- 投稿日:2019-11-29T23:48:44+09:00
Twitterでのコード投稿の見栄えどうにかならんのと思った話
たぶん、長い投稿
きっかけ(こんな呟きを見かけた
ソースコードをツイートするときに
— えるは個人えんじにゃー(喪中) (@ellnore_pad_267) November 2, 2019<br>source code<br>
ってやってマークダウンみたいに引用文にして欲しい。
ここはもうURLとかハッシュタグとかも全部エスケープして欲しい。出来たもの
作成の過程で収穫物
- Rails5.2での追加分(Active Record Storage含む
- Twitter Login方法と仕組み、そのたTwitterあれこれ
- JSの基礎(getElementByIdやsetAttribute、文字カウントなど
- AWS S3の使い方
- XSS対策
未だ残る改修すべき箇所
- 検索結果画面のリダイレクトエラー(多分route.rbの書き順番由来
- js辺りのエラー(動いてるけど、consoleではjs/mapのルーティングが何とか
- スマホで
タグ等を打つの面倒なので、なにか投稿補助ボタンでも- 本来の目的をよく考えたら、マークダウンの方は不要なのでは。
作成要件
- マークダウン投稿、シンタックスハイライト
- gem: redcarpet, rouge(結局syntax-hightlightだけは反映されないまま
- 投稿から画像生成
- AWS S3にog:image用の画像を保存
作成の流れ:予定
- rails new codr, git init, heroku create、Active Storage
- AWS S3あれこれ
- twitter登録、ログイン機能作成
開発環境
- vm : Linux Ubuntu (virtualbox + vagrant)
- Ruby 2.5.1p57
- Rails 5.2.3
- Postgresql
実作業: アプリ作成、諸準備
rails new codr -d postgresql # DB設定等は割愛Gem
今回は公開にまで至る予定なので、railsやdeviseの日本語化等も。が、想定ユーザはエンジニアだしと思い、殆ど英語になった。
Gemfilegem 'mini_racer' # uncomment gem 'rails-i18n' # japanize # authetication gem 'devise' # login gem 'omniauth' # SNS login gem 'omniauth-twitter' # twitter login gem 'devise-i18n' # japanize devise gem 'devise-i18n-views' gem 'redcarpet' # for markdown gem 'rouge' # for syntax highlight gem 'meta-tags' gem 'aws-sdk-s3' # for aws s3kpumuk/meta-tags:Search Engine Optimization (SEO) for Ruby on Rails applications.は割愛。
gitignore => rails.credentials.yml
当初は.
gitignoreとgem 'dotenv'等を使っていた。が、作成途中でRails5.2からのrails.credentials.ymlを知り、利用した。rails.credentials.ymlは暗号化されており、なお、復号化には/config/master.key`を利用。irb# editor setting EDITOR="vi" bin/rails credentials:edit # edit credentials.yml rails credentials:edit # show credential.yml rails credentials.yml:show # herokuにmaster.keyを環境変数として指定 heroku config:set ENV_VAR="環境変数" --app "アプリ名" # 追加した変数を使用するには Rails.application.credentials.dig(:twitter, :API_Key)rails gあれこれ
# devise # install devise rails g devise:install rails g devise User name:String # Add Admin column to User rails g migration AddAdminToUsers # add setting at /db/migrate/20191103141531_add_admin_to_users.rb add_column :users, :admin, :boolean, default: false # add views and controllers to modify devise rails g devise:controllers users rails g devise:views users # japanize # add at /config/application.rb config.i18n.default_locale = :ja => create /config/locale/devise.view.ja.yml# scaffold post rails g scaffold Post user:references name:string content:text date:datetimeActive Record Associations関連付け
/app/model/user.rbhas_many :posts/app/model/post.rbbelongs_to :user投稿関連
マークダウン投稿
基本:
Redcarpet::Markdown.new(renderer, extensions = {}).render(@post.content)
オプションやXSS対策等を追加したく、helperメソッドを作成した。app/helpers/posts_helper.rbModule PostsHelper require 'rouge/plugins/redcarpet' class RougeRedcarpetRenderer < Redcarpet::Render::HTML include Rouge::Plugins::Redcarpet def header(text, level) # #や##等がh2、h3となるようにした。 level += 1 "<h#{level}>#{text}</h#{level}>" end end def markdown(text) render_options = { filter_html: true, # do not allow any user-inputted HTML in the output. hard_wrap: true, } extensions = { autolink: true, # <>で囲まれていない時は、リンクとして認識しない fenced_code_blocks: true, # ```\n ```内をコード部分と見做す lax_spacing: true, no_intra_emphasis: true, strikethrough: true, superscript: true, tables: false, # テーブルを認識しない highlight: true, disable_indented_code_blocks: true, space_after_headers: false # #の後にスペースが無くても、h1等とする。 } renderer = RougeRedcarpetRenderer.new(render_options) Redcarpet::Markdown.new(renderer, extensions).render(text).html_safe end endhtml_safe => sanitize
html_safeではXSS対策としては駄目と知った。名前詐欺である。
sanitizeヘルパーを使用した。ホワイトリスト方式。要参照app/views/posts/index.html.erb# sanitize(html, options = {}) <div id="capture" class="content"> <%= sanitize(markdown(@post.content), tags: %w(div img h1 h2 h3 h4 h5 strong em a p pre code ), attributes: %w(class href)) %> </div>投稿内容のデータ化、AWSへの画像保存
最初はTwitterAPIを利用して、投稿から作成、DBに直接保存した画像でTwitter投稿しようとした。だが、Herokuでは画像が保持されない事、TwitterAPIの変更などいろいろ面倒なことが発生したので、最終的には画像をAWS S3に保存し、og:imageに添付する形を取った。
- Webアプリ内で通常投稿
- showページ表示(同時にhtml2canvasでBase64としてデータ取得、hidden_fieldに格納
- Tweetボタン押す(Postされ、postモデル内でbase64をデコード
- Active Storageを通して、AWS S3に保存
Active Storage
Rail5.2からの機能で、今までのcarrievaveやpaperclip等を使わずに、クラウドストレージ等へのアップロードが容易になる。今回はAWS S3を使った。
irb# set up rails active_storage:install # 今回は画像が紐づくPostテーブルが既にあるので、不要 # rails g resource comment content:text rails db:migrateapp/models/post.rbclass Post < ApplicationRecord # 今回は1つの投稿につき、1枚の画像なので。複数なら => has_many_attached :prtscs has_one_attached :prtsc endapp/config/enviroments/# ファイル保存先変更 # development.rb config.active_storage.service = :local # production.rb config.active_storage.service = :amazon
rails credentials:editでAWSアクセスキーとシークレットキーを追加。config/credentials.yml.encaws: access_key_id: secret_access_key:config/storage.ymltest: service: Disk root: <%= Rails.root.join("tmp/storage") %> local: service: Disk root: <%= Rails.root.join("storage") %> amazon: service: S3 access_key_id: <%= Rails.application.credentials.dig(:aws, :access_key_id) %> secret_access_key: <%= Rails.application.credentials.dig(:aws, :secret_access_key) %> region: ap-northeast-1 bucket: codr0Gemfile# gemが必要 gem 'aws-sdk-s3', require: false # 今回は不要だったので、入れず。 gem 'mini_magick'html2canvas
参考:htmlを画像化する方法(html2canvasの使い方)
jsはProgateレベルだったので、DOM操作は初めてで、なんか楽しかったぞ。
- Tweetボタン押下時に、画像をPostするためのフォーム、hidden_fieldを用意
html2canvas.jsをapp/assets/javascriptsディレクトリ配下に保存。- html上に置くscriptコードを改修
app/views/posts/show.html.erb<%= form_with(model: @post, local: true) do |form| %> <%= form.hidden_field :id, value: @post.id %> <%= form.hidden_field :prtsc, value: "" %> # idはpost_prtscになる。 <%= form.submit "Post", class:"btn btn-outline-dark", id:"tweet", value:"tweet" %> <% end %>app/views/layouts/application.html.erb<script type="text/javascript"> html2canvas(document.querySelector("#capture"),{scale:1, width:600}).then(canvas => { var base64 = canvas.toDataURL('image/jpeg', 1.0); document.getElementById('post_prtsc').setAttribute('value', base64); }); </script>Base64デコード
大学で画像処理していたとはいえ、 Base64とは?Blobとは?となり、良い機会だった。
app/models/post.rbattr_accessor :img def parse_base64(img) if img.present? # data:image/jpeg;base64,/9j/4AAQSkZJRgABA・・・から/9j/4AA以降を選択取得 content = img.split(',')[1] # 今回は、ユーザによる画像アップロード投稿ではなく、拡張子が決まっている filename = Time.zone.now.to_s + '.jpg' decoded_data = Base64.decode64(content) # String.IO.newにより、アプリ内に一時ファイルを作成しなくて済む prtsc.attach(io: StringIO.new(decoded_data), filename: filename) end endあとはposts_controllerで、paramsから受け取ったBase64データを上の
parse_base64(img)で変換し、保存すれば完了。AWS S3
AWS上での登録、設定、バケット作成等は割愛。
Tweet button
公式で生成されるTweetボタンのURLを利用し、押下時にwindow.openでTweet投稿ページを開くようにした。rubyonrailsで用意した変数をjsに渡す
gem 'gon'も考えたが、見送った。app/views/layouts/application.html.erb<script> var base = 'https://twitter.com/intent/tweet?url='; var pageUrl = 'https://codr0.herokuapp.com/posts/' + document.getElementById('post_id').value; var option = '&button_hashtag=Codr0&ref_src=twsrc%5Etfw'; var href = base + pageUrl + option; var twit = document.getElementById('tweet'); twit.addEventListener('click', function() { window.open( href ); }); </script>og:imageに画像添付
なお、headのmeta情報セットには、
gem 'meta-tags'を使用。参照 : kpumuk/meta-tagsservice_url()とurl_for()
基本的にはどちらも、ActiveStorageに保存したデータのUrlを取得するメソッドの様だ。
どちらもセキュリティの為にリンクの有効期限が短いみたいだが、違いが分からなかった。今回はTweetボタン押下し、Tweetした際にog:imageとして表示されればいい。app/views/posts/show.html.erb# 画像がActive StorageでAWS S3に保存されて入れば <% if @post.prtsc.attached? %> <% set_meta_tags og:{image: @post.prtsc.service_url} %> <% end %>Twitterログイン
TwitterDeveloperAccountが必要。割愛。
なお、omniauthは脆弱性が見つかっており、githubの方でもアラートが来るのだが、パッチが無いのだが。クックパッドの人が対処してくれたので、感謝したい。
app/models/user.rb# 参考ページと同じ基礎的な所は割愛する。 class User < ApplicationRecord def self.from_omniauth(auth) find_or_create_by!(provider: auth['provider'], uid: auth['uid']) do |user| # 一部割愛 user.username = auth['info']['nickname'] # SNS登録時は、ダミーメールを登録 user.email = User.dummy_email(auth) end end # SNS登録(providerが存在する)時は、パスワード要求をしない def password_required? super && provider.blank? end def self.new_with_session(params, session) if session['devise.user_attributes'] new(session['devise.user_attributes']) do |user| user.attributes = params end else super end end private def self.dummy_email(auth) "#{auth.uid}-#{auth.provider}@example.com" end endTwitterのニックネームが取得できるようになったので、元からあるUserのnameテーブルは削除した。
css
今回はBootstrapを部分的に使用した。cssの優先順位など収穫があった。
改修(加筆
メディアクエリ
想定ユーザは殆どスマホなのに、PCで作成し、CSSをPCの見た目でやってた。折角SCSSでやってるので、変数を利用した。
app/assets/stylesheets/scaffold.scss# ディスプレイサイズが680pxまでなら。 $tab: 680px; @mixin tab { @media (max-width: ($tab)) { @content; } } // .box { // @include tab { // background-color: blue; // }; // }最後に
gist等がコードスクショをog:imageで表示してくれたら全て済むんじゃと思った。
因みにもう1段階先のWebアプリを考えてあるけど、たぶんjsの知識が足りないので、今は無理。
転職活動中の無職です。働きたい。。。。

- 投稿日:2019-11-29T23:32:28+09:00
ストレスのない分散チーム開発 AWS編
Global Mobility Service株式会社(以下GMS)というスタートアップでソフトウェアエンジニアをしているkooogeです。
Global Mobility Serviceのアドベントカレンダーの3日目です。
昨日は、インターンのShirubaさんのエンジニアの教養、フレームワーク解剖学【Express編】でした。
弊社もついにアドベントカレンダーデビュー、組織の成長を感じています。サービスの成長とともにチームの規模が拡大していくにつれ、本来のシステム開発とは異なる部分に時間がかかるようになりました。この記事では、分散したチームにおいて、ストレスの(すく)ないシステム開発手法の実現に向け、弊社の事例を紹介します。
地理的に分散したチームと1つのAWSアカウントの限界
スタートアップでは、リーンにシステム開発を進め、必要になったときにスケールさせていく、ということはよくあると思います。AWSの利用方法に関しても同様に、多くのスタートアップは、1つのAWSアカウント、1つのEC2インスタンスから始まったのではないでしょうか。
弊社は、日本、フィリピン、カンボジア、インドネシア、韓国に拠点があり、各1人~10人ほどの小規模な開発チームが存在し、それぞれ連携はするもののチームごとに別々のシステム開発を行っています。当初これらのシステムは、日本のインフラ担当が管理運用する1つのAWSアカウントで開発を行っていました。サービスがスタートしたばかりの頃は、この構成でも大きな問題はありませんでしたが、チームが拡大してすぐに限界を迎えました。
XXXXを作ってください。が辛くなった
EC2作ってもらえますか?
まず、(当たり前ですが)インフラ担当が、リソース作成や管理に時間を取られるようになります。サービスの立ち上げ時にリソースを作成を依頼されていましたが、プロダクション環境用のリソースだけでなく、ステージングや開発用の環境も作成が必要な場合があり、倍々に作業が増えていきました。これに関しては、Cloud FormationやTerraformである程度の構成管理と設定の再利用が可能です。しかし、インフラ担当不在の組織においては、サービスの直接の価値ではない部分に学習コストをかける必要があるため、厳しいと思います。
また、リソースは作成するだけでなく、設定変更のたびに作業が必要となります。チームの拡大に伴ってインフラ担当の仕事量が純粋に多くなり、いずれ作業が追いつかなくなります。XXXXは今どういう状況ですか?が辛くなった
サービスの待ち受けポートを増やしたいのですが、AWSの設定を確認してもらえますか?
など、インフラの固定の管理者がいる場合、各チームはリソースの設定の変更だけでなく、単なる確認もインフラ担当に行うようになります。これは、チームがAWSの学習の機会を与えられていないためです。これに関しては、自由にAWSリソースの状況を見れるIAM Userを配布することで解決は可能ですが、実際にリソースを触ってみないと身に付かないことは多いと思います。
XXXXを使いたいけど、インフラ担当が多忙ですぐに使えなかった
インフラの担当が多忙となり、リソース作成や設定変更に時間がかかるようになり、サービス開発のボトルネックとなってしまいます。
また弊社では、国をまたぐチーム間の作業依頼がオーバーヘッドとなりました。アジアに展開する各チームの母語は日本語、タガログ語、クメール語、インドネシア語、韓国語とバラバラです。英語が意思疎通を図る言語となりますが、それぞれの第2言語であり、完璧ではありません。作業依頼は通常以上のオーバーヘッドとなります。
管理者を増やしつつ、権限分離をしたいけどIAM辛かった
インフラ担当が忙殺されたある時を境に、インフラの管理者を各拠点に設ける作戦に変更しました。ただし、全員が全権限を持つ管理者になるというわけではありません。
うっかり他拠点のリソースに干渉できることのないようにしようという権限分離を実現すべく、このためにIAM Policyを細かく設定しなければなりませんでした。IAMは地味ながらAWSで一番重要なサービスなんじゃないかと思っていますが、きちんと使おうとするととにかく複雑です。やっていくうちに、いくつか矛盾が発生してしまう部分がでてしまいました。IAMで完璧な権限分離をやりきるプラクティスは存在するとは思いますが、IAMに時間を避けるIAMマスターがいないと厳しいと感じました。また、会計管理の関係で各国の拠点毎にAWSの利用料を算出する必要がありました。リソースに特定のTagを含めるようにお願いし、そのTagを元に集計していましたが、Tagに対応していないリソースがあったり、Tagをつけ忘れたりなど、正確ではなく大雑把なものとなってしまいました。
XXXXを試しに使ってみたいけど、インフラ担当に依頼するのが面倒だった
各チームが成長してくると、AWS LambdaなりAmazon CloudFrontなり自由にAWSのサービスを駆使して自分たちのサービス開発したい、という要望がでてくるようになります。しかし、これは前述の複雑なIAMによる権限分離のおかげで、インフラ管理者の設定の見直しが必要となってしまってしまいました。このような状況が続いてしまうと、高いコミュニケーションコストを払ってまでインフラを洗練したくない、という心理的障壁が少なからず生じています。実際に各チームは多少効率が悪くても、自分たちができる範囲内でやろうとしてしまっていました。素早いサービス開発によって顧客に価値を提供するために、使いときすぐ使えるインフラを提供できることが本来あるべき姿であり、インフラ担当としても本位ではないではずです。
AWSアカウントの分離
1つのAWSアカウント内で共存するのが辛くなると、複数アカウントを使い分ける方法がプラクティスとして存在します。これにより、複雑なIAMの設定は不要となり、アカウントの全ての権限を持つユーザーを配布するのみとなります。加えて、利用料の算出も、そのアカウント全体の利用料となるため、設定も不要で明快です。
アカウントの分け方
アカウントを分割する際に、まず検討するのが、どの粒度でアカウントを分割するのか?です。これには権限分離と運用工数のトレードオフがあります。次の記事が参考になります。
https://dev.classmethod.jp/cloud/aws/account-and-vpc-dividing-pattern/
弊社では、"2. システムの種類でAWSアカウントを分割する" のパターンを採用しました。利用者側も複数AWSアカウントを持つ意味、管理者としての運用方法を学習する必要があるため、無用に複雑にすることを避ける必要もあります。特にスタートアップにおいては、必要になったときに更なるアカウント分割を実施する、という方針でよいと思います。
AWS Organizations
単に複数アカウントに分割すると、アカウント毎にユーザーを作成する必要があります。つまり、利用者が複数のアカウントを利用したい場合はIAM Userをアカウント毎に持ち、管理しなくてはなりません。そこで、AWS Organizationsを使って、すべてのアカウントを、つながりをもつ1つのアカウント群として扱うようにします。利用者は、他のアカウントのIAM RoleにスイッチできるIAM Userをただ1つ管理だするだけで済みます。
支払いの一括化や、リザーブドインスタンスの共有の他、アカウント間でのリソースの参照やスナップショットのコピーなども出来るため、複数AWSアカウント運用において、AWS Organizationsを利用しない手は無いでしょう。
ユーザー作成は1つのアカウントにまとめる
プラクティスとして、ユーザーはどこか1つのユーザー管理用のアカウントでまとめて管理するのが良いでしょう。このアカウントは、親アカウントでも子アカウントでも可能です。
インフラ管理者は、AWSアカウントの管理と、このユーザー管理がメインの業務となるでしょう。ユーザーを作成し、どのアカウントにAssumeRoleできるかを設定する必要があります。これにはIAM Groupを用いてある程度ユーザーをグループで分けると良いでしょう。アカウント間でリソースを移動するのは大変
アカウント間でAWSのリソースを移動することは、同じOrganizationであっても出来ません。最初に1つのAWSアカウントで開発進め、後に分割した場合、いずれかの手段によってあるべきアカウントに移動させる必要があります。
リソースを消す
説明不要と思いますが、まずそのリソースが不要な場合、リソースの削除を試みましょう。1つのAWSアカウントで長いこと運用を続けていると、どのリソースが使われているのか、何のためにあるのかを精査するのが地味に大変です。インフラをコード管理すればある程度把握できると思いますが、コード管理されていない場合は、泥臭くてもスプレッドシートなどでリソース管理台帳があることが望ましいです。(とはいえ台帳は実態と乖離していくものです。ないよりマシ程度に考えてください)
別のリソースとして作り直す
状態を持たない単なるリソースの場合、別のアカウントにリソースを作り直せば良いです。ただし、これに関してもProvisioning方法がわからなくなったなど、サーバーのミドルウェア情報や設定方法が不明となり、動かせないということがよくあると思います。規模な大きな物だけでもコード化(最悪は台帳管理)しておきましょう。
リソースを作り直した上で、データを移動する
DBやデータストアなどの移行は時間がかかります。リアルタイムに必要のないデータはバッチを作成し、順次コピーしていきましょう。RDSなどSecurity Group内のリソースは、VPC Peeringなどを用いて、アカウント間のデータ移行を行いましょう。完全オンラインでデータ移行をすることは難易度が高くなるため、計画的にダウンタイムを設定し、リソースの移動を行いましょう。
アカウント間で共有したいリソースをどうするか
アカウントを分割しても、いくつかアカウント間で共有したいリソースがあると思います。この場合、基本的には共有用のアカウントを作り、そのアカウントへのアクセスは、そのアカウントの利用者が等しく行えるようにしておくプラクティスが良いと思います。
開発用のサブドメインを配ると便利
AWS Route 53で作成したドメインに関して、開発用や社内ツール用に共有したいという要望がありました。このとき、レコード管理はインフラ管理者が管理するようにしまっては、アカウントを分けて権限分離した恩恵を得られません。このような場合に、AAA.XXXX.YYY、BBB.XXXX.YYYのようにサブドメインを作成し、各アカウントに配ると便利です。AWSアカウント毎にホストゾーンを作成し、AAA.XXXX.YYY、BBB.XXXX.YYYのよNSレコードを作成することで自由に使えるサブドメインが配布可能です。
CloudTrailで監査ログを集約する
AWSアカウントの管理で欠かせない機能として、AWS CloudTrailがあります。AWSのリソース変更などをロギングする監査用の機能です。このような機能は、Organizationsの全てのAWSアカウントに対して有効にしておきましょう。1つのS3バケットに監査ログを集約しておき、管理者がいつでも閲覧できるようにしておきましょう。
まとめ
AWSを用いて分散チーム開発をする場合のインフラ管理について、事例を交えて説明しました。
組織の成長の合わせ、インフラの利用方法も適切にスケールさせる必要があります。これはAWSのアカウント利用に関しても、同じことが言えます。AWS Organizationsを利用し、各チームにAWSアカウントを配布することで、AWSの運用が楽になり、チームも自由にストレスなくAWSを使い倒せるようになります。GMSで、よりよいチーム開発についてお話ししませんか ٩( ᐛ )و
- 投稿日:2019-11-29T23:21:58+09:00
AWS CLIでMFAトークンを使用してAPI実行するメモ
前提
- IAMユーザーを作成済であること
- プログラムからアクセス
- 仮想MFAを設定済み(ARNを控えておく)
- 以下のポリシーをインラインポリシーで設定済み
{ "Version": "2012-10-17", "Statement": [ { "Sid": "AllDenyWithoutMFA", "Effect": "Deny", "Action": [ "*" ], "Resource": [ "*" ], "Condition": { "BoolIfExists": { "aws:MultiFactorAuthPresent": false } } } ] }コマンド例
以下で一時クレデンシャルを取得可能
% aws sts get-session-token --serial-number [MFAのARN] --token-code [MFAトークン]メモ
- 上記「前提」記載の通り、
get-session-tokenの実行にはいかなるIAMポリシーも不要
- ただし、
get-session-tokenで取得した一時クレデンシャルを用いた時に実行できるのは上記ポリシーで許可された操作だけなので、一時クレデンシャルを用いて実行したい操作はあらかじめポリシーで許可する必要があるまた、IAM ユーザーは、一時的セキュリティ認証情報を作成するために GetSessionToken を呼び出すこともできます。ユーザーが GetSessionToken を呼び出すためには、アクセス権限を必要としません。このオペレーションの目的は、MFA を使用してユーザーを認証することです。認証を制御するためにポリシーを使用することはできません。つまり、IAM ユーザーが GetSessionToken を呼び出して、一時的な認証情報を作成することを回避することはできません。
https://aws.amazon.com/jp/premiumsupport/knowledge-center/authenticate-mfa-cli/
- 投稿日:2019-11-29T23:13:20+09:00
AWS LambdaでJavaのフレームワークを使うには!?
TL;DR
AWS LambdaでJavaのフレームワーク、たとえばSpringBootなどを使いたいって思ったことありませんか?
結論としては、AWS Lambdaの上に、aws-serverless-java-containerフレームワークというプロキシフレームワークを入れれば比較的簡単に実現可能です。
今日は、そのあたりを、このAWSブログを軽く意訳しつつ書いていきたいと思います。
AWS Open Source Blog Running APIs Written in Java on AWS Lambda
背景
Java開発者は、SpringやSpring BootからJersey、Sparkといった慣れ親しんだフレームワークで開発していることが多いのではないでしょうか。
これらのフレームワークは、Tomcatなどのサーブレットコンテナを用いて、ビルドされたWarやJarをデプロイするか、アプリケーションを内包した実行可能なJarとして利用することができます。
AWSのサーバーレスでは、AWS LambdaとAmazon API GatewayでWEBのバックエンドが構築できますが、Lambdaがコンピュートを担い、API GatewayがRESTの管理を担います。
この記事では、Lambdaで使える、aws-serverless-java-containerフレームワークをご紹介します。
仕組み
簡単に言うと、aws-serverless-java-containerは、Spring、Spring Boot、Jersey、Sparkなどのフレームワークで作られたアプリケーションを、簡単に、最小限のコード変更でAWS Lambda内で実行できるようにするものです。
aws-serverless-java-containerは、Lambdaランタイムと選択したフレームワーク間のプロキシとして機能し、サーブレットエンジンのふりをして、API GatewayからのEventをフレームワークが理解できるリクエストオブジェクトに変換し、アプリケーションからのレスポンスオブジェクトをAPI Gatewayの理解できる形式に変換します。
Spring Boot2をLambdaにのせて独自アプリを構築したい場合は、こちらに詳しい導入方法が紹介されています。
Quick start Spring Boot2サンプルアプリダウンロード
awslabからaws-serverless-java-containerをcloneしてきましょう。この中に様々なJavaフレームワークのプロキシとサンプルコードが含まれています。
$ git clone https://github.com/awslabs/aws-serverless-java-container.git独自アプリケーション用のプロキシはこちら
- aws-serverless-java-container-jersey
- aws-serverless-java-container-spark
- aws-serverless-java-container-spring
- aws-serverless-java-container-springboot2
- aws-serverless-java-container-struts2
独自アプリを構築するにはこれらを使えばいいのですが、この記事では簡単のために、Spring Boot2のサンプルを利用したいと思います。
Spring Boot2のLambdaへの導入
まず、以下の前提条件を満たしておきましょう。
まず、mvnコマンドを使って、Javaアプリケーションをビルドしましょう。
$ cd aws-serverless-java-container/samples/springboot2/pet-store/ $ mvn packagemvnコマンドが成功すると、
serverless-spring-boot-example-1.0-SNAPSHOT.jarが、targetディレクトリにできているはずです。つぎに、AWS SAMを使って、Lambdaにデプロイするpackageを作ります。
<YOUR S3 BUCKET NAME>には、適当なS3バケット名を指定しておきます。$ aws cloudformation package --template-file sam.yaml --output-template-file output-sam.yaml --s3-bucket <YOUR S3 BUCKET NAME>デプロイ用のパッケージができたら、次はいよいよLambdaへのデプロイです。このデプロイによってロジックを処理するAWS Lambdaと、HTTPSリクエストを受け取ってLambdaを呼び出すAPI Gatewayがデプロイされます。
$ aws cloudformation deploy --template-file output-sam.yaml --stack-name ServerlessSpringBootSample --capabilities CAPABILITY_IAMデプロイが成功すると、以下のコマンドで実際に作られた、APIのエンドポイントを知ることができます。
$ aws cloudformation describe-stacks --stack-name ServerlessSpringBootSample { "Stacks": [ { "StackId": "arn:aws:cloudformation:us-west-2:xxxxxxxx:stack/JerseySample/xxxxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxx", "Description": "Example Pet Store API written with spark with the aws-serverless-java-container library", "Tags": [], "Outputs": [ { "Description": "URL for application", "OutputKey": "SpringBootPetStoreApi", "OutputValue": "https://xxxxxxx.execute-api.us-west-2.amazonaws.com/Prod/pets" } ], "CreationTime": "2016-12-13T22:59:31.552Z", "Capabilities": [ "CAPABILITY_IAM" ], "StackName": "JerseySample", "NotificationARNs": [], "StackStatus": "UPDATE_COMPLETE" } ] }
OutputValueに指定されているAPIエンドポイントが、今回デプロイされ起動したAPIのURIになります。動作確認してみましょう。
$ curl https://xxxxxxx.execute-api.us-west-2.amazonaws.com/Prod/pets結果のJSONが返ってきたら成功です!
いかがだったでしょうか?サンプルアプリの導入がこんなに簡単にできました。
次のステップに進むには?
Spring Boot2は素晴らしいフレームワークで上の手順に従うことでLambdaにのせて実行させることは簡単にできるのですが、もっと小回りの効く、小さなフレームワークを導入したいといった場合
SparkやMicronautにも挑戦してみてください。また、Lambdaの初回起動時のLatencyが気になるワークロードについてはOracle社が提供しているGraalVMを利用したNative実行も可能です。
MicronautとGraalVMを使ったNative化のサンプルはこちら
Micronaut X GraalVMサンプルペットショップこの記事の関連情報としてJJUG CCC 2019 Fallの登壇資料がありますので、参考にしてください。


- 投稿日:2019-11-29T21:57:51+09:00
WorkSpacesにCloudWatchAgentを導入してログ転送する方法
はじめに
WorkSpacesにCloudWatchAgentを導入してログ転送するのに1日かかってしまったので覚書。
方法は二つあるのでそれぞれ軽くメモ。前提事項
SSM AgentではなくCloudWatchAgentを使用する。理由はSSM Agentを使用したログ転送が将来的にサポートされなくなるから。
WorkSpacesにはIAMロールをアタッチできないのでオンプレミス環境とみなしてCloudWatchAgentを導入していく。上記URLからWindows Server向けのリンクを探しパッケージを落としてインストール。
ロール
IAMユーザーにCloudWatchAgentAdminPolicyをつけておく。
ログ転送やメトリクスなど用途に応じて削っても問題はないと思われる。(未検証)方法1
まずは環境変数にアクセスキーを入れておく方法。この方法は楽だがアクセスキーとシークレットアクセスキーが環境変数に直書きされてしまうのが難点。
環境変数
下記3つの環境変数を設定する。
AWS_REGION
AWS_SECRET_ACCESS_KEY
AWS_ACCESS_KEY_ID
ユーザーの環境変数ではなくシステムの環境変数に入れなければならない。またここで入力するアクセスキーはCloudWatchAgentAdminPolicyを先につけたユーザーの物。コマンド
PowerShellを管理者権限で実行。PowerShellでのスクリプト実行が無効にされているので適時
powershell -ExecutionPolicy RemoteSignedを付けて実行。
下記コマンドで設定ウィザードを実行。cd "C:\Program Files\Amazon\AmazonCloudWatchAgent" amazon-cloudwatch-agent-config-wizard.exe設定ウィザードで質問にEC2かオンプレミスか聞くものがあるが、これはオンプレミスを選択。
設定ウィザード終了後は次のコマンド.\amazon-cloudwatch-agent-ctl.ps1 -a fetch-config -c file:config.json成功したらサービス再起動
起動 .\amazon-cloudwatch-agent-ctl.ps1 -a start 停止 .\amazon-cloudwatch-agent-ctl.ps1 -a stop ステータス .\amazon-cloudwatch-agent-ctl.ps1 -a status方法2
AWS CLIを使う方法。この方法だと環境変数に直書きはなくなる。デメリットとしてD:配下のファイルに設定をしていくのでバンドル化したときに設定が消えてしまう。
AWS CLIのインストール
リンクにあるようにインストーラーを使用してAWS CLIをインストールする。
https://docs.aws.amazon.com/ja_jp/cli/latest/userguide/install-windows.html#install-msi-on-windows:embed:citeプロファイルの作成
インストールしたら
aws configure --profile AmazonCloudWatchAgentでプロファイルを作成する。アクセスキー、シークレットアクセスキー、リージョン、出力形式を聞かれるので入力。キーは先にロールをアタッチしたユーザーの物。リージョンはログを転送するリージョン。出力形式はjsonでもtextでも大丈夫です。CloudWatchAgentの設定
PowerShellを管理者権限で実行。PowerShellでのスクリプト実行が無効にされているので適時
powershell -ExecutionPolicy RemoteSignedを付けて実行。
下記コマンドで設定ウィザードを実行。cd "C:\Program Files\Amazon\AmazonCloudWatchAgent" amazon-cloudwatch-agent-config-wizard.exe設定ウィザードで質問にEC2かオンプレミスか聞くものがあるが、これはオンプレミスを選択。
設定ウィザード終了後は次のコマンド.\amazon-cloudwatch-agent-ctl.ps1 -a fetch-config -c file:config.jsonCloudWatchAgentの設定変更
common-config.tomlを編集します。ファイルは
C:\ProgramData\Amazon\AmazonCloudWatchAgentにあります。# This common-config is used to configure items used for both ssm and cloudwatch access ## Configuration for shared credential. ## Default credential strategy will be used if it is absent here: ## Instance role is used for EC2 case by default. ## AmazonCloudWatchAgent profile is used for onPremise case by default. # [credentials] # shared_credential_profile = "{profile_name}" # shared_credential_file= "{file_name}" ## Configuration for proxy. ## System-wide environment-variable will be read if it is absent here. ## i.e. HTTP_PROXY/http_proxy; HTTPS_PROXY/https_proxy; NO_PROXY/no_proxy ## Note: system-wide environment-variable is not accessible when using ssm run-command. ## Absent in both here and environment-variable means no proxy will be used. # [proxy] # http_proxy = "{http_url}" # https_proxy = "{https_url}" # no_proxy = "{domain}これを編集して以下のようにします。
# This common-config is used to configure items used for both ssm and cloudwatch access ## Configuration for shared credential. ## Default credential strategy will be used if it is absent here: ## Instance role is used for EC2 case by default. ## AmazonCloudWatchAgent profile is used for onPremise case by default. [credentials] shared_credential_profile = "AmazonCloudWatchAgent" shared_credential_file= "D:\\Documents and Settings\\username\\.aws\\credentials" ## Configuration for proxy. ## System-wide environment-variable will be read if it is absent here. ## i.e. HTTP_PROXY/http_proxy; HTTPS_PROXY/https_proxy; NO_PROXY/no_proxy ## Note: system-wide environment-variable is not accessible when using ssm run-command. ## Absent in both here and environment-variable means no proxy will be used. # [proxy] # http_proxy = "{http_url}" # https_proxy = "{https_url}" # no_proxy = "{domain}要注意なのが公式ドキュメントでは
C:\\Documents and Settings\\username\\.aws\\credentialsにあると書かれていますがこれがWorkSpacesではD:\\Documents and Settings\\username\\.aws\\credentialsになります。CドライブではなくDドライブにユーザーのファイルが置かれています。あとは\が\\になる点も地味に注意です。起動
後は起動して終了です。起動には下記コマンドを実行。
起動 .\amazon-cloudwatch-agent-ctl.ps1 -a start 停止 .\amazon-cloudwatch-agent-ctl.ps1 -a stop ステータス .\amazon-cloudwatch-agent-ctl.ps1 -a status
- 投稿日:2019-11-29T21:42:41+09:00
LambdaからDynamoDBへ接続
学生アルバイトのsosonoです!!
プロジェクトでゲーム制作のサーバ側を主に担当しています!!
AWSを触り始めた頃って何が何だかの状況で、難しいサイトも一杯なので、必要なことを簡潔に書いてみます!!
serverless frameworkってのを使うことも可能なのですが、まずはコンソール(ブラウザ上のサイト)での操作から初めてみます!!Lambda
関数の作成
- 単純な関数を作りましょう(以下に従ってポチポチして下さい!!)
- 関数の作成
- 一から作成
- [関数名]を入力
- 実行ロールの選択または作成::基本的なLambdaアクセス権限で新しいロールを作成
- 以上の手順でデフォルトの処理が記述されたLambda関数をゲットです!!
DynamoDB
データベースの作成
単純なデータベースを作りましょう(以下ポチして下さい!!)
- テーブルの作成
- テーブル名はmydynamoにしときましょう
- プライマリーキーは、 user_id にして、文字列の部分を数値に変更してあげます
単純なテーブルを作りましょう
- 先ほど作成したデータベースを選択
- 項目→項目の作成をクリック
- userIdの右のVALUEには「1」を入れましょう
- 左の➕を押して、「Append」「String」を選択
- 新しく出来たFIELDに「name」を、VALUEには「hanako」 を入力
LambdaでDynamoDBを覗いてあげましょう
実行ロール(IAM)の追加
- 最初の手順でLambdaにロール(役割)を付与しましたが、DynamoDBを扱うロールが入っていません。追加します。
- Lambdaに戻り、先程作成した関数を選択
- 下の方の「実行ロール」の中から、リンクっぽく青色になっている「ロールを表示」をクリック
- 青色の「ポリシーをアタッチします」をクリック
- 検索欄に「dynamo」と入れると数個ポリシーが残るので、その中から「AmazonDynamoDBAmazonDynamoDBFullAccess」の左のボックスにチェックをし、「ポリシーのアタッチ」をポチっ
- Lambdaに戻りましょう
- 保存しちゃいましょう
コードを編集
- 覗くためのコードを書きます。コピペでも何でもいいのでデフォルトで書いてあるものを上書きしましょう!
var AWS = require('aws-sdk'); var dynamo = new AWS.DynamoDB.DocumentClient(); exports.handler = (event,context,callback) => { var params = { TableName : "mydynamo", Key : { user_id: 1 } }; dynamo.get(params, function(err,data){ if (err){ context.fail(err); } else { context.succeed(data); } }); };
- 右上の「保存」(オレンジ色)をクリック
- 保存の隣の「テスト」をクリック
- 画面が出てきますが、名前のところに適当に「hello」とでも入力して、気にせず先に進みましょう
- もう一度「テスト」をクリックしましょう
- 上の方に行くと.....「成功」となり、「詳細」をクリックすると、先程DynamoDBに入力したものがゲットできていませんでしょうか??
これで基本的な手順は完了です。
さらにさらに
LambdaもDynamoDBもまだまだいじるところがたくさんあります。基本の操作に慣れたら、より難しいことに挑戦してみましょう。
今回はコードをコピペした訳ですが、要点は
- パラメータでデータベースの名前と、idをキーにして
- getを実行し結果を取得、みたいな流れです
ここもカスタマイズの余地しかないので、是非お試しを。
基本的な操作を説明してくれているページって案外ないから、自分もこのような操作がすぐ出来ればなぁと今になって思います。
お疲れ様でした。
- 投稿日:2019-11-29T21:40:01+09:00
AWS 認定 Alexa スキルビルダー取得にむけて、全然わからんので用語を整理してみる
はじめに
AWS認定資格としてAWS 認定 Alexa スキルビルダーが気がつけば追加されていた。
Amazon Lexならともかく、AlexaってAWSの仲間なの? 的な疑問はさておき、AWSなのにBlackbeltに説明もなく仕様も良くわからん。というのが正直なところ。
資格取得はまあ置いといて、とりあえずカスタムスキルの概略まで頑張って理解した時のメモ。アカウント管理
AWSな人たちが触れる最初の壁。
Alexa開発視点でまとめると、こうなる?
- AWS 開発者コンソール(Amazon Developer)
- 2019.11現在「Alexa Skills Kit(ASK)」「Alexa Voice Service(AVS)」の開発に対応。
- ASKがAlexaスキルの設定の要となるもの。
- AVSは今回は省略。
- AWSアカウント
- (AWS使いには)おなじみアカウント
- Alexaスキルのバックエンドのリソースを構築・設定するところ。
- 基本はAWS Lambda、EC2/Fargate等でいい感じに処理すればOK。
- AlexaとJSONの受け渡しが出来れば、ぶっちゃけHerokuとかでもOK。
もういよいよAWSじゃないじゃんAlexaスキル
Alexaのスキルは大きく分けて、下記の3つが代表的。
- スマートホームスキル
- 対応機器を操作する為のAlexaスキル
- 要は、声でのリモコン操作
- スキル名(呼び出し名)を言わなくても使える
- 例:テレビつけて、今日の天気は?
- フラッシュブリーフィングスキル
- 在りもののコンテンツを読み上げ/再生する為のAlexaスキル
- RSSをAlexaに読み上げさせたり、音声を再生したり?
- カスタムスキル
- バックエンドにAWS LambdaやWEBサーバなどの処理部分を開発者が用意し、柔軟な動作をするAlexaスキル。
- Alexaスキルを作りこみたい時は、コレ!
- Alexa スキルビルダー対策としてはこの辺の知識が必要なのかな。
カスタムスキルの利用例
カスタムスキル周りでは用語がたくさん出てくるが、用語の示す概念を理解するのが難しい。
実例に即して理解を試みたい。結果としてごちゃついたが……
- ユーザーが「アレクサ、俺の寿司予約くんを起動して、マグロづくしセットを注文して。」とAlexa対応デバイス(Echo)に話しかける
- アレクサ = ウェイクワード
- Alexaを起動させるためのワード。いわゆる「鏡よ鏡」。
- 起動して = 起動フレーズ
- Alexaスキルを起動させるためのワード。後述するスロットや注文フレーズが決まってなくても、起動フレーズさえあればとりあえずAlexaスキルは動く。
- Echoがデバイス内のAlexaに音声を渡す。
- Alexaは文脈を解析し、呼び出し名、呼び出しフレーズとスロットを抽出する。
- 俺の寿司予約くん = 呼び出し名
- Alexaスキルを呼び出す際の名前。スキル名とは別の概念なので、呼び出し名とスキル名は同じでも別でもいい。
- この例でもわかる通り、家族・来客等の前で呼べる名前にしましょう。
- 注文して。 = 呼び出しフレーズ
- マグロづくしセット = スロット
- 呼び出し名に対応するカスタムスキルが以下を行う。
- 呼び出しフレーズに対応するインテント(発話意図)にスロットを渡す。
- インテントは例えばMySushiReserver-Intentと定義する。
- (インテントの)呼び出しフレーズ:例えば予約するんだ、注文してと定義する。
- この設定の場合、呼び出しフレーズ外の内容を言ってもインテントは呼び出されない
- OK例:「マグロづくしセットを予約するんだ」「マグロづくしセットを注文して」
- NG例:「マグロづくしセットを注文するんだ」「マグロづくしセットを頼んで」
- インテントのインテントスキーマ(対話シナリオの定義のようなもの)に、以下を設定する。
- 標準ビルトインインテント
- ストップ、キャンセル、ヘルプなどの一般的なアクション。
- スロットは一部()を除いて非対応。
- 一部=AMAZON.SelectIntent等。スロットの変更は不可。
- カスタムインテント
- スロットを引数として、バックエンドプログラムの関数(dialogue関数?)を呼び出すアクション。
- スロットは名前、タイプ(型)を指定する。
- 定義するのが面倒ならカスタムスロット設定することで、定義していない言葉をいい感じにスロット化する。
- ただ、カスタムスロットはファジーな作りなのでAmazon的には非推奨っぽい?オウム返しスキルとか有名ですが…
カスタムインテントではAlexaから受け取ったJSONを、Lambda等のバックエンドが処理。レスポンスをAlexaへJSONで渡す。
- バックエンドの詳細は割愛。
インテントスキーマに沿ってAlexaが発話する。
ざっくりこんな感じ、カスタムスキルは絵で描かないと大変ね。
おまけ
- 投稿日:2019-11-29T19:33:58+09:00
Lambda+APIGateway設定で「CORS の有効化」をオンにしたのにCORSエラーになる
「CORS の有効化」をオンにしたのに
ハマりポイント
APIGateway設定で「CORS の有効化」をオンにしているのに,
Access to XMLHttpRequest at 'https://xxxxxxx.execute-api.ap-northeast-1.amazonaws.com/xxx/xxxx' from origin 'http://xxxxx' has been blocked by CORS policy: No 'Access-Control-Allow-Origin' header is present on the requested resource.
とエラーが返ってくる.
解決策
Lambdaのreturnのヘッダーに以下のように,Access-Contraolについて書かなきゃダメだった.
return { 'isBase64Encoded': False, "headers": { "Access-Control-Allow-Origin" : "*", "Access-Control-Allow-Credentials": "true" }, 'statusCode': 200, 'body': {} }
- 投稿日:2019-11-29T19:18:09+09:00
Amazonlinux2にgoofys入れてS3をマウントした件
メ〇スは激怒した。普通にgoのインストールもyumでやってみたらバージョンが低いと怒られたのだ。
題名の通り。ちょっと工程往復する羽目になったので作業記録として遺しておく。
下準備
git はgoofys入れるために fuseはgoofysと依存
yum install git fuse -y実作業的な奴
goを入れる
cd /usr/local/src/ wget https://dl.google.com/go/go1.13.4.linux-amd64.tar.gz tar -C /usr/local -xzf /usr/local/src/go1.13.4.linux-amd64.tar.gz~/.bash_profileに書く(めんどう
export GOROOT=/usr/local/go export GOPATH=${HOME}/go export PATH=${PATH}:${GOROOT}/bin export PATH=${PATH}:${GOPATH}/bingoofys入れる
go get github.com/kahing/goofys go install github.com/kahing/goofysさあマウントしよう。ゴールはもうすぐそこだ。
今回はWPのDocumentRootとして使ってみたかったので、
権限とかゆるゆるで作ってみた。goofys -o nonempty -o allow_other --uid=[uid] --gid=[gid] --dir-mode=0775 --file-mode=0664 バケット名 マウントポイント/etc/fstab に記述して再起動後も安心
/root/go/bin/goofys#バケット名 マウントポイント fuse _netdev,allow_other,--dir-mode=0777,--file-mode=0666,--uid=1002,--gid=48 0 0達成されなかった目論見
ファイルのアップロードとか色々やったら一瞬で無料枠が持っていかれた。
多分ヘルスチェックで何回もアクセスされているのもあると思う。結論としては世の人たちがやっているようにWPの静的な一部分だけをS3に落とし込んでやるのが一番よさそうである。
冗長化の際にはお気をつけて。
- 投稿日:2019-11-29T18:15:58+09:00
CloudFormationの nested stack が使いづらい件
一言で言うと 子スタックのチェンジセットが一切見えない ので使いづらい。
いろいろ検索してみたけど日本語の結果が出てこなかったので検索用メモとして。
(こういうときにつけるタグってなんだろう。。。)nested stack1
ネストされたスタックは、他のスタックの一部として作成されたスタックです。
複数のスタックを連携させる方法としては出力値を用いたクロススタック参照2などもあるが、それよりももっと直接にスタックの親子関係を構築する仕組み。
例
以下のような複数のテンプレートがあるときに、
- parent.yaml に対して
aws cloudformation packageを実行する- package処理結果のyamlに対して
aws cloudformation deployを実行するという手順を踏むことで、子テンプレートの内容を含めてまとめて parent.yaml のスタックでリソース管理できる。
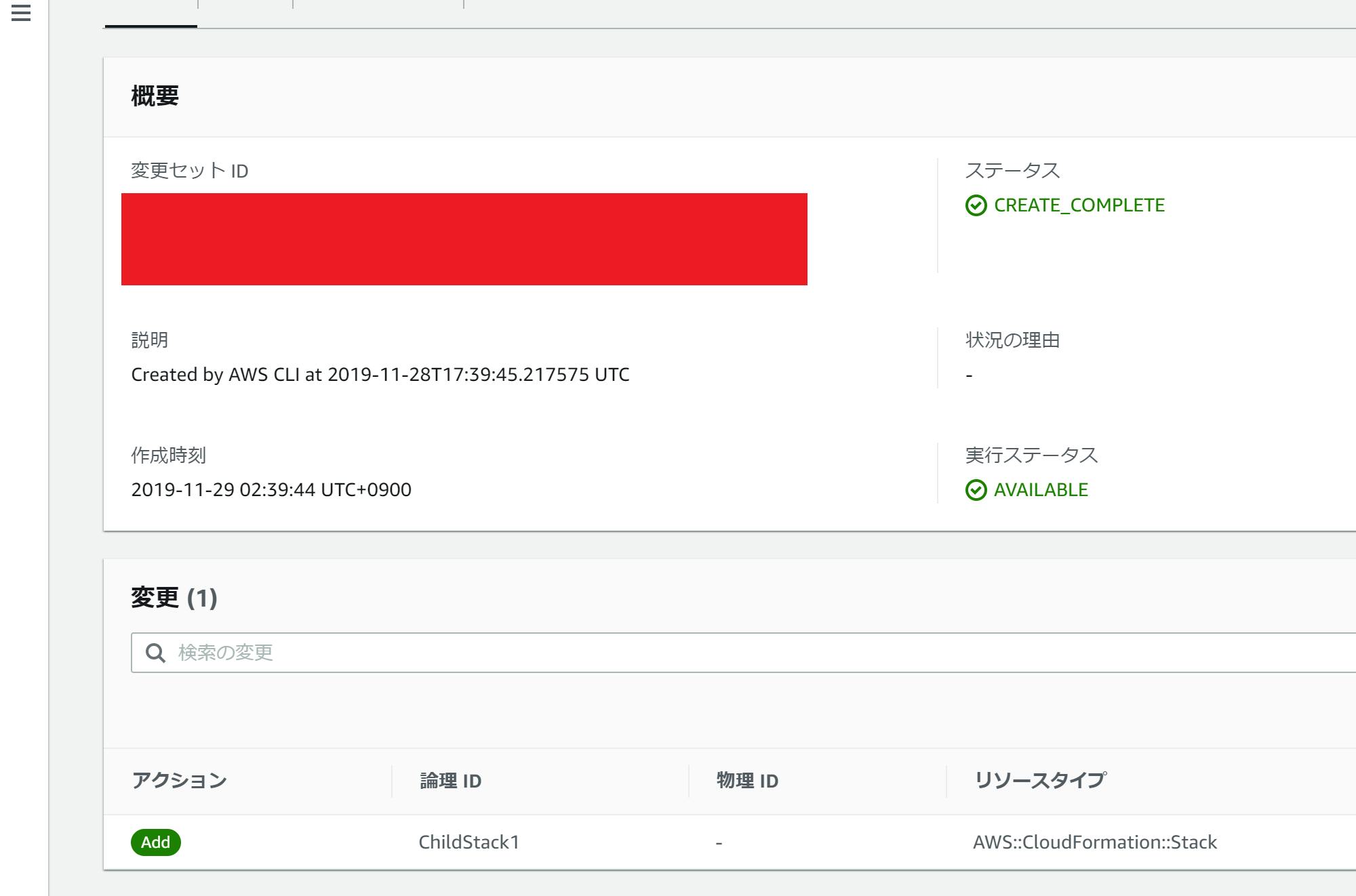
parent.yamlAWSTemplateFormatVersion: 2010-09-09 Description: parent template # 他のスタックをリソースとして定義 Resources: ChildStack1: Type: "AWS::CloudFormation::Stack" Properties: TemplateURL: ./child1.yaml Outputs: Child1Policy: Description: child 1 policy Value: !GetAtt ChildStack1.Outputs.Policy # 子スタックの出力値を参照できる Export: Name: child1-policychild1.yamlAWSTemplateFormatVersion: 2010-09-09 Description: child 1 stack # サンプルとしてIAMポリシーを定義 Resources: SamplePolicy: Type: "AWS::IAM::ManagedPolicy" Properties: Description: SamplePolicy Path: / PolicyDocument: Version: 2012-10-17 Statement: - Effect: Allow Action: lambda:InvokeFunction Resource: "*" Outputs: Policy: Description: child 1 policy Value: !Ref SamplePolicy実行手順# 関連リソースをパッケージング # -- child1.yaml が関連リソースとしてS3へアップロードされる # -- アップ先のバケットは先に用意しておくこと $ aws cloudformation package --template-file parent.yaml \ --s3-bucket sample-bucket-1234567890 \ --output-template-file packaged-parent.yaml # スタックにチェンジセットを作成(まだリソース作成は行わない) $ aws cloudformation deploy --no-execute-changeset \ --template-file packaged-parent.yaml \ --stack-name sample-stackこれを実行すると sample-stackに以下のチェンジセットが作成される。
親スタックからは子スタックが新規リソース(更新時は変更リソース)として扱われる。
問題点
この時点では ChildStack1 の管理スタックはまだ作成されておらず、このチェンジセットを適用すると child1.yaml の内容はチェンジセットなしに直接適用される。
更新についても同様で、aws cloudformation deploy --no-execute-changesetで作成されるチェンジセットで確認できるのは子スタックが変更されるという内容のみで、子のチェンジセット内で何が変更されるかはわからない という状況になる。関連情報
英語圏だと関係しそうな情報が出てきた。
- Change set support for nested stacks? - Discussion Forums
- 3年前に起票されてから対応してほしいという人がちょこちょこ+1している状況
- Using Change Sets with Nested CloudFormation Stacks
- それっぽいタイトルのサイトになっているが、要は子スタックを直接GUIなりCLIから操作すればチェンジセットも作れるという内容
- 現状はそのぐらいがんばならないとできないらしい。。
- 投稿日:2019-11-29T17:52:55+09:00
WafCharmを始めるときに知っておきたいTips
最近WafCharmを導入したのですが、公式以外にあまり情報がなかったので公式サイトに記載がないTipsなどをまとめることにしました。
WafCharmとは何?
WafCharm公式
サイバーセキュリティクラウドが提供する、AWS WAF運用を支援してくれるサービスです。WafCharm自体はWAFではありません。Managed Rulesとも違います。
あくまでAWS WAFの支援サービスなので、利用できるのはAWS WAFに対応しているCloudFront, ALB, API Gatewayのみです。
2019年11月28日時点ではAWS WAF v2に対応しておらず、AWS WAF Classicのみ対応しています。導入の注意
WafCharm以外の費用
WafCharmの利用コスト以外に、
- AWS WAFの利用費用
- CloudFront, ALB, API GatewayアクセスログログのS3保存費用
がかかります。
さらに、攻撃通知メールを受信するために
- Kinesis Data Firehose
- Lambda
を設定する必要があり、こちらも費用がかかります。参考までに1.7億リクエストでKinesis Data Firehoseのコストは25USD程度でした。
AWS WAFに限らず、WAF運用は誤検知や検知漏れの対応が鍵になるため、攻撃通知メールの受信は実質必須といってよいでしょう。導入作業
作業ドキュメントはありますが、自分でCloudFrontやAWS WAF, Kinesisなどの設定が必要です。基本的にAWSを自分で設定できることが導入の前提になります。
Cyber Security Cloud Managed Rules for AWS WAFとの違い
同じサイバーセキュリティクラウドが提供しているCyber Security Cloud Managed Rules for AWS WAFは全く別のサービスで、OWASP Top 10に準拠したAWS WAF v2/Classic対応のマネージドルールです。なお、WafCharmとの共存も可能で、WafCharmのProfessional以上に契約すると、このマネージドルールのサポートも受けられます。
導入
導入方法はマニュアルを参照してください。
攻撃通知や月次の統計情報設定方法は契約者向けページに記載されているので、ここではリンクしません。Tips
ACLセットはまとめるべきか?
ACLセットはリージョン単位(CloudFront用ACLはus-east-1(バージニア北部)扱い)で使い回せます。ACLセットごとにAWS WAF, WafCharmそれぞれ課金が発生するので、なるべく使い回したいところ。
現在はサービスごとに1ルールにまとめて運用しています。(本番環境、ステージング環境などすべて1ルール)脆弱性診断との兼ね合い
WafCharmがブロックモードになっている場合、脆弱性診断を行ってもブロックされてしまい、アプリケーションに脆弱性があるかどうか調べられません。
しかし仮に脆弱性が見つかった場合、WAFでブロックされることの確認が必要です。そこで基本的に脆弱性診断環境はWAFを設定せず、脆弱性が見つかった場合は有効化して攻撃がブロックされることを調べる方針にしています。攻撃通知と誤検知の対応
WAFによくある現在の攻撃ステータスをリアルタイム表示する機能はありません。月次レポート表示はできますが、月単位で更新されるためリアルタイム性はありません。
リアルタイムな攻撃通知はメール通知で行われます。
メール通知はアカウント登録時に使ったメールアドレスに送られ、他のアドレスに送信したり複数アドレスに送信する機能はありません。(近日実装予定だそうです)
そのため、メール送信でSlackに通知することなどはできません。ACLごとに別のアドレスに通知することもできません。このあたりは今後の開発に期待したいところ。ルールの更新
WAF運用で一番大変なルールのチューニングは、アクセスログを分析して自動的に行われます。誤検知があれば、サポートに連絡することで修正してもらえます。幸い今のところ誤検知は起きていませんが。
ルールのチューニングは概ね1日ごとに行われるそうですが、通知はありません。更新を確認したい場合はCloudTrailが使えます。
- 投稿日:2019-11-29T16:50:57+09:00
Azure ADでSAML認証してAWSCLIを実行する方法
概要
- セキュリティポリシーでIAM Userの作成/使用が原則禁止されている現場ってありますよね?
- AWSのAPIKey流出事故は何度も見聞きしているので、IAMUser作成を禁止するのは理解できます。
- IAMUserを使わずにログインする方法の一つとして、AzureAD経由でSAML認証する方法があります。
- AzureAD側でMFAログインを必須化することもできて、とてもセキュアな設計なのですが、AWS CLIを使うのにひと手間かかります。
- 今回はその手間を省くツールaws-azure-loginを見つけたので、使い方をメモしておきます。
インストール方法
$ npm install -g aws-azure-login
- インストールは簡単ですね。
初期設定の手順
$ aws-azure-login --configure --profile <profile_name>
- READMEに書いてある通り設定していきます。
Configuring profile '<profile_name>' ? Azure Tenant ID:
- いきなりつまずきます。
Azure Tenant IDとはなんぞや?トラブルシューティングのためにブラウザで SAML レスポンスを表示する方法を参考にSAMLレスポンスを抜き出してみました。
レスポンスの中にそれらしき値を発見
<Attribute Name="http://schemas.microsoft.com/identity/claims/tenantid"><AttributeValue>xxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxx</AttributeValue>↑のAttributeValueを入力します。
? Azure App ID URI:
- 今度は
Azure App ID URIを聞かれます。Azure側のなにかのURLかと思いましたが、MSが提供しているドキュメントによると、https://signin.aws.amazon.com/samlを設定すべしと書いてあります。なんだAWSのサインインURLのことだったのですね。ということで↑のURLを入力します。? Default Username:
- AzureADにログインするユーザ名を入力します。
? Default Role ARN (if multiple):
- Role ARNを聞かれます。SAML認証用のIAMRoleのARNを入力します。例:
arn:aws:sts::<account_id>:assumed-role/<role_name>? Default Session Duration Hours (up to 12): (1)
- セッションの有効期間を聞かれますので、入力します。
ログイン手順
$ aws-azure-login --profile <profile_name>
- PassWord, MFA-token等を聞かれるので、よしなに入力してください。
- 先の手順でUserName等にはデフォルト値が登録されていると思います。
AWSCLI実行
$ aws s3 ls --profile <profile_name>
- これでAWSCLIを実行できるはずです

参考資料
- 投稿日:2019-11-29T15:35:13+09:00
VS Code で AWS Lambda のローカルデバッグを行う方法
VS Code で AWS Lambda のローカルデバッグを行う方法
この記事はSRA Advent Calendar 2019の12月4日の記事です。
こんにちは、2019年入社の産業第2事業部の羽田です。
初のQiita投稿です。
VScodeを使用したAWS Lambdaのローカルデバッグは
記事がほかにもありますが、
個人的に詰まったところがあったので作成しました。はじめに
AWS Lambda をローカル環境(VScode)でデバッグ操作ができるようにします。
- ブレークポイント設定、ステップ実行など
以下公式
AWS Toolkit for Visual Studio Code は、Visual Studio Code 用のオープンソースプラグインで、アマゾン ウェブ サービス上でのアプリケーションの作成、デバッグ、デプロイを容易にします。AWS Toolkit for Visual Studio Code を使用すると、AWS 上での Visual Studio Code を使用したアプリケーションの構築をより迅速に開始でき、生産性が向上します。このツールキットは、使用開始のサポート、ステップ実行によるデバッグ、および IDE からのデプロイを含む、サーバーレスアプリケーションの統合開発環境を提供します。
必須
- AWS アカウント
- 使用するサービスに対する権限を持つ
- Lambda,S3とか
- Toolkit fot VScode
- Windows,macOS.linux をサポートしている
- VScode のバージョン 1.31.1 以上
使用可能言語
- 以下三種の言語を使用可能
- .NET SDK: https://dotnet.microsoft.com/download
- Node.js SDK: https://nodejs.org/en/download
- 今回はこれを選択
- Python SDK: https://www.python.org/downloads
オプション(実質必須)
- AWS SAM CLI
- 無くても toolkit はインストールできるが、サーバレスアプリケーションには必須
- Docker
- AWS SAM CLI に OSS コンテナプラットフォームが必要
- 詳細は下記のダウンロードの説明に
AWS SAM CLI と Docker のインストール方法(windows)
公式ドキュメントに従ってAWS SAM CLI と Dockerのインストールを行う
以下参照 (公式ドキュメント)
https://docs.aws.amazon.com/ja_jp/serverless-application-model/latest/developerguide/serverless-sam-cli-install-windows.htmlAWS Toolkit for VScode インストール
- vscode エディタを開く
- アクティヴィティバー>拡張機能>マーケットを開く
- AWS Toolkit for VScode で検索
- インストールし、エディタを再起動
VScode の configure
- VScode から AWS のリソースにアクセスできるように Credential を流し込む
- コマンドパレットを開く
- windows>Ctrl + Shift + P
- AWS で検索
- AWS:Create Credentials Profile を選択
- name,ID,PassWord を入力
アプリケーションをデバッグするまでのステップ
- コマンドパレットを開く
- AWS で検索
- AWS: Create new AWS SAM Application を選択
- Node10.x を選択
- 保存先のローカルフォルダとアプリケーション名を入力
ローカルにアプリケーションが作成されているので選択
- フォルダ内の app.js を開く
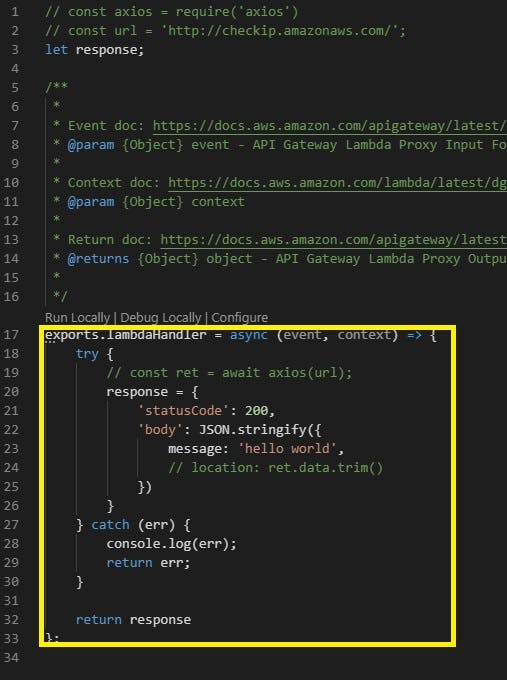
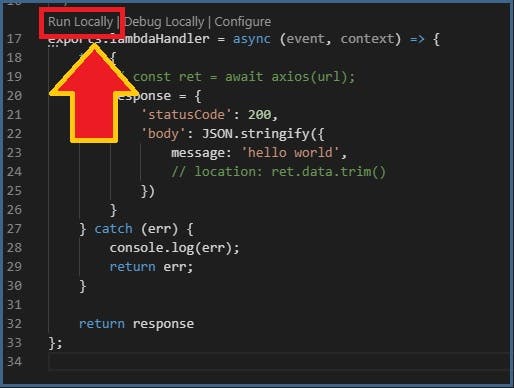
lambda を編集
- 以下黄色枠はデフォルトで書かれているもの
- ここを消して Lambda 関数を書く
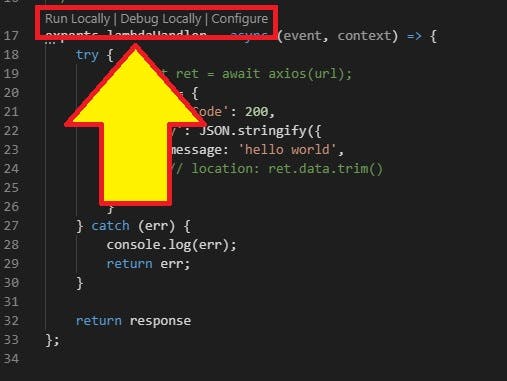
17 行目あたりにRun Locally|Debug Loccally|Condigure
Run Locally を選択
- ローカルで lambda の実行ができる
Debug Locally を選択
- ローカルでデバッグできる
補足
- ローカルで作成し、AWS上にデプロイできます。
デプロイ用のS3バケットを用意する必要があります。
以下公式ドキュメント
数回のクリックでサーバーレスアプリケーションをデプロイします。
参考
- AWS Toolkit for Visual Studio Code (開発者向けプレビュー版) が マーケットプレイスからインストールできるようになったので、もう、コンパイルしなくてもレビューできます〜\(^o^)/

- 投稿日:2019-11-29T15:29:40+09:00
VS Code で AWS Lambda のローカルデバッグを行う方法
VS Code で AWS Lambda のローカルデバッグを行う方法
この記事はSRA Advent Calendar 2019の12月4日の記事です。
こんにちは、産業第2事業部の羽田です。
初のQiita投稿です。
はじめに
AWS Lambda をローカル環境(VScode)でデバッグ操作ができるようにします。
- ブレークポイント設定、ステップ実行など
以下公式
AWS Toolkit for Visual Studio Code は、Visual Studio Code 用のオープンソースプラグインで、アマゾン ウェブ サービス上でのアプリケーションの作成、デバッグ、デプロイを容易にします。AWS Toolkit for Visual Studio Code を使用すると、AWS 上での Visual Studio Code を使用したアプリケーションの構築をより迅速に開始でき、生産性が向上します。このツールキットは、使用開始のサポート、ステップ実行によるデバッグ、および IDE からのデプロイを含む、サーバーレスアプリケーションの統合開発環境を提供します。
必須
- AWS アカウント
- 使用するサービスに対する権限を持つ
- Lambda,S3とか
- Toolkit fot VScode
- Windows,macOS.linux をサポートしている
- VScode のバージョン 1.31.1 以上
使用可能言語
- 以下三種の言語を使用可能
- .NET SDK: https://dotnet.microsoft.com/download
- Node.js SDK: https://nodejs.org/en/download
- 今回はこれを選択
- Python SDK: https://www.python.org/downloads
オプション(実質必須)
- AWS SAM CLI
- 無くても toolkit はインストールできるが、サーバレスアプリケーションには必須
- Docker
- AWS SAM CLI に OSS コンテナプラットフォームが必要
- 詳細は下記のダウンロードの説明に
AWS SAM CLI と Docker のインストール方法(windows)
公式ドキュメントに従ってAWS SAM CLI と Dockerのインストールを行う
以下参照 (公式ドキュメント)
https://docs.aws.amazon.com/ja_jp/serverless-application-model/latest/developerguide/serverless-sam-cli-install-windows.htmlAWS Toolkit for VScode インストール
- vscode エディタを開く
- アクティヴィティバー>拡張機能>マーケットを開く
- AWS Toolkit for VScode で検索
- インストールし、エディタを再起動
VScode の configure
- VScode から AWS のリソースにアクセスできるように Credential を流し込む
- コマンドパレットを開く
- windows>Ctrl + Shift + P
- AWS で検索
- AWS:Create Credentials Profile を選択
- name,ID,PassWord を入力
アプリケーションをデバッグするまでのステップ
- コマンドパレットを開く
- AWS で検索
- AWS: Create new AWS SAM Application を選択
- Node10.x を選択
- 保存先のローカルフォルダとアプリケーション名を入力
- ローカルにアプリケーションが作成されているので選択
- フォルダ内の app.js を開く
- lambda を編集
- 以下黄色枠はデフォルトで書かれているもの
- ここを消して Lambda 関数を書く
- 17 行目あたりにRun Locally|Debug Loccally|Condigure
- Run Locally を選択
- ローカルで lambda の実行ができる
- Debug Locally を選択
- ローカルでデバッグできる
補足
- ローカルで作成し、AWS上にデプロイできます。
デプロイ用のS3バケットを用意する必要があります。
以下公式ドキュメント
数回のクリックでサーバーレスアプリケーションをデプロイします。
参考
- AWS Toolkit for Visual Studio Code (開発者向けプレビュー版) が マーケットプレイスからインストールできるようになったので、もう、コンパイルしなくてもレビューできます〜\(^o^)/
- 投稿日:2019-11-29T14:47:58+09:00
【随時追記】AWS 認定ソリューションアーキテクト – アソシエイトのメモ
AWS 認定ソリューションアーキテクト – アソシエイト を取得するための勉強メモ。
AWS 認定ソリューションアーキテクト – アソシエイトの出題範囲
試験範囲 比率 分野1: 回復性の高いアーキテクチャを設計する 34% 分野2: パフォーマンスに優れたアーキテクチャを定義する 24% 分野3: セキュアなアプリケーションおよびアーキテクチャを規定する 26% 分野4: コスト最適化アーキテクチャを設計する 10% 分野5: オペレーションエクセレンスを備えたアーキテクチャを定義する 6% 分野1: 回復性の高いアーキテクチャを設計する
- 信頼性と回復性の高いストレージを選択する
- AWS サービスを使用した分離機構を設計する方法を定義する
- 多層アーキテクチャソリューションを設計する方法を定義する
- 可用性またはフォルトトレラント性 (あるいはその両方) が高いアーキテクチャを設計する 方法を定義する
分野2: パフォーマンスに優れたアーキテクチャを定義する
- パフォーマンスの高いストレージとデータベースを選択する
- キャッシュを使用してパフォーマンスを向上させる
- 伸縮性と拡張性を備えたソリューションを設計する
分野3: セキュアなアプリケーションおよびアーキテクチャを規定する
- アプリケーション層をセキュリティ保護する方法を定義する
- データをセキュリティ保護する方法を定義する
- 単一のVPCアプリケーション用ネットワークインフラストラクチャーを定義する
分野4: コスト最適化アーキテクチャを設計する
- コスト最適化ストレージを設計する方法を定義する
- コスト最適化コンピューティングを設計する方法を定義する
分野5: オペレーショナルエクセレンスを備えたアーキテクチャを定義する
- オペレーションエクセレンスを実現するソリューションの設計特性を選択する
AWSの仕組み
- AWSはインフラやアプリ開発に必要な機能がオンデマンドのパーツサービスとして提供されている
- インフラやシステム機能をブロックパーツのように、オンライン上で組み合わせて好きな構成をつくることができる
アンマネージド型とマネージド型
アンマネージド型
スケーリング/耐障害性/可用性を利用者側で設定し、管理する必要がある。
- メリット
- 設定が柔軟に可能
- デメリット
- 管理が面倒
マネージド型
スケーリング/対障害性/可用性がサービスに組み込ませており、AWS側で管理されている
- メリット
- 管理が楽
- デメリット
- 設定が限定的
AWSのグローバルインフラ構造
リージョン > アベイラビリティゾーン > エッジロケーション
AWSマネジメントコンソール
AWSマネジメントコンソールはWeb画面からAWSを設定できるGUIツール
インスタンス接続
設置したインスタンス(サーバー)の操作はWindowsサーバーやLinuxサーバーなどの標準に準じたソフトウェアを利用
基本操作
AWSの設定・操作は、まずマネジメントコンソールでインスタンス等を設置し、SSHで接続して操作するのが基本。
AWS CLI
コマンドラインからAWSを制御・管理することができる。
- 投稿日:2019-11-29T14:15:34+09:00
AWSでドキュメントサイトを最速で公開する方法。自動デプロイもあるよ!
Global Mobility Service株式会社でインフラエンジニアをしているodaです。
Global Mobility Serviceのアドベントカレンダーの1日目です。当社のインフラ環境では、AWSを全面的に採用しています。
先日、ユーザ向けにドキュメントサイトを公開しました。
このドキュメントサイトをどのように構築したかを紹介したいと思います。概要
- ドキュメント作成にはMkDocsを使い、Markdownで静的サイトを作成する
- S3とCloudFrontで静的サイトを公開する
- ドキュメントのリポジトリにはGitHubを利用する
- ドキュメントの変更のたびにCodeBuildで最新のドキュメントをデプロイする
MkDocsを使う
MkDocsはMarkdownでドキュメントサイトを作成可能な静的サイトジェネレーターです。
https://www.mkdocs.org/インストール
pipでインストールします。
$ pip install mkdocsまたはbrewでもインストール可能です。
$ brew install mkdocsプロジェクト作成
MkDocsをインストールすると、
mkdocsコマンドが使えます。
プロジェクトを作成します。$ mkdocs new my-project $ cd my-project
docsディレクトリにMarkdownファイルを作成して、ドキュメントを作ることができます。ローカルで動作確認
ローカルで開発用のサーバを立ち上げて、動作を確認することができます。
$ mkdocs serve静的サイトのエクスポート
Markdownで書いた内容をhtml等の静的コンテンツにして、エクスポートできます。
$ mkdocs buildデフォルトだと、
siteディレクトリに静的コンテンツが作成されます。S3に静的コンテンツを配置する
S3のバケットを作成します。
$ BUCKET_NAME=hi1280-project $ aws s3api create-bucket --bucket ${BUCKET_NAME} --region us-east-1静的コンテンツをS3に配置します。
siteディレクトリに静的コンテンツがあるので、S3のバケットとローカルのディレクトを同期するコマンドでコンテンツを配置しています。$ aws s3 sync site s3://${BUCKET_NAME}ルートディレクトリ、サブディレクトリに配置されたindex.htmlを表示するために、静的ウェブサイトホスティングを有効にします。
$ aws s3 website s3://${BUCKET_NAME} --index-document index.htmlS3のバケットをパブリックでアクセス可能にします。
$ cat << EOF > public.json { "Version": "2012-10-17", "Id": "PublicRead", "Statement": [ { "Sid": "ReadAccess", "Effect": "Allow", "Principal": "*", "Action": "s3:GetObject", "Resource": "arn:aws:s3:::${BUCKET_NAME}/*" } ] } EOF $ aws s3api put-bucket-policy --bucket ${BUCKET_NAME} --policy file://public.jsonCloudFrontで公開する
CloudFrontのリソースを作成する
CloudFrontからS3による静的ウェブサイトホスティングのURLを参照します。
S3のバケットを直接参照するとルート指定でindex.htmlが表示できないので注意が必要です。$ aws cloudfront create-distribution --origin-domain-name ${BUCKET_NAME}.s3-website-us-east-1.amazonaws.comサイトを表示する
CloudFrontのドメイン名にアクセスします。
ちゃんと表示されてます!
この時点のソースをGitHubのリポジトリにPushしておきます。
CodeBuildでデプロイする
CodeBuildのプロジェクト作成
設定が必要な箇所のみを示します。その他の項目はデフォルトの設定で作成しています。
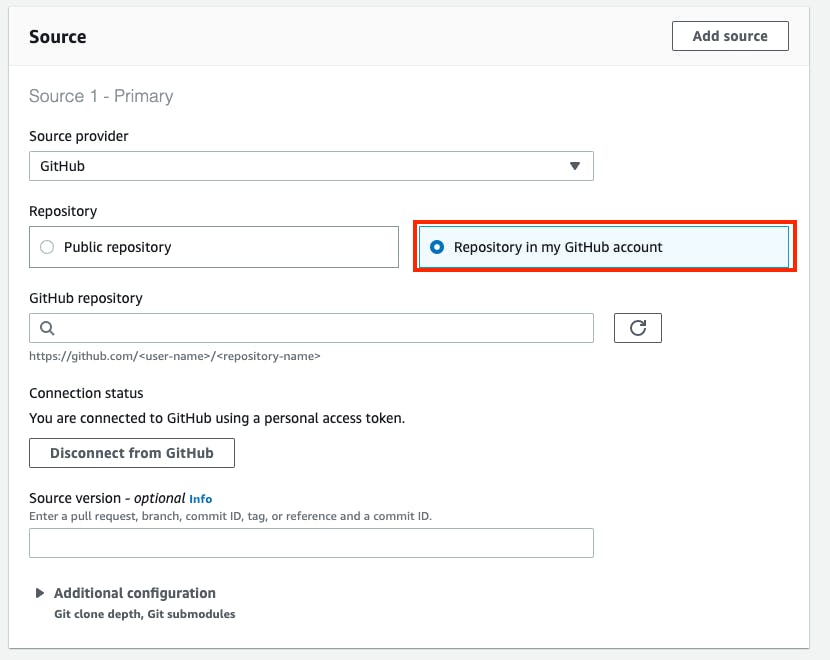
GitHubアカウントとの接続を行います。
詳細は以下にあります。
https://docs.aws.amazon.com/ja_jp/codebuild/latest/userguide/sample-access-tokens.html
リポジトリが変更されるたびにビルドを実行するように設定します。
この後のbuildspecでPythonのランタイムを使いたいので、Amazon Linux 2 standard image 1.0を指定します。
buiidspecファイルの用意
buildspecファイルはCodeBuildの実行内容を決めるファイルです。
プロジェクトの直下にこのファイルを作成して、リポジトリにPushします。buildspec.ymlversion: 0.2 phases: install: runtime-versions: python: 3.7 pre_build: commands: - pip install --upgrade pip - pip install mkdocs build: commands: - mkdocs build - aws s3 sync --delete site s3://hi1280-project - aws cloudfront create-invalidation --distribution-id E2XXXXXX --paths '/*'
aws s3 syncに--deleteオプションをつけることで、同期元にないファイルは同期先でも削除されます。
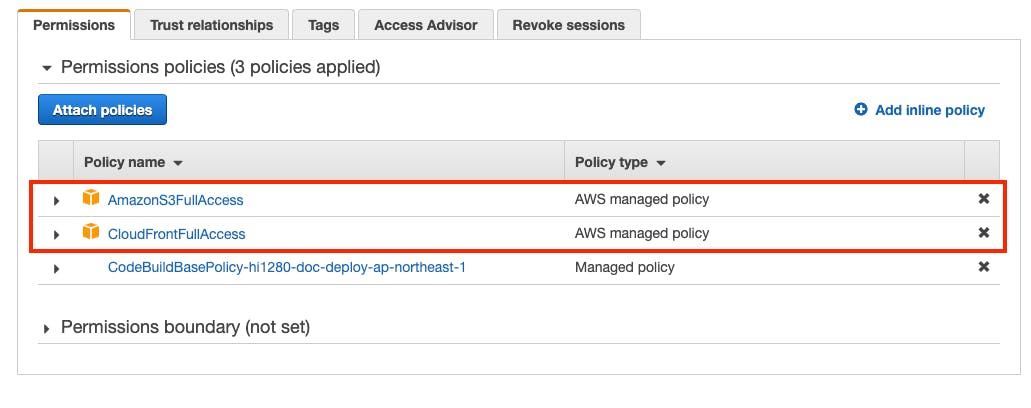
aws cloudfront create-invaidationで、CloudFrontのキャッシュを削除して、最新のドキュメントが直ぐに反映されるようにしています。CodebuildのIAMロールに権限を設定
CodeBuildのプロジェクト作成時に、CodeBuild向けのIAMロールが作られています。
CodeBuildのビルドではS3とCloudFrontにアクセスするので、IAM権限を設定します。
完成
これ以降はリポジトリの変更のたびにドキュメントがデプロイされます。
この方法の良いところ
AWSを使うことでAWS上の様々なサービスとの連携が可能になります。
Lambda@Edge
CloudFrontにはLambda@Edgeがあります。
これはCloudFrontから静的コンテンツへのHTTPリクエストやレスポンスの間にLambda関数を実行できる機能です。今回のドキュメントサイトを構築するにあたり、限られたユーザのみからアクセスを可能にするために認証機能が必要でした。
Lambda@Edgeを使用することで静的サイトのコンテンツを変更することなく、認証機能を追加できました。以下の例にあるようにLambda@Edgeは様々な利用が可能です。
https://docs.aws.amazon.com/ja_jp/AmazonCloudFront/latest/DeveloperGuide/lambda-examples.htmlまとめ
最速かどうかは正直よく分からないですが、気軽にドキュメントサイトを公開できたと思います。
AWSをメインのインフラとして使用している場合には参考にしてもらえればと思います。
今回はMkDocsについてあまり触れませんでしたが、簡単に使えて機能も豊富な静的サイトジェネレーターなのでこちらもオススメです。おわりに
Global Mobility SerivceではAWSを使い倒したいエンジニアを募集しています。
明日のアドベントカレンダーの担当は期待の新星Shirubaさんです。



- 投稿日:2019-11-29T13:18:33+09:00
AWSからS3にデータをダウンロードするときの個人的メモ(その他ファイル操作に関しても)
S3からローカルにデータを引っ張ってくる
1.準備
AWS CLIをインストール。
参考- AWS CLI 公式ドキュメントインストール後、
aws configureを打ち、設定を行う。aws configure AWS Access Key ID [None]: AMIアクセスキーを入力 AWS Secret Access Key [None]: AMIシークレットキーを入力 Default region name [None]: S3バケットの利用しているリージョンを記入(ap-northeast-1など) Default output format [None]: 利用するフォーマットを入力(適当でいい?text jsonなど)2. 作業
AWS S3バケットからデータをダウンロードする。
aws s3 cp s3://バケット名/... /ローカルで保存したい場所`aws s3 cp s3://bucket-name/log/access.log /local/directory/access.logダウンロードが開始され、保存が完了する。
トラブルなど
EC2からS3(S3からEC2)へ上記を行う際、"An error occurred (AccessDenied) when calling the GetObject operation: Access Denied"と表示され、ダウンロードできない。
EC2に割り当てられているIAMロールのポリシー設定にて、ファイルの操作(GetObject, PutObjectなど)が許可されていない可能性が高いです。
手順:
AWSマネジメントコンソールからEC2に入り、該当するEC2インスタンスを選択。
画面下に表示されている「説明」タブの中に「IAM ロール」に割り当てられているロール名をクリック。
「アクセス権限」タブ→「Permissions policies 」→ポリシー名(前ページのロール名}をクリックし、「サービス」の中から「S3」をクリック。
こちらを参考に、実行したいアクションを許可する。最後に
今回の作業に関して、こちらの記事を参考にさせていただきました。
Amazon S3にGUI・CLIでファイルをアップロード・ダウンロードする方法
- 投稿日:2019-11-29T12:41:33+09:00
PWA+Angular8+AWS amplifyを試す PART#1
きっかけ
最近話題のPWAを試してみようと思い、メモを兼ねてQiitaへの投稿を始めてみた。
本業は組込みシステムのソフトウェアに携わっており、WEB系は初心者です。
初心者ながら少しずつ成長する姿を見守っていただければ幸いです。
アドバイス等頂けると助かります。PART1
・Angularの雛形を作る
・angular/cliをインストール
・ブラウザに表示されるかテスト環境
_ _ ____ _ ___ / \ _ __ __ _ _ _| | __ _ _ __ / ___| | |_ _| / △ \ | '_ \ / _` | | | | |/ _` | '__| | | | | | | / ___ \| | | | (_| | |_| | | (_| | | | |___| |___ | | /_/ \_\_| |_|\__, |\__,_|_|\__,_|_| \____|_____|___| |___/ Angular CLI: 8.3.20 Node: 12.13.1 OS: win32 x64 Angular: 8.2.14 ... animations, common, compiler, compiler-cli, core, forms ... language-service, platform-browser, platform-browser-dynamic ... router Package Version ----------------------------------------------------------- @angular-devkit/architect 0.803.20 @angular-devkit/build-angular 0.803.20 @angular-devkit/build-optimizer 0.803.20 @angular-devkit/build-webpack 0.803.20 @angular-devkit/core 8.3.20 @angular-devkit/schematics 8.3.20 @angular/cli 8.3.20 @ngtools/webpack 8.3.20 @schematics/angular 8.3.20 @schematics/update 0.803.20 rxjs 6.4.0 typescript 3.5.3 webpack 4.39.2Visual studio code/1.40.1を使用しています。
Angularの雛形を作る
md angular-pwa cd angular-pwaangular/cliをインストール
npm i @angular/ci今回はローカル環境にangular/cliをインストールする。
ローカルインストールの為、-gを付けないng newでangular雛形を作成
npx ng new angular-pwa --directory=./ --routing=true --style=scssプロジェクトフォルダは先に作成しているので、--directoryオプションでインストール先をカレントに指定する。
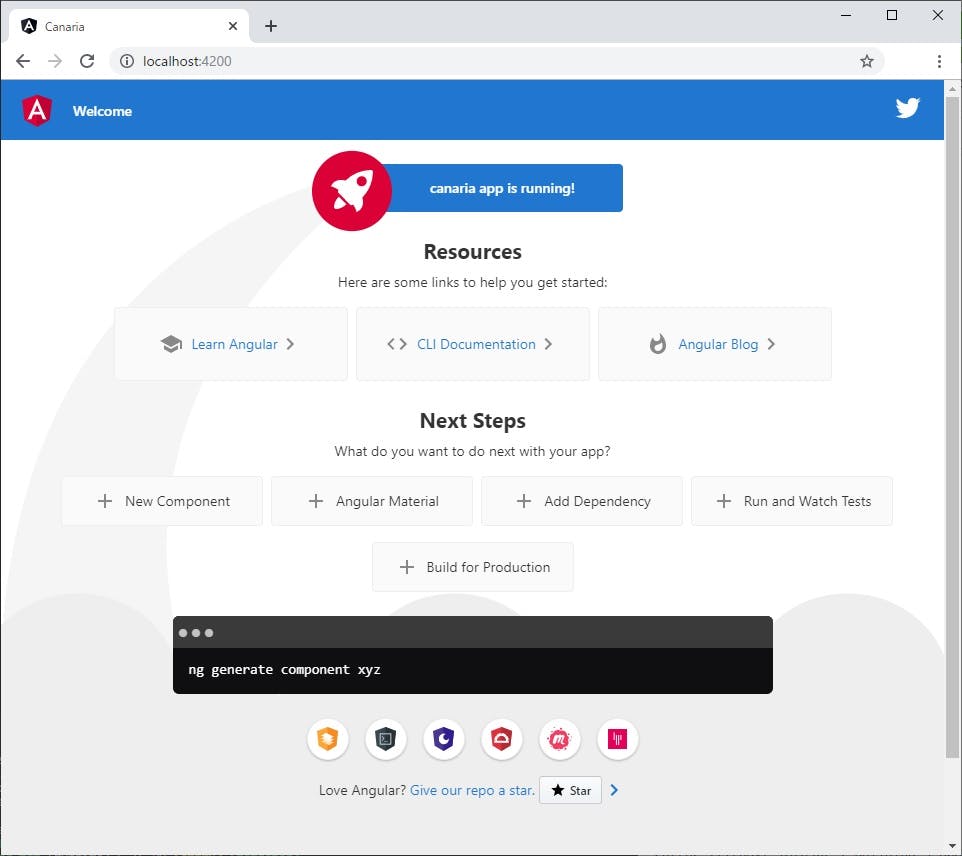
--routing, styleオプションはお好みで。ブラウザに表示されるかテスト
npx ng servehttp://localhost:4200/にアクセスして以下のような表示になれば成功。
次回
今回は、angularのインストールから動作確認まで行いました。
次回は作成したプロジェクトをgithubにレポジトリを作成して管理します。
- 投稿日:2019-11-29T11:50:42+09:00
既存EC2インスタンスにAWS Cloud9を構築する
前提条件
- EC2 インスタンスが既に構築済み
- 対象インスタンスのセキュリティグループを変更可能(運用的に)
- EC2に外部IPがある
- regionが東京である(東京ではない場合、22portを許可する帯域を調べる必要がある)
- 踏み台を使って構築することも可能だが今回は行わない
手順
- EC2のセキュリティグループに18.179.48.128/27,18.179.48.96/27を22portに対して許可
- AWS Cloud9にアクセスする
- 「Create environment」を押す
- 適当なNameとDescriptionを入れてNextStep
- 「Connect and run in remote server (SSH)」を選択し、「View public SSH key」をクリックして表示される公開鍵を対象のEC2インスタンスの/home/{User}/.ssh/authorized_keysに追加する
- 「User」「Port」に適切な値を入力し、「Host」にGIPを入力する
- 「Next Step」を押し、内容に間違いないことを確認したら「Create environment」でcloud9構築準備完了。画面で進捗が確認できます。
Appendix
作成したユーザ以外からアクセスできるようにする
- cloud9にログインし、右上の「Share」をクリック
- 「Invite Members」の欄にIAM User名を入力して「Invite」ボタンを押す
- 投稿日:2019-11-29T10:35:15+09:00
AWSで開発環境自動構築とslackからのデプロイを実現した話
本記事はサムザップ #1 Advent Calendar 2019の初日の記事です。
ゲーム開発においてどんな環境で開発を行っているのかを少し紹介できたらなと思います。本題に入る前に
初日の投稿ということで少し会社のことを紹介させていただきます。
私の所属しているサムザップは2009年に設立した会社で、サイバーエージェントの子会社になります。スマートフォンゲームの企画・運営・配信事業を行っている会社で、先日このファン
の事前登録を開始しました。興味がありましたらぜひ登録お願いします。私自身は現在SREチームに所属しており、システムの構築・改善・効率化などを主に行っております。
ということで前置きはこのくらいにして
早速....
タイトルで上げている内容に移っていきます。前提
・ インフラ歴2半年
・ GCP歴2年
・ 新規プロジェクト始動時にアサイン
・ AWSは今回初挑戦!!
・ 基本的にterraformで構築
・ 実装期間(作業時間ベース)2週間くらい目指したこと
・ とりあえずコンテナ使いたいよね
・ 2017年のアドベントカレンダーでAWSちょっとさわった時のノウハウを使う
・ なるべくコストは抑えたい(みんなそうだよね)
・ 今どきっぽいデプロイしたいよね構築したデプロイの流れ
今回作成したデプロイシステムは主に2種類あります。
1. gitへのpushを契機に開発環境を自動生成
2. slackから固定環境へのデプロイ
1.のシステム
まず1. のシステムから説明してきます。
今回はデプロイ周りをメインに紹介したいので、各リソースの作成は予め行っている前提で話を進めます。
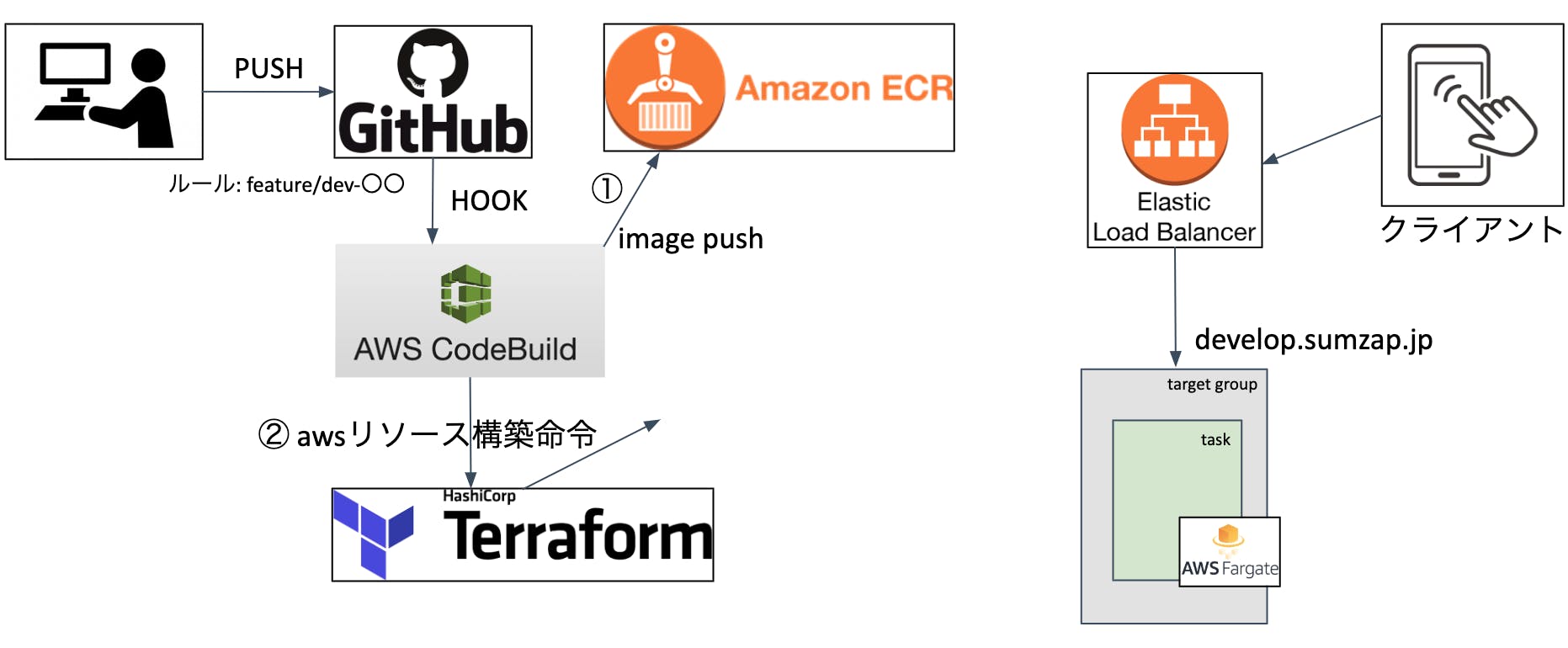
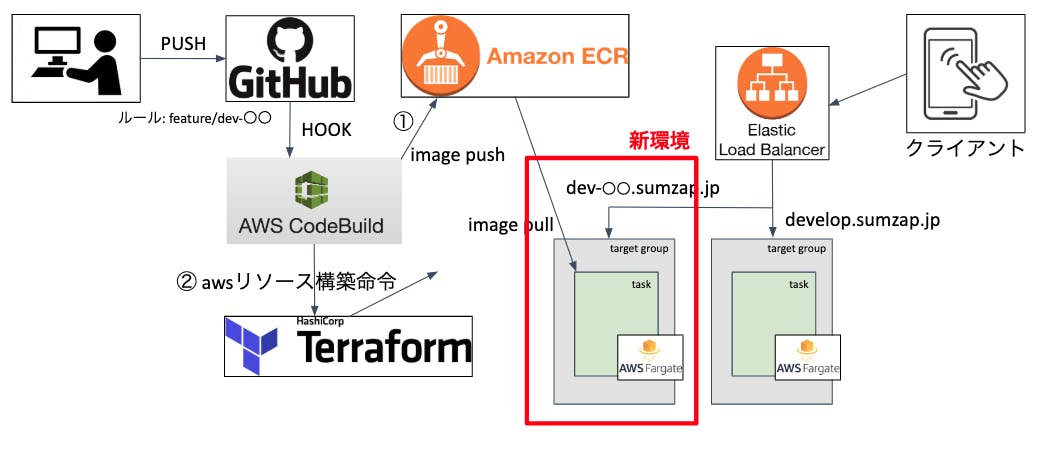
開発環境の構成は下記の図のようになっています。
構成だけ見るとめっちゃシンプルですね上記環境に対してデプロイを行う処理の流れは以下です。
↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
1-1. githubへの特定リポジトリの特定ブランチ(feature/dev-〇〇)をCodeBuildでhook。
1-2. 特定ブランチ内のbuildspec.ymlを読み込んでユニットテスト実行
1-3. ユニットテストが成功したらイメージを作成
1-4. 作成されたイメージをECRにPUSH
1-5. DBの作成とマイグレーション
1-6. TerraformでLBのターゲットグループとFargateのサービスを作成※ DBは予めAuroraを1クラスター立てておき、その中でブランチ名をサフィックスにしてDBを作成しています。
※ Cacheは予めElastiCacheを1クラスター立てておき、キャッシュキーにブランチ名をサフィックスとして保存しています。
2.の構成
次に2. のシステムを説明します。
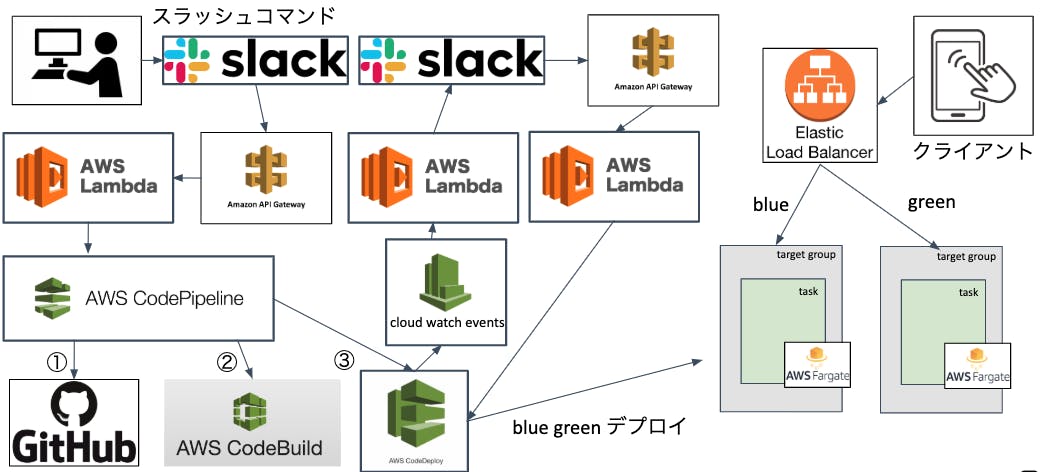
デプロイを行う環境自体は1.の構成と変わりありませんが、別環境を用意します。デプロイを行う処理の流れは以下です。
図がカオス2-1. slackからスラッシュコマンドを発行
2-2. API Gateway①を通してLambda①を起動
2-3. Lambda①が対象のCodePipelineを起動
2-4. CodePipelineがgithubからソースを取得
2-5. ソースの取得が終わったらCodeBuildを起動し、イメージ作成+ECRへPUSH
(ここでDBのマイグレーションも行っている)
2-6. イメージの作成が終わったらCodeDeployが起動しBlue Greenデプロイ開始
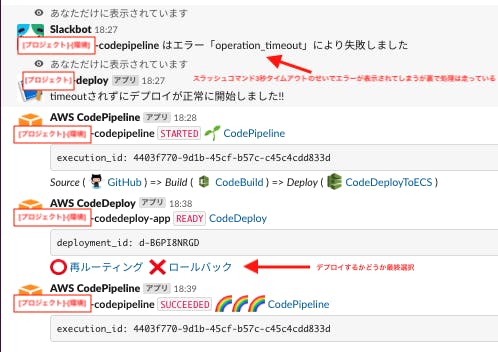
2-7. 再ルーティング待ち状態をCloud Watch Eventsで拾ってLambda(2)を起動
2-8. Lambda②からslackに通知
2-9. デプロイが正しいかテストを行い「再ルーティング」か「ロールバック」かを選択
2-10. 選択結果をAPI Gateway②が拾いLambda③を起動
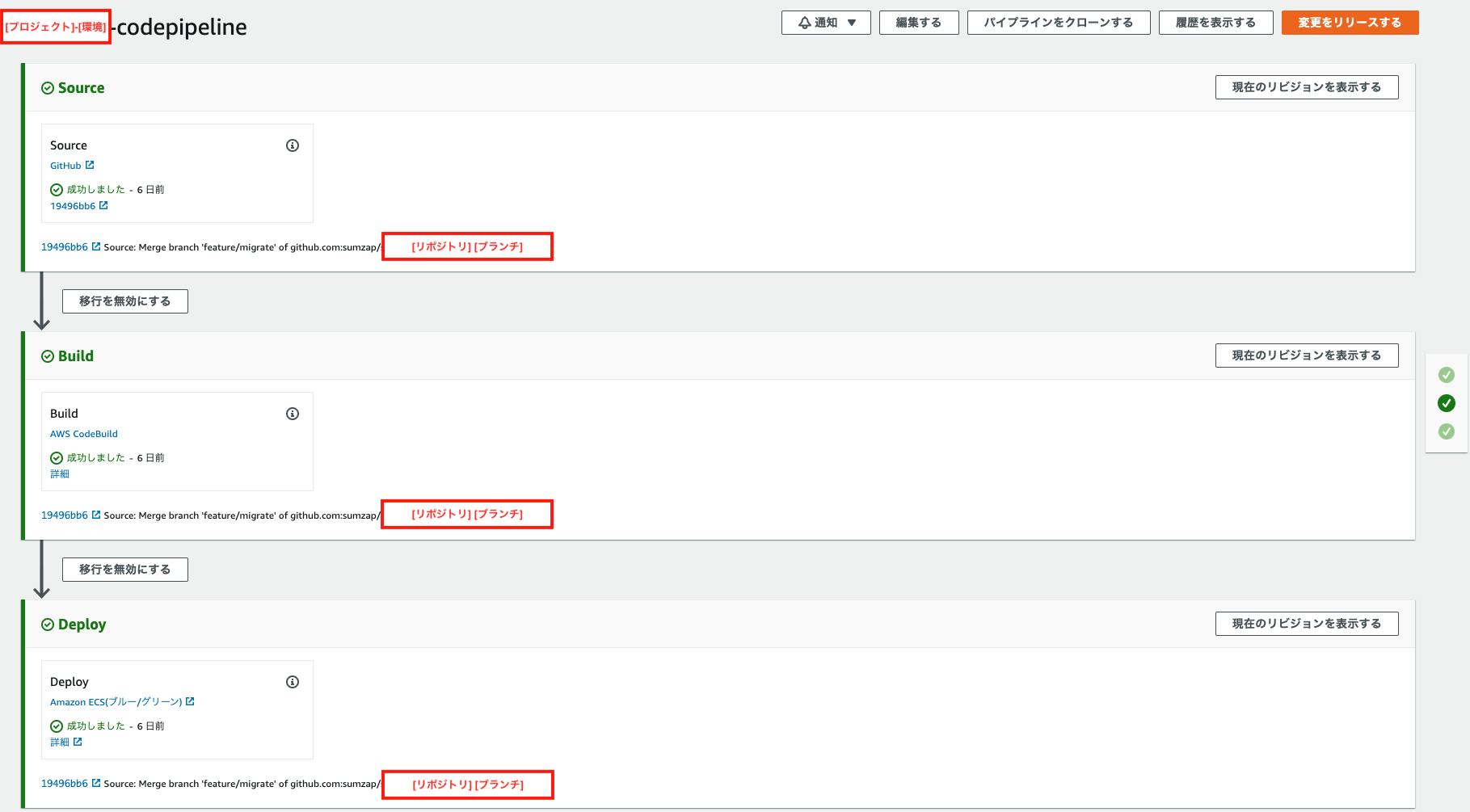
2-11. lambda③がCodedeployのステータスを変更するパイプラインは現在ステージが3つ
slackでの実行結果はこのようになります。
まとめ
今回は使用状況に合わせて2つのデプロイシステムを構築しました。
1.のシステムは開発の初期段階から導入をしています。
デプロイ周りの実装は今まで優先順位が低くなりがちで開発後期に回されることが多かったですが、はじめにしっかり設計することでかなり効率的に開発を進めることができています。もしこのあたりの実装を後回しにしていたり、そもそも自動化されていないシステムで運用しているところがあるならば、かなりの工数をロスしていることになります。ぜひ参考にしていただき取り入れていただきたいです。2.のシステムは固定環境構築時に合わせて実装したデプロイシステムです。
どのような環境かというと例えばアプリをストアに申請する際に使用する環境とか、プロモーションなどで使用する環境です。このような環境はアクセス先を固定化する必要があるので動的に環境を構築するのではなく、必要な時に必要なアップデートを対象の環境に行う必要があります。またステージング環境や本番環境もこちらに属しますね。こういった環境のデプロイもアプリ開発においてはとても多く、またミスも許されない状況が多いです。なのでシステム化をしっかりしてミスを無くすと共に、slackから手軽にデプロイできる仕組みはとても有効だと思います。今後の改善
上記で上げているようなデプロイの仕組みが既に開発フローとして定着しつつあります。
ただ、これで完成!!!ということではなく、やはりまだまだ改善しなくてはいけない点は多々あります。
本番までには対応しないとなとざっくり思っていることを下記に上げて今回はしめたいと思います。・ CodeBuildの処理高速化
-> 毎回デプロイするのに5分以上かかっている
こちらの原因はいろいろ合って、対応手段もあるのですが、1つ大きな原因だけ上げておきます。
現在のプロジェクトがPHPを使用しているためCodeBuild上でイメージを作成する際にcomposer installを行っているのですが、イメージを作成後にmigrationをするためにCodeBuildが入っているサーバでもcomposer installを走らせています。つまり時間のかかる処理が2重に走っていることになります。ここだけ解消するだけでもかなり時間を短縮できると思います。なので作成したイメージを使ってdocker runからのexecでmigrationする方法に変更対応を入れるつもりです。・ slackのスラッシュコマンドをボットに変更
-> slackのスラッシュコマンドでは3つほど問題があります。
1. デプロイ可能ユーザを制限できない(頑張れば可能だが) - ボット化してデプロイできるチャンネルを制限
2. レスポンスタイムアウトが3秒である - そのためエラーメッセージが出る
3. インタラクティブメッセージが使えない - ボタンが使えない、選択ボタンが消えない
この辺は最初から分かっていたことですが、ボットを作っている工数が無かったのでスラッシュコマンドで済ませてしまった感じです。機能は揃っているので開発には問題ないですが、ステージング環境以降はユーザ制限やミス防止は必須ですので、取り入れて行こうと思います。参考
ECSでCodeDeployを使用したBlue/Green Deploymentがサポートされたので早速試してみた
AWS CodePipeline で ECS(Fargate) へ Blue/Green デプロイする
CodePipelineのステータスをSlackへ通知
slack スラッシュコマンドでaws cliを実行させる方法
明日は @ozaki_shinya の記事です。

- 投稿日:2019-11-29T10:29:40+09:00
[AWS SSO] SAML認証で追加したアカウントへのsts一時認証キーの取得方法
AWS SSO SAML認証で追加したアカウントへのsts一時キーの取得方法
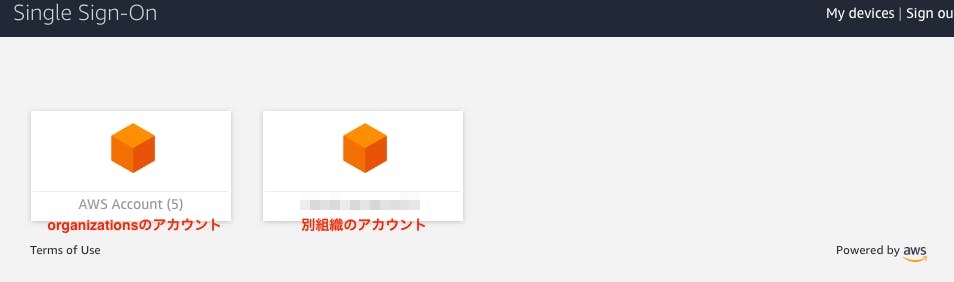
AWS SSOってとにかく便利! そう思っている今日このごろです今回はAWS SSOを使って2種類のアカウントへのアクセスkeyの取得を試しました
- AWS organizations配下のアカウントをSSO配下に参加させるパターン
- 別組織のアカウントをSAML認証によりSSO配下に参加させるパターン
AWS organizations配下のアクセスkeyの取得
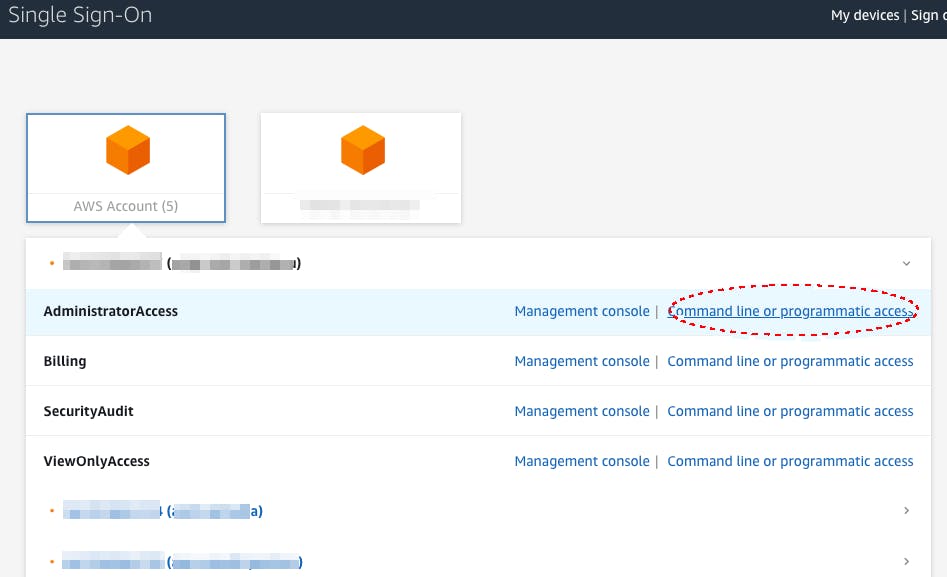
まず、こちらはすごく便利ですね。
コンソールからボタンポチポチで追加できますし、一時keyの発行もブラウザベースで簡単に可能です。対象のアカウントを選択して
command line or programmatic accessをポチると
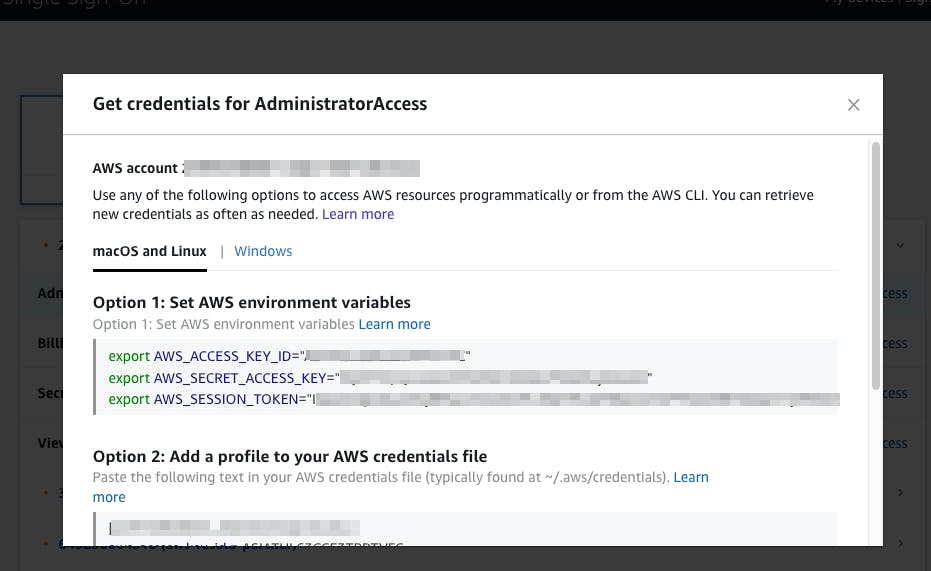
これだけで一時アクセスkeyが取得できます。
ひじょーに簡単ですね。
AWS CLI v2 がつい先日リリースされましたがSSOに対応しているのでもっと楽にできるかもしれませんね。SAML認証により追加したアカウントのkeyの取得
今回の主題はこっちです。
SAML認証で別アカウントを追加した場合 この画面がありません。
その場合のアクセスkeyの取得方法です。
(※前提としてすでにSSO配下にアカウントが追加されいてるとします。追加方法はこちら)そして今回解説する元記事はこちら (AWS CLI を使用して SAML 認証情報を呼び出し、保存する方法を教えてください。)
簡単に書くと、以下の3つを準備します。
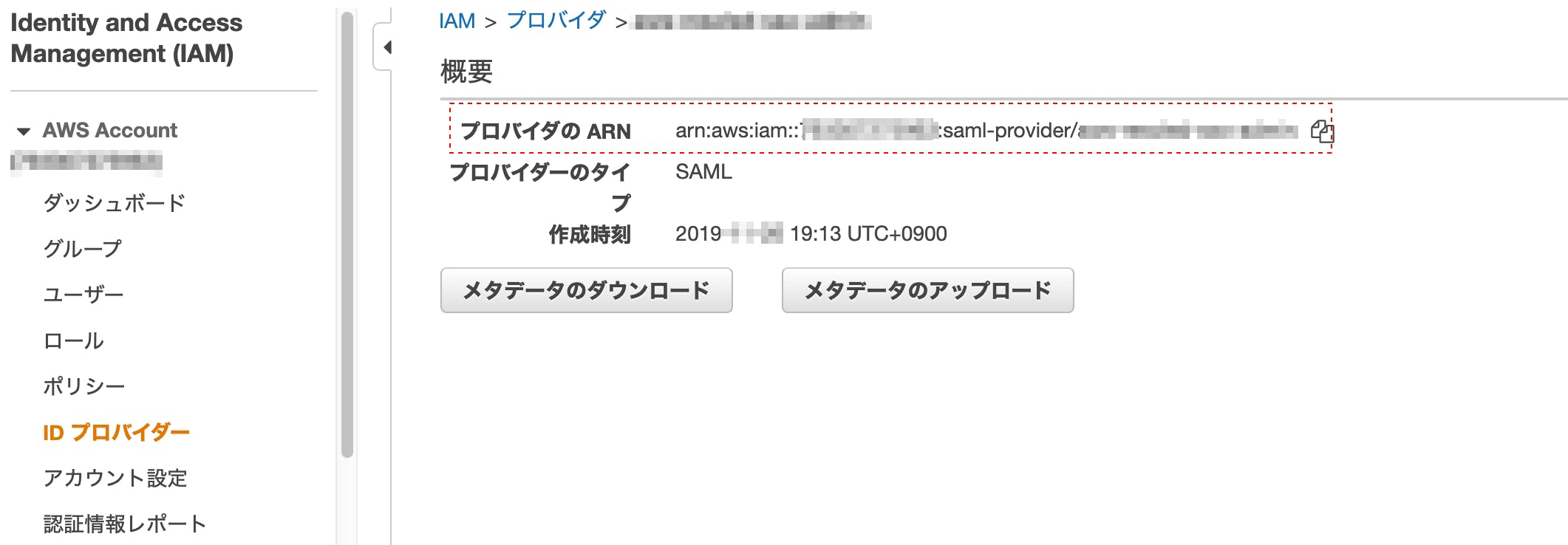
- IAM のプロバイダの ARN [※一度取得したら変わらない]
- ロール ARN [※一度取得したら変わらない]
- assume-role-with-samlを使用しますが、そこで使うSAML認証の情報の取得 [※都度取得必要]
1. IAM のプロバイダの ARN
keyを取得したいアカウントのIAMから↓を取得
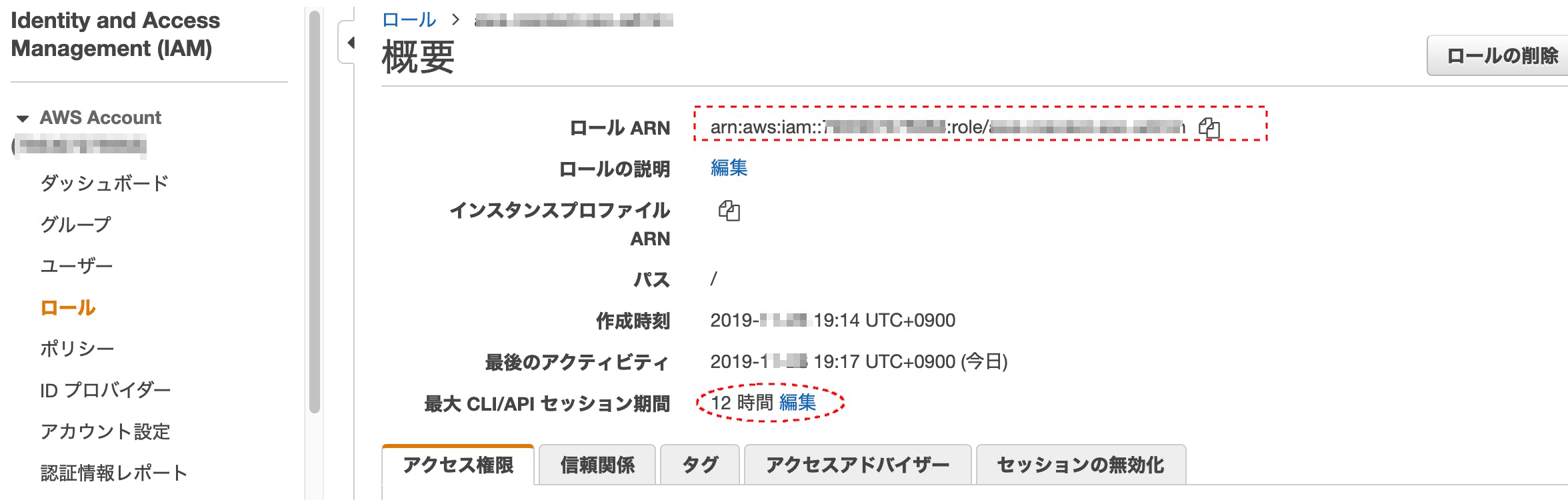
2. ロール ARN
keyを取得したいアカウントのIAMから↓を取得
(注: 最大セッション期間は任意に設定してください)
3. SAMLの認証情報の取得
問題はこれです。
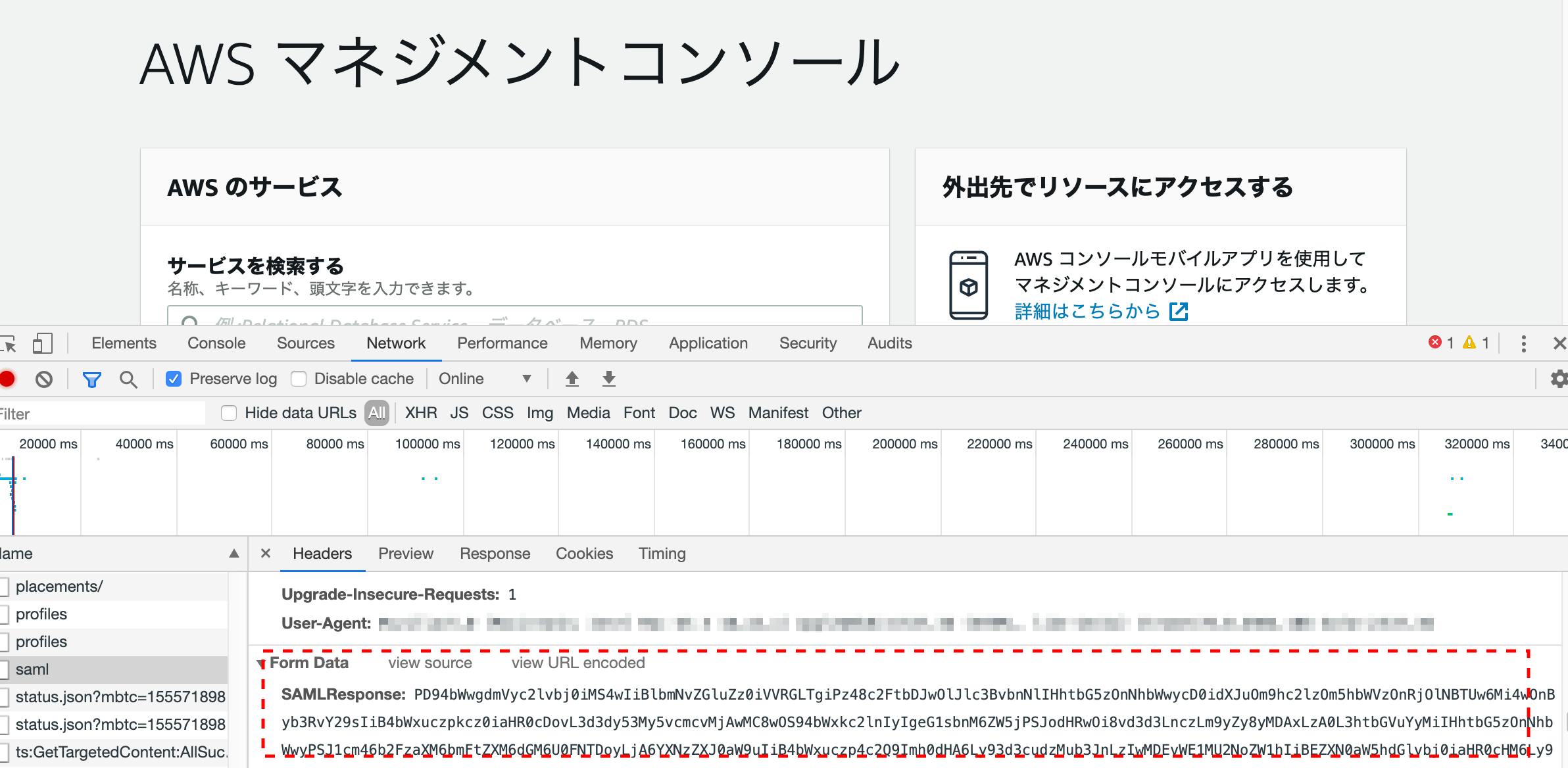
SAMLの認証情報ってどうやって取るんや。。。って話ですね。google chromeなら↓で取れます。 NetworkのPreseverlogをOnにした状態で、
SSOからアカウントを選択し、その瞬間に検証を有効にするとsamlという 名前の行があります。
ただこれを表示させるには、スピードとタイミングが命です! 遅いとでてきませんw
↑を選択して下の方に、SAMLResponse:があります。超長いですが全部コピります。
手順的にかなり大変なので、google 拡張の SAML-Trancer というのを使わせていただくと割と
簡単に取得できます。
1〜3の情報を元にcliを使い一時認証keyを発行します。
aws cliがインストールされている環境で以下bashを実行します
(多分awkの中のRSが参考にしたサイトは間違っている? ので自分で実装しました)
注:SAML取得後 5分以内に取得しないと、タイムオーバでkeyの取得に失敗します#!/bin/bash prvider_arn="arn:aws:iam::xxxxxxx:saml-provider/xxxx" # 1.の値 role_arn="arn:aws:iam::xxxx:role/xxxxx" # 2.の値 saml_response=$(cat ./saml_data) # 3.の値をsaml_dataというファイルに貼り付けています seconds="43200" # 認証keyの有効時間です。 ロールの最大時間をオーバするとエラーになります aws sts assume-role-with-saml --role-arn ${role_arn} --principal-arn ${prvider_arn} --saml-assertion ${saml_response} --duration-seconds ${seconds} | awk -F':' ' BEGIN { print "[account]"} /:/{ gsub(/"/, "", $2) } { gsub(/,/, "", $2) } /AccessKeyId/{ print "aws_access_key_id = " $2 } /SecretAccessKey/{ print "aws_secret_access_key = " $2 } /SessionToken/{ print "aws_session_token = " $2 } ' exit実行結果
$ ./sample.sh [account] aws_access_key_id = ASIAXXXXXXXXXXXXXXXX aws_secret_access_key = NjXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX aws_session_token = FwoGZXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXXX= $これを~/.aws/credentialsにはりcliを発行すると接続ができるようになります!
試しにs3をlsしてみます。 問題なくバケットの一覧が返ってきました ! $ aws --profile account s3 ls 2019-08-09 13:42:23 xxxxxxxx 2019-09-24 17:00:25 xxxxxxxx (略) ]$以上がkeyの発行手順になります。
SAML認証で追加したアカウントのkeyの発行は結構めんどくさいですね。
慣れると結構時間をかけずにできるようになりますw (いいのか...?)できれば、AWS organizations配下にアカウントを作るほうがメンテが楽なのでおすすめします。
やむを得ずの方はこの方法をお試しください。今回はAWS SSOに関する記事が少なかったので記載しました
よかったら いいね お願いします。では、よいAWSライフを!


- 投稿日:2019-11-29T10:21:52+09:00
Flutterで作ったアプリから入力した電話番号あてにAWS SNSからSMSの送信をする方法(ざっくり)
Flutterで作ったアプリから入力した電話番号あてにAWS SNSからSMSの送信をする方法
やりたいこと
入力された電話番号あてにPINを送信したい!
使うもの
AWS | DynamoDB | API Gateway | Lambda | L Node.js 12x L SNS Flutter L http 0.12.0+2DynamoDBの準備
PINコード保存用のテーブルを作成します。
"pin": { "user_id":"", "pin":"", "ttl":"" //TTL設定 }Lambdaの準備
SMSの送信は
publish()を使うことで簡単に送ることができます。const AWS = require('aws-sdk'); const sns = new AWS.SNS(); const documentClient = new AWS.DynamoDB.DocumentClient(); exports.handler = async (event) => { //eventをparseする let body = JSON.parse(event.body); //電話番号とユーザーIDを取得 let phone_number = body.phone_number; let user_id = body.user_id; //PINを生成してデータベースに保存する let pin = await getPIN(user_id); if(pin == false){ return false; }else{ //ユーザーにPINを送る const phone_number = '+819012345678';// E.164番号の形式 (例: 08012345678 -> +818012345678) const message = "あなたの確認コードは${pin}です"; await sendSMS(phone_number, message); } } //PINを生成してDBに保存する async function genPIN(user_id){ //今から10分後のエポック秒を生成 let date = new Date(); let epoc10min = Math.floor(date.setMinutes(date.getMinutes() + 10) / 1000); //PINコードの作成 let pin = {pinを生成するコード}; // DBに保存するパラメータ let params = { 'TableName': 'pin', 'Item': { 'user_id': user_id, 'pin': pin, 'ttl': epoc10min } }; try{ await documentClient.put(params).promise(); return pin; }catch(err){ console.log(err); return false; } } //SMSを送信する async function sendSMS(phone_number, message) { // ユーザーにPINを早く、確実に送りたいのでSMSの送信タイプをTransactionalにする // もし重要度の低い情報であれば、DefaultSMSTypeのValueをPromotionalにする const sms_params = { attributes: { 'DefaultSMSType': 'Transactional', } } //送信タイプの設定 var setSMSTypePromise = new AWS.SNS({ apiVersion: '2010-03-31' }).setSMSAttributes(sms_params).promise(); setSMSTypePromise.then( function (data) { console.log(data); }).catch( function (err) { console.error(err, err.stack); }); //送信用パラメータの設定 var params = { Message: message, PhoneNumber: phone_number, }; let result; // SMS送信 try { await sns.publish(params).promise(); result = true; } catch (e) { console.log(e); result = false; } return result; }API Gatewayの設定
Lambda統合プロキシでAPI GatewayとLambdaをつないでください。
メソッドはPOSTで。
テスト
Postmanを使ってJSON形式のデータを送ります
{ "phone_number": "+818012345678", "user_id": "hoge" }SMSが送信されてきたらOK
Flutter側
このクラスhttp classを使って、作ったAPIあてにPOSTする
- 投稿日:2019-11-29T09:30:53+09:00
PWA+Angular8+AWS amplifyを試す PART1
きっかけ
最近話題のPWAを試してみようと思い、メモを兼ねてQiitaへの投稿を始めてみた。
本業は組込みシステムのソフトウェアに携わっており、WEB系は初心者です。
初心者ながら少しずつ成長する姿を見守っていただければ幸いです。
アドバイス等頂けると助かります。PART1
・Angularの雛形を作る
・angular/cliをインストール
・ブラウザに表示されるかテスト環境
_ _ ____ _ ___ / \ _ __ __ _ _ _| | __ _ _ __ / ___| | |_ _| / △ \ | '_ \ / _` | | | | |/ _` | '__| | | | | | | / ___ \| | | | (_| | |_| | | (_| | | | |___| |___ | | /_/ \_\_| |_|\__, |\__,_|_|\__,_|_| \____|_____|___| |___/ Angular CLI: 8.3.20 Node: 12.13.1 OS: win32 x64 Angular: 8.2.14 ... animations, common, compiler, compiler-cli, core, forms ... language-service, platform-browser, platform-browser-dynamic ... router Package Version ----------------------------------------------------------- @angular-devkit/architect 0.803.20 @angular-devkit/build-angular 0.803.20 @angular-devkit/build-optimizer 0.803.20 @angular-devkit/build-webpack 0.803.20 @angular-devkit/core 8.3.20 @angular-devkit/schematics 8.3.20 @angular/cli 8.3.20 @ngtools/webpack 8.3.20 @schematics/angular 8.3.20 @schematics/update 0.803.20 rxjs 6.4.0 typescript 3.5.3 webpack 4.39.2Visual studio code/1.40.1を使用しています。
Angularの雛形を作る
md angular-pwa cd angular-pwaangular/cliをインストール
npm i @angular/ci今回はローカル環境にangular/cliをインストールする。
ローカルインストールの為、-gを付けないng newでangular雛形を作成
npx ng new angular-pwa --directory=./ --routing=true --style=scssプロジェクトフォルダは先に作成しているので、--directoryオプションでインストール先をカレントに指定する。
--routing, styleオプションはお好みで。ブラウザに表示されるかテスト
npx ng servehttp://localhost:4200/にアクセスして以下のような表示になれば成功。
次回
今回は、angularのインストールから動作確認まで行いました。
次回は作成したプロジェクトをgithubにレポジトリを作成して管理します。
- 投稿日:2019-11-29T09:00:15+09:00
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #18 (ロボット工学)
Amazon Web Services (AWS)のサービスで正式名称や略称はともかく、読み方がわからずに困ることがよくあるのでまとめてみました。
Amazon Web Services (AWS) - Cloud Computing Services
https://aws.amazon.com/まとめルールについては下記を参考ください。
Amazon Web Services (AWS)サービスの正式名称・略称・読み方まとめ #1 (コンピューティング) - Qiita
https://qiita.com/kai_kou/items/a6795dbab7e707b0d1a6間違いや、こんな呼び方あるよーなどありましたらコメントお願いします!
Robotics - ロボット工学
AWS RoboMaker
- 正式名称: AWS RoboMaker
- https://docs.aws.amazon.com/robomaker/?id=docs_gateway
- 読み方: ロボメーカー
- 略称: なし
- 俗称: なし
- 投稿日:2019-11-29T08:53:12+09:00
aws cliを自作しています
aws cliを自作しています。AWSの中身を理解するためにAPIを叩きまくろうと思ってです。Pythonのboto3を使っています。Pythonの練習でもあります。おかげでかはわかりませんが、前よりもずっとAWS触りやすくなりました。
自作ツールではAWSのリソースの閲覧に特化して、いちいちヘルプを見なくても使えることを目指しています。
aws cliで感じてること
aws cliは help を見れば使い方がわかりますが、サブコマンドごとにいちいちヘルプを見ないといけません。またパラメータが非常に多いサブコマンドもあり、ヘルプを見ながらコマンドを打っていくのがつらいです。こんな長いコマンドはなかなかすらすら打てるようにはならないです。
# とても長い覚えられないコマンドの例 $ aws cloudwatch get-metric-statistics --namespace AWS/Lambda --metric-name Duration \ --dimensions 'Name=FunctionName,Value=xxxx' --start-time ... ... ...慣れたらすらすらできるようになるのだろうか。APIと直接対応しているので、APIを把握していればいいんでしょうけど。
この長いコマンドにたどり着くにはこんな道のり。
# cloudwatchのAPIを探す $ aws cloudwatch help # それっぽいのを見つけた。get-metric-statistics だな $ aws cloudwatch get-metric-statistics help # パラメータがいっぱいあってたいへんだ・・・ # 日時はどういうフォーマットだろう # periodとかどう書くんだ # いっぱいググる $ aws cloudwatch get-metric-statistics --namespace AWS/Lambda --metric-name Duration --start-time xxxx --end-time xxxx --period xxxx At least one of the parameters Statistics and ExtendedStatistics must be specified. # え、必須パラメータがたりないのか・・・ # Statisticsってどう指定するのか、もう一度ヘルプを見る $ aws cloudwatch get-metric-statistics help $ aws cloudwatch get-metric-statistics --namespace AWS/Lambda --metric-name Duration --start-time xxxx --end-time xxxx --period xxxx --statistics xxxx # やっとできた # けど本当はdimensionも指定したい。どう書くのやら自作ツールで目指しているもの
自作のツールではこうなります。
※boto3というコマンド名は仮称です。こういう名前のコマンドが一般に存在するわけではありません
# lambdaのメトリックスを見たいので、まずはlambdaと打つ # (cloudwatchからでもたどれます) $ boto3 lambda functions layers # このように表示されたら、見たいものを選んで、パラメータに追加して再実行する # 見たいメトリックスは関数に紐づくので今回はfunctionsを選ぶ $ boto3 lambda functions xxxx yyyy # 関数の一覧が出てくるので、この中から見たい関数を選ぶ $ boto3 lambda functions xxxx code configuration metrics # この中から見たいものを選ぶ $ boto3 lambda functions xxxx metrics duration errors invocations throttles # この中から見たいものを選ぶ $ boto3 lambda functions xxxx metrics duration # see-also: aws cloudwatch get-metric-statistics --namespace AWS/Lambda --metric-name Duration --dimensions Name=FunctionName,Value=xxxx --start-time 2019-10-10T13:03:00 --end-time 2019-10-11T13:03:00 --period 60 --statistics Average --output text 2019-10-10T13:03:00+00:00 1713.59 Milliseconds 2019-10-10T13:04:00+00:00 1736.76 Milliseconds ... # 見たいものが見れました。細かいパラメータをいじって詳細を見たいのであれば、上の
# see-also:で表示される本家aws cliを叩けばよいです。本家aws cliの必要なパラメータが全部出ているので、これをいじるだけなら楽です。以上。
- 投稿日:2019-11-29T01:10:39+09:00
AWS CLIでKMSを試すメモ
前提(用語)
- カスタマーマスターキー(CMK)
- AWS側で管理される鍵
- データの暗号化には直接利用しない
- マネジメントコンソールであらかじめ作成しておく(持ち込みも可能らしい)
- カスタマーデータキー(CDK)
- ユーザーがデータの暗号化に用いる鍵
- 通常はAWSで暗号化されて保存されており、データの暗号時/複号時に、都度復号化して取得する
概要
データを暗号化/復号化する流れ。暗号化/復号化に用いる鍵(CDK)をKMSで管理する。
CMKはあらかじめ作成しておくこと。手順メモ
1. カスタマーデータキーを作成する
% aws kms generate-data-key --key-id "[CMKのキーID]" --key-spec "AES_256" { "Plaintext": "[平文のカスタマーデータキー]", "KeyId": "[CMKのARN]", "CiphertextBlob": "[暗号化されたカスタマーデータキー]" }2. データの暗号化
お好きなツールで
[平文のカスタマーデータキー]を使ってデータを暗号化3.
[平文のカスタマーデータキー]は破棄する4.
[暗号化されたカスタマーデータキー]を保存するBase64デコードして保存しておく(後に、平文のカスタマーデータキーの取得に必要)
echo [暗号化されたカスタマーデータキー] | base64 -d > enc.txt
5.
[平文のカスタマーデータキー]を取得する暗号化されたカスタマーデータキーを用いて
[平文のカスタマーデータキー]を取得してdata-key.txtファイルに保存する。data-key.txtに保存される内容は前段で取得した[平文のカスタマーデータキー]と同じ文字列が保存される。aws kms decrypt --ciphertext-blob fileb://enc --query Plaintext --output text > data-key.txt6. データの復号化
取得した
data-key.txtを用いてお好きなツールで復号化する。参考
AWS Black Belt Online Seminar AWS Key Management Service (KMS) https://www.slideshare.net/AmazonWebServicesJapan/aws-black-belt-online-seminar-aws-key-management-service-kms
AWS KMSを使って秘密鍵を管理する | DACエンジニアブログ:アドテクゑびす界 http://yebisupress.dac.co.jp/2017/03/30/aws-kms%E3%82%92%E4%BD%BF%E3%81%A3%E3%81%A6%E7%A7%98%E5%AF%86%E9%8D%B5%E3%82%92%E7%AE%A1%E7%90%86%E3%81%99%E3%82%8B/
[JAWS-UG CLI] Amazon KMS 入門 (2) データの暗号化・復号化 - Qiita https://qiita.com/domokun70cm/items/a863ae60d4467fc7a790
- 投稿日:2019-11-29T00:51:38+09:00
SQLで緯度経度からメッシュコードを計算する
メッシュコードについて
メッシュとは緯度経度に基づいて、地域を格子状に分割したもので、
メッシュコードとは、この地域メッシュに割り当てられたユニークな識別番号になります。
測地系は平成14年4月1日以前は日本測地系でしたが、それ以降は世界測地系に準じているようです。
この記事では、私がよく使うPostgreSQLとAWS Athena(Presto SQL)で緯度経度からメッシュコードを計算するクエリを紹介いたします。計算方法の参考文献:http://www.stat.go.jp/data/mesh/pdf/gaiyo1.pdf#page=7
クエリ
紹介するクエリは以下のSQLで動作することを確認しております。
- PostgreSQL
- PrestoSQL(AWS Athena)
今回はlon, latがともに世界測地系であることを前提としています。
1次メッシュ
- 辺の長さ:約80km
- 経度差:1度
- 緯度差:40分
WITH t AS ( SELECT 139.71475 AS lon, 35.70078 AS lat ) SELECT CONCAT( CAST(CAST(floor(lat*60/40) AS INTEGER) AS VARCHAR), CAST(CAST(floor(lon-100) AS INTEGER) AS VARCHAR) ) AS mcode FROM t> 533942次メッシュ
- 辺の長さ:約10km
- 経度差:7分30秒
- 緯度差:5分
WITH t AS ( SELECT 139.71475 AS lon, 35.70078 AS lat ) SELECT CONCAT( CAST(CAST(floor(lat*60/40) AS INTEGER) AS VARCHAR), CAST(CAST(floor(lon-100) AS INTEGER) AS VARCHAR), CAST(CAST(floor((lat*60)%40/5) AS INTEGER) AS VARCHAR), CAST(CAST(floor((lon-floor(lon))*60/7.5) AS INTEGER) AS VARCHAR) ) AS mcode FROM t> 5339453次メッシュ
- 辺の長さ:約1km
- 経度差:45秒
- 緯度差:30秒
WITH t AS ( SELECT 139.71475 AS lon, 35.70078 AS lat ) SELECT CONCAT( CAST(CAST(floor(lat*60/40) AS INTEGER) AS VARCHAR), CAST(CAST(floor(lon-100) AS INTEGER) AS VARCHAR), CAST(CAST(floor((lat*60)%40/5) AS INTEGER) AS VARCHAR), CAST(CAST(floor((lon-floor(lon))*60/7.5) AS INTEGER) AS VARCHAR), CAST(CAST(floor(((lat*60)%40)%5*60/30) AS INTEGER) AS VARCHAR), CAST(CAST(floor(((lon-floor(lon))*60)%7.5*60/45) AS INTEGER) AS VARCHAR) ) AS mcode FROM t> 533945472分の1地域メッシュ
- 辺の長さ:約500m
- 経度差:22.5秒
- 緯度差:15秒
WITH t AS ( SELECT 139.71475 AS lon, 35.70078 AS lat ) SELECT CONCAT( CAST(CAST(floor(lat*60/40) AS INTEGER) AS VARCHAR), CAST(CAST(floor(lon-100) AS INTEGER) AS VARCHAR), CAST(CAST(floor((lat*60)%40/5) AS INTEGER) AS VARCHAR), CAST(CAST(floor((lon-floor(lon))*60/7.5) AS INTEGER) AS VARCHAR), CAST(CAST(floor(((lat*60)%40)%5*60/30) AS INTEGER) AS VARCHAR), CAST(CAST(floor(((lon-floor(lon))*60)%7.5*60/45) AS INTEGER) AS VARCHAR), CAST(CAST(floor(((lat*60)%40)%5*60%30/15)*2 + floor(((lon-floor(lon))*60)%7.5*60%45/22.5)+1 AS INTEGER) AS VARCHAR) ) AS mcode FROM t> 5339454714分の1地域メッシュ
- 辺の長さ:約250m
- 経度差:11.25秒
- 緯度差:7.5秒
WITH t AS ( SELECT 139.71475 AS lon, 35.70078 AS lat ) SELECT CONCAT( CAST(CAST(floor(lat*60/40) AS INTEGER) AS VARCHAR), CAST(CAST(floor(lon-100) AS INTEGER) AS VARCHAR), CAST(CAST(floor((lat*60)%40/5) AS INTEGER) AS VARCHAR), CAST(CAST(floor((lon-floor(lon))*60/7.5) AS INTEGER) AS VARCHAR), CAST(CAST(floor(((lat*60)%40)%5*60/30) AS INTEGER) AS VARCHAR), CAST(CAST(floor(((lon-floor(lon))*60)%7.5*60/45) AS INTEGER) AS VARCHAR), CAST(CAST(floor(((lat*60)%40)%5*60%30/15)*2 + floor(((lon-floor(lon))*60)%7.5*60%45/22.5)+1 AS INTEGER) AS VARCHAR), CAST(CAST(floor(((lat*60)%40)%5*60%30%15/7.5)*2 + floor(((lon-floor(lon))*60)%7.5*60%45%22.5/11.25)+1 AS INTEGER) AS VARCHAR) ) AS mcode FROM t> 5339454711プログラミングのように変数にできれば、もっと綺麗に計算できるのですがクエリだとどうしても力技になってしまいます。
しかし、テーブルにメッシュコードのカラムを付与することができれば簡単にメッシュごとの統計処理を行えるようになります。
是非ご検討ください。
- 投稿日:2019-11-29T00:40:00+09:00
