].
If seed=1 and processes=4, subprocess seeds are [4, 5, 6, 7].
process_seeds = np.arange(args.processes) + args.seed * args.processes assert process_seeds.max() < 2 ** 32 if not os.path.exists(args.outdir): os.makedirs(args.outdir)function
def make_env(process_idx, test): env = gym.make(args.env) # Use different random seeds for train and test envs process_seed = int(process_seeds[process_idx]) env_seed = 2 ** 32 - 1 - process_seed if test else process_seed env.seed(env_seed) # Cast observations to float32 because our model uses float32 env = chainerrl.wrappers.CastObservationToFloat32(env) if args.monitor and process_idx == 0: env = chainerrl.wrappers.Monitor(env, args.outdir) if not test: # Scale rewards (and thus returns) to a reasonable range so that # training is easier env = chainerrl.wrappers.ScaleReward(env, args.reward_scale_factor) if args.render and process_idx == 0 and not test: env = chainerrl.wrappers.Render(env) return envsetup
sample_env = gym.make(args.env) timestep_limit = sample_env.spec.tags.get( 'wrapper_config.TimeLimit.max_episode_steps') obs_space = sample_env.observation_space action_space = sample_env.action_space if isinstance(action_space, spaces.Box): model = acer.ACERSDNSeparateModel( pi=policies.FCGaussianPolicy( obs_space.low.size, action_space.low.size, n_hidden_channels=args.n_hidden_channels, n_hidden_layers=args.n_hidden_layers, bound_mean=True, min_action=action_space.low, max_action=action_space.high), v=v_functions.FCVFunction( obs_space.low.size, n_hidden_channels=args.n_hidden_channels, n_hidden_layers=args.n_hidden_layers), adv=q_functions.FCSAQFunction( obs_space.low.size, action_space.low.size, n_hidden_channels=args.n_hidden_channels // 4, n_hidden_layers=args.n_hidden_layers), ) else: model = acer.ACERSeparateModel( pi=links.Sequence( L.Linear(obs_space.low.size, args.n_hidden_channels), F.relu, L.Linear(args.n_hidden_channels, action_space.n, initialW=LeCunNormal(1e-3)), SoftmaxDistribution), q=links.Sequence( L.Linear(obs_space.low.size, args.n_hidden_channels), F.relu, L.Linear(args.n_hidden_channels, action_space.n, initialW=LeCunNormal(1e-3)), DiscreteActionValue), )optimizer
opt = rmsprop_async.RMSpropAsync( lr=args.lr, eps=args.rmsprop_epsilon, alpha=0.99) opt.setup(model) opt.add_hook(chainer.optimizer.GradientClipping(40))Agent
replay_buffer = EpisodicReplayBuffer(args.replay_capacity) agent = acer.ACER(model, opt, t_max=args.t_max, gamma=0.99, replay_buffer=replay_buffer, n_times_replay=args.n_times_replay, replay_start_size=args.replay_start_size, disable_online_update=args.disable_online_update, use_trust_region=True, trust_region_delta=args.trust_region_delta, truncation_threshold=args.truncation_threshold, beta=args.beta) if args.load: agent.load(args.load)train
experiments.train_agent_async( agent=agent, outdir=args.outdir, processes=args.processes, make_env=make_env, profile=args.profile, steps=args.steps, eval_n_steps=None, eval_n_episodes=args.eval_n_runs, eval_interval=args.eval_interval, max_episode_len=timestep_limit) agent.save(args.outdir+'/agent')import pandas as pd import glob import os score_files = glob.glob(args.outdir+'/scores.txt') score_files.sort(key=os.path.getmtime) score_file = score_files[-1] df = pd.read_csv(score_file, delimiter='\t' ) dfdf.plot(x='steps',y='average_value')from pyvirtualdisplay import Display display = Display(visible=0, size=(1024, 768)) display.start()from JSAnimation.IPython_display import display_animation from matplotlib import animation import matplotlib.pyplot as plt %matplotlib inlineframes = [] env = gym.make(args.env) process_seeds = np.arange(args.processes) + args.seed * args.processes assert process_seeds.max() < 2 ** 32 env_seed = int(process_seeds[0]) env.seed(env_seed) env = chainerrl.wrappers.CastObservationToFloat32(env) env = chainerrl.wrappers.ScaleReward(env, args.reward_scale_factor) envw = gym.wrappers.Monitor(env, args.outdir, force=True) for i in range(3): obs = envw.reset() done = False R = 0 t = 0 while not done and t < 200: frames.append(envw.render(mode = 'rgb_array')) action = agent.act(obs) obs, r, done, _ = envw.step(action) R += r t += 1 print('test episode:', i, 'R:', R) agent.stop_episode() envw.close() from IPython.display import HTML plt.figure(figsize=(frames[0].shape[1]/72.0, frames[0].shape[0]/72.0),dpi=72) patch = plt.imshow(frames[0]) plt.axis('off') def animate(i): patch.set_data(frames[i]) anim = animation.FuncAnimation(plt.gcf(), animate, frames=len(frames),interval=50) anim.save(args.outdir+'/test.mp4') HTML(anim.to_jshtml())
- 投稿日:2019-11-29T14:08:56+09:00
PyWebViewを使ったプロジェクトをPyInstallerでexeにできない
現在(PyWebView 3.1時点)、PyWebViewを使ったアプリをそのままPyInstallerでexeにしようとすると、
Pyinstaller hook can't find WebBrowserInterop.x64.dllというエラーメッセージでコンパイルが中断する問題が発生しているようです。大まかには上記Issueの通りなのですが、PyInstaller用のWebhookが正しいパスを指していないようで、エラーになってしまうとのこと。
上記を見た感じ最新版では修正は済んでいるものの、公開モジュールへの反映はまだ という感じのようです。
で、直るまで手作業でwebhookを直して回るのは面倒くさいので、PowerShellスクリプトを書きました。
うちでは、PyInstallerでのコンパイルにPowerShellスクリプトを使っているので、ファイル内でPyInstallerを使う前に、次のコードを呼び出します。
if(Select-String "library = join\(sitepack, 'lib', dll_name\)" -Path .\.venv\Lib\site-packages\PyInstaller\hooks\hook-webview.py){ Write-Host "> Fix PyInstaller\hooks\hook-webview.py" $data = Get-Content .\.venv\Lib\site-packages\PyInstaller\hooks\hook-webview.py | % {$_ -replace "library = join\(sitepack, 'lib', dll_name\)","library = join(sitepack, 'webview', 'lib', dll_name)"} $data | Out-File .\.venv\Lib\site-packages\PyInstaller\hooks\hook-webview.py }ただし、PowerShell 5.xはBOMなしUTF-8を扱えないため、このままだとPyInstallerが正常に読めないwebhookファイルができてしまいます。
PowerShell 6.xなら問題なく使えるので、事前にChocolateyなどから`pwsh(PowerShell 6.x)をインストールし、PowerShell 6上でこのスクリプトを実行するようにしましょう。
うっかりPowerShell 5.xで実行しそうになってしまったときのために、PowerShell 5.xでスクリプトを起動しようとしたら落とすコードも追加しておきます。
if(!($PSVersionTable["PSCompatibleVersions"].Major -contains 6)){ Write-Host @' This script must be PowerShell version 6 or higher before it will work properly. The shell currently running is PowerShell version 5 or lower. Use the `pwsh` command to change to PowerShell 6. '@ exit }これを先頭行に書いておけば安心です。警告が出るので気付くでしょう。
- 投稿日:2019-11-29T13:58:33+09:00
MacでTensorFlow Liteを実装する【2019年版】
MacでTensorFlow Liteを動かすまでの流れを解説していきます。
環境
動作確認済の環境は以下の通りです。
・macOS Catalina バージョン10.15
・Python 3.7.4
・conda 4.7.12
・TensorFlow 1.15.0
・keras 2.2.4環境構築
以下のURLよりAnacondaをインストール
https://www.anaconda.com/distribution/
ダウンロードしたインストーラパッケージをダブルクリックして起動します。 利用規約に同意し、保存先を決めてインストールします。
HomeからJupyter Notebookを起動します。
作業場所を決めて、NEW→Python3でipynbファイルを作成します。
ファイルを開くとこのようにプログラムを書ける画面に移ります。ここにプログラムを書いていきます。
次にTensorFlowを動作させるためのパッケージをインストールします。
「Enviroments」→「Create」で新しい環境を作ります。base(root)を使用する場合は不要です。
検索条件を「Not installed」に変更し、「tensorflow」と検索します。
そして出てきたパッケージの「keras」、「tensorflow」を選択し、Applyをクリックします。
先程のようにJupyterを起動して次のようにプログラムを書いて実行します。
実行は「control + Enter」もしくは「Shift + Enter」です。
エラーが出ていないことがわかります。使い方はざっとこんな感じです。追記
nomkl、matplotlib、pillowもインストールしておいてください。
nomklはtensorflowを実行する際にカーネルが死ぬのを防げるみたいです。
matplotlibは画像を表示するために使用します。
pillowは画像をロードするために使用します。モデルを構築する
TensorFlow Liteのモデルを生成するために、まずはTensorFlowのモデルを作る必要があります。
今回は、cifar10というデータセットを使用します。
https://www.cs.toronto.edu/~kriz/cifar.html
cifar10は、6万枚の画像にラベル付けされたデータセットです。飛行機、自動車、鳥、猫、鹿、犬、カエル、馬、船、トラックに分けられています。これを学習させ、画像分類できるモデルを作っていきます。以下、画像を学習させるためのコードです。
epoch数を20に設定しているのでかなり時間がかかります。""" 必要なライブラリのインポートと画像の前処理 """ from keras.models import Sequential from keras.layers.convolutional import Conv2D from keras.layers.pooling import MaxPool2D from keras.layers.core import Dense,Activation,Dropout,Flatten from keras.datasets import cifar10 from keras.utils import np_utils #cifar10をダウンロード (x_train,y_train),(x_test,y_test)=cifar10.load_data() #画像を0-1の範囲で正規化 x_train=x_train.astype('float32')/255.0 x_test=x_test.astype('float32')/255.0 #正解ラベルをOne-Hot表現に変換 y_train=np_utils.to_categorical(y_train,10) y_test=np_utils.to_categorical(y_test,10) """ TensorFlowのモデルを構築 """ model=Sequential() model.add(Conv2D(32,(3,3),padding='same',input_shape=(32,32,3))) model.add(Activation('relu')) model.add(Conv2D(32,(3,3),padding='same')) model.add(Activation('relu')) model.add(MaxPool2D(pool_size=(2,2))) model.add(Dropout(0.25)) model.add(Conv2D(64,(3,3),padding='same')) model.add(Activation('relu')) model.add(Conv2D(64,(3,3),padding='same')) model.add(Activation('relu')) model.add(MaxPool2D(pool_size=(2,2))) model.add(Dropout(0.25)) model.add(Flatten()) model.add(Dense(512)) model.add(Activation('relu')) model.add(Dropout(0.5)) model.add(Dense(10,activation='softmax')) model.compile(optimizer='adam',loss='categorical_crossentropy',metrics=['accuracy']) history=model.fit(x_train,y_train,batch_size=128,nb_epoch=20,verbose=1,validation_split=0.1) #モデルと重みを保存 json_string=model.to_json() open('cifar10_cnn.json',"w").write(json_string) model.save_weights('cifar10_cnn.h5') model.save('cifar10_cnn_model.h5') #モデルの表示 model.summary() #評価 score=model.evaluate(x_test,y_test,verbose=0) print('Test loss:',score[0]) print('Test accuracy:',score[1])実行すると
「cifar10_cnn.h5」と「cifar10_cnn_model.h5」というファイルが生成されているかと思います。
「cifar10_cnn.h5」はモデルの重みのみが保存され、「cifar10_cnn_model.h5」はモデル構造と重みが保存されています。精度は78%でした。実際に画像分類してみる
保存したモデルを使って画像分類していきます。
まず、予測する画像を用意します。
コードに書かれている階層に合わせてフォルダを作成し、その中に画像を入れ、以下のコードを実行します。
""" 拾った画像を使って予測する """ from keras.models import model_from_json import matplotlib.pyplot as plt from keras.preprocessing.image import img_to_array, load_img from tensorflow.python.keras.models import load_model #画像読み込み temp_img=load_img("./images/airplane1.jpeg",target_size=(32,32)) #画像を配列に変換し0-1で正規化 temp_img_array=img_to_array(temp_img) temp_img_array=temp_img_array.astype('float32')/255.0 temp_img_array=temp_img_array.reshape((1,32,32,3)) #学習済みのモデルと重みを読み込む json_string=open('cifar10_cnn.json').read() model=model_from_json(json_string) model.compile(optimizer='adam',loss='categorical_crossentropy',metrics=['accuracy']) model.load_weights('cifar10_cnn.h5') # model = load_model('cifar10_cnn_model.h5') #モデルを表示 model.summary() #画像を予想 img_pred=model.predict_classes(temp_img_array) print('\npredict_classes=',img_pred) print('model=',model) plt.imshow(temp_img) plt.title('pred:{}'.format(img_pred)) plt.show() """ 0 - airplane 1 - automobile 2 - bird 3 - cat 4 - deer 5 - dog 6 - frog 7 - horse 8 - ship 9 - truck """上手くいくと、画像とインデックス番号が出力されます。
↑こんな感じ
インデックス番号と画像が一致していることがわかります。画像分類成功です。TensorFlow Lite用モデルに変換
そして、先程生成したモデルをTensorFlowLite用に変換します。
#既存のKeras用モデル(cifar10_cnn_model.h5)から、TensorFlow Lite用モデル(cifar10_cnn.tflite)を作成 import tensorflow as tf if __name__ == '__main__': converter = tf.lite.TFLiteConverter.from_keras_model_file("cifar10_cnn_model.h5") tflite_model = converter.convert() open("cifar10_cnn.tflite", "wb").write(tflite_model)こちらのコードを実行すると「cifar10_cnn.tflite」が生成されます。
これがTensorFlowLite用のモデルです。このモデルを使用して、画像分類してみます。
#TensorFlow Lite用モデルを使って、入力画像からジャンル識別する import tensorflow as tf import numpy as np from keras.models import model_from_json import matplotlib.pyplot as plt from keras.preprocessing.image import img_to_array, load_img from tensorflow.python.keras.models import load_model if __name__ == '__main__': # prepara input image #画像読み込み temp_img=load_img("./images/dog1.jpeg",target_size=(32,32)) #画像を配列に変換し0-1で正規化 temp_img_array=img_to_array(temp_img) img=temp_img_array.astype('float32')/255.0 img=temp_img_array.reshape((1,32,32,3)) # load model interpreter = tf.lite.Interpreter(model_path="cifar10_cnn.tflite") interpreter.allocate_tensors() input_details = interpreter.get_input_details() output_details = interpreter.get_output_details() # set input tensor interpreter.set_tensor(input_details[0]['index'], img) # run interpreter.invoke() # get outpu tensor probs = interpreter.get_tensor(output_details[0]['index']) # print result result = np.argmax(probs[0]) score = probs[0][result] print("予測した画像インデックス:{} [{:.2f}]".format(result, score)) plt.imshow(temp_img) plt.title('pred:{}'.format(img_pred)) plt.show() """ 0 - airplane 1 - automobile 2 - bird 3 - cat 4 - deer 5 - dog 6 - frog 7 - horse 8 - ship 9 - truck """こちらも上手くいくと画像とインデックス番号が出力されます。
TensorflowとTensorflowLiteの比較
以下の比較は画像データによって左右されますので参考程度にしてください。
画像を予測するためにかかった時間をそれぞれ計測しました。keras用のモデル 経過時間:0.8839559555053711 経過時間:0.6288352012634277 経過時間:0.5877768993377686 経過時間:0.5789699554443359 経過時間:0.5908827781677246 経過時間:0.7207329273223877 経過時間:0.7104830741882324 経過時間:0.6035618782043457 経過時間:0.5244758129119873 経過時間:0.5348677635192871 平均経過時間:0.636454225TensorflowLite用のモデル 経過時間:0.27948904037475586 経過時間:0.05380606651306152 経過時間:0.022572994232177734 経過時間:0.06809115409851074 経過時間:0.07050800323486328 経過時間:0.06940007209777832 経過時間:0.12052798271179199 経過時間:0.17615199089050293 経過時間:0.12544798851013184 経過時間:0.027255773544311523 平均経過時間:0.101325107TensorflowLiteの方が早いですね。
しかしその分精度に差があります。keras用のモデルで予測できなかった画像はCatのみでした。
一方でTensorflowLiteのモデルでは、airplane、Bird、cat、Frogが予測することができませんでした。
TensorflowLite用に変換したモデルはかなり精度が下がっているようです。99.4%の精度を持つMNISTのモデルで実行した場合はkeras用もTensorflowLite用も同じくらい予測することができました。TensorflowLiteを使用する場合は、かなり高い精度を持つモデルを用意する必要がありそうです。

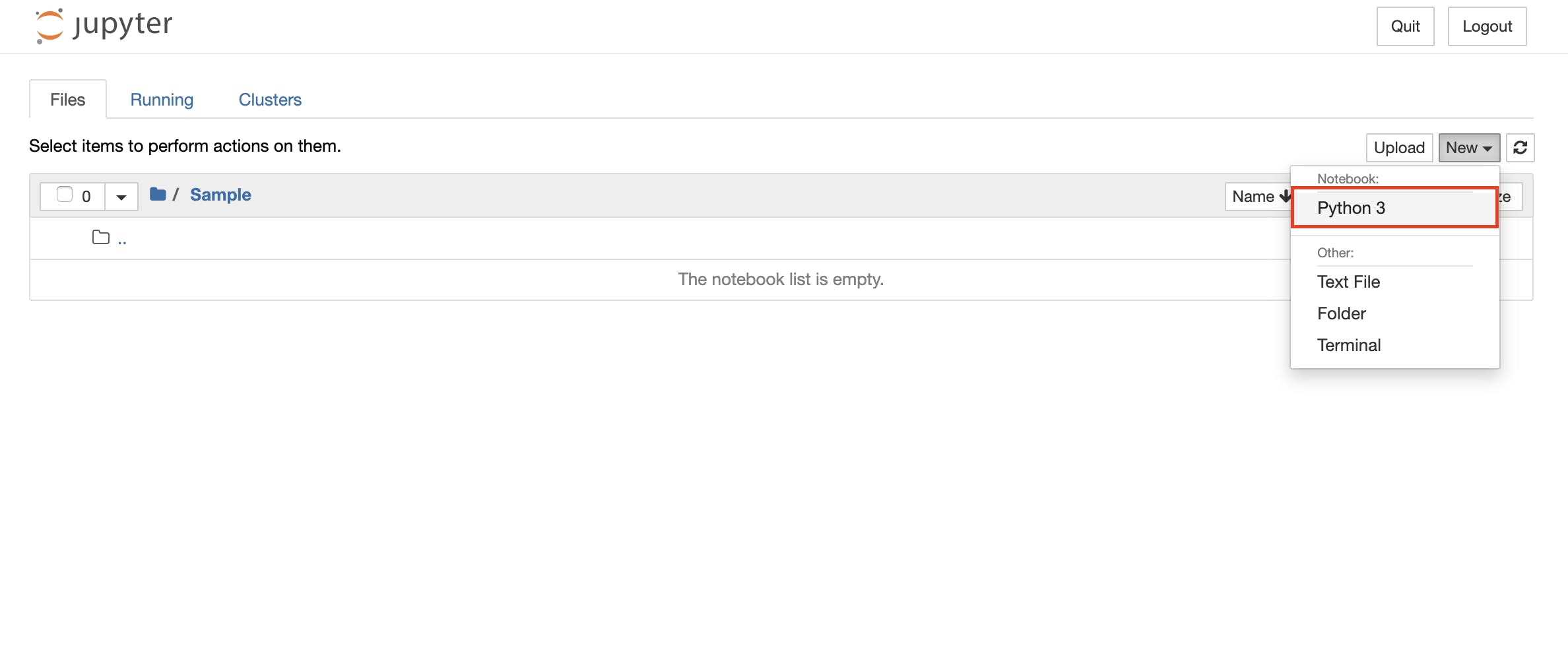

- 投稿日:2019-11-29T13:40:03+09:00
検証用に Python で Big Data を自作する
Hadoop と RDB でどれくらい処理時間に差が出るか手元で検証してみたかったので Python で Big Data を自作しました。
データ構成
テーブル 説明 売上 100,000,000 件の売上明細。 店舗 1,000,000 件の店舗。 エリア 1,000 件の店舗エリア。 商品 10,000,000 件の商品。 分類 10,000 件の商品分類。
Big Data 生成
$ cd ~ $ ls generate_big_data.py $ sudo apt install python3 -y $ python3 generate_big_data.py $ du -h ./* 184K /home/vagrant/category.csv 8.0K /home/vagrant/generate_big_data.py 122M /home/vagrant/product.csv 3.8G /home/vagrant/sales.csv 11M /home/vagrant/shop.csvプログラム
一定の件数ごとにファイルに吐き出すようにし OOM にならないようにしました。
import random import datetime import time # 店舗数: 1,000,000 SHOP_CNT = 1000000 # エリア数: 1,000 AREA_CNT = 1000 # 商品数: 10,000,000 PRODCUT_CNT = 10000000 # 商品区分: 10,000 CATEGORY_CNT = 10000 # 売上数: 100,000,000 SALES_CNT = 100000000 # 最大価格: 100,000 PRICE_MAX = 100000 # 最大購入数: 100 COUNT_MAX = 100 SHOP_DST = 'shop.csv' AREA_DST = 'area.txt' PRODUCT_DST = 'product.csv' CATEGORY_DST = 'category.csv' SALES_DST = 'sales.csv' # Table: shop # Column: id,area_code # id: 1 - 1,000,000 # area_code: 1 - 1,000 print('{} start: generate shop csv'.format(datetime.datetime.now().strftime('%Y/%m/%d %H:%M:%S'))) start = time.time() rows = [] # header # rows.append('id,area_code\n') for i in range(SHOP_CNT): shop_id = str(i + 1) area_code = str(random.randrange(1, AREA_CNT, 1)) rows.append('{},{}\n'.format(shop_id, area_code)) # 100,000 件ごとに出力する if((i + 1) % 100000 == 0): cnt = i + 1 print('shop rows: {}'.format(cnt)) with open(SHOP_DST, 'a', encoding='utf-8') as f: f.writelines(rows) rows = [] elapsed_time = time.time() - start print('{} finish: generate shop csv({} sec)'.format(datetime.datetime.now().strftime('%Y/%m/%d %H:%M:%S'), elapsed_time)) # Table: area # Column: area_code,area_name # area_code: 1 - 1,000 # area_name: area_0 - area_1000 print('{} start: generate area csv'.format(datetime.datetime.now().strftime('%Y/%m/%d %H:%M:%S'))) start = time.time() rows = [] # header # rows.append('area_code,area_name\n') for i in range(AREA_CNT): area_code = str(i + 1) area_name = 'area_' + str(i + 1) rows.append('{},{}\n'.format(area_code, area_name)) # 100 件ごとに出力する if((i + 1) % 100 == 0): cnt = i + 1 print('area rows: {}'.format(cnt)) with open(AREA_DST, 'a', encoding='utf-8') as f: f.writelines(rows) rows = [] elapsed_time = time.time() - start print('{} finish: generate area csv({} sec)'.format(datetime.datetime.now().strftime('%Y/%m/%d %H:%M:%S'), elapsed_time)) # Table: product # Column: id,category_code # id: 1 - 10,000,000 # category_code: 1 - 10,000 print('{} start: generate product csv'.format(datetime.datetime.now().strftime('%Y/%m/%d %H:%M:%S'))) start = time.time() rows = [] # header # rows.append('id,category_code\n') for i in range(PRODCUT_CNT): product_id = str(i + 1) category_code = str(random.randrange(1, CATEGORY_CNT, 1)) rows.append('{},{}\n'.format(product_id, category_code)) # 1,000,000 件ごとに出力する if((i + 1) % 1000000 == 0): cnt = i + 1 print('product rows: {}'.format(cnt)) with open(PRODUCT_DST, 'a', encoding='utf-8') as f: f.writelines(rows) rows = [] elapsed_time = time.time() - start print('{} finish: generate product csv({} sec)'.format(datetime.datetime.now().strftime('%Y/%m/%d %H:%M:%S'), elapsed_time)) # Table: category # Column: category_code,name # category_code: 1 - 10,000 # name: category_1 - category_10000 print('{} start: generate category csv'.format(datetime.datetime.now().strftime('%Y/%m/%d %H:%M:%S'))) start = time.time() rows = [] # header # rows.append('id,name\n') for i in range(CATEGORY_CNT): category_code = str(i + 1) category_name = 'category_' + str(i + 1) rows.append('{},{}\n'.format(category_code, category_name)) # 1,000 件ごとに出力する if((i + 1) % 1000 == 0): cnt = i + 1 print('category rows: {}'.format(cnt)) with open(CATEGORY_DST, 'a', encoding='utf-8') as f: f.writelines(rows) rows = [] elapsed_time = time.time() - start print('{} finish: generate category csv({} sec)'.format(datetime.datetime.now().strftime('%Y/%m/%d %H:%M:%S'), elapsed_time)) # Table: sales # Column: id,shop_id,product_id,price,count,total_price # id: 1 - 10,000,000 print('{} start: generate sales csv'.format(datetime.datetime.now().strftime('%Y/%m/%d %H:%M:%S'))) start = time.time() rows = [] # header # rows.append('id,shop_id,product_id,price,count,total_price\n') cnt = 0 for i in range(SALES_CNT): sales_id = str(i + 1) shop_id = str(random.randrange(1, SHOP_CNT, 1)) product_id = str(random.randrange(1, PRODCUT_CNT, 1)) price = str(random.randrange(1, PRICE_MAX, 10)) count = str(random.randrange(1, COUNT_MAX, 1)) total_price = str(int(price) * int(count)) rows.append('{},{},{},{},{},{}\n'.format(sales_id, shop_id, product_id, price, count, total_price)) # 10,000,000 件ごとに出力する if((i + 1) % 10000000 == 0): cnt = i + 1 print('sales rows: {}'.format(cnt)) with open(SALES_DST, 'a', encoding='utf-8') as f: f.writelines(rows) rows = [] elapsed_time = time.time() - start print('{} finish: generate sales csv({} sec)'.format(datetime.datetime.now().strftime('%Y/%m/%d %H:%M:%S'), elapsed_time))
- 投稿日:2019-11-29T13:29:19+09:00
機械学習/回帰モデルの性能評価を行ってみる
1.はじめに
今回は、機械学習に使われる回帰モデルの性能評価を、コードを作りながら行ってみます。
2.データセット
使用するデータセットは、sklearnに付属しているボストン住宅価格です。
import numpy as np import pandas as pd import matplotlib.pyplot as plt from sklearn.datasets import load_boston from sklearn.preprocessing import StandardScaler from sklearn.model_selection import train_test_split from sklearn.linear_model import LinearRegression,Ridge from sklearn.tree import DecisionTreeRegressor from sklearn.ensemble import RandomForestRegressor,GradientBoostingRegressor from sklearn.pipeline import Pipeline from sklearn.metrics import r2_score from sklearn.model_selection import cross_val_score from sklearn.utils import shuffle # -------- データセットの読み込み --------- dataset = load_boston() X = pd.DataFrame(dataset.data, columns=dataset.feature_names) y = pd.Series(dataset.target, name='y') print('X.shape = ', X.shape) print(X.join(y).head())
データは全部で506個、特徴量は13項目、yがターゲットとなる住宅価格です。3.回帰モデル
今回使用する回帰モデルは5つです。後で、使い易い様に、パイプラインの形でまとめます。ハイパーパラメータは、デフォルトです。
# ---------- パイプラインの設定 ----------- pipelines = { '1.Linear': Pipeline([('std',StandardScaler()), ('est',LinearRegression())]), '2.Ridge' : Pipeline([('std',StandardScaler()), ('est',Ridge(random_state=0))]), '3.Tree' : Pipeline([('std',StandardScaler()), ('est',DecisionTreeRegressor(random_state=0))]), '4.Random': Pipeline([('std',StandardScaler()), ('est',RandomForestRegressor(random_state=0, n_estimators=100))]), '5.GBoost': Pipeline([('std',StandardScaler()), ('est',GradientBoostingRegressor(random_state=0))]) }1.Linear
最小二乗法を使った線形回帰モデル(Linear)です。2.Ridge
線形回帰モデルに、L2正則化項目を追加して、過学習を抑制したリッジ回帰モデル(Ridge)です。3.Tree
決定木(Decision Tree)による回帰モデルです。4.Random
ランダムに選んだ特徴量から複数の決定木を作成し、全ての決定木の予測を平均して出力する、ランダムフォレスト(Random Forest)です。5.GBoost
既存のツリー群が説明しきれない情報(残差)を後続のツリーが説明しようとする形で、予測精度を高める、勾配ブースティング(Gradient Boosting)です。4.評価指標
誤差指標は、R2_scoreを使用します。これは、予測と実測の二乗誤差Σが、実測と実測平均の二乗誤差Σに対してどれだけ小さく出来るかというものです。
予測が実測と全て一致すれば指標は1、予測があまりにも悪いと指標はマイナスにもなり得ます。
5.ホールドアウト法
まず、モデルの性能評価をする一般的な方法である、ホールドアウト法を行います。データを 学習データ:テストデータ=8:2 に分割し、学習データで学習後、未知のテストデータで評価することによって、汎化性能をみるわけです。
# ----------- ホールドアウト法 ----------- X_train,X_test,y_train,y_test = train_test_split(X, y, test_size=0.20, random_state=1) scores = {} for pipe_name, pipeline in pipelines.items(): pipeline.fit(X_train, y_train) scores[(pipe_name,'train')] = r2_score(y_train, pipeline.predict(X_train)) scores[(pipe_name,'test')] = r2_score(y_test, pipeline.predict(X_test)) print(pd.Series(scores).unstack())
未知のテストデータで評価した結果、精度が一番高い(0.924750)のは 5.GBoostでした。学習データでは、精度の一番高い(1.0000) 3.Tree は、テストデータでは(0.821282)と大きく後退しており、過学習に陥っていることが分かります。
2.Ridge は 1.Linear の改良版のはずですが、テストデータでは精度が僅かに逆転しています。これはホールドアウト法による精度測定に、ある程度バラツキがあるためで、後でもっと厳密なk-fold法で性能比較を行います。
6.残差プロット
モデル性能を可視化するために、残差プロットを行います。これは、横軸に予測値、縦軸に予測値と実際値の差を取り、学習データとテストデータをプロットするものです。
# ------------- 残差プロット ------------ for pipe_name, est in pipelines.items(): y_train_pred = est.predict(X_train) y_test_pred = est.predict(X_test) plt.scatter(y_train_pred, y_train_pred - y_train, c = 'blue', alpha=0.5, marker = 'o', label = 'train') plt.scatter(y_test_pred, y_test_pred - y_test, c = 'red', marker ='x', label= 'test' ) plt.hlines(y = 0, xmin = 0, xmax = 50, color = 'black') plt.ylim([-20, 20]) plt.xlabel('Predicted values') plt.ylabel('Residuals') plt.title(pipe_name) plt.legend() plt.show()コードの出力としては、1.Linear 〜 5.GBoost まで5つの残差プロットされますが、ここでは代表的なものを3つだけ上げます。
線形回帰モデルです。学習データ、テストデータとも、ほぼ同じ様な残差のバラツキに成っています。
決定木です。学習データでは完全な残差ゼロ(精度100%)な一方で、テストデータは大きく残差がバラついています。典型的な過学習です。
勾配ブースティングです。学習データ、テストデータとも、残差のバラツキが抑えられています。7.k-hold法
ホールドアウト法よりも厳密なモデル評価が出来るのが k-hold法 (k分割交差検証)です。
具体的な手順は、まずデータをk個に分割し、1つづつ順番に選んでテストデータとし、残りのk-1個を学習データとします。
そして、学習データで学習を行い、テストデータで精度測定を行うことをk回繰り返し、得られた精度の平均を取りモデルの精度とするのが k-hold法 です。ここでは、k=5で行います(cv = 5 で指定)。
なお、cross_val_score は、train_test_split の様に、自動でデータをシャッフルしませんので、最初にユーティリティー shuffle を使って、データをシャッフルしてから処理を行います。
# -------------- k-fold法 -------------- X_shuffle, y_shuffle =shuffle(X, y, random_state= 1) # データシャッフル scores={} for pipe_name, est in pipelines.items(): cv_results = cross_val_score(est, X_shuffle, y_shuffle, cv=5, scoring='r2') scores[(pipe_name,'avg')] = cv_results.mean() scores[(pipe_name,'score')] = np.round(cv_results,5) # np.roundは桁調整 print(pd.Series(scores).unstack())
avgの横にある[ ]に囲まれた5つの数字scoreが、1回毎に算出した精度です。1.Linearを見ると、最低0.64681〜最高0.76342までバラついていることが分かります。この数字を平均することで、厳密なモデル評価を行うわけです。2.Ridgeは、1.Linearより僅かですが、精度が向上していることが分かると思います。
最終的に、ボストン住宅価格において、最も優秀なモデルは、5.GBoost でした。
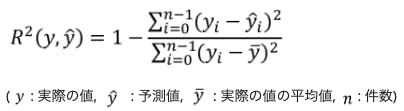
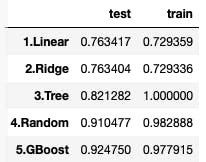
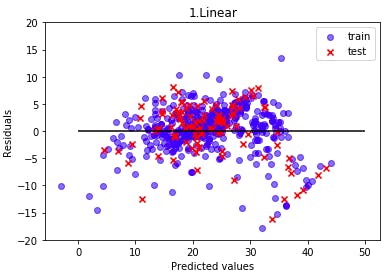
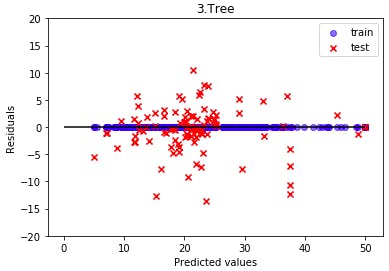
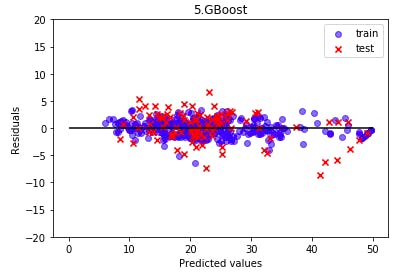
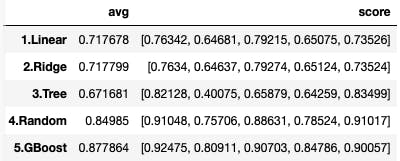
- 投稿日:2019-11-29T13:22:34+09:00
強化学習23 Colaboratoryで自分用のmoduleを作って使う
Colaboratoryで自分用のmoduleを作って使う方法です。
まず、GoogleDriveにmodule用のフォルダを作ります。
名前は、chokozainerRLにしました。
chokozainerRL内に、空のファイル __init__.py を作ります。
VSCodeでファイルを作って、アップロードしました。
次に、以下のようなtest.pyファイルを作ってアップロードします。test.pyclass Test: def sayStr(self, str): print(str)chokozainer フォルダ内 __test__.py test.pynotebookは以下のような感じです。
import google.colab.drive google.colab.drive.mount('gdrive') !ln -s gdrive/My\ Drive mydrive !ln -s gdrive/My\ Drive/chokozainer chokozainerfrom chokozainerRL import test a=test.Test() a.sayStr("Hello Papa")プログラムが大きくなってくると、自分用のmoduleを作ったほうが便利になります。
- 投稿日:2019-11-29T13:01:17+09:00
Python -辞書包括表記を元の形に戻してみた-
現在、内包表記の一つの辞書包括表記を勉強中です。
その途中で、辞書包括表記を元の長めのコードに戻してみたら成功したので、記事に残しておこうと思いました。内包表記とは
そもそも内包表記とは、一つ以上のイテレータからPythonデータ構造をコンパクトに作れるものです。(引用:Bill Lubanovic著 斎藤 康毅 監訳 長尾 高弘 訳 『入門Python3』 P.104
出版社:オライリー・ジャパン ISBN 978-4-87311-738-6)辞書包括表記は内包表記の一つで、キーとバリューを用いた辞書の形式で内包表記をしていくものです。
辞書包括表記を書いてみる
まずは、辞書包括表記を書いていきます。
文字列「python」の一文字ずつをキーとして、それぞれの文字のインデックスをバリューとします。辞書包括表記word = "python" letter_count = {letter:word.index(letter) for letter in word} print(letter_count) >> {"p": 0, "y": 1, "t": 2, "h": 3, "o": 4, "n": 5}このように辞書包括表記をはじめとした内包表記を利用すれば、forループを回して「python」の文字列の辞書を、一行で記述することができます。
まだ慣れるまで時間がかかると思いますけど、きっとめちゃくちゃ楽にコードを書いていけることでしょう!(多分)辞書包括表記を元の形に戻してみる
では、Pythonの練習がてら辞書包括表記を元の形に戻していきます。
元の形へー、戻れword = "python" letter_count = {} for letter in word: letter_count[letter] = word.index(letter) print(letter_count) >> {"p": 0, "y": 1, "t": 2, "h": 3, "o": 4, "n": 5}やはり、空辞書を作ってちゃんとforループを使ってletter_countを辞書を作ると、コードが長くなりました。辞書包括表記が、有用であることがよく分かります。
でも、元の形に戻したらPythonの練習になったし、新しい練習方法を見つけられたので良かったです。
引用
Bill Lubanovic著 斎藤 康毅 監訳 長尾 高弘 訳 『入門Python3』
出版社:オライリー・ジャパン ISBN 978-4-87311-738-6
- 投稿日:2019-11-29T12:54:35+09:00
opencvによるリアルタイムでの画像処理基礎
はじめに
パソコンについているカメラで、リアルタイムでその画面を表示させるプログラムの紹介
環境
言語:python3
ライブラリ:opencv
エディタ:jupyter notebookソースコード
import cv2 #captureの準備 cap = cv2.VideoCapture(0) #起動と画面表示まで while(1): #capture frameの作成 _, frame = cap.read() cv2.imshow('Original', frame) #originalの反転(鏡状態) original = cv2.flip(frame, 1) cv2.imshow('Inversion', original) #binarization gray = cv2.cvtColor(original, cv2.COLOR_RGB2GRAY) cv2.imshow('Binarization', gray) k = cv2.waitKey(5) & 0xFF if k == 27: break cv2.destroyAllWindows() cap.release()"Original"はカメラによってとらえられた本体である。
"Inversion"はoriginalの画面の反転を行うことにより、鏡のように見せている。
"Binarization"はInversionの画面を二値化(=binarization)をしたものであり、白黒になる。今回は処理がわかりやすいが、コードを書く人によっては以下のように並べ替えられる。
import cv2 #captureの準備 cap = cv2.VideoCapture(0) #起動と画面表示まで while(1): #capture frameの作成 _, frame = cap.read() #originalの反転(鏡状態) original = cv2.flip(frame, 1) #binarization gray = cv2.cvtColor(original, cv2.COLOR_RGB2GRAY) k = cv2.waitKey(5) & 0xFF if k == 27: break cv2.imshow('Original', frame) cv2.imshow('Inversion', original) cv2.imshow('Binarization', gray) cv2.destroyAllWindows() cap.release()何も処理自体は変わらない。しかし、処理の塊としてみるには下記の方がプログラマーとしては見やすいかもしれない。いちいち一個ずつ処理してるように見えてしまうからである。
さいごに
今回は基礎中の基礎をやった。これを応用したものもこれから書いていくし、ほかのライブラリを含めて様々なことができるので、やってみるといい。