- 投稿日:2019-07-24T23:17:47+09:00
pytorchで勾配法
はじめに
この記事は古川研究室 Workout calendar 9日目の記事です. 本記事は古川研究室の学生が学習の一環として書いたものです.
Workout_calendar盛り上がって嬉しいです。今週の金曜にいよいよ新入生の投稿が始まります!
本記事の目的
Pytorchの自動微分機能を使って, 勾配法を実現します!
[これを実装します]
最急降下法
勾配法として最も単純な方法である。
勾配法は $n$次ベクトル $\mathbf{x} = (x_1,x_2,...,x_n)$を引数とする写像 $f(\mathbf{x})$ の極値を求める手法の一つである.
反復法, 学習を繰り返して $\mathbf{x}$を更新する.
$t$時刻目の学習の解が$\mathbf{x}^{(t)}$であるとき, 最急降下法では次のように値を更新する.\begin{align} \mathbf{x}^{(t+1)} &= \mathbf{x}^{(t)}-\eta \operatorname{grad} f\left(\mathbf{x}^{(t)}\right) \\ \\ &= \mathbf{x}^{(t)}-\eta \left[\begin{array}{c}{\frac{\partial f\left(\mathbf{x}^{(t)}\right)}{\partial x_{1}^{(t)}}} \\ {\frac{\partial f\left(\mathbf{x}^{(t)}\right)}{\partial x_{2}^{(t)}}} \\ {\frac{\partial f\left(\mathbf{x}^{(t)}\right)}{\partial x_{2}^{(k)}}} \\ ・\\ {\frac{\partial f\left(\mathbf{x}^{(t)}\right)}{\partial x_{n}^{(k)}}}\end{array}\right] \end{align}ここで$\eta$はステップ幅である. ステップ幅が大きくなると更新量は大きくなるが発散の恐れがある. 逆にステップ幅が小さすぎると学習は遅れてしまう.
実装
今回使う写像(関数): $$ E(\mathbf{x}) = x_1^2 + x_2^2$$
gradient_descent.pyn_epoch = 200 # 学習回数 eta = 0.01 # ステップ幅 x = torch.tensor([2.0,2.0],requires_grad=True) # (x_1, x_2) A = torch.tensor([[1.0,0.0],[0.0,1.0]]) for epoch in range(n_epoch): quad = torch.einsum("i,ij,j",x,A,x) # f quad.backward() with torch.no_grad(): x = x - eta * x.grad x.requires_grad = True実装メモ
$\mathbf{x}$: optionにrequires_grad = Trueが必要.
$quad$ : 偏導関数はスカラー値である必要がある.結果
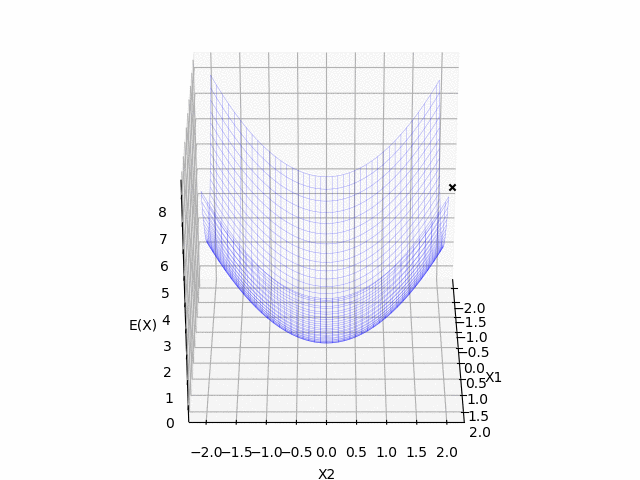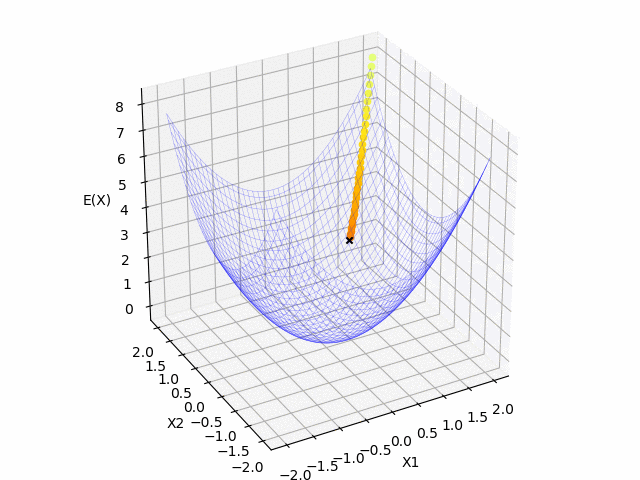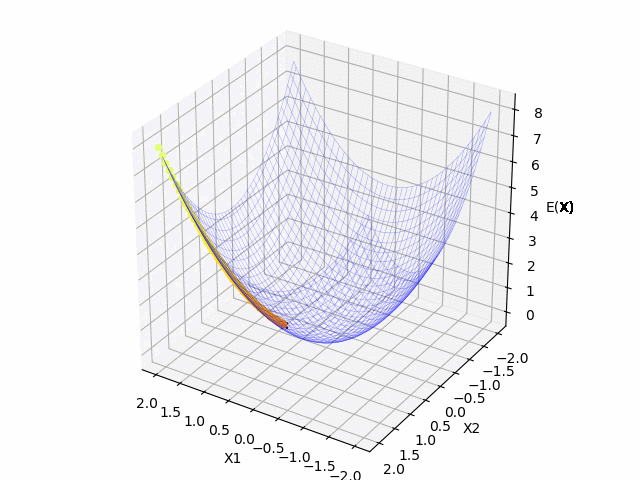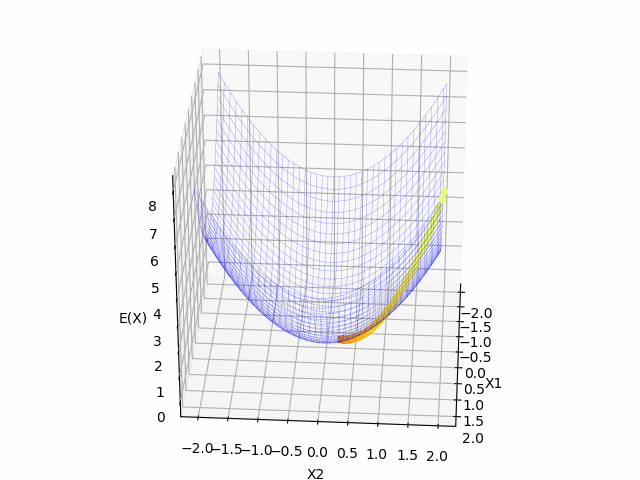
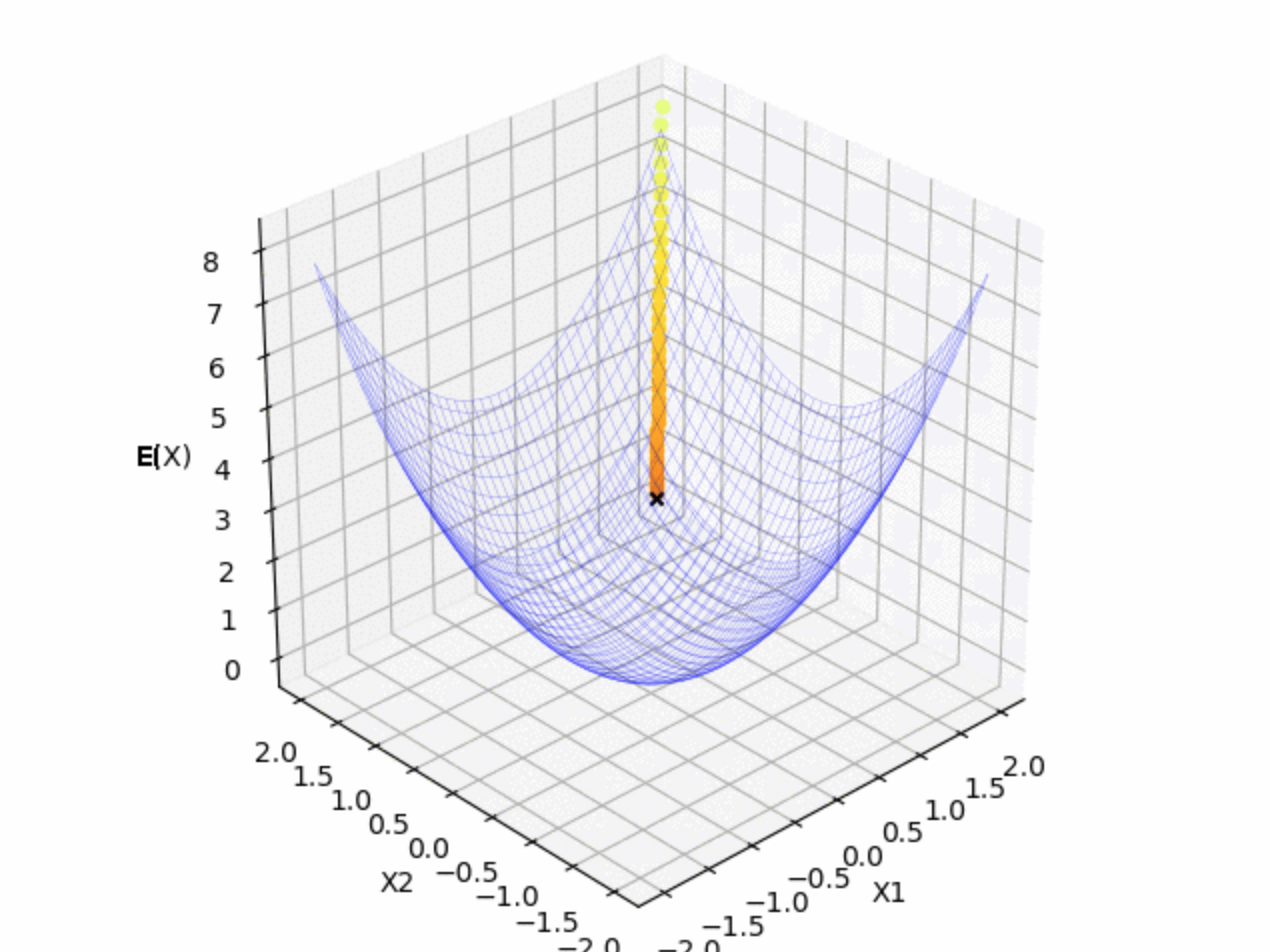
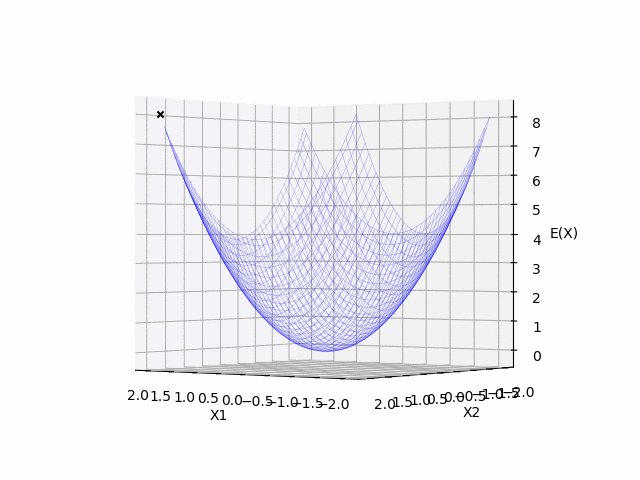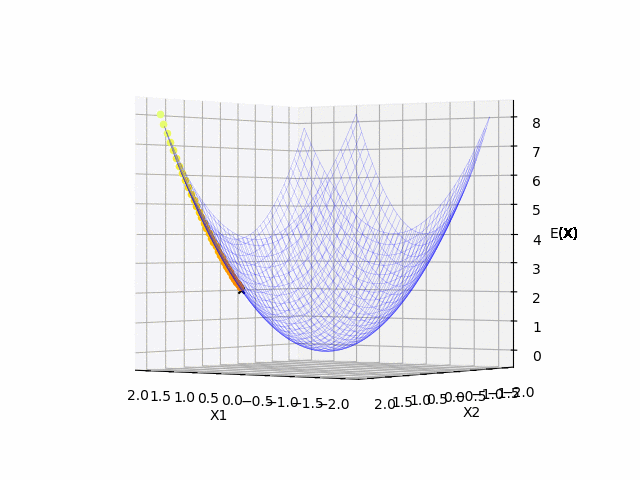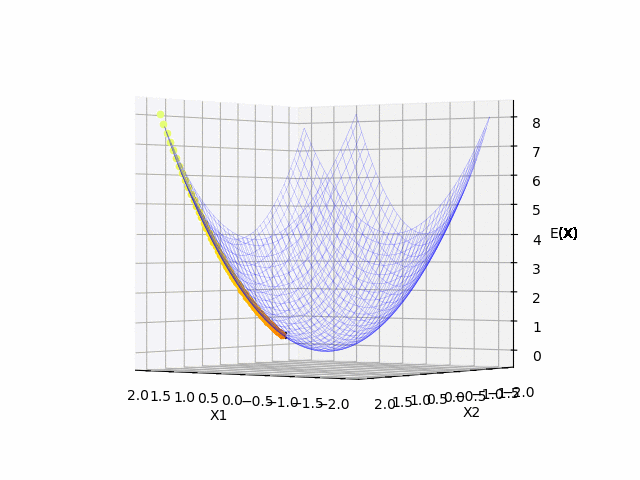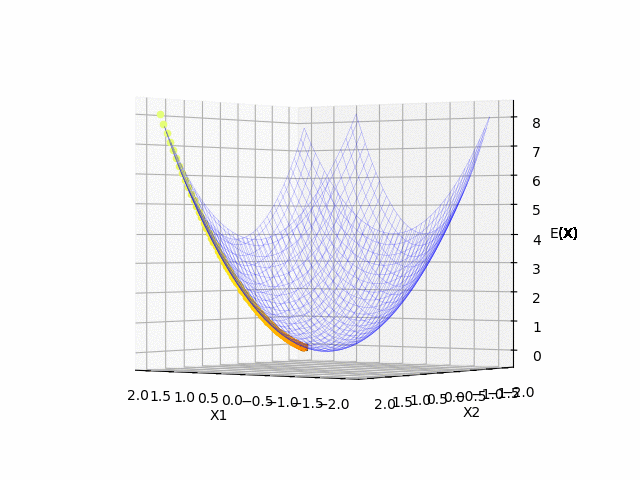
青のマットは今回の関数の形で, 黒の $x$ は $t$ 時刻目の更新する点です. 黄色の点線は学習の軌跡になっています. 横軸(x,y)が$\mathbf{x}$の成分で, 縦軸(z)が関数の値になっています.
$(x_1, x_2) = (2.0, 2.0)$ を初期値として, 関数の最小値に向かっていることが確認できました.
まとめ
次はこれと前回あげた Nadaraya-Watson推定 の実装を組み合わせて, 自分の研究の基盤技術を実現しようと思います.
参考ページ
ソースコード
今回もGithubとColabにソースコードあげております.
ビューワーありで動かしたい方はよかったら参考にしてください.Special Thanks
コード提供: Watanabe さん
- 投稿日:2019-07-24T23:06:04+09:00
AtCoder Beginners Selection 体験記
AtCoder Beginners Selection 体験記
AtCoder Beginner Contest に一度挑戦してみたいなーと思って、練習のために AtCoder Beginners Selection を解いてみた. 言語は、性能が辛ければ Go で、そうでなければ Python 3 にしようと思って提出フォームを見たら、選択肢に Python 2 があって、print にカッコつけるのダルいなと思って Python 2 になった(ダメ人間).
PracticeA - Welcome to AtCoder
8分で完了. どっかの記事で Python で AtCoder するときは入力を
input()で受け取るというのを見ていて、使うの初めてながら使ってみたらSyntaxError: unexpected EOF while parsingが出て ??? ってなりながらraw_input()に変えて突破. 問題自体は簡単すぎて特に何も言うことはない.a = int(raw_input()) b, c = [int(e) for e in raw_input().split()] s = raw_input() print "%d %s" % (a + b + c, s)ABC086A - Product
2分で完了. 簡単すぎて特に何も言うことはない.
a, b = [int(e) for e in raw_input().split()] if a * b % 2 == 0: print 'Even' else: print 'Odd'ABC081A - Placing Marbles
4分で完了. 簡単すぎて特に何も言うことはない.
print len([c for c in raw_input() if c == '1'])ABC081B - Shift only
9分で完了.
anyの使い方を思い出せば特に難しいことはない.n = int(raw_input()) a = [int(e) for e in raw_input().split()] i = 0 while True: if any(e % 2 == 1 for e in a): break i += 1 a = [e / 2 for e in a] print iABC087B - Coins
4分で完了. まあ、総当たりでいいだろうで、終わりではある. 0..n なので
rangeに+ 1するのを忘れなければよいだけ.a = int(raw_input()) b = int(raw_input()) c = int(raw_input()) x = int(raw_input()) result = 0 for i in range(a + 1): for j in range(b + 1): for k in range(c + 1): if i * 500 + j * 100 + k * 50 == x: result += 1 print resultABC083B - Some Sums
6分で完了. 各桁の和は一回文字列に変換して、各桁毎に数値に戻せばいいやで、後は総当りすれば OK.
a <= x <= yみたいに書けるのは知ってたけど、初めて書いたかも. 普通の言語ではa <= x and x <= yになるのにねー.n, a, b = [int(e) for e in raw_input().split()] result = 0 for i in range(1, n + 1): if a <= sum(int(e) for e in str(i)) <= b: result += i print resultABC088B - Card Game for Two
7分で完了. 最後の行に
n = int(raw_input()) a = [int(e) for e in raw_input().split()] a.sort() a.reverse() print sum(a[::2]) - sum(a[1::2])ABC085B - Kagami Mochi
3分で完了. 同じ直径のものは積めないってことは、要するに直径の unique を取ればよいわけで、Python は set に突っ込めば一発でそれを取れるので、後は set の要素数を取ってお終い.
n = int(raw_input()) d = [int(raw_input()) for i in range(n)] print len(set(d))ABC085C - Otoshidama
7分で完了. 最初
k = n + 1 - i - jになっていて WA. 総当りするだけなので特に難しいことはない.import sys n, y = [int(e) for e in raw_input().split()] for i in range(n + 1): for j in range(n + 1 - i): k = n - i - j if 10000 * i + 5000 * j + 1000 * k == y: print "%d %d %d" % (i, j, k) sys.exit() print "-1 -1 -1"ABC049C - 白昼夢 / Daydream
1時間くらいで完了. 最初は再帰関数で書いて RE を食らい、あー
maximum recursion depth exceededかーと言いながらループ版に書き直し. これが TLE を食らいマジどーしよとなったけど、s.find(t + w) == 0ってO(n^2)じゃねと思い、O(n)なs.startswith(t + w)ならどうだろうと試してみたら通った.import sys s = raw_input() ts = [''] while True: nts= [] for t in ts: for w in ['dreamer', 'eraser', 'dream', 'erase']: if s == t + w: print 'YES' sys.exit() if s.startswith(t + w): nts.append(t + w) if len(nts) == 0: print 'NO' sys.exit() ts = ntsABC086C - Traveling
40分くらいで完了. 到着した後の残り時間が偶数なら良いんでしょとさらさらっと書き上げて出したら WA. 延々考えてどう考えてもあってるやんけーってなった後に、前の問題と違って Yes / No が大文字小文字混じりであることに気づいた orz. しょうもねえミスすぎた.
import sys n = int(raw_input()) data = [map(int, raw_input().split()) for i in range(n)] t = 0 x = 0 y = 0 for d in data: duration = d[0] - t distance = abs(x - d[1]) + abs(y - d[2]) if (distance > duration) or ((duration - distance) % 2 == 1): print 'No' sys.exit() t = d[0] x = d[1] y = d[2] print 'Yes'
- 投稿日:2019-07-24T22:17:13+09:00
Google Apps Scriptで作った無料翻訳APIを使う
はじめに
初心者の備忘録です。
Pythonで翻訳できないかな~、Google Cloud Translationは有料か~、おっgoogletransとかいうモジュールがあるんか~→エラーが出て使えない...
こんな状況だったときに以下の記事を見つけました。
3 分で作る無料の翻訳 API with Google Apps Script使い方
まず、記事の通りにウェブアプリケーションとして導入してURLが表示されるまで進めます。
アクセス方法は、 exec の後に ?text=翻訳したい文字列&source=翻訳前言語&target=翻訳後言語 を指定して GET リクエストする。
とあります。
試しに"cat"を翻訳してみました。
取得したURLはhttps://script.google.com/macros/s/AKfycbzPH7k0wm5QqP78MtGXt2cOZ_dR0X0G-jMxJODwZvQM3hG89Cct/exec
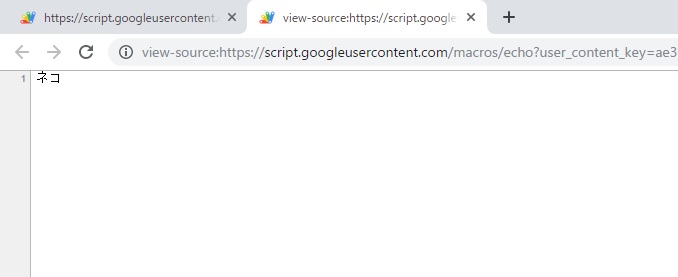
なので ?text=cat&source=en&target=ja を末尾に追加します。アクセスしてソースを確認すると以下のようになっています。
"cat"が翻訳されて"ネコ"と表示されました。それ以外はなにもありません。翻訳結果を取得する
GETリクエストを送ってページからデータを取得できます。
PythonではRequestsモジュールのrequests.get()でGETリクエストできます。
params=で指定することで取得するデータを決められますが、先ほど開いたページでは翻訳されたテキスト以外何もデータがないのでrequests.get()にURLだけを放り込んで全部取得します。以下はhogeを受け取って、翻訳結果を返す関数です。
from Requests import get def trans(hoge): trans_from = 'en'#翻訳元の言語(英語) trans_to = 'ja' #翻訳先の言語(日本語) trans_url = ( 'https://script.google.com/macros/s/AKfycbzPH7k0wm5QqP78MtGXt2cOZ_dR0X0G-jMxJODwZvQM3hG89Cct/exec' + '?text=' + hoge + '&source=' + trans_from + '&target=' + trans_to ) res = get(trans_url) translated_hoge = res.text return translated_hogereturnの上2行でGETリクエストを送って、翻訳結果を取得しています。
res = get(trans_url) print("res: {}" .format(res)) #res: <Response [200]> translated_hoge = res.text print("res.text: {}" .foramt(translated_hoge)) #res.text: 翻訳された結果getの戻り値はレスポンス内容が格納されたオブジェクトです。resを出力するとResponse [200]となります。
textという属性にページのhtmlが格納されているので、翻訳結果が欲しい場合はres.textとしなければなりません。参考
- 投稿日:2019-07-24T22:12:42+09:00
SESとPythonでメールの送信者が文字化けしないようにする
Pythonを使ってSESでメールを送る際、送信者(From)に日本語を使うと文字化けします。
https://docs.aws.amazon.com/ja_jp/ses/latest/DeveloperGuide/send-using-sdk-python.html
↑の公式サンプルコードをもとにメールを送信してみます。
文字化けするパターン
まずは何も考えず、そのまま宛先に日本語をセットしたパターンです。
ses_send.pyimport boto3 from botocore.exceptions import ClientError # Replace sender@example.com with your "From" address. # This address must be verified with Amazon SES. SENDER = "テスト <hoge+sender@gmail.com>" # Replace recipient@example.com with a "To" address. If your account # is still in the sandbox, this address must be verified. RECIPIENT = "fuga@gmail.com" # If necessary, replace us-west-2 with the AWS Region you're using for Amazon SES. AWS_REGION = "us-east-1" # The subject line for the email. SUBJECT = "Amazon SES テスト (SDK for Python)" # The email body for recipients with non-HTML email clients. BODY_TEXT = ("Amazon SES テスト (Python)\r\n" "This email was sent with Amazon SES using the " "AWS SDK for Python (Boto)." ) # The HTML body of the email. BODY_HTML = """<html> <head></head> <body> <h1>Amazon SES テスト (SDK for Python)</h1> <p>This email was sent with <a href='https://aws.amazon.com/ses/'>Amazon SES</a> using the <a href='https://aws.amazon.com/sdk-for-python/'> AWS SDK for Python (Boto)</a>.</p> </body> </html> """ # The character encoding for the email. CHARSET = "UTF-8" # Create a new SES resource and specify a region. client = boto3.client('ses',region_name=AWS_REGION) # Try to send the email. try: #Provide the contents of the email. response = client.send_email( Destination={ 'ToAddresses': [ RECIPIENT, ], }, Message={ 'Body': { 'Text': { 'Charset': CHARSET, 'Data': BODY_TEXT, }, }, 'Subject': { 'Charset': CHARSET, 'Data': SUBJECT, }, }, Source=SENDER ) # Display an error if something goes wrong. except ClientError as e: print(e.response['Error']['Message']) else: print("Email sent! Message ID:"), print(response['MessageId'])実行します。
>python ses_send.py Email sent! Message ID: 0100016c23fd79b6-efee9a81-212b-4c27-a5b7-81249789bdb0-000000受信したメール。
MIME-Version: 1.0 Date: Wed, 24 Jul 2019 21:38:32 +0900 From: =?utf-8?Q?=C6=B9=EF=BF=BD?= <hoge+sender@gmail.com> Subject: =?utf-8?Q?Amazon_SES_=E3=83=86=E3=82=B9=E3=83=88_(SDK_for_Python)?= Thread-Topic: =?utf-8?Q?Amazon_SES_=E3=83=86=E3=82=B9=E3=83=88_(SDK_for_Python)?= To: "fuga@gmail.com" <fuga@gmail.com> Content-Transfer-Encoding: quoted-printable Content-Type: text/plain; charset="utf-8" Amazon SES =E3=83=86=E3=82=B9=E3=83=88 (Python) This email was sent with Amazon SES using the AWS SDK for Python (Boto).同じテストという文言がFromの部分だけエンコードが違っています。
これは、テスト <hoge+sender@gmail.com>という文字列全体にマルチバイトを考慮しないエンコードがかかることで引き起こされる現象です。このためメーラーで開いたときに送信者だけが化けてしまいます。
文字化けしないパターン
Fromにセットするときに、送信者とメールアドレスを分けてエンコードがすると文字化けしません。
先ほどのスクリプトに手を加えます。
ses_send.pyimport boto3 from botocore.exceptions import ClientError from email.header import Header # eemail.headerをインポート # Replace sender@example.com with your "From" address. # This address must be verified with Amazon SES. # 送信者の名前とアドレスに変数を分ける SENDER_NAME = "テスト" SENDER_ADDR = "hoge+sender@gmail.com" # Replace recipient@example.com with a "To" address. If your account # is still in the sandbox, this address must be verified. RECIPIENT = "fuga@gmail.com" # If necessary, replace us-west-2 with the AWS Region you're using for Amazon SES. AWS_REGION = "us-east-1" # The subject line for the email. SUBJECT = "Amazon SES テスト (SDK for Python)" # The email body for recipients with non-HTML email clients. BODY_TEXT = ("Amazon SES テスト (Python)\r\n" "This email was sent with Amazon SES using the " "AWS SDK for Python (Boto)." ) # The HTML body of the email. BODY_HTML = """<html> <head></head> <body> <h1>Amazon SES テスト (SDK for Python)</h1> <p>This email was sent with <a href='https://aws.amazon.com/ses/'>Amazon SES</a> using the <a href='https://aws.amazon.com/sdk-for-python/'> AWS SDK for Python (Boto)</a>.</p> </body> </html> """ # The character encoding for the email. CHARSET = "UTF-8" # Create a new SES resource and specify a region. client = boto3.client('ses',region_name=AWS_REGION) # Try to send the email. try: #Provide the contents of the email. response = client.send_email( Destination={ 'ToAddresses': [ RECIPIENT, ], }, Message={ 'Body': { 'Text': { 'Charset': CHARSET, 'Data': BODY_TEXT, }, }, 'Subject': { 'Charset': CHARSET, 'Data': SUBJECT, }, }, # Header関数を使いISO-2022-JPにエンコード Source='%s <%s>'%(Header(SENDER_NAME.encode('iso-2022-jp'),'iso-2022-jp').encode(),SENDER_ADDR) ) # Display an error if something goes wrong. except ClientError as e: print(e.response['Error']['Message']) else: print("Email sent! Message ID:"), print(response['MessageId'])これで実行します。
>python ses_send.py Email sent! Message ID: 0100016c241237ba-ca70ada5-4add-4641-8f97-dfaf904f8de7-000000受信したメール。
MIME-Version: 1.0 Date: Wed, 24 Jul 2019 22:01:11 +0900 From: =?utf-8?Q?=E3=83=86=E3=82=B9=E3=83=88?= <hoge+sender@gmail.com> Subject: =?utf-8?Q?Amazon_SES_=E3=83=86=E3=82=B9=E3=83=88_(SDK_for_Python)?= Thread-Topic: =?utf-8?Q?Amazon_SES_=E3=83=86=E3=82=B9=E3=83=88_(SDK_for_Python)?= To: "fuga@gmail.com" <fuga@gmail.com> Content-Transfer-Encoding: quoted-printable Content-Type: text/plain; charset="utf-8" Amazon SES =E3=83=86=E3=82=B9=E3=83=88 (Python) This email was sent with Amazon SES using the AWS SDK for Python (Boto).先ほどとFromのエンコードが変わり、メーラでも日本語が化けずに表示されます。
- 投稿日:2019-07-24T21:23:37+09:00
Pythonでソートアルゴリズムの再発明をしてみる: 選択ソート
概要
- Pythonでソートアルゴリズムを再発明してみるだけ
- 今回は選択ソートについて
- 参考サイトのサンプルコードをできるだけ見ずに実装する
- とりあえず昇順ソートのみの対応とする
選択ソートの概要
要素を一通りなめて、最小だった値を左端の要素と交換するということを繰り返すアルゴリズム1
シンプルで実装が容易である一方、基本的に遅い
不安定ソート
基本的な手順
- 左端の要素を「最小値」と見立てる
- 配列を左から走査して「最小値」と比較し、より小さい値があれば「最小値」を更新する。これを右端に到達するまで行う
- 左端の要素と最小値の位置を入れ替える(この時点では、「最小値」は本当の最小値になっているはず)
- 左端の要素は処理の対象外として、また手順1から繰り返す
- 全ての要素が処理対象外になったらソート完了
ソース
import random def selection_sort(lst): # 処理全体のループ # iの値が更新されることで処理対象範囲が狭まる for i in range(len(lst)): # 処理対象範囲の中での左端を仮の「最小値」とする min_value = lst[i] min_index = i # 処理対象範囲の中での、本当の最小値を探すループ for j in range(i+1, len(lst)): if min_value > lst[j]: min_value = lst[j] min_index = j # 処理対象範囲の中での、左端と最小値を入れ替える lst[i], lst[min_index] = lst[min_index], lst[i] lst = list(range(10)) random.shuffle(lst) print("ソート前: " + str(lst)) selection_sort(lst) print("ソート後: " + str(lst))参考サイト
最大値を探して右端の要素と交換するという手順でも可能ですが、ここでは最小値でやることとします。 ↩
- 投稿日:2019-07-24T21:15:43+09:00
Connpass API でIT勉強会の情報を手軽にランダム1件検索
前書き
多種多様に開催されているIT勉強会。
自分は開催情報を知るきっかけの一つに「Connpass」をよく利用しています。connpass - エンジニアをつなぐIT勉強会支援プラットフォーム
https://connpass.com/IT勉強会を「Python」で検索してみました。
結果、251件ヒット。かなりの数のIT勉強会が開催されていますね。
都道府県で絞ればもう少し数も絞れるとはいえ、
開催数が多くて、選び出すところでひと苦労してしまう。。。自分はまさにそんな感じの人です orz
何がしたいのか
もっと積極的にIT勉強会へ参加する。
そのきっかけに「手軽なIT勉強会の検索処理」を作りたい!やったこと
Connpass API からIT勉強会の情報を、
お手軽にランダム1件検索する処理を書いてみました。なぜランダム1件検索?
何が検索されるか分からない
ガチャ的なwワクワク感と、
検索を敢えて1件に絞って情報量を減らすことで、
検索結果をしっかり読むきっかけにできないかと考えました。Connpass API
Connpassはイベントサーチ用APIを提供しており、
誰でも利用することができるようになっています。
こちらを利用させていただきました。Connpass API
https://connpass.com/about/api/実行結果
先に処理の実行結果から。
pythonコマンドで該当処理を「検索キーワード」をつけて実行します。
検索キーワードを「Python」にしてみます。python connpass_search.py python実行結果はこんな感じになりました。
(一応伏せ字にしましたが、実際の実行結果は全ての情報が閲覧可能です。)--------------------------------------------- # (・∀・) connpassイベント 何がでるかな? # 機能:ランダムで1件 イベントを検索します --------------------------------------------- 検索中・・・ ■ 検索結果 イベント名:Fintech,Pyt…気。。。略 開 催 日:2019-07-24T19:3。。。略 場 所:東京都港区。。。略 会 場:Cre。。。略 詳細ページ:https://cuc。。。略 参加者定員:17 参 加 者:7 補 欠 者:0 主催グループ名 :Cuc。。。略 主催グループURL:https://cuc。。。略 ↑ピン!ときたら、ぜひ参加してみよう! ---------------------------------------------また「検索キーワード」は「複数指定(AND検索)」もできます。
検索キーワードを「Python」「大阪」にしてみます。python connpass_search.py python,大阪実行結果はこんな感じになりました。
(一応伏せ字にしましたが、実際の実行結果は全ての情報が閲覧可能です。)--------------------------------------------- # (・∀・) connpassイベント 何がでるかな? # 機能:ランダムで1件 イベントを検索します --------------------------------------------- 検索中・・・ ■ 検索結果 イベント名:阪医pyth。。。略 開 催 日:2019-07-26T1:。。。略 場 所:大阪府大阪市。。。略 会 場:PLU。。。略 詳細ページ:https://ou。。。略 参加者定員:30 参 加 者:17 補 欠 者:0 主催グループ名 :阪医pyth。。。略 主催グループURL:https://ou。。。略 ↑ピン!ときたら、ぜひ参加してみよう! ---------------------------------------------検索結果は原則、ランダムになります。
コマンドを叩くたびに違う勉強会の情報を読めるのは、ちょっと楽しい!処理の実装
実装はこちらになります。
Python 3 で書いています。import sys import random import requests import time from datetime import datetime def main(): args = sys.argv keywords = [] ym = "" print('---------------------------------------------') print('# (・∀・) connpassイベント 何がでるかな?') print('# 機能:ランダムで1件 イベントを検索します') print('---------------------------------------------') keywords, ym = _check(args) print('') print('検索中・・・') print('') event_data = _req(keywords, ym, 10) if len(event_data['events']) == 1: print('■ 検索結果') else: time.sleep(1) event_data = _req(keywords, ym, 1) if len(event_data['events']) == 1: print('■ 検索結果') else: print('(*_*;) 検索失敗 該当するイベントが見つかりませんでした') exit() for event in event_data['events']: if event['catch'] is not None: print('イベント名:' + event['title'] + ' ' + event['catch']) else: print('イベント名:' + event['title']) if event['started_at'] is not None: print('開 催 日:' + event['started_at']) if event['address'] is not None: print('場 所:' + event['address']) if event['place'] is not None: print('会 場:' + event['place']) if event['event_url'] is not None: print('詳細ページ:' + event['event_url']) if event['limit'] is not None: print('参加者定員:' + str(event['limit'])) if event['accepted'] is not None: print('参 加 者:' + str(event['accepted'])) if event['waiting'] is not None: print('補 欠 者:' + str(event['waiting'])) # if event['description'] is not None: # print('概 要:' + event['description']) if event['series'] is not None: if event['series']['title'] is not None: print('主催グループ名 :' + event['series']['title']) if event['series']['url'] is not None: print('主催グループURL:' + event['series']['url']) print('') print('↑ピン!ときたら、ぜひ参加してみよう!') print('---------------------------------------------') def _check(args): if len(args) == 1: print('(*_*;) INPUT ERROR:第1引数(検索キーワード)は必須です') exit() keywords = args[1] ym = datetime.now().strftime("%Y%m") if len(args) == 3: if (len(args[2]) == 6 or len(args[2]) == 8) and args[2].isdigit(): ym = args[2] else: print('(*_*;) INPUT ERROR:第2引数(開催年月)の入力時は「yyyymm」または「yyyymmdd」の形式で入力してください') exit() return keywords, ym def _req(keywords, ym, rand): params = { 'keyword': keywords, 'order': random.randint(1, 3), 'start': random.randint(1, rand), 'count': 1 } if len(ym) == 6: params['ym'] = ym else: params['ymd'] = ym url = 'https://connpass.com/api/v1/event/' r = requests.get(url, params=params) return r.json() if __name__ == '__main__': main()実装詳細
まずはコマンドライン引数の仕様について。
上記例では「検索キーワード」だけを指定しましたが、
実際にはもう1つ「開催年月日」を指定できるようにしています。「開催年月日」は毎回打つのが手間ですので、
省略時は「システム年月」を自動で設定するようにしました。
「開催年月日」を指定する時は「yyyymm」か「yyyymmdd」を入力します。コマンドライン引数関連の処理
def _check(args): if len(args) == 1: print('(*_*;) INPUT ERROR:第1引数(検索キーワード)は必須です') exit() keywords = args[1] ym = datetime.now().strftime("%Y%m") if len(args) == 3: if (len(args[2]) == 6 or len(args[2]) == 8) and args[2].isdigit(): ym = args[2] else: print('(*_*;) INPUT ERROR:第2引数(開催年月)の入力時は「yyyymm」または「yyyymmdd」の形式で入力してください') exit() return keywords, ym続いて Connpass API へのリクエストについて。
ランダム1件検索と謳っておりますが、正しくは以下の仕様としています。1. 「更新日時順」「開催日時順」「新着順」のいずれかランダムの検索で 「検索上位10件から1件」をランダム出力する 2. 上記1で該当がない(検索結果が10件以下の場合にランダム指定した数が検索数以上だった時)は 1秒待ってから「更新日時順」「開催日時順」「新着順」のいずれかランダムの検索で 「検索上位1件」に絞って出力する 3. 上記2で該当がない場合は「検索失敗」とするですので、ピンポイントな「検索キーワード」を指定した場合は、
Connpass API へ2回リクエストを飛ばすこともある。という仕様になっています。ConnpassAPI へのリクエストパラメータは params で定義しました。
概要はリファレンスを見ていただければ幸いです。
https://connpass.com/about/api/(ちなみにリファレンスを見るとわかるのですが、
先述の例で「Python」「大阪」で「大阪の勉強会」が検索できたケース。
実際には「検索キーワード」は「イベント概要内の文字列」までを見にいきますので、
「大阪」と入れたのに「東京の勉強会」がヒットした、といったケースもあり。
(例:「東京の勉強会」だけど講師の方のプロフィールに「大阪出身」と書いていた…etc)
何か良い解決方法はないものか・・・。)ConnpassAPI へのリクエスト関連処理
print('') print('検索中・・・') print('') event_data = _req(keywords, ym, 10) if len(event_data['events']) == 1: print('■ 検索結果') else: time.sleep(1) event_data = _req(keywords, ym, 1) if len(event_data['events']) == 1: print('■ 検索結果') else: print('(*_*;) 検索失敗 該当するイベントが見つかりませんでした') exit() : 中略 : def _req(keywords, ym, rand): params = { 'keyword': keywords, 'order': random.randint(1, 3), 'start': random.randint(1, rand), 'count': 1 } if len(ym) == 6: params['ym'] = ym else: params['ymd'] = ym url = 'https://connpass.com/api/v1/event/' r = requests.get(url, params=params) return r.json()そして最後に、検索結果の表示。
ここでは、やたら if で要素の存在確認を行っています。その理由は、Connpass イベントの必須入力項目は、
イベントの「タイトル」のみだからです。
だから「タイトル」以外はNULLがあり得る。チェックが必要と考えました。
それにしても、イベント名だけでイベント登録が完了する潔さ。
思わず自分もIT勉強会を企画してみようかと思ってしまう!
(って、そんな立派なネタないでしょorz)検索結果の表示関連処理
for event in event_data['events']: if event['catch'] is not None: print('イベント名:' + event['title'] + ' ' + event['catch']) else: print('イベント名:' + event['title']) if event['started_at'] is not None: print('開 催 日:' + event['started_at']) if event['address'] is not None: print('場 所:' + event['address']) if event['place'] is not None: print('会 場:' + event['place']) if event['event_url'] is not None: print('詳細ページ:' + event['event_url']) if event['limit'] is not None: print('参加者定員:' + str(event['limit'])) if event['accepted'] is not None: print('参 加 者:' + str(event['accepted'])) if event['waiting'] is not None: print('補 欠 者:' + str(event['waiting'])) # if event['description'] is not None: # print('概 要:' + event['description']) if event['series'] is not None: if event['series']['title'] is not None: print('主催グループ名 :' + event['series']['title']) if event['series']['url'] is not None: print('主催グループURL:' + event['series']['url']) print('') print('↑ピン!ときたら、ぜひ参加してみよう!') print('---------------------------------------------')まとめ
ConnpassAPIを使って勉強会情報を検索するようにしてみました。
情報量を敢えて減らすことで、公式サイトでの検索とは違った楽しさを味わえればと感じた次第。
何より黒画面だから仕事中にこっそり検索できるwwwこちらの実装は、git hub でも公開中です。
git hub には本件を対話型のインプットで組んだ処理もあげております。
荒削りにも程がありますけど、ご興味ある方はぜひどうそ。
https://github.com/masashi-sawai/python-learning/tree/master/tools/conpass_searchそんなわけで、
みなさまご自身の強みにつながる「良い勉強会との出会い」に、
本投稿が少しでも役立てば幸いです!
- 投稿日:2019-07-24T21:15:43+09:00
connpass API でIT勉強会の情報を手軽にランダム1件検索
前書き
多種多様に開催されているIT勉強会。
自分は開催情報を知るきっかけの一つに「connpass」をよく利用しています。connpass - エンジニアをつなぐIT勉強会支援プラットフォーム
https://connpass.com/IT勉強会を「Python」で検索してみました。
結果、251件ヒット。かなりの数のIT勉強会が開催されていますね。
都道府県で絞ればもう少し数も絞れるとはいえ、
開催数が多くて、選び出すところでひと苦労してしまう。。。自分はまさにそんな感じの人です orz
何がしたいのか
もっと積極的にIT勉強会へ参加する。
そのきっかけに「手軽なIT勉強会の検索処理」を作りたい!やったこと
connpass API からIT勉強会の情報を、
お手軽にランダム1件検索する処理を書いてみました。なぜランダム1件検索?
何が検索されるか分からない
ガチャ的なwワクワク感と、
検索を敢えて1件に絞って情報量を減らすことで、
検索結果をしっかり読むきっかけにできないかと考えました。connpass API
connpassはイベントサーチ用APIを提供しており、
誰でも利用することができるようになっています。
こちらを利用させていただきました。connpass API
https://connpass.com/about/api/実行結果
先に処理の実行結果から。
pythonコマンドで該当処理を「検索キーワード」をつけて実行します。
検索キーワードを「Python」にしてみます。python connpass_search.py python実行結果はこんな感じになりました。
(一応伏せ字にしましたが、実際の実行結果は全ての情報が閲覧可能です。)--------------------------------------------- # (・∀・) connpassイベント 何がでるかな? # 機能:ランダムで1件 イベントを検索します --------------------------------------------- 検索中・・・ ■ 検索結果 イベント名:Fintech,Pyt…気。。。略 開 催 日:2019-07-24T19:3。。。略 場 所:東京都港区。。。略 会 場:Cre。。。略 詳細ページ:https://cuc。。。略 参加者定員:17 参 加 者:7 補 欠 者:0 主催グループ名 :Cuc。。。略 主催グループURL:https://cuc。。。略 ↑ピン!ときたら、ぜひ参加してみよう! ---------------------------------------------また「検索キーワード」は「複数指定(AND検索)」もできます。
検索キーワードを「Python」「大阪」にしてみます。python connpass_search.py python,大阪実行結果はこんな感じになりました。
(一応伏せ字にしましたが、実際の実行結果は全ての情報が閲覧可能です。)--------------------------------------------- # (・∀・) connpassイベント 何がでるかな? # 機能:ランダムで1件 イベントを検索します --------------------------------------------- 検索中・・・ ■ 検索結果 イベント名:阪医pyth。。。略 開 催 日:2019-07-26T1:。。。略 場 所:大阪府大阪市。。。略 会 場:PLU。。。略 詳細ページ:https://ou。。。略 参加者定員:30 参 加 者:17 補 欠 者:0 主催グループ名 :阪医pyth。。。略 主催グループURL:https://ou。。。略 ↑ピン!ときたら、ぜひ参加してみよう! ---------------------------------------------検索結果は原則、ランダムになります。
コマンドを叩くたびに違う勉強会の情報を読めるのは、ちょっと楽しい!実装
実装はこちらになります。
Python 3 で書いています。import sys import random import requests import time from datetime import datetime def main(): args = sys.argv keywords = [] ym = "" print('---------------------------------------------') print('# (・∀・) connpassイベント 何がでるかな?') print('# 機能:ランダムで1件 イベントを検索します') print('---------------------------------------------') keywords, ym = _check(args) print('') print('検索中・・・') print('') event_data = _req(keywords, ym, 10) if len(event_data['events']) == 1: print('■ 検索結果') else: time.sleep(1) event_data = _req(keywords, ym, 1) if len(event_data['events']) == 1: print('■ 検索結果') else: print('(*_*;) 検索失敗 該当するイベントが見つかりませんでした') exit() for event in event_data['events']: if event['catch'] is not None: print('イベント名:' + event['title'] + ' ' + event['catch']) else: print('イベント名:' + event['title']) if event['started_at'] is not None: print('開 催 日:' + event['started_at']) if event['address'] is not None: print('場 所:' + event['address']) if event['place'] is not None: print('会 場:' + event['place']) if event['event_url'] is not None: print('詳細ページ:' + event['event_url']) if event['limit'] is not None: print('参加者定員:' + str(event['limit'])) if event['accepted'] is not None: print('参 加 者:' + str(event['accepted'])) if event['waiting'] is not None: print('補 欠 者:' + str(event['waiting'])) # if event['description'] is not None: # print('概 要:' + event['description']) if event['series'] is not None: if event['series']['title'] is not None: print('主催グループ名 :' + event['series']['title']) if event['series']['url'] is not None: print('主催グループURL:' + event['series']['url']) print('') print('↑ピン!ときたら、ぜひ参加してみよう!') print('---------------------------------------------') def _check(args): if len(args) == 1: print('(*_*;) INPUT ERROR:第1引数(検索キーワード)は必須です') exit() keywords = args[1] ym = datetime.now().strftime("%Y%m") if len(args) == 3: if (len(args[2]) == 6 or len(args[2]) == 8) and args[2].isdigit(): ym = args[2] else: print('(*_*;) INPUT ERROR:第2引数(開催年月)の入力時は「yyyymm」または「yyyymmdd」の形式で入力してください') exit() return keywords, ym def _req(keywords, ym, rand): params = { 'keyword': keywords, 'order': random.randint(1, 3), 'start': random.randint(1, rand), 'count': 1 } if len(ym) == 6: params['ym'] = ym else: params['ymd'] = ym url = 'https://connpass.com/api/v1/event/' r = requests.get(url, params=params) return r.json() if __name__ == '__main__': main()実装詳細
まずはコマンドライン引数の仕様について。
上記例では「検索キーワード」だけを指定しましたが、
実際にはもう1つ「開催年月日」を指定できるようにしています。「開催年月日」は毎回打つのが手間ですので、
省略時は「システム年月」を自動で設定するようにしました。
「開催年月日」を指定する時は「yyyymm」か「yyyymmdd」を入力します。コマンドライン引数関連の処理
def _check(args): if len(args) == 1: print('(*_*;) INPUT ERROR:第1引数(検索キーワード)は必須です') exit() keywords = args[1] ym = datetime.now().strftime("%Y%m") if len(args) == 3: if (len(args[2]) == 6 or len(args[2]) == 8) and args[2].isdigit(): ym = args[2] else: print('(*_*;) INPUT ERROR:第2引数(開催年月)の入力時は「yyyymm」または「yyyymmdd」の形式で入力してください') exit() return keywords, ym続いて connpass API へのリクエストについて。
ランダム1件検索と謳っておりますが、正しくは以下の仕様としています。1. 「更新日時順」「開催日時順」「新着順」のいずれかランダムの検索で 「検索上位10件から1件」をランダム出力する 2. 上記1で該当がない(検索結果が10件以下の場合にランダム指定した数が検索数以上だった時)は 1秒待ってから「更新日時順」「開催日時順」「新着順」のいずれかランダムの検索で 「検索上位1件」に絞って出力する 3. 上記2で該当がない場合は「検索失敗」とするですので、ピンポイントな「検索キーワード」を指定した場合は、
connpass API へ2回リクエストを飛ばすこともある。という仕様になっています。connpassAPI へのリクエストパラメータは params で定義しました。
概要はリファレンスを見ていただければ幸いです。
https://connpass.com/about/api/(ちなみにリファレンスを見るとわかるのですが、
先述の例で「Python」「大阪」で「大阪の勉強会」が検索できたケース。
実際には「検索キーワード」は「イベント概要内の文字列」までを見にいきますので、
「大阪」と入れたのに「東京の勉強会」がヒットした、といったケースもあり。
(例:「東京の勉強会」だけど講師の方のプロフィールに「大阪出身」と書いていた…etc)
何か良い解決方法はないものか・・・。)connpassAPI へのリクエスト関連処理
print('') print('検索中・・・') print('') event_data = _req(keywords, ym, 10) if len(event_data['events']) == 1: print('■ 検索結果') else: time.sleep(1) event_data = _req(keywords, ym, 1) if len(event_data['events']) == 1: print('■ 検索結果') else: print('(*_*;) 検索失敗 該当するイベントが見つかりませんでした') exit() : 中略 : def _req(keywords, ym, rand): params = { 'keyword': keywords, 'order': random.randint(1, 3), 'start': random.randint(1, rand), 'count': 1 } if len(ym) == 6: params['ym'] = ym else: params['ymd'] = ym url = 'https://connpass.com/api/v1/event/' r = requests.get(url, params=params) return r.json()そして最後に、検索結果の表示。
ここでは、やたら if で要素の存在確認を行っています。その理由は、connpass イベントの必須入力項目は、
イベントの「タイトル」のみだからです。
だから「タイトル」以外はNULLがあり得る。チェックが必要と考えました。
それにしても、イベント名だけでイベント登録が完了する潔さ。
思わず自分もIT勉強会を企画してみようかと思ってしまう!
(って、そんな立派なネタないでしょorz)検索結果の表示関連処理
for event in event_data['events']: if event['catch'] is not None: print('イベント名:' + event['title'] + ' ' + event['catch']) else: print('イベント名:' + event['title']) if event['started_at'] is not None: print('開 催 日:' + event['started_at']) if event['address'] is not None: print('場 所:' + event['address']) if event['place'] is not None: print('会 場:' + event['place']) if event['event_url'] is not None: print('詳細ページ:' + event['event_url']) if event['limit'] is not None: print('参加者定員:' + str(event['limit'])) if event['accepted'] is not None: print('参 加 者:' + str(event['accepted'])) if event['waiting'] is not None: print('補 欠 者:' + str(event['waiting'])) # if event['description'] is not None: # print('概 要:' + event['description']) if event['series'] is not None: if event['series']['title'] is not None: print('主催グループ名 :' + event['series']['title']) if event['series']['url'] is not None: print('主催グループURL:' + event['series']['url']) print('') print('↑ピン!ときたら、ぜひ参加してみよう!') print('---------------------------------------------')まとめ
connpassAPIを使って勉強会情報を検索するようにしてみました。
情報量を敢えて減らすことで、公式サイトでの検索とは違った楽しさを味わえればと感じた次第。
何より黒画面だから仕事中にこっそり検索できるwwwこちらの実装は、git hub でも公開中です。
git hub には本件を対話型のインプットで組んだ処理もあげております。
荒削りにも程がありますけど、ご興味ある方はぜひどうそ。
https://github.com/masashi-sawai/python-learning/tree/master/tools/conpass_searchそんなわけで、
みなさまご自身の強みにつながる「良い勉強会との出会い」に、
本投稿が少しでも役立てば幸いです!
- 投稿日:2019-07-24T19:16:50+09:00
[初心者向け]稀有だと思うけど、外部ライブラリ使わずに表形式加工
タイトルの通りになりますが、お仕事の内容によってはこの様なレアなケースもあるかと思います。
使った構文等をメモがてらに残していこうと思います。
Pythonのバージョンは3.6です。
Python初心者のため、間違い等ありましたら、コメント頂けますと幸いです。目標
2つの表形式の.tsvファイルから必要なデータを取り出し1つの表形式データにしたい。
importしたもの
import.pyimport gzip #圧縮ファイルを処理する場合必要 import csv #csvやtsvで書き込む場合必要 import sys #コマンド実行時 引数をとる場合必要ファイル読み込み
2種類の方法を検討しました
open関数
open.py#読み込みモードでファイルを開く file = open("data.tsv","rt") ###処理等### #ファイルを閉じる file.close()・詳細のモードの設定など
この場合、テキストでの読み込みをしています。
モードを指定することで書き込みなどもできる様になります。
close()を忘れずに。with open
withopen.pywith open("data.tsv", "rt") as file大きな違いはclose()が必要なく、勝手にファイルをクローズしてくれます。
with構文は通信やデータベースへのアクセスにも使えて、これらも勝手にクローズや終了をしてくれます。
こちらもモードを指定することで書き込みもできます。
今回はこちらを採用いたしました。実行時の引数を取得
pythonの実行時に引数を入れることでそれに応じた処理をさせたい時に利用できます。
例えばこんな感じで実行
$ python sys.py 12 24 36sys.pyargs = sys.argv #宣言 引数2個以上の場合、配列になる #args[0]にはスクリプトファイル名が入るため、args[1]から取得していく num1 = args[1] #num1 = 12 num2 = args[2] #num2 = 24 num3 = args[3] #num3 = 36必要な列のデータを取得
表形式なので、表を縦に分割して、必要な列を取り出します。
file1:
ア行 カ行 サ行 あ か さ い き し う く す file2:
サ行 タ行 ナ行 さ た な す つ ぬ せ て ね これはテーブル型なので、少しややこしいですが、データはtsvなので、表形式でタブ区切りのものです。
そのタブを区切り文字として指定することで列を取得できます。
列はカラムを含めると4つデータを取得する必要がありますので、for文で繰り返し処理をします。
今回はfile1からア行とサ行を、file2からサ行とナ行を取得します。split.pydata1 = [] data2 = [] data3 = [] data4 = [] for line1 in file1: list1 = file1.split('\t') #タブを区切り文字にして分割 data1.append(list1[1]) #[あ、い、う] data2.append(list1[3]) #[さ、し、す] for line2 in file2: list2 = file2.split('\t') data3.append(list2[1]) #[さ、す、せ] data4.append(list2[3]) #[な、ぬ、ね]for文の条件にfileを指定するとファイルの中身が終わるまで処理をしてくれます。
dataは配列で入るため、事前に宣言をしています。表形式結合
SQLでテーブルを結合させる際は、共通のデータを照らし合わせます。
その様な動きを条件文を使ってやってみます。
file1から取得したデータとfile2から取得したデータをそれぞれfor文で回し、データの内容が一致するものを格納する流れにします。
今回はサ行のデータを条件にします。join.pytable = [] for i in range(len(data1)): #4 range(len('変数名'))でデータの数を返します。 for j in range(len(data3)): if data2[i] == data3[j]: table.append([data1[i], data2[i], data4[j])
ア行 サ行 ナ行 あ さ な う す ぬ この様に表形式のデータを結合することができました。
ファイル書き込み
このデータを新たなファイルに書き込んでいきます。
write.pywith open.gzip("data.tsv.gz", "rt") as file: write = csv.writer(file, lineterminator = '\n', delimiter = '\t') for output_data in table: writer.writerow(output_data)最初にcsvライブラリをimportしましたが、ここで登場します。
Pythonの標準ライブラリにcsvモジュールはcsvやtsvで読み込みや書き込みを行うことが可能です。
・csvライブラリ
区切り文字(delimiter)をタブにすることでtsvファイルでの保存が可能になります。
lineterninatorは改行文字です。また、with open.gzipとすることでgzファイルに圧縮することも可能です。
まとめ
標準ライブラリの使用のみで表形式データを加工することができました。
結合以外にも変換や、datatime処理をしましたが、それはまた書く気になったら別で書きます。僕自身、初めてのPythonだったのですが、配列関係、インデント関係のエラーで結構詰まりました。
その辺りは他の丁寧に書かれている記事を参考にしてください(逃げます)最後に.....
表形式を加工する場合、よっぽどの理由がない限りは、外部ライブラリのpandasやNumpyの使用をオススメします。
- 投稿日:2019-07-24T19:04:30+09:00
[備忘録]MoveIt!の使い方
はじめに
この記事は,ここ数年でかなり使われるようになってきた,ロボットの動作計画ライブラリMoveIt!について紹介していきます.基本的には,マニピュレータを使ったものについて解説していきたいと思います.ここでは,ROSの基本構造は理解していること,ROSのチュートリアルは終了していることにします.まだインストールしてない方は,http://wiki.ros.org/ja から始めてみましょう.
MoveIt!を始めよう!
ここでは,OSをUbuntu 16.04 LTS,ROSのバージョンはKineticとなっています.バージョンが違うとコードも若干変わってくるのでKineticを前提として話を進めていきます.Ubuntu18.04のROS Melodic は環境が整えば書きたいと思います.なお参考文献はROS Melodicを前提に解説してあります.
既存のROSパッケージを更新する
rosdep update sudo apt-get updateMoveIt!のインストール
sudo apt install ros-kinetic-moveitワークスペースを作る
sudo apt install ros-kinetic-moveitGitHubからパッケージをダウンロード
GitHubにチュートリアル用のパッケージをダウンロードします.オプション-bの後にバージョンを指定します.
cd ~/ws_moveit/src git clone https://github.com/ros-planning/moveit_tutorials.git -b kinetic-devel git clone https://github.com/ros-planning/panda_moveit_config.git -b kinetic-develワークスペースのビルド
依存関係にあるパッケージをまとめてインストールします.オプション--rosdistroの後にバージョンを指定します.
cd ~/ws_moveit/src rosdep install -y --from-paths . --ignore-src --rosdistro kineticパッケージをビルドします.
cd ~/ws_moveit/ catkin_make環境設定ファイルを適用します.
source ~/ws_moveit/devel/setup.bashさあ,これでMoveIt!が使えるようになります.ビルドに失敗している場合は,足りないパッケージをインストールするなどのコードを実行する必要があります.
参考文献
- 投稿日:2019-07-24T19:04:30+09:00
MoveIt!の使い方
はじめに
この記事は,ここ数年でかなり使われるようになってきた,ロボットの動作計画ライブラリMoveIt!について紹介していきます.基本的には,マニピュレータを使ったものについて解説していきたいと思います.ここでは,ROSの基本構造は理解していること,ROSのチュートリアルは終了していることにします.まだインストールしてない方は,http://wiki.ros.org/ja から始めてみましょう.
MoveIt!を始めよう!
ここでは,OSをUbuntu 16.04 LTS,ROSのバージョンはKineticとなっています.バージョンが違うとコードも若干変わってくるのでKineticを前提として話を進めていきます.Ubuntu18.04のROS Melodic は環境が整えば書きたいと思います.なお参考文献はROS Melodicを前提に解説してあります.
既存のROSパッケージを更新する
rosdep update sudo apt-get updateMoveIt!のインストール
sudo apt install ros-kinetic-moveitワークスペースを作る
mkdir -p ~/ws_moveit/srcGitHubからパッケージをダウンロード
GitHubにチュートリアル用のパッケージをダウンロードします.オプション-bの後にバージョンを指定します.
cd ~/ws_moveit/src git clone https://github.com/ros-planning/moveit_tutorials.git -b kinetic-devel git clone https://github.com/ros-planning/panda_moveit_config.git -b kinetic-develワークスペースのビルド
依存関係にあるパッケージをまとめてインストールします.オプション--rosdistroの後にバージョンを指定します.
cd ~/ws_moveit/src rosdep install -y --from-paths . --ignore-src --rosdistro kineticパッケージをビルドします.
cd ~/ws_moveit/ catkin_make環境設定ファイルを適用します.
source ~/ws_moveit/devel/setup.bashさあ,これでMoveIt!が使えるようになります.ビルドに失敗している場合は,足りないパッケージをインストールするなどのコードを実行する必要があります.
参考文献
https://moveit.ros.org/
https://ros-planning.github.io/moveit_tutorials/doc/getting_started/getting_started.html
- 投稿日:2019-07-24T18:18:39+09:00
EC2を特定の時間に自動で起動/停止する
概要
いったい何番煎じだよという感じですが、Lambda上にデプロイしたコードから、EC2のインスタンスを定期的に起動/停止させます。
今の時代、こちらの記事にある通り、プログラムを書かずともLambdaの定期起動/停止ができてしまいます。
それでも、本記事のコードをデプロイした後であれば、EC2インスタンスを立てるたびにCloudWatchの設定をいじる必要もなく、立てたEC2インスタンスにタグを追加するだけで自動起動/停止の設定ができるようになり、便利です。Lambdaの設定
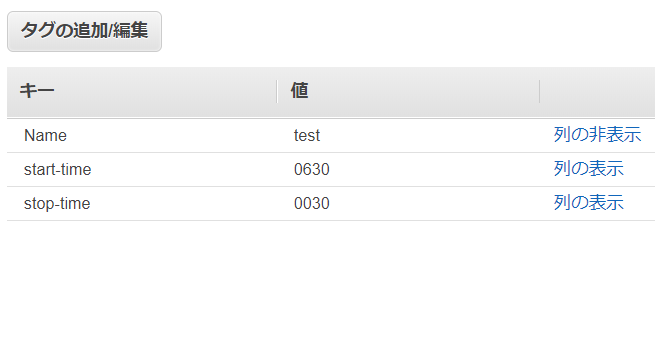
本記事のコードは、Lambdaに設定されているタグを見て、インスタンスの起動/停止を行います。そのため、自動設定対象にしたいEC2インスタンスには、以下のように
start-time,stop-timeのタグをつけます。それぞれ、起動時間と停止時間をHHMM形式で表します。
コード
以下のコードを、Lambdaにデプロイします。もちろん、EC2を起動や停止するための、適当なIAMロールをつけます。
manage_ec2.pyimport boto3; import datetime; # 最初に呼ばれる関数 def lambda_handler(event, context): client = boto3.client('ec2', 'ap-northeast-1') # boto3でec2の全インスタンスの情報を取得 response = client.describe_instances() # 必要な情報のみを抜き出したリストを作成 instance_list = extract_instance_info(response) # 上のリストを基に、必要であればインスタンスを起動/停止する manage_instances(instance_list) # ec2インスタンスのリストを作成 def extract_instance_info(response): return_val = [] for instance_data in response['Reservations'][0]['Instances']: try: tmp = {} # インスタンスのid tmp['id'] = instance_data['InstanceId'] # タグで指定されている起動時間 tmp['start_time'] = convert_time([tag['Value'] for tag in instance_data['Tags'] if tag['Key'] == 'start-time'][0]) # タグで指定されている終了時間 tmp['stop_time'] = convert_time([tag['Value'] for tag in instance_data['Tags'] if tag['Key'] == 'stop-time'][0]) # 現在のインスタンスの起動状況 tmp['status'] = instance_data['State']['Name'] return_val.append(tmp) except: # かなり乱暴なのは承知ですが、自動起動/停止対象外のインスタンス(タグが設定されていないもの)があれば、例外を発生させて無視します continue print(return_val) return return_val # タグで指定されている起動/停止時間を、datetime.time型に変換 def convert_time(str_time): hour = int(str_time[:2]) min = int(str_time[2:4]) return datetime.time(hour,min) # インスタンスの起動/停止を行う def manage_instances(instance_list): # 現在時刻をdatetime.time型で取得 current_time = datetime.datetime.now().time() for instance in instance_list: # インスタンス停止中で、起動時間を過ぎていれば、インスタンスを立ち上げる if instance['status'] != 'running' and current_time >= instance['start_time']: response = ec2.start_instances( InstanceIds=[ instance['id'] ] ) print(response) # インスタンス起動中で、停止時間を過ぎていれば、インスタンスを停止する elif instance['status'] == 'running' and current_time <= instance['stop_time']: response = ec2.stop_instances( InstanceIds=[ instance['id'] ] ) print(response) else: # 何もすることないけど、ログだけ出しとく print('no action was taken')このコードをデプロイしたLambda関数を、CloudWatchで30分おきなどで実行させれば、完成です。
上のコードでは現在時刻を取得するコードが含まれているので、Lambdaの環境変数に、必ず
TZ:Asia/Tokyoを付け加えてください。
- 投稿日:2019-07-24T18:18:39+09:00
EC2をタグに基づいて、特定の時間に自動で起動/停止する
概要
いったい何番煎じだよという感じですが、Lambda上にデプロイしたコードから、EC2のインスタンスを定期的に起動/停止させます。
今の時代、こちらの記事にある通り、プログラムを書かずともLambdaの定期起動/停止ができてしまいます。
それでも、本記事のコードをデプロイした後であれば、EC2インスタンスを立てるたびにCloudWatchの設定をいじる必要もなく、インスタンスにタグを追加するだけで自動起動/停止の設定ができるようになり、便利です。Lambdaの設定
本記事のコードは、EC2に設定されているタグを見て、インスタンスの起動/停止を行います。そのため、自動設定対象にしたいEC2インスタンスには、以下のように
start-time,stop-timeのタグをつけます。それぞれ、起動時間と停止時間をHHMM形式で表します。
コード
以下のコードを、Lambdaにデプロイします。もちろん、LambdaにはEC2を起動や停止するための、適当なIAMロールをつけます。
manage_ec2.pyimport boto3; import datetime; # 最初に呼ばれる関数 def lambda_handler(event, context): client = boto3.client('ec2', 'ap-northeast-1') # boto3でec2の全インスタンスの情報を取得 response = client.describe_instances() # 必要な情報のみを抜き出したリストを作成 instance_list = extract_instance_info(response) # 上のリストを基に、必要であればインスタンスを起動/停止する manage_instances(instance_list) # ec2インスタンスのリストを作成 def extract_instance_info(response): return_val = [] for instance_data in response['Reservations'][0]['Instances']: try: tmp = {} # インスタンスのid tmp['id'] = instance_data['InstanceId'] # タグで指定されている起動時間 tmp['start_time'] = convert_time([tag['Value'] for tag in instance_data['Tags'] if tag['Key'] == 'start-time'][0]) # タグで指定されている終了時間 tmp['stop_time'] = convert_time([tag['Value'] for tag in instance_data['Tags'] if tag['Key'] == 'stop-time'][0]) # 現在のインスタンスの起動状況 tmp['status'] = instance_data['State']['Name'] return_val.append(tmp) except: # かなり乱暴なのは承知ですが、自動起動/停止対象外のインスタンス(タグが設定されていないもの)があれば、例外を発生させて無視します continue print(return_val) return return_val # タグで指定されている起動/停止時間を、datetime.time型に変換 def convert_time(str_time): hour = int(str_time[:2]) min = int(str_time[2:4]) return datetime.time(hour,min) # インスタンスの起動/停止を行う def manage_instances(instance_list): # 現在時刻をdatetime.time型で取得 current_time = datetime.datetime.now().time() for instance in instance_list: # インスタンス停止中で、起動時間を過ぎていれば、インスタンスを立ち上げる if instance['status'] != 'running' and current_time >= instance['start_time']: response = ec2.start_instances( InstanceIds=[ instance['id'] ] ) print(response) # インスタンス起動中で、停止時間を過ぎていれば、インスタンスを停止する elif instance['status'] == 'running' and current_time <= instance['stop_time']: response = ec2.stop_instances( InstanceIds=[ instance['id'] ] ) print(response) else: # 何もすることないけど、ログだけ出しとく print('no action was taken')このコードをデプロイしたLambda関数を、CloudWatchで30分おきなどで実行させれば、完成です。
上のコードでは現在時刻を取得するコードが含まれているので、Lambdaの環境変数に、必ず
TZ:Asia/Tokyoを付け加えてください。
- 投稿日:2019-07-24T16:47:33+09:00
COTOHAで文章の類似度を取得してみる
COTOHA
実装
- COTOHAというNTTが提供している自然言語系のAPIを触ってみます。
- 文章と文章の類似度を算出するAPIを使います。
- Ipython形式で実装します。
ライブラリのインポート
import json import numpy as np import pandas as pd import urllib.request from os import path情報の定義
- アカウントホームのデータを定義する。
- Developer API Base URLとAccess Token Publish URLは全ユーザー共通だと思いますが、念のため各自登録してお調べください。
 base_url = [Developer API Base URL] developer_id = [Developer Client id] secret = [Developer Client secret] token_url = [Access Token Publish URL] 'Content-Type': 'application/json', }
base_url = [Developer API Base URL] developer_id = [Developer Client id] secret = [Developer Client secret] token_url = [Access Token Publish URL] 'Content-Type': 'application/json', }アクセストークンの取得
- アクセストークンを取得するため、POSTでアクセストークン取得用のAPIにアクセスします。
data = { 'grantType': 'client_credentials', 'clientId': developer_id, 'clientSecret': secret } req = urllib.request.Request(token_url, json.dumps(data).encode(), headers=headers, method='POST') with urllib.request.urlopen(req) as res: access_info = json.load(res)print(access_info['access_token'])単語文章同士の類似度取得
*取得したアクセストークンをヘッダーに詰めて、類似度取得APIにアクセスします。
def similarity_api(s1: str, s2: str): data = { 's1': s1, 's2': s2, 'type': 'default' } headers = { 'Content-Type': 'application/json;charset=UTF-8', 'Authorization': 'Bearer {}'.format(access_info['access_token']) } url = base_url + 'nlp/v1/similarity' req = urllib.request.Request(url, json.dumps(data).encode(), headers=headers, method='POST') with urllib.request.urlopen(req) as res: body = json.load(res) return bodysimilarity_api('近くのレストランはどこですか?', 'このあたりの定食屋はどこにありますか?')所感
- 単語や文章の類似度の算出は、tf-idf、word2vecやdoc2vecで割と世の中に出回っているため、目新しさはないです。
- ただ、機械学習に慣れていない方には比較的に簡単に扱えるため、便利だと思います。
- また、wikipediaのデータで自分で学習したword2vecのモデルより、対応している単語も多くかつ、類似度の精度も高い印象でした。

- 投稿日:2019-07-24T16:44:08+09:00
Pythonのurllib.requestで配列を含んだクエリを使ってGETリクエストする方法
はじめに
PythonであるURLにGETリクエストを行おうとした際に、クエリに数字配列と文字列配列が含まれており、ハンドリングに困ったので備忘録として解決策を残します。
解決策
以下のように渡すことで解決しました。
- 数値(
param1)はクォーテーションで囲わずに渡す- 文字列(
param2)はクォーテーションで囲って渡す- 数値配列(
param3)は[]で囲って渡す
- 各要素はクォーテーションで囲わない
- 文字列配列(
param4)はparam4[0]、param4[1]のように添え字を含めて、要素数分だけ記載して渡す
- 各要素はクォーテーションで囲う
requesttest.py# 読み込み import urllib.request # URLとクエリを定義 url = "http://hogehoge.com" params = { 'param1':123, 'param2':'abc', 'param3':[0,2,3,4,5], 'param4[0]':'aaaaaa', 'param4[1]':'bbbbbb', } # リクエスト実行 req = urllib.request.Request('{}?{}'.format(url, urllib.parse.urlencode(params))) with urllib.request.urlopen(req) as res: body = res.read()
- 投稿日:2019-07-24T16:32:08+09:00
[Rust] PyO3 でモジュール構造を持つ Python パッケージ
前記事 の続きです.
中規模以上のパッケージの場合, 関数を複数のモジュールに分けたくなると思います (SciPy の
scipy.optimize,scipy.integrateのように). ほぼ前回の記事通りですが, 若干ハマった部分があるので詳しく書いておきます.モジュールの作成
具体的に英語と日本語で hello world を出力する
languageパッケージをつくってみます. まずはモジュールを普通につくります.src/en.rsuse pyo3::prelude::*; use pyo3::wrap_pyfunction; #[pyfunction] fn hello() -> PyResult<()> { println!("Hello, world!"); Ok(()) } #[pymodule] fn english(_py: Python, m: &PyModule) -> PyResult<()> { m.add_wrapped(wrap_pyfunction!(hello))?; Ok(()) }src/ja.rsuse pyo3::prelude::*; use pyo3::wrap_pyfunction; #[pyfunction] fn hello() -> PyResult<()> { println!("こんにちは, 世界!"); Ok(()) } #[pymodule] fn japanese(_py: Python, m: &PyModule) -> PyResult<()> { m.add_wrapped(wrap_pyfunction!(hello))?; Ok(()) }ここで, 本体 (
src/lib.rs) から参照することになるenglish,japanese関数にpubを付ける必要はありません. というのも,#[pymodule]アトリビュートによりラッパー関数が自動的に生成され, そちらを読み込みに行くからです. その結果, 本体は次のようなコードになります.src/lib.rsuse pyo3::prelude::*; use pyo3::wrap_pymodule; mod en; use en::*; mod ja; use ja::*; #[pymodule] fn language(_py: Python, m: &PyModule) -> PyResult<()> { m.add_wrapped(wrap_pymodule!(english))?; m.add_wrapped(wrap_pymodule!(japanese))?; Ok(()) }ここで例えば
use en::english;とするとコンパイルエラーになります. これは, 上で指摘したように,language関数内でen::english関数を呼び出しているように見えますが,wrap_pymoduleマクロのために実際に呼び出している関数はen::PyInit_english関数だからです (なのでこの関数を直接useしても動きます).Python から呼び出し
Cargo.tomlやコンパイル,.soファイルの配置などは前記事通りです.$ python3 Python 3.7.2 (default, Jan 24 2019, 15:36:28) [GCC 6.3.0 20170516] on linux Type "help", "copyright", "credits" or "license" for more information. >>> import language >>> >>> language.english.hello() Hello, world! >>> language.japanese.hello() こんにちは, 世界! >>>
- 投稿日:2019-07-24T16:22:11+09:00
Pythonのスライスのテクニック
スライスにはstep機能がある
Pythonのlistのスライスには指定した数ごとに値を取り出してくれるstep機能があります。
具体的には
list[start:stop:step]
と普通のスライスの後にコロン(:)とstepの値を追加してあげます。以下に具体例をあげときます。
num_list = [1, 2, 3, 4, 5, 6, 7]
print(num_list[1:6])
print(num_list[::2])
print(num_list[1::2])
print(num_list[:6:2])
print(num_list[1:6:2])
実行結果
[2, 3, 4, 5, 6]
[1, 3, 5, 7]
[2, 4, 6]
[1, 3, 5]
[2, 4, 6]
こんな感じになります。
- 投稿日:2019-07-24T16:22:11+09:00
Pythonのスライスのstep機能
スライスにはstep機能がある
Pythonのlistのスライスには指定した数ごとに値を取り出してくれるstep機能があります。
具体的には
list[start:stop:step]
と普通のスライスの後にコロン(:)とstepの値を追加してあげます。以下に具体例をあげときます。
num_list = [1, 2, 3, 4, 5, 6, 7] print(num_list[1:6]) print(num_list[::2]) print(num_list[1::2]) print(num_list[:6:2]) print(num_list[1:6:2]) #実行結果 [2, 3, 4, 5, 6] [1, 3, 5, 7] [2, 4, 6] [1, 3, 5] [2, 4, 6]こんな感じになります。
- 投稿日:2019-07-24T16:13:44+09:00
pythonでtraitみたいなこと
Overview
ruby の
extendみたいな感じにやりたい話。$ python -V Python 3.7.2振る舞いだけ別で定義して後から mixin みたいなことは、言語の機能としてはできないっぽいけど、
typeでその場で class 生成して、対象の__class__に設定すると動的多重継承みたいにできるらしい。委譲で済むならその方が良いと思うけど。
a.pyclass TraitA: def m1(self): print(self, "m1") def m2(self): print(self, "m2") class TraitB: def m1(self): print(self, "m1") def m2(self): print(self, "m2") class Base: @classmethod def factory(cls, val): x = cls(val) if val == "A": trait = TraitA else: trait = TraitB x.__class__ = type("{}+{}".format(cls.__name__, trait.__name__), (cls, trait), {}) return x def __init__(self, val): self.val = val def __repr__(self): return "<{}>\t{}".format(self.__class__.__name__, str(self.__dict__)) def is_A(self): return isinstance(self, TraitA) def is_B(self): return isinstance(self, TraitB) if __name__ == "__main__": a = Base.factory("A") a.m1() a.m2() print(a.is_A()) print(a.is_B()) print("-"*30) b = Base.factory("B") b.m1() b.m2() print(b.is_A()) print(b.is_B())実行
$ python a.py <Base+TraitA> {'val': 'A'} m1 <Base+TraitA> {'val': 'A'} m2 True False ------------------------------ <Base+TraitB> {'val': 'B'} m1 <Base+TraitB> {'val': 'B'} m2 False True
- 投稿日:2019-07-24T16:05:10+09:00
AtCoder Beginner Contest 004
- 投稿日:2019-07-24T15:58:38+09:00
R ユーザーへの pandas 実践ガイド
概要
R で tidyverse (dplyr+tidyr) に使い慣れているが, Python に乗り換えると
pandasがどうも使いにくい, と感じている人の視点で, Rのdplyrなどとの比較を通して,pandasの効率的な使い方について書いています. そのため, 「R ユーザーへの」と書きましたが, R経験のない pandas ユーザーであってもなんらかの役に立つと思います. また, 自社インターン学生に対する教材も兼ねています. どちらかというと, 初歩を覚えたての初心者向けの記事となっています.データ分析は一発で終わることはまずなく, 集計・前処理を探索的に行う必要があります. よって, プログラムを頻繁に書き直す必要があり, 普段以上に保守性のある書き方, 例えば参照透過性を考慮した書き方をしたほうが便利です. R の
tidyverseの強みとして, 再帰代入をする必要がほとんどなく, 複雑な処理であってもかなりをワンライナーで書ける, というものがあります. 関数が, 集計, グループ化, 列の追加, というように, 機能の分け方が SQL 風になっているのもとっつきやすさにつながっていると思います. 一方で, Python のpandasは, メソッドチェーンでdplyrのパイプに近い機能を持たせるなど,tidyverseに影響された機能も多いですが, 普通に書こうとすると再帰代入を頻繁に要求されます.結果として, pandas を効率的に書くテクニックは存在しますが, 公式ドキュメントではあまり強調されていません. そこで, ここでは,
pandasで実現可能な, 効率的なデータ分析作業をする方法について紹介します.導入
この記事の記述の多くは, 以下を参考にしています.
- 『Pandas 公式チートシートを翻訳しました』
- 『Python/pandasのデータ処理で再帰代入撲滅委員会』
- 『dplyr のアレを Pandas でやる』
- 『dplyr使いのためのpandas dfplyすごい編』
最低限, [1] を読んでいて, pandas の基本的な操作を知っていることを前提としています. そして今回は, 公式チートシートを踏まえて, より効率的なやり方をいろいろと紹介します. よって,
ilocとlocの違いなど, 公式チートシートに書いてある話はあえて繰り返すことはありません. また, 教材という目的のため, 上記 [2]-[4] で紹介されている内容の繰り返しになっている箇所も多いですが, ご容赦ください.なお, 動作確認は python 3.6, pandas 0.25, dfply 0.3.3でやっています.
今回紹介するものは, 以下のようにして作成したデータフレームを使っています.
import pandas as pd import numpy as np from dfply import * np.random.seed(42) df = pd.DataFrame( { 'x': np.random.normal(size=50*3), 'y': np.random.normal(size=50*3), 'col': list('ABCDE') * 10 * 3, }) pd.options.display.max_rows = 10 # これはなくてもいいです pd.options.display.precision = 2 # これはなくてもいいです参考記事のおさらい
データフレームの再帰代入をやめる
このセクションは, 参考記事 [2] の内容と被る箇所がほとんどですが, いくつか異なる点もあります. 冗長ですが今一度確認します.
行の選択・列の作成
上記に挙げた記事では
lambda演算子を使う方法が紹介されていました.
これがなぜ必要なのか. 例えば, 以下の2つはどちらも同じです.df.assign(z=lambda d: d['x']**2) df.assign(z=df['x']**2)
x y col z 0 0.50 0.25 A 0.25 1 -0.14 0.35 B 0.02 2 0.65 -0.68 C 0.42 3 1.52 0.23 D 2.32 4 -0.23 0.29 E 0.05 ... ... ... ... ... 145 0.78 -0.69 A 0.61 146 -1.24 0.90 B 1.53 147 -1.32 0.31 C 1.74 148 0.52 0.81 D 0.27 149 0.30 0.63 E 0.09 これだけだと何がいいのかわかりませんが, メソッドチェーンを連結していくと
lambdaが便利であることがわかります. 例えば,
colの値ごとにグループ別合計をとりxの値が正の行だけを取り出しyの数値を2乗したzを新たに作成するという処理を,
lambdaを使う場合と使わない場合とで考えてみます. 以下の1行目がlambdaを使った場合, 2行目が使わない場合です. いずれも同じ結果を返します.df.groupby('col').sum().loc[lambda d: d['x'] > 0].assign(z=lambda d: d['y']**2)
x y z col A 1.6 -1.64 2.68 B 1.9 3.28 10.77 df.groupby('col').sum().loc[df.groupby('col').sum()['x'] > 0].assign( z=df.groupby('col').sum().loc[df.groupby('col').sum()['x'] > 0]['y'] ** 2)
x y z col A 1.6 -1.64 2.68 B 1.9 3.28 10.77 メソッドチェーンはデータフレームを書き換えるわけではないので, 集計後の値を参照する場合は, このように同一の集計処理を何度も書く必要があり, 非常に冗長となります. 何度もやり直すことが普通なデータ分析の作業で, 同じ処理を何度も書き直すのは効率が悪く, 変更時に書き間違える可能性が増します.
このように, 処理が複雑になり, メソッドチェーンが深くなるほどlambdaを使った参照透過性は重要になっていきます.参考記事 [2] では,
df.pipeを使って SQL の select-where 構文の処理を実行していますが, 参考記事 [3] のここ にあるように, このような処理は実際にはdf.locで済むことが多いです.pipeメソッドは, 以下にあるようにデータフレーム全体に関数を適用したい際に使う (lambdaも関数ですが) ものです.『Python pandas データのイテレーションと関数適用、pipe - StatsFragrments』
すべての列 or 行に適用する
mutate_all相当の処理は, apply を使います. こちらでもlambdaを使えます.# mutate_all() # s は DataFrame ではなく Series であることに注意 df.select_dtypes(exclude='object').apply(lambda s: s - [10] * s.shape[0], axis=0) # row-wise に適用したい場合 df.select_dtypes(exclude='object').apply(lambda s: s - [10] * s.shape[0], axis=1)
x y 0 -9.50 -9.75 1 -10.14 -9.65 2 -9.35 -10.68 3 -8.48 -9.77 4 -10.23 -9.71 ... ... ... 145 -9.22 -10.69 146 -11.24 -9.10 147 -11.32 -9.69 148 -9.48 -9.19 149 -9.70 -9.37 補足: assign と eval
dplyr使いのためのpandas 基本編 にあるように,
evalメソッドは文字列を評価して,assignと同様のことができます. 参照透過性も担保されているため, 再帰代入も必要ありません. 最初の例でevalを使うなら, 以下のようになります.df.groupby('col').sum().loc[lambda d: d['x'] > 0].eval('z = y**2')
x y z col A 1.6 -1.64 2.68 B 1.9 3.28 10.77 処理が多い場合は, dict で与える手もあります. リスト内包表記と組み合わせれば複雑な処理も比較的シンプルに書けるかもしれません.
df.assign(**{'a': lambda d: d['x']**2, 'col2': lambda d: d['col'] + '_2'})
x y col a col2 0 0.50 0.25 A 0.25 A_2 1 -0.14 0.35 B 0.02 B_2 2 0.65 -0.68 C 0.42 C_2 3 1.52 0.23 D 2.32 D_2 4 -0.23 0.29 E 0.05 E_2 ... ... ... ... ... ... 145 0.78 -0.69 A 0.61 A_2 146 -1.24 0.90 B 1.53 B_2 147 -1.32 0.31 C 1.74 C_2 148 0.52 0.81 D 0.27 D_2 149 0.30 0.63 E 0.09 E_2 補足: ドットか括弧か
参考記事ではいずれも, 列を参照するとき,
d.xという書き方をしていますが, この記事ではd['x']という書き方をしています..で列にアクセスする場合は, 列名とデータフレームのメソッドと名前が重複していると, 列ではなくメソッドが呼び出されてしまいます.
そこで, 名前の衝突回避のためlambda d: d['col']のような書き方をすると安全です. ただし, 括弧の多用により, 少し見づらくなります. どちらを使うかは好みの問題でしょう.補足: inplace を使うべきか
これも必ずこうしたほうがいい, というより好みの問題です. pandas のメソッドのほとんどはデータフレームを返すので, 結果を自身に代入するオプションとして,
inplace引数が多くのメソッドに用意されています. しかし, メソッドチェーンの中でinplace=Trueするとエラーになりますが, 末尾にinplace=Trueしても何もエラーが発生しません. また,assignなどinplaceがないメソッドもあります. そのため, 何度も処理の組み合わせを変更しているうちにおかしなコードになってしまう恐れがあるので, 私はinplace=Trueを使わず, なるべく=代入の形で統一するようにしています.列選択
上記の例では,
assignと.locでの行選択でlambdaを使っていますが, 列選択にも使うことができます.
dplyr::select()に対応する操作は,df[['A', 'B']]やdf.loc[]です. 前者は列名のリストによる指定ですが, 後者は.locを使うことでインデックスまたはブーリアンによる指定になっています.しかし, もう少し複雑な条件で取り出したいときはもあります. そのような場合, 以下のようなメソッドが使えます.
1. 正規表現で列名にマッチするdf.filter
2. 列の型で条件付けて取り出すdf.select_dtypes
3.dplyrのstarts_with,ends_with,containsに対応するdf.columns.str.startswith/endswith/containsなどがあります.
df.loc[lambda d: d['x'] > 0, lambda d: d.filter(regex='x').columns]
x 0 0.50 2 0.65 3 1.52 6 1.58 7 0.77 ... ... 143 0.18 144 0.26 145 0.78 148 0.52 149 0.30 df.filter(regex='x').loc[lambda d: d['x'] > 0]
x 0 0.50 2 0.65 3 1.52 6 1.58 7 0.77 ... ... 143 0.18 144 0.26 145 0.78 148 0.52 149 0.30 この例では, メソッドチェーンが浅いため,
filterを先に持ってきて,lambdaを使わないほうがむしろシンプルになります. しかし, もっと複雑な処理でも, このようにlambda内で.filter()など,pandas.DataFrameの持つ便利なメソッドを呼び出せることを覚えておいてください.long to wide
wide (いわゆる横持ち) から long (いわゆる縦持ち) への変換は,
pd.DataFrame.melt1がtidyr::gatherとほぼ同じなので省略します. 問題は long から wide への変換の場合です. 公式チートシートではpivotになっていますが...df.pivot(columns='col', values=['x', 'y'])
x y col A B C D E A B C D E 0 0.50 NaN NaN NaN NaN 0.25 NaN NaN NaN NaN 1 NaN -0.14 NaN NaN NaN NaN 0.35 NaN NaN NaN 2 NaN NaN 0.65 NaN NaN NaN NaN -0.68 NaN NaN 3 NaN NaN NaN 1.52 NaN NaN NaN NaN 0.23 NaN 4 NaN NaN NaN NaN -0.23 NaN NaN NaN NaN 0.29 ... ... ... ... ... ... ... ... ... ... ... 145 0.78 NaN NaN NaN NaN -0.69 NaN NaN NaN NaN 146 NaN -1.24 NaN NaN NaN NaN 0.90 NaN NaN NaN 147 NaN NaN -1.32 NaN NaN NaN NaN 0.31 NaN NaN 148 NaN NaN NaN 0.52 NaN NaN NaN NaN 0.81 NaN 149 NaN NaN NaN NaN 0.30 NaN NaN NaN NaN 0.63 この通り大失敗です.
そもそもこれは,
pivotの名前の通り, 本来ピボットテーブルを作るのが目的のメソッドです. 行に対応する軸を指定しなければ, 意図したとおりに変形してくれません. これはunstackでも同様です.今回は, A-E の5要素で1グループとしたいので, 変換後の行に対応する行インデックスを新たに作る必要があります. 以下のように
df.assign( row=lambda x: sorted(list(range(x.shape[0] // x.col.nunique())) * x.col.nunique()) ).head(10)
x y col row 0 0.50 0.25 A 0 1 -0.14 0.35 B 0 2 0.65 -0.68 C 0 3 1.52 0.23 D 0 4 -0.23 0.29 E 0 5 -0.23 -0.71 A 1 6 1.58 1.87 B 1 7 0.77 0.47 C 1 8 -0.47 -1.19 D 1 9 0.54 0.66 E 1 列を作ってから
pivotを呼び出します.df.assign( row=lambda x: sorted(list(range(x.shape[0] // x.col.nunique())) * x.col.nunique()) ).pivot(index='row', columns='col', values=['x', 'y'])
x y col A B C D E A B C D E row 0 0.50 -0.14 0.65 1.52 -0.23 0.25 0.35 -0.68 0.23 0.29 1 -0.23 1.58 0.77 -0.47 0.54 -0.71 1.87 0.47 -1.19 0.66 2 -0.46 -0.47 0.24 -1.91 -1.72 -0.97 0.79 1.16 -0.82 0.96 3 -0.56 -1.01 0.31 -0.91 -1.41 0.41 0.82 1.90 -0.25 -0.75 4 1.47 -0.23 0.07 -1.42 -0.54 -0.89 -0.82 -0.08 0.34 0.28 ... ... ... ... ... ... ... ... ... ... ... 25 2.19 -0.99 -0.57 0.10 -0.50 0.46 0.20 -0.60 0.07 -0.39 26 -1.55 0.07 -1.06 0.47 -0.92 0.11 0.66 1.59 -1.24 2.13 27 1.55 -0.78 -0.32 0.81 -1.23 -1.95 -0.15 0.59 0.28 -0.62 28 0.23 1.31 -1.61 0.18 0.26 -0.21 -0.49 -0.59 0.85 0.36 29 0.78 -1.24 -1.32 0.52 0.30 -0.69 0.90 0.31 0.81 0.63
unstackでもほぼ同じですdf.assign( row=lambda x: sorted(list(range(x.shape[0] // x.col.nunique())) * x.col.nunique()) ).set_index(['row', 'col']).unstack(1)
x y col A B C D E A B C D E row 0 0.50 -0.14 0.65 1.52 -0.23 0.25 0.35 -0.68 0.23 0.29 1 -0.23 1.58 0.77 -0.47 0.54 -0.71 1.87 0.47 -1.19 0.66 2 -0.46 -0.47 0.24 -1.91 -1.72 -0.97 0.79 1.16 -0.82 0.96 3 -0.56 -1.01 0.31 -0.91 -1.41 0.41 0.82 1.90 -0.25 -0.75 4 1.47 -0.23 0.07 -1.42 -0.54 -0.89 -0.82 -0.08 0.34 0.28 ... ... ... ... ... ... ... ... ... ... ... 25 2.19 -0.99 -0.57 0.10 -0.50 0.46 0.20 -0.60 0.07 -0.39 26 -1.55 0.07 -1.06 0.47 -0.92 0.11 0.66 1.59 -1.24 2.13 27 1.55 -0.78 -0.32 0.81 -1.23 -1.95 -0.15 0.59 0.28 -0.62 28 0.23 1.31 -1.61 0.18 0.26 -0.21 -0.49 -0.59 0.85 0.36 29 0.78 -1.24 -1.32 0.52 0.30 -0.69 0.90 0.31 0.81 0.63
pandas.DataFrame.pivotがtidyr::spreadと同じという説明はかなりミスリードです.pivotは複数列を同時に処理できますが, 行インデックスも指定しなければうまくいきません. 一方でspreadは1列づつしか処理できませんが, 当然行インデックスは存在しないので不要です.なお, tidyr 1.0 ではまた新たな構文が追加される予定らしい2 3 ですが, これに対応する機能は当然まだありません. 個人的には1関数1機能のほうが直感的でわかりやすいです.
unstackやpivotの詳しい挙動は以下も参考にしてください.
- [3] の『縦持ち横持ち変換 tidyr::gather tidyr::spread』のセクション
- 公式ドキュメントの "Reshaping and pivot tables"
データの要約
[3] の 『グループ化 dplyr::group_by と集約 dplyr::summarise』セクションにあるように, pandas で各列を要約する
aggメソッドは, 任意の列に任意の要約関数 (sumやcountなど, 列の全要素から計算する関数群のこと) を適用するdplyr::summariseとは機能が異なります. すべての列に要約関数を適用するsummarise_atかsummarise_allに近いです.基本的な要約関数ならば,
aggを使わなくとも呼び出せます. 使える関数は, [1] などを参考にしてください.df.groupby('col').mean()
x y col A 0.05 -0.05 B 0.06 0.11 C -0.11 0.16 D -0.07 -0.07 E -0.35 0.21 df.groupby('col').agg({'x': [np.min, np.max]})
x amin amax col A -1.92 2.19 B -1.24 1.89 C -1.96 1.48 D -1.91 2.46 E -2.62 1.03 0.25 からの新機能
以下では, 最近追加された機能で特に便利なものをピックアップします
要約処理の改善
pandas 0.25 からは, pd.NamedAgg という新しい構文が追加され,
NEW_COLUMN=pd.NamedAgg(column='COL', aggfunc=FUNCTION)という構文で,dplyr::summariseに近いことができるようになりました. 詳細は以下の公式ドキュメントを確認してください.例えば,
x列に対して最大, 最小, 中央値をグループ別に集計し, それぞれx_min,x_max,x_medという列名にしたい場合は, 以下のように,df.groupby('col').agg( x_min=pd.NamedAgg('x', 'min'), x_max=pd.NamedAgg('x', 'max'), x_med=pd.NamedAgg('x', 'median') )
x_min x_max x_med col A -1.92 2.19 0.17 B -1.24 1.89 -0.05 C -1.96 1.48 -0.02 D -1.91 2.46 0.05 E -2.62 1.03 -0.23 と書けます. さらに省略して, (列名, 関数) のタプルだけで表現できる構文も用意されています. これはかなり便利になりました.
df.groupby('col').agg( x_min=('x', 'min'), x_max=('x', 'max'), x_med=('x', 'median') )
x_min x_max x_med col A -1.92 2.19 0.17 B -1.24 1.89 -0.05 C -1.96 1.48 -0.02 D -1.91 2.46 0.05 E -2.62 1.03 -0.23 ネスト/アンネスト
python で使う機会はあまりなさそうな気もしますが, R の
tibbleのように, データフレームの要素にさらにテーブル構造のデータが入れ子になっている場合を考えます.
pandasはtibbleのようにデータフレームの要素にデータフレームを入れることもできますが,nest/unnestはサポートされていません.
ただし, 要素がリストであるなら, 0.25 以降は行に展開するexplodeメソッドが使えます.以下では, それ以外の方法も紹介されています.
* How to unnest (explode) a column in a pandas DataFrame? - Stack Overflowdf_nested = pd.DataFrame({'x': [1, 2], 'y': [df, df]})
ilocで要素 (=データフレーム) を取り出せます.df_nested.iloc[0, 1]
x y col 0 0.50 0.25 A 1 -0.14 0.35 B 2 0.65 -0.68 C 3 1.52 0.23 D 4 -0.23 0.29 E ... ... ... ... 145 0.78 -0.69 A 146 -1.24 0.90 B 147 -1.32 0.31 C 148 0.52 0.81 D 149 0.30 0.63 E
explodeは正確にはunnestと対応する処理ではありませんが, 場合によっては代用になります.df_nested = pd.DataFrame({'a': [1, 2], 'y': [['A', 1], ['B', 2]]}) df_nested
a y 0 1 [A, 1] 1 2 [B, 2] df_nested.explode('y')
a y 0 1 A 0 1 1 1 2 B 1 2 2 メソッドチェーンでできないことをできるように
しかし, 頻繁に必要になるもののメソッドチェーンで完結できない処理というものが pandas ではまだいくつかあります. ここでは, いくつか解消方法を紹介します.
列に MultiIndex がある場合
インデックスは
tidyverseにはない機能でした. pandas に乗り換えたユーザーにとって一番戸惑うのがindexの扱いだと思います.grouobyで集計したらindex, データフレーム同士を結合したらindex,pivotしたらindex, というように何かにつけてindexが出てきます. とはいえ, 基本的にはreset_indexメソッドを使えば列に戻すことができるので, さほど問題にはなりません.厄介なのは, 列名が
MultiIndexになっている場合です. これはreset_insexで解消できません. これはまさに, 先ほど紹介したpivotやunstackをしたとき, あるいはaggで複数の要約関数を適用した場合にも発生します.df_test = df.assign( row=lambda x: sorted(list(range(x.shape[0] // x.col.nunique())) * x.col.nunique()) ).set_index(['row', 'col']).unstack(1).reset_index()列名が
MultiIndexで入れ子になっている場合, タプルを使って列にアクセスします.df_test.columnsMultiIndex([('row', ''), ( 'x', 'A'), ( 'x', 'B'), ( 'x', 'C'), ( 'x', 'D'), ( 'x', 'E'), ( 'y', 'A'), ( 'y', 'B'), ( 'y', 'C'), ( 'y', 'D'), ( 'y', 'E')], names=[None, 'col'])df_test[[('row', ''), ('x', 'A')]]
row x col A 0 0 0.50 1 1 -0.23 2 2 -0.46 3 3 -0.56 4 4 1.47 ... ... ... 25 25 2.19 26 26 -1.55 27 27 1.55 28 28 0.23 29 29 0.78 すると, 3点の問題が発生します:
1.df.xのようにドットで列にアクセスできなくなる
2.df.filterでの列名マッチがしづらくなる
3. 列をstrで解く的できなくなる(1) はともかくとして, (2, 3) が問題です.
seabornやplotnineは便利ですが, タプルでは列を指定できません. これ以外にも文字列だけで列名を指定できたほうが便利な場面は多いです. そこで, タプルを文字列に置き換える必要がでてきますが, この機能をもつビルトインメソッドは存在しません.
この問題に対して, 以下では新しくメソッドを定義する方法が提案されています."Method chaining solution to drop column level in pandas DataFrame"
ここで提案されている方法を少し修正して, メソッドチェーン内で列インデックスの変換をする方法を紹介します.
def reset_column_index(self, inplace=False, sep='_'): if inplace: self.columns = [sep.join(filter(None, tup)) for tup in self.columns] else: c = self.copy() c.columns = [sep.join(filter(None, tup)) for tup in c.columns] return c # 横持ちに変換して multiindex 列を作成 df_wide = df.assign( row=lambda x: sorted(list(range(x.shape[0] // x.col.nunique())) * x.col.nunique()) ).pivot(index='row', columns='col', values=['x', 'y']) df_wide.pipe(reset_column_index)
x_A x_B x_C x_D x_E y_A y_B y_C y_D y_E row 0 0.50 -0.14 0.65 1.52 -0.23 0.25 0.35 -0.68 0.23 0.29 1 -0.23 1.58 0.77 -0.47 0.54 -0.71 1.87 0.47 -1.19 0.66 2 -0.46 -0.47 0.24 -1.91 -1.72 -0.97 0.79 1.16 -0.82 0.96 3 -0.56 -1.01 0.31 -0.91 -1.41 0.41 0.82 1.90 -0.25 -0.75 4 1.47 -0.23 0.07 -1.42 -0.54 -0.89 -0.82 -0.08 0.34 0.28 ... ... ... ... ... ... ... ... ... ... ... 25 2.19 -0.99 -0.57 0.10 -0.50 0.46 0.20 -0.60 0.07 -0.39 26 -1.55 0.07 -1.06 0.47 -0.92 0.11 0.66 1.59 -1.24 2.13 27 1.55 -0.78 -0.32 0.81 -1.23 -1.95 -0.15 0.59 0.28 -0.62 28 0.23 1.31 -1.61 0.18 0.26 -0.21 -0.49 -0.59 0.85 0.36 29 0.78 -1.24 -1.32 0.52 0.30 -0.69 0.90 0.31 0.81 0.63 修正点は2つです. 1つは, 今回では
row列のように, 列インデックスが1層しかないものはセパレータ "_" がつかないようになっています. もう1つは, メソッドとして与えるのではなく,.pipeで与えているという点です. この修正もほとんど個人的な好みの問題なので, 上記のリンクそのままの使い方でもかまいません.再帰的な計算処理
assign, apply でできるのは, element/row/column-wise な処理です. また,
groupbyメソッドならばグループ別集計ができます. 1つ前の要素も参照して処理するようなことはできません. つまり, ラグ演算や累積的な集計処理です. いちおう, pandas にはラグ計算専用のメソッドがいくつか用意されています
cumsum(累積和)cumprod(累積積)cummax(累積最大値)cummin(累積最小値)なぜか累積平均がありませんが, チートシート[1] の
expandingメソッドを使えば実現できます.df.expanding().mean()
x y 0 0.50 0.25 1 0.18 0.30 2 0.34 -0.03 3 0.63 0.04 4 0.46 0.09 ... ... ... 145 -0.07 0.06 146 -0.08 0.06 147 -0.09 0.06 148 -0.08 0.07 149 -0.08 0.07 グループ化にも適用できます.
df.groupby('col').expanding().mean()
x y col A 0 0.50 0.25 5 0.13 -0.23 10 -0.07 -0.48 15 -0.19 -0.26 20 0.14 -0.38 ... ... ... ... E 129 -0.34 0.15 134 -0.36 0.22 139 -0.39 0.19 144 -0.37 0.20 149 -0.35 0.21 移動平均を取りたいならば,
rollingや, 指数加重移動平均を取るewmaメソッドがあります."Exponentially-weighted moving window functions"
しかし, より一般的な再帰式で表現されるような処理はこれらでは処理できません. つまり,
$$
x_{t+1} = f(x_t)\
t=0, 1, 2, ...
$$のような, 行ごとの再帰的な計算をしたい場合です. これは R の
dplyrでもできない処理ですが, tidyverse に属するpurrr::accumulateを組み合わせるとできます.pandas の場合, $f$ に対応する関数を与えるだけで計算してくれるメソッドは存在しません4. そこで, 簡易的な代替方法として, 以下のような関数を用意します. 以下ならば, 1階差分方程式で表現できる計算ができるはずです.
def recurrence(x, func): x = x.copy() for i in range(1, x.shape[0]): x[i] = func(x[i-1]) return x例として, $f(x) = 2(x+1)$ を適用します.
df.assign(x2=lambda d: recurrence(d['x'], lambda x: (x+1)*2))
x y col x2 0 0.50 0.25 A 4.97e-01 1 -0.14 0.35 B 2.99e+00 2 0.65 -0.68 C 7.99e+00 3 1.52 0.23 D 1.80e+01 4 -0.23 0.29 E 3.79e+01 ... ... ... ... ... 145 0.78 -0.69 A 1.11e+44 146 -1.24 0.90 B 2.23e+44 147 -1.32 0.31 C 4.45e+44 148 0.52 0.81 D 8.91e+44 149 0.30 0.63 E 1.78e+45 ラムダが多すぎる
ここまで, 参照透過性のため
lambdaを多用してきましたが, そもそもdplyrではlambdaすら必要ないため, pandas ではコードが冗長になりがちです. そこで,dplyr風の構文を python 上で再現することを目指したdfplyを紹介します.https://github.com/kieferk/dfply
日本語での使用法の解説は, 最初に挙げた参考記事 [4] があります.
見てわかるように, パイプ演算子なども再現しています. 一方で, 現時点での
dfplyの問題点として,
pandas.DataFrameではない独自のクラスを返すため,dfplyのメソッドで処理を完結しなければならない- すべて python で書かれているため, (
pandasに比べ) さほど早くない5.- Python の構文上,
>>の直後に改行することができない (コードが見づらくなる)という点が挙げられます.
具体的な操作方法は,
dplyrをすでに使っているのなら [4] を読めばあとは直感でできるので, ここでは詳しい説明を省略します.
以前dfplyを見つけたときは使いやすそうだと思いましたが,lambdaの利用や pandas 0.25 の新機能によりだいぶ使いやすくなったので, 個人的にはそこまでして使う必要はないかな, という考えに移りつつあります. 特に大きなデータを扱う場合は.
インターネット上のスニペットでは
pd.meltを使っている例も多いですが, 0.20 以降はデータフレームのメソッドとしても呼び出せます. ↩Issues では「そのうち追加したい」機能という程度の優先順位に位置づけられています. https://github.com/pandas-dev/pandas/issues/4567 ↩
すべて確認したわけではないですが, たとえば pandas の
sort_valuesと dfply のarrangeとでは, 後者のほうが顕著に時間がかかります. 余計なコピーが発生しているため? ↩
- 投稿日:2019-07-24T14:36:09+09:00
Pythonで独立性の検定(カイ2乗検定・フィッシャーの直接確率検定)
概要
「独立性の検定」に関するメモ、実施のためのPythonコードです。
「カイ2乗検定」と「フィッシャーの直接確率検定」の内容を含みます。関連エントリ
設定
問題例として、次のような設定(状況)を考えていきたいと思います。
ある学校では、学期末に自由記述欄を含んだ授業評価アンケートを実施している。
このアンケートは、担当教員が「紙形式」か「ウェブ形式」を選んで実施している。今後、アンケートを有効活用していくために、実施形式の違いが、自由記述欄(任意)への記入の有無に対して影響してくるのか?を知りたい。これを検討するための資料として、現在、手元には次のようなデータ(標本)が得られているとします。表内の数値は観測度数になります。
自由記述欄に記入あり 自由記述欄に記入なし 紙形式 140 150 ウェブ形式 160 180 カイ2乗検定(独立性の検定)
「実施形式が(自由記述欄に対するコメントの)記入の有無に影響するのか?」、つまり「『実施形式』と『記入の有無』には関連性があるのか、それともそれらは独立していて関連性がないのか?」を判断していきます。この独立性を評価するために、カイ2乗検定($\chi^2$ 検定)を利用することができます(フィッシャーの直接確率検定は後ほど)。
カイ2乗検定では「変数間に関連性がない」を帰無仮説とします(ここでは「実施形式」と「記入有無」が変数となります)。そして、その「変数間に関連性がない」という仮定が正しいとして、仮に何度も標本を無作為抽出したときに「今回のような標本や、さらに極端な標本が得られるケース」がどの程度の確率で発生するのか?という値($p$ 値)を求め、それと事前設定した有意水準 $\alpha$ を比較して判断します。
なお、「さらに極端な標本」とは「(手元にある標本よりも)変数間に関連性がありそうなことを匂わせる標本」のことです、例えば「紙形式では記入割合が $5\%$、ウェブ形式では記入割合が $85\%$」のような標本のことです。
Pythonで実行
カイ2乗検定を行なうPythonコードを以下に示します。データはpandasのDataFrameに格納されていることを想定しています。
カイ2乗検定(Python)import pandas as pd import scipy.stats as st df = pd.DataFrame([[140,150], # 紙形式 で 記入ありの度数, 記入なしの度数 [160,180]]) # ウェブ形式 で 記入ありの度数, 記入なしの度数 x2, p, dof, e = st.chi2_contingency(df,correction=False) print(f'p値 = {p :.3f}') print(f'カイ2乗値 = {x2:.2f}') print(f'自由度 = {dof}')実行結果p値 = 0.760 カイ2乗値 = 0.09 自由度 = 1あらかじめ決めておいた有意水準 $\alpha$ が $5\%$($=0.05$)とすれば、実行結果は $p\ge0.05$ となるので帰無仮説を採択します。つまり、統計学的には「実施形式」と「記入の有無」に関連性はない(それらは独立している)と結論付けます。つまり「アンケートの自由記述欄にコメントが書かれるかどうかは、アンケートの実施形式には無関係」といえそうです。
なお、以下のように行と列を入れ替えても、同じ実行結果となります。
df = pd.DataFrame([[140,160], [150,180]])ところで、上記では、
chi2_contingencyに引数correction=Falseを指定しています。これは「イェーツの補正(イェーツの連続修正)」を適用しない、というオプションになります。カイ2乗検定の原理について解説しているページなどを見ながら試すような場合には、「イェーツの補正をしない」に設定しておくとよいです。なお、デフォルトでは
correction=Trueになります。Wikipediaによれば「イェイツの修正の効果はデータのサンプル数が少ない時に統計学的な重要性を過大に見積もりすぎることを防ぐことである」とのことです。correction=Trueとして実行すると、次のような結果となります。実行結果(イェーツ補正あり)p値 = 0.822 カイ2乗値 = 0.05 自由度 = 1どのようにp値は計算されるのか
帰無仮説が正しく「実施形式」と「記入の有無」に変数間に関連性がないとき、つまり変数は独立であるときに期待される度数(これを期待度数という)と、実際の観測度数の差の2乗を、期待度数で割ったものの総和(これをカイ2乗値という)を求め、これとカイ2乗分布から $p$ 値を計算します。
期待度数は、変数が独立であるとすれば、次式が成立するはずということに基づき計算できます。
- 紙形式で記入ありの割合=(紙形式の割合)$\times$(記入ありの割合)
- 紙形式で記入なしの割合=(紙形式の割合)$\times$(記入なしの割合)
- ウェブ形式で記入ありの割合=(ウェブ形式の割合)$\times$(記入ありの割合)
- ウェブ形式で記入なしの割合=(ウェブ形式の割合)$\times$(記入なしの割合)
期待度数を実際に求めてみます。まず、観測度数は次のようになっていました(合計欄を追加しました)。
記入あり 記入なし 計 紙形式 140 150 290 ウェブ形式 160 180 340 計 300 330 630 ここで、「紙形式の割合」は表の4列目から $290/630\risingdotseq 0.46$ 、「ウェブ形式の割合」は $340/630\risingdotseq 0.54$ のように求めることができます。また、表の4行目から「記入ありの割合」は $300/630\risingdotseq 0.48$、「記入なしの割合」は $330/630\risingdotseq0.52$ となります。
あとは、これらを使って「紙形式で記入ありの割合=(紙形式の割合)$\times$(記入ありの割合)=$(290/630)\times(300/630)\risingdotseq0.219$」を求めます。そして、それに $630$ をかけると、次のように期待度数が求まります。
記入あり 記入なし 紙形式 138.1 151.9 ウェブ形式 161.9 178.1 この期待度数と観測度数の差の2乗を、期待度数で割ったものの総和(=カイ2乗値)を求め、これとカイ2乗分布から $p$ 値を計算します(詳細は、別資料参照ください)。なお、期待度数は次のように
st.chi2_contingencyの戻値の4番目に格納されています。import pandas as pd import scipy.stats as st df = pd.DataFrame([[140,150], [160,180]]) x2, p, dof, e= st.chi2_contingency(df,correction=False) print(f'期待度数 : \n {e}')実行結果期待度数 : [[138.0952381 151.9047619] [161.9047619 178.0952381]]フィッシャーの直接確率検定
カイ2乗検定は、一部に極端に小さい観測度数(5未満?)を含んでいる場合に適切な検定ができないことが知られています。特に問題例のように $2\times2$(2行2列)のケースでは、すべての観測度数が10以上であることが望ましいようです(参考資料[5])。そのような場合では、カイ2乗検定ではなくフィッシャーの直接確率検定(フィッシャーの正確確率検定)を使用します。
なお、十分な観測度数が得られている標本に対してもフィッシャーの直接確率検定は有効です。ただし、フィッシャーの直接確率検定は、観測度数の階乗計算を含むため、計算が大変になることがデメリットになります(問題例では観測度数に140がありますが、140の階乗はとても大きな数になるため計算に工夫が必要です)。Pythonのライブラリを利用するうえでは、あまり気になりませんが。
フィッシャーの正確確率検定(Python)import pandas as pd import scipy.stats as st df = pd.DataFrame([[140,150], [160,180]]) _, p = st.fisher_exact(df) print(f'p値 = {p :.3f}')実行結果p値 = 0.810有意水準 $\alpha$ が $5\%$($=0.05$)とすれば、実行結果は $p\ge0.05$ となるので帰無仮説を採択します。
R版
フィッシャーの正確確率検定(R)m=matrix(c(140, 150, 160, 180), nrow=2, byrow=T) fisher.test(m)実行結果Fisher's Exact Test for Count Data data: m p-value = 0.8103 alternative hypothesis: true odds ratio is not equal to 1 95 percent confidence interval: 0.757838 1.454709 sample estimates: odds ratio 1.049888結論
Pythonで独立性の検定を行なう場合は、フィッシャーの直接確率検定を利用するのが良いようです。
参考資料
- [1] 小島寛之 著「完全独習 統計学入門」
- [2] 大村平 著「今日から使える統計解析 普及版」
- [3] 平井明代 編著「教育・心理系研究のためのデータ分析入門」
- [4] 向後千春 著「統計学がわかる ハンバーガーショップでむり無く学ぶ、やさしく楽しい統計学」
- [5] χ2乗検定とFisher正確確率検定 ~χ2乗検定の不適切使用をしていませんか?~
- 投稿日:2019-07-24T14:36:09+09:00
PythonとRで独立性の検定(カイ2乗検定・フィッシャーの直接確率検定)
概要
「独立性の検定」に関するメモ、実施のためのPythonコード、Rコードです。
「カイ2乗検定」と「フィッシャーの直接確率検定」の内容を含みます。関連エントリ
設定
問題例として、次のような設定(状況)を考えていきたいと思います。
ある学校では、学期末に自由記述欄を含んだ授業評価アンケートを実施している。
このアンケートは、担当教員が「紙形式」か「ウェブ形式」を選んで実施している。今後、アンケートを有効活用していくために、実施形式の違いが、自由記述欄(任意)への記入の有無に対して影響してくるのか?を知りたい。これを検討するための資料として、現在、手元には次のようなデータ(標本)が得られているとします。表内の数値は観測度数になります。
自由記述欄に記入あり 自由記述欄に記入なし 紙形式 140 150 ウェブ形式 160 180 カイ2乗検定(独立性の検定)
「実施形式が(自由記述欄に対するコメントの)記入の有無に影響するのか?」、つまり「『実施形式』と『記入の有無』には関連性があるのか、それともそれらは独立していて関連性がないのか?」を判断していきます。この独立性を評価するために、カイ2乗検定($\chi^2$ 検定)を利用することができます(フィッシャーの直接確率検定は後ほど)。
カイ2乗検定では「変数間に関連性がない」を帰無仮説とします(ここでは「実施形式」と「記入有無」が変数となります)。そして、その「変数間に関連性がない」という仮定が正しいとして、仮に何度も標本を無作為抽出したときに「今回のような標本や、さらに極端な標本が得られるケース」がどの程度の確率で発生するのか?という値($p$ 値)を求め、それと事前設定した有意水準 $\alpha$ を比較して判断します。
なお、「さらに極端な標本」とは「(手元にある標本よりも)変数間に関連性がありそうなことを匂わせる標本」のことです、例えば「紙形式では記入割合が $5\%$、ウェブ形式では記入割合が $85\%$」のような標本のことです。
Pythonで実行
カイ2乗検定を行なうPythonコードを以下に示します。データはpandasのDataFrameに格納されていることを想定しています。
カイ2乗検定(Python版)import pandas as pd import scipy.stats as st df = pd.DataFrame([[140,150], # 紙形式 で 記入ありの度数, 記入なしの度数 [160,180]]) # ウェブ形式 で 記入ありの度数, 記入なしの度数 x2, p, dof, e = st.chi2_contingency(df,correction=False) print(f'p値 = {p :.3f}') print(f'カイ2乗値 = {x2:.2f}') print(f'自由度 = {dof}')実行結果p値 = 0.760 カイ2乗値 = 0.09 自由度 = 1あらかじめ決めておいた有意水準 $\alpha$ が $5\%$($=0.05$)とすれば、実行結果は $p\ge0.05$ となるので帰無仮説を採択します。つまり、統計学的には「実施形式」と「記入の有無」に関連性はない(それらは独立している)と結論付けます。つまり「アンケートの自由記述欄にコメントが書かれるかどうかは、アンケートの実施形式には無関係」といえそうです。
なお、以下のように行と列を入れ替えても、同じ実行結果となります。
df = pd.DataFrame([[140,160], [150,180]])ところで、上記では、
chi2_contingencyに引数correction=Falseを指定しています。これは「イェーツの補正(イェーツの連続修正)」を適用しない、というオプションになります。カイ2乗検定の原理について解説しているページなどを見ながら試すような場合には、「イェーツの補正をしない」に設定しておくとよいです。なお、デフォルトでは
correction=Trueになります。Wikipediaによれば「イェイツの修正の効果はデータのサンプル数が少ない時に統計学的な重要性を過大に見積もりすぎることを防ぐことである」とのことです。correction=Trueとして実行すると、次のような結果となります。実行結果(イェーツ補正あり)p値 = 0.822 カイ2乗値 = 0.05 自由度 = 1R版
同様のことを R を使って行ないました。
カイ2乗検定_イェーツの補正なし(R版)m=matrix(c(140, 150, 160, 180), nrow=2, byrow=T) chisq.test(m,correct=F)実行結果Pearson's Chi-squared test data: m X-squared = 0.092937, df = 1, p-value = 0.7605つづいて、イェーツの補正ありのバージョンです。
カイ2乗検定_イェーツの補正あり(R)m=matrix(c(140, 150, 160, 180), nrow=2, byrow=T) chisq.test(m)実行結果Pearson's Chi-squared test with Yates' continuity correction data: m X-squared = 0.050549, df = 1, p-value = 0.8221どのようにp値は計算されるのか
帰無仮説が正しく「実施形式」と「記入の有無」に変数間に関連性がないとき、つまり変数は独立であるときに期待される度数(これを期待度数という)と、実際の観測度数の差の2乗を、期待度数で割ったものの総和(これをカイ2乗値という)を求め、これとカイ2乗分布から $p$ 値を計算します。
期待度数は、変数が独立であるとすれば、次式が成立するはずということに基づき計算できます。
- 紙形式で記入ありの割合=(紙形式の割合)$\times$(記入ありの割合)
- 紙形式で記入なしの割合=(紙形式の割合)$\times$(記入なしの割合)
- ウェブ形式で記入ありの割合=(ウェブ形式の割合)$\times$(記入ありの割合)
- ウェブ形式で記入なしの割合=(ウェブ形式の割合)$\times$(記入なしの割合)
期待度数を実際に求めてみます。まず、観測度数は次のようになっていました(合計欄を追加しました)。
記入あり 記入なし 計 紙形式 140 150 290 ウェブ形式 160 180 340 計 300 330 630 ここで、「紙形式の割合」は表の4列目から $290/630\risingdotseq 0.46$ 、「ウェブ形式の割合」は $340/630\risingdotseq 0.54$ のように求めることができます。また、表の4行目から「記入ありの割合」は $300/630\risingdotseq 0.48$、「記入なしの割合」は $330/630\risingdotseq0.52$ となります。
あとは、これらを使って「紙形式で記入ありの割合=(紙形式の割合)$\times$(記入ありの割合)=$(290/630)\times(300/630)\risingdotseq0.219$」を求めます。そして、それに $630$ をかけると、次のように期待度数が求まります。
記入あり 記入なし 紙形式 138.1 151.9 ウェブ形式 161.9 178.1 この期待度数と観測度数の差の2乗を、期待度数で割ったものの総和(=カイ2乗値)を求め、これとカイ2乗分布から $p$ 値を計算します(詳細は、別資料参照ください)。なお、期待度数は次のように
st.chi2_contingencyの戻値の4番目に格納されています。import pandas as pd import scipy.stats as st df = pd.DataFrame([[140,150], [160,180]]) x2, p, dof, e= st.chi2_contingency(df,correction=False) print(f'期待度数 : \n {e}')実行結果期待度数 : [[138.0952381 151.9047619] [161.9047619 178.0952381]]フィッシャーの直接確率検定
カイ2乗検定は、一部に極端に小さい観測度数(5未満?)を含んでいる場合に適切な検定ができないことが知られています。特に問題例のように $2\times2$(2行2列)のケースでは、すべての観測度数が10以上であることが望ましいようです(参考資料[5])。そのような場合では、カイ2乗検定ではなくフィッシャーの直接確率検定(フィッシャーの正確確率検定)を使用します。
なお、十分な観測度数が得られている標本に対してもフィッシャーの直接確率検定は有効です。ただし、フィッシャーの直接確率検定は、観測度数の階乗計算を含むため、計算が大変になることがデメリットになります(問題例では観測度数に140がありますが、140の階乗はとても大きな数になるため計算に工夫が必要です)。Pythonのライブラリを利用するうえでは、あまり気になりませんが。
フィッシャーの正確確率検定(Python)import pandas as pd import scipy.stats as st df = pd.DataFrame([[140,150], [160,180]]) _, p = st.fisher_exact(df) print(f'p値 = {p :.3f}')実行結果p値 = 0.810有意水準 $\alpha$ が $5\%$($=0.05$)とすれば、実行結果は $p\ge0.05$ となるので帰無仮説を採択します。
R版
フィッシャーの正確確率検定(R)m=matrix(c(140, 150, 160, 180), nrow=2, byrow=T) fisher.test(m)実行結果Fisher's Exact Test for Count Data data: m p-value = 0.8103 alternative hypothesis: true odds ratio is not equal to 1 95 percent confidence interval: 0.757838 1.454709 sample estimates: odds ratio 1.049888結論
PythonやRで独立性の検定を行なう場合は、フィッシャーの直接確率検定を利用するのが良いようです。
参考資料
- [1] 小島寛之 著「完全独習 統計学入門」
- [2] 大村平 著「今日から使える統計解析 普及版」
- [3] 平井明代 編著「教育・心理系研究のためのデータ分析入門」
- [4] 向後千春 著「統計学がわかる ハンバーガーショップでむり無く学ぶ、やさしく楽しい統計学」
- [5] χ2乗検定とFisher正確確率検定 ~χ2乗検定の不適切使用をしていませんか?~
- 投稿日:2019-07-24T14:30:14+09:00
VSCode で anaconda の python を使う(設定編)
構文チェックで 「import できねぇぜw」って出るまで気が付かなかった。
以下の設定が必要python.condaPath example)E:\python\anaconda\condabin\conda.bat python.pythonPath example)E:\python\anaconda\envs\hoge\python.exeどうやら、パスの指定にエスケープは必要ないらしい。って書きたかった記事。
- 投稿日:2019-07-24T13:56:27+09:00
LeetCode / Remove Duplicates from Sorted List
(ブログ記事からの転載)
[https://leetcode.com/problems/remove-duplicates-from-sorted-list/]
Given a sorted linked list, delete all duplicates such that each element appear only once.
Example 1:
Input: 1->1->2
Output: 1->2Example 2:
Input: 1->1->2->3->3
Output: 1->2->3LeetCode頻出のLinkedListの問題。以前の記事にも登場してます。
今回の記事も長くはないですが、裏には数多の苦悩の道のりがありました。
LinkedListの性質(より正確には、Pythonの変数間の参照)がどうにも理解できず、youtubeでインドの方の解説動画とかを読み漁りました。解答・解説
解法1
公式のJavaの解答をPythonに翻訳したのが以下です(余談ですが、LeetCodeをやってると高級言語から入った人でもC++とかJavaが段々読めるようになってくるのがおトクですね)。
class Solution: def deleteDuplicates(self, head: ListNode) -> ListNode: # currentとheadの間で参照を渡して、headの各nodeをcurrentを動かしながら移動し、重複nodeを発見・削除する current = head while current and current.next: # 重複nodeを発見したら、重複nodeの次のnodeにcurrent.nextをポイントさせて、重複nodeを削除する if current.next.val == current.val: current.next = current.next.next # 重複nodeでなかったら、通常のiterationを進める(currentを次のnodeにポイントさせる) else: current = current.next return head、、、ということなんですが、皆さん分かりますか?
私はさっぱり分かりませんでした。current.next = current.next.nextだとnodeは削除されるのに、current = current.nextだとnodeは削除されないのはなぜ?どうにも困ったので、慣れ親しんだデータ型であるlistで同様の状況を再現してみて、改めて考えてみました。
head = [1,1,2] current = head while current and current[1:]: if current[1] == current[0]: current[1:] = current[2:] else: current = current[1:] print('current:{}'.format(current), 'head:{}'.format(head)) head # ---> current:[1, 2] head:[1, 2] # ---> current:[2] head:[1, 2] # ---> [1, 2]分かりやすいように、print文でIterationの途中のcurrent, headの値を吐き出すようにしました。
この結果から、朧げながら私の理解は、
current[1:] = current[2:]ではcurrentとheadの間の参照は保持したまま値が代入されている(のでheadの値も変わる)が、
current = current[1:]では参照自体が1つ先に移動する(のでheadの値が変わるわけではない)、
ということかと思いました。間違っていたら是非是非ご指摘ください。
- 投稿日:2019-07-24T12:46:29+09:00
"pip install nagisa"でいろいろやった話
"pip install nagisa" に失敗する
タイトル通り。早速入れようと意気込んでいたらコケた。
エラーその1
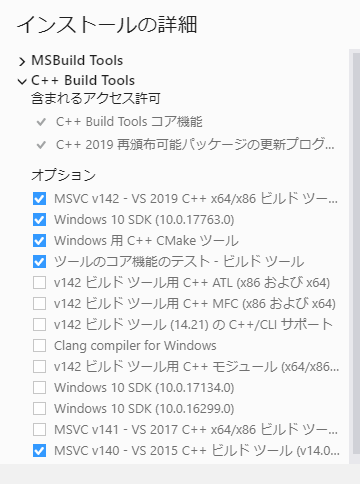
Microsoft Visual C++ 14.0 is required.ググったら同じ現象の方が大勢いらっしゃるようで。
https://visualstudio.microsoft.com/ja/downloads/
のVisual Studio 2019 のツールからBuild Tools for Visual Studio 2019をダウンロード。起動して、一番左上のC++ Build Toolsにチェックを入れる。
右側に詳細が出るので、デフォルトで入っているものの他に、MSCV v140にもチェックを入れる。
エラーその2
LINK : fatal error LNK1158: 'rc.exe' を実行できません。
など。
こちらについてはQiitaの記事がありました。
tslearnのpipインストールで"LINK : fatal error LNK1158: 'rc.exe' を実行できません。"が出た時の対処 - Qiita
の エラーと対処 の項目を実行します。
無事インストールできた。ヨカッタ。
......今後新たなエラーが起きないことを祈りつつ。
- 投稿日:2019-07-24T12:32:44+09:00
【Python】リスト内の特定要素存在チェック方法を比較
はじめに
Python でリストに特定条件を満たす要素が存在するか判定したい時って結局どう書くのが良いんだろう? と疑問だったので、いくつかの方法の速度を計測、比較してみました。
単純に'1' in ['1', '2', '3']のようにリスト内要素の値をそのまま指定できる場合は悩む必要はないので、要素に対して何らかの操作(ここではメンバ変数参照)が必要な場合を想定しています。存在チェック方法
class
Personのリストからメンバー変数last_nameが'紀伊田'と一致する要素が存在するかチェックする、という前提で以下 4つの方法を比較しました。
- in 演算子 :
'紀伊田' in (p.last_name for p in personlist)
→ 内包表記によりメンバー変数 last_name のみを抽出して in 演算子を使えるようにしたパターン。- any 関数 :
any(p.last_name == '紀伊田' for p in personlist)
→ 内包表記により要素ごとに条件を満たすかどうかの bool 値を抽出して any 関数を使ったパターン。- any 関数2 :
any(True for p in personlist if p.last_name == '紀伊田')
→ 2.の亜種で if 文により条件を満たす要素のみ True を抽出して any 関数を使うパターン。- next 関数 :
next((True for p in personlist if p.last_name == '紀伊田'), False)
→ 3.と同じことを any 関数ではなく next 関数で判定するパターン。
personlistの要素数は 10000 個、last_nameは Faker で生成し、5001 番目のみ紀伊田で上書きして 1 つだけ存在する状態にしています。
上記はジェネレーター式で記載していますがリスト内包表記とセット内包表記の場合についても計測しました。計測結果
1. ~ 4. の方法を
for _ in range(100000):で 100000 回実行するのに掛かった時間です(at Google Colaboratory)。
3. の if文で条件指定したジェネレーター式を any 関数で評価するのが一番速い という結果になりました。
1.in 式 2.any 式 3.any if式 4.next if式 in any any if next forのみ リスト内包表記 84.067628 99.620646 78.945970 NaN 5.785986 3.312556 0.017510 NaN 0.004489 セット内包表記 71.618741 84.979072 76.397498 NaN 0.008912 0.016706 0.015983 NaN 0.004158 ジェネレーター式 52.239412 58.766906 38.168067 39.631893 NaN NaN NaN NaN 0.004978 ※1. 5 ~ 8 列目は 1. ~ 4. の内包表記の式をforの外側に逃がして計測した参考値
※2. 同じジェネレーターを複数回評価できないためジェネレーター式の 5 ~ 8 は未計測内包表記による違い
ジェネレーター式$>$セット内包表記$>$リスト内包表記の順に速い結果となりました。
ジェネレーター式が速いのは予想どおりですが、リスト内包表記よりセット内包表記の方が速いのは意外でした。Faker の生成したlast_nameのユニーク値が 52 個しかなかったので、セットの重複チェック処理よりリストのメモリ拡張処理の方が結果に影響したのだと考えられます。判定方法による違い
3. any 関数2$\geqq$4. next 関数$>$1. in 演算子$>$2. any 関数の順に速い結果となりました。
if文のありなしが異なる 2. と 3. で3. any 関数2$>$2. any 関数となったのは、2. ではp.last_name == '紀伊田'の判定が False のものも列挙されるので、True が出現するまで(今回は 5000 個)の Falseも any で再判定するのに対し、3. ではp.last_name == '紀伊田'が True になった要素のみ列挙されるため any の再判定は 1 回のみである点が速度に寄与しているのではないかと思います。この理屈が正しければ3. any 関数2$>$1. in 演算子となるのも納得できます。
1. in 演算子$>$2. any 関数はどちらも True になるまでの False(5000 個)の要素を判定する点は変わりませんが、1. の方は文字列一致判定が 1 回に対し、2. は==演算子と any 関数 で 2 回判定される違いが速度差に現れたのだと思われます。結論
if文で条件指定したジェネレーター式を any 関数で評価するのが一番速い
おわりに
以前からの疑問に対して答えが出たので満足です。python の中身を把握しているわけではないので本当のところは違うかも知れませんが、測定結果に対してそれっぽい理由はつけられたと思いますので、結論としては合ってるのではないかと思います。
ユニーク値の割合や、一致する要素が何番目にあるのかなどで結果も変わってくるでしょうが、基本は if 文つきジェネレーター式と any 関数の組合せが安定すると思います。
当たり前ですが数回の判定なら体感差は出ないので、速度を気にしない、タイプ量が少ない、分かりやすいとかで in 演算子やその他方法も適宜使えば良いと思います。
もっと良い方法を知ってるという方は教えていただけると嬉しいです。おまけ:計測コード(Colaboratory)
(折りたたみ)
!pip install Faker > /dev/null import time from faker import Factory import pandas as pdclass Person: def __init__(self, first_name: str, last_name: str): self.first_name = first_name self.last_name = last_name def __str__(self): return f'{self.last_name} {self.first_name}'fake = Factory.create('ja_JP') personlist = [ Person(fake.first_name(), fake.last_name()) for _ in range(10000) ] print(f'紀伊田 in persons : {"紀伊田" in (p.last_name for p in personlist)}') personlist[5000].first_name = 'きい太' personlist[5000].last_name = '紀伊田' print(f'紀伊田 in persons : {"紀伊田" in (p.last_name for p in personlist)}') print('') print(' / '.join(str(p) for p in personlist[4996:5005]))紀伊田 in persons : False 紀伊田 in persons : True 工藤 太郎 / 中津川 淳 / 工藤 加奈 / 原田 幹 / 紀伊田 きい太 / 若松 涼平 / 廣川 さゆり / 大垣 零 / 斉藤 英樹trials = 1 index = ['in 式', 'any 式', 'any if式', 'next if式', 'in', 'any', 'any if', 'next if', 'forのみ']# リスト内包表記 series1 = pd.Series(0., index=index) series1['next if式'] = None series1['next if'] = None for _ in range(trials): tm = time.time() for _ in range(100000): '紀伊田' in [p.last_name for p in personlist] series1['in 式'] += time.time() - tm tm = time.time() for _ in range(100000): any([p.last_name == '紀伊田' for p in personlist]) series1['any 式'] += time.time() - tm tm = time.time() for _ in range(100000): any([True for p in personlist if p.last_name == '紀伊田']) series1['any if式'] += time.time() - tm persons = [p.last_name for p in personlist] tm = time.time() for _ in range(100000): '紀伊田' in persons series1['in'] += time.time() - tm persons = [p.last_name == '紀伊田' for p in personlist] tm = time.time() for _ in range(100000): any(persons) series1['any'] += time.time() - tm persons = [True for p in personlist if p.last_name == '紀伊田'] tm = time.time() for _ in range(100000): any(persons) series1['any if'] += time.time() - tm tm = time.time() for _ in range(100000): pass series1['forのみ'] += time.time() - tm series1 /= trials# セット内包表記 series2 = pd.Series(0., index=index) series2['next if式'] = None series2['next if'] = None for _ in range(trials): tm = time.time() for _ in range(100000): '紀伊田' in {p.last_name for p in personlist} series2['in 式'] += time.time() - tm tm = time.time() for _ in range(100000): any({p.last_name == '紀伊田' for p in personlist}) series2['any 式'] += time.time() - tm tm = time.time() for _ in range(100000): any({True for p in personlist if p.last_name == '紀伊田'}) series2['any if式'] += time.time() - tm persons = {p.last_name for p in personlist} tm = time.time() for _ in range(100000): '紀伊田' in persons series2['in'] += time.time() - tm persons = {p.last_name == '紀伊田' for p in personlist} tm = time.time() for _ in range(100000): any(persons) series2['any'] += time.time() - tm persons = {True for p in personlist if p.last_name == '紀伊田'} tm = time.time() for _ in range(100000): any(persons) series2['any if'] += time.time() - tm tm = time.time() for _ in range(100000): pass series2['forのみ'] += time.time() - tm series2 /= trials# ジェネレーター式 series3 = pd.Series(0., index=index) series3['in'] = None series3['any'] = None series3['any if'] = None series3['next if'] = None for _ in range(trials): tm = time.time() for _ in range(100000): '紀伊田' in (p.last_name for p in personlist) series3['in 式'] += time.time() - tm tm = time.time() for _ in range(100000): any(p.last_name == '紀伊田' for p in personlist) series3['any 式'] += time.time() - tm tm = time.time() for _ in range(100000): any(True for p in personlist if p.last_name == '紀伊田') series3['any if式'] += time.time() - tm tm = time.time() for _ in range(100000): next((True for p in personlist if p.last_name == '紀伊田'), False) series3['next if式'] += time.time() - tm tm = time.time() for _ in range(100000): pass series3['forのみ'] += time.time() - tm series3 /= trialsdf = pd.DataFrame({ 'リスト内包表記': series1, 'セット内包表記': series2, 'ジェネレータ式': series3, }) df.T
- 投稿日:2019-07-24T12:27:14+09:00
【精度対決】MobileNet V3 vs V2
皆さん、エッジAIを使っていますか?
エッジAIといえば、MobileNet V2ですよね。
先日、後継機となるMobileNet V3が論文発表されました。世界中のエンジニアが、MobileNet V3のベンチマークを既に行っていますが、
自分でもベンチマークをしたくなりました。本稿では、MobileNet V3のベンチマークをKerasで行いたいと思います。
(図は論文より引用)
コード全体はGithubで公開しています。設定
MobileNet V3
- コードはこちらから拝借しています。
- 重みは初期化された状態で学習します。
- V3には
smallとlargeがありますが、ラズパイのCPUで動かすことを想定してsmallを採用しました。- $\alpha$の値によって、モデルサイズが変動します。$\alpha$は大きいほど精度が出ますが、速度は遅くなります。
MobileNet V2
- KerasにはV2が標準装備されており、これを使います。
- 重みは学習済が用意されていますが、V3と同じく初期化された状態で学習します。
- $\alpha$はV3と同じ仕様です。
その他
- データセットはcifar-10を使用します。
- 実験はColaboratory(GPU)で実施しました。
- バッチサイズは1024、エポックは100、最適化手法はAdam(lr=0.001)、DataAugmentationを使用。
結果
精度の比較
早速、気になる精度を見てみましょう。
下の図は各モデルを10回学習させたときの精度の結果です。
V2に対し、V3は精度も良く、ばらつきも少ないです。
V3の推論時間が速ければ、V3を使った方が良さそうです。推論時間の比較
Colaboratoryで1000回実行して中央値などを取り出そうとしましたが、Colaboratoryに
クセがあるのか、実行する度に計測時間が変動しました。(メモリや使用時間の影響?)ただし、相対的な推論時間の関係は崩れなかったので、相対比較はある程度信用できそうです。
下の図は、各モデルを1000回実行させたときの推論時間の平均値です。
※推論時間の数値は信用しないでください。
※()の値は$\alpha$の数値です。きれいな右肩上がりになっており、V2(0.5)とV2(1)の差が大きい印象です。
また、$V2(1)\fallingdotseq V3(0.2)$となっていて、精度を考慮するとV3(0.2)を
採用する方が良いようです。表にまとめます。
速度 精度 V2(0.5) 速い 悪い V3 small(0.2) 中 中 V3 small(0.5) 遅い 良い 今のところ、V2(0.5)の代替品はV3で存在しないようです。
学習時間の比較
前述のとおり、実行する度に計測時間が変わったため、ここでは計測できませんでした。
ただ、V2とV3でそこまで学習時間の差は生まれない印象です。重みのサイズの比較
$\alpha$ 重みのサイズ(MB) MobileNet V2 0.5 3.3 MobileNet V2 1 9.5 MobileNet V3 small 0.2 11.3 MobileNet V3 small 0.5 11.7 V2の方が圧倒的に軽い結果となりました。
また、V3の重みのサイズは、$\alpha$にあまり依存しないようです。転移学習について
実際に使うことを考えると、モデルをゼロから学習させることは稀だと思います。
通常は転移学習を使いますが、今のところ、Kerasで学習済の重み(V3)は公開され
ていません。しかし、Pytorchでは公開されています。https://github.com/d-li14/mobilenetv3.pytorch
PytorchモデルをKerasやTensorFlow liteモデルへ変換する方法は、
以下の記事が参考になると思います。https://qiita.com/lain21/items/9f9f9707ebad4bbc627d
皆さんも、どんどん転移学習しましょう。
ラズパイで実行してみた
ラズパイでリアルタイム認識をしてみました。
コードはこちら。
- 使用機器:Raspberry Pi3 model B
- 外付けGPU:未使用
- V3 smallの$\alpha=0.2$
- 入力画像サイズ:32 x 32 x 3
だいたい15~20FPSの速度が出ました。
この速度なら、リアルタイムの処理もできそうです。ちなみに、入力サイズ:96 x 96 x 3だと、10FPSになりました。
まとめ
- MobileNet V3はV2の代替品になるわけではなく、延長線上という印象。すなわち、「V2よりも精度を出したいけど、多少処理速度が遅くなってもOK」というときに使うと良い。
- ただ、V3であっても速度はそこまで遅くはならない。
- 最終的には、入力画像サイズを小さくすればV3の速度は上がるため、チューニングすれば、「V2と速度は同じだけど精度は上回る」という可能性もあり得る。
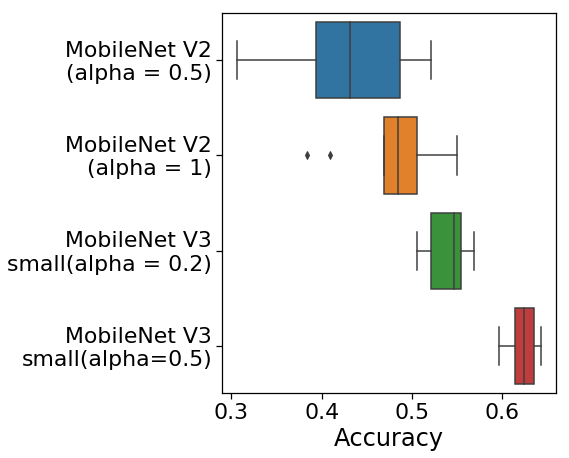
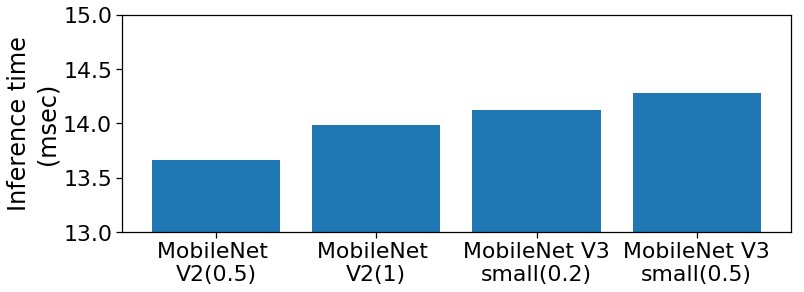
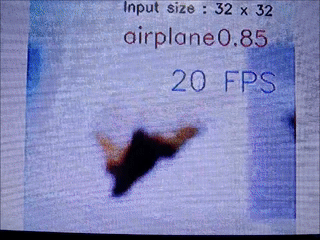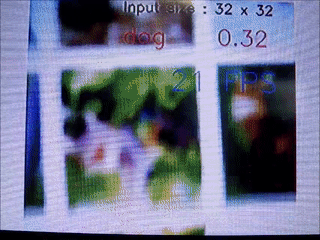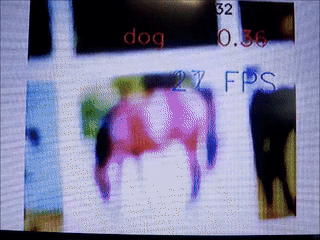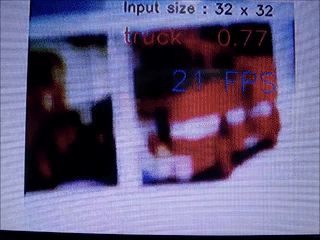
- 投稿日:2019-07-24T11:19:15+09:00
ラズパイに初めて触る人が、Slackから自宅のエアコンを制御する
はじまり
暑い夏が来る前に、家に着く前にエアコンをつけれる環境が欲しい。
あと、ラズパイ触ってみたい。そんな時に、格安スマートリモコンの作り方を発見
部品と金額まで書いてある…ラズパイを用いて、Slackから自宅のエアコンを制御してみよう!!!
ラズパイでリモコンを作る記事は溢れているのになぜ書いたのか
やってみたら、意外と詰まった。
その際、記事を探し回ったので、助けられた内容をまとめておく。
初めてなりの悩み
触り慣れている人からしたら当たり前が詰まっているかもしれないけど、初めて触る人の参考になればと。
ShellとPythonがわかれば良いくらいにしたい(今わかるのそれくらい)
今回の目的はお家の外からエアコンを制御するです。
ラズパイでSlackbotを飼って(Raspberry PiでSlackbotを飼う)、赤外線を飛ばすくらいなら、Pythonのみでできました(まだ理解していないがゆえの不都合が考えられるのですが…)。必要なもの
作成手順
ラズパイのインストール・設定
あまり余計なものは買いたくないと思い、変換プラグ不要で設定できる方法を探した。
Raspberry Pi Zero Wをディスプレイやキーボードなしで初期設定、Wi-Fi接続がわかりやすく、大変参考になった。ラズパイの起動
電源をさしてから少し待たないと、
sshできない。
当たり前のことではあるが、最初戸惑った。ラズパイにPython及びPipをインストール
普段使っているのがpyenvだったので、同様の環境の方が楽だと思い、pyenvを導入しました。
RaspberryPiにpyenvを導入を参考にすれば、インストールできます(僕は3.6.6をインストールしました)。
pipのインストールはしなくても入ってました。つまり、
% sudo apt-get install -y git openssl libssl-dev libbz2-dev libreadline-dev libsqlite3-dev % git clone git://github.com/yyuu/pyenv.git ~/.pyenvShellごとに合わせた設定をして、sourceする。
% pyenv install 3.6.6 % pyenv global 3.6.6と、pythonもpipも入ります。
ちなみに、今回pipでインストールしたのは% pip install Slackbot pigpio
pyenv install x.x.xすぐは終わらないです。
長そうだったので、朝出かける前にインストールをはじめて半日後帰宅して確認したら、終わってました。赤外線送受信回路作成
格安スマートリモコンの作り方及び赤外線LEDドライブ回路の決定版 | 電脳伝説の通りです。
回路におけるLEDの向きについて
これも当たり前かもしれないですが、長い方がアノード、短い方がカソードです。
今回の場合、短い方がGNDと接続するようにしてください。ラズパイで回路を制御
格安スマートリモコンの作り方を参考に、pigpioを用いた制御を行います。
インストール及び起動設定
% sudo apt-get update % sudo apt-get upgrade % sudo apt-get install pigpio % sudo systemctl enable pigpiod.service % sudo systemctl start pigpiod % pip install pigpioGPIOの設定
% echo 'm 17 w w 17 0 m 18 r pud 18 u' > /dev/pigpio % crontab -e @reboot until echo 'm 17 w w 17 0 m 18 r pud 18 u' > /dev/pigpio; do sleep 1s; donepigpioによる送受信プログラム
pigpioの作者自らが作ったIR Record and Playbackをベースにしました。
格安スマートリモコンの作り方の手法をそのまま踏襲すると、pythonコード内でsubprocessとして
irrp.pyを呼び出すことになります。
そのため、irrp.pyをclass化して、pythonのコード内で呼び出せるようにしました(多分、subprocessとして呼び出してもうまく行くと思います)。
この際、引数として、オプションで取っていた値を与えるようにしています。学習と送信に関しては、格安スマートリモコンの作り方に記載がある通りです。
pigpio.error: 'chain is too long'我が家のエアコン(ダイキン)の信号は長すぎたようです。
ラズパイでエアコン対応の赤外線学習リモコンを pigpioライブラリを使って作る方法、Goodbye LIRC (Raspbian Stretchでエアコン対応の赤外線リモコンを動かす、ややこしい LIRCを使わないで IR機器を制御)を参考に、対応しました。
端的に述べると、学習した信号を三つに分割して送信するようにしています。
学習した信号をどこで切るか等はリンク先を参考にしてください。Slackbotの導入
Raspberry PiでSlackbotを飼うを参考にしました。
とりあえず以下のような感じで、RecordとPlayを行うようにしています。SlackBotPlugin.py#!/usr/bin/env python # -*- coding: utf-8 -*- import re import pigpio from slackbot.bot import listen_to, respond_to from irrp_class import irrp @listen_to('Record .*') @respond_to('Record .*') def record(message, *something): pi = pigpio.pi() if not pi.connected: exit(0) name = message.body['text'].replace('Record ', '') args = { 'gpio': 18, 'file': 'pigpio.json', 'id': name, 'freq': 38.0, 'gap': 100, 'glitch': 100, 'post': 130, 'pre': 200, 'short': 10, 'tolerance': 15, 'verbose': False, 'no_confirm': True } ir = irrp(pi, args) ir.record() message.reply(f'Recorded {name}') pi.stop() @listen_to('Play .*') @respond_to('Play .*') def play(message, *something): 略実際、Slackでやってみると、こんな感じです。
完成!!!
じゃあ、早速試そうと思い使ってみたものの、
学習はうまくいったけど、送信できない…(pigpio.error: 'chain is too long'とエラーが出ました)そのエラーを上記のように解決した結果、
送信は行われているようだが、エアコンがピクリともしない…一旦落ち着いて、テレビのOnOffをやらせてみると、あっさりできる…
送信は正常に行われていることがわかったので、エアコンにラズパイを近づけてみると…(30 cmくらいの距離)
クーラーがついた!とは言え、そんな距離に電源を確保するのも大変…と思い、色々試した結果。
2 mくらいの距離でもうまくいきました。
重要なのはLEDの向きでした(当たり前だろって感じだと思いますけど)。まとめると
LEDがエアコンにきちんと向いていれば、2 mくらいの距離でもエアコンは信号を受信してくれました(電源は5V/2.4A)。
最後に
これで無事夏を乗り切れそうな気がする!(ちょうど今日から地獄のような暑さが到来してますね)
デバイスに触れて作業するのは久々でしたけど、なかなか楽しかったですね。
今度はラズパイ + カメラにチャレンジしようと思います。以下の問題を抱えている気がするので、今後考えます。
* 連続稼働による影響
* ブレッドボードのままなのでユニバーサル基板に移行してハンダ付け
* ラズパイへの理解が未熟であることに起因する何か実際使っているコードは載せれるといいなぁと思っています。
参照した記事を示して、説明は参照先を見てください状態なので、書き直した方が良いのかなぁとも思っています。Ref.
