- 投稿日:2019-05-26T18:21:45+09:00
挫折しかけた人のためのPyTorchの初歩の初歩 〜系列モデルを組んでみよう〜
趣旨
- 自然言語処理を独学して9ヶ月になります
- 深層学習のフレームワークをまさに勉強中で,四苦八苦しながら少しずつ覚えている最中です
- 自分と似たような境遇の方に少しでも参考になればと思い,ごく基本的な事項をまとめてみました
- 誤りなどあればぜひ教えてください!
このような方のために
- RNN, LSTM, GRUについて一通り知っていて,Pythonも一通り書けるが,実装したことはない
- 『ゼロからつくるDeep Learning 2』を読んでスクラッチ実装した経験はあるが,深層学習のフレームワークを触ったことはない
- 深層学習のフレームワークを触ってみたいが,苦手意識がある
- PyTorchのチュートリアルやドキュメントを読んだが,フレームワークの複雑さに諦めかけたことがある
内容
- 簡単なニューラルネットワークの構造をつくる
- ネットワークに推論させる
- PyTorch version 1.1.0 を使用しています
ここで扱わないこと
- 具体的な自然言語処理のタスク
- PyTorchのインストールなどの環境構築
- ニューラルなアプローチを含む自然言語処理の知識
- データの前処理や入力, 訓練の実装や回し方, 誤差関数の実装など
1. RNNを組む
1-1. ネットワークをつくる
実はRNNのネットワークは比較的短いコードで組むことができます。
まずモジュールをインポートします:import torch import torch.nn as nn「入力が3次元で,隠れ状態の表現が4次元の,1層のRNN」を組みたいときは次のように書きます:
dim_input = 3 dim_hidden = 4 n_layer = 1 # 入力3次元, 隠れ状態4次元, 1層のRNN model = nn.RNN(dim_input, dim_hidden, n_layer)なんとたったこれだけでRNNの完成です!
双方向RNN
双方向RNN(BiDirectional RNN)を組むこともできます:
# 入力5次元, 隠れ状態8次元, 1層の双方向RNN model2 = nn.RNN(5, 8, 1, bidirectional=True)多層のRNN
また,多層のRNNを組むこともできます:
# 入力3次元, 隠れ状態6次元, 2層のRNN model3 = nn.RNN(3, 6, 2)1-2. RNNコンストラクタの引数
torch.nn.RNNのコンストラクタに入れることのできる引数は以下のとおりです。
ただ,実際に変更することのあるパラメーターはおそらくbidirectionalくらいでしょう。model = torch.nn.RNN(input_size, hidden_size, num_layers=1, nonlinearity='tanh', bias=True, batch_first=False, dropout=0, bidirectional=False) input_size: int -> 入力ベクトルの次元数 hidden_size: int -> 隠れ状態の次元数 *num_layers: int -> RNNの層数。多層にしたいときは2以上に *nonlinearity: ('tanh','relu') -> 活性化関数 *bias: bool -> バイアスを使うかどうか *batch_first: bool *dropout: float -> 途中の隠れ状態にDropoutを適用する確率 *bidirectional: bool -> 双方向RNNにするかどうか1-3. シーケンス長は決まっていなくてよい
ここでのポイントは,隠れ状態をいくつ並べるのかは,モデルの構築時に決める必要がないということです。
このRNNが隠れ状態の時相をいくつ持つのかは,入力に応じて柔軟に決まります。
たとえば,長さ2のシーケンスを入力した時は,自動的にRNNも隠れ状態を(初期のものも含めて)3つ持つものとして扱われます。
入力シーケンス長が5なら,自動的にRNNの隠れ状態も(初期のものも含めて)6つになります。
入力シーケンス長が変わっても,同じネットワークのオブジェクトを使い回すことができ,ネットワークを作り直す必要がないのは便利です。
1-4. RNNのパラメーターの確認
RNNの重み行列やバイアスといったパラメーターは,モデルが作られた段階で適当な値に初期化されています。
実際にパラメーターの値がどうなっているかを見てみましょう。for param_name, param in model.named_parameters(): print(param_name, param)次のような出力が得られるはずです:
weight_ih_l0 Parameter containing: tensor([[ 0.3952, 0.2076, -0.4457], [ 0.4347, 0.4305, -0.4006], [-0.2418, 0.2938, 0.3902], [ 0.2993, -0.4796, 0.3057]], requires_grad=True) weight_hh_l0 Parameter containing: tensor([[ 0.2947, 0.1054, -0.2473, 0.0123], [-0.4304, -0.1026, -0.2625, 0.2118], [-0.3104, -0.3083, -0.1775, -0.4657], [-0.3112, 0.2688, -0.0175, 0.1982]], requires_grad=True) bias_ih_l0 Parameter containing: tensor([ 0.2956, 0.0737, -0.3413, 0.2683], requires_grad=True) bias_hh_l0 Parameter containing: tensor([-0.4708, 0.1364, -0.0254, -0.3953], requires_grad=True)これらの出力は次のようなことを意味します。
RNNの隠れ層で行われているのは次のような演算でした:h_{t}=(W_{ih}x_{t}+b_{ih})+(W_{hh}h_{t-1}+b_{hh})RNNのパラメーターとして扱われるのは$W_{ih}$,$W_{hh}$,$b_{ih}$,$b_{hh}$の4つの行列もしくはベクトルです。
上の出力例をみると,$W_{ih}$,$W_{hh}$,$b_{ih}$,$b_{hh}$の中身がこの順で出力されていることがわかります。
先ほど
modelを入力3次元,隠れ状態4次元のRNNとしてつくっていたことを思い出せば,$W_{ih}$,$W_{hh}$が4×3行列,$b_{ih}$,$b_{hh}$が4次元ベクトルとなっていることは納得がいきます。1-5. RNNに推論させる
このRNNに何かを入力して,何らかの出力を得てみましょう。
もちろんこのRNNは初期化された状態のままであり,一切の学習を行なっていないため,でたらめな値を吐き出します。まず,入力テンソルと初期の隠れ状態を,正規分布に従ってランダムに生成させます。
テンソルの次元を間違えないように気をつけましょう:n_sample = 2 seq_length = 5 # 入力 # ここでは dim_input = 3 X = torch.randn(n_seq, n_sample, dim_input) # 初期の隠れ状態 # ここでは n_layer = 1, n_hidden = 4 h0 = torch.randn(n_layer, n_sample, n_hidden)あとは構築したネットワークを引数を与えて呼び出すだけです:
# Y:出力, hn:最終の隠れ状態 Y, hn = model(X, h0)これで推論させることができました!
出力内容の確認
実際の出力内容を見てみましょう:
print(Y) print(hn)
Yには時系列(ここでは長さ5)に対応するすべての出力がまとめて格納されていることが読み取れます。
hnはここでは隠れ状態の次元と同じ,4次元ベクトルですね。tensor([[[-0.5985, -0.5996, 0.3071, 0.8372], [-0.6360, 0.3991, 0.8016, 0.2106]], [[-0.7843, 0.2241, 0.6805, 0.4661], [-0.7905, -0.2255, -0.6491, 0.7182]], [[-0.8067, 0.1700, 0.4610, 0.5975], [-0.4348, -0.5121, -0.6546, 0.0738]], [[-0.8926, 0.2469, -0.3201, 0.8214], [-0.8078, -0.3981, 0.2478, 0.9111]], [[-0.7735, 0.3182, 0.7366, 0.5397], [-0.8512, 0.0490, 0.2640, 0.6170]]], grad_fn=<StackBackward>) tensor([[[-0.7735, 0.3182, 0.7366, 0.5397], [-0.8512, 0.0490, 0.2640, 0.6170]]], grad_fn=<StackBackward>)
YにSoftmax関数を通せば,各サンプルの各時系列のベクトルの成分を確率に変換することができます:import torch.nn.functional as F Y_prob = F.softmax(Y, dim=2) print(Y_prob)たしかに各行の合計が1になり,正規化されていることがわかります:
tensor([[[0.1153, 0.1152, 0.2851, 0.4845], [0.0965, 0.2718, 0.4065, 0.2251]], [[0.0865, 0.2371, 0.3743, 0.3021], [0.1186, 0.2087, 0.1366, 0.5361]], [[0.0886, 0.2354, 0.3149, 0.3610], [0.2277, 0.2108, 0.1828, 0.3787]], [[0.0873, 0.2730, 0.1548, 0.4849], [0.0913, 0.1375, 0.2622, 0.5091]], [[0.0818, 0.2437, 0.3703, 0.3041], [0.0922, 0.2267, 0.2811, 0.4001]]], grad_fn=<SoftmaxBackward>)2. LSTMを組む
2-1. ネットワークをつくる
LSTMもRNNとほぼ全く同じように組むことができます:
import torch import torch.nn as nn # 入力2次元, 隠れ状態3次元, 1層のLSTM dim_input, dim_hidden, n_layer = 2, 3, 1 model = nn.LSTM(dim_input, dim_hidden, n_layer)双方向LSTM, 多層LSTMもRNNのときと同様です:
# 入力5次元, 隠れ状態8次元, 1層の双方向LSTM model2 = nn.LSTM(5, 8, 1, bidirectional=True) # 入力3次元, 隠れ状態6次元, 2層のLSTM model3 = nn.LSTM(3, 6, 2)2-2. LSTMコンストラクタの引数
torch.nn.LSTMのコンストラクタに入れることのできる引数は以下のとおりです。
RNNのコンストラクタとほぼ変わりありません。
RNNとの違いは活性化関数を指定する項目がない点くらいでしょう。model = torch.nn.LSTM(input_size, hidden_size, num_layers=1, bias=True, batch_first=False, dropout=0, bidirectional=False) input_size: int -> 入力ベクトルの次元数 hidden_size: int -> 隠れ状態の次元数 *num_layers: int -> LSTMの層数。多層にしたいときは2以上に *bias: bool -> バイアスを使うかどうか *batch_first: bool *dropout: float -> 途中の隠れ状態にDropoutを適用する確率 *bidirectional: bool -> 双方向LSTMにするかどうか2-3. LSTMのパラメーターの確認
LSTMのパラメーターもまた,ネットワークを組んだ時点で適当な値で初期化されています。
現在のパラメーターの様子をみてみましょう:for param_name, param in model.named_parameters(): print(param_name, param)次のような出力が得られるはずです:
weight_ih_l0 Parameter containing: tensor([[ 0.2848, -0.1366], [-0.5757, 0.2086], [ 0.4995, 0.4271], [-0.1745, -0.3294], [ 0.4708, -0.0210], [ 0.4829, -0.4076], [ 0.4412, 0.3948], [ 0.4969, -0.0128], [ 0.4600, 0.4799], [ 0.3268, 0.2755], [ 0.2120, 0.0517], [ 0.1208, -0.1436]], requires_grad=True) weight_hh_l0 Parameter containing: tensor([[-0.0824, 0.3834, -0.0103], [ 0.5396, 0.3769, 0.1899], [-0.4365, -0.5241, -0.2395], [ 0.4210, -0.5123, 0.1195], [-0.3324, 0.2434, 0.3067], [-0.2196, 0.3060, -0.3943], [ 0.1774, -0.2787, 0.0273], [-0.2064, -0.4244, -0.0538], [ 0.1785, 0.0495, 0.4612], [ 0.1111, 0.4128, 0.5325], [ 0.0116, -0.2142, 0.3397], [ 0.2183, -0.2899, 0.1467]], requires_grad=True) bias_ih_l0 Parameter containing: tensor([ 0.2030, -0.3873, 0.5769, -0.3200, 0.0116, -0.0453, -0.5763, -0.0194, -0.1736, -0.0692, 0.2100, -0.0362], requires_grad=True) bias_hh_l0 Parameter containing: tensor([ 0.1686, -0.3883, -0.3789, -0.3639, 0.1766, 0.0311, -0.4657, 0.3933, -0.0357, 0.2844, 0.3898, 0.3525], requires_grad=True)これらの出力は次のようなことを意味します。
LSTMの隠れ層で行われているのは次のような演算でした:i_{t}=\sigma ((W_{ii}x_{t}+b_{ii})+(W_{hi}h_{t-1}+b_{hi}))\\ f_{t}=\sigma ((W_{if}x_{t}+b_{if})+(W_{hf}h_{t-1}+b_{hf}))\\ g_{t}=tanh((W_{ig}x_{t}+b_{ig})+(W_{hg}h_{t-1}+b_{hg}))\\ c_{t}=f_{t}\cdot c_{t-1} + i_{t}\cdot g_{t}\\ o_{t}=\sigma ((W_{io}x_{t}+b_{io})+(W_{ho}h_{t-1}+b_{ho}))\\ h_{t}=o_{t}\cdot tanh(c_{t})LSTMのパラメーターとして扱われるのは$W_{ii}$,$W_{if}$,$W_{ig}$,$W_{io}$,$W_{hi}$,$W_{hf}$,$W_{hg}$,$W_{ho}$,$b_{ii}$,$b_{if}$,$b_{ig}$,$b_{io}$,$b_{hi}$,$b_{hf}$,$b_{hg}$,$b_{ho}$の16の行列もしくはベクトルです。
上の出力例では,
weight_ih_l0 Parameterに$W_{ii}$,$W_{if}$,$W_{ig}$,$W_{io}$がまとめて格納されて出力され,
weight_hh_l0 Parameterに$W_{hi}$,$W_{hf}$,$W_{hg}$,$W_{ho}$がまとめて格納されて出力され,
bias_ih_l0 Parameterに$b_{ii}$,$b_{if}$,$b_{ig}$,$b_{io}$がまとめて格納されて出力され,
bias_hh_l0 Parameterに$b_{hi}$,$b_{hf}$,$b_{hg}$,$b_{ho}$がまとめて格納されて出力されています。2-4. LSTMに推論させる
このLSTMに何かを入力して,何らかの出力を得てみましょう。
もちろんこのLSTMは初期化された状態のままであり,一切の学習を行なっていないため,でたらめな値を吐き出します。n_sample = 2 seq_length = 5 # 入力 X = torch.randn(seq_length, n_sample, dim_input) # 初期の隠れ状態 h0 = torch.randn(n_layer, n_sample, dim_hidden) # 初期のメモリセル c0 = torch.randn(n_layer, n_sample, dim_hidden) # Y:出力, hn:最終の隠れ状態, cn:最終のメモリセル # (h0,c0)を省略するとh0,c0には零ベクトルが代入される Y, (hn,cn) = lstm(X, (h0,c0)) print(Y, hn, cn, sep='\n')次のような出力が得られるはずです:
tensor([[[-0.0608, 0.0157, -0.3091], [-0.1908, 0.1270, -0.0131]], [[-0.0604, 0.1197, -0.2682], [-0.1019, 0.1923, -0.1177]], [[-0.0411, -0.0321, -0.2204], [-0.1566, 0.3992, 0.1179]], [[-0.0693, 0.0297, -0.1263], [-0.0999, 0.4723, 0.2208]], [[-0.0499, 0.2873, 0.0223], [-0.1095, 0.2102, 0.2421]]], grad_fn=<StackBackward>) tensor([[[-0.0499, 0.2873, 0.0223], [-0.1095, 0.2102, 0.2421]]], grad_fn=<StackBackward>) tensor([[[-0.0972, 0.4610, 0.0448], [-0.2396, 0.3879, 0.4673]]], grad_fn=<StackBackward>)3. GRUを組む
3-1. ネットワークをつくる
GRUもRNNとほぼ全く同じように組むことができます:
import torch import torch.nn as nn # 入力2次元, 隠れ状態3次元, 1層のGRU dim_input, dim_hidden, n_layer = 2, 3, 1 model = nn.GRU(dim_input, dim_hidden, n_layer)双方向GRU, 多層GRUもRNNのときと同様です:
# 入力5次元, 隠れ状態8次元, 1層の双方向GRU model2 = nn.GRU(5, 8, 1, bidirectional=True) # 入力3次元, 隠れ状態6次元, 2層のGRU model3 = nn.GRU(3, 6, 2)3-2. GRUコンストラクタの引数
torch.nn.GRUのコンストラクタに入れることのできる引数は以下のとおりです。
RNNのコンストラクタとほぼ変わりありません。
RNNとの違いは活性化関数を指定する項目がない点くらいでしょう。model = torch.nn.GRU(input_size, hidden_size, num_layers=1, bias=True, batch_first=False, dropout=0, bidirectional=False) input_size: int -> 入力ベクトルの次元数 hidden_size: int -> 隠れ状態の次元数 *num_layers: int -> GRUの層数。多層にしたいときは2以上に *bias: bool -> バイアスを使うかどうか *batch_first: bool *dropout: float -> 途中の隠れ状態にDropoutを適用する確率 *bidirectional: bool -> 双方向GRUにするかどうか3-3. GRUのパラメーターの確認
GRUのパラメーターもまた,ネットワークを組んだ時点で適当な値で初期化されています。
現在のパラメーターの様子をみてみましょう:for param_name, param in model.named_parameters(): print(param_name, param)次のような出力が得られるはずです:
weight_ih_l0 Parameter containing: tensor([[ 0.3526, 0.2047], [ 0.5587, 0.3424], [ 0.3634, 0.0156], [-0.0418, 0.1831], [-0.4068, 0.4114], [-0.5638, -0.2389], [-0.1970, 0.0833], [-0.2401, -0.2788], [ 0.4896, -0.2670]], requires_grad=True) weight_hh_l0 Parameter containing: tensor([[ 0.1349, -0.0746, -0.4713], [-0.1361, -0.4540, -0.0641], [-0.1179, -0.3632, -0.2545], [ 0.1209, 0.5216, 0.2496], [ 0.2362, 0.1309, 0.1757], [ 0.0641, -0.4424, 0.0094], [ 0.0433, -0.2761, 0.3010], [-0.3071, -0.0923, -0.2459], [ 0.2349, 0.3862, 0.5465]], requires_grad=True) bias_ih_l0 Parameter containing: tensor([ 0.5506, 0.4258, 0.0540, -0.3532, -0.5515, -0.3412, -0.1674, 0.2784, -0.2394], requires_grad=True) bias_hh_l0 Parameter containing: tensor([ 0.1500, 0.2692, 0.2734, 0.1079, 0.2887, -0.5322, 0.1495, -0.0939, 0.2837], requires_grad=True)これらの出力は次のようなことを意味します。
GRUの隠れ層で行われているのは次のような演算でした:r_{t}=\sigma ((W_{ir}x_{t}+b_{ir})+(W_{hr}h_{t-1}+b_{hr}))\\ z_{t}=\sigma ((W_{iz}x_{t}+b_{iz})+(W_{hz}h_{t-1}+b_{hz}))\\ n_{t}=tanh(r_{t}\cdot (W_{hn}h_{t-1}+b_{hn})+(W_{in}x_{t}+b_{in}))\\ h_{t}=(1-z_{t})\cdot n_{t} + z_{t}\cdot h_{t-1}GRUのパラメーターとして扱われるのは$W_{ir}$,$W_{iz}$,$W_{in}$,$W_{hr}$,$W_{hz}$,$W_{hn}$,$b_{ir}$,$b_{iz}$,$b_{in}$,$b_{hr}$,$b_{hz}$,$b_{hn}$の12の行列もしくはベクトルです。
上の出力例では,
weight_ih_l0 Parameterに$W_{ir}$,$W_{iz}$,$W_{in}$がまとめて格納されて出力され,
weight_hh_l0 Parameterに$W_{hr}$,$W_{hz}$,$W_{hn}$がまとめて格納されて出力され,
bias_ih_l0 Parameterに$b_{ir}$,$b_{iz}$,$b_{in}$がまとめて格納されて出力され,
bias_hh_l0 Parameterに$b_{hr}$,$b_{hz}$,$b_{hn}$がまとめて格納されて出力されています。3-4. GRUに推論させる
このGRUに何かを入力して,何らかの出力を得てみましょう。
もちろんこのGRUは初期化された状態のままであり,一切の学習を行なっていないため,でたらめな値を吐き出します。n_sample = 2 seq_length = 5 # 入力 X = torch.randn(seq_length, n_sample, dim_input) # 初期の隠れ状態 h0 = torch.randn(n_layer, n_sample, dim_hidden) # Y:出力, hn:最終の隠れ状態 # h0を省略するとh0には零ベクトルが代入される Y, hn = gru(X, h0) print(Y, hn, sep='\n')次のような出力が得られるはずです:
tensor([[[ 0.5822, -0.4229, 0.4796], [ 0.0419, 0.0228, 0.4883]], [[ 0.0915, 0.1967, 0.6127], [ 0.0900, -0.0312, -0.0792]], [[ 0.0548, -0.0761, 0.2387], [-0.0706, -0.1772, 0.1976]], [[ 0.0956, 0.1815, -0.1227], [-0.1522, 0.1317, 0.4051]], [[-0.0466, -0.0572, 0.0450], [-0.3013, -0.1203, 0.7980]]], grad_fn=<StackBackward>) tensor([[[-0.0466, -0.0572, 0.0450], [-0.3013, -0.1203, 0.7980]]], grad_fn=<StackBackward>)4. より複雑なネットワークを組むには(1)
ここまで,RNN,LSTM,GRUがPyTorchのモジュールを1つ使うだけで簡単に組めることがわかりました。
4-1.はじめに
PyTorchでネットワークを組む方法にはいくつかの方法があります:
- a. 既存のモジュールを1つ使う(これまでのように)
- b. 既存のモジュールを複数組み合わせる
- c. 自分で独自のモジュールを定義する
a.の「既存のモジュールを1つ使う」はこれまでに試してきた通りです。
RNN, LSTM, GRUについては,内部処理を記述することなくモジュール1つで簡単にネットワークを組むことができます。c.の「自分で独自のモジュールを定義する」はもっとも自由度の高いカスタマイズが可能ですが,PyTorchへの理解を深める必要がありそうです。
ここでは比較的簡単な,b.の「既存のモジュールを複数組み合わせる」方法についてみていきましょう。
4-2.既存のモジュールを複数組み合わせるには
以下,時系列ネットワークからは離れた話になることをご了承ください。
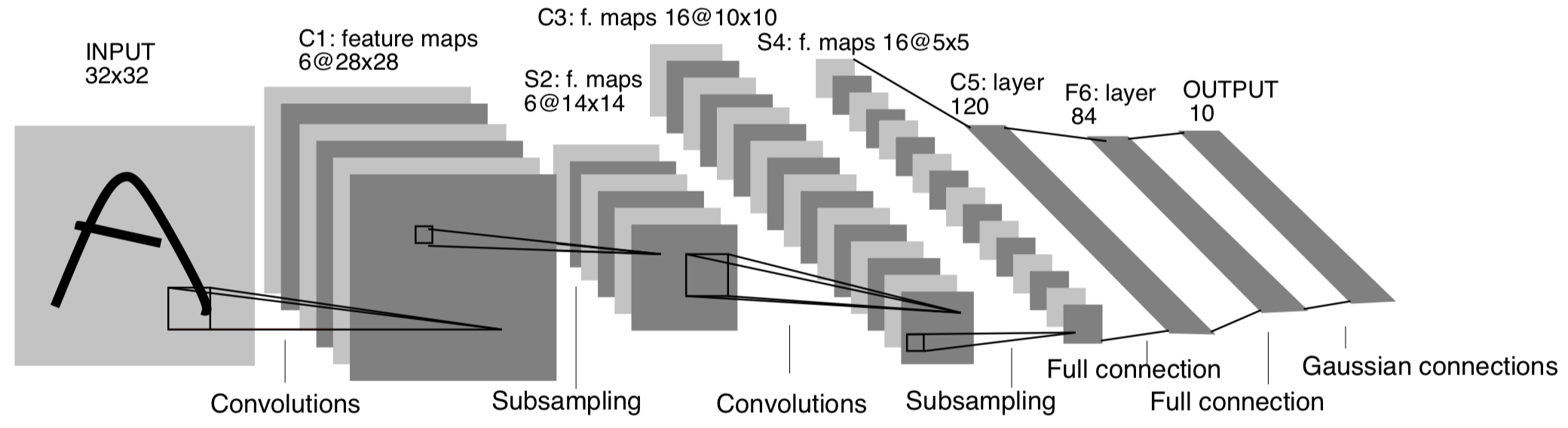
たとえば,次のようなCNN(の一部分)を組みたいとします:
Yann LeCun et al. Object Recognition with Gradient-Based Learning
上図は画像認識へのCNNの普及のきっかけとなったLeNetの論文から引用した図です。
このうち,全結合層の手前にあたる部分に似せた,下記を実装してみようと思います:
- 畳み込み層1
- 入力チャネル数1, 出力チャネル数6, カーネルサイズ5x5
- MaxPooling層1
- カーネルサイズ2x2
- 活性化(ReLU)1
- 畳み込み層2
- 入力チャネル数6, 出力チャネル数16, カーネルサイズ5x5
- MaxPooling層2
- カーネルサイズ2x2
- 活性化(ReLU)2
どのようにすればこれらを1つのネットワークとして表現できるでしょうか?
方法1: 入出力を順次渡していく
畳み込み層,MaxPooling層,活性化はそれぞれが独立したモジュールとして提供されています。
このため,前の層の出力を次の層の入力へと順次渡していくことで一連のネットワークとしての処理が可能です:import torch import torch.nn as nn # 入力 # requires_grad=Trueとしておくとのちほど訓練しやすい # Xを使って計算されたテンソルをすべて追跡して勾配計算を繋いでくれる X = torch.randn(10, 1, 32, 32, requires_grad=True) # モジュールを用意 conv1 = nn.Conv2d(1, 6, 5) relu1 = nn.ReLU() maxpool1 = nn.MaxPool2d(2) conv2 = nn.Conv2d(6, 16, 5) relu2 = nn.ReLU() maxpool2 = nn.MaxPool2d(2) # 推論させたいときは out = conv1(X) out = relu1(out) out = maxpool1(out) out = conv2(out) out = relu2(out) Y = maxpool2(out)ただし,のちほど学習を進める際,勾配や重みなどのパラメーター全体を統一して扱いにくい印象があります。
方法2: モデルをひとまとめにする
PyTorchには複数のモジュールを1つのモジュールへとまとめるための
torch.nn.Sequentialが用意されており,まとめた後のモジュールを用いて一括で推論を行うことができます:# conv1, relu1, maxpool1, conv2, relu2, maxpool2を用意するところまでは方法1と同じ # 一連の処理を1つのモデルにまとめる model = nn.Sequential(conv1, relu1, maxpool1, conv2, relu2, maxpool2) # 推論させたいときは Y = model(X)もしくは,順序つき辞書
OrderedDictを作成して代入しても構いません:# 個々のモジュールを用意 from collections import OrderedDict layers = OrderedDict([('conv1', nn.Conv2d(1,6,5)),('relu1',nn.ReLU()),('conv2',nn.Conv2d(6,16,5)),('relu2',nn.ReLU())]) # 1つのモデルにまとめる model = nn.Sequential(layers) # 推論させたいときは Y = model(X)この方法では,モデル全体のパラメーターが
model.parameters()やmodel.named_parameters()に一括で格納されるため,統一して扱いやすくなります。しかし,細やかな処理が得意ではないのが最大の欠点です。
たとえば,CNNの全結合層を定義するにはテンソルをreshapeしてベクトルへとほどいてやる必要がありますが,reshapeの操作を行ってくれるレイヤーは存在しません。
このため,レイヤーの積み重ねである
nn.Sequentialでは,画像認識システムは完成させられないことになってしまいます
(参考:What is the reshape layer in pytorch?)。4-3.torch.nnのモジュール
PyTorchのtorch.nnの内部に用意されているモジュールの例を以下に挙げます。
眺めていると,ネットワークを組むのに必要な道具がだいたい揃っているように思えるのではないでしょうか。
ポイントは,「単体でネットワークとして使えるもの」と,通常は単体では使用されることはなく「ネットワークの処理の一部を担うもの」の2種類に分けられる点です:
- 単体でもネットワークとして使えるもの
- 時系列ネットワーク
torch.nn.RNNtorch.nn.LSTMtorch.nn.GRU- 通常単体では使用されないもの(ネットワークの処理の一部を担う)
- 行列計算を行うもの
torch.nn.Identitytorch.nn.Linearなど- 活性化関数の適用を行うもの
torch.nn.ReLUtorch.nn.LeakyReLUtorch.nn.PReLUtorch.nn.LogSigmoidtorch.nn.Tanhtorch.nn.Hardtanhなど- パディング(padding)を行うもの
torch.nn.ZeroPad2dtorch.nn.ConstantPad2dtorch.nn.ReflectionPad2dtorch.nn.ReplicationPad2dなど- 畳み込み(convolution)を行うもの
torch.nn.Conv2dなど- プーリング(pooling)を行うもの
torch.nn.MaxPool2dtorch.nn.AvgPool2dなど- 正規化(normalization)を行うもの
torch.nn.BatchNorm2dtorch.nn.LocalResponseNormなど- ドロップアウト(dropout)を行うもの
torch.nn.Dropout2dなど- Softmax関数などの適用を行うもの
torch.nn.Softmaxなど- 画像処理を行うもの
torch.nn.PixelShuffletorch.nn.Upsampleなど- 時系列ネットワークの部品を提供するもの
torch.nn.RNNCelltorch.nn.LSTMCelltorch.nn.GRUCell5. より複雑なネットワークを組むには(2)
先ほど,複数のモジュールをつなぎ合わせる方法は,やはり柔軟性に欠けており,限界があることを確認しました。
次に,「自分で独自のモジュールを定義する」方法で,より自由なモデルを作成してみます。独自のモジュールは次のように抽象クラス
torch.nn.Moduleを継承することで定義します:import torch import torch.nn as nn class MyModule(nn.Module): def __init__(self): super().__init__() # 親クラス torch.nn.Module のコンストラクタを呼ぶ hogehoge # モジュールの内容やパラメーターを定義 def forward(self): fugafuga # 推論するときの挙動を定義このとき,
forward()メソッドは必ずoverrideしないと例外NotImplementedErrorが返ることに注意してください。6. まとめ
PyTorchのモジュールを用いて,ネットワークのごく大雑把な組み方を把握してみました。
実際のネットワークの学習に必要な,損失関数の計算,誤差逆伝播,パラメーター更新などはまだ扱っていません。
のちほど追って他の記事に載せようと思っています。参考文献
PyTorch.org Package reference
#1 Neural Networks : PyTorchチュートリアルをやってみた
- 投稿日:2019-05-26T18:21:45+09:00
挫折しかけた人のためのPyTorch:RNN,LSTM,GRU,CNNのモデルを組もう
趣旨
- 自然言語処理を独学して9ヶ月になります
- 深層学習のフレームワークをまさに勉強中で,四苦八苦しながら少しずつ覚えている最中です
- 自分と似たような境遇の方に少しでも参考になればと思い,ごく基本的な事項をまとめてみました
- 誤りなどあればぜひ教えてください!
このような方のために
- RNN, LSTM, GRUについて一通り知っていて,Pythonも一通り書けるが,実装したことはない
- 『ゼロからつくるDeep Learning 2』を読んでスクラッチ実装した経験はあるが,深層学習のフレームワークを触ったことはない
- 深層学習のフレームワークを触ってみたいが,苦手意識がある
- PyTorchのチュートリアルやドキュメントを読んだが,フレームワークの複雑さに諦めかけたことがある
内容
- 簡単なニューラルネットワークの構造をつくる
- ネットワークに推論させる
- PyTorch version 1.1.0 を使用しています
ここで扱わないこと
- 具体的な自然言語処理のタスク
- PyTorchのインストールなどの環境構築
- ニューラルなアプローチを含む自然言語処理の知識
- データの前処理や入力, 訓練の実装や回し方, 誤差関数の実装など
1. RNNを組む
1-1. ネットワークをつくる
実はRNNのネットワークは比較的短いコードで組むことができます。
まずモジュールをインポートします:import torch import torch.nn as nn「入力が3次元で,隠れ状態の表現が4次元の,1層のRNN」を組みたいときは次のように書きます:
dim_input = 3 dim_hidden = 4 n_layer = 1 # 入力3次元, 隠れ状態4次元, 1層のRNN model = nn.RNN(dim_input, dim_hidden, n_layer)なんとたったこれだけでRNNの完成です!
双方向RNN
双方向RNN(BiDirectional RNN)を組むこともできます:
# 入力5次元, 隠れ状態8次元, 1層の双方向RNN model2 = nn.RNN(5, 8, 1, bidirectional=True)多層のRNN
また,多層のRNNを組むこともできます:
# 入力3次元, 隠れ状態6次元, 2層のRNN model3 = nn.RNN(3, 6, 2)1-2. RNNコンストラクタの引数
torch.nn.RNNのコンストラクタに入れることのできる引数は以下のとおりです。
ただ,実際に変更することのあるパラメーターはおそらくbidirectionalくらいでしょう。model = torch.nn.RNN(input_size, hidden_size, num_layers=1, nonlinearity='tanh', bias=True, batch_first=False, dropout=0, bidirectional=False) input_size: int -> 入力ベクトルの次元数 hidden_size: int -> 隠れ状態の次元数 *num_layers: int -> RNNの層数。多層にしたいときは2以上に *nonlinearity: ('tanh','relu') -> 活性化関数 *bias: bool -> バイアスを使うかどうか *batch_first: bool *dropout: float -> 途中の隠れ状態にDropoutを適用する確率 *bidirectional: bool -> 双方向RNNにするかどうか1-3. シーケンス長は決まっていなくてよい
ここでのポイントは,隠れ状態をいくつ並べるのかは,モデルの構築時に決める必要がないということです。
このRNNが隠れ状態の時相をいくつ持つのかは,入力に応じて柔軟に決まります。
たとえば,長さ2のシーケンスを入力した時は,自動的にRNNも隠れ状態を(初期のものも含めて)3つ持つものとして扱われます。
入力シーケンス長が5なら,自動的にRNNの隠れ状態も(初期のものも含めて)6つになります。
入力シーケンス長が変わっても,同じネットワークのオブジェクトを使い回すことができ,ネットワークを作り直す必要がないのは便利です。
1-4. RNNのパラメーターの確認
RNNの重み行列やバイアスといったパラメーターは,モデルが作られた段階で適当な値に初期化されています。
実際にパラメーターの値がどうなっているかを見てみましょう。for param_name, param in model.named_parameters(): print(param_name, param)次のような出力が得られるはずです:
weight_ih_l0 Parameter containing: tensor([[ 0.3952, 0.2076, -0.4457], [ 0.4347, 0.4305, -0.4006], [-0.2418, 0.2938, 0.3902], [ 0.2993, -0.4796, 0.3057]], requires_grad=True) weight_hh_l0 Parameter containing: tensor([[ 0.2947, 0.1054, -0.2473, 0.0123], [-0.4304, -0.1026, -0.2625, 0.2118], [-0.3104, -0.3083, -0.1775, -0.4657], [-0.3112, 0.2688, -0.0175, 0.1982]], requires_grad=True) bias_ih_l0 Parameter containing: tensor([ 0.2956, 0.0737, -0.3413, 0.2683], requires_grad=True) bias_hh_l0 Parameter containing: tensor([-0.4708, 0.1364, -0.0254, -0.3953], requires_grad=True)これらの出力は次のようなことを意味します。
RNNの隠れ層で行われているのは次のような演算でした:h_{t}=(W_{ih}x_{t}+b_{ih})+(W_{hh}h_{t-1}+b_{hh})RNNのパラメーターとして扱われるのは$W_{ih}$,$W_{hh}$,$b_{ih}$,$b_{hh}$の4つの行列もしくはベクトルです。
上の出力例をみると,$W_{ih}$,$W_{hh}$,$b_{ih}$,$b_{hh}$の中身がこの順で出力されていることがわかります。
先ほど
modelを入力3次元,隠れ状態4次元のRNNとしてつくっていたことを思い出せば,$W_{ih}$,$W_{hh}$が4×3行列,$b_{ih}$,$b_{hh}$が4次元ベクトルとなっていることは納得がいきます。1-5. RNNに推論させる
このRNNに何かを入力して,何らかの出力を得てみましょう。
もちろんこのRNNは初期化された状態のままであり,一切の学習を行なっていないため,でたらめな値を吐き出します。まず,入力テンソルと初期の隠れ状態を,正規分布に従ってランダムに生成させます。
テンソルの次元を間違えないように気をつけましょう:n_sample = 2 seq_length = 5 # 入力 # ここでは dim_input = 3 X = torch.randn(n_seq, n_sample, dim_input) # 初期の隠れ状態 # ここでは n_layer = 1, n_hidden = 4 h0 = torch.randn(n_layer, n_sample, n_hidden)あとは構築したネットワークを引数を与えて呼び出すだけです:
# Y:出力, hn:最終の隠れ状態 Y, hn = model(X, h0)これで推論させることができました!
出力内容の確認
実際の出力内容を見てみましょう:
print(Y) print(hn)
Yには時系列(ここでは長さ5)に対応するすべての出力がまとめて格納されていることが読み取れます。
hnはここでは隠れ状態の次元と同じ,4次元ベクトルですね。tensor([[[-0.5985, -0.5996, 0.3071, 0.8372], [-0.6360, 0.3991, 0.8016, 0.2106]], [[-0.7843, 0.2241, 0.6805, 0.4661], [-0.7905, -0.2255, -0.6491, 0.7182]], [[-0.8067, 0.1700, 0.4610, 0.5975], [-0.4348, -0.5121, -0.6546, 0.0738]], [[-0.8926, 0.2469, -0.3201, 0.8214], [-0.8078, -0.3981, 0.2478, 0.9111]], [[-0.7735, 0.3182, 0.7366, 0.5397], [-0.8512, 0.0490, 0.2640, 0.6170]]], grad_fn=<StackBackward>) tensor([[[-0.7735, 0.3182, 0.7366, 0.5397], [-0.8512, 0.0490, 0.2640, 0.6170]]], grad_fn=<StackBackward>)
YにSoftmax関数を通せば,各サンプルの各時系列のベクトルの成分を確率に変換することができます:import torch.nn.functional as F Y_prob = F.softmax(Y, dim=2) print(Y_prob)たしかに各行の合計が1になり,正規化されていることがわかります:
tensor([[[0.1153, 0.1152, 0.2851, 0.4845], [0.0965, 0.2718, 0.4065, 0.2251]], [[0.0865, 0.2371, 0.3743, 0.3021], [0.1186, 0.2087, 0.1366, 0.5361]], [[0.0886, 0.2354, 0.3149, 0.3610], [0.2277, 0.2108, 0.1828, 0.3787]], [[0.0873, 0.2730, 0.1548, 0.4849], [0.0913, 0.1375, 0.2622, 0.5091]], [[0.0818, 0.2437, 0.3703, 0.3041], [0.0922, 0.2267, 0.2811, 0.4001]]], grad_fn=<SoftmaxBackward>)2. LSTMを組む
2-1. ネットワークをつくる
LSTMもRNNとほぼ全く同じように組むことができます:
import torch import torch.nn as nn # 入力2次元, 隠れ状態3次元, 1層のLSTM dim_input, dim_hidden, n_layer = 2, 3, 1 model = nn.LSTM(dim_input, dim_hidden, n_layer)双方向LSTM, 多層LSTMもRNNのときと同様です:
# 入力5次元, 隠れ状態8次元, 1層の双方向LSTM model2 = nn.LSTM(5, 8, 1, bidirectional=True) # 入力3次元, 隠れ状態6次元, 2層のLSTM model3 = nn.LSTM(3, 6, 2)2-2. LSTMコンストラクタの引数
torch.nn.LSTMのコンストラクタに入れることのできる引数は以下のとおりです。
RNNのコンストラクタとほぼ変わりありません。
RNNとの違いは活性化関数を指定する項目がない点くらいでしょう。model = torch.nn.LSTM(input_size, hidden_size, num_layers=1, bias=True, batch_first=False, dropout=0, bidirectional=False) input_size: int -> 入力ベクトルの次元数 hidden_size: int -> 隠れ状態の次元数 *num_layers: int -> LSTMの層数。多層にしたいときは2以上に *bias: bool -> バイアスを使うかどうか *batch_first: bool *dropout: float -> 途中の隠れ状態にDropoutを適用する確率 *bidirectional: bool -> 双方向LSTMにするかどうか2-3. LSTMのパラメーターの確認
LSTMのパラメーターもまた,ネットワークを組んだ時点で適当な値で初期化されています。
現在のパラメーターの様子をみてみましょう:for param_name, param in model.named_parameters(): print(param_name, param)次のような出力が得られるはずです:
weight_ih_l0 Parameter containing: tensor([[ 0.2848, -0.1366], [-0.5757, 0.2086], [ 0.4995, 0.4271], [-0.1745, -0.3294], [ 0.4708, -0.0210], [ 0.4829, -0.4076], [ 0.4412, 0.3948], [ 0.4969, -0.0128], [ 0.4600, 0.4799], [ 0.3268, 0.2755], [ 0.2120, 0.0517], [ 0.1208, -0.1436]], requires_grad=True) weight_hh_l0 Parameter containing: tensor([[-0.0824, 0.3834, -0.0103], [ 0.5396, 0.3769, 0.1899], [-0.4365, -0.5241, -0.2395], [ 0.4210, -0.5123, 0.1195], [-0.3324, 0.2434, 0.3067], [-0.2196, 0.3060, -0.3943], [ 0.1774, -0.2787, 0.0273], [-0.2064, -0.4244, -0.0538], [ 0.1785, 0.0495, 0.4612], [ 0.1111, 0.4128, 0.5325], [ 0.0116, -0.2142, 0.3397], [ 0.2183, -0.2899, 0.1467]], requires_grad=True) bias_ih_l0 Parameter containing: tensor([ 0.2030, -0.3873, 0.5769, -0.3200, 0.0116, -0.0453, -0.5763, -0.0194, -0.1736, -0.0692, 0.2100, -0.0362], requires_grad=True) bias_hh_l0 Parameter containing: tensor([ 0.1686, -0.3883, -0.3789, -0.3639, 0.1766, 0.0311, -0.4657, 0.3933, -0.0357, 0.2844, 0.3898, 0.3525], requires_grad=True)これらの出力は次のようなことを意味します。
LSTMの隠れ層で行われているのは次のような演算でした:i_{t}=\sigma ((W_{ii}x_{t}+b_{ii})+(W_{hi}h_{t-1}+b_{hi}))\\ f_{t}=\sigma ((W_{if}x_{t}+b_{if})+(W_{hf}h_{t-1}+b_{hf}))\\ g_{t}=tanh((W_{ig}x_{t}+b_{ig})+(W_{hg}h_{t-1}+b_{hg}))\\ c_{t}=f_{t}\cdot c_{t-1} + i_{t}\cdot g_{t}\\ o_{t}=\sigma ((W_{io}x_{t}+b_{io})+(W_{ho}h_{t-1}+b_{ho}))\\ h_{t}=o_{t}\cdot tanh(c_{t})LSTMのパラメーターとして扱われるのは$W_{ii}$,$W_{if}$,$W_{ig}$,$W_{io}$,$W_{hi}$,$W_{hf}$,$W_{hg}$,$W_{ho}$,$b_{ii}$,$b_{if}$,$b_{ig}$,$b_{io}$,$b_{hi}$,$b_{hf}$,$b_{hg}$,$b_{ho}$の16の行列もしくはベクトルです。
上の出力例では,
weight_ih_l0 Parameterに$W_{ii}$,$W_{if}$,$W_{ig}$,$W_{io}$がまとめて格納されて出力され,
weight_hh_l0 Parameterに$W_{hi}$,$W_{hf}$,$W_{hg}$,$W_{ho}$がまとめて格納されて出力され,
bias_ih_l0 Parameterに$b_{ii}$,$b_{if}$,$b_{ig}$,$b_{io}$がまとめて格納されて出力され,
bias_hh_l0 Parameterに$b_{hi}$,$b_{hf}$,$b_{hg}$,$b_{ho}$がまとめて格納されて出力されています。2-4. LSTMに推論させる
このLSTMに何かを入力して,何らかの出力を得てみましょう。
もちろんこのLSTMは初期化された状態のままであり,一切の学習を行なっていないため,でたらめな値を吐き出します。n_sample = 2 seq_length = 5 # 入力 X = torch.randn(seq_length, n_sample, dim_input) # 初期の隠れ状態 h0 = torch.randn(n_layer, n_sample, dim_hidden) # 初期のメモリセル c0 = torch.randn(n_layer, n_sample, dim_hidden) # Y:出力, hn:最終の隠れ状態, cn:最終のメモリセル # (h0,c0)を省略するとh0,c0には零ベクトルが代入される Y, (hn,cn) = lstm(X, (h0,c0)) print(Y, hn, cn, sep='\n')次のような出力が得られるはずです:
tensor([[[-0.0608, 0.0157, -0.3091], [-0.1908, 0.1270, -0.0131]], [[-0.0604, 0.1197, -0.2682], [-0.1019, 0.1923, -0.1177]], [[-0.0411, -0.0321, -0.2204], [-0.1566, 0.3992, 0.1179]], [[-0.0693, 0.0297, -0.1263], [-0.0999, 0.4723, 0.2208]], [[-0.0499, 0.2873, 0.0223], [-0.1095, 0.2102, 0.2421]]], grad_fn=<StackBackward>) tensor([[[-0.0499, 0.2873, 0.0223], [-0.1095, 0.2102, 0.2421]]], grad_fn=<StackBackward>) tensor([[[-0.0972, 0.4610, 0.0448], [-0.2396, 0.3879, 0.4673]]], grad_fn=<StackBackward>)3. GRUを組む
3-1. ネットワークをつくる
GRUもRNNとほぼ全く同じように組むことができます:
import torch import torch.nn as nn # 入力2次元, 隠れ状態3次元, 1層のGRU dim_input, dim_hidden, n_layer = 2, 3, 1 model = nn.GRU(dim_input, dim_hidden, n_layer)双方向GRU, 多層GRUもRNNのときと同様です:
# 入力5次元, 隠れ状態8次元, 1層の双方向GRU model2 = nn.GRU(5, 8, 1, bidirectional=True) # 入力3次元, 隠れ状態6次元, 2層のGRU model3 = nn.GRU(3, 6, 2)3-2. GRUコンストラクタの引数
torch.nn.GRUのコンストラクタに入れることのできる引数は以下のとおりです。
RNNのコンストラクタとほぼ変わりありません。
RNNとの違いは活性化関数を指定する項目がない点くらいでしょう。model = torch.nn.GRU(input_size, hidden_size, num_layers=1, bias=True, batch_first=False, dropout=0, bidirectional=False) input_size: int -> 入力ベクトルの次元数 hidden_size: int -> 隠れ状態の次元数 *num_layers: int -> GRUの層数。多層にしたいときは2以上に *bias: bool -> バイアスを使うかどうか *batch_first: bool *dropout: float -> 途中の隠れ状態にDropoutを適用する確率 *bidirectional: bool -> 双方向GRUにするかどうか3-3. GRUのパラメーターの確認
GRUのパラメーターもまた,ネットワークを組んだ時点で適当な値で初期化されています。
現在のパラメーターの様子をみてみましょう:for param_name, param in model.named_parameters(): print(param_name, param)次のような出力が得られるはずです:
weight_ih_l0 Parameter containing: tensor([[ 0.3526, 0.2047], [ 0.5587, 0.3424], [ 0.3634, 0.0156], [-0.0418, 0.1831], [-0.4068, 0.4114], [-0.5638, -0.2389], [-0.1970, 0.0833], [-0.2401, -0.2788], [ 0.4896, -0.2670]], requires_grad=True) weight_hh_l0 Parameter containing: tensor([[ 0.1349, -0.0746, -0.4713], [-0.1361, -0.4540, -0.0641], [-0.1179, -0.3632, -0.2545], [ 0.1209, 0.5216, 0.2496], [ 0.2362, 0.1309, 0.1757], [ 0.0641, -0.4424, 0.0094], [ 0.0433, -0.2761, 0.3010], [-0.3071, -0.0923, -0.2459], [ 0.2349, 0.3862, 0.5465]], requires_grad=True) bias_ih_l0 Parameter containing: tensor([ 0.5506, 0.4258, 0.0540, -0.3532, -0.5515, -0.3412, -0.1674, 0.2784, -0.2394], requires_grad=True) bias_hh_l0 Parameter containing: tensor([ 0.1500, 0.2692, 0.2734, 0.1079, 0.2887, -0.5322, 0.1495, -0.0939, 0.2837], requires_grad=True)これらの出力は次のようなことを意味します。
GRUの隠れ層で行われているのは次のような演算でした:r_{t}=\sigma ((W_{ir}x_{t}+b_{ir})+(W_{hr}h_{t-1}+b_{hr}))\\ z_{t}=\sigma ((W_{iz}x_{t}+b_{iz})+(W_{hz}h_{t-1}+b_{hz}))\\ n_{t}=tanh(r_{t}\cdot (W_{hn}h_{t-1}+b_{hn})+(W_{in}x_{t}+b_{in}))\\ h_{t}=(1-z_{t})\cdot n_{t} + z_{t}\cdot h_{t-1}GRUのパラメーターとして扱われるのは$W_{ir}$,$W_{iz}$,$W_{in}$,$W_{hr}$,$W_{hz}$,$W_{hn}$,$b_{ir}$,$b_{iz}$,$b_{in}$,$b_{hr}$,$b_{hz}$,$b_{hn}$の12の行列もしくはベクトルです。
上の出力例では,
weight_ih_l0 Parameterに$W_{ir}$,$W_{iz}$,$W_{in}$がまとめて格納されて出力され,
weight_hh_l0 Parameterに$W_{hr}$,$W_{hz}$,$W_{hn}$がまとめて格納されて出力され,
bias_ih_l0 Parameterに$b_{ir}$,$b_{iz}$,$b_{in}$がまとめて格納されて出力され,
bias_hh_l0 Parameterに$b_{hr}$,$b_{hz}$,$b_{hn}$がまとめて格納されて出力されています。3-4. GRUに推論させる
このGRUに何かを入力して,何らかの出力を得てみましょう。
もちろんこのGRUは初期化された状態のままであり,一切の学習を行なっていないため,でたらめな値を吐き出します。n_sample = 2 seq_length = 5 # 入力 X = torch.randn(seq_length, n_sample, dim_input) # 初期の隠れ状態 h0 = torch.randn(n_layer, n_sample, dim_hidden) # Y:出力, hn:最終の隠れ状態 # h0を省略するとh0には零ベクトルが代入される Y, hn = gru(X, h0) print(Y, hn, sep='\n')次のような出力が得られるはずです:
tensor([[[ 0.5822, -0.4229, 0.4796], [ 0.0419, 0.0228, 0.4883]], [[ 0.0915, 0.1967, 0.6127], [ 0.0900, -0.0312, -0.0792]], [[ 0.0548, -0.0761, 0.2387], [-0.0706, -0.1772, 0.1976]], [[ 0.0956, 0.1815, -0.1227], [-0.1522, 0.1317, 0.4051]], [[-0.0466, -0.0572, 0.0450], [-0.3013, -0.1203, 0.7980]]], grad_fn=<StackBackward>) tensor([[[-0.0466, -0.0572, 0.0450], [-0.3013, -0.1203, 0.7980]]], grad_fn=<StackBackward>)4. より複雑なネットワークを組むには
ここまで,RNN,LSTM,GRUがPyTorchのモジュールを1つ使うだけで簡単に組めることがわかりました。
4-1.はじめに
PyTorchでネットワークを組む方法にはいくつかの方法があります:
- a. 既存のモジュールを1つ使う(これまでのように)
- b. 既存のモジュールを複数組み合わせる
- c. 自分で独自のモジュールを定義する
a.の「既存のモジュールを1つ使う」はこれまでに試してきた通りです。
RNN, LSTM, GRUについては,内部処理を記述することなくモジュール1つで簡単にネットワークを組むことができます。c.の「自分で独自のモジュールを定義する」はもっとも自由度の高いカスタマイズが可能ですが,PyTorchへの理解を深める必要がありそうです。
ここでは比較的簡単な,b.の「既存のモジュールを複数組み合わせる」方法についてみていきましょう。
4-2.既存のモジュールを複数組み合わせるには
以下,時系列ネットワークからは離れた話になることをご了承ください。
たとえば,次のようなCNN(の一部分)を組みたいとします:
- 畳み込み層1
- 入力チャネル数1, 出力チャネル数6, カーネルサイズ5x5
- MaxPooling層1
- カーネルサイズ2x2
- 活性化(ReLU)1
- 畳み込み層2
- 入力チャネル数6, 出力チャネル数16, カーネルサイズ5x5
- MaxPooling層2
- カーネルサイズ2x2
- 活性化(ReLU)2
どのようにすればこれらを1つのネットワークとして表現できるでしょうか?
方法1: 入出力を順次渡していく
畳み込み層,MaxPooling層,活性化はそれぞれが独立したモジュールとして提供されています。
このため,前の層の出力を次の層の入力へと順次渡していくことで一連のネットワークとしての処理が可能です:import torch import torch.nn as nn # 入力 # requires_grad=Trueとしておくとのちほど訓練しやすい # Xを使って計算されたテンソルをすべて追跡して勾配計算を繋いでくれる X = torch.randn(10, 1, 32, 32, requires_grad=True) # モジュールを用意 conv1 = nn.Conv2d(1, 6, 5) relu1 = nn.ReLU() maxpool1 = nn.MaxPool2d(2) conv2 = nn.Conv2d(6, 16, 5) relu2 = nn.ReLU() maxpool2 = nn.MaxPool2d(2) # 推論させたいときは out = conv1(X) out = relu1(out) out = maxpool1(out) out = conv2(out) out = relu2(out) Y = maxpool2(out)方法2: モデルをひとまとめにする
PyTorchには複数のモジュールを1つのモジュールへとまとめるための
torch.nn.Sequentialが用意されており,まとめた後のモジュールを用いて一括で推論を行うことができます:# conv1, relu1, maxpool1, conv2, relu2, maxpool2を用意するところまでは方法1と同じ # 一連の処理を1つのモデルにまとめる model = nn.Sequential(conv1, relu1, maxpool1, conv2, relu2, maxpool2) # 推論させたいときは Y = model(X)もしくは,順序つき辞書
OrderedDictを作成して代入しても構いません:# 個々のモジュールを用意 layers = OrderedDict([('conv1', nn.Conv2d(1,6,5)),('relu1',nn.ReLU()),('conv2',nn.Conv2d(6,16,5)),('relu2',nn.ReLU())]) # 1つのモデルにまとめる model = nn.Sequential(layers) # 推論させたいときは Y = model(X)4-3.torch.nnのモジュール
PyTorchのtorch.nnの内部に用意されているモジュールの例を以下に挙げます。
眺めていると,ネットワークを組むのに必要な道具がだいたい揃っているように思えるのではないでしょうか。
ポイントは,「単体でネットワークとして使えるもの」と,通常は単体では使用されることはなく「ネットワークの処理の一部を担うもの」の2種類に分けられる点です:
- 単体でもネットワークとして使えるもの
- 時系列ネットワーク
torch.nn.RNNtorch.nn.LSTMtorch.nn.GRU- 通常単体では使用されないもの(ネットワークの処理の一部を担う)
- 行列計算を行うもの
torch.nn.Identitytorch.nn.Linearなど- 活性化関数の適用を行うもの
torch.nn.ReLUtorch.nn.LeakyReLUtorch.nn.PReLUtorch.nn.LogSigmoidtorch.nn.Tanhtorch.nn.Hardtanhなど- パディング(padding)を行うもの
torch.nn.ZeroPad2dtorch.nn.ConstantPad2dtorch.nn.ReflectionPad2dtorch.nn.ReplicationPad2dなど- 畳み込み(convolution)を行うもの
torch.nn.Conv2dなど- プーリング(pooling)を行うもの
torch.nn.MaxPool2dtorch.nn.AvgPool2dなど- 正規化(normalization)を行うもの
torch.nn.BatchNorm2dtorch.nn.LocalResponseNormなど- ドロップアウト(dropout)を行うもの
torch.nn.Dropout2dなど- Softmax関数などの適用を行うもの
torch.nn.Softmaxなど- 画像処理を行うもの
torch.nn.PixelShuffletorch.nn.Upsampleなど- 時系列ネットワークの部品を提供するもの
torch.nn.RNNCelltorch.nn.LSTMCelltorch.nn.GRUCell5. まとめ
PyTorchのモジュールを用いて,ネットワークのごく大雑把な組み方を把握してみました。
実際のネットワークの学習に必要な,損失関数の計算,誤差逆伝播,パラメーター更新などはまだ扱っていません。
のちほど追って他の記事に載せようと思っています。参考文献
PyTorch.org Package reference
#1 Neural Networks : PyTorchチュートリアルをやってみた
- 投稿日:2019-05-26T18:21:45+09:00
挫折しかけた人のPyTorch:RNN,LSTM,GRU,CNNのモデルを組もう
趣旨
- 自然言語処理を独学して9ヶ月になります
- 深層学習のフレームワークをまさに勉強中で,四苦八苦しながら少しずつ覚えている最中です
- 自分と似たような境遇の方に少しでも参考になればと思い,ごく基本的な事項をまとめてみました
- 誤りなどあればぜひ教えてください!
このような方のために
- RNN, LSTM, GRUについて一通り知っていて,Pythonも一通り書けるが,実装したことはない
- 『ゼロからつくるDeep Learning 2』を読んでスクラッチ実装した経験はあるが,深層学習のフレームワークを触ったことはない
- 深層学習のフレームワークを触ってみたいが,苦手意識がある
- PyTorchのチュートリアルやドキュメントを読んだが,フレームワークの複雑さに諦めかけたことがある
内容
- 簡単なニューラルネットワークの構造をつくる
- ネットワークに推論させる
- PyTorch version 1.1.0 を使用しています
ここで扱わないこと
- 具体的な自然言語処理のタスク
- PyTorchのインストールなどの環境構築
- ニューラルなアプローチを含む自然言語処理の知識
- データの前処理や入力, 訓練の実装や回し方, 誤差関数の実装など
1. RNNを組む
1-1. ネットワークをつくる
実はRNNのネットワークは比較的短いコードで組むことができます。
まずモジュールをインポートします:import torch import torch.nn as nn「入力が3次元で,隠れ状態の表現が4次元の,1層のRNN」を組みたいときは次のように書きます:
dim_input = 3 dim_hidden = 4 n_layer = 1 # 入力3次元, 隠れ状態4次元, 1層のRNN model = nn.RNN(dim_input, dim_hidden, n_layer)なんとたったこれだけでRNNの完成です!
双方向RNN
双方向RNN(BiDirectional RNN)を組むこともできます:
# 入力5次元, 隠れ状態8次元, 1層の双方向RNN model2 = nn.RNN(5, 8, 1, bidirectional=True)多層のRNN
また,多層のRNNを組むこともできます:
# 入力3次元, 隠れ状態6次元, 2層のRNN model3 = nn.RNN(3, 6, 2)1-2. RNNコンストラクタの引数
torch.nn.RNNのコンストラクタに入れることのできる引数は以下のとおりです。
ただ,実際に変更することのあるパラメーターはおそらくbidirectionalくらいでしょう。model = torch.nn.RNN(input_size, hidden_size, num_layers=1, nonlinearity='tanh', bias=True, batch_first=False, dropout=0, bidirectional=False) input_size: int -> 入力ベクトルの次元数 hidden_size: int -> 隠れ状態の次元数 *num_layers: int -> RNNの層数。多層にしたいときは2以上に *nonlinearity: ('tanh','relu') -> 活性化関数 *bias: bool -> バイアスを使うかどうか *batch_first: bool *dropout: float -> 途中の隠れ状態にDropoutを適用する確率 *bidirectional: bool -> 双方向RNNにするかどうか1-3. シーケンス長は決まっていなくてよい
ここでのポイントは,隠れ状態をいくつ並べるのかは,モデルの構築時に決める必要がないということです。
このRNNが隠れ状態の時相をいくつ持つのかは,入力に応じて柔軟に決まります。
たとえば,長さ2のシーケンスを入力した時は,自動的にRNNも隠れ状態を(初期のものも含めて)3つ持つものとして扱われます。
入力シーケンス長が5なら,自動的にRNNの隠れ状態も(初期のものも含めて)6つになります。
入力シーケンス長が変わっても,同じネットワークのオブジェクトを使い回すことができ,ネットワークを作り直す必要がないのは便利です。
1-4. RNNのパラメーターの確認
RNNの重み行列やバイアスといったパラメーターは,モデルが作られた段階で適当な値に初期化されています。
実際にパラメーターの値がどうなっているかを見てみましょう。for param_name, param in model.named_parameters(): print(param_name, param)次のような出力が得られるはずです:
weight_ih_l0 Parameter containing: tensor([[ 0.3952, 0.2076, -0.4457], [ 0.4347, 0.4305, -0.4006], [-0.2418, 0.2938, 0.3902], [ 0.2993, -0.4796, 0.3057]], requires_grad=True) weight_hh_l0 Parameter containing: tensor([[ 0.2947, 0.1054, -0.2473, 0.0123], [-0.4304, -0.1026, -0.2625, 0.2118], [-0.3104, -0.3083, -0.1775, -0.4657], [-0.3112, 0.2688, -0.0175, 0.1982]], requires_grad=True) bias_ih_l0 Parameter containing: tensor([ 0.2956, 0.0737, -0.3413, 0.2683], requires_grad=True) bias_hh_l0 Parameter containing: tensor([-0.4708, 0.1364, -0.0254, -0.3953], requires_grad=True)これらの出力は次のようなことを意味します。
RNNの隠れ層で行われているのは次のような演算でした:h_{t}=(W_{ih}x_{t}+b_{ih})+(W_{hh}h_{t-1}+b_{hh})RNNのパラメーターとして扱われるのは$W_{ih}$,$W_{hh}$,$b_{ih}$,$b_{hh}$の4つの行列もしくはベクトルです。
上の出力例をみると,$W_{ih}$,$W_{hh}$,$b_{ih}$,$b_{hh}$の中身がこの順で出力されていることがわかります。
先ほど
modelを入力3次元,隠れ状態4次元のRNNとしてつくっていたことを思い出せば,$W_{ih}$,$W_{hh}$が4×3行列,$b_{ih}$,$b_{hh}$が4次元ベクトルとなっていることは納得がいきます。1-5. RNNに推論させる
このRNNに何かを入力して,何らかの出力を得てみましょう。
もちろんこのRNNは初期化された状態のままであり,一切の学習を行なっていないため,でたらめな値を吐き出します。まず,入力テンソルと初期の隠れ状態を,正規分布に従ってランダムに生成させます。
テンソルの次元を間違えないように気をつけましょう:n_sample = 2 seq_length = 5 # 入力 # ここでは dim_input = 3 X = torch.randn(n_seq, n_sample, dim_input) # 初期の隠れ状態 # ここでは n_layer = 1, n_hidden = 4 h0 = torch.randn(n_layer, n_sample, n_hidden)あとは構築したネットワークを引数を与えて呼び出すだけです:
# Y:出力, hn:最終の隠れ状態 Y, hn = model(X, h0)これで推論させることができました!
出力内容の確認
実際の出力内容を見てみましょう:
print(Y) print(hn)
Yには時系列(ここでは長さ5)に対応するすべての出力がまとめて格納されていることが読み取れます。
hnはここでは隠れ状態の次元と同じ,4次元ベクトルですね。tensor([[[-0.5985, -0.5996, 0.3071, 0.8372], [-0.6360, 0.3991, 0.8016, 0.2106]], [[-0.7843, 0.2241, 0.6805, 0.4661], [-0.7905, -0.2255, -0.6491, 0.7182]], [[-0.8067, 0.1700, 0.4610, 0.5975], [-0.4348, -0.5121, -0.6546, 0.0738]], [[-0.8926, 0.2469, -0.3201, 0.8214], [-0.8078, -0.3981, 0.2478, 0.9111]], [[-0.7735, 0.3182, 0.7366, 0.5397], [-0.8512, 0.0490, 0.2640, 0.6170]]], grad_fn=<StackBackward>) tensor([[[-0.7735, 0.3182, 0.7366, 0.5397], [-0.8512, 0.0490, 0.2640, 0.6170]]], grad_fn=<StackBackward>)
YにSoftmax関数を通せば,各サンプルの各時系列のベクトルの成分を確率に変換することができます:import torch.nn.functional as F Y_prob = F.softmax(Y, dim=2) print(Y_prob)たしかに各行の合計が1になり,正規化されていることがわかります:
tensor([[[0.1153, 0.1152, 0.2851, 0.4845], [0.0965, 0.2718, 0.4065, 0.2251]], [[0.0865, 0.2371, 0.3743, 0.3021], [0.1186, 0.2087, 0.1366, 0.5361]], [[0.0886, 0.2354, 0.3149, 0.3610], [0.2277, 0.2108, 0.1828, 0.3787]], [[0.0873, 0.2730, 0.1548, 0.4849], [0.0913, 0.1375, 0.2622, 0.5091]], [[0.0818, 0.2437, 0.3703, 0.3041], [0.0922, 0.2267, 0.2811, 0.4001]]], grad_fn=<SoftmaxBackward>)2. LSTMを組む
2-1. ネットワークをつくる
LSTMもRNNとほぼ全く同じように組むことができます:
import torch import torch.nn as nn # 入力2次元, 隠れ状態3次元, 1層のLSTM dim_input, dim_hidden, n_layer = 2, 3, 1 model = nn.LSTM(dim_input, dim_hidden, n_layer)双方向LSTM, 多層LSTMもRNNのときと同様です:
# 入力5次元, 隠れ状態8次元, 1層の双方向LSTM model2 = nn.LSTM(5, 8, 1, bidirectional=True) # 入力3次元, 隠れ状態6次元, 2層のLSTM model3 = nn.LSTM(3, 6, 2)2-2. LSTMコンストラクタの引数
torch.nn.LSTMのコンストラクタに入れることのできる引数は以下のとおりです。
RNNのコンストラクタとほぼ変わりありません。
RNNとの違いは活性化関数を指定する項目がない点くらいでしょう。model = torch.nn.LSTM(input_size, hidden_size, num_layers=1, bias=True, batch_first=False, dropout=0, bidirectional=False) input_size: int -> 入力ベクトルの次元数 hidden_size: int -> 隠れ状態の次元数 *num_layers: int -> LSTMの層数。多層にしたいときは2以上に *bias: bool -> バイアスを使うかどうか *batch_first: bool *dropout: float -> 途中の隠れ状態にDropoutを適用する確率 *bidirectional: bool -> 双方向LSTMにするかどうか2-3. LSTMのパラメーターの確認
LSTMのパラメーターもまた,ネットワークを組んだ時点で適当な値で初期化されています。
現在のパラメーターの様子をみてみましょう:for param_name, param in model.named_parameters(): print(param_name, param)次のような出力が得られるはずです:
weight_ih_l0 Parameter containing: tensor([[ 0.2848, -0.1366], [-0.5757, 0.2086], [ 0.4995, 0.4271], [-0.1745, -0.3294], [ 0.4708, -0.0210], [ 0.4829, -0.4076], [ 0.4412, 0.3948], [ 0.4969, -0.0128], [ 0.4600, 0.4799], [ 0.3268, 0.2755], [ 0.2120, 0.0517], [ 0.1208, -0.1436]], requires_grad=True) weight_hh_l0 Parameter containing: tensor([[-0.0824, 0.3834, -0.0103], [ 0.5396, 0.3769, 0.1899], [-0.4365, -0.5241, -0.2395], [ 0.4210, -0.5123, 0.1195], [-0.3324, 0.2434, 0.3067], [-0.2196, 0.3060, -0.3943], [ 0.1774, -0.2787, 0.0273], [-0.2064, -0.4244, -0.0538], [ 0.1785, 0.0495, 0.4612], [ 0.1111, 0.4128, 0.5325], [ 0.0116, -0.2142, 0.3397], [ 0.2183, -0.2899, 0.1467]], requires_grad=True) bias_ih_l0 Parameter containing: tensor([ 0.2030, -0.3873, 0.5769, -0.3200, 0.0116, -0.0453, -0.5763, -0.0194, -0.1736, -0.0692, 0.2100, -0.0362], requires_grad=True) bias_hh_l0 Parameter containing: tensor([ 0.1686, -0.3883, -0.3789, -0.3639, 0.1766, 0.0311, -0.4657, 0.3933, -0.0357, 0.2844, 0.3898, 0.3525], requires_grad=True)これらの出力は次のようなことを意味します。
LSTMの隠れ層で行われているのは次のような演算でした:i_{t}=\sigma ((W_{ii}x_{t}+b_{ii})+(W_{hi}h_{t-1}+b_{hi}))\\ f_{t}=\sigma ((W_{if}x_{t}+b_{if})+(W_{hf}h_{t-1}+b_{hf}))\\ g_{t}=tanh((W_{ig}x_{t}+b_{ig})+(W_{hg}h_{t-1}+b_{hg}))\\ c_{t}=f_{t}\cdot c_{t-1} + i_{t}\cdot g_{t}\\ o_{t}=\sigma ((W_{io}x_{t}+b_{io})+(W_{ho}h_{t-1}+b_{ho}))\\ h_{t}=o_{t}\cdot tanh(c_{t})LSTMのパラメーターとして扱われるのは$W_{ii}$,$W_{if}$,$W_{ig}$,$W_{io}$,$W_{hi}$,$W_{hf}$,$W_{hg}$,$W_{ho}$,$b_{ii}$,$b_{if}$,$b_{ig}$,$b_{io}$,$b_{hi}$,$b_{hf}$,$b_{hg}$,$b_{ho}$の16の行列もしくはベクトルです。
上の出力例では,
weight_ih_l0 Parameterに$W_{ii}$,$W_{if}$,$W_{ig}$,$W_{io}$がまとめて格納されて出力され,
weight_hh_l0 Parameterに$W_{hi}$,$W_{hf}$,$W_{hg}$,$W_{ho}$がまとめて格納されて出力され,
bias_ih_l0 Parameterに$b_{ii}$,$b_{if}$,$b_{ig}$,$b_{io}$がまとめて格納されて出力され,
bias_hh_l0 Parameterに$b_{hi}$,$b_{hf}$,$b_{hg}$,$b_{ho}$がまとめて格納されて出力されています。2-4. LSTMに推論させる
このLSTMに何かを入力して,何らかの出力を得てみましょう。
もちろんこのLSTMは初期化された状態のままであり,一切の学習を行なっていないため,でたらめな値を吐き出します。n_sample = 2 seq_length = 5 # 入力 X = torch.randn(seq_length, n_sample, dim_input) # 初期の隠れ状態 h0 = torch.randn(n_layer, n_sample, dim_hidden) # 初期のメモリセル c0 = torch.randn(n_layer, n_sample, dim_hidden) # Y:出力, hn:最終の隠れ状態, cn:最終のメモリセル # (h0,c0)を省略するとh0,c0には零ベクトルが代入される Y, (hn,cn) = lstm(X, (h0,c0)) print(Y, hn, cn, sep='\n')次のような出力が得られるはずです:
tensor([[[-0.0608, 0.0157, -0.3091], [-0.1908, 0.1270, -0.0131]], [[-0.0604, 0.1197, -0.2682], [-0.1019, 0.1923, -0.1177]], [[-0.0411, -0.0321, -0.2204], [-0.1566, 0.3992, 0.1179]], [[-0.0693, 0.0297, -0.1263], [-0.0999, 0.4723, 0.2208]], [[-0.0499, 0.2873, 0.0223], [-0.1095, 0.2102, 0.2421]]], grad_fn=<StackBackward>) tensor([[[-0.0499, 0.2873, 0.0223], [-0.1095, 0.2102, 0.2421]]], grad_fn=<StackBackward>) tensor([[[-0.0972, 0.4610, 0.0448], [-0.2396, 0.3879, 0.4673]]], grad_fn=<StackBackward>)3. GRUを組む
3-1. ネットワークをつくる
GRUもRNNとほぼ全く同じように組むことができます:
import torch import torch.nn as nn # 入力2次元, 隠れ状態3次元, 1層のGRU dim_input, dim_hidden, n_layer = 2, 3, 1 model = nn.GRU(dim_input, dim_hidden, n_layer)双方向GRU, 多層GRUもRNNのときと同様です:
# 入力5次元, 隠れ状態8次元, 1層の双方向GRU model2 = nn.GRU(5, 8, 1, bidirectional=True) # 入力3次元, 隠れ状態6次元, 2層のGRU model3 = nn.GRU(3, 6, 2)3-2. GRUコンストラクタの引数
torch.nn.GRUのコンストラクタに入れることのできる引数は以下のとおりです。
RNNのコンストラクタとほぼ変わりありません。
RNNとの違いは活性化関数を指定する項目がない点くらいでしょう。model = torch.nn.GRU(input_size, hidden_size, num_layers=1, bias=True, batch_first=False, dropout=0, bidirectional=False) input_size: int -> 入力ベクトルの次元数 hidden_size: int -> 隠れ状態の次元数 *num_layers: int -> GRUの層数。多層にしたいときは2以上に *bias: bool -> バイアスを使うかどうか *batch_first: bool *dropout: float -> 途中の隠れ状態にDropoutを適用する確率 *bidirectional: bool -> 双方向GRUにするかどうか3-3. GRUのパラメーターの確認
GRUのパラメーターもまた,ネットワークを組んだ時点で適当な値で初期化されています。
現在のパラメーターの様子をみてみましょう:for param_name, param in model.named_parameters(): print(param_name, param)次のような出力が得られるはずです:
weight_ih_l0 Parameter containing: tensor([[ 0.3526, 0.2047], [ 0.5587, 0.3424], [ 0.3634, 0.0156], [-0.0418, 0.1831], [-0.4068, 0.4114], [-0.5638, -0.2389], [-0.1970, 0.0833], [-0.2401, -0.2788], [ 0.4896, -0.2670]], requires_grad=True) weight_hh_l0 Parameter containing: tensor([[ 0.1349, -0.0746, -0.4713], [-0.1361, -0.4540, -0.0641], [-0.1179, -0.3632, -0.2545], [ 0.1209, 0.5216, 0.2496], [ 0.2362, 0.1309, 0.1757], [ 0.0641, -0.4424, 0.0094], [ 0.0433, -0.2761, 0.3010], [-0.3071, -0.0923, -0.2459], [ 0.2349, 0.3862, 0.5465]], requires_grad=True) bias_ih_l0 Parameter containing: tensor([ 0.5506, 0.4258, 0.0540, -0.3532, -0.5515, -0.3412, -0.1674, 0.2784, -0.2394], requires_grad=True) bias_hh_l0 Parameter containing: tensor([ 0.1500, 0.2692, 0.2734, 0.1079, 0.2887, -0.5322, 0.1495, -0.0939, 0.2837], requires_grad=True)これらの出力は次のようなことを意味します。
GRUの隠れ層で行われているのは次のような演算でした:r_{t}=\sigma ((W_{ir}x_{t}+b_{ir})+(W_{hr}h_{t-1}+b_{hr}))\\ z_{t}=\sigma ((W_{iz}x_{t}+b_{iz})+(W_{hz}h_{t-1}+b_{hz}))\\ n_{t}=tanh(r_{t}\cdot (W_{hn}h_{t-1}+b_{hn})+(W_{in}x_{t}+b_{in}))\\ h_{t}=(1-z_{t})\cdot n_{t} + z_{t}\cdot h_{t-1}GRUのパラメーターとして扱われるのは$W_{ir}$,$W_{iz}$,$W_{in}$,$W_{hr}$,$W_{hz}$,$W_{hn}$,$b_{ir}$,$b_{iz}$,$b_{in}$,$b_{hr}$,$b_{hz}$,$b_{hn}$の12の行列もしくはベクトルです。
上の出力例では,
weight_ih_l0 Parameterに$W_{ir}$,$W_{iz}$,$W_{in}$がまとめて格納されて出力され,
weight_hh_l0 Parameterに$W_{hr}$,$W_{hz}$,$W_{hn}$がまとめて格納されて出力され,
bias_ih_l0 Parameterに$b_{ir}$,$b_{iz}$,$b_{in}$がまとめて格納されて出力され,
bias_hh_l0 Parameterに$b_{hr}$,$b_{hz}$,$b_{hn}$がまとめて格納されて出力されています。3-4. GRUに推論させる
このGRUに何かを入力して,何らかの出力を得てみましょう。
もちろんこのGRUは初期化された状態のままであり,一切の学習を行なっていないため,でたらめな値を吐き出します。n_sample = 2 seq_length = 5 # 入力 X = torch.randn(seq_length, n_sample, dim_input) # 初期の隠れ状態 h0 = torch.randn(n_layer, n_sample, dim_hidden) # Y:出力, hn:最終の隠れ状態 # h0を省略するとh0には零ベクトルが代入される Y, hn = gru(X, h0) print(Y, hn, sep='\n')次のような出力が得られるはずです:
tensor([[[ 0.5822, -0.4229, 0.4796], [ 0.0419, 0.0228, 0.4883]], [[ 0.0915, 0.1967, 0.6127], [ 0.0900, -0.0312, -0.0792]], [[ 0.0548, -0.0761, 0.2387], [-0.0706, -0.1772, 0.1976]], [[ 0.0956, 0.1815, -0.1227], [-0.1522, 0.1317, 0.4051]], [[-0.0466, -0.0572, 0.0450], [-0.3013, -0.1203, 0.7980]]], grad_fn=<StackBackward>) tensor([[[-0.0466, -0.0572, 0.0450], [-0.3013, -0.1203, 0.7980]]], grad_fn=<StackBackward>)4. より複雑なネットワークを組むには(1)
ここまで,RNN,LSTM,GRUがPyTorchのモジュールを1つ使うだけで簡単に組めることがわかりました。
4-1.はじめに
PyTorchでネットワークを組む方法にはいくつかの方法があります:
- a. 既存のモジュールを1つ使う(これまでのように)
- b. 既存のモジュールを複数組み合わせる
- c. 自分で独自のモジュールを定義する
a.の「既存のモジュールを1つ使う」はこれまでに試してきた通りです。
RNN, LSTM, GRUについては,内部処理を記述することなくモジュール1つで簡単にネットワークを組むことができます。c.の「自分で独自のモジュールを定義する」はもっとも自由度の高いカスタマイズが可能ですが,PyTorchへの理解を深める必要がありそうです。
ここでは比較的簡単な,b.の「既存のモジュールを複数組み合わせる」方法についてみていきましょう。
4-2.既存のモジュールを複数組み合わせるには
以下,時系列ネットワークからは離れた話になることをご了承ください。
たとえば,次のようなCNN(の一部分)を組みたいとします:
Yann LeCun et al. Object Recognition with Gradient-Based Learning
上図は画像認識へのCNNの普及のきっかけとなったLeNetの論文から引用した図です。
このうち,全結合層の手前にあたる部分に似せた,下記を実装してみようと思います:
- 畳み込み層1
- 入力チャネル数1, 出力チャネル数6, カーネルサイズ5x5
- MaxPooling層1
- カーネルサイズ2x2
- 活性化(ReLU)1
- 畳み込み層2
- 入力チャネル数6, 出力チャネル数16, カーネルサイズ5x5
- MaxPooling層2
- カーネルサイズ2x2
- 活性化(ReLU)2
どのようにすればこれらを1つのネットワークとして表現できるでしょうか?
方法1: 入出力を順次渡していく
畳み込み層,MaxPooling層,活性化はそれぞれが独立したモジュールとして提供されています。
このため,前の層の出力を次の層の入力へと順次渡していくことで一連のネットワークとしての処理が可能です:import torch import torch.nn as nn # 入力 # requires_grad=Trueとしておくとのちほど訓練しやすい # Xを使って計算されたテンソルをすべて追跡して勾配計算を繋いでくれる X = torch.randn(10, 1, 32, 32, requires_grad=True) # モジュールを用意 conv1 = nn.Conv2d(1, 6, 5) relu1 = nn.ReLU() maxpool1 = nn.MaxPool2d(2) conv2 = nn.Conv2d(6, 16, 5) relu2 = nn.ReLU() maxpool2 = nn.MaxPool2d(2) # 推論させたいときは out = conv1(X) out = relu1(out) out = maxpool1(out) out = conv2(out) out = relu2(out) Y = maxpool2(out)ただし,のちほど学習を進める際,勾配や重みなどのパラメーター全体を統一して扱いにくい印象があります。
方法2: モデルをひとまとめにする
PyTorchには複数のモジュールを1つのモジュールへとまとめるための
torch.nn.Sequentialが用意されており,まとめた後のモジュールを用いて一括で推論を行うことができます:# conv1, relu1, maxpool1, conv2, relu2, maxpool2を用意するところまでは方法1と同じ # 一連の処理を1つのモデルにまとめる model = nn.Sequential(conv1, relu1, maxpool1, conv2, relu2, maxpool2) # 推論させたいときは Y = model(X)もしくは,順序つき辞書
OrderedDictを作成して代入しても構いません:# 個々のモジュールを用意 from collections import OrderedDict layers = OrderedDict([('conv1', nn.Conv2d(1,6,5)),('relu1',nn.ReLU()),('conv2',nn.Conv2d(6,16,5)),('relu2',nn.ReLU())]) # 1つのモデルにまとめる model = nn.Sequential(layers) # 推論させたいときは Y = model(X)この方法では,モデル全体のパラメーターが
model.parameters()やmodel.named_parameters()に一括で格納されるため,統一して扱いやすくなります。しかし,細やかな処理が得意ではないのが最大の欠点です。
たとえば,CNNの全結合層を定義するにはテンソルをreshapeしてベクトルへとほどいてやる必要がありますが,reshapeの操作を行ってくれるレイヤーは存在しません。
このため,レイヤーの積み重ねである
nn.Sequentialでは,画像認識システムは完成させられないことになってしまいます
(参考:What is the reshape layer in pytorch?)。4-3.torch.nnのモジュール
PyTorchのtorch.nnの内部に用意されているモジュールの例を以下に挙げます。
眺めていると,ネットワークを組むのに必要な道具がだいたい揃っているように思えるのではないでしょうか。
ポイントは,「単体でネットワークとして使えるもの」と,通常は単体では使用されることはなく「ネットワークの処理の一部を担うもの」の2種類に分けられる点です:
- 単体でもネットワークとして使えるもの
- 時系列ネットワーク
torch.nn.RNNtorch.nn.LSTMtorch.nn.GRU- 通常単体では使用されないもの(ネットワークの処理の一部を担う)
- 行列計算を行うもの
torch.nn.Identitytorch.nn.Linearなど- 活性化関数の適用を行うもの
torch.nn.ReLUtorch.nn.LeakyReLUtorch.nn.PReLUtorch.nn.LogSigmoidtorch.nn.Tanhtorch.nn.Hardtanhなど- パディング(padding)を行うもの
torch.nn.ZeroPad2dtorch.nn.ConstantPad2dtorch.nn.ReflectionPad2dtorch.nn.ReplicationPad2dなど- 畳み込み(convolution)を行うもの
torch.nn.Conv2dなど- プーリング(pooling)を行うもの
torch.nn.MaxPool2dtorch.nn.AvgPool2dなど- 正規化(normalization)を行うもの
torch.nn.BatchNorm2dtorch.nn.LocalResponseNormなど- ドロップアウト(dropout)を行うもの
torch.nn.Dropout2dなど- Softmax関数などの適用を行うもの
torch.nn.Softmaxなど- 画像処理を行うもの
torch.nn.PixelShuffletorch.nn.Upsampleなど- 時系列ネットワークの部品を提供するもの
torch.nn.RNNCelltorch.nn.LSTMCelltorch.nn.GRUCell5. まとめ
PyTorchのモジュールを用いて,ネットワークのごく大雑把な組み方を把握してみました。
実際のネットワークの学習に必要な,損失関数の計算,誤差逆伝播,パラメーター更新などはまだ扱っていません。
のちほど追って他の記事に載せようと思っています。参考文献
PyTorch.org Package reference
#1 Neural Networks : PyTorchチュートリアルをやってみた
- 投稿日:2019-05-26T15:12:14+09:00
ディープラーニング用のGPU Dockerサーバーを作る
はじめに
最近、機械学習の勉強をしていて問題になるのが開発環境。Pythonの依存関係なども複雑で、環境構築や動かすまで一苦労する事が多く作っては壊せる環境が欲しくなります。AWSでGPUインスタンスを立ち上げるほどではないけど、GPUを使える環境が欲しい。Google Colabも便利だけど、実際に実行環境の構築部分も気になります。某所ではDGX-Stationを買ったりと景気の良い話もあるけれど、とてもそんな予算請求できません...。
という事でゲーミングPCをベースにしてnvidia-dockerでディープラーニング用の開発環境を構築しました。
前提
予算:15万円
目的:nvidia-dockerが動く環境
環境:Ubuntuスペック予定
- NVIDIA GTX or RTX
- Core i7
- SSD 500Gくらい
OS不要!
※前にWindows10のゲーミングPCを機械学習目的で購入したけどサクサクで便利過ぎて、環境を壊したくなくなったがそもそものキッカケ。
ハード構成
上をみたらキリがないので予算を15万として検討。10万くらいで買えるGTX1050ノートも考えましたが、常時ONが前提なので省スペースデスクトップをツクモでBTOする事にしました。
G-GEAR mini GI7J-C190/T
Corei7-8700(6Core HT 3.2GHz) / OS無し / 32GB / GeForce RTX2060
SSD 500GB + HDD 2TB(無償アップグレード)という構成で、本体税抜き15.5万でした(ギリ)。DVDドライブベイが無く高さが低いケースなので足元にも置きやすいです。メモリーを(少しBTO価格は高い気がしますが)多めにしておきました。ストレージはキャンペーンで2倍だったので、ちょうど良いくらいですね。
どうせ買うならということで、GPUはTensorコアがついているRTX2060にしました。また、(過去の経験から)無用なトラブルを回避するためになんとなくRayzenは避けました。
予定納期より1日短く4日で届きました♪
参考:小さくても速い!! コンパクトゲーミングPC「G-GEAR mini」の実力を試す (1/2)
https://www.itmedia.co.jp/pcuser/articles/1510/23/news078.html環境構築
OSインストール
ここはサクッとUbuntu Desktop 18.04.02 LTSをインストールします。USB起動でインストールしました。このあたりはごく普通なので省略します。SSD側をOSのメインドライブ、HDDをデータとして使う予定です。
メモ:19.04を試しに入れてみたらさくっとNVIDIAのカードを認識していましたので将来的には次からの環境構築の半分は不要になりそうな気がします。
OSアップデート
お約束でインストール後はupdate & upgradeをしておきます。
sudo apt update sudo apt upgrade sudo apt install net-tools sshNVIDIAドライバーのレポジトリー追加
sudo add-apt-repository ppa:graphics-drivers/ppa一応ずらずらでます。たぶん読み飛ばしOK。実行結果は少し変わるかと思います。
$ sudo add-apt-repository ppa:graphics-drivers/ppa Fresh drivers from upstream, currently shipping Nvidia. ## Current Status Current long-lived branch release: `nvidia-410` (410.66) Dropped support for Fermi series (https://nvidia.custhelp.com/app/answers/detail/a_id/4656) Old long-lived branch release: `nvidia-390` (390.87) For GF1xx GPUs use `nvidia-390` (390.87) For G8x, G9x and GT2xx GPUs use `nvidia-340` (340.107) For NV4x and G7x GPUs use `nvidia-304` (304.137) End-Of-Life! Support timeframes for Unix legacy GPU releases: https://nvidia.custhelp.com/app/answers/detail/a_id/3142 ## What we're working on right now: - Normal driver updates - Help Wanted: Mesa Updates for Intel/AMD users, ping us if you want to help do this work, we're shorthanded. ## WARNINGS: This PPA is currently in testing, you should be experienced with packaging before you dive in here: Volunteers welcome! ### How you can help: ## Install PTS and benchmark your gear: sudo apt-get install phoronix-test-suite Run the benchmark: phoronix-test-suite default-benchmark openarena xonotic tesseract gputest unigine-valley and then say yes when it asks you to submit your results to openbechmarking.org. Then grab a cup of coffee, it takes a bit for the benchmarks to run. Depending on the version of Ubuntu you're using it might preferable for you to grabs PTS from upstream directly: http://www.phoronix-test-suite.com/?k=downloads ## Share your results with the community: Post a link to your results (or any other feedback to): https://launchpad.net/~graphics-drivers-testers Remember to rerun and resubmit the benchmarks after driver upgrades, this will allow us to gather a bunch of data on performance that we can share with everybody. If you run into old documentation referring to other PPAs, you can help us by consolidating references to this PPA. If someone wants to go ahead and start prototyping on `software-properties-gtk` on what the GUI should look like, please start hacking! ## Help us Help You! We use the donation funds to get the developers hardware to test and upload these drivers, please consider donating to the "community" slider on the donation page if you're loving this PPA: http://www.ubuntu.com/download/desktop/contribute More info: https://launchpad.net/~graphics-drivers/+archive/ubuntu/ppa Press [ENTER] to continue or Ctrl-c to cancel adding it. Hit:1 http://jp.archive.ubuntu.com/ubuntu bionic InRelease Hit:2 http://jp.archive.ubuntu.com/ubuntu bionic-updates InRelease Hit:3 http://jp.archive.ubuntu.com/ubuntu bionic-backports InRelease Get:4 http://security.ubuntu.com/ubuntu bionic-security InRelease [88.7 kB] Get:5 http://ppa.launchpad.net/graphics-drivers/ppa/ubuntu bionic InRelease [21.3 kB] Get:6 http://ppa.launchpad.net/graphics-drivers/ppa/ubuntu bionic/main i386 Packages [18.3 kB] Get:7 http://ppa.launchpad.net/graphics-drivers/ppa/ubuntu bionic/main amd64 Packages [23.8 kB] Get:8 http://ppa.launchpad.net/graphics-drivers/ppa/ubuntu bionic/main Translation-en [6,096 B] Fetched 158 kB in 8s (20.6 kB/s) Reading package lists… Done適合するドライバーの検索
ubuntu-drivers devices$ ubuntu-drivers devices == /sys/devices/pci0000:00/0000:00:01.0/0000:01:00.0 == modalias : pci:v000010DEd00001F08sv000019DAsd00004520bc03sc00i00 vendor : NVIDIA Corporation driver : nvidia-driver-415 - third-party free driver : nvidia-driver-418 - third-party free driver : nvidia-driver-430 - third-party free recommended driver : xserver-xorg-video-nouveau - distro free builtinドライバーインストール
とりあえず、recommendedのnvidia-driver-430をインストールします。
sudo apt install nvidia-driver-430GPUの動作確認
nvidia-smiコマンドで認識状態を確認します。下記のように出れば認識できています。
$ nvidia-smi Fri May 10 16:41:24 2019 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 430.09 Driver Version: 430.09 CUDA Version: 10.1 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 GeForce RTX 2060 Off | 00000000:01:00.0 On | N/A | | 41% 40C P8 13W / 160W | 159MiB / 5900MiB | 0% Default | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| | 0 1145 G /usr/lib/xorg/Xorg 105MiB | | 0 1184 G /usr/bin/gnome-shell 52MiB | +-----------------------------------------------------------------------------+Dockerインストール
公式情報
https://docs.docker.com/install/linux/docker-ce/ubuntu/#install-docker-ce必要なパッケージをインストールしておきます。
sudo apt-get install \ apt-transport-https \ ca-certificates \ curl \ gnupg-agent \ software-properties-commonDockerをインストールし、現在にユーザーにdockerの実行権限を与えます。
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add - sudo add-apt-repository \ "deb [arch=amd64] https://download.docker.com/linux/ubuntu \ $(lsb_release -cs) \ stable” sudo apt-get install docker-ce docker-ce-cli containerd.io sudo usermod -aG docker $USERDockerのバージョン確認
以下のコマンドでインストールさればバージョンの確認を行います。
docker version$ docker version Client: Version: 18.09.6 API version: 1.39 Go version: go1.10.8 Git commit: 481bc77 Built: Sat May 4 02:35:57 2019 OS/Arch: linux/amd64 Experimental: false Server: Docker Engine - Community Engine: Version: 18.09.6 API version: 1.39 (minimum version 1.12) Go version: go1.10.8 Git commit: 481bc77 Built: Sat May 4 01:59:36 2019 OS/Arch: linux/amd64 Experimental: falsenvidia-dockerのインストール
GPU対応のためにnvidia-dockerをインストールします。
公式の情報は下記になります。
https://nvidia.github.io/nvidia-docker/sudo apt-get install nvidia-docker2 sudo pkill -SIGHUP dockerdnvidia-docker動作確認
うまくインストールが完了すれば、下記のコマンドにてnvida/cudaのイメージを実行することがきます。
docker run --runtime=nvidia --rm nvidia/cuda:9.0-base nvidia-smi
下記のようにローカルで実行した時と同じようにGPU情報が表示されれば成功です。
$ docker run --runtime=nvidia --rm nvidia/cuda:9.0-base nvidia-smi Unable to find image 'nvidia/cuda:9.0-base' locally 9.0-base: Pulling from nvidia/cuda 34667c7e4631: Pull complete d18d76a881a4: Pull complete 119c7358fbfc: Pull complete 2aaf13f3eff0: Pull complete 4d96b2dafaa5: Pull complete f8c41b380cab: Pull complete d2c1b4858446: Pull complete Digest: sha256:0afacc402b0eb2333d1075d051e237710483b29cdd51c4e7de5d60be4cb1468f Status: Downloaded newer image for nvidia/cuda:9.0-base Fri May 10 07:51:32 2019 +-----------------------------------------------------------------------------+ | NVIDIA-SMI 430.09 Driver Version: 430.09 CUDA Version: 10.1 | |-------------------------------+----------------------+----------------------+ | GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC | | Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. | |===============================+======================+======================| | 0 GeForce RTX 2060 Off | 00000000:01:00.0 On | N/A | | 41% 35C P8 12W / 160W | 222MiB / 5900MiB | 0% Default | +-------------------------------+----------------------+----------------------+ +-----------------------------------------------------------------------------+ | Processes: GPU Memory | | GPU PID Type Process name Usage | |=============================================================================| +-----------------------------------------------------------------------------+docker-composeのインストール
やはり複数コンテナの管理ができるdocker-composeを入れた方が便利なので入れておきます。
公式サイト手順:
https://docs.docker.com/compose/install/sudo curl -L "https://github.com/docker/compose/releases/download/1.24.0/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose sudo chmod +x /usr/local/bin/docker-compose完了
これでdocker-nvidiaによりGPUを思う存分使える環境を構築することができました。
2週間ほど使っているのですが、手元の環境をpyenv等を使って細工していたのを、汚さずに何度でも新しい環境ベースでテストできるのは非常に便利です。dockerを常に利用する事で再現性のある環境を作ることを心がけるようになりました。また、別環境にした事でゴミdockerイメージによる SSDの圧迫もなくなりました(これが大きい。
